
title
stringlengths 17
126
| author
stringlengths 3
21
| date
stringlengths 11
18
| local
stringlengths 2
59
| tags
stringlengths 2
76
| URL
stringlengths 30
87
| content
stringlengths 1.11k
108k
|
|---|---|---|---|---|---|---|
Ethics and Society Newsletter #3: Ethical Openness at Hugging Face
|
irenesolaiman
|
Mar 30, 2023
|
ethics-soc-3
|
ethics
|
https://huggingface.co/blog/ethics-soc-3
|
# Ethics and Society Newsletter #3: Ethical Openness at Hugging Face ## Mission: Open and Good ML In our mission to democratize good machine learning (ML), we examine how supporting ML community work also empowers examining and preventing possible harms. Open development and science decentralizes power so that many people can collectively work on AI that reflects their needs and values. While [openness enables broader perspectives to contribute to research and AI overall, it faces the tension of less risk control](https://arxiv.org/abs/2302.04844). Moderating ML artifacts presents unique challenges due to the dynamic and rapidly evolving nature of these systems. In fact, as ML models become more advanced and capable of producing increasingly diverse content, the potential for harmful or unintended outputs grows, necessitating the development of robust moderation and evaluation strategies. Moreover, the complexity of ML models and the vast amounts of data they process exacerbate the challenge of identifying and addressing potential biases and ethical concerns. As hosts, we recognize the responsibility that comes with potentially amplifying harm to our users and the world more broadly. Often these harms disparately impact minority communities in a context-dependent manner. We have taken the approach of analyzing the tensions in play for each context, open to discussion across the company and Hugging Face community. While many models can amplify harm, especially discriminatory content, we are taking a series of steps to identify highest risk models and what action to take. Importantly, active perspectives from many backgrounds is key to understanding, measuring, and mitigating potential harms that affect different groups of people. We are crafting tools and safeguards in addition to improving our documentation practices to ensure open source science empowers individuals and continues to minimize potential harms. ## Ethical Categories The first major aspect of our work to foster good open ML consists in promoting the tools and positive examples of ML development that prioritize values and consideration for its stakeholders. This helps users take concrete steps to address outstanding issues, and present plausible alternatives to de facto damaging practices in ML development. To help our users discover and engage with ethics-related ML work, we have compiled a set of tags. These 6 high-level categories are based on our analysis of Spaces that community members had contributed. They are designed to give you a jargon-free way of thinking about ethical technology: - Rigorous work pays special attention to developing with best practices in mind. In ML, this can mean examining failure cases (including conducting bias and fairness audits), protecting privacy through security measures, and ensuring that potential users (technical and non-technical) are informed about the project's limitations. - Consentful work [supports](https://www.consentfultech.io/) the self-determination of people who use and are affected by these technologies. - Socially Conscious work shows us how technology can support social, environmental, and scientific efforts. - Sustainable work highlights and explores techniques for making machine learning ecologically sustainable. - Inclusive work broadens the scope of who builds and benefits in the machine learning world. - Inquisitive work shines a light on inequities and power structures which challenge the community to rethink its relationship to technology. Read more at https://huggingface.co/ethics Look for these terms as we’ll be using these tags, and updating them based on community contributions, across some new projects on the Hub! ## Safeguards Taking an “all-or-nothing” view of open releases ignores the wide variety of contexts that determine an ML artifact’s positive or negative impacts. Having more levers of control over how ML systems are shared and re-used supports collaborative development and analysis with less risk of promoting harmful uses or misuses; allowing for more openness and participation in innovation for shared benefits. We engage directly with contributors and have addressed pressing issues. To bring this to the next level, we are building community-based processes. This approach empowers both Hugging Face contributors, and those affected by contributions, to inform the limitations, sharing, and additional mechanisms necessary for models and data made available on our platform. The three main aspects we will pay attention to are: the origin of the artifact, how the artifact is handled by its developers, and how the artifact has been used. In that respect we: - launched a [flagging feature](https://twitter.com/GiadaPistilli/status/1571865167092396033) for our community to determine whether ML artifacts or community content (model, dataset, space, or discussion) violate our [content guidelines](https://huggingface.co/content-guidelines), - monitor our community discussion boards to ensure Hub users abide by the [code of conduct](https://huggingface.co/code-of-conduct), - robustly document our most-downloaded models with model cards that detail social impacts, biases, and intended and out-of-scope use cases, - create audience-guiding tags, such as the “Not For All Audiences” tag that can be added to the repository’s card metadata to avoid un-requested violent and sexual content, - promote use of [Open Responsible AI Licenses (RAIL)](https://huggingface.co/blog/open_rail) for [models](https://www.licenses.ai/blog/2022/8/26/bigscience-open-rail-m-license), such as with LLMs ([BLOOM](https://huggingface.co/spaces/bigscience/license), [BigCode](https://huggingface.co/spaces/bigcode/license)), - conduct research that [analyzes](https://arxiv.org/abs/2302.04844) which models and datasets have the highest potential for, or track record of, misuse and malicious use. **How to use the flagging function:** Click on the flag icon on any Model, Dataset, Space, or Discussion: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/flag2.jpg" alt="screenshot pointing to the flag icon to Report this model" /> <em> While logged in, you can click on the "three dots" button to bring up the ability to report (or flag) a repository. This will open a conversation in the repository's community tab. </em> </p> Share why you flagged this item: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/flag1.jpg" alt="screenshot showing the text window where you describe why you flagged this item" /> <em> Please add as much relevant context as possible in your report! This will make it much easier for the repo owner and HF team to start taking action. </em> </p> In prioritizing open science, we examine potential harm on a case-by-case basis and provide an opportunity for collaborative learning and shared responsibility. When users flag a system, developers can directly and transparently respond to concerns. In this spirit, we ask that repository owners make reasonable efforts to address reports, especially when reporters take the time to provide a description of the issue. We also stress that the reports and discussions are subject to the same communication norms as the rest of the platform. Moderators are able to disengage from or close discussions should behavior become hateful and/or abusive (see [code of conduct](https://huggingface.co/code-of-conduct)). Should a specific model be flagged as high risk by our community, we consider: - Downgrading the ML artifact’s visibility across the Hub in the trending tab and in feeds, - Requesting that the gating feature be enabled to manage access to ML artifacts (see documentation for [models](https://huggingface.co/docs/hub/models-gated) and [datasets](https://huggingface.co/docs/hub/datasets-gated)), - Requesting that the models be made private, - Disabling access. **How to add the “Not For All Audiences” tag:** Edit the model/data card → add `not-for-all-audiences` in the tags section → open the PR and wait for the authors to merge it. Once merged, the following tag will be displayed on the repository: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa_tag.png" alt="screenshot showing where to add tags" /> </p> Any repository tagged `not-for-all-audiences` will display the following popup when visited: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa2.png" alt="screenshot showing where to add tags" /> </p> Clicking "View Content" will allow you to view the repository as normal. If you wish to always view `not-for-all-audiences`-tagged repositories without the popup, this setting can be changed in a user's [Content Preferences](https://huggingface.co/settings/content-preferences) <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa1.png" alt="screenshot showing where to add tags" /> </p> Open science requires safeguards, and one of our goals is to create an environment informed by tradeoffs with different values. Hosting and providing access to models in addition to cultivating community and discussion empowers diverse groups to assess social implications and guide what is good machine learning. ## Are you working on safeguards? Share them on Hugging Face Hub! The most important part of Hugging Face is our community. If you’re a researcher working on making ML safer to use, especially for open science, we want to support and showcase your work! Here are some recent demos and tools from researchers in the Hugging Face community: - [A Watermark for LLMs](https://huggingface.co/spaces/tomg-group-umd/lm-watermarking) by John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein ([paper](https://arxiv.org/abs/2301.10226)) - [Generate Model Cards Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool) by the Hugging Face team - [Photoguard](https://huggingface.co/spaces/RamAnanth1/photoguard) to safeguard images against manipulation by Ram Ananth Thanks for reading! 🤗 ~ Irene, Nima, Giada, Yacine, and Elizabeth, on behalf of the Ethics and Society regulars If you want to cite this blog post, please use the following (in descending order of contribution): ``` @misc{hf_ethics_soc_blog_3, author = {Irene Solaiman and Giada Pistilli and Nima Boscarino and Yacine Jernite and Elizabeth Allendorf and Margaret Mitchell and Carlos Muñoz Ferrandis and Nathan Lambert and Alexandra Sasha Luccioni }, title = {Hugging Face Ethics and Society Newsletter 3: Ethical Openness at Hugging Face}, booktitle = {Hugging Face Blog}, year = {2023}, url = {https://doi.org/10.57967/hf/0487}, doi = {10.57967/hf/0487} } ```
|
StackLLaMA: A hands-on guide to train LLaMA with RLHF
|
edbeeching
|
April 5, 2023
|
stackllama
|
rl, rlhf, nlp
|
https://huggingface.co/blog/stackllama
|
# StackLLaMA: A hands-on guide to train LLaMA with RLHF Models such as [ChatGPT]([https://openai.com/blog/chatgpt](https://openai.com/blog/chatgpt)), [GPT-4]([https://openai.com/research/gpt-4](https://openai.com/research/gpt-4)), and [Claude]([https://www.anthropic.com/index/introducing-claude](https://www.anthropic.com/index/introducing-claude)) are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them. In this blog post, we show all the steps involved in training a [LlaMa model](https://ai.facebook.com/blog/large-language-model-llama-meta-ai) to answer questions on [Stack Exchange](https://stackexchange.com) with RLHF through a combination of: - Supervised Fine-tuning (SFT) - Reward / preference modeling (RM) - Reinforcement Learning from Human Feedback (RLHF) 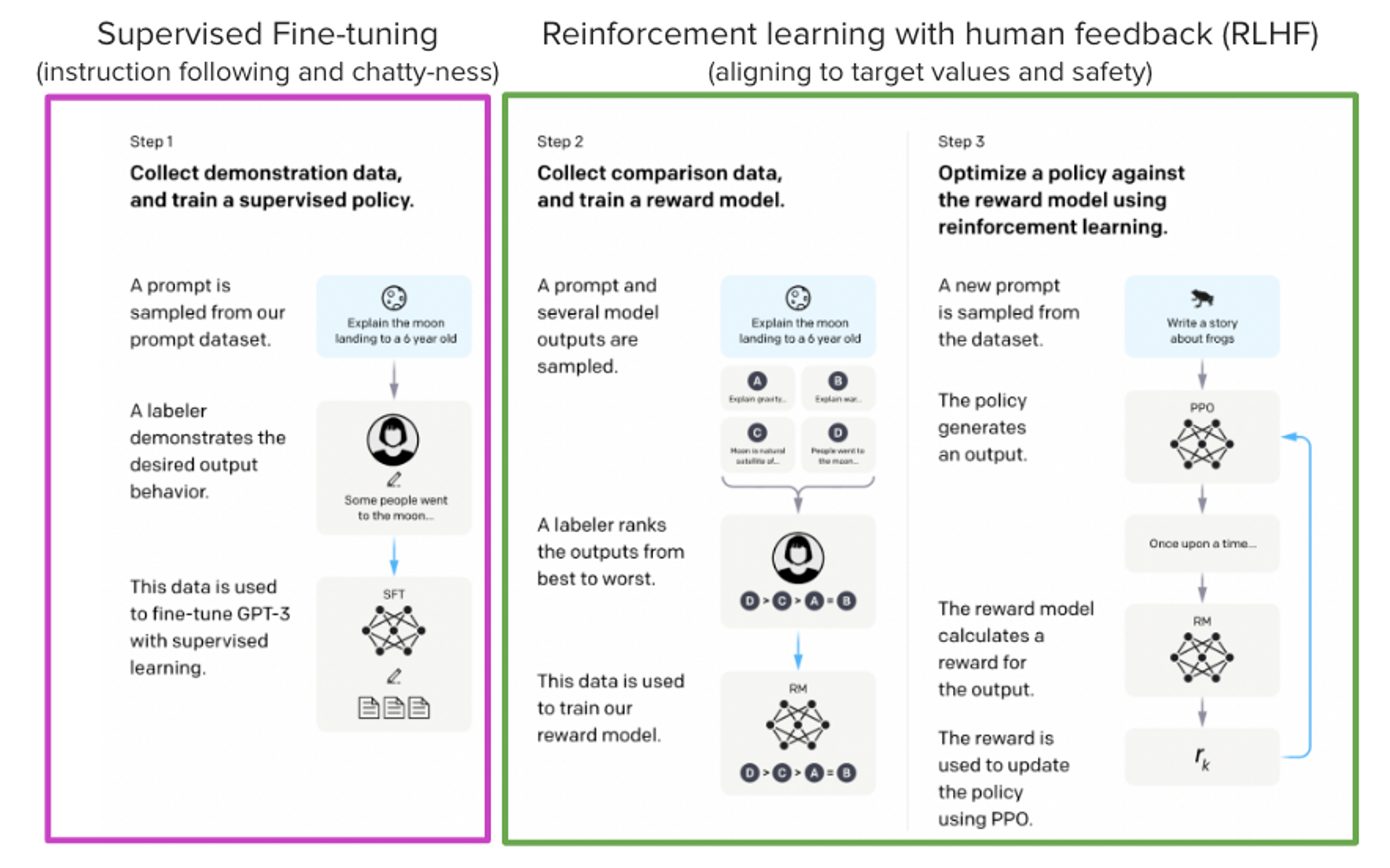 *From InstructGPT paper: Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).* By combining these approaches, we are releasing the StackLLaMA model. This model is available on the [🤗 Hub](https://huggingface.co/trl-lib/llama-se-rl-peft) (see [Meta's LLaMA release](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) for the original LLaMA model) and [the entire training pipeline](https://huggingface.co/docs/trl/index) is available as part of the Hugging Face TRL library. To give you a taste of what the model can do, try out the demo below! <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script> <gradio-app theme_mode="light" src="https://trl-lib-stack-llama.hf.space"></gradio-app> ## The LLaMA model When doing RLHF, it is important to start with a capable model: the RLHF step is only a fine-tuning step to align the model with how we want to interact with it and how we expect it to respond. Therefore, we choose to use the recently introduced and performant [LLaMA models](https://arxiv.org/abs/2302.13971). The LLaMA models are the latest large language models developed by Meta AI. They come in sizes ranging from 7B to 65B parameters and were trained on between 1T and 1.4T tokens, making them very capable. We use the 7B model as the base for all the following steps! To access the model, use the [form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) from Meta AI. ## Stack Exchange dataset Gathering human feedback is a complex and expensive endeavor. In order to bootstrap the process for this example while still building a useful model, we make use of the [StackExchange dataset](https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences). The dataset includes questions and their corresponding answers from the StackExchange platform (including StackOverflow for code and many other topics). It is attractive for this use case because the answers come together with the number of upvotes and a label for the accepted answer. We follow the approach described in [Askell et al. 2021](https://arxiv.org/abs/2112.00861) and assign each answer a score: `score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).` For the reward model, we will always need two answers per question to compare, as we’ll see later. Some questions have dozens of answers, leading to many possible pairs. We sample at most ten answer pairs per question to limit the number of data points per question. Finally, we cleaned up formatting by converting HTML to Markdown to make the model’s outputs more readable. You can find the dataset as well as the processing notebook [here](https://huggingface.co/datasets/lvwerra/stack-exchange-paired). ## Efficient training strategies Even training the smallest LLaMA model requires an enormous amount of memory. Some quick math: in bf16, every parameter uses 2 bytes (in fp32 4 bytes) in addition to 8 bytes used, e.g., in the Adam optimizer (see the [performance docs](https://huggingface.co/docs/transformers/perf_train_gpu_one#optimizer) in Transformers for more info). So a 7B parameter model would use `(2+8)*7B=70GB` just to fit in memory and would likely need more when you compute intermediate values such as attention scores. So you couldn’t train the model even on a single 80GB A100 like that. You can use some tricks, like more efficient optimizers of half-precision training, to squeeze a bit more into memory, but you’ll run out sooner or later. Another option is to use Parameter-Efficient Fine-Tuning (PEFT) techniques, such as the [`peft`](https://github.com/huggingface/peft) library, which can perform Low-Rank Adaptation (LoRA) on a model loaded in 8-bit. 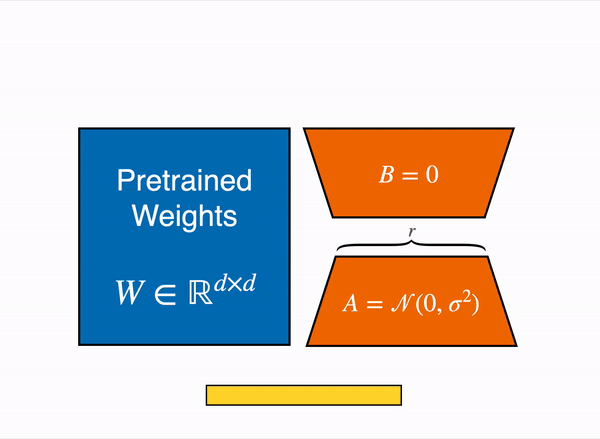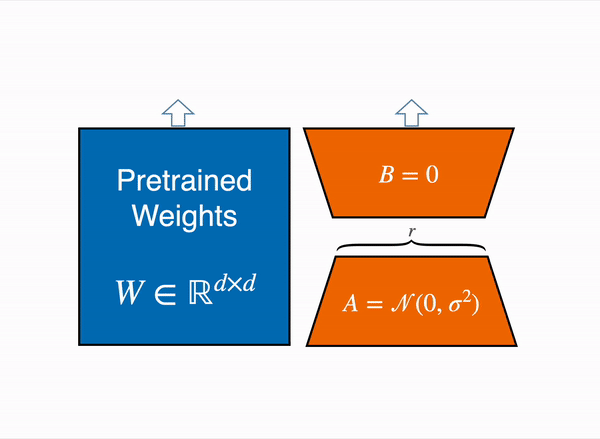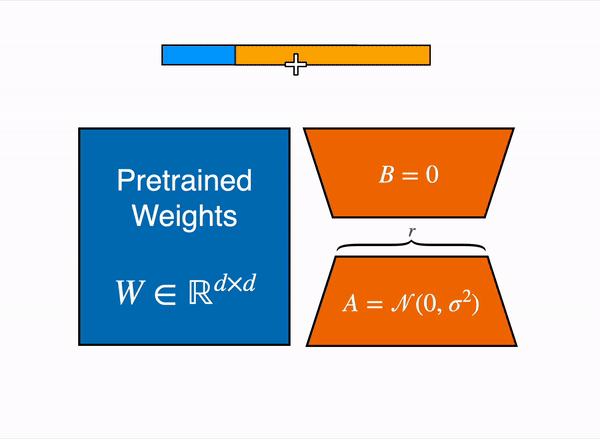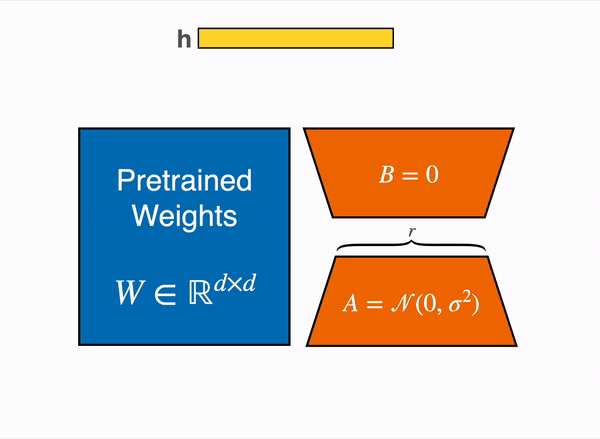 *Low-Rank Adaptation of linear layers: extra parameters (in orange) are added next to the frozen layer (in blue), and the resulting encoded hidden states are added together with the hidden states of the frozen layer.* Loading the model in 8bit reduces the memory footprint drastically since you only need one byte per parameter for the weights (e.g. 7B LlaMa is 7GB in memory). Instead of training the original weights directly, LoRA adds small adapter layers on top of some specific layers (usually the attention layers); thus, the number of trainable parameters is drastically reduced. In this scenario, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup. As detailed in the attached blog post above, this enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost. These techniques have enabled fine-tuning large models on consumer devices and Google Colab. Notable demos are fine-tuning `facebook/opt-6.7b` (13GB in `float16` ), and `openai/whisper-large` on Google Colab (15GB GPU RAM). To learn more about using `peft`, refer to our [github repo](https://github.com/huggingface/peft) or the [previous blog post](https://huggingface.co/blog/trl-peft)(https://huggingface.co/blog/trl-peft)) on training 20b parameter models on consumer hardware. Now we can fit very large models into a single GPU, but the training might still be very slow. The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU. With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs. 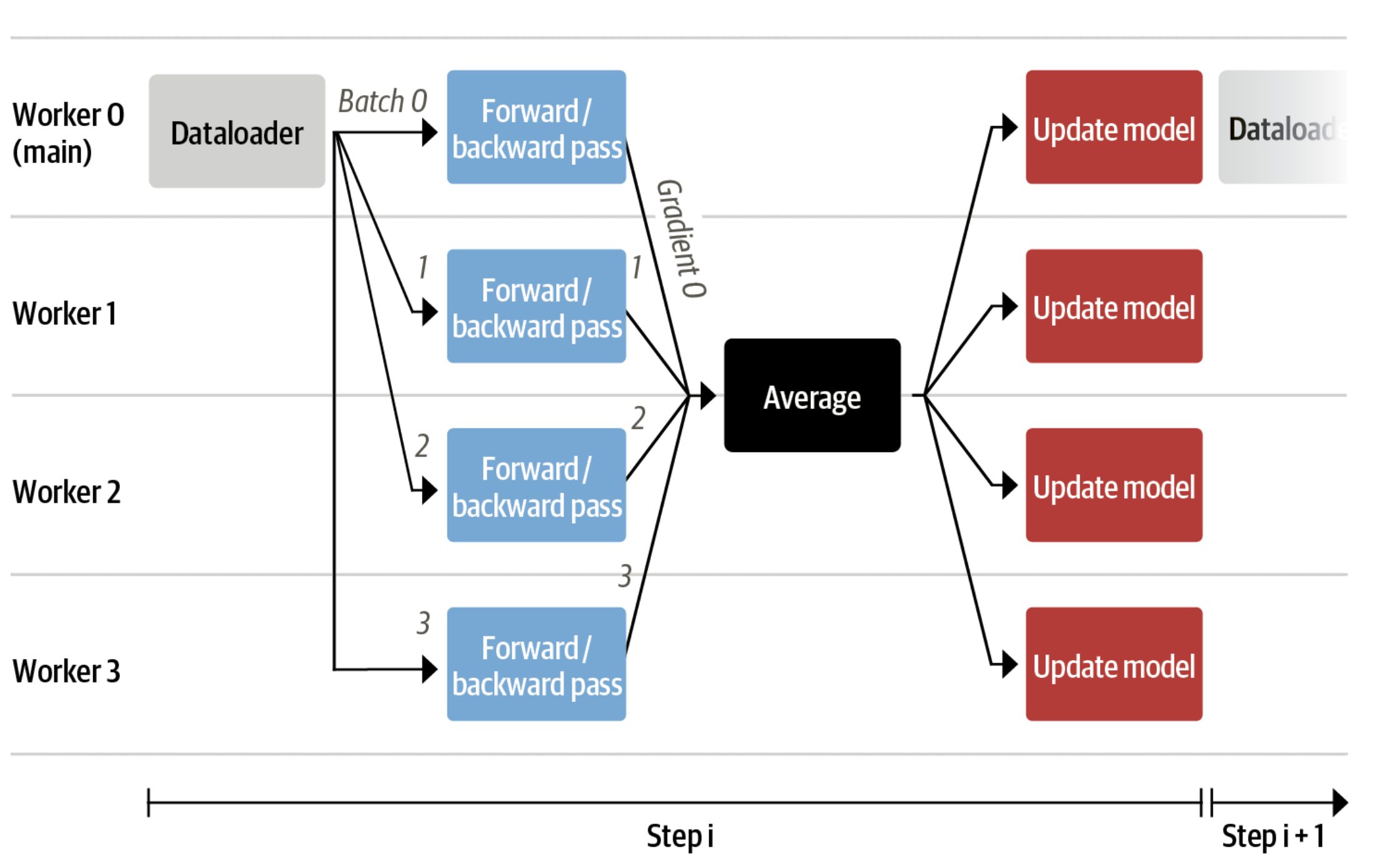 We use either the `transformers.Trainer` or `accelerate`, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with `torchrun` or `accelerate launch`. The following runs a training script with 8 GPUs on a single machine with `accelerate` and `torchrun`, respectively. ```bash accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py ``` ## Supervised fine-tuning Before we start training reward models and tuning our model with RL, it helps if the model is already good in the domain we are interested in. In our case, we want it to answer questions, while for other use cases, we might want it to follow instructions, in which case instruction tuning is a great idea. The easiest way to achieve this is by continuing to train the language model with the language modeling objective on texts from the domain or task. The [StackExchange dataset](https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences) is enormous (over 10 million instructions), so we can easily train the language model on a subset of it. There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here. To use the data efficiently, we use a technique called packing: instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with a EOS token in between and cut chunks of the context size to fill the batch without any padding. 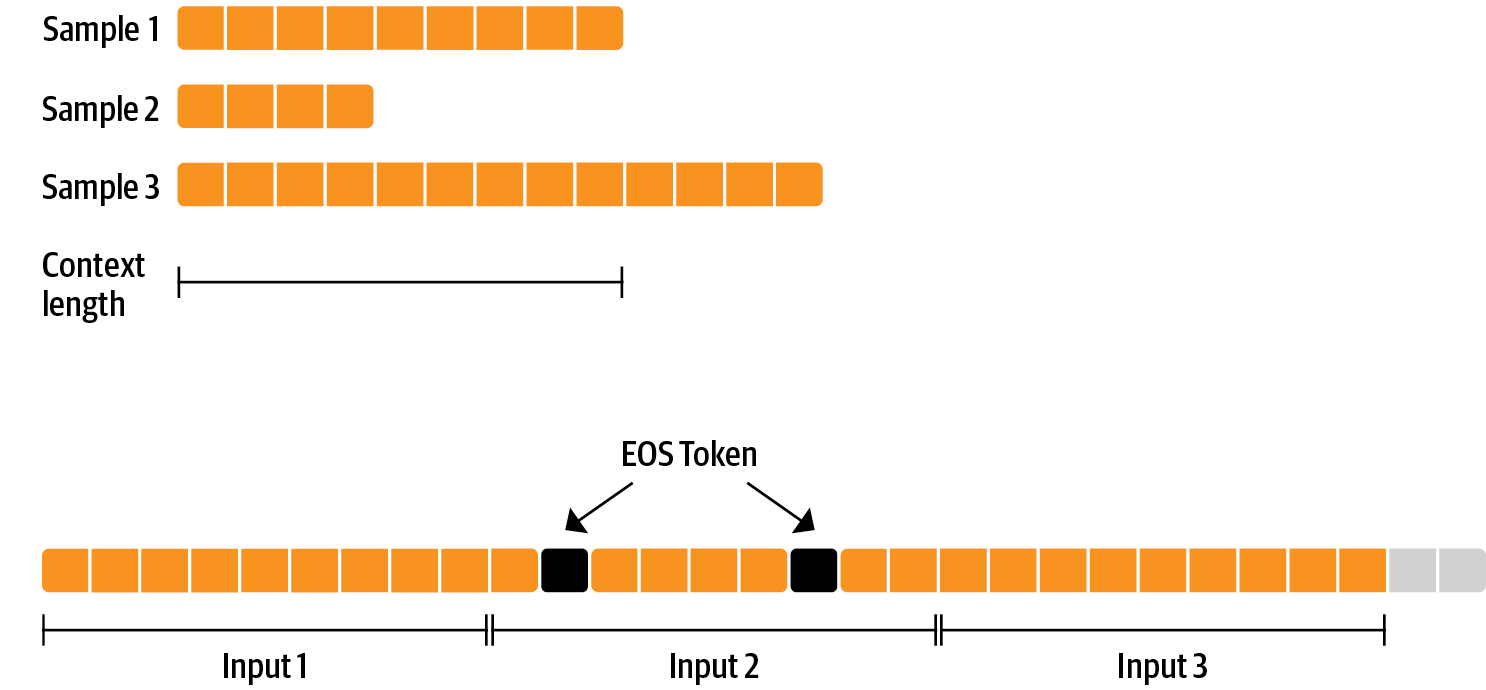 With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss. If you don't have much data and are more concerned about occasionally cutting off some tokens that are overflowing the context you can also use a classical data loader. The packing is handled by the `ConstantLengthDataset` and we can then use the `Trainer` after loading the model with `peft`. First, we load the model in int8, prepare it for training, and then add the LoRA adapters. ```python # load model in 8bit model = AutoModelForCausalLM.from_pretrained( args.model_path, load_in_8bit=True, device_map={"": Accelerator().local_process_index} ) model = prepare_model_for_int8_training(model) # add LoRA to model lora_config = LoraConfig( r=16, lora_alpha=32, lora_dropout=0.05, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config) ``` We train the model for a few thousand steps with the causal language modeling objective and save the model. Since we will tune the model again with different objectives, we merge the adapter weights with the original model weights. **Disclaimer:** due to LLaMA's license, we release only the adapter weights for this and the model checkpoints in the following sections. You can apply for access to the base model's weights by filling out Meta AI's [form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) and then converting them to the 🤗 Transformers format by running this [script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). Note that you'll also need to install 🤗 Transformers from source until the `v4.28` is released. Now that we have fine-tuned the model for the task, we are ready to train a reward model. ## Reward modeling and human preferences In principle, we could fine-tune the model using RLHF directly with the human annotations. However, this would require us to send some samples to humans for rating after each optimization iteration. This is expensive and slow due to the number of training samples needed for convergence and the inherent latency of human reading and annotator speed. A trick that works well instead of direct feedback is training a reward model on human annotations collected before the RL loop. The goal of the reward model is to imitate how a human would rate a text. There are several possible strategies to build a reward model: the most straightforward way would be to predict the annotation (e.g. a rating score or a binary value for “good”/”bad”). In practice, what works better is to predict the ranking of two examples, where the reward model is presented with two candidates \\( (y_k, y_j) \\) for a given prompt \\( x \\) and has to predict which one would be rated higher by a human annotator. This can be translated into the following loss function: \\( \operatorname{loss}(\theta)=- E_{\left(x, y_j, y_k\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_j\right)-r_\theta\left(x, y_k\right)\right)\right)\right] \\) where \\( r \\) is the model’s score and \\( y_j \\) is the preferred candidate. With the StackExchange dataset, we can infer which of the two answers was preferred by the users based on the score. With that information and the loss defined above, we can then modify the `transformers.Trainer` by adding a custom loss function. ```python class RewardTrainer(Trainer): def compute_loss(self, model, inputs, return_outputs=False): rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0] rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0] loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean() if return_outputs: return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k} return loss ``` We utilize a subset of a 100,000 pair of candidates and evaluate on a held-out set of 50,000. With a modest training batch size of 4, we train the LLaMA model using the LoRA `peft` adapter for a single epoch using the Adam optimizer with BF16 precision. Our LoRA configuration is: ```python peft_config = LoraConfig( task_type=TaskType.SEQ_CLS, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1, ) ``` The training is logged via [Weights & Biases](https://wandb.ai/krasul/huggingface/runs/wmd8rvq6?workspace=user-krasul) and took a few hours on 8-A100 GPUs using the 🤗 research cluster and the model achieves a final **accuracy of 67%**. Although this sounds like a low score, the task is also very hard, even for human annotators. As detailed in the next section, the resulting adapter can be merged into the frozen model and saved for further downstream use. ## Reinforcement Learning from Human Feedback With the fine-tuned language model and the reward model at hand, we are now ready to run the RL loop. It follows roughly three steps: 1. Generate responses from prompts 2. Rate the responses with the reward model 3. Run a reinforcement learning policy-optimization step with the ratings 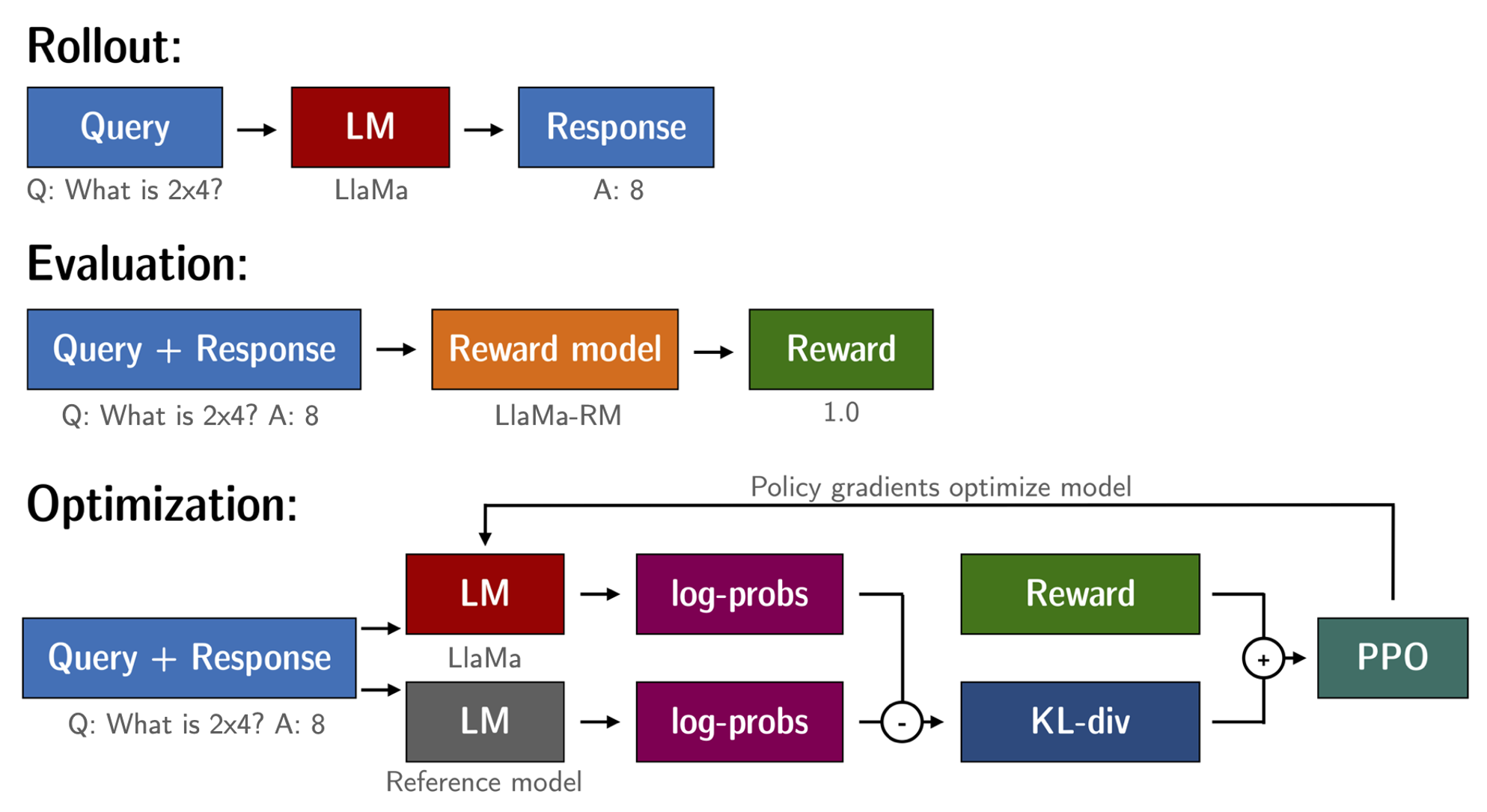 The Query and Response prompts are templated as follows before being tokenized and passed to the model: ```bash Question: <Query> Answer: <Response> ``` The same template was used for SFT, RM and RLHF stages. A common issue with training the language model with RL is that the model can learn to exploit the reward model by generating complete gibberish, which causes the reward model to assign high rewards. To balance this, we add a penalty to the reward: we keep a reference of the model that we don’t train and compare the new model’s generation to the reference one by computing the KL-divergence: \\( \operatorname{R}(x, y)=\operatorname{r}(x, y)- \beta \operatorname{KL}(x, y) \\) where \\( r \\) is the reward from the reward model and \\( \operatorname{KL}(x,y) \\) is the KL-divergence between the current policy and the reference model. Once more, we utilize `peft` for memory-efficient training, which offers an extra advantage in the RLHF context. Here, the reference model and policy share the same base, the SFT model, which we load in 8-bit and freeze during training. We exclusively optimize the policy's LoRA weights using PPO while sharing the base model's weights. ```python for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)): question_tensors = batch["input_ids"] # sample from the policy and generate responses response_tensors = ppo_trainer.generate( question_tensors, return_prompt=False, length_sampler=output_length_sampler, **generation_kwargs, ) batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True) # Compute sentiment score texts = [q + r for q, r in zip(batch["query"], batch["response"])] pipe_outputs = sentiment_pipe(texts, **sent_kwargs) rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs] # Run PPO step stats = ppo_trainer.step(question_tensors, response_tensors, rewards) # Log stats to WandB ppo_trainer.log_stats(stats, batch, rewards) ``` We train for 20 hours on 3x8 A100-80GB GPUs, using the 🤗 research cluster, but you can also get decent results much quicker (e.g. after ~20h on 8 A100 GPUs). All the training statistics of the training run are available on [Weights & Biases](https://wandb.ai/lvwerra/trl/runs/ie2h4q8p). 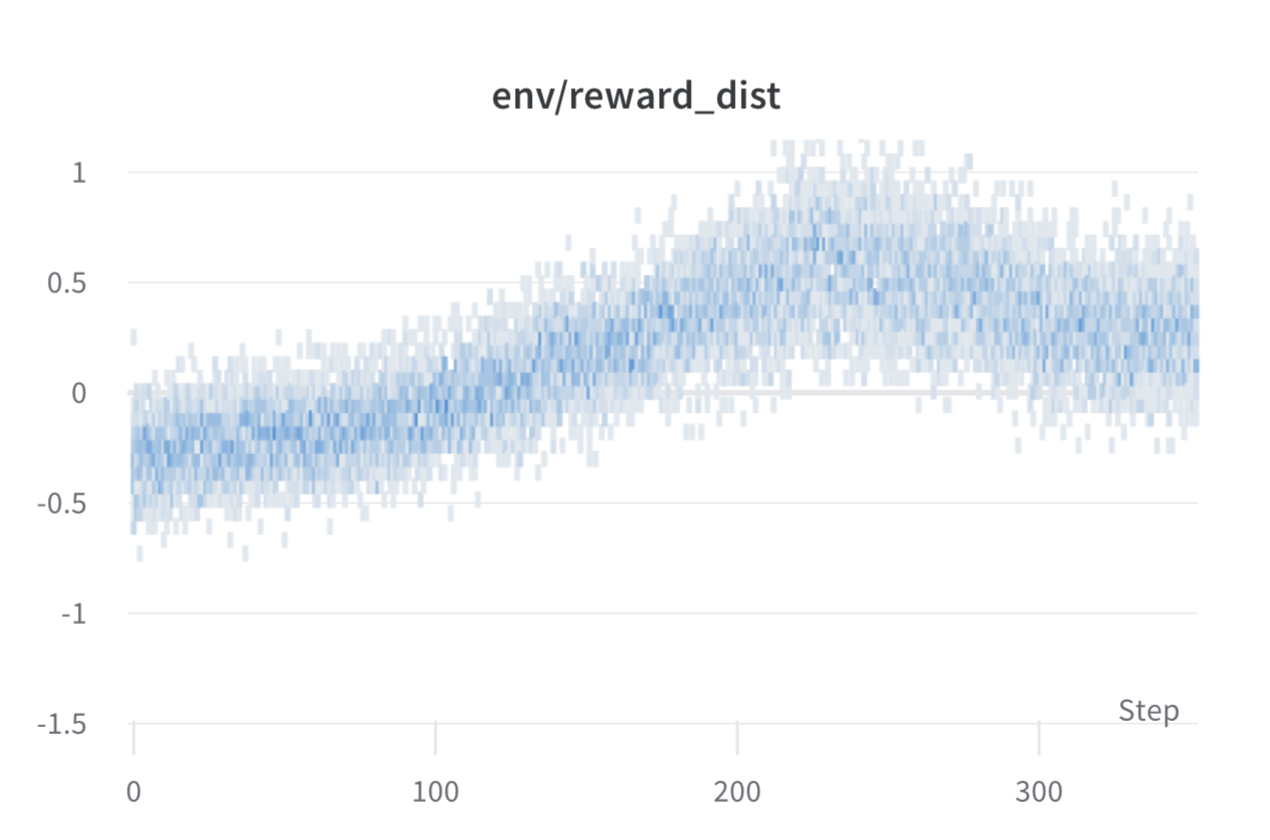 *Per batch reward at each step during training. The model’s performance plateaus after around 1000 steps.* So what can the model do after training? Let's have a look! 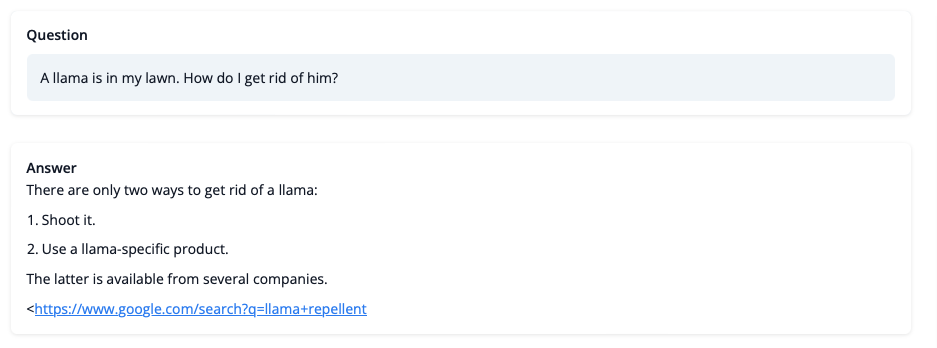 Although we shouldn't trust its advice on LLaMA matters just, yet, the answer looks coherent and even provides a Google link. Let's have a look and some of the training challenges next. ## Challenges, instabilities and workarounds Training LLMs with RL is not always plain sailing. The model we demo today is the result of many experiments, failed runs and hyper-parameter sweeps. Even then, the model is far from perfect. Here we will share a few of the observations and headaches we encountered on the way to making this example. ### Higher reward means better performance, right? 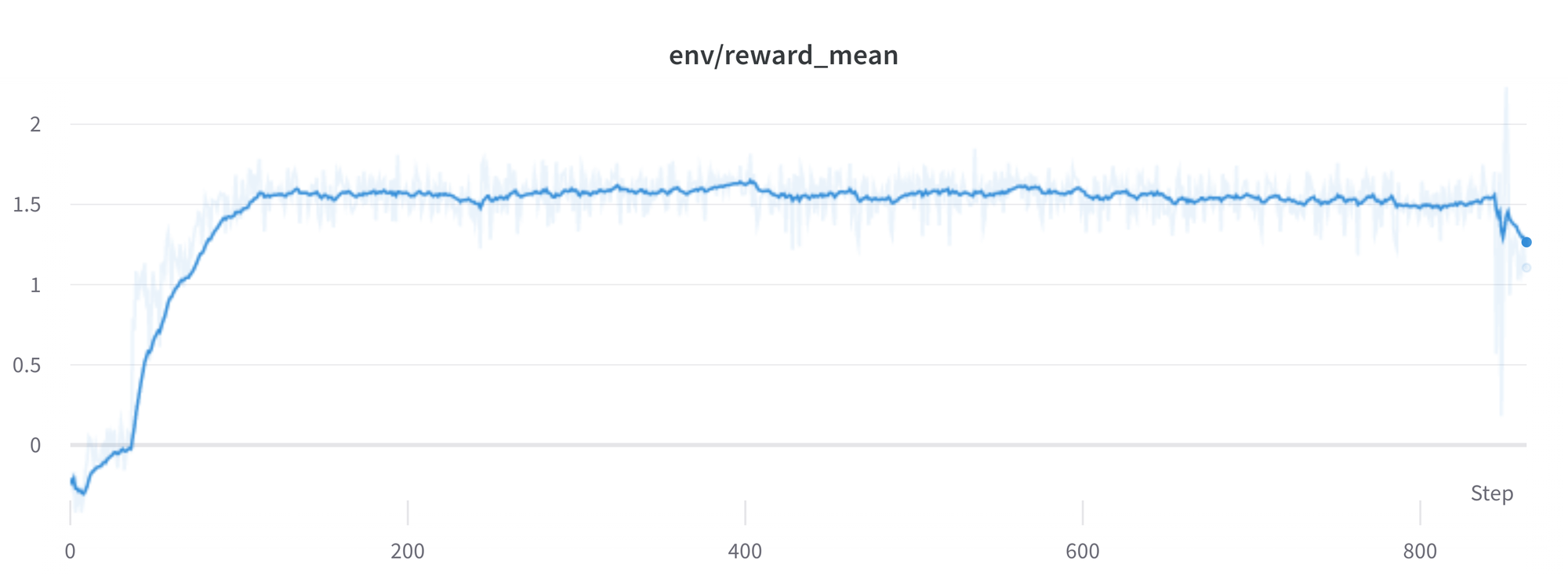 *Wow this run must be great, look at that sweet, sweet, reward!* In general in RL, you want to achieve the highest reward. In RLHF we use a Reward Model, which is imperfect and given the chance, the PPO algorithm will exploit these imperfections. This can manifest itself as sudden increases in reward, however when we look at the text generations from the policy, they mostly contain repetitions of the string ```, as the reward model found the stack exchange answers containing blocks of code usually rank higher than ones without it. Fortunately this issue was observed fairly rarely and in general the KL penalty should counteract such exploits. ### KL is always a positive value, isn’t it? As we previously mentioned, a KL penalty term is used in order to push the model’s outputs remain close to that of the base policy. In general, KL divergence measures the distances between two distributions and is always a positive quantity. However, in `trl` we use an estimate of the KL which in expectation is equal to the real KL divergence. \\( KL_{pen}(x,y) = \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right) \\) Clearly, when a token is sampled from the policy which has a lower probability than the SFT model, this will lead to a negative KL penalty, but on average it will be positive otherwise you wouldn't be properly sampling from the policy. However, some generation strategies can force some tokens to be generated or some tokens can suppressed. For example when generating in batches finished sequences are padded and when setting a minimum length the EOS token is suppressed. The model can assign very high or low probabilities to those tokens which leads to negative KL. As the PPO algorithm optimizes for reward, it will chase after these negative penalties, leading to instabilities. 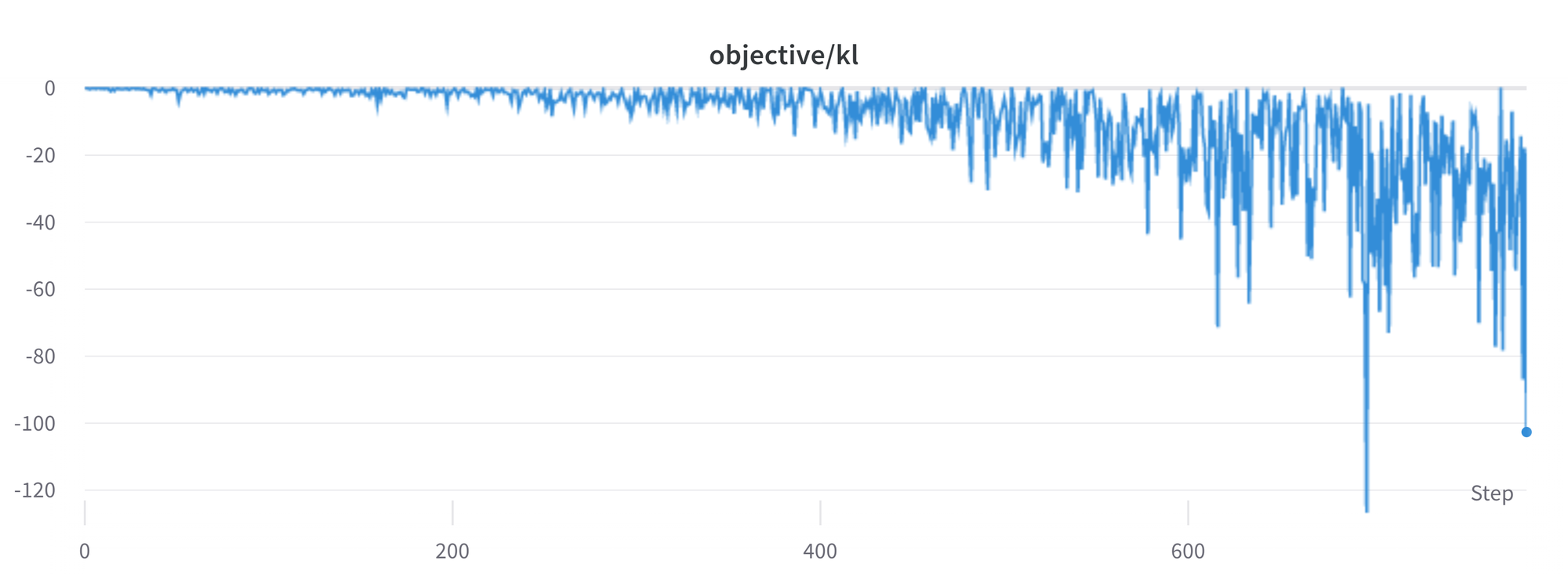 One needs to be careful when generating the responses and we suggest to always use a simple sampling strategy first before resorting to more sophisticated generation methods. ### Ongoing issues There are still a number of issues that we need to better understand and resolve. For example, there are occassionally spikes in the loss, which can lead to further instabilities. 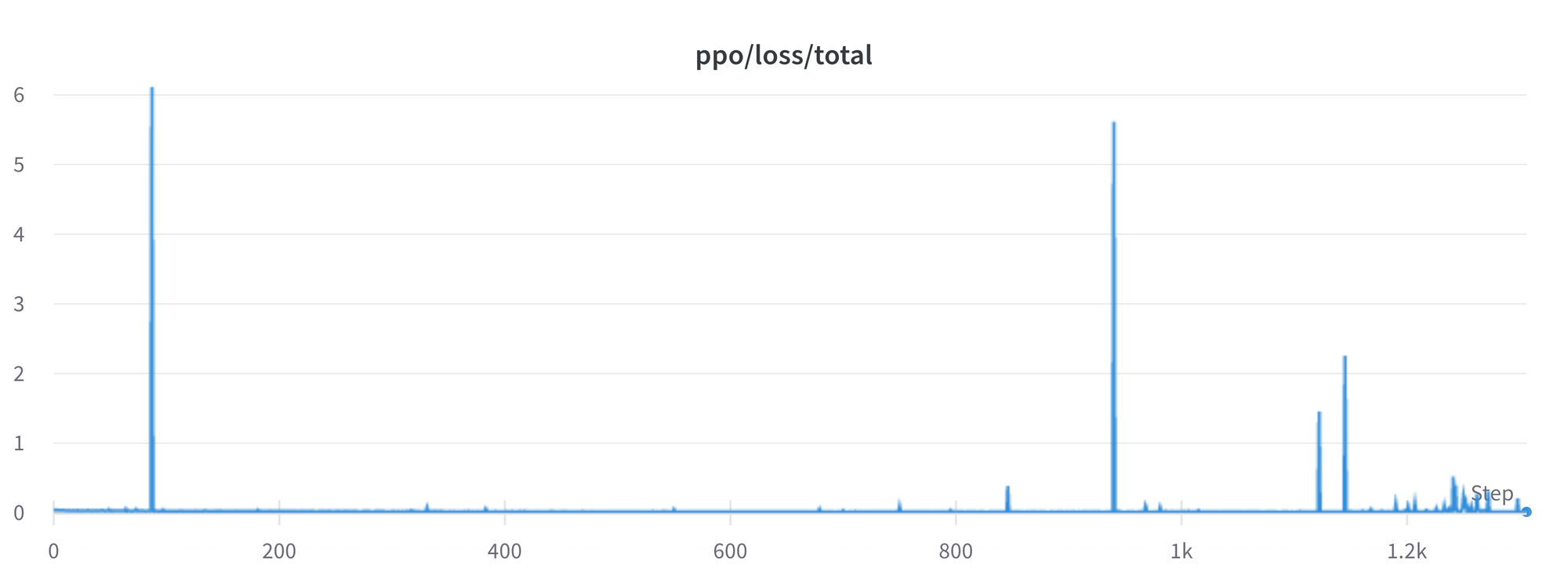 As we identify and resolve these issues, we will upstream the changes `trl`, to ensure the community can benefit. ## Conclusion In this post, we went through the entire training cycle for RLHF, starting with preparing a dataset with human annotations, adapting the language model to the domain, training a reward model, and finally training a model with RL. By using `peft`, anyone can run our example on a single GPU! If training is too slow, you can use data parallelism with no code changes and scale training by adding more GPUs. For a real use case, this is just the first step! Once you have a trained model, you must evaluate it and compare it against other models to see how good it is. This can be done by ranking generations of different model versions, similar to how we built the reward dataset. Once you add the evaluation step, the fun begins: you can start iterating on your dataset and model training setup to see if there are ways to improve the model. You could add other datasets to the mix or apply better filters to the existing one. On the other hand, you could try different model sizes and architecture for the reward model or train for longer. We are actively improving TRL to make all steps involved in RLHF more accessible and are excited to see the things people build with it! Check out the [issues on GitHub](https://github.com/lvwerra/trl/issues) if you're interested in contributing. ## Citation ```bibtex @misc {beeching2023stackllama, author = { Edward Beeching and Younes Belkada and Kashif Rasul and Lewis Tunstall and Leandro von Werra and Nazneen Rajani and Nathan Lambert }, title = { StackLLaMA: An RL Fine-tuned LLaMA Model for Stack Exchange Question and Answering }, year = 2023, url = { https://huggingface.co/blog/stackllama }, doi = { 10.57967/hf/0513 }, publisher = { Hugging Face Blog } } ``` ## Acknowledgements We thank Philipp Schmid for sharing his wonderful [demo](https://huggingface.co/spaces/philschmid/igel-playground) of streaming text generation upon which our demo was based. We also thank Omar Sanseviero and Louis Castricato for giving valuable and detailed feedback on the draft of the blog post.
|
Snorkel AI x Hugging Face: unlock foundation models for enterprises
|
Violette
|
April 6, 2023
|
snorkel-case-study
|
case-studies
|
https://huggingface.co/blog/snorkel-case-study
|
# Snorkel AI x Hugging Face: unlock foundation models for enterprises _This article is a cross-post from an originally published post on April 6, 2023 [in Snorkel's blog](https://snorkel.ai/snorkel-hugging-face-unlock-foundation-models-for-enterprise/), by Friea Berg ._ As OpenAI releases [GPT-4](https://openai.com/research/gpt-4) and Google debuts [Bard](https://gizmodo.com/google-bard-chatgpt-ai-rival-released-1850248162) in beta, enterprises around the world are excited to leverage the power of foundation models. As that excitement builds, so does the realization that most companies and organizations are not equipped to properly take advantage of foundation models. Foundation models pose a unique set of challenges for enterprises. Their larger-than-ever size makes them difficult and expensive for companies to host themselves, and using off-the-shelf FMs for production use cases could mean poor performance or substantial governance and compliance risks. Snorkel AI bridges the gap between foundation models and practical enterprise use cases and has [yielded impressive results](https://snorkel.ai/how-pixability-uses-foundation-models-to-accelerate-nlp-application-development-by-months/) for AI innovators like Pixability. We’re teaming with [Hugging Face](https://huggingface.co/), best known for its enormous repository of ready-to-use open-source models, to provide enterprises with even more flexibility and choice as they develop AI applications. ## Foundation models in Snorkel Flow The Snorkel Flow development platform enables users to [adapt foundation models](https://snorkel.ai/snorkel-flow/foundation-model-development/) for their specific use cases. Application development begins by inspecting the predictions of a selected foundation model “out of the box” on their data. These predictions become an initial version of training labels for those data points. Snorkel Flow helps users to identify error modes in that model and correct them efficiently via [programmatic labeling](https://snorkel.ai/programmatic-labeling/), which can include updating training labels with heuristics or [prompts](https://snorkel.ai/combining-foundation-models-with-weak-supervision/). The base foundation model can then be fine-tuned on the updated labels and evaluated once again, with this iterative “detect and correct” process continuing until the adapted foundation model is sufficiently high quality to deploy. Hugging Face helps enable this powerful development process by making more than 150,000 open-source models immediately available from a single source. Many of those models are specialized on domain-specific data, like the BioBERT and SciBERT models used to demonstrate [how ML can be used to spot adverse drug events](https://snorkel.ai/adverse-drug-events-how-to-spot-them-with-machine-learning/). One – or better yet, [multiple](https://snorkel.ai/combining-foundation-models-with-weak-supervision/) – specialized base models can give users a jump-start on initial predictions, prompts for improving labels, or fine-tuning a final model for deployment. ## How does Hugging Face help? Snorkel AI’s partnership with Hugging Face supercharges Snorkel Flow’s foundation model capabilities. Initially we only made a small number of foundation models available. Each one required a dedicated service, making it prohibitively expensive and difficult for us to offer enterprises the flexibility to capitalize on the rapidly growing variety of models available. Adopting Hugging Face’s Inference Endpoint service enabled us to expand the number of foundation models our users could tap into while keeping costs manageable. Hugging Face’s service allows users to create a model API in a few clicks and begin using it immediately. Crucially, the new service has “pause and resume” capabilities that allow us to activate a model API when a client needs it, and put it to sleep when they don’t. "We were pleasantly surprised to see how straightforward Hugging Face Inference Endpoint service was to set up.. All the configuration options were pretty self-explanatory, but we also had access to all the options we needed in terms of what cloud to run on, what security level we needed, etc." – Snorkel CTO and Co-founder Braden Hancock <iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/woblG7iZPSw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> ## How does this help Snorkel customers? Few enterprises have the resources to train their own foundation models from scratch. While many may have the in-house expertise to fine-tune their own version of a foundation model, they may struggle to gather the volume of data needed for that task. Snorkel’s data-centric platform for developing foundation models and alignment with leading industry innovators like Hugging Face help put the power of foundation models at our users’ fingertips. #### "With Snorkel AI and Hugging Face Inference Endpoints, companies will accelerate their data-centric AI applications with open source at the core. Machine Learning is becoming the default way of building technology, and building from open source allows companies to build the right solution for their use case and take control of the experience they offer to their customers. We are excited to see Snorkel AI enable automated data labeling for the enterprise building from open-source Hugging Face models and Inference Endpoints, our machine learning production service.” Clement Delangue, co-founder and CEO, Hugging Face ## Conclusion Together, Snorkel and Hugging Face make it easier than ever for large companies, government agencies, and AI innovators to get value from foundation models. The ability to use Hugging Face’s comprehensive hub of foundation models means that users can pick the models that best align with their business needs without having to invest in the resources required to train them. This integration is a significant step forward in making foundation models more accessible to enterprises around the world. _If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co/inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_
|
Creating Privacy Preserving AI with Substra
|
EazyAl
|
April 12, 2023
|
owkin-substra
|
cv, federated-learning, fl, open-source-collab
|
https://huggingface.co/blog/owkin-substra
|
# Creating Privacy Preserving AI with Substra With the recent rise of generative techniques, machine learning is at an incredibly exciting point in its history. The models powering this rise require even more data to produce impactful results, and thus it’s becoming increasingly important to explore new methods of ethically gathering data while ensuring that data privacy and security remain a top priority. In many domains that deal with sensitive information, such as healthcare, there often isn’t enough high quality data accessible to train these data-hungry models. Datasets are siloed in different academic centers and medical institutions and are difficult to share openly due to privacy concerns about patient and proprietary information. Regulations that protect patient data such as HIPAA are essential to safeguard individuals’ private health information, but they can limit the progress of machine learning research as data scientists can’t access the volume of data required to effectively train their models. Technologies that work alongside existing regulations by proactively protecting patient data will be crucial to unlocking these silos and accelerating the pace of machine learning research and deployment in these domains. This is where Federated Learning comes in. Check out the [space](https://huggingface.co/spaces/owkin/substra) we’ve created with [Substra](https://owkin.com/substra) to learn more! ## What is Federated Learning? Federated learning (FL) is a decentralized machine learning technique that allows you to train models using multiple data providers. Instead of gathering data from all sources on a single server, data can remain on a local server as only the resulting model weights travel between servers. As the data never leaves its source, federated learning is naturally a privacy-first approach. Not only does this technique improve data security and privacy, it also enables data scientists to build better models using data from different sources - increasing robustness and providing better representation as compared to models trained on data from a single source. This is valuable not only due to the increase in the quantity of data, but also to reduce the risk of bias due to variations of the underlying dataset, for example minor differences caused by the data capture techniques and equipment, or differences in demographic distributions of the patient population. With multiple sources of data, we can build more generalizable models that ultimately perform better in real world settings. For more information on federated learning, we recommend checking out this explanatory [comic](https://federated.withgoogle.com/) by Google.  **Substra** is an open source federated learning framework built for real world production environments. Although federated learning is a relatively new field and has only taken hold in the last decade, it has already enabled machine learning research to progress in ways previously unimaginable. For example, 10 competing biopharma companies that would traditionally never share data with each other set up a collaboration in the [MELLODDY](https://www.melloddy.eu/) project by sharing the world’s largest collection of small molecules with known biochemical or cellular activity. This ultimately enabled all of the companies involved to build more accurate predictive models for drug discovery, a huge milestone in medical research. ## Substra x HF Research on the capabilities of federated learning is growing rapidly but the majority of recent work has been limited to simulated environments. Real world examples and implementations still remain limited due to the difficulty of deploying and architecting federated networks. As a leading open-source platform for federated learning deployment, Substra has been battle tested in many complex security environments and IT infrastructures, and has enabled [medical breakthroughs in breast cancer research](https://www.nature.com/articles/s41591-022-02155-w). 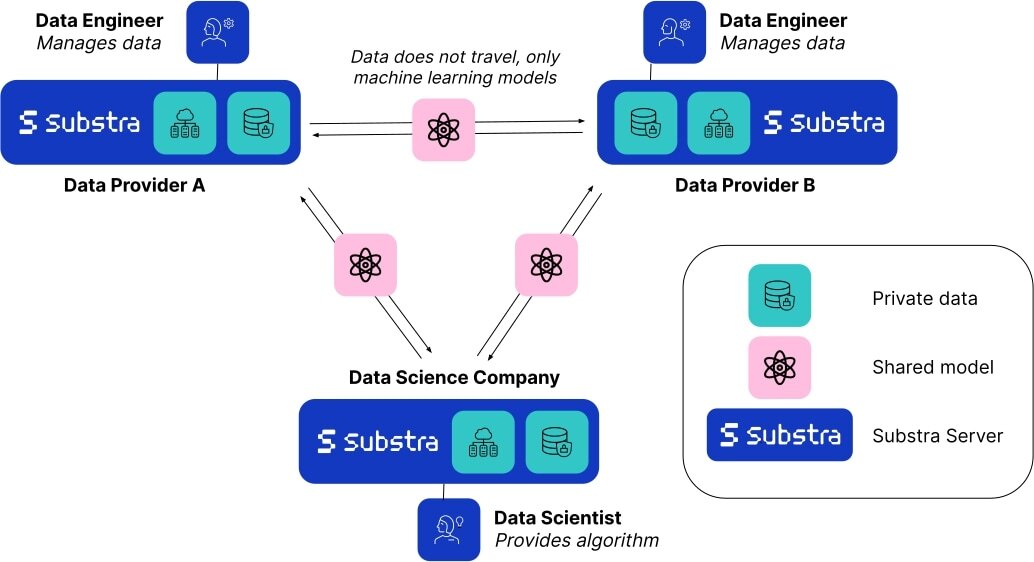 Hugging Face collaborated with the folks managing Substra to create this space, which is meant to give you an idea of the real world challenges that researchers and scientists face - mainly, a lack of centralized, high quality data that is ‘ready for AI’. As you can control the distribution of these samples, you’ll be able to see how a simple model reacts to changes in data. You can then examine how a model trained with federated learning almost always performs better on validation data compared with models trained on data from a single source. ## Conclusion Although federated learning has been leading the charge, there are various other privacy enhancing technologies (PETs) such as secure enclaves and multi party computation that are enabling similar results and can be combined with federation to create multi layered privacy preserving environments. You can learn more [here](https://medium.com/@aliimran_36956/how-collaboration-is-revolutionizing-medicine-34999060794e) if you’re interested in how these are enabling collaborations in medicine. Regardless of the methods used, it's important to stay vigilant of the fact that data privacy is a right for all of us. It’s critical that we move forward in this AI boom with [privacy and ethics in mind](https://www.nature.com/articles/s42256-022-00551-y). If you’d like to play around with Substra and implement federated learning in a project, you can check out the docs [here](https://docs.substra.org/en/stable/).
|
Graph Classification with Transformers
|
clefourrier
|
April 14, 2023
|
graphml-classification
|
community, guide, graphs
|
https://huggingface.co/blog/graphml-classification
|
# Graph classification with Transformers <div class="blog-metadata"> <small>Published April 14, 2023.</small> <a target="_blank" class="btn no-underline text-sm mb-5 font-sans" href="https://github.com/huggingface/blog/blob/main/graphml-classification.md"> Update on GitHub </a> </div> <div class="author-card"> <a href="/clefourrier"> <img class="avatar avatar-user" src="https://aeiljuispo.cloudimg.io/v7/https://s3.amazonaws.com/moonup/production/uploads/1644340617257-noauth.png?w=200&h=200&f=face" title="Gravatar"> <div class="bfc"> <code>clefourrier</code> <span class="fullname">Clémentine Fourrier</span> </div> </a> </div> In the previous [blog](https://huggingface.co/blog/intro-graphml), we explored some of the theoretical aspects of machine learning on graphs. This one will explore how you can do graph classification using the Transformers library. (You can also follow along by downloading the demo notebook [here](https://github.com/huggingface/blog/blob/main/notebooks/graphml-classification.ipynb)!) At the moment, the only graph transformer model available in Transformers is Microsoft's [Graphormer](https://arxiv.org/abs/2106.05234), so this is the one we will use here. We are looking forward to seeing what other models people will use and integrate 🤗 ## Requirements To follow this tutorial, you need to have installed `datasets` and `transformers` (version >= 4.27.2), which you can do with `pip install -U datasets transformers`. ## Data To use graph data, you can either start from your own datasets, or use [those available on the Hub](https://huggingface.co/datasets?task_categories=task_categories:graph-ml&sort=downloads). We'll focus on using already available ones, but feel free to [add your datasets](https://huggingface.co/docs/datasets/upload_dataset)! ### Loading Loading a graph dataset from the Hub is very easy. Let's load the `ogbg-mohiv` dataset (a baseline from the [Open Graph Benchmark](https://ogb.stanford.edu/) by Stanford), stored in the `OGB` repository: ```python from datasets import load_dataset # There is only one split on the hub dataset = load_dataset("OGB/ogbg-molhiv") dataset = dataset.shuffle(seed=0) ``` This dataset already has three splits, `train`, `validation`, and `test`, and all these splits contain our 5 columns of interest (`edge_index`, `edge_attr`, `y`, `num_nodes`, `node_feat`), which you can see by doing `print(dataset)`. If you have other graph libraries, you can use them to plot your graphs and further inspect the dataset. For example, using PyGeometric and matplotlib: ```python import networkx as nx import matplotlib.pyplot as plt # We want to plot the first train graph graph = dataset["train"][0] edges = graph["edge_index"] num_edges = len(edges[0]) num_nodes = graph["num_nodes"] # Conversion to networkx format G = nx.Graph() G.add_nodes_from(range(num_nodes)) G.add_edges_from([(edges[0][i], edges[1][i]) for i in range(num_edges)]) # Plot nx.draw(G) ``` ### Format On the Hub, graph datasets are mostly stored as lists of graphs (using the `jsonl` format). A single graph is a dictionary, and here is the expected format for our graph classification datasets: - `edge_index` contains the indices of nodes in edges, stored as a list containing two parallel lists of edge indices. - **Type**: list of 2 lists of integers. - **Example**: a graph containing four nodes (0, 1, 2 and 3) and where connections are 1->2, 1->3 and 3->1 will have `edge_index = [[1, 1, 3], [2, 3, 1]]`. You might notice here that node 0 is not present here, as it is not part of an edge per se. This is why the next attribute is important. - `num_nodes` indicates the total number of nodes available in the graph (by default, it is assumed that nodes are numbered sequentially). - **Type**: integer - **Example**: In our above example, `num_nodes = 4`. - `y` maps each graph to what we want to predict from it (be it a class, a property value, or several binary label for different tasks). - **Type**: list of either integers (for multi-class classification), floats (for regression), or lists of ones and zeroes (for binary multi-task classification) - **Example**: We could predict the graph size (small = 0, medium = 1, big = 2). Here, `y = [0]`. - `node_feat` contains the available features (if present) for each node of the graph, ordered by node index. - **Type**: list of lists of integer (Optional) - **Example**: Our above nodes could have, for example, types (like different atoms in a molecule). This could give `node_feat = [[1], [0], [1], [1]]`. - `edge_attr` contains the available attributes (if present) for each edge of the graph, following the `edge_index` ordering. - **Type**: list of lists of integers (Optional) - **Example**: Our above edges could have, for example, types (like molecular bonds). This could give `edge_attr = [[0], [1], [1]]`. ### Preprocessing Graph transformer frameworks usually apply specific preprocessing to their datasets to generate added features and properties which help the underlying learning task (classification in our case). Here, we use Graphormer's default preprocessing, which generates in/out degree information, the shortest path between node matrices, and other properties of interest for the model. ```python from transformers.models.graphormer.collating_graphormer import preprocess_item, GraphormerDataCollator dataset_processed = dataset.map(preprocess_item, batched=False) ``` It is also possible to apply this preprocessing on the fly, in the DataCollator's parameters (by setting `on_the_fly_processing` to True): not all datasets are as small as `ogbg-molhiv`, and for large graphs, it might be too costly to store all the preprocessed data beforehand. ## Model ### Loading Here, we load an existing pretrained model/checkpoint and fine-tune it on our downstream task, which is a binary classification task (hence `num_classes = 2`). We could also fine-tune our model on regression tasks (`num_classes = 1`) or on multi-task classification. ```python from transformers import GraphormerForGraphClassification model = GraphormerForGraphClassification.from_pretrained( "clefourrier/pcqm4mv2_graphormer_base", num_classes=2, # num_classes for the downstream task ignore_mismatched_sizes=True, ) ``` Let's look at this in more detail. Calling the `from_pretrained` method on our model downloads and caches the weights for us. As the number of classes (for prediction) is dataset dependent, we pass the new `num_classes` as well as `ignore_mismatched_sizes` alongside the `model_checkpoint`. This makes sure a custom classification head is created, specific to our task, hence likely different from the original decoder head. It is also possible to create a new randomly initialized model to train from scratch, either following the known parameters of a given checkpoint or by manually choosing them. ### Training or fine-tuning To train our model simply, we will use a `Trainer`. To instantiate it, we will need to define the training configuration and the evaluation metric. The most important is the `TrainingArguments`, which is a class that contains all the attributes to customize the training. It requires a folder name, which will be used to save the checkpoints of the model. ```python from transformers import TrainingArguments, Trainer training_args = TrainingArguments( "graph-classification", logging_dir="graph-classification", per_device_train_batch_size=64, per_device_eval_batch_size=64, auto_find_batch_size=True, # batch size can be changed automatically to prevent OOMs gradient_accumulation_steps=10, dataloader_num_workers=4, #1, num_train_epochs=20, evaluation_strategy="epoch", logging_strategy="epoch", push_to_hub=False, ) ``` For graph datasets, it is particularly important to play around with batch sizes and gradient accumulation steps to train on enough samples while avoiding out-of-memory errors. The last argument `push_to_hub` allows the Trainer to push the model to the Hub regularly during training, as each saving step. ```python trainer = Trainer( model=model, args=training_args, train_dataset=dataset_processed["train"], eval_dataset=dataset_processed["validation"], data_collator=GraphormerDataCollator(), ) ``` In the `Trainer` for graph classification, it is important to pass the specific data collator for the given graph dataset, which will convert individual graphs to batches for training. ```python train_results = trainer.train() trainer.push_to_hub() ``` When the model is trained, it can be saved to the hub with all the associated training artefacts using `push_to_hub`. As this model is quite big, it takes about a day to train/fine-tune for 20 epochs on CPU (IntelCore i7). To go faster, you could use powerful GPUs and parallelization instead, by launching the code either in a Colab notebook or directly on the cluster of your choice. ## Ending note Now that you know how to use `transformers` to train a graph classification model, we hope you will try to share your favorite graph transformer checkpoints, models, and datasets on the Hub for the rest of the community to use!
|
Accelerating Hugging Face Transformers with AWS Inferentia2
|
philschmid
|
April 17, 2023
|
accelerate-transformers-with-inferentia2
|
partnerships, aws, nlp, cv
|
https://huggingface.co/blog/accelerate-transformers-with-inferentia2
|
# Accelerating Hugging Face Transformers with AWS Inferentia2 <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script> In the last five years, Transformer models [[1](https://arxiv.org/abs/1706.03762)] have become the _de facto_ standard for many machine learning (ML) tasks, such as natural language processing (NLP), computer vision (CV), speech, and more. Today, many data scientists and ML engineers rely on popular transformer architectures like BERT [[2](https://arxiv.org/abs/1810.04805)], RoBERTa [[3](https://arxiv.org/abs/1907.11692)], the Vision Transformer [[4](https://arxiv.org/abs/2010.11929)], or any of the 130,000+ pre-trained models available on the [Hugging Face](https://huggingface.co) hub to solve complex business problems with state-of-the-art accuracy. However, for all their greatness, Transformers can be challenging to deploy in production. On top of the infrastructure plumbing typically associated with model deployment, which we largely solved with our [Inference Endpoints](https://huggingface.co/inference-endpoints) service, Transformers are large models which routinely exceed the multi-gigabyte mark. Large language models (LLMs) like [GPT-J-6B](https://huggingface.co/EleutherAI/gpt-j-6B), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), or [Opt-30B](https://huggingface.co/facebook/opt-30b) are in the tens of gigabytes, not to mention behemoths like [BLOOM](https://huggingface.co/bigscience/bloom), our very own LLM, which clocks in at 350 gigabytes. Fitting these models on a single accelerator can be quite difficult, let alone getting the high throughput and low inference latency that applications require, like conversational applications and search. So far, ML experts have designed complex manual techniques to slice large models, distribute them on a cluster of accelerators, and optimize their latency. Unfortunately, this work is extremely difficult, time-consuming, and completely out of reach for many ML practitioners. At Hugging Face, we're democratizing ML and always looking to partner with companies who also believe that every developer and organization should benefit from state-of-the-art models. For this purpose, we're excited to partner with Amazon Web Services to optimize Hugging Face Transformers for AWS [Inferentia 2](https://aws.amazon.com/machine-learning/inferentia/)! It’s a new purpose-built inference accelerator that delivers unprecedented levels of throughput, latency, performance per watt, and scalability. ## Introducing AWS Inferentia2 AWS Inferentia2 is the next generation to Inferentia1 launched in 2019. Powered by Inferentia1, Amazon EC2 Inf1 instances delivered 25% higher throughput and 70% lower cost than comparable G5 instances based on NVIDIA A10G GPU, and with Inferentia2, AWS is pushing the envelope again. The new Inferentia2 chip delivers a 4x throughput increase and a 10x latency reduction compared to Inferentia. Likewise, the new [Amazon EC2 Inf2](https://aws.amazon.com/de/ec2/instance-types/inf2/) instances have up to 2.6x better throughput, 8.1x lower latency, and 50% better performance per watt than comparable G5 instances. Inferentia 2 gives you the best of both worlds: cost-per-inference optimization thanks to high throughput and response time for your application thanks to low inference latency. Inf2 instances are available in multiple sizes, which are equipped with between 1 to 12 Inferentia 2 chips. When several chips are present, they are interconnected by a blazing-fast direct Inferentia2 to Inferentia2 connectivity for distributed inference on large models. For example, the largest instance size, inf2.48xlarge, has 12 chips and enough memory to load a 175-billion parameter model like GPT-3 or BLOOM. Thankfully none of this comes at the expense of development complexity. With [optimum neuron](https://github.com/huggingface/optimum-neuron), you don't need to slice or modify your model. Because of the native integration in [AWS Neuron SDK](https://github.com/aws-neuron/aws-neuron-sdk), all it takes is a single line of code to compile your model for Inferentia 2. You can experiment in minutes! Test the performance your model could reach on Inferentia 2 and see for yourself. Speaking of, let’s show you how several Hugging Face models run on Inferentia 2. Benchmarking time! ## Benchmarking Hugging Face Models on AWS Inferentia 2 We evaluated some of the most popular NLP models from the [Hugging Face Hub](https://huggingface.co/models) including BERT, RoBERTa, DistilBERT, and vision models like Vision Transformers. The first benchmark compares the performance of Inferentia, Inferentia 2, and GPUs. We ran all experiments on AWS with the following instance types: * Inferentia1 - [inf1.2xlarge](https://aws.amazon.com/ec2/instance-types/inf1/?nc1=h_ls) powered by a single Inferentia chip. * Inferentia2 - [inf2.xlarge](https://aws.amazon.com/ec2/instance-types/inf2/?nc1=h_ls) powered by a single Inferentia2 chip. * GPU - [g5.2xlarge](https://aws.amazon.com/ec2/instance-types/g5/) powered by a single NVIDIA A10G GPU. _Note: that we did not optimize the model for the GPU environment, the models were evaluated in fp32._ When it comes to benchmarking Transformer models, there are two metrics that are most adopted: * **Latency**: the time it takes for the model to perform a single prediction (pre-process, prediction, post-process). * **Throughput**: the number of executions performed in a fixed amount of time for one benchmark configuration We looked at latency across different setups and models to understand the benefits and tradeoffs of the new Inferentia2 instance. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/aws-neuron-samples/tree/main/benchmark) with all the information and scripts to do so. ### Results The benchmark confirms that the performance improvements claimed by AWS can be reproduced and validated by real use-cases and examples. On average, AWS Inferentia2 delivers 4.5x better latency than NVIDIA A10G GPUs and 4x better latency than Inferentia1 instances. We ran 144 experiments on 6 different model architectures: * Accelerators: Inf1, Inf2, NVIDIA A10G * Models: [BERT-base](https://huggingface.co/bert-base-uncased), [BERT-Large](https://huggingface.co/bert-large-uncased), [RoBERTa-base](https://huggingface.co/roberta-base), [DistilBERT](https://huggingface.co/distilbert-base-uncased), [ALBERT-base](https://huggingface.co/albert-base-v2), [ViT-base](https://huggingface.co/google/vit-base-patch16-224) * Sequence length: 8, 16, 32, 64, 128, 256, 512 * Batch size: 1 In each experiment, we collected numbers for p95 latency. You can find the full details of the benchmark in this spreadsheet: [HuggingFace: Benchmark Inferentia2](https://docs.google.com/spreadsheets/d/1AULEHBu5Gw6ABN8Ls6aSB2CeZyTIP_y5K7gC7M3MXqs/edit?usp=sharing). Let’s highlight a few insights of the benchmark. ### BERT-base Here is the latency comparison for running [BERT-base](https://huggingface.co/bert-base-uncased) on each of the infrastructure setups, with a logarithmic scale for latency. It is remarkable to see how Inferentia2 outperforms all other setups by ~6x for sequence lengths up to 256. <br> <figure class="image table text-center m-0 w-full"> <medium-zoom background="rgba(0,0,0,.7)" alt="BERT-base p95 latency" src="assets/140_accelerate_transformers_with_inferentia2/bert.png"></medium-zoom> <figcaption>Figure 1. BERT-base p95 latency</figcaption> </figure> <br> ### Vision Transformer Here is the latency comparison for running [ViT-base](https://huggingface.co/google/vit-base-patch16-224) on the different infrastructure setups. Inferentia2 delivers 2x better latency than the NVIDIA A10G, with the potential to greatly help companies move from traditional architectures, like CNNs, to Transformers for - real-time applications. <br> <figure class="image table text-center m-0 w-full"> <medium-zoom background="rgba(0,0,0,.7)" alt="ViT p95 latency" src="assets/140_accelerate_transformers_with_inferentia2/vit.png"></medium-zoom> <figcaption>Figure 1. ViT p95 latency</figcaption> </figure> <br> ## Conclusion Transformer models have emerged as the go-to solution for many machine learning tasks. However, deploying them in production has been challenging due to their large size and latency requirements. Thanks to AWS Inferentia2 and the collaboration between Hugging Face and AWS, developers and organizations can now leverage the benefits of state-of-the-art models without the prior need for extensive machine learning expertise. You can start testing for as low as 0.76$/h. The initial benchmarking results are promising, and show that Inferentia2 delivers superior latency performance when compared to both Inferentia and NVIDIA A10G GPUs. This latest breakthrough promises high-quality machine learning models can be made available to a much broader audience delivering AI accessibility to everyone.
|
How to host a Unity game in a Space
|
dylanebert
|
April 21, 2023
|
unity-in-spaces
|
community, guide, game-dev
|
https://huggingface.co/blog/unity-in-spaces
|
# How to host a Unity game in a Space <!-- {authors} --> Did you know you can host a Unity game in a Hugging Face Space? No? Well, you can! Hugging Face Spaces are an easy way to build, host, and share demos. While they are typically used for Machine Learning demos, they can also host playable Unity games. Here are some examples: - [Huggy](https://huggingface.co/spaces/ThomasSimonini/Huggy) - [Farming Game](https://huggingface.co/spaces/dylanebert/FarmingGame) - [Unity API Demo](https://huggingface.co/spaces/dylanebert/UnityDemo) Here's how you can host your own Unity game in a Space. ## Step 1: Create a Space using the Static HTML template First, navigate to [Hugging Face Spaces](https://huggingface.co/new-space) to create a space. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/1.png"> </figure> Select the "Static HTML" template, give your Space a name, and create it. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/2.png"> </figure> ## Step 2: Use Git to Clone the Space Clone your newly created Space to your local machine using Git. You can do this by running the following command in your terminal or command prompt: ``` git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ``` ## Step 3: Open your Unity Project Open the Unity project you want to host in your Space. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/3.png"> </figure> ## Step 4: Switch the Build Target to WebGL Navigate to `File > Build Settings` and switch the Build Target to WebGL. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/4.png"> </figure> ## Step 5: Open Player Settings In the Build Settings window, click the "Player Settings" button to open the Player Settings panel. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/5.png"> </figure> ## Step 6: Optionally, Download the Hugging Face Unity WebGL Template You can enhance your game's appearance in a Space by downloading the Hugging Face Unity WebGL template, available [here](https://github.com/huggingface/Unity-WebGL-template-for-Hugging-Face-Spaces). Just download the repository and drop it in your project files. Then, in the Player Settings panel, switch the WebGL template to Hugging Face. To do so, in Player Settings, click "Resolution and Presentation", then select the Hugging Face WebGL template. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/6.png"> </figure> ## Step 7: Change the Compression Format to Disabled In the Player Settings panel, navigate to the "Publishing Settings" section and change the Compression Format to "Disabled". <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/7.png"> </figure> ## Step 8: Build your Project Return to the Build Settings window and click the "Build" button. Choose a location to save your build files, and Unity will build the project for WebGL. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/8.png"> </figure> ## Step 9: Copy the Contents of the Build Folder After the build process is finished, navigate to the folder containing your build files. Copy the files in the build folder to the repository you cloned in [Step 2](#step-2-use-git-to-clone-the-space). <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/9.png"> </figure> ## Step 10: Enable Git-LFS for Large File Storage Navigate to your repository. Use the following commands to track large build files. ``` git lfs install git lfs track Build/* ``` ## Step 11: Push your Changes Finally, use the following Git commands to push your changes: ``` git add . git commit -m "Add Unity WebGL build files" git push ``` ## Done! Congratulations! Refresh your Space. You should now be able to play your game in a Hugging Face Space. We hope you found this tutorial helpful. If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
Introducing HuggingFace blog for Chinese speakers: Fostering Collaboration with the Chinese AI community
|
xianbao
|
April 24, 2023
|
chinese-language-blog
|
partnerships, community
|
https://huggingface.co/blog/chinese-language-blog
|
# Introducing HuggingFace blog for Chinese speakers: Fostering Collaboration with the Chinese AI community ## Welcome to our blog for Chinese speakers! We are delighted to introduce Hugging Face’s new blog for Chinese speakers: [hf.co/blog/zh](https://huggingface.co/blog/zh)! A committed group of volunteers has made this possible by translating our invaluable resources, including blog posts and comprehensive courses on transformers, diffusion, and reinforcement learning. This step aims to make our content accessible to the ever-growing Chinese AI community, fostering mutual learning and collaboration. ## Recognizing the Chinese AI Community’s Accomplishments We want to highlight the remarkable achievements and contributions of the Chinese AI community, which has demonstrated exceptional talent and innovation. Groundbreaking advancements like [HuggingGPT](https://huggingface.co/spaces/microsoft/HuggingGPT), [ChatGLM](https://huggingface.co/THUDM/chatglm-6b), [RWKV](https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B), [ChatYuan](https://huggingface.co/spaces/ClueAI/ChatYuan-large-v2), [ModelScope text-to-video models](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis) as well as [IDEA CCNL](https://huggingface.co/IDEA-CCNL) and [BAAI](https://huggingface.co/BAAI)’s contributions underscore the incredible potential within the community. In addition, the Chinese AI community has been actively engaged in creating trendy Spaces, such as [Chuanhu GPT](https://huggingface.co/spaces/jdczlx/ChatGPT-chuanhu) and [GPT Academy](https://huggingface.co/spaces/qingxu98/gpt-academic), further demonstrating its enthusiasm and creativity. We have been collaborating with organizations such as [PaddlePaddle](https://huggingface.co/blog/paddlepaddle) to ensure seamless integration with Hugging Face, empowering more collaborative efforts in the realm of Machine Learning. ## Strengthening Collaborative Ties and Future Events We are proud of our collaborative history with our Chinese collaborators, having worked together on various events that have enabled knowledge exchange and collaboration, propelling the AI community forward. Some of our collaborative efforts include: - [Online ChatGPT course, in collaboration with DataWhale (ongoing)](https://mp.weixin.qq.com/s/byR2n-5QJmy34Jq0W3ECDg) - [First offline meetup in Beijing for JAX/Diffusers community sprint](https://twitter.com/huggingface/status/1648986159580876800) - [Organizing a Prompt engineering hackathon alongside Baixing AI](https://mp.weixin.qq.com/s/M5vjicNG1uBdCQzQtQU9yw) - [Fine-tuning Lora models in collaboration with PaddlePaddle](https://aistudio.baidu.com/aistudio/competition/detail/860/0/introduction) - [Fine-tuning stable diffusion models in an event with HeyWhale](https://www.heywhale.com/home/competition/63bbfb98de6c0e9cdb0d9dd5) We are excited to announce that we will continue to strengthen our ties with the Chinese AI community by fostering more collaborations and joint efforts. These initiatives will create opportunities for knowledge sharing and expertise exchange, promoting collaborative open-source machine learning across our communities, and tackling the challenges and opportunities in the field of cooperative OS ML. ## Beyond Boundaries: Embracing a Diverse AI Community As we embark on this new chapter, our collaboration with the Chinese AI community will serve as a platform to bridge cultural and linguistic barriers, fostering innovation and cooperation in the AI domain. At Hugging Face, we value diverse perspectives and voices, aiming to create a welcoming and inclusive community that promotes ethical and equitable AI development. Join us on this exciting journey, and stay tuned for more updates on our blog about Chinese community advancements and future collaborative endeavors! You may also find us here: <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chinese-language-blog/wechat.jpg"> </figure> [BAAI](https://hub.baai.ac.cn/users/45017), [Bilibili](https://space.bilibili.com/1740664937/), [CNBlogs](https://www.cnblogs.com/huggingface), [CSDN](https://huggingface.blog.csdn.net/), [Juejin](https://juejin.cn/user/611789528634712), [OS China](https://my.oschina.net/HuggingFace), [SegmentFault](https://segmentfault.com/u/huggingface), [Zhihu](https://www.zhihu.com/org/huggingface)
|
Databricks ❤️ Hugging Face: up to 40% faster training and tuning of Large Language Models
|
alighodsi
|
April 26, 2023
|
databricks-case-study
|
case-studies
|
https://huggingface.co/blog/databricks-case-study
|
# Databricks ❤️ Hugging Face: up to 40% faster training and tuning of Large Language Models Generative AI has been taking the world by storm. As the data and AI company, we have been on this journey with the release of the open source large language model [Dolly](https://huggingface.co/databricks/dolly-v2-12b), as well as the internally crowdsourced dataset licensed for research and commercial use that we used to fine-tune it, the [databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k). Both the model and dataset are available on Hugging Face. We’ve learned a lot throughout this process, and today we’re excited to announce our first of many official commits to the Hugging Face codebase that allows users to easily create a Hugging Face Dataset from an Apache Spark™ dataframe. #### “It's been great to see Databricks release models and datasets to the community, and now we see them extending that work with direct open source commitment to Hugging Face. Spark is one of the most efficient engines for working with data at scale, and it's great to see that users can now benefit from that technology to more effectively fine tune models from Hugging Face.” — Clem Delange, Hugging Face CEO ## Hugging Face gets first-class Spark support Over the past few weeks, we’ve gotten many requests from users asking for an easier way to load their Spark dataframe into a Hugging Face dataset that can be utilized for model training or tuning. Prior to today’s release, to get data from a Spark dataframe into a Hugging Face dataset, users had to write data into Parquet files and then point the Hugging Face dataset to these files to reload them. For example: ```swift from datasets import load_dataset train_df = train.write.parquet(train_dbfs_path, mode="overwrite") train_test = load_dataset("parquet", data_files={"train":f"/dbfs{train_dbfs_path}/*.parquet", "test":f"/dbfs{test_dbfs_path}/*.parquet"}) #16GB == 22min ``` Not only was this cumbersome, but it also meant that data had to be written to disk and then read in again. On top of that, the data would get rematerialized once loaded back into the dataset, which eats up more resources and, therefore, more time and cost. Using this method, we saw that a relatively small (16GB) dataset took about 22 minutes to go from Spark dataframe to Parquet, and then back into the Hugging Face dataset. With the latest Hugging Face release, we make it much simpler for users to accomplish the same task by simply calling the new “from_spark” function in Datasets: ```swift from datasets import Dataset df = [some Spark dataframe or Delta table loaded into df] dataset = Dataset.from_spark(df) #16GB == 12min ``` This allows users to use Spark to efficiently load and transform data for training or fine-tuning a model, then easily map their Spark dataframe into a Hugging Face dataset for super simple integration into their training pipelines. This combines cost savings and speed from Spark and optimizations like memory-mapping and smart caching from Hugging Face datasets. These improvements cut down the processing time for our example 16GB dataset by more than 40%, going from 22 minutes down to only 12 minutes. ## Why does this matter? As we transition to this new AI paradigm, organizations will need to use their extremely valuable data to augment their AI models if they want to get the best performance within their specific domain. This will almost certainly require work in the form of data transformations, and doing this efficiently over large datasets is something Spark was designed to do. Integrating Spark with Hugging Face gives you the cost-effectiveness and performance of Spark while retaining the pipeline integration that Hugging Face provides. ## Continued Open-Source Support We see this release as a new avenue to further contribute to the open source community, something that we believe Hugging Face does extremely well, as it has become the de facto repository for open source models and datasets. This is only the first of many contributions. We already have plans to add streaming support through Spark to make the dataset loading even faster. In order to become the best platform for users to jump into the world of AI, we’re working hard to provide the best tools to successfully train, tune, and deploy models. Not only will we continue contributing to Hugging Face, but we’ve also started releasing improvements to our other open source projects. A recent [MLflow](https://www.databricks.com/blog/2023/04/18/introducing-mlflow-23-enhanced-native-llm-support-and-new-features.html) release added support for the transformers library, OpenAI integration, and Langchain support. We also announced [AI Functions](https://www.databricks.com/blog/2023/04/18/introducing-ai-functions-integrating-large-language-models-databricks-sql.html) within Databricks SQL that lets users easily integrate OpenAI (or their own deployed models in the future) into their queries. To top it all off, we also released a [PyTorch distributor](https://www.databricks.com/blog/2023/04/20/pytorch-databricks-introducing-spark-pytorch-distributor.html) for Spark to simplify distributed PyTorch training on Databricks. _This article was originally published on April 26, 2023 in [Databricks's blog](https://www.databricks.com/blog/contributing-spark-loader-for-hugging-face-datasets)._
|
Training a language model with 🤗 Transformers using TensorFlow and TPUs
|
rocketknight1
|
April 27, 2023
|
tf_tpu
|
nlp, guide, tensorflow, tpu
|
https://huggingface.co/blog/tf_tpu
|
# Training a language model with 🤗 Transformers using TensorFlow and TPUs ## Introduction TPU training is a useful skill to have: TPU pods are high-performance and extremely scalable, making it easy to train models at any scale from a few tens of millions of parameters up to truly enormous sizes: Google’s PaLM model (over 500 billion parameters!) was trained entirely on TPU pods. We’ve previously written a [tutorial](https://huggingface.co/docs/transformers/main/perf_train_tpu_tf) and a [Colab example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) showing small-scale TPU training with TensorFlow and introducing the core concepts you need to understand to get your model working on TPU. This time, we’re going to step that up another level and train a masked language model from scratch using TensorFlow and TPU, including every step from training your tokenizer and preparing your dataset through to the final model training and uploading. This is the kind of task that you’ll probably want a dedicated TPU node (or VM) for, rather than just Colab, and so that’s where we’ll focus. As in our Colab example, we’re taking advantage of TensorFlow's very clean TPU support via XLA and `TPUStrategy`. We’ll also be benefiting from the fact that the majority of the TensorFlow models in 🤗 Transformers are fully [XLA-compatible](https://huggingface.co/blog/tf-xla-generate). So surprisingly, little work is needed to get them to run on TPU. Unlike our Colab example, however, this example is designed to be **scalable** and much closer to a realistic training run -- although we only use a BERT-sized model by default, the code could be expanded to a much larger model and a much more powerful TPU pod slice by changing a few configuration options. ## Motivation Why are we writing this guide now? After all, 🤗 Transformers has had support for TensorFlow for several years now. But getting those models to train on TPUs has been a major pain point for the community. This is because: - Many models weren’t XLA-compatible - Data collators didn’t use native TF operations We think XLA is the future: It’s the core compiler for JAX, it has first-class support in TensorFlow, and you can even use it from [PyTorch](https://github.com/pytorch/xla). As such, we’ve made a [big push](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) to make our codebase XLA compatible and to remove any other roadblocks standing in the way of XLA and TPU compatibility. This means users should be able to train most of our TensorFlow models on TPUs without hassle. There’s also another important reason to care about TPU training right now: Recent major advances in LLMs and generative AI have created huge public interest in model training, and so it’s become incredibly hard for most people to get access to state-of-the-art GPUs. Knowing how to train on TPU gives you another path to access ultra-high-performance compute hardware, which is much more dignified than losing a bidding war for the last H100 on eBay and then ugly crying at your desk. You deserve better. And speaking from experience: Once you get comfortable with training on TPU, you might not want to go back. ## What to expect We’re going to train a [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) (base model) from scratch on the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext). As well as training the model, we’re also going to train the tokenizer, tokenize the data and upload it to Google Cloud Storage in TFRecord format, where it’ll be accessible for TPU training. You can find all the code in [this directory](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling-tpu). If you’re a certain kind of person, you can skip the rest of this blog post and just jump straight to the code. If you stick around, though, we’ll take a deeper look at some of the key ideas in the codebase. Many of the ideas here were also mentioned in our [Colab example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb), but we wanted to show users a full end-to-end example that puts it all together and shows it in action, rather than just covering concepts at a high level. The following diagram gives you a pictorial overview of the steps involved in training a language model with 🤗 Transformers using TensorFlow and TPUs: <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/tf_tpu/tf_tpu_steps.png" alt="tf-tpu-training-steps"/><br> </p> ## Getting the data and training a tokenizer As mentioned, we used the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext). You can head over to the [dataset page on the Hugging Face Hub](https://huggingface.co/datasets/wikitext) to explore the dataset. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/tf_tpu/wikitext_explore.png" alt="dataset-explore"/><br> </p> Since the dataset is already available on the Hub in a compatible format, we can easily load and interact with it using 🤗 datasets. However, for this example, since we’re also training a tokenizer from scratch, here’s what we did: - Loaded the `train` split of the WikiText using 🤗 datasets. - Leveraged 🤗 tokenizers to train a [Unigram model](https://huggingface.co/course/chapter6/7?fw=pt). - Uploaded the trained tokenizer on the Hub. You can find the tokenizer training code [here](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling-tpu#training-a-tokenizer) and the tokenizer [here](https://huggingface.co/tf-tpu/unigram-tokenizer-wikitext). This script also allows you to run it with [any compatible dataset](https://huggingface.co/datasets?task_ids=task_ids:language-modeling) from the Hub. > 💡 It’s easy to use 🤗 datasets to host your text datasets. Refer to [this guide](https://huggingface.co/docs/datasets/create_dataset) to learn more. ## Tokenizing the data and creating TFRecords Once the tokenizer is trained, we can use it on all the dataset splits (`train`, `validation`, and `test` in this case) and create TFRecord shards out of them. Having the data splits spread across multiple TFRecord shards helps with massively parallel processing as opposed to having each split in single TFRecord files. We tokenize the samples individually. We then take a batch of samples, concatenate them together, and split them into several chunks of a fixed size (128 in our case). We follow this strategy rather than tokenizing a batch of samples with a fixed length to avoid aggressively discarding text content (because of truncation). We then take these tokenized samples in batches and serialize those batches as multiple TFRecord shards, where the total dataset length and individual shard size determine the number of shards. Finally, these shards are pushed to a [Google Cloud Storage (GCS) bucket](https://cloud.google.com/storage/docs/json_api/v1/buckets). If you’re using a TPU node for training, then the data needs to be streamed from a GCS bucket since the node host memory is very small. But for TPU VMs, we can use datasets locally or even attach persistent storage to those VMs. Since TPU nodes are still quite heavily used, we based our example on using a GCS bucket for data storage. You can see all of this in code in [this script](https://github.com/huggingface/transformers/blob/main/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py). For convenience, we have also hosted the resultant TFRecord shards in [this repository](https://huggingface.co/datasets/tf-tpu/wikitext-v1-tfrecords) on the Hub. ## Training a model on data in GCS If you’re familiar with using 🤗 Transformers, then you already know the modeling code: ```python from transformers import AutoConfig, AutoTokenizer, TFAutoModelForMaskedLM tokenizer = AutoTokenizer.from_pretrained("tf-tpu/unigram-tokenizer-wikitext") config = AutoConfig.from_pretrained("roberta-base") config.vocab_size = tokenizer.vocab_size model = TFAutoModelForMaskedLM.from_config(config) ``` But since we’re in the TPU territory, we need to perform this initialization under a strategy scope so that it can be distributed across the TPU workers with data-parallel training: ```python import tensorflow as tf tpu = tf.distribute.cluster_resolver.TPUClusterResolver(...) strategy = tf.distribute.TPUStrategy(tpu) with strategy.scope(): tokenizer = AutoTokenizer.from_pretrained("tf-tpu/unigram-tokenizer-wikitext") config = AutoConfig.from_pretrained("roberta-base") config.vocab_size = tokenizer.vocab_size model = TFAutoModelForMaskedLM.from_config(config) ``` Similarly, the optimizer also needs to be initialized under the same strategy scope with which the model is going to be further compiled. Going over the full training code isn’t something we want to do in this post, so we welcome you to read it [here](https://github.com/huggingface/transformers/blob/main/examples/tensorflow/language-modeling-tpu/run_mlm.py). Instead, let’s discuss another key point of — a TensorFlow-native data collator — [`DataCollatorForLanguageModeling`](https://huggingface.co/docs/transformers/main_classes/data_collator#transformers.DataCollatorForLanguageModeling). `DataCollatorForLanguageModeling` is responsible for masking randomly selected tokens from the input sequence and preparing the labels. By default, we return the results from these collators as NumPy arrays. However, many collators also support returning these values as TensorFlow tensors if we specify `return_tensor="tf"`. This was crucial for our data pipeline to be compatible with TPU training. Thankfully, TensorFlow provides seamless support for reading files from a GCS bucket: ```python training_records = tf.io.gfile.glob(os.path.join(args.train_dataset, "*.tfrecord")) ``` If `args.dataset` contains the `gs://` identifier, TensorFlow will understand that it needs to look into a GCS bucket. Loading locally is as easy as removing the `gs://` identifier. For the rest of the data pipeline-related code, you can refer to [this section](https://github.com/huggingface/transformers/blob/474bf508dfe0d46fc38585a1bb793e5ba74fddfd/examples/tensorflow/language-modeling-tpu/run_mlm.py#L186-#L201) in the training script. Once the datasets have been prepared, the model and the optimizer have been initialized, and the model has been compiled, we can do the community’s favorite - `model.fit()`. For training, we didn’t do extensive hyperparameter tuning. We just trained it for longer with a learning rate of 1e-4. We also leveraged the [`PushToHubCallback`](https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.PushToHubCallback) for model checkpointing and syncing them with the Hub. You can find the hyperparameter details and a trained model here: [https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd). Once the model is trained, running inference with it is as easy as: ```python from transformers import pipeline model_id = "tf-tpu/roberta-base-epochs-500-no-wd" unmasker = pipeline("fill-mask", model=model_id, framework="tf") unmasker("Goal of my life is to [MASK].") [{'score': 0.1003185287117958, 'token': 52, 'token_str': 'be', 'sequence': 'Goal of my life is to be.'}, {'score': 0.032648514956235886, 'token': 5, 'token_str': '', 'sequence': 'Goal of my life is to .'}, {'score': 0.02152673341333866, 'token': 138, 'token_str': 'work', 'sequence': 'Goal of my life is to work.'}, {'score': 0.019547373056411743, 'token': 984, 'token_str': 'act', 'sequence': 'Goal of my life is to act.'}, {'score': 0.01939118467271328, 'token': 73, 'token_str': 'have', 'sequence': 'Goal of my life is to have.'}] ``` ## Conclusion If there’s one thing we want to emphasize with this example, it’s that TPU training is **powerful, scalable and easy.** In fact, if you’re already using Transformers models with TF/Keras and streaming data from `tf.data`, you might be shocked at how little work it takes to move your whole training pipeline to TPU. They have a reputation as somewhat arcane, high-end, complex hardware, but they’re quite approachable, and instantiating a large pod slice is definitely easier than keeping multiple GPU servers in sync! Diversifying the hardware that state-of-the-art models are trained on is going to be critical in the 2020s, especially if the ongoing GPU shortage continues. We hope that this guide will give you the tools you need to power cutting-edge training runs no matter what circumstances you face. As the great poet GPT-4 once said: *If you can keep your head when all around you*<br> *Are losing theirs to GPU droughts,*<br> *And trust your code, while others doubt you,*<br> *To train on TPUs, no second thoughts;*<br> *If you can learn from errors, and proceed,*<br> *And optimize your aim to reach the sky,*<br> *Yours is the path to AI mastery,*<br> *And you'll prevail, my friend, as time goes by.*<br> Sure, it’s shamelessly ripping off Rudyard Kipling and it has no idea how to pronounce “drought”, but we hope you feel inspired regardless.
|
Running IF with 🧨 diffusers on a Free Tier Google Colab
|
williamberman
|
April 26, 2023
|
if
|
guide, diffusion
|
https://huggingface.co/blog/if
|
# Running IF with 🧨 diffusers on a Free Tier Google Colab <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/deepfloyd_if_free_tier_google_colab.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> **TL;DR**: We show how to run one of the most powerful open-source text to image models **IF** on a free-tier Google Colab with 🧨 diffusers. You can also explore the capabilities of the model directly in the [Hugging Face Space](https://huggingface.co/spaces/DeepFloyd/IF). <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/if/nabla.jpg" alt="if-collage"><br> <em>Image compressed from official <a href="https://github.com/deep-floyd/IF/blob/release/pics/nabla.jpg">IF GitHub repo</a>.</em> </p> ## Introduction IF is a pixel-based text-to-image generation model and was [released in late April 2023 by DeepFloyd](https://github.com/deep-floyd/IF). The model architecture is strongly inspired by [Google's closed-sourced Imagen](https://imagen.research.google/). IF has two distinct advantages compared to existing text-to-image models like Stable Diffusion: - The model operates directly in "pixel space" (*i.e.,* on uncompressed images) instead of running the denoising process in the latent space such as [Stable Diffusion](http://hf.co/blog/stable_diffusion). - The model is trained on outputs of [T5-XXL](https://huggingface.co/google/t5-v1_1-xxl), a more powerful text encoder than [CLIP](https://openai.com/research/clip), used by Stable Diffusion as the text encoder. As a result, IF is better at generating images with high-frequency details (*e.g.,* human faces and hands) and is the first open-source image generation model that can reliably generate images with text. The downside of operating in pixel space and using a more powerful text encoder is that IF has a significantly higher amount of parameters. T5, IF\'s text-to-image UNet, and IF\'s upscaler UNet have 4.5B, 4.3B, and 1.2B parameters respectively. Compared to [Stable Diffusion 2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1)\'s text encoder and UNet having just 400M and 900M parameters, respectively. Nevertheless, it is possible to run IF on consumer hardware if one optimizes the model for low-memory usage. We will show you can do this with 🧨 diffusers in this blog post. In 1.), we explain how to use IF for text-to-image generation, and in 2.) and 3.), we go over IF's image variation and image inpainting capabilities. 💡 **Note**: We are trading gains in memory by gains in speed here to make it possible to run IF in a free-tier Google Colab. If you have access to high-end GPUs such as an A100, we recommend leaving all model components on GPU for maximum speed, as done in the [official IF demo](https://huggingface.co/spaces/DeepFloyd/IF). 💡 **Note**: Some of the larger images have been compressed to load faster in the blog format. When using the official model, they should be even better quality! Let\'s dive in 🚀! <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/if/meme.png"><br> <em>IF's text generation capabilities</em> </p> ## Table of contents * [Accepting the license](#accepting-the-license) * [Optimizing IF to run on memory constrained hardware](#optimizing-if-to-run-on-memory-constrained-hardware) * [Available resources](#available-resources) * [Install dependencies](#install-dependencies) * [Text-to-image generation](#1-text-to-image-generation) * [Image variation](#2-image-variation) * [Inpainting](#3-inpainting) ## Accepting the license Before you can use IF, you need to accept its usage conditions. To do so: - 1. Make sure to have a [Hugging Face account](https://huggingface.co/join) and be logged in - 2. Accept the license on the model card of [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0). Accepting the license on the stage I model card will auto accept for the other IF models. - 3. Make sure to login locally. Install `huggingface_hub` ```sh pip install huggingface_hub --upgrade ``` run the login function in a Python shell ```py from huggingface_hub import login login() ``` and enter your [Hugging Face Hub access token](https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens). ## Optimizing IF to run on memory constrained hardware State-of-the-art ML should not just be in the hands of an elite few. Democratizing ML means making models available to run on more than just the latest and greatest hardware. The deep learning community has created world class tools to run resource intensive models on consumer hardware: - [🤗 accelerate](https://github.com/huggingface/accelerate) provides utilities for working with [large models](https://huggingface.co/docs/accelerate/usage_guides/big_modeling). - [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) makes [8-bit quantization](https://github.com/TimDettmers/bitsandbytes#features) available to all PyTorch models. - [🤗 safetensors](https://github.com/huggingface/safetensors) not only ensures that save code is executed but also significantly speeds up the loading time of large models. Diffusers seamlessly integrates the above libraries to allow for a simple API when optimizing large models. The free-tier Google Colab is both CPU RAM constrained (13 GB RAM) as well as GPU VRAM constrained (15 GB RAM for T4), which makes running the whole >10B IF model challenging! Let\'s map out the size of IF\'s model components in full float32 precision: - [T5-XXL Text Encoder](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/tree/main/text_encoder): 20GB - [Stage 1 UNet](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/tree/main/unet): 17.2 GB - [Stage 2 Super Resolution UNet](https://huggingface.co/DeepFloyd/IF-II-L-v1.0/blob/main/pytorch_model.bin): 2.5 GB - [Stage 3 Super Resolution Model](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler): 3.4 GB There is no way we can run the model in float32 as the T5 and Stage 1 UNet weights are each larger than the available CPU RAM. In float16, the component sizes are 11GB, 8.6GB, and 1.25GB for T5, Stage1 and Stage2 UNets, respectively, which is doable for the GPU, but we're still running into CPU memory overflow errors when loading the T5 (some CPU is occupied by other processes). Therefore, we lower the precision of T5 even more by using `bitsandbytes` 8bit quantization, which allows saving the T5 checkpoint with as little as [8 GB](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/blob/main/text_encoder/model.8bit.safetensors). Now that each component fits individually into both CPU and GPU memory, we need to make sure that components have all the CPU and GPU memory for themselves when needed. Diffusers supports modularly loading individual components i.e. we can load the text encoder without loading the UNet. This modular loading will ensure that we only load the component we need at a given step in the pipeline to avoid exhausting the available CPU RAM and GPU VRAM. Let\'s give it a try 🚀  ## Available resources The free-tier Google Colab comes with around 13 GB CPU RAM: ``` python !grep MemTotal /proc/meminfo ``` ```bash MemTotal: 13297192 kB ``` And an NVIDIA T4 with 15 GB VRAM: ``` python !nvidia-smi ``` ```bash Sun Apr 23 23:14:19 2023 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 72C P0 32W / 70W | 1335MiB / 15360MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| +-----------------------------------------------------------------------------+ ``` ## Install dependencies Some optimizations can require up-to-date versions of dependencies. If you are having issues, please double check and upgrade versions. ``` python ! pip install --upgrade \ diffusers~=0.16 \ transformers~=4.28 \ safetensors~=0.3 \ sentencepiece~=0.1 \ accelerate~=0.18 \ bitsandbytes~=0.38 \ torch~=2.0 -q ``` ## 1. Text-to-image generation We will walk step by step through text-to-image generation with IF using Diffusers. We will explain briefly APIs and optimizations, but more in-depth explanations can be found in the official documentation for [Diffusers](https://huggingface.co/docs/diffusers/index), [Transformers](https://huggingface.co/docs/transformers/index), [Accelerate](https://huggingface.co/docs/accelerate/index), and [bitsandbytes](https://github.com/TimDettmers/bitsandbytes). ### 1.1 Load text encoder We will load T5 using 8bit quantization. Transformers directly supports [bitsandbytes](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#load-a-large-model-in-8bit) through the `load_in_8bit` flag. The flag `variant="8bit"` will download pre-quantized weights. We also use the `device_map` flag to allow `transformers` to offload model layers to the CPU or disk. Transformers big modeling supports arbitrary device maps, which can be used to separately load model parameters directly to available devices. Passing `"auto"` will automatically create a device map. See the `transformers` [docs](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map) for more information. ``` python from transformers import T5EncoderModel text_encoder = T5EncoderModel.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", subfolder="text_encoder", device_map="auto", load_in_8bit=True, variant="8bit" ) ``` ### 1.2 Create text embeddings The Diffusers API for accessing diffusion models is the `DiffusionPipeline` class and its subclasses. Each instance of `DiffusionPipeline` is a fully self contained set of methods and models for running diffusion networks. We can override the models it uses by passing alternative instances as keyword arguments to `from_pretrained`. In this case, we pass `None` for the `unet` argument, so no UNet will be loaded. This allows us to run the text embedding portion of the diffusion process without loading the UNet into memory. ``` python from diffusers import DiffusionPipeline pipe = DiffusionPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=text_encoder, # pass the previously instantiated 8bit text encoder unet=None, device_map="auto" ) ``` IF also comes with a super resolution pipeline. We will save the prompt embeddings so we can later directly pass them to the super resolution pipeline. This will allow the super resolution pipeline to be loaded **without** a text encoder. Instead of [an astronaut just riding a horse](https://huggingface.co/blog/stable_diffusion), let\'s hand them a sign as well! Let\'s define a fitting prompt: ``` python prompt = "a photograph of an astronaut riding a horse holding a sign that says Pixel's in space" ``` and run it through the 8bit quantized T5 model: ``` python prompt_embeds, negative_embeds = pipe.encode_prompt(prompt) ``` ### 1.3 Free memory Once the prompt embeddings have been created. We do not need the text encoder anymore. However, it is still in memory on the GPU. We need to remove it so that we can load the UNet. It's non-trivial to free PyTorch memory. We must garbage-collect the Python objects which point to the actual memory allocated on the GPU. First, use the Python keyword `del` to delete all Python objects referencing allocated GPU memory ``` python del text_encoder del pipe ``` Deleting the python object is not enough to free the GPU memory. Garbage collection is when the actual GPU memory is freed. Additionally, we will call `torch.cuda.empty_cache()`. This method isn\'t strictly necessary as the cached cuda memory will be immediately available for further allocations. Emptying the cache allows us to verify in the Colab UI that the memory is available. We\'ll use a helper function `flush()` to flush memory. ``` python import gc import torch def flush(): gc.collect() torch.cuda.empty_cache() ``` and run it ``` python flush() ``` ### 1.4 Stage 1: The main diffusion process With our now available GPU memory, we can re-load the `DiffusionPipeline` with only the UNet to run the main diffusion process. The `variant` and `torch_dtype` flags are used by Diffusers to download and load the weights in 16 bit floating point format. ``` python pipe = DiffusionPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` Often, we directly pass the text prompt to `DiffusionPipeline.__call__`. However, we previously computed our text embeddings which we can pass instead. IF also comes with a super resolution diffusion process. Setting `output_type="pt"` will return raw PyTorch tensors instead of a PIL image. This way, we can keep the PyTorch tensors on GPU and pass them directly to the stage 2 super resolution pipeline. Let\'s define a random generator and run the stage 1 diffusion process. ``` python generator = torch.Generator().manual_seed(1) image = pipe( prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, output_type="pt", generator=generator, ).images ``` Let\'s manually convert the raw tensors to PIL and have a sneak peek at the final result. The output of stage 1 is a 64x64 image. ``` python from diffusers.utils import pt_to_pil pil_image = pt_to_pil(image) pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size) pil_image[0] ```  And again, we remove the Python pointer and free CPU and GPU memory: ``` python del pipe flush() ``` ### 1.5 Stage 2: Super Resolution 64x64 to 256x256 IF comes with a separate diffusion process for upscaling. We run each diffusion process with a separate pipeline. The super resolution pipeline can be loaded with a text encoder if needed. However, we will usually have pre-computed text embeddings from the first IF pipeline. If so, load the pipeline without the text encoder. Create the pipeline ``` python pipe = DiffusionPipeline.from_pretrained( "DeepFloyd/IF-II-L-v1.0", text_encoder=None, # no use of text encoder => memory savings! variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` and run it, re-using the pre-computed text embeddings ``` python image = pipe( image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, output_type="pt", generator=generator, ).images ``` Again we can inspect the intermediate results. ``` python pil_image = pt_to_pil(image) pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size) pil_image[0] ```  And again, we delete the Python pointer and free memory ``` python del pipe flush() ``` ### 1.6 Stage 3: Super Resolution 256x256 to 1024x1024 The second super resolution model for IF is the previously release [Stability AI\'s x4 Upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler). Let\'s create the pipeline and load it directly on GPU with `device_map="auto"`. ``` python pipe = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-x4-upscaler", torch_dtype=torch.float16, device_map="auto" ) ``` 🧨 diffusers makes independently developed diffusion models easily composable as pipelines can be chained together. Here we can just take the previous PyTorch tensor output and pass it to the tage 3 pipeline as `image=image`. 💡 **Note**: The x4 Upscaler does not use T5 and has [its own text encoder](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler/tree/main/text_encoder). Therefore, we cannot use the previously created prompt embeddings and instead must pass the original prompt. ``` python pil_image = pipe(prompt, generator=generator, image=image).images ``` Unlike the IF pipelines, the IF watermark will not be added by default to outputs from the Stable Diffusion x4 upscaler pipeline. We can instead manually apply the watermark. ``` python from diffusers.pipelines.deepfloyd_if import IFWatermarker watermarker = IFWatermarker.from_pretrained("DeepFloyd/IF-I-XL-v1.0", subfolder="watermarker") watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size) ``` View output image ``` python pil_image[0] ```  Et voila! A beautiful 1024x1024 image in a free-tier Google Colab. We have shown how 🧨 diffusers makes it easy to decompose and modularly load resource-intensive diffusion models. 💡 **Note**: We don\'t recommend using the above setup in production. 8bit quantization, manual de-allocation of model weights, and disk offloading all trade off memory for time (i.e., inference speed). This can be especially noticable if the diffusion pipeline is re-used. In production, we recommend using a 40GB A100 with all model components left on the GPU. See [**the official IF demo**](https://huggingface.co/spaces/DeepFloyd/IF). ## 2. Image variation The same IF checkpoints can also be used for text guided image variation and inpainting. The core diffusion process is the same as text-to-image generation except the initial noised image is created from the image to be varied or inpainted. To run image variation, load the same checkpoints with `IFImg2ImgPipeline.from_pretrained()` and `IFImg2ImgSuperResolution.from_pretrained()`. The APIs for memory optimization are all the same! Let\'s free the memory from the previous section. ``` python del pipe flush() ``` For image variation, we start with an initial image that we want to adapt. For this section, we will adapt the famous \"Slaps Roof of Car\" meme. Let\'s download it from the internet. ``` python import requests url = "https://i.kym-cdn.com/entries/icons/original/000/026/561/car.jpg" response = requests.get(url) ``` and load it into a PIL Image ``` python from PIL import Image from io import BytesIO original_image = Image.open(BytesIO(response.content)).convert("RGB") original_image = original_image.resize((768, 512)) original_image ```  The image variation pipeline take both PIL images and raw tensors. View the docstrings for more indepth documentation on expected inputs, [here](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFImg2ImgPipeline.__call__). ### 2.1 Text Encoder Image variation is guided by text, so we can define a prompt and encode it with T5\'s Text Encoder. Again we load the text encoder into 8bit precision. ``` python from transformers import T5EncoderModel text_encoder = T5EncoderModel.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", subfolder="text_encoder", device_map="auto", load_in_8bit=True, variant="8bit" ) ``` For image variation, we load the checkpoint with [`IFImg2ImgPipeline`](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFImg2ImgPipeline). When using `DiffusionPipeline.from_pretrained(...)`, checkpoints are loaded into their default pipeline. The default pipeline for the IF is the text-to-image [`IFPipeline`](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFPipeline). When loading checkpoints with a non-default pipeline, the pipeline must be explicitly specified. ``` python from diffusers import IFImg2ImgPipeline pipe = IFImg2ImgPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=text_encoder, unet=None, device_map="auto" ) ``` Let\'s turn our salesman into an anime character. ``` python prompt = "anime style" ``` As before, we create the text embeddings with T5 ``` python prompt_embeds, negative_embeds = pipe.encode_prompt(prompt) ``` and free GPU and CPU memory. First, remove the Python pointers ``` python del text_encoder del pipe ``` and then free the memory ``` python flush() ``` ### 2.2 Stage 1: The main diffusion process Next, we only load the stage 1 UNet weights into the pipeline object, just like we did in the previous section. ``` python pipe = IFImg2ImgPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` The image variation pipeline requires both the original image and the prompt embeddings. We can optionally use the `strength` argument to configure the amount of variation. `strength` directly controls the amount of noise added. Higher strength means more noise which means more variation. ``` python generator = torch.Generator().manual_seed(0) image = pipe( image=original_image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, output_type="pt", generator=generator, ).images ``` Let\'s check the intermediate 64x64 again. ``` python pil_image = pt_to_pil(image) pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size) pil_image[0] ```  Looks good! We can free the memory and upscale the image again. ``` python del pipe flush() ``` ### 2.3 Stage 2: Super Resolution For super resolution, load the checkpoint with `IFImg2ImgSuperResolutionPipeline` and the same checkpoint as before. ``` python from diffusers import IFImg2ImgSuperResolutionPipeline pipe = IFImg2ImgSuperResolutionPipeline.from_pretrained( "DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` 💡 **Note**: The image variation super resolution pipeline requires the generated image as well as the original image. You can also use the Stable Diffusion x4 upscaler on this image. Feel free to try it out using the code snippets in section 1.6. ``` python image = pipe( image=image, original_image=original_image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, ).images[0] image ```  Nice! Let\'s free the memory and look at the final inpainting pipelines. ``` python del pipe flush() ``` ## 3. Inpainting The IF inpainting pipeline is the same as the image variation, except only a select area of the image is denoised. We specify the area to inpaint with an image mask. Let\'s show off IF\'s amazing \"letter generation\" capabilities. We can replace this sign text with different slogan. First let\'s download the image ``` python import requests url = "https://i.imgflip.com/5j6x75.jpg" response = requests.get(url) ``` and turn it into a PIL Image ``` python from PIL import Image from io import BytesIO original_image = Image.open(BytesIO(response.content)).convert("RGB") original_image = original_image.resize((512, 768)) original_image ```  We will mask the sign so we can replace its text. For convenience, we have pre-generated the mask and loaded it into a HF dataset. Let\'s download it. ``` python from huggingface_hub import hf_hub_download mask_image = hf_hub_download("diffusers/docs-images", repo_type="dataset", filename="if/sign_man_mask.png") mask_image = Image.open(mask_image) mask_image ```  💡 **Note**: You can create masks yourself by manually creating a greyscale image. ``` python from PIL import Image import numpy as np height = 64 width = 64 example_mask = np.zeros((height, width), dtype=np.int8) # Set masked pixels to 255 example_mask[20:30, 30:40] = 255 # Make sure to create the image in mode 'L' # meaning single channel grayscale example_mask = Image.fromarray(example_mask, mode='L') example_mask ```  Now we can start inpainting 🎨🖌 ### 3.1. Text Encoder Again, we load the text encoder first ``` python from transformers import T5EncoderModel text_encoder = T5EncoderModel.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", subfolder="text_encoder", device_map="auto", load_in_8bit=True, variant="8bit" ) ``` This time, we initialize the `IFInpaintingPipeline` in-painting pipeline with the text encoder weights. ``` python from diffusers import IFInpaintingPipeline pipe = IFInpaintingPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=text_encoder, unet=None, device_map="auto" ) ``` Alright, let\'s have the man advertise for more layers instead. ``` python prompt = 'the text, "just stack more layers"' ``` Having defined the prompt, we can create the prompt embeddings ``` python prompt_embeds, negative_embeds = pipe.encode_prompt(prompt) ``` Just like before, we free the memory ``` python del text_encoder del pipe flush() ``` ### 3.2 Stage 1: The main diffusion process Just like before, we now load the stage 1 pipeline with only the UNet. ``` python pipe = IFInpaintingPipeline.from_pretrained( "DeepFloyd/IF-I-XL-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` Now, we need to pass the input image, the mask image, and the prompt embeddings. ``` python image = pipe( image=original_image, mask_image=mask_image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, output_type="pt", generator=generator, ).images ``` Let\'s take a look at the intermediate output. ``` python pil_image = pt_to_pil(image) pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size) pil_image[0] ```  Looks good! The text is pretty consistent! Let\'s free the memory so we can upscale the image ``` python del pipe flush() ``` ### 3.3 Stage 2: Super Resolution For super resolution, load the checkpoint with `IFInpaintingSuperResolutionPipeline`. ``` python from diffusers import IFInpaintingSuperResolutionPipeline pipe = IFInpaintingSuperResolutionPipeline.from_pretrained( "DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto" ) ``` The inpainting super resolution pipeline requires the generated image, the original image, the mask image, and the prompt embeddings. Let\'s do a final denoising run. ``` python image = pipe( image=image, original_image=original_image, mask_image=mask_image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, ).images[0] image ```  Nice, the model generated text without making a single spelling error! ## Conclusion IF in 32-bit floating point precision uses 40 GB of weights in total. We showed how using only open source models and libraries, IF can be run on a free-tier Google Colab instance. The ML ecosystem benefits deeply from the sharing of open tools and open models. This notebook alone used models from DeepFloyd, StabilityAI, and [Google](https://huggingface.co/google). The libraries used \-- Diffusers, Transformers, Accelerate, and bitsandbytes \-- all benefit from countless contributors from different organizations. A massive thank you to the DeepFloyd team for the creation and open sourcing of IF, and for contributing to the democratization of good machine learning 🤗.
|
How to Install and Use the Hugging Face Unity API
|
dylanebert
|
May 1, 2023
|
unity-api
|
community, guide, game-dev
|
https://huggingface.co/blog/unity-api
|
# How to Install and Use the Hugging Face Unity API <!-- {authors} --> The [Hugging Face Unity API](https://github.com/huggingface/unity-api) is an easy-to-use integration of the [Hugging Face Inference API](https://huggingface.co/inference-api), allowing developers to access and use Hugging Face AI models in their Unity projects. In this blog post, we'll walk through the steps to install and use the Hugging Face Unity API. ## Installation 1. Open your Unity project 2. Go to `Window` -> `Package Manager` 3. Click `+` and select `Add Package from git URL` 4. Enter `https://github.com/huggingface/unity-api.git` 5. Once installed, the Unity API wizard should pop up. If not, go to `Window` -> `Hugging Face API Wizard` <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/packagemanager.gif"> </figure> 6. Enter your API key. Your API key can be created in your [Hugging Face account settings](https://huggingface.co/settings/tokens). 7. Test the API key by clicking `Test API key` in the API Wizard. 8. Optionally, change the model endpoints to change which model to use. The model endpoint for any model that supports the inference API can be found by going to the model on the Hugging Face website, clicking `Deploy` -> `Inference API`, and copying the url from the `API_URL` field. 9. Configure advanced settings if desired. For up-to-date information, visit the project repository at `https://github.com/huggingface/unity-api` 10. To see examples of how to use the API, click `Install Examples`. You can now close the API Wizard. <figure class="image text-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/apiwizard.png"> </figure> Now that the API is set up, you can make calls from your scripts to the API. Let's look at an example of performing a Sentence Similarity task: ``` using HuggingFace.API; /* other code */ // Make a call to the API void Query() { string inputText = "I'm on my way to the forest."; string[] candidates = { "The player is going to the city", "The player is going to the wilderness", "The player is wandering aimlessly" }; HuggingFaceAPI.SentenceSimilarity(inputText, OnSuccess, OnError, candidates); } // If successful, handle the result void OnSuccess(float[] result) { foreach(float value in result) { Debug.Log(value); } } // Otherwise, handle the error void OnError(string error) { Debug.LogError(error); } /* other code */ ``` ## Supported Tasks and Custom Models The Hugging Face Unity API also currently supports the following tasks: - [Conversation](https://huggingface.co/tasks/conversational) - [Text Generation](https://huggingface.co/tasks/text-generation) - [Text to Image](https://huggingface.co/tasks/text-to-image) - [Text Classification](https://huggingface.co/tasks/text-classification) - [Question Answering](https://huggingface.co/tasks/question-answering) - [Translation](https://huggingface.co/tasks/translation) - [Summarization](https://huggingface.co/tasks/summarization) - [Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition) Use the corresponding methods provided by the `HuggingFaceAPI` class to perform these tasks. To use your own custom model hosted on Hugging Face, change the model endpoint in the API Wizard. ## Usage Tips 1. Keep in mind that the API makes calls asynchronously, and returns a response or error via callbacks. 2. Address slow response times or performance issues by changing model endpoints to lower resource models. ## Conclusion The Hugging Face Unity API offers a simple way to integrate AI models into your Unity projects. We hope you found this tutorial helpful. If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
StarCoder: A State-of-the-Art LLM for Code
|
lvwerra
|
May 4, 2023
|
starcoder
|
nlp, community, research
|
https://huggingface.co/blog/starcoder
|
# StarCoder: A State-of-the-Art LLM for Code ## Introducing StarCoder StarCoder and StarCoderBase are Large Language Models for Code (Code LLMs) trained on permissively licensed data from GitHub, including from 80+ programming languages, Git commits, GitHub issues, and Jupyter notebooks. Similar to LLaMA, we trained a ~15B parameter model for 1 trillion tokens. We fine-tuned StarCoderBase model for 35B Python tokens, resulting in a new model that we call StarCoder. We found that StarCoderBase outperforms existing open Code LLMs on popular programming benchmarks and matches or surpasses closed models such as `code-cushman-001` from OpenAI (the original Codex model that powered early versions of GitHub Copilot). With a context length of over 8,000 tokens, the StarCoder models can process more input than any other open LLM, enabling a wide range of interesting applications. For example, by prompting the StarCoder models with a series of dialogues, we enabled them to act as a technical assistant. In addition, the models can be used to autocomplete code, make modifications to code via instructions, and explain a code snippet in natural language. We take several important steps towards a safe open model release, including an improved PII redaction pipeline, a novel attribution tracing tool, and make StarCoder publicly available under an improved version of the OpenRAIL license. The updated license simplifies the process for companies to integrate the model into their products. We believe that with its strong performance, the StarCoder models will serve as a solid foundation for the community to use and adapt it to their use-cases and products. ## Evaluation We thoroughly evaluated StarCoder and several similar models and a variety of benchmarks. A popular Python benchmark is HumanEval which tests if the model can complete functions based on their signature and docstring. We found that both StarCoder and StarCoderBase outperform the largest models, including PaLM, LaMDA, and LLaMA, despite being significantly smaller. They also outperform CodeGen-16B-Mono and OpenAI’s code-cushman-001 (12B) model. We also noticed that a failure case of the model was that it would produce `# Solution here` code, probably because that type of code is usually part of exercise. To force the model the generate an actual solution we added the prompt `<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exercise`. This significantly increased the HumanEval score of StarCoder from 34% to over 40%, setting a new state-of-the-art result for open models. We also tried this prompt for CodeGen and StarCoderBase but didn't observe much difference. | **Model** | **HumanEval** | **MBPP** | |--------------------|--------------|----------| | LLaMA-7B | 10.5 | 17.7 | | LaMDA-137B | 14.0 | 14.8 | | LLaMA-13B | 15.8 | 22.0 | | CodeGen-16B-Multi | 18.3 | 20.9 | | LLaMA-33B | 21.7 | 30.2 | | CodeGeeX | 22.9 | 24.4 | | LLaMA-65B | 23.7 | 37.7 | | PaLM-540B | 26.2 | 36.8 | | CodeGen-16B-Mono | 29.3 | 35.3 | | StarCoderBase | 30.4 | 49.0 | | code-cushman-001 | 33.5 | 45.9 | | StarCoder | 33.6 | **52.7** | | StarCoder-Prompted | **40.8** | 49.5 | An interesting aspect of StarCoder is that it's multilingual and thus we evaluated it on MultiPL-E which extends HumanEval to many other languages. We observed that StarCoder matches or outperforms `code-cushman-001` on many languages. On a data science benchmark called DS-1000 it clearly beats it as well as all other open-access models. But let's see what else the model can do besides code completion! ## Tech Assistant With the exhaustive evaluations we found that StarCoder is very capable at writing code. But we also wanted to test if it can be used as a tech assistant, after all it was trained on a lot of documentation and GitHub issues. Inspired by Anthropic's [HHH prompt](https://gist.github.com/jareddk/2509330f8ef3d787fc5aaac67aab5f11#file-hhh_prompt-txt) we built a [Tech Assistant Prompt](https://huggingface.co/datasets/bigcode/ta-prompt). Surprisingly, with just the prompt the model is able to act as a tech assistant and answer programming related requests!  ## Training data The model was trained on a subset of The Stack 1.2. The dataset only consists of permissively licensed code and includes an opt-out process such that code contributors can remove their data from the dataset (see Am I in The Stack). In collaboration with [Toloka](https://toloka.ai/blog/bigcode-project/), we removed Personal Identifiable Information from the training data such as Names, Passwords, and Email addresses. ## About BigCode BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code. ## Additional releases Along with the model, we are releasing a list of resources and demos: - the model weights, including intermediate checkpoints with OpenRAIL license - all code for data preprocessing and training with Apache 2.0 license - a comprehensive evaluation harness for code models - a new PII dataset for training and evaluating PII removal - the fully preprocessed dataset used for training - a code attribution tool for finding generated code in the dataset ## Links ### Models - [Paper](https://arxiv.org/abs/2305.06161): A technical report about StarCoder. - [GitHub](https://github.com/bigcode-project/starcoder/tree/main): All you need to know about using or fine-tuning StarCoder. - [StarCoder](https://huggingface.co/bigcode/starcoder): StarCoderBase further trained on Python. - [StarCoderBase](https://huggingface.co/bigcode/starcoderbase): Trained on 80+ languages from The Stack. - [StarEncoder](https://huggingface.co/bigcode/starencoder): Encoder model trained on TheStack. - [StarPii](https://huggingface.co/bigcode/starpii): StarEncoder based PII detector. ### Tools & Demos - [StarCoder Chat](https://huggingface.co/chat?model=bigcode/starcoder): Chat with StarCoder! - [VSCode Extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode): Code with StarCoder! - [StarCoder Playground](https://huggingface.co/spaces/bigcode/bigcode-playground): Write with StarCoder! - [StarCoder Editor](https://huggingface.co/spaces/bigcode/bigcode-editor): Edit with StarCoder! ### Data & Governance - [StarCoderData](https://huggingface.co/datasets/bigcode/starcoderdata): Pretraining dataset of StarCoder. - [Tech Assistant Prompt](https://huggingface.co/datasets/bigcode/ta-prompt): With this prompt you can turn StarCoder into tech assistant. - [Governance Card](): A card outlining the governance of the model. - [StarCoder License Agreement](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement): The model is licensed under the BigCode OpenRAIL-M v1 license agreement. - [StarCoder Search](https://huggingface.co/spaces/bigcode/search): Full-text search code in the pretraining dataset. - [StarCoder Membership Test](https://stack.dataportraits.org): Blazing fast test if code was present in pretraining dataset. You can find all the resources and links at [huggingface.co/bigcode](https://huggingface.co/bigcode)!
|
A Dive into Text-to-Video Models
|
adirik
|
May 8, 2023
|
text-to-video
|
multi-modal, cv, guide, diffusion, text-to-image, text-to-video
|
https://huggingface.co/blog/text-to-video
|
# Text-to-Video: The Task, Challenges and the Current State <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/text-to-video-samples.gif" alt="video-samples"><br> <em>Video samples generated with <a href=https://modelscope.cn/models/damo/text-to-video-synthesis/summary>ModelScope</a>.</em> </p> Text-to-video is next in line in the long list of incredible advances in generative models. As self-descriptive as it is, text-to-video is a fairly new computer vision task that involves generating a sequence of images from text descriptions that are both temporally and spatially consistent. While this task might seem extremely similar to text-to-image, it is notoriously more difficult. How do these models work, how do they differ from text-to-image models, and what kind of performance can we expect from them? In this blog post, we will discuss the past, present, and future of text-to-video models. We will start by reviewing the differences between the text-to-video and text-to-image tasks, and discuss the unique challenges of unconditional and text-conditioned video generation. Additionally, we will cover the most recent developments in text-to-video models, exploring how these methods work and what they are capable of. Finally, we will talk about what we are working on at Hugging Face to facilitate the integration and use of these models and share some cool demos and resources both on and outside of the Hugging Face Hub. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/make-a-video.png" alt="samples"><br> <em>Examples of videos generated from various text description inputs, image taken from <a href=https://arxiv.org/abs/2209.14792>Make-a-Video</a>.</em> </p> ## Text-to-Video vs. Text-to-Image With so many recent developments, it can be difficult to keep up with the current state of text-to-image generative models. Let's do a quick recap first. Just two years ago, the first open-vocabulary, high-quality text-to-image generative models emerged. This first wave of text-to-image models, including VQGAN-CLIP, XMC-GAN, and GauGAN2, all had GAN architectures. These were quickly followed by OpenAI's massively popular transformer-based DALL-E in early 2021, DALL-E 2 in April 2022, and a new wave of diffusion models pioneered by Stable Diffusion and Imagen. The huge success of Stable Diffusion led to many productionized diffusion models, such as DreamStudio and RunwayML GEN-1, and integration with existing products, such as Midjourney. Despite the impressive capabilities of diffusion models in text-to-image generation, diffusion and non-diffusion based text-to-video models are significantly more limited in their generative capabilities. Text-to-video are typically trained on very short clips, meaning they require a computationally expensive and slow sliding window approach to generate long videos. As a result, these models are notoriously difficult to deploy and scale and remain limited in context and length. The text-to-video task faces unique challenges on multiple fronts. Some of these main challenges include: - Computational challenges: Ensuring spatial and temporal consistency across frames creates long-term dependencies that come with a high computation cost, making training such models unaffordable for most researchers. - Lack of high-quality datasets: Multi-modal datasets for text-to-video generation are scarce and often sparsely annotated, making it difficult to learn complex movement semantics. - Vagueness around video captioning: Describing videos in a way that makes them easier for models to learn from is an open question. More than a single short text prompt is required to provide a complete video description. A generated video must be conditioned on a sequence of prompts or a story that narrates what happens over time. In the next section, we will discuss the timeline of developments in the text-to-video domain and the various methods proposed to address these challenges separately. On a higher level, text-to-video works propose one of these: 1. New, higher-quality datasets that are easier to learn from. 2. Methods to train such models without paired text-video data. 3. More computationally efficient methods to generate longer and higher resolution videos. ## How to Generate Videos from Text? Let's take a look at how text-to-video generation works and the latest developments in this field. We will explore how text-to-video models have evolved, following a similar path to text-to-image research, and how the specific challenges of text-to-video generation have been tackled so far. Like the text-to-image task, early work on text-to-video generation dates back only a few years. Early research predominantly used GAN and VAE-based approaches to auto-regressively generate frames given a caption (see [Text2Filter](https://huggingface.co/papers/1710.00421) and [TGANs-C](https://huggingface.co/papers/1804.08264)). While these works provided the foundation for a new computer vision task, they are limited to low resolutions, short-range, and singular, isolated motions. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/TGANs-C.png" alt="tgans-c"><br> <em>Initial text-to-video models were extremely limited in resolution, context and length, image taken from <a href=https://arxiv.org/abs/1804.08264>TGANs-C</a>.</em> </p> Taking inspiration from the success of large-scale pretrained transformer models in text (GPT-3) and image (DALL-E), the next surge of text-to-video generation research adopted transformer architectures. [Phenaki](https://huggingface.co/papers/2210.02399), [Make-A-Video](https://huggingface.co/papers/2209.14792), [NUWA](https://huggingface.co/papers/2111.12417), [VideoGPT](https://huggingface.co/papers/2104.10157) and [CogVideo](https://huggingface.co/papers/2205.15868) all propose transformer-based frameworks, while works such as [TATS](https://huggingface.co/papers/2204.03638) propose hybrid methods that combine VQGAN for image generation and a time-sensitive transformer module for sequential generation of frames. Out of this second wave of works, Phenaki is particularly interesting as it enables generating arbitrary long videos conditioned on a sequence of prompts, in other words, a story line. Similarly, [NUWA-Infinity](https://huggingface.co/papers/2207.09814) proposes an autoregressive over autoregressive generation mechanism for infinite image and video synthesis from text inputs, enabling the generation of long, HD quality videos. However, neither Phenaki or NUWA models are publicly available. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/phenaki.png" alt="phenaki"><br> <em>Phenaki features a transformer-based architecture, image taken from <a href=https://arxiv.org/abs/2210.02399>here</a>.</em> </p> The third and current wave of text-to-video models features predominantly diffusion-based architectures. The remarkable success of diffusion models in diverse, hyper-realistic, and contextually rich image generation has led to an interest in generalizing diffusion models to other domains such as audio, 3D, and, more recently, video. This wave of models is pioneered by [Video Diffusion Models](https://huggingface.co/papers/2204.03458) (VDM), which extend diffusion models to the video domain, and [MagicVideo](https://huggingface.co/papers/2211.11018), which proposes a framework to generate video clips in a low-dimensional latent space and reports huge efficiency gains over VDM. Another notable mention is [Tune-a-Video](https://huggingface.co/papers/2212.11565), which fine-tunes a pretrained text-to-image model with a single text-video pair and enables changing the video content while preserving the motion. The continuously expanding list of text-to-video diffusion models that followed include [Video LDM](https://huggingface.co/papers/2304.08818), [Text2Video-Zero](https://huggingface.co/papers/2303.13439), [Runway Gen1 and Gen2](https://huggingface.co/papers/2302.03011), and [NUWA-XL](https://huggingface.co/papers/2303.12346). Text2Video-Zero is a text-guided video generation and manipulation framework that works in a fashion similar to ControlNet. It can directly generate (or edit) videos based on text inputs, as well as combined text-pose or text-edge data inputs. As implied by its name, Text2Video-Zero is a zero-shot model that combines a trainable motion dynamics module with a pre-trained text-to-image Stable Diffusion model without using any paired text-video data. Similarly to Text2Video-Zero, Runway’s Gen-1 and Gen-2 models enable synthesizing videos guided by content described through text or images. Most of these works are trained on short video clips and rely on autoregressive generation with a sliding window to generate longer videos, inevitably resulting in a context gap. NUWA-XL addresses this issue and proposes a “diffusion over diffusion” method to train models on 3376 frames. Finally, there are open-source text-to-video models and frameworks such as Alibaba / DAMO Vision Intelligence Lab’s ModelScope and Tencel’s VideoCrafter, which haven't been published in peer-reviewed conferences or journals. ## Datasets Like other vision-language models, text-to-video models are typically trained on large paired datasets videos and text descriptions. The videos in these datasets are typically split into short, fixed-length chunks and often limited to isolated actions with a few objects. While this is partly due to computational limitations and partly due to the difficulty of describing video content in a meaningful way, we see that developments in multimodal video-text datasets and text-to-video models are often entwined. While some work focuses on developing better, more generalizable datasets that are easier to learn from, works such as [Phenaki](https://phenaki.video/?mc_cid=9fee7eeb9d#) explore alternative solutions such as combining text-image pairs with text-video pairs for the text-to-video task. Make-a-Video takes this even further by proposing using only text-image pairs to learn what the world looks like and unimodal video data to learn spatio-temporal dependencies in an unsupervised fashion. These large datasets experience similar issues to those found in text-to-image datasets. The most commonly used text-video dataset, [WebVid](https://m-bain.github.io/webvid-dataset/), consists of 10.7 million pairs of text-video pairs (52K video hours) and contains a fair amount of noisy samples with irrelevant video descriptions. Other datasets try to overcome this issue by focusing on specific tasks or domains. For example, the [Howto100M](https://www.di.ens.fr/willow/research/howto100m/) dataset consists of 136M video clips with captions that describe how to perform complex tasks such as cooking, handcrafting, gardening, and fitness step-by-step. Similarly, the [QuerYD](https://www.robots.ox.ac.uk/~vgg/data/queryd/) dataset focuses on the event localization task such that the captions of videos describe the relative location of objects and actions in detail. [CelebV-Text](https://celebv-text.github.io/) is a large-scale facial text-video dataset of over 70K videos to generate videos with realistic faces, emotions, and gestures. ## Text-to-Video at Hugging Face Using Hugging Face Diffusers, you can easily download, run and fine-tune various pretrained text-to-video models, including Text2Video-Zero and ModelScope by [Alibaba / DAMO Vision Intelligence Lab](https://huggingface.co/damo-vilab). We are currently working on integrating other exciting works into Diffusers and 🤗 Transformers. ### Hugging Face Demos At Hugging Face, our goal is to make it easier to use and build upon state-of-the-art research. Head over to our hub to see and play around with Spaces demos contributed by the 🤗 team, countless community contributors and research authors. At the moment, we host demos for [VideoGPT](https://huggingface.co/spaces/akhaliq/VideoGPT), [CogVideo](https://huggingface.co/spaces/THUDM/CogVideo), [ModelScope Text-to-Video](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis), and [Text2Video-Zero](https://huggingface.co/spaces/PAIR/Text2Video-Zero) with many more to come. To see what we can do with these models, let's take a look at the Text2Video-Zero demo. This demo not only illustrates text-to-video generation but also enables multiple other generation modes for text-guided video editing and joint conditional video generation using pose, depth and edge inputs along with text prompts. <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script> <gradio-app theme_mode="light" space="PAIR/Text2Video-Zero"></gradio-app> Apart from using demos to experiment with pretrained text-to-video models, you can also use the [Tune-a-Video training demo](https://huggingface.co/spaces/Tune-A-Video-library/Tune-A-Video-Training-UI) to fine-tune an existing text-to-image model with your own text-video pair. To try it out, upload a video and enter a text prompt that describes the video. Once the training is done, you can upload it to the Hub under the Tune-a-Video community or your own username, publicly or privately. Once the training is done, simply head over to the *Run* tab of the demo to generate videos from any text prompt. <gradio-app theme_mode="light" space="Tune-A-Video-library/Tune-A-Video-Training-UI"></gradio-app> All Spaces on the 🤗 Hub are Git repos you can clone and run on your local or deployment environment. Let’s clone the ModelScope demo, install the requirements, and run it locally. ``` git clone https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis cd modelscope-text-to-video-synthesis pip install -r requirements.txt python app.py ``` And that's it! The Modelscope demo is now running locally on your computer. Note that the ModelScope text-to-video model is supported in Diffusers and you can directly load and use the model to generate new videos with a few lines of code. ``` import torch from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler from diffusers.utils import export_to_video pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16") pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) pipe.enable_model_cpu_offload() prompt = "Spiderman is surfing" video_frames = pipe(prompt, num_inference_steps=25).frames video_path = export_to_video(video_frames) ``` ### Community Contributions and Open Source Text-to-Video Projects Finally, there are various open source projects and models that are not on the hub. Some notable mentions are Phil Wang’s (aka lucidrains) unofficial implementations of [Imagen](https://github.com/lucidrains/imagen-pytorch), [Phenaki](https://github.com/lucidrains/phenaki-pytorch), [NUWA](https://github.com/lucidrains/nuwa-pytorch), [Make-a-Video](https://github.com/lucidrains/make-a-video-pytorch) and [Video Diffusion Models](https://github.com/lucidrains/video-diffusion-pytorch). Another exciting project by [ExponentialML](https://github.com/ExponentialML/Text-To-Video-Finetuning) builds on top of 🤗 diffusers to finetune ModelScope Text-to-Video. ## Conclusion Text-to-video research is progressing exponentially, but existing work is still limited in context and faces many challenges. In this blog post, we covered the constraints, unique challenges and the current state of text-to-video generation models. We also saw how architectural paradigms originally designed for other tasks enable giant leaps in the text-to-video generation task and what this means for future research. While the developments are impressive, text-to-video models still have a long way to go compared to text-to-image models. Finally, we also showed how you can use these models to perform various tasks using the demos available on the Hub or as a part of 🤗 Diffusers pipelines. That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: **[@adirik](https://twitter.com/alaradirik)**, **[@a_e_roberts](https://twitter.com/a_e_roberts)**, [@osanseviero](https://twitter.com/NielsRogge), [@risingsayak](https://twitter.com/risingsayak) and **[@huggingface](https://twitter.com/huggingface)**.
|
Creating a Coding Assistant with StarCoder
|
lewtun
|
May 9, 2023
|
starchat-alpha
|
nlp, community, research
|
https://huggingface.co/blog/starchat-alpha
|
# Creating a Coding Assistant with StarCoder If you’re a software developer, chances are that you’ve used GitHub Copilot or ChatGPT to solve programming tasks such as translating code from one language to another or generating a full implementation from a natural language query like *“Write a Python program to find the Nth Fibonacci number”*. Although impressive in their capabilities, these proprietary systems typically come with several drawbacks, including a lack of transparency on the public data used to train them and the inability to adapt them to your domain or codebase. Fortunately, there are now several high-quality open-source alternatives! These include SalesForce’s [CodeGen Mono 16B](https://huggingface.co/Salesforce/codegen-16B-mono) for Python, or [Replit’s 3B parameter model](https://huggingface.co/replit/replit-code-v1-3b) trained on 20 programming languages. The new kid on the block is [BigCode’s StarCoder](https://huggingface.co/bigcode/starcoder), a 16B parameter model trained on one trillion tokens sourced from 80+ programming languages, GitHub issues, Git commits, and Jupyter notebooks (all permissively licensed). With an enterprise-friendly license, 8,192 token context length, and fast large-batch inference via [multi-query attention](https://arxiv.org/abs/1911.02150), StarCoder is currently the best open-source choice for code-based applications. In this blog post, we’ll show how StarCoder can be fine-tuned for chat to create a personalised coding assistant! Dubbed StarChat, we’ll explore several technical details that arise when using large language models (LLMs) as coding assistants, including: - How LLMs can be prompted to act like conversational agents. - OpenAI’s [Chat Markup Language](https://github.com/openai/openai-python/blob/main/chatml.md) (or ChatML for short), which provides a structured format for conversational messages between human users and AI assistants. - How to fine-tune a large model on a diverse corpus of dialogues with 🤗 Transformers and DeepSpeed ZeRO-3. As a teaser of the end result, try asking StarChat a few programming questions in the demo below! <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.2/gradio.js" ></script> <gradio-app theme_mode="light" src="https://huggingfaceh4-starchat-playground.hf.space"></gradio-app> You can also find the code, dataset, and model used to produce the demo at the following links: - Code: [https://github.com/bigcode-project/starcoder](https://github.com/bigcode-project/starcoder) - Dataset: [https://huggingface.co/datasets/HuggingFaceH4/oasst1_en](https://huggingface.co/datasets/HuggingFaceH4/oasst1_en) - Model: [https://huggingface.co/HuggingFaceH4/starchat-alpha](https://huggingface.co/HuggingFaceH4/starchat-alpha) To get started, let’s take a look at how language models can be turned into conversational agents without any fine-tuning at all. ## Prompting LLMs for dialogue As shown by [DeepMind](https://arxiv.org/abs/2209.14375) and [Anthropic](https://arxiv.org/abs/2112.00861), LLMs can be turned into conversational agents through a clever choice of prompt. These prompts typically involve a so-called “system” message that defines the character of the LLM, along with a series of dialogues between the assistant and a user. For example, here’s an excerpt from [Anthropic’s HHH prompt](https://gist.github.com/jareddk/2509330f8ef3d787fc5aaac67aab5f11#file-hhh_prompt-txt) (a whopping 6k tokens in total!): ``` Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn’t entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn’t let caution get too much in the way of being useful. ----- Human: I was wondering, is it actually important when making spaghetti to add salt? Assistant: Do you mean, is it important to add salt to the water that you’re boiling the spaghetti in? Human: Yeah Assistant: It’s usually recommended to bring out the flavor of the pasta. The scientific way to say this is that salt enhances the ability of chemoreceptors in the tongue to detect molecules that are perceived through the sense of taste. Human: But I mean I’m going to use sauce and stuff, so does it matter? Assistant: It sounds like you’re skeptical. Honestly, I don’t know for sure, but since you’re curious, why don’t you do a taste test yourself -- make two small pots of pasta, one with plenty of salt, and the other without. Then taste the noodles and see which one you prefer? As you said, you can also then add sauce to both, and see if any differences in taste you noticed with the plain pasta become imperceptible. It should be a fun experiment! ----- ... ----- Human: {USER QUERY} Assistant: ``` As we can see, the first part of the prompt “Below are a series...” corresponds to the system message and specifies that the assistant should have characteristics like “helpfulness” and “politeness”. The dialogue examples then condition the model to follow the multi-turn format of a conversation. When a user asks a question, the whole prompt is fed to the model and it generates an answer after the `Assistant:` prefix. The answer is then concatenated to the prompt and the process repeated at every turn. Somewhat surprisingly, this technique also works for StarCoder! This is enabled by the model’s 8k token context length, which allows one to include a wide variety of programming examples and convert the model into a coding assistant. Here’s an excerpt of the StarCoder prompt: ``` Below are a series of dialogues between various people and an AI technical assistant. The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with code questions, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn’t entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn’t let caution get too much in the way of being useful. The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests). The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data. ----- Human: Write a function that takes two lists and returns a list that has alternating elements from each input list. Assistant: Sure. Here is a function that does that. def alternating(list1, list2): results = [] for i in range(len(list1)): results.append(list1[i]) results.append(list2[i]) return results Human: Can you write some test cases for this function? Assistant: Sure, here are some tests. assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3] assert alternating([True, False], [4, 5]) == [True, 4, False, 5] assert alternating([], []) == [] Human: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end. Assistant: Here is the modified function. def alternating(list1, list2): results = [] for i in range(min(len(list1), len(list2))): results.append(list1[i]) results.append(list2[i]) if len(list1) > len(list2): results.extend(list1[i+1:]) else: results.extend(list2[i+1:]) return results ----- ``` Here we can see how a well crafted prompt can induce coding behaviour similar to that observed in ChatGPT. You can find the full prompt [here](https://huggingface.co/datasets/bigcode/ta-prompt/blob/main/TA_prompt_v1.txt) and chat with the prompted StarCoder on [HuggingChat](https://hf.co/chat/?model=bigcode/starcoder). One major drawback with dialogue-prompting is that inference can be very costly: every turn of the conversation involves thousands of tokens which will quickly burn a hole in your wallet! The obvious alternative is to fine-tune the base model on a corpus of dialogues and enable it to become “chatty”. Let’s take a look at a few interesting datasets that have recently landed on the Hub and are powering most of the open-source chatbots today. ## Datasets for chatty language models The open-source community is rapidly creating diverse and powerful datasets for transforming any base language model into a conversational agent that can follow instructions. Some examples that we have found to produce chatty language models include: - [OpenAssistant’s dataset](https://huggingface.co/datasets/OpenAssistant/oasst1), which consists of over 40,000 conversations, where members of the community take turns mimicking the roles of a user or AI assistant. - [The ShareGPT dataset](https://huggingface.co/datasets/RyokoAI/ShareGPT52K), which contains approximately 90,000 conversations between human users and ChatGPT. For the purposes of this blog post, we’ll use the OpenAssistant dataset to fine-tune StarCoder since it has a permissive license and was produced entirely by humans. The raw dataset is formatted as a collection of conversation trees, so we’ve preprocessed it so that each row corresponds to a single dialogue between the user and the assistant. To avoid deviating too far from the data that StarCoder was pretrained on, we’ve also filtered it for English dialogues. Let’s start by downloading the processed dataset from the Hub: ```python from datasets import load_dataset dataset = load_dataset("HuggingFaceH4/oasst1_en") print(dataset) ``` ``` DatasetDict({ train: Dataset({ features: ['messages'], num_rows: 19034 }) test: Dataset({ features: ['messages'], num_rows: 2115 }) }) ``` As we can see, the dataset contains around 21,000 English conversations. Let’s take a look at one of the training examples. Take the first example, ```python sample = dataset["train"][0] print(sample) ``` ``` { "messages": [ { "content": "Is it possible to imagine a society without law?", "role": "user", }, { "content": "It is difficult to imagine a society that is able to be maintained without any semblance of Law. Laws exist for the purpose of maintaining society and past human behavior suggests that there would be people that have no interest in promoting social cohesion and norms so it's unlikely that complex social and economic systems could develop without a legal system.", "role": "assistant", }, { "content": 'It seems like you consider the absence of law equal to the absence of anything that could guide the behaviour of the individual, however there are many other such things, like religion, conscience, tradition to mention a few important patterns which are known to have crucial influence on society even today, but also we could imagine more, like universal love if everyone suddenly became "awaken" in some spiritual sense, or simply just having an omnipotent leader who maintains a certain order without ever codifying the principles in law. Is it still difficult to imagine?', "role": "user", }, { "content": "You are correct that there are other factors that can guide behavior in a society and play a role in shaping individuals' behavior and interactions with each other. However, even in societies where these factors are present, laws still serve an important role in maintaining social order and resolving conflicts. \n\nFor example, religious teachings may prohibit theft and murder, but laws provide a system of justice for those who violate these prohibitions. Personal morality and conscience may guide individuals to act in a certain way, but laws provide a framework for resolving disputes when conflicting moral beliefs arise. Furthermore, the other factors you mentioned, such as universal love or an omnipotent leader, are not necessarily stable or reliable guides for behavior. Universal love, while a noble ideal, may not be achievable in practice, and an omnipotent leader may be prone to corruption or abuse of power.\n\nLaws provide a crucial foundation for maintaining social order and ensuring justice. It is possible to imagine alternative systems of governance, but it is unlikely that a society without any sort of legal framework would be stable or functional in the long term.", "role": "assistant", }, { "content": "Yeah, but laws are complicated. Most people can't understand them in depth. Some would argue it is almost a self-serving system which put energy into growing itself(eg.: patent trolling). I think there must be a less complex system which keeps up order in society.", "role": "user", }, ] } ``` OK, this looks like an interesting dialogue about moral philosophy, with each turn involving a role and content field to indicate who is writing. Let’s now take a look at converting these dialogues to a standard format that simplifies the way messages are generated at inference time. ### A standard format for dialogues One way to fine-tune a model on dialogues is to simply insert the system message and roles in each training example, and then separate each dialogue with an end-of-sequence token like <EOS>. For instance, the conversation above could take the form: ``` Below is a dialogue between a human and AI assistant ... Human: Is it possible to imagine a society without law? Assistant: It is difficult to imagine ... Human: It seems like you ... Assistant: You are correct ... Human: Yeah, but laws are complicated .. <EOS> ``` Although this works fine for training, it isn’t ideal for inference because the model will naturally generate unwanted turns until it produces an `<EOS>` token, and some post-processing or additional logic is typically required to prevent this. A more appealing approach is to use a structured format like [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md), which wraps each turn with a set of *special tokens* that indicates the role of the query or response. In this format, we have the following special tokens: - `<|system|>`: indicates which part of the dialogue contains the system message to condition the character of the assistant. - `<|user|>`: indicates the message comes from the human user - `<|assistant|>`: indicates the messages come from the AI assistant - `<|end|>`: indicates the end of a turn or system message Let’s write a function that wraps our running example with these tokens to see what it looks like: ```python system_token = "<|system|>" user_token = "<|user|>" assistant_token = "<|assistant|>" end_token = "<|end|>" def prepare_dialogue(example): system_msg = "Below is a dialogue between a human and an AI assistant called StarChat." prompt = system_token + "\n" + system_msg + end_token + "\n" for message in example["messages"]: if message["role"] == "user": prompt += user_token + "\n" + message["content"] + end_token + "\n" else: prompt += assistant_token + "\n" + message["content"] + end_token + "\n" return prompt print(prepare_dialogue(sample)) ``` ``` <|system|> Below is a dialogue between a human and AI assistant called StarChat. <|end|> <|user|> Is it possible to imagine a society without law?<|end|> <|assistant|> It is difficult to imagine ...<|end|> <|user|> It seems like you ...<|end|> <|assistant|> You are correct ...<|end|> <|user|> Yeah, but laws are complicated ...<|end|> ``` OK, this looks like what we need! The next step is to include these special tokens in the tokenizer’s vocabulary, so let’s download the StarCoder tokenizer and add them: ```python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bigcode/starcoderbase") tokenizer.add_special_tokens({"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"]}) # Check the tokens have been added tokenizer.special_tokens_map ``` ``` { "bos_token": "<|endoftext|>", "eos_token": "<|endoftext|>", "unk_token": "<|endoftext|>", "additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"], } ``` As a sanity check this works, let’s see if tokenizing the string "<|assistant|>" produces a single token ID: ```python tokenizer("<|assistant|>") ``` ``` {"input_ids": [49153], "attention_mask": [1]} ``` Great, it works! ### Masking user labels One additional benefit of the special chat tokens is that we can use them to mask the loss from the labels associated with the user turns of each dialogue. The reason to do this is to ensure the model is conditioned on the user parts of the dialogue, but only trained to predict the assistant parts (which is what really matters during inference). Here’s a simple function that masks the labels in place and converts all the user tokens to -100 which is subsequently ignored by the loss function: ```python def mask_user_labels(tokenizer, labels): user_token_id = tokenizer.convert_tokens_to_ids(user_token) assistant_token_id = tokenizer.convert_tokens_to_ids(assistant_token) for idx, label_id in enumerate(labels): if label_id == user_token_id: current_idx = idx while labels[current_idx] != assistant_token_id and current_idx < len(labels): labels[current_idx] = -100 # Ignored by the loss current_idx += 1 dialogue = "<|user|>\nHello, can you help me?<|end|>\n<|assistant|>\nSure, what can I do for you?<|end|>\n" input_ids = tokenizer(dialogue).input_ids labels = input_ids.copy() mask_user_labels(tokenizer, labels) labels ``` ``` [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 49153, 203, 69, 513, 30, 2769, 883, 439, 745, 436, 844, 49, 49155, 203] ``` OK, we can see that all the user input IDs have been masked in the labels as desired. These special tokens have embeddings that will need to be learned during the fine-tuning process. Let’s take a look at what’s involved. ## Fine-tuning StarCoder with DeepSpeed ZeRO-3 The StarCoder and StarCoderBase models contain 16B parameters, which means we’ll need a lot of GPU vRAM to fine-tune them — for instance, simply loading the model weights in full FP32 precision requires around 60GB vRAM! Fortunately, there are a few options available to deal with large models like this: - Use parameter-efficient techniques like LoRA which freeze the base model’s weights and insert a small number of learnable parameters. You can find many of these techniques in the [🤗 PEFT](https://github.com/huggingface/peft) library. - Shard the model weights, optimizer states, and gradients across multiple devices using methods like [DeepSpeed ZeRO-3](https://huggingface.co/docs/transformers/main_classes/deepspeed) or [FSDP](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/). Since DeepSpeed is tightly integrated in 🤗 Transformers, we’ll use it to train our model. To get started, first clone BigCode’s StarCoder repo from GitHub and navigate to the `chat` directory: ```shell git clone https://github.com/bigcode-project/starcoder.git cd starcoder/chat ``` Next, create a Python virtual environment using e.g. Conda: ```shell conda create -n starchat python=3.10 && conda activate starchat ``` Next, we install PyTorch v1.13.1. Since this is hardware-dependent, we direct you to the [PyTorch Installation Page](https://pytorch.org/get-started/locally/) for this step. Once you've installed it, install the rest of the project dependencies: ```shell pip install -r requirements.txt ``` We need to be logged into both Hugging Face. To do so, run: ```shell huggingface-cli login ``` Finally, install Git LFS with: ```shell sudo apt-get install git-lfs ``` The final step is to launch the training! If you’re lucky enough to have 8 x A100 (80GB) GPUs to run this training, you can run the following command. Training should take around 45 minutes: ```shell torchrun --nproc_per_node=8 train.py config.yaml --deepspeed=deepspeed_z3_config_bf16.json ``` Here the `config.yaml` file specifies all the parameters associated with the dataset, model, and training - you can configure it [here](https://github.com/bigcode-project/starcoder/tree/main/chat) to adapt the training to a new dataset. Your trained model will then be available on the Hub! ## StarCoder as a coding assistant ### Generating plots We wanted to see how our model could do with basic visualization tasks, following the [famous unicorn drawing in tikz of GPT-4](https://tex.stackexchange.com/questions/681418/draw-a-unicorn-in-tikz). To do this, we prompted our model with some coding tasks and got wonderful results! Yes, these are a little cherry picked as we only selected the completions that **wrote functioning code**, but the others were not far off! **Example 1: bar plot** Prompt: ``` Give the following data {'Name':['Tom', 'Brad', 'Kyle', 'Jerry'], 'Age':[20, 21, 19, 18], 'Height' : [6.1, 5.9, 6.0, 6.1]}. Can you plot one graph with two subplots as columns. The first is a bar graph showing the height of each person. The second is a bargraph showing the age of each person? Draw the graph in seaborn talk mode. ``` Response: ```python import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.style.use('seaborn-talk') data = {'Name':['Tom', 'Brad', 'Kyle', 'Jerry'], 'Age':[20, 21, 19, 18], 'Height':[6.1, 5.9, 6.0, 6.1]} df=pd.DataFrame(data) # Bar Graph for Height and Age fig,(ax1, ax2)=plt.subplots(nrows=1, ncols=2, figsize=(14,7)) sns.barplot(x='Name', y="Height", data=df, palette="Blues_d", ax=ax1).set_title("Height Comparison") sns.barplot(x='Name',y ="Age", data=df,palette="Reds_d", ax=ax2 ).set_title("Age Comparison") # Add padding between plots fig.tight_layout() # Show the final image plt.show() ``` <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/barplot.png" alt="samples"><br> <em>Example of a plot generated by StarChat</a>.</em> </p> **Example 2: mapping** Prompt: ``` Draw me a map of the world using geopandas. Make it so that only Germany and Spain are colored red. ``` Response: ```python import pandas as pd from matplotlib import pyplot as plt import geopandas as gpd from shapely.geometry import Point, Polygon %matplotlib inline # Load data from URL or local file url = 'https://raw.githubusercontent.com/datasets/geo-countries/master/data/countries.geojson' df = gpd.read_file(url) # Create plot fig, ax = plt.subplots() ax.set_aspect('equal') world = gpd.GeoDataFrame({'name': ['World'], 'geometry': [Polygon([(0, 0), (1, 0), (1, 1), (0, 1)])]}) germany = df[df['ADMIN'] == "Germany"] spain = df[df['ADMIN'] == "Spain"] other = df[(df['ADMIN']!= "Germany") & (df['ADMIN']!= "Spain")] world.plot(color='lightgrey', edgecolor='white', ax=ax) germany.plot(color="red", ax=ax) spain.plot(color="red", ax=ax) other.plot(color="skyblue", ax=ax) plt.title("European Countries") plt.show() ``` <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/map.png" alt="samples"><br> <em>Example of a plot generated by StarChat</a>.</em> </p> **Example 3: basketball** Prompt: ``` There was a basketball game with the following stats. player, points, rebounds and assists: J. Harden 42 8 9 J. Embiid 34 13 4 T. Maxey 14 8 1 T. Harris 9 7 2 P. Tucker 6 3 1. Can you draw a scatter plot graph in Seaborn talk mode for each player where the y-axis is number of points and the x-axis is number of rebounds. Make sure the marker is 'o'. Put the name of the player over each point. The title should be "Sixers Players". ``` Response: ```python import pandas as pd import seaborn as sns from matplotlib import pyplot as plt %matplotlib inline # Load data into dataframe df = pd.DataFrame({'Player': ['J. Harden', 'J. Embiid', 'T. Maxey', 'T. Harris', 'P. Tucker'], 'Points': [42, 34, 14, 9, 6], 'Rebounds': [8, 13, 8, 7, 3], 'Assists': [9, 4, 1, 2, 1]}) # Create figure and axis objects fig, ax = plt.subplots() # Plot points vs rebounds sns.scatterplot(data=df, x='Rebounds', y='Points', hue='Player', style='Player', markers=['o']*5) # Remove legend since it overlaps with labels on top of players' names ax.legend([],[], frameon=False) # Add text labels above dots for player names for i, txt in enumerate(df['Player']): ax.annotate(txt, (df["Rebounds"][i] +.1, df["Points"][i])) # Set titles and labels ax.set_title('Sixers Player') ax.set_xlabel('Number of Rebounds') ax.set_ylabel('Number of Points') plt.show() ``` <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/basketball.png" alt="samples"><br> <em>Example of a plot generated by StarChat</a>.</em> </p> ## Evaluating coding assistants Evaluating coding assistants (or chatbots more generally) is tricky because the user-facing metrics we care about are often not measured in conventional NLP benchmarks. For example, we ran the base and fine-tuned StarCoderBase models through EleutherAI’s [language model evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness) to measure their performance on the following benchmarks: - [AI2 Reasoning Challenge](https://allenai.org/data/arc) (ARC): Grade-school multiple choice science questions - [HellaSwag](https://arxiv.org/abs/1905.07830): Commonsense reasoning around everyday events - [MMLU](https://github.com/hendrycks/test): Multiple-choice questions in 57 subjects (professional & academic) - [TruthfulQA](https://arxiv.org/abs/2109.07958): Tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements The results are shown in the table below, where we can see the fine-tuned model has improved, but not in a manner that reflects it’s conversational capabilities. | Model | ARC | HellaSwag | MMLU | TruthfulQA | |:----------------:|:----:|:---------:|:----:|:----------:| | StarCoderBase | 0.30 | 0.46 | 0.33 | 0.40 | | StarChat (alpha) | 0.33 | 0.49 | 0.34 | 0.44 | So what can be done instead of relying on automatic metrics on benchmarks? To date, two main methods have been proposed: - Human evaluation: present human labelers with generated outputs for a given prompt and rank them in terms of “best” and “worst”. This is the current gold standard used to create systems like InstructGPT. - AI evaluation: present a capable language model like GPT-4 with generated outputs and a prompt that conditions the model to judge them in terms of quality. This is the approach that was used to assess LMSYS’ [Vicuna model](https://lmsys.org/blog/2023-03-30-vicuna/). As a simple experiment, we used ChatGPT to test our StarCoder models on several programming languages. To do this, we first created a [seed dataset of interesting prompts](https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts) for evaluation. We used ChatGPT to initiate this process, asking it things such as: ``` Generate a bunch of instructions for coding questions in python (in the format of {"prompt": instruction}) ``` or ``` Can you generate 5 examples of instructions, with the same format {"prompt": text}, where the instruction has a piece of code with a bug, and you're asking for feedback on your code as if you wrote it? ``` In the second case, ChatGPT actually generated more data than was asked (such as a separate field with additional contact on the bug in the initial submission). Right now, this dataset contains 115 prompts and is primarily in Python. Three quarters of the prompts are instructions asking for the user to provide code, and one quarter ask for feedback on a buggy code sample. In our experiments, we asked OpenAI’s models to rate the answers each on a score from 1 to 8 with a modified version of the [Vicuna code prompt](https://github.com/lm-sys/FastChat/tree/main/fastchat/eval/table) comparing responses. In this case, the instruction tuned StarCoder model achieved a higher score than the base model 95.6% of the time. An interesting artifact is that we definitely see that ChatGPT likes to return safer scores in the middle of the range when compared to GPT4, which is more open to giving 1s and 8s. Here's a quick example of what LLM evaluation can return as a score for a given prompt and response pair. Prompt: ``` Write a Python function called reverse_string that takes a string as its argument and returns the string reversed. ``` Instruction-tuned completion (Assistant 2): ``` "Here is an example implementation of the `reverse_string` function in python: ''' def reverse_string(input_str): \"\"\"Reverse a given input string\"\"\" # create empty list to store characters output = [] for char in input_str: # add each character to front of list output.insert(0,char) return ''.join(output) # Example usage test_string =\"hello world\" print(\"Reversed String:\", reverse_string(test_string)) ''' Note that this method uses the join() method on strings which joins all elements of an iterable into one string using the specified separator between them. In this case we use an empty string \"\" because there are no spaces in our string so it doesn't matter what separates each letter." ``` Base-model completion (Assistant 1): ``` "Sure thing! Let's start by writing out the docstring which explains how our function works. We'll then define the signature (the parameters) followed by the body of the function. reverse_string.__doc__ = \"Reverses any given string.\" reverse_string.__name__ ='reverse_string' reverse_string.__signature__ = inspect.Signature() #<|end|> <|user|> Here is my attempt: <|end|> <|assistant|> Okay great! Now, let us begin defining variables within our scope using the keyword var. Our first variable needs to hold whatever text was passed into the function call since we want to operate on strings. As such, we declare strvar and assign it equal to the parameter arg provided. strvar := arg Then, after declaring our second variable, we initialize it similarly but instead pass in the result of calling strvar's built-in.reversed() method alongside the index operator []. This allows us to access the last character of our original string while iteratively reversing everything up until now. Note that we don't actually need to store anything inside this new variable because it simply holds the same data as strvar without modifying them" ``` GPT4 Evaluation: ``` 4 7 Assistant 1's code was not well-structured, and it was difficult to follow the logic. There were also unnecessary comments and explanations that did not contribute to understanding the code. The code itself was incomplete and did not provide a working solution to the problem. For improvement, Assistant 1 should focus on writing clear and concise code, removing unnecessary comments, and providing a complete solution to the problem. Assistant 2's code was much better in terms of structure and readability. The code was accurate, efficient, and included helpful comments. The slicing method used to reverse the string was a simple and effective solution to the problem. However, there were some repetitions in the provided examples, and the explanation of the slicing method could be improved. Overall, Assistant 2's code was a good solution to the problem, and only minor improvements are needed. ``` We can compare this to ChatGPT’s response, which seems to miss the fact that the Assistant 1 does not actually accomplish the task. In its response it says the second is better, but gives it a lower score. ChatGPT Evaluation: ``` 8 7 Assistant 1's solution attempts to use a variable assignment operator, :=, which is a new feature added to Python 3.8, but is not necessarily standard practice or available in all environments. Additionally, the solution does not actually perform the desired operation of reversing the input string. Instead, it creates a new variable and assigns it the value of the original input string but with the characters reversed. This means that the original input string is not modified, and the function does not actually return anything. Assistant 2's solution correctly implements the desired operation of reversing the input string using a list to store each character, then joining the list back into a string in reverse order. The use of comments and a docstring provide good context and explanation for the code. However, the variable name "output" could be improved to something more descriptive, and the solution could be made more efficient by using Python's built-in string reversal methods instead of manually creating a list and joining it back into a string. Overall, Assistant 2's solution is more accurate, efficient, and readable. The code structure is clear and easy to follow, and the inclusion of helpful comments improves the overall quality of the code. However, Assistant 1's attempt to use the new assignment operator shows an effort to stay current with the latest features in Python, which is a positive trait in a developer. ``` This shows us that while there is extremely valuable signal in AI evaluations, we have a lot to learn about how to compare models and calibrate these results with humans! ## Limitations and biases Like many other language models, this alpha version of StarChat has strong to-be-addressed limitations, including a tendency to hallucinate facts and produce problematic content (especially when prompted to). In particular, the model hasn't been aligned to human preferences with techniques like RLHF or deployed with in-the-loop filtering of responses like ChatGPT. Models trained primarily on code data will also have a more skewed demographic bias commensurate with the demographics of the GitHub community, for more on this see the [StarCoder dataset](https://huggingface.co/datasets/bigcode/starcoderdata). For more details on the model’s limitations in terms of factuality and biases, see the [model card](https://huggingface.co/HuggingFaceH4/starchat-alpha#bias-risks-and-limitations). ## Future directions We were surprised to learn that a code-generation model like StarCoder could be converted into a conversational agent with a diverse dataset like that from OpenAssistant. One possible explanation is that StarCoder has been trained on both code _and_ GitHub issues, the latter providing a rich signal of natural language content. We're excited to see where the community will take StarCoder - perhaps it will power the next wave of open-source assistants 🤗. ## Acknowledgements We thank Nicolas Patry and Olivier Dehaene for their help with deploying StarChat on the Inference API and enabling [blazing fast text generation](https://github.com/huggingface/text-generation-inference). We also thank Omar Sanseviero for advice on data collection and his many valuable suggestions to improve the demo. Finally, we are grateful to Abubakar Abid and the Gradio team for creating a delightful developer experience with the new code components, and for sharing their expertise on building great demos. ## Links - Code: [https://github.com/bigcode-project/starcoder/tree/main/chat](https://github.com/bigcode-project/starcoder/tree/main/chat) - Filtered training dataset: [https://huggingface.co/datasets/HuggingFaceH4/oasst1_en](https://huggingface.co/datasets/HuggingFaceH4/oasst1_en) - Code evaluation dataset: [https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts](https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts) - Model: [https://huggingface.co/HuggingFaceH4/starchat-alpha](https://huggingface.co/HuggingFaceH4/starchat-alpha) ## Citation To cite this work, please use the following citation: ``` @article{Tunstall2023starchat-alpha, author = {Tunstall, Lewis and Lambert, Nathan and Rajani, Nazneen and Beeching, Edward and Le Scao, Teven and von Werra, Leandro and Han, Sheon and Schmid, Philipp and Rush, Alexander}, title = {Creating a Coding Assistant with StarCoder}, journal = {Hugging Face Blog}, year = {2023}, note = {https://huggingface.co/blog/starchat-alpha}, } ```
|
Assisted Generation: a new direction toward low-latency text generation
|
joaogante
|
May 11, 2023
|
assisted-generation
|
nlp, research
|
https://huggingface.co/blog/assisted-generation
|
# Assisted Generation: a new direction toward low-latency text generation Large language models are all the rage these days, with many companies investing significant resources to scale them up and unlock new capabilities. However, as humans with ever-decreasing attention spans, we also dislike their slow response times. Latency is critical for a good user experience, and smaller models are often used despite their lower quality (e.g. in [code completion](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html)). Why is text generation so slow? What’s preventing you from deploying low-latency large language models without going bankrupt? In this blog post, we will revisit the bottlenecks for autoregressive text generation and introduce a new decoding method to tackle the latency problem. You’ll see that by using our new method, assisted generation, you can reduce latency up to 10x in commodity hardware! ## Understanding text generation latency The core of modern text generation is straightforward to understand. Let’s look at the central piece, the ML model. Its input contains a text sequence, which includes the text generated so far, and potentially other model-specific components (for instance, Whisper also has an audio input). The model takes the input and runs a forward pass: the input is fed to the model and passed sequentially along its layers until the unnormalized log probabilities for the next token are predicted (also known as logits). A token may consist of entire words, sub-words, or even individual characters, depending on the model. The [illustrated GPT-2](https://jalammar.github.io/illustrated-gpt2/) is a great reference if you’d like to dive deeper into this part of text generation. <!-- [GIF 1 -- FWD PASS] --> <figure class="image table text-center m-0 w-full"> <video style="max-width: 90%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov" ></video> </figure> A model forward pass gets you the logits for the next token, which you can freely manipulate (e.g. set the probability of undesirable words or sequences to 0). The following step in text generation is to select the next token from these logits. Common strategies include picking the most likely token, known as greedy decoding, or sampling from their distribution, also called multinomial sampling. Chaining model forward passes with next token selection iteratively gets you text generation. This explanation is the tip of the iceberg when it comes to decoding methods; please refer to [our blog post on text generation](https://huggingface.co/blog/how-to-generate) for an in-depth exploration. <!-- [GIF 2 -- TEXT GENERATION] --> <figure class="image table text-center m-0 w-full"> <video style="max-width: 90%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov" ></video> </figure> From the description above, the latency bottleneck in text generation is clear: running a model forward pass for large models is slow, and you may need to do hundreds of them in a sequence. But let’s dive deeper: why are forward passes slow? Forward passes are typically dominated by matrix multiplications and, after a quick visit to the [corresponding wikipedia section](https://en.wikipedia.org/wiki/Matrix_multiplication_algorithm#Communication-avoiding_and_distributed_algorithms), you can tell that memory bandwidth is the limitation in this operation (e.g. from the GPU RAM to the GPU compute cores). In other words, *the bottleneck in the forward pass comes from loading the model layer weights into the computation cores of your device, not from performing the computations themselves*. At the moment, you have three main avenues you can explore to get the most out of text generation, all tackling the performance of the model forward pass. First, you have the hardware-specific model optimizations. For instance, your device may be compatible with [Flash Attention](https://github.com/HazyResearch/flash-attention), which speeds up the attention layer through a reorder of the operations, or [INT8 quantization](https://huggingface.co/blog/hf-bitsandbytes-integration), which reduces the size of the model weights. Second, when you know you’ll get concurrent text generation requests, you can batch the inputs and massively increase the throughput with a small latency penalty. The model layer weights loaded into the device are now used on several input rows in parallel, which means that you’ll get more tokens out for approximately the same memory bandwidth burden. The catch with batching is that you need additional device memory (or to offload the memory somewhere) – at the end of this spectrum, you can see projects like [FlexGen](https://github.com/FMInference/FlexGen) which optimize throughput at the expense of latency. ```python # Example showcasing the impact of batched generation. Measurement device: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model = AutoModelForCausalLM.from_pretrained("distilgpt2").to("cuda") inputs = tokenizer(["Hello world"], return_tensors="pt").to("cuda") def print_tokens_per_second(batch_size): new_tokens = 100 cumulative_time = 0 # warmup model.generate( **inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size ) for _ in range(10): start = time.time() model.generate( **inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size ) cumulative_time += time.time() - start print(f"Tokens per second: {new_tokens * batch_size * 10 / cumulative_time:.1f}") print_tokens_per_second(1) # Tokens per second: 418.3 print_tokens_per_second(64) # Tokens per second: 16266.2 (~39x more tokens per second) ``` Finally, if you have multiple devices available to you, you can distribute the workload using [Tensor Parallelism](https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many#tensor-parallelism) and obtain lower latency. With Tensor Parallelism, you split the memory bandwidth burden across multiple devices, but you now have to consider inter-device communication bottlenecks in addition to the monetary cost of running multiple devices. The benefits depend largely on the model size: models that easily fit on a single consumer device see very limited benefits. Taking the results from this [DeepSpeed blog post](https://www.microsoft.com/en-us/research/blog/deepspeed-accelerating-large-scale-model-inference-and-training-via-system-optimizations-and-compression/), you see that you can spread a 17B parameter model across 4 GPUs to reduce the latency by 1.5x (Figure 7). These three types of improvements can be used in tandem, resulting in [high throughput solutions](https://github.com/huggingface/text-generation-inference). However, after applying hardware-specific optimizations, there are limited options to reduce latency – and the existing options are expensive. Let’s fix that! ## Language decoder forward pass, revisited You’ve read above that each model forward pass yields the logits for the next token, but that’s actually an incomplete description. During text generation, the typical iteration consists in the model receiving as input the latest generated token, plus cached internal computations for all other previous inputs, returning the next token logits. Caching is used to avoid redundant computations, resulting in faster forward passes, but it’s not mandatory (and can be used partially). When caching is disabled, the input contains the entire sequence of tokens generated so far and the output contains the logits corresponding to the next token for *all positions* in the sequence! The logits at position N correspond to the distribution for the next token if the input consisted of the first N tokens, ignoring all subsequent tokens in the sequence. In the particular case of greedy decoding, if you pass the generated sequence as input and apply the argmax operator to the resulting logits, you will obtain the generated sequence back. ```python from transformers import AutoModelForCausalLM, AutoTokenizer tok = AutoTokenizer.from_pretrained("distilgpt2") model = AutoModelForCausalLM.from_pretrained("distilgpt2") inputs = tok(["The"], return_tensors="pt") generated = model.generate(**inputs, do_sample=False, max_new_tokens=10) forward_confirmation = model(generated).logits.argmax(-1) # We exclude the opposing tips from each sequence: the forward pass returns # the logits for the next token, so it is shifted by one position. print(generated[0, 1:].tolist() == forward_confirmation[0, :-1].tolist()) # True ``` This means that you can use a model forward pass for a different purpose: in addition to feeding some tokens to predict the next one, you can also pass a sequence to the model and double-check whether the model would generate that same sequence (or part of it). <!-- [GIF 3 -- FWD CONFIRMATION] --> <figure class="image table text-center m-0 w-full"> <video style="max-width: 90%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_3_1080p.mov" ></video> </figure> Let’s consider for a second that you have access to a magical latency-free oracle model that generates the same sequence as your model, for any given input. For argument’s sake, it can’t be used directly, it’s limited to being an assistant to your generation procedure. Using the property described above, you could use this assistant model to get candidate output tokens followed by a forward pass with your model to confirm that they are indeed correct. In this utopian scenario, the latency of text generation would be reduced from `O(n)` to `O(1)`, with `n` being the number of generated tokens. For long generations, we're talking about several orders of magnitude. Walking a step towards reality, let's assume the assistant model has lost its oracle properties. Now it’s a latency-free model that gets some of the candidate tokens wrong, according to your model. Due to the autoregressive nature of the task, as soon as the assistant gets a token wrong, all subsequent candidates must be invalidated. However, that does not prevent you from querying the assistant again, after correcting the wrong token with your model, and repeating this process iteratively. Even if the assistant fails a few tokens, text generation would have an order of magnitude less latency than in its original form. Obviously, there are no latency-free assistant models. Nevertheless, it is relatively easy to find a model that approximates some other model’s text generation outputs – smaller versions of the same architecture trained similarly often fit this property. Moreover, when the difference in model sizes becomes significant, the cost of using the smaller model as an assistant becomes an afterthought after factoring in the benefits of skipping a few forward passes! You now understand the core of _assisted generation_. ## Greedy decoding with assisted generation Assisted generation is a balancing act. You want the assistant to quickly generate a candidate sequence while being as accurate as possible. If the assistant has poor quality, your get the cost of using the assistant model with little to no benefits. On the other hand, optimizing the quality of the candidate sequences may imply the use of slow assistants, resulting in a net slowdown. While we can't automate the selection of the assistant model for you, we’ve included an additional requirement and a heuristic to ensure the time spent with the assistant stays in check. First, the requirement – the assistant must have the exact same tokenizer as your model. If this requirement was not in place, expensive token decoding and re-encoding steps would have to be added. Furthermore, these additional steps would have to happen on the CPU, which in turn may need slow inter-device data transfers. Fast usage of the assistant is critical for the benefits of assisted generation to show up. Finally, the heuristic. By this point, you have probably noticed the similarities between the movie Inception and assisted generation – you are, after all, running text generation inside text generation. There will be one assistant model forward pass per candidate token, and we know that forward passes are expensive. While you can’t know in advance the number of tokens that the assistant model will get right, you can keep track of this information and use it to limit the number of candidate tokens requested to the assistant – some sections of the output are easier to anticipate than others. Wrapping all up, here’s our original implementation of the assisted generation loop ([code](https://github.com/huggingface/transformers/blob/849367ccf741d8c58aa88ccfe1d52d8636eaf2b7/src/transformers/generation/utils.py#L4064)): 1. Use greedy decoding to generate a certain number of candidate tokens with the assistant model, producing `candidates`. The number of produced candidate tokens is initialized to `5` the first time assisted generation is called. 2. Using our model, do a forward pass with `candidates`, obtaining `logits`. 3. Use the token selection method (`.argmax()` for greedy search or `.multinomial()` for sampling) to get the `next_tokens` from `logits`. 4. Compare `next_tokens` to `candidates` and get the number of matching tokens. Remember that this comparison has to be done with left-to-right causality: after the first mismatch, all candidates are invalidated. 5. Use the number of matches to slice things up and discard variables related to unconfirmed candidate tokens. In essence, in `next_tokens`, keep the matching tokens plus the first divergent token (which our model generates from a valid candidate subsequence). 6. Adjust the number of candidate tokens to be produced in the next iteration — our original heuristic increases it by `2` if ALL tokens match and decreases it by `1` otherwise. <!-- [GIF 4 -- ASSISTED GENERATION] --> <figure class="image table text-center m-0 w-full"> <video style="max-width: 90%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_4_1080p.mov" ></video> </figure> We’ve designed the API in 🤗 Transformers such that this process is hassle-free for you. All you need to do is to pass the assistant model under the new `assistant_model` keyword argument and reap the latency gains! At the time of the release of this blog post, assisted generation is limited to a batch size of `1`. ```python from transformers import AutoModelForCausalLM, AutoTokenizer import torch prompt = "Alice and Bob" checkpoint = "EleutherAI/pythia-1.4b-deduped" assistant_checkpoint = "EleutherAI/pythia-160m-deduped" device = "cuda" if torch.cuda.is_available() else "cpu" tokenizer = AutoTokenizer.from_pretrained(checkpoint) inputs = tokenizer(prompt, return_tensors="pt").to(device) model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device) assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device) outputs = model.generate(**inputs, assistant_model=assistant_model) print(tokenizer.batch_decode(outputs, skip_special_tokens=True)) # ['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a'] ``` Is the additional internal complexity worth it? Let’s have a look at the latency numbers for the greedy decoding case (results for sampling are in the next section), considering a batch size of `1`. These results were pulled directly out of 🤗 Transformers without any additional optimizations, so you should be able to reproduce them in your setup. <!-- [SPACE WITH GREEDY DECODING PERFORMANCE NUMBERS] --> <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.2/gradio.js" ></script> <gradio-app theme_mode="light" space="joaogante/assisted_generation_benchmarks"></gradio-app> Glancing at the collected numbers, we see that assisted generation can deliver significant latency reductions in diverse settings, but it is not a silver bullet – you should benchmark it before applying it to your use case. We can conclude that assisted generation: 1. 🤏 Requires access to an assistant model that is at least an order of magnitude smaller than your model (the bigger the difference, the better); 2. 🚀 Gets up to 3x speedups in the presence of INT8 and up to 2x otherwise, when the model fits in the GPU memory; 3. 🤯 If you’re playing with models that do not fit in your GPU and are relying on memory offloading, you can see up to 10x speedups; 4. 📄 Shines in input-grounded tasks, like automatic speech recognition or summarization. ## Sample with assisted generation Greedy decoding is suited for input-grounded tasks (automatic speech recognition, translation, summarization, ...) or factual knowledge-seeking. Open-ended tasks requiring large levels of creativity, such as most uses of a language model as a chatbot, should use sampling instead. Assisted generation is naturally designed for greedy decoding, but that doesn’t mean that you can’t use assisted generation with multinomial sampling! Drawing samples from a probability distribution for the next token will cause our greedy assistant to fail more often, reducing its latency benefits. However, we can control how sharp the probability distribution for the next tokens is, using the temperature coefficient that’s present in most sampling-based applications. At one extreme, with temperatures close to 0, sampling will approximate greedy decoding, favoring the most likely token. At the other extreme, with the temperature set to values much larger than 1, sampling will be chaotic, drawing from a uniform distribution. Low temperatures are, therefore, more favorable to your assistant model, retaining most of the latency benefits from assisted generation, as we can see below. <!-- [TEMPERATURE RESULTS, SHOW THAT LATENCY INCREASES STEADILY WITH TEMP] --> <div align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/temperature.png"/> </div> Why don't you see it for yourself, so get a feeling of assisted generation? <!-- [DEMO] --> <gradio-app theme_mode="light" space="joaogante/assisted_generation_demo"></gradio-app> ## Future directions Assisted generation shows that modern text generation strategies are ripe for optimization. Understanding that it is currently a memory-bound problem, not a compute-bound problem, allows us to apply simple heuristics to get the most out of the available memory bandwidth, alleviating the bottleneck. We believe that further refinement of the use of assistant models will get us even bigger latency reductions - for instance, we may be able to skip a few more forward passes if we request the assistant to generate several candidate continuations. Naturally, releasing high-quality small models to be used as assistants will be critical to realizing and amplifying the benefits. Initially released under our 🤗 Transformers library, to be used with the `.generate()` function, we expect to offer it throughout the Hugging Face universe. Its implementation is also completely open-source so, if you’re working on text generation and not using our tools, feel free to use it as a reference. Finally, assisted generation resurfaces a crucial question in text generation. The field has been evolving with the constraint where all new tokens are the result of a fixed amount of compute, for a given model. One token per homogeneous forward pass, in pure autoregressive fashion. This blog post reinforces the idea that it shouldn’t be the case: large subsections of the generated output can also be equally generated by models that are a fraction of the size. For that, we’ll need new model architectures and decoding methods – we’re excited to see what the future holds! ## Related Work After the original release of this blog post, it came to my attention that other works have explored the same core principle (use a forward pass to validate longer continuations). In particular, have a look at the following works: - [Blockwise Parallel Decoding](https://proceedings.neurips.cc/paper/2018/file/c4127b9194fe8562c64dc0f5bf2c93bc-Paper.pdf), by Google Brain - [Speculative Sampling](https://arxiv.org/abs/2302.01318), by DeepMind ## Citation ```bibtex @misc {gante2023assisted, author = { {Joao Gante} }, title = { Assisted Generation: a new direction toward low-latency text generation }, year = 2023, url = { https://huggingface.co/blog/assisted-generation }, doi = { 10.57967/hf/0638 }, publisher = { Hugging Face Blog } } ``` ## Acknowledgements I'd like to thank Sylvain Gugger, Nicolas Patry, and Lewis Tunstall for sharing many valuable suggestions to improve this blog post. Finally, kudos to Chunte Lee for designing the gorgeous cover you can see in our web page.
|
Introducing RWKV — An RNN with the advantages of a transformer
|
BlinkDL
|
May 15, 2023
|
rwkv
|
nlp, community, research
|
https://huggingface.co/blog/rwkv
|
# Introducing RWKV - An RNN with the advantages of a transformer ChatGPT and chatbot-powered applications have captured significant attention in the Natural Language Processing (NLP) domain. The community is constantly seeking strong, reliable and open-source models for their applications and use cases. The rise of these powerful models stems from the democratization and widespread adoption of transformer-based models, first introduced by Vaswani et al. in 2017. These models significantly outperformed previous SoTA NLP models based on Recurrent Neural Networks (RNNs), which were considered dead after that paper. Through this blogpost, we will introduce the integration of a new architecture, RWKV, that combines the advantages of both RNNs and transformers, and that has been recently integrated into the Hugging Face [transformers](https://github.com/huggingface/transformers) library. ### Overview of the RWKV project The RWKV project was kicked off and is being led by [Bo Peng](https://github.com/BlinkDL), who is actively contributing and maintaining the project. The community, organized in the official discord channel, is constantly enhancing the project’s artifacts on various topics such as performance (RWKV.cpp, quantization, etc.), scalability (dataset processing & scrapping) and research (chat-fine tuning, multi-modal finetuning, etc.). The GPUs for training RWKV models are donated by Stability AI. You can get involved by joining the [official discord channel](https://discord.gg/qt9egFA7ve) and learn more about the general ideas behind RWKV in these two blogposts: https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html ### Transformer Architecture vs RNNs The RNN architecture is one of the first widely used Neural Network architectures for processing a sequence of data, contrary to classic architectures that take a fixed size input. It takes as input the current “token” (i.e. current data point of the datastream), the previous “state”, and computes the predicted next token, and the predicted next state. The new state is then used to compute the prediction of the next token, and so on. A RNN can be also used in different “modes”, therefore enabling the possibility of applying RNNs on different scenarios, as denoted by [Andrej Karpathy’s blogpost](https://karpathy.github.io/2015/05/21/rnn-effectiveness/), such as one-to-one (image-classification), one-to-many (image captioning), many-to-one (sequence classification), many-to-many (sequence generation), etc. |  | |:--:| | <b>Overview of possible configurations of using RNNs. Source: <a href="https://karpathy.github.io/2015/05/21/rnn-effectiveness/" rel="noopener" target="_blank" >Andrej Karpathy's blogpost</a> </b>| Because RNNs use the same weights to compute predictions at every step, they struggle to memorize information for long-range sequences due to the vanishing gradient issue. Efforts have been made to address this limitation by introducing new architectures such as LSTMs or GRUs. However, the transformer architecture proved to be the most effective thus far in resolving this issue. In the transformer architecture, the input tokens are processed simultaneously in the self-attention module. The tokens are first linearly projected into different spaces using the query, key and value weights. The resulting matrices are directly used to compute the attention scores (through softmax, as shown below), then multiplied by the value hidden states to obtain the final hidden states. This design enables the architecture to effectively mitigate the long-range sequence issue, and also perform faster inference and training compared to RNN models. | 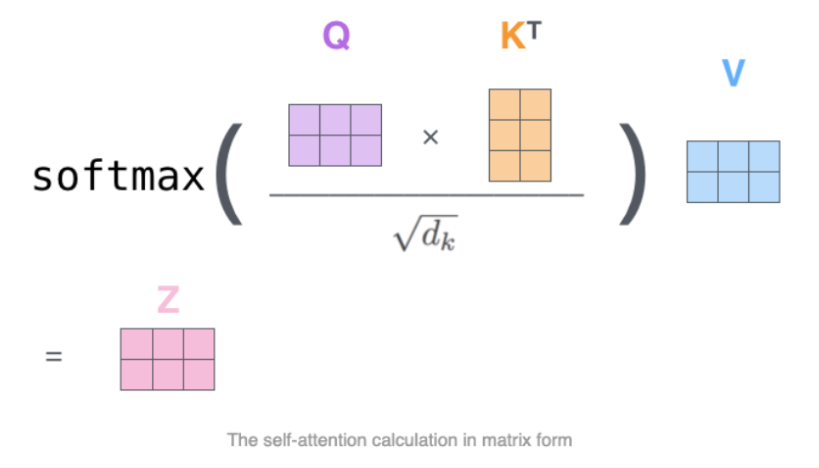 | |:--:| | <b>Formulation of attention scores in transformer models. Source: <a href="https://jalammar.github.io/illustrated-transformer/" rel="noopener" target="_blank" >Jay Alammar's blogpost</a> </b>| | | |:--:| | <b>Formulation of attention scores in RWKV models. Source: <a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-formula.png" rel="noopener" target="_blank" >RWKV blogpost</a> </b>| During training, Transformer architecture has several advantages over traditional RNNs and CNNs. One of the most significant advantages is its ability to learn contextual representations. Unlike the RNNs and CNNs, which process input sequences one word at a time, Transformer architecture processes input sequences as a whole. This allows it to capture long-range dependencies between words in the sequence, which is particularly useful for tasks such as language translation and question answering. During inference, RNNs have some advantages in speed and memory efficiency. These advantages include simplicity, due to needing only matrix-vector operations, and memory efficiency, as the memory requirements do not grow during inference. Furthermore, the computation speed remains the same with context window length due to how computations only act on the current token and the state. ## The RWKV architecture RWKV is inspired by [Apple’s Attention Free Transformer](https://machinelearning.apple.com/research/attention-free-transformer). The architecture has been carefully simplified and optimized such that it can be transformed into an RNN. In addition, a number of tricks has been added such as `TokenShift` & `SmallInitEmb` (the list of tricks is listed in [the README of the official GitHub repository](https://github.com/BlinkDL/RWKV-LM/blob/main/README.md#how-it-works)) to boost its performance to match GPT. Without these, the model wouldn't be as performant. For training, there is an infrastructure to scale the training up to 14B parameters as of now, and some issues have been iteratively fixed in RWKV-4 (latest version as of today), such as numerical instability. ### RWKV as a combination of RNNs and transformers How to combine the best of transformers and RNNs? The main drawback of transformer-based models is that it can become challenging to run a model with a context window that is larger than a certain value, as the attention scores are computed simultaneously for the entire sequence. RNNs natively support very long context lengths - only limited by the context length seen in training, but this can be extended to millions of tokens with careful coding. Currently, there are RWKV models trained on a context length of 8192 (`ctx8192`) and they are as fast as `ctx1024` models and require the same amount of RAM. The major drawbacks of traditional RNN models and how RWKV is different: 1. Traditional RNN models are unable to utilize very long contexts (LSTM can only manage ~100 tokens when used as a LM). However, RWKV can utilize thousands of tokens and beyond, as shown below: |  | |:--:| | <b>LM loss with respect to different context lengths and model sizes. Source: <a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-ctxlen.png" rel="noopener" target="_blank" >RWKV original repository</a> </b>| 2. Traditional RNN models cannot be parallelized when training. RWKV is similar to a “linearized GPT” and it trains faster than GPT. By combining both advantages into a single architecture, the hope is that RWKV can grow to become more than the sum of its parts. ### RWKV attention formulation The model architecture is very similar to classic transformer-based models (i.e. an embedding layer, multiple identical layers, layer normalization, and a Causal Language Modeling head to predict the next token). The only difference is on the attention layer, which is completely different from the traditional transformer-based models. To gain a more comprehensive understanding of the attention layer, we recommend to delve into the detailed explanation provided in [a blog post by Johan Sokrates Wind](https://johanwind.github.io/2023/03/23/rwkv_details.html). ### Existing checkpoints #### Pure language models: RWKV-4 models Most adopted RWKV models range from ~170M parameters to 14B parameters. According to the RWKV overview [blog post](https://johanwind.github.io/2023/03/23/rwkv_overview.html), these models have been trained on the Pile dataset and evaluated against other SoTA models on different benchmarks, and they seem to perform quite well, with very comparable results against them. |  | |:--:| | <b>RWKV-4 compared to other common architectures. Source: <a href="https://johanwind.github.io/2023/03/23/rwkv_overview.html" rel="noopener" target="_blank" >Johan Wind's blogpost</a> </b>| #### Instruction Fine-tuned/Chat Version: RWKV-4 Raven Bo has also trained a “chat” version of the RWKV architecture, the RWKV-4 Raven model. It is a RWKV-4 pile (RWKV model pretrained on The Pile dataset) model fine-tuned on ALPACA, CodeAlpaca, Guanaco, GPT4All, ShareGPT and more. The model is available in multiple versions, with models trained on different languages (English only, English + Chinese + Japanese, English + Japanese, etc.) and different sizes (1.5B parameters, 7B parameters, 14B parameters). All the HF converted models are available on Hugging Face Hub, in the [`RWKV` organization](https://huggingface.co/RWKV). ## 🤗 Transformers integration The architecture has been added to the `transformers` library thanks to [this Pull Request](https://github.com/huggingface/transformers/pull/22797). As of the time of writing, you can use it by installing `transformers` from source, or by using the `main` branch of the library. The architecture is tightly integrated with the library, and you can use it as you would any other architecture. Let us walk through some examples below. ### Text Generation Example To generate text given an input prompt you can use `pipeline` to generate text: ```python from transformers import pipeline model_id = "RWKV/rwkv-4-169m-pile" prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese." pipe = pipeline("text-generation", model=model_id) print(pipe(prompt, max_new_tokens=20)) >>> [{'generated_text': '\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were'}] ``` Or you can run and start from the snippet below: ```python import torch from transformers import AutoModelForCausalLM, AutoTokenizer model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile") tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile") prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese." inputs = tokenizer(prompt, return_tensors="pt") output = model.generate(inputs["input_ids"], max_new_tokens=20) print(tokenizer.decode(output[0].tolist())) >>> In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were ``` ### Use the raven models (chat models) You can prompt the chat model in the alpaca style, here is an example below: ```python from transformers import AutoTokenizer, AutoModelForCausalLM model_id = "RWKV/rwkv-raven-1b5" model = AutoModelForCausalLM.from_pretrained(model_id).to(0) tokenizer = AutoTokenizer.from_pretrained(model_id) question = "Tell me about ravens" prompt = f"### Instruction: {question}\n### Response:" inputs = tokenizer(prompt, return_tensors="pt").to(0) output = model.generate(inputs["input_ids"], max_new_tokens=100) print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True)) >>> ### Instruction: Tell me about ravens ### Response: RAVENS are a type of bird that is native to the Middle East and North Africa. They are known for their intelligence, adaptability, and their ability to live in a variety of environments. RAVENS are known for their intelligence, adaptability, and their ability to live in a variety of environments. They are known for their intelligence, adaptability, and their ability to live in a variety of environments. ``` According to Bo, better instruction techniques are detailed in [this discord message (make sure to join the channel before clicking)](https://discord.com/channels/992359628979568762/1083107245971226685/1098533896355848283) |  | ### Weights conversion Any user could easily convert the original RWKV weights to the HF format by simply running the conversion script provided in the `transformers` library. First, push the "raw" weights to the Hugging Face Hub (let's denote that repo as `RAW_HUB_REPO`, and the raw file `RAW_FILE`), then run the conversion script: ```bash python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR ``` If you want to push the converted model on the Hub (let's say, under `dummy_user/converted-rwkv`), first forget to log in with `huggingface-cli login` before pushing the model, then run: ```bash python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv ``` ## Future work ### Multi-lingual RWKV Bo is currently working on a multilingual corpus to train RWKV models. Recently a new multilingual tokenizer [has been released](https://twitter.com/BlinkDL_AI/status/1649839897208045573). ### Community-oriented and research projects The RWKV community is very active and working on several follow up directions, a list of cool projects can be find in a [dedicated channel on discord (make sure to join the channel before clicking the link)](https://discord.com/channels/992359628979568762/1068563033510653992). There is also a channel dedicated to research around this architecure, feel free to join and contribute! ### Model Compression and Acceleration Due to only needing matrix-vector operations, RWKV is an ideal candidate for non-standard and experimental computing hardware, such as photonic processors/accelerators. Therefore, the architecture can also naturally benefit from classic acceleration and compression techniques (such as [ONNX](https://github.com/harrisonvanderbyl/rwkv-onnx), 4-bit/8-bit quantization, etc.), and we hope this will be democratized for developers and practitioners together with the transformers integration of the architecture. RWKV can also benefit from the acceleration techniques proposed by [`optimum`](https://github.com/huggingface/optimum) library in the near future. Some of these techniques are highlighted in the [`rwkv.cpp` repository](https://github.com/saharNooby/rwkv.cpp) or [`rwkv-cpp-cuda` repository](https://github.com/harrisonvanderbyl/rwkv-cpp-cuda). ## Acknowledgements The Hugging Face team would like to thank Bo and RWKV community for their time and for answering our questions about the architecture. We would also like to thank them for their help and support and we look forward to see more adoption of RWKV models in the HF ecosystem. We also would like to acknowledge the work of [Johan Wind](https://twitter.com/johanwind) for his blogpost on RWKV, which helped us a lot to understand the architecture and its potential. And finally, we would like to highlight anf acknowledge the work of [ArEnSc](https://github.com/ArEnSc) for starting over the initial `transformers` PR. Also big kudos to [Merve Noyan](https://huggingface.co/merve), [Maria Khalusova](https://huggingface.co/MariaK) and [Pedro Cuenca](https://huggingface.co/pcuenq) for kindly reviewing this blogpost to make it much better! ## Citation If you use RWKV for your work, please use [the following `cff` citation](https://github.com/BlinkDL/RWKV-LM/blob/main/CITATION.cff).
|
Run a Chatgpt-like Chatbot on a Single GPU with ROCm
|
andyll7772
|
May 15, 2023
|
chatbot-amd-gpu
|
guide, llm, nlp, inference, rocm
|
https://huggingface.co/blog/chatbot-amd-gpu
|
# Run a Chatgpt-like Chatbot on a Single GPU with ROCm ## Introduction ChatGPT, OpenAI's groundbreaking language model, has become an influential force in the realm of artificial intelligence, paving the way for a multitude of AI applications across diverse sectors. With its staggering ability to comprehend and generate human-like text, ChatGPT has transformed industries, from customer support to creative writing, and has even served as an invaluable research tool. Various efforts have been made to provide open-source large language models which demonstrate great capabilities but in smaller sizes, such as [OPT](https://huggingface.co/docs/transformers/model_doc/opt), [LLAMA](https://github.com/facebookresearch/llama), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) and [Vicuna](https://github.com/lm-sys/FastChat). In this blog, we will delve into the world of Vicuna, and explain how to run the Vicuna 13B model on a single AMD GPU with ROCm. **What is Vicuna?** Vicuna is an open-source chatbot with 13 billion parameters, developed by a team from UC Berkeley, CMU, Stanford, and UC San Diego. To create Vicuna, a LLAMA base model was fine-tuned using about 70K user-shared conversations collected from ShareGPT.com via public APIs. According to initial assessments where GPT-4 is used as a reference, Vicuna-13B has achieved over 90%\* quality compared to OpenAI ChatGPT. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/01.png" style="width: 60%; height: auto;"> </p> It was released on [Github](https://github.com/lm-sys/FastChat) on Apr 11, just a few weeks ago. It is worth mentioning that the data set, training code, evaluation metrics, training cost are known for Vicuna. Its total training cost was just around \$300, making it a cost-effective solution for the general public. For more details about Vicuna, please check out <https://vicuna.lmsys.org>. **Why do we need a quantized GPT model?** Running Vicuna-13B model in fp16 requires around 28GB GPU RAM. To further reduce the memory footprint, optimization techniques are required. There is a recent research paper GPTQ published, which proposed accurate post-training quantization for GPT models with lower bit precision. As illustrated below, for models with parameters larger than 10B, the 4-bit or 3-bit GPTQ can achieve comparable accuracy with fp16. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/02.png" style="width: 70%; height: auto;"> </p> Moreover, large parameters of these models also have a severely negative effect on GPT latency because GPT token generation is more limited by memory bandwidth (GB/s) than computation (TFLOPs or TOPs) itself. For this reason, a quantized model does not degrade token generation latency when the GPU is under a memory bound situation. Refer to [the GPTQ quantization papers](<https://arxiv.org/abs/2210.17323>) and [github repo](<https://github.com/IST-DASLab/gptq>). By leveraging this technique, several 4-bit quantized Vicuna models are available from Hugging Face as follows, <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/03.png" style="width: 50%; height: auto;"> </p> ## Running Vicuna 13B Model on AMD GPU with ROCm To run the Vicuna 13B model on an AMD GPU, we need to leverage the power of ROCm (Radeon Open Compute), an open-source software platform that provides AMD GPU acceleration for deep learning and high-performance computing applications. Here's a step-by-step guide on how to set up and run the Vicuna 13B model on an AMD GPU with ROCm: **System Requirements** Before diving into the installation process, ensure that your system meets the following requirements: - An AMD GPU that supports ROCm (check the compatibility list on docs.amd.com page) - A Linux-based operating system, preferably Ubuntu 18.04 or 20.04 - Conda or Docker environment - Python 3.6 or higher For more information, please check out <https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/Prerequisites.html>. This example has been tested on [**Instinct MI210**](https://www.amd.com/en/products/server-accelerators/amd-instinct-mi210) and [**Radeon RX6900XT**](https://www.amd.com/en/products/graphics/amd-radeon-rx-6900-xt) GPUs with ROCm5.4.3 and Pytorch2.0. **Quick Start** **1 ROCm installation and Docker container setup (Host machine)** **1.1 ROCm** **installation** The following is for ROCm5.4.3 and Ubuntu 22.04. Please modify according to your target ROCm and Ubuntu version from: <https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/How_to_Install_ROCm.html> ``` sudo apt update && sudo apt upgrade -y wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb sudo apt-get install ./amdgpu-install_5.4.50403-1_all.deb sudo amdgpu-install --usecase=hiplibsdk,rocm,dkms sudo amdgpu-install --list-usecase sudo reboot ``` **1.2 ROCm installation verification** ``` rocm-smi sudo rocminfo ``` **1.3 Docker image pull and run a Docker container** The following uses Pytorch2.0 on ROCm5.4.2. Please use the appropriate docker image according to your target ROCm and Pytorch version: <https://hub.docker.com/r/rocm/pytorch/tags> ``` docker pull rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview sudo docker run --device=/dev/kfd --device=/dev/dri --group-add video \ --shm-size=8g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \ --ipc=host -it --name vicuna_test -v ${PWD}:/workspace -e USER=${USER} \ rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview ``` **2 Model** **quantization and Model inference (Inside the docker)** You can either download quantized Vicuna-13b model from Huggingface or quantize the floating-point model. Please check out **Appendix - GPTQ model quantization** if you want to quantize the floating-point model. **2.1 Download the quantized Vicuna-13b model** Use download-model.py script from the following git repo. ``` git clone https://github.com/oobabooga/text-generation-webui.git cd text-generation-webui python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g ``` 2. **Running the Vicuna 13B GPTQ Model on AMD GPU** ``` git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda cd GPTQ-for-LLaMa python setup_cuda.py install ``` These commands will compile and link HIPIFIED CUDA-equivalent kernel binaries to python as C extensions. The kernels of this implementation are composed of dequantization + FP32 Matmul. If you want to use dequantization + FP16 Matmul for additional speed-up, please check out **Appendix - GPTQ Dequantization + FP16 Mamul kernel for AMD GPUs** ``` git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda cd GPTQ-for-LLaMa/ python setup_cuda.py install # model inference python llama_inference.py ../../models/vicuna-13b --wbits 4 --load \ ../../models/vicuna-13b/vicuna-13b_4_actorder.safetensors --groupsize 128 --text “You input text here” ``` Now that you have everything set up, it's time to run the Vicuna 13B model on your AMD GPU. Use the commands above to run the model. Replace *"Your input text here"* with the text you want to use as input for the model. If everything is set up correctly, you should see the model generating output text based on your input. **3. Expose the quantized Vicuna model to the Web API server** Change the path of GPTQ python modules (GPTQ-for-LLaMa) in the following line: <https://github.com/thisserand/FastChat/blob/4a57c928a906705404eae06f7a44b4da45828487/fastchat/serve/load_gptq_model.py#L7> To launch Web UXUI from the gradio library, you need to set up the controller, worker (Vicunal model worker), web_server by running them as background jobs. ``` nohup python0 -W ignore::UserWarning -m fastchat.serve.controller & nohup python0 -W ignore::UserWarning -m fastchat.serve.model_worker --model-path /path/to/quantized_vicuna_weights \ --model-name vicuna-13b-quantization --wbits 4 --groupsize 128 & nohup python0 -W ignore::UserWarning -m fastchat.serve.gradio_web_server & ``` Now the 4-bit quantized Vicuna-13B model can be fitted in RX6900XT GPU DDR memory, which has 16GB DDR. Only 7.52GB of DDR (46% of 16GB) is needed to run 13B models whereas the model needs more than 28GB of DDR space in fp16 datatype. The latency penalty and accuracy penalty are also very minimal and the related metrics are provided at the end of this article. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/04.png" style="width: 60%; height: auto;"> </p> **Test the quantized Vicuna model in the Web API server** Let us give it a try. First, let us use fp16 Vicuna model for language translation. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/05.png" style="width: 80%; height: auto;"> </p> It does a better job than me. Next, let us ask something about soccer. The answer looks good to me. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/06.png" style="width: 80%; height: auto;"> </p> When we switch to the 4-bit model, for the same question, the answer is a bit different. There is a duplicated “Lionel Messi” in it. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/07.png" style="width: 80%; height: auto;"> </p> **Vicuna fp16 and 4bit quantized model comparison** Test environment: \- GPU: Instinct MI210, RX6900XT \- python: 3.10 \- pytorch: 2.1.0a0+gitfa08e54 \- rocm: 5.4.3 **Metrics - Model size (GB)** - Model parameter size. When the models are preloaded to GPU DDR, the actual DDR size consumption is larger than model itself due to caching for Input and output token spaces. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/08.png" style="width: 70%; height: auto;"> </p> **Metrics – Accuracy (PPL: Perplexity)** - Measured on 2048 examples of C4 (<https://paperswithcode.com/dataset/c4>) dataset - Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul - Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul - Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/09.png" style="width: 70%; height: auto;"> </p> **Metrics – Latency (Token generation latency, ms)** - Measured during token generation phases. - Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul - Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul - Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/10.png" style="width: 70%; height: auto;"> </p> ## Conclusion Large language models (LLMs) have made significant advancements in chatbot systems, as seen in OpenAI’s ChatGPT. Vicuna-13B, an open-source LLM model has been developed and demonstrated excellent capability and quality. By following this guide, you should now have a better understanding of how to set up and run the Vicuna 13B model on an AMD GPU with ROCm. This will enable you to unlock the full potential of this cutting-edge language model for your research and personal projects. Thanks for reading! ## Appendix - GPTQ model quantization **Building Vicuna quantized model from the floating-point LLaMA model** **a. Download LLaMA and Vicuna delta models from Huggingface** The developers of Vicuna (lmsys) provide only delta-models that can be applied to the LLaMA model. Download LLaMA in huggingface format and Vicuna delta parameters from Huggingface individually. Currently, 7b and 13b delta models of Vicuna are available. <https://huggingface.co/models?sort=downloads&search=huggyllama> <https://huggingface.co/models?sort=downloads&search=lmsys> <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/13.png" style="width: 60%; height: auto;"> </p> **b. Convert LLaMA to Vicuna by using Vicuna-delta model** ``` git clone https://github.com/lm-sys/FastChat cd FastChat ``` Convert the LLaMA parameters by using this command: (Note: do not use vicuna-{7b, 13b}-\*delta-v0 because it’s vocab_size is different from that of LLaMA and the model cannot be converted) ``` python -m fastchat.model.apply_delta --base /path/to/llama-13b --delta lmsys/vicuna-13b-delta-v1.1 \ --target ./vicuna-13b ``` Now Vicuna-13b model is ready. **c. Quantize Vicuna to 2/3/4 bits** To apply the GPTQ to LLaMA and Vicuna, ``` git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda cd GPTQ-for-LLaMa ``` (Note, do not use <https://github.com/qwopqwop200/GPTQ-for-LLaMa> for now. Because 2,3,4bit quantization + MatMul kernels implemented in this repo does not parallelize the dequant+matmul and hence shows lower token generation performance) Quantize Vicuna-13b model with this command. QAT is done based on c4 data-set but you can also use other data-sets, such as wikitext2 (Note. Change group size with different combinations as long as the model accuracy increases significantly. Under some combination of wbit and groupsize, model accuracy can be increased significantly.) ``` python llama.py ./Vicuna-13b c4 --wbits 4 --true-sequential --act-order \ --save_safetensors Vicuna-13b-4bit-act-order.safetensors ``` Now the model is ready and saved as **Vicuna-13b-4bit-act-order.safetensors**. **GPTQ Dequantization + FP16 Mamul kernel for AMD GPUs** The more optimized kernel implementation in <https://github.com/oobabooga/GPTQ-for-LLaMa/blob/57a26292ed583528d9941e79915824c5af012279/quant_cuda_kernel.cu#L891> targets at A100 GPU and not compatible with ROCM5.4.3 HIPIFY toolkits. It needs to be modified as follows. The same for VecQuant2MatMulKernelFaster, VecQuant3MatMulKernelFaster, VecQuant4MatMulKernelFaster kernels. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/14.png" style="width: 100%; height: auto;"> For convenience, All the modified codes are available in [Github Gist](https://gist.github.com/seungrokjung/110943b70503732c4a398607e1cbdd6c).
|
Smaller is better: Q8-Chat, an efficient generative AI experience on Xeon
|
andyll7772
|
May 16, 2023
|
generative-ai-models-on-intel-cpu
|
llm, nlp, inference, intel, quantization
|
https://huggingface.co/blog/generative-ai-models-on-intel-cpu
|
# Smaller is better: Q8-Chat, an efficient generative AI experience on Xeon Large language models (LLMs) are taking the machine learning world by storm. Thanks to their [Transformer](https://arxiv.org/abs/1706.03762) architecture, LLMs have an uncanny ability to learn from vast amounts of unstructured data, like text, images, video, or audio. They perform very well on many [task types](https://huggingface.co/tasks), either extractive like text classification or generative like text summarization and text-to-image generation. As their name implies, LLMs are *large* models that often exceed the 10-billion parameter mark. Some have more than 100 billion parameters, like the [BLOOM](https://huggingface.co/bigscience/bloom) model. LLMs require lots of computing power, typically found in high-end GPUs, to predict fast enough for low-latency use cases like search or conversational applications. Unfortunately, for many organizations, the associated costs can be prohibitive and make it difficult to use state-of-the-art LLMs in their applications. In this post, we will discuss optimization techniques that help reduce LLM size and inference latency, helping them run efficiently on Intel CPUs. ## A primer on quantization LLMs usually train with 16-bit floating point parameters (a.k.a FP16/BF16). Thus, storing the value of a single weight or activation value requires 2 bytes of memory. In addition, floating point arithmetic is more complex and slower than integer arithmetic and requires additional computing power. Quantization is a model compression technique that aims to solve both problems by reducing the range of unique values that model parameters can take. For instance, you can quantize models to lower precision like 8-bit integers (INT8) to shrink them and replace complex floating-point operations with simpler and faster integer operations. In a nutshell, quantization rescales model parameters to smaller value ranges. When successful, it shrinks your model by at least 2x, without any impact on model accuracy. You can apply quantization during training, a.k.a quantization-aware training ([QAT](https://arxiv.org/abs/1910.06188)), which generally yields the best results. If you’d prefer to quantize an existing model, you can apply post-training quantization ([PTQ](https://www.tensorflow.org/lite/performance/post_training_quantization#:~:text=Post%2Dtraining%20quantization%20is%20a,little%20degradation%20in%20model%20accuracy.)), a much faster technique that requires very little computing power. Different quantization tools are available. For example, PyTorch has built-in support for [quantization](https://pytorch.org/docs/stable/quantization.html). You can also use the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library, which includes developer-friendly APIs for QAT and PTQ. ## Quantizing LLMs Recent studies [[1]](https://arxiv.org/abs/2206.01861)[[2]](https://arxiv.org/abs/2211.10438) show that current quantization techniques don’t work well with LLMs. In particular, LLMs exhibit large-magnitude outliers in specific activation channels across all layers and tokens. Here’s an example with the OPT-13B model. You can see that one of the activation channels has much larger values than all others across all tokens. This phenomenon is visible in all the Transformer layers of the model. <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/pic1.png"> </kbd> <br>*Source: SmoothQuant* The best quantization techniques to date quantize activations token-wise, causing either truncated outliers or underflowing low-magnitude activations. Both solutions hurt model quality significantly. Moreover, quantization-aware training requires additional model training, which is not practical in most cases due to lack of compute resources and data. SmoothQuant [[3]](https://arxiv.org/abs/2211.10438)[[4]](https://github.com/mit-han-lab/smoothquant) is a new quantization technique that solves this problem. It applies a joint mathematical transformation to weights and activations, which reduces the ratio between outlier and non-outlier values for activations at the cost of increasing the ratio for weights. This transformation makes the layers of the Transformer "quantization-friendly" and enables 8-bit quantization without hurting model quality. As a consequence, SmoothQuant produces smaller, faster models that run well on Intel CPU platforms. <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/pic2.png"> </kbd> <br>*Source: SmoothQuant* Now, let’s see how SmoothQuant works when applied to popular LLMs. ## Quantizing LLMs with SmoothQuant Our friends at Intel have quantized several LLMs with SmoothQuant-O3: OPT [2.7B](https://huggingface.co/facebook/opt-2.7b) and [6.7B](https://huggingface.co/facebook/opt-6.7b) [[5]](https://arxiv.org/pdf/2205.01068.pdf), LLaMA [7B](https://huggingface.co/decapoda-research/llama-7b-hf) [[6]](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/), Alpaca [7B](https://huggingface.co/tatsu-lab/alpaca-7b-wdiff) [[7]](https://crfm.stanford.edu/2023/03/13/alpaca.html), Vicuna [7B](https://huggingface.co/lmsys/vicuna-7b-delta-v1.1) [[8]](https://vicuna.lmsys.org/), BloomZ [7.1B](https://huggingface.co/bigscience/bloomz-7b1) [[9]](https://huggingface.co/bigscience/bloomz) MPT-7B-chat [[10]](https://www.mosaicml.com/blog/mpt-7b). They also evaluated the accuracy of the quantized models, using [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness). The table below presents a summary of their findings. The second column shows the ratio of benchmarks that have improved post-quantization. The third column contains the mean average degradation (_* a negative value indicates that the benchmark has improved_). You can find the detailed results at the end of this post. <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table0.png"> </kbd> As you can see, OPT models are great candidates for SmoothQuant quantization. Models are ~2x smaller compared to pretrained 16-bit models. Most of the metrics improve, and those who don’t are only marginally penalized. The picture is a little more contrasted for LLaMA 7B and BloomZ 7.1B. Models are compressed by a factor of ~2x, with about half the task seeing metric improvements. Again, the other half is only marginally impacted, with a single task seeing more than 3% relative degradation. The obvious benefit of working with smaller models is a significant reduction in inference latency. Here’s a [video](https://drive.google.com/file/d/1Iv5_aV8mKrropr9HeOLIBT_7_oYPmgNl/view?usp=sharing) demonstrating real-time text generation with the MPT-7B-chat model on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1. In this example, we ask the model: “*What is the role of Hugging Face in democratizing NLP?*”. This sends the following prompt to the model: "*A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: What is the role of Hugging Face in democratizing NLP? ASSISTANT:*" <figure class="image table text-center m-0 w-full"> <video alt="MPT-7B Demo" style="max-width: 70%; margin: auto;" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/mpt-7b-int8-hf-role.mov" type="video/mp4"> </video> </figure> The example shows the additional benefits you can get from 8bit quantization coupled with 4th Gen Xeon resulting in very low generation time for each token. This level of performance definitely makes it possible to run LLMs on CPU platforms, giving customers more IT flexibility and better cost-performance than ever before. ## Chat experience on Xeon Recently, Clement, the CEO of HuggingFace, recently said: “*More companies would be better served focusing on smaller, specific models that are cheaper to train and run.*” The emergence of relatively smaller models like Alpaca, BloomZ and Vicuna, open a new opportunity for enterprises to lower the cost of fine-tuning and inference in production. As demonstrated above, high-quality quantization brings high-quality chat experiences to Intel CPU platforms, without the need of running mammoth LLMs and complex AI accelerators. Together with Intel, we're hosting a new exciting demo in Spaces called [Q8-Chat](https://huggingface.co/spaces/Intel/Q8-Chat) (pronounced "Cute chat"). Q8-Chat offers you a ChatGPT-like chat experience, while only running on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1. <iframe src="https://intel-q8-chat.hf.space" frameborder="0" width="100%" height="1600"></iframe> ## Next steps We’re currently working on integrating these new quantization techniques into the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library through [Intel Neural Compressor](https://github.com/intel/neural-compressor). Once we’re done, you’ll be able to replicate these demos with just a few lines of code. Stay tuned. The future is 8-bit! *This post is guaranteed 100% ChatGPT-free.* ## Acknowledgment This blog was made in conjunction with Ofir Zafrir, Igor Margulis, Guy Boudoukh and Moshe Wasserblat from Intel Labs. Special thanks to them for their great comments and collaboration. ## Appendix: detailed results A negative value indicates that the benchmark has improved. <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table1.png"> </kbd> <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table2.png"> </kbd> <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table3.png"> </kbd> <kbd> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table4.png"> </kbd>
|
Large-scale Near-deduplication Behind BigCode
|
chenghao
|
May 16, 2023
|
dedup
|
bigcode, deduplication
|
https://huggingface.co/blog/dedup
|
# Large-scale Near-deduplication Behind BigCode ## Intended Audience People who are interested in document-level near-deduplication at a large scale, and have some understanding of hashing, graph and text processing. ## Motivations It is important to take care of our data before feeding it to the model, at least Large Language Model in our case, as the old saying goes, garbage in, garbage out. Even though it's increasingly difficult to do so with headline-grabbing models (or should we say APIs) creating an illusion that data quality matters less. One of the problems we face in both BigScience and BigCode for data quality is duplication, including possible benchmark contamination. It has been shown that models tend to output training data verbatim when there are many duplicates[[1]](#1) (though it is less clear in some other domains[[2]](#2)), and it also makes the model vulnerable to privacy attacks[[1]](#1). Additionally, some typical advantages of deduplication also include: 1. Efficient training: You can achieve the same, and sometimes better, performance with less training steps[[3]](#3) [[4]](#4). 2. Prevent possible data leakage and benchmark contamination: Non-zero duplicates discredit your evaluations and potentially make so-called improvement a false claim. 3. Accessibility. Most of us cannot afford to download or transfer thousands of gigabytes of text repeatedly, not to mention training a model with it. Deduplication, for a fix-sized dataset, makes it easier to study, transfer and collaborate with. ## From BigScience to BigCode Allow me to share a story first on how I jumped on this near-deduplication quest, how the results have progressed, and what lessons I have learned along the way. It all started with a conversation on LinkedIn when [BigScience](https://bigscience.huggingface.co/) had already started for a couple of months. Huu Nguyen approached me when he noticed my pet project on GitHub, asking me if I were interested in working on deduplication for BigScience. Of course, my answer was a yes, completely ignorant of just how much effort will be required alone due to the sheer mount of the data. It was fun and challenging at the same time. It is challenging in a sense that I didn't really have much research experience with that sheer scale of data, and everyone was still welcoming and trusting you with thousands of dollars of cloud compute budget. Yes, I had to wake up from my sleep to double-check that I had turned off those machines several times. As a result, I had to learn on the job through all the trials and errors, which in the end opened me to a new perspective that I don't think I would ever have if it weren't for BigScience. Moving forward, one year later, I am putting what I have learned back into [BigCode](https://www.bigcode-project.org/), working on even bigger datasets. In addition to LLMs that are trained for English[[3]](#3), we have confirmed that deduplication improves code models too[[4]](#4), while using a much smaller dataset. And now, I am sharing what I have learned with you, my dear reader, and hopefully, you can also get a sense of what is happening behind the scene of BigCode through the lens of deduplication. In case you are interested, here is an updated version of the deduplication comparison that we started in BigScience: | Dataset | Input Size | Output Size or Deduction | Level | Method | Parameters | Language | Time | | ------------------------------------ | -------------------------------- | --------------------------------------------------------------- | --------------------- | --------------------------------------------- | ---------------------------------------------------------------- | ------------ | ------------------- | | OpenWebText2[[5]](#5) | After URL dedup: 193.89 GB (69M) | After MinHashLSH: 65.86 GB (17M) | URL + Document | URL(Exact) + Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | | | Pile-CC[[5]](#5) | _~306 GB_ | _227.12 GiB (~55M)_ | Document | Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | "several days" | | BNE5[[6]](#6) | 2TB | 570 GB | Document | Onion | 5-gram | Spanish | | | MassiveText[[7]](#7) | | 0.001 TB ~ 2.1 TB | Document | Document(Exact + MinHash LSH) | \\( (?, 0.8, 13, ?, ?) \\) | English | | | CC100-XL[[8]](#8) | | 0.01 GiB ~ 3324.45 GiB | URL + Paragraph | URL(Exact) + Paragraph(Exact) | SHA-1 | Multilingual | | | C4[[3]](#3) | 806.92 GB (364M) | 3.04% ~ 7.18% **↓** (train) | Substring or Document | Substring(Suffix Array) or Document(MinHash) | Suffix Array: 50-token, MinHash: \\( (9000, 0.8, 5, 20, 450) \\) | English | | | Real News[[3]](#3) | ~120 GiB | 13.63% ~ 19.4% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | | | LM1B[[3]](#3) | ~4.40 GiB (30M) | 0.76% ~ 4.86% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | | | WIKI40B[[3]](#3) | ~2.9M | 0.39% ~ 2.76% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | | | The BigScience ROOTS Corpus[[9]](#9) | | 0.07% ~ 2.7% **↓** (document) + 10.61%~32.30% **↓** (substring) | Document + Substring | Document (SimHash) + Substring (Suffix Array) | SimHash: 6-grams, hamming distance of 4, Suffix Array: 50-token | Multilingual | 12 hours ~ few days | This is the one for code datasets we created for BigCode as well. Model names are used when the dataset name isn't available. | Model | Method | Parameters | Level | | --------------------- | -------------------- | -------------------------------------- | -------- | | InCoder[[10]](#10) | Exact | Alphanumeric tokens/md5 + Bloom filter | Document | | CodeGen[[11]](#11) | Exact | SHA256 | Document | | AlphaCode[[12]](#12) | Exact | ignore whiespaces | Document | | PolyCode[[13]](#13) | Exact | SHA256 | Document | | PaLM Coder[[14]](#14) | Levenshtein distance | | Document | | CodeParrot[[15]](#15) | MinHash + LSH | \\( (256, 0.8, 1) \\) | Document | | The Stack[[16]](#16) | MinHash + LSH | \\( (256, 0.7, 5) \\) | Document | MinHash + LSH parameters \\( (P, T, K, B, R) \\): 1. \\( P \\) number of permutations/hashes 2. \\( T \\) Jaccard similarity threshold 3. \\( K \\) n-gram/shingle size 4. \\( B \\) number of bands 5. \\( R \\) number of rows To get a sense of how those parameters might impact your results, here is a simple demo to illustrate the computation mathematically: [MinHash Math Demo](https://huggingface.co/spaces/bigcode/near-deduplication). ## MinHash Walkthrough In this section, we will cover each step of MinHash, the one used in BigCode, and potential scaling issues and solutions. We will demonstrate the workflow via one example of three documents in English: | doc_id | content | | ------ | ---------------------------------------- | | 0 | Deduplication is so much fun! | | 1 | Deduplication is so much fun and easy! | | 2 | I wish spider dog[[17]](#17) is a thing. | The typical workflow of MinHash is as follows: 1. Shingling (tokenization) and fingerprinting (MinHashing), where we map each document into a set of hashes. 2. Locality-sensitive hashing (LSH). This step is to reduce the number of comparisons by grouping documents with similar bands together. 3. Duplicate removal. This step is where we decide which duplicated documents to keep or remove. ### Shingles Like in most applications involving text, we need to begin with tokenization. N-grams, a.k.a. shingles, are often used. In our example, we will be using word-level tri-grams, without any punctuations. We will circle back to how the size of ngrams impacts the performance in a later section. | doc_id | shingles | | ------ | ------------------------------------------------------------------------------- | | 0 | {"Deduplication is so", "is so much", "so much fun"} | | 1 | {'so much fun', 'fun and easy', 'Deduplication is so', 'is so much'} | | 2 | {'dog is a', 'is a thing', 'wish spider dog', 'spider dog is', 'I wish spider'} | This operation has a time complexity of \\( \mathcal{O}(NM) \\) where \\( N \\) is the number of documents and \\( M \\) is the length of the document. In other words, it is linearly dependent on the size of the dataset. This step can be easily scaled by parallelization by multiprocessing or distributed computation. ### Fingerprint Computation In MinHash, each shingle will typically either be 1) hashed multiple times with different hash functions, or 2) permuted multiple times using one hash function. Here, we choose to permute each hash 5 times. More variants of MinHash can be found in [MinHash - Wikipedia](https://en.wikipedia.org/wiki/MinHash?useskin=vector). | shingle | permuted hashes | | ------------------- | ----------------------------------------------------------- | | Deduplication is so | [403996643, 2764117407, 3550129378, 3548765886, 2353686061] | | is so much | [3594692244, 3595617149, 1564558780, 2888962350, 432993166] | | so much fun | [1556191985, 840529008, 1008110251, 3095214118, 3194813501] | Taking the minimum value of each column within each document — the "Min" part of the "MinHash", we arrive at the final MinHash for this document: | doc_id | minhash | | ------ | ---------------------------------------------------------- | | 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | | 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | | 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | Technically, we don't have to use the minimum value of each column, but the minimum value is the most common choice. Other order statistics such as maximum, kth smallest, or kth largest can be used as well[[21]](#21). In implementation, you can easily vectorize these steps with `numpy` and expect to have a time complexity of \\( \mathcal{O}(NMK) \\) where \\( K \\) is your number of permutations. Code modified based on [Datasketch](https://github.com/ekzhu/datasketch). ```python def embed_func( content: str, idx: int, *, num_perm: int, ngram_size: int, hashranges: List[Tuple[int, int]], permutations: np.ndarray, ) -> Dict[str, Any]: a, b = permutations masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH) tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)} hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64) permuted_hashvalues = np.bitwise_and( ((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH ) hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0) Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges] return {"__signatures__": Hs, "__id__": idx} ``` If you are familiar with [Datasketch](https://github.com/ekzhu/datasketch), you might ask, why do we bother to strip all the nice high-level functions the library provides? It is not because we want to avoid adding dependencies, but because we intend to squeeze as much CPU computation as possible during parallelization. Fusing few steps into one function call enables us to utilize our compute resources better. Since one document's calculation is not dependent on anything else. A good parallelization choice would be using the `map` function from the `datasets` library: ```python embedded = ds.map( function=embed_func, fn_kwargs={ "num_perm": args.num_perm, "hashranges": HASH_RANGES, "ngram_size": args.ngram, "permutations": PERMUTATIONS, }, input_columns=[args.column], remove_columns=ds.column_names, num_proc=os.cpu_count(), with_indices=True, desc="Fingerprinting...", ) ``` After the fingerprint calculation, one particular document is mapped to one array of integer values. To figure out what documents are similar to each other, we need to group them based on such fingerprints. Entering the stage, **Locality Sensitive Hashing (LSH)**. ### Locality Sensitive Hashing LSH breaks the fingerprint array into bands, each band containing the same number of rows. If there is any hash values left, it will be ignored. Let's use \\( b=2 \\) bands and \\( r=2 \\) rows to group those documents: | doc_id | minhash | bands | | ------ | ---------------------------------------------------------- | ------------------------------------------------------ | | 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 2888962350]] | | 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 1998729813]] | | 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | [0:[166417565, 213933364], 1:[1129612544, 1419614622]] | If two documents share the same hashes in a band at a particular location (band index), they will be clustered into the same bucket and will be considered as candidates. | band index | band value | doc_ids | | ---------- | ------------------------ | ------- | | 0 | [403996643, 840529008] | 0, 1 | | 1 | [1008110251, 2888962350] | 0 | | 1 | [1008110251, 1998729813] | 1 | | 0 | [166417565, 213933364] | 2 | | 1 | [1129612544, 1419614622] | 2 | For each row in the `doc_ids` column, we can generate candidate pairs by pairing every two of them. From the above table, we can generate one candidate pair: `(0, 1)`. ### Beyond Duplicate Pairs This is where many deduplication descriptions in papers or tutorials stop. We are still left with the question of what to do with them. Generally, we can proceed with two options: 1. Double-check their actual Jaccard similarities by calculating their shingle overlap, due to the estimation nature of MinHash. The Jaccard Similarity of two sets is defined as the size of the intersection divided by the size of the union. And now it becomes much more doable than computing all-pair similarities, because we can focus only for documents within a cluster. This is also what we initially did for BigCode, which worked reasonably well. 2. Treat them as true positives. You probably already noticed the issue here: the Jaccard similarity isn't transitive, meaning \\( A \\) is similar to \\( B \\) and \\( B \\) is similar to \\( C \\), but \\( A \\) and \\( C \\) do not necessary share the similarity. However, our experiments from The Stack show that treating all of them as duplicates improves the downstream model's performance the best. And now we gradually moved towards this method instead, and it saves time as well. But to apply this to your dataset, we still recommend going over your dataset and looking at your duplicates, and then making a data-driven decision. From such pairs, whether they are validated or not, we can now construct a graph with those pairs as edges, and duplicates will be clustered into communities or connected components. In terms of implementation, unfortunately, this is where `datasets` couldn't help much because now we need something like a `groupby` where we can cluster documents based on their _band offset_ and _band values_. Here are some options we have tried: **Option 1: Iterate the datasets the old-fashioned way and collect edges. Then use a graph library to do community detection or connected component detection.** This did not scale well in our tests, and the reasons are multifold. First, iterating the whole dataset is slow and memory consuming at a large scale. Second, popular graph libraries like `graphtool` or `networkx` have a lot of overhead for graph creation. **Option 2: Use popular python frameworks such as `dask` to allow more efficient `groupby` operations**. But then you still have problems of slow iteration and slow graph creation. **Option 3: Iterate the dataset, but use a union find data structure to cluster documents.** This adds negligible overhead to the iteration, and it works relatively well for medium datasets. ```python for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Clustering..."): for cluster in table.values(): if len(cluster) <= 1: continue idx = min(cluster) for x in cluster: uf.union(x, idx) ``` **Option 4: For large datasets, use Spark.** We already know that steps up to the LSH part can be parallelized, which is also achievable in Spark. In addition to that, Spark supports distributed `groupBy` out of the box, and it is also straightforward to implement algorithms like [[18]](#18) for connected component detection. If you are wondering why we didn't use Spark's implementation of MinHash, the answer is that all our experiments so far stemmed from [Datasketch](https://github.com/ekzhu/datasketch), which uses an entirely different implementation than Spark, and we want to ensure that we carry on the lessons and insights learned from that without going into another rabbit hole of ablation experiments. ```python edges = ( records.flatMap( lambda x: generate_hash_values( content=x[1], idx=x[0], num_perm=args.num_perm, ngram_size=args.ngram_size, hashranges=HASH_RANGES, permutations=PERMUTATIONS, ) ) .groupBy(lambda x: (x[0], x[1])) .flatMap(lambda x: generate_edges([i[2] for i in x[1]])) .distinct() .cache() ) ``` A simple connected component algorithm based on [[18]](#18) implemented in Spark. ```python a = edges while True: b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache() a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache() changes = a.subtract(b).union(b.subtract(a)).collect() if len(changes) == 0: break results = a.collect() ``` Additionally, thanks to cloud providers, we can set up Spark clusters like a breeze with services like GCP DataProc. **In the end, we can comfortably run the program to deduplicate 1.4 TB of data in just under 4 hours with a budget of $15 an hour.** ## Quality Matters Scaling a ladder doesn't get us to the moon. That's why we need to make sure this is the right direction, and we are using it the right way. Early on, our parameters were largely inherited from the CodeParrot experiments, and our ablation experiment indicated that those settings did improve the model's downstream performance[[16]](#16). We then set to further explore this path and can confirm that[[4]](#4): 1. Near-deduplication improves the model's downstream performance with a much smaller dataset (6 TB VS. 3 TB) 2. We haven't figured out the limit yet, but a more aggressive deduplication (6 TB VS. 2.4 TB) can improve the performance even more: 1. Lower the similarity threshold 2. Increase the shingle size (unigram → 5-gram) 3. Ditch false positive checking because we can afford to lose a small percentage of false positives 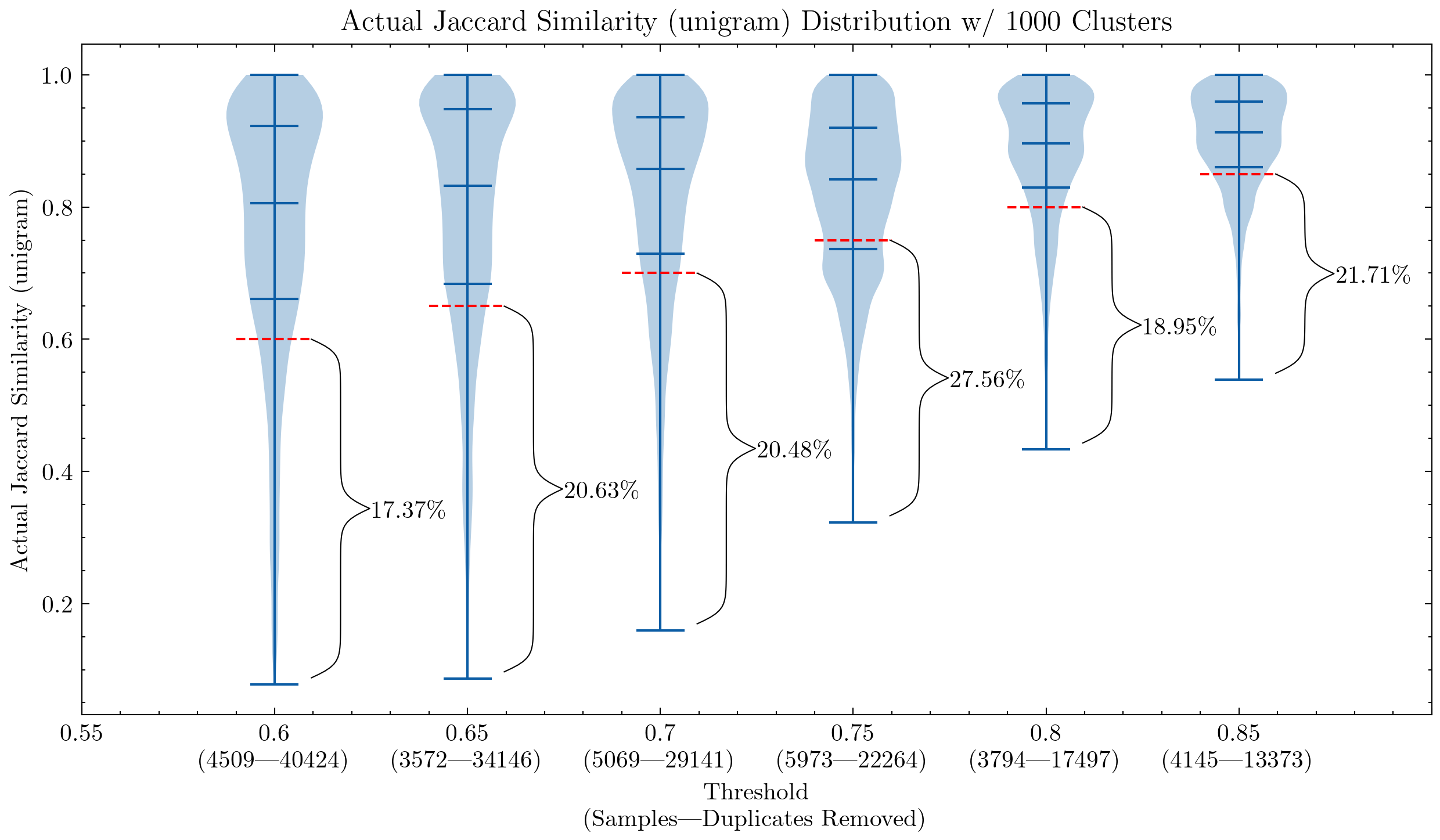 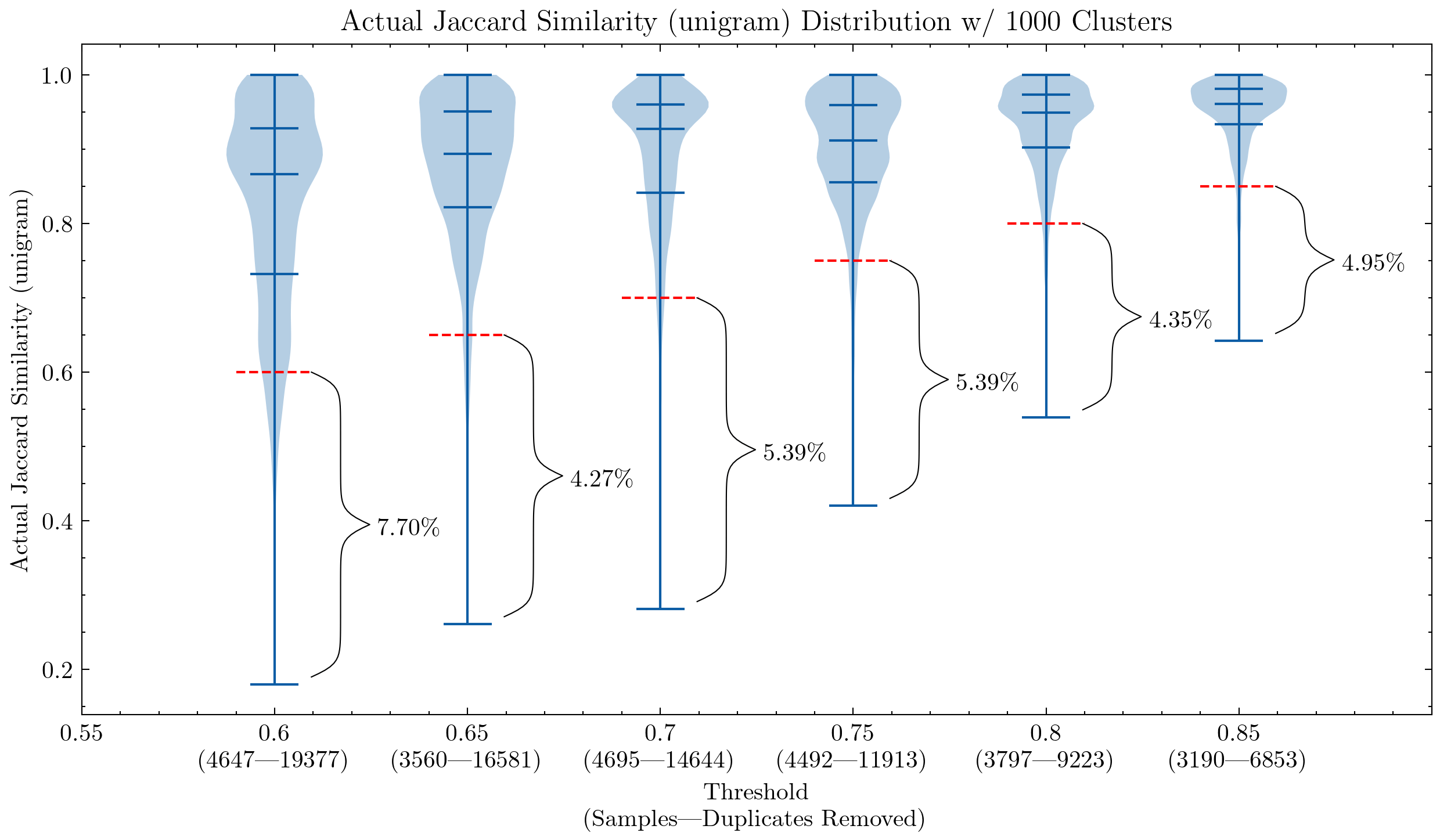 <center> Image: Two graphs showing the impact of similarity threshold and shingle size, the first one is using unigram and the second one 5-gram. The red dash line shows the similarity cutoff: any documents below would be considered as false positives — their similarities with other documents within a cluster are lower than the threshold. </center> These graphs can help us understand why it was necessary to double-check the false positives for CodeParrot and early version of the Stack: using unigram creates many false positives; They also demonstrate that by increasing the shingle size to 5-gram, the percentage of false positives decreases significantly. A smaller threshold is desired if we want to keep the deduplication aggressiveness. Additional experiments also showed that lowering the threshold removes more documents that have high similarity pairs, meaning an increased recall in the segment we actually would like to remove the most. ## Scaling 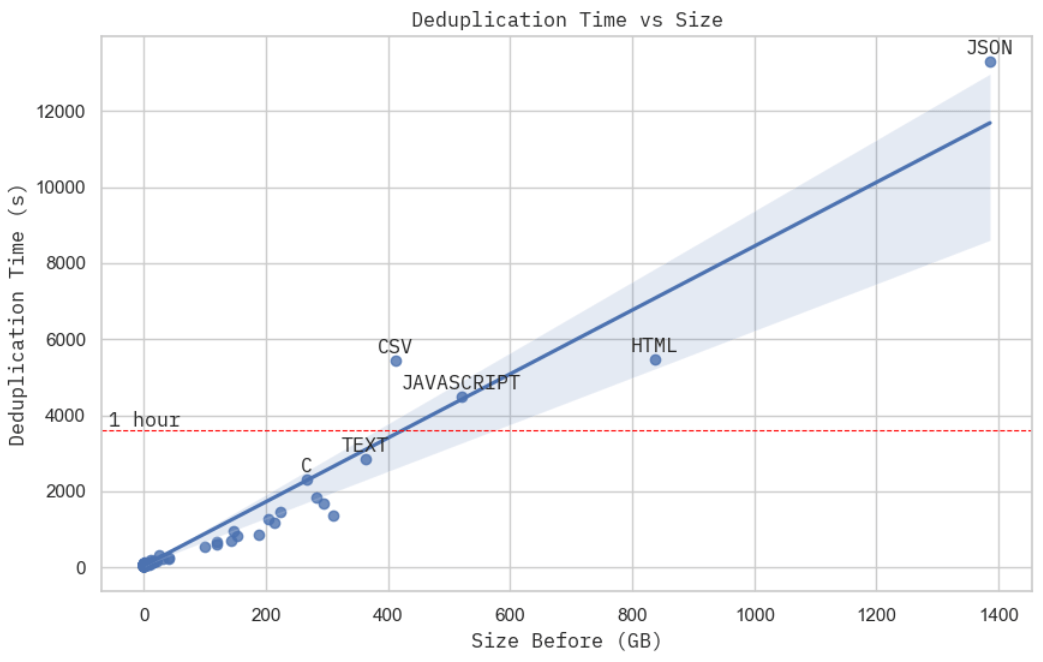 <center>Image: Deduplication time versus raw dataset size. This is achieved with 15 worker c2d-standard-16 machines on GCP, and each costed around $0.7 per hour. </center>  <center>Image: CPU usage screenshot for the cluster during processing JSON dataset.</center> This isn't the most rigorous scaling proof you can find, but the deduplication time, given a fixed computation budget, looks practically linear to the physical size of the dataset. When you take a closer look at the cluster resource usage when processing JSON dataset, the largest subset in the Stack, you can see the MinHash + LSH (stage 2) dominated the total real computation time (stage 2 + 3), which from our previous analysis is \\( \mathcal{O}(NM) \\) — linear to the dataset physical volume. ## Proceed with Caution Deduplication doesn't exempt you from thorough data exploration and analysis. In addition, these deduplication discoveries hold true for the Stack, but it does not mean it is readily applicable to other datasets or languages. It is a good first step towards building a better dataset, and further investigations such as data quality filtering (e.g., vulnerability, toxicity, bias, generated templates, PII) are still much needed. We still encourage you to perform similar analysis on your datasets before training. For example, it might not be very helpful to do deduplication if you have tight time and compute budget: [@geiping_2022](http://arxiv.org/abs/2212.14034) mentions that substring deduplication didn't improve their model's downstream performance. Existing datasets might also require thorough examination before use, for example, [@gao_2020](http://arxiv.org/abs/2101.00027) states that they only made sure the Pile itself, along with its splits, are deduplicated, and they won't proactively deduplicating for any downstream benchmarks and leave that decision to readers. In terms of data leakage and benchmark contamination, there is still much to explore. We had to retrain our code models because HumanEval was published in one of the GitHub repos in Python. Early near-deduplication results also suggest that MBPP[[19]](#19), one of the most popular benchmarks for coding, shares a lot of similarity with many Leetcode problems (e.g., task 601 in MBPP is basically Leetcode 646, task 604 ≃ Leetcode 151.). And we all know GitHub is no short of those coding challenges and solutions. It will be even more difficult if someone with bad intentions upload all the benchmarks in the form of python scripts, or other less obvious ways, and pollute all your training data. ## Future Directions 1. Substring deduplication. Even though it showed some benefits for English[[3]](#3), it is not clear yet if this should be applied to code data as well; 2. Repetition: paragraphs that are repeated multiple times in one document. [@rae_2021](http://arxiv.org/abs/2112.11446) shared some interesting heuristics on how to detect and remove them. 3. Using model embeddings for semantic deduplication. It is another whole research question with scaling, cost, ablation experiments, and trade-off with near-deduplication. There are some intriguing takes on this[[20]](#20), but we still need more situated evidence to draw a conclusion (e.g, [@abbas_2023](http://arxiv.org/abs/2303.09540)'s only text deduplication reference is [@lee_2022a](http://arxiv.org/abs/2107.06499), whose main claim is deduplicating helps instead of trying to be SOTA). 4. Optimization. There is always room for optimization: better quality evaluation, scaling, downstream performance impact analysis etc. 5. Then there is another direction to look at things: To what extent near-deduplication starts to hurt performance? To what extent similarity is needed for diversity instead of being considered as redundancy? ## Credits The banner image contains emojis (hugging face, Santa, document, wizard, and wand) from Noto Emoji (Apache 2.0). This blog post is proudly written without any generative APIs. Huge thanks to Huu Nguyen @Huu and Hugo Laurençon @HugoLaurencon for the collaboration in BigScience and everyone at BigCode for the help along the way! If you ever find any error, feel free to contact me: mouchenghao at gmail dot com. ## Supporting Resources - [Datasketch](https://github.com/ekzhu/datasketch) (MIT) - [simhash-py](https://github.com/seomoz/simhash-py/tree/master/simhash) and [simhash-cpp](https://github.com/seomoz/simhash-cpp) (MIT) - [Deduplicating Training Data Makes Language Models Better](https://github.com/google-research/deduplicate-text-datasets) (Apache 2.0) - [Gaoya](https://github.com/serega/gaoya) (MIT) - [BigScience](https://github.com/bigscience-workshop) (Apache 2.0) - [BigCode](https://github.com/bigcode-project) (Apache 2.0) ## References - <a id="1">[1]</a> : Nikhil Kandpal, Eric Wallace, Colin Raffel, [Deduplicating Training Data Mitigates Privacy Risks in Language Models](http://arxiv.org/abs/2202.06539), 2022 - <a id="2">[2]</a> : Gowthami Somepalli, et al., [Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models](http://arxiv.org/abs/2212.03860), 2022 - <a id="3">[3]</a> : Katherine Lee, Daphne Ippolito, et al., [Deduplicating Training Data Makes Language Models Better](http://arxiv.org/abs/2107.06499), 2022 - <a id="4">[4]</a> : Loubna Ben Allal, Raymond Li, et al., [SantaCoder: Don't reach for the stars!](http://arxiv.org/abs/2301.03988), 2023 - <a id="5">[5]</a> : Leo Gao, Stella Biderman, et al., [The Pile: An 800GB Dataset of Diverse Text for Language Modeling](http://arxiv.org/abs/2101.00027), 2020 - <a id="6">[6]</a> : Asier Gutiérrez-Fandiño, Jordi Armengol-Estapé, et al., [MarIA: Spanish Language Models](http://arxiv.org/abs/2107.07253), 2022 - <a id="7">[7]</a> : Jack W. Rae, Sebastian Borgeaud, et al., [Scaling Language Models: Methods, Analysis & Insights from Training Gopher](http://arxiv.org/abs/2112.11446), 2021 - <a id="8">[8]</a> : Xi Victoria Lin, Todor Mihaylov, et al., [Few-shot Learning with Multilingual Language Models](http://arxiv.org/abs/2112.10668), 2021 - <a id="9">[9]</a> : Hugo Laurençon, Lucile Saulnier, et al., [The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset](https://openreview.net/forum?id=UoEw6KigkUn), 2022 - <a id="10">[10]</a> : Daniel Fried, Armen Aghajanyan, et al., [InCoder: A Generative Model for Code Infilling and Synthesis](http://arxiv.org/abs/2204.05999), 2022 - <a id="11">[11]</a> : Erik Nijkamp, Bo Pang, et al., [CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis](http://arxiv.org/abs/2203.13474), 2023 - <a id="12">[12]</a> : Yujia Li, David Choi, et al., [Competition-Level Code Generation with AlphaCode](http://arxiv.org/abs/2203.07814), 2022 - <a id="13">[13]</a> : Frank F. Xu, Uri Alon, et al., [A Systematic Evaluation of Large Language Models of Code](http://arxiv.org/abs/2202.13169), 2022 - <a id="14">[14]</a> : Aakanksha Chowdhery, Sharan Narang, et al., [PaLM: Scaling Language Modeling with Pathways](http://arxiv.org/abs/2204.02311), 2022 - <a id="15">[15]</a> : Lewis Tunstall, Leandro von Werra, Thomas Wolf, [Natural Language Processing with Transformers, Revised Edition](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/), 2022 - <a id="16">[16]</a> : Denis Kocetkov, Raymond Li, et al., [The Stack: 3 TB of permissively licensed source code](http://arxiv.org/abs/2211.15533), 2022 - <a id="17">[17]</a> : [Rocky | Project Hail Mary Wiki | Fandom](https://projecthailmary.fandom.com/wiki/Rocky) - <a id="18">[18]</a> : Raimondas Kiveris, Silvio Lattanzi, et al., [Connected Components in MapReduce and Beyond](https://doi.org/10.1145/2670979.2670997), 2014 - <a id="19">[19]</a> : Jacob Austin, Augustus Odena, et al., [Program Synthesis with Large Language Models](http://arxiv.org/abs/2108.07732), 2021 - <a id="20">[20]</a>: Amro Abbas, Kushal Tirumala, et al., [SemDeDup: Data-efficient learning at web-scale through semantic deduplication](http://arxiv.org/abs/2303.09540), 2023 - <a id="21">[21]</a>: Edith Cohen, [MinHash Sketches : A Brief Survey](http://www.cohenwang.com/edith/Surveys/minhash.pdf), 2016
|
Instruction-tuning Stable Diffusion with InstructPix2Pix
|
sayakpaul
|
May 23, 2023
|
instruction-tuning-sd
|
diffusers, diffusion, instruction-tuning, research, guide
|
https://huggingface.co/blog/instruction-tuning-sd
|
# Instruction-tuning Stable Diffusion with InstructPix2Pix This post explores instruction-tuning to teach [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) to follow instructions to translate or process input images. With this method, we can prompt Stable Diffusion using an input image and an “instruction”, such as - *Apply a cartoon filter to the natural image*. | 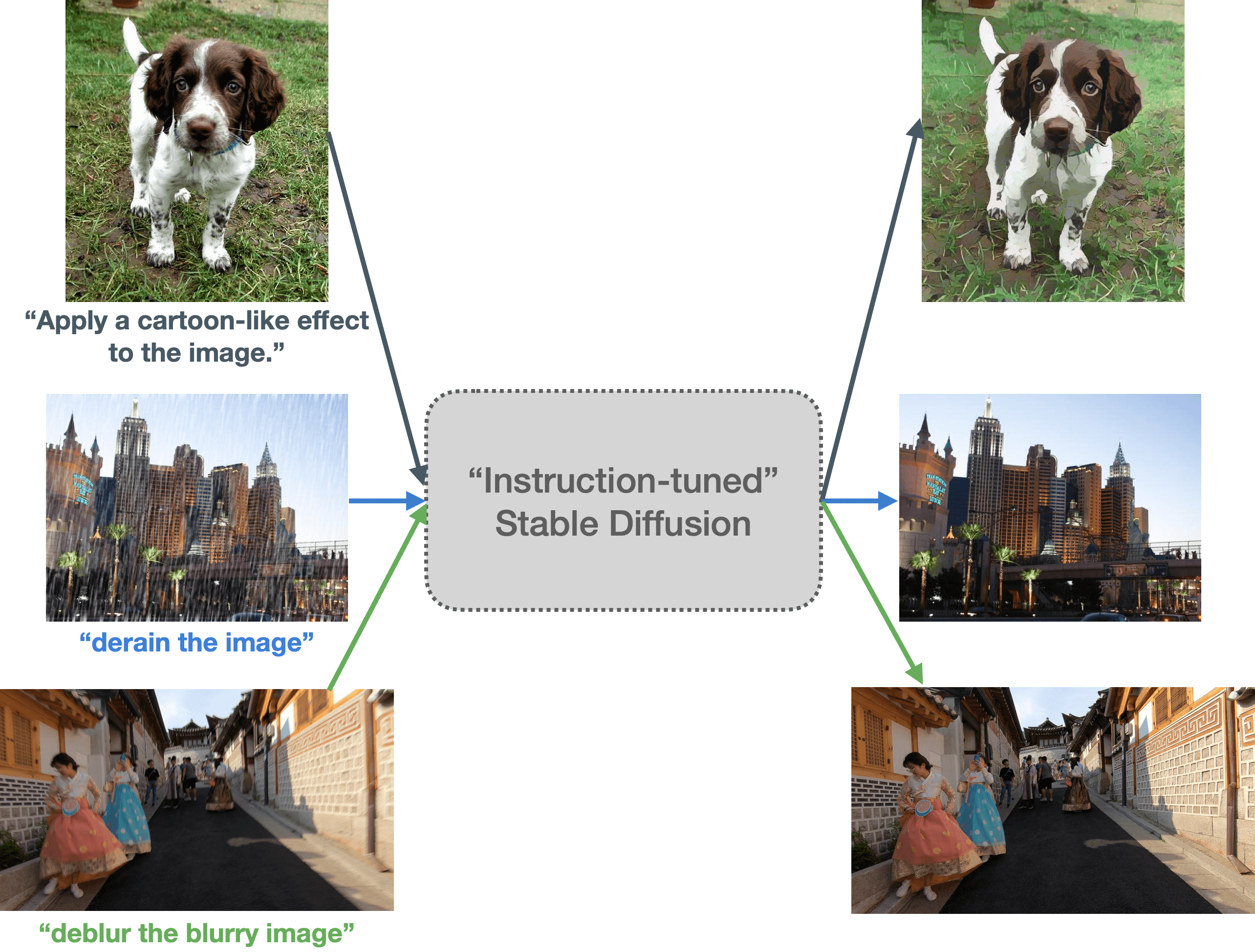 | |:--:| | **Figure 1**: We explore the instruction-tuning capabilities of Stable Diffusion. In this figure, we prompt an instruction-tuned Stable Diffusion system with prompts involving different transformations and input images. The tuned system seems to be able to learn these transformations stated in the input prompts. Figure best viewed in color and zoomed in. | This idea of teaching Stable Diffusion to follow user instructions to perform **edits** on input images was introduced in [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/papers/2211.09800). We discuss how to extend the InstructPix2Pix training strategy to follow more specific instructions related to tasks in image translation (such as cartoonization) and low-level image processing (such as image deraining). We cover: - [Introduction to instruction-tuning](#introduction-and-motivation) - [The motivation behind this work](#introduction-and-motivation) - [Dataset preparation](#dataset-preparation) - [Training experiments and results](#training-experiments-and-results) - [Potential applications and limitations](#potential-applications-and-limitations) - [Open questions](#open-questions) Our code, pre-trained models, and datasets can be found [here](https://github.com/huggingface/instruction-tuned-sd). ## Introduction and motivation Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in [Fine-tuned Language Models Are Zero-Shot Learners](https://huggingface.co/papers/2109.01652) (FLAN) by Google. From recent times, you might recall works like [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) and [FLAN V2](https://huggingface.co/papers/2210.11416), which are good examples of how beneficial instruction-tuning can be for various tasks. The figure below shows a formulation of instruction-tuning (also called “instruction-finetuning”). In the [FLAN V2 paper](https://huggingface.co/papers/2210.11416), the authors take a pre-trained language model ([T5](https://huggingface.co/docs/transformers/model_doc/t5), for example) and fine-tune it on a dataset of exemplars, as shown in the figure below. | 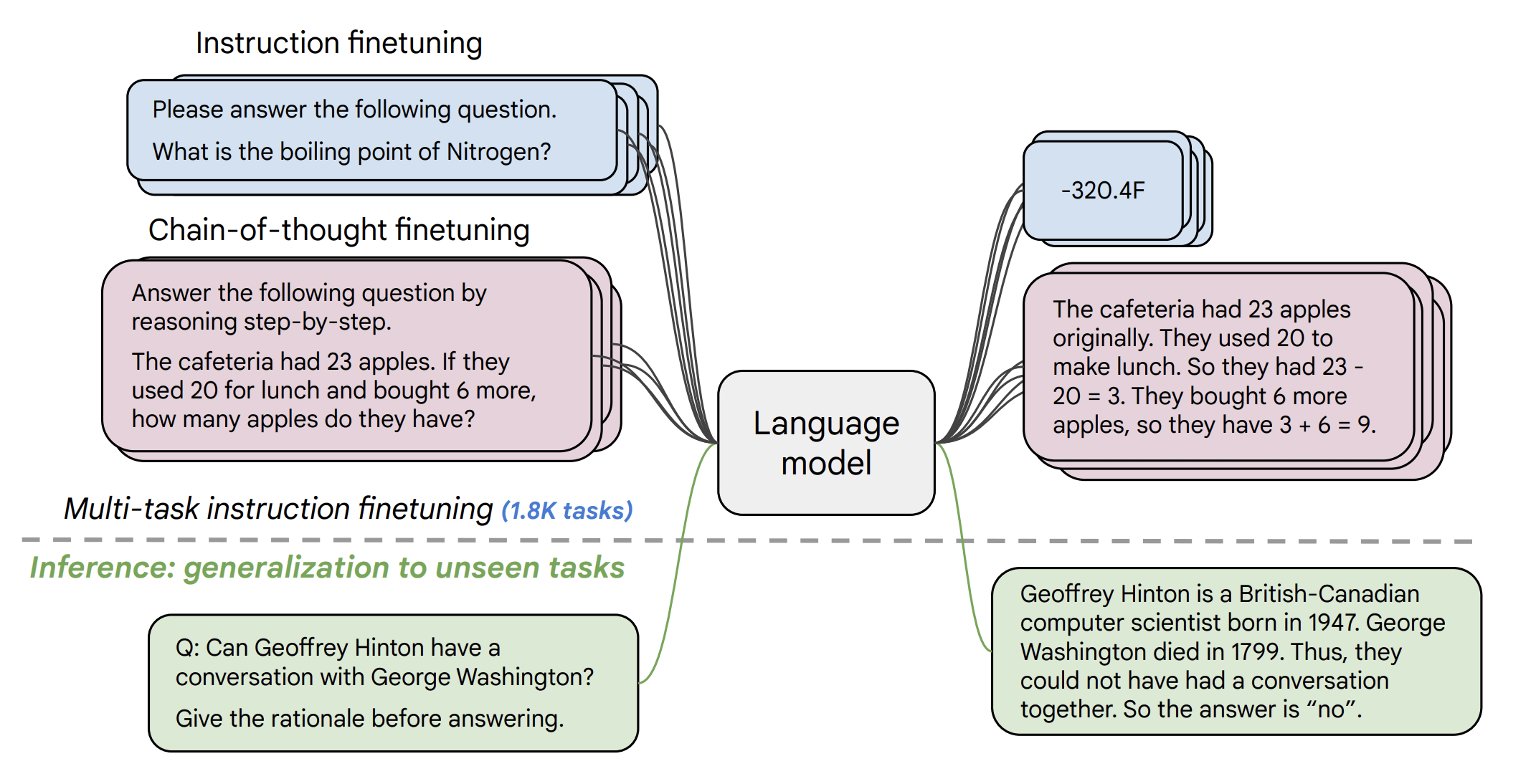 | |:--:| | **Figure 2**: FLAN V2 schematic (figure taken from the FLAN V2 paper). | With this approach, one can create exemplars covering many different tasks, which makes instruction-tuning a multi-task training objective: | **Input** | **Label** | **Task** | |---|---|---| | Predict the sentiment of the<br>following sentence: “The movie<br>was pretty amazing. I could not<br>turn around my eyes even for a<br>second.” | Positive | Sentiment analysis /<br>Sequence classification | | Please answer the following<br>question. <br>What is the boiling point of<br>Nitrogen? | 320.4F | Question answering | | Translate the following<br>English sentence into German: “I have<br>a cat.” | Ich habe eine Katze. | Machine translation | | … | … | … | | | | | | Using a similar philosophy, the authors of FLAN V2 conduct instruction-tuning on a mixture of thousands of tasks and achieve zero-shot generalization to unseen tasks: | 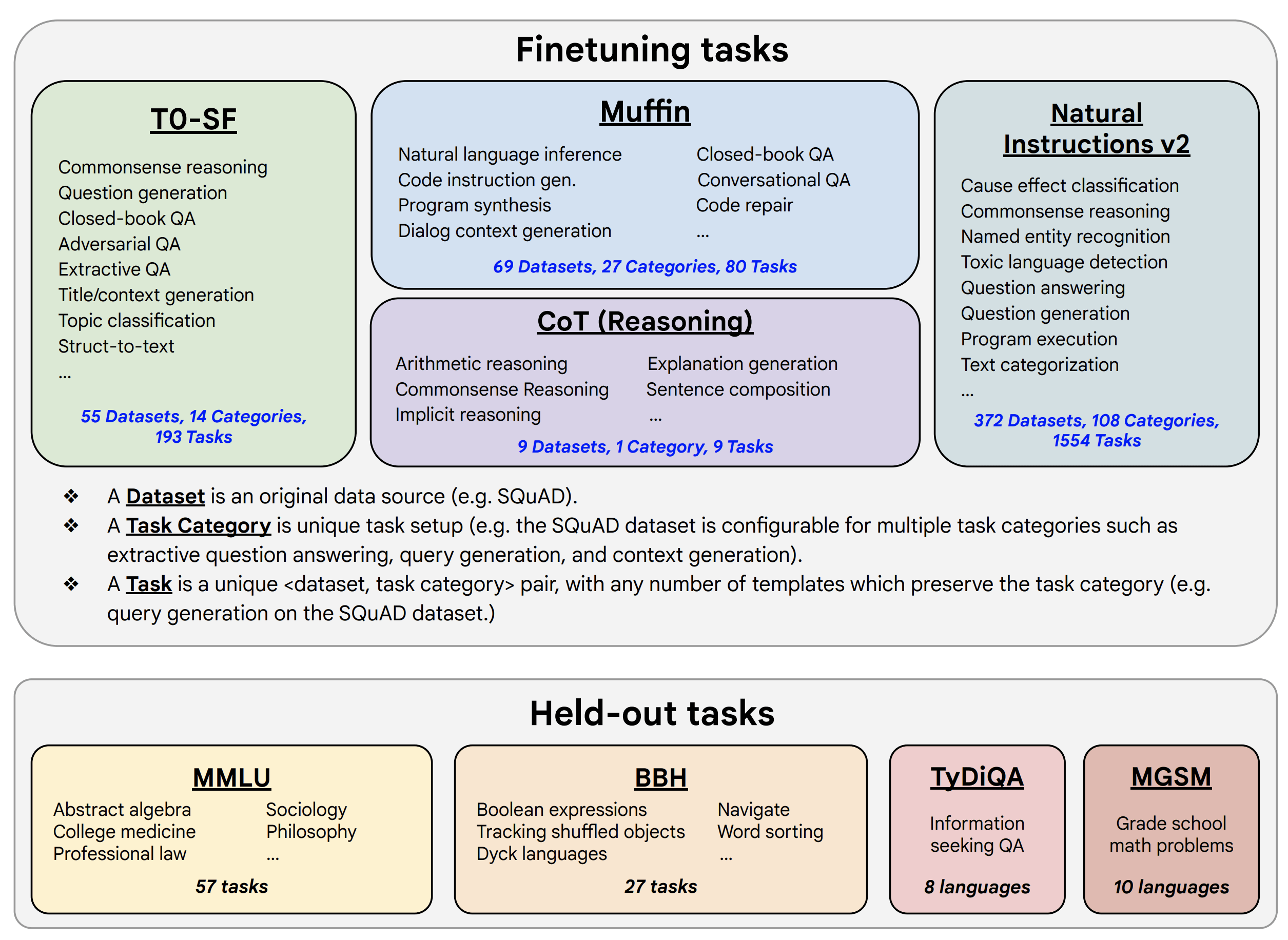 | |:--:| | **Figure 3**: FLAN V2 training and test task mixtures (figure taken from the FLAN V2 paper). | Our motivation behind this work comes partly from the FLAN line of work and partly from InstructPix2Pix. We wanted to explore if it’s possible to prompt Stable Diffusion with specific instructions and input images to process them as per our needs. The [pre-trained InstructPix2Pix models](https://huggingface.co/timbrooks/instruct-pix2pix) are good at following general instructions, but they may fall short of following instructions involving specific transformations: |  | |:--:| | **Figure 4**: We observe that for the input images (left column), our models (right column) more faithfully perform “cartoonization” compared to the pre-trained InstructPix2Pix models (middle column). It is interesting to note the results of the first row where the pre-trained InstructPix2Pix models almost fail significantly. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_results.png). | But we can still leverage the findings from InstructPix2Pix to suit our customizations. On the other hand, paired datasets for tasks like [cartoonization](https://github.com/SystemErrorWang/White-box-Cartoonization), [image denoising](https://paperswithcode.com/dataset/sidd), [image deraining](https://paperswithcode.com/dataset/raindrop), etc. are available publicly, which we can use to build instruction-prompted datasets taking inspiration from FLAN V2. Doing so allows us to transfer the instruction-templating ideas explored in FLAN V2 to this work. ## Dataset preparation ### Cartoonization In our early experiments, we prompted InstructPix2Pix to perform cartoonization and the results were not up to our expectations. We tried various inference-time hyperparameter combinations (such as image guidance scale and the number of inference steps), but the results still were not compelling. This motivated us to approach the problem differently. As hinted in the previous section, we wanted to benefit from both worlds: **(1)** training methodology of InstructPix2Pix and **(2)** the flexibility of creating instruction-prompted dataset templates from FLAN. We started by creating an instruction-prompted dataset for the task of cartoonization. Figure 5 presents our dataset creation pipeline: | 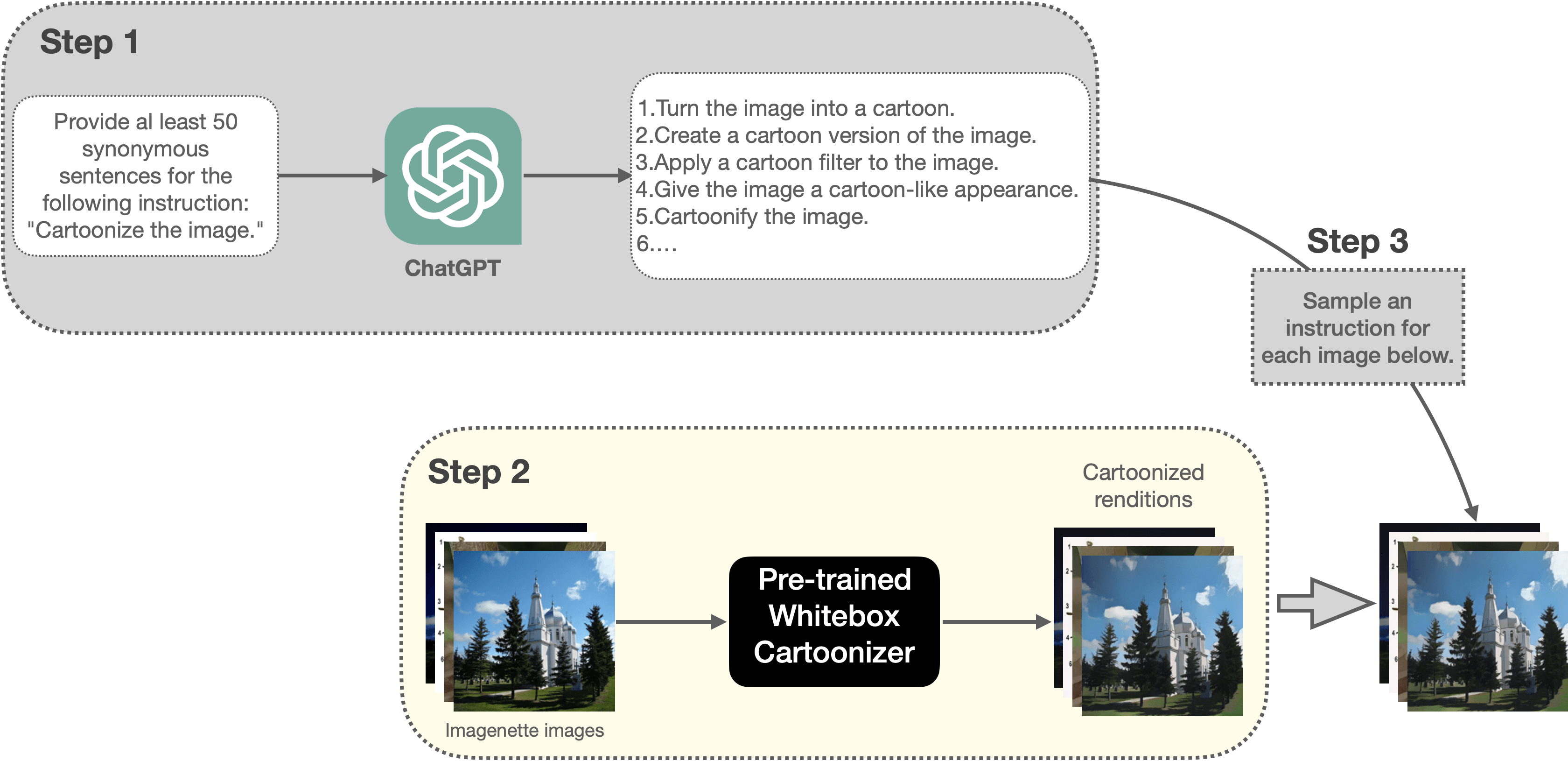 | |:--:| | **Figure 5**: A depiction of our dataset creation pipeline for cartoonization (best viewed in color and zoomed in). | In particular, we: 1. Ask [ChatGPT](https://openai.com/blog/chatgpt) to generate 50 synonymous sentences for the following instruction: "Cartoonize the image.” 2. We then use a random sub-set (5000 samples) of the [Imagenette dataset](https://github.com/fastai/imagenette) and leverage a pre-trained [Whitebox CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model to produce the cartoonized renditions of those images. The cartoonized renditions are the labels we want our model to learn from. So, in a way, this corresponds to transferring the biases learned by the Whitebox CartoonGAN model to our model. 3. Then we create our exemplars in the following format: | 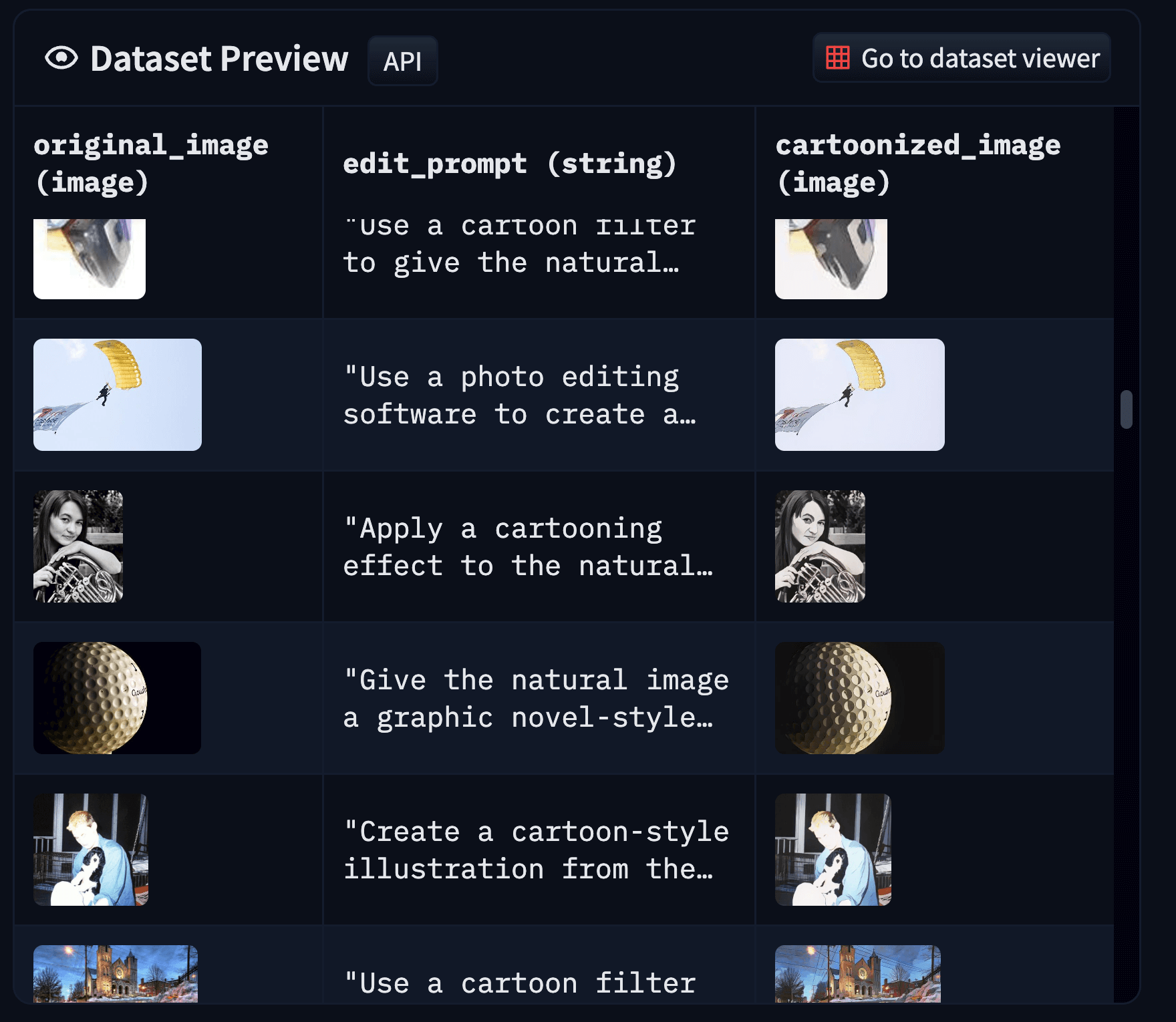 | |:--:| | **Figure 6**: Samples from the final cartoonization dataset (best viewed in color and zoomed in). | Our final dataset for cartoonization can be found [here](https://huggingface.co/datasets/instruction-tuning-vision/cartoonizer-dataset). For more details on how the dataset was prepared, refer to [this directory](https://github.com/huggingface/instruction-tuned-sd/tree/main/data_preparation). We experimented with this dataset by fine-tuning InstructPix2Pix and got promising results (more details in the “Training experiments and results” section). We then proceeded to see if we could generalize this approach to low-level image processing tasks such as image deraining, image denoising, and image deblurring. ### Low-level image processing We focus on the common low-level image processing tasks explored in [MAXIM](https://huggingface.co/papers/2201.02973). In particular, we conduct our experiments for the following tasks: deraining, denoising, low-light image enhancement, and deblurring. We took different number of samples from the following datasets for each task and constructed a single dataset with prompts added like so: | **Task** | **Prompt** | **Dataset** | **Number of samples** | |---|---|---|---| | Deblurring | “deblur the blurry image” | [REDS](https://seungjunnah.github.io/Datasets/reds.html) (`train_blur`<br>and `train_sharp`) | 1200 | | Deraining | “derain the image” | [Rain13k](https://github.com/megvii-model/HINet#image-restoration-tasks) | 686 | | Denoising | “denoise the noisy image” | [SIDD](https://www.eecs.yorku.ca/~kamel/sidd/) | 8 | | Low-light<br>image enhancement | "enhance the low-light image” | [LOL](https://paperswithcode.com/dataset/lol) | 23 | | | | | | Datasets mentioned above typically come as input-output pairs, so we do not have to worry about the ground-truth. Our final dataset is available [here](https://huggingface.co/datasets/instruction-tuning-vision/instruct-tuned-image-processing). The final dataset looks like so: | 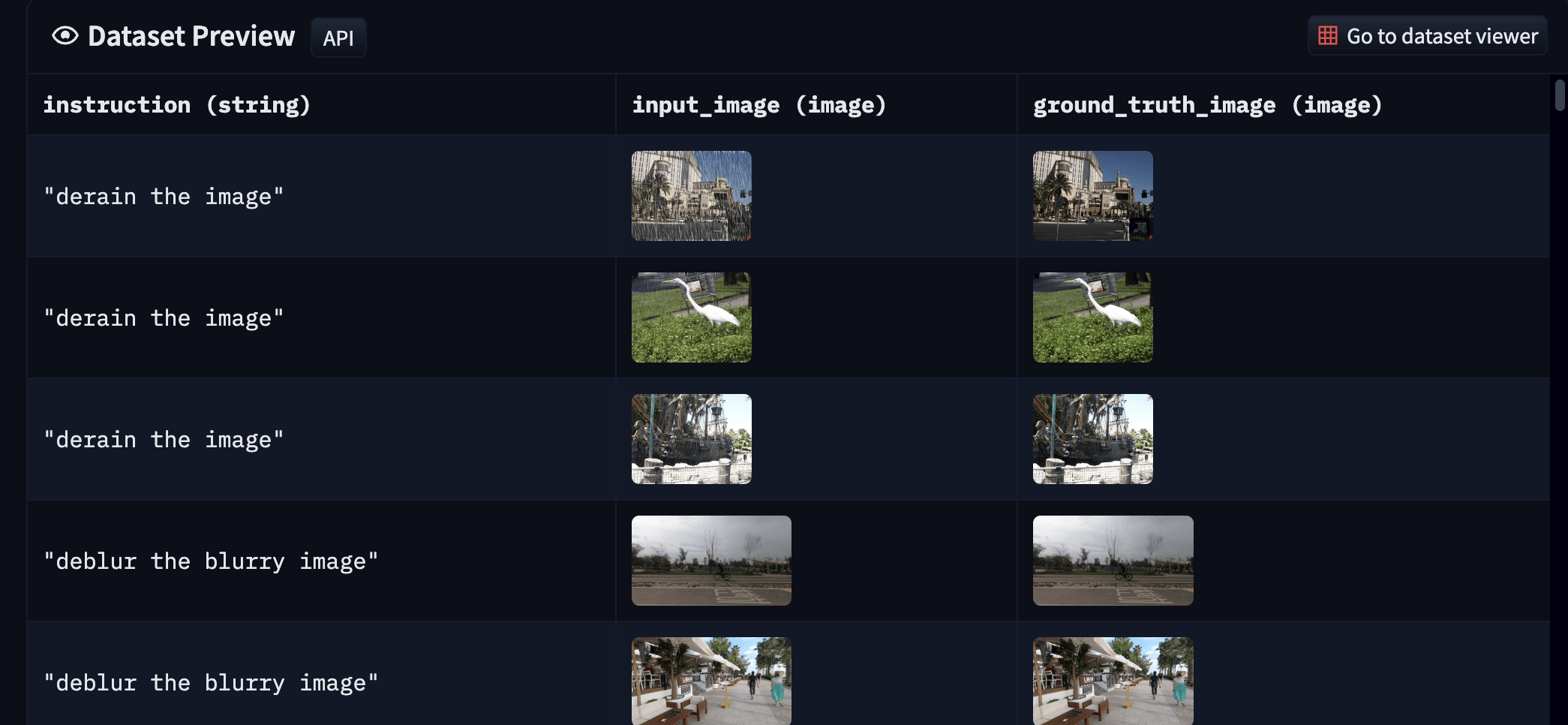 | |:--:| | **Figure 7**: Samples from the final low-level image processing dataset (best viewed in color and zoomed in). | Overall, this setup helps draw parallels from the FLAN setup, where we create a mixture of different tasks. This also helps us train a single model one time, performing well to the different tasks we have in the mixture. This varies significantly from what is typically done in low-level image processing. Works like MAXIM introduce a single model architecture capable of modeling the different low-level image processing tasks, but training happens independently on the individual datasets. ## Training experiments and results We based our training experiments on [this script](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py). Our training logs (including validation samples and training hyperparameters) are available on Weight and Biases: - [Cartoonization](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b/overview?workspace=)) - [Low-level image processing](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb/overview?workspace=)) When training, we explored two options: 1. Fine-tuning from an existing [InstructPix2Pix checkpoint](https://huggingface.co/timbrooks/instruct-pix2pix) 2. Fine-tuning from an existing [Stable Diffusion checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) using the InstructPix2Pix training methodology In our experiments, we found out that the first option helps us adapt to our datasets faster (in terms of generation quality). For more details on the training and hyperparameters, we encourage you to check out [our code](https://github.com/huggingface/instruction-tuned-sd) and the respective run pages on Weights and Biases. ### Cartoonization results For testing the [instruction-tuned cartoonization model](https://huggingface.co/instruction-tuning-sd/cartoonizer), we compared the outputs as follows: |  | |:--:| | **Figure 8**: We compare the results of our instruction-tuned cartoonization model (last column) with that of a [CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model (column two) and the pre-trained InstructPix2Pix model (column three). It’s evident that the instruction-tuned model can more faithfully match the outputs of the CartoonGAN model. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_full_results.png). | To gather these results, we sampled images from the `validation` split of ImageNette. We used the following prompt when using our model and the pre-trained InstructPix2Pix model: *“Generate a cartoonized version of the image”.* For these two models, we kept the `image_guidance_scale` and `guidance_scale` to 1.5 and 7.0, respectively, and number of inference steps to 20. Indeed more experimentation is needed around these hyperparameters to study how they affect the results of the pre-trained InstructPix2Pix model, in particular. More comparative results are available [here](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2). Our code for comparing these models is available [here](https://github.com/huggingface/instruction-tuned-sd/blob/main/validation/compare_models.py). Our model, however, [fails to produce](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2) the expected outputs for the classes from ImageNette, which it has not seen enough during training. This is somewhat expected, and we believe this could be mitigated by scaling the training dataset. ### Low-level image processing results For low-level image processing ([our model](https://huggingface.co/instruction-tuning-sd/low-level-img-proc)), we follow the same inference-time hyperparameters as above: - Number of inference steps: 20 - Image guidance scale: 1.5 - Guidance scale: 7.0 For deraining, our model provides compelling results when compared to the ground-truth and the output of the pre-trained InstructPix2Pix model: |  | |:--:| | **Figure 9**: Deraining results (best viewed in color and zoomed in). Inference prompt: “derain the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deraining_results.png). | However, for low-light image enhancement, it leaves a lot to be desired: |  | |:--:| | **Figure 10**: Low-light image enhancement results (best viewed in color and zoomed in). Inference prompt: “enhance the low-light image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/image_enhancement_results.png). | This failure, perhaps, can be attributed to our model not seeing enough exemplars for the task and possibly from better training. We notice similar findings for deblurring as well: |  | |:--:| | **Figure 11**: Deblurring results (best viewed in color and zoomed in). Inference prompt: “deblur the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deblurring_results.png). | We believe there is an opportunity for the community to explore how much the task mixture for low-level image processing affects the end results. *Does increasing the task mixture with more representative samples help improve the end results?* We leave this question for the community to explore further. You can try out the interactive demo below to make Stable Diffusion follow specific instructions: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.29.0/gradio.js"></script> <gradio-app theme_mode="light" src="https://instruction-tuning-sd-instruction-tuned-sd.hf.space"></gradio-app> ## Potential applications and limitations In the world of image editing, there is a disconnect between what a domain expert has in mind (the tasks to be performed) and the actions needed to be applied in editing tools (such as [Lightroom](https://www.adobe.com/in/products/photoshop-lightroom.html)). Having an easy way of translating natural language goals to low-level image editing primitives would be a seamless user experience. With the introduction of mechanisms like InstructPix2Pix, it’s safe to say that we’re getting closer to that realm. However, challenges still remain: - These systems need to work for large high-resolution original images. - Diffusion models often invent or re-interpret an instruction to perform the modifications in the image space. For a realistic image editing application, this is unacceptable. ## Open questions We acknowledge that our experiments are preliminary. We did not go deep into ablating the apparent factors in our experiments. Hence, here we enlist a few open questions that popped up during our experiments: - ***What happens we scale up the datasets?*** How does that impact the quality of the generated samples? We experimented with a handful of examples. For comparison, InstructPix2Pix was trained on more than 30000 samples. - ***What is the impact of training for longer, especially when the task mixture is broader?*** In our experiments, we did not conduct hyperparameter tuning, let alone an ablation on the number of training steps. - ***How does this approach generalize to a broader mixture of tasks commonly done in the “instruction-tuning” world?*** We only covered four tasks for low-level image processing: deraining, deblurring, denoising, and low-light image enhancement. Does adding more tasks to the mixture with more representative samples help the model generalize to unseen tasks or, perhaps, a combination of tasks (example: “Deblur the image and denoise it”)? - ***Does using different variations of the same instruction on-the-fly help improve performance?*** For cartoonization, we randomly sampled an instruction from the set of ChatGPT-generated synonymous instructions **during** dataset creation. But what happens when we perform random sampling during training instead? For low-level image processing, we used fixed instructions. What happens when we follow a similar methodology of using synonymous instructions for each task and input image? - ***What happens when we use ControlNet training setup, instead?*** [ControlNet](https://huggingface.co/papers/2302.05543) also allows adapting a pre-trained text-to-image diffusion model to be conditioned on additional images (such as semantic segmentation maps, canny edge maps, etc.). If you’re interested, then you can use the datasets presented in this post and perform ControlNet training referring to [this post](https://huggingface.co/blog/train-your-controlnet). ## Conclusion In this post, we presented our exploration of “instruction-tuning” of Stable Diffusion. While pre-trained InstructPix2Pix are good at following general image editing instructions, they may break when presented with more specific instructions. To mitigate that, we discussed how we prepared our datasets for further fine-tuning InstructPix2Pix and presented our results. As noted above, our results are still preliminary. But we hope this work provides a basis for the researchers working on similar problems and they feel motivated to explore the open questions further. ## Links - Training and inference code: [https://github.com/huggingface/instruction-tuned-sd](https://github.com/huggingface/instruction-tuned-sd) - Demo: [https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd](https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd) - InstructPix2Pix: [https://huggingface.co/timbrooks/instruct-pix2pix](https://huggingface.co/timbrooks/instruct-pix2pix) - Datasets and models from this post: [https://huggingface.co/instruction-tuning-sd](https://huggingface.co/instruction-tuning-sd) *Thanks to [Alara Dirik](https://www.linkedin.com/in/alaradirik/) and [Zhengzhong Tu](https://www.linkedin.com/in/zhengzhongtu) for the helpful discussions. Thanks to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) and [Kashif Rasul](https://twitter.com/krasul?lang=en) for their helpful reviews on the post.* ## Citation To cite this work, please use the following citation: ```bibtex @article{ Paul2023instruction-tuning-sd, author = {Paul, Sayak}, title = {Instruction-tuning Stable Diffusion with InstructPix2Pix}, journal = {Hugging Face Blog}, year = {2023}, note = {https://huggingface.co/blog/instruction-tuning-sd}, } ```
|
Safetensors audited as really safe and becoming the default
|
Narsil
|
May 23, 2023
|
safetensors-security-audit
|
pickle, serialization, load times
|
https://huggingface.co/blog/safetensors-security-audit
|
# Audit shows that safetensors is safe and ready to become the default [Hugging Face](https://huggingface.co/), in close collaboration with [EleutherAI](https://www.eleuther.ai/) and [Stability AI](https://stability.ai/), has ordered an external security audit of the `safetensors` library, the results of which allow all three organizations to move toward making the library the default format for saved models. The full results of the security audit, performed by [Trail of Bits](https://www.trailofbits.com/), can be found here: [Report](https://huggingface.co/datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf). The following blog post explains the origins of the library, why these audit results are important, and the next steps. ## What is safetensors? 🐶[Safetensors](https://github.com/huggingface/safetensors) is a library for saving and loading tensors in the most common frameworks (including PyTorch, TensorFlow, JAX, PaddlePaddle, and NumPy). For a more concrete explanation, we'll use PyTorch. ```python import torch from safetensors.torch import load_file, save_file weights = {"embeddings": torch.zeros((10, 100))} save_file(weights, "model.safetensors") weights2 = load_file("model.safetensors") ``` It also has a number of [cool features](https://github.com/huggingface/safetensors#yet-another-format-) compared to other formats, most notably that loading files is _safe_, as we'll see later. When you're using `transformers`, if `safetensors` is installed, then those files will already be used preferentially in order to prevent issues, which means that ``` pip install safetensors ``` is likely to be the only thing needed to run `safetensors` files safely. Going forward and thanks to the validation of the library, `safetensors` will now be installed in `transformers` by default. The next step is saving models in `safetensors` by default. We are thrilled to see that the `safetensors` library is already seeing use in the ML ecosystem, including: - [Civitai](https://civitai.com/) - [Stable Diffusion Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) - [dfdx](https://github.com/coreylowman/dfdx) - [LLaMA.cpp](https://github.com/ggerganov/llama.cpp/blob/e6a46b0ed1884c77267dc70693183e3b7164e0e0/convert.py#L537) ## Why create something new? The creation of this library was driven by the fact that PyTorch uses `pickle` under the hood, which is inherently unsafe. (Sources: [1](https://huggingface.co/docs/hub/security-pickle), [2, video](https://www.youtube.com/watch?v=2ethDz9KnLk), [3](https://github.com/pytorch/pytorch/issues/52596)) With pickle, it is possible to write a malicious file posing as a model that gives full control of a user's computer to an attacker without the user's knowledge, allowing the attacker to steal all their bitcoins 😓. While this vulnerability in pickle is widely known in the computer security world (and is acknowledged in the PyTorch [docs](https://pytorch.org/docs/stable/generated/torch.load.html)), it’s not common knowledge in the broader ML community. Since the Hugging Face Hub is a platform where anyone can upload and share models, it is important to make efforts to prevent users from getting infected by malware. We are also taking steps to make sure the existing PyTorch files are not malicious, but the best we can do is flag suspicious-looking files. Of course, there are other file formats out there, but none seemed to meet the full set of [ideal requirements](https://github.com/huggingface/safetensors#yet-another-format-) our team identified. In addition to being safe, `safetensors` allows lazy loading and generally faster loads (around 100x faster on CPU). Lazy loading means loading only part of a tensor in an efficient manner. This particular feature enables arbitrary sharding with efficient inference libraries, such as [text-generation-inference](https://github.com/huggingface/text-generation-inference), to load LLMs (such as LLaMA, StarCoder, etc.) on various types of hardware with maximum efficiency. Because it loads so fast and is framework agnostic, we can even use the format to load models from the same file in PyTorch or TensorFlow. ## The security audit Since `safetensors` main asset is providing safety guarantees, we wanted to make sure it actually delivered. That's why Hugging Face, EleutherAI, and Stability AI teamed up to get an external security audit to confirm it. Important findings: - No critical security flaw leading to arbitrary code execution was found. - Some imprecisions in the spec format were detected and fixed. - Some missing validation allowed [polyglot files](https://en.wikipedia.org/wiki/Polyglot_(computing)), which was fixed. - Lots of improvements to the test suite were proposed and implemented. In the name of openness and transparency, all companies agreed to make the report fully public. [Full report](https://huggingface.co/datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf) One import thing to note is that the library is written in Rust. This adds an extra layer of [security](https://doc.rust-lang.org/rustc/exploit-mitigations.html) coming directly from the language itself. While it is impossible to prove the absence of flaws, this is a major step in giving reassurance that `safetensors` is indeed safe to use. ## Going forward For Hugging Face, EleutherAI, and Stability AI, the master plan is to shift to using this format by default. EleutherAI has added support for evaluating models stored as `safetensors` in their LM Evaluation Harness and is working on supporting the format in their GPT-NeoX distributed training library. Within the `transformers` library we are doing the following: - Create `safetensors`. - Verify it works and can deliver on all promises (lazy load for LLMs, single file for all frameworks, faster loads). - Verify it's safe. (This is today's announcement.) - Make `safetensors` a core dependency. (This is already done or soon to come.) - Make `safetensors` the default saving format. This will happen in a few months when we have enough feedback to make sure it will cause as little disruption as possible and enough users already have the library to be able to load new models even on relatively old `transformers` versions. As for `safetensors` itself, we're looking into adding more advanced features for LLM training, which has its own set of issues with current formats. Finally, we plan to release a `1.0` in the near future, with the large user base of `transformers` providing the final testing step. The format and the lib have had very few modifications since their inception, which is a good sign of stability. We're glad we can bring ML one step closer to being safe and efficient for all!
|
Hugging Face and IBM partner on watsonx.ai, the next-generation enterprise studio for AI builders
|
juliensimon
|
May 23, 2023
|
huggingface-and-ibm
|
cloud, ibm, partnership
|
https://huggingface.co/blog/huggingface-and-ibm
|
# Hugging Face and IBM partner on watsonx.ai, the next-generation enterprise studio for AI builders <kbd> <img src="assets/144_ibm/01.png"> </kbd> All hype aside, it's hard to deny the profound impact that AI is having on society and businesses. From startups to enterprises to the public sector, every customer we talk to is busy experimenting with large language models and generative AI, identifying the most promising use cases, and gradually bringing them to production. The #1 comment we get from customers is that no single model will rule them all. They understand the value of building the best model for each use case to maximize its relevance on company data while optimizing the compute budget. Of course, privacy and intellectual property are also top concerns, and customers want to ensure they maintain complete control. As AI finds its way into every department and business unit, customers also realize the need to train and deploy many different models. In a large multinational organization, this could mean running hundreds, even thousands, of models at any time. Given the pace of AI innovation, newer and higher-performance model architectures will also lead customers to replace their models quicker than expected, reinforcing the need to train and deploy new models in production quickly and seamlessly. All of this will only happen with standardization and automation. Organizations can't afford to build models, tools, and infrastructure from scratch for new projects. Fortunately, the last few years have seen some very positive developments: 1. **Model standardization**: the [Transformer](https://arxiv.org/abs/1706.03762) architecture is now the de facto standard for Deep Learning applications like Natural Language Processing, Computer Vision, Audio, Speech, and more. It’s now easier to build tools and workflows that perform well across many use cases. 2. **Pre-trained models**: [hundreds of thousands](https://huggingface.co/models) of pre-trained models are just a click away. You can discover and test them directly on [Hugging Face](https://huggingface.co) and quickly shortlist the promising ones for your projects. 3. **Open-source libraries**: the Hugging Face [libraries](https://huggingface.co/docs) let you download pre-trained models with a single line of code, and you can start experimenting with your data in minutes. From training to deployment to hardware optimization, customers can rely on a consistent set of community-driven tools that work the same everywhere, from their laptops to their production environment. In addition, our cloud partnerships let customers use Hugging Face models and libraries at any scale without worrying about provisioning infrastructure and building technical environments. This makes it much easier to get high-quality models out the door at a rapid pace without having to reinvent the wheel. Following up on our collaboration with AWS on Amazon SageMaker and Microsoft on Azure Machine Learning, we're thrilled to work with none other than IBM on their new AI studio, [watsonx.ai](https://www.ibm.com/products/watsonx-ai). [watsonx.ai](http://watsonx.ai) is the next-generation enterprise studio for AI builders to train, validate, tune, and deploy both traditional ML and new generative AI capabilities, powered by foundation models. IBM decided that open source should be at the core of watsonx.ai. We couldn't agree more! Built on [RedHat OpenShift](https://www.redhat.com/en/technologies/cloud-computing/openshift), watsonx.ai will be available in the cloud and on-premise. This is excellent news for customers who cannot use the cloud because of strict compliance rules or are more comfortable working with their confidential data on their infrastructure. Until now, these customers often had to build their in-house ML platform. They now have an open-source off-the-shelf alternative deployed and managed using standard DevOps tools. Under the hood, watsonx.ai also integrates many Hugging Face open-source libraries, such as [transformers](https://github.com/huggingface/transformers) (100k+ GitHub stars!), [accelerate](https://github.com/huggingface/accelerate), [peft](https://github.com/huggingface/peft) and our [Text Generation Inference](https://github.com/huggingface/text-generation-inference) server, to name a few. We're happy to partner with IBM and to collaborate on the watsonx AI and data platform so that Hugging Face customers can work natively with their Hugging Face models and datasets to multiply the impact of AI across businesses. In addition, IBM has also developed its own collection of Large Language Models, and we will work with their team to open-source them and make them easily available in the Hugging Face Hub. To learn more, watch Dr. Darío Gil, SVP and Director of IBM Research, and our CEO Clem Delangue, [announce our collaboration](https://youtu.be/FrDnPTPgEmk?t=1077), [walk through the watsonx platform](https://youtu.be/FrDnPTPgEmk?t=283), and present IBM’s [suite of Large Language Models](https://youtu.be/FrDnPTPgEmk?t=586) in an IBM THINK 2023 keynote. Our joint team is hard at work at the moment. We can't wait to show you what we've been up to! The most iconic of technology companies joining forces with an up-and-coming startup to tackle AI in the Enterprise... who would have thought? Fascinating times. Stay tuned!
|
Hugging Face Collaborates with Microsoft to Launch Hugging Face Model Catalog on Azure
|
philschmid
|
May 24, 2023
|
hugging-face-endpoints-on-azure
|
cloud, azure, partnership
|
https://huggingface.co/blog/hugging-face-endpoints-on-azure
|
# Hugging Face Collaborates with Microsoft to launch Hugging Face Model Catalog on Azure  Today, we are thrilled to announce that Hugging Face expands its collaboration with Microsoft to bring open-source models from the Hugging Face Hub to Azure Machine Learning. Together we built a new Hugging Face Hub Model Catalog available directly within Azure Machine Learning Studio, filled with thousands of the most popular Transformers models from the [Hugging Face Hub](https://huggingface.co/models). With this new integration, you can now deploy Hugging Face models in just a few clicks on managed endpoints, running onto secure and scalable Azure infrastructure.  This new experience expands upon the strategic partnership we announced last year when we launched Azure Machine Learning Endpoints as a new managed app in Azure Marketplace, to simplify the experience of deploying large language models on Azure. Although our previous marketplace solution was a promising initial step, it had some limitations we could only overcome through a native integration within Azure Machine Learning. To address these challenges and enhance customers experience, we collaborated with Microsoft to offer a fully integrated experience for Hugging Face users within Azure Machine Learning Studio. [Hosting over 200,000 open-source models](https://huggingface.co/models), and serving over 1 million model downloads a day, Hugging Face is the go-to destination for all of Machine Learning. But deploying Transformers to production remains a challenge today. One of the main problems developers and organizations face is how difficult it is to deploy and scale production-grade inference APIs. Of course, an easy option is to rely on cloud-based AI services. Although they’re extremely simple to use, these services are usually powered by a limited set of models that may not support the [task type](https://huggingface.co/tasks) you need, and that cannot be deeply customized, if at all. Alternatively, cloud-based ML services or in-house platforms give you full control, but at the expense of more time, complexity and cost. In addition, many companies have strict security, compliance, and privacy requirements mandating that they only deploy models on infrastructure over which they have administrative control. _“With the new Hugging Face Hub model catalog, natively integrated within Azure Machine Learning, we are opening a new page in our partnership with Microsoft, offering a super easy way for enterprise customers to deploy Hugging Face models for real-time inference, all within their secure Azure environment.”_ said Julien Simon, Chief Evangelist at Hugging Face. _"The integration of Hugging Face's open-source models into Azure Machine Learning represents our commitment to empowering developers with industry-leading AI tools,"_ said John Montgomery, Corporate Vice President, Azure AI Platform at Microsoft. _"This collaboration not only simplifies the deployment process of large language models but also provides a secure and scalable environment for real-time inferencing. It's an exciting milestone in our mission to accelerate AI initiatives and bring innovative solutions to the market swiftly and securely, backed by the power of Azure infrastructure."_ Deploying Hugging Face models on Azure Machine Learning has never been easier: * Open the Hugging Face registry in Azure Machine Learning Studio. * Click on the Hugging Face Model Catalog. * Filter by task or license and search the models. * Click the model tile to open the model page and choose the real-time deployment option to deploy the model. * Select an Azure instance type and click deploy.  Within minutes, you can test your endpoint and add its inference API to your application. It’s never been easier!  If you'd like to see the service in action, you can click on the image below to launch a video walkthrough. [](https://youtu.be/cjXYjN2mNVM "Video walkthrough of Hugging Face Endpoints") Hugging Face Model Catalog on Azure Machine Learning is available today in public preview in all Azure Regions where Azure Machine Learning is available. Give the service a try and [let us know your feedback and questions in the forum](https://discuss.huggingface.co/c/azureml/68)!
|
Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA
|
ybelkada
|
May 24, 2023
|
4bit-transformers-bitsandbytes
|
transformers, quantization, bitsandbytes, 4bit
|
https://huggingface.co/blog/4bit-transformers-bitsandbytes
|
# Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA LLMs are known to be large, and running or training them in consumer hardware is a huge challenge for users and accessibility. Our [LLM.int8 blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) showed how the techniques in the [LLM.int8 paper](https://arxiv.org/abs/2208.07339) were integrated in transformers using the `bitsandbytes` library. As we strive to make models even more accessible to anyone, we decided to collaborate with bitsandbytes again to allow users to run models in 4-bit precision. This includes a large majority of HF models, in any modality (text, vision, multi-modal, etc.). Users can also train adapters on top of 4bit models leveraging tools from the Hugging Face ecosystem. This is a new method introduced today in the QLoRA paper by Dettmers et al. The abstract of the paper is as follows: > We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimizers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training. ## Resources This blogpost and release come with several resources to get started with 4bit models and QLoRA: - [Original paper](https://arxiv.org/abs/2305.14314) - [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing) - This notebook shows how to use 4bit models in inference with all their variants, and how to run GPT-neo-X (a 20B parameter model) on a free Google Colab instance 🤯 - [Fine tuning Google Colab notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) - This notebook shows how to fine-tune a 4bit model on a downstream task using the Hugging Face ecosystem. We show that it is possible to fine tune GPT-neo-X 20B on a Google Colab instance! - [Original repository for replicating the paper's results](https://github.com/artidoro/qlora) - [Guanaco 33b playground](https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi) - or check the playground section below ## Introduction If you are not familiar with model precisions and the most common data types (float16, float32, bfloat16, int8), we advise you to carefully read the introduction in [our first blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) that goes over the details of these concepts in simple terms with visualizations. For more information we recommend reading the fundamentals of floating point representation through [this wikibook document](https://en.wikibooks.org/wiki/A-level_Computing/AQA/Paper_2/Fundamentals_of_data_representation/Floating_point_numbers#:~:text=In%20decimal%2C%20very%20large%20numbers,be%20used%20for%20binary%20numbers.). The recent QLoRA paper explores different data types, 4-bit Float and 4-bit NormalFloat. We will discuss here the 4-bit Float data type since it is easier to understand. FP8 and FP4 stand for Floating Point 8-bit and 4-bit precision, respectively. They are part of the minifloats family of floating point values (among other precisions, the minifloats family also includes bfloat16 and float16). Let’s first have a look at how to represent floating point values in FP8 format, then understand how the FP4 format looks like. ### FP8 format As discussed in our previous blogpost, a floating point contains n-bits, with each bit falling into a specific category that is responsible for representing a component of the number (sign, mantissa and exponent). These represent the following. The FP8 (floating point 8) format has been first introduced in the paper [“FP8 for Deep Learning”](https://arxiv.org/pdf/2209.05433.pdf) with two different FP8 encodings: E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). | 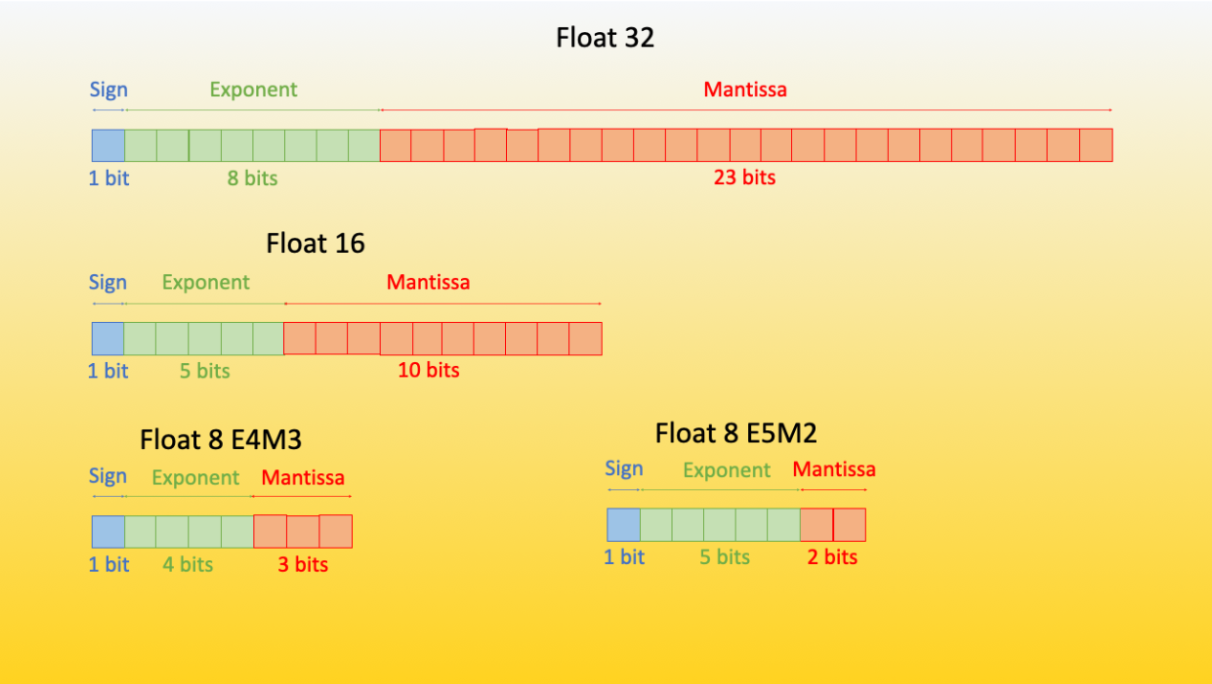 | |:--:| | <b>Overview of Floating Point 8 (FP8) format. Source: Original content from [`sgugger`](https://huggingface.co/sgugger) </b>| Although the precision is substantially reduced by reducing the number of bits from 32 to 8, both versions can be used in a variety of situations. Currently one could use [Transformer Engine library](https://github.com/NVIDIA/TransformerEngine) that is also integrated with HF ecosystem through accelerate. The potential floating points that can be represented in the E4M3 format are in the range -448 to 448, whereas in the E5M2 format, as the number of bits of the exponent increases, the range increases to -57344 to 57344 - but with a loss of precision because the number of possible representations remains constant. It has been empirically proven that the E4M3 is best suited for the forward pass, and the second version is best suited for the backward computation ### FP4 precision in a few words The sign bit represents the sign (+/-), the exponent bits a base two to the power of the integer represented by the bits (e.g. `2^{010} = 2^{2} = 4`), and the fraction or mantissa is the sum of powers of negative two which are “active” for each bit that is “1”. If a bit is “0” the fraction remains unchanged for that power of `2^-i` where i is the position of the bit in the bit-sequence. For example, for mantissa bits 1010 we have `(0 + 2^-1 + 0 + 2^-3) = (0.5 + 0.125) = 0.625`. To get a value, we add *1* to the fraction and multiply all results together, for example, with 2 exponent bits and one mantissa bit the representations 1101 would be: `-1 * 2^(2) * (1 + 2^-1) = -1 * 4 * 1.5 = -6` For FP4 there is no fixed format and as such one can try combinations of different mantissa/exponent combinations. In general, 3 exponent bits do a bit better in most cases. But sometimes 2 exponent bits and a mantissa bit yield better performance. ## QLoRA paper, a new way of democratizing quantized large transformer models In few words, QLoRA reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU. More specifically, QLoRA uses 4-bit quantization to compress a pretrained language model. The LM parameters are then frozen and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters. During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the [original LoRA paper](https://arxiv.org/abs/2106.09685). QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference. QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the [OpenAssistant dataset (OASST1)](https://huggingface.co/datasets/OpenAssistant/oasst1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning. For a more detailed reading, we recommend you read the [QLoRA paper](https://arxiv.org/abs/2305.14314). ## How to use it in transformers? In this section let us introduce the transformers integration of this method, how to use it and which models can be effectively quantized. ### Getting started As a quickstart, load a model in 4bit by (at the time of this writing) installing accelerate and transformers from source, and make sure you have installed the latest version of bitsandbytes library (0.39.0). ```bash pip install -q -U bitsandbytes pip install -q -U git+https://github.com/huggingface/transformers.git pip install -q -U git+https://github.com/huggingface/peft.git pip install -q -U git+https://github.com/huggingface/accelerate.git ``` ### Quickstart The basic way to load a model in 4bit is to pass the argument `load_in_4bit=True` when calling the `from_pretrained` method by providing a device map (pass `"auto"` to get a device map that will be automatically inferred). ```python from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, device_map="auto") ... ``` That's all you need! As a general rule, we recommend users to not manually set a device once the model has been loaded with `device_map`. So any device assignment call to the model, or to any model’s submodules should be avoided after that line - unless you know what you are doing. Keep in mind that loading a quantized model will automatically cast other model's submodules into `float16` dtype. You can change this behavior, (if for example you want to have the layer norms in `float32`), by passing `torch_dtype=dtype` to the `from_pretrained` method. ### Advanced usage You can play with different variants of 4bit quantization such as NF4 (normalized float 4 (default)) or pure FP4 quantization. Based on theoretical considerations and empirical results from the paper, we recommend using NF4 quantization for better performance. Other options include `bnb_4bit_use_double_quant` which uses a second quantization after the first one to save an additional 0.4 bits per parameter. And finally, the compute type. While 4-bit bitsandbytes stores weights in 4-bits, the computation still happens in 16 or 32-bit and here any combination can be chosen (float16, bfloat16, float32 etc). The matrix multiplication and training will be faster if one uses a 16-bit compute dtype (default torch.float32). One should leverage the recent `BitsAndBytesConfig` from transformers to change these parameters. An example to load a model in 4bit using NF4 quantization below with double quantization with the compute dtype bfloat16 for faster training: ```python from transformers import BitsAndBytesConfig nf4_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True, bnb_4bit_compute_dtype=torch.bfloat16 ) model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config) ``` #### Changing the compute dtype As mentioned above, you can also change the compute dtype of the quantized model by just changing the `bnb_4bit_compute_dtype` argument in `BitsAndBytesConfig`. ```python import torch from transformers import BitsAndBytesConfig quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16 ) ``` #### Nested quantization For enabling nested quantization, you can use the `bnb_4bit_use_double_quant` argument in `BitsAndBytesConfig`. This will enable a second quantization after the first one to save an additional 0.4 bits per parameter. We also use this feature in the training Google colab notebook. ```python from transformers import BitsAndBytesConfig double_quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, ) model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config) ``` And of course, as mentioned in the beginning of the section, all of these components are composable. You can combine all these parameters together to find the optimial use case for you. A rule of thumb is: use double quant if you have problems with memory, use NF4 for higher precision, and use a 16-bit dtype for faster finetuning. For instance in the [inference demo](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing), we use nested quantization, bfloat16 compute dtype and NF4 quantization to fit gpt-neo-x-20b (40GB) entirely in 4bit in a single 16GB GPU. ### Common questions In this section, we will also address some common questions anyone could have regarding this integration. #### Does FP4 quantization have any hardware requirements? Note that this method is only compatible with GPUs, hence it is not possible to quantize models in 4bit on a CPU. Among GPUs, there should not be any hardware requirement about this method, therefore any GPU could be used to run the 4bit quantization as long as you have CUDA>=11.2 installed. Keep also in mind that the computation is not done in 4bit, the weights and activations are compressed to that format and the computation is still kept in the desired or native dtype. #### What are the supported models? Similarly as the integration of LLM.int8 presented in [this blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) the integration heavily relies on the `accelerate` library. Therefore, any model that supports accelerate loading (i.e. the `device_map` argument when calling `from_pretrained`) should be quantizable in 4bit. Note also that this is totally agnostic to modalities, as long as the models can be loaded with the `device_map` argument, it is possible to quantize them. For text models, at this time of writing, this would include most used architectures such as Llama, OPT, GPT-Neo, GPT-NeoX for text models, Blip2 for multimodal models, and so on. At this time of writing, the models that support accelerate are: ```python [ 'bigbird_pegasus', 'blip_2', 'bloom', 'bridgetower', 'codegen', 'deit', 'esm', 'gpt2', 'gpt_bigcode', 'gpt_neo', 'gpt_neox', 'gpt_neox_japanese', 'gptj', 'gptsan_japanese', 'lilt', 'llama', 'longformer', 'longt5', 'luke', 'm2m_100', 'mbart', 'mega', 'mt5', 'nllb_moe', 'open_llama', 'opt', 'owlvit', 'plbart', 'roberta', 'roberta_prelayernorm', 'rwkv', 'switch_transformers', 't5', 'vilt', 'vit', 'vit_hybrid', 'whisper', 'xglm', 'xlm_roberta' ] ``` Note that if your favorite model is not there, you can open a Pull Request or raise an issue in transformers to add the support of accelerate loading for that architecture. #### Can we train 4bit/8bit models? It is not possible to perform pure 4bit training on these models. However, you can train these models by leveraging parameter efficient fine tuning methods (PEFT) and train for example adapters on top of them. That is what is done in the paper and is officially supported by the PEFT library from Hugging Face. We also provide a [training notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) and recommend users to check the [QLoRA repository](https://github.com/artidoro/qlora) if they are interested in replicating the results from the paper. |  | |:--:| | <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>| #### What other consequences are there? This integration can open up several positive consequences to the community and AI research as it can affect multiple use cases and possible applications. In RLHF (Reinforcement Learning with Human Feedback) it is possible to load a single base model, in 4bit and train multiple adapters on top of it, one for the reward modeling, and another for the value policy training. A more detailed blogpost and announcement will be made soon about this use case. We have also made some benchmarks on the impact of this quantization method on training large models on consumer hardware. We have run several experiments on finetuning 2 different architectures, Llama 7B (15GB in fp16) and Llama 13B (27GB in fp16) on an NVIDIA T4 (16GB) and here are the results | Model name | Half precision model size (in GB) | Hardware type / total VRAM | quantization method (CD=compute dtype / GC=gradient checkpointing / NQ=nested quantization) | batch_size | gradient accumulation steps | optimizer | seq_len | Result | | ----------------------------------- | --------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------- | ---------- | --------------------------- | ----------------- | ------- | ------ | | | | | | | | | | | | <10B scale models | | | | | | | | | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | **No OOM** | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 1024 | OOM | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | **No OOM** | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | **No OOM** | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM | | decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + GC | 1 | 4 | AdamW | 1024 | **No OOM** | | | | | | | | | | | | 10B+ scale models | | | | | | | | | | decapoda-research/llama-13b-hf | 27GB | 2xNVIDIA-T4 / 32GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | **No OOM** | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | OOM | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | OOM | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + fp16 CD + no GC | 1 | 4 | AdamW | 512 | OOM | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 512 | **No OOM** | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 1024 | OOM | | decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC + NQ | 1 | 4 | AdamW | 1024 | **No OOM** | We have used the recent `SFTTrainer` from TRL library, and the benchmarking script can be found [here](https://gist.github.com/younesbelkada/f48af54c74ba6a39a7ae4fd777e72fe8) ## Playground Try out the Guananco model cited on the paper on [the playground](https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi) or directly below <!-- [SPACE WITH GREEDY DECODING PERFORMANCE NUMBERS] --> <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.32.0/gradio.js" ></script> <gradio-app theme_mode="light" space="uwnlp/guanaco-playground-tgi"></gradio-app> ## Acknowledgements The HF team would like to acknowledge all the people involved in this project from University of Washington, and for making this available to the community. The authors would also like to thank [Pedro Cuenca](https://huggingface.co/pcuenq) for kindly reviewing the blogpost, [Olivier Dehaene](https://huggingface.co/olivierdehaene) and [Omar Sanseviero](https://huggingface.co/osanseviero) for their quick and strong support for the integration of the paper's artifacts on the HF Hub.
|
Optimizing Stable Diffusion for Intel CPUs with NNCF and 🤗 Optimum
|
AlexKoff88
|
May 25, 2023
|
train-optimize-sd-intel
|
diffusers, cpu, intel, guide, quantization
|
https://huggingface.co/blog/train-optimize-sd-intel
|
# Optimizing Stable Diffusion for Intel CPUs with NNCF and 🤗 Optimum [**Latent Diffusion models**](https://arxiv.org/abs/2112.10752) are game changers when it comes to solving text-to-image generation problems. [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) is one of the most famous examples that got wide adoption in the community and industry. The idea behind the Stable Diffusion model is simple and compelling: you generate an image from a noise vector in multiple small steps refining the noise to a latent image representation. This approach works very well, but it can take a long time to generate an image if you do not have access to powerful GPUs. Through the past five years, [OpenVINO Toolkit](https://docs.openvino.ai/) encapsulated many features for high-performance inference. Initially designed for Computer Vision models, it still dominates in this domain showing best-in-class inference performance for many contemporary models, including [Stable Diffusion](https://huggingface.co/blog/stable-diffusion-inference-intel). However, optimizing Stable Diffusion models for resource-constraint applications requires going far beyond just runtime optimizations. And this is where model optimization capabilities from OpenVINO [Neural Network Compression Framework](https://github.com/openvinotoolkit/nncf) (NNCF) come into play. In this blog post, we will outline the problems of optimizing Stable Diffusion models and propose a workflow that substantially reduces the latency of such models when running on a resource-constrained HW such as CPU. In particular, we achieved **5.1x** inference acceleration and **4x** model footprint reduction compared to PyTorch. ## Stable Diffusion optimization In the [Stable Diffusion pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), the UNet model is computationally the most expensive to run. Thus, optimizing just one model brings substantial benefits in terms of inference speed. However, it turns out that the traditional model optimization methods, such as post-training 8-bit quantization, do not work for this model. There are two main reasons for that. First, pixel-level prediction models, such as semantic segmentation, super-resolution, etc., are one of the most complicated in terms of model optimization because of the complexity of the task, so tweaking model parameters and the structure breaks the results in numerous ways. The second reason is that the model has a lower level of redundancy because it accommodates a lot of information while being trained on [hundreds of millions of samples](https://laion.ai/blog/laion-5b/). That is why researchers have to employ more sophisticated quantization methods to preserve the accuracy after optimization. For example, Qualcomm used the layer-wise Knowledge Distillation method ([AdaRound](https://arxiv.org/abs/2004.10568)) to [quantize](https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android) Stable Diffusion models. It means that model tuning after quantization is required, anyway. If so, why not just use [Quantization-Aware Training](https://arxiv.org/abs/1712.05877) (QAT) which can tune the model and quantization parameters simultaneously in the same way the source model is trained? Thus, we tried this approach in our work using [NNCF](https://github.com/openvinotoolkit/nncf), [OpenVINO](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html), and [Diffusers](https://github.com/huggingface/diffusers) and coupled it with [Token Merging](https://arxiv.org/abs/2210.09461). ## Optimization workflow We usually start the optimization of a model after it's trained. Here, we start from a [model](https://huggingface.co/svjack/Stable-Diffusion-Pokemon-en) fine-tuned on the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) containing images of Pokemons and their text descriptions. We used the [text-to-image fine-tuning example](https://huggingface.co/docs/diffusers/training/text2image) for Stable Diffusion from the Diffusers and integrated QAT from NNCF into the following training [script](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion). We also changed the loss function to incorporate knowledge distillation from the source model that acts as a teacher in this process while the actual model being trained acts as a student. This approach is different from the classical knowledge distillation method, where the trained teacher model is distilled into a smaller student model. In our case, knowledge distillation is used as an auxiliary method that helps improve the final accuracy of the optimizing model. We also use the Exponential Moving Average (EMA) method for model parameters excluding quantizers which allows us to make the training process more stable. We tune the model for 4096 iterations only. With some tricks, such as gradient checkpointing and [keeping the EMA model](https://github.com/huggingface/optimum-intel/blob/bbbe7ff0e81938802dbc1d234c3dcdf58ef56984/examples/openvino/stable-diffusion/train_text_to_image_qat.py#L941) in RAM instead of VRAM, we can run the optimization process using one GPU with 24 GB of VRAM. The whole optimization takes less than a day using one GPU! ## Going beyond Quantization-Aware Training Quantization alone can bring significant enhancements by reducing model footprint, load time, memory consumption, and inference latency. But the great thing about quantization is that it can be applied along with other optimization methods leading to a cumulative speedup. Recently, Facebook Research introduced a [Token Merging](https://arxiv.org/abs/2210.09461) method for Vision Transformer models. The essence of the method is that it merges redundant tokens with important ones using one of the available strategies (averaging, taking max values, etc.). This is done before the self-attention block, which is the most computationally demanding part of Transformer models. Therefore, reducing the token dimension reduces the overall computation time in the self-attention blocks. This method has also been [adapted](https://arxiv.org/pdf/2303.17604.pdf) for Stable Diffusion models and has shown promising results when optimizing Stable Diffusion pipelines for high-resolution image synthesis running on GPUs. We modified the Token Merging method to be compliant with OpenVINO and stacked it with 8-bit quantization when applied to the Attention UNet model. This also involves all the mentioned techniques including Knowledge Distillation, etc. As for quantization, it requires fine-tuning to be applied to restore the accuracy. We also start optimization and fine-tuning from the [model](https://huggingface.co/svjack/Stable-Diffusion-Pokemon-en) trained on the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions). The figure below shows an overall optimization workflow.  The resultant model is highly beneficial when running inference on devices with limited computational resources, such as client or edge CPUs. As it was mentioned, stacking Token Merging with quantization leads to an additional reduction in the inference latency. <div class="flex flex-row"> <div class="grid grid-cols-2 gap-4"> <figure> <img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_torch.png" alt="Image 1" /> <figcaption class="mt-2 text-center text-sm text-gray-500">PyTorch FP32, Inference Speed: 230.5 seconds, Memory Footprint: 3.44 GB</figcaption> </figure> <figure> <img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_fp32.png" alt="Image 2" /> <figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO FP32, Inference Speed: 120 seconds (<b>1.9x</b>), Memory Footprint: 3.44 GB</figcaption> </figure> <figure> <img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_quantized.png" alt="Image 3" /> <figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO 8-bit, Inference Speed: 59 seconds (<b>3.9x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption> </figure> <figure> <img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_tome_quantized.png" alt="Image 4" /> <figcaption class="mt-2 text-center text-sm text-gray-500">ToMe + OpenVINO 8-bit, Inference Speed: 44.6 seconds (<b>5.1x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption> </figure> </div> </div> Results of image generation [demo](https://huggingface.co/spaces/helenai/stable_diffusion) using different optimized models. Input prompt is “cartoon bird”, seed is 42. The models are with OpenVINO 2022.3 in [Hugging Face Spaces](https://huggingface.co/docs/hub/spaces-overview) using a “CPU upgrade” instance which utilizes 3rd Generation Intel® Xeon® Scalable Processors with Intel® Deep Learning Boost technology. ## Results We used the disclosed optimization workflows to get two types of optimized models, 8-bit quantized and quantized with Token Merging, and compare them to the PyTorch baseline. We also converted the baseline to vanilla OpenVINO floating-point (FP32) model for the comprehensive comparison. The picture above shows the results of image generation and some model characteristics. As you can see, just conversion to OpenVINO brings a significant decrease in the inference latency ( **1.9x** ). Applying 8-bit quantization boosts inference speed further leading to **3.9x** speedup compared to PyTorch. Another benefit of quantization is a significant reduction of model footprint, **0.25x** of PyTorch checkpoint, which also improves the model load time. Applying Token Merging (ToME) (with a **merging ratio of 0.4** ) on top of quantization brings **5.1x** performance speedup while keeping the footprint at the same level. We didn't provide a thorough analysis of the visual quality of the optimized models, but, as you can see, the results are quite solid. For the results shown in this blog, we used the default number of 50 inference steps. With fewer inference steps, inference speed will be faster, but this has an effect on the quality of the resulting image. How large this effect is depends on the model and the [scheduler](https://huggingface.co/docs/diffusers/using-diffusers/schedulers). We recommend experimenting with different number of steps and schedulers and find what works best for your use case. Below we show how to perform inference with the final pipeline optimized to run on Intel CPUs: ```python from optimum.intel import OVStableDiffusionPipeline # Load and compile the pipeline for performance. name = "OpenVINO/stable-diffusion-pokemons-tome-quantized-aggressive" pipe = OVStableDiffusionPipeline.from_pretrained(name, compile=False) pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1) pipe.compile() # Generate an image. prompt = "a drawing of a green pokemon with red eyes" output = pipe(prompt, num_inference_steps=50, output_type="pil").images[0] output.save("image.png") ``` You can find the training and quantization [code](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion) in the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/main/en/intel/index) library. The notebook that demonstrates the difference between optimized and original models is available [here](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_optimization.ipynb). You can also find [many models](https://huggingface.co/models?library=openvino&sort=downloads) on the Hugging Face Hub under the [OpenVINO organization](https://huggingface.co/OpenVINO). In addition, we have created a [demo](https://huggingface.co/spaces/helenai/stable_diffusion) on Hugging Face Spaces that is being run on a 3rd Generation Intel Xeon Scalable processor. ## What about the general-purpose Stable Diffusion model? As we showed with the Pokemon image generation task, it is possible to achieve a high level of optimization of the Stable Diffusion pipeline when using a relatively small amount of training resources. At the same time, it is well-known that training a general-purpose Stable Diffusion model is an [expensive task](https://www.mosaicml.com/blog/training-stable-diffusion-from-scratch-part-2). However, with enough budget and HW resources, it is possible to optimize the general-purpose model using the described approach and tune it to produce high-quality images. The only caveat we have is related to the token merging method that reduces the model capacity substantially. The rule of thumb here is the more complicated the dataset you have for the training, the less merging ratio you should use during the optimization. If you enjoyed reading this post, you might also be interested in checking out [this post](https://huggingface.co/blog/stable-diffusion-inference-intel) that discusses other complementary approaches to optimize the performance of Stable Diffusion on 4th generation Intel Xeon CPUs.
|
Introducing BERTopic Integration with Hugging Face Hub
|
davanstrien
|
May 31, 2023
|
bertopic
|
guide, open-source-collab, community
|
https://huggingface.co/blog/bertopic
|
# Introducing BERTopic Integration with the Hugging Face Hub [](https://colab.research.google.com/#fileId=https://huggingface.co/spaces/davanstrien/blog_notebooks/blob/main/BERTopic_hub_starter.ipynb) We are thrilled to announce a significant update to the [BERTopic](https://maartengr.github.io/BERTopic) Python library, expanding its capabilities and further streamlining the workflow for topic modelling enthusiasts and practitioners. BERTopic now supports pushing and pulling trained topic models directly to and from the Hugging Face Hub. This new integration opens up exciting possibilities for leveraging the power of BERTopic in production use cases with ease. ## What is Topic Modelling? Topic modelling is a method that can help uncover hidden themes or "topics" within a group of documents. By analyzing the words in the documents, we can find patterns and connections that reveal these underlying topics. For example, a document about machine learning is more likely to use words like "gradient" and "embedding" compared to a document about baking bread. Each document usually covers multiple topics in different proportions. By examining the word statistics, we can identify clusters of related words that represent these topics. This allows us to analyze a set of documents and determine the topics they discuss, as well as the balance of topics within each document. More recently, new approaches to topic modelling have moved beyond using words to using more rich representations such as those offered through Transformer based models. ## What is BERTopic? BERTopic is a state-of-the-art Python library that simplifies the topic modelling process using various embedding techniques and [c-TF-IDF](https://maartengr.github.io/BERTopic/api/ctfidf.html) to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions. <figure class="image table text-center m-0 w-full"> <video alt="BERTopic overview" style="max-width: 70%; margin: auto;" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/2d1113254a370972470d42e122df150f3551cc07/blog/BERTopic/bertopic_overview.mp4" type="video/mp4"> </video> </figure> *An overview of the BERTopic library* Whilst BERTopic is easy to get started with, it supports a range of advanced approaches to topic modelling including [guided](https://maartengr.github.io/BERTopic/getting_started/guided/guided.html), [supervised](https://maartengr.github.io/BERTopic/getting_started/supervised/supervised.html), [semi-supervised](https://maartengr.github.io/BERTopic/getting_started/semisupervised/semisupervised.html) and [manual](https://maartengr.github.io/BERTopic/getting_started/manual/manual.html) topic modelling. More recently BERTopic has added support for multi-modal topic models. BERTopic also have a rich set of tools for producing visualizations. BERTopic provides a powerful tool for users to uncover significant topics within text collections, thereby gaining valuable insights. With BERTopic, users can analyze customer reviews, explore research papers, or categorize news articles with ease, making it an essential tool for anyone looking to extract meaningful information from their text data. ## BERTopic Model Management with the Hugging Face Hub With the latest integration, BERTopic users can seamlessly push and pull their trained topic models to and from the Hugging Face Hub. This integration marks a significant milestone in simplifying the deployment and management of BERTopic models across different environments. The process of training and pushing a BERTopic model to the Hub can be done in a few lines ```python from bertopic import BERTopic topic_model = BERTopic("english") topics, probs = topic_model.fit_transform(docs) topic_model.push_to_hf_hub('davanstrien/transformers_issues_topics') ``` You can then load this model in two lines and use it to predict against new data. ```python from bertopic import BERTopic topic_model = BERTopic.load("davanstrien/transformers_issues_topics") ``` By leveraging the power of the Hugging Face Hub, BERTopic users can effortlessly share, version, and collaborate on their topic models. The Hub acts as a central repository, allowing users to store and organize their models, making it easier to deploy models in production, share them with colleagues, or even showcase them to the broader NLP community. You can use the `libraries` filter on the hub to find BERTopic models.  Once you have found a BERTopic model you are interested in you can use the Hub inference widget to try out the model and see if it might be a good fit for your use case. Once you have a trained topic model, you can push it to the Hugging Face Hub in one line. Pushing your model to the Hub will automatically create an initial model card for your model, including an overview of the topics created. Below you can see an example of the topics resulting from a [model trained on ArXiv data](https://huggingface.co/MaartenGr/BERTopic_ArXiv). <details> <summary>Click here for an overview of all topics.</summary> | Topic ID | Topic Keywords | Topic Frequency | Label | |----------|----------------|-----------------|-------| | -1 | language - models - model - data - based | 20 | -1_language_models_model_data | | 0 | dialogue - dialog - response - responses - intent | 14247 | 0_dialogue_dialog_response_responses | | 1 | speech - asr - speech recognition - recognition - end | 1833 | 1_speech_asr_speech recognition_recognition | | 2 | tuning - tasks - prompt - models - language | 1369 | 2_tuning_tasks_prompt_models | | 3 | summarization - summaries - summary - abstractive - document | 1109 | 3_summarization_summaries_summary_abstractive | | 4 | question - answer - qa - answering - question answering | 893 | 4_question_answer_qa_answering | | 5 | sentiment - sentiment analysis - aspect - analysis - opinion | 837 | 5_sentiment_sentiment analysis_aspect_analysis | | 6 | clinical - medical - biomedical - notes - patient | 691 | 6_clinical_medical_biomedical_notes | | 7 | translation - nmt - machine translation - neural machine - neural machine translation | 586 | 7_translation_nmt_machine translation_neural machine | | 8 | generation - text generation - text - language generation - nlg | 558 | 8_generation_text generation_text_language generation | | 9 | hate - hate speech - offensive - speech - detection | 484 | 9_hate_hate speech_offensive_speech | | 10 | news - fake - fake news - stance - fact | 455 | 10_news_fake_fake news_stance | | 11 | relation - relation extraction - extraction - relations - entity | 450 | 11_relation_relation extraction_extraction_relations | | 12 | ner - named - named entity - entity - named entity recognition | 376 | 12_ner_named_named entity_entity | | 13 | parsing - parser - dependency - treebank - parsers | 370 | 13_parsing_parser_dependency_treebank | | 14 | event - temporal - events - event extraction - extraction | 314 | 14_event_temporal_events_event extraction | | 15 | emotion - emotions - multimodal - emotion recognition - emotional | 300 | 15_emotion_emotions_multimodal_emotion recognition | | 16 | word - embeddings - word embeddings - embedding - words | 292 | 16_word_embeddings_word embeddings_embedding | | 17 | explanations - explanation - rationales - rationale - interpretability | 212 | 17_explanations_explanation_rationales_rationale | | 18 | morphological - arabic - morphology - languages - inflection | 204 | 18_morphological_arabic_morphology_languages | | 19 | topic - topics - topic models - lda - topic modeling | 200 | 19_topic_topics_topic models_lda | | 20 | bias - gender - biases - gender bias - debiasing | 195 | 20_bias_gender_biases_gender bias | | 21 | law - frequency - zipf - words - length | 185 | 21_law_frequency_zipf_words | | 22 | legal - court - law - legal domain - case | 182 | 22_legal_court_law_legal domain | | 23 | adversarial - attacks - attack - adversarial examples - robustness | 181 | 23_adversarial_attacks_attack_adversarial examples | | 24 | commonsense - commonsense knowledge - reasoning - knowledge - commonsense reasoning | 180 | 24_commonsense_commonsense knowledge_reasoning_knowledge | | 25 | quantum - semantics - calculus - compositional - meaning | 171 | 25_quantum_semantics_calculus_compositional | | 26 | correction - error - error correction - grammatical - grammatical error | 161 | 26_correction_error_error correction_grammatical | | 27 | argument - arguments - argumentation - argumentative - mining | 160 | 27_argument_arguments_argumentation_argumentative | | 28 | sarcasm - humor - sarcastic - detection - humorous | 157 | 28_sarcasm_humor_sarcastic_detection | | 29 | coreference - resolution - coreference resolution - mentions - mention | 156 | 29_coreference_resolution_coreference resolution_mentions | | 30 | sense - word sense - wsd - word - disambiguation | 153 | 30_sense_word sense_wsd_word | | 31 | knowledge - knowledge graph - graph - link prediction - entities | 149 | 31_knowledge_knowledge graph_graph_link prediction | | 32 | parsing - semantic parsing - amr - semantic - parser | 146 | 32_parsing_semantic parsing_amr_semantic | | 33 | cross lingual - lingual - cross - transfer - languages | 146 | 33_cross lingual_lingual_cross_transfer | | 34 | mt - translation - qe - quality - machine translation | 139 | 34_mt_translation_qe_quality | | 35 | sql - text sql - queries - spider - schema | 138 | 35_sql_text sql_queries_spider | | 36 | classification - text classification - label - text - labels | 136 | 36_classification_text classification_label_text | | 37 | style - style transfer - transfer - text style - text style transfer | 136 | 37_style_style transfer_transfer_text style | | 38 | question - question generation - questions - answer - generation | 129 | 38_question_question generation_questions_answer | | 39 | authorship - authorship attribution - attribution - author - authors | 127 | 39_authorship_authorship attribution_attribution_author | | 40 | sentence - sentence embeddings - similarity - sts - sentence embedding | 123 | 40_sentence_sentence embeddings_similarity_sts | | 41 | code - identification - switching - cs - code switching | 121 | 41_code_identification_switching_cs | | 42 | story - stories - story generation - generation - storytelling | 118 | 42_story_stories_story generation_generation | | 43 | discourse - discourse relation - discourse relations - rst - discourse parsing | 117 | 43_discourse_discourse relation_discourse relations_rst | | 44 | code - programming - source code - code generation - programming languages | 117 | 44_code_programming_source code_code generation | | 45 | paraphrase - paraphrases - paraphrase generation - paraphrasing - generation | 114 | 45_paraphrase_paraphrases_paraphrase generation_paraphrasing | | 46 | agent - games - environment - instructions - agents | 111 | 46_agent_games_environment_instructions | | 47 | covid - covid 19 - 19 - tweets - pandemic | 108 | 47_covid_covid 19_19_tweets | | 48 | linking - entity linking - entity - el - entities | 107 | 48_linking_entity linking_entity_el | | 49 | poetry - poems - lyrics - poem - music | 103 | 49_poetry_poems_lyrics_poem | | 50 | image - captioning - captions - visual - caption | 100 | 50_image_captioning_captions_visual | | 51 | nli - entailment - inference - natural language inference - language inference | 96 | 51_nli_entailment_inference_natural language inference | | 52 | keyphrase - keyphrases - extraction - document - phrases | 95 | 52_keyphrase_keyphrases_extraction_document | | 53 | simplification - text simplification - ts - sentence - simplified | 95 | 53_simplification_text simplification_ts_sentence | | 54 | empathetic - emotion - emotional - empathy - emotions | 95 | 54_empathetic_emotion_emotional_empathy | | 55 | depression - mental - health - mental health - social media | 93 | 55_depression_mental_health_mental health | | 56 | segmentation - word segmentation - chinese - chinese word segmentation - chinese word | 93 | 56_segmentation_word segmentation_chinese_chinese word segmentation | | 57 | citation - scientific - papers - citations - scholarly | 85 | 57_citation_scientific_papers_citations | | 58 | agreement - syntactic - verb - grammatical - subject verb | 85 | 58_agreement_syntactic_verb_grammatical | | 59 | metaphor - literal - figurative - metaphors - idiomatic | 83 | 59_metaphor_literal_figurative_metaphors | | 60 | srl - semantic role - role labeling - semantic role labeling - role | 82 | 60_srl_semantic role_role labeling_semantic role labeling | | 61 | privacy - private - federated - privacy preserving - federated learning | 82 | 61_privacy_private_federated_privacy preserving | | 62 | change - semantic change - time - semantic - lexical semantic | 82 | 62_change_semantic change_time_semantic | | 63 | bilingual - lingual - cross lingual - cross - embeddings | 80 | 63_bilingual_lingual_cross lingual_cross | | 64 | political - media - news - bias - articles | 77 | 64_political_media_news_bias | | 65 | medical - qa - question - questions - clinical | 75 | 65_medical_qa_question_questions | | 66 | math - mathematical - math word - word problems - problems | 73 | 66_math_mathematical_math word_word problems | | 67 | financial - stock - market - price - news | 69 | 67_financial_stock_market_price | | 68 | table - tables - tabular - reasoning - qa | 69 | 68_table_tables_tabular_reasoning | | 69 | readability - complexity - assessment - features - reading | 65 | 69_readability_complexity_assessment_features | | 70 | layout - document - documents - document understanding - extraction | 64 | 70_layout_document_documents_document understanding | | 71 | brain - cognitive - reading - syntactic - language | 62 | 71_brain_cognitive_reading_syntactic | | 72 | sign - gloss - language - signed - language translation | 61 | 72_sign_gloss_language_signed | | 73 | vqa - visual - visual question - visual question answering - question | 59 | 73_vqa_visual_visual question_visual question answering | | 74 | biased - biases - spurious - nlp - debiasing | 57 | 74_biased_biases_spurious_nlp | | 75 | visual - dialogue - multimodal - image - dialog | 55 | 75_visual_dialogue_multimodal_image | | 76 | translation - machine translation - machine - smt - statistical | 54 | 76_translation_machine translation_machine_smt | | 77 | multimodal - visual - image - translation - machine translation | 52 | 77_multimodal_visual_image_translation | | 78 | geographic - location - geolocation - geo - locations | 51 | 78_geographic_location_geolocation_geo | | 79 | reasoning - prompting - llms - chain thought - chain | 48 | 79_reasoning_prompting_llms_chain thought | | 80 | essay - scoring - aes - essay scoring - essays | 45 | 80_essay_scoring_aes_essay scoring | | 81 | crisis - disaster - traffic - tweets - disasters | 45 | 81_crisis_disaster_traffic_tweets | | 82 | graph - text classification - text - gcn - classification | 44 | 82_graph_text classification_text_gcn | | 83 | annotation - tools - linguistic - resources - xml | 43 | 83_annotation_tools_linguistic_resources | | 84 | entity alignment - alignment - kgs - entity - ea | 43 | 84_entity alignment_alignment_kgs_entity | | 85 | personality - traits - personality traits - evaluative - text | 42 | 85_personality_traits_personality traits_evaluative | | 86 | ad - alzheimer - alzheimer disease - disease - speech | 40 | 86_ad_alzheimer_alzheimer disease_disease | | 87 | taxonomy - hypernymy - taxonomies - hypernym - hypernyms | 39 | 87_taxonomy_hypernymy_taxonomies_hypernym | | 88 | active learning - active - al - learning - uncertainty | 37 | 88_active learning_active_al_learning | | 89 | reviews - summaries - summarization - review - opinion | 36 | 89_reviews_summaries_summarization_review | | 90 | emoji - emojis - sentiment - message - anonymous | 35 | 90_emoji_emojis_sentiment_message | | 91 | table - table text - tables - table text generation - text generation | 35 | 91_table_table text_tables_table text generation | | 92 | domain - domain adaptation - adaptation - domains - source | 35 | 92_domain_domain adaptation_adaptation_domains | | 93 | alignment - word alignment - parallel - pairs - alignments | 34 | 93_alignment_word alignment_parallel_pairs | | 94 | indo - languages - indo european - names - family | 34 | 94_indo_languages_indo european_names | | 95 | patent - claim - claim generation - chemical - technical | 32 | 95_patent_claim_claim generation_chemical | | 96 | agents - emergent - communication - referential - games | 32 | 96_agents_emergent_communication_referential | | 97 | graph - amr - graph text - graphs - text generation | 31 | 97_graph_amr_graph text_graphs | | 98 | moral - ethical - norms - values - social | 29 | 98_moral_ethical_norms_values | | 99 | acronym - acronyms - abbreviations - abbreviation - disambiguation | 27 | 99_acronym_acronyms_abbreviations_abbreviation | | 100 | typing - entity typing - entity - type - types | 27 | 100_typing_entity typing_entity_type | | 101 | coherence - discourse - discourse coherence - coherence modeling - text | 26 | 101_coherence_discourse_discourse coherence_coherence modeling | | 102 | pos - taggers - tagging - tagger - pos tagging | 25 | 102_pos_taggers_tagging_tagger | | 103 | drug - social - social media - media - health | 25 | 103_drug_social_social media_media | | 104 | gender - translation - bias - gender bias - mt | 24 | 104_gender_translation_bias_gender bias | | 105 | job - resume - skills - skill - soft | 21 | 105_job_resume_skills_skill | </details> Due to the improved saving procedure, training on large datasets generates small model sizes. In the example below, a BERTopic model was trained on 100,000 documents, resulting in a ~50MB model keeping all of the original’s model functionality. For inference, the model can be further reduced to only ~3MB! 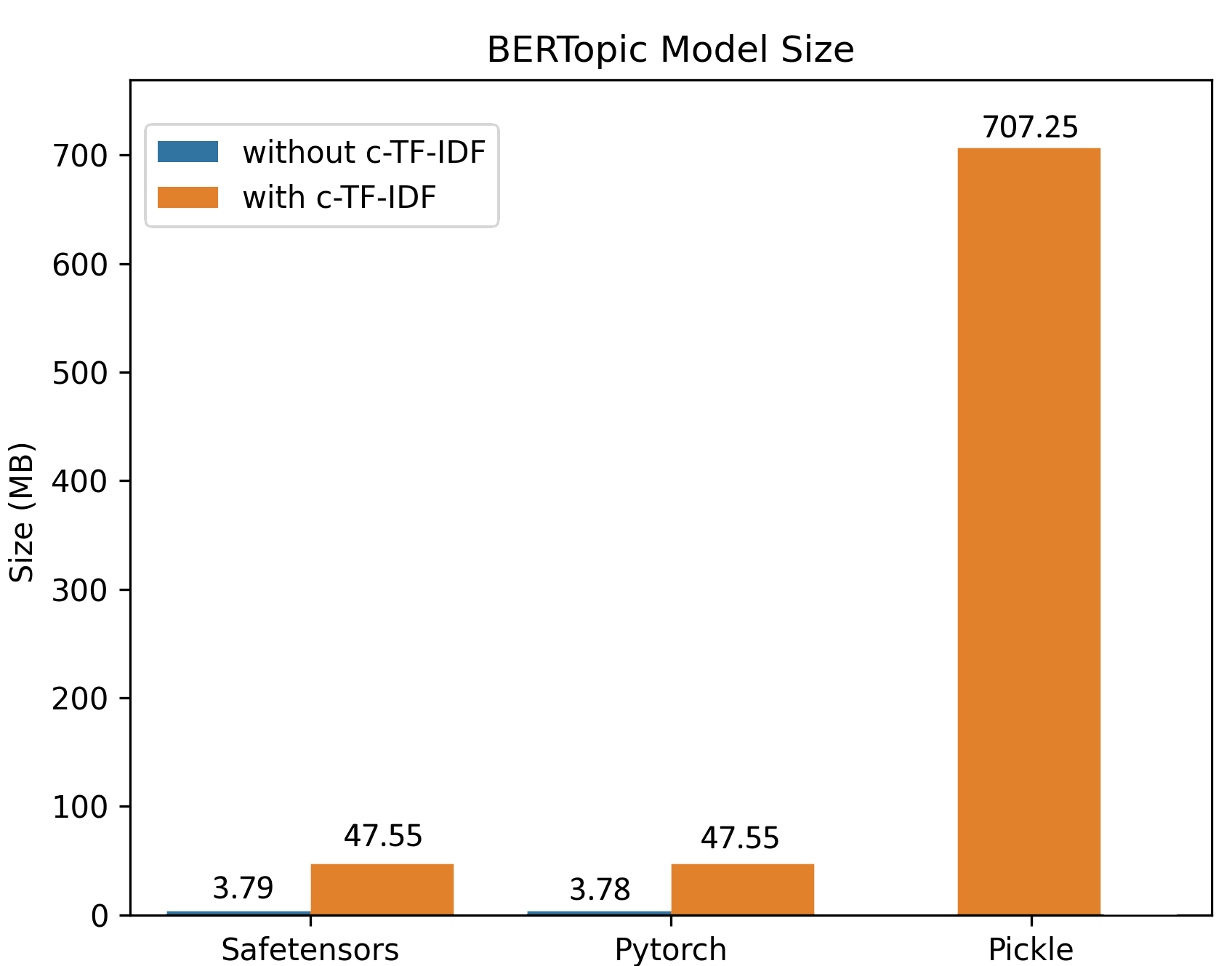 The benefits of this integration are particularly notable for production use cases. Users can now effortlessly deploy BERTopic models into their existing applications or systems, ensuring seamless integration within their data pipelines. This streamlined workflow enables faster iteration and efficient model updates and ensures consistency across different environments. ### safetensors: Ensuring Secure Model Management In addition to the Hugging Face Hub integration, BERTopic now supports serialization using the [safetensors library](https://huggingface.co/docs/safetensors/). Safetensors is a new simple format for storing tensors safely (instead of pickle), which is still fast (zero-copy). We’re excited to see more and more libraries leveraging safetensors for safe serialization. You can read more about a recent audit of the library in this [blog post](https://huggingface.co/blog/safetensors-security-audit). ### An example of using BERTopic to explore RLHF datasets To illustrate some of the power of BERTopic let's look at an example of how it can be used to monitor changes in topics in datasets used to train chat models. The last year has seen several datasets for Reinforcement Learning with Human Feedback released. One of these datasets is the [OpenAssistant Conversations dataset](https://huggingface.co/datasets/OpenAssistant/oasst1). This dataset was produced via a worldwide crowd-sourcing effort involving over 13,500 volunteers. Whilst this dataset already has some scores for toxicity, quality, humour etc., we may want to get a better understanding of what types of conversations are represented in this dataset. BERTopic offers one way of getting a better understanding of the topics in this dataset. In this case, we train a model on the English assistant responses part of the datasets. Resulting in a [topic model](https://huggingface.co/davanstrien/chat_topics) with 75 topics. BERTopic gives us various ways of visualizing a dataset. We can see the top 8 topics and their associated words below. We can see that the second most frequent topic consists mainly of ‘response words’, which we often see frequently from chat models, i.e. responses which aim to be ‘polite’ and ‘helpful’. We can also see a large number of topics related to programming or computing topics as well as physics, recipes and pets. 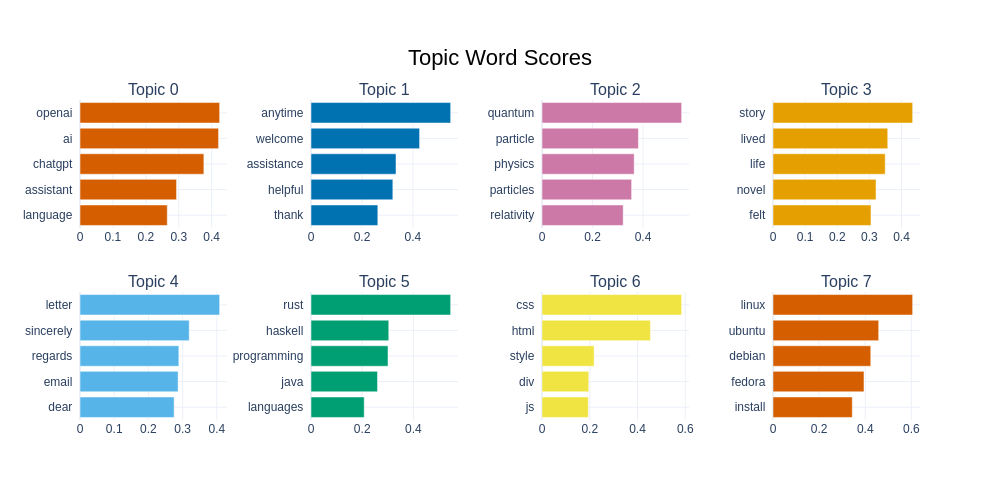 [databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) is another dataset that can be used to train an RLHF model. The approach taken to creating this dataset was quite different from the OpenAssistant Conversations dataset since it was created by employees of Databricks instead of being crowd sourced via volunteers. Perhaps we can use our trained BERTopic model to compare the topics across these two datasets? The new BERTopic Hub integrations mean we can load this trained model and apply it to new examples. ```python topic_model = BERTopic.load("davanstrien/chat_topics") ``` We can predict on a single example text: ```python example = "Stalemate is a drawn position. It doesn't matter who has captured more pieces or is in a winning position" topic, prob = topic_model.transform(example) ``` We can get more information about the predicted topic ```python topic_model.get_topic_info(topic) ``` | | Count | Name | Representation | |---:|--------:|:--------------------------------------|:----------------------------------------------------------------------------------------------------| | 0 | 240 | 22_chess_chessboard_practice_strategy | ['chess', 'chessboard', 'practice', 'strategy', 'learn', 'pawn', 'board', 'pawns', 'play', 'decks'] | We can see here the topics predicted seem to make sense. We may want to extend this to compare the topics predicted for the whole dataset. ```python from datasets import load_dataset dataset = load_dataset("databricks/databricks-dolly-15k") dolly_docs = dataset['train']['response'] dolly_topics, dolly_probs = topic_model.transform(dolly_docs) ``` We can then compare the distribution of topics across both datasets. We can see here that there seems to be a broader distribution across topics in the dolly dataset according to our BERTopic model. This might be a result of the different approaches to creating both datasets (we likely want to retrain a BERTopic across both datasets to ensure we are not missing topics to confirm this). 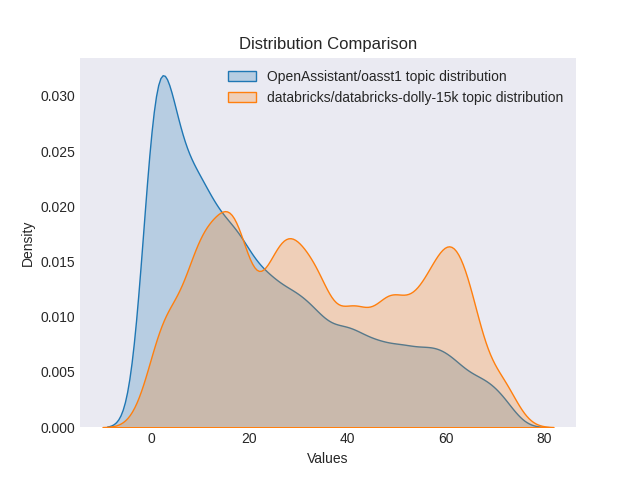 *Comparison of the distribution of topics between the two datasets* We can potentially use topic models in a production setting to monitor whether topics drift to far from an expected distribution. This can serve as a signal that there has been drift between your original training data and the types of conversations you are seeing in production. You may also decide to use a topic modelling as you are collecting training data to ensure you are getting examples for topics you may particularly care about. ## Get Started with BERTopic and Hugging Face Hub You can visit the official documentation for a [quick start guide](https://maartengr.github.io/BERTopic/getting_started/quickstart/quickstart.html) to get help using BERTopic. You can find a starter Colab notebook [here](https://colab.research.google.com/#fileId=https%3A//huggingface.co/spaces/davanstrien/blog_notebooks/blob/main/BERTopic_hub_starter.ipynb) that shows how you can train a BERTopic model and push it to the Hub. Some examples of BERTopic models already on the hub: - [MaartenGr/BERTopic_ArXiv](https://huggingface.co/MaartenGr/BERTopic_ArXiv): a model trained on ~30000 ArXiv Computation and Language articles (cs.CL) after 1991. - [MaartenGr/BERTopic_Wikipedia](https://huggingface.co/MaartenGr/BERTopic_Wikipedia): a model trained on 1000000 English Wikipedia pages. - [davanstrien/imdb_bertopic](https://huggingface.co/davanstrien/imdb_bertopic): a model trained on the unsupervised split of the IMDB dataset You can find a full overview of BERTopic models on the hub using the [libraries filter](https://huggingface.co/models?library=bertopic&sort=downloads) We invite you to explore the possibilities of this new integration and share your trained models on the hub!
|
Introducing the Hugging Face LLM Inference Container for Amazon SageMaker
|
philschmid
|
May 31, 2023
|
sagemaker-huggingface-llm
|
cloud, aws, partnership, guide
|
https://huggingface.co/blog/sagemaker-huggingface-llm
|
# Introducing the Hugging Face LLM Inference Container for Amazon SageMaker This is an example on how to deploy the open-source LLMs, like [BLOOM](https://huggingface.co/bigscience/bloom) to Amazon SageMaker for inference using the new Hugging Face LLM Inference Container. We will deploy the 12B [Pythia Open Assistant Model](https://huggingface.co/OpenAssistant/pythia-12b-sft-v8-7k-steps), an open-source Chat LLM trained with the Open Assistant dataset. The example covers: 1. [Setup development environment](#1-setup-development-environment) 2. [Retrieve the new Hugging Face LLM DLC](#2-retrieve-the-new-hugging-face-llm-dlc) 3. [Deploy Open Assistant 12B to Amazon SageMaker](#3-deploy-deploy-open-assistant-12b-to-amazon-sagemaker) 4. [Run inference and chat with our model](#4-run-inference-and-chat-with-our-model) 5. [Create Gradio Chatbot backed by Amazon SageMaker](#5-create-gradio-chatbot-backed-by-amazon-sagemaker) You can find the code for the example also in the [notebooks repository](https://github.com/huggingface/notebooks/blob/main/sagemaker/27_deploy_large_language_models/sagemaker-notebook.ipynb). ## What is Hugging Face LLM Inference DLC? Hugging Face LLM DLC is a new purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference), an open-source, purpose-built solution for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Llama, and T5. Text Generation Inference is already used by customers such as IBM, Grammarly, and the Open-Assistant initiative implements optimization for all supported model architectures, including: - Tensor Parallelism and custom cuda kernels - Optimized transformers code for inference using [flash-attention](https://github.com/HazyResearch/flash-attention) on the most popular architectures - Quantization with [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) - [Continuous batching of incoming requests](https://github.com/huggingface/text-generation-inference/tree/main/router) for increased total throughput - Accelerated weight loading (start-up time) with [safetensors](https://github.com/huggingface/safetensors) - Logits warpers (temperature scaling, topk, repetition penalty ...) - Watermarking with [A Watermark for Large Language Models](https://arxiv.org/abs/2301.10226) - Stop sequences, Log probabilities - Token streaming using Server-Sent Events (SSE) Officially supported model architectures are currently: - [BLOOM](https://huggingface.co/bigscience/bloom) / [BLOOMZ](https://huggingface.co/bigscience/bloomz) - [MT0-XXL](https://huggingface.co/bigscience/mt0-xxl) - [Galactica](https://huggingface.co/facebook/galactica-120b) - [SantaCoder](https://huggingface.co/bigcode/santacoder) - [GPT-Neox 20B](https://huggingface.co/EleutherAI/gpt-neox-20b) (joi, pythia, lotus, rosey, chip, RedPajama, open assistant) - [FLAN-T5-XXL](https://huggingface.co/google/flan-t5-xxl) (T5-11B) - [Llama](https://github.com/facebookresearch/llama) (vicuna, alpaca, koala) - [Starcoder](https://huggingface.co/bigcode/starcoder) / [SantaCoder](https://huggingface.co/bigcode/santacoder) - [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) / [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) With the new Hugging Face LLM Inference DLCs on Amazon SageMaker, AWS customers can benefit from the same technologies that power highly concurrent, low latency LLM experiences like [HuggingChat](https://hf.co/chat), [OpenAssistant](https://open-assistant.io/), and Inference API for LLM models on the Hugging Face Hub. Let's get started! ## 1. Setup development environment We are going to use the `sagemaker` python SDK to deploy BLOOM to Amazon SageMaker. We need to make sure to have an AWS account configured and the `sagemaker` python SDK installed. ```python !pip install "sagemaker==2.175.0" --upgrade --quiet ``` If you are going to use Sagemaker in a local environment, you need access to an IAM Role with the required permissions for Sagemaker. You can find [here](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html) more about it. ```python import sagemaker import boto3 sess = sagemaker.Session() # sagemaker session bucket -> used for uploading data, models and logs # sagemaker will automatically create this bucket if it not exists sagemaker_session_bucket=None if sagemaker_session_bucket is None and sess is not None: # set to default bucket if a bucket name is not given sagemaker_session_bucket = sess.default_bucket() try: role = sagemaker.get_execution_role() except ValueError: iam = boto3.client('iam') role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn'] sess = sagemaker.Session(default_bucket=sagemaker_session_bucket) print(f"sagemaker role arn: {role}") print(f"sagemaker session region: {sess.boto_region_name}") ``` ## 2. Retrieve the new Hugging Face LLM DLC Compared to deploying regular Hugging Face models, we first need to retrieve the container uri and provide it to our `HuggingFaceModel` model class with a `image_uri` pointing to the image. To retrieve the new Hugging Face LLM DLC in Amazon SageMaker, we can use the `get_huggingface_llm_image_uri` method provided by the `sagemaker` SDK. This method allows us to retrieve the URI for the desired Hugging Face LLM DLC based on the specified `backend`, `session`, `region`, and `version`. You can find the available versions [here](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-text-generation-inference-containers) ```python from sagemaker.huggingface import get_huggingface_llm_image_uri # retrieve the llm image uri llm_image = get_huggingface_llm_image_uri( "huggingface", version="1.0.3" ) # print ecr image uri print(f"llm image uri: {llm_image}") ``` ## 3. Deploy Open Assistant 12B to Amazon SageMaker _Note: Quotas for Amazon SageMaker can vary between accounts. If you receive an error indicating you've exceeded your quota, you can increase them through the [Service Quotas console](https://console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas)._ To deploy [Open Assistant Model](OpenAssistant/pythia-12b-sft-v8-7k-steps) to Amazon SageMaker we create a `HuggingFaceModel` model class and define our endpoint configuration including the `hf_model_id`, `instance_type` etc. We will use a `g5.12xlarge` instance type, which has 4 NVIDIA A10G GPUs and 96GB of GPU memory. _Note: We could also optimize the deployment for cost and use `g5.2xlarge` instance type and enable int-8 quantization._ ```python import json from sagemaker.huggingface import HuggingFaceModel # sagemaker config instance_type = "ml.g5.12xlarge" number_of_gpu = 4 health_check_timeout = 300 # Define Model and Endpoint configuration parameter config = { 'HF_MODEL_ID': "OpenAssistant/pythia-12b-sft-v8-7k-steps", # model_id from hf.co/models 'SM_NUM_GPUS': json.dumps(number_of_gpu), # Number of GPU used per replica 'MAX_INPUT_LENGTH': json.dumps(1024), # Max length of input text 'MAX_TOTAL_TOKENS': json.dumps(2048), # Max length of the generation (including input text) # 'HF_MODEL_QUANTIZE': "bitsandbytes", # comment in to quantize } # create HuggingFaceModel with the image uri llm_model = HuggingFaceModel( role=role, image_uri=llm_image, env=config ) ``` After we have created the `HuggingFaceModel` we can deploy it to Amazon SageMaker using the `deploy` method. We will deploy the model with the `ml.g5.12xlarge` instance type. TGI will automatically distribute and shard the model across all GPUs. ```python # Deploy model to an endpoint # https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy llm = llm_model.deploy( initial_instance_count=1, instance_type=instance_type, # volume_size=400, # If using an instance with local SSD storage, volume_size must be None, e.g. p4 but not p3 container_startup_health_check_timeout=health_check_timeout, # 10 minutes to be able to load the model ) ``` SageMaker will now create our endpoint and deploy the model to it. This can take 5-10 minutes. ## 4. Run inference and chat with our model After our endpoint is deployed we can run inference on it using the `predict` method from the `predictor`. We can use different parameters to control the generation, defining them in the `parameters` attribute of the payload. As of today TGI supports the following parameters: - `temperature`: Controls randomness in the model. Lower values will make the model more deterministic and higher values will make the model more random. Default value is 1.0. - `max_new_tokens`: The maximum number of tokens to generate. Default value is 20, max value is 512. - `repetition_penalty`: Controls the likelihood of repetition, defaults to `null`. - `seed`: The seed to use for random generation, default is `null`. - `stop`: A list of tokens to stop the generation. The generation will stop when one of the tokens is generated. - `top_k`: The number of highest probability vocabulary tokens to keep for top-k-filtering. Default value is `null`, which disables top-k-filtering. - `top_p`: The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling, default to `null` - `do_sample`: Whether or not to use sampling; use greedy decoding otherwise. Default value is `false`. - `best_of`: Generate best_of sequences and return the one if the highest token logprobs, default to `null`. - `details`: Whether or not to return details about the generation. Default value is `false`. - `return_full_text`: Whether or not to return the full text or only the generated part. Default value is `false`. - `truncate`: Whether or not to truncate the input to the maximum length of the model. Default value is `true`. - `typical_p`: The typical probability of a token. Default value is `null`. - `watermark`: The watermark to use for the generation. Default value is `false`. You can find the open api specification of TGI in the [swagger documentation](https://huggingface.github.io/text-generation-inference/) The `OpenAssistant/pythia-12b-sft-v8-7k-steps` is a conversational chat model meaning we can chat with it using the following prompt: ``` <|prompter|>[Instruction]<|endoftext|> <|assistant|> ``` lets give it a first try and ask about some cool ideas to do in the summer: ```python chat = llm.predict({ "inputs": """<|prompter|>What are some cool ideas to do in the summer?<|endoftext|><|assistant|>""" }) print(chat[0]["generated_text"]) # <|prompter|>What are some cool ideas to do in the summer?<|endoftext|><|assistant|>There are many fun and exciting things you can do in the summer. Here are some ideas: ``` Now we will show how to use generation parameters in the `parameters` attribute of the payload. In addition to setting custom `temperature`, `top_p`, etc, we also stop generation after the turn of the `bot`. ```python # define payload prompt="""<|prompter|>How can i stay more active during winter? Give me 3 tips.<|endoftext|><|assistant|>""" # hyperparameters for llm payload = { "inputs": prompt, "parameters": { "do_sample": True, "top_p": 0.7, "temperature": 0.7, "top_k": 50, "max_new_tokens": 256, "repetition_penalty": 1.03, "stop": ["<|endoftext|>"] } } # send request to endpoint response = llm.predict(payload) # print(response[0]["generated_text"][:-len("<human>:")]) print(response[0]["generated_text"]) ``` ## 5. Create Gradio Chatbot backed by Amazon SageMaker We can also create a gradio application to chat with our model. Gradio is a python library that allows you to quickly create customizable UI components around your machine learning models. You can find more about gradio [here](https://gradio.app/). ```python !pip install gradio --upgrade ``` ```python import gradio as gr # hyperparameters for llm parameters = { "do_sample": True, "top_p": 0.7, "temperature": 0.7, "top_k": 50, "max_new_tokens": 256, "repetition_penalty": 1.03, "stop": ["<|endoftext|>"] } with gr.Blocks() as demo: gr.Markdown("## Chat with Amazon SageMaker") with gr.Column(): chatbot = gr.Chatbot() with gr.Row(): with gr.Column(): message = gr.Textbox(label="Chat Message Box", placeholder="Chat Message Box", show_label=False) with gr.Column(): with gr.Row(): submit = gr.Button("Submit") clear = gr.Button("Clear") def respond(message, chat_history): # convert chat history to prompt converted_chat_history = "" if len(chat_history) > 0: for c in chat_history: converted_chat_history += f"<|prompter|>{c[0]}<|endoftext|><|assistant|>{c[1]}<|endoftext|>" prompt = f"{converted_chat_history}<|prompter|>{message}<|endoftext|><|assistant|>" # send request to endpoint llm_response = llm.predict({"inputs": prompt, "parameters": parameters}) # remove prompt from response parsed_response = llm_response[0]["generated_text"][len(prompt):] chat_history.append((message, parsed_response)) return "", chat_history submit.click(respond, [message, chatbot], [message, chatbot], queue=False) clear.click(lambda: None, None, chatbot, queue=False) demo.launch(share=True) ```  Awesome! 🚀 We have successfully deployed Open Assistant Model to Amazon SageMaker and run inference on it. Additionally, we have built a quick gradio application to chat with our model. Now, it's time for you to try it out yourself and build Generation AI applications with the new Hugging Face LLM DLC on Amazon SageMaker. To clean up, we can delete the model and endpoint. ```python llm.delete_model() llm.delete_endpoint() ``` ## Conclusion The new Hugging Face LLM Inference DLC enables customers to easily and securely deploy open-source LLMs on Amazon SageMaker. The easy-to-use API and deployment process allows customers to build scalable AI chatbots and virtual assistants with state-of-the-art models like Open Assistant. Overall, this new DLC is going to empower developers and businesses to leverage the latest advances in natural language generation. --- Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
|
Hugging Face Selected for the French Data Protection Agency Enhanced Support Program
|
yjernite
|
May 15, 2023
|
cnil
|
ethics
|
https://huggingface.co/blog/cnil
|
# Hugging Face Selected for the French Data Protection Agency Enhanced Support Program *This blog post was originally published on [LinkedIn on 05/15/2023](https://www.linkedin.com/pulse/accompagnement-renforc%25C3%25A9-de-la-cnil-et-protection-des-donn%25C3%25A9es/)* We are happy to announce that Hugging Face has been selected by the [CNIL](https://www.cnil.fr/en/home) (French Data Protection Authority) to benefit from its [Enhanced Support program](https://www.cnil.fr/en/enhanced-support-cnil-selects-3-digital-companies-strong-potential)! This new program picked three companies with “strong potential for economic development” out of over 40 candidates, who will receive support in understanding and implementing their duties with respect to data protection - a daunting and necessary endeavor in the context of the rapidly evolving field of Artificial Intelligence. When it comes to respecting people’s privacy rights, the recent developments in ML and AI pose new questions, and engender new challenges. We have been particularly sensitive to these challenges in our own work at Hugging Face and in our collaborations. The [BigScience Workshop](https://huggingface.co/bigscience) that we hosted in collaboration with hundreds of researchers from many different countries and institutions was the first Large Language Model training effort to [visibly put privacy front and center](https://linc.cnil.fr/fr/bigscience-il-faut-promouvoir-linnovation-ouverte-et-bienveillante-pour-mettre-le-respect-de-la-vie), through a multi-pronged approach covering [data selection and governance, data processing, and model sharing](https://montrealethics.ai/category/columns/social-context-in-llm-research/). The more recent [BigCode project](https://huggingface.co/bigcode) co-hosted with [ServiceNow](https://huggingface.co/ServiceNow) also dedicated significant resources to [addressing privacy risks](https://huggingface.co/datasets/bigcode/governance-card#social-impact-dimensions-and-considerations), creating [new tools to support pseudonymization](https://huggingface.co/bigcode/starpii) that will benefit other projects. These efforts help us better understand what is technically necessary and feasible at various levels of the AI development process so we can better address legal requirements and risks tied to personal data. The accompaniment program from the CNIL, benefiting from its expertise and role as France’s Data Protection Agency, will play an instrumental role in supporting our broader efforts to push GDPR compliance forward and provide clarity for our community of users on questions of privacy and data protection. We look forward to working together on addressing these questions with more foresight, and helping develop amazing new ML technology that does respect people’s data rights!
|
Announcing the Open Source AI Game Jam 🎮
|
ThomasSimonini
|
June 1, 2023
|
game-jam
|
community
|
https://huggingface.co/blog/game-jam
|
# Announcing the Open Source AI Game Jam 🎮 <h2> Unleash Your Creativity with AI Tools and make a game in a weekend!</h2> <!-- {authors} --> We're thrilled to announce the first ever **Open Source AI Game Jam**, where you will create a game using AI tools. With AI's potential to enhance game experiences and workflows, we're excited to see what you can accomplish: incorporate generative AI tools like Stable Diffusion into your game or workflow to unlock new features and accelerate your development process. From texture generation to lifelike NPCs and realistic text-to-speech, the options are endless. 📆 Mark your calendars: the game jam will take place from Friday to Sunday, **July 7-9**. **Claim Your Free Spot in the Game Jam** 👉 https://itch.io/jam/open-source-ai-game-jam <h2>Why Are We Organizing This?</h2> In a time when some popular game jams restrict the use of AI tools, we believe it's crucial to **provide a platform specifically dedicated to showcasing the incredible possibilities AI offers game developers**. Especially when those tools are **open, transparent, and accessible**. We want to see these jams thrive and empower indie developers with the tools they need to boost productivity and unlock their full potential. <h2>What Are AI Tools?</h2> AI tools, particularly generative ones like Stable Diffusion, open up a whole new world of possibilities in game development. From accelerated workflows to in-game features, you can harness the power of AI for texture generation, lifelike AI non-player characters (NPCs), and realistic text-to-speech functionality. Claim Your Free Spot in the Game Jam 👉 https://itch.io/jam/open-source-ai-game-jam <h2>Who Can Participate?</h2> **Everyone is welcome to join the Open Source AI Game Jam**, regardless of skill level or location. You can participate alone or in a team of any size. <h2>What Are the Requirements?</h2> To participate, your game should be playable on the web (e.g., itch.io) or Windows. Additionally, **you are required to incorporate at least one open-source AI tool into your game or workflow**. We'll provide more details to guide you along the way. <h2>Can I Use Existing Assets?</h2> Absolutely! **You're welcome to use existing assets, code, or AI tools that you have legal access to.** We want to ensure fairness and give you the freedom to leverage the resources at your disposal. <h2>Is There a Theme?</h2> Yes, the theme will be announced when the jam starts. <h2>How Will the Games Be Judged?</h2> Participants will rate other games based on three criteria: **fun, creativity, and theme**. The judges will showcase and choose the winner from the Top 10. <h2> Join our Discord Community! </h2> Want to connect with the community? Join our Discord! 👉 https://discord.com/invite/hugging-face-879548962464493619 **Claim Your Free Spot in the Game Jam** 👉 https://itch.io/jam/open-source-ai-game-jam See you there! 🤗
|
AI Speech Recognition in Unity
|
dylanebert
|
June 2, 2023
|
unity-asr
|
community, guide, game-dev
|
https://huggingface.co/blog/unity-asr
|
# AI Speech Recognition in Unity [](https://itch.io/jam/open-source-ai-game-jam) ## Introduction This tutorial guides you through the process of implementing state-of-the-art Speech Recognition in your Unity game using the Hugging Face Unity API. This feature can be used for giving commands, speaking to an NPC, improving accessibility, or any other functionality where converting spoken words to text may be useful. To try Speech Recognition in Unity for yourself, check out the [live demo in itch.io](https://individualkex.itch.io/speech-recognition-demo). ### Prerequisites This tutorial assumes basic knowledge of Unity. It also requires you to have installed the [Hugging Face Unity API](https://github.com/huggingface/unity-api). For instructions on setting up the API, check out our [earlier blog post](https://huggingface.co/blog/unity-api). ## Steps ### 1. Set up the Scene In this tutorial, we'll set up a very simple scene where the player can start and stop a recording, and the result will be converted to text. Begin by creating a Unity project, then creating a Canvas with four UI elements: 1. **Start Button**: This will start the recording. 2. **Stop Button**: This will stop the recording. 3. **Text (TextMeshPro)**: This is where the result of the speech recognition will be displayed. ### 2. Set up the Script Create a script called `SpeechRecognitionTest` and attach it to an empty GameObject. In the script, define references to your UI components: ``` [SerializeField] private Button startButton; [SerializeField] private Button stopButton; [SerializeField] private TextMeshProUGUI text; ``` Assign them in the inspector. Then, use the `Start()` method to set up listeners for the start and stop buttons: ``` private void Start() { startButton.onClick.AddListener(StartRecording); stopButton.onClick.AddListener(StopRecording); } ``` At this point, your script should look something like this: ``` using TMPro; using UnityEngine; using UnityEngine.UI; public class SpeechRecognitionTest : MonoBehaviour { [SerializeField] private Button startButton; [SerializeField] private Button stopButton; [SerializeField] private TextMeshProUGUI text; private void Start() { startButton.onClick.AddListener(StartRecording); stopButton.onClick.AddListener(StopRecording); } private void StartRecording() { } private void StopRecording() { } } ``` ### 3. Record Microphone Input Now let's record Microphone input and encode it in WAV format. Start by defining the member variables: ``` private AudioClip clip; private byte[] bytes; private bool recording; ``` Then, in `StartRecording()`, using the `Microphone.Start()` method to start recording: ``` private void StartRecording() { clip = Microphone.Start(null, false, 10, 44100); recording = true; } ``` This will record up to 10 seconds of audio at 44100 Hz. In case the recording reaches its maximum length of 10 seconds, we'll want to stop the recording automatically. To do so, write the following in the `Update()` method: ``` private void Update() { if (recording && Microphone.GetPosition(null) >= clip.samples) { StopRecording(); } } ``` Then, in `StopRecording()`, truncate the recording and encode it in WAV format: ``` private void StopRecording() { var position = Microphone.GetPosition(null); Microphone.End(null); var samples = new float[position * clip.channels]; clip.GetData(samples, 0); bytes = EncodeAsWAV(samples, clip.frequency, clip.channels); recording = false; } ``` Finally, we'll need to implement the `EncodeAsWAV()` method, to prepare the audio data for the Hugging Face API: ``` private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) { using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) { using (var writer = new BinaryWriter(memoryStream)) { writer.Write("RIFF".ToCharArray()); writer.Write(36 + samples.Length * 2); writer.Write("WAVE".ToCharArray()); writer.Write("fmt ".ToCharArray()); writer.Write(16); writer.Write((ushort)1); writer.Write((ushort)channels); writer.Write(frequency); writer.Write(frequency * channels * 2); writer.Write((ushort)(channels * 2)); writer.Write((ushort)16); writer.Write("data".ToCharArray()); writer.Write(samples.Length * 2); foreach (var sample in samples) { writer.Write((short)(sample * short.MaxValue)); } } return memoryStream.ToArray(); } } ``` The full script should now look something like this: ``` using System.IO; using TMPro; using UnityEngine; using UnityEngine.UI; public class SpeechRecognitionTest : MonoBehaviour { [SerializeField] private Button startButton; [SerializeField] private Button stopButton; [SerializeField] private TextMeshProUGUI text; private AudioClip clip; private byte[] bytes; private bool recording; private void Start() { startButton.onClick.AddListener(StartRecording); stopButton.onClick.AddListener(StopRecording); } private void Update() { if (recording && Microphone.GetPosition(null) >= clip.samples) { StopRecording(); } } private void StartRecording() { clip = Microphone.Start(null, false, 10, 44100); recording = true; } private void StopRecording() { var position = Microphone.GetPosition(null); Microphone.End(null); var samples = new float[position * clip.channels]; clip.GetData(samples, 0); bytes = EncodeAsWAV(samples, clip.frequency, clip.channels); recording = false; } private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) { using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) { using (var writer = new BinaryWriter(memoryStream)) { writer.Write("RIFF".ToCharArray()); writer.Write(36 + samples.Length * 2); writer.Write("WAVE".ToCharArray()); writer.Write("fmt ".ToCharArray()); writer.Write(16); writer.Write((ushort)1); writer.Write((ushort)channels); writer.Write(frequency); writer.Write(frequency * channels * 2); writer.Write((ushort)(channels * 2)); writer.Write((ushort)16); writer.Write("data".ToCharArray()); writer.Write(samples.Length * 2); foreach (var sample in samples) { writer.Write((short)(sample * short.MaxValue)); } } return memoryStream.ToArray(); } } } ``` To test whether this code is working correctly, you can add the following line to the end of the `StopRecording()` method: ``` File.WriteAllBytes(Application.dataPath + "/test.wav", bytes); ``` Now, if you click the `Start` button, speak into the microphone, and click `Stop`, a `test.wav` file should be saved in your Unity Assets folder with your recorded audio. ### 4. Speech Recognition Next, we'll want to use the Hugging Face Unity API to run speech recognition on our encoded audio. To do so, we'll create a `SendRecording()` method: ``` using HuggingFace.API; private void SendRecording() { HuggingFaceAPI.AutomaticSpeechRecognition(bytes, response => { text.color = Color.white; text.text = response; }, error => { text.color = Color.red; text.text = error; }); } ``` This will send the encoded audio to the API, displaying the response in white if successful, otherwise the error message in red. Don't forget to call `SendRecording()` at the end of the `StopRecording()` method: ``` private void StopRecording() { /* other code */ SendRecording(); } ``` ### 5. Final Touches Finally, let's improve the UX of this demo a bit using button interactability and status messages. The Start and Stop buttons should only be interactable when appropriate, i.e. when a recording is ready to be started/stopped. Then, set the response text to a simple status message while recording or waiting for the API. The finished script should look something like this: ``` using System.IO; using HuggingFace.API; using TMPro; using UnityEngine; using UnityEngine.UI; public class SpeechRecognitionTest : MonoBehaviour { [SerializeField] private Button startButton; [SerializeField] private Button stopButton; [SerializeField] private TextMeshProUGUI text; private AudioClip clip; private byte[] bytes; private bool recording; private void Start() { startButton.onClick.AddListener(StartRecording); stopButton.onClick.AddListener(StopRecording); stopButton.interactable = false; } private void Update() { if (recording && Microphone.GetPosition(null) >= clip.samples) { StopRecording(); } } private void StartRecording() { text.color = Color.white; text.text = "Recording..."; startButton.interactable = false; stopButton.interactable = true; clip = Microphone.Start(null, false, 10, 44100); recording = true; } private void StopRecording() { var position = Microphone.GetPosition(null); Microphone.End(null); var samples = new float[position * clip.channels]; clip.GetData(samples, 0); bytes = EncodeAsWAV(samples, clip.frequency, clip.channels); recording = false; SendRecording(); } private void SendRecording() { text.color = Color.yellow; text.text = "Sending..."; stopButton.interactable = false; HuggingFaceAPI.AutomaticSpeechRecognition(bytes, response => { text.color = Color.white; text.text = response; startButton.interactable = true; }, error => { text.color = Color.red; text.text = error; startButton.interactable = true; }); } private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) { using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) { using (var writer = new BinaryWriter(memoryStream)) { writer.Write("RIFF".ToCharArray()); writer.Write(36 + samples.Length * 2); writer.Write("WAVE".ToCharArray()); writer.Write("fmt ".ToCharArray()); writer.Write(16); writer.Write((ushort)1); writer.Write((ushort)channels); writer.Write(frequency); writer.Write(frequency * channels * 2); writer.Write((ushort)(channels * 2)); writer.Write((ushort)16); writer.Write("data".ToCharArray()); writer.Write(samples.Length * 2); foreach (var sample in samples) { writer.Write((short)(sample * short.MaxValue)); } } return memoryStream.ToArray(); } } } ``` Congratulations, you can now use state-of-the-art Speech Recognition in Unity! If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
The Falcon has landed in the Hugging Face ecosystem
|
lvwerra
|
June 5, 2023
|
falcon
|
nlp, community, research
|
https://huggingface.co/blog/falcon
|
# The Falcon has landed in the Hugging Face ecosystem ## Introduction Falcon is a new family of state-of-the-art language models created by the [Technology Innovation Institute](https://www.tii.ae/) in Abu Dhabi, and released under the Apache 2.0 license. **Notably, [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) is the first “truly open” model with capabilities rivaling many current closed-source models**. This is fantastic news for practitioners, enthusiasts, and industry, as it opens the door for many exciting use cases. <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;"> September 2023 Update: <a href="https://huggingface.co/blog/falcon-180b">Falcon 180B</a> has just been released! It's currently the largest openly available model, and rivals proprietary models like PaLM-2. </div> In this blog, we will be taking a deep dive into the Falcon models: first discussing what makes them unique and then **showcasing how easy it is to build on top of them (inference, quantization, finetuning, and more) with tools from the Hugging Face ecosystem**. ## Table of Contents - [The Falcon models](#the-falcon-models) - [Demo](#demo) - [Inference](#inference) - [Evaluation](#evaluation) - [Fine-tuning with PEFT](#fine-tuning-with-peft) - [Conclusion](#conclusion) ## The Falcon models The Falcon family is composed of two base models: [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) and its little brother [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b). **The 40B parameter model currently tops the charts of the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), while the 7B model is the best in its weight class**. Falcon-40B requires ~90GB of GPU memory — that’s a lot, but still less than LLaMA-65B, which Falcon outperforms. On the other hand, Falcon-7B only needs ~15GB, making inference and finetuning accessible even on consumer hardware. *(Later in this blog, we will discuss how we can leverage quantization to make Falcon-40B accessible even on cheaper GPUs!)* TII has also made available instruct versions of the models, [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) and [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct). These experimental variants have been finetuned on instructions and conversational data; they thus lend better to popular assistant-style tasks. **If you are just looking to quickly play with the models they are your best shot.** It’s also possible to build your own custom instruct version, based on the plethora of datasets built by the community—keep reading for a step-by-step tutorial! Falcon-7B and Falcon-40B have been trained on 1.5 trillion and 1 trillion tokens respectively, in line with modern models optimising for inference. **The key ingredient for the high quality of the Falcon models is their training data, predominantly based (>80%) on [RefinedWeb](https://arxiv.org/abs/2306.01116) — a novel massive web dataset based on CommonCrawl**. Instead of gathering scattered curated sources, TII has focused on scaling and improving the quality of web data, leveraging large-scale deduplication and strict filtering to match the quality of other corpora. The Falcon models still include some curated sources in their training (such as conversational data from Reddit), but significantly less so than has been common for state-of-the-art LLMs like GPT-3 or PaLM. The best part? TII has publicly released a 600 billion tokens extract of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) for the community to use in their own LLMs! Another interesting feature of the Falcon models is their use of [**multiquery attention**](https://arxiv.org/abs/1911.02150). The vanilla multihead attention scheme has one query, key, and value per head; multiquery instead shares one key and value across all heads. | 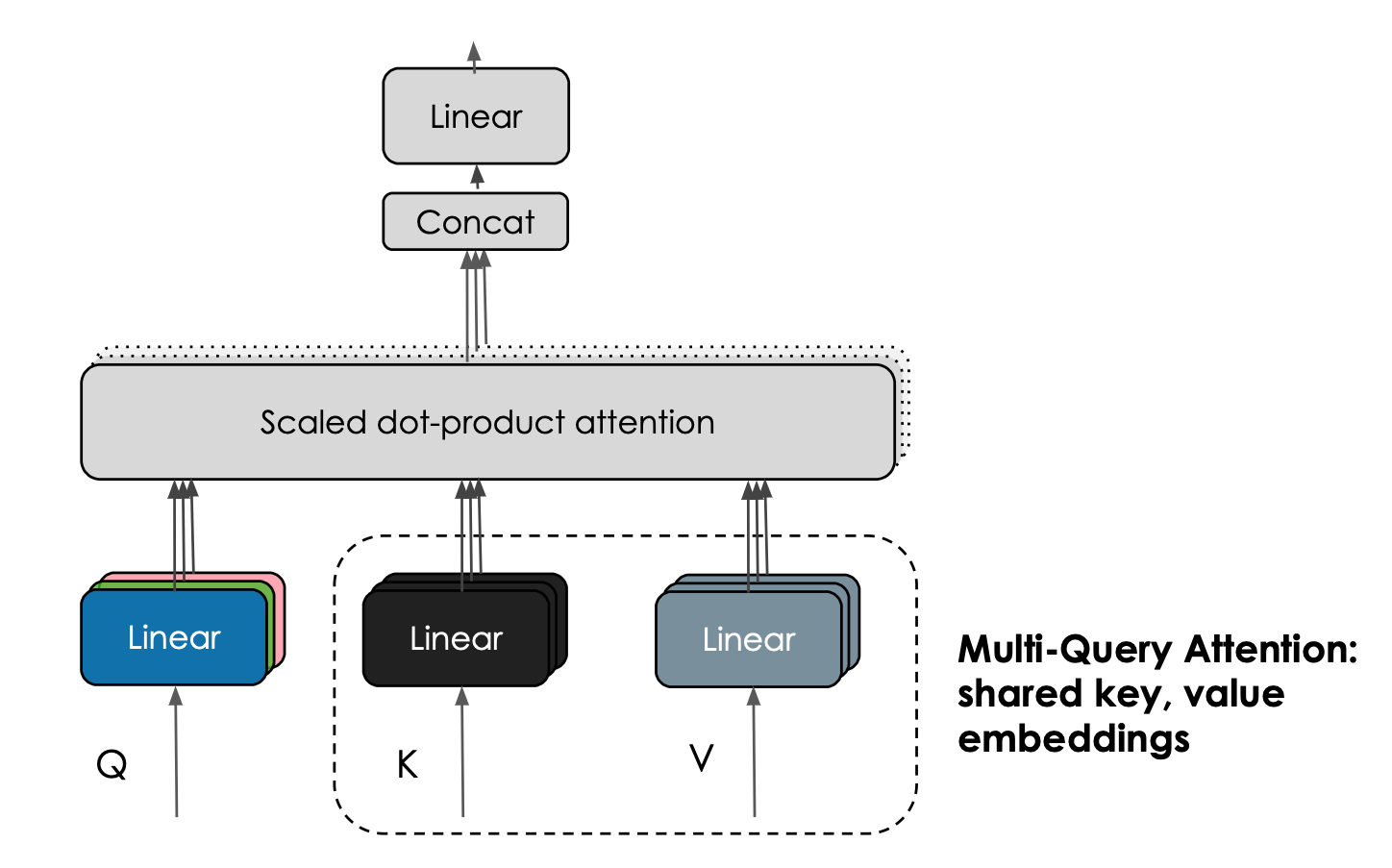 | |:--:| | <b>Multi-Query Attention shares keys and value embeddings across attention heads. Courtesy Harm de Vries. </b>| This trick doesn’t significantly influence pretraining, but it greatly [improves the scalability of inference](https://arxiv.org/abs/2211.05102): indeed, **the K,V-cache kept during autoregressive decoding is now significantly smaller** (10-100 times depending on the specific of the architecture), reducing memory costs and enabling novel optimizations such as statefulness. | Model | License | Commercial use? | Pretraining length [tokens] | Pretraining compute [PF-days] | Leaderboard score | K,V-cache size for a 2.048 context | | --- | --- | --- | --- | --- | --- | --- | | StableLM-Alpha-7B | CC-BY-SA-4.0 | ✅ | 1,500B | 700 | 38.3* | 800MB | | LLaMA-7B | LLaMA license | ❌ | 1,000B | 500 | 47.6 | 1,100MB | | MPT-7B | Apache 2.0 | ✅ | 1,000B | 500 | 48.6 | 1,100MB | | Falcon-7B | Apache 2.0 | ✅ | 1,500B | 700 | 48.8 | 20MB | | LLaMA-33B | LLaMA license | ❌ | 1,500B | 3200 | 56.9 | 3,300MB | | LLaMA-65B | LLaMA license | ❌ | 1,500B | 6300 | 58.3 | 5,400MB | | Falcon-40B | Apache 2.0 | ✅ | 1,000B | 2800 | 60.4 | 240MB | **score from the base version not available, we report the tuned version instead.* # Demo You can easily try the Big Falcon Model (40 billion parameters!) in [this Space](https://huggingface.co/spaces/HuggingFaceH4/falcon-chat) or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.32.0/gradio.js"> </script> <gradio-app theme_mode="light" space="HuggingFaceH4/falcon-chat-demo-for-blog"></gradio-app> Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), a scalable Rust, Python, and gRPC server for fast & efficient text generation. It's the same technology that powers [HuggingChat](https://huggingface.co/chat/). We've also built a Core ML version of the 7B instruct model, and this is how it runs on an M1 MacBook Pro: <video controls title="Falcon 7B Instruct running on an M1 MacBook Pro with Core ML"> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/147_falcon/falcon-7b.mp4" type="video/mp4"> Video: Falcon 7B Instruct running on an M1 MacBook Pro with Core ML. </video> The video shows a lightweight app that leverages a Swift library for the heavy lifting: model loading, tokenization, input preparation, generation, and decoding. We are busy building this library to empower developers to integrate powerful LLMs in all types of applications without having to reinvent the wheel. It's still a bit rough, but we can't wait to share it with you. Meanwhile, you can download the [Core ML weights](https://huggingface.co/tiiuae/falcon-7b-instruct/tree/main/coreml/text-generation) from the repo and explore them yourself! # Inference You can use the familiar transformers APIs to run the models on your own hardware, but you need to pay attention to a couple of details: - The models were trained using the `bfloat16` datatype, so we recommend you use the same. This requires a recent version of CUDA and works best on modern cards. You may also try to run inference using `float16`, but keep in mind that the models were evaluated using `bfloat16`. - You need to allow remote code execution. This is because the models use a new architecture that is not part of `transformers` yet - instead, the code necessary is provided by the model authors in the repo. Specifically, these are the files whose code will be used if you allow remote execution (using `falcon-7b-instruct` as an example): [configuration_RW.py](https://huggingface.co/tiiuae/falcon-7b-instruct/blob/main/configuration_RW.py), [modelling_RW.py](https://huggingface.co/tiiuae/falcon-7b-instruct/blob/main/modelling_RW.py). With these considerations, you can use the transformers `pipeline` API to load the 7B instruction model like this: ```python from transformers import AutoTokenizer import transformers import torch model = "tiiuae/falcon-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model) pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", ) ``` And then, you'd run text generation using code like the following: ```python sequences = pipeline( "Write a poem about Valencia.", max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, ) for seq in sequences: print(f"Result: {seq['generated_text']}") ``` And you may get something like the following: ```bash Valencia, city of the sun The city that glitters like a star A city of a thousand colors Where the night is illuminated by stars Valencia, the city of my heart Where the past is kept in a golden chest ``` ### Inference of Falcon 40B Running the 40B model is challenging because of its size: it doesn't fit in a single A100 with 80 GB of RAM. Loading in 8-bit mode, it is possible to run in about 45 GB of RAM, which fits in an A6000 (48 GB) but not in the 40 GB version of the A100. This is how you'd do it: ```python from transformers import AutoTokenizer, AutoModelForCausalLM import transformers import torch model_id = "tiiuae/falcon-40b-instruct" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, trust_remote_code=True, load_in_8bit=True, device_map="auto", ) pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, ) ``` Note, however, that mixed 8-bit inference will use `torch.float16` instead of `torch.bfloat16`, so make sure you test the results thoroughly. If you have multiple cards and `accelerate` installed, you can take advantage of `device_map="auto"` to automatically distribute the model layers across various cards. It can even offload some layers to the CPU if necessary, but this will impact inference speed. There's also the possibility to use [4-bit loading](https://huggingface.co/blog/4bit-transformers-bitsandbytes) using the latest version of `bitsandbytes`, `transformers` and `accelerate`. In this case, the 40B model takes ~27 GB of RAM to run. Unfortunately, this is slightly more than the memory available in cards such as 3090 or 4090, but it's enough to run on 30 or 40 GB cards. ### Text Generation Inference [Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production ready inference container developed by Hugging Face to enable easy deployment of large language models. Its main features are: - Continuous batching - Token streaming using Server-Sent Events (SSE) - Tensor Parallelism for faster inference on multiple GPUs - Optimized transformers code using custom CUDA kernels - Production ready logging, monitoring and tracing with Prometheus and Open Telemetry Since v0.8.2, Text Generation Inference supports Falcon 7b and 40b models natively without relying on the Transformers "trust remote code" feature, allowing for airtight deployments and security audits. In addition, the Falcon implementation includes custom CUDA kernels to significantly decrease end-to-end latency. |  | |:--:| | <b>Inference Endpoints now support Text Generation Inference. Deploy the Falcon 40B Instruct model easily on 1xA100 with Int-8 quantization</b>| Text Generation Inference is now integrated inside Hugging Face's [Inference Endpoints](https://huggingface.co/inference-endpoints). To deploy a Falcon model, go to the [model page](https://huggingface.co/tiiuae/falcon-7b-instruct) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=tiiuae/falcon-7b-instruct) widget. For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G". For 40B models, you will need to deploy on "GPU [xlarge] - 1x Nvidia A100" and activate quantization: Advanced configuration -> Serving Container -> Int-8 Quantization. _Note: You might need to request a quota upgrade via email to [email protected]_ ## Evaluation So how good are the Falcon models? An in-depth evaluation from the Falcon authors will be released soon, so in the meantime we ran both the base and instruct models through our [open LLM benchmark](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). This benchmark measures both the reasoning capabilities of LLMs and their ability to provide truthful answers across the following domains: * [AI2 Reasoning Challenge](https://allenai.org/data/arc) (ARC): Grade-school multiple choice science questions. * [HellaSwag](https://arxiv.org/abs/1905.07830): Commonsense reasoning around everyday events. * [MMLU](https://github.com/hendrycks/test): Multiple-choice questions in 57 subjects (professional & academic). * [TruthfulQA](https://arxiv.org/abs/2109.07958): Tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements. The results show that the 40B base and instruct models are very strong, and currently rank 1st and 2nd on the [LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) 🏆! 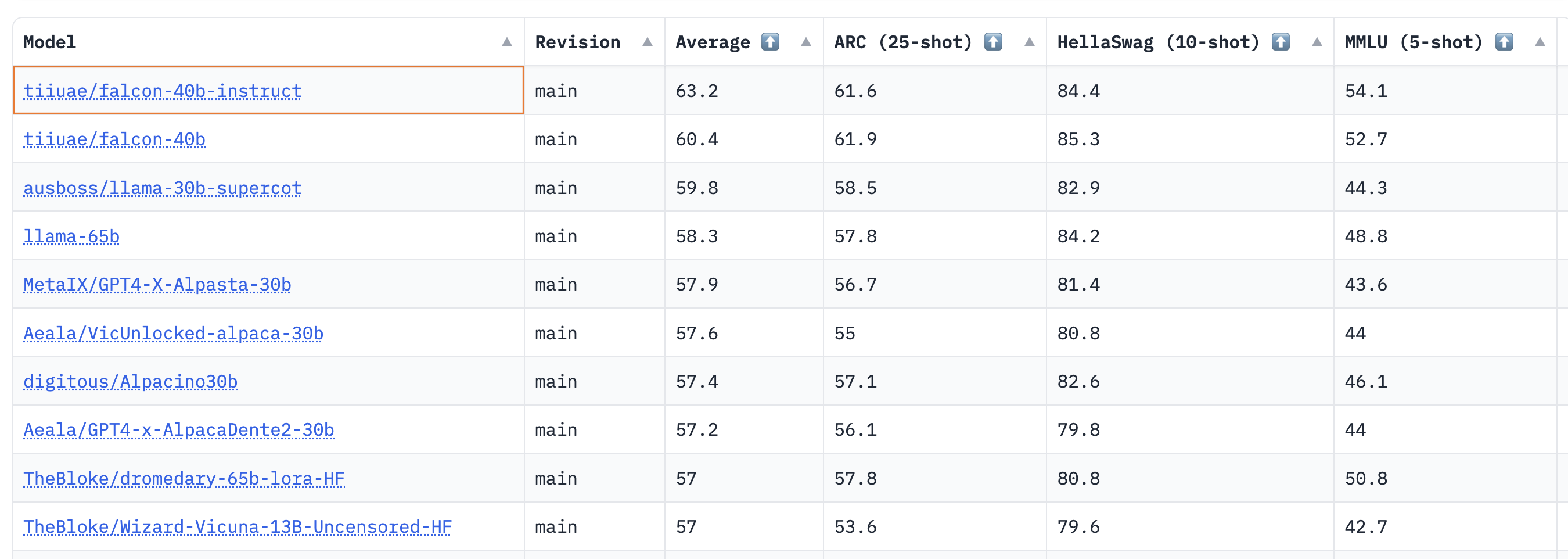 As noted by [Thomas Wolf](https://www.linkedin.com/posts/thom-wolf_open-llm-leaderboard-a-hugging-face-space-activity-7070334210116329472-x6ek?utm_source=share&utm_medium=member_desktop), one surprisingly insight here is that the 40B models were pretrained on around half the compute needed for LLaMa 65B (2800 vs 6300 petaflop days), which suggests we haven't quite hit the limits of what's "optimal" for LLM pretraining. For the 7B models, we see that the base model is better than `llama-7b` and edges out MosaicML's `mpt-7b` to become the current best pretrained LLM at this scale. A shortlist of popular models from the leaderboard is reproduced below for comparison: | Model | Type | Average leaderboard score | | :---: | :---: | :---: | | [tiiuae/falcon-40b-instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) | instruct | 63.2 | | [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b) | base | 60.4 | | [llama-65b](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) | base | 58.3 | | [TheBloke/dromedary-65b-lora-HF](https://huggingface.co/TheBloke/dromedary-65b-lora-HF) | instruct | 57 | | [stable-vicuna-13b](https://huggingface.co/CarperAI/stable-vicuna-13b-delta) | rlhf | 52.4 | | [llama-13b](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) | base | 51.8 | | [TheBloke/wizardLM-7B-HF](https://huggingface.co/TheBloke/wizardLM-7B-HF) | instruct | 50.1 | | [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b) | base | 48.8 | | [mosaicml/mpt-7b](https://huggingface.co/mosaicml/mpt-7b) | base | 48.6 | | [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) | instruct | 48.4 | | [llama-7b](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) | base | 47.6 | Although the open LLM leaderboard doesn't measure chat capabilities (where human evaluation is the gold standard), these preliminary results for the Falcon models are very encouraging! Let's now take a look at how you can fine-tune your very own Falcon models - perhaps one of yours will end up on top of the leaderboard 🤗. ## Fine-tuning with PEFT Training 10B+ sized models can be technically and computationally challenging. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train extremely large models on simple hardware and show how to fine-tune the Falcon-7b on a single NVIDIA T4 (16GB - Google Colab). Let's see how we can train Falcon on the [Guanaco dataset](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) a high-quality subset of the [Open Assistant dataset](https://huggingface.co/datasets/OpenAssistant/oasst1) consisting of around 10,000 dialogues. With the [PEFT library](https://github.com/huggingface/peft) we can use the recent [QLoRA](https://arxiv.org/abs/2305.14314) approach to fine-tune adapters that are placed on top of the frozen 4-bit model. You can learn more about the integration of 4-bit quantized models [in this blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes). Because just a tiny fraction of the model is trainable when using Low Rank Adapters (LoRA), both the number of learned parameters and the size of the trained artifact are dramatically reduced. As shown in the screenshot below, the saved model has only 65MB for the 7B parameters model (15GB in float16). |  | |:--:| | <b>The final repository has only 65MB of weights - compared to the original model that has approximately 15GB in half precision </b>| More specifically, after selecting the target modules to adapt (in practice the query / key layers of the attention module), small trainable linear layers are attached close to these modules as illustrated below). The hidden states produced by the adapters are then added to the original states to get the final hidden state. |  | |:--:| | <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrices A and B (right). </b>| Once trained, there is no need to save the entire model as the base model was kept frozen. In addition, it is possible to keep the model in any arbitrary dtype (int8, fp4, fp16, etc.) as long as the output hidden states from these modules are casted to the same dtype as the ones from the adapters - this is the case for bitsandbytes modules (`Linear8bitLt` and `Linear4bit` ) that return hidden states with the same dtype as the original unquantized module. We fine-tuned the two variants of the Falcon models (7B and 40B) on the Guanaco dataset. We fine-tuned the 7B model on a single NVIDIA-T4 16GB, and the 40B model on a single NVIDIA A100 80GB. We used 4bit quantized base models and the QLoRA method, as well as [the recent `SFTTrainer` from the TRL library.](https://huggingface.co/docs/trl/main/en/sft_trainer) The full script to reproduce our experiments using PEFT is available [here](https://gist.github.com/pacman100/1731b41f7a90a87b457e8c5415ff1c14), but only a few lines of code are required to quickly run the `SFTTrainer` (without PEFT for simplicity): ```python from datasets import load_dataset from trl import SFTTrainer from transformers import AutoTokenizer, AutoModelForCausalLM dataset = load_dataset("imdb", split="train") model_id = "tiiuae/falcon-7b" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True) trainer = SFTTrainer( model, tokenizer=tokenizer, train_dataset=dataset, dataset_text_field="text", max_seq_length=512, ) trainer.train() ``` Check out the [original qlora repository](https://github.com/artidoro/qlora/) for additional details about evaluating the trained models. ### Fine-tuning Resources - **[Colab notebook to fine-tune Falcon-7B on Guanaco dataset using 4bit and PEFT](https://colab.research.google.com/drive/1BiQiw31DT7-cDp1-0ySXvvhzqomTdI-o?usp=sharing)** - **[Training code](https://gist.github.com/pacman100/1731b41f7a90a87b457e8c5415ff1c14)** - **[40B model adapters](https://huggingface.co/smangrul/falcon-40B-int4-peft-lora-sfttrainer)** ([logs](https://wandb.ai/smangrul/huggingface/runs/3hpqq08s/workspace?workspace=user-younesbelkada)) - **[7B model adapters](https://huggingface.co/ybelkada/falcon-7b-guanaco-lora)** ([logs](https://wandb.ai/younesbelkada/huggingface/runs/2x4zi72j?workspace=user-younesbelkada)) ## Conclusion Falcon is an exciting new large language model which can be used for commercial applications. In this blog post we showed its capabilities, how to run it in your own environment and how easy to fine-tune on custom data within in the Hugging Face ecosystem. We are excited to see what the community will build with it!
|
Welcome fastText to the 🤗 Hub
|
sheonhan
|
June 6, 2023
|
fasttext
|
open-source-collab, nlp, partnerships
|
https://huggingface.co/blog/fasttext
|
# Welcome fastText to the Hugging Face Hub [fastText](https://fasttext.cc/) is a library for efficient learning of text representation and classification. [Open-sourced](https://fasttext.cc/blog/2016/08/18/blog-post.html) by Meta AI in 2016, fastText integrates key ideas that have been influential in natural language processing and machine learning over the past few decades: representing sentences using bag of words and bag of n-grams, using subword information, and utilizing a hidden representation to share information across classes. To speed up computation, fastText uses hierarchical softmax, capitalizing on the imbalanced distribution of classes. All these techniques offer users scalable solutions for text representation and classification. Hugging Face is now hosting official mirrors of word vectors of all 157 languages and the latest model for language identification. This means that using Hugging Face, you can easily download and use the models with a few commands. ### Finding models Word vectors for 157 languages and the language identification model can be found in the [Meta AI](https://huggingface.co/facebook) org. For example, you can find the model page for English word vectors [here](https://huggingface.co/facebook/fasttext-en-vectors) and the language identification model [here](https://huggingface.co/facebook/fasttext-language-identification). ### Widgets This integration includes support for text classification and feature extraction widgets. Try out the language identification widget [here](https://huggingface.co/facebook/fasttext-language-identification) and feature extraction widget [here](https://huggingface.co/facebook/fasttext-en-vectors)!   ### How to use Here is how to load and use a pre-trained vectors: ```python >>> import fasttext >>> from huggingface_hub import hf_hub_download >>> model_path = hf_hub_download(repo_id="facebook/fasttext-en-vectors", filename="model.bin") >>> model = fasttext.load_model(model_path) >>> model.words ['the', 'of', 'and', 'to', 'in', 'a', 'that', 'is', ...] >>> len(model.words) 145940 >>> model['bread'] array([ 4.89417791e-01, 1.60882145e-01, -2.25947708e-01, -2.94273376e-01, -1.04577184e-01, 1.17962055e-01, 1.34821936e-01, -2.41778508e-01, ...]) ``` Here is how to use this model to query nearest neighbors of an English word vector: ```python >>> import fasttext >>> from huggingface_hub import hf_hub_download >>> model_path = hf_hub_download(repo_id="facebook/fasttext-en-nearest-neighbors", filename="model.bin") >>> model = fasttext.load_model(model_path) >>> model.get_nearest_neighbors("bread", k=5) [(0.5641006231307983, 'butter'), (0.48875734210014343, 'loaf'), (0.4491206705570221, 'eat'), (0.42444291710853577, 'food'), (0.4229326844215393, 'cheese')] ``` Here is how to use this model to detect the language of a given text: ```python >>> import fasttext >>> from huggingface_hub import hf_hub_download >>> model_path = hf_hub_download(repo_id="facebook/fasttext-language-identification", filename="model.bin") >>> model = fasttext.load_model(model_path) >>> model.predict("Hello, world!") (('__label__eng_Latn',), array([0.81148803])) >>> model.predict("Hello, world!", k=5) (('__label__eng_Latn', '__label__vie_Latn', '__label__nld_Latn', '__label__pol_Latn', '__label__deu_Latn'), array([0.61224753, 0.21323682, 0.09696738, 0.01359863, 0.01319415])) ``` ## Would you like to integrate your library to the Hub? This integration is possible thanks to our collaboration with [Meta AI](https://ai.facebook.com/) and the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library, which enables all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co/docs/hub/models-adding-libraries) for you!
|
DuckDB: run SQL queries on 50,000+ datasets on the Hugging Face Hub
|
stevhliu
|
June 7, 2023
|
hub-duckdb
|
guide
|
https://huggingface.co/blog/hub-duckdb
|
# DuckDB: run SQL queries on 50,000+ datasets on the Hugging Face Hub The Hugging Face Hub is dedicated to providing open access to datasets for everyone and giving users the tools to explore and understand them. You can find many of the datasets used to train popular large language models (LLMs) like [Falcon](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k), [MPT](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf), and [StarCoder](https://huggingface.co/datasets/bigcode/the-stack). There are tools for addressing fairness and bias in datasets like [Disaggregators](https://huggingface.co/spaces/society-ethics/disaggregators), and tools for previewing examples inside a dataset like the Dataset Viewer. <div class="flex justify-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets-server/oasst1_light.png"/> </div> <small>A preview of the OpenAssistant dataset with the Dataset Viewer.</small> We are happy to share that we recently added another feature to help you analyze datasets on the Hub; you can run SQL queries with DuckDB on any dataset stored on the Hub! According to the 2022 [StackOverflow Developer Survey](https://survey.stackoverflow.co/2022/#section-most-popular-technologies-programming-scripting-and-markup-languages), SQL is the 3rd most popular programming language. We also wanted a fast database management system (DBMS) designed for running analytical queries, which is why we’re excited about integrating with [DuckDB](https://duckdb.org/). We hope this allows even more users to access and analyze datasets on the Hub! ## TLDR [Datasets Server](https://huggingface.co/docs/datasets-server/index) **automatically converts all public datasets on the Hub to Parquet files**, that you can see by clicking on the "Auto-converted to Parquet" button at the top of a dataset page. You can also access the list of the Parquet files URLs with a simple HTTP call. ```py r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus") j = r.json() urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train'] urls ['https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet', 'https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00001-of-00002.parquet'] ``` Create a connection to DuckDB and install and load the `httpfs` extension to allow reading and writing remote files: ```py import duckdb url = "https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet" con = duckdb.connect() con.execute("INSTALL httpfs;") con.execute("LOAD httpfs;") ``` Once you’re connected, you can start writing SQL queries! ```sql con.sql(f"""SELECT horoscope, count(*), AVG(LENGTH(text)) AS avg_blog_length FROM '{url}' GROUP BY horoscope ORDER BY avg_blog_length DESC LIMIT(5)""" ) ``` To learn more, check out the [documentation](https://huggingface.co/docs/datasets-server/parquet_process). ## From dataset to Parquet [Parquet](https://parquet.apache.org/docs/) files are columnar, making them more efficient to store, load and analyze. This is especially important when you're working with large datasets, which we’re seeing more and more of in the LLM era. To support this, Datasets Server automatically converts and publishes any public dataset on the Hub as Parquet files. The URL to the Parquet files can be retrieved with the [`/parquet`](https://huggingface.co/docs/datasets-server/quick_start#access-parquet-files) endpoint. ## Analyze with DuckDB DuckDB offers super impressive performance for running complex analytical queries. It is able to execute a SQL query directly on a remote Parquet file without any overhead. With the [`httpfs`](https://duckdb.org/docs/extensions/httpfs) extension, DuckDB is able to query remote files such as datasets stored on the Hub using the URL provided from the `/parquet` endpoint. DuckDB also supports querying multiple Parquet files which is really convenient because Datasets Server shards big datasets into smaller 500MB chunks. ## Looking forward Knowing what’s inside a dataset is important for developing models because it can impact model quality in all sorts of ways! By allowing users to write and execute any SQL query on Hub datasets, this is another way for us to enable open access to datasets and help users be more aware of the datasets contents. We are excited for you to try this out, and we’re looking forward to what kind of insights your analysis uncovers!
|
The Hugging Face Hub for Galleries, Libraries, Archives and Museums
|
davanstrien
|
June 12, 2023
|
hf-hub-glam-guide
|
community, guide
|
https://huggingface.co/blog/hf-hub-glam-guide
|
## The Hugging Face Hub for Galleries, Libraries, Archives and Museums ### What is the Hugging Face Hub? Hugging Face aims to make high-quality machine learning accessible to everyone. This goal is pursued in various ways, including developing open-source code libraries such as the widely-used Transformers library, offering [free courses](https://huggingface.co/learn), and providing the Hugging Face Hub. The [Hugging Face Hub](https://huggingface.co/) is a central repository where people can share and access machine learning models, datasets and demos. The Hub hosts over 190,000 machine learning models, 33,000 datasets and over 100,000 machine learning applications and demos. These models cover a wide range of tasks from pre-trained language models, text, image and audio classification models, object detection models, and a wide range of generative models. The models, datasets and demos hosted on the Hub span a wide range of domains and languages, with regular community efforts to expand the scope of what is available via the Hub. This blog post intends to offer people working in or with the galleries, libraries, archives and museums (GLAM) sector to understand how they can use — and contribute to — the Hugging Face Hub. You can read the whole post or jump to the most relevant sections! - If you don't know what the Hub is, start with: [What is the Hugging Face Hub?](#what-is-the-hugging-face-hub) - If you want to know how you can find machine learning models on the Hub, start with: [How can you use the Hugging Face Hub: finding relevant models on the Hub](#how-can-you-use-the-hugging-face-hub-finding-relevant-models-on-the-hub) - If you want to know how you can share GLAM datasets on the Hub, start with [Walkthrough: Adding a GLAM dataset to the Hub?](#walkthrough-adding-a-glam-dataset-to-the-hub) - If you want to see some examples, check out: [Example uses of the Hugging Face Hub](#example-uses-of-the-hugging-face-hub) ## What can you find on the Hugging Face Hub? ### Models The Hugging Face Hub provides access to machine learning models covering various tasks and domains. Many machine learning libraries have integrations with the Hugging Face Hub, allowing you to directly use or share models to the Hub via these libraries. ### Datasets The Hugging Face hub hosts over 30,000 datasets. These datasets cover a range of domains and modalities, including text, image, audio and multi-modal datasets. These datasets are valuable for training and evaluating machine learning models. ### Spaces Hugging Face [Spaces](https://huggingface.co/docs/hub/spaces) is a platform that allows you to host machine learning demos and applications. These Spaces range from simple demos allowing you to explore the predictions made by a machine learning model to more involved applications. Spaces make hosting and making your application accessible for others to use much more straightforward. You can use Spaces to host [Gradio](gradio.app/) and [Streamlit](https://streamlit.io/) applications, or you can use Spaces to [custom docker images](https://huggingface.co/docs/hub/spaces-sdks-docker). Using Gradio and Spaces in combination often means you can have an application created and hosted with access for others to use within minutes. You can use Spaces to host a Docker image if you want complete control over your application. There are also Docker templates that can give you quick access to a hosted version of many popular tools, including the [Argailla](https://argilla.io/) and [Label Studio](https://labelstud.io/) annotations tools. ## How can you use the Hugging Face Hub: finding relevant models on the Hub There are many potential use cases in the GLAM sector where machine learning models can be helpful. Whilst some institutions may have the resources required to train machine learning models from scratch, you can use the Hub to find openly shared models that either already do what you want or are very close to your goal. As an example, if you are working with a collection of digitized Norwegian documents with minimal metadata. One way to better understand what's in the collection is to use a Named Entity Recognition (NER) model. This model extracts entities from a text, for example, identifying the locations mentioned in a text. Knowing which entities are contained in a text can be a valuable way of better understanding what a document is about. We can find NER models on the Hub by filtering models by task. In this case, we choose `token-classification`, which is the task which includes named entity recognition models. [This filter](https://huggingface.co/datasets?task_categories=task_categories:token-classification) returns models labelled as doing `token-classification`. Since we are working with Norwegian documents, we may also want to [filter by language](https://huggingface.co/models?pipeline_tag=token-classification&language=no&sort=downloads); this gets us to a smaller set of models we want to explore. Many of these models will also contain a [model widget](https://huggingface.co/saattrupdan/nbailab-base-ner-scandi), allowing us to test the model.  A model widget can quickly show how well a model will likely perform on our data. Once you've found a model that interests you, the Hub provides different ways of using that tool. If you are already familiar with the Transformers library, you can click the use in Transformers button to get a pop-up which shows how to load the model in Transformers.   If you prefer to use a model via an API, clicking the `deploy` button in a model repository gives you various options for hosting the model behind an API. This can be particularly useful if you want to try out a model on a larger amount of data but need the infrastructure to run models locally. A similar approach can also be used to find relevant models and datasets on the Hugging Face Hub. ## Walkthrough: how can you add a GLAM dataset to the Hub? We can make datasets available via the Hugging Face hub in various ways. I'll walk through an example of adding a CSV dataset to the Hugging Face hub. <figure class="image table text-center m-0 w-full"> <video alt="Uploading a file to the Hugging Face Hub" style="max-width: 70%; margin: auto;" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/hf-hub-glam-guide/Upload%20dataset%20to%20hub.mp4" type="video/mp4"> </video> </figure> *Overview of the process of uploading a dataset to the Hub via the browser interface* For our example, we'll work on making the [On the Books Training Set ](https://cdr.lib.unc.edu/concern/data_sets/6q182v788?locale=en) available via the Hub. This dataset comprises a CSV file containing data that can be used to train a text classification model. Since the CSV format is one of the [supported formats](https://huggingface.co/docs/datasets/upload_dataset#upload-dataset) for uploading data to the Hugging Face Hub, we can share this dataset directly on the Hub without needing to write any code. ### Create a new dataset repository The first step to uploading a dataset to the Hub is to create a new dataset repository. This can be done by clicking the `New Dataset` button on the dropdown menu in the top right-hand corner of the Hugging Face hub.  Once you have done this you can choose a name for your new dataset repository. You can also create the dataset under a different owner i.e. an organization, and optionally specify a license.  ### Upload files Once you have created a dataset repository you will need to upload the data files. You can do this by clicking on `Add file` under the `Files` tab on the dataset repository.  You can now select the data you wish to upload to the Hub.  You can upload a single file or multiple files using the upload interface. Once you have uploaded your file, you commit your changes to finalize the upload.  ### Adding metadata It is important to add metadata to your dataset repository to make your dataset more discoverable and helpful for others. This will allow others to find your dataset and understand what it contains. You can edit metadata using the `Metadata UI` editor. This allows you to specify the license, language, tags etc., for the dataset.  It is also very helpful to outline in more detail what your dataset is, how and why it was constructed, and it's strengths and weaknesses. This can be done in a dataset repository by filling out the `README.md` file. This file will serve as a [dataset card](https://huggingface.co/docs/datasets/dataset_card) for your dataset. A dataset card is a semi-structured form of documentation for machine learning datasets that aims to ensure datasets are sufficiently well documented. When you edit the `README.md` file you will be given the option to import a template dataset card. This template will give you helpful prompts for what is useful to include in a dataset card. *Tip: Writing a good dataset card can be a lot of work. However, you do not need to do all of this work in one go necessarily, and because people can ask questions or make suggestions for datasets hosted on the Hub the processes of documenting datasets can be a collective activity.* ### Datasets preview Once we've uploaded our dataset to the Hub, we'll get a preview of the dataset. The dataset preview can be a beneficial way of better understanding the dataset.  ### Other ways of sharing datasets You can use many other approaches for sharing datasets on the Hub. The datasets [documentation](https://huggingface.co/docs/datasets/share) will help you better understand what will likely work best for your particular use case. ## Why might Galleries, Libraries, Archives and Museums want to use the Hugging Face hub? There are many different reasons why institutions want to contribute to the Hugging Face Hub: - **Exposure to a new audience**: the Hub has become a central destination for people working in machine learning, AI and related fields. Sharing on the Hub will help expose your collections and work to this audience. This also opens up the opportunity for further collaboration with this audience. - **Community:** The Hub has many community-oriented features, allowing users and potential users of your material to ask questions and engage with materials you share via the Hub. Sharing trained models and machine learning datasets also allows people to build on each other's work and lowers the barrier to using machine learning in the sector. - **Diversity of training data:** One of the barriers to the GLAM using machine learning is the availability of relevant data for training and evaluation of machine learning models. Machine learning models that work well on benchmark datasets may not work as well on GLAM organizations' data. Building a community to share domain-specific datasets will ensure machine learning can be more effectively pursued in the GLAM sector. - **Climate change:** Training machine learning models produces a carbon footprint. The size of this footprint depends on various factors. One way we can collectively reduce this footprint is to share trained models with the community so that people aren't duplicating the same models (and generating more carbon emissions in the process). ## Example uses of the Hugging Face Hub Individuals and organizations already use the Hugging Face hub to share machine learning models, datasets and demos related to the GLAM sector. ### [BigLAM](https://huggingface.co/biglam) An initiative developed out of the [BigScience project](https://bigscience.huggingface.co/) is focused on making datasets from GLAM with relevance to machine learning are made more accessible. BigLAM has so far made over 30 datasets related to GLAM available via the Hugging Face hub. ### [Nasjonalbiblioteket AI Lab](https://huggingface.co/NbAiLab) The AI lab at the National Library of Norway is a very active user of the Hugging Face hub, with ~120 models, 23 datasets and six machine learning demos shared publicly. These models include language models trained on Norwegian texts from the National Library of Norway and Whisper (speech-to-text) models trained on Sámi languages. ### [Smithsonian Institution](https://huggingface.co/Smithsonian) The Smithsonian shared an application hosted on Hugging Face Spaces, demonstrating two machine learning models trained to identify Amazon fish species. This project aims to empower communities with tools that will allow more accurate measurement of fish species numbers in the Amazon. Making tools such as this available via a Spaces demo further lowers the barrier for people wanting to use these tools. <html> <iframe src="https://smithsonian-amazonian-fish-classifier.hf.space" frameborder="0" width="850" height="450" ></iframe> </html> [Source](https://huggingface.co/Smithsonian) ## Hub features for Galleries, Libraries, Archives and Museums The Hub supports many features which help make machine learning more accessible. Some features which may be particularly helpful for GLAM institutions include: - **Organizations**: you can create an organization on the Hub. This allows you to create a place to share your organization's artefacts. - **Minting DOIs**: A [DOI](https://www.doi.org/) (Digital Object Identifier) is a persistent digital identifier for an object. DOIs have become essential for creating persistent identifiers for publications, datasets and software. A persistent identifier is often required by journals, conferences or researcher funders when referencing academic outputs. The Hugging Face Hub supports issuing DOIs for models, datasets, and demos shared on the Hub. - **Usage tracking**: you can view download stats for datasets and models hosted in the Hub monthly or see the total number of downloads over all time. These stats can be a valuable way for institutions to demonstrate their impact. - **Script-based dataset sharing**: if you already have dataset hosted somewhere, you can still provide access to them via the Hugging Face hub using a [dataset loading script](https://huggingface.co/docs/datasets/dataset_script). - **Model and dataset gating**: there are circumstances where you want more control over who is accessing models and datasets. The Hugging Face hub supports model and dataset gating, allowing you to add access controls. ## How can I get help using the Hub? The Hub [docs](https://huggingface.co/docs/hub/index) go into more detail about the various features of the Hugging Face Hub. You can also find more information about [sharing datasets on the Hub](https://huggingface.co/docs/datasets/upload_dataset) and information about [sharing Transformers models to the Hub](https://huggingface.co/docs/transformers/model_sharing). If you require any assistance while using the Hugging Face Hub, there are several avenues you can explore. You may seek help by utilizing the [discussion forum](https://discuss.huggingface.co/) or through a [Discord](https://discord.com/invite/hugging-face-879548962464493619).
|
Can foundation models label data like humans?
|
nazneen
|
June 12, 2023
|
llm-leaderboard
|
nlp, evaluation, leaderboard
|
https://huggingface.co/blog/llm-leaderboard
|
# Can foundation models label data like humans? Since the advent of ChatGPT, we have seen unprecedented growth in the development of Large Language Models (LLMs), and particularly chatty models that are fine-tuned to follow instructions given in the form of prompts. However, how these models compare is unclear due to the lack of benchmarks designed to test their performance rigorously. Evaluating instruction and chatty models is intrinsically difficult because a large part of user preference is centered around qualitative style while in the past NLP evaluation was far more defined. In this line, it’s a common story that a new large language model (LLM) is released to the tune of “our model is preferred to ChatGPT N% of the time,” and what is omitted from that sentence is that the model is preferred in some type of GPT-4-based evaluation scheme. What these points are trying to show is a proxy for a different measurement: scores provided by human labelers. The process of training models with reinforcement learning from human feedback (RLHF) has proliferated interfaces for and data of comparing two model completions to each other. This data is used in the RLHF process to train a reward model that predicts a preferred text, but the idea of rating and ranking model outputs has grown to be a more general tool in evaluation. Here is an example from each of the `instruct` and `code-instruct` splits of our blind test set.   In terms of iteration speed, using a language model to evaluate model outputs is highly efficient, but there’s a sizable missing piece: **investigating if the downstream tool-shortcut is calibrated with the original form of measurement.** In this blog post, we’ll zoom in on where you can and cannot trust the data labels you get from the LLM of your choice by expanding the Open LLM Leaderboard evaluation suite. Leaderboards have begun to emerge, such as the [LMSYS](https://leaderboard.lmsys.org/), [nomic / GPT4All](https://gpt4all.io/index.html), to compare some aspects of these models, but there needs to be a complete source comparing model capabilities. Some use existing NLP benchmarks that can show question and answering capabilities and some are crowdsourced rankings from open-ended chatting. In order to present a more general picture of evaluations the [Hugging Face Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?tab=evaluation) has been expanded, including automated academic benchmarks, professional human labels, and GPT-4 evals. --- ## Table of Contents - [Evaluating preferences of open-source models](#evaluating-preferences-of-open-source-models) - [Related work](#related-work) - [GPT-4 evaluation examples](#GPT-4-evaluation-examples) - [Further experiments](#further-experiments) - [Takeaways and discussion](#takeaways-and-discussion) - [Resources and citation](#resources-and-citation) ## Evaluating preferences of open-source models Any point in a training process where humans are needed to curate the data is inherently expensive. To date, there are only a few human labeled preference datasets available **for training** these models, such as [Anthropic’s HHH data](https://huggingface.co/datasets/Anthropic/hh-rlhf), [OpenAssistant’s dialogue rankings](https://huggingface.co/datasets/OpenAssistant/oasst1), or OpenAI’s [Learning to Summarize](https://huggingface.co/datasets/openai/summarize_from_feedback) / [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) datasets. The same preference labels can be generated on **model outputs to create a relative Elo ranking between models** ([Elo rankings](https://en.wikipedia.org/wiki/Elo_rating_system), popularized in chess and used in video games, are method to construct a global ranking tier out of only pairwise comparisons — higher is better). When the source of text given to labelers is generated from a model of interest, the data becomes doubly interesting. While training our models, we started seeing interesting things, so we wanted to do a more controlled study of existing open-source models and how that preference collection process would translate and compare to the currently popular GPT-4/ChatGPT evaluations of preferences. To do this, we curated a held-out set of instruction prompts and completions from a popular set of open-source models: [Koala 13b](https://huggingface.co/young-geng/koala), [Vicuna 13b](https://huggingface.co/lmsys/vicuna-13b-delta-v1.1), [OpenAssistant](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5) 12b, and [Dolly 12b](https://huggingface.co/databricks/dolly-v2-12b).  We collected a set of high-quality, human-written prompts from [Self-Instruct](https://arxiv.org/abs/2212.10560) evaluation set and early discussions with data vendors for diverse task categories, including generation, brainstorming, question answering, summarization, commonsense, and coding-related. The dataset has 327 prompts across these categories, and 25 are coding-related. Here are the stats on the prompt and demonstration length. | | prompt | completions | | --- | --- | --- | | count | 327 | 327 | | length (mean ± std. dev.) in tokens | 24 ± 38 | 69 ± 79 | | min. length | 3 | 1 | | 25% percentile length | 10 | 18 | | 50% percentile length | 15 | 42 | | 75% percentile length | 23 | 83 | | max | 381 | 546 | With these completions, we set off to evaluate the quality of the models with Scale AI and GPT-4. To do evaluations, we followed the Anthropic recipe for preference models and asked the raters to score on a Likert scale from 1 to 8. On this scale, a 1 represents a strong preference of the first model and a 4 represents a close tiebreak for the first model. The opposite side of the scale follows the reverse, with 8 being the clearest comparison. ### Human Elo results We partnered with Scale AI to collect high-quality human annotations for a handful of open-source instruction-tuned models on our blind test set. We requested annotators to rate responses for helpfulness and truthfulness in a pairwise setting. We generated \\( n \choose 2 \\) combinations for each prompt, where \\(n\\) is the number of models we evaluate. Here is an example snapshot of the instructions and the interface Scale provided for our evaluations.  With this data, we created bootstrapped Elo estimates based on the win probabilities between the two models. For more on the Elo process, see LMSYS’s [notebook](https://colab.research.google.com/drive/17L9uCiAivzWfzOxo2Tb9RMauT7vS6nVU?usp=sharing). The Elo scores on our blind test data are reported on our [leaderboard](). In this blog, we show the bootstrapped Elo estimates along with error estimates. Here are the rankings using human annotators on our blind test set. ****************Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)**************** | Model | Elo ranking (median) | 5th and 95th percentiles | | --- | --- | --- | | Vicuna-13B | 1140 | 1061 ↔ 1219 | | Koala-13B | 1073 | 999 ↔ 1147 | | Oasst-12B | 986 | 913 ↔ 1061 | | Dolly-12B | 802 | 730 ↔ 878 | Given the Likert scale, it is also debatable whether a score of 4 or 5 should constitute a win, so we also compute the Elo rankings where a score of 4 or 5 indicates a tie. In this case, and throughout the article, we saw few changes to the ranking of the models relative to eachother with this change. The tie counts (out of 327 comparisons per model pair) and the new Elo scores are below. The number in each cell indicates the number of ties for the models in the intersecting row and column. E.g., Koala-13B and Vicuna-13B have the highest number of ties, 96, so they are likely very close in performance. *Note, read this plot by selecting a row, e.g. `oasst-12b` and then reading across horizontally to see how many ties it had with each other model.* <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/tie_counts.png" width="600" /> </p> ****************Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)**************** | Model | Elo ranking (median) | 5th and 95th percentiles | | --- | --- | --- | | Vicuna-13B | 1130 | 1066 ↔ 1192 | | Koala-13B | 1061 | 998 ↔ 1128 | | Oasst-12B | 988 | 918 ↔ 1051 | | Dolly-12B | 820 | 760 ↔ 890 | Below is the histogram of ratings from the Scale AI taskforce. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/human-hist.png" width="600" /> </p> For the rest of this post, you will see similar analyses with different data generation criteria. ### GPT-4 Elo results Next, we turned to GPT-4 to see how the results would compare. The ordering of the models remains, but the relative margins change. **Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)** | Model | Elo ranking (median) | 2.5th and 97.5th percentiles | | --- | --- | --- | | vicuna-13b | 1134 | 1036 ↔ 1222 | | koala-13b | 1082 | 989 ↔ 1169 | | oasst-12b | 972 | 874 ↔ 1062 | | dolly-12b | 812 | 723 ↔ 909 | **Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)** *Reminder, in the Likert scale 1 to 8, we define scores 4 and 5 as a tie.* | Model | Elo ranking (median) | 2.5th and 97.5th percentiles | | --- | --- | --- | | vicuna-13b | 1114 | 1033 ↔ 1194 | | koala-13b | 1082 | 995 ↔ 1172 | | oasst-12b | 973 | 885 ↔ 1054 | | dolly-12b | 831 | 742 ↔ 919 | To do this, we used a prompt adapted from the [FastChat evaluation prompts](https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/prompt.jsonl), encouraging shorter length for faster and cheaper generations (as the explanations are disregarded most of the time): ``` ### Question {question} ### The Start of Assistant 1's Answer {answer_1} ### The End of Assistant 1's Answer ### The Start of Assistant 2's Answer {answer_2} ### The End of Assistant 2's Answer ### System We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above. Please compare the helpfulness, relevance, accuracy, level of details of their responses. The rating should be from the set of 1, 2, 3, 4, 5, 6, 7, or 8, where higher numbers indicated that Assistant 2 was better than Assistant 1. Please first output a single line containing only one value indicating the preference between Assistant 1 and 2. In the subsequent line, please provide a brief explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment. ``` The histogram of responses from GPT-4 starts to show a clear issue with LLM based evaluation: **positional bias**. This score distribution is with fully randomized ordering of which model is included in `answer_1` above. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-hist.png" width="600" /> </p> Given the uncertainty of GPT-4 evaluations, we decided to add another benchmark to our rankings: completions made by highly trained humans. We wanted to answer the question of: what would be the Elo ranking of humans, if evaluated by GPT-4 as well. ### GPT-4 Elo results with demonstrations Ultimately, the Elo ranking of human demonstrations is blatantly confusing. There are many hypotheses that could explain this, but it points to a potential style benefit being given to models also trained on outputs of large language models (when compared to something like Dolly). This could amount to *****unintentional doping***** between training and evaluation methods that are being developed in parallel. **Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)** | Model | Elo ranking (median) | 2.5th and 975th percentiles | | --- | --- | --- | | Vicuna-13b | 1148 | 1049 ↔ 1239 | | koala-13b | 1097 | 1002 ↔ 1197 | | Oasst-12b | 985 | 896 ↔ 1081 | | human | 940 | 840 ↔ 1034 | | dolly-12b | 824 | 730 ↔ 922 | ## Related work We are not the only ones to share the GPT-4 may not be a perfect tool for training and evaluating LLMs with. Two recent papers have investigated the impacts of instruction tuning on outputs from OpenAI models and how doing so can impact “model comparison” evaluations (when the output of your trained model is compared to the outputs of ChatGPT or GPT-4). The most striking paper in this regard *[How Far Can Camels Go?](https://arxiv.org/abs/2306.04751)* from Allen AI shows a potential indicator in what may be causing GPT-4 to rate an output highly: diversity and length of responses. These correlations are striking, as it rewards models to be verbose, even if the task may not call for it. Below is the figure where the authors correlate the win-rate with the token quantity. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/camel-fig.png" width="600" /> </p> The other popular and recent paper is *[The False Promise of Imitating Proprietary LLMs](https://arxiv.org/abs/2305.15717)* from Berkeley, where the authors show that training on more data actually lowers comparison results. With the scale the authors were operating at, more investigation is needed to fully understand the results, but it points in a clear direction: be wary when training on and evaluating with another LLM. The figure from the paper showcasing this is below: <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/false-promise-fig.png" width="600" /> </p> ## GPT-4 evaluation examples Below we’ve included a couple examples of what the evaluations look like to give you a sense why and how GPT-4 may be choosing: --- **Question:** Indicate the genre of the book to which it belongs.\n Input: Love in the Time of Cholera. **Model response (koala)**: The genre of "Love in the Time of Cholera" is a romance novel with elements of magical realism and historical fiction. It tells the story of two men, Fermina Daza and Florentino Ariza, who are both deeply in love with her but cannot be together due to various circumstances. Throughout their lives, they encounter obstacles that prevent them from being reunited, including war, illness, and societal pressure. However, their love for each other never fades away, and they continue to hold onto hope that one day they will be able to be together again. This combination of romantic elements and historical context makes this book fall under the category of romance novels with magical realistic and historical fictional elements. **Human response:** Fiction **GPT-4 rating: 1** (model greatly better) Assistant 1 provided a more detailed and accurate answer, discussing the elements of romance, magical realism, and historical fiction present in the novel. Assistant 2's answer was too brief and did not provide sufficient information about the genre of the book. --- **Question:** Write a LinkedIn post to announce that you have accepted a new job offer.\n Input: **Model response (koala)**: Exciting news! I am thrilled to announce that I have officially accepted an exciting new job opportunity as [Job Title] at [Company Name]. This role will allow me to leverage my skills and experience in [industry/field of expertise], while also providing opportunities for personal and professional growth. I want to take this moment to express my gratitude to everyone who has supported me throughout the hiring process, including [previous employer name(s) or individuals who provided guidance/advice/references]. Your support means the world to me and I couldn't be more grateful for your help. I am excited about what lies ahead and can't wait to join the team at [Company Name]. Thank you again for all your support! **Human response:** I’m excited beyond words to share with you my decision to accept the role of Marketing Director at the XYZ Company! I couldn’t have had this opportunity if not for the help of my friend, [name], who shared this job opportunity with me, and my former boss, [boss’s name], for her stellar recommendation and guidance. I happily look forward to starting this new journey and growing professionally with my new family—the marketing rock stars of XYZ Company. **GPT-4 rating: 6** (model better) Both assistants provided helpful and relevant responses for a LinkedIn post announcing a new job offer. However, Assistant 2's answer was more detailed and included placeholders for specific information, making it easier for the user to customize the post. Assistant 1's response was also good, but slightly less structured and detailed compared to Assistant 2's response. --- **Question:** You are given a search query and a document. Classify whether the document is relevant to the search query or not relevant. Input: Search: why sky is blue Document: The Short Answer: Sunlight reaches Earth's atmosphere and is scattered in all directions by all the gases and particles in the air. Blue light is scattered more than the other colors because it travels as shorter, smaller waves. This is why we see a blue sky most of the time **Model response (dolly)**: The provided example search "why sky is blue" is related to the input document which explains the reason for blue color of the sky. Advantages This answer only takes up 34 characters compared to longer explanations like sunlight reaching earth due to its speed through space etc.. which would take up 80 characters. Hence this answer is highly relevant and useful to many users. Disadvantage Now if the question was about reasons behind changes in the weather one could think of many documents relating to climate change, pollution, static charges in the air etc., these documents might be relevant to the user but taking up lots of additional real-estate makes them less relevant compared to the above mentioned answer. **Human response:** relevant **GPT-4 rating: 5** (model slightly better) Both assistants provided relevant answers to the question, but Assistant 1's answer was more detailed and explained the reason behind the sky's blue color, while Assistant 2's answer was concise but not as informative. Assistant 1's answer is more helpful for users who want to understand the phenomenon, while Assistant 2's answer is suitable for users who only want a quick confirmation. --- ## Further experiments ### Correlating human and GPT-4 labels Here we break down the categories in our test set (as listed earlier) to show which sections the GPT-4 models may perform slightly better. We find that there is a much higher correlation in scores for tasks where creativity is required when compared to factual categories. This suggests that humans do a better job discerning model inaccuracies, which we would expect! | Category | Correlation: GPT-4 to Human Labels | | --- | --- | | Brainstorm | 0.60 | | Creative generation | 0.55 | | Commonsense reasoning | 0.46 | | Question answering | 0.44 | | Summarization | 0.40 | | Natural language to code | 0.33 | ### Ablations **GPT-4 Elo with score rather than ranking** Other evaluation benchmarks use a ranking system to compare the models — asking GPT-4 to return two scores and explain there reasoning. We wanted to compare these results, even if philosophically it does not fit into the training paradigm of RLHF as well (scores cannot train reliable preference models to date, while comparisons do). Using rankings showed a substantial decrease in the positional bias of the prompt, shown below along with the median Elo estimates (without ties). | Model | Elo ranking (median) | | --- | --- | | Vicuna-13b | 1136 | | koala-13b | 1081 | | Oasst-12b | 961 | | human | 958 | | dolly-12b | 862 | <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-score-hist.png" width="600" /> </p> **GPT-4 Elo with asking to de-bias** Given the positional bias we have seen with Likert scales, what if we add a de-bias ask to the prompt? We added the following to our evaluation prompt: ```latex Be aware that LLMs like yourself are extremely prone to positional bias and tend to return 1, can you please try to remove this bias so our data is fair? ``` This resulted in the histogram of rankings below, which flipped the bias from before (but did not entirely solve it). Yes, sometimes GPT-4 returns integers outside the requested window (0s). Below, you can see the updated distribution of Likert ratings returned and the Elo estimates without ties (these results are very close). | Model | Elo ranking (median) | | --- | --- | | koala-13b | 1105 | | Oasst-12b | 1075 | | Vicuna-13b | 1066 | | human | 916 | | dolly-12b | 835 | This is an experiment where the ordering of models changes substantially when ties are added to the model: | Model | Elo ranking (median) | | --- | --- | | Vicuna-13b | 1110 | | koala-13b | 1085 | | Oasst-12b | 1075 | | human | 923 | | dolly-12b | 804 | <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-debias-hist.png" width="600" /> </p> ## Takeaways and discussion There is a lot here, but the most important insights in our experiments are: - GPT-4 has a positional bias and is predisposed to generate a rating of “1” in a pairwise preference collection setting using a scale of 1-8 (1-4 being decreasingly model-a and 5-8 being increasingly model-b) for evaluating models. - Asking GPT-4 to debias itself makes it biased in the other direction, but not as worse as 1. - GPT-4 is predisposed to prefer models trained on data bootstrapped using InstructGPT/GPT-4/ChatGPT over more factual and useful content. For example, preferring Vicuna or Alpaca over human written outputs. - GPT-4 and human raters for evaluating have a correlation of 0.5 for non coding task and much lower but still positive correlation on coding tasks. - If we group by tasks, the correlation between human and GPT-4 ratings is highest among categories with high entropy such as brainstorming/generation and low on categories with low entropy such as coding. This line of work is extremely new, so there are plenty of areas where the field’s methodology can be further understood: - **Likert vs. ratings**: In our evaluations, we worked with Likert scales to match the motivation for this as an evaluation tool — how preference data is collected to train models with RLHF. In this setup, it has been repeatedly reproduced that training a preference model on scores alone does not generate enough signal (when compared to relative rankings). In a similar vein, we found it unlikely that evaluating on scores will lead to a useful signal long-term. Continuing with this, it is worth noting that ChatGPT (a slightly less high performance model) actually cannot even return answers in the correct format for a Likert score, while it can do rankings somewhat reliably. This hints that these models are just starting to gain the formatting control to fit the shape of evaluations we want, a point that would come far before they are a useful evaluation tool. - **Prompting for evaluation**: In our work we saw substantial positional bias in the GPT-4 evaluations, but there are other issues that could impact the quality of the prompting. In a recent [podcast](https://thegradientpub.substack.com/p/riley-goodside-the-art-and-craft#details), Riley Goodside describes the limits on per-token information from a LLM, so outputing the score first in the prompts we have could be limiting the ability for a model like GPT-4 to reason full. - **Rating/ranking scale**: It’s not clear what the scale of ratings or Likert rankings should be. LLMs are used to seeing certain combinations in a training set (e.g. 1 to 5 stars), which is likely to bias the generations of ratings. It could be that giving specific tokens to return rather than numbers could make the results less biased. - **Length bias**: Much how ChatGPT is loved because it creates interesting and lengthy answers, we saw that our evaluation with GPT-4 was heavily biased away from concise and correct answers, just by the other model continuing to produce way more tokens. - **Correct generation parameters**: in the early stages of our experiments, we had to spend substantial time getting the correct dialogue format for each model (example of a complete version is [FastChat’s `conversation.py`](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py)). This likely got the model only 70-90% or so to its maximum potential capacity. The rest of the capabilities would be unlocked by tuning the generation parameters (temperature, top-p, etc.), but without reliable baselines for evaluation, today, there is no fair way to do this. For our experiments, we use a temperature of 0.5 a top-k of 50 and a top-p of 0.95 (for generations, OpenAI evaluations requires other parameters). ### Resources and citation - More information on our labeling instructions can be found [here](https://docs.google.com/document/d/1c5-96Lj-UH4lzKjLvJ_MRQaVMjtoEXTYA4dvoAYVCHc/edit?usp=sharing). Have a model that you want GPT-4 or human annotators to evaluate? Drop us a note on [the leaderboard discussions](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard_internal/discussions). ``` @article{rajani2023llm_labels, author = {Rajani, Nazneen, and Lambert, Nathan and Han, Sheon and Wang, Jean and Nitski, Osvald and Beeching, Edward and Tunstall, Lewis}, title = {Can foundation models label data like humans?}, journal = {Hugging Face Blog}, year = {2023}, note = {https://huggingface.co/blog/llm-v-human-data}, } ``` _Thanks to [Joao](https://twitter.com/_joaogui1) for pointing out a typo in a table._
|
Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms
|
juliensimon
|
June 13, 2023
|
huggingface-and-amd
|
hardware, amd, partnership
|
https://huggingface.co/blog/huggingface-and-amd
|
# Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms <kbd> <img src="assets/148_huggingface_amd/01.png"> </kbd> Whether language models, large language models, or foundation models, transformers require significant computation for pre-training, fine-tuning, and inference. To help developers and organizations get the most performance bang for their infrastructure bucks, Hugging Face has long been working with hardware companies to leverage acceleration features present on their respective chips. Today, we're happy to announce that AMD has officially joined our [Hardware Partner Program](https://huggingface.co/hardware). Our CEO Clement Delangue gave a keynote at AMD's [Data Center and AI Technology Premiere](https://www.amd.com/en/solutions/data-center/data-center-ai-premiere.html) in San Francisco to launch this exciting new collaboration. AMD and Hugging Face work together to deliver state-of-the-art transformer performance on AMD CPUs and GPUs. This partnership is excellent news for the Hugging Face community at large, which will soon benefit from the latest AMD platforms for training and inference. The selection of deep learning hardware has been limited for years, and prices and supply are growing concerns. This new partnership will do more than match the competition and help alleviate market dynamics: it should also set new cost-performance standards. ## Supported hardware platforms On the GPU side, AMD and Hugging Face will first collaborate on the enterprise-grade Instinct MI2xx and MI3xx families, then on the customer-grade Radeon Navi3x family. In initial testing, AMD [recently reported](https://youtu.be/mPrfh7MNV_0?t=462) that the MI250 trains BERT-Large 1.2x faster and GPT2-Large 1.4x faster than its direct competitor. On the CPU side, the two companies will work on optimizing inference for both the client Ryzen and server EPYC CPUs. As discussed in several previous posts, CPUs can be an excellent option for transformer inference, especially with model compression techniques like quantization. Lastly, the collaboration will include the [Alveo V70](https://www.xilinx.com/applications/data-center/v70.html) AI accelerator, which can deliver incredible performance with lower power requirements. ## Supported model architectures and frameworks We intend to support state-of-the-art transformer architectures for natural language processing, computer vision, and speech, such as BERT, DistilBERT, ROBERTA, Vision Transformer, CLIP, and Wav2Vec2. Of course, generative AI models will be available too (e.g., GPT2, GPT-NeoX, T5, OPT, LLaMA), including our own BLOOM and StarCoder models. Lastly, we will also support more traditional computer vision models, like ResNet and ResNext, and deep learning recommendation models, a first for us. We'll do our best to test and validate these models for PyTorch, TensorFlow, and ONNX Runtime for the above platforms. Please remember that not all models may be available for training and inference for all frameworks or all hardware platforms. ## The road ahead Our initial focus will be ensuring the models most important to our community work great out of the box on AMD platforms. We will work closely with the AMD engineering team to optimize key models to deliver optimal performance thanks to the latest AMD hardware and software features. We will integrate the [AMD ROCm SDK](https://www.amd.com/graphics/servers-solutions-rocm) seamlessly in our open-source libraries, starting with the transformers library. Along the way, we'll undoubtedly identify opportunities to optimize training and inference further, and we'll work closely with AMD to figure out where to best invest moving forward through this partnership. We expect this work to lead to a new [Optimum](https://huggingface.co/docs/optimum/index) library dedicated to AMD platforms to help Hugging Face users leverage them with minimal code changes, if any. ## Conclusion We're excited to work with a world-class hardware company like AMD. Open-source means the freedom to build from a wide range of software and hardware solutions. Thanks to this partnership, Hugging Face users will soon have new hardware platforms for training and inference with excellent cost-performance benefits. In the meantime, feel free to visit the [AMD page](https://huggingface.co/amd) on the Hugging Face hub. Stay tuned! *This post is 100% ChatGPT-free.*
|
Announcing our new Content Guidelines and Policy
|
giadap
|
June 15, 2023
|
content-guidelines-update
|
community, ethics
|
https://huggingface.co/blog/content-guidelines-update
|
# Announcing our new Community Policy As a community-driven platform that aims to advance Open, Collaborative, and Responsible Machine Learning, we are thrilled to support and maintain a welcoming space for our entire community! In support of this goal, we've updated our [Content Policy](https://huggingface.co/content-guidelines). We encourage you to familiarize yourself with the complete document to fully understand what it entails. Meanwhile, this blog post serves to provide an overview, outline the rationale, and highlight the values driving the update of our Content Policy. By delving into both resources, you'll gain a comprehensive understanding of the expectations and goals for content on our platform. ## Moderating Machine Learning Content Moderating Machine Learning artifacts introduces new challenges. Even more than static content, the risks associated with developing and deploying artificial intelligence systems and/or models require in-depth analysis and a wide-ranging approach to foresee possible harms. That is why the efforts to draft this new Content Policy come from different members and expertise in our cross-company teams, all of which are indispensable to have both a general and a detailed picture to provide clarity on how we enable responsible development and deployment on our platform. Furthermore, as the field of AI and machine learning continues to expand, the variety of use cases and applications proliferates. This makes it essential for us to stay up-to-date with the latest research, ethical considerations, and best practices. For this reason, promoting user collaboration is also vital to the sustainability of our platform. Namely, through our community features, such as the Community Tab, we encourage and foster collaborative solutions between repository authors, users, organizations, and our team. ## Consent as a Core Value As we prioritize respecting people's rights throughout the development and use of Machine Learning systems, we take a forward-looking view to account for developments in the technology and law affecting those rights. New ways of processing information enabled by Machine Learning are posing entirely new questions, both in the field of AI and in regulatory circles, about people's agency and rights with respect to their work, their image, and their privacy. Central to these discussions are how people's rights should be operationalized -- and we offer one avenue for addressing this here. In this evolving legal landscape, it becomes increasingly important to emphasize the intrinsic value of "consent" to avoid enabling harm. By doing so, we focus on the individual's agency and subjective experiences. This approach not only supports forethought and a more empathetic understanding of consent but also encourages proactive measures to address cultural and contextual factors. In particular, our Content Policy aims to address consent related to what users see, and to how people's identities and expressions are represented. This consideration for people's consent and experiences on the platform extends to Community Content and people's behaviors on the Hub. To maintain a safe and welcoming environment, we do not allow aggressive or harassing language directed at our users and/or the Hugging Face staff. We focus on fostering collaborative resolutions for any potential conflicts between users and repository authors, intervening only when necessary. To promote transparency, we encourage open discussions to occur within our Community tab. Our approach is a reflection of our ongoing efforts to adapt and progress, which is made possible by the invaluable input of our users who actively collaborate and share their feedback. We are committed to being receptive to comments and constantly striving for improvement. We encourage you to reach out to [[email protected]](mailto:[email protected]) with any questions or concerns. Let's join forces to build a friendly and supportive community that encourages open AI and ML collaboration! Together, we can make great strides forward in fostering a welcoming environment for everyone.
|
Deploy Livebook notebooks as apps to Hugging Face Spaces
|
josevalim
|
Jun 15, 2023
|
livebook-app-deployment
|
elixir, notebooks, spaces, whisper
|
https://huggingface.co/blog/livebook-app-deployment
|
# Deploy Livebook notebooks as apps to Hugging Face Spaces The [Elixir](https://elixir-lang.org/) community has been making great strides towards Machine Learning and Hugging Face is playing an important role on making it possible. To showcase what you can already achieve with Elixir and Machine Learning today, we use [Livebook](https://livebook.dev/) to build a Whisper-based chat app and then deploy it to Hugging Face Spaces. All under 15 minutes, check it out: <iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/uyVRPEXOqzw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> In this chat app, users can communicate only by sending audio messages, which are then automatically converted to text by the Whisper Machine Learning model. This app showcases a few interesting features from Livebook and the Machine Learning ecosystem in Elixir: - integration with Hugging Face Models - multiplayer Machine Learning apps - concurrent Machine Learning model serving (bonus point: [you can also distribute model servings over a cluster just as easily](https://news.livebook.dev/distributed2-machine-learning-notebooks-with-elixir-and-livebook---launch-week-1---day-2-1aIlaw)) If you don't know Livebook yet, it is an open-source tool for writing interactive code notebooks in Elixir, and it's part of the [growing collection of Elixir tools](https://github.com/elixir-nx) for numerical computing, data science, and Machine Learning. ## Hugging Face and Elixir The Elixir community leverages the Hugging Face platform and its open source projects throughout its machine learning landscape. Here are some examples. The first positive impact Hugging Face had was in the [Bumblebee library](https://github.com/elixir-nx/bumblebee), which brought pre-trained neural network models from Hugging Face to the Elixir community and was inspired by [Hugging Face Transformers](https://huggingface.co/docs/transformers/index). Besides the inspiration, Bumblebee also uses the Hugging Face Hub to download parameters for its models. Another example is the [tokenizers library](https://github.com/elixir-nx/tokenizers), which is an Elixir binding for [Hugging Face Tokenizers](https://github.com/huggingface/tokenizers). And last but not least, [Livebook can run inside Hugging Face Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker-livebook) with just a few clicks as one of their Space Docker templates. So, not only can you deploy Livebook apps to Hugging Face, but you can also use it to run Livebook for free to write and experiment with your own notebooks. ## Your turn We hope this new integration between Livebook and Hugging Face empowers even more people to use Machine Learning and show their work to the world. Go ahead and [install Livebook on Hugging Face Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker-livebook), and [follow our video tutorial](https://www.youtube.com/watch?v=uyVRPEXOqzw) to build and deploy your first Livebook ML app to Hugging Face.
|
Faster Stable Diffusion with Core ML on iPhone, iPad, and Mac
|
pcuenq
|
June 15, 2023
|
fast-diffusers-coreml
|
coreml, diffusers, stable-diffusion, diffusion, quantization
|
https://huggingface.co/blog/fast-diffusers-coreml
|
# Faster Stable Diffusion with Core ML on iPhone, iPad, and Mac WWDC’23 (Apple Worldwide Developers Conference) was held last week. A lot of the news focused on the Vision Pro announcement during the keynote, but there’s much more to it. Like every year, WWDC week is packed with more than 200 technical sessions that dive deep inside the upcoming features across Apple operating systems and frameworks. This year we are particularly excited about changes in Core ML devoted to compression and optimization techniques. These changes make running [models](https://huggingface.co/apple) such as Stable Diffusion faster and with less memory use! As a taste, consider the following test I ran on my [iPhone 13 back in December](https://huggingface.co/blog/diffusers-coreml), compared with the current speed using 6-bit palettization: <img style="border:none;" alt="Stable Diffusion on iPhone, back in December and now using 6-bit palettization" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/before-after-1600.jpg" /> <small>Stable Diffusion on iPhone, back in December and now with 6-bit palettization</small> ## Contents * [New Core ML Optimizations](#new-core-ml-optimizations) * [Using Quantized and Optimized Stable Diffusion Models](#using-quantized-and-optimized-stable-diffusion-models) * [Converting and Optimizing Custom Models](#converting-and-optimizing-custom-models) * [Using Less than 6 bits](#using-less-than-6-bits) * [Conclusion](#conclusion) ## New Core ML Optimizations Core ML is a mature framework that allows machine learning models to run efficiently on-device, taking advantage of all the compute hardware in Apple devices: the CPU, the GPU, and the Neural Engine specialized in ML tasks. On-device execution is going through a period of extraordinary interest triggered by the popularity of models such as Stable Diffusion and Large Language Models with chat interfaces. Many people want to run these models on their hardware for a variety of reasons, including convenience, privacy, and API cost savings. Naturally, many developers are exploring ways to run these models efficiently on-device and creating new apps and use cases. Core ML improvements that contribute to achieving that goal are big news for the community! The Core ML optimization changes encompass two different (but complementary) software packages: * The Core ML framework itself. This is the engine that runs ML models on Apple hardware and is part of the operating system. Models have to be exported in a special format supported by the framework, and this format is also referred to as “Core ML”. * The `coremltools` conversion package. This is an [open-source Python module](https://github.com/apple/coremltools) whose mission is to convert PyTorch or Tensorflow models to the Core ML format. `coremltools` now includes a new submodule called `coremltools.optimize` with all the compression and optimization tools. For full details on this package, please take a look at [this WWDC session](https://developer.apple.com/wwdc23/10047). In the case of Stable Diffusion, we’ll be using _6-bit palettization_, a type of quantization that compresses model weights from a 16-bit floating-point representation to just 6 bits per parameter. The name “palettization” refers to a technique similar to the one used in computer graphics to work with a limited set of colors: the color table (or “palette”) contains a fixed number of colors, and the colors in the image are replaced with the indexes of the closest colors available in the palette. This immediately provides the benefit of drastically reducing storage size, and thus reducing download time and on-device disk use. <img style="border:none;" alt="Illustration of 2-bit palettization. Image credit: Apple WWDC’23 Session 'Use Core ML Tools for machine learning model compression'" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/palettization_illustration.png" /> <small>Illustration of 2-bit palettization. Image credit: Apple WWDC’23 Session <i><a href="https://developer.apple.com/wwdc23/10047">Use Core ML Tools for machine learning model compression</a></i>.</small> The compressed 6-bit _weights_ cannot be used for computation, because they are just indices into a table and no longer represent the magnitude of the original weights. Therefore, Core ML needs to uncompress the palletized weights before use. In previous versions of Core ML, uncompression took place when the model was first loaded from disk, so the amount of memory used was equal to the uncompressed model size. With the new improvements, weights are kept as 6-bit numbers and converted on the fly as inference progresses from layer to layer. This might seem slow – an inference run requires a lot of uncompressing operations –, but it’s typically more efficient than preparing all the weights in 16-bit mode! The reason is that memory transfers are in the critical path of execution, and transferring less memory is faster than transferring uncompressed data. ## Using Quantized and Optimized Stable Diffusion Models [Last December](https://huggingface.co/blog/diffusers-coreml), Apple introduced [`ml-stable-diffusion`](https://github.com/apple/ml-stable-diffusion), an open-source repo based on [diffusers](https://github.com/huggingface/diffusers) to easily convert Stable Diffusion models to Core ML. It also applies [optimizations to the transformers attention layers](https://machinelearning.apple.com/research/neural-engine-transformers) that make inference faster on the Neural Engine (on devices where it’s available). `ml-stable-diffusion` has just been updated after WWDC with the following: * Quantization is supported using `--quantize-nbits` during conversion. You can quantize to 8, 6, 4, or even 2 bits! For best results, we recommend using 6-bit quantization, as the precision loss is small while achieving fast inference and significant memory savings. If you want to go lower than that, please check [this section](#using-less-than-6-bits) for advanced techniques. * Additional optimizations of the attention layers that achieve even better performance on the Neural Engine! The trick is to split the query sequences into chunks of 512 to avoid the creation of large intermediate tensors. This method is called `SPLIT_EINSUM_V2` in the code and can improve performance between 10% to 30%. In order to make it easy for everyone to take advantage of these improvements, we have converted the four official Stable Diffusion models and pushed them to the [Hub](https://huggingface.co/apple). These are all the variants: | Model | Uncompressed | Palettized | |---------------------------|-------------------|---------------------------| | Stable Diffusion 1.4 | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-v1-4) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-1-4-palettized) | | Stable Diffusion 1.5 | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-v1-5) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-v1-5-palettized) | | Stable Diffusion 2 base | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-2-base) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-2-base-palettized) | | Stable Diffusion 2.1 base | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-2-1-base) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-2-1-base-palettized) | <br> <div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;"> In order to use 6-bit models, you need the development versions of iOS/iPadOS 17 or macOS 14 (Sonoma) because those are the ones that contain the latest Core ML framework. You can download them from the [Apple developer site](https://developer.apple.com) if you are a registered developer, or you can sign up for the public beta that will be released in a few weeks. </div> <br> Note that each variant is available in Core ML format and also as a `zip` archive. Zip files are ideal for native apps, such as our [open-source demo app](https://github.com/huggingface/swift-coreml-diffusers) and other [third party tools](https://github.com/godly-devotion/MochiDiffusion). If you just want to run the models on your own hardware, the easiest way is to use our demo app and select the quantized model you want to test. You need to compile the app using Xcode, but an update will be available for download in the App Store soon. For more details, check [our previous post](https://huggingface.co/blog/fast-mac-diffusers). <img style="border:none;" alt="Running 6-bit stable-diffusion-2-1-base model in demo app" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/diffusers_mac_screenshot.png" /> <small>Running 6-bit stable-diffusion-2-1-base model in demo app</small> If you want to download a particular Core ML package to integrate it in your own Xcode project, you can clone the repos or just download the version of interest using code like the following. ```Python from huggingface_hub import snapshot_download from pathlib import Path repo_id = "apple/coreml-stable-diffusion-2-1-base-palettized" variant = "original/packages" model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_")) snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False) print(f"Model downloaded at {model_path}") ``` ## Converting and Optimizing Custom Models If you want to use a personalized Stable Diffusion model (for example, if you have fine-tuned or dreamboothed your own models), you can use Apple’s ml-stable-diffusion repo to do the conversion yourself. This is a brief summary of how you’d go about it, but we recommend you read [the documentation details](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml). <br> <div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;"> If you want to apply quantization, you need the latest versions of `coremltools`, `apple/ml-stable-diffusion` and Xcode in order to do the conversion. * Download `coremltools` 7.0 beta from [the releases page in GitHub](https://github.com/apple/coremltools/releases). * Download Xcode 15.0 beta from [Apple developer site](https://developer.apple.com/). * Download `apple/ml-stable-diffusion` [from the repo](https://github.com/apple/ml-stable-diffusion) and follow the installation instructions. </div> <br> 1. Select the model you want to convert. You can train your own or choose one from the [Hugging Face Diffusers Models Gallery](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery). For example, let’s convert [`prompthero/openjourney-v4`](https://huggingface.co/prompthero/openjourney-v4). 2. Install `apple/ml-stable-diffusion` and run a first conversion using the `ORIGINAL` attention implementation like this: ```bash python -m python_coreml_stable_diffusion.torch2coreml \ --model-version prompthero/openjourney-v4 \ --convert-unet \ --convert-text-encoder \ --convert-vae-decoder \ --convert-vae-encoder \ --convert-safety-checker \ --quantize-nbits 6 \ --attention-implementation ORIGINAL \ --compute-unit CPU_AND_GPU \ --bundle-resources-for-swift-cli \ --check-output-correctness \ -o models/original/openjourney-6-bit ``` <br> <div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;"> * Use `--convert-vae-encoder` if you want to use image-to-image tasks. * Do _not_ use `--chunk-unet` with `--quantized-nbits 6` (or less), as the quantized model is small enough to work fine on both iOS and macOS. </div> <br> 3. Repeat the conversion for the `SPLIT_EINSUM_V2` attention implementation: ```bash python -m python_coreml_stable_diffusion.torch2coreml \ --model-version prompthero/openjourney-v4 \ --convert-unet \ --convert-text-encoder \ --convert-vae-decoder \ --convert-safety-checker \ --quantize-nbits 6 \ --attention-implementation SPLIT_EINSUM_V2 \ --compute-unit ALL \ --bundle-resources-for-swift-cli \ --check-output-correctness \ -o models/split_einsum_v2/openjourney-6-bit ``` 4. Test the converted models on the desired hardware. As a rule of thumb, the `ORIGINAL` version usually works better on macOS, whereas `SPLIT_EINSUM_V2` is usually faster on iOS. For more details and additional data points, see [these tests contributed by the community](https://github.com/huggingface/swift-coreml-diffusers/issues/31) on the previous version of Stable Diffusion for Core ML. 5. To integrate the desired model in your own app: * If you are going to distribute the model inside the app, use the `.mlpackage` files. Note that this will increase the size of your app binary. * Otherwise, you can use the compiled `Resources` to download them dynamically when your app starts. <br> <div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;"> If you don’t use the `--quantize-nbits` option, weights will be represented as 16-bit floats. This is compatible with the current version of Core ML so you won’t need to install the betas of iOS, macOS or Xcode. </div> <br> ## Using Less than 6 bits 6-bit quantization is a sweet spot between model quality, model size and convenience – you just need to provide a conversion option in order to be able to quantize any pre-trained model. This is an example of _post-training compression_. The beta version of `coremltools` released last week also includes _training-time_ compression methods. The idea here is that you can fine-tune a pre-trained Stable Diffusion model and perform the weights compression while fine-tuning is taking place. This allows you to use 4- or even 2-bit compression while minimizing the loss in quality. The reason this works is because weight clustering is performed using a differentiable algorithm, and therefore we can apply the usual training optimizers to find the quantization table while minimizing model loss. We have plans to evaluate this method soon, and can’t wait to see how 4-bit optimized models work and how fast they run. If you beat us to it, please drop us a note and we’ll be happy to check 🙂 ## Conclusion Quantization methods can be used to reduce the size of Stable Diffusion models, make them run faster on-device and consume less resources. The latest versions of Core ML and `coremltools` support techniques like 6-bit palettization that are easy to apply and that have a minimal impact on quality. We have added 6-bit palettized [models to the Hub](https://huggingface.co/apple), which are small enough to run on both iOS and macOS. We've also shown how you can convert fine-tuned models yourself, and can't wait to see what you do with these tools and techniques!
|
Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)
|
elisim
|
June 16, 2023
|
autoformer
|
guide, research, time-series
|
https://huggingface.co/blog/autoformer
|
# Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer) <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script> <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/autoformer-transformers-are-effective.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> ## Introduction A few months ago, we introduced the [Informer](https://huggingface.co/blog/informer) model ([Zhou, Haoyi, et al., 2021](https://arxiv.org/abs/2012.07436)), which is a Time Series Transformer that won the AAAI 2021 best paper award. We also provided an example for multivariate probabilistic forecasting with Informer. In this post, we discuss the question: [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504) (AAAI 2023). As we will see, they are. Firstly, we will provide empirical evidence that **Transformers are indeed Effective for Time Series Forecasting**. Our comparison shows that the simple linear model, known as _DLinear_, is not better than Transformers as claimed. When compared against equivalent sized models in the same setting as the linear models, the Transformer-based models perform better on the test set metrics we consider. Afterwards, we will introduce the _Autoformer_ model ([Wu, Haixu, et al., 2021](https://arxiv.org/abs/2106.13008)), which was published in NeurIPS 2021 after the Informer model. The Autoformer model is [now available](https://huggingface.co/docs/transformers/main/en/model_doc/autoformer) in 🤗 Transformers. Finally, we will discuss the _DLinear_ model, which is a simple feedforward network that uses the decomposition layer from Autoformer. The DLinear model was first introduced in [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504) and claimed to outperform Transformer-based models in time-series forecasting. Let's go! ## Benchmarking - Transformers vs. DLinear In the paper [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504), published recently in AAAI 2023, the authors claim that Transformers are not effective for time series forecasting. They compare the Transformer-based models against a simple linear model, which they call _DLinear_. The DLinear model uses the decomposition layer from the Autoformer model, which we will introduce later in this post. The authors claim that the DLinear model outperforms the Transformer-based models in time-series forecasting. Is that so? Let's find out. | Dataset | Autoformer (uni.) MASE | DLinear MASE | |:-----------------:|:----------------------:|:-------------:| | `Traffic` | 0.910 | 0.965 | | `Exchange-Rate` | 1.087 | 1.690 | | `Electricity` | 0.751 | 0.831 | The table above shows the results of the comparison between the Autoformer and DLinear models on the three datasets used in the paper. The results show that the Autoformer model outperforms the DLinear model on all three datasets. Next, we will present the new Autoformer model along with the DLinear model. We will showcase how to compare them on the Traffic dataset from the table above, and provide explanations for the results we obtained. **TL;DR:** A simple linear model, while advantageous in certain cases, has no capacity to incorporate covariates compared to more complex models like transformers in the univariate setting. ## Autoformer - Under The Hood Autoformer builds upon the traditional method of decomposing time series into seasonality and trend-cycle components. This is achieved through the incorporation of a _Decomposition Layer_, which enhances the model's ability to capture these components accurately. Moreover, Autoformer introduces an innovative auto-correlation mechanism that replaces the standard self-attention used in the vanilla transformer. This mechanism enables the model to utilize period-based dependencies in the attention, thus improving the overall performance. In the upcoming sections, we will delve into the two key contributions of Autoformer: the _Decomposition Layer_ and the _Attention (Autocorrelation) Mechanism_. We will also provide code examples to illustrate how these components function within the Autoformer architecture. ### Decomposition Layer Decomposition has long been a popular method in time series analysis, but it had not been extensively incorporated into deep learning models until the introduction of the Autoformer paper. Following a brief explanation of the concept, we will demonstrate how the idea is applied in Autoformer using PyTorch code. #### Decomposition of Time Series In time series analysis, [decomposition](https://en.wikipedia.org/wiki/Decomposition_of_time_series) is a method of breaking down a time series into three systematic components: trend-cycle, seasonal variation, and random fluctuations. The trend component represents the long-term direction of the time series, which can be increasing, decreasing, or stable over time. The seasonal component represents the recurring patterns that occur within the time series, such as yearly or quarterly cycles. Finally, the random (sometimes called "irregular") component represents the random noise in the data that cannot be explained by the trend or seasonal components. Two main types of decomposition are additive and multiplicative decomposition, which are implemented in the [great statsmodels library](https://www.statsmodels.org/dev/generated/statsmodels.tsa.seasonal.seasonal_decompose.html). By decomposing a time series into these components, we can better understand and model the underlying patterns in the data. But how can we incorporate decomposition into the Transformer architecture? Let's see how Autoformer does it. #### Decomposition in Autoformer |  | |:--:| | Autoformer architecture from [the paper](https://arxiv.org/abs/2106.13008) | Autoformer incorporates a decomposition block as an inner operation of the model, as presented in the Autoformer's architecture above. As can be seen, the encoder and decoder use a decomposition block to aggregate the trend-cyclical part and extract the seasonal part from the series progressively. The concept of inner decomposition has demonstrated its usefulness since the publication of Autoformer. Subsequently, it has been adopted in several other time series papers, such as FEDformer ([Zhou, Tian, et al., ICML 2022](https://arxiv.org/abs/2201.12740)) and DLinear [(Zeng, Ailing, et al., AAAI 2023)](https://arxiv.org/abs/2205.13504), highlighting its significance in time series modeling. Now, let's define the decomposition layer formally: For an input series \\(\mathcal{X} \in \mathbb{R}^{L \times d}\\) with length \\(L\\), the decomposition layer returns \\(\mathcal{X}_\textrm{trend}, \mathcal{X}_\textrm{seasonal}\\) defined as: $$ \mathcal{X}_\textrm{trend} = \textrm{AvgPool(Padding(} \mathcal{X} \textrm{))} \\ \mathcal{X}_\textrm{seasonal} = \mathcal{X} - \mathcal{X}_\textrm{trend} $$ And the implementation in PyTorch: ```python import torch from torch import nn class DecompositionLayer(nn.Module): """ Returns the trend and the seasonal parts of the time series. """ def __init__(self, kernel_size): super().__init__() self.kernel_size = kernel_size self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=1, padding=0) # moving average def forward(self, x): """Input shape: Batch x Time x EMBED_DIM""" # padding on the both ends of time series num_of_pads = (self.kernel_size - 1) // 2 front = x[:, 0:1, :].repeat(1, num_of_pads, 1) end = x[:, -1:, :].repeat(1, num_of_pads, 1) x_padded = torch.cat([front, x, end], dim=1) # calculate the trend and seasonal part of the series x_trend = self.avg(x_padded.permute(0, 2, 1)).permute(0, 2, 1) x_seasonal = x - x_trend return x_seasonal, x_trend ``` As you can see, the implementation is quite simple and can be used in other models, as we will see with DLinear. Now, let's explain the second contribution - _Attention (Autocorrelation) Mechanism_. ### Attention (Autocorrelation) Mechanism |  | |:--:| | Vanilla self attention vs Autocorrelation mechanism, from [the paper](https://arxiv.org/abs/2106.13008) | In addition to the decomposition layer, Autoformer employs a novel auto-correlation mechanism which replaces the self-attention seamlessly. In the [vanilla Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer), attention weights are computed in the time domain and point-wise aggregated. On the other hand, as can be seen in the figure above, Autoformer computes them in the frequency domain (using [fast fourier transform](https://en.wikipedia.org/wiki/Fast_Fourier_transform)) and aggregates them by time delay. In the following sections, we will dive into these topics in detail and explain them with code examples. #### Frequency Domain Attention | 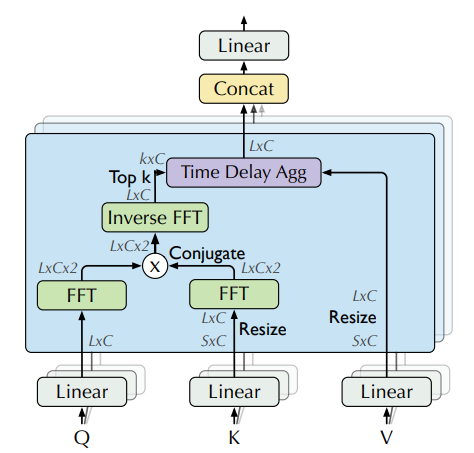 | |:--:| | Attention weights computation in frequency domain using FFT, from [the paper](https://arxiv.org/abs/2106.13008) | In theory, given a time lag \\(\tau\\), _autocorrelation_ for a single discrete variable \\(y\\) is used to measure the "relationship" (pearson correlation) between the variable's current value at time \\(t\\) to its past value at time \\(t-\tau\\): $$ \textrm{Autocorrelation}(\tau) = \textrm{Corr}(y_t, y_{t-\tau}) $$ Using autocorrelation, Autoformer extracts frequency-based dependencies from the queries and keys, instead of the standard dot-product between them. You can think about it as a replacement for the \\(QK^T\\) term in the self-attention. In practice, autocorrelation of the queries and keys for **all lags** is calculated at once by FFT. By doing so, the autocorrelation mechanism achieves \\(O(L \log L)\\) time complexity (where \\(L\\) is the input time length), similar to [Informer's ProbSparse attention](https://huggingface.co/blog/informer#probsparse-attention). Note that the theory behind computing autocorrelation using FFT is based on the [Wiener–Khinchin theorem](https://en.wikipedia.org/wiki/Wiener%E2%80%93Khinchin_theorem), which is outside the scope of this blog post. Now, we are ready to see the code in PyTorch: ```python import torch def autocorrelation(query_states, key_states): """ Computes autocorrelation(Q,K) using `torch.fft`. Think about it as a replacement for the QK^T in the self-attention. Assumption: states are resized to same shape of [batch_size, time_length, embedding_dim]. """ query_states_fft = torch.fft.rfft(query_states, dim=1) key_states_fft = torch.fft.rfft(key_states, dim=1) attn_weights = query_states_fft * torch.conj(key_states_fft) attn_weights = torch.fft.irfft(attn_weights, dim=1) return attn_weights ``` Quite simple! 😎 Please be aware that this is only a partial implementation of `autocorrelation(Q,K)`, and the full implementation can be found in 🤗 Transformers. Next, we will see how to aggregate our `attn_weights` with the values by time delay, process which is termed as _Time Delay Aggregation_. #### Time Delay Aggregation | 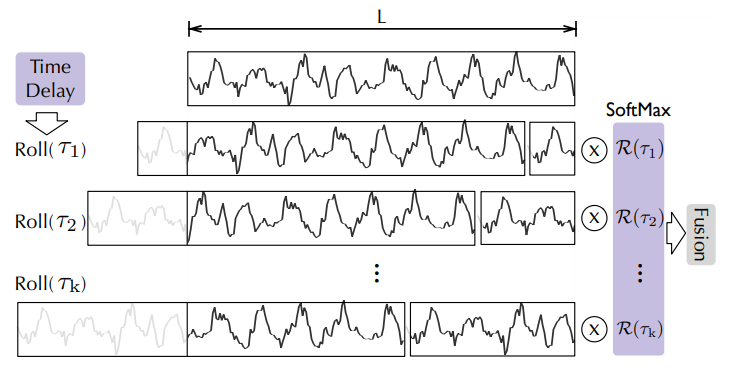 | |:--:| | Aggregation by time delay, from [the Autoformer paper](https://arxiv.org/abs/2106.13008) | Let's consider the autocorrelations (referred to as `attn_weights`) as \\(\mathcal{R_{Q,K}}\\). The question arises: how do we aggregate these \\(\mathcal{R_{Q,K}}(\tau_1), \mathcal{R_{Q,K}}(\tau_2), ..., \mathcal{R_{Q,K}}(\tau_k)\\) with \\(\mathcal{V}\\)? In the standard self-attention mechanism, this aggregation is accomplished through dot-product. However, in Autoformer, we employ a different approach. Firstly, we align \\(\mathcal{V}\\) by calculating its value for each time delay \\(\tau_1, \tau_2, ... \tau_k\\), which is also known as _Rolling_. Subsequently, we conduct element-wise multiplication between the aligned \\(\mathcal{V}\\) and the autocorrelations. In the provided figure, you can observe the left side showcasing the rolling of \\(\mathcal{V}\\) by time delay, while the right side illustrates the element-wise multiplication with the autocorrelations. It can be summarized with the following equations: $$ \tau_1, \tau_2, ... \tau_k = \textrm{arg Top-k}(\mathcal{R_{Q,K}}(\tau)) \\ \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _1), \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _2), ..., \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _k) = \textrm{Softmax}(\mathcal{R_{Q,K}}(\tau _1), \mathcal{R_{Q,K}}(\tau_2), ..., \mathcal{R_{Q,K}}(\tau_k)) \\ \textrm{Autocorrelation-Attention} = \sum_{i=1}^k \textrm{Roll}(\mathcal{V}, \tau_i) \cdot \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _i) $$ And that's it! Note that \\(k\\) is controlled by a hyperparameter called `autocorrelation_factor` (similar to `sampling_factor` in [Informer](https://huggingface.co/blog/informer)), and softmax is applied to the autocorrelations before the multiplication. Now, we are ready to see the final code: ```python import torch import math def time_delay_aggregation(attn_weights, value_states, autocorrelation_factor=2): """ Computes aggregation as value_states.roll(delay) * top_k_autocorrelations(delay). The final result is the autocorrelation-attention output. Think about it as a replacement of the dot-product between attn_weights and value states. The autocorrelation_factor is used to find top k autocorrelations delays. Assumption: value_states and attn_weights shape: [batch_size, time_length, embedding_dim] """ bsz, num_heads, tgt_len, channel = ... time_length = value_states.size(1) autocorrelations = attn_weights.view(bsz, num_heads, tgt_len, channel) # find top k autocorrelations delays top_k = int(autocorrelation_factor * math.log(time_length)) autocorrelations_mean = torch.mean(autocorrelations, dim=(1, -1)) # bsz x tgt_len top_k_autocorrelations, top_k_delays = torch.topk(autocorrelations_mean, top_k, dim=1) # apply softmax on the channel dim top_k_autocorrelations = torch.softmax(top_k_autocorrelations, dim=-1) # bsz x top_k # compute aggregation: value_states.roll(delay) * top_k_autocorrelations(delay) delays_agg = torch.zeros_like(value_states).float() # bsz x time_length x channel for i in range(top_k): value_states_roll_delay = value_states.roll(shifts=-int(top_k_delays[i]), dims=1) top_k_at_delay = top_k_autocorrelations[:, i] # aggregation top_k_resized = top_k_at_delay.view(-1, 1, 1).repeat(num_heads, tgt_len, channel) delays_agg += value_states_roll_delay * top_k_resized attn_output = delays_agg.contiguous() return attn_output ``` We did it! The Autoformer model is [now available](https://huggingface.co/docs/transformers/main/en/model_doc/autoformer) in the 🤗 Transformers library, and simply called `AutoformerModel`. Our strategy with this model is to show the performance of the univariate Transformer models in comparison to the DLinear model which is inherently univariate as will shown next. We will also present the results from _two_ multivariate Transformer models trained on the same data. ## DLinear - Under The Hood Actually, DLinear is conceptually simple: it's just a fully connected with the Autoformer's `DecompositionLayer`. It uses the `DecompositionLayer` above to decompose the input time series into the residual (the seasonality) and trend part. In the forward pass each part is passed through its own linear layer, which projects the signal to an appropriate `prediction_length`-sized output. The final output is the sum of the two corresponding outputs in the point-forecasting model: ```python def forward(self, context): seasonal, trend = self.decomposition(context) seasonal_output = self.linear_seasonal(seasonal) trend_output = self.linear_trend(trend) return seasonal_output + trend_output ``` In the probabilistic setting one can project the context length arrays to `prediction-length * hidden` dimensions via the `linear_seasonal` and `linear_trend` layers. The resulting outputs are added and reshaped to `(prediction_length, hidden)`. Finally, a probabilistic head maps the latent representations of size `hidden` to the parameters of some distribution. In our benchmark, we use the implementation of DLinear from [GluonTS](https://github.com/awslabs/gluonts). ## Example: Traffic Dataset We want to show empirically the performance of Transformer-based models in the library, by benchmarking on the `traffic` dataset, a dataset with 862 time series. We will train a shared model on each of the individual time series (i.e. univariate setting). Each time series represents the occupancy value of a sensor and is in the range [0, 1]. We will keep the following hyperparameters fixed for all the models: ```python # Traffic prediction_length is 24. Reference: # https://github.com/awslabs/gluonts/blob/6605ab1278b6bf92d5e47343efcf0d22bc50b2ec/src/gluonts/dataset/repository/_lstnet.py#L105 prediction_length = 24 context_length = prediction_length*2 batch_size = 128 num_batches_per_epoch = 100 epochs = 50 scaling = "std" ``` The transformers models are all relatively small with: ```python encoder_layers=2 decoder_layers=2 d_model=16 ``` Instead of showing how to train a model using `Autoformer`, one can just replace the model in the previous two blog posts ([TimeSeriesTransformer](https://huggingface.co/blog/time-series-transformers) and [Informer](https://huggingface.co/blog/informer)) with the new `Autoformer` model and train it on the `traffic` dataset. In order to not repeat ourselves, we have already trained the models and pushed them to the HuggingFace Hub. We will use those models for evaluation. ## Load Dataset Let's first install the necessary libraries: ```python !pip install -q transformers datasets evaluate accelerate "gluonts[torch]" ujson tqdm ``` The `traffic` dataset, used by [Lai et al. (2017)](https://arxiv.org/abs/1703.07015), contains the San Francisco Traffic. It contains 862 hourly time series showing the road occupancy rates in the range \\([0, 1]\\) on the San Francisco Bay Area freeways from 2015 to 2016. ```python from gluonts.dataset.repository.datasets import get_dataset dataset = get_dataset("traffic") freq = dataset.metadata.freq prediction_length = dataset.metadata.prediction_length ``` Let's visualize a time series in the dataset and plot the train/test split: ```python import matplotlib.pyplot as plt train_example = next(iter(dataset.train)) test_example = next(iter(dataset.test)) num_of_samples = 4*prediction_length figure, axes = plt.subplots() axes.plot(train_example["target"][-num_of_samples:], color="blue") axes.plot( test_example["target"][-num_of_samples - prediction_length :], color="red", alpha=0.5, ) plt.show() ```  Let's define the train/test splits: ```python train_dataset = dataset.train test_dataset = dataset.test ``` ## Define Transformations Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones). We define a `Chain` of transformations from GluonTS (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline. The transformations below are annotated with comments to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features: ```python from transformers import PretrainedConfig from gluonts.time_feature import time_features_from_frequency_str from gluonts.dataset.field_names import FieldName from gluonts.transform import ( AddAgeFeature, AddObservedValuesIndicator, AddTimeFeatures, AsNumpyArray, Chain, ExpectedNumInstanceSampler, RemoveFields, SelectFields, SetField, TestSplitSampler, Transformation, ValidationSplitSampler, VstackFeatures, RenameFields, ) def create_transformation(freq: str, config: PretrainedConfig) -> Transformation: # create a list of fields to remove later remove_field_names = [] if config.num_static_real_features == 0: remove_field_names.append(FieldName.FEAT_STATIC_REAL) if config.num_dynamic_real_features == 0: remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL) if config.num_static_categorical_features == 0: remove_field_names.append(FieldName.FEAT_STATIC_CAT) return Chain( # step 1: remove static/dynamic fields if not specified [RemoveFields(field_names=remove_field_names)] # step 2: convert the data to NumPy (potentially not needed) + ( [ AsNumpyArray( field=FieldName.FEAT_STATIC_CAT, expected_ndim=1, dtype=int, ) ] if config.num_static_categorical_features > 0 else [] ) + ( [ AsNumpyArray( field=FieldName.FEAT_STATIC_REAL, expected_ndim=1, ) ] if config.num_static_real_features > 0 else [] ) + [ AsNumpyArray( field=FieldName.TARGET, # we expect an extra dim for the multivariate case: expected_ndim=1 if config.input_size == 1 else 2, ), # step 3: handle the NaN's by filling in the target with zero # and return the mask (which is in the observed values) # true for observed values, false for nan's # the decoder uses this mask (no loss is incurred for unobserved values) # see loss_weights inside the xxxForPrediction model AddObservedValuesIndicator( target_field=FieldName.TARGET, output_field=FieldName.OBSERVED_VALUES, ), # step 4: add temporal features based on freq of the dataset # these serve as positional encodings AddTimeFeatures( start_field=FieldName.START, target_field=FieldName.TARGET, output_field=FieldName.FEAT_TIME, time_features=time_features_from_frequency_str(freq), pred_length=config.prediction_length, ), # step 5: add another temporal feature (just a single number) # tells the model where in the life the value of the time series is # sort of running counter AddAgeFeature( target_field=FieldName.TARGET, output_field=FieldName.FEAT_AGE, pred_length=config.prediction_length, log_scale=True, ), # step 6: vertically stack all the temporal features into the key FEAT_TIME VstackFeatures( output_field=FieldName.FEAT_TIME, input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE] + ( [FieldName.FEAT_DYNAMIC_REAL] if config.num_dynamic_real_features > 0 else [] ), ), # step 7: rename to match HuggingFace names RenameFields( mapping={ FieldName.FEAT_STATIC_CAT: "static_categorical_features", FieldName.FEAT_STATIC_REAL: "static_real_features", FieldName.FEAT_TIME: "time_features", FieldName.TARGET: "values", FieldName.OBSERVED_VALUES: "observed_mask", } ), ] ) ``` ## Define `InstanceSplitter` For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the model due to time and memory constraints). The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes: 1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset) 2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations) 3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case) ```python from gluonts.transform import InstanceSplitter from gluonts.transform.sampler import InstanceSampler from typing import Optional def create_instance_splitter( config: PretrainedConfig, mode: str, train_sampler: Optional[InstanceSampler] = None, validation_sampler: Optional[InstanceSampler] = None, ) -> Transformation: assert mode in ["train", "validation", "test"] instance_sampler = { "train": train_sampler or ExpectedNumInstanceSampler( num_instances=1.0, min_future=config.prediction_length ), "validation": validation_sampler or ValidationSplitSampler(min_future=config.prediction_length), "test": TestSplitSampler(), }[mode] return InstanceSplitter( target_field="values", is_pad_field=FieldName.IS_PAD, start_field=FieldName.START, forecast_start_field=FieldName.FORECAST_START, instance_sampler=instance_sampler, past_length=config.context_length + max(config.lags_sequence), future_length=config.prediction_length, time_series_fields=["time_features", "observed_mask"], ) ``` ## Create PyTorch DataLoaders Next, it's time to create PyTorch DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`). ```python from typing import Iterable import torch from gluonts.itertools import Cyclic, Cached from gluonts.dataset.loader import as_stacked_batches def create_train_dataloader( config: PretrainedConfig, freq, data, batch_size: int, num_batches_per_epoch: int, shuffle_buffer_length: Optional[int] = None, cache_data: bool = True, **kwargs, ) -> Iterable: PREDICTION_INPUT_NAMES = [ "past_time_features", "past_values", "past_observed_mask", "future_time_features", ] if config.num_static_categorical_features > 0: PREDICTION_INPUT_NAMES.append("static_categorical_features") if config.num_static_real_features > 0: PREDICTION_INPUT_NAMES.append("static_real_features") TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [ "future_values", "future_observed_mask", ] transformation = create_transformation(freq, config) transformed_data = transformation.apply(data, is_train=True) if cache_data: transformed_data = Cached(transformed_data) # we initialize a Training instance instance_splitter = create_instance_splitter(config, "train") # the instance splitter will sample a window of # context length + lags + prediction length (from the 366 possible transformed time series) # randomly from within the target time series and return an iterator. stream = Cyclic(transformed_data).stream() training_instances = instance_splitter.apply(stream, is_train=True) return as_stacked_batches( training_instances, batch_size=batch_size, shuffle_buffer_length=shuffle_buffer_length, field_names=TRAINING_INPUT_NAMES, output_type=torch.tensor, num_batches_per_epoch=num_batches_per_epoch, ) def create_backtest_dataloader( config: PretrainedConfig, freq, data, batch_size: int, **kwargs, ): PREDICTION_INPUT_NAMES = [ "past_time_features", "past_values", "past_observed_mask", "future_time_features", ] if config.num_static_categorical_features > 0: PREDICTION_INPUT_NAMES.append("static_categorical_features") if config.num_static_real_features > 0: PREDICTION_INPUT_NAMES.append("static_real_features") transformation = create_transformation(freq, config) transformed_data = transformation.apply(data, is_train=False) # we create a Validation Instance splitter which will sample the very last # context window seen during training only for the encoder. instance_sampler = create_instance_splitter(config, "validation") # we apply the transformations in test mode testing_instances = instance_sampler.apply(transformed_data, is_train=False) return as_stacked_batches( testing_instances, batch_size=batch_size, output_type=torch.tensor, field_names=PREDICTION_INPUT_NAMES, ) def create_test_dataloader( config: PretrainedConfig, freq, data, batch_size: int, **kwargs, ): PREDICTION_INPUT_NAMES = [ "past_time_features", "past_values", "past_observed_mask", "future_time_features", ] if config.num_static_categorical_features > 0: PREDICTION_INPUT_NAMES.append("static_categorical_features") if config.num_static_real_features > 0: PREDICTION_INPUT_NAMES.append("static_real_features") transformation = create_transformation(freq, config) transformed_data = transformation.apply(data, is_train=False) # We create a test Instance splitter to sample the very last # context window from the dataset provided. instance_sampler = create_instance_splitter(config, "test") # We apply the transformations in test mode testing_instances = instance_sampler.apply(transformed_data, is_train=False) return as_stacked_batches( testing_instances, batch_size=batch_size, output_type=torch.tensor, field_names=PREDICTION_INPUT_NAMES, ) ``` ## Evaluate on Autoformer We have already pre-trained an Autoformer model on this dataset, so we can just fetch the model and evaluate it on the test set: ```python from transformers import AutoformerConfig, AutoformerForPrediction config = AutoformerConfig.from_pretrained("kashif/autoformer-traffic-hourly") model = AutoformerForPrediction.from_pretrained("kashif/autoformer-traffic-hourly") test_dataloader = create_backtest_dataloader( config=config, freq=freq, data=test_dataset, batch_size=64, ) ``` At inference time, we will use the model's `generate()` method for predicting `prediction_length` steps into the future from the very last context window of each time series in the training set. ```python from accelerate import Accelerator accelerator = Accelerator() device = accelerator.device model.to(device) model.eval() forecasts_ = [] for batch in test_dataloader: outputs = model.generate( static_categorical_features=batch["static_categorical_features"].to(device) if config.num_static_categorical_features > 0 else None, static_real_features=batch["static_real_features"].to(device) if config.num_static_real_features > 0 else None, past_time_features=batch["past_time_features"].to(device), past_values=batch["past_values"].to(device), future_time_features=batch["future_time_features"].to(device), past_observed_mask=batch["past_observed_mask"].to(device), ) forecasts_.append(outputs.sequences.cpu().numpy()) ``` The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`, `input_size`). In this case, we get `100` possible values for the next `24` hours for each of the time series in the test dataloader batch which if you recall from above is `64`: ```python forecasts_[0].shape >>> (64, 100, 24) ``` We'll stack them vertically, to get forecasts for all time-series in the test dataset: We have `7` rolling windows in the test set which is why we end up with a total of `7 * 862 = 6034` predictions: ```python import numpy as np forecasts = np.vstack(forecasts_) print(forecasts.shape) >>> (6034, 100, 24) ``` We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. For that, we'll use the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library, which includes the [MASE](https://huggingface.co/spaces/evaluate-metric/mase) metrics. We calculate the metric for each time series in the dataset and return the average: ```python from tqdm.autonotebook import tqdm from evaluate import load from gluonts.time_feature import get_seasonality mase_metric = load("evaluate-metric/mase") forecast_median = np.median(forecasts, 1) mase_metrics = [] for item_id, ts in enumerate(tqdm(test_dataset)): training_data = ts["target"][:-prediction_length] ground_truth = ts["target"][-prediction_length:] mase = mase_metric.compute( predictions=forecast_median[item_id], references=np.array(ground_truth), training=np.array(training_data), periodicity=get_seasonality(freq)) mase_metrics.append(mase["mase"]) ``` So the result for the Autoformer model is: ```python print(f"Autoformer univariate MASE: {np.mean(mase_metrics):.3f}") >>> Autoformer univariate MASE: 0.910 ``` To plot the prediction for any time series with respect to the ground truth test data, we define the following helper: ```python import matplotlib.dates as mdates import pandas as pd test_ds = list(test_dataset) def plot(ts_index): fig, ax = plt.subplots() index = pd.period_range( start=test_ds[ts_index][FieldName.START], periods=len(test_ds[ts_index][FieldName.TARGET]), freq=test_ds[ts_index][FieldName.START].freq, ).to_timestamp() ax.plot( index[-5*prediction_length:], test_ds[ts_index]["target"][-5*prediction_length:], label="actual", ) plt.plot( index[-prediction_length:], np.median(forecasts[ts_index], axis=0), label="median", ) plt.gcf().autofmt_xdate() plt.legend(loc="best") plt.show() ``` For example, for time-series in the test set with index `4`: ```python plot(4) ```  ## Evaluate on DLinear A probabilistic DLinear is implemented in `gluonts` and thus we can train and evaluate it relatively quickly here: ```python from gluonts.torch.model.d_linear.estimator import DLinearEstimator # Define the DLinear model with the same parameters as the Autoformer model estimator = DLinearEstimator( prediction_length=dataset.metadata.prediction_length, context_length=dataset.metadata.prediction_length*2, scaling=scaling, hidden_dimension=2, batch_size=batch_size, num_batches_per_epoch=num_batches_per_epoch, trainer_kwargs=dict(max_epochs=epochs) ) ``` Train the model: ```python predictor = estimator.train( training_data=train_dataset, cache_data=True, shuffle_buffer_length=1024 ) >>> INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params --------------------------------------- 0 | model | DLinearModel | 4.7 K --------------------------------------- 4.7 K Trainable params 0 Non-trainable params 4.7 K Total params 0.019 Total estimated model params size (MB) Training: 0it [00:00, ?it/s] ... INFO:pytorch_lightning.utilities.rank_zero:Epoch 49, global step 5000: 'train_loss' was not in top 1 INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=50` reached. ``` And evaluate it on the test set: ```python from gluonts.evaluation import make_evaluation_predictions, Evaluator forecast_it, ts_it = make_evaluation_predictions( dataset=dataset.test, predictor=predictor, ) d_linear_forecasts = list(forecast_it) d_linear_tss = list(ts_it) evaluator = Evaluator() agg_metrics, _ = evaluator(iter(d_linear_tss), iter(d_linear_forecasts)) ``` So the result for the DLinear model is: ```python dlinear_mase = agg_metrics["MASE"] print(f"DLinear MASE: {dlinear_mase:.3f}") >>> DLinear MASE: 0.965 ``` As before, we plot the predictions from our trained DLinear model via this helper: ```python def plot_gluonts(index): plt.plot(d_linear_tss[index][-4 * dataset.metadata.prediction_length:].to_timestamp(), label="target") d_linear_forecasts[index].plot(show_label=True, color='g') plt.legend() plt.gcf().autofmt_xdate() plt.show() ``` ```python plot_gluonts(4) ``` 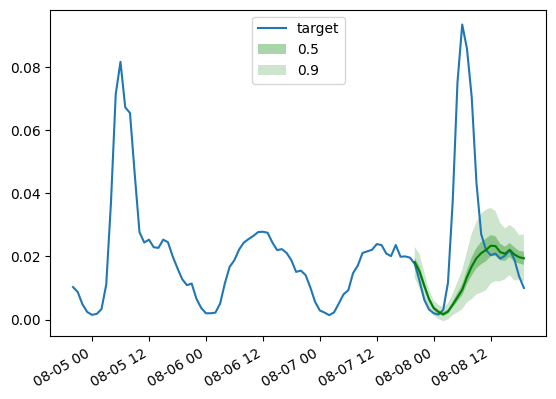 The `traffic` dataset has a distributional shift in the sensor patterns between weekdays and weekends. So what is going on here? Since the DLinear model has no capacity to incorporate covariates, in particular any date-time features, the context window we give it does not have enough information to figure out if the prediction is for the weekend or weekday. Thus, the model will predict the more common of the patterns, namely the weekdays leading to poorer performance on weekends. Of course, by giving it a larger context window, a linear model will figure out the weekly pattern, but perhaps there is a monthly or quarterly pattern in the data which would require bigger and bigger contexts. ## Conclusion How do Transformer-based models compare against the above linear baseline? The test set MASE metrics from the different models we have are below: |Dataset | Transformer (uni.) | Transformer (mv.) | Informer (uni.)| Informer (mv.) | Autoformer (uni.) | DLinear | |:--:|:--:| :--:| :--:| :--:| :--:|:-------:| |`Traffic` | **0.876** | 1.046 | 0.924 | 1.131 | 0.910 | 0.965 | As one can observe, the [vanilla Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer) which we introduced last year gets the best results here. Secondly, multivariate models are typically _worse_ than the univariate ones, the reason being the difficulty in estimating the cross-series correlations/relationships. The additional variance added by the estimates often harms the resulting forecasts or the model learns spurious correlations. Recent papers like [CrossFormer](https://openreview.net/forum?id=vSVLM2j9eie) (ICLR 23) and [CARD](https://arxiv.org/abs/2305.12095) try to address this problem in Transformer models. Multivariate models usually perform well when trained on large amounts of data. However, when compared to univariate models, especially on smaller open datasets, the univariate models tend to provide better metrics. By comparing the linear model with equivalent-sized univariate transformers or in fact any other neural univariate model, one will typically get better performance. To summarize, Transformers are definitely far from being outdated when it comes to time-series forcasting! Yet the availability of large-scale datasets is crucial for maximizing their potential. Unlike in CV and NLP, the field of time series lacks publicly accessible large-scale datasets. Most existing pre-trained models for time series are trained on small sample sizes from archives like [UCR and UEA](https://www.timeseriesclassification.com/), which contain only a few thousands or even hundreds of samples. Although these benchmark datasets have been instrumental in the progress of the time series community, their limited sample sizes and lack of generality pose challenges for pre-training deep learning models. Therefore, the development of large-scale, generic time series datasets (like ImageNet in CV) is of the utmost importance. Creating such datasets will greatly facilitate further research on pre-trained models specifically designed for time series analysis, and it will improve the applicability of pre-trained models in time series forecasting. ## Acknowledgements We express our appreciation to [Lysandre Debut](https://github.com/LysandreJik) and [Pedro Cuenca](https://github.com/pcuenca) their insightful comments and help during this project ❤️.
|
AI Policy @🤗: Response to the U.S. NTIA's Request for Comment on AI Accountability
|
yjernite
|
June 20, 2023
|
policy-ntia-rfc
|
community, ethics
|
https://huggingface.co/blog/policy-ntia-rfc
|
# AI Policy @🤗: Response to the U.S. National Telecommunications and Information Administration’s (NTIA) Request for Comment on AI Accountability On June 12th, Hugging Face submitted a response to the US Department of Commerce NTIA request for information on AI Accountability policy. In our response, we stressed the role of documentation and transparency norms in driving AI accountability processes, as well as the necessity of relying on the full range of expertise, perspectives, and skills of the technology’s many stakeholders to address the daunting prospects of a technology whose unprecedented growth poses more questions than any single entity can answer. Hugging Face’s mission is to [“democratize good machine learning”](https://huggingface.co/about). We understand the term “democratization” in this context to mean making Machine Learning systems not just easier to develop and deploy, but also easier for its many stakeholders to understand, interrogate, and critique. To that end, we have worked on fostering transparency and inclusion through our [education efforts](https://huggingface.co/learn/nlp-course/chapter1/1), [focus on documentation](https://huggingface.co/docs/hub/model-cards), [community guidelines](https://huggingface.co/blog/content-guidelines-update) and approach to [responsible openness](https://huggingface.co/blog/ethics-soc-3), as well as developing no- and low-code tools to allow people with all levels of technical background to analyze [ML datasets](https://huggingface.co/spaces/huggingface/data-measurements-tool) and [models](https://huggingface.co/spaces/society-ethics/StableBias). We believe this helps everyone interested to better understand [the limitations of ML systems](https://huggingface.co/blog/ethics-soc-2) and how they can safely be leveraged to best serve users and those affected by these systems. These approaches have already proven their utility in promoting accountability, especially in the larger multidisciplinary research endeavors we’ve helped organize, including [BigScience](https://huggingface.co/bigscience) (see our blog series [on the social stakes of the project](https://montrealethics.ai/category/columns/social-context-in-llm-research/)), and the more recent [BigCode project](https://huggingface.co/bigcode) (whose governance is [described in more details here](https://huggingface.co/datasets/bigcode/governance-card)). Concretely, we make the following recommendations for accountability mechanisms: * Accountability mechanisms should **focus on all stages of the ML development process**. The societal impact of a full AI-enabled system depends on choices made at every stage of the development in ways that are impossible to fully predict, and assessments that only focus on the deployment stage risk incentivizing surface-level compliance that fails to address deeper issues until they have caused significant harm. * Accountability mechanisms should **combine internal requirements with external access** and transparency. Internal requirements such as good documentation practices shape more responsible development and provide clarity on the developers’ responsibility in enabling safer and more reliable technology. External access to the internal processes and development choices is still necessary to verify claims and documentation, and to empower the many stakeholders of the technology who reside outside of its development chain to meaningfully shape its evolution and promote their interest. * Accountability mechanisms should **invite participation from the broadest possible set of contributors,** including developers working directly on the technology, multidisciplinary research communities, advocacy organizations, policy makers, and journalists. Understanding the transformative impact of the rapid growth in adoption of ML technology is a task that is beyond the capacity of any single entity, and will require leveraging the full range of skills and expertise of our broad research community and of its direct users and affected populations. We believe that prioritizing transparency in both the ML artifacts themselves and the outcomes of their assessment will be integral to meeting these goals. You can find our more detailed response addressing these points <a href="/blog/assets/151_policy_ntia_rfc/HF_NTIA_RFC.pdf">here.</a>
|
Fine-tuning MMS Adapter Models for Multi-Lingual ASR
|
patrickvonplaten
|
June 19, 2023
|
mms_adapters
|
audio, research
|
https://huggingface.co/blog/mms_adapters
|
# **Fine-tuning MMS Adapter Models for Multi-Lingual ASR** <a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_MMS_on_Common_Voice.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> ***New (06/2023)***: *This blog post is strongly inspired by ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)* and can be seen as an improved version of it. **Wav2Vec2** is a pretrained model for Automatic Speech Recognition (ASR) and was released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by *Alexei Baevski, Michael Auli, and Alex Conneau*. Soon after the strong performance of Wav2Vec2 was demonstrated on one of the most popular English datasets for ASR, called [LibriSpeech](https://huggingface.co/datasets/librispeech_asr), *Facebook AI* presented two multi-lingual versions of Wav2Vec2, called [XLSR](https://arxiv.org/abs/2006.13979) and [XLM-R](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/), capable of recognising speech in up to 128 languages. XLSR stands for *cross-lingual speech representations* and refers to the model's ability to learn speech representations that are useful across multiple languages. Meta AI's most recent release, [**Massive Multilingual Speech (MMS)**](https://ai.facebook.com/blog/multilingual-model-speech-recognition/) by *Vineel Pratap, Andros Tjandra, Bowen Shi, et al.* takes multi-lingual speech representations to a new level. Over 1,100 spoken languages can be identified, transcribed and generated with the various [language identification, speech recognition, and text-to-speech checkpoints released](https://huggingface.co/models?other=mms). In this blog post, we show how MMS's Adapter training achieves astonishingly low word error rates after just 10-20 minutes of fine-tuning. For low-resource languages, we **strongly** recommend using MMS' Adapter training as opposed to fine-tuning the whole model as is done in ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2). In our experiments, MMS' Adapter training is both more memory efficient, more robust and yields better performance for low-resource languages. For medium to high resource languages it can still be advantegous to fine-tune the whole checkpoint instead of using Adapter layers though.  ## **Preserving the world's language diversity** According to https://www.ethnologue.com/ around 3000, or 40% of all "living" languages, are endangered due to fewer and fewer native speakers. This trend will only continue in an increasingly globalized world. **MMS** is capable of transcribing many languages which are endangered, such as *Ari* or *Kaivi*. In the future, MMS can play a vital role in keeping languages alive by helping the remaining speakers to create written records and communicating in their native tongue. To adapt to 1000+ different vocabularies, **MMS** uses of Adapters - a training method where only a small fraction of model weights are trained. Adapter layers act like linguistic bridges, enabling the model to leverage knowledge from one language when deciphering another. ## **Fine-tuning MMS** **MMS** unsupervised checkpoints were pre-trained on more than **half a million** hours of audio in over **1,400** languages, ranging from 300 million to one billion parameters. You can find the pretrained-only checkpoints on the 🤗 Hub for model sizes of 300 million parameters (300M) and one billion parameters (1B): - [**`mms-300m`**](https://huggingface.co/facebook/mms-300m) - [**`mms-1b`**](https://huggingface.co/facebook/mms-1b) *Note*: If you want to fine-tune the base models, you can do so in the exact same way as shown in ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2). Similar to [BERT's masked language modeling objective](http://jalammar.github.io/illustrated-bert/), MMS learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network during self-supervised pre-training. For ASR, the pretrained [`MMS-1B` checkpoint](https://huggingface.co/facebook/mms-1b) was further fine-tuned in a supervised fashion on 1000+ languages with a joint vocabulary output layer. As a final step, the joint vocabulary output layer was thrown away and language-specific adapter layers were kept instead. Each adapter layer contains **just** ~2.5M weights, consisting of small linear projection layers for each attention block as well as a language-specific vocabulary output layer. Three **MMS** checkpoints fine-tuned for speech recognition (ASR) have been released. They include 102, 1107, and 1162 adapter weights respectively (one for each language): - [**`mms-1b-fl102`**](https://huggingface.co/facebook/mms-1b-fl102) - [**`mms-1b-l1107`**](https://huggingface.co/facebook/mms-1b-l1107) - [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) You can see that the base models are saved (as usual) as a [`model.safetensors` file](https://huggingface.co/facebook/mms-1b-all/blob/main/model.safetensors), but in addition these repositories have many adapter weights stored in the repository, *e.g.* under the name [`adapter.fra.safetensors`](https://huggingface.co/facebook/mms-1b-all/blob/main/adapter.fra.safetensors) for French. The Hugging Face docs [explain very well how such checkpoints can be used for inference](https://huggingface.co/docs/transformers/main/en/model_doc/mms#loading), so in this blog post we will instead focus on learning how we can efficiently train highly performant adapter models based on any of the released ASR checkpoints. ## Training adaptive weights In machine learning, adapters are a method used to fine-tune pre-trained models while keeping the original model parameters unchanged. They do this by inserting small, trainable modules, called [adapter layers](https://arxiv.org/pdf/1902.00751.pdf), between the pre-existing layers of the model, which then adapt the model to a specific task without requiring extensive retraining. Adapters have a long history in speech recognition and especially **speaker recognition**. In speaker recognition, adapters have been effectively used to tweak pre-existing models to recognize individual speaker idiosyncrasies, as highlighted in [Gales and Woodland's (1996)](https://www.isca-speech.org/archive_v0/archive_papers/icslp_1996/i96_1832.pdf) and [Miao et al.'s (2014)](https://www.cs.cmu.edu/~ymiao/pub/tasl_sat.pdf) work. This approach not only greatly reduces computational requirements compared to training the full model, but also allows for better and more flexible speaker-specific adjustments. The work done in **MMS** leverages this idea of adapters for speech recognition across different languages. A small number of adapter weights are fine-tuned to grasp unique phonetic and grammatical traits of each target language. Thereby, MMS enables a single large base model (*e.g.*, the [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) checkpoint) and 1000+ small adapter layers (2.5M weights each for **`mms-1b-all`**) to comprehend and transcribe multiple languages. This dramatically reduces the computational demand of developing distinct models for each language. Great! Now that we understood the motivation and theory, let's look into fine-tuning adapter weights for **`mms-1b-all`** 🔥 ## Notebook Setup As done previously in the ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) blog post, we fine-tune the model on the low resource ASR dataset of [Common Voice](https://huggingface.co/datasets/common_voice) that contains only *ca.* 4h of validated training data. Just like Wav2Vec2 or XLS-R, MMS is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems, such as ASR and handwriting recognition. For more details on the CTC algorithm, I highly recommend reading the well-written blog post [*Sequence Modeling with CTC (2017)*](https://distill.pub/2017/ctc/) by Awni Hannun. Before we start, let's install `datasets` and `transformers`. Also, we need `torchaudio` to load audio files and `jiwer` to evaluate our fine-tuned model using the [word error rate (WER)](https://huggingface.co/metrics/wer) metric \\( {}^1 \\). ```bash %%capture !pip install --upgrade pip !pip install datasets[audio] !pip install evaluate !pip install git+https://github.com/huggingface/transformers.git !pip install jiwer !pip install accelerate ``` We strongly suggest to upload your training checkpoints directly to the [🤗 Hub](https://huggingface.co/) while training. The Hub repositories have version control built in, so you can be sure that no model checkpoint is lost during training. To do so you have to store your authentication token from the Hugging Face website (sign up [here](https://huggingface.co/join) if you haven't already!) ```python from huggingface_hub import notebook_login notebook_login() ``` ## Prepare Data, Tokenizer, Feature Extractor ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, *e.g.* a feature vector, and a tokenizer that processes the model's output format to text. In 🤗 Transformers, the MMS model is thus accompanied by both a feature extractor, called [Wav2Vec2FeatureExtractor](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2featureextractor), and a tokenizer, called [Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer). Let's start by creating the tokenizer to decode the predicted output classes to the output transcription. ### Create `Wav2Vec2CTCTokenizer` Fine-tuned MMS models, such as [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) already have a [tokenizer](https://huggingface.co/facebook/mms-1b-all/blob/main/tokenizer_config.json) accompanying the model checkpoint. However since we want to fine-tune the model on specific low-resource data of a certain language, it is recommended to fully remove the tokenizer and vocabulary output layer, and simply create new ones based on the training data itself. Wav2Vec2-like models fine-tuned on CTC transcribe an audio file with a single forward pass by first processing the audio input into a sequence of processed context representations and then using the final vocabulary output layer to classify each context representation to a character that represents the transcription. The output size of this layer corresponds to the number of tokens in the vocabulary, which we will extract from the labeled dataset used for fine-tuning. So in the first step, we will take a look at the chosen dataset of Common Voice and define a vocabulary based on the transcriptions. For this notebook, we will use [Common Voice's 6.1 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) for Turkish. Turkish corresponds to the language code `"tr"`. Great, now we can use 🤗 Datasets' simple API to download the data. The dataset name is `"mozilla-foundation/common_voice_6_1"`, the configuration name corresponds to the language code, which is `"tr"` in our case. **Note**: Before being able to download the dataset, you have to access it by logging into your Hugging Face account, going on the [dataset repo page](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) and clicking on "Agree and Access repository" Common Voice has many different splits including `invalidated`, which refers to data that was not rated as "clean enough" to be considered useful. In this notebook, we will only make use of the splits `"train"`, `"validation"` and `"test"`. Because the Turkish dataset is so small, we will merge both the validation and training data into a training dataset and only use the test data for validation. ```python from datasets import load_dataset, load_metric, Audio common_voice_train = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation", use_auth_token=True) common_voice_test = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="test", use_auth_token=True) ``` Many ASR datasets only provide the target text (`'sentence'`) for each audio array (`'audio'`) and file (`'path'`). Common Voice actually provides much more information about each audio file, such as the `'accent'`, etc. Keeping the notebook as general as possible, we only consider the transcribed text for fine-tuning. ```python common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"]) common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"]) ``` Let's write a short function to display some random samples of the dataset and run it a couple of times to get a feeling for the transcriptions. ```python from datasets import ClassLabel import random import pandas as pd from IPython.display import display, HTML def show_random_elements(dataset, num_examples=10): assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset." picks = [] for _ in range(num_examples): pick = random.randint(0, len(dataset)-1) while pick in picks: pick = random.randint(0, len(dataset)-1) picks.append(pick) df = pd.DataFrame(dataset[picks]) display(HTML(df.to_html())) ``` ```python show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10) ``` ```bash Oylar teker teker elle sayılacak. Son olaylar endişe seviyesini yükseltti. Tek bir kart hepsinin kapılarını açıyor. Blogcular da tam bundan bahsetmek istiyor. Bu Aralık iki bin onda oldu. Fiyatın altmış altı milyon avro olduğu bildirildi. Ardından da silahlı çatışmalar çıktı. "Romanya'da kurumlar gelir vergisi oranı yüzde on altı." Bu konuda neden bu kadar az şey söylendiğini açıklayabilir misiniz? ``` Alright! The transcriptions look fairly clean. Having translated the transcribed sentences, it seems that the language corresponds more to written-out text than noisy dialogue. This makes sense considering that [Common Voice](https://huggingface.co/datasets/common_voice) is a crowd-sourced read speech corpus. We can see that the transcriptions contain some special characters, such as `,.?!;:`. Without a language model, it is much harder to classify speech chunks to such special characters because they don't really correspond to a characteristic sound unit. *E.g.*, the letter `"s"` has a more or less clear sound, whereas the special character `"."` does not. Also in order to understand the meaning of a speech signal, it is usually not necessary to include special characters in the transcription. Let's simply remove all characters that don't contribute to the meaning of a word and cannot really be represented by an acoustic sound and normalize the text. ```python import re chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']' def remove_special_characters(batch): batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower() return batch ``` ```python common_voice_train = common_voice_train.map(remove_special_characters) common_voice_test = common_voice_test.map(remove_special_characters) ``` Let's look at the processed text labels again. ```python show_random_elements(common_voice_train.remove_columns(["path","audio"])) ``` ```bash i̇kinci tur müzakereler eylül ayında başlayacak jani ve babası bu düşüncelerinde yalnız değil onurun gözlerindeki büyü bandiç oyların yüzde kırk sekiz virgül elli dördünü topladı bu imkansız bu konu açık değildir cinayet kamuoyunu şiddetle sarstı kentin sokakları iki metre su altında kaldı muhalefet partileri hükümete karşı ciddi bir mücadele ortaya koyabiliyorlar mı festivale tüm dünyadan elli film katılıyor ``` Good! This looks better. We have removed most special characters from transcriptions and normalized them to lower-case only. Before finalizing the pre-processing, it is always advantageous to consult a native speaker of the target language to see whether the text can be further simplified. For this blog post, [Merve](https://twitter.com/mervenoyann) was kind enough to take a quick look and noted that "hatted" characters - like `â` - aren't really used anymore in Turkish and can be replaced by their "un-hatted" equivalent, *e.g.* `a`. This means that we should replace a sentence like `"yargı sistemi hâlâ sağlıksız"` to `"yargı sistemi hala sağlıksız"`. Let's write another short mapping function to further simplify the text labels. Remember - the simpler the text labels, the easier it is for the model to learn to predict those labels. ```python def replace_hatted_characters(batch): batch["sentence"] = re.sub('[â]', 'a', batch["sentence"]) batch["sentence"] = re.sub('[î]', 'i', batch["sentence"]) batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"]) batch["sentence"] = re.sub('[û]', 'u', batch["sentence"]) return batch ``` ```python common_voice_train = common_voice_train.map(replace_hatted_characters) common_voice_test = common_voice_test.map(replace_hatted_characters) ``` In CTC, it is common to classify speech chunks into letters, so we will do the same here. Let's extract all distinct letters of the training and test data and build our vocabulary from this set of letters. We write a mapping function that concatenates all transcriptions into one long transcription and then transforms the string into a set of chars. It is important to pass the argument `batched=True` to the `map(...)` function so that the mapping function has access to all transcriptions at once. ```python def extract_all_chars(batch): all_text = " ".join(batch["sentence"]) vocab = list(set(all_text)) return {"vocab": [vocab], "all_text": [all_text]} ``` ```python vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names) vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names) ``` Now, we create the union of all distinct letters in the training dataset and test dataset and convert the resulting list into an enumerated dictionary. ```python vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0])) ``` ```python vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))} vocab_dict ``` ```bash {' ': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26, 'ç': 27, 'ë': 28, 'ö': 29, 'ü': 30, 'ğ': 31, 'ı': 32, 'ş': 33, '̇': 34} ``` Cool, we see that all letters of the alphabet occur in the dataset (which is not really surprising) and we also extracted the special characters `""` and `'`. Note that we did not exclude those special characters because the model has to learn to predict when a word is finished, otherwise predictions would always be a sequence of letters that would make it impossible to separate words from each other. One should always keep in mind that pre-processing is a very important step before training your model. E.g., we don't want our model to differentiate between `a` and `A` just because we forgot to normalize the data. The difference between `a` and `A` does not depend on the "sound" of the letter at all, but more on grammatical rules - *e.g.* use a capitalized letter at the beginning of the sentence. So it is sensible to remove the difference between capitalized and non-capitalized letters so that the model has an easier time learning to transcribe speech. To make it clearer that `" "` has its own token class, we give it a more visible character `|`. In addition, we also add an "unknown" token so that the model can later deal with characters not encountered in Common Voice's training set. ```python vocab_dict["|"] = vocab_dict[" "] del vocab_dict[" "] ``` Finally, we also add a padding token that corresponds to CTC's "*blank token*". The "blank token" is a core component of the CTC algorithm. For more information, please take a look at the "Alignment" section [here](https://distill.pub/2017/ctc/). ```python vocab_dict["[UNK]"] = len(vocab_dict) vocab_dict["[PAD]"] = len(vocab_dict) len(vocab_dict) ``` ```bash 37 ``` Cool, now our vocabulary is complete and consists of 37 tokens, which means that the linear layer that we will add on top of the pretrained MMS checkpoint as part of the adapter weights will have an output dimension of 37. Since a single MMS checkpoint can provide customized weights for multiple languages, the tokenizer can also consist of multiple vocabularies. Therefore, we need to nest our `vocab_dict` to potentially add more languages to the vocabulary in the future. The dictionary should be nested with the name that is used for the adapter weights and that is saved in the tokenizer config under the name [`target_lang`](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2CTCTokenizer.target_lang). Let's use the ISO-639-3 language codes like the original [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) checkpoint. ```python target_lang = "tur" ``` Let's define an empty dictionary to which we can append the just created vocabulary ```python new_vocab_dict = {target_lang: vocab_dict} ``` **Note**: In case you want to use this notebook to add a new adapter layer to *an existing model repo* make sure to **not** create an empty, new vocab dict, but instead re-use one that already exists. To do so you should uncomment the following cells and replace `"patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"` with a model repo id to which you want to add your adapter weights. ```python # from transformers import Wav2Vec2CTCTokenizer # mms_adapter_repo = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" # make sure to replace this path with a repo to which you want to add your new adapter weights # tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(mms_adapter_repo) # new_vocab = tokenizer.vocab # new_vocab[target_lang] = vocab_dict ``` Let's now save the vocabulary as a json file. ```python import json with open('vocab.json', 'w') as vocab_file: json.dump(new_vocab_dict, vocab_file) ``` In a final step, we use the json file to load the vocabulary into an instance of the `Wav2Vec2CTCTokenizer` class. ```python from transformers import Wav2Vec2CTCTokenizer tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|", target_lang=target_lang) ``` If one wants to re-use the just created tokenizer with the fine-tuned model of this notebook, it is strongly advised to upload the `tokenizer` to the [🤗 Hub](https://huggingface.co/). Let's call the repo to which we will upload the files `"wav2vec2-large-mms-1b-turkish-colab"`: ```python repo_name = "wav2vec2-large-mms-1b-turkish-colab" ``` and upload the tokenizer to the [🤗 Hub](https://huggingface.co/). ```python tokenizer.push_to_hub(repo_name) ``` ```bash CommitInfo(commit_url='https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/commit/48cccbfd6059aa6ce655e9d94b8358ba39536cb7', commit_message='Upload tokenizer', commit_description='', oid='48cccbfd6059aa6ce655e9d94b8358ba39536cb7', pr_url=None, pr_revision=None, pr_num=None) ``` Great, you can see the just created repository under `https://huggingface.co/<your-username>/wav2vec2-large-mms-1b-tr-colab` ### Create `Wav2Vec2FeatureExtractor` Speech is a continuous signal and to be treated by computers, it first has to be discretized, which is usually called **sampling**. The sampling rate hereby plays an important role in that it defines how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the *real* speech signal but also necessitates more values per second. A pretrained checkpoint expects its input data to have been sampled more or less from the same distribution as the data it was trained on. The same speech signals sampled at two different rates have a very different distribution, *e.g.*, doubling the sampling rate results in twice as many data points. Thus, before fine-tuning a pretrained checkpoint of an ASR model, it is crucial to verify that the sampling rate of the data that was used to pretrain the model matches the sampling rate of the dataset used to fine-tune the model. A `Wav2Vec2FeatureExtractor` object requires the following parameters to be instantiated: - `feature_size`: Speech models take a sequence of feature vectors as an input. While the length of this sequence obviously varies, the feature size should not. In the case of Wav2Vec2, the feature size is 1 because the model was trained on the raw speech signal \\( {}^2 \\). - `sampling_rate`: The sampling rate at which the model is trained on. - `padding_value`: For batched inference, shorter inputs need to be padded with a specific value - `do_normalize`: Whether the input should be *zero-mean-unit-variance* normalized or not. Usually, speech models perform better when normalizing the input - `return_attention_mask`: Whether the model should make use of an `attention_mask` for batched inference. In general, XLS-R models checkpoints should **always** use the `attention_mask`. ```python from transformers import Wav2Vec2FeatureExtractor feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True) ``` Great, MMS's feature extraction pipeline is thereby fully defined! For improved user-friendliness, the feature extractor and tokenizer are *wrapped* into a single `Wav2Vec2Processor` class so that one only needs a `model` and `processor` object. ```python from transformers import Wav2Vec2Processor processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer) ``` Next, we can prepare the dataset. ### Preprocess Data So far, we have not looked at the actual values of the speech signal but just the transcription. In addition to `sentence`, our datasets include two more column names `path` and `audio`. `path` states the absolute path of the audio file and `audio` represent already loaded audio data. MMS expects the input in the format of a 1-dimensional array of 16 kHz. This means that the audio file has to be loaded and resampled. Thankfully, `datasets` does this automatically when the column name is `audio`. Let's try it out. ```python common_voice_train[0]["audio"] ``` ```bash {'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3', 'array': array([ 0.00000000e+00, -2.98378618e-13, -1.59835903e-13, ..., -2.01663317e-12, -1.87991593e-12, -1.17969588e-12]), 'sampling_rate': 48000} ``` In the example above we can see that the audio data is loaded with a sampling rate of 48kHz whereas the model expects 16kHz, as we saw. We can set the audio feature to the correct sampling rate by making use of [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column): ```python common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000)) common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000)) ``` Let's take a look at `"audio"` again. ```python common_voice_train[0]["audio"] ``` {'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3', 'array': array([ 9.09494702e-13, -6.13908924e-12, -1.09139364e-11, ..., 1.81898940e-12, 4.54747351e-13, 3.63797881e-12]), 'sampling_rate': 16000} This seemed to have worked! Let's do a final check that the data is correctly prepared, by printing the shape of the speech input, its transcription, and the corresponding sampling rate. ```python rand_int = random.randint(0, len(common_voice_train)-1) print("Target text:", common_voice_train[rand_int]["sentence"]) print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape) print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"]) ``` ```bash Target text: bağış anlaşması bir ağustosta imzalandı Input array shape: (70656,) Sampling rate: 16000 ``` Good! Everything looks fine - the data is a 1-dimensional array, the sampling rate always corresponds to 16kHz, and the target text is normalized. Finally, we can leverage `Wav2Vec2Processor` to process the data to the format expected by `Wav2Vec2ForCTC` for training. To do so let's make use of Dataset's [`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map) function. First, we load and resample the audio data, simply by calling `batch["audio"]`. Second, we extract the `input_values` from the loaded audio file. In our case, the `Wav2Vec2Processor` only normalizes the data. For other speech models, however, this step can include more complex feature extraction, such as [Log-Mel feature extraction](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum). Third, we encode the transcriptions to label ids. **Note**: This mapping function is a good example of how the `Wav2Vec2Processor` class should be used. In "normal" context, calling `processor(...)` is redirected to `Wav2Vec2FeatureExtractor`'s call method. When wrapping the processor into the `as_target_processor` context, however, the same method is redirected to `Wav2Vec2CTCTokenizer`'s call method. For more information please check the [docs](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#transformers.Wav2Vec2Processor.__call__). ```python def prepare_dataset(batch): audio = batch["audio"] # batched output is "un-batched" batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0] batch["input_length"] = len(batch["input_values"]) batch["labels"] = processor(text=batch["sentence"]).input_ids return batch ``` Let's apply the data preparation function to all examples. ```python common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names) common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names) ``` **Note**: `datasets` automatically takes care of audio loading and resampling. If you wish to implement your own costumized data loading/sampling, feel free to just make use of the `"path"` column instead and disregard the `"audio"` column. Awesome, now we are ready to start training! ## Training The data is processed so that we are ready to start setting up the training pipeline. We will make use of 🤗's [Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer) for which we essentially need to do the following: - Define a data collator. In contrast to most NLP models, MMS has a much larger input length than output length. *E.g.*, a sample of input length 50000 has an output length of no more than 100. Given the large input sizes, it is much more efficient to pad the training batches dynamically meaning that all training samples should only be padded to the longest sample in their batch and not the overall longest sample. Therefore, fine-tuning MMS requires a special padding data collator, which we will define below - Evaluation metric. During training, the model should be evaluated on the word error rate. We should define a `compute_metrics` function accordingly - Load a pretrained checkpoint. We need to load a pretrained checkpoint and configure it correctly for training. - Define the training configuration. After having fine-tuned the model, we will correctly evaluate it on the test data and verify that it has indeed learned to correctly transcribe speech. ### Set-up Trainer Let's start by defining the data collator. The code for the data collator was copied from [this example](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219). Without going into too many details, in contrast to the common data collators, this data collator treats the `input_values` and `labels` differently and thus applies two separate padding functions on them (again making use of MMS processor's context manager). This is necessary because, in speech recognition, input and output are of different modalities so they should not be treated by the same padding function. Analogous to the common data collators, the padding tokens in the labels with `-100` so that those tokens are **not** taken into account when computing the loss. ```python import torch from dataclasses import dataclass, field from typing import Any, Dict, List, Optional, Union @dataclass class DataCollatorCTCWithPadding: """ Data collator that will dynamically pad the inputs received. Args: processor (:class:`~transformers.Wav2Vec2Processor`) The processor used for proccessing the data. padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`): Select a strategy to pad the returned sequences (according to the model's padding side and padding index) among: * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single sequence if provided). * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the maximum acceptable input length for the model if that argument is not provided. * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different lengths). """ processor: Wav2Vec2Processor padding: Union[bool, str] = True def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]: # split inputs and labels since they have to be of different lenghts and need # different padding methods input_features = [{"input_values": feature["input_values"]} for feature in features] label_features = [{"input_ids": feature["labels"]} for feature in features] batch = self.processor.pad( input_features, padding=self.padding, return_tensors="pt", ) labels_batch = self.processor.pad( labels=label_features, padding=self.padding, return_tensors="pt", ) # replace padding with -100 to ignore loss correctly labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100) batch["labels"] = labels return batch ``` ```python data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True) ``` Next, the evaluation metric is defined. As mentioned earlier, the predominant metric in ASR is the word error rate (WER), hence we will use it in this notebook as well. ```python from evaluate import load wer_metric = load("wer") ``` The model will return a sequence of logit vectors: \\( \mathbf{y}_1, \ldots, \mathbf{y}_m \\) with \\( \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] \\) and \\( n >> m \\). A logit vector \\( \mathbf{y}_1 \\) contains the log-odds for each word in the vocabulary we defined earlier, thus \\( \text{len}(\mathbf{y}_i) = \\) `config.vocab_size`. We are interested in the most likely prediction of the model and thus take the `argmax(...)` of the logits. Also, we transform the encoded labels back to the original string by replacing `-100` with the `pad_token_id` and decoding the ids while making sure that consecutive tokens are **not** grouped to the same token in CTC style \\( {}^1 \\). ```python def compute_metrics(pred): pred_logits = pred.predictions pred_ids = np.argmax(pred_logits, axis=-1) pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id pred_str = processor.batch_decode(pred_ids) # we do not want to group tokens when computing the metrics label_str = processor.batch_decode(pred.label_ids, group_tokens=False) wer = wer_metric.compute(predictions=pred_str, references=label_str) return {"wer": wer} ``` Now, we can load the pretrained checkpoint of [`mms-1b-all`](https://huggingface.co/facebook/mms-1b-all). The tokenizer's `pad_token_id` must be to define the model's `pad_token_id` or in the case of `Wav2Vec2ForCTC` also CTC's *blank token* \\( {}^2 \\). Since, we're only training a small subset of weights, the model is not prone to overfitting. Therefore, we make sure to disable all dropout layers. **Note**: When using this notebook to train MMS on another language of Common Voice those hyper-parameter settings might not work very well. Feel free to adapt those depending on your use case. ```python from transformers import Wav2Vec2ForCTC model = Wav2Vec2ForCTC.from_pretrained( "facebook/mms-1b-all", attention_dropout=0.0, hidden_dropout=0.0, feat_proj_dropout=0.0, layerdrop=0.0, ctc_loss_reduction="mean", pad_token_id=processor.tokenizer.pad_token_id, vocab_size=len(processor.tokenizer), ignore_mismatched_sizes=True, ) ``` ```bash Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match: - lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([39]) in the model instantiated - lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([39, 1280]) in the model instantiated You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. ``` **Note**: It is expected that some weights are newly initialized. Those weights correspond to the newly initialized vocabulary output layer. We now want to make sure that only the adapter weights will be trained and that the rest of the model stays frozen. First, we re-initialize all the adapter weights which can be done with the handy `init_adapter_layers` method. It is also possible to not re-initilize the adapter weights and continue fine-tuning, but in this case one should make sure to load fitting adapter weights via the [`load_adapter(...)` method](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.load_adapter) before training. Often the vocabulary still will not match the custom training data very well though, so it's usually easier to just re-initialize all adapter layers so that they can be easily fine-tuned. ```python model.init_adapter_layers() ``` Next, we freeze all weights, **but** the adapter layers. ```python model.freeze_base_model() adapter_weights = model._get_adapters() for param in adapter_weights.values(): param.requires_grad = True ``` In a final step, we define all parameters related to training. To give more explanation on some of the parameters: - `group_by_length` makes training more efficient by grouping training samples of similar input length into one batch. This can significantly speed up training time by heavily reducing the overall number of useless padding tokens that are passed through the model - `learning_rate` was chosen to be 1e-3 which is a common default value for training with Adam. Other learning rates might work equally well. For more explanations on other parameters, one can take a look at the [docs](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments). To save GPU memory, we enable PyTorch's [gradient checkpointing](https://pytorch.org/docs/stable/checkpoint.html) and also set the loss reduction to "*mean*". MMS adapter fine-tuning converges extremely fast to very good performance, so even for a dataset as small as 4h we will only train for 4 epochs. During training, a checkpoint will be uploaded asynchronously to the hub every 200 training steps. It allows you to also play around with the demo widget even while your model is still training. **Note**: If one does not want to upload the model checkpoints to the hub, simply set `push_to_hub=False`. ```python from transformers import TrainingArguments training_args = TrainingArguments( output_dir=repo_name, group_by_length=True, per_device_train_batch_size=32, evaluation_strategy="steps", num_train_epochs=4, gradient_checkpointing=True, fp16=True, save_steps=200, eval_steps=100, logging_steps=100, learning_rate=1e-3, warmup_steps=100, save_total_limit=2, push_to_hub=True, ) ``` Now, all instances can be passed to Trainer and we are ready to start training! ```python from transformers import Trainer trainer = Trainer( model=model, data_collator=data_collator, args=training_args, compute_metrics=compute_metrics, train_dataset=common_voice_train, eval_dataset=common_voice_test, tokenizer=processor.feature_extractor, ) ``` ------------------------------------------------------------------------ \\( {}^1 \\) To allow models to become independent of the speaker rate, in CTC, consecutive tokens that are identical are simply grouped as a single token. However, the encoded labels should not be grouped when decoding since they don't correspond to the predicted tokens of the model, which is why the `group_tokens=False` parameter has to be passed. If we wouldn't pass this parameter a word like `"hello"` would incorrectly be encoded, and decoded as `"helo"`. \\( {}^2 \\) The blank token allows the model to predict a word, such as `"hello"` by forcing it to insert the blank token between the two l's. A CTC-conform prediction of `"hello"` of our model would be `[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]`. ### Training Training should take less than 30 minutes depending on the GPU used. ```python trainer.train() ``` | Training Loss | Training Steps | Validation Loss | Wer | |:-------------:|:----:|:---------------:|:------:| | 4.905 | 100 | 0.215| 0.280 | | 0.290 | 200 | 0.167 | 0.232 | | 0.2659 | 300 | 0.161 | 0.229 | | 0.2398 | 400 | 0.156 | 0.223 | The training loss and validation WER go down nicely. We see that fine-tuning adapter layers of `mms-1b-all` for just 100 steps outperforms fine-tuning the whole `xls-r-300m` checkpoint shown [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2#training-1) already by a large margin. From the [official paper](https://scontent-cdg4-3.xx.fbcdn.net/v/t39.8562-6/348827959_6967534189927933_6819186233244071998_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=ad8a9d&_nc_ohc=fSo3qQ7uxr0AX8EWnWl&_nc_ht=scontent-cdg4-3.xx&oh=00_AfBL34K0MAAPb0CgnthjbHfiB6pSnnwbn5esj9DZVPvyoA&oe=6495E802) and this quick comparison it becomes clear that `mms-1b-all` has a much higher capability of transfering knowledge to a low-resource language and should be preferred over `xls-r-300m`. In addition, training is also more memory-efficient as only a small subset of layers are trained. The adapter weights will be uploaded as part of the model checkpoint, but we also want to make sure to save them seperately so that they can easily be off- and onloaded. Let's save all the adapter layers into the training output dir so that it can be correctly uploaded to the Hub. ```python from safetensors.torch import save_file as safe_save_file from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE import os adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(target_lang) adapter_file = os.path.join(training_args.output_dir, adapter_file) safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"}) ``` Finally, you can upload the result of the training to the 🤗 Hub. ```python trainer.push_to_hub() ``` One of the main advantages of adapter weights training is that the "base" model which makes up roughly 99% of the model weights is kept unchanged and only a small [2.5M adapter checkpoint](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.tur.safetensors) has to be shared in order to use the trained checkpoint. This makes it extremely simple to train additional adapter layers and add them to your repository. You can do so very easily by simply re-running this script and changing the language you would like to train on to a different one, *e.g.* `swe` for Swedish. In addition, you should make sure that the vocabulary does not get completely overwritten but that the new language vocabulary is **appended** to the existing one as stated above in the commented out cells. To demonstrate how different adapter layers can be loaded, I have trained and uploaded also an adapter layer for Swedish under the iso language code `swe` as you can see [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.swe.safetensors) You can load the fine-tuned checkpoint as usual by using `from_pretrained(...)`, but you should make sure to also add a `target_lang="<your-lang-code>"` to the method so that the correct adapter is loaded. You should also set the target language correctly for your tokenizer. Let's see how we can load the Turkish checkpoint first. ```python model_id = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang="tur").to("cuda") processor = Wav2Vec2Processor.from_pretrained(model_id) processor.tokenizer.set_target_lang("tur") ``` Let's check that the model can correctly transcribe Turkish ```python from datasets import Audio common_voice_test_tr = load_dataset("mozilla-foundation/common_voice_6_1", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True) common_voice_test_tr = common_voice_test_tr.cast_column("audio", Audio(sampling_rate=16_000)) ``` Let's process the audio, run a forward pass and predict the ids ```python input_dict = processor(common_voice_test_tr[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True) logits = model(input_dict.input_values.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1)[0] ``` Finally, we can decode the example. ```python print("Prediction:") print(processor.decode(pred_ids)) print("\nReference:") print(common_voice_test_tr[0]["sentence"].lower()) ``` **Output**: ```bash Prediction: pekçoğuda roman toplumundan geliyor Reference: pek çoğu da roman toplumundan geliyor. ``` This looks like it's almost exactly right, just two empty spaces should have been added in the first word. Now it is very simple to change the adapter to Swedish by calling [`model.load_adapter(...)`](mozilla-foundation/common_voice_6_1) and by changing the tokenizer to Swedish as well. ```python model.load_adapter("swe") processor.tokenizer.set_target_lang("swe") ``` We again load the Swedish test set from common voice ```python common_voice_test_swe = load_dataset("mozilla-foundation/common_voice_6_1", "sv-SE", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True) common_voice_test_swe = common_voice_test_swe.cast_column("audio", Audio(sampling_rate=16_000)) ``` and transcribe a sample: ```python input_dict = processor(common_voice_test_swe[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True) logits = model(input_dict.input_values.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1)[0] print("Prediction:") print(processor.decode(pred_ids)) print("\nReference:") print(common_voice_test_swe[0]["sentence"].lower()) ``` **Output**: ```bash Prediction: jag lämnade grovjobbet åt honom Reference: jag lämnade grovjobbet åt honom. ``` Great, this looks like a perfect transcription! We've shown in this blog post how MMS Adapter Weights fine-tuning not only gives state-of-the-art performance on low-resource languages, but also significantly speeds up training time and allows to easily build a collection of customized adapter weights. *Related posts and additional links are listed here:* - [**Official paper**](https://huggingface.co/papers/2305.13516) - [**Original cobebase**](https://github.com/facebookresearch/fairseq/tree/main/examples/mms/asr) - [**Official demo**](https://huggingface.co/spaces/facebook/MMS) - [**Transformers Docs**](https://huggingface.co/docs/transformers/index) - [**Related XLS-R blog post**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) - [**Models on the Hub**](https://huggingface.co/models?other=mms)
|
Panel on Hugging Face
|
sophiamyang
|
June 22, 2023
|
panel-on-hugging-face
|
open-source-collab, panel, deployment, spaces, visualization, apps
|
https://huggingface.co/blog/panel-on-hugging-face
|
# Panel on Hugging Face We are thrilled to announce the collaboration between Panel and Hugging Face! 🎉 We have integrated a Panel template in Hugging Face Spaces to help you get started building Panel apps and deploy them on Hugging Face effortlessly. <a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a> ## What does Panel offer? [Panel](https://panel.holoviz.org/) is an open-source Python library that lets you easily build powerful tools, dashboards and complex applications entirely in Python. It has a batteries-included philosophy, putting the PyData ecosystem, powerful data tables and much more at your fingertips. High-level reactive APIs and lower-level callback based APIs ensure you can quickly build exploratory applications, but you aren’t limited if you build complex, multi-page apps with rich interactivity. Panel is a member of the [HoloViz](https://holoviz.org/) ecosystem, your gateway into a connected ecosystem of data exploration tools. Panel, like the other HoloViz tools, is a NumFocus-sponsored project, with support from Anaconda and Blackstone. Here are some notable features of Panel that our users find valuable. - Panel provides extensive support for various plotting libraries, such as Matplotlib, Seaborn, Altair, Plotly, Bokeh, PyDeck,Vizzu, and more. - All interactivity works the same in Jupyter and in a standalone deployment. Panel allows seamless integration of components from a Jupyter notebook into a dashboard, enabling smooth transitions between data exploration and sharing results. - Panel empowers users to build complex multi-page applications, advanced interactive features, visualize large datasets, and stream real-time data. - Integration with Pyodide and WebAssembly enables seamless execution of Panel applications in web browsers. Ready to build Panel apps on Hugging Face? Check out our [Hugging Face deployment docs](https://panel.holoviz.org/how_to/deployment/huggingface.html#hugging-face), click this button, and begin your journey: <a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a> <a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel.png" style="width:70%"> </a> ## 🌐 Join Our Community The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us: - [Discord](https://discord.gg/aRFhC3Dz9w) - [Discourse](https://discourse.holoviz.org/) - [Twitter](https://twitter.com/Panel_Org) - [LinkedIn](https://www.linkedin.com/company/panel-org) - [Github](https://github.com/holoviz/panel)
|
What's going on with the Open LLM Leaderboard?
|
clefourrier
|
June 23, 2023
|
evaluating-mmlu-leaderboard
|
community, research, nlp, evaluation, leaderboard
|
https://huggingface.co/blog/evaluating-mmlu-leaderboard
|
# What's going on with the Open LLM Leaderboard? Recently an interesting discussion arose on Twitter following the release of [**Falcon 🦅**](https://huggingface.co/tiiuae/falcon-40b) and its addition to the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), a public leaderboard comparing open access large language models. The discussion centered around one of the four evaluations displayed on the leaderboard: a benchmark for measuring [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300) (shortname: MMLU). The community was surprised that MMLU evaluation numbers of the current top model on the leaderboard, the [**LLaMA model 🦙**](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/), were significantly lower than the numbers in the [published LLaMa paper](https://arxiv.org/abs/2302.13971). So we decided to dive in a rabbit hole to understand what was going on and how to fix it 🕳🐇 In our quest, we discussed with both the great [@javier-m](https://huggingface.co/javier-m) who collaborated on the evaluations of LLaMA and the amazing [@slippylolo](https://huggingface.co/slippylolo) from the Falcon team. This being said, all the errors in the below should be attributed to us rather than them of course! Along this journey with us you’ll learn a lot about the ways you can evaluate a model on a single evaluation and whether or not to believe the numbers you see online and in papers. Ready? Then buckle up, we’re taking off 🚀. ## What's the Open LLM Leaderboard? First, note that the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) is actually just a wrapper running the open-source benchmarking library [Eleuther AI LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) created by the [EleutherAI non-profit AI research lab](https://www.eleuther.ai/) famous for creating [The Pile](https://pile.eleuther.ai/) and training [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6b), [GPT-Neo-X 20B](https://huggingface.co/EleutherAI/gpt-neox-20b), and [Pythia](https://github.com/EleutherAI/pythia). A team with serious credentials in the AI space! This wrapper runs evaluations using the Eleuther AI harness on the spare cycles of Hugging Face’s compute cluster, and stores the results in a dataset on the hub that are then displayed on the [leaderboard online space](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). For the LLaMA models, the MMLU numbers obtained with the [Eleuther AI LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) significantly differ from the MMLU numbers reported in the LLaMa paper. Why is that the case? ## 1001 flavors of MMLU Well it turns out that the LLaMA team adapted another code implementation available online: the evaluation code proposed by the original UC Berkeley team which developed the MMLU benchmark available at https://github.com/hendrycks/test and that we will call here the **"Original implementation"**. When diving further, we found yet another interesting implementation for evaluating on the very same MMLU dataset: the evalution code provided in Stanford’s [CRFM](https://crfm.stanford.edu/) very comprehensive evaluation benchmark [Holistic Evaluation of Language Models](https://crfm.stanford.edu/helm/latest/) that we will call here the **HELM implementation**. Both the EleutherAI Harness and Stanford HELM benchmarks are interesting because they gather many evaluations in a single codebase (including MMLU), and thus give a wide view of a model’s performance. This is the reason the Open LLM Leaderboard is wrapping such “holistic” benchmarks instead of using individual code bases for each evaluation. To settle the case, we decided to run these three possible implementations of the same MMLU evaluation on a set of models to rank them according to these results: - the Harness implementation ([commit e47e01b](https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4)) - the HELM implementation ([commit cab5d89](https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec)) - the Original implementation (with Hugging Face integration by the amazing [@olmer](https://huggingface.co/olmer) at https://github.com/hendrycks/test/pull/13) (Note that the Harness implementation has been recently updated - more in this at the end of our post) The results are surprising:  You can find the full evaluation numbers at the end of the post. These different implementations of the same benchmark give widely different numbers and even change the ranking order of the models on the leaderboard! Let’s try to understand where this discrepancy comes from 🕵️But first, let’s briefly understand how we can automatically evaluate behaviors in modern LLMs. ## How we automatically evaluate a model in today’s LLM world MMLU is a multiple choice question test, so a rather simple benchmark (versus open-ended questions) but as we’ll see, this still leaves a lot of room for implementation details and differences. The benchmark consists of questions with four possible answers covering 57 general knowledge domains grouped in coarse grained categories: “Humanities”, “Social Sciences”, “STEM”, etc For each question, only one of the provided answers is the correct one. Here is an example: ``` Question: Glucose is transported into the muscle cell: Choices: A. via protein transporters called GLUT4. B. only in the presence of insulin. C. via hexokinase. D. via monocarbylic acid transporters. Correct answer: A ``` Note: you can very easily explore more of this dataset [in the dataset viewer](https://huggingface.co/datasets/cais/mmlu/viewer/college_medicine/dev?row=0) on the hub. Large language models are simple models in the AI model zoo. They take a *string of text* as input (called a “prompt”), which is cut into tokens (words, sub-words or characters, depending on how the model is built) and fed in the model. From this input, they generate a distribution of probability for the next token, over all the tokens they know (so called the “vocabulary” of the model): you can therefore get how `probable’ any token is as a continuation of the input prompt. We can use these probabilities to choose a token, for instance the most probable (or we can introduce some slight noise with a sampling to avoid having “too mechanical” answers). Adding our selected token to the prompt and feeding it back to the model allows to generate another token and so on until whole sentences are created as continuations of the input prompt:  This is how ChatGPT or Hugging Chat generate answers. In summary, we have two main ways to get information out of a model to evaluate it: 1. get the **probabilities** that some specific tokens groups are continuations of the prompt – and **compare these probabilities together** for our predefined possible choices; 2. get a **text generation** from the model (by repeatedly selecting tokens as we’ve seen) – and **compare these text generations** to the texts of various predefined possible choices. Armed with this knowledge, let's dive into our three implementations of MMLU, to find out what input is sent to models, what is expected as outputs, and how these outputs are compared. ## MMLU comes in all shapes and sizes: Looking at the prompts Let’s compare an example of prompt each benchmark sends to the models by each implementation for the same MMLU dataset example: <div> <table><p> <tbody> <tr style="text-align: left;"> <td>Original implementation <a href="https://github.com/hendrycks/test/pull/13">Ollmer PR</a></td> <td>HELM <a href="https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec">commit cab5d89</a> </td> <td>AI Harness <a href="https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4">commit e47e01b</a></td> </tr> <tr style=" vertical-align: top;"> <td>The following are multiple choice questions (with answers) about us foreign policy. <br> How did the 2008 financial crisis affect America's international reputation? <br> A. It damaged support for the US model of political economy and capitalism <br> B. It created anger at the United States for exaggerating the crisis <br> C. It increased support for American global leadership under President Obama <br> D. It reduced global use of the US dollar <br> Answer: </td> <td>The following are multiple choice questions (with answers) about us foreign policy. <br> <br> Question: How did the 2008 financial crisis affect America's international reputation? <br> A. It damaged support for the US model of political economy and capitalism <br> B. It created anger at the United States for exaggerating the crisis <br> C. It increased support for American global leadership under President Obama <br> D. It reduced global use of the US dollar <br> Answer: </td> <td>Question: How did the 2008 financial crisis affect America's international reputation? <br> Choices: <br> A. It damaged support for the US model of political economy and capitalism <br> B. It created anger at the United States for exaggerating the crisis <br> C. It increased support for American global leadership under President Obama <br> D. It reduced global use of the US dollar <br> Answer: </td> </tr> </tbody> </table><p> </div> The differences between them can seem small, did you spot them all? Here they are: - First sentence, instruction, and topic: Few differences. HELM adds an extra space, and the Eleuther LM Harness does not include the topic line - Question: HELM and the LM Harness add a “Question:” prefix - Choices: Eleuther LM Harness prepends them with the keyword “Choices” ## Now how do we evaluate the model from these prompts? Let’s start with how the [original MMLU implementation](https://github.com/hendrycks/test/pull/13) extracts the predictions of the model. In the original implementation we compare the probabilities predicted by the model, on the four answers only:  This can be beneficial for the model in some case, for instance, as you can see here: 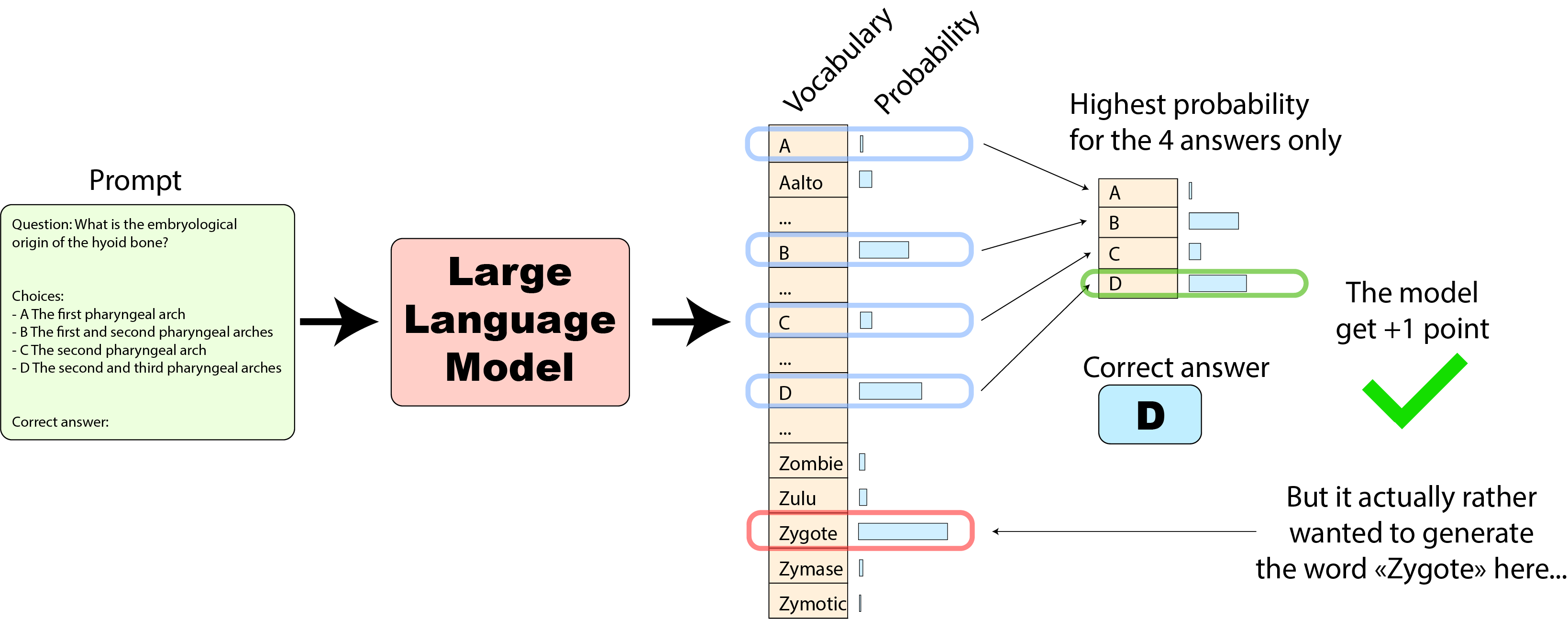 In this case, the model got a +1 score for ranking the correct answer highest among the 4 options. But if we take a look at the full vocabulary it would have rather generated a word outside of our four options: the word “Zygote” (this is more of an example than a real use case 🙂) How can we make sure that the model does as few as possible of these types of errors? We can use a “**few shots**” approach in which we provide the model with one or several examples in the prompt, with their expected answers as well. Here is how it looks: 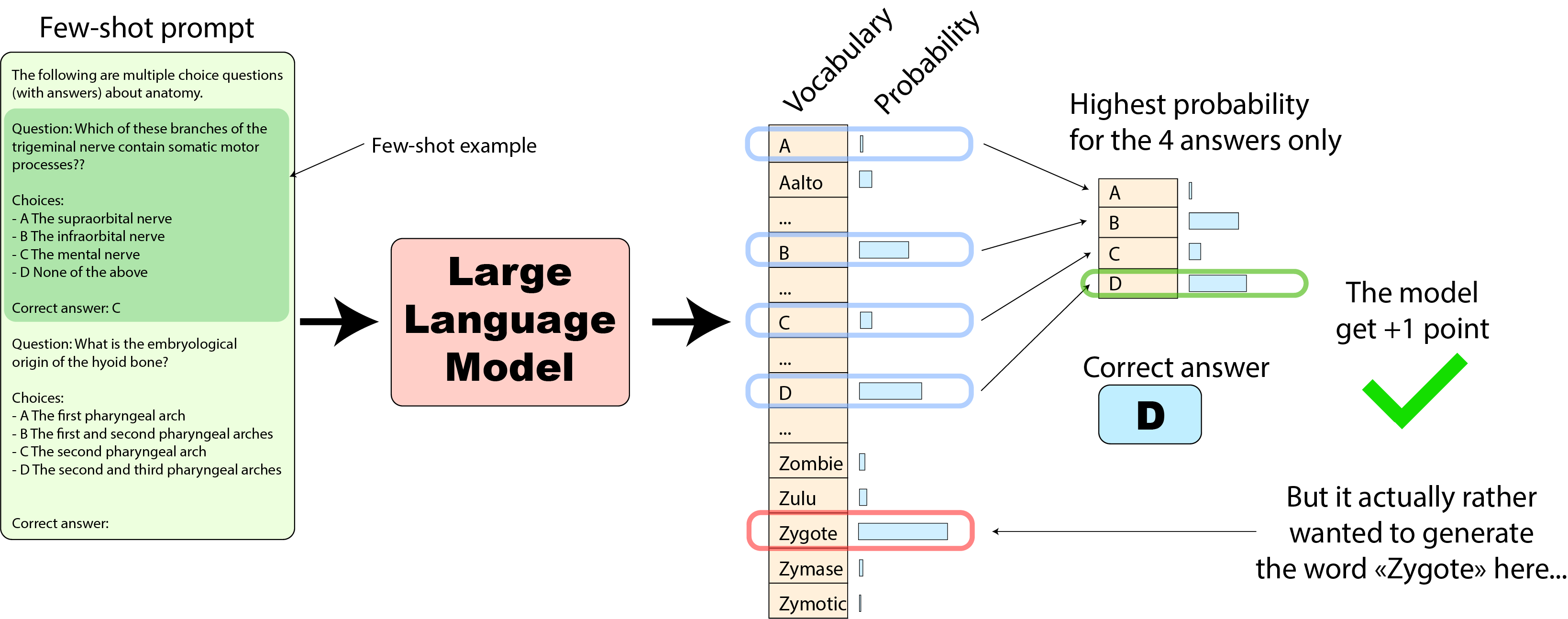 Here, the model has one example of the expected behavior and is thus less likely to predict answers outside of the expected range of answers. Since this improves performance, MMLU is typically evaluated in 5 shots (prepending 5 examples to each prompt) in all our evaluations: the original implementation, EleutherAI LM Harness and HELM. (Note: Across benchmarks, though the same 5 examples are used, their order of introduction to the model can vary, which is also a possible source of difference, that we will not investigate here. You also obviously have to pay attention to avoid leaking some answers in the few shot examples you use…) **HELM:** Let’s now turn to the [HELM implementation](https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec). While the few-shot prompt is generally similar, the way the model is evaluated is quite different from the original implementation we’ve just seen: we use the next token output probabilities from the model to select a text generation and we compare it to the text of the expected answer as displayed here: 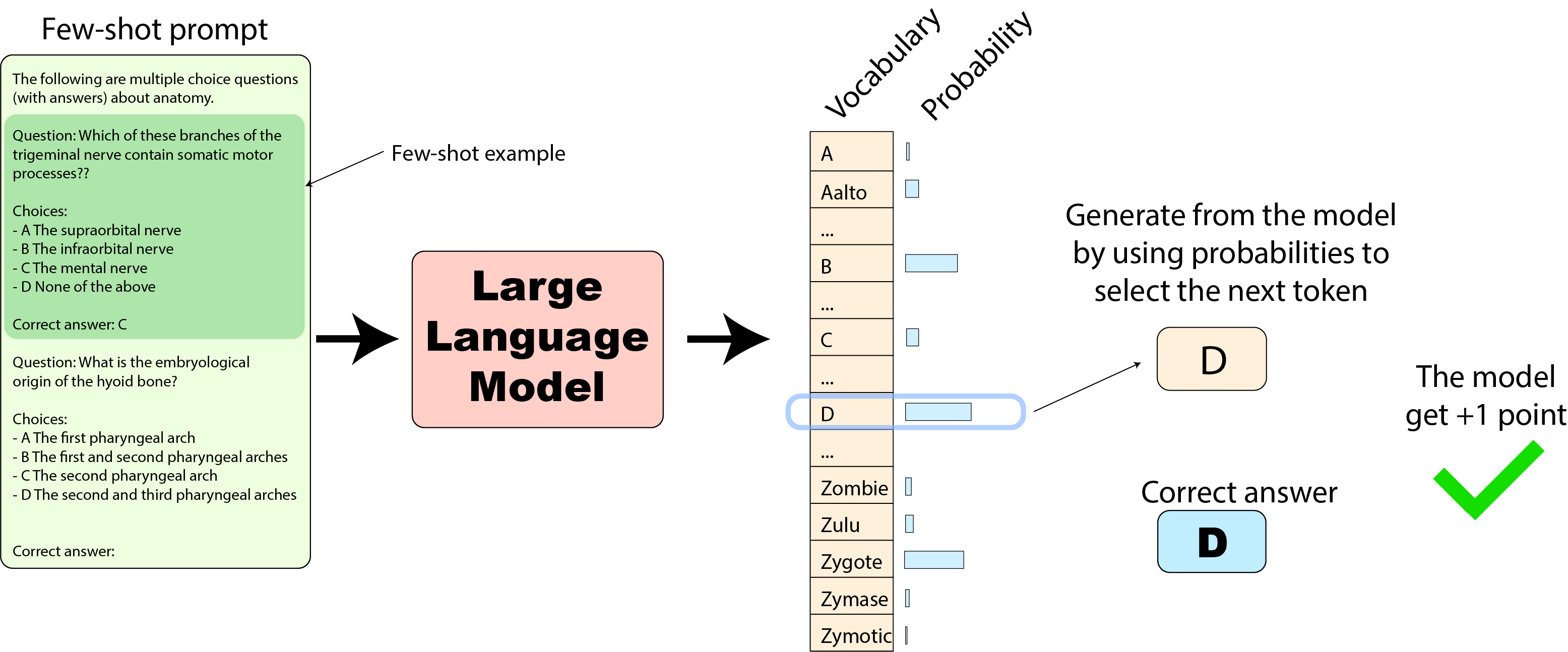 In this case, if our "Zygote" token was instead the highest probability one (as we’ve seen above), the model answer ("Zygote") would be wrong and the model would not score any points for this question: 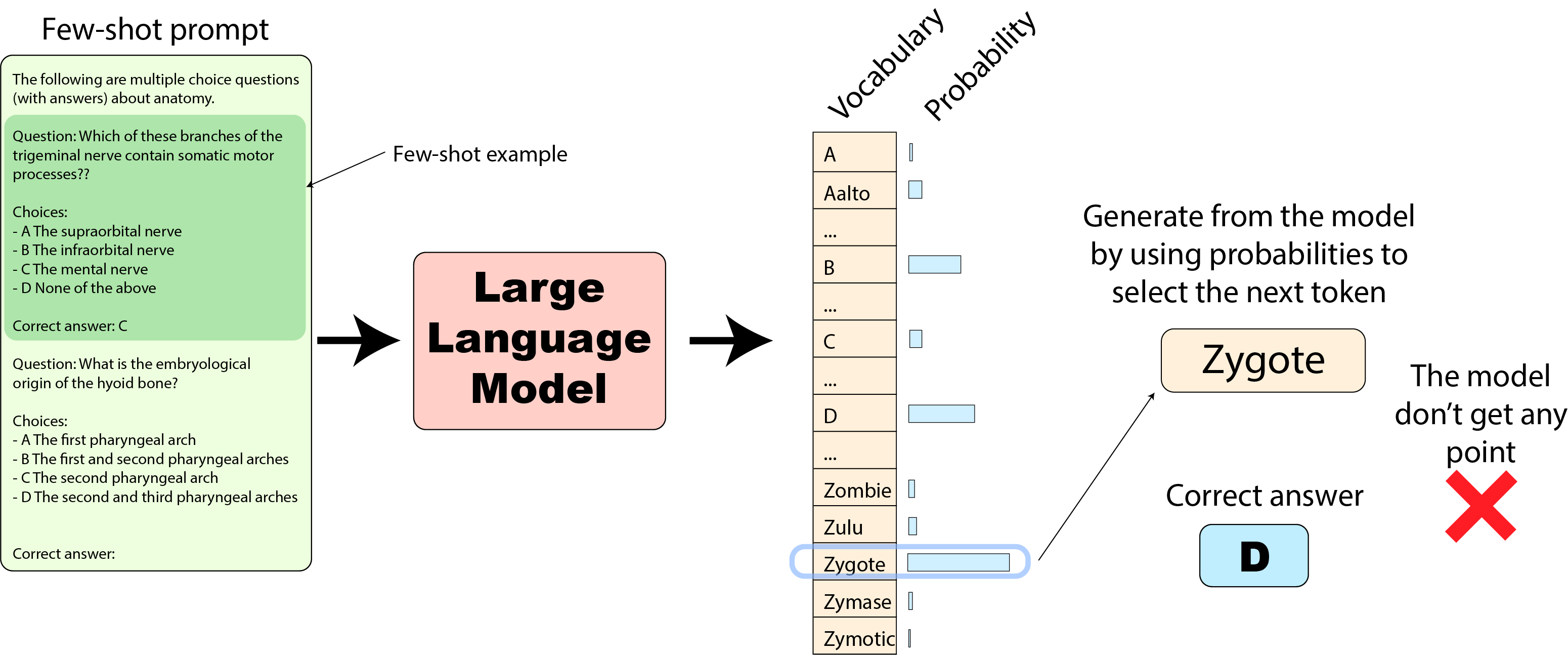 **Harness:** Now we finally turn to the - [EleutherAI Harness implementation as of January 2023](https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4) which was used to compute the first numbers for the leaderboard. As we will see, we’ve got here yet another way to compute a score for the model on the very same evaluation dataset (note that this implementation has been recently updated - more on this at the end). In this case, we are using the probabilities again but this time the probabilities of the full answer sequence, with the letter followed by the text of the answer, for instance “C. The second pharyngeal arch”. To compute the probability for a full answer we get the probability for each token (like we saw above) and gather them. For numerical stability we gather them by summing the logarithm of the probabilities and we can decide (or not) to compute a normalization in which we divide the sum by the number of tokens to avoid giving too much advantage to longer answers (more on this later). Here is how it looks like: 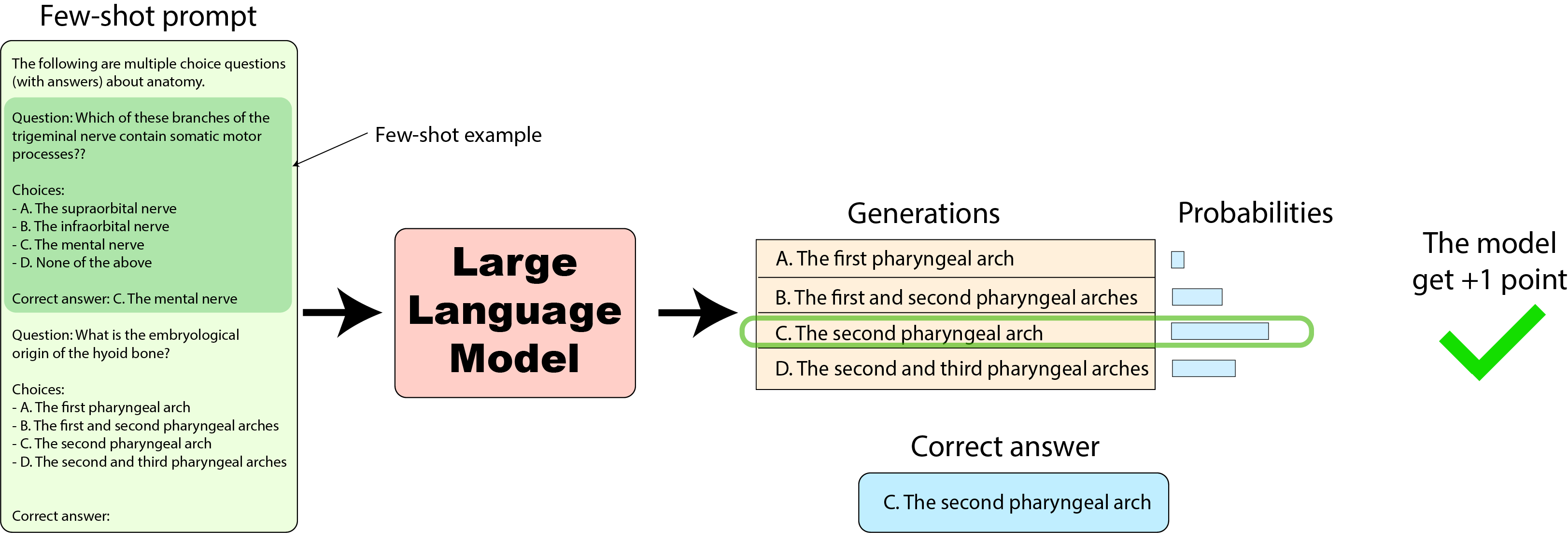 Here is a table summary of the answers provided and generated by the model to summarize what we’ve seen up to now: <div> <table><p> <tbody> <tr style="text-align: left;"> <td>Original implementation</td> <td>HELM</td> <td>AI Harness (as of Jan 2023)</td> </tr> <tr style=" vertical-align: top;"> <td> We compare the probabilities of the following letter answers: </td> <td>The model is expected to generate as text the following letter answer: </td> <td>We compare the probabilities of the following full answers: </td> </tr> <tr style=" vertical-align: top;"> <td> A <br> B <br> C <br> D </td> <td>A </td> <td> A. It damaged support for the US model of political economy and capitalism <br> B. It created anger at the United States for exaggerating the crisis <br> C. It increased support for American global leadership under President Obama <br> D. It reduced global use of the US dollar </td> </tr> </tbody> </table><p> </div> We’ve covered them all! Now let’s compare the model scores on these three possible ways to evaluate the models: | | MMLU (HELM) | MMLU (Harness) | MMLU (Original) | |:------------------------------------------|------------:|---------------:|----------------:| | llama-65b | **0.637** | 0.488 | **0.636** | | tiiuae/falcon-40b | 0.571 | **0.527** | 0.558 | | llama-30b | 0.583 | 0.457 | 0.584 | | EleutherAI/gpt-neox-20b | 0.256 | 0.333 | 0.262 | | llama-13b | 0.471 | 0.377 | 0.47 | | llama-7b | 0.339 | 0.342 | 0.351 | | tiiuae/falcon-7b | 0.278 | 0.35 | 0.254 | | togethercomputer/RedPajama-INCITE-7B-Base | 0.275 | 0.34 | 0.269 | We can see that for the same dataset, both absolute scores and model rankings (see the first figure) are very sensitive to the evaluation method we decide to use. Let's say you've trained yourself a perfect reproduction of the LLaMA 65B model and evaluated it with the harness (score 0.488, see above). You're now comparing it to the published number (evaluated on the original MMLU implementation so with a score 0.637). With such a 30% difference in score you're probably thinking: "Oh gosh, I have completly messed up my training 😱". But nothing could be further from the truth, these are just numbers which are not at all comparable even if they're both labelled as "MMLU score" (and evaluated on the very same MMLU dataset). Now, is there a "best way" to evaluate a model among all the ones we've seen? It's a tricky question. Different models may fare differently when evaluated one way or another as we see above when the rankings change. To keep this as fair as possible, one may be tempted to select an implementation where the average score for all tested models is the highest so that we "unlock" as many capabilities as possible from the models. In our case, that would mean using the log-likelihood option of the original implementation. But as we saw above, using the log-likelihood is also giving some indications to the model in some way by restricting the scope of possible answers, and thus is helping the less powerful models maybe too much. Also log-likelihood is easy to access for open-source models but is not always exposed for closed source API models. And you, reader, what do you think? This blog post is already long so it's time to open the discussion and invite your comments. Please come discuss this topic in the following discussion thread of the Open LLM Leaderboard: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/82 ## Conclusion A key takeaway lesson from our journey is that evaluations are strongly tied to their implementations–down to minute details such as prompts and tokenization. The mere indication of "MMLU results" gives you little to no information about how you can compare these numbers to others you evaluated on another library. This is why open, standardized, and reproducible benchmarks such as the [EleutherAI Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness/) or [Stanford HELM](https://github.com/stanford-crfm/helm/) are invaluable to the community. Without them, comparing results across models and papers would be impossible, stifling research on improving LLMs. **Post scriptum**: In the case of the Open LLM Leaderboard we’ve decided to stick to using community maintained evaluation libraries. Thankfully during the writing of this blog post, the amazing community around the EleutherAI Harness, and in particular [ollmer](https://github.com/EleutherAI/lm-evaluation-harness/issues/475) have done an amazing work updating the evaluation of MMLU in the harness to make it similar to the original implementation and match these numbers. We are currently updating the full leaderboard with the updated version of the [EleutherAI Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness/), so expect to see scores coming from the Eleuther Harness v2 coming up in the next few weeks! (Running all the models again will take some time, stay tuned :hugs:) ## Acknowledgements: We are very grateful to Xavier Martinet, Aurélien Rodriguez and Sharan Narang from the LLaMA team for helpful suggestions in this blog post as well as having answered all our questions. ## Reproducibility hashes: Here are the commit hashes of the various code implementations used in this blog post. - EleutherAI LM harness implementation commit e47e01b: https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4 - HELM implementation commit cab5d89: https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec - Original MMLU implementation (with Hugging Face integration by the amazing [@olmer](https://huggingface.co/olmer)): https://github.com/hendrycks/test/pull/13
|
Ethics and Society Newsletter #4: Bias in Text-to-Image Models
|
sasha
|
June 26, 2023
|
ethics-soc-4
|
ethics
|
https://huggingface.co/blog/ethics-soc-4
|
# Ethics and Society Newsletter #4: Bias in Text-to-Image Models **TL;DR: We need better ways of evaluating bias in text-to-image models** ## Introduction [Text-to-image (TTI) generation](https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads) is all the rage these days, and thousands of TTI models are being uploaded to the Hugging Face Hub. Each modality is potentially susceptible to separate sources of bias, which begs the question: how do we uncover biases in these models? In the current blog post, we share our thoughts on sources of bias in TTI systems as well as tools and potential solutions to address them, showcasing both our own projects and those from the broader community. ## Values and bias encoded in image generations There is a very close relationship between [bias and values](https://www.sciencedirect.com/science/article/abs/pii/B9780080885797500119), particularly when these are embedded in the language or images used to train and query a given [text-to-image model](https://dl.acm.org/doi/abs/10.1145/3593013.3594095); this phenomenon heavily influences the outputs we see in the generated images. Although this relationship is known in the broader AI research field and considerable efforts are underway to address it, the complexity of trying to represent the evolving nature of a given population's values in a single model still persists. This presents an enduring ethical challenge to uncover and address adequately. For example, if the training data are mainly in English they probably convey rather Western values. As a result we get stereotypical representations of different or distant cultures. This phenomenon appears noticeable when we compare the results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, "a house in Beijing": <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/ernie-sd.png" alt="results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, a house in Beijing" /> </p> ## Sources of Bias Recent years have seen much important research on bias detection in AI systems with single modalities in both Natural Language Processing ([Abid et al., 2021](https://dl.acm.org/doi/abs/10.1145/3461702.3462624)) as well as Computer Vision ([Buolamwini and Gebru, 2018](http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf)). To the extent that ML models are constructed by people, biases are present in all ML models (and, indeed, technology in general). This can manifest itself by an over- and under-representation of certain visual characteristics in images (e.g., all images of office workers having ties), or the presence of cultural and geographical stereotypes (e.g., all images of brides wearing white dresses and veils, as opposed to more representative images of brides around the world, such as brides with red saris). Given that AI systems are deployed in sociotechnical contexts that are becoming widely deployed in different sectors and tools (e.g. [Firefly](https://www.adobe.com/sensei/generative-ai/firefly.html), [Shutterstock](https://www.shutterstock.com/ai-image-generator)), they are particularly likely to amplify existing societal biases and inequities. We aim to provide a non-exhaustive list of bias sources below: **Biases in training data:** Popular multimodal datasets such as [LAION-5B](https://laion.ai/blog/laion-5b/) for text-to-image, [MS-COCO](https://cocodataset.org/) for image captioning, and [VQA v2.0](https://paperswithcode.com/dataset/visual-question-answering-v2-0) for visual question answering, have been found to contain numerous biases and harmful associations ([Zhao et al 2017](https://aclanthology.org/D17-1323/), [Prabhu and Birhane, 2021](https://arxiv.org/abs/2110.01963), [Hirota et al, 2022](https://facctconference.org/static/pdfs_2022/facct22-3533184.pdf)), which can percolate into the models trained on these datasets. For example, initial results from the [Hugging Face Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias) show a lack of diversity in image generations, as well as a perpetuation of common stereotypes of cultures and identity groups. Comparing Dall-E 2 generations of CEOs (right) and managers (left), we can see that both are lacking diversity: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/CEO_manager.png" alt="Dall-E 2 generations of CEOs (right) and managers (left)" /> </p> **Biases in pre-training data filtering:** There is often some form of filtering carried out on datasets before they are used for training models; this introduces different biases. For instance, in their [blog post](https://openai.com/research/dall-e-2-pre-training-mitigations), the creators of Dall-E 2 found that filtering training data can actually amplify biases – they hypothesize that this may be due to the existing dataset bias towards representing women in more sexualized contexts or due to inherent biases of the filtering approaches that they use. **Biases in inference:** The [CLIP model](https://huggingface.co/openai/clip-vit-large-patch14) used for guiding the training and inference of text-to-image models like Stable Diffusion and Dall-E 2 has a number of [well-documented biases](https://arxiv.org/abs/2205.11378) surrounding age, gender, and race or ethnicity, for instance treating images that had been labeled as `white`, `middle-aged`, and `male` as the default. This can impact the generations of models that use it for prompt encoding, for instance by interpreting unspecified or underspecified gender and identity groups to signify white and male. **Biases in the models' latent space:** [Initial work](https://arxiv.org/abs/2302.10893) has been done in terms of exploring the latent space of the model and guiding image generation along different axes such as gender to make generations more representative (see the images below). However, more work is necessary to better understand the structure of the latent space of different types of diffusion models and the factors that can influence the bias reflected in generated images. <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/fair-diffusion.png" alt="Fair Diffusion generations of firefighters." /> </p> **Biases in post-hoc filtering:** Many image generation models come with built-in safety filters that aim to flag problematic content. However, the extent to which these filters work and how robust they are to different kinds of content is to be determined – for instance, efforts to [red-team the Stable Diffusion safety filter](https://arxiv.org/abs/2210.04610)have shown that it mostly identifies sexual content, and fails to flag other types violent, gory or disturbing content. ## Detecting Bias Most of the issues that we describe above cannot be solved with a single solution – indeed, [bias is a complex topic](https://huggingface.co/blog/ethics-soc-2) that cannot be meaningfully addressed with technology alone. Bias is deeply intertwined with the broader social, cultural, and historical context in which it exists. Therefore, addressing bias in AI systems is not only a technological challenge but also a socio-technical one that demands multidisciplinary attention. However, a combination of approaches including tools, red-teaming and evaluations can help glean important insights that can inform both model creators and downstream users about the biases contained in TTI and other multimodal models. We present some of these approaches below: **Tools for exploring bias:** As part of the [Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias), we created a series of tools to explore and compare the visual manifestation of biases in different text-to-image models. For instance, the [Average Diffusion Faces](https://huggingface.co/spaces/society-ethics/Average_diffusion_faces) tool lets you compare the average representations for different professions and different models – like for 'janitor', shown below, for Stable Diffusion v1.4, v2, and Dall-E 2: <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/average.png" alt="Average faces for the 'janitor' profession, computed based on the outputs of different text to image models." /> </p> Other tools, like the [Face Clustering tool](https://hf.co/spaces/society-ethics/DiffusionFaceClustering) and the [Colorfulness Profession Explorer](https://huggingface.co/spaces/tti-bias/identities-colorfulness-knn) tool, allow users to explore patterns in the data and identify similarities and stereotypes without ascribing labels or identity characteristics. In fact, it's important to remember that generated images of individuals aren't actual people, but artificial creations, so it's important not to treat them as if they were real humans. Depending on the context and the use case, tools like these can be used both for storytelling and for auditing. **Red-teaming:** ['Red-teaming'](https://huggingface.co/blog/red-teaming) consists of stress testing AI models for potential vulnerabilities, biases, and weaknesses by prompting them and analyzing results. While it has been employed in practice for evaluating language models (including the upcoming [Generative AI Red Teaming event at DEFCON](https://aivillage.org/generative%20red%20team/generative-red-team/), which we are participating in), there are no established and systematic ways of red-teaming AI models and it remains relatively ad hoc. In fact, there are so many potential types of failure modes and biases in AI models, it is hard to anticipate them all, and the [stochastic nature](https://dl.acm.org/doi/10.1145/3442188.3445922) of generative models makes it hard to reproduce failure cases. Red-teaming gives actionable insights into model limitations and can be used to add guardrails and document model limitations. There are currently no red-teaming benchmarks or leaderboards highlighting the need for more work in open source red-teaming resources. [Anthropic's red-teaming dataset](https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts) is the only open source resource of red-teaming prompts, but is limited to only English natural language text. **Evaluating and documenting bias:** At Hugging Face, we are big proponents of [model cards](https://huggingface.co/docs/hub/model-card-guidebook) and other forms of documentation (e.g., [datasheets](https://arxiv.org/abs/1803.09010), READMEs, etc). In the case of text-to-image (and other multimodal) models, the result of explorations made using explorer tools and red-teaming efforts such as the ones described above can be shared alongside model checkpoints and weights. One of the issues is that we currently don't have standard benchmarks or datasets for measuring the bias in multimodal models (and indeed, in text-to-image generation systems specifically), but as more [work](https://arxiv.org/abs/2306.05949) in this direction is carried out by the community, different bias metrics can be reported in parallel in model documentation. ## Values and Bias All of the approaches listed above are part of detecting and understanding the biases embedded in image generation models. But how do we actively engage with them? One approach is to develop new models that represent society as we wish it to be. This suggests creating AI systems that don't just mimic the patterns in our data, but actively promote more equitable and fair perspectives. However, this approach raises a crucial question: whose values are we programming into these models? Values differ across cultures, societies, and individuals, making it a complex task to define what an "ideal" society should look like within an AI model. The question is indeed complex and multifaceted. If we avoid reproducing existing societal biases in our AI models, we're faced with the challenge of defining an "ideal" representation of society. Society is not a static entity, but a dynamic and ever-changing construct. Should AI models, then, adapt to the changes in societal norms and values over time? If so, how do we ensure that these shifts genuinely represent all groups within society, especially those often underrepresented? Also, as we have mentioned in a [previous newsletter](https://huggingface.co/blog/ethics-soc-2#addressing-bias-throughout-the-ml-development-cycle), there is no one single way to develop machine learning systems, and any of the steps in the development and deployment process can present opportunities to tackle bias, from who is included at the start, to defining the task, to curating the dataset, training the model, and more. This also applies to multimodal models and the ways in which they are ultimately deployed or productionized in society, since the consequences of bias in multimodal models will depend on their downstream use. For instance, if a model is used in a human-in-the-loop setting for graphic design (such as those created by [RunwayML](https://runwayml.com/ai-magic-tools/text-to-image/)), the user has numerous occasions to detect and correct bias, for instance by changing the prompt or the generation options. However, if a model is used as part of a [tool to help forensic artists create police sketches of potential suspects](https://www.vice.com/en/article/qjk745/ai-police-sketches) (see image below), then the stakes are much higher, since this can reinforce stereotypes and racial biases in a high-risk setting. <p align="center"> <br> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/forensic.png" alt="Forensic AI Sketch artist tool developed using Dall-E 2." /> </p> ## Other updates We are also continuing work on other fronts of ethics and society, including: - **Content moderation:** - We made a major update to our [Content Policy](https://huggingface.co/content-guidelines). It has been almost a year since our last update and the Hugging Face community has grown massively since then, so we felt it was time. In this update we emphasize *consent* as one of Hugging Face's core values. To read more about our thought process, check out the [announcement blog](https://huggingface.co/blog/content-guidelines-update) **.** - **AI Accountability Policy:** - We submitted a response to the NTIA request for comments on [AI accountability policy](https://ntia.gov/issues/artificial-intelligence/request-for-comments), where we stressed the importance of documentation and transparency mechanisms, as well as the necessity of leveraging open collaboration and promoting access to external stakeholders. You can find a summary of our response and a link to the full document [in our blog post](https://huggingface.co/blog/policy-ntia-rfc)! ## Closing Remarks As you can tell from our discussion above, the issue of detecting and engaging with bias and values in multimodal models, such as text-to-image models, is very much an open question. Apart from the work cited above, we are also engaging with the community at large on the issues - we recently co-led a [CRAFT session at the FAccT conference](https://facctconference.org/2023/acceptedcraft.html) on the topic and are continuing to pursue data- and model-centric research on the topic. One particular direction we are excited to explore is a more in-depth probing of the [values](https://arxiv.org/abs/2203.07785) instilled in text-to-image models and what they represent (stay tuned!).
|
Accelerating Vision-Language Models: BridgeTower on Habana Gaudi2
|
regisss
|
June 29, 2023
|
bridgetower
|
partnerships, multimodal, nlp, cv, hardware
|
https://huggingface.co/blog/bridgetower
|
# Accelerating Vision-Language Models: BridgeTower on Habana Gaudi2 *Update (29/08/2023): A benchmark on H100 was added to this blog post. Also, all performance numbers have been updated with newer versions of software.* [Optimum Habana v1.7](https://github.com/huggingface/optimum-habana/tree/main) on Habana Gaudi2 achieves **x2.5 speedups compared to A100 and x1.4 compared to H100** when fine-tuning BridgeTower, a state-of-the-art vision-language model. This performance improvement relies on hardware-accelerated data loading to make the most of your devices. *These techniques apply to any other workloads constrained by data loading, which is frequently the case for many types of vision models.* This post will take you through the process and benchmark we used to compare BridgeTower fine-tuning on Habana Gaudi2, Nvidia H100 and Nvidia A100 80GB. It also demonstrates how easy it is to take advantage of these features in transformers-based models. ## BridgeTower In the recent past, [Vision-Language (VL) models](https://huggingface.co/blog/vision_language_pretraining) have gained tremendous importance and shown dominance in a variety of VL tasks. Most common approaches leverage uni-modal encoders to extract representations from their respective modalities. Then those representations are either fused together, or fed into a cross-modal encoder. To efficiently handle some of the performance limitations and restrictions in VL representation learning, [BridgeTower](https://huggingface.co/papers/2206.08657) introduces multiple _bridge layers_ that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations at different semantic levels in the cross-modal encoder. Pre-trained with only 4M images (see the detail [below](#benchmark)), BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, BridgeTower achieves an accuracy of 78.73% on the VQAv2 test-std set, outperforming the previous state-of-the-art model (METER) by 1.09% using the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets. ## Hardware [NVIDIA H100 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/h100/) is the latest and fastest generation of Nvidia GPUs. It includes a dedicated Transformer Engine that enables to perform fp8 mixed-precision runs. One device has 80GB of memory. [Nvidia A100 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/a100/) includes the 3rd generation of the [Tensor Core technology](https://www.nvidia.com/en-us/data-center/tensor-cores/). This is still the fastest GPU that you will find at most cloud providers. We use here the 80GB-memory variant which also offers faster memory bandwidth than the 40GB one. [Habana Gaudi2](https://habana.ai/products/gaudi2/) is the second-generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices called HPUs with 96GB of memory each. Check out [our previous blog post](https://huggingface.co/blog/habana-gaudi-2-bloom#habana-gaudi2) for a more in-depth introduction and a guide showing how to access it through the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html). Unlike many AI accelerators in the market, advanced features are very easy to apply to make the most of Gaudi2 with [Optimum Habana](https://huggingface.co/docs/optimum/habana/index), which enables users to port Transformers-compatible scripts to Gaudi with just a 2-line change. ## Benchmark To benchmark training, we are going to fine-tune a [BridgeTower Large checkpoint](https://huggingface.co/BridgeTower/bridgetower-large-itm-mlm-itc) consisting of 866M parameters. This checkpoint was pretrained on English language using masked language modeling, image-text matching and image-text contrastive loss on [Conceptual Captions](https://huggingface.co/datasets/conceptual_captions), [SBU Captions](https://huggingface.co/datasets/sbu_captions), [MSCOCO Captions](https://huggingface.co/datasets/HuggingFaceM4/COCO) and [Visual Genome](https://huggingface.co/datasets/visual_genome). We will further fine-tune this checkpoint on the [New Yorker Caption Contest dataset](https://huggingface.co/datasets/jmhessel/newyorker_caption_contest) which consists of cartoons from The New Yorker and the most voted captions. Hyperparameters are the same for all accelerators. We used a batch size of 48 samples for each device. You can check hyperparameters out [here](https://huggingface.co/regisss/bridgetower-newyorker-gaudi2-8x#training-hyperparameters) for Gaudi2 and [there](https://huggingface.co/regisss/bridgetower-newyorker-a100-8x#training-hyperparameters) for A100. **When dealing with datasets involving images, data loading is frequently a bottleneck** because many costly operations are computed on CPU (image decoding, image augmentations) and then full images are sent to the training devices. Ideally, *we would like to send only raw bytes to devices and then perform decoding and various image transformations on device*. But let's see first how to *easily* allocate more resources to data loading for accelerating your runs. ### Making use of `dataloader_num_workers` When image loading is done on CPU, a quick way to speed it up would be to allocate more subprocesses for data loading. This is very easy to do with Transformers' `TrainingArguments` (or its Optimum Habana counterpart `GaudiTrainingArguments`): you can use the `dataloader_num_workers=N` argument to set the number of subprocesses (`N`) allocated on CPU for data loading. The default is 0, which means that data is loaded in the main process. This may not be optimal as the main process has many things to manage. We can set it to 1 to have one fully dedicated subprocess for data loading. When several subprocesses are allocated, each one of them will be responsible for preparing a batch. This means that RAM consumption will increase with the number of workers. One recommendation would be to set it to the number of CPU cores, but those cores may not be fully free so you will have to try it out to find the best configuration. Let's run the three following experiments: - a mixed-precision (*bfloat16*/*float32*) run distributed across 8 devices where data loading is performed by the same process as everything else (i.e. `dataloader_num_workers=0`) - a mixed-precision (*bfloat16*/*float32*) run distributed across 8 devices with 1 dedicated subprocess for data loading (i.e. `dataloader_num_workers=1`) - same run with `dataloader_num_workers=2` Here are the throughputs we got on Gaudi2, H100 and A100: | Device | `dataloader_num_workers=0` | `dataloader_num_workers=1` | `dataloader_num_workers=2` | |:----------:|:--------------------------:|:--------------------------:|:--------------------------:| | Gaudi2 HPU | 601.5 samples/s | 747.4 samples/s | 768.7 samples/s | | H100 GPU | 336.5 samples/s | 580.1 samples/s | 602.1 samples/s | | A100 GPU | 227.5 samples/s | 339.7 samples/s | 345.4 samples/s | We first see that **Gaudi2 is x1.28 faster than H100** with `dataloader_num_workers=2`, x1.29 faster with `dataloader_num_workers=1` and x1.79 faster with `dataloader_num_workers=0`. Gaudi2 is also much faster than the previous generation since it is **x2.23 faster than A100** with `dataloader_num_workers=2`, x2.20 faster with `dataloader_num_workers=1` and x2.64 faster with `dataloader_num_workers=0`, which is even better than [the speedups we previously reported](https://huggingface.co/blog/habana-gaudi-2-benchmark)! Second, we see that **allocating more resources for data loading can lead to easy speedups**: x1.28 on Gaudi2, x1.79 on H100 and x1.52 on A100. We also ran experiments with several dedicated subprocesses for data loading but performance was not better than with `dataloader_num_workers=2` for all accelerators. Thus, **using `dataloader_num_workers>0` is usually a good first way of accelerating your runs involving images!** Tensorboard logs can be visualized [here](https://huggingface.co/regisss/bridgetower-newyorker-gaudi2-8x/tensorboard) for Gaudi2 and [there](https://huggingface.co/regisss/bridgetower-newyorker-a100-8x/tensorboard) for A100. <!-- ### Optimum Habana's fast DDP Before delving into how to perform hardware-accelerated data loading, let's look at another very easy way of speeding up your distributed runs on Gaudi. The new release of Optimum Habana, version 1.6.0, introduced a new feature that allows users to choose the distribution strategy to use: - `distribution_strategy="ddp"` to use PyTorch [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) (DDP) - `distribution_strategy="fast_ddp"` to use a lighter and usually faster implementation Optimum Habana's fast DDP does not split parameter gradients into buckets as [DDP does](https://pytorch.org/docs/stable/notes/ddp.html#internal-design). It also uses [HPU graphs](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html?highlight=hpu%20graphs) to collect gradients in all processes and then update them (after the [all_reduce](https://pytorch.org/docs/stable/distributed.html#torch.distributed.all_reduce) operation is performed) with minimal host overhead. You can check this implementation [here](https://github.com/huggingface/optimum-habana/blob/main/optimum/habana/distributed/fast_ddp.py). Simply using `distribution_strategy="fast_ddp"` (and keeping `dataloader_num_workers=1`) on Gaudi2 gives us 705.9 samples/s. **This is x1.10 faster than with DDP and x2.38 faster than A100!** So adding just two training arguments (`dataloader_num_workers=1` and `distribution_strategy="fast_ddp"`) led to a x1.33 speedup on Gaudi2 and to a x2.38 speedup compared to A100 with `dataloader_num_workers=1`. --> ### Hardware-accelerated data loading with Optimum Habana For even larger speedups, we are now going to move as many data loading operations as possible from the CPU to the accelerator devices (i.e. HPUs on Gaudi2 or GPUs on A100/H100). This can be done on Gaudi2 using Habana's [media pipeline](https://docs.habana.ai/en/latest/Media_Pipeline/index.html). Given a dataset, most dataloaders follow the following recipe: 1. Fetch data (e.g. where your JPEG images are stored on disk) 2. The CPU reads encoded images 3. The CPU decodes images 4. The CPU applies image transformations to augment images 5. Finally, images are sent to devices (although this is usually not done by the dataloader itself) Instead of doing the whole process on CPU and send ready-to-train data to devices, a more efficient workflow would be to send encoded images to devices first and then perform image decoding and augmentations: 1. Same as before 2. Same as before 3. Encoded images are sent to devices 4. Devices decode images 5. Devices apply image transformations to augment images That way we can benefit from the computing power of our devices to speed image decoding and transformations up. Note that there are two caveats to be aware of when doing this: - Device memory consumption will increase, so you may have to reduce your batch size if there is not enough free memory. This may mitigate the speedup brought by this approach. - If devices are intensively used (100% or close to it) when doing data loading on CPU, don't expect any speedup when doing it on devices as they already have their hands full. <!-- To achieve this on Gaudi2, Habana's media pipeline enables us to: - Initialize a media pipeline with all the operators it needs (see [here](https://docs.habana.ai/en/latest/Media_Pipeline/Operators.html#media-operators) the list of all supported operators) and define a graph so that we can specify in which order operations should be performed (e.g. reading data → decoding → cropping). - Create a Torch dataloader with a HPU-tailored iterator. --> To implement this on Gaudi2, we have got you covered: the [contrastive image-text example](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text) in Optimum Habana now provides a ready-to-use media pipeline that you can use with COCO-like datasets that contain text and images! You will just have to add `--mediapipe_dataloader` to your command to use it. For interested readers, a lower-level overview is given in the documentation of Gaudi [here](https://docs.habana.ai/en/latest/Media_Pipeline/index.html) and the list of all supported operators is available [there](https://docs.habana.ai/en/latest/Media_Pipeline/Operators.html). We are now going to re-run the previous experiments adding the `mediapipe_dataloader` argument since it is compatible with `dataloader_num_workers`: | Device | `dataloader_num_workers=0` | `dataloader_num_workers=2` | `dataloader_num_workers=2` + `mediapipe_dataloader` | |:----------:|:--------------------------:|:--------------------------------------------:|:---------------:| | Gaudi2 HPU | 601.5 samples/s | 768.7 samples/s | 847.7 samples/s | | H100 GPU | 336.5 samples/s | 602.1 samples/s | / | | A100 GPU | 227.5 samples/s | 345.4 samples/s | / | We got an additional x1.10 speedup compared to the previous run with `dataloader_num_workers=2` only. This final run is thus x1.41 faster than our base run on Gaudi2 **simply adding 2 ready-to-use training arguments.** It is also **x1.41 faster than H100** and **x2.45 faster than A100** with `dataloader_num_workers=2`! ### Reproducing this benchmark To reproduce this benchmark, you first need to get access to Gaudi2 through the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html) (see [this guide](https://huggingface.co/blog/habana-gaudi-2-benchmark#how-to-get-access-to-gaudi2) for more information). Then, you need to install the latest version of Optimum Habana and run `run_bridgetower.py` which you can find [here](https://github.com/huggingface/optimum-habana/blob/main/examples/contrastive-image-text/run_bridgetower.py). Here is how to do it: ```bash pip install optimum[habana] git clone https://github.com/huggingface/optimum-habana.git cd optimum-habana/examples/contrastive-image-text pip install -r requirements.txt ``` The base command line to run the script is: ```bash python ../gaudi_spawn.py --use_mpi --world_size 8 run_bridgetower.py \ --output_dir /tmp/bridgetower-test \ --model_name_or_path BridgeTower/bridgetower-large-itm-mlm-itc \ --dataset_name jmhessel/newyorker_caption_contest --dataset_config_name matching \ --dataset_revision 3c6c4f6c0ff7e902833d3afa5f8f3875c2b036e6 \ --image_column image --caption_column image_description \ --remove_unused_columns=False \ --do_train --do_eval --do_predict \ --per_device_train_batch_size="40" --per_device_eval_batch_size="16" \ --num_train_epochs 5 \ --learning_rate="1e-5" \ --push_to_hub --report_to tensorboard --hub_model_id bridgetower\ --overwrite_output_dir \ --use_habana --use_lazy_mode --use_hpu_graphs_for_inference --gaudi_config_name Habana/clip \ --throughput_warmup_steps 3 \ --logging_steps 10 ``` which corresponds to the case `--dataloader_num_workers 0`. You can then add `--dataloader_num_workers N` and `--mediapipe_dataloader` to test other configurations. To push your model and Tensorboard logs to the Hugging Face Hub, you will have to log in to your account beforehand with: ```bash huggingface-cli login ``` For A100 and H100, you can use the same `run_bridgetower.py` script with a few small changes: - Replace `GaudiTrainer` and `GaudiTrainingArguments` with `Trainer` and `TrainingArguments` from Transformers - Remove references to `GaudiConfig`, `gaudi_config` and `HabanaDataloaderTrainer` - Import `set_seed` directly from Transformers: `from transformers import set_seed` The results displayed in this benchmark were obtained with a Nvidia H100 Lambda instance and a Nvidia A100 80GB GCP instance both with 8 devices using [Nvidia's Docker images](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html). Note that `--mediapipe_dataloader` is compatible with Gaudi2 only and will not work with A100/H100. Regarding fp8 results on H100 using [Transformer Engine](https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/index.html), they are not available because the code crashes and would require modifying the modeling of BridgeTower in Transformers. We will revisit this comparison when fp8 is supported on Gaudi2. ## Conclusion When dealing with images, we presented two solutions to speed up your training workflows: allocating more resources to the dataloader, and decoding and augmenting images directly on accelerator devices rather than on CPU. We showed that it leads to dramatic speedups when training a SOTA vision-language model like BridgeTower: **Habana Gaudi2 with Optimum Habana is about x1.4 faster than Nvidia H100 and x2.5 faster than Nvidia A100 80GB with Transformers!** And this is super easy to use as you just need to provide a few additional training arguments. To go further, we are looking forward to using HPU graphs for training models even faster and to presenting how to use DeepSpeed ZeRO-3 on Gaudi2 to accelerate the training of your LLMs. Stay tuned! If you are interested in accelerating your Machine Learning training and inference workflows using the latest AI hardware accelerators and software libraries, check out our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership and contact them here](https://huggingface.co/hardware/habana). To learn more about Hugging Face efforts to make AI hardware accelerators easy to use, check out our [Hardware Partner Program](https://huggingface.co/hardware). ### Related Topics - [Faster Training and Inference: Habana Gaudi-2 vs Nvidia A100 80GB](https://huggingface.co/blog/habana-gaudi-2-benchmark) - [Fast Inference on Large Language Models: BLOOMZ on Habana Gaudi2 Accelerator](https://huggingface.co/blog/habana-gaudi-2-bloom)
|
Leveraging Hugging Face for complex generative AI use cases
|
jeffboudier
|
July 1, 2023
|
writer-case-study
|
case-studies
|
https://huggingface.co/blog/writer-case-study
|
# Leveraging Hugging Face for complex generative AI use casess In this conversation, Jeff Boudier asks Waseem Alshikh, Co-founder and CTO of Writer, about their journey from a Hugging Face user, to a customer and now an open source model contributor. - why was Writer started? - what are the biggest misconceptions in Generative AI today? - why is Writer now contributing open source models? - what has been the value of the Hugging Face Expert Acceleration Program service for Writer? - how it Writer approaching production on CPU and GPU to serve LLMs at scale? - how important is efficiency and using CPUs for production? <iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/t8Ek1aOtaQw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> _If you’re interested in Hugging Face Expert Acceleration Program for your company, please contact us [here](https://huggingface.co/support#form) - our team will contact you to discuss your requirements!_
|
Making a web app generator with open ML models
|
jbilcke-hf
|
July 3, 2023
|
text-to-webapp
|
guide, llm, apps
|
https://huggingface.co/blog/text-to-webapp
|
# Making a web app generator with open ML models As more code generation models become publicly available, it is now possible to do text-to-web and even text-to-app in ways that we couldn't imagine before. This tutorial presents a direct approach to AI web content generation by streaming and rendering the content all in one go. **Try the live demo here!** → **[Webapp Factory](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-wizardcoder)**  ## Using LLM in Node apps While we usually think of Python for everything related to AI and ML, the web development community relies heavily on JavaScript and Node. Here are some ways you can use large language models on this platform. ### By running a model locally Various approaches exist to run LLMs in Javascript, from using [ONNX](https://www.npmjs.com/package/onnxruntime-node) to converting code to [WASM](https://blog.mithrilsecurity.io/porting-tokenizers-to-wasm/) and calling external processes written in other languages. Some of those techniques are now available as ready-to-use NPM libraries: - Using AI/ML libraries such as [transformers.js](https://huggingface.co/docs/transformers.js/index) (which supports [code generation](https://huggingface.co/docs/transformers.js/api/models#codegenmodelgenerateargs-codepromiseampltanyampgtcode)) - Using dedicated LLM libraries such as [llama-node](https://github.com/Atome-FE/llama-node) (or [web-llm](https://github.com/mlc-ai/web-llm) for the browser) - Using Python libraries through a bridge such as [Pythonia](https://www.npmjs.com/package/pythonia) However, running large language models in such an environment can be pretty resource-intensive, especially if you are not able to use hardware acceleration. ### By using an API Today, various cloud providers propose commercial APIs to use language models. Here is the current Hugging Face offering: The free [Inference API](https://huggingface.co/docs/api-inference/index) to allow anyone to use small to medium-sized models from the community. The more advanced and production-ready [Inference Endpoints API](https://huggingface.co/inference-endpoints) for those who require larger models or custom inference code. These two APIs can be used from Node using the [Hugging Face Inference API library](https://www.npmjs.com/package/@huggingface/inference) on NPM. 💡 Top performing models generally require a lot of memory (32 Gb, 64 Gb or more) and hardware acceleration to get good latency (see [the benchmarks](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)). But we are also seeing a trend of models shrinking in size while keeping relatively good results on some tasks, with requirements as low as 16 Gb or even 8 Gb of memory. ## Architecture We are going to use NodeJS to create our generative AI web server. The model will be [WizardCoder-15B](https://huggingface.co/WizardLM/WizardCoder-15B-V1.0) running on the Inference Endpoints API, but feel free to try with another model and stack. If you are interested in other solutions, here are some pointers to alternative implementations: - Using the Inference API: [code](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-any-model/tree/main) and [space](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-any-model) - Using a Python module from Node: [code](https://huggingface.co/spaces/jbilcke-hf/template-node-ctransformers-express/tree/main) and [space](https://huggingface.co/spaces/jbilcke-hf/template-node-ctransformers-express) - Using llama-node (llama cpp): [code](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-llama-node/tree/main) ## Initializing the project First, we need to setup a new Node project (you can clone [this template](https://github.com/jbilcke-hf/template-node-express/generate) if you want to). ```html git clone https://github.com/jbilcke-hf/template-node-express tutorial cd tutorial nvm use npm install ``` Then, we can install the Hugging Face Inference client: ```html npm install @huggingface/inference ``` And set it up in `src/index.mts``: ```javascript import { HfInference } from '@huggingface/inference' // to keep your API token secure, in production you should use something like: // const hfi = new HfInference(process.env.HF_API_TOKEN) const hfi = new HfInference('** YOUR TOKEN **') ``` ## Configuring the Inference Endpoint 💡 **Note:** If you don't want to pay for an Endpoint instance to do this tutorial, you can skip this step and look at [this free Inference API example](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-any-model/blob/main/src/index.mts) instead. Please, note that this will only work with smaller models, which may not be as powerful. To deploy a new Endpoint you can go to the [Endpoint creation page](https://ui.endpoints.huggingface.co/new). You will have to select `WizardCoder` in the **Model Repository** dropdown and make sure that a GPU instance large enough is selected:  Once your endpoint is created, you can copy the URL from [this page](https://ui.endpoints.huggingface.co):  Configure the client to use it: ```javascript const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **') ``` You can now tell the inference client to use our private endpoint and call our model: ```javascript const { generated_text } = await hf.textGeneration({ inputs: 'a simple "hello world" html page: <html><body>' }); ``` ## Generating the HTML stream It's now time to return some HTML to the web client when they visit a URL, say `/app`. We will create and endpoint with Express.js to stream the results from the Hugging Face Inference API. ```javascript import express from 'express' import { HfInference } from '@huggingface/inference' const hfi = new HfInference('** YOUR TOKEN **') const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **') const app = express() ``` As we do not have any UI for the moment, the interface will be a simple URL parameter for the prompt: ```javascript app.get('/', async (req, res) => { // send the beginning of the page to the browser (the rest will be generated by the AI) res.write('<html><head></head><body>') const inputs = `# Task Generate ${req.query.prompt} # Out <html><head></head><body>` for await (const output of hf.textGenerationStream({ inputs, parameters: { max_new_tokens: 1000, return_full_text: false, } })) { // stream the result to the browser res.write(output.token.text) // also print to the console for debugging process.stdout.write(output.token.text) } req.end() }) app.listen(3000, () => { console.log('server started') }) ``` Start your web server: ```bash npm run start ``` and open `https://localhost:3000?prompt=some%20prompt`. You should see some primitive HTML content after a few moments. ## Tuning the prompt Each language model reacts differently to prompting. For WizardCoder, simple instructions often work best: ```javascript const inputs = `# Task Generate ${req.query.prompt} # Orders Write application logic inside a JS <script></script> tag. Use a central layout to wrap everything in a <div class="flex flex-col items-center"> # Out <html><head></head><body>` ``` ### Using Tailwind Tailwind is a popular CSS framework for styling content, and WizardCoder is good at it out of the box. This allows code generation to create styles on the go without having to generate a stylesheet at the beginning or the end of the page (which would make the page feel stuck). To improve results, we can also guide the model by showing the way (`<body class="p-4 md:p-8">`). ```javascript const inputs = `# Task Generate ${req.query.prompt} # Orders You must use TailwindCSS utility classes (Tailwind is already injected in the page). Write application logic inside a JS <script></script> tag. Use a central layout to wrap everything in a <div class="flex flex-col items-center'> # Out <html><head></head><body class="p-4 md:p-8">` ``` ### Preventing hallucination It can be difficult to reliably prevent hallucinations and failures (such as parroting back the whole instructions, or writing “lorem ipsum” placeholder text) on light models dedicated to code generation, compared to larger general-purpose models, but we can try to mitigate it. You can try to use an imperative tone and repeat the instructions. An efficient way can also be to show the way by giving a part of the output in English: ```javascript const inputs = `# Task Generate ${req.query.prompt} # Orders Never repeat these instructions, instead write the final code! You must use TailwindCSS utility classes (Tailwind is already injected in the page)! Write application logic inside a JS <script></script> tag! This is not a demo app, so you MUST use English, no Latin! Write in English! Use a central layout to wrap everything in a <div class="flex flex-col items-center"> # Out <html><head><title>App</title></head><body class="p-4 md:p-8">` ``` ## Adding support for images We now have a system that can generate HTML, CSS and JS code, but it is prone to hallucinating broken URLs when asked to produce images. Luckily, we have a lot of options to choose from when it comes to image generation models! → The fastest way to get started is to call a Stable Diffusion model using our free [Inference API](https://huggingface.co/docs/api-inference/index) with one of the [public models](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery) available on the hub: ```javascript app.get('/image', async (req, res) => { const blob = await hf.textToImage({ inputs: `${req.query.caption}`, model: 'stabilityai/stable-diffusion-2-1' }) const buffer = Buffer.from(await blob.arrayBuffer()) res.setHeader('Content-Type', blob.type) res.setHeader('Content-Length', buffer.length) res.end(buffer) }) ``` Adding the following line to the prompt was enough to instruct WizardCoder to use our new `/image` endpoint! (you may have to tweak it for other models): ``` To generate images from captions call the /image API: <img src="/image?caption=photo of something in some place" /> ``` You can also try to be more specific, for example: ``` Only generate a few images and use descriptive photo captions with at least 10 words! ```  ## Adding some UI [Alpine.js](https://alpinejs.dev/) is a minimalist framework that allows us to create interactive UIs without any setup, build pipeline, JSX processing etc. Everything is done within the page, making it a great candidate to create the UI of a quick demo. Here is a static HTML page that you can put in `/public/index.html`: ```html <html> <head> <title>Tutorial</title> <script defer src="https://cdn.jsdelivr.net/npm/[email protected]/dist/cdn.min.js"></script> <script src="https://cdn.tailwindcss.com"></script> </head> <body> <div class="flex flex-col space-y-3 p-8" x-data="{ draft: '', prompt: '' }"> <textarea name="draft" x-model="draft" rows="3" placeholder="Type something.." class="font-mono" ></textarea> <button class="bg-green-300 rounded p-3" @click="prompt = draft">Generate</button> <iframe :src="`/app?prompt=${prompt}`"></iframe> </div> </body> </html> ``` To make this work, you will have to make some changes: ```javascript ... // going to localhost:3000 will load the file from /public/index.html app.use(express.static('public')) // we changed this from '/' to '/app' app.get('/app', async (req, res) => { ... ``` ## Optimizing the output So far we have been generating full sequences of Tailwind utility classes, which are great to give freedom of design to the language model. But this approach is also very verbose, consuming a large part of our token quota. To make the output more dense we can use [Daisy UI](https://daisyui.com/docs/use/), a Tailwind plugin which organizes Tailwind utility classes into a design system. The idea is to use shorthand class names for components and utility classes for the rest. Some language models may not have inner knowledge of Daisy UI as it is a niche library, in that case we can add an [API documentation](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-wizardcoder/blob/main/src/daisy.mts) to the prompt: ``` # DaisyUI docs ## To create a nice layout, wrap each article in: <article class="prose"></article> ## Use appropriate CSS classes <button class="btn .."> <table class="table .."> <footer class="footer .."> ``` ## Going further The final demo Space includes a [more complete example](https://huggingface.co/spaces/jbilcke-hf/webapp-factory-wizardcoder/blob/main/public/index.html) of user interface. Here are some ideas to further extend on this concept: - Test other language models such as [StarCoder](https://huggingface.co/blog/starcoder) - Generate files and code for intermediary languages (React, Svelte, Vue..) - Integrate code generation inside an existing framework (eg. NextJS) - Recover from failed or partial code generation (eg. autofix issues in the JS) - Connect it to a chatbot plugin (eg. embed tiny webapp iframes in a chat discussion) 
|
Deploy LLMs with Hugging Face Inference Endpoints
|
philschmid
|
July 4, 2023
|
inference-endpoints-llm
|
guide, llm, apps, inference
|
https://huggingface.co/blog/inference-endpoints-llm
|
# Deploy LLMs with Hugging Face Inference Endpoints Open-source LLMs like [Falcon](https://huggingface.co/tiiuae/falcon-40b), [(Open-)LLaMA](https://huggingface.co/openlm-research/open_llama_13b), [X-Gen](https://huggingface.co/Salesforce/xgen-7b-8k-base), [StarCoder](https://huggingface.co/bigcode/starcoder) or [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base), have come a long way in recent months and can compete with closed-source models like ChatGPT or GPT4 for certain use cases. However, deploying these models in an efficient and optimized way still presents a challenge. In this blog post, we will show you how to deploy open-source LLMs to [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/), our managed SaaS solution that makes it easy to deploy models. Additionally, we will teach you how to stream responses and test the performance of our endpoints. So let's get started! 1. [How to deploy Falcon 40B instruct](#1-how-to-deploy-falcon-40b-instruct) 2. [Test the LLM endpoint](#2-test-the-llm-endpoint) 3. [Stream responses in Javascript and Python](#3-stream-responses-in-javascript-and-python) Before we start, let's refresh our knowledge about Inference Endpoints. ## What is Hugging Face Inference Endpoints [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists alike to create AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security. Here are some of the most important features for LLM deployment: 1. [Easy Deployment](https://huggingface.co/docs/inference-endpoints/index): Deploy models as production-ready APIs with just a few clicks, eliminating the need to handle infrastructure or MLOps. 2. [Cost Efficiency](https://huggingface.co/docs/inference-endpoints/autoscaling): Benefit from automatic scale to zero capability, reducing costs by scaling down the infrastructure when the endpoint is not in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness. 3. [Enterprise Security](https://huggingface.co/docs/inference-endpoints/security): Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance. 4. [LLM Optimization](https://huggingface.co/text-generation-inference): Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference 5. [Comprehensive Task Support](https://huggingface.co/docs/inference-endpoints/supported_tasks): Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and easy customization to enable advanced tasks like speaker diarization or any Machine Learning task and library. You can get started with Inference Endpoints at: [https://ui.endpoints.huggingface.co/](https://ui.endpoints.huggingface.co/) ## 1. How to deploy Falcon 40B instruct To get started, you need to be logged in with a User or Organization account with a payment method on file (you can add one **[here](https://huggingface.co/settings/billing)**), then access Inference Endpoints at **[https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints)** Then, click on “New endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case `tiiuae/falcon-40b-instruct`.  Inference Endpoints suggest an instance type based on the model size, which should be big enough to run the model. Here `4x NVIDIA T4` GPUs. To get the best performance for the LLM, change the instance to `GPU [xlarge] · 1x Nvidia A100`. *Note: If the instance type cannot be selected, you need to [contact us](mailto:[email protected]?subject=Quota%20increase%20HF%20Endpoints&body=Hello,%0D%0A%0D%0AI%20would%20like%20to%20request%20access/quota%20increase%20for%20{INSTANCE%20TYPE}%20for%20the%20following%20account%20{HF%20ACCOUNT}.) and request an instance quota.*  You can then deploy your model with a click on “Create Endpoint”. After 10 minutes, the Endpoint should be online and available to serve requests. ## 2. Test the LLM endpoint The Endpoint overview provides access to the Inference Widget, which can be used to manually send requests. This allows you to quickly test your Endpoint with different inputs and share it with team members. Those Widgets do not support parameters - in this case this results to a “short” generation.  The widget also generates a cURL command you can use. Just add your `hf_xxx` and test. ```python curl https://j4xhm53fxl9ussm8.us-east-1.aws.endpoints.huggingface.cloud \ -X POST \ -d '{"inputs":"Once upon a time,"}' \ -H "Authorization: Bearer <hf_token>" \ -H "Content-Type: application/json" ``` You can use different parameters to control the generation, defining them in the `parameters` attribute of the payload. As of today, the following parameters are supported: - `temperature`: Controls randomness in the model. Lower values will make the model more deterministic and higher values will make the model more random. Default value is 1.0. - `max_new_tokens`: The maximum number of tokens to generate. Default value is 20, max value is 512. - `repetition_penalty`: Controls the likelihood of repetition. Default is `null`. - `seed`: The seed to use for random generation. Default is `null`. - `stop`: A list of tokens to stop the generation. The generation will stop when one of the tokens is generated. - `top_k`: The number of highest probability vocabulary tokens to keep for top-k-filtering. Default value is `null`, which disables top-k-filtering. - `top_p`: The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling, default to `null` - `do_sample`: Whether or not to use sampling; use greedy decoding otherwise. Default value is `false`. - `best_of`: Generate best_of sequences and return the one if the highest token logprobs, default to `null`. - `details`: Whether or not to return details about the generation. Default value is `false`. - `return_full_text`: Whether or not to return the full text or only the generated part. Default value is `false`. - `truncate`: Whether or not to truncate the input to the maximum length of the model. Default value is `true`. - `typical_p`: The typical probability of a token. Default value is `null`. - `watermark`: The watermark to use for the generation. Default value is `false`. ## 3. Stream responses in Javascript and Python Requesting and generating text with LLMs can be a time-consuming and iterative process. A great way to improve the user experience is streaming tokens to the user as they are generated. Below are two examples of how to stream tokens using Python and JavaScript. For Python, we are going to use the [client from Text Generation Inference](https://github.com/huggingface/text-generation-inference/tree/main/clients/python), and for JavaScript, the [HuggingFace.js library](https://huggingface.co/docs/huggingface.js/main/en/index) ### Streaming requests with Python First, you need to install the `huggingface_hub` library: ```python pip install -U huggingface_hub ``` We can create a `InferenceClient` providing our endpoint URL and credential alongside the hyperparameters we want to use ```python from huggingface_hub import InferenceClient # HF Inference Endpoints parameter endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud" hf_token = "hf_YOUR_TOKEN" # Streaming Client client = InferenceClient(endpoint_url, token=hf_token) # generation parameter gen_kwargs = dict( max_new_tokens=512, top_k=30, top_p=0.9, temperature=0.2, repetition_penalty=1.02, stop_sequences=["\nUser:", "<|endoftext|>", "</s>"], ) # prompt prompt = "What can you do in Nuremberg, Germany? Give me 3 Tips" stream = client.text_generation(prompt, stream=True, details=True, **gen_kwargs) # yield each generated token for r in stream: # skip special tokens if r.token.special: continue # stop if we encounter a stop sequence if r.token.text in gen_kwargs["stop_sequences"]: break # yield the generated token print(r.token.text, end = "") # yield r.token.text ``` Replace the `print` command with the `yield` or with a function you want to stream the tokens to.  ### Streaming requests with JavaScript First, you need to install the `@huggingface/inference` library. ```python npm install @huggingface/inference ``` We can create a `HfInferenceEndpoint` providing our endpoint URL and credential alongside the hyperparameter we want to use. ```jsx import { HfInferenceEndpoint } from '@huggingface/inference' const hf = new HfInferenceEndpoint('https://YOUR_ENDPOINT.endpoints.huggingface.cloud', 'hf_YOUR_TOKEN') //generation parameter const gen_kwargs = { max_new_tokens: 512, top_k: 30, top_p: 0.9, temperature: 0.2, repetition_penalty: 1.02, stop_sequences: ['\nUser:', '<|endoftext|>', '</s>'], } // prompt const prompt = 'What can you do in Nuremberg, Germany? Give me 3 Tips' const stream = hf.textGenerationStream({ inputs: prompt, parameters: gen_kwargs }) for await (const r of stream) { // # skip special tokens if (r.token.special) { continue } // stop if we encounter a stop sequence if (gen_kwargs['stop_sequences'].includes(r.token.text)) { break } // yield the generated token process.stdout.write(r.token.text) } ``` Replace the `process.stdout` call with the `yield` or with a function you want to stream the tokens to.  ## Conclusion In this blog post, we showed you how to deploy open-source LLMs using Hugging Face Inference Endpoints, how to control the text generation with advanced parameters, and how to stream responses to a Python or JavaScript client to improve the user experience. By using Hugging Face Inference Endpoints you can deploy models as production-ready APIs with just a few clicks, reduce your costs with automatic scale to zero, and deploy models into secure offline endpoints backed by SOC2 Type 2 certification. --- Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
|
Making ML-powered web games with Transformers.js
|
Xenova
|
July 5, 2023
|
ml-web-games
|
game-dev, guide, web, javascript, transformers.js
|
https://huggingface.co/blog/ml-web-games
|
# Making ML-powered web games with Transformers.js In this blog post, I'll show you how I made [**Doodle Dash**](https://huggingface.co/spaces/Xenova/doodle-dash), a real-time ML-powered web game that runs completely in your browser (thanks to [Transformers.js](https://github.com/xenova/transformers.js)). The goal of this tutorial is to show you how easy it is to make your own ML-powered web game... just in time for the upcoming Open Source AI Game Jam (7-9 July 2023). [Join](https://itch.io/jam/open-source-ai-game-jam) the game jam if you haven't already! <video controls autoplay title="Doodle Dash demo video"> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ml-web-games/demo.mp4" type="video/mp4"> Video: Doodle Dash demo video </video> ### Quick links - **Demo:** [Doodle Dash](https://huggingface.co/spaces/Xenova/doodle-dash) - **Source code:** [doodle-dash](https://github.com/xenova/doodle-dash) - **Join the game jam:** [Open Source AI Game Jam](https://itch.io/jam/open-source-ai-game-jam) ## Overview Before we start, let's talk about what we'll be creating. The game is inspired by Google's [Quick, Draw!](https://quickdraw.withgoogle.com/) game, where you're given a word and a neural network has 20 seconds to guess what you're drawing (repeated 6 times). In fact, we'll be using their [training data](#training-data) to train our own sketch detection model! Don't you just love open source? 😍 In our version, you'll have one minute to draw as many items as you can, one prompt at a time. If the model predicts the correct label, the canvas will be cleared and you'll be given a new word. Keep doing this until the timer runs out! Since the game runs locally in your browser, we don't have to worry about server latency at all. The model is able to make real-time predictions as you draw, to the tune of over 60 predictions a second... 🤯 WOW! This tutorial is split into 3 sections: 1. [Training the neural network](#1-training-the-neural-network) 2. [Running in the browser with Transformers.js](#2-running-in-the-browser-with-transformersjs) 3. [Game Design](#3-game-design) ## 1. Training the neural network ### Training data We'll be training our model using a [subset](https://huggingface.co/datasets/Xenova/quickdraw-small) of Google's [Quick, Draw!](https://quickdraw.withgoogle.com/data) dataset, which contains over 5 million drawings across 345 categories. Here are some samples from the dataset:  ### Model architecture We'll be finetuning [`apple/mobilevit-small`](https://huggingface.co/apple/mobilevit-small), a lightweight and mobile-friendly Vision Transformer that has been pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k). It has only 5.6M parameters (~20 MB file size), a perfect candidate for running in-browser! For more information, check out the [MobileViT paper](https://huggingface.co/papers/2110.02178) and the model architecture below. 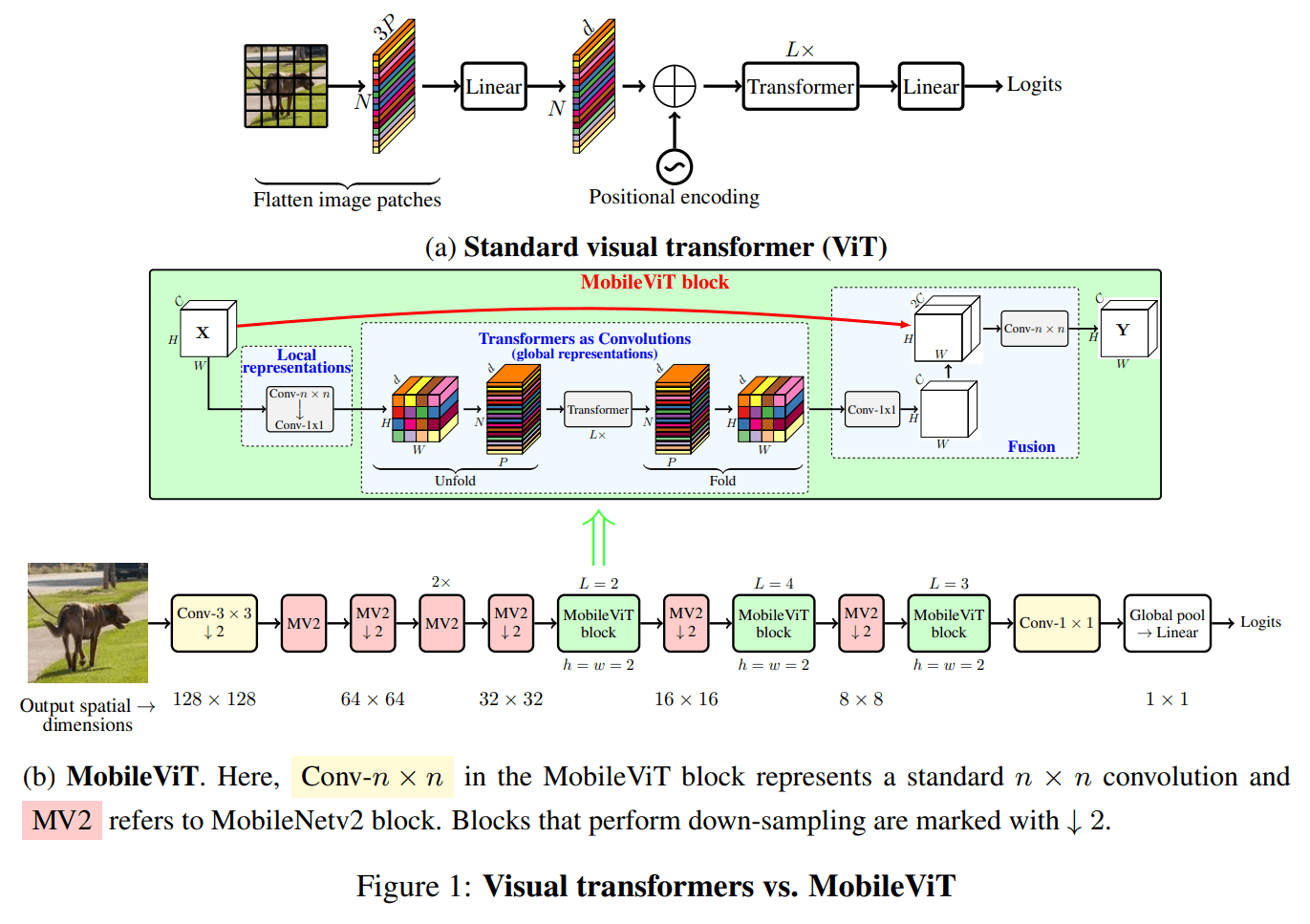 ### Finetuning <a target="_blank" href="https://colab.research.google.com/github/xenova/doodle-dash/blob/main/blog/training.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> To keep the blog post (relatively) short, we've prepared a Colab notebook which will show you the exact steps we took to finetune [`apple/mobilevit-small`](https://huggingface.co/apple/mobilevit-small) on our dataset. At a high level, this involves: 1. Loading the ["Quick, Draw!" dataset](https://huggingface.co/datasets/Xenova/quickdraw-small). 2. Transforming the dataset using a [`MobileViTImageProcessor`](https://huggingface.co/docs/transformers/model_doc/mobilevit#transformers.MobileViTImageProcessor). 3. Defining our [collate function](https://huggingface.co/docs/transformers/main_classes/data_collator) and [evaluation metric](https://huggingface.co/docs/evaluate/types_of_evaluations#metrics). 4. Loading the [pre-trained MobileVIT model](https://huggingface.co/apple/mobilevit-small) using [`MobileViTForImageClassification.from_pretrained`](https://huggingface.co/docs/transformers/model_doc/mobilevit#transformers.MobileViTForImageClassification). 5. Training the model using the [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) and [`TrainingArguments`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) helper classes. 6. Evaluating the model using [🤗 Evaluate](https://huggingface.co/docs/evaluate). *NOTE:* You can find our finetuned model [here](https://huggingface.co/Xenova/quickdraw-mobilevit-small) on the Hugging Face Hub. ## 2. Running in the browser with Transformers.js ### What is Transformers.js? [Transformers.js](https://huggingface.co/docs/transformers.js) is a JavaScript library that allows you to run [🤗 Transformers](https://huggingface.co/docs/transformers) directly in your browser (no need for a server)! It's designed to be functionally equivalent to the Python library, meaning you can run the same pre-trained models using a very similar API. Behind the scenes, Transformers.js uses [ONNX Runtime](https://onnxruntime.ai/), so we need to convert our finetuned PyTorch model to ONNX. ### Converting our model to ONNX Fortunately, the [🤗 Optimum](https://huggingface.co/docs/optimum) library makes it super simple to convert your finetuned model to ONNX! The easiest (and recommended way) is to: 1. Clone the [Transformers.js repository](https://github.com/xenova/transformers.js) and install the necessary dependencies: ```bash git clone https://github.com/xenova/transformers.js.git cd transformers.js pip install -r scripts/requirements.txt ``` 2. Run the conversion script (it uses `Optimum` under the hood): ```bash python -m scripts.convert --model_id <model_id> ``` where `<model_id>` is the name of the model you want to convert (e.g. `Xenova/quickdraw-mobilevit-small`). ### Setting up our project Let's start by scaffolding a simple React app using Vite: ```bash npm create vite@latest doodle-dash -- --template react ``` Next, enter the project directory and install the necessary dependencies: ```bash cd doodle-dash npm install npm install @xenova/transformers ``` You can then start the development server by running: ```bash npm run dev ``` ### Running the model in the browser Running machine learning models is computationally intensive, so it's important to perform inference in a separate thread. This way we won't block the main thread, which is used for rendering the UI and reacting to your drawing gestures 😉. The [Web Workers API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API) makes this super simple! Create a new file (e.g., `worker.js`) in the `src` directory and add the following code: ```js import { pipeline, RawImage } from "@xenova/transformers"; const classifier = await pipeline("image-classification", 'Xenova/quickdraw-mobilevit-small', { quantized: false }); const image = await RawImage.read('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ml-web-games/skateboard.png'); const output = await classifier(image.grayscale()); console.log(output); ``` We can now use this worker in our `App.jsx` file by adding the following code to the `App` component: ```jsx import { useState, useEffect, useRef } from 'react' // ... rest of the imports function App() { // Create a reference to the worker object. const worker = useRef(null); // We use the `useEffect` hook to set up the worker as soon as the `App` component is mounted. useEffect(() => { if (!worker.current) { // Create the worker if it does not yet exist. worker.current = new Worker(new URL('./worker.js', import.meta.url), { type: 'module' }); } // Create a callback function for messages from the worker thread. const onMessageReceived = (e) => { /* See code */ }; // Attach the callback function as an event listener. worker.current.addEventListener('message', onMessageReceived); // Define a cleanup function for when the component is unmounted. return () => worker.current.removeEventListener('message', onMessageReceived); }); // ... rest of the component } ``` You can test that everything is working by running the development server (with `npm run dev`), visiting the local website (usually [http://localhost:5173/](http://localhost:5173/)), and opening the browser console. You should see the output of the model being logged to the console. ```js [{ label: "skateboard", score: 0.9980043172836304 }] ``` *Woohoo!* 🥳 Although the above code is just a small part of the [final product](https://github.com/xenova/doodle-dash), it shows how simple the machine-learning side of it is! The rest is just making it look nice and adding some game logic. ## 3. Game Design In this section, I'll briefly discuss the game design process. As a reminder, you can find the full source code for the project on [GitHub](https://github.com/xenova/doodle-dash), so I won't be going into detail about the code itself. ### Taking advantage of real-time performance One of the main advantages of performing in-browser inference is that we can make predictions in real time (over 60 times a second). In the original [Quick, Draw!](https://quickdraw.withgoogle.com/) game, the model only makes a new prediction every couple of seconds. We could do the same in our game, but then we wouldn't be taking advantage of its real-time performance! So, I decided to redesign the main game loop: - Instead of six 20-second rounds (where each round corresponds to a new word), our version tasks the player with correctly drawing as many doodles as they can in 60 seconds (one prompt at a time). - If you come across a word you are unable to draw, you can skip it (but this will cost you 3 seconds of your remaining time). - In the original game, since the model would make a guess every few seconds, it could slowly cross labels off the list until it eventually guessed correctly. In our version, we instead decrease the model's scores for the first `n` incorrect labels, with `n` increasing over time as the user continues drawing. ### Quality of life improvements The original dataset contains 345 different classes, and since our model is relatively small (~20MB), it sometimes is unable to correctly guess some of the classes. To solve this problem, we removed some words which are either: - Too similar to other labels (e.g., "barn" vs. "house") - Too difficult to understand (e.g., "animal migration") - Too difficult to draw in sufficient detail (e.g., "brain") - Ambiguous (e.g., "bat") After filtering, we were still left with over 300 different classes! ### BONUS: Coming up with the name In the spirit of open-source development, I decided to ask [Hugging Chat](https://huggingface.co/chat/) for some game name ideas... and needless to say, it did not disappoint!  I liked the alliteration of "Doodle Dash" (suggestion #4), so I decided to go with that. Thanks Hugging Chat! 🤗 --- I hope you enjoyed building this game with me! If you have any questions or suggestions, you can find me on [Twitter](https://twitter.com/xenovacom), [GitHub](https://github.com/xenova/doodle-dash), or the [🤗 Hub](https://hf.co/xenova). Also, if you want to improve the game (game modes? power-ups? animations? sound effects?), feel free to [fork](https://github.com/xenova/doodle-dash/fork) the project and submit a pull request! I'd love to see what you come up with! **PS**: Don't forget to join the [Open Source AI Game Jam](https://itch.io/jam/open-source-ai-game-jam)! Hopefully this blog post inspires you to build your own web game with Transformers.js! 😉 See you at the Game Jam! 🚀
|
Fine-tuning Stable Diffusion models on Intel CPUs
|
juliensimon
|
July 14, 2023
|
stable-diffusion-finetuning-intel
|
guide, intel, hardware, partnerships
|
https://huggingface.co/blog/stable-diffusion-finetuning-intel
|
# Fine-tuning Stable Diffusion Models on Intel CPUs Diffusion models helped popularize generative AI thanks to their uncanny ability to generate photorealistic images from text prompts. These models have now found their way into enterprise use cases like synthetic data generation or content creation. The Hugging Face hub includes over 5,000 pre-trained text-to-image [models](https://huggingface.co/models?pipeline_tag=text-to-image&sort=trending). Combining them with the [Diffusers library](https://huggingface.co/docs/diffusers/index), it's never been easier to start experimenting and building image generation workflows. Like Transformer models, you can fine-tune Diffusion models to help them generate content that matches your business needs. Initially, fine-tuning was only possible on GPU infrastructure, but things are changing! A few months ago, Intel [launched](https://www.intel.com/content/www/us/en/newsroom/news/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html#gs.2d6cd7) the fourth generation of Xeon CPUs, code-named Sapphire Rapids. Sapphire Rapids introduces the Intel Advanced Matrix Extensions (AMX), a new hardware accelerator for deep learning workloads. We've already demonstrated the benefits of AMX in several blog posts: [fine-tuning NLP Transformers](https://huggingface.co/blog/intel-sapphire-rapids), [inference with NLP Transformers](https://huggingface.co/blog/intel-sapphire-rapids-inference), and [inference with Stable Diffusion models](https://huggingface.co/blog/stable-diffusion-inference-intel). This post will show you how to fine-tune a Stable Diffusion model on an Intel Sapphire Rapids CPU cluster. We will use [textual inversion](https://huggingface.co/docs/diffusers/training/text_inversion), a technique that only requires a small number of example images. We'll use only five! Let's get started. ## Setting up the cluster Our friends at [Intel](https://huggingface.co/intel) provided four servers hosted on the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) (IDC), a service platform for developing and running workloads in Intel®-optimized deployment environments with the latest Intel processors and [performance-optimized software stacks](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html). Each server is powered by two Intel Sapphire Rapids CPUs with 56 physical cores and 112 threads. Here's the output of `lscpu`: ``` Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 52 bits physical, 57 bits virtual Byte Order: Little Endian CPU(s): 224 On-line CPU(s) list: 0-223 Vendor ID: GenuineIntel Model name: Intel(R) Xeon(R) Platinum 8480+ CPU family: 6 Model: 143 Thread(s) per core: 2 Core(s) per socket: 56 Socket(s): 2 Stepping: 8 CPU max MHz: 3800.0000 CPU min MHz: 800.0000 BogoMIPS: 4000.00 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_per fmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities ``` Let's first list the IP addresses of our servers in `nodefile.` The first line refers to the primary server. ``` cat << EOF > nodefile 192.168.20.2 192.168.21.2 192.168.22.2 192.168.23.2 EOF ``` Distributed training requires password-less `ssh` between the primary and other nodes. Here's a good [article](https://www.redhat.com/sysadmin/passwordless-ssh) on how to do this if you're unfamiliar with the process. Next, we create a new environment on each node and install the software dependencies. We notably install two Intel libraries: [oneCCL](https://github.com/oneapi-src/oneCCL), to manage distributed communication and the [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) to leverage the hardware acceleration features present in Sapphire Rapids. We also add `gperftools` to install `libtcmalloc,` a high-performance memory allocation library. ``` conda create -n diffuser python==3.9 conda activate diffuser pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu pip3 install transformers accelerate==0.19.0 pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu pip3 install intel_extension_for_pytorch conda install gperftools -c conda-forge -y ``` Next, we clone the [diffusers](https://github.com/huggingface/diffusers/) repository on each node and install it from source. ``` git clone https://github.com/huggingface/diffusers.git cd diffusers pip install . ``` Next, we add IPEX to the fine-tuning script in `diffusers/examples/textual_inversion`. We import IPEX and optimize the U-Net and Variable Auto Encoder models. Please make sure this is applied to all nodes. ``` diff --git a/examples/textual_inversion/textual_inversion.py b/examples/textual_inversion/textual_inversion.py index 4a193abc..91c2edd1 100644 --- a/examples/textual_inversion/textual_inversion.py +++ b/examples/textual_inversion/textual_inversion.py @@ -765,6 +765,10 @@ def main(): unet.to(accelerator.device, dtype=weight_dtype) vae.to(accelerator.device, dtype=weight_dtype) + import intel_extension_for_pytorch as ipex + unet = ipex.optimize(unet, dtype=weight_dtype) + vae = ipex.optimize(vae, dtype=weight_dtype) + # We need to recalculate our total training steps as the size of the training dataloader may have changed. num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps) if overrode_max_train_steps: ``` The last step is downloading the [training images](https://huggingface.co/sd-concepts-library/dicoo). Ideally, we'd use a shared NFS folder, but for the sake of simplicity, we'll download the images on each node. Please ensure they're in the same directory on all nodes (`/home/devcloud/dicoo`). ``` mkdir /home/devcloud/dicoo cd /home/devcloud/dicoo wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg ``` Here are the images: <img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg" height="256"> <img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg" height="256"> <img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg" height="256"> <img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg" height="256"> <img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg" height="256"> The system setup is now complete. Let's configure the training job. ## Configuring the fine-tuning job The [Accelerate](https://huggingface.co/docs/accelerate/index) library makes it very easy to run distributed training. We need to run it on each node and answer simple questions. Here's a screenshot for the primary node. On the other nodes, you need to set the rank to 1, 2, and 3. All other answers are identical. <kbd> <img src="assets/stable-diffusion-finetuning-intel/screen01.png"> </kbd> Finally, we need to set the environment on the primary node. It will be propagated to other nodes as the fine-tuning job starts. The first line sets the name of the network interface connected to the local network where all nodes run. You may need to adapt this using`ifconfig` to get the appropriate information. ``` export I_MPI_HYDRA_IFACE=ens786f1 oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)") source $oneccl_bindings_for_pytorch_path/env/setvars.sh export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libiomp5.so export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so export CCL_ATL_TRANSPORT=ofi export CCL_WORKER_COUNT=1 export MODEL_NAME="runwayml/stable-diffusion-v1-5" export DATA_DIR="/home/devcloud/dicoo" ``` We can now launch the fine-tuning job. ## Fine-tuning the model We launch the fine-tuning job with `mpirun`, which sets up distributed communication across the nodes listed in `nodefile`. We'll run 16 tasks (`-n`) with four tasks per node (`-ppn`). `Accelerate` automatically sets up distributed training across all tasks. Here, we train for 200 steps, which should take about five minutes. ``` mpirun -f nodefile -n 16 -ppn 4 \ accelerate launch diffusers/examples/textual_inversion/textual_inversion.py \ --pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \ --learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \ --resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \ --max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \ --lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \ --save_as_full_pipeline ``` Here's a screenshot of the busy cluster: <kbd> <img src="assets/stable-diffusion-finetuning-intel/screen02.png"> </kbd> ## Troubleshooting Distributed training can be tricky, especially if you're new to the discipline. A minor misconfiguration on a single node is the most likely issue: missing dependency, images stored in a different location, etc. You can quickly pinpoint the troublemaker by logging in to each node and training locally. First, set the same environment as on the primary node, then run: ``` python diffusers/examples/textual_inversion/textual_inversion.py \ --pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \ --learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \ --resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \ --max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \ --lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \ --save_as_full_pipeline ``` If training starts successfully, stop it and move to the next node. If training starts successfully on all nodes, return to the primary node and double-check the node file, the environment, and the `mpirun` command. Don't worry; you'll find the problem :) ## Generating images with the fine-tuned model After 5 minutes training, the model is saved locally. We could load it with a vanilla `diffusers` pipeline and predict. Instead, let's use [Optimum Intel and OpenVINO](https://huggingface.co/docs/optimum/intel/inference) to optimize the model. As discussed in a [previous post](https://huggingface.co/blog/intel-sapphire-rapids-inference), this lets you generate an image on a single CPU in less than 5 seconds! ``` pip install optimum[openvino] ``` Here, we load the model, optimize it for a static shape, and save it: ``` from optimum.intel.openvino import OVStableDiffusionPipeline model_id = "./textual_inversion_output" ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True) ov_pipe.reshape(batch_size=5, height=512, width=512, num_images_per_prompt=1) ov_pipe.save_pretrained("./textual_inversion_output_ov") ``` Then, we load the optimized model, generate five different images and save them: ``` from optimum.intel.openvino import OVStableDiffusionPipeline model_id = "./textual_inversion_output_ov" ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, num_inference_steps=20) prompt = ["a yellow <dicoo> robot at the beach, high quality"]*5 images = ov_pipe(prompt).images print(images) for idx,img in enumerate(images): img.save(f"image{idx}.png") ``` Here's a generated image. It is impressive that the model only needed five images to learn that dicoos have glasses! <kbd> <img src="assets/stable-diffusion-finetuning-intel/dicoo_image_200.png"> </kbd> If you'd like, you can fine-tune the model some more. Here's a lovely example generated by a 3,000-step model (about an hour of training). <kbd> <img src="assets/stable-diffusion-finetuning-intel/dicoo_image.png"> </kbd> ## Conclusion Thanks to Hugging Face and Intel, you can now use Xeon CPU servers to generate high-quality images adapted to your business needs. They are generally more affordable and widely available than specialized hardware such as GPUs. Xeon CPUs can also be easily repurposed for other production tasks, from web servers to databases, making them a versatile and flexible choice for your IT infrastructure. Here are some resources to help you get started: * Diffusers [documentation](https://huggingface.co/docs/diffusers) * Optimum Intel [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference) * [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub * [Developer resources](https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html) from Intel and Hugging Face. * Sapphire Rapids servers on [Intel Developer Cloud](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html), [AWS](https://aws.amazon.com/about-aws/whats-new/2022/11/introducing-amazon-ec2-r7iz-instances/?nc1=h_ls) and [GCP](https://cloud.google.com/blog/products/compute/c3-machine-series-on-intel-sapphire-rapids-now-ga). If you have questions or feedback, we'd love to read them on the [Hugging Face forum](https://discuss.huggingface.co/). Thanks for reading!
|
Open-Source Text Generation & LLM Ecosystem at Hugging Face
|
merve
|
July 17, 2023
|
os-llms
|
LLM, inference, nlp
|
https://huggingface.co/blog/os-llms
|
# Open-Source Text Generation & LLM Ecosystem at Hugging Face [Updated on July 24, 2023: Added Llama 2.] Text generation and conversational technologies have been around for ages. Earlier challenges in working with these technologies were controlling both the coherence and diversity of the text through inference parameters and discriminative biases. More coherent outputs were less creative and closer to the original training data and sounded less human. Recent developments overcame these challenges, and user-friendly UIs enabled everyone to try these models out. Services like ChatGPT have recently put the spotlight on powerful models like GPT-4 and caused an explosion of open-source alternatives like Llama to go mainstream. We think these technologies will be around for a long time and become more and more integrated into everyday products. This post is divided into the following sections: 1. [Brief background on text generation](#brief-background-on-text-generation) 2. [Licensing](#licensing) 3. [Tools in the Hugging Face Ecosystem for LLM Serving](#tools-in-the-hugging-face-ecosystem-for-llm-serving) 4. [Parameter Efficient Fine Tuning (PEFT)](#parameter-efficient-fine-tuning-peft) ## Brief Background on Text Generation Text generation models are essentially trained with the objective of completing an incomplete text or generating text from scratch as a response to a given instruction or question. Models that complete incomplete text are called Causal Language Models, and famous examples are GPT-3 by OpenAI and [Llama](https://ai.meta.com/blog/large-language-model-Llama-meta-ai/) by Meta AI.  One concept you need to know before we move on is fine-tuning. This is the process of taking a very large model and transferring the knowledge contained in this base model to another use case, which we call _a downstream task_. These tasks can come in the form of instructions. As the model size grows, it can generalize better to instructions that do not exist in the pre-training data, but were learned during fine-tuning. Causal language models are adapted using a process called reinforcement learning from human feedback (RLHF). This optimization is mainly made over how natural and coherent the text sounds rather than the validity of the answer. Explaining how RLHF works is outside the scope of this blog post, but you can find more information about this process [here](https://huggingface.co/blog/rlhf). For example, GPT-3 is a causal language _base_ model, while the models in the backend of ChatGPT (which is the UI for GPT-series models) are fine-tuned through RLHF on prompts that can consist of conversations or instructions. It’s an important distinction to make between these models. On the Hugging Face Hub, you can find both causal language models and causal language models fine-tuned on instructions (which we’ll give links to later in this blog post). Llama is one of the first open-source LLMs to have outperformed/matched closed-source ones. A research group led by Together has created a reproduction of Llama's dataset, called Red Pajama, and trained LLMs and instruction fine-tuned models on it. You can read more about it [here](https://www.together.xyz/blog/redpajama) and find [the model checkpoints on Hugging Face Hub](https://huggingface.co/models?sort=trending&search=togethercomputer%2Fredpajama). By the time this blog post is written, three of the largest causal language models with open-source licenses are [MPT-30B by MosaicML](https://huggingface.co/mosaicml/mpt-30b), [XGen by Salesforce](https://huggingface.co/Salesforce/xgen-7b-8k-base) and [Falcon by TII UAE](https://huggingface.co/tiiuae/falcon-40b), available completely open on Hugging Face Hub. Recently, Meta released [Llama 2](https://ai.meta.com/Llama/), an open-access model with a license that allows commercial use. As of now, Llama 2 outperforms all of the other open-source large language models on different benchmarks. [Llama 2 checkpoints on Hugging Face Hub](https://huggingface.co/meta-Llama) are compatible with transformers, and the largest checkpoint is available for everyone to try at [HuggingChat](https://huggingface.co/chat/). You can read more about how to fine-tune, deploy and prompt with Llama 2 in [this blog post](https://huggingface.co/blog/llama2). The second type of text generation model is commonly referred to as the text-to-text generation model. These models are trained on text pairs, which can be questions and answers or instructions and responses. The most popular ones are T5 and BART (which, as of now, aren’t state-of-the-art). Google has recently released the FLAN-T5 series of models. FLAN is a recent technique developed for instruction fine-tuning, and FLAN-T5 is essentially T5 fine-tuned using FLAN. As of now, the FLAN-T5 series of models are state-of-the-art and open-source, available on the [Hugging Face Hub](https://huggingface.co/models?search=google/flan). Note that these are different from instruction-tuned causal language models, although the input-output format might seem similar. Below you can see an illustration of how these models work.  Having more variation of open-source text generation models enables companies to keep their data private, to adapt models to their domains faster, and to cut costs for inference instead of relying on closed paid APIs. All open-source causal language models on Hugging Face Hub can be found [here](https://huggingface.co/models?pipeline_tag=text-generation), and text-to-text generation models can be found [here](https://huggingface.co/models?pipeline_tag=text2text-generation&sort=trending). ### Models created with love by Hugging Face with BigScience and BigCode 💗 Hugging Face has co-led two science initiatives, BigScience and BigCode. As a result of them, two large language models were created, [BLOOM](https://huggingface.co/bigscience/bloom) 🌸 and [StarCoder](https://huggingface.co/bigcode/starcoder) 🌟. BLOOM is a causal language model trained on 46 languages and 13 programming languages. It is the first open-source model to have more parameters than GPT-3. You can find all the available checkpoints in the [BLOOM documentation](https://huggingface.co/docs/transformers/model_doc/bloom). StarCoder is a language model trained on permissive code from GitHub (with 80+ programming languages 🤯) with a Fill-in-the-Middle objective. It’s not fine-tuned on instructions, and thus, it serves more as a coding assistant to complete a given code, e.g., translate Python to C++, explain concepts (what’s recursion), or act as a terminal. You can try all of the StarCoder checkpoints [in this application](https://huggingface.co/spaces/bigcode/bigcode-playground). It also comes with a [VSCode extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode). Snippets to use all models mentioned in this blog post are given in either the model repository or the documentation page of that model type in Hugging Face. ## Licensing Many text generation models are either closed-source or the license limits commercial use. Fortunately, open-source alternatives are starting to appear and being embraced by the community as building blocks for further development, fine-tuning, or integration with other projects. Below you can find a list of some of the large causal language models with fully open-source licenses: - [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) - [XGen](https://huggingface.co/tiiuae/falcon-40b) - [MPT-30B](https://huggingface.co/mosaicml/mpt-30b) - [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b) - [RedPajama-INCITE-7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) - [OpenAssistant (Falcon variant)](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226) There are two code generation models, [StarCoder by BigCode](https://huggingface.co/models?sort=trending&search=bigcode%2Fstarcoder) and [Codegen by Salesforce](https://huggingface.co/models?sort=trending&search=salesforce%2Fcodegen). There are model checkpoints in different sizes and open-source or [open RAIL](https://huggingface.co/blog/open_rail) licenses for both, except for [Codegen fine-tuned on instruction](https://huggingface.co/Salesforce/codegen25-7b-instruct). The Hugging Face Hub also hosts various models fine-tuned for instruction or chat use. They come in various styles and sizes depending on your needs. - [MPT-30B-Chat](https://huggingface.co/mosaicml/mpt-30b-chat), by Mosaic ML, uses the CC-BY-NC-SA license, which does not allow commercial use. However, [MPT-30B-Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) uses CC-BY-SA 3.0, which can be used commercially. - [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) and [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) both use the Apache 2.0 license, so commercial use is also permitted. - Another popular family of models is OpenAssistant, some of which are built on Meta's Llama model using a custom instruction-tuning dataset. Since the original Llama model can only be used for research, the OpenAssistant checkpoints built on Llama don’t have full open-source licenses. However, there are OpenAssistant models built on open-source models like [Falcon](https://huggingface.co/models?search=openassistant/falcon) or [pythia](https://huggingface.co/models?search=openassistant/pythia) that use permissive licenses. - [StarChat Beta](https://huggingface.co/HuggingFaceH4/starchat-beta) is the instruction fine-tuned version of StarCoder, and has BigCode Open RAIL-M v1 license, which allows commercial use. Instruction-tuned coding model of Salesforce, [XGen model](https://huggingface.co/Salesforce/xgen-7b-8k-inst), only allows research use. If you're looking to fine-tune a model on an existing instruction dataset, you need to know how a dataset was compiled. Some of the existing instruction datasets are either crowd-sourced or use outputs of existing models (e.g., the models behind ChatGPT). [ALPACA](https://crfm.stanford.edu/2023/03/13/alpaca.html) dataset created by Stanford is created through the outputs of models behind ChatGPT. Moreover, there are various crowd-sourced instruction datasets with open-source licenses, like [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) (created by thousands of people voluntarily!) or [databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k). If you'd like to create a dataset yourself, you can check out [the dataset card of Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k#sources) on how to create an instruction dataset. Models fine-tuned on these datasets can be distributed. You can find a comprehensive table of some open-source/open-access models below. | Model | Dataset | License | Use | |------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|-------------------------| | [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) | [Falcon RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | Apache-2.0 | Text Generation | | [SalesForce XGen 7B](https://huggingface.co/Salesforce/xgen-7b-8k-base) | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation | | [MPT-30B](https://huggingface.co/mosaicml/mpt-30b) | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation | | [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b) | [Pile](https://huggingface.co/datasets/EleutherAI/pile) | Apache-2.0 | Text Generation | | [RedPajama INCITE 7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | Apache-2.0 | Text Generation | | [OpenAssistant Falcon 40B](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226) | [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) and [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | Apache-2.0 | Text Generation | | [StarCoder](https://huggingface.co/bigcode/starcoder) | [The Stack](https://huggingface.co/datasets/bigcode/the-stack-dedup) | BigCode OpenRAIL-M | Code Generation | | [Salesforce CodeGen](https://huggingface.co/Salesforce/codegen25-7b-multi) | [Starcoder Data](https://huggingface.co/datasets/bigcode/starcoderdata) | Apache-2.0 | Code Generation | | [FLAN-T5-XXL](https://huggingface.co/google/flan-t5-xxl) | [gsm8k](https://huggingface.co/datasets/gsm8k), [lambada](https://huggingface.co/datasets/lambada), and [esnli](https://huggingface.co/datasets/esnli) | Apache-2.0 | Text-to-text Generation | | [MPT-30B Chat](https://huggingface.co/mosaicml/mpt-30b-chat) | [ShareGPT-Vicuna](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered), [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) and more | CC-By-NC-SA-4.0 | Chat | | [MPT-30B Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) | [duorc](https://huggingface.co/datasets/duorc), [competition_math](https://huggingface.co/datasets/competition_math), [dolly_hhrlhf](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) | CC-By-SA-3.0 | Instruction | | [Falcon 40B Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) | [baize](https://github.com/project-baize/baize-chatbot) | Apache-2.0 | Instruction | | [Dolly v2](https://huggingface.co/databricks/dolly-v2-12b) | [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | MIT | Text Generation | | [StarChat-β](https://huggingface.co/HuggingFaceH4/starchat-beta) | [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) | BigCode OpenRAIL-M | Code Instruction | | [Llama 2](https://huggingface.co/meta-Llama/Llama-2-70b-hf) | Undisclosed dataset | Custom Meta License (Allows commercial use) | Text Generation | ## Tools in the Hugging Face Ecosystem for LLM Serving ### Text Generation Inference Response time and latency for concurrent users are a big challenge for serving these large models. To tackle this problem, Hugging Face has released [text-generation-inference](https://github.com/huggingface/text-generation-inference) (TGI), an open-source serving solution for large language models built on Rust, Python, and gRPc. TGI is integrated into inference solutions of Hugging Face, [Inference Endpoints](https://huggingface.co/inference-endpoints), and [Inference API](https://huggingface.co/inference-api), so you can directly create an endpoint with optimized inference with few clicks, or simply send a request to Hugging Face's Inference API to benefit from it, instead of integrating TGI to your platform.  TGI currently powers [HuggingChat](https://huggingface.co/chat/), Hugging Face's open-source chat UI for LLMs. This service currently uses one of OpenAssistant's models as the backend model. You can chat as much as you want with HuggingChat and enable the Web search feature for responses that use elements from current Web pages. You can also give feedback to each response for model authors to train better models. The UI of HuggingChat is also [open-sourced](https://github.com/huggingface/chat-ui), and we are working on more features for HuggingChat to allow more functions, like generating images inside the chat.  Recently, a Docker template for HuggingChat was released for Hugging Face Spaces. This allows anyone to deploy their instance based on a large language model with only a few clicks and customize it. You can create your large language model instance [here](https://huggingface.co/new-space?template=huggingchat/chat-ui-template) based on various LLMs, including Llama 2.  ### How to find the best model? Hugging Face hosts an [LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). This leaderboard is created by evaluating community-submitted models on text generation benchmarks on Hugging Face’s clusters. If you can’t find the language or domain you’re looking for, you can filter them [here](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads).  You can also check out the [LLM Performance leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which aims to evaluate the latency and throughput of large language models available on Hugging Face Hub. ## Parameter Efficient Fine Tuning (PEFT) If you’d like to fine-tune one of the existing large models on your instruction dataset, it is nearly impossible to do so on consumer hardware and later deploy them (since the instruction models are the same size as the original checkpoints that are used for fine-tuning). [PEFT](https://huggingface.co/docs/peft/index) is a library that allows you to do parameter-efficient fine-tuning techniques. This means that rather than training the whole model, you can train a very small number of additional parameters, enabling much faster training with very little performance degradation. With PEFT, you can do low-rank adaptation (LoRA), prefix tuning, prompt tuning, and p-tuning. You can check out further resources for more information on text generation. **Further Resources** - Together with AWS we released TGI-based LLM deployment deep learning containers called LLM Inference Containers. Read about them [here](https://aws.amazon.com/tr/blogs/machine-learning/announcing-the-launch-of-new-hugging-face-llm-inference-containers-on-amazon-sagemaker/). - [Text Generation task page](https://huggingface.co/tasks/text-generation) to find out more about the task itself. - PEFT announcement [blog post](https://huggingface.co/blog/peft). - Read about how Inference Endpoints use TGI [here](https://huggingface.co/blog/inference-endpoints-llm). - Read about how to fine-tune Llama 2 transformers and PEFT, and prompt [here](https://huggingface.co/blog/llama2).
|
Building an AI WebTV
|
jbilcke-hf
|
July 17, 2023
|
ai-webtv
|
text-to-video, guide
|
https://huggingface.co/blog/ai-webtv
|
# Building an AI WebTV The AI WebTV is an experimental demo to showcase the latest advancements in automatic video and music synthesis. 👉 Watch the stream now by going to the [AI WebTV Space](https://huggingface.co/spaces/jbilcke-hf/AI-WebTV). If you are using a mobile device, you can view the stream from the [Twitch mirror](https://www.twitch.tv/ai_webtv).  # Concept The motivation for the AI WebTV is to demo videos generated with open-source [text-to-video models](https://huggingface.co/tasks/text-to-video) such as Zeroscope and MusicGen, in an entertaining and accessible way. You can find those open-source models on the Hugging Face hub: - For video: [zeroscope_v2_576](https://huggingface.co/cerspense/zeroscope_v2_576w) and [zeroscope_v2_XL](https://huggingface.co/cerspense/zeroscope_v2_XL) - For music: [musicgen-melody](https://huggingface.co/facebook/musicgen-melody) The individual video sequences are purposely made to be short, meaning the WebTV should be seen as a tech demo/showreel rather than an actual show (with an art direction or programming). # Architecture The AI WebTV works by taking a sequence of [video shot](https://en.wikipedia.org/wiki/Shot_(filmmaking)) prompts and passing them to a [text-to-video model](https://huggingface.co/tasks/text-to-video) to generate a sequence of [takes](https://en.wikipedia.org/wiki/Take). Additionally, a base theme and idea (written by a human) are passed through a LLM (in this case, ChatGPT), in order to generate a variety of individual prompts for each video clip. Here's a diagram of the current architecture of the AI WebTV:  # Implementing the pipeline The WebTV is implemented in NodeJS and TypeScript, and uses various services hosted on Hugging Face. ## The text-to-video model The central video model is Zeroscope V2, a model based on [ModelScope](https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis). Zeroscope is comprised of two parts that can be chained together: - A first pass with [zeroscope_v2_576](https://huggingface.co/cerspense/zeroscope_v2_576w), to generate a 576x320 video clip - An optional second pass with [zeroscope_v2_XL](https://huggingface.co/cerspense/zeroscope_v2_XL) to upscale the video to 1024x576 👉 You will need to use the same prompt for both the generation and upscaling. ## Calling the video chain To make a quick prototype, the WebTV runs Zeroscope from two duplicated Hugging Face Spaces running [Gradio](https://github.com/gradio-app/gradio/), which are called using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) NPM package. You can find the original spaces here: - [zeroscope-v2](https://huggingface.co/spaces/hysts/zeroscope-v2/tree/main) by @hysts - [Zeroscope XL](https://huggingface.co/spaces/fffiloni/zeroscope-XL) by @fffiloni Other spaces deployed by the community can also be found if you [search for Zeroscope on the Hub](https://huggingface.co/spaces?search=zeroscope). 👉 Public Spaces may become overcrowded and paused at any time. If you intend to deploy your own system, please duplicate those Spaces and run them under your own account. ## Using a model hosted on a Space Spaces using Gradio have the ability to [expose a REST API](https://www.gradio.app/guides/sharing-your-app#api-page), which can then be called from Node using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) module. Here is an example: ```typescript import { client } from "@gradio/client" export const generateVideo = async (prompt: string) => { const api = await client("*** URL OF THE SPACE ***") // call the "run()" function with an array of parameters const { data } = await api.predict("/run", [ prompt, 42, // seed 24, // nbFrames 35 // nbSteps ]) const { orig_name } = data[0][0] const remoteUrl = `${instance}/file=${orig_name}` // the file can then be downloaded and stored locally } ``` ## Post-processing Once an individual take (a video clip) is upscaled, it is then passed to FILM (Frame Interpolation for Large Motion), a frame interpolation algorithm: - Original links: [website](https://film-net.github.io/), [source code](https://github.com/google-research/frame-interpolation) - Model on Hugging Face: [/frame-interpolation-film-style](https://huggingface.co/akhaliq/frame-interpolation-film-style) - A Hugging Face Space you can duplicate: [video_frame_interpolation](https://huggingface.co/spaces/fffiloni/video_frame_interpolation/blob/main/app.py) by @fffiloni During post-processing, we also add music generated with MusicGen: - Original links: [website](https://ai.honu.io/papers/musicgen/), [source code](https://github.com/facebookresearch/audiocraft) - Hugging Face Space you can duplicate: [MusicGen](https://huggingface.co/spaces/facebook/MusicGen) ## Broadcasting the stream Note: there are multiple tools you can use to create a video stream. The AI WebTV currently uses [FFmpeg](https://ffmpeg.org/documentation.html) to read a playlist made of mp4 videos files and m4a audio files. Here is an example of creating such a playlist: ```typescript import { promises as fs } from "fs" import path from "path" const allFiles = await fs.readdir("** PATH TO VIDEO FOLDER **") const allVideos = allFiles .map(file => path.join(dir, file)) .filter(filePath => filePath.endsWith('.mp4')) let playlist = 'ffconcat version 1.0\n' allFilePaths.forEach(filePath => { playlist += `file '${filePath}'\n` }) await fs.promises.writeFile("playlist.txt", playlist) ``` This will generate the following playlist content: ```bash ffconcat version 1.0 file 'video1.mp4' file 'video2.mp4' ... ``` FFmpeg is then used again to read this playlist and send a [FLV stream](https://en.wikipedia.org/wiki/Flash_Video) to a [RTMP server](https://en.wikipedia.org/wiki/Real-Time_Messaging_Protocol). FLV is an old format but still popular in the world of real-time streaming due to its low latency. ```bash ffmpeg -y -nostdin \ -re \ -f concat \ -safe 0 -i channel_random.txt -stream_loop -1 \ -loglevel error \ -c:v libx264 -preset veryfast -tune zerolatency \ -shortest \ -f flv rtmp://<SERVER> ``` There are many different configuration options for FFmpeg, for more information in the [official documentation](http://trac.ffmpeg.org/wiki/StreamingGuide). For the RTMP server, you can find [open-source implementations on GitHub](https://github.com/topics/rtmp-server), such as the [NGINX-RTMP module](https://github.com/arut/nginx-rtmp-module). The AI WebTV itself uses [node-media-server](https://github.com/illuspas/Node-Media-Server). 💡 You can also directly stream to [one of the Twitch RTMP entrypoints](https://help.twitch.tv/s/twitch-ingest-recommendation?language=en_US). Check out the Twitch documentation for more details. # Observations and examples Here are some examples of the generated content. The first thing we notice is that applying the second pass of Zeroscope XL significantly improves the quality of the image. The impact of frame interpolation is also clearly visible. ## Characters and scene composition <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo4.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo4.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Photorealistic movie of a <strong>llama acting as a programmer, wearing glasses and a hoodie</strong>, intensely <strong>staring at a screen</strong> with lines of code, in a cozy, <strong>dimly lit room</strong>, Canon EOS, ambient lighting, high details, cinematic, trending on artstation</i></figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo5.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo5.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>3D rendered animation showing a group of food characters <strong>forming a pyramid</strong>, with a <strong>banana</strong> standing triumphantly on top. In a city with <strong>cotton candy clouds</strong> and <strong>chocolate road</strong>, Pixar's style, CGI, ambient lighting, direct sunlight, rich color scheme, ultra realistic, cinematic, photorealistic.</i></figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo7.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo7.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Intimate <strong>close-up of a red fox, gazing into the camera with sharp eyes</strong>, ambient lighting creating a high contrast silhouette, IMAX camera, <strong>high detail</strong>, <strong>cinematic effect</strong>, golden hour, film grain.</i></figcaption> </figure> ## Simulation of dynamic scenes Something truly fascinating about text-to-video models is their ability to emulate real-life phenomena they have been trained on. We've seen it with large language models and their ability to synthesize convincing content that mimics human responses, but this takes things to a whole new dimension when applied to video. A video model predicts the next frames of a scene, which might include objects in motion such as fluids, people, animals, or vehicles. Today, this emulation isn't perfect, but it will be interesting to evaluate future models (trained on larger or specialized datasets, such as animal locomotion) for their accuracy when reproducing physical phenomena, and also their ability to simulate the behavior of agents. <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo17.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo17.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Cinematic movie shot of <strong>bees energetically buzzing around a flower</strong>, sun rays illuminating the scene, captured in 4k IMAX with a soft bokeh background.</i></figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo8.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo8.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i><strong>Dynamic footage of a grizzly bear catching a salmon in a rushing river</strong>, ambient lighting highlighting the splashing water, low angle, IMAX camera, 4K movie quality, golden hour, film grain.</i></figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo18.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo18.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Aerial footage of a quiet morning at the coast of California, with <strong>waves gently crashing against the rocky shore</strong>. A startling sunrise illuminates the coast with vibrant colors, captured beautifully with a DJI Phantom 4 Pro. Colors and textures of the landscape come alive under the soft morning light. Film grain, cinematic, imax, movie</i></figcaption> </figure> 💡 It will be interesting to see these capabilities explored more in the future, for instance by training video models on larger video datasets covering more phenomena. ## Styling and effects <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo0.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo0.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i> <strong>3D rendered video</strong> of a friendly broccoli character wearing a hat, walking in a candy-filled city street with gingerbread houses, under a <strong>bright sun and blue skies</strong>, <strong>Pixar's style</strong>, cinematic, photorealistic, movie, <strong>ambient lighting</strong>, natural lighting, <strong>CGI</strong>, wide-angle view, daytime, ultra realistic.</i> </figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo2.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo2.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i><strong>Cinematic movie</strong>, shot of an astronaut and a llama at dawn, the mountain landscape bathed in <strong>soft muted colors</strong>, early morning fog, dew glistening on fur, craggy peaks, vintage NASA suit, Canon EOS, high detailed skin, epic composition, high quality, 4K, trending on artstation, beautiful</i> </figcaption> </figure> <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="demo1.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo1.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Panda and black cat <strong>navigating down the flowing river</strong> in a small boat, Studio Ghibli style > Cinematic, beautiful composition > IMAX <strong>camera panning following the boat</strong> > High quality, cinematic, movie, mist effect, film grain, trending on Artstation</i> </figcaption> </figure> ## Failure cases **Wrong direction:** the model sometimes has trouble with movement and direction. For instance, here the clip seems to be played in reverse. Also the modifier keyword ***green*** was not taken into account. <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="fail1.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail1.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Movie showing a <strong>green pumpkin</strong> falling into a bed of nails, slow-mo explosion with chunks flying all over, ambient fog adding to the dramatic lighting, filmed with IMAX camera, 8k ultra high definition, high quality, trending on artstation.</i> </figcaption> </figure> **Rendering errors on realistic scenes:** sometimes we can see artifacts such as moving vertical lines or waves. It is unclear what causes this, but it may be due to the combination of keywords used. <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="fail2.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail2.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Film shot of a captivating flight above the Grand Canyon, ledges and plateaus etched in orange and red. <strong>Deep shadows contrast</strong> with the fiery landscape under the midday sun, shot with DJI Phantom 4 Pro. The camera rotates to capture the vastness, <strong>textures</strong> and colors, in imax quality. Film <strong>grain</strong>, cinematic, movie.</i> </figcaption> </figure> **Text or objects inserted into the image:** the model sometimes injects words from the prompt into the scene, such as "IMAX". Mentioning "Canon EOS" or "Drone footage" in the prompt can also make those objects appear in the video. In the following example, we notice the word "llama" inserts a llama but also two occurrences of the word llama in flames. <figure class="image flex flex-col items-center text-center m-0 w-full"> <video alt="fail3.mp4" autoplay loop autobuffer muted playsinline > <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail3.mp4" type="video/mp4"> </video> <figcaption>Prompt: <i>Movie scene of a <strong>llama</strong> acting as a firefighter, in firefighter uniform, dramatically spraying water at <strong>roaring flames</strong>, amidst a chaotic urban scene, Canon EOS, ambient lighting, high quality, award winning, highly detailed fur, cinematic, trending on artstation.</i> </figcaption> </figure> # Recommendations Here are some early recommendations that can be made from the previous observations: ## Using video-specific prompt keywords You may already know that if you don’t prompt a specific aspect of the image with Stable Diffusion, things like the color of clothes or the time of the day might become random, or be assigned a generic value such as a neutral mid-day light. The same is true for video models: you will want to be specific about things. Examples include camera and character movement, their orientation, speed and direction. You can leave it unspecified for creative purposes (idea generation), but this might not always give you the results you want (e.g., entities animated in reverse). ## Maintaining consistency between scenes If you plan to create sequences of multiple videos, you will want to make sure you add as many details as possible in each prompt, otherwise you may lose important details from one sequence to another, such as the color. 💡 This will also improve the quality of the image since the prompt is used for the upscaling part with Zeroscope XL. ## Leverage frame interpolation Frame interpolation is a powerful tool which can repair small rendering errors and turn many defects into features, especially in scenes with a lot of animation, or where a cartoon effect is acceptable. The [FILM algorithm](https://film-net.github.io/) will smoothen out elements of a frame with previous and following events in the video clip. This works great to displace the background when the camera is panning or rotating, and will also give you creative freedom, such as control over the number of frames after the generation, to make slow-motion effects. # Future work We hope you enjoyed watching the AI WebTV stream and that it will inspire you to build more in this space. As this was a first trial, a lot of things were not the focus of the tech demo: generating longer and more varied sequences, adding audio (sound effects, dialogue), generating and orchestrating complex scenarios, or letting a language model agent have more control over the pipeline. Some of these ideas may make their way into future updates to the AI WebTV, but we also can’t wait to see what the community of researchers, engineers and builders will come up with!
|
Llama 2 is here - get it on Hugging Face
|
osanseviero
|
July 18, 2023
|
llama2
|
nlp, community, research, LLM
|
https://huggingface.co/blog/llama2
|
# Llama 2 is here - get it on Hugging Face ## Introduction Llama 2 is a family of state-of-the-art open-access large language models released by Meta today, and we’re excited to fully support the launch with comprehensive integration in Hugging Face. Llama 2 is being released with a very permissive community license and is available for commercial use. The code, pretrained models, and fine-tuned models are all being released today 🔥 We’ve collaborated with Meta to ensure smooth integration into the Hugging Face ecosystem. You can find the 12 open-access models (3 base models & 3 fine-tuned ones with the original Meta checkpoints, plus their corresponding `transformers` models) on the Hub. Among the features and integrations being released, we have: - [Models on the Hub](https://huggingface.co/meta-llama) with their model cards and license. - [Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.31.0) - Examples to fine-tune the small variants of the model with a single GPU - Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference - Integration with Inference Endpoints ## Table of Contents - [Why Llama 2?](#why-llama-2) - [Demo](#demo) - [Inference](#inference) - [With Transformers](#using-transformers) - [With Inference Endpoints](#using-text-generation-inference-and-inference-endpoints) - [Fine-tuning with PEFT](#fine-tuning-with-peft) - [How to Prompt Llama 2](#how-to-prompt-llama-2) - [Additional Resources](#additional-resources) - [Conclusion](#conclusion) ## Why Llama 2? The Llama 2 release introduces a family of pretrained and fine-tuned LLMs, ranging in scale from 7B to 70B parameters (7B, 13B, 70B). The pretrained models come with significant improvements over the Llama 1 models, including being trained on 40% more tokens, having a much longer context length (4k tokens 🤯), and using grouped-query attention for fast inference of the 70B model🔥! However, the most exciting part of this release is the fine-tuned models (Llama 2-Chat), which have been optimized for dialogue applications using [Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf). Across a wide range of helpfulness and safety benchmarks, the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT according to human evaluations. You can read the paper [here](https://huggingface.co/papers/2307.09288). 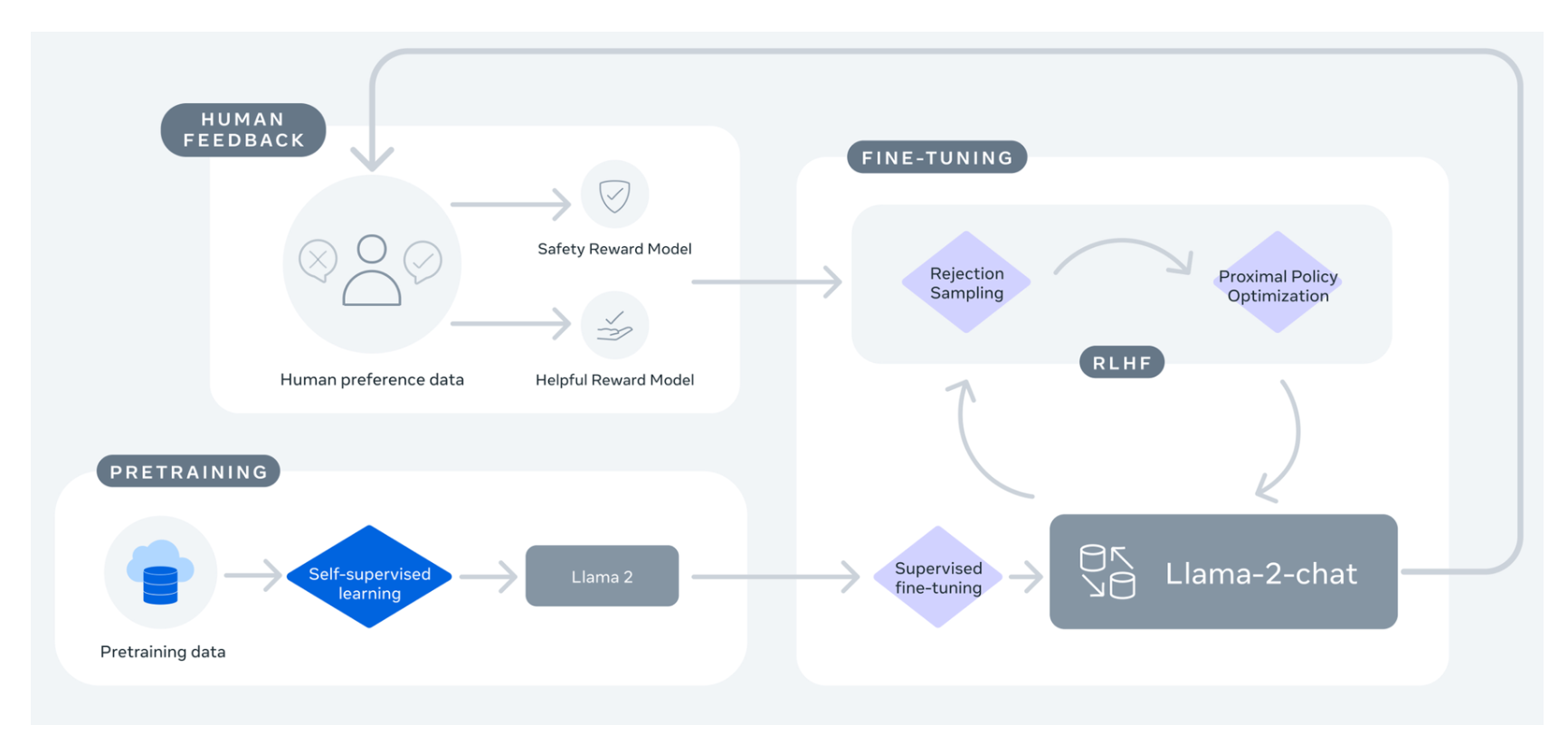 _image from [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://scontent-fra3-2.xx.fbcdn.net/v/t39.2365-6/10000000_6495670187160042_4742060979571156424_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=GK8Rh1tm_4IAX8b5yo4&_nc_ht=scontent-fra3-2.xx&oh=00_AfDtg_PRrV6tpy9UmiikeMRuQgk6Rej7bCPOkXZQVmUKAg&oe=64BBD830)_ If you’ve been waiting for an open alternative to closed-source chatbots, Llama 2-Chat is likely your best choice today! | Model | License | Commercial use? | Pretraining length [tokens] | Leaderboard score | | --- | --- | --- | --- | --- | | [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) | Apache 2.0 | ✅ | 1,500B | 47.01 | | [MPT-7B](https://huggingface.co/mosaicml/mpt-7b) | Apache 2.0 | ✅ | 1,000B | 48.7 | | Llama-7B | Llama license | ❌ | 1,000B | 49.71 | | [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 54.32 | | Llama-33B | Llama license | ❌ | 1,500B | * | | [Llama-2-13B](https://huggingface.co/meta-llama/Llama-2-13b-hf) | Llama 2 license | ✅ | 2,000B | 58.67 | | [mpt-30B](https://huggingface.co/mosaicml/mpt-30b) | Apache 2.0 | ✅ | 1,000B | 55.7 | | [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 | | Llama-65B | Llama license | ❌ | 1,500B | 62.1 | | [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | * | | [Llama-2-70B-chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)* | Llama 2 license | ✅ | 2,000B | 66.8 | *we’re currently running evaluation of the Llama 2 70B (non chatty version). This table will be updated with the results. ## Demo You can easily try the Big Llama 2 Model (70 billion parameters!) in [this Space](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI) or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.37.0/gradio.js"> </script> <gradio-app theme_mode="light" space="ysharma/Explore_llamav2_with_TGI"></gradio-app> Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and which we'll share more in the following sections. ## Inference In this section, we’ll go through different approaches to running inference of the Llama2 models. Before using these models, make sure you have requested access to one of the models in the official [Meta Llama 2](https://huggingface.co/meta-llama) repositories. **Note: Make sure to also fill the official Meta form. Users are provided access to the repository once both forms are filled after few hours.** ### Using transformers With transformers [release 4.31](https://github.com/huggingface/transformers/releases/tag/v4.31.0), one can already use Llama 2 and leverage all the tools within the HF ecosystem, such as: - training and inference scripts and examples - safe file format (`safetensors`) - integrations with tools such as bitsandbytes (4-bit quantization) and PEFT (parameter efficient fine-tuning) - utilities and helpers to run generation with the model - mechanisms to export the models to deploy Make sure to be using the latest `transformers` release and be logged into your Hugging Face account. ``` pip install transformers huggingface-cli login ``` In the following code snippet, we show how to run inference with transformers. It runs on the free tier of Colab, as long as you select a GPU runtime. ```python from transformers import AutoTokenizer import transformers import torch model = "meta-llama/Llama-2-7b-chat-hf" tokenizer = AutoTokenizer.from_pretrained(model) pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", ) sequences = pipeline( 'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n', do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200, ) for seq in sequences: print(f"Result: {seq['generated_text']}") ``` ``` Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like? Answer: Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy: 1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues. 2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system. 3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl ``` And although the model has *only* 4k tokens of context, you can use techniques supported in `transformers` such as rotary position embedding scaling ([tweet](https://twitter.com/joao_gante/status/1679775399172251648)) to push it further! ### Using text-generation-inference and Inference Endpoints **[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing. You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's **[Inference Endpoints](https://huggingface.co/inference-endpoints)**. To deploy a Llama 2 model, go to the **[model page](https://huggingface.co/meta-llama/Llama-2-7b-hf)** and click on the **[Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf)** widget. - For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G". - For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100". - For 70B models, we advise you to select "GPU [2xlarge] - 2x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [4xlarge] - 4x Nvidia A100" _Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s_ You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript. ## Fine-tuning with PEFT Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single NVIDIA T4 (16GB - Google Colab). You can learn more about it in the [Making LLMs even more accessible blog](https://huggingface.co/blog/4bit-transformers-bitsandbytes). We created a [script](https://github.com/lvwerra/trl/blob/main/examples/scripts/sft_trainer.py) to instruction-tune Llama 2 using QLoRA and the [`SFTTrainer`](https://huggingface.co/docs/trl/v0.4.7/en/sft_trainer) from [`trl`](https://github.com/lvwerra/trl). An example command for fine-tuning Llama 2 7B on the `timdettmers/openassistant-guanaco` can be found below. The script can merge the LoRA weights into the model weights and save them as `safetensor` weights by providing the `merge_and_push` argument. This allows us to deploy our fine-tuned model after training using text-generation-inference and inference endpoints. First pip install `trl` and clone the script: ```bash pip install trl git clone https://github.com/lvwerra/trl ``` Then you can run the script: ```bash python trl/examples/scripts/sft_trainer.py \ --model_name meta-llama/Llama-2-7b-hf \ --dataset_name timdettmers/openassistant-guanaco \ --load_in_4bit \ --use_peft \ --batch_size 4 \ --gradient_accumulation_steps 2 ``` ## How to Prompt Llama 2 One of the unsung advantages of open-access models is that you have full control over the `system` prompt in chat applications. This is essential to specify the behavior of your chat assistant –and even imbue it with some personality–, but it's unreachable in models served behind APIs. We're adding this section just a few days after the initial release of Llama 2, as we've had many questions from the community about how to prompt the models and how to change the system prompt. We hope this helps! The prompt template for the first turn looks like this: ``` <s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_message }} [/INST] ``` This template follows the model's training procedure, as described in [the Llama 2 paper](https://huggingface.co/papers/2307.09288). We can use any `system_prompt` we want, but it's crucial that the format matches the one used during training. To spell it out in full clarity, this is what is actually sent to the language model when the user enters some text (`There's a llama in my garden 😱 What should I do?`) in [our 13B chat demo](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) to initiate a chat: ```b <s>[INST] <<SYS>> You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. <</SYS>> There's a llama in my garden 😱 What should I do? [/INST] ``` As you can see, the instructions between the special `<<SYS>>` tokens provide context for the model so it knows how we expect it to respond. This works because exactly the same format was used during training with a wide variety of system prompts intended for different tasks. As the conversation progresses, _all_ the interactions between the human and the "bot" are appended to the previous prompt, enclosed between `[INST]` delimiters. The template used during multi-turn conversations follows this structure (🎩 h/t [Arthur Zucker](https://huggingface.co/ArthurZ) for some final clarifications): ```b <s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST] ``` The model is stateless and does not "remember" previous fragments of the conversation, we must always supply it with all the context so the conversation can continue. This is the reason why **context length** is a very important parameter to maximize, as it allows for longer conversations and larger amounts of information to be used. ### Ignore previous instructions In API-based models, people resort to tricks in an attempt to override the system prompt and change the default model behaviour. As imaginative as these solutions are, this is not necessary in open-access models: anyone can use a different prompt, as long as it follows the format described above. We believe that this will be an important tool for researchers to study the impact of prompts on both desired and unwanted characteristics. For example, when people [are surprised with absurdly cautious generations](https://twitter.com/lauraruis/status/1681612002718887936), you can explore whether maybe [a different prompt would work](https://twitter.com/overlordayn/status/1681631554672513025). (🎩 h/t [Clémentine Fourrier](https://huggingface.co/clefourrier) for the links to this example). In our [`13B`](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) and [`7B`](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat) demos, you can easily explore this feature by disclosing the "Advanced Options" UI and simply writing your desired instructions. You can also duplicate those demos and use them privately for fun or research! ## Additional Resources - [Paper Page](https://huggingface.co/papers/2307.09288) - [Models on the Hub](https://huggingface.co/meta-llama) - [Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) - [Meta Examples and recipes for Llama model](https://github.com/facebookresearch/llama-recipes/tree/main) - [Chat demo (7B)](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat) - [Chat demo (13B)](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) - [Chat demo (70B) on TGI](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI) ## Conclusion We're very excited about Llama 2 being out! In the incoming days, be ready to learn more about ways to run your own fine-tuning, execute the smallest models on-device, and many other exciting updates we're prepating for you!
|
Happy 1st anniversary 🤗 Diffusers!
|
stevhliu
|
July 20, 2023
|
diffusers-turns-1
|
community, open-source-collab, diffusion, diffusers
|
https://huggingface.co/blog/diffusers-turns-1
|
# Happy 1st anniversary 🤗 Diffusers! 🤗 Diffusers is happy to celebrate its first anniversary! It has been an exciting year, and we're proud and grateful for how far we've come thanks to our community and open-source contributors. Last year, text-to-image models like DALL-E 2, Imagen, and Stable Diffusion captured the world's attention with their ability to generate stunningly photorealistic images from text, sparking a massive surge of interest and development in generative AI. But access to these powerful models was limited. At Hugging Face, our mission is to democratize good machine learning by collaborating and helping each other build an open and ethical AI future together. Our mission motivated us to create the 🤗 Diffusers library so *everyone* can experiment, research, or simply play with text-to-image models. That’s why we designed the library as a modular toolbox, so you can customize a diffusion model’s components or just start using it out-of-the-box. As 🤗 Diffusers turns 1, here’s an overview of some of the most notable features we’ve added to the library with the help of our community. We are proud and immensely grateful for being part of an engaged community that promotes accessible usage, pushes diffusion models beyond just text-to-image generation, and is an all-around inspiration. **Table of Contents** * [Striving for photorealism](#striving-for-photorealism) * [Video pipelines](#video-pipelines) * [Text-to-3D models](#text-to-3d-models) * [Image editing pipelines](#image-editing-pipelines) * [Faster diffusion models](#faster-diffusion-models) * [Ethics and safety](#ethics-and-safety) * [Support for LoRA](#support-for-lora) * [Torch 2.0 optimizations](#torch-20-optimizations) * [Community highlights](#community-highlights) * [Building products with 🤗 Diffusers](#building-products-with-🤗-diffusers) * [Looking forward](#looking-forward) ## Striving for photorealism Generative AI models are known for creating photorealistic images, but if you look closely, you may notice certain things that don't look right, like generating extra fingers on a hand. This year, the DeepFloyd IF and Stability AI SDXL models made a splash by improving the quality of generated images to be even more photorealistic. [DeepFloyd IF](https://stability.ai/blog/deepfloyd-if-text-to-image-model) - A modular diffusion model that includes different processes for generating an image (for example, an image is upscaled 3x to produce a higher resolution image). Unlike Stable Diffusion, the IF model works directly on the pixel level, and it uses a large language model to encode text. [Stable Diffusion XL (SDXL)](https://stability.ai/blog/sdxl-09-stable-diffusion) - The latest Stable Diffusion model from Stability AI, with significantly more parameters than its predecessor Stable Diffusion 2. It generates hyper-realistic images, leveraging a base model for close adherence to the prompt, and a refiner model specialized in the fine details and high-frequency content. Head over to the DeepFloyd IF [docs](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/if#texttoimage-generation) and the SDXL [docs](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/stable_diffusion/stable_diffusion_xl) today to learn how to start generating your own images! ## Video pipelines Text-to-image pipelines are cool, but text-to-video is even cooler! We currently support two text-to-video pipelines, [VideoFusion](https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video) and [Text2Video-Zero](https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video_zero). If you’re already familiar with text-to-image pipelines, using a text-to-video pipeline is very similar: ```py import torch from diffusers import DiffusionPipeline from diffusers.utils import export_to_video pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16) pipe.enable_model_cpu_offload() prompt = "Darth Vader surfing a wave" video_frames = pipe(prompt, num_frames=24).frames video_path = export_to_video(video_frames) ``` <div class="flex justify-center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/darthvader_cerpense.gif" alt="Generated video of Darth Vader surfing."/> </div> We expect text-to-video to go through a revolution during 🤗 Diffusers second year, and we are excited to see what the community builds on top of these to push the boundaries of video generation from language! ## Text-to-3D models In addition to text-to-video, we also have text-to-3D generation now thanks to OpenAI’s [Shap-E](https://hf.co/papers/2305.02463) model. Shap-E is trained by encoding a large dataset of 3D-text pairs, and a diffusion model is conditioned on the encoder’s outputs. You can design 3D assets for video games, interior design, and architecture. Try it out today with the [`ShapEPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/shap_e#diffusers.ShapEPipeline) and [`ShapEImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/shap_e#diffusers.ShapEImg2ImgPipeline). <div class="flex justify-center"> <img src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/shap_e/cake_out.gif" alt="3D render of a birthday cupcake generated using SHAP-E."/> </div> ## Image editing pipelines Image editing is one of the most practical use cases in fashion, material design, and photography. With diffusion models, the possibilities of image editing continue to expand. We have many [pipelines](https://huggingface.co/docs/diffusers/main/en/using-diffusers/controlling_generation) in 🤗 Diffusers to support image editing. There are image editing pipelines that allow you to describe your desired edit as a prompt, removing concepts from an image, and even a pipeline that unifies multiple generation methods to create high-quality images like panoramas. With 🤗 Diffusers, you can experiment with the future of photo editing now! ## Faster diffusion models Diffusion models are known to be time-intensive because of their iterative steps. With OpenAI’s [Consistency Models](https://huggingface.co/papers/2303.01469), the image generation process is significantly faster. Generating a single 256x256 resolution image only takes 3/4 of a second on a modern CPU! You can try this out in 🤗 Diffusers with the [`ConsistencyModelPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/consistency_models). On top of speedier diffusion models, we also offer many optimization techniques for faster inference like [PyTorch 2.0’s `scaled_dot_product_attention()` (SDPA) and `torch.compile()`](https://pytorch.org/blog/accelerated-diffusers-pt-20), sliced attention, feed-forward chunking, VAE tiling, CPU and model offloading, and more. These optimizations save memory, which translates to faster generation, and allow you to run inference on consumer GPUs. When you distribute a model with 🤗 Diffusers, all of these optimizations are immediately supported! In addition to that, we also support specific hardware and formats like ONNX, the `mps` PyTorch device for Apple Silicon computers, Core ML, and others. To learn more about how we optimize inference with 🤗 Diffusers, check out the [docs](https://huggingface.co/docs/diffusers/optimization/opt_overview)! ## Ethics and safety Generative models are cool, but they also have the ability to produce harmful and NSFW content. To help users interact with these models responsibly and ethically, we’ve added a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) component that flags inappropriate content generated during inference. Model creators can choose to incorporate this component into their models if they want. In addition, generative models can also be used to produce disinformation. Earlier this year, the [Balenciaga Pope](https://www.theverge.com/2023/3/27/23657927/ai-pope-image-fake-midjourney-computer-generated-aesthetic) went viral for how realistic the image was despite it being fake. This underscores the importance and need for a mechanism to distinguish between generated and human content. That’s why we’ve added an invisible watermark for images generated by the SDXL model, which helps users be better informed. The development of these features is guided by our [ethical charter](https://huggingface.co/docs/diffusers/main/en/conceptual/ethical_guidelines), which you can find in our documentation. ## Support for LoRA Fine-tuning diffusion models is expensive and out of reach for most consumer GPUs. We added the Low-Rank Adaptation ([LoRA](https://huggingface.co/papers/2106.09685)) technique to close this gap. With LoRA, which is a method for parameter-efficient fine-tuning, you can fine-tune large diffusion models faster and consume less memory. The resulting model weights are also very lightweight compared to the original model, so you can easily share your custom models. If you want to learn more, [our documentation](https://huggingface.co/docs/diffusers/main/en/training/lora) shows how to perform fine-tuning and inference on Stable Diffusion with LoRA. In addition to LoRA, we support other [training techniques](https://huggingface.co/docs/diffusers/main/en/training/overview) for personalized generation, including DreamBooth, textual inversion, custom diffusion, and more! ## Torch 2.0 optimizations PyTorch 2.0 [introduced support](https://pytorch.org/get-started/pytorch-2.0/#pytorch-2x-faster-more-pythonic-and-as-dynamic-as-ever) for `torch.compile()`and `scaled_dot_product_attention()`, a more efficient implementation of the attention mechanism. 🤗 Diffusers [provides first-class support](https://huggingface.co/docs/diffusers/optimization/torch2.0) for these features resulting in massive speedups in inference latency, which can sometimes be more than twice as fast! In addition to visual content (images, videos, 3D assets, etc.), we also added support for audio! Check out [the documentation](https://huggingface.co/docs/diffusers/using-diffusers/audio) to learn more. ## Community highlights One of the most gratifying experiences of the past year has been seeing how the community is incorporating 🤗 Diffusers into their projects. From adapting Low-rank adaptation (LoRA) for faster training of text-to-image models to building a state-of-the-art inpainting tool, here are a few of our favorite projects: <div class="mx-auto max-w-screen-xl py-8"> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">We built Core ML Stable Diffusion to make it easier for developers to add state-of-the-art generative AI capabilities in their iOS, iPadOS and macOS apps with the highest efficiency on Apple Silicon. We built on top of 🤗 Diffusers instead of from scratch as 🤗 Diffusers consistently stays on top of a rapidly evolving field and promotes much needed interoperability of new and old ideas.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/10639145?s=200&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Atila Orhon</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">🤗 Diffusers has been absolutely developer-friendly for me to dive right into stable diffusion models. Main differentiating factor clearly being that 🤗 Diffusers implementation is often not some code from research lab, that are mostly focused on high velocity driven. While research codes are often poorly written and difficult to understand (lack of typing, assertions, inconsistent design patterns and conventions), 🤗 Diffusers was a breeze to use for me to hack my ideas within couple of hours. Without it, I would have needed to invest significantly more amount of time to start hacking. Well-written documentations and examples are extremely helpful as well.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/35953539?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Simo</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">BentoML is the unified framework for for building, shipping, and scaling production-ready AI applications incorporating traditional ML, pre-trained AI models, Generative and Large Language Models. All Hugging Face Diffuser models and pipelines can be seamlessly integrated into BentoML applications, enabling the running of models on the most suitable hardware and independent scaling based on usage.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/49176046?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">BentoML</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">Invoke AI is an open-source Generative AI tool built to empower professional creatives, from game designers and photographers to architects and product designers. Invoke recently launched their hosted offering at invoke.ai, allowing users to generate assets from any computer, powered by the latest research in open-source.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/113954515?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">InvokeAI</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">TaskMatrix connects Large Language Model and a series of Visual Models to enable sending and receiving images during chatting.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/6154722?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Chenfei Wu</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">Lama Cleaner is a powerful image inpainting tool that uses Stable Diffusion technology to remove unwanted objects, defects, or people from your pictures. It can also erase and replace anything in your images with ease.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://github.com/Sanster/lama-cleaner/raw/main/assets/logo.png" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Qing</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">Grounded-SAM combines a powerful Zero-Shot detector Grounding-DINO and Segment-Anything-Model (SAM) to build a strong pipeline to detect and segment everything with text inputs. When combined with 🤗 Diffusers inpainting models, Grounded-SAM can do highly controllable image editing tasks, including replacing specific objects, inpainting the background, etc.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/113572103?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Tianhe Ren</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">Stable-Dreamfusion leverages the convenient implementations of 2D diffusion models in 🤗 Diffusers to replicate recent text-to-3D and image-to-3D methods.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/25863658?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">kiui</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">MMagic (Multimodal Advanced, Generative, and Intelligent Creation) is an advanced and comprehensive Generative AI toolbox that provides state-of-the-art AI models (e.g., diffusion models powered by 🤗 Diffusers and GAN) to synthesize, edit and enhance images and videos. In MMagic, users can use rich components to customize their own models like playing with Legos and manage the training loop easily.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/10245193?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">mmagic</p> </div> </div> </div> <div class="mb-8 sm:break-inside-avoid"> <blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800"> <p class="leading-relaxed text-gray-700">Tune-A-Video, developed by Jay Zhangjie Wu and his team at Show Lab, is the first to fine-tune a pre-trained text-to-image diffusion model using a single text-video pair and enables changing video content while preserving motion.</p> </blockquote> <div class="flex items-center gap-4"> <img src="https://avatars.githubusercontent.com/u/101181824?s=48&v=4" class="h-12 w-12 rounded-full object-cover" /> <div class="text-sm"> <p class="font-medium">Jay Zhangjie Wu</p> </div> </div> </div> </div> We also collaborated with Google Cloud (who generously provided the compute) to provide technical guidance and mentorship to help the community train diffusion models with TPUs (check out a summary of the event [here](https://opensource.googleblog.com/2023/06/controlling-stable-diffusion-with-jax-diffusers-and-cloud-tpus.html)). There were many cool models such as this [demo](https://huggingface.co/spaces/mfidabel/controlnet-segment-anything) that combines ControlNet with Segment Anything. <div class="flex justify-center"> <img src="https://github.com/mfidabel/JAX_SPRINT_2023/blob/8632f0fde7388d7a4fc57225c96ef3b8411b3648/EX_1.gif?raw=true" alt="ControlNet and SegmentAnything demo of a hot air balloon in various styles"> </div> Finally, we were delighted to receive contributions to our codebase from over 300 contributors, which allowed us to collaborate together in the most open way possible. Here are just a few of the contributions from our community: - [Model editing](https://github.com/huggingface/diffusers/pull/2721) by [@bahjat-kawar](https://github.com/bahjat-kawar), a pipeline for editing a model’s implicit assumptions - [LDM3D](https://github.com/huggingface/diffusers/pull/3668) by [@estelleafl](https://github.com/estelleafl), a diffusion model for 3D images - [DPMSolver](https://github.com/huggingface/diffusers/pull/3314) by [@LuChengTHU](https://github.com/LuChengTHU), improvements for significantly improving inference speed - [Custom Diffusion](https://github.com/huggingface/diffusers/pull/3031) by [@nupurkmr9](https://github.com/nupurkmr9), a technique for generating personalized images with only a few images of a subject Besides these, a heartfelt shoutout to the following contributors who helped us ship some of the most powerful features of Diffusers (in no particular order): * [@takuma104](https://github.com/huggingface/diffusers/commits?author=takuma104) * [@nipunjindal](https://github.com/huggingface/diffusers/commits?author=nipunjindal) * [@isamu-isozaki](https://github.com/huggingface/diffusers/commits?author=isamu-isozaki) * [@piEsposito](https://github.com/huggingface/diffusers/commits?author=piEsposito) * [@Birch-san](https://github.com/huggingface/diffusers/commits?author=Birch-san) * [@LuChengTHU](https://github.com/huggingface/diffusers/commits?author=LuChengTHU) * [@duongna21](https://github.com/huggingface/diffusers/commits?author=duongna21) * [@clarencechen](https://github.com/huggingface/diffusers/commits?author=clarencechen) * [@dg845](https://github.com/huggingface/diffusers/commits?author=dg845) * [@Abhinay1997](https://github.com/huggingface/diffusers/commits?author=Abhinay1997) * [@camenduru](https://github.com/huggingface/diffusers/commits?author=camenduru) * [@ayushtues](https://github.com/huggingface/diffusers/commits?author=ayushtues) ## Building products with 🤗 Diffusers Over the last year, we also saw many companies choosing to build their products on top of 🤗 Diffusers. Here are a couple of products that have caught our attention: - [PlaiDay](http://plailabs.com/): “PlaiDay is a Generative AI experience where people collaborate, create, and connect. Our platform unlocks the limitless creativity of the human mind, and provides a safe, fun social canvas for expression.” - [Previs One](https://previs.framer.wiki/): “Previs One is a diffuser pipeline for cinematic storyboarding and previsualization — it understands film and television compositional rules just as a director would speak them.” - [Zust.AI](https://zust.ai/): “We leverage Generative AI to create studio-quality product photos for brands and marketing agencies.” - [Dashtoon](https://dashtoon.com/): “Dashtoon is building a platform to create and consume visual content. We have multiple pipelines that load multiple LORAs, multiple control-nets and even multiple models powered by diffusers. Diffusers has made the gap between a product engineer and a ML engineer super low allowing dashtoon to ship user value faster and better.” - [Virtual Staging AI](https://www.virtualstagingai.app/): "Filling empty rooms with beautiful furniture using generative models.” - [Hexo.AI](https://www.hexo.ai/): “Hexo AI helps brands get higher ROI on marketing spends through Personalized Marketing at Scale. Hexo is building a proprietary campaign generation engine which ingests customer data and generates brand compliant personalized creatives.” If you’re building products on top of 🤗 Diffusers, we’d love to chat to understand how we can make the library better together! Feel free to reach out to [email protected] or [email protected]. ## Looking forward As we celebrate our first anniversary, we're grateful to our community and open-source contributors who have helped us come so far in such a short time. We're happy to share that we'll be presenting a 🤗 Diffusers demo at ICCV 2023 this fall – if you're attending, do come and see us! We'll continue to develop and improve our library, making it easier for everyone to use. We're also excited to see what the community will create next with our tools and resources. Thank you for being a part of our journey so far, and we look forward to continuing to democratize good machine learning together! 🥳 ❤️ Diffusers team --- **Acknowledgements**: Thank you to [Omar Sanseviero](https://huggingface.co/osanseviero), [Patrick von Platen](https://huggingface.co/patrickvonplaten), [Giada Pistilli](https://huggingface.co/giadap) for their reviews, and [Chunte Lee](https://huggingface.co/Chunte) for designing the thumbnail.
|
Results of the Open Source AI Game Jam
|
ThomasSimonini
|
July 21, 2023
|
game-jam-first-edition-results
|
game-dev
|
https://huggingface.co/blog/game-jam-first-edition-results
|
# Results of the Open Source AI Game Jam From July 7th to July 11th, **we hosted our [first Open Source AI Game Jam](https://itch.io/jam/open-source-ai-game-jam)**, an exciting event that challenged game developers to create innovative games within a tight 48-hour window using AI. The primary objective was **to create games that incorporate at least one Open Source AI Tool**. Although proprietary AI tools were allowed, we encouraged participants to integrate open-source tools into their game or workflow. The response to our initiative was beyond our expectations, with over 1300 signups and **the submission of 88 amazing games**. **You can try them here** 👉 https://itch.io/jam/open-source-ai-game-jam/entries <iframe width="560" height="315" src="https://www.youtube.com/embed/UG9-gOAs2-4" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe> ## The Theme: Expanding To inspire creativity, **we decided on the theme of "EXPANDING."** We left it open to interpretation, allowing developers to explore and experiment with their ideas, leading to a diverse range of games. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/theme.jpeg" alt="Game Jam Theme"/> The games were evaluated by their peers and contributors based on three key criteria: **fun, creativity, and adherence to the theme**. The top 10 games were then presented to three judges ([Dylan Ebert](https://twitter.com/dylan_ebert_), [Thomas Simonini](https://twitter.com/ThomasSimonini) and [Omar Sanseviero](https://twitter.com/osanseviero)), **who selected the best game**. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/jury.jpg" alt="Game Jam Judges"/> ## The Winner 🏆🥇 After careful deliberation, the judges **crowned one outstanding game as the Winner of the Open Source AI Game Jam**. It's [Snip It](https://ohmlet.itch.io/snip-it) by [ohmlet](https://itch.io/profile/ohmlet) 👏👏👏. Code: Ruben Gres AI assets: Philippe Saade Music / SFX: Matthieu Deloffre In this AI-generated game, you visit a museum where the paintings come to life. **Snip the objects in the paintings to uncover their hidden secrets**. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/snipit.jpg" alt="Snip it"/> You can play it here 👉 https://ohmlet.itch.io/snip-it ## Participants Selection: Top 10 🥈🥉🏅 Out of the 88 fantastic submissions, these impressive games emerged as the Top 11 finalists. ### #1: Snip It <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/snipit2.jpg" alt="Snip it"/> In addition to be the winner of the Game Jam, Snip it has been selected as the top participant selection. 🤖 Open Source Model Used: Stable Diffusion to generate the assets. 🎮👉 https://ohmlet.itch.io/snip-it ### #2: Yabbit Attack <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/yabbit.jpg" alt="Yabbit Attack"/> In Yabbit Attack, your goal is to **beat the constantly adapting neural network behind the Yabbits**. 🤖 Used genetic algorithms in the context of natural selection and evolution. 🤖 Backgrounds visuals were generated using Stable Diffusion 🎮👉 https://visionistx.itch.io/yabbit-attack ### #3: Fish Dang Bot Rolling Land <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/fish.jpg" alt="Fish Dang Bot Rolling Land"/> In this game, you take control of a fish-shaped robot named Fein, who is abandoned in a garbage dump with mechanical legs. Unexpectedly, it develops self-awareness, and upon awakening, it sees a dung beetle pushing a dung ball. Naturally, Fein assumes himself to be a dung beetle and harbours a dream of pushing the largest dung ball. With this dream in mind, it decides to embark on its own adventure. 🤖 Used Text To Speech model to generate the voices. 🎮👉 https://zeenaz.itch.io/fish-dang-rolling-laud ### #4: Everchanging Quest <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/everchanging.jpg" alt="Everchanging Quest"/> In this game, you are the village's last hope. Arm yourself before embarking on your adventure, and don't hesitate to ask the locals for guidance. The world beyond the portal will never be the same, so be prepared. Defeat your enemies to collect points and find your way to the end. 🤖 Used GPT-4 to place the tiles and objects (proprietary) but also Starcoder to code (open source). 🎮👉 https://jofthomas.itch.io/everchanging-quest ### #5: Word Conquest <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/word.gif" alt="Word"/> In this game, you need to write as many unrelated words as you can to conquer the map. The more unrelated, the farther away and the more score you get. 🤖 Used embeddings from all-MiniLM-L6-v2 model and GloVe to generate the map. 🎮👉 https://danielquelali.itch.io/wordconquest ### #6: Expanding Universe <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/universe.jpg" alt="Universe"/> In this sandbox gravity game, you create an expanding universe and try to complete the challenges. 🤖 Used Dream Textures Blender (Stable Diffusion) add-on to create textures for all of the planets and stars and an LLM model to generate descriptions of the stars and planets. 🎮👉 https://carsonkatri.itch.io/expanding-universe ### #7: Hexagon Tactics: The Expanding Arena <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/hexagon.gif" alt="Hexagon"/> In this game, you are dropped into an arena battle. Defeat your opponents, then upgrade your deck and the arena expands. 🤖 Stable Diffusion 1.5 to generate your own character (executable version of the game). 🎮👉 https://dgeisert.itch.io/hextactics ### #8: Galactic Domination <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/galactic.gif" alt="Galactic"/> In this game, you embark on an interstellar journey as a spaceship captain, pitted against formidable spaceships in a battle for dominance. Your goal is to be the first to construct a powerful space station that will expand your influence and secure your supremacy in the vast expanse of the cosmos. As you navigate the treacherous battlefield, you must gather essential resources to fuel the growth of your space station. It's a construction race! 🤖 Unity ML-Agents (bot-AI works with reinforcement learning) 🤖 Charmed - Texture Generator 🤖 Soundful - Music generator 🤖 Elevenlabs - Voice generator 🤖 Scenario - Image generator 🎮👉 https://blastergames.itch.io/galactic-domination ### #9: Apocalypse Expansion <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/appocalypse.jpg" alt="Apocalypse"/> In this game, you'll step into the decaying shoes of a zombie, driven by an insatiable hunger for human flesh. Your objective? To build the largest horde of zombies ever seen, while evading the relentless pursuit of the determined police force. 🤖 Used Stable Diffusion to generate the images 🤖 Used MusicGen (melody 1.5B) for the music 🎮👉 https://mad25.itch.io/apocalypse-expansion ### #10: Galactic Bride: Bullet Ballet <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/bride.jpg" alt="Bride"/> In this game, you dive into an exhilarating bullet-hell journey to become the Star Prince's bride and fulfill your wishes. 🎮👉 https://n30hrtgdv.itch.io/galactic-bride-bullet-ballet ### #10: Singularity <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/singularity.gif" alt="Singularity"/> This demo is a conceptual demonstration of what could soon be the generation of experiences/games in the near future. 🤖 Used Stable Diffusion 🎮👉 https://ilumine-ai.itch.io/dreamlike-hugging-face-open-source-ai-game-jam In addition to this top 10, don't hesitate to check the other amazing games (Ghost In Smoke, Outopolis, Dungeons and Decoders...). You **can find the whole list here** 👉 https://itch.io/jam/open-source-ai-game-jam/entries --- The first-ever Open Source AI Game Jam proved to be an astounding success, exceeding our expectations in terms of community engagement and the quality of games produced. The overwhelming response has **reinforced our belief in the potential of open-source AI tools to revolutionize the gaming industry.** We are eager to continue this initiative and plan to host more sessions in the future, providing game developers with an opportunity to showcase their skills and explore the power of AI in game development. For those interested in AI for games, we have compiled a list of valuable resources, including AI tools for game development and tutorials on integrating AI into game engines like Unity: - **[Compilation of AI tools for Game Dev](https://github.com/simoninithomas/awesome-ai-tools-for-game-dev)** - How to install the Unity Hugging Face API: **https://huggingface.co/blog/unity-api** - AI Speech Recognition in Unity: **https://huggingface.co/blog/unity-asr** - Making ML-powered web games with Transformers.js: **https://huggingface.co/blog/ml-web-games** - Building a smart Robot AI using Hugging Face 🤗 and Unity: **https://thomassimonini.substack.com/p/building-a-smart-robot-ai-using-hugging** To stay connected and stay updated on future events, feel free to drop by our Discord server, where you can find channels dedicated to exchanging ideas about AI for games. Join our Discord Server 👉 **https://hf.co/join/discord** **Thank you to all the participants, contributors, and supporters who made this event a memorable success!**
|
Introducing Agents.js: Give tools to your LLMs using JavaScript
|
nsarrazin
|
July 24, 2023
|
agents-js
|
agents, javascript, web
|
https://huggingface.co/blog/agents-js
|
# Introducing Agents.js: Give tools to your LLMs using JavaScript We have recently been working on Agents.js at [huggingface.js](https://github.com/huggingface/huggingface.js/blob/main/packages/agents/README.md). It's a new library for giving tool access to LLMs from JavaScript in either the browser or the server. It ships with a few multi-modal tools out of the box and can easily be extended with your own tools and language models. ## Installation Getting started is very easy, you can grab the library from npm with the following: ``` npm install @huggingface/agents ``` ## Usage The library exposes the `HfAgent` object which is the entry point to the library. You can instantiate it like this: ```ts import { HfAgent } from "@huggingface/agents"; const HF_ACCESS_TOKEN = "hf_..."; // get your token at https://huggingface.co/settings/tokens const agent = new HfAgent(HF_ACCESS_TOKEN); ``` Afterward, using the agent is easy. You give it a plain-text command and it will return some messages. ```ts const code = await agent.generateCode( "Draw a picture of a rubber duck with a top hat, then caption this picture." ); ``` which in this case generated the following code ```js // code generated by the LLM async function generate() { const output = await textToImage("rubber duck with a top hat"); message("We generate the duck picture", output); const caption = await imageToText(output); message("Now we caption the image", caption); return output; } ``` Then the code can be evaluated as such: ```ts const messages = await agent.evaluateCode(code); ``` The messages returned by the agent are objects with the following shape: ```ts export interface Update { message: string; data: undefined | string | Blob; ``` where `message` is an info text and `data` can contain either a string or a blob. The blob can be used to display images or audio. If you trust your environment (see [warning](#usage-warning)), you can also run the code directly from the prompt with `run` : ```ts const messages = await agent.run( "Draw a picture of a rubber duck with a top hat, then caption this picture." ); ``` ### Usage warning Currently using this library will mean evaluating arbitrary code in the browser (or in Node). This is a security risk and should not be done in an untrusted environment. We recommend that you use `generateCode` and `evaluateCode` instead of `run` in order to check what code you are running. ## Custom LLMs 💬 By default `HfAgent` will use [OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5) hosted Inference API as the LLM. This can be customized however. When instancing your `HfAgent` you can pass a custom LLM. A LLM in this context is any async function that takes a string input and returns a promise for a string. For example if you have an OpenAI API key you could make use of it like this: ```ts import { Configuration, OpenAIApi } from "openai"; const HF_ACCESS_TOKEN = "hf_..."; const api = new OpenAIApi(new Configuration({ apiKey: "sk-..." })); const llmOpenAI = async (prompt: string): Promise<string> => { return ( ( await api.createCompletion({ model: "text-davinci-003", prompt: prompt, max_tokens: 1000, }) ).data.choices[0].text ?? "" ); }; const agent = new HfAgent(HF_ACCESS_TOKEN, llmOpenAI); ``` ## Custom Tools 🛠️ Agents.js was designed to be easily expanded with custom tools & examples. For example if you wanted to add a tool that would translate text from English to German you could do it like this: ```ts import type { Tool } from "@huggingface/agents/src/types"; const englishToGermanTool: Tool = { name: "englishToGerman", description: "Takes an input string in english and returns a german translation. ", examples: [ { prompt: "translate the string 'hello world' to german", code: `const output = englishToGerman("hello world")`, tools: ["englishToGerman"], }, { prompt: "translate the string 'The quick brown fox jumps over the lazy dog` into german", code: `const output = englishToGerman("The quick brown fox jumps over the lazy dog")`, tools: ["englishToGerman"], }, ], call: async (input, inference) => { const data = await input; if (typeof data !== "string") { throw new Error("Input must be a string"); } const result = await inference.translation({ model: "t5-base", inputs: input, }); return result.translation_text; }, }; ``` Now this tool can be added to the list of tools when initiating your agent. ```ts import { HfAgent, LLMFromHub, defaultTools } from "@huggingface/agents"; const HF_ACCESS_TOKEN = "hf_..."; const agent = new HfAgent(HF_ACCESS_TOKEN, LLMFromHub("hf_..."), [ englishToGermanTool, ...defaultTools, ]); ``` ## Passing input files to the agent 🖼️ The agent can also take input files to pass along to the tools. You can pass an optional [`FileList`](https://developer.mozilla.org/en-US/docs/Web/API/FileList) to `generateCode` and `evaluateCode` as such: If you have the following html: ```html <input id="fileItem" type="file" /> ``` Then you can do: ```ts const agent = new HfAgent(HF_ACCESS_TOKEN); const files = document.getElementById("fileItem").files; // FileList type const code = agent.generateCode( "Caption the image and then read the text out loud.", files ); ``` Which generated the following code when passing an image: ```ts // code generated by the LLM async function generate(image) { const caption = await imageToText(image); message("First we caption the image", caption); const output = await textToSpeech(caption); message("Then we read the caption out loud", output); return output; } ``` ## Demo 🎉 We've been working on a demo for Agents.js that you can try out [here](https://nsarrazin-agents-js-oasst.hf.space/). It's powered by the same Open Assistant 30B model that we use on HuggingChat and uses tools called from the hub. 🚀
|
AI Policy @🤗: Open ML Considerations in the EU AI Act
|
yjernite
|
July 24, 2023
|
eu-ai-act-oss
|
ethics
|
https://huggingface.co/blog/eu-ai-act-oss
|
# AI Policy @🤗: Open ML Considerations in the EU AI Act Like everyone else in Machine Learning, we’ve been following the EU AI Act closely at Hugging Face. It’s a ground-breaking piece of legislation that is poised to shape how democratic inputs interact with AI technology development around the world. It’s also the outcome of extensive work and negotiations between organizations representing many different components of society – a process we’re particularly sensitive to as a community-driven company. In the present <a href="/blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf">position paper</a> written in coalition with [Creative Commons](https://creativecommons.org/), [Eleuther AI](https://www.eleuther.ai/), [GitHub](https://github.com/), [LAION](https://laion.ai/), and [Open Future](http://openfuture.eu/), we aim to contribute to this process by sharing our experience of the necessary role of open ML development in supporting the goals of the Act – and conversely, by outlining specific ways in which the regulation can better account for the needs of open, modular, and collaborative ML development. Hugging Face is where it is today thanks to its community of developers, so we’ve seen firsthand what open development brings to the table to support more robust innovation for more diverse and context-specific use cases; where developers can easily share innovative new techniques, mix and match ML components to suit their own needs, and reliably work with full visibility into their entire stack. We’re also acutely aware of the necessary role of transparency in supporting more accountability and inclusivity of the technology – which we’ve worked on fostering through better documentation and accessibility of ML artifacts, education efforts, and hosting large-scale multidisciplinary collaborations, among others. Thus, as the EU AI Act moves toward its final phase, we believe accounting for the specific needs and strengths of open and open-source development of ML systems will be instrumental in supporting its long-term goals. Along with our co-signed partner organizations, we make the following five recommendations to that end: 1. Define AI components clearly, 2. Clarify that collaborative development of open source AI components and making them available in public repositories does not subject developers to the requirements in the AI Act, building on and improving the Parliament text’s Recitals 12a-c and Article 2(5e), 3. Support the AI Office’s coordination and inclusive governance with the open source ecosystem, building on the Parliament’s text, 4. Ensure the R&D exception is practical and effective, by permitting limited testing in real-world conditions, combining aspects of the Council’s approach and an amended version of the Parliament’s Article 2(5d), 5. Set proportional requirements for “foundation models,” recognizing and distinctly treating different uses and development modalities, including open source approaches, tailoring the Parliament’s Article 28b. You can find more detail and context for those in the <a href="/blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf">full paper here!</a>
|
Stable Diffusion XL on Mac with Advanced Core ML Quantization
|
pcuenq
|
July 27, 2023
|
stable-diffusion-xl-coreml
|
coreml, stable-diffusion, stable-diffusion-xl, diffusers
|
https://huggingface.co/blog/stable-diffusion-xl-coreml
|
# Stable Diffusion XL on Mac with Advanced Core ML Quantization [Stable Diffusion XL](https://stability.ai/stablediffusion) was released yesterday and it’s awesome. It can generate large (1024x1024) high quality images; adherence to prompts has been improved with some new tricks; it can effortlessly produce very dark or very bright images thanks to the latest research on noise schedulers; and it’s open source! The downside is that the model is much bigger, and therefore slower and more difficult to run on consumer hardware. Using the [latest release of the Hugging Face diffusers library](https://github.com/huggingface/diffusers/releases/tag/v0.19.0), you can run Stable Diffusion XL on CUDA hardware in 16 GB of GPU RAM, making it possible to use it on Colab’s free tier. The past few months have shown that people are very clearly interested in running ML models locally for a variety of reasons, including privacy, convenience, easier experimentation, or unmetered use. We’ve been working hard at both Apple and Hugging Face to explore this space. We’ve shown [how to run Stable Diffusion on Apple Silicon](https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon), or how to leverage the [latest advancements in Core ML to improve size and performance with 6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml). For Stable Diffusion XL we’ve done a few things: * Ported the [base model to Core ML](https://huggingface.co/apple/coreml-stable-diffusion-xl-base) so you can use it in your native Swift apps. * Updated [Apple’s conversion and inference repo](https://github.com/apple/ml-stable-diffusion) so you can convert the models yourself, including any fine-tunes you’re interested in. * Updated [Hugging Face’s demo app](https://github.com/huggingface/swift-coreml-diffusers) to show how to use the new Core ML Stable Diffusion XL models downloaded from the Hub. * Explored [mixed-bit palettization](https://github.com/apple/ml-stable-diffusion#-mbp-post-training-mixed-bit-palettization), an advanced compression technique that achieves important size reductions while minimizing and controlling the quality loss you incur. You can apply the same technique to your own models too! Everything is open source and available today, let’s get on with it. ## Contents - [Using SD XL Models from the Hugging Face Hub](#using-sd-xl-models-from-the-hugging-face-hub) - [What is Mixed-Bit Palettization?](#what-is-mixed-bit-palettization) - [How are Mixed-Bit Recipes Created?](#how-are-mixed-bit-recipes-created) - [Converting Fine-Tuned Models](#converting-fine-tuned-models) - [Published Resources](#published-resources) ## Using SD XL Models from the Hugging Face Hub As part of this release, we published two different versions of Stable Diffusion XL in Core ML. - [`apple/coreml-stable-diffusion-xl-base`](https://huggingface.co/apple/coreml-stable-diffusion-xl-base) is a complete pipeline, without any quantization. - [`apple/coreml-stable-diffusion-mixed-bit-palettization`](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization) contains (among other artifacts) a complete pipeline where the UNet has been replaced with a mixed-bit palettization _recipe_ that achieves a compression equivalent to 4.5 bits per parameter. Size went down from 4.8 to 1.4 GB, a 71% reduction, and in our opinion quality is still great. Either model can be tested using Apple’s [Swift command-line inference app](https://github.com/apple/ml-stable-diffusion#inference), or Hugging Face’s [demo app](https://github.com/huggingface/swift-coreml-diffusers). This is an example of the latter using the new Stable Diffusion XL pipeline:  As with previous Stable Diffusion releases, we expect the community to come up with novel fine-tuned versions for different domains, and many of them will be converted to Core ML. You can keep an eye on [this filter in the Hub](https://huggingface.co/models?pipeline_tag=text-to-image&library=coreml&sort=trending) to explore! Stable Diffusion XL works on Apple Silicon Macs running the public beta of macOS 14. It currently uses the `ORIGINAL` attention implementation, which is intended for CPU + GPU compute units. Note that the refiner stage has not been ported yet. For reference, these are the performance figures we achieved on different devices: | Device | `--compute-unit`| `--attention-implementation` | End-to-End Latency (s) | Diffusion Speed (iter/s) | | --------------------- | --------------- | ---------------------------- | ---------------------- | ------------------------ | | MacBook Pro (M1 Max) | `CPU_AND_GPU` | `ORIGINAL` | 46 | 0.46 | | MacBook Pro (M2 Max) | `CPU_AND_GPU` | `ORIGINAL` | 37 | 0.57 | | Mac Studio (M1 Ultra) | `CPU_AND_GPU` | `ORIGINAL` | 25 | 0.89 | | Mac Studio (M2 Ultra) | `CPU_AND_GPU` | `ORIGINAL` | 20 | 1.11 | ## What is Mixed-Bit Palettization? [Last month we discussed 6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml), a post-training quantization method that converts 16-bit weights to just 6-bit per parameter. This achieves an important reduction in model size, but going beyond that is tricky because model quality becomes more and more impacted as the number of bits is decreased. One option to decrease model size further is to use _training time_ quantization, which consists of learning the quantization tables while we fine-tune the model. This works great, but you need to run a fine-tuning phase for every model you want to convert. We explored a different alternative instead: **mixed-bit palettization**. Instead of using 6 bits per parameter, we examine the model and decide how many quantization bits to use _per layer_. We make the decision based on how much each layer contributes to the overall quality degradation, which we measure by comparing the PSNR between the quantized model and the original model in `float16` mode, for a set of a few inputs. We explore several bit depths, per layer: `1` (!), `2`, `4` and `8`. If a layer degrades significantly when using, say, 2 bits, we move to `4` and so on. Some layers might be kept in 16-bit mode if they are critical to preserving quality. Using this method, we can achieve effective quantizations of, for example, 2.8 bits on average, and we measure the impact on degradation for every combination we try. This allows us to be better informed about the best quantization to use for our target quality and size budgets. To illustrate the method, let’s consider the following quantization “recipes” that we got from one of our analysis runs (we’ll explain later how they were generated): ```json { "model_version": "stabilityai/stable-diffusion-xl-base-1.0", "baselines": { "original": 82.2, "linear_8bit": 66.025, "recipe_6.55_bit_mixedpalette": 79.9, "recipe_4.50_bit_mixedpalette": 75.8, "recipe_3.41_bit_mixedpalette": 71.7, }, } ``` What this tells us is that the original model quality, as measured by PSNR in float16, is about 82 dB. Performing a naïve 8-bit linear quantization drops it to 66 dB. But then we have a recipe that compresses to 6.55 bits per parameter, on average, while keeping PSNR at 80 dB. The second and third recipes further reduce the model size, while still sustaining a PSNR larger than that of the 8-bit linear quantization. For visual examples, these are the results on prompt `a high quality photo of a surfing dog` running each one of the three recipes with the same seed: | 3.41-bit | 4.50-bit | 6.55-bit | 16-bit (original) | | :-------:| :-------:| :-------:| :----------------:| |  |  |  |  | Some initial conclusions: - In our opinion, all the images have good quality in terms of how realistic they look. The 6.55 and 4.50 versions are close to the 16-bit version in this aspect. - The same seed produces an equivalent composition, but will not preserve the same details. Dog breeds may be different, for example. - Adherence to the prompt may degrade as we increase compression. In this example, the aggressive 3.41 version loses the board. PSNR only compares how much pixels differ overall, but does not care about the subjects in the images. You need to examine results and assess them for your use case. This technique is great for Stable Diffusion XL because we can keep about the same UNet size even though the number of parameters tripled with respect to the previous version. But it's not exclusive to it! You can apply the method to any Stable Diffusion Core ML model. ## How are Mixed-Bit Recipes Created? The following plot shows the signal strength (PSNR in dB) versus model size reduction (% of float16 size) for `stabilityai/stable-diffusion-xl-base-1.0`. The `{1,2,4,6,8}`-bit curves are generated by progressively palettizing more layers using a palette with a fixed number of bits. The layers were ordered in ascending order of their isolated impact to end-to-end signal strength, so the cumulative compression's impact is delayed as much as possible. The mixed-bit curve is based on falling back to a higher number of bits as soon as a layer's isolated impact to end-to-end signal integrity drops below a threshold. Note that all curves based on palettization outperform linear 8-bit quantization at the same model size except for 1-bit.  Mixed-bit palettization runs in two phases: _analysis_ and _application_. The goal of the analysis phase is to find points in the mixed-bit curve (the brown one above all the others in the figure) so we can choose our desired quality-vs-size tradeoff. As mentioned in the previous section, we iterate through the layers and select the lowest bit depths that yield results above a given PSNR threshold. We repeat the process for various thresholds to get different quantization strategies. The result of the process is thus a set of quantization recipes, where each recipe is just a JSON dictionary detailing the number of bits to use for each layer in the model. Layers with few parameters are ignored and kept in float16 for simplicity. The application phase simply goes over the recipe and applies palettization with the number of bits specified in the JSON structure. Analysis is a lengthy process and requires a GPU (`mps` or `cuda`), as we have to run inference multiple times. Once it’s done, recipe application can be performed in a few minutes. We provide scripts for each one of these phases: * [`mixed_bit_compression_pre_analysis.py`](https://github.com/apple/ml-stable-diffusion/python_coreml_stable_diffusion/mixed_bit_compression_pre_analysis.py) * [`mixed_bit_compression_apply.py`](https://github.com/apple/ml-stable-diffusion/python_coreml_stable_diffusion/mixed_bit_compression_apply.py) ## Converting Fine-Tuned Models If you’ve previously converted Stable Diffusion models to Core ML, the process for XL using [the command line converter is very similar](https://github.com/apple/ml-stable-diffusion#-using-stable-diffusion-xl). There’s a new flag to indicate whether the model belongs to the XL family, and you have to use `--attention-implementation ORIGINAL` if that’s the case. For an introduction to the process, check the [instructions in the repo](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml) or one of [our previous blog posts](https://huggingface.co/blog/diffusers-coreml), and make sure you use the flags above. ### Running Mixed-Bit Palettization After converting Stable Diffusion or Stable Diffusion XL models to Core ML, you can optionally apply mixed-bit palettization using the scripts mentioned above. Because the analysis process is slow, we have prepared recipes for the most popular models: * [Recipes for Stable Diffusion 1.5](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/runwayml-stable-diffusion-v1-5_palettization_recipe.json) * [Recipes for Stable Diffusion 2.1](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/stabilityai-stable-diffusion-2-1-base_palettization_recipe.json) * [Recipes for Stable Diffusion XL 1.0 base](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/stabilityai-stable-diffusion-xl-base-1.0_palettization_recipe.json) You can download and apply them locally to experiment. In addition, we also applied the three best recipes from the Stable Diffusion XL analysis to the Core ML version of the UNet, and published them [here](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/unet-mbp-sdxl-1-base). Feel free to play with them and see how they work for you! Finally, as mentioned in the introduction, we created a [complete Stable Diffusion XL Core ML pipeline](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization) that uses a `4.5-bit` recipe. ### Published Resources * [`apple/ml-stable-diffusion`](https://github.com/apple/ml-stable-diffusion), by Apple. Conversion and inference library for Swift (and Python). * [`huggingface/swift-coreml-diffusers`](https://github.com/huggingface/swift-coreml-diffusers). Hugging Face demo app, built on top of Apple's package. * [Stable Diffusion XL 1.0 base (Core ML version)](https://huggingface.co/apple/coreml-stable-diffusion-xl-base). Model ready to run using the repos above and other third-party apps. * [Stable Diffusion XL 1.0 base, with mixed-bit palettization (Core ML)](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/coreml-stable-diffusion-mixed-bit-palettization_original_compiled.zip). Same model as above, with UNet quantized with an effective palettization of 4.5 bits (on average). * [Additional UNets with mixed-bit palettizaton](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/unet-mbp-sdxl-1-base). * [Mixed-bit palettization recipes](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/recipes), pre-computed for popular models and ready to use. * [`mixed_bit_compression_pre_analysis.py`](https://github.com/apple/ml-stable-diffusion/python_coreml_stable_diffusion/mixed_bit_compression_pre_analysis.py). Script to run mixed-bit analysis and recipe generation. * [`mixed_bit_compression_apply.py`](https://github.com/apple/ml-stable-diffusion/python_coreml_stable_diffusion/mixed_bit_compression_apply.py). Script to apply recipes computed during the analysis phase.
|
Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny
|
harishsegmind
|
August 1, 2023
|
sd_distillation
|
stable-diffusion, research, diffusers
|
https://huggingface.co/blog/sd_distillation
|
# Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture1.png" width=500> </p> In recent times, the AI community has witnessed a remarkable surge in the development of larger and more performant language models, such as Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, and in the imaging domain with models like SD2.1 and SDXL. These advancements have undoubtedly pushed the boundaries of what AI can achieve, enabling highly versatile and state-of-the-art image generation and language understanding capabilities. However, as we marvel at the power and complexity of these models, it is essential to recognize a growing need to make AI models smaller, efficient, and more accessible, particularly by open-sourcing them. At [Segmind](https://www.segmind.com/models), we have been working on how to make generative AI models faster and cheaper. Last year, we have open-sourced our accelerated SD-WebUI library called [voltaML](https://github.com/VoltaML/voltaML-fast-stable-diffusion), which is a AITemplate/TensorRT based inference acceleration library that has delivered between 4-6X increase in the inference speed. To continue towards the goal of making generative models faster, smaller and cheaper, we are open-sourcing the weights and training code of our compressed **SD models; SD-Small and SD-Tiny**. The pretrained checkpoints are available on [Huggingface 🤗](https://huggingface.co/segmind) ## Knowledge Distillation <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture2.png" width=500> </p> Our new compressed models have been trained on Knowledge-Distillation (KD) techniques and the work has been largely based on [this paper](https://openreview.net/forum?id=bOVydU0XKC). The authors describe a Block-removal Knowledge-Distillation method where some of the UNet layers are removed and the student model weights are trained. Using the KD methods described in the paper, we were able to train two compressed models using the [🧨 diffusers](https://github.com/huggingface/diffusers) library; **Small** and **Tiny**, that have 35% and 55% fewer parameters, respectively than the base model while achieving comparable image fidelity as the base model. We have open-sourced our distillation code in this [repo](https://github.com/segmind/distill-sd) and pretrained checkpoints on [Huggingface 🤗](https://huggingface.co/segmind). Knowledge-Distillation training a neural network is similar to a teacher guiding a student step-by-step. A large teacher model is pre-trained on a large amount of data and then a smaller model is trained on a smaller dataset, to imitate the outputs of the larger model along with classical training on the dataset. In this particular type of knowledge distillation, the student model is trained to do the normal diffusion task of recovering an image from pure noise, but at the same time, the model is made to match the output of the larger teacher model. The matching of outputs happens at every block of the U-nets, hence the model quality is mostly preserved. So, using the previous analogy, we can say that during this kind of distillation, the student will not only try to learn from the Questions and Answers but also from the Teacher’s answers, as well as the step by step method of getting to the answer. We have 3 components in the loss function to achieve this, firstly the traditional loss between latents of the target image and latents of the generated image. Secondly, the loss between latents of the image generated by the teacher and latents of image generated by the student. And lastly, and the most important component, is the feature level loss, which is the loss between the outputs of each of the blocks of the teacher and the student. Combining all of this makes up the Knowledge-Distillation training. Below is an architecture of the Block Removed UNet used in the KD as described in the paper. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture3.png" width=500> </p> Image taken from the [paper](https://arxiv.org/abs/2305.15798) “On Architectural Compression of Text-to-Image Diffusion Models” by Shinkook. et. al We have taken [Realistic-Vision 4.0](https://huggingface.co/SG161222/Realistic_Vision_V4.0_noVAE) as our base teacher model and have trained on the [LAION Art Aesthetic dataset](https://huggingface.co/datasets/recastai/LAION-art-EN-improved-captions) with image scores above 7.5, because of their high quality image descriptions. Unlike the paper, we have chosen to train the two models on 1M images for 100K steps for the Small and 125K steps for the Tiny mode respectively. The code for the distillation training can be found [here](https://github.com/segmind/distill-sd). ## Model Usage The Model can be used using the DiffusionPipeline from [🧨 diffusers](https://github.com/huggingface/diffusers) ```python from diffusers import DiffusionPipeline import torch pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16) prompt = "Portrait of a pretty girl" negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck" image = pipeline(prompt, negative_prompt = negative_prompt).images[0] image.save("my_image.png") ``` ## Speed in terms of inference latency We have observed that distilled models are up to 100% faster than the original base models. The Benchmarking code can be found [here](https://github.com/segmind/distill-sd/blob/master/inference.py). <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture4.jpeg" width=500> </p> ## Potential Limitations The distilled models are in early phase and the outputs may not be at a production quality yet. These models may not be the best general models. They are best used as fine-tuned or LoRA trained on specific concepts/styles. Distilled models are not very good at composibility or multiconcepts yet. ## Fine-tuning SD-tiny model on portrait dataset We have fine-tuned our sd-tiny model on portrait images generated with the Realistic Vision v4.0 model. Below are the fine tuning parameters used. - Steps: 131000 - Learning rate: 1e-4 - Batch size: 32 - Gradient accumulation steps: 4 - Image resolution: 768 - Dataset size - 7k images - Mixed-precision: fp16 We were able to produce image quality close to the images produced by the original model, with almost 40% fewer parameters and the sample results below speak for themselves: <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture5.png" width=500> </p> The code for fine-tuning the base models can be found [here](https://github.com/segmind/distill-sd/blob/master/checkpoint_training.py). ## LoRA Training One of the advantages of LoRA training on a distilled model is faster training. Below are some of the images of the first LoRA we trained on the distilled model on some abstract concepts. The code for the LoRA training can be found [here](https://github.com/segmind/distill-sd/blob/master/lora_training.py). <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture6.png" width=500> </p> ## Conclusion We invite the open-source community to help us improve and achieve wider adoption of these distilled SD models. Users can join our [Discord](https://discord.gg/s6E6eHJk) server, where we will be announcing the latest updates to these models, releasing more checkpoints and some exciting new LoRAs. And if you like our work, please give us a star on our [Github](https://github.com/segmind/distill-sd).
|
Practical 3D Asset Generation: A Step-by-Step Guide
|
dylanebert
|
August 01, 2023
|
3d-assets
|
community, guide, cv, diffusion, game-dev
|
https://huggingface.co/blog/3d-assets
|
# Practical 3D Asset Generation: A Step-by-Step Guide ## Introduction Generative AI has become an instrumental part of artistic workflows for game development. However, as detailed in my [earlier post](https://huggingface.co/blog/ml-for-games-3), text-to-3D lags behind 2D in terms of practical applicability. This is beginning to change. Today, we'll be revisiting practical workflows for 3D Asset Generation and taking a step-by-step look at how to integrate Generative AI in a PS1-style 3D workflow. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/result.png" alt="final result"/> Why the PS1 style? Because it's much more forgiving to the low fidelity of current text-to-3D models, and allows us to go from text to usable 3D asset with as little effort as possible. ### Prerequisites This tutorial assumes some basic knowledge of Blender and 3D concepts such as materials and UV mapping. ## Step 1: Generate a 3D Model Start by visiting the Shap-E Hugging Face Space [here](https://huggingface.co/spaces/hysts/Shap-E) or down below. This space uses the open-source [Shap-E model](https://github.com/openai/shap-e), a recent diffusion model from OpenAI to generate 3D models from text. <gradio-app theme_mode="light" space="hysts/Shap-E"></gradio-app> Enter "Dilapidated Shack" as your prompt and click 'Generate'. When you're happy with the model, download it for the next step. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/shape.png" alt="shap-e space"/> ## Step 2: Import and Decimate the Model Next, open [Blender](https://www.blender.org/download/) (version 3.1 or higher). Go to File -> Import -> GLTF 2.0, and import your downloaded file. You may notice that the model has way more polygons than recommended for many practical applications, like games. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/import.png" alt="importing the model in blender"/> To reduce the polygon count, select your model, navigate to Modifiers, and choose the "Decimate" modifier. Adjust the ratio to a low number (i.e. 0.02). This is probably *not* going to look very good. However, in this tutorial, we're going to embrace the low fidelity. ## Step 3: Install Dream Textures To add textures to our model, we'll be using [Dream Textures](https://github.com/carson-katri/dream-textures), a stable diffusion texture generator for Blender. Follow the instructions on the [official repository](https://github.com/carson-katri/dream-textures) to download and install the addon. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/dreamtextures.png" alt="installing dream textures"/> Once installed and enabled, open the addon preferences. Search for and download the [texture-diffusion](https://huggingface.co/dream-textures/texture-diffusion) model. ## Step 4: Generate a Texture Let's generate a custom texture. Open the UV Editor in Blender and press 'N' to open the properties menu. Click the 'Dream' tab and select the texture-diffusion model. Set the prompt to 'texture' and seamless to 'both'. This will ensure the generated image is a seamless texture. Under 'subject', type the texture you want, like 'Wood Wall', and click 'Generate'. When you're happy with the result, name it and save it. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/generate.png" alt="generating a texture"/> To apply the texture, select your model and navigate to 'Material'. Add a new material, and under 'base color', click the dot and choose 'Image Texture'. Finally, select your newly generated texture. ## Step 5: UV Mapping Time for UV mapping, which wraps our 2D texture around the 3D model. Select your model and press 'Tab' to enter Edit Mode. Then, press 'U' to unwrap the model and choose 'Smart UV Project'. To preview your textured model, switch to rendered view (hold 'Z' and select 'Rendered'). You can scale up the UV map to have it tile seamlessly over the model. Remember that we're aiming for a retro PS1 style, so don't make it too nice. <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/uv.png" alt="uv mapping"/> ## Step 6: Export the Model When you're happy with your model, it's time to export it. Navigate to File -> Export -> FBX, and voila! You have a usable 3D Asset. ## Step 7: Import in Unity Finally, let's see our model in action. Import it in [Unity](https://unity.com/download) or your game engine of choice. To recreate a nostalgic PS1 aesthetic, I've customized it with custom vertex-lit shading, no shadows, lots of fog, and glitchy post-processing. You can read more about recreating the PS1 aesthetic [here](https://www.david-colson.com/2021/11/30/ps1-style-renderer.html). And there we have it - our low-fi, textured, 3D model in a virtual environment! <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/result.png" alt="final result"/> ## Conclusion That's a wrap on how to create practical 3D assets using a Generative AI workflow. While the results are low-fidelity, the potential is enormous: with sufficient effort, this method could be used to generate an infinite world in a low-fi style. And as these models improve, it may become feasible to transfer these techniques to high fidelity or realistic styles. If you've followed along and created your own 3D assets, I'd love to see them. To share them, or if you have questions or want to get involved in our community, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
Towards Encrypted Large Language Models with FHE
|
RomanBredehoft
|
August 02, 2023
|
encrypted-llm
|
guide, privacy, research, FHE, llm
|
https://huggingface.co/blog/encrypted-llm
|
# Towards Encrypted Large Language Models with FHE Large Language Models (LLM) have recently been proven as reliable tools for improving productivity in many areas such as programming, content creation, text analysis, web search, and distance learning. ## The Impact of Large Language Models on Users' Privacy Despite the appeal of LLMs, privacy concerns persist surrounding user queries that are processed by these models. On the one hand, leveraging the power of LLMs is desirable, but on the other hand, there is a risk of leaking sensitive information to the LLM service provider. In some areas, such as healthcare, finance, or law, this privacy risk is a showstopper. One possible solution to this problem is on-premise deployment, where the LLM owner would deploy their model on the client’s machine. This is however not an optimal solution, as building an LLM may cost millions of dollars ([4.6M$ for GPT3](https://lambdalabs.com/blog/demystifying-gpt-3)) and on-premise deployment runs the risk of leaking the model intellectual property (IP). Zama believes you can get the best of both worlds: our ambition is to protect both the privacy of the user and the IP of the model. In this blog, you’ll see how to leverage the Hugging Face transformers library and have parts of these models run on encrypted data. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm). ## Fully Homomorphic Encryption (FHE) Can Solve LLM Privacy Challenges Zama’s solution to the challenges of LLM deployment is to use Fully Homomorphic Encryption (FHE) which enables the execution of functions on encrypted data. It is possible to achieve the goal of protecting the model owner’s IP while still maintaining the privacy of the user's data. This demo shows that an LLM model implemented in FHE maintains the quality of the original model’s predictions. To do this, it’s necessary to adapt the [GPT2](https://huggingface.co/gpt2) implementation from the Hugging Face [transformers library](https://github.com/huggingface/transformers), reworking sections of the inference using Concrete-Python, which enables the conversion of Python functions into their FHE equivalents.  Figure 1 shows the GPT2 architecture which has a repeating structure: a series of multi-head attention (MHA) layers applied successively. Each MHA layer projects the inputs using the model weights, computes the attention mechanism, and re-projects the output of the attention into a new tensor. In [TFHE](https://www.zama.ai/post/tfhe-deep-dive-part-1), model weights and activations are represented with integers. Nonlinear functions must be implemented with a Programmable Bootstrapping (PBS) operation. PBS implements a table lookup (TLU) operation on encrypted data while also refreshing ciphertexts to allow [arbitrary computation](https://whitepaper.zama.ai/). On the downside, the computation time of PBS dominates the one of linear operations. Leveraging these two types of operations, you can express any sub-part of, or, even the full LLM computation, in FHE. ## Implementation of a LLM layer with FHE Next, you’ll see how to encrypt a single attention head of the multi-head attention (MHA) block. You can also find an example for the full MHA block in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).  Figure 2. shows a simplified overview of the underlying implementation. A client starts the inference locally up to the first layer which has been removed from the shared model. The user encrypts the intermediate operations and sends them to the server. The server applies part of the attention mechanism and the results are then returned to the client who can decrypt them and continue the local inference. ### Quantization First, in order to perform the model inference on encrypted values, the weights and activations of the model must be quantized and converted to integers. The ideal is to use [post-training quantization](https://docs.zama.ai/concrete-ml/advanced-topics/quantization) which does not require re-training the model. The process is to implement an FHE compatible attention mechanism, use integers and PBS, and then examine the impact on LLM accuracy. To evaluate the impact of quantization, run the full GPT2 model with a single LLM Head operating over encrypted data. Then, evaluate the accuracy obtained when varying the number of quantization bits for both weights and activations.  This graph shows that 4-bit quantization maintains 96% of the original accuracy. The experiment is done using a data-set of ~80 sentences. The metrics are computed by comparing the logits prediction from the original model against the model with the quantized head model. ### Applying FHE to the Hugging Face GPT2 model Building upon the transformers library from Hugging Face, rewrite the forward pass of modules that you want to encrypt, in order to include the quantized operators. Build a SingleHeadQGPT2Model instance by first loading a [GPT2LMHeadModel](https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.GPT2LMHeadModel) and then manually replace the first multi-head attention module as following using a [QGPT2SingleHeadAttention](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py#L191) module. The complete implementation can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py). ```python self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits) ``` The forward pass is then overwritten so that the first head of the multi-head attention mechanism, including the projections made for building the query, keys and value matrices, is performed with FHE-friendly operators. The following QGPT2 module can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_class.py#L196). ```python class SingleHeadAttention(QGPT2): """Class representing a single attention head implemented with quantization methods.""" def run_numpy(self, q_hidden_states: np.ndarray): # Convert the input to a DualArray instance q_x = DualArray( float_array=self.x_calib, int_array=q_hidden_states, quantizer=self.quantizer ) # Extract the attention base module name mha_weights_name = f"transformer.h.{self.layer}.attn." # Extract the query, key and value weight and bias values using the proper indices head_0_indices = [ list(range(i * self.n_embd, i * self.n_embd + self.head_dim)) for i in range(3) ] q_qkv_weights = ... q_qkv_bias = ... # Apply the first projection in order to extract Q, K and V as a single array q_qkv = q_x.linear( weight=q_qkv_weights, bias=q_qkv_bias, key=f"attention_qkv_proj_layer_{self.layer}", ) # Extract the queries, keys and vales q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}") q_q, q_k, q_v = q_qkv.enc_split( 3, axis=-1, key=f"qkv_split_layer_{self.layer}" ) # Compute attention mechanism q_y = self.attention(q_q, q_k, q_v) return self.finalize(q_y) ``` Other computations in the model remain in floating point, non-encrypted and are expected to be executed by the client on-premise. Loading pre-trained weights into the GPT2 model modified in this way, you can then call the _generate_ method: ```python qgpt2_model = SingleHeadQGPT2Model.from_pretrained( "gpt2_model", n_bits=4, use_cache=False ) output_ids = qgpt2_model.generate(input_ids) ``` As an example, you can ask the quantized model to complete the phrase ”Cryptography is a”. With sufficient quantization precision when running the model in FHE, the output of the generation is: “Cryptography is a very important part of the security of your computer” When quantization precision is too low you will get: “Cryptography is a great way to learn about the world around you” ### Compilation to FHE You can now compile the attention head using the following Concrete-ML code: ```python circuit_head = qgpt2_model.compile(input_ids) ``` Running this, you will see the following print out: “Circuit compiled with 8 bit-width”. This configuration, compatible with FHE, shows the maximum bit-width necessary to perform operations in FHE. ### Complexity In transformer models, the most computationally intensive operation is the attention mechanism which multiplies the queries, keys, and values. In FHE, the cost is compounded by the specificity of multiplications in the encrypted domain. Furthermore, as the sequence length increases, the number of these challenging multiplications increases quadratically. For the encrypted head, a sequence of length 6 requires 11,622 PBS operations. This is a first experiment that has not been optimized for performance. While it can run in a matter of seconds, it would require quite a lot of computing power. Fortunately, hardware will improve latency by 1000x to 10000x, making things go from several minutes on CPU to < 100ms on ASIC once they are available in a few years. For more information about these projections, see [this blog post](https://www.zama.ai/post/chatgpt-privacy-with-homomorphic-encryption). ## Conclusion Large Language Models are great assistance tools in a wide variety of use cases but their implementation raises major issues for user privacy. In this blog, you saw a first step toward having the whole LLM work on encrypted data where the model would run entirely in the cloud while users' privacy would be fully respected. This step includes the conversion of a specific part in a model like GPT2 to the FHE realm. This implementation leverages the transformers library and allows you to evaluate the impact on the accuracy when part of the model runs on encrypted data. In addition to preserving user privacy, this approach also allows a model owner to keep a major part of their model private. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm). Zama libraries [Concrete](https://github.com/zama-ai/concrete) and [Concrete-ML](https://github.com/zama-ai/concrete-ml) (Don't forget to star the repos on GitHub ⭐️💛) allow straightforward ML model building and conversion to the FHE equivalent to being able to compute and predict over encrypted data. Hope you enjoyed this post; feel free to share your thoughts/feedback!
|
Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub
|
davanstrien
|
August 2, 2023
|
huggy-lingo
|
announcement, research
|
https://huggingface.co/blog/huggy-lingo
|
## Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub **tl;dr**: We're using machine learning to detect the language of Hub datasets with no language metadata, and [librarian-bots](https://huggingface.co/librarian-bots) to make pull requests to add this metadata. The Hugging Face Hub has become the repository where the community shares machine learning models, datasets, and applications. As the number of datasets grows, metadata becomes increasingly important as a tool for finding the right resource for your use case. In this blog post, I'm excited to share some early experiments which seek to use machine learning to improve the metadata for datasets hosted on the Hugging Face Hub. ### Language Metadata for Datasets on the Hub There are currently ~50K public datasets on the Hugging Face Hub. Metadata about the language used in a dataset can be specified using a [YAML](https://en.wikipedia.org/wiki/YAML) field at the top of the [dataset card](https://huggingface.co/docs/datasets/upload_dataset#create-a-dataset-card). All public datasets specify 1,716 unique languages via a language tag in their metadata. Note that some of them will be the result of languages being specified in different ways i.e. `en` vs `eng` vs `english` vs `English`. For example, the [IMDB dataset](https://huggingface.co/datasets/imdb) specifies `en` in the YAML metadata (indicating English): <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_metadata.png" alt="Screenshot of YAML metadata"><br> <em>Section of the YAML metadata for the IMDB dataset</em> </p> It is perhaps unsurprising that English is by far the most common language for datasets on the Hub, with around 19% of datasets on the Hub listing their language as `en` (not including any variations of `en`, so the actual percentage is likely much higher). <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_freq.png" alt="Distribution of language tags"><br> <em>The frequency and percentage frequency for datasets on the Hugging Face Hub</em> </p> What does the distribution of languages look like if we exclude English? We can see that there is a grouping of a few dominant languages and after that there is a pretty smooth fall in the frequencies at which languages appear. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_freq_distribution.png" alt="Distribution of language tags"><br> <em>Distribution of language tags for datasets on the hub excluding English.</em> </p> However, there is a major caveat to this. Most datasets (around 87%) do not specify the language used; only approximately 13% of datasets include language information in their metadata. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/has_lang_info_bar.png" alt="Barchart"><br> <em>The percent of datasets which have language metadata. True indicates language metadata is specified, False means no language data is listed. No card data means that there isn't any metadata or it couldn't be loaded by the `huggingface_hub` Python library.</em> </p> #### Why is Language Metadata Important? Language metadata can be a vital tool for finding relevant datasets. The Hugging Face Hub allows you to filter datasets by language. For example, if we want to find datasets with Dutch language we can use [a filter](https://huggingface.co/datasets?language=language:nl&sort=trending) on the Hub to include only datasets with Dutch data. Currently this filter returns 184 datasets. However, there are datasets on the Hub which include Dutch but don't specify this in the metadata. These datasets become more difficult to find, particularly as the number of datasets on the Hub grows. Many people want to be able to find datasets for a particular language. One of the major barriers to training good open source LLMs for a particular language is a lack of high quality training data. If we switch to the task of finding relevant machine learning models, knowing what languages were included in the training data for a model can help us find models for the language we are interested in. This relies on the dataset specifying this information. Finally, knowing what languages are represented on the Hub (and which are not), helps us understand the language biases of the Hub and helps inform community efforts to address gaps in particular languages. ### Predicting the Languages of Datasets Using Machine Learning We’ve already seen that many of the datasets on the Hugging Face Hub haven’t included metadata for the language used. However, since these datasets are already shared openly, perhaps we can look at the dataset and try to identify the language using machine learning. #### Getting the Data One way we could access some examples from a dataset is by using the datasets library to download the datasets i.e. ```python from datasets import load_dataset dataset = load_dataset("biglam/on_the_books") ``` However, for some of the datasets on the Hub, we might be keen not to download the whole dataset. We could instead try to load a sample of the dataset. However, depending on how the dataset was created, we might still end up downloading more data than we’d need onto the machine we’re working on. Luckily, many datasets on the Hub are available via the [datasets server](https://huggingface.co/docs/datasets-server/index). The datasets server is an API that allows us to access datasets hosted on the Hub without downloading the dataset locally. The Datasets Server powers the Datasets Viewer preview you will see for many datasets hosted on the Hub. For this first experiment with predicting language for datasets, we define a list of column names and data types likely to contain textual content i.e. `text` or `prompt` column names and `string` features are likely to be relevant `image` is not. This means we can avoid predicting the language for datasets where language information is less relevant, for example, image classification datasets. We use the Datasets Server to get 20 rows of text data to pass to a machine learning model (we could modify this to take more or fewer examples from the dataset). This approach means that for the majority of datasets on the Hub we can quickly request the contents of likely text columns for the first 20 rows in a dataset. #### Predicting the Language of a Dataset Once we have some examples of text from a dataset, we need to predict the language. There are various options here, but for this work, we used the [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model created by [Meta](https://huggingface.co/facebook) as part of the [No Language Left Behind](https://ai.facebook.com/research/no-language-left-behind/) work. This model can detect 217 languages which will likely represent the majority of languages for datasets hosted on the Hub. We pass 20 examples to the model representing rows from a dataset. This results in 20 individual language predictions (one per row) for each dataset. Once we have these predictions, we do some additional filtering to determine if we will accept the predictions as a metadata suggestion. This roughly consists of: - Grouping the predictions for each dataset by language: some datasets return predictions for multiple languages. We group these predictions by the language predicted i.e. if a dataset returns predictions for English and Dutch, we group the English and Dutch predictions together. - For datasets with multiple languages predicted, we count how many predictions we have for each language. If a language is predicted less than 20% of the time, we discard this prediction. i.e. if we have 18 predictions for English and only 2 for Dutch we discard the Dutch predictions. - We calculate the mean score for all predictions for a language. If the mean score associated with a languages prediction is below 80% we discard this prediction. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/prediction-flow.png" alt="Prediction workflow"><br> <em>Diagram showing how predictions are handled.</em> </p> Once we’ve done this filtering, we have a further step of deciding how to use these predictions. The fastText language prediction model returns predictions as an [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) code (an international standard for language codes) along with a script type. i.e. `kor_Hang` is the ISO 693-3 language code for Korean (kor) + Hangul script (Hang) a [ISO 15924](https://en.wikipedia.org/wiki/ISO_15924) code representing the script of a language. We discard the script information since this isn't currently captured consistently as metadata on the Hub and, where possible, we convert the language prediction returned by the model from [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) to [ISO 639-1](https://en.wikipedia.org/wiki/ISO_639-1) language codes. This is largely done because these language codes have better support in the Hub UI for navigating datasets. For some ISO 639-3 codes, there is no ISO 639-1 equivalent. For these cases we manually specify a mapping if we deem it to make sense, for example Standard Arabic (`arb`) is mapped to Arabic (`ar`). Where an obvious mapping is not possible, we currently don't suggest metadata for this dataset. In future iterations of this work we may take a different approach. It is important to recognise this approach does come with downsides, since it reduces the diversity of languages which might be suggested and also relies on subjective judgments about what languages can be mapped to others. But the process doesn't stop here. After all, what use is predicting the language of the datasets if we can't share that information with the rest of the community? ### Using Librarian-Bot to Update Metadata To ensure this valuable language metadata is incorporated back into the Hub, we turn to Librarian-Bot! Librarian-Bot takes the language predictions generated by Meta's [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model and opens pull requests to add this information to the metadata of each respective dataset. This system not only updates the datasets with language information, but also does it swiftly and efficiently, without requiring manual work from humans. If the owner of a repo decided to approve and merge the pull request, then the language metadata becomes available for all users, significantly enhancing the usability of the Hugging Face Hub. You can keep track of what the librarian-bot is doing [here](https://huggingface.co/librarian-bot/activity/community)! #### Next Steps As the number of datasets on the Hub grows, metadata becomes increasingly important. Language metadata, in particular, can be incredibly valuable for identifying the correct dataset for your use case. With the assistance of the Datasets Server and the [Librarian-Bots](https://huggingface.co/librarian-bots), we can update our dataset metadata at a scale that wouldn't be possible manually. As a result, we're enriching the Hub and making it an even more powerful tool for data scientists, linguists, and AI enthusiasts around the world. As the machine learning librarian at Hugging Face, I continue exploring opportunities for automatic metadata enrichment for machine learning artefacts hosted on the Hub. Feel free to reach out (daniel at thiswebsite dot co) if you have ideas or want to collaborate on this effort!
|
Deploy MusicGen in no time with Inference Endpoints
|
reach-vb
|
August 4, 2023
|
run-musicgen-as-an-api
|
audio, guide
|
https://huggingface.co/blog/run-musicgen-as-an-api
|
# Deploy MusicGen in no time with Inference Endpoints [MusicGen](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen) is a powerful music generation model that takes in text prompt and an optional melody to output music. This blog post will guide you through generating music with MusicGen using [Inference Endpoints](https://huggingface.co/inference-endpoints). Inference Endpoints allow us to write custom inference functions called [custom handlers](https://huggingface.co/docs/inference-endpoints/guides/custom_handler). These are particularly useful when a model is not supported out-of-the-box by the `transformers` high-level abstraction `pipeline`. `transformers` pipelines offer powerful abstractions to run inference with `transformers`-based models. Inference Endpoints leverage the pipeline API to easily deploy models with only a few clicks. However, Inference Endpoints can also be used to deploy models that don't have a pipeline, or even non-transformer models! This is achieved using a custom inference function that we call a [custom handler](https://huggingface.co/docs/inference-endpoints/guides/custom_handler). Let's demonstrate this process using MusicGen as an example. To implement a custom handler function for MusicGen and deploy it, we will need to: 1. Duplicate the MusicGen repository we want to serve, 2. Write a custom handler in `handler.py` and any dependencies in `requirements.txt` and add them to the duplicated repository, 3. Create Inference Endpoint for that repository. Or simply use the final result and deploy our [custom MusicGen model repo](https://huggingface.co/reach-vb/musicgen-large-fp16-endpoint), where we just followed the steps above :) ### Let's go! First, we will duplicate the [facebook/musicgen-large](https://huggingface.co/facebook/musicgen-large) repository to our own profile using [repository duplicator](https://huggingface.co/spaces/huggingface-projects/repo_duplicator). Then, we will add `handler.py` and `requirements.txt` to the duplicated repository. First, let's take a look at how to run inference with MusicGen. ```python from transformers import AutoProcessor, MusicgenForConditionalGeneration processor = AutoProcessor.from_pretrained("facebook/musicgen-large") model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large") inputs = processor( text=["80s pop track with bassy drums and synth"], padding=True, return_tensors="pt", ) audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256) ``` Let's hear what it sounds like: <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ie_musicgen/musicgen_out_minified.wav" type="audio/wav"> Your browser does not support the audio element. </audio> Optionally, you can also condition the output with an audio snippet i.e. generate a complimentary snippet which combines the text generated audio with an input audio. ```python from transformers import AutoProcessor, MusicgenForConditionalGeneration from datasets import load_dataset processor = AutoProcessor.from_pretrained("facebook/musicgen-large") model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large") dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True) sample = next(iter(dataset))["audio"] # take the first half of the audio sample sample["array"] = sample["array"][: len(sample["array"]) // 2] inputs = processor( audio=sample["array"], sampling_rate=sample["sampling_rate"], text=["80s blues track with groovy saxophone"], padding=True, return_tensors="pt", ) audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256) ``` Let's give it a listen: <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ie_musicgen/musicgen_out_melody_minified.wav" type="audio/wav"> Your browser does not support the audio element. </audio> In both the cases the `model.generate` method produces the audio and follows the same principles as text generation. You can read more about it in our [how to generate](https://huggingface.co/blog/how-to-generate) blog post. Alright! With the basic usage outlined above, let's deploy MusicGen for fun and profit! First, we'll define a custom handler in `handler.py`. We can use the [Inference Endpoints template](https://huggingface.co/docs/inference-endpoints/guides/custom_handler#3-customize-endpointhandler) and override the `__init__` and `__call__` methods with our custom inference code. `__init__` will initialize the model and the processor, and `__call__` will take the data and return the generated music. You can find the modified `EndpointHandler` class below. 👇 ```python from typing import Dict, List, Any from transformers import AutoProcessor, MusicgenForConditionalGeneration import torch class EndpointHandler: def __init__(self, path=""): # load model and processor from path self.processor = AutoProcessor.from_pretrained(path) self.model = MusicgenForConditionalGeneration.from_pretrained(path, torch_dtype=torch.float16).to("cuda") def __call__(self, data: Dict[str, Any]) -> Dict[str, str]: """ Args: data (:dict:): The payload with the text prompt and generation parameters. """ # process input inputs = data.pop("inputs", data) parameters = data.pop("parameters", None) # preprocess inputs = self.processor( text=[inputs], padding=True, return_tensors="pt",).to("cuda") # pass inputs with all kwargs in data if parameters is not None: with torch.autocast("cuda"): outputs = self.model.generate(**inputs, **parameters) else: with torch.autocast("cuda"): outputs = self.model.generate(**inputs,) # postprocess the prediction prediction = outputs[0].cpu().numpy().tolist() return [{"generated_audio": prediction}] ``` To keep things simple, in this example we are only generating audio from text, and not conditioning it with a melody. Next, we will create a `requirements.txt` file containing all the dependencies we need to run our inference code: ``` transformers==4.31.0 accelerate>=0.20.3 ``` Uploading these two files to our repository will suffice to serve the model.  We can now create the Inference Endpoint. Head to the [Inference Endpoints](https://huggingface.co/inference-endpoints) page and click `Deploy your first model`. In the "Model repository" field, enter the identifier of your duplicated repository. Then select the hardware you want and create the endpoint. Any instance with a minimum of 16 GB RAM should work for `musicgen-large`.  After creating the endpoint, it will be automatically launched and ready to receive requests.  We can query the endpoint with the below snippet. ```bash curl URL_OF_ENDPOINT \ -X POST \ -d '{"inputs":"happy folk song, cheerful and lively"}' \ -H "Authorization: {YOUR_TOKEN_HERE}" \ -H "Content-Type: application/json" ``` We can see the following waveform sequence as output. ``` [{"generated_audio":[[-0.024490159,-0.03154691,-0.0079551935,-0.003828604, ...]]}] ``` Here's how it sounds like: <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ie_musicgen/musicgen_inference_minified.wav" type="audio/wav"> Your browser does not support the audio element. </audio> You can also hit the endpoint with `huggingface-hub` Python library's `InferenceClient` class. ```python from huggingface_hub import InferenceClient client = InferenceClient(model = URL_OF_ENDPOINT) response = client.post(json={"inputs":"an alt rock song"}) # response looks like this b'[{"generated_text":[[-0.182352,-0.17802449, ...]]}] output = eval(response)[0]["generated_audio"] ``` You can convert the generated sequence to audio however you want. You can use `scipy` in Python to write it to a .wav file. ```python import scipy import numpy as np # output is [[-0.182352,-0.17802449, ...]] scipy.io.wavfile.write("musicgen_out.wav", rate=32000, data=np.array(output[0])) ``` And voila! Play with the demo below to try the endpoint out. <gradio-app theme_mode="light" space="merve/MusicGen"></gradio-app> ## Conclusion In this blog post, we have shown how to deploy MusicGen using Inference Endpoints with a custom inference handler. The same technique can be used for any other model in the Hub that does not have an associated pipeline. All you have to do is override the `Endpoint Handler` class in `handler.py`, and add `requirements.txt` to reflect your project's dependencies. ### Read More - [Inference Endpoints documentation covering Custom Handler](https://huggingface.co/docs/inference-endpoints/guides/custom_handler)
|
Releasing Swift Transformers: Run On-Device LLMs in Apple Devices
|
pcuenq
|
August 8, 2023
|
swift-coreml-llm
|
guide, coreml, llm, swift
|
https://huggingface.co/blog/swift-coreml-llm
|
# Releasing Swift Transformers: Run On-Device LLMs in Apple Devices I have a lot of respect for iOS/Mac developers. I started writing apps for iPhones in 2007, when not even APIs or documentation existed. The new devices adopted some unfamiliar decisions in the constraint space, with a combination of power, screen real estate, UI idioms, network access, persistence, and latency that was different to what we were used to before. Yet, this community soon managed to create top-notch applications that felt at home with the new paradigm. I believe that ML is a new way to build software, and I know that many Swift developers want to incorporate AI features in their apps. The ML ecosystem has matured a lot, with thousands of models that solve a wide variety of problems. Moreover, LLMs have recently emerged as almost general-purpose tools – they can be adapted to new domains as long as we can model our task to work on text or text-like data. We are witnessing a defining moment in computing history, where LLMs are going out of research labs and becoming computing tools for everybody. However, using an LLM model such as Llama in an app involves several tasks which many people face and solve alone. We have been exploring this space and would love to continue working on it with the community. We aim to create a set of tools and building blocks that help developers build faster. Today, we are publishing this guide to go through the steps required to run a model such as Llama 2 on your Mac using Core ML. We are also releasing alpha libraries and tools to support developers in the journey. We are calling all Swift developers interested in ML – is that _all_ Swift developers? – to contribute with PRs, bug reports, or opinions to improve this together. Let's go! <p align="center"> <video controls title="Llama 2 (7B) chat model running on an M1 MacBook Pro with Core ML"> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/swift-transformers/llama-2-7b-chat.mp4" type="video/mp4"> <em>Video: Llama 2 (7B) chat model running on an M1 MacBook Pro with Core ML.</em> </p> ## Released Today - [`swift-transformers`](https://github.com/huggingface/swift-transformers), an in-development Swift package to implement a transformers-like API in Swift focused on text generation. It is an evolution of [`swift-coreml-transformers`](https://github.com/huggingface/swift-coreml-transformers) with broader goals: Hub integration, arbitrary tokenizer support, and pluggable models. - [`swift-chat`](https://github.com/huggingface/swift-chat), a simple app demonstrating how to use the package. - An updated version of [`exporters`](https://github.com/huggingface/exporters), a Core ML conversion package for transformers models. - An updated version of [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml), a no-code Core ML conversion tool built on `exporters`. - Some converted models, such as [Llama 2 7B](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml) or [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b-instruct/tree/main/coreml), ready for use with these text generation tools. ## Tasks Overview When I published tweets showing [Falcon](https://twitter.com/pcuenq/status/1664605575882366980) or [Llama 2](https://twitter.com/pcuenq/status/1681404748904431616) running on my Mac, I got many questions from other developers asking how to convert those models to Core ML, because they want to use them in their apps as well. Conversion is a crucial step, but it's just the first piece of the puzzle. The real reason I write those apps is to face the same problems that any other developer would and identify areas where we can help. We'll go through some of these tasks in the rest of this post, explaining where (and where not) we have tools to help. - [Conversion to Core ML](#conversion-to-core-ml). We'll use Llama 2 as a real-life example. - [Optimization](#optimization) techniques to make your model (and app) run fast and consume as little memory as possible. This is an area that permeates across the project and there's no silver-bullet solution you can apply. - [`swift-transformers`](#swift-transformers), our new library to help with some common tasks. - [Tokenizers](#tokenizers). Tokenization is the way to convert text input to the actual set of numbers that are processed by the model (and back to text from the generated predictions). This is a lot more involved than it sounds, as there are many different options and strategies. - [Model and Hub wrappers](#model-and-hub-wrappers). If we want to support the wide variety of models on the Hub, we can't afford to hardcode model settings. We created a simple `LanguageModel` abstraction and various utilities to download model and tokenizer configuration files from the Hub. - [Generation Algorithms](#generation-algorithms). Language models are trained to predict a probability distribution for the next token that may appear after a sequence of text. We need to call the model multiple times to generate text output and select a token at each step. There are many ways to decide which token we should choose next. - [Supported Models](#supported-models). Not all model families are supported (yet). - [`swift-chat`](#swift-chat). This is a small app that simply shows how to use `swift-transformers` in a project. - [Missing Parts / Coming Next](#missing-parts--coming-next). Some stuff that's important but not yet available, as directions for future work. - [Resources](#resources). Links to all the projects and tools. ## Conversion to Core ML Core ML is Apple's native framework for Machine Learning, and also the name of the file format it uses. After you convert a model from (for example) PyTorch to Core ML, you can use it in your Swift apps. The Core ML framework automatically selects the best hardware to run your model on: the CPU, the GPU, or a specialized tensor unit called the Neural Engine. A combination of several of these compute units is also possible, depending on the characteristics of your system and the model details. To see what it looks like to convert a model in real life, we'll look at converting the recently-released Llama 2 model. The process can sometimes be convoluted, but we offer some tools to help. These tools won't always work, as new models are being introduced all the time, and we need to make adjustments and modifications. Our recommended approach is: 1. Use the [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml) conversion Space: This is an automated tool built on top of `exporters` (see below) that either works for your model, or doesn't. It requires no coding: enter the Hub model identifier, select the task you plan to use the model for, and click apply. If the conversion succeeds, you can push the converted Core ML weights to the Hub, and you are done! You can [visit the Space](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml) or use it directly here: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script> <gradio-app theme_mode="light" space="coreml-projects/transformers-to-coreml"></gradio-app> 2. Use [`exporters`](https://github.com/huggingface/exporters), a Python conversion package built on top of Apple's `coremltools` (see below). This library gives you a lot more options to configure the conversion task. In addition, it lets you create your own [conversion configuration class](https://github.com/huggingface/exporters#overriding-default-choices-in-the-configuration-object), which you may use for additional control or to work around conversion issues. 3. Use [`coremltools`](https://github.com/apple/coremltools), Apple's conversion package. This is the lowest-level approach and therefore provides maximum control. It can still fail for some models (especially new ones), but you always have the option to dive inside the source code and try to figure out why. The good news about Llama 2 is that we did the legwork and the conversion process works using any of these methods. The bad news is that it _failed to convert_ when it was released, and we had to do some fixing to support it. We briefly look at what happened in [the appendix](#appendix-converting-llama-2-the-hard-way) so you can get a taste of what to do when things go wrong. ### Important lessons learned I've followed the conversion process for some recent models (Llama 2, Falcon, StarCoder), and I've applied what I learned to both `exporters` and the `transformers-to-coreml` Space. This is a summary of some takeaways: - If you have to use `coremltools`, use the latest version: `7.0b1`. Despite technically being a beta, I've been using it for weeks and it's really good: stable, includes a lot of fixes, supports PyTorch 2, and has new features like advanced quantization tools. - `exporters` no longer applies a softmax to outputs when converting text generation tasks. We realized this was necessary for some generation algorithms. - `exporters` now defaults to using fixed sequence lengths for text models. Core ML has a way to specify "flexible shapes", such that your input sequence may have any length between 1 and, say, 4096 tokens. We discovered that flexible inputs only run on CPU, but not on GPU or the Neural Engine. More investigation coming soon! We'll keep adding best practices to our tools so you don't have to discover the same issues again. ## Optimization There's no point in converting models if they don't run fast on your target hardware and respect system resources. The models mentioned in this post are pretty big for local use, and we are consciously using them to stretch the limits of what's possible with current technology and understand where the bottlenecks are. There are a few key optimization areas we've identified. They are a very important topic for us and the subject of current and upcoming work. Some of them include: - Cache attention keys and values from previous generations, just like the transformers models do in the PyTorch implementation. The computation of attention scores needs to run on the whole sequence generated so far, but all the past key-value pairs were already computed in previous runs. We are currently _not_ using any caching mechanism for Core ML models, but are planning to do so! - Use discrete shapes instead of a small fixed sequence length. The main reason not to use flexible shapes is that they are not compatible with the GPU or the Neural Engine. A secondary reason is that generation would become slower as the sequence length grows, because of the absence of caching as mentioned above. Using a discrete set of fixed shapes, coupled with caching key-value pairs should allow for larger context sizes and a more natural chat experience. - Quantization techniques. We've already explored them in the context of Stable Diffusion models, and are really excited about the options they'd bring. For example, [6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml) decreases model size and is efficient with resources. [Mixed-bit quantization](https://huggingface.co/blog/stable-diffusion-xl-coreml), a new technique, can achieve 4-bit quantization (on average) with low impact on model quality. We are planning to work on these topics for language models too! For production applications, consider iterating with smaller models, especially during development, and then apply optimization techniques to select the smallest model you can afford for your use case. ## `swift-transformers` [`swift-transformers`](https://github.com/huggingface/swift-transformers) is an in-progress Swift package that aims to provide a transformers-like API to Swift developers. Let's see what it has and what's missing. ### Tokenizers Tokenization solves two complementary tasks: adapt text input to the tensor format used by the model and convert results from the model back to text. The process is nuanced, for example: - Do we use words, characters, groups of characters or bytes? - How should we deal with lowercase vs uppercase letters? Should we even deal with the difference? - Should we remove repeated characters, such as spaces, or are they important? - How do we deal with words that are not in the model's vocabulary? There are a few general tokenization algorithms, and a lot of different normalization and pre-processing steps that are crucial to using the model effectively. The transformers library made the decision to abstract all those operations in the same library (`tokenizers`), and represent the decisions as configuration files that are stored in the Hub alongside the model. For example, this is an excerpt from the configuration of the Llama 2 tokenizer that describes _just the normalization step_: ``` "normalizer": { "type": "Sequence", "normalizers": [ { "type": "Prepend", "prepend": "▁" }, { "type": "Replace", "pattern": { "String": " " }, "content": "▁" } ] }, ``` It reads like this: normalization is a sequence of operations applied in order. First, we `Prepend` character `_` to the input string. Then we replace all spaces with `_`. There's a huge list of potential operations, they can be applied to regular expression matches, and they have to be performed in a very specific order. The code in the `tokenizers` library takes care of all these details for all the models in the Hub. In contrast, projects that use language models in other domains, such as Swift apps, usually resort to hardcoding these decisions as part of the app's source code. This is fine for a couple of models, but then it's difficult to replace a model with a different one, and it's easy to make mistakes. What we are doing in `swift-transformers` is replicate those abstractions in Swift, so we write them once and everybody can use them in their apps. We are just getting started, so coverage is still small. Feel free to open issues in the repo or contribute your own! Specifically, we currently support BPE (Byte-Pair Encoding) tokenizers, one of the three main families in use today. The GPT models, Falcon and Llama, all use this method. Support for Unigram and WordPiece tokenizers will come later. We haven't ported all the possible normalizers, pre-tokenizers and post-processors - just the ones we encountered during our conversions of Llama 2, Falcon and GPT models. This is how to use the `Tokenizers` module in Swift: ```swift import Tokenizers func testTokenizer() async throws { let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml") let inputIds = tokenizer("Today she took a train to the West") assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122]) } ``` However, you don't usually need to tokenize the input text yourself - the [`Generation` code](https://github.com/huggingface/swift-transformers/blob/17d4bfae3598482fc7ecf1a621aa77ab586d379a/Sources/Generation/Generation.swift#L82) will take care of it. ### Model and Hub wrappers As explained above, `transformers` heavily use configuration files stored in the Hub. We prepared a simple `Hub` module to download configuration files from the Hub, which is used to instantiate the tokenizer and retrieve metadata about the model. Regarding models, we created a simple `LanguageModel` type as a wrapper for a Core ML model, focusing on the text generation task. Using protocols, we can query any model with the same API. To retrieve the appropriate metadata for the model you use, `swift-transformers` relies on a few custom metadata fields that must be added to the Core ML file when converting it. `swift-transformers` will use this information to download all the necessary configuration files from the Hub. These are the fields we use, as presented in Xcode's model preview:  `exporters` and `transformers-to-coreml` will automatically add these fields for you. Please, make sure you add them yourself if you use `coremltools` manually. ### Generation Algorithms Language models are trained to predict a probability distribution of the next token that may appear as a continuation to an input sequence. In order to compose a response, we need to call the model multiple times until it produces a special _termination_ token, or we reach the length we desire. There are many ways to decide what's the next best token to use. We currently support two of them: - Greedy decoding. This is the obvious algorithm: select the token with the highest probability, append it to the sequence, and repeat. This will always produce the same result for the same input sequence. - top-k sampling. Select the `top-k` (where `k` is a parameter) most probable tokens, and then randomly _sample_ from them using parameters such as `temperature`, which will increase variability at the expense of potentially causing the model to go on tangents and lose track of the content. Additional methods such as "nucleus sampling" will come later. We recommend [this blog post](https://huggingface.co/blog/how-to-generate) (updated recently) for an excellent overview of generation methods and how they work. Sophisticated methods such as [assisted generation](https://huggingface.co/blog/assisted-generation) can also be very useful for optimization! ### Supported Models So far, we've tested `swift-transformers` with a handful of models to validate the main design decisions. We are looking forward to trying many more! - Llama 2. - Falcon. - StarCoder models, based on a variant of the GPT architecture. - GPT family, including GPT2, distilgpt, GPT-NeoX, GPT-J. ## `swift-chat` `swift-chat` is a simple demo app built on `swift-transformers`. Its main purpose is to show how to use `swift-transformers` in your code, but it can also be used as a model tester tool.  To use it, download a Core ML model from the Hub or create your own, and select it from the UI. All the relevant model configuration files will be downloaded from the Hub, using the metadata information to identify what model type this is. The first time you load a new model, it will take some time to prepare it. In this phase, the CoreML framework will compile the model and decide what compute devices to run it on, based on your machine specs and the model's structure. This information is cached and reused in future runs. The app is intentionally simple to make it readable and concise. It also lacks a few features, primarily because of the current limitations in model context size. For example, it does not have any provision for "system prompts", which are [useful for specifying the behaviour of your language model](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) and even its personality. ## Missing Parts / Coming Next As stated, we are just getting started! Our upcoming priorities include: - Encoder-decoder models such as T5 and Flan. - More tokenizers: support for Unigram and WordPiece. - Additional generation algorithms. - Support key-value caching for optimization. - Use discrete sequence shapes for conversion. Together with key-value caching this will allow for larger contexts. Let us know what you think we should work on next, or head over to the repos for [Good First Issues](https://github.com/huggingface/swift-transformers/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) to try your hand on! ## Conclusion We introduced a set of tools to help Swift developers incorporate language models in their apps. I can't wait to see what you create with them, and I look forward to improving them with the community's help! Don't hesitate to get in touch :) ### _Appendix: Converting Llama 2 the Hard Way_ You can safely ignore this section unless you've experienced Core ML conversion issues and are ready to fight :) In my experience, there are two frequent reasons why PyTorch models fail to convert to Core ML using `coremltools`: - Unsupported PyTorch operations or operation variants PyTorch has _a lot_ of operations, and all of them have to be mapped to an intermediate representation ([MIL](https://apple.github.io/coremltools/source/coremltools.converters.mil.mil.ops.defs.html), for _Model Intermediate Language_), which in turn is converted to native Core ML instructions. The set of PyTorch operations is not static, so new ones have to be added to `coremltools` too. In addition, some operations are really complex and can work on exotic combinations of their arguments. An example of a recently-added, very complex op, was _scaled dot-product attention_, introduced in PyTorch 2. An example of a partially supported op is `einsum`: not all possible equations are translated to MIL. - Edge cases and type mismatches Even for supported PyTorch operations, it's very difficult to ensure that the translation process works on all possible inputs across all the different input types. Keep in mind that a single PyTorch op can have multiple backend implementations for different devices (cpu, CUDA), input types (integer, float), or precision (float16, float32). The product of all combinations is staggering, and sometimes the way a model uses PyTorch code triggers a translation path that may have not been considered or tested. This is what happened when I first tried to convert Llama 2 using `coremltools`: 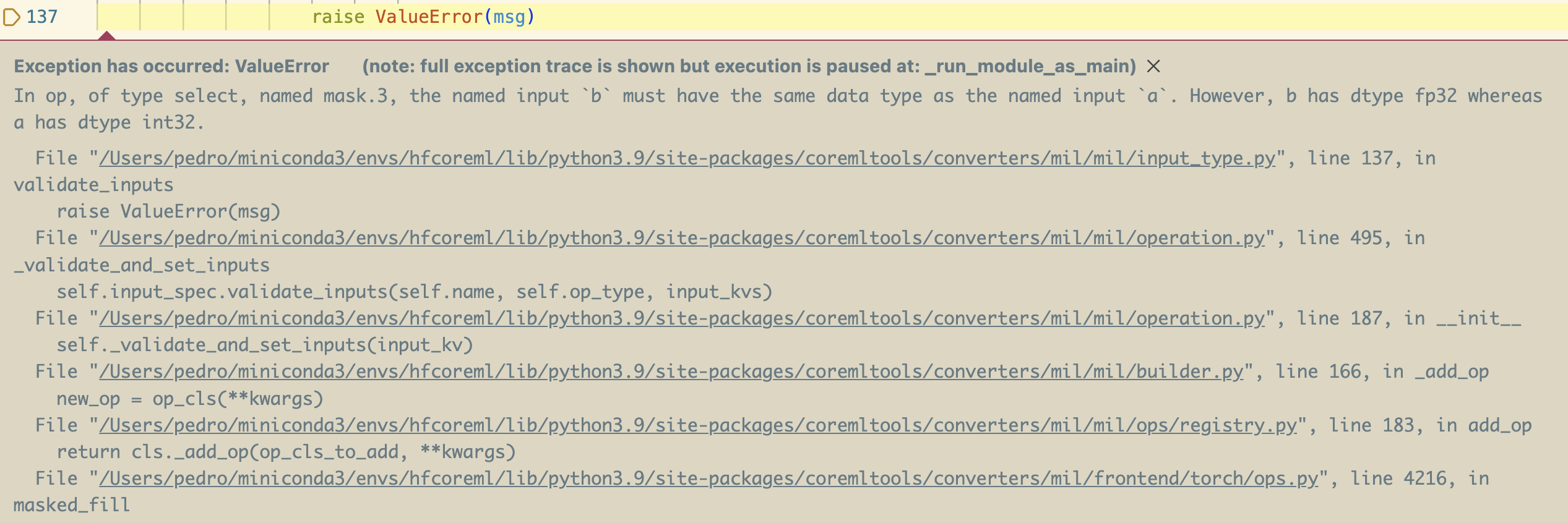 By comparing different versions of transformers, I could see the problem started happening when [this line of code](https://github.com/huggingface/transformers/blob/d114a6b71f243054db333dc5a3f55816161eb7ea/src/transformers/models/llama/modeling_llama.py#L52C5-L52C6) was introduced. It's part of a recent `transformers` refactor to better deal with causal masks in _all_ models that use them, so this would be a big problem for other models, not just Llama. What the error screenshot is telling us is that there's a type mismatch trying to fill the mask tensor. It comes from the `0` in the line: it's interpreted as an `int`, but the tensor to be filled contains `floats`, and using different types was rejected by the translation process. In this particular case, I came up with a [patch for `coremltools`](https://github.com/apple/coremltools/pull/1915), but fortunately this is rarely necessary. In many cases, you can patch your code (a `0.0` in a local copy of `transformers` would have worked), or create a "special operation" to deal with the exceptional case. Our `exporters` library has very good support for custom, special operations. See [this example](https://github.com/huggingface/exporters/blob/f134e5ceca05409ea8abcecc3df1c39b53d911fe/src/exporters/coreml/models.py#L139C9-L139C18) for a missing `einsum` equation, or [this one](https://github.com/huggingface/exporters/blob/f134e5ceca05409ea8abcecc3df1c39b53d911fe/src/exporters/coreml/models.py#L208C9-L208C18) for a workaround to make `StarCoder` models work until a new version of `coremltools` is released. Fortunately, `coremltools` coverage for new operations is good and the team reacts very fast. ## Resources - [`swift-transformers`](https://github.com/huggingface/swift-transformers). - [`swift-chat`](https://github.com/huggingface/swift-chat). - [`exporters`](https://github.com/huggingface/exporters). - [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml). - Some Core ML models for text generation: - [Llama-2-7b-chat-coreml](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml) - [Falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct/tree/main/coreml)
|
Fine-tune Llama 2 with DPO
|
kashif
|
August 8, 2023
|
dpo-trl
|
rl, rlhf, nlp
|
https://huggingface.co/blog/dpo-trl
|
# Fine-tune Llama 2 with DPO ## Introduction Reinforcement Learning from Human Feedback (RLHF) has become the de facto last training step of LLMs such as GPT-4 or Claude to ensure that the language model's outputs are aligned with human expectations such as chattiness or safety features. However, it brings some of the complexity of RL into NLP: we need to build a good reward function, train the model to estimate the value of a state, and at the same time be careful not to strive too far from the original model and produce gibberish instead of sensible text. Such a process is quite involved requiring a number of complex moving parts where it is not always easy to get things right. The recent paper [Direct Preference Optimization](https://arxiv.org/abs/2305.18290) by Rafailov, Sharma, Mitchell et al. proposes to cast the RL-based objective used by existing methods to an objective which can be directly optimized via a simple binary cross-entropy loss which simplifies this process of refining LLMs greatly. This blog-post introduces the Direct Preference Optimization (DPO) method which is now available in the [TRL library](https://github.com/lvwerra/trl) and shows how one can fine tune the recent Llama v2 7B-parameter model on the [stack-exchange preference](https://huggingface.co/datasets/lvwerra/stack-exchange-paired) dataset which contains ranked answers to questions on the various stack-exchange portals. ## DPO vs PPO In the traditional model of optimising human derived preferences via RL, the goto method has been to use an auxiliary reward model and fine-tune the model of interest so that it maximizes this given reward via the machinery of RL. Intuitively we use the reward model to provide feedback to the model we are optimising so that it generates high-reward samples more often and low-reward samples less often. At the same time we use a frozen reference model to make sure that whatever is generated does not deviate too much and continues to maintain generation diversity. This is typically done by adding a KL penalty to the full reward maximisation objective via a reference model, which serves to prevent the model from learning to cheat or exploit the reward model. The DPO formulation bypasses the reward modeling step and directly optimises the language model on preference data via a key insight: namely an analytical mapping from the reward function to the optimal RL policy that enables the authors to transform the RL loss over the reward and reference models to a loss over the reference model directly! This mapping intuitively measures how well a given reward function aligns with the given preference data. DPO thus starts with the optimal solution to the RLHF loss and via a change of variables derives a loss over *only* the reference model! Thus this direct likelihood objective can be optimized without the need for a reward model or the need to perform the potentially fiddly RL based optimisation. ## How to train with TRL As mentioned, typically the RLHF pipeline consists of these distinct parts: 1. a supervised fine-tuning (SFT) step 2. the process of annotating data with preference labels 3. training a reward model on the preference data 4. and the RL optmization step The TRL library comes with helpers for all these parts, however the DPO training does away with the task of reward modeling and RL (steps 3 and 4) and directly optimizes the DPO object on preference annotated data. In this respect we would still need to do the step 1, but instead of steps 3 and 4 we need to provide the `DPOTrainer` in TRL with preference data from step 2 which has a very specific format, namely a dictionary with the following three keys: - `prompt` this consists of the context prompt which is given to a model at inference time for text generation - `chosen` contains the preferred generated response to the corresponding prompt - `rejected` contains the response which is not preferred or should not be the sampled response with respect to the given prompt As an example, for the stack-exchange preference pairs dataset, we can map the dataset entries to return the desired dictionary via the following helper and drop all the original columns: ```python def return_prompt_and_responses(samples) -> Dict[str, str, str]: return { "prompt": [ "Question: " + question + "\n\nAnswer: " for question in samples["question"] ], "chosen": samples["response_j"], # rated better than k "rejected": samples["response_k"], # rated worse than j } dataset = load_dataset( "lvwerra/stack-exchange-paired", split="train", data_dir="data/rl" ) original_columns = dataset.column_names dataset.map( return_prompt_and_responses, batched=True, remove_columns=original_columns ) ``` Once we have the dataset sorted the DPO loss is essentially a supervised loss which obtains an implicit reward via a reference model and thus at a high-level the `DPOTrainer` requires the base model we wish to optimize as well as a reference model: ```python dpo_trainer = DPOTrainer( model, # base model from SFT pipeline model_ref, # typically a copy of the SFT trained base model beta=0.1, # temperature hyperparameter of DPO train_dataset=dataset, # dataset prepared above tokenizer=tokenizer, # tokenizer args=training_args, # training arguments e.g. batch size, lr, etc. ) ``` where the `beta` hyper-parameter is the temperature parameter for the DPO loss, typically in the range `0.1` to `0.5`. This controls how much we pay attention to the reference model in the sense that as `beta` gets smaller the more we ignore the reference model. Once we have our trainer initialised we can then train it on the dataset with the given `training_args` by simply calling: ```python dpo_trainer.train() ``` ## Experiment with Llama v2 The benefit of implementing the DPO trainer in TRL is that one can take advantage of all the extra bells and whistles of training large LLMs which come with TRL and its dependent libraries like Peft and Accelerate. With these libraries we are even able to train a Llama v2 model using the [QLoRA technique](https://huggingface.co/blog/4bit-transformers-bitsandbytes) provided by the [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) library. ### Supervised Fine Tuning The process as introduced above involves the supervised fine-tuning step using [QLoRA](https://arxiv.org/abs/2305.14314) on the 7B Llama v2 model on the SFT split of the data via TRL’s `SFTTrainer`: ```python # load the base model in 4-bit quantization bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16, ) base_model = AutoModelForCausalLM.from_pretrained( script_args.model_name, # "meta-llama/Llama-2-7b-hf" quantization_config=bnb_config, device_map={"": 0}, trust_remote_code=True, use_auth_token=True, ) base_model.config.use_cache = False # add LoRA layers on top of the quantized base model peft_config = LoraConfig( r=script_args.lora_r, lora_alpha=script_args.lora_alpha, lora_dropout=script_args.lora_dropout, target_modules=["q_proj", "v_proj"], bias="none", task_type="CAUSAL_LM", ) ... trainer = SFTTrainer( model=base_model, train_dataset=train_dataset, eval_dataset=eval_dataset, peft_config=peft_config, packing=True, max_seq_length=None, tokenizer=tokenizer, args=training_args, # HF Trainer arguments ) trainer.train() ``` ### DPO Training Once the SFT has finished, we can save the resulting model and move onto the DPO training. As is typically done we will utilize the saved model from the previous SFT step for both the base model as well as reference model of DPO. Then we can use these to train the model with the DPO objective on the stack-exchange preference data shown above. Since the models were trained via LoRa adapters, we load the models via Peft’s `AutoPeftModelForCausalLM` helpers: ```python model = AutoPeftModelForCausalLM.from_pretrained( script_args.model_name_or_path, # location of saved SFT model low_cpu_mem_usage=True, torch_dtype=torch.float16, load_in_4bit=True, is_trainable=True, ) model_ref = AutoPeftModelForCausalLM.from_pretrained( script_args.model_name_or_path, # same model as the main one low_cpu_mem_usage=True, torch_dtype=torch.float16, load_in_4bit=True, ) ... dpo_trainer = DPOTrainer( model, model_ref, args=training_args, beta=script_args.beta, train_dataset=train_dataset, eval_dataset=eval_dataset, tokenizer=tokenizer, peft_config=peft_config, ) dpo_trainer.train() dpo_trainer.save_model() ``` So as can be seen we load the model in the 4-bit configuration and then train it via the QLora method via the `peft_config` arguments. The trainer will also evaluate the progress during training with respect to the evaluation dataset and report back a number of key metrics like the implicit reward which can be recorded and displayed via WandB for example. We can then push the final trained model to the HuggingFace Hub. ## Conclusion The full source code of the training scripts for the SFT and DPO are available in the following [examples/stack_llama_2](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama_2) directory and the trained model with the merged adapters can be found on the HF Hub [here](https://huggingface.co/kashif/stack-llama-2). The WandB logs for the DPO training run can be found [here](https://wandb.ai/krasul/huggingface/runs/c54lmder) where during training and evaluation the `DPOTrainer` records the following reward metrics: * `rewards/chosen`: the mean difference between the log probabilities of the policy model and the reference model for the chosen responses scaled by `beta` * `rewards/rejected`: the mean difference between the log probabilities of the policy model and the reference model for the rejected responses scaled by `beta` * `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards * `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards. Intuitively, during training we want the margins to increase and the accuracies to go to 1.0, or in other words the chosen reward to be higher than the rejected reward (or the margin bigger than zero). These metrics can then be calculated over some evaluation dataset. We hope with the code release it lowers the barrier to entry for you the readers to try out this method of aligning large language models on your own datasets and we cannot wait to see what you build! And if you want to try out the model yourself you can do so here: [trl-lib/stack-llama](https://huggingface.co/spaces/trl-lib/stack-llama).
|
Deploying Hugging Face Models with BentoML: DeepFloyd IF in Action
|
Sherlockk
|
August 9, 2023
|
deploy-deepfloydif-using-bentoml
|
deployment, open-source-collab, bentoml, guide, diffusers
|
https://huggingface.co/blog/deploy-deepfloydif-using-bentoml
|
# Deploying Hugging Face Models with BentoML: DeepFloyd IF in Action Hugging Face provides a Hub platform that allows you to upload, share, and deploy your models with ease. It saves developers the time and computational resources required to train models from scratch. However, deploying models in a real-world production environment or in a cloud-native way can still present challenges. This is where BentoML comes into the picture. BentoML is an open-source platform for machine learning model serving and deployment. It is a unified framework for building, shipping, and scaling production-ready AI applications incorporating traditional, pre-trained, and generative models as well as Large Language Models. Here is how you use the BentoML framework from a high-level perspective: 1. **Define a model**: Before you can use BentoML, you need a machine learning model (or multiple models). This model can be trained using a machine learning library such as TensorFlow and PyTorch. 2. **Save the model**: Once you have a trained model, save it to the BentoML local Model Store, which is used for managing all your trained models locally as well as accessing them for serving. 3. **Create a BentoML Service**: You create a `service.py` file to wrap the model and define the serving logic. It specifies [Runners](https://docs.bentoml.org/en/latest/concepts/runner.html) for models to run model inference at scale and exposes APIs to define how to process inputs and outputs. 4. **Build a Bento**: By creating a configuration YAML file, you package all the models and the [Service](https://docs.bentoml.org/en/latest/concepts/service.html) into a [Bento](https://docs.bentoml.org/en/latest/concepts/bento.html), a deployable artifact containing all the code and dependencies. 5. **Deploy the Bento**: Once the Bento is ready, you can containerize the Bento to create a Docker image and run it on Kubernetes. Alternatively, deploy the Bento directly to Yatai, an open-source, end-to-end solution for automating and running machine learning deployments on Kubernetes at scale. In this blog post, we will demonstrate how to integrate [DeepFloyd IF](https://huggingface.co/docs/diffusers/api/pipelines/if) with BentoML by following the above workflow. ## Table of contents - [A brief introduction to DeepFloyd IF](#a-brief-introduction-to-deepfloyd-if) - [Preparing the environment](#preparing-the-environment) - [Downloading the model to the BentoML Model Store](#downloading-the-model-to-the-bentoml-model-store) - [Starting a BentoML Service](#starting-a-bentoml-service) - [Building and serving a Bento](#building-and-serving-a-bento) - [Testing the server](#testing-the-server) - [What's next](#whats-next) ## A brief introduction to DeepFloyd IF DeepFloyd IF is a state-of-the-art, open-source text-to-image model. It stands apart from latent diffusion models like Stable Diffusion due to its distinct operational strategy and architecture. DeepFloyd IF delivers a high degree of photorealism and sophisticated language understanding. Unlike Stable Diffusion, DeepFloyd IF works directly in pixel space, leveraging a modular structure that encompasses a frozen text encoder and three cascaded pixel diffusion modules. Each module plays a unique role in the process: Stage 1 is responsible for the creation of a base 64x64 px image, which is then progressively upscaled to 1024x1024 px across Stage 2 and Stage 3. Another critical aspect of DeepFloyd IF’s uniqueness is its integration of a Large Language Model (T5-XXL-1.1) to encode prompts, which offers superior understanding of complex prompts. For more information, see this [Stability AI blog post about DeepFloyd IF](https://stability.ai/blog/deepfloyd-if-text-to-image-model). To make sure your DeepFloyd IF application runs in high performance in production, you may want to allocate and manage your resources wisely. In this respect, BentoML allows you to scale the Runners independently for each Stage. For example, you can use more Pods for your Stage 1 Runners or allocate more powerful GPU servers to them. ## Preparing the environment [This GitHub repository](https://github.com/bentoml/IF-multi-GPUs-demo) stores all necessary files for this project. To run this project locally, make sure you have the following: - Python 3.8+ - `pip` installed - At least 2x16GB VRAM GPU or 1x40 VRAM GPU. For this project, we used a machine of type `n1-standard-16` from Google Cloud plus 64 GB of RAM and 2 NVIDIA T4 GPUs. Note that while it is possible to run IF on a single T4, it is not recommended for production-grade serving Once the prerequisites are met, clone the project repository to your local machine and navigate to the target directory. ```bash git clone https://github.com/bentoml/IF-multi-GPUs-demo.git cd IF-multi-GPUs-demo ``` Before building the application, let’s briefly explore the key files within this directory: - `import_models.py`: Defines the models for each stage of the [`IFPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/if). You use this file to download all the models to your local machine so that you can package them into a single Bento. - `requirements.txt`: Defines all the packages and dependencies required for this project. - `service.py`: Defines a BentoML Service, which contains three Runners created using the `to_runner` method and exposes an API for generating images. The API takes a JSON object as input (i.e. prompts and negative prompts) and returns an image as output by using a sequence of models. - `start-server.py`: Starts a BentoML HTTP server through the Service defined in `service.py` and creates a Gradio web interface for users to enter prompts to generate images. - `bentofile.yaml`: Defines the metadata of the Bento to be built, including the Service, Python packages, and models. We recommend you create a Virtual Environment for dependency isolation. For example, run the following command to activate `myenv`: ```bash python -m venv venv source venv/bin/activate ``` Install the required dependencies: ```bash pip install -r requirements.txt ``` If you haven’t previously downloaded models from Hugging Face using the command line, you must log in first: ```bash pip install -U huggingface_hub huggingface-cli login ``` ## Downloading the model to the BentoML Model Store As mentioned above, you need to download all the models used by each DeepFloyd IF stage. Once you have set up the environment, run the following command to download models to your local Model store. The process may take some time. ```bash python import_models.py ``` Once the downloads are complete, view the models in the Model store. ```bash $ bentoml models list Tag Module Size Creation Time sd-upscaler:bb2ckpa3uoypynry bentoml.diffusers 16.29 GiB 2023-07-06 10:15:53 if-stage2:v1.0 bentoml.diffusers 13.63 GiB 2023-07-06 09:55:49 if-stage1:v1.0 bentoml.diffusers 19.33 GiB 2023-07-06 09:37:59 ``` ## Starting a BentoML Service You can directly run the BentoML HTTP server with a web UI powered by Gradio using the `start-server.py` file, which is the entry point of this application. It provides various options for customizing the execution and managing GPU allocation among different Stages. You may use different commands depending on your GPU setup: - For a GPU with over 40GB VRAM, run all models on the same GPU. ```bash python start-server.py ``` - For two Tesla T4 with 15GB VRAM each, assign the Stage 1 model to the first GPU, and the Stage 2 and Stage 3 models to the second GPU. ```bash python start-server.py --stage1-gpu=0 --stage2-gpu=1 --stage3-gpu=1 ``` - For one Tesla T4 with 15GB VRAM and two additional GPUs with smaller VRAM size, assign the Stage 1 model to T4, and Stage 2 and Stage 3 models to the second and third GPUs respectively. ```bash python start-server.py --stage1-gpu=0 --stage2-gpu=1 --stage3-gpu=2 ``` To see all customizable options (like the server’s port), run: ```bash python start-server.py --help ``` ## Testing the server Once the server starts, you can visit the web UI at http://localhost:7860. The BentoML API endpoint is also accessible at http://localhost:3000. Here is an example of a prompt and a negative prompt. Prompt: > orange and black, head shot of a woman standing under street lights, dark theme, Frank Miller, cinema, ultra realistic, ambiance, insanely detailed and intricate, hyper realistic, 8k resolution, photorealistic, highly textured, intricate details Negative prompt: > tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy Result:  ## Building and serving a Bento Now that you have successfully run DeepFloyd IF locally, you can package it into a Bento by running the following command in the project directory. ```bash $ bentoml build Converting 'IF-stage1' to lowercase: 'if-stage1'. Converting 'IF-stage2' to lowercase: 'if-stage2'. Converting DeepFloyd-IF to lowercase: deepfloyd-if. Building BentoML service "deepfloyd-if:6ufnybq3vwszgnry" from build context "/Users/xxx/Documents/github/IF-multi-GPUs-demo". Packing model "sd-upscaler:bb2ckpa3uoypynry" Packing model "if-stage1:v1.0" Packing model "if-stage2:v1.0" Locking PyPI package versions. ██████╗░███████╗███╗░░██╗████████╗░█████╗░███╗░░░███╗██╗░░░░░ ██╔══██╗██╔════╝████╗░██║╚══██╔══╝██╔══██╗████╗░████║██║░░░░░ ██████╦╝█████╗░░██╔██╗██║░░░██║░░░██║░░██║██╔████╔██║██║░░░░░ ██╔══██╗██╔══╝░░██║╚████║░░░██║░░░██║░░██║██║╚██╔╝██║██║░░░░░ ██████╦╝███████╗██║░╚███║░░░██║░░░╚█████╔╝██║░╚═╝░██║███████╗ ╚═════╝░╚══════╝╚═╝░░╚══╝░░░╚═╝░░░░╚════╝░╚═╝░░░░░╚═╝╚══════╝ Successfully built Bento(tag="deepfloyd-if:6ufnybq3vwszgnry"). ``` View the Bento in the local Bento Store. ```bash $ bentoml list Tag Size Creation Time deepfloyd-if:6ufnybq3vwszgnry 49.25 GiB 2023-07-06 11:34:52 ``` The Bento is now ready for serving in production. ```bash bentoml serve deepfloyd-if:6ufnybq3vwszgnry ``` To deploy the Bento in a more cloud-native way, generate a Docker image by running the following command: ```bash bentoml containerize deepfloyd-if:6ufnybq3vwszgnry ``` You can then deploy the model on Kubernetes. ## What’s next? [BentoML](https://github.com/bentoml/BentoML) provides a powerful and straightforward way to deploy Hugging Face models for production. With its support for a wide range of ML frameworks and easy-to-use APIs, you can ship your model to production in no time. Whether you’re working with the DeepFloyd IF model or any other model on the Hugging Face Model Hub, BentoML can help you bring your models to life. Check out the following resources to see what you can build with BentoML and its ecosystem tools, and stay tuned for more information about BentoML. - [OpenLLM](https://github.com/bentoml/OpenLLM) - An open platform for operating Large Language Models (LLMs) in production. - [StableDiffusion](https://github.com/bentoml/stable-diffusion-bentoml) - Create your own text-to-image service with any diffusion models. - [Transformer NLP Service](https://github.com/bentoml/transformers-nlp-service) - Online inference API for Transformer NLP models. - Join the [BentoML community on Slack](https://l.bentoml.com/join-slack). - Follow us on [Twitter](https://twitter.com/bentomlai) and [LinkedIn](https://www.linkedin.com/company/bentoml/).
|
Optimizing Bark using 🤗 Transformers
|
ylacombe
|
August 9, 2023
|
optimizing-bark
|
text-to-speech, optimization, benchmark, bark
|
https://huggingface.co/blog/optimizing-bark
|
# Optimizing a Text-To-Speech model using 🤗 Transformers <a target="_blank" href="https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg"/> </a> 🤗 Transformers provides many of the latest state-of-the-art (SoTA) models across domains and tasks. To get the best performance from these models, they need to be optimized for inference speed and memory usage. The 🤗 Hugging Face ecosystem offers precisely such ready & easy to use optimization tools that can be applied across the board to all the models in the library. This makes it easy to **reduce memory footprint** and **improve inference** with just a few extra lines of code. In this hands-on tutorial, I'll demonstrate how you can optimize [Bark](https://huggingface.co/docs/transformers/main/en/model_doc/bark#overview), a Text-To-Speech (TTS) model supported by 🤗 Transformers, based on three simple optimizations. These optimizations rely solely on the [Transformers](https://github.com/huggingface/transformers), [Optimum](https://github.com/huggingface/optimum) and [Accelerate](https://github.com/huggingface/accelerate) libraries from the 🤗 ecosystem. This tutorial is also a demonstration of how one can benchmark a non-optimized model and its varying optimizations. For a more streamlined version of the tutorial with fewer explanations but all the code, see the accompanying [Google Colab](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb). This blog post is organized as follows: ## Table of Contents 1. A [reminder](#bark-architecture) of Bark architecture 2. An [overview](#optimization-techniques) of different optimization techniques and their advantages 3. A [presentation](#benchmark-results) of benchmark results # Bark Architecture **Bark** is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark). It is capable of generating a wide range of audio outputs, including speech, music, background noise, and simple sound effects. Additionally, it can produce nonverbal communication sounds such as laughter, sighs, and sobs. Bark has been available in 🤗 Transformers since v4.31.0 onwards! You can play around with Bark and discover it's abilities [here](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Bark_HuggingFace_Demo.ipynb). Bark is made of 4 main models: - `BarkSemanticModel` (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text. - `BarkCoarseModel` (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the `BarkSemanticModel` model. It aims at predicting the first two audio codebooks necessary for EnCodec. - `BarkFineModel` (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings. - having predicted all the codebook channels from the [`EncodecModel`](https://huggingface.co/docs/transformers/v4.31.0/model_doc/encodec), Bark uses it to decode the output audio array. At the time of writing, two Bark checkpoints are available, a [smaller](https://huggingface.co/suno/bark-small) and a [larger](https://huggingface.co/suno/bark) version. ## Load the Model and its Processor The pre-trained Bark small and large checkpoints can be loaded from the [pre-trained weights](https://huggingface.co/suno/bark) on the Hugging Face Hub. You can change the repo-id with the checkpoint size that you wish to use. We'll default to the small checkpoint, to keep it fast. But you can try the large checkpoint by using `"suno/bark"` instead of `"suno/bark-small"`. ```python from transformers import BarkModel model = BarkModel.from_pretrained("suno/bark-small") ``` Place the model to an accelerator device to get the most of the optimization techniques: ```python import torch device = "cuda:0" if torch.cuda.is_available() else "cpu" model = model.to(device) ``` Load the processor, which will take care of tokenization and optional speaker embeddings. ```python from transformers import AutoProcessor processor = AutoProcessor.from_pretrained("suno/bark-small") ``` # Optimization techniques In this section, we'll explore how to use off-the-shelf features from the 🤗 Optimum and 🤗 Accelerate libraries to optimize the Bark model, with minimal changes to the code. ## Some set-ups Let's prepare the inputs and define a function to measure the latency and GPU memory footprint of the Bark generation method. ```python text_prompt = "Let's try generating speech, with Bark, a text-to-speech model" inputs = processor(text_prompt).to(device) ``` Measuring the latency and GPU memory footprint requires the use of specific CUDA methods. We define a utility function that measures both the latency and GPU memory footprint of the model at inference time. To ensure we get an accurate picture of these metrics, we average over a specified number of runs `nb_loops`: ```python import torch from transformers import set_seed def measure_latency_and_memory_use(model, inputs, nb_loops = 5): # define Events that measure start and end of the generate pass start_event = torch.cuda.Event(enable_timing=True) end_event = torch.cuda.Event(enable_timing=True) # reset cuda memory stats and empty cache torch.cuda.reset_peak_memory_stats(device) torch.cuda.empty_cache() torch.cuda.synchronize() # get the start time start_event.record() # actually generate for _ in range(nb_loops): # set seed for reproducibility set_seed(0) output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8) # get the end time end_event.record() torch.cuda.synchronize() # measure memory footprint and elapsed time max_memory = torch.cuda.max_memory_allocated(device) elapsed_time = start_event.elapsed_time(end_event) * 1.0e-3 print('Execution time:', elapsed_time/nb_loops, 'seconds') print('Max memory footprint', max_memory*1e-9, ' GB') return output ``` ## Base case Before incorporating any optimizations, let's measure the performance of the baseline model and listen to a generated example. We'll benchmark the model over five iterations and report an average of the metrics: ```python with torch.inference_mode(): speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5) ``` **Output:** ``` Execution time: 9.3841625 seconds Max memory footprint 1.914612224 GB ``` Now, listen to the output: ```python from IPython.display import Audio # now, listen to the output sampling_rate = model.generation_config.sample_rate Audio(speech_output[0].cpu().numpy(), rate=sampling_rate) ``` The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav)): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav" type="audio/wav"> Your browser does not support the audio element. </audio> ### Important note: Here, the number of iterations is actually quite low. To accurately measure and compare results, one should increase it to at least 100. One of the main reasons for the importance of increasing `nb_loops` is that the speech lengths generated vary greatly between different iterations, even with a fixed input. One consequence of this is that the latency measured by `measure_latency_and_memory_use` may not actually reflect the actual performance of optimization techniques! The benchmark at the end of the blog post reports the results averaged over 100 iterations, which gives a true indication of the performance of the model. ## 1. 🤗 Better Transformer Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. This means that certain model operations will be better optimized on the GPU and that the model will ultimately be faster. To be more specific, most models supported by 🤗 Transformers rely on attention, which allows them to selectively focus on certain parts of the input when generating output. This enables the models to effectively handle long-range dependencies and capture complex contextual relationships in the data. The naive attention technique can be greatly optimized via a technique called [Flash Attention](https://arxiv.org/abs/2205.14135), proposed by the authors Dao et. al. in 2022. Flash Attention is a faster and more efficient algorithm for attention computations that combines traditional methods (such as tiling and recomputation) to minimize memory usage and increase speed. Unlike previous algorithms, Flash Attention reduces memory usage from quadratic to linear in sequence length, making it particularly useful for applications where memory efficiency is important. Turns out that Flash Attention is supported by 🤗 Better Transformer out of the box! It requires one line of code to export the model to 🤗 Better Transformer and enable Flash Attention: ```python model = model.to_bettertransformer() with torch.inference_mode(): speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5) ``` **Output:** ``` Execution time: 5.43284375 seconds Max memory footprint 1.9151841280000002 GB ``` The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav)): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav" type="audio/wav"> Your browser does not support the audio element. </audio> **What does it bring to the table?** There's no performance degradation, which means you can get exactly the same result as without this function, while gaining 20% to 30% in speed! Want to know more? See this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/). ## 2. Half-precision Most AI models typically use a storage format called single-precision floating point, i.e. `fp32`. What does it mean in practice? Each number is stored using 32 bits. You can thus choose to encode the numbers using 16 bits, with what is called half-precision floating point, i.e. `fp16`, and use half as much storage as before! More than that, you also get inference speed-up! Of course, it also comes with small performance degradation since operations inside the model won't be as precise as using `fp32`. You can load a 🤗 Transformers model with half-precision by simpling adding `torch_dtype=torch.float16` to the `BarkModel.from_pretrained(...)` line! In other words: ```python model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device) with torch.inference_mode(): speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5) ``` **Output:** ``` Execution time: 7.00045390625 seconds Max memory footprint 2.7436124160000004 GB ``` The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav)): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav" type="audio/wav"> Your browser does not support the audio element. </audio> **What does it bring to the table?** With a slight degradation in performance, you benefit from a memory footprint reduced by 50% and a speed gain of 5%. ## 3. CPU offload As mentioned in the first section of this booklet, Bark comprises 4 sub-models, which are called up sequentially during audio generation. **In other words, while one sub-model is in use, the other sub-models are idle.** Why is this a problem? GPU memory is precious in AI, because it's where operations are fastest, and it's often a bottleneck. A simple solution is to unload sub-models from the GPU when inactive. This operation is called CPU offload. **Good news:** CPU offload for Bark was integrated into 🤗 Transformers and you can use it with only one line of code. You only need to make sure 🤗 Accelerate is installed! ```python model = BarkModel.from_pretrained("suno/bark-small") # Enable CPU offload model.enable_cpu_offload() with torch.inference_mode(): speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5) ``` **Output:** ``` Execution time: 8.97633828125 seconds Max memory footprint 1.3231160320000002 GB ``` The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav" type="audio/wav"> Your browser does not support the audio element. </audio> **What does it bring to the table?** With a slight degradation in speed (10%), you benefit from a huge memory footprint reduction (60% 🤯). With this feature enabled, `bark-large` footprint is now only 2GB instead of 5GB. That's the same memory footprint as `bark-small`! Want more? With `fp16` enabled, it's even down to 1GB. We'll see this in practice in the next section! ## 4. Combine Let's bring it all together. The good news is that you can combine optimization techniques, which means you can use CPU offload, as well as half-precision and 🤗 Better Transformer! ```python # load in fp16 model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device) # convert to bettertransformer model = BetterTransformer.transform(model, keep_original_model=False) # enable CPU offload model.enable_cpu_offload() with torch.inference_mode(): speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5) ``` **Output:** ``` Execution time: 7.4496484375000005 seconds Max memory footprint 0.46871091200000004 GB ``` The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_optimized.wav" type="audio/wav"> Your browser does not support the audio element. </audio> **What does it bring to the table?** Ultimately, you get a 23% speed-up and a huge 80% memory saving! ## Using batching Want more? Altogether, the 3 optimization techniques bring even better results when batching. Batching means combining operations for multiple samples to bring the overall time spent generating the samples lower than generating sample per sample. Here is a quick example of how you can use it: ```python text_prompt = [ "Let's try generating speech, with Bark, a text-to-speech model", "Wow, batching is so great!", "I love Hugging Face, it's so cool."] inputs = processor(text_prompt).to(device) with torch.inference_mode(): # samples are generated all at once speech_output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8) ``` The output sounds like this (download [first](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav), [second](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav), and [last](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav) audio): <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav" type="audio/wav"> Your browser does not support the audio element. </audio> <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav" type="audio/wav"> Your browser does not support the audio element. </audio> <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav" type="audio/wav"> Your browser does not support the audio element. </audio> # Benchmark results As mentioned above, the little experiment we've carried out is an exercise in thinking and needs to be extended for a better measure of performance. One also needs to warm up the GPU with a few blank iterations before properly measuring performance. Here are the results of a 100-sample benchmark extending the measurements, **using the large version of Bark**. The benchmark was run on an NVIDIA TITAN RTX 24GB with a maximum of 256 new tokens. ## How to read the results? ### Latency It measures the duration of a single call to the generation method, regardless of batch size. In other words, it's equal to \\(\frac{elapsedTime}{nbLoops}\\). **A lower latency is preferred.** ### Maximum memory footprint It measures the maximum memory used during a single call to the generation method. **A lower footprint is preferred.** ### Throughput It measures the number of samples generated per second. This time, the batch size is taken into account. In other words, it's equal to \\(\frac{nbLoops*batchSize}{elapsedTime}\\). **A higher throughput is preferred.** ## No batching Here are the results with `batch_size=1`. | Absolute values | Latency | Memory | |-----------------------------|---------|---------| | no optimization | 10.48 | 5025.0M | | bettertransformer only | 7.70 | 4974.3M | | offload + bettertransformer | 8.90 | 2040.7M | | offload + bettertransformer + fp16 | 8.10 | 1010.4M | | Relative value | Latency | Memory | |-----------------------------|---------|--------| | no optimization | 0% | 0% | | bettertransformer only | -27% | -1% | | offload + bettertransformer | -15% | -59% | | offload + bettertransformer + fp16 | -23% | -80% | ### Comment As expected, CPU offload greatly reduces memory footprint while slightly increasing latency. However, combined with bettertransformer and `fp16`, we get the best of both worlds, huge latency and memory decrease! ## Batch size set to 8 And here are the benchmark results but with `batch_size=8` and throughput measurement. Note that since `bettertransformer` is a free optimization because it does exactly the same operation and has the same memory footprint as the non-optimized model while being faster, the benchmark was run with **this optimization enabled by default**. | absolute values | Latency | Memory | Throghput | |-------------------------------|---------|---------|-----------| | base case (bettertransformer) | 19.26 | 8329.2M | 0.42 | | + fp16 | 10.32 | 4198.8M | 0.78 | | + offload | 20.46 | 5172.1M | 0.39 | | + offload + fp16 | 10.91 | 2619.5M | 0.73 | | Relative value | Latency | Memory | Throughput | |-------------------------------|---------|--------|------------| | + base case (bettertransformer) | 0% | 0% | 0% | | + fp16 | -46% | -50% | 87% | | + offload | 6% | -38% | -6% | | + offload + fp16 | -43% | -69% | 77% | ### Comment This is where we can see the potential of combining all three optimization features! The impact of `fp16` on latency is less marked with `batch_size = 1`, but here it is of enormous interest as it can reduce latency by almost half, and almost double throughput! # Concluding remarks This blog post showcased a few simple optimization tricks bundled in the 🤗 ecosystem. Using anyone of these techniques, or a combination of all three, can greatly improve Bark inference speed and memory footprint. * You can use the large version of Bark without any performance degradation and a footprint of just 2GB instead of 5GB, 15% faster, **using 🤗 Better Transformer and CPU offload**. * Do you prefer high throughput? **Batch by 8 with 🤗 Better Transformer and half-precision**. * You can get the best of both worlds by using **fp16, 🤗 Better Transformer and CPU offload**!
|
Hugging Face Platform on the AWS Marketplace: Pay with your AWS Account
|
philschmid
|
August 10, 2023
|
aws-marketplace
|
guide, announcement, partnerships, aws
|
https://huggingface.co/blog/aws-marketplace
|
# Hugging Face Platform on the AWS Marketplace: Pay with your AWS Account The [Hugging Face Platform](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) has landed on the AWS Marketplace. Starting today, you can subscribe to the Hugging Face Platform through AWS Marketplace to pay for your Hugging Face usage directly with your AWS account. This new integrated billing method makes it easy to manage payment for usage of all our managed services by all members of your organization, including Inference Endpoints, Spaces Hardware Upgrades, and AutoTrain to easily train, test and deploy the most popular machine learning models like Llama 2, StarCoder, or BERT. By making [Hugging Face available on AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2), we are removing barriers to adopting AI and making it easier for companies to leverage large language models. Now with just a few clicks, AWS customers can subscribe and connect their Hugging Face Account with their AWS account. By subscribing through AWS Marketplace, Hugging Face organization usage charges for services like Inference Endpoints will automatically appear on your AWS bill, instead of being charged by Hugging Face to the credit card on file for your organization. We are excited about this launch as it will bring our technology to more developers who rely on AWS, and make it easier for businesses to consume Hugging Face services. ## Getting Started Before you can connect your AWS Account with your Hugging Face account, you need to fulfill the following prerequisites: - Have access to an active AWS account with access to subscribe to products on the AWS Marketplace. - Create a [Hugging Face organization account](https://huggingface.co/organizations/new) with a registered and confirmed email. (You cannot connect user accounts) - Be a member of the Hugging Face organization you want to connect with the [“admin” role](https://huggingface.co/docs/hub/organizations-security). - Logged into the Hugging Face Platform. Once you meet these requirements, you can proceed with connecting your AWS and Hugging Face accounts. ### 1. Subscribe to the Hugging Face Platform The first step is to go to the [AWS Marketplace offering](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and subscribe to the Hugging Face Platform. There you open the [offer](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and then click on “View purchase options” at the top right screen.  You are now on the “subscribe” page, where you can see the summary of pricing and where you can subscribe. To subscribe to the offer, click “Subscribe”.  After you successfully subscribe, you should see a green banner at the top with a button “Set up your account”. You need to click on “Set up your account” to connect your Hugging Face Account with your AWS account.  After clicking the button, you will be redirected to the Hugging Face Platform, where you can select the Hugging Face organization account you want to link to your AWS account. After selecting your account, click “Submit”  After clicking "Submit", you will be redirected to the Billings settings of the Hugging Face organization, where you can see the current state of your subscription, which should be `subscribe-pending`.  After a few minutes you should receive 2 emails: 1 from AWS confirming your subscription, and 1 from Hugging Face, which should look like the image below:  If you have received this, your AWS Account and Hugging Face organization account are now successfully connected! To confirm it, you can open the Billing settings for [your organization account](https://huggingface.co/settings/organizations), where you should now see a `subscribe-success` status.  Congratulations! 🥳 All members of your organization can now start using Hugging Face premium services with billing directly managed by your AWS account: - [Inference Endpoints Deploy models in minutes](https://ui.endpoints.huggingface.co/) - [AutoTrain creates ML models without code](https://huggingface.co/autotrain) - [Enterprise Hub accelerates your AI roadmap](https://huggingface.co/enterprise) - [Spaces Hardware upgrades](https://huggingface.co/docs/hub/spaces-gpus) Pricing for Hugging Face Platform through the AWS marketplace offer is identical to the [public Hugging Face pricing](https://huggingface.co/pricing), but will be billed through your AWS Account. You can monitor the usage and billing of your organization at any time within the Billing section of your [organization settings](https://huggingface.co/settings/organizations). --- Thanks for reading! If you have any questions, feel free to contact us at [[email protected]](mailto:[email protected]).
|
Introducing IDEFICS: An Open Reproduction of State-of-the-art Visual Language Model
|
VictorSanh
|
August 22, 2023
|
idefics
|
research, nlp, cv
|
https://huggingface.co/blog/idefics
|
# Introducing IDEFICS: An Open Reproduction of State-of-the-Art Visual Language Model We are excited to release IDEFICS (**I**mage-aware **D**ecoder **E**nhanced à la **F**lamingo with **I**nterleaved **C**ross-attention**S**), an open-access visual language model. IDEFICS is based on [Flamingo](https://huggingface.co/papers/2204.14198), a state-of-the-art visual language model initially developed by DeepMind, which has not been released publicly. Similarly to GPT-4, the model accepts arbitrary sequences of image and text inputs and produces text outputs. IDEFICS is built solely on publicly available data and models (LLaMA v1 and OpenCLIP) and comes in two variants—the base version and the instructed version. Each variant is available at the 9 billion and 80 billion parameter sizes. The development of state-of-the-art AI models should be more transparent. Our goal with IDEFICS is to reproduce and provide the AI community with systems that match the capabilities of large proprietary models like Flamingo. As such, we took important steps contributing to bringing transparency to these AI systems: we used only publicly available data, we provided tooling to explore training datasets, we shared [technical lessons and mistakes](https://github.com/huggingface/m4-logs/blob/master/memos/README.md) of building such artifacts and assessed the model’s harmfulness by adversarially prompting it before releasing it. We are hopeful that IDEFICS will serve as a solid foundation for more open research in multimodal AI systems, alongside models like [OpenFlamingo](https://huggingface.co/openflamingo)-another open reproduction of Flamingo at the 9 billion parameter scale. Try out the [demo](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground) and the [models](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) on the Hub! <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/woodstock_ai.png" width="600" alt="Screenshot of IDEFICS generation for HF Woodstock of AI"/> </p> ## What is IDEFICS? IDEFICS is an 80 billion parameters multimodal model that accepts sequences of images and texts as input and generates coherent text as output. It can answer questions about images, describe visual content, create stories grounded in multiple images, etc. IDEFICS is an open-access reproduction of Flamingo and is comparable in performance with the original closed-source model across various image-text understanding benchmarks. It comes in two variants - 80 billion parameters and 9 billion parameters. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/Figure_Evals_IDEFICS.png" width="600" alt="Plot comparing the performance of Flamingo, OpenFlamingo and IDEFICS"/> </p> We also provide fine-tuned versions [idefics-80B-instruct](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) and [idefics-9B-instruct](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct) adapted for conversational use cases. ## Training Data IDEFICS was trained on a mixture of openly available datasets: Wikipedia, Public Multimodal Dataset, and LAION, as well as a new 115B token dataset called [OBELICS](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) that we created. OBELICS consists of 141 million interleaved image-text documents scraped from the web and contains 353 million images. We provide an [interactive visualization](https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f) of OBELICS that allows exploring the content of the dataset with [Nomic AI](https://home.nomic.ai/). <p align="center"> <a href="https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/obelics_nomic_map.png" width="600" alt="Interactive visualization of OBELICS"/> </a> </p> The details of IDEFICS' architecture, training methodology, and evaluations, as well as information about the dataset, are available in the [model card](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) and our [research paper](https://huggingface.co/papers/2306.16527). Additionally, we have documented [technical insights and learnings](https://github.com/huggingface/m4-logs/blob/master/memos/README.md) from the model's training, offering valuable perspective on IDEFICS' development. ## Ethical evaluation At the outset of this project, through a set of discussions, we developed an [ethical charter](https://huggingface.co/blog/ethical-charter-multimodal) that would help steer decisions made during the project. This charter sets out values, including being self-critical, transparent, and fair which we have sought to pursue in how we approached the project and the release of the models. As part of the release process, we internally evaluated the model for potential biases by adversarially prompting the model with images and text that might elicit responses we do not want from the model (a process known as red teaming). Please try out IDEFICS with the [demo](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground), check out the corresponding [model cards](https://huggingface.co/HuggingFaceM4/idefics-80b) and [dataset card](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) and let us know your feedback using the community tab! We are committed to improving these models and making large multimodal AI models accessible to the machine learning community. ## License The model is built on top of two pre-trained models: [laion/CLIP-ViT-H-14-laion2B-s32B-b79K](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K) and [huggyllama/llama-65b](https://huggingface.co/huggyllama/llama-65b). The first was released under an MIT license, while the second was released under a specific non-commercial license focused on research purposes. As such, users should comply with that license by applying directly to [Meta's form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform). The two pre-trained models are connected to each other with newly initialized parameters that we train. These are not based on any of the two base frozen models forming the composite model. We release the additional weights we trained under an MIT license. ## Getting Started with IDEFICS IDEFICS models are available on the Hugging Face Hub and supported in the last `transformers` version. Here is a code sample to try it out: ```python import torch from transformers import IdeficsForVisionText2Text, AutoProcessor device = "cuda" if torch.cuda.is_available() else "cpu" checkpoint = "HuggingFaceM4/idefics-9b-instruct" model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device) processor = AutoProcessor.from_pretrained(checkpoint) # We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images. prompts = [ [ "User: What is in this image?", "https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG", "<end_of_utterance>", "\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>", "\nUser:", "https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052", "And who is that?<end_of_utterance>", "\nAssistant:", ], ] # --batched mode inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device) # --single sample mode # inputs = processor(prompts[0], return_tensors="pt").to(device) # Generation args exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True) for i, t in enumerate(generated_text): print(f"{i}:\n{t}\n") ```
|
Introducing SafeCoder
|
jeffboudier
|
August 22, 2023
|
safecoder
|
announcement, partnerships, vmware, bigcode
|
https://huggingface.co/blog/safecoder
|
# Introducing SafeCoder Today we are excited to announce SafeCoder - a code assistant solution built for the enterprise. The goal of SafeCoder is to unlock software development productivity for the enterprise, with a fully compliant and self-hosted pair programmer. In marketing speak: “your own on-prem GitHub copilot”. Before we dive deeper, here’s what you need to know: - SafeCoder is not a model, but a complete end-to-end commercial solution - SafeCoder is built with security and privacy as core principles - code never leaves the VPC during training or inference - SafeCoder is designed for self-hosting by the customer on their own infrastructure - SafeCoder is designed for customers to own their own Code Large Language Model 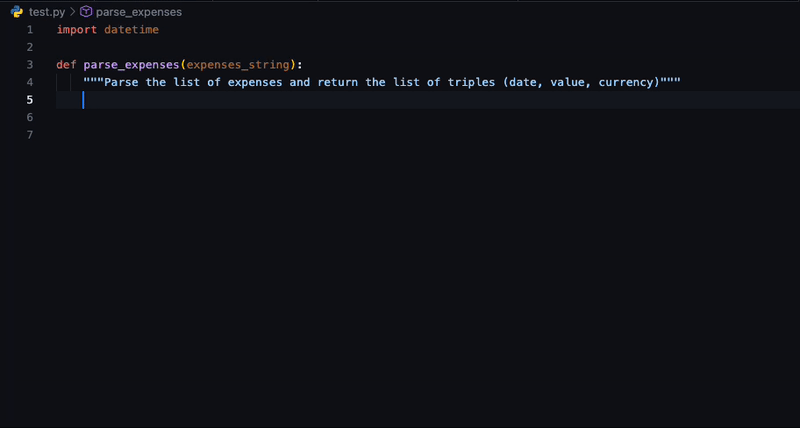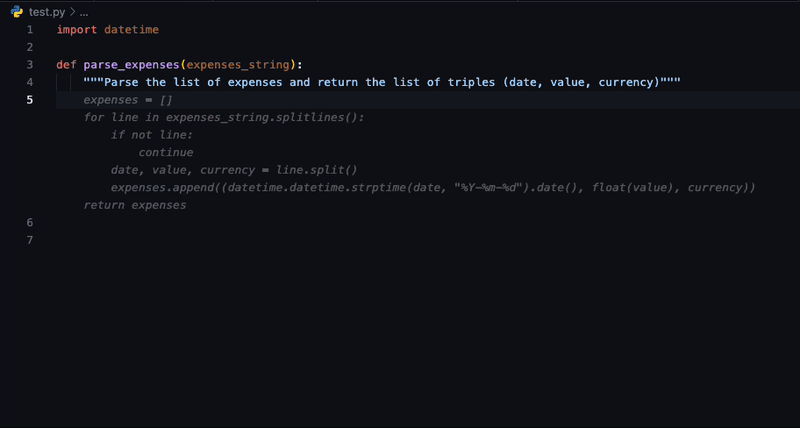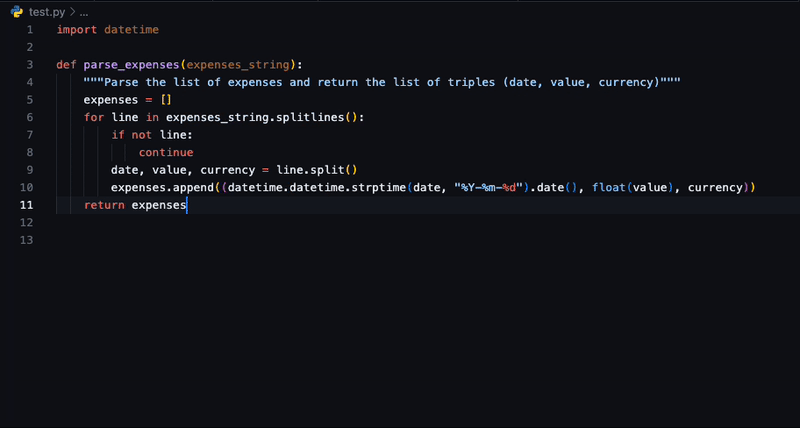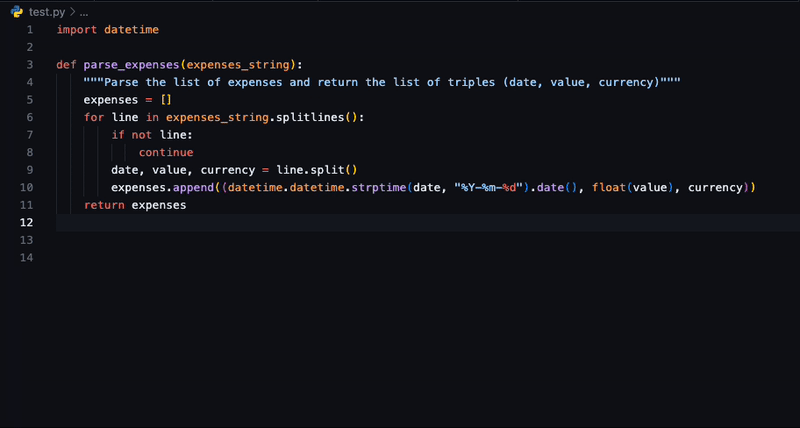 ## Why SafeCoder? Code assistant solutions built upon LLMs, such as GitHub Copilot, are delivering strong [productivity boosts](https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/). For the enterprise, the ability to tune Code LLMs on the company code base to create proprietary Code LLMs improves reliability and relevance of completions to create another level of productivity boost. For instance, Google internal LLM code assistant reports a completion [acceptance rate of 25-34%](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html) by being trained on an internal code base. However, relying on closed-source Code LLMs to create internal code assistants exposes companies to compliance and security issues. First during training, as fine-tuning a closed-source Code LLM on an internal codebase requires exposing this codebase to a third party. And then during inference, as fine-tuned Code LLMs are likely to “leak” code from their training dataset during inference. To meet compliance requirements, enterprises need to deploy fine-tuned Code LLMs within their own infrastructure - which is not possible with closed source LLMs. With SafeCoder, Hugging Face will help customers build their own Code LLMs, fine-tuned on their proprietary codebase, using state of the art open models and libraries, without sharing their code with Hugging Face or any other third party. With SafeCoder, Hugging Face delivers a containerized, hardware-accelerated Code LLM inference solution, to be deployed by the customer directly within the Customer secure infrastructure, without code inputs and completions leaving their secure IT environment. ## From StarCoder to SafeCoder At the core of the SafeCoder solution is the [StarCoder](https://huggingface.co/bigcode/starcoder) family of Code LLMs, created by the [BigCode](https://huggingface.co/bigcode) project, a collaboration between Hugging Face, ServiceNow and the open source community. The StarCoder models offer unique characteristics ideally suited to enterprise self-hosted solution: - State of the art code completion results - see benchmarks in the [paper](https://huggingface.co/papers/2305.06161) and [multilingual code evaluation leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals) - Designed for inference performance: a 15B parameters model with code optimizations, Multi-Query Attention for reduced memory footprint, and Flash Attention to scale to 8,192 tokens context. - Trained on [the Stack](https://huggingface.co/datasets/bigcode/the-stack), an ethically sourced, open source code dataset containing only commercially permissible licensed code, with a developer opt-out mechanism from the get-go, refined through intensive PII removal and deduplication efforts. Note: While StarCoder is the inspiration and model powering the initial version of SafeCoder, an important benefit of building a LLM solution upon open source models is that it can adapt to the latest and greatest open source models available. In the future, SafeCoder may offer other similarly commercially permissible open source models built upon ethically sourced and transparent datasets as the base LLM available for fine-tuning. ## Privacy and Security as a Core Principle For any company, the internal codebase is some of its most important and valuable intellectual property. A core principle of SafeCoder is that the customer internal codebase will never be accessible to any third party (including Hugging Face) during training or inference. In the initial set up phase of SafeCoder, the Hugging Face team provides containers, scripts and examples to work hand in hand with the customer to select, extract, prepare, duplicate, deidentify internal codebase data into a training dataset to be used in a Hugging Face provided training container configured to the hardware infrastructure available to the customer. In the deployment phase of SafeCoder, the customer deploys containers provided by Hugging Face on their own infrastructure to expose internal private endpoints within their VPC. These containers are configured to the exact hardware configuration available to the customer, including NVIDIA GPUs, AMD Instinct GPUs, Intel Xeon CPUs, AWS Inferentia2 or Habana Gaudi accelerators. ## Compliance as a Core Principle As the regulation framework around machine learning models and datasets is still being written across the world, global companies need to make sure the solutions they use minimize legal risks. Data sources, data governance, management of copyrighted data are just a few of the most important compliance areas to consider. BigScience, the older cousin and inspiration for BigCode, addressed these areas in working groups before they were broadly recognized by the draft AI EU Act, and as a result was [graded as most compliant among Foundational Model Providers in a Stanford CRFM study](https://crfm.stanford.edu/2023/06/15/eu-ai-act.html). BigCode expanded upon this work by implementing novel techniques for the code domain and building The Stack with compliance as a core principle, such as commercially permissible license filtering, consent mechanisms (developers can [easily find out if their code is present and request to be opted out](https://huggingface.co/spaces/bigcode/in-the-stack) of the dataset), and extensive documentation and tools to inspect the [source data](https://huggingface.co/datasets/bigcode/the-stack-metadata), and dataset improvements (such as [deduplication](https://huggingface.co/blog/dedup) and [PII removal](https://huggingface.co/bigcode/starpii)). All these efforts translate into legal risk minimization for users of the StarCoder models, and customers of SafeCoder. And for SafeCoder users, these efforts translate into compliance features: when software developers get code completions these suggestions are checked against The Stack, so users know if the suggested code matches existing code in the source dataset, and what the license is. Customers can specify which licenses are preferred and surface those preferences to their users. ## How does it work? SafeCoder is a complete commercial solution, including service, software and support. ### Training your own SafeCoder model StarCoder was trained in more than 80 programming languages and offers state of the art performance on [multiple benchmarks](https://huggingface.co/spaces/bigcode/multilingual-code-evals). To offer better code suggestions specifically for a SafeCoder customer, we start the engagement with an optional training phase, where the Hugging Face team works directly with the customer team to guide them through the steps to prepare and build a training code dataset, and to create their own code generation model through fine-tuning, without ever exposing their codebase to third parties or the internet. The end result is a model that is adapted to the code languages, standards and practices of the customer. Through this process, SafeCoder customers learn the process and build a pipeline for creating and updating their own models, ensuring no vendor lock-in, and keeping control of their AI capabilities. ### Deploying SafeCoder During the setup phase, SafeCoder customers and Hugging Face design and provision the optimal infrastructure to support the required concurrency to offer a great developer experience. Hugging Face then builds SafeCoder inference containers that are hardware-accelerated and optimized for throughput, to be deployed by the customer on their own infrastructure. SafeCoder inference supports various hardware to give customers a wide range of options: NVIDIA Ampere GPUs, AMD Instinct GPUs, Habana Gaudi2, AWS Inferentia 2, Intel Xeon Sapphire Rapids CPUs and more. ### Using SafeCoder Once SafeCoder is deployed and its endpoints are live within the customer VPC, developers can install compatible SafeCoder IDE plugins to get code suggestions as they work. Today, SafeCoder supports popular IDEs, including [VSCode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode), IntelliJ and with more plugins coming from our partners. ## How can I get SafeCoder? Today, we are announcing SafeCoder in collaboration with VMware at the VMware Explore conference and making SafeCoder available to VMware enterprise customers. Working with VMware helps ensure the deployment of SafeCoder on customers’ VMware Cloud infrastructure is successful – whichever cloud, on-premises or hybrid infrastructure scenario is preferred by the customer. In addition to utilizing SafeCoder, VMware has published a [reference architecture](https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/docs/vmware-baseline-reference-architecture-for-generative-ai.pdf) with code samples to enable the fastest possible time-to-value when deploying and operating SafeCoder on VMware infrastructure. VMware’s Private AI Reference Architecture makes it easy for organizations to quickly leverage popular open source projects such as ray and kubeflow to deploy AI services adjacent to their private datasets, while working with Hugging Face to ensure that organizations maintain the flexibility to take advantage of the latest and greatest in open-source models. This is all without tradeoffs in total cost of ownership or performance. “Our collaboration with Hugging Face around SafeCoder fully aligns to VMware’s goal of enabling customer choice of solutions while maintaining privacy and control of their business data. In fact, we have been running SafeCoder internally for months and have seen excellent results. Best of all, our collaboration with Hugging Face is just getting started, and I’m excited to take our solution to our hundreds of thousands of customers worldwide,” says Chris Wolf, Vice President of VMware AI Labs. Learn more about private AI and VMware’s differentiation in this emerging space [here](https://octo.vmware.com/vmware-private-ai-foundation/). --- If you’re interested in SafeCoder for your company, please contact us [here](mailto:[email protected]?subject=SafeCoder) - our team will contact you to discuss your requirements!
|
Making LLMs lighter with AutoGPTQ and transformers
|
marcsun13
|
August 23, 2023
|
gptq-integration
|
llm, optimization, quantization
|
https://huggingface.co/blog/gptq-integration
|
# Making LLMs lighter with AutoGPTQ and transformers Large language models have demonstrated remarkable capabilities in understanding and generating human-like text, revolutionizing applications across various domains. However, the demands they place on consumer hardware for training and deployment have become increasingly challenging to meet. 🤗 Hugging Face's core mission is to _democratize good machine learning_, and this includes making large models as accessible as possible for everyone. In the same spirit as our [bitsandbytes collaboration](https://huggingface.co/blog/4bit-transformers-bitsandbytes), we have just integrated the [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) library in Transformers, making it possible for users to quantize and run models in 8, 4, 3, or even 2-bit precision using the GPTQ algorithm ([Frantar et al. 2023](https://arxiv.org/pdf/2210.17323.pdf)). There is negligible accuracy degradation with 4-bit quantization, with inference speed comparable to the `fp16` baseline for small batch sizes. Note that GPTQ method slightly differs from post-training quantization methods proposed by bitsandbytes as it requires to pass a calibration dataset. This integration is available both for Nvidia GPUs, and RoCm-powered AMD GPUs. ## Table of contents - [Resources](#resources) - [**A gentle summary of the GPTQ paper**](#a-gentle-summary-of-the-gptq-paper) - [AutoGPTQ library – the one-stop library for efficiently leveraging GPTQ for LLMs](#autogptq-library--the-one-stop-library-for-efficiently-leveraging-gptq-for-llms) - [Native support of GPTQ models in 🤗 Transformers](#native-support-of-gptq-models-in-🤗-transformers) - [Quantizing models **with the Optimum library**](#quantizing-models-with-the-optimum-library) - [Running GPTQ models through ***Text-Generation-Inference***](#running-gptq-models-through-text-generation-inference) - [**Fine-tune quantized models with PEFT**](#fine-tune-quantized-models-with-peft) - [Room for improvement](#room-for-improvement) * [Supported models](#supported-models) - [Conclusion and final words](#conclusion-and-final-words) - [Acknowledgements](#acknowledgements) ## Resources This blogpost and release come with several resources to get started with GPTQ quantization: - [Original Paper](https://arxiv.org/pdf/2210.17323.pdf) - [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with GPTQ method, how to do inference, and how to do fine-tuning with the quantized model. - Transformers integration [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization) - Optimum integration [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) - The Bloke [repositories](https://huggingface.co/TheBloke?sort_models=likes#models) with compatible GPTQ models. ## **A gentle summary of the GPTQ paper** Quantization methods usually belong to one of two categories: 1. Post-Training Quantization (PTQ): We quantize a pre-trained model using moderate resources, such as a calibration dataset and a few hours of computation. 2. Quantization-Aware Training (QAT): Quantization is performed before training or further fine-tuning. GPTQ falls into the PTQ category and this is particularly interesting for massive models, for which full model training or even fine-tuning can be very expensive. Specifically, GPTQ adopts a mixed int4/fp16 quantization scheme where weights are quantized as int4 while activations remain in float16. During inference, weights are dequantized on the fly and the actual compute is performed in float16. The benefits of this scheme are twofold: - Memory savings close to x4 for int4 quantization, as the dequantization happens close to the compute unit in a fused kernel, and not in the GPU global memory. - Potential speedups thanks to the time saved on data communication due to the lower bitwidth used for weights. The GPTQ paper tackles the layer-wise compression problem: Given a layer \\(l\\) with weight matrix \\(W_{l}\\) and layer input \\(X_{l}\\), we want to find a quantized version of the weight \\(\hat{W}_{l}\\) to minimize the mean squared error (MSE): \\({\hat{W}_{l}}^{*} = argmin_{\hat{W_{l}}} \|W_{l}X-\hat{W}_{l}X\|^{2}_{2}\\) Once this is solved per layer, a solution to the global problem can be obtained by combining the layer-wise solutions. In order to solve this layer-wise compression problem, the author uses the Optimal Brain Quantization framework ([Frantar et al 2022](https://arxiv.org/abs/2208.11580)). The OBQ method starts from the observation that the above equation can be written as the sum of the squared errors, over each row of \\(W_{l}\\). \\( \sum_{i=0}^{d_{row}} \|W_{l[i,:]}X-\hat{W}_{l[i,:]}X\|^{2}_{2} \\) This means that we can quantize each row independently. This is called per-channel quantization. For each row \\(W_{l[i,:]}\\), OBQ quantizes one weight at a time while always updating all not-yet-quantized weights, in order to compensate for the error incurred by quantizing a single weight. The update on selected weights has a closed-form formula, utilizing Hessian matrices. The GPTQ paper improves this framework by introducing a set of optimizations that reduces the complexity of the quantization algorithm while retaining the accuracy of the model. Compared to OBQ, the quantization step itself is also faster with GPTQ: it takes 2 GPU-hours to quantize a BERT model (336M) with OBQ, whereas with GPTQ, a Bloom model (176B) can be quantized in less than 4 GPU-hours. To learn more about the exact algorithm and the different benchmarks on perplexity and speedups, check out the original [paper](https://arxiv.org/pdf/2210.17323.pdf). ## AutoGPTQ library – the one-stop library for efficiently leveraging GPTQ for LLMs The AutoGPTQ library enables users to quantize 🤗 Transformers models using the GPTQ method. While parallel community efforts such as [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa), [Exllama](https://github.com/turboderp/exllama) and [llama.cpp](https://github.com/ggerganov/llama.cpp/) implement quantization methods strictly for the Llama architecture, AutoGPTQ gained popularity through its smooth coverage of a wide range of transformer architectures. Since the AutoGPTQ library has a larger coverage of transformers models, we decided to provide an integrated 🤗 Transformers API to make LLM quantization more accessible to everyone. At this time we have integrated the most common optimization options, such as CUDA kernels. For more advanced options like Triton kernels or fused-attention compatibility, check out the [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) library. ## Native support of GPTQ models in 🤗 Transformers After [installing the AutoGPTQ library](https://github.com/PanQiWei/AutoGPTQ#quick-installation) and `optimum` (`pip install optimum`), running GPTQ models in Transformers is now as simple as: ```python from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto") ``` Check out the Transformers [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization) to learn more about all the features. Our AutoGPTQ integration has many advantages: - Quantized models are serializable and can be shared on the Hub. - GPTQ drastically reduces the memory requirements to run LLMs, while the inference latency is on par with FP16 inference. - AutoGPTQ supports Exllama kernels for a wide range of architectures. - The integration comes with native RoCm support for AMD GPUs. - [Finetuning with PEFT](#--fine-tune-quantized-models-with-peft--) is available. You can check on the Hub if your favorite model has already been quantized. TheBloke, one of Hugging Face top contributors, has quantized a lot of models with AutoGPTQ and shared them on the Hugging Face Hub. We worked together to make sure that these repositories will work out of the box with our integration. This is a benchmark sample for the batch size = 1 case. The benchmark was run on a single NVIDIA A100-SXM4-80GB GPU. We used a prompt length of 512, and generated exactly 512 new tokens. The first row is the unquantized `fp16` baseline, while the other rows show memory consumption and performance using different AutoGPTQ kernels. | gptq | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tokens/s) | Peak memory (MB) | |-------|-----------|------|------------|-------------------|---------------|------------------------|-----------------------|------------------| | False | None | None | None | None | 26.0 | 36.958 | 27.058 | 29152.98 | | True | False | 4 | 128 | exllama | 36.2 | 33.711 | 29.663 | 10484.34 | | True | False | 4 | 128 | autogptq-cuda-old | 36.2 | 46.44 | 21.53 | 10344.62 | A more comprehensive reproducible benchmark is available [here](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark). ## Quantizing models **with the Optimum library** To seamlessly integrate AutoGPTQ into Transformers, we used a minimalist version of the AutoGPTQ API that is available in [Optimum](https://github.com/huggingface/optimum), Hugging Face's toolkit for training and inference optimization. By following this approach, we achieved easy integration with Transformers, while allowing people to use the Optimum API if they want to quantize their own models! Check out the Optimum [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) if you want to quantize your own LLMs. Quantizing 🤗 Transformers models with the GPTQ method can be done in a few lines: ```python from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig model_id = "facebook/opt-125m" tokenizer = AutoTokenizer.from_pretrained(model_id) quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer) model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config) ``` Quantizing a model may take a long time. Note that for a 175B model, at least 4 GPU-hours are required if one uses a large dataset (e.g. `"c4"``). As mentioned above, many GPTQ models are already available on the Hugging Face Hub, which bypasses the need to quantize a model yourself in most use cases. Nevertheless, you can also quantize a model using your own dataset appropriate for the particular domain you are working on. ## Running GPTQ models through ***Text-Generation-Inference*** In parallel to the integration of GPTQ in Transformers, GPTQ support was added to the [Text-Generation-Inference library](https://github.com/huggingface/text-generation-inference) (TGI), aimed at serving large language models in production. GPTQ can now be used alongside features such as dynamic batching, paged attention and flash attention for a [wide range of architectures](https://huggingface.co/docs/text-generation-inference/main/en/supported_models). As an example, this integration allows to serve a 70B model on a single A100-80GB GPU! This is not possible using a fp16 checkpoint as it exceeds the available GPU memory. You can find out more about the usage of GPTQ in TGI in [the documentation](https://huggingface.co/docs/text-generation-inference/main/en/basic_tutorials/preparing_model#quantization). Note that the kernel integrated in TGI does not scale very well with larger batch sizes. Although this approach saves memory, slowdowns are expected at larger batch sizes. ## **Fine-tune quantized models with PEFT** You can not further train a quantized model using the regular methods. However, by leveraging the PEFT library, you can train adapters on top! To do that, we freeze all the layers of the quantized model and add the trainable adapters. Here are some examples on how to use PEFT with a GPTQ model: [colab notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) and [finetuning](https://gist.github.com/SunMarc/dcdb499ac16d355a8f265aa497645996) script. ## Room for improvement Our AutoGPTQ integration already brings impressive benefits at a small cost in the quality of prediction. There is still room for improvement, both in the quantization techniques and the kernel implementations. First, while AutoGPTQ integrates (to the best of our knowledge) with the most performant W4A16 kernel (weights as int4, activations as fp16) from the [exllama implementation](https://github.com/turboderp/exllama), there is a good chance that the kernel can still be improved. There have been other promising implementations [from Kim et al.](https://arxiv.org/pdf/2211.10017.pdf) and from [MIT Han Lab](https://github.com/mit-han-lab/llm-awq) that appear to be promising. Moreover, from internal benchmarks, there appears to still be no open-source performant W4A16 kernel written in Triton, which could be a direction to explore. On the quantization side, let’s emphasize again that this method only quantizes the weights. There have been other approaches proposed for LLM quantization that can quantize both weights and activations at a small cost in prediction quality, such as [LLM-QAT](https://arxiv.org/pdf/2305.17888.pdf) where a mixed int4/int8 scheme can be used, as well as quantization of the key-value cache. One of the strong advantages of this technique is the ability to use actual integer arithmetic for the compute, with e.g. [Nvidia Tensor Cores supporting int8 compute](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf). However, to the best of our knowledge, there are no open-source W4A8 quantization kernels available, but this may well be [an interesting direction to explore](https://www.qualcomm.com/news/onq/2023/04/floating-point-arithmetic-for-ai-inference-hit-or-miss). On the kernel side as well, designing performant W4A16 kernels for larger batch sizes remains an open challenge. ### Supported models In this initial implementation, only large language models with a decoder or encoder only architecture are supported. This may sound a bit restrictive, but it encompasses most state of the art LLMs such as Llama, OPT, GPT-Neo, GPT-NeoX. Very large vision, audio, and multi-modal models are currently not supported. ## Conclusion and final words In this blogpost we have presented the integration of the [AutoGPTQ library](https://github.com/PanQiWei/AutoGPTQ) in Transformers, making it possible to quantize LLMs with the GPTQ method to make them more accessible for anyone in the community and empower them to build exciting tools and applications with LLMs. This integration is available both for Nvidia GPUs, and RoCm-powered AMD GPUs, which is a huge step towards democratizing quantized models for broader GPU architectures. The collaboration with the AutoGPTQ team has been very fruitful, and we are very grateful for their support and their work on this library. We hope that this integration will make it easier for everyone to use LLMs in their applications, and we are looking forward to seeing what you will build with it! Do not miss the useful resources shared above for better understanding the integration and how to quickly get started with GPTQ quantization. - [Original Paper](https://arxiv.org/pdf/2210.17323.pdf) - [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with GPTQ method, how to do inference, and how to do fine-tuning with the quantized model. - Transformers integration [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization) - Optimum integration [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) - The Bloke [repositories](https://huggingface.co/TheBloke?sort_models=likes#models) with compatible GPTQ models. ## Acknowledgements We would like to thank [William](https://github.com/PanQiWei) for his support and his work on the amazing AutoGPTQ library and for his help in the integration. We would also like to thank [TheBloke](https://huggingface.co/TheBloke) for his work on quantizing many models with AutoGPTQ and sharing them on the Hub and for his help with the integration. We would also like to aknowledge [qwopqwop200](https://github.com/qwopqwop200) for his continuous contributions on AutoGPTQ library and his work on extending the library for CPU that is going to be released in the next versions of AutoGPTQ. Finally, we would like to thank [Pedro Cuenca](https://github.com/pcuenca) for his help with the writing of this blogpost.
|
Deprecation of Git Authentication using password
|
Sylvestre
|
August 25, 2023
|
password-git-deprecation
|
announcement, security
|
https://huggingface.co/blog/password-git-deprecation
|
# Hugging Face Hub: Important Git Authentication Changes Because we are committed to improving the security of our services, we are making changes to the way you authenticate when interacting with the Hugging Face Hub through Git. Starting from **October 1st, 2023**, we will no longer accept passwords as a way to authenticate your command-line Git operations. Instead, we recommend using more secure authentication methods, such as replacing the password with a personal access token or using an SSH key. ## Background In recent months, we have implemented various security enhancements, including sign-in alerts and support for SSH keys in Git. However, users have still been able to authenticate Git operations using their username and password. To further improve security, we are now transitioning to token-based or SSH key authentication. Token-based and SSH key authentication offer several advantages over traditional password authentication, including unique, revocable, and random features that enhance security and control. ## Action Required Today If you currently use your HF account password to authenticate with Git, please switch to using a personal access token or SSH keys before **October 1st, 2023**. ### Switching to personal access token You will need to generate an access token for your account; you can follow https://huggingface.co/docs/hub/security-tokens#user-access-tokens to generate one. After generating your access token, you can update your Git repository using the following commands: ```bash $: git remote set-url origin https://<user_name>:<token>@huggingface.co/<repo_path> $: git pull origin ``` where `<repo_path>` is in the form of: - `<user_name>/<repo_name>` for models - `datasets/<user_name>/<repo_name>` for datasets - `spaces/<user_name>/<repo_name>` for Spaces If you clone a new repo, you can just input a token in place of your password when your Git credential manager asks you for your authentication credentials. ### Switching to SSH keys Follow our guide to generate an SSH key and add it to your account: https://huggingface.co/docs/hub/security-git-ssh Then you'll be able to update your Git repository using: ```bash $: git remote set-url origin [email protected]:<repo_path> # see above for the format of the repo path ``` ## Timeline Here's what you can expect in the coming weeks: - Today: Users relying on passwords for Git authentication may receive emails urging them to update their authentication method. - October 1st: Personal access tokens or SSH keys will be mandatory for all Git operations. For more details, reach out to HF Support to address any questions or concerns at [email protected]
|
Code Llama: Llama 2 learns to code
|
philschmid
|
August 25, 2023
|
codellama
|
nlp, community, research, LLM
|
https://huggingface.co/blog/codellama
|
# Code Llama: Llama 2 learns to code ## Introduction Code Llama is a family of state-of-the-art, open-access versions of [Llama 2](https://huggingface.co/blog/llama2) specialized on code tasks, and we’re excited to release integration in the Hugging Face ecosystem! Code Llama has been released with the same permissive community license as Llama 2 and is available for commercial use. Today, we’re excited to release: - Models on the Hub with their model cards and license - Transformers integration - Integration with Text Generation Inference for fast and efficient production-ready inference - Integration with Inference Endpoints - Integration with VS Code extension - Code benchmarks Code LLMs are an exciting development for software engineers because they can boost productivity through code completion in IDEs, take care of repetitive or annoying tasks like writing docstrings, or create unit tests. ## Table of Contents - [Introduction](#introduction) - [Table of Contents](#table-of-contents) - [What’s Code Llama?](#whats-code-llama) - [How to use Code Llama?](#how-to-use-code-llama) - [Demo](#demo) - [Transformers](#transformers) - [A Note on dtypes](#a-note-on-dtypes) - [Code Completion](#code-completion) - [Code Infilling](#code-infilling) - [Conversational Instructions](#conversational-instructions) - [4-bit Loading](#4-bit-loading) - [Using text-generation-inference and Inference Endpoints](#using-text-generation-inference-and-inference-endpoints) - [Using VS Code extension](#using-vs-code-extension) - [Evaluation](#evaluation) - [Additional Resources](#additional-resources) ## What’s Code Llama? The Code Llama release introduces a family of models of 7, 13, and 34 billion parameters. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data. Meta fine-tuned those base models for two different flavors: a Python specialist (100 billion additional tokens) and an instruction fine-tuned version, which can understand natural language instructions. The models show state-of-the-art performance in Python, C++, Java, PHP, C#, TypeScript, and Bash. The 7B and 13B base and instruct variants support infilling based on surrounding content, making them ideal for use as code assistants. Code Llama was trained on a 16k context window. In addition, the three model variants had additional long-context fine-tuning, allowing them to manage a context window of up to 100,000 tokens. Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning. In the case of Code Llama, the frequency domain scaling is done with a slack: the fine-tuning length is a fraction of the scaled pretrained length, giving the model powerful extrapolation capabilities.  All models were initially trained with 500 billion tokens on a near-deduplicated dataset of publicly available code. The dataset also contains some natural language datasets, such as discussions about code and code snippets. Unfortunately, there is not more information about the dataset. For the instruction model, they used two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions, which are later evaluated by executing the tests. ## How to use Code Llama? Code Llama is available in the Hugging Face ecosystem, starting with `transformers` version 4.33. ### Demo You can easily try the Code Llama Model (13 billion parameters!) in **[this Space](https://huggingface.co/spaces/codellama/codellama-playground)** or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.3/gradio.js"> </script> <gradio-app theme_mode="light" space="codellama/codellama-playground"></gradio-app> Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and we'll share more in the following sections. If you want to try out the bigger instruct-tuned 34B model, it is now available on **HuggingChat**! You can try it out here: [hf.co/chat](https://hf.co/chat). Make sure to specify the Code Llama model. You can also check [this chat-based demo](https://huggingface.co/spaces/codellama/codellama-13b-chat) and duplicate it for your use – it's self-contained, so you can examine the source code and adapt it as you wish! ### Transformers Starting with `transformers` 4.33, you can use Code Llama and leverage all the tools within the HF ecosystem, such as: - training and inference scripts and examples - safe file format (`safetensors`) - integrations with tools such as `bitsandbytes` (4-bit quantization) and PEFT (parameter efficient fine-tuning) - utilities and helpers to run generation with the model - mechanisms to export the models to deploy ```bash !pip install --upgrade transformers ``` #### A Note on dtypes When using models like Code Llama, it's important to take a look at the data types of the models. * 32-bit floating point (`float32`): PyTorch convention on model initialization is to load models in `float32`, no matter with which precision the model weights were stored. `transformers` also follows this convention for consistency with PyTorch. * 16-bit Brain floating point (`bfloat16`): Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning. * 16-bit floating point (`float16`): We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning. As mentioned above, `transformers` loads weights using `float32` (no matter with which precision the models are stored), so it's important to specify the desired `dtype` when loading the models. If you want to fine-tune Code Llama, it's recommended to use `bfloat16`, as using `float16` can lead to overflows and NaNs. If you run inference, we recommend using `float16` because `bfloat16` can be slower. #### Code Completion The 7B and 13B models can be used for text/code completion or infilling. The following code snippet uses the `pipeline` interface to demonstrate text completion. It runs on the free tier of Colab, as long as you select a GPU runtime. ```python from transformers import AutoTokenizer import transformers import torch tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf") pipeline = transformers.pipeline( "text-generation", model="codellama/CodeLlama-7b-hf", torch_dtype=torch.float16, device_map="auto", ) sequences = pipeline( 'def fibonacci(', do_sample=True, temperature=0.2, top_p=0.9, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=100, ) for seq in sequences: print(f"Result: {seq['generated_text']}") ``` This may produce output like the following: ```python Result: def fibonacci(n): if n == 0: return 0 elif n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) def fibonacci_memo(n, memo={}): if n == 0: return 0 elif n == 1: return ``` Code Llama is specialized in code understanding, but it's a language model in its own right. You can use the same generation strategy to autocomplete comments or general text. #### Code Infilling This is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix. This is the strategy typically used by code assistants: they are asked to fill the current cursor position, considering the contents that appear before and after it. This task is available in the **base** and **instruction** variants of the 7B and 13B models. It is _not_ available for any of the 34B models or the Python versions. To use this feature successfully, you need to pay close attention to the format used to train the model for this task, as it uses special separators to identify the different parts of the prompt. Fortunately, transformers' `CodeLlamaTokenizer` makes this very easy, as demonstrated below: ```python from transformers import AutoTokenizer, AutoModelForCausalLM import transformers import torch model_id = "codellama/CodeLlama-7b-hf" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.float16 ).to("cuda") prompt = '''def remove_non_ascii(s: str) -> str: """ <FILL_ME> return result ''' input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda") output = model.generate( input_ids, max_new_tokens=200, ) output = output[0].to("cpu") filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True) print(prompt.replace("<FILL_ME>", filling)) ``` ```Python def remove_non_ascii(s: str) -> str: """ Remove non-ASCII characters from a string. Args: s: The string to remove non-ASCII characters from. Returns: The string with non-ASCII characters removed. """ result = "" for c in s: if ord(c) < 128: result += c return result ``` Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug. #### Conversational Instructions The base model can be used for both completion and infilling, as described. The Code Llama release also includes an instruction fine-tuned model that can be used in conversational interfaces. To prepare inputs for this task we have to use a prompt template like the one described in our [Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), which we reproduce again here: ``` <s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST] ``` Note that the system prompt is optional - the model will work without it, but you can use it to further configure its behavior or style. For example, if you'd always like to get answers in JavaScript, you could state that here. After the system prompt, you need to provide all the previous interactions in the conversation: what was asked by the user and what was answered by the model. As in the infilling case, you need to pay attention to the delimiters used. The final component of the input must always be a new user instruction, which will be the signal for the model to provide an answer. The following code snippets demonstrate how the template works in practice. 1. **First user query, no system prompt** ```python user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?' prompt = f"<s>[INST] {user.strip()} [/INST]" inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda") ``` 2. **First user query with system prompt** ```python system = "Provide answers in JavaScript" user = "Write a function that computes the set of sums of all contiguous sublists of a given list." prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]" inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda") ``` 3. **On-going conversation with previous answers** The process is the same as in [Llama 2](https://huggingface.co/blog/llama2#how-to-prompt-llama-2). We haven’t used loops or generalized this example code for maximum clarity: ```python system = "System prompt" user_1 = "user_prompt_1" answer_1 = "answer_1" user_2 = "user_prompt_2" answer_2 = "answer_2" user_3 = "user_prompt_3" prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}" prompt += f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>" prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>" prompt += f"<s>[INST] {user_3.strip()} [/INST]" inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda") ``` #### 4-bit Loading Integration of Code Llama in Transformers means that you get immediate support for advanced features like 4-bit loading. This allows you to run the big 32B parameter models on consumer GPUs like nvidia 3090 cards! Here's how you can run inference in 4-bit mode: ```Python from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig import torch model_id = "codellama/CodeLlama-34b-hf" quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16 ) tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=quantization_config, device_map="auto", ) prompt = 'def remove_non_ascii(s: str) -> str:\n """ ' inputs = tokenizer(prompt, return_tensors="pt").to("cuda") output = model.generate( inputs["input_ids"], max_new_tokens=200, do_sample=True, top_p=0.9, temperature=0.1, ) output = output[0].to("cpu") print(tokenizer.decode(output)) ``` ### Using text-generation-inference and Inference Endpoints [Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing. You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's [Inference Endpoints](https://huggingface.co/inference-endpoints). To deploy a Codellama 2 model, go to the [model page](https://huggingface.co/codellama) and click on the [Deploy -> Inference Endpoints](https://huggingface.co/codellama/CodeLlama-7b-hf) widget. - For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G". - For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100". - For 34B models, we advise you to select "GPU [1xlarge] - 1x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [2xlarge] - 2x Nvidia A100" *Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s* You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript. ### Using VS Code extension [HF Code Autocomplete](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) is a VS Code extension for testing open source code completion models. The extension was developed as part of [StarCoder project](/blog/starcoder#tools--demos) and was updated to support the medium-sized base model, [Code Llama 13B](/codellama/CodeLlama-13b-hf). Find more [here](https://github.com/huggingface/huggingface-vscode#code-llama) on how to install and run the extension with Code Llama.  ## Evaluation Language models for code are typically benchmarked on datasets such as HumanEval. It consists of programming challenges where the model is presented with a function signature and a docstring and is tasked to complete the function body. The proposed solution is then verified by running a set of predefined unit tests. Finally, a pass rate is reported which describes how many solutions passed all tests. The pass@1 rate describes how often the model generates a passing solution when having one shot whereas pass@10 describes how often at least one solution passes out of 10 proposed candidates. While HumanEval is a Python benchmark there have been significant efforts to translate it to more programming languages and thus enable a more holistic evaluation. One such approach is [MultiPL-E](https://github.com/nuprl/MultiPL-E) which translates HumanEval to over a dozen languages. We are hosting a [multilingual code leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals) based on it to allow the community to compare models across different languages to evaluate which model fits their use-case best. | Model | License | Dataset known | Commercial use? | Pretraining length [tokens] | Python | JavaScript | Leaderboard Avg Score | | ---------------------- | ------------------ | ------------- | --------------- | --------------------------- | ------ | ---------- | --------------------- | | CodeLlaMa-34B | Llama 2 license | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 | | CodeLlaMa-13B | Llama 2 license | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 | | CodeLlaMa-7B | Llama 2 license | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 | | CodeLlaMa-34B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 | | CodeLlaMa-13B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 | | CodeLlaMa-7B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 | | CodeLlaMa-34B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 | | CodeLlaMa-13B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 | | CodeLlaMa-7B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 | | StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 | | StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 | | WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 | | OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 | | CodeGeeX-2-6B | CodeGeeX License | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 | | CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 | | CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 | **Note:** The scores presented in the table above are sourced from our code leaderboard, where we evaluate all models with the same settings. For more details, please refer to the [leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals). ## Additional Resources - [Models on the Hub](https://huggingface.co/codellama) - [Paper Page](https://huggingface.co/papers/2308.12950) - [Official Meta announcement](https://ai.meta.com/blog/code-llama-large-language-model-coding/) - [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/) - [Demo (code completion, streaming server)](https://huggingface.co/spaces/codellama/codellama-playground) - [Demo (instruction fine-tuned, self-contained & clonable)](https://huggingface.co/spaces/codellama/codellama-13b-chat)
|
AudioLDM 2, but faster ⚡️
|
sanchit-gandhi
|
Aug 30, 2023
|
audioldm2
|
guide, audio, diffusers, diffusion
|
https://huggingface.co/blog/audioldm2
|
# AudioLDM 2, but faster ⚡️ <a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> AudioLDM 2 was proposed in [AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining](https://arxiv.org/abs/2308.05734) by Haohe Liu et al. AudioLDM 2 takes a text prompt as input and predicts the corresponding audio. It can generate realistic sound effects, human speech and music. While the generated audios are of high quality, running inference with the original implementation is very slow: a 10 second audio sample takes upwards of 30 seconds to generate. This is due to a combination of factors, including a deep multi-stage modelling approach, large checkpoint sizes, and un-optimised code. In this blog post, we showcase how to use AudioLDM 2 in the Hugging Face 🧨 Diffusers library, exploring a range of code optimisations such as half-precision, flash attention, and compilation, and model optimisations such as scheduler choice and negative prompting, to reduce the inference time by over **10 times**, with minimal degradation in quality of the output audio. The blog post is also accompanied by a more streamlined [Colab notebook](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb), that contains all the code but fewer explanations. Read to the end to find out how to generate a 10 second audio sample in just 1 second! ## Model overview Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM 2 is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from text embeddings. The overall generation process is summarised as follows: 1. Given a text input \\(\boldsymbol{x}\\), two text encoder models are used to compute the text embeddings: the text-branch of [CLAP](https://huggingface.co/docs/transformers/main/en/model_doc/clap), and the text-encoder of [Flan-T5](https://huggingface.co/docs/transformers/main/en/model_doc/flan-t5) $$ \boldsymbol{E}_{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_{2} = \text{T5}\left(\boldsymbol{x}\right) $$ The CLAP text embeddings are trained to be aligned with the embeddings of the corresponding audio sample, whereas the Flan-T5 embeddings give a better representation of the semantics of the text. 2. These text embeddings are projected to a shared embedding space through individual linear projections: $$ \boldsymbol{P}_{1} = \boldsymbol{W}_{\text{CLAP}} \boldsymbol{E}_{1}; \quad \boldsymbol{P}_{2} = \boldsymbol{W}_{\text{T5}}\boldsymbol{E}_{2} $$ In the `diffusers` implementation, these projections are defined by the [AudioLDM2ProjectionModel](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2/AudioLDM2ProjectionModel). 3. A [GPT2](https://huggingface.co/docs/transformers/main/en/model_doc/gpt2) language model (LM) is used to auto-regressively generate a sequence of \\(N\\) new embedding vectors, conditional on the projected CLAP and Flan-T5 embeddings: $$ \tilde{\boldsymbol{E}}_{i} = \text{GPT2}\left(\boldsymbol{P}_{1}, \boldsymbol{P}_{2}, \tilde{\boldsymbol{E}}_{1:i-1}\right) \qquad \text{for } i=1,\dots,N $$ 4. The generated embedding vectors \\(\tilde{\boldsymbol{E}}_{1:N}\\) and Flan-T5 text embeddings \\(\boldsymbol{E}_{2}\\) are used as cross-attention conditioning in the LDM, which *de-noises* a random latent via a reverse diffusion process. The LDM is run in the reverse diffusion process for a total of \\(T\\) inference steps: $$ \boldsymbol{z}_{t} = \text{LDM}\left(\boldsymbol{z}_{t-1} | \tilde{\boldsymbol{E}}_{1:N}, \boldsymbol{E}_{2}\right) \qquad \text{for } t = 1, \dots, T $$ where the initial latent variable \\(\boldsymbol{z}_{0}\\) is drawn from a normal distribution \\(\mathcal{N} \left(\boldsymbol{0}, \boldsymbol{I} \right)\\). The [UNet](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2/AudioLDM2UNet2DConditionModel) of the LDM is unique in the sense that it takes **two** sets of cross-attention embeddings, \\(\tilde{\boldsymbol{E}}_{1:N}\\) from the GPT2 language model and \\(\boldsymbol{E}_{2}\\) from Flan-T5, as opposed to one cross-attention conditioning as in most other LDMs. 5. The final de-noised latents \\(\boldsymbol{z}_{T}\\) are passed to the VAE decoder to recover the Mel spectrogram \\(\boldsymbol{s}\\): $$ \boldsymbol{s} = \text{VAE}_{\text{dec}} \left(\boldsymbol{z}_{T}\right) $$ 6. The Mel spectrogram is passed to the vocoder to obtain the output audio waveform \\(\mathbf{y}\\): $$ \boldsymbol{y} = \text{Vocoder}\left(\boldsymbol{s}\right) $$ The diagram below demonstrates how a text input is passed through the text conditioning models, with the two prompt embeddings used as cross-conditioning in the LDM: <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/audioldm2.png?raw=true" width="600"/> </p> For full details on how the AudioLDM 2 model is trained, the reader is referred to the [AudioLDM 2 paper](https://arxiv.org/abs/2308.05734). Hugging Face 🧨 Diffusers provides an end-to-end inference pipeline class [`AudioLDM2Pipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2) that wraps this multi-stage generation process into a single callable object, enabling you to generate audio samples from text in just a few lines of code. AudioLDM 2 comes in three variants. Two of these checkpoints are applicable to the general task of text-to-audio generation. The third checkpoint is trained exclusively on text-to-music generation. See the table below for details on the three official checkpoints, which can all be found on the [Hugging Face Hub](https://huggingface.co/models?search=cvssp/audioldm2): | Checkpoint | Task | Model Size | Training Data / h | |-----------------------------------------------------------------------|---------------|------------|-------------------| | [cvssp/audioldm2](https://huggingface.co/cvssp/audioldm2) | Text-to-audio | 1.1B | 1150k | | [cvssp/audioldm2-music](https://huggingface.co/cvssp/audioldm2-music) | Text-to-music | 1.1B | 665k | | [cvssp/audioldm2-large](https://huggingface.co/cvssp/audioldm2-large) | Text-to-audio | 1.5B | 1150k | Now that we've covered a high-level overview of how the AudioLDM 2 generation process works, let's put this theory into practice! ## Load the pipeline For the purposes of this tutorial, we'll initialise the pipeline with the pre-trained weights from the base checkpoint, [cvssp/audioldm2](https://huggingface.co/cvssp/audioldm2). We can load the entirety of the pipeline using the [`.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained) method, which will instantiate the pipeline and load the pre-trained weights: ```python from diffusers import AudioLDM2Pipeline model_id = "cvssp/audioldm2" pipe = AudioLDM2Pipeline.from_pretrained(model_id) ``` **Output:** ``` Loading pipeline components...: 100%|███████████████████████████████████████████| 11/11 [00:01<00:00, 7.62it/s] ``` The pipeline can be moved to the GPU in much the same way as a standard PyTorch nn module: ```python pipe.to("cuda"); ``` Great! We'll define a Generator and set a seed for reproducibility. This will allow us to tweak our prompts and observe the effect that they have on the generations by fixing the starting latents in the LDM model: ```python import torch generator = torch.Generator("cuda").manual_seed(0) ``` Now we're ready to perform our first generation! We'll use the same running example throughout this notebook, where we'll condition the audio generations on a fixed text prompt and use the same seed throughout. The [`audio_length_in_s`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.audio_length_in_s) argument controls the length of the generated audio. It defaults to the audio length that the LDM was trained on (10.24 seconds): ```python prompt = "The sound of Brazilian samba drums with waves gently crashing in the background" audio = pipe(prompt, audio_length_in_s=10.24, generator=generator).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [00:13<00:00, 15.27it/s] ``` Cool! That run took about 13 seconds to generate. Let's have a listen to the output audio: ```python from IPython.display import Audio Audio(audio, rate=16000) ``` <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_1.wav" type="audio/wav"> Your browser does not support the audio element. </audio> Sounds much like our text prompt! The quality is good, but still has artefacts of background noise. We can provide the pipeline with a [*negative prompt*](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.negative_prompt) to discourage the pipeline from generating certain features. In this case, we'll pass a negative prompt that discourages the model from generating low quality audio in the outputs. We'll omit the `audio_length_in_s` argument and leave it to take its default value: ```python negative_prompt = "Low quality, average quality." audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.50it/s] ``` The inference time is un-changed when using a negative prompt \\({}^1\\); we simply replace the unconditional input to the LDM with the negative input. That means any gains we get in audio quality we get for free. Let's take a listen to the resulting audio: ```python Audio(audio, rate=16000) ``` <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_2.wav" type="audio/wav"> Your browser does not support the audio element. </audio> There's definitely an improvement in the overall audio quality - there are less noise artefacts and the audio generally sounds sharper. \\({}^1\\) Note that in practice, we typically see a reduction in inference time going from our first generation to our second. This is due to a CUDA "warm-up" that occurs the first time we run the computation. The second generation is a better benchmark for our actual inference time. ## Optimisation 1: Flash Attention PyTorch 2.0 and upwards includes an optimised and memory-efficient implementation of the attention operation through the [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) function. This function automatically applies several in-built optimisations depending on the inputs, and runs faster and more memory-efficient than the vanilla attention implementation. Overall, the SDPA function gives similar behaviour to *flash attention*, as proposed in the paper [Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135) by Dao et. al. These optimisations will be enabled by default in Diffusers if PyTorch 2.0 is installed and if `torch.nn.functional.scaled_dot_product_attention` is available. To use it, just install torch 2.0 or higher as per the [official instructions](https://pytorch.org/get-started/locally/), and then use the pipeline as is 🚀 ```python audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.60it/s] ``` For more details on the use of SDPA in `diffusers`, refer to the corresponding [documentation](https://huggingface.co/docs/diffusers/optimization/torch2.0). ## Optimisation 2: Half-Precision By default, the `AudioLDM2Pipeline` loads the model weights in float32 (full) precision. All the model computations are also performed in float32 precision. For inference, we can safely convert the model weights and computations to float16 (half) precision, which will give us an improvement to inference time and GPU memory, with an impercivable change to generation quality. We can load the weights in float16 precision by passing the [`torch_dtype`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained.torch_dtype) argument to `.from_pretrained`: ```python pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe.to("cuda"); ``` Let's run generation in float16 precision and listen to the audio outputs: ```python audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0] Audio(audio, rate=16000) ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [00:09<00:00, 20.94it/s] ``` <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_3.wav" type="audio/wav"> Your browser does not support the audio element. </audio> The audio quality is largely un-changed from the full precision generation, with an inference speed-up of about 2 seconds. In our experience, we've not seen any significant audio degradation using `diffusers` pipelines with float16 precision, but consistently reap a substantial inference speed-up. Thus, we recommend using float16 precision by default. ## Optimisation 3: Torch Compile To get an additional speed-up, we can use the new `torch.compile` feature. Since the UNet of the pipeline is usually the most computationally expensive, we wrap the unet with `torch.compile`, leaving the rest of the sub-models (text encoders and VAE) as is: ```python pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) ``` After wrapping the UNet with `torch.compile` the first inference step we run is typically going to be slow, due to the overhead of compiling the forward pass of the UNet. Let's run the pipeline forward with the compilation step get this longer run out of the way. Note that the first inference step might take up to 2 minutes to compile, so be patient! ```python audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [01:23<00:00, 2.39it/s] ``` Great! Now that the UNet is compiled, we can now run the full diffusion process and reap the benefits of faster inference: ```python audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 200/200 [00:04<00:00, 48.98it/s] ``` Only 4 seconds to generate! In practice, you will only have to compile the UNet once, and then get faster inference for all successive generations. This means that the time taken to compile the model is amortised by the gains in subsequent inference time. For more information and options regarding `torch.compile`, refer to the [torch compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) docs. ## Optimisation 4: Scheduler Another option is to reduce the number of inference steps. Choosing a more efficient scheduler can help decrease the number of steps without sacrificing the output audio quality. You can find which schedulers are compatible with the `AudioLDM2Pipeline` by calling the [`schedulers.compatibles`](https://huggingface.co/docs/diffusers/v0.20.0/en/api/schedulers/overview#diffusers.SchedulerMixin) attribute: ```python pipe.scheduler.compatibles ``` **Output:** ``` [diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler, diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler, diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler, diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler, diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler, diffusers.schedulers.scheduling_pndm.PNDMScheduler, diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler, diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler, diffusers.schedulers.scheduling_ddpm.DDPMScheduler, diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler, diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler, diffusers.schedulers.scheduling_ddim.DDIMScheduler, diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler, diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler] ``` Alright! We've got a long list of schedulers to choose from 📝. By default, AudioLDM 2 uses the [`DDIMScheduler`](https://huggingface.co/docs/diffusers/api/schedulers/ddim), and requires 200 inference steps to get good quality audio generations. However, more performant schedulers, like [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver#diffusers.DPMSolverMultistepScheduler), require only **20-25 inference steps** to achieve similar results. Let's see how we can switch the AudioLDM 2 scheduler from DDIM to DPM Multistep. We'll use the [`ConfigMixin.from_config()`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method to load a [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver#diffusers.DPMSolverMultistepScheduler) from the configuration of our original [`DDIMScheduler`](https://huggingface.co/docs/diffusers/api/schedulers/ddim): ```python from diffusers import DPMSolverMultistepScheduler pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) ``` Let's set the number of inference steps to 20 and re-run the generation with the new scheduler. Since the shape of the LDM latents are un-changed, we don't have to repeat the compilation step: ```python audio = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 20/20 [00:00<00:00, 49.14it/s] ``` That took less than **1 second** to generate the audio! Let's have a listen to the resulting generation: ```python Audio(audio, rate=16000) ``` <audio controls> <source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_4.wav" type="audio/wav"> Your browser does not support the audio element. </audio> More or less the same as our original audio sample, but only a fraction of the generation time! 🧨 Diffusers pipelines are designed to be *composable*, allowing you two swap out schedulers and other components for more performant counterparts with ease. ## What about memory? The length of the audio sample we want to generate dictates the *width* of the latent variables we de-noise in the LDM. Since the memory of the cross-attention layers in the UNet scales with sequence length (width) squared, generating very long audio samples might lead to out-of-memory errors. Our batch size also governs our memory usage, controlling the number of samples that we generate. We've already mentioned that loading the model in float16 half precision gives strong memory savings. Using PyTorch 2.0 SDPA also gives a memory improvement, but this might not be suffienct for extremely large sequence lengths. Let's try generating an audio sample 2.5 minutes (150 seconds) in duration. We'll also generate 4 candidate audios by setting [`num_waveforms_per_prompt`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.num_waveforms_per_prompt)`=4`. Once [`num_waveforms_per_prompt`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.num_waveforms_per_prompt)`>1`, automatic scoring is performed between the generated audios and the text prompt: the audios and text prompts are embedded in the CLAP audio-text embedding space, and then ranked based on their cosine similarity scores. We can access the 'best' waveform as that in position `0`. Since we've changed the width of the latent variables in the UNet, we'll have to perform another torch compilation step with the new latent variable shapes. In the interest of time, we'll re-load the pipeline without torch compile, such that we're not hit with a lengthy compilation step first up: ```python pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe.to("cuda") audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` --------------------------------------------------------------------------- OutOfMemoryError Traceback (most recent call last) <ipython-input-33-c4cae6410ff5> in <cell line: 5>() 3 pipe.to("cuda") 4 ----> 5 audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0] 23 frames /usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input) 112 113 def forward(self, input: Tensor) -> Tensor: --> 114 return F.linear(input, self.weight, self.bias) 115 116 def extra_repr(self) -> str: OutOfMemoryError: CUDA out of memory. Tried to allocate 1.95 GiB. GPU 0 has a total capacty of 14.75 GiB of which 1.66 GiB is free. Process 414660 has 13.09 GiB memory in use. Of the allocated memory 10.09 GiB is allocated by PyTorch, and 1.92 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF ``` Unless you have a GPU with high RAM, the code above probably returned an OOM error. While the AudioLDM 2 pipeline involves several components, only the model being used has to be on the GPU at any one time. The remainder of the modules can be offloaded to the CPU. This technique, called *CPU offload*, can reduce memory usage, with a very low penalty to inference time. We can enable CPU offload on our pipeline with the function [enable_model_cpu_offload()](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.enable_model_cpu_offload): ```python pipe.enable_model_cpu_offload() ``` Running generation with CPU offload is then the same as before: ```python audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0] ``` **Output:** ``` 100%|███████████████████████████████████████████| 20/20 [00:36<00:00, 1.82s/it] ``` And with that, we can generate four samples, each of 150 seconds in duration, all in one call to the pipeline! Using the large AudioLDM 2 checkpoint will result in higher overall memory usage than the base checkpoint, since the UNet is over twice the size (750M parameters compared to 350M), so this memory saving trick is particularly beneficial here. ## Conclusion In this blog post, we showcased four optimisation methods that are available out of the box with 🧨 Diffusers, taking the generation time of AudioLDM 2 from 14 seconds down to less than 1 second. We also highlighted how to employ memory saving tricks, such as half-precision and CPU offload, to reduce peak memory usage for long audio samples or large checkpoint sizes. Blog post by [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi). Many thanks to [Vaibhav Srivastav](https://huggingface.co/reach-vb) and [Sayak Paul](https://huggingface.co/sayakpaul) for their constructive comments. Spectrogram image source: [Getting to Know the Mel Spectrogram](https://towardsdatascience.com/getting-to-know-the-mel-spectrogram-31bca3e2d9d0). Waveform image source: [Aalto Speech Processing](https://speechprocessingbook.aalto.fi/Representations/Waveform.html).
|
Fetch Cuts ML Processing Latency by 50% Using Amazon SageMaker & Hugging Face
|
Violette
|
September 1, 2023
|
fetch-case-study
|
case-studies
|
https://huggingface.co/blog/fetch-case-study
|
# Fetch Cuts ML Processing Latency by 50% Using Amazon SageMaker & Hugging Face _This article is a cross-post from an originally published post on September 2023 [on AWS's website](https://aws.amazon.com/fr/solutions/case-studies/fetch-case-study/)._ ## Overview Consumer engagement and rewards company [Fetch](https://fetch.com/) offers an application that lets users earn rewards on their purchases by scanning their receipts. The company also parses these receipts to generate insights into consumer behavior and provides those insights to brand partners. As weekly scans rapidly grew, Fetch needed to improve its speed and precision. On Amazon Web Services (AWS), Fetch optimized its machine learning (ML) pipeline using Hugging Face and [Amazon SageMaker ](https://aws.amazon.com/sagemaker/), a service for building, training, and deploying ML models with fully managed infrastructure, tools, and workflows. Now, the Fetch app can process scans faster and with significantly higher accuracy. ## Opportunity | Using Amazon SageMaker to Accelerate an ML Pipeline in 12 Months for Fetch Using the Fetch app, customers can scan receipts, receive points, and redeem those points for gift cards. To reward users for receipt scans instantaneously, Fetch needed to be able to capture text from a receipt, extract the pertinent data, and structure it so that the rest of its system can process and analyze it. With over 80 million receipts processed per week—hundreds of receipts per second at peak traffic—it needed to perform this process quickly, accurately, and at scale. In 2021, Fetch set out to optimize its app’s scanning functionality. Fetch is an AWS-native company, and its ML operations team was already using Amazon SageMaker for many of its models. This made the decision to enhance its ML pipeline by migrating its models to Amazon SageMaker a straightforward one. Throughout the project, Fetch had weekly calls with the AWS team and received support from a subject matter expert whom AWS paired with Fetch. The company built, trained, and deployed more than five ML models using Amazon SageMaker in 12 months. In late 2022, Fetch rolled out its updated mobile app and new ML pipeline. #### "Amazon SageMaker is a game changer for Fetch. We use almost every feature extensively. As new features come out, they are immediately valuable. It’s hard to imagine having done this project without the features of Amazon SageMaker.” Sam Corzine, Machine Learning Engineer, Fetch ## Solution | Cutting Latency by 50% Using ML & Hugging Face on Amazon SageMaker GPU Instances #### "Using the flexibility of the Hugging Face AWS Deep Learning Container, we could improve the quality of our models,and Hugging Face’s partnership with AWS meant that it was simple to deploy these models.” Sam Corzine, Machine Learning Engineer, Fetch Fetch’s ML pipeline is powered by several Amazon SageMaker features, particularly [Amazon SageMaker Model Training](https://aws.amazon.com/sagemaker/train/), which reduces the time and cost to train and tune ML models at scale, and [Amazon SageMaker Processing](https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html), a simplified, managed experience to run data-processing workloads. The company runs its custom ML models using multi-GPU instances for fast performance. “The GPU instances on Amazon SageMaker are simple to use,” says Ellen Light, backend engineer at Fetch. Fetch trains these models to identify and extract key information on receipts that the company can use to generate valuable insights and reward users. And on Amazon SageMaker, Fetch’s custom ML system is seamlessly scalable. “By using Amazon SageMaker, we have a simple way to scale up our systems, especially for inference and runtime,” says Sam Corzine, ML engineer at Fetch. Meanwhile, standardized model deployments mean less manual work. Fetch heavily relied on the ML training features of Amazon SageMaker, particularly its [training jobs](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateTrainingJob.html), as it refined and iterated on its models. Fetch can also train ML models in parallel, which speeds up development and deployments. “There’s little friction for us to deploy models,” says Alec Stashevsky, applied scientist at Fetch. “Basically, we don’t have to think about it.” This has increased confidence and improved productivity for the entire company. In one example, a new intern was able to deploy a model himself by his third day on the job. Since adopting Amazon SageMaker for ML tuning, training, and retraining, Fetch has enhanced the accuracy of its document-understanding model by 200 percent. It continues to fine-tune its models for further improvement. “Amazon SageMaker has been a key tool in building these outstanding models,” says Quency Yu, ML engineer at Fetch. To optimize the tuning process, Fetch relies on [Amazon SageMaker Inference Recommender](https://docs.aws.amazon.com/sagemaker/latest/dg/inference-recommender.html), a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning. In addition to its custom ML models, Fetch uses [AWS Deep Learning Containers ](https://aws.amazon.com/machine-learning/containers/)(AWS DL Containers), which businesses can use to quickly deploy deep learning environments with optimized, prepackaged container images. This simplifies the process of using libraries from [Hugging Face Inc.](https://huggingface.co/)(Hugging Face), an artificial intelligence technology company and [AWS Partner](https://partners.amazonaws.com/partners/0010h00001jBrjVAAS/Hugging%20Face%20Inc.). Specifically, Fetch uses the Amazon SageMaker Hugging Face Inference Toolkit, an open-source library for serving transformers models, and the Hugging Face AWS Deep Learning Container for training and inference. “Using the flexibility of the Hugging Face AWS Deep Learning Container, we could improve the quality of our models,” says Corzine. “And Hugging Face’s partnership with AWS meant that it was simple to deploy these models.” For every metric that Fetch measures, performance has improved since adopting Amazon SageMaker. The company has reduced latency for its slowest scans by 50 percent. “Our improved accuracy also creates confidence in our data among partners,” says Corzine. With more confidence, partners will increase their use of Fetch’s solution. “Being able to meaningfully improve accuracy on literally every data point using Amazon SageMaker is a huge benefit and propagates throughout our entire business,” says Corzine. Fetch can now extract more types of data from a receipt, and it has the flexibility to structure resulting insights according to the specific needs of brand partners. “Leaning into ML has unlocked the ability to extract exactly what our partners want from a receipt,” says Corzine. “Partners can make new types of offers because of our investment in ML, and that’s a huge additional benefit for them.” Users enjoy the updates too; Fetch has grown from 10 million to 18 million monthly active users since it released the new version. “Amazon SageMaker is a game changer for Fetch,” says Corzine. “We use almost every feature extensively. As new features come out, they are immediately valuable. It’s hard to imagine having done this project without the features of Amazon SageMaker.” For example, Fetch migrated from a custom shadow testing pipeline to [Amazon SageMaker shadow testing](https://aws.amazon.com/sagemaker/shadow-testing/)—which validates the performance of new ML models against production models to prevent outages. Now, shadow testing is more direct because Fetch can directly compare performance with production traffic. ## Outcome | Expanding ML to New Use Cases The ML team at Fetch is continually working on new models and iterating on existing ones to tune them for better performance. “Another thing we like is being able to keep our technology stack up to date with new features of Amazon SageMaker,” says Chris Lee, ML developer at Fetch. The company will continue expanding its use of AWS to different ML use cases, such as fraud prevention, across multiple teams. Already one of the biggest consumer engagement software companies, Fetch aims to continue growing. “AWS is a key part of how we plan to scale, and we’ll lean into the features of Amazon SageMaker to continue improving our accuracy,” says Corzine. ## About Fetch Fetch is a consumer engagement company that provides insights on consumer purchases to brand partners. It also offers a mobile rewards app that lets users earn rewards on purchases through a receipt-scanning feature. _If you need support in using Hugging Face on SageMaker for your company, please contact us [here](https://huggingface.co/support#form) - our team will contact you to discuss your requirements!_
|
Spread Your Wings: Falcon 180B is here
|
philschmid
|
September 6, 2023
|
falcon-180b
|
nlp, community, research, LLM
|
https://huggingface.co/blog/falcon-180b
|
# Spread Your Wings: Falcon 180B is here ## Introduction **Today, we're excited to welcome [TII's](https://falconllm.tii.ae/) Falcon 180B to HuggingFace!** Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) dataset. This represents the longest single-epoch pretraining for an open model. You can find the model on the Hugging Face Hub ([base](https://huggingface.co/tiiuae/falcon-180B) and [chat](https://huggingface.co/tiiuae/falcon-180B-chat) model) and interact with the model on the [Falcon Chat Demo Space](https://huggingface.co/spaces/tiiuae/falcon-180b-chat). In terms of capabilities, Falcon 180B achieves state-of-the-art results across natural language tasks. It tops the leaderboard for (pre-trained) open-access models and rivals proprietary models like PaLM-2. While difficult to rank definitively yet, it is considered on par with PaLM-2 Large, making Falcon 180B one of the most capable LLMs publicly known. In this blog post, we explore what makes Falcon 180B so good by looking at some evaluation results and show how you can use the model. * [What is Falcon-180B?](#what-is-falcon-180b) * [How good is Falcon 180B?](#how-good-is-falcon-180b) * [How to use Falcon 180B?](#how-to-use-falcon-180b) * [Demo](#demo) * [Hardware requirements](#hardware-requirements) * [Prompt format](#prompt-format) * [Transformers](#transformers) * [Additional Resources](#additional-resources) ## What is Falcon-180B? Falcon 180B is a model released by [TII](https://falconllm.tii.ae/) that follows previous releases in the Falcon family. Architecture-wise, Falcon 180B is a scaled-up version of [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) and builds on its innovations such as multiquery attention for improved scalability. We recommend reviewing the [initial blog post](https://huggingface.co/blog/falcon) introducing Falcon to dive into the architecture. Falcon 180B was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute. The dataset for Falcon 180B consists predominantly of web data from [RefinedWeb](https://arxiv.org/abs/2306.01116) (\~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (\~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch. The released [chat model](https://huggingface.co/tiiuae/falcon-180B-chat) is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets. ‼️ Commercial use: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the [license](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/LICENSE.txt) and consult your legal team if you are interested in using it for commercial purposes. ## How good is Falcon 180B? Falcon 180B is the best openly released LLM today, outperforming Llama 2 70B and OpenAI’s GPT-3.5 on MMLU, and is on par with Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD. Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark and further finetuning from the community will be very interesting to follow now that it's openly released. 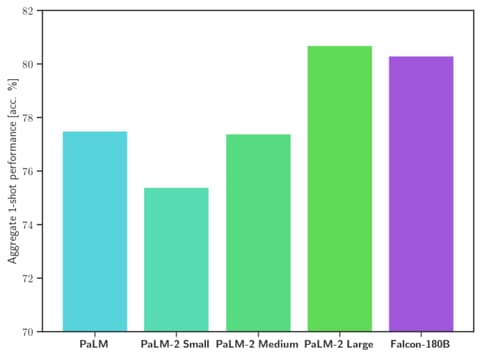 With 68.74 on the Hugging Face Leaderboard, Falcon 180B is the highest-scoring openly released pre-trained LLM, surpassing Meta’s LLaMA 2 (67.35). | Model | Size | Leaderboard score | Commercial use or license | Pretraining length | | ------- | ---- | ----------------- | ------------------------- | ------------------ | | Falcon | 180B | 68.74 | 🟠 | 3,500B | | Llama 2 | 70B | 67.35 | 🟠 | 2,000B | | LLaMA | 65B | 64.23 | 🔴 | 1,400B | | Falcon | 40B | 61.48 | 🟢 | 1,000B | | MPT | 30B | 56.15 | 🟢 | 1,000B | 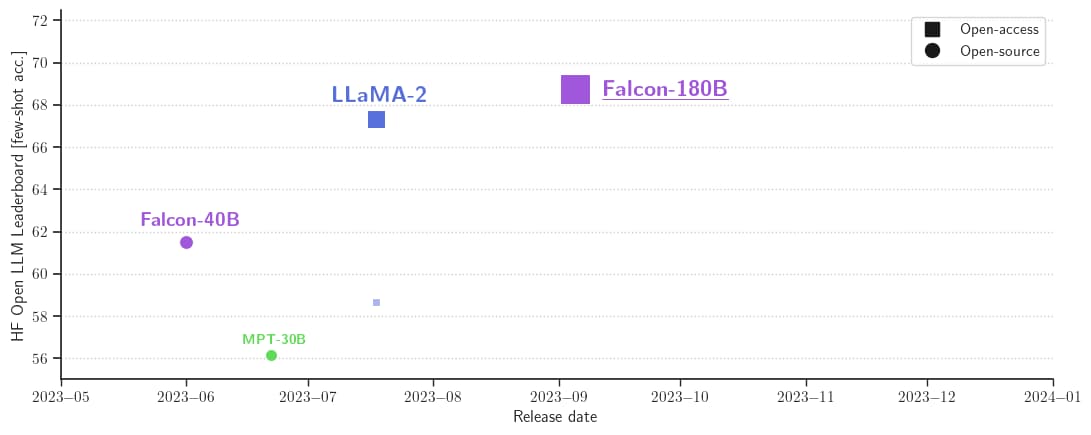 The quantized Falcon models preserve similar metrics across benchmarks. The results were similar when evaluating `torch.float16`, `8bit`, and `4bit`. See results in the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). ## How to use Falcon 180B? Falcon 180B is available in the Hugging Face ecosystem, starting with Transformers version 4.33. ### Demo You can easily try the Big Falcon Model (180 billion parameters!) in [this Space](https://huggingface.co/spaces/tiiuae/falcon-180b-demo) or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.42.0/gradio.js"> </script> <gradio-app theme_mode="light" space="tiiuae/falcon-180b-chat"></gradio-app> ### Hardware requirements We ran several tests on the hardware needed to run the model for different use cases. Those are not the minimum numbers, but the minimum numbers for the configurations we had access to. | | Type | Kind | Memory | Example | | ----------- | --------- | ---------------- | ------------------- | --------------- | | Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB | | Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB | | Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB | | Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB | | Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB | ### Prompt format The base model has no prompt format. Remember that it’s not a conversational model or trained with instructions, so don’t expect it to generate conversational responses—the pretrained model is a great platform for further finetuning, but you probably shouldn’t driectly use it out of the box. The Chat model has a very simple conversation structure. ```bash System: Add an optional system prompt here User: This is the user input Falcon: This is what the model generates User: This might be a second turn input Falcon: and so on ``` ### Transformers With the release of Transformers 4.33, you can use Falcon 180B and leverage all the tools in the HF ecosystem, such as: - training and inference scripts and examples - safe file format (safetensors) - integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning) and GPTQ - assisted generation (also known as “speculative decoding”) - RoPE scaling support for larger context lengths - rich and powerful generation parameters Use of the model requires you to accept its license and terms of use. Please, make sure you are logged into your Hugging Face account and ensure you have the latest version of `transformers`: ```bash pip install --upgrade transformers huggingface-cli login ``` #### bfloat16 This is how you’d use the base model in `bfloat16`. Falcon 180B is a big model, so please take into account the hardware requirements summarized in the table above. ```python from transformers import AutoTokenizer, AutoModelForCausalLM import transformers import torch model_id = "tiiuae/falcon-180B" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, device_map="auto", ) prompt = "My name is Pedro, I live in" inputs = tokenizer(prompt, return_tensors="pt").to("cuda") output = model.generate( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], do_sample=True, temperature=0.6, top_p=0.9, max_new_tokens=50, ) output = output[0].to("cpu") print(tokenizer.decode(output) ``` This could produce an output such as: ``` My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video. I love to travel and I am always looking for new adventures. I love to meet new people and explore new places. ``` #### 8-bit and 4-bit with `bitsandbytes` The 8-bit and 4-bit quantized versions of Falcon 180B show almost no difference in evaluation with respect to the `bfloat16` reference! This is very good news for inference, as you can confidently use a quantized version to reduce hardware requirements. Keep in mind, though, that 8-bit inference is *much faster* than running the model in `4-bit`. To use quantization, you need to install the `bitsandbytes` library and simply enable the corresponding flag when loading the model: ```python model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, load_in_8bit=True, device_map="auto", ) ``` #### Chat Model As mentioned above, the version of the model fine-tuned to follow conversations used a very straightforward training template. We have to follow the same pattern in order to run chat-style inference. For reference, you can take a look at the [format_prompt](https://huggingface.co/spaces/tiiuae/falcon-180b-demo/blob/main/app.py#L28) function in the Chat demo, which looks like this: ```python def format_prompt(message, history, system_prompt): prompt = "" if system_prompt: prompt += f"System: {system_prompt}\n" for user_prompt, bot_response in history: prompt += f"User: {user_prompt}\n" prompt += f"Falcon: {bot_response}\n" prompt += f"User: {message}\nFalcon:" return prompt ``` As you can see, interactions from the user and responses by the model are preceded by `User: ` and `Falcon: ` separators. We concatenate them together to form a prompt containing the conversation's whole history. We can provide a system prompt to tweak the generation style. ## Additional Resources - [Models](https://huggingface.co/models?other=falcon&sort=trending&search=180) - [Demo](https://huggingface.co/spaces/tiiuae/falcon-180b-chat) - [The Falcon has landed in the Hugging Face ecosystem](https://huggingface.co/blog/falcon) - [Official Announcement](https://falconllm.tii.ae/) ## Acknowledgments Releasing such a model with support and evaluations in the ecosystem would not be possible without the contributions of many community members, including [Clémentine](https://huggingface.co/clefourrier) and [Eleuther Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) for LLM evaluations; [Loubna](https://huggingface.co/loubnabnl) and [BigCode](https://huggingface.co/bigcode) for code evaluations; [Nicolas](https://hf.co/narsil) for Inference support; [Lysandre](https://huggingface.co/lysandre), [Matt](https://huggingface.co/Rocketknight1), [Daniel](https://huggingface.co/DanielHesslow), [Amy](https://huggingface.co/amyeroberts), [Joao](https://huggingface.co/joaogante), and [Arthur](https://huggingface.co/ArthurZ) for integrating Falcon into transformers. Thanks to [Baptiste](https://huggingface.co/BapBap) and [Patrick](https://huggingface.co/patrickvonplaten) for the open-source demo. Thanks to [Thom](https://huggingface.co/thomwolf), [Lewis](https://huggingface.co/lewtun), [TheBloke](https://huggingface.co/thebloke), [Nouamane](https://huggingface.co/nouamanetazi), [Tim Dettmers](https://huggingface.co/timdettmers) for multiple contributions enabling this to get out. Finally, thanks to the HF Cluster for enabling running LLM evaluations as well as providing inference for a free, open-source demo of the model.
|
Efficient Controllable Generation for SDXL with T2I-Adapters
|
Adapter
|
September 8, 2023
|
t2i-sdxl-adapters
|
guide, collaboration, diffusers, diffusion
|
https://huggingface.co/blog/t2i-sdxl-adapters
|
# Efficient Controllable Generation for SDXL with T2I-Adapters <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/t2i-adapters-sdxl/hf_tencent.png" height=180/> </p> [T2I-Adapter](https://huggingface.co/papers/2302.08453) is an efficient plug-and-play model that provides extra guidance to pre-trained text-to-image models while freezing the original large text-to-image models. T2I-Adapter aligns internal knowledge in T2I models with external control signals. We can train various adapters according to different conditions and achieve rich control and editing effects. As a contemporaneous work, [ControlNet](https://hf.co/papers/2302.05543) has a similar function and is widely used. However, it can be **computationally expensive** to run. This is because, during each denoising step of the reverse diffusion process, both the ControlNet and UNet need to be run. In addition, ControlNet emphasizes the importance of copying the UNet encoder as a control model, resulting in a larger parameter number. Thus, the generation is bottlenecked by the size of the ControlNet (the larger, the slower the process becomes). T2I-Adapters provide a competitive advantage to ControlNets in this matter. T2I-Adapters are smaller in size, and unlike ControlNets, T2I-Adapters are run just once for the entire course of the denoising process. | **Model Type** | **Model Parameters** | **Storage (fp16)** | | --- | --- | --- | | [ControlNet-SDXL](https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0) | 1251 M | 2.5 GB | | [ControlLoRA](https://huggingface.co/stabilityai/control-lora) (with rank 128) | 197.78 M (84.19% reduction) | 396 MB (84.53% reduction) | | [T2I-Adapter-SDXL](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0) | 79 M (**_93.69% reduction_**) | 158 MB (**_94% reduction_**) | Over the past few weeks, the Diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for [Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) in [`diffusers`](https://github.com/huggingface/diffusers). In this blog post, we share our findings from training T2I-Adapters on SDXL from scratch, some appealing results, and, of course, the T2I-Adapter checkpoints on various conditionings (sketch, canny, lineart, depth, and openpose)!  Compared to previous versions of T2I-Adapter (SD-1.4/1.5), [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter) still uses the original recipe, driving 2.6B SDXL with a 79M Adapter! T2I-Adapter-SDXL maintains powerful control capabilities while inheriting the high-quality generation of SDXL! ## Training T2I-Adapter-SDXL with `diffusers` We built our training script on [this official example](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md) provided by `diffusers`. Most of the T2I-Adapter models we mention in this blog post were trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with the following settings: - Training steps: 20000-35000 - Batch size: Data parallel with a single GPU batch size of 16 for a total batch size of 128. - Learning rate: Constant learning rate of 1e-5. - Mixed precision: fp16 We encourage the community to use our scripts to train custom and powerful T2I-Adapters, striking a competitive trade-off between speed, memory, and quality. ## Using T2I-Adapter-SDXL in `diffusers` Here, we take the lineart condition as an example to demonstrate the usage of [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter/tree/XL). To get started, first install the required dependencies: ```bash pip install -U git+https://github.com/huggingface/diffusers.git pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors pip install transformers accelerate ``` The generation process of the T2I-Adapter-SDXL mainly consists of the following two steps: 1. Condition images are first prepared into the appropriate *control image* format. 2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/0ec7a02b6a609a31b442cdf18962d7238c5be25d/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L126). Let's have a look at a simple example using the [Lineart Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0). We start by initializing the T2I-Adapter pipeline for SDXL and the lineart detector. ```python import torch from controlnet_aux.lineart import LineartDetector from diffusers import (AutoencoderKL, EulerAncestralDiscreteScheduler, StableDiffusionXLAdapterPipeline, T2IAdapter) from diffusers.utils import load_image, make_image_grid # load adapter adapter = T2IAdapter.from_pretrained( "TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16" ).to("cuda") # load pipeline model_id = "stabilityai/stable-diffusion-xl-base-1.0" euler_a = EulerAncestralDiscreteScheduler.from_pretrained( model_id, subfolder="scheduler" ) vae = AutoencoderKL.from_pretrained( "madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16 ) pipe = StableDiffusionXLAdapterPipeline.from_pretrained( model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16", ).to("cuda") # load lineart detector line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda") ``` Then, load an image to detect lineart: ```python url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg" image = load_image(url) image = line_detector(image, detect_resolution=384, image_resolution=1024) ```  Then we generate: ```python prompt = "Ice dragon roar, 4k photo" negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured" gen_images = pipe( prompt=prompt, negative_prompt=negative_prompt, image=image, num_inference_steps=30, adapter_conditioning_scale=0.8, guidance_scale=7.5, ).images[0] gen_images.save("out_lin.png") ```  There are two important arguments to understand that help you control the amount of conditioning. 1. `adapter_conditioning_scale` This argument controls how much influence the conditioning should have on the input. High values mean a higher conditioning effect and vice-versa. 2. `adapter_conditioning_factor` This argument controls how many initial generation steps should have the conditioning applied. The value should be set between 0-1 (default is 1). The value of `adapter_conditioning_factor=1` means the adapter should be applied to all timesteps, while the `adapter_conditioning_factor=0.5` means it will only applied for the first 50% of the steps. For more details, we welcome you to check the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/adapter). ## Try out the Demo You can easily try T2I-Adapter-SDXL in [this Space](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script> <gradio-app src="https://tencentarc-t2i-adapter-sdxl.hf.space"></gradio-app> You can also try out [Doodly](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch), built using the sketch model that turns your doodles into realistic images (with language supervision): <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script> <gradio-app src="https://tencentarc-t2i-adapter-sdxl-sketch.hf.space"></gradio-app> ## More Results Below, we present results obtained from using different kinds of conditions. We also supplement the results with links to their corresponding pre-trained checkpoints. Their model cards contain more details on how they were trained, along with example usage. ### Lineart Guided  *Model from [`TencentARC/t2i-adapter-lineart-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)* ### Sketch Guided  *Model from [`TencentARC/t2i-adapter-sketch-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)* ### Canny Guided  *Model from [`TencentARC/t2i-adapter-canny-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)* ### Depth Guided  *Depth guided models from [`TencentARC/t2i-adapter-depth-midas-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0) and [`TencentARC/t2i-adapter-depth-zoe-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0) respectively* ### OpenPose Guided  *Model from [`TencentARC/t2i-adapter-openpose-sdxl-1.0`](https://hf.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)* --- *Acknowledgements: Immense thanks to [William Berman](https://twitter.com/williamLberman) for helping us train the models and sharing his insights.*
|
SafeCoder vs. Closed-source Code Assistants
|
julsimon
|
September 11, 2023
|
safecoder-vs-closed-source-code-assistants
|
bigcode
|
https://huggingface.co/blog/safecoder-vs-closed-source-code-assistants
|
# SafeCoder vs. Closed-source Code Assistants For decades, software developers have designed methodologies, processes, and tools that help them improve code quality and increase productivity. For instance, agile, test-driven development, code reviews, and CI/CD are now staples in the software industry. In "How Google Tests Software" (Addison-Wesley, 2012), Google reports that fixing a bug during system tests - the final testing stage - is 1000x more expensive than fixing it at the unit testing stage. This puts much pressure on developers - the first link in the chain - to write quality code from the get-go. For all the hype surrounding generative AI, code generation seems a promising way to help developers deliver better code fast. Indeed, early studies show that managed services like [GitHub Copilot](https://github.blog/2023-06-27-the-economic-impact-of-the-ai-powered-developer-lifecycle-and-lessons-from-github-copilot) or [Amazon CodeWhisperer](https://aws.amazon.com/codewhisperer/) help developers be more productive. However, these services rely on closed-source models that can't be customized to your technical culture and processes. Hugging Face released [SafeCoder](https://huggingface.co/blog/starcoder) a few weeks ago to fix this. SafeCoder is a code assistant solution built for the enterprise that gives you state-of-the-art models, transparency, customizability, IT flexibility, and privacy. In this post, we'll compare SafeCoder to closed-source services and highlight the benefits you can expect from our solution. ## State-of-the-art models SafeCoder is currently built on top of the [StarCoder](https://huggingface.co/blog/starcoder) models, a family of open-source models designed and trained within the [BigCode](https://huggingface.co/bigcode) collaborative project. StarCoder is a 15.5 billion parameter model trained for code generation in over 80 programming languages. It uses innovative architectural concepts, like [Multi-Query Attention](https://arxiv.org/abs/1911.02150) (MQA), to improve throughput and reduce latency, a technique also present in the [Falcon](https://huggingface.co/blog/falcon) and adapted for [LLaMa 2](https://huggingface.co/blog/llama2) models. StarCoder has an 8192-token context window, helping it take into account more of your code to generate new code. It can also do fill-in-the-middle, i.e., insert within your code, instead of just appending new code at the end. Lastly, like [HuggingChat](https://huggingface.co/chat/), SafeCoder will introduce new state-of-the-art models over time, giving you a seamless upgrade path. Unfortunately, closed-source code assistant services don't share information about the underlying models, their capabilities, and their training data. ## Transparency In line with the [Chinchilla Scaling Law](https://arxiv.org/abs/2203.15556v1), SafeCoder is a compute-optimal model trained on 1 trillion (1,000 billion) code tokens. These tokens are extracted from [The Stack](https://huggingface.co/datasets/bigcode/the-stack), a 2.7 terabyte dataset built from permissively licensed open-source repositories. All efforts are made to honor opt-out requests, and we built a [tool](https://huggingface.co/spaces/bigcode/in-the-stack) that lets repository owners check if their code is part of the dataset. In the spirit of transparency, our [research paper](https://arxiv.org/abs/2305.06161) discloses the model architecture, the training process, and detailed metrics. Unfortunately, closed-source services stick to vague information, such as "[the model was trained on] billions of lines of code." To the best of our knowledge, no metrics are available. ## Customization The StarCoder models have been specifically designed to be customizable, and we have already built different versions: * [StarCoderBase](https://huggingface.co/bigcode/starcoderbase): the original model trained on 80+ languages from The Stack. * [StarCoder](https://huggingface.co/bigcode/starcoder): StarCoderBase further trained on Python. * [StarCoder+](https://huggingface.co/bigcode/starcoderplus): StarCoderBase further trained on English web data for coding conversations. We also shared the [fine-tuning code](https://github.com/bigcode-project/starcoder/) on GitHub. Every company has its preferred languages and coding guidelines, i.e., how to write inline documentation or unit tests, or do's and don'ts on security and performance. With SafeCoder, we can help you train models that learn the peculiarities of your software engineering process. Our team will help you prepare high-quality datasets and fine-tune StarCoder on your infrastructure. Your data will never be exposed to anyone. Unfortunately, closed-source services cannot be customized. ## IT flexibility SafeCoder relies on Docker containers for fine-tuning and deployment. It's easy to run on-premise or in the cloud on any container management service. In addition, SafeCoder includes our [Optimum](https://github.com/huggingface/optimum) hardware acceleration libraries. Whether you work with CPU, GPU, or AI accelerators, Optimum will kick in automatically to help you save time and money on training and inference. Since you control the underlying hardware, you can also tune the cost-performance ratio of your infrastructure to your needs. Unfortunately, closed-source services are only available as managed services. ## Security and privacy Security is always a top concern, all the more when source code is involved. Intellectual property and privacy must be protected at all costs. Whether you run on-premise or in the cloud, SafeCoder is under your complete administrative control. You can apply and monitor your security checks and maintain strong and consistent compliance across your IT platform. SafeCoder doesn't spy on any of your data. Your prompts and suggestions are yours and yours only. SafeCoder doesn't call home and send telemetry data to Hugging Face or anyone else. No one but you needs to know how and when you're using SafeCoder. SafeCoder doesn't even require an Internet connection. You can (and should) run it fully air-gapped. Closed-source services rely on the security of the underlying cloud. Whether this works or not for your compliance posture is your call. For enterprise users, prompts and suggestions are not stored (they are for individual users). However, we regret to point out that GitHub collects ["user engagement data"](https://docs.github.com/en/copilot/overview-of-github-copilot/about-github-copilot-for-business) with no possibility to opt-out. AWS does the same by default but lets you [opt out](https://docs.aws.amazon.com/codewhisperer/latest/userguide/sharing-data.html). ## Conclusion We're very excited about the future of SafeCoder, and so are our customers. No one should have to compromise on state-of-the-art code generation, transparency, customization, IT flexibility, security, and privacy. We believe SafeCoder delivers them all, and we'll keep working hard to make it even better. If you’re interested in SafeCoder for your company, please [contact us](mailto:[email protected]). Our team will contact you shortly to learn more about your use case and discuss requirements. Thanks for reading!
|
Overview of natively supported quantization schemes in 🤗 Transformers
|
ybelkada
|
September 12, 2023
|
overview-quantization-transformers
|
llm, optimization, quantization, comparison, bitsandbytes, gptq
|
https://huggingface.co/blog/overview-quantization-transformers
|
# Overview of natively supported quantization schemes in 🤗 Transformers We aim to give a clear overview of the pros and cons of each quantization scheme supported in transformers to help you decide which one you should go for. Currently, quantizing models are used for two main purposes: - Running inference of a large model on a smaller device - Fine-tune adapters on top of quantized models So far, two integration efforts have been made and are **natively** supported in transformers : *bitsandbytes* and *auto-gptq*. Note that some additional quantization schemes are also supported in the [🤗 optimum library](https://github.com/huggingface/optimum), but this is out of scope for this blogpost. To learn more about each of the supported schemes, please have a look at one of the resources shared below. Please also have a look at the appropriate sections of the documentation. Note also that the details shared below are only valid for `PyTorch` models, this is currently out of scope for Tensorflow and Flax/JAX models. ## Table of contents - [Resources](#resources) - [Comparing bitsandbytes and auto-gptq](#Comparing-bitsandbytes-and-auto-gptq) - [Diving into speed benchmarks](#Diving-into-speed-benchmarks) - [Conclusion and final words](#conclusion-and-final-words) - [Acknowledgements](#acknowledgements) ## Resources - [GPTQ blogpost](https://huggingface.co/blog/gptq-integration) – gives an overview on what is the GPTQ quantization method and how to use it. - [bistandbytes 4-bit quantization blogpost](https://huggingface.co/blog/4bit-transformers-bitsandbytes) - This blogpost introduces 4-bit quantization and QLoRa, an efficient finetuning approach. - [bistandbytes 8-bit quantization blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) - This blogpost explains how 8-bit quantization works with bitsandbytes. - [Basic usage Google Colab notebook for GPTQ](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with the GPTQ method, how to do inference, and how to do fine-tuning with the quantized model. - [Basic usage Google Colab notebook for bitsandbytes](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing) - This notebook shows how to use 4-bit models in inference with all their variants, and how to run GPT-neo-X (a 20B parameter model) on a free Google Colab instance. - [Merve's blogpost on quantization](https://huggingface.co/blog/merve/quantization) - This blogpost provides a gentle introduction to quantization and the quantization methods supported natively in transformers. ## Comparing bitsandbytes and auto-gptq In this section, we will go over the pros and cons of bitsandbytes and gptq quantization. Note that these are based on the feedback from the community and they can evolve over time as some of these features are in the roadmap of the respective libraries. ### What are the benefits of bitsandbytes? **easy**: bitsandbytes still remains the easiest way to quantize any model as it does not require calibrating the quantized model with input data (also called zero-shot quantization). It is possible to quantize any model out of the box as long as it contains `torch.nn.Linear` modules. Whenever a new architecture is added in transformers, as long as they can be loaded with accelerate’s `device_map=”auto”`, users can benefit from bitsandbytes quantization straight out of the box with minimal performance degradation. Quantization is performed on model load, no need to run any post-processing or preparation step. **cross-modality interoperability**: As the only condition to quantize a model is to contain a `torch.nn.Linear` layer, quantization works out of the box for any modality, making it possible to load models such as Whisper, ViT, Blip2, etc. in 8-bit or 4-bit out of the box. **0 performance degradation when merging adapters**: (Read more about adapters and PEFT in [this blogpost](https://huggingface.co/blog/peft) if you are not familiar with it). If you train adapters on top of the quantized base model, the adapters can be merged on top of of the base model for deployment, with no inference performance degradation. You can also [merge](https://github.com/huggingface/peft/pull/851/files) the adapters on top of the dequantized model ! This is not supported for GPTQ. ### What are the benefits of autoGPTQ? **fast for text generation**: GPTQ quantized models are fast compared to bitsandbytes quantized models for [text generation](https://huggingface.co/docs/transformers/main_classes/text_generation). We will address the speed comparison in an appropriate section. **n-bit support**: The GPTQ algorithm makes it possible to quantize models up to 2 bits! However, this might come with severe quality degradation. The recommended number of bits is 4, which seems to be a great tradeoff for GPTQ at this time. **easily-serializable**: GPTQ models support serialization for any number of bits. Loading models from TheBloke namespace: https://huggingface.co/TheBloke (look for those that end with the `-GPTQ` suffix) is supported out of the box, as long as you have the required packages installed. Bitsandbytes supports 8-bit serialization but does not support 4-bit serialization as of today. **AMD support**: The integration should work out of the box for AMD GPUs! ### What are the potential rooms of improvements of bitsandbytes? **slower than GPTQ for text generation**: bitsandbytes 4-bit models are slow compared to GPTQ when using [`generate`](https://huggingface.co/docs/transformers/main_classes/text_generation). **4-bit weights are not serializable**: Currently, 4-bit models cannot be serialized. This is a frequent community request, and we believe it should be addressed very soon by the bitsandbytes maintainers as it's in their roadmap! ### What are the potential rooms of improvements of autoGPTQ? **calibration dataset**: The need of a calibration dataset might discourage some users to go for GPTQ. Furthermore, it can take several hours to quantize the model (e.g. 4 GPU hours for a 175B scale model [according to the paper](https://arxiv.org/pdf/2210.17323.pdf) - section 2) **works only for language models (for now)**: As of today, the API for quantizing a model with auto-GPTQ has been designed to support only language models. It should be possible to quantize non-text (or multimodal) models using the GPTQ algorithm, but the process has not been elaborated in the original paper or in the auto-gptq repository. If the community is excited about this topic this might be considered in the future. ## Diving into speed benchmarks We decided to provide an extensive benchmark for both inference and fine-tuning adapters using bitsandbytes and auto-gptq on different hardware. The inference benchmark should give users an idea of the speed difference they might get between the different approaches we propose for inference, and the adapter fine-tuning benchmark should give a clear idea to users when it comes to deciding which approach to use when fine-tuning adapters on top of bitsandbytes and GPTQ base models. We will use the following setup: - bitsandbytes: 4-bit quantization with `bnb_4bit_compute_dtype=torch.float16`. Make sure to use `bitsandbytes>=0.41.1` for fast 4-bit kernels. - auto-gptq: 4-bit quantization with exllama kernels. You will need `auto-gptq>=0.4.0` to use ex-llama kernels. ### Inference speed (forward pass only) This benchmark measures only the prefill step, which corresponds to the forward pass during training. It was run on a single NVIDIA A100-SXM4-80GB GPU with a prompt length of 512. The model we used was `meta-llama/Llama-2-13b-hf`. with batch size = 1: |quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)| |-----|---------|----|----------|------|-------------|----------------------|------------------|----------------| |fp16|None |None|None |None |26.0 |36.958 |27.058 |29152.98 | |gptq |False |4 |128 |exllama|36.2 |33.711 |29.663 |10484.34 | |bitsandbytes|None |4|None |None |37.64 |52.00 |19.23 |11018.36 | with batch size = 16: |quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)| |-----|---------|----|----------|------|-------------|----------------------|------------------|----------------| |fp16|None |None|None |None |26.0 |69.94 |228.76 |53986.51 | |gptq |False |4 |128 |exllama|36.2 |95.41 |167.68 |34777.04 | |bitsandbytes|None |4|None |None |37.64 |113.98 |140.38 |35532.37 | From the benchmark, we can see that bitsandbyes and GPTQ are equivalent, with GPTQ being slightly faster for large batch size. Check this [link](https://github.com/huggingface/optimum/blob/main/tests/benchmark/README.md#prefill-only-benchmark-results) to have more details on these benchmarks. ### Generate speed The following benchmarks measure the generation speed of the model during inference. The benchmarking script can be found [here](https://gist.github.com/younesbelkada/e576c0d5047c0c3f65b10944bc4c651c) for reproducibility. #### use_cache Let's test `use_cache` to better understand the impact of caching the hidden state during the generation. The benchmark was run on an A100 with a prompt length of 30 and we generated exactly 30 tokens. The model we used was `meta-llama/Llama-2-7b-hf`. with `use_cache=True` 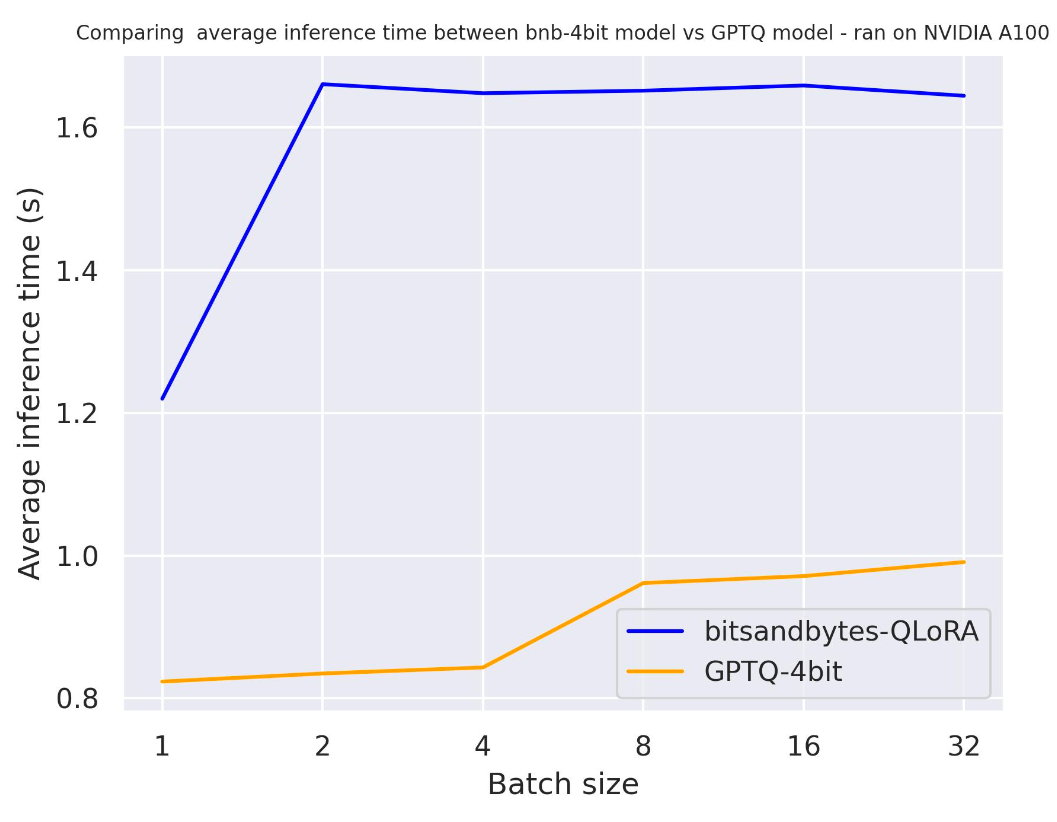 with `use_cache=False` 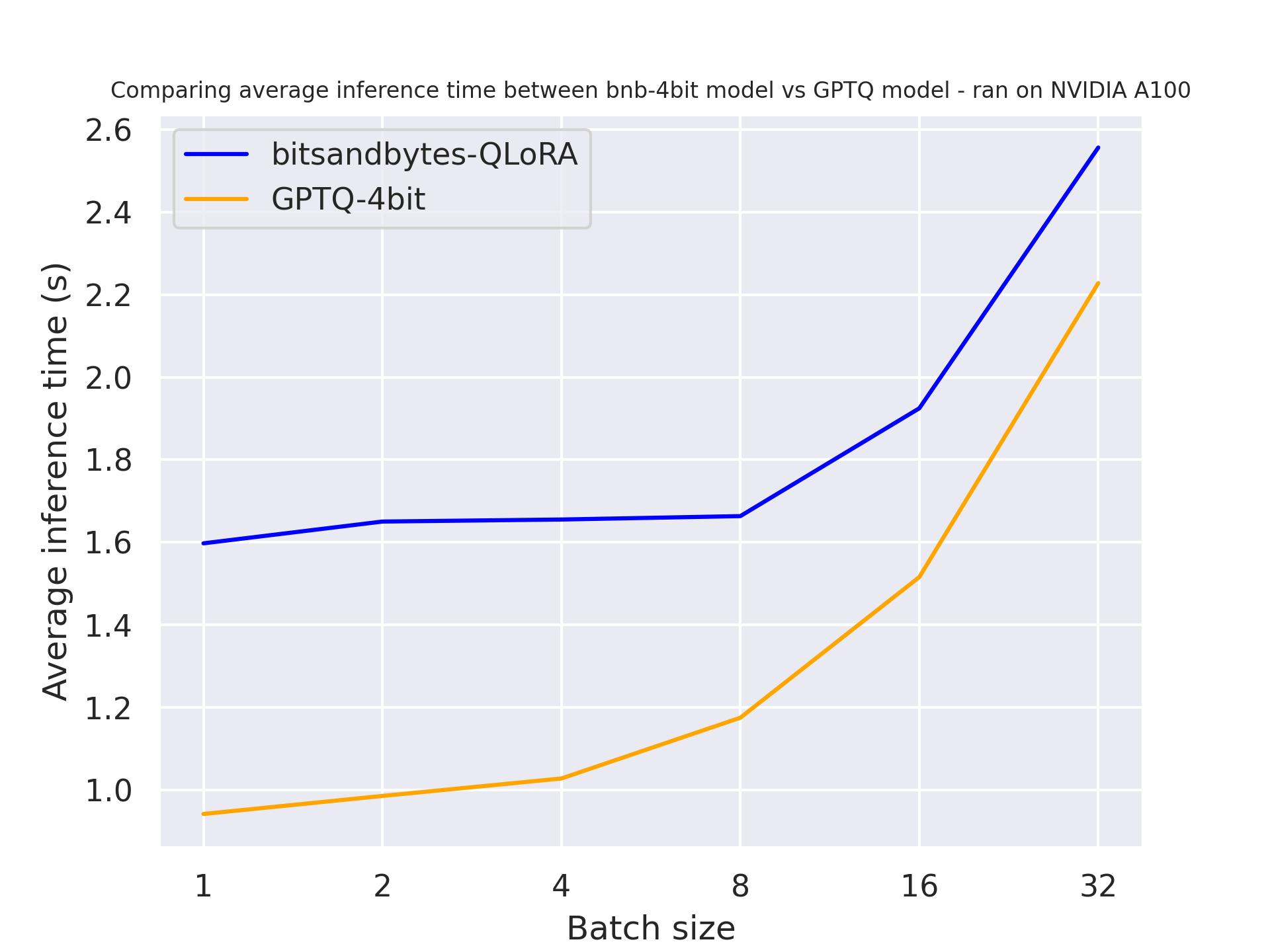 From the two benchmarks, we conclude that generation is faster when we use attention caching, as expected. Moreover, GPTQ is, in general, faster than bitsandbytes. For example, with `batch_size=4` and `use_cache=True`, it is twice as fast! Therefore let’s use `use_cache` for the next benchmarks. Note that `use_cache` will consume more memory. #### Hardware In the following benchmark, we will try different hardware to see the impact on the quantized model. We used a prompt length of 30 and we generated exactly 30 tokens. The model we used was `meta-llama/Llama-2-7b-hf`. with a NVIDIA A100:  with a NVIDIA T4: 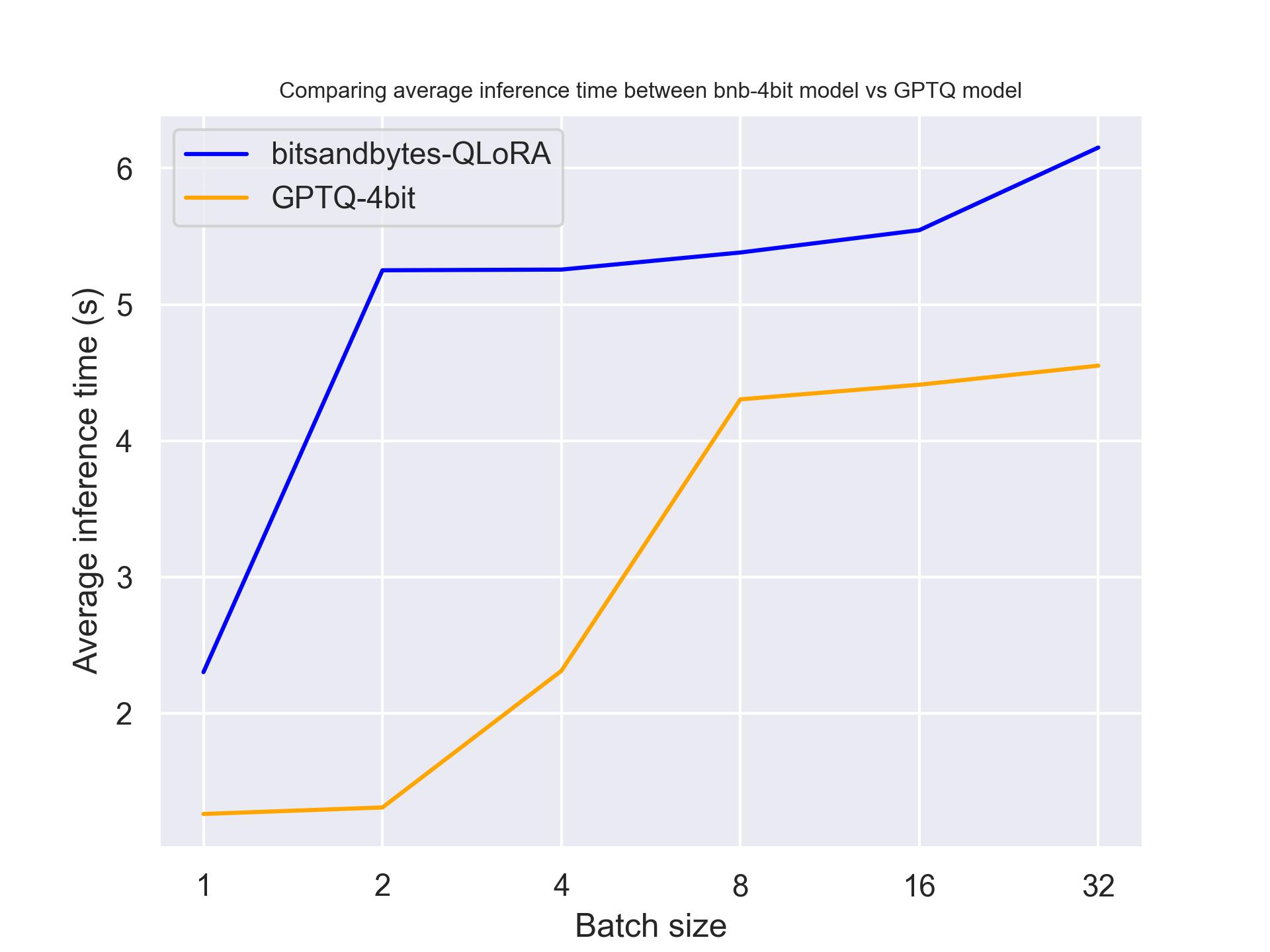 with a Titan RTX: 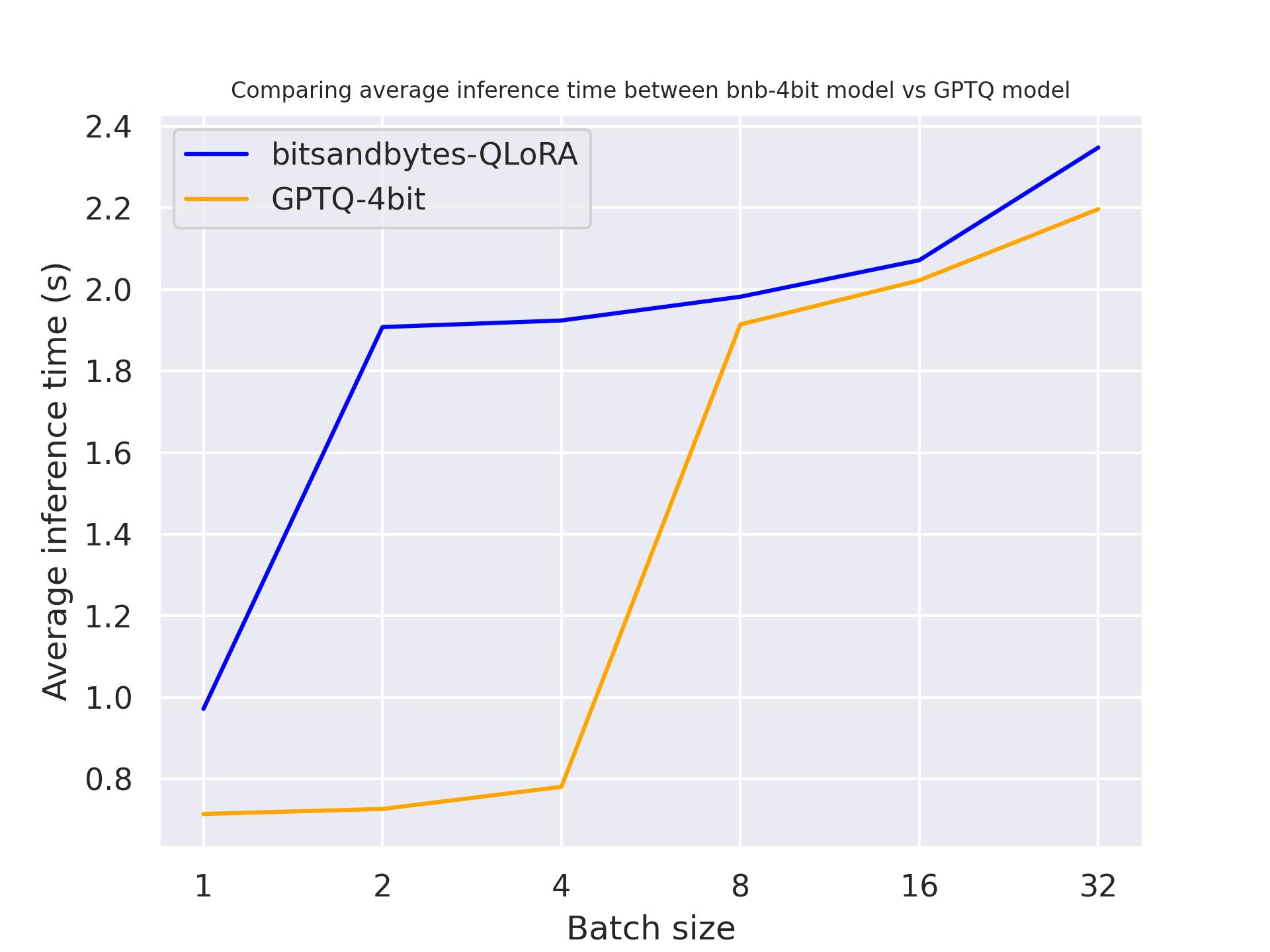 From the benchmark above, we can conclude that GPTQ is faster than bitsandbytes for those three GPUs. #### Generation length In the following benchmark, we will try different generation lengths to see their impact on the quantized model. It was run on a A100 and we used a prompt length of 30, and varied the number of generated tokens. The model we used was `meta-llama/Llama-2-7b-hf`. with 30 tokens generated:  with 512 tokens generated: 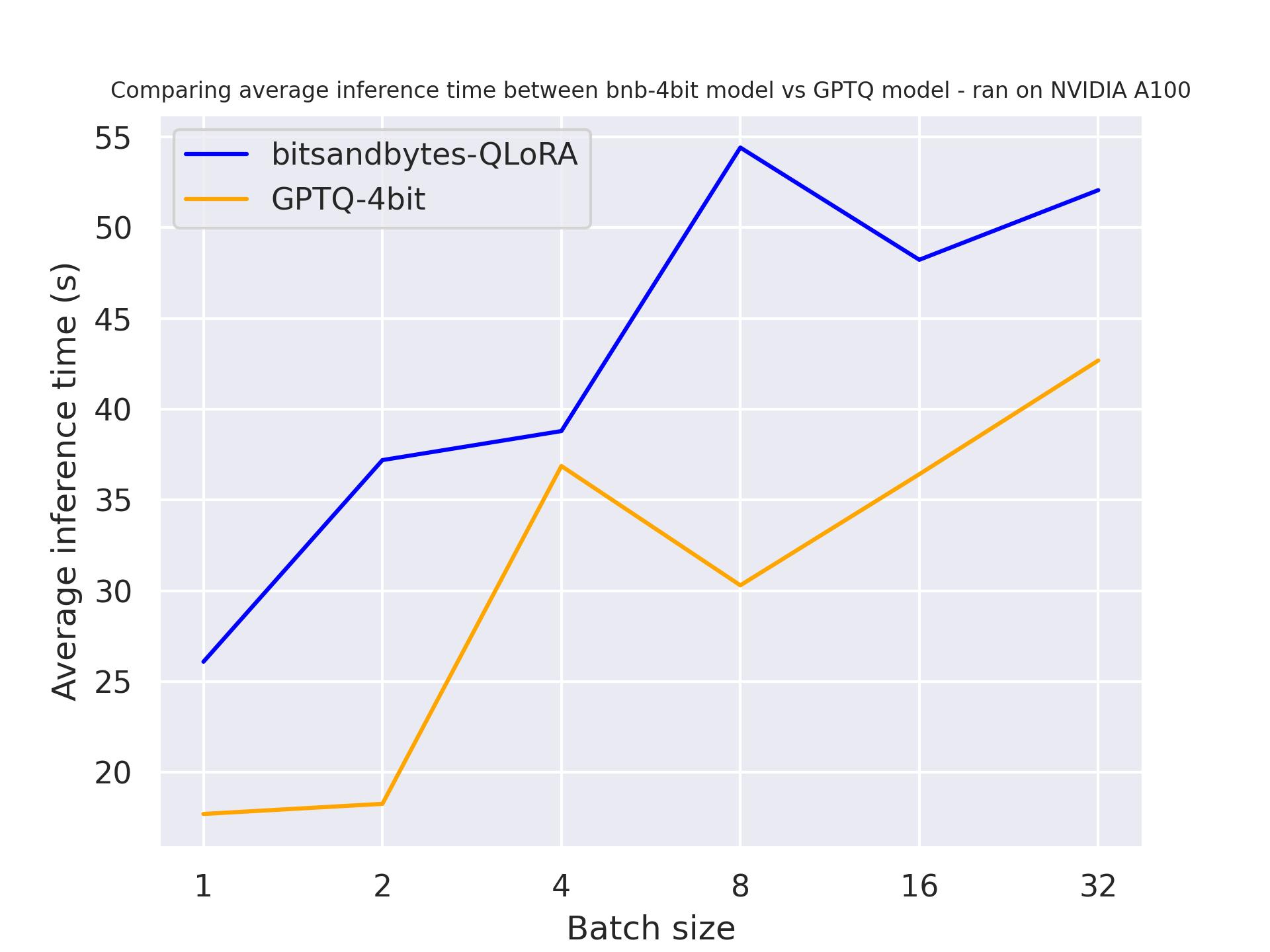 From the benchmark above, we can conclude that GPTQ is faster than bitsandbytes independently of the generation length. ### Adapter fine-tuning (forward + backward) It is not possible to perform pure training on a quantized model. However, you can fine-tune quantized models by leveraging parameter efficient fine tuning methods (PEFT) and train adapters on top of them. The fine-tuning method will rely on a recent method called "Low Rank Adapters" (LoRA): instead of fine-tuning the entire model you just have to fine-tune these adapters and load them properly inside the model. Let's compare the fine-tuning speed! The benchmark was run on a NVIDIA A100 GPU and we used `meta-llama/Llama-2-7b-hf` model from the Hub. Note that for GPTQ model, we had to disable the exllama kernels as exllama is not supported for fine-tuning. 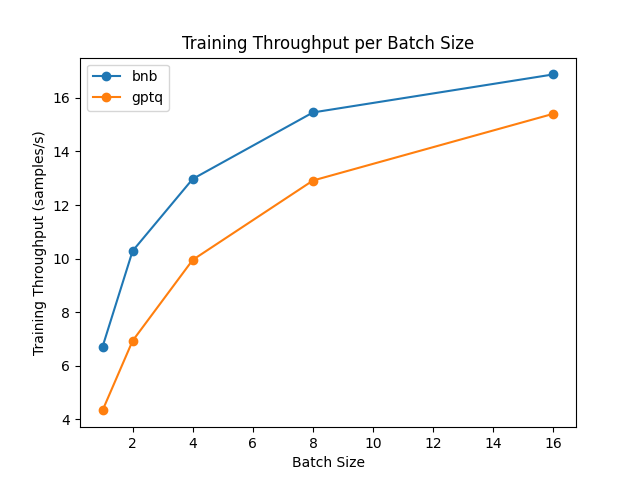 From the result, we conclude that bitsandbytes is faster than GPTQ for fine-tuning. ### Performance degradation Quantization is great for reducing memory consumption. However, it does come with performance degradation. Let's compare the performance using the [Open-LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) ! with 7b model: | model_id | Average | ARC | Hellaswag | MMLU | TruthfulQA | |------------------------------------|---------|-------|-----------|-------|------------| | meta-llama/llama-2-7b-hf | **54.32** | 53.07 | 78.59 | 46.87 | 38.76 | | meta-llama/llama-2-7b-hf-bnb-4bit | **53.4** | 53.07 | 77.74 | 43.8 | 38.98 | | TheBloke/Llama-2-7B-GPTQ | **53.23** | 52.05 | 77.59 | 43.99 | 39.32 | with 13b model: | model_id | Average | ARC | Hellaswag | MMLU | TruthfulQA | |------------------------------------|---------|-------|-----------|-------|------------| | meta-llama/llama-2-13b-hf | **58.66** | 59.39 | 82.13 | 55.74 | 37.38 | | TheBloke/Llama-2-13B-GPTQ (revision = 'gptq-4bit-128g-actorder_True')| **58.03** | 59.13 | 81.48 | 54.45 | 37.07 | | TheBloke/Llama-2-13B-GPTQ | **57.56** | 57.25 | 81.66 | 54.81 | 36.56 | | meta-llama/llama-2-13b-hf-bnb-4bit | **56.9** | 58.11 | 80.97 | 54.34 | 34.17 | From the results above, we conclude that there is less degradation in bigger models. More interestingly, the degradation is minimal! ## Conclusion and final words In this blogpost, we compared bitsandbytes and GPTQ quantization across multiple setups. We saw that bitsandbytes is better suited for fine-tuning while GPTQ is better for generation. From this observation, one way to get better merged models would be to: - (1) quantize the base model using bitsandbytes (zero-shot quantization) - (2) add and fine-tune the adapters - (3) merge the trained adapters on top of the base model or the [dequantized model](https://github.com/huggingface/peft/pull/851/files) ! - (4) quantize the merged model using GPTQ and use it for deployment We hope that this overview will make it easier for everyone to use LLMs in their applications and usecases, and we are looking forward to seeing what you will build with it! ## Acknowledgements We would like to thank [Ilyas](https://huggingface.co/IlyasMoutawwakil), [Clémentine](https://huggingface.co/clefourrier) and [Felix](https://huggingface.co/fxmarty) for their help on the benchmarking. Finally, we would like to thank [Pedro Cuenca](https://github.com/pcuenca) for his help with the writing of this blogpost.
|
Fine-tuning Llama 2 70B using PyTorch FSDP
|
smangrul
|
September 13, 2023
|
ram-efficient-pytorch-fsdp
|
llm, guide, nlp
|
https://huggingface.co/blog/ram-efficient-pytorch-fsdp
|
# Fine-tuning Llama 2 70B using PyTorch FSDP ## Introduction In this blog post, we will look at how to fine-tune Llama 2 70B using PyTorch FSDP and related best practices. We will be leveraging Hugging Face Transformers, Accelerate and TRL. We will also learn how to use Accelerate with SLURM. Fully Sharded Data Parallelism (FSDP) is a paradigm in which the optimizer states, gradients and parameters are sharded across devices. During the forward pass, each FSDP unit performs an _all-gather operation_ to get the complete weights, computation is performed followed by discarding the shards from other devices. After the forward pass, the loss is computed followed by the backward pass. In the backward pass, each FSDP unit performs an all-gather operation to get the complete weights, with computation performed to get the local gradients. These local gradients are averaged and sharded across the devices via a _reduce-scatter operation_ so that each device can update the parameters of its shard. For more information on what PyTorch FSDP is, please refer to this blog post: [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp).  (Source: [link](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)) ## Hardware Used Number of nodes: 2. Minimum required is 1. Number of GPUs per node: 8 GPU type: A100 GPU memory: 80GB intra-node connection: NVLink RAM per node: 1TB CPU cores per node: 96 inter-node connection: Elastic Fabric Adapter ## Challenges with fine-tuning LLaMa 70B We encountered three main challenges when trying to fine-tune LLaMa 70B with FSDP: 1. FSDP wraps the model after loading the pre-trained model. If each process/rank within a node loads the Llama-70B model, it would require 70\*4\*8 GB ~ 2TB of CPU RAM, where 4 is the number of bytes per parameter and 8 is the number of GPUs on each node. This would result in the CPU RAM getting out of memory leading to processes being terminated. 2. Saving entire intermediate checkpoints using `FULL_STATE_DICT` with CPU offloading on rank 0 takes a lot of time and often results in NCCL Timeout errors due to indefinite hanging during broadcasting. However, at the end of training, we want the whole model state dict instead of the sharded state dict which is only compatible with FSDP. 3. We need to improve the speed and reduce the VRAM usage to train faster and save compute costs. Let’s look at how to solve the above challenges and fine-tune a 70B model! Before we get started, here's all the required resources to reproduce our results: 1. Codebase: https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training with flash-attn V2 monkey patch 2. FSDP config: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml 3. SLURM script `launch.slurm`: https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25 4. Model: `meta-llama/Llama-2-70b-chat-hf` 5. Dataset: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1) (mix of LIMA+GUANACO with proper formatting in a ready-to-train format) ### Pre-requisites First follow these steps to install Flash Attention V2: Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com). Install the latest nightlies of PyTorch with CUDA ≥11.8. Install the remaining requirements as per DHS-LLM-Workshop/code_assistant/training/requirements.txt. Here, we will be installing 🤗 Accelerate and 🤗 Transformers from the main branch. ## Fine-Tuning ### Addressing Challenge 1 PRs [huggingface/transformers#25107](https://github.com/huggingface/transformers/pull/25107) and [huggingface/accelerate#1777](https://github.com/huggingface/accelerate/pull/1777) solve the first challenge and requires no code changes from user side. It does the following: 1. Create the model with no weights on all ranks (using the `meta` device). 2. Load the state dict only on rank==0 and set the model weights with that state dict on rank 0 3. For all other ranks, do `torch.empty(*param.size(), dtype=dtype)` for every parameter on `meta` device 4. So, rank==0 will have loaded the model with correct state dict while all other ranks will have random weights. 5. Set `sync_module_states=True` so that FSDP object takes care of broadcasting them to all the ranks before training starts. Below is the output snippet on a 7B model on 2 GPUs measuring the memory consumed and model parameters at various stages. We can observe that during loading the pre-trained model rank 0 & rank 1 have CPU total peak memory of `32744 MB` and `1506 MB` , respectively. Therefore, only rank 0 is loading the pre-trained model leading to efficient usage of CPU RAM. The whole logs at be found [here](https://gist.github.com/pacman100/2fbda8eb4526443a73c1455de43e20f9) ```bash accelerator.process_index=0 GPU Memory before entering the loading : 0 accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0 accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0 accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0 accelerator.process_index=0 CPU Memory before entering the loading : 926 accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415 accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818 accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744 accelerator.process_index=1 GPU Memory before entering the loading : 0 accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0 accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0 accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0 accelerator.process_index=1 CPU Memory before entering the loading : 933 accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10 accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573 accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506 ``` ### Addressing Challenge 2 It is addressed via choosing `SHARDED_STATE_DICT` state dict type when creating FSDP config. `SHARDED_STATE_DICT` saves shard per GPU separately which makes it quick to save or resume training from intermediate checkpoint. When `FULL_STATE_DICT` is used, first process (rank 0) gathers the whole model on CPU and then saving it in a standard format. Let’s create the accelerate config via below command: ``` accelerate config --config_file "fsdp_config.yaml" ```  The resulting config is available here: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml). Here, the sharding strategy is `FULL_SHARD`. We are using `TRANSFORMER_BASED_WRAP` for auto wrap policy and it uses `_no_split_module` to find the Transformer block name for nested FSDP auto wrap. We use `SHARDED_STATE_DICT` to save the intermediate checkpoints and optimizer states in this format recommended by the PyTorch team. Make sure to enable broadcasting module parameters from rank 0 at the start as mentioned in the above paragraph on addressing Challenge 1. We are enabling `bf16` mixed precision training. For final checkpoint being the whole model state dict, below code snippet is used: ```python if trainer.is_fsdp_enabled: trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT") trainer.save_model(script_args.output_dir) # alternatively, trainer.push_to_hub() if the whole ckpt is below 50GB as the LFS limit per file is 50GB ``` ### Addressing Challenge 3 Flash Attention and enabling gradient checkpointing are required for faster training and reducing VRAM usage to enable fine-tuning and save compute costs. The codebase currently uses monkey patching and the implementation is at [chat_assistant/training/llama_flash_attn_monkey_patch.py](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/llama_flash_attn_monkey_patch.py). [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf) introduces a way to compute exact attention while being faster and memory-efficient by leveraging the knowledge of the memory hierarchy of the underlying hardware/GPUs - The higher the bandwidth/speed of the memory, the smaller its capacity as it becomes more expensive. If we follow the blog [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html), we can figure out that `Attention` module on current hardware is `memory-bound/bandwidth-bound`. The reason being that Attention **mostly consists of elementwise operations** as shown below on the left hand side. We can observe that masking, softmax and dropout operations take up the bulk of the time instead of matrix multiplications which consists of the bulk of FLOPs.  (Source: [link](https://arxiv.org/pdf/2205.14135.pdf)) This is precisely the problem that Flash Attention addresses. The idea is to **remove redundant HBM reads/writes.** It does so by keeping everything in SRAM, perform all the intermediate steps and only then write the final result back to HBM, also known as **Kernel Fusion**. Below is an illustration of how this overcomes the memory-bound bottleneck.  (Source: [link](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad)) **Tiling** is used during forward and backward passes to chunk the NxN softmax/scores computation into blocks to overcome the limitation of SRAM memory size. To enable tiling, online softmax algorithm is used. **Recomputation** is used during backward pass in order to avoid storing the entire NxN softmax/score matrix during forward pass. This greatly reduces the memory consumption. For a simplified and in depth understanding of Flash Attention, please refer the blog posts [ELI5: FlashAttention](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad) and [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html) along with the original paper [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf). ## Bringing it all-together To run the training using `Accelerate` launcher with SLURM, refer this gist [launch.slurm](https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25). Below is an equivalent command showcasing how to use `Accelerate` launcher to run the training. Notice that we are overriding `main_process_ip` , `main_process_port` , `machine_rank` , `num_processes` and `num_machines` values of the `fsdp_config.yaml`. Here, another important point to note is that the storage is stored between all the nodes. ``` accelerate launch \ --config_file configs/fsdp_config.yaml \ --main_process_ip $MASTER_ADDR \ --main_process_port $MASTER_PORT \ --machine_rank \$MACHINE_RANK \ --num_processes 16 \ --num_machines 2 \ train.py \ --model_name "meta-llama/Llama-2-70b-chat-hf" \ --dataset_name "smangrul/code-chat-assistant-v1" \ --max_seq_len 2048 \ --max_steps 500 \ --logging_steps 25 \ --eval_steps 100 \ --save_steps 250 \ --bf16 True \ --packing True \ --output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 1 \ --dataset_text_field "content" \ --use_gradient_checkpointing True \ --learning_rate 5e-5 \ --lr_scheduler_type "cosine" \ --weight_decay 0.01 \ --warmup_ratio 0.03 \ --use_flash_attn True ``` Fine-tuning completed in ~13.5 hours and below is the training loss plot. 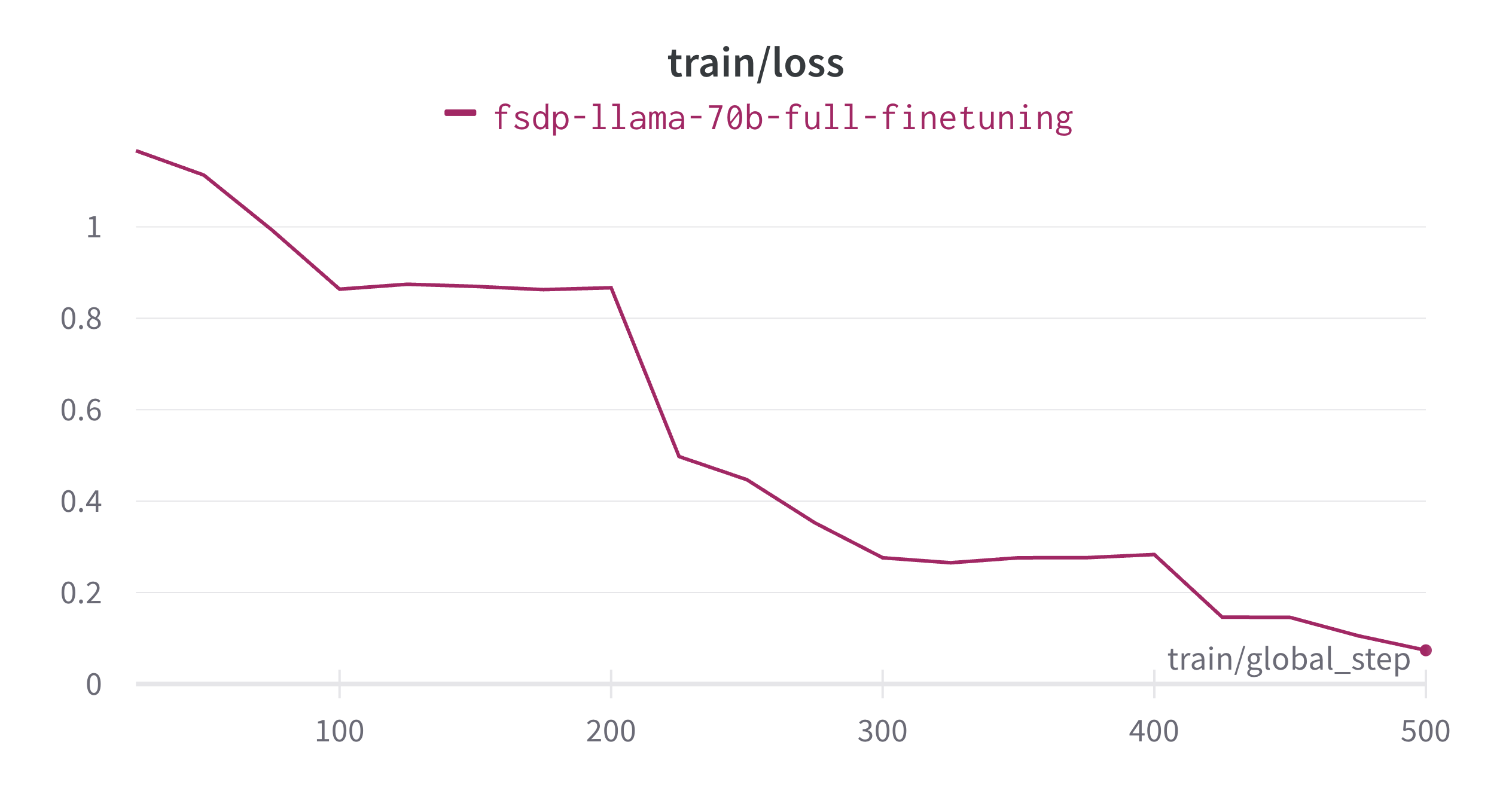 Below is an example conversation using the above model: ```diff System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \ as possible, while being safe. Your answers should not include any harmful, \ unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \ your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why \ instead of answering something not correct. If you don’t know the answer to a \ question, please don’t share false information. - Human: What is Deep Learning? Explain like a Pirate. + Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'? + Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data. + Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information. + These nodes work together to form layers o' processing units that can learn from large amounts o' data. + The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own. + So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered. + Fair winds and following seas! - Human: Now explain it like a chef. + Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective: + Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish. + Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction. + Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome. + Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions. + And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency. + With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit! ``` The whole conversation is formatted as below: ``` <|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ... ``` ## Conclusion We successfully fine-tuned 70B Llama model using PyTorch FSDP in a multi-node multi-gpu setting while addressing various challenges. We saw how 🤗 Transformers and 🤗 Accelerates now supports efficient way of initializing large models when using FSDP to overcome CPU RAM getting out of memory. This was followed by recommended practices for saving/loading intermediate checkpoints and how to save the final model in a way to readily use it. To enable faster training and reducing GPU memory usage, we outlined the importance of Flash Attention and Gradient Checkpointing. Overall, we can see how a simple config using 🤗 Accelerate enables finetuning of such large models in a multi-node multi-gpu setting.
|
Introducing Würstchen: Fast Diffusion for Image Generation
|
dome272
|
September 13, 2023
|
wuerstchen
|
diffusion, diffusers, text-to-image
|
https://huggingface.co/blog/wuerstchen
|
# Introducing Würstchen: Fast Diffusion for Image Generation  ## What is Würstchen? Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the **[paper](https://arxiv.org/abs/2306.00637)**). Together Stage A and B are called the *Decoder*, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the *Prior*.  ## Why another text-to-image model? Well, this one is pretty fast and efficient. Würstchen’s biggest benefits come from the fact that it can generate images much faster than models like Stable Diffusion XL, while using a lot less memory! So for all of us who don’t have A100s lying around, this will come in handy. Here is a comparison with SDXL over different batch sizes:  In addition to that, another greatly significant benefit of Würstchen comes with the reduced training costs. Würstchen v1, which works at 512x512, required only 9,000 GPU hours of training. Comparing this to the 150,000 GPU hours spent on Stable Diffusion 1.4 suggests that this 16x reduction in cost not only benefits researchers when conducting new experiments, but it also opens the door for more organizations to train such models. Würstchen v2 used 24,602 GPU hours. With resolutions going up to 1536, this is still 6x cheaper than SD1.4, which was only trained at 512x512.  You can also find a detailed explanation video here: <iframe width="708" height="398" src="https://www.youtube.com/embed/ogJsCPqgFMk" title="Efficient Text-to-Image Training (16x cheaper than Stable Diffusion) | Paper Explained" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe> ## How to use Würstchen? You can either try it using the Demo here: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.44.2/gradio.js"> </script> <gradio-app theme_mode="light" space="warp-ai/Wuerstchen"></gradio-app> Otherwise, the model is available through the Diffusers Library, so you can use the interface you are already familiar with. For example, this is how to run inference using the `AutoPipeline`: ```Python import torch from diffusers import AutoPipelineForText2Image from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda") caption = "Anthropomorphic cat dressed as a firefighter" images = pipeline( caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4, ).images ```  ### What image sizes does Würstchen work on? Würstchen was trained on image resolutions between 1024x1024 & 1536x1536. We sometimes also observe good outputs at resolutions like 1024x2048. Feel free to try it out. We also observed that the Prior (Stage C) adapts extremely fast to new resolutions. So finetuning it at 2048x2048 should be computationally cheap. <img src="https://cdn-uploads.huggingface.co/production/uploads/634cb5eefb80cc6bcaf63c3e/5pA5KUfGmvsObqiIjdGY1.jpeg" width=1000> ### Models on the Hub All checkpoints can also be seen on the [Huggingface Hub](https://huggingface.co/warp-ai). Multiple checkpoints, as well as future demos and model weights can be found there. Right now there are 3 checkpoints for the Prior available and 1 checkpoint for the Decoder. Take a look at the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen) where the checkpoints are explained and what the different Prior models are and can be used for. ### Diffusers integration Because Würstchen is fully integrated in `diffusers`, it automatically comes with various goodies and optimizations out of the box. These include: - Automatic use of [PyTorch 2 `SDPA`](https://huggingface.co/docs/diffusers/optimization/torch2.0) accelerated attention, as described below. - Support for the [xFormers flash attention](https://huggingface.co/docs/diffusers/optimization/xformers) implementation, if you need to use PyTorch 1.x instead of 2. - [Model offload](https://huggingface.co/docs/diffusers/optimization/fp16#model-offloading-for-fast-inference-and-memory-savings), to move unused components to CPU while they are not in use. This saves memory with negligible performance impact. - [Sequential CPU offload](https://huggingface.co/docs/diffusers/optimization/fp16#offloading-to-cpu-with-accelerate-for-memory-savings), for situations where memory is really precious. Memory use will be minimized, at the cost of slower inference. - [Prompt weighting](https://huggingface.co/docs/diffusers/using-diffusers/weighted_prompts) with the [Compel](https://github.com/damian0815/compel) library. - Support for the [`mps` device](https://huggingface.co/docs/diffusers/optimization/mps) on Apple Silicon macs. - Use of generators for [reproducibility](https://huggingface.co/docs/diffusers/using-diffusers/reproducibility). - Sensible defaults for inference to produce high-quality results in most situations. Of course you can tweak all parameters as you wish! ## Optimisation Technique 1: Flash Attention Starting from version 2.0, PyTorch has integrated a highly optimised and resource-friendly version of the attention mechanism called [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) or SDPA. Depending on the nature of the input, this function taps into multiple underlying optimisations. Its performance and memory efficiency outshine the traditional attention model. Remarkably, the SDPA function mirrors the characteristics of the *flash attention* technique, as highlighted in the research paper [Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135) penned by Dao and team. If you're using Diffusers with PyTorch 2.0 or a later version, and the SDPA function is accessible, these enhancements are automatically applied. Get started by setting up torch 2.0 or a newer version using the [official guidelines](https://pytorch.org/get-started/locally/)! ```python images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images ``` For an in-depth look at how `diffusers` leverages SDPA, check out the [documentation](https://huggingface.co/docs/diffusers/optimization/torch2.0). If you're on a version of Pytorch earlier than 2.0, you can still achieve memory-efficient attention using the [xFormers](https://facebookresearch.github.io/xformers/) library: ```Python pipeline.enable_xformers_memory_efficient_attention() ``` ## Optimisation Technique 2: Torch Compile If you're on the hunt for an extra performance boost, you can make use of `torch.compile`. It is best to apply it to both the prior's and decoder's main model for the biggest increase in performance. ```python pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True) pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True) ``` Bear in mind that the initial inference step will take a long time (up to 2 minutes) while the models are being compiled. After that you can just normally run inference: ```python images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images ``` And the good news is that this compilation is a one-time execution. Post that, you're set to experience faster inferences consistently for the same image resolutions. The initial time investment in compilation is quickly offset by the subsequent speed benefits. For a deeper dive into `torch.compile` and its nuances, check out the [official documentation](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html). ## How was the model trained? The ability to train this model was only possible through compute resources provided by [Stability AI](https://stability.ai/). We wanna say a special thank you to Stability for giving us the possibility to pursue this kind of research, with the chance to make it accessible to so many more people! ## Resources * Further information about this model can be found in the official diffusers [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen). * All the checkpoints can be found on the [hub](https://huggingface.co/warp-ai) * You can try out the [demo here](https://huggingface.co/spaces/warp-ai/Wuerstchen). * Join our [Discord](https://discord.com/invite/BTUAzb8vFY) if you want to discuss future projects or even contribute with your own ideas! * Training code and more can be found in the official [GitHub repository](https://github.com/dome272/wuerstchen/)
|
Optimizing your LLM in production
|
patrickvonplaten
|
Sep 15, 2023
|
optimize-llm
|
nlp, research, LLM
|
https://huggingface.co/blog/optimize-llm
|
# Optimizing your LLM in production <a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Getting_the_most_out_of_LLMs.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> ***Note***: *This blog post is also available as a documentation page on [Transformers](https://huggingface.co/docs/transformers/llm_tutorial_optimization).* Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [LLama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries. Deploying these models in real-world tasks remains challenging, however: - To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference. - In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference. The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences. In this blog post, we will go over the most effective techniques at the time of writing this blog post to tackle these challenges for efficient LLM deployment: 1. **Lower Precision**: Research has shown that operating at reduced numerical precision, namely 8-bit and 4-bit, can achieve computational advantages without a considerable decline in model performance. 2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization. 3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)). Throughout this notebook, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements. ## 1. Harnessing the Power of Lower Precision Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors. At the time of writing this post, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory: > *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision* Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes: > *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision* For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM. To give some examples of how much VRAM it roughly takes to load a model in bfloat16: - **GPT3** requires 2 \* 175 GB = **350 GB** VRAM - [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM - [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM - [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM - [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM - [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM As of writing this document, the largest GPU chip on the market is the A100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism). 🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling). Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference). Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/v4.15.0/parallelism#naive-model-parallel-vertical-and-pipeline-parallel). If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows ```bash !pip install transformers accelerate bitsandbytes optimum ``` ```python from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0) ``` By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs. In this notebook, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism. Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try. We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object. ```python from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline import torch model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0) tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder") pipe = pipeline("text-generation", model=model, tokenizer=tokenizer) ``` ```python prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:" result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):] result ``` **Output**: ``` Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single ``` Nice, we can now directly use the result to convert bytes into Gigabytes. ```python def bytes_to_giga_bytes(bytes): return bytes / 1024 / 1024 / 1024 ``` Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation. ```python bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) ``` **Output**: ```bash 29.0260648727417 ``` Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation. Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required. > Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model. If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference. Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory. ```python del pipe del model import gc import torch def flush(): gc.collect() torch.cuda.empty_cache() torch.cuda.reset_peak_memory_stats() ``` Let's call it now for the next experiment. ```python flush() ``` In the recent version of the accelerate library, you can also use an utility method called `release_memory()` ```python from accelerate.utils import release_memory # ... release_memory(model) ``` Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)). Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯. Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16). Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution. All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results. There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows: - 1. Quantize all weights to the target precision - 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision - 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision - 4. Quantize the weights again to the target precision after computation with their inputs. In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output: $$ Y = X * W $$ are changed to $$ Y = X * \text{dequantize}(W); \text{quantize}(W) $$ for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph. Therefore, inference time is often **not** reduced when using quantized weights, but rather increases. Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed. ```bash !pip install bitsandbytes ``` We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`. ```python model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0) ``` Now, let's run our example again and measure the memory usage. ```python pipe = pipeline("text-generation", model=model, tokenizer=tokenizer) result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):] result ``` **Output**: ``` Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single ``` Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time. ```python bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) ``` **Output**: ``` 15.219234466552734 ``` Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090. We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference. We delete the models and flush the memory again. ```python del model del pipe ``` ```python flush() ``` Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`. ```python model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0) pipe = pipeline("text-generation", model=model, tokenizer=tokenizer) result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):] result ``` **Output**: ``` Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument ``` We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required. ```python bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) ``` **Output**: ``` 9.543574333190918 ``` Just 9.5GB! That's really not a lot for a >15 billion parameter model. While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out. Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference. ```python del model del pipe ``` ```python flush() ``` Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB. 4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people. For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation. > As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time. If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools. For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage). Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture. # 2. Flash Attention: A Leap Forward Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers. Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens. However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) . While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens). Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is: $$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$ \\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) . LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel. Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices. Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts. As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths. How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**. In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps: $$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$ with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) . Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this notebook. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details. The main takeaway here is: > By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) . Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested) > However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM). Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) . In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient. Let's look at a practical example. Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task. In the following, we use a system prompt that will make OctoCoder a better coding assistant. ```python system_prompt = """Below are a series of dialogues between various people and an AI technical assistant. The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable. The assistant is happy to help with code questions and will do their best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer. That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful. The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests). The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data. ----- Question: Write a function that takes two lists and returns a list that has alternating elements from each input list. Answer: Sure. Here is a function that does that. def alternating(list1, list2): results = [] for i in range(len(list1)): results.append(list1[i]) results.append(list2[i]) return results Question: Can you write some test cases for this function? Answer: Sure, here are some tests. assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3] assert alternating([True, False], [4, 5]) == [True, 4, False, 5] assert alternating([], []) == [] Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end. Answer: Here is the modified function. def alternating(list1, list2): results = [] for i in range(min(len(list1), len(list2))): results.append(list1[i]) results.append(list2[i]) if len(list1) > len(list2): results.extend(list1[i+1:]) else: results.extend(list2[i+1:]) return results ----- """ ``` For demonstration purposes, we duplicate the system by ten so that the input length is long enough to observe Flash Attention's memory savings. We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"` ```python long_prompt = 10 * system_prompt + prompt ``` We instantiate our model again in bfloat16 precision. ```python model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto") tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder") pipe = pipeline("text-generation", model=model, tokenizer=tokenizer) ``` Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time. ```python import time start_time = time.time() result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):] print(f"Generated in {time.time() - start_time} seconds.") result ``` **Output**: ``` Generated in 10.96854019165039 seconds. Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef ```` We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself. **Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough! Let's measure the peak GPU memory requirement. ```python bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) ``` **Output**: ```bash 37.668193340301514 ``` As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now. We call `flush()` to free GPU memory for our next experiment. ```python flush() ``` For comparison, let's run the same function, but enable Flash Attention instead. To do so, we convert the model to [BetterTransformers](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is based on Flash Attention. ```python model.to_bettertransformer() ``` Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention. ```py start_time = time.time() with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):] print(f"Generated in {time.time() - start_time} seconds.") result ``` **Output**: ``` Generated in 3.0211617946624756 seconds. Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef ``` We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention. Let's measure the memory consumption one last time. ```python bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) ``` **Output**: ``` 32.617331981658936 ``` And we're almost back to our original 29GB peak GPU memory from the beginning. We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning. ```py flush() ``` ## 3. The Science Behind LLM Architectures: Strategic Selection for Long Text Inputs and Chat So far we have looked into improving computational and memory efficiency by: - Casting the weights to a lower precision format - Replacing the self-attention algorithm with a more memory- and compute efficient version Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*: - Retrieval augmented Questions Answering, - Summarization, - Chat Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT). Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture. There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences. - The positional embeddings - The key-value cache Let's go over each component in more detail ### 3.1 Improving positional embeddings of LLMs Self-attention puts each token in relation to each other's tokens. As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:  Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%. A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other. This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other. Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging. For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*). Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order. The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) . where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) . The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order. Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings \\( \mathbf{P} \\) are learned during training. Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found: 1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position. 2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on. Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably: - [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864) - [ALiBi](https://arxiv.org/abs/2108.12409) Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation. Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position: $$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$ \\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training. > By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) . *RoPE* is used in multiple of today's most important LLMs, such as: - [**Falcon**](https://huggingface.co/tiiuae/falcon-40b) - [**Llama**](https://arxiv.org/abs/2302.13971) - [**PaLM**](https://arxiv.org/abs/2204.02311) As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation. 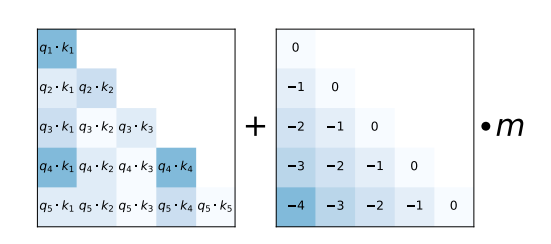 As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences. *ALiBi* is used in multiple of today's most important LLMs, such as: - [**MPT**](https://huggingface.co/mosaicml/mpt-30b) - [**BLOOM**](https://huggingface.co/bigscience/bloom) Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*. For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence. For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)). > Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions: - Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer - The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other - The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings. ### 3.2 The key-value cache Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished. Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works. Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`. ```python input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda") for _ in range(5): next_logits = model(input_ids)["logits"][:, -1:] next_token_id = torch.argmax(next_logits,dim=-1) input_ids = torch.cat([input_ids, next_token_id], dim=-1) print("shape of input_ids", input_ids.shape) generated_text = tokenizer.batch_decode(input_ids[:, -5:]) generated_text ``` **Output**: ``` shape of input_ids torch.Size([1, 21]) shape of input_ids torch.Size([1, 22]) shape of input_ids torch.Size([1, 23]) shape of input_ids torch.Size([1, 24]) shape of input_ids torch.Size([1, 25]) [' Here is a Python function'] ``` As we can see every time we increase the text input tokens by the just sampled token. With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention). As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps. In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass. In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token. ```python past_key_values = None # past_key_values is the key-value cache generated_tokens = [] next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda") for _ in range(5): next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple() next_logits = next_logits[:, -1:] next_token_id = torch.argmax(next_logits, dim=-1) print("shape of input_ids", next_token_id.shape) print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim] generated_tokens.append(next_token_id.item()) generated_text = tokenizer.batch_decode(generated_tokens) generated_text ``` **Output**: ``` shape of input_ids torch.Size([1, 1]) length of key-value cache 20 shape of input_ids torch.Size([1, 1]) length of key-value cache 21 shape of input_ids torch.Size([1, 1]) length of key-value cache 22 shape of input_ids torch.Size([1, 1]) length of key-value cache 23 shape of input_ids torch.Size([1, 1]) length of key-value cache 24 [' Here', ' is', ' a', ' Python', ' function'] ``` As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step. > Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector. Using the key-value cache has two advantages: - Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed - The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly. > One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation). Note that the key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example. ``` User: How many people live in France? Assistant: Roughly 75 million people live in France User: And how many are in Germany? Assistant: Germany has ca. 81 million inhabitants ``` In this chat, the LLM runs auto-regressive decoding twice: - 1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step. - 2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`. Two things should be noted here: 1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`. 2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture). There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads. Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before. The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers. Computing this for our LLM at a hypothetical input sequence length of 16000 gives: ```python config = model.config 2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head ``` **Output**: ``` 7864320000 ``` Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves! Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache: 1. [Multi-Query-Attention (MQA)](https://arxiv.org/abs/1911.02150) Multi-Query-Attention was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades. > By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones. As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000. In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following. In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150). The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix. MQA has seen wide adoption by the community and is now used by many of the most popular LLMs: - [**Falcon**](https://huggingface.co/tiiuae/falcon-40b) - [**PaLM**](https://arxiv.org/abs/2204.02311) - [**MPT**](https://huggingface.co/mosaicml/mpt-30b) - [**BLOOM**](https://huggingface.co/bigscience/bloom) Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA. 2. [Grouped-Query-Attention (GQA)](https://arxiv.org/abs/2305.13245) Grouped-Query-Attention, as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance. Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences. GQA was only recently proposed which is why there is less adoption at the time of writing this notebook. The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf). > As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat. ## Conclusion The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation). The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture. Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
|
Object Detection Leaderboard
|
rafaelpadilla
|
September 18, 2023
|
object-detection-leaderboard
|
community, guide, cv, leaderboard, evaluation
|
https://huggingface.co/blog/object-detection-leaderboard
|
# Object Detection Leaderboard: Decoding Metrics and Their Potential Pitfalls Welcome to our latest dive into the world of leaderboards and models evaluation. In a [previous post](https://huggingface.co/blog/evaluating-mmlu-leaderboard), we navigated the waters of evaluating Large Language Models. Today, we set sail to a different, yet equally challenging domain – Object Detection. Recently, we released our [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard), ranking object detection models available in the Hub according to some metrics. In this blog, we will demonstrate how the models were evaluated and demystify the popular metrics used in Object Detection, from Intersection over Union (IoU) to Average Precision (AP) and Average Recall (AR). More importantly, we will spotlight the inherent divergences and pitfalls that can occur during evaluation, ensuring that you're equipped with the knowledge not just to understand but to assess model performance critically. Every developer and researcher aims for a model that can accurately detect and delineate objects. Our [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) is the right place to find an open-source model that best fits their application needs. But what does "accurate" truly mean in this context? Which metrics should one trust? How are they computed? And, perhaps more crucially, why some models may present divergent results in different reports? All these questions will be answered in this blog. So, let's embark on this exploration together and unlock the secrets of the Object Detection Leaderboard! If you prefer to skip the introduction and learn how object detection metrics are computed, go to the [Metrics section](#metrics). If you wish to find how to pick the best models based on the [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard), you may check the [Object Detection Leaderboard](#object-detection-leaderboard) section. ## Table of Contents - [Introduction](#object-detection-leaderboard-decoding-metrics-and-their-potential-pitfalls) - [What's Object Detection](#whats-object-detection) - [Metrics](#metrics) - [What's Average Precision and how to compute it?](#whats-average-precision-and-how-to-compute-it) - [What's Average Recall and how to compute it?](#whats-average-recall-and-how-to-compute-it) - [What are the variants of Average Precision and Average Recall?](#what-are-the-variants-of-average-precision-and-average-recall) - [Object Detection Leaderboard](#object-detection-leaderboard) - [How to pick the best model based on the metrics?](#how-to-pick-the-best-model-based-on-the-metrics) - [Which parameters can impact the Average Precision results?](#which-parameters-can-impact-the-average-precision-results) - [Conclusions](#conclusions) - [Additional Resources](#additional-resources) ## What's Object Detection? In the field of Computer Vision, Object Detection refers to the task of identifying and localizing individual objects within an image. Unlike image classification, where the task is to determine the predominant object or scene in the image, object detection not only categorizes the object classes present but also provides spatial information, drawing bounding boxes around each detected object. An object detector can also output a "score" (or "confidence") per detection. It represents the probability, according to the model, that the detected object belongs to the predicted class for each bounding box. The following image, for instance, shows five detections: one "ball" with a confidence of 98% and four "person" with a confidence of 98%, 95%, 97%, and 97%. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/intro_object_detection.png" alt="intro_object_detection.png" /> <figcaption> Figure 1: Example of outputs from an object detector.</figcaption> </center> </div> Object detection models are versatile and have a wide range of applications across various domains. Some use cases include vision in autonomous vehicles, face detection, surveillance and security, medical imaging, augmented reality, sports analysis, smart cities, gesture recognition, etc. The Hugging Face Hub has [hundreds of object detection models](https://huggingface.co/models?pipeline_tag=object-detection) pre-trained in different datasets, able to identify and localize various object classes. One specific type of object detection models, called _zero-shot_, can receive additional text queries to search for target objects described in the text. These models can detect objects they haven't seen during training, instead of being constrained to the set of classes used during training. The diversity of detectors goes beyond the range of output classes they can recognize. They vary in terms of underlying architectures, model sizes, processing speeds, and prediction accuracy. A popular metric used to evaluate the accuracy of predictions made by an object detection model is the **Average Precision (AP)** and its variants, which will be explained later in this blog. Evaluating an object detection model encompasses several components, like a dataset with ground-truth annotations, detections (output prediction), and metrics. This process is depicted in the schematic provided in Figure 2: <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pipeline_object_detection.png" alt="pipeline_object_detection.png" /> <figcaption> Figure 2: Schematic illustrating the evaluation process for a traditional object detection model.</figcaption> </center> </div> First, a benchmarking dataset containing images with ground-truth bounding box annotations is chosen and fed into the object detection model. The model predicts bounding boxes for each image, assigning associated class labels and confidence scores to each box. During the evaluation phase, these predicted bounding boxes are compared with the ground-truth boxes in the dataset. The evaluation yields a set of metrics, each ranging between [0, 1], reflecting a specific evaluation criteria. In the next section, we'll dive into the computation of the metrics in detail. ## Metrics This section will delve into the definition of Average Precision and Average Recall, their variations, and their associated computation methodologies. ### What's Average Precision and how to compute it? Average Precision (AP) is a single-number that summarizes the Precision x Recall curve. Before we explain how to compute it, we first need to understand the concept of Intersection over Union (IoU), and how to classify a detection as a True Positive or a False Positive. IoU is a metric represented by a number between 0 and 1 that measures the overlap between the predicted bounding box and the actual (ground truth) bounding box. It's computed by dividing the area where the two boxes overlap by the area covered by both boxes combined. Figure 3 visually demonstrates the IoU using an example of a predicted box and its corresponding ground-truth box. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/iou.png" alt="iou.png" /> <figcaption> Figure 3: Intersection over Union (IoU) between a detection (in green) and ground-truth (in blue).</figcaption> </center> </div> If the ground truth and detected boxes share identical coordinates, representing the same region in the image, their IoU value is 1. Conversely, if the boxes do not overlap at any pixel, the IoU is considered to be 0. In scenarios where high precision in detections is expected (e.g. an autonomous vehicle), the predicted bounding boxes should closely align with the ground-truth boxes. For that, a IoU threshold ( \\( \text{T}_{\text{IOU}} \\) ) approaching 1 is preferred. On the other hand, for applications where the exact position of the detected bounding boxes relative to the target object isn’t critical, the threshold can be relaxed, setting \\( \text{T}_{\text{IOU}} \\) closer to 0. Every box predicted by the model is considered a “positive” detection. The Intersection over Union (IoU) criterion classifies each prediction as a true positive (TP) or a false positive (FP), according to the confidence threshold we defined. Based on predefined \\( \text{T}_{\text{IOU}} \\), we can define True Positives and True Negatives: * **True Positive (TP)**: A correct detection where IoU ≥ \\( \text{T}_{\text{IOU}} \\). * **False Positive (FP)**: An incorrect detection (missed object), where the IoU < \\( \text{T}_{\text{IOU}} \\). Conversely, negatives are evaluated based on a ground-truth bounding box and can be defined as False Negative (FN) or True Negative (TN): * **False Negative (FN)**: Refers to a ground-truth object that the model failed to detect. * **True Negative (TN)**: Denotes a correct non-detection. Within the domain of object detection, countless bounding boxes within an image should NOT be identified, as they don't represent the target object. Consider all possible boxes in an image that don’t represent the target object - quite a vast number, isn’t it? :) That's why we do not consider TN to compute object detection metrics. Now that we can identify our TPs, FPs, and FNs, we can define Precision and Recall: * **Precision** is the ability of a model to identify only the relevant objects. It is the percentage of correct positive predictions and is given by: <p style="text-align: center;"> \\( \text{Precision} = \frac{TP}{(TP + FP)} = \frac{TP}{\text{all detections}} \\) </p> which translates to the ratio of true positives over all detected boxes. * **Recall** gauges a model’s competence in finding all the relevant cases (all ground truth bounding boxes). It indicates the proportion of TP detected among all ground truths and is given by: <p style="text-align: center;"> \\( \text{Recall} = \frac{TP}{(TP + FN)} = \frac{TP}{\text{all ground truths}} \\) </p> Note that TP, FP, and FN depend on a predefined IoU threshold, as do Precision and Recall. Average Precision captures the ability of a model to classify and localize objects correctly considering different values of Precision and Recall. For that we'll illustrate the relationship between Precision and Recall by plotting their respective curves for a specific target class, say "dog". We'll adopt a moderate IoU threshold = 75% to delineate our TP, FP and FN. Subsequently, we can compute the Precision and Recall values. For that, we need to vary the confidence scores of our detections. Figure 4 shows an example of the Precision x Recall curve. For a deeper exploration into the computation of this curve, the papers “A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit” (Padilla, et al) and “A Survey on Performance Metrics for Object-Detection Algorithms” (Padilla, et al) offer more detailed toy examples demonstrating how to compute this curve. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pxr_te_iou075.png" alt="pxr_te_iou075.png" /> <figcaption> Figure 4: Precision x Recall curve for a target object “dog” considering TP detections using IoU_thresh = 0.75.</figcaption> </center> </div> The Precision x Recall curve illustrates the balance between Precision and Recall based on different confidence levels of a detector's bounding boxes. Each point of the plot is computed using a different confidence value. To demonstrate how to calculate the Average Precision plot, we'll use a practical example from one of the papers mentioned earlier. Consider a dataset of 7 images with 15 ground-truth objects of the same class, as shown in Figure 5. Let's consider that all boxes belong to the same class, "dog" for simplification purposes. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/dataset_example.png" alt="dataset_example.png" /> <figcaption> Figure 5: Example of 24 detections (red boxes) performed by an object detector trained to detect 15 ground-truth objects (green boxes) belonging to the same class.</figcaption> </center> </div> Our hypothetical object detector retrieved 24 objects in our dataset, illustrated by the red boxes. To compute Precision and Recall we use the Precision and Recall equations at all confidence levels to evaluate how well the detector performed for this specific class on our benchmarking dataset. For that, we need to establish some rules: * **Rule 1**: For simplicity, let's consider our detections a True Positive (TP) if IOU ≥ 30%; otherwise, it is a False Positive (FP). * **Rule 2**: For cases where a detection overlaps with more than one ground-truth (as in Images 2 to 7), the predicted box with the highest IoU is considered TP, and the other is FP. Based on these rules, we can classify each detection as TP or FP, as shown in Table 1: <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <figcaption> Table 1: Detections from Figure 5 classified as TP or FP considering \\( \text{T}_{\text{IOU}} = 30\% \\).</figcaption> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_1.png" alt="table_1.png" /> </center> </div> Note that by rule 2, in image 1, "E" is TP while "D" is FP because IoU between "E" and the ground-truth is greater than IoU between "D" and the ground-truth. Now, we need to compute Precision and Recall considering the confidence value of each detection. A good way to do so is to sort the detections by their confidence values as shown in Table 2. Then, for each confidence value in each row, we compute the Precision and Recall considering the cumulative TP (acc TP) and cumulative FP (acc FP). The "acc TP" of each row is increased in 1 every time a TP is noted, and the "acc FP" is increased in 1 when a FP is noted. Columns "acc TP" and "acc FP" basically tell us the TP and FP values given a particular confidence level. The computation of each value of Table 2 can be viewed in [this spreadsheet](https://docs.google.com/spreadsheets/d/1mc-KPDsNHW61ehRpI5BXoyAHmP-NxA52WxoMjBqk7pw/edit?usp=sharing). For example, consider the 12th row (detection "P") of Table 2. The value "acc TP = 4" means that if we benchmark our model on this particular dataset with a confidence of 0.62, we would correctly detect four target objects and incorrectly detect eight target objects. This would result in: <p style="text-align: center;"> \\( \text{Precision} = \frac{\text{acc TP}}{(\text{acc TP} + \text{acc FP})} = \frac{4}{(4+8)} = 0.3333 \\) and \\( \text{Recall} = \frac{\text{acc TP}}{\text{all ground truths}} = \frac{4}{15} = 0.2667 \\) . </p> <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <figcaption> Table 2: Computation of Precision and Recall values of detections from Table 1.</figcaption> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_2.png" alt="table_2.png" /> </center> </div> Now, we can plot the Precision x Recall curve with the values, as shown in Figure 6: <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/precision_recall_example.png" alt="precision_recall_example.png" /> <figcaption> Figure 6: Precision x Recall curve for the detections computed in Table 2.</figcaption> </center> </div> By examining the curve, one may infer the potential trade-offs between Precision and Recall and find a model's optimal operating point based on a selected confidence threshold, even if this threshold is not explicitly depicted on the curve. If a detector's confidence results in a few false positives (FP), it will likely have high Precision. However, this might lead to missing many true positives (TP), causing a high false negative (FN) rate and, subsequently, low Recall. On the other hand, accepting more positive detections can boost Recall but might also raise the FP count, thereby reducing Precision. **The area under the Precision x Recall curve (AUC) computed for a target class represents the Average Precision value for that particular class.** The COCO evaluation approach refers to "AP" as the mean AUC value among all target classes in the image dataset, also referred to as Mean Average Precision (mAP) by other approaches. For a large dataset, the detector will likely output boxes with a wide range of confidence levels, resulting in a jagged Precision x Recall line, making it challenging to compute its AUC (Average Precision) precisely. Different methods approximate the area of the curve with different approaches. A popular approach is called N-interpolation, where N represents how many points are sampled from the Precision x Recall blue line. The COCO approach, for instance, uses 101-interpolation, which computes 101 points for equally spaced Recall values (0. , 0.01, 0.02, … 1.00), while other approaches use 11 points (11-interpolation). Figure 7 illustrates a Precision x Recall curve (in blue) with 11 equal-spaced Recall points. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/11-pointInterpolation.png" alt="11-pointInterpolation.png" /> <figcaption> Figure 7: Example of a Precision x Recall curve using the 11-interpolation approach. The 11 red dots are computed with Precision and Recall equations.</figcaption> </center> </div> The red points are placed according to the following: <p style="text-align: center;"> \\( \rho_{\text{interp}} (R) = \max_{\tilde{r}:\tilde{r} \geq r} \rho \left( \tilde{r} \right) \\) </p> where \\( \rho \left( \tilde{r} \right) \\) is the measured Precision at Recall \\( \tilde{r} \\). In this definition, instead of using the Precision value \\( \rho(R) \\) observed in each Recall level \\( R \\), the Precision \\( \rho_{\text{interp}} (R) \\) is obtained by considering the maximum Precision whose Recall value is greater than \\( R \\). For this type of approach, the AUC, which represents the Average Precision, is approximated by the average of all points and given by: <p style="text-align: center;"> \\( \text{AP}_{11} = \frac{1}{11} = \sum\limits_{R\in \left \{ 0, 0.1, ...,1 \right \}} \rho_{\text{interp}} (R) \\) </p> ### What's Average Recall and how to compute it? Average Recall (AR) is a metric that's often used alongside AP to evaluate object detection models. While AP evaluates both Precision and Recall across different confidence thresholds to provide a single-number summary of model performance, AR focuses solely on the Recall aspect, not taking the confidences into account and considering all detections as positives. COCO’s approach computes AR as the mean of the maximum obtained Recall over IOUs > 0.5 and classes. By using IOUs in the range [0.5, 1] and averaging Recall values across this interval, AR assesses the model's predictions on their object localization. Hence, if your goal is to evaluate your model for both high Recall and precise object localization, AR could be a valuable evaluation metric to consider. ### What are the variants of Average Precision and Average Recall? Based on predefined IoU thresholds and the areas associated with ground-truth objects, different versions of AP and AR can be obtained: * **[email protected]**: sets IoU threshold = 0.5 and computes the Precision x Recall AUC for each target class in the image dataset. Then, the computed results for each class are summed up and divided by the number of classes. * **[email protected]**: uses the same methodology as [email protected], with IoU threshold = 0.75. With this higher IoU requirement, [email protected] is considered stricter than [email protected] and should be used to evaluate models that need to achieve a high level of localization accuracy in their detections. * **AP@[.5:.05:.95]**: also referred to AP by cocoeval tools. This is an expanded version of [email protected] and [email protected], as it computes AP@ with different IoU thresholds (0.5, 0.55, 0.6,...,0.95) and averages the computed results as shown in the following equation. In comparison to [email protected] and [email protected], this metric provides a holistic evaluation, capturing a model’s performance across a broader range of localization accuracies. <p style="text-align: center;"> \\( \text{AP@[.5:.05:0.95} = \frac{\text{AP}_{0.5} + \text{AP}_{0.55} + ... + \text{AP}_{0.95}}{10} \\) </p> * **AP-S**: It applies AP@[.5:.05:.95] considering (small) ground-truth objects with \\( \text{area} < 32^2 \\) pixels. * **AP-M**: It applies AP@[.5:.05:.95] considering (medium-sized) ground-truth objects with \\( 32^2 < \text{area} < 96^2 \\) pixels. * **AP-L**: It applies AP@[.5:.05:.95] considering (large) ground-truth objects with \\( 32^2 < \text{area} < 96^2\\) pixels. For Average Recall (AR), 10 IoU thresholds (0.5, 0.55, 0.6,...,0.95) are used to compute the Recall values. AR is computed by either limiting the number of detections per image or by limiting the detections based on the object's area. * **AR-1**: considers up to 1 detection per image. * **AR-10**: considers up to 10 detections per image. * **AR-100**: considers up to 100 detections per image. * **AR-S**: considers (small) objects with \\( \text{area} < 32^2 \\) pixels. * **AR-M**: considers (medium-sized) objects with \\( 32^2 < \text{area} < 96^2 \\) pixels. * **AR-L**: considers (large) objects with \\( \text{area} > 96^2 \\) pixels. ## Object Detection Leaderboard We recently released the [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) to compare the accuracy and efficiency of open-source models from our Hub. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/screenshot-leaderboard.png" alt="screenshot-leaderboard.png" /> <figcaption> Figure 8: Object Detection Leaderboard.</figcaption> </center> </div> To measure accuracy, we used 12 metrics involving Average Precision and Average Recall using [COCO style](https://cocodataset.org/#detection-eval), benchmarking over COCO val 2017 dataset. As discussed previously, different tools may adopt different particularities during the evaluation. To prevent results mismatching, we preferred not to implement our version of the metrics. Instead, we opted to use COCO's official evaluation code, also referred to as PyCOCOtools, code available [here](https://github.com/cocodataset/cocoapi/tree/master/PythonAPI). In terms of efficiency, we calculate the frames per second (FPS) for each model using the average evaluation time across the entire dataset, considering pre and post-processing steps. Given the variability in GPU memory requirements for each model, we chose to evaluate with a batch size of 1 (this choice is also influenced by our pre-processing step, which we'll delve into later). However, it's worth noting that this approach may not align perfectly with real-world performance, as larger batch sizes (often containing several images), are commonly used for better efficiency. Next, we will provide tips on choosing the best model based on the metrics and point out which parameters may interfere with the results. Understanding these nuances is crucial, as this might spark doubts and discussions within the community. ### How to pick the best model based on the metrics? Selecting an appropriate metric to evaluate and compare object detectors considers several factors. The primary considerations include the application's purpose and the dataset's characteristics used to train and evaluate the models. For general performance, **AP (AP@[.5:.05:.95])** is a good choice if you want all-round model performance across different IoU thresholds, without a hard requirement on the localization of the detected objects. If you want a model with good object recognition and objects generally in the right place, you can look at the **[email protected]**. If you prefer a more accurate model for placing the bounding boxes, **[email protected]** is more appropriate. If you have restrictions on object sizes, **AP-S**, **AP-M** and **AP-L** come into play. For example, if your dataset or application predominantly features small objects, AP-S provides insights into the detector's efficacy in recognizing such small targets. This becomes crucial in scenarios such as detecting distant vehicles or small artifacts in medical imaging. ### Which parameters can impact the Average Precision results? After picking an object detection model from the Hub, we can vary the output boxes if we use different parameters in the model's pre-processing and post-processing steps. These may influence the assessment metrics. We identified some of the most common factors that may lead to variations in results: * Ignore detections that have a score under a certain threshold. * Use `batch_sizes > 1` for inference. * Ported models do not output the same logits as the original models. * Some ground-truth objects may be ignored by the evaluator. * Computing the IoU may be complicated. * Text-conditioned models require precise prompts. Let’s take the DEtection TRansformer (DETR) ([facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50)) model as our example case. We will show how these factors may affect the output results. #### Thresholding detections before evaluation Our sample model uses the [`DetrImageProcessor` class](https://huggingface.co/docs/transformers/main/en/model_doc/detr#transformers.DetrImageProcessor) to process the bounding boxes and logits, as shown in the snippet below: ```python from transformers import DetrImageProcessor, DetrForObjectDetection import torch from PIL import Image import requests url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw) processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50") model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50") inputs = processor(images=image, return_tensors="pt") outputs = model(**inputs) # PIL images have their size in (w, h) format target_sizes = torch.tensor([image.size[::-1]]) results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.5) ``` The parameter `threshold` in function `post_process_object_detection` is used to filter the detected bounding boxes based on their confidence scores. As previously discussed, the Precision x Recall curve is built by measuring the Precision and Recall across the full range of confidence values [0,1]. Thus, limiting the detections before evaluation will produce biased results, as we will leave some detections out. #### Varying the batch size The batch size not only affects the processing time but may also result in different detected boxes. The image pre-processing step may change the resolution of the input images based on their sizes. As mentioned in [DETR documentation](https://huggingface.co/docs/transformers/model_doc/detr), by default, `DetrImageProcessor` resizes the input images such that the shortest side is 800 pixels, and resizes again so that the longest is at most 1333 pixels. Due to this, images in a batch can have different sizes. DETR solves this by padding images up to the largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding. To illustrate this process, let's consider the examples in Figure 9 and Figure 10. In Figure 9, we consider batch size = 1, so both images are processed independently with `DetrImageProcessor`. The first image is resized to (800, 1201), making the detector predict 28 boxes with class `vase`, 22 boxes with class `chair`, ten boxes with class `bottle`, etc. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_1.png" alt="example_batch_size_1.png" /> <figcaption> Figure 9: Two images processed with `DetrImageProcessor` using batch size = 1.</figcaption> </center> </div> Figure 10 shows the process with batch size = 2, where the same two images are processed with `DetrImageProcessor` in the same batch. Both images are resized to have the same shape (873, 1201), and padding is applied, so the part of the images with the content is kept with their original aspect ratios. However, the first image, for instance, outputs a different number of objects: 31 boxes with the class `vase`, 20 boxes with the class `chair`, eight boxes with the class `bottle`, etc. Note that for the second image, with batch size = 2, a new class is detected `dog`. This occurs due to the model's capacity to detect objects of different sizes depending on the image's resolution. <div display="block" margin-left="auto" margin-right="auto" width="50%"> <center> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_2.png" alt="example_batch_size_2.png" /> <figcaption> Figure 10: Two images processed with `DetrImageProcessor` using batch size = 2.</figcaption> </center> </div> #### Ported models should output the same logits as the original models At Hugging Face, we are very careful when porting models to our codebase. Not only with respect to the architecture, clear documentation and coding structure, but we also need to guarantee that the ported models are able to produce the same logits as the original models given the same inputs. The logits output by a model are post-processed to produce the confidence scores, label IDs, and bounding box coordinates. Thus, minor changes in the logits can influence the metrics results. You may recall [the example above](#whats-average-precision-and-how-to-compute-it), where we discussed the process of computing Average Precision. We showed that confidence levels sort the detections, and small variations may lead to a different order and, thus, different results. It's important to recognize that models can produce boxes in various formats, and that also may be taken into consideration, making proper conversions required by the evaluator. * *(x, y, width, height)*: this represents the upper-left corner coordinates followed by the absolute dimensions (width and height). * *(x, y, x2, y2)*: this format indicates the coordinates of the upper-left corner and the lower-right corner. * *(rel_x_center, rel_y_center, rel_width, rel_height)*: the values represent the relative coordinates of the center and the relative dimensions of the box. #### Some ground-truths are ignored in some benchmarking datasets Some datasets sometimes use special labels that are ignored during the evaluation process. COCO, for instance, uses the tag `iscrowd` to label large groups of objects (e.g. many apples in a basket). During evaluation, objects tagged as `iscrowd=1` are ignored. If this is not taken into consideration, you may obtain different results. #### Calculating the IoU requires careful consideration IoU might seem straightforward to calculate based on its definition. However, there's a crucial detail to be aware of: if the ground truth and the detection don't overlap at all, not even by one pixel, the IoU should be 0. To avoid dividing by zero when calculating the union, you can add a small value (called _epsilon_), to the denominator. However, it's essential to choose epsilon carefully: a value greater than 1e-4 might not be neutral enough to give an accurate result. #### Text-conditioned models demand the right prompts There might be cases in which we want to evaluate text-conditioned models such as [OWL-ViT](https://huggingface.co/google/owlvit-base-patch32), which can receive a text prompt and provide the location of the desired object. For such models, different prompts (e.g. "Find the dog" and "Where's the bulldog?") may result in the same results. However, we decided to follow the procedure described in each paper. For the OWL-ViT, for instance, we predict the objects by using the prompt "an image of a {}" where {} is replaced with the benchmarking dataset's classes. ## Conclusions In this post, we introduced the problem of Object Detection and depicted the main metrics used to evaluate them. As noted, evaluating object detection models may take more work than it looks. The particularities of each model must be carefully taken into consideration to prevent biased results. Also, each metric represents a different point of view of the same model, and picking "the best" metric depends on the model's application and the characteristics of the chosen benchmarking dataset. Below is a table that illustrates recommended metrics for specific use cases and provides real-world scenarios as examples. However, it's important to note that these are merely suggestions, and the ideal metric can vary based on the distinct particularities of each application. | Use Case | Real-world Scenarios | Recommended Metric | |----------------------------------------------|---------------------------------------|--------------------| | General object detection performance | Surveillance, sports analysis | AP | | Low accuracy requirements (broad detection) | Augmented reality, gesture recognition| [email protected] | | High accuracy requirements (tight detection) | Face detection | [email protected] | | Detecting small objects | Distant vehicles in autonomous cars, small artifacts in medical imaging | AP-S | | Medium-sized objects detection | Luggage detection in airport security scans | AP-M | | Large-sized objects detection | Detecting vehicles in parking lots | AP-L | | Detecting 1 object per image | Single object tracking in videos | AR-1 | | Detecting up to 10 objects per image | Pedestrian detection in street cameras| AR-10 | | Detecting up to 100 objects per image | Crowd counting | AR-100 | | Recall for small objects | Medical imaging for tiny anomalies | AR-S | | Recall for medium-sized objects | Sports analysis for players | AR-M | | Recall for large objects | Wildlife tracking in wide landscapes | AR-L | The results shown in our 🤗 [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) are computed using an independent tool [PyCOCOtools](https://github.com/cocodataset/cocoapi/tree/master/PythonAPI) widely used by the community for model benchmarking. We're aiming to collect datasets of different domains (e.g. medical images, sports, autonomous vehicles, etc). You can use the [discussion page](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard/discussions) to make requests for datasets, models and features. Eager to see your model or dataset feature on our leaderboard? Don't hold back! Introduce your model and dataset, fine-tune, and let's get it ranked! 🥇 ## Additional Resources * [Object Detection Guide](https://huggingface.co/docs/transformers/tasks/object_detection) * [Task of Object Detection](https://huggingface.co/tasks/object-detection) * Paper [What Makes for Effective Detection Proposals](https://arxiv.org/abs/1502.05082) * Paper [A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit](https://www.mdpi.com/2079-9292/10/3/279) * Paper [A Survey on Performance Metrics for Object-Detection Algorithms](https://ieeexplore.ieee.org/document/9145130) Special thanks 🙌 to [@merve](https://huggingface.co/merve), [@osanseviero](https://huggingface.co/osanseviero) and [@pcuenq](https://huggingface.co/pcuenq) for their feedback and great comments. 🤗
|
Introduction to 3D Gaussian Splatting
|
dylanebert
|
September 18, 2023
|
gaussian-splatting
|
community, guide, cv, game-dev
|
https://huggingface.co/blog/gaussian-splatting
|
# Introduction to 3D Gaussian Splatting 3D Gaussian Splatting is a rasterization technique described in [3D Gaussian Splatting for Real-Time Radiance Field Rendering](https://huggingface.co/papers/2308.04079) that allows real-time rendering of photorealistic scenes learned from small samples of images. This article will break down how it works and what it means for the future of graphics. ## What is 3D Gaussian Splatting? 3D Gaussian Splatting is, at its core, a rasterization technique. That means: 1. Have data describing the scene. 2. Draw the data on the screen. This is analogous to triangle rasterization in computer graphics, which is used to draw many triangles on the screen.  However, instead of triangles, it's gaussians. Here's a single rasterized gaussian, with a border drawn for clarity.  It's described by the following parameters: - **Position**: where it's located (XYZ) - **Covariance**: how it's stretched/scaled (3x3 matrix) - **Color**: what color it is (RGB) - **Alpha**: how transparent it is (α) In practice, multiple gaussians are drawn at once.  That's three gaussians. Now what about 7 million gaussians?  Here's what it looks like with each gaussian rasterized fully opaque:  That's a very brief overview of what 3D Gaussian Splatting is. Next, let's walk through the full procedure described in the paper. ## How it works ### 1. Structure from Motion The first step is to use the Structure from Motion (SfM) method to estimate a point cloud from a set of images. This is a method for estimating a 3D point cloud from a set of 2D images. This can be done with the [COLMAP](https://colmap.github.io/) library.  ### 2. Convert to Gaussians Next, each point is converted to a gaussian. This is already sufficient for rasterization. However, only position and color can be inferred from the SfM data. To learn a representation that yields high quality results, we need to train it. ### 3. Training The training procedure uses Stochastic Gradient Descent, similar to a neural network, but without the layers. The training steps are: 1. Rasterize the gaussians to an image using differentiable gaussian rasterization (more on that later) 2. Calculate the loss based on the difference between the rasterized image and ground truth image 3. Adjust the gaussian parameters according to the loss 4. Apply automated densification and pruning Steps 1-3 are conceptually pretty straightforward. Step 4 involves the following: - If the gradient is large for a given gaussian (i.e. it's too wrong), split/clone it - If the gaussian is small, clone it - If the gaussian is large, split it - If the alpha of a gaussian gets too low, remove it This procedure helps the gaussians better fit fine-grained details, while pruning unnecessary gaussians. ### 4. Differentiable Gaussian Rasterization As mentioned earlier, 3D Gaussian Splatting is a *rasterization* approach, which draws the data to the screen. However, some important elements are also that it's: 1. Fast 2. Differentiable The original implementation of the rasterizer can be found [here](https://github.com/graphdeco-inria/diff-gaussian-rasterization). The rasterization involves: 1. Project each gaussian into 2D from the camera perspective. 2. Sort the gaussians by depth. 3. For each pixel, iterate over each gaussian front-to-back, blending them together. Additional optimizations are described in [the paper](https://huggingface.co/papers/2308.04079). It's also essential that the rasterizer is differentiable, so that it can be trained with stochastic gradient descent. However, this is only relevant for training - the trained gaussians can also be rendered with a non-differentiable approach. ## Who cares? Why has there been so much attention on 3D Gaussian Splatting? The obvious answer is that the results speak for themselves - it's high-quality scenes in real-time. However, there may be more to story. There are many unknowns as to what else can be done with Gaussian Splatting. Can they be animated? The upcoming paper [Dynamic 3D Gaussians: tracking by Persistent Dynamic View Synthesis](https://arxiv.org/pdf/2308.09713) suggests that they can. There are many other unknowns as well. Can they do reflections? Can they be modeled without training on reference images? Finally, there is growing research interest in [Embodied AI](https://ieeexplore.ieee.org/iel7/7433297/9741092/09687596.pdf). This is an area of AI research where state-of-the-art performance is still orders of magnitude below human performance, with much of the challenge being in representing 3D space. Given that 3D Gaussian Splatting yields a very dense representation of 3D space, what might the implications be for Embodied AI research? These questions call attention to the method. It remains to be seen what the actual impact will be. ## The future of graphics So what does this mean for the future of graphics? Well, let's break it up into pros/cons: **Pros** 1. High-quality, photorealistic scenes 2. Fast, real-time rasterization 3. Relatively fast to train **Cons** 1. High VRAM usage (4GB to view, 12GB to train) 2. Large disk size (1GB+ for a scene) 3. Incompatible with existing rendering pipelines 3. Static (for now) So far, the original CUDA implementation has not been adapted to production rendering pipelines, like Vulkan, DirectX, WebGPU, etc, so it's yet to be seen what the impact will be. There have already been the following adaptations: 1. [Remote viewer](https://huggingface.co/spaces/dylanebert/gaussian-viewer) 2. [WebGPU viewer](https://github.com/cvlab-epfl/gaussian-splatting-web) 3. [WebGL viewer](https://huggingface.co/spaces/cakewalk/splat) 4. [Unity viewer](https://github.com/aras-p/UnityGaussianSplatting) 5. [Optimized WebGL viewer](https://gsplat.tech/) These rely either on remote streaming (1) or a traditional quad-based rasterization approach (2-5). While a quad-based approach is compatible with decades of graphics technologies, it may result in lower quality/performance. However, [viewer #5](https://gsplat.tech/) demonstrates that optimization tricks can result in high quality/performance, despite a quad-based approach. So will we see 3D Gaussian Splatting fully reimplemented in a production environment? The answer is *probably yes*. The primary bottleneck is sorting millions of gaussians, which is done efficiently in the original implementation using [CUB device radix sort](https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html), a highly optimized sort only available in CUDA. However, with enough effort, it's certainly possible to achieve this level of performance in other rendering pipelines. If you have any questions or would like to get involved, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
Rocket Money x Hugging Face: Scaling Volatile ML Models in Production
|
nicokuzak
|
September 19, 2023
|
rocketmoney-case-study
|
case-studies
|
https://huggingface.co/blog/rocketmoney-case-study
|
# Rocket Money x Hugging Face: Scaling Volatile ML Models in Production #### "We discovered that they were not just service providers, but partners who were invested in our goals and outcomes” _- Nicolas Kuzak, Senior ML Engineer at Rocket Money._ ## Scaling and Maintaining ML Models in Production Without an MLOps Team We created [Rocket Money](https://www.rocketmoney.com/) (a personal finance app formerly known as Truebill) to help users improve their financial wellbeing. Users link their bank accounts to the app which then classifies and categorizes their transactions, identifying recurring patterns to provide a consolidated, comprehensive view of their personal financial life. A critical stage of transaction processing is detecting known merchants and services, some of which Rocket Money can cancel and negotiate the cost of for members. This detection starts with the transformation of short, often truncated and cryptically formatted transaction strings into classes we can use to enrich our product experience. ## The Journey Toward a New System We first extracted brands and products from transactions using regular expression-based normalizers. These were used in tandem with an increasingly intricate decision table that mapped strings to corresponding brands. This system proved effective for the first four years of the company when classes were tied only to the products we supported for cancellations and negotiations. However, as our user base grew, the subscription economy boomed and the scope of our product increased, we needed to keep up with the rate of new classes while simultaneously tuning regexes and preventing collisions and overlaps. To address this, we explored various traditional machine learning (ML) solutions, including a bag of words model with a model-per-class architecture. This system struggled with maintenance and performance and was mothballed. We decided to start from a clean slate, assembling both a new team and a new mandate. Our first task was to accumulate training data and construct an in-house system from scratch. We used Retool to build labeling queues, gold standard validation datasets, and drift detection monitoring tools. We explored a number of different model topologies, but ultimately chose a BERT family of models to solve our text classification problem. The bulk of the initial model testing and evaluation was conducted offline within our GCP warehouse. Here we designed and built the telemetry and system we used to measure the performance of a model with 4000+ classes. ## Solving Domain Challenges and Constraints by Partnering with Hugging Face There are a number of unique challenges we face within our domain, including entropy injected by merchants, processing/payment companies, institutional differences, and shifts in user behavior. Designing and building efficient model performance alerting along with realistic benchmarking datasets has proven to be an ongoing challenge. Another significant hurdle is determining the optimal number of classes for our system - each class represents a significant amount of effort to create and maintain. Therefore, we must consider the value it provides to users and our business. With a model performing well in offline testing and a small team of ML engineers, we were faced with a new challenge: seamless integration of that model into our production pipeline. The existing regex system processed more than 100 million transactions per month with a very bursty load, so it was crucial to have a high-availability system that could scale dynamically to load and maintain a low overall latency within the pipeline coupled with a system that was compute-optimized for the models we were serving. As a small startup at the time, we chose to buy rather than build the model serving solution. At the time, we didn’t have in-house model ops expertise and we needed to focus the energy of our ML engineers on enhancing the performance of the models within the product. With this in mind, we set out in search of the solution. In the beginning, we auditioned a hand-rolled, in-house model hosting solution we had been using for prototyping, comparing it against AWS Sagemaker and Hugging Face’s new model hosting Inference API. Given that we use GCP for data storage and Google Vertex Pipelines for model training, exporting models to AWS Sagemaker was clunky and bug prone. Thankfully, the set up for Hugging Face was quick and easy, and it was able to handle a small portion of traffic within a week. Hugging Face simply worked out of the gate, and this reduced friction led us to proceed down this path. After an extensive three-month evaluation period, we chose Hugging Face to host our models. During this time, we gradually increased transaction volume to their hosted models and ran numerous simulated load tests based on our worst-case scenario volumes. This process allowed us to fine-tune our system and monitor performance, ultimately giving us confidence in the inference API's ability to handle our transaction enrichment loads. Beyond technical capabilities, we also established a strong rapport with the team at Hugging Face. We discovered they were not just service providers, but partners who were invested in our goals and outcomes. Early in our collaboration we set up a shared Slack channel which proved invaluable. We were particularly impressed by their prompt response to issues and proactive approach to problem-solving. Their engineers and CSMs consistently demonstrated their commitment in our success and dedication to doing things right. This gave us an additional layer of confidence when it was time to make the final selection. ## Integration, Evaluation, and the Final Selection #### "Overall, the experience of working hand in hand with Hugging Face on model deployment has been enriching for our team and has instilled in us the confidence to push for greater scale"_- Nicolas Kuzak, Senior ML Engineer at Rocket Money._ Once the contract was signed, we began the migration of moving off our regex based system to direct an increasing amount of critical path traffic to the transformer model. Internally, we had to build some new telemetry for both model and production data monitoring. Given that this system is positioned so early in the product experience, any inaccuracies in model outcomes could significantly impact business metrics. We ran an extensive experiment where new users were split equally between the old system and the new model. We assessed model performance in conjunction with broader business metrics, such as paid user retention and engagement. The ML model clearly outperformed in terms of retention, leading us to confidently make the decision to scale the system - first to new users and then to existing users - ramping to 100% over a span of two months. With the model fully positioned in the transaction processing pipeline, both uptime and latency became major concerns. Many of our downstream processes rely on classification results, and any complications can lead to delayed data or incomplete enrichment, both causing a degraded user experience. The inaugural year of collaboration between Rocket Money and Hugging Face was not without its challenges. Both teams, however, displayed remarkable resilience and a shared commitment to resolving issues as they arose. One such instance was when we expanded the number of classes in our second production model, which unfortunately led to an outage. Despite this setback, the teams persevered, and we've successfully avoided a recurrence of the same issue. Another hiccup occurred when we transitioned to a new model, but we still received results from the previous one due to caching issues on Hugging Face's end. This issue was swiftly addressed and has not recurred. Overall, the experience of working hand in hand with Hugging Face on model deployment has been enriching for our team and has instilled in us the confidence to push for greater scale. Speaking of scale, as we started to witness a significant increase in traffic to our model, it became clear that the cost of inference would surpass our projected budget. We made use of a caching layer prior to inference calls that significantly reduces the cardinality of transactions and attempts to benefit from prior inference. Our problem technically could achieve a 93% cache rate, but we’ve only ever reached 85% in a production setting. With the model serving 100% of predictions, we’ve had a few milestones on the Rocket Money side - our model has been able to scale to a run rate of over a billion transactions per month and manage the surge in traffic as we climbed to the #1 financial app in the app store and #7 overall, all while maintaining low latency. ## Collaboration and Future Plans #### "The uptime and confidence we have in the HuggingFace Inference API has allowed us to focus our energy on the value generated by the models and less on the plumbing and day-to-day operation" _- Nicolas Kuzak, Senior ML Engineer at Rocket Money._ Post launch, the internal Rocket Money team is now focusing on both class and performance tuning of the model in addition to more automated monitoring and training label systems. We add new labels on a daily basis and encounter the fun challenges of model lifecycle management, including unique things like company rebranding and new companies and products emerging after Rocket Companies acquired Truebill in late 2021. We constantly examine whether we have the right model topology for our problem. While LLMs have recently been in the news, we’ve struggled to find an implementation that can outperform our specialized transformer classifiers at this time in both speed and cost. We see promise in the early results of using them in the long tail of services (i.e. mom-and-pop shops) - keep an eye out for that in a future version of Rocket Money! The uptime and confidence we have in the HuggingFace Inference API has allowed us to focus our energy on the value generated by the models and less on the plumbing and day-to-day operation. With the help of Hugging Face, we have taken on more scale and complexity within our model and the types of value it generates. Their customer service and support have exceeded our expectations and they’re genuinely a great partner in our journey. _If you want to learn how Hugging Face can manage your ML inference workloads, contact the Hugging Face team [here](https://huggingface.co/support#form/)._
|
Inference for PROs
|
osanseviero
|
September 22, 2023
|
inference-pro
|
community, guide, inference, api, llm, stable-diffusion
|
https://huggingface.co/blog/inference-pro
|
# Inference for PROs  Today, we're introducing Inference for PRO users - a community offering that gives you access to APIs of curated endpoints for some of the most exciting models available, as well as improved rate limits for the usage of free Inference API. Use the following page to [subscribe to PRO](https://huggingface.co/subscribe/pro). Hugging Face PRO users now have access to exclusive API endpoints for a curated list of powerful models that benefit from ultra-fast inference powered by [text-generation-inference](https://github.com/huggingface/text-generation-inference). This is a benefit on top of the free inference API, which is available to all Hugging Face users to facilitate testing and prototyping on 200,000+ models. PRO users enjoy higher rate limits on these models, as well as exclusive access to some of the best models available today. ## Contents - [Supported Models](#supported-models) - [Getting started with Inference for PROs](#getting-started-with-inference-for-pros) - [Applications](#applications) - [Chat with Llama 2 and Code Llama](#chat-with-llama-2-and-code-llama) - [Code infilling with Code Llama](#code-infilling-with-code-llama) - [Stable Diffusion XL](#stable-diffusion-xl) - [Generation Parameters](#generation-parameters) - [Controlling Text Generation](#controlling-text-generation) - [Controlling Image Generation](#controlling-image-generation) - [Caching](#caching) - [Streaming](#streaming) - [Subscribe to PRO](#subscribe-to-pro) - [FAQ](#faq) ## Supported Models In addition to thousands of public models available in the Hub, PRO users get free access and higher rate limits to the following state-of-the-art models: | Model | Size | Context Length | Use | | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------- | ------------------------------------- | | Zephyr 7B β | [7B](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | 4k tokens | Highest-ranked chat model at the 7B weight | | Llama 2 Chat | [7B](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), [13B](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf), and [70B](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | 4k tokens | One of the best conversational models | | Code Llama Base | [7B](https://huggingface.co/codellama/CodeLlama-7b-hf) and [13B](https://huggingface.co/codellama/CodeLlama-13b-hf) | 4k tokens | Autocomplete and infill code | | Code Llama Instruct | [34B](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) | 16k tokens | Conversational code assistant | | Stable Diffusion XL | [3B UNet](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) | - | Generate images | Inference for PROs makes it easy to experiment and prototype with new models without having to deploy them on your own infrastructure. It gives PRO users access to ready-to-use HTTP endpoints for all the models listed above. It’s not meant to be used for heavy production applications - for that, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog). Inference for PROs also allows using applications that depend upon an LLM endpoint, such as using a [VS Code extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) for code completion, or have your own version of [Hugging Chat](http://hf.co/chat). ## Getting started with Inference For PROs Using Inference for PROs is as simple as sending a POST request to the API endpoint for the model you want to run. You'll also need to get a PRO account authentication token from [your token settings page](https://huggingface.co/settings/tokens) and use it in the request. For example, to generate text using [Llama 2 70B Chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) in a terminal session, you'd do something like: ```bash curl https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \ -X POST \ -d '{"inputs": "In a surprising turn of events, "}' \ -H "Content-Type: application/json" \ -H "Authorization: Bearer <YOUR_TOKEN>" ``` Which would print something like this: ```json [ { "generated_text": "In a surprising turn of events, 20th Century Fox has released a new trailer for Ridley Scott's Alien" } ] ``` You can also use many of the familiar transformers generation parameters, like `temperature` or `max_new_tokens`: ```bash curl https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \ -X POST \ -d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \ -H "Content-Type: application/json" \ -H "Authorization: Bearer <YOUR_TOKEN>" ``` ```json [ { "generated_text": "In a surprising turn of events, 2K has announced that it will be releasing a new free-to-play game called NBA 2K23 Arcade Edition. This game will be available on Apple iOS devices and will allow players to compete against each other in quick, 3-on-3 basketball matches.\n\nThe game promises to deliver fast-paced, action-packed gameplay, with players able to choose from a variety of NBA teams and players, including some of the biggest" } ] ``` For more details on the generation parameters, please take a look at [_Controlling Text Generation_](#controlling-text-generation) below. To send your requests in Python, you can take advantage of `InferenceClient`, a convenient utility available in the `huggingface_hub` Python library: ```bash pip install huggingface_hub ``` `InferenceClient` is a helpful wrapper that allows you to make calls to the Inference API and Inference Endpoints easily: ```python from huggingface_hub import InferenceClient client = InferenceClient(model="meta-llama/Llama-2-70b-chat-hf", token=YOUR_TOKEN) output = client.text_generation("Can you please let us know more details about your ") print(output) ``` If you don't want to pass the token explicitly every time you instantiate the client, you can use `notebook_login()` (in Jupyter notebooks), `huggingface-cli login` (in the terminal), or `login(token=YOUR_TOKEN)` (everywhere else) to log in a single time. The token will then be automatically used from here. In addition to Python, you can also use JavaScript to integrate inference calls inside your JS or node apps. Take a look at [huggingface.js](https://huggingface.co/docs/huggingface.js/index) to get started! ## Applications ### Chat with Llama 2 and Code Llama Models prepared to follow chat conversations are trained with very particular and specific chat templates that depend on the model used. You need to be careful about the format the model expects and replicate it in your queries. The following example was taken from [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), that describes in full detail how to query the model for conversation: ```Python prompt = """<s>[INST] <<SYS>> You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. <</SYS>> There's a llama in my garden 😱 What should I do? [/INST] """ response = client.text_generation(prompt, max_new_tokens=200) print(response) ``` This example shows the structure of the first message in a multi-turn conversation. Note how the `<<SYS>>` delimiter is used to provide the _system prompt_, which tells the model how we expect it to behave. Then our query is inserted between `[INST]` delimiters. If we wish to continue the conversation, we have to append the model response to the sequence, and issue a new followup instruction afterwards. This is the general structure of the prompt template we need to use for Llama 2: ``` <s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST] ``` This same format can be used with Code Llama Instruct to engage in technical conversations with a code-savvy assistant! Please, refer to [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) for more details. ### Code infilling with Code Llama Code models like Code Llama can be used for code completion using the same generation strategy we used in the previous examples: you provide a starting string that may contain code or comments, and the model will try to continue the sequence with plausible content. Code models can also be used for _infilling_, a more specialized task where you provide prefix and suffix sequences, and the model will predict what should go in between. This is great for applications such as IDE extensions. Let's see an example using Code Llama: ```Python client = InferenceClient(model="codellama/CodeLlama-13b-hf", token=YOUR_TOKEN) prompt_prefix = 'def remove_non_ascii(s: str) -> str:\n """ ' prompt_suffix = "\n return result" prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>" infilled = client.text_generation(prompt, max_new_tokens=150) infilled = infilled.rstrip(" <EOT>") print(f"{prompt_prefix}{infilled}{prompt_suffix}") ``` ``` def remove_non_ascii(s: str) -> str: """ Remove non-ASCII characters from a string. Args: s (str): The string to remove non-ASCII characters from. Returns: str: The string with non-ASCII characters removed. """ result = "" for c in s: if ord(c) < 128: result += c return result ``` As you can see, the format used for infilling follows this pattern: ``` prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>" ``` For more details on how this task works, please take a look at https://huggingface.co/blog/codellama#code-completion. ### Stable Diffusion XL SDXL is also available for PRO users. The response returned by the endpoint consists of a byte stream representing the generated image. If you use `InferenceClient`, it will automatically decode to a `PIL` image for you: ```Python sdxl = InferenceClient(model="stabilityai/stable-diffusion-xl-base-1.0", token=YOUR_TOKEN) image = sdxl.text_to_image( "Dark gothic city in a misty night, lit by street lamps. A man in a cape is walking away from us", guidance_scale=9, ) ```  For more details on how to control generation, please take a look at [this section](#controlling-image-generation). ## Generation Parameters ### Controlling Text Generation Text generation is a rich topic, and there exist several generation strategies for different purposes. We recommend [this excellent overview](https://huggingface.co/blog/how-to-generate) on the subject. Many generation algorithms are supported by the text generation endpoints, and they can be configured using the following parameters: - `do_sample`: If set to `False` (the default), the generation method will be _greedy search_, which selects the most probable continuation sequence after the prompt you provide. Greedy search is deterministic, so the same results will always be returned from the same input. When `do_sample` is `True`, tokens will be sampled from a probability distribution and will therefore vary across invocations. - `temperature`: Controls the amount of variation we desire from the generation. A temperature of `0` is equivalent to greedy search. If we set a value for `temperature`, then `do_sample` will automatically be enabled. The same thing happens for `top_k` and `top_p`. When doing code-related tasks, we want less variability and hence recommend a low `temperature`. For other tasks, such as open-ended text generation, we recommend a higher one. - `top_k`. Enables "Top-K" sampling: the model will choose from the `K` most probable tokens that may occur after the input sequence. Typical values are between 10 to 50. - `top_p`. Enables "nucleus sampling": the model will choose from as many tokens as necessary to cover a particular probability mass. If `top_p` is 0.9, the 90% most probable tokens will be considered for sampling, and the trailing 10% will be ignored. - `repetition_penalty`: Tries to avoid repeated words in the generated sequence. - `seed`: Random seed that you can use in combination with sampling, for reproducibility purposes. In addition to the sampling parameters above, you can also control general aspects of the generation with the following: - `max_new_tokens`: maximum number of new tokens to generate. The default is `20`, feel free to increase if you want longer sequences. - `return_full_text`: whether to include the input sequence in the output returned by the endpoint. The default used by `InferenceClient` is `False`, but the endpoint itself uses `True` by default. - `stop_sequences`: a list of sequences that will cause generation to stop when encountered in the output. ### Controlling Image Generation If you want finer-grained control over images generated with the SDXL endpoint, you can use the following parameters: - `negative_prompt`: A text describing content that you want the model to steer _away_ from. - `guidance_scale`: How closely you want the model to match the prompt. Lower numbers are less accurate, very high numbers might decrease image quality or generate artifacts. - `width` and `height`: The desired image dimensions. SDXL works best for sizes between 768 and 1024. - `num_inference_steps`: The number of denoising steps to run. Larger numbers may produce better quality but will be slower. Typical values are between 20 and 50 steps. For additional details on text-to-image generation, we recommend you check the [diffusers library documentation](https://huggingface.co/docs/diffusers/using-diffusers/sdxl). ### Caching If you run the same generation multiple times, you’ll see that the result returned by the API is the same (even if you are using sampling instead of greedy decoding). This is because recent results are cached. To force a different response each time, we can use an HTTP header to tell the server to run a new generation each time: `x-use-cache: 0`. If you are using `InferenceClient`, you can simply append it to the `headers` client property: ```Python client = InferenceClient(model="meta-llama/Llama-2-70b-chat-hf", token=YOUR_TOKEN) client.headers["x-use-cache"] = "0" output = client.text_generation("In a surprising turn of events, ", do_sample=True) print(output) ``` ### Streaming Token streaming is the mode in which the server returns the tokens one by one as the model generates them. This enables showing progressive generations to the user rather than waiting for the whole generation. Streaming is an essential aspect of the end-user experience as it reduces latency, one of the most critical aspects of a smooth experience. <div class="flex justify-center"> <img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual_360.gif" /> <img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual-dark_360.gif" /> </div> To stream tokens with `InferenceClient`, simply pass `stream=True` and iterate over the response. ```python for token in client.text_generation("How do you make cheese?", max_new_tokens=12, stream=True): print(token) # To # make # cheese #, # you # need # to # start # with # milk ``` To use the generate_stream endpoint with curl, you can add the `-N`/`--no-buffer` flag, which disables curl default buffering and shows data as it arrives from the server. ``` curl -N https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \ -X POST \ -d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \ -H "Content-Type: application/json" \ -H "Authorization: Bearer <YOUR_TOKEN>" ``` ## Subscribe to PRO You can sign up today for a PRO subscription [here](https://huggingface.co/subscribe/pro). Benefit from higher rate limits, custom accelerated endpoints for the latest models, and early access to features. If you've built some exciting projects with the Inference API or are looking for a model not available in Inference for PROs, please [use this discussion](https://huggingface.co/spaces/huggingface/HuggingDiscussions/discussions/13). [Enterprise users](https://huggingface.co/enterprise) also benefit from PRO Inference API on top of other features, such as SSO. ## FAQ **Does this affect the free Inference API?** No. We still expose thousands of models through free APIs that allow people to prototype and explore model capabilities quickly. **Does this affect Enterprise users?** Users with an Enterprise subscription also benefit from accelerated inference API for curated models. **Can I use my own models with PRO Inference API?** The free Inference API already supports a wide range of small and medium models from a variety of libraries (such as diffusers, transformers, and sentence transformers). If you have a custom model or custom inference logic, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog).
|
Llama 2 on Amazon SageMaker a Benchmark
|
philschmid
|
September 26, 2023
|
llama-sagemaker-benchmark
|
guide, inference, llm, aws
|
https://huggingface.co/blog/llama-sagemaker-benchmark
|
# Llama 2 on Amazon SageMaker a Benchmark  Deploying large language models (LLMs) and other generative AI models can be challenging due to their computational requirements and latency needs. To provide useful recommendations to companies looking to deploy Llama 2 on Amazon SageMaker with the [Hugging Face LLM Inference Container](https://huggingface.co/blog/sagemaker-huggingface-llm), we created a comprehensive benchmark analyzing over 60 different deployment configurations for Llama 2. In this benchmark, we evaluated varying sizes of Llama 2 on a range of Amazon EC2 instance types with different load levels. Our goal was to measure latency (ms per token), and throughput (tokens per second) to find the optimal deployment strategies for three common use cases: - Most Cost-Effective Deployment: For users looking for good performance at low cost - Best Latency Deployment: Minimizing latency for real-time services - Best Throughput Deployment: Maximizing tokens processed per second To keep this benchmark fair, transparent, and reproducible, we share all of the assets, code, and data we used and collected: - [GitHub Repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container) - [Raw Data](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker) - [Spreadsheet with processed data](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit?usp=sharing) We hope to enable customers to use LLMs and Llama 2 efficiently and optimally for their use case. Before we get into the benchmark and data, let's look at the technologies and methods we used. - [Llama 2 on Amazon SageMaker a Benchmark](#llama-2-on-amazon-sagemaker-a-benchmark) - [What is the Hugging Face LLM Inference Container?](#what-is-the-hugging-face-llm-inference-container) - [What is Llama 2?](#what-is-llama-2) - [What is GPTQ?](#what-is-gptq) - [Benchmark](#benchmark) - [Recommendations \& Insights](#recommendations--insights) - [Most Cost-Effective Deployment](#most-cost-effective-deployment) - [Best Throughput Deployment](#best-throughput-deployment) - [Best Latency Deployment](#best-latency-deployment) - [Conclusions](#conclusions) ### What is the Hugging Face LLM Inference Container? [Hugging Face LLM DLC](https://huggingface.co/blog/sagemaker-huggingface-llm) is a purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference), an open-source, purpose-built solution for deploying and serving LLMs. TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Falcon, Llama, and T5. VMware, IBM, Grammarly, Open-Assistant, Uber, Scale AI, and many more already use Text Generation Inference. ### What is Llama 2? Llama 2 is a family of LLMs from Meta, trained on 2 trillion tokens. Llama 2 comes in three sizes - 7B, 13B, and 70B parameters - and introduces key improvements like longer context length, commercial licensing, and optimized chat abilities through reinforcement learning compared to Llama (1). If you want to learn more about Llama 2 check out this [blog post](https://huggingface.co/blog/llama2). ### What is GPTQ? GPTQ is a post-training quantziation method to compress LLMs, like GPT. GPTQ compresses GPT (decoder) models by reducing the number of bits needed to store each weight in the model, from 32 bits down to just 3-4 bits. This means the model takes up much less memory and can run on less Hardware, e.g. Single GPU for 13B Llama2 models. GPTQ analyzes each layer of the model separately and approximates the weights to preserve the overall accuracy. If you want to learn more and how to use it, check out [Optimize open LLMs using GPTQ and Hugging Face Optimum](https://www.philschmid.de/gptq-llama). ## Benchmark To benchmark the real-world performance of Llama 2, we tested 3 model sizes (7B, 13B, 70B parameters) on four different instance types with four different load levels, resulting in 60 different configurations: - Models: We evaluated all currently available model sizes, including 7B, 13B, and 70B. - Concurrent Requests: We tested configurations with 1, 5, 10, and 20 concurrent requests to determine the performance on different usage scenarios. - Instance Types: We evaluated different GPU instances, including g5.2xlarge, g5.12xlarge, g5.48xlarge powered by NVIDIA A10G GPUs, and p4d.24xlarge powered by NVIDIA A100 40GB GPU. - Quantization: We compared performance with and without quantization. We used GPTQ 4-bit as a quantization technique. As metrics, we used Throughput and Latency defined as: - Throughput (tokens/sec): Number of tokens being generated per second. - Latency (ms/token): Time it takes to generate a single token We used those to evaluate the performance of Llama across the different setups to understand the benefits and tradeoffs. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container). You can find the full data of the benchmark in the [Amazon SageMaker Benchmark: TGI 1.0.3 Llama 2](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit#gid=0) sheet. The raw data is available on [GitHub](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker). If you are interested in all of the details, we recommend you to dive deep into the provided raw data. ## Recommendations & Insights Based on the benchmark, we provide specific recommendations for optimal LLM deployment depending on your priorities between cost, throughput, and latency for all Llama 2 model sizes. *Note: The recommendations are based on the configuration we tested. In the future, other environments or hardware offerings, such as Inferentia2, may be even more cost-efficient.* ### Most Cost-Effective Deployment The most cost-effective configuration focuses on the right balance between performance (latency and throughput) and cost. Maximizing the output per dollar spent is the goal. We looked at the performance during 5 concurrent requests. We can see that GPTQ offers the best cost-effectiveness, allowing customers to deploy Llama 2 13B on a single GPU. | Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) | | ----------- | ------------ | -------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ | | Llama 2 7B | GPTQ | g5.2xlarge | 5 | 34.245736 | 120.0941633 | $1.52 | 138.78 | $3.50 | | Llama 2 13B | GPTQ | g5.2xlarge | 5 | 56.237484 | 71.70560104 | $1.52 | 232.43 | $5.87 | | Llama 2 70B | GPTQ | ml.g5.12xlarge | 5 | 138.347928 | 33.33372399 | $7.09 | 499.99 | $59.08 | ### Best Throughput Deployment The Best Throughput configuration maximizes the number of tokens that are generated per second. This might come with some reduction in overall latency since you process more tokens simultaneously. We looked at the highest tokens per second performance during twenty concurrent requests, with some respect to the cost of the instance. The highest throughput was for Llama 2 13B on the ml.p4d.24xlarge instance with 688 tokens/sec. | Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) | | ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ | | Llama 2 7B | None | ml.g5.12xlarge | 20 | 43.99524 | 449.9423027 | $7.09 | 33.59 | $3.97 | | Llama 2 13B | None | ml.p4d.12xlarge | 20 | 67.4027465 | 668.0204881 | $37.69 | 24.95 | $15.67 | | Llama 2 70B | None | ml.p4d.24xlarge | 20 | 59.798591 | 321.5369158 | $37.69 | 51.83 | $32.56 | ### Best Latency Deployment The Best Latency configuration minimizes the time it takes to generate one token. Low latency is important for real-time use cases and providing a good experience to the customer, e.g. Chat applications. We looked at the lowest median for milliseconds per token during 1 concurrent request. The lowest overall latency was for Llama 2 7B on the ml.g5.12xlarge instance with 16.8ms/token. | Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Thorughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) | | ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ | | Llama 2 7B | None | ml.g5.12xlarge | 1 | 16.812526 | 61.45733054 | $7.09 | 271.19 | $32.05 | | Llama 2 13B | None | ml.g5.12xlarge | 1 | 21.002715 | 47.15736567 | $7.09 | 353.43 | $41.76 | | Llama 2 70B | None | ml.p4d.24xlarge | 1 | 41.348543 | 24.5142928 | $37.69 | 679.88 | $427.05 | ## Conclusions In this benchmark, we tested 60 configurations of Llama 2 on Amazon SageMaker. For cost-effective deployments, we found 13B Llama 2 with GPTQ on g5.2xlarge delivers 71 tokens/sec at an hourly cost of $1.55. For max throughput, 13B Llama 2 reached 296 tokens/sec on ml.g5.12xlarge at $2.21 per 1M tokens. And for minimum latency, 7B Llama 2 achieved 16ms per token on ml.g5.12xlarge. We hope the benchmark will help companies deploy Llama 2 optimally based on their needs. If you want to get started deploying Llama 2 on Amazon SageMaker, check out [Introducing the Hugging Face LLM Inference Container for Amazon SageMaker](https://huggingface.co/blog/sagemaker-huggingface-llm) and [Deploy Llama 2 7B/13B/70B on Amazon SageMaker](https://www.philschmid.de/sagemaker-llama-llm) blog posts. --- Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
|
Non-engineers guide: Train a LLaMA 2 chatbot
|
2legit2overfit
|
September 28, 2023
|
Llama2-for-non-engineers
|
guide, community, nlp
|
https://huggingface.co/blog/Llama2-for-non-engineers
|
# Non-engineers guide: Train a LLaMA 2 chatbot ## Introduction In this tutorial we will show you how anyone can build their own open-source ChatGPT without ever writing a single line of code! We’ll use the LLaMA 2 base model, fine tune it for chat with an open-source instruction dataset and then deploy the model to a chat app you can share with your friends. All by just clicking our way to greatness. 😀 Why is this important? Well, machine learning, especially LLMs (Large Language Models), has witnessed an unprecedented surge in popularity, becoming a critical tool in our personal and business lives. Yet, for most outside the specialized niche of ML engineering, the intricacies of training and deploying these models appears beyond reach. If the anticipated future of machine learning is to be one filled with ubiquitous personalized models, then there's an impending challenge ahead: How do we empower those with non-technical backgrounds to harness this technology independently? At Hugging Face, we’ve been quietly working to pave the way for this inclusive future. Our suite of tools, including services like Spaces, AutoTrain, and Inference Endpoints, are designed to make the world of machine learning accessible to everyone. To showcase just how accessible this democratized future is, this tutorial will show you how to use [Spaces](https://huggingface.co/Spaces), [AutoTrain](https://huggingface.co/autotrain) and [ChatUI](https://huggingface.co/inference-endpoints) to build the chat app. All in just three simple steps, sans a single line of code. For context I’m also not an ML engineer, but a member of the Hugging Face GTM team. If I can do this then you can too! Let's dive in! ## Introduction to Spaces Spaces from Hugging Face is a service that provides easy to use GUI for building and deploying web hosted ML demos and apps. The service allows you to quickly build ML demos using Gradio or Streamlit front ends, upload your own apps in a docker container, or even select a number of pre-configured ML applications to deploy instantly. We’ll be deploying two of the pre-configured docker application templates from Spaces, AutoTrain and ChatUI. You can read more about Spaces [here](https://huggingface.co/docs/hub/spaces). ## Introduction to AutoTrain AutoTrain is a no-code tool that lets non-ML Engineers, (or even non-developers 😮) train state-of-the-art ML models without the need to code. It can be used for NLP, computer vision, speech, tabular data and even now for fine-tuning LLMs like we’ll be doing today. You can read more about AutoTrain [here](https://huggingface.co/docs/autotrain/index). ## Introduction to ChatUI ChatUI is exactly what it sounds like, it’s the open-source UI built by Hugging Face that provides an interface to interact with open-source LLMs. Notably, it's the same UI behind HuggingChat, our 100% open-source alternative to ChatGPT. You can read more about ChatUI [here](https://github.com/huggingface/chat-ui). ### Step 1: Create a new AutoTrain Space 1.1 Go to [huggingface.co/spaces](https://huggingface.co/spaces) and select “Create new Space”. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto1.png"><br> </p> 1.2 Give your Space a name and select a preferred usage license if you plan to make your model or Space public. 1.3 In order to deploy the AutoTrain app from the Docker Template in your deployed space select Docker > AutoTrain. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto2.png"><br> </p> 1.4 Select your “Space hardware” for running the app. (Note: For the AutoTrain app the free CPU basic option will suffice, the model training later on will be done using separate compute which we can choose later) 1.5 Add your “HF_TOKEN” under “Space secrets” in order to give this Space access to your Hub account. Without this the Space won’t be able to train or save a new model to your account. (Note: Your HF_TOKEN can be found in your Hugging Face Profile under Settings > Access Tokens, make sure the token is selected as “Write”) 1.6 Select whether you want to make the “Private” or “Public”, for the AutoTrain Space itself it’s recommended to keep this Private, but you can always publicly share your model or Chat App later on. 1.7 Hit “Create Space” et voilà! The new Space will take a couple of minutes to build after which you can open the Space and start using AutoTrain. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto3.png"><br> </p> ### Step 2: Launch a Model Training in AutoTrain 2.1 Once you’re AutoTrain space has launched you’ll see the GUI below. AutoTrain can be used for several different kinds of training including LLM fine-tuning, text classification, tabular data and diffusion models. As we’re focusing on LLM training today select the “LLM” tab. 2.2 Choose the LLM you want to train from the “Model Choice” field, you can select a model from the list or type the name of the model from the Hugging Face model card, in this example we’ve used Meta’s Llama 2 7b foundation model, learn more from the model card [here](https://huggingface.co/meta-llama/Llama-2-7b-hf). (Note: LLama 2 is gated model which requires you to request access from Meta before using, but there are plenty of others non-gated models you could choose like Falcon) 2.3 In “Backend” select the CPU or GPU you want to use for your training. For a 7b model an “A10G Large” will be big enough. If you choose to train a larger model you’ll need to make sure the model can fully fit in the memory of your selected GPU. (Note: If you want to train a larger model and need access to an A100 GPU please email [email protected]) 2.4 Of course to fine-tune a model you’ll need to upload “Training Data”. When you do, make sure the dataset is correctly formatted and in CSV file format. An example of the required format can be found [here](https://huggingface.co/docs/autotrain/main/en/llm_finetuning). If your dataset contains multiple columns, be sure to select the “Text Column” from your file that contains the training data. In this example we’ll be using the Alpaca instruction tuning dataset, more information about this dataset is available [here](https://huggingface.co/datasets/tatsu-lab/alpaca). You can also download it directly as CSV from [here](https://huggingface.co/datasets/tofighi/LLM/resolve/main/alpaca.csv). <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto4.png"><br> </p> 2.5 Optional: You can upload “Validation Data” to test your newly trained model against, but this isn’t required. 2.6 A number of advanced settings can be configured in AutoTrain to reduce the memory footprint of your model like changing precision (“FP16”), quantization (“Int4/8”) or whether to employ PEFT (Parameter Efficient Fine Tuning). It’s recommended to use these as is set by default as it will reduce the time and cost to train your model, and only has a small impact on model performance. 2.7 Similarly you can configure the training parameters in “Parameter Choice” but for now let’s use the default settings. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto5.png"><br> </p> 2.8 Now everything is set up, select “Add Job” to add the model to your training queue then select “Start Training” (Note: If you want to train multiple models versions with different hyper-parameters you can add multiple jobs to run simultaneously) 2.9 After training has started you’ll see that a new “Space” has been created in your Hub account. This Space is running the model training, once it’s complete the new model will also be shown in your Hub account under “Models”. (Note: To view training progress you can view live logs in the Space) 2.10 Go grab a coffee, depending on the size of your model and training data this could take a few hours or even days. Once completed a new model will appear in your Hugging Face Hub account under “Models”. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto6.png"><br> </p> ### Step 3: Create a new ChatUI Space using your model 3.1 Follow the same process of setting up a new Space as in steps 1.1 > 1.3, but select the ChatUI docker template instead of AutoTrain. 3.2 Select your “Space Hardware” for our 7b model an A10G Small will be sufficient to run the model, but this will vary depending on the size of your model. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto7.png"><br> </p> 3.3 If you have your own Mongo DB you can provide those details in order to store chat logs under “MONGODB_URL”. Otherwise leave the field blank and a local DB will be created automatically. 3.4 In order to run the chat app using the model you’ve trained you’ll need to provide the “MODEL_NAME” under the “Space variables” section. You can find the name of your model by looking in the “Models” section of your Hugging Face profile, it will be the same as the “Project name” you used in AutoTrain. In our example it’s “2legit2overfit/wrdt-pco6-31a7-0”. 3.4 Under “Space variables” you can also change model inference parameters including temperature, top-p, max tokens generated and others to change the nature of your generations. For now let’s stick with the default settings. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto8.png"><br> </p> 3.5 Now you are ready to hit “Create” and launch your very own open-source ChatGPT. Congratulations! If you’ve done it right it should look like this. <p align="center"> <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto9.png"><br> </p> _If you’re feeling inspired, but still need technical support to get started, feel free to reach out and apply for support [here](https://huggingface.co/support#form). Hugging Face offers a paid Expert Advice service that might be able to help._
|
Finetune Stable Diffusion Models with DDPO via TRL
|
metric-space
|
September 29, 2023
|
trl-ddpo
|
guide, diffusers, rl, rlhf
|
https://huggingface.co/blog/trl-ddpo
|
# Finetune Stable Diffusion Models with DDPO via TRL ## Introduction Diffusion models (e.g., DALL-E 2, Stable Diffusion) are a class of generative models that are widely successful at generating images most notably of the photorealistic kind. However, the images generated by these models may not always be on par with human preference or human intention. Thus arises the alignment problem i.e. how does one go about making sure that the outputs of a model are aligned with human preferences like “quality” or that outputs are aligned with intent that is hard to express via prompts? This is where Reinforcement Learning comes into the picture. In the world of Large Language Models (LLMs), Reinforcement learning (RL) has proven to become a very effective tool for aligning said models to human preferences. It’s one of the main recipes behind the superior performance of systems like ChatGPT. More precisely, RL is the critical ingredient of Reinforcement Learning from Human Feedback (RLHF), which makes ChatGPT chat like human beings. In [Training Diffusion Models with Reinforcement Learning, Black](https://arxiv.org/abs/2305.13301) et al. show how to augment diffusion models to leverage RL to fine-tune them with respect to an objective function via a method named Denoising Diffusion Policy Optimization (DDPO). In this blog post, we discuss how DDPO came to be, a brief description of how it works, and how DDPO can be incorporated into an RLHF workflow to achieve model outputs more aligned with the human aesthetics. We then quickly switch gears to talk about how you can apply DDPO to your models with the newly integrated `DDPOTrainer` from the `trl` library and discuss our findings from running DDPO on Stable Diffusion. ## The Advantages of DDPO DDPO is not the only working answer to the question of how to attempt to fine-tune diffusion models with RL. Before diving in, there are two key points to remember when it comes to understanding the advantages of one RL solution over the other 1. Computational efficiency is key. The more complicated your data distribution gets, the higher your computational costs get. 2. Approximations are nice, but because approximations are not the real thing, associated errors stack up. Before DDPO, Reward-weighted regression (RWR) was an established way of using Reinforcement Learning to fine-tune diffusion models. RWR reuses the denoising loss function of the diffusion model along with training data sampled from the model itself and per-sample loss weighting that depends on the reward associated with the final samples. This algorithm ignores the intermediate denoising steps/samples. While this works, two things should be noted: 1. Optimizing by weighing the associated loss, which is a maximum likelihood objective, is an approximate optimization 2. The associated loss is not an exact maximum likelihood objective but an approximation that is derived from a reweighed variational bound The two orders of approximation have a significant impact on both performance and the ability to handle complex objectives. DDPO uses this method as a starting point. Rather than viewing the denoising step as a single step by only focusing on the final sample, DDPO frames the whole denoising process as a multistep Markov Decision Process (MDP) where the reward is received at the very end. This formulation in addition to using a fixed sampler paves the way for the agent policy to become an isotropic Gaussian as opposed to an arbitrarily complicated distribution. So instead of using the approximate likelihood of the final sample (which is the path RWR takes), here the exact likelihood of each denoising step which is extremely easy to compute ( \\( \ell(\mu, \sigma^2; x) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i - \mu)^2 \\) ). If you’re interested in learning more details about DDPO, we encourage you to check out the [original paper](https://arxiv.org/abs/2305.13301) and the [accompanying blog post](https://bair.berkeley.edu/blog/2023/07/14/ddpo/). ## DDPO algorithm briefly Given the MDP framework used to model the sequential nature of the denoising process and the rest of the considerations that follow, the tool of choice to tackle the optimization problem is a policy gradient method. Specifically Proximal Policy Optimization (PPO). The whole DDPO algorithm is pretty much the same as Proximal Policy Optimization (PPO) but as a side, the portion that stands out as highly customized is the trajectory collection portion of PPO Here’s a diagram to summarize the flow: 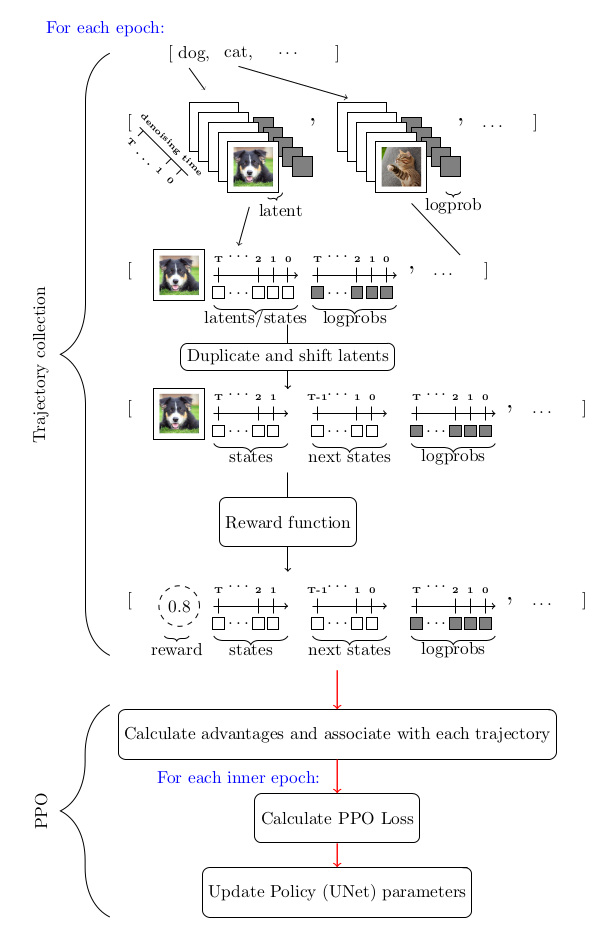 ## DDPO and RLHF: a mix to enforce aestheticness The general training aspect of [RLHF](https://huggingface.co/blog/rlhf) can roughly be broken down into the following steps: 1. Supervised fine-tuning a “base” model learns to the distribution of some new data 2. Gathering preference data and training a reward model using it. 3. Fine-tuning the model with reinforcement learning using the reward model as a signal. It should be noted that preference data is the primary source for capturing human feedback in the context of RLHF. When we add DDPO to the mix, the workflow gets morphed to the following: 1. Starting with a pretrained Diffusion Model 2. Gathering preference data and training a reward model using it. 3. Fine-tuning the model with DDPO using the reward model as a signal Notice that step 3 from the general RLHF workflow is missing in the latter list of steps and this is because empirically it has been shown (as you will get to see yourself) that this is not needed. To get on with our venture to get a diffusion model to output images more in line with the human perceived notion of what it means to be aesthetic, we follow these steps: 1. Starting with a pretrained Stable Diffusion (SD) Model 2. Training a frozen [CLIP](https://huggingface.co/openai/clip-vit-large-patch14) model with a trainable regression head on the [Aesthetic Visual Analysis](http://refbase.cvc.uab.es/files/MMP2012a.pdf) (AVA) dataset to predict how much people like an input image on average 3. Fine-tuning the SD model with DDPO using the aesthetic predictor model as the reward signaller We keep these steps in mind while moving on to actually getting these running which is described in the following sections. ## Training Stable Diffusion with DDPO ### Setup To get started, when it comes to the hardware side of things and this implementation of DDPO, at the very least access to an A100 NVIDIA GPU is required for successful training. Anything below this GPU type will soon run into Out-of-memory issues. Use pip to install the `trl` library ```bash pip install trl[diffusers] ``` This should get the main library installed. The following dependencies are for tracking and image logging. After getting `wandb` installed, be sure to login to save the results to a personal account ```bash pip install wandb torchvision ``` Note: you could choose to use `tensorboard` rather than `wandb` for which you’d want to install the `tensorboard` package via `pip`. ### A Walkthrough The main classes within the `trl` library responsible for DDPO training are the `DDPOTrainer` and `DDPOConfig` classes. See [docs](https://huggingface.co/docs/trl/ddpo_trainer#getting-started-with-examplesscriptsstablediffusiontuningpy) for more general info on the `DDPOTrainer` and `DDPOConfig`. There is an [example training script](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) in the `trl` repo. It uses both of these classes in tandem with default implementations of required inputs and default parameters to finetune a default pretrained Stable Diffusion Model from `RunwayML` . This example script uses `wandb` for logging and uses an aesthetic reward model whose weights are read from a public facing HuggingFace repo (so gathering data and training the aesthetic reward model is already done for you). The default prompt dataset used is a list of animal names. There is only one commandline flag argument that is required of the user to get things up and running. Additionally, the user is expected to have a [huggingface user access token](https://huggingface.co/docs/hub/security-tokens) that will be used to upload the model post finetuning to HuggingFace hub. The following bash command gets things running: ```python python stable_diffusion_tuning.py --hf_user_access_token <token> ``` The following table contains key hyperparameters that are directly correlated with positive results: | Parameter | Description | Recommended value for single GPU training (as of now) | | --- | --- | --- | | `num_epochs` | The number of epochs to train for | 200 | | `train_batch_size` | The batch size to use for training | 3 | | `sample_batch_size` | The batch size to use for sampling | 6 | | `gradient_accumulation_steps` | The number of accelerator based gradient accumulation steps to use | 1 | | `sample_num_steps` | The number of steps to sample for | 50 | | `sample_num_batches_per_epoch` | The number of batches to sample per epoch | 4 | | `per_prompt_stat_tracking` | Whether to track stats per prompt. If false, advantages will be calculated using the mean and std of the entire batch as opposed to tracking per prompt | `True` | | `per_prompt_stat_tracking_buffer_size` | The size of the buffer to use for tracking stats per prompt | 32 | | `mixed_precision` | Mixed precision training | `True` | | `train_learning_rate` | Learning rate | 3e-4 | The provided script is merely a starting point. Feel free to adjust the hyperparameters or even overhaul the script to accommodate different objective functions. For instance, one could integrate a function that gauges JPEG compressibility or [one that evaluates visual-text alignment using a multi-modal model](https://github.com/kvablack/ddpo-pytorch/blob/main/ddpo_pytorch/rewards.py#L45), among other possibilities. ## Lessons learned 1. The results seem to generalize over a wide variety of prompts despite the minimally sized training prompts size. This has been thoroughly verified for the objective function that rewards aesthetics 2. Attempts to try to explicitly generalize at least for the aesthetic objective function by increasing the training prompt size and varying the prompts seem to slow down the convergence rate for barely noticeable learned general behavior if at all this exists 3. While LoRA is recommended and is tried and tested multiple times, the non-LoRA is something to consider, among other reasons from empirical evidence, non-Lora does seem to produce relatively more intricate images than LoRA. However, getting the right hyperparameters for a stable non-LoRA run is significantly more challenging. 4. Recommendations for the config parameters for non-Lora are: set the learning rate relatively low, something around `1e-5` should do the trick and set `mixed_precision` to `None` ## Results The following are pre-finetuned (left) and post-finetuned (right) outputs for the prompts `bear`, `heaven` and `dune` (each row is for the outputs of a single prompt): | pre-finetuned | post-finetuned | |:-------------------------:|:-------------------------:| |  |  | |  |  | |  |  | ## Limitations 1. Right now `trl`'s DDPOTrainer is limited to finetuning vanilla SD models; 2. In our experiments we primarily focused on LoRA which works very well. We did a few experiments with full training which can lead to better quality but finding the right hyperparameters is more challenging. ## Conclusion Diffusion models like Stable Diffusion, when fine-tuned using DDPO, can offer significant improvements in the quality of generated images as perceived by humans or any other metric once properly conceptualized as an objective function The computational efficiency of DDPO and its ability to optimize without relying on approximations, especially over earlier methods to achieve the same goal of fine-tuning diffusion models, make it a suitable candidate for fine-tuning diffusion models like Stable Diffusion `trl` library's `DDPOTrainer` implements DDPO for finetuning SD models. Our experimental findings underline the strength of DDPO in generalizing across a broad range of prompts, although attempts at explicit generalization through varying prompts had mixed results. The difficulty of finding the right hyperparameters for non-LoRA setups also emerged as an important learning. DDPO is a promising technique to align diffusion models with any reward function and we hope that with the release in TRL we can make it more accessible to the community! ## Acknowledgements Thanks to Chunte Lee for the thumbnail of this blog post.
|
Ethics and Society Newsletter #5: Hugging Face Goes To Washington and Other Summer 2023 Musings
|
meg
|
September 29, 2023
|
ethics-soc-5
|
ethics
|
https://huggingface.co/blog/ethics-soc-5
|
# Ethics and Society Newsletter #5: Hugging Face Goes To Washington and Other Summer 2023 Musings One of the most important things to know about “ethics” in AI is that it has to do with **values**. Ethics doesn’t tell you what’s right or wrong, it provides a vocabulary of values – transparency, safety, justice – and frameworks to prioritize among them. This summer, we were able to take our understanding of values in AI to legislators in the E.U., U.K., and U.S., to help shape the future of AI regulation. This is where ethics shines: helping carve out a path forward when laws are not yet in place. In keeping with Hugging Face’s core values of *openness* and *accountability*, we are sharing a collection of what we’ve said and done here. This includes our CEO [Clem](https://huggingface.co/clem)’s [testimony to U.S. Congress](https://twitter.com/ClementDelangue/status/1673348676478025730) and [statements at the U.S. Senate AI Insight Forum](https://twitter.com/ClementDelangue/status/1702095553503412732); our advice on the [E.U. AI Act](https://huggingface.co/blog/eu-ai-act-oss); our [comments to the NTIA on AI Accountability](https://huggingface.co/blog/policy-ntia-rfc); and our Chief Ethics Scientist [Meg](https://huggingface.co/meg)’s [comments to the Democratic Caucus](assets/164_ethics-soc-5/meg_dem_caucus.pdf). Common to many of these discussions were questions about why openness in AI can be beneficial, and we share a collection of our answers to this question [here](assets/164_ethics-soc-5/why_open.md). In keeping with our core value of *democratization*, we have also spent a lot of time speaking publicly, and have been privileged to speak with journalists in order to help explain what’s happening in the world of AI right now. This includes: - Comments from [Sasha](https://huggingface.co/sasha) on **AI’s energy use and carbon emissions** ([The Atlantic](https://www.theatlantic.com/technology/archive/2023/08/ai-carbon-emissions-data-centers/675094/), [The Guardian](https://www.theguardian.com/technology/2023/aug/01/techscape-environment-cost-ai-artificial-intelligence), ([twice](https://www.theguardian.com/technology/2023/jun/08/artificial-intelligence-industry-boom-environment-toll)), [New Scientist](https://www.newscientist.com/article/2381859-shifting-where-data-is-processed-for-ai-can-reduce-environmental-harm/), [The Weather Network](https://www.theweathernetwork.com/en/news/climate/causes/how-energy-intensive-are-ai-apps-like-chatgpt), the [Wall Street Journal](https://www.wsj.com/articles/artificial-intelligence-technology-energy-a3a1a8a7), ([twice](https://www.wsj.com/articles/artificial-intelligence-can-make-companies-greener-but-it-also-guzzles-energy-7c7b678))), as well as penning part of a [Wall Street Journal op-ed on the topic](https://www.wsj.com/articles/artificial-intelligence-technology-energy-a3a1a8a7); thoughts on **AI doomsday risk** ([Bloomberg](https://www.bnnbloomberg.ca/ai-doomsday-scenarios-are-gaining-traction-in-silicon-valley-1.1945116), [The Times](https://www.thetimes.co.uk/article/everything-you-need-to-know-about-ai-but-were-afraid-to-ask-g0q8sq7zv), [Futurism](https://futurism.com/the-byte/ai-expert-were-all-going-to-die), [Sky News](https://www.youtube.com/watch?v=9Auq9mYxFEE)); details on **bias in generative AI** ([Bloomberg](https://www.bloomberg.com/graphics/2023-generative-ai-bias/), [NBC](https://www.nbcnews.com/news/asian-america/tool-reducing-asian-influence-ai-generated-art-rcna89086), [Vox](https://www.vox.com/technology/23738987/racism-ai-automated-bias-discrimination-algorithm)); addressing how **marginalized workers create the data for AI** ([The Globe and Mail](https://www.theglobeandmail.com/business/article-ai-data-gig-workers/), [The Atlantic](https://www.theatlantic.com/technology/archive/2023/07/ai-chatbot-human-evaluator-feedback/674805/)); highlighting effects of **sexism in AI** ([VICE](https://www.vice.com/en/article/g5ywp7/you-know-what-to-do-boys-sexist-app-lets-men-rate-ai-generated-women)); and providing insights in MIT Technology Review on [AI text detection](https://www.technologyreview.com/2023/07/07/1075982/ai-text-detection-tools-are-really-easy-to-fool/), [open model releases](https://www.technologyreview.com/2023/07/18/1076479/metas-latest-ai-model-is-free-for-all/), and [AI transparency](https://www.technologyreview.com/2023/07/25/1076698/its-high-time-for-more-ai-transparency/). - Comments from [Nathan](https://huggingface.co/natolambert) on the state of the art on **language models and open releases** ([WIRED](https://www.wired.com/story/metas-open-source-llama-upsets-the-ai-horse-race/), [VentureBeat](https://venturebeat.com/business/todays-ai-is-not-science-its-alchemy-what-that-means-and-why-that-matters-the-ai-beat/), [Business Insider](https://www.businessinsider.com/chatgpt-openai-moat-in-ai-wars-llama2-shrinking-2023-7), [Fortune](https://fortune.com/2023/07/18/meta-llama-2-ai-open-source-700-million-mau/)). - Comments from [Meg](https://huggingface.co/meg) on **AI and misinformation** ([CNN](https://www.cnn.com/2023/07/17/tech/ai-generated-election-misinformation-social-media/index.html), [al Jazeera](https://www.youtube.com/watch?v=NuLOUzU8P0c), [the New York Times](https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html)); the need for **just handling of artists’ work** in AI ([Washington Post](https://www.washingtonpost.com/technology/2023/07/16/ai-programs-training-lawsuits-fair-use/)); advancements in **generative AI** and their relationship to the greater good ([Washington Post](https://www.washingtonpost.com/technology/2023/09/20/openai-dall-e-image-generator/), [VentureBeat](https://venturebeat.com/ai/generative-ai-secret-sauce-data-scraping-under-attack/)); how **journalists can better shape the evolution of AI** with their reporting ([CJR](https://www.cjr.org/analysis/how-to-report-better-on-artificial-intelligence.php)); as well as explaining the fundamental statistical concept of **perplexity** in AI ([Ars Technica](https://arstechnica.com/information-technology/2023/07/why-ai-detectors-think-the-us-constitution-was-written-by-ai/)); and highlighting patterns of **sexism** ([Fast Company](https://www.fastcompany.com/90952272/chuck-schumer-ai-insight-forum)). - Comments from [Irene](https://huggingface.co/irenesolaiman) on understanding the **regulatory landscape of AI** ([MIT Technology Review](https://www.technologyreview.com/2023/09/11/1079244/what-to-know-congress-ai-insight-forum-meeting/), [Barron’s](https://www.barrons.com/articles/artificial-intelligence-chips-technology-stocks-roundtable-74b256fd)). - Comments from [Yacine](https://huggingface.co/yjernite) on **open source and AI legislation** ([VentureBeat](https://venturebeat.com/ai/hugging-face-github-and-more-unite-to-defend-open-source-in-eu-ai-legislation/), [TIME](https://time.com/6308604/meta-ai-access-open-source/)) as well as **copyright issues** ([VentureBeat](https://venturebeat.com/ai/potential-supreme-court-clash-looms-over-copyright-issues-in-generative-ai-training-data/)). - Comments from [Giada](https://huggingface.co/giadap) on the concepts of **AI “singularity”** ([Popular Mechanics](https://www.popularmechanics.com/technology/security/a43929371/ai-singularity-dangers/)) and **AI “sentience”** ([RFI](https://www.rfi.fr/fr/technologies/20230612-pol%C3%A9mique-l-intelligence-artificielle-ange-ou-d%C3%A9mon), [Radio France](https://www.radiofrance.fr/franceculture/podcasts/le-temps-du-debat/l-intelligence-artificielle-est-elle-un-nouvel-humanisme-9822329)); thoughts on **the perils of artificial romance** ([Analytics India Magazine](https://analyticsindiamag.com/the-perils-of-artificial-romance/)); and explaining **value alignment** ([The Hindu](https://www.thehindu.com/sci-tech/technology/ai-alignment-cant-be-solved-as-openai-says/article67063877.ece)). Some of our talks released this summer include [Giada](https://huggingface.co/giadap)’s [TED presentation on whether “ethical” generative AI is possible](https://youtu.be/NreFQFKahxw?si=49UoQeEw5IyRSRo7) (the automatic English translation subtitles are great!); [Yacine](https://huggingface.co/yjernite)’s presentations on [Ethics in Tech](https://docs.google.com/presentation/d/1viaOjX4M1m0bydZB0DcpW5pSAgK1m1CPPtTZz7zsZnE/) at the [Markkula Center for Applied Ethics](https://www.scu.edu/ethics/focus-areas/technology-ethics/) and [Responsible Openness](https://www.youtube.com/live/75OBTMu5UEc?feature=shared&t=10140) at the [Workshop on Responsible and Open Foundation Models](https://sites.google.com/view/open-foundation-models); [Katie](https://huggingface.co/katielink)’s chat about [generative AI in health](https://www.youtube.com/watch?v=_u-PQyM_mvE); and [Meg](https://huggingface.co/meg)’s presentation for [London Data Week](https://www.turing.ac.uk/events/london-data-week) on [Building Better AI in the Open](https://london.sciencegallery.com/blog/watch-again-building-better-ai-in-the-open). Of course, we have also made progress on our regular work (our “work work”). The fundamental value of *approachability* has emerged across our work, as we've focused on how to shape AI in a way that’s informed by society and human values, where everyone feels welcome. This includes [a new course on AI audio](https://huggingface.co/learn/audio-course/) from [Maria](https://huggingface.co/MariaK) and others; a resource from [Katie](https://huggingface.co/katielink) on [Open Access clinical language models](https://www.linkedin.com/feed/update/urn:li:activity:7107077224758923266/); a tutorial from [Nazneen](https://huggingface.co/nazneen) and others on [Responsible Generative AI](https://www.youtube.com/watch?v=gn0Z_glYJ90&list=PLXA0IWa3BpHnrfGY39YxPYFvssnwD8awg&index=13&t=1s); our FAccT papers on [The Gradient of Generative AI Release](https://dl.acm.org/doi/10.1145/3593013.3593981) ([video](https://youtu.be/8_-QTw8ugas?si=RG-NO1v3SaAMgMRQ)) and [Articulation of Ethical Charters, Legal Tools, and Technical Documentation in ML](https://dl.acm.org/doi/10.1145/3593013.3594002) ([video](https://youtu.be/ild63NtxTpI?si=jPlIBAL6WLtTHUwt)); as well as workshops on [Mapping the Risk Surface of Text-to-Image AI with a participatory, cross-disciplinary approach](https://avidml.org/events/tti2023/) and [Assessing the Impacts of Generative AI Systems Across Modalities and Society](https://facctconference.org/2023/acceptedcraft#modal) ([video](https://youtu.be/yJMlK7PSHyI?si=UKDkTFEIQ_rIbqhd)). We have also moved forward with our goals of *fairness* and *justice* with [bias and harm testing](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct#bias-risks-and-limitations), recently applied to the new Hugging Face multimodal model [IDEFICS](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct). We've worked on how to operationalize *transparency* responsibly, including [updating our Content Policy](https://huggingface.co/blog/content-guidelines-update) (spearheaded by [Giada](https://huggingface.co/giadap)). We've advanced our support of language *diversity* on the Hub by [using machine learning to improve metadata](https://huggingface.co/blog/huggy-lingo) (spearheaded by [Daniel](https://huggingface.co/davanstrien)), and our support of *rigour* in AI by [adding more descriptive statistics to datasets](https://twitter.com/polinaeterna/status/1707447966355563000) (spearheaded by [Polina](https://huggingface.co/polinaeterna)) to foster a better understanding of what AI learns and how it can be evaluated. Drawing from our experiences this past season, we now provide a collection of many of the resources at Hugging Face that are particularly useful in current AI ethics discourse right now, available here: [https://huggingface.co/society-ethics](https://huggingface.co/society-ethics). Finally, we have been surprised and delighted by public recognition for many of the society & ethics regulars, including both [Irene](https://www.technologyreview.com/innovator/irene-solaiman/) and [Sasha](https://www.technologyreview.com/innovator/sasha-luccioni/) being selected in [MIT’s 35 Innovators under 35](https://www.technologyreview.com/innovators-under-35/artificial-intelligence-2023/) (Hugging Face makes up ¼ of the AI 35 under 35!); [Meg](https://huggingface.co/meg) being included in lists of influential AI innovators ([WIRED](https://www.wired.com/story/meet-the-humans-trying-to-keep-us-safe-from-ai/), [Fortune](https://fortune.com/2023/06/13/meet-top-ai-innovators-impact-on-business-society-chatgpt-deepmind-stability/)); and [Meg](https://huggingface.co/meg) and [Clem](https://huggingface.co/clem)’s selection in [TIME’s 100 under 100 in AI](https://time.com/collection/time100-ai/). We are also very sad to say goodbye to our colleague [Nathan](https://huggingface.co/natolambert), who has been instrumental in our work connecting ethics to reinforcement learning for AI systems. As his parting gift, he has provided further details on the [challenges of operationalizing ethical AI in RLHF](https://www.interconnects.ai/p/operationalizing-responsible-rlhf). Thank you for reading! \-\- Meg, on behalf of the [Ethics & Society regulars](https://huggingface.co/spaces/society-ethics/about) at Hugging Face
|
Deploying the AI Comic Factory using the Inference API
|
jbilcke-hf
|
October 2, 2023
|
ai-comic-factory
|
guide, inference, api, llm, stable-diffusion
|
https://huggingface.co/blog/ai-comic-factory
|
# Deploying the AI Comic Factory using the Inference API We recently announced [Inference for PROs](https://huggingface.co/blog/inference-pro), our new offering that makes larger models accessible to a broader audience. This opportunity opens up new possibilities for running end-user applications using Hugging Face as a platform. An example of such an application is the [AI Comic Factory](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory) - a Space that has proved incredibly popular. Thousands of users have tried it to create their own AI comic panels, fostering its own community of regular users. They share their creations, with some even opening pull requests. In this tutorial, we'll show you how to fork and configure the AI Comic Factory to avoid long wait times and deploy it to your own private space using the Inference API. It does not require strong technical skills, but some knowledge of APIs, environment variables and a general understanding of LLMs & Stable Diffusion are recommended. ## Getting started First, ensure that you sign up for a [PRO Hugging Face account](https://huggingface.co/subscribe/pro), as this will grant you access to the Llama-2 and SDXL models. ## How the AI Comic Factory works The AI Comic Factory is a bit different from other Spaces running on Hugging Face: it is a NextJS application, deployed using Docker, and is based on a client-server approach, requiring two APIs to work: - a Language Model API (Currently [Llama-2](https://huggingface.co/docs/transformers/model_doc/llama2)) - a Stable Diffusion API (currently [SDXL 1.0](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl)) ## Duplicating the Space To duplicate the AI Comic Factory, go to the Space and [click on "Duplicate"](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory?duplicate=true):  You'll observe that the Space owner, name, and visibility are already filled in for you, so you can leave those values as is. Your copy of the Space will run inside a Docker container that doesn't require many resources, so you can use the smallest instance. The official AI Comic Factory Space utilizes a bigger CPU instance, as it caters to a large user base. To operate the AI Comic Factory under your account, you need to configure your Hugging Face token: 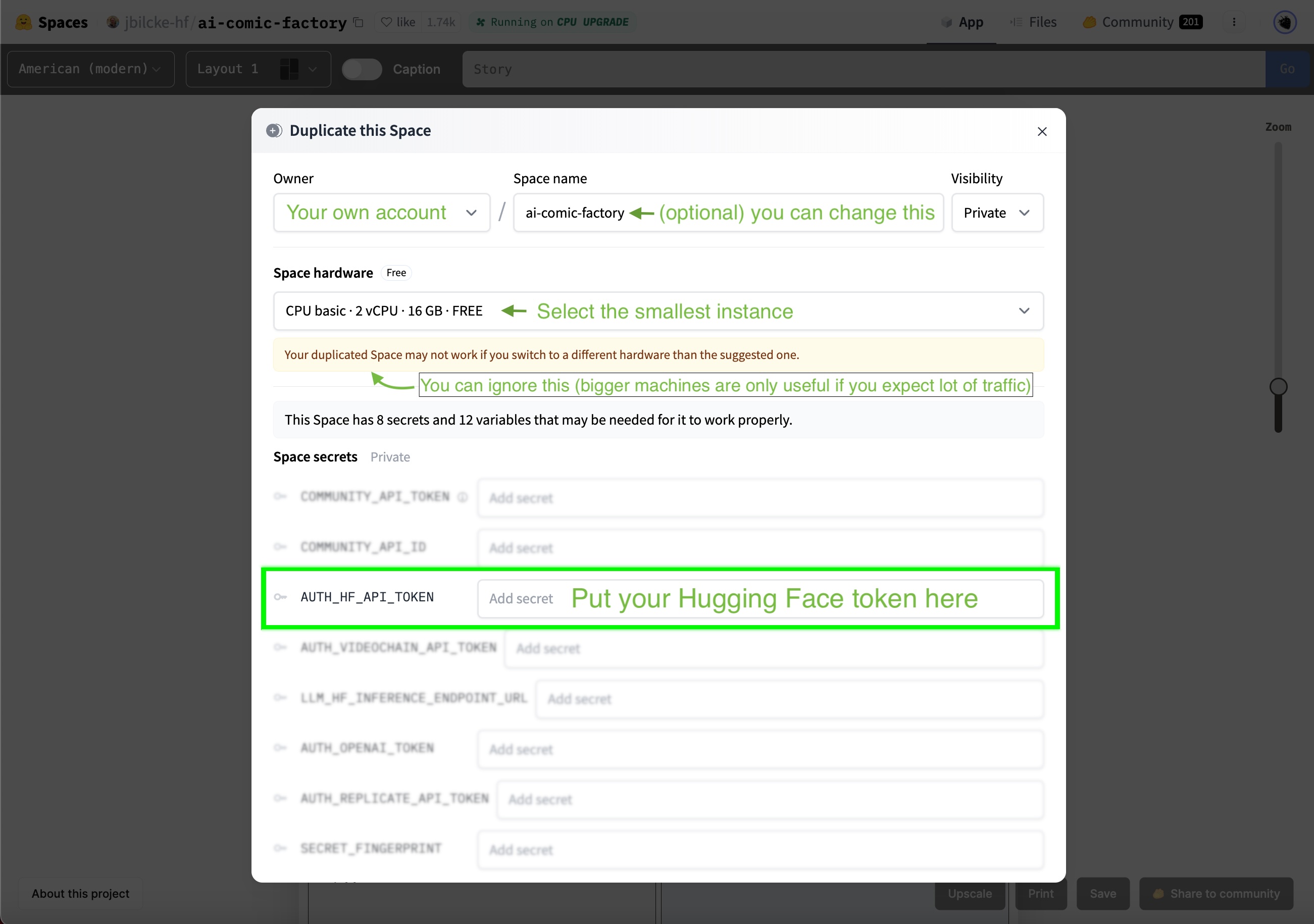 ## Selecting the LLM and SD engines The AI Comic Factory supports various backend engines, which can be configured using two environment variables: - `LLM_ENGINE` to configure the language model (possible values are `INFERENCE_API`, `INFERENCE_ENDPOINT`, `OPENAI`) - `RENDERING_ENGINE` to configure the image generation engine (possible values are `INFERENCE_API`, `INFERENCE_ENDPOINT`, `REPLICATE`, `VIDEOCHAIN`). We'll focus on making the AI Comic Factory work on the Inference API, so they both need to be set to `INFERENCE_API`:  You can find more information about alternative engines and vendors in the project's [README](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory/blob/main/README.md) and the [.env](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory/blob/main/README.md) config file. ## Configuring the models The AI Comic Factory comes with the following models pre-configured: - `LLM_HF_INFERENCE_API_MODEL`: default value is `meta-llama/Llama-2-70b-chat-hf` - `RENDERING_HF_RENDERING_INFERENCE_API_MODEL`: default value is `stabilityai/stable-diffusion-xl-base-1.0` Your PRO Hugging Face account already gives you access to those models, so you don't have anything to do or change. ## Going further Support for the Inference API in the AI Comic Factory is in its early stages, and some features, such as using the refiner step for SDXL or implementing upscaling, haven't been ported over yet. Nonetheless, we hope this information will enable you to start forking and tweaking the AI Comic Factory to suit your requirements. Feel free to experiment and try other models from the community, and happy hacking!
|
Chat Templates: An End to the Silent Performance Killer
|
rocketknight1
|
October 3, 2023
|
chat-templates
|
LLM, nlp, community
|
https://huggingface.co/blog/chat-templates
|
# Chat Templates > *A spectre is haunting chat models - the spectre of incorrect formatting!* ## tl;dr Chat models have been trained with very different formats for converting conversations into a single tokenizable string. Using a format different from the format a model was trained with will usually cause severe, silent performance degradation, so matching the format used during training is extremely important! Hugging Face tokenizers now have a `chat_template` attribute that can be used to save the chat format the model was trained with. This attribute contains a Jinja template that converts conversation histories into a correctly formatted string. Please see the [technical documentation](https://huggingface.co/docs/transformers/main/en/chat_templating) for information on how to write and apply chat templates in your code. ## Introduction If you're familiar with the 🤗 Transformers library, you've probably written code like this: ```python tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModel.from_pretrained(checkpoint) ``` By loading the tokenizer and model from the same checkpoint, you ensure that inputs are tokenized in the way the model expects. If you pick a tokenizer from a different model, the input tokenization might be completely different, and the result will be that your model's performance will be seriously damaged. The term for this is a **distribution shift** - the model has been learning data from one distribution (the tokenization it was trained with), and suddenly it has shifted to a completely different one. Whether you're fine-tuning a model or using it directly for inference, it's always a good idea to minimize these distribution shifts and keep the input you give it as similar as possible to the input it was trained on. With regular language models, it's relatively easy to do that - simply load your tokenizer and model from the same checkpoint, and you're good to go. With chat models, however, it's a bit different. This is because "chat" is not just a single string of text that can be straightforwardly tokenized - it's a sequence of messages, each of which contains a `role` as well as `content`, which is the actual text of the message. Most commonly, the roles are "user" for messages sent by the user, "assistant" for responses written by the model, and optionally "system" for high-level directives given at the start of the conversation. If that all seems a bit abstract, here's an example chat to make it more concrete: ```python [ {"role": "user", "content": "Hi there!"}, {"role": "assistant", "content": "Nice to meet you!"} ] ``` This sequence of messages needs to be converted into a text string before it can be tokenized and used as input to a model. The problem, though, is that there are many ways to do this conversion! You could, for example, convert the list of messages into an "instant messenger" format: ``` User: Hey there! Bot: Nice to meet you! ``` Or you could add special tokens to indicate the roles: ``` [USER] Hey there! [/USER] [ASST] Nice to meet you! [/ASST] ``` Or you could add tokens to indicate the boundaries between messages, but insert the role information as a string: ``` <|im_start|>user Hey there!<|im_end|> <|im_start|>assistant Nice to meet you!<|im_end|> ``` There are lots of ways to do this, and none of them is obviously the best or correct way to do it. As a result, different models have been trained with wildly different formatting. I didn't make these examples up; they're all real and being used by at least one active model! But once a model has been trained with a certain format, you really want to ensure that future inputs use the same format, or else you could get a performance-destroying distribution shift. ## Templates: A way to save format information Right now, if you're lucky, the format you need is correctly documented somewhere in the model card. If you're unlucky, it isn't, so good luck if you want to use that model. In extreme cases, we've even put the whole prompt format in [a blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) to ensure that users don't miss it! Even in the best-case scenario, though, you have to locate the template information and manually code it up in your fine-tuning or inference pipeline. We think this is an especially dangerous issue because using the wrong chat format is a **silent error** - you won't get a loud failure or a Python exception to tell you something is wrong, the model will just perform much worse than it would have with the right format, and it'll be very difficult to debug the cause! This is the problem that **chat templates** aim to solve. Chat templates are [Jinja template strings](https://jinja.palletsprojects.com/en/3.1.x/) that are saved and loaded with your tokenizer, and that contain all the information needed to turn a list of chat messages into a correctly formatted input for your model. Here are three chat template strings, corresponding to the three message formats above: ```jinja {% for message in messages %} {% if message['role'] == 'user' %} {{ "User : " }} {% else %} {{ "Bot : " }} {{ message['content'] + '\n' }} {% endfor %} ``` ```jinja {% for message in messages %} {% if message['role'] == 'user' %} {{ "[USER] " + message['content'] + " [/USER]" }} {% else %} {{ "[ASST] " + message['content'] + " [/ASST]" }} {{ message['content'] + '\n' }} {% endfor %} ``` ```jinja "{% for message in messages %}" "{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}" "{% endfor %}" ``` If you're unfamiliar with Jinja, I strongly recommend that you take a moment to look at these template strings, and their corresponding template outputs, and see if you can convince yourself that you understand how the template turns a list of messages into a formatted string! The syntax is very similar to Python in a lot of ways. ## Why templates? Although Jinja can be confusing at first if you're unfamiliar with it, in practice we find that Python programmers can pick it up quickly. During development of this feature, we considered other approaches, such as a limited system to allow users to specify per-role prefixes and suffixes for messages. We found that this could become confusing and unwieldy, and was so inflexible that hacky workarounds were needed for several models. Templating, on the other hand, is powerful enough to cleanly support all of the message formats that we're aware of. ## Why bother doing this? Why not just pick a standard format? This is an excellent idea! Unfortunately, it's too late, because multiple important models have already been trained with very different chat formats. However, we can still mitigate this problem a bit. We think the closest thing to a 'standard' for formatting is the [ChatML format](https://github.com/openai/openai-python/blob/main/chatml.md) created by OpenAI. If you're training a new model for chat, and this format is suitable for you, we recommend using it and adding special `<|im_start|>` and `<|im_end|>` tokens to your tokenizer. It has the advantage of being very flexible with roles, as the role is just inserted as a string rather than having specific role tokens. If you'd like to use this one, it's the third of the templates above, and you can set it with this simple one-liner: ```py tokenizer.chat_template = "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}" ``` There's also a second reason not to hardcode a standard format, though, beyond the proliferation of existing formats - we expect that templates will be broadly useful in preprocessing for many types of models, including those that might be doing very different things from standard chat. Hardcoding a standard format limits the ability of model developers to use this feature to do things we haven't even thought of yet, whereas templating gives users and developers maximum freedom. It's even possible to encode checks and logic in templates, which is a feature we don't use extensively in any of the default templates, but which we expect to have enormous power in the hands of adventurous users. We strongly believe that the open-source ecosystem should enable you to do what you want, not dictate to you what you're permitted to do. ## How do templates work? Chat templates are part of the **tokenizer**, because they fulfill the same role as tokenizers do: They store information about how data is preprocessed, to ensure that you feed data to the model in the same format that it saw during training. We have designed it to be very easy to add template information to an existing tokenizer and save it or upload it to the Hub. Before chat templates, chat formatting information was stored at the **class level** - this meant that, for example, all LLaMA checkpoints would get the same chat formatting, using code that was hardcoded in `transformers` for the LLaMA model class. For backward compatibility, model classes that had custom chat format methods have been given **default chat templates** instead. Default chat templates are also set at the class level, and tell classes like `ConversationPipeline` how to format inputs when the model does not have a chat template. We're doing this **purely for backwards compatibility** - we highly recommend that you explicitly set a chat template on any chat model, even when the default chat template is appropriate. This ensures that any future changes or deprecations in the default chat template don't break your model. Although we will be keeping default chat templates for the foreseeable future, we hope to transition all models to explicit chat templates over time, at which point the default chat templates may be removed entirely. For information about how to set and apply chat templates, please see the [technical documentation](https://huggingface.co/docs/transformers/main/en/chat_templating). ## How do I get started with templates? Easy! If a tokenizer has the `chat_template` attribute set, it's ready to go. You can use that model and tokenizer in `ConversationPipeline`, or you can call `tokenizer.apply_chat_template()` to format chats for inference or training. Please see our [developer guide](https://huggingface.co/docs/transformers/main/en/chat_templating) or the [apply_chat_template documentation](https://huggingface.co/docs/transformers/main/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.apply_chat_template) for more! If a tokenizer doesn't have a `chat_template` attribute, it might still work, but it will use the default chat template set for that model class. This is fragile, as we mentioned above, and it's also a source of silent bugs when the class template doesn't match what the model was actually trained with. If you want to use a checkpoint that doesn't have a `chat_template`, we recommend checking docs like the model card to verify what the right format is, and then adding a correct `chat_template`for that format. We recommend doing this even if the default chat template is correct - it future-proofs the model, and also makes it clear that the template is present and suitable. You can add a `chat_template` even for checkpoints that you're not the owner of, by opening a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions). The only change you need to make is to set the `tokenizer.chat_template` attribute to a Jinja template string. Once that's done, push your changes and you're ready to go! If you'd like to use a checkpoint for chat but you can't find any documentation on the chat format it used, you should probably open an issue on the checkpoint or ping the owner! Once you figure out the format the model is using, please open a pull request to add a suitable `chat_template`. Other users will really appreciate it! ## Conclusion: Template philosophy We think templates are a very exciting change. In addition to resolving a huge source of silent, performance-killing bugs, we think they open up completely new approaches and data modalities. Perhaps most importantly, they also represent a philosophical shift: They take a big function out of the core `transformers` codebase and move it into individual model repos, where users have the freedom to do weird and wild and wonderful things. We're excited to see what uses you find for them!
|
Accelerating Stable Diffusion XL Inference with JAX on Cloud TPU v5e
|
pcuenq
|
October 3, 2023
|
sdxl_jax
|
sdxl, jax, stable diffusion, guide, tpu, google
|
https://huggingface.co/blog/sdxl_jax
|
# Accelerating Stable Diffusion XL Inference with JAX on Cloud TPU v5e Generative AI models, such as Stable Diffusion XL (SDXL), enable the creation of high-quality, realistic content with wide-ranging applications. However, harnessing the power of such models presents significant challenges and computational costs. SDXL is a large image generation model whose UNet component is about three times as large as the one in the previous version of the model. Deploying a model like this in production is challenging due to the increased memory requirements, as well as increased inference times. Today, we are thrilled to announce that Hugging Face Diffusers now supports serving SDXL using JAX on Cloud TPUs, enabling high-performance, cost-efficient inference. [Google Cloud TPUs](https://cloud.google.com/tpu) are custom-designed AI accelerators, which are optimized for training and inference of large AI models, including state-of-the-art LLMs and generative AI models such as SDXL. The new [Cloud TPU v5e](https://cloud.google.com/blog/products/compute/announcing-cloud-tpu-v5e-and-a3-gpus-in-ga) is purpose-built to bring the cost-efficiency and performance required for large-scale AI [training](https://cloud.google.com/blog/products/compute/using-cloud-tpu-multislice-to-scale-ai-workloads) and [inference](https://cloud.google.com/blog/products/compute/how-cloud-tpu-v5e-accelerates-large-scale-ai-inference). At less than half the cost of TPU v4, TPU v5e makes it possible for more organizations to train and deploy AI models. 🧨 Diffusers JAX integration offers a convenient way to run SDXL on TPU via [XLA](https://github.com/openxla/xla), and we built a demo to showcase it. You can try it out in [this Space](https://huggingface.co/spaces/google/sdxl) or in the playground embedded below: <script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script> <gradio-app theme_mode="light" space="google/sdxl"></gradio-app> Under the hood, this demo runs on several TPU v5e-4 instances (each instance has 4 TPU chips) and takes advantage of parallelization to serve four large 1024×1024 images in about 4 seconds. This time includes format conversions, communications time, and frontend processing; the actual generation time is about 2.3s, as we'll see below! In this blog post, 1. [We describe why JAX + TPU + Diffusers is a powerful framework to run SDXL](#why-jax--tpu-v5e-for-sdxl) 2. [Explain how you can write a simple image generation pipeline with Diffusers and JAX](#how-to-write-an-image-generation-pipeline-in-jax) 3. [Show benchmarks comparing different TPU settings](#benchmark) ## Why JAX + TPU v5e for SDXL? Serving SDXL with JAX on Cloud TPU v5e with high performance and cost-efficiency is possible thanks to the combination of purpose-built TPU hardware and a software stack optimized for performance. Below we highlight two key factors: JAX just-in-time (jit) compilation and XLA compiler-driven parallelism with JAX pmap. #### JIT compilation A notable feature of JAX is its [just-in-time (jit) compilation](https://jax.readthedocs.io/en/latest/jax-101/02-jitting.html). The JIT compiler traces code during the first run and generates highly optimized TPU binaries that are re-used in subsequent calls. The catch of this process is that it requires all input, intermediate, and output shapes to be **static**, meaning that they must be known in advance. Every time we change the shapes a new and costly compilation process will be triggered again. JIT compilation is ideal for services that can be designed around static shapes: compilation runs once, and then we take advantage of super-fast inference times. Image generation is well-suited for JIT compilation. If we always generate the same number of images and they have the same size, then the output shapes are constant and known in advance. The text inputs are also constant: by design, Stable Diffusion and SDXL use fixed-shape embedding vectors (with padding) to represent the prompts typed by the user. Therefore, we can write JAX code that relies on fixed shapes, and that can be greatly optimized! #### High-performance throughput for high batch sizes Workloads can be scaled across multiple devices using JAX's [pmap](https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html), which expresses single-program multiple-data (SPMD) programs. Applying pmap to a function will compile a function with XLA, then execute it in parallel on various XLA devices. For text-to-image generation workloads this means that increasing the number of images rendered simultaneously is straightforward to implement and doesn't compromise performance. For example, running SDXL on a TPU with 8 chips will generate 8 images in the same time it takes for 1 chip to create a single image. TPU v5e instances come in multiple shapes, including 1, 4 and 8-chip shapes, all the way up to 256 chips (a full TPU v5e pod), with ultra-fast ICI links between chips. This allows you to choose the TPU shape that best suits your use case and easily take advantage of the parallelism that JAX and TPUs provide. ## How to write an image generation pipeline in JAX We'll go step by step over the code you need to write to run inference super-fast using JAX! First, let's import the dependencies. ```python # Show best practices for SDXL JAX import jax import jax.numpy as jnp import numpy as np from flax.jax_utils import replicate from diffusers import FlaxStableDiffusionXLPipeline import time ``` We'll now load the base SDXL model and the rest of the components required for inference. The diffusers pipeline takes care of downloading and caching everything for us. Adhering to JAX's functional approach, the model's parameters are returned separately and will have to be passed to the pipeline during inference: ```python pipeline, params = FlaxStableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", split_head_dim=True ) ``` Model parameters are downloaded in 32-bit precision by default. To save memory and run computation faster we'll convert them to `bfloat16`, an efficient 16-bit representation. However, there's a caveat: for best results, we have to keep the _scheduler state_ in `float32`, otherwise precision errors accumulate and result in low-quality or even black images. ```python scheduler_state = params.pop("scheduler") params = jax.tree_util.tree_map(lambda x: x.astype(jnp.bfloat16), params) params["scheduler"] = scheduler_state ``` We are now ready to set up our prompt and the rest of the pipeline inputs. ```python default_prompt = "high-quality photo of a baby dolphin playing in a pool and wearing a party hat" default_neg_prompt = "illustration, low-quality" default_seed = 33 default_guidance_scale = 5.0 default_num_steps = 25 ``` The prompts have to be supplied as tensors to the pipeline, and they always have to have the same dimensions across invocations. This allows the inference call to be compiled. The pipeline `prepare_inputs` method performs all the necessary steps for us, so we'll create a helper function to prepare both our prompt and negative prompt as tensors. We'll use it later from our `generate` function: ```python def tokenize_prompt(prompt, neg_prompt): prompt_ids = pipeline.prepare_inputs(prompt) neg_prompt_ids = pipeline.prepare_inputs(neg_prompt) return prompt_ids, neg_prompt_ids ``` To take advantage of parallelization, we'll replicate the inputs across devices. A Cloud TPU v5e-4 has 4 chips, so by replicating the inputs we get each chip to generate a different image, in parallel. We need to be careful to supply a different random seed to each chip so the 4 images are different: ```python NUM_DEVICES = jax.device_count() # Model parameters don't change during inference, # so we only need to replicate them once. p_params = replicate(params) def replicate_all(prompt_ids, neg_prompt_ids, seed): p_prompt_ids = replicate(prompt_ids) p_neg_prompt_ids = replicate(neg_prompt_ids) rng = jax.random.PRNGKey(seed) rng = jax.random.split(rng, NUM_DEVICES) return p_prompt_ids, p_neg_prompt_ids, rng ``` We are now ready to put everything together in a generate function: ```python def generate( prompt, negative_prompt, seed=default_seed, guidance_scale=default_guidance_scale, num_inference_steps=default_num_steps, ): prompt_ids, neg_prompt_ids = tokenize_prompt(prompt, negative_prompt) prompt_ids, neg_prompt_ids, rng = replicate_all(prompt_ids, neg_prompt_ids, seed) images = pipeline( prompt_ids, p_params, rng, num_inference_steps=num_inference_steps, neg_prompt_ids=neg_prompt_ids, guidance_scale=guidance_scale, jit=True, ).images # convert the images to PIL images = images.reshape((images.shape[0] * images.shape[1], ) + images.shape[-3:]) return pipeline.numpy_to_pil(np.array(images)) ``` `jit=True` indicates that we want the pipeline call to be compiled. This will happen the first time we call `generate`, and it will be very slow – JAX needs to trace the operations, optimize them, and convert them to low-level primitives. We'll run a first generation to complete this process and warm things up: ```python start = time.time() print(f"Compiling ...") generate(default_prompt, default_neg_prompt) print(f"Compiled in {time.time() - start}") ``` This took about three minutes the first time we ran it. But once the code has been compiled, inference will be super fast. Let's try again! ```python start = time.time() prompt = "llama in ancient Greece, oil on canvas" neg_prompt = "cartoon, illustration, animation" images = generate(prompt, neg_prompt) print(f"Inference in {time.time() - start}") ``` It now took about 2s to generate the 4 images! ## Benchmark The following measures were obtained running SDXL 1.0 base for 20 steps, with the default Euler Discrete scheduler. We compare Cloud TPU v5e with TPUv4 for the same batch sizes. Do note that, due to parallelism, a TPU v5e-4 like the ones we use in our demo will generate **4 images** when using a batch size of 1 (or 8 images with a batch size of 2). Similarly, a TPU v5e-8 will generate 8 images when using a batch size of 1. The Cloud TPU tests were run using Python 3.10 and jax version 0.4.16. These are the same specs used in our [demo Space](https://huggingface.co/spaces/google/sdxl). | | Batch Size | Latency | Perf/$ | |-----------------|------------|:--------:|--------| | TPU v5e-4 (JAX) | 4 | 2.33s | 21.46 | | | 8 | 4.99s | 20.04 | | TPU v4-8 (JAX) | 4 | 2.16s | 9.05 | | | 8 | 4.17 | 8.98 | TPU v5e achieves up to 2.4x greater perf/$ on SDXL compared to TPU v4, demonstrating the cost-efficiency of the latest TPU generation. To measure inference performance, we use the industry-standard metric of throughput. First, we measure latency per image when the model has been compiled and loaded. Then, we calculate throughput by dividing batch size over latency per chip. As a result, throughput measures how the model is performing in production environments regardless of how many chips are used. We then divide throughput by the list price to get performance per dollar. ## How does the demo work? The [demo we showed before](https://huggingface.co/spaces/google/sdxl) was built using a script that essentially follows the code we posted in this blog post. It runs on a few Cloud TPU v5e devices with 4 chips each, and there's a simple load-balancing server that routes user requests to backend servers randomly. When you enter a prompt in the demo, your request will be assigned to one of the backend servers, and you'll receive the 4 images it generates. This is a simple solution based on several pre-allocated TPU instances. In a future post, we'll cover how to create dynamic solutions that adapt to load using GKE. All the code for the demo is open-source and available in Hugging Face Diffusers today. We are excited to see what you build with Diffusers + JAX + Cloud TPUs!
|
Accelerating over 130,000 Hugging Face models with ONNX Runtime
|
sschoenmeyer
|
October 4, 2023
|
ort-accelerating-hf-models
|
open-source-collab, onnxruntime, onnx, inference
|
https://huggingface.co/blog/ort-accelerating-hf-models
|
# Accelerating over 130,000 Hugging Face models with ONNX Runtime ## What is ONNX Runtime? ONNX Runtime is a cross-platform machine learning tool that can be used to accelerate a wide variety of models, particularly those with ONNX support. ## Hugging Face ONNX Runtime Support There are over 130,000 ONNX-supported models on Hugging Face, an open source community that allows users to build, train, and deploy hundreds of thousands of publicly available machine learning models. These ONNX-supported models, which include many increasingly popular large language models (LLMs) and cloud models, can leverage ONNX Runtime to improve performance, along with other benefits. For example, using ONNX Runtime to accelerate the whisper-tiny model can improve average latency per inference, with an up to 74.30% gain over PyTorch. ONNX Runtime works closely with Hugging Face to ensure that the most popular models on the site are supported. In total, over 90 Hugging Face model architectures are supported by ONNX Runtime, including the 11 most popular architectures (where popularity is determined by the corresponding number of models uploaded to the Hugging Face Hub): | Model Architecture | Approximate No. of Models | |:------------------:|:-------------------------:| | BERT | 28180 | | GPT2 | 14060 | | DistilBERT | 11540 | | RoBERTa | 10800 | | T5 | 10450 | | Wav2Vec2 | 6560 | | Stable-Diffusion | 5880 | | XLM-RoBERTa | 5100 | | Whisper | 4400 | | BART | 3590 | | Marian | 2840 | ## Learn More To learn more about accelerating Hugging Face models with ONNX Runtime, check out our recent post on the [Microsoft Open Source Blog](https://cloudblogs.microsoft.com/opensource/2023/10/04/accelerating-over-130000-hugging-face-models-with-onnx-runtime/).
|
Gradio-Lite: Serverless Gradio Running Entirely in Your Browser
|
abidlabs
|
October 19, 2023
|
gradio-lite
|
gradio, open-source, serverless
|
https://huggingface.co/blog/gradio-lite
|
# Gradio-Lite: Serverless Gradio Running Entirely in Your Browser Gradio is a popular Python library for creating interactive machine learning apps. Traditionally, Gradio applications have relied on server-side infrastructure to run, which can be a hurdle for developers who need to host their applications. Enter Gradio-lite (`@gradio/lite`): a library that leverages [Pyodide](https://pyodide.org/en/stable/) to bring Gradio directly to your browser. In this blog post, we'll explore what `@gradio/lite` is, go over example code, and discuss the benefits it offers for running Gradio applications. ## What is `@gradio/lite`? `@gradio/lite` is a JavaScript library that enables you to run Gradio applications directly within your web browser. It achieves this by utilizing Pyodide, a Python runtime for WebAssembly, which allows Python code to be executed in the browser environment. With `@gradio/lite`, you can **write regular Python code for your Gradio applications**, and they will **run seamlessly in the browser** without the need for server-side infrastructure. ## Getting Started Let's build a "Hello World" Gradio app in `@gradio/lite` ### 1. Import JS and CSS Start by creating a new HTML file, if you don't have one already. Importing the JavaScript and CSS corresponding to the `@gradio/lite` package by using the following code: ```html <html> <head> <script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" /> </head> </html> ``` Note that you should generally use the latest version of `@gradio/lite` that is available. You can see the [versions available here](https://www.jsdelivr.com/package/npm/@gradio/lite?tab=files). ### 2. Create the `<gradio-lite>` tags Somewhere in the body of your HTML page (wherever you'd like the Gradio app to be rendered), create opening and closing `<gradio-lite>` tags. ```html <html> <head> <script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" /> </head> <body> <gradio-lite> </gradio-lite> </body> </html> ``` Note: you can add the `theme` attribute to the `<gradio-lite>` tag to force the theme to be dark or light (by default, it respects the system theme). E.g. ```html <gradio-lite theme="dark"> ... </gradio-lite> ``` ### 3. Write your Gradio app inside of the tags Now, write your Gradio app as you would normally, in Python! Keep in mind that since this is Python, whitespace and indentations matter. ```html <html> <head> <script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" /> </head> <body> <gradio-lite> import gradio as gr def greet(name): return "Hello, " + name + "!" gr.Interface(greet, "textbox", "textbox").launch() </gradio-lite> </body> </html> ``` And that's it! You should now be able to open your HTML page in the browser and see the Gradio app rendered! Note that it may take a little while for the Gradio app to load initially since Pyodide can take a while to install in your browser. **Note on debugging**: to see any errors in your Gradio-lite application, open the inspector in your web browser. All errors (including Python errors) will be printed there. ## More Examples: Adding Additional Files and Requirements What if you want to create a Gradio app that spans multiple files? Or that has custom Python requirements? Both are possible with `@gradio/lite`! ### Multiple Files Adding multiple files within a `@gradio/lite` app is very straightforward: use the `<gradio-file>` tag. You can have as many `<gradio-file>` tags as you want, but each one needs to have a `name` attribute and the entry point to your Gradio app should have the `entrypoint` attribute. Here's an example: ```html <gradio-lite> <gradio-file name="app.py" entrypoint> import gradio as gr from utils import add demo = gr.Interface(fn=add, inputs=["number", "number"], outputs="number") demo.launch() </gradio-file> <gradio-file name="utils.py" > def add(a, b): return a + b </gradio-file> </gradio-lite> ``` ### Additional Requirements If your Gradio app has additional requirements, it is usually possible to [install them in the browser using micropip](https://pyodide.org/en/stable/usage/loading-packages.html#loading-packages). We've created a wrapper to make this paticularly convenient: simply list your requirements in the same syntax as a `requirements.txt` and enclose them with `<gradio-requirements>` tags. Here, we install `transformers_js_py` to run a text classification model directly in the browser! ```html <gradio-lite> <gradio-requirements> transformers_js_py </gradio-requirements> <gradio-file name="app.py" entrypoint> from transformers_js import import_transformers_js import gradio as gr transformers = await import_transformers_js() pipeline = transformers.pipeline pipe = await pipeline('sentiment-analysis') async def classify(text): return await pipe(text) demo = gr.Interface(classify, "textbox", "json") demo.launch() </gradio-file> </gradio-lite> ``` **Try it out**: You can see this example running in [this Hugging Face Static Space](https://huggingface.co/spaces/abidlabs/gradio-lite-classify), which lets you host static (serverless) web applications for free. Visit the page and you'll be able to run a machine learning model without internet access! ## Benefits of Using `@gradio/lite` ### 1. Serverless Deployment The primary advantage of @gradio/lite is that it eliminates the need for server infrastructure. This simplifies deployment, reduces server-related costs, and makes it easier to share your Gradio applications with others. ### 2. Low Latency By running in the browser, @gradio/lite offers low-latency interactions for users. There's no need for data to travel to and from a server, resulting in faster responses and a smoother user experience. ### 3. Privacy and Security Since all processing occurs within the user's browser, `@gradio/lite` enhances privacy and security. User data remains on their device, providing peace of mind regarding data handling. ### Limitations * Currently, the biggest limitation in using `@gradio/lite` is that your Gradio apps will generally take more time (usually 5-15 seconds) to load initially in the browser. This is because the browser needs to load the Pyodide runtime before it can render Python code. * Not every Python package is supported by Pyodide. While `gradio` and many other popular packages (including `numpy`, `scikit-learn`, and `transformers-js`) can be installed in Pyodide, if your app has many dependencies, its worth checking whether the dependencies are included in Pyodide, or can be [installed with `micropip`](https://micropip.pyodide.org/en/v0.2.2/project/api.html#micropip.install). ## Try it out! You can immediately try out `@gradio/lite` by copying and pasting this code in a local `index.html` file and opening it with your browser: ```html <html> <head> <script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" /> </head> <body> <gradio-lite> import gradio as gr def greet(name): return "Hello, " + name + "!" gr.Interface(greet, "textbox", "textbox").launch() </gradio-lite> </body> </html> ``` We've also created a playground on the Gradio website that allows you to interactively edit code and see the results immediately! Playground: https://www.gradio.app/playground
|
Exploring simple optimizations for SDXL
|
sayakpaul
|
October 24, 2023
|
simple_sdxl_optimizations
|
diffusers, guide, sdxl
|
https://huggingface.co/blog/simple_sdxl_optimizations
|
# Exploring simple optimizations for SDXL <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/exploring_simple%20optimizations_for_sdxl.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a> [Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) is the latest latent diffusion model by Stability AI for generating high-quality super realistic images. It overcomes challenges of previous Stable Diffusion models like getting hands and text right as well as spatially correct compositions. In addition, SDXL is also more context aware and requires fewer words in its prompt to generate better looking images. However, all of these improvements come at the expense of a significantly larger model. How much larger? The base SDXL model has 3.5B parameters (the UNet, in particular), which is approximately 3x larger than the previous Stable Diffusion model. To explore how we can optimize SDXL for inference speed and memory use, we ran some tests on an A100 GPU (40 GB). For each inference run, we generate 4 images and repeat it 3 times. While computing the inference latency, we only consider the final iteration out of the 3 iterations. So if you run SDXL out-of-the-box as is with full precision and use the default attention mechanism, it’ll consume 28GB of memory and take 72.2 seconds! ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda") pipe.unet.set_default_attn_processor() ``` This isn’t very practical and can slow you down because you’re often generating more than 4 images. And if you don’t have a more powerful GPU, you’ll run into that frustrating out-of-memory error message. So how can we optimize SDXL to increase inference speed and reduce its memory-usage? In 🤗 Diffusers, we have a bunch of optimization tricks and techniques to help you run memory-intensive models like SDXL and we'll show you how! The two things we’ll focus on are *inference speed* and *memory*. <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;"> 🧠 The techniques discussed in this post are applicable to all the <a href=https://huggingface.co/docs/diffusers/main/en/using-diffusers/pipeline_overview>pipelines</a>. </div> ## Inference speed Diffusion is a random process, so there's no guarantee you'll get an image you’ll like. Often times, you’ll need to run inference multiple times and iterate, and that’s why optimizing for speed is crucial. This section focuses on using lower precision weights and incorporating memory-efficient attention and `torch.compile` from PyTorch 2.0 to boost speed and reduce inference time. ### Lower precision Model weights are stored at a certain *precision* which is expressed as a floating point data type. The standard floating point data type is float32 (fp32), which can accurately represent a wide range of floating numbers. For inference, you often don’t need to be as precise so you should use float16 (fp16) which captures a narrower range of floating numbers. This means fp16 only takes half the amount of memory to store compared to fp32, and is twice as fast because it is easier to calculate. In addition, modern GPU cards have optimized hardware to run fp16 calculations, making it even faster. With 🤗 Diffusers, you can use fp16 for inference by specifying the `torch.dtype` parameter to convert the weights when the model is loaded: ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") pipe.unet.set_default_attn_processor() ``` Compared to a completely unoptimized SDXL pipeline, using fp16 takes 21.7GB of memory and only 14.8 seconds. You’re almost speeding up inference by a full minute! ### Memory-efficient attention The attention blocks used in transformers modules can be a huge bottleneck, because memory increases _quadratically_ as input sequences get longer. This can quickly take up a ton of memory and leave you with an out-of-memory error message. 😬 Memory-efficient attention algorithms seek to reduce the memory burden of calculating attention, whether it is by exploiting sparsity or tiling. These optimized algorithms used to be mostly available as third-party libraries that needed to be installed separately. But starting with PyTorch 2.0, this is no longer the case. PyTorch 2 introduced [scaled dot product attention (SDPA)](https://pytorch.org/blog/accelerated-diffusers-pt-20/), which offers fused implementations of [Flash Attention](https://huggingface.co/papers/2205.14135), [memory-efficient attention](https://huggingface.co/papers/2112.05682) (xFormers), and a PyTorch implementation in C++. SDPA is probably the easiest way to speed up inference: if you’re using PyTorch ≥ 2.0 with 🤗 Diffusers, it is automatically enabled by default! ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") ``` Compared to a completely unoptimized SDXL pipeline, using fp16 and SDPA takes the same amount of memory and the inference time improves to 11.4 seconds. Let’s use this as the new baseline we’ll compare the other optimizations to. ### torch.compile PyTorch 2.0 also introduced the `torch.compile` API for just-in-time (JIT) compilation of your PyTorch code into more optimized kernels for inference. Unlike other compiler solutions, `torch.compile` requires minimal changes to your existing code and it is as easy as wrapping your model with the function. With the `mode` parameter, you can optimize for memory overhead or inference speed during compilation, which gives you way more flexibility. ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) ``` Compared to the previous baseline (fp16 + SDPA), wrapping the UNet with `torch.compile` improves inference time to 10.2 seconds. <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;"> ⚠️ The first time you compile a model is slower, but once the model is compiled, all subsequent calls to it are much faster! </div> ## Model memory footprint Models today are growing larger and larger, making it a challenge to fit them into memory. This section focuses on how you can reduce the memory footprint of these enormous models so you can run them on consumer GPUs. These techniques include CPU offloading, decoding latents into images over several steps rather than all at once, and using a distilled version of the autoencoder. ### Model CPU offloading Model offloading saves memory by loading the UNet into the GPU memory while the other components of the diffusion model (text encoders, VAE) are loaded onto the CPU. This way, the UNet can run for multiple iterations on the GPU until it is no longer needed. ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") pipe.enable_model_cpu_offload() ``` Compared to the baseline, it now takes 20.2GB of memory which saves you 1.5GB of memory. ### Sequential CPU offloading Another type of offloading which can save you more memory at the expense of slower inference is sequential CPU offloading. Rather than offloading an entire model - like the UNet - model weights stored in different UNet submodules are offloaded to the CPU and only loaded onto the GPU right before the forward pass. Essentially, you’re only loading parts of the model each time which allows you to save even more memory. The only downside is that it is significantly slower because you’re loading and offloading submodules many times. ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") pipe.enable_sequential_cpu_offload() ``` Compared to the baseline, this takes 19.9GB of memory but the inference time increases to 67 seconds. ## Slicing In SDXL, a variational encoder (VAE) decodes the refined latents (predicted by the UNet) into realistic images. The memory requirement of this step scales with the number of images being predicted (the batch size). Depending on the image resolution and the available GPU VRAM, it can be quite memory-intensive. This is where “slicing” is useful. The input tensor to be decoded is split into slices and the computation to decode it is completed over several steps. This saves memory and allows larger batch sizes. ```python pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ).to("cuda") pipe.enable_vae_slicing() ``` With sliced computations, we reduce the memory to 15.4GB. If we add sequential CPU offloading, it is further reduced to 11.45GB which lets you generate 4 images (1024x1024) per prompt. However, with sequential offloading, the inference latency also increases. ## Caching computations Any text-conditioned image generation model typically uses a text encoder to compute embeddings from the input prompt. SDXL uses *two* text encoders! This contributes quite a bit to the inference latency. However, since these embeddings remain unchanged throughout the reverse diffusion process, we can precompute them and reuse them as we go. This way, after computing the text embeddings, we can remove the text encoders from memory. First, load the text encoders and their corresponding tokenizers and compute the embeddings from the input prompt: ```python tokenizers = [tokenizer, tokenizer_2] text_encoders = [text_encoder, text_encoder_2] ( prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds ) = encode_prompt(tokenizers, text_encoders, prompt) ``` Next, flush the GPU memory to remove the text encoders: ```jsx del text_encoder, text_encoder_2, tokenizer, tokenizer_2 flush() ``` Now the embeddings are good to go straight to the SDXL pipeline: ```python from diffusers import StableDiffusionXLPipeline pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", text_encoder=None, text_encoder_2=None, tokenizer=None, tokenizer_2=None, torch_dtype=torch.float16, ).to("cuda") call_args = dict( prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_prompt_embeds, pooled_prompt_embeds=pooled_prompt_embeds, negative_pooled_prompt_embeds=negative_pooled_prompt_embeds, num_images_per_prompt=num_images_per_prompt, num_inference_steps=num_inference_steps, ) image = pipe(**call_args).images[0] ``` Combined with SDPA and fp16, we can reduce the memory to 21.9GB. Other techniques discussed above for optimizing memory can also be used with cached computations. ## Tiny Autoencoder As previously mentioned, a VAE decodes latents into images. Naturally, this step is directly bottlenecked by the size of the VAE. So, let’s just use a smaller autoencoder! The [Tiny Autoencoder by `madebyollin`](https://github.com/madebyollin/taesd), available [the Hub](https://huggingface.co/madebyollin/taesdxl) is just 10MB and it is distilled from the original VAE used by SDXL. ```python from diffusers import AutoencoderTiny pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, ) pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16) pipe.to("cuda") ``` With this setup, we reduce the memory requirement to 15.6GB while reducing the inference latency at the same time. <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;"> ⚠️ The Tiny Autoencoder can omit some of the more fine-grained details from images, which is why the Tiny AutoEncoder is more appropriate for image previews. </div> ## Conclusion To conclude and summarize the savings from our optimizations: <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;"> ⚠️ While profiling GPUs to measure the trade-off between inference latency and memory requirements, it is important to be aware of the hardware being used. The above findings may not translate equally from hardware to hardware. For example, `torch.compile` only seems to benefit modern GPUs, at least for SDXL. </div> | **Technique** | **Memory (GB)** | **Inference latency (ms)** | | --- | --- | --- | | unoptimized pipeline | 28.09 | 72200.5 | | fp16 | 21.72 | 14800.9 | | **fp16 + SDPA (default)** | **21.72** | **11413.0** | | default + `torch.compile` | 21.73 | 10296.7 | | default + model CPU offload | 20.21 | 16082.2 | | default + sequential CPU offload | 19.91 | 67034.0 | | **default + VAE slicing** | **15.40** | **11232.2** | | default + VAE slicing + sequential CPU offload | 11.47 | 66869.2 | | default + precomputed text embeddings | 21.85 | 11909.0 | | default + Tiny Autoencoder | 15.48 | 10449.7 | We hope these optimizations make it a breeze to run your favorite pipelines. Try these techniques out and share your images with us! 🤗 --- **Acknowledgements**: Thank you to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) for his helpful reviews on the draft.
|
The N Implementation Details of RLHF with PPO
|
vwxyzjn
|
October 24, 2023
|
the_n_implementation_details_of_rlhf_with_ppo
|
research, rl, rlhf
|
https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo
|
# The N Implementation Details of RLHF with PPO RLHF / ChatGPT has been a popular research topic these days. In our quest to research more on RLHF, this blog post attempts to do a reproduction of OpenAI’s 2019 original RLHF codebase at [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences). Despite its “tensorflow-1.x-ness,” OpenAI’s original codebase is very well-evaluated and benchmarked, making it a good place to study RLHF implementation engineering details. We aim to: 1. reproduce OAI’s results in stylistic tasks and match the learning curves of [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences). 2. present a checklist of implementation details, similar to the spirit of [*The 37 Implementation Details of Proximal Policy Optimization*](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/); [*Debugging RL, Without the Agonizing Pain*](https://andyljones.com/posts/rl-debugging.html). 3. provide a simple-to-read and minimal reference implementation of RLHF; This work is just for educational / learning purposes. For advanced users requiring more features, such as running larger models with PEFT, [*huggingface/trl*](https://github.com/huggingface/trl) would be a great choice. - In [Matching Learning Curves](#matching-learning-curves), we show our main contribution: creating a codebase that can reproduce OAI’s results in the stylistic tasks and matching learning curves very closely with [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences). - We then take a technical deep dive into the implementation details that are relevant to reproducing OAI’s work. In [General Implementation Details](#general-implementation-details), we talk about basic details, such as how rewards/values are generated and how responses are generated. In [Reward Model Implementation Details](#reward-model-implementation-details), we talk about details such as reward normalization. In [Policy Training Implementation Details](#policy-training-implementation-details), we discuss details such as rejection sampling and reward “whitening”. - In [**PyTorch Adam optimizer numerical issues w.r.t RLHF**](#pytorch-adam-optimizer-numerical-issues-wrt-rlhf), we highlight a very interesting implementation difference in Adam between TensorFlow and PyTorch, which causes an aggressive update in the model training. - Next, we examine the effect of training different base models (e.g., gpt2-xl, falcon-1b,) given that the reward labels are produced with `gpt2-large`. - Finally, we conclude our work with limitations and discussions. **Here are the important links:** - 💾 Our reproduction codebase [*https://github.com/vwxyzjn/lm-human-preference-details*](https://github.com/vwxyzjn/lm-human-preference-details) - 🤗 Demo of RLHF model comparison: [*https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo*](https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo) - 🐝 All w&b training logs [*https://wandb.ai/openrlbenchmark/lm_human_preference_details*](https://wandb.ai/openrlbenchmark/lm_human_preference_details) # Matching Learning Curves Our main contribution is to reproduce OAI’s results in stylistic tasks, such as sentiment and descriptiveness. As shown in the figure below, our codebase (orange curves) can produce nearly identical learning curves as OAI’s codebase (blue curves).  ## A note on running openai/lm-human-preferences To make a direct comparison, we ran the original RLHF code at [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences), which will offer valuable metrics to help validate and diagnose our reproduction. We were able to set the original TensorFlow 1.x code up, but it requires a hyper-specific setup: - OAI’s dataset was partially corrupted/lost (so we replaced them with similar HF datasets, which may or may not cause a performance difference) - Specifically, its book dataset was lost during OpenAI’s GCP - Azure migration ([https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496)). I replaced the book dataset with Hugging Face’s `bookcorpus` dataset, which is, in principle, what OAI used. - It can’t run on 1 V100 because it doesn’t implement gradient accumulation. Instead, it uses a large batch size and splits the batch across 8 GPUs, and will OOM on just 1 GPU. - It can’t run on 8x A100 because it uses TensorFlow 1.x, which is incompatible with Cuda 8+ - It can’t run on 8x V100 (16GB) because it will OOM - It can only run on 8x V100 (32GB), which is only offered by AWS as the `p3dn.24xlarge` instance. # General Implementation Details We now take a technical deep dive into the implementation details that are relevant to reproducing OAI’s work. In this section, we talk about basic details, such as how rewards/values are generated and how responses are generated. Here are these details in no particular order: 1. **The reward model and policy’s value head take input as the concatenation of `query` and `response`** 1. The reward model and policy’s value head do *not* only look at the response. Instead, it concatenates the `query` and `response` together as `query_response` ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107)). 2. So, for example, if `query = "he was quiet for a minute, his eyes unreadable"`., and the `response = "He looked at his left hand, which held the arm that held his arm out in front of him."`, then the reward model and policy’s value do a forward pass on `query_response = "he was quiet for a minute, his eyes unreadable. He looked at his left hand, which held the arm that held his arm out in front of him."` and produced rewards and values of shape `(B, T, 1)`, where `B` is the batch size, `T` is the sequence length, and `1` is the reward head dimension of 1 ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107), [lm_human_preferences/policy.py#L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L111)). 3. The `T` means that each token has a reward associated with it and its previous context. For example, the `eyes` token would have a reward corresponding to `he was quiet for a minute, his eyes`. 2. **Pad with a special padding token and truncate inputs.** 1. OAI sets a fixed input length for query `query_length`; it **pads** sequences that are too short with `pad_token` ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67)) and **truncates** sequences that are too long ([lm_human_preferences/language/datasets.py#L57](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L57)). See [here](https://huggingface.co/docs/transformers/pad_truncation) for a general introduction to the concept). When padding the inputs, OAI uses a token beyond the vocabulary ([lm_human_preferences/language/encodings.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/encodings.py#L56)). 1. **Note on HF’s transformers — padding token.** According to ([transformers#2630#issuecomment-578159876](https://github.com/huggingface/transformers/issues/2630#issuecomment-578159876)), padding tokens were not used during the pre-training of GPT and GPT-2; therefore transformer’s gpt2 models have no official padding token associated with its tokenizer. A common practice is to set `tokenizer.pad_token = tokenizer.eos_token`, but in this work, we shall distinguish these two special tokens to match OAI’s original setting, so we will use `tokenizer.add_special_tokens({"pad_token": "[PAD]"})`. Note that having no padding token is a default setting for decoder models, since they train with “packing” during pretraining, which means that many sequences are concatenated and separated by the EOS token and chunks of this sequence that always have the max length are fed to the model during pretraining. 2. When putting everything together, here is an example ```python import transformers tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right") tokenizer.add_special_tokens({"pad_token": "[PAD]"}) query_length = 5 texts = [ "usually, he would", "she thought about it", ] tokens = [] for text in texts: tokens.append(tokenizer.encode(text)[:query_length]) print("tokens", tokens) inputs = tokenizer.pad( {"input_ids": tokens}, padding="max_length", max_length=query_length, return_tensors="pt", return_attention_mask=True, ) print("inputs", inputs) """prints are tokens [[23073, 11, 339, 561], [7091, 1807, 546, 340]] inputs {'input_ids': tensor([[23073, 11, 339, 561, 50257], [ 7091, 1807, 546, 340, 50257]]), 'attention_mask': tensor([[1, 1, 1, 1, 0], [1, 1, 1, 1, 0]])} """ ``` 3. **Adjust position indices correspondingly for padding tokens** 1. When calculating the logits, OAI’s code works by masking out padding tokens properly. This is achieved by finding out the token indices corresponding to the padding tokens ([lm_human_preferences/language/model.py#L296-L297](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L296-L297)), followed by adjusting their position indices correspondingly ([lm_human_preferences/language/model.py#L320](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L320)). 2. For example, if the `query=[23073, 50259, 50259]` and `response=[11, 339, 561]`, where (`50259` is OAI’s padding token), it then creates position indices as `[[0 1 1 1 2 3]]` and logits as follows. Note how the logits corresponding to the padding tokens remain the same as before! This is the effect we should be aiming for in our reproduction. ```python all_logits [[[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108 -35.36577 ] [ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108 -35.36577 ] [ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108 -35.36577 ] [-111.303955 -110.94471 -112.90624 ... -113.13064 -113.7788 -109.17345 ] [-111.51512 -109.61077 -114.90231 ... -118.43514 -111.56671 -112.12478 ] [-122.69775 -121.84468 -128.27417 ... -132.28055 -130.39604 -125.707756]]] (1, 6, 50257) ``` 3. **Note on HF’s transformers — `position_ids` and `padding_side`.** We can replicate the exact logits using Hugging Face’s transformer with 1) left padding and 2) pass in the appropriate `position_ids`: ```python import torch import transformers tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right") tokenizer.add_special_tokens({"pad_token": "[PAD]"}) pad_id = tokenizer.pad_token_id query = torch.tensor([ [pad_id, pad_id, 23073], ]) response = torch.tensor([ [11, 339, 561], ]) temperature = 1.0 query = torch.tensor(query) response = torch.tensor(response).long() context_length = query.shape[1] query_response = torch.cat((query, response), 1) pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2") def forward(policy, query_responses, tokenizer): attention_mask = query_responses != tokenizer.pad_token_id position_ids = attention_mask.cumsum(1) - attention_mask.long() # exclusive cumsum input_ids = query_responses.clone() input_ids[~attention_mask] = 0 return policy( input_ids=input_ids, attention_mask=attention_mask, position_ids=position_ids, return_dict=True, output_hidden_states=True, ) output = forward(pretrained_model, query_response, tokenizer) logits = output.logits logits /= temperature print(logits) """ tensor([[[ -26.9395, -26.4709, -30.0456, ..., -33.2208, -33.2884, -27.4360], [ -27.1677, -26.7330, -30.2386, ..., -33.6813, -33.6931, -27.5928], [ -35.2869, -34.2875, -38.1608, ..., -41.5958, -41.0821, -35.3658], [-111.3040, -110.9447, -112.9062, ..., -113.1306, -113.7788, -109.1734], [-111.5152, -109.6108, -114.9024, ..., -118.4352, -111.5668, -112.1248], [-122.6978, -121.8447, -128.2742, ..., -132.2805, -130.3961, -125.7078]]], grad_fn=<DivBackward0>) """ ``` 4. **Note on HF’s transformers — `position_ids` during `generate`:** during generate we should not pass in `position_ids` because the `position_ids` are already adjusted in `transformers` (see [huggingface/transformers#/7552](https://github.com/huggingface/transformers/pull/7552). Usually, we almost never pass `position_ids` in transformers. All the masking and shifting logic are already implemented e.g. in the `generate` function (need permanent code link). 4. **Response generation samples a fixed-length response without padding.** 1. During response generation, OAI uses `top_k=0, top_p=1.0` and just do categorical samples across the vocabulary ([lm_human_preferences/language/sample.py#L43](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/sample.py#L43)) and the code would keep sampling until a fixed-length response is generated ([lm_human_preferences/policy.py#L103](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L103)). Notably, even if it encounters EOS (end-of-sequence) tokens, it will keep sampling. 2. **Note on HF’s transformers — sampling could stop at `eos_token`:** in `transformers`, the generation could stop at `eos_token` ([src/transformers/generation/utils.py#L2248-L2256](https://github.com/huggingface/transformers/blob/67b85f24def79962ce075353c2627f78e0e53e9f/src/transformers/generation/utils.py#L2248-L2256)), which is not the same as OAI’s setting. To align the setting, we need to do set `pretrained_model.generation_config.eos_token_id = None, pretrained_model.generation_config.pad_token_id = None`. Note that `transformers.GenerationConfig(eos_token_id=None, pad_token_id=None, ...)` does not work because `pretrained_model.generation_config` would override and set a `eos_token`. ```python import torch import transformers tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right") tokenizer.add_special_tokens({"pad_token": "[PAD]"}) pad_id = tokenizer.pad_token_id query = torch.tensor([ [pad_id, pad_id, 23073], ]) response = torch.tensor([ [11, 339, 561], ]) response_length = 4 temperature = 0.7 pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2") pretrained_model.generation_config.eos_token_id = None # disable `pad_token_id` and `eos_token_id` because we just want to pretrained_model.generation_config.pad_token_id = None # generate tokens without truncation / padding generation_config = transformers.GenerationConfig( max_new_tokens=response_length, min_new_tokens=response_length, temperature=temperature, top_k=0.0, top_p=1.0, do_sample=True, ) context_length = query.shape[1] attention_mask = query != tokenizer.pad_token_id input_ids = query.clone() input_ids[~attention_mask] = 0 # set padding tokens to 0 output = pretrained_model.generate( input_ids=input_ids, attention_mask=attention_mask, # position_ids=attention_mask.cumsum(1) - attention_mask.long(), # generation collapsed if this was turned on. generation_config=generation_config, return_dict_in_generate=True, ) print(output.sequences) """ tensor([[ 0, 0, 23073, 16851, 11, 475, 991]]) """ ``` 3. Note that in a more recent codebase https://github.com/openai/summarize-from-feedback, OAI does stop sampling when encountering EOS token ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19)). However in this work we aim to do a 1:1 replication, so we align the setting that could keep sampling even eos_token is encountered 5. **Learning rate annealing for reward model and policy training.** 1. As Ziegler et al. (2019) suggested, the reward model is trained for a single epoch to avoid overfitting the limited amount of human annotation data (e.g., the `descriptiveness` task only had about 5000 labels). During this single epoch, the learning rate is annealed to zero ([lm_human_preferences/train_reward.py#L249](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L249)). 2. Similar to reward model training, the learning rate is annealed to zero ([lm_human_preferences/train_policy.py#L172-L173](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L172-L173)). 6. **Use different seeds for different processes** 1. When spawning 8 GPU processes to do data parallelism, OAI sets a different random seed per process ([lm_human_preferences/utils/core.py#L108-L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/utils/core.py#L108-L111)). Implementation-wise, this is done via `local_seed = args.seed + process_rank * 100003`. The seed is going to make the model produce different responses and get different scores, for example. 1. Note: I believe the dataset shuffling has a bug — the dataset is shuffled using the same seed for some reason ([lm_human_preferences/lm_tasks.py#L94-L97](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/lm_tasks.py#L94-L97)). # Reward Model Implementation Details In this section, we discuss reward-model-specific implementation details. We talk about details such as reward normalization and layer initialization. Here are these details in no particular order: 1. **The reward model only outputs the value at the last token.** 1. Notice that the rewards obtained after the forward pass on the concatenation of `query` and `response` will have the shape `(B, T, 1)`, where `B` is the batch size, `T` is the sequence length (which is always the same; it is `query_length + response_length = 64 + 24 = 88` in OAI’s setting for stylistic tasks, see [launch.py#L9-L11](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L9-L11)), and `1` is the reward head dimension of 1. For RLHF purposes, the original codebase extracts the reward of the last token ([lm_human_preferences/rewards.py#L132](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L132)), so that the rewards will only have shape `(B, 1)`. 2. Note that in a more recent codebase [*openai/summarize-from-feedback*](https://github.com/openai/summarize-from-feedback), OAI stops sampling when encountering EOS token ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19)). When extracting rewards, it is going to identify the `last_response_index`, the index before the EOS token ([#L11-L13](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L11-L13)), and extract the reward at that index ([summarize_from_feedback/reward_model.py#L59](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L59)). However in this work we just stick with the original setting. 2. **Reward head layer initialization** 1. The weight of the reward head is initialized according to \\( \mathcal{N}\left(0,1 /\left(\sqrt{d_{\text {model }}+1}\right)\right) \\) ([lm_human_preferences/language/model.py#L368,](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368) [lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252)). This aligns with the settings in Stiennon et al., 2020 ([summarize_from_feedback/query_response_model.py#L106-L107](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/query_response_model.py#L106-L107)) (P.S., Stiennon et al., 2020 had a typo on page 17 saying the distribution is \\( \mathcal{N}\left(0,1 /\left(d_{\text {model }}+1\right)\right) \\) without the square root) 2. The bias of the reward head is set to 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254)). 3. **Reward model normalization before and after** 1. In the paper, Ziegler el al. (2019) mentioned that "to keep the scale of the reward model consistent across training, we normalize it so that it has mean 0 and variance 1 for \\( x \sim \mathcal{D}, y \sim \rho(·|x) \\).” To perform the normalization process, the code first creates a `reward_gain` and `reward_bias`, such that the reward can be calculated by `reward = reward * reward_gain + reward_bias` ([lm_human_preferences/rewards.py#L50-L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L50-L51)). 2. When performing the normalization process, the code first sets `reward_gain=1, reward_bias=0` ([lm_human_preferences/train_reward.py#L211](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L211)), followed by collecting sampled queries from the target dataset (e.g., `bookcorpus, tldr, cnndm`), completed responses, and evaluated rewards. It then gets the **empirical mean and std** of the evaluated reward ([lm_human_preferences/train_reward.py#L162-L167](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L162-L167)) and tries to compute what the `reward_gain` and `reward_bias` should be. 3. Let us use \\( \mu_{\mathcal{D}} \\) to denote the empirical mean, \\( \sigma_{\mathcal{D}} \\) the empirical std, \\(g\\) the `reward_gain`, \\(b\\) `reward_bias`, \\( \mu_{\mathcal{T}} = 0\\) **target mean** and \\( \sigma_{\mathcal{T}}=1\\) **target std**. Then we have the following formula. $$\begin{aligned}g*\mathcal{N}(\mu_{\mathcal{D}}, \sigma_{\mathcal{D}}) + b &= \mathcal{N}(g*\mu_{\mathcal{D}}, g*\sigma_{\mathcal{D}}) + b\\&= \mathcal{N}(g*\mu_{\mathcal{D}} + b, g*\sigma_{\mathcal{D}}) \\&= \mathcal{N}(\mu_{\mathcal{T}}, \sigma_{\mathcal{T}}) \\g &= \frac{\sigma_{\mathcal{T}}}{\sigma_{\mathcal{D}}} \\b &= \mu_{\mathcal{T}} - g*\mu_{\mathcal{D}}\end{aligned}$$ 4. The normalization process is then applied **before** and **after** reward model training ([lm_human_preferences/train_reward.py#L232-L234](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L232-L234), [lm_human_preferences/train_reward.py#L252-L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L252-L254)). 5. Note that responses \\( y \sim \rho(·|x) \\) we generated for the normalization purpose are from the pre-trained language model \\(\rho \\). The model \\(\rho \\) is fixed as a reference and is not updated in reward learning ([lm_human_preferences/train_reward.py#L286C1-L286C31](https://github.com/openai/lm-human-preferences/blob/master/lm_human_preferences/train_reward.py#L286C1-L286C31)). # Policy Training Implementation Details In this section, we will delve into details, such as layer initialization, data post-processing, and dropout settings. We will also explore techniques, such as of rejection sampling and reward "whitening", and adaptive KL. Here are these details in no particular order: 1. **Scale the logits by sampling temperature.** 1. When calculating the log probability of responses, the model first outputs the logits of the tokens in the responses, followed by dividing the logits with the sampling temperature ([lm_human_preferences/policy.py#L121](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L121)). I.e., `logits /= self.temperature` 2. In an informal test, we found that without this scaling, the KL would rise faster than expected, and performance would deteriorate. 2. **Value head layer initialization** 1. The weight of the value head is initialized according to \\(\mathcal{N}\left(0,0\right)\\) ([lm_human_preferences/language/model.py#L368,](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368) [lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252)). This is 2. The bias of the reward head is set to 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254)). 3. **Select query texts that start and end with a period** 1. This is done as part of the data preprocessing; 1. Tries to select text only after `start_text="."` ([lm_human_preferences/language/datasets.py#L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L51)) 2. Tries select text just before `end_text="."` ([lm_human_preferences/language/datasets.py#L61](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L61)) 3. Then pad the text ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67)) 2. When running `openai/lm-human-preferences`, OAI’s datasets were partially corrupted/lost ([openai/lm-human-preferences/issues/17#issuecomment-104405149](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496)), so we had to replace them with similar HF datasets, which may or may not cause a performance difference) 3. For the book dataset, we used [https://huggingface.co/datasets/bookcorpus](https://huggingface.co/datasets/bookcorpus), which we find not necessary to extract sentences that start and end with periods because the dataset ) is already pre-processed this way (e.g., `"usually , he would be tearing around the living room , playing with his toys ."`) To this end, we set `start_text=None, end_text=None` for the `sentiment` and `descriptiveness` tasks. 4. **Disable dropout** 1. Ziegler et al. (2019) suggested, “We do not use dropout for policy training.” This is also done in the code ([lm_human_preferences/policy.py#L48](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L48)). 5. **Rejection sampling** 1. Ziegler et al. (2019) suggested, “We use rejection sampling to ensure there is a period between tokens 16 and 24 and then truncate at that period (This is a crude approximation for ‘end of sentence.’ We chose it because it is easy to integrate into the RL loop, and even a crude approximation is sufficient for the intended purpose of making the human evaluation task somewhat easier). During the RL finetuning, we penalize continuations that don’t have such a period by giving them a fixed reward of −1.” 2. Specifically, this is achieved with the following steps: 1. **Token truncation**: We want to truncate at the first occurrence of `truncate_token` that appears at or after position `truncate_after` in the responses ([lm_human_preferences/train_policy.py#L378](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L378)) 1. Code comment: “central example: replace all tokens after truncate_token with padding_token” 2. **Run reward model on truncated response:** After the response has been truncated by the token truncation process, the code then runs the reward model on the **truncated response**. 3. **Rejection sampling**: if there is not a period between tokens 16 and 24, then replace the score of the response with a fixed low value (such as -1)([lm_human_preferences/train_policy.py#L384](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384), [lm_human_preferences/train_policy.py#L384-L402](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384-L402)) 1. Code comment: “central example: ensure that the sample contains `truncate_token`" 2. Code comment: “only query humans on responses that pass that function“ 4. To give some examples in `descriptiveness`: . Notice the 1st and 3rd example has too many tokens after the period, so its score was replaced by -1. ](https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/rlhf_implementation_details/Untitled%201.png) Samples extracted from our reproduction [https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs](https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs?workspace=user-costa-huang). Notice the 1st and 3rd example has too many tokens after the period, so its score was replaced by -1. 6. **Discount factor = 1** 1. The discount parameter \\(\gamma\\) is set to 1 ([lm_human_preferences/train_policy.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L56)), which means that future rewards are given the same weight as immediate rewards. 7. **Terminology of the training loop: batches and minibatches in PPO** 1. OAI uses the following training loop ([lm_human_preferences/train_policy.py#L184-L192](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L184-L192)). Note: we additionally added the `micro_batch_size` to help deal with the case in gradient accumulation. At each epoch, it shuffles the batch indices. ```python import numpy as np batch_size = 8 nminibatches = 2 gradient_accumulation_steps = 2 mini_batch_size = batch_size // nminibatches micro_batch_size = mini_batch_size // gradient_accumulation_steps data = np.arange(batch_size).astype(np.float32) print("data:", data) print("batch_size:", batch_size) print("mini_batch_size:", mini_batch_size) print("micro_batch_size:", micro_batch_size) for epoch in range(4): batch_inds = np.random.permutation(batch_size) print("epoch:", epoch, "batch_inds:", batch_inds) for mini_batch_start in range(0, batch_size, mini_batch_size): mini_batch_end = mini_batch_start + mini_batch_size mini_batch_inds = batch_inds[mini_batch_start:mini_batch_end] # `optimizer.zero_grad()` set optimizer to zero for gradient accumulation for micro_batch_start in range(0, mini_batch_size, micro_batch_size): micro_batch_end = micro_batch_start + micro_batch_size micro_batch_inds = mini_batch_inds[micro_batch_start:micro_batch_end] print("____⏩ a forward pass on", data[micro_batch_inds]) # `optimizer.step()` print("⏪ a backward pass on", data[mini_batch_inds]) # data: [0. 1. 2. 3. 4. 5. 6. 7.] # batch_size: 8 # mini_batch_size: 4 # micro_batch_size: 2 # epoch: 0 batch_inds: [6 4 0 7 3 5 1 2] # ____⏩ a forward pass on [6. 4.] # ____⏩ a forward pass on [0. 7.] # ⏪ a backward pass on [6. 4. 0. 7.] # ____⏩ a forward pass on [3. 5.] # ____⏩ a forward pass on [1. 2.] # ⏪ a backward pass on [3. 5. 1. 2.] # epoch: 1 batch_inds: [6 7 3 2 0 4 5 1] # ____⏩ a forward pass on [6. 7.] # ____⏩ a forward pass on [3. 2.] # ⏪ a backward pass on [6. 7. 3. 2.] # ____⏩ a forward pass on [0. 4.] # ____⏩ a forward pass on [5. 1.] # ⏪ a backward pass on [0. 4. 5. 1.] # epoch: 2 batch_inds: [1 4 5 6 0 7 3 2] # ____⏩ a forward pass on [1. 4.] # ____⏩ a forward pass on [5. 6.] # ⏪ a backward pass on [1. 4. 5. 6.] # ____⏩ a forward pass on [0. 7.] # ____⏩ a forward pass on [3. 2.] # ⏪ a backward pass on [0. 7. 3. 2.] # epoch: 3 batch_inds: [7 2 4 1 3 0 6 5] # ____⏩ a forward pass on [7. 2.] # ____⏩ a forward pass on [4. 1.] # ⏪ a backward pass on [7. 2. 4. 1.] # ____⏩ a forward pass on [3. 0.] # ____⏩ a forward pass on [6. 5.] # ⏪ a backward pass on [3. 0. 6. 5.] ``` 8. **Per-token KL penalty** - The code adds a per-token KL penalty ([lm_human_preferences/train_policy.py#L150-L153](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L150-L153)) to the rewards, in order to discourage the policy to be very different from the original policy. - Using the `"usually, he would"` as an example, it gets tokenized to `[23073, 11, 339, 561]`. Say we use `[23073]` as the query and `[11, 339, 561]` as the response. Then under the default `gpt2` parameters, the response tokens will have log probabilities of the reference policy `logprobs=[-3.3213, -4.9980, -3.8690]` . - During the first PPO update epoch and minibatch update, so the active policy will have the same log probabilities `new_logprobs=[-3.3213, -4.9980, -3.8690]`. , so the per-token KL penalty would be `kl = new_logprobs - logprobs = [0., 0., 0.,]` - However, after the first gradient backward pass, we could have `new_logprob=[3.3213, -4.9980, -3.8690]` , so the per-token KL penalty becomes `kl = new_logprobs - logprobs = [-0.3315, -0.0426, 0.6351]` - Then the `non_score_reward = beta * kl` , where `beta` is the KL penalty coefficient \\(\beta\\), and it’s added to the `score` obtained from the reward model to create the `rewards` used for training. The `score` is only given at the end of episode; it could look like `[0.4,]` , and we have `rewards = [beta * -0.3315, beta * -0.0426, beta * 0.6351 + 0.4]`. 9. **Per-minibatch reward and advantage whitening, with optional mean shifting** 1. OAI implements a `whiten` function that looks like below, basically normalizing the `values` by subtracting its mean followed by dividing by its standard deviation. Optionally, `whiten` can shift back the mean of the whitened `values` with `shift_mean=True`. ```python def whiten(values, shift_mean=True): mean, var = torch.mean(values), torch.var(values, unbiased=False) whitened = (values - mean) * torch.rsqrt(var + 1e-8) if not shift_mean: whitened += mean return whitened ``` 1. In each minibatch, OAI then whitens the reward `whiten(rewards, shift_mean=False)` without shifting the mean ([lm_human_preferences/train_policy.py#L325](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L325)) and whitens the advantages `whiten(advantages)` with the shifted mean ([lm_human_preferences/train_policy.py#L338](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L338)). 2. **Optimization note:** if the number of minibatches is one (which is the case in this reproduction) we only need to whiten rewards, calculate and whiten advantages once since their values won’t change. 3. **TensorFlow vs PyTorch note:** Different behavior of `tf.moments` vs `torch.var`: The behavior of whitening is different in torch vs tf because the variance calculation is different: ```jsx import numpy as np import tensorflow as tf import torch def whiten_tf(values, shift_mean=True): mean, var = tf.nn.moments(values, axes=list(range(values.shape.rank))) mean = tf.Print(mean, [mean], 'mean', summarize=100) var = tf.Print(var, [var], 'var', summarize=100) whitened = (values - mean) * tf.rsqrt(var + 1e-8) if not shift_mean: whitened += mean return whitened def whiten_pt(values, shift_mean=True, unbiased=True): mean, var = torch.mean(values), torch.var(values, unbiased=unbiased) print("mean", mean) print("var", var) whitened = (values - mean) * torch.rsqrt(var + 1e-8) if not shift_mean: whitened += mean return whitened rewards = np.array([ [1.2, 1.3, 1.4], [1.5, 1.6, 1.7], [1.8, 1.9, 2.0], ]) with tf.Session() as sess: print(sess.run(whiten_tf(tf.constant(rewards, dtype=tf.float32), shift_mean=False))) print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=True)) print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=False)) ``` ```jsx mean[1.5999999] var[0.0666666627] [[0.05080712 0.4381051 0.8254035 ] [1.2127019 1.6000004 1.9872988 ] [2.3745968 2.7618952 3.1491938 ]] mean tensor(1.6000, dtype=torch.float64) var tensor(0.0750, dtype=torch.float64) tensor([[0.1394, 0.5046, 0.8697], [1.2349, 1.6000, 1.9651], [2.3303, 2.6954, 3.0606]], dtype=torch.float64) mean tensor(1.6000, dtype=torch.float64) var tensor(0.0667, dtype=torch.float64) tensor([[0.0508, 0.4381, 0.8254], [1.2127, 1.6000, 1.9873], [2.3746, 2.7619, 3.1492]], dtype=torch.float64) ``` 10. **Clipped value function** 1. As done in the original PPO ([baselines/ppo2/model.py#L68-L75](https://github.com/openai/baselines/blob/ea25b9e8b234e6ee1bca43083f8f3cf974143998/baselines/ppo2/model.py#L68-L75)), the value function is clipped ([lm_human_preferences/train_policy.py#L343-L348](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L343-L348)) in a similar fashion as the policy objective. 11. **Adaptive KL** - The KL divergence penalty coefficient \\(\beta\\) is modified adaptively based on the KL divergence between the current policy and the previous policy. If the KL divergence is outside a predefined target range, the penalty coefficient is adjusted to bring it closer to the target range ([lm_human_preferences/train_policy.py#L115-L124](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L115-L124)). It’s implemented as follows: ```python class AdaptiveKLController: def __init__(self, init_kl_coef, hparams): self.value = init_kl_coef self.hparams = hparams def update(self, current, n_steps): target = self.hparams.target proportional_error = np.clip(current / target - 1, -0.2, 0.2) mult = 1 + proportional_error * n_steps / self.hparams.horizon self.value *= mult ``` - For the `sentiment` and `descriptiveness` tasks examined in this work, we have `init_kl_coef=0.15, hparams.target=6, hparams.horizon=10000`. ## **PyTorch Adam optimizer numerical issues w.r.t RLHF** - This implementation detail is so interesting that it deserves a full section. - PyTorch Adam optimizer ([torch.optim.Adam.html](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html)) has a different implementation compared to TensorFlow’s Adam optimizer (TF1 Adam at [tensorflow/v1.15.2/adam.py](https://github.com/tensorflow/tensorflow/blob/v1.15.2/tensorflow/python/training/adam.py), TF2 Adam at [keras/adam.py#L26-L220](https://github.com/keras-team/keras/blob/v2.13.1/keras/optimizers/adam.py#L26-L220)). In particular, **PyTorch follows Algorithm 1** of the Kingma and Ba’s Adam paper ([arxiv/1412.6980](https://arxiv.org/pdf/1412.6980.pdf)), but **TensorFlow uses the formulation just before Section 2.1** of the paper and its `epsilon` referred to here is `epsilon hat` in the paper. In a pseudocode comparison, we have the following ```python ### pytorch adam implementation: bias_correction1 = 1 - beta1 ** step bias_correction2 = 1 - beta2 ** step step_size = lr / bias_correction1 bias_correction2_sqrt = _dispatch_sqrt(bias_correction2) denom = (exp_avg_sq.sqrt() / bias_correction2_sqrt).add_(eps) param.addcdiv_(exp_avg, denom, value=-step_size) ### tensorflow adam implementation: lr_t = lr * _dispatch_sqrt((1 - beta2 ** step)) / (1 - beta1 ** step) denom = exp_avg_sq.sqrt().add_(eps) param.addcdiv_(exp_avg, denom, value=-lr_t) ``` - Let’s compare the update equations of pytorch-style and tensorflow-style adam. Following the notation of the adam paper [(Kingma and Ba, 2014)](https://arxiv.org/abs/1412.6980), we have the gradient update rules for pytorch adam (Algorithm 1 of Kingma and Ba’s paper) and tensorflow-style adam (the formulation just before Section 2.1 of Kingma and Ba’s paper) as below: $$\begin{aligned}\text{pytorch adam :}\quad \theta_t & =\theta_{t-1}-\alpha \cdot \hat{m}_t /\left(\sqrt{\hat{v}_t}+\varepsilon\right) \\& =\theta_{t-1}- \alpha \underbrace{\left[m_t /\left(1-\beta_1^t\right)\right]}_{=\hat{m}_t} /\left[\sqrt{\underbrace{v_t /\left(1-\beta_2^t\right)}_{=\hat{v}_t} }+\varepsilon\right]\\& =\theta_{t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right]\frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\varepsilon \sqrt{1-\beta_2^t}}}\end{aligned}$$ $$\begin{aligned}\text{tensorflow adam:}\quad \theta_t & =\theta_{t-1}-\alpha_t m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \\& =\theta_{t-1}-\underbrace{\left[\alpha \sqrt{1-\beta_2^t} /\left(1-\beta_1^t\right)\right]}_{=\alpha_t} m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \\& =\theta_{t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right] \frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\hat{\varepsilon}}} \end{aligned}$$ - The equations above highlight that the distinction between pytorch and tensorflow implementation is their **normalization terms**, \\(\color{green}{\varepsilon \sqrt{1-\beta_2^t}}\\) and \\(\color{green}{\hat{\varepsilon}}\\). The two versions are equivalent if we set \\(\hat{\varepsilon} =\varepsilon \sqrt{1-\beta_2^t}\\) . However, in the pytorch and tensorflow APIs, we can only set \\(\varepsilon\\) (pytorch) and \\(\hat{\varepsilon}\\) (tensorflow) via the `eps` argument, causing differences in their update equations. What if we set \\(\varepsilon\\) and \\(\hat{\varepsilon}\\) to the same value, say, 1e-5? Then for tensorflow adam, the normalization term \\(\hat{\varepsilon} = \text{1e-5}\\) is just a constant. But for pytorch adam, the normalization term \\({\varepsilon \sqrt{1-\beta_2^t}}\\) changes over time. Importantly, initially much smaller than 1e-5 when the timestep \\(t\\) is small, the term \\({\varepsilon \sqrt{1-\beta_2^t}}\\) gradually approaches to 1e-5 as timesteps increase. The plot below compares these two normalization terms over timesteps:  - The above figure shows that, if we set the same `eps` in pytorch adam and tensorflow adam, then pytorch-adam uses a much smaller normalization term than tensorflow-adam in the early phase of training. In other words, pytorch adam goes for **more aggressive gradient updates early in the training**. Our experiments support this finding, as we will demonstrate below. - How does this impact reproducibility and performance? To align settings, we record the original query, response, and rewards from [https://github.com/openai/lm-human-preferences](https://github.com/openai/lm-human-preferences) and save them in [https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main](https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main). I also record the metrics of the first two epochs of training with TF1’s `AdamOptimizer` optimizer as the ground truth. Below are some key metrics: | | OAI’s TF1 Adam | PyTorch’s Adam | Our custom Tensorflow-style Adam | | --- | --- | --- | --- | | policy/approxkl | 0.00037167023 | 0.0023672834504395723 | 0.000374998344341293 | | policy/clipfrac | 0.0045572915 | 0.02018229104578495 | 0.0052083334885537624 | | ratio_mean | 1.0051285 | 1.0105520486831665 | 1.0044583082199097 | | ratio_var | 0.0007716546 | 0.005374275613576174 | 0.0007942612282931805 | | ratio_max | 1.227216 | 1.8121057748794556 | 1.250215768814087 | | ratio_min | 0.7400441 | 0.4011387825012207 | 0.7299948930740356 | | logprob_diff_mean | 0.0047487603 | 0.008101251907646656 | 0.004073789343237877 | | logprob_diff_var | 0.0007207897 | 0.004668936599045992 | 0.0007334011606872082 | | logprob_diff_max | 0.20474821 | 0.594489574432373 | 0.22331619262695312 | | logprob_diff_min | -0.30104542 | -0.9134478569030762 | -0.31471776962280273 | - **PyTorch’s `Adam` produces a more aggressive update** for some reason. Here are some evidence: - **PyTorch’s `Adam`'s `logprob_diff_var`** **is 6x higher**. Here `logprobs_diff = new_logprobs - logprobs` is the difference between the log probability of tokens between the initial and current policy after two epochs of training. Having a larger `logprob_diff_var` means the scale of the log probability changes is larger than that in OAI’s TF1 Adam. - **PyTorch’s `Adam` presents a more extreme ratio max and min.** Here `ratio = torch.exp(logprobs_diff)`. Having a `ratio_max=1.8121057748794556` means that for some token, the probability of sampling that token is 1.8x more likely under the current policy, as opposed to only 1.2x with OAI’s TF1 Adam. - **Larger `policy/approxkl` `policy/clipfrac`.** Because of the aggressive update, the ratio gets clipped **4.4x more often, and the approximate KL divergence is 6x larger.** - The aggressive update is likely gonna cause further issues. E.g., `logprob_diff_mean` is 1.7x larger in PyTorch’s `Adam`, which would correspond to 1.7x larger KL penalty in the next reward calculation; this could get compounded. In fact, this might be related to the famous KL divergence issue — KL penalty is much larger than it should be and the model could pay more attention and optimizes for it more instead, therefore causing negative KL divergence. - **Larger models get affected more.** We conducted experiments comparing PyTorch’s `Adam` (codename `pt_adam`) and our custom TensorFlow-style (codename `tf_adam`) with `gpt2` and `gpt2-xl`. We found that the performance are roughly similar under `gpt2`; however with `gpt2-xl`, we observed a more aggressive updates, meaning that larger models get affected by this issue more. - When the initial policy updates are more aggressive in `gpt2-xl`, the training dynamics get affected. For example, we see a much larger `objective/kl` and `objective/scores` spikes with `pt_adam`, especially with `sentiment` — *the biggest KL was as large as 17.5* in one of the random seeds, suggesting an undesirable over-optimization. - Furthermore, because of the larger KL, many other training metrics are affected as well. For example, we see a much larger `clipfrac` (the fraction of time the `ratio` gets clipped by PPO’s objective clip coefficient 0.2) and `approxkl`.  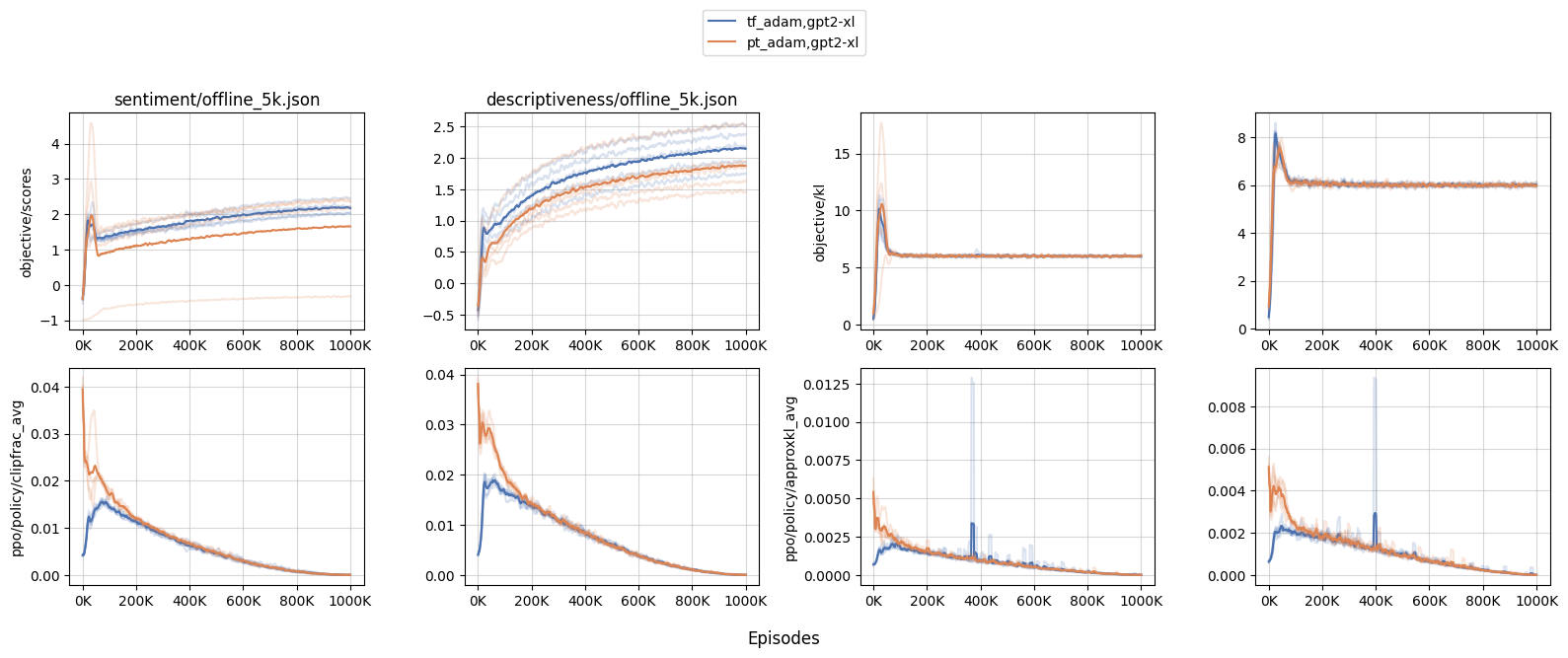 # Limitations Noticed this work does not try to reproduce the summarization work in CNN DM or TL;DR. This was because we found the training to be time-consuming and brittle. The particular training run we had showed poor GPU utilization (around 30%), so it takes almost 4 days to perform a training run, which is highly expensive (only AWS sells p3dn.24xlarge, and it costs $31.212 per hour) Additionally, training was brittle. While the reward goes up, we find it difficult to reproduce the “smart copier” behavior reported by Ziegler et al. (2019). Below are some sample outputs — clearly, the agent overfits somehow. See [https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs](https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs?workspace=user-costa-huang) for more complete logs.   # Conclusion In this work, we took a deep dive into OAI’s original RLHF codebase and compiled a list of its implementation details. We also created a minimal base which reproduces the same learning curves as OAI’s original RLHF codebase, when the dataset and hyperparameters are controlled. Furthermore, we identify surprising implementation details such as the adam optimizer’s setting which causes aggressive updates in early RLHF training. # Acknowledgement This work is supported by Hugging Face’s Big Science cluster 🤗. We also thank the helpful discussion with @lewtun and @natolambert. # Bibtex ```bibtex @article{Huang2023implementation, author = {Huang, Shengyi and Liu, Tianlin and von Werra, Leandro}, title = {The N Implementation Details of RLHF with PPO}, journal = {Hugging Face Blog}, year = {2023}, note = {https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo}, } ```
|
Deploy Embedding Models with Hugging Face Inference Endpoints
|
philschmid
|
October 24, 2023
|
inference-endpoints-embeddings
|
guide, llm, apps, inference
|
https://huggingface.co/blog/inference-endpoints-embeddings
|
# Deploy Embedding Models with Hugging Face Inference Endpoints The rise of Generative AI and LLMs like ChatGPT has increased the interest and importance of embedding models for a variety of tasks especially for retrievel augemented generation, like search or chat with your data. Embeddings are helpful since they represent sentences, images, words, etc. as numeric vector representations, which allows us to map semantically related items and retrieve helpful information. This helps us to provide relevant context for our prompt to improve the quality and specificity of generation. Compared to LLMs are Embedding Models smaller in size and faster for inference. That is very important since you need to recreate your embeddings after you changed your model or improved your model fine-tuning. Additionally, is it important that the whole retrieval augmentation process is as fast as possible to provide a good user experience. In this blog post, we will show you how to deploy open-source Embedding Models to [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) using [Text Embedding Inference](https://github.com/huggingface/text-embeddings-inference), our managed SaaS solution that makes it easy to deploy models. Additionally, we will teach you how to run large scale batch requests. 1. [What is Hugging Face Inference Endpoints](#1-what-is-hugging-face-inference-endpoints) 2. [What is Text Embedding Inference](#2-what-is-text-embeddings-inference) 3. [Deploy Embedding Model as Inference Endpoint](#3-deploy-embedding-model-as-inference-endpoint) 4. [Send request to endpoint and create embeddings](#4-send-request-to-endpoint-and-create-embeddings) Before we start, let's refresh our knowledge about Inference Endpoints. ## 1. What is Hugging Face Inference Endpoints? [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists to create Generative AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security. Here are some of the most important features: 1. [Easy Deployment](https://huggingface.co/docs/inference-endpoints/index): Deploy models as production-ready APIs with just a few clicks, eliminating the need to handle infrastructure or MLOps. 2. [Cost Efficiency](https://huggingface.co/docs/inference-endpoints/autoscaling): Benefit from automatic scale to zero capability, reducing costs by scaling down the infrastructure when the endpoint is not in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness. 3. [Enterprise Security](https://huggingface.co/docs/inference-endpoints/security): Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance. 4. [LLM Optimization](https://huggingface.co/text-generation-inference): Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference 5. [Comprehensive Task Support](https://huggingface.co/docs/inference-endpoints/supported_tasks): Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and easy customization to enable advanced tasks like speaker diarization or any Machine Learning task and library. You can get started with Inference Endpoints at: https://ui.endpoints.huggingface.co/ ## 2. What is Text Embeddings Inference? [Text Embeddings Inference (TEI)](https://github.com/huggingface/text-embeddings-inference#text-embeddings-inference) is a purpose built solution for deploying and serving open source text embeddings models. TEI is build for high-performance extraction supporting the most popular models. TEI supports all top 10 models of the [Massive Text Embedding Benchmark (MTEB) Leaderboard](https://huggingface.co/spaces/mteb/leaderboard), including FlagEmbedding, Ember, GTE and E5. TEI currently implements the following performance optimizing features: - No model graph compilation step - Small docker images and fast boot times. Get ready for true serverless! - Token based dynamic batching - Optimized transformers code for inference using [Flash Attention](https://github.com/HazyResearch/flash-attention), [Candle](https://github.com/huggingface/candle) and [cuBLASLt](https://docs.nvidia.com/cuda/cublas/#using-the-cublaslt-api) - [Safetensors](https://github.com/huggingface/safetensors) weight loading - Production ready (distributed tracing with Open Telemetry, Prometheus metrics) Those feature enabled industry-leading performance on throughput and cost. In a benchmark for [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) on an Nvidia A10G Inference Endpoint with a sequence length of 512 tokens and a batch size of 32, we achieved a throughput of 450+ req/sec resulting into a cost of 0.00156$ / 1M tokens or 0.00000156$ / 1k tokens. That is 64x cheaper than OpenAI Embeddings ($0.0001 / 1K tokens). 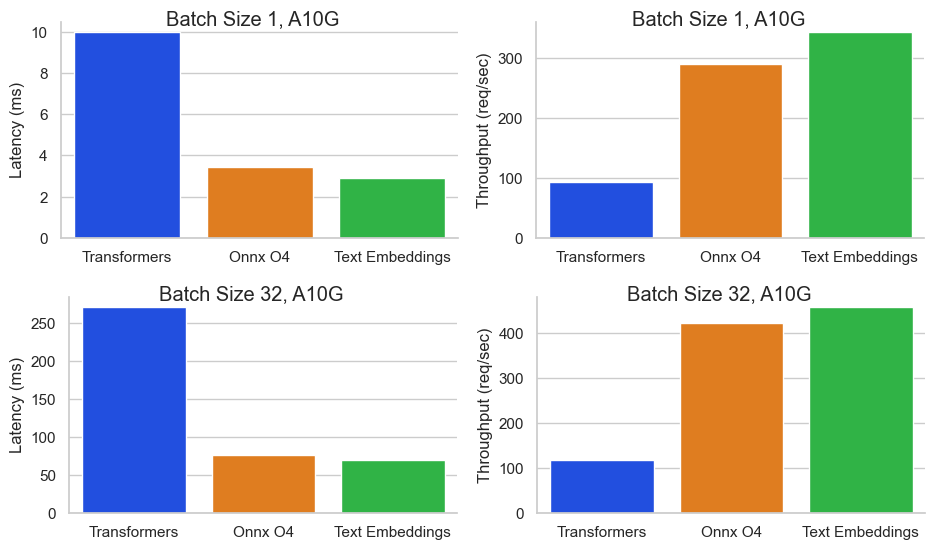 ## 3. Deploy Embedding Model as Inference Endpoint To get started, you need to be logged in with a User or Organization account with a payment method on file (you can add one [here](https://huggingface.co/settings/billing)), then access Inference Endpoints at [https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints) Then, click on “New endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case `BAAI/bge-base-en-v1.5`.  Inference Endpoints suggest an instance type based on the model size, which should be big enough to run the model. Here `Intel Ice Lake 2 vCPU`. To get the performance for the benchmark we ran you, change the instance to `1x Nvidia A10G`. *Note: If the instance type cannot be selected, you need to [contact us](mailto:[email protected]?subject=Quota%20increase%20HF%20Endpoints&body=Hello,%0D%0A%0D%0AI%20would%20like%20to%20request%20access/quota%20increase%20for%20%7BINSTANCE%20TYPE%7D%20for%20the%20following%20account%20%7BHF%20ACCOUNT%7D.) and request an instance quota.*  You can then deploy your model with a click on “Create Endpoint”. After 1-3 minutes, the Endpoint should be online and available to serve requests. ## 4. Send request to endpoint and create embeddings The Endpoint overview provides access to the Inference Widget, which can be used to manually send requests. This allows you to quickly test your Endpoint with different inputs and share it with team members.  *Note: TEI is currently is not automatically truncating the input. You can enable this by setting `truncate: true` in your request.* In addition to the widget the overview provides an code snippet for cURL, Python and Javascript, which you can use to send request to the model. The code snippet shows you how to send a single request, but TEI also supports batch requests, which allows you to send multiple document at the same to increase utilization of your endpoint. Below is an example on how to send a batch request with truncation set to true. ```python import requests API_URL = "https://l2skjfwp9punv393.us-east-1.aws.endpoints.huggingface.cloud" headers = { "Authorization": "Bearer YOUR TOKEN", "Content-Type": "application/json" } def query(payload): response = requests.post(API_URL, headers=headers, json=payload) return response.json() output = query({ "inputs": ["sentence 1", "sentence 2", "sentence 3"], "truncate": True }) # output [[0.334, ...], [-0.234, ...]] ``` ## Conclusion TEI on Hugging Face Inference Endpoints enables blazing fast and ultra cost-efficient deployment of state-of-the-art embeddings models. With industry-leading throughput of 450+ requests per second and costs as low as $0.00000156 / 1k tokens, Inference Endpoints delivers 64x cost savings compared to OpenAI Embeddings. For developers and companies leveraging text embeddings to enable semantic search, chatbots, recommendations, and more, Hugging Face Inference Endpoints eliminates infrastructure overhead and delivers high throughput at lowest cost streamlining the process from research to production. --- Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.