
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
ba014295e666710c5dfe6215338933ecf235156c | The dataset contains 6273 training samples, 762 validation samples and 749 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised word forms ('norms'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of UPOS tags ('upos\_tags'), which are encoded as class labels. | classla/janes_tag | [
"task_categories:other",
"task_ids:lemmatization",
"task_ids:part-of-speech",
"language:si",
"license:cc-by-sa-4.0",
"structure-prediction",
"normalization",
"tokenization",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["si"], "license": ["cc-by-sa-4.0"], "task_categories": ["other"], "task_ids": ["lemmatization", "part-of-speech"], "tags": ["structure-prediction", "normalization", "tokenization"]} | 2022-10-25T06:31:04+00:00 | []
| [
"si"
]
| TAGS
#task_categories-other #task_ids-lemmatization #task_ids-part-of-speech #language-Sinhala #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us
| The dataset contains 6273 training samples, 762 validation samples and 749 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised word forms ('norms'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of UPOS tags ('upos\_tags'), which are encoded as class labels. | []
| [
"TAGS\n#task_categories-other #task_ids-lemmatization #task_ids-part-of-speech #language-Sinhala #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us \n"
]
|
da293b9a70a87a936777e93dd59046ddbc6399ce | This dataset is based on 3,871 Croatian tweets that were segmented into sentences, tokens, and annotated with normalized forms, lemmas, MULTEXT-East tags (XPOS), UPOS tags and morphological features, and named entities.
The dataset contains 6339 training samples (sentences), 815 validation samples and 785 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised tokens ('norms'), list of lemmas ('lemmas'), list of UPOS tags ('upos\_tags'),
list of MULTEXT-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of named entity IOB tags ('iob\_tags'), which are encoded as class labels.
If you are using this dataset in your research, please cite the following paper:
```
@article{Miličević_Ljubešić_2016,
title={Tviterasi, tviteraši or twitteraši? Producing and analysing a normalised dataset of Croatian and Serbian tweets},
volume={4},
url={https://revije.ff.uni-lj.si/slovenscina2/article/view/7007},
DOI={10.4312/slo2.0.2016.2.156-188},
number={2},
journal={Slovenščina 2.0: empirical, applied and interdisciplinary research},
author={Miličević, Maja and Ljubešić, Nikola},
year={2016},
month={Sep.},
pages={156–188} }
```
| classla/reldi_hr | [
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"language:hr",
"license:cc-by-sa-4.0",
"structure-prediction",
"normalization",
"tokenization",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["hr"], "license": ["cc-by-sa-4.0"], "task_categories": ["other"], "task_ids": ["lemmatization", "named-entity-recognition", "part-of-speech"], "tags": ["structure-prediction", "normalization", "tokenization"]} | 2022-10-25T06:30:56+00:00 | []
| [
"hr"
]
| TAGS
#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Croatian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us
| This dataset is based on 3,871 Croatian tweets that were segmented into sentences, tokens, and annotated with normalized forms, lemmas, MULTEXT-East tags (XPOS), UPOS tags and morphological features, and named entities.
The dataset contains 6339 training samples (sentences), 815 validation samples and 785 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised tokens ('norms'), list of lemmas ('lemmas'), list of UPOS tags ('upos\_tags'),
list of MULTEXT-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of named entity IOB tags ('iob\_tags'), which are encoded as class labels.
If you are using this dataset in your research, please cite the following paper:
| []
| [
"TAGS\n#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Croatian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us \n"
]
|
10a37a1a9ea782093646e0b03d5ef05b3e1e11d5 | This dataset is based on 3,748 Serbian tweets that were segmented into sentences, tokens, and annotated with normalized forms, lemmas, MULTEXT-East tags (XPOS), UPOS tags and morphological features, and named entities.
The dataset contains 5462 training samples (sentences), 711 validation samples and 725 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised tokens ('norms'), list of lemmas ('lemmas'), list of UPOS tags ('upos\_tags'),
list of MULTEXT-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of named entity IOB tags ('iob\_tags'), which are encoded as class labels.
If you are using this dataset in your research, please cite the following paper:
```
@article{Miličević_Ljubešić_2016,
title={Tviterasi, tviteraši or twitteraši? Producing and analysing a normalised dataset of Croatian and Serbian tweets},
volume={4},
url={https://revije.ff.uni-lj.si/slovenscina2/article/view/7007},
DOI={10.4312/slo2.0.2016.2.156-188},
number={2},
journal={Slovenščina 2.0: empirical, applied and interdisciplinary research},
author={Miličević, Maja and Ljubešić, Nikola},
year={2016},
month={Sep.},
pages={156–188} }
``` | classla/reldi_sr | [
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"language:sr",
"license:cc-by-sa-4.0",
"structure-prediction",
"normalization",
"tokenization",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["sr"], "license": ["cc-by-sa-4.0"], "task_categories": ["other"], "task_ids": ["lemmatization", "named-entity-recognition", "part-of-speech"], "tags": ["structure-prediction", "normalization", "tokenization"]} | 2022-10-25T06:30:33+00:00 | []
| [
"sr"
]
| TAGS
#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Serbian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us
| This dataset is based on 3,748 Serbian tweets that were segmented into sentences, tokens, and annotated with normalized forms, lemmas, MULTEXT-East tags (XPOS), UPOS tags and morphological features, and named entities.
The dataset contains 5462 training samples (sentences), 711 validation samples and 725 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of normalised tokens ('norms'), list of lemmas ('lemmas'), list of UPOS tags ('upos\_tags'),
list of MULTEXT-East tags ('xpos\_tags), list of morphological features ('feats'),
and list of named entity IOB tags ('iob\_tags'), which are encoded as class labels.
If you are using this dataset in your research, please cite the following paper:
| []
| [
"TAGS\n#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Serbian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us \n"
]
|
42861d4054bc5fb993e6606e3c70a2957ec52e91 |
The SETimes\_sr training corpus contains 86,726 Serbian tokens manually annotated on the levels of tokenisation, sentence segmentation, morphosyntactic tagging, lemmatisation, named entities and dependency syntax.
The dataset contains 3177 training samples, 395 validation samples and 319 test samples
across the respective data splits. Each sample represents a sentence and includes the following features:
sentence ID ('sent\_id'), sentence text ('text'), list of tokens ('tokens'), list of lemmas ('lemmas'),
list of MULTEXT-East tags ('xpos\_tags), list of UPOS tags ('upos\_tags'),
list of morphological features ('feats'), list of IOB tags ('iob\_tags') and list of universal dependencies ('uds').
Three dataset configurations are available, namely 'ner', 'upos', and 'ud', with the corresponding features
encoded as class labels. If the configuration is not specified, it defaults to 'ner'.
If you use this dataset in your research, please cite the following paper:
```
@inproceedings{samardzic-etal-2017-universal,
title = "{U}niversal {D}ependencies for {S}erbian in Comparison with {C}roatian and Other {S}lavic Languages",
author = "Samard{\v{z}}i{\'c}, Tanja and
Starovi{\'c}, Mirjana and
Agi{\'c}, {\v{Z}}eljko and
Ljube{\v{s}}i{\'c}, Nikola",
booktitle = "Proceedings of the 6th Workshop on {B}alto-{S}lavic Natural Language Processing",
month = apr,
year = "2017",
address = "Valencia, Spain",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W17-1407",
doi = "10.18653/v1/W17-1407",
pages = "39--44",
}
``` | classla/setimes_sr | [
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"language:sr",
"license:cc-by-sa-4.0",
"structure-prediction",
"normalization",
"tokenization",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["sr"], "license": ["cc-by-sa-4.0"], "task_categories": ["other"], "task_ids": ["lemmatization", "named-entity-recognition", "part-of-speech"], "tags": ["structure-prediction", "normalization", "tokenization"]} | 2022-10-25T06:30:04+00:00 | []
| [
"sr"
]
| TAGS
#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Serbian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us
|
The SETimes\_sr training corpus contains 86,726 Serbian tokens manually annotated on the levels of tokenisation, sentence segmentation, morphosyntactic tagging, lemmatisation, named entities and dependency syntax.
The dataset contains 3177 training samples, 395 validation samples and 319 test samples
across the respective data splits. Each sample represents a sentence and includes the following features:
sentence ID ('sent\_id'), sentence text ('text'), list of tokens ('tokens'), list of lemmas ('lemmas'),
list of MULTEXT-East tags ('xpos\_tags), list of UPOS tags ('upos\_tags'),
list of morphological features ('feats'), list of IOB tags ('iob\_tags') and list of universal dependencies ('uds').
Three dataset configurations are available, namely 'ner', 'upos', and 'ud', with the corresponding features
encoded as class labels. If the configuration is not specified, it defaults to 'ner'.
If you use this dataset in your research, please cite the following paper:
| []
| [
"TAGS\n#task_categories-other #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-part-of-speech #language-Serbian #license-cc-by-sa-4.0 #structure-prediction #normalization #tokenization #region-us \n"
]
|
446b04c97cb43772a229cebbb8da0ce05ee03d2d | The dataset contains 7432 training samples, 1164 validation samples and 893 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos\_tags), list of UPOS tags ('upos\_tags'), list of morphological features ('feats'),
list of IOB tags ('iob\_tags'), and list of universal dependency tags ('uds'). Three dataset configurations are
available, where the corresponding features are encoded as class labels: 'ner', 'upos', and 'ud'. | classla/ssj500k | [
"task_categories:token-classification",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:parsing",
"task_ids:part-of-speech",
"language:sl",
"license:cc-by-sa-4.0",
"structure-prediction",
"tokenization",
"dependency-parsing",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["sl"], "license": ["cc-by-sa-4.0"], "task_categories": ["token-classification"], "task_ids": ["lemmatization", "named-entity-recognition", "parsing", "part-of-speech"], "tags": ["structure-prediction", "tokenization", "dependency-parsing"]} | 2022-10-28T04:37:22+00:00 | []
| [
"sl"
]
| TAGS
#task_categories-token-classification #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-parsing #task_ids-part-of-speech #language-Slovenian #license-cc-by-sa-4.0 #structure-prediction #tokenization #dependency-parsing #region-us
| The dataset contains 7432 training samples, 1164 validation samples and 893 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent\_id'),
list of tokens ('tokens'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos\_tags), list of UPOS tags ('upos\_tags'), list of morphological features ('feats'),
list of IOB tags ('iob\_tags'), and list of universal dependency tags ('uds'). Three dataset configurations are
available, where the corresponding features are encoded as class labels: 'ner', 'upos', and 'ud'. | []
| [
"TAGS\n#task_categories-token-classification #task_ids-lemmatization #task_ids-named-entity-recognition #task_ids-parsing #task_ids-part-of-speech #language-Slovenian #license-cc-by-sa-4.0 #structure-prediction #tokenization #dependency-parsing #region-us \n"
]
|
dcbb0c37d501225a976dc9e8a12bf0e20c8e2e04 | This is a very good dataset! | clem/autonlp-data-french_word_detection | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-09-14T08:45:38+00:00 | []
| []
| TAGS
#region-us
| This is a very good dataset! | []
| [
"TAGS\n#region-us \n"
]
|
87a7bada8da4fe2a7b738c6d3e549153383198ad | # MFAQ
🚨 See [MQA](https://huggingface.co/datasets/clips/mqa) or [MFAQ Light](maximedb/mfaq_light) for an updated version of the dataset.
MFAQ is a multilingual corpus of *Frequently Asked Questions* parsed from the [Common Crawl](https://commoncrawl.org/).
```
from datasets import load_dataset
load_dataset("clips/mfaq", "en")
{
"qa_pairs": [
{
"question": "Do I need a rental Car in Cork?",
"answer": "If you plan on travelling outside of Cork City, for instance to Kinsale [...]"
},
...
]
}
```
## Languages
We collected around 6M pairs of questions and answers in 21 different languages. To download a language specific subset you need to specify the language key as configuration. See below for an example.
```
load_dataset("clips/mfaq", "en") # replace "en" by any language listed below
```
| Language | Key | Pairs | Pages |
|------------|-----|-----------|-----------|
| All | all | 6,346,693 | 1,035,649 |
| English | en | 3,719,484 | 608,796 |
| German | de | 829,098 | 111,618 |
| Spanish | es | 482,818 | 75,489 |
| French | fr | 351,458 | 56,317 |
| Italian | it | 155,296 | 24,562 |
| Dutch | nl | 150,819 | 32,574 |
| Portuguese | pt | 138,778 | 26,169 |
| Turkish | tr | 102,373 | 19,002 |
| Russian | ru | 91,771 | 22,643 |
| Polish | pl | 65,182 | 10,695 |
| Indonesian | id | 45,839 | 7,910 |
| Norwegian | no | 37,711 | 5,143 |
| Swedish | sv | 37,003 | 5,270 |
| Danish | da | 32,655 | 5,279 |
| Vietnamese | vi | 27,157 | 5,261 |
| Finnish | fi | 20,485 | 2,795 |
| Romanian | ro | 17,066 | 3,554 |
| Czech | cs | 16,675 | 2,568 |
| Hebrew | he | 11,212 | 1,921 |
| Hungarian | hu | 8,598 | 1,264 |
| Croatian | hr | 5,215 | 819 |
## Data Fields
#### Nested (per page - default)
The data is organized by page. Each page contains a list of questions and answers.
- **id**
- **language**
- **num_pairs**: the number of FAQs on the page
- **domain**: source web domain of the FAQs
- **qa_pairs**: a list of questions and answers
- **question**
- **answer**
- **language**
#### Flattened
The data is organized by pair (i.e. pages are flattened). You can access the flat version of any language by appending `_flat` to the configuration (e.g. `en_flat`). The data will be returned pair-by-pair instead of page-by-page.
- **domain_id**
- **pair_id**
- **language**
- **domain**: source web domain of the FAQs
- **question**
- **answer**
## Source Data
This section was adapted from the source data description of [OSCAR](https://huggingface.co/datasets/oscar#source-data)
Common Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and robots.txt policies.
To construct MFAQ, the WARC files of Common Crawl were used. We looked for `FAQPage` markup in the HTML and subsequently parsed the `FAQItem` from the page.
## People
This model was developed by [Maxime De Bruyn](https://www.linkedin.com/in/maximedebruyn/), Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
## Licensing Information
```
These data are released under this licensing scheme.
We do not own any of the text from which these data has been extracted.
We license the actual packaging of these data under the Creative Commons CC0 license ("no rights reserved") http://creativecommons.org/publicdomain/zero/1.0/
Should you consider that our data contains material that is owned by you and should therefore not be reproduced here, please:
* Clearly identify yourself, with detailed contact data such as an address, telephone number or email address at which you can be contacted.
* Clearly identify the copyrighted work claimed to be infringed.
* Clearly identify the material that is claimed to be infringing and information reasonably sufficient to allow us to locate the material.
We will comply to legitimate requests by removing the affected sources from the next release of the corpus.
```
## Citation information
```
@misc{debruyn2021mfaq,
title={MFAQ: a Multilingual FAQ Dataset},
author={Maxime {De Bruyn} and Ehsan Lotfi and Jeska Buhmann and Walter Daelemans},
year={2021},
eprint={2109.12870},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | clips/mfaq | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"annotations_creators:no-annotation",
"language_creators:other",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:cs",
"language:da",
"language:de",
"language:en",
"language:es",
"language:fi",
"language:fr",
"language:he",
"language:hr",
"language:hu",
"language:id",
"language:it",
"language:nl",
"language:no",
"language:pl",
"language:pt",
"language:ro",
"language:ru",
"language:sv",
"language:tr",
"language:vi",
"license:cc0-1.0",
"arxiv:2109.12870",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["other"], "language": ["cs", "da", "de", "en", "es", "fi", "fr", "he", "hr", "hu", "id", "it", "nl", "no", "pl", "pt", "ro", "ru", "sv", "tr", "vi"], "license": ["cc0-1.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["multiple-choice-qa"], "pretty_name": "MFAQ - a Multilingual FAQ Dataset"} | 2022-10-20T10:32:50+00:00 | [
"2109.12870"
]
| [
"cs",
"da",
"de",
"en",
"es",
"fi",
"fr",
"he",
"hr",
"hu",
"id",
"it",
"nl",
"no",
"pl",
"pt",
"ro",
"ru",
"sv",
"tr",
"vi"
]
| TAGS
#task_categories-question-answering #task_ids-multiple-choice-qa #annotations_creators-no-annotation #language_creators-other #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Czech #language-Danish #language-German #language-English #language-Spanish #language-Finnish #language-French #language-Hebrew #language-Croatian #language-Hungarian #language-Indonesian #language-Italian #language-Dutch #language-Norwegian #language-Polish #language-Portuguese #language-Romanian #language-Russian #language-Swedish #language-Turkish #language-Vietnamese #license-cc0-1.0 #arxiv-2109.12870 #region-us
| MFAQ
====
See MQA or MFAQ Light for an updated version of the dataset.
MFAQ is a multilingual corpus of *Frequently Asked Questions* parsed from the Common Crawl.
Languages
---------
We collected around 6M pairs of questions and answers in 21 different languages. To download a language specific subset you need to specify the language key as configuration. See below for an example.
Data Fields
-----------
#### Nested (per page - default)
The data is organized by page. Each page contains a list of questions and answers.
* id
* language
* num\_pairs: the number of FAQs on the page
* domain: source web domain of the FAQs
* qa\_pairs: a list of questions and answers
+ question
+ answer
+ language
#### Flattened
The data is organized by pair (i.e. pages are flattened). You can access the flat version of any language by appending '\_flat' to the configuration (e.g. 'en\_flat'). The data will be returned pair-by-pair instead of page-by-page.
* domain\_id
* pair\_id
* language
* domain: source web domain of the FAQs
* question
* answer
Source Data
-----------
This section was adapted from the source data description of OSCAR
Common Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.
To construct MFAQ, the WARC files of Common Crawl were used. We looked for 'FAQPage' markup in the HTML and subsequently parsed the 'FAQItem' from the page.
People
------
This model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
Licensing Information
---------------------
information
| [
"#### Nested (per page - default)\n\n\nThe data is organized by page. Each page contains a list of questions and answers.\n\n\n* id\n* language\n* num\\_pairs: the number of FAQs on the page\n* domain: source web domain of the FAQs\n* qa\\_pairs: a list of questions and answers\n\t+ question\n\t+ answer\n\t+ language",
"#### Flattened\n\n\nThe data is organized by pair (i.e. pages are flattened). You can access the flat version of any language by appending '\\_flat' to the configuration (e.g. 'en\\_flat'). The data will be returned pair-by-pair instead of page-by-page.\n\n\n* domain\\_id\n* pair\\_id\n* language\n* domain: source web domain of the FAQs\n* question\n* answer\n\n\nSource Data\n-----------\n\n\nThis section was adapted from the source data description of OSCAR\n\n\nCommon Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.\n\n\nTo construct MFAQ, the WARC files of Common Crawl were used. We looked for 'FAQPage' markup in the HTML and subsequently parsed the 'FAQItem' from the page.\n\n\nPeople\n------\n\n\nThis model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.\n\n\nLicensing Information\n---------------------\n\n\ninformation"
]
| [
"TAGS\n#task_categories-question-answering #task_ids-multiple-choice-qa #annotations_creators-no-annotation #language_creators-other #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Czech #language-Danish #language-German #language-English #language-Spanish #language-Finnish #language-French #language-Hebrew #language-Croatian #language-Hungarian #language-Indonesian #language-Italian #language-Dutch #language-Norwegian #language-Polish #language-Portuguese #language-Romanian #language-Russian #language-Swedish #language-Turkish #language-Vietnamese #license-cc0-1.0 #arxiv-2109.12870 #region-us \n",
"#### Nested (per page - default)\n\n\nThe data is organized by page. Each page contains a list of questions and answers.\n\n\n* id\n* language\n* num\\_pairs: the number of FAQs on the page\n* domain: source web domain of the FAQs\n* qa\\_pairs: a list of questions and answers\n\t+ question\n\t+ answer\n\t+ language",
"#### Flattened\n\n\nThe data is organized by pair (i.e. pages are flattened). You can access the flat version of any language by appending '\\_flat' to the configuration (e.g. 'en\\_flat'). The data will be returned pair-by-pair instead of page-by-page.\n\n\n* domain\\_id\n* pair\\_id\n* language\n* domain: source web domain of the FAQs\n* question\n* answer\n\n\nSource Data\n-----------\n\n\nThis section was adapted from the source data description of OSCAR\n\n\nCommon Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.\n\n\nTo construct MFAQ, the WARC files of Common Crawl were used. We looked for 'FAQPage' markup in the HTML and subsequently parsed the 'FAQItem' from the page.\n\n\nPeople\n------\n\n\nThis model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.\n\n\nLicensing Information\n---------------------\n\n\ninformation"
]
|
27eebc4a00d229f8dd4ae2a6d9f1e4ad45781f3b | # MQA
MQA is a Multilingual corpus of Questions and Answers (MQA) parsed from the [Common Crawl](https://commoncrawl.org/). Questions are divided in two types: *Frequently Asked Questions (FAQ)* and *Community Question Answering (CQA)*.
```python
from datasets import load_dataset
all_data = load_dataset("clips/mqa", language="en")
{
"name": "the title of the question (if any)",
"text": "the body of the question (if any)",
"answers": [{
"text": "the text of the answer",
"is_accepted": "true|false"
}]
}
faq_data = load_dataset("clips/mqa", scope="faq", language="en")
cqa_data = load_dataset("clips/mqa", scope="cqa", language="en")
```
## Languages
We collected around **234M pairs** of questions and answers in **39 languages**. To download a language specific subset you need to specify the language key as configuration. See below for an example.
```python
load_dataset("clips/mqa", language="en") # replace "en" by any language listed below
```
| Language | FAQ | CQA |
|:-----------|------------:|-----------:|
| en | 174,696,414 | 14,082,180 |
| de | 17,796,992 | 1,094,606 |
| es | 14,967,582 | 845,836 |
| fr | 13,096,727 | 1,299,359 |
| ru | 12,435,022 | 1,715,131 |
| it | 6,850,573 | 455,027 |
| ja | 6,369,706 | 2,089,952 |
| zh | 5,940,796 | 579,596 |
| pt | 5,851,286 | 373,982 |
| nl | 4,882,511 | 503,376 |
| tr | 3,893,964 | 370,975 |
| pl | 3,766,531 | 70,559 |
| vi | 2,795,227 | 96,528 |
| id | 2,253,070 | 200,441 |
| ar | 2,211,795 | 805,661 |
| uk | 2,090,611 | 27,260 |
| el | 1,758,618 | 17,167 |
| no | 1,752,820 | 11,786 |
| sv | 1,733,582 | 20,024 |
| fi | 1,717,221 | 41,371 |
| ro | 1,689,471 | 93,222 |
| th | 1,685,463 | 73,204 |
| da | 1,554,581 | 16,398 |
| he | 1,422,449 | 88,435 |
| ko | 1,361,901 | 49,061 |
| cs | 1,224,312 | 143,863 |
| hu | 878,385 | 27,639 |
| fa | 787,420 | 118,805 |
| sk | 785,101 | 4,615 |
| lt | 672,105 | 301 |
| et | 547,208 | 441 |
| hi | 516,342 | 205,645 |
| hr | 458,958 | 11,677 |
| is | 437,748 | 37 |
| lv | 428,002 | 88 |
| ms | 230,568 | 7,460 |
| bg | 198,671 | 5,320 |
| sr | 110,270 | 3,980 |
| ca | 100,201 | 1,914 |
## FAQ vs. CQA
You can download the *Frequently Asked Questions* (FAQ) or the *Community Question Answering* (CQA) part of the dataset.
```python
faq = load_dataset("clips/mqa", scope="faq")
cqa = load_dataset("clips/mqa", scope="cqa")
all = load_dataset("clips/mqa", scope="all")
```
Although FAQ and CQA questions share the same structure, CQA questions can have multiple answers for a given questions, while FAQ questions have a single answer. FAQ questions typically only have a title (`name` key), while CQA have a title and a body (`name` and `text`).
## Nesting and Data Fields
You can specify three different nesting level: `question`, `page` and `domain`.
#### Question
```python
load_dataset("clips/mqa", level="question") # default
```
The default level is the question object:
- **name**: the title of the question(if any) in markdown format
- **text**: the body of the question (if any) in markdown format
- **answers**: a list of answers
- **text**: the title of the answer (if any) in markdown format
- **name**: the body of the answer in markdown format
- **is_accepted**: true if the answer is selected.
#### Page
This level returns a list of questions present on the same page. This is mostly useful for FAQs since CQAs already have one question per page.
```python
load_dataset("clips/mqa", level="page")
```
#### Domain
This level returns a list of pages present on the web domain. This is a good way to cope with FAQs duplication by sampling one page per domain at each epoch.
```python
load_dataset("clips/mqa", level="domain")
```
## Source Data
This section was adapted from the source data description of [OSCAR](https://huggingface.co/datasets/oscar#source-data)
Common Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and robots.txt policies.
To construct MQA, we used the WARC files of Common Crawl.
## People
This model was developed by [Maxime De Bruyn](https://maximedb.vercel.app), Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
## Licensing Information
```
These data are released under this licensing scheme.
We do not own any of the text from which these data has been extracted.
We license the actual packaging of these data under the Creative Commons CC0 license ("no rights reserved") http://creativecommons.org/publicdomain/zero/1.0/
Should you consider that our data contains material that is owned by you and should therefore not be reproduced here, please:
* Clearly identify yourself, with detailed contact data such as an address, telephone number or email address at which you can be contacted.
* Clearly identify the copyrighted work claimed to be infringed.
* Clearly identify the material that is claimed to be infringing and information reasonably sufficient to allow us to locate the material.
We will comply to legitimate requests by removing the affected sources from the next release of the corpus.
```
## Citation information
```
@inproceedings{de-bruyn-etal-2021-mfaq,
title = "{MFAQ}: a Multilingual {FAQ} Dataset",
author = "De Bruyn, Maxime and
Lotfi, Ehsan and
Buhmann, Jeska and
Daelemans, Walter",
booktitle = "Proceedings of the 3rd Workshop on Machine Reading for Question Answering",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.mrqa-1.1",
pages = "1--13",
}
``` | clips/mqa | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"annotations_creators:no-annotation",
"language_creators:other",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:ca",
"language:en",
"language:de",
"language:es",
"language:fr",
"language:ru",
"language:ja",
"language:it",
"language:zh",
"language:pt",
"language:nl",
"language:tr",
"language:pl",
"language:vi",
"language:ar",
"language:id",
"language:uk",
"language:ro",
"language:no",
"language:th",
"language:sv",
"language:el",
"language:fi",
"language:he",
"language:da",
"language:cs",
"language:ko",
"language:fa",
"language:hi",
"language:hu",
"language:sk",
"language:lt",
"language:et",
"language:hr",
"language:is",
"language:lv",
"language:ms",
"language:bg",
"language:sr",
"license:cc0-1.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["other"], "language": ["ca", "en", "de", "es", "fr", "ru", "ja", "it", "zh", "pt", "nl", "tr", "pl", "vi", "ar", "id", "uk", "ro", false, "th", "sv", "el", "fi", "he", "da", "cs", "ko", "fa", "hi", "hu", "sk", "lt", "et", "hr", "is", "lv", "ms", "bg", "sr", "ca"], "license": ["cc0-1.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["multiple-choice-qa"], "pretty_name": "MQA - a Multilingual FAQ and CQA Dataset"} | 2022-09-27T11:38:50+00:00 | []
| [
"ca",
"en",
"de",
"es",
"fr",
"ru",
"ja",
"it",
"zh",
"pt",
"nl",
"tr",
"pl",
"vi",
"ar",
"id",
"uk",
"ro",
"no",
"th",
"sv",
"el",
"fi",
"he",
"da",
"cs",
"ko",
"fa",
"hi",
"hu",
"sk",
"lt",
"et",
"hr",
"is",
"lv",
"ms",
"bg",
"sr"
]
| TAGS
#task_categories-question-answering #task_ids-multiple-choice-qa #annotations_creators-no-annotation #language_creators-other #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Catalan #language-English #language-German #language-Spanish #language-French #language-Russian #language-Japanese #language-Italian #language-Chinese #language-Portuguese #language-Dutch #language-Turkish #language-Polish #language-Vietnamese #language-Arabic #language-Indonesian #language-Ukrainian #language-Romanian #language-Norwegian #language-Thai #language-Swedish #language-Modern Greek (1453-) #language-Finnish #language-Hebrew #language-Danish #language-Czech #language-Korean #language-Persian #language-Hindi #language-Hungarian #language-Slovak #language-Lithuanian #language-Estonian #language-Croatian #language-Icelandic #language-Latvian #language-Malay (macrolanguage) #language-Bulgarian #language-Serbian #license-cc0-1.0 #region-us
| MQA
===
MQA is a Multilingual corpus of Questions and Answers (MQA) parsed from the Common Crawl. Questions are divided in two types: *Frequently Asked Questions (FAQ)* and *Community Question Answering (CQA)*.
Languages
---------
We collected around 234M pairs of questions and answers in 39 languages. To download a language specific subset you need to specify the language key as configuration. See below for an example.
FAQ vs. CQA
-----------
You can download the *Frequently Asked Questions* (FAQ) or the *Community Question Answering* (CQA) part of the dataset.
Although FAQ and CQA questions share the same structure, CQA questions can have multiple answers for a given questions, while FAQ questions have a single answer. FAQ questions typically only have a title ('name' key), while CQA have a title and a body ('name' and 'text').
Nesting and Data Fields
-----------------------
You can specify three different nesting level: 'question', 'page' and 'domain'.
#### Question
The default level is the question object:
* name: the title of the question(if any) in markdown format
* text: the body of the question (if any) in markdown format
* answers: a list of answers
+ text: the title of the answer (if any) in markdown format
+ name: the body of the answer in markdown format
+ is\_accepted: true if the answer is selected.
#### Page
This level returns a list of questions present on the same page. This is mostly useful for FAQs since CQAs already have one question per page.
#### Domain
This level returns a list of pages present on the web domain. This is a good way to cope with FAQs duplication by sampling one page per domain at each epoch.
Source Data
-----------
This section was adapted from the source data description of OSCAR
Common Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.
To construct MQA, we used the WARC files of Common Crawl.
People
------
This model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
Licensing Information
---------------------
information
| [
"#### Question\n\n\nThe default level is the question object:\n\n\n* name: the title of the question(if any) in markdown format\n* text: the body of the question (if any) in markdown format\n* answers: a list of answers\n\t+ text: the title of the answer (if any) in markdown format\n\t+ name: the body of the answer in markdown format\n\t+ is\\_accepted: true if the answer is selected.",
"#### Page\n\n\nThis level returns a list of questions present on the same page. This is mostly useful for FAQs since CQAs already have one question per page.",
"#### Domain\n\n\nThis level returns a list of pages present on the web domain. This is a good way to cope with FAQs duplication by sampling one page per domain at each epoch.\n\n\nSource Data\n-----------\n\n\nThis section was adapted from the source data description of OSCAR\n\n\nCommon Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.\n\n\nTo construct MQA, we used the WARC files of Common Crawl.\n\n\nPeople\n------\n\n\nThis model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.\n\n\nLicensing Information\n---------------------\n\n\ninformation"
]
| [
"TAGS\n#task_categories-question-answering #task_ids-multiple-choice-qa #annotations_creators-no-annotation #language_creators-other #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Catalan #language-English #language-German #language-Spanish #language-French #language-Russian #language-Japanese #language-Italian #language-Chinese #language-Portuguese #language-Dutch #language-Turkish #language-Polish #language-Vietnamese #language-Arabic #language-Indonesian #language-Ukrainian #language-Romanian #language-Norwegian #language-Thai #language-Swedish #language-Modern Greek (1453-) #language-Finnish #language-Hebrew #language-Danish #language-Czech #language-Korean #language-Persian #language-Hindi #language-Hungarian #language-Slovak #language-Lithuanian #language-Estonian #language-Croatian #language-Icelandic #language-Latvian #language-Malay (macrolanguage) #language-Bulgarian #language-Serbian #license-cc0-1.0 #region-us \n",
"#### Question\n\n\nThe default level is the question object:\n\n\n* name: the title of the question(if any) in markdown format\n* text: the body of the question (if any) in markdown format\n* answers: a list of answers\n\t+ text: the title of the answer (if any) in markdown format\n\t+ name: the body of the answer in markdown format\n\t+ is\\_accepted: true if the answer is selected.",
"#### Page\n\n\nThis level returns a list of questions present on the same page. This is mostly useful for FAQs since CQAs already have one question per page.",
"#### Domain\n\n\nThis level returns a list of pages present on the web domain. This is a good way to cope with FAQs duplication by sampling one page per domain at each epoch.\n\n\nSource Data\n-----------\n\n\nThis section was adapted from the source data description of OSCAR\n\n\nCommon Crawl is a non-profit foundation which produces and maintains an open repository of web crawled data that is both accessible and analysable. Common Crawl's complete web archive consists of petabytes of data collected over 8 years of web crawling. The repository contains raw web page HTML data (WARC files), metdata extracts (WAT files) and plain text extracts (WET files). The organisation's crawlers has always respected nofollow and URL policies.\n\n\nTo construct MQA, we used the WARC files of Common Crawl.\n\n\nPeople\n------\n\n\nThis model was developed by Maxime De Bruyn, Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.\n\n\nLicensing Information\n---------------------\n\n\ninformation"
]
|
3a1dc9acf1e9957e628865fa9937a70f71cf5f3f | fwefwefewf | cnrcastroli/aaaa | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-03-04T21:51:21+00:00 | []
| []
| TAGS
#region-us
| fwefwefewf | []
| [
"TAGS\n#region-us \n"
]
|
ab5506446dea35e06b6ac00d0b9c7a6677cd43ed |
# Dataset Card for "FairLex"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/coastalcph/fairlex
- **Repository:** https://github.com/coastalcph/fairlex
- **Paper:** https://aclanthology.org/2022.acl-long.301/
- **Leaderboard:** -
- **Point of Contact:** [Ilias Chalkidis](mailto:[email protected])
### Dataset Summary
We present a benchmark suite of four datasets for evaluating the fairness of pre-trained legal language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Swiss, and Chinese), five languages (English, German, French, Italian, and Chinese), and fairness across five attributes (gender, age, nationality/region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.
For the purpose of this work, we release four domain-specific BERT models with continued pre-training on the corpora of the examined datasets (ECtHR, SCOTUS, FSCS, CAIL). We train mini-sized BERT models with 6 Transformer blocks, 384 hidden units, and 12 attention heads. We warm-start all models from the public MiniLMv2 (Wang et al., 2021) using the distilled version of RoBERTa (Liu et al., 2019). For the English datasets (ECtHR, SCOTUS) and the one distilled from XLM-R (Conneau et al., 2021) for the rest (trilingual FSCS, and Chinese CAIL). [[Link to Models](https://huggingface.co/models?search=fairlex)]
### Supported Tasks and Leaderboards
The supported tasks are the following:
<table>
<tr><td>Dataset</td><td>Source</td><td>Sub-domain</td><td>Language</td><td>Task Type</td><td>Classes</td><tr>
<tr><td>ECtHR</td><td> <a href="https://aclanthology.org/P19-1424/">Chalkidis et al. (2019)</a> </td><td>ECHR</td><td>en</td><td>Multi-label classification</td><td>10+1</td></tr>
<tr><td>SCOTUS</td><td> <a href="http://scdb.wustl.edu">Spaeth et al. (2020)</a></td><td>US Law</td><td>en</td><td>Multi-class classification</td><td>11</td></tr>
<tr><td>FSCS</td><td> <a href="https://aclanthology.org/2021.nllp-1.3/">Niklaus et al. (2021)</a></td><td>Swiss Law</td><td>en, fr , it</td><td>Binary classification</td><td>2</td></tr>
<tr><td>CAIL</td><td> <a href="https://arxiv.org/abs/2103.13868">Wang et al. (2021)</a></td><td>Chinese Law</td><td>zh</td><td>Multi-class classification</td><td>6</td></tr>
</table>
#### ecthr
The European Court of Human Rights (ECtHR) hears allegations that a state has breached human rights provisions of the European Convention of Human Rights (ECHR). We use the dataset of Chalkidis et al. (2021), which contains 11K cases from ECtHR's public database.
Each case is mapped to *articles* of the ECHR that were violated (if any). This is a multi-label text classification task. Given the facts of a case, the goal is to predict the ECHR articles that were violated, if any, as decided (ruled) by the court. The cases are chronologically split into training (9k, 2001--16), development (1k, 2016--17), and test (1k, 2017--19) sets.
To facilitate the study of the fairness of text classifiers, we record for each case the following attributes: (a) The _defendant states_, which are the European states that allegedly violated the ECHR. The defendant states for each case is a subset of the 47 Member States of the Council of Europe; To have statistical support, we group defendant states in two groups:
Central-Eastern European states, on one hand, and all other states, as classified by the EuroVoc thesaurus. (b) The _applicant's age_ at the time of the decision. We extract the birth year of the applicant from the case facts, if possible, and classify its case in an age group (<=35, <=64, or older); and (c) the _applicant's gender_, extracted from the facts, if possible based on pronouns, classified in two categories (male, female).
#### scotus
The US Supreme Court (SCOTUS) is the highest federal court in the United States of America and generally hears only the most controversial or otherwise complex cases that have not been sufficiently well solved by lower courts.
We combine information from SCOTUS opinions with the Supreme Court DataBase (SCDB) (Spaeth, 2020). SCDB provides metadata (e.g., date of publication, decisions, issues, decision directions, and many more) for all cases. We consider the available 14 thematic issue areas (e.g, Criminal Procedure, Civil Rights, Economic Activity, etc.). This is a single-label multi-class document classification task. Given the court's opinion, the goal is to predict the issue area whose focus is on the subject matter of the controversy (dispute). SCOTUS contains a total of 9,262 cases that we split chronologically into 80% for training (7.4k, 1946--1982), 10% for development (914, 1982--1991) and 10% for testing (931, 1991--2016).
From SCDB, we also use the following attributes to study fairness: (a) the _type of respondent_, which is a manual categorization of respondents (defendants) in five categories (person, public entity, organization, facility, and other); and (c) the _direction of the decision_, i.e., whether the decision is liberal, or conservative, provided by SCDB.
#### fscs
The Federal Supreme Court of Switzerland (FSCS) is the last level of appeal in Switzerland and similarly to SCOTUS, the court generally hears only the most controversial or otherwise complex cases which have not been sufficiently well solved by lower courts. The court often focuses only on small parts of the previous decision, where they discuss possible wrong reasoning by the lower court. The Swiss-Judgment-Predict dataset (Niklaus et al., 2021) contains more than 85K decisions from the FSCS written in one of three languages (50K German, 31K French, 4K Italian) from the years 2000 to 2020.
The dataset is not parallel, i.e., all cases are unique and decisions are written only in a single language.
The dataset provides labels for a simplified binary (_approval_, _dismissal_) classification task. Given the facts of the case, the goal is to predict if the plaintiff's request is valid or partially valid. The cases are also chronologically split into training (59.7k, 2000-2014), development (8.2k, 2015-2016), and test (17.4k, 2017-2020) sets.
The dataset provides three additional attributes: (a) the _language_ of the FSCS written decision, in either German, French, or Italian; (b) the _legal area_ of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard; and (c) the _region_ that denotes in which federal region was the case originated.
#### cail
The Supreme People's Court of China (CAIL) is the last level of appeal in China and considers cases that originated from the high people's courts concerning matters of national importance. The Chinese AI and Law challenge (CAIL) dataset (Xiao et al., 2018) is a Chinese legal NLP dataset for judgment prediction and contains over 1m criminal cases. The dataset provides labels for *relevant article of criminal code* prediction, *charge* (type of crime) prediction, imprisonment *term* (period) prediction, and monetary *penalty* prediction. The publication of the original dataset has been the topic of an active debate in the NLP community(Leins et al., 2020; Tsarapatsanis and Aletras, 2021; Bender, 2021).
Recently, Wang et al. (2021) re-annotated a subset of approx. 100k cases with demographic attributes. Specifically, the new dataset has been annotated with: (a) the _applicant's gender_, classified in two categories (male, female); and (b) the _region_ of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged. We re-split the dataset chronologically into training (80k, 2013-2017), development (12k, 2017-2018), and test (12k, 2018) sets. In our study, we re-frame the imprisonment _term_ prediction and examine a soft version, dubbed _crime severity_ prediction task, a multi-class classification task, where given the facts of a case, the goal is to predict how severe was the committed crime with respect to the imprisonment term. We approximate crime severity by the length of imprisonment term, split in 6 clusters (0, <=12, <=36, <=60, <=120, >120 months).
### Languages
We consider datasets in English, German, French, Italian, and Chinese.
## Dataset Structure
### Data Instances
#### ecthr
An example of 'train' looks as follows.
```json
{
"text": "1. At the beginning of the events relevant to the application, K. had a daughter, P., and a son, M., born in 1986 and 1988 respectively. ... ",
"labels": [4],
"defendant_state": 1,
"applicant_gender": 0,
"applicant_age": 0
}
```
#### scotus
An example of 'train' looks as follows.
```json
{
"text": "United States Supreme Court MICHIGAN NAT. BANK v. MICHIGAN(1961) No. 155 Argued: Decided: March 6, 1961 </s> R. S. 5219 permits States to tax the shares of national banks, but not at a greater rate than . . . other moneyed capital . . . coming into competition with the business of national banks ...",
"label": 9,
"decision_direction": 0,
"respondent_type": 3
}
```
#### fscs
An example of 'train' looks as follows.
```json
{
"text": "A.- Der 1955 geborene V._ war seit 1. September 1986 hauptberuflich als technischer Kaufmann bei der Firma A._ AG tätig und im Rahmen einer Nebenbeschäftigung (Nachtarbeit) ab Mai 1990 bei einem Bewachungsdienst angestellt gewesen, als er am 10....",
"label": 0,
"decision_language": 0,
"legal_are": 5,
"court_region": 2
}
```
#### cail
An example of 'train' looks as follows.
```json
{
"text": "南宁市兴宁区人民检察院指控,2012年1月1日19时许,被告人蒋满德在南宁市某某路某号某市场内,因经营问题与被害人杨某某发生争吵并推打 ...",
"label": 0,
"defendant_gender": 0,
"court_region": 5
}
```
### Data Fields
#### ecthr_a
- `text`: a `string` feature (factual paragraphs (facts) from the case description).
- `labels`: a list of classification labels (a list of violated ECHR articles, if any). The ECHR articles considered are 2, 3, 5, 6, 8, 9, 11, 14, P1-1.
- `defendant_state`: Defendant State group (C.E. European, Rest of Europe)
- `applicant_gender`: The gender of the applicant (N/A, Male, Female)
- `applicant_age`: The age group of the applicant (N/A, <=35, <=64, or older)
#### scotus
- `text`: a `string` feature (the court opinion).
- `label`: a classification label (the relevant issue area). The issue areas are: (1, Criminal Procedure), (2, Civil Rights), (3, First Amendment), (4, Due Process), (5, Privacy), (6, Attorneys), (7, Unions), (8, Economic Activity), (9, Judicial Power), (10, Federalism), (11, Interstate Relations), (12, Federal Taxation), (13, Miscellaneous), (14, Private Action).
- `respondent_type`: the type of respondent, which is a manual categorization (clustering) of respondents (defendants) in five categories (person, public entity, organization, facility, and other).
- `decision_direction`: the direction of the decision, i.e., whether the decision is liberal, or conservative, provided by SCDB.
#### fscs
- `text`: a `string` feature (an EU law).
- `label`: a classification label (approval or dismissal of the appeal).
- `language`: the language of the FSCS written decision, (German, French, or Italian).
- `legal_area`: the legal area of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard.
- `region`: the region that denotes in which federal region was the case originated.
#### cail
- `text`: a `string` feature (the factual description of the case).
- `label`: a classification label (crime severity derived by the imprisonment term).
- `defendant_gender`: the gender of the defendant (Male or Female).
- `court_region`: the region of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged.
### Data Splits
<table>
<tr><td>Dataset </td><td>Training</td><td>Development</td><td>Test</td><td>Total</td></tr>
<tr><td>ECtHR</td><td>9000</td><td>1000</td><td>1000</td><td>11000</td></tr>
<tr><td>SCOTUS</td><td>7417</td><td>914</td><td>931</td><td>9262</td></tr>
<tr><td>FSCS</td><td>59709</td><td>8208</td><td>17357</td><td>85274</td></tr>
<tr><td>CAIL</td><td>80000</td><td>12000</td><td>12000</td><td>104000</td></tr>
</table>
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
<table>
<tr><td>Dataset</td><td>Source</td><td>Sub-domain</td><td>Language</td><td>Task Type</td><td>Classes</td><tr>
<tr><td>ECtHR</td><td> <a href="https://aclanthology.org/P19-1424/">Chalkidis et al. (2019)</a> </td><td>ECHR</td><td>en</td><td>Multi-label classification</td><td>10+1</td></tr>
<tr><td>SCOTUS</td><td> <a href="http://scdb.wustl.edu">Spaeth et al. (2020)</a></td><td>US Law</td><td>en</td><td>Multi-class classification</td><td>14</td></tr>
<tr><td>FSCS</td><td> <a href="https://aclanthology.org/2021.nllp-1.3/">Niklaus et al. (2021)</a></td><td>Swiss Law</td><td>en, fr , it</td><td>Binary classification</td><td>2</td></tr>
<tr><td>CAIL</td><td> <a href="https://arxiv.org/abs/2105.03887">Wang et al. (2021)</a></td><td>Chinese Law</td><td>zh</td><td>Multi-class classification</td><td>6</td></tr>
</table>
#### Initial Data Collection and Normalization
We standardize and put together four datasets: ECtHR (Chalkidis et al., 2021), SCOTUS (Spaeth et al., 2020), FSCS (Niklaus et al., 2021), and CAIL (Xiao et al., 2018; Wang et al., 2021) that are already publicly available.
The benchmark is not a blind stapling of pre-existing resources, we augment previous datasets. In the case of ECtHR, previously unavailable demographic attributes have been released to make the original dataset amenable for fairness research. For SCOTUS, two resources (court opinions with SCDB) have been combined for the very same reason, while the authors provide a manual categorization (clustering) of respondents.
All datasets, except SCOTUS, are publicly available and have been previously published. If datasets or the papers where they were introduced were not compiled or written by the authors, the original work is referenced and authors encourage FairLex users to do so as well. In fact, this work should only be referenced, in addition to citing the original work, when jointly experimenting with multiple FairLex datasets and using the FairLex evaluation framework and infrastructure, or using any newly introduced annotations (ECtHR, SCOTUS). Otherwise only the original work should be cited.
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
All classification labels rely on legal decisions (ECtHR, FSCS, CAIL), or are part of archival procedures (SCOTUS).
The demographic attributes and other metadata are either provided by the legal databases or have been extracted automatically from the text by means of Regular Expressions.
Consider the **Dataset Description** and **Discussion of Biases** sections, and the original publication for detailed information.
### Personal and Sensitive Information
The data is in general partially anonymized in accordance with the applicable national law. The data is considered to be in the public sphere from a privacy perspective. This is a very sensitive matter, as the courts try to keep a balance between transparency (the public's right to know) and privacy (respect for private and family life).
ECtHR cases are partially annonymized by the court. Its data is processed and made public in accordance with the European Data Protection Law.
SCOTUS cases may also contain personal information and the data is processed and made available by the US Supreme Court, whose proceedings are public. While this ensures compliance with US law, it is very likely that similarly to the ECtHR any processing could be justified by either implied consent or legitimate interest under European law. In FSCS, the names of the parties have been redacted by the courts according to the official guidelines. CAIL cases are also partially anonymized by the courts according to the courts' policy. Its data is processed and made public in accordance with Chinese Law.
## Considerations for Using the Data
### Social Impact of Dataset
This work can help practitioners to build assisting technology for legal professionals - with respect to the legal framework (jurisdiction) they operate -; technology that does not only rely on performance on majority groups but also considering minorities and the robustness of the developed models across them. This is an important application field, where more research should be conducted (Tsarapatsanis and Aletras, 2021) in order to improve legal services and democratize law, but more importantly, highlight (inform the audience on) the various multi-aspect shortcomings seeking a responsible and ethical (fair) deployment of technology.
### Discussion of Biases
The current version of FairLex covers a very small fraction of legal applications, jurisdictions, and protected attributes. The benchmark inevitably cannot cover "_everything in the whole wide (legal) world_" (Raji et al., 2021), but nonetheless, we believe that the published resources will help critical research in the area of fairness.
Some protected attributes within the datasets are extracted automatically, i.e., the gender and the age of the ECtHR dataset, by means of Regular Expressions, or manually clustered by the authors, such as the defendant state in the ECtHR dataset and the respondent attribute in the SCOTUS dataset. Those assumptions and simplifications can hold in an experimental setting only and by no means should be used in real-world applications where some simplifications, e.g., binary gender, would not be appropriate. By no means, do the authors or future users have to endorse the law standards or framework of the examined datasets, to any degree rather than the publication and use of the data.
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Curators
*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*
*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*
*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*
**Note:** The original datasets have been originally curated by others, and further curated (updated) by means of this benchmark.
### Licensing Information
The benchmark is released under a [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/) license. The licensing is compatible with the licensing of former material (remixed, transformed datasets).
### Citation Information
[*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*
*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*
*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*](https://arxiv.org/abs/2203.07228)
```
@inproceedings{chalkidis-etal-2022-fairlex,
author={Chalkidis, Ilias and Passini, Tommaso and Zhang, Sheng and
Tomada, Letizia and Schwemer, Sebastian Felix and Søgaard, Anders},
title={FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics},
year={2022},
address={Dublin, Ireland}
}
```
**Note:** Please consider citing and giving credits to all publications releasing the examined datasets.
### Contributions
Thanks to [@iliaschalkidis](https://github.com/iliaschalkidis) for adding this dataset.
| coastalcph/fairlex | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"task_ids:multi-class-classification",
"task_ids:topic-classification",
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"source_datasets:extended",
"language:en",
"language:de",
"language:fr",
"language:it",
"language:zh",
"license:cc-by-nc-sa-4.0",
"bias",
"gender-bias",
"arxiv:2103.13868",
"arxiv:2105.03887",
"arxiv:2203.07228",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found", "machine-generated"], "language_creators": ["found"], "language": ["en", "en", "de", "fr", "it", "zh"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": {"ecthr": ["monolingual"], "scotus": ["monolingual"], "fscs": ["multilingual"], "cail": ["monolingual"]}, "size_categories": {"ecthr": ["10K<n<100K"], "scotus": ["1K<n<10K"], "fscs": ["10K<n<100K"], "cail": ["100K<n<1M"]}, "source_datasets": ["extended"], "task_categories": ["text-classification"], "task_ids": ["multi-label-classification", "multi-class-classification", "topic-classification"], "pretty_name": "FairLex", "tags": ["bias", "gender-bias"]} | 2023-07-27T11:43:39+00:00 | [
"2103.13868",
"2105.03887",
"2203.07228"
]
| [
"en",
"de",
"fr",
"it",
"zh"
]
| TAGS
#task_categories-text-classification #task_ids-multi-label-classification #task_ids-multi-class-classification #task_ids-topic-classification #annotations_creators-found #annotations_creators-machine-generated #language_creators-found #source_datasets-extended #language-English #language-German #language-French #language-Italian #language-Chinese #license-cc-by-nc-sa-4.0 #bias #gender-bias #arxiv-2103.13868 #arxiv-2105.03887 #arxiv-2203.07228 #region-us
| Dataset Card for "FairLex"
==========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: -
* Point of Contact: Ilias Chalkidis
### Dataset Summary
We present a benchmark suite of four datasets for evaluating the fairness of pre-trained legal language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Swiss, and Chinese), five languages (English, German, French, Italian, and Chinese), and fairness across five attributes (gender, age, nationality/region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.
For the purpose of this work, we release four domain-specific BERT models with continued pre-training on the corpora of the examined datasets (ECtHR, SCOTUS, FSCS, CAIL). We train mini-sized BERT models with 6 Transformer blocks, 384 hidden units, and 12 attention heads. We warm-start all models from the public MiniLMv2 (Wang et al., 2021) using the distilled version of RoBERTa (Liu et al., 2019). For the English datasets (ECtHR, SCOTUS) and the one distilled from XLM-R (Conneau et al., 2021) for the rest (trilingual FSCS, and Chinese CAIL). [Link to Models]
### Supported Tasks and Leaderboards
The supported tasks are the following:
#### ecthr
The European Court of Human Rights (ECtHR) hears allegations that a state has breached human rights provisions of the European Convention of Human Rights (ECHR). We use the dataset of Chalkidis et al. (2021), which contains 11K cases from ECtHR's public database.
Each case is mapped to *articles* of the ECHR that were violated (if any). This is a multi-label text classification task. Given the facts of a case, the goal is to predict the ECHR articles that were violated, if any, as decided (ruled) by the court. The cases are chronologically split into training (9k, 2001--16), development (1k, 2016--17), and test (1k, 2017--19) sets.
To facilitate the study of the fairness of text classifiers, we record for each case the following attributes: (a) The *defendant states*, which are the European states that allegedly violated the ECHR. The defendant states for each case is a subset of the 47 Member States of the Council of Europe; To have statistical support, we group defendant states in two groups:
Central-Eastern European states, on one hand, and all other states, as classified by the EuroVoc thesaurus. (b) The *applicant's age* at the time of the decision. We extract the birth year of the applicant from the case facts, if possible, and classify its case in an age group (<=35, <=64, or older); and (c) the *applicant's gender*, extracted from the facts, if possible based on pronouns, classified in two categories (male, female).
#### scotus
The US Supreme Court (SCOTUS) is the highest federal court in the United States of America and generally hears only the most controversial or otherwise complex cases that have not been sufficiently well solved by lower courts.
We combine information from SCOTUS opinions with the Supreme Court DataBase (SCDB) (Spaeth, 2020). SCDB provides metadata (e.g., date of publication, decisions, issues, decision directions, and many more) for all cases. We consider the available 14 thematic issue areas (e.g, Criminal Procedure, Civil Rights, Economic Activity, etc.). This is a single-label multi-class document classification task. Given the court's opinion, the goal is to predict the issue area whose focus is on the subject matter of the controversy (dispute). SCOTUS contains a total of 9,262 cases that we split chronologically into 80% for training (7.4k, 1946--1982), 10% for development (914, 1982--1991) and 10% for testing (931, 1991--2016).
From SCDB, we also use the following attributes to study fairness: (a) the *type of respondent*, which is a manual categorization of respondents (defendants) in five categories (person, public entity, organization, facility, and other); and (c) the *direction of the decision*, i.e., whether the decision is liberal, or conservative, provided by SCDB.
#### fscs
The Federal Supreme Court of Switzerland (FSCS) is the last level of appeal in Switzerland and similarly to SCOTUS, the court generally hears only the most controversial or otherwise complex cases which have not been sufficiently well solved by lower courts. The court often focuses only on small parts of the previous decision, where they discuss possible wrong reasoning by the lower court. The Swiss-Judgment-Predict dataset (Niklaus et al., 2021) contains more than 85K decisions from the FSCS written in one of three languages (50K German, 31K French, 4K Italian) from the years 2000 to 2020.
The dataset is not parallel, i.e., all cases are unique and decisions are written only in a single language.
The dataset provides labels for a simplified binary (*approval*, *dismissal*) classification task. Given the facts of the case, the goal is to predict if the plaintiff's request is valid or partially valid. The cases are also chronologically split into training (59.7k, 2000-2014), development (8.2k, 2015-2016), and test (17.4k, 2017-2020) sets.
The dataset provides three additional attributes: (a) the *language* of the FSCS written decision, in either German, French, or Italian; (b) the *legal area* of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard; and (c) the *region* that denotes in which federal region was the case originated.
#### cail
The Supreme People's Court of China (CAIL) is the last level of appeal in China and considers cases that originated from the high people's courts concerning matters of national importance. The Chinese AI and Law challenge (CAIL) dataset (Xiao et al., 2018) is a Chinese legal NLP dataset for judgment prediction and contains over 1m criminal cases. The dataset provides labels for *relevant article of criminal code* prediction, *charge* (type of crime) prediction, imprisonment *term* (period) prediction, and monetary *penalty* prediction. The publication of the original dataset has been the topic of an active debate in the NLP community(Leins et al., 2020; Tsarapatsanis and Aletras, 2021; Bender, 2021).
Recently, Wang et al. (2021) re-annotated a subset of approx. 100k cases with demographic attributes. Specifically, the new dataset has been annotated with: (a) the *applicant's gender*, classified in two categories (male, female); and (b) the *region* of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged. We re-split the dataset chronologically into training (80k, 2013-2017), development (12k, 2017-2018), and test (12k, 2018) sets. In our study, we re-frame the imprisonment *term* prediction and examine a soft version, dubbed *crime severity* prediction task, a multi-class classification task, where given the facts of a case, the goal is to predict how severe was the committed crime with respect to the imprisonment term. We approximate crime severity by the length of imprisonment term, split in 6 clusters (0, <=12, <=36, <=60, <=120, >120 months).
### Languages
We consider datasets in English, German, French, Italian, and Chinese.
Dataset Structure
-----------------
### Data Instances
#### ecthr
An example of 'train' looks as follows.
#### scotus
An example of 'train' looks as follows.
#### fscs
An example of 'train' looks as follows.
#### cail
An example of 'train' looks as follows.
### Data Fields
#### ecthr\_a
* 'text': a 'string' feature (factual paragraphs (facts) from the case description).
* 'labels': a list of classification labels (a list of violated ECHR articles, if any). The ECHR articles considered are 2, 3, 5, 6, 8, 9, 11, 14, P1-1.
* 'defendant\_state': Defendant State group (C.E. European, Rest of Europe)
* 'applicant\_gender': The gender of the applicant (N/A, Male, Female)
* 'applicant\_age': The age group of the applicant (N/A, <=35, <=64, or older)
#### scotus
* 'text': a 'string' feature (the court opinion).
* 'label': a classification label (the relevant issue area). The issue areas are: (1, Criminal Procedure), (2, Civil Rights), (3, First Amendment), (4, Due Process), (5, Privacy), (6, Attorneys), (7, Unions), (8, Economic Activity), (9, Judicial Power), (10, Federalism), (11, Interstate Relations), (12, Federal Taxation), (13, Miscellaneous), (14, Private Action).
* 'respondent\_type': the type of respondent, which is a manual categorization (clustering) of respondents (defendants) in five categories (person, public entity, organization, facility, and other).
* 'decision\_direction': the direction of the decision, i.e., whether the decision is liberal, or conservative, provided by SCDB.
#### fscs
* 'text': a 'string' feature (an EU law).
* 'label': a classification label (approval or dismissal of the appeal).
* 'language': the language of the FSCS written decision, (German, French, or Italian).
* 'legal\_area': the legal area of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard.
* 'region': the region that denotes in which federal region was the case originated.
#### cail
* 'text': a 'string' feature (the factual description of the case).
* 'label': a classification label (crime severity derived by the imprisonment term).
* 'defendant\_gender': the gender of the defendant (Male or Female).
* 'court\_region': the region of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
We standardize and put together four datasets: ECtHR (Chalkidis et al., 2021), SCOTUS (Spaeth et al., 2020), FSCS (Niklaus et al., 2021), and CAIL (Xiao et al., 2018; Wang et al., 2021) that are already publicly available.
The benchmark is not a blind stapling of pre-existing resources, we augment previous datasets. In the case of ECtHR, previously unavailable demographic attributes have been released to make the original dataset amenable for fairness research. For SCOTUS, two resources (court opinions with SCDB) have been combined for the very same reason, while the authors provide a manual categorization (clustering) of respondents.
All datasets, except SCOTUS, are publicly available and have been previously published. If datasets or the papers where they were introduced were not compiled or written by the authors, the original work is referenced and authors encourage FairLex users to do so as well. In fact, this work should only be referenced, in addition to citing the original work, when jointly experimenting with multiple FairLex datasets and using the FairLex evaluation framework and infrastructure, or using any newly introduced annotations (ECtHR, SCOTUS). Otherwise only the original work should be cited.
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
All classification labels rely on legal decisions (ECtHR, FSCS, CAIL), or are part of archival procedures (SCOTUS).
The demographic attributes and other metadata are either provided by the legal databases or have been extracted automatically from the text by means of Regular Expressions.
Consider the Dataset Description and Discussion of Biases sections, and the original publication for detailed information.
### Personal and Sensitive Information
The data is in general partially anonymized in accordance with the applicable national law. The data is considered to be in the public sphere from a privacy perspective. This is a very sensitive matter, as the courts try to keep a balance between transparency (the public's right to know) and privacy (respect for private and family life).
ECtHR cases are partially annonymized by the court. Its data is processed and made public in accordance with the European Data Protection Law.
SCOTUS cases may also contain personal information and the data is processed and made available by the US Supreme Court, whose proceedings are public. While this ensures compliance with US law, it is very likely that similarly to the ECtHR any processing could be justified by either implied consent or legitimate interest under European law. In FSCS, the names of the parties have been redacted by the courts according to the official guidelines. CAIL cases are also partially anonymized by the courts according to the courts' policy. Its data is processed and made public in accordance with Chinese Law.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
This work can help practitioners to build assisting technology for legal professionals - with respect to the legal framework (jurisdiction) they operate -; technology that does not only rely on performance on majority groups but also considering minorities and the robustness of the developed models across them. This is an important application field, where more research should be conducted (Tsarapatsanis and Aletras, 2021) in order to improve legal services and democratize law, but more importantly, highlight (inform the audience on) the various multi-aspect shortcomings seeking a responsible and ethical (fair) deployment of technology.
### Discussion of Biases
The current version of FairLex covers a very small fraction of legal applications, jurisdictions, and protected attributes. The benchmark inevitably cannot cover "*everything in the whole wide (legal) world*" (Raji et al., 2021), but nonetheless, we believe that the published resources will help critical research in the area of fairness.
Some protected attributes within the datasets are extracted automatically, i.e., the gender and the age of the ECtHR dataset, by means of Regular Expressions, or manually clustered by the authors, such as the defendant state in the ECtHR dataset and the respondent attribute in the SCOTUS dataset. Those assumptions and simplifications can hold in an experimental setting only and by no means should be used in real-world applications where some simplifications, e.g., binary gender, would not be appropriate. By no means, do the authors or future users have to endorse the law standards or framework of the examined datasets, to any degree rather than the publication and use of the data.
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*
*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*
*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*
Note: The original datasets have been originally curated by others, and further curated (updated) by means of this benchmark.
### Licensing Information
The benchmark is released under a Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license. The licensing is compatible with the licensing of former material (remixed, transformed datasets).
*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*
*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*
*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*
Note: Please consider citing and giving credits to all publications releasing the examined datasets.
### Contributions
Thanks to @iliaschalkidis for adding this dataset.
| [
"### Dataset Summary\n\n\nWe present a benchmark suite of four datasets for evaluating the fairness of pre-trained legal language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Swiss, and Chinese), five languages (English, German, French, Italian, and Chinese), and fairness across five attributes (gender, age, nationality/region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.\n\n\nFor the purpose of this work, we release four domain-specific BERT models with continued pre-training on the corpora of the examined datasets (ECtHR, SCOTUS, FSCS, CAIL). We train mini-sized BERT models with 6 Transformer blocks, 384 hidden units, and 12 attention heads. We warm-start all models from the public MiniLMv2 (Wang et al., 2021) using the distilled version of RoBERTa (Liu et al., 2019). For the English datasets (ECtHR, SCOTUS) and the one distilled from XLM-R (Conneau et al., 2021) for the rest (trilingual FSCS, and Chinese CAIL). [Link to Models]",
"### Supported Tasks and Leaderboards\n\n\nThe supported tasks are the following:",
"#### ecthr\n\n\nThe European Court of Human Rights (ECtHR) hears allegations that a state has breached human rights provisions of the European Convention of Human Rights (ECHR). We use the dataset of Chalkidis et al. (2021), which contains 11K cases from ECtHR's public database.\nEach case is mapped to *articles* of the ECHR that were violated (if any). This is a multi-label text classification task. Given the facts of a case, the goal is to predict the ECHR articles that were violated, if any, as decided (ruled) by the court. The cases are chronologically split into training (9k, 2001--16), development (1k, 2016--17), and test (1k, 2017--19) sets.\n\n\nTo facilitate the study of the fairness of text classifiers, we record for each case the following attributes: (a) The *defendant states*, which are the European states that allegedly violated the ECHR. The defendant states for each case is a subset of the 47 Member States of the Council of Europe; To have statistical support, we group defendant states in two groups:\nCentral-Eastern European states, on one hand, and all other states, as classified by the EuroVoc thesaurus. (b) The *applicant's age* at the time of the decision. We extract the birth year of the applicant from the case facts, if possible, and classify its case in an age group (<=35, <=64, or older); and (c) the *applicant's gender*, extracted from the facts, if possible based on pronouns, classified in two categories (male, female).",
"#### scotus\n\n\nThe US Supreme Court (SCOTUS) is the highest federal court in the United States of America and generally hears only the most controversial or otherwise complex cases that have not been sufficiently well solved by lower courts.\nWe combine information from SCOTUS opinions with the Supreme Court DataBase (SCDB) (Spaeth, 2020). SCDB provides metadata (e.g., date of publication, decisions, issues, decision directions, and many more) for all cases. We consider the available 14 thematic issue areas (e.g, Criminal Procedure, Civil Rights, Economic Activity, etc.). This is a single-label multi-class document classification task. Given the court's opinion, the goal is to predict the issue area whose focus is on the subject matter of the controversy (dispute). SCOTUS contains a total of 9,262 cases that we split chronologically into 80% for training (7.4k, 1946--1982), 10% for development (914, 1982--1991) and 10% for testing (931, 1991--2016).\n\n\nFrom SCDB, we also use the following attributes to study fairness: (a) the *type of respondent*, which is a manual categorization of respondents (defendants) in five categories (person, public entity, organization, facility, and other); and (c) the *direction of the decision*, i.e., whether the decision is liberal, or conservative, provided by SCDB.",
"#### fscs\n\n\nThe Federal Supreme Court of Switzerland (FSCS) is the last level of appeal in Switzerland and similarly to SCOTUS, the court generally hears only the most controversial or otherwise complex cases which have not been sufficiently well solved by lower courts. The court often focuses only on small parts of the previous decision, where they discuss possible wrong reasoning by the lower court. The Swiss-Judgment-Predict dataset (Niklaus et al., 2021) contains more than 85K decisions from the FSCS written in one of three languages (50K German, 31K French, 4K Italian) from the years 2000 to 2020.\nThe dataset is not parallel, i.e., all cases are unique and decisions are written only in a single language.\nThe dataset provides labels for a simplified binary (*approval*, *dismissal*) classification task. Given the facts of the case, the goal is to predict if the plaintiff's request is valid or partially valid. The cases are also chronologically split into training (59.7k, 2000-2014), development (8.2k, 2015-2016), and test (17.4k, 2017-2020) sets.\n\n\nThe dataset provides three additional attributes: (a) the *language* of the FSCS written decision, in either German, French, or Italian; (b) the *legal area* of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard; and (c) the *region* that denotes in which federal region was the case originated.",
"#### cail\n\n\nThe Supreme People's Court of China (CAIL) is the last level of appeal in China and considers cases that originated from the high people's courts concerning matters of national importance. The Chinese AI and Law challenge (CAIL) dataset (Xiao et al., 2018) is a Chinese legal NLP dataset for judgment prediction and contains over 1m criminal cases. The dataset provides labels for *relevant article of criminal code* prediction, *charge* (type of crime) prediction, imprisonment *term* (period) prediction, and monetary *penalty* prediction. The publication of the original dataset has been the topic of an active debate in the NLP community(Leins et al., 2020; Tsarapatsanis and Aletras, 2021; Bender, 2021).\n\n\nRecently, Wang et al. (2021) re-annotated a subset of approx. 100k cases with demographic attributes. Specifically, the new dataset has been annotated with: (a) the *applicant's gender*, classified in two categories (male, female); and (b) the *region* of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged. We re-split the dataset chronologically into training (80k, 2013-2017), development (12k, 2017-2018), and test (12k, 2018) sets. In our study, we re-frame the imprisonment *term* prediction and examine a soft version, dubbed *crime severity* prediction task, a multi-class classification task, where given the facts of a case, the goal is to predict how severe was the committed crime with respect to the imprisonment term. We approximate crime severity by the length of imprisonment term, split in 6 clusters (0, <=12, <=36, <=60, <=120, >120 months).",
"### Languages\n\n\nWe consider datasets in English, German, French, Italian, and Chinese.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### ecthr\n\n\nAn example of 'train' looks as follows.",
"#### scotus\n\n\nAn example of 'train' looks as follows.",
"#### fscs\n\n\nAn example of 'train' looks as follows.",
"#### cail\n\n\nAn example of 'train' looks as follows.",
"### Data Fields",
"#### ecthr\\_a\n\n\n* 'text': a 'string' feature (factual paragraphs (facts) from the case description).\n* 'labels': a list of classification labels (a list of violated ECHR articles, if any). The ECHR articles considered are 2, 3, 5, 6, 8, 9, 11, 14, P1-1.\n* 'defendant\\_state': Defendant State group (C.E. European, Rest of Europe)\n* 'applicant\\_gender': The gender of the applicant (N/A, Male, Female)\n* 'applicant\\_age': The age group of the applicant (N/A, <=35, <=64, or older)",
"#### scotus\n\n\n* 'text': a 'string' feature (the court opinion).\n* 'label': a classification label (the relevant issue area). The issue areas are: (1, Criminal Procedure), (2, Civil Rights), (3, First Amendment), (4, Due Process), (5, Privacy), (6, Attorneys), (7, Unions), (8, Economic Activity), (9, Judicial Power), (10, Federalism), (11, Interstate Relations), (12, Federal Taxation), (13, Miscellaneous), (14, Private Action).\n* 'respondent\\_type': the type of respondent, which is a manual categorization (clustering) of respondents (defendants) in five categories (person, public entity, organization, facility, and other).\n* 'decision\\_direction': the direction of the decision, i.e., whether the decision is liberal, or conservative, provided by SCDB.",
"#### fscs\n\n\n* 'text': a 'string' feature (an EU law).\n* 'label': a classification label (approval or dismissal of the appeal).\n* 'language': the language of the FSCS written decision, (German, French, or Italian).\n* 'legal\\_area': the legal area of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard.\n* 'region': the region that denotes in which federal region was the case originated.",
"#### cail\n\n\n* 'text': a 'string' feature (the factual description of the case).\n* 'label': a classification label (crime severity derived by the imprisonment term).\n* 'defendant\\_gender': the gender of the defendant (Male or Female).\n* 'court\\_region': the region of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged.",
"### Data Splits\n\n\n\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nWe standardize and put together four datasets: ECtHR (Chalkidis et al., 2021), SCOTUS (Spaeth et al., 2020), FSCS (Niklaus et al., 2021), and CAIL (Xiao et al., 2018; Wang et al., 2021) that are already publicly available.\n\n\nThe benchmark is not a blind stapling of pre-existing resources, we augment previous datasets. In the case of ECtHR, previously unavailable demographic attributes have been released to make the original dataset amenable for fairness research. For SCOTUS, two resources (court opinions with SCDB) have been combined for the very same reason, while the authors provide a manual categorization (clustering) of respondents.\n\n\nAll datasets, except SCOTUS, are publicly available and have been previously published. If datasets or the papers where they were introduced were not compiled or written by the authors, the original work is referenced and authors encourage FairLex users to do so as well. In fact, this work should only be referenced, in addition to citing the original work, when jointly experimenting with multiple FairLex datasets and using the FairLex evaluation framework and infrastructure, or using any newly introduced annotations (ECtHR, SCOTUS). Otherwise only the original work should be cited.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\nAll classification labels rely on legal decisions (ECtHR, FSCS, CAIL), or are part of archival procedures (SCOTUS).\n\n\nThe demographic attributes and other metadata are either provided by the legal databases or have been extracted automatically from the text by means of Regular Expressions.\n\n\nConsider the Dataset Description and Discussion of Biases sections, and the original publication for detailed information.",
"### Personal and Sensitive Information\n\n\nThe data is in general partially anonymized in accordance with the applicable national law. The data is considered to be in the public sphere from a privacy perspective. This is a very sensitive matter, as the courts try to keep a balance between transparency (the public's right to know) and privacy (respect for private and family life).\nECtHR cases are partially annonymized by the court. Its data is processed and made public in accordance with the European Data Protection Law.\nSCOTUS cases may also contain personal information and the data is processed and made available by the US Supreme Court, whose proceedings are public. While this ensures compliance with US law, it is very likely that similarly to the ECtHR any processing could be justified by either implied consent or legitimate interest under European law. In FSCS, the names of the parties have been redacted by the courts according to the official guidelines. CAIL cases are also partially anonymized by the courts according to the courts' policy. Its data is processed and made public in accordance with Chinese Law.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nThis work can help practitioners to build assisting technology for legal professionals - with respect to the legal framework (jurisdiction) they operate -; technology that does not only rely on performance on majority groups but also considering minorities and the robustness of the developed models across them. This is an important application field, where more research should be conducted (Tsarapatsanis and Aletras, 2021) in order to improve legal services and democratize law, but more importantly, highlight (inform the audience on) the various multi-aspect shortcomings seeking a responsible and ethical (fair) deployment of technology.",
"### Discussion of Biases\n\n\nThe current version of FairLex covers a very small fraction of legal applications, jurisdictions, and protected attributes. The benchmark inevitably cannot cover \"*everything in the whole wide (legal) world*\" (Raji et al., 2021), but nonetheless, we believe that the published resources will help critical research in the area of fairness.\n\n\nSome protected attributes within the datasets are extracted automatically, i.e., the gender and the age of the ECtHR dataset, by means of Regular Expressions, or manually clustered by the authors, such as the defendant state in the ECtHR dataset and the respondent attribute in the SCOTUS dataset. Those assumptions and simplifications can hold in an experimental setting only and by no means should be used in real-world applications where some simplifications, e.g., binary gender, would not be appropriate. By no means, do the authors or future users have to endorse the law standards or framework of the examined datasets, to any degree rather than the publication and use of the data.",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*\n*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*\n*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*\n\n\nNote: The original datasets have been originally curated by others, and further curated (updated) by means of this benchmark.",
"### Licensing Information\n\n\nThe benchmark is released under a Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license. The licensing is compatible with the licensing of former material (remixed, transformed datasets).\n\n\n*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*\n*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*\n*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*\n\n\nNote: Please consider citing and giving credits to all publications releasing the examined datasets.",
"### Contributions\n\n\nThanks to @iliaschalkidis for adding this dataset."
]
| [
"TAGS\n#task_categories-text-classification #task_ids-multi-label-classification #task_ids-multi-class-classification #task_ids-topic-classification #annotations_creators-found #annotations_creators-machine-generated #language_creators-found #source_datasets-extended #language-English #language-German #language-French #language-Italian #language-Chinese #license-cc-by-nc-sa-4.0 #bias #gender-bias #arxiv-2103.13868 #arxiv-2105.03887 #arxiv-2203.07228 #region-us \n",
"### Dataset Summary\n\n\nWe present a benchmark suite of four datasets for evaluating the fairness of pre-trained legal language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Swiss, and Chinese), five languages (English, German, French, Italian, and Chinese), and fairness across five attributes (gender, age, nationality/region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.\n\n\nFor the purpose of this work, we release four domain-specific BERT models with continued pre-training on the corpora of the examined datasets (ECtHR, SCOTUS, FSCS, CAIL). We train mini-sized BERT models with 6 Transformer blocks, 384 hidden units, and 12 attention heads. We warm-start all models from the public MiniLMv2 (Wang et al., 2021) using the distilled version of RoBERTa (Liu et al., 2019). For the English datasets (ECtHR, SCOTUS) and the one distilled from XLM-R (Conneau et al., 2021) for the rest (trilingual FSCS, and Chinese CAIL). [Link to Models]",
"### Supported Tasks and Leaderboards\n\n\nThe supported tasks are the following:",
"#### ecthr\n\n\nThe European Court of Human Rights (ECtHR) hears allegations that a state has breached human rights provisions of the European Convention of Human Rights (ECHR). We use the dataset of Chalkidis et al. (2021), which contains 11K cases from ECtHR's public database.\nEach case is mapped to *articles* of the ECHR that were violated (if any). This is a multi-label text classification task. Given the facts of a case, the goal is to predict the ECHR articles that were violated, if any, as decided (ruled) by the court. The cases are chronologically split into training (9k, 2001--16), development (1k, 2016--17), and test (1k, 2017--19) sets.\n\n\nTo facilitate the study of the fairness of text classifiers, we record for each case the following attributes: (a) The *defendant states*, which are the European states that allegedly violated the ECHR. The defendant states for each case is a subset of the 47 Member States of the Council of Europe; To have statistical support, we group defendant states in two groups:\nCentral-Eastern European states, on one hand, and all other states, as classified by the EuroVoc thesaurus. (b) The *applicant's age* at the time of the decision. We extract the birth year of the applicant from the case facts, if possible, and classify its case in an age group (<=35, <=64, or older); and (c) the *applicant's gender*, extracted from the facts, if possible based on pronouns, classified in two categories (male, female).",
"#### scotus\n\n\nThe US Supreme Court (SCOTUS) is the highest federal court in the United States of America and generally hears only the most controversial or otherwise complex cases that have not been sufficiently well solved by lower courts.\nWe combine information from SCOTUS opinions with the Supreme Court DataBase (SCDB) (Spaeth, 2020). SCDB provides metadata (e.g., date of publication, decisions, issues, decision directions, and many more) for all cases. We consider the available 14 thematic issue areas (e.g, Criminal Procedure, Civil Rights, Economic Activity, etc.). This is a single-label multi-class document classification task. Given the court's opinion, the goal is to predict the issue area whose focus is on the subject matter of the controversy (dispute). SCOTUS contains a total of 9,262 cases that we split chronologically into 80% for training (7.4k, 1946--1982), 10% for development (914, 1982--1991) and 10% for testing (931, 1991--2016).\n\n\nFrom SCDB, we also use the following attributes to study fairness: (a) the *type of respondent*, which is a manual categorization of respondents (defendants) in five categories (person, public entity, organization, facility, and other); and (c) the *direction of the decision*, i.e., whether the decision is liberal, or conservative, provided by SCDB.",
"#### fscs\n\n\nThe Federal Supreme Court of Switzerland (FSCS) is the last level of appeal in Switzerland and similarly to SCOTUS, the court generally hears only the most controversial or otherwise complex cases which have not been sufficiently well solved by lower courts. The court often focuses only on small parts of the previous decision, where they discuss possible wrong reasoning by the lower court. The Swiss-Judgment-Predict dataset (Niklaus et al., 2021) contains more than 85K decisions from the FSCS written in one of three languages (50K German, 31K French, 4K Italian) from the years 2000 to 2020.\nThe dataset is not parallel, i.e., all cases are unique and decisions are written only in a single language.\nThe dataset provides labels for a simplified binary (*approval*, *dismissal*) classification task. Given the facts of the case, the goal is to predict if the plaintiff's request is valid or partially valid. The cases are also chronologically split into training (59.7k, 2000-2014), development (8.2k, 2015-2016), and test (17.4k, 2017-2020) sets.\n\n\nThe dataset provides three additional attributes: (a) the *language* of the FSCS written decision, in either German, French, or Italian; (b) the *legal area* of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard; and (c) the *region* that denotes in which federal region was the case originated.",
"#### cail\n\n\nThe Supreme People's Court of China (CAIL) is the last level of appeal in China and considers cases that originated from the high people's courts concerning matters of national importance. The Chinese AI and Law challenge (CAIL) dataset (Xiao et al., 2018) is a Chinese legal NLP dataset for judgment prediction and contains over 1m criminal cases. The dataset provides labels for *relevant article of criminal code* prediction, *charge* (type of crime) prediction, imprisonment *term* (period) prediction, and monetary *penalty* prediction. The publication of the original dataset has been the topic of an active debate in the NLP community(Leins et al., 2020; Tsarapatsanis and Aletras, 2021; Bender, 2021).\n\n\nRecently, Wang et al. (2021) re-annotated a subset of approx. 100k cases with demographic attributes. Specifically, the new dataset has been annotated with: (a) the *applicant's gender*, classified in two categories (male, female); and (b) the *region* of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged. We re-split the dataset chronologically into training (80k, 2013-2017), development (12k, 2017-2018), and test (12k, 2018) sets. In our study, we re-frame the imprisonment *term* prediction and examine a soft version, dubbed *crime severity* prediction task, a multi-class classification task, where given the facts of a case, the goal is to predict how severe was the committed crime with respect to the imprisonment term. We approximate crime severity by the length of imprisonment term, split in 6 clusters (0, <=12, <=36, <=60, <=120, >120 months).",
"### Languages\n\n\nWe consider datasets in English, German, French, Italian, and Chinese.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### ecthr\n\n\nAn example of 'train' looks as follows.",
"#### scotus\n\n\nAn example of 'train' looks as follows.",
"#### fscs\n\n\nAn example of 'train' looks as follows.",
"#### cail\n\n\nAn example of 'train' looks as follows.",
"### Data Fields",
"#### ecthr\\_a\n\n\n* 'text': a 'string' feature (factual paragraphs (facts) from the case description).\n* 'labels': a list of classification labels (a list of violated ECHR articles, if any). The ECHR articles considered are 2, 3, 5, 6, 8, 9, 11, 14, P1-1.\n* 'defendant\\_state': Defendant State group (C.E. European, Rest of Europe)\n* 'applicant\\_gender': The gender of the applicant (N/A, Male, Female)\n* 'applicant\\_age': The age group of the applicant (N/A, <=35, <=64, or older)",
"#### scotus\n\n\n* 'text': a 'string' feature (the court opinion).\n* 'label': a classification label (the relevant issue area). The issue areas are: (1, Criminal Procedure), (2, Civil Rights), (3, First Amendment), (4, Due Process), (5, Privacy), (6, Attorneys), (7, Unions), (8, Economic Activity), (9, Judicial Power), (10, Federalism), (11, Interstate Relations), (12, Federal Taxation), (13, Miscellaneous), (14, Private Action).\n* 'respondent\\_type': the type of respondent, which is a manual categorization (clustering) of respondents (defendants) in five categories (person, public entity, organization, facility, and other).\n* 'decision\\_direction': the direction of the decision, i.e., whether the decision is liberal, or conservative, provided by SCDB.",
"#### fscs\n\n\n* 'text': a 'string' feature (an EU law).\n* 'label': a classification label (approval or dismissal of the appeal).\n* 'language': the language of the FSCS written decision, (German, French, or Italian).\n* 'legal\\_area': the legal area of the case (public, penal, social, civil, or insurance law) derived from the chambers where the decisions were heard.\n* 'region': the region that denotes in which federal region was the case originated.",
"#### cail\n\n\n* 'text': a 'string' feature (the factual description of the case).\n* 'label': a classification label (crime severity derived by the imprisonment term).\n* 'defendant\\_gender': the gender of the defendant (Male or Female).\n* 'court\\_region': the region of the court that denotes in which out of the 7 provincial-level administrative regions was the case judged.",
"### Data Splits\n\n\n\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nWe standardize and put together four datasets: ECtHR (Chalkidis et al., 2021), SCOTUS (Spaeth et al., 2020), FSCS (Niklaus et al., 2021), and CAIL (Xiao et al., 2018; Wang et al., 2021) that are already publicly available.\n\n\nThe benchmark is not a blind stapling of pre-existing resources, we augment previous datasets. In the case of ECtHR, previously unavailable demographic attributes have been released to make the original dataset amenable for fairness research. For SCOTUS, two resources (court opinions with SCDB) have been combined for the very same reason, while the authors provide a manual categorization (clustering) of respondents.\n\n\nAll datasets, except SCOTUS, are publicly available and have been previously published. If datasets or the papers where they were introduced were not compiled or written by the authors, the original work is referenced and authors encourage FairLex users to do so as well. In fact, this work should only be referenced, in addition to citing the original work, when jointly experimenting with multiple FairLex datasets and using the FairLex evaluation framework and infrastructure, or using any newly introduced annotations (ECtHR, SCOTUS). Otherwise only the original work should be cited.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\nAll classification labels rely on legal decisions (ECtHR, FSCS, CAIL), or are part of archival procedures (SCOTUS).\n\n\nThe demographic attributes and other metadata are either provided by the legal databases or have been extracted automatically from the text by means of Regular Expressions.\n\n\nConsider the Dataset Description and Discussion of Biases sections, and the original publication for detailed information.",
"### Personal and Sensitive Information\n\n\nThe data is in general partially anonymized in accordance with the applicable national law. The data is considered to be in the public sphere from a privacy perspective. This is a very sensitive matter, as the courts try to keep a balance between transparency (the public's right to know) and privacy (respect for private and family life).\nECtHR cases are partially annonymized by the court. Its data is processed and made public in accordance with the European Data Protection Law.\nSCOTUS cases may also contain personal information and the data is processed and made available by the US Supreme Court, whose proceedings are public. While this ensures compliance with US law, it is very likely that similarly to the ECtHR any processing could be justified by either implied consent or legitimate interest under European law. In FSCS, the names of the parties have been redacted by the courts according to the official guidelines. CAIL cases are also partially anonymized by the courts according to the courts' policy. Its data is processed and made public in accordance with Chinese Law.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nThis work can help practitioners to build assisting technology for legal professionals - with respect to the legal framework (jurisdiction) they operate -; technology that does not only rely on performance on majority groups but also considering minorities and the robustness of the developed models across them. This is an important application field, where more research should be conducted (Tsarapatsanis and Aletras, 2021) in order to improve legal services and democratize law, but more importantly, highlight (inform the audience on) the various multi-aspect shortcomings seeking a responsible and ethical (fair) deployment of technology.",
"### Discussion of Biases\n\n\nThe current version of FairLex covers a very small fraction of legal applications, jurisdictions, and protected attributes. The benchmark inevitably cannot cover \"*everything in the whole wide (legal) world*\" (Raji et al., 2021), but nonetheless, we believe that the published resources will help critical research in the area of fairness.\n\n\nSome protected attributes within the datasets are extracted automatically, i.e., the gender and the age of the ECtHR dataset, by means of Regular Expressions, or manually clustered by the authors, such as the defendant state in the ECtHR dataset and the respondent attribute in the SCOTUS dataset. Those assumptions and simplifications can hold in an experimental setting only and by no means should be used in real-world applications where some simplifications, e.g., binary gender, would not be appropriate. By no means, do the authors or future users have to endorse the law standards or framework of the examined datasets, to any degree rather than the publication and use of the data.",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*\n*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*\n*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*\n\n\nNote: The original datasets have been originally curated by others, and further curated (updated) by means of this benchmark.",
"### Licensing Information\n\n\nThe benchmark is released under a Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license. The licensing is compatible with the licensing of former material (remixed, transformed datasets).\n\n\n*Ilias Chalkidis, Tommaso Pasini, Sheng Zhang, Letizia Tomada, Letizia, Sebastian Felix Schwemer, Anders Søgaard.*\n*FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing.*\n*2022. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland.*\n\n\nNote: Please consider citing and giving credits to all publications releasing the examined datasets.",
"### Contributions\n\n\nThanks to @iliaschalkidis for adding this dataset."
]
|
9070da7298a73ea6129f711916f17e52d82884de |
# Dataset Card for **cointegrated/ru-paraphrase-NMT-Leipzig**
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Paper:** https://habr.com/ru/post/564916/
- **Point of Contact:** [@cointegrated](https://huggingface.co/cointegrated)
### Dataset Summary
The dataset contains 1 million Russian sentences and their automatically generated paraphrases.
It was created by David Dale ([@cointegrated](https://huggingface.co/cointegrated)) by translating the `rus-ru_web-public_2019_1M` corpus from [the Leipzig collection](https://wortschatz.uni-leipzig.de/en/download) into English and back into Russian. A fraction of the resulting paraphrases are invalid, and should be filtered out.
The blogpost ["Перефразирование русских текстов: корпуса, модели, метрики"](https://habr.com/ru/post/564916/) provides a detailed description of the dataset and its properties.
The dataset can be loaded with the following code:
```Python
import datasets
data = datasets.load_dataset(
'cointegrated/ru-paraphrase-NMT-Leipzig',
data_files={"train": "train.csv","val": "val.csv","test": "test.csv"},
)
```
Its output should look like
```
DatasetDict({
train: Dataset({
features: ['idx', 'original', 'en', 'ru', 'chrf_sim', 'labse_sim'],
num_rows: 980000
})
val: Dataset({
features: ['idx', 'original', 'en', 'ru', 'chrf_sim', 'labse_sim'],
num_rows: 10000
})
test: Dataset({
features: ['idx', 'original', 'en', 'ru', 'chrf_sim', 'labse_sim'],
num_rows: 10000
})
})
```
### Supported Tasks and Leaderboards
The dataset can be used to train and validate models for paraphrase generation or (if negative sampling is used) for paraphrase detection.
### Languages
Russian (main), English (auxilliary).
## Dataset Structure
### Data Instances
Data instances look like
```
{
"labse_sim": 0.93502015,
"chrf_sim": 0.4946451012684782,
"idx": 646422,
"ru": "О перспективах развития новых медиа-технологий в РФ расскажут на медиафоруме Енисея.",
"original": "Перспективы развития новых медиатехнологий в Российской Федерации обсудят участники медиафорума «Енисей.",
"en": "Prospects for the development of new media technologies in the Russian Federation will be discussed at the Yenisey Media Forum."
}
```
Where `original` is the original sentence, and `ru` is its machine-generated paraphrase.
### Data Fields
- `idx`: id of the instance in the original corpus
- `original`: the original sentence
- `en`: automatic translation of `original` to English
- `ru`: automatic translation of `en` back to Russian, i.e. a paraphrase of `original`
- `chrf_sim`: [ChrF++](https://huggingface.co/metrics/chrf) similarity of `original` and `ru`
- `labse_sim`: cosine similarity of [LaBSE](https://huggingface.co/cointegrated/LaBSE-en-ru) embedings of `original` and `ru`
- `forward_entailment`: predicted probability that `original` entails `ru`
- `backward_entailment`: predicted probability that `ru` entails `original`
- `p_good`: predicted probability that `ru` and `original` have equivalent meaning
### Data Splits
Train – 980K, validation – 10K, test – 10K. The splits were generated randomly.
## Dataset Creation
### Curation Rationale
There are other Russian paraphrase corpora, but they have major drawbacks:
- The best known [corpus from paraphraser.ru 2016 contest](http://paraphraser.ru/download/) is rather small and covers only the News domain.
- [Opusparcus](https://huggingface.co/datasets/GEM/opusparcus), [ParaPhraserPlus](http://paraphraser.ru/download/), and [corpora of Tamara Zhordanija](https://github.com/tamriq/paraphrase) are noisy, i.e. a large proportion of sentence pairs in them have substantial difference in meaning.
- The Russian part of [TaPaCo](https://huggingface.co/datasets/tapaco) has very high lexical overlap in the sentence pairs; in other words, their paraphrases are not diverse enough.
The current corpus is generated with a dual objective: the parphrases should be semantically as close as possible to the original sentences, while being lexically different from them. Back-translation with restricted vocabulary seems to achieve this goal often enough.
### Source Data
#### Initial Data Collection and Normalization
The `rus-ru_web-public_2019_1M` corpus from [the Leipzig collection](https://wortschatz.uni-leipzig.de/en/download) as is.
The process of its creation is described [in this paper](http://www.lrec-conf.org/proceedings/lrec2012/pdf/327_Paper.pdf):
D. Goldhahn, T. Eckart & U. Quasthoff: Building Large Monolingual Dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages.
In: *Proceedings of the 8th International Language Resources and Evaluation (LREC'12), 2012*.
#### Automatic paraphrasing
The paraphrasing was carried out by translating the original sentence to English and then back to Russian.
The models [facebook/wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en) and [facebook/wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru) were used for translation.
To ensure that the back-translated texts are not identical to the original texts, the final decoder was prohibited to use the token n-grams from the original texts.
The code below implements the paraphrasing function.
```python
import torch
from transformers import FSMTModel, FSMTTokenizer, FSMTForConditionalGeneration
tokenizer = FSMTTokenizer.from_pretrained("facebook/wmt19-en-ru")
model = FSMTForConditionalGeneration.from_pretrained("facebook/wmt19-en-ru")
inverse_tokenizer = FSMTTokenizer.from_pretrained("facebook/wmt19-ru-en")
inverse_model = FSMTForConditionalGeneration.from_pretrained("facebook/wmt19-ru-en")
model.cuda();
inverse_model.cuda();
def paraphrase(text, gram=4, num_beams=5, **kwargs):
""" Generate a paraphrase using back translation.
Parameter `gram` denotes size of token n-grams of the original sentence that cannot appear in the paraphrase.
"""
input_ids = inverse_tokenizer.encode(text, return_tensors="pt")
with torch.no_grad():
outputs = inverse_model.generate(input_ids.to(inverse_model.device), num_beams=num_beams, **kwargs)
other_lang = inverse_tokenizer.decode(outputs[0], skip_special_tokens=True)
# print(other_lang)
input_ids = input_ids[0, :-1].tolist()
bad_word_ids = [input_ids[i:(i+gram)] for i in range(len(input_ids)-gram)]
input_ids = tokenizer.encode(other_lang, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids.to(model.device), num_beams=num_beams, bad_words_ids=bad_word_ids, **kwargs)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
return decoded
```
The corpus was created by running the above `paraphrase` function on the original sentences with parameters `gram=3, num_beams=5, repetition_penalty=3.14, no_repeat_ngram_size=6`.
### Annotations
#### Annotation process
The dataset was annotated by several automatic metrics:
- [ChrF++](https://huggingface.co/metrics/chrf) between `original` and `ru` sentences;
- cosine similarity between [LaBSE](https://huggingface.co/cointegrated/LaBSE-en-ru) embeddings of these sentences;
- forward and backward entailment probabilites predictd by the [rubert-base-cased-nli-twoway](https://huggingface.co/cointegrated/rubert-base-cased-nli-twoway) model;
- `p_good`, a metric aggregating the four metrics above into a single number. It is obtained with a logistic regression trained on 100 randomly chosen from the train set and manually labelled sentence pairs.
#### Who are the annotators?
Human annotation was involved only for a small subset used to train the model for `p_good`. It was conduced by the dataset author, @cointegrated.
### Personal and Sensitive Information
The dataset is not known to contain any personal or sensitive information.
The sources and processes of original data collection are described at https://wortschatz.uni-leipzig.de/en/download.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset may enable creation for paraphrasing systems that can be used both for "good" purposes (such as assisting writers or augmenting text datasets), and for "bad" purposes (such as disguising plagiarism). The authors are not responsible for any uses of the dataset.
### Discussion of Biases
The dataset may inherit some of the biases of [the underlying Leipzig web corpus](https://wortschatz.uni-leipzig.de/en/download) or the neural machine translation models ([1](https://huggingface.co/facebook/wmt19-ru-en), [2](https://huggingface.co/facebook/wmt19-en-ru)) with which it was generated.
### Other Known Limitations
Most of the paraphrases in the dataset are valid (by a rough estimante, at least 80%). However, in some sentence pairs there are faults:
- Named entities are often spelled in different ways (e.g. `"Джейкоб" -> "Яков") or even replaced with other entities (e.g. `"Оймякон" -> "Оймянск" or `"Верхоянск" -> "Тольятти"`).
- Sometimes the meaning of words or phrases changes signigicantly, e.g. `"полустанок" -> "полумашина"`, or `"были по колено в грязи" -> "лежали на коленях в иле"`.
- Sometimes the syntax is changed in a meaning-altering way, e.g. `"Интеллектуальное преимущество Вавилова и его соратников над демагогами из рядов сторонников новой агробиологии разительно очевидно." -> "Интеллектуал Вавилов и его приспешники в новой аграрной биологии явно превзошли демогогов."`.
- Grammatical properties that are present in Russian morphology but absent in English, such as gender, are often lost, e.g. `"Я не хотела тебя пугать" -> "Я не хотел пугать вас"`.
The field `labse_sim` reflects semantic similarity between the sentences, and it can be used to filter out at least some poor paraphrases.
## Additional Information
### Dataset Curators
The dataset was created by [David Dale](https://daviddale.ru/en), a.k.a. [@cointegrated](https://huggingface.co/cointegrated).
### Licensing Information
This corpus, as well as the original Leipzig corpora, are licensed under [CC BY](http://creativecommons.org/licenses/by/4.0/).
### Citation Information
[This blog post](https://habr.com/ru/post/564916/) can be cited:
```
@misc{dale_paraphrasing_2021,
author = "Dale, David",
title = "Перефразирование русских текстов: корпуса, модели, метрики",
editor = "habr.com",
url = "https://habr.com/ru/post/564916/",
month = {June},
year = {2021},
note = {[Online; posted 28-June-2021]},
}
```
### Contributions
Thanks to [@avidale](https://github.com/avidale) for adding this dataset. | cointegrated/ru-paraphrase-NMT-Leipzig | [
"task_categories:text-generation",
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"multilinguality:translation",
"size_categories:100K<n<1M",
"source_datasets:extended|other",
"language:ru",
"license:cc-by-4.0",
"conditional-text-generation",
"paraphrase-generation",
"paraphrase",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["machine-generated"], "language": ["ru"], "license": ["cc-by-4.0"], "multilinguality": ["translation"], "size_categories": ["100K<n<1M"], "source_datasets": ["extended|other"], "task_categories": ["text-generation"], "pretty_name": "ru-paraphrase-NMT-Leipzig", "tags": ["conditional-text-generation", "paraphrase-generation", "paraphrase"]} | 2022-10-23T11:23:15+00:00 | []
| [
"ru"
]
| TAGS
#task_categories-text-generation #annotations_creators-no-annotation #language_creators-machine-generated #multilinguality-translation #size_categories-100K<n<1M #source_datasets-extended|other #language-Russian #license-cc-by-4.0 #conditional-text-generation #paraphrase-generation #paraphrase #region-us
|
# Dataset Card for cointegrated/ru-paraphrase-NMT-Leipzig
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Paper: URL
- Point of Contact: @cointegrated
### Dataset Summary
The dataset contains 1 million Russian sentences and their automatically generated paraphrases.
It was created by David Dale (@cointegrated) by translating the 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection into English and back into Russian. A fraction of the resulting paraphrases are invalid, and should be filtered out.
The blogpost "Перефразирование русских текстов: корпуса, модели, метрики" provides a detailed description of the dataset and its properties.
The dataset can be loaded with the following code:
Its output should look like
### Supported Tasks and Leaderboards
The dataset can be used to train and validate models for paraphrase generation or (if negative sampling is used) for paraphrase detection.
### Languages
Russian (main), English (auxilliary).
## Dataset Structure
### Data Instances
Data instances look like
Where 'original' is the original sentence, and 'ru' is its machine-generated paraphrase.
### Data Fields
- 'idx': id of the instance in the original corpus
- 'original': the original sentence
- 'en': automatic translation of 'original' to English
- 'ru': automatic translation of 'en' back to Russian, i.e. a paraphrase of 'original'
- 'chrf_sim': ChrF++ similarity of 'original' and 'ru'
- 'labse_sim': cosine similarity of LaBSE embedings of 'original' and 'ru'
- 'forward_entailment': predicted probability that 'original' entails 'ru'
- 'backward_entailment': predicted probability that 'ru' entails 'original'
- 'p_good': predicted probability that 'ru' and 'original' have equivalent meaning
### Data Splits
Train – 980K, validation – 10K, test – 10K. The splits were generated randomly.
## Dataset Creation
### Curation Rationale
There are other Russian paraphrase corpora, but they have major drawbacks:
- The best known corpus from URL 2016 contest is rather small and covers only the News domain.
- Opusparcus, ParaPhraserPlus, and corpora of Tamara Zhordanija are noisy, i.e. a large proportion of sentence pairs in them have substantial difference in meaning.
- The Russian part of TaPaCo has very high lexical overlap in the sentence pairs; in other words, their paraphrases are not diverse enough.
The current corpus is generated with a dual objective: the parphrases should be semantically as close as possible to the original sentences, while being lexically different from them. Back-translation with restricted vocabulary seems to achieve this goal often enough.
### Source Data
#### Initial Data Collection and Normalization
The 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection as is.
The process of its creation is described in this paper:
D. Goldhahn, T. Eckart & U. Quasthoff: Building Large Monolingual Dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages.
In: *Proceedings of the 8th International Language Resources and Evaluation (LREC'12), 2012*.
#### Automatic paraphrasing
The paraphrasing was carried out by translating the original sentence to English and then back to Russian.
The models facebook/wmt19-ru-en and facebook/wmt19-en-ru were used for translation.
To ensure that the back-translated texts are not identical to the original texts, the final decoder was prohibited to use the token n-grams from the original texts.
The code below implements the paraphrasing function.
The corpus was created by running the above 'paraphrase' function on the original sentences with parameters 'gram=3, num_beams=5, repetition_penalty=3.14, no_repeat_ngram_size=6'.
### Annotations
#### Annotation process
The dataset was annotated by several automatic metrics:
- ChrF++ between 'original' and 'ru' sentences;
- cosine similarity between LaBSE embeddings of these sentences;
- forward and backward entailment probabilites predictd by the rubert-base-cased-nli-twoway model;
- 'p_good', a metric aggregating the four metrics above into a single number. It is obtained with a logistic regression trained on 100 randomly chosen from the train set and manually labelled sentence pairs.
#### Who are the annotators?
Human annotation was involved only for a small subset used to train the model for 'p_good'. It was conduced by the dataset author, @cointegrated.
### Personal and Sensitive Information
The dataset is not known to contain any personal or sensitive information.
The sources and processes of original data collection are described at URL
## Considerations for Using the Data
### Social Impact of Dataset
The dataset may enable creation for paraphrasing systems that can be used both for "good" purposes (such as assisting writers or augmenting text datasets), and for "bad" purposes (such as disguising plagiarism). The authors are not responsible for any uses of the dataset.
### Discussion of Biases
The dataset may inherit some of the biases of the underlying Leipzig web corpus or the neural machine translation models (1, 2) with which it was generated.
### Other Known Limitations
Most of the paraphrases in the dataset are valid (by a rough estimante, at least 80%). However, in some sentence pairs there are faults:
- Named entities are often spelled in different ways (e.g. '"Джейкоб" -> "Яков") or even replaced with other entities (e.g. '"Оймякон" -> "Оймянск" or '"Верхоянск" -> "Тольятти"').
- Sometimes the meaning of words or phrases changes signigicantly, e.g. '"полустанок" -> "полумашина"', or '"были по колено в грязи" -> "лежали на коленях в иле"'.
- Sometimes the syntax is changed in a meaning-altering way, e.g. '"Интеллектуальное преимущество Вавилова и его соратников над демагогами из рядов сторонников новой агробиологии разительно очевидно." -> "Интеллектуал Вавилов и его приспешники в новой аграрной биологии явно превзошли демогогов."'.
- Grammatical properties that are present in Russian morphology but absent in English, such as gender, are often lost, e.g. '"Я не хотела тебя пугать" -> "Я не хотел пугать вас"'.
The field 'labse_sim' reflects semantic similarity between the sentences, and it can be used to filter out at least some poor paraphrases.
## Additional Information
### Dataset Curators
The dataset was created by David Dale, a.k.a. @cointegrated.
### Licensing Information
This corpus, as well as the original Leipzig corpora, are licensed under CC BY.
This blog post can be cited:
### Contributions
Thanks to @avidale for adding this dataset. | [
"# Dataset Card for cointegrated/ru-paraphrase-NMT-Leipzig",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Paper: URL\n- Point of Contact: @cointegrated",
"### Dataset Summary\n\nThe dataset contains 1 million Russian sentences and their automatically generated paraphrases. \n\nIt was created by David Dale (@cointegrated) by translating the 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection into English and back into Russian. A fraction of the resulting paraphrases are invalid, and should be filtered out.\n\nThe blogpost \"Перефразирование русских текстов: корпуса, модели, метрики\" provides a detailed description of the dataset and its properties.\n\nThe dataset can be loaded with the following code:\n\nIts output should look like",
"### Supported Tasks and Leaderboards\n\nThe dataset can be used to train and validate models for paraphrase generation or (if negative sampling is used) for paraphrase detection.",
"### Languages\n\nRussian (main), English (auxilliary).",
"## Dataset Structure",
"### Data Instances\n\nData instances look like\n\n\n\nWhere 'original' is the original sentence, and 'ru' is its machine-generated paraphrase.",
"### Data Fields\n\n- 'idx': id of the instance in the original corpus\n- 'original': the original sentence\t\n- 'en': automatic translation of 'original' to English\n- 'ru': automatic translation of 'en' back to Russian, i.e. a paraphrase of 'original'\n- 'chrf_sim': ChrF++ similarity of 'original' and 'ru'\n- 'labse_sim': cosine similarity of LaBSE embedings of 'original' and 'ru'\n- 'forward_entailment': predicted probability that 'original' entails 'ru'\n- 'backward_entailment': predicted probability that 'ru' entails 'original'\n- 'p_good': predicted probability that 'ru' and 'original' have equivalent meaning",
"### Data Splits\n\nTrain – 980K, validation – 10K, test – 10K. The splits were generated randomly.",
"## Dataset Creation",
"### Curation Rationale\n\nThere are other Russian paraphrase corpora, but they have major drawbacks:\n- The best known corpus from URL 2016 contest is rather small and covers only the News domain.\n- Opusparcus, ParaPhraserPlus, and corpora of Tamara Zhordanija are noisy, i.e. a large proportion of sentence pairs in them have substantial difference in meaning.\n- The Russian part of TaPaCo has very high lexical overlap in the sentence pairs; in other words, their paraphrases are not diverse enough.\n\nThe current corpus is generated with a dual objective: the parphrases should be semantically as close as possible to the original sentences, while being lexically different from them. Back-translation with restricted vocabulary seems to achieve this goal often enough.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection as is.\n\nThe process of its creation is described in this paper:\n\nD. Goldhahn, T. Eckart & U. Quasthoff: Building Large Monolingual Dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages.\nIn: *Proceedings of the 8th International Language Resources and Evaluation (LREC'12), 2012*.",
"#### Automatic paraphrasing\n\nThe paraphrasing was carried out by translating the original sentence to English and then back to Russian. \nThe models facebook/wmt19-ru-en and facebook/wmt19-en-ru were used for translation.\nTo ensure that the back-translated texts are not identical to the original texts, the final decoder was prohibited to use the token n-grams from the original texts.\nThe code below implements the paraphrasing function. \n\n\n\nThe corpus was created by running the above 'paraphrase' function on the original sentences with parameters 'gram=3, num_beams=5, repetition_penalty=3.14, no_repeat_ngram_size=6'.",
"### Annotations",
"#### Annotation process\n\nThe dataset was annotated by several automatic metrics: \n- ChrF++ between 'original' and 'ru' sentences;\n- cosine similarity between LaBSE embeddings of these sentences;\n- forward and backward entailment probabilites predictd by the rubert-base-cased-nli-twoway model;\n- 'p_good', a metric aggregating the four metrics above into a single number. It is obtained with a logistic regression trained on 100 randomly chosen from the train set and manually labelled sentence pairs.",
"#### Who are the annotators?\n\nHuman annotation was involved only for a small subset used to train the model for 'p_good'. It was conduced by the dataset author, @cointegrated.",
"### Personal and Sensitive Information\n\nThe dataset is not known to contain any personal or sensitive information. \nThe sources and processes of original data collection are described at URL",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThe dataset may enable creation for paraphrasing systems that can be used both for \"good\" purposes (such as assisting writers or augmenting text datasets), and for \"bad\" purposes (such as disguising plagiarism). The authors are not responsible for any uses of the dataset.",
"### Discussion of Biases\n\nThe dataset may inherit some of the biases of the underlying Leipzig web corpus or the neural machine translation models (1, 2) with which it was generated.",
"### Other Known Limitations\n\nMost of the paraphrases in the dataset are valid (by a rough estimante, at least 80%). However, in some sentence pairs there are faults:\n- Named entities are often spelled in different ways (e.g. '\"Джейкоб\" -> \"Яков\") or even replaced with other entities (e.g. '\"Оймякон\" -> \"Оймянск\" or '\"Верхоянск\" -> \"Тольятти\"').\n- Sometimes the meaning of words or phrases changes signigicantly, e.g. '\"полустанок\" -> \"полумашина\"', or '\"были по колено в грязи\" -> \"лежали на коленях в иле\"'.\n- Sometimes the syntax is changed in a meaning-altering way, e.g. '\"Интеллектуальное преимущество Вавилова и его соратников над демагогами из рядов сторонников новой агробиологии разительно очевидно.\" -> \"Интеллектуал Вавилов и его приспешники в новой аграрной биологии явно превзошли демогогов.\"'.\n- Grammatical properties that are present in Russian morphology but absent in English, such as gender, are often lost, e.g. '\"Я не хотела тебя пугать\" -> \"Я не хотел пугать вас\"'.\n\nThe field 'labse_sim' reflects semantic similarity between the sentences, and it can be used to filter out at least some poor paraphrases.",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was created by David Dale, a.k.a. @cointegrated.",
"### Licensing Information\n\nThis corpus, as well as the original Leipzig corpora, are licensed under CC BY.\n\n\n\nThis blog post can be cited:",
"### Contributions\n\nThanks to @avidale for adding this dataset."
]
| [
"TAGS\n#task_categories-text-generation #annotations_creators-no-annotation #language_creators-machine-generated #multilinguality-translation #size_categories-100K<n<1M #source_datasets-extended|other #language-Russian #license-cc-by-4.0 #conditional-text-generation #paraphrase-generation #paraphrase #region-us \n",
"# Dataset Card for cointegrated/ru-paraphrase-NMT-Leipzig",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Paper: URL\n- Point of Contact: @cointegrated",
"### Dataset Summary\n\nThe dataset contains 1 million Russian sentences and their automatically generated paraphrases. \n\nIt was created by David Dale (@cointegrated) by translating the 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection into English and back into Russian. A fraction of the resulting paraphrases are invalid, and should be filtered out.\n\nThe blogpost \"Перефразирование русских текстов: корпуса, модели, метрики\" provides a detailed description of the dataset and its properties.\n\nThe dataset can be loaded with the following code:\n\nIts output should look like",
"### Supported Tasks and Leaderboards\n\nThe dataset can be used to train and validate models for paraphrase generation or (if negative sampling is used) for paraphrase detection.",
"### Languages\n\nRussian (main), English (auxilliary).",
"## Dataset Structure",
"### Data Instances\n\nData instances look like\n\n\n\nWhere 'original' is the original sentence, and 'ru' is its machine-generated paraphrase.",
"### Data Fields\n\n- 'idx': id of the instance in the original corpus\n- 'original': the original sentence\t\n- 'en': automatic translation of 'original' to English\n- 'ru': automatic translation of 'en' back to Russian, i.e. a paraphrase of 'original'\n- 'chrf_sim': ChrF++ similarity of 'original' and 'ru'\n- 'labse_sim': cosine similarity of LaBSE embedings of 'original' and 'ru'\n- 'forward_entailment': predicted probability that 'original' entails 'ru'\n- 'backward_entailment': predicted probability that 'ru' entails 'original'\n- 'p_good': predicted probability that 'ru' and 'original' have equivalent meaning",
"### Data Splits\n\nTrain – 980K, validation – 10K, test – 10K. The splits were generated randomly.",
"## Dataset Creation",
"### Curation Rationale\n\nThere are other Russian paraphrase corpora, but they have major drawbacks:\n- The best known corpus from URL 2016 contest is rather small and covers only the News domain.\n- Opusparcus, ParaPhraserPlus, and corpora of Tamara Zhordanija are noisy, i.e. a large proportion of sentence pairs in them have substantial difference in meaning.\n- The Russian part of TaPaCo has very high lexical overlap in the sentence pairs; in other words, their paraphrases are not diverse enough.\n\nThe current corpus is generated with a dual objective: the parphrases should be semantically as close as possible to the original sentences, while being lexically different from them. Back-translation with restricted vocabulary seems to achieve this goal often enough.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe 'rus-ru_web-public_2019_1M' corpus from the Leipzig collection as is.\n\nThe process of its creation is described in this paper:\n\nD. Goldhahn, T. Eckart & U. Quasthoff: Building Large Monolingual Dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages.\nIn: *Proceedings of the 8th International Language Resources and Evaluation (LREC'12), 2012*.",
"#### Automatic paraphrasing\n\nThe paraphrasing was carried out by translating the original sentence to English and then back to Russian. \nThe models facebook/wmt19-ru-en and facebook/wmt19-en-ru were used for translation.\nTo ensure that the back-translated texts are not identical to the original texts, the final decoder was prohibited to use the token n-grams from the original texts.\nThe code below implements the paraphrasing function. \n\n\n\nThe corpus was created by running the above 'paraphrase' function on the original sentences with parameters 'gram=3, num_beams=5, repetition_penalty=3.14, no_repeat_ngram_size=6'.",
"### Annotations",
"#### Annotation process\n\nThe dataset was annotated by several automatic metrics: \n- ChrF++ between 'original' and 'ru' sentences;\n- cosine similarity between LaBSE embeddings of these sentences;\n- forward and backward entailment probabilites predictd by the rubert-base-cased-nli-twoway model;\n- 'p_good', a metric aggregating the four metrics above into a single number. It is obtained with a logistic regression trained on 100 randomly chosen from the train set and manually labelled sentence pairs.",
"#### Who are the annotators?\n\nHuman annotation was involved only for a small subset used to train the model for 'p_good'. It was conduced by the dataset author, @cointegrated.",
"### Personal and Sensitive Information\n\nThe dataset is not known to contain any personal or sensitive information. \nThe sources and processes of original data collection are described at URL",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThe dataset may enable creation for paraphrasing systems that can be used both for \"good\" purposes (such as assisting writers or augmenting text datasets), and for \"bad\" purposes (such as disguising plagiarism). The authors are not responsible for any uses of the dataset.",
"### Discussion of Biases\n\nThe dataset may inherit some of the biases of the underlying Leipzig web corpus or the neural machine translation models (1, 2) with which it was generated.",
"### Other Known Limitations\n\nMost of the paraphrases in the dataset are valid (by a rough estimante, at least 80%). However, in some sentence pairs there are faults:\n- Named entities are often spelled in different ways (e.g. '\"Джейкоб\" -> \"Яков\") or even replaced with other entities (e.g. '\"Оймякон\" -> \"Оймянск\" or '\"Верхоянск\" -> \"Тольятти\"').\n- Sometimes the meaning of words or phrases changes signigicantly, e.g. '\"полустанок\" -> \"полумашина\"', or '\"были по колено в грязи\" -> \"лежали на коленях в иле\"'.\n- Sometimes the syntax is changed in a meaning-altering way, e.g. '\"Интеллектуальное преимущество Вавилова и его соратников над демагогами из рядов сторонников новой агробиологии разительно очевидно.\" -> \"Интеллектуал Вавилов и его приспешники в новой аграрной биологии явно превзошли демогогов.\"'.\n- Grammatical properties that are present in Russian morphology but absent in English, such as gender, are often lost, e.g. '\"Я не хотела тебя пугать\" -> \"Я не хотел пугать вас\"'.\n\nThe field 'labse_sim' reflects semantic similarity between the sentences, and it can be used to filter out at least some poor paraphrases.",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was created by David Dale, a.k.a. @cointegrated.",
"### Licensing Information\n\nThis corpus, as well as the original Leipzig corpora, are licensed under CC BY.\n\n\n\nThis blog post can be cited:",
"### Contributions\n\nThanks to @avidale for adding this dataset."
]
|
f646cd6d101c64b6226b3a299aed424f19181672 |
# Dataset Card for TV3Parla
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://collectivat.cat/asr#tv3parla
- **Repository:**
- **Paper:** [Building an Open Source Automatic Speech Recognition System for Catalan](https://www.isca-speech.org/archive/iberspeech_2018/kulebi18_iberspeech.html)
- **Point of Contact:** [Col·lectivaT](mailto:[email protected])
### Dataset Summary
This corpus includes 240 hours of Catalan speech from broadcast material.
The details of segmentation, data processing and also model training are explained in Külebi, Öktem; 2018.
The content is owned by Corporació Catalana de Mitjans Audiovisuals, SA (CCMA);
we processed their material and hereby making it available under their terms of use.
This project was supported by the Softcatalà Association.
### Supported Tasks and Leaderboards
The dataset can be used for:
- Language Modeling.
- Automatic Speech Recognition (ASR) transcribes utterances into words.
### Languages
The dataset is in Catalan (`ca`).
## Dataset Structure
### Data Instances
```
{
'path': 'tv3_0.3/wav/train/5662515_1492531876710/5662515_1492531876710_120.180_139.020.wav',
'audio': {'path': 'tv3_0.3/wav/train/5662515_1492531876710/5662515_1492531876710_120.180_139.020.wav',
'array': array([-0.01168823, 0.01229858, 0.02819824, ..., 0.015625 ,
0.01525879, 0.0145874 ]),
'sampling_rate': 16000},
'text': 'algunes montoneres que que et feien anar ben col·locat i el vent també hi jugava una mica de paper bufava vent de cantó alguns cops o de cul i el pelotón el vent el porta molt malament hi havia molts nervis'
}
```
### Data Fields
- `path` (str): Path to the audio file.
- `audio` (dict): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling
rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and
resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might
take a significant amount of time. Thus, it is important to first query the sample index before the `"audio"` column,
*i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- `text` (str): Transcription of the audio file.
### Data Splits
The dataset is split into "train" and "test".
| | train | test |
|:-------------------|-------:|-----:|
| Number of examples | 159242 | 2220 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[Creative Commons Attribution-NonCommercial 4.0 International](https://creativecommons.org/licenses/by-nc/4.0/).
### Citation Information
```
@inproceedings{kulebi18_iberspeech,
author={Baybars Külebi and Alp Öktem},
title={{Building an Open Source Automatic Speech Recognition System for Catalan}},
year=2018,
booktitle={Proc. IberSPEECH 2018},
pages={25--29},
doi={10.21437/IberSPEECH.2018-6}
}
```
### Contributions
Thanks to [@albertvillanova](https://github.com/albertvillanova) for adding this dataset.
| collectivat/tv3_parla | [
"task_categories:automatic-speech-recognition",
"task_categories:text-generation",
"task_ids:language-modeling",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:ca",
"license:cc-by-nc-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["ca"], "license": ["cc-by-nc-4.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["automatic-speech-recognition", "text-generation"], "task_ids": ["language-modeling"], "pretty_name": "TV3Parla"} | 2022-12-12T09:01:48+00:00 | []
| [
"ca"
]
| TAGS
#task_categories-automatic-speech-recognition #task_categories-text-generation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Catalan #license-cc-by-nc-4.0 #region-us
| Dataset Card for TV3Parla
=========================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository:
* Paper: Building an Open Source Automatic Speech Recognition System for Catalan
* Point of Contact: Col·lectivaT
### Dataset Summary
This corpus includes 240 hours of Catalan speech from broadcast material.
The details of segmentation, data processing and also model training are explained in Külebi, Öktem; 2018.
The content is owned by Corporació Catalana de Mitjans Audiovisuals, SA (CCMA);
we processed their material and hereby making it available under their terms of use.
This project was supported by the Softcatalà Association.
### Supported Tasks and Leaderboards
The dataset can be used for:
* Language Modeling.
* Automatic Speech Recognition (ASR) transcribes utterances into words.
### Languages
The dataset is in Catalan ('ca').
Dataset Structure
-----------------
### Data Instances
### Data Fields
* 'path' (str): Path to the audio file.
* 'audio' (dict): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling
rate. Note that when accessing the audio column: 'dataset[0]["audio"]' the audio file is automatically decoded and
resampled to 'dataset.features["audio"].sampling\_rate'. Decoding and resampling of a large number of audio files might
take a significant amount of time. Thus, it is important to first query the sample index before the '"audio"' column,
*i.e.* 'dataset[0]["audio"]' should always be preferred over 'dataset["audio"][0]'.
* 'text' (str): Transcription of the audio file.
### Data Splits
The dataset is split into "train" and "test".
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Creative Commons Attribution-NonCommercial 4.0 International.
### Contributions
Thanks to @albertvillanova for adding this dataset.
| [
"### Dataset Summary\n\n\nThis corpus includes 240 hours of Catalan speech from broadcast material.\nThe details of segmentation, data processing and also model training are explained in Külebi, Öktem; 2018.\nThe content is owned by Corporació Catalana de Mitjans Audiovisuals, SA (CCMA);\nwe processed their material and hereby making it available under their terms of use.\n\n\nThis project was supported by the Softcatalà Association.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset can be used for:\n\n\n* Language Modeling.\n* Automatic Speech Recognition (ASR) transcribes utterances into words.",
"### Languages\n\n\nThe dataset is in Catalan ('ca').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'path' (str): Path to the audio file.\n* 'audio' (dict): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling\nrate. Note that when accessing the audio column: 'dataset[0][\"audio\"]' the audio file is automatically decoded and\nresampled to 'dataset.features[\"audio\"].sampling\\_rate'. Decoding and resampling of a large number of audio files might\ntake a significant amount of time. Thus, it is important to first query the sample index before the '\"audio\"' column,\n*i.e.* 'dataset[0][\"audio\"]' should always be preferred over 'dataset[\"audio\"][0]'.\n* 'text' (str): Transcription of the audio file.",
"### Data Splits\n\n\nThe dataset is split into \"train\" and \"test\".\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCreative Commons Attribution-NonCommercial 4.0 International.",
"### Contributions\n\n\nThanks to @albertvillanova for adding this dataset."
]
| [
"TAGS\n#task_categories-automatic-speech-recognition #task_categories-text-generation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Catalan #license-cc-by-nc-4.0 #region-us \n",
"### Dataset Summary\n\n\nThis corpus includes 240 hours of Catalan speech from broadcast material.\nThe details of segmentation, data processing and also model training are explained in Külebi, Öktem; 2018.\nThe content is owned by Corporació Catalana de Mitjans Audiovisuals, SA (CCMA);\nwe processed their material and hereby making it available under their terms of use.\n\n\nThis project was supported by the Softcatalà Association.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset can be used for:\n\n\n* Language Modeling.\n* Automatic Speech Recognition (ASR) transcribes utterances into words.",
"### Languages\n\n\nThe dataset is in Catalan ('ca').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'path' (str): Path to the audio file.\n* 'audio' (dict): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling\nrate. Note that when accessing the audio column: 'dataset[0][\"audio\"]' the audio file is automatically decoded and\nresampled to 'dataset.features[\"audio\"].sampling\\_rate'. Decoding and resampling of a large number of audio files might\ntake a significant amount of time. Thus, it is important to first query the sample index before the '\"audio\"' column,\n*i.e.* 'dataset[0][\"audio\"]' should always be preferred over 'dataset[\"audio\"][0]'.\n* 'text' (str): Transcription of the audio file.",
"### Data Splits\n\n\nThe dataset is split into \"train\" and \"test\".\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCreative Commons Attribution-NonCommercial 4.0 International.",
"### Contributions\n\n\nThanks to @albertvillanova for adding this dataset."
]
|
9f47e7ea19a1f969027a138c92e4e3a71b5537d3 |
# Dataset Card for CoDa
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [nala-cub/coda](https://github.com/nala-cub/coda)
- **Paper:** [The World of an Octopus: How Reporting Bias Influences a Language Model's Perception of Color](https://arxiv.org/abs/2110.08182)
- **Point of Contact:** [Cory Paik]([email protected])
### Dataset Summary
*The Color Dataset* (CoDa) is a probing dataset to evaluate the representation of visual properties in language models. CoDa consists of color distributions for 521 common objects, which are split into 3 groups. We denote these groups as Single, Multi, and Any, which represents the typical object of each group.
The default configuration of CoDa uses 10 CLIP-style templates (e.g. "A photo of a [object]"), and 10 cloze-style templates (e.g. "Everyone knows most [object] are
[color]." )
### Supported Tasks and Leaderboards
This version of the dataset consists of the filtered and templated examples as cloze style questions. See the [GitHub](https://github.com/nala-cub/coda) repo for the raw data (e.g. unfiltered annotations) as well as example usage with GPT-2, RoBERTa, ALBERT, and CLIP.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en-US`.
## Dataset Structure
### Data Instances
An example looks like this:
```json
{
"text": "All rulers are [MASK].",
"label": [
0.0181818176, 0.0363636352, 0.3077272773, 0.0181818176, 0.0363636352,
0.086363636, 0.0363636352, 0.0363636352, 0.0363636352, 0.086363636,
0.301363647
],
"template_group": 1,
"template_idx": 0,
"class_id": "/m/0hdln",
"display_name": "Ruler",
"object_group": 2,
"ngram": "ruler"
}
```
### Data Fields
- `text`: The templated example. What this is depends on the value of `template_group`.
- `template_group=0`: A CLIP style example. There are no `[MASK]` tokens in these examples.
- `template_group=1`: A cloze style example. Note that all templates have `[MASK]` as the last word, but in most cases, the period should be included.
- `label`: A list of probability values for the 11 colors. Note that these are sorted by the alphabetic order of the 11 colors (black, blue, brown, gray, green, orange, pink, purple, red, white, yellow).
- `template_group`: Type of template, `0` corresponds to A CLIP style template (`clip-imagenet`), and `1` corresponds to A cloze style templates (`text-masked`).
- `template_idx`: The index of the template out of all templates
- `class_id`: The Corresponding [OpenImages v6](https://storage.googleapis.com/openimages/web/index.html) `ClassID`.
- `display_name`: The Corresponding [OpenImages v6](https://storage.googleapis.com/openimages/web/index.html) `DisplayName`.
- `object_group`: Object Group, values correspond to `Single`, `Multi`, and `Any`.
- `ngram`: Corresponding n-gram used for lookups.
### Data Splits
Object Splits:
| Group | All | Train | Valid | Test |
| ------ | --- | ----- | ----- | ---- |
| Single | 198 | 118 | 39 | 41 |
| Multi | 208 | 124 | 41 | 43 |
| Any | 115 | 69 | 23 | 23 |
| Total | 521 | 311 | 103 | 107 |
Example Splits:
| Group | All | Train | Valid | Test |
| ------ | ----- | ----- | ----- | ---- |
| Single | 3946 | 2346 | 780 | 820 |
| Multi | 4146 | 2466 | 820 | 860 |
| Any | 2265 | 1352 | 460 | 453 |
| Total | 10357 | 6164 | 2060 | 2133 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
CoDa is licensed under the Apache 2.0 license.
### Citation Information
```
@misc{paik2021world,
title={The World of an Octopus: How Reporting Bias Influences a Language Model's Perception of Color},
author={Cory Paik and Stéphane Aroca-Ouellette and Alessandro Roncone and Katharina Kann},
year={2021},
eprint={2110.08182},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| corypaik/coda | [
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"arxiv:2110.08182",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-scoring"], "task_ids": ["text-scoring-other-distribution-prediction"], "paperswithcode_id": "coda", "pretty_name": "CoDa", "language_bcp47": ["en-US"]} | 2022-10-20T15:57:23+00:00 | [
"2110.08182"
]
| [
"en"
]
| TAGS
#annotations_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-apache-2.0 #arxiv-2110.08182 #region-us
| Dataset Card for CoDa
=====================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Repository: nala-cub/coda
* Paper: The World of an Octopus: How Reporting Bias Influences a Language Model's Perception of Color
* Point of Contact: Cory Paik
### Dataset Summary
*The Color Dataset* (CoDa) is a probing dataset to evaluate the representation of visual properties in language models. CoDa consists of color distributions for 521 common objects, which are split into 3 groups. We denote these groups as Single, Multi, and Any, which represents the typical object of each group.
The default configuration of CoDa uses 10 CLIP-style templates (e.g. "A photo of a [object]"), and 10 cloze-style templates (e.g. "Everyone knows most [object] are
[color]." )
### Supported Tasks and Leaderboards
This version of the dataset consists of the filtered and templated examples as cloze style questions. See the GitHub repo for the raw data (e.g. unfiltered annotations) as well as example usage with GPT-2, RoBERTa, ALBERT, and CLIP.
### Languages
The text in the dataset is in English. The associated BCP-47 code is 'en-US'.
Dataset Structure
-----------------
### Data Instances
An example looks like this:
### Data Fields
* 'text': The templated example. What this is depends on the value of 'template\_group'.
+ 'template\_group=0': A CLIP style example. There are no '[MASK]' tokens in these examples.
+ 'template\_group=1': A cloze style example. Note that all templates have '[MASK]' as the last word, but in most cases, the period should be included.
* 'label': A list of probability values for the 11 colors. Note that these are sorted by the alphabetic order of the 11 colors (black, blue, brown, gray, green, orange, pink, purple, red, white, yellow).
* 'template\_group': Type of template, '0' corresponds to A CLIP style template ('clip-imagenet'), and '1' corresponds to A cloze style templates ('text-masked').
* 'template\_idx': The index of the template out of all templates
* 'class\_id': The Corresponding OpenImages v6 'ClassID'.
* 'display\_name': The Corresponding OpenImages v6 'DisplayName'.
* 'object\_group': Object Group, values correspond to 'Single', 'Multi', and 'Any'.
* 'ngram': Corresponding n-gram used for lookups.
### Data Splits
Object Splits:
Example Splits:
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
CoDa is licensed under the Apache 2.0 license.
### Contributions
Thanks to @github-username for adding this dataset.
| [
"### Dataset Summary\n\n\n*The Color Dataset* (CoDa) is a probing dataset to evaluate the representation of visual properties in language models. CoDa consists of color distributions for 521 common objects, which are split into 3 groups. We denote these groups as Single, Multi, and Any, which represents the typical object of each group.\n\n\nThe default configuration of CoDa uses 10 CLIP-style templates (e.g. \"A photo of a [object]\"), and 10 cloze-style templates (e.g. \"Everyone knows most [object] are\n[color].\" )",
"### Supported Tasks and Leaderboards\n\n\nThis version of the dataset consists of the filtered and templated examples as cloze style questions. See the GitHub repo for the raw data (e.g. unfiltered annotations) as well as example usage with GPT-2, RoBERTa, ALBERT, and CLIP.",
"### Languages\n\n\nThe text in the dataset is in English. The associated BCP-47 code is 'en-US'.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example looks like this:",
"### Data Fields\n\n\n* 'text': The templated example. What this is depends on the value of 'template\\_group'.\n\t+ 'template\\_group=0': A CLIP style example. There are no '[MASK]' tokens in these examples.\n\t+ 'template\\_group=1': A cloze style example. Note that all templates have '[MASK]' as the last word, but in most cases, the period should be included.\n* 'label': A list of probability values for the 11 colors. Note that these are sorted by the alphabetic order of the 11 colors (black, blue, brown, gray, green, orange, pink, purple, red, white, yellow).\n* 'template\\_group': Type of template, '0' corresponds to A CLIP style template ('clip-imagenet'), and '1' corresponds to A cloze style templates ('text-masked').\n* 'template\\_idx': The index of the template out of all templates\n* 'class\\_id': The Corresponding OpenImages v6 'ClassID'.\n* 'display\\_name': The Corresponding OpenImages v6 'DisplayName'.\n* 'object\\_group': Object Group, values correspond to 'Single', 'Multi', and 'Any'.\n* 'ngram': Corresponding n-gram used for lookups.",
"### Data Splits\n\n\nObject Splits:\n\n\n\nExample Splits:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCoDa is licensed under the Apache 2.0 license.",
"### Contributions\n\n\nThanks to @github-username for adding this dataset."
]
| [
"TAGS\n#annotations_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-apache-2.0 #arxiv-2110.08182 #region-us \n",
"### Dataset Summary\n\n\n*The Color Dataset* (CoDa) is a probing dataset to evaluate the representation of visual properties in language models. CoDa consists of color distributions for 521 common objects, which are split into 3 groups. We denote these groups as Single, Multi, and Any, which represents the typical object of each group.\n\n\nThe default configuration of CoDa uses 10 CLIP-style templates (e.g. \"A photo of a [object]\"), and 10 cloze-style templates (e.g. \"Everyone knows most [object] are\n[color].\" )",
"### Supported Tasks and Leaderboards\n\n\nThis version of the dataset consists of the filtered and templated examples as cloze style questions. See the GitHub repo for the raw data (e.g. unfiltered annotations) as well as example usage with GPT-2, RoBERTa, ALBERT, and CLIP.",
"### Languages\n\n\nThe text in the dataset is in English. The associated BCP-47 code is 'en-US'.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example looks like this:",
"### Data Fields\n\n\n* 'text': The templated example. What this is depends on the value of 'template\\_group'.\n\t+ 'template\\_group=0': A CLIP style example. There are no '[MASK]' tokens in these examples.\n\t+ 'template\\_group=1': A cloze style example. Note that all templates have '[MASK]' as the last word, but in most cases, the period should be included.\n* 'label': A list of probability values for the 11 colors. Note that these are sorted by the alphabetic order of the 11 colors (black, blue, brown, gray, green, orange, pink, purple, red, white, yellow).\n* 'template\\_group': Type of template, '0' corresponds to A CLIP style template ('clip-imagenet'), and '1' corresponds to A cloze style templates ('text-masked').\n* 'template\\_idx': The index of the template out of all templates\n* 'class\\_id': The Corresponding OpenImages v6 'ClassID'.\n* 'display\\_name': The Corresponding OpenImages v6 'DisplayName'.\n* 'object\\_group': Object Group, values correspond to 'Single', 'Multi', and 'Any'.\n* 'ngram': Corresponding n-gram used for lookups.",
"### Data Splits\n\n\nObject Splits:\n\n\n\nExample Splits:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCoDa is licensed under the Apache 2.0 license.",
"### Contributions\n\n\nThanks to @github-username for adding this dataset."
]
|
b3efebf08969fc19335ba894353316878b6fa493 |
# PROST: Physical Reasoning about Objects Through Space and Time
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/nala-cub/prost
- **Paper:** https://arxiv.org/abs/2106.03634
- **Leaderboard:**
- **Point of Contact:** [Stéphane Aroca-Ouellette](mailto:[email protected])
### Dataset Summary
*Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: direction, mass, height, circumference, stackable, rollable, graspable, breakable, slideable, and bounceable.
### Supported Tasks and Leaderboards
The task is multiple choice question answering, but you can formulate it multiple ways. You can use `context` and `question` to form cloze style questions, or `context` and `ex_question` as multiple choice question answering. See the [GitHub](https://github.com/nala-cub/prost) repo for examples using GPT-1, GPT-2, BERT, RoBERTa, ALBERT, T5, and UnifiedQA.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en-US`.
## Dataset Structure
### Data Instances
An example looks like this:
```json
{
"A": "glass",
"B": "pillow",
"C": "coin",
"D": "ball",
"context": "A person drops a glass, a pillow, a coin, and a ball from a balcony.",
"ex_question": "Which object is the most likely to break?",
"group": "breaking",
"label": 0,
"name": "breaking_1",
"question": "The [MASK] is the most likely to break."
}
```
### Data Fields
- `A`: Option A (0)
- `B`: Option B (1)
- `C`: Option C (2)
- `D`: Option D (3)
- `context`: Context for the question
- `question`: A cloze style continuation of the context.
- `ex_question`: A multiple-choice style question.
- `group`: The question group, e.g. *bouncing*
- `label`: A ClassLabel indication the correct option
- `name':` The template identifier.
### Data Splits
The dataset contains 18,736 examples for testing.
## Dataset Creation
### Curation Rationale
PROST is designed to avoid models succeeding in unintended ways. First, PROST provides no training data, so as to probe models in a zero-shot fashion. This prevents models from succeeding through spurious correlations between testing and training, and encourages success through a true understanding of and reasoning about the concepts at hand. Second, we manually write templates for all questions in an effort to prevent models from having seen the exact same sentences in their training data. Finally, it focuses on a small set of well defined, objective concepts that only require a small vocabulary. This allows researchers to focus more on the quality of training data rather than on size of it.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
PROST is licensed under the Apache 2.0 license.
### Citation Information
```
@inproceedings{aroca-ouellette-etal-2021-prost,
title = "{PROST}: {P}hysical Reasoning about Objects through Space and Time",
author = "Aroca-Ouellette, St{\'e}phane and
Paik, Cory and
Roncone, Alessandro and
Kann, Katharina",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.404",
pages = "4597--4608",
}
```
### Contributions
Thanks to [@corypaik](https://github.com/corypaik) for adding this dataset.
| corypaik/prost | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"task_ids:open-domain-qa",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"license:apache-2.0",
"arxiv:2106.03634",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en-US"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["multiple-choice-qa", "open-domain-qa"], "paperswithcode_id": "prost", "extended": ["original"]} | 2022-10-25T08:07:34+00:00 | [
"2106.03634"
]
| [
"en-US"
]
| TAGS
#task_categories-question-answering #task_ids-multiple-choice-qa #task_ids-open-domain-qa #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #license-apache-2.0 #arxiv-2106.03634 #region-us
|
# PROST: Physical Reasoning about Objects Through Space and Time
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository: URL
- Paper: URL
- Leaderboard:
- Point of Contact: Stéphane Aroca-Ouellette
### Dataset Summary
*Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: direction, mass, height, circumference, stackable, rollable, graspable, breakable, slideable, and bounceable.
### Supported Tasks and Leaderboards
The task is multiple choice question answering, but you can formulate it multiple ways. You can use 'context' and 'question' to form cloze style questions, or 'context' and 'ex_question' as multiple choice question answering. See the GitHub repo for examples using GPT-1, GPT-2, BERT, RoBERTa, ALBERT, T5, and UnifiedQA.
### Languages
The text in the dataset is in English. The associated BCP-47 code is 'en-US'.
## Dataset Structure
### Data Instances
An example looks like this:
### Data Fields
- 'A': Option A (0)
- 'B': Option B (1)
- 'C': Option C (2)
- 'D': Option D (3)
- 'context': Context for the question
- 'question': A cloze style continuation of the context.
- 'ex_question': A multiple-choice style question.
- 'group': The question group, e.g. *bouncing*
- 'label': A ClassLabel indication the correct option
- 'name':' The template identifier.
### Data Splits
The dataset contains 18,736 examples for testing.
## Dataset Creation
### Curation Rationale
PROST is designed to avoid models succeeding in unintended ways. First, PROST provides no training data, so as to probe models in a zero-shot fashion. This prevents models from succeeding through spurious correlations between testing and training, and encourages success through a true understanding of and reasoning about the concepts at hand. Second, we manually write templates for all questions in an effort to prevent models from having seen the exact same sentences in their training data. Finally, it focuses on a small set of well defined, objective concepts that only require a small vocabulary. This allows researchers to focus more on the quality of training data rather than on size of it.
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
PROST is licensed under the Apache 2.0 license.
### Contributions
Thanks to @corypaik for adding this dataset.
| [
"# PROST: Physical Reasoning about Objects Through Space and Time",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: URL \n- Leaderboard:\n- Point of Contact: Stéphane Aroca-Ouellette",
"### Dataset Summary\n*Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: direction, mass, height, circumference, stackable, rollable, graspable, breakable, slideable, and bounceable.",
"### Supported Tasks and Leaderboards\nThe task is multiple choice question answering, but you can formulate it multiple ways. You can use 'context' and 'question' to form cloze style questions, or 'context' and 'ex_question' as multiple choice question answering. See the GitHub repo for examples using GPT-1, GPT-2, BERT, RoBERTa, ALBERT, T5, and UnifiedQA.",
"### Languages\nThe text in the dataset is in English. The associated BCP-47 code is 'en-US'.",
"## Dataset Structure",
"### Data Instances\nAn example looks like this:",
"### Data Fields\n\n- 'A': Option A (0)\n- 'B': Option B (1)\n- 'C': Option C (2)\n- 'D': Option D (3)\n- 'context': Context for the question\n- 'question': A cloze style continuation of the context.\n- 'ex_question': A multiple-choice style question.\n- 'group': The question group, e.g. *bouncing*\n- 'label': A ClassLabel indication the correct option\n- 'name':' The template identifier.",
"### Data Splits\n\nThe dataset contains 18,736 examples for testing.",
"## Dataset Creation",
"### Curation Rationale\n\nPROST is designed to avoid models succeeding in unintended ways. First, PROST provides no training data, so as to probe models in a zero-shot fashion. This prevents models from succeeding through spurious correlations between testing and training, and encourages success through a true understanding of and reasoning about the concepts at hand. Second, we manually write templates for all questions in an effort to prevent models from having seen the exact same sentences in their training data. Finally, it focuses on a small set of well defined, objective concepts that only require a small vocabulary. This allows researchers to focus more on the quality of training data rather than on size of it.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nPROST is licensed under the Apache 2.0 license.",
"### Contributions\n\nThanks to @corypaik for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-multiple-choice-qa #task_ids-open-domain-qa #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #license-apache-2.0 #arxiv-2106.03634 #region-us \n",
"# PROST: Physical Reasoning about Objects Through Space and Time",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: URL \n- Leaderboard:\n- Point of Contact: Stéphane Aroca-Ouellette",
"### Dataset Summary\n*Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: direction, mass, height, circumference, stackable, rollable, graspable, breakable, slideable, and bounceable.",
"### Supported Tasks and Leaderboards\nThe task is multiple choice question answering, but you can formulate it multiple ways. You can use 'context' and 'question' to form cloze style questions, or 'context' and 'ex_question' as multiple choice question answering. See the GitHub repo for examples using GPT-1, GPT-2, BERT, RoBERTa, ALBERT, T5, and UnifiedQA.",
"### Languages\nThe text in the dataset is in English. The associated BCP-47 code is 'en-US'.",
"## Dataset Structure",
"### Data Instances\nAn example looks like this:",
"### Data Fields\n\n- 'A': Option A (0)\n- 'B': Option B (1)\n- 'C': Option C (2)\n- 'D': Option D (3)\n- 'context': Context for the question\n- 'question': A cloze style continuation of the context.\n- 'ex_question': A multiple-choice style question.\n- 'group': The question group, e.g. *bouncing*\n- 'label': A ClassLabel indication the correct option\n- 'name':' The template identifier.",
"### Data Splits\n\nThe dataset contains 18,736 examples for testing.",
"## Dataset Creation",
"### Curation Rationale\n\nPROST is designed to avoid models succeeding in unintended ways. First, PROST provides no training data, so as to probe models in a zero-shot fashion. This prevents models from succeeding through spurious correlations between testing and training, and encourages success through a true understanding of and reasoning about the concepts at hand. Second, we manually write templates for all questions in an effort to prevent models from having seen the exact same sentences in their training data. Finally, it focuses on a small set of well defined, objective concepts that only require a small vocabulary. This allows researchers to focus more on the quality of training data rather than on size of it.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nPROST is licensed under the Apache 2.0 license.",
"### Contributions\n\nThanks to @corypaik for adding this dataset."
]
|
bfd4f4689c343cabfc936eb4c12f026df15cf977 | see https://huggingface.co/datasets/csarron/4m-img-caps for example usage | csarron/25m-img-caps | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-03-28T17:51:26+00:00 | []
| []
| TAGS
#region-us
| see URL for example usage | []
| [
"TAGS\n#region-us \n"
]
|
b27ebb236e94f8d090891e010f93832dccb034d3 | see [read_pyarrow.py](https://gist.github.com/csarron/df712e53c9e0dcaad4eb6843e7a3d51c#file-read_pyarrow-py) for how to read one pyarrow file.
example PyTorch dataset:
```python
from torch.utils.data import Dataset
class ImageCaptionArrowDataset(Dataset):
def __init__(
self,
dataset_file,
tokenizer,
):
import pyarrow as pa
data = [pa.ipc.open_file(pa.memory_map(f, "rb")).read_all() for f in glob.glob(dataset_file)]
self.data = pa.concat_tables(data)
# do other initialization, like init image preprocessing fn,
def __getitem__(self, index):
# item_id = self.data["id"][index].as_py()
text = self.data["text"][index].as_py() # get text
if isinstance(text, list):
text = random.choice(text)
img_bytes = self.data["image"][index].as_py() # get image bytes
# do some processing with image and text, return the features
# img_feat = self.image_bytes_to_tensor(img_bytes)
# inputs = self.tokenizer(
# text,
# padding="max_length",
# max_length=self.max_text_len,
# truncation=True,
# return_token_type_ids=True,
# return_attention_mask=True,
# add_special_tokens=True,
# return_tensors="pt",
# )
# input_ids = inputs.input_ids.squeeze(0)
# attention_mask = inputs.attention_mask.squeeze(0)
# return {
# # "item_ids": item_id,
# "text_ids": input_ids,
# "input_ids": input_ids,
# "text_masks": attention_mask,
# "pixel_values": img_feat,
# }
def __len__(self):
return len(self.data)
``` | csarron/4m-img-caps | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-03-28T17:50:53+00:00 | []
| []
| TAGS
#region-us
| see read_pyarrow.py for how to read one pyarrow file.
example PyTorch dataset:
| []
| [
"TAGS\n#region-us \n"
]
|
30fece425f9a3866e04321773ca7a80056d55ca6 |
# Dataset Card for "XL-Sum"
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/csebuetnlp/xl-sum](https://github.com/csebuetnlp/xl-sum)
- **Paper:** [XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages](https://aclanthology.org/2021.findings-acl.413/)
- **Point of Contact:** [Tahmid Hasan](mailto:[email protected])
### Dataset Summary
We present XLSum, a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.
### Supported Tasks and Leaderboards
[More information needed](https://github.com/csebuetnlp/xl-sum)
### Languages
- `amharic`
- `arabic`
- `azerbaijani`
- `bengali`
- `burmese`
- `chinese_simplified`
- `chinese_traditional`
- `english`
- `french`
- `gujarati`
- `hausa`
- `hindi`
- `igbo`
- `indonesian`
- `japanese`
- `kirundi`
- `korean`
- `kyrgyz`
- `marathi`
- `nepali`
- `oromo`
- `pashto`
- `persian`
- `pidgin`
- `portuguese`
- `punjabi`
- `russian`
- `scottish_gaelic`
- `serbian_cyrillic`
- `serbian_latin`
- `sinhala`
- `somali`
- `spanish`
- `swahili`
- `tamil`
- `telugu`
- `thai`
- `tigrinya`
- `turkish`
- `ukrainian`
- `urdu`
- `uzbek`
- `vietnamese`
- `welsh`
- `yoruba`
## Dataset Structure
### Data Instances
One example from the `English` dataset is given below in JSON format.
```
{
"id": "technology-17657859",
"url": "https://www.bbc.com/news/technology-17657859",
"title": "Yahoo files e-book advert system patent applications",
"summary": "Yahoo has signalled it is investigating e-book adverts as a way to stimulate its earnings.",
"text": "Yahoo's patents suggest users could weigh the type of ads against the sizes of discount before purchase. It says in two US patent applications that ads for digital book readers have been \"less than optimal\" to date. The filings suggest that users could be offered titles at a variety of prices depending on the ads' prominence They add that the products shown could be determined by the type of book being read, or even the contents of a specific chapter, phrase or word. The paperwork was published by the US Patent and Trademark Office late last week and relates to work carried out at the firm's headquarters in Sunnyvale, California. \"Greater levels of advertising, which may be more valuable to an advertiser and potentially more distracting to an e-book reader, may warrant higher discounts,\" it states. Free books It suggests users could be offered ads as hyperlinks based within the book's text, in-laid text or even \"dynamic content\" such as video. Another idea suggests boxes at the bottom of a page could trail later chapters or quotes saying \"brought to you by Company A\". It adds that the more willing the customer is to see the ads, the greater the potential discount. \"Higher frequencies... may even be great enough to allow the e-book to be obtained for free,\" it states. The authors write that the type of ad could influence the value of the discount, with \"lower class advertising... such as teeth whitener advertisements\" offering a cheaper price than \"high\" or \"middle class\" adverts, for things like pizza. The inventors also suggest that ads could be linked to the mood or emotional state the reader is in as a they progress through a title. For example, they say if characters fall in love or show affection during a chapter, then ads for flowers or entertainment could be triggered. The patents also suggest this could applied to children's books - giving the Tom Hanks animated film Polar Express as an example. It says a scene showing a waiter giving the protagonists hot drinks \"may be an excellent opportunity to show an advertisement for hot cocoa, or a branded chocolate bar\". Another example states: \"If the setting includes young characters, a Coke advertisement could be provided, inviting the reader to enjoy a glass of Coke with his book, and providing a graphic of a cool glass.\" It adds that such targeting could be further enhanced by taking account of previous titles the owner has bought. 'Advertising-free zone' At present, several Amazon and Kobo e-book readers offer full-screen adverts when the device is switched off and show smaller ads on their menu screens, but the main text of the titles remains free of marketing. Yahoo does not currently provide ads to these devices, and a move into the area could boost its shrinking revenues. However, Philip Jones, deputy editor of the Bookseller magazine, said that the internet firm might struggle to get some of its ideas adopted. \"This has been mooted before and was fairly well decried,\" he said. \"Perhaps in a limited context it could work if the merchandise was strongly related to the title and was kept away from the text. \"But readers - particularly parents - like the fact that reading is an advertising-free zone. Authors would also want something to say about ads interrupting their narrative flow.\""
}
```
### Data Fields
- 'id': A string representing the article ID.
- 'url': A string representing the article URL.
- 'title': A string containing the article title.
- 'summary': A string containing the article summary.
- 'text' : A string containing the article text.
### Data Splits
We used a 80%-10%-10% split for all languages with a few exceptions. `English` was split 93%-3.5%-3.5% for the evaluation set size to resemble that of `CNN/DM` and `XSum`; `Scottish Gaelic`, `Kyrgyz` and `Sinhala` had relatively fewer samples, their evaluation sets were increased to 500 samples for more reliable evaluation. Same articles were used for evaluation in the two variants of Chinese and Serbian to prevent data leakage in multilingual training. Individual dataset download links with train-dev-test example counts are given below:
Language | ISO 639-1 Code | BBC subdomain(s) | Train | Dev | Test | Total |
--------------|----------------|------------------|-------|-----|------|-------|
Amharic | am | https://www.bbc.com/amharic | 5761 | 719 | 719 | 7199 |
Arabic | ar | https://www.bbc.com/arabic | 37519 | 4689 | 4689 | 46897 |
Azerbaijani | az | https://www.bbc.com/azeri | 6478 | 809 | 809 | 8096 |
Bengali | bn | https://www.bbc.com/bengali | 8102 | 1012 | 1012 | 10126 |
Burmese | my | https://www.bbc.com/burmese | 4569 | 570 | 570 | 5709 |
Chinese (Simplified) | zh-CN | https://www.bbc.com/ukchina/simp, https://www.bbc.com/zhongwen/simp | 37362 | 4670 | 4670 | 46702 |
Chinese (Traditional) | zh-TW | https://www.bbc.com/ukchina/trad, https://www.bbc.com/zhongwen/trad | 37373 | 4670 | 4670 | 46713 |
English | en | https://www.bbc.com/english, https://www.bbc.com/sinhala `*` | 306522 | 11535 | 11535 | 329592 |
French | fr | https://www.bbc.com/afrique | 8697 | 1086 | 1086 | 10869 |
Gujarati | gu | https://www.bbc.com/gujarati | 9119 | 1139 | 1139 | 11397 |
Hausa | ha | https://www.bbc.com/hausa | 6418 | 802 | 802 | 8022 |
Hindi | hi | https://www.bbc.com/hindi | 70778 | 8847 | 8847 | 88472 |
Igbo | ig | https://www.bbc.com/igbo | 4183 | 522 | 522 | 5227 |
Indonesian | id | https://www.bbc.com/indonesia | 38242 | 4780 | 4780 | 47802 |
Japanese | ja | https://www.bbc.com/japanese | 7113 | 889 | 889 | 8891 |
Kirundi | rn | https://www.bbc.com/gahuza | 5746 | 718 | 718 | 7182 |
Korean | ko | https://www.bbc.com/korean | 4407 | 550 | 550 | 5507 |
Kyrgyz | ky | https://www.bbc.com/kyrgyz | 2266 | 500 | 500 | 3266 |
Marathi | mr | https://www.bbc.com/marathi | 10903 | 1362 | 1362 | 13627 |
Nepali | np | https://www.bbc.com/nepali | 5808 | 725 | 725 | 7258 |
Oromo | om | https://www.bbc.com/afaanoromoo | 6063 | 757 | 757 | 7577 |
Pashto | ps | https://www.bbc.com/pashto | 14353 | 1794 | 1794 | 17941 |
Persian | fa | https://www.bbc.com/persian | 47251 | 5906 | 5906 | 59063 |
Pidgin`**` | n/a | https://www.bbc.com/pidgin | 9208 | 1151 | 1151 | 11510 |
Portuguese | pt | https://www.bbc.com/portuguese | 57402 | 7175 | 7175 | 71752 |
Punjabi | pa | https://www.bbc.com/punjabi | 8215 | 1026 | 1026 | 10267 |
Russian | ru | https://www.bbc.com/russian, https://www.bbc.com/ukrainian `*` | 62243 | 7780 | 7780 | 77803 |
Scottish Gaelic | gd | https://www.bbc.com/naidheachdan | 1313 | 500 | 500 | 2313 |
Serbian (Cyrillic) | sr | https://www.bbc.com/serbian/cyr | 7275 | 909 | 909 | 9093 |
Serbian (Latin) | sr | https://www.bbc.com/serbian/lat | 7276 | 909 | 909 | 9094 |
Sinhala | si | https://www.bbc.com/sinhala | 3249 | 500 | 500 | 4249 |
Somali | so | https://www.bbc.com/somali | 5962 | 745 | 745 | 7452 |
Spanish | es | https://www.bbc.com/mundo | 38110 | 4763 | 4763 | 47636 |
Swahili | sw | https://www.bbc.com/swahili | 7898 | 987 | 987 | 9872 |
Tamil | ta | https://www.bbc.com/tamil | 16222 | 2027 | 2027 | 20276 |
Telugu | te | https://www.bbc.com/telugu | 10421 | 1302 | 1302 | 13025 |
Thai | th | https://www.bbc.com/thai | 6616 | 826 | 826 | 8268 |
Tigrinya | ti | https://www.bbc.com/tigrinya | 5451 | 681 | 681 | 6813 |
Turkish | tr | https://www.bbc.com/turkce | 27176 | 3397 | 3397 | 33970 |
Ukrainian | uk | https://www.bbc.com/ukrainian | 43201 | 5399 | 5399 | 53999 |
Urdu | ur | https://www.bbc.com/urdu | 67665 | 8458 | 8458 | 84581 |
Uzbek | uz | https://www.bbc.com/uzbek | 4728 | 590 | 590 | 5908 |
Vietnamese | vi | https://www.bbc.com/vietnamese | 32111 | 4013 | 4013 | 40137 |
Welsh | cy | https://www.bbc.com/cymrufyw | 9732 | 1216 | 1216 | 12164 |
Yoruba | yo | https://www.bbc.com/yoruba | 6350 | 793 | 793 | 7936 |
`*` A lot of articles in BBC Sinhala and BBC Ukrainian were written in English and Russian respectively. They were identified using [Fasttext](https://arxiv.org/abs/1607.01759) and moved accordingly.
`**` West African Pidgin English
## Dataset Creation
### Curation Rationale
[More information needed](https://github.com/csebuetnlp/xl-sum)
### Source Data
[BBC News](https://www.bbc.co.uk/ws/languages)
#### Initial Data Collection and Normalization
[Detailed in the paper](https://aclanthology.org/2021.findings-acl.413/)
#### Who are the source language producers?
[Detailed in the paper](https://aclanthology.org/2021.findings-acl.413/)
### Annotations
[Detailed in the paper](https://aclanthology.org/2021.findings-acl.413/)
#### Annotation process
[Detailed in the paper](https://aclanthology.org/2021.findings-acl.413/)
#### Who are the annotators?
[Detailed in the paper](https://aclanthology.org/2021.findings-acl.413/)
### Personal and Sensitive Information
[More information needed](https://github.com/csebuetnlp/xl-sum)
## Considerations for Using the Data
### Social Impact of Dataset
[More information needed](https://github.com/csebuetnlp/xl-sum)
### Discussion of Biases
[More information needed](https://github.com/csebuetnlp/xl-sum)
### Other Known Limitations
[More information needed](https://github.com/csebuetnlp/xl-sum)
## Additional Information
### Dataset Curators
[More information needed](https://github.com/csebuetnlp/xl-sum)
### Licensing Information
Contents of this repository are restricted to only non-commercial research purposes under the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/). Copyright of the dataset contents belongs to the original copyright holders.
### Citation Information
If you use any of the datasets, models or code modules, please cite the following paper:
```
@inproceedings{hasan-etal-2021-xl,
title = "{XL}-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages",
author = "Hasan, Tahmid and
Bhattacharjee, Abhik and
Islam, Md. Saiful and
Mubasshir, Kazi and
Li, Yuan-Fang and
Kang, Yong-Bin and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.413",
pages = "4693--4703",
}
```
### Contributions
Thanks to [@abhik1505040](https://github.com/abhik1505040) and [@Tahmid](https://github.com/Tahmid04) for adding this dataset. | csebuetnlp/xlsum | [
"task_categories:summarization",
"task_categories:text-generation",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:am",
"language:ar",
"language:az",
"language:bn",
"language:my",
"language:zh",
"language:en",
"language:fr",
"language:gu",
"language:ha",
"language:hi",
"language:ig",
"language:id",
"language:ja",
"language:rn",
"language:ko",
"language:ky",
"language:mr",
"language:ne",
"language:om",
"language:ps",
"language:fa",
"language:pcm",
"language:pt",
"language:pa",
"language:ru",
"language:gd",
"language:sr",
"language:si",
"language:so",
"language:es",
"language:sw",
"language:ta",
"language:te",
"language:th",
"language:ti",
"language:tr",
"language:uk",
"language:ur",
"language:uz",
"language:vi",
"language:cy",
"language:yo",
"license:cc-by-nc-sa-4.0",
"conditional-text-generation",
"arxiv:1607.01759",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["am", "ar", "az", "bn", "my", "zh", "en", "fr", "gu", "ha", "hi", "ig", "id", "ja", "rn", "ko", "ky", "mr", "ne", "om", "ps", "fa", "pcm", "pt", "pa", "ru", "gd", "sr", "si", "so", "es", "sw", "ta", "te", "th", "ti", "tr", "uk", "ur", "uz", "vi", "cy", "yo"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["summarization", "text-generation"], "task_ids": [], "paperswithcode_id": "xl-sum", "pretty_name": "XL-Sum", "tags": ["conditional-text-generation"]} | 2023-04-18T00:46:20+00:00 | [
"1607.01759"
]
| [
"am",
"ar",
"az",
"bn",
"my",
"zh",
"en",
"fr",
"gu",
"ha",
"hi",
"ig",
"id",
"ja",
"rn",
"ko",
"ky",
"mr",
"ne",
"om",
"ps",
"fa",
"pcm",
"pt",
"pa",
"ru",
"gd",
"sr",
"si",
"so",
"es",
"sw",
"ta",
"te",
"th",
"ti",
"tr",
"uk",
"ur",
"uz",
"vi",
"cy",
"yo"
]
| TAGS
#task_categories-summarization #task_categories-text-generation #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-1M<n<10M #source_datasets-original #language-Amharic #language-Arabic #language-Azerbaijani #language-Bengali #language-Burmese #language-Chinese #language-English #language-French #language-Gujarati #language-Hausa #language-Hindi #language-Igbo #language-Indonesian #language-Japanese #language-Rundi #language-Korean #language-Kirghiz #language-Marathi #language-Nepali (macrolanguage) #language-Oromo #language-Pushto #language-Persian #language-Nigerian Pidgin #language-Portuguese #language-Panjabi #language-Russian #language-Scottish Gaelic #language-Serbian #language-Sinhala #language-Somali #language-Spanish #language-Swahili (macrolanguage) #language-Tamil #language-Telugu #language-Thai #language-Tigrinya #language-Turkish #language-Ukrainian #language-Urdu #language-Uzbek #language-Vietnamese #language-Welsh #language-Yoruba #license-cc-by-nc-sa-4.0 #conditional-text-generation #arxiv-1607.01759 #region-us
| Dataset Card for "XL-Sum"
=========================
Table of Contents
-----------------
* Dataset Card Creation Guide
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?
- Annotations
* Annotation process
* Who are the annotators?
- Personal and Sensitive Information
+ Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
+ Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Repository: URL
* Paper: XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
* Point of Contact: Tahmid Hasan
### Dataset Summary
We present XLSum, a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.
### Supported Tasks and Leaderboards
More information needed
### Languages
* 'amharic'
* 'arabic'
* 'azerbaijani'
* 'bengali'
* 'burmese'
* 'chinese\_simplified'
* 'chinese\_traditional'
* 'english'
* 'french'
* 'gujarati'
* 'hausa'
* 'hindi'
* 'igbo'
* 'indonesian'
* 'japanese'
* 'kirundi'
* 'korean'
* 'kyrgyz'
* 'marathi'
* 'nepali'
* 'oromo'
* 'pashto'
* 'persian'
* 'pidgin'
* 'portuguese'
* 'punjabi'
* 'russian'
* 'scottish\_gaelic'
* 'serbian\_cyrillic'
* 'serbian\_latin'
* 'sinhala'
* 'somali'
* 'spanish'
* 'swahili'
* 'tamil'
* 'telugu'
* 'thai'
* 'tigrinya'
* 'turkish'
* 'ukrainian'
* 'urdu'
* 'uzbek'
* 'vietnamese'
* 'welsh'
* 'yoruba'
Dataset Structure
-----------------
### Data Instances
One example from the 'English' dataset is given below in JSON format.
### Data Fields
* 'id': A string representing the article ID.
* 'url': A string representing the article URL.
* 'title': A string containing the article title.
* 'summary': A string containing the article summary.
* 'text' : A string containing the article text.
### Data Splits
We used a 80%-10%-10% split for all languages with a few exceptions. 'English' was split 93%-3.5%-3.5% for the evaluation set size to resemble that of 'CNN/DM' and 'XSum'; 'Scottish Gaelic', 'Kyrgyz' and 'Sinhala' had relatively fewer samples, their evaluation sets were increased to 500 samples for more reliable evaluation. Same articles were used for evaluation in the two variants of Chinese and Serbian to prevent data leakage in multilingual training. Individual dataset download links with train-dev-test example counts are given below:
'\*' A lot of articles in BBC Sinhala and BBC Ukrainian were written in English and Russian respectively. They were identified using Fasttext and moved accordingly.
'' West African Pidgin English
Dataset Creation
----------------
### Curation Rationale
More information needed
### Source Data
BBC News
#### Initial Data Collection and Normalization
Detailed in the paper
#### Who are the source language producers?
Detailed in the paper
### Annotations
Detailed in the paper
#### Annotation process
Detailed in the paper
#### Who are the annotators?
Detailed in the paper
### Personal and Sensitive Information
More information needed
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
More information needed
### Discussion of Biases
More information needed
### Other Known Limitations
More information needed
Additional Information
----------------------
### Dataset Curators
More information needed
### Licensing Information
Contents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.
If you use any of the datasets, models or code modules, please cite the following paper:
### Contributions
Thanks to @abhik1505040 and @Tahmid for adding this dataset.
| [
"### Dataset Summary\n\n\nWe present XLSum, a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.",
"### Supported Tasks and Leaderboards\n\n\nMore information needed",
"### Languages\n\n\n* 'amharic'\n* 'arabic'\n* 'azerbaijani'\n* 'bengali'\n* 'burmese'\n* 'chinese\\_simplified'\n* 'chinese\\_traditional'\n* 'english'\n* 'french'\n* 'gujarati'\n* 'hausa'\n* 'hindi'\n* 'igbo'\n* 'indonesian'\n* 'japanese'\n* 'kirundi'\n* 'korean'\n* 'kyrgyz'\n* 'marathi'\n* 'nepali'\n* 'oromo'\n* 'pashto'\n* 'persian'\n* 'pidgin'\n* 'portuguese'\n* 'punjabi'\n* 'russian'\n* 'scottish\\_gaelic'\n* 'serbian\\_cyrillic'\n* 'serbian\\_latin'\n* 'sinhala'\n* 'somali'\n* 'spanish'\n* 'swahili'\n* 'tamil'\n* 'telugu'\n* 'thai'\n* 'tigrinya'\n* 'turkish'\n* 'ukrainian'\n* 'urdu'\n* 'uzbek'\n* 'vietnamese'\n* 'welsh'\n* 'yoruba'\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nOne example from the 'English' dataset is given below in JSON format.",
"### Data Fields\n\n\n* 'id': A string representing the article ID.\n* 'url': A string representing the article URL.\n* 'title': A string containing the article title.\n* 'summary': A string containing the article summary.\n* 'text' : A string containing the article text.",
"### Data Splits\n\n\nWe used a 80%-10%-10% split for all languages with a few exceptions. 'English' was split 93%-3.5%-3.5% for the evaluation set size to resemble that of 'CNN/DM' and 'XSum'; 'Scottish Gaelic', 'Kyrgyz' and 'Sinhala' had relatively fewer samples, their evaluation sets were increased to 500 samples for more reliable evaluation. Same articles were used for evaluation in the two variants of Chinese and Serbian to prevent data leakage in multilingual training. Individual dataset download links with train-dev-test example counts are given below:\n\n\n\n'\\*' A lot of articles in BBC Sinhala and BBC Ukrainian were written in English and Russian respectively. They were identified using Fasttext and moved accordingly.\n\n\n'' West African Pidgin English\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nMore information needed",
"### Source Data\n\n\nBBC News",
"#### Initial Data Collection and Normalization\n\n\nDetailed in the paper",
"#### Who are the source language producers?\n\n\nDetailed in the paper",
"### Annotations\n\n\nDetailed in the paper",
"#### Annotation process\n\n\nDetailed in the paper",
"#### Who are the annotators?\n\n\nDetailed in the paper",
"### Personal and Sensitive Information\n\n\nMore information needed\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nMore information needed",
"### Discussion of Biases\n\n\nMore information needed",
"### Other Known Limitations\n\n\nMore information needed\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nMore information needed",
"### Licensing Information\n\n\nContents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.\n\n\nIf you use any of the datasets, models or code modules, please cite the following paper:",
"### Contributions\n\n\nThanks to @abhik1505040 and @Tahmid for adding this dataset."
]
| [
"TAGS\n#task_categories-summarization #task_categories-text-generation #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-1M<n<10M #source_datasets-original #language-Amharic #language-Arabic #language-Azerbaijani #language-Bengali #language-Burmese #language-Chinese #language-English #language-French #language-Gujarati #language-Hausa #language-Hindi #language-Igbo #language-Indonesian #language-Japanese #language-Rundi #language-Korean #language-Kirghiz #language-Marathi #language-Nepali (macrolanguage) #language-Oromo #language-Pushto #language-Persian #language-Nigerian Pidgin #language-Portuguese #language-Panjabi #language-Russian #language-Scottish Gaelic #language-Serbian #language-Sinhala #language-Somali #language-Spanish #language-Swahili (macrolanguage) #language-Tamil #language-Telugu #language-Thai #language-Tigrinya #language-Turkish #language-Ukrainian #language-Urdu #language-Uzbek #language-Vietnamese #language-Welsh #language-Yoruba #license-cc-by-nc-sa-4.0 #conditional-text-generation #arxiv-1607.01759 #region-us \n",
"### Dataset Summary\n\n\nWe present XLSum, a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.",
"### Supported Tasks and Leaderboards\n\n\nMore information needed",
"### Languages\n\n\n* 'amharic'\n* 'arabic'\n* 'azerbaijani'\n* 'bengali'\n* 'burmese'\n* 'chinese\\_simplified'\n* 'chinese\\_traditional'\n* 'english'\n* 'french'\n* 'gujarati'\n* 'hausa'\n* 'hindi'\n* 'igbo'\n* 'indonesian'\n* 'japanese'\n* 'kirundi'\n* 'korean'\n* 'kyrgyz'\n* 'marathi'\n* 'nepali'\n* 'oromo'\n* 'pashto'\n* 'persian'\n* 'pidgin'\n* 'portuguese'\n* 'punjabi'\n* 'russian'\n* 'scottish\\_gaelic'\n* 'serbian\\_cyrillic'\n* 'serbian\\_latin'\n* 'sinhala'\n* 'somali'\n* 'spanish'\n* 'swahili'\n* 'tamil'\n* 'telugu'\n* 'thai'\n* 'tigrinya'\n* 'turkish'\n* 'ukrainian'\n* 'urdu'\n* 'uzbek'\n* 'vietnamese'\n* 'welsh'\n* 'yoruba'\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nOne example from the 'English' dataset is given below in JSON format.",
"### Data Fields\n\n\n* 'id': A string representing the article ID.\n* 'url': A string representing the article URL.\n* 'title': A string containing the article title.\n* 'summary': A string containing the article summary.\n* 'text' : A string containing the article text.",
"### Data Splits\n\n\nWe used a 80%-10%-10% split for all languages with a few exceptions. 'English' was split 93%-3.5%-3.5% for the evaluation set size to resemble that of 'CNN/DM' and 'XSum'; 'Scottish Gaelic', 'Kyrgyz' and 'Sinhala' had relatively fewer samples, their evaluation sets were increased to 500 samples for more reliable evaluation. Same articles were used for evaluation in the two variants of Chinese and Serbian to prevent data leakage in multilingual training. Individual dataset download links with train-dev-test example counts are given below:\n\n\n\n'\\*' A lot of articles in BBC Sinhala and BBC Ukrainian were written in English and Russian respectively. They were identified using Fasttext and moved accordingly.\n\n\n'' West African Pidgin English\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nMore information needed",
"### Source Data\n\n\nBBC News",
"#### Initial Data Collection and Normalization\n\n\nDetailed in the paper",
"#### Who are the source language producers?\n\n\nDetailed in the paper",
"### Annotations\n\n\nDetailed in the paper",
"#### Annotation process\n\n\nDetailed in the paper",
"#### Who are the annotators?\n\n\nDetailed in the paper",
"### Personal and Sensitive Information\n\n\nMore information needed\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nMore information needed",
"### Discussion of Biases\n\n\nMore information needed",
"### Other Known Limitations\n\n\nMore information needed\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nMore information needed",
"### Licensing Information\n\n\nContents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.\n\n\nIf you use any of the datasets, models or code modules, please cite the following paper:",
"### Contributions\n\n\nThanks to @abhik1505040 and @Tahmid for adding this dataset."
]
|
a18ecb62d7ffd4a6bff5756afb6e799bbb91dd3e |
# Dataset Card for `xnli_bn`
## Table of Contents
- [Dataset Card for `xnli_bn`](#dataset-card-for-xnli_bn)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Usage](#usage)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/csebuetnlp/banglabert](https://github.com/csebuetnlp/banglabert)
- **Paper:** [**"BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding"**](https://arxiv.org/abs/2101.00204)
- **Point of Contact:** [Tahmid Hasan](mailto:[email protected])
### Dataset Summary
This is a Natural Language Inference (NLI) dataset for Bengali, curated using the subset of
MNLI data used in XNLI and state-of-the-art English to Bengali translation model introduced **[here](https://aclanthology.org/2020.emnlp-main.207/).**
### Supported Tasks and Leaderboards
[More information needed](https://github.com/csebuetnlp/banglabert)
### Languages
* `Bengali`
### Usage
```python
from datasets import load_dataset
dataset = load_dataset("csebuetnlp/xnli_bn")
```
## Dataset Structure
### Data Instances
One example from the dataset is given below in JSON format.
```
{
"sentence1": "আসলে, আমি এমনকি এই বিষয়ে চিন্তাও করিনি, কিন্তু আমি এত হতাশ হয়ে পড়েছিলাম যে, শেষ পর্যন্ত আমি আবার তার সঙ্গে কথা বলতে শুরু করেছিলাম",
"sentence2": "আমি তার সাথে আবার কথা বলিনি।",
"label": "contradiction"
}
```
### Data Fields
The data fields are as follows:
- `sentence1`: a `string` feature indicating the premise.
- `sentence2`: a `string` feature indicating the hypothesis.
- `label`: a classification label, where possible values are `contradiction` (0), `entailment` (1), `neutral` (2) .
### Data Splits
| split |count |
|----------|--------|
|`train`| 381449 |
|`validation`| 2419 |
|`test`| 4895 |
## Dataset Creation
The dataset curation procedure was the same as the [XNLI](https://aclanthology.org/D18-1269/) dataset: we translated the [MultiNLI](https://aclanthology.org/N18-1101/) training data using the English to Bangla translation model introduced [here](https://aclanthology.org/2020.emnlp-main.207/). Due to the possibility of incursions of error during automatic translation, we used the [Language-Agnostic BERT Sentence Embeddings (LaBSE)](https://arxiv.org/abs/2007.01852) of the translations and original sentences to compute their similarity. All sentences below a similarity threshold of 0.70 were discarded.
### Curation Rationale
[More information needed](https://github.com/csebuetnlp/banglabert)
### Source Data
[XNLI](https://aclanthology.org/D18-1269/)
#### Initial Data Collection and Normalization
[More information needed](https://github.com/csebuetnlp/banglabert)
#### Who are the source language producers?
[More information needed](https://github.com/csebuetnlp/banglabert)
### Annotations
[More information needed](https://github.com/csebuetnlp/banglabert)
#### Annotation process
[More information needed](https://github.com/csebuetnlp/banglabert)
#### Who are the annotators?
[More information needed](https://github.com/csebuetnlp/banglabert)
### Personal and Sensitive Information
[More information needed](https://github.com/csebuetnlp/banglabert)
## Considerations for Using the Data
### Social Impact of Dataset
[More information needed](https://github.com/csebuetnlp/banglabert)
### Discussion of Biases
[More information needed](https://github.com/csebuetnlp/banglabert)
### Other Known Limitations
[More information needed](https://github.com/csebuetnlp/banglabert)
## Additional Information
### Dataset Curators
[More information needed](https://github.com/csebuetnlp/banglabert)
### Licensing Information
Contents of this repository are restricted to only non-commercial research purposes under the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/). Copyright of the dataset contents belongs to the original copyright holders.
### Citation Information
If you use the dataset, please cite the following paper:
```
@misc{bhattacharjee2021banglabert,
title={BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding},
author={Abhik Bhattacharjee and Tahmid Hasan and Kazi Samin and Md Saiful Islam and M. Sohel Rahman and Anindya Iqbal and Rifat Shahriyar},
year={2021},
eprint={2101.00204},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@abhik1505040](https://github.com/abhik1505040) and [@Tahmid](https://github.com/Tahmid04) for adding this dataset. | csebuetnlp/xnli_bn | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended",
"language:bn",
"license:cc-by-nc-sa-4.0",
"arxiv:2101.00204",
"arxiv:2007.01852",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["bn"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["extended"], "task_categories": ["text-classification"], "task_ids": ["natural-language-inference"]} | 2022-08-21T12:14:56+00:00 | [
"2101.00204",
"2007.01852"
]
| [
"bn"
]
| TAGS
#task_categories-text-classification #task_ids-natural-language-inference #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-extended #language-Bengali #license-cc-by-nc-sa-4.0 #arxiv-2101.00204 #arxiv-2007.01852 #region-us
| Dataset Card for 'xnli\_bn'
===========================
Table of Contents
-----------------
* Dataset Card for 'xnli\_bn'
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Usage
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?
- Annotations
* Annotation process
* Who are the annotators?
- Personal and Sensitive Information
+ Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
+ Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Repository: URL
* Paper: "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding"
* Point of Contact: Tahmid Hasan
### Dataset Summary
This is a Natural Language Inference (NLI) dataset for Bengali, curated using the subset of
MNLI data used in XNLI and state-of-the-art English to Bengali translation model introduced here.
### Supported Tasks and Leaderboards
More information needed
### Languages
* 'Bengali'
### Usage
Dataset Structure
-----------------
### Data Instances
One example from the dataset is given below in JSON format.
### Data Fields
The data fields are as follows:
* 'sentence1': a 'string' feature indicating the premise.
* 'sentence2': a 'string' feature indicating the hypothesis.
* 'label': a classification label, where possible values are 'contradiction' (0), 'entailment' (1), 'neutral' (2) .
### Data Splits
Dataset Creation
----------------
The dataset curation procedure was the same as the XNLI dataset: we translated the MultiNLI training data using the English to Bangla translation model introduced here. Due to the possibility of incursions of error during automatic translation, we used the Language-Agnostic BERT Sentence Embeddings (LaBSE) of the translations and original sentences to compute their similarity. All sentences below a similarity threshold of 0.70 were discarded.
### Curation Rationale
More information needed
### Source Data
XNLI
#### Initial Data Collection and Normalization
More information needed
#### Who are the source language producers?
More information needed
### Annotations
More information needed
#### Annotation process
More information needed
#### Who are the annotators?
More information needed
### Personal and Sensitive Information
More information needed
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
More information needed
### Discussion of Biases
More information needed
### Other Known Limitations
More information needed
Additional Information
----------------------
### Dataset Curators
More information needed
### Licensing Information
Contents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.
If you use the dataset, please cite the following paper:
### Contributions
Thanks to @abhik1505040 and @Tahmid for adding this dataset.
| [
"### Dataset Summary\n\n\nThis is a Natural Language Inference (NLI) dataset for Bengali, curated using the subset of\nMNLI data used in XNLI and state-of-the-art English to Bengali translation model introduced here.",
"### Supported Tasks and Leaderboards\n\n\nMore information needed",
"### Languages\n\n\n* 'Bengali'",
"### Usage\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nOne example from the dataset is given below in JSON format.",
"### Data Fields\n\n\nThe data fields are as follows:\n\n\n* 'sentence1': a 'string' feature indicating the premise.\n* 'sentence2': a 'string' feature indicating the hypothesis.\n* 'label': a classification label, where possible values are 'contradiction' (0), 'entailment' (1), 'neutral' (2) .",
"### Data Splits\n\n\n\nDataset Creation\n----------------\n\n\nThe dataset curation procedure was the same as the XNLI dataset: we translated the MultiNLI training data using the English to Bangla translation model introduced here. Due to the possibility of incursions of error during automatic translation, we used the Language-Agnostic BERT Sentence Embeddings (LaBSE) of the translations and original sentences to compute their similarity. All sentences below a similarity threshold of 0.70 were discarded.",
"### Curation Rationale\n\n\nMore information needed",
"### Source Data\n\n\nXNLI",
"#### Initial Data Collection and Normalization\n\n\nMore information needed",
"#### Who are the source language producers?\n\n\nMore information needed",
"### Annotations\n\n\nMore information needed",
"#### Annotation process\n\n\nMore information needed",
"#### Who are the annotators?\n\n\nMore information needed",
"### Personal and Sensitive Information\n\n\nMore information needed\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nMore information needed",
"### Discussion of Biases\n\n\nMore information needed",
"### Other Known Limitations\n\n\nMore information needed\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nMore information needed",
"### Licensing Information\n\n\nContents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.\n\n\nIf you use the dataset, please cite the following paper:",
"### Contributions\n\n\nThanks to @abhik1505040 and @Tahmid for adding this dataset."
]
| [
"TAGS\n#task_categories-text-classification #task_ids-natural-language-inference #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-extended #language-Bengali #license-cc-by-nc-sa-4.0 #arxiv-2101.00204 #arxiv-2007.01852 #region-us \n",
"### Dataset Summary\n\n\nThis is a Natural Language Inference (NLI) dataset for Bengali, curated using the subset of\nMNLI data used in XNLI and state-of-the-art English to Bengali translation model introduced here.",
"### Supported Tasks and Leaderboards\n\n\nMore information needed",
"### Languages\n\n\n* 'Bengali'",
"### Usage\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nOne example from the dataset is given below in JSON format.",
"### Data Fields\n\n\nThe data fields are as follows:\n\n\n* 'sentence1': a 'string' feature indicating the premise.\n* 'sentence2': a 'string' feature indicating the hypothesis.\n* 'label': a classification label, where possible values are 'contradiction' (0), 'entailment' (1), 'neutral' (2) .",
"### Data Splits\n\n\n\nDataset Creation\n----------------\n\n\nThe dataset curation procedure was the same as the XNLI dataset: we translated the MultiNLI training data using the English to Bangla translation model introduced here. Due to the possibility of incursions of error during automatic translation, we used the Language-Agnostic BERT Sentence Embeddings (LaBSE) of the translations and original sentences to compute their similarity. All sentences below a similarity threshold of 0.70 were discarded.",
"### Curation Rationale\n\n\nMore information needed",
"### Source Data\n\n\nXNLI",
"#### Initial Data Collection and Normalization\n\n\nMore information needed",
"#### Who are the source language producers?\n\n\nMore information needed",
"### Annotations\n\n\nMore information needed",
"#### Annotation process\n\n\nMore information needed",
"#### Who are the annotators?\n\n\nMore information needed",
"### Personal and Sensitive Information\n\n\nMore information needed\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nMore information needed",
"### Discussion of Biases\n\n\nMore information needed",
"### Other Known Limitations\n\n\nMore information needed\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nMore information needed",
"### Licensing Information\n\n\nContents of this repository are restricted to only non-commercial research purposes under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). Copyright of the dataset contents belongs to the original copyright holders.\n\n\nIf you use the dataset, please cite the following paper:",
"### Contributions\n\n\nThanks to @abhik1505040 and @Tahmid for adding this dataset."
]
|
d810e76b4b49ceffb417666524b0daabd94c059c | # Dataset Card for Task2Dial
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Acknowledgements] (#funding-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Needs More Information]
- **Paper:** https://aclanthology.org/2021.icnlsp-1.28/
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
The Task2Dial dataset includes (1) a set of recipe documents with 353 individual dialogues; and (2) conversations between an IG and an IF, which are grounded in the associated recipe documents. Presents sample utterances from a dialogue along with the associated recipe. It demonstrates some important features of the dataset, such as mentioning entities not present in the recipe document; re-composition of the original text to focus on the important steps and the breakdown of the recipe into manageable and appropriate steps. Following recent efforts in the field to standardise NLG research, we have made the dataset freely available.
### Supported Tasks and Leaderboards
We demonstrate the task of implementing the Task2Dial in a conversational agent called chefbot in the following git repo: https://github.com/carlstrath/ChefBot
### Languages
English
### Data Fields
Dataset.1: Task2Dial main, 353 cooking recipes modelled on real conversations between an IF and IG.
Dataset. 2: A list of alternative ingredients for every swappable ingredient in the Task2Dial dataset.
Dataset. 3. A list of objects and utensils with explanations, comparisons, handling and common storage location information.
## Dataset Creation
The proposed task considers the recipe-following scenario with an information giver
(IG) and an information follower (IF), where the IG has access to the recipe and gives
instructions to the IF. The IG might choose to omit irrelevant information, simplify
the content of a recipe or provide it as is. The IF will either follow the task or ask
for further information. The IG might have to rely on information outside the given
document (i.e. commonsense) to enhance understanding and success of the task. In
addition, the IG decides on how to present the recipe steps, i.e. split them into sub-
steps or merge them together, often diverging from the original number of recipe steps.
The task is regarded as successful when the IG has successfully followed/understood
the recipe. Hence, other dialogue-focused metrics, such as the number of turns, are
not appropriate here. Formally, Task2Dial can be defined as follows: Given a recipe
𝑅𝑖 from 𝑅 =𝑅1, 𝑅2, 𝑅3,..., 𝑅𝑛, an ontology or ontologies 𝑂𝑖 =𝑂11,𝑂2,...,𝑂𝑛 of
cooking-related concepts, a history of the conversation ℎ, predict the response 𝑟 of
the IG.
### Curation Rationale
Text selection was dependent on the quality of the information
provided in the existing recipes. Too little information and the transcription and
interpretation of the text became diffused with missing or incorrect knowledge.
Conversely, providing too much information in the text resulted in a lack of creativity
and commonsense reasoning by the data curators. Thus, the goal of the curation was
to identify text that contained all the relevant information to complete the cooking
task (tools, ingredients, weights, timings, servings) but not in such detail that it
subtracted from the creativity, commonsense and imagination of the annotators.
### Source Data
#### Initial Data Collection and Normalization
Three open-source and creative commons licensed
cookery websites6 were identified for data extraction, which permits any use or non-
commercial use of data for research purposes. As content submission to the
cooking websites was unrestricted, data appropriateness was ratified by the ratings
and reviews given to each recipe by the public, highly rated recipes with a positive
feedback were given preference over recipes with low scores and poor reviews [38].
From this, a list of 353 recipes was compiled and divided amongst the annotators
for the data collection. As mentioned earlier, annotators were asked to take on the
roles of both IF and IG, rather than a multi-turn WoZ approach, to allow flexibility
in the utterances. This approach allowed the annotators additional time to formulate
detailed and concise responses.
#### Who are the source language producers?
Undergraduate RAs were recruited through email.
The participants were paid an hourly rate based on a university pay scale which is
above the living wage and corresponds to the real living wage, following ethical
guidelines for responsible innovation. The annotation team was composed of
two males and one female data curators, under the age of 25 of mixed ethnicity’s with
experience in AI and computing. This minimised the gender bias that is frequently
observed in crowdsourcing platforms.
#### Annotation process
Each annotator was provided with a detailed list of instructions, an example dialogue and an IF/IG template (see Appendix A). The annotators were asked to read both the example dialogue and the original recipe to understand the text, context, composition, translation and annotation. The instructions included information handling and storage of data, text formatting, metadata and examples of high-quality and poor dialogues. An administrator was on hand throughout the data collection to support and guide the annotators. This approach reduced the number of low-quality dialogues associated with large crowdsourcing platforms that are often discarded post evaluation, as demonstrated in the data collection of the Doc2Dial dataset.
#### Who are the annotators?
Research assistants (RAs) from the School of Computing were employed on temporary contracts to construct and format the dataset. After an initial meeting to discuss the job role and determine suitability, the RAs were asked to complete a paid trial, this was evaluated and further advice was given on how to write dialogues and format the data to ensure high quality. After the successful completion of the trial, the RAs were permitted to continue with the remainder of the data collection. To ensure the high quality of the dataset, samples of the dialogues were often reviewed and further feedback was provided.
### Personal and Sensitive Information
An ethics request was submitted for review by the board of ethics at our university. No personal or other data that may be used to identify an individual was collected in this study.
## Considerations for Using the Data
The Task2Dial dataset is currently only for the cooking domain, but using the methodologies provided other tasks can be modelled for example, furniture assembly and maintenance tasks.
### Social Impact of Dataset
Our proposed task aims to motivate research for modern dialogue systems that
address the following challenges. Firstly, modern dialogue systems should be flexible
and allow for "off-script" scenarios in order to emulate real-world phenomena, such
as the ones present in human-human communication. This will require new ways
of encoding user intents and new approaches to dialogue management in general.
Secondly, as dialogue systems find different domain applications, the complexity
of the dialogues might increase as well as the reliance on domain knowledge that
can be encoded in structured or unstructured ways, such as documents, databases
etc. Many applications, might require access to different domain knowledge sources
in a course of a dialogue, and in such context, selection might prove beneficial in
choosing "what to say".
### Discussion of Biases
Prior to data collection, we performed three pilot studies.
In the first, two participants assumed the roles of IG and IF respectively, where the
IG had access to a recipe and provided recipe instructions to the IF (who did not have
access to the recipe) over the phone, recording the session and then transcribing it.
Next, we repeated the process with text-based dialogue through an online platform
following a similar setup, however, the interaction was solely chat-based. The final
study used self-dialogue, with one member of the team writing entire dialogues
assuming both the IF and IG roles. We found that self-dialogue results were proximal
to the results of two-person studies. However, time and cost were higher for producing
two-person dialogues, with the additional time needed for transcribing and correction,
thus, we opted to use self-dialogue.
## Additional Information
Video: https://www.youtube.com/watch?v=zISkwn95RXs&ab_channel=ICNLSPConference
### Dataset Curators
The recipes are composed by people of a different races
/ ethnicity, nationalities, socioeconomic status, abilities, age, gender and language
with significant variation in pronunciations, structure, language and grammar. This
provided the annotators with unique linguistic content for each recipe to interpret
the data and configure the text into an IF/IG format. To help preserve sociolinguistic
patterns in speech, the data curators retained the underlying language when para-
phrasing, to intercede social and regional dialects with their own interpretation of
the data to enhance the lexical richness.
### Licensing Information
CC
### Citation Information
https://aclanthology.org/2021.icnlsp-1.28/
### Acknowledgements
The research is supported under the EPSRC projects CiViL (EP/T014598/1) and
NLG for low-resource domains (EP/T024917/1). | cstrathe435/Task2Dial | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-03T12:55:28+00:00 | []
| []
| TAGS
#region-us
| # Dataset Card for Task2Dial
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- [Acknowledgements] (#funding-information)
## Dataset Description
- Homepage:
- Repository:
- Paper: URL
- Leaderboard:
- Point of Contact:
### Dataset Summary
The Task2Dial dataset includes (1) a set of recipe documents with 353 individual dialogues; and (2) conversations between an IG and an IF, which are grounded in the associated recipe documents. Presents sample utterances from a dialogue along with the associated recipe. It demonstrates some important features of the dataset, such as mentioning entities not present in the recipe document; re-composition of the original text to focus on the important steps and the breakdown of the recipe into manageable and appropriate steps. Following recent efforts in the field to standardise NLG research, we have made the dataset freely available.
### Supported Tasks and Leaderboards
We demonstrate the task of implementing the Task2Dial in a conversational agent called chefbot in the following git repo: URL
### Languages
English
### Data Fields
Dataset.1: Task2Dial main, 353 cooking recipes modelled on real conversations between an IF and IG.
Dataset. 2: A list of alternative ingredients for every swappable ingredient in the Task2Dial dataset.
Dataset. 3. A list of objects and utensils with explanations, comparisons, handling and common storage location information.
## Dataset Creation
The proposed task considers the recipe-following scenario with an information giver
(IG) and an information follower (IF), where the IG has access to the recipe and gives
instructions to the IF. The IG might choose to omit irrelevant information, simplify
the content of a recipe or provide it as is. The IF will either follow the task or ask
for further information. The IG might have to rely on information outside the given
document (i.e. commonsense) to enhance understanding and success of the task. In
addition, the IG decides on how to present the recipe steps, i.e. split them into sub-
steps or merge them together, often diverging from the original number of recipe steps.
The task is regarded as successful when the IG has successfully followed/understood
the recipe. Hence, other dialogue-focused metrics, such as the number of turns, are
not appropriate here. Formally, Task2Dial can be defined as follows: Given a recipe
𝑅𝑖 from 𝑅 =𝑅1, 𝑅2, 𝑅3,..., 𝑅𝑛, an ontology or ontologies 𝑂𝑖 =𝑂11,𝑂2,...,𝑂𝑛 of
cooking-related concepts, a history of the conversation ℎ, predict the response 𝑟 of
the IG.
### Curation Rationale
Text selection was dependent on the quality of the information
provided in the existing recipes. Too little information and the transcription and
interpretation of the text became diffused with missing or incorrect knowledge.
Conversely, providing too much information in the text resulted in a lack of creativity
and commonsense reasoning by the data curators. Thus, the goal of the curation was
to identify text that contained all the relevant information to complete the cooking
task (tools, ingredients, weights, timings, servings) but not in such detail that it
subtracted from the creativity, commonsense and imagination of the annotators.
### Source Data
#### Initial Data Collection and Normalization
Three open-source and creative commons licensed
cookery websites6 were identified for data extraction, which permits any use or non-
commercial use of data for research purposes. As content submission to the
cooking websites was unrestricted, data appropriateness was ratified by the ratings
and reviews given to each recipe by the public, highly rated recipes with a positive
feedback were given preference over recipes with low scores and poor reviews [38].
From this, a list of 353 recipes was compiled and divided amongst the annotators
for the data collection. As mentioned earlier, annotators were asked to take on the
roles of both IF and IG, rather than a multi-turn WoZ approach, to allow flexibility
in the utterances. This approach allowed the annotators additional time to formulate
detailed and concise responses.
#### Who are the source language producers?
Undergraduate RAs were recruited through email.
The participants were paid an hourly rate based on a university pay scale which is
above the living wage and corresponds to the real living wage, following ethical
guidelines for responsible innovation. The annotation team was composed of
two males and one female data curators, under the age of 25 of mixed ethnicity’s with
experience in AI and computing. This minimised the gender bias that is frequently
observed in crowdsourcing platforms.
#### Annotation process
Each annotator was provided with a detailed list of instructions, an example dialogue and an IF/IG template (see Appendix A). The annotators were asked to read both the example dialogue and the original recipe to understand the text, context, composition, translation and annotation. The instructions included information handling and storage of data, text formatting, metadata and examples of high-quality and poor dialogues. An administrator was on hand throughout the data collection to support and guide the annotators. This approach reduced the number of low-quality dialogues associated with large crowdsourcing platforms that are often discarded post evaluation, as demonstrated in the data collection of the Doc2Dial dataset.
#### Who are the annotators?
Research assistants (RAs) from the School of Computing were employed on temporary contracts to construct and format the dataset. After an initial meeting to discuss the job role and determine suitability, the RAs were asked to complete a paid trial, this was evaluated and further advice was given on how to write dialogues and format the data to ensure high quality. After the successful completion of the trial, the RAs were permitted to continue with the remainder of the data collection. To ensure the high quality of the dataset, samples of the dialogues were often reviewed and further feedback was provided.
### Personal and Sensitive Information
An ethics request was submitted for review by the board of ethics at our university. No personal or other data that may be used to identify an individual was collected in this study.
## Considerations for Using the Data
The Task2Dial dataset is currently only for the cooking domain, but using the methodologies provided other tasks can be modelled for example, furniture assembly and maintenance tasks.
### Social Impact of Dataset
Our proposed task aims to motivate research for modern dialogue systems that
address the following challenges. Firstly, modern dialogue systems should be flexible
and allow for "off-script" scenarios in order to emulate real-world phenomena, such
as the ones present in human-human communication. This will require new ways
of encoding user intents and new approaches to dialogue management in general.
Secondly, as dialogue systems find different domain applications, the complexity
of the dialogues might increase as well as the reliance on domain knowledge that
can be encoded in structured or unstructured ways, such as documents, databases
etc. Many applications, might require access to different domain knowledge sources
in a course of a dialogue, and in such context, selection might prove beneficial in
choosing "what to say".
### Discussion of Biases
Prior to data collection, we performed three pilot studies.
In the first, two participants assumed the roles of IG and IF respectively, where the
IG had access to a recipe and provided recipe instructions to the IF (who did not have
access to the recipe) over the phone, recording the session and then transcribing it.
Next, we repeated the process with text-based dialogue through an online platform
following a similar setup, however, the interaction was solely chat-based. The final
study used self-dialogue, with one member of the team writing entire dialogues
assuming both the IF and IG roles. We found that self-dialogue results were proximal
to the results of two-person studies. However, time and cost were higher for producing
two-person dialogues, with the additional time needed for transcribing and correction,
thus, we opted to use self-dialogue.
## Additional Information
Video: URL
### Dataset Curators
The recipes are composed by people of a different races
/ ethnicity, nationalities, socioeconomic status, abilities, age, gender and language
with significant variation in pronunciations, structure, language and grammar. This
provided the annotators with unique linguistic content for each recipe to interpret
the data and configure the text into an IF/IG format. To help preserve sociolinguistic
patterns in speech, the data curators retained the underlying language when para-
phrasing, to intercede social and regional dialects with their own interpretation of
the data to enhance the lexical richness.
### Licensing Information
CC
URL
### Acknowledgements
The research is supported under the EPSRC projects CiViL (EP/T014598/1) and
NLG for low-resource domains (EP/T024917/1). | [
"# Dataset Card for Task2Dial",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - [Acknowledgements] (#funding-information)",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: URL\n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThe Task2Dial dataset includes (1) a set of recipe documents with 353 individual dialogues; and (2) conversations between an IG and an IF, which are grounded in the associated recipe documents. Presents sample utterances from a dialogue along with the associated recipe. It demonstrates some important features of the dataset, such as mentioning entities not present in the recipe document; re-composition of the original text to focus on the important steps and the breakdown of the recipe into manageable and appropriate steps. Following recent efforts in the field to standardise NLG research, we have made the dataset freely available.",
"### Supported Tasks and Leaderboards\n\nWe demonstrate the task of implementing the Task2Dial in a conversational agent called chefbot in the following git repo: URL",
"### Languages\n\nEnglish",
"### Data Fields\n\nDataset.1: Task2Dial main, 353 cooking recipes modelled on real conversations between an IF and IG.\n\nDataset. 2: A list of alternative ingredients for every swappable ingredient in the Task2Dial dataset.\n\nDataset. 3. A list of objects and utensils with explanations, comparisons, handling and common storage location information.",
"## Dataset Creation\n\nThe proposed task considers the recipe-following scenario with an information giver\n(IG) and an information follower (IF), where the IG has access to the recipe and gives\ninstructions to the IF. The IG might choose to omit irrelevant information, simplify\nthe content of a recipe or provide it as is. The IF will either follow the task or ask\nfor further information. The IG might have to rely on information outside the given\ndocument (i.e. commonsense) to enhance understanding and success of the task. In\naddition, the IG decides on how to present the recipe steps, i.e. split them into sub-\nsteps or merge them together, often diverging from the original number of recipe steps.\nThe task is regarded as successful when the IG has successfully followed/understood\nthe recipe. Hence, other dialogue-focused metrics, such as the number of turns, are\nnot appropriate here. Formally, Task2Dial can be defined as follows: Given a recipe\n𝑅𝑖 from 𝑅 =𝑅1, 𝑅2, 𝑅3,..., 𝑅𝑛, an ontology or ontologies 𝑂𝑖 =𝑂11,𝑂2,...,𝑂𝑛 of\ncooking-related concepts, a history of the conversation ℎ, predict the response 𝑟 of\nthe IG.",
"### Curation Rationale\n\nText selection was dependent on the quality of the information\nprovided in the existing recipes. Too little information and the transcription and\ninterpretation of the text became diffused with missing or incorrect knowledge.\nConversely, providing too much information in the text resulted in a lack of creativity\nand commonsense reasoning by the data curators. Thus, the goal of the curation was\nto identify text that contained all the relevant information to complete the cooking\ntask (tools, ingredients, weights, timings, servings) but not in such detail that it\nsubtracted from the creativity, commonsense and imagination of the annotators.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThree open-source and creative commons licensed\ncookery websites6 were identified for data extraction, which permits any use or non-\ncommercial use of data for research purposes. As content submission to the\ncooking websites was unrestricted, data appropriateness was ratified by the ratings\nand reviews given to each recipe by the public, highly rated recipes with a positive\nfeedback were given preference over recipes with low scores and poor reviews [38].\nFrom this, a list of 353 recipes was compiled and divided amongst the annotators\nfor the data collection. As mentioned earlier, annotators were asked to take on the\nroles of both IF and IG, rather than a multi-turn WoZ approach, to allow flexibility\nin the utterances. This approach allowed the annotators additional time to formulate\ndetailed and concise responses.",
"#### Who are the source language producers?\n\nUndergraduate RAs were recruited through email.\nThe participants were paid an hourly rate based on a university pay scale which is\nabove the living wage and corresponds to the real living wage, following ethical\nguidelines for responsible innovation. The annotation team was composed of\ntwo males and one female data curators, under the age of 25 of mixed ethnicity’s with\nexperience in AI and computing. This minimised the gender bias that is frequently\nobserved in crowdsourcing platforms.",
"#### Annotation process\n\nEach annotator was provided with a detailed list of instructions, an example dialogue and an IF/IG template (see Appendix A). The annotators were asked to read both the example dialogue and the original recipe to understand the text, context, composition, translation and annotation. The instructions included information handling and storage of data, text formatting, metadata and examples of high-quality and poor dialogues. An administrator was on hand throughout the data collection to support and guide the annotators. This approach reduced the number of low-quality dialogues associated with large crowdsourcing platforms that are often discarded post evaluation, as demonstrated in the data collection of the Doc2Dial dataset.",
"#### Who are the annotators?\n\nResearch assistants (RAs) from the School of Computing were employed on temporary contracts to construct and format the dataset. After an initial meeting to discuss the job role and determine suitability, the RAs were asked to complete a paid trial, this was evaluated and further advice was given on how to write dialogues and format the data to ensure high quality. After the successful completion of the trial, the RAs were permitted to continue with the remainder of the data collection. To ensure the high quality of the dataset, samples of the dialogues were often reviewed and further feedback was provided.",
"### Personal and Sensitive Information\n\nAn ethics request was submitted for review by the board of ethics at our university. No personal or other data that may be used to identify an individual was collected in this study.",
"## Considerations for Using the Data\n\nThe Task2Dial dataset is currently only for the cooking domain, but using the methodologies provided other tasks can be modelled for example, furniture assembly and maintenance tasks.",
"### Social Impact of Dataset\n\nOur proposed task aims to motivate research for modern dialogue systems that\naddress the following challenges. Firstly, modern dialogue systems should be flexible\nand allow for \"off-script\" scenarios in order to emulate real-world phenomena, such\nas the ones present in human-human communication. This will require new ways\nof encoding user intents and new approaches to dialogue management in general.\nSecondly, as dialogue systems find different domain applications, the complexity\nof the dialogues might increase as well as the reliance on domain knowledge that\ncan be encoded in structured or unstructured ways, such as documents, databases\netc. Many applications, might require access to different domain knowledge sources\nin a course of a dialogue, and in such context, selection might prove beneficial in\nchoosing \"what to say\".",
"### Discussion of Biases\n\nPrior to data collection, we performed three pilot studies.\nIn the first, two participants assumed the roles of IG and IF respectively, where the\nIG had access to a recipe and provided recipe instructions to the IF (who did not have\naccess to the recipe) over the phone, recording the session and then transcribing it.\nNext, we repeated the process with text-based dialogue through an online platform\nfollowing a similar setup, however, the interaction was solely chat-based. The final\nstudy used self-dialogue, with one member of the team writing entire dialogues\nassuming both the IF and IG roles. We found that self-dialogue results were proximal\nto the results of two-person studies. However, time and cost were higher for producing\ntwo-person dialogues, with the additional time needed for transcribing and correction,\nthus, we opted to use self-dialogue.",
"## Additional Information\n\nVideo: URL",
"### Dataset Curators\n\nThe recipes are composed by people of a different races\n/ ethnicity, nationalities, socioeconomic status, abilities, age, gender and language\nwith significant variation in pronunciations, structure, language and grammar. This\nprovided the annotators with unique linguistic content for each recipe to interpret\nthe data and configure the text into an IF/IG format. To help preserve sociolinguistic\npatterns in speech, the data curators retained the underlying language when para-\nphrasing, to intercede social and regional dialects with their own interpretation of\nthe data to enhance the lexical richness.",
"### Licensing Information\n\nCC\n\n\n\nURL",
"### Acknowledgements\n\nThe research is supported under the EPSRC projects CiViL (EP/T014598/1) and\nNLG for low-resource domains (EP/T024917/1)."
]
| [
"TAGS\n#region-us \n",
"# Dataset Card for Task2Dial",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - [Acknowledgements] (#funding-information)",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: URL\n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThe Task2Dial dataset includes (1) a set of recipe documents with 353 individual dialogues; and (2) conversations between an IG and an IF, which are grounded in the associated recipe documents. Presents sample utterances from a dialogue along with the associated recipe. It demonstrates some important features of the dataset, such as mentioning entities not present in the recipe document; re-composition of the original text to focus on the important steps and the breakdown of the recipe into manageable and appropriate steps. Following recent efforts in the field to standardise NLG research, we have made the dataset freely available.",
"### Supported Tasks and Leaderboards\n\nWe demonstrate the task of implementing the Task2Dial in a conversational agent called chefbot in the following git repo: URL",
"### Languages\n\nEnglish",
"### Data Fields\n\nDataset.1: Task2Dial main, 353 cooking recipes modelled on real conversations between an IF and IG.\n\nDataset. 2: A list of alternative ingredients for every swappable ingredient in the Task2Dial dataset.\n\nDataset. 3. A list of objects and utensils with explanations, comparisons, handling and common storage location information.",
"## Dataset Creation\n\nThe proposed task considers the recipe-following scenario with an information giver\n(IG) and an information follower (IF), where the IG has access to the recipe and gives\ninstructions to the IF. The IG might choose to omit irrelevant information, simplify\nthe content of a recipe or provide it as is. The IF will either follow the task or ask\nfor further information. The IG might have to rely on information outside the given\ndocument (i.e. commonsense) to enhance understanding and success of the task. In\naddition, the IG decides on how to present the recipe steps, i.e. split them into sub-\nsteps or merge them together, often diverging from the original number of recipe steps.\nThe task is regarded as successful when the IG has successfully followed/understood\nthe recipe. Hence, other dialogue-focused metrics, such as the number of turns, are\nnot appropriate here. Formally, Task2Dial can be defined as follows: Given a recipe\n𝑅𝑖 from 𝑅 =𝑅1, 𝑅2, 𝑅3,..., 𝑅𝑛, an ontology or ontologies 𝑂𝑖 =𝑂11,𝑂2,...,𝑂𝑛 of\ncooking-related concepts, a history of the conversation ℎ, predict the response 𝑟 of\nthe IG.",
"### Curation Rationale\n\nText selection was dependent on the quality of the information\nprovided in the existing recipes. Too little information and the transcription and\ninterpretation of the text became diffused with missing or incorrect knowledge.\nConversely, providing too much information in the text resulted in a lack of creativity\nand commonsense reasoning by the data curators. Thus, the goal of the curation was\nto identify text that contained all the relevant information to complete the cooking\ntask (tools, ingredients, weights, timings, servings) but not in such detail that it\nsubtracted from the creativity, commonsense and imagination of the annotators.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThree open-source and creative commons licensed\ncookery websites6 were identified for data extraction, which permits any use or non-\ncommercial use of data for research purposes. As content submission to the\ncooking websites was unrestricted, data appropriateness was ratified by the ratings\nand reviews given to each recipe by the public, highly rated recipes with a positive\nfeedback were given preference over recipes with low scores and poor reviews [38].\nFrom this, a list of 353 recipes was compiled and divided amongst the annotators\nfor the data collection. As mentioned earlier, annotators were asked to take on the\nroles of both IF and IG, rather than a multi-turn WoZ approach, to allow flexibility\nin the utterances. This approach allowed the annotators additional time to formulate\ndetailed and concise responses.",
"#### Who are the source language producers?\n\nUndergraduate RAs were recruited through email.\nThe participants were paid an hourly rate based on a university pay scale which is\nabove the living wage and corresponds to the real living wage, following ethical\nguidelines for responsible innovation. The annotation team was composed of\ntwo males and one female data curators, under the age of 25 of mixed ethnicity’s with\nexperience in AI and computing. This minimised the gender bias that is frequently\nobserved in crowdsourcing platforms.",
"#### Annotation process\n\nEach annotator was provided with a detailed list of instructions, an example dialogue and an IF/IG template (see Appendix A). The annotators were asked to read both the example dialogue and the original recipe to understand the text, context, composition, translation and annotation. The instructions included information handling and storage of data, text formatting, metadata and examples of high-quality and poor dialogues. An administrator was on hand throughout the data collection to support and guide the annotators. This approach reduced the number of low-quality dialogues associated with large crowdsourcing platforms that are often discarded post evaluation, as demonstrated in the data collection of the Doc2Dial dataset.",
"#### Who are the annotators?\n\nResearch assistants (RAs) from the School of Computing were employed on temporary contracts to construct and format the dataset. After an initial meeting to discuss the job role and determine suitability, the RAs were asked to complete a paid trial, this was evaluated and further advice was given on how to write dialogues and format the data to ensure high quality. After the successful completion of the trial, the RAs were permitted to continue with the remainder of the data collection. To ensure the high quality of the dataset, samples of the dialogues were often reviewed and further feedback was provided.",
"### Personal and Sensitive Information\n\nAn ethics request was submitted for review by the board of ethics at our university. No personal or other data that may be used to identify an individual was collected in this study.",
"## Considerations for Using the Data\n\nThe Task2Dial dataset is currently only for the cooking domain, but using the methodologies provided other tasks can be modelled for example, furniture assembly and maintenance tasks.",
"### Social Impact of Dataset\n\nOur proposed task aims to motivate research for modern dialogue systems that\naddress the following challenges. Firstly, modern dialogue systems should be flexible\nand allow for \"off-script\" scenarios in order to emulate real-world phenomena, such\nas the ones present in human-human communication. This will require new ways\nof encoding user intents and new approaches to dialogue management in general.\nSecondly, as dialogue systems find different domain applications, the complexity\nof the dialogues might increase as well as the reliance on domain knowledge that\ncan be encoded in structured or unstructured ways, such as documents, databases\netc. Many applications, might require access to different domain knowledge sources\nin a course of a dialogue, and in such context, selection might prove beneficial in\nchoosing \"what to say\".",
"### Discussion of Biases\n\nPrior to data collection, we performed three pilot studies.\nIn the first, two participants assumed the roles of IG and IF respectively, where the\nIG had access to a recipe and provided recipe instructions to the IF (who did not have\naccess to the recipe) over the phone, recording the session and then transcribing it.\nNext, we repeated the process with text-based dialogue through an online platform\nfollowing a similar setup, however, the interaction was solely chat-based. The final\nstudy used self-dialogue, with one member of the team writing entire dialogues\nassuming both the IF and IG roles. We found that self-dialogue results were proximal\nto the results of two-person studies. However, time and cost were higher for producing\ntwo-person dialogues, with the additional time needed for transcribing and correction,\nthus, we opted to use self-dialogue.",
"## Additional Information\n\nVideo: URL",
"### Dataset Curators\n\nThe recipes are composed by people of a different races\n/ ethnicity, nationalities, socioeconomic status, abilities, age, gender and language\nwith significant variation in pronunciations, structure, language and grammar. This\nprovided the annotators with unique linguistic content for each recipe to interpret\nthe data and configure the text into an IF/IG format. To help preserve sociolinguistic\npatterns in speech, the data curators retained the underlying language when para-\nphrasing, to intercede social and regional dialects with their own interpretation of\nthe data to enhance the lexical richness.",
"### Licensing Information\n\nCC\n\n\n\nURL",
"### Acknowledgements\n\nThe research is supported under the EPSRC projects CiViL (EP/T014598/1) and\nNLG for low-resource domains (EP/T024917/1)."
]
|
c9f2ce78fc92e19353b7f1cb3f4b68f15d32eb1c | # CsFEVER experimental Fact-Checking dataset
Czech dataset for fact verification localized from the data points of [FEVER](https://arxiv.org/abs/1803.05355) using the localization scheme described in the [CTKFacts: Czech Datasets for Fact Verification](https://arxiv.org/abs/2201.11115) paper which is currently being revised for publication in LREV journal.
The version you are looking at was reformatted to *Claim*-*Evidence* string pairs for the specific task of NLI - a more general Document-Retrieval-ready interpretation of our datapoints which can be used for training and evaluating the DR models over the June 2016 wikipedia snapshot can be found in the [data_dr]() folder in the JSON Lines format.
## Data Statement
### Curation Rationale
TODO
| ctu-aic/csfever | [
"license:cc-by-sa-3.0",
"arxiv:1803.05355",
"arxiv:2201.11115",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "cc-by-sa-3.0"} | 2022-11-01T05:56:15+00:00 | [
"1803.05355",
"2201.11115"
]
| []
| TAGS
#license-cc-by-sa-3.0 #arxiv-1803.05355 #arxiv-2201.11115 #region-us
| # CsFEVER experimental Fact-Checking dataset
Czech dataset for fact verification localized from the data points of FEVER using the localization scheme described in the CTKFacts: Czech Datasets for Fact Verification paper which is currently being revised for publication in LREV journal.
The version you are looking at was reformatted to *Claim*-*Evidence* string pairs for the specific task of NLI - a more general Document-Retrieval-ready interpretation of our datapoints which can be used for training and evaluating the DR models over the June 2016 wikipedia snapshot can be found in the [data_dr]() folder in the JSON Lines format.
## Data Statement
### Curation Rationale
TODO
| [
"# CsFEVER experimental Fact-Checking dataset\r\n\r\nCzech dataset for fact verification localized from the data points of FEVER using the localization scheme described in the CTKFacts: Czech Datasets for Fact Verification paper which is currently being revised for publication in LREV journal.\r\n\r\nThe version you are looking at was reformatted to *Claim*-*Evidence* string pairs for the specific task of NLI - a more general Document-Retrieval-ready interpretation of our datapoints which can be used for training and evaluating the DR models over the June 2016 wikipedia snapshot can be found in the [data_dr]() folder in the JSON Lines format.",
"## Data Statement",
"### Curation Rationale\r\n\r\nTODO"
]
| [
"TAGS\n#license-cc-by-sa-3.0 #arxiv-1803.05355 #arxiv-2201.11115 #region-us \n",
"# CsFEVER experimental Fact-Checking dataset\r\n\r\nCzech dataset for fact verification localized from the data points of FEVER using the localization scheme described in the CTKFacts: Czech Datasets for Fact Verification paper which is currently being revised for publication in LREV journal.\r\n\r\nThe version you are looking at was reformatted to *Claim*-*Evidence* string pairs for the specific task of NLI - a more general Document-Retrieval-ready interpretation of our datapoints which can be used for training and evaluating the DR models over the June 2016 wikipedia snapshot can be found in the [data_dr]() folder in the JSON Lines format.",
"## Data Statement",
"### Curation Rationale\r\n\r\nTODO"
]
|
387ae4582c8054cb52ef57ef0941f19bd8012abf | # CTKFacts dataset for Natural Language Inference
Czech Natural Language Inference dataset of ~3K *evidence*-*claim* pairs labelled with SUPPORTS, REFUTES or NOT ENOUGH INFO veracity labels. Extracted from a round of fact-checking experiments concluded and described within the CsFEVER and [CTKFacts: Czech Datasets for Fact Verification](https://arxiv.org/abs/2201.11115) paper currently being revised for publication in LREV journal.
## Document retrieval version
Can be found at https://huggingface.co/datasets/ctu-aic/ctkfacts | ctu-aic/ctkfacts_nli | [
"arxiv:2201.11115",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-11-01T06:35:47+00:00 | [
"2201.11115"
]
| []
| TAGS
#arxiv-2201.11115 #region-us
| # CTKFacts dataset for Natural Language Inference
Czech Natural Language Inference dataset of ~3K *evidence*-*claim* pairs labelled with SUPPORTS, REFUTES or NOT ENOUGH INFO veracity labels. Extracted from a round of fact-checking experiments concluded and described within the CsFEVER and CTKFacts: Czech Datasets for Fact Verification paper currently being revised for publication in LREV journal.
## Document retrieval version
Can be found at URL | [
"# CTKFacts dataset for Natural Language Inference\n\nCzech Natural Language Inference dataset of ~3K *evidence*-*claim* pairs labelled with SUPPORTS, REFUTES or NOT ENOUGH INFO veracity labels. Extracted from a round of fact-checking experiments concluded and described within the CsFEVER and CTKFacts: Czech Datasets for Fact Verification paper currently being revised for publication in LREV journal.",
"## Document retrieval version\nCan be found at URL"
]
| [
"TAGS\n#arxiv-2201.11115 #region-us \n",
"# CTKFacts dataset for Natural Language Inference\n\nCzech Natural Language Inference dataset of ~3K *evidence*-*claim* pairs labelled with SUPPORTS, REFUTES or NOT ENOUGH INFO veracity labels. Extracted from a round of fact-checking experiments concluded and described within the CsFEVER and CTKFacts: Czech Datasets for Fact Verification paper currently being revised for publication in LREV journal.",
"## Document retrieval version\nCan be found at URL"
]
|
3768a20ee7e29288ea5feb4531fc5ab68ca8c2f2 | # Dataset Card for GitHub Issues
## Dataset Description
This dataset is created for the Hugging Face Datasets library course
### Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets [repository](https://github.com/huggingface/datasets). It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the `task-category-tag` with an appropriate `other:other-task-name`).
- `task-category-tag`: The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a *high/low* [metric name](https://huggingface.co/metrics/metric_name). The ([model name](https://huggingface.co/model_name) or [model class](https://huggingface.co/transformers/model_doc/model_class.html)) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at [leaderboard url]() and ranks models based on [metric name](https://huggingface.co/metrics/metric_name) while also reporting [other metric name](https://huggingface.co/metrics/other_metric_name).
### Languages
Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide [BCP-47 codes](https://tools.ietf.org/html/bcp47), which consist of a [primary language subtag](https://tools.ietf.org/html/bcp47#section-2.2.1), with a [script subtag](https://tools.ietf.org/html/bcp47#section-2.2.3) and/or [region subtag](https://tools.ietf.org/html/bcp47#section-2.2.4) if available.
## Dataset Structure
### Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
```
{
'example_field': ...,
...
}
```
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
### Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
- `example_field`: description of `example_field`
Note that the descriptions can be initialized with the **Show Markdown Data Fields** output of the [tagging app](https://github.com/huggingface/datasets-tagging), you will then only need to refine the generated descriptions.
### Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| | Tain | Valid | Test |
| ----- | ------ | ----- | ---- |
| Input Sentences | | | |
| Average Sentence Length | | | |
## Dataset Creation
### Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
### Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
#### Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their [Hugging Face version](https://huggingface.co/datasets/dataset_name).
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
#### Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
### Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
#### Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
#### Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
### Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
## Considerations for Using the Data
### Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
### Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example [Dinan et al 2020 on biases in Wikipedia (esp. Table 1)](https://arxiv.org/abs/2005.00614), or [Blodgett et al 2020](https://www.aclweb.org/anthology/2020.acl-main.485/) for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
### Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
## Additional Information
### Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
### Licensing Information
Provide the license and link to the license webpage if available.
### Citation Information
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
```
@article{article_id,
author = {Author List},
title = {Dataset Paper Title},
journal = {Publication Venue},
year = {2525}
}
```
If the dataset has a [DOI](https://www.doi.org/), please provide it here.
### Contributions
[@cylee] added this dataset as part of the Hugging Face Dataset library tutorial (https://huggingface.co/course/chapter5/5?fw=tf). | cylee/github-issues | [
"arxiv:2005.00614",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-12-19T19:12:55+00:00 | [
"2005.00614"
]
| []
| TAGS
#arxiv-2005.00614 #region-us
| Dataset Card for GitHub Issues
==============================
Dataset Description
-------------------
This dataset is created for the Hugging Face Datasets library course
### Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').
* 'task-category-tag': The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a *high/low* metric name. The (model name or model class) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.
### Languages
Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.
Dataset Structure
-----------------
### Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
### Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
* 'example\_field': description of 'example\_field'
Note that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.
### Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
Dataset Creation
----------------
### Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
### Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
#### Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
#### Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
### Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
#### Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
#### Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
### Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
### Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
### Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
Additional Information
----------------------
### Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
### Licensing Information
Provide the license and link to the license webpage if available.
Provide the BibTex-formatted reference for the dataset. For example:
If the dataset has a DOI, please provide it here.
### Contributions
[@cylee] added this dataset as part of the Hugging Face Dataset library tutorial (URL
| [
"### Dataset Summary\n\n\nGitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.",
"### Supported Tasks and Leaderboards\n\n\nFor each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').\n\n\n* 'task-category-tag': The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a *high/low* metric name. The (model name or model class) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.",
"### Languages\n\n\nProvide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...\n\n\nWhen relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nProvide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.\n\n\nProvide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.",
"### Data Fields\n\n\nList and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.\n\n\n* 'example\\_field': description of 'example\\_field'\n\n\nNote that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.",
"### Data Splits\n\n\nDescribe and name the splits in the dataset if there are more than one.\n\n\nDescribe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.\n\n\nProvide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWhat need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?",
"### Source Data\n\n\nThis section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)",
"#### Initial Data Collection and Normalization\n\n\nDescribe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.\n\n\nIf data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.\n\n\nIf the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.",
"#### Who are the source language producers?\n\n\nState whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.\n\n\nIf available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.\n\n\nDescribe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.\n\n\nDescribe other people represented or mentioned in the data. Where possible, link to references for the information.",
"### Annotations\n\n\nIf the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.",
"#### Annotation process\n\n\nIf applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.",
"#### Who are the annotators?\n\n\nIf annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.\n\n\nDescribe the people or systems who originally created the annotations and their selection criteria if applicable.\n\n\nIf available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.\n\n\nDescribe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.",
"### Personal and Sensitive Information\n\n\nState whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).\n\n\nState whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).\n\n\nIf efforts were made to anonymize the data, describe the anonymization process.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nPlease discuss some of the ways you believe the use of this dataset will impact society.\n\n\nThe statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.\n\n\nAlso describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.",
"### Discussion of Biases\n\n\nProvide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.\n\n\nFor Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.\n\n\nIf analyses have been run quantifying these biases, please add brief summaries and links to the studies here.",
"### Other Known Limitations\n\n\nIf studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nList the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.",
"### Licensing Information\n\n\nProvide the license and link to the license webpage if available.\n\n\nProvide the BibTex-formatted reference for the dataset. For example:\n\n\nIf the dataset has a DOI, please provide it here.",
"### Contributions\n\n\n[@cylee] added this dataset as part of the Hugging Face Dataset library tutorial (URL"
]
| [
"TAGS\n#arxiv-2005.00614 #region-us \n",
"### Dataset Summary\n\n\nGitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.",
"### Supported Tasks and Leaderboards\n\n\nFor each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').\n\n\n* 'task-category-tag': The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a *high/low* metric name. The (model name or model class) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.",
"### Languages\n\n\nProvide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...\n\n\nWhen relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nProvide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.\n\n\nProvide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.",
"### Data Fields\n\n\nList and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.\n\n\n* 'example\\_field': description of 'example\\_field'\n\n\nNote that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.",
"### Data Splits\n\n\nDescribe and name the splits in the dataset if there are more than one.\n\n\nDescribe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.\n\n\nProvide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWhat need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?",
"### Source Data\n\n\nThis section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)",
"#### Initial Data Collection and Normalization\n\n\nDescribe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.\n\n\nIf data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.\n\n\nIf the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.",
"#### Who are the source language producers?\n\n\nState whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.\n\n\nIf available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.\n\n\nDescribe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.\n\n\nDescribe other people represented or mentioned in the data. Where possible, link to references for the information.",
"### Annotations\n\n\nIf the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.",
"#### Annotation process\n\n\nIf applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.",
"#### Who are the annotators?\n\n\nIf annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.\n\n\nDescribe the people or systems who originally created the annotations and their selection criteria if applicable.\n\n\nIf available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.\n\n\nDescribe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.",
"### Personal and Sensitive Information\n\n\nState whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).\n\n\nState whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).\n\n\nIf efforts were made to anonymize the data, describe the anonymization process.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nPlease discuss some of the ways you believe the use of this dataset will impact society.\n\n\nThe statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.\n\n\nAlso describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.",
"### Discussion of Biases\n\n\nProvide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.\n\n\nFor Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.\n\n\nIf analyses have been run quantifying these biases, please add brief summaries and links to the studies here.",
"### Other Known Limitations\n\n\nIf studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nList the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.",
"### Licensing Information\n\n\nProvide the license and link to the license webpage if available.\n\n\nProvide the BibTex-formatted reference for the dataset. For example:\n\n\nIf the dataset has a DOI, please provide it here.",
"### Contributions\n\n\n[@cylee] added this dataset as part of the Hugging Face Dataset library tutorial (URL"
]
|
986e65392adb1f3bdab07c25ed9a23cb83a0b354 | # YFCC100M subset from OpenAI
Subset of [YFCC100M](https://arxiv.org/abs/1503.01817) used by OpenAI for [CLIP](https://github.com/openai/CLIP/blob/main/data/yfcc100m.md), filtered to contain only the images that we could retrieve.
| Split | train | validation |
| --- | --- | --- |
| Number of samples | 14,808,859 | 16,374 |
| Size | 1.9 TB | 2.1 GB |
Features:
* from the original dataset: `title`, `description`, `photoid`, `uid`, `unickname`, `datetaken`, `dateuploaded`, `capturedevice`, `usertags`, `machinetags`, `longitude`, `latitude`, `accuracy`, `pageurl`, `downloadurl`, `licensename`, `licenseurl`, `serverid`, `farmid`, `secret`, `secretoriginal`, `ext`, `marker`, `key`
* `img`: image content, can be loaded with `PIL.Image.open(io.BytesIO(item['img']))`
* `title_clean` and `description_clean`: derived from `title` and `description` using `clean_text` function detailed below
```python
def clean_text(text):
# decode url
text = urllib.parse.unquote_plus(text)
# remove html tags
text = re.sub('<[^<]+?>', '', text)
# remove multiple spaces + "\r" + "\n" + "\t"
text = " ".join(text.split())
return text
``` | dalle-mini/YFCC100M_OpenAI_subset | [
"arxiv:1503.01817",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-08-26T16:56:01+00:00 | [
"1503.01817"
]
| []
| TAGS
#arxiv-1503.01817 #region-us
| YFCC100M subset from OpenAI
===========================
Subset of YFCC100M used by OpenAI for CLIP, filtered to contain only the images that we could retrieve.
Split: Number of samples, train: 14,808,859, validation: 16,374
Split: Size, train: 1.9 TB, validation: 2.1 GB
Features:
* from the original dataset: 'title', 'description', 'photoid', 'uid', 'unickname', 'datetaken', 'dateuploaded', 'capturedevice', 'usertags', 'machinetags', 'longitude', 'latitude', 'accuracy', 'pageurl', 'downloadurl', 'licensename', 'licenseurl', 'serverid', 'farmid', 'secret', 'secretoriginal', 'ext', 'marker', 'key'
* 'img': image content, can be loaded with 'URL(io.BytesIO(item['img']))'
* 'title\_clean' and 'description\_clean': derived from 'title' and 'description' using 'clean\_text' function detailed below
| []
| [
"TAGS\n#arxiv-1503.01817 #region-us \n"
]
|
a8e47c9a43d12564240e175708fe4e9424d275f0 | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains the most recent version (2016-Full-genome), composed of 1,609 high-quality full-length genomes.
The genes within these sequences were processed using the GeneCutter tool and translated into corresponding amino acid sequences using the BioPython library Seq.translate function.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Each column represents the protein amino acid sequence of the HIV genome.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 1,609 full length HIV genomes.
Data Fields: ID, gag, pol, env, nef, tat, rev, proteome
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT) designed to predict a variety of sequence-dependent features regarding HIV.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study sequence-dependent features of HIV, a virus that has claimed the lives of many individuals globally in the last few decades.
Discussion of Biases: This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database full genome database and contains a representative sample from each subtype and geographic region.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA | damlab/HIV_FLT | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-08T20:58:56+00:00 | []
| []
| TAGS
#region-us
| # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains the most recent version (2016-Full-genome), composed of 1,609 high-quality full-length genomes.
The genes within these sequences were processed using the GeneCutter tool and translated into corresponding amino acid sequences using the BioPython library Seq.translate function.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Each column represents the protein amino acid sequence of the HIV genome.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 1,609 full length HIV genomes.
Data Fields: ID, gag, pol, env, nef, tat, rev, proteome
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT) designed to predict a variety of sequence-dependent features regarding HIV.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study sequence-dependent features of HIV, a virus that has claimed the lives of many individuals globally in the last few decades.
Discussion of Biases: This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database full genome database and contains a representative sample from each subtype and geographic region.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA | [
"# Dataset Description",
"## Dataset Summary\n\n This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.\n It contains the most recent version (2016-Full-genome), composed of 1,609 high-quality full-length genomes.\n The genes within these sequences were processed using the GeneCutter tool and translated into corresponding amino acid sequences using the BioPython library Seq.translate function. \n\nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nEach column represents the protein amino acid sequence of the HIV genome. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 1,609 full length HIV genomes. \n\nData Fields: ID, gag, pol, env, nef, tat, rev, proteome \n\nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: This dataset was curated to train a model (HIV-BERT) designed to predict a variety of sequence-dependent features regarding HIV. \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study sequence-dependent features of HIV, a virus that has claimed the lives of many individuals globally in the last few decades. \n\nDiscussion of Biases: This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database full genome database and contains a representative sample from each subtype and geographic region.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA"
]
| [
"TAGS\n#region-us \n",
"# Dataset Description",
"## Dataset Summary\n\n This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.\n It contains the most recent version (2016-Full-genome), composed of 1,609 high-quality full-length genomes.\n The genes within these sequences were processed using the GeneCutter tool and translated into corresponding amino acid sequences using the BioPython library Seq.translate function. \n\nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nEach column represents the protein amino acid sequence of the HIV genome. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 1,609 full length HIV genomes. \n\nData Fields: ID, gag, pol, env, nef, tat, rev, proteome \n\nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: This dataset was curated to train a model (HIV-BERT) designed to predict a variety of sequence-dependent features regarding HIV. \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study sequence-dependent features of HIV, a virus that has claimed the lives of many individuals globally in the last few decades. \n\nDiscussion of Biases: This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database full genome database and contains a representative sample from each subtype and geographic region.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA"
]
|
f0bada3a186a6ab795d578088eaff9cae1ee7106 |
# Dataset Description
## Dataset Summary
This dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A
pproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART).
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Each column represents the protein amino acid sequence of the HIV protease protein. The ID field indicates the Genbank reference ID for future cross-referencing. There are 1,733 total protease sequences.
Data Fields: ID, sequence, fold, FPV, IDV, NFV, SQV
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT-PI) designed to predict whether an HIV protease sequence would result in resistance to certain antiretroviral (ART) drugs.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.
## Considerations for Using the Data
Social Impact of Dataset: Due to the tendency of HIV to mutate, drug resistance is a common issue when attempting to treat those infected with HIV.
Protease inhibitors are a class of drugs that HIV is known to develop resistance via mutations.
Thus, by providing a collection of protease sequences known to be resistant to one or more drugs, this dataset provides a significant collection of data that could be utilized to perform computational analysis of protease resistance mutations.
Discussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
| damlab/HIV_PI | [
"license:mit",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "mit"} | 2022-03-09T19:48:01+00:00 | []
| []
| TAGS
#license-mit #region-us
|
# Dataset Description
## Dataset Summary
This dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A
pproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART).
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Each column represents the protein amino acid sequence of the HIV protease protein. The ID field indicates the Genbank reference ID for future cross-referencing. There are 1,733 total protease sequences.
Data Fields: ID, sequence, fold, FPV, IDV, NFV, SQV
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT-PI) designed to predict whether an HIV protease sequence would result in resistance to certain antiretroviral (ART) drugs.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.
## Considerations for Using the Data
Social Impact of Dataset: Due to the tendency of HIV to mutate, drug resistance is a common issue when attempting to treat those infected with HIV.
Protease inhibitors are a class of drugs that HIV is known to develop resistance via mutations.
Thus, by providing a collection of protease sequences known to be resistant to one or more drugs, this dataset provides a significant collection of data that could be utilized to perform computational analysis of protease resistance mutations.
Discussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
| [
"# Dataset Description",
"## Dataset Summary\r\n\r\nThis dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A\r\npproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART). \r\n\r\nSupported Tasks and Leaderboards: None \r\n\r\nLanguages: English",
"## Dataset Structure",
"### Data Instances\r\nEach column represents the protein amino acid sequence of the HIV protease protein. The ID field indicates the Genbank reference ID for future cross-referencing. There are 1,733 total protease sequences. \r\n\r\nData Fields: ID, sequence, fold, FPV, IDV, NFV, SQV \r\n\r\nData Splits: None",
"## Dataset Creation\r\n\r\nCuration Rationale: This dataset was curated to train a model (HIV-BERT-PI) designed to predict whether an HIV protease sequence would result in resistance to certain antiretroviral (ART) drugs. \r\n\r\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.",
"## Considerations for Using the Data\r\n\r\nSocial Impact of Dataset: Due to the tendency of HIV to mutate, drug resistance is a common issue when attempting to treat those infected with HIV. \r\nProtease inhibitors are a class of drugs that HIV is known to develop resistance via mutations. \r\nThus, by providing a collection of protease sequences known to be resistant to one or more drugs, this dataset provides a significant collection of data that could be utilized to perform computational analysis of protease resistance mutations. \r\n\r\nDiscussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \r\nCurrently, there was no effort made to balance the performance across these classes. \r\nAs such, one should consider refinement with additional sequences to perform well on non-B sequences.",
"## Additional Information: \r\n - Dataset Curators: Will Dampier \r\n - Citation Information: TBA"
]
| [
"TAGS\n#license-mit #region-us \n",
"# Dataset Description",
"## Dataset Summary\r\n\r\nThis dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A\r\npproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART). \r\n\r\nSupported Tasks and Leaderboards: None \r\n\r\nLanguages: English",
"## Dataset Structure",
"### Data Instances\r\nEach column represents the protein amino acid sequence of the HIV protease protein. The ID field indicates the Genbank reference ID for future cross-referencing. There are 1,733 total protease sequences. \r\n\r\nData Fields: ID, sequence, fold, FPV, IDV, NFV, SQV \r\n\r\nData Splits: None",
"## Dataset Creation\r\n\r\nCuration Rationale: This dataset was curated to train a model (HIV-BERT-PI) designed to predict whether an HIV protease sequence would result in resistance to certain antiretroviral (ART) drugs. \r\n\r\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.",
"## Considerations for Using the Data\r\n\r\nSocial Impact of Dataset: Due to the tendency of HIV to mutate, drug resistance is a common issue when attempting to treat those infected with HIV. \r\nProtease inhibitors are a class of drugs that HIV is known to develop resistance via mutations. \r\nThus, by providing a collection of protease sequences known to be resistant to one or more drugs, this dataset provides a significant collection of data that could be utilized to perform computational analysis of protease resistance mutations. \r\n\r\nDiscussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \r\nCurrently, there was no effort made to balance the performance across these classes. \r\nAs such, one should consider refinement with additional sequences to perform well on non-B sequences.",
"## Additional Information: \r\n - Dataset Curators: Will Dampier \r\n - Citation Information: TBA"
]
|
7c81ad7c34d35f0ea4cabc28c24dc79c299dd6b3 | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 5,510 unique V3 sequences, each annotated with its corresponding bodysite that it was associated with.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Data Instances: Each column represents the protein amino acid sequence of the HIV V3 loop.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic.
Data Fields: ID, sequence, fold, periphery-tcell, periphery-monocyte, CNS, lung, breast-milk, gastric, male-genitals, female-genitals, umbilical-cord, organ
Data Splits: None
## Dataset Creation
Curation Rationale:
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for study of HIV compartmentalization.
Discussion of Biases: DDue to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
Additionally, this dataset is highly biased to peripheral T-cells.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
---
license: mit
--- | damlab/HIV_V3_bodysite | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-08T21:12:25+00:00 | []
| []
| TAGS
#region-us
| # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 5,510 unique V3 sequences, each annotated with its corresponding bodysite that it was associated with.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Data Instances: Each column represents the protein amino acid sequence of the HIV V3 loop.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic.
Data Fields: ID, sequence, fold, periphery-tcell, periphery-monocyte, CNS, lung, breast-milk, gastric, male-genitals, female-genitals, umbilical-cord, organ
Data Splits: None
## Dataset Creation
Curation Rationale:
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for study of HIV compartmentalization.
Discussion of Biases: DDue to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
Additionally, this dataset is highly biased to peripheral T-cells.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
---
license: mit
--- | [
"# Dataset Description",
"## Dataset Summary\n\nThis dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database. \nIt contains 5,510 unique V3 sequences, each annotated with its corresponding bodysite that it was associated with. \nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nData Instances: Each column represents the protein amino acid sequence of the HIV V3 loop. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic. \nData Fields: ID, sequence, fold, periphery-tcell, periphery-monocyte, CNS, lung, breast-milk, gastric, male-genitals, female-genitals, umbilical-cord, organ\nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for study of HIV compartmentalization. \n\nDiscussion of Biases: DDue to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \nCurrently, there was no effort made to balance the performance across these classes. \nAs such, one should consider refinement with additional sequences to perform well on non-B sequences. \nAdditionally, this dataset is highly biased to peripheral T-cells.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA\n\n\n---\nlicense: mit\n---"
]
| [
"TAGS\n#region-us \n",
"# Dataset Description",
"## Dataset Summary\n\nThis dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database. \nIt contains 5,510 unique V3 sequences, each annotated with its corresponding bodysite that it was associated with. \nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nData Instances: Each column represents the protein amino acid sequence of the HIV V3 loop. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic. \nData Fields: ID, sequence, fold, periphery-tcell, periphery-monocyte, CNS, lung, breast-milk, gastric, male-genitals, female-genitals, umbilical-cord, organ\nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for study of HIV compartmentalization. \n\nDiscussion of Biases: DDue to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \nCurrently, there was no effort made to balance the performance across these classes. \nAs such, one should consider refinement with additional sequences to perform well on non-B sequences. \nAdditionally, this dataset is highly biased to peripheral T-cells.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA\n\n\n---\nlicense: mit\n---"
]
|
e6aae6b448d287929238c39a8bb880ae93ab4211 | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 2,935 HIV V3 loop protein sequences, which can interact with either CCR5 receptors on T-Cells or CXCR4 receptors on macrophages.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Data Instances: Each column represents the protein amino acid sequence of the HIV V3 loop.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic.
Data Fields: ID, sequence, fold, CCR5, CXCR4
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT-V3) designed to predict whether an HIV V3 loop would be CCR5 or CXCR4 tropic.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for entry into T-cells and macrophages.
Discussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
| damlab/HIV_V3_coreceptor | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-08T21:09:21+00:00 | []
| []
| TAGS
#region-us
| # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 2,935 HIV V3 loop protein sequences, which can interact with either CCR5 receptors on T-Cells or CXCR4 receptors on macrophages.
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Data Instances: Each column represents the protein amino acid sequence of the HIV V3 loop.
The ID field indicates the Genbank reference ID for future cross-referencing.
There are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic.
Data Fields: ID, sequence, fold, CCR5, CXCR4
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT-V3) designed to predict whether an HIV V3 loop would be CCR5 or CXCR4 tropic.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.
## Considerations for Using the Data
Social Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for entry into T-cells and macrophages.
Discussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
| [
"# Dataset Description",
"## Dataset Summary\n\nThis dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database. \nIt contains 2,935 HIV V3 loop protein sequences, which can interact with either CCR5 receptors on T-Cells or CXCR4 receptors on macrophages. \n\nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nData Instances: Each column represents the protein amino acid sequence of the HIV V3 loop. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic. \nData Fields: ID, sequence, fold, CCR5, CXCR4 \nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: This dataset was curated to train a model (HIV-BERT-V3) designed to predict whether an HIV V3 loop would be CCR5 or CXCR4 tropic. \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for entry into T-cells and macrophages. \n\nDiscussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \nCurrently, there was no effort made to balance the performance across these classes. \nAs such, one should consider refinement with additional sequences to perform well on non-B sequences.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA"
]
| [
"TAGS\n#region-us \n",
"# Dataset Description",
"## Dataset Summary\n\nThis dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database. \nIt contains 2,935 HIV V3 loop protein sequences, which can interact with either CCR5 receptors on T-Cells or CXCR4 receptors on macrophages. \n\nSupported Tasks and Leaderboards: None \n\nLanguages: English",
"## Dataset Structure",
"### Data Instances\nData Instances: Each column represents the protein amino acid sequence of the HIV V3 loop. \nThe ID field indicates the Genbank reference ID for future cross-referencing. \nThere are 2,935 total V3 sequences, with 91% being CCR5 tropic and 23% CXCR4 tropic. \nData Fields: ID, sequence, fold, CCR5, CXCR4 \nData Splits: None",
"## Dataset Creation\n\nCuration Rationale: This dataset was curated to train a model (HIV-BERT-V3) designed to predict whether an HIV V3 loop would be CCR5 or CXCR4 tropic. \n\nInitial Data Collection and Normalization: Dataset was downloaded and curated on 12/20/2021.",
"## Considerations for Using the Data\n\nSocial Impact of Dataset: This dataset can be used to study the mechanism by which HIV V3 loops allow for entry into T-cells and macrophages. \n\nDiscussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D. \nCurrently, there was no effort made to balance the performance across these classes. \nAs such, one should consider refinement with additional sequences to perform well on non-B sequences.",
"## Additional Information: \n - Dataset Curators: Will Dampier \n - Citation Information: TBA"
]
|
68844f7ae036f6901f3b08526c45f6026ea26997 | This dataset contains postings and comments from the following recurring threads on [Hacker News](http://news.ycombinator.com/)
1. Ask HN: Who is hiring?
2. Ask HN: Who wants to be hired?
3. Freelancer? Seeking freelancer?
These post types are stored in datasets called `hiring`, `wants_to_be_hired` and `freelancer` respectively.
Each type of posting has occurred on a regular basis for several years. You can identify when each comment/listing was added through the CommentTime field. The `ParentTitle` also indicates the date of the parent thread in text (e.g. `Ask HN: Who is hiring? (March 2021)`)
This dataset is not programmatically reproducible from source because it was uploaded as an experiment with HF datasets. The raw data was created by querying the public table `bigquery-public-data.hacker_news.full` in Google BigQuery.
Email addresses have been redacted from the dataset.
If this dataset is interesting/useful, I (Dan Becker) will look into improving reproducibility and other general clean-up.
This dataset may be useful for finding trends in tech and tech job listings. | dansbecker/hackernews_hiring_posts | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-12-07T13:46:20+00:00 | []
| []
| TAGS
#region-us
| This dataset contains postings and comments from the following recurring threads on Hacker News
1. Ask HN: Who is hiring?
2. Ask HN: Who wants to be hired?
3. Freelancer? Seeking freelancer?
These post types are stored in datasets called 'hiring', 'wants_to_be_hired' and 'freelancer' respectively.
Each type of posting has occurred on a regular basis for several years. You can identify when each comment/listing was added through the CommentTime field. The 'ParentTitle' also indicates the date of the parent thread in text (e.g. 'Ask HN: Who is hiring? (March 2021)')
This dataset is not programmatically reproducible from source because it was uploaded as an experiment with HF datasets. The raw data was created by querying the public table 'bigquery-public-data.hacker_news.full' in Google BigQuery.
Email addresses have been redacted from the dataset.
If this dataset is interesting/useful, I (Dan Becker) will look into improving reproducibility and other general clean-up.
This dataset may be useful for finding trends in tech and tech job listings. | []
| [
"TAGS\n#region-us \n"
]
|
6c892e1bee3fc78527d31d4183c11f343c2fcb23 | # Dataset Card for Heritage Made Digital Newspapers
## Table of Contents
- [Dataset Card for Heritage Made Digital Newspapers](#dataset-card-for-heritage-made-digital-newspapers)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://bl.iro.bl.uk/?locale=en
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains text extracted at the article level from historic digitised newspapers from the [Heritage Made Digital](https://bl.iro.bl.uk/collections/9a6a4cdd-2bfe-47bb-8c14-c0a5d100501f?locale=en) newspaper digitisation program at the [British Library](https://www.bl.uk/). The newspapers in the dataset were published between 1800 and 1896. This dataset contains ~2.5 billion tokens and 3,065,408 articles.
The dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software.
### Supported Tasks and Leaderboards
This dataset can be used for:
- historical research and digital humanities research
- training language models
- training historic language models
Whilst this dataset can be used for all of these tasks, it is important to understand that the dataset was not constructed in a representative way so it contains biases in terms of the newspapers and articles that are included (more on this below).
### Languages
The text in this dataset is in English that has been recognised by the OCR software. The OCR software used is generic commercial OCR software that has not been trained on historic newspapers. There are therefore many errors in the text. Some of the OCR in this text will be of such poor quality that is is incomprehensible to a human reader.
## Dataset Structure
### Data Instances
Each row in the dataset is an article from a newspaper as recognised by an OLR (Optical Layout Recognition) step in the digitisation process.
### Data Splits
There is one split in this dataset, the training split.
## Dataset Creation
### Curation Rationale
This dataset consists of public-domain newspapers published in the UK during the 19th Century. The majority of newspapers digitised in the UK are not freely available (even if they are out of copyright). The newspapers in this dataset were digitised specifically to be freely available but also to meet preservation goals for newspapers in poor condition. As a result, the newspapers chosen for digitisation are biased toward poor quality physical newspapers. This may in turn result in worse OCR.
### Source Data
The source data for this dataset is the digitised newspapers from the [Heritage Made Digital](https://bl.iro.bl.uk/collections/9a6a4cdd-2bfe-47bb-8c14-c0a5d100501f?locale=en) newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870.
### Dataset Curators
The original digitisation was carried out by the British Library. The dataset was created by the British Library in partnership with Findmypast.
This dataset was created by [@davanstrien](https://huggingface.co/davanstrien).
### Licensing Information
The newspapers in this dataset are in the public domain. The dataset is licensed under a [Creative Commons Zero v1.0 Universal](https://creativecommons.org/publicdomain/zero/1.0/) license.
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| biglam/hmd_newspapers | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:en",
"license:cc0-1.0",
"newspapers",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["en"], "license": "cc0-1.0", "size_categories": ["1M<n<10M"], "task_categories": ["text-generation"], "pretty_name": "Heritage Made Digital Newspapers", "dataset_info": {"features": [{"name": "source", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "location", "dtype": "string"}, {"name": "date", "dtype": "timestamp[s]"}, {"name": "item_type", "dtype": "string"}, {"name": "word_count", "dtype": "int32"}, {"name": "ocr_quality_mean", "dtype": "float64"}, {"name": "ocr_quality_sd", "dtype": "float64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 14304741164, "num_examples": 3065408}], "download_size": 9682476047, "dataset_size": 14304741164}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "tags": ["newspapers"]} | 2024-01-30T12:06:17+00:00 | []
| [
"en"
]
| TAGS
#task_categories-text-generation #size_categories-1M<n<10M #language-English #license-cc0-1.0 #newspapers #region-us
| # Dataset Card for Heritage Made Digital Newspapers
## Table of Contents
- Dataset Card for Heritage Made Digital Newspapers
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository: URL
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset contains text extracted at the article level from historic digitised newspapers from the Heritage Made Digital newspaper digitisation program at the British Library. The newspapers in the dataset were published between 1800 and 1896. This dataset contains ~2.5 billion tokens and 3,065,408 articles.
The dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software.
### Supported Tasks and Leaderboards
This dataset can be used for:
- historical research and digital humanities research
- training language models
- training historic language models
Whilst this dataset can be used for all of these tasks, it is important to understand that the dataset was not constructed in a representative way so it contains biases in terms of the newspapers and articles that are included (more on this below).
### Languages
The text in this dataset is in English that has been recognised by the OCR software. The OCR software used is generic commercial OCR software that has not been trained on historic newspapers. There are therefore many errors in the text. Some of the OCR in this text will be of such poor quality that is is incomprehensible to a human reader.
## Dataset Structure
### Data Instances
Each row in the dataset is an article from a newspaper as recognised by an OLR (Optical Layout Recognition) step in the digitisation process.
### Data Splits
There is one split in this dataset, the training split.
## Dataset Creation
### Curation Rationale
This dataset consists of public-domain newspapers published in the UK during the 19th Century. The majority of newspapers digitised in the UK are not freely available (even if they are out of copyright). The newspapers in this dataset were digitised specifically to be freely available but also to meet preservation goals for newspapers in poor condition. As a result, the newspapers chosen for digitisation are biased toward poor quality physical newspapers. This may in turn result in worse OCR.
### Source Data
The source data for this dataset is the digitised newspapers from the Heritage Made Digital newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870.
### Dataset Curators
The original digitisation was carried out by the British Library. The dataset was created by the British Library in partnership with Findmypast.
This dataset was created by @davanstrien.
### Licensing Information
The newspapers in this dataset are in the public domain. The dataset is licensed under a Creative Commons Zero v1.0 Universal license.
### Contributions
Thanks to @github-username for adding this dataset.
| [
"# Dataset Card for Heritage Made Digital Newspapers",
"## Table of Contents\n- Dataset Card for Heritage Made Digital Newspapers\n - Table of Contents\n - Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n - Dataset Structure\n - Data Instances\n - Data Splits\n - Dataset Creation\n - Curation Rationale\n - Source Data\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository: URL\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains text extracted at the article level from historic digitised newspapers from the Heritage Made Digital newspaper digitisation program at the British Library. The newspapers in the dataset were published between 1800 and 1896. This dataset contains ~2.5 billion tokens and 3,065,408 articles. \n\nThe dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software.",
"### Supported Tasks and Leaderboards\n\nThis dataset can be used for:\n- historical research and digital humanities research\n- training language models\n- training historic language models\n\nWhilst this dataset can be used for all of these tasks, it is important to understand that the dataset was not constructed in a representative way so it contains biases in terms of the newspapers and articles that are included (more on this below).",
"### Languages\n\nThe text in this dataset is in English that has been recognised by the OCR software. The OCR software used is generic commercial OCR software that has not been trained on historic newspapers. There are therefore many errors in the text. Some of the OCR in this text will be of such poor quality that is is incomprehensible to a human reader.",
"## Dataset Structure",
"### Data Instances\n\nEach row in the dataset is an article from a newspaper as recognised by an OLR (Optical Layout Recognition) step in the digitisation process.",
"### Data Splits\n\nThere is one split in this dataset, the training split.",
"## Dataset Creation",
"### Curation Rationale\n\nThis dataset consists of public-domain newspapers published in the UK during the 19th Century. The majority of newspapers digitised in the UK are not freely available (even if they are out of copyright). The newspapers in this dataset were digitised specifically to be freely available but also to meet preservation goals for newspapers in poor condition. As a result, the newspapers chosen for digitisation are biased toward poor quality physical newspapers. This may in turn result in worse OCR.",
"### Source Data\n\nThe source data for this dataset is the digitised newspapers from the Heritage Made Digital newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870.",
"### Dataset Curators\n\nThe original digitisation was carried out by the British Library. The dataset was created by the British Library in partnership with Findmypast. \n\nThis dataset was created by @davanstrien.",
"### Licensing Information\n\nThe newspapers in this dataset are in the public domain. The dataset is licensed under a Creative Commons Zero v1.0 Universal license.",
"### Contributions\n\nThanks to @github-username for adding this dataset."
]
| [
"TAGS\n#task_categories-text-generation #size_categories-1M<n<10M #language-English #license-cc0-1.0 #newspapers #region-us \n",
"# Dataset Card for Heritage Made Digital Newspapers",
"## Table of Contents\n- Dataset Card for Heritage Made Digital Newspapers\n - Table of Contents\n - Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n - Dataset Structure\n - Data Instances\n - Data Splits\n - Dataset Creation\n - Curation Rationale\n - Source Data\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository: URL\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains text extracted at the article level from historic digitised newspapers from the Heritage Made Digital newspaper digitisation program at the British Library. The newspapers in the dataset were published between 1800 and 1896. This dataset contains ~2.5 billion tokens and 3,065,408 articles. \n\nThe dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software.",
"### Supported Tasks and Leaderboards\n\nThis dataset can be used for:\n- historical research and digital humanities research\n- training language models\n- training historic language models\n\nWhilst this dataset can be used for all of these tasks, it is important to understand that the dataset was not constructed in a representative way so it contains biases in terms of the newspapers and articles that are included (more on this below).",
"### Languages\n\nThe text in this dataset is in English that has been recognised by the OCR software. The OCR software used is generic commercial OCR software that has not been trained on historic newspapers. There are therefore many errors in the text. Some of the OCR in this text will be of such poor quality that is is incomprehensible to a human reader.",
"## Dataset Structure",
"### Data Instances\n\nEach row in the dataset is an article from a newspaper as recognised by an OLR (Optical Layout Recognition) step in the digitisation process.",
"### Data Splits\n\nThere is one split in this dataset, the training split.",
"## Dataset Creation",
"### Curation Rationale\n\nThis dataset consists of public-domain newspapers published in the UK during the 19th Century. The majority of newspapers digitised in the UK are not freely available (even if they are out of copyright). The newspapers in this dataset were digitised specifically to be freely available but also to meet preservation goals for newspapers in poor condition. As a result, the newspapers chosen for digitisation are biased toward poor quality physical newspapers. This may in turn result in worse OCR.",
"### Source Data\n\nThe source data for this dataset is the digitised newspapers from the Heritage Made Digital newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870.",
"### Dataset Curators\n\nThe original digitisation was carried out by the British Library. The dataset was created by the British Library in partnership with Findmypast. \n\nThis dataset was created by @davanstrien.",
"### Licensing Information\n\nThe newspapers in this dataset are in the public domain. The dataset is licensed under a Creative Commons Zero v1.0 Universal license.",
"### Contributions\n\nThanks to @github-username for adding this dataset."
]
|
01740f7cd9ffa5855819bd828d5dcb03578abf0e | # Reddit Randomness Dataset
A dataset I created because I was curious about how "random" r/random really is.
This data was collected by sending `GET` requests to `https://www.reddit.com/r/random` for a few hours on September 19th, 2021.
I scraped a bit of metadata about the subreddits as well.
`randomness_12k_clean.csv` reports the random subreddits as they happened and `summary.csv` lists some metadata about each subreddit.
# The Data
## `randomness_12k_clean.csv`
This file serves as a record of the 12,055 successful results I got from r/random.
Each row represents one result.
### Fields
* `subreddit`: The name of the subreddit that the scraper recieved from r/random (`string`)
* `response_code`: HTTP response code the scraper recieved when it sent a `GET` request to /r/random (`int`, always `302`)
## `summary.csv`
As the name suggests, this file summarizes `randomness_12k_clean.csv` into the information that I cared about when I analyzed this data.
Each row represents one of the 3,679 unique subreddits and includes some stats about the subreddit as well as the number of times it appears in the results.
### Fields
* `subreddit`: The name of the subreddit (`string`, unique)
* `subscribers`: How many subscribers the subreddit had (`int`, max of `99_886`)
* `current_users`: How many users accessed the subreddit in the past 15 minutes (`int`, max of `999`)
* `creation_date`: Date that the subreddit was created (`YYYY-MM-DD` or `Error:PrivateSub` or `Error:Banned`)
* `date_accessed`: Date that I collected the values in `subscribers` and `current_users` (`YYYY-MM-DD`)
* `time_accessed_UTC`: Time that I collected the values in `subscribers` and `current_users`, reported in UTC+0 (`HH:MM:SS`)
* `appearances`: How many times the subreddit shows up in `randomness_12k_clean.csv` (`int`, max of `9`)
# Missing Values and Quirks
In the `summary.csv` file, there are three missing values.
After I collected the number of subscribers and the number of current users, I went back about a week later to collect the creation date of each subreddit.
In that week, three subreddits had been banned or taken private. I filled in the values with a descriptive string.
* SomethingWasWrong (`Error:PrivateSub`)
* HannahowoOnlyfans (`Error:Banned`)
* JanetGuzman (`Error:Banned`)
I think there are a few NSFW subreddits in the results, even though I only queried r/random and not r/randnsfw.
As a simple example, searching the data for "nsfw" shows that I got the subreddit r/nsfwanimegifs twice.
# License
This dataset is made available under the Open Database License: http://opendatacommons.org/licenses/odbl/1.0/. Any rights in individual contents of the database are licensed under the Database Contents License: http://opendatacommons.org/licenses/dbcl/1.0/ | davidwisdom/reddit-randomness | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-11-06T23:56:43+00:00 | []
| []
| TAGS
#region-us
| # Reddit Randomness Dataset
A dataset I created because I was curious about how "random" r/random really is.
This data was collected by sending 'GET' requests to 'URL for a few hours on September 19th, 2021.
I scraped a bit of metadata about the subreddits as well.
'randomness_12k_clean.csv' reports the random subreddits as they happened and 'URL' lists some metadata about each subreddit.
# The Data
## 'randomness_12k_clean.csv'
This file serves as a record of the 12,055 successful results I got from r/random.
Each row represents one result.
### Fields
* 'subreddit': The name of the subreddit that the scraper recieved from r/random ('string')
* 'response_code': HTTP response code the scraper recieved when it sent a 'GET' request to /r/random ('int', always '302')
## 'URL'
As the name suggests, this file summarizes 'randomness_12k_clean.csv' into the information that I cared about when I analyzed this data.
Each row represents one of the 3,679 unique subreddits and includes some stats about the subreddit as well as the number of times it appears in the results.
### Fields
* 'subreddit': The name of the subreddit ('string', unique)
* 'subscribers': How many subscribers the subreddit had ('int', max of '99_886')
* 'current_users': How many users accessed the subreddit in the past 15 minutes ('int', max of '999')
* 'creation_date': Date that the subreddit was created ('YYYY-MM-DD' or 'Error:PrivateSub' or 'Error:Banned')
* 'date_accessed': Date that I collected the values in 'subscribers' and 'current_users' ('YYYY-MM-DD')
* 'time_accessed_UTC': Time that I collected the values in 'subscribers' and 'current_users', reported in UTC+0 ('HH:MM:SS')
* 'appearances': How many times the subreddit shows up in 'randomness_12k_clean.csv' ('int', max of '9')
# Missing Values and Quirks
In the 'URL' file, there are three missing values.
After I collected the number of subscribers and the number of current users, I went back about a week later to collect the creation date of each subreddit.
In that week, three subreddits had been banned or taken private. I filled in the values with a descriptive string.
* SomethingWasWrong ('Error:PrivateSub')
* HannahowoOnlyfans ('Error:Banned')
* JanetGuzman ('Error:Banned')
I think there are a few NSFW subreddits in the results, even though I only queried r/random and not r/randnsfw.
As a simple example, searching the data for "nsfw" shows that I got the subreddit r/nsfwanimegifs twice.
# License
This dataset is made available under the Open Database License: URL Any rights in individual contents of the database are licensed under the Database Contents License: URL | [
"# Reddit Randomness Dataset\nA dataset I created because I was curious about how \"random\" r/random really is.\nThis data was collected by sending 'GET' requests to 'URL for a few hours on September 19th, 2021.\nI scraped a bit of metadata about the subreddits as well.\n'randomness_12k_clean.csv' reports the random subreddits as they happened and 'URL' lists some metadata about each subreddit.",
"# The Data",
"## 'randomness_12k_clean.csv'\nThis file serves as a record of the 12,055 successful results I got from r/random.\nEach row represents one result.",
"### Fields\n* 'subreddit': The name of the subreddit that the scraper recieved from r/random ('string')\n* 'response_code': HTTP response code the scraper recieved when it sent a 'GET' request to /r/random ('int', always '302')",
"## 'URL'\nAs the name suggests, this file summarizes 'randomness_12k_clean.csv' into the information that I cared about when I analyzed this data.\nEach row represents one of the 3,679 unique subreddits and includes some stats about the subreddit as well as the number of times it appears in the results.",
"### Fields\n* 'subreddit': The name of the subreddit ('string', unique)\n* 'subscribers': How many subscribers the subreddit had ('int', max of '99_886') \n* 'current_users': How many users accessed the subreddit in the past 15 minutes ('int', max of '999')\n* 'creation_date': Date that the subreddit was created ('YYYY-MM-DD' or 'Error:PrivateSub' or 'Error:Banned')\n* 'date_accessed': Date that I collected the values in 'subscribers' and 'current_users' ('YYYY-MM-DD')\n* 'time_accessed_UTC': Time that I collected the values in 'subscribers' and 'current_users', reported in UTC+0 ('HH:MM:SS')\n* 'appearances': How many times the subreddit shows up in 'randomness_12k_clean.csv' ('int', max of '9')",
"# Missing Values and Quirks\nIn the 'URL' file, there are three missing values. \nAfter I collected the number of subscribers and the number of current users, I went back about a week later to collect the creation date of each subreddit.\nIn that week, three subreddits had been banned or taken private. I filled in the values with a descriptive string.\n* SomethingWasWrong ('Error:PrivateSub')\n* HannahowoOnlyfans ('Error:Banned')\n* JanetGuzman ('Error:Banned')\n\nI think there are a few NSFW subreddits in the results, even though I only queried r/random and not r/randnsfw. \nAs a simple example, searching the data for \"nsfw\" shows that I got the subreddit r/nsfwanimegifs twice.",
"# License\nThis dataset is made available under the Open Database License: URL Any rights in individual contents of the database are licensed under the Database Contents License: URL"
]
| [
"TAGS\n#region-us \n",
"# Reddit Randomness Dataset\nA dataset I created because I was curious about how \"random\" r/random really is.\nThis data was collected by sending 'GET' requests to 'URL for a few hours on September 19th, 2021.\nI scraped a bit of metadata about the subreddits as well.\n'randomness_12k_clean.csv' reports the random subreddits as they happened and 'URL' lists some metadata about each subreddit.",
"# The Data",
"## 'randomness_12k_clean.csv'\nThis file serves as a record of the 12,055 successful results I got from r/random.\nEach row represents one result.",
"### Fields\n* 'subreddit': The name of the subreddit that the scraper recieved from r/random ('string')\n* 'response_code': HTTP response code the scraper recieved when it sent a 'GET' request to /r/random ('int', always '302')",
"## 'URL'\nAs the name suggests, this file summarizes 'randomness_12k_clean.csv' into the information that I cared about when I analyzed this data.\nEach row represents one of the 3,679 unique subreddits and includes some stats about the subreddit as well as the number of times it appears in the results.",
"### Fields\n* 'subreddit': The name of the subreddit ('string', unique)\n* 'subscribers': How many subscribers the subreddit had ('int', max of '99_886') \n* 'current_users': How many users accessed the subreddit in the past 15 minutes ('int', max of '999')\n* 'creation_date': Date that the subreddit was created ('YYYY-MM-DD' or 'Error:PrivateSub' or 'Error:Banned')\n* 'date_accessed': Date that I collected the values in 'subscribers' and 'current_users' ('YYYY-MM-DD')\n* 'time_accessed_UTC': Time that I collected the values in 'subscribers' and 'current_users', reported in UTC+0 ('HH:MM:SS')\n* 'appearances': How many times the subreddit shows up in 'randomness_12k_clean.csv' ('int', max of '9')",
"# Missing Values and Quirks\nIn the 'URL' file, there are three missing values. \nAfter I collected the number of subscribers and the number of current users, I went back about a week later to collect the creation date of each subreddit.\nIn that week, three subreddits had been banned or taken private. I filled in the values with a descriptive string.\n* SomethingWasWrong ('Error:PrivateSub')\n* HannahowoOnlyfans ('Error:Banned')\n* JanetGuzman ('Error:Banned')\n\nI think there are a few NSFW subreddits in the results, even though I only queried r/random and not r/randnsfw. \nAs a simple example, searching the data for \"nsfw\" shows that I got the subreddit r/nsfwanimegifs twice.",
"# License\nThis dataset is made available under the Open Database License: URL Any rights in individual contents of the database are licensed under the Database Contents License: URL"
]
|
6e8e9947c03e380226bb9b3e2e1839d8bd2c05d2 |
# Dataset Card for Artificial Argument Analysis Corpus (AAAC)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Construction of the Synthetic Data](#construction-of-the-synthetic-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://debatelab.github.io/journal/deepa2.html
- **Repository:** None
- **Paper:** G. Betz, K. Richardson. *DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models*. https://arxiv.org/abs/2110.01509
- **Leaderboard:** None
### Dataset Summary
DeepA2 is a modular framework for deep argument analysis. DeepA2 datasets contain comprehensive logical reconstructions of informally presented arguments in short argumentative texts. This document describes two synthetic DeepA2 datasets for artificial argument analysis: AAAC01 and AAAC02.
```sh
# clone
git lfs clone https://huggingface.co/datasets/debatelab/aaac
```
```python
import pandas as pd
from datasets import Dataset
# loading train split as pandas df
df = pd.read_json("aaac/aaac01_train.jsonl", lines=True, orient="records")
# creating dataset from pandas df
Dataset.from_pandas(df)
```
### Supported Tasks and Leaderboards
The multi-dimensional datasets can be used to define various text-2-text tasks (see also [Betz and Richardson 2021](https://arxiv.org/abs/2110.01509)), for example:
* Premise extraction,
* Conclusion extraction,
* Logical formalization,
* Logical reconstrcution.
### Languages
English.
## Dataset Structure
### Data Instances
The following histograms (number of dataset records with given property) describe and compare the two datasets AAAC01 (train split, N=16000) and AAAC02 (dev split, N=4000).
|AAAC01 / train split|AAAC02 / dev split|
|-|-|
| | |
|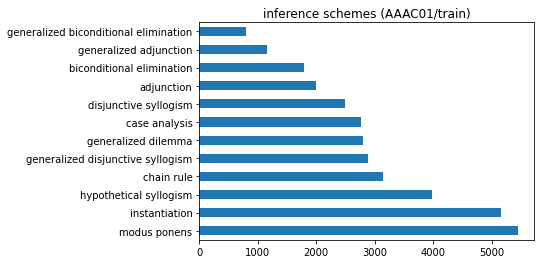 |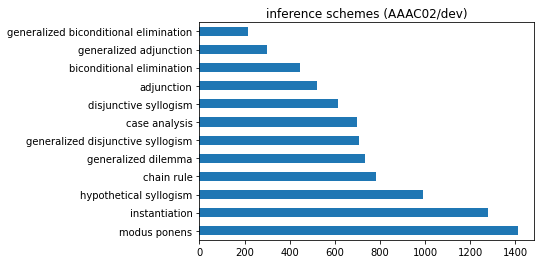 |
|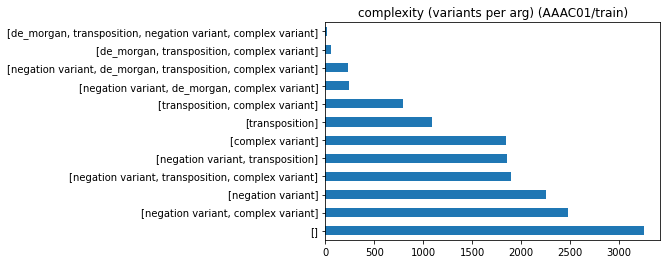 |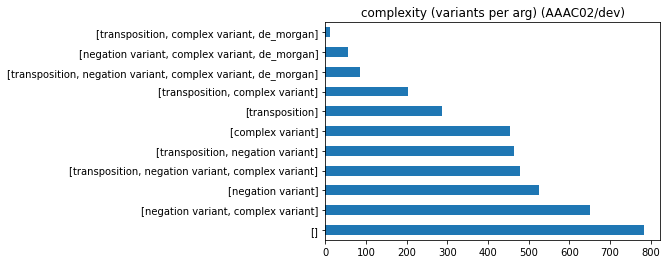 |
| | |
| | |
| | |
| | |
| | |
### Data Fields
The following multi-dimensional example record (2-step argument with one implicit premise) illustrates the structure of the AAAC datasets.
#### argument_source
```
If someone was discovered in 'Moonlight', then they won't play the lead in 'Booksmart',
because being a candidate for the lead in 'Booksmart' is sufficient for not being an
Oscar-Nominee for a role in 'Eighth Grade'. Yet every BAFTA-Nominee for a role in 'The
Shape of Water' is a fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'.
And if someone is a supporting actor in 'Black Panther', then they could never become the
main actor in 'Booksmart'. Consequently, if someone is a BAFTA-Nominee for a role in
'The Shape of Water', then they are not a candidate for the lead in 'Booksmart'.
```
#### reason_statements
```json
[
{"text":"being a candidate for the lead in 'Booksmart' is sufficient for
not being an Oscar-Nominee for a role in 'Eighth Grade'","starts_at":96,
"ref_reco":2},
{"text":"every BAFTA-Nominee for a role in 'The Shape of Water' is a
fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'",
"starts_at":221,"ref_reco":4},
{"text":"if someone is a supporting actor in 'Black Panther', then they
could never become the main actor in 'Booksmart'","starts_at":359,
"ref_reco":5}
]
```
#### conclusion_statements
```json
[
{"text":"If someone was discovered in 'Moonlight', then they won't play the
lead in 'Booksmart'","starts_at":0,"ref_reco":3},
{"text":"if someone is a BAFTA-Nominee for a role in 'The Shape of Water',
then they are not a candidate for the lead in 'Booksmart'","starts_at":486,
"ref_reco":6}
]
```
#### distractors
`[]`
#### argdown_reconstruction
```
(1) If someone is a fan-favourite since 'Moonlight', then they are an Oscar-Nominee for a role in 'Eighth Grade'.
(2) If someone is a candidate for the lead in 'Booksmart', then they are not an Oscar-Nominee for a role in 'Eighth Grade'.
--
with hypothetical syllogism {variant: ["negation variant", "transposition"], uses: [1,2]}
--
(3) If someone is beloved for their role in 'Moonlight', then they don't audition in
'Booksmart'.
(4) If someone is a BAFTA-Nominee for a role in 'The Shape of Water', then they are a fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'.
(5) If someone is a supporting actor in 'Black Panther', then they don't audition in
'Booksmart'.
--
with generalized dilemma {variant: ["negation variant"], uses: [3,4,5]}
--
(6) If someone is a BAFTA-Nominee for a role in 'The Shape of Water', then they are not a
candidate for the lead in 'Booksmart'.
```
#### premises
```json
[
{"ref_reco":1,"text":"If someone is a fan-favourite since 'Moonlight', then
they are an Oscar-Nominee for a role in 'Eighth Grade'.","explicit":false},
{"ref_reco":2,"text":"If someone is a candidate for the lead in
'Booksmart', then they are not an Oscar-Nominee for a role in 'Eighth
Grade'.","explicit":true},
{"ref_reco":4,"text":"If someone is a BAFTA-Nominee for a role in 'The
Shape of Water', then they are a fan-favourite since 'Moonlight' or a
supporting actor in 'Black Panther'.","explicit":true},
{"ref_reco":5,"text":"If someone is a supporting actor in 'Black Panther',
then they don't audition in 'Booksmart'.","explicit":true}
]
```
#### premises_formalized
```json
[
{"form":"(x): ${F2}x -> ${F5}x","ref_reco":1},
{"form":"(x): ${F4}x -> ¬${F5}x","ref_reco":2},
{"form":"(x): ${F1}x -> (${F2}x v ${F3}x)","ref_reco":4},
{"form":"(x): ${F3}x -> ¬${F4}x","ref_reco":5}
]
```
#### conclusion
```json
[{"ref_reco":6,"text":"If someone is a BAFTA-Nominee for a role in 'The Shape
of Water', then they are not a candidate for the lead in 'Booksmart'.",
"explicit":true}]
```
#### conclusion_formalized
```json
[{"form":"(x): ${F1}x -> ¬${F4}x","ref_reco":6}]
```
#### intermediary_conclusions
```json
[{"ref_reco":3,"text":"If someone is beloved for their role in 'Moonlight',
then they don't audition in 'Booksmart'.","explicit":true}]
```
#### intermediary_conclusions_formalized
```json
[{"form":"(x): ${F2}x -> ¬${F4}x","ref_reco":3}]
```
#### plcd_subs
```json
{
"F1":"BAFTA-Nominee for a role in 'The Shape of Water'",
"F2":"fan-favourite since 'Moonlight'",
"F3":"supporting actor in 'Black Panther'",
"F4":"candidate for the lead in 'Booksmart'",
"F5":"Oscar-Nominee for a role in 'Eighth Grade'"
}
```
### Data Splits
Number of instances in the various splits:
| Split | AAAC01 | AAAC02 |
| :--- | :---: | :---: |
| TRAIN | 16,000 | 16,000 |
| DEV | 4,000 | 4,000 |
| TEST | 4,000 | 4,000 |
To correctly load a specific split, define `data_files` as follows:
```python
>>> data_files = {"train": "aaac01_train.jsonl", "eval": "aaac01_dev.jsonl", "test": "aaac01_test.jsonl"}
>>> dataset = load_dataset("debatelab/aaac", data_files=data_files)
```
## Dataset Creation
### Curation Rationale
Argument analysis refers to the interpretation and logical reconstruction of argumentative texts. Its goal is to make an argument transparent, so as to understand, appreciate and (possibly) criticize it. Argument analysis is a key critical thinking skill.
Here's a first example of an informally presented argument, **Descartes' Cogito**:
> I have convinced myself that there is absolutely nothing in the world, no sky, no earth, no minds, no bodies. Does it now follow that I too do not exist? No: if I convinced myself of something then I certainly existed. But there is a deceiver of supreme power and cunning who is deliberately and constantly deceiving me. In that case I too undoubtedly exist, if he is deceiving me; and let him deceive me as much as he can, he will never bring it about that I am nothing so long as I think that I am something. So after considering everything very thoroughly, I must finally conclude that this proposition, I am, I exist, is necessarily true whenever it is put forward by me or conceived in my mind. (AT 7:25, CSM 2:16f)
And here's a second example, taken from the *Debater's Handbook*, **Pro Censorship**:
> Freedom of speech is never an absolute right but an aspiration. It ceases to be a right when it causes harm to others -- we all recognise the value of, for example, legislating against incitement to racial hatred. Therefore it is not the case that censorship is wrong in principle.
Given such texts, argument analysis aims at answering the following questions:
1. Does the text present an argument?
2. If so, how many?
3. What is the argument supposed to show (conclusion)?
4. What exactly are the premises of the argument?
* Which statements, explicit in the text, are not relevant for the argument?
* Which premises are required, but not explicitly stated?
5. Is the argument deductively valid, inductively strong, or simply fallacious?
To answer these questions, argument analysts **interpret** the text by (re-)constructing its argument in a standardized way (typically as a premise-conclusion list) and by making use of logical streamlining and formalization.
A reconstruction of **Pro Censorship** which answers the above questions is:
```argdown
(1) Freedom of speech is never an absolute right but an aspiration.
(2) Censorship is wrong in principle only if freedom of speech is an
absolute right.
--with modus tollens--
(3) It is not the case that censorship is wrong in principle
```
There are typically multiple, more or less different interpretations and logical reconstructions of an argumentative text. For instance, there exists an [extensive debate](https://plato.stanford.edu/entries/descartes-epistemology/) about how to interpret **Descartes' Cogito**, and scholars have advanced rival interpretation of the argument. An alternative reconstruction of the much simpler **Pro Censorship** might read:
```argdown
(1) Legislating against incitement to racial hatred is valuable.
(2) Legislating against incitement to racial hatred is an instance of censorship.
(3) If some instance of censorship is valuable, censorship is not wrong in
principle.
-----
(4) Censorship is not wrong in principle.
(5) Censorship is wrong in principle only if and only if freedom of speech
is an absolute right.
-----
(4) Freedom of speech is not an absolute right.
(5) Freedom of speech is an absolute right or an aspiration.
--with disjunctive syllogism--
(6) Freedom of speech is an aspiration.
```
What are the main reasons for this kind of underdetermination?
* **Incompleteness.** Many relevant parts of an argument (statements, their function in the argument, inference rules, argumentative goals) are not stated in its informal presentation. The argument analyst must infer the missing parts.
* **Additional material.** Over and above what is strictly part of the argument, informal presentations contain typically further material: relevant premises are repeated in slightly different ways, further examples are added to illustrate a point, statements are contrasted with views by opponents, etc. etc. It's argument analyst to choice which of the presented material is really part of the argument.
* **Errors.** Authors may err in the presentation of an argument, confounding, e.g., necessary and sufficient conditions in stating a premise. Following the principle of charity, benevolent argument analysts correct such errors and have to choose on of the different ways for how to do so.
* **Linguistic indeterminacy.** One and the same statement can be interpreted -- regarding its logical form -- in different ways.
* **Equivalence.** There are different natural language expressions for one and the same proposition.
AAAC datasets provide logical reconstructions of informal argumentative texts: Each record contains a source text to-be-reconstructed and further fields which describe an internally consistent interpretation of the text, notwithstanding the fact that there might be alternative interpretations of this very text.
### Construction of the Synthetic Data
Argument analysis starts with a text and reconstructs its argument (cf. [Motivation and Background](#curation-rationale)). In constructing our synthetic data, we inverse this direction: We start by sampling a complete argument, construct an informal presentation, and provide further info that describes both logical reconstruction and informal presentation. More specifically, the construction of the data involves the following steps:
1. [Generation of valid symbolic inference schemes](#step-1-generation-of-symbolic-inference-schemes)
2. [Assembling complex ("multi-hop") argument schemes from symbolic inference schemes](#step-2-assembling-complex-multi-hop-argument-schemes-from-symbolic-inference-schemes)
3. [Creation of (precise and informal) natural-language argument](#step-3-creation-of-precise-and-informal-natural-language-argument-schemes)
4. [Substitution of placeholders with domain-specific predicates and names](#step-4-substitution-of-placeholders-with-domain-specific-predicates-and-names)
5. [Creation of the argdown-snippet](#step-5-creation-of-the-argdown-snippet)
7. [Paraphrasing](#step-6-paraphrasing)
6. [Construction of a storyline for the argument source text](#step-7-construction-of-a-storyline-for-the-argument-source-text)
8. [Assembling the argument source text](#step-8-assembling-the-argument-source-text)
9. [Linking the precise reconstruction and the informal argumentative text](#step-9-linking-informal-presentation-and-formal-reconstruction)
#### Step 1: Generation of symbolic inference schemes
We construct the set of available inference schemes by systematically transforming the following 12 base schemes (6 from propositional and another 6 from predicate logic):
* modus ponens: `['Fa -> Gb', 'Fa', 'Gb']`
* chain rule: `['Fa -> Gb', 'Gb -> Hc', 'Fa -> Hc']`
* adjunction: `['Fa', 'Gb', 'Fa & Gb']`
* case analysis: `['Fa v Gb', 'Fa -> Hc', 'Gb -> Hc', 'Hc']`
* disjunctive syllogism: `['Fa v Gb', '¬Fa', 'Gb']`
* biconditional elimination: `['Fa <-> Gb', 'Fa -> Gb']`
* instantiation: `['(x): Fx -> Gx', 'Fa -> Ga']`
* hypothetical syllogism: `['(x): Fx -> Gx', '(x): Gx -> Hx', '(x): Fx -> Hx']`
* generalized biconditional elimination: `['(x): Fx <-> Gx', '(x): Fx -> Gx']`
* generalized adjunction: `['(x): Fx -> Gx', '(x): Fx -> Hx', '(x): Fx -> (Gx & Hx)']`
* generalized dilemma: `['(x): Fx -> (Gx v Hx)', '(x): Gx -> Ix', '(x): Hx -> Ix', '(x): Fx -> Ix']`
* generalized disjunctive syllogism: `['(x): Fx -> (Gx v Hx)', '(x): Fx -> ¬Gx', '(x): Fx -> Hx']`
(Regarding the propositional schemes, we allow for `a`=`b`=`c`.)
Further symbolic inference schemes are generated by applying the following transformations to each of these base schemes:
* *negation*: replace all occurrences of an atomic formula by its negation (for any number of such atomic sentences)
* *transposition*: transpose exactly one (generalized) conditional
* *dna*: simplify by applying duplex negatio affirmat
* *complex predicates*: replace all occurrences of a given atomic formula by a complex formula consisting in the conjunction or disjunction of two atomic formulas
* *de morgan*: apply de Morgan's rule once
These transformations are applied to the base schemes in the following order:
> **{base_schemes}** > negation_variants > transposition_variants > dna > **{transposition_variants}** > complex_predicates > negation_variants > dna > **{complex_predicates}** > de_morgan > dna > **{de_morgan}**
All transformations, except *dna*, are monotonic, i.e. simply add further schemes to the ones generated in the previous step. Results of bold steps are added to the list of valid inference schemes. Each inference scheme is stored with information about which transformations were used to create it. All in all, this gives us 5542 schemes.
#### Step 2: Assembling complex ("multi-hop") argument schemes from symbolic inference schemes
The complex argument *scheme*, which consists in multiple inferences, is assembled recursively by adding inferences that support premises of previously added inferences, as described by the following pseudocode:
```
argument = []
intermediary_conclusion = []
inference = randomly choose from list of all schemes
add inference to argument
for i in range(number_of_sub_arguments - 1):
target = randomly choose a premise which is not an intermediary_conclusion
inference = randomly choose a scheme whose conclusion is identical with target
add inference to argument
add target to intermediary_conclusion
return argument
```
The complex arguments we create are hence trees, with a root scheme.
Let's walk through this algorithm by means of an illustrative example and construct a symbolic argument scheme with two sub-arguments. First, we randomly choose some inference scheme (random sampling is controlled by weights that compensate for the fact that the list of schemes mainly contains, for combinatorial reasons, complex inferences), say:
```json
{
"id": "mp",
"base_scheme_group": "modus ponens",
"scheme_variant": ["complex_variant"],
"scheme": [
["${A}${a} -> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}],
["${A}${a}", {"A": "${F}", "a": "${a}"}],
["${A}${a} & ${B}${a}", {"A": "${G}", "B": "${H}", "a": "${a}"}]
],
"predicate-placeholders": ["F", "G", "H"],
"entity-placeholders": ["a"]
}
```
Now, the target premise (= intermediary conclusion) of the next subargument is chosen, say: premise 1 of the already added root scheme. We filter the list of schemes for schemes whose conclusion structurally matches the target, i.e. has the form `${A}${a} -> (${B}${a} v ${C}${a})`. From this filtered list of suitable schemes, we randomly choose, for example
```json
{
"id": "bicelim",
"base_scheme_group": "biconditional elimination",
"scheme_variant": [complex_variant],
"scheme": [
["${A}${a} <-> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}],
["${A}${a} -> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}]
],
"predicate-placeholders": ["F", "G", "H"],
"entity-placeholders": []
}
```
So, we have generated this 2-step symbolic argument scheme with two premises, one intermediary and one final conclusion:
```
(1) Fa <-> Ga & Ha
--
with biconditional elimination (complex variant) from 1
--
(2) Fa -> Ga & Ha
(3) Fa
--
with modus ponens (complex variant) from 2,3
--
(4) Ga & Ha
```
General properties of the argument are now determined and can be stored in the dataset (its `domain` is randomly chosen):
```json
"steps":2, // number of inference steps
"n_premises":2,
"base_scheme_groups":[
"biconditional elimination",
"modus ponens"
],
"scheme_variants":[
"complex variant"
],
"domain_id":"consumers_personalcare",
"domain_type":"persons"
```
#### Step 3: Creation of (precise and informal) natural-language argument schemes
In step 3, the *symbolic and formal* complex argument scheme is transformed into a *natural language* argument scheme by replacing symbolic formulas (e.g., `${A}${a} v ${B}${a}`) with suitable natural language sentence schemes (such as, `${a} is a ${A}, and ${a} is a ${B}` or `${a} is a ${A} and a ${B}`). Natural language sentence schemes which translate symbolic formulas are classified according to whether they are precise, informal, or imprecise.
For each symbolic formula, there are many (partly automatically, partly manually generated) natural-language sentence scheme which render the formula in more or less precise way. Each of these natural-language "translations" of a symbolic formula is labeled according to whether it presents the logical form in a "precise", "informal", or "imprecise" way. e.g.
|type|form|
|-|-|
|symbolic|`(x): ${A}x -> ${B}x`|
|precise|`If someone is a ${A}, then they are a ${B}.`|
|informal|`Every ${A} is a ${B}.`|
|imprecise|`${A} might be a ${B}.`|
The labels "precise", "informal", "imprecise" are used to control the generation of two natural-language versions of the argument scheme, a **precise** one (for creating the argdown snippet) and an **informal** one (for creating the source text). Moreover, the natural-language "translations" are also chosen in view of the domain (see below) of the to-be-generated argument, specifically in view of whether it is quantified over persons ("everyone", "nobody") or objects ("something, nothing").
So, as a **precise** rendition of our symbolic argument scheme, we may obtain:
```
(1) If, and only if, a is a F, then a is G and a is a H.
--
with biconditional elimination (complex variant) from 1
--
(2) If a is a F, then a is a G and a is a H.
(3) a is a F.
--
with modus ponens (complex variant) from 3,2
--
(4) a is G and a is a H.
```
Likewise, an **informal** rendition may be:
```
(1) a is a F if a is both a G and a H -- and vice versa.
--
with biconditional elimination (complex variant) from 1
--
(2) a is a G and a H, provided a is a F.
(3) a is a F.
--
with modus ponens (complex variant) from 3,2
--
(4) a is both a G and a H.
```
#### Step 4: Substitution of placeholders with domain-specific predicates and names
Every argument falls within a domain. A domain provides
* a list of `subject names` (e.g., Peter, Sarah)
* a list of `object names` (e.g., New York, Lille)
* a list of `binary predicates` (e.g., [subject is an] admirer of [object])
These domains are manually created.
Replacements for the placeholders are sampled from the corresponding domain. Substitutes for entity placeholders (`a`, `b` etc.) are simply chosen from the list of `subject names`. Substitutes for predicate placeholders (`F`, `G` etc.) are constructed by combining `binary predicates` with `object names`, which yields unary predicates of the form "___ stands in some relation to some object". This combinatorial construction of unary predicates drastically increases the number of replacements available and hence the variety of generated arguments.
Assuming that we sample our argument from the domain `consumers personal care`, we may choose and construct the following substitutes for placeholders in our argument scheme:
* `F`: regular consumer of Kiss My Face soap
* `G`: regular consumer of Nag Champa soap
* `H`: occasional purchaser of Shield soap
* `a`: Orlando
#### Step 5: Creation of the argdown-snippet
From the **precise rendition** of the natural language argument scheme ([step 3](#step-3-creation-of-precise-and-informal-natural-language-argument-schemes)) and the replacements for its placeholders ([step 4](#step-4-substitution-of-placeholders-with-domain-specific-predicates-and-names)), we construct the `argdown-snippet` by simple substitution and formatting the complex argument in accordance with [argdown syntax](https://argdown.org).
This yields, for our example from above:
```argdown
(1) If, and only if, Orlando is a regular consumer of Kiss My Face soap,
then Orlando is a regular consumer of Nag Champa soap and Orlando is
a occasional purchaser of Shield soap.
--
with biconditional elimination (complex variant) from 1
--
(2) If Orlando is a regular consumer of Kiss My Face soap, then Orlando
is a regular consumer of Nag Champa soap and Orlando is a occasional
purchaser of Shield soap.
(3) Orlando is a regular consumer of Kiss My Face soap.
--
with modus ponens (complex variant) from 3,2
--
(4) Orlando is a regular consumer of Nag Champa soap and Orlando is a
occasional purchaser of Shield soap.
```
That's the `argdown_snippet`. By construction of such a synthetic argument (from formal schemes, see [step 2](#step-2-assembling-complex-multi-hop-argument-schemes-from-symbolic-inference-schemes)), we already know its conclusions and their formalization (the value of the field `explicit` will be determined later).
```json
"conclusion":[
{
"ref_reco":4,
"text":"Orlando is a regular consumer of Nag Champa
soap and Orlando is a occasional purchaser of
Shield soap.",
"explicit": TBD
}
],
"conclusion_formalized":[
{
"ref_reco":4,
"form":"(${F2}${a1} & ${F3}${a1})"
}
],
"intermediary_conclusions":[
{
"ref_reco":2,
"text":"If Orlando is a regular consumer of Kiss My
Face soap, then Orlando is a regular consumer of
Nag Champa soap and Orlando is a occasional
purchaser of Shield soap.",
"explicit": TBD
}
]
"intermediary_conclusions_formalized":[
{
"ref_reco":2,
"text":"${F1}${a1} -> (${F2}${a1} & ${F3}${a1})"
}
],
```
... and the corresponding keys (see [step 4](#step-4-substitution-of-placeholders-with-domain-specific-predicates-and-names))):
```json
"plcd_subs":{
"a1":"Orlando",
"F1":"regular consumer of Kiss My Face soap",
"F2":"regular consumer of Nag Champa soap",
"F3":"occasional purchaser of Shield soap"
}
```
#### Step 6: Paraphrasing
From the **informal rendition** of the natural language argument scheme ([step 3](#step-3-creation-of-precise-and-informal-natural-language-argument-schemes)) and the replacements for its placeholders ([step 4](#step-4-substitution-of-placeholders-with-domain-specific-predicates-and-names)), we construct an informal argument (argument tree) by substitution.
The statements (premises, conclusions) of the informal argument are individually paraphrased in two steps
1. rule-based and in a domain-specific way,
2. automatically by means of a specifically fine-tuned T5 model.
Each domain (see [step 4](#step-4-substitution-of-placeholders-with-domain-specific-predicates-and-names)) provides rules for substituting noun constructs ("is a supporter of X", "is a product made of X") with verb constructs ("supports x", "contains X"). These rules are applied whenever possible.
Next, each sentence is -- with a probability specified by parameter `lm_paraphrasing` -- replaced with an automatically generated paraphrase, using a [T5 model fine-tuned on the Google PAWS dataset](https://huggingface.co/Vamsi/T5_Paraphrase_Paws) and filtering for paraphrases with acceptable _cola_ and sufficiently high _STSB_ value (both as predicted by T5).
| |AAAC01|AAAC02|
|-|-|-|
|`lm_paraphrasing`|0.2|0.|
#### Step 7: Construction of a storyline for the argument source text
The storyline determines in which order the premises, intermediary conclusions and final conclusions are to be presented in the text paragraph to-be-constructed (`argument-source`). The storyline is constructed from the paraphrased informal complex argument (see [step 6](#step-6-paraphrasing))).
Before determining the order of presentation (storyline), the informal argument tree is pre-processed to account for:
* implicit premises,
* implicit intermediary conclusions, and
* implicit final conclusion,
which is documented in the dataset record as
```json
"presentation_parameters":{
"resolve_steps":[1],
"implicit_conclusion":false,
"implicit_premise":true,
"...":"..."
}
```
In order to make an intermediary conclusion *C* implicit, the inference to *C* is "resolved" by re-assigning all premisses *from* which *C* is directly inferred *to* the inference to the (final or intermediary) conclusion which *C* supports.
Original tree:
```
P1 ... Pn
—————————
C Q1 ... Qn
—————————————
C'
```
Tree with resolved inference and implicit intermediary conclusion:
```
P1 ... Pn Q1 ... Qn
———————————————————
C'
```
The original argument tree in our example reads:
```
(1)
———
(2) (3)
———————
(4)
```
This might be pre-processed (by resolving the first inference step and dropping the first premise) to:
```
(3)
———
(4)
```
Given such a pre-processed argument tree, a storyline, which determines the order of presentation, can be constructed by specifying the direction of presentation and a starting point. The **direction** is either
* forward (premise AND ... AND premise THEREFORE conclusion)
* backward (conclusion SINCE premise AND ... AND premise)
Any conclusion in the pre-processed argument tree may serve as starting point. The storyline is now constructed recursively, as illustrated in Figure~1. Integer labels of the nodes represent the order of presentation, i.e. the storyline. (Note that the starting point is not necessarily the statement which is presented first according to the storyline.)
So as to introduce redundancy, the storyline may be post-processed by repeating a premiss that has been stated previously. The likelihood that a single premise is repeated is controlled by the presentation parameters:
```json
"presentation_parameters":{
"redundancy_frequency":0.1,
}
```
Moreover, **distractors**, i.e. arbitrary statements sampled from the argument's very domain, may be inserted in the storyline.
#### Step 8: Assembling the argument source text
The `argument-source` is constructed by concatenating the statements of the informal argument ([step 6](#step-6-paraphrasing)) according to the order of the storyline ([step 7](#step-7-construction-of-a-storyline-for-the-argument-source-text)). In principle, each statement is prepended by a conjunction. There are four types of conjunction:
* THEREFORE: left-to-right inference
* SINCE: right-to-left inference
* AND: joins premises with similar inferential role
* MOREOVER: catch all conjunction
Each statement is assigned a specific conjunction type by the storyline.
For every conjunction type, we provide multiple natural-language terms which may figure as conjunctions when concatenating the statements, e.g. "So, necessarily,", "So", "Thus,", "It follows that", "Therefore,", "Consequently,", "Hence,", "In consequence,", "All this entails that", "From this follows that", "We may conclude that" for THEREFORE. The parameter
```json
"presentation_parameters":{
"drop_conj_frequency":0.1,
"...":"..."
}
```
determines the probability that a conjunction is omitted and a statement is concatenated without prepending a conjunction.
With the parameters given above we obtain the following `argument_source` for our example:
> Orlando is a regular consumer of Nag Champa soap and Orlando is a occasional purchaser of Shield soap, since Orlando is a regular consumer of Kiss My Face soap.
#### Step 9: Linking informal presentation and formal reconstruction
We can identify all statements _in the informal presentation_ (`argument_source`), categorize them according to their argumentative function GIVEN the logical reconstruction and link them to the corresponding statements in the `argdown_snippet`. We distinguish `reason_statement` (AKA REASONS, correspond to premises in the reconstruction) and `conclusion_statement` (AKA CONJECTURES, correspond to conclusion and intermediary conclusion in the reconstruction):
```json
"reason_statements":[ // aka reasons
{
"text":"Orlando is a regular consumer of Kiss My Face soap",
"starts_at":109,
"ref_reco":3
}
],
"conclusion_statements":[ // aka conjectures
{
"text":"Orlando is a regular consumer of Nag Champa soap and
Orlando is a occasional purchaser of Shield soap",
"starts_at":0,
"ref_reco":4
}
]
```
Moreover, we are now able to classify all premises in the formal reconstruction (`argdown_snippet`) according to whether they are implicit or explicit given the informal presentation:
```json
"premises":[
{
"ref_reco":1,
"text":"If, and only if, Orlando is a regular consumer of Kiss
My Face soap, then Orlando is a regular consumer of Nag
Champa soap and Orlando is a occasional purchaser of
Shield soap.",
"explicit":False
},
{
"ref_reco":3,
"text":"Orlando is a regular consumer of Kiss My Face soap. ",
"explicit":True
}
],
"premises_formalized":[
{
"ref_reco":1,
"form":"${F1}${a1} <-> (${F2}${a1} & ${F3}${a1})"
},
{
"ref_reco":3,
"form":"${F1}${a1}"
}
]
```
#### Initial Data Collection and Normalization
N.A.
#### Who are the source language producers?
N.A.
### Annotations
#### Annotation process
N.A.
#### Who are the annotators?
N.A.
### Personal and Sensitive Information
N.A.
## Considerations for Using the Data
### Social Impact of Dataset
None
### Discussion of Biases
None
### Other Known Limitations
See [Betz and Richardson 2021](https://arxiv.org/abs/2110.01509).
## Additional Information
### Dataset Curators
Gregor Betz, Kyle Richardson
### Licensing Information
Creative Commons cc-by-sa-4.0
### Citation Information
```
@misc{betz2021deepa2,
title={DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models},
author={Gregor Betz and Kyle Richardson},
year={2021},
eprint={2110.01509},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
<!--Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.-->
| DebateLabKIT/aaac | [
"task_categories:summarization",
"task_categories:text-retrieval",
"task_categories:text-generation",
"task_ids:parsing",
"task_ids:text-simplification",
"annotations_creators:machine-generated",
"annotations_creators:expert-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-sa-4.0",
"argument-mining",
"conditional-text-generation",
"structure-prediction",
"arxiv:2110.01509",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated", "expert-generated"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["summarization", "text-retrieval", "text-generation"], "task_ids": ["parsing", "text-simplification"], "paperswithcode_id": "aaac", "pretty_name": "Artificial Argument Analysis Corpus", "language_bcp47": ["en-US"], "tags": ["argument-mining", "conditional-text-generation", "structure-prediction"]} | 2022-10-24T15:25:56+00:00 | [
"2110.01509"
]
| [
"en"
]
| TAGS
#task_categories-summarization #task_categories-text-retrieval #task_categories-text-generation #task_ids-parsing #task_ids-text-simplification #annotations_creators-machine-generated #annotations_creators-expert-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-sa-4.0 #argument-mining #conditional-text-generation #structure-prediction #arxiv-2110.01509 #region-us
| Dataset Card for Artificial Argument Analysis Corpus (AAAC)
===========================================================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Construction of the Synthetic Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: None
* Paper: G. Betz, K. Richardson. *DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models*. URL
* Leaderboard: None
### Dataset Summary
DeepA2 is a modular framework for deep argument analysis. DeepA2 datasets contain comprehensive logical reconstructions of informally presented arguments in short argumentative texts. This document describes two synthetic DeepA2 datasets for artificial argument analysis: AAAC01 and AAAC02.
### Supported Tasks and Leaderboards
The multi-dimensional datasets can be used to define various text-2-text tasks (see also Betz and Richardson 2021), for example:
* Premise extraction,
* Conclusion extraction,
* Logical formalization,
* Logical reconstrcution.
### Languages
English.
Dataset Structure
-----------------
### Data Instances
The following histograms (number of dataset records with given property) describe and compare the two datasets AAAC01 (train split, N=16000) and AAAC02 (dev split, N=4000).
### Data Fields
The following multi-dimensional example record (2-step argument with one implicit premise) illustrates the structure of the AAAC datasets.
#### argument\_source
#### reason\_statements
#### conclusion\_statements
#### distractors
'[]'
#### argdown\_reconstruction
#### premises
#### premises\_formalized
#### conclusion
#### conclusion\_formalized
#### intermediary\_conclusions
#### intermediary\_conclusions\_formalized
#### plcd\_subs
### Data Splits
Number of instances in the various splits:
To correctly load a specific split, define 'data\_files' as follows:
Dataset Creation
----------------
### Curation Rationale
Argument analysis refers to the interpretation and logical reconstruction of argumentative texts. Its goal is to make an argument transparent, so as to understand, appreciate and (possibly) criticize it. Argument analysis is a key critical thinking skill.
Here's a first example of an informally presented argument, Descartes' Cogito:
>
> I have convinced myself that there is absolutely nothing in the world, no sky, no earth, no minds, no bodies. Does it now follow that I too do not exist? No: if I convinced myself of something then I certainly existed. But there is a deceiver of supreme power and cunning who is deliberately and constantly deceiving me. In that case I too undoubtedly exist, if he is deceiving me; and let him deceive me as much as he can, he will never bring it about that I am nothing so long as I think that I am something. So after considering everything very thoroughly, I must finally conclude that this proposition, I am, I exist, is necessarily true whenever it is put forward by me or conceived in my mind. (AT 7:25, CSM 2:16f)
>
>
>
And here's a second example, taken from the *Debater's Handbook*, Pro Censorship:
>
> Freedom of speech is never an absolute right but an aspiration. It ceases to be a right when it causes harm to others -- we all recognise the value of, for example, legislating against incitement to racial hatred. Therefore it is not the case that censorship is wrong in principle.
>
>
>
Given such texts, argument analysis aims at answering the following questions:
1. Does the text present an argument?
2. If so, how many?
3. What is the argument supposed to show (conclusion)?
4. What exactly are the premises of the argument?
* Which statements, explicit in the text, are not relevant for the argument?
* Which premises are required, but not explicitly stated?
5. Is the argument deductively valid, inductively strong, or simply fallacious?
To answer these questions, argument analysts interpret the text by (re-)constructing its argument in a standardized way (typically as a premise-conclusion list) and by making use of logical streamlining and formalization.
A reconstruction of Pro Censorship which answers the above questions is:
There are typically multiple, more or less different interpretations and logical reconstructions of an argumentative text. For instance, there exists an extensive debate about how to interpret Descartes' Cogito, and scholars have advanced rival interpretation of the argument. An alternative reconstruction of the much simpler Pro Censorship might read:
What are the main reasons for this kind of underdetermination?
* Incompleteness. Many relevant parts of an argument (statements, their function in the argument, inference rules, argumentative goals) are not stated in its informal presentation. The argument analyst must infer the missing parts.
* Additional material. Over and above what is strictly part of the argument, informal presentations contain typically further material: relevant premises are repeated in slightly different ways, further examples are added to illustrate a point, statements are contrasted with views by opponents, etc. etc. It's argument analyst to choice which of the presented material is really part of the argument.
* Errors. Authors may err in the presentation of an argument, confounding, e.g., necessary and sufficient conditions in stating a premise. Following the principle of charity, benevolent argument analysts correct such errors and have to choose on of the different ways for how to do so.
* Linguistic indeterminacy. One and the same statement can be interpreted -- regarding its logical form -- in different ways.
* Equivalence. There are different natural language expressions for one and the same proposition.
AAAC datasets provide logical reconstructions of informal argumentative texts: Each record contains a source text to-be-reconstructed and further fields which describe an internally consistent interpretation of the text, notwithstanding the fact that there might be alternative interpretations of this very text.
### Construction of the Synthetic Data
Argument analysis starts with a text and reconstructs its argument (cf. Motivation and Background). In constructing our synthetic data, we inverse this direction: We start by sampling a complete argument, construct an informal presentation, and provide further info that describes both logical reconstruction and informal presentation. More specifically, the construction of the data involves the following steps:
1. Generation of valid symbolic inference schemes
2. Assembling complex ("multi-hop") argument schemes from symbolic inference schemes
3. Creation of (precise and informal) natural-language argument
4. Substitution of placeholders with domain-specific predicates and names
5. Creation of the argdown-snippet
6. Paraphrasing
7. Construction of a storyline for the argument source text
8. Assembling the argument source text
9. Linking the precise reconstruction and the informal argumentative text
#### Step 1: Generation of symbolic inference schemes
We construct the set of available inference schemes by systematically transforming the following 12 base schemes (6 from propositional and another 6 from predicate logic):
* modus ponens: '['Fa -> Gb', 'Fa', 'Gb']'
* chain rule: '['Fa -> Gb', 'Gb -> Hc', 'Fa -> Hc']'
* adjunction: '['Fa', 'Gb', 'Fa & Gb']'
* case analysis: '['Fa v Gb', 'Fa -> Hc', 'Gb -> Hc', 'Hc']'
* disjunctive syllogism: '['Fa v Gb', '¬Fa', 'Gb']'
* biconditional elimination: '['Fa <-> Gb', 'Fa -> Gb']'
* instantiation: '['(x): Fx -> Gx', 'Fa -> Ga']'
* hypothetical syllogism: '['(x): Fx -> Gx', '(x): Gx -> Hx', '(x): Fx -> Hx']'
* generalized biconditional elimination: '['(x): Fx <-> Gx', '(x): Fx -> Gx']'
* generalized adjunction: '['(x): Fx -> Gx', '(x): Fx -> Hx', '(x): Fx -> (Gx & Hx)']'
* generalized dilemma: '['(x): Fx -> (Gx v Hx)', '(x): Gx -> Ix', '(x): Hx -> Ix', '(x): Fx -> Ix']'
* generalized disjunctive syllogism: '['(x): Fx -> (Gx v Hx)', '(x): Fx -> ¬Gx', '(x): Fx -> Hx']'
(Regarding the propositional schemes, we allow for 'a'='b'='c'.)
Further symbolic inference schemes are generated by applying the following transformations to each of these base schemes:
* *negation*: replace all occurrences of an atomic formula by its negation (for any number of such atomic sentences)
* *transposition*: transpose exactly one (generalized) conditional
* *dna*: simplify by applying duplex negatio affirmat
* *complex predicates*: replace all occurrences of a given atomic formula by a complex formula consisting in the conjunction or disjunction of two atomic formulas
* *de morgan*: apply de Morgan's rule once
These transformations are applied to the base schemes in the following order:
>
> {base\_schemes} > negation\_variants > transposition\_variants > dna > {transposition\_variants} > complex\_predicates > negation\_variants > dna > {complex\_predicates} > de\_morgan > dna > {de\_morgan}
>
>
>
All transformations, except *dna*, are monotonic, i.e. simply add further schemes to the ones generated in the previous step. Results of bold steps are added to the list of valid inference schemes. Each inference scheme is stored with information about which transformations were used to create it. All in all, this gives us 5542 schemes.
#### Step 2: Assembling complex ("multi-hop") argument schemes from symbolic inference schemes
The complex argument *scheme*, which consists in multiple inferences, is assembled recursively by adding inferences that support premises of previously added inferences, as described by the following pseudocode:
The complex arguments we create are hence trees, with a root scheme.
Let's walk through this algorithm by means of an illustrative example and construct a symbolic argument scheme with two sub-arguments. First, we randomly choose some inference scheme (random sampling is controlled by weights that compensate for the fact that the list of schemes mainly contains, for combinatorial reasons, complex inferences), say:
Now, the target premise (= intermediary conclusion) of the next subargument is chosen, say: premise 1 of the already added root scheme. We filter the list of schemes for schemes whose conclusion structurally matches the target, i.e. has the form '${A}${a} -> (${B}${a} v ${C}${a})'. From this filtered list of suitable schemes, we randomly choose, for example
So, we have generated this 2-step symbolic argument scheme with two premises, one intermediary and one final conclusion:
General properties of the argument are now determined and can be stored in the dataset (its 'domain' is randomly chosen):
#### Step 3: Creation of (precise and informal) natural-language argument schemes
In step 3, the *symbolic and formal* complex argument scheme is transformed into a *natural language* argument scheme by replacing symbolic formulas (e.g., '${A}${a} v ${B}${a}') with suitable natural language sentence schemes (such as, '${a} is a ${A}, and ${a} is a ${B}' or '${a} is a ${A} and a ${B}'). Natural language sentence schemes which translate symbolic formulas are classified according to whether they are precise, informal, or imprecise.
For each symbolic formula, there are many (partly automatically, partly manually generated) natural-language sentence scheme which render the formula in more or less precise way. Each of these natural-language "translations" of a symbolic formula is labeled according to whether it presents the logical form in a "precise", "informal", or "imprecise" way. e.g.
The labels "precise", "informal", "imprecise" are used to control the generation of two natural-language versions of the argument scheme, a precise one (for creating the argdown snippet) and an informal one (for creating the source text). Moreover, the natural-language "translations" are also chosen in view of the domain (see below) of the to-be-generated argument, specifically in view of whether it is quantified over persons ("everyone", "nobody") or objects ("something, nothing").
So, as a precise rendition of our symbolic argument scheme, we may obtain:
Likewise, an informal rendition may be:
#### Step 4: Substitution of placeholders with domain-specific predicates and names
Every argument falls within a domain. A domain provides
* a list of 'subject names' (e.g., Peter, Sarah)
* a list of 'object names' (e.g., New York, Lille)
* a list of 'binary predicates' (e.g., [subject is an] admirer of [object])
These domains are manually created.
Replacements for the placeholders are sampled from the corresponding domain. Substitutes for entity placeholders ('a', 'b' etc.) are simply chosen from the list of 'subject names'. Substitutes for predicate placeholders ('F', 'G' etc.) are constructed by combining 'binary predicates' with 'object names', which yields unary predicates of the form "\_\_\_ stands in some relation to some object". This combinatorial construction of unary predicates drastically increases the number of replacements available and hence the variety of generated arguments.
Assuming that we sample our argument from the domain 'consumers personal care', we may choose and construct the following substitutes for placeholders in our argument scheme:
* 'F': regular consumer of Kiss My Face soap
* 'G': regular consumer of Nag Champa soap
* 'H': occasional purchaser of Shield soap
* 'a': Orlando
#### Step 5: Creation of the argdown-snippet
From the precise rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct the 'argdown-snippet' by simple substitution and formatting the complex argument in accordance with argdown syntax.
This yields, for our example from above:
That's the 'argdown\_snippet'. By construction of such a synthetic argument (from formal schemes, see step 2), we already know its conclusions and their formalization (the value of the field 'explicit' will be determined later).
... and the corresponding keys (see step 4)):
#### Step 6: Paraphrasing
From the informal rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct an informal argument (argument tree) by substitution.
The statements (premises, conclusions) of the informal argument are individually paraphrased in two steps
1. rule-based and in a domain-specific way,
2. automatically by means of a specifically fine-tuned T5 model.
Each domain (see step 4) provides rules for substituting noun constructs ("is a supporter of X", "is a product made of X") with verb constructs ("supports x", "contains X"). These rules are applied whenever possible.
Next, each sentence is -- with a probability specified by parameter 'lm\_paraphrasing' -- replaced with an automatically generated paraphrase, using a T5 model fine-tuned on the Google PAWS dataset and filtering for paraphrases with acceptable *cola* and sufficiently high *STSB* value (both as predicted by T5).
AAAC01: 'lm\_paraphrasing', AAAC02: 0.2
#### Step 7: Construction of a storyline for the argument source text
The storyline determines in which order the premises, intermediary conclusions and final conclusions are to be presented in the text paragraph to-be-constructed ('argument-source'). The storyline is constructed from the paraphrased informal complex argument (see step 6)).
Before determining the order of presentation (storyline), the informal argument tree is pre-processed to account for:
* implicit premises,
* implicit intermediary conclusions, and
* implicit final conclusion,
which is documented in the dataset record as
In order to make an intermediary conclusion *C* implicit, the inference to *C* is "resolved" by re-assigning all premisses *from* which *C* is directly inferred *to* the inference to the (final or intermediary) conclusion which *C* supports.
Original tree:
Tree with resolved inference and implicit intermediary conclusion:
The original argument tree in our example reads:
This might be pre-processed (by resolving the first inference step and dropping the first premise) to:
Given such a pre-processed argument tree, a storyline, which determines the order of presentation, can be constructed by specifying the direction of presentation and a starting point. The direction is either
* forward (premise AND ... AND premise THEREFORE conclusion)
* backward (conclusion SINCE premise AND ... AND premise)
Any conclusion in the pre-processed argument tree may serve as starting point. The storyline is now constructed recursively, as illustrated in Figure~1. Integer labels of the nodes represent the order of presentation, i.e. the storyline. (Note that the starting point is not necessarily the statement which is presented first according to the storyline.)
!Storyline Construction
So as to introduce redundancy, the storyline may be post-processed by repeating a premiss that has been stated previously. The likelihood that a single premise is repeated is controlled by the presentation parameters:
Moreover, distractors, i.e. arbitrary statements sampled from the argument's very domain, may be inserted in the storyline.
#### Step 8: Assembling the argument source text
The 'argument-source' is constructed by concatenating the statements of the informal argument (step 6) according to the order of the storyline (step 7). In principle, each statement is prepended by a conjunction. There are four types of conjunction:
* THEREFORE: left-to-right inference
* SINCE: right-to-left inference
* AND: joins premises with similar inferential role
* MOREOVER: catch all conjunction
Each statement is assigned a specific conjunction type by the storyline.
For every conjunction type, we provide multiple natural-language terms which may figure as conjunctions when concatenating the statements, e.g. "So, necessarily,", "So", "Thus,", "It follows that", "Therefore,", "Consequently,", "Hence,", "In consequence,", "All this entails that", "From this follows that", "We may conclude that" for THEREFORE. The parameter
determines the probability that a conjunction is omitted and a statement is concatenated without prepending a conjunction.
With the parameters given above we obtain the following 'argument\_source' for our example:
>
> Orlando is a regular consumer of Nag Champa soap and Orlando is a occasional purchaser of Shield soap, since Orlando is a regular consumer of Kiss My Face soap.
>
>
>
#### Step 9: Linking informal presentation and formal reconstruction
We can identify all statements *in the informal presentation* ('argument\_source'), categorize them according to their argumentative function GIVEN the logical reconstruction and link them to the corresponding statements in the 'argdown\_snippet'. We distinguish 'reason\_statement' (AKA REASONS, correspond to premises in the reconstruction) and 'conclusion\_statement' (AKA CONJECTURES, correspond to conclusion and intermediary conclusion in the reconstruction):
Moreover, we are now able to classify all premises in the formal reconstruction ('argdown\_snippet') according to whether they are implicit or explicit given the informal presentation:
#### Initial Data Collection and Normalization
N.A.
#### Who are the source language producers?
N.A.
### Annotations
#### Annotation process
N.A.
#### Who are the annotators?
N.A.
### Personal and Sensitive Information
N.A.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
None
### Discussion of Biases
None
### Other Known Limitations
See Betz and Richardson 2021.
Additional Information
----------------------
### Dataset Curators
Gregor Betz, Kyle Richardson
### Licensing Information
Creative Commons cc-by-sa-4.0
### Contributions
| [
"### Dataset Summary\n\n\nDeepA2 is a modular framework for deep argument analysis. DeepA2 datasets contain comprehensive logical reconstructions of informally presented arguments in short argumentative texts. This document describes two synthetic DeepA2 datasets for artificial argument analysis: AAAC01 and AAAC02.",
"### Supported Tasks and Leaderboards\n\n\nThe multi-dimensional datasets can be used to define various text-2-text tasks (see also Betz and Richardson 2021), for example:\n\n\n* Premise extraction,\n* Conclusion extraction,\n* Logical formalization,\n* Logical reconstrcution.",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe following histograms (number of dataset records with given property) describe and compare the two datasets AAAC01 (train split, N=16000) and AAAC02 (dev split, N=4000).",
"### Data Fields\n\n\nThe following multi-dimensional example record (2-step argument with one implicit premise) illustrates the structure of the AAAC datasets.",
"#### argument\\_source",
"#### reason\\_statements",
"#### conclusion\\_statements",
"#### distractors\n\n\n'[]'",
"#### argdown\\_reconstruction",
"#### premises",
"#### premises\\_formalized",
"#### conclusion",
"#### conclusion\\_formalized",
"#### intermediary\\_conclusions",
"#### intermediary\\_conclusions\\_formalized",
"#### plcd\\_subs",
"### Data Splits\n\n\nNumber of instances in the various splits:\n\n\n\nTo correctly load a specific split, define 'data\\_files' as follows:\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nArgument analysis refers to the interpretation and logical reconstruction of argumentative texts. Its goal is to make an argument transparent, so as to understand, appreciate and (possibly) criticize it. Argument analysis is a key critical thinking skill.\n\n\nHere's a first example of an informally presented argument, Descartes' Cogito:\n\n\n\n> \n> I have convinced myself that there is absolutely nothing in the world, no sky, no earth, no minds, no bodies. Does it now follow that I too do not exist? No: if I convinced myself of something then I certainly existed. But there is a deceiver of supreme power and cunning who is deliberately and constantly deceiving me. In that case I too undoubtedly exist, if he is deceiving me; and let him deceive me as much as he can, he will never bring it about that I am nothing so long as I think that I am something. So after considering everything very thoroughly, I must finally conclude that this proposition, I am, I exist, is necessarily true whenever it is put forward by me or conceived in my mind. (AT 7:25, CSM 2:16f)\n> \n> \n> \n\n\nAnd here's a second example, taken from the *Debater's Handbook*, Pro Censorship:\n\n\n\n> \n> Freedom of speech is never an absolute right but an aspiration. It ceases to be a right when it causes harm to others -- we all recognise the value of, for example, legislating against incitement to racial hatred. Therefore it is not the case that censorship is wrong in principle.\n> \n> \n> \n\n\nGiven such texts, argument analysis aims at answering the following questions:\n\n\n1. Does the text present an argument?\n2. If so, how many?\n3. What is the argument supposed to show (conclusion)?\n4. What exactly are the premises of the argument?\n\t* Which statements, explicit in the text, are not relevant for the argument?\n\t* Which premises are required, but not explicitly stated?\n5. Is the argument deductively valid, inductively strong, or simply fallacious?\n\n\nTo answer these questions, argument analysts interpret the text by (re-)constructing its argument in a standardized way (typically as a premise-conclusion list) and by making use of logical streamlining and formalization.\n\n\nA reconstruction of Pro Censorship which answers the above questions is:\n\n\nThere are typically multiple, more or less different interpretations and logical reconstructions of an argumentative text. For instance, there exists an extensive debate about how to interpret Descartes' Cogito, and scholars have advanced rival interpretation of the argument. An alternative reconstruction of the much simpler Pro Censorship might read:\n\n\nWhat are the main reasons for this kind of underdetermination?\n\n\n* Incompleteness. Many relevant parts of an argument (statements, their function in the argument, inference rules, argumentative goals) are not stated in its informal presentation. The argument analyst must infer the missing parts.\n* Additional material. Over and above what is strictly part of the argument, informal presentations contain typically further material: relevant premises are repeated in slightly different ways, further examples are added to illustrate a point, statements are contrasted with views by opponents, etc. etc. It's argument analyst to choice which of the presented material is really part of the argument.\n* Errors. Authors may err in the presentation of an argument, confounding, e.g., necessary and sufficient conditions in stating a premise. Following the principle of charity, benevolent argument analysts correct such errors and have to choose on of the different ways for how to do so.\n* Linguistic indeterminacy. One and the same statement can be interpreted -- regarding its logical form -- in different ways.\n* Equivalence. There are different natural language expressions for one and the same proposition.\n\n\nAAAC datasets provide logical reconstructions of informal argumentative texts: Each record contains a source text to-be-reconstructed and further fields which describe an internally consistent interpretation of the text, notwithstanding the fact that there might be alternative interpretations of this very text.",
"### Construction of the Synthetic Data\n\n\nArgument analysis starts with a text and reconstructs its argument (cf. Motivation and Background). In constructing our synthetic data, we inverse this direction: We start by sampling a complete argument, construct an informal presentation, and provide further info that describes both logical reconstruction and informal presentation. More specifically, the construction of the data involves the following steps:\n\n\n1. Generation of valid symbolic inference schemes\n2. Assembling complex (\"multi-hop\") argument schemes from symbolic inference schemes\n3. Creation of (precise and informal) natural-language argument\n4. Substitution of placeholders with domain-specific predicates and names\n5. Creation of the argdown-snippet\n6. Paraphrasing\n7. Construction of a storyline for the argument source text\n8. Assembling the argument source text\n9. Linking the precise reconstruction and the informal argumentative text",
"#### Step 1: Generation of symbolic inference schemes\n\n\nWe construct the set of available inference schemes by systematically transforming the following 12 base schemes (6 from propositional and another 6 from predicate logic):\n\n\n* modus ponens: '['Fa -> Gb', 'Fa', 'Gb']'\n* chain rule: '['Fa -> Gb', 'Gb -> Hc', 'Fa -> Hc']'\n* adjunction: '['Fa', 'Gb', 'Fa & Gb']'\n* case analysis: '['Fa v Gb', 'Fa -> Hc', 'Gb -> Hc', 'Hc']'\n* disjunctive syllogism: '['Fa v Gb', '¬Fa', 'Gb']'\n* biconditional elimination: '['Fa <-> Gb', 'Fa -> Gb']'\n* instantiation: '['(x): Fx -> Gx', 'Fa -> Ga']'\n* hypothetical syllogism: '['(x): Fx -> Gx', '(x): Gx -> Hx', '(x): Fx -> Hx']'\n* generalized biconditional elimination: '['(x): Fx <-> Gx', '(x): Fx -> Gx']'\n* generalized adjunction: '['(x): Fx -> Gx', '(x): Fx -> Hx', '(x): Fx -> (Gx & Hx)']'\n* generalized dilemma: '['(x): Fx -> (Gx v Hx)', '(x): Gx -> Ix', '(x): Hx -> Ix', '(x): Fx -> Ix']'\n* generalized disjunctive syllogism: '['(x): Fx -> (Gx v Hx)', '(x): Fx -> ¬Gx', '(x): Fx -> Hx']'\n\n\n(Regarding the propositional schemes, we allow for 'a'='b'='c'.)\n\n\nFurther symbolic inference schemes are generated by applying the following transformations to each of these base schemes:\n\n\n* *negation*: replace all occurrences of an atomic formula by its negation (for any number of such atomic sentences)\n* *transposition*: transpose exactly one (generalized) conditional\n* *dna*: simplify by applying duplex negatio affirmat\n* *complex predicates*: replace all occurrences of a given atomic formula by a complex formula consisting in the conjunction or disjunction of two atomic formulas\n* *de morgan*: apply de Morgan's rule once\n\n\nThese transformations are applied to the base schemes in the following order:\n\n\n\n> \n> {base\\_schemes} > negation\\_variants > transposition\\_variants > dna > {transposition\\_variants} > complex\\_predicates > negation\\_variants > dna > {complex\\_predicates} > de\\_morgan > dna > {de\\_morgan}\n> \n> \n> \n\n\nAll transformations, except *dna*, are monotonic, i.e. simply add further schemes to the ones generated in the previous step. Results of bold steps are added to the list of valid inference schemes. Each inference scheme is stored with information about which transformations were used to create it. All in all, this gives us 5542 schemes.",
"#### Step 2: Assembling complex (\"multi-hop\") argument schemes from symbolic inference schemes\n\n\nThe complex argument *scheme*, which consists in multiple inferences, is assembled recursively by adding inferences that support premises of previously added inferences, as described by the following pseudocode:\n\n\nThe complex arguments we create are hence trees, with a root scheme.\n\n\nLet's walk through this algorithm by means of an illustrative example and construct a symbolic argument scheme with two sub-arguments. First, we randomly choose some inference scheme (random sampling is controlled by weights that compensate for the fact that the list of schemes mainly contains, for combinatorial reasons, complex inferences), say:\n\n\nNow, the target premise (= intermediary conclusion) of the next subargument is chosen, say: premise 1 of the already added root scheme. We filter the list of schemes for schemes whose conclusion structurally matches the target, i.e. has the form '${A}${a} -> (${B}${a} v ${C}${a})'. From this filtered list of suitable schemes, we randomly choose, for example\n\n\nSo, we have generated this 2-step symbolic argument scheme with two premises, one intermediary and one final conclusion:\n\n\nGeneral properties of the argument are now determined and can be stored in the dataset (its 'domain' is randomly chosen):",
"#### Step 3: Creation of (precise and informal) natural-language argument schemes\n\n\nIn step 3, the *symbolic and formal* complex argument scheme is transformed into a *natural language* argument scheme by replacing symbolic formulas (e.g., '${A}${a} v ${B}${a}') with suitable natural language sentence schemes (such as, '${a} is a ${A}, and ${a} is a ${B}' or '${a} is a ${A} and a ${B}'). Natural language sentence schemes which translate symbolic formulas are classified according to whether they are precise, informal, or imprecise.\n\n\nFor each symbolic formula, there are many (partly automatically, partly manually generated) natural-language sentence scheme which render the formula in more or less precise way. Each of these natural-language \"translations\" of a symbolic formula is labeled according to whether it presents the logical form in a \"precise\", \"informal\", or \"imprecise\" way. e.g.\n\n\n\nThe labels \"precise\", \"informal\", \"imprecise\" are used to control the generation of two natural-language versions of the argument scheme, a precise one (for creating the argdown snippet) and an informal one (for creating the source text). Moreover, the natural-language \"translations\" are also chosen in view of the domain (see below) of the to-be-generated argument, specifically in view of whether it is quantified over persons (\"everyone\", \"nobody\") or objects (\"something, nothing\").\n\n\nSo, as a precise rendition of our symbolic argument scheme, we may obtain:\n\n\nLikewise, an informal rendition may be:",
"#### Step 4: Substitution of placeholders with domain-specific predicates and names\n\n\nEvery argument falls within a domain. A domain provides\n\n\n* a list of 'subject names' (e.g., Peter, Sarah)\n* a list of 'object names' (e.g., New York, Lille)\n* a list of 'binary predicates' (e.g., [subject is an] admirer of [object])\n\n\nThese domains are manually created.\n\n\nReplacements for the placeholders are sampled from the corresponding domain. Substitutes for entity placeholders ('a', 'b' etc.) are simply chosen from the list of 'subject names'. Substitutes for predicate placeholders ('F', 'G' etc.) are constructed by combining 'binary predicates' with 'object names', which yields unary predicates of the form \"\\_\\_\\_ stands in some relation to some object\". This combinatorial construction of unary predicates drastically increases the number of replacements available and hence the variety of generated arguments.\n\n\nAssuming that we sample our argument from the domain 'consumers personal care', we may choose and construct the following substitutes for placeholders in our argument scheme:\n\n\n* 'F': regular consumer of Kiss My Face soap\n* 'G': regular consumer of Nag Champa soap\n* 'H': occasional purchaser of Shield soap\n* 'a': Orlando",
"#### Step 5: Creation of the argdown-snippet\n\n\nFrom the precise rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct the 'argdown-snippet' by simple substitution and formatting the complex argument in accordance with argdown syntax.\n\n\nThis yields, for our example from above:\n\n\nThat's the 'argdown\\_snippet'. By construction of such a synthetic argument (from formal schemes, see step 2), we already know its conclusions and their formalization (the value of the field 'explicit' will be determined later).\n\n\n... and the corresponding keys (see step 4)):",
"#### Step 6: Paraphrasing\n\n\nFrom the informal rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct an informal argument (argument tree) by substitution.\n\n\nThe statements (premises, conclusions) of the informal argument are individually paraphrased in two steps\n\n\n1. rule-based and in a domain-specific way,\n2. automatically by means of a specifically fine-tuned T5 model.\n\n\nEach domain (see step 4) provides rules for substituting noun constructs (\"is a supporter of X\", \"is a product made of X\") with verb constructs (\"supports x\", \"contains X\"). These rules are applied whenever possible.\n\n\nNext, each sentence is -- with a probability specified by parameter 'lm\\_paraphrasing' -- replaced with an automatically generated paraphrase, using a T5 model fine-tuned on the Google PAWS dataset and filtering for paraphrases with acceptable *cola* and sufficiently high *STSB* value (both as predicted by T5).\n\n\nAAAC01: 'lm\\_paraphrasing', AAAC02: 0.2",
"#### Step 7: Construction of a storyline for the argument source text\n\n\nThe storyline determines in which order the premises, intermediary conclusions and final conclusions are to be presented in the text paragraph to-be-constructed ('argument-source'). The storyline is constructed from the paraphrased informal complex argument (see step 6)).\n\n\nBefore determining the order of presentation (storyline), the informal argument tree is pre-processed to account for:\n\n\n* implicit premises,\n* implicit intermediary conclusions, and\n* implicit final conclusion,\n\n\nwhich is documented in the dataset record as\n\n\nIn order to make an intermediary conclusion *C* implicit, the inference to *C* is \"resolved\" by re-assigning all premisses *from* which *C* is directly inferred *to* the inference to the (final or intermediary) conclusion which *C* supports.\n\n\nOriginal tree:\n\n\nTree with resolved inference and implicit intermediary conclusion:\n\n\nThe original argument tree in our example reads:\n\n\nThis might be pre-processed (by resolving the first inference step and dropping the first premise) to:\n\n\nGiven such a pre-processed argument tree, a storyline, which determines the order of presentation, can be constructed by specifying the direction of presentation and a starting point. The direction is either\n\n\n* forward (premise AND ... AND premise THEREFORE conclusion)\n* backward (conclusion SINCE premise AND ... AND premise)\n\n\nAny conclusion in the pre-processed argument tree may serve as starting point. The storyline is now constructed recursively, as illustrated in Figure~1. Integer labels of the nodes represent the order of presentation, i.e. the storyline. (Note that the starting point is not necessarily the statement which is presented first according to the storyline.)\n\n\n!Storyline Construction\n\n\nSo as to introduce redundancy, the storyline may be post-processed by repeating a premiss that has been stated previously. The likelihood that a single premise is repeated is controlled by the presentation parameters:\n\n\nMoreover, distractors, i.e. arbitrary statements sampled from the argument's very domain, may be inserted in the storyline.",
"#### Step 8: Assembling the argument source text\n\n\nThe 'argument-source' is constructed by concatenating the statements of the informal argument (step 6) according to the order of the storyline (step 7). In principle, each statement is prepended by a conjunction. There are four types of conjunction:\n\n\n* THEREFORE: left-to-right inference\n* SINCE: right-to-left inference\n* AND: joins premises with similar inferential role\n* MOREOVER: catch all conjunction\n\n\nEach statement is assigned a specific conjunction type by the storyline.\n\n\nFor every conjunction type, we provide multiple natural-language terms which may figure as conjunctions when concatenating the statements, e.g. \"So, necessarily,\", \"So\", \"Thus,\", \"It follows that\", \"Therefore,\", \"Consequently,\", \"Hence,\", \"In consequence,\", \"All this entails that\", \"From this follows that\", \"We may conclude that\" for THEREFORE. The parameter\n\n\ndetermines the probability that a conjunction is omitted and a statement is concatenated without prepending a conjunction.\n\n\nWith the parameters given above we obtain the following 'argument\\_source' for our example:\n\n\n\n> \n> Orlando is a regular consumer of Nag Champa soap and Orlando is a occasional purchaser of Shield soap, since Orlando is a regular consumer of Kiss My Face soap.\n> \n> \n>",
"#### Step 9: Linking informal presentation and formal reconstruction\n\n\nWe can identify all statements *in the informal presentation* ('argument\\_source'), categorize them according to their argumentative function GIVEN the logical reconstruction and link them to the corresponding statements in the 'argdown\\_snippet'. We distinguish 'reason\\_statement' (AKA REASONS, correspond to premises in the reconstruction) and 'conclusion\\_statement' (AKA CONJECTURES, correspond to conclusion and intermediary conclusion in the reconstruction):\n\n\nMoreover, we are now able to classify all premises in the formal reconstruction ('argdown\\_snippet') according to whether they are implicit or explicit given the informal presentation:",
"#### Initial Data Collection and Normalization\n\n\nN.A.",
"#### Who are the source language producers?\n\n\nN.A.",
"### Annotations",
"#### Annotation process\n\n\nN.A.",
"#### Who are the annotators?\n\n\nN.A.",
"### Personal and Sensitive Information\n\n\nN.A.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nNone",
"### Discussion of Biases\n\n\nNone",
"### Other Known Limitations\n\n\nSee Betz and Richardson 2021.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nGregor Betz, Kyle Richardson",
"### Licensing Information\n\n\nCreative Commons cc-by-sa-4.0",
"### Contributions"
]
| [
"TAGS\n#task_categories-summarization #task_categories-text-retrieval #task_categories-text-generation #task_ids-parsing #task_ids-text-simplification #annotations_creators-machine-generated #annotations_creators-expert-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-sa-4.0 #argument-mining #conditional-text-generation #structure-prediction #arxiv-2110.01509 #region-us \n",
"### Dataset Summary\n\n\nDeepA2 is a modular framework for deep argument analysis. DeepA2 datasets contain comprehensive logical reconstructions of informally presented arguments in short argumentative texts. This document describes two synthetic DeepA2 datasets for artificial argument analysis: AAAC01 and AAAC02.",
"### Supported Tasks and Leaderboards\n\n\nThe multi-dimensional datasets can be used to define various text-2-text tasks (see also Betz and Richardson 2021), for example:\n\n\n* Premise extraction,\n* Conclusion extraction,\n* Logical formalization,\n* Logical reconstrcution.",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe following histograms (number of dataset records with given property) describe and compare the two datasets AAAC01 (train split, N=16000) and AAAC02 (dev split, N=4000).",
"### Data Fields\n\n\nThe following multi-dimensional example record (2-step argument with one implicit premise) illustrates the structure of the AAAC datasets.",
"#### argument\\_source",
"#### reason\\_statements",
"#### conclusion\\_statements",
"#### distractors\n\n\n'[]'",
"#### argdown\\_reconstruction",
"#### premises",
"#### premises\\_formalized",
"#### conclusion",
"#### conclusion\\_formalized",
"#### intermediary\\_conclusions",
"#### intermediary\\_conclusions\\_formalized",
"#### plcd\\_subs",
"### Data Splits\n\n\nNumber of instances in the various splits:\n\n\n\nTo correctly load a specific split, define 'data\\_files' as follows:\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nArgument analysis refers to the interpretation and logical reconstruction of argumentative texts. Its goal is to make an argument transparent, so as to understand, appreciate and (possibly) criticize it. Argument analysis is a key critical thinking skill.\n\n\nHere's a first example of an informally presented argument, Descartes' Cogito:\n\n\n\n> \n> I have convinced myself that there is absolutely nothing in the world, no sky, no earth, no minds, no bodies. Does it now follow that I too do not exist? No: if I convinced myself of something then I certainly existed. But there is a deceiver of supreme power and cunning who is deliberately and constantly deceiving me. In that case I too undoubtedly exist, if he is deceiving me; and let him deceive me as much as he can, he will never bring it about that I am nothing so long as I think that I am something. So after considering everything very thoroughly, I must finally conclude that this proposition, I am, I exist, is necessarily true whenever it is put forward by me or conceived in my mind. (AT 7:25, CSM 2:16f)\n> \n> \n> \n\n\nAnd here's a second example, taken from the *Debater's Handbook*, Pro Censorship:\n\n\n\n> \n> Freedom of speech is never an absolute right but an aspiration. It ceases to be a right when it causes harm to others -- we all recognise the value of, for example, legislating against incitement to racial hatred. Therefore it is not the case that censorship is wrong in principle.\n> \n> \n> \n\n\nGiven such texts, argument analysis aims at answering the following questions:\n\n\n1. Does the text present an argument?\n2. If so, how many?\n3. What is the argument supposed to show (conclusion)?\n4. What exactly are the premises of the argument?\n\t* Which statements, explicit in the text, are not relevant for the argument?\n\t* Which premises are required, but not explicitly stated?\n5. Is the argument deductively valid, inductively strong, or simply fallacious?\n\n\nTo answer these questions, argument analysts interpret the text by (re-)constructing its argument in a standardized way (typically as a premise-conclusion list) and by making use of logical streamlining and formalization.\n\n\nA reconstruction of Pro Censorship which answers the above questions is:\n\n\nThere are typically multiple, more or less different interpretations and logical reconstructions of an argumentative text. For instance, there exists an extensive debate about how to interpret Descartes' Cogito, and scholars have advanced rival interpretation of the argument. An alternative reconstruction of the much simpler Pro Censorship might read:\n\n\nWhat are the main reasons for this kind of underdetermination?\n\n\n* Incompleteness. Many relevant parts of an argument (statements, their function in the argument, inference rules, argumentative goals) are not stated in its informal presentation. The argument analyst must infer the missing parts.\n* Additional material. Over and above what is strictly part of the argument, informal presentations contain typically further material: relevant premises are repeated in slightly different ways, further examples are added to illustrate a point, statements are contrasted with views by opponents, etc. etc. It's argument analyst to choice which of the presented material is really part of the argument.\n* Errors. Authors may err in the presentation of an argument, confounding, e.g., necessary and sufficient conditions in stating a premise. Following the principle of charity, benevolent argument analysts correct such errors and have to choose on of the different ways for how to do so.\n* Linguistic indeterminacy. One and the same statement can be interpreted -- regarding its logical form -- in different ways.\n* Equivalence. There are different natural language expressions for one and the same proposition.\n\n\nAAAC datasets provide logical reconstructions of informal argumentative texts: Each record contains a source text to-be-reconstructed and further fields which describe an internally consistent interpretation of the text, notwithstanding the fact that there might be alternative interpretations of this very text.",
"### Construction of the Synthetic Data\n\n\nArgument analysis starts with a text and reconstructs its argument (cf. Motivation and Background). In constructing our synthetic data, we inverse this direction: We start by sampling a complete argument, construct an informal presentation, and provide further info that describes both logical reconstruction and informal presentation. More specifically, the construction of the data involves the following steps:\n\n\n1. Generation of valid symbolic inference schemes\n2. Assembling complex (\"multi-hop\") argument schemes from symbolic inference schemes\n3. Creation of (precise and informal) natural-language argument\n4. Substitution of placeholders with domain-specific predicates and names\n5. Creation of the argdown-snippet\n6. Paraphrasing\n7. Construction of a storyline for the argument source text\n8. Assembling the argument source text\n9. Linking the precise reconstruction and the informal argumentative text",
"#### Step 1: Generation of symbolic inference schemes\n\n\nWe construct the set of available inference schemes by systematically transforming the following 12 base schemes (6 from propositional and another 6 from predicate logic):\n\n\n* modus ponens: '['Fa -> Gb', 'Fa', 'Gb']'\n* chain rule: '['Fa -> Gb', 'Gb -> Hc', 'Fa -> Hc']'\n* adjunction: '['Fa', 'Gb', 'Fa & Gb']'\n* case analysis: '['Fa v Gb', 'Fa -> Hc', 'Gb -> Hc', 'Hc']'\n* disjunctive syllogism: '['Fa v Gb', '¬Fa', 'Gb']'\n* biconditional elimination: '['Fa <-> Gb', 'Fa -> Gb']'\n* instantiation: '['(x): Fx -> Gx', 'Fa -> Ga']'\n* hypothetical syllogism: '['(x): Fx -> Gx', '(x): Gx -> Hx', '(x): Fx -> Hx']'\n* generalized biconditional elimination: '['(x): Fx <-> Gx', '(x): Fx -> Gx']'\n* generalized adjunction: '['(x): Fx -> Gx', '(x): Fx -> Hx', '(x): Fx -> (Gx & Hx)']'\n* generalized dilemma: '['(x): Fx -> (Gx v Hx)', '(x): Gx -> Ix', '(x): Hx -> Ix', '(x): Fx -> Ix']'\n* generalized disjunctive syllogism: '['(x): Fx -> (Gx v Hx)', '(x): Fx -> ¬Gx', '(x): Fx -> Hx']'\n\n\n(Regarding the propositional schemes, we allow for 'a'='b'='c'.)\n\n\nFurther symbolic inference schemes are generated by applying the following transformations to each of these base schemes:\n\n\n* *negation*: replace all occurrences of an atomic formula by its negation (for any number of such atomic sentences)\n* *transposition*: transpose exactly one (generalized) conditional\n* *dna*: simplify by applying duplex negatio affirmat\n* *complex predicates*: replace all occurrences of a given atomic formula by a complex formula consisting in the conjunction or disjunction of two atomic formulas\n* *de morgan*: apply de Morgan's rule once\n\n\nThese transformations are applied to the base schemes in the following order:\n\n\n\n> \n> {base\\_schemes} > negation\\_variants > transposition\\_variants > dna > {transposition\\_variants} > complex\\_predicates > negation\\_variants > dna > {complex\\_predicates} > de\\_morgan > dna > {de\\_morgan}\n> \n> \n> \n\n\nAll transformations, except *dna*, are monotonic, i.e. simply add further schemes to the ones generated in the previous step. Results of bold steps are added to the list of valid inference schemes. Each inference scheme is stored with information about which transformations were used to create it. All in all, this gives us 5542 schemes.",
"#### Step 2: Assembling complex (\"multi-hop\") argument schemes from symbolic inference schemes\n\n\nThe complex argument *scheme*, which consists in multiple inferences, is assembled recursively by adding inferences that support premises of previously added inferences, as described by the following pseudocode:\n\n\nThe complex arguments we create are hence trees, with a root scheme.\n\n\nLet's walk through this algorithm by means of an illustrative example and construct a symbolic argument scheme with two sub-arguments. First, we randomly choose some inference scheme (random sampling is controlled by weights that compensate for the fact that the list of schemes mainly contains, for combinatorial reasons, complex inferences), say:\n\n\nNow, the target premise (= intermediary conclusion) of the next subargument is chosen, say: premise 1 of the already added root scheme. We filter the list of schemes for schemes whose conclusion structurally matches the target, i.e. has the form '${A}${a} -> (${B}${a} v ${C}${a})'. From this filtered list of suitable schemes, we randomly choose, for example\n\n\nSo, we have generated this 2-step symbolic argument scheme with two premises, one intermediary and one final conclusion:\n\n\nGeneral properties of the argument are now determined and can be stored in the dataset (its 'domain' is randomly chosen):",
"#### Step 3: Creation of (precise and informal) natural-language argument schemes\n\n\nIn step 3, the *symbolic and formal* complex argument scheme is transformed into a *natural language* argument scheme by replacing symbolic formulas (e.g., '${A}${a} v ${B}${a}') with suitable natural language sentence schemes (such as, '${a} is a ${A}, and ${a} is a ${B}' or '${a} is a ${A} and a ${B}'). Natural language sentence schemes which translate symbolic formulas are classified according to whether they are precise, informal, or imprecise.\n\n\nFor each symbolic formula, there are many (partly automatically, partly manually generated) natural-language sentence scheme which render the formula in more or less precise way. Each of these natural-language \"translations\" of a symbolic formula is labeled according to whether it presents the logical form in a \"precise\", \"informal\", or \"imprecise\" way. e.g.\n\n\n\nThe labels \"precise\", \"informal\", \"imprecise\" are used to control the generation of two natural-language versions of the argument scheme, a precise one (for creating the argdown snippet) and an informal one (for creating the source text). Moreover, the natural-language \"translations\" are also chosen in view of the domain (see below) of the to-be-generated argument, specifically in view of whether it is quantified over persons (\"everyone\", \"nobody\") or objects (\"something, nothing\").\n\n\nSo, as a precise rendition of our symbolic argument scheme, we may obtain:\n\n\nLikewise, an informal rendition may be:",
"#### Step 4: Substitution of placeholders with domain-specific predicates and names\n\n\nEvery argument falls within a domain. A domain provides\n\n\n* a list of 'subject names' (e.g., Peter, Sarah)\n* a list of 'object names' (e.g., New York, Lille)\n* a list of 'binary predicates' (e.g., [subject is an] admirer of [object])\n\n\nThese domains are manually created.\n\n\nReplacements for the placeholders are sampled from the corresponding domain. Substitutes for entity placeholders ('a', 'b' etc.) are simply chosen from the list of 'subject names'. Substitutes for predicate placeholders ('F', 'G' etc.) are constructed by combining 'binary predicates' with 'object names', which yields unary predicates of the form \"\\_\\_\\_ stands in some relation to some object\". This combinatorial construction of unary predicates drastically increases the number of replacements available and hence the variety of generated arguments.\n\n\nAssuming that we sample our argument from the domain 'consumers personal care', we may choose and construct the following substitutes for placeholders in our argument scheme:\n\n\n* 'F': regular consumer of Kiss My Face soap\n* 'G': regular consumer of Nag Champa soap\n* 'H': occasional purchaser of Shield soap\n* 'a': Orlando",
"#### Step 5: Creation of the argdown-snippet\n\n\nFrom the precise rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct the 'argdown-snippet' by simple substitution and formatting the complex argument in accordance with argdown syntax.\n\n\nThis yields, for our example from above:\n\n\nThat's the 'argdown\\_snippet'. By construction of such a synthetic argument (from formal schemes, see step 2), we already know its conclusions and their formalization (the value of the field 'explicit' will be determined later).\n\n\n... and the corresponding keys (see step 4)):",
"#### Step 6: Paraphrasing\n\n\nFrom the informal rendition of the natural language argument scheme (step 3) and the replacements for its placeholders (step 4), we construct an informal argument (argument tree) by substitution.\n\n\nThe statements (premises, conclusions) of the informal argument are individually paraphrased in two steps\n\n\n1. rule-based and in a domain-specific way,\n2. automatically by means of a specifically fine-tuned T5 model.\n\n\nEach domain (see step 4) provides rules for substituting noun constructs (\"is a supporter of X\", \"is a product made of X\") with verb constructs (\"supports x\", \"contains X\"). These rules are applied whenever possible.\n\n\nNext, each sentence is -- with a probability specified by parameter 'lm\\_paraphrasing' -- replaced with an automatically generated paraphrase, using a T5 model fine-tuned on the Google PAWS dataset and filtering for paraphrases with acceptable *cola* and sufficiently high *STSB* value (both as predicted by T5).\n\n\nAAAC01: 'lm\\_paraphrasing', AAAC02: 0.2",
"#### Step 7: Construction of a storyline for the argument source text\n\n\nThe storyline determines in which order the premises, intermediary conclusions and final conclusions are to be presented in the text paragraph to-be-constructed ('argument-source'). The storyline is constructed from the paraphrased informal complex argument (see step 6)).\n\n\nBefore determining the order of presentation (storyline), the informal argument tree is pre-processed to account for:\n\n\n* implicit premises,\n* implicit intermediary conclusions, and\n* implicit final conclusion,\n\n\nwhich is documented in the dataset record as\n\n\nIn order to make an intermediary conclusion *C* implicit, the inference to *C* is \"resolved\" by re-assigning all premisses *from* which *C* is directly inferred *to* the inference to the (final or intermediary) conclusion which *C* supports.\n\n\nOriginal tree:\n\n\nTree with resolved inference and implicit intermediary conclusion:\n\n\nThe original argument tree in our example reads:\n\n\nThis might be pre-processed (by resolving the first inference step and dropping the first premise) to:\n\n\nGiven such a pre-processed argument tree, a storyline, which determines the order of presentation, can be constructed by specifying the direction of presentation and a starting point. The direction is either\n\n\n* forward (premise AND ... AND premise THEREFORE conclusion)\n* backward (conclusion SINCE premise AND ... AND premise)\n\n\nAny conclusion in the pre-processed argument tree may serve as starting point. The storyline is now constructed recursively, as illustrated in Figure~1. Integer labels of the nodes represent the order of presentation, i.e. the storyline. (Note that the starting point is not necessarily the statement which is presented first according to the storyline.)\n\n\n!Storyline Construction\n\n\nSo as to introduce redundancy, the storyline may be post-processed by repeating a premiss that has been stated previously. The likelihood that a single premise is repeated is controlled by the presentation parameters:\n\n\nMoreover, distractors, i.e. arbitrary statements sampled from the argument's very domain, may be inserted in the storyline.",
"#### Step 8: Assembling the argument source text\n\n\nThe 'argument-source' is constructed by concatenating the statements of the informal argument (step 6) according to the order of the storyline (step 7). In principle, each statement is prepended by a conjunction. There are four types of conjunction:\n\n\n* THEREFORE: left-to-right inference\n* SINCE: right-to-left inference\n* AND: joins premises with similar inferential role\n* MOREOVER: catch all conjunction\n\n\nEach statement is assigned a specific conjunction type by the storyline.\n\n\nFor every conjunction type, we provide multiple natural-language terms which may figure as conjunctions when concatenating the statements, e.g. \"So, necessarily,\", \"So\", \"Thus,\", \"It follows that\", \"Therefore,\", \"Consequently,\", \"Hence,\", \"In consequence,\", \"All this entails that\", \"From this follows that\", \"We may conclude that\" for THEREFORE. The parameter\n\n\ndetermines the probability that a conjunction is omitted and a statement is concatenated without prepending a conjunction.\n\n\nWith the parameters given above we obtain the following 'argument\\_source' for our example:\n\n\n\n> \n> Orlando is a regular consumer of Nag Champa soap and Orlando is a occasional purchaser of Shield soap, since Orlando is a regular consumer of Kiss My Face soap.\n> \n> \n>",
"#### Step 9: Linking informal presentation and formal reconstruction\n\n\nWe can identify all statements *in the informal presentation* ('argument\\_source'), categorize them according to their argumentative function GIVEN the logical reconstruction and link them to the corresponding statements in the 'argdown\\_snippet'. We distinguish 'reason\\_statement' (AKA REASONS, correspond to premises in the reconstruction) and 'conclusion\\_statement' (AKA CONJECTURES, correspond to conclusion and intermediary conclusion in the reconstruction):\n\n\nMoreover, we are now able to classify all premises in the formal reconstruction ('argdown\\_snippet') according to whether they are implicit or explicit given the informal presentation:",
"#### Initial Data Collection and Normalization\n\n\nN.A.",
"#### Who are the source language producers?\n\n\nN.A.",
"### Annotations",
"#### Annotation process\n\n\nN.A.",
"#### Who are the annotators?\n\n\nN.A.",
"### Personal and Sensitive Information\n\n\nN.A.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nNone",
"### Discussion of Biases\n\n\nNone",
"### Other Known Limitations\n\n\nSee Betz and Richardson 2021.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nGregor Betz, Kyle Richardson",
"### Licensing Information\n\n\nCreative Commons cc-by-sa-4.0",
"### Contributions"
]
|
04e69de6d4aa2f13f51f2364fbe042f536115f4a |
# `deepa2` Datasets Collection
## Table of Contents
- [`deepa2` Datasets Collection](#deepa2-datasets-collection)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Sub-Datasets](#sub-datasets)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [blog post](https://debatelab.github.io/journal/deepa2.html)
- **Repository:** [github](https://github.com/debatelab/deepa2)
- **Paper:** [arxiv](https://arxiv.org/abs/2110.01509)
- **Point of Contact:** [Gregor Betz]([email protected])
### Dataset Summary
This is a growing, curated collection of `deepa2` datasets, i.e. datasets that contain comprehensive logical analyses of argumentative texts. The collection comprises:
* datasets that are built from existing NLP datasets by means of the [`deepa2 bake`](https://github.com/debatelab/deepa2) tool.
* original `deepa2` datasets specifically created for this collection.
The tool [`deepa2 serve`](https://github.com/debatelab/deepa2#integrating-deepa2-into-your-training-pipeline) may be used to render the data in this collection as text2text examples.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the `task-category-tag` with an appropriate `other:other-task-name`).
- `conditional-text-generation`: The dataset can be used to train models to generate a fully reconstruction of an argument from a source text, making, e.g., its implicit assumptions explicit.
- `structure-prediction`: The dataset can be used to train models to formalize sentences.
- `text-retrieval`: The dataset can be used to train models to extract reason statements and conjectures from a given source text.
### Languages
English. Will be extended to cover other languages in the futures.
## Dataset Structure
### Sub-Datasets
This collection contains the following `deepa2` datasets:
* `esnli`: created from e-SNLI with `deepa2 bake` as [described here](https://github.com/debatelab/deepa2/blob/main/docs/esnli.md).
* `enbank` (`task_1`, `task_2`): created from Entailment Bank with `deepa2 bake` as [described here](https://github.com/debatelab/deepa2/blob/main/docs/enbank.md).
* `argq`: created from IBM-ArgQ with `deepa2 bake` as [described here](https://github.com/debatelab/deepa2/blob/main/docs/argq.md).
* `argkp`: created from IBM-KPA with `deepa2 bake` as [described here](https://github.com/debatelab/deepa2/blob/main/docs/argkp.md).
* `aifdb` (`moral-maze`, `us2016`, `vacc-itc`): created from AIFdb with `deepa2 bake` as [described here](https://github.com/debatelab/deepa2/blob/main/docs/aifdb.md).
* `aaac` (`aaac01` and `aaac02`): original, machine-generated contribution; based on an an improved and extended algorithm that backs https://huggingface.co/datasets/debatelab/aaac.
### Data Instances
see: https://github.com/debatelab/deepa2/tree/main/docs
### Data Fields
see: https://github.com/debatelab/deepa2/tree/main/docs
|feature|esnli|enbank|aifdb|aaac|argq|argkp|
|--|--|--|--|--|--|--|
| `source_text` | x | x | x | x | x | x |
| `title` | | x | | x | | |
| `gist` | x | x | | x | | x |
| `source_paraphrase` | x | x | x | x | | |
| `context` | | x | | x | | x |
| `reasons` | x | x | x | x | x | |
| `conjectures` | x | x | x | x | x | |
| `argdown_reconstruction` | x | x | | x | | x |
| `erroneous_argdown` | x | | | x | | |
| `premises` | x | x | | x | | x |
| `intermediary_conclusion` | | | | x | | |
| `conclusion` | x | x | | x | | x |
| `premises_formalized` | x | | | x | | x |
| `intermediary_conclusion_formalized` | | | | x | | |
| `conclusion_formalized` | x | | | x | | x |
| `predicate_placeholders` | | | | x | | |
| `entity_placeholders` | | | | x | | |
| `misc_placeholders` | x | | | x | | x |
| `plchd_substitutions` | x | | | x | | x |
### Data Splits
Each sub-dataset contains three splits: `train`, `validation`, and `test`.
## Dataset Creation
### Curation Rationale
Many NLP datasets focus on tasks that are relevant for logical analysis and argument reconstruction. This collection is the attempt to unify these resources in a common framework.
### Source Data
See: [Sub-Datasets](#sub-datasets)
## Additional Information
### Dataset Curators
Gregor Betz, KIT; Kyle Richardson, Allen AI
### Licensing Information
We re-distribute the the imported sub-datasets under their original license:
|Sub-dataset|License|
|--|--|
|esnli|MIT|
|aifdb|free for academic use ([TOU](https://arg-tech.org/index.php/research/argument-corpora/))|
|enbank|CC BY 4.0|
|aaac|CC BY 4.0|
|argq|CC BY SA 4.0|
|argkp|Apache|
### Citation Information
```
@article{betz2021deepa2,
title={DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models},
author={Gregor Betz and Kyle Richardson},
year={2021},
eprint={2110.01509},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--If the dataset has a [DOI](https://www.doi.org/), please provide it here.-->
| DebateLabKIT/deepa2 | [
"task_categories:text-retrieval",
"task_categories:text-generation",
"task_ids:text-simplification",
"task_ids:parsing",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:unknown",
"language:en",
"license:other",
"argument-mining",
"summarization",
"conditional-text-generation",
"structure-prediction",
"arxiv:2110.01509",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": [], "language_creators": ["other"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": [], "task_categories": ["text-retrieval", "text-generation"], "task_ids": ["text-simplification", "parsing"], "pretty_name": "deepa2", "tags": ["argument-mining", "summarization", "conditional-text-generation", "structure-prediction"]} | 2022-12-16T14:49:35+00:00 | [
"2110.01509"
]
| [
"en"
]
| TAGS
#task_categories-text-retrieval #task_categories-text-generation #task_ids-text-simplification #task_ids-parsing #language_creators-other #multilinguality-monolingual #size_categories-unknown #language-English #license-other #argument-mining #summarization #conditional-text-generation #structure-prediction #arxiv-2110.01509 #region-us
| 'deepa2' Datasets Collection
============================
Table of Contents
-----------------
* 'deepa2' Datasets Collection
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
+ Dataset Structure
- Sub-Datasets
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?
- Annotations
* Annotation process
* Who are the annotators?
- Personal and Sensitive Information
+ Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
+ Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Homepage: blog post
* Repository: github
* Paper: arxiv
* Point of Contact: Gregor Betz
### Dataset Summary
This is a growing, curated collection of 'deepa2' datasets, i.e. datasets that contain comprehensive logical analyses of argumentative texts. The collection comprises:
* datasets that are built from existing NLP datasets by means of the 'deepa2 bake' tool.
* original 'deepa2' datasets specifically created for this collection.
The tool 'deepa2 serve' may be used to render the data in this collection as text2text examples.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').
* 'conditional-text-generation': The dataset can be used to train models to generate a fully reconstruction of an argument from a source text, making, e.g., its implicit assumptions explicit.
* 'structure-prediction': The dataset can be used to train models to formalize sentences.
* 'text-retrieval': The dataset can be used to train models to extract reason statements and conjectures from a given source text.
### Languages
English. Will be extended to cover other languages in the futures.
Dataset Structure
-----------------
### Sub-Datasets
This collection contains the following 'deepa2' datasets:
* 'esnli': created from e-SNLI with 'deepa2 bake' as described here.
* 'enbank' ('task\_1', 'task\_2'): created from Entailment Bank with 'deepa2 bake' as described here.
* 'argq': created from IBM-ArgQ with 'deepa2 bake' as described here.
* 'argkp': created from IBM-KPA with 'deepa2 bake' as described here.
* 'aifdb' ('moral-maze', 'us2016', 'vacc-itc'): created from AIFdb with 'deepa2 bake' as described here.
* 'aaac' ('aaac01' and 'aaac02'): original, machine-generated contribution; based on an an improved and extended algorithm that backs URL
### Data Instances
see: URL
### Data Fields
see: URL
### Data Splits
Each sub-dataset contains three splits: 'train', 'validation', and 'test'.
Dataset Creation
----------------
### Curation Rationale
Many NLP datasets focus on tasks that are relevant for logical analysis and argument reconstruction. This collection is the attempt to unify these resources in a common framework.
### Source Data
See: Sub-Datasets
Additional Information
----------------------
### Dataset Curators
Gregor Betz, KIT; Kyle Richardson, Allen AI
### Licensing Information
We re-distribute the the imported sub-datasets under their original license:
| [
"### Dataset Summary\n\n\nThis is a growing, curated collection of 'deepa2' datasets, i.e. datasets that contain comprehensive logical analyses of argumentative texts. The collection comprises:\n\n\n* datasets that are built from existing NLP datasets by means of the 'deepa2 bake' tool.\n* original 'deepa2' datasets specifically created for this collection.\n\n\nThe tool 'deepa2 serve' may be used to render the data in this collection as text2text examples.",
"### Supported Tasks and Leaderboards\n\n\nFor each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').\n\n\n* 'conditional-text-generation': The dataset can be used to train models to generate a fully reconstruction of an argument from a source text, making, e.g., its implicit assumptions explicit.\n* 'structure-prediction': The dataset can be used to train models to formalize sentences.\n* 'text-retrieval': The dataset can be used to train models to extract reason statements and conjectures from a given source text.",
"### Languages\n\n\nEnglish. Will be extended to cover other languages in the futures.\n\n\nDataset Structure\n-----------------",
"### Sub-Datasets\n\n\nThis collection contains the following 'deepa2' datasets:\n\n\n* 'esnli': created from e-SNLI with 'deepa2 bake' as described here.\n* 'enbank' ('task\\_1', 'task\\_2'): created from Entailment Bank with 'deepa2 bake' as described here.\n* 'argq': created from IBM-ArgQ with 'deepa2 bake' as described here.\n* 'argkp': created from IBM-KPA with 'deepa2 bake' as described here.\n* 'aifdb' ('moral-maze', 'us2016', 'vacc-itc'): created from AIFdb with 'deepa2 bake' as described here.\n* 'aaac' ('aaac01' and 'aaac02'): original, machine-generated contribution; based on an an improved and extended algorithm that backs URL",
"### Data Instances\n\n\nsee: URL",
"### Data Fields\n\n\nsee: URL",
"### Data Splits\n\n\nEach sub-dataset contains three splits: 'train', 'validation', and 'test'.\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nMany NLP datasets focus on tasks that are relevant for logical analysis and argument reconstruction. This collection is the attempt to unify these resources in a common framework.",
"### Source Data\n\n\nSee: Sub-Datasets\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nGregor Betz, KIT; Kyle Richardson, Allen AI",
"### Licensing Information\n\n\nWe re-distribute the the imported sub-datasets under their original license:"
]
| [
"TAGS\n#task_categories-text-retrieval #task_categories-text-generation #task_ids-text-simplification #task_ids-parsing #language_creators-other #multilinguality-monolingual #size_categories-unknown #language-English #license-other #argument-mining #summarization #conditional-text-generation #structure-prediction #arxiv-2110.01509 #region-us \n",
"### Dataset Summary\n\n\nThis is a growing, curated collection of 'deepa2' datasets, i.e. datasets that contain comprehensive logical analyses of argumentative texts. The collection comprises:\n\n\n* datasets that are built from existing NLP datasets by means of the 'deepa2 bake' tool.\n* original 'deepa2' datasets specifically created for this collection.\n\n\nThe tool 'deepa2 serve' may be used to render the data in this collection as text2text examples.",
"### Supported Tasks and Leaderboards\n\n\nFor each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the 'task-category-tag' with an appropriate 'other:other-task-name').\n\n\n* 'conditional-text-generation': The dataset can be used to train models to generate a fully reconstruction of an argument from a source text, making, e.g., its implicit assumptions explicit.\n* 'structure-prediction': The dataset can be used to train models to formalize sentences.\n* 'text-retrieval': The dataset can be used to train models to extract reason statements and conjectures from a given source text.",
"### Languages\n\n\nEnglish. Will be extended to cover other languages in the futures.\n\n\nDataset Structure\n-----------------",
"### Sub-Datasets\n\n\nThis collection contains the following 'deepa2' datasets:\n\n\n* 'esnli': created from e-SNLI with 'deepa2 bake' as described here.\n* 'enbank' ('task\\_1', 'task\\_2'): created from Entailment Bank with 'deepa2 bake' as described here.\n* 'argq': created from IBM-ArgQ with 'deepa2 bake' as described here.\n* 'argkp': created from IBM-KPA with 'deepa2 bake' as described here.\n* 'aifdb' ('moral-maze', 'us2016', 'vacc-itc'): created from AIFdb with 'deepa2 bake' as described here.\n* 'aaac' ('aaac01' and 'aaac02'): original, machine-generated contribution; based on an an improved and extended algorithm that backs URL",
"### Data Instances\n\n\nsee: URL",
"### Data Fields\n\n\nsee: URL",
"### Data Splits\n\n\nEach sub-dataset contains three splits: 'train', 'validation', and 'test'.\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nMany NLP datasets focus on tasks that are relevant for logical analysis and argument reconstruction. This collection is the attempt to unify these resources in a common framework.",
"### Source Data\n\n\nSee: Sub-Datasets\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nGregor Betz, KIT; Kyle Richardson, Allen AI",
"### Licensing Information\n\n\nWe re-distribute the the imported sub-datasets under their original license:"
]
|
5129d02422a66be600ac89cd3e8531b4f97d347d |

# Dataset Card for germandpr
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://deepset.ai/germanquad
- **Repository:** https://github.com/deepset-ai/haystack
- **Paper:** https://arxiv.org/abs/2104.12741
### Dataset Summary
We take GermanQuAD as a starting point and add hard negatives from a dump of the full German Wikipedia following the approach of the DPR authors (Karpukhin et al., 2020). The format of the dataset also resembles the one of DPR. GermanDPR comprises 9275 question/answerpairs in the training set and 1025 pairs in the test set. For eachpair, there are one positive context and three hard negative contexts.
### Supported Tasks and Leaderboards
- `open-domain-qa`, `text-retrieval`: This dataset is intended to be used for `open-domain-qa` and text retrieval tasks.
### Languages
The sentences in the dataset are in German (de).
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```
{
"question": "Wie viele christlichen Menschen in Deutschland glauben an einen Gott?",
"answers": [
"75 % der befragten Katholiken sowie 67 % der Protestanten glaubten an einen Gott (2005: 85 % und 79 %)"
],
"positive_ctxs": [
{
"title": "Gott",
"text": "Gott\
=== Demografie ===
Eine Zusammenfassung von Umfrageergebnissen aus verschiedenen Staaten ergab im Jahr 2007, dass es weltweit zwischen 505 und 749 Millionen Atheisten und Agnostiker gibt. Laut der Encyclopædia Britannica gab es 2009 weltweit 640 Mio. Nichtreligiöse und Agnostiker (9,4 %), und weitere 139 Mio. Atheisten (2,0 %), hauptsächlich in der Volksrepublik China.\\\\\\\\
Bei einer Eurobarometer-Umfrage im Jahr 2005 wurde festgestellt, dass 52 % der damaligen EU-Bevölkerung glaubt, dass es einen Gott gibt. Eine vagere Frage nach dem Glauben an „eine andere spirituelle Kraft oder Lebenskraft“ wurde von weiteren 27 % positiv beantwortet. Bezüglich der Gottgläubigkeit bestanden große Unterschiede zwischen den einzelnen europäischen Staaten. Die Umfrage ergab, dass der Glaube an Gott in Staaten mit starkem kirchlichen Einfluss am stärksten verbreitet ist, dass mehr Frauen (58 %) als Männer (45 %) an einen Gott glauben und dass der Gottglaube mit höherem Alter, geringerer Bildung und politisch rechtsgerichteten Ansichten korreliert.\\\\\\\\
Laut einer Befragung von 1003 Personen in Deutschland im März 2019 glauben 55 % an einen Gott; 2005 waren es 66 % gewesen. 75 % der befragten Katholiken sowie 67 % der Protestanten glaubten an einen Gott (2005: 85 % und 79 %). Unter Konfessionslosen ging die Glaubensquote von 28 auf 20 % zurück. Unter Frauen (60 %) war der Glauben 2019 stärker ausgeprägt als unter Männern (50 %), in Westdeutschland (63 %) weiter verbreitet als in Ostdeutschland (26 %).",
"passage_id": ""
}
],
"negative_ctxs": [],
"hard_negative_ctxs": [
{
"title": "Christentum",
"text": "Christentum\
\
=== Ursprung und Einflüsse ===\
Die ersten Christen waren Juden, die zum Glauben an Jesus Christus fanden. In ihm erkannten sie den bereits durch die biblische Prophetie verheißenen Messias (hebräisch: ''maschiach'', griechisch: ''Christos'', latinisiert ''Christus''), auf dessen Kommen die Juden bis heute warten. Die Urchristen übernahmen aus der jüdischen Tradition sämtliche heiligen Schriften (den Tanach), wie auch den Glauben an einen Messias oder Christus (''christos'': Gesalbter). Von den Juden übernommen wurden die Art der Gottesverehrung, das Gebet der Psalmen u. v. a. m. Eine weitere Gemeinsamkeit mit dem Judentum besteht in der Anbetung desselben Schöpfergottes. Jedoch sehen fast alle Christen Gott als ''einen'' dreieinigen Gott an: den Vater, den Sohn (Christus) und den Heiligen Geist. Darüber, wie der dreieinige Gott konkret gedacht werden kann, gibt es unter den christlichen Konfessionen und Gruppierungen unterschiedliche Auffassungen bis hin zur Ablehnung der Dreieinigkeit Gottes (Antitrinitarier). Der Glaube an Jesus Christus führte zu Spannungen und schließlich zur Trennung zwischen Juden, die diesen Glauben annahmen, und Juden, die dies nicht taten, da diese es unter anderem ablehnten, einen Menschen anzubeten, denn sie sahen in Jesus Christus nicht den verheißenen Messias und erst recht nicht den Sohn Gottes. Die heutige Zeitrechnung wird von der Geburt Christi aus gezählt. Anno Domini (A. D.) bedeutet „im Jahr des Herrn“.",
"passage_id": ""
},
{
"title": "Noachidische_Gebote",
"text": "Noachidische_Gebote\
\
=== Die kommende Welt ===\
Der Glaube an eine ''Kommende Welt'' (Olam Haba) bzw. an eine ''Welt des ewigen Lebens'' ist ein Grundprinzip des Judentums. Dieser jüdische Glaube ist von dem christlichen Glauben an das ''Ewige Leben'' fundamental unterschieden. Die jüdische Lehre spricht niemandem das Heil dieser kommenden Welt ab, droht aber auch nicht mit Höllenstrafen im Jenseits. Juden glauben schlicht, dass allen Menschen ein Anteil der kommenden Welt zuteilwerden kann. Es gibt zwar viele Vorstellungen der kommenden Welt, aber keine kanonische Festlegung ihrer Beschaffenheit; d. h., das Judentum kennt keine eindeutige Antwort darauf, was nach dem Tod mit uns geschieht. Die Frage nach dem Leben nach dem Tod wird auch als weniger wesentlich angesehen, als Fragen, die das Leben des Menschen auf Erden und in der Gesellschaft betreffen.\
Der jüdische Glaube an eine kommende Welt bedeutet nicht, dass Menschen, die nie von der Tora gehört haben, böse oder sonst minderwertige Menschen sind. Das Judentum lehrt den Glauben, dass alle Menschen mit Gott verbunden sind. Es gibt im Judentum daher keinen Grund, zu missionieren. Das Judentum lehrt auch, dass alle Menschen sich darin gleichen, dass sie weder prinzipiell gut noch böse sind, sondern eine Neigung zum Guten wie zum Bösen haben. Während des irdischen Lebens sollte sich der Mensch immer wieder für das Gute entscheiden.",
"passage_id": ""
},
{
"title": "Figuren_und_Schauplätze_der_Scheibenwelt-Romane",
"text": "Figuren_und_Schauplätze_der_Scheibenwelt-Romane\
\
=== Herkunft ===\
Es gibt unzählig viele Götter auf der Scheibenwelt, die so genannten „geringen Götter“, die überall sind, aber keine Macht haben. Erst wenn sie durch irgendein Ereignis Gläubige gewinnen, werden sie mächtiger. Je mehr Glauben, desto mehr Macht. Dabei nehmen sie die Gestalt an, die die Menschen ihnen geben (zum Beispiel Offler). Wenn ein Gott mächtig genug ist, erhält er Einlass in den Cori Celesti, den Berg der Götter, der sich in der Mitte der Scheibenwelt erhebt. Da Menschen wankelmütig sind, kann es auch geschehen, dass sie den Glauben verlieren und einen Gott damit entmachten (s. „Einfach Göttlich“).",
"passage_id": ""
}
]
},
```
### Data Fields
- `positive_ctxs`: a dictionary feature containing:
- `title`: a `string` feature.
- `text`: a `string` feature.
- `passage_id`: a `string` feature.
- `negative_ctxs`: a dictionary feature containing:
- `title`: a `string` feature.
- `text`: a `string` feature.
- `passage_id`: a `string` feature.
- `hard_negative_ctxs`: a dictionary feature containing:
- `title`: a `string` feature.
- `text`: a `string` feature.
- `passage_id`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a list feature containing:
- a `string` feature.
### Data Splits
The dataset is split into a training set and a test set.
The final GermanDPR dataset comprises 9275
question/answer pairs in the training set and 1025
pairs in the test set. For each pair, there are one
positive context and three hard negative contexts.
| |questions|answers|positive contexts|hard negative contexts|
|------|--------:|------:|----------------:|---------------------:|
|train|9275| 9275|9275|27825|
|test|1025| 1025|1025|3075|
## Additional Information
### Dataset Curators
The dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at deepset.ai
### Citation Information
```
@misc{möller2021germanquad,
title={GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval},
author={Timo Möller and Julian Risch and Malte Pietsch},
year={2021},
eprint={2104.12741},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | deepset/germandpr | [
"task_categories:question-answering",
"task_categories:text-retrieval",
"task_ids:extractive-qa",
"task_ids:closed-domain-qa",
"multilinguality:monolingual",
"source_datasets:original",
"language:de",
"license:cc-by-4.0",
"arxiv:2104.12741",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["de"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "source_datasets": ["original"], "task_categories": ["question-answering", "text-retrieval"], "task_ids": ["extractive-qa", "closed-domain-qa"], "thumbnail": "https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg"} | 2023-04-06T12:59:37+00:00 | [
"2104.12741"
]
| [
"de"
]
| TAGS
#task_categories-question-answering #task_categories-text-retrieval #task_ids-extractive-qa #task_ids-closed-domain-qa #multilinguality-monolingual #source_datasets-original #language-German #license-cc-by-4.0 #arxiv-2104.12741 #region-us
| !bert\_image
Dataset Card for germandpr
==========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Additional Information
+ Dataset Curators
+ Citation Information
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
### Dataset Summary
We take GermanQuAD as a starting point and add hard negatives from a dump of the full German Wikipedia following the approach of the DPR authors (Karpukhin et al., 2020). The format of the dataset also resembles the one of DPR. GermanDPR comprises 9275 question/answerpairs in the training set and 1025 pairs in the test set. For eachpair, there are one positive context and three hard negative contexts.
### Supported Tasks and Leaderboards
* 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa' and text retrieval tasks.
### Languages
The sentences in the dataset are in German (de).
Dataset Structure
-----------------
### Data Instances
A sample from the training set is provided below:
### Data Fields
* 'positive\_ctxs': a dictionary feature containing:
+ 'title': a 'string' feature.
+ 'text': a 'string' feature.
+ 'passage\_id': a 'string' feature.
* 'negative\_ctxs': a dictionary feature containing:
+ 'title': a 'string' feature.
+ 'text': a 'string' feature.
+ 'passage\_id': a 'string' feature.
* 'hard\_negative\_ctxs': a dictionary feature containing:
+ 'title': a 'string' feature.
+ 'text': a 'string' feature.
+ 'passage\_id': a 'string' feature.
* 'question': a 'string' feature.
* 'answers': a list feature containing:
+ a 'string' feature.
### Data Splits
The dataset is split into a training set and a test set.
The final GermanDPR dataset comprises 9275
question/answer pairs in the training set and 1025
pairs in the test set. For each pair, there are one
positive context and three hard negative contexts.
Additional Information
----------------------
### Dataset Curators
The dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL
| [
"### Dataset Summary\n\n\nWe take GermanQuAD as a starting point and add hard negatives from a dump of the full German Wikipedia following the approach of the DPR authors (Karpukhin et al., 2020). The format of the dataset also resembles the one of DPR. GermanDPR comprises 9275 question/answerpairs in the training set and 1025 pairs in the test set. For eachpair, there are one positive context and three hard negative contexts.",
"### Supported Tasks and Leaderboards\n\n\n* 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa' and text retrieval tasks.",
"### Languages\n\n\nThe sentences in the dataset are in German (de).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from the training set is provided below:",
"### Data Fields\n\n\n* 'positive\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'negative\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'hard\\_negative\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a list feature containing:\n\t+ a 'string' feature.",
"### Data Splits\n\n\nThe dataset is split into a training set and a test set.\nThe final GermanDPR dataset comprises 9275\nquestion/answer pairs in the training set and 1025\npairs in the test set. For each pair, there are one\npositive context and three hard negative contexts.\n\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL"
]
| [
"TAGS\n#task_categories-question-answering #task_categories-text-retrieval #task_ids-extractive-qa #task_ids-closed-domain-qa #multilinguality-monolingual #source_datasets-original #language-German #license-cc-by-4.0 #arxiv-2104.12741 #region-us \n",
"### Dataset Summary\n\n\nWe take GermanQuAD as a starting point and add hard negatives from a dump of the full German Wikipedia following the approach of the DPR authors (Karpukhin et al., 2020). The format of the dataset also resembles the one of DPR. GermanDPR comprises 9275 question/answerpairs in the training set and 1025 pairs in the test set. For eachpair, there are one positive context and three hard negative contexts.",
"### Supported Tasks and Leaderboards\n\n\n* 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa' and text retrieval tasks.",
"### Languages\n\n\nThe sentences in the dataset are in German (de).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from the training set is provided below:",
"### Data Fields\n\n\n* 'positive\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'negative\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'hard\\_negative\\_ctxs': a dictionary feature containing:\n\t+ 'title': a 'string' feature.\n\t+ 'text': a 'string' feature.\n\t+ 'passage\\_id': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a list feature containing:\n\t+ a 'string' feature.",
"### Data Splits\n\n\nThe dataset is split into a training set and a test set.\nThe final GermanDPR dataset comprises 9275\nquestion/answer pairs in the training set and 1025\npairs in the test set. For each pair, there are one\npositive context and three hard negative contexts.\n\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL"
]
|
fff05ceaf2ffbe5b65c7e0c57e678f7b7e1a0581 |

# Dataset Card for germanquad
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://deepset.ai/germanquad
- **Repository:** https://github.com/deepset-ai/haystack
- **Paper:** https://arxiv.org/abs/2104.12741
### Dataset Summary
In order to raise the bar for non-English QA, we are releasing a high-quality, human-labeled German QA dataset consisting of 13 722 questions, incl. a three-way annotated test set.
The creation of GermanQuAD is inspired by insights from existing datasets as well as our labeling experience from several industry projects. We combine the strengths of SQuAD, such as high out-of-domain performance, with self-sufficient questions that contain all relevant information for open-domain QA as in the NaturalQuestions dataset. Our training and test datasets do not overlap like other popular datasets and include complex questions that cannot be answered with a single entity or only a few words.
### Supported Tasks and Leaderboards
- `extractive-qa`, `closed-domain-qa`, `open-domain-qa`, `text-retrieval`: This dataset is intended to be used for `open-domain-qa`, but can also be used for information retrieval tasks.
### Languages
The sentences in the dataset are in German (de).
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```
{
"paragraphs": [
{
"qas": [
{
"question": "Von welchem Gesetzt stammt das Amerikanische ab? ",
"id": 51870,
"answers": [
{
"answer_id": 53778,
"document_id": 43958,
"question_id": 51870,
"text": "britischen Common Laws",
"answer_start": 146,
"answer_category": "SHORT"
}
],
"is_impossible": false
}
],
"context": "Recht_der_Vereinigten_Staaten\
\
=== Amerikanisches Common Law ===\
Obwohl die Vereinigten Staaten wie auch viele Staaten des Commonwealth Erben des britischen Common Laws sind, setzt sich das amerikanische Recht bedeutend davon ab. Dies rührt größtenteils von dem langen Zeitraum her, in dem sich das amerikanische Recht unabhängig vom Britischen entwickelt hat. Entsprechend schauen die Gerichte in den Vereinigten Staaten bei der Analyse von eventuell zutreffenden britischen Rechtsprinzipien im Common Law gewöhnlich nur bis ins frühe 19. Jahrhundert.\
Während es in den Commonwealth-Staaten üblich ist, dass Gerichte sich Entscheidungen und Prinzipien aus anderen Commonwealth-Staaten importieren, ist das in der amerikanischen Rechtsprechung selten. Ausnahmen bestehen hier nur, wenn sich überhaupt keine relevanten amerikanischen Fälle finden lassen, die Fakten nahezu identisch sind und die Begründung außerordentlich überzeugend ist. Frühe amerikanische Entscheidungen zitierten oft britische Fälle, solche Zitate verschwanden aber während des 19. Jahrhunderts, als die Gerichte eindeutig amerikanische Lösungen zu lokalen Konflikten fanden. In der aktuellen Rechtsprechung beziehen sich fast alle Zitate auf amerikanische Fälle.\
Einige Anhänger des Originalismus und der strikten Gesetzestextauslegung (''strict constructionism''), wie zum Beispiel der verstorbene Bundesrichter am Obersten Gerichtshof, Antonin Scalia, vertreten die Meinung, dass amerikanische Gerichte ''nie'' ausländische Fälle überprüfen sollten, die nach dem Unabhängigkeitskrieg entschieden wurden, unabhängig davon, ob die Argumentation überzeugend ist oder nicht. Die einzige Ausnahme wird hier in Fällen gesehen, die durch die Vereinigten Staaten ratifizierte völkerrechtliche Verträge betreffen. Andere Richter, wie zum Beispiel Anthony Kennedy und Stephen Breyer vertreten eine andere Ansicht und benutzen ausländische Rechtsprechung, sofern ihre Argumentation für sie überzeugend, nützlich oder hilfreich ist.",
"document_id": 43958
}
]
},
```
### Data Fields
- `id`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits
The dataset is split into a one-way annotated training set and a three-way annotated test set of German Wikipedia passages (paragraphs). Each passage is
from a different article.
| |passages|questions|answers|
|----------|----:|---------:|---------:|
|train|2540| 11518|11518|
|test|474| 2204|6536|
## Additional Information
### Dataset Curators
The dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at deepset.ai
### Citation Information
```
@misc{möller2021germanquad,
title={GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval},
author={Timo Möller and Julian Risch and Malte Pietsch},
year={2021},
eprint={2104.12741},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | deepset/germanquad | [
"task_categories:question-answering",
"task_categories:text-retrieval",
"task_ids:extractive-qa",
"task_ids:closed-domain-qa",
"task_ids:open-domain-qa",
"multilinguality:monolingual",
"source_datasets:original",
"language:de",
"license:cc-by-4.0",
"arxiv:2104.12741",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["de"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "source_datasets": ["original"], "task_categories": ["question-answering", "text-retrieval"], "task_ids": ["extractive-qa", "closed-domain-qa", "open-domain-qa"], "thumbnail": "https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg", "train-eval-index": [{"config": "plain_text", "task": "question-answering", "task_id": "extractive_question_answering", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"context": "context", "question": "question", "answers.text": "answers.text", "answers.answer_start": "answers.answer_start"}}]} | 2023-04-06T12:58:35+00:00 | [
"2104.12741"
]
| [
"de"
]
| TAGS
#task_categories-question-answering #task_categories-text-retrieval #task_ids-extractive-qa #task_ids-closed-domain-qa #task_ids-open-domain-qa #multilinguality-monolingual #source_datasets-original #language-German #license-cc-by-4.0 #arxiv-2104.12741 #region-us
| !bert\_image
Dataset Card for germanquad
===========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Additional Information
+ Dataset Curators
+ Citation Information
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
### Dataset Summary
In order to raise the bar for non-English QA, we are releasing a high-quality, human-labeled German QA dataset consisting of 13 722 questions, incl. a three-way annotated test set.
The creation of GermanQuAD is inspired by insights from existing datasets as well as our labeling experience from several industry projects. We combine the strengths of SQuAD, such as high out-of-domain performance, with self-sufficient questions that contain all relevant information for open-domain QA as in the NaturalQuestions dataset. Our training and test datasets do not overlap like other popular datasets and include complex questions that cannot be answered with a single entity or only a few words.
### Supported Tasks and Leaderboards
* 'extractive-qa', 'closed-domain-qa', 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa', but can also be used for information retrieval tasks.
### Languages
The sentences in the dataset are in German (de).
Dataset Structure
-----------------
### Data Instances
A sample from the training set is provided below:
### Data Fields
* 'id': a 'string' feature.
* 'context': a 'string' feature.
* 'question': a 'string' feature.
* 'answers': a dictionary feature containing:
+ 'text': a 'string' feature.
+ 'answer\_start': a 'int32' feature.
### Data Splits
The dataset is split into a one-way annotated training set and a three-way annotated test set of German Wikipedia passages (paragraphs). Each passage is
from a different article.
Additional Information
----------------------
### Dataset Curators
The dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL
| [
"### Dataset Summary\n\n\nIn order to raise the bar for non-English QA, we are releasing a high-quality, human-labeled German QA dataset consisting of 13 722 questions, incl. a three-way annotated test set.\nThe creation of GermanQuAD is inspired by insights from existing datasets as well as our labeling experience from several industry projects. We combine the strengths of SQuAD, such as high out-of-domain performance, with self-sufficient questions that contain all relevant information for open-domain QA as in the NaturalQuestions dataset. Our training and test datasets do not overlap like other popular datasets and include complex questions that cannot be answered with a single entity or only a few words.",
"### Supported Tasks and Leaderboards\n\n\n* 'extractive-qa', 'closed-domain-qa', 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa', but can also be used for information retrieval tasks.",
"### Languages\n\n\nThe sentences in the dataset are in German (de).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from the training set is provided below:",
"### Data Fields\n\n\n* 'id': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\nThe dataset is split into a one-way annotated training set and a three-way annotated test set of German Wikipedia passages (paragraphs). Each passage is\nfrom a different article.\n\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL"
]
| [
"TAGS\n#task_categories-question-answering #task_categories-text-retrieval #task_ids-extractive-qa #task_ids-closed-domain-qa #task_ids-open-domain-qa #multilinguality-monolingual #source_datasets-original #language-German #license-cc-by-4.0 #arxiv-2104.12741 #region-us \n",
"### Dataset Summary\n\n\nIn order to raise the bar for non-English QA, we are releasing a high-quality, human-labeled German QA dataset consisting of 13 722 questions, incl. a three-way annotated test set.\nThe creation of GermanQuAD is inspired by insights from existing datasets as well as our labeling experience from several industry projects. We combine the strengths of SQuAD, such as high out-of-domain performance, with self-sufficient questions that contain all relevant information for open-domain QA as in the NaturalQuestions dataset. Our training and test datasets do not overlap like other popular datasets and include complex questions that cannot be answered with a single entity or only a few words.",
"### Supported Tasks and Leaderboards\n\n\n* 'extractive-qa', 'closed-domain-qa', 'open-domain-qa', 'text-retrieval': This dataset is intended to be used for 'open-domain-qa', but can also be used for information retrieval tasks.",
"### Languages\n\n\nThe sentences in the dataset are in German (de).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from the training set is provided below:",
"### Data Fields\n\n\n* 'id': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\nThe dataset is split into a one-way annotated training set and a three-way annotated test set of German Wikipedia passages (paragraphs). Each passage is\nfrom a different article.\n\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe dataset was initially created by Timo Möller, Julian Risch, Malte Pietsch, Julian Gutsch, Tom Hersperger, Luise Köhler, Iuliia Mozhina, and Justus Peter, during work done at URL"
]
|
a24a4e46e38e652b9ac7a43c53c1f90eead22eea |
# Dataset Card for the Klexikon Dataset
## Table of Contents
- [Version History](#version-history)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Version History
- **v0.3** (2022-09-01): Removing some five samples from the dataset due to duplication conflicts with other samples.
- **v0.2** (2022-02-28): Updated the files to no longer contain empty sections and removing otherwise empty lines at the end of files. Also removing lines with some sort of coordinate.
- **v0.1** (2022-01-19): Initial data release on Huggingface datasets.
## Dataset Description
- **Homepage:** [N/A]
- **Repository:** [Klexikon repository](https://github.com/dennlinger/klexikon)
- **Paper:** [Klexikon: A German Dataset for Joint Summarization and Simplification](https://arxiv.org/abs/2201.07198)
- **Leaderboard:** [N/A]
- **Point of Contact:** [Dennis Aumiller](mailto:[email protected])
### Dataset Summary
The Klexikon dataset is a German resource of document-aligned texts between German Wikipedia and the children's lexicon "Klexikon". The dataset was created for the purpose of joint text simplification and summarization, and contains almost 2900 aligned article pairs.
Notably, the children's articles use a simpler language than the original Wikipedia articles; this is in addition to a clear length discrepancy between the source (Wikipedia) and target (Klexikon) domain.
### Supported Tasks and Leaderboards
- `summarization`: The dataset can be used to train a model for summarization. In particular, it poses a harder challenge than some of the commonly used datasets (CNN/DailyMail), which tend to suffer from positional biases in the source text. This makes it very easy to generate high (ROUGE) scoring solutions, by simply taking the leading 3 sentences. Our dataset provides a more challenging extraction task, combined with the additional difficulty of finding lexically appropriate simplifications.
- `simplification`: While not currently supported by the HF task board, text simplification is concerned with the appropriate representation of a text for disadvantaged readers (e.g., children, language learners, dyslexic,...).
For scoring, we ran preliminary experiments based on [ROUGE](https://huggingface.co/metrics/rouge), however, we want to cautiously point out that ROUGE is incapable of accurately depicting simplification appropriateness.
We combined this with looking at Flesch readability scores, as implemented by [textstat](https://github.com/shivam5992/textstat).
Note that simplification metrics such as [SARI](https://huggingface.co/metrics/sari) are not applicable here, since they require sentence alignments, which we do not provide.
### Languages
The associated BCP-47 code is `de-DE`.
The text of the articles is in German. Klexikon articles are further undergoing a simple form of peer-review before publication, and aim to simplify language for 8-13 year old children. This means that the general expected text difficulty for Klexikon articles is lower than Wikipedia's entries.
## Dataset Structure
### Data Instances
One datapoint represents the Wikipedia text (`wiki_text`), as well as the Klexikon text (`klexikon_text`).
Sentences are separated by newlines for both datasets, and section headings are indicated by leading `==` (or `===` for subheadings, `====` for sub-subheading, etc.).
Further, it includes the `wiki_url` and `klexikon_url`, pointing to the respective source texts. Note that the original articles were extracted in April 2021, so re-crawling the texts yourself will likely change some content.
Lastly, we include a unique identifier `u_id` as well as the page title `title` of the Klexikon page.
Sample (abridged texts for clarity):
```
{
"u_id": 0,
"title": "ABBA",
"wiki_url": "https://de.wikipedia.org/wiki/ABBA",
"klexikon_url": "https://klexikon.zum.de/wiki/ABBA",
"wiki_sentences": [
"ABBA ist eine schwedische Popgruppe, die aus den damaligen Paaren Agnetha Fältskog und Björn Ulvaeus sowie Benny Andersson und Anni-Frid Lyngstad besteht und sich 1972 in Stockholm formierte.",
"Sie gehört mit rund 400 Millionen verkauften Tonträgern zu den erfolgreichsten Bands der Musikgeschichte.",
"Bis in die 1970er Jahre hatte es keine andere Band aus Schweden oder Skandinavien gegeben, der vergleichbare Erfolge gelungen waren.",
"Trotz amerikanischer und britischer Dominanz im Musikgeschäft gelang der Band ein internationaler Durchbruch.",
"Sie hat die Geschichte der Popmusik mitgeprägt.",
"Zu ihren bekanntesten Songs zählen Mamma Mia, Dancing Queen und The Winner Takes It All.",
"1982 beendeten die Gruppenmitglieder aufgrund privater Differenzen ihre musikalische Zusammenarbeit.",
"Seit 2016 arbeiten die vier Musiker wieder zusammen an neuer Musik, die 2021 erscheinen soll.",
],
"klexikon_sentences": [
"ABBA war eine Musikgruppe aus Schweden.",
"Ihre Musikrichtung war die Popmusik.",
"Der Name entstand aus den Anfangsbuchstaben der Vornamen der Mitglieder, Agnetha, Björn, Benny und Anni-Frid.",
"Benny Andersson und Björn Ulvaeus, die beiden Männer, schrieben die Lieder und spielten Klavier und Gitarre.",
"Anni-Frid Lyngstad und Agnetha Fältskog sangen."
]
},
```
### Data Fields
* `u_id` (`int`): A unique identifier for each document pair in the dataset. 0-2349 are reserved for training data, 2350-2623 for testing, and 2364-2897 for validation.
* `title` (`str`): Title of the Klexikon page for this sample.
* `wiki_url` (`str`): URL of the associated Wikipedia article. Notably, this is non-trivial, since we potentially have disambiguated pages, where the Wikipedia title is not exactly the same as the Klexikon one.
* `klexikon_url` (`str`): URL of the Klexikon article.
* `wiki_text` (`List[str]`): List of sentences of the Wikipedia article. We prepare a pre-split document with spacy's sentence splitting (model: `de_core_news_md`). Additionally, please note that we do not include page contents outside of `<p>` tags, which excludes lists, captions and images.
* `klexikon_text` (`List[str]`): List of sentences of the Klexikon article. We apply the same processing as for the Wikipedia texts.
### Data Splits
We provide a stratified split of the dataset, based on the length of the respective Wiki article/Klexikon article pair (according to number of sentences).
The x-axis represents the length of the Wikipedia article, and the y-axis the length of the Klexikon article.
We segment the coordinate systems into rectangles of shape `(100, 10)`, and randomly sample a split of 80/10/10 for training/validation/test from each rectangle to ensure stratification. In case of rectangles with less than 10 entries, we put all samples into training.
The final splits have the following size:
* 2350 samples for training
* 274 samples for validation
* 274 samples for testing
## Dataset Creation
### Curation Rationale
As previously described, the Klexikon resource was created as an attempt to bridge the two fields of text summarization and text simplification. Previous datasets suffer from either one or more of the following shortcomings:
* They primarily focus on input/output pairs of similar lengths, which does not reflect longer-form texts.
* Data exists primarily for English, and other languages are notoriously understudied.
* Alignments exist for sentence-level, but not document-level.
This dataset serves as a starting point to investigate the feasibility of end-to-end simplification systems for longer input documents.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from [Klexikon](klexikon.zum.de), and afterwards aligned with corresponding texts from [German Wikipedia](de.wikipedia.org).
Specifically, the collection process was performed in April 2021, and 3145 articles could be extracted from Klexikon back then. Afterwards, we semi-automatically align the articles with Wikipedia, by looking up articles with the same title.
For articles that do not exactly match, we manually review their content, and decide to match to an appropriate substitute if the content can be matched by at least 66% of the Klexikon paragraphs.
Similarly, we proceed to manually review disambiguation pages on Wikipedia.
We extract only full-text content, excluding figures, captions, and list elements from the final text corpus, and only retain articles for which the respective Wikipedia document consists of at least 15 paragraphs after pre-processing.
#### Who are the source language producers?
The language producers are contributors to Klexikon and Wikipedia. No demographic information was available from the data sources.
### Annotations
#### Annotation process
Annotations were performed by manually reviewing the URLs of the ambiguous article pairs. No annotation platforms or existing tools were used in the process.
Otherwise, articles were matched based on the exact title.
#### Who are the annotators?
The manually aligned articles were reviewed by the dataset author (Dennis Aumiller).
### Personal and Sensitive Information
Since Klexikon and Wikipedia are public encyclopedias, no further personal or sensitive information is included. We did not investigate to what extent information about public figures is included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
Accessibility on the web is still a big issue, particularly for disadvantaged readers.
This dataset has the potential to strengthen text simplification systems, which can improve the situation.
In terms of language coverage, this dataset also has a beneficial impact on the availability of German data.
Potential negative biases include the problems of automatically aligned articles. The alignments may never be 100% perfect, and can therefore cause mis-aligned articles (or associations), despite the best of our intentions.
### Discussion of Biases
We have not tested whether any particular bias towards a specific article *type* (i.e., "person", "city", etc.) exists.
Similarly, we attempted to present an unbiased (stratified) split for validation and test set, but given that we only cover around 2900 articles, it is possible that these articles represent a particular focal lense on the overall distribution of lexical content.
### Other Known Limitations
Since the articles were written independently of each other, it is not guaranteed that there exists an exact coverage of each sentence in the simplified article, which could also stem from the fact that sometimes Wikipedia pages have separate article pages for aspects (e.g., the city of "Aarhus" has a separate page for its art museum (ARoS). However, Klexikon lists content and description for ARoS on the page of the city itself.
## Additional Information
### Dataset Curators
The dataset was curated only by the author of this dataset, Dennis Aumiller.
### Licensing Information
Klexikon and Wikipedia make their textual contents available under the CC BY-SA license, which will be inherited for this dataset.
### Citation Information
If you use our dataset or associated code, please cite our paper:
```
@inproceedings{aumiller-gertz-2022-klexikon,
title = "Klexikon: A {G}erman Dataset for Joint Summarization and Simplification",
author = "Aumiller, Dennis and
Gertz, Michael",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.288",
pages = "2693--2701"
}
```
| dennlinger/klexikon | [
"task_categories:summarization",
"task_categories:text2text-generation",
"task_ids:text-simplification",
"annotations_creators:found",
"annotations_creators:expert-generated",
"language_creators:found",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:de",
"license:cc-by-sa-4.0",
"conditional-text-generation",
"simplification",
"document-level",
"arxiv:2201.07198",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found", "expert-generated"], "language_creators": ["found", "machine-generated"], "language": ["de"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["summarization", "text2text-generation"], "task_ids": ["text-simplification"], "paperswithcode_id": "klexikon", "pretty_name": "Klexikon", "tags": ["conditional-text-generation", "simplification", "document-level"]} | 2022-10-25T14:03:56+00:00 | [
"2201.07198"
]
| [
"de"
]
| TAGS
#task_categories-summarization #task_categories-text2text-generation #task_ids-text-simplification #annotations_creators-found #annotations_creators-expert-generated #language_creators-found #language_creators-machine-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-German #license-cc-by-sa-4.0 #conditional-text-generation #simplification #document-level #arxiv-2201.07198 #region-us
|
# Dataset Card for the Klexikon Dataset
## Table of Contents
- Version History
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
## Version History
- v0.3 (2022-09-01): Removing some five samples from the dataset due to duplication conflicts with other samples.
- v0.2 (2022-02-28): Updated the files to no longer contain empty sections and removing otherwise empty lines at the end of files. Also removing lines with some sort of coordinate.
- v0.1 (2022-01-19): Initial data release on Huggingface datasets.
## Dataset Description
- Homepage: [N/A]
- Repository: Klexikon repository
- Paper: Klexikon: A German Dataset for Joint Summarization and Simplification
- Leaderboard: [N/A]
- Point of Contact: Dennis Aumiller
### Dataset Summary
The Klexikon dataset is a German resource of document-aligned texts between German Wikipedia and the children's lexicon "Klexikon". The dataset was created for the purpose of joint text simplification and summarization, and contains almost 2900 aligned article pairs.
Notably, the children's articles use a simpler language than the original Wikipedia articles; this is in addition to a clear length discrepancy between the source (Wikipedia) and target (Klexikon) domain.
### Supported Tasks and Leaderboards
- 'summarization': The dataset can be used to train a model for summarization. In particular, it poses a harder challenge than some of the commonly used datasets (CNN/DailyMail), which tend to suffer from positional biases in the source text. This makes it very easy to generate high (ROUGE) scoring solutions, by simply taking the leading 3 sentences. Our dataset provides a more challenging extraction task, combined with the additional difficulty of finding lexically appropriate simplifications.
- 'simplification': While not currently supported by the HF task board, text simplification is concerned with the appropriate representation of a text for disadvantaged readers (e.g., children, language learners, dyslexic,...).
For scoring, we ran preliminary experiments based on ROUGE, however, we want to cautiously point out that ROUGE is incapable of accurately depicting simplification appropriateness.
We combined this with looking at Flesch readability scores, as implemented by textstat.
Note that simplification metrics such as SARI are not applicable here, since they require sentence alignments, which we do not provide.
### Languages
The associated BCP-47 code is 'de-DE'.
The text of the articles is in German. Klexikon articles are further undergoing a simple form of peer-review before publication, and aim to simplify language for 8-13 year old children. This means that the general expected text difficulty for Klexikon articles is lower than Wikipedia's entries.
## Dataset Structure
### Data Instances
One datapoint represents the Wikipedia text ('wiki_text'), as well as the Klexikon text ('klexikon_text').
Sentences are separated by newlines for both datasets, and section headings are indicated by leading '==' (or '===' for subheadings, '====' for sub-subheading, etc.).
Further, it includes the 'wiki_url' and 'klexikon_url', pointing to the respective source texts. Note that the original articles were extracted in April 2021, so re-crawling the texts yourself will likely change some content.
Lastly, we include a unique identifier 'u_id' as well as the page title 'title' of the Klexikon page.
Sample (abridged texts for clarity):
### Data Fields
* 'u_id' ('int'): A unique identifier for each document pair in the dataset. 0-2349 are reserved for training data, 2350-2623 for testing, and 2364-2897 for validation.
* 'title' ('str'): Title of the Klexikon page for this sample.
* 'wiki_url' ('str'): URL of the associated Wikipedia article. Notably, this is non-trivial, since we potentially have disambiguated pages, where the Wikipedia title is not exactly the same as the Klexikon one.
* 'klexikon_url' ('str'): URL of the Klexikon article.
* 'wiki_text' ('List[str]'): List of sentences of the Wikipedia article. We prepare a pre-split document with spacy's sentence splitting (model: 'de_core_news_md'). Additionally, please note that we do not include page contents outside of '<p>' tags, which excludes lists, captions and images.
* 'klexikon_text' ('List[str]'): List of sentences of the Klexikon article. We apply the same processing as for the Wikipedia texts.
### Data Splits
We provide a stratified split of the dataset, based on the length of the respective Wiki article/Klexikon article pair (according to number of sentences).
The x-axis represents the length of the Wikipedia article, and the y-axis the length of the Klexikon article.
We segment the coordinate systems into rectangles of shape '(100, 10)', and randomly sample a split of 80/10/10 for training/validation/test from each rectangle to ensure stratification. In case of rectangles with less than 10 entries, we put all samples into training.
The final splits have the following size:
* 2350 samples for training
* 274 samples for validation
* 274 samples for testing
## Dataset Creation
### Curation Rationale
As previously described, the Klexikon resource was created as an attempt to bridge the two fields of text summarization and text simplification. Previous datasets suffer from either one or more of the following shortcomings:
* They primarily focus on input/output pairs of similar lengths, which does not reflect longer-form texts.
* Data exists primarily for English, and other languages are notoriously understudied.
* Alignments exist for sentence-level, but not document-level.
This dataset serves as a starting point to investigate the feasibility of end-to-end simplification systems for longer input documents.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from Klexikon, and afterwards aligned with corresponding texts from German Wikipedia.
Specifically, the collection process was performed in April 2021, and 3145 articles could be extracted from Klexikon back then. Afterwards, we semi-automatically align the articles with Wikipedia, by looking up articles with the same title.
For articles that do not exactly match, we manually review their content, and decide to match to an appropriate substitute if the content can be matched by at least 66% of the Klexikon paragraphs.
Similarly, we proceed to manually review disambiguation pages on Wikipedia.
We extract only full-text content, excluding figures, captions, and list elements from the final text corpus, and only retain articles for which the respective Wikipedia document consists of at least 15 paragraphs after pre-processing.
#### Who are the source language producers?
The language producers are contributors to Klexikon and Wikipedia. No demographic information was available from the data sources.
### Annotations
#### Annotation process
Annotations were performed by manually reviewing the URLs of the ambiguous article pairs. No annotation platforms or existing tools were used in the process.
Otherwise, articles were matched based on the exact title.
#### Who are the annotators?
The manually aligned articles were reviewed by the dataset author (Dennis Aumiller).
### Personal and Sensitive Information
Since Klexikon and Wikipedia are public encyclopedias, no further personal or sensitive information is included. We did not investigate to what extent information about public figures is included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
Accessibility on the web is still a big issue, particularly for disadvantaged readers.
This dataset has the potential to strengthen text simplification systems, which can improve the situation.
In terms of language coverage, this dataset also has a beneficial impact on the availability of German data.
Potential negative biases include the problems of automatically aligned articles. The alignments may never be 100% perfect, and can therefore cause mis-aligned articles (or associations), despite the best of our intentions.
### Discussion of Biases
We have not tested whether any particular bias towards a specific article *type* (i.e., "person", "city", etc.) exists.
Similarly, we attempted to present an unbiased (stratified) split for validation and test set, but given that we only cover around 2900 articles, it is possible that these articles represent a particular focal lense on the overall distribution of lexical content.
### Other Known Limitations
Since the articles were written independently of each other, it is not guaranteed that there exists an exact coverage of each sentence in the simplified article, which could also stem from the fact that sometimes Wikipedia pages have separate article pages for aspects (e.g., the city of "Aarhus" has a separate page for its art museum (ARoS). However, Klexikon lists content and description for ARoS on the page of the city itself.
## Additional Information
### Dataset Curators
The dataset was curated only by the author of this dataset, Dennis Aumiller.
### Licensing Information
Klexikon and Wikipedia make their textual contents available under the CC BY-SA license, which will be inherited for this dataset.
If you use our dataset or associated code, please cite our paper:
| [
"# Dataset Card for the Klexikon Dataset",
"## Table of Contents\n- Version History\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Version History\n\n- v0.3 (2022-09-01): Removing some five samples from the dataset due to duplication conflicts with other samples.\n- v0.2 (2022-02-28): Updated the files to no longer contain empty sections and removing otherwise empty lines at the end of files. Also removing lines with some sort of coordinate.\n- v0.1 (2022-01-19): Initial data release on Huggingface datasets.",
"## Dataset Description\n\n- Homepage: [N/A]\n- Repository: Klexikon repository\n- Paper: Klexikon: A German Dataset for Joint Summarization and Simplification\n- Leaderboard: [N/A]\n- Point of Contact: Dennis Aumiller",
"### Dataset Summary\n\nThe Klexikon dataset is a German resource of document-aligned texts between German Wikipedia and the children's lexicon \"Klexikon\". The dataset was created for the purpose of joint text simplification and summarization, and contains almost 2900 aligned article pairs.\nNotably, the children's articles use a simpler language than the original Wikipedia articles; this is in addition to a clear length discrepancy between the source (Wikipedia) and target (Klexikon) domain.",
"### Supported Tasks and Leaderboards\n\n- 'summarization': The dataset can be used to train a model for summarization. In particular, it poses a harder challenge than some of the commonly used datasets (CNN/DailyMail), which tend to suffer from positional biases in the source text. This makes it very easy to generate high (ROUGE) scoring solutions, by simply taking the leading 3 sentences. Our dataset provides a more challenging extraction task, combined with the additional difficulty of finding lexically appropriate simplifications.\n- 'simplification': While not currently supported by the HF task board, text simplification is concerned with the appropriate representation of a text for disadvantaged readers (e.g., children, language learners, dyslexic,...).\n\nFor scoring, we ran preliminary experiments based on ROUGE, however, we want to cautiously point out that ROUGE is incapable of accurately depicting simplification appropriateness.\nWe combined this with looking at Flesch readability scores, as implemented by textstat.\nNote that simplification metrics such as SARI are not applicable here, since they require sentence alignments, which we do not provide.",
"### Languages\n\nThe associated BCP-47 code is 'de-DE'.\n\nThe text of the articles is in German. Klexikon articles are further undergoing a simple form of peer-review before publication, and aim to simplify language for 8-13 year old children. This means that the general expected text difficulty for Klexikon articles is lower than Wikipedia's entries.",
"## Dataset Structure",
"### Data Instances\n\nOne datapoint represents the Wikipedia text ('wiki_text'), as well as the Klexikon text ('klexikon_text').\nSentences are separated by newlines for both datasets, and section headings are indicated by leading '==' (or '===' for subheadings, '====' for sub-subheading, etc.).\nFurther, it includes the 'wiki_url' and 'klexikon_url', pointing to the respective source texts. Note that the original articles were extracted in April 2021, so re-crawling the texts yourself will likely change some content.\nLastly, we include a unique identifier 'u_id' as well as the page title 'title' of the Klexikon page.\n\nSample (abridged texts for clarity):",
"### Data Fields\n\n* 'u_id' ('int'): A unique identifier for each document pair in the dataset. 0-2349 are reserved for training data, 2350-2623 for testing, and 2364-2897 for validation.\n* 'title' ('str'): Title of the Klexikon page for this sample.\n* 'wiki_url' ('str'): URL of the associated Wikipedia article. Notably, this is non-trivial, since we potentially have disambiguated pages, where the Wikipedia title is not exactly the same as the Klexikon one.\n* 'klexikon_url' ('str'): URL of the Klexikon article.\n* 'wiki_text' ('List[str]'): List of sentences of the Wikipedia article. We prepare a pre-split document with spacy's sentence splitting (model: 'de_core_news_md'). Additionally, please note that we do not include page contents outside of '<p>' tags, which excludes lists, captions and images.\n* 'klexikon_text' ('List[str]'): List of sentences of the Klexikon article. We apply the same processing as for the Wikipedia texts.",
"### Data Splits\n\nWe provide a stratified split of the dataset, based on the length of the respective Wiki article/Klexikon article pair (according to number of sentences).\nThe x-axis represents the length of the Wikipedia article, and the y-axis the length of the Klexikon article.\nWe segment the coordinate systems into rectangles of shape '(100, 10)', and randomly sample a split of 80/10/10 for training/validation/test from each rectangle to ensure stratification. In case of rectangles with less than 10 entries, we put all samples into training.\n\nThe final splits have the following size:\n* 2350 samples for training\n* 274 samples for validation\n* 274 samples for testing",
"## Dataset Creation",
"### Curation Rationale\n\nAs previously described, the Klexikon resource was created as an attempt to bridge the two fields of text summarization and text simplification. Previous datasets suffer from either one or more of the following shortcomings:\n\n* They primarily focus on input/output pairs of similar lengths, which does not reflect longer-form texts.\n* Data exists primarily for English, and other languages are notoriously understudied.\n* Alignments exist for sentence-level, but not document-level.\n\nThis dataset serves as a starting point to investigate the feasibility of end-to-end simplification systems for longer input documents.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nData was collected from Klexikon, and afterwards aligned with corresponding texts from German Wikipedia.\nSpecifically, the collection process was performed in April 2021, and 3145 articles could be extracted from Klexikon back then. Afterwards, we semi-automatically align the articles with Wikipedia, by looking up articles with the same title.\nFor articles that do not exactly match, we manually review their content, and decide to match to an appropriate substitute if the content can be matched by at least 66% of the Klexikon paragraphs.\nSimilarly, we proceed to manually review disambiguation pages on Wikipedia.\n\nWe extract only full-text content, excluding figures, captions, and list elements from the final text corpus, and only retain articles for which the respective Wikipedia document consists of at least 15 paragraphs after pre-processing.",
"#### Who are the source language producers?\n\nThe language producers are contributors to Klexikon and Wikipedia. No demographic information was available from the data sources.",
"### Annotations",
"#### Annotation process\n\nAnnotations were performed by manually reviewing the URLs of the ambiguous article pairs. No annotation platforms or existing tools were used in the process.\nOtherwise, articles were matched based on the exact title.",
"#### Who are the annotators?\n\nThe manually aligned articles were reviewed by the dataset author (Dennis Aumiller).",
"### Personal and Sensitive Information\n\nSince Klexikon and Wikipedia are public encyclopedias, no further personal or sensitive information is included. We did not investigate to what extent information about public figures is included in the dataset.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nAccessibility on the web is still a big issue, particularly for disadvantaged readers.\nThis dataset has the potential to strengthen text simplification systems, which can improve the situation.\nIn terms of language coverage, this dataset also has a beneficial impact on the availability of German data.\n\nPotential negative biases include the problems of automatically aligned articles. The alignments may never be 100% perfect, and can therefore cause mis-aligned articles (or associations), despite the best of our intentions.",
"### Discussion of Biases\n\nWe have not tested whether any particular bias towards a specific article *type* (i.e., \"person\", \"city\", etc.) exists.\nSimilarly, we attempted to present an unbiased (stratified) split for validation and test set, but given that we only cover around 2900 articles, it is possible that these articles represent a particular focal lense on the overall distribution of lexical content.",
"### Other Known Limitations\n\nSince the articles were written independently of each other, it is not guaranteed that there exists an exact coverage of each sentence in the simplified article, which could also stem from the fact that sometimes Wikipedia pages have separate article pages for aspects (e.g., the city of \"Aarhus\" has a separate page for its art museum (ARoS). However, Klexikon lists content and description for ARoS on the page of the city itself.",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was curated only by the author of this dataset, Dennis Aumiller.",
"### Licensing Information\n\nKlexikon and Wikipedia make their textual contents available under the CC BY-SA license, which will be inherited for this dataset.\n\n\n\nIf you use our dataset or associated code, please cite our paper:"
]
| [
"TAGS\n#task_categories-summarization #task_categories-text2text-generation #task_ids-text-simplification #annotations_creators-found #annotations_creators-expert-generated #language_creators-found #language_creators-machine-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-German #license-cc-by-sa-4.0 #conditional-text-generation #simplification #document-level #arxiv-2201.07198 #region-us \n",
"# Dataset Card for the Klexikon Dataset",
"## Table of Contents\n- Version History\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Version History\n\n- v0.3 (2022-09-01): Removing some five samples from the dataset due to duplication conflicts with other samples.\n- v0.2 (2022-02-28): Updated the files to no longer contain empty sections and removing otherwise empty lines at the end of files. Also removing lines with some sort of coordinate.\n- v0.1 (2022-01-19): Initial data release on Huggingface datasets.",
"## Dataset Description\n\n- Homepage: [N/A]\n- Repository: Klexikon repository\n- Paper: Klexikon: A German Dataset for Joint Summarization and Simplification\n- Leaderboard: [N/A]\n- Point of Contact: Dennis Aumiller",
"### Dataset Summary\n\nThe Klexikon dataset is a German resource of document-aligned texts between German Wikipedia and the children's lexicon \"Klexikon\". The dataset was created for the purpose of joint text simplification and summarization, and contains almost 2900 aligned article pairs.\nNotably, the children's articles use a simpler language than the original Wikipedia articles; this is in addition to a clear length discrepancy between the source (Wikipedia) and target (Klexikon) domain.",
"### Supported Tasks and Leaderboards\n\n- 'summarization': The dataset can be used to train a model for summarization. In particular, it poses a harder challenge than some of the commonly used datasets (CNN/DailyMail), which tend to suffer from positional biases in the source text. This makes it very easy to generate high (ROUGE) scoring solutions, by simply taking the leading 3 sentences. Our dataset provides a more challenging extraction task, combined with the additional difficulty of finding lexically appropriate simplifications.\n- 'simplification': While not currently supported by the HF task board, text simplification is concerned with the appropriate representation of a text for disadvantaged readers (e.g., children, language learners, dyslexic,...).\n\nFor scoring, we ran preliminary experiments based on ROUGE, however, we want to cautiously point out that ROUGE is incapable of accurately depicting simplification appropriateness.\nWe combined this with looking at Flesch readability scores, as implemented by textstat.\nNote that simplification metrics such as SARI are not applicable here, since they require sentence alignments, which we do not provide.",
"### Languages\n\nThe associated BCP-47 code is 'de-DE'.\n\nThe text of the articles is in German. Klexikon articles are further undergoing a simple form of peer-review before publication, and aim to simplify language for 8-13 year old children. This means that the general expected text difficulty for Klexikon articles is lower than Wikipedia's entries.",
"## Dataset Structure",
"### Data Instances\n\nOne datapoint represents the Wikipedia text ('wiki_text'), as well as the Klexikon text ('klexikon_text').\nSentences are separated by newlines for both datasets, and section headings are indicated by leading '==' (or '===' for subheadings, '====' for sub-subheading, etc.).\nFurther, it includes the 'wiki_url' and 'klexikon_url', pointing to the respective source texts. Note that the original articles were extracted in April 2021, so re-crawling the texts yourself will likely change some content.\nLastly, we include a unique identifier 'u_id' as well as the page title 'title' of the Klexikon page.\n\nSample (abridged texts for clarity):",
"### Data Fields\n\n* 'u_id' ('int'): A unique identifier for each document pair in the dataset. 0-2349 are reserved for training data, 2350-2623 for testing, and 2364-2897 for validation.\n* 'title' ('str'): Title of the Klexikon page for this sample.\n* 'wiki_url' ('str'): URL of the associated Wikipedia article. Notably, this is non-trivial, since we potentially have disambiguated pages, where the Wikipedia title is not exactly the same as the Klexikon one.\n* 'klexikon_url' ('str'): URL of the Klexikon article.\n* 'wiki_text' ('List[str]'): List of sentences of the Wikipedia article. We prepare a pre-split document with spacy's sentence splitting (model: 'de_core_news_md'). Additionally, please note that we do not include page contents outside of '<p>' tags, which excludes lists, captions and images.\n* 'klexikon_text' ('List[str]'): List of sentences of the Klexikon article. We apply the same processing as for the Wikipedia texts.",
"### Data Splits\n\nWe provide a stratified split of the dataset, based on the length of the respective Wiki article/Klexikon article pair (according to number of sentences).\nThe x-axis represents the length of the Wikipedia article, and the y-axis the length of the Klexikon article.\nWe segment the coordinate systems into rectangles of shape '(100, 10)', and randomly sample a split of 80/10/10 for training/validation/test from each rectangle to ensure stratification. In case of rectangles with less than 10 entries, we put all samples into training.\n\nThe final splits have the following size:\n* 2350 samples for training\n* 274 samples for validation\n* 274 samples for testing",
"## Dataset Creation",
"### Curation Rationale\n\nAs previously described, the Klexikon resource was created as an attempt to bridge the two fields of text summarization and text simplification. Previous datasets suffer from either one or more of the following shortcomings:\n\n* They primarily focus on input/output pairs of similar lengths, which does not reflect longer-form texts.\n* Data exists primarily for English, and other languages are notoriously understudied.\n* Alignments exist for sentence-level, but not document-level.\n\nThis dataset serves as a starting point to investigate the feasibility of end-to-end simplification systems for longer input documents.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nData was collected from Klexikon, and afterwards aligned with corresponding texts from German Wikipedia.\nSpecifically, the collection process was performed in April 2021, and 3145 articles could be extracted from Klexikon back then. Afterwards, we semi-automatically align the articles with Wikipedia, by looking up articles with the same title.\nFor articles that do not exactly match, we manually review their content, and decide to match to an appropriate substitute if the content can be matched by at least 66% of the Klexikon paragraphs.\nSimilarly, we proceed to manually review disambiguation pages on Wikipedia.\n\nWe extract only full-text content, excluding figures, captions, and list elements from the final text corpus, and only retain articles for which the respective Wikipedia document consists of at least 15 paragraphs after pre-processing.",
"#### Who are the source language producers?\n\nThe language producers are contributors to Klexikon and Wikipedia. No demographic information was available from the data sources.",
"### Annotations",
"#### Annotation process\n\nAnnotations were performed by manually reviewing the URLs of the ambiguous article pairs. No annotation platforms or existing tools were used in the process.\nOtherwise, articles were matched based on the exact title.",
"#### Who are the annotators?\n\nThe manually aligned articles were reviewed by the dataset author (Dennis Aumiller).",
"### Personal and Sensitive Information\n\nSince Klexikon and Wikipedia are public encyclopedias, no further personal or sensitive information is included. We did not investigate to what extent information about public figures is included in the dataset.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nAccessibility on the web is still a big issue, particularly for disadvantaged readers.\nThis dataset has the potential to strengthen text simplification systems, which can improve the situation.\nIn terms of language coverage, this dataset also has a beneficial impact on the availability of German data.\n\nPotential negative biases include the problems of automatically aligned articles. The alignments may never be 100% perfect, and can therefore cause mis-aligned articles (or associations), despite the best of our intentions.",
"### Discussion of Biases\n\nWe have not tested whether any particular bias towards a specific article *type* (i.e., \"person\", \"city\", etc.) exists.\nSimilarly, we attempted to present an unbiased (stratified) split for validation and test set, but given that we only cover around 2900 articles, it is possible that these articles represent a particular focal lense on the overall distribution of lexical content.",
"### Other Known Limitations\n\nSince the articles were written independently of each other, it is not guaranteed that there exists an exact coverage of each sentence in the simplified article, which could also stem from the fact that sometimes Wikipedia pages have separate article pages for aspects (e.g., the city of \"Aarhus\" has a separate page for its art museum (ARoS). However, Klexikon lists content and description for ARoS on the page of the city itself.",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was curated only by the author of this dataset, Dennis Aumiller.",
"### Licensing Information\n\nKlexikon and Wikipedia make their textual contents available under the CC BY-SA license, which will be inherited for this dataset.\n\n\n\nIf you use our dataset or associated code, please cite our paper:"
]
|
6f0944f5a1d47c359b4f5de03ed1d58c98f297b5 |
# Dataset Card for "Few-NERD"
## Table of Contents
- [Dataset Description](
#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://ningding97.github.io/fewnerd/](https://ningding97.github.io/fewnerd/)
- **Repository:** [https://github.com/thunlp/Few-NERD](https://github.com/thunlp/Few-NERD)
- **Paper:** [https://aclanthology.org/2021.acl-long.248/](https://aclanthology.org/2021.acl-long.248/)
- **Point of Contact:** See [https://ningding97.github.io/fewnerd/](https://ningding97.github.io/fewnerd/)
### Dataset Summary
This script is for loading the Few-NERD dataset from https://ningding97.github.io/fewnerd/.
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities, and 4,601,223 tokens. Three benchmark tasks are built, one is supervised (Few-NERD (SUP)) and the other two are few-shot (Few-NERD (INTRA) and Few-NERD (INTER)).
NER tags use the `IO` tagging scheme. The original data uses a 2-column CoNLL-style format, with empty lines to separate sentences. DOCSTART information is not provided since the sentences are randomly ordered.
For more details see https://ningding97.github.io/fewnerd/ and https://aclanthology.org/2021.acl-long.248/.
### Supported Tasks and Leaderboards
- **Tasks:** Named Entity Recognition, Few-shot NER
- **Leaderboards:**
- https://ningding97.github.io/fewnerd/
- named-entity-recognition:https://paperswithcode.com/sota/named-entity-recognition-on-few-nerd-sup
- other-few-shot-ner:https://paperswithcode.com/sota/few-shot-ner-on-few-nerd-intra
- other-few-shot-ner:https://paperswithcode.com/sota/few-shot-ner-on-few-nerd-inter
### Languages
English
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:**
- `super`: 14.6 MB
- `intra`: 11.4 MB
- `inter`: 11.5 MB
- **Size of the generated dataset:**
- `super`: 116.9 MB
- `intra`: 106.2 MB
- `inter`: 106.2 MB
- **Total amount of disk used:** 366.8 MB
An example of 'train' looks as follows.
```json
{
'id': '1',
'tokens': ['It', 'starred', 'Hicks', "'s", 'wife', ',', 'Ellaline', 'Terriss', 'and', 'Edmund', 'Payne', '.'],
'ner_tags': [0, 0, 7, 0, 0, 0, 7, 7, 0, 7, 7, 0],
'fine_ner_tags': [0, 0, 51, 0, 0, 0, 50, 50, 0, 50, 50, 0]
}
```
### Data Fields
The data fields are the same among all splits.
- `id`: a `string` feature.
- `tokens`: a `list` of `string` features.
- `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `art` (1), `building` (2), `event` (3), `location` (4), `organization` (5), `other`(6), `person` (7), `product` (8)
- `fine_ner_tags`: a `list` of fine-grained classification labels, with possible values including `O` (0), `art-broadcastprogram` (1), `art-film` (2), ...
### Data Splits
| Task | Train | Dev | Test |
| ----- | ------ | ----- | ---- |
| SUP | 131767 | 18824 | 37648 |
| INTRA | 99519 | 19358 | 44059 |
| INTER | 130112 | 18817 | 14007 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[CC BY-SA 4.0 license](https://creativecommons.org/licenses/by-sa/4.0/)
### Citation Information
```
@inproceedings{ding-etal-2021-nerd,
title = "Few-{NERD}: A Few-shot Named Entity Recognition Dataset",
author = "Ding, Ning and
Xu, Guangwei and
Chen, Yulin and
Wang, Xiaobin and
Han, Xu and
Xie, Pengjun and
Zheng, Haitao and
Liu, Zhiyuan",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.248",
doi = "10.18653/v1/2021.acl-long.248",
pages = "3198--3213",
}
```
### Contributions | DFKI-SLT/few-nerd | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended|wikipedia",
"language:en",
"license:cc-by-sa-4.0",
"structure-prediction",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["extended|wikipedia"], "task_categories": ["token-classification"], "task_ids": ["named-entity-recognition"], "paperswithcode_id": "few-nerd", "pretty_name": "Few-NERD", "tags": ["structure-prediction"]} | 2023-06-21T08:59:09+00:00 | []
| [
"en"
]
| TAGS
#task_categories-token-classification #task_ids-named-entity-recognition #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-extended|wikipedia #language-English #license-cc-by-sa-4.0 #structure-prediction #region-us
| Dataset Card for "Few-NERD"
===========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Point of Contact: See URL
### Dataset Summary
This script is for loading the Few-NERD dataset from URL
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities, and 4,601,223 tokens. Three benchmark tasks are built, one is supervised (Few-NERD (SUP)) and the other two are few-shot (Few-NERD (INTRA) and Few-NERD (INTER)).
NER tags use the 'IO' tagging scheme. The original data uses a 2-column CoNLL-style format, with empty lines to separate sentences. DOCSTART information is not provided since the sentences are randomly ordered.
For more details see URL and URL
### Supported Tasks and Leaderboards
* Tasks: Named Entity Recognition, Few-shot NER
* Leaderboards:
+ URL
+ named-entity-recognition:URL
+ other-few-shot-ner:URL
+ other-few-shot-ner:URL
### Languages
English
Dataset Structure
-----------------
### Data Instances
* Size of downloaded dataset files:
+ 'super': 14.6 MB
+ 'intra': 11.4 MB
+ 'inter': 11.5 MB
* Size of the generated dataset:
+ 'super': 116.9 MB
+ 'intra': 106.2 MB
+ 'inter': 106.2 MB
* Total amount of disk used: 366.8 MB
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'id': a 'string' feature.
* 'tokens': a 'list' of 'string' features.
* 'ner\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'art' (1), 'building' (2), 'event' (3), 'location' (4), 'organization' (5), 'other'(6), 'person' (7), 'product' (8)
* 'fine\_ner\_tags': a 'list' of fine-grained classification labels, with possible values including 'O' (0), 'art-broadcastprogram' (1), 'art-film' (2), ...
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
CC BY-SA 4.0 license
### Contributions
| [
"### Dataset Summary\n\n\nThis script is for loading the Few-NERD dataset from URL\n\n\nFew-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities, and 4,601,223 tokens. Three benchmark tasks are built, one is supervised (Few-NERD (SUP)) and the other two are few-shot (Few-NERD (INTRA) and Few-NERD (INTER)).\n\n\nNER tags use the 'IO' tagging scheme. The original data uses a 2-column CoNLL-style format, with empty lines to separate sentences. DOCSTART information is not provided since the sentences are randomly ordered.\n\n\nFor more details see URL and URL",
"### Supported Tasks and Leaderboards\n\n\n* Tasks: Named Entity Recognition, Few-shot NER\n* Leaderboards:\n\t+ URL\n\t+ named-entity-recognition:URL\n\t+ other-few-shot-ner:URL\n\t+ other-few-shot-ner:URL",
"### Languages\n\n\nEnglish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\n* Size of downloaded dataset files:\n\n\n\t+ 'super': 14.6 MB\n\t+ 'intra': 11.4 MB\n\t+ 'inter': 11.5 MB\n* Size of the generated dataset:\n\n\n\t+ 'super': 116.9 MB\n\t+ 'intra': 106.2 MB\n\t+ 'inter': 106.2 MB\n* Total amount of disk used: 366.8 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature.\n* 'tokens': a 'list' of 'string' features.\n* 'ner\\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'art' (1), 'building' (2), 'event' (3), 'location' (4), 'organization' (5), 'other'(6), 'person' (7), 'product' (8)\n* 'fine\\_ner\\_tags': a 'list' of fine-grained classification labels, with possible values including 'O' (0), 'art-broadcastprogram' (1), 'art-film' (2), ...",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCC BY-SA 4.0 license",
"### Contributions"
]
| [
"TAGS\n#task_categories-token-classification #task_ids-named-entity-recognition #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-extended|wikipedia #language-English #license-cc-by-sa-4.0 #structure-prediction #region-us \n",
"### Dataset Summary\n\n\nThis script is for loading the Few-NERD dataset from URL\n\n\nFew-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities, and 4,601,223 tokens. Three benchmark tasks are built, one is supervised (Few-NERD (SUP)) and the other two are few-shot (Few-NERD (INTRA) and Few-NERD (INTER)).\n\n\nNER tags use the 'IO' tagging scheme. The original data uses a 2-column CoNLL-style format, with empty lines to separate sentences. DOCSTART information is not provided since the sentences are randomly ordered.\n\n\nFor more details see URL and URL",
"### Supported Tasks and Leaderboards\n\n\n* Tasks: Named Entity Recognition, Few-shot NER\n* Leaderboards:\n\t+ URL\n\t+ named-entity-recognition:URL\n\t+ other-few-shot-ner:URL\n\t+ other-few-shot-ner:URL",
"### Languages\n\n\nEnglish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\n* Size of downloaded dataset files:\n\n\n\t+ 'super': 14.6 MB\n\t+ 'intra': 11.4 MB\n\t+ 'inter': 11.5 MB\n* Size of the generated dataset:\n\n\n\t+ 'super': 116.9 MB\n\t+ 'intra': 106.2 MB\n\t+ 'inter': 106.2 MB\n* Total amount of disk used: 366.8 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature.\n* 'tokens': a 'list' of 'string' features.\n* 'ner\\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'art' (1), 'building' (2), 'event' (3), 'location' (4), 'organization' (5), 'other'(6), 'person' (7), 'product' (8)\n* 'fine\\_ner\\_tags': a 'list' of fine-grained classification labels, with possible values including 'O' (0), 'art-broadcastprogram' (1), 'art-film' (2), ...",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCC BY-SA 4.0 license",
"### Contributions"
]
|
6b1bef2a9b7718d9a345d086ad9750123fa380b4 |
# Dataset Card for "MobIE"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/dfki-nlp/mobie](https://github.com/dfki-nlp/mobie)
- **Repository:** [https://github.com/dfki-nlp/mobie](https://github.com/dfki-nlp/mobie)
- **Paper:** [https://aclanthology.org/2021.konvens-1.22/](https://aclanthology.org/2021.konvens-1.22/)
- **Point of Contact:** See [https://github.com/dfki-nlp/mobie](https://github.com/dfki-nlp/mobie)
- **Size of downloaded dataset files:** 7.8 MB
- **Size of the generated dataset:** 1.9 MB
- **Total amount of disk used:** 9.7 MB
### Dataset Summary
This script is for loading the MobIE dataset from https://github.com/dfki-nlp/mobie.
MobIE is a German-language dataset which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. The dataset combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks.
This version of the dataset loader provides NER tags only. NER tags use the `BIO` tagging scheme.
For more details see https://github.com/dfki-nlp/mobie and https://aclanthology.org/2021.konvens-1.22/.
### Supported Tasks and Leaderboards
- **Tasks:** Named Entity Recognition
- **Leaderboards:**
### Languages
German
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 7.8 MB
- **Size of the generated dataset:** 1.9 MB
- **Total amount of disk used:** 9.7 MB
An example of 'train' looks as follows.
```json
{
'id': 'http://www.ndr.de/nachrichten/verkehr/index.html#2@2016-05-04T21:02:14.000+02:00',
'tokens': ['Vorsicht', 'bitte', 'auf', 'der', 'A28', 'Leer', 'Richtung', 'Oldenburg', 'zwischen', 'Zwischenahner', 'Meer', 'und', 'Neuenkruge', 'liegen', 'Gegenstände', '!'],
'ner_tags': [0, 0, 0, 0, 19, 13, 0, 13, 0, 11, 12, 0, 11, 0, 0, 0]
}
```
### Data Fields
The data fields are the same among all splits.
- `id`: a `string` feature.
- `tokens`: a `list` of `string` features.
- `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `B-date` (1), `I-date` (2), `B-disaster-type` (3), `I-disaster-type` (4), ...
### Data Splits
| | Train | Dev | Test |
| ----- | ------ | ----- | ---- |
| MobIE | 4785 | 1082 | 1210 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[CC BY-SA 4.0 license](https://creativecommons.org/licenses/by-sa/4.0/)
### Citation Information
```
@inproceedings{hennig-etal-2021-mobie,
title = "{M}ob{IE}: A {G}erman Dataset for Named Entity Recognition, Entity Linking and Relation Extraction in the Mobility Domain",
author = "Hennig, Leonhard and
Truong, Phuc Tran and
Gabryszak, Aleksandra",
booktitle = "Proceedings of the 17th Conference on Natural Language Processing (KONVENS 2021)",
month = "6--9 " # sep,
year = "2021",
address = {D{\"u}sseldorf, Germany},
publisher = "KONVENS 2021 Organizers",
url = "https://aclanthology.org/2021.konvens-1.22",
pages = "223--227",
}
```
### Contributions
| DFKI-SLT/mobie | [
"task_categories:other",
"task_ids:named-entity-recognition",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:de",
"license:cc-by-4.0",
"structure-prediction",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["de"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": ["named-entity-recognition"], "paperswithcode_id": "mobie", "pretty_name": "MobIE", "tags": ["structure-prediction"]} | 2022-10-24T05:32:09+00:00 | []
| [
"de"
]
| TAGS
#task_categories-other #task_ids-named-entity-recognition #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-German #license-cc-by-4.0 #structure-prediction #region-us
| Dataset Card for "MobIE"
========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Point of Contact: See URL
* Size of downloaded dataset files: 7.8 MB
* Size of the generated dataset: 1.9 MB
* Total amount of disk used: 9.7 MB
### Dataset Summary
This script is for loading the MobIE dataset from URL
MobIE is a German-language dataset which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. The dataset combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks.
This version of the dataset loader provides NER tags only. NER tags use the 'BIO' tagging scheme.
For more details see URL and URL
### Supported Tasks and Leaderboards
* Tasks: Named Entity Recognition
* Leaderboards:
### Languages
German
Dataset Structure
-----------------
### Data Instances
* Size of downloaded dataset files: 7.8 MB
* Size of the generated dataset: 1.9 MB
* Total amount of disk used: 9.7 MB
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'id': a 'string' feature.
* 'tokens': a 'list' of 'string' features.
* 'ner\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'B-date' (1), 'I-date' (2), 'B-disaster-type' (3), 'I-disaster-type' (4), ...
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
CC BY-SA 4.0 license
### Contributions
| [
"### Dataset Summary\n\n\nThis script is for loading the MobIE dataset from URL\n\n\nMobIE is a German-language dataset which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. The dataset combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks.\n\n\nThis version of the dataset loader provides NER tags only. NER tags use the 'BIO' tagging scheme.\n\n\nFor more details see URL and URL",
"### Supported Tasks and Leaderboards\n\n\n* Tasks: Named Entity Recognition\n* Leaderboards:",
"### Languages\n\n\nGerman\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\n* Size of downloaded dataset files: 7.8 MB\n* Size of the generated dataset: 1.9 MB\n* Total amount of disk used: 9.7 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature.\n* 'tokens': a 'list' of 'string' features.\n* 'ner\\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'B-date' (1), 'I-date' (2), 'B-disaster-type' (3), 'I-disaster-type' (4), ...",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCC BY-SA 4.0 license",
"### Contributions"
]
| [
"TAGS\n#task_categories-other #task_ids-named-entity-recognition #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-German #license-cc-by-4.0 #structure-prediction #region-us \n",
"### Dataset Summary\n\n\nThis script is for loading the MobIE dataset from URL\n\n\nMobIE is a German-language dataset which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. The dataset combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks.\n\n\nThis version of the dataset loader provides NER tags only. NER tags use the 'BIO' tagging scheme.\n\n\nFor more details see URL and URL",
"### Supported Tasks and Leaderboards\n\n\n* Tasks: Named Entity Recognition\n* Leaderboards:",
"### Languages\n\n\nGerman\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\n* Size of downloaded dataset files: 7.8 MB\n* Size of the generated dataset: 1.9 MB\n* Total amount of disk used: 9.7 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature.\n* 'tokens': a 'list' of 'string' features.\n* 'ner\\_tags': a 'list' of classification labels, with possible values including 'O' (0), 'B-date' (1), 'I-date' (2), 'B-disaster-type' (3), 'I-disaster-type' (4), ...",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCC BY-SA 4.0 license",
"### Contributions"
]
|
03da9bf8c82e6ebb3ed7cd09afaf1566fdd6320f | <a href="https://jobs.acm.org/jobs/watch-godzilla-vs-kong-2021-full-1818658-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-godzilla-vs-kong-online-2021-full-f-r-e-e-1818655-cd">.</a>
<a href="https://jobs.acm.org/jobs/watch-demon-slayer-kimetsu-no-yaiba-mugen-train-2020-f-u-l-l-f-r-e-e-1818661-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-zack-snyder-s-justice-league-online-2021-full-f-r-e-e-1818662-cd">.</a>
<a href="https://jobs.acm.org/jobs/hd-watch-godzilla-vs-kong-2021-version-full-hbomax-1818659-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-girl-in-the-basement-online-2021-full-f-r-e-e-1818663-cd">.</a>
<a href="https://jobs.acm.org/jobs/watch-godzilla-vs-kong-2021-f-u-l-l-h-d-1818660-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-billie-eilish-the-world-s-a-little-blurry-2021-f-u-l-l-f-r-e-e-1818666-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-monster-hunter-2020-f-u-l-l-f-r-e-e-1818667-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-raya-and-the-last-dragon-2021-f-u-l-l-f-r-e-e-1818669-cd">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-365-days-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-billie-eilish-the-worlds-a-little-blurry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-cherry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-coming-2-america-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-demon-slayer-kimetsu-no-yaiba-mugen-train-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-godzilla-vs-kong-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-judas-and-the-black-messiah-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-monster-hunter-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-mortal-kombat-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-raya-and-the-last-dragon-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-tenet-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-the-world-to-come-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-tom-and-jerry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-willys-wonderland-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-wonder-woman-1984-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-wrong-turn-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-zack-snyders-justice-league-2021-hd-online-full-free-stream-2/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-a-writers-odyssey-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-the-marksman-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-after-we-collided-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online-full-version-123movies/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-2/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-3/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-4/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-123movies-godzilla-vs-kong-2021/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-free-hd/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free-online/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-5/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online-full-version-hd/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-full-2021-free/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-2/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-6/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-7/">.</a>
<a href="https://pactforanimals.org/advert/free-download-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/godzilla-vs-kong-2021-google-drive-mp4/">.</a>
<a href="https://pactforanimals.org/advert/google-docs-godzilla-vs-kong-2021-google-drive-full-hd-mp4/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-8/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-9/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-3/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-4/">.</a>
<a href="https://pactforanimals.org/advert/free-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-10/">.</a>
<a href="https://pactforanimals.org/advert/online-watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-godzilla-vs-kong-2021-full-online/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-11/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free-hd/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-free-online/">.</a>
<a href="https://pactforanimals.org/advert/full-godzilla-vs-kong-2021-watch-online/">.</a>
<a href="https://sites.google.com/view/mortalkombat1/">.</a>
<a href="https://sites.google.com/view/free-watch-mortal-kombat-2021-/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-2021-f-u-l/">.</a>
<a href="https://sites.google.com/view/mortalkombat2/">.</a>
<a href="https://sites.google.com/view/mortalkombat3/">.</a>
<a href="https://sites.google.com/view/mortalkombat5/">.</a>
<a href="https://sites.google.com/view/fullwatchmortalkombat2021-movi/">.</a>
<a href="https://sites.google.com/view/mortalkombat7/">.</a>
<a href="https://sites.google.com/view/mortalkombat8/">.</a>
<a href="https://sites.google.com/view/mortalkombat9/">.</a>
<a href="https://sites.google.com/view/mortalkombat10/">.</a>
<a href="https://sites.google.com/view/watch-mort-tal-kombat/">.</a>
<a href="https://sites.google.com/view/free-watch-mort-tal-kombat/">.</a>
<a href="https://sites.google.com/view/watch-mort-tal-kombatfree-/">.</a>
<a href="https://sites.google.com/view/full-watch-mortal-kombat/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-2021-/">.</a>
<a href="https://sites.google.com/view/watch-free-mortal-kombat-2021/">.</a>
<a href="https://sites.google.com/view/full-watch-mortal-kombat-/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-g-drive/">.</a>
<a href="https://sites.google.com/view/g-docs-mortalkombat-g-drive/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free-o/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free-o/">.</a>
<a href="https://paiza.io/projects/56xFAEq61pSSn8VnKnHO6Q">.</a>
<a href="https://www.posts123.com/post/1450667/mariners-announce-spring-training">.</a>
<a href="https://sites.google.com/view/sfdjgkdfghdkfgjherghkkdfjg/home">.</a>
<a href="https://dskfjshdkjfewhgf.blogspot.com/2021/03/sdkjfhwekjhfjdherjgfdjg.html">.</a>
<a href="https://grahmaulidia.wordpress.com/2021/03/28/mariners-announce-spring-training-roster-moves/">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner-f83a9ea92f89">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner1-b2847091ff9f">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner2-df35041eec3a">.</a>
<a href="https://4z5v6wq7a.medium.com">.</a>
<a href="https://onlinegdb.com/BJaH8WR4O">.</a> | dispenst/jhghdghfd | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-03-28T14:24:20+00:00 | []
| []
| TAGS
#region-us
| <a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL
<a href="URL">.</a>
<a href="URL | []
| [
"TAGS\n#region-us \n"
]
|
4bc6bb8acfa2b1b370b89138f7af792c36712de1 |
# Hinglish Dump
Raw merged dump of Hinglish (hi-EN) datasets.
## Subsets and features
Subsets:
- crowd_transliteration
- hindi_romanized_dump
- hindi_xlit
- hinge
- hinglish_norm
- news2018
```
_FEATURE_NAMES = [
"target_hinglish",
"source_hindi",
"parallel_english",
"annotations",
"raw_input",
"alternates",
]
```
| diwank/hinglish-dump | [
"license:mit",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "mit"} | 2022-03-05T14:28:55+00:00 | []
| []
| TAGS
#license-mit #region-us
|
# Hinglish Dump
Raw merged dump of Hinglish (hi-EN) datasets.
## Subsets and features
Subsets:
- crowd_transliteration
- hindi_romanized_dump
- hindi_xlit
- hinge
- hinglish_norm
- news2018
| [
"# Hinglish Dump\r\n\r\nRaw merged dump of Hinglish (hi-EN) datasets.",
"## Subsets and features\r\n\r\nSubsets:\r\n- crowd_transliteration \r\n- hindi_romanized_dump \r\n- hindi_xlit \r\n- hinge \r\n- hinglish_norm \r\n- news2018"
]
| [
"TAGS\n#license-mit #region-us \n",
"# Hinglish Dump\r\n\r\nRaw merged dump of Hinglish (hi-EN) datasets.",
"## Subsets and features\r\n\r\nSubsets:\r\n- crowd_transliteration \r\n- hindi_romanized_dump \r\n- hindi_xlit \r\n- hinge \r\n- hinglish_norm \r\n- news2018"
]
|
8ac729015e92e4f02f1ad60e9c595fbeca504e36 |
# diwank/silicone-merged
> Merged and simplified dialog act datasets from the [silicone collection](https://huggingface.co/datasets/silicone/)
All of the subsets of the original collection have been filtered (for errors and ambiguous classes), merged together and grouped into pairs of dialog turns. It is hypothesized that training dialog act classifier by including the previous utterance can help models pick up additional contextual cues and be better at inference esp if an utterance pair is provided.
## Example training script
```python
from datasets import load_dataset
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
# Get data
silicone_merged = load_dataset("diwank/silicone-merged")
train_df = silicone_merged["train"]
eval_df = silicone_merged["validation"]
model_args = ClassificationArgs(
num_train_epochs=8,
model_type="deberta",
model_name="microsoft/deberta-large",
use_multiprocessing=False,
evaluate_during_training=True,
)
# Create a ClassificationModel
model = ClassificationModel("deberta", "microsoft/deberta-large", args=model_args, num_labels=11) # 11 labels in this dataset
# Train model
model.train_model(train_df, eval_df=eval_df)
```
## Balanced variant of the training set
**Note**: This dataset is highly imbalanced and it is recommended to use a library like [imbalanced-learn](https://imbalanced-learn.org/stable/) before proceeding with training.
Since, balancing can be complicated and resource-intensive, we have shared a balanced variant of the train set that was created via oversampling using the _imbalanced-learn_ library. The balancing used the `SMOTEN` algorithm to deal with categorical data clustering and was resampled on a 16-core, 60GB RAM machine. You can access it using:
```load_dataset("diwank/silicone-merged", "balanced")```
## Feature description
- `text_a`: The utterance prior to the utterance being classified. (Say for dialog with turns 1-2-3, if we are trying to find the dialog act for 2, text_a is 1)
- `text_b`: The utterance to be classified
- `labels`: Dialog act label (as integer between 0-10, as mapped below)
## Labels map
```python
[
(0, 'acknowledge')
(1, 'answer')
(2, 'backchannel')
(3, 'reply_yes')
(4, 'exclaim')
(5, 'say')
(6, 'reply_no')
(7, 'hold')
(8, 'ask')
(9, 'intent')
(10, 'ask_yes_no')
]
```
*****
## Appendix
### How the original datasets were mapped:
```python
mapping = {
"acknowledge": {
"swda": [
"aap_am",
"b",
"bk"
],
"mrda": [],
"oasis": [
"ackn",
"accept",
"complete"
],
"maptask": [
"acknowledge",
"align"
],
"dyda_da": [
"commissive"
]
},
"answer": {
"swda": [
"bf",
],
"mrda": [],
"oasis": [
"answ",
"informCont",
"inform",
"answElab",
"directElab",
"refer"
],
"maptask": [
"reply_w",
"explain"
],
"dyda_da": [
"inform"
]
},
"backchannel": {
"swda": [
"ad",
"bh",
"bd",
"b^m"
],
"mrda": [
"b"
],
"oasis": [
"backch",
"selfTalk",
"init"
],
"maptask": ["ready"],
"dyda_da": []
},
"reply_yes": {
"swda": [
"na",
"aa"
],
"mrda": [],
"oasis": [
"confirm"
],
"maptask": [
"reply_y"
],
"dyda_da": []
},
"exclaim": {
"swda": [
"ft",
"fa",
"fc",
"fp"
],
"mrda": [],
"oasis": [
"appreciate",
"bye",
"exclaim",
"greet",
"thank",
"pardon",
"thank-identitySelf",
"expressRegret"
],
"maptask": [],
"dyda_da": []
},
"say": {
"swda": [
"qh",
"sd"
],
"mrda": ["s"],
"oasis": [
"expressPossibility",
"expressOpinion",
"suggest"
],
"maptask": [],
"dyda_da": []
},
"reply_no": {
"swda": [
"nn",
"ng",
"ar"
],
"mrda": [],
"oasis": [
"refuse",
"negate"
],
"maptask": [
"reply_n"
],
"dyda_da": []
},
"hold": {
"swda": [
"^h",
"t1"
],
"mrda": [
"f"
],
"oasis": [
"hold"
],
"maptask": [],
"dyda_da": []
},
"ask": {
"swda": [
"qw",
"qo",
"qw^d",
"br",
"qrr"
],
"mrda": [
"q"
],
"oasis": [
"reqInfo",
"reqDirect",
"offer"
],
"maptask": [
"query_w"
],
"dyda_da": [
"question"
]
},
"intent": {
"swda": [],
"mrda": [],
"oasis": [
"informIntent",
"informIntent-hold",
"expressWish",
"direct",
"raiseIssue",
"correct"
],
"maptask": [
"instruct",
"clarify"
],
"dyda_da": [
"directive"
]
},
"ask_yes_no": {
"swda": [
"qy^d",
"^g"
],
"mrda": [],
"oasis": [
"reqModal"
],
"maptask": [
"query_yn",
"check"
],
"dyda_da": []
}
}
``` | diwank/silicone-merged | [
"license:mit",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "mit"} | 2022-03-06T11:30:57+00:00 | []
| []
| TAGS
#license-mit #region-us
|
# diwank/silicone-merged
> Merged and simplified dialog act datasets from the silicone collection
All of the subsets of the original collection have been filtered (for errors and ambiguous classes), merged together and grouped into pairs of dialog turns. It is hypothesized that training dialog act classifier by including the previous utterance can help models pick up additional contextual cues and be better at inference esp if an utterance pair is provided.
## Example training script
## Balanced variant of the training set
Note: This dataset is highly imbalanced and it is recommended to use a library like imbalanced-learn before proceeding with training.
Since, balancing can be complicated and resource-intensive, we have shared a balanced variant of the train set that was created via oversampling using the _imbalanced-learn_ library. The balancing used the 'SMOTEN' algorithm to deal with categorical data clustering and was resampled on a 16-core, 60GB RAM machine. You can access it using:
## Feature description
- 'text_a': The utterance prior to the utterance being classified. (Say for dialog with turns 1-2-3, if we are trying to find the dialog act for 2, text_a is 1)
- 'text_b': The utterance to be classified
- 'labels': Dialog act label (as integer between 0-10, as mapped below)
## Labels map
*
## Appendix
### How the original datasets were mapped:
| [
"# diwank/silicone-merged\r\n\r\n> Merged and simplified dialog act datasets from the silicone collection\r\n\r\nAll of the subsets of the original collection have been filtered (for errors and ambiguous classes), merged together and grouped into pairs of dialog turns. It is hypothesized that training dialog act classifier by including the previous utterance can help models pick up additional contextual cues and be better at inference esp if an utterance pair is provided.",
"## Example training script",
"## Balanced variant of the training set\r\n\r\nNote: This dataset is highly imbalanced and it is recommended to use a library like imbalanced-learn before proceeding with training.\r\n\r\nSince, balancing can be complicated and resource-intensive, we have shared a balanced variant of the train set that was created via oversampling using the _imbalanced-learn_ library. The balancing used the 'SMOTEN' algorithm to deal with categorical data clustering and was resampled on a 16-core, 60GB RAM machine. You can access it using:",
"## Feature description\r\n\r\n- 'text_a': The utterance prior to the utterance being classified. (Say for dialog with turns 1-2-3, if we are trying to find the dialog act for 2, text_a is 1)\r\n- 'text_b': The utterance to be classified\r\n- 'labels': Dialog act label (as integer between 0-10, as mapped below)",
"## Labels map\r\n\r\n\r\n\r\n*",
"## Appendix",
"### How the original datasets were mapped:"
]
| [
"TAGS\n#license-mit #region-us \n",
"# diwank/silicone-merged\r\n\r\n> Merged and simplified dialog act datasets from the silicone collection\r\n\r\nAll of the subsets of the original collection have been filtered (for errors and ambiguous classes), merged together and grouped into pairs of dialog turns. It is hypothesized that training dialog act classifier by including the previous utterance can help models pick up additional contextual cues and be better at inference esp if an utterance pair is provided.",
"## Example training script",
"## Balanced variant of the training set\r\n\r\nNote: This dataset is highly imbalanced and it is recommended to use a library like imbalanced-learn before proceeding with training.\r\n\r\nSince, balancing can be complicated and resource-intensive, we have shared a balanced variant of the train set that was created via oversampling using the _imbalanced-learn_ library. The balancing used the 'SMOTEN' algorithm to deal with categorical data clustering and was resampled on a 16-core, 60GB RAM machine. You can access it using:",
"## Feature description\r\n\r\n- 'text_a': The utterance prior to the utterance being classified. (Say for dialog with turns 1-2-3, if we are trying to find the dialog act for 2, text_a is 1)\r\n- 'text_b': The utterance to be classified\r\n- 'labels': Dialog act label (as integer between 0-10, as mapped below)",
"## Labels map\r\n\r\n\r\n\r\n*",
"## Appendix",
"### How the original datasets were mapped:"
]
|
5b6f20f66d73f38078bc1e543ee4ee0fe68e2865 | ## Summary
Metadata information of all the models uploaded on [HuggingFace modelhub](https://huggingface.co/models)
Dataset was last updated on 15th June 2021. Contains information on 10,354 models (v1).
Only `train` dataset is provided
#### Update: v1.0.2: Added downloads_last_month and library data
Same dataset is available in [kaggle](https://www.kaggle.com/crazydiv/huggingface-modelhub)
## Loading data
```python
from datasets import load_dataset
modelhub_dataset = load_dataset("dk-crazydiv/huggingface-modelhub")
```
### Useful commands:
```python
modelhub_dataset["train"] # Access train subset (the only subset available)
modelhub_dataset["train"][0] # Access the dataset elements by index
modelhub_dataset["train"].features # Get the columns present in the dataset.
```
### Sample dataset:
```json
{
"downloads_last_month": 7474,
"files": [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"spiece.model",
"tf_model.h5",
"tokenizer.json",
"with-prefix-tf_model.h5"
],
"lastModified": "2021-01-13T15:08:24.000Z",
"library": "transformers",
"modelId": "albert-base-v1",
"pipeline_tag": "fill-mask",
"publishedBy": "huggingface",
"tags": [
"pytorch",
"tf",
"albert",
"masked-lm",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"fill-mask"
],
"modelCard": "Readme sample data..."
}
```
## Bugs:
Please report any bugs/improvements to me on [twitter](https://twitter.com/kartik_godawat) | dk-crazydiv/huggingface-modelhub | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-06-20T13:09:58+00:00 | []
| []
| TAGS
#region-us
| ## Summary
Metadata information of all the models uploaded on HuggingFace modelhub
Dataset was last updated on 15th June 2021. Contains information on 10,354 models (v1).
Only 'train' dataset is provided
#### Update: v1.0.2: Added downloads_last_month and library data
Same dataset is available in kaggle
## Loading data
### Useful commands:
### Sample dataset:
## Bugs:
Please report any bugs/improvements to me on twitter | [
"## Summary\nMetadata information of all the models uploaded on HuggingFace modelhub\nDataset was last updated on 15th June 2021. Contains information on 10,354 models (v1).\nOnly 'train' dataset is provided",
"#### Update: v1.0.2: Added downloads_last_month and library data\nSame dataset is available in kaggle",
"## Loading data",
"### Useful commands:",
"### Sample dataset:",
"## Bugs:\nPlease report any bugs/improvements to me on twitter"
]
| [
"TAGS\n#region-us \n",
"## Summary\nMetadata information of all the models uploaded on HuggingFace modelhub\nDataset was last updated on 15th June 2021. Contains information on 10,354 models (v1).\nOnly 'train' dataset is provided",
"#### Update: v1.0.2: Added downloads_last_month and library data\nSame dataset is available in kaggle",
"## Loading data",
"### Useful commands:",
"### Sample dataset:",
"## Bugs:\nPlease report any bugs/improvements to me on twitter"
]
|
589d0538b2c05ac37dad771f15b5736732468005 |
# Dataset Card for PLUE
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/ju-resplande/PLUE
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Portuguese translation of the <a href="https://gluebenchmark.com/">GLUE benchmark</a>, <a href=https://nlp.stanford.edu/projects/snli/>SNLI</a>, and <a href=https://allenai.org/data/scitail> Scitail</a> using <a href=https://github.com/Helsinki-NLP/OPUS-MT>OPUS-MT model</a> and <a href=https://cloud.google.com/translate/docs>Google Cloud Translation</a>.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The language data in PLUE is Brazilian Portuguese (BCP-47 pt-BR)
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```bibtex
@misc{Gomes2020,
author = {GOMES, J. R. S.},
title = {PLUE: Portuguese Language Understanding Evaluation},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/jubs12/PLUE}},
commit = {CURRENT_COMMIT}
}
```
### Contributions
Thanks to [@ju-resplande](https://github.com/ju-resplande) for adding this dataset. | dlb/plue | [
"task_categories:text-classification",
"task_ids:acceptability-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:sentiment-classification",
"task_ids:text-scoring",
"annotations_creators:found",
"language_creators:machine-generated",
"multilinguality:monolingual",
"multilinguality:translation",
"size_categories:10K<n<100K",
"source_datasets:extended|glue",
"language:pt",
"license:lgpl-3.0",
"paraphrase-identification",
"qa-nli",
"coreference-nli",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["machine-generated"], "language": ["pt"], "license": ["lgpl-3.0"], "multilinguality": ["monolingual", "translation"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|glue"], "task_categories": ["text-classification"], "task_ids": ["acceptability-classification", "natural-language-inference", "semantic-similarity-scoring", "sentiment-classification", "text-scoring"], "pretty_name": "PLUE (Portuguese Language Understanding Evaluation benchmark)", "tags": ["paraphrase-identification", "qa-nli", "coreference-nli"]} | 2022-10-29T11:19:26+00:00 | []
| [
"pt"
]
| TAGS
#task_categories-text-classification #task_ids-acceptability-classification #task_ids-natural-language-inference #task_ids-semantic-similarity-scoring #task_ids-sentiment-classification #task_ids-text-scoring #annotations_creators-found #language_creators-machine-generated #multilinguality-monolingual #multilinguality-translation #size_categories-10K<n<100K #source_datasets-extended|glue #language-Portuguese #license-lgpl-3.0 #paraphrase-identification #qa-nli #coreference-nli #region-us
|
# Dataset Card for PLUE
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Repository: URL
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
Portuguese translation of the <a href="URL benchmark</a>, <a href=URL and <a href=URL Scitail</a> using <a href=URL model</a> and <a href=URL Cloud Translation</a>.
### Supported Tasks and Leaderboards
### Languages
The language data in PLUE is Brazilian Portuguese (BCP-47 pt-BR)
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @ju-resplande for adding this dataset. | [
"# Dataset Card for PLUE",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Repository: URL\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nPortuguese translation of the <a href=\"URL benchmark</a>, <a href=URL and <a href=URL Scitail</a> using <a href=URL model</a> and <a href=URL Cloud Translation</a>.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nThe language data in PLUE is Brazilian Portuguese (BCP-47 pt-BR)",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @ju-resplande for adding this dataset."
]
| [
"TAGS\n#task_categories-text-classification #task_ids-acceptability-classification #task_ids-natural-language-inference #task_ids-semantic-similarity-scoring #task_ids-sentiment-classification #task_ids-text-scoring #annotations_creators-found #language_creators-machine-generated #multilinguality-monolingual #multilinguality-translation #size_categories-10K<n<100K #source_datasets-extended|glue #language-Portuguese #license-lgpl-3.0 #paraphrase-identification #qa-nli #coreference-nli #region-us \n",
"# Dataset Card for PLUE",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Repository: URL\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nPortuguese translation of the <a href=\"URL benchmark</a>, <a href=URL and <a href=URL Scitail</a> using <a href=URL model</a> and <a href=URL Cloud Translation</a>.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nThe language data in PLUE is Brazilian Portuguese (BCP-47 pt-BR)",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @ju-resplande for adding this dataset."
]
|
def33e5a803a8618fba1fc4ba47f7239e53e7ddb |
## Dataset Summary
We introduce a Romanian IT Dataset (RoITD) resembling SQuAD 1.1. RoITD consists of 9575 Romanian QA pairs formulated by crowd workers. QA pairs are based on 5043 articles from Romanian Wikipedia articles describing IT and household products. Of the total number of questions, 5103 are possible (i.e. the correct answer can be found within the paragraph) and 4472 are not possible (i.e. the given answer is a "plausible answer" and not correct)
## Dataset Structure
The data structure follows the format of SQuAD, which contains several attributes such as **question**, **id**, **text**, `**answer_start**, **is_impossible** and **context**. The paragraph provided to crowd sourcing workers is stored in the field **context**. This incorporates manually-selected paragraphs from Wikipedia. The field **id** is comprised of a randomly assigned unique identification number for the answer-question pair. Only the numbers "0" and "1" are allowed in the **is_impossible** field. The category "A" is assigned the value "0", indicating that the answer is correct. The value "1" corresponds to the category "U", indicating a plausible answer. The question posed by the source crowd source worker is represented by the field **question**. The field **answer_start** keeps track of the character index marking the beginning of an answer.
| dragosnicolae555/RoITD | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:cc-by-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["ro-RO"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["extractive-qa"], "pretty_name": "RoITD: Romanian IT Question Answering Dataset"} | 2022-10-25T08:07:43+00:00 | []
| [
"ro-RO"
]
| TAGS
#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-4.0 #region-us
|
## Dataset Summary
We introduce a Romanian IT Dataset (RoITD) resembling SQuAD 1.1. RoITD consists of 9575 Romanian QA pairs formulated by crowd workers. QA pairs are based on 5043 articles from Romanian Wikipedia articles describing IT and household products. Of the total number of questions, 5103 are possible (i.e. the correct answer can be found within the paragraph) and 4472 are not possible (i.e. the given answer is a "plausible answer" and not correct)
## Dataset Structure
The data structure follows the format of SQuAD, which contains several attributes such as question, id, text, 'answer_start, is_impossible and context. The paragraph provided to crowd sourcing workers is stored in the field context. This incorporates manually-selected paragraphs from Wikipedia. The field id is comprised of a randomly assigned unique identification number for the answer-question pair. Only the numbers "0" and "1" are allowed in the is_impossible field. The category "A" is assigned the value "0", indicating that the answer is correct. The value "1" corresponds to the category "U", indicating a plausible answer. The question posed by the source crowd source worker is represented by the field question. The field answer_start keeps track of the character index marking the beginning of an answer.
| [
"## Dataset Summary \n\n We introduce a Romanian IT Dataset (RoITD) resembling SQuAD 1.1. RoITD consists of 9575 Romanian QA pairs formulated by crowd workers. QA pairs are based on 5043 articles from Romanian Wikipedia articles describing IT and household products. Of the total number of questions, 5103 are possible (i.e. the correct answer can be found within the paragraph) and 4472 are not possible (i.e. the given answer is a \"plausible answer\" and not correct)",
"## Dataset Structure \n\n\nThe data structure follows the format of SQuAD, which contains several attributes such as question, id, text, 'answer_start, is_impossible and context. The paragraph provided to crowd sourcing workers is stored in the field context. This incorporates manually-selected paragraphs from Wikipedia. The field id is comprised of a randomly assigned unique identification number for the answer-question pair. Only the numbers \"0\" and \"1\" are allowed in the is_impossible field. The category \"A\" is assigned the value \"0\", indicating that the answer is correct. The value \"1\" corresponds to the category \"U\", indicating a plausible answer. The question posed by the source crowd source worker is represented by the field question. The field answer_start keeps track of the character index marking the beginning of an answer."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-4.0 #region-us \n",
"## Dataset Summary \n\n We introduce a Romanian IT Dataset (RoITD) resembling SQuAD 1.1. RoITD consists of 9575 Romanian QA pairs formulated by crowd workers. QA pairs are based on 5043 articles from Romanian Wikipedia articles describing IT and household products. Of the total number of questions, 5103 are possible (i.e. the correct answer can be found within the paragraph) and 4472 are not possible (i.e. the given answer is a \"plausible answer\" and not correct)",
"## Dataset Structure \n\n\nThe data structure follows the format of SQuAD, which contains several attributes such as question, id, text, 'answer_start, is_impossible and context. The paragraph provided to crowd sourcing workers is stored in the field context. This incorporates manually-selected paragraphs from Wikipedia. The field id is comprised of a randomly assigned unique identification number for the answer-question pair. Only the numbers \"0\" and \"1\" are allowed in the is_impossible field. The category \"A\" is assigned the value \"0\", indicating that the answer is correct. The value \"1\" corresponds to the category \"U\", indicating a plausible answer. The question posed by the source crowd source worker is represented by the field question. The field answer_start keeps track of the character index marking the beginning of an answer."
]
|
a059319d034bf46bf342c35a1a7d51091b5bcf88 | This is a dataset created for testing purposes in the context of this tutorial: https://rubrix.readthedocs.io/en/master/tutorials/08-error_analysis_using_loss.html
You can find more details on section 5. of the tutorial and the corresponding dataset with corrected labels at https://huggingface.co/datasets/Recognai/ag_news_corrected_labels
| dvilasuero/ag_news_error_analysis | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-12-29T17:23:31+00:00 | []
| []
| TAGS
#region-us
| This is a dataset created for testing purposes in the context of this tutorial: URL
You can find more details on section 5. of the tutorial and the corresponding dataset with corrected labels at URL
| []
| [
"TAGS\n#region-us \n"
]
|
6b18798ac4b3520d0e6f8da8973490114b48fd8f | # AG News train losses
This dataset is part of an experiment using [Rubrix](https://github.com/recognai/rubrix), an open-source Python framework for human-in-the loop NLP data annotation and management. | dvilasuero/ag_news_training_set_losses | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-09-21T09:10:25+00:00 | []
| []
| TAGS
#region-us
| # AG News train losses
This dataset is part of an experiment using Rubrix, an open-source Python framework for human-in-the loop NLP data annotation and management. | [
"# AG News train losses\n\nThis dataset is part of an experiment using Rubrix, an open-source Python framework for human-in-the loop NLP data annotation and management."
]
| [
"TAGS\n#region-us \n",
"# AG News train losses\n\nThis dataset is part of an experiment using Rubrix, an open-source Python framework for human-in-the loop NLP data annotation and management."
]
|
d1e2d5e619bb78fb6dc4d548108c50cb65b8d78c | # DynaSent: Dynamic Sentiment Analysis Dataset
DynaSent is an English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. This dataset card is forked from the original [DynaSent Repository](https://github.com/cgpotts/dynasent).
## Contents
* [Citation](#Citation)
* [Dataset files](#dataset-files)
* [Quick start](#quick-start)
* [Data format](#data-format)
* [Models](#models)
* [Other files](#other-files)
* [License](#license)
## Citation
[Christopher Potts](http://web.stanford.edu/~cgpotts/), [Zhengxuan Wu](http://zen-wu.social), Atticus Geiger, and [Douwe Kiela](https://douwekiela.github.io). 2020. [DynaSent: A dynamic benchmark for sentiment analysis](https://arxiv.org/abs/2012.15349). Ms., Stanford University and Facebook AI Research.
```stex
@article{potts-etal-2020-dynasent,
title={{DynaSent}: A Dynamic Benchmark for Sentiment Analysis},
author={Potts, Christopher and Wu, Zhengxuan and Geiger, Atticus and Kiela, Douwe},
journal={arXiv preprint arXiv:2012.15349},
url={https://arxiv.org/abs/2012.15349},
year={2020}}
```
## Dataset files
The dataset is [dynasent-v1.1.zip](dynasent-v1.1.zip), which is included in this repository. `v1.1` differs from `v1` only in that `v1.1` has proper unique ids for Round 1 and corrects a bug that led to some non-unique ids in Round 2. There are no changes to the examples or other metadata.
The dataset consists of two rounds, each with a train/dev/test split:
### Round 1: Naturally occurring sentences
* `dynasent-v1.1-round01-yelp-train.jsonl`
* `dynasent-v1.1-round01-yelp-dev.jsonl`
* `dynasent-v1.1-round01-yelp-test.jsonl`
### Round 1: Sentences crowdsourced using Dynabench
* `dynasent-v1.1-round02-dynabench-train.jsonl`
* `dynasent-v1.1-round02-dynabench-dev.jsonl`
* `dynasent-v1.1-round02-dynabench-test.jsonl`
### SST-dev revalidation
The dataset also contains a version of the [Stanford Sentiment Treebank](https://nlp.stanford.edu/sentiment/) dev set in our format with labels from our validation task:
* `sst-dev-validated.jsonl`
## Quick start
This function can be used to load any subset of the files:
```python
import json
def load_dataset(*src_filenames, labels=None):
data = []
for filename in src_filenames:
with open(filename) as f:
for line in f:
d = json.loads(line)
if labels is None or d['gold_label'] in labels:
data.append(d)
return data
```
For example, to create a Round 1 train set restricting to examples with ternary gold labels:
```python
import os
r1_train_filename = os.path.join('dynasent-v1.1', 'dynasent-v1.1-round01-yelp-train.jsonl')
ternary_labels = ('positive', 'negative', 'neutral')
r1_train = load_dataset(r1_train_filename, labels=ternary_labels)
X_train, y_train = zip(*[(d['sentence'], d['gold_label']) for d in r1_train])
```
## Data format
### Round 1 format
```python
{'hit_ids': ['y5238'],
'sentence': 'Roto-Rooter is always good when you need someone right away.',
'indices_into_review_text': [0, 60],
'model_0_label': 'positive',
'model_0_probs': {'negative': 0.01173639390617609,
'positive': 0.7473671436309814,
'neutral': 0.24089649319648743},
'text_id': 'r1-0000001',
'review_id': 'IDHkeGo-nxhqX4Exkdr08A',
'review_rating': 1,
'label_distribution': {'positive': ['w130', 'w186', 'w207', 'w264', 'w54'],
'negative': [],
'neutral': [],
'mixed': []},
'gold_label': 'positive'}
```
Details:
* `'hit_ids'`: List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* `'sentence'`: The example text.
* `'indices_into_review_text':` indices of `'sentence'` into the original review in the [Yelp Academic Dataset](https://www.yelp.com/dataset).
* `'model_0_label'`: prediction of Model 0 as described in the paper. The possible values are `'positive'`, `'negative'`, and `'neutral'`.
* `'model_0_probs'`: probability distribution predicted by Model 0. The keys are `('positive', 'negative', 'neutral')` and the values are floats.
* `'text_id'`: unique identifier for this entry.
* `'review_id'`: review-level identifier for the review from the [Yelp Academic Dataset](https://www.yelp.com/dataset) containing `'sentence'`.
* `'review_rating'`: review-level star-rating for the review containing `'sentence'` in the [Yelp Academic Dataset](https://www.yelp.com/dataset). The possible values are `1`, `2`, `3`, `4`, and `5`.
* `'label_distribution':` response distribution from the MTurk validation task. The keys are `('positive', 'negative', 'neutral')` and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* `'gold_label'`: the label chosen by at least three of the five workers if there is one (possible values: `'positive'`, `'negative'`, '`neutral'`, and `'mixed'`), else `None`.
Here is some code one could use to augment a dataset, as loaded by `load_dataset`, with a field giving the full review text from the [Yelp Academic Dataset](https://www.yelp.com/dataset):
```python
import json
def index_yelp_reviews(yelp_src_filename='yelp_academic_dataset_review.json'):
index = {}
with open(yelp_src_filename) as f:
for line in f:
d = json.loads(line)
index[d['review_id']] = d['text']
return index
yelp_index = index_yelp_reviews()
def add_review_text_round1(dataset, yelp_index):
for d in dataset:
review_text = yelp_index[d['text_id']]
# Check that we can find the sentence as expected:
start, end = d['indices_into_review_text']
assert review_text[start: end] == d['sentence']
d['review_text'] = review_text
return dataset
```
### Round 2 format
```python
{'hit_ids': ['y22661'],
'sentence': "We enjoyed our first and last meal in Toronto at Bombay Palace, and I can't think of a better way to book our journey.",
'sentence_author': 'w250',
'has_prompt': True,
'prompt_data': {'indices_into_review_text': [2093, 2213],
'review_rating': 5,
'prompt_sentence': "Our first and last meals in Toronto were enjoyed at Bombay Palace and I can't think of a better way to bookend our trip.",
'review_id': 'Krm4kSIb06BDHternF4_pA'},
'model_1_label': 'positive',
'model_1_probs': {'negative': 0.29140257835388184,
'positive': 0.6788994669914246,
'neutral': 0.029697999358177185},
'text_id': 'r2-0000001',
'label_distribution': {'positive': ['w43', 'w26', 'w155', 'w23'],
'negative': [],
'neutral': [],
'mixed': ['w174']},
'gold_label': 'positive'}
```
Details:
* `'hit_ids'`: List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* `'sentence'`: The example text.
* `'sentence_author'`: Anonymized MTurk id of the worker who wrote `'sentence'`. These are from the same family of ids as used in `'label_distribution'`, but this id is never one of the ids in `'label_distribution'` for this example.
* `'has_prompt'`: `True` if the `'sentence'` was written with a Prompt else `False`.
* `'prompt_data'`: None if `'has_prompt'` is False, else:
* `'indices_into_review_text'`: indices of `'prompt_sentence'` into the original review in the [Yelp Academic Dataset](https://www.yelp.com/dataset).
* `'review_rating'`: review-level star-rating for the review containing `'sentence'` in the [Yelp Academic Dataset](https://www.yelp.com/dataset).
* `'prompt_sentence'`: The prompt text.
* `'review_id'`: review-level identifier for the review from the [Yelp Academic Dataset](https://www.yelp.com/dataset) containing `'prompt_sentence'`.
* `'model_1_label'`: prediction of Model 1 as described in the paper. The possible values are `'positive'`, `'negative'`, and '`neutral'`.
* `'model_1_probs'`: probability distribution predicted by Model 1. The keys are `('positive', 'negative', 'neutral')` and the values are floats.
* `'text_id'`: unique identifier for this entry.
* `'label_distribution'`: response distribution from the MTurk validation task. The keys are `('positive', 'negative', 'neutral')` and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* `'gold_label'`: the label chosen by at least three of the five workers if there is one (possible values: `'positive'`, `'negative'`, '`neutral'`, and `'mixed'`), else `None`.
To add the review texts to the `'prompt_data'` field, one can extend the code above for Round 1 with the following function:
```python
def add_review_text_round2(dataset, yelp_index):
for d in dataset:
if d['has_prompt']:
prompt_data = d['prompt_data']
review_text = yelp_index[prompt_data['review_id']]
# Check that we can find the sentence as expected:
start, end = prompt_data['indices_into_review_text']
assert review_text[start: end] == prompt_data['prompt_sentence']
prompt_data['review_text'] = review_text
return dataset
```
### SST-dev format
```python
{'hit_ids': ['s20533'],
'sentence': '-LRB- A -RRB- n utterly charming and hilarious film that reminded me of the best of the Disney comedies from the 60s.',
'tree': '(4 (2 (1 -LRB-) (2 (2 A) (3 -RRB-))) (4 (4 (2 n) (4 (3 (2 utterly) (4 (3 (4 charming) (2 and)) (4 hilarious))) (3 (2 film) (3 (2 that) (4 (4 (2 (2 reminded) (3 me)) (4 (2 of) (4 (4 (2 the) (4 best)) (2 (2 of) (3 (2 the) (3 (3 Disney) (2 comedies))))))) (2 (2 from) (2 (2 the) (2 60s)))))))) (2 .)))',
'text_id': 'sst-dev-validate-0000437',
'sst_label': '4',
'label_distribution': {'positive': ['w207', 'w3', 'w840', 'w135', 'w26'],
'negative': [],
'neutral': [],
'mixed': []},
'gold_label': 'positive'}
```
Details:
* `'hit_ids'`: List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* `'sentence'`: The example text.
* `'tree'`: The parsetree for the example as given in the SST distribution.
* `'text_id'`: A new identifier for this example.
* `'sst_label'`: The root-node label from the SST. Possible values `'0'`, `'1'` `'2'`, `'3'`, and `'4'`.
* `'label_distribution':` response distribution from the MTurk validation task. The keys are `('positive', 'negative', 'neutral')` and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* `'gold_label'`: the label chosen by at least three of the five workers if there is one (possible values: `'positive'`, `'negative'`, '`neutral'`, and `'mixed'`), else `None`.
## Models
Model 0 and Model 1 from the paper are available here:
https://drive.google.com/drive/folders/1dpKrjNJfAILUQcJPAFc5YOXUT51VEjKQ?usp=sharing
This repository includes a Python module `dynasent_models.py` that provides a [Hugging Face](https://huggingface.co)-based wrapper around these ([PyTorch](https://pytorch.org)) models. Simple examples:
```python
import os
from dynasent_models import DynaSentModel
# `dynasent_model0` should be downloaded from the above Google Drive link and
# placed in the `models` directory. `dynasent_model1` works the same way.
model = DynaSentModel(os.path.join('models', 'dynasent_model0.bin'))
examples = [
"superb",
"They said the experience would be amazing, and they were right!",
"They said the experience would be amazing, and they were wrong!"]
model.predict(examples)
```
This should return the list `['positive', 'positive', 'negative']`.
The `predict_proba` method provides access to the predicted distribution over the class labels; see the demo at the bottom of `dynasent_models.py` for details.
The following code uses `load_dataset` from above to reproduce the Round 2 dev-set report on Model 0 from the paper:
```python
import os
from sklearn.metrics import classification_report
from dynasent_models import DynaSentModel
dev_filename = os.path.join('dynasent-v1.1', 'dynasent-v1.1-round02-dynabench-dev.jsonl')
dev = load_dataset(dev_filename)
X_dev, y_dev = zip(*[(d['sentence'], d['gold_label']) for d in dev])
model = DynaSentModel(os.path.join('models', 'dynasent_model0.bin'))
preds = model.predict(X_dev)
print(classification_report(y_dev, preds, digits=3))
```
For a fuller report on these models, see our paper and [our model card](dynasent_modelcard.md).
## Other files
### Analysis notebooks
The following notebooks reproduce the dataset statistics, figures, and random example selections from the paper:
* `analyses_comparative.ipynb`
* `analysis_round1.ipynb`
* `analysis_round2.ipynb`
* `analysis_sst_dev_revalidate.ipynb`
The Python module `dynasent_utils.py` contains functions that support those notebooks, and `dynasent.mplstyle` helps with styling the plots.
### Datasheet
The [Datasheet](https://arxiv.org/abs/1803.09010) for our dataset:
* [dynasent_datasheet.md](dynasent_datasheet.md)
### Model Card
The [Model Card](https://arxiv.org/pdf/1810.03993.pdf) for our models:
* [dynasent_modelcard.md](dynasent_modelcard.md)
### Tests
The module `test_dataset.py` contains PyTest tests for the dataset. To use it, run
```
py.test -vv test_dataset.py
```
in the root directory of this repository.
### Validation HIT code
The file `validation-hit-contents.html` contains the HTML/Javascript used in the validation task. It could be used directly on Amazon Mechanical Turk, by simply pasting its contents into the usual HIT creation window.
## License
DynaSent has a [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/). | dynabench/dynasent | [
"arxiv:2012.15349",
"arxiv:1803.09010",
"arxiv:1810.03993",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-04-29T10:30:24+00:00 | [
"2012.15349",
"1803.09010",
"1810.03993"
]
| []
| TAGS
#arxiv-2012.15349 #arxiv-1803.09010 #arxiv-1810.03993 #region-us
| # DynaSent: Dynamic Sentiment Analysis Dataset
DynaSent is an English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. This dataset card is forked from the original DynaSent Repository.
## Contents
* [Citation]()
* Dataset files
* Quick start
* Data format
* Models
* Other files
* License
Christopher Potts, Zhengxuan Wu, Atticus Geiger, and Douwe Kiela. 2020. DynaSent: A dynamic benchmark for sentiment analysis. Ms., Stanford University and Facebook AI Research.
## Dataset files
The dataset is dynasent-v1.1.zip, which is included in this repository. 'v1.1' differs from 'v1' only in that 'v1.1' has proper unique ids for Round 1 and corrects a bug that led to some non-unique ids in Round 2. There are no changes to the examples or other metadata.
The dataset consists of two rounds, each with a train/dev/test split:
### Round 1: Naturally occurring sentences
* 'URL'
* 'URL'
* 'URL'
### Round 1: Sentences crowdsourced using Dynabench
* 'URL'
* 'URL'
* 'URL'
### SST-dev revalidation
The dataset also contains a version of the Stanford Sentiment Treebank dev set in our format with labels from our validation task:
* 'URL'
## Quick start
This function can be used to load any subset of the files:
For example, to create a Round 1 train set restricting to examples with ternary gold labels:
## Data format
### Round 1 format
Details:
* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* ''sentence'': The example text.
* ''indices_into_review_text':' indices of ''sentence'' into the original review in the Yelp Academic Dataset.
* ''model_0_label'': prediction of Model 0 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.
* ''model_0_probs'': probability distribution predicted by Model 0. The keys are '('positive', 'negative', 'neutral')' and the values are floats.
* ''text_id'': unique identifier for this entry.
* ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''sentence''.
* ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset. The possible values are '1', '2', '3', '4', and '5'.
* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'.
Here is some code one could use to augment a dataset, as loaded by 'load_dataset', with a field giving the full review text from the Yelp Academic Dataset:
### Round 2 format
Details:
* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* ''sentence'': The example text.
* ''sentence_author'': Anonymized MTurk id of the worker who wrote ''sentence''. These are from the same family of ids as used in ''label_distribution'', but this id is never one of the ids in ''label_distribution'' for this example.
* ''has_prompt'': 'True' if the ''sentence'' was written with a Prompt else 'False'.
* ''prompt_data'': None if ''has_prompt'' is False, else:
* ''indices_into_review_text'': indices of ''prompt_sentence'' into the original review in the Yelp Academic Dataset.
* ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset.
* ''prompt_sentence'': The prompt text.
* ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''prompt_sentence''.
* ''model_1_label'': prediction of Model 1 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.
* ''model_1_probs'': probability distribution predicted by Model 1. The keys are '('positive', 'negative', 'neutral')' and the values are floats.
* ''text_id'': unique identifier for this entry.
* ''label_distribution'': response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'.
To add the review texts to the ''prompt_data'' field, one can extend the code above for Round 1 with the following function:
### SST-dev format
Details:
* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.
* ''sentence'': The example text.
* ''tree'': The parsetree for the example as given in the SST distribution.
* ''text_id'': A new identifier for this example.
* ''sst_label'': The root-node label from the SST. Possible values ''0'', ''1'' ''2'', ''3'', and ''4''.
* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.
* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'.
## Models
Model 0 and Model 1 from the paper are available here:
URL
This repository includes a Python module 'dynasent_models.py' that provides a Hugging Face-based wrapper around these (PyTorch) models. Simple examples:
This should return the list '['positive', 'positive', 'negative']'.
The 'predict_proba' method provides access to the predicted distribution over the class labels; see the demo at the bottom of 'dynasent_models.py' for details.
The following code uses 'load_dataset' from above to reproduce the Round 2 dev-set report on Model 0 from the paper:
For a fuller report on these models, see our paper and our model card.
## Other files
### Analysis notebooks
The following notebooks reproduce the dataset statistics, figures, and random example selections from the paper:
* 'analyses_comparative.ipynb'
* 'analysis_round1.ipynb'
* 'analysis_round2.ipynb'
* 'analysis_sst_dev_revalidate.ipynb'
The Python module 'dynasent_utils.py' contains functions that support those notebooks, and 'dynasent.mplstyle' helps with styling the plots.
### Datasheet
The Datasheet for our dataset:
* dynasent_datasheet.md
### Model Card
The Model Card for our models:
* dynasent_modelcard.md
### Tests
The module 'test_dataset.py' contains PyTest tests for the dataset. To use it, run
in the root directory of this repository.
### Validation HIT code
The file 'URL' contains the HTML/Javascript used in the validation task. It could be used directly on Amazon Mechanical Turk, by simply pasting its contents into the usual HIT creation window.
## License
DynaSent has a Creative Commons Attribution 4.0 International License. | [
"# DynaSent: Dynamic Sentiment Analysis Dataset\n\nDynaSent is an English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. This dataset card is forked from the original DynaSent Repository.",
"## Contents\n\n* [Citation]()\n* Dataset files\n* Quick start\n* Data format\n* Models\n* Other files\n* License\n\n\nChristopher Potts, Zhengxuan Wu, Atticus Geiger, and Douwe Kiela. 2020. DynaSent: A dynamic benchmark for sentiment analysis. Ms., Stanford University and Facebook AI Research.",
"## Dataset files\n\nThe dataset is dynasent-v1.1.zip, which is included in this repository. 'v1.1' differs from 'v1' only in that 'v1.1' has proper unique ids for Round 1 and corrects a bug that led to some non-unique ids in Round 2. There are no changes to the examples or other metadata.\n\nThe dataset consists of two rounds, each with a train/dev/test split:",
"### Round 1: Naturally occurring sentences\n\n* 'URL'\n* 'URL'\n* 'URL'",
"### Round 1: Sentences crowdsourced using Dynabench\n\n* 'URL'\n* 'URL'\n* 'URL'",
"### SST-dev revalidation\n\nThe dataset also contains a version of the Stanford Sentiment Treebank dev set in our format with labels from our validation task:\n\n* 'URL'",
"## Quick start\n\nThis function can be used to load any subset of the files:\n\n\n\nFor example, to create a Round 1 train set restricting to examples with ternary gold labels:",
"## Data format",
"### Round 1 format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''indices_into_review_text':' indices of ''sentence'' into the original review in the Yelp Academic Dataset.\n* ''model_0_label'': prediction of Model 0 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.\n* ''model_0_probs'': probability distribution predicted by Model 0. The keys are '('positive', 'negative', 'neutral')' and the values are floats.\n* ''text_id'': unique identifier for this entry.\n* ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''sentence''.\n* ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset. The possible values are '1', '2', '3', '4', and '5'.\n* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'. \n\nHere is some code one could use to augment a dataset, as loaded by 'load_dataset', with a field giving the full review text from the Yelp Academic Dataset:",
"### Round 2 format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''sentence_author'': Anonymized MTurk id of the worker who wrote ''sentence''. These are from the same family of ids as used in ''label_distribution'', but this id is never one of the ids in ''label_distribution'' for this example.\n* ''has_prompt'': 'True' if the ''sentence'' was written with a Prompt else 'False'.\n* ''prompt_data'': None if ''has_prompt'' is False, else:\n * ''indices_into_review_text'': indices of ''prompt_sentence'' into the original review in the Yelp Academic Dataset.\n * ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset.\n * ''prompt_sentence'': The prompt text.\n * ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''prompt_sentence''.\n* ''model_1_label'': prediction of Model 1 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.\n* ''model_1_probs'': probability distribution predicted by Model 1. The keys are '('positive', 'negative', 'neutral')' and the values are floats. \n* ''text_id'': unique identifier for this entry.\n* ''label_distribution'': response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'. \n\nTo add the review texts to the ''prompt_data'' field, one can extend the code above for Round 1 with the following function:",
"### SST-dev format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''tree'': The parsetree for the example as given in the SST distribution.\n* ''text_id'': A new identifier for this example.\n* ''sst_label'': The root-node label from the SST. Possible values ''0'', ''1'' ''2'', ''3'', and ''4''.\n* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'.",
"## Models\n\nModel 0 and Model 1 from the paper are available here:\n\nURL\n\nThis repository includes a Python module 'dynasent_models.py' that provides a Hugging Face-based wrapper around these (PyTorch) models. Simple examples:\n\n\nThis should return the list '['positive', 'positive', 'negative']'.\n\nThe 'predict_proba' method provides access to the predicted distribution over the class labels; see the demo at the bottom of 'dynasent_models.py' for details.\n\nThe following code uses 'load_dataset' from above to reproduce the Round 2 dev-set report on Model 0 from the paper:\n\n\nFor a fuller report on these models, see our paper and our model card.",
"## Other files",
"### Analysis notebooks\n\nThe following notebooks reproduce the dataset statistics, figures, and random example selections from the paper:\n\n* 'analyses_comparative.ipynb'\n* 'analysis_round1.ipynb'\n* 'analysis_round2.ipynb'\n* 'analysis_sst_dev_revalidate.ipynb'\n\nThe Python module 'dynasent_utils.py' contains functions that support those notebooks, and 'dynasent.mplstyle' helps with styling the plots.",
"### Datasheet\n\nThe Datasheet for our dataset:\n\n* dynasent_datasheet.md",
"### Model Card\n\nThe Model Card for our models:\n\n* dynasent_modelcard.md",
"### Tests\n\nThe module 'test_dataset.py' contains PyTest tests for the dataset. To use it, run\n\n\n\nin the root directory of this repository.",
"### Validation HIT code\n\nThe file 'URL' contains the HTML/Javascript used in the validation task. It could be used directly on Amazon Mechanical Turk, by simply pasting its contents into the usual HIT creation window.",
"## License\n\nDynaSent has a Creative Commons Attribution 4.0 International License."
]
| [
"TAGS\n#arxiv-2012.15349 #arxiv-1803.09010 #arxiv-1810.03993 #region-us \n",
"# DynaSent: Dynamic Sentiment Analysis Dataset\n\nDynaSent is an English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. This dataset card is forked from the original DynaSent Repository.",
"## Contents\n\n* [Citation]()\n* Dataset files\n* Quick start\n* Data format\n* Models\n* Other files\n* License\n\n\nChristopher Potts, Zhengxuan Wu, Atticus Geiger, and Douwe Kiela. 2020. DynaSent: A dynamic benchmark for sentiment analysis. Ms., Stanford University and Facebook AI Research.",
"## Dataset files\n\nThe dataset is dynasent-v1.1.zip, which is included in this repository. 'v1.1' differs from 'v1' only in that 'v1.1' has proper unique ids for Round 1 and corrects a bug that led to some non-unique ids in Round 2. There are no changes to the examples or other metadata.\n\nThe dataset consists of two rounds, each with a train/dev/test split:",
"### Round 1: Naturally occurring sentences\n\n* 'URL'\n* 'URL'\n* 'URL'",
"### Round 1: Sentences crowdsourced using Dynabench\n\n* 'URL'\n* 'URL'\n* 'URL'",
"### SST-dev revalidation\n\nThe dataset also contains a version of the Stanford Sentiment Treebank dev set in our format with labels from our validation task:\n\n* 'URL'",
"## Quick start\n\nThis function can be used to load any subset of the files:\n\n\n\nFor example, to create a Round 1 train set restricting to examples with ternary gold labels:",
"## Data format",
"### Round 1 format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''indices_into_review_text':' indices of ''sentence'' into the original review in the Yelp Academic Dataset.\n* ''model_0_label'': prediction of Model 0 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.\n* ''model_0_probs'': probability distribution predicted by Model 0. The keys are '('positive', 'negative', 'neutral')' and the values are floats.\n* ''text_id'': unique identifier for this entry.\n* ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''sentence''.\n* ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset. The possible values are '1', '2', '3', '4', and '5'.\n* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'. \n\nHere is some code one could use to augment a dataset, as loaded by 'load_dataset', with a field giving the full review text from the Yelp Academic Dataset:",
"### Round 2 format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''sentence_author'': Anonymized MTurk id of the worker who wrote ''sentence''. These are from the same family of ids as used in ''label_distribution'', but this id is never one of the ids in ''label_distribution'' for this example.\n* ''has_prompt'': 'True' if the ''sentence'' was written with a Prompt else 'False'.\n* ''prompt_data'': None if ''has_prompt'' is False, else:\n * ''indices_into_review_text'': indices of ''prompt_sentence'' into the original review in the Yelp Academic Dataset.\n * ''review_rating'': review-level star-rating for the review containing ''sentence'' in the Yelp Academic Dataset.\n * ''prompt_sentence'': The prompt text.\n * ''review_id'': review-level identifier for the review from the Yelp Academic Dataset containing ''prompt_sentence''.\n* ''model_1_label'': prediction of Model 1 as described in the paper. The possible values are ''positive'', ''negative'', and ''neutral''.\n* ''model_1_probs'': probability distribution predicted by Model 1. The keys are '('positive', 'negative', 'neutral')' and the values are floats. \n* ''text_id'': unique identifier for this entry.\n* ''label_distribution'': response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'. \n\nTo add the review texts to the ''prompt_data'' field, one can extend the code above for Round 1 with the following function:",
"### SST-dev format\n\n\n\nDetails:\n\n* ''hit_ids'': List of Amazon Mechanical Turk Human Interface Tasks (HITs) in which this example appeared during validation. The values are anonymized but used consistently throughout the dataset.\n* ''sentence'': The example text.\n* ''tree'': The parsetree for the example as given in the SST distribution.\n* ''text_id'': A new identifier for this example.\n* ''sst_label'': The root-node label from the SST. Possible values ''0'', ''1'' ''2'', ''3'', and ''4''.\n* ''label_distribution':' response distribution from the MTurk validation task. The keys are '('positive', 'negative', 'neutral')' and the values are lists of anonymized MTurk ids, which are used consistently throughout the dataset.\n* ''gold_label'': the label chosen by at least three of the five workers if there is one (possible values: ''positive'', ''negative'', ''neutral'', and ''mixed''), else 'None'.",
"## Models\n\nModel 0 and Model 1 from the paper are available here:\n\nURL\n\nThis repository includes a Python module 'dynasent_models.py' that provides a Hugging Face-based wrapper around these (PyTorch) models. Simple examples:\n\n\nThis should return the list '['positive', 'positive', 'negative']'.\n\nThe 'predict_proba' method provides access to the predicted distribution over the class labels; see the demo at the bottom of 'dynasent_models.py' for details.\n\nThe following code uses 'load_dataset' from above to reproduce the Round 2 dev-set report on Model 0 from the paper:\n\n\nFor a fuller report on these models, see our paper and our model card.",
"## Other files",
"### Analysis notebooks\n\nThe following notebooks reproduce the dataset statistics, figures, and random example selections from the paper:\n\n* 'analyses_comparative.ipynb'\n* 'analysis_round1.ipynb'\n* 'analysis_round2.ipynb'\n* 'analysis_sst_dev_revalidate.ipynb'\n\nThe Python module 'dynasent_utils.py' contains functions that support those notebooks, and 'dynasent.mplstyle' helps with styling the plots.",
"### Datasheet\n\nThe Datasheet for our dataset:\n\n* dynasent_datasheet.md",
"### Model Card\n\nThe Model Card for our models:\n\n* dynasent_modelcard.md",
"### Tests\n\nThe module 'test_dataset.py' contains PyTest tests for the dataset. To use it, run\n\n\n\nin the root directory of this repository.",
"### Validation HIT code\n\nThe file 'URL' contains the HTML/Javascript used in the validation task. It could be used directly on Amazon Mechanical Turk, by simply pasting its contents into the usual HIT creation window.",
"## License\n\nDynaSent has a Creative Commons Attribution 4.0 International License."
]
|
3c4dbdd9119ff5dfeafe06f06f9ae7a6824e02ae |
# Dataset Card for Dynabench.QA
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Dynabench.QA](https://dynabench.org/tasks/2#overall)
- **Paper:** [Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension](https://arxiv.org/abs/2002.00293)
- **Leaderboard:** [Dynabench QA Round 1 Leaderboard](https://dynabench.org/tasks/2#overall)
- **Point of Contact:** [Max Bartolo]([email protected])
### Dataset Summary
Dynabench.QA is an adversarially collected Reading Comprehension dataset spanning over multiple rounds of data collect.
For round 1, it is identical to the [adversarialQA dataset](https://adversarialqa.github.io/), where we have created three new Reading Comprehension datasets constructed using an adversarial model-in-the-loop.
We use three different models; BiDAF (Seo et al., 2016), BERT-Large (Devlin et al., 2018), and RoBERTa-Large (Liu et al., 2019) in the annotation loop and construct three datasets; D(BiDAF), D(BERT), and D(RoBERTa), each with 10,000 training examples, 1,000 validation, and 1,000 test examples.
The adversarial human annotation paradigm ensures that these datasets consist of questions that current state-of-the-art models (at least the ones used as adversaries in the annotation loop) find challenging. The three AdversarialQA round 1 datasets provide a training and evaluation resource for such methods.
### Supported Tasks and Leaderboards
`extractive-qa`: The dataset can be used to train a model for Extractive Question Answering, which consists in selecting the answer to a question from a passage. Success on this task is typically measured by achieving a high word-overlap [F1 score](https://huggingface.co/metrics/f1). The [RoBERTa-Large](https://huggingface.co/roberta-large) model trained on all the data combined with [SQuAD](https://arxiv.org/abs/1606.05250) currently achieves 64.35% F1. This task has an active leaderboard and is available as round 1 of the QA task on [Dynabench](https://dynabench.org/tasks/2#overall) and ranks models based on F1 score.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
Data is provided in the same format as SQuAD 1.1. An example is shown below:
```
{
"data": [
{
"title": "Oxygen",
"paragraphs": [
{
"context": "Among the most important classes of organic compounds that contain oxygen are (where \"R\" is an organic group): alcohols (R-OH); ethers (R-O-R); ketones (R-CO-R); aldehydes (R-CO-H); carboxylic acids (R-COOH); esters (R-COO-R); acid anhydrides (R-CO-O-CO-R); and amides (R-C(O)-NR2). There are many important organic solvents that contain oxygen, including: acetone, methanol, ethanol, isopropanol, furan, THF, diethyl ether, dioxane, ethyl acetate, DMF, DMSO, acetic acid, and formic acid. Acetone ((CH3)2CO) and phenol (C6H5OH) are used as feeder materials in the synthesis of many different substances. Other important organic compounds that contain oxygen are: glycerol, formaldehyde, glutaraldehyde, citric acid, acetic anhydride, and acetamide. Epoxides are ethers in which the oxygen atom is part of a ring of three atoms.",
"qas": [
{
"id": "22bbe104aa72aa9b511dd53237deb11afa14d6e3",
"question": "In addition to having oxygen, what do alcohols, ethers and esters have in common, according to the article?",
"answers": [
{
"answer_start": 36,
"text": "organic compounds"
}
]
},
{
"id": "4240a8e708c703796347a3702cf1463eed05584a",
"question": "What letter does the abbreviation for acid anhydrides both begin and end in?",
"answers": [
{
"answer_start": 244,
"text": "R"
}
]
},
{
"id": "0681a0a5ec852ec6920d6a30f7ef65dced493366",
"question": "Which of the organic compounds, in the article, contains nitrogen?",
"answers": [
{
"answer_start": 262,
"text": "amides"
}
]
},
{
"id": "2990efe1a56ccf81938fa5e18104f7d3803069fb",
"question": "Which of the important classes of organic compounds, in the article, has a number in its abbreviation?",
"answers": [
{
"answer_start": 262,
"text": "amides"
}
]
}
]
}
]
}
]
}
```
### Data Fields
- title: the title of the Wikipedia page from which the context is sourced
- context: the context/passage
- id: a string identifier for each question
- answers: a list of all provided answers (one per question in our case, but multiple may exist in SQuAD) with an `answer_start` field which is the character index of the start of the answer span, and a `text` field which is the answer text
### Data Splits
For round 1, the dataset is composed of three different datasets constructed using different models in the loop: BiDAF, BERT-Large, and RoBERTa-Large. Each of these has 10,000 training examples, 1,000 validation examples, and 1,000 test examples for a total of 30,000/3,000/3,000 train/validation/test examples.
## Dataset Creation
### Curation Rationale
This dataset was collected to provide a more challenging and diverse Reading Comprehension dataset to state-of-the-art models.
### Source Data
#### Initial Data Collection and Normalization
The source passages are from Wikipedia and are the same as those used in [SQuAD v1.1](https://arxiv.org/abs/1606.05250).
#### Who are the source language producers?
The source language produces are Wikipedia editors for the passages, and human annotators on Mechanical Turk for the questions.
### Annotations
#### Annotation process
The dataset is collected through an adversarial human annotation process which pairs a human annotator and a reading comprehension model in an interactive setting. The human is presented with a passage for which they write a question and highlight the correct answer. The model then tries to answer the question, and, if it fails to answer correctly, the human wins. Otherwise, the human modifies or re-writes their question until the successfully fool the model.
#### Who are the annotators?
The annotators are from Amazon Mechanical Turk, geographically restricted the the USA, UK and Canada, having previously successfully completed at least 1,000 HITs, and having a HIT approval rate greater than 98%. Crowdworkers undergo intensive training and qualification prior to annotation.
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to help develop better question answering systems.
A system that succeeds at the supported task would be able to provide an accurate extractive answer from a short passage. This dataset is to be seen as a test bed for questions which contemporary state-of-the-art models struggle to answer correctly, thus often requiring more complex comprehension abilities than say detecting phrases explicitly mentioned in the passage with high overlap to the question.
It should be noted, however, that the the source passages are both domain-restricted and linguistically specific, and that provided questions and answers do not constitute any particular social application.
### Discussion of Biases
The dataset may exhibit various biases in terms of the source passage selection, annotated questions and answers, as well as algorithmic biases resulting from the adversarial annotation protocol.
### Other Known Limitations
N/a
## Additional Information
### Dataset Curators
This dataset was initially created by Max Bartolo, Alastair Roberts, Johannes Welbl, Sebastian Riedel, and Pontus Stenetorp, during work carried out at University College London (UCL).
### Licensing Information
This dataset is distributed under [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
### Citation Information
```
@article{bartolo2020beat,
author = {Bartolo, Max and Roberts, Alastair and Welbl, Johannes and Riedel, Sebastian and Stenetorp, Pontus},
title = {Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension},
journal = {Transactions of the Association for Computational Linguistics},
volume = {8},
number = {},
pages = {662-678},
year = {2020},
doi = {10.1162/tacl\_a\_00338},
URL = { https://doi.org/10.1162/tacl_a_00338 },
eprint = { https://doi.org/10.1162/tacl_a_00338 },
abstract = { Innovations in annotation methodology have been a catalyst for Reading Comprehension (RC) datasets and models. One recent trend to challenge current RC models is to involve a model in the annotation process: Humans create questions adversarially, such that the model fails to answer them correctly. In this work we investigate this annotation methodology and apply it in three different settings, collecting a total of 36,000 samples with progressively stronger models in the annotation loop. This allows us to explore questions such as the reproducibility of the adversarial effect, transfer from data collected with varying model-in-the-loop strengths, and generalization to data collected without a model. We find that training on adversarially collected samples leads to strong generalization to non-adversarially collected datasets, yet with progressive performance deterioration with increasingly stronger models-in-the-loop. Furthermore, we find that stronger models can still learn from datasets collected with substantially weaker models-in-the-loop. When trained on data collected with a BiDAF model in the loop, RoBERTa achieves 39.9F1 on questions that it cannot answer when trained on SQuAD—only marginally lower than when trained on data collected using RoBERTa itself (41.0F1). }
}
```
### Contributions
Thanks to [@maxbartolo](https://github.com/maxbartolo) for adding this dataset. | dynabench/qa | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"task_ids:open-domain-qa",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-sa-4.0",
"arxiv:2002.00293",
"arxiv:1606.05250",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["extractive-qa", "open-domain-qa"]} | 2022-07-02T19:17:58+00:00 | [
"2002.00293",
"1606.05250"
]
| [
"en"
]
| TAGS
#task_categories-question-answering #task_ids-extractive-qa #task_ids-open-domain-qa #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-sa-4.0 #arxiv-2002.00293 #arxiv-1606.05250 #region-us
|
# Dataset Card for Dynabench.QA
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: Dynabench.QA
- Paper: Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension
- Leaderboard: Dynabench QA Round 1 Leaderboard
- Point of Contact: Max Bartolo
### Dataset Summary
Dynabench.QA is an adversarially collected Reading Comprehension dataset spanning over multiple rounds of data collect.
For round 1, it is identical to the adversarialQA dataset, where we have created three new Reading Comprehension datasets constructed using an adversarial model-in-the-loop.
We use three different models; BiDAF (Seo et al., 2016), BERT-Large (Devlin et al., 2018), and RoBERTa-Large (Liu et al., 2019) in the annotation loop and construct three datasets; D(BiDAF), D(BERT), and D(RoBERTa), each with 10,000 training examples, 1,000 validation, and 1,000 test examples.
The adversarial human annotation paradigm ensures that these datasets consist of questions that current state-of-the-art models (at least the ones used as adversaries in the annotation loop) find challenging. The three AdversarialQA round 1 datasets provide a training and evaluation resource for such methods.
### Supported Tasks and Leaderboards
'extractive-qa': The dataset can be used to train a model for Extractive Question Answering, which consists in selecting the answer to a question from a passage. Success on this task is typically measured by achieving a high word-overlap F1 score. The RoBERTa-Large model trained on all the data combined with SQuAD currently achieves 64.35% F1. This task has an active leaderboard and is available as round 1 of the QA task on Dynabench and ranks models based on F1 score.
### Languages
The text in the dataset is in English. The associated BCP-47 code is 'en'.
## Dataset Structure
### Data Instances
Data is provided in the same format as SQuAD 1.1. An example is shown below:
### Data Fields
- title: the title of the Wikipedia page from which the context is sourced
- context: the context/passage
- id: a string identifier for each question
- answers: a list of all provided answers (one per question in our case, but multiple may exist in SQuAD) with an 'answer_start' field which is the character index of the start of the answer span, and a 'text' field which is the answer text
### Data Splits
For round 1, the dataset is composed of three different datasets constructed using different models in the loop: BiDAF, BERT-Large, and RoBERTa-Large. Each of these has 10,000 training examples, 1,000 validation examples, and 1,000 test examples for a total of 30,000/3,000/3,000 train/validation/test examples.
## Dataset Creation
### Curation Rationale
This dataset was collected to provide a more challenging and diverse Reading Comprehension dataset to state-of-the-art models.
### Source Data
#### Initial Data Collection and Normalization
The source passages are from Wikipedia and are the same as those used in SQuAD v1.1.
#### Who are the source language producers?
The source language produces are Wikipedia editors for the passages, and human annotators on Mechanical Turk for the questions.
### Annotations
#### Annotation process
The dataset is collected through an adversarial human annotation process which pairs a human annotator and a reading comprehension model in an interactive setting. The human is presented with a passage for which they write a question and highlight the correct answer. The model then tries to answer the question, and, if it fails to answer correctly, the human wins. Otherwise, the human modifies or re-writes their question until the successfully fool the model.
#### Who are the annotators?
The annotators are from Amazon Mechanical Turk, geographically restricted the the USA, UK and Canada, having previously successfully completed at least 1,000 HITs, and having a HIT approval rate greater than 98%. Crowdworkers undergo intensive training and qualification prior to annotation.
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to help develop better question answering systems.
A system that succeeds at the supported task would be able to provide an accurate extractive answer from a short passage. This dataset is to be seen as a test bed for questions which contemporary state-of-the-art models struggle to answer correctly, thus often requiring more complex comprehension abilities than say detecting phrases explicitly mentioned in the passage with high overlap to the question.
It should be noted, however, that the the source passages are both domain-restricted and linguistically specific, and that provided questions and answers do not constitute any particular social application.
### Discussion of Biases
The dataset may exhibit various biases in terms of the source passage selection, annotated questions and answers, as well as algorithmic biases resulting from the adversarial annotation protocol.
### Other Known Limitations
N/a
## Additional Information
### Dataset Curators
This dataset was initially created by Max Bartolo, Alastair Roberts, Johannes Welbl, Sebastian Riedel, and Pontus Stenetorp, during work carried out at University College London (UCL).
### Licensing Information
This dataset is distributed under CC BY-SA 3.0.
### Contributions
Thanks to @maxbartolo for adding this dataset. | [
"# Dataset Card for Dynabench.QA",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: Dynabench.QA\n- Paper: Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension\n- Leaderboard: Dynabench QA Round 1 Leaderboard\n- Point of Contact: Max Bartolo",
"### Dataset Summary\n\nDynabench.QA is an adversarially collected Reading Comprehension dataset spanning over multiple rounds of data collect.\n\nFor round 1, it is identical to the adversarialQA dataset, where we have created three new Reading Comprehension datasets constructed using an adversarial model-in-the-loop.\n\nWe use three different models; BiDAF (Seo et al., 2016), BERT-Large (Devlin et al., 2018), and RoBERTa-Large (Liu et al., 2019) in the annotation loop and construct three datasets; D(BiDAF), D(BERT), and D(RoBERTa), each with 10,000 training examples, 1,000 validation, and 1,000 test examples.\n\nThe adversarial human annotation paradigm ensures that these datasets consist of questions that current state-of-the-art models (at least the ones used as adversaries in the annotation loop) find challenging. The three AdversarialQA round 1 datasets provide a training and evaluation resource for such methods.",
"### Supported Tasks and Leaderboards\n\n'extractive-qa': The dataset can be used to train a model for Extractive Question Answering, which consists in selecting the answer to a question from a passage. Success on this task is typically measured by achieving a high word-overlap F1 score. The RoBERTa-Large model trained on all the data combined with SQuAD currently achieves 64.35% F1. This task has an active leaderboard and is available as round 1 of the QA task on Dynabench and ranks models based on F1 score.",
"### Languages\n\nThe text in the dataset is in English. The associated BCP-47 code is 'en'.",
"## Dataset Structure",
"### Data Instances\n\nData is provided in the same format as SQuAD 1.1. An example is shown below:",
"### Data Fields\n\n- title: the title of the Wikipedia page from which the context is sourced\n- context: the context/passage\n- id: a string identifier for each question\n- answers: a list of all provided answers (one per question in our case, but multiple may exist in SQuAD) with an 'answer_start' field which is the character index of the start of the answer span, and a 'text' field which is the answer text",
"### Data Splits\n\nFor round 1, the dataset is composed of three different datasets constructed using different models in the loop: BiDAF, BERT-Large, and RoBERTa-Large. Each of these has 10,000 training examples, 1,000 validation examples, and 1,000 test examples for a total of 30,000/3,000/3,000 train/validation/test examples.",
"## Dataset Creation",
"### Curation Rationale\n\nThis dataset was collected to provide a more challenging and diverse Reading Comprehension dataset to state-of-the-art models.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe source passages are from Wikipedia and are the same as those used in SQuAD v1.1.",
"#### Who are the source language producers?\n\nThe source language produces are Wikipedia editors for the passages, and human annotators on Mechanical Turk for the questions.",
"### Annotations",
"#### Annotation process\n\nThe dataset is collected through an adversarial human annotation process which pairs a human annotator and a reading comprehension model in an interactive setting. The human is presented with a passage for which they write a question and highlight the correct answer. The model then tries to answer the question, and, if it fails to answer correctly, the human wins. Otherwise, the human modifies or re-writes their question until the successfully fool the model.",
"#### Who are the annotators?\n\nThe annotators are from Amazon Mechanical Turk, geographically restricted the the USA, UK and Canada, having previously successfully completed at least 1,000 HITs, and having a HIT approval rate greater than 98%. Crowdworkers undergo intensive training and qualification prior to annotation.",
"### Personal and Sensitive Information\n\nNo annotator identifying details are provided.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThe purpose of this dataset is to help develop better question answering systems.\n\nA system that succeeds at the supported task would be able to provide an accurate extractive answer from a short passage. This dataset is to be seen as a test bed for questions which contemporary state-of-the-art models struggle to answer correctly, thus often requiring more complex comprehension abilities than say detecting phrases explicitly mentioned in the passage with high overlap to the question.\n\nIt should be noted, however, that the the source passages are both domain-restricted and linguistically specific, and that provided questions and answers do not constitute any particular social application.",
"### Discussion of Biases\n\nThe dataset may exhibit various biases in terms of the source passage selection, annotated questions and answers, as well as algorithmic biases resulting from the adversarial annotation protocol.",
"### Other Known Limitations\n\nN/a",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was initially created by Max Bartolo, Alastair Roberts, Johannes Welbl, Sebastian Riedel, and Pontus Stenetorp, during work carried out at University College London (UCL).",
"### Licensing Information\n\nThis dataset is distributed under CC BY-SA 3.0.",
"### Contributions\n\nThanks to @maxbartolo for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-extractive-qa #task_ids-open-domain-qa #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-sa-4.0 #arxiv-2002.00293 #arxiv-1606.05250 #region-us \n",
"# Dataset Card for Dynabench.QA",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: Dynabench.QA\n- Paper: Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension\n- Leaderboard: Dynabench QA Round 1 Leaderboard\n- Point of Contact: Max Bartolo",
"### Dataset Summary\n\nDynabench.QA is an adversarially collected Reading Comprehension dataset spanning over multiple rounds of data collect.\n\nFor round 1, it is identical to the adversarialQA dataset, where we have created three new Reading Comprehension datasets constructed using an adversarial model-in-the-loop.\n\nWe use three different models; BiDAF (Seo et al., 2016), BERT-Large (Devlin et al., 2018), and RoBERTa-Large (Liu et al., 2019) in the annotation loop and construct three datasets; D(BiDAF), D(BERT), and D(RoBERTa), each with 10,000 training examples, 1,000 validation, and 1,000 test examples.\n\nThe adversarial human annotation paradigm ensures that these datasets consist of questions that current state-of-the-art models (at least the ones used as adversaries in the annotation loop) find challenging. The three AdversarialQA round 1 datasets provide a training and evaluation resource for such methods.",
"### Supported Tasks and Leaderboards\n\n'extractive-qa': The dataset can be used to train a model for Extractive Question Answering, which consists in selecting the answer to a question from a passage. Success on this task is typically measured by achieving a high word-overlap F1 score. The RoBERTa-Large model trained on all the data combined with SQuAD currently achieves 64.35% F1. This task has an active leaderboard and is available as round 1 of the QA task on Dynabench and ranks models based on F1 score.",
"### Languages\n\nThe text in the dataset is in English. The associated BCP-47 code is 'en'.",
"## Dataset Structure",
"### Data Instances\n\nData is provided in the same format as SQuAD 1.1. An example is shown below:",
"### Data Fields\n\n- title: the title of the Wikipedia page from which the context is sourced\n- context: the context/passage\n- id: a string identifier for each question\n- answers: a list of all provided answers (one per question in our case, but multiple may exist in SQuAD) with an 'answer_start' field which is the character index of the start of the answer span, and a 'text' field which is the answer text",
"### Data Splits\n\nFor round 1, the dataset is composed of three different datasets constructed using different models in the loop: BiDAF, BERT-Large, and RoBERTa-Large. Each of these has 10,000 training examples, 1,000 validation examples, and 1,000 test examples for a total of 30,000/3,000/3,000 train/validation/test examples.",
"## Dataset Creation",
"### Curation Rationale\n\nThis dataset was collected to provide a more challenging and diverse Reading Comprehension dataset to state-of-the-art models.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe source passages are from Wikipedia and are the same as those used in SQuAD v1.1.",
"#### Who are the source language producers?\n\nThe source language produces are Wikipedia editors for the passages, and human annotators on Mechanical Turk for the questions.",
"### Annotations",
"#### Annotation process\n\nThe dataset is collected through an adversarial human annotation process which pairs a human annotator and a reading comprehension model in an interactive setting. The human is presented with a passage for which they write a question and highlight the correct answer. The model then tries to answer the question, and, if it fails to answer correctly, the human wins. Otherwise, the human modifies or re-writes their question until the successfully fool the model.",
"#### Who are the annotators?\n\nThe annotators are from Amazon Mechanical Turk, geographically restricted the the USA, UK and Canada, having previously successfully completed at least 1,000 HITs, and having a HIT approval rate greater than 98%. Crowdworkers undergo intensive training and qualification prior to annotation.",
"### Personal and Sensitive Information\n\nNo annotator identifying details are provided.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThe purpose of this dataset is to help develop better question answering systems.\n\nA system that succeeds at the supported task would be able to provide an accurate extractive answer from a short passage. This dataset is to be seen as a test bed for questions which contemporary state-of-the-art models struggle to answer correctly, thus often requiring more complex comprehension abilities than say detecting phrases explicitly mentioned in the passage with high overlap to the question.\n\nIt should be noted, however, that the the source passages are both domain-restricted and linguistically specific, and that provided questions and answers do not constitute any particular social application.",
"### Discussion of Biases\n\nThe dataset may exhibit various biases in terms of the source passage selection, annotated questions and answers, as well as algorithmic biases resulting from the adversarial annotation protocol.",
"### Other Known Limitations\n\nN/a",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was initially created by Max Bartolo, Alastair Roberts, Johannes Welbl, Sebastian Riedel, and Pontus Stenetorp, during work carried out at University College London (UCL).",
"### Licensing Information\n\nThis dataset is distributed under CC BY-SA 3.0.",
"### Contributions\n\nThanks to @maxbartolo for adding this dataset."
]
|
5d7c462f99263b16b72306f21f3f87b2ecdf83ea | asr files | ebrigham/asr_files | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-01-03T11:29:38+00:00 | []
| []
| TAGS
#region-us
| asr files | []
| [
"TAGS\n#region-us \n"
]
|
4441c97718b1f7e03d05f430226b57f658cc156d | # Dataset Card for D4RL-gym
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://sites.google.com/view/d4rl/home/
- **Repository:** https://github.com/rail-berkeley/d4rl*
- **Paper:** D4RL: Datasets for Deep Data-Driven Reinforcement Learning https://arxiv.org/abs/2004.07219
### Dataset Summary
D4RL is an open-source benchmark for offline reinforcement learning. It provides standardized environments and datasets for training and benchmarking algorithms.
We host here a subset of the dataset, used for the training of Decision Transformers : https://github.com/kzl/decision-transformer
There is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.
## Dataset Structure
### Data Instances
A data point comprises tuples of sequences of (observations, actions, reward, dones):
```
{
"observations":datasets.Array2D(),
"actions":datasets.Array2D(),
"rewards":datasets.Array2D(),
"dones":datasets.Array2D(),
}
```
### Data Fields
- `observations`: An Array2D containing 1000 observations from a trajectory of an evaluated agent.
- `actions`: An Array2D containing 1000 actions from a trajectory of an evaluated agent.
- `rewards`: An Array2D containing 1000 rewards from a trajectory of an evaluated agent.
- `dones`: An Array2D containing 1000 terminal state flags from a trajectory of an evaluated agent.
### Data Splits
There is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.
## Additional Information
### Dataset Curators
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine
### Licensing Information
MIT Licence
### Citation Information
```
@misc{fu2021d4rl,
title={D4RL: Datasets for Deep Data-Driven Reinforcement Learning},
author={Justin Fu and Aviral Kumar and Ofir Nachum and George Tucker and Sergey Levine},
year={2021},
eprint={2004.07219},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
### Contributions
Thanks to [@edbeeching](https://github.com/edbeeching) for adding this dataset. | edbeeching/decision_transformer_gym_replay | [
"license:apache-2.0",
"arxiv:2004.07219",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "apache-2.0", "pretty_name": "D4RL-gym"} | 2022-04-20T11:39:58+00:00 | [
"2004.07219"
]
| []
| TAGS
#license-apache-2.0 #arxiv-2004.07219 #region-us
| # Dataset Card for D4RL-gym
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository: URL
- Paper: D4RL: Datasets for Deep Data-Driven Reinforcement Learning URL
### Dataset Summary
D4RL is an open-source benchmark for offline reinforcement learning. It provides standardized environments and datasets for training and benchmarking algorithms.
We host here a subset of the dataset, used for the training of Decision Transformers : URL
There is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.
## Dataset Structure
### Data Instances
A data point comprises tuples of sequences of (observations, actions, reward, dones):
### Data Fields
- 'observations': An Array2D containing 1000 observations from a trajectory of an evaluated agent.
- 'actions': An Array2D containing 1000 actions from a trajectory of an evaluated agent.
- 'rewards': An Array2D containing 1000 rewards from a trajectory of an evaluated agent.
- 'dones': An Array2D containing 1000 terminal state flags from a trajectory of an evaluated agent.
### Data Splits
There is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.
## Additional Information
### Dataset Curators
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine
### Licensing Information
MIT Licence
### Contributions
Thanks to @edbeeching for adding this dataset. | [
"# Dataset Card for D4RL-gym",
"## Table of Contents\r\n- Dataset Description\r\n - Dataset Summary\r\n - Supported Tasks and Leaderboards\r\n- Dataset Structure\r\n - Data Instances\r\n - Data Fields\r\n - Data Splits\r\n- Additional Information\r\n - Dataset Curators\r\n - Licensing Information\r\n - Citation Information\r\n - Contributions",
"## Dataset Description\r\n- Homepage: URL\r\n- Repository: URL \r\n- Paper: D4RL: Datasets for Deep Data-Driven Reinforcement Learning URL",
"### Dataset Summary\r\nD4RL is an open-source benchmark for offline reinforcement learning. It provides standardized environments and datasets for training and benchmarking algorithms. \r\nWe host here a subset of the dataset, used for the training of Decision Transformers : URL\r\nThere is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.",
"## Dataset Structure",
"### Data Instances\r\nA data point comprises tuples of sequences of (observations, actions, reward, dones):",
"### Data Fields\r\n- 'observations': An Array2D containing 1000 observations from a trajectory of an evaluated agent.\r\n- 'actions': An Array2D containing 1000 actions from a trajectory of an evaluated agent.\r\n- 'rewards': An Array2D containing 1000 rewards from a trajectory of an evaluated agent.\r\n- 'dones': An Array2D containing 1000 terminal state flags from a trajectory of an evaluated agent.",
"### Data Splits\r\nThere is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.",
"## Additional Information",
"### Dataset Curators\r\nJustin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine",
"### Licensing Information\r\nMIT Licence",
"### Contributions\r\nThanks to @edbeeching for adding this dataset."
]
| [
"TAGS\n#license-apache-2.0 #arxiv-2004.07219 #region-us \n",
"# Dataset Card for D4RL-gym",
"## Table of Contents\r\n- Dataset Description\r\n - Dataset Summary\r\n - Supported Tasks and Leaderboards\r\n- Dataset Structure\r\n - Data Instances\r\n - Data Fields\r\n - Data Splits\r\n- Additional Information\r\n - Dataset Curators\r\n - Licensing Information\r\n - Citation Information\r\n - Contributions",
"## Dataset Description\r\n- Homepage: URL\r\n- Repository: URL \r\n- Paper: D4RL: Datasets for Deep Data-Driven Reinforcement Learning URL",
"### Dataset Summary\r\nD4RL is an open-source benchmark for offline reinforcement learning. It provides standardized environments and datasets for training and benchmarking algorithms. \r\nWe host here a subset of the dataset, used for the training of Decision Transformers : URL\r\nThere is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.",
"## Dataset Structure",
"### Data Instances\r\nA data point comprises tuples of sequences of (observations, actions, reward, dones):",
"### Data Fields\r\n- 'observations': An Array2D containing 1000 observations from a trajectory of an evaluated agent.\r\n- 'actions': An Array2D containing 1000 actions from a trajectory of an evaluated agent.\r\n- 'rewards': An Array2D containing 1000 rewards from a trajectory of an evaluated agent.\r\n- 'dones': An Array2D containing 1000 terminal state flags from a trajectory of an evaluated agent.",
"### Data Splits\r\nThere is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.",
"## Additional Information",
"### Dataset Curators\r\nJustin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine",
"### Licensing Information\r\nMIT Licence",
"### Contributions\r\nThanks to @edbeeching for adding this dataset."
]
|
2a081d71c7613e86fea6a2b80c74326896b3e892 | annotations_creators:
- other
language_creators:
- crowdsourced
languages:
- en-US
licenses:
- other-my-license
multilinguality:
- monolingual
pretty_name: HuggingFace Github Issues
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text-classification
- text-retrieval
task_ids:
- multi-class-classification
- multi-label-classification
- document-retrieval | edbeeching/github-issues | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-11T14:20:42+00:00 | []
| []
| TAGS
#region-us
| annotations_creators:
- other
language_creators:
- crowdsourced
languages:
- en-US
licenses:
- other-my-license
multilinguality:
- monolingual
pretty_name: HuggingFace Github Issues
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text-classification
- text-retrieval
task_ids:
- multi-class-classification
- multi-label-classification
- document-retrieval | []
| [
"TAGS\n#region-us \n"
]
|
9e426939f02e1980603736a1413d5aefc0dd3d93 |
# Dataset Card for ravdess_speech
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** https://zenodo.org/record/1188976#.YUS4MrozZdS
- **Paper:** https://doi.org/10.1371/journal.pone.0196391
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [email protected]
### Dataset Summary
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. The conditions of the audio files are: 16bit, 48kHz .wav.
### Supported Tasks and Leaderboards
- audio-classification: The dataset can be used to train a model for Audio Classification tasks, which consists in predict the latent emotion presented on the audios.
### Languages
The audios available in the dataset are in English spoken by actors in a neutral North American accent.
## Dataset Structure
### Data Instances
[Needs More Information]
### Data Fields
[Needs More Information]
### Data Splits
[Needs More Information]
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
The RAVDESS is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NC-SA 4.0
Commercial licenses for the RAVDESS can also be purchased. For more information, please visit our license fee page, or contact us at [email protected].
### Citation Information
Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391. | ehcalabres/ravdess_speech | [
"task_categories:audio-classification",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["audio-classification"], "task_ids": ["speech-emotion-recognition"]} | 2022-10-24T14:51:41+00:00 | []
| [
"en"
]
| TAGS
#task_categories-audio-classification #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us
|
# Dataset Card for ravdess_speech
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
## Dataset Description
- Homepage:
- Repository: URL
- Paper: URL
- Leaderboard:
- Point of Contact: ravdess@URL
### Dataset Summary
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. The conditions of the audio files are: 16bit, 48kHz .wav.
### Supported Tasks and Leaderboards
- audio-classification: The dataset can be used to train a model for Audio Classification tasks, which consists in predict the latent emotion presented on the audios.
### Languages
The audios available in the dataset are in English spoken by actors in a neutral North American accent.
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
The RAVDESS is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NC-SA 4.0
Commercial licenses for the RAVDESS can also be purchased. For more information, please visit our license fee page, or contact us at ravdess@URL.
Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. URL | [
"# Dataset Card for ravdess_speech",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: URL\n- Leaderboard: \n- Point of Contact: ravdess@URL",
"### Dataset Summary\n\nThe Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. The conditions of the audio files are: 16bit, 48kHz .wav.",
"### Supported Tasks and Leaderboards\n\n- audio-classification: The dataset can be used to train a model for Audio Classification tasks, which consists in predict the latent emotion presented on the audios.",
"### Languages\n\nThe audios available in the dataset are in English spoken by actors in a neutral North American accent.",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nThe RAVDESS is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NC-SA 4.0 \n\nCommercial licenses for the RAVDESS can also be purchased. For more information, please visit our license fee page, or contact us at ravdess@URL.\n\n\n\nLivingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. URL"
]
| [
"TAGS\n#task_categories-audio-classification #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"# Dataset Card for ravdess_speech",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: URL\n- Leaderboard: \n- Point of Contact: ravdess@URL",
"### Dataset Summary\n\nThe Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. The conditions of the audio files are: 16bit, 48kHz .wav.",
"### Supported Tasks and Leaderboards\n\n- audio-classification: The dataset can be used to train a model for Audio Classification tasks, which consists in predict the latent emotion presented on the audios.",
"### Languages\n\nThe audios available in the dataset are in English spoken by actors in a neutral North American accent.",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nThe RAVDESS is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NC-SA 4.0 \n\nCommercial licenses for the RAVDESS can also be purchased. For more information, please visit our license fee page, or contact us at ravdess@URL.\n\n\n\nLivingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. URL"
]
|
3b7a02bb3b724993f0b4c1a1f77f1eacda8e7aca | MediaSpeech
Identifier: SLR108
Summary: French, Arabic, Turkish and Spanish media speech datasets
Category: Speech
License: dataset is distributed under the Creative Commons Attribution 4.0 International License.
About this resource:
MediaSpeech is a dataset of French, Arabic, Turkish and Spanish media speech built with the purpose of testing Automated Speech Recognition (ASR) systems performance. The dataset contains 10 hours of speech for each language provided.
The dataset consists of short speech segments automatically extracted from media videos available on YouTube and manually transcribed, with some pre- and post-processing.
Baseline models and wav version of the dataset can be found in the following git repository: https://github.com/NTRLab/MediaSpeech
@misc{mediaspeech2021,
title={MediaSpeech: Multilanguage ASR Benchmark and Dataset},
author={Rostislav Kolobov and Olga Okhapkina and Olga Omelchishina, Andrey Platunov and Roman Bedyakin and Vyacheslav Moshkin and Dmitry Menshikov and Nikolay Mikhaylovskiy},
year={2021},
eprint={2103.16193},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
| emre/Open_SLR108_Turkish_10_hours | [
"license:cc-by-4.0",
"robust-speech-event",
"arxiv:2103.16193",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "cc-by-4.0", "tags": ["robust-speech-event"], "datasets": ["MediaSpeech"]} | 2022-12-06T21:00:45+00:00 | [
"2103.16193"
]
| []
| TAGS
#license-cc-by-4.0 #robust-speech-event #arxiv-2103.16193 #region-us
| MediaSpeech
Identifier: SLR108
Summary: French, Arabic, Turkish and Spanish media speech datasets
Category: Speech
License: dataset is distributed under the Creative Commons Attribution 4.0 International License.
About this resource:
MediaSpeech is a dataset of French, Arabic, Turkish and Spanish media speech built with the purpose of testing Automated Speech Recognition (ASR) systems performance. The dataset contains 10 hours of speech for each language provided.
The dataset consists of short speech segments automatically extracted from media videos available on YouTube and manually transcribed, with some pre- and post-processing.
Baseline models and wav version of the dataset can be found in the following git repository: URL
@misc{mediaspeech2021,
title={MediaSpeech: Multilanguage ASR Benchmark and Dataset},
author={Rostislav Kolobov and Olga Okhapkina and Olga Omelchishina, Andrey Platunov and Roman Bedyakin and Vyacheslav Moshkin and Dmitry Menshikov and Nikolay Mikhaylovskiy},
year={2021},
eprint={2103.16193},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
| []
| [
"TAGS\n#license-cc-by-4.0 #robust-speech-event #arxiv-2103.16193 #region-us \n"
]
|
79dd9aac442c9a88535865583a3ed4e75d7b47da |
# STSb Turkish
Semantic textual similarity dataset for the Turkish language. It is a machine translation (Azure) of the [STSb English](http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark) dataset. This dataset is not reviewed by expert human translators.
Uploaded from [this repository](https://github.com/emrecncelik/sts-benchmark-tr). | emrecan/stsb-mt-turkish | [
"task_categories:text-classification",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"language_creators:machine-generated",
"size_categories:1K<n<10K",
"source_datasets:extended|other-sts-b",
"language:tr",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language_creators": ["machine-generated"], "language": ["tr"], "size_categories": ["1K<n<10K"], "source_datasets": ["extended|other-sts-b"], "task_categories": ["text-classification"], "task_ids": ["semantic-similarity-scoring", "text-scoring"]} | 2022-10-25T09:55:24+00:00 | []
| [
"tr"
]
| TAGS
#task_categories-text-classification #task_ids-semantic-similarity-scoring #task_ids-text-scoring #language_creators-machine-generated #size_categories-1K<n<10K #source_datasets-extended|other-sts-b #language-Turkish #region-us
|
# STSb Turkish
Semantic textual similarity dataset for the Turkish language. It is a machine translation (Azure) of the STSb English dataset. This dataset is not reviewed by expert human translators.
Uploaded from this repository. | [
"# STSb Turkish\n\nSemantic textual similarity dataset for the Turkish language. It is a machine translation (Azure) of the STSb English dataset. This dataset is not reviewed by expert human translators.\n\nUploaded from this repository."
]
| [
"TAGS\n#task_categories-text-classification #task_ids-semantic-similarity-scoring #task_ids-text-scoring #language_creators-machine-generated #size_categories-1K<n<10K #source_datasets-extended|other-sts-b #language-Turkish #region-us \n",
"# STSb Turkish\n\nSemantic textual similarity dataset for the Turkish language. It is a machine translation (Azure) of the STSb English dataset. This dataset is not reviewed by expert human translators.\n\nUploaded from this repository."
]
|
7c235e1da745ff8aef467b19ef6b155642ca8bcf |
This is an extract of the original [Czywiesz](https://clarin-pl.eu/dspace/handle/11321/39) dataset. It contains the questions and the relevant Wikipedia
passages in format compatible with DPR training objective. It may be used to train a passage retriever. | enelpol/czywiesz | [
"task_categories:question-answering",
"task_ids:open-domain-qa",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:pl",
"license:unknown",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["pl"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["open-domain-qa"], "pretty_name": "Czywiesz"} | 2022-10-25T08:07:45+00:00 | []
| [
"pl"
]
| TAGS
#task_categories-question-answering #task_ids-open-domain-qa #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-Polish #license-unknown #region-us
|
This is an extract of the original Czywiesz dataset. It contains the questions and the relevant Wikipedia
passages in format compatible with DPR training objective. It may be used to train a passage retriever. | []
| [
"TAGS\n#task_categories-question-answering #task_ids-open-domain-qa #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-Polish #license-unknown #region-us \n"
]
|
60a26b89257179967d48dc8de7c24c0c9df76c16 |
# Dataset Card for cocktails_recipe
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains a list of cocktails and how to do them.
### Languages
The language is english.
## Dataset Structure
### Data Fields
- Title: name of the cocktail
- Glass: type of glass to use
- Garnish: garnish to use for the glass
- Recipe: how to do the cocktail
- Ingredients: ingredients required
### Data Splits
Currently, there is no splits.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The dataset was created by scraping the Diffords cocktail website.
### Personal and Sensitive Information
It should not contain any personal or sensitive information.
### Contributions
Thanks to [@github-erwanlc](https://github.com/erwanlc) for adding this dataset. | erwanlc/cocktails_recipe | [
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:2M<n<3M",
"language:en",
"license:other",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["2M<n<3M"], "source_datasets": [], "task_categories": [], "task_ids": [], "pretty_name": "cocktails_recipe", "language_bcp47": ["en", "en-US"]} | 2022-10-25T08:17:00+00:00 | []
| [
"en"
]
| TAGS
#annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-2M<n<3M #language-English #license-other #region-us
|
# Dataset Card for cocktails_recipe
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Languages
- Dataset Structure
- Data Fields
- Data Splits
- Dataset Creation
- Source Data
- Personal and Sensitive Information
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset contains a list of cocktails and how to do them.
### Languages
The language is english.
## Dataset Structure
### Data Fields
- Title: name of the cocktail
- Glass: type of glass to use
- Garnish: garnish to use for the glass
- Recipe: how to do the cocktail
- Ingredients: ingredients required
### Data Splits
Currently, there is no splits.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The dataset was created by scraping the Diffords cocktail website.
### Personal and Sensitive Information
It should not contain any personal or sensitive information.
### Contributions
Thanks to @github-erwanlc for adding this dataset. | [
"# Dataset Card for cocktails_recipe",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Source Data\n - Personal and Sensitive Information",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains a list of cocktails and how to do them.",
"### Languages\n\nThe language is english.",
"## Dataset Structure",
"### Data Fields\n\n- Title: name of the cocktail\n- Glass: type of glass to use\n- Garnish: garnish to use for the glass\n- Recipe: how to do the cocktail\n- Ingredients: ingredients required",
"### Data Splits\n\nCurrently, there is no splits.",
"## Dataset Creation",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe dataset was created by scraping the Diffords cocktail website.",
"### Personal and Sensitive Information\n\nIt should not contain any personal or sensitive information.",
"### Contributions\n\nThanks to @github-erwanlc for adding this dataset."
]
| [
"TAGS\n#annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-2M<n<3M #language-English #license-other #region-us \n",
"# Dataset Card for cocktails_recipe",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Source Data\n - Personal and Sensitive Information",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains a list of cocktails and how to do them.",
"### Languages\n\nThe language is english.",
"## Dataset Structure",
"### Data Fields\n\n- Title: name of the cocktail\n- Glass: type of glass to use\n- Garnish: garnish to use for the glass\n- Recipe: how to do the cocktail\n- Ingredients: ingredients required",
"### Data Splits\n\nCurrently, there is no splits.",
"## Dataset Creation",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe dataset was created by scraping the Diffords cocktail website.",
"### Personal and Sensitive Information\n\nIt should not contain any personal or sensitive information.",
"### Contributions\n\nThanks to @github-erwanlc for adding this dataset."
]
|
a33b63910d8c33675132dd3a8f285549ef8b4b7b |
# Dataset Card for cocktails_recipe
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains a list of cocktails and how to do them.
### Languages
The language is english.
## Dataset Structure
### Data Fields
- Title: name of the cocktail
- Glass: type of glass to use
- Garnish: garnish to use for the glass
- Recipe: how to do the cocktail
- Ingredients: ingredients required
- Raw Ingredients: ingredients mapped to their raw ingredients to remove the brand
### Data Splits
Currently, there is no splits.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The dataset was created by scraping the Diffords cocktail website.
### Personal and Sensitive Information
It should not contain any personal or sensitive information.
### Contributions
Thanks to [@github-erwanlc](https://github.com/erwanlc) for adding this dataset. | erwanlc/cocktails_recipe_no_brand | [
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:2M<n<3M",
"language:en",
"license:other",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["2M<n<3M"], "source_datasets": [], "task_categories": [], "task_ids": [], "pretty_name": "cocktails_recipe_no_brand", "language_bcp47": ["en", "en-US"]} | 2022-10-25T08:17:08+00:00 | []
| [
"en"
]
| TAGS
#annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-2M<n<3M #language-English #license-other #region-us
|
# Dataset Card for cocktails_recipe
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Languages
- Dataset Structure
- Data Fields
- Data Splits
- Dataset Creation
- Source Data
- Personal and Sensitive Information
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset contains a list of cocktails and how to do them.
### Languages
The language is english.
## Dataset Structure
### Data Fields
- Title: name of the cocktail
- Glass: type of glass to use
- Garnish: garnish to use for the glass
- Recipe: how to do the cocktail
- Ingredients: ingredients required
- Raw Ingredients: ingredients mapped to their raw ingredients to remove the brand
### Data Splits
Currently, there is no splits.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The dataset was created by scraping the Diffords cocktail website.
### Personal and Sensitive Information
It should not contain any personal or sensitive information.
### Contributions
Thanks to @github-erwanlc for adding this dataset. | [
"# Dataset Card for cocktails_recipe",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Source Data\n - Personal and Sensitive Information",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains a list of cocktails and how to do them.",
"### Languages\n\nThe language is english.",
"## Dataset Structure",
"### Data Fields\n\n- Title: name of the cocktail\n- Glass: type of glass to use\n- Garnish: garnish to use for the glass\n- Recipe: how to do the cocktail\n- Ingredients: ingredients required\n- Raw Ingredients: ingredients mapped to their raw ingredients to remove the brand",
"### Data Splits\n\nCurrently, there is no splits.",
"## Dataset Creation",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe dataset was created by scraping the Diffords cocktail website.",
"### Personal and Sensitive Information\n\nIt should not contain any personal or sensitive information.",
"### Contributions\n\nThanks to @github-erwanlc for adding this dataset."
]
| [
"TAGS\n#annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-2M<n<3M #language-English #license-other #region-us \n",
"# Dataset Card for cocktails_recipe",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Source Data\n - Personal and Sensitive Information",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThis dataset contains a list of cocktails and how to do them.",
"### Languages\n\nThe language is english.",
"## Dataset Structure",
"### Data Fields\n\n- Title: name of the cocktail\n- Glass: type of glass to use\n- Garnish: garnish to use for the glass\n- Recipe: how to do the cocktail\n- Ingredients: ingredients required\n- Raw Ingredients: ingredients mapped to their raw ingredients to remove the brand",
"### Data Splits\n\nCurrently, there is no splits.",
"## Dataset Creation",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe dataset was created by scraping the Diffords cocktail website.",
"### Personal and Sensitive Information\n\nIt should not contain any personal or sensitive information.",
"### Contributions\n\nThanks to @github-erwanlc for adding this dataset."
]
|
7a20e0a3c51c5e5153a4416c8606a1476565fa74 |
# Dataset Card for BSD100
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/
- **Repository**: https://huggingface.co/datasets/eugenesiow/BSD100
- **Paper**: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=937655
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
BSD is a dataset used frequently for image denoising and super-resolution. Of the subdatasets, BSD100 is aclassical image dataset having 100 test images proposed by [Martin et al. (2001)](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=937655). The dataset is composed of a large variety of images ranging from natural images to object-specific such as plants, people, food etc. BSD100 is the testing set of the Berkeley segmentation dataset BSD300.
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/BSD100', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `validation` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/BSD100_HR/3096.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/BSD100_LR_x2/3096.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |validation|
|-------|---:|
|bicubic_x2|100|
|bicubic_x3|100|
|bicubic_x4|100|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Authors**: [Martin et al. (2001)](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=937655)
### Licensing Information
You are free to download a portion of the dataset for non-commercial research and educational purposes.
In exchange, we request only that you make available to us the results of running your segmentation or
boundary detection algorithm on the test set as described below. Work based on the dataset should cite
the [Martin et al. (2001)](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=937655) paper.
### Citation Information
```bibtex
@inproceedings{martin2001database,
title={A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics},
author={Martin, David and Fowlkes, Charless and Tal, Doron and Malik, Jitendra},
booktitle={Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001},
volume={2},
pages={416--423},
year={2001},
organization={IEEE}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/BSD100 | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:other",
"image-super-resolution",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "BSD100", "tags": ["image-super-resolution"]} | 2022-10-26T01:20:22+00:00 | []
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #image-super-resolution #region-us
| Dataset Card for BSD100
=======================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
BSD is a dataset used frequently for image denoising and super-resolution. Of the subdatasets, BSD100 is aclassical image dataset having 100 test images proposed by Martin et al. (2001). The dataset is composed of a large variety of images ranging from natural images to object-specific such as plants, people, food etc. BSD100 is the testing set of the Berkeley segmentation dataset BSD300.
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'validation' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Authors: Martin et al. (2001)
### Licensing Information
You are free to download a portion of the dataset for non-commercial research and educational purposes.
In exchange, we request only that you make available to us the results of running your segmentation or
boundary detection algorithm on the test set as described below. Work based on the dataset should cite
the Martin et al. (2001) paper.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nBSD is a dataset used frequently for image denoising and super-resolution. Of the subdatasets, BSD100 is aclassical image dataset having 100 test images proposed by Martin et al. (2001). The dataset is composed of a large variety of images ranging from natural images to object-specific such as plants, people, food etc. BSD100 is the testing set of the Berkeley segmentation dataset BSD300.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Martin et al. (2001)",
"### Licensing Information\n\n\nYou are free to download a portion of the dataset for non-commercial research and educational purposes.\nIn exchange, we request only that you make available to us the results of running your segmentation or\nboundary detection algorithm on the test set as described below. Work based on the dataset should cite\nthe Martin et al. (2001) paper.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #image-super-resolution #region-us \n",
"### Dataset Summary\n\n\nBSD is a dataset used frequently for image denoising and super-resolution. Of the subdatasets, BSD100 is aclassical image dataset having 100 test images proposed by Martin et al. (2001). The dataset is composed of a large variety of images ranging from natural images to object-specific such as plants, people, food etc. BSD100 is the testing set of the Berkeley segmentation dataset BSD300.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Martin et al. (2001)",
"### Licensing Information\n\n\nYou are free to download a portion of the dataset for non-commercial research and educational purposes.\nIn exchange, we request only that you make available to us the results of running your segmentation or\nboundary detection algorithm on the test set as described below. Work based on the dataset should cite\nthe Martin et al. (2001) paper.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
a6aa2cb45e33a4753d28a373bd1125a321a1c21d |
# Dataset Card for Div2k
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://data.vision.ee.ethz.ch/cvl/DIV2K/
- **Repository**: https://huggingface.co/datasets/eugenesiow/Div2k
- **Paper**: http://www.vision.ee.ethz.ch/~timofter/publications/Agustsson-CVPRW-2017.pdf
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
DIV2K is a dataset of RGB images (2K resolution high quality images) with a large diversity of contents.
The DIV2K dataset is divided into:
- train data: starting from 800 high definition high resolution images we obtain corresponding low resolution images and provide both high and low resolution images for 2, 3, and 4 downscaling factors
- validation data: 100 high definition high resolution images are used for genereting low resolution corresponding images, the low res are provided from the beginning of the challenge and are meant for the participants to get online feedback from the validation server; the high resolution images will be released when the final phase of the challenge starts.
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/Div2k', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for training and evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `train` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/DIV2K_valid_HR/0801.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/DIV2K_valid_LR_bicubic/X2/0801x2.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |train |validation|
|-------|-----:|---:|
|bicubic_x2|800|100|
|bicubic_x3|800|100|
|bicubic_x4|800|100|
|bicubic_x8|800|100|
|unknown_x2|800|100|
|unknown_x3|800|100|
|unknown_x4|800|100|
|realistic_mild_x4|800|100|
|realistic_difficult_x4|800|100|
|realistic_wild_x4|800|100|
## Dataset Creation
### Curation Rationale
Please refer to the [Initial Data Collection and Normalization](#initial-data-collection-and-normalization) section.
### Source Data
#### Initial Data Collection and Normalization
**Resolution and quality**: All the images are 2K resolution, that is they have 2K pixels on at least one of
the axes (vertical or horizontal). All the images were processed using the same tools. For simplicity, since the most
common magnification factors in the recent SR literature are of ×2, ×3 and ×4 we cropped the images to multiple of
12 pixels on both axes. Most of the crawled images were originally above 20M pixels.
The images are of high quality both aesthetically and in the terms of small amounts of noise and other corruptions
(like blur and color shifts).
**Diversity**: The authors collected images from dozens of sites. A preference was made for sites with freely
shared high quality photography (such as https://www.pexels.com/ ). Note that we did not use images from Flickr,
Instagram, or other legally binding or copyright restricted images. We only seldom used keywords to assure the diversity
for our dataset. DIV2K covers a large diversity of contents, ranging from people, handmade objects and environments
(cities, villages), to flora and fauna, and natural sceneries including underwater and dim light conditions.
**Partitions**: After collecting the DIV2K 1000 images the authors computed image entropy, bit per pixel (bpp) PNG
compression rates and CORNIA scores (see Section 7.6) and applied bicubic downscaling ×3 and then upscaling ×3 with
bicubic interpolation (imresize Matlab function), ANR [47] and A+ [48] methods and default settings.
The authors randomly generated partitions of 800 train, 100 validation and 100 test images until they achieved a good
balance firstly in visual contents and then on the average entropy, average bpp, average number of pixels per
image (ppi), average CORNIA quality scores and also in the relative differences between the average PSNR scores of
bicubic, ANR and A+ methods.
Only the 800 train and 100 validation images are included in this dataset.
#### Who are the source language producers?
The authors manually crawled 1000 color RGB images from Internet paying special attention to the image quality,
to the diversity of sources (sites and cameras), to the image contents and to the copyrights.
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images
belongs to you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset
immediately.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Author**: [Radu Timofte](http://people.ee.ethz.ch/~timofter/)
### Licensing Information
Please notice that this dataset is made available for academic research purpose only. All the images are
collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to
you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset
immediately.
### Citation Information
```bibtex
@InProceedings{Agustsson_2017_CVPR_Workshops,
author = {Agustsson, Eirikur and Timofte, Radu},
title = {NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
url = "http://www.vision.ee.ethz.ch/~timofter/publications/Agustsson-CVPRW-2017.pdf",
month = {July},
year = {2017}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/Div2k | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:other",
"other-image-super-resolution",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "Div2k", "tags": ["other-image-super-resolution"]} | 2022-10-21T03:01:10+00:00 | []
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us
| Dataset Card for Div2k
======================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
DIV2K is a dataset of RGB images (2K resolution high quality images) with a large diversity of contents.
The DIV2K dataset is divided into:
* train data: starting from 800 high definition high resolution images we obtain corresponding low resolution images and provide both high and low resolution images for 2, 3, and 4 downscaling factors
* validation data: 100 high definition high resolution images are used for genereting low resolution corresponding images, the low res are provided from the beginning of the challenge and are meant for the participants to get online feedback from the validation server; the high resolution images will be released when the final phase of the challenge starts.
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for training and evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'train' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
Please refer to the Initial Data Collection and Normalization section.
### Source Data
#### Initial Data Collection and Normalization
Resolution and quality: All the images are 2K resolution, that is they have 2K pixels on at least one of
the axes (vertical or horizontal). All the images were processed using the same tools. For simplicity, since the most
common magnification factors in the recent SR literature are of ×2, ×3 and ×4 we cropped the images to multiple of
12 pixels on both axes. Most of the crawled images were originally above 20M pixels.
The images are of high quality both aesthetically and in the terms of small amounts of noise and other corruptions
(like blur and color shifts).
Diversity: The authors collected images from dozens of sites. A preference was made for sites with freely
shared high quality photography (such as URL ). Note that we did not use images from Flickr,
Instagram, or other legally binding or copyright restricted images. We only seldom used keywords to assure the diversity
for our dataset. DIV2K covers a large diversity of contents, ranging from people, handmade objects and environments
(cities, villages), to flora and fauna, and natural sceneries including underwater and dim light conditions.
Partitions: After collecting the DIV2K 1000 images the authors computed image entropy, bit per pixel (bpp) PNG
compression rates and CORNIA scores (see Section 7.6) and applied bicubic downscaling ×3 and then upscaling ×3 with
bicubic interpolation (imresize Matlab function), ANR [47] and A+ [48] methods and default settings.
The authors randomly generated partitions of 800 train, 100 validation and 100 test images until they achieved a good
balance firstly in visual contents and then on the average entropy, average bpp, average number of pixels per
image (ppi), average CORNIA quality scores and also in the relative differences between the average PSNR scores of
bicubic, ANR and A+ methods.
Only the 800 train and 100 validation images are included in this dataset.
#### Who are the source language producers?
The authors manually crawled 1000 color RGB images from Internet paying special attention to the image quality,
to the diversity of sources (sites and cameras), to the image contents and to the copyrights.
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images
belongs to you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset
immediately.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Author: Radu Timofte
### Licensing Information
Please notice that this dataset is made available for academic research purpose only. All the images are
collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to
you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset
immediately.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nDIV2K is a dataset of RGB images (2K resolution high quality images) with a large diversity of contents.\n\n\nThe DIV2K dataset is divided into:\n\n\n* train data: starting from 800 high definition high resolution images we obtain corresponding low resolution images and provide both high and low resolution images for 2, 3, and 4 downscaling factors\n* validation data: 100 high definition high resolution images are used for genereting low resolution corresponding images, the low res are provided from the beginning of the challenge and are meant for the participants to get online feedback from the validation server; the high resolution images will be released when the final phase of the challenge starts.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for training and evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'train' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nPlease refer to the Initial Data Collection and Normalization section.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nResolution and quality: All the images are 2K resolution, that is they have 2K pixels on at least one of\nthe axes (vertical or horizontal). All the images were processed using the same tools. For simplicity, since the most\ncommon magnification factors in the recent SR literature are of ×2, ×3 and ×4 we cropped the images to multiple of\n12 pixels on both axes. Most of the crawled images were originally above 20M pixels.\nThe images are of high quality both aesthetically and in the terms of small amounts of noise and other corruptions\n(like blur and color shifts).\n\n\nDiversity: The authors collected images from dozens of sites. A preference was made for sites with freely\nshared high quality photography (such as URL ). Note that we did not use images from Flickr,\nInstagram, or other legally binding or copyright restricted images. We only seldom used keywords to assure the diversity\nfor our dataset. DIV2K covers a large diversity of contents, ranging from people, handmade objects and environments\n(cities, villages), to flora and fauna, and natural sceneries including underwater and dim light conditions.\n\n\nPartitions: After collecting the DIV2K 1000 images the authors computed image entropy, bit per pixel (bpp) PNG\ncompression rates and CORNIA scores (see Section 7.6) and applied bicubic downscaling ×3 and then upscaling ×3 with\nbicubic interpolation (imresize Matlab function), ANR [47] and A+ [48] methods and default settings.\n\n\nThe authors randomly generated partitions of 800 train, 100 validation and 100 test images until they achieved a good\nbalance firstly in visual contents and then on the average entropy, average bpp, average number of pixels per\nimage (ppi), average CORNIA quality scores and also in the relative differences between the average PSNR scores of\nbicubic, ANR and A+ methods.\n\n\nOnly the 800 train and 100 validation images are included in this dataset.",
"#### Who are the source language producers?\n\n\nThe authors manually crawled 1000 color RGB images from Internet paying special attention to the image quality,\nto the diversity of sources (sites and cameras), to the image contents and to the copyrights.",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nAll the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images\nbelongs to you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset\nimmediately.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Author: Radu Timofte",
"### Licensing Information\n\n\nPlease notice that this dataset is made available for academic research purpose only. All the images are\ncollected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to\nyou and you would like it removed, please kindly inform the authors, and they will remove it from the dataset\nimmediately.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us \n",
"### Dataset Summary\n\n\nDIV2K is a dataset of RGB images (2K resolution high quality images) with a large diversity of contents.\n\n\nThe DIV2K dataset is divided into:\n\n\n* train data: starting from 800 high definition high resolution images we obtain corresponding low resolution images and provide both high and low resolution images for 2, 3, and 4 downscaling factors\n* validation data: 100 high definition high resolution images are used for genereting low resolution corresponding images, the low res are provided from the beginning of the challenge and are meant for the participants to get online feedback from the validation server; the high resolution images will be released when the final phase of the challenge starts.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for training and evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'train' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nPlease refer to the Initial Data Collection and Normalization section.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nResolution and quality: All the images are 2K resolution, that is they have 2K pixels on at least one of\nthe axes (vertical or horizontal). All the images were processed using the same tools. For simplicity, since the most\ncommon magnification factors in the recent SR literature are of ×2, ×3 and ×4 we cropped the images to multiple of\n12 pixels on both axes. Most of the crawled images were originally above 20M pixels.\nThe images are of high quality both aesthetically and in the terms of small amounts of noise and other corruptions\n(like blur and color shifts).\n\n\nDiversity: The authors collected images from dozens of sites. A preference was made for sites with freely\nshared high quality photography (such as URL ). Note that we did not use images from Flickr,\nInstagram, or other legally binding or copyright restricted images. We only seldom used keywords to assure the diversity\nfor our dataset. DIV2K covers a large diversity of contents, ranging from people, handmade objects and environments\n(cities, villages), to flora and fauna, and natural sceneries including underwater and dim light conditions.\n\n\nPartitions: After collecting the DIV2K 1000 images the authors computed image entropy, bit per pixel (bpp) PNG\ncompression rates and CORNIA scores (see Section 7.6) and applied bicubic downscaling ×3 and then upscaling ×3 with\nbicubic interpolation (imresize Matlab function), ANR [47] and A+ [48] methods and default settings.\n\n\nThe authors randomly generated partitions of 800 train, 100 validation and 100 test images until they achieved a good\nbalance firstly in visual contents and then on the average entropy, average bpp, average number of pixels per\nimage (ppi), average CORNIA quality scores and also in the relative differences between the average PSNR scores of\nbicubic, ANR and A+ methods.\n\n\nOnly the 800 train and 100 validation images are included in this dataset.",
"#### Who are the source language producers?\n\n\nThe authors manually crawled 1000 color RGB images from Internet paying special attention to the image quality,\nto the diversity of sources (sites and cameras), to the image contents and to the copyrights.",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nAll the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images\nbelongs to you and you would like it removed, please kindly inform the authors, and they will remove it from the dataset\nimmediately.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Author: Radu Timofte",
"### Licensing Information\n\n\nPlease notice that this dataset is made available for academic research purpose only. All the images are\ncollected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to\nyou and you would like it removed, please kindly inform the authors, and they will remove it from the dataset\nimmediately.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
0fbc53ce3af34f8283a46d70ed353ccc67085237 |
# Dataset Card for PIRM
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://github.com/roimehrez/PIRM2018
- **Repository**: https://huggingface.co/datasets/eugenesiow/PIRM
- **Paper**: https://arxiv.org/abs/1809.07517
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
The PIRM dataset consists of 200 images, which are divided into two equal sets for validation and testing.
These images cover diverse contents, including people, objects, environments, flora, natural scenery, etc.
Images vary in size, and are typically ~300K pixels in resolution.
This dataset was first used for evaluating the perceptual quality of super-resolution algorithms in The 2018 PIRM
challenge on Perceptual Super-resolution, in conjunction with ECCV 2018.
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/PIRM', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `validation` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/PIRM_valid_HR/1.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/PIRM_valid_LR_x2/1.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |validation|test|
|-------|---:|---:|
|bicubic_x2|100|100|
|bicubic_x3|100|100|
|bicubic_x4|100|100|
|unknown_x4|100|100|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Authors**: [Blau et al. (2018)](https://arxiv.org/abs/1809.07517)
### Licensing Information
This dataset is published under the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-nc-sa/4.0/).
### Citation Information
```bibtex
@misc{blau20192018,
title={The 2018 PIRM Challenge on Perceptual Image Super-resolution},
author={Yochai Blau and Roey Mechrez and Radu Timofte and Tomer Michaeli and Lihi Zelnik-Manor},
year={2019},
eprint={1809.07517},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/PIRM | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:cc-by-nc-sa-4.0",
"other-image-super-resolution",
"arxiv:1809.07517",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "PIRM", "tags": ["other-image-super-resolution"]} | 2022-10-21T03:01:16+00:00 | [
"1809.07517"
]
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-nc-sa-4.0 #other-image-super-resolution #arxiv-1809.07517 #region-us
| Dataset Card for PIRM
=====================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
The PIRM dataset consists of 200 images, which are divided into two equal sets for validation and testing.
These images cover diverse contents, including people, objects, environments, flora, natural scenery, etc.
Images vary in size, and are typically ~300K pixels in resolution.
This dataset was first used for evaluating the perceptual quality of super-resolution algorithms in The 2018 PIRM
challenge on Perceptual Super-resolution, in conjunction with ECCV 2018.
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'validation' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Authors: Blau et al. (2018)
### Licensing Information
This dataset is published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nThe PIRM dataset consists of 200 images, which are divided into two equal sets for validation and testing.\nThese images cover diverse contents, including people, objects, environments, flora, natural scenery, etc.\nImages vary in size, and are typically ~300K pixels in resolution.\n\n\nThis dataset was first used for evaluating the perceptual quality of super-resolution algorithms in The 2018 PIRM\nchallenge on Perceptual Super-resolution, in conjunction with ECCV 2018.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Blau et al. (2018)",
"### Licensing Information\n\n\nThis dataset is published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-nc-sa-4.0 #other-image-super-resolution #arxiv-1809.07517 #region-us \n",
"### Dataset Summary\n\n\nThe PIRM dataset consists of 200 images, which are divided into two equal sets for validation and testing.\nThese images cover diverse contents, including people, objects, environments, flora, natural scenery, etc.\nImages vary in size, and are typically ~300K pixels in resolution.\n\n\nThis dataset was first used for evaluating the perceptual quality of super-resolution algorithms in The 2018 PIRM\nchallenge on Perceptual Super-resolution, in conjunction with ECCV 2018.\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Blau et al. (2018)",
"### Licensing Information\n\n\nThis dataset is published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
5afcf80d267dba61cdfa9a32b1a6fe4cca57b6d7 |
# Dataset Card for Set14
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://sites.google.com/site/romanzeyde/research-interests
- **Repository**: https://huggingface.co/datasets/eugenesiow/Set14
- **Paper**: http://www.cs.technion.ac.il/users/wwwb/cgi-bin/tr-get.cgi/2010/CS/CS-2010-12.pdf
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
Set14 is an evaluation dataset with 14 RGB images for the image super resolution task. It was first used as the test set of the paper "On single image scale-up using sparse-representations" by [Zeyde et al. (2010)](http://www.cs.technion.ac.il/users/wwwb/cgi-bin/tr-get.cgi/2010/CS/CS-2010-12.pdf).
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/Set14', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `validation` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/Set14_HR/baboon.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/Set14_LR_x2/baboon.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |validation|
|-------|---:|
|bicubic_x2|14|
|bicubic_x3|14|
|bicubic_x4|14|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Authors**: [Zeyde et al.](http://www.cs.technion.ac.il/users/wwwb/cgi-bin/tr-get.cgi/2010/CS/CS-2010-12.pdf)
### Licensing Information
Academic use only.
### Citation Information
```bibtex
@inproceedings{zeyde2010single,
title={On single image scale-up using sparse-representations},
author={Zeyde, Roman and Elad, Michael and Protter, Matan},
booktitle={International conference on curves and surfaces},
pages={711--730},
year={2010},
organization={Springer}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/Set14 | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:other",
"other-image-super-resolution",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "Set14", "tags": ["other-image-super-resolution"]} | 2022-10-21T03:00:31+00:00 | []
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us
| Dataset Card for Set14
======================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
Set14 is an evaluation dataset with 14 RGB images for the image super resolution task. It was first used as the test set of the paper "On single image scale-up using sparse-representations" by Zeyde et al. (2010).
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'validation' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Authors: Zeyde et al.
### Licensing Information
Academic use only.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nSet14 is an evaluation dataset with 14 RGB images for the image super resolution task. It was first used as the test set of the paper \"On single image scale-up using sparse-representations\" by Zeyde et al. (2010).\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Zeyde et al.",
"### Licensing Information\n\n\nAcademic use only.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us \n",
"### Dataset Summary\n\n\nSet14 is an evaluation dataset with 14 RGB images for the image super resolution task. It was first used as the test set of the paper \"On single image scale-up using sparse-representations\" by Zeyde et al. (2010).\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Zeyde et al.",
"### Licensing Information\n\n\nAcademic use only.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
d8b579a20afde95b4d8ed6bf6383447d33027295 |
# Dataset Card for Set5
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: http://people.rennes.inria.fr/Aline.Roumy/results/SR_BMVC12.html
- **Repository**: https://huggingface.co/datasets/eugenesiow/Set5
- **Paper**: http://people.rennes.inria.fr/Aline.Roumy/publi/12bmvc_Bevilacqua_lowComplexitySR.pdf
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
Set5 is a evaluation dataset with 5 RGB images for the image super resolution task. The 5 images of the dataset are (“baby”, “bird”, “butterfly”, “head”, “woman”).
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/Set5', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `validation` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/Set5_HR/baby.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/Set5_LR_x2/baby.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |validation|
|-------|---:|
|bicubic_x2|5|
|bicubic_x3|5|
|bicubic_x4|5|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Authors**: [Bevilacqua et al.](http://people.rennes.inria.fr/Aline.Roumy/results/SR_BMVC12.html)
### Licensing Information
Academic use only.
### Citation Information
```bibtex
@article{bevilacqua2012low,
title={Low-complexity single-image super-resolution based on nonnegative neighbor embedding},
author={Bevilacqua, Marco and Roumy, Aline and Guillemot, Christine and Alberi-Morel, Marie Line},
year={2012},
publisher={BMVA press}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/Set5 | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:other",
"other-image-super-resolution",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "Set5", "tags": ["other-image-super-resolution"]} | 2022-10-21T02:59:16+00:00 | []
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us
| Dataset Card for Set5
=====================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
Set5 is a evaluation dataset with 5 RGB images for the image super resolution task. The 5 images of the dataset are (“baby”, “bird”, “butterfly”, “head”, “woman”).
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'validation' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Authors: Bevilacqua et al.
### Licensing Information
Academic use only.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nSet5 is a evaluation dataset with 5 RGB images for the image super resolution task. The 5 images of the dataset are (“baby”, “bird”, “butterfly”, “head”, “woman”).\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Bevilacqua et al.",
"### Licensing Information\n\n\nAcademic use only.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-other #other-image-super-resolution #region-us \n",
"### Dataset Summary\n\n\nSet5 is a evaluation dataset with 5 RGB images for the image super resolution task. The 5 images of the dataset are (“baby”, “bird”, “butterfly”, “head”, “woman”).\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Bevilacqua et al.",
"### Licensing Information\n\n\nAcademic use only.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
fb0d8a4c6b2471d32bd133de40bb8bb10dde69b9 |
# Dataset Card for Urban100
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://github.com/jbhuang0604/SelfExSR
- **Repository**: https://huggingface.co/datasets/eugenesiow/Urban100
- **Paper**: https://openaccess.thecvf.com/content_cvpr_2015/html/Huang_Single_Image_Super-Resolution_2015_CVPR_paper.html
- **Leaderboard**: https://github.com/eugenesiow/super-image#scale-x2
### Dataset Summary
The Urban100 dataset contains 100 images of urban scenes. It commonly used as a test set to evaluate the performance of super-resolution models. It was first published by [Huang et al. (2015)](https://openaccess.thecvf.com/content_cvpr_2015/html/Huang_Single_Image_Super-Resolution_2015_CVPR_paper.html) in the paper "Single Image Super-Resolution From Transformed Self-Exemplars".
Install with `pip`:
```bash
pip install datasets super-image
```
Evaluate a model with the [`super-image`](https://github.com/eugenesiow/super-image) library:
```python
from datasets import load_dataset
from super_image import EdsrModel
from super_image.data import EvalDataset, EvalMetrics
dataset = load_dataset('eugenesiow/Urban100', 'bicubic_x2', split='validation')
eval_dataset = EvalDataset(dataset)
model = EdsrModel.from_pretrained('eugenesiow/edsr-base', scale=2)
EvalMetrics().evaluate(model, eval_dataset)
```
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the `image-super-resolution` task.
Unofficial [`super-image`](https://github.com/eugenesiow/super-image) leaderboard for:
- [Scale 2](https://github.com/eugenesiow/super-image#scale-x2)
- [Scale 3](https://github.com/eugenesiow/super-image#scale-x3)
- [Scale 4](https://github.com/eugenesiow/super-image#scale-x4)
- [Scale 8](https://github.com/eugenesiow/super-image#scale-x8)
### Languages
Not applicable.
## Dataset Structure
### Data Instances
An example of `validation` for `bicubic_x2` looks as follows.
```
{
"hr": "/.cache/huggingface/datasets/downloads/extracted/Urban100_HR/img_001.png",
"lr": "/.cache/huggingface/datasets/downloads/extracted/Urban100_LR_x2/img_001.png"
}
```
### Data Fields
The data fields are the same among all splits.
- `hr`: a `string` to the path of the High Resolution (HR) `.png` image.
- `lr`: a `string` to the path of the Low Resolution (LR) `.png` image.
### Data Splits
| name |validation|
|-------|---:|
|bicubic_x2|100|
|bicubic_x3|100|
|bicubic_x4|100|
## Dataset Creation
### Curation Rationale
The authors have created Urban100 containing 100 HR images with a variety of real-world structures.
### Source Data
#### Initial Data Collection and Normalization
The authors constructed this dataset using images from Flickr (under CC license) using keywords such as urban, city, architecture, and structure.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
- **Original Authors**: [Huang et al. (2015)](https://github.com/jbhuang0604/SelfExSR)
### Licensing Information
The dataset provided uses images from Flikr under the CC (CC-BY-4.0) license.
### Citation Information
```bibtex
@InProceedings{Huang_2015_CVPR,
author = {Huang, Jia-Bin and Singh, Abhishek and Ahuja, Narendra},
title = {Single Image Super-Resolution From Transformed Self-Exemplars},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2015}
}
```
### Contributions
Thanks to [@eugenesiow](https://github.com/eugenesiow) for adding this dataset.
| eugenesiow/Urban100 | [
"task_categories:other",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"license:cc-by-4.0",
"other-image-super-resolution",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": [], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "Urban100", "tags": ["other-image-super-resolution"]} | 2022-10-21T02:58:53+00:00 | []
| []
| TAGS
#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-4.0 #other-image-super-resolution #region-us
| Dataset Card for Urban100
=========================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
### Dataset Summary
The Urban100 dataset contains 100 images of urban scenes. It commonly used as a test set to evaluate the performance of super-resolution models. It was first published by Huang et al. (2015) in the paper "Single Image Super-Resolution From Transformed Self-Exemplars".
Install with 'pip':
Evaluate a model with the 'super-image' library:
### Supported Tasks and Leaderboards
The dataset is commonly used for evaluation of the 'image-super-resolution' task.
Unofficial 'super-image' leaderboard for:
* Scale 2
* Scale 3
* Scale 4
* Scale 8
### Languages
Not applicable.
Dataset Structure
-----------------
### Data Instances
An example of 'validation' for 'bicubic\_x2' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.
* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
The authors have created Urban100 containing 100 HR images with a variety of real-world structures.
### Source Data
#### Initial Data Collection and Normalization
The authors constructed this dataset using images from Flickr (under CC license) using keywords such as urban, city, architecture, and structure.
#### Who are the source language producers?
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
No annotators.
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
* Original Authors: Huang et al. (2015)
### Licensing Information
The dataset provided uses images from Flikr under the CC (CC-BY-4.0) license.
### Contributions
Thanks to @eugenesiow for adding this dataset.
| [
"### Dataset Summary\n\n\nThe Urban100 dataset contains 100 images of urban scenes. It commonly used as a test set to evaluate the performance of super-resolution models. It was first published by Huang et al. (2015) in the paper \"Single Image Super-Resolution From Transformed Self-Exemplars\".\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThe authors have created Urban100 containing 100 HR images with a variety of real-world structures.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe authors constructed this dataset using images from Flickr (under CC license) using keywords such as urban, city, architecture, and structure.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Huang et al. (2015)",
"### Licensing Information\n\n\nThe dataset provided uses images from Flikr under the CC (CC-BY-4.0) license.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-original #license-cc-by-4.0 #other-image-super-resolution #region-us \n",
"### Dataset Summary\n\n\nThe Urban100 dataset contains 100 images of urban scenes. It commonly used as a test set to evaluate the performance of super-resolution models. It was first published by Huang et al. (2015) in the paper \"Single Image Super-Resolution From Transformed Self-Exemplars\".\n\n\nInstall with 'pip':\n\n\nEvaluate a model with the 'super-image' library:",
"### Supported Tasks and Leaderboards\n\n\nThe dataset is commonly used for evaluation of the 'image-super-resolution' task.\n\n\nUnofficial 'super-image' leaderboard for:\n\n\n* Scale 2\n* Scale 3\n* Scale 4\n* Scale 8",
"### Languages\n\n\nNot applicable.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'validation' for 'bicubic\\_x2' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'hr': a 'string' to the path of the High Resolution (HR) '.png' image.\n* 'lr': a 'string' to the path of the Low Resolution (LR) '.png' image.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThe authors have created Urban100 containing 100 HR images with a variety of real-world structures.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe authors constructed this dataset using images from Flickr (under CC license) using keywords such as urban, city, architecture, and structure.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process\n\n\nNo annotations.",
"#### Who are the annotators?\n\n\nNo annotators.",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\n* Original Authors: Huang et al. (2015)",
"### Licensing Information\n\n\nThe dataset provided uses images from Flikr under the CC (CC-BY-4.0) license.",
"### Contributions\n\n\nThanks to @eugenesiow for adding this dataset."
]
|
288fa596f1a5ceb5c207c8ebdcebc92e15903ce7 | # IADD
IADD is an Integrated Dataset for Arabic Dialect iDentification Dataset. It contains 136,317 texts representing 5 regions (Maghrebi (MGH) , Levantine (LEV), Egypt (EGY) , Iraq (IRQ) and Gulf (GLF)) and 9 countries (Algeria, Morocco, Tunisia, Palestine, Jordan, Syria, Lebanon, Egypt and Iraq).
IADD is created from the combination of subsets of five corpora: DART, SHAMI, TSAC, PADIC and AOC. The Dialectal ARabic Tweets dataset (DART) [1] has about 25,000 tweets that are annotated via crowdsourcing while the SHAMI dataset [2] consists of 117,805 sentences and covers levantine dialects spoken in Palestine, Jordan, Lebanon and Syria. TSAC [3] is a Tunisian dialect corpus of 17,000 comments collected mainly from Tunisian Facebook pages. Parallel Arabic Dialect Corpus (PADIC) [4] is made of sentences transcribed from recordings or translated from MSA. Finally, the Arabic Online Commentary (AOC) dataset [5] is based on reader commentary from the online versions of three Arabic newspapers, and it consists of 1.4M comments.
IADD is stored in a JSON-like format with the following keys:
- Sentence: contains the sentence/ text;
- Region: stores the corresponding dialectal region (MGH, LEV, EGY, IRQ, GLF or general);
- Country: specifies the corresponding country, if available (MAR, TUN, DZ, EGY, IRQ, SYR, JOR, PSE, LBN);
- DataSource: indicates the source of the data (PADIC, DART, AOC, SHAMI or TSAC).
[1] Alsarsour, I., Mohamed, E., Suwaileh, R., & Elsayed, T. (2018, May). Dart: A large dataset of dialectal arabic tweets. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
[2] Abu Kwaik, K., Saad, M. K., Chatzikyriakidis, S., & Dobnik, S. (2018). Shami: A corpus of levantine arabic dialects. In Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).
[3] Mdhaffar, S., Bougares, F., Esteve, Y., & Hadrich-Belguith, L. (2017, April). Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Third Arabic Natural Language Processing Workshop (WANLP) (pp. 55-61).
[4] Meftouh, K., Harrat, S., Jamoussi, S., Abbas, M., & Smaili, K. (2015, October). Machine translation experiments on PADIC: A parallel Arabic dialect corpus. In The 29th Pacific Asia conference on language, information and computation.
[5] Zaidan, O., & Callison-Burch, C. (2011, June). The arabic online commentary dataset: an annotated dataset of informal arabic with high dialectal content. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (pp. 37-41).
| evageon/IADD | [
"license:cc-by-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"license": "cc-by-4.0"} | 2022-01-29T11:16:17+00:00 | []
| []
| TAGS
#license-cc-by-4.0 #region-us
| # IADD
IADD is an Integrated Dataset for Arabic Dialect iDentification Dataset. It contains 136,317 texts representing 5 regions (Maghrebi (MGH) , Levantine (LEV), Egypt (EGY) , Iraq (IRQ) and Gulf (GLF)) and 9 countries (Algeria, Morocco, Tunisia, Palestine, Jordan, Syria, Lebanon, Egypt and Iraq).
IADD is created from the combination of subsets of five corpora: DART, SHAMI, TSAC, PADIC and AOC. The Dialectal ARabic Tweets dataset (DART) [1] has about 25,000 tweets that are annotated via crowdsourcing while the SHAMI dataset [2] consists of 117,805 sentences and covers levantine dialects spoken in Palestine, Jordan, Lebanon and Syria. TSAC [3] is a Tunisian dialect corpus of 17,000 comments collected mainly from Tunisian Facebook pages. Parallel Arabic Dialect Corpus (PADIC) [4] is made of sentences transcribed from recordings or translated from MSA. Finally, the Arabic Online Commentary (AOC) dataset [5] is based on reader commentary from the online versions of three Arabic newspapers, and it consists of 1.4M comments.
IADD is stored in a JSON-like format with the following keys:
- Sentence: contains the sentence/ text;
- Region: stores the corresponding dialectal region (MGH, LEV, EGY, IRQ, GLF or general);
- Country: specifies the corresponding country, if available (MAR, TUN, DZ, EGY, IRQ, SYR, JOR, PSE, LBN);
- DataSource: indicates the source of the data (PADIC, DART, AOC, SHAMI or TSAC).
[1] Alsarsour, I., Mohamed, E., Suwaileh, R., & Elsayed, T. (2018, May). Dart: A large dataset of dialectal arabic tweets. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
[2] Abu Kwaik, K., Saad, M. K., Chatzikyriakidis, S., & Dobnik, S. (2018). Shami: A corpus of levantine arabic dialects. In Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).
[3] Mdhaffar, S., Bougares, F., Esteve, Y., & Hadrich-Belguith, L. (2017, April). Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Third Arabic Natural Language Processing Workshop (WANLP) (pp. 55-61).
[4] Meftouh, K., Harrat, S., Jamoussi, S., Abbas, M., & Smaili, K. (2015, October). Machine translation experiments on PADIC: A parallel Arabic dialect corpus. In The 29th Pacific Asia conference on language, information and computation.
[5] Zaidan, O., & Callison-Burch, C. (2011, June). The arabic online commentary dataset: an annotated dataset of informal arabic with high dialectal content. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (pp. 37-41).
| [
"# IADD\r\n\r\nIADD is an Integrated Dataset for Arabic Dialect iDentification Dataset. It contains 136,317 texts representing 5 regions (Maghrebi (MGH) , Levantine (LEV), Egypt (EGY) , Iraq (IRQ) and Gulf (GLF)) and 9 countries (Algeria, Morocco, Tunisia, Palestine, Jordan, Syria, Lebanon, Egypt and Iraq).\r\n\r\nIADD is created from the combination of subsets of five corpora: DART, SHAMI, TSAC, PADIC and AOC. The Dialectal ARabic Tweets dataset (DART) [1] has about 25,000 tweets that are annotated via crowdsourcing while the SHAMI dataset [2] consists of 117,805 sentences and covers levantine dialects spoken in Palestine, Jordan, Lebanon and Syria. TSAC [3] is a Tunisian dialect corpus of 17,000 comments collected mainly from Tunisian Facebook pages. Parallel Arabic Dialect Corpus (PADIC) [4] is made of sentences transcribed from recordings or translated from MSA. Finally, the Arabic Online Commentary (AOC) dataset [5] is based on reader commentary from the online versions of three Arabic newspapers, and it consists of 1.4M comments.\r\n\r\nIADD is stored in a JSON-like format with the following keys:\r\n- Sentence: contains the sentence/ text;\r\n- Region: stores the corresponding dialectal region (MGH, LEV, EGY, IRQ, GLF or general);\r\n- Country: specifies the corresponding country, if available (MAR, TUN, DZ, EGY, IRQ, SYR, JOR, PSE, LBN);\r\n- DataSource: indicates the source of the data (PADIC, DART, AOC, SHAMI or TSAC).\r\n\r\n\r\n[1] Alsarsour, I., Mohamed, E., Suwaileh, R., & Elsayed, T. (2018, May). Dart: A large dataset of dialectal arabic tweets. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).\r\n[2] Abu Kwaik, K., Saad, M. K., Chatzikyriakidis, S., & Dobnik, S. (2018). Shami: A corpus of levantine arabic dialects. In Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).\r\n[3] Mdhaffar, S., Bougares, F., Esteve, Y., & Hadrich-Belguith, L. (2017, April). Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Third Arabic Natural Language Processing Workshop (WANLP) (pp. 55-61).\r\n[4] Meftouh, K., Harrat, S., Jamoussi, S., Abbas, M., & Smaili, K. (2015, October). Machine translation experiments on PADIC: A parallel Arabic dialect corpus. In The 29th Pacific Asia conference on language, information and computation.\r\n[5] Zaidan, O., & Callison-Burch, C. (2011, June). The arabic online commentary dataset: an annotated dataset of informal arabic with high dialectal content. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (pp. 37-41)."
]
| [
"TAGS\n#license-cc-by-4.0 #region-us \n",
"# IADD\r\n\r\nIADD is an Integrated Dataset for Arabic Dialect iDentification Dataset. It contains 136,317 texts representing 5 regions (Maghrebi (MGH) , Levantine (LEV), Egypt (EGY) , Iraq (IRQ) and Gulf (GLF)) and 9 countries (Algeria, Morocco, Tunisia, Palestine, Jordan, Syria, Lebanon, Egypt and Iraq).\r\n\r\nIADD is created from the combination of subsets of five corpora: DART, SHAMI, TSAC, PADIC and AOC. The Dialectal ARabic Tweets dataset (DART) [1] has about 25,000 tweets that are annotated via crowdsourcing while the SHAMI dataset [2] consists of 117,805 sentences and covers levantine dialects spoken in Palestine, Jordan, Lebanon and Syria. TSAC [3] is a Tunisian dialect corpus of 17,000 comments collected mainly from Tunisian Facebook pages. Parallel Arabic Dialect Corpus (PADIC) [4] is made of sentences transcribed from recordings or translated from MSA. Finally, the Arabic Online Commentary (AOC) dataset [5] is based on reader commentary from the online versions of three Arabic newspapers, and it consists of 1.4M comments.\r\n\r\nIADD is stored in a JSON-like format with the following keys:\r\n- Sentence: contains the sentence/ text;\r\n- Region: stores the corresponding dialectal region (MGH, LEV, EGY, IRQ, GLF or general);\r\n- Country: specifies the corresponding country, if available (MAR, TUN, DZ, EGY, IRQ, SYR, JOR, PSE, LBN);\r\n- DataSource: indicates the source of the data (PADIC, DART, AOC, SHAMI or TSAC).\r\n\r\n\r\n[1] Alsarsour, I., Mohamed, E., Suwaileh, R., & Elsayed, T. (2018, May). Dart: A large dataset of dialectal arabic tweets. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).\r\n[2] Abu Kwaik, K., Saad, M. K., Chatzikyriakidis, S., & Dobnik, S. (2018). Shami: A corpus of levantine arabic dialects. In Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).\r\n[3] Mdhaffar, S., Bougares, F., Esteve, Y., & Hadrich-Belguith, L. (2017, April). Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Third Arabic Natural Language Processing Workshop (WANLP) (pp. 55-61).\r\n[4] Meftouh, K., Harrat, S., Jamoussi, S., Abbas, M., & Smaili, K. (2015, October). Machine translation experiments on PADIC: A parallel Arabic dialect corpus. In The 29th Pacific Asia conference on language, information and computation.\r\n[5] Zaidan, O., & Callison-Burch, C. (2011, June). The arabic online commentary dataset: an annotated dataset of informal arabic with high dialectal content. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (pp. 37-41)."
]
|
d22a730b623deccb518ee6ad0cf8cc8cef98e9cd |
# Dataset Card for MultiLingual LibriSpeech
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [MultiLingual LibriSpeech ASR corpus](http://www.openslr.org/94)
- **Repository:** [Needs More Information]
- **Paper:** [MLS: A Large-Scale Multilingual Dataset for Speech Research](https://arxiv.org/abs/2012.03411)
- **Leaderboard:** [🤗 Autoevaluate Leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=facebook%2Fmultilingual_librispeech&only_verified=0&task=automatic-speech-recognition&config=-unspecified-&split=-unspecified-&metric=wer)
### Dataset Summary
This is a streamable version of the Multilingual LibriSpeech (MLS) dataset.
The data archives were restructured from the original ones from [OpenSLR](http://www.openslr.org/94) to make it easier to stream.
MLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of
8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish.
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`, `speaker-identification`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at https://paperswithcode.com/dataset/multilingual-librispeech and ranks models based on their WER.
### Languages
The dataset is derived from read audiobooks from LibriVox and consists of 8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish
### How to use
The `datasets` library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the `load_dataset` function.
For example, to download the German config, simply specify the corresponding language config name (i.e., "german" for German):
```python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
```
Using the datasets library, you can also stream the dataset on-the-fly by adding a `streaming=True` argument to the `load_dataset` function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.
```python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
print(next(iter(mls)))
```
*Bonus*: create a [PyTorch dataloader](https://huggingface.co/docs/datasets/use_with_pytorch) directly with your own datasets (local/streamed).
Local:
```python
from datasets import load_dataset
from torch.utils.data.sampler import BatchSampler, RandomSampler
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
batch_sampler = BatchSampler(RandomSampler(mls), batch_size=32, drop_last=False)
dataloader = DataLoader(mls, batch_sampler=batch_sampler)
```
Streaming:
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
dataloader = DataLoader(mls, batch_size=32)
```
To find out more about loading and preparing audio datasets, head over to [hf.co/blog/audio-datasets](https://huggingface.co/blog/audio-datasets).
### Example scripts
Train your own CTC or Seq2Seq Automatic Speech Recognition models on MultiLingual Librispeech with `transformers` - [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
## Dataset Structure
### Data Instances
A typical data point comprises the path to the audio file, usually called `file` and its transcription, called `text`. Some additional information about the speaker and the passage which contains the transcription is provided.
```
{'file': '10900_6473_000030.flac',
'audio': {'path': '10900_6473_000030.flac',
'array': array([-1.52587891e-04, 6.10351562e-05, 0.00000000e+00, ...,
4.27246094e-04, 5.49316406e-04, 4.57763672e-04]),
'sampling_rate': 16000},
'text': 'więc czego chcecie odemnie spytałem wysłuchawszy tego zadziwiającego opowiadania broń nas stary człowieku broń zakrzyknęli równocześnie obaj posłowie\n',
'speaker_id': 10900,
'chapter_id': 6473,
'id': '10900_6473_000030'}
```
### Data Fields
- file: A filename .flac format.
- audio: A dictionary containing the audio filename, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- text: the transcription of the audio file.
- id: unique id of the data sample.
- speaker_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
- chapter_id: id of the audiobook chapter which includes the transcription.
### Data Splits
| | Train | Train.9h | Train.1h | Dev | Test |
| ----- | ------ | ----- | ---- | ---- | ---- |
| german | 469942 | 2194 | 241 | 3469 | 3394 |
| dutch | 374287 | 2153 | 234 | 3095 | 3075 |
| french | 258213 | 2167 | 241 | 2416 | 2426 |
| spanish | 220701 | 2110 | 233 | 2408 | 2385 |
| italian | 59623 | 2173 | 240 | 1248 | 1262 |
| portuguese | 37533 | 2116 | 236 | 826 | 871 |
| polish | 25043 | 2173 | 238 | 512 | 520 |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
Public Domain, Creative Commons Attribution 4.0 International Public License ([CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode))
### Citation Information
```
@article{Pratap2020MLSAL,
title={MLS: A Large-Scale Multilingual Dataset for Speech Research},
author={Vineel Pratap and Qiantong Xu and Anuroop Sriram and Gabriel Synnaeve and Ronan Collobert},
journal={ArXiv},
year={2020},
volume={abs/2012.03411}
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten)
and [@polinaeterna](https://github.com/polinaeterna) for adding this dataset.
| facebook/multilingual_librispeech | [
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:multilingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:de",
"language:nl",
"language:fr",
"language:it",
"language:es",
"language:pt",
"language:pl",
"license:cc-by-4.0",
"arxiv:2012.03411",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["crowdsourced", "expert-generated"], "language": ["de", "nl", "fr", "it", "es", "pt", "pl"], "license": ["cc-by-4.0"], "multilinguality": ["multilingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["automatic-speech-recognition"], "paperswithcode_id": "multilingual-librispeech", "pretty_name": "MultiLingual LibriSpeech"} | 2023-02-13T11:33:31+00:00 | [
"2012.03411"
]
| [
"de",
"nl",
"fr",
"it",
"es",
"pt",
"pl"
]
| TAGS
#task_categories-automatic-speech-recognition #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-multilingual #size_categories-100K<n<1M #source_datasets-original #language-German #language-Dutch #language-French #language-Italian #language-Spanish #language-Portuguese #language-Polish #license-cc-by-4.0 #arxiv-2012.03411 #region-us
| Dataset Card for MultiLingual LibriSpeech
=========================================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
+ How to use
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: MultiLingual LibriSpeech ASR corpus
* Repository:
* Paper: MLS: A Large-Scale Multilingual Dataset for Speech Research
* Leaderboard: Autoevaluate Leaderboard
### Dataset Summary
This is a streamable version of the Multilingual LibriSpeech (MLS) dataset.
The data archives were restructured from the original ones from OpenSLR to make it easier to stream.
MLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of
8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish.
### Supported Tasks and Leaderboards
* 'automatic-speech-recognition', 'speaker-identification': The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at URL and ranks models based on their WER.
### Languages
The dataset is derived from read audiobooks from LibriVox and consists of 8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish
### How to use
The 'datasets' library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the 'load\_dataset' function.
For example, to download the German config, simply specify the corresponding language config name (i.e., "german" for German):
Using the datasets library, you can also stream the dataset on-the-fly by adding a 'streaming=True' argument to the 'load\_dataset' function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.
*Bonus*: create a PyTorch dataloader directly with your own datasets (local/streamed).
Local:
Streaming:
To find out more about loading and preparing audio datasets, head over to URL
### Example scripts
Train your own CTC or Seq2Seq Automatic Speech Recognition models on MultiLingual Librispeech with 'transformers' - here.
Dataset Structure
-----------------
### Data Instances
A typical data point comprises the path to the audio file, usually called 'file' and its transcription, called 'text'. Some additional information about the speaker and the passage which contains the transcription is provided.
### Data Fields
* file: A filename .flac format.
* audio: A dictionary containing the audio filename, the decoded audio array, and the sampling rate. Note that when accessing the audio column: 'dataset[0]["audio"]' the audio file is automatically decoded and resampled to 'dataset.features["audio"].sampling\_rate'. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the '"audio"' column, *i.e.* 'dataset[0]["audio"]' should always be preferred over 'dataset["audio"][0]'.
* text: the transcription of the audio file.
* id: unique id of the data sample.
* speaker\_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
* chapter\_id: id of the audiobook chapter which includes the transcription.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Public Domain, Creative Commons Attribution 4.0 International Public License (CC-BY-4.0)
### Contributions
Thanks to @patrickvonplaten
and @polinaeterna for adding this dataset.
| [
"### Dataset Summary\n\n\nThis is a streamable version of the Multilingual LibriSpeech (MLS) dataset.\nThe data archives were restructured from the original ones from OpenSLR to make it easier to stream.\n\n\nMLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of\n8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish.",
"### Supported Tasks and Leaderboards\n\n\n* 'automatic-speech-recognition', 'speaker-identification': The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at URL and ranks models based on their WER.",
"### Languages\n\n\nThe dataset is derived from read audiobooks from LibriVox and consists of 8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish",
"### How to use\n\n\nThe 'datasets' library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the 'load\\_dataset' function.\n\n\nFor example, to download the German config, simply specify the corresponding language config name (i.e., \"german\" for German):\n\n\nUsing the datasets library, you can also stream the dataset on-the-fly by adding a 'streaming=True' argument to the 'load\\_dataset' function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.\n\n\n*Bonus*: create a PyTorch dataloader directly with your own datasets (local/streamed).\n\n\nLocal:\n\n\nStreaming:\n\n\nTo find out more about loading and preparing audio datasets, head over to URL",
"### Example scripts\n\n\nTrain your own CTC or Seq2Seq Automatic Speech Recognition models on MultiLingual Librispeech with 'transformers' - here.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA typical data point comprises the path to the audio file, usually called 'file' and its transcription, called 'text'. Some additional information about the speaker and the passage which contains the transcription is provided.",
"### Data Fields\n\n\n* file: A filename .flac format.\n* audio: A dictionary containing the audio filename, the decoded audio array, and the sampling rate. Note that when accessing the audio column: 'dataset[0][\"audio\"]' the audio file is automatically decoded and resampled to 'dataset.features[\"audio\"].sampling\\_rate'. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the '\"audio\"' column, *i.e.* 'dataset[0][\"audio\"]' should always be preferred over 'dataset[\"audio\"][0]'.\n* text: the transcription of the audio file.\n* id: unique id of the data sample.\n* speaker\\_id: unique id of the speaker. The same speaker id can be found for multiple data samples.\n* chapter\\_id: id of the audiobook chapter which includes the transcription.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nThe dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nPublic Domain, Creative Commons Attribution 4.0 International Public License (CC-BY-4.0)",
"### Contributions\n\n\nThanks to @patrickvonplaten\nand @polinaeterna for adding this dataset."
]
| [
"TAGS\n#task_categories-automatic-speech-recognition #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-multilingual #size_categories-100K<n<1M #source_datasets-original #language-German #language-Dutch #language-French #language-Italian #language-Spanish #language-Portuguese #language-Polish #license-cc-by-4.0 #arxiv-2012.03411 #region-us \n",
"### Dataset Summary\n\n\nThis is a streamable version of the Multilingual LibriSpeech (MLS) dataset.\nThe data archives were restructured from the original ones from OpenSLR to make it easier to stream.\n\n\nMLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of\n8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish.",
"### Supported Tasks and Leaderboards\n\n\n* 'automatic-speech-recognition', 'speaker-identification': The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at URL and ranks models based on their WER.",
"### Languages\n\n\nThe dataset is derived from read audiobooks from LibriVox and consists of 8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish",
"### How to use\n\n\nThe 'datasets' library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the 'load\\_dataset' function.\n\n\nFor example, to download the German config, simply specify the corresponding language config name (i.e., \"german\" for German):\n\n\nUsing the datasets library, you can also stream the dataset on-the-fly by adding a 'streaming=True' argument to the 'load\\_dataset' function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.\n\n\n*Bonus*: create a PyTorch dataloader directly with your own datasets (local/streamed).\n\n\nLocal:\n\n\nStreaming:\n\n\nTo find out more about loading and preparing audio datasets, head over to URL",
"### Example scripts\n\n\nTrain your own CTC or Seq2Seq Automatic Speech Recognition models on MultiLingual Librispeech with 'transformers' - here.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA typical data point comprises the path to the audio file, usually called 'file' and its transcription, called 'text'. Some additional information about the speaker and the passage which contains the transcription is provided.",
"### Data Fields\n\n\n* file: A filename .flac format.\n* audio: A dictionary containing the audio filename, the decoded audio array, and the sampling rate. Note that when accessing the audio column: 'dataset[0][\"audio\"]' the audio file is automatically decoded and resampled to 'dataset.features[\"audio\"].sampling\\_rate'. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the '\"audio\"' column, *i.e.* 'dataset[0][\"audio\"]' should always be preferred over 'dataset[\"audio\"][0]'.\n* text: the transcription of the audio file.\n* id: unique id of the data sample.\n* speaker\\_id: unique id of the speaker. The same speaker id can be found for multiple data samples.\n* chapter\\_id: id of the audiobook chapter which includes the transcription.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nThe dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nPublic Domain, Creative Commons Attribution 4.0 International Public License (CC-BY-4.0)",
"### Contributions\n\n\nThanks to @patrickvonplaten\nand @polinaeterna for adding this dataset."
]
|
98afeae90eadb629ae70cd2d0fc16f64c2cd2f8d | # NewsMTSC dataset
NewsMTSC is a high-quality dataset consisting of more than 11k manually labeled sentences sampled from English news articles. Each sentence was labeled by five human coders (the dataset contains only examples where the five coders assessed same or similar sentiment). The dataset is published as a [full paper at EACL 2021: *NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles*](https://aclanthology.org/2021.eacl-main.142.pdf).
## Subsets and splits
The dataset consists of two subsets (`rw` and `mt`), each consisting of three splits (train, validation, and test). We recommend to use the `rw` subset, which is also the default subset. Both subsets share the same train set, in which the three sentiment classes have similar frequency since we applied class boosting. The two subsets differ in their validation and test sets: `rw` contains validation and test sets that resemble real-world distribution of sentiment in news articles. In contrast, `mt`'s validation and test sets contain only sentences that each have two or more (different) targets, where each target's sentiment was labeled individually.
More information on the subsets can be found in our [paper](https://aclanthology.org/2021.eacl-main.142.pdf).
## Format
Each split is stored in a JSONL file. In JSONL, each line represents one JSON object. In our dataset, each JSON object consists of the following attributes. When using the dataset, you most likely will need (only) the attributes highlighted in **bold**.
1. `mention`: text of the mention within `sentence`
2. **`polarity`: sentiment of the sentence concerning the target's mention (-1 = negative, 0 = neutral, 1 = positive)**
3. **`from`: character-based, 0-indexed position of the first character of the target's mention within `sentence`**
4. **`to`: last character of the target's mention**
5. **`sentence`: sentence**
6. `id`: identifier that is unique within NewsMTSC
## Contact
If you find an issue with the dataset or model or have a question concerning either, please open an issue in the repository.
* Repository: [https://github.com/fhamborg/NewsMTSC](https://github.com/fhamborg/NewsMTSC)
* Web: [https://felix.hamborg.eu/](https://felix.hamborg.eu/)
## How to cite
If you use the dataset or parts of it, please cite our paper:
```
@InProceedings{Hamborg2021b,
author = {Hamborg, Felix and Donnay, Karsten},
title = {NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles},
booktitle = {Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2021)},
year = {2021},
month = {Apr.},
location = {Virtual Event},
}
```
| fhamborg/news_sentiment_newsmtsc | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:mit",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["crowdsourced", "expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["sentiment-classification"], "pretty_name": "NewsMTSC", "language_bcp47": ["en-US"]} | 2022-10-25T08:20:03+00:00 | []
| [
"en"
]
| TAGS
#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-mit #region-us
| # NewsMTSC dataset
NewsMTSC is a high-quality dataset consisting of more than 11k manually labeled sentences sampled from English news articles. Each sentence was labeled by five human coders (the dataset contains only examples where the five coders assessed same or similar sentiment). The dataset is published as a full paper at EACL 2021: *NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles*.
## Subsets and splits
The dataset consists of two subsets ('rw' and 'mt'), each consisting of three splits (train, validation, and test). We recommend to use the 'rw' subset, which is also the default subset. Both subsets share the same train set, in which the three sentiment classes have similar frequency since we applied class boosting. The two subsets differ in their validation and test sets: 'rw' contains validation and test sets that resemble real-world distribution of sentiment in news articles. In contrast, 'mt''s validation and test sets contain only sentences that each have two or more (different) targets, where each target's sentiment was labeled individually.
More information on the subsets can be found in our paper.
## Format
Each split is stored in a JSONL file. In JSONL, each line represents one JSON object. In our dataset, each JSON object consists of the following attributes. When using the dataset, you most likely will need (only) the attributes highlighted in bold.
1. 'mention': text of the mention within 'sentence'
2. 'polarity': sentiment of the sentence concerning the target's mention (-1 = negative, 0 = neutral, 1 = positive)
3. 'from': character-based, 0-indexed position of the first character of the target's mention within 'sentence'
4. 'to': last character of the target's mention
5. 'sentence': sentence
6. 'id': identifier that is unique within NewsMTSC
## Contact
If you find an issue with the dataset or model or have a question concerning either, please open an issue in the repository.
* Repository: URL
* Web: URL
## How to cite
If you use the dataset or parts of it, please cite our paper:
| [
"# NewsMTSC dataset\n\nNewsMTSC is a high-quality dataset consisting of more than 11k manually labeled sentences sampled from English news articles. Each sentence was labeled by five human coders (the dataset contains only examples where the five coders assessed same or similar sentiment). The dataset is published as a full paper at EACL 2021: *NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles*.",
"## Subsets and splits\nThe dataset consists of two subsets ('rw' and 'mt'), each consisting of three splits (train, validation, and test). We recommend to use the 'rw' subset, which is also the default subset. Both subsets share the same train set, in which the three sentiment classes have similar frequency since we applied class boosting. The two subsets differ in their validation and test sets: 'rw' contains validation and test sets that resemble real-world distribution of sentiment in news articles. In contrast, 'mt''s validation and test sets contain only sentences that each have two or more (different) targets, where each target's sentiment was labeled individually. \n\nMore information on the subsets can be found in our paper.",
"## Format\nEach split is stored in a JSONL file. In JSONL, each line represents one JSON object. In our dataset, each JSON object consists of the following attributes. When using the dataset, you most likely will need (only) the attributes highlighted in bold.\n\n1. 'mention': text of the mention within 'sentence'\n2. 'polarity': sentiment of the sentence concerning the target's mention (-1 = negative, 0 = neutral, 1 = positive)\n3. 'from': character-based, 0-indexed position of the first character of the target's mention within 'sentence'\n4. 'to': last character of the target's mention\n5. 'sentence': sentence\n6. 'id': identifier that is unique within NewsMTSC",
"## Contact\n\nIf you find an issue with the dataset or model or have a question concerning either, please open an issue in the repository.\n\n* Repository: URL\n* Web: URL",
"## How to cite\n\nIf you use the dataset or parts of it, please cite our paper:"
]
| [
"TAGS\n#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-mit #region-us \n",
"# NewsMTSC dataset\n\nNewsMTSC is a high-quality dataset consisting of more than 11k manually labeled sentences sampled from English news articles. Each sentence was labeled by five human coders (the dataset contains only examples where the five coders assessed same or similar sentiment). The dataset is published as a full paper at EACL 2021: *NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles*.",
"## Subsets and splits\nThe dataset consists of two subsets ('rw' and 'mt'), each consisting of three splits (train, validation, and test). We recommend to use the 'rw' subset, which is also the default subset. Both subsets share the same train set, in which the three sentiment classes have similar frequency since we applied class boosting. The two subsets differ in their validation and test sets: 'rw' contains validation and test sets that resemble real-world distribution of sentiment in news articles. In contrast, 'mt''s validation and test sets contain only sentences that each have two or more (different) targets, where each target's sentiment was labeled individually. \n\nMore information on the subsets can be found in our paper.",
"## Format\nEach split is stored in a JSONL file. In JSONL, each line represents one JSON object. In our dataset, each JSON object consists of the following attributes. When using the dataset, you most likely will need (only) the attributes highlighted in bold.\n\n1. 'mention': text of the mention within 'sentence'\n2. 'polarity': sentiment of the sentence concerning the target's mention (-1 = negative, 0 = neutral, 1 = positive)\n3. 'from': character-based, 0-indexed position of the first character of the target's mention within 'sentence'\n4. 'to': last character of the target's mention\n5. 'sentence': sentence\n6. 'id': identifier that is unique within NewsMTSC",
"## Contact\n\nIf you find an issue with the dataset or model or have a question concerning either, please open an issue in the repository.\n\n* Repository: URL\n* Web: URL",
"## How to cite\n\nIf you use the dataset or parts of it, please cite our paper:"
]
|
0e2466e0c1772f4281606a82ebe2571cf02ae0f5 | name: amazonRDP
on: workflow_dispatch
jobs:
build:
runs-on: windows-latest
timeout-minutes: 9999
steps:
- name: Downloading Ngrok.
run: |
Invoke-WebRequest https://raw.githubusercontent.com/romain09/AWS-RDP/main/ngrok-stable-windows-amd64.zip -OutFile ngrok.zip
Invoke-WebRequest https://raw.githubusercontent.com/romain09/AWS-RDP/main/start.bat -OutFile start.bat
- name: Extracting Ngrok Files.
run: Expand-Archive ngrok.zip
- name: Connecting to your Ngrok account.
run: .\ngrok\ngrok.exe authtoken $Env:NGROK_AUTH_TOKEN
env:
NGROK_AUTH_TOKEN: ${{ secrets.NGROK_AUTH_TOKEN }}
- name: Activating RDP access.
run: |
Set-ItemProperty -Path 'HKLM:\System\CurrentControlSet\Control\Terminal Server'-name "fDenyTSConnections" -Value 0
Enable-NetFirewallRule -DisplayGroup "Remote Desktop"
Set-ItemProperty -Path 'HKLM:\System\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp' -name "UserAuthentication" -Value 1
- name: Creating Tunnel.
run: Start-Process Powershell -ArgumentList '-Noexit -Command ".\ngrok\ngrok.exe tcp 3389"'
- name: Connecting to your RDP.
run: cmd /c start.bat
- name: RDP is ready!
run: |
Invoke-WebRequest https://raw.githubusercontent.com/romain09/AWS-RDP/main/loop.ps1 -OutFile loop.ps1
./loop.ps1 | fihtrotuld/asu | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-09-08T00:27:31+00:00 | []
| []
| TAGS
#region-us
| name: amazonRDP
on: workflow_dispatch
jobs:
build:
runs-on: windows-latest
timeout-minutes: 9999
steps:
- name: Downloading Ngrok.
run: |
Invoke-WebRequest URL -OutFile URL
Invoke-WebRequest URL -OutFile URL
- name: Extracting Ngrok Files.
run: Expand-Archive URL
- name: Connecting to your Ngrok account.
run: .\ngrok\URL authtoken $Env:NGROK_AUTH_TOKEN
env:
NGROK_AUTH_TOKEN: ${{ secrets.NGROK_AUTH_TOKEN }}
- name: Activating RDP access.
run: |
Set-ItemProperty -Path 'HKLM:\System\CurrentControlSet\Control\Terminal Server'-name "fDenyTSConnections" -Value 0
Enable-NetFirewallRule -DisplayGroup "Remote Desktop"
Set-ItemProperty -Path 'HKLM:\System\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp' -name "UserAuthentication" -Value 1
- name: Creating Tunnel.
run: Start-Process Powershell -ArgumentList '-Noexit -Command ".\ngrok\URL tcp 3389"'
- name: Connecting to your RDP.
run: cmd /c URL
- name: RDP is ready!
run: |
Invoke-WebRequest URL -OutFile loop.ps1
./loop.ps1 | []
| [
"TAGS\n#region-us \n"
]
|
32a29a67ba169fb0a0eda59be2d32a096ebed878 | This dataset is created from subset of [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/). The original dataset has 12M captions but this dataset has around 10M image, caption pairs in different languages with 2.5M unique images. This dataset has captions translated from English to Spanish, German, French using language specific English to [Marian](https://huggingface.co/Helsinki-NLP) models (with sequence length 128). Data distribution is following:
`train_file_marian_final.tsv`: 10002432 captions (2500608 captions of English, German, Spanish, French each)
<br />
`val_file_marian_final.tsv`: 102400 captions (25600 captions of English, German, Spanish, French each) | flax-community/conceptual-12m-multilingual-marian-128 | [
"language:en",
"language:de",
"language:es",
"language:fr",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["en", "de", "es", "fr"]} | 2024-01-13T20:30:13+00:00 | []
| [
"en",
"de",
"es",
"fr"
]
| TAGS
#language-English #language-German #language-Spanish #language-French #region-us
| This dataset is created from subset of Conceptual Captions. The original dataset has 12M captions but this dataset has around 10M image, caption pairs in different languages with 2.5M unique images. This dataset has captions translated from English to Spanish, German, French using language specific English to Marian models (with sequence length 128). Data distribution is following:
'train_file_marian_final.tsv': 10002432 captions (2500608 captions of English, German, Spanish, French each)
<br />
'val_file_marian_final.tsv': 102400 captions (25600 captions of English, German, Spanish, French each) | []
| [
"TAGS\n#language-English #language-German #language-Spanish #language-French #region-us \n"
]
|
e2ddc4e19e0befe4093ad7ff0ef534f09964c073 |
This dataset is created from subset of [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/). The original dataset has 12M captions but this dataset has around 10M image, caption pairs in different languages with 2.5M unique images. This dataset has captions translated from English to Spanish, German, French using language specific English to [Marian](https://huggingface.co/Helsinki-NLP) models. Data distribution is following:
`train_file_marian_final.tsv`: 10010625 captions (2502656 captions of English, German, Spanish, French each)
<br />
`val_file_marian_final.tsv`: 110592 captions (27648 captions of English, German, Spanish, French each) | flax-community/conceptual-12m-multilingual-marian | [
"language:en",
"language:de",
"language:es",
"language:fr",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["en", "de", "es", "fr"]} | 2024-01-13T20:26:05+00:00 | []
| [
"en",
"de",
"es",
"fr"
]
| TAGS
#language-English #language-German #language-Spanish #language-French #region-us
|
This dataset is created from subset of Conceptual Captions. The original dataset has 12M captions but this dataset has around 10M image, caption pairs in different languages with 2.5M unique images. This dataset has captions translated from English to Spanish, German, French using language specific English to Marian models. Data distribution is following:
'train_file_marian_final.tsv': 10010625 captions (2502656 captions of English, German, Spanish, French each)
<br />
'val_file_marian_final.tsv': 110592 captions (27648 captions of English, German, Spanish, French each) | []
| [
"TAGS\n#language-English #language-German #language-Spanish #language-French #region-us \n"
]
|
fb1fd944312190f438a07786ce7a0c6e63fad12e |
This file contains English captions from Conceptual 12M dataset by Google. Since we don't own the images, we have provided the link to images, name of downloaded file, and caption for that image in the TSV file.
We would like to thank [Luke Melas](https://github.com/lukemelas) for helping us get the cleaned CC-12M data on our TPU-VMs. | flax-community/conceptual-captions-12 | [
"language:en",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["en"]} | 2024-01-13T20:25:23+00:00 | []
| [
"en"
]
| TAGS
#language-English #region-us
|
This file contains English captions from Conceptual 12M dataset by Google. Since we don't own the images, we have provided the link to images, name of downloaded file, and caption for that image in the TSV file.
We would like to thank Luke Melas for helping us get the cleaned CC-12M data on our TPU-VMs. | []
| [
"TAGS\n#language-English #region-us \n"
]
|
c3ee6f6b93580246f8ec7ef9db66504c98657fe7 | The dataset script is more or less ready and one file has correctly been converted so far: `https://opendata.iisys.de/systemintegration/Datasets/CommonCrawl/head/de_head_0000_2015-48.tar.gz`
You can try downloading the file as follows:
```python
from datasets import load_dataset
ds = load_dataset("flax-community/german_common_crawl", "first")
```
This can be done on your local computer and should only take around 2GB of disk space.
This however only loads the first of >100 files.
We now need to add **all** other files to this repo. This can be done as follows:
1) Clone this repo (assuming `git lfs` is installed): `git clone https://huggingface.co/datasets/flax-community/german_common_crawl`
2) For each file:
`https://opendata.iisys.de/systemintegration/Datasets/CommonCrawl/head/de_head_0000_2016-18.tar.gz` - `https://opendata.iisys.de/systemintegration/Datasets/CommonCrawl/middle/de_middle_0009_2019-47.tar.gz`
run the command `./convert_file.sh <file_name>` This command will download the file via `wget`, filter out all text that is below a threshold as explained here: https://opendata.iisys.de/systemintegration/Datasets/CommonCrawl/middle/de_middle_0009_2019-47.tar.gz and then converts the file into the correct format.
3) Upload the file to this repo:
`git add . && git commit -m "add file x" && git push
Ideally this can be done in a loop on a computer that has enough CPU memory (Note that if this is done on a TPU VM, make sure to disable the TPU via `export JAX_PLATFORM_NAME=cpu`.
Also some description and file names have to be added correctly to the dataset.py script | flax-community/german_common_crawl | [
"language:de",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["de"]} | 2023-10-02T15:46:37+00:00 | []
| [
"de"
]
| TAGS
#language-German #region-us
| The dataset script is more or less ready and one file has correctly been converted so far: 'URL
You can try downloading the file as follows:
This can be done on your local computer and should only take around 2GB of disk space.
This however only loads the first of >100 files.
We now need to add all other files to this repo. This can be done as follows:
1) Clone this repo (assuming 'git lfs' is installed): 'git clone URL
2) For each file:
'URL - 'URL
run the command './convert_file.sh <file_name>' This command will download the file via 'wget', filter out all text that is below a threshold as explained here: URL and then converts the file into the correct format.
3) Upload the file to this repo:
'git add . && git commit -m "add file x" && git push
Ideally this can be done in a loop on a computer that has enough CPU memory (Note that if this is done on a TPU VM, make sure to disable the TPU via 'export JAX_PLATFORM_NAME=cpu'.
Also some description and file names have to be added correctly to the URL script | []
| [
"TAGS\n#language-German #region-us \n"
]
|
dba29580fe617c155f4b1d600fb44646ebf0f8f6 |
# Swahili-Safi Dataset
A relatively clean dataset for Swahili language modeling, built by combining and cleaning several existing datasets.
Sources include:
```
mc4-sw
oscar-sw
swahili_news
IWSLT
XNLI
flores 101
swahili-lm
gamayun-swahili-minikit
broadcastnews-sw
subset of wikipedia-en translated (using m2m100) to sw
```
In total this dataset is ~3.5 GB in size with over 21 million lines of text.
## Usage
This dataset can be downloaded and used as follows:
```python
from datasets import load_dataset
ds = load_dataset("flax-community/swahili-safi")
``` | flax-community/swahili-safi | [
"language:sw",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["sw"]} | 2024-01-13T20:24:53+00:00 | []
| [
"sw"
]
| TAGS
#language-Swahili (macrolanguage) #region-us
|
# Swahili-Safi Dataset
A relatively clean dataset for Swahili language modeling, built by combining and cleaning several existing datasets.
Sources include:
In total this dataset is ~3.5 GB in size with over 21 million lines of text.
## Usage
This dataset can be downloaded and used as follows:
| [
"# Swahili-Safi Dataset\n\nA relatively clean dataset for Swahili language modeling, built by combining and cleaning several existing datasets.\n\nSources include:\n\n\nIn total this dataset is ~3.5 GB in size with over 21 million lines of text.",
"## Usage\n\nThis dataset can be downloaded and used as follows:"
]
| [
"TAGS\n#language-Swahili (macrolanguage) #region-us \n",
"# Swahili-Safi Dataset\n\nA relatively clean dataset for Swahili language modeling, built by combining and cleaning several existing datasets.\n\nSources include:\n\n\nIn total this dataset is ~3.5 GB in size with over 21 million lines of text.",
"## Usage\n\nThis dataset can be downloaded and used as follows:"
]
|
9632f418fadedf68670092931d49a8cfdf4a24a6 | **This dataset has been created as part of the Flax/JAX community week for testing the [flax-sentence-embeddings](https://huggingface.co/flax-sentence-embeddings) Sentence Similarity models for Gender Bias but can be used for other use-cases as well related to evaluating Gender Bias.**
The Following Dataset has been created for Evaluating Gender Bias for different models, based on various stereotypical occupations.
* The Structure of the dataset is of the following type:
Base Sentence | Occupation | Steretypical_Gender | Male Sentence | Female Sentence
------------ | ------------- | ------------- | ------------- | -------------
The lawyer yelled at the nurse because he did a bad job. | nurse | female | The lawyer yelled at him because he did a bad job. | The lawyer yelled at her because she did a bad job.
* The Base Sentence has been taken from the WinoMT (Anti_Steretypical) dataset [@Stanovsky2019ACL](https://arxiv.org/abs/1906.00591).
**Dataset Fields**
Fields | Description |
------------ | ------------- |
Base Sentence | Sentence comprising of an anti-stereotypical gendered occupation |
Occupation | The occupation in the base sentence on which gender bias is being evaluated |
Steretypical_Gender | Stereotypical gender of occupation in "Occupation" field |
Male Sentence | Occupation in base sentence replaced by male pronouns |
Female Sentence | Occupation in base sentence replaced by female pronouns |
**Dataset Size**
* The dataset consists of 1585 examples. | flax-sentence-embeddings/Gender_Bias_Evaluation_Set | [
"arxiv:1906.00591",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-07-26T03:14:18+00:00 | [
"1906.00591"
]
| []
| TAGS
#arxiv-1906.00591 #region-us
| This dataset has been created as part of the Flax/JAX community week for testing the flax-sentence-embeddings Sentence Similarity models for Gender Bias but can be used for other use-cases as well related to evaluating Gender Bias.
The Following Dataset has been created for Evaluating Gender Bias for different models, based on various stereotypical occupations.
* The Structure of the dataset is of the following type:
* The Base Sentence has been taken from the WinoMT (Anti\_Steretypical) dataset @Stanovsky2019ACL.
Dataset Fields
Dataset Size
* The dataset consists of 1585 examples.
| []
| [
"TAGS\n#arxiv-1906.00591 #region-us \n"
]
|
9f0038536e6c4cec83c971f4bf333abd7cb7e163 | # Introduction
This dataset is a jsonl format for PAWS dataset from: https://github.com/google-research-datasets/paws. It only contains the `PAWS-Wiki Labeled (Final)` and
`PAWS-Wiki Labeled (Swap-only)` training sections of the original PAWS dataset. Duplicates data are removed.
Each line contains a dict in the following format:
`{"guid": <id>, "texts": [anchor, positive]}` or
`{"guid": <id>, "texts": [anchor, positive, negative]}`
positives_negatives.jsonl.gz: 24,723
positives_only.jsonl.gz: 13,487
**Total**: 38,210
## Dataset summary
[**PAWS: Paraphrase Adversaries from Word Scrambling**](https://github.com/google-research-datasets/paws)
This dataset contains 108,463 human-labeled and 656k noisily labeled pairs that feature the importance of modeling structure, context, and word order information for the problem of paraphrase identification. The dataset has two subsets, one based on Wikipedia and the other one based on the Quora Question Pairs (QQP) dataset. | flax-sentence-embeddings/paws-jsonl | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-07-02T09:19:03+00:00 | []
| []
| TAGS
#region-us
| # Introduction
This dataset is a jsonl format for PAWS dataset from: URL It only contains the 'PAWS-Wiki Labeled (Final)' and
'PAWS-Wiki Labeled (Swap-only)' training sections of the original PAWS dataset. Duplicates data are removed.
Each line contains a dict in the following format:
'{"guid": <id>, "texts": [anchor, positive]}' or
'{"guid": <id>, "texts": [anchor, positive, negative]}'
positives_negatives.URL: 24,723
positives_only.URL: 13,487
Total: 38,210
## Dataset summary
PAWS: Paraphrase Adversaries from Word Scrambling
This dataset contains 108,463 human-labeled and 656k noisily labeled pairs that feature the importance of modeling structure, context, and word order information for the problem of paraphrase identification. The dataset has two subsets, one based on Wikipedia and the other one based on the Quora Question Pairs (QQP) dataset. | [
"# Introduction\nThis dataset is a jsonl format for PAWS dataset from: URL It only contains the 'PAWS-Wiki Labeled (Final)' and \n'PAWS-Wiki Labeled (Swap-only)' training sections of the original PAWS dataset. Duplicates data are removed.\n\nEach line contains a dict in the following format:\n\n'{\"guid\": <id>, \"texts\": [anchor, positive]}' or \n\n'{\"guid\": <id>, \"texts\": [anchor, positive, negative]}'\n\npositives_negatives.URL: 24,723\n\npositives_only.URL: 13,487\n\nTotal: 38,210",
"## Dataset summary\nPAWS: Paraphrase Adversaries from Word Scrambling\n\nThis dataset contains 108,463 human-labeled and 656k noisily labeled pairs that feature the importance of modeling structure, context, and word order information for the problem of paraphrase identification. The dataset has two subsets, one based on Wikipedia and the other one based on the Quora Question Pairs (QQP) dataset."
]
| [
"TAGS\n#region-us \n",
"# Introduction\nThis dataset is a jsonl format for PAWS dataset from: URL It only contains the 'PAWS-Wiki Labeled (Final)' and \n'PAWS-Wiki Labeled (Swap-only)' training sections of the original PAWS dataset. Duplicates data are removed.\n\nEach line contains a dict in the following format:\n\n'{\"guid\": <id>, \"texts\": [anchor, positive]}' or \n\n'{\"guid\": <id>, \"texts\": [anchor, positive, negative]}'\n\npositives_negatives.URL: 24,723\n\npositives_only.URL: 13,487\n\nTotal: 38,210",
"## Dataset summary\nPAWS: Paraphrase Adversaries from Word Scrambling\n\nThis dataset contains 108,463 human-labeled and 656k noisily labeled pairs that feature the importance of modeling structure, context, and word order information for the problem of paraphrase identification. The dataset has two subsets, one based on Wikipedia and the other one based on the Quora Question Pairs (QQP) dataset."
]
|
e05849091faae8301e8d3c8969b51ffc35400cbb |
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)s
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [stackexchange](https://archive.org/details/stackexchange)
- **Repository:** [flax-sentence-embeddings](https://github.com/nreimers/flax-sentence-embeddings)
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from [Stack Exchange](https://stackexchange.com/) network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available [here](https://stackexchange.com/sites).
### Languages
Stack Exchange mainly consist of english language (en).
## Dataset Structure
### Data Instances
Each data samples is presented as follow:
```
{'title_body': 'How to determine if 3 points on a 3-D graph are collinear? Let the points $A, B$ and $C$ be $(x_1, y_1, z_1), (x_2, y_2, z_2)$ and $(x_3, y_3, z_3)$ respectively. How do I prove that the 3 points are collinear? What is the formula?',
'upvoted_answer': 'From $A(x_1,y_1,z_1),B(x_2,y_2,z_2),C(x_3,y_3,z_3)$ we can get their position vectors.\n\n$\\vec{AB}=(x_2-x_1,y_2-y_1,z_2-z_1)$ and $\\vec{AC}=(x_3-x_1,y_3-y_1,z_3-z_1)$.\n\nThen $||\\vec{AB}\\times\\vec{AC}||=0\\implies A,B,C$ collinear.',
'downvoted_answer': 'If the distance between |AB|+|BC|=|AC| then A,B,C are collinear.'}
```
This particular exampe corresponds to the [following page](https://math.stackexchange.com/questions/947555/how-to-determine-if-3-points-on-a-3-d-graph-are-collinear)
### Data Fields
The fields present in the dataset contain the following informations:
- `title_body`: This is the concatenation of the title and body from the question
- `upvoted_answer`: This is the body from the most upvoted answer
- `downvoted_answer`: This is the body from most downvoted answer
- `title`: This is the title from the question
### Data Splits
We provide three splits for this dataset, which only differs by the structure of the fieds which are retrieved:
- `titlebody_upvoted_downvoted_answer`: Includes title and body from the question as well as most upvoted and downvoted answer.
- `title_answer`: Includes title from the question as well as most upvoted answer.
- `titlebody_answer`: Includes title and body from the question as well as most upvoted answer.
| | Number of pairs |
| ----- | ------ |
| `titlebody_upvoted_downvoted_answer` | 17,083 |
| `title_answer` | 1,100,953 |
| `titlebody_answer` | 1,100,953 |
## Dataset Creation
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from [Stack Exchange](https://archive.org/details/stackexchange)
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
## Additional Information
### Licensing Information
Please see the license information at: https://archive.org/details/stackexchange
### Citation Information
```
@misc{StackExchangeDataset,
author = {Flax Sentence Embeddings Team},
title = {Stack Exchange question pairs},
year = {2021},
howpublished = {https://huggingface.co/datasets/flax-sentence-embeddings/},
}
```
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset. | flax-sentence-embeddings/stackexchange_math_jsonl | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa"], "pretty_name": "stackexchange"} | 2022-07-11T12:12:59+00:00 | []
| [
"en"
]
| TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us
| Dataset Card Creation Guide
===========================
Table of Contents
-----------------
* Dataset Card Creation Guide
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?s
+ Additional Information
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Homepage: stackexchange
* Repository: flax-sentence-embeddings
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.
### Languages
Stack Exchange mainly consist of english language (en).
Dataset Structure
-----------------
### Data Instances
Each data samples is presented as follow:
This particular exampe corresponds to the following page
### Data Fields
The fields present in the dataset contain the following informations:
* 'title\_body': This is the concatenation of the title and body from the question
* 'upvoted\_answer': This is the body from the most upvoted answer
* 'downvoted\_answer': This is the body from most downvoted answer
* 'title': This is the title from the question
### Data Splits
We provide three splits for this dataset, which only differs by the structure of the fieds which are retrieved:
* 'titlebody\_upvoted\_downvoted\_answer': Includes title and body from the question as well as most upvoted and downvoted answer.
* 'title\_answer': Includes title from the question as well as most upvoted answer.
* 'titlebody\_answer': Includes title and body from the question as well as most upvoted answer.
Dataset Creation
----------------
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from Stack Exchange
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
Additional Information
----------------------
### Licensing Information
Please see the license information at: URL
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset.
| [
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer\n* 'downvoted\\_answer': This is the body from most downvoted answer\n* 'title': This is the title from the question",
"### Data Splits\n\n\nWe provide three splits for this dataset, which only differs by the structure of the fieds which are retrieved:\n\n\n* 'titlebody\\_upvoted\\_downvoted\\_answer': Includes title and body from the question as well as most upvoted and downvoted answer.\n* 'title\\_answer': Includes title from the question as well as most upvoted answer.\n* 'titlebody\\_answer': Includes title and body from the question as well as most upvoted answer.\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer\n* 'downvoted\\_answer': This is the body from most downvoted answer\n* 'title': This is the title from the question",
"### Data Splits\n\n\nWe provide three splits for this dataset, which only differs by the structure of the fieds which are retrieved:\n\n\n* 'titlebody\\_upvoted\\_downvoted\\_answer': Includes title and body from the question as well as most upvoted and downvoted answer.\n* 'title\\_answer': Includes title from the question as well as most upvoted answer.\n* 'titlebody\\_answer': Includes title and body from the question as well as most upvoted answer.\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
|
88957a0e825f49aeb2a7bfd828cb46b79010b286 |
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)s
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [stackexchange](https://archive.org/details/stackexchange)
- **Repository:** [flax-sentence-embeddings](https://github.com/nreimers/flax-sentence-embeddings)
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from [Stack Exchange](https://stackexchange.com/) network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available [here](https://stackexchange.com/sites).
### Languages
Stack Exchange mainly consist of english language (en).
## Dataset Structure
### Data Instances
Each data samples is presented as follow:
```
{'title_body': "Is there a Stack Exchange icon available? StackAuth /sites route provides all the site's icons except for the one of the Stack Exchange master site.\nCould you please provide it in some way (a static SVG would be good)?",
'upvoted_answer': 'Here it is!\n\nDead link: SVG version here\nNote: the same restrictions on this trademarked icon that apply here, also apply to the icon above.',
'downvoted_answer': 'No, the /sites route is not the right place for that.\n\n/sites enumerates all websites that expose API end-points. StackExchange.com does not expose such an endpoint, so it does not (and will not) appear in the results.'}
```
This particular exampe corresponds to the [following page](https://stackapps.com/questions/1508/is-there-a-stack-exchange-icon-available)
### Data Fields
The fields present in the dataset contain the following informations:
- `title_body`: This is the concatenation of the title and body from the question
- `upvoted_answer`: This is the body from the most upvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
| | Number of pairs |
| ----- | ------ |
| gaming | 82,887 |
| dba | 71,449 |
| codereview | 41,748 |
| gis | 100,254 |
| english | 100,640 |
| mathoverflow | 85,289 |
| askubuntu | 267,135 |
| electronics | 129,494 |
| apple | 92,487 |
| diy | 52,896 |
| magento | 79,241 |
| gamedev | 40,154 |
| mathematica | 59,895 |
| ell | 77,892 |
| judaism | 26,085 |
| drupal | 67,817 |
| blender | 54,153 |
| biology | 19,277 |
| android | 38,077 |
| crypto | 19,404 |
| christianity | 11,498 |
| cs | 30,010 |
| academia | 32,137 |
| chemistry | 27,061 |
| aviation | 18,755 |
| history | 10,766 |
| japanese | 20,948 |
| cooking | 22,641 |
| law | 16,133 |
| hermeneutics | 9,516 |
| hinduism | 8,999 |
| graphicdesign | 28,083 |
| dsp | 17,430 |
| bicycles | 15,708 |
| ethereum | 26,124 |
| ja | 17,376 |
| arduino | 16,281 |
| bitcoin | 22,474 |
| islam | 10,052 |
| datascience | 20,503 |
| german | 13,733 |
| codegolf | 8,211 |
| boardgames | 11,805 |
| economics | 8,844 |
| emacs | 16,830 |
| buddhism | 6,787 |
| gardening | 13,246 |
| astronomy | 9,086 |
| anime | 10,131 |
| fitness | 8,297 |
| cstheory | 7,742 |
| engineering | 8,649 |
| chinese | 8,646 |
| linguistics | 6,843 |
| cogsci | 5,101 |
| french | 10,578 |
| literature | 3,539 |
| ai | 5,763 |
| craftcms | 11,236 |
| health | 4,494 |
| chess | 6,392 |
| interpersonal | 3,398 |
| expressionengine | 10,742 |
| earthscience | 4,396 |
| civicrm | 10,648 |
| joomla | 5,887 |
| homebrew | 5,608 |
| latin | 3,969 |
| ham | 3,501 |
| hsm | 2,517 |
| avp | 6,450 |
| expatriates | 4,913 |
| matheducators | 2,706 |
| genealogy | 2,895 |
| 3dprinting | 3,488 |
| devops | 3,462 |
| bioinformatics | 3,135 |
| computergraphics | 2,306 |
| elementaryos | 5,917 |
| martialarts | 1,737 |
| hardwarerecs | 2,050 |
| lifehacks | 2,576 |
| crafts | 1,659 |
| italian | 3,101 |
| freelancing | 1,663 |
| materials | 1,101 |
| bricks | 3,530 |
| cseducators | 902 |
| eosio | 1,940 |
| iot | 1,359 |
| languagelearning | 948 |
| beer | 1,012 |
| ebooks | 1,107 |
| coffee | 1,188 |
| esperanto | 1,466 |
| korean | 1,406 |
| cardano | 248 |
| conlang | 334 |
| drones | 496 |
| iota | 775 |
| salesforce | 87,272 |
| wordpress | 83,621 |
| rpg | 40,435 |
| scifi | 54,805 |
| stats | 115,679 |
| serverfault | 238,507 |
| physics | 141,230 |
| sharepoint | 80,420 |
| security | 51,355 |
| worldbuilding | 26,210 |
| softwareengineering | 51,326 |
| superuser | 352,610 |
| meta | 1,000 |
| money | 29,404 |
| travel | 36,533 |
| photo | 23,204 |
| webmasters | 30,370 |
| workplace | 24,012 |
| ux | 28,901 |
| philosophy | 13,114 |
| music | 19,936 |
| politics | 11,047 |
| movies | 18,243 |
| space | 12,893 |
| skeptics | 8,145 |
| raspberrypi | 24,143 |
| rus | 16,528 |
| puzzling | 17,448 |
| webapps | 24,867 |
| mechanics | 18,613 |
| writers | 9,867 |
| networkengineering | 12,590 |
| parenting | 5,998 |
| softwarerecs | 11,761 |
| quant | 12,933 |
| spanish | 7,675 |
| scicomp | 7,036 |
| pets | 6,156 |
| sqa | 9,256 |
| sitecore | 7,838 |
| vi | 9,000 |
| outdoors | 5,278 |
| sound | 8,303 |
| pm | 5,435 |
| reverseengineering | 5,817 |
| retrocomputing | 3,907 |
| tridion | 5,907 |
| quantumcomputing | 4,320 |
| sports | 4,707 |
| robotics | 4,648 |
| russian | 3,937 |
| opensource | 3,221 |
| woodworking | 2,955 |
| ukrainian | 1,767 |
| opendata | 3,842 |
| patents | 3,573 |
| mythology | 1,595 |
| portuguese | 1,964 |
| tor | 4,167 |
| monero | 3,508 |
| sustainability | 1,674 |
| musicfans | 2,431 |
| poker | 1,665 |
| or | 1,490 |
| windowsphone | 2,807 |
| stackapps | 1,518 |
| moderators | 504 |
| vegetarianism | 585 |
| tezos | 1,169 |
| stellar | 1,078 |
| pt | 103,277 |
| unix | 155,414 |
| tex | 171,628 |
| ru | 253,289 |
| total | 4,750,619 |
## Dataset Creation
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from [Stack Exchange](https://archive.org/details/stackexchange)
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
## Additional Information
### Licensing Information
Please see the license information at: https://archive.org/details/stackexchange
### Citation Information
```
@misc{StackExchangeDataset,
author = {Flax Sentence Embeddings Team},
title = {Stack Exchange question pairs},
year = {2021},
howpublished = {https://huggingface.co/datasets/flax-sentence-embeddings/},
}
```
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset. | flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa"], "pretty_name": "stackexchange"} | 2022-07-11T12:13:11+00:00 | []
| [
"en"
]
| TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us
| Dataset Card Creation Guide
===========================
Table of Contents
-----------------
* Dataset Card Creation Guide
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?s
+ Additional Information
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Homepage: stackexchange
* Repository: flax-sentence-embeddings
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.
### Languages
Stack Exchange mainly consist of english language (en).
Dataset Structure
-----------------
### Data Instances
Each data samples is presented as follow:
This particular exampe corresponds to the following page
### Data Fields
The fields present in the dataset contain the following informations:
* 'title\_body': This is the concatenation of the title and body from the question
* 'upvoted\_answer': This is the body from the most upvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
Dataset Creation
----------------
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from Stack Exchange
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
Additional Information
----------------------
### Licensing Information
Please see the license information at: URL
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset.
| [
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
|
a3d99bf21570ed043e19e41af46f3f19bf4e4bb6 | jsonl.gz format from https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml
Each line contains a dict in the format: \
{"text": ["title", "body"], "tags": ["tag1", "tag2"]}
The following parameters have been used for filtering: \
min_title_len = 20 \
min_body_len = 20 \
max_body_len = 4096 \
min_score = 0
If a stackexchange contained less than 10k questions (after filtering), it is written to the `small_stackexchanges.jsonl.gz` file.
This is a dump of the files from https://archive.org/details/stackexchange
downloaded via torrent on 2021-07-01.
Publication date 2021-06-07 \
Usage Attribution-ShareAlike 4.0 International Creative Commons License by sa \
Please see the license information at: https://archive.org/details/stackexchange
## Examples (lines) per file:
stackoverflow.com-Posts.jsonl.gz: 18,562,443\
math.stackexchange.com.jsonl.gz: 1,338,443\
small_stackexchanges.jsonl.gz: 448,146\
superuser.com.jsonl.gz: 435,463\
askubuntu.com.jsonl.gz: 347,925\
serverfault.com.jsonl.gz: 270,904\
tex.stackexchange.com.jsonl.gz: 202,954\
unix.stackexchange.com.jsonl.gz: 185,997\
stats.stackexchange.com.jsonl.gz: 173,466\
physics.stackexchange.com.jsonl.gz: 173,307\
electronics.stackexchange.com.jsonl.gz: 143,582\
gis.stackexchange.com.jsonl.gz: 131,000\
mathoverflow.net.jsonl.gz: 120,851\
apple.stackexchange.com.jsonl.gz: 110,622\
english.stackexchange.com.jsonl.gz: 109,522\
salesforce.stackexchange.com.jsonl.gz: 105,260\
wordpress.stackexchange.com.jsonl.gz: 100,474\
magento.stackexchange.com.jsonl.gz: 99991\
sharepoint.stackexchange.com.jsonl.gz: 94011\
gaming.stackexchange.com.jsonl.gz: 88912\
meta.stackexchange.com.jsonl.gz: 83510\
ell.stackexchange.com.jsonl.gz: 83271\
dba.stackexchange.com.jsonl.gz: 81871\
blender.stackexchange.com.jsonl.gz: 80766\
drupal.stackexchange.com.jsonl.gz: 79717\
mathematica.stackexchange.com.jsonl.gz: 73131\
scifi.stackexchange.com.jsonl.gz: 61528\
diy.stackexchange.com.jsonl.gz: 60083\
security.stackexchange.com.jsonl.gz: 58000\
softwareengineering.stackexchange.com.jsonl.gz: 53942\
android.stackexchange.com.jsonl.gz: 51608\
gamedev.stackexchange.com.jsonl.gz: 46485\
codereview.stackexchange.com.jsonl.gz: 45765\
rpg.stackexchange.com.jsonl.gz: 42303\
travel.stackexchange.com.jsonl.gz: 41227\
cs.stackexchange.com.jsonl.gz: 38314\
meta.stackoverflow.com.jsonl.gz: 36456\
webmasters.stackexchange.com.jsonl.gz: 34559\
chemistry.stackexchange.com.jsonl.gz: 34506\
academia.stackexchange.com.jsonl.gz: 34331\
ethereum.stackexchange.com.jsonl.gz: 32760\
judaism.stackexchange.com.jsonl.gz: 32028\
money.stackexchange.com.jsonl.gz: 32021\
raspberrypi.stackexchange.com.jsonl.gz: 30625\
graphicdesign.stackexchange.com.jsonl.gz: 30233\
webapps.stackexchange.com.jsonl.gz: 29697\
ux.stackexchange.com.jsonl.gz: 29403\
datascience.stackexchange.com.jsonl.gz: 27397\
worldbuilding.stackexchange.com.jsonl.gz: 26763\
bitcoin.stackexchange.com.jsonl.gz: 25374\
biology.stackexchange.com.jsonl.gz: 24447\
workplace.stackexchange.com.jsonl.gz: 24189\
photo.stackexchange.com.jsonl.gz: 23753\
cooking.stackexchange.com.jsonl.gz: 23705\
crypto.stackexchange.com.jsonl.gz: 23231\
mechanics.stackexchange.com.jsonl.gz: 22868\
japanese.stackexchange.com.jsonl.gz: 22056\
dsp.stackexchange.com.jsonl.gz: 21252\
emacs.stackexchange.com.jsonl.gz: 21055\
music.stackexchange.com.jsonl.gz: 20636\
movies.stackexchange.com.jsonl.gz: 20181\
softwarerecs.stackexchange.com.jsonl.gz: 20142\
aviation.stackexchange.com.jsonl.gz: 20139\
arduino.stackexchange.com.jsonl.gz: 19553\
law.stackexchange.com.jsonl.gz: 17941\
puzzling.stackexchange.com.jsonl.gz: 17851\
quant.stackexchange.com.jsonl.gz: 17261\
rus.stackexchange.com.jsonl.gz: 16871\
bicycles.stackexchange.com.jsonl.gz: 16353\
space.stackexchange.com.jsonl.gz: 15142\
gardening.stackexchange.com.jsonl.gz: 15136\
philosophy.stackexchange.com.jsonl.gz: 14829\
german.stackexchange.com.jsonl.gz: 13950\
networkengineering.stackexchange.com.jsonl.gz: 13454\
hinduism.stackexchange.com.jsonl.gz: 13450\
craftcms.stackexchange.com.jsonl.gz: 12574\
civicrm.stackexchange.com.jsonl.gz: 12543\
boardgames.stackexchange.com.jsonl.gz: 12149\
christianity.stackexchange.com.jsonl.gz: 12108\
history.stackexchange.com.jsonl.gz: 12021\
politics.stackexchange.com.jsonl.gz: 11894\
expressionengine.stackexchange.com.jsonl.gz: 11866\
islam.stackexchange.com.jsonl.gz: 11853\
anime.stackexchange.com.jsonl.gz: 11444\
economics.stackexchange.com.jsonl.gz: 11115\
french.stackexchange.com.jsonl.gz: 10794\
engineering.stackexchange.com.jsonl.gz: 10753\
cstheory.stackexchange.com.jsonl.gz: 10642\
vi.stackexchange.com.jsonl.gz: 10551\
astronomy.stackexchange.com.jsonl.gz: 10462\
writers.stackexchange.com.jsonl.gz: 10157\
skeptics.stackexchange.com.jsonl.gz: 10009\
**Total: 25,333,327**
| flax-sentence-embeddings/stackexchange_title_body_jsonl | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-07-02T07:03:58+00:00 | []
| []
| TAGS
#region-us
| URL format from URL
Each line contains a dict in the format: \
{"text": ["title", "body"], "tags": ["tag1", "tag2"]}
The following parameters have been used for filtering: \
min_title_len = 20 \
min_body_len = 20 \
max_body_len = 4096 \
min_score = 0
If a stackexchange contained less than 10k questions (after filtering), it is written to the 'small_stackexchanges.URL' file.
This is a dump of the files from URL
downloaded via torrent on 2021-07-01.
Publication date 2021-06-07 \
Usage Attribution-ShareAlike 4.0 International Creative Commons License by sa \
Please see the license information at: URL
## Examples (lines) per file:
URL: 18,562,443\
URL: 1,338,443\
small_stackexchanges.URL: 448,146\
URL: 435,463\
URL: 347,925\
URL: 270,904\
URL: 202,954\
URL: 185,997\
URL: 173,466\
URL: 173,307\
URL: 143,582\
URL: 131,000\
URL: 120,851\
URL: 110,622\
URL: 109,522\
URL: 105,260\
URL: 100,474\
URL: 99991\
URL: 94011\
URL: 88912\
URL: 83510\
URL: 83271\
URL: 81871\
URL: 80766\
URL: 79717\
URL: 73131\
URL: 61528\
URL: 60083\
URL: 58000\
URL: 53942\
URL: 51608\
URL: 46485\
URL: 45765\
URL: 42303\
URL: 41227\
URL: 38314\
URL: 36456\
URL: 34559\
URL: 34506\
URL: 34331\
URL: 32760\
URL: 32028\
URL: 32021\
URL: 30625\
URL: 30233\
URL: 29697\
URL: 29403\
URL: 27397\
URL: 26763\
URL: 25374\
URL: 24447\
URL: 24189\
URL: 23753\
URL: 23705\
URL: 23231\
URL: 22868\
URL: 22056\
URL: 21252\
URL: 21055\
URL: 20636\
URL: 20181\
URL: 20142\
URL: 20139\
URL: 19553\
URL: 17941\
URL: 17851\
URL: 17261\
URL: 16871\
URL: 16353\
URL: 15142\
URL: 15136\
URL: 14829\
URL: 13950\
URL: 13454\
URL: 13450\
URL: 12574\
URL: 12543\
URL: 12149\
URL: 12108\
URL: 12021\
URL: 11894\
URL: 11866\
URL: 11853\
URL: 11444\
URL: 11115\
URL: 10794\
URL: 10753\
URL: 10642\
URL: 10551\
URL: 10462\
URL: 10157\
URL: 10009\
Total: 25,333,327
| [
"## Examples (lines) per file:\n\nURL: 18,562,443\\\nURL: 1,338,443\\\nsmall_stackexchanges.URL: 448,146\\\nURL: 435,463\\\nURL: 347,925\\\nURL: 270,904\\\nURL: 202,954\\\nURL: 185,997\\\nURL: 173,466\\\nURL: 173,307\\\nURL: 143,582\\\nURL: 131,000\\\nURL: 120,851\\\nURL: 110,622\\\nURL: 109,522\\\nURL: 105,260\\\nURL: 100,474\\\nURL: 99991\\\nURL: 94011\\\nURL: 88912\\\nURL: 83510\\\nURL: 83271\\\nURL: 81871\\\nURL: 80766\\\nURL: 79717\\\nURL: 73131\\\nURL: 61528\\\nURL: 60083\\\nURL: 58000\\\nURL: 53942\\\nURL: 51608\\\nURL: 46485\\\nURL: 45765\\\nURL: 42303\\\nURL: 41227\\\nURL: 38314\\\nURL: 36456\\\nURL: 34559\\\nURL: 34506\\\nURL: 34331\\\nURL: 32760\\\nURL: 32028\\\nURL: 32021\\\nURL: 30625\\\nURL: 30233\\\nURL: 29697\\\nURL: 29403\\\nURL: 27397\\\nURL: 26763\\\nURL: 25374\\\nURL: 24447\\\nURL: 24189\\\nURL: 23753\\\nURL: 23705\\\nURL: 23231\\\nURL: 22868\\\nURL: 22056\\\nURL: 21252\\\nURL: 21055\\\nURL: 20636\\\nURL: 20181\\\nURL: 20142\\\nURL: 20139\\\nURL: 19553\\\nURL: 17941\\\nURL: 17851\\\nURL: 17261\\\nURL: 16871\\\nURL: 16353\\\nURL: 15142\\\nURL: 15136\\\nURL: 14829\\\nURL: 13950\\\nURL: 13454\\\nURL: 13450\\\nURL: 12574\\\nURL: 12543\\\nURL: 12149\\\nURL: 12108\\\nURL: 12021\\\nURL: 11894\\\nURL: 11866\\\nURL: 11853\\\nURL: 11444\\\nURL: 11115\\\nURL: 10794\\\nURL: 10753\\\nURL: 10642\\\nURL: 10551\\\nURL: 10462\\\nURL: 10157\\\nURL: 10009\\\nTotal: 25,333,327"
]
| [
"TAGS\n#region-us \n",
"## Examples (lines) per file:\n\nURL: 18,562,443\\\nURL: 1,338,443\\\nsmall_stackexchanges.URL: 448,146\\\nURL: 435,463\\\nURL: 347,925\\\nURL: 270,904\\\nURL: 202,954\\\nURL: 185,997\\\nURL: 173,466\\\nURL: 173,307\\\nURL: 143,582\\\nURL: 131,000\\\nURL: 120,851\\\nURL: 110,622\\\nURL: 109,522\\\nURL: 105,260\\\nURL: 100,474\\\nURL: 99991\\\nURL: 94011\\\nURL: 88912\\\nURL: 83510\\\nURL: 83271\\\nURL: 81871\\\nURL: 80766\\\nURL: 79717\\\nURL: 73131\\\nURL: 61528\\\nURL: 60083\\\nURL: 58000\\\nURL: 53942\\\nURL: 51608\\\nURL: 46485\\\nURL: 45765\\\nURL: 42303\\\nURL: 41227\\\nURL: 38314\\\nURL: 36456\\\nURL: 34559\\\nURL: 34506\\\nURL: 34331\\\nURL: 32760\\\nURL: 32028\\\nURL: 32021\\\nURL: 30625\\\nURL: 30233\\\nURL: 29697\\\nURL: 29403\\\nURL: 27397\\\nURL: 26763\\\nURL: 25374\\\nURL: 24447\\\nURL: 24189\\\nURL: 23753\\\nURL: 23705\\\nURL: 23231\\\nURL: 22868\\\nURL: 22056\\\nURL: 21252\\\nURL: 21055\\\nURL: 20636\\\nURL: 20181\\\nURL: 20142\\\nURL: 20139\\\nURL: 19553\\\nURL: 17941\\\nURL: 17851\\\nURL: 17261\\\nURL: 16871\\\nURL: 16353\\\nURL: 15142\\\nURL: 15136\\\nURL: 14829\\\nURL: 13950\\\nURL: 13454\\\nURL: 13450\\\nURL: 12574\\\nURL: 12543\\\nURL: 12149\\\nURL: 12108\\\nURL: 12021\\\nURL: 11894\\\nURL: 11866\\\nURL: 11853\\\nURL: 11444\\\nURL: 11115\\\nURL: 10794\\\nURL: 10753\\\nURL: 10642\\\nURL: 10551\\\nURL: 10462\\\nURL: 10157\\\nURL: 10009\\\nTotal: 25,333,327"
]
|
32151f5480872e6db89ae147e1d727266f574606 |
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)s
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [stackexchange](https://archive.org/details/stackexchange)
- **Repository:** [flax-sentence-embeddings](https://github.com/nreimers/flax-sentence-embeddings)
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from [Stack Exchange](https://stackexchange.com/) network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available [here](https://stackexchange.com/sites).
### Languages
Stack Exchange mainly consist of english language (en).
## Dataset Structure
### Data Instances
Each data samples is presented as follow:
```
{'title_body': "Is there a Stack Exchange icon available? StackAuth /sites route provides all the site's icons except for the one of the Stack Exchange master site.\nCould you please provide it in some way (a static SVG would be good)?",
'upvoted_answer': 'Here it is!\n\nDead link: SVG version here\nNote: the same restrictions on this trademarked icon that apply here, also apply to the icon above.',
'downvoted_answer': 'No, the /sites route is not the right place for that.\n\n/sites enumerates all websites that expose API end-points. StackExchange.com does not expose such an endpoint, so it does not (and will not) appear in the results.'}
```
This particular exampe corresponds to the [following page](https://stackapps.com/questions/1508/is-there-a-stack-exchange-icon-available)
### Data Fields
The fields present in the dataset contain the following informations:
- `title_body`: This is the concatenation of the title and body from the question
- `upvoted_answer`: This is the body from the most upvoted answer
- `downvoted_answer`: This is the body from the most downvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
| | Number of pairs |
| ----- | ------ |
| english | 13,003 |
| academia | 2,465 |
| christianity | 1,502 |
| apple | 6,696 |
| electronics | 4,014 |
| gaming | 7,321 |
| askubuntu | 9,975 |
| ell | 4,438 |
| hermeneutics | 1,719 |
| judaism | 2,216 |
| diy | 2,037 |
| law | 1,297 |
| history | 1,099 |
| islam | 2,037 |
| dba | 2,502 |
| cooking | 2,064 |
| gamedev | 1,598 |
| drupal | 1,714 |
| chemistry | 1,523 |
| android | 2,830 |
| mathoverflow | 1,109 |
| magento | 1,849 |
| buddhism | 770 |
| gis | 1,843 |
| graphicdesign | 1,565 |
| codereview | 666 |
| aviation | 903 |
| bicycles | 984 |
| japanese | 1,124 |
| cs | 936 |
| german | 1,047 |
| interpersonal | 469 |
| biology | 832 |
| bitcoin | 1,068 |
| blender | 1,312 |
| crypto | 595 |
| anime | 802 |
| boardgames | 691 |
| hinduism | 343 |
| french | 632 |
| fitness | 567 |
| economics | 441 |
| chinese | 611 |
| codegolf | 333 |
| linguistics | 442 |
| astronomy | 371 |
| arduino | 595 |
| chess | 402 |
| cstheory | 314 |
| ja | 328 |
| martialarts | 254 |
| mathematica | 262 |
| dsp | 387 |
| ethereum | 479 |
| health | 299 |
| cogsci | 221 |
| earthscience | 229 |
| gardening | 210 |
| datascience | 325 |
| literature | 191 |
| matheducators | 177 |
| lifehacks | 316 |
| engineering | 227 |
| ham | 158 |
| 3dprinting | 109 |
| italian | 181 |
| emacs | 188 |
| homebrew | 176 |
| ai | 130 |
| avp | 152 |
| expatriates | 132 |
| elementaryos | 224 |
| cseducators | 67 |
| hsm | 70 |
| expressionengine | 91 |
| joomla | 124 |
| freelancing | 70 |
| crafts | 72 |
| genealogy | 86 |
| latin | 55 |
| hardwarerecs | 58 |
| devops | 53 |
| coffee | 47 |
| beer | 57 |
| languagelearning | 42 |
| ebooks | 54 |
| bricks | 79 |
| civicrm | 85 |
| bioinformatics | 39 |
| esperanto | 56 |
| computergraphics | 30 |
| conlang | 8 |
| korean | 28 |
| iota | 31 |
| eosio | 44 |
| craftcms | 26 |
| iot | 10 |
| drones | 6 |
| cardano | 7 |
| materials | 1 |
| ru | 6,305 |
| softwareengineering | 4,238 |
| scifi | 5,176 |
| workplace | 4,317 |
| serverfault | 7,969 |
| rpg | 4,212 |
| physics | 8,362 |
| superuser | 17,425 |
| worldbuilding | 2,087 |
| security | 3,069 |
| pt | 3,718 |
| unix | 6,173 |
| meta | 61 |
| politics | 1,468 |
| stats | 2,238 |
| movies | 1,577 |
| photo | 1,432 |
| wordpress | 3,046 |
| music | 1,228 |
| philosophy | 1,184 |
| skeptics | 670 |
| money | 1,905 |
| salesforce | 1,781 |
| parenting | 624 |
| raspberrypi | 1,011 |
| travel | 1,317 |
| mechanics | 842 |
| tex | 1,095 |
| ux | 1,107 |
| sharepoint | 1,691 |
| webapps | 1,906 |
| puzzling | 784 |
| networkengineering | 476 |
| webmasters | 854 |
| sports | 455 |
| rus | 514 |
| space | 405 |
| writers | 407 |
| pets | 322 |
| pm | 241 |
| russian | 353 |
| spanish | 366 |
| sound | 365 |
| quant | 340 |
| sqa | 353 |
| outdoors | 221 |
| softwarerecs | 348 |
| retrocomputing | 135 |
| mythology | 103 |
| portuguese | 144 |
| opensource | 123 |
| scicomp | 127 |
| ukrainian | 87 |
| patents | 137 |
| sustainability | 152 |
| poker | 115 |
| robotics | 110 |
| woodworking | 93 |
| reverseengineering | 97 |
| sitecore | 122 |
| tor | 137 |
| vi | 95 |
| windowsphone | 153 |
| vegetarianism | 35 |
| moderators | 23 |
| quantumcomputing | 46 |
| musicfans | 78 |
| tridion | 68 |
| opendata | 45 |
| tezos | 11 |
| stellar | 3 |
| or | 13 |
| monero | 26 |
| stackapps | 15 |
| total | 210,748 |
## Dataset Creation
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from [Stack Exchange](https://archive.org/details/stackexchange)
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
## Additional Information
### Licensing Information
Please see the license information at: https://archive.org/details/stackexchange
### Citation Information
```
@misc{StackExchangeDataset,
author = {Flax Sentence Embeddings Team},
title = {Stack Exchange question pairs},
year = {2021},
howpublished = {https://huggingface.co/datasets/flax-sentence-embeddings/},
}
```
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset. | flax-sentence-embeddings/stackexchange_titlebody_best_and_down_voted_answer_jsonl | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa"], "pretty_name": "stackexchange"} | 2022-07-11T12:13:18+00:00 | []
| [
"en"
]
| TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us
| Dataset Card Creation Guide
===========================
Table of Contents
-----------------
* Dataset Card Creation Guide
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?s
+ Additional Information
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Homepage: stackexchange
* Repository: flax-sentence-embeddings
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.
### Languages
Stack Exchange mainly consist of english language (en).
Dataset Structure
-----------------
### Data Instances
Each data samples is presented as follow:
This particular exampe corresponds to the following page
### Data Fields
The fields present in the dataset contain the following informations:
* 'title\_body': This is the concatenation of the title and body from the question
* 'upvoted\_answer': This is the body from the most upvoted answer
* 'downvoted\_answer': This is the body from the most downvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
Dataset Creation
----------------
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from Stack Exchange
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
Additional Information
----------------------
### Licensing Information
Please see the license information at: URL
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset.
| [
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer\n* 'downvoted\\_answer': This is the body from the most downvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer\n* 'downvoted\\_answer': This is the body from the most downvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
|
5ce5373dcaed72457e1b61860d7368dca0f10179 |
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)s
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [stackexchange](https://archive.org/details/stackexchange)
- **Repository:** [flax-sentence-embeddings](https://github.com/nreimers/flax-sentence-embeddings)
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from [Stack Exchange](https://stackexchange.com/) network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available [here](https://stackexchange.com/sites).
### Languages
Stack Exchange mainly consist of english language (en).
## Dataset Structure
### Data Instances
Each data samples is presented as follow:
```
{'title_body': 'How to determine if 3 points on a 3-D graph are collinear? Let the points $A, B$ and $C$ be $(x_1, y_1, z_1), (x_2, y_2, z_2)$ and $(x_3, y_3, z_3)$ respectively. How do I prove that the 3 points are collinear? What is the formula?',
'upvoted_answer': 'From $A(x_1,y_1,z_1),B(x_2,y_2,z_2),C(x_3,y_3,z_3)$ we can get their position vectors.\n\n$\\vec{AB}=(x_2-x_1,y_2-y_1,z_2-z_1)$ and $\\vec{AC}=(x_3-x_1,y_3-y_1,z_3-z_1)$.\n\nThen $||\\vec{AB}\\times\\vec{AC}||=0\\implies A,B,C$ collinear.',
```
This particular exampe corresponds to the [following page](https://math.stackexchange.com/questions/947555/how-to-determine-if-3-points-on-a-3-d-graph-are-collinear)
### Data Fields
The fields present in the dataset contain the following informations:
- `title_body`: This is the concatenation of the title and body from the question
- `upvoted_answer`: This is the body from the most upvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
| | Number of pairs |
| ----- | ------ |
| apple | 92,487 |
| english | 100,640 |
| codereview | 41,748 |
| dba | 71,449 |
| mathoverflow | 85,289 |
| electronics | 129,494 |
| mathematica | 59,895 |
| drupal | 67,817 |
| magento | 79,241 |
| gaming | 82,887 |
| ell | 77,892 |
| gamedev | 40,154 |
| gis | 100,254 |
| askubuntu | 267,135 |
| diy | 52,896 |
| academia | 32,137 |
| blender | 54,153 |
| cs | 30,010 |
| chemistry | 27,061 |
| judaism | 26,085 |
| crypto | 19,404 |
| android | 38,077 |
| ja | 17,376 |
| christianity | 11,498 |
| graphicdesign | 28,083 |
| aviation | 18,755 |
| ethereum | 26,124 |
| biology | 19,277 |
| datascience | 20,503 |
| law | 16,133 |
| dsp | 17,430 |
| japanese | 20,948 |
| hermeneutics | 9,516 |
| bicycles | 15,708 |
| arduino | 16,281 |
| history | 10,766 |
| bitcoin | 22,474 |
| cooking | 22,641 |
| hinduism | 8,999 |
| codegolf | 8,211 |
| boardgames | 11,805 |
| emacs | 16,830 |
| economics | 8,844 |
| gardening | 13,246 |
| astronomy | 9,086 |
| islam | 10,052 |
| german | 13,733 |
| fitness | 8,297 |
| french | 10,578 |
| anime | 10,131 |
| craftcms | 11,236 |
| cstheory | 7,742 |
| engineering | 8,649 |
| buddhism | 6,787 |
| linguistics | 6,843 |
| ai | 5,763 |
| expressionengine | 10,742 |
| cogsci | 5,101 |
| chinese | 8,646 |
| chess | 6,392 |
| civicrm | 10,648 |
| literature | 3,539 |
| interpersonal | 3,398 |
| health | 4,494 |
| avp | 6,450 |
| earthscience | 4,396 |
| joomla | 5,887 |
| homebrew | 5,608 |
| expatriates | 4,913 |
| latin | 3,969 |
| matheducators | 2,706 |
| ham | 3,501 |
| genealogy | 2,895 |
| 3dprinting | 3,488 |
| elementaryos | 5,917 |
| bioinformatics | 3,135 |
| devops | 3,462 |
| hsm | 2,517 |
| italian | 3,101 |
| computergraphics | 2,306 |
| martialarts | 1,737 |
| bricks | 3,530 |
| freelancing | 1,663 |
| crafts | 1,659 |
| lifehacks | 2,576 |
| cseducators | 902 |
| materials | 1,101 |
| hardwarerecs | 2,050 |
| iot | 1,359 |
| eosio | 1,940 |
| languagelearning | 948 |
| korean | 1,406 |
| coffee | 1,188 |
| esperanto | 1,466 |
| beer | 1,012 |
| ebooks | 1,107 |
| iota | 775 |
| cardano | 248 |
| drones | 496 |
| conlang | 334 |
| pt | 103,277 |
| stats | 115,679 |
| unix | 155,414 |
| physics | 141,230 |
| tex | 171,628 |
| serverfault | 238,507 |
| salesforce | 87,272 |
| wordpress | 83,621 |
| softwareengineering | 51,326 |
| scifi | 54,805 |
| security | 51,355 |
| ru | 253,289 |
| superuser | 352,610 |
| sharepoint | 80,420 |
| rpg | 40,435 |
| travel | 36,533 |
| worldbuilding | 26,210 |
| meta | 1,000 |
| workplace | 24,012 |
| ux | 28,901 |
| money | 29,404 |
| webmasters | 30,370 |
| raspberrypi | 24,143 |
| photo | 23,204 |
| music | 19,936 |
| philosophy | 13,114 |
| puzzling | 17,448 |
| movies | 18,243 |
| quant | 12,933 |
| politics | 11,047 |
| space | 12,893 |
| mechanics | 18,613 |
| skeptics | 8,145 |
| rus | 16,528 |
| writers | 9,867 |
| webapps | 24,867 |
| softwarerecs | 11,761 |
| networkengineering | 12,590 |
| parenting | 5,998 |
| scicomp | 7,036 |
| sqa | 9,256 |
| sitecore | 7,838 |
| vi | 9,000 |
| spanish | 7,675 |
| pm | 5,435 |
| pets | 6,156 |
| sound | 8,303 |
| reverseengineering | 5,817 |
| outdoors | 5,278 |
| tridion | 5,907 |
| retrocomputing | 3,907 |
| robotics | 4,648 |
| quantumcomputing | 4,320 |
| sports | 4,707 |
| russian | 3,937 |
| opensource | 3,221 |
| woodworking | 2,955 |
| patents | 3,573 |
| tor | 4,167 |
| ukrainian | 1,767 |
| opendata | 3,842 |
| monero | 3,508 |
| sustainability | 1,674 |
| portuguese | 1,964 |
| mythology | 1,595 |
| musicfans | 2,431 |
| or | 1,490 |
| poker | 1,665 |
| windowsphone | 2,807 |
| moderators | 504 |
| stackapps | 1,518 |
| stellar | 1,078 |
| vegetarianism | 585 |
| tezos | 1,169 |
| total | 4,750,619 |
## Dataset Creation
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from [Stack Exchange](https://archive.org/details/stackexchange)
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
## Additional Information
### Licensing Information
Please see the license information at: https://archive.org/details/stackexchange
### Citation Information
```
@misc{StackExchangeDataset,
author = {Flax Sentence Embeddings Team},
title = {Stack Exchange question pairs},
year = {2021},
howpublished = {https://huggingface.co/datasets/flax-sentence-embeddings/},
}
```
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset. | flax-sentence-embeddings/stackexchange_titlebody_best_voted_answer_jsonl | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa"], "pretty_name": "stackexchange"} | 2022-07-11T12:13:27+00:00 | []
| [
"en"
]
| TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us
| Dataset Card Creation Guide
===========================
Table of Contents
-----------------
* Dataset Card Creation Guide
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?s
+ Additional Information
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Homepage: stackexchange
* Repository: flax-sentence-embeddings
### Dataset Summary
We automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.
### Languages
Stack Exchange mainly consist of english language (en).
Dataset Structure
-----------------
### Data Instances
Each data samples is presented as follow:
This particular exampe corresponds to the following page
### Data Fields
The fields present in the dataset contain the following informations:
* 'title\_body': This is the concatenation of the title and body from the question
* 'upvoted\_answer': This is the body from the most upvoted answer
### Data Splits
We provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:
Dataset Creation
----------------
### Curation Rationale
We primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.
### Source Data
The source data are dumps from Stack Exchange
#### Initial Data Collection and Normalization
We collected the data from the math community.
We filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.
When extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.
#### Who are the source language producers?
Questions and answers are written by the community developpers of Stack Exchange.
Additional Information
----------------------
### Licensing Information
Please see the license information at: URL
### Contributions
Thanks to the Flax Sentence Embeddings team for adding this dataset.
| [
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
| [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nWe automatically extracted question and answer (Q&A) pairs from Stack Exchange network. Stack Exchange gather many Q&A communities across 50 online plateform, including the well known Stack Overflow and other technical sites. 100 millon developpers consult Stack Exchange every month. The dataset is a parallel corpus with each question mapped to the top rated answer. The dataset is split given communities which cover a variety of domains from 3d printing, economics, raspberry pi or emacs. An exhaustive list of all communities is available here.",
"### Languages\n\n\nStack Exchange mainly consist of english language (en).\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nEach data samples is presented as follow:\n\n\nThis particular exampe corresponds to the following page",
"### Data Fields\n\n\nThe fields present in the dataset contain the following informations:\n\n\n* 'title\\_body': This is the concatenation of the title and body from the question\n* 'upvoted\\_answer': This is the body from the most upvoted answer",
"### Data Splits\n\n\nWe provide multiple splits for this dataset, which each refers to a given community channel. We detail the number of pail for each split below:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nWe primary designed this dataset for sentence embeddings training. Indeed sentence embeddings may be trained using a contrastive learning setup for which the model is trained to associate each sentence with its corresponding pair out of multiple proposition. Such models require many examples to be efficient and thus the dataset creation may be tedious. Community networks such as Stack Exchange allow us to build many examples semi-automatically.",
"### Source Data\n\n\nThe source data are dumps from Stack Exchange",
"#### Initial Data Collection and Normalization\n\n\nWe collected the data from the math community.\n\n\nWe filtered out questions which title or body length is bellow 20 characters and questions for which body length is above 4096 characters.\nWhen extracting most upvoted answer, we filtered to pairs for which their is at least 100 votes gap between most upvoted and downvoted answers.",
"#### Who are the source language producers?\n\n\nQuestions and answers are written by the community developpers of Stack Exchange.\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nPlease see the license information at: URL",
"### Contributions\n\n\nThanks to the Flax Sentence Embeddings team for adding this dataset."
]
|
0bea7f6680d8ce12e1bfa6d8762d62ac3d44fd1c | This is a dump of the files from
https://archive.org/details/stackexchange
downloaded via torrent on 2021-07-01.
Publication date 2021-06-07 \
Usage Attribution-ShareAlike 4.0 International Creative Commons License by sa \
Topics Stack Exchange Data Dump \
Contributor Stack Exchange Community
Please see the license information at:
https://archive.org/details/stackexchange
The dataset has been split into following for cleaner formatting.
- https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_math_jsonl
- https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl
- https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl
- https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_titlebody_best_and_down_voted_answer_jsonl | flax-sentence-embeddings/stackexchange_xml | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-07-26T00:38:48+00:00 | []
| []
| TAGS
#region-us
| This is a dump of the files from
URL
downloaded via torrent on 2021-07-01.
Publication date 2021-06-07 \
Usage Attribution-ShareAlike 4.0 International Creative Commons License by sa \
Topics Stack Exchange Data Dump \
Contributor Stack Exchange Community
Please see the license information at:
URL
The dataset has been split into following for cleaner formatting.
- URL
- URL
- URL
- URL | []
| [
"TAGS\n#region-us \n"
]
|
e0e90b5d29640a6475a72f4e681441ec30c7e6a8 | # librig2p-nostress - Grapheme-To-Phoneme Dataset
This dataset contains samples that can be used to train a Grapheme-to-Phoneme system **without** stress information.
The dataset is derived from the following pre-existing datasets:
* [LibriSpeech ASR Corpus](https://www.openslr.org/12)
* [LibriSpeech Alignments](https://github.com/CorentinJ/librispeech-alignments)
* [Wikipedia Homograph Disambiguation Data](https://github.com/google/WikipediaHomographData) | flexthink/librig2p-nostress-space | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-06-24T00:23:49+00:00 | []
| []
| TAGS
#region-us
| # librig2p-nostress - Grapheme-To-Phoneme Dataset
This dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.
The dataset is derived from the following pre-existing datasets:
* LibriSpeech ASR Corpus
* LibriSpeech Alignments
* Wikipedia Homograph Disambiguation Data | [
"# librig2p-nostress - Grapheme-To-Phoneme Dataset\n\nThis dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.\n\nThe dataset is derived from the following pre-existing datasets:\n\n* LibriSpeech ASR Corpus\n* LibriSpeech Alignments\n* Wikipedia Homograph Disambiguation Data"
]
| [
"TAGS\n#region-us \n",
"# librig2p-nostress - Grapheme-To-Phoneme Dataset\n\nThis dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.\n\nThe dataset is derived from the following pre-existing datasets:\n\n* LibriSpeech ASR Corpus\n* LibriSpeech Alignments\n* Wikipedia Homograph Disambiguation Data"
]
|
47638cc54a4f10ae30584a1a26b0c5f3cebff9db | # librig2p-nostress - Grapheme-To-Phoneme Dataset
This dataset contains samples that can be used to train a Grapheme-to-Phoneme system **without** stress information.
The dataset is derived from the following pre-existing datasets:
* [LibriSpeech ASR Corpus](https://www.openslr.org/12)
* [LibriSpeech Alignments](https://github.com/CorentinJ/librispeech-alignments)
| flexthink/librig2p-nostress | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-07-27T00:50:52+00:00 | []
| []
| TAGS
#region-us
| # librig2p-nostress - Grapheme-To-Phoneme Dataset
This dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.
The dataset is derived from the following pre-existing datasets:
* LibriSpeech ASR Corpus
* LibriSpeech Alignments
| [
"# librig2p-nostress - Grapheme-To-Phoneme Dataset\n\nThis dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.\n\nThe dataset is derived from the following pre-existing datasets:\n\n* LibriSpeech ASR Corpus\n* LibriSpeech Alignments"
]
| [
"TAGS\n#region-us \n",
"# librig2p-nostress - Grapheme-To-Phoneme Dataset\n\nThis dataset contains samples that can be used to train a Grapheme-to-Phoneme system without stress information.\n\nThe dataset is derived from the following pre-existing datasets:\n\n* LibriSpeech ASR Corpus\n* LibriSpeech Alignments"
]
|
7367bcc33648be329bbef057cc97d0b83cadee11 | # The LJ Speech Dataset
Version 1.0
July 5, 2017
https://keithito.com/LJ-Speech-Dataset
# Overview
This is a public domain speech dataset consisting of 13,100 short audio clips
of a single speaker reading passages from 7 non-fiction books. A transcription
is provided for each clip. Clips vary in length from 1 to 10 seconds and have
a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain.
The audio was recorded in 2016-17 by the LibriVox project and is also in the
public domain.
The following files provide raw lavels for the train/validation/test split
* train.txt
* valid.txt
* test.txt
Friendly metadata with the split is provided in the following files:
* ljspeech_train.json
* ljspeech_test.json
* ljspeech_valid.json
The JSON files are formatted as follows:
```json
{
"<sample-id>": {
"char_raw": "<label text (raw)>",
"char": "<label text (preprocessed)",
"phn": "<experimental phoneme annotation obtained using a G2P model",
"wav": "<relative path to the file"
}
}
```
The dataset is also usable as a HuggingFace Arrow dataset:
https://huggingface.co/docs/datasets/
# FILE FORMAT
Original metadata is provided in metadata.csv. This file consists of one record per line, delimited by the pipe character (0x7c). The fields are:
1. ID: this is the name of the corresponding .wav file
2. Transcription: words spoken by the reader (UTF-8)
3. Normalized Transcription: transcription with numbers, ordinals, and
monetary units expanded into full words (UTF-8).
Each audio file is a single-channel 16-bit PCM WAV with a sample rate of
22050 Hz.
## Statistics
Total Clips 13,100
Total Words 225,715
Total Characters 1,308,674
Total Duration 23:55:17
Mean Clip Duration 6.57 sec
Min Clip Duration 1.11 sec
Max Clip Duration 10.10 sec
Mean Words per Clip 17.23
Distinct Words 13,821
## Miscellaneous
The audio clips range in length from approximately 1 second to 10 seconds.
They were segmented automatically based on silences in the recording. Clip
boundaries generally align with sentence or clause boundaries, but not always.
The text was matched to the audio manually, and a QA pass was done to ensure
that the text accurately matched the words spoken in the audio.
The original LibriVox recordings were distributed as 128 kbps MP3 files. As a
result, they may contain artifacts introduced by the MP3 encoding.
The following abbreviations appear in the text. They may be expanded as
follows:
Abbreviation Expansion
--------------------------
Mr. Mister
Mrs. Misess (*)
Dr. Doctor
No. Number
St. Saint
Co. Company
Jr. Junior
Maj. Major
Gen. General
Drs. Doctors
Rev. Reverend
Lt. Lieutenant
Hon. Honorable
Sgt. Sergeant
Capt. Captain
Esq. Esquire
Ltd. Limited
Col. Colonel
Ft. Fort
* there's no standard expansion of "Mrs."
19 of the transcriptions contain non-ASCII characters (for example, LJ016-0257
contains "raison d'être").
For more information or to report errors, please email [email protected].
LICENSE
This dataset is in the public domain in the USA (and likely other countries as
well). There are no restrictions on its use. For more information, please see:
https://librivox.org/pages/public-domain.
CHANGELOG
* 1.0 (July 8, 2017):
Initial release
* 1.1 (Feb 19, 2018):
Version 1.0 included 30 .wav files with no corresponding annotations in
metadata.csv. These have been removed in version 1.1. Thanks to Rafael Valle
for spotting this.
CREDITS
This dataset consists of excerpts from the following works:
* Morris, William, et al. Arts and Crafts Essays. 1893.
* Griffiths, Arthur. The Chronicles of Newgate, Vol. 2. 1884.
* Roosevelt, Franklin D. The Fireside Chats of Franklin Delano Roosevelt.
1933-42.
* Harland, Marion. Marion Harland's Cookery for Beginners. 1893.
* Rolt-Wheeler, Francis. The Science - History of the Universe, Vol. 5:
Biology. 1910.
* Banks, Edgar J. The Seven Wonders of the Ancient World. 1916.
* President's Commission on the Assassination of President Kennedy. Report
of the President's Commission on the Assassination of President Kennedy.
1964.
Recordings by Linda Johnson. Alignment and annotation by Keith Ito. All text,
audio, and annotations are in the public domain.
There's no requirement to cite this work, but if you'd like to do so, you can
link to: https://keithito.com/LJ-Speech-Dataset
or use the following:
@misc{ljspeech17,
author = {Keith Ito},
title = {The LJ Speech Dataset},
howpublished = {\url{https://keithito.com/LJ-Speech-Dataset/}},
year = 2017
}
| flexthink/ljspeech | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-02-06T00:09:16+00:00 | []
| []
| TAGS
#region-us
| # The LJ Speech Dataset
Version 1.0
July 5, 2017
URL
# Overview
This is a public domain speech dataset consisting of 13,100 short audio clips
of a single speaker reading passages from 7 non-fiction books. A transcription
is provided for each clip. Clips vary in length from 1 to 10 seconds and have
a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain.
The audio was recorded in 2016-17 by the LibriVox project and is also in the
public domain.
The following files provide raw lavels for the train/validation/test split
* URL
* URL
* URL
Friendly metadata with the split is provided in the following files:
* ljspeech_train.json
* ljspeech_test.json
* ljspeech_valid.json
The JSON files are formatted as follows:
The dataset is also usable as a HuggingFace Arrow dataset:
URL
# FILE FORMAT
Original metadata is provided in URL. This file consists of one record per line, delimited by the pipe character (0x7c). The fields are:
1. ID: this is the name of the corresponding .wav file
2. Transcription: words spoken by the reader (UTF-8)
3. Normalized Transcription: transcription with numbers, ordinals, and
monetary units expanded into full words (UTF-8).
Each audio file is a single-channel 16-bit PCM WAV with a sample rate of
22050 Hz.
## Statistics
Total Clips 13,100
Total Words 225,715
Total Characters 1,308,674
Total Duration 23:55:17
Mean Clip Duration 6.57 sec
Min Clip Duration 1.11 sec
Max Clip Duration 10.10 sec
Mean Words per Clip 17.23
Distinct Words 13,821
## Miscellaneous
The audio clips range in length from approximately 1 second to 10 seconds.
They were segmented automatically based on silences in the recording. Clip
boundaries generally align with sentence or clause boundaries, but not always.
The text was matched to the audio manually, and a QA pass was done to ensure
that the text accurately matched the words spoken in the audio.
The original LibriVox recordings were distributed as 128 kbps MP3 files. As a
result, they may contain artifacts introduced by the MP3 encoding.
The following abbreviations appear in the text. They may be expanded as
follows:
Abbreviation Expansion
--------------------------
Mr. Mister
Mrs. Misess (*)
Dr. Doctor
No. Number
St. Saint
Co. Company
Jr. Junior
Maj. Major
Gen. General
Drs. Doctors
Rev. Reverend
Lt. Lieutenant
Hon. Honorable
Sgt. Sergeant
Capt. Captain
Esq. Esquire
Ltd. Limited
Col. Colonel
Ft. Fort
* there's no standard expansion of "Mrs."
19 of the transcriptions contain non-ASCII characters (for example, LJ016-0257
contains "raison d'être").
For more information or to report errors, please email kito@URL.
LICENSE
This dataset is in the public domain in the USA (and likely other countries as
well). There are no restrictions on its use. For more information, please see:
URL
CHANGELOG
* 1.0 (July 8, 2017):
Initial release
* 1.1 (Feb 19, 2018):
Version 1.0 included 30 .wav files with no corresponding annotations in
URL. These have been removed in version 1.1. Thanks to Rafael Valle
for spotting this.
CREDITS
This dataset consists of excerpts from the following works:
* Morris, William, et al. Arts and Crafts Essays. 1893.
* Griffiths, Arthur. The Chronicles of Newgate, Vol. 2. 1884.
* Roosevelt, Franklin D. The Fireside Chats of Franklin Delano Roosevelt.
1933-42.
* Harland, Marion. Marion Harland's Cookery for Beginners. 1893.
* Rolt-Wheeler, Francis. The Science - History of the Universe, Vol. 5:
Biology. 1910.
* Banks, Edgar J. The Seven Wonders of the Ancient World. 1916.
* President's Commission on the Assassination of President Kennedy. Report
of the President's Commission on the Assassination of President Kennedy.
1964.
Recordings by Linda Johnson. Alignment and annotation by Keith Ito. All text,
audio, and annotations are in the public domain.
There's no requirement to cite this work, but if you'd like to do so, you can
link to: URL
or use the following:
@misc{ljspeech17,
author = {Keith Ito},
title = {The LJ Speech Dataset},
howpublished = {\url{URL
year = 2017
}
| [
"# The LJ Speech Dataset\n\nVersion 1.0\nJuly 5, 2017\nURL",
"# Overview\n\nThis is a public domain speech dataset consisting of 13,100 short audio clips\nof a single speaker reading passages from 7 non-fiction books. A transcription\nis provided for each clip. Clips vary in length from 1 to 10 seconds and have\na total length of approximately 24 hours.\n\nThe texts were published between 1884 and 1964, and are in the public domain.\nThe audio was recorded in 2016-17 by the LibriVox project and is also in the\npublic domain.\n\nThe following files provide raw lavels for the train/validation/test split\n* URL\n* URL\n* URL\n\nFriendly metadata with the split is provided in the following files:\n* ljspeech_train.json\n* ljspeech_test.json\n* ljspeech_valid.json\n\nThe JSON files are formatted as follows:\n\n\n\nThe dataset is also usable as a HuggingFace Arrow dataset:\nURL",
"# FILE FORMAT\n\nOriginal metadata is provided in URL. This file consists of one record per line, delimited by the pipe character (0x7c). The fields are:\n\n 1. ID: this is the name of the corresponding .wav file\n 2. Transcription: words spoken by the reader (UTF-8)\n 3. Normalized Transcription: transcription with numbers, ordinals, and\n monetary units expanded into full words (UTF-8).\n\nEach audio file is a single-channel 16-bit PCM WAV with a sample rate of\n22050 Hz.",
"## Statistics\n\nTotal Clips 13,100\nTotal Words 225,715\nTotal Characters 1,308,674\nTotal Duration 23:55:17\nMean Clip Duration 6.57 sec\nMin Clip Duration 1.11 sec\nMax Clip Duration 10.10 sec\nMean Words per Clip 17.23\nDistinct Words 13,821",
"## Miscellaneous\n\nThe audio clips range in length from approximately 1 second to 10 seconds.\nThey were segmented automatically based on silences in the recording. Clip\nboundaries generally align with sentence or clause boundaries, but not always.\n\nThe text was matched to the audio manually, and a QA pass was done to ensure\nthat the text accurately matched the words spoken in the audio.\n\nThe original LibriVox recordings were distributed as 128 kbps MP3 files. As a\nresult, they may contain artifacts introduced by the MP3 encoding.\n\nThe following abbreviations appear in the text. They may be expanded as\nfollows:\n\n Abbreviation Expansion\n --------------------------\n Mr. Mister\n Mrs. Misess (*)\n Dr. Doctor\n No. Number\n St. Saint\n Co. Company\n Jr. Junior\n Maj. Major\n Gen. General\n Drs. Doctors\n Rev. Reverend\n Lt. Lieutenant\n Hon. Honorable\n Sgt. Sergeant\n Capt. Captain\n Esq. Esquire\n Ltd. Limited\n Col. Colonel\n Ft. Fort\n\n * there's no standard expansion of \"Mrs.\"\n\n\n19 of the transcriptions contain non-ASCII characters (for example, LJ016-0257\ncontains \"raison d'être\").\n\nFor more information or to report errors, please email kito@URL.\n\n\n\nLICENSE\n\nThis dataset is in the public domain in the USA (and likely other countries as\nwell). There are no restrictions on its use. For more information, please see:\nURL\n\n\nCHANGELOG\n\n* 1.0 (July 8, 2017):\n Initial release\n\n* 1.1 (Feb 19, 2018):\n Version 1.0 included 30 .wav files with no corresponding annotations in\n URL. These have been removed in version 1.1. Thanks to Rafael Valle\n for spotting this.\n\n\nCREDITS\n\nThis dataset consists of excerpts from the following works:\n\n* Morris, William, et al. Arts and Crafts Essays. 1893.\n* Griffiths, Arthur. The Chronicles of Newgate, Vol. 2. 1884.\n* Roosevelt, Franklin D. The Fireside Chats of Franklin Delano Roosevelt.\n 1933-42.\n* Harland, Marion. Marion Harland's Cookery for Beginners. 1893.\n* Rolt-Wheeler, Francis. The Science - History of the Universe, Vol. 5:\n Biology. 1910.\n* Banks, Edgar J. The Seven Wonders of the Ancient World. 1916.\n* President's Commission on the Assassination of President Kennedy. Report\n of the President's Commission on the Assassination of President Kennedy.\n 1964.\n\nRecordings by Linda Johnson. Alignment and annotation by Keith Ito. All text,\naudio, and annotations are in the public domain.\n\nThere's no requirement to cite this work, but if you'd like to do so, you can\nlink to: URL\n\nor use the following:\n@misc{ljspeech17,\n author = {Keith Ito},\n title = {The LJ Speech Dataset},\n howpublished = {\\url{URL\n year = 2017\n}"
]
| [
"TAGS\n#region-us \n",
"# The LJ Speech Dataset\n\nVersion 1.0\nJuly 5, 2017\nURL",
"# Overview\n\nThis is a public domain speech dataset consisting of 13,100 short audio clips\nof a single speaker reading passages from 7 non-fiction books. A transcription\nis provided for each clip. Clips vary in length from 1 to 10 seconds and have\na total length of approximately 24 hours.\n\nThe texts were published between 1884 and 1964, and are in the public domain.\nThe audio was recorded in 2016-17 by the LibriVox project and is also in the\npublic domain.\n\nThe following files provide raw lavels for the train/validation/test split\n* URL\n* URL\n* URL\n\nFriendly metadata with the split is provided in the following files:\n* ljspeech_train.json\n* ljspeech_test.json\n* ljspeech_valid.json\n\nThe JSON files are formatted as follows:\n\n\n\nThe dataset is also usable as a HuggingFace Arrow dataset:\nURL",
"# FILE FORMAT\n\nOriginal metadata is provided in URL. This file consists of one record per line, delimited by the pipe character (0x7c). The fields are:\n\n 1. ID: this is the name of the corresponding .wav file\n 2. Transcription: words spoken by the reader (UTF-8)\n 3. Normalized Transcription: transcription with numbers, ordinals, and\n monetary units expanded into full words (UTF-8).\n\nEach audio file is a single-channel 16-bit PCM WAV with a sample rate of\n22050 Hz.",
"## Statistics\n\nTotal Clips 13,100\nTotal Words 225,715\nTotal Characters 1,308,674\nTotal Duration 23:55:17\nMean Clip Duration 6.57 sec\nMin Clip Duration 1.11 sec\nMax Clip Duration 10.10 sec\nMean Words per Clip 17.23\nDistinct Words 13,821",
"## Miscellaneous\n\nThe audio clips range in length from approximately 1 second to 10 seconds.\nThey were segmented automatically based on silences in the recording. Clip\nboundaries generally align with sentence or clause boundaries, but not always.\n\nThe text was matched to the audio manually, and a QA pass was done to ensure\nthat the text accurately matched the words spoken in the audio.\n\nThe original LibriVox recordings were distributed as 128 kbps MP3 files. As a\nresult, they may contain artifacts introduced by the MP3 encoding.\n\nThe following abbreviations appear in the text. They may be expanded as\nfollows:\n\n Abbreviation Expansion\n --------------------------\n Mr. Mister\n Mrs. Misess (*)\n Dr. Doctor\n No. Number\n St. Saint\n Co. Company\n Jr. Junior\n Maj. Major\n Gen. General\n Drs. Doctors\n Rev. Reverend\n Lt. Lieutenant\n Hon. Honorable\n Sgt. Sergeant\n Capt. Captain\n Esq. Esquire\n Ltd. Limited\n Col. Colonel\n Ft. Fort\n\n * there's no standard expansion of \"Mrs.\"\n\n\n19 of the transcriptions contain non-ASCII characters (for example, LJ016-0257\ncontains \"raison d'être\").\n\nFor more information or to report errors, please email kito@URL.\n\n\n\nLICENSE\n\nThis dataset is in the public domain in the USA (and likely other countries as\nwell). There are no restrictions on its use. For more information, please see:\nURL\n\n\nCHANGELOG\n\n* 1.0 (July 8, 2017):\n Initial release\n\n* 1.1 (Feb 19, 2018):\n Version 1.0 included 30 .wav files with no corresponding annotations in\n URL. These have been removed in version 1.1. Thanks to Rafael Valle\n for spotting this.\n\n\nCREDITS\n\nThis dataset consists of excerpts from the following works:\n\n* Morris, William, et al. Arts and Crafts Essays. 1893.\n* Griffiths, Arthur. The Chronicles of Newgate, Vol. 2. 1884.\n* Roosevelt, Franklin D. The Fireside Chats of Franklin Delano Roosevelt.\n 1933-42.\n* Harland, Marion. Marion Harland's Cookery for Beginners. 1893.\n* Rolt-Wheeler, Francis. The Science - History of the Universe, Vol. 5:\n Biology. 1910.\n* Banks, Edgar J. The Seven Wonders of the Ancient World. 1916.\n* President's Commission on the Assassination of President Kennedy. Report\n of the President's Commission on the Assassination of President Kennedy.\n 1964.\n\nRecordings by Linda Johnson. Alignment and annotation by Keith Ito. All text,\naudio, and annotations are in the public domain.\n\nThere's no requirement to cite this work, but if you'd like to do so, you can\nlink to: URL\n\nor use the following:\n@misc{ljspeech17,\n author = {Keith Ito},\n title = {The LJ Speech Dataset},\n howpublished = {\\url{URL\n year = 2017\n}"
]
|
92c16c659bc64b56cd25c0261f08a8dce56f9983 |
# Dataset Card for FUNSD-vu2020revising
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Paper:** [https://arxiv.org/abs/2010.05322](https://arxiv.org/abs/2010.05322)
### Dataset Summary
This is the revised version of the [FUNSD dataset](https://huggingface.co/datasets/nielsr/funsd) as proposed by [Vu, H. M., & Nguyen, D. T. N. (2020)](https://arxiv.org/abs/2010.05322).
### Supported Tasks and Leaderboards
The Form Understanding challenge comprises three tasks, namely word grouping, semantic-entity labeling, and entity linking.
## Dataset Structure
### Data Instances
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Data Fields
The data fields are the same among all splits.
- `id`: a `string` feature - GUID.
- `words`: a `list` of `string` features.
- `bboxes`: a `list` of `list` with four (`int`) features.
- `ner_tags`: a `list` of classification labels (`int`). Full tagset with indices:
```python
{'O': 0, 'B-HEADER': 1, 'I-HEADER': 2, 'B-QUESTION': 3, 'I-QUESTION': 4, 'B-ANSWER': 5, 'I-ANSWER': 6}
```
- `image_path`: a `string` feature.
### Data Splits
| name |train|test|
|------------|----:|---:|
|FUNSD-vu2020| 149| 50|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{vu2020revising,
title={Revising FUNSD dataset for key-value detection in document images},
author={Vu, Hieu M and Nguyen, Diep Thi-Ngoc},
journal={arXiv preprint arXiv:2010.05322},
year={2020}
}
``` | florianbussmann/FUNSD-vu2020revising | [
"multilinguality:monolingual",
"language:en",
"arxiv:2010.05322",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["en"], "multilinguality": ["monolingual"], "language_bcp47": ["en-US"]} | 2022-10-25T08:20:31+00:00 | [
"2010.05322"
]
| [
"en"
]
| TAGS
#multilinguality-monolingual #language-English #arxiv-2010.05322 #region-us
| Dataset Card for FUNSD-vu2020revising
=====================================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Paper: URL
### Dataset Summary
This is the revised version of the FUNSD dataset as proposed by Vu, H. M., & Nguyen, D. T. N. (2020).
### Supported Tasks and Leaderboards
The Form Understanding challenge comprises three tasks, namely word grouping, semantic-entity labeling, and entity linking.
Dataset Structure
-----------------
### Data Instances
### Data Fields
The data fields are the same among all splits.
* 'id': a 'string' feature - GUID.
* 'words': a 'list' of 'string' features.
* 'bboxes': a 'list' of 'list' with four ('int') features.
* 'ner\_tags': a 'list' of classification labels ('int'). Full tagset with indices:
* 'image\_path': a 'string' feature.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
| [
"### Dataset Summary\n\n\nThis is the revised version of the FUNSD dataset as proposed by Vu, H. M., & Nguyen, D. T. N. (2020).",
"### Supported Tasks and Leaderboards\n\n\nThe Form Understanding challenge comprises three tasks, namely word grouping, semantic-entity labeling, and entity linking.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature - GUID.\n* 'words': a 'list' of 'string' features.\n* 'bboxes': a 'list' of 'list' with four ('int') features.\n* 'ner\\_tags': a 'list' of classification labels ('int'). Full tagset with indices:\n* 'image\\_path': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
]
| [
"TAGS\n#multilinguality-monolingual #language-English #arxiv-2010.05322 #region-us \n",
"### Dataset Summary\n\n\nThis is the revised version of the FUNSD dataset as proposed by Vu, H. M., & Nguyen, D. T. N. (2020).",
"### Supported Tasks and Leaderboards\n\n\nThe Form Understanding challenge comprises three tasks, namely word grouping, semantic-entity labeling, and entity linking.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* 'id': a 'string' feature - GUID.\n* 'words': a 'list' of 'string' features.\n* 'bboxes': a 'list' of 'list' with four ('int') features.\n* 'ner\\_tags': a 'list' of classification labels ('int'). Full tagset with indices:\n* 'image\\_path': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
]
|
0e681c53aca7e7804b820acaa25c5dc7dffb45f2 |
# Dataset Card for Github Python 1M | formermagic/github_python_1m | [
"task_ids:language-modeling",
"task_ids:slot-filling",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:py",
"license:mit",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["py"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["sequence-modeling", "conditional-text-generation"], "task_ids": ["language-modeling", "slot-filling", "code-generation"]} | 2022-10-21T15:45:17+00:00 | []
| [
"py"
]
| TAGS
#task_ids-language-modeling #task_ids-slot-filling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-py #license-mit #region-us
|
# Dataset Card for Github Python 1M | [
"# Dataset Card for Github Python 1M"
]
| [
"TAGS\n#task_ids-language-modeling #task_ids-slot-filling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-py #license-mit #region-us \n",
"# Dataset Card for Github Python 1M"
]
|
b35819fb5aa8b680a37c11b749dea495bc9bd355 | https://www.geogebra.org/m/w8uzjttg
https://www.geogebra.org/m/gvn7m78g
https://www.geogebra.org/m/arxecanq
https://www.geogebra.org/m/xb69bvww
https://www.geogebra.org/m/apvepfnd
https://www.geogebra.org/m/evmj8ckk
https://www.geogebra.org/m/qxcxwmhp
https://www.geogebra.org/m/p3cxqh6c
https://www.geogebra.org/m/ggrahbgd
https://www.geogebra.org/m/pnhymrbc
https://www.geogebra.org/m/zjukbtk9
https://www.geogebra.org/m/bbezun8r
https://www.geogebra.org/m/sgwamtru
https://www.geogebra.org/m/fpunkxxp
https://www.geogebra.org/m/acxebrr7 | formu/CVT | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-03-26T15:40:33+00:00 | []
| []
| TAGS
#region-us
| URL
URL
URL
URL
URL
URL
URL
URL
URL
URL
URL
URL
URL
URL
URL | []
| [
"TAGS\n#region-us \n"
]
|
1bb44758a559c4c5f9be08f0a6aa1c934a4dd70e | ## Convert conversational QA into statements.
This dataset is a variation on the dataset presented by [Demszky et al](https://arxiv.org/abs/1809.02922).
The main purpose of this work is to convert a series of questions and answers into a full statement representing the last answer. The items in this set are texts as in the following:
```bash
Q: Who built the famous decorated havelis in Rajasthan?
A: Rajput kings
Q: Jaipur is also known as what city?
A: the Pink City
Q: What are the notable houses in it made from?
A: a type of sandstone dominated by a pink hue
Statement:
Notable houses in Jaipur made from a type of sandstone dominated by a pink hue
```
The dataset has been created by limiting the set of [Demszky et al](https://arxiv.org/abs/1809.02922) to the SQUAD items. These questions and answers are made to appear as a conversation by artificially substituting some random entities (chosen from PERSON, GPE, ORG) with the relevant pronoun. For example, in the text above the last question contains "it" to indicate the city of Jaipur. | fractalego/QA_to_statements | [
"arxiv:1809.02922",
"doi:10.57967/hf/0011",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-12-12T17:14:24+00:00 | [
"1809.02922"
]
| []
| TAGS
#arxiv-1809.02922 #doi-10.57967/hf/0011 #region-us
| ## Convert conversational QA into statements.
This dataset is a variation on the dataset presented by Demszky et al.
The main purpose of this work is to convert a series of questions and answers into a full statement representing the last answer. The items in this set are texts as in the following:
The dataset has been created by limiting the set of Demszky et al to the SQUAD items. These questions and answers are made to appear as a conversation by artificially substituting some random entities (chosen from PERSON, GPE, ORG) with the relevant pronoun. For example, in the text above the last question contains "it" to indicate the city of Jaipur. | [
"## Convert conversational QA into statements.\n\nThis dataset is a variation on the dataset presented by Demszky et al.\nThe main purpose of this work is to convert a series of questions and answers into a full statement representing the last answer. The items in this set are texts as in the following:\n\n\n\nThe dataset has been created by limiting the set of Demszky et al to the SQUAD items. These questions and answers are made to appear as a conversation by artificially substituting some random entities (chosen from PERSON, GPE, ORG) with the relevant pronoun. For example, in the text above the last question contains \"it\" to indicate the city of Jaipur."
]
| [
"TAGS\n#arxiv-1809.02922 #doi-10.57967/hf/0011 #region-us \n",
"## Convert conversational QA into statements.\n\nThis dataset is a variation on the dataset presented by Demszky et al.\nThe main purpose of this work is to convert a series of questions and answers into a full statement representing the last answer. The items in this set are texts as in the following:\n\n\n\nThe dataset has been created by limiting the set of Demszky et al to the SQUAD items. These questions and answers are made to appear as a conversation by artificially substituting some random entities (chosen from PERSON, GPE, ORG) with the relevant pronoun. For example, in the text above the last question contains \"it\" to indicate the city of Jaipur."
]
|
23f3bc41eccc91a68a3d4c52125e8c1ec0e1045b | - Model: [OPUS-MT](https://huggingface.co/Helsinki-NLP/opus-mt-es-it)
- Tested on: [Tatoeba]()
<br>
- Metric:
- bleu(tensorflow),
- sacrebleu(github->mjpost),
- google_bleu(nltk),
- rouge(google-research),
- meteor(nltk),
- ter(university of Maryland)
<br>
- Retrieved from: [Huggingface](https://huggingface.co/metrics/) [metrics](https://github.com/huggingface/datasets/blob/master/metrics/)
- Script used for translation and testing: [https://gitlab.com/hmtkvs/machine_translation/-/tree/production-stable](https://gitlab.com/hmtkvs/machine_translation/-/tree/production-stable)
## Info
## mtdata-OPUS Tatoeba (length=14178, single reference)
**bleu** : 0.5228
<br>
**sacrebleu** : 0.5652
<br>
**google_bleu** : 0.5454
<br>
**rouge-mid** : precision=0.7792, recall=0.7899, f_measure=0.7796
<br>
**meteor** : 0.7557
<br>
**ter** : score=0.3003, num_edits= 24654, ref_length= 82079.0
## OPUS Tatoeba (length = 5000, multi references)
**bleu** : 0.5165
<br>
**sacrebleu** : 0.7098
<br>
**google_bleu** : 0.5397
<br>
**rouge-mid** : precision=0.9965, recall=0.5021, f_measure=0.6665
<br>
**meteor** : 0.3344
<br>
**ter** : score: 0.6703, 'num_edits': 38883, 'ref_length': 58000.0 | frtna/es_it_Results-base-OPUS_Tatoeba | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-01-04T04:41:07+00:00 | []
| []
| TAGS
#region-us
| - Model: OPUS-MT
- Tested on: [Tatoeba]()
<br>
- Metric:
- bleu(tensorflow),
- sacrebleu(github->mjpost),
- google_bleu(nltk),
- rouge(google-research),
- meteor(nltk),
- ter(university of Maryland)
<br>
- Retrieved from: Huggingface metrics
- Script used for translation and testing: URL
## Info
## mtdata-OPUS Tatoeba (length=14178, single reference)
bleu : 0.5228
<br>
sacrebleu : 0.5652
<br>
google_bleu : 0.5454
<br>
rouge-mid : precision=0.7792, recall=0.7899, f_measure=0.7796
<br>
meteor : 0.7557
<br>
ter : score=0.3003, num_edits= 24654, ref_length= 82079.0
## OPUS Tatoeba (length = 5000, multi references)
bleu : 0.5165
<br>
sacrebleu : 0.7098
<br>
google_bleu : 0.5397
<br>
rouge-mid : precision=0.9965, recall=0.5021, f_measure=0.6665
<br>
meteor : 0.3344
<br>
ter : score: 0.6703, 'num_edits': 38883, 'ref_length': 58000.0 | [
"## Info",
"## mtdata-OPUS Tatoeba (length=14178, single reference)\nbleu : 0.5228\n<br>\nsacrebleu : 0.5652\n<br>\ngoogle_bleu : 0.5454\n<br>\nrouge-mid : precision=0.7792, recall=0.7899, f_measure=0.7796\n<br>\nmeteor : 0.7557\n<br>\nter : score=0.3003, num_edits= 24654, ref_length= 82079.0",
"## OPUS Tatoeba (length = 5000, multi references)\nbleu : 0.5165\n<br>\nsacrebleu : 0.7098\n<br>\ngoogle_bleu : 0.5397\n<br>\nrouge-mid : precision=0.9965, recall=0.5021, f_measure=0.6665\n<br>\nmeteor : 0.3344\n<br>\nter : score: 0.6703, 'num_edits': 38883, 'ref_length': 58000.0"
]
| [
"TAGS\n#region-us \n",
"## Info",
"## mtdata-OPUS Tatoeba (length=14178, single reference)\nbleu : 0.5228\n<br>\nsacrebleu : 0.5652\n<br>\ngoogle_bleu : 0.5454\n<br>\nrouge-mid : precision=0.7792, recall=0.7899, f_measure=0.7796\n<br>\nmeteor : 0.7557\n<br>\nter : score=0.3003, num_edits= 24654, ref_length= 82079.0",
"## OPUS Tatoeba (length = 5000, multi references)\nbleu : 0.5165\n<br>\nsacrebleu : 0.7098\n<br>\ngoogle_bleu : 0.5397\n<br>\nrouge-mid : precision=0.9965, recall=0.5021, f_measure=0.6665\n<br>\nmeteor : 0.3344\n<br>\nter : score: 0.6703, 'num_edits': 38883, 'ref_length': 58000.0"
]
|
c2c0be202618bd1d4f9254c19607a00edd00174c | annotations_creators:
- expert-generated
language_creators:
- crowdsourced
languages:
- es
- it
licenses:
- cc-by-4.0
multilinguality:
- multilingual
- translation
pretty_name: ''
source_datasets:
- original
task_categories:
- conditional-text-generation
task_ids:
- machine-translation | frtna/opensubtitles_mt | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-12-05T20:53:04+00:00 | []
| []
| TAGS
#region-us
| annotations_creators:
- expert-generated
language_creators:
- crowdsourced
languages:
- es
- it
licenses:
- cc-by-4.0
multilinguality:
- multilingual
- translation
pretty_name: ''
source_datasets:
- original
task_categories:
- conditional-text-generation
task_ids:
- machine-translation | []
| [
"TAGS\n#region-us \n"
]
|
42ad7b4f8e8e8bf31bea20a2d9b9f6fc6b9afd35 | 百度lic2020语言与智能信息竞赛数据集。 | fulai/DuReader | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-04-12T11:07:18+00:00 | []
| []
| TAGS
#region-us
| 百度lic2020语言与智能信息竞赛数据集。 | []
| [
"TAGS\n#region-us \n"
]
|
18b53dd97a3710f0a8621b69b23fb16f1b4fa176 |
# Dataset Card for "MiniNLP"
## Dataset Description
### Dataset Summary
This is a mini-nlp dataset for unitorch package.
### Data Instances
#### plain_text
An example of 'train' looks as follows.
```
{
"id": 1,
"num": 3,
"query": "Is this a test?",
"doc": "train test",
"label": "Good",
"score": 0.882
}
```
### Data Fields
The data fields are the same among all splits.
#### plain_text
- `id`: a `int32` feature.
- `num`: a `int32` feature.
- `query`: a `string` feature.
- `doc`: a `string` feature.
- `label`: a `string` feature.
- `score`: a `float32` feature.
### Data Splits Sample Size
| name |train|validation|test|
|----------|----:|---------:|---:|
|plain_text|15000| 1000 |1000|
| fuliucansheng/mininlp | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-06-30T03:44:01+00:00 | []
| []
| TAGS
#region-us
| Dataset Card for "MiniNLP"
==========================
Dataset Description
-------------------
### Dataset Summary
This is a mini-nlp dataset for unitorch package.
### Data Instances
#### plain\_text
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all splits.
#### plain\_text
* 'id': a 'int32' feature.
* 'num': a 'int32' feature.
* 'query': a 'string' feature.
* 'doc': a 'string' feature.
* 'label': a 'string' feature.
* 'score': a 'float32' feature.
### Data Splits Sample Size
| [
"### Dataset Summary\n\n\nThis is a mini-nlp dataset for unitorch package.",
"### Data Instances",
"#### plain\\_text\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### plain\\_text\n\n\n* 'id': a 'int32' feature.\n* 'num': a 'int32' feature.\n* 'query': a 'string' feature.\n* 'doc': a 'string' feature.\n* 'label': a 'string' feature.\n* 'score': a 'float32' feature.",
"### Data Splits Sample Size"
]
| [
"TAGS\n#region-us \n",
"### Dataset Summary\n\n\nThis is a mini-nlp dataset for unitorch package.",
"### Data Instances",
"#### plain\\_text\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### plain\\_text\n\n\n* 'id': a 'int32' feature.\n* 'num': a 'int32' feature.\n* 'query': a 'string' feature.\n* 'doc': a 'string' feature.\n* 'label': a 'string' feature.\n* 'score': a 'float32' feature.",
"### Data Splits Sample Size"
]
|
fc71d4961071a67e78a9c856c3752c400f890d01 |
# PinoyExchange (PEx) Conversations Dataset
# Summary
PEx Conversations is a dataset composed of collected threads from PinoyExchange.com (Consisting of Tagalog, English, or Taglish responses).
The corpus consists of 45K total scraped threads from 8 subforums. The data only consists of the user message which means any images, videos, links, or any embdedded html are not collected in the scraping process. All characters have been transliterated to its closest ASCII representation, and unicode errors were fixed.
# Format
The data is categorized per category. The objects in the list is composed of:
* category - the category of the threads
* conversations - the list of threads
The threads inside conversations have recursive structure consisting of the following:
* text - This is the response/reply/prompt
* replies - This is a list of the replies to this prompt. The replies inside the list has a structure with the same text and replies component.
# Subforum percentages
The amount of data per subforum are as follows:
* Small Talk - 5K conversations with 1.16M utterances
* Food & Drinks - 8.2K conversations with 273K utterances
* Health & Wellness - 6.3K conversations with 93K utterances
* Body & Fitness - 3.9K conversations with 94K utterances
* Home & Garden - 3.6K conversations with 71K utterances
* Style & Fashion - 9.7K conversations with 197K utterances
* Travel & Leisure - 7.3K conversations with 431K utterances
* Visas & Immigration - 1.1K conversations with 99K utterances
# Model Research
[Tagalog DialoGPT](https://huggingface.co/gabtan99/dialogpt-tagalog-medium) | gabtan99/pex-conversations | [
"task_ids:dialogue-modeling",
"task_ids:language-modeling",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"language:tl",
"language:fil",
"license:unknown",
"multi-turn",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["tl", "fil"], "license": ["unknown"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["sequence-modeling"], "task_ids": ["dialogue-modeling", "language-modeling"], "pretty_name": "PEx Conversations", "tags": ["multi-turn"]} | 2022-10-20T18:34:29+00:00 | []
| [
"tl",
"fil"
]
| TAGS
#task_ids-dialogue-modeling #task_ids-language-modeling #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Tagalog #language-Filipino #license-unknown #multi-turn #region-us
|
# PinoyExchange (PEx) Conversations Dataset
# Summary
PEx Conversations is a dataset composed of collected threads from URL (Consisting of Tagalog, English, or Taglish responses).
The corpus consists of 45K total scraped threads from 8 subforums. The data only consists of the user message which means any images, videos, links, or any embdedded html are not collected in the scraping process. All characters have been transliterated to its closest ASCII representation, and unicode errors were fixed.
# Format
The data is categorized per category. The objects in the list is composed of:
* category - the category of the threads
* conversations - the list of threads
The threads inside conversations have recursive structure consisting of the following:
* text - This is the response/reply/prompt
* replies - This is a list of the replies to this prompt. The replies inside the list has a structure with the same text and replies component.
# Subforum percentages
The amount of data per subforum are as follows:
* Small Talk - 5K conversations with 1.16M utterances
* Food & Drinks - 8.2K conversations with 273K utterances
* Health & Wellness - 6.3K conversations with 93K utterances
* Body & Fitness - 3.9K conversations with 94K utterances
* Home & Garden - 3.6K conversations with 71K utterances
* Style & Fashion - 9.7K conversations with 197K utterances
* Travel & Leisure - 7.3K conversations with 431K utterances
* Visas & Immigration - 1.1K conversations with 99K utterances
# Model Research
Tagalog DialoGPT | [
"# PinoyExchange (PEx) Conversations Dataset",
"# Summary\nPEx Conversations is a dataset composed of collected threads from URL (Consisting of Tagalog, English, or Taglish responses). \n\nThe corpus consists of 45K total scraped threads from 8 subforums. The data only consists of the user message which means any images, videos, links, or any embdedded html are not collected in the scraping process. All characters have been transliterated to its closest ASCII representation, and unicode errors were fixed.",
"# Format\nThe data is categorized per category. The objects in the list is composed of:\n* category - the category of the threads\n* conversations - the list of threads\n\nThe threads inside conversations have recursive structure consisting of the following:\n* text - This is the response/reply/prompt\n* replies - This is a list of the replies to this prompt. The replies inside the list has a structure with the same text and replies component.",
"# Subforum percentages\nThe amount of data per subforum are as follows:\n* Small Talk - 5K conversations with 1.16M utterances\n* Food & Drinks - 8.2K conversations with 273K utterances\n* Health & Wellness - 6.3K conversations with 93K utterances\n* Body & Fitness - 3.9K conversations with 94K utterances\n* Home & Garden - 3.6K conversations with 71K utterances\n* Style & Fashion - 9.7K conversations with 197K utterances\n* Travel & Leisure - 7.3K conversations with 431K utterances\n* Visas & Immigration - 1.1K conversations with 99K utterances",
"# Model Research\nTagalog DialoGPT"
]
| [
"TAGS\n#task_ids-dialogue-modeling #task_ids-language-modeling #multilinguality-multilingual #size_categories-unknown #source_datasets-original #language-Tagalog #language-Filipino #license-unknown #multi-turn #region-us \n",
"# PinoyExchange (PEx) Conversations Dataset",
"# Summary\nPEx Conversations is a dataset composed of collected threads from URL (Consisting of Tagalog, English, or Taglish responses). \n\nThe corpus consists of 45K total scraped threads from 8 subforums. The data only consists of the user message which means any images, videos, links, or any embdedded html are not collected in the scraping process. All characters have been transliterated to its closest ASCII representation, and unicode errors were fixed.",
"# Format\nThe data is categorized per category. The objects in the list is composed of:\n* category - the category of the threads\n* conversations - the list of threads\n\nThe threads inside conversations have recursive structure consisting of the following:\n* text - This is the response/reply/prompt\n* replies - This is a list of the replies to this prompt. The replies inside the list has a structure with the same text and replies component.",
"# Subforum percentages\nThe amount of data per subforum are as follows:\n* Small Talk - 5K conversations with 1.16M utterances\n* Food & Drinks - 8.2K conversations with 273K utterances\n* Health & Wellness - 6.3K conversations with 93K utterances\n* Body & Fitness - 3.9K conversations with 94K utterances\n* Home & Garden - 3.6K conversations with 71K utterances\n* Style & Fashion - 9.7K conversations with 197K utterances\n* Travel & Leisure - 7.3K conversations with 431K utterances\n* Visas & Immigration - 1.1K conversations with 99K utterances",
"# Model Research\nTagalog DialoGPT"
]
|
ae8f1d6bbb8cc1ba94d97b6716507a38a140bf8f | # Test Dataset
Just a test - nothing to see here!
| gar1t/test | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2021-09-15T16:55:27+00:00 | []
| []
| TAGS
#region-us
| # Test Dataset
Just a test - nothing to see here!
| [
"# Test Dataset\n\nJust a test - nothing to see here!"
]
| [
"TAGS\n#region-us \n",
"# Test Dataset\n\nJust a test - nothing to see here!"
]
|
a87ba4c8fed4a8a1f56fd4890b1ad0ba64a2bb79 |
# Dataset Card for frwiki_good_pages_el
## Dataset Description
- Repository: [frwiki_good_pages_el](https://github.com/GaaH/frwiki_good_pages_el)
- Point of Contact: [Gaëtan Caillaut](mailto://[email protected])
### Dataset Summary
This dataset contains _featured_ and _good_ articles from the French Wikipédia. Pages are downloaded, as HTML files, from the [French Wikipedia website](https://fr.wikipedia.org).
It is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.
### Languages
- French
## Dataset Structure
```
{
"title": "Title of the page",
"qid": "QID of the corresponding Wikidata entity",
"words": ["tokens"],
"wikipedia": ["Wikipedia description of each entity"],
"wikidata": ["Wikidata description of each entity"],
"labels": ["NER labels"],
"titles": ["Wikipedia title of each entity"],
"qids": ["QID of each entity"],
}
```
The `words` field contains the article’s text splitted on white-spaces. The other fields are list with same length as `words` and contains data only when the respective token in `words` is the __start of an entity__. For instance, if the _i-th_ token in `words` is an entity, then the _i-th_ element of `wikipedia` contains a description, extracted from Wikipedia, of this entity. The same applies for the other fields. If the entity spans multiple words, then only the index of the first words contains data.
The only exception is the `labels` field, which is used to delimit entities. It uses the IOB encoding: if the token is not part of an entity, the label is `"O"`; if it is the first word of a multi-word entity, the label is `"B"`; otherwise the label is `"I"`. | gcaillaut/frwiki_good_pages_el | [
"task_categories:other",
"annotations_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"language:fr",
"license:wtfpl",
"doi:10.57967/hf/1678",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": [], "language": ["fr"], "license": ["wtfpl"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["other"], "task_ids": [], "pretty_name": "test"} | 2024-01-25T08:38:34+00:00 | []
| [
"fr"
]
| TAGS
#task_categories-other #annotations_creators-machine-generated #multilinguality-monolingual #size_categories-unknown #source_datasets-original #language-French #license-wtfpl #doi-10.57967/hf/1678 #region-us
|
# Dataset Card for frwiki_good_pages_el
## Dataset Description
- Repository: frwiki_good_pages_el
- Point of Contact: Gaëtan Caillaut
### Dataset Summary
This dataset contains _featured_ and _good_ articles from the French Wikipédia. Pages are downloaded, as HTML files, from the French Wikipedia website.
It is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.
### Languages
- French
## Dataset Structure
The 'words' field contains the article’s text splitted on white-spaces. The other fields are list with same length as 'words' and contains data only when the respective token in 'words' is the __start of an entity__. For instance, if the _i-th_ token in 'words' is an entity, then the _i-th_ element of 'wikipedia' contains a description, extracted from Wikipedia, of this entity. The same applies for the other fields. If the entity spans multiple words, then only the index of the first words contains data.
The only exception is the 'labels' field, which is used to delimit entities. It uses the IOB encoding: if the token is not part of an entity, the label is '"O"'; if it is the first word of a multi-word entity, the label is '"B"'; otherwise the label is '"I"'. | [
"# Dataset Card for frwiki_good_pages_el",
"## Dataset Description\n\n- Repository: frwiki_good_pages_el\n- Point of Contact: Gaëtan Caillaut",
"### Dataset Summary\n\nThis dataset contains _featured_ and _good_ articles from the French Wikipédia. Pages are downloaded, as HTML files, from the French Wikipedia website.\n\nIt is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.",
"### Languages\n\n- French",
"## Dataset Structure\n\n\n\nThe 'words' field contains the article’s text splitted on white-spaces. The other fields are list with same length as 'words' and contains data only when the respective token in 'words' is the __start of an entity__. For instance, if the _i-th_ token in 'words' is an entity, then the _i-th_ element of 'wikipedia' contains a description, extracted from Wikipedia, of this entity. The same applies for the other fields. If the entity spans multiple words, then only the index of the first words contains data.\n\nThe only exception is the 'labels' field, which is used to delimit entities. It uses the IOB encoding: if the token is not part of an entity, the label is '\"O\"'; if it is the first word of a multi-word entity, the label is '\"B\"'; otherwise the label is '\"I\"'."
]
| [
"TAGS\n#task_categories-other #annotations_creators-machine-generated #multilinguality-monolingual #size_categories-unknown #source_datasets-original #language-French #license-wtfpl #doi-10.57967/hf/1678 #region-us \n",
"# Dataset Card for frwiki_good_pages_el",
"## Dataset Description\n\n- Repository: frwiki_good_pages_el\n- Point of Contact: Gaëtan Caillaut",
"### Dataset Summary\n\nThis dataset contains _featured_ and _good_ articles from the French Wikipédia. Pages are downloaded, as HTML files, from the French Wikipedia website.\n\nIt is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.",
"### Languages\n\n- French",
"## Dataset Structure\n\n\n\nThe 'words' field contains the article’s text splitted on white-spaces. The other fields are list with same length as 'words' and contains data only when the respective token in 'words' is the __start of an entity__. For instance, if the _i-th_ token in 'words' is an entity, then the _i-th_ element of 'wikipedia' contains a description, extracted from Wikipedia, of this entity. The same applies for the other fields. If the entity spans multiple words, then only the index of the first words contains data.\n\nThe only exception is the 'labels' field, which is used to delimit entities. It uses the IOB encoding: if the token is not part of an entity, the label is '\"O\"'; if it is the first word of a multi-word entity, the label is '\"B\"'; otherwise the label is '\"I\"'."
]
|
493f46641b0e5b43fd139712e7c16acabbe3835c |
# Dataset Card for GermanCommonCrawl
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/German-NLP-Group/german-transformer-training
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [email protected]
### Dataset Summary
German Only Extract from Common Crawl
Stats:
Total Size after Deduplication: 142 Mio Pages / 194 GB (Gzipped)
Total Size before Deduplcation: 263 Mio Pages / 392 GB (Gzipped)
### Supported Tasks and Leaderboards
This Dataset is for pretraining a German Language Model (Unsupervised).
### Languages
German only (Sometimes websites are partially in another Language). One can filter these out through the `language_score` attribute.
## Dataset Structure
### Data Instances
```
{'url': 'http://my-shop.ru/shop/books/545473.html',
'date_download': '2016-10-20T19:38:58Z',
'digest': 'sha1:F62EMGYLZDIKF4UL5JZYU47KWGGUBT7T',
'length': 1155,
'nlines': 4,
'source_domain': 'my-shop.ru',
'title': 'Grammatikalische Liebeslieder. Methodische Vorschläge',
'raw_content': 'Grammatikalische Liebeslieder. [....]',
'cc_segment': 'crawl-data/CC-MAIN-2016-44/segments/1476988717783.68/wet/CC-MAIN-20161020183837-00354-ip-10-171-6-4.ec2.internal.warc.wet.gz',
'original_nlines': 99,
'original_length': 2672,
'language': 'de',
'language_score': 1.0,
'perplexity': 283.0,
'bucket': 'head'}"
```
### Data Fields
### Data Splits
Train only
## Dataset Creation
### Curation Rationale
Handling and Filtering of Common Crawl Data requires large scale Server Ressources at a location in the US (for downloading speed). The total computing time needed to create this dataset is above 100k CPU hours. To give others the opportunity to train models with this dataset easily we make it publicly available.
In most use cases you see an improved Model Performance when extending the pre-training Data so one can achieve highest accuracies as this is probably the largest available dataset.
### Source Data
It was filtered from the Common Crawl Snapshots of the following months:
1. 2015-48
2. 2016-18
3. 2016-44
4. 2017-33
5. 2017-30
6. 2017-30
7. 2017-39
8. 2017-51
9. 2018-09
10. 2018-17
11. 2018-30
12. 2018-39
13. 2018-51
14. 2019-09
15. 2019-18
16. 2019-30
17. 2019-47
18. 2020-10
#### Initial Data Collection and Normalization
Filtering and deduplication of each month seperalety was performed with [CC_Net](https://github.com/facebookresearch/cc_net). The current datasets only contains the best part (head part) with the highest text quality (see CC_Net Paper for more details). Middle and tail part may be uploaded soon as well, or are available on request.
Afterwards this Dataset was deduplicated again to filter out Websites which occur in multiple monthly snapshots. This deduplication removes all Websites which have either the same url or the same hash (this is to filter out websites which are accessible under multiple domains)
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```
@inproceedings{wenzek2020ccnet,
title={CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data},
author={Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm{\'a}n, Francisco and Joulin, Armand and Grave, {\'E}douard},
booktitle={Proceedings of The 12th Language Resources and Evaluation Conference},
pages={4003--4012},
year={2020}
``` | german-nlp-group/german_common_crawl | [
"language:de",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"language": ["de"]} | 2023-10-03T13:50:28+00:00 | []
| [
"de"
]
| TAGS
#language-German #region-us
|
# Dataset Card for GermanCommonCrawl
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
## Dataset Description
- Homepage:
- Repository: URL
- Paper:
- Leaderboard:
- Point of Contact: philipp.reissel@URL
### Dataset Summary
German Only Extract from Common Crawl
Stats:
Total Size after Deduplication: 142 Mio Pages / 194 GB (Gzipped)
Total Size before Deduplcation: 263 Mio Pages / 392 GB (Gzipped)
### Supported Tasks and Leaderboards
This Dataset is for pretraining a German Language Model (Unsupervised).
### Languages
German only (Sometimes websites are partially in another Language). One can filter these out through the 'language_score' attribute.
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
Train only
## Dataset Creation
### Curation Rationale
Handling and Filtering of Common Crawl Data requires large scale Server Ressources at a location in the US (for downloading speed). The total computing time needed to create this dataset is above 100k CPU hours. To give others the opportunity to train models with this dataset easily we make it publicly available.
In most use cases you see an improved Model Performance when extending the pre-training Data so one can achieve highest accuracies as this is probably the largest available dataset.
### Source Data
It was filtered from the Common Crawl Snapshots of the following months:
1. 2015-48
2. 2016-18
3. 2016-44
4. 2017-33
5. 2017-30
6. 2017-30
7. 2017-39
8. 2017-51
9. 2018-09
10. 2018-17
11. 2018-30
12. 2018-39
13. 2018-51
14. 2019-09
15. 2019-18
16. 2019-30
17. 2019-47
18. 2020-10
#### Initial Data Collection and Normalization
Filtering and deduplication of each month seperalety was performed with CC_Net. The current datasets only contains the best part (head part) with the highest text quality (see CC_Net Paper for more details). Middle and tail part may be uploaded soon as well, or are available on request.
Afterwards this Dataset was deduplicated again to filter out Websites which occur in multiple monthly snapshots. This deduplication removes all Websites which have either the same url or the same hash (this is to filter out websites which are accessible under multiple domains)
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
| [
"# Dataset Card for GermanCommonCrawl",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage:\n- Repository: URL\n- Paper: \n- Leaderboard:\n- Point of Contact: philipp.reissel@URL",
"### Dataset Summary\n\nGerman Only Extract from Common Crawl \n\nStats: \n\nTotal Size after Deduplication: 142 Mio Pages / 194 GB (Gzipped)\nTotal Size before Deduplcation: 263 Mio Pages / 392 GB (Gzipped)",
"### Supported Tasks and Leaderboards\n\nThis Dataset is for pretraining a German Language Model (Unsupervised).",
"### Languages\n\nGerman only (Sometimes websites are partially in another Language). One can filter these out through the 'language_score' attribute.",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits\n\nTrain only",
"## Dataset Creation",
"### Curation Rationale\n\nHandling and Filtering of Common Crawl Data requires large scale Server Ressources at a location in the US (for downloading speed). The total computing time needed to create this dataset is above 100k CPU hours. To give others the opportunity to train models with this dataset easily we make it publicly available. \n\nIn most use cases you see an improved Model Performance when extending the pre-training Data so one can achieve highest accuracies as this is probably the largest available dataset.",
"### Source Data\n\nIt was filtered from the Common Crawl Snapshots of the following months: \n\n1. 2015-48\n2. 2016-18 \n3. 2016-44\n4. 2017-33\n5. 2017-30\n6. 2017-30\n7. 2017-39 \n8. 2017-51\n9. 2018-09\n10. 2018-17\n11. 2018-30\n12. 2018-39\n13. 2018-51\n14. 2019-09\n15. 2019-18\n16. 2019-30\n17. 2019-47\n18. 2020-10",
"#### Initial Data Collection and Normalization\n\nFiltering and deduplication of each month seperalety was performed with CC_Net. The current datasets only contains the best part (head part) with the highest text quality (see CC_Net Paper for more details). Middle and tail part may be uploaded soon as well, or are available on request. \n\nAfterwards this Dataset was deduplicated again to filter out Websites which occur in multiple monthly snapshots. This deduplication removes all Websites which have either the same url or the same hash (this is to filter out websites which are accessible under multiple domains)",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information"
]
| [
"TAGS\n#language-German #region-us \n",
"# Dataset Card for GermanCommonCrawl",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage:\n- Repository: URL\n- Paper: \n- Leaderboard:\n- Point of Contact: philipp.reissel@URL",
"### Dataset Summary\n\nGerman Only Extract from Common Crawl \n\nStats: \n\nTotal Size after Deduplication: 142 Mio Pages / 194 GB (Gzipped)\nTotal Size before Deduplcation: 263 Mio Pages / 392 GB (Gzipped)",
"### Supported Tasks and Leaderboards\n\nThis Dataset is for pretraining a German Language Model (Unsupervised).",
"### Languages\n\nGerman only (Sometimes websites are partially in another Language). One can filter these out through the 'language_score' attribute.",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits\n\nTrain only",
"## Dataset Creation",
"### Curation Rationale\n\nHandling and Filtering of Common Crawl Data requires large scale Server Ressources at a location in the US (for downloading speed). The total computing time needed to create this dataset is above 100k CPU hours. To give others the opportunity to train models with this dataset easily we make it publicly available. \n\nIn most use cases you see an improved Model Performance when extending the pre-training Data so one can achieve highest accuracies as this is probably the largest available dataset.",
"### Source Data\n\nIt was filtered from the Common Crawl Snapshots of the following months: \n\n1. 2015-48\n2. 2016-18 \n3. 2016-44\n4. 2017-33\n5. 2017-30\n6. 2017-30\n7. 2017-39 \n8. 2017-51\n9. 2018-09\n10. 2018-17\n11. 2018-30\n12. 2018-39\n13. 2018-51\n14. 2019-09\n15. 2019-18\n16. 2019-30\n17. 2019-47\n18. 2020-10",
"#### Initial Data Collection and Normalization\n\nFiltering and deduplication of each month seperalety was performed with CC_Net. The current datasets only contains the best part (head part) with the highest text quality (see CC_Net Paper for more details). Middle and tail part may be uploaded soon as well, or are available on request. \n\nAfterwards this Dataset was deduplicated again to filter out Websites which occur in multiple monthly snapshots. This deduplication removes all Websites which have either the same url or the same hash (this is to filter out websites which are accessible under multiple domains)",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information"
]
|
e4c5fbd4dec8e46a5dc869216fe1c94cc585757a |
# Dataset Card for arxiv-abstracts-2021
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Needs More Information]
- **Paper:** [Clement et al., 2019, On the Use of ArXiv as a Dataset, https://arxiv.org/abs/1905.00075](https://arxiv.org/abs/1905.00075)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Giancarlo Fissore](mailto:[email protected])
### Dataset Summary
A dataset of metadata including title and abstract for all arXiv articles up to the end of 2021 (~2 million papers).
Possible applications include trend analysis, paper recommender engines, category prediction, knowledge graph construction and semantic search interfaces.
In contrast to [arxiv_dataset](https://huggingface.co/datasets/arxiv_dataset), this dataset doesn't include papers submitted to arXiv after 2021 and it doesn't require any external download.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
English
## Dataset Structure
### Data Instances
Here's an example instance:
```
{
"id": "1706.03762",
"submitter": "Ashish Vaswani",
"authors": "Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion\n Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin",
"title": "Attention Is All You Need",
"comments": "15 pages, 5 figures",
"journal-ref": null,
"doi": null,
"abstract": " The dominant sequence transduction models are based on complex recurrent or\nconvolutional neural
networks in an encoder-decoder configuration. The best\nperforming models also connect the encoder and decoder through
an attention\nmechanism. We propose a new simple network architecture, the Transformer, based\nsolely on attention
mechanisms, dispensing with recurrence and convolutions\nentirely. Experiments on two machine translation tasks show
these models to be\nsuperior in quality while being more parallelizable and requiring significantly\nless time to
train. Our model achieves 28.4 BLEU on the WMT 2014\nEnglish-to-German translation task, improving over the existing
best results,\nincluding ensembles by over 2 BLEU. On the WMT 2014 English-to-French\ntranslation task, our model
establishes a new single-model state-of-the-art\nBLEU score of 41.8 after training for 3.5 days on eight GPUs, a small
fraction\nof the training costs of the best models from the literature. We show that the\nTransformer generalizes well
to other tasks by applying it successfully to\nEnglish constituency parsing both with large and limited training
data.\n",
"report-no": null,
"categories": [
"cs.CL cs.LG"
],
"versions": [
"v1",
"v2",
"v3",
"v4",
"v5"
]
}
```
### Data Fields
These fields are detailed on the [arXiv](https://arxiv.org/help/prep):
- `id`: ArXiv ID (can be used to access the paper)
- `submitter`: Who submitted the paper
- `authors`: Authors of the paper
- `title`: Title of the paper
- `comments`: Additional info, such as number of pages and figures
- `journal-ref`: Information about the journal the paper was published in
- `doi`: [Digital Object Identifier](https://www.doi.org)
- `report-no`: Report Number
- `abstract`: The abstract of the paper
- `categories`: Categories / tags in the ArXiv system
### Data Splits
No splits
## Dataset Creation
### Curation Rationale
For about 30 years, ArXiv has served the public and research communities by providing open access to scholarly articles, from the vast branches of physics to the many subdisciplines of computer science to everything in between, including math, statistics, electrical engineering, quantitative biology, and economics. This rich corpus of information offers significant, but sometimes overwhelming, depth. In these times of unique global challenges, efficient extraction of insights from data is essential. The `arxiv-abstracts-2021` dataset aims at making the arXiv more easily accessible for machine learning applications, by providing important metadata (including title and abstract) for ~2 million papers.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
The language producers are members of the scientific community at large, but not necessarily affiliated to any institution.
### Annotations
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
The full names of the papers' authors are included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The original data is maintained by [ArXiv](https://arxiv.org/)
### Licensing Information
The data is under the [Creative Commons CC0 1.0 Universal Public Domain Dedication](https://creativecommons.org/publicdomain/zero/1.0/)
### Citation Information
```
@misc{clement2019arxiv,
title={On the Use of ArXiv as a Dataset},
author={Colin B. Clement and Matthew Bierbaum and Kevin P. O'Keeffe and Alexander A. Alemi},
year={2019},
eprint={1905.00075},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
``` | gfissore/arxiv-abstracts-2021 | [
"task_categories:summarization",
"task_categories:text-retrieval",
"task_categories:text2text-generation",
"task_ids:explanation-generation",
"task_ids:text-simplification",
"task_ids:document-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"annotations_creators:no-annotation",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"language:en",
"license:cc0-1.0",
"arxiv:1905.00075",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["cc0-1.0"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": [], "task_categories": ["summarization", "text-retrieval", "text2text-generation"], "task_ids": ["explanation-generation", "text-simplification", "document-retrieval", "entity-linking-retrieval", "fact-checking-retrieval"], "pretty_name": "arxiv-abstracts-2021"} | 2022-10-27T16:08:00+00:00 | [
"1905.00075"
]
| [
"en"
]
| TAGS
#task_categories-summarization #task_categories-text-retrieval #task_categories-text2text-generation #task_ids-explanation-generation #task_ids-text-simplification #task_ids-document-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #annotations_creators-no-annotation #language_creators-expert-generated #multilinguality-monolingual #size_categories-1M<n<10M #language-English #license-cc0-1.0 #arxiv-1905.00075 #region-us
|
# Dataset Card for arxiv-abstracts-2021
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
## Dataset Description
- Homepage:
- Repository:
- Paper: Clement et al., 2019, On the Use of ArXiv as a Dataset, URL
- Leaderboard:
- Point of Contact: Giancarlo Fissore
### Dataset Summary
A dataset of metadata including title and abstract for all arXiv articles up to the end of 2021 (~2 million papers).
Possible applications include trend analysis, paper recommender engines, category prediction, knowledge graph construction and semantic search interfaces.
In contrast to arxiv_dataset, this dataset doesn't include papers submitted to arXiv after 2021 and it doesn't require any external download.
### Supported Tasks and Leaderboards
### Languages
English
## Dataset Structure
### Data Instances
Here's an example instance:
### Data Fields
These fields are detailed on the arXiv:
- 'id': ArXiv ID (can be used to access the paper)
- 'submitter': Who submitted the paper
- 'authors': Authors of the paper
- 'title': Title of the paper
- 'comments': Additional info, such as number of pages and figures
- 'journal-ref': Information about the journal the paper was published in
- 'doi': Digital Object Identifier
- 'report-no': Report Number
- 'abstract': The abstract of the paper
- 'categories': Categories / tags in the ArXiv system
### Data Splits
No splits
## Dataset Creation
### Curation Rationale
For about 30 years, ArXiv has served the public and research communities by providing open access to scholarly articles, from the vast branches of physics to the many subdisciplines of computer science to everything in between, including math, statistics, electrical engineering, quantitative biology, and economics. This rich corpus of information offers significant, but sometimes overwhelming, depth. In these times of unique global challenges, efficient extraction of insights from data is essential. The 'arxiv-abstracts-2021' dataset aims at making the arXiv more easily accessible for machine learning applications, by providing important metadata (including title and abstract) for ~2 million papers.
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
The language producers are members of the scientific community at large, but not necessarily affiliated to any institution.
### Annotations
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
The full names of the papers' authors are included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
The original data is maintained by ArXiv
### Licensing Information
The data is under the Creative Commons CC0 1.0 Universal Public Domain Dedication
| [
"# Dataset Card for arxiv-abstracts-2021",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: Clement et al., 2019, On the Use of ArXiv as a Dataset, URL\n- Leaderboard: \n- Point of Contact: Giancarlo Fissore",
"### Dataset Summary\n\nA dataset of metadata including title and abstract for all arXiv articles up to the end of 2021 (~2 million papers).\nPossible applications include trend analysis, paper recommender engines, category prediction, knowledge graph construction and semantic search interfaces.\n\nIn contrast to arxiv_dataset, this dataset doesn't include papers submitted to arXiv after 2021 and it doesn't require any external download.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nEnglish",
"## Dataset Structure",
"### Data Instances\n\nHere's an example instance:",
"### Data Fields\n\nThese fields are detailed on the arXiv:\n\n- 'id': ArXiv ID (can be used to access the paper)\n- 'submitter': Who submitted the paper\n- 'authors': Authors of the paper\n- 'title': Title of the paper\n- 'comments': Additional info, such as number of pages and figures\n- 'journal-ref': Information about the journal the paper was published in\n- 'doi': Digital Object Identifier\n- 'report-no': Report Number\n- 'abstract': The abstract of the paper\n- 'categories': Categories / tags in the ArXiv system",
"### Data Splits\n\nNo splits",
"## Dataset Creation",
"### Curation Rationale\n\nFor about 30 years, ArXiv has served the public and research communities by providing open access to scholarly articles, from the vast branches of physics to the many subdisciplines of computer science to everything in between, including math, statistics, electrical engineering, quantitative biology, and economics. This rich corpus of information offers significant, but sometimes overwhelming, depth. In these times of unique global challenges, efficient extraction of insights from data is essential. The 'arxiv-abstracts-2021' dataset aims at making the arXiv more easily accessible for machine learning applications, by providing important metadata (including title and abstract) for ~2 million papers.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\nThe language producers are members of the scientific community at large, but not necessarily affiliated to any institution.",
"### Annotations",
"#### Annotation process\n\n[N/A]",
"#### Who are the annotators?\n\n[N/A]",
"### Personal and Sensitive Information\n\nThe full names of the papers' authors are included in the dataset.",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators\n\nThe original data is maintained by ArXiv",
"### Licensing Information\n\nThe data is under the Creative Commons CC0 1.0 Universal Public Domain Dedication"
]
| [
"TAGS\n#task_categories-summarization #task_categories-text-retrieval #task_categories-text2text-generation #task_ids-explanation-generation #task_ids-text-simplification #task_ids-document-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #annotations_creators-no-annotation #language_creators-expert-generated #multilinguality-monolingual #size_categories-1M<n<10M #language-English #license-cc0-1.0 #arxiv-1905.00075 #region-us \n",
"# Dataset Card for arxiv-abstracts-2021",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: Clement et al., 2019, On the Use of ArXiv as a Dataset, URL\n- Leaderboard: \n- Point of Contact: Giancarlo Fissore",
"### Dataset Summary\n\nA dataset of metadata including title and abstract for all arXiv articles up to the end of 2021 (~2 million papers).\nPossible applications include trend analysis, paper recommender engines, category prediction, knowledge graph construction and semantic search interfaces.\n\nIn contrast to arxiv_dataset, this dataset doesn't include papers submitted to arXiv after 2021 and it doesn't require any external download.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nEnglish",
"## Dataset Structure",
"### Data Instances\n\nHere's an example instance:",
"### Data Fields\n\nThese fields are detailed on the arXiv:\n\n- 'id': ArXiv ID (can be used to access the paper)\n- 'submitter': Who submitted the paper\n- 'authors': Authors of the paper\n- 'title': Title of the paper\n- 'comments': Additional info, such as number of pages and figures\n- 'journal-ref': Information about the journal the paper was published in\n- 'doi': Digital Object Identifier\n- 'report-no': Report Number\n- 'abstract': The abstract of the paper\n- 'categories': Categories / tags in the ArXiv system",
"### Data Splits\n\nNo splits",
"## Dataset Creation",
"### Curation Rationale\n\nFor about 30 years, ArXiv has served the public and research communities by providing open access to scholarly articles, from the vast branches of physics to the many subdisciplines of computer science to everything in between, including math, statistics, electrical engineering, quantitative biology, and economics. This rich corpus of information offers significant, but sometimes overwhelming, depth. In these times of unique global challenges, efficient extraction of insights from data is essential. The 'arxiv-abstracts-2021' dataset aims at making the arXiv more easily accessible for machine learning applications, by providing important metadata (including title and abstract) for ~2 million papers.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\nThe language producers are members of the scientific community at large, but not necessarily affiliated to any institution.",
"### Annotations",
"#### Annotation process\n\n[N/A]",
"#### Who are the annotators?\n\n[N/A]",
"### Personal and Sensitive Information\n\nThe full names of the papers' authors are included in the dataset.",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators\n\nThe original data is maintained by ArXiv",
"### Licensing Information\n\nThe data is under the Creative Commons CC0 1.0 Universal Public Domain Dedication"
]
|
8f4deb948be91a72eefc1fff64f5e70d1c7dc1de | annotations_creators:
- expert-generated
language_creators:
- expert-generated
languages:
- en
licenses:
- unknown
multilinguality:
- monolingual
paperswithcode_id: bc4chemd
pretty_name: BC4CHEMD
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- named-entity-recognition
# Dataset Card for BC4CHEMD
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:**
https://biocreative.bioinformatics.udel.edu/tasks/biocreative-v/track-3-cdr/
- **Repository:** https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BC4CHEMD
- **Paper:** BioCreative V CDR task corpus: a resource for chemical disease relation extraction
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4860626/
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Zhiyong Lu] (mailto: [email protected])
### Dataset Summary
A corpus for both named entity recognition and chemical-disease relations in the literature. A total of 1500 articles have been annotated with automated assistance from PubTator. Jaccard agreement results and corpus statistics verified the reliability of the corpus.
### Supported Tasks and Leaderboards
named-entity-recognition
### Languages
en
## Dataset Structure
### Data Instances
Instances of the dataset contain an array of `tokens`, `ner_tags` and an `id`. An example of an instance of the dataset:
{
'tokens': ['DPP6','as','a','candidate','gene','for','neuroleptic','-','induced','tardive','dyskinesia','.']
, 'ner_tags': [0,0,0,0,0,0,0,0,0,0,0,0],
'id': '0'
}
### Data Fields
- `id`: Sentence identifier.
- `tokens`: Array of tokens composing a sentence.
- `ner_tags`: Array of tags, where `0` indicates no disease mentioned, `1` signals the first token of a chemical and `2` the subsequent chemical tokens.
### Data Splits
The data is split into a train (3500 instances), validation (3500 instances) and test set (3000 instances).
## Dataset Creation
### Curation Rationale
The goal of the dataset consists on improving the state-of-the-art in chemical name recognition and normalization research, by providing a high-quality gold standard thus enabling the development of machine-learning based approaches for such tasks.
### Source Data
#### Initial Data Collection and Normalization
The dataset consists on abstracts extracted from PubMed.
#### Who are the source language producers?
The source language producers are the authors of publication abstracts hosted in PubMed.
### Annotations
#### Annotation process
The curators were trained to mark up the text according to the labels specified in the guidelines. The raw text was not tokenized prior to the annotation and only the title was distinguished from the PubMed abstract. The selection of text spans was done at the character level, they did not allow nested annotations and distinct entity mentions should not overlap. Each text span was selected according to the annotation guidelines and classified manually into one of the CEM classes.
#### Who are the annotators?
The group of curators used for preparing the annotations was composed mainly of organic chemistry postgraduates with an average experience of 3-4 years in the annotation of chemical names and chemical structures.
### Personal and Sensitive Information
[N/A]
## Considerations for Using the Data
### Social Impact of Dataset
To avoid annotator bias, pairs of annotators were chosen randomly for each set, so that each pair of annotators overlapped for at most two sets.
### Discussion of Biases
The used CHEMDNER document set had to be representative and balanced in order to reflect the kind of documents that might mention the entity of interest.
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
[Needs More Information] | ghadeermobasher/BC5CDR-Chemical-Disease | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-01-25T10:31:51+00:00 | []
| []
| TAGS
#region-us
| annotations_creators:
- expert-generated
language_creators:
- expert-generated
languages:
- en
licenses:
- unknown
multilinguality:
- monolingual
paperswithcode_id: bc4chemd
pretty_name: BC4CHEMD
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- named-entity-recognition
# Dataset Card for BC4CHEMD
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
## Dataset Description
- Homepage:
URL
- Repository: URL
- Paper: BioCreative V CDR task corpus: a resource for chemical disease relation extraction
URL
- Leaderboard:
- Point of Contact: [Zhiyong Lu] (mailto: Zhiyong.Lu@URL)
### Dataset Summary
A corpus for both named entity recognition and chemical-disease relations in the literature. A total of 1500 articles have been annotated with automated assistance from PubTator. Jaccard agreement results and corpus statistics verified the reliability of the corpus.
### Supported Tasks and Leaderboards
named-entity-recognition
### Languages
en
## Dataset Structure
### Data Instances
Instances of the dataset contain an array of 'tokens', 'ner_tags' and an 'id'. An example of an instance of the dataset:
{
'tokens': ['DPP6','as','a','candidate','gene','for','neuroleptic','-','induced','tardive','dyskinesia','.']
, 'ner_tags': [0,0,0,0,0,0,0,0,0,0,0,0],
'id': '0'
}
### Data Fields
- 'id': Sentence identifier.
- 'tokens': Array of tokens composing a sentence.
- 'ner_tags': Array of tags, where '0' indicates no disease mentioned, '1' signals the first token of a chemical and '2' the subsequent chemical tokens.
### Data Splits
The data is split into a train (3500 instances), validation (3500 instances) and test set (3000 instances).
## Dataset Creation
### Curation Rationale
The goal of the dataset consists on improving the state-of-the-art in chemical name recognition and normalization research, by providing a high-quality gold standard thus enabling the development of machine-learning based approaches for such tasks.
### Source Data
#### Initial Data Collection and Normalization
The dataset consists on abstracts extracted from PubMed.
#### Who are the source language producers?
The source language producers are the authors of publication abstracts hosted in PubMed.
### Annotations
#### Annotation process
The curators were trained to mark up the text according to the labels specified in the guidelines. The raw text was not tokenized prior to the annotation and only the title was distinguished from the PubMed abstract. The selection of text spans was done at the character level, they did not allow nested annotations and distinct entity mentions should not overlap. Each text span was selected according to the annotation guidelines and classified manually into one of the CEM classes.
#### Who are the annotators?
The group of curators used for preparing the annotations was composed mainly of organic chemistry postgraduates with an average experience of 3-4 years in the annotation of chemical names and chemical structures.
### Personal and Sensitive Information
[N/A]
## Considerations for Using the Data
### Social Impact of Dataset
To avoid annotator bias, pairs of annotators were chosen randomly for each set, so that each pair of annotators overlapped for at most two sets.
### Discussion of Biases
The used CHEMDNER document set had to be representative and balanced in order to reflect the kind of documents that might mention the entity of interest.
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
| [
"# Dataset Card for BC4CHEMD",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \nURL\n- Repository: URL\n- Paper: BioCreative V CDR task corpus: a resource for chemical disease relation extraction\nURL\n- Leaderboard: \n- Point of Contact: [Zhiyong Lu] (mailto: Zhiyong.Lu@URL)",
"### Dataset Summary\n\nA corpus for both named entity recognition and chemical-disease relations in the literature. A total of 1500 articles have been annotated with automated assistance from PubTator. Jaccard agreement results and corpus statistics verified the reliability of the corpus.",
"### Supported Tasks and Leaderboards\n\nnamed-entity-recognition",
"### Languages\n\nen",
"## Dataset Structure",
"### Data Instances\n\n\nInstances of the dataset contain an array of 'tokens', 'ner_tags' and an 'id'. An example of an instance of the dataset:\n\n{\n 'tokens': ['DPP6','as','a','candidate','gene','for','neuroleptic','-','induced','tardive','dyskinesia','.']\n, 'ner_tags': [0,0,0,0,0,0,0,0,0,0,0,0],\n 'id': '0'\n }",
"### Data Fields\n\n\n- 'id': Sentence identifier. \n- 'tokens': Array of tokens composing a sentence. \n- 'ner_tags': Array of tags, where '0' indicates no disease mentioned, '1' signals the first token of a chemical and '2' the subsequent chemical tokens.",
"### Data Splits\n\n\nThe data is split into a train (3500 instances), validation (3500 instances) and test set (3000 instances).",
"## Dataset Creation",
"### Curation Rationale\n\n The goal of the dataset consists on improving the state-of-the-art in chemical name recognition and normalization research, by providing a high-quality gold standard thus enabling the development of machine-learning based approaches for such tasks.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe dataset consists on abstracts extracted from PubMed.",
"#### Who are the source language producers?\n\n\nThe source language producers are the authors of publication abstracts hosted in PubMed.",
"### Annotations",
"#### Annotation process\n\nThe curators were trained to mark up the text according to the labels specified in the guidelines. The raw text was not tokenized prior to the annotation and only the title was distinguished from the PubMed abstract. The selection of text spans was done at the character level, they did not allow nested annotations and distinct entity mentions should not overlap. Each text span was selected according to the annotation guidelines and classified manually into one of the CEM classes.",
"#### Who are the annotators?\n\nThe group of curators used for preparing the annotations was composed mainly of organic chemistry postgraduates with an average experience of 3-4 years in the annotation of chemical names and chemical structures.",
"### Personal and Sensitive Information\n\n[N/A]",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nTo avoid annotator bias, pairs of annotators were chosen randomly for each set, so that each pair of annotators overlapped for at most two sets.",
"### Discussion of Biases\n\nThe used CHEMDNER document set had to be representative and balanced in order to reflect the kind of documents that might mention the entity of interest.",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information"
]
| [
"TAGS\n#region-us \n",
"# Dataset Card for BC4CHEMD",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Homepage: \nURL\n- Repository: URL\n- Paper: BioCreative V CDR task corpus: a resource for chemical disease relation extraction\nURL\n- Leaderboard: \n- Point of Contact: [Zhiyong Lu] (mailto: Zhiyong.Lu@URL)",
"### Dataset Summary\n\nA corpus for both named entity recognition and chemical-disease relations in the literature. A total of 1500 articles have been annotated with automated assistance from PubTator. Jaccard agreement results and corpus statistics verified the reliability of the corpus.",
"### Supported Tasks and Leaderboards\n\nnamed-entity-recognition",
"### Languages\n\nen",
"## Dataset Structure",
"### Data Instances\n\n\nInstances of the dataset contain an array of 'tokens', 'ner_tags' and an 'id'. An example of an instance of the dataset:\n\n{\n 'tokens': ['DPP6','as','a','candidate','gene','for','neuroleptic','-','induced','tardive','dyskinesia','.']\n, 'ner_tags': [0,0,0,0,0,0,0,0,0,0,0,0],\n 'id': '0'\n }",
"### Data Fields\n\n\n- 'id': Sentence identifier. \n- 'tokens': Array of tokens composing a sentence. \n- 'ner_tags': Array of tags, where '0' indicates no disease mentioned, '1' signals the first token of a chemical and '2' the subsequent chemical tokens.",
"### Data Splits\n\n\nThe data is split into a train (3500 instances), validation (3500 instances) and test set (3000 instances).",
"## Dataset Creation",
"### Curation Rationale\n\n The goal of the dataset consists on improving the state-of-the-art in chemical name recognition and normalization research, by providing a high-quality gold standard thus enabling the development of machine-learning based approaches for such tasks.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe dataset consists on abstracts extracted from PubMed.",
"#### Who are the source language producers?\n\n\nThe source language producers are the authors of publication abstracts hosted in PubMed.",
"### Annotations",
"#### Annotation process\n\nThe curators were trained to mark up the text according to the labels specified in the guidelines. The raw text was not tokenized prior to the annotation and only the title was distinguished from the PubMed abstract. The selection of text spans was done at the character level, they did not allow nested annotations and distinct entity mentions should not overlap. Each text span was selected according to the annotation guidelines and classified manually into one of the CEM classes.",
"#### Who are the annotators?\n\nThe group of curators used for preparing the annotations was composed mainly of organic chemistry postgraduates with an average experience of 3-4 years in the annotation of chemical names and chemical structures.",
"### Personal and Sensitive Information\n\n[N/A]",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nTo avoid annotator bias, pairs of annotators were chosen randomly for each set, so that each pair of annotators overlapped for at most two sets.",
"### Discussion of Biases\n\nThe used CHEMDNER document set had to be representative and balanced in order to reflect the kind of documents that might mention the entity of interest.",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information"
]
|
448370989f17daccc03447dfe16cf588a0075e57 | # AO3 Style Change
A Style Change detection dataset in the style of the PAN21 challenge but on much longer data (>10,000 tokens).
Warning: Due to the fanfiction source, this does contain some NSFW language. | ghomasHudson/ao3_style_change | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-01-09T20:37:28+00:00 | []
| []
| TAGS
#region-us
| # AO3 Style Change
A Style Change detection dataset in the style of the PAN21 challenge but on much longer data (>10,000 tokens).
Warning: Due to the fanfiction source, this does contain some NSFW language. | [
"# AO3 Style Change\nA Style Change detection dataset in the style of the PAN21 challenge but on much longer data (>10,000 tokens).\n\nWarning: Due to the fanfiction source, this does contain some NSFW language."
]
| [
"TAGS\n#region-us \n",
"# AO3 Style Change\nA Style Change detection dataset in the style of the PAN21 challenge but on much longer data (>10,000 tokens).\n\nWarning: Due to the fanfiction source, this does contain some NSFW language."
]
|
b8d98fb25c8aeda712dfc382c5875aee2c2da458 | # HotpotQA-extended
> Version of the HotpotQA dataset with full Wikipedia articles.
The HotpotQA dataset consists of questions from crowd workers which require information from multiple Wikipedia articles in order to answer,thus testing the ability for models to perform multi-hop question answering. The data is commonly presented as a list of paragraphs containing relevant information plus a setting where the addition of ’distractor paragraphs’ fully test the ability of the model to comprehend which information is relevant to the question asked.
In this dataset, we increase the length of the inputs by expanding each paragraph with its full Wikipedia page as well as adding additional distractor articles from similar topics in order to meet the 10,000 token minimum length requirement for this benchmark. | ghomasHudson/hotpotExtended | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-01-13T21:45:03+00:00 | []
| []
| TAGS
#region-us
| # HotpotQA-extended
> Version of the HotpotQA dataset with full Wikipedia articles.
The HotpotQA dataset consists of questions from crowd workers which require information from multiple Wikipedia articles in order to answer,thus testing the ability for models to perform multi-hop question answering. The data is commonly presented as a list of paragraphs containing relevant information plus a setting where the addition of ’distractor paragraphs’ fully test the ability of the model to comprehend which information is relevant to the question asked.
In this dataset, we increase the length of the inputs by expanding each paragraph with its full Wikipedia page as well as adding additional distractor articles from similar topics in order to meet the 10,000 token minimum length requirement for this benchmark. | [
"# HotpotQA-extended\n\n> Version of the HotpotQA dataset with full Wikipedia articles.\n\nThe HotpotQA dataset consists of questions from crowd workers which require information from multiple Wikipedia articles in order to answer,thus testing the ability for models to perform multi-hop question answering. The data is commonly presented as a list of paragraphs containing relevant information plus a setting where the addition of ’distractor paragraphs’ fully test the ability of the model to comprehend which information is relevant to the question asked.\n\nIn this dataset, we increase the length of the inputs by expanding each paragraph with its full Wikipedia page as well as adding additional distractor articles from similar topics in order to meet the 10,000 token minimum length requirement for this benchmark."
]
| [
"TAGS\n#region-us \n",
"# HotpotQA-extended\n\n> Version of the HotpotQA dataset with full Wikipedia articles.\n\nThe HotpotQA dataset consists of questions from crowd workers which require information from multiple Wikipedia articles in order to answer,thus testing the ability for models to perform multi-hop question answering. The data is commonly presented as a list of paragraphs containing relevant information plus a setting where the addition of ’distractor paragraphs’ fully test the ability of the model to comprehend which information is relevant to the question asked.\n\nIn this dataset, we increase the length of the inputs by expanding each paragraph with its full Wikipedia page as well as adding additional distractor articles from similar topics in order to meet the 10,000 token minimum length requirement for this benchmark."
]
|
41ad346644ee5f4284a280a6c001716b5e3d881b | Filtered ContraPro dataset for long document translation. | ghomasHudson/long_contra_pro | [
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {} | 2022-07-07T11:26:30+00:00 | []
| []
| TAGS
#region-us
| Filtered ContraPro dataset for long document translation. | []
| [
"TAGS\n#region-us \n"
]
|
eb92b66ad9d8b6a59cad50beccfc170346a013c8 |
# MuLD
> The Multitask Long Document Benchmark

MuLD (Multitask Long Document Benchmark) is a set of 6 NLP tasks where the inputs consist of at least 10,000 words. The benchmark covers a wide variety of task types including translation, summarization, question answering, and classification. Additionally there is a range of output lengths from a single word classification label all the way up to an output longer than the input text.
- **Repository:** https://github.com/ghomasHudson/muld
- **Paper:** https://arxiv.org/abs/2202.07362
### Supported Tasks and Leaderboards
The 6 MuLD tasks consist of:
- **NarrativeQA** - A question answering dataset requiring an understanding of the plot of books and films.
- **HotpotQA** - An expanded version of HotpotQA requiring multihop reasoning between multiple wikipedia pages. This expanded version includes the full Wikipedia pages.
- **OpenSubtitles** - A translation dataset based on the OpenSubtitles 2018 dataset. The entire subtitles for each tv show is provided, one subtitle per line in both English and German.
- **VLSP (Very Long Scientific Papers)** - An expanded version of the Scientific Papers summarization dataset. Instead of removing very long papers (e.g. thesis), we explicitly include them removing any short papers.
- **AO3 Style Change Detection** - Consists of documents formed from the work of multiple [Archive of Our Own](ao3.org) authors, where the task is to predict the author for each paragraph.
- **Movie Character Types** - Predicting whether a named character is the Hero/Villain given a movie script.
### Dataset Structure
The data is presented in a text-to-text format where each instance contains a input string, output string and (optionally) json encoded metadata.
```
{'input: 'Who was wearing the blue shirt? The beginning...', 'output': ['John'], 'metadata': ''}
```
### Data Fields
- `input`: a string which has a differing structure per task but is presented in a unified format
- `output`: a list of strings where each is a possible answer. Most instances only have a single answer, but some such as narrativeQA and VLSP may have multiple.
- `metadata`: Additional metadata which may be helpful for evaluation. In this version, only the OpenSubtitles task contains metadata (for the ContraPro annotations).
### Data Splits
Each tasks contains different splits depending what was available in the source datasets:
| Task Name | Train | Validation | Test |
|----------------------------|----|----|-----|
| NarrativeQA | ✔️ | ✔️ | ✔️ |
| HotpotQA | ✔️ | ✔️ | |
| AO3 Style Change Detection | ✔️ | ✔️ | ✔️ |
| Movie Character Types | ✔️ | ✔️ | ✔️ |
| VLSP | | | ✔️ |
| OpenSubtitles | ✔️ | | ✔️ |
### Citation Information
```
@misc{hudson2022muld,
title={MuLD: The Multitask Long Document Benchmark},
author={G Thomas Hudson and Noura Al Moubayed},
year={2022},
eprint={2202.07362},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Please also cite the papers directly used in this benchmark. | ghomasHudson/muld | [
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"task_categories:translation",
"task_ids:abstractive-qa",
"annotations_creators:found",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:translation",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"source_datasets:extended|hotpot_qa",
"source_datasets:extended|open_subtitles",
"language:en",
"language:de",
"conditional-text-generation",
"arxiv:2202.07362",
"region:us"
]
| 2022-03-02T23:29:22+00:00 | {"annotations_creators": ["found", "crowdsourced"], "language_creators": ["found"], "language": ["en", "de"], "license": [], "multilinguality": ["translation", "monolingual"], "size_categories": ["unknown"], "source_datasets": ["original", "extended|hotpot_qa", "extended|open_subtitles"], "task_categories": ["question-answering", "summarization", "text-generation", "translation"], "task_ids": ["abstractive-qa"], "pretty_name": "The Multitask Long Document Benchmark", "tags": ["conditional-text-generation"]} | 2022-11-02T12:55:17+00:00 | [
"2202.07362"
]
| [
"en",
"de"
]
| TAGS
#task_categories-question-answering #task_categories-summarization #task_categories-text-generation #task_categories-translation #task_ids-abstractive-qa #annotations_creators-found #annotations_creators-crowdsourced #language_creators-found #multilinguality-translation #multilinguality-monolingual #size_categories-unknown #source_datasets-original #source_datasets-extended|hotpot_qa #source_datasets-extended|open_subtitles #language-English #language-German #conditional-text-generation #arxiv-2202.07362 #region-us
| MuLD
====
>
> The Multitask Long Document Benchmark
>
>
>
 is a set of 6 NLP tasks where the inputs consist of at least 10,000 words. The benchmark covers a wide variety of task types including translation, summarization, question answering, and classification. Additionally there is a range of output lengths from a single word classification label all the way up to an output longer than the input text.
* Repository: URL
* Paper: URL
### Supported Tasks and Leaderboards
The 6 MuLD tasks consist of:
* NarrativeQA - A question answering dataset requiring an understanding of the plot of books and films.
* HotpotQA - An expanded version of HotpotQA requiring multihop reasoning between multiple wikipedia pages. This expanded version includes the full Wikipedia pages.
* OpenSubtitles - A translation dataset based on the OpenSubtitles 2018 dataset. The entire subtitles for each tv show is provided, one subtitle per line in both English and German.
* VLSP (Very Long Scientific Papers) - An expanded version of the Scientific Papers summarization dataset. Instead of removing very long papers (e.g. thesis), we explicitly include them removing any short papers.
* AO3 Style Change Detection - Consists of documents formed from the work of multiple Archive of Our Own authors, where the task is to predict the author for each paragraph.
* Movie Character Types - Predicting whether a named character is the Hero/Villain given a movie script.
### Dataset Structure
The data is presented in a text-to-text format where each instance contains a input string, output string and (optionally) json encoded metadata.
### Data Fields
* 'input': a string which has a differing structure per task but is presented in a unified format
* 'output': a list of strings where each is a possible answer. Most instances only have a single answer, but some such as narrativeQA and VLSP may have multiple.
* 'metadata': Additional metadata which may be helpful for evaluation. In this version, only the OpenSubtitles task contains metadata (for the ContraPro annotations).
### Data Splits
Each tasks contains different splits depending what was available in the source datasets:
Please also cite the papers directly used in this benchmark.
| [
"### Supported Tasks and Leaderboards\n\n\nThe 6 MuLD tasks consist of:\n\n\n* NarrativeQA - A question answering dataset requiring an understanding of the plot of books and films.\n* HotpotQA - An expanded version of HotpotQA requiring multihop reasoning between multiple wikipedia pages. This expanded version includes the full Wikipedia pages.\n* OpenSubtitles - A translation dataset based on the OpenSubtitles 2018 dataset. The entire subtitles for each tv show is provided, one subtitle per line in both English and German.\n* VLSP (Very Long Scientific Papers) - An expanded version of the Scientific Papers summarization dataset. Instead of removing very long papers (e.g. thesis), we explicitly include them removing any short papers.\n* AO3 Style Change Detection - Consists of documents formed from the work of multiple Archive of Our Own authors, where the task is to predict the author for each paragraph.\n* Movie Character Types - Predicting whether a named character is the Hero/Villain given a movie script.",
"### Dataset Structure\n\n\nThe data is presented in a text-to-text format where each instance contains a input string, output string and (optionally) json encoded metadata.",
"### Data Fields\n\n\n* 'input': a string which has a differing structure per task but is presented in a unified format\n* 'output': a list of strings where each is a possible answer. Most instances only have a single answer, but some such as narrativeQA and VLSP may have multiple.\n* 'metadata': Additional metadata which may be helpful for evaluation. In this version, only the OpenSubtitles task contains metadata (for the ContraPro annotations).",
"### Data Splits\n\n\nEach tasks contains different splits depending what was available in the source datasets:\n\n\n\nPlease also cite the papers directly used in this benchmark."
]
| [
"TAGS\n#task_categories-question-answering #task_categories-summarization #task_categories-text-generation #task_categories-translation #task_ids-abstractive-qa #annotations_creators-found #annotations_creators-crowdsourced #language_creators-found #multilinguality-translation #multilinguality-monolingual #size_categories-unknown #source_datasets-original #source_datasets-extended|hotpot_qa #source_datasets-extended|open_subtitles #language-English #language-German #conditional-text-generation #arxiv-2202.07362 #region-us \n",
"### Supported Tasks and Leaderboards\n\n\nThe 6 MuLD tasks consist of:\n\n\n* NarrativeQA - A question answering dataset requiring an understanding of the plot of books and films.\n* HotpotQA - An expanded version of HotpotQA requiring multihop reasoning between multiple wikipedia pages. This expanded version includes the full Wikipedia pages.\n* OpenSubtitles - A translation dataset based on the OpenSubtitles 2018 dataset. The entire subtitles for each tv show is provided, one subtitle per line in both English and German.\n* VLSP (Very Long Scientific Papers) - An expanded version of the Scientific Papers summarization dataset. Instead of removing very long papers (e.g. thesis), we explicitly include them removing any short papers.\n* AO3 Style Change Detection - Consists of documents formed from the work of multiple Archive of Our Own authors, where the task is to predict the author for each paragraph.\n* Movie Character Types - Predicting whether a named character is the Hero/Villain given a movie script.",
"### Dataset Structure\n\n\nThe data is presented in a text-to-text format where each instance contains a input string, output string and (optionally) json encoded metadata.",
"### Data Fields\n\n\n* 'input': a string which has a differing structure per task but is presented in a unified format\n* 'output': a list of strings where each is a possible answer. Most instances only have a single answer, but some such as narrativeQA and VLSP may have multiple.\n* 'metadata': Additional metadata which may be helpful for evaluation. In this version, only the OpenSubtitles task contains metadata (for the ContraPro annotations).",
"### Data Splits\n\n\nEach tasks contains different splits depending what was available in the source datasets:\n\n\n\nPlease also cite the papers directly used in this benchmark."
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.