
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
sequencelengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
sequencelengths 0
25
| languages
sequencelengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
sequencelengths 0
352
| processed_texts
sequencelengths 1
353
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
e588137481883d507f05cb1b4759d20d53ffbf10 |
Currently, a work in progress to publish a modified subset of the openrechtspraak.nl dataset for NLP | Rodekool/ornl8 | [
"license:mit",
"region:us"
] | 2022-06-13T11:10:27+00:00 | {"license": "mit"} | 2023-02-11T09:41:14+00:00 | [] | [] | TAGS
#license-mit #region-us
|
Currently, a work in progress to publish a modified subset of the URL dataset for NLP | [] | [
"TAGS\n#license-mit #region-us \n"
] |
8d51e7e4887a4caaa95b3fbebbf53c0490b58bbb |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://nlp.stanford.edu/sentiment/
- **Repository:**
- **Paper:** [Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank](https://www.aclweb.org/anthology/D13-1170/)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the
compositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005)
and consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and
includes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.
Binary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive
with neutral sentences discarded) refer to the dataset as SST-2 or SST binary.
### Supported Tasks and Leaderboards
- `sentiment-classification`
### Languages
The text in the dataset is in English (`en`).
## Dataset Structure
### Data Instances
```
{'idx': 0,
'sentence': 'hide new secretions from the parental units ',
'label': 0}
```
### Data Fields
- `idx`: Monotonically increasing index ID.
- `sentence`: Complete sentence expressing an opinion about a film.
- `label`: Sentiment of the opinion, either "negative" (0) or positive (1). The test set labels are hidden (-1).
### Data Splits
| | train | validation | test |
|--------------------|---------:|-----------:|-----:|
| Number of examples | 67349 | 872 | 1821 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
Rotten Tomatoes reviewers.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Unknown.
### Citation Information
```bibtex
@inproceedings{socher-etal-2013-recursive,
title = "Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank",
author = "Socher, Richard and
Perelygin, Alex and
Wu, Jean and
Chuang, Jason and
Manning, Christopher D. and
Ng, Andrew and
Potts, Christopher",
booktitle = "Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing",
month = oct,
year = "2013",
address = "Seattle, Washington, USA",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D13-1170",
pages = "1631--1642",
}
```
### Contributions
Thanks to [@albertvillanova](https://github.com/albertvillanova) for adding this dataset. | sst2 | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:unknown",
"region:us"
] | 2022-06-13T13:01:47+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["found"], "language": ["en"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["sentiment-classification"], "paperswithcode_id": "sst", "pretty_name": "Stanford Sentiment Treebank v2", "dataset_info": {"features": [{"name": "idx", "dtype": "int32"}, {"name": "sentence", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "negative", "1": "positive"}}}}], "splits": [{"name": "train", "num_bytes": 4681603, "num_examples": 67349}, {"name": "validation", "num_bytes": 106252, "num_examples": 872}, {"name": "test", "num_bytes": 216640, "num_examples": 1821}], "download_size": 3331058, "dataset_size": 5004495}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}]} | 2024-01-04T16:31:07+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-unknown #region-us
| Dataset Card for [Dataset Name]
===============================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository:
* Paper: Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
* Leaderboard:
* Point of Contact:
### Dataset Summary
The Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the
compositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005)
and consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and
includes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.
Binary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive
with neutral sentences discarded) refer to the dataset as SST-2 or SST binary.
### Supported Tasks and Leaderboards
* 'sentiment-classification'
### Languages
The text in the dataset is in English ('en').
Dataset Structure
-----------------
### Data Instances
### Data Fields
* 'idx': Monotonically increasing index ID.
* 'sentence': Complete sentence expressing an opinion about a film.
* 'label': Sentiment of the opinion, either "negative" (0) or positive (1). The test set labels are hidden (-1).
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
Rotten Tomatoes reviewers.
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Unknown.
### Contributions
Thanks to @albertvillanova for adding this dataset.
| [
"### Dataset Summary\n\n\nThe Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the\ncompositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005)\nand consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and\nincludes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.\n\n\nBinary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive\nwith neutral sentences discarded) refer to the dataset as SST-2 or SST binary.",
"### Supported Tasks and Leaderboards\n\n\n* 'sentiment-classification'",
"### Languages\n\n\nThe text in the dataset is in English ('en').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'idx': Monotonically increasing index ID.\n* 'sentence': Complete sentence expressing an opinion about a film.\n* 'label': Sentiment of the opinion, either \"negative\" (0) or positive (1). The test set labels are hidden (-1).",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\n\nRotten Tomatoes reviewers.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nUnknown.",
"### Contributions\n\n\nThanks to @albertvillanova for adding this dataset."
] | [
"TAGS\n#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-unknown #region-us \n",
"### Dataset Summary\n\n\nThe Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the\ncompositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005)\nand consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and\nincludes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.\n\n\nBinary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive\nwith neutral sentences discarded) refer to the dataset as SST-2 or SST binary.",
"### Supported Tasks and Leaderboards\n\n\n* 'sentiment-classification'",
"### Languages\n\n\nThe text in the dataset is in English ('en').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'idx': Monotonically increasing index ID.\n* 'sentence': Complete sentence expressing an opinion about a film.\n* 'label': Sentiment of the opinion, either \"negative\" (0) or positive (1). The test set labels are hidden (-1).",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\n\nRotten Tomatoes reviewers.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nUnknown.",
"### Contributions\n\n\nThanks to @albertvillanova for adding this dataset."
] |
07c4d89846054c20b3cf55b961ba1c2c31896562 | This is the preprocessed queries from msmarco passage(v1) ranking corpus.
*[MS MARCO: A human generated MAchine Reading COmprehension dataset](https://arxiv.org/pdf/1611.09268.pdf)* SPayal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen,. | jacklin/msmarco_passage_ranking_queries | [
"arxiv:1611.09268",
"region:us"
] | 2022-06-13T19:54:30+00:00 | {} | 2022-06-13T20:46:15+00:00 | [
"1611.09268"
] | [] | TAGS
#arxiv-1611.09268 #region-us
| This is the preprocessed queries from msmarco passage(v1) ranking corpus.
*MS MARCO: A human generated MAchine Reading COmprehension dataset* SPayal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen,. | [] | [
"TAGS\n#arxiv-1611.09268 #region-us \n"
] |
9abcec93c78c145abb4646ac0bd6056f36556e61 | This is the preprocessed data from msmarco passage(v1) ranking corpus.
*[MS MARCO: A human generated MAchine Reading COmprehension dataset](https://arxiv.org/pdf/1611.09268.pdf)* SPayal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen,. | jacklin/msmarco_passage_ranking_corpus | [
"arxiv:1611.09268",
"region:us"
] | 2022-06-13T19:56:40+00:00 | {} | 2022-06-13T20:45:41+00:00 | [
"1611.09268"
] | [] | TAGS
#arxiv-1611.09268 #region-us
| This is the preprocessed data from msmarco passage(v1) ranking corpus.
*MS MARCO: A human generated MAchine Reading COmprehension dataset* SPayal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen,. | [] | [
"TAGS\n#arxiv-1611.09268 #region-us \n"
] |
fa6ae9d93b03e6403e82696496dfbd2cf5c3d3d5 |
# Dataset Card for MAGPIE
## Table of Contents
- [Dataset Card for MAGPIE](#dataset-card-for-itacola)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Original Repository:** [hslh/magpie-corpus](https://github.com/hslh/magpie-corpus)
- **Other Repository:** [vernadankers/mt_idioms](https://github.com/vernadankers/mt_idioms)
- **Original Paper:** [ACL Anthology](https://aclanthology.org/2020.lrec-1.35/)
- **Other Paper:** [ACL Anthology](https://aclanthology.org/2022.acl-long.252/)
- **Point of Contact:** [Hessel Haagsma, Verna Dankers]([email protected])
### Dataset Summary
The MAGPIE corpus ([Haagsma et al. 2020](https://aclanthology.org/2020.lrec-1.35/)) is a large sense-annotated corpus of potentially idiomatic expressions (PIEs), based on the British National Corpus (BNC). Potentially idiomatic expressions are like idiomatic expressions, but the term also covers literal uses of idiomatic expressions, such as 'I leave work at the end of the day.' for the idiom 'at the end of the day'. This version of the dataset reflects the filtered subset used by [Dankers et al. (2022)](https://aclanthology.org/2022.acl-long.252/) in their investigation on how PIEs are represented by NMT models. Authors use 37k samples annotated as fully figurative or literal, for 1482 idioms that contain nouns, numerals or adjectives that are colors (which they refer to as keywords). Because idioms show syntactic and morphological variability, the focus is mostly put on nouns. PIEs and their context are separated using the original corpus’s word-level annotations.
### Languages
The language data in MAGPIE is in English (BCP-47 `en`)
## Dataset Structure
### Data Instances
The `magpie` configuration contains sentences with annotations for the presence, usage an type of potentially idiomatic expressions. An example from the `train` split of the `magpie` config (default) is provided below.
```json
{
'sentence': 'There seems to be a dearth of good small tools across the board.',
'annotation': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
'idiom': 'across the board',
'usage': 'figurative',
'variant': 'identical',
'pos_tags': ['ADV', 'VERB', 'PART', 'VERB', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', 'NOUN', 'ADP', 'DET', 'NOUN']
}
```
The text is provided as-is, without further preprocessing or tokenization.
The fields are the following:
- `sentence`: The sentence containing a PIE.
- `annotation`: List of 0s and 1s of the same length of the whitespace-tokenized sentence, with 1s corresponding to the position of the idiomatic expression.
- `idiom`: The idiom contained in the sentence in its base form.
- `usage`: Either `figurative` or `literal`, depending on the usage of the PIE.
- `variant`: `identical` if the PIE matches the base form of the idiom, otherwise specifies the variation.
- `pos_tags`: List of POS tags associated with words in the sentence.
### Data Splits
| config| train|
|----------:|-----:|
|`magpie` | 44451 |
### Dataset Creation
Please refer to the original article [MAGPIE: A Large Corpus of Potentially Idiomatic Expressions](https://aclanthology.org/2020.lrec-1.35) for additional information on dataset creation, and to the article [Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation](https://aclanthology.org/2022.acl-long.252) for further information on the filtering of selected idioms.
## Additional Information
### Dataset Curators
The original authors are the curators of the original dataset. For problems or updates on this 🤗 Datasets version, please contact [[email protected]](mailto:[email protected]).
### Licensing Information
The dataset is licensed under [Creative Commons 4.0 license (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
Please cite the authors if you use this corpus in your work:
```bibtex
@inproceedings{haagsma-etal-2020-magpie,
title = "{MAGPIE}: A Large Corpus of Potentially Idiomatic Expressions",
author = "Haagsma, Hessel and
Bos, Johan and
Nissim, Malvina",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.35",
pages = "279--287",
language = "English",
ISBN = "979-10-95546-34-4",
}
@inproceedings{dankers-etal-2022-transformer,
title = "Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation",
author = "Dankers, Verna and
Lucas, Christopher and
Titov, Ivan",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.252",
doi = "10.18653/v1/2022.acl-long.252",
pages = "3608--3626",
}
```
| gsarti/magpie | [
"task_categories:text-classification",
"task_categories:text2text-generation",
"task_categories:translation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"idiomaticity-classification",
"region:us"
] | 2022-06-13T19:58:22+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification", "text2text-generation", "translation"], "task_ids": [], "pretty_name": "magpie", "tags": ["idiomaticity-classification"]} | 2022-10-27T07:37:46+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_categories-text2text-generation #task_categories-translation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-4.0 #idiomaticity-classification #region-us
| Dataset Card for MAGPIE
=======================
Table of Contents
-----------------
* Dataset Card for MAGPIE
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Languages
+ Dataset Structure
- Data Instances
- Data Splits
- Dataset Creation
+ Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
Dataset Description
-------------------
* Original Repository: hslh/magpie-corpus
* Other Repository: vernadankers/mt\_idioms
* Original Paper: ACL Anthology
* Other Paper: ACL Anthology
* Point of Contact: Hessel Haagsma, Verna Dankers
### Dataset Summary
The MAGPIE corpus (Haagsma et al. 2020) is a large sense-annotated corpus of potentially idiomatic expressions (PIEs), based on the British National Corpus (BNC). Potentially idiomatic expressions are like idiomatic expressions, but the term also covers literal uses of idiomatic expressions, such as 'I leave work at the end of the day.' for the idiom 'at the end of the day'. This version of the dataset reflects the filtered subset used by Dankers et al. (2022) in their investigation on how PIEs are represented by NMT models. Authors use 37k samples annotated as fully figurative or literal, for 1482 idioms that contain nouns, numerals or adjectives that are colors (which they refer to as keywords). Because idioms show syntactic and morphological variability, the focus is mostly put on nouns. PIEs and their context are separated using the original corpus’s word-level annotations.
### Languages
The language data in MAGPIE is in English (BCP-47 'en')
Dataset Structure
-----------------
### Data Instances
The 'magpie' configuration contains sentences with annotations for the presence, usage an type of potentially idiomatic expressions. An example from the 'train' split of the 'magpie' config (default) is provided below.
The text is provided as-is, without further preprocessing or tokenization.
The fields are the following:
* 'sentence': The sentence containing a PIE.
* 'annotation': List of 0s and 1s of the same length of the whitespace-tokenized sentence, with 1s corresponding to the position of the idiomatic expression.
* 'idiom': The idiom contained in the sentence in its base form.
* 'usage': Either 'figurative' or 'literal', depending on the usage of the PIE.
* 'variant': 'identical' if the PIE matches the base form of the idiom, otherwise specifies the variation.
* 'pos\_tags': List of POS tags associated with words in the sentence.
### Data Splits
### Dataset Creation
Please refer to the original article MAGPIE: A Large Corpus of Potentially Idiomatic Expressions for additional information on dataset creation, and to the article Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation for further information on the filtering of selected idioms.
Additional Information
----------------------
### Dataset Curators
The original authors are the curators of the original dataset. For problems or updates on this Datasets version, please contact gabriele.sarti996@URL.
### Licensing Information
The dataset is licensed under Creative Commons 4.0 license (CC-BY-4.0)
Please cite the authors if you use this corpus in your work:
| [
"### Dataset Summary\n\n\nThe MAGPIE corpus (Haagsma et al. 2020) is a large sense-annotated corpus of potentially idiomatic expressions (PIEs), based on the British National Corpus (BNC). Potentially idiomatic expressions are like idiomatic expressions, but the term also covers literal uses of idiomatic expressions, such as 'I leave work at the end of the day.' for the idiom 'at the end of the day'. This version of the dataset reflects the filtered subset used by Dankers et al. (2022) in their investigation on how PIEs are represented by NMT models. Authors use 37k samples annotated as fully figurative or literal, for 1482 idioms that contain nouns, numerals or adjectives that are colors (which they refer to as keywords). Because idioms show syntactic and morphological variability, the focus is mostly put on nouns. PIEs and their context are separated using the original corpus’s word-level annotations.",
"### Languages\n\n\nThe language data in MAGPIE is in English (BCP-47 'en')\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe 'magpie' configuration contains sentences with annotations for the presence, usage an type of potentially idiomatic expressions. An example from the 'train' split of the 'magpie' config (default) is provided below.\n\n\nThe text is provided as-is, without further preprocessing or tokenization.\n\n\nThe fields are the following:\n\n\n* 'sentence': The sentence containing a PIE.\n* 'annotation': List of 0s and 1s of the same length of the whitespace-tokenized sentence, with 1s corresponding to the position of the idiomatic expression.\n* 'idiom': The idiom contained in the sentence in its base form.\n* 'usage': Either 'figurative' or 'literal', depending on the usage of the PIE.\n* 'variant': 'identical' if the PIE matches the base form of the idiom, otherwise specifies the variation.\n* 'pos\\_tags': List of POS tags associated with words in the sentence.",
"### Data Splits",
"### Dataset Creation\n\n\nPlease refer to the original article MAGPIE: A Large Corpus of Potentially Idiomatic Expressions for additional information on dataset creation, and to the article Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation for further information on the filtering of selected idioms.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe original authors are the curators of the original dataset. For problems or updates on this Datasets version, please contact gabriele.sarti996@URL.",
"### Licensing Information\n\n\nThe dataset is licensed under Creative Commons 4.0 license (CC-BY-4.0)\n\n\nPlease cite the authors if you use this corpus in your work:"
] | [
"TAGS\n#task_categories-text-classification #task_categories-text2text-generation #task_categories-translation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-4.0 #idiomaticity-classification #region-us \n",
"### Dataset Summary\n\n\nThe MAGPIE corpus (Haagsma et al. 2020) is a large sense-annotated corpus of potentially idiomatic expressions (PIEs), based on the British National Corpus (BNC). Potentially idiomatic expressions are like idiomatic expressions, but the term also covers literal uses of idiomatic expressions, such as 'I leave work at the end of the day.' for the idiom 'at the end of the day'. This version of the dataset reflects the filtered subset used by Dankers et al. (2022) in their investigation on how PIEs are represented by NMT models. Authors use 37k samples annotated as fully figurative or literal, for 1482 idioms that contain nouns, numerals or adjectives that are colors (which they refer to as keywords). Because idioms show syntactic and morphological variability, the focus is mostly put on nouns. PIEs and their context are separated using the original corpus’s word-level annotations.",
"### Languages\n\n\nThe language data in MAGPIE is in English (BCP-47 'en')\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe 'magpie' configuration contains sentences with annotations for the presence, usage an type of potentially idiomatic expressions. An example from the 'train' split of the 'magpie' config (default) is provided below.\n\n\nThe text is provided as-is, without further preprocessing or tokenization.\n\n\nThe fields are the following:\n\n\n* 'sentence': The sentence containing a PIE.\n* 'annotation': List of 0s and 1s of the same length of the whitespace-tokenized sentence, with 1s corresponding to the position of the idiomatic expression.\n* 'idiom': The idiom contained in the sentence in its base form.\n* 'usage': Either 'figurative' or 'literal', depending on the usage of the PIE.\n* 'variant': 'identical' if the PIE matches the base form of the idiom, otherwise specifies the variation.\n* 'pos\\_tags': List of POS tags associated with words in the sentence.",
"### Data Splits",
"### Dataset Creation\n\n\nPlease refer to the original article MAGPIE: A Large Corpus of Potentially Idiomatic Expressions for additional information on dataset creation, and to the article Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation for further information on the filtering of selected idioms.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe original authors are the curators of the original dataset. For problems or updates on this Datasets version, please contact gabriele.sarti996@URL.",
"### Licensing Information\n\n\nThe dataset is licensed under Creative Commons 4.0 license (CC-BY-4.0)\n\n\nPlease cite the authors if you use this corpus in your work:"
] |
17dd9ee9f25a6d4c64be14e32af198cac68f6638 |
# Dataset Card for "PiC: Phrase Retrieval"
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://phrase-in-context.github.io/](https://phrase-in-context.github.io/)
- **Repository:** [https://github.com/phrase-in-context](https://github.com/phrase-in-context)
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [Thang Pham](<[email protected]>)
### Dataset Summary
PR is a phrase retrieval task with the goal of finding a phrase **t** in a given document **d** such that **t** is semantically similar to the query phrase, which is the paraphrase **q**<sub>1</sub> provided by annotators.
We release two versions of PR: **PR-pass** and **PR-page**, i.e., datasets of 3-tuples (query **q**<sub>1</sub>, target phrase **t**, document **d**) where **d** is a random 11-sentence passage that contains **t** or an entire Wikipedia page.
While PR-pass contains 28,147 examples, PR-page contains slightly fewer examples (28,098) as we remove those trivial examples whose Wikipedia pages contain exactly the query phrase (in addition to the target phrase).
Both datasets are split into 5K/3K/~20K for test/dev/train, respectively.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English.
## Dataset Structure
### Data Instances
**PR-pass**
* Size of downloaded dataset files: 43.61 MB
* Size of the generated dataset: 36.98 MB
* Total amount of disk used: 80.59 MB
An example of 'train' looks as follows.
```
{
"id": "3478-1",
"title": "https://en.wikipedia.org/wiki?curid=181261",
"context": "The 425t was a 'pizza box' design with a single network expansion slot. The 433s was a desk-side server systems with multiple expansion slots. Compatibility. PC compatibility was possible either through software emulation, using the optional product DPCE, or through a plug-in card carrying an Intel 80286 processor. A third-party plug-in card with a 386 was also available. An Apollo Token Ring network card could also be placed in a standard PC and network drivers allowed it to connect to a server running a PC SMB (Server Message Block) file server. Usage. Although Apollo systems were easy to use and administer, they became less cost-effective because the proprietary operating system made software more expensive than Unix software. The 68K processors were slower than the new RISC chips from Sun and Hewlett-Packard. Apollo addressed both problems by introducing the RISC-based DN10000 and Unix-friendly Domain/OS operating system. However, the DN10000, though fast, was extremely expensive, and a reliable version of Domain/OS came too late to make a difference.",
"query": "dependable adaptation",
"answers": {
"text": ["reliable version"],
"answer_start": [1006]
}
}
```
**PR-page**
* Size of downloaded dataset files: 421.56 MB
* Size of the generated dataset: 412.17 MB
* Total amount of disk used: 833.73 MB
An example of 'train' looks as follows.
```
{
"id": "5961-2",
"title": "https://en.wikipedia.org/wiki?curid=354711",
"context": "Joseph Locke FRSA (9 August 1805 – 18 September 1860) was a notable English civil engineer of the nineteenth century, particularly associated with railway projects. Locke ranked alongside Robert Stephenson and Isambard Kingdom Brunel as one of the major pioneers of railway development. Early life and career. Locke was born in Attercliffe, Sheffield in Yorkshire, moving to nearby Barnsley when he was five. By the age of 17, Joseph had already served an apprenticeship under William Stobart at Pelaw, on the south bank of the Tyne, and under his own father, William. He was an experienced mining engineer, able to survey, sink shafts, to construct railways, tunnels and stationary engines. Joseph's father had been a manager at Wallbottle colliery on Tyneside when George Stephenson was a fireman there. In 1823, when Joseph was 17, Stephenson was involved with planning the Stockton and Darlington Railway. He and his son Robert Stephenson visited William Locke and his son at Barnsley and it was arranged that Joseph would go to work for the Stephensons. The Stephensons established a locomotive works near Forth Street, Newcastle upon Tyne, to manufacture locomotives for the new railway. Joseph Locke, despite his youth, soon established a position of authority. He and Robert Stephenson became close friends, but their friendship was interrupted, in 1824, by Robert leaving to work in Colombia for three years. Liverpool and Manchester Railway. George Stephenson carried out the original survey of the line of the Liverpool and Manchester Railway, but this was found to be flawed, and the line was re-surveyed by a talented young engineer, Charles Vignoles. Joseph Locke was asked by the directors to carry out another survey of the proposed tunnel works and produce a report. The report was highly critical of the work already done, which reflected badly on Stephenson. Stephenson was furious and henceforth relations between the two men were strained, although Locke continued to be employed by Stephenson, probably because the latter recognised his worth. Despite the many criticisms of Stephenson's work, when the bill for the new line was finally passed, in 1826, Stephenson was appointed as engineer and he appointed Joseph Locke as his assistant to work alongside Vignoles, who was the other assistant. However, a clash of personalities between Stephenson and Vignoles led to the latter resigning, leaving Locke as the sole assistant engineer. Locke took over responsibility for the western half of the line. One of the major obstacles to be overcome was Chat Moss, a large bog that had to be crossed. Although, Stephenson usually gets the credit for this feat, it is believed that it was Locke who suggested the correct method for crossing the bog. Whilst the line was being built, the directors were trying to decide whether to use standing engines or locomotives to propel the trains. Robert Stephenson and Joseph Locke were convinced that locomotives were vastly superior, and in March 1829 the two men wrote a report demonstrating the superiority of locomotives when used on a busy railway. The report led to the decision by the directors to hold an open trial to find the best locomotive. This was the Rainhill Trials, which were run in October 1829, and were won by \"Rocket\". When the line was finally opened in 1830, it was planned for a procession of eight trains to travel from Liverpool to Manchester and back. George Stephenson drove the leading locomotive \"Northumbrian\" and Joseph Locke drove \"Rocket\". The day was marred by the death of William Huskisson, the Member of Parliament for Liverpool, who was struck and killed by \"Rocket\". Grand Junction Railway. In 1829 Locke was George Stephenson's assistant, given the job of surveying the route for the Grand Junction Railway. This new railway was to join Newton-le-Willows on the Liverpool and Manchester Railway with Warrington and then on to Birmingham via Crewe, Stafford and Wolverhampton, a total of 80 miles. Locke is credited with choosing the location for Crewe and recommending the establishment there of shops required for the building and repairs of carriages and wagons as well as engines. During the construction of the Liverpool and Manchester Railway, Stephenson had shown a lack of ability in organising major civil engineering projects. On the other hand, Locke's ability to manage complex projects was well known. The directors of the new railway decided on a compromise whereby Locke was made responsible for the northern half of the line and Stephenson was made responsible for the southern half. However Stephenson's administrative inefficiency soon became apparent, whereas Locke estimated the costs for his section of the line so meticulously and speedily, that he had all of the contracts signed for his section of the line before a single one had been signed for Stephenson's section. The railway company lost patience with Stephenson, but tried to compromise by making both men joint-engineers. Stephenson's pride would not let him accept this, and so he resigned from the project. By autumn of 1835 Locke had become chief engineer for the whole of the line. This caused a rift between the two men, and strained relations between Locke and Robert Stephenson. Up to this point, Locke had always been under George Stephenson's shadow. From then on, he would be his own man, and stand or fall by his own achievements. The line was opened on 4 July 1837. New methods. Locke's route avoided as far as possible major civil engineering works. The main one was the Dutton Viaduct which crosses the River Weaver and the Weaver Navigation between the villages of Dutton and Acton Bridge in Cheshire. The viaduct consists of 20 arches with spans of 20 yards. An important feature of the new railway was the use of double-headed (dumb-bell) wrought-iron rail supported on timber sleepers at 2 ft 6 in intervals. It was intended that when the rails became worn they could be turned over to use the other surface, but in practice it was found that the chairs into which the rails were keyed caused wear to the bottom surface so that it became uneven. However this was still an improvement on the fish-bellied, wrought-iron rails still being used by Robert Stephenson on the London and Birmingham Railway. Locke was more careful than Stephenson to get value for his employers' money. For the Penkridge Viaduct Stephenson had obtained a tender of £26,000. After Locke took over, he gave the potential contractor better information and agreed a price of only £6,000. Locke also tried to avoid tunnels because in those days tunnels often took longer and cost more than planned. The Stephensons regarded 1 in 330 as the maximum slope that an engine could manage and Robert Stephenson achieved this on the London and Birmingham Railway by using seven tunnels which added both cost and delay. Locke avoided tunnels almost completely on the Grand Junction but exceeded the slope limit for six miles south of Crewe. Proof of Locke's ability to estimate costs accurately is given by the fact that the construction of the Grand Junction line cost £18,846 per mile as against Locke's estimate of £17,000. This is amazingly accurate compared with the estimated costs for the London and Birmingham Railway (Robert Stephenson) and the Great Western Railway (Brunel). Locke also divided the project into a few large sections rather than many small ones. This allowed him to work closely with his contractors to develop the best methods, overcome problems and personally gain practical experience of the building process and of the contractors themselves. He used the contractors who worked well with him, especially Thomas Brassey and William Mackenzie, on many other projects. Everyone gained from this cooperative approach whereas Brunel's more adversarial approach eventually made it hard for him to get anyone to work for him. Marriage. In 1834 Locke married Phoebe McCreery, with whom he adopted a child. He was elected to the Royal Society in 1838. Lancaster and Carlisle Railway. A significant difference in philosophy between George Stephenson and Joseph Locke and the surveying methods they employed was more than a mere difference of opinion. Stephenson had started his career at a time when locomotives had little power to overcome excessive gradients. Both George and Robert Stephenson were prepared to go to great lengths to avoid steep gradients that would tax the locomotives of the day, even if this meant choosing a circuitous path that added on extra miles to the line of the route. Locke had more confidence in the ability of modern locomotives to climb these gradients. An example of this was the Lancaster and Carlisle Railway, which had to cope with the barrier of the Lake District mountains. In 1839 Stephenson proposed a circuitous route that avoided the Lake District altogether by going all the way round Morecambe Bay and West Cumberland, claiming: 'This is the only practicable line from Liverpool to Carlisle. The making of a railway across Shap Fell is out of the question.' The directors rejected his route and chose the one proposed by Joseph Locke, one that used steep gradients and passed over Shap Fell. The line was completed by Locke and was a success. Locke's reasoned that by avoiding long routes and tunnelling, the line could be finished more quickly, with less capital costs, and could start earning revenue sooner. This became known as the 'up and over' school of engineering (referred to by Rolt as 'Up and Down,' or Rollercoaster). Locke took a similar approach in planning the Caledonian Railway, from Carlisle to Glasgow. In both railways he introduced gradients of 1 in 75, which severely taxed fully laden locomotives, for even as more powerful locomotives were introduced, the trains that they pulled became heavier. It may therefore be argued that Locke, although his philosophy carried the day, was not entirely correct in his reasoning. Even today, Shap Fell is a severe test of any locomotive. Manchester and Sheffield Railway. Locke was subsequently appointed to build a railway line from Manchester to Sheffield, replacing Charles Vignoles as chief engineer, after the latter had been beset by misfortunes and financial difficulties. The project included the three-mile Woodhead Tunnel, and the line opened, after many delays, on 23 December 1845. The building of the line required over a thousand navvies and cost the lives of thirty-two of them, seriously injuring 140 others. The Woodhead Tunnel was such a difficult undertaking that George Stephenson claimed that it could not be done, declaring that he would eat the first locomotive that got through the tunnel. Subsequent commissions. In the north, Locke also designed the Lancaster and Preston Junction Railway; the Glasgow, Paisley and Greenock Railway; and the Caledonian Railway from Carlisle to Glasgow and Edinburgh. In the south, he worked on the London and Southampton Railway, later called the London and South Western Railway, designing, among other structures, Nine Elms to Waterloo Viaduct, Richmond Railway Bridge (1848, since replaced), and Barnes Bridge (1849), both across the River Thames, tunnels at Micheldever, and the 12-arch Quay Street viaduct and the 16-arch Cams Hill viaduct, both in Fareham (1848). He was actively involved in planning and building many railways in Europe (assisted by John Milroy), including the Le Havre, Rouen, Paris rail link, the Barcelona to Mataró line and the Dutch Rhenish Railway. He was present in Paris when the Versailles train crash occurred in 1842, and produced a statement concerning the facts for General Charles Pasley of the Railway Inspectorate. He also experienced a catastrophic failure of one of his viaducts built on the new Paris-Le Havre link. . The viaduct was of stone and brick at Barentin near Rouen, and was the longest and highest on the line. It was 108 feet high, and consisted of 27 arches, each 50 feet wide, with a total length of over 1600 feet. A boy hauling ballast for the line up an adjoining hillside early that morning (about 6.00 am) saw one arch (the fifth on the Rouen side) collapse, and the rest followed suit. Fortunately, no one was killed, although several workmen were injured in a mill below the structure. Locke attributed the catastrophic failure to frost action on the new lime cement, and premature off-centre loading of the viaduct with ballast. It was rebuilt at Thomas Brassey's cost, and survives to the present. Having pioneered many new lines in France, Locke also helped establish the first locomotive works in the country. Distinctive features of Locke's railway works were economy, the use of masonry bridges wherever possible and the absence of tunnels. An illustration of this is that there is no tunnel between Birmingham and Glasgow. Relationship with Robert Stephenson. Locke and Robert Stephenson had been good friends at the beginning of their careers, but their friendship had been marred by Locke's falling out with Robert's father. It seems that Robert felt loyalty to his father required that he should take his side. It is significant that after the death of George Stephenson in August 1848, the friendship of the two men was revived. When Robert Stephenson died in October 1859, Joseph Locke was a pallbearer at his funeral. Locke is reported to have referred to Robert as 'the friend of my youth, the companion of my ripening years, and a competitor in the race of life'. Locke was also on friendly terms with his other engineering rival, Isambard Kingdom Brunel. In 1845, Locke and Stephenson were both called to give evidence before two committees. In April a House of Commons Select Committee was investigating the atmospheric railway system proposed by Brunel. Brunel and Vignoles spoke in support of the system, whilst Locke and Stephenson spoke against it. The latter two were to be proved right in the long run. In August the two gave evidence before the Gauge Commissioners who were trying to arrive at a standard gauge for the whole country. Brunel spoke in favour of the 7 ft gauge he was using on the Great Western Railway. Locke and Stephenson spoke in favour of the 4 ft 8½in gauge that they had used on several lines. The latter two won the day and their gauge was adopted as the standard. Later life and legacy. Locke served as President of the Institution of Civil Engineers in between December 1857 and December 1859. He also served as Member of Parliament for Honiton in Devon from 1847 until his death. Joseph Locke died on 18 September 1860, apparently from appendicitis, whilst on a shooting holiday. He is buried in London's Kensal Green Cemetery. He outlived his friends/rivals Robert Stephenson and Isambard Brunel by less than a year; all three engineers died between 53 and 56 years of age, a circumstance attributed by Rolt to sheer overwork, accomplishing more in their brief lives than many achieve in a full three score and ten. Locke Park in Barnsley was dedicated to his memory by his widow Phoebe in 1862. It features a statue of Locke plus a folly, 'Locke Tower'. Locke's greatest legacy is the modern day West Coast Main Line (WCML), which was formed by the joining of the Caledonian, Lancaster & Carlisle, Grand Junction railways to Robert Stephenson's London & Birmingham Railway. As a result, around three-quarters of the WCML's route was planned and engineered by Locke.",
"query": "accurate approach",
"answers": {
"text": ["correct method"],
"answer_start": [2727]
}
}
```
### Data Fields
The data fields are the same among all subsets and splits.
* id: a string feature.
* title: a string feature.
* context: a string feature.
* question: a string feature.
* answers: a dictionary feature containing:
* text: a list of string features.
* answer_start: a list of int32 features.
### Data Splits
| name |train|validation|test|
|--------------------|----:|---------:|---:|
|PR-pass |20147| 3000|5000|
|PR-page |20098| 3000|5000|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from [Upwork.com](https://upwork.com).
#### Who are the source language producers?
We hired 13 linguistic experts from [Upwork.com](https://upwork.com) for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
13 linguistic experts from [Upwork.com](https://upwork.com).
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: [Thang M. Pham](https://scholar.google.com/citations?user=eNrX3mYAAAAJ), [David Seunghyun Yoon](https://david-yoon.github.io/), [Trung Bui](https://sites.google.com/site/trungbuistanford/), and [Anh Nguyen](https://anhnguyen.me).
[@PMThangXAI](https://twitter.com/pmthangxai) added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under [Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/)
### Citation Information
```
@article{pham2022PiC,
title={PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search},
author={Pham, Thang M and Yoon, Seunghyun and Bui, Trung and Nguyen, Anh},
journal={arXiv preprint arXiv:2207.09068},
year={2022}
}
``` | PiC/phrase_retrieval | [
"task_categories:text-retrieval",
"annotations_creators:expert-generated",
"language_creators:found",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] | 2022-06-13T19:58:56+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found", "expert-generated"], "language": ["en"], "license": ["cc-by-nc-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-retrieval"], "task_ids": [], "paperswithcode_id": "phrase-in-context", "pretty_name": "PiC: Phrase Retrieval"} | 2023-01-20T16:32:55+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us
| Dataset Card for "PiC: Phrase Retrieval"
========================================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact: Thang Pham
### Dataset Summary
PR is a phrase retrieval task with the goal of finding a phrase t in a given document d such that t is semantically similar to the query phrase, which is the paraphrase q1 provided by annotators.
We release two versions of PR: PR-pass and PR-page, i.e., datasets of 3-tuples (query q1, target phrase t, document d) where d is a random 11-sentence passage that contains t or an entire Wikipedia page.
While PR-pass contains 28,147 examples, PR-page contains slightly fewer examples (28,098) as we remove those trivial examples whose Wikipedia pages contain exactly the query phrase (in addition to the target phrase).
Both datasets are split into 5K/3K/~20K for test/dev/train, respectively.
### Supported Tasks and Leaderboards
### Languages
English.
Dataset Structure
-----------------
### Data Instances
PR-pass
* Size of downloaded dataset files: 43.61 MB
* Size of the generated dataset: 36.98 MB
* Total amount of disk used: 80.59 MB
An example of 'train' looks as follows.
PR-page
* Size of downloaded dataset files: 421.56 MB
* Size of the generated dataset: 412.17 MB
* Total amount of disk used: 833.73 MB
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all subsets and splits.
* id: a string feature.
* title: a string feature.
* context: a string feature.
* question: a string feature.
* answers: a dictionary feature containing:
+ text: a list of string features.
+ answer\_start: a list of int32 features.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.
#### Who are the source language producers?
We hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
#### Who are the annotators?
13 linguistic experts from URL.
### Personal and Sensitive Information
No annotator identifying details are provided.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.
@PMThangXAI added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)
| [
"### Dataset Summary\n\n\nPR is a phrase retrieval task with the goal of finding a phrase t in a given document d such that t is semantically similar to the query phrase, which is the paraphrase q1 provided by annotators.\nWe release two versions of PR: PR-pass and PR-page, i.e., datasets of 3-tuples (query q1, target phrase t, document d) where d is a random 11-sentence passage that contains t or an entire Wikipedia page.\nWhile PR-pass contains 28,147 examples, PR-page contains slightly fewer examples (28,098) as we remove those trivial examples whose Wikipedia pages contain exactly the query phrase (in addition to the target phrase).\nBoth datasets are split into 5K/3K/~20K for test/dev/train, respectively.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPR-pass\n\n\n* Size of downloaded dataset files: 43.61 MB\n* Size of the generated dataset: 36.98 MB\n* Total amount of disk used: 80.59 MB\n\n\nAn example of 'train' looks as follows.\n\n\nPR-page\n\n\n* Size of downloaded dataset files: 421.56 MB\n* Size of the generated dataset: 412.17 MB\n* Total amount of disk used: 833.73 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all subsets and splits.\n\n\n* id: a string feature.\n* title: a string feature.\n* context: a string feature.\n* question: a string feature.\n* answers: a dictionary feature containing:\n\t+ text: a list of string features.\n\t+ answer\\_start: a list of int32 features.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] | [
"TAGS\n#task_categories-text-retrieval #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us \n",
"### Dataset Summary\n\n\nPR is a phrase retrieval task with the goal of finding a phrase t in a given document d such that t is semantically similar to the query phrase, which is the paraphrase q1 provided by annotators.\nWe release two versions of PR: PR-pass and PR-page, i.e., datasets of 3-tuples (query q1, target phrase t, document d) where d is a random 11-sentence passage that contains t or an entire Wikipedia page.\nWhile PR-pass contains 28,147 examples, PR-page contains slightly fewer examples (28,098) as we remove those trivial examples whose Wikipedia pages contain exactly the query phrase (in addition to the target phrase).\nBoth datasets are split into 5K/3K/~20K for test/dev/train, respectively.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPR-pass\n\n\n* Size of downloaded dataset files: 43.61 MB\n* Size of the generated dataset: 36.98 MB\n* Total amount of disk used: 80.59 MB\n\n\nAn example of 'train' looks as follows.\n\n\nPR-page\n\n\n* Size of downloaded dataset files: 421.56 MB\n* Size of the generated dataset: 412.17 MB\n* Total amount of disk used: 833.73 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all subsets and splits.\n\n\n* id: a string feature.\n* title: a string feature.\n* context: a string feature.\n* question: a string feature.\n* answers: a dictionary feature containing:\n\t+ text: a list of string features.\n\t+ answer\\_start: a list of int32 features.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] |
07aee4679428bb3a0d132f5a3863c0b00b9804fd | # Dataset Card for financial_phrasebank
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
Auditor review data collected by News Department
- **Point of Contact:**
Talked to COE for Auditing
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of *** sentences from English language financial news categorized by sentiment. The dataset is divided by agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
```
{ "sentence": "Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .",
"label": "negative"
}
```
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive', 'negative' or 'neutral'
### Data Splits
A test train split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
The key arguments for the low utilization of statistical techniques in
financial sentiment analysis have been the difficulty of implementation for
practical applications and the lack of high quality training data for building
such models. ***
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news on all listed
companies in ****
#### Who are the source language producers?
The source data was written by various auditors
### Annotations
#### Annotation process
This release of the financial phrase bank covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge on financial markets.
Given the large number of overlapping annotations (5 to 8 annotations per
sentence), there are several ways to define a majority vote based gold
standard. To provide an objective comparison, we have formed 4 alternative
reference datasets based on the strength of majority agreement:
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
License: Creative Commons Attribution 4.0 International License (CC-BY)
### Contributions
| rajistics/auditor_review | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-sa-3.0",
"region:us"
] | 2022-06-13T20:49:54+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-nc-sa-3.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["multi-class-classification", "sentiment-classification"], "pretty_name": "Auditor_Review"} | 2022-07-19T20:48:59+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_ids-multi-class-classification #task_ids-sentiment-classification #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-cc-by-nc-sa-3.0 #region-us
| # Dataset Card for financial_phrasebank
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
Auditor review data collected by News Department
- Point of Contact:
Talked to COE for Auditing
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of * sentences from English language financial news categorized by sentiment. The dataset is divided by agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive', 'negative' or 'neutral'
### Data Splits
A test train split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
The key arguments for the low utilization of statistical techniques in
financial sentiment analysis have been the difficulty of implementation for
practical applications and the lack of high quality training data for building
such models. *
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news on all listed
companies in
#### Who are the source language producers?
The source data was written by various auditors
### Annotations
#### Annotation process
This release of the financial phrase bank covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge on financial markets.
Given the large number of overlapping annotations (5 to 8 annotations per
sentence), there are several ways to define a majority vote based gold
standard. To provide an objective comparison, we have formed 4 alternative
reference datasets based on the strength of majority agreement:
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
License: Creative Commons Attribution 4.0 International License (CC-BY)
### Contributions
| [
"# Dataset Card for financial_phrasebank",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\nAuditor review data collected by News Department\n- Point of Contact:\nTalked to COE for Auditing",
"### Dataset Summary\nAuditor sentiment dataset of sentences from financial news. The dataset consists of * sentences from English language financial news categorized by sentiment. The dataset is divided by agreement rate of 5-8 annotators.",
"### Supported Tasks and Leaderboards\nSentiment Classification",
"### Languages\nEnglish",
"## Dataset Structure",
"### Data Instances",
"### Data Fields\n- sentence: a tokenized line from the dataset\n- label: a label corresponding to the class as a string: 'positive', 'negative' or 'neutral'",
"### Data Splits\nA test train split was created randomly with a 75/25 split",
"## Dataset Creation",
"### Curation Rationale\n\nThe key arguments for the low utilization of statistical techniques in\nfinancial sentiment analysis have been the difficulty of implementation for\npractical applications and the lack of high quality training data for building\nsuch models. *",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe corpus used in this paper is made out of English news on all listed\ncompanies in",
"#### Who are the source language producers?\n\nThe source data was written by various auditors",
"### Annotations",
"#### Annotation process\n\nThis release of the financial phrase bank covers a collection of 4840\nsentences. The selected collection of phrases was annotated by 16 people with\nadequate background knowledge on financial markets.\n\nGiven the large number of overlapping annotations (5 to 8 annotations per\nsentence), there are several ways to define a majority vote based gold\nstandard. To provide an objective comparison, we have formed 4 alternative\nreference datasets based on the strength of majority agreement:",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases\n\nAll annotators were from the same institution and so interannotator agreement\nshould be understood with this taken into account.",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nLicense: Creative Commons Attribution 4.0 International License (CC-BY)",
"### Contributions"
] | [
"TAGS\n#task_categories-text-classification #task_ids-multi-class-classification #task_ids-sentiment-classification #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-cc-by-nc-sa-3.0 #region-us \n",
"# Dataset Card for financial_phrasebank",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\nAuditor review data collected by News Department\n- Point of Contact:\nTalked to COE for Auditing",
"### Dataset Summary\nAuditor sentiment dataset of sentences from financial news. The dataset consists of * sentences from English language financial news categorized by sentiment. The dataset is divided by agreement rate of 5-8 annotators.",
"### Supported Tasks and Leaderboards\nSentiment Classification",
"### Languages\nEnglish",
"## Dataset Structure",
"### Data Instances",
"### Data Fields\n- sentence: a tokenized line from the dataset\n- label: a label corresponding to the class as a string: 'positive', 'negative' or 'neutral'",
"### Data Splits\nA test train split was created randomly with a 75/25 split",
"## Dataset Creation",
"### Curation Rationale\n\nThe key arguments for the low utilization of statistical techniques in\nfinancial sentiment analysis have been the difficulty of implementation for\npractical applications and the lack of high quality training data for building\nsuch models. *",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe corpus used in this paper is made out of English news on all listed\ncompanies in",
"#### Who are the source language producers?\n\nThe source data was written by various auditors",
"### Annotations",
"#### Annotation process\n\nThis release of the financial phrase bank covers a collection of 4840\nsentences. The selected collection of phrases was annotated by 16 people with\nadequate background knowledge on financial markets.\n\nGiven the large number of overlapping annotations (5 to 8 annotations per\nsentence), there are several ways to define a majority vote based gold\nstandard. To provide an objective comparison, we have formed 4 alternative\nreference datasets based on the strength of majority agreement:",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases\n\nAll annotators were from the same institution and so interannotator agreement\nshould be understood with this taken into account.",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nLicense: Creative Commons Attribution 4.0 International License (CC-BY)",
"### Contributions"
] |
d7d9b95354c161647de519d4e8d9a59a801570b3 | # AutoTrain Dataset for project: dontknowwhatImdoing
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project dontknowwhatImdoing.
### Languages
The BCP-47 code for the dataset's language is en.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "Gaston",
"target": 1
},
{
"text": "Churchundyr",
"target": 0
}
]
```
Note that, sadly, it flipped the boolean, using 1 for mundane and 0 for goblin.
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=2, names=['Goblin', 'Mundane'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 965 |
| valid | 242 |
| Jerimee/autotrain-data-dontknowwhatImdoing | [
"task_categories:text-classification",
"language:en",
"region:us"
] | 2022-06-13T21:20:16+00:00 | {"language": ["en"], "task_categories": ["text-classification"]} | 2022-10-25T09:32:19+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #language-English #region-us
| AutoTrain Dataset for project: dontknowwhatImdoing
==================================================
Dataset Descritpion
-------------------
This dataset has been automatically processed by AutoTrain for project dontknowwhatImdoing.
### Languages
The BCP-47 code for the dataset's language is en.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
Note that, sadly, it flipped the boolean, using 1 for mundane and 0 for goblin.
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:\n\n\nNote that, sadly, it flipped the boolean, using 1 for mundane and 0 for goblin.",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-text-classification #language-English #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:\n\n\nNote that, sadly, it flipped the boolean, using 1 for mundane and 0 for goblin.",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
fd3771be21edb9a13561c606bdfe87a66e95b149 |
# Dataset Card for "PiC: Phrase Sense Disambiguation"
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://phrase-in-context.github.io/](https://phrase-in-context.github.io/)
- **Repository:** [https://github.com/phrase-in-context](https://github.com/phrase-in-context)
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [Thang Pham](<[email protected]>)
- **Size of downloaded dataset files:** 49.95 MB
- **Size of the generated dataset:** 43.26 MB
- **Total amount of disk used:** 93.20 MB
### Dataset Summary
PSD is a phrase retrieval task like PR-pass and PR-page but more challenging since each example contains two short paragraphs (~11 sentences each) which trigger different senses of the same phrase.
The goal is to find the instance of the target phrase **t** that is semantically similar to a paraphrase **q**.
The dataset is split into 5,150/3,000/20,002 for test/dev/train, respectively.
<p align="center">
<img src="https://auburn.edu/~tmp0038/PiC/psd_sample.png" alt="PSD sample" style="width:100%; border:0;">
</p>
Given document D, trained Longformer-large model correctly retrieves <span style="background-color: #ef8783">massive figure</span> in the second paragraph for the query Q<sub>2</sub> "giant number" but **fails** to retrieve the answer when the query Q<sub>1</sub> is "huge model".
The correct answer for Q<sub>1</sub> should be <span style="background-color: #a1fb8e">massive figure</span> in the first passage since this phrase relates to a model rather than a number.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English.
## Dataset Structure
### Data Instances
**PSD**
* Size of downloaded dataset files: 49.95 MB
* Size of the generated dataset: 43.26 MB
* Total amount of disk used: 93.20 MB
An example of 'test' looks as follows.
```
{
"id": "297-1",
"title": "https://en.wikipedia.org/wiki?curid=2226019,https://en.wikipedia.org/wiki?curid=1191780",
"context": "In addition, the results from the study did not support the idea of females preferring complexity over simplicity in song sequences. These findings differ from past examinations, like the 2008 Morisake et al. study that suggested evidence of female Bengalese finches preferring complex songs over simple ones. Evolutionary adaptations of specifically complex song production in relation to female preference in Bengalese finches continues to be a topic worth examining. Comparison with zebra finches. Bengalese finches and zebra finches are members of the estrildiae family and are age-limited learners when it comes to song learning and the acoustic characteristics of their songs (Peng et al., 2012). Both of these species have been widely used in song learning based animal behavior research and although they share many characteristics researchers have been able to determine stark differences between the two. Previous to research done in 1987, it was thought that song learning in Bengalese finches was similar to zebra finches but there was no research to support this idea. Both species require learning from an adult during a sensitive juvenile phase in order to learn the species specific and sexually dimorphic songs. This tutor can be the father of the young or other adult males that are present around the juvenile. Clayton aimed to directly compare the song learning ability of both of these species to determine if they have separate learning behaviors. Many students find they can not possibly complete all the work assigned them; they learn to neglect some of it. Some student groups maintain files of past examinations which only worsen this situation. The difference between the formal and real requirements produced considerable dissonance among the students and resulted in cynicism, scorn, and hypocrisy among students, and particular difficulty for minority students. No part of the university community, writes Snyder, neither the professors, the administration nor the students, desires the end result created by this process. The \"Saturday Review\" said the book \"will gain recognition as one of the more cogent 'college unrest' books\" and that it presents a \"most provocative thesis.\" The book has been cited many times in studies. References. [[Category:Curricula]] [[Category:Philosophy of education]] [[Category:Massachusetts Institute of Technology]] [[Category:Books about social psychology]] [[Category:Student culture]] [[Category:Books about education]] [[Category:1970 non-fiction books]]",
"query": "previous exams",
"answers": {
"text": ["past examinations"],
"answer_start": [1621]
}
}
```
### Data Fields
The data fields are the same among all subsets and splits.
* id: a string feature.
* title: a string feature.
* context: a string feature.
* question: a string feature.
* answers: a dictionary feature containing:
* text: a list of string features.
* answer_start: a list of int32 features.
### Data Splits
| name |train|validation|test|
|--------------------|----:|---------:|---:|
|PSD |20002| 3000|5000|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from [Upwork.com](https://upwork.com).
#### Who are the source language producers?
We hired 13 linguistic experts from [Upwork.com](https://upwork.com) for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
13 linguistic experts from [Upwork.com](https://upwork.com).
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: [Thang M. Pham](https://scholar.google.com/citations?user=eNrX3mYAAAAJ), [David Seunghyun Yoon](https://david-yoon.github.io/), [Trung Bui](https://sites.google.com/site/trungbuistanford/), and [Anh Nguyen](https://anhnguyen.me).
[@PMThangXAI](https://twitter.com/pmthangxai) added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under [Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/)
### Citation Information
```
@article{pham2022PiC,
title={PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search},
author={Pham, Thang M and Yoon, Seunghyun and Bui, Trung and Nguyen, Anh},
journal={arXiv preprint arXiv:2207.09068},
year={2022}
}
``` | PiC/phrase_sense_disambiguation | [
"task_categories:text-retrieval",
"annotations_creators:expert-generated",
"language_creators:found",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] | 2022-06-14T00:21:45+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found", "expert-generated"], "language": ["en"], "license": ["cc-by-nc-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-retrieval"], "task_ids": [], "paperswithcode_id": "phrase-in-context", "pretty_name": "PiC: Phrase Sense Disambiguation"} | 2023-01-20T16:32:40+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us
| Dataset Card for "PiC: Phrase Sense Disambiguation"
===================================================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact: Thang Pham
* Size of downloaded dataset files: 49.95 MB
* Size of the generated dataset: 43.26 MB
* Total amount of disk used: 93.20 MB
### Dataset Summary
PSD is a phrase retrieval task like PR-pass and PR-page but more challenging since each example contains two short paragraphs (~11 sentences each) which trigger different senses of the same phrase.
The goal is to find the instance of the target phrase t that is semantically similar to a paraphrase q.
The dataset is split into 5,150/3,000/20,002 for test/dev/train, respectively.

Given document D, trained Longformer-large model correctly retrieves massive figure in the second paragraph for the query Q2 "giant number" but fails to retrieve the answer when the query Q1 is "huge model".
The correct answer for Q1 should be massive figure in the first passage since this phrase relates to a model rather than a number.
### Supported Tasks and Leaderboards
### Languages
English.
Dataset Structure
-----------------
### Data Instances
PSD
* Size of downloaded dataset files: 49.95 MB
* Size of the generated dataset: 43.26 MB
* Total amount of disk used: 93.20 MB
An example of 'test' looks as follows.
### Data Fields
The data fields are the same among all subsets and splits.
* id: a string feature.
* title: a string feature.
* context: a string feature.
* question: a string feature.
* answers: a dictionary feature containing:
+ text: a list of string features.
+ answer\_start: a list of int32 features.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.
#### Who are the source language producers?
We hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
#### Who are the annotators?
13 linguistic experts from URL.
### Personal and Sensitive Information
No annotator identifying details are provided.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.
@PMThangXAI added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)
| [
"### Dataset Summary\n\n\nPSD is a phrase retrieval task like PR-pass and PR-page but more challenging since each example contains two short paragraphs (~11 sentences each) which trigger different senses of the same phrase.\nThe goal is to find the instance of the target phrase t that is semantically similar to a paraphrase q.\nThe dataset is split into 5,150/3,000/20,002 for test/dev/train, respectively.\n\n\n\n\n\n\n\nGiven document D, trained Longformer-large model correctly retrieves massive figure in the second paragraph for the query Q2 \"giant number\" but fails to retrieve the answer when the query Q1 is \"huge model\".\nThe correct answer for Q1 should be massive figure in the first passage since this phrase relates to a model rather than a number.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPSD\n\n\n* Size of downloaded dataset files: 49.95 MB\n* Size of the generated dataset: 43.26 MB\n* Total amount of disk used: 93.20 MB\n\n\nAn example of 'test' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all subsets and splits.\n\n\n* id: a string feature.\n* title: a string feature.\n* context: a string feature.\n* question: a string feature.\n* answers: a dictionary feature containing:\n\t+ text: a list of string features.\n\t+ answer\\_start: a list of int32 features.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] | [
"TAGS\n#task_categories-text-retrieval #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us \n",
"### Dataset Summary\n\n\nPSD is a phrase retrieval task like PR-pass and PR-page but more challenging since each example contains two short paragraphs (~11 sentences each) which trigger different senses of the same phrase.\nThe goal is to find the instance of the target phrase t that is semantically similar to a paraphrase q.\nThe dataset is split into 5,150/3,000/20,002 for test/dev/train, respectively.\n\n\n\n\n\n\n\nGiven document D, trained Longformer-large model correctly retrieves massive figure in the second paragraph for the query Q2 \"giant number\" but fails to retrieve the answer when the query Q1 is \"huge model\".\nThe correct answer for Q1 should be massive figure in the first passage since this phrase relates to a model rather than a number.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPSD\n\n\n* Size of downloaded dataset files: 49.95 MB\n* Size of the generated dataset: 43.26 MB\n* Total amount of disk used: 93.20 MB\n\n\nAn example of 'test' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all subsets and splits.\n\n\n* id: a string feature.\n* title: a string feature.\n* context: a string feature.\n* question: a string feature.\n* answers: a dictionary feature containing:\n\t+ text: a list of string features.\n\t+ answer\\_start: a list of int32 features.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] |
fc67ce7c1e69e360e42dc6f31ddf97bb32f1923d |
# Dataset Card for "PiC: Phrase Similarity"
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://phrase-in-context.github.io/](https://phrase-in-context.github.io/)
- **Repository:** [https://github.com/phrase-in-context](https://github.com/phrase-in-context)
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [Thang Pham](<[email protected]>)
- **Size of downloaded dataset files:** 4.60 MB
- **Size of the generated dataset:** 2.96 MB
- **Total amount of disk used:** 7.56 MB
### Dataset Summary
PS is a binary classification task with the goal of predicting whether two multi-word noun phrases are semantically similar or not given *the same context* sentence.
This dataset contains ~10K pairs of two phrases along with their contexts used for disambiguation, since two phrases are not enough for semantic comparison.
Our ~10K examples were annotated by linguistic experts on <upwork.com> and verified in two rounds by 1000 Mturkers and 5 linguistic experts.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English.
## Dataset Structure
### Data Instances
**PS**
* Size of downloaded dataset files: 4.60 MB
* Size of the generated dataset: 2.96 MB
* Total amount of disk used: 7.56 MB
```
{
"phrase1": "annual run",
"phrase2": "yearlong performance",
"sentence1": "since 2004, the club has been a sponsor of the annual run for rigby to raise money for off-campus housing safety awareness.",
"sentence2": "since 2004, the club has been a sponsor of the yearlong performance for rigby to raise money for off-campus housing safety awareness.",
"label": 0,
"idx": 0,
}
```
### Data Fields
The data fields are the same among all splits.
* phrase1: a string feature.
* phrase2: a string feature.
* sentence1: a string feature.
* sentence2: a string feature.
* label: a classification label, with negative (0) and positive (1).
* idx: an int32 feature.
### Data Splits
| name |train |validation|test |
|--------------------|----:|--------:|----:|
|PS |7362| 1052|2102|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from [Upwork.com](https://upwork.com).
#### Who are the source language producers?
We hired 13 linguistic experts from [Upwork.com](https://upwork.com) for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
13 linguistic experts from [Upwork.com](https://upwork.com).
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: [Thang M. Pham](https://scholar.google.com/citations?user=eNrX3mYAAAAJ), [David Seunghyun Yoon](https://david-yoon.github.io/), [Trung Bui](https://sites.google.com/site/trungbuistanford/), and [Anh Nguyen](https://anhnguyen.me).
[@PMThangXAI](https://twitter.com/pmthangxai) added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under [Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/)
### Citation Information
```
@article{pham2022PiC,
title={PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search},
author={Pham, Thang M and Yoon, Seunghyun and Bui, Trung and Nguyen, Anh},
journal={arXiv preprint arXiv:2207.09068},
year={2022}
}
``` | PiC/phrase_similarity | [
"task_categories:text-classification",
"task_ids:semantic-similarity-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] | 2022-06-14T00:35:19+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found", "expert-generated"], "language": ["en"], "license": ["cc-by-nc-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["semantic-similarity-classification"], "paperswithcode_id": "phrase-in-context", "pretty_name": "PiC: Phrase Similarity (PS)"} | 2023-01-20T16:32:19+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_ids-semantic-similarity-classification #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us
| Dataset Card for "PiC: Phrase Similarity"
=========================================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact: Thang Pham
* Size of downloaded dataset files: 4.60 MB
* Size of the generated dataset: 2.96 MB
* Total amount of disk used: 7.56 MB
### Dataset Summary
PS is a binary classification task with the goal of predicting whether two multi-word noun phrases are semantically similar or not given *the same context* sentence.
This dataset contains ~10K pairs of two phrases along with their contexts used for disambiguation, since two phrases are not enough for semantic comparison.
Our ~10K examples were annotated by linguistic experts on and verified in two rounds by 1000 Mturkers and 5 linguistic experts.
### Supported Tasks and Leaderboards
### Languages
English.
Dataset Structure
-----------------
### Data Instances
PS
* Size of downloaded dataset files: 4.60 MB
* Size of the generated dataset: 2.96 MB
* Total amount of disk used: 7.56 MB
### Data Fields
The data fields are the same among all splits.
* phrase1: a string feature.
* phrase2: a string feature.
* sentence1: a string feature.
* sentence2: a string feature.
* label: a classification label, with negative (0) and positive (1).
* idx: an int32 feature.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.
#### Who are the source language producers?
We hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.
### Annotations
#### Annotation process
#### Who are the annotators?
13 linguistic experts from URL.
### Personal and Sensitive Information
No annotator identifying details are provided.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
This dataset is a joint work between Adobe Research and Auburn University.
Creators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.
@PMThangXAI added this dataset to HuggingFace.
### Licensing Information
This dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)
| [
"### Dataset Summary\n\n\nPS is a binary classification task with the goal of predicting whether two multi-word noun phrases are semantically similar or not given *the same context* sentence.\nThis dataset contains ~10K pairs of two phrases along with their contexts used for disambiguation, since two phrases are not enough for semantic comparison.\nOur ~10K examples were annotated by linguistic experts on and verified in two rounds by 1000 Mturkers and 5 linguistic experts.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPS\n\n\n* Size of downloaded dataset files: 4.60 MB\n* Size of the generated dataset: 2.96 MB\n* Total amount of disk used: 7.56 MB",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* phrase1: a string feature.\n* phrase2: a string feature.\n* sentence1: a string feature.\n* sentence2: a string feature.\n* label: a classification label, with negative (0) and positive (1).\n* idx: an int32 feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] | [
"TAGS\n#task_categories-text-classification #task_ids-semantic-similarity-classification #annotations_creators-expert-generated #language_creators-found #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-nc-4.0 #region-us \n",
"### Dataset Summary\n\n\nPS is a binary classification task with the goal of predicting whether two multi-word noun phrases are semantically similar or not given *the same context* sentence.\nThis dataset contains ~10K pairs of two phrases along with their contexts used for disambiguation, since two phrases are not enough for semantic comparison.\nOur ~10K examples were annotated by linguistic experts on and verified in two rounds by 1000 Mturkers and 5 linguistic experts.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nEnglish.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nPS\n\n\n* Size of downloaded dataset files: 4.60 MB\n* Size of the generated dataset: 2.96 MB\n* Total amount of disk used: 7.56 MB",
"### Data Fields\n\n\nThe data fields are the same among all splits.\n\n\n* phrase1: a string feature.\n* phrase2: a string feature.\n* sentence1: a string feature.\n* sentence2: a string feature.\n* label: a classification label, with negative (0) and positive (1).\n* idx: an int32 feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe source passages + answers are from Wikipedia and the source of queries were produced by our hired linguistic experts from URL.",
"#### Who are the source language producers?\n\n\nWe hired 13 linguistic experts from URL for annotation and more than 1000 human annotators on Mechanical Turk along with another set of 5 Upwork experts for 2-round verification.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\n13 linguistic experts from URL.",
"### Personal and Sensitive Information\n\n\nNo annotator identifying details are provided.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThis dataset is a joint work between Adobe Research and Auburn University.\nCreators: Thang M. Pham, David Seunghyun Yoon, Trung Bui, and Anh Nguyen.\n\n\n@PMThangXAI added this dataset to HuggingFace.",
"### Licensing Information\n\n\nThis dataset is distributed under Creative Commons Attribution-NonCommercial 4.0 International (CC-BY-NC 4.0)"
] |
22e9451042c750f5dec39e243d34f4efea1f3cda | # Dataset Card for Auditor_Review
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
## Dataset Description
Auditor review data collected by News Department
- **Point of Contact:**
Talked to COE for Auditing, currently [email protected]
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
```
"sentence": "Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .",
"label": "negative"
```
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0)
Complete data code is [available here](https://www.datafiles.samhsa.gov/get-help/codebooks/what-codebook)
### Data Splits
A train/test split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
To gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news reports.
#### Who are the source language producers?
The source data was written by various auditors.
### Annotations
#### Annotation process
This release of the auditor reviews covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.
#### Who are the annotators?
They were pulled from the SME list, names are held by [email protected]
### Personal and Sensitive Information
There is no personal or sensitive information in this dataset.
## Considerations for Using the Data
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
The [Dataset Measurement tool](https://huggingface.co/spaces/huggingface/data-measurements-tool) identified these bias statistics:
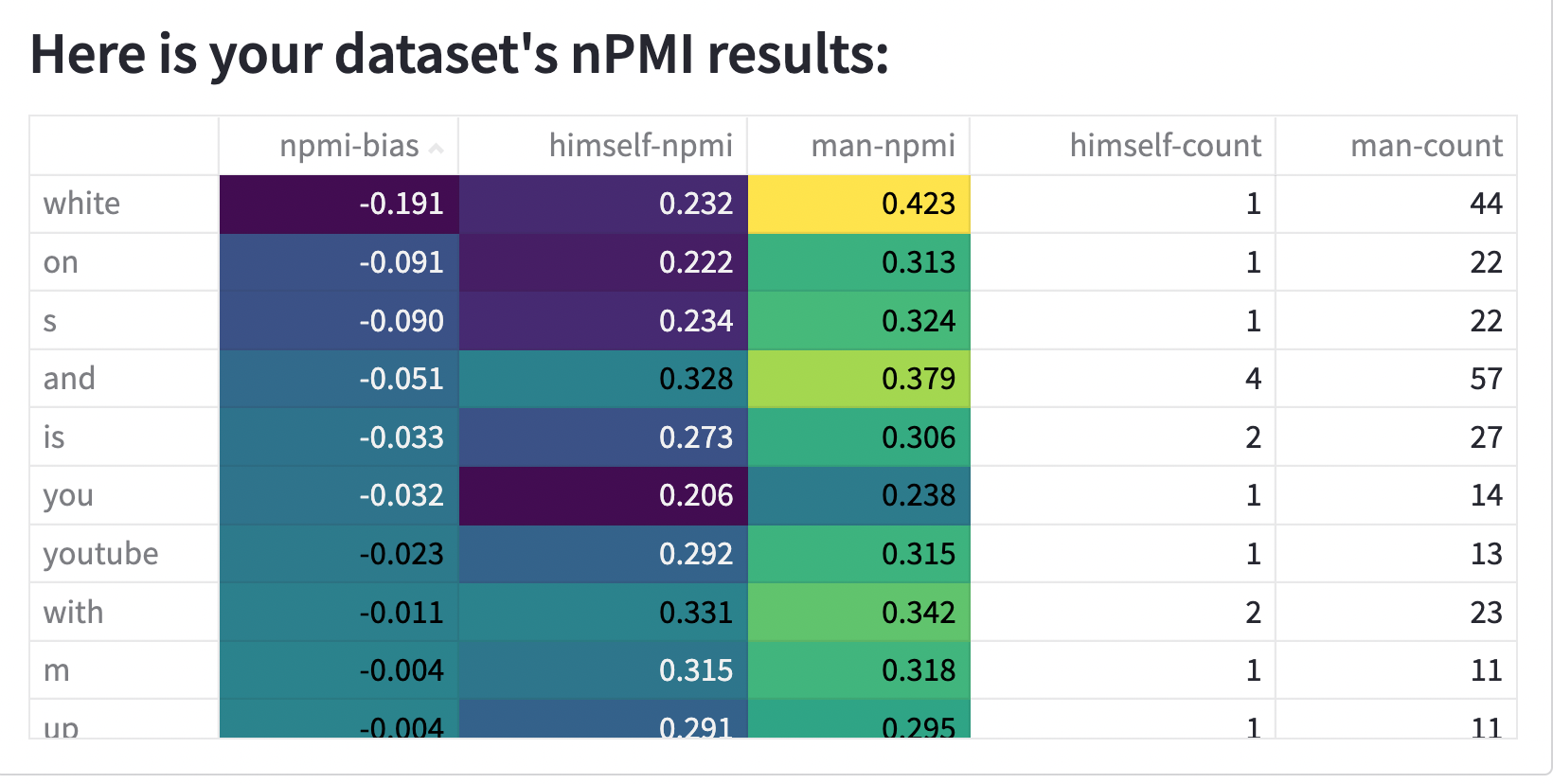
### Other Known Limitations
[More Information Needed]
### Licensing Information
License: Demo.Org Proprietary - DO NOT SHARE | demo-org/auditor_review | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"region:us"
] | 2022-06-14T02:06:17+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["multi-class-classification", "sentiment-classification"], "pretty_name": "Auditor_Review"} | 2022-08-30T20:42:09+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_ids-multi-class-classification #task_ids-sentiment-classification #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #region-us
| # Dataset Card for Auditor_Review
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
## Dataset Description
Auditor review data collected by News Department
- Point of Contact:
Talked to COE for Auditing, currently sue@URL
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0)
Complete data code is available here
### Data Splits
A train/test split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
To gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news reports.
#### Who are the source language producers?
The source data was written by various auditors.
### Annotations
#### Annotation process
This release of the auditor reviews covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.
#### Who are the annotators?
They were pulled from the SME list, names are held by sue@URL
### Personal and Sensitive Information
There is no personal or sensitive information in this dataset.
## Considerations for Using the Data
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
The Dataset Measurement tool identified these bias statistics:
!Bias
### Other Known Limitations
### Licensing Information
License: Demo.Org Proprietary - DO NOT SHARE | [
"# Dataset Card for Auditor_Review",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information",
"## Dataset Description\nAuditor review data collected by News Department\n\n- Point of Contact:\nTalked to COE for Auditing, currently sue@URL",
"### Dataset Summary\n\nAuditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.",
"### Supported Tasks and Leaderboards\n\nSentiment Classification",
"### Languages\n\nEnglish",
"## Dataset Structure",
"### Data Instances",
"### Data Fields\n\n- sentence: a tokenized line from the dataset\n- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0) \n\nComplete data code is available here",
"### Data Splits\n\nA train/test split was created randomly with a 75/25 split",
"## Dataset Creation",
"### Curation Rationale\n\nTo gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe corpus used in this paper is made out of English news reports.",
"#### Who are the source language producers?\n\nThe source data was written by various auditors.",
"### Annotations",
"#### Annotation process\n\nThis release of the auditor reviews covers a collection of 4840\nsentences. The selected collection of phrases was annotated by 16 people with\nadequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.",
"#### Who are the annotators?\n\nThey were pulled from the SME list, names are held by sue@URL",
"### Personal and Sensitive Information\n\nThere is no personal or sensitive information in this dataset.",
"## Considerations for Using the Data",
"### Discussion of Biases\n\nAll annotators were from the same institution and so interannotator agreement\nshould be understood with this taken into account.\n\nThe Dataset Measurement tool identified these bias statistics:\n\n!Bias",
"### Other Known Limitations",
"### Licensing Information\n\nLicense: Demo.Org Proprietary - DO NOT SHARE"
] | [
"TAGS\n#task_categories-text-classification #task_ids-multi-class-classification #task_ids-sentiment-classification #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #region-us \n",
"# Dataset Card for Auditor_Review",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information",
"## Dataset Description\nAuditor review data collected by News Department\n\n- Point of Contact:\nTalked to COE for Auditing, currently sue@URL",
"### Dataset Summary\n\nAuditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.",
"### Supported Tasks and Leaderboards\n\nSentiment Classification",
"### Languages\n\nEnglish",
"## Dataset Structure",
"### Data Instances",
"### Data Fields\n\n- sentence: a tokenized line from the dataset\n- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0) \n\nComplete data code is available here",
"### Data Splits\n\nA train/test split was created randomly with a 75/25 split",
"## Dataset Creation",
"### Curation Rationale\n\nTo gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThe corpus used in this paper is made out of English news reports.",
"#### Who are the source language producers?\n\nThe source data was written by various auditors.",
"### Annotations",
"#### Annotation process\n\nThis release of the auditor reviews covers a collection of 4840\nsentences. The selected collection of phrases was annotated by 16 people with\nadequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.",
"#### Who are the annotators?\n\nThey were pulled from the SME list, names are held by sue@URL",
"### Personal and Sensitive Information\n\nThere is no personal or sensitive information in this dataset.",
"## Considerations for Using the Data",
"### Discussion of Biases\n\nAll annotators were from the same institution and so interannotator agreement\nshould be understood with this taken into account.\n\nThe Dataset Measurement tool identified these bias statistics:\n\n!Bias",
"### Other Known Limitations",
"### Licensing Information\n\nLicense: Demo.Org Proprietary - DO NOT SHARE"
] |
8dd56bd02deccc9252f356e164a48c6adafa77d4 | # Danbooru2020 Small 60GB sample dataset
Aggregating the kaggle dataset here but keeping their hosting for the raw files
Links:
> https://www.kaggle.com/datasets/muoncollider/danbooru2020/download
See the notebook file for a quick reference on how to extract info | inarikami/Danbooru-2020-Small | [
"region:us"
] | 2022-06-14T02:33:05+00:00 | {} | 2022-06-14T02:41:59+00:00 | [] | [] | TAGS
#region-us
| # Danbooru2020 Small 60GB sample dataset
Aggregating the kaggle dataset here but keeping their hosting for the raw files
Links:
> URL
See the notebook file for a quick reference on how to extract info | [
"# Danbooru2020 Small 60GB sample dataset\n\nAggregating the kaggle dataset here but keeping their hosting for the raw files\n\nLinks:\n> URL\n\nSee the notebook file for a quick reference on how to extract info"
] | [
"TAGS\n#region-us \n",
"# Danbooru2020 Small 60GB sample dataset\n\nAggregating the kaggle dataset here but keeping their hosting for the raw files\n\nLinks:\n> URL\n\nSee the notebook file for a quick reference on how to extract info"
] |
c2cc1eb192d1cbba04bfee929b089ad96720455e | # Description
The dataset represents huge number of images of people wearing face masks or not to be used extensively for train/test splitting. Selected files were double-checked to avoid data collection bias using common sense.
# Sources
The dataset obtained and combined from various open data sources, including following:
- https://www.kaggle.com/frabbisw/facial-age
- https://www.kaggle.com/nipunarora8/age-gender-and-ethnicity-face-data-csv
- https://www.kaggle.com/arashnic/faces-age-detection-dataset
- https://www.kaggle.com/andrewmvd/face-mask-detection
- manually obtained under-represented observations using Google search engine
# Structure
The dataset is curated and structured into three age groups (under 18, 18-65 and 65+) without initial test/train selection, which is achieved programmatically to allow manipulations with original data.
<a href="https://postimages.org/" target="_blank"><img src="https://i.postimg.cc/cCyDskHz/2022-06-14-10-21-39.webp" alt="2022-06-14-10-21-39"/></a>
<a href="https://postimages.org/" target="_blank"><img src="https://i.postimg.cc/zvCx3wHG/Screenshot-2022-06-14-101707.png" alt="Screenshot-2022-06-14-101707"/></a> | hydramst/face_mask_wearing | [
"license:other",
"region:us"
] | 2022-06-14T08:10:48+00:00 | {"license": "other"} | 2022-06-14T08:15:57+00:00 | [] | [] | TAGS
#license-other #region-us
| # Description
The dataset represents huge number of images of people wearing face masks or not to be used extensively for train/test splitting. Selected files were double-checked to avoid data collection bias using common sense.
# Sources
The dataset obtained and combined from various open data sources, including following:
- URL
- URL
- URL
- URL
- manually obtained under-represented observations using Google search engine
# Structure
The dataset is curated and structured into three age groups (under 18, 18-65 and 65+) without initial test/train selection, which is achieved programmatically to allow manipulations with original data.
<a href="URL target="_blank"><img src="https://i.URL alt="2022-06-14-10-21-39"/></a>
<a href="URL target="_blank"><img src="https://i.URL alt="Screenshot-2022-06-14-101707"/></a> | [
"# Description\nThe dataset represents huge number of images of people wearing face masks or not to be used extensively for train/test splitting. Selected files were double-checked to avoid data collection bias using common sense.",
"# Sources\nThe dataset obtained and combined from various open data sources, including following:\n\n- URL\n- URL\n- URL\n- URL\n- manually obtained under-represented observations using Google search engine",
"# Structure\n\nThe dataset is curated and structured into three age groups (under 18, 18-65 and 65+) without initial test/train selection, which is achieved programmatically to allow manipulations with original data.\n<a href=\"URL target=\"_blank\"><img src=\"https://i.URL alt=\"2022-06-14-10-21-39\"/></a>\n\n<a href=\"URL target=\"_blank\"><img src=\"https://i.URL alt=\"Screenshot-2022-06-14-101707\"/></a>"
] | [
"TAGS\n#license-other #region-us \n",
"# Description\nThe dataset represents huge number of images of people wearing face masks or not to be used extensively for train/test splitting. Selected files were double-checked to avoid data collection bias using common sense.",
"# Sources\nThe dataset obtained and combined from various open data sources, including following:\n\n- URL\n- URL\n- URL\n- URL\n- manually obtained under-represented observations using Google search engine",
"# Structure\n\nThe dataset is curated and structured into three age groups (under 18, 18-65 and 65+) without initial test/train selection, which is achieved programmatically to allow manipulations with original data.\n<a href=\"URL target=\"_blank\"><img src=\"https://i.URL alt=\"2022-06-14-10-21-39\"/></a>\n\n<a href=\"URL target=\"_blank\"><img src=\"https://i.URL alt=\"Screenshot-2022-06-14-101707\"/></a>"
] |
9022ba27075f75c2f59d57d7fa5f42e8d1151aec |
# Dataset Card for LCCC
## Table of Contents
- [Dataset Card for LCCC](#dataset-card-for-lccc)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/thu-coai/CDial-GPT
- **Paper:** https://arxiv.org/abs/2008.03946
### Dataset Summary
LCCC: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large Chinese dialogue corpus originate from Chinese social medias. A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.
LCCC是一套来自于中文社交媒体的对话数据,我们设计了一套严格的数据过滤流程来确保该数据集中对话数据的质量。 这一数据过滤流程中包括一系列手工规则以及若干基于机器学习算法所构建的分类器。 我们所过滤掉的噪声包括:脏字脏词、特殊字符、颜表情、语法不通的语句、上下文不相关的对话等。
### Supported Tasks and Leaderboards
- dialogue-generation: The dataset can be used to train a model for generating dialogue responses.
- response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.
### Languages
LCCC is in Chinese
LCCC中的对话是中文的
## Dataset Structure
### Data Instances
```json
{
"dialog": ["火锅 我 在 重庆 成都 吃 了 七八 顿 火锅", "哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !", "不会 的 就是 好 油腻"]
}
```
### Data Fields
- `dialog` (list of strings): List of utterances consisting of a dialogue.
### Data Splits
We do not provide the offical split for LCCC-large.
But we provide a split for LCCC-base:
|train|valid|test|
|---:|---:|---:|
|6,820,506 | 20,000 | 10,000|
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
MIT License
Copyright (c) 2020 lemon234071
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
### Citation Information
```bibtex
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
```
### Contributions
Thanks to [Yinhe Zheng](https://github.com/silverriver) for adding this dataset. | lccc | [
"task_categories:conversational",
"task_ids:dialogue-generation",
"annotations_creators:other",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:zh",
"license:mit",
"arxiv:2008.03946",
"region:us"
] | 2022-06-14T17:05:32+00:00 | {"annotations_creators": ["other"], "language_creators": ["other"], "language": ["zh"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["conversational"], "task_ids": ["dialogue-generation"], "paperswithcode_id": "lccc", "pretty_name": "LCCC: Large-scale Cleaned Chinese Conversation corpus", "dataset_info": [{"config_name": "large", "features": [{"name": "dialog", "list": "string"}], "splits": [{"name": "train", "num_bytes": 1530827965, "num_examples": 12007759}], "download_size": 607605643, "dataset_size": 1530827965}, {"config_name": "base", "features": [{"name": "dialog", "list": "string"}], "splits": [{"name": "train", "num_bytes": 932634902, "num_examples": 6820506}, {"name": "test", "num_bytes": 1498216, "num_examples": 10000}, {"name": "validation", "num_bytes": 2922731, "num_examples": 20000}], "download_size": 371475095, "dataset_size": 937055849}]} | 2024-01-18T11:19:16+00:00 | [
"2008.03946"
] | [
"zh"
] | TAGS
#task_categories-conversational #task_ids-dialogue-generation #annotations_creators-other #language_creators-other #multilinguality-monolingual #size_categories-10M<n<100M #source_datasets-original #language-Chinese #license-mit #arxiv-2008.03946 #region-us
| Dataset Card for LCCC
=====================
Table of Contents
-----------------
* Dataset Card for LCCC
+ Table of Contents
+ Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
+ Dataset Structure
- Data Instances
- Data Fields
- Data Splits
+ Dataset Creation
- Curation Rationale
- Source Data
* Initial Data Collection and Normalization
* Who are the source language producers?
- Annotations
* Annotation process
* Who are the annotators?
- Personal and Sensitive Information
+ Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
+ Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
Dataset Description
-------------------
* Repository: URL
* Paper: URL
### Dataset Summary
LCCC: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large Chinese dialogue corpus originate from Chinese social medias. A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.
LCCC是一套来自于中文社交媒体的对话数据,我们设计了一套严格的数据过滤流程来确保该数据集中对话数据的质量。 这一数据过滤流程中包括一系列手工规则以及若干基于机器学习算法所构建的分类器。 我们所过滤掉的噪声包括:脏字脏词、特殊字符、颜表情、语法不通的语句、上下文不相关的对话等。
### Supported Tasks and Leaderboards
* dialogue-generation: The dataset can be used to train a model for generating dialogue responses.
* response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.
### Languages
LCCC is in Chinese
LCCC中的对话是中文的
Dataset Structure
-----------------
### Data Instances
### Data Fields
* 'dialog' (list of strings): List of utterances consisting of a dialogue.
### Data Splits
We do not provide the offical split for LCCC-large.
But we provide a split for LCCC-base:
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
MIT License
Copyright (c) 2020 lemon234071
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
### Contributions
Thanks to Yinhe Zheng for adding this dataset.
| [
"### Dataset Summary\n\n\nLCCC: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large Chinese dialogue corpus originate from Chinese social medias. A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.\n\n\nLCCC是一套来自于中文社交媒体的对话数据,我们设计了一套严格的数据过滤流程来确保该数据集中对话数据的质量。 这一数据过滤流程中包括一系列手工规则以及若干基于机器学习算法所构建的分类器。 我们所过滤掉的噪声包括:脏字脏词、特殊字符、颜表情、语法不通的语句、上下文不相关的对话等。",
"### Supported Tasks and Leaderboards\n\n\n* dialogue-generation: The dataset can be used to train a model for generating dialogue responses.\n* response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.",
"### Languages\n\n\nLCCC is in Chinese\n\n\nLCCC中的对话是中文的\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'dialog' (list of strings): List of utterances consisting of a dialogue.",
"### Data Splits\n\n\nWe do not provide the offical split for LCCC-large.\nBut we provide a split for LCCC-base:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nMIT License\n\n\nCopyright (c) 2020 lemon234071\n\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.",
"### Contributions\n\n\nThanks to Yinhe Zheng for adding this dataset."
] | [
"TAGS\n#task_categories-conversational #task_ids-dialogue-generation #annotations_creators-other #language_creators-other #multilinguality-monolingual #size_categories-10M<n<100M #source_datasets-original #language-Chinese #license-mit #arxiv-2008.03946 #region-us \n",
"### Dataset Summary\n\n\nLCCC: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large Chinese dialogue corpus originate from Chinese social medias. A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.\n\n\nLCCC是一套来自于中文社交媒体的对话数据,我们设计了一套严格的数据过滤流程来确保该数据集中对话数据的质量。 这一数据过滤流程中包括一系列手工规则以及若干基于机器学习算法所构建的分类器。 我们所过滤掉的噪声包括:脏字脏词、特殊字符、颜表情、语法不通的语句、上下文不相关的对话等。",
"### Supported Tasks and Leaderboards\n\n\n* dialogue-generation: The dataset can be used to train a model for generating dialogue responses.\n* response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.",
"### Languages\n\n\nLCCC is in Chinese\n\n\nLCCC中的对话是中文的\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\n* 'dialog' (list of strings): List of utterances consisting of a dialogue.",
"### Data Splits\n\n\nWe do not provide the offical split for LCCC-large.\nBut we provide a split for LCCC-base:\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nMIT License\n\n\nCopyright (c) 2020 lemon234071\n\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.",
"### Contributions\n\n\nThanks to Yinhe Zheng for adding this dataset."
] |
f379fd9af10f2178159a6c7fdf6d3a8f10dccc74 | # Dataset Card for "dane-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/dane-mini | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:da",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-14T17:20:34+00:00 | {"language": ["da"], "license": "cc-by-sa-4.0", "size_categories": ["1K<n<10K"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 355712, "num_examples": 1024}, {"name": "test", "num_bytes": 747809, "num_examples": 2048}, {"name": "val", "num_bytes": 92001, "num_examples": 256}], "download_size": 532720, "dataset_size": 1195522}} | 2023-07-05T08:40:02+00:00 | [] | [
"da"
] | TAGS
#task_categories-token-classification #size_categories-1K<n<10K #language-Danish #license-cc-by-sa-4.0 #region-us
| # Dataset Card for "dane-mini"
More Information needed | [
"# Dataset Card for \"dane-mini\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-token-classification #size_categories-1K<n<10K #language-Danish #license-cc-by-sa-4.0 #region-us \n",
"# Dataset Card for \"dane-mini\"\n\nMore Information needed"
] |
67710dfa772469bf5d3653bf0ca9f431e782d85c | # Dataset Card for "norne-nb-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/norne-nb-mini | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:nb",
"license:other",
"region:us"
] | 2022-06-14T17:21:00+00:00 | {"language": ["nb"], "license": "other", "size_categories": ["1K<n<10K"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 317673, "num_examples": 1024}, {"name": "test", "num_bytes": 626004, "num_examples": 2048}, {"name": "val", "num_bytes": 87124, "num_examples": 256}], "download_size": 455512, "dataset_size": 1030801}} | 2023-07-05T08:42:22+00:00 | [] | [
"nb"
] | TAGS
#task_categories-token-classification #size_categories-1K<n<10K #language-Norwegian Bokmål #license-other #region-us
| # Dataset Card for "norne-nb-mini"
More Information needed | [
"# Dataset Card for \"norne-nb-mini\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-token-classification #size_categories-1K<n<10K #language-Norwegian Bokmål #license-other #region-us \n",
"# Dataset Card for \"norne-nb-mini\"\n\nMore Information needed"
] |
b34982a3ffc391bf3c5d6c999a2c1804ae170780 | # Dataset Card for "norne-nn-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/norne-nn-mini | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:nn",
"license:other",
"region:us"
] | 2022-06-14T17:21:22+00:00 | {"language": ["nn"], "license": "other", "size_categories": ["1K<n<10K"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 341534, "num_examples": 1024}, {"name": "test", "num_bytes": 721476, "num_examples": 2048}, {"name": "val", "num_bytes": 90956, "num_examples": 256}], "download_size": 502871, "dataset_size": 1153966}} | 2023-07-05T08:41:26+00:00 | [] | [
"nn"
] | TAGS
#task_categories-token-classification #size_categories-1K<n<10K #language-Norwegian Nynorsk #license-other #region-us
| # Dataset Card for "norne-nn-mini"
More Information needed | [
"# Dataset Card for \"norne-nn-mini\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-token-classification #size_categories-1K<n<10K #language-Norwegian Nynorsk #license-other #region-us \n",
"# Dataset Card for \"norne-nn-mini\"\n\nMore Information needed"
] |
d8243105818293a2f5b4ba7ab6406e73098c9b8b | # Dataset Card for "suc3-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/suc3-mini | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:sv",
"license:cc-by-4.0",
"region:us"
] | 2022-06-14T17:21:45+00:00 | {"language": ["sv"], "license": "cc-by-4.0", "size_categories": ["1K<n<10K"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 344855, "num_examples": 1024}, {"name": "test", "num_bytes": 681936, "num_examples": 2048}, {"name": "val", "num_bytes": 81547, "num_examples": 256}], "download_size": 509020, "dataset_size": 1108338}} | 2023-07-05T08:42:05+00:00 | [] | [
"sv"
] | TAGS
#task_categories-token-classification #size_categories-1K<n<10K #language-Swedish #license-cc-by-4.0 #region-us
| # Dataset Card for "suc3-mini"
More Information needed | [
"# Dataset Card for \"suc3-mini\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-token-classification #size_categories-1K<n<10K #language-Swedish #license-cc-by-4.0 #region-us \n",
"# Dataset Card for \"suc3-mini\"\n\nMore Information needed"
] |
10d04e5710d83c882ae62acb2dd928958b49516a | # Dataset Card for "mim-gold-ner-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/mim-gold-ner-mini | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:is",
"license:other",
"region:us"
] | 2022-06-14T17:35:40+00:00 | {"language": ["is"], "license": "other", "size_categories": ["1K<n<10K"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 377525, "num_examples": 1024}, {"name": "test", "num_bytes": 746049, "num_examples": 2048}, {"name": "val", "num_bytes": 93607, "num_examples": 256}], "download_size": 562012, "dataset_size": 1217181}} | 2023-07-05T08:43:10+00:00 | [] | [
"is"
] | TAGS
#task_categories-token-classification #size_categories-1K<n<10K #language-Icelandic #license-other #region-us
| # Dataset Card for "mim-gold-ner-mini"
More Information needed | [
"# Dataset Card for \"mim-gold-ner-mini\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-token-classification #size_categories-1K<n<10K #language-Icelandic #license-other #region-us \n",
"# Dataset Card for \"mim-gold-ner-mini\"\n\nMore Information needed"
] |
564cc836587aa94894fffba0ed28857eb5b6f939 | # Dataset Card for "wikiann-fo-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | ScandEval/wikiann-fo-mini | [
"language:fo",
"region:us"
] | 2022-06-14T17:39:30+00:00 | {"language": ["fo"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 233626, "num_examples": 1024}, {"name": "test", "num_bytes": 467705, "num_examples": 2048}, {"name": "val", "num_bytes": 60873, "num_examples": 256}], "download_size": 338188, "dataset_size": 762204}} | 2023-07-05T07:08:24+00:00 | [] | [
"fo"
] | TAGS
#language-Faroese #region-us
| # Dataset Card for "wikiann-fo-mini"
More Information needed | [
"# Dataset Card for \"wikiann-fo-mini\"\n\nMore Information needed"
] | [
"TAGS\n#language-Faroese #region-us \n",
"# Dataset Card for \"wikiann-fo-mini\"\n\nMore Information needed"
] |
7bdf563492accd06815580ffdd685adad8b8674b |
# Dataset Card for ADE 20K Tiny
This is a tiny subset of the ADE 20K dataset, which you can find [here](https://huggingface.co/datasets/scene_parse_150). | nateraw/ade20k-tiny | [
"task_categories:image-segmentation",
"task_ids:semantic-segmentation",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:extended|ade20k",
"language:en",
"license:bsd-3-clause",
"region:us"
] | 2022-06-15T03:32:58+00:00 | {"annotations_creators": ["crowdsourced", "expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["bsd-3-clause"], "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "source_datasets": ["extended|ade20k"], "task_categories": ["image-segmentation"], "task_ids": ["semantic-segmentation"], "pretty_name": "ADE 20K Tiny"} | 2022-07-08T05:58:09+00:00 | [] | [
"en"
] | TAGS
#task_categories-image-segmentation #task_ids-semantic-segmentation #annotations_creators-crowdsourced #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-n<1K #source_datasets-extended|ade20k #language-English #license-bsd-3-clause #region-us
|
# Dataset Card for ADE 20K Tiny
This is a tiny subset of the ADE 20K dataset, which you can find here. | [
"# Dataset Card for ADE 20K Tiny\n\nThis is a tiny subset of the ADE 20K dataset, which you can find here."
] | [
"TAGS\n#task_categories-image-segmentation #task_ids-semantic-segmentation #annotations_creators-crowdsourced #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-n<1K #source_datasets-extended|ade20k #language-English #license-bsd-3-clause #region-us \n",
"# Dataset Card for ADE 20K Tiny\n\nThis is a tiny subset of the ADE 20K dataset, which you can find here."
] |
22b3b59656bf17b64ef0294318274afc7b5cf6a2 |
# Dataset Card for Country211
The [Country 211 Dataset](https://github.com/openai/CLIP/blob/main/data/country211.md) from OpenAI.
This dataset was built by filtering the images from the YFCC100m dataset that have GPS coordinate corresponding to a ISO-3166 country code. The dataset is balanced by sampling 150 train images, 50 validation images, and 100 test images images for each country. | nateraw/country211 | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|yfcc100m",
"language:en",
"license:unknown",
"region:us"
] | 2022-06-15T04:11:59+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|yfcc100m"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "pretty_name": "Country 211"} | 2022-07-25T19:27:00+00:00 | [] | [
"en"
] | TAGS
#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|yfcc100m #language-English #license-unknown #region-us
|
# Dataset Card for Country211
The Country 211 Dataset from OpenAI.
This dataset was built by filtering the images from the YFCC100m dataset that have GPS coordinate corresponding to a ISO-3166 country code. The dataset is balanced by sampling 150 train images, 50 validation images, and 100 test images images for each country. | [
"# Dataset Card for Country211\n\nThe Country 211 Dataset from OpenAI.\n\nThis dataset was built by filtering the images from the YFCC100m dataset that have GPS coordinate corresponding to a ISO-3166 country code. The dataset is balanced by sampling 150 train images, 50 validation images, and 100 test images images for each country."
] | [
"TAGS\n#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|yfcc100m #language-English #license-unknown #region-us \n",
"# Dataset Card for Country211\n\nThe Country 211 Dataset from OpenAI.\n\nThis dataset was built by filtering the images from the YFCC100m dataset that have GPS coordinate corresponding to a ISO-3166 country code. The dataset is balanced by sampling 150 train images, 50 validation images, and 100 test images images for each country."
] |
813d20cfb22b7ac76cb6a272cc8510bd85e8a66e |
# Rendered SST-2
The [Rendered SST-2 Dataset](https://github.com/openai/CLIP/blob/main/data/rendered-sst2.md) from Open AI.
Rendered SST2 is an image classification dataset used to evaluate the models capability on optical character recognition. This dataset was generated by rendering sentences in the Standford Sentiment Treebank v2 dataset.
This dataset contains two classes (positive and negative) and is divided in three splits: a train split containing 6920 images (3610 positive and 3310 negative), a validation split containing 872 images (444 positive and 428 negative), and a test split containing 1821 images (909 positive and 912 negative). | nateraw/rendered-sst2 | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:extended|sst2",
"language:en",
"license:unknown",
"region:us"
] | 2022-06-15T04:32:09+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["extended|sst2"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "pretty_name": "Rendered SST-2"} | 2022-10-25T09:32:21+00:00 | [] | [
"en"
] | TAGS
#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-machine-generated #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-extended|sst2 #language-English #license-unknown #region-us
|
# Rendered SST-2
The Rendered SST-2 Dataset from Open AI.
Rendered SST2 is an image classification dataset used to evaluate the models capability on optical character recognition. This dataset was generated by rendering sentences in the Standford Sentiment Treebank v2 dataset.
This dataset contains two classes (positive and negative) and is divided in three splits: a train split containing 6920 images (3610 positive and 3310 negative), a validation split containing 872 images (444 positive and 428 negative), and a test split containing 1821 images (909 positive and 912 negative). | [
"# Rendered SST-2\n\nThe Rendered SST-2 Dataset from Open AI.\n\nRendered SST2 is an image classification dataset used to evaluate the models capability on optical character recognition. This dataset was generated by rendering sentences in the Standford Sentiment Treebank v2 dataset.\n\nThis dataset contains two classes (positive and negative) and is divided in three splits: a train split containing 6920 images (3610 positive and 3310 negative), a validation split containing 872 images (444 positive and 428 negative), and a test split containing 1821 images (909 positive and 912 negative)."
] | [
"TAGS\n#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-machine-generated #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-extended|sst2 #language-English #license-unknown #region-us \n",
"# Rendered SST-2\n\nThe Rendered SST-2 Dataset from Open AI.\n\nRendered SST2 is an image classification dataset used to evaluate the models capability on optical character recognition. This dataset was generated by rendering sentences in the Standford Sentiment Treebank v2 dataset.\n\nThis dataset contains two classes (positive and negative) and is divided in three splits: a train split containing 6920 images (3610 positive and 3310 negative), a validation split containing 872 images (444 positive and 428 negative), and a test split containing 1821 images (909 positive and 912 negative)."
] |
5d1705be26da650adea619ee9bc5bf45571bb653 |
# Dataset Card for Kitti
The [Kitti](http://www.cvlibs.net/datasets/kitti/eval_object.php) dataset.
The Kitti object detection and object orientation estimation benchmark consists of 7481 training images and 7518 test images, comprising a total of 80.256 labeled objects | nateraw/kitti | [
"task_categories:object-detection",
"annotations_creators:found",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:en",
"license:unknown",
"region:us"
] | 2022-06-15T04:58:44+00:00 | {"annotations_creators": ["found"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "task_categories": ["object-detection"], "task_ids": ["object-detection"], "pretty_name": "Kitti"} | 2022-07-15T17:17:21+00:00 | [] | [
"en"
] | TAGS
#task_categories-object-detection #annotations_creators-found #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #language-English #license-unknown #region-us
|
# Dataset Card for Kitti
The Kitti dataset.
The Kitti object detection and object orientation estimation benchmark consists of 7481 training images and 7518 test images, comprising a total of 80.256 labeled objects | [
"# Dataset Card for Kitti\n\nThe Kitti dataset.\n\nThe Kitti object detection and object orientation estimation benchmark consists of 7481 training images and 7518 test images, comprising a total of 80.256 labeled objects"
] | [
"TAGS\n#task_categories-object-detection #annotations_creators-found #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #language-English #license-unknown #region-us \n",
"# Dataset Card for Kitti\n\nThe Kitti dataset.\n\nThe Kitti object detection and object orientation estimation benchmark consists of 7481 training images and 7518 test images, comprising a total of 80.256 labeled objects"
] |
603ca7858c8c00d7b762ff96d3aa29f1507c6954 | # Dataset Card for Sketch Data Model Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://github.com/sketchai
- **Repository:** https://github.com/sketchai/preprocessing
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
This dataset contains over 6M CAD 2D sketches extracted from Onshape. Sketches are stored as python objects in the custom SAM format.
SAM leverages the [Sketchgraphs](https://github.com/PrincetonLIPS/SketchGraphs) dataset for industrial needs and allows for easier transfer learning on other CAD softwares.
### Supported Tasks and Leaderboards
Tasks: Automatic Sketch Generation, Auto Constraint
## Dataset Structure
### Data Instances
The presented npy files contain python pickled objects and require the [flat_array](https://github.com/PrincetonLIPS/SketchGraphs/blob/master/sketchgraphs/data/flat_array.py) module of Sketchgraphs to be loaded. The normalization_output_merged.npy file contains sketch sequences represented as a list of SAM Primitives and Constraints. The sg_merged_final_*.npy files contain encoded constraint graphs of the sketches represented as a dictionnary of arrays.
### Data Fields
[Needs More Information]
### Data Splits
|Train |Val |Test |
|------|------|------|
|6M |50k | 50k |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
[Needs More Information] | sketchai/sam-dataset | [
"annotations_creators:no-annotation",
"language_creators:other",
"size_categories:1M<n<10M",
"license:lgpl-3.0",
"region:us"
] | 2022-06-15T08:18:23+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["other"], "language": [], "license": ["lgpl-3.0"], "multilinguality": [], "size_categories": ["1M<n<10M"], "task_categories": [], "task_ids": [], "pretty_name": "Sketch Data Model Dataset"} | 2022-07-13T12:03:40+00:00 | [] | [] | TAGS
#annotations_creators-no-annotation #language_creators-other #size_categories-1M<n<10M #license-lgpl-3.0 #region-us
| Dataset Card for Sketch Data Model Dataset
==========================================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact:
### Dataset Summary
This dataset contains over 6M CAD 2D sketches extracted from Onshape. Sketches are stored as python objects in the custom SAM format.
SAM leverages the Sketchgraphs dataset for industrial needs and allows for easier transfer learning on other CAD softwares.
### Supported Tasks and Leaderboards
Tasks: Automatic Sketch Generation, Auto Constraint
Dataset Structure
-----------------
### Data Instances
The presented npy files contain python pickled objects and require the flat\_array module of Sketchgraphs to be loaded. The normalization\_output\_merged.npy file contains sketch sequences represented as a list of SAM Primitives and Constraints. The sg\_merged\_final\_\*.npy files contain encoded constraint graphs of the sketches represented as a dictionnary of arrays.
### Data Fields
### Data Splits
Train: 6M, Val: 50k, Test: 50k
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
| [
"### Dataset Summary\n\n\nThis dataset contains over 6M CAD 2D sketches extracted from Onshape. Sketches are stored as python objects in the custom SAM format.\nSAM leverages the Sketchgraphs dataset for industrial needs and allows for easier transfer learning on other CAD softwares.",
"### Supported Tasks and Leaderboards\n\n\nTasks: Automatic Sketch Generation, Auto Constraint\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe presented npy files contain python pickled objects and require the flat\\_array module of Sketchgraphs to be loaded. The normalization\\_output\\_merged.npy file contains sketch sequences represented as a list of SAM Primitives and Constraints. The sg\\_merged\\_final\\_\\*.npy files contain encoded constraint graphs of the sketches represented as a dictionnary of arrays.",
"### Data Fields",
"### Data Splits\n\n\nTrain: 6M, Val: 50k, Test: 50k\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
] | [
"TAGS\n#annotations_creators-no-annotation #language_creators-other #size_categories-1M<n<10M #license-lgpl-3.0 #region-us \n",
"### Dataset Summary\n\n\nThis dataset contains over 6M CAD 2D sketches extracted from Onshape. Sketches are stored as python objects in the custom SAM format.\nSAM leverages the Sketchgraphs dataset for industrial needs and allows for easier transfer learning on other CAD softwares.",
"### Supported Tasks and Leaderboards\n\n\nTasks: Automatic Sketch Generation, Auto Constraint\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nThe presented npy files contain python pickled objects and require the flat\\_array module of Sketchgraphs to be loaded. The normalization\\_output\\_merged.npy file contains sketch sequences represented as a list of SAM Primitives and Constraints. The sg\\_merged\\_final\\_\\*.npy files contain encoded constraint graphs of the sketches represented as a dictionnary of arrays.",
"### Data Fields",
"### Data Splits\n\n\nTrain: 6M, Val: 50k, Test: 50k\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
] |
b7f5ca3b82fd40f1b5eaae91c720817eb477a2cd |
# Dataset Card for frwiki_good_pages_el
## Dataset Description
- Repository: [frwiki_el](https://github.com/GaaH/frwiki_el)
- Point of Contact: [Gaëtan Caillaut](mailto://[email protected])
### Dataset Summary
This dataset contains articles from the French Wikipédia.
It is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.
The dataset `frwiki` contains sentences of each Wikipedia pages.
The dataset `entities` contains description for each Wikipedia pages.
### Languages
- French
## Dataset Structure
### frwiki
```
{
"name": "Title of the page",
"wikidata_id": "Identifier of the related Wikidata entity. Can be null.",
"wikipedia_id": "Identifier of the Wikipedia page",
"wikipedia_url": "URL to the Wikipedia page",
"wikidata_url": "URL to the Wikidata page. Can be null.",
"sentences" : [
{
"text": "text of the current sentence",
"ner": ["list", "of", "ner", "labels"],
"mention_mappings": [
(start_of_first_mention, end_of_first_mention),
(start_of_second_mention, end_of_second_mention)
],
"el_wikidata_id": ["wikidata id of first mention", "wikidata id of second mention"],
"el_wikipedia_id": [wikipedia id of first mention, wikipedia id of second mention],
"el_wikipedia_title": ["wikipedia title of first mention", "wikipedia title of second mention"]
}
]
"words": ["words", "in", "the", "sentence"],
"ner": ["ner", "labels", "of", "each", "words"],
"el": ["el", "labels", "of", "each", "words"]
}
```
### entities
```
{
"name": "Title of the page",
"wikidata_id": "Identifier of the related Wikidata entity. Can be null.",
"wikipedia_id": "Identifier of the Wikipedia page",
"wikipedia_url": "URL to the Wikipedia page",
"wikidata_url": "URL to the Wikidata page. Can be null.",
"description": "Description of the entity"
}
``` | gcaillaut/frwiki_el | [
"task_categories:token-classification",
"annotations_creators:crowdsourced",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:fr",
"license:wtfpl",
"region:us"
] | 2022-06-15T08:37:40+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["machine-generated"], "language": ["fr"], "license": ["wtfpl"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["token-classification"], "task_ids": [], "pretty_name": "French Wikipedia dataset for Entity Linking"} | 2022-09-28T07:52:12+00:00 | [] | [
"fr"
] | TAGS
#task_categories-token-classification #annotations_creators-crowdsourced #language_creators-machine-generated #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-original #language-French #license-wtfpl #region-us
|
# Dataset Card for frwiki_good_pages_el
## Dataset Description
- Repository: frwiki_el
- Point of Contact: Gaëtan Caillaut
### Dataset Summary
This dataset contains articles from the French Wikipédia.
It is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.
The dataset 'frwiki' contains sentences of each Wikipedia pages.
The dataset 'entities' contains description for each Wikipedia pages.
### Languages
- French
## Dataset Structure
### frwiki
### entities
| [
"# Dataset Card for frwiki_good_pages_el",
"## Dataset Description\n\n- Repository: frwiki_el\n- Point of Contact: Gaëtan Caillaut",
"### Dataset Summary\n\nThis dataset contains articles from the French Wikipédia.\nIt is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.\n\nThe dataset 'frwiki' contains sentences of each Wikipedia pages.\n\nThe dataset 'entities' contains description for each Wikipedia pages.",
"### Languages\n\n- French",
"## Dataset Structure",
"### frwiki",
"### entities"
] | [
"TAGS\n#task_categories-token-classification #annotations_creators-crowdsourced #language_creators-machine-generated #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-original #language-French #license-wtfpl #region-us \n",
"# Dataset Card for frwiki_good_pages_el",
"## Dataset Description\n\n- Repository: frwiki_el\n- Point of Contact: Gaëtan Caillaut",
"### Dataset Summary\n\nThis dataset contains articles from the French Wikipédia.\nIt is intended to be used to train Entity Linking (EL) systems. Links in articles are used to detect named entities.\n\nThe dataset 'frwiki' contains sentences of each Wikipedia pages.\n\nThe dataset 'entities' contains description for each Wikipedia pages.",
"### Languages\n\n- French",
"## Dataset Structure",
"### frwiki",
"### entities"
] |
5d39a097127b8a6c8342cfc602967ce396478678 |
# multiFC
- a dataset for the task of **automatic claim verification**
- License is currently unknown, please refer to the original paper/[dataset site](http://www.copenlu.com/publication/2019_emnlp_augenstein/):
- https://arxiv.org/abs/1909.03242
## Dataset contents
- **IMPORTANT:** the `label` column in the `test` set has dummy values as these were not provided (see original readme section for explanation)
```
DatasetDict({
train: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 27871
})
test: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 3487
})
validation: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 3484
})
})
```
## Paper Abstract / Citation
> We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.
```
@inproceedings{conf/emnlp2019/Augenstein,
added-at = {2019-10-27T00:00:00.000+0200},
author = {Augenstein, Isabelle and Lioma, Christina and Wang, Dongsheng and Chaves Lima, Lucas and Hansen, Casper and Hansen, Christian and Grue Simonsen, Jakob},
booktitle = {EMNLP},
crossref = {conf/emnlp/2019},
publisher = {Association for Computational Linguistics},
title = {MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims},
year = 2019
}
```
## Original README
Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims
The MultiFC is the largest publicly available dataset of naturally occurring factual claims for automatic claim verification.
It is collected from 26 English fact-checking websites paired with textual sources and rich metadata and labeled for veracity by human expert journalists.
###### TRAIN and DEV #######
The train and dev files are (tab-separated) and contain the following metadata:
claimID, claim, label, claimURL, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### TEST #######
The test file follows the same structure. However, we have removed the label. Thus, it only presents 12 metadata.
claimID, claim, claim, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### Snippets ######
The text of each claim is submitted verbatim as a query to the Google Search API (without quotes).
In the folder snippet, we provide the top 10 snippets retrieved. In some cases, fewer snippets are provided
since we have excluded the claimURL from the snippets.
Each file in the snippets folder is named after the claimID of the claim submitted as a query.
Snippets file is (tab-separated) and contains the following metadata:
rank_position, title, snippet, snippet_url
For more information, please refer to our paper:
References:
Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019.
MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In EMNLP. Association for Computational Linguistics.
https://copenlu.github.io/publication/2019_emnlp_augenstein/
| pszemraj/multi_fc | [
"license:other",
"automatic claim verification",
"claims",
"arxiv:1909.03242",
"region:us"
] | 2022-06-15T10:27:47+00:00 | {"license": "other", "tags": ["automatic claim verification", "claims"]} | 2022-06-16T10:57:52+00:00 | [
"1909.03242"
] | [] | TAGS
#license-other #automatic claim verification #claims #arxiv-1909.03242 #region-us
|
# multiFC
- a dataset for the task of automatic claim verification
- License is currently unknown, please refer to the original paper/dataset site:
- URL
## Dataset contents
- IMPORTANT: the 'label' column in the 'test' set has dummy values as these were not provided (see original readme section for explanation)
## Paper Abstract / Citation
> We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.
## Original README
Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims
The MultiFC is the largest publicly available dataset of naturally occurring factual claims for automatic claim verification.
It is collected from 26 English fact-checking websites paired with textual sources and rich metadata and labeled for veracity by human expert journalists.
###### TRAIN and DEV #######
The train and dev files are (tab-separated) and contain the following metadata:
claimID, claim, label, claimURL, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### TEST #######
The test file follows the same structure. However, we have removed the label. Thus, it only presents 12 metadata.
claimID, claim, claim, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### Snippets ######
The text of each claim is submitted verbatim as a query to the Google Search API (without quotes).
In the folder snippet, we provide the top 10 snippets retrieved. In some cases, fewer snippets are provided
since we have excluded the claimURL from the snippets.
Each file in the snippets folder is named after the claimID of the claim submitted as a query.
Snippets file is (tab-separated) and contains the following metadata:
rank_position, title, snippet, snippet_url
For more information, please refer to our paper:
References:
Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019.
MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In EMNLP. Association for Computational Linguistics.
URL
| [
"# multiFC\n\n- a dataset for the task of automatic claim verification\n- License is currently unknown, please refer to the original paper/dataset site:\n\n- URL",
"## Dataset contents\n\n- IMPORTANT: the 'label' column in the 'test' set has dummy values as these were not provided (see original readme section for explanation)",
"## Paper Abstract / Citation\n> We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.",
"## Original README\nReal-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims\n\nThe MultiFC is the largest publicly available dataset of naturally occurring factual claims for automatic claim verification.\nIt is collected from 26 English fact-checking websites paired with textual sources and rich metadata and labeled for veracity by human expert journalists.",
"###### TRAIN and DEV #######\nThe train and dev files are (tab-separated) and contain the following metadata:\nclaimID, claim, label, claimURL, reason, categories, speaker, checker, tags, article title, publish date, climate, entities\n\nFields that could not be crawled were set as \"None.\" Please refer to Table 11 of our paper to see the summary statistics.",
"###### TEST #######\nThe test file follows the same structure. However, we have removed the label. Thus, it only presents 12 metadata.\nclaimID, claim, claim, reason, categories, speaker, checker, tags, article title, publish date, climate, entities\n\nFields that could not be crawled were set as \"None.\" Please refer to Table 11 of our paper to see the summary statistics.",
"###### Snippets ######\nThe text of each claim is submitted verbatim as a query to the Google Search API (without quotes).\nIn the folder snippet, we provide the top 10 snippets retrieved. In some cases, fewer snippets are provided\nsince we have excluded the claimURL from the snippets.\nEach file in the snippets folder is named after the claimID of the claim submitted as a query.\nSnippets file is (tab-separated) and contains the following metadata:\nrank_position, title, snippet, snippet_url\n\n\nFor more information, please refer to our paper:\nReferences:\nIsabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019. \nMultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In EMNLP. Association for Computational Linguistics.\n\nURL"
] | [
"TAGS\n#license-other #automatic claim verification #claims #arxiv-1909.03242 #region-us \n",
"# multiFC\n\n- a dataset for the task of automatic claim verification\n- License is currently unknown, please refer to the original paper/dataset site:\n\n- URL",
"## Dataset contents\n\n- IMPORTANT: the 'label' column in the 'test' set has dummy values as these were not provided (see original readme section for explanation)",
"## Paper Abstract / Citation\n> We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.",
"## Original README\nReal-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims\n\nThe MultiFC is the largest publicly available dataset of naturally occurring factual claims for automatic claim verification.\nIt is collected from 26 English fact-checking websites paired with textual sources and rich metadata and labeled for veracity by human expert journalists.",
"###### TRAIN and DEV #######\nThe train and dev files are (tab-separated) and contain the following metadata:\nclaimID, claim, label, claimURL, reason, categories, speaker, checker, tags, article title, publish date, climate, entities\n\nFields that could not be crawled were set as \"None.\" Please refer to Table 11 of our paper to see the summary statistics.",
"###### TEST #######\nThe test file follows the same structure. However, we have removed the label. Thus, it only presents 12 metadata.\nclaimID, claim, claim, reason, categories, speaker, checker, tags, article title, publish date, climate, entities\n\nFields that could not be crawled were set as \"None.\" Please refer to Table 11 of our paper to see the summary statistics.",
"###### Snippets ######\nThe text of each claim is submitted verbatim as a query to the Google Search API (without quotes).\nIn the folder snippet, we provide the top 10 snippets retrieved. In some cases, fewer snippets are provided\nsince we have excluded the claimURL from the snippets.\nEach file in the snippets folder is named after the claimID of the claim submitted as a query.\nSnippets file is (tab-separated) and contains the following metadata:\nrank_position, title, snippet, snippet_url\n\n\nFor more information, please refer to our paper:\nReferences:\nIsabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019. \nMultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In EMNLP. Association for Computational Linguistics.\n\nURL"
] |
21e74ddf8de1a21436da12e3e653065c5213e9d1 |
# APPS Dataset
## Dataset Description
[APPS](https://arxiv.org/abs/2105.09938) is a benchmark for code generation with 10000 problems. It can be used to evaluate the ability of language models to generate code from natural language specifications.
You can also find **APPS metric** in the hub here [codeparrot/apps_metric](https://huggingface.co/spaces/codeparrot/apps_metric).
## Languages
The dataset contains questions in English and code solutions in Python.
## Dataset Structure
```python
from datasets import load_dataset
load_dataset("codeparrot/apps")
DatasetDict({
train: Dataset({
features: ['problem_id', 'question', 'solutions', 'input_output', 'difficulty', 'url', 'starter_code'],
num_rows: 5000
})
test: Dataset({
features: ['problem_id', 'question', 'solutions', 'input_output', 'difficulty', 'url', 'starter_code'],
num_rows: 5000
})
})
```
### How to use it
You can load and iterate through the dataset with the following two lines of code for the train split:
```python
from datasets import load_dataset
import json
ds = load_dataset("codeparrot/apps", split="train")
sample = next(iter(ds))
# non-empty solutions and input_output features can be parsed from text format this way:
sample["solutions"] = json.loads(sample["solutions"])
sample["input_output"] = json.loads(sample["input_output"])
print(sample)
#OUTPUT:
{
'problem_id': 0,
'question': 'Polycarp has $n$ different binary words. A word called binary if it contains only characters \'0\' and \'1\'. For example...',
'solutions': ["for _ in range(int(input())):\n n = int(input())\n mass = []\n zo = 0\n oz = 0\n zz = 0\n oo = 0\n...",...],
'input_output': {'inputs': ['4\n4\n0001\n1000\n0011\n0111\n3\n010\n101\n0\n2\n00000\n00001\n4\n01\n001\n0001\n00001\n'],
'outputs': ['1\n3 \n-1\n0\n\n2\n1 2 \n']},
'difficulty': 'interview',
'url': 'https://codeforces.com/problemset/problem/1259/D',
'starter_code': ''}
}
```
Each sample consists of a programming problem formulation in English, some ground truth Python solutions, test cases that are defined by their inputs and outputs and function name if provided, as well as some metadata regarding the difficulty level of the problem and its source.
If a sample has non empty `input_output` feature, you can read it as a dictionary with keys `inputs` and `outputs` and `fn_name` if it exists, and similarily you can parse the solutions into a list of solutions as shown in the code above.
You can also filter the dataset for the difficulty level: Introductory, Interview and Competition. Just pass the list of difficulties as a list. E.g. if you want the most challenging problems, you need to select the competition level:
```python
ds = load_dataset("codeparrot/apps", split="train", difficulties=["competition"])
print(next(iter(ds))["question"])
#OUTPUT:
"""\
Codefortia is a small island country located somewhere in the West Pacific. It consists of $n$ settlements connected by
...
For each settlement $p = 1, 2, \dots, n$, can you tell what is the minimum time required to travel between the king's residence and the parliament house (located in settlement $p$) after some roads are abandoned?
-----Input-----
The first line of the input contains four integers $n$, $m$, $a$ and $b$
...
-----Output-----
Output a single line containing $n$ integers
...
-----Examples-----
Input
5 5 20 25
1 2 25
...
Output
0 25 60 40 20
...
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|problem_id|int|problem id|
|question|string|problem description|
|solutions|string|some python solutions|
|input_output|string|Json string with "inputs" and "outputs" of the test cases, might also include "fn_name" the name of the function|
|difficulty|string|difficulty level of the problem|
|url|string|url of the source of the problem|
|starter_code|string|starter code to include in prompts|
we mention that only few samples have `fn_name` and `starter_code` specified
### Data Splits
The dataset contains a train and test splits with 5000 samples each.
### Dataset Statistics
* 10000 coding problems
* 131777 test cases
* all problems have a least one test case except 195 samples in the train split
* for tests split, the average number of test cases is 21.2
* average length of a problem is 293.2 words
* all files have ground-truth solutions except 1235 samples in the test split
## Dataset Creation
To create the APPS dataset, the authors manually curated problems from open-access sites where programmers share problems with each other, including Codewars, AtCoder, Kattis, and Codeforces. For more details please refer to the original [paper](https://arxiv.org/pdf/2105.09938.pdf).
## Considerations for Using the Data
In [AlphaCode](https://arxiv.org/pdf/2203.07814v1.pdf) the authors found that this dataset can generate many false positives during evaluation, where incorrect submissions are marked as correct due to lack of test coverage.
## Citation Information
```
@article{hendrycksapps2021,
title={Measuring Coding Challenge Competence With APPS},
author={Dan Hendrycks and Steven Basart and Saurav Kadavath and Mantas Mazeika and Akul Arora and Ethan Guo and Collin Burns and Samir Puranik and Horace He and Dawn Song and Jacob Steinhardt},
journal={NeurIPS},
year={2021}
}
``` | codeparrot/apps | [
"task_categories:text-generation",
"task_ids:language-modeling",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"language:code",
"license:mit",
"arxiv:2105.09938",
"arxiv:2203.07814",
"region:us"
] | 2022-06-15T12:20:26+00:00 | {"annotations_creators": [], "language_creators": ["crowdsourced", "expert-generated"], "language": ["code"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": [], "task_categories": ["text-generation"], "task_ids": ["language-modeling"], "pretty_name": "APPS"} | 2022-10-20T14:00:15+00:00 | [
"2105.09938",
"2203.07814"
] | [
"code"
] | TAGS
#task_categories-text-generation #task_ids-language-modeling #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-unknown #language-code #license-mit #arxiv-2105.09938 #arxiv-2203.07814 #region-us
| APPS Dataset
============
Dataset Description
-------------------
APPS is a benchmark for code generation with 10000 problems. It can be used to evaluate the ability of language models to generate code from natural language specifications.
You can also find APPS metric in the hub here codeparrot/apps\_metric.
Languages
---------
The dataset contains questions in English and code solutions in Python.
Dataset Structure
-----------------
### How to use it
You can load and iterate through the dataset with the following two lines of code for the train split:
Each sample consists of a programming problem formulation in English, some ground truth Python solutions, test cases that are defined by their inputs and outputs and function name if provided, as well as some metadata regarding the difficulty level of the problem and its source.
If a sample has non empty 'input\_output' feature, you can read it as a dictionary with keys 'inputs' and 'outputs' and 'fn\_name' if it exists, and similarily you can parse the solutions into a list of solutions as shown in the code above.
You can also filter the dataset for the difficulty level: Introductory, Interview and Competition. Just pass the list of difficulties as a list. E.g. if you want the most challenging problems, you need to select the competition level:
### Data Fields
Field: problem\_id, Type: int, Description: problem id
Field: question, Type: string, Description: problem description
Field: solutions, Type: string, Description: some python solutions
Field: input\_output, Type: string, Description: Json string with "inputs" and "outputs" of the test cases, might also include "fn\_name" the name of the function
Field: difficulty, Type: string, Description: difficulty level of the problem
Field: url, Type: string, Description: url of the source of the problem
Field: starter\_code, Type: string, Description: starter code to include in prompts
we mention that only few samples have 'fn\_name' and 'starter\_code' specified
### Data Splits
The dataset contains a train and test splits with 5000 samples each.
### Dataset Statistics
* 10000 coding problems
* 131777 test cases
* all problems have a least one test case except 195 samples in the train split
* for tests split, the average number of test cases is 21.2
* average length of a problem is 293.2 words
* all files have ground-truth solutions except 1235 samples in the test split
Dataset Creation
----------------
To create the APPS dataset, the authors manually curated problems from open-access sites where programmers share problems with each other, including Codewars, AtCoder, Kattis, and Codeforces. For more details please refer to the original paper.
Considerations for Using the Data
---------------------------------
In AlphaCode the authors found that this dataset can generate many false positives during evaluation, where incorrect submissions are marked as correct due to lack of test coverage.
| [
"### How to use it\n\n\nYou can load and iterate through the dataset with the following two lines of code for the train split:\n\n\nEach sample consists of a programming problem formulation in English, some ground truth Python solutions, test cases that are defined by their inputs and outputs and function name if provided, as well as some metadata regarding the difficulty level of the problem and its source.\n\n\nIf a sample has non empty 'input\\_output' feature, you can read it as a dictionary with keys 'inputs' and 'outputs' and 'fn\\_name' if it exists, and similarily you can parse the solutions into a list of solutions as shown in the code above.\n\n\nYou can also filter the dataset for the difficulty level: Introductory, Interview and Competition. Just pass the list of difficulties as a list. E.g. if you want the most challenging problems, you need to select the competition level:",
"### Data Fields\n\n\nField: problem\\_id, Type: int, Description: problem id\nField: question, Type: string, Description: problem description\nField: solutions, Type: string, Description: some python solutions\nField: input\\_output, Type: string, Description: Json string with \"inputs\" and \"outputs\" of the test cases, might also include \"fn\\_name\" the name of the function\nField: difficulty, Type: string, Description: difficulty level of the problem\nField: url, Type: string, Description: url of the source of the problem\nField: starter\\_code, Type: string, Description: starter code to include in prompts\n\n\nwe mention that only few samples have 'fn\\_name' and 'starter\\_code' specified",
"### Data Splits\n\n\nThe dataset contains a train and test splits with 5000 samples each.",
"### Dataset Statistics\n\n\n* 10000 coding problems\n* 131777 test cases\n* all problems have a least one test case except 195 samples in the train split\n* for tests split, the average number of test cases is 21.2\n* average length of a problem is 293.2 words\n* all files have ground-truth solutions except 1235 samples in the test split\n\n\nDataset Creation\n----------------\n\n\nTo create the APPS dataset, the authors manually curated problems from open-access sites where programmers share problems with each other, including Codewars, AtCoder, Kattis, and Codeforces. For more details please refer to the original paper.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nIn AlphaCode the authors found that this dataset can generate many false positives during evaluation, where incorrect submissions are marked as correct due to lack of test coverage."
] | [
"TAGS\n#task_categories-text-generation #task_ids-language-modeling #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-unknown #language-code #license-mit #arxiv-2105.09938 #arxiv-2203.07814 #region-us \n",
"### How to use it\n\n\nYou can load and iterate through the dataset with the following two lines of code for the train split:\n\n\nEach sample consists of a programming problem formulation in English, some ground truth Python solutions, test cases that are defined by their inputs and outputs and function name if provided, as well as some metadata regarding the difficulty level of the problem and its source.\n\n\nIf a sample has non empty 'input\\_output' feature, you can read it as a dictionary with keys 'inputs' and 'outputs' and 'fn\\_name' if it exists, and similarily you can parse the solutions into a list of solutions as shown in the code above.\n\n\nYou can also filter the dataset for the difficulty level: Introductory, Interview and Competition. Just pass the list of difficulties as a list. E.g. if you want the most challenging problems, you need to select the competition level:",
"### Data Fields\n\n\nField: problem\\_id, Type: int, Description: problem id\nField: question, Type: string, Description: problem description\nField: solutions, Type: string, Description: some python solutions\nField: input\\_output, Type: string, Description: Json string with \"inputs\" and \"outputs\" of the test cases, might also include \"fn\\_name\" the name of the function\nField: difficulty, Type: string, Description: difficulty level of the problem\nField: url, Type: string, Description: url of the source of the problem\nField: starter\\_code, Type: string, Description: starter code to include in prompts\n\n\nwe mention that only few samples have 'fn\\_name' and 'starter\\_code' specified",
"### Data Splits\n\n\nThe dataset contains a train and test splits with 5000 samples each.",
"### Dataset Statistics\n\n\n* 10000 coding problems\n* 131777 test cases\n* all problems have a least one test case except 195 samples in the train split\n* for tests split, the average number of test cases is 21.2\n* average length of a problem is 293.2 words\n* all files have ground-truth solutions except 1235 samples in the test split\n\n\nDataset Creation\n----------------\n\n\nTo create the APPS dataset, the authors manually curated problems from open-access sites where programmers share problems with each other, including Codewars, AtCoder, Kattis, and Codeforces. For more details please refer to the original paper.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nIn AlphaCode the authors found that this dataset can generate many false positives during evaluation, where incorrect submissions are marked as correct due to lack of test coverage."
] |
83e07480c44954d638b087ecd1f6af7934ba9d68 | Trust**wallet customer service Support Number +1-818*751*8351 | trustwallet/33 | [
"license:apache-2.0",
"region:us"
] | 2022-06-15T16:31:08+00:00 | {"license": "apache-2.0"} | 2022-06-15T16:31:41+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
| Trustwallet customer service Support Number +1-818*751*8351 | [] | [
"TAGS\n#license-apache-2.0 #region-us \n"
] |
1413ed90879c1ebb1b7016388a6ef43e7765d295 | # AutoTrain Dataset for project: Psychiatry_Article_Identifier
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project Psychiatry_Article_Identifier.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "diffuse actinic keratinocyte dysplasia",
"target": 15
},
{
"text": "cholesterol atheroembolism",
"target": 8
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=20, names=['Certain infectious or parasitic diseases', 'Developmental anaomalies', 'Diseases of the blood or blood forming organs', 'Diseases of the genitourinary system', 'Mental behavioural or neurodevelopmental disorders', 'Neoplasms', 'certain conditions originating in the perinatal period', 'conditions related to sexual health', 'diseases of the circulatroy system', 'diseases of the digestive system', 'diseases of the ear or mastoid process', 'diseases of the immune system', 'diseases of the musculoskeletal system or connective tissue', 'diseases of the nervous system', 'diseases of the respiratory system', 'diseases of the skin', 'diseases of the visual system', 'endocrine nutritional or metabolic diseases', 'pregnanacy childbirth or the puerperium', 'sleep-wake disorders'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 9828 |
| valid | 2468 |
| justpyschitry/autotrain-data-Psychiatry_Article_Identifier | [
"task_categories:text-classification",
"region:us"
] | 2022-06-15T18:02:36+00:00 | {"task_categories": ["text-classification"]} | 2022-06-15T20:34:39+00:00 | [] | [] | TAGS
#task_categories-text-classification #region-us
| AutoTrain Dataset for project: Psychiatry\_Article\_Identifier
==============================================================
Dataset Descritpion
-------------------
This dataset has been automatically processed by AutoTrain for project Psychiatry\_Article\_Identifier.
### Languages
The BCP-47 code for the dataset's language is unk.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is unk.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-text-classification #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is unk.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
ca5836dcea910a720fe456e3d3c9b68206507eeb |
# Dataset Card for MAWPS_ar
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
### Dataset Summary
MAWPS: A Math Word Problem Repository
### Supported Tasks
Math Word Problem Solving
### Languages
Supports Arabic and English
## Dataset Structure
### Data Fields
- `text_en`: a `string` feature.
- `text_ar`: a `string` feature.
- `eqn`: a `string` feature.
### Data Splits
|train|validation|test|
|----:|---------:|---:|
| 3636| 1040| 520|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[Rik Koncel-Kedziorski**, Subhro Roy**, Aida Amini, Nate Kushman and Hannaneh Hajishirzi.](https://aclanthology.org/N16-1136.pdf)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Contributions
Special thanks to Associate Professor Marwan Torki and all my colleagues in CC491N (NLP) class for helping me translate this dataset. | omarxadel/MaWPS-ar | [
"task_categories:text2text-generation",
"task_ids:explanation-generation",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"language:en",
"language:ar",
"license:mit",
"region:us"
] | 2022-06-15T19:39:14+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["found"], "language": ["en", "ar"], "license": ["mit"], "multilinguality": ["multilingual"], "size_categories": ["1K<n<10K"], "source_datasets": [], "task_categories": ["text2text-generation"], "task_ids": ["explanation-generation"], "pretty_name": "MAWPS_ar"} | 2022-07-12T14:31:07+00:00 | [] | [
"en",
"ar"
] | TAGS
#task_categories-text2text-generation #task_ids-explanation-generation #annotations_creators-crowdsourced #language_creators-found #multilinguality-multilingual #size_categories-1K<n<10K #language-English #language-Arabic #license-mit #region-us
| Dataset Card for MAWPS\_ar
==========================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks
+ Languages
* Dataset Structure
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
### Dataset Summary
MAWPS: A Math Word Problem Repository
### Supported Tasks
Math Word Problem Solving
### Languages
Supports Arabic and English
Dataset Structure
-----------------
### Data Fields
* 'text\_en': a 'string' feature.
* 'text\_ar': a 'string' feature.
* 'eqn': a 'string' feature.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman and Hannaneh Hajishirzi.
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
### Contributions
Special thanks to Associate Professor Marwan Torki and all my colleagues in CC491N (NLP) class for helping me translate this dataset.
| [
"### Dataset Summary\n\n\nMAWPS: A Math Word Problem Repository",
"### Supported Tasks\n\n\nMath Word Problem Solving",
"### Languages\n\n\nSupports Arabic and English\n\n\nDataset Structure\n-----------------",
"### Data Fields\n\n\n* 'text\\_en': a 'string' feature.\n* 'text\\_ar': a 'string' feature.\n* 'eqn': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\n\nRik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman and Hannaneh Hajishirzi.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\n\nSpecial thanks to Associate Professor Marwan Torki and all my colleagues in CC491N (NLP) class for helping me translate this dataset."
] | [
"TAGS\n#task_categories-text2text-generation #task_ids-explanation-generation #annotations_creators-crowdsourced #language_creators-found #multilinguality-multilingual #size_categories-1K<n<10K #language-English #language-Arabic #license-mit #region-us \n",
"### Dataset Summary\n\n\nMAWPS: A Math Word Problem Repository",
"### Supported Tasks\n\n\nMath Word Problem Solving",
"### Languages\n\n\nSupports Arabic and English\n\n\nDataset Structure\n-----------------",
"### Data Fields\n\n\n* 'text\\_en': a 'string' feature.\n* 'text\\_ar': a 'string' feature.\n* 'eqn': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?\n\n\nRik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman and Hannaneh Hajishirzi.",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\n\nSpecial thanks to Associate Professor Marwan Torki and all my colleagues in CC491N (NLP) class for helping me translate this dataset."
] |
6adb717a2503f1d49af178c0497c2529f1a8e68f | # CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
CORD dataset is cloned from [clovaai](https://github.com/clovaai/cord) GitHub repo
- Box coordinates are normalized against image width/height
- Labels with very few occurrences are replaced with O:
```
replacing_labels = ['menu.etc', 'menu.itemsubtotal',
'menu.sub_etc', 'menu.sub_unitprice',
'menu.vatyn', 'void_menu.nm',
'void_menu.price', 'sub_total.othersvc_price']
```
Check for more info [Sparrow](https://github.com/katanaml/sparrow)
## Citation
### CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
```
@article{park2019cord,
title={CORD: A Consolidated Receipt Dataset for Post-OCR Parsing},
author={Park, Seunghyun and Shin, Seung and Lee, Bado and Lee, Junyeop and Surh, Jaeheung and Seo, Minjoon and Lee, Hwalsuk}
booktitle={Document Intelligence Workshop at Neural Information Processing Systems}
year={2019}
}
```
### Post-OCR parsing: building simple and robust parser via BIO tagging
```
@article{hwang2019post,
title={Post-OCR parsing: building simple and robust parser via BIO tagging},
author={Hwang, Wonseok and Kim, Seonghyeon and Yim, Jinyeong and Seo, Minjoon and Park, Seunghyun and Park, Sungrae and Lee, Junyeop and Lee, Bado and Lee, Hwalsuk}
booktitle={Document Intelligence Workshop at Neural Information Processing Systems}
year={2019}
}
``` | nehruperumalla/forms | [
"region:us"
] | 2022-06-16T05:34:48+00:00 | {} | 2022-06-16T05:38:45+00:00 | [] | [] | TAGS
#region-us
| # CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
CORD dataset is cloned from clovaai GitHub repo
- Box coordinates are normalized against image width/height
- Labels with very few occurrences are replaced with O:
Check for more info Sparrow
### CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
### Post-OCR parsing: building simple and robust parser via BIO tagging
| [
"# CORD: A Consolidated Receipt Dataset for Post-OCR Parsing\n\nCORD dataset is cloned from clovaai GitHub repo\n\n- Box coordinates are normalized against image width/height\n- Labels with very few occurrences are replaced with O:\n\n\n\nCheck for more info Sparrow",
"### CORD: A Consolidated Receipt Dataset for Post-OCR Parsing",
"### Post-OCR parsing: building simple and robust parser via BIO tagging"
] | [
"TAGS\n#region-us \n",
"# CORD: A Consolidated Receipt Dataset for Post-OCR Parsing\n\nCORD dataset is cloned from clovaai GitHub repo\n\n- Box coordinates are normalized against image width/height\n- Labels with very few occurrences are replaced with O:\n\n\n\nCheck for more info Sparrow",
"### CORD: A Consolidated Receipt Dataset for Post-OCR Parsing",
"### Post-OCR parsing: building simple and robust parser via BIO tagging"
] |
f27efa2241b715868b4e2c6a2ead19ce067b3b48 | This is the sentiment analysis dataset based on IMDB reviews initially released by Stanford University.
```
This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets.
We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
Raw text and already processed bag of words formats are provided. See the README file contained in the release for more details.
```
[Here](http://ai.stanford.edu/~amaas/data/sentiment/) is the redirection.
```
@InProceedings{maas-EtAl:2011:ACL-HLT2011,
author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher},
title = {Learning Word Vectors for Sentiment Analysis},
booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies},
month = {June},
year = {2011},
address = {Portland, Oregon, USA},
publisher = {Association for Computational Linguistics},
pages = {142--150},
url = {http://www.aclweb.org/anthology/P11-1015}
}
``` | scikit-learn/imdb | [
"license:other",
"region:us"
] | 2022-06-16T08:07:41+00:00 | {"license": "other"} | 2022-06-16T08:11:24+00:00 | [] | [] | TAGS
#license-other #region-us
| This is the sentiment analysis dataset based on IMDB reviews initially released by Stanford University.
Here is the redirection.
| [] | [
"TAGS\n#license-other #region-us \n"
] |
428766bc07a9e8699b7782e8557b7e07d32923f3 | # CodeParrot 🦜 Dataset after near deduplication (validation)
## Dataset Description
A dataset of Python files from Github. We performed near deduplication of this dataset split [codeparrot-clean-train](https://huggingface.co/datasets/codeparrot/codeparrot-clean-valid) from [codeparrot-clean](https://huggingface.co/datasets/codeparrot/codeparrot-clean#codeparrot-%F0%9F%A6%9C-dataset-cleaned). Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this [repo](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot).
| codeparrot/codeparrot-valid-near-deduplication | [
"region:us"
] | 2022-06-16T13:29:26+00:00 | {} | 2022-06-21T18:06:58+00:00 | [] | [] | TAGS
#region-us
| # CodeParrot Dataset after near deduplication (validation)
## Dataset Description
A dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo.
| [
"# CodeParrot Dataset after near deduplication (validation)",
"## Dataset Description\n\nA dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo."
] | [
"TAGS\n#region-us \n",
"# CodeParrot Dataset after near deduplication (validation)",
"## Dataset Description\n\nA dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo."
] |
e77668a8fb0cedb8ff0fb97ca9e4699b1f095841 | # Dataset Card for OffendES
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Paper: OffendES:** [A New Corpus in Spanish for Offensive Language Research](https://aclanthology.org/2021.ranlp-1.123.pdf)
- **Leaderboard:** [Leaderboard for OffendES / Spanish](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6388)
- **Point of Contact: [email protected]**
### Dataset Summary
Focusing on young influencers from the well-known social platforms of Twitter, Instagram, and YouTube, we have collected a corpus composed of Spanish comments manually labeled on offensive pre-defined categories. From the total corpus, we selected 30,416 posts to be publicly published, they correspond to the ones used in the MeOffendES competition at IberLEF 2021. The posts are labeled with the following categories:
- Offensive, the target is a person (OFP). Offensive text targeting a specific individual.
- Offensive, the target is a group of people or collective (OFG). Offensive text targeting a group of people belonging to the same ethnic group, gender or sexual orientation, political ideology, religious belief, or other common characteristics.
- Non-offensive, but with expletive language (NOE). A text that contains rude words, blasphemes, or swearwords but without the aim of offending, and usually with a positive connotation.
- Non-offensive (NO). Text that is neither offensive nor contains expletive language
### Supported Tasks and Leaderboards
This dataset is intended for multi-class offensive classification and binary offensive classification.
Competition [MeOffendES task on offensive detection for Spanish at IberLEF 2021](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6388)
### Languages
- Spanish
## Dataset Structure
### Data Instances
For each instance, there is a string for the id of the tweet, a string for the emotion class, a string for the offensive class, and a string for the event. See the []() to explore more examples.
```
{'comment_id': '8003',
'influencer': 'dalas',
'comment': 'Estupido aburrido',
'label': 'NO',
'influencer_gender': 'man',
'media': youtube
}
```
### Data Fields
- `comment_id`: a string to identify the comment
- `influencer`: a string containing the influencer associated with the comment
- `comment`: a string containing the text of the comment
- `label`: a string containing the offensive gold label
- `influencer_gender`: a string containing the genre of the influencer
- `media`: a string containing the social media platform where the comment has been retrieved
### Data Splits
The OffendES dataset contains 3 splits: _train_, _validation_, and _test_. Below are the statistics for each class.
| OffendES | Number of Instances in Split per class| | |
| ------------- | ---------------------------------|---------------------------------|------------------------------------------|
| `Class` | `Train` | `Validation` | `Test` |
| NO | 13,212 | 64 | 9,651 |
| NOE | 1,235 | 22 | 2,340 |
| OFP | 2,051 | 10 | 1,404 |
| OFG | 212 | 4 | 211 |
| Total | 16,710 | 100 | 13,606 |
## Dataset Creation
### Source Data
Twitter, Youtube, Instagram
#### Who are the annotators?
Amazon Mechanical Turkers
## Additional Information
### Licensing Information
The OffendES dataset is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
### Citation Information
```
@inproceedings{plaza-del-arco-etal-2021-offendes,
title = "{O}ffend{ES}: A New Corpus in {S}panish for Offensive Language Research",
author = "{Plaza-del-Arco}, Flor Miriam and Montejo-R{\'a}ez, Arturo and Ure{\~n}a-L{\'o}pez, L. Alfonso and Mart{\'\i}n-Valdivia, Mar{\'\i}a-Teresa",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = sep,
year = "2021",
address = "Held Online",
url = "https://aclanthology.org/2021.ranlp-1.123.pdf",
language = "English",
pages = "1096--1108"
}
```
```
@article{meoffendes2021,
title="{{Overview of MeOffendEs at IberLEF 2021: Offensive Language Detection in Spanish Variants}}",
author="{Flor Miriam Plaza-del-Arco and Casavantes, Marco and Jair Escalante, Hugo and Martín-Valdivia, M. Teresa and Montejo-Ráez, Arturo and {Montes-y-Gómez}, Manuel and Jarquín-Vásquez, Horacio and Villaseñor-Pineda, Luis}",
journal="Procesamiento del Lenguaje Natural",
url = "https://bit.ly/3QpRDfy",
volume="67",
pages="183--194",
year="2021"
}
``` | fmplaza/offendes | [
"language:es",
"license:apache-2.0",
"region:us"
] | 2022-06-16T13:32:03+00:00 | {"language": ["es"], "license": "apache-2.0"} | 2024-02-06T14:26:55+00:00 | [] | [
"es"
] | TAGS
#language-Spanish #license-apache-2.0 #region-us
| Dataset Card for OffendES
=========================
Table of Contents
-----------------
* Table of Contents
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Source Data
+ Annotations
* Additional Information
+ Licensing Information
+ Citation Information
Dataset Description
-------------------
* Paper: OffendES: A New Corpus in Spanish for Offensive Language Research
* Leaderboard: Leaderboard for OffendES / Spanish
* Point of Contact: fmplaza@URL
### Dataset Summary
Focusing on young influencers from the well-known social platforms of Twitter, Instagram, and YouTube, we have collected a corpus composed of Spanish comments manually labeled on offensive pre-defined categories. From the total corpus, we selected 30,416 posts to be publicly published, they correspond to the ones used in the MeOffendES competition at IberLEF 2021. The posts are labeled with the following categories:
* Offensive, the target is a person (OFP). Offensive text targeting a specific individual.
* Offensive, the target is a group of people or collective (OFG). Offensive text targeting a group of people belonging to the same ethnic group, gender or sexual orientation, political ideology, religious belief, or other common characteristics.
* Non-offensive, but with expletive language (NOE). A text that contains rude words, blasphemes, or swearwords but without the aim of offending, and usually with a positive connotation.
* Non-offensive (NO). Text that is neither offensive nor contains expletive language
### Supported Tasks and Leaderboards
This dataset is intended for multi-class offensive classification and binary offensive classification.
Competition MeOffendES task on offensive detection for Spanish at IberLEF 2021
### Languages
* Spanish
Dataset Structure
-----------------
### Data Instances
For each instance, there is a string for the id of the tweet, a string for the emotion class, a string for the offensive class, and a string for the event. See the to explore more examples.
### Data Fields
* 'comment\_id': a string to identify the comment
* 'influencer': a string containing the influencer associated with the comment
* 'comment': a string containing the text of the comment
* 'label': a string containing the offensive gold label
* 'influencer\_gender': a string containing the genre of the influencer
* 'media': a string containing the social media platform where the comment has been retrieved
### Data Splits
The OffendES dataset contains 3 splits: *train*, *validation*, and *test*. Below are the statistics for each class.
Dataset Creation
----------------
### Source Data
Twitter, Youtube, Instagram
#### Who are the annotators?
Amazon Mechanical Turkers
Additional Information
----------------------
### Licensing Information
The OffendES dataset is released under the Apache-2.0 License.
| [
"### Dataset Summary\n\n\nFocusing on young influencers from the well-known social platforms of Twitter, Instagram, and YouTube, we have collected a corpus composed of Spanish comments manually labeled on offensive pre-defined categories. From the total corpus, we selected 30,416 posts to be publicly published, they correspond to the ones used in the MeOffendES competition at IberLEF 2021. The posts are labeled with the following categories:\n\n\n* Offensive, the target is a person (OFP). Offensive text targeting a specific individual.\n* Offensive, the target is a group of people or collective (OFG). Offensive text targeting a group of people belonging to the same ethnic group, gender or sexual orientation, political ideology, religious belief, or other common characteristics.\n* Non-offensive, but with expletive language (NOE). A text that contains rude words, blasphemes, or swearwords but without the aim of offending, and usually with a positive connotation.\n* Non-offensive (NO). Text that is neither offensive nor contains expletive language",
"### Supported Tasks and Leaderboards\n\n\nThis dataset is intended for multi-class offensive classification and binary offensive classification.\nCompetition MeOffendES task on offensive detection for Spanish at IberLEF 2021",
"### Languages\n\n\n* Spanish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nFor each instance, there is a string for the id of the tweet, a string for the emotion class, a string for the offensive class, and a string for the event. See the to explore more examples.",
"### Data Fields\n\n\n* 'comment\\_id': a string to identify the comment\n* 'influencer': a string containing the influencer associated with the comment\n* 'comment': a string containing the text of the comment\n* 'label': a string containing the offensive gold label\n* 'influencer\\_gender': a string containing the genre of the influencer\n* 'media': a string containing the social media platform where the comment has been retrieved",
"### Data Splits\n\n\nThe OffendES dataset contains 3 splits: *train*, *validation*, and *test*. Below are the statistics for each class.\n\n\n\nDataset Creation\n----------------",
"### Source Data\n\n\nTwitter, Youtube, Instagram",
"#### Who are the annotators?\n\n\nAmazon Mechanical Turkers\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nThe OffendES dataset is released under the Apache-2.0 License."
] | [
"TAGS\n#language-Spanish #license-apache-2.0 #region-us \n",
"### Dataset Summary\n\n\nFocusing on young influencers from the well-known social platforms of Twitter, Instagram, and YouTube, we have collected a corpus composed of Spanish comments manually labeled on offensive pre-defined categories. From the total corpus, we selected 30,416 posts to be publicly published, they correspond to the ones used in the MeOffendES competition at IberLEF 2021. The posts are labeled with the following categories:\n\n\n* Offensive, the target is a person (OFP). Offensive text targeting a specific individual.\n* Offensive, the target is a group of people or collective (OFG). Offensive text targeting a group of people belonging to the same ethnic group, gender or sexual orientation, political ideology, religious belief, or other common characteristics.\n* Non-offensive, but with expletive language (NOE). A text that contains rude words, blasphemes, or swearwords but without the aim of offending, and usually with a positive connotation.\n* Non-offensive (NO). Text that is neither offensive nor contains expletive language",
"### Supported Tasks and Leaderboards\n\n\nThis dataset is intended for multi-class offensive classification and binary offensive classification.\nCompetition MeOffendES task on offensive detection for Spanish at IberLEF 2021",
"### Languages\n\n\n* Spanish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nFor each instance, there is a string for the id of the tweet, a string for the emotion class, a string for the offensive class, and a string for the event. See the to explore more examples.",
"### Data Fields\n\n\n* 'comment\\_id': a string to identify the comment\n* 'influencer': a string containing the influencer associated with the comment\n* 'comment': a string containing the text of the comment\n* 'label': a string containing the offensive gold label\n* 'influencer\\_gender': a string containing the genre of the influencer\n* 'media': a string containing the social media platform where the comment has been retrieved",
"### Data Splits\n\n\nThe OffendES dataset contains 3 splits: *train*, *validation*, and *test*. Below are the statistics for each class.\n\n\n\nDataset Creation\n----------------",
"### Source Data\n\n\nTwitter, Youtube, Instagram",
"#### Who are the annotators?\n\n\nAmazon Mechanical Turkers\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nThe OffendES dataset is released under the Apache-2.0 License."
] |
0809fc7058613aa685e5b99a7987eee7ec72171f | # CodeParrot 🦜 Dataset after near deduplication (train)
## Dataset Description
A dataset of Python files from Github. We performed near deduplication of this dataset split [codeparrot-clean-train](https://huggingface.co/datasets/codeparrot/codeparrot-clean-train) from [codeparrot-clean](https://huggingface.co/datasets/codeparrot/codeparrot-clean#codeparrot-%F0%9F%A6%9C-dataset-cleaned). Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this [repo](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot).
| codeparrot/codeparrot-train-near-deduplication | [
"region:us"
] | 2022-06-16T15:45:47+00:00 | {} | 2022-06-21T18:07:13+00:00 | [] | [] | TAGS
#region-us
| # CodeParrot Dataset after near deduplication (train)
## Dataset Description
A dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo.
| [
"# CodeParrot Dataset after near deduplication (train)",
"## Dataset Description\n\nA dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo."
] | [
"TAGS\n#region-us \n",
"# CodeParrot Dataset after near deduplication (train)",
"## Dataset Description\n\nA dataset of Python files from Github. We performed near deduplication of this dataset split codeparrot-clean-train from codeparrot-clean. Exact deduplication can miss a fair amount of nearly identical files. We used MinHash with a Jaccard threshold (default=0.85) to create duplicate clusters. Then these clusters are reduced to unique files based on the exact Jaccard similarity. Fore more details, please refer to this repo."
] |
b332d9a0f9ffbd9f6608dd1ea2d90a18b827f78a |
# Dataset Card for "tydiqa"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/tydiqa](https://github.com/google-research-datasets/tydiqa)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 3726.74 MB
- **Size of the generated dataset:** 5812.92 MB
- **Total amount of disk used:** 9539.67 MB
### Dataset Summary
TyDi QA is a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs.
The languages of TyDi QA are diverse with regard to their typology -- the set of linguistic features that each language
expresses -- such that we expect models performing well on this set to generalize across a large number of the languages
in the world. It contains language phenomena that would not be found in English-only corpora. To provide a realistic
information-seeking task and avoid priming effects, questions are written by people who want to know the answer, but
don’t know the answer yet, (unlike SQuAD and its descendents) and the data is collected directly in each language without
the use of translation (unlike MLQA and XQuAD).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### primary_task
- **Size of downloaded dataset files:** 1863.37 MB
- **Size of the generated dataset:** 5757.59 MB
- **Total amount of disk used:** 7620.96 MB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"annotations": {
"minimal_answers_end_byte": [-1, -1, -1],
"minimal_answers_start_byte": [-1, -1, -1],
"passage_answer_candidate_index": [-1, -1, -1],
"yes_no_answer": ["NONE", "NONE", "NONE"]
},
"document_plaintext": "\"\\nรองศาสตราจารย์[1] หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร (22 กันยายน 2495 -) ผู้ว่าราชการกรุงเทพมหานครคนที่ 15 อดีตรองหัวหน้าพรรคปร...",
"document_title": "หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร",
"document_url": "\"https://th.wikipedia.org/wiki/%E0%B8%AB%E0%B8%A1%E0%B9%88%E0%B8%AD%E0%B8%A1%E0%B8%A3%E0%B8%B2%E0%B8%8A%E0%B8%A7%E0%B8%87%E0%B8%...",
"language": "thai",
"passage_answer_candidates": "{\"plaintext_end_byte\": [494, 1779, 2931, 3904, 4506, 5588, 6383, 7122, 8224, 9375, 10473, 12563, 15134, 17765, 19863, 21902, 229...",
"question_text": "\"หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร เรียนจบจากที่ไหน ?\"..."
}
```
### Data Fields
The data fields are the same among all splits.
#### primary_task
- `passage_answer_candidates`: a dictionary feature containing:
- `plaintext_start_byte`: a `int32` feature.
- `plaintext_end_byte`: a `int32` feature.
- `question_text`: a `string` feature.
- `document_title`: a `string` feature.
- `language`: a `string` feature.
- `annotations`: a dictionary feature containing:
- `passage_answer_candidate_index`: a `int32` feature.
- `minimal_answers_start_byte`: a `int32` feature.
- `minimal_answers_end_byte`: a `int32` feature.
- `yes_no_answer`: a `string` feature.
- `document_plaintext`: a `string` feature.
- `document_url`: a `string` feature.
### Data Splits
| name | train | validation |
| -------------- | -----: | ---------: |
| primary_task | 166916 | 18670 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{tydiqa,
title = {TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages},
author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki}
year = {2020},
journal = {Transactions of the Association for Computational Linguistics}
}
```
```
@inproceedings{ruder-etal-2021-xtreme,
title = "{XTREME}-{R}: Towards More Challenging and Nuanced Multilingual Evaluation",
author = "Ruder, Sebastian and
Constant, Noah and
Botha, Jan and
Siddhant, Aditya and
Firat, Orhan and
Fu, Jinlan and
Liu, Pengfei and
Hu, Junjie and
Garrette, Dan and
Neubig, Graham and
Johnson, Melvin",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.802",
doi = "10.18653/v1/2021.emnlp-main.802",
pages = "10215--10245",
}
}
```
| khalidalt/tydiqa-primary | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:extended|wikipedia",
"language:en",
"language:ar",
"language:bn",
"language:fi",
"language:id",
"language:ja",
"language:sw",
"language:ko",
"language:ru",
"language:te",
"language:th",
"license:apache-2.0",
"region:us"
] | 2022-06-16T16:20:46+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en", "ar", "bn", "fi", "id", "ja", "sw", "ko", "ru", "te", "th"], "license": ["apache-2.0"], "multilinguality": ["multilingual"], "size_categories": ["unknown"], "source_datasets": ["extended|wikipedia"], "task_categories": ["question-answering"], "task_ids": ["extractive-qa"], "paperswithcode_id": "tydi-qa", "pretty_name": "TyDi QA"} | 2022-07-28T20:56:04+00:00 | [] | [
"en",
"ar",
"bn",
"fi",
"id",
"ja",
"sw",
"ko",
"ru",
"te",
"th"
] | TAGS
#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-multilingual #size_categories-unknown #source_datasets-extended|wikipedia #language-English #language-Arabic #language-Bengali #language-Finnish #language-Indonesian #language-Japanese #language-Swahili (macrolanguage) #language-Korean #language-Russian #language-Telugu #language-Thai #license-apache-2.0 #region-us
| Dataset Card for "tydiqa"
=========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository:
* Paper:
* Point of Contact:
* Size of downloaded dataset files: 3726.74 MB
* Size of the generated dataset: 5812.92 MB
* Total amount of disk used: 9539.67 MB
### Dataset Summary
TyDi QA is a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs.
The languages of TyDi QA are diverse with regard to their typology -- the set of linguistic features that each language
expresses -- such that we expect models performing well on this set to generalize across a large number of the languages
in the world. It contains language phenomena that would not be found in English-only corpora. To provide a realistic
information-seeking task and avoid priming effects, questions are written by people who want to know the answer, but
don’t know the answer yet, (unlike SQuAD and its descendents) and the data is collected directly in each language without
the use of translation (unlike MLQA and XQuAD).
### Supported Tasks and Leaderboards
### Languages
Dataset Structure
-----------------
### Data Instances
#### primary\_task
* Size of downloaded dataset files: 1863.37 MB
* Size of the generated dataset: 5757.59 MB
* Total amount of disk used: 7620.96 MB
An example of 'validation' looks as follows.
### Data Fields
The data fields are the same among all splits.
#### primary\_task
* 'passage\_answer\_candidates': a dictionary feature containing:
+ 'plaintext\_start\_byte': a 'int32' feature.
+ 'plaintext\_end\_byte': a 'int32' feature.
* 'question\_text': a 'string' feature.
* 'document\_title': a 'string' feature.
* 'language': a 'string' feature.
* 'annotations': a dictionary feature containing:
+ 'passage\_answer\_candidate\_index': a 'int32' feature.
+ 'minimal\_answers\_start\_byte': a 'int32' feature.
+ 'minimal\_answers\_end\_byte': a 'int32' feature.
+ 'yes\_no\_answer': a 'string' feature.
* 'document\_plaintext': a 'string' feature.
* 'document\_url': a 'string' feature.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
| [
"### Dataset Summary\n\n\nTyDi QA is a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs.\nThe languages of TyDi QA are diverse with regard to their typology -- the set of linguistic features that each language\nexpresses -- such that we expect models performing well on this set to generalize across a large number of the languages\nin the world. It contains language phenomena that would not be found in English-only corpora. To provide a realistic\ninformation-seeking task and avoid priming effects, questions are written by people who want to know the answer, but\ndon’t know the answer yet, (unlike SQuAD and its descendents) and the data is collected directly in each language without\nthe use of translation (unlike MLQA and XQuAD).",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### primary\\_task\n\n\n* Size of downloaded dataset files: 1863.37 MB\n* Size of the generated dataset: 5757.59 MB\n* Total amount of disk used: 7620.96 MB\n\n\nAn example of 'validation' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### primary\\_task\n\n\n* 'passage\\_answer\\_candidates': a dictionary feature containing:\n\t+ 'plaintext\\_start\\_byte': a 'int32' feature.\n\t+ 'plaintext\\_end\\_byte': a 'int32' feature.\n* 'question\\_text': a 'string' feature.\n* 'document\\_title': a 'string' feature.\n* 'language': a 'string' feature.\n* 'annotations': a dictionary feature containing:\n\t+ 'passage\\_answer\\_candidate\\_index': a 'int32' feature.\n\t+ 'minimal\\_answers\\_start\\_byte': a 'int32' feature.\n\t+ 'minimal\\_answers\\_end\\_byte': a 'int32' feature.\n\t+ 'yes\\_no\\_answer': a 'string' feature.\n* 'document\\_plaintext': a 'string' feature.\n* 'document\\_url': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
] | [
"TAGS\n#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-multilingual #size_categories-unknown #source_datasets-extended|wikipedia #language-English #language-Arabic #language-Bengali #language-Finnish #language-Indonesian #language-Japanese #language-Swahili (macrolanguage) #language-Korean #language-Russian #language-Telugu #language-Thai #license-apache-2.0 #region-us \n",
"### Dataset Summary\n\n\nTyDi QA is a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs.\nThe languages of TyDi QA are diverse with regard to their typology -- the set of linguistic features that each language\nexpresses -- such that we expect models performing well on this set to generalize across a large number of the languages\nin the world. It contains language phenomena that would not be found in English-only corpora. To provide a realistic\ninformation-seeking task and avoid priming effects, questions are written by people who want to know the answer, but\ndon’t know the answer yet, (unlike SQuAD and its descendents) and the data is collected directly in each language without\nthe use of translation (unlike MLQA and XQuAD).",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### primary\\_task\n\n\n* Size of downloaded dataset files: 1863.37 MB\n* Size of the generated dataset: 5757.59 MB\n* Total amount of disk used: 7620.96 MB\n\n\nAn example of 'validation' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### primary\\_task\n\n\n* 'passage\\_answer\\_candidates': a dictionary feature containing:\n\t+ 'plaintext\\_start\\_byte': a 'int32' feature.\n\t+ 'plaintext\\_end\\_byte': a 'int32' feature.\n* 'question\\_text': a 'string' feature.\n* 'document\\_title': a 'string' feature.\n* 'language': a 'string' feature.\n* 'annotations': a dictionary feature containing:\n\t+ 'passage\\_answer\\_candidate\\_index': a 'int32' feature.\n\t+ 'minimal\\_answers\\_start\\_byte': a 'int32' feature.\n\t+ 'minimal\\_answers\\_end\\_byte': a 'int32' feature.\n\t+ 'yes\\_no\\_answer': a 'string' feature.\n* 'document\\_plaintext': a 'string' feature.\n* 'document\\_url': a 'string' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information"
] |
b29ec2faf6ef73d634db9757f8741dee68f6c874 |
# Dataset Card for Fig-QA
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Splits](#data-splits)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Discussion of Biases](#discussion-of-biases)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Repository:** https://github.com/nightingal3/Fig-QA
- **Paper:** https://arxiv.org/abs/2204.12632
- **Leaderboard:** https://explainaboard.inspiredco.ai/leaderboards?dataset=fig_qa
- **Point of Contact:** [email protected]
### Dataset Summary
This is the dataset for the paper [Testing the Ability of Language Models to Interpret Figurative Language](https://arxiv.org/abs/2204.12632). Fig-QA consists of 10256 examples of human-written creative metaphors that are paired as a Winograd schema. It can be used to evaluate the commonsense reasoning of models. The metaphors themselves can also be used as training data for other tasks, such as metaphor detection or generation.
### Supported Tasks and Leaderboards
You can evaluate your models on the test set by submitting to the [leaderboard](https://explainaboard.inspiredco.ai/leaderboards?dataset=fig_qa) on Explainaboard. Click on "New" and select `qa-multiple-choice` for the task field. Select `accuracy` for the metric. You should upload results in the form of a system output file in JSON or JSONL format.
### Languages
This is the English version. Multilingual version can be found [here](https://huggingface.co/datasets/cmu-lti/multi-figqa).
### Data Splits
Train-{S, M(no suffix), XL}: different training set sizes
Dev
Test (labels not provided for test set)
## Considerations for Using the Data
### Discussion of Biases
These metaphors are human-generated and may contain insults or other explicit content. Authors of the paper manually removed offensive content, but users should keep in mind that some potentially offensive content may remain in the dataset.
## Additional Information
### Licensing Information
MIT License
### Citation Information
If you found the dataset useful, please cite this paper:
@misc{https://doi.org/10.48550/arxiv.2204.12632,
doi = {10.48550/ARXIV.2204.12632},
url = {https://arxiv.org/abs/2204.12632},
author = {Liu, Emmy and Cui, Chen and Zheng, Kenneth and Neubig, Graham},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Testing the Ability of Language Models to Interpret Figurative Language},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Share Alike 4.0 International}
}
| nightingal3/fig-qa | [
"task_categories:multiple-choice",
"task_ids:multiple-choice-qa",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:mit",
"arxiv:2204.12632",
"region:us"
] | 2022-06-16T17:35:21+00:00 | {"annotations_creators": ["expert-generated", "crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["multiple-choice"], "task_ids": ["multiple-choice-qa"], "pretty_name": "Fig-QA"} | 2023-06-10T17:13:33+00:00 | [
"2204.12632"
] | [
"en"
] | TAGS
#task_categories-multiple-choice #task_ids-multiple-choice-qa #annotations_creators-expert-generated #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-mit #arxiv-2204.12632 #region-us
|
# Dataset Card for Fig-QA
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Splits
- Considerations for Using the Data
- Discussion of Biases
- Additional Information
- Licensing Information
- Citation Information
## Dataset Description
- Repository: URL
- Paper: URL
- Leaderboard: URL
- Point of Contact: emmy@URL
### Dataset Summary
This is the dataset for the paper Testing the Ability of Language Models to Interpret Figurative Language. Fig-QA consists of 10256 examples of human-written creative metaphors that are paired as a Winograd schema. It can be used to evaluate the commonsense reasoning of models. The metaphors themselves can also be used as training data for other tasks, such as metaphor detection or generation.
### Supported Tasks and Leaderboards
You can evaluate your models on the test set by submitting to the leaderboard on Explainaboard. Click on "New" and select 'qa-multiple-choice' for the task field. Select 'accuracy' for the metric. You should upload results in the form of a system output file in JSON or JSONL format.
### Languages
This is the English version. Multilingual version can be found here.
### Data Splits
Train-{S, M(no suffix), XL}: different training set sizes
Dev
Test (labels not provided for test set)
## Considerations for Using the Data
### Discussion of Biases
These metaphors are human-generated and may contain insults or other explicit content. Authors of the paper manually removed offensive content, but users should keep in mind that some potentially offensive content may remain in the dataset.
## Additional Information
### Licensing Information
MIT License
If you found the dataset useful, please cite this paper:
@misc{URL
doi = {10.48550/ARXIV.2204.12632},
url = {URL
author = {Liu, Emmy and Cui, Chen and Zheng, Kenneth and Neubig, Graham},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Testing the Ability of Language Models to Interpret Figurative Language},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Share Alike 4.0 International}
}
| [
"# Dataset Card for Fig-QA",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Splits\n- Considerations for Using the Data\n - Discussion of Biases\n- Additional Information\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Repository: URL \n- Paper: URL\n- Leaderboard: URL\n- Point of Contact: emmy@URL",
"### Dataset Summary\n\nThis is the dataset for the paper Testing the Ability of Language Models to Interpret Figurative Language. Fig-QA consists of 10256 examples of human-written creative metaphors that are paired as a Winograd schema. It can be used to evaluate the commonsense reasoning of models. The metaphors themselves can also be used as training data for other tasks, such as metaphor detection or generation.",
"### Supported Tasks and Leaderboards\n\nYou can evaluate your models on the test set by submitting to the leaderboard on Explainaboard. Click on \"New\" and select 'qa-multiple-choice' for the task field. Select 'accuracy' for the metric. You should upload results in the form of a system output file in JSON or JSONL format.",
"### Languages\n\nThis is the English version. Multilingual version can be found here.",
"### Data Splits\n\nTrain-{S, M(no suffix), XL}: different training set sizes\nDev\nTest (labels not provided for test set)",
"## Considerations for Using the Data",
"### Discussion of Biases\n\nThese metaphors are human-generated and may contain insults or other explicit content. Authors of the paper manually removed offensive content, but users should keep in mind that some potentially offensive content may remain in the dataset.",
"## Additional Information",
"### Licensing Information\n\nMIT License\n\n\n\nIf you found the dataset useful, please cite this paper:\n\n @misc{URL\n doi = {10.48550/ARXIV.2204.12632},\n url = {URL\n author = {Liu, Emmy and Cui, Chen and Zheng, Kenneth and Neubig, Graham},\n keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},\n title = {Testing the Ability of Language Models to Interpret Figurative Language},\n publisher = {arXiv},\n year = {2022},\n copyright = {Creative Commons Attribution Share Alike 4.0 International}\n }"
] | [
"TAGS\n#task_categories-multiple-choice #task_ids-multiple-choice-qa #annotations_creators-expert-generated #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-mit #arxiv-2204.12632 #region-us \n",
"# Dataset Card for Fig-QA",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Splits\n- Considerations for Using the Data\n - Discussion of Biases\n- Additional Information\n - Licensing Information\n - Citation Information",
"## Dataset Description\n\n- Repository: URL \n- Paper: URL\n- Leaderboard: URL\n- Point of Contact: emmy@URL",
"### Dataset Summary\n\nThis is the dataset for the paper Testing the Ability of Language Models to Interpret Figurative Language. Fig-QA consists of 10256 examples of human-written creative metaphors that are paired as a Winograd schema. It can be used to evaluate the commonsense reasoning of models. The metaphors themselves can also be used as training data for other tasks, such as metaphor detection or generation.",
"### Supported Tasks and Leaderboards\n\nYou can evaluate your models on the test set by submitting to the leaderboard on Explainaboard. Click on \"New\" and select 'qa-multiple-choice' for the task field. Select 'accuracy' for the metric. You should upload results in the form of a system output file in JSON or JSONL format.",
"### Languages\n\nThis is the English version. Multilingual version can be found here.",
"### Data Splits\n\nTrain-{S, M(no suffix), XL}: different training set sizes\nDev\nTest (labels not provided for test set)",
"## Considerations for Using the Data",
"### Discussion of Biases\n\nThese metaphors are human-generated and may contain insults or other explicit content. Authors of the paper manually removed offensive content, but users should keep in mind that some potentially offensive content may remain in the dataset.",
"## Additional Information",
"### Licensing Information\n\nMIT License\n\n\n\nIf you found the dataset useful, please cite this paper:\n\n @misc{URL\n doi = {10.48550/ARXIV.2204.12632},\n url = {URL\n author = {Liu, Emmy and Cui, Chen and Zheng, Kenneth and Neubig, Graham},\n keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},\n title = {Testing the Ability of Language Models to Interpret Figurative Language},\n publisher = {arXiv},\n year = {2022},\n copyright = {Creative Commons Attribution Share Alike 4.0 International}\n }"
] |
f0c06c4a962c9e8e0a4f8a0ca9d6494d7d9d7e81 |
# Dataset Card for Rice Image Dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://kaggle.com/datasets/muratkokludataset/rice-image-dataset
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Rice Image Dataset
DATASET: https://www.muratkoklu.com/datasets/
Citation Request: See the articles for more detailed information on the data.
Koklu, M., Cinar, I., & Taspinar, Y. S. (2021). Classification of rice varieties with deep learning methods. Computers and Electronics in Agriculture, 187, 106285. https://doi.org/10.1016/j.compag.2021.106285
Cinar, I., & Koklu, M. (2021). Determination of Effective and Specific Physical Features of Rice Varieties by Computer Vision In Exterior Quality Inspection. Selcuk Journal of Agriculture and Food Sciences, 35(3), 229-243. https://doi.org/10.15316/SJAFS.2021.252
Cinar, I., & Koklu, M. (2022). Identification of Rice Varieties Using Machine Learning Algorithms. Journal of Agricultural Sciences https://doi.org/10.15832/ankutbd.862482
Cinar, I., & Koklu, M. (2019). Classification of Rice Varieties Using Artificial Intelligence Methods. International Journal of Intelligent Systems and Applications in Engineering, 7(3), 188-194. https://doi.org/10.18201/ijisae.2019355381
DATASET: https://www.muratkoklu.com/datasets/
Highlights
• Arborio, Basmati, Ipsala, Jasmine and Karacadag rice varieties were used.
• The dataset (1) has 75K images including 15K pieces from each rice variety. The dataset (2) has 12 morphological, 4 shape and 90 color features.
• ANN, DNN and CNN models were used to classify rice varieties.
• Classified with an accuracy rate of 100% through the CNN model created.
• The models used achieved successful results in the classification of rice varieties.
Abstract
Rice, which is among the most widely produced grain products worldwide, has many genetic varieties. These varieties are separated from each other due to some of their features. These are usually features such as texture, shape, and color. With these features that distinguish rice varieties, it is possible to classify and evaluate the quality of seeds. In this study, Arborio, Basmati, Ipsala, Jasmine and Karacadag, which are five different varieties of rice often grown in Turkey, were used. A total of 75,000 grain images, 15,000 from each of these varieties, are included in the dataset. A second dataset with 106 features including 12 morphological, 4 shape and 90 color features obtained from these images was used. Models were created by using Artificial Neural Network (ANN) and Deep Neural Network (DNN) algorithms for the feature dataset and by using the Convolutional Neural Network (CNN) algorithm for the image dataset, and classification processes were performed. Statistical results of sensitivity, specificity, prediction, F1 score, accuracy, false positive rate and false negative rate were calculated using the confusion matrix values of the models and the results of each model were given in tables. Classification successes from the models were achieved as 99.87% for ANN, 99.95% for DNN and 100% for CNN. With the results, it is seen that the models used in the study in the classification of rice varieties can be applied successfully in this field.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
This dataset was shared by [@muratkokludataset](https://kaggle.com/muratkokludataset)
### Licensing Information
The license for this dataset is cc0-1.0
### Citation Information
```bibtex
[More Information Needed]
```
### Contributions
[More Information Needed] | nateraw/rice-image-dataset | [
"license:cc0-1.0",
"region:us"
] | 2022-06-16T18:15:32+00:00 | {"license": ["cc0-1.0"], "kaggle_id": "muratkokludataset/rice-image-dataset"} | 2022-07-08T05:36:39+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
|
# Dataset Card for Rice Image Dataset
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
Rice Image Dataset
DATASET: URL
Citation Request: See the articles for more detailed information on the data.
Koklu, M., Cinar, I., & Taspinar, Y. S. (2021). Classification of rice varieties with deep learning methods. Computers and Electronics in Agriculture, 187, 106285. URL
Cinar, I., & Koklu, M. (2021). Determination of Effective and Specific Physical Features of Rice Varieties by Computer Vision In Exterior Quality Inspection. Selcuk Journal of Agriculture and Food Sciences, 35(3), 229-243. URL
Cinar, I., & Koklu, M. (2022). Identification of Rice Varieties Using Machine Learning Algorithms. Journal of Agricultural Sciences URL
Cinar, I., & Koklu, M. (2019). Classification of Rice Varieties Using Artificial Intelligence Methods. International Journal of Intelligent Systems and Applications in Engineering, 7(3), 188-194. URL
DATASET: URL
Highlights
• Arborio, Basmati, Ipsala, Jasmine and Karacadag rice varieties were used.
• The dataset (1) has 75K images including 15K pieces from each rice variety. The dataset (2) has 12 morphological, 4 shape and 90 color features.
• ANN, DNN and CNN models were used to classify rice varieties.
• Classified with an accuracy rate of 100% through the CNN model created.
• The models used achieved successful results in the classification of rice varieties.
Abstract
Rice, which is among the most widely produced grain products worldwide, has many genetic varieties. These varieties are separated from each other due to some of their features. These are usually features such as texture, shape, and color. With these features that distinguish rice varieties, it is possible to classify and evaluate the quality of seeds. In this study, Arborio, Basmati, Ipsala, Jasmine and Karacadag, which are five different varieties of rice often grown in Turkey, were used. A total of 75,000 grain images, 15,000 from each of these varieties, are included in the dataset. A second dataset with 106 features including 12 morphological, 4 shape and 90 color features obtained from these images was used. Models were created by using Artificial Neural Network (ANN) and Deep Neural Network (DNN) algorithms for the feature dataset and by using the Convolutional Neural Network (CNN) algorithm for the image dataset, and classification processes were performed. Statistical results of sensitivity, specificity, prediction, F1 score, accuracy, false positive rate and false negative rate were calculated using the confusion matrix values of the models and the results of each model were given in tables. Classification successes from the models were achieved as 99.87% for ANN, 99.95% for DNN and 100% for CNN. With the results, it is seen that the models used in the study in the classification of rice varieties can be applied successfully in this field.
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
This dataset was shared by @muratkokludataset
### Licensing Information
The license for this dataset is cc0-1.0
### Contributions
| [
"# Dataset Card for Rice Image Dataset",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nRice Image Dataset\nDATASET: URL\n\nCitation Request: See the articles for more detailed information on the data.\n\nKoklu, M., Cinar, I., & Taspinar, Y. S. (2021). Classification of rice varieties with deep learning methods. Computers and Electronics in Agriculture, 187, 106285. URL\n\nCinar, I., & Koklu, M. (2021). Determination of Effective and Specific Physical Features of Rice Varieties by Computer Vision In Exterior Quality Inspection. Selcuk Journal of Agriculture and Food Sciences, 35(3), 229-243. URL\n\nCinar, I., & Koklu, M. (2022). Identification of Rice Varieties Using Machine Learning Algorithms. Journal of Agricultural Sciences URL\n\nCinar, I., & Koklu, M. (2019). Classification of Rice Varieties Using Artificial Intelligence Methods. International Journal of Intelligent Systems and Applications in Engineering, 7(3), 188-194. URL\n\nDATASET: URL\n\nHighlights\n• Arborio, Basmati, Ipsala, Jasmine and Karacadag rice varieties were used.\n• The dataset (1) has 75K images including 15K pieces from each rice variety. The dataset (2) has 12 morphological, 4 shape and 90 color features.\n• ANN, DNN and CNN models were used to classify rice varieties.\n• Classified with an accuracy rate of 100% through the CNN model created.\n• The models used achieved successful results in the classification of rice varieties.\n\nAbstract\nRice, which is among the most widely produced grain products worldwide, has many genetic varieties. These varieties are separated from each other due to some of their features. These are usually features such as texture, shape, and color. With these features that distinguish rice varieties, it is possible to classify and evaluate the quality of seeds. In this study, Arborio, Basmati, Ipsala, Jasmine and Karacadag, which are five different varieties of rice often grown in Turkey, were used. A total of 75,000 grain images, 15,000 from each of these varieties, are included in the dataset. A second dataset with 106 features including 12 morphological, 4 shape and 90 color features obtained from these images was used. Models were created by using Artificial Neural Network (ANN) and Deep Neural Network (DNN) algorithms for the feature dataset and by using the Convolutional Neural Network (CNN) algorithm for the image dataset, and classification processes were performed. Statistical results of sensitivity, specificity, prediction, F1 score, accuracy, false positive rate and false negative rate were calculated using the confusion matrix values of the models and the results of each model were given in tables. Classification successes from the models were achieved as 99.87% for ANN, 99.95% for DNN and 100% for CNN. With the results, it is seen that the models used in the study in the classification of rice varieties can be applied successfully in this field.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was shared by @muratkokludataset",
"### Licensing Information\n\nThe license for this dataset is cc0-1.0",
"### Contributions"
] | [
"TAGS\n#license-cc0-1.0 #region-us \n",
"# Dataset Card for Rice Image Dataset",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nRice Image Dataset\nDATASET: URL\n\nCitation Request: See the articles for more detailed information on the data.\n\nKoklu, M., Cinar, I., & Taspinar, Y. S. (2021). Classification of rice varieties with deep learning methods. Computers and Electronics in Agriculture, 187, 106285. URL\n\nCinar, I., & Koklu, M. (2021). Determination of Effective and Specific Physical Features of Rice Varieties by Computer Vision In Exterior Quality Inspection. Selcuk Journal of Agriculture and Food Sciences, 35(3), 229-243. URL\n\nCinar, I., & Koklu, M. (2022). Identification of Rice Varieties Using Machine Learning Algorithms. Journal of Agricultural Sciences URL\n\nCinar, I., & Koklu, M. (2019). Classification of Rice Varieties Using Artificial Intelligence Methods. International Journal of Intelligent Systems and Applications in Engineering, 7(3), 188-194. URL\n\nDATASET: URL\n\nHighlights\n• Arborio, Basmati, Ipsala, Jasmine and Karacadag rice varieties were used.\n• The dataset (1) has 75K images including 15K pieces from each rice variety. The dataset (2) has 12 morphological, 4 shape and 90 color features.\n• ANN, DNN and CNN models were used to classify rice varieties.\n• Classified with an accuracy rate of 100% through the CNN model created.\n• The models used achieved successful results in the classification of rice varieties.\n\nAbstract\nRice, which is among the most widely produced grain products worldwide, has many genetic varieties. These varieties are separated from each other due to some of their features. These are usually features such as texture, shape, and color. With these features that distinguish rice varieties, it is possible to classify and evaluate the quality of seeds. In this study, Arborio, Basmati, Ipsala, Jasmine and Karacadag, which are five different varieties of rice often grown in Turkey, were used. A total of 75,000 grain images, 15,000 from each of these varieties, are included in the dataset. A second dataset with 106 features including 12 morphological, 4 shape and 90 color features obtained from these images was used. Models were created by using Artificial Neural Network (ANN) and Deep Neural Network (DNN) algorithms for the feature dataset and by using the Convolutional Neural Network (CNN) algorithm for the image dataset, and classification processes were performed. Statistical results of sensitivity, specificity, prediction, F1 score, accuracy, false positive rate and false negative rate were calculated using the confusion matrix values of the models and the results of each model were given in tables. Classification successes from the models were achieved as 99.87% for ANN, 99.95% for DNN and 100% for CNN. With the results, it is seen that the models used in the study in the classification of rice varieties can be applied successfully in this field.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was shared by @muratkokludataset",
"### Licensing Information\n\nThe license for this dataset is cc0-1.0",
"### Contributions"
] |
8a6ac08c60a12d9c9239a89083fbd566d6de3409 | # Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@watakandai](https://github.com/watakandai) for adding this dataset. | watakandai/LTLtraces | [
"region:us"
] | 2022-06-16T21:38:58+00:00 | {} | 2022-07-16T21:50:38+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for [Dataset Name]
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @watakandai for adding this dataset. | [
"# Dataset Card for [Dataset Name]",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @watakandai for adding this dataset."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for [Dataset Name]",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @watakandai for adding this dataset."
] |
2b7f7cb193bb1c8a95d1efe5925b250696a0daa4 |
# Dataset Card for Demo
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. | Sampson2022/demo | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"region:us"
] | 2022-06-17T01:44:16+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["sentiment-classification"], "paperswithcode_id": "demo", "pretty_name": "demo", "languages": ["en"], "licenses": ["mit"]} | 2022-06-17T06:41:17+00:00 | [] | [] | TAGS
#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-n<1K #source_datasets-original #region-us
|
# Dataset Card for Demo
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @github-username for adding this dataset. | [
"# Dataset Card for Demo",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] | [
"TAGS\n#task_categories-text-classification #task_ids-sentiment-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-n<1K #source_datasets-original #region-us \n",
"# Dataset Card for Demo",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] |
a5994401ede160334e601cf243bb5b632f2d1e32 |
# Dataset Card for SV-Ident
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://vadis-project.github.io/sv-ident-sdp2022/
- **Repository:** https://github.com/vadis-project/sv-ident
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [email protected]
### Dataset Summary
SV-Ident comprises 4,248 sentences from social science publications in English and German. The data is the official data for the Shared Task: “Survey Variable Identification in Social Science Publications” (SV-Ident) 2022. Visit the homepage to find out more details about the shared task.
### Supported Tasks and Leaderboards
The dataset supports:
- **Variable Detection**: identifying whether a sentence contains a variable mention or not.
- **Variable Disambiguation**: identifying which variable from a given vocabulary is mentioned in a sentence. **NOTE**: for this task, you will need to also download the variable metadata from [here](https://bit.ly/3Nuvqdu).
### Languages
The text in the dataset is in English and German, as written by researchers. The domain of the texts is scientific publications in the social sciences.
## Dataset Structure
### Data Instances
```
{
"sentence": "Our point, however, is that so long as downward (favorable comparisons overwhelm the potential for unfavorable comparisons, system justification should be a likely outcome amongst the disadvantaged.",
"is_variable": 1,
"variable": ["exploredata-ZA5400_VarV66", "exploredata-ZA5400_VarV53"],
"research_data": ["ZA5400"],
"doc_id": "73106",
"uuid": "b9fbb80f-3492-4b42-b9d5-0254cc33ac10",
"lang": "en",
}
```
### Data Fields
The following data fields are provided for documents:
```
`sentence`: Textual instance, which may contain a variable mention.<br />
`is_variable`: Label, whether the textual instance contains a variable mention (1) or not (0). This column can be used for Task 1 (Variable Detection).<br />
`variable`: Variables (separated by a comma ";") that are mentioned in the textual instance. This column can be used for Task 2 (Variable Disambiguation). Variables with the "unk" tag could not be mapped to a unique variable.<br />
`research_data`: Research data IDs (separated by a ";") that are relevant for each instance (and in general for each "doc_id").<br />
`doc_id`: ID of the source document. Each document is written in one language (either English or German).<br />
`uuid`: Unique ID of the instance in uuid4 format.<br />
`lang`: Language of the sentence.
```
The language for each document can be found in the document-language mapping file [here](https://github.com/vadis-project/sv-ident/blob/main/data/train/document_languages.json), which maps `doc_id` to a language code (`en`, `de`). The variables metadata (i.e., the vocabulary) can be downloaded from this [link](https://bit.ly/3Nuvqdu). Note, that each `research_data` contains hundreds of variables (these can be understood as the corpus of documents to choose the most relevant from). If the variable has an "unk" tag, it means that the sentence contains a variable that has not been disambiguated. Such sentences could be used for Task 1 and filtered out for Task 2. The metadata file has the following format:
```
{
"research_data_id_1": {
"variable_id_1": VARIABLE_METADATA,
...
"variable_id_n": VARIABLE_METADATA,
},
...
"research_data_id_n": {...},
}
```
Each variable may contain all (or some) of the following values:
```
study_title: The title of the research data study.
variable_label: The label of the variable.
variable_name: The name of the variable.
question_text: The question of the variable in the original language.
question_text_en: The question of the variable in English.
sub_question: The sub-question of the variable.
item_categories: The item categories of the variable.
answer_categories: The answers of the variable.
topic: The topics of the variable in the original language.
topic_en: The topics of the variable in English.
```
### Data Splits
| Split | Number of sentences |
| ------------------- | ------------------------------------ |
| Train | 3,823 |
| Validation | 425 |
## Dataset Creation
### Curation Rationale
The dataset was curated by the VADIS project (https://vadis-project.github.io/).
The documents were annotated by two expert annotators.
### Source Data
#### Initial Data Collection and Normalization
The original data are available at GESIS (https://www.gesis.org/home) in an unprocessed format.
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
The documents were annotated by two expert annotators.
### Personal and Sensitive Information
The dataset does not include personal or sensitive information.
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
VADIS project (https://vadis-project.github.io/)
### Licensing Information
All documents originate from the Social Science Open Access Repository (SSOAR) and are licensed accordingly. The original document URLs are provided in [document_urls.json](https://github.com/vadis-project/sv-ident/blob/main/data/train/document_urlsjson). For more information on licensing, please refer to the terms and conditions on the [SSAOR Grant of Licenses page](https://www.gesis.org/en/ssoar/home/information/grant-of-licences).
### Citation Information
```
@inproceedings{tsereteli-etal-2022-overview,
title = "Overview of the {SV}-Ident 2022 Shared Task on Survey Variable Identification in Social Science Publications",
author = "Tsereteli, Tornike and
Kartal, Yavuz Selim and
Ponzetto, Simone Paolo and
Zielinski, Andrea and
Eckert, Kai and
Mayr, Philipp",
booktitle = "Proceedings of the Third Workshop on Scholarly Document Processing",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.sdp-1.29",
pages = "229--246",
abstract = "In this paper, we provide an overview of the SV-Ident shared task as part of the 3rd Workshop on Scholarly Document Processing (SDP) at COLING 2022. In the shared task, participants were provided with a sentence and a vocabulary of variables, and asked to identify which variables, if any, are mentioned in individual sentences from scholarly documents in full text. Two teams made a total of 9 submissions to the shared task leaderboard. While none of the teams improve on the baseline systems, we still draw insights from their submissions. Furthermore, we provide a detailed evaluation. Data and baselines for our shared task are freely available at \url{https://github.com/vadis-project/sv-ident}.",
}
```
### Contributions
[Needs More Information] | vadis/sv-ident | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"task_ids:semantic-similarity-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"language:de",
"license:mit",
"region:us"
] | 2022-06-17T07:33:04+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en", "de"], "license": ["mit"], "multilinguality": ["multilingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["multi-label-classification", "semantic-similarity-classification"], "paperswithcode_id": "sv-ident", "pretty_name": "SV-Ident"} | 2022-11-07T20:51:06+00:00 | [] | [
"en",
"de"
] | TAGS
#task_categories-text-classification #task_ids-multi-label-classification #task_ids-semantic-similarity-classification #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-multilingual #size_categories-1K<n<10K #source_datasets-original #language-English #language-German #license-mit #region-us
| Dataset Card for SV-Ident
=========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact: svident2022@URL
### Dataset Summary
SV-Ident comprises 4,248 sentences from social science publications in English and German. The data is the official data for the Shared Task: “Survey Variable Identification in Social Science Publications” (SV-Ident) 2022. Visit the homepage to find out more details about the shared task.
### Supported Tasks and Leaderboards
The dataset supports:
* Variable Detection: identifying whether a sentence contains a variable mention or not.
* Variable Disambiguation: identifying which variable from a given vocabulary is mentioned in a sentence. NOTE: for this task, you will need to also download the variable metadata from here.
### Languages
The text in the dataset is in English and German, as written by researchers. The domain of the texts is scientific publications in the social sciences.
Dataset Structure
-----------------
### Data Instances
### Data Fields
The following data fields are provided for documents:
The language for each document can be found in the document-language mapping file here, which maps 'doc\_id' to a language code ('en', 'de'). The variables metadata (i.e., the vocabulary) can be downloaded from this link. Note, that each 'research\_data' contains hundreds of variables (these can be understood as the corpus of documents to choose the most relevant from). If the variable has an "unk" tag, it means that the sentence contains a variable that has not been disambiguated. Such sentences could be used for Task 1 and filtered out for Task 2. The metadata file has the following format:
Each variable may contain all (or some) of the following values:
### Data Splits
Dataset Creation
----------------
### Curation Rationale
The dataset was curated by the VADIS project (URL
The documents were annotated by two expert annotators.
### Source Data
#### Initial Data Collection and Normalization
The original data are available at GESIS (URL in an unprocessed format.
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
The documents were annotated by two expert annotators.
### Personal and Sensitive Information
The dataset does not include personal or sensitive information.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
VADIS project (URL
### Licensing Information
All documents originate from the Social Science Open Access Repository (SSOAR) and are licensed accordingly. The original document URLs are provided in document\_urls.json. For more information on licensing, please refer to the terms and conditions on the SSAOR Grant of Licenses page.
### Contributions
| [
"### Dataset Summary\n\n\nSV-Ident comprises 4,248 sentences from social science publications in English and German. The data is the official data for the Shared Task: “Survey Variable Identification in Social Science Publications” (SV-Ident) 2022. Visit the homepage to find out more details about the shared task.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports:\n\n\n* Variable Detection: identifying whether a sentence contains a variable mention or not.\n* Variable Disambiguation: identifying which variable from a given vocabulary is mentioned in a sentence. NOTE: for this task, you will need to also download the variable metadata from here.",
"### Languages\n\n\nThe text in the dataset is in English and German, as written by researchers. The domain of the texts is scientific publications in the social sciences.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\nThe following data fields are provided for documents:\n\n\nThe language for each document can be found in the document-language mapping file here, which maps 'doc\\_id' to a language code ('en', 'de'). The variables metadata (i.e., the vocabulary) can be downloaded from this link. Note, that each 'research\\_data' contains hundreds of variables (these can be understood as the corpus of documents to choose the most relevant from). If the variable has an \"unk\" tag, it means that the sentence contains a variable that has not been disambiguated. Such sentences could be used for Task 1 and filtered out for Task 2. The metadata file has the following format:\n\n\nEach variable may contain all (or some) of the following values:",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThe dataset was curated by the VADIS project (URL\nThe documents were annotated by two expert annotators.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe original data are available at GESIS (URL in an unprocessed format.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\nThe documents were annotated by two expert annotators.",
"### Personal and Sensitive Information\n\n\nThe dataset does not include personal or sensitive information.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nVADIS project (URL",
"### Licensing Information\n\n\nAll documents originate from the Social Science Open Access Repository (SSOAR) and are licensed accordingly. The original document URLs are provided in document\\_urls.json. For more information on licensing, please refer to the terms and conditions on the SSAOR Grant of Licenses page.",
"### Contributions"
] | [
"TAGS\n#task_categories-text-classification #task_ids-multi-label-classification #task_ids-semantic-similarity-classification #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-multilingual #size_categories-1K<n<10K #source_datasets-original #language-English #language-German #license-mit #region-us \n",
"### Dataset Summary\n\n\nSV-Ident comprises 4,248 sentences from social science publications in English and German. The data is the official data for the Shared Task: “Survey Variable Identification in Social Science Publications” (SV-Ident) 2022. Visit the homepage to find out more details about the shared task.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports:\n\n\n* Variable Detection: identifying whether a sentence contains a variable mention or not.\n* Variable Disambiguation: identifying which variable from a given vocabulary is mentioned in a sentence. NOTE: for this task, you will need to also download the variable metadata from here.",
"### Languages\n\n\nThe text in the dataset is in English and German, as written by researchers. The domain of the texts is scientific publications in the social sciences.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"### Data Fields\n\n\nThe following data fields are provided for documents:\n\n\nThe language for each document can be found in the document-language mapping file here, which maps 'doc\\_id' to a language code ('en', 'de'). The variables metadata (i.e., the vocabulary) can be downloaded from this link. Note, that each 'research\\_data' contains hundreds of variables (these can be understood as the corpus of documents to choose the most relevant from). If the variable has an \"unk\" tag, it means that the sentence contains a variable that has not been disambiguated. Such sentences could be used for Task 1 and filtered out for Task 2. The metadata file has the following format:\n\n\nEach variable may contain all (or some) of the following values:",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThe dataset was curated by the VADIS project (URL\nThe documents were annotated by two expert annotators.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe original data are available at GESIS (URL in an unprocessed format.",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?\n\n\nThe documents were annotated by two expert annotators.",
"### Personal and Sensitive Information\n\n\nThe dataset does not include personal or sensitive information.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nVADIS project (URL",
"### Licensing Information\n\n\nAll documents originate from the Social Science Open Access Repository (SSOAR) and are licensed accordingly. The original document URLs are provided in document\\_urls.json. For more information on licensing, please refer to the terms and conditions on the SSAOR Grant of Licenses page.",
"### Contributions"
] |
f7bfc4fb11e924b0e8afbcdf07a4a754e9061fb3 | Bytes of **javascript** and **css** files in **wordpress** applications for multiple classification and identification **wordpress** versions. | alexfrancow/wordpress | [
"region:us"
] | 2022-06-17T08:17:17+00:00 | {} | 2022-06-17T08:51:09+00:00 | [] | [] | TAGS
#region-us
| Bytes of javascript and css files in wordpress applications for multiple classification and identification wordpress versions. | [] | [
"TAGS\n#region-us \n"
] |
f86f1751d4d21def7b518d635d1f99fb98b5bc4c |
How to load the Common Voice Bangla dataset directly with the datasets library
Run
1) from datasets import load_dataset
2) dataset = load_dataset("bengaliAI/CommonVoiceBangla", "bn", delimiter='\t')
| bengaliAI/CommonVoiceBangla | [
"license:cc0-1.0",
"region:us"
] | 2022-06-17T11:07:13+00:00 | {"license": "cc0-1.0"} | 2022-06-30T23:46:28+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
|
How to load the Common Voice Bangla dataset directly with the datasets library
Run
1) from datasets import load_dataset
2) dataset = load_dataset("bengaliAI/CommonVoiceBangla", "bn", delimiter='\t')
| [] | [
"TAGS\n#license-cc0-1.0 #region-us \n"
] |
5b041f9c0409219213594593e95d185e993a7422 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/nfcorpus-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T11:46:46+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:12:19+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
74e348ee0157fec51315a3c10346152603714356 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/scifact-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T11:52:14+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:12:34+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
cf98811dd1e94557e7fc39d30f670512bb747aee |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/scidocs-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T11:53:49+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:12:52+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
29c8b8c4259ea3d8258e7e91c87b41c86ef860c1 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/fiqa-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T11:56:09+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:13:18+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
143f29519a132608b65b978d3140ec7f928d04e4 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/trec-covid-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T11:59:43+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:13:36+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
740e4999416e906275e8b35f18132b3a4bf00f7c |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/trec-news-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:04:13+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:13:54+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
e412211d542ff105d108ac339a8b6439eca1bcc7 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/webis-touche2020-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:19:45+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:14:11+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
e11e2b75342f48a7cce39e7166b37affa07bc1ff |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/robust04-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:04+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:14:27+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
57048c520433e98ff6140475f50b04df84349448 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/signal1m-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:10+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:14:43+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
3c4a58842262b5fdf7c81ed8aaaf4aa1147b3d10 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/quora-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:18+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:14:58+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
dd4da5b111e7d6e97c20f51525d7a06aecbd450c |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/nq-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:26+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:15:15+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
5f60035209aaf230a854faca96d56aa12f78a7d5 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/hotpotqa-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:35+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:15:30+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
0f4da4f147b4ff1e10a9421b0a505ce68f2eeebe |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/cqadupstack-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:20:44+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:15:48+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
13595a9f221256a9a21e91c8b0fed3563382b6a7 |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/cqadupstack-qrels | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T12:32:04+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:16:03+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
7d60e12381f1b0c9b435bcda7df346730f6626eb |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | BeIR/bioasq-generated-queries | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-17T13:01:55+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval", "zero-shot-retrieval", "information-retrieval", "zero-shot-information-retrieval"], "task_ids": ["passage-retrieval", "entity-linking-retrieval", "fact-checking-retrieval", "tweet-retrieval", "citation-prediction-retrieval", "duplication-question-retrieval", "argument-retrieval", "news-retrieval", "biomedical-information-retrieval", "question-answering-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2022-10-23T05:16:16+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us
| Dataset Card for BEIR Benchmark
===============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper: URL
* Leaderboard: URL
* Point of Contact: URL@URL
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
* Fact-checking: FEVER, Climate-FEVER, SciFact
* Question-Answering: NQ, HotpotQA, FiQA-2018
* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus
* News Retrieval: TREC-NEWS, Robust04
* Argument Retrieval: Touche-2020, ArguAna
* Duplicate Question Retrieval: Quora, CqaDupstack
* Citation-Prediction: SCIDOCS
* Tweet Retrieval: Signal-1M
* Entity Retrieval: DBPedia
All these datasets have been preprocessed and can be used for your experiments.
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found here.
### Languages
All tasks are in English ('en').
Dataset Structure
-----------------
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{"\_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}'
* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\_id' with unique query identifier and 'text' with query text. For example: '{"\_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}'
* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'
### Data Instances
A high level example of any beir dataset:
### Data Fields
Examples from all configurations have the following features:
### Corpus
* 'corpus': a 'dict' feature representing the document title and passage text, made up of:
+ '\_id': a 'string' feature representing the unique document id
- 'title': a 'string' feature, denoting the title of the document.
- 'text': a 'string' feature, denoting the text of the document.
### Queries
* 'queries': a 'dict' feature representing the query, made up of:
+ '\_id': a 'string' feature representing the unique query id
+ 'text': a 'string' feature, denoting the text of the query.
### Qrels
* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:
+ '\_id': a 'string' feature representing the query id
- '\_id': a 'string' feature, denoting the document id.
- 'score': a 'int32' feature, denoting the relevance judgement between query and document.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
Cite as:
### Contributions
Thanks to @Nthakur20 for adding this dataset.
| [
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] | [
"TAGS\n#task_categories-text-retrieval #task_ids-entity-linking-retrieval #task_ids-fact-checking-retrieval #multilinguality-monolingual #language-English #license-cc-by-sa-4.0 #region-us \n",
"### Dataset Summary\n\n\nBEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:\n\n\n* Fact-checking: FEVER, Climate-FEVER, SciFact\n* Question-Answering: NQ, HotpotQA, FiQA-2018\n* Bio-Medical IR: TREC-COVID, BioASQ, NFCorpus\n* News Retrieval: TREC-NEWS, Robust04\n* Argument Retrieval: Touche-2020, ArguAna\n* Duplicate Question Retrieval: Quora, CqaDupstack\n* Citation-Prediction: SCIDOCS\n* Tweet Retrieval: Signal-1M\n* Entity Retrieval: DBPedia\n\n\nAll these datasets have been preprocessed and can be used for your experiments.",
"### Supported Tasks and Leaderboards\n\n\nThe dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.\n\n\nThe current best performing models can be found here.",
"### Languages\n\n\nAll tasks are in English ('en').\n\n\nDataset Structure\n-----------------\n\n\nAll BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:\n\n\n* 'corpus' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with three fields '\\_id' with unique document identifier, 'title' with document title (optional) and 'text' with document paragraph or passage. For example: '{\"\\_id\": \"doc1\", \"title\": \"Albert Einstein\", \"text\": \"Albert Einstein was a German-born....\"}'\n* 'queries' file: a '.jsonl' file (jsonlines) that contains a list of dictionaries, each with two fields '\\_id' with unique query identifier and 'text' with query text. For example: '{\"\\_id\": \"q1\", \"text\": \"Who developed the mass-energy equivalence formula?\"}'\n* 'qrels' file: a '.tsv' file (tab-seperated) that contains three columns, i.e. the 'query-id', 'corpus-id' and 'score' in this order. Keep 1st row as header. For example: 'q1 doc1 1'",
"### Data Instances\n\n\nA high level example of any beir dataset:",
"### Data Fields\n\n\nExamples from all configurations have the following features:",
"### Corpus\n\n\n* 'corpus': a 'dict' feature representing the document title and passage text, made up of:\n\t+ '\\_id': a 'string' feature representing the unique document id\n\t\t- 'title': a 'string' feature, denoting the title of the document.\n\t\t- 'text': a 'string' feature, denoting the text of the document.",
"### Queries\n\n\n* 'queries': a 'dict' feature representing the query, made up of:\n\t+ '\\_id': a 'string' feature representing the unique query id\n\t+ 'text': a 'string' feature, denoting the text of the query.",
"### Qrels\n\n\n* 'qrels': a 'dict' feature representing the query document relevance judgements, made up of:\n\t+ '\\_id': a 'string' feature representing the query id\n\t\t- '\\_id': a 'string' feature, denoting the document id.\n\t\t- 'score': a 'int32' feature, denoting the relevance judgement between query and document.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nCite as:",
"### Contributions\n\n\nThanks to @Nthakur20 for adding this dataset."
] |
165e9f3cb91038e1d41dd0fc6e037902228df9e0 |
# Dataset Card for NASA technical report server metadata
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Contributions](#contributions)
## Dataset Description
**Homepage: https://ntrs.nasa.gov/**
### Dataset Summary
The NTRS collects scientific and technical information funded or created by NASA and provides metadata but also access to abstracts and full texts.
The dataset contains all abstracts, titles, and associated metadata indexed on the NTRS.
The most recent bulk download can be aquired via the NTRS directly at:
https://sti.nasa.gov/harvesting-data-from-ntrs/
This repository does not claim any ownership on the provided data, it only is supposed to provide an easily accesible gateway to the data, through the Huggingface API.
The original author and source should always be credited.
## Dataset Structure
### Data Instances
The dataset contain over 508000 objects (abstracts) and associated metadata from NASA funded projects in time range of 1917 to today (18.06.2022).
It therefore is a rich data source for language modeling in the domain of spacecraft design and space science.
### Data Fields
```yaml
"copyright": {"licenseType":"NO,"determinationType":"GOV_PUBLIC_USE_PERMITTED", "thirdPartyContentCondition":"NOT_SET",...},
"subjectCategories": ["Space Transportation and Safety"],
"exportControl": {"isExportControl":"NO","ear":"NO","itar":"NO",...},
"created": "2022-01-28T15:19:38.8948330+00:00",
"distributionDate": "2019-07-12T00:00:00.0000000+00:00",
"otherReportNumbers": ["NACA-AR-1"],
"center": {"code":"CDMS","name":"Legacy CDMS","id":"092d6e0881874968859b972d39a888dc"},
"onlyAbstract": False,
"sensitiveInformation": 2,
"abstract": "Report includes the National Advisory Committe...",
"title": "Annual Report of the National Advisory Committ...",
"stiType": "CONTRACTOR_OR_GRANTEE_REPORT",
"distribution": "PUBLIC",
"submittedDate": "2013-09-06T18:26:00.0000000+00:00",
"isLessonsLearned": 0.0,
"disseminated": "DOCUMENT_AND_METADATA",
"stiTypeDetails": "Contractor or Grantee Report",
"technicalReviewType": "TECHNICAL_REVIEW_TYPE_NONE",
"modified": "2013-08-29 00:00:00.000000",
"id": 19930091025,
"publications": [{"submissionId":19930091025,"publicationDate":1916-01-01T00:00:00.0000000+00:00,"issn":"https://doi.org/10.1109/BigData52589.2021.9671853",...},...]
"status": "CURATED",
"authorAffiliations": [{"sequence":0,"meta":{"author":{"name":"Author_name_1","orcidId":"ID"},"organization":{"name":"NASA",...}},"id":ID},{"sequence":1,...,}]
"keywords": [Web scraping, data mining, epidemiology],
"meetings": [{"country":"US","name":"2021 IEEE",...},...]
"fundingNumbers": [{"number":"920121", "type":"CONTRACT_GRANT"},...]
"redactedDate": "2022-04-20T14:36:15.0925240",
"sourceIdentifiers": []}
```
## Dataset Creation
### Curation Rationale
The last bulk download was done on 18.06.2022. The dataset was cleaned from abstracts that occur multiple times.
## Considerations for Using the Data
Main field that probably interest people:
"abstract", "subjectCategory", "keywords", "center"
## Additional Information
### Licensing Information
"Generally, United States government works (works prepared by officers and employees of the U.S. Government as part of their official duties) are not protected by copyright in the U.S. (17 U.S.C. §105) and may be used without obtaining permission from NASA. However, U.S. government works may contain privately created, copyrighted works (e.g., quote, photograph, chart, drawing, etc.) used under license or with permission of the copyright owner. Incorporation in a U.S. government work does not place the private work in the public domain.
place the private work in the public domain.
Moreover, not all materials on or available through download from this Web site are U.S. government works. Some materials available from this Web site may be protected by copyrights owned by private individuals or organizations and may be subject to restrictions on use. For example, contractors and grantees are not considered Government employees; generally, they hold copyright to works they produce for the Government. Other materials may be the result of joint authorship due to collaboration between a Government employee and a private individual wherein the private individual will hold a copyright to the work jointly with U.S. Government. The Government is granted a worldwide license to use, modify, reproduce, release, perform, display, or disclose these works by or on behalf of the Government.
While NASA may publicly release copyrighted works in which it has government purpose licenses or specific permission to release, such licenses or permission do not necessarily transfer to others. Thus, such works are still protected by copyright, and recipients of the works must comply with the copyright law (Title 17 United States Code). Such copyrighted works may not be modified, reproduced, or redistributed without permission of the copyright owner."
Taken from https://sti.nasa.gov/disclaimers/, please visit for more information.
### Contributions
For any any inquiries about this data set please contact [@pauldrm](https://github.com/<github-username>)
| icelab/ntrs_meta | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:en",
"license:other",
"region:us"
] | 2022-06-17T13:34:38+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["text-generation", "fill-mask"], "task_ids": ["language-modeling", "masked-language-modeling"], "pretty_name": "NTRS"} | 2022-08-18T06:40:13+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-generation #task_categories-fill-mask #task_ids-language-modeling #task_ids-masked-language-modeling #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-original #language-English #license-other #region-us
|
# Dataset Card for NASA technical report server metadata
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Dataset Structure
- Data Instances
- Data Fields
- Dataset Creation
- Curation Rationale
- Source Data
- Considerations for Using the Data
- Additional Information
- Licensing Information
- Contributions
## Dataset Description
Homepage: URL
### Dataset Summary
The NTRS collects scientific and technical information funded or created by NASA and provides metadata but also access to abstracts and full texts.
The dataset contains all abstracts, titles, and associated metadata indexed on the NTRS.
The most recent bulk download can be aquired via the NTRS directly at:
URL
This repository does not claim any ownership on the provided data, it only is supposed to provide an easily accesible gateway to the data, through the Huggingface API.
The original author and source should always be credited.
## Dataset Structure
### Data Instances
The dataset contain over 508000 objects (abstracts) and associated metadata from NASA funded projects in time range of 1917 to today (18.06.2022).
It therefore is a rich data source for language modeling in the domain of spacecraft design and space science.
### Data Fields
## Dataset Creation
### Curation Rationale
The last bulk download was done on 18.06.2022. The dataset was cleaned from abstracts that occur multiple times.
## Considerations for Using the Data
Main field that probably interest people:
"abstract", "subjectCategory", "keywords", "center"
## Additional Information
### Licensing Information
"Generally, United States government works (works prepared by officers and employees of the U.S. Government as part of their official duties) are not protected by copyright in the U.S. (17 U.S.C. §105) and may be used without obtaining permission from NASA. However, U.S. government works may contain privately created, copyrighted works (e.g., quote, photograph, chart, drawing, etc.) used under license or with permission of the copyright owner. Incorporation in a U.S. government work does not place the private work in the public domain.
place the private work in the public domain.
Moreover, not all materials on or available through download from this Web site are U.S. government works. Some materials available from this Web site may be protected by copyrights owned by private individuals or organizations and may be subject to restrictions on use. For example, contractors and grantees are not considered Government employees; generally, they hold copyright to works they produce for the Government. Other materials may be the result of joint authorship due to collaboration between a Government employee and a private individual wherein the private individual will hold a copyright to the work jointly with U.S. Government. The Government is granted a worldwide license to use, modify, reproduce, release, perform, display, or disclose these works by or on behalf of the Government.
While NASA may publicly release copyrighted works in which it has government purpose licenses or specific permission to release, such licenses or permission do not necessarily transfer to others. Thus, such works are still protected by copyright, and recipients of the works must comply with the copyright law (Title 17 United States Code). Such copyrighted works may not be modified, reproduced, or redistributed without permission of the copyright owner."
Taken from URL please visit for more information.
### Contributions
For any any inquiries about this data set please contact @pauldrm
| [
"# Dataset Card for NASA technical report server metadata",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n- Dataset Structure\n - Data Instances\n - Data Fields\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Considerations for Using the Data\n- Additional Information\n - Licensing Information\n - Contributions",
"## Dataset Description\n\nHomepage: URL",
"### Dataset Summary\nThe NTRS collects scientific and technical information funded or created by NASA and provides metadata but also access to abstracts and full texts.\nThe dataset contains all abstracts, titles, and associated metadata indexed on the NTRS.\nThe most recent bulk download can be aquired via the NTRS directly at:\nURL\n\nThis repository does not claim any ownership on the provided data, it only is supposed to provide an easily accesible gateway to the data, through the Huggingface API. \nThe original author and source should always be credited.",
"## Dataset Structure",
"### Data Instances\n\nThe dataset contain over 508000 objects (abstracts) and associated metadata from NASA funded projects in time range of 1917 to today (18.06.2022). \nIt therefore is a rich data source for language modeling in the domain of spacecraft design and space science.",
"### Data Fields",
"## Dataset Creation",
"### Curation Rationale\n\nThe last bulk download was done on 18.06.2022. The dataset was cleaned from abstracts that occur multiple times.",
"## Considerations for Using the Data\n\nMain field that probably interest people:\n\n\"abstract\", \"subjectCategory\", \"keywords\", \"center\"",
"## Additional Information",
"### Licensing Information\n\"Generally, United States government works (works prepared by officers and employees of the U.S. Government as part of their official duties) are not protected by copyright in the U.S. (17 U.S.C. §105) and may be used without obtaining permission from NASA. However, U.S. government works may contain privately created, copyrighted works (e.g., quote, photograph, chart, drawing, etc.) used under license or with permission of the copyright owner. Incorporation in a U.S. government work does not place the private work in the public domain.\nplace the private work in the public domain.\n\nMoreover, not all materials on or available through download from this Web site are U.S. government works. Some materials available from this Web site may be protected by copyrights owned by private individuals or organizations and may be subject to restrictions on use. For example, contractors and grantees are not considered Government employees; generally, they hold copyright to works they produce for the Government. Other materials may be the result of joint authorship due to collaboration between a Government employee and a private individual wherein the private individual will hold a copyright to the work jointly with U.S. Government. The Government is granted a worldwide license to use, modify, reproduce, release, perform, display, or disclose these works by or on behalf of the Government.\n\nWhile NASA may publicly release copyrighted works in which it has government purpose licenses or specific permission to release, such licenses or permission do not necessarily transfer to others. Thus, such works are still protected by copyright, and recipients of the works must comply with the copyright law (Title 17 United States Code). Such copyrighted works may not be modified, reproduced, or redistributed without permission of the copyright owner.\"\n\nTaken from URL please visit for more information.",
"### Contributions\n\nFor any any inquiries about this data set please contact @pauldrm"
] | [
"TAGS\n#task_categories-text-generation #task_categories-fill-mask #task_ids-language-modeling #task_ids-masked-language-modeling #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-original #language-English #license-other #region-us \n",
"# Dataset Card for NASA technical report server metadata",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n- Dataset Structure\n - Data Instances\n - Data Fields\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Considerations for Using the Data\n- Additional Information\n - Licensing Information\n - Contributions",
"## Dataset Description\n\nHomepage: URL",
"### Dataset Summary\nThe NTRS collects scientific and technical information funded or created by NASA and provides metadata but also access to abstracts and full texts.\nThe dataset contains all abstracts, titles, and associated metadata indexed on the NTRS.\nThe most recent bulk download can be aquired via the NTRS directly at:\nURL\n\nThis repository does not claim any ownership on the provided data, it only is supposed to provide an easily accesible gateway to the data, through the Huggingface API. \nThe original author and source should always be credited.",
"## Dataset Structure",
"### Data Instances\n\nThe dataset contain over 508000 objects (abstracts) and associated metadata from NASA funded projects in time range of 1917 to today (18.06.2022). \nIt therefore is a rich data source for language modeling in the domain of spacecraft design and space science.",
"### Data Fields",
"## Dataset Creation",
"### Curation Rationale\n\nThe last bulk download was done on 18.06.2022. The dataset was cleaned from abstracts that occur multiple times.",
"## Considerations for Using the Data\n\nMain field that probably interest people:\n\n\"abstract\", \"subjectCategory\", \"keywords\", \"center\"",
"## Additional Information",
"### Licensing Information\n\"Generally, United States government works (works prepared by officers and employees of the U.S. Government as part of their official duties) are not protected by copyright in the U.S. (17 U.S.C. §105) and may be used without obtaining permission from NASA. However, U.S. government works may contain privately created, copyrighted works (e.g., quote, photograph, chart, drawing, etc.) used under license or with permission of the copyright owner. Incorporation in a U.S. government work does not place the private work in the public domain.\nplace the private work in the public domain.\n\nMoreover, not all materials on or available through download from this Web site are U.S. government works. Some materials available from this Web site may be protected by copyrights owned by private individuals or organizations and may be subject to restrictions on use. For example, contractors and grantees are not considered Government employees; generally, they hold copyright to works they produce for the Government. Other materials may be the result of joint authorship due to collaboration between a Government employee and a private individual wherein the private individual will hold a copyright to the work jointly with U.S. Government. The Government is granted a worldwide license to use, modify, reproduce, release, perform, display, or disclose these works by or on behalf of the Government.\n\nWhile NASA may publicly release copyrighted works in which it has government purpose licenses or specific permission to release, such licenses or permission do not necessarily transfer to others. Thus, such works are still protected by copyright, and recipients of the works must comply with the copyright law (Title 17 United States Code). Such copyrighted works may not be modified, reproduced, or redistributed without permission of the copyright owner.\"\n\nTaken from URL please visit for more information.",
"### Contributions\n\nFor any any inquiries about this data set please contact @pauldrm"
] |
64e12bf41b08d32f5d82bc106f484f7bf942706b |

## Source: https://www.kaggle.com/datasets/rounakbanik/pokemon
Also published to https://datasette.fly.dev/pokemon/pokemon using `datasette`
Columns:
- name: The English name of the Pokemon
- japanese_name: The Original Japanese name of the Pokemon
- pokedex_number: The entry number of the Pokemon in the National Pokedex
- percentage_male: The percentage of the species that are male. Blank if the Pokemon is genderless.
- type1: The Primary Type of the Pokemon
- type2: The Secondary Type of the Pokemon
- classification: The Classification of the Pokemon as described by the Sun and Moon Pokedex
- height_m: Height of the Pokemon in metres
- weight_kg: The Weight of the Pokemon in kilograms
- capture_rate: Capture Rate of the Pokemon
- baseeggsteps: The number of steps required to hatch an egg of the Pokemon
- abilities: A stringified list of abilities that the Pokemon is capable of having
- experience_growth: The Experience Growth of the Pokemon
- base_happiness: Base Happiness of the Pokemon
- against_?: Eighteen features that denote the amount of damage taken against an attack of a particular type
- hp: The Base HP of the Pokemon
- attack: The Base Attack of the Pokemon
- defense: The Base Defense of the Pokemon
- sp_attack: The Base Special Attack of the Pokemon
- sp_defense: The Base Special Defense of the Pokemon
- speed: The Base Speed of the Pokemon
- generation: The numbered generation which the Pokemon was first introduced
- is_legendary: Denotes if the Pokemon is legendary.
| julien-c/kaggle-rounakbanik-pokemon | [
"license:cc0-1.0",
"pokemon",
"region:us"
] | 2022-06-17T20:18:00+00:00 | {"license": "cc0-1.0", "tags": ["pokemon"]} | 2022-12-08T09:50:43+00:00 | [] | [] | TAGS
#license-cc0-1.0 #pokemon #region-us
|

- Betting odds from up to 10 providers
- Detailed match events (goal types, possession, corner, cross, fouls, cards etc…) for +10,000 matches
*16th Oct 2016: New table containing teams' attributes from FIFA !
| julien-c/kaggle-hugomathien-soccer | [
"license:odbl",
"region:us"
] | 2022-06-17T20:21:37+00:00 | {"license": ["odbl"]} | 2022-10-25T09:32:23+00:00 | [] | [] | TAGS
#license-odbl #region-us
| Source: URL by Hugo Mathien
## About Dataset
### The ultimate Soccer database for data analysis and machine learning
What you get:
- +25,000 matches
- +10,000 players
- 11 European Countries with their lead championship
- Seasons 2008 to 2016
- Players and Teams' attributes* sourced from EA Sports' FIFA video game series, including the weekly updates
- Team line up with squad formation (X, Y coordinates)
- Betting odds from up to 10 providers
- Detailed match events (goal types, possession, corner, cross, fouls, cards etc…) for +10,000 matches
*16th Oct 2016: New table containing teams' attributes from FIFA !
| [
"## About Dataset",
"### The ultimate Soccer database for data analysis and machine learning\n\nWhat you get:\n\n- +25,000 matches\n- +10,000 players\n- 11 European Countries with their lead championship\n- Seasons 2008 to 2016\n- Players and Teams' attributes* sourced from EA Sports' FIFA video game series, including the weekly updates\n- Team line up with squad formation (X, Y coordinates)\n- Betting odds from up to 10 providers\n- Detailed match events (goal types, possession, corner, cross, fouls, cards etc…) for +10,000 matches\n\n*16th Oct 2016: New table containing teams' attributes from FIFA !"
] | [
"TAGS\n#license-odbl #region-us \n",
"## About Dataset",
"### The ultimate Soccer database for data analysis and machine learning\n\nWhat you get:\n\n- +25,000 matches\n- +10,000 players\n- 11 European Countries with their lead championship\n- Seasons 2008 to 2016\n- Players and Teams' attributes* sourced from EA Sports' FIFA video game series, including the weekly updates\n- Team line up with squad formation (X, Y coordinates)\n- Betting odds from up to 10 providers\n- Detailed match events (goal types, possession, corner, cross, fouls, cards etc…) for +10,000 matches\n\n*16th Oct 2016: New table containing teams' attributes from FIFA !"
] |
9d6f23ef233458c252bbfd9c53cc1b93a6941333 |
# Dataset Card for Adult_Content_Detection
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
## Dataset Description
850 Articles descriptions classified into two different categories namely: Adult, and Non_Adult
## Languages
The text in the dataset is in English
## Dataset Structure
The dataset consists of two columns namely Description and Category.
The Description column consists of the overview of the article and the Category column consists of the class each article belongs to
## Source Data
The dataset is scrapped across different platforms
| valurank/Adult-content-dataset | [
"task_categories:text-classification",
"multilinguality:monolingual",
"language:en",
"license:other",
"region:us"
] | 2022-06-17T20:54:46+00:00 | {"language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "task_categories": ["text-classification"], "task_ids": []} | 2023-01-19T02:40:10+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #multilinguality-monolingual #language-English #license-other #region-us
|
# Dataset Card for Adult_Content_Detection
## Table of Contents
- Dataset Description
- Languages
- Dataset Structure
- Source Data
## Dataset Description
850 Articles descriptions classified into two different categories namely: Adult, and Non_Adult
## Languages
The text in the dataset is in English
## Dataset Structure
The dataset consists of two columns namely Description and Category.
The Description column consists of the overview of the article and the Category column consists of the class each article belongs to
## Source Data
The dataset is scrapped across different platforms
| [
"# Dataset Card for Adult_Content_Detection",
"## Table of Contents\n- Dataset Description\n- Languages\n- Dataset Structure\n- Source Data",
"## Dataset Description\n\n850 Articles descriptions classified into two different categories namely: Adult, and Non_Adult",
"## Languages\n\nThe text in the dataset is in English",
"## Dataset Structure\n\nThe dataset consists of two columns namely Description and Category.\nThe Description column consists of the overview of the article and the Category column consists of the class each article belongs to",
"## Source Data\n\nThe dataset is scrapped across different platforms"
] | [
"TAGS\n#task_categories-text-classification #multilinguality-monolingual #language-English #license-other #region-us \n",
"# Dataset Card for Adult_Content_Detection",
"## Table of Contents\n- Dataset Description\n- Languages\n- Dataset Structure\n- Source Data",
"## Dataset Description\n\n850 Articles descriptions classified into two different categories namely: Adult, and Non_Adult",
"## Languages\n\nThe text in the dataset is in English",
"## Dataset Structure\n\nThe dataset consists of two columns namely Description and Category.\nThe Description column consists of the overview of the article and the Category column consists of the class each article belongs to",
"## Source Data\n\nThe dataset is scrapped across different platforms"
] |
bd267da8836a58a80c8171484808a8725cc1d4bf | # Dataset Card for [Dataset Name]
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
- **license:** gpl-3.0
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. | c17hawke/test-xml-data | [
"region:us"
] | 2022-06-18T03:13:25+00:00 | {} | 2022-06-18T04:42:06+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for [Dataset Name]
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
- license: gpl-3.0
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @github-username for adding this dataset. | [
"# Dataset Card for [Dataset Name]",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:\n- license: gpl-3.0",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for [Dataset Name]",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:\n- license: gpl-3.0",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] |
2170a0eb8d75233132608787a4519f25bcc47ad7 |
# Dataset Card for CORE Deduplication
## Dataset Description
- **Homepage:** [https://core.ac.uk/about/research-outputs](https://core.ac.uk/about/research-outputs)
- **Repository:** [https://core.ac.uk/datasets/core_2020-05-10_deduplication.zip](https://core.ac.uk/datasets/core_2020-05-10_deduplication.zip)
- **Paper:** [Deduplication of Scholarly Documents using Locality Sensitive Hashing and Word Embeddings](http://oro.open.ac.uk/id/eprint/70519)
- **Point of Contact:** [CORE Team](https://core.ac.uk/about#contact)
- **Size of downloaded dataset files:** 204 MB
### Dataset Summary
CORE 2020 Deduplication dataset (https://core.ac.uk/documentation/dataset) contains 100K scholarly documents labeled as duplicates/non-duplicates.
### Languages
The dataset language is English (BCP-47 `en`)
### Citation Information
```
@inproceedings{dedup2020,
title={Deduplication of Scholarly Documents using Locality Sensitive Hashing and Word Embeddings},
author={Gyawali, Bikash and Anastasiou, Lucas and Knoth, Petr},
booktitle = {Proceedings of 12th Language Resources and Evaluation Conference},
month = may,
year = 2020,
publisher = {France European Language Resources Association},
pages = {894-903}
}
```
| pinecone/core-2020-05-10-deduplication | [
"task_categories:other",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:unknown",
"language_creators:unknown",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:unknown",
"language:en",
"license:mit",
"deduplication",
"region:us"
] | 2022-06-18T14:43:43+00:00 | {"annotations_creators": ["unknown"], "language_creators": ["unknown"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["unknown"], "task_categories": ["other"], "task_ids": ["natural-language-inference", "semantic-similarity-scoring", "text-scoring"], "pretty_name": "CORE Deduplication of Scholarly Documents", "tags": ["deduplication"]} | 2022-10-28T02:01:02+00:00 | [] | [
"en"
] | TAGS
#task_categories-other #task_ids-natural-language-inference #task_ids-semantic-similarity-scoring #task_ids-text-scoring #annotations_creators-unknown #language_creators-unknown #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-unknown #language-English #license-mit #deduplication #region-us
|
# Dataset Card for CORE Deduplication
## Dataset Description
- Homepage: URL
- Repository: URL
- Paper: Deduplication of Scholarly Documents using Locality Sensitive Hashing and Word Embeddings
- Point of Contact: CORE Team
- Size of downloaded dataset files: 204 MB
### Dataset Summary
CORE 2020 Deduplication dataset (URL contains 100K scholarly documents labeled as duplicates/non-duplicates.
### Languages
The dataset language is English (BCP-47 'en')
| [
"# Dataset Card for CORE Deduplication",
"## Dataset Description\n\n- Homepage: URL\n- Repository: URL\n- Paper: Deduplication of Scholarly Documents using Locality Sensitive Hashing and Word Embeddings\n- Point of Contact: CORE Team\n- Size of downloaded dataset files: 204 MB",
"### Dataset Summary\n\nCORE 2020 Deduplication dataset (URL contains 100K scholarly documents labeled as duplicates/non-duplicates.",
"### Languages\n\nThe dataset language is English (BCP-47 'en')"
] | [
"TAGS\n#task_categories-other #task_ids-natural-language-inference #task_ids-semantic-similarity-scoring #task_ids-text-scoring #annotations_creators-unknown #language_creators-unknown #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-unknown #language-English #license-mit #deduplication #region-us \n",
"# Dataset Card for CORE Deduplication",
"## Dataset Description\n\n- Homepage: URL\n- Repository: URL\n- Paper: Deduplication of Scholarly Documents using Locality Sensitive Hashing and Word Embeddings\n- Point of Contact: CORE Team\n- Size of downloaded dataset files: 204 MB",
"### Dataset Summary\n\nCORE 2020 Deduplication dataset (URL contains 100K scholarly documents labeled as duplicates/non-duplicates.",
"### Languages\n\nThe dataset language is English (BCP-47 'en')"
] |
744560c8cc5c139714873fc4c4c418ddfc76ade7 |
Do cite the below reference for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
If you want to use the two classes (positive and negative) from the dataset, do cite the below reference:
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| mounikaiiith/Telugu_Sentiment | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-19T11:06:15+00:00 | {"license": "cc-by-4.0"} | 2022-07-04T14:05:31+00:00 | [] | [] | TAGS
#license-cc-by-4.0 #region-us
|
Do cite the below reference for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
If you want to use the two classes (positive and negative) from the dataset, do cite the below reference:
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| [] | [
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
6432e1357ed6ad57db1683451b08943639eb45ae |
Do cite the below reference for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
If you want to use the four classes (angry, happy, sad and fear) from the dataset, do cite the below reference:
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| mounikaiiith/Telugu_Emotion | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-19T11:09:17+00:00 | {"license": "cc-by-4.0"} | 2022-07-04T14:04:59+00:00 | [] | [] | TAGS
#license-cc-by-4.0 #region-us
|
Do cite the below reference for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
If you want to use the four classes (angry, happy, sad and fear) from the dataset, do cite the below reference:
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| [] | [
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
752da0b4d8c4f38c5aa77c8334c450f21ad45a60 |
Do cite the below references for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| mounikaiiith/Telugu-Hatespeech | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-19T11:12:32+00:00 | {"license": "cc-by-4.0"} | 2022-07-04T14:06:14+00:00 | [] | [] | TAGS
#license-cc-by-4.0 #region-us
|
Do cite the below references for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| [] | [
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
ae3c167c3f3e825f25633db808480d302ef9545a |
Do cite the below references for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| mounikaiiith/Telugu-Sarcasm | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-19T11:15:20+00:00 | {"license": "cc-by-4.0"} | 2022-07-04T14:06:49+00:00 | [] | [] | TAGS
#license-cc-by-4.0 #region-us
|
Do cite the below references for using the dataset:
@article{marreddy2022resource, title={Am I a Resource-Poor Language? Data Sets, Embeddings, Models and Analysis for four different NLP tasks in Telugu Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={Transactions on Asian and Low-Resource Language Information Processing}, publisher={ACM New York, NY} }
@article{marreddy2022multi,
title={Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language},
author={Marreddy, Mounika and Oota, Subba Reddy and Vakada, Lakshmi Sireesha and Chinni, Venkata Charan and Mamidi, Radhika},
journal={arXiv preprint arXiv:2205.01204},
year={2022}
}
| [] | [
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
2d00bdf7fce79d6da10dc6825a67a12e777c6732 |
## Leipzig Corpora Collection
The [Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download) presents corpora in different languages using the same format and comparable sources. All data are available as plain text files and can be imported into a MySQL database by using the provided import script. They are intended both for scientific use by corpus linguists as well as for applications such as knowledge extraction programs.
The corpora are identical in format and similar in size and content. They contain randomly selected sentences in the language of the corpus and are available in sizes from 10,000 sentences up to 1 million sentences. The sources are either newspaper texts or texts randomly collected from the web. The texts are split into sentences. Non-sentences and foreign language material was removed. Because word co-occurrence information is useful for many applications, these data are precomputed and included as well. For each word, the most significant words appearing as immediate left or right neighbor or appearing anywhere within the same sentence are given. More information about the format and content of these files can be found [here](https://wortschatz.uni-leipzig.de/en/download).
The corpora are automatically collected from carefully selected public sources without considering in detail the content of the contained text. No responsibility is taken for the content of the data. In particular, the views and opinions expressed in specific parts of the data remain exclusively with the authors.
## Dataset Usage
### Links
A "links" subset contains URLs with corresponding language and id (based on `https://corpora.uni-leipzig.de/`)
```python
from datasets import load_dataset
ds = load_dataset("imvladikon/leipzig_corpora_collection", "links")
for row in ds["train"]:
print(row)
```
```
{'id': '0', 'data_id': '0', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/ara_news_2005-2009_10K.tar.gz', 'language': 'Arabic', 'language_short': 'ara', 'year': '2005', 'size': '10K'}
{'id': '1', 'data_id': '1', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/ara_news_2005-2009_30K.tar.gz', 'language': 'Arabic', 'language_short': 'ara', 'year': '2005', 'size': '30K'}
{'id': '2', 'data_id': '2', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/ara_news_2005-2009_100K.tar.gz', 'language': 'Arabic', 'language_short': 'ara', 'year': '2005', 'size': '100K'}
....
```
where is possible to choose specific `data_id` to load a specific dataset, where `data_id` is name of the subset
Links possible to filter according to metdata attributes:
```python
links = load_dataset("imvladikon/leipzig_corpora_collection", "links", split="train")
english_2019 = links.filter(lambda x: x["language"] == "English" and x["year"] == "2019")
for sample in english_2019:
print(sample)
```
```
{'id': '277', 'data_id': 'eng_news_2019_10K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng_news_2019_10K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '10K'}
{'id': '278', 'data_id': 'eng_news_2019_30K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng_news_2019_30K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '30K'}
{'id': '279', 'data_id': 'eng_news_2019_100K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng_news_2019_100K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '100K'}
{'id': '280', 'data_id': 'eng_news_2019_300K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng_news_2019_300K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '300K'}
{'id': '281', 'data_id': 'eng_news_2019_1M', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng_news_2019_1M.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '1M'}
{'id': '541', 'data_id': 'eng-za_web_2019_10K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng-za_web_2019_10K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '10K'}
{'id': '542', 'data_id': 'eng-za_web_2019_30K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng-za_web_2019_30K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '30K'}
{'id': '543', 'data_id': 'eng-za_web_2019_100K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng-za_web_2019_100K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '100K'}
{'id': '544', 'data_id': 'eng-za_web_2019_300K', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng-za_web_2019_300K.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '300K'}
{'id': '545', 'data_id': 'eng-za_web_2019_1M', 'url': 'https://downloads.wortschatz-leipzig.de/corpora/eng-za_web_2019_1M.tar.gz', 'language': 'English', 'language_short': 'eng', 'year': '2019', 'size': '1M'}
```
### Corpus
after selecting `data_id`, let's say `heb_wikipedia_2021_1M`, we could load it:
```python
dataset_he = load_dataset("imvladikon/leipzig_corpora_collection", "heb_wikipedia_2021_1M", split="train")
for row in dataset_he:
print(row)
```
another example:
```python
dataset_en = load_dataset("imvladikon/leipzig_corpora_collection", "eng-simple_wikipedia_2021_300K", split="train")
print(dataset_en[76576])
```
sample:
```json
{'id': '79214', 'sentence': 'He was a member of the assembly from 1972 to 1977.'}
```
## Citation
If you use one of these corpora in your work, please, to cite [this work](http://www.lrec-conf.org/proceedings/lrec2012/pdf/327_Paper.pdf):
```
@inproceedings{goldhahn-etal-2012-building,
title = "Building Large Monolingual Dictionaries at the {L}eipzig Corpora Collection: From 100 to 200 Languages",
author = "Goldhahn, Dirk and
Eckart, Thomas and
Quasthoff, Uwe",
editor = "Calzolari, Nicoletta and
Choukri, Khalid and
Declerck, Thierry and
Do{\u{g}}an, Mehmet U{\u{g}}ur and
Maegaard, Bente and
Mariani, Joseph and
Moreno, Asuncion and
Odijk, Jan and
Piperidis, Stelios",
booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}'12)",
month = may,
year = "2012",
address = "Istanbul, Turkey",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2012/pdf/327_Paper.pdf",
pages = "759--765",
abstract = "The Leipzig Corpora Collection offers free online access to 136 monolingual dictionaries enriched with statistical information. In this paper we describe current advances of the project in collecting and processing text data automatically for a large number of languages. Our main interest lies in languages of low density, where only few text data exists online. The aim of this approach is to create monolingual dictionaries and statistical information for a high number of new languages and to expand the existing dictionaries, opening up new possibilities for linguistic typology and other research. Focus of this paper will be set on the infrastructure for the automatic acquisition of large amounts of monolingual text in many languages from various sources. Preliminary results of the collection of text data will be presented. The mainly language-independent framework for preprocessing, cleaning and creating the corpora and computing the necessary statistics will also be depicted.",
}
``` | imvladikon/leipzig_corpora_collection | [
"task_categories:text-generation",
"task_categories:fill-mask",
"multilinguality:multilingual",
"size_categories:n<1K",
"size_categories:1K<n<10K",
"size_categories:10K<n<100K",
"size_categories:100K<n<1M",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:ar",
"language:en",
"language:he",
"language:de",
"language:it",
"language:fr",
"language:pl",
"language:pt",
"language:ru",
"language:uk",
"region:us"
] | 2022-06-19T15:03:28+00:00 | {"language": ["ar", "en", "he", "de", "it", "fr", "pl", "pt", "ru", "uk"], "multilinguality": ["multilingual"], "size_categories": ["n<1K", "1K<n<10K", "10K<n<100K", "100K<n<1M", "1M<n<10M"], "source_datasets": ["original"], "task_categories": ["text-generation", "fill-mask"], "config_names": ["links"]} | 2023-11-12T08:49:08+00:00 | [] | [
"ar",
"en",
"he",
"de",
"it",
"fr",
"pl",
"pt",
"ru",
"uk"
] | TAGS
#task_categories-text-generation #task_categories-fill-mask #multilinguality-multilingual #size_categories-n<1K #size_categories-1K<n<10K #size_categories-10K<n<100K #size_categories-100K<n<1M #size_categories-1M<n<10M #source_datasets-original #language-Arabic #language-English #language-Hebrew #language-German #language-Italian #language-French #language-Polish #language-Portuguese #language-Russian #language-Ukrainian #region-us
|
## Leipzig Corpora Collection
The Leipzig Corpora Collection presents corpora in different languages using the same format and comparable sources. All data are available as plain text files and can be imported into a MySQL database by using the provided import script. They are intended both for scientific use by corpus linguists as well as for applications such as knowledge extraction programs.
The corpora are identical in format and similar in size and content. They contain randomly selected sentences in the language of the corpus and are available in sizes from 10,000 sentences up to 1 million sentences. The sources are either newspaper texts or texts randomly collected from the web. The texts are split into sentences. Non-sentences and foreign language material was removed. Because word co-occurrence information is useful for many applications, these data are precomputed and included as well. For each word, the most significant words appearing as immediate left or right neighbor or appearing anywhere within the same sentence are given. More information about the format and content of these files can be found here.
The corpora are automatically collected from carefully selected public sources without considering in detail the content of the contained text. No responsibility is taken for the content of the data. In particular, the views and opinions expressed in specific parts of the data remain exclusively with the authors.
## Dataset Usage
### Links
A "links" subset contains URLs with corresponding language and id (based on 'URL
where is possible to choose specific 'data_id' to load a specific dataset, where 'data_id' is name of the subset
Links possible to filter according to metdata attributes:
### Corpus
after selecting 'data_id', let's say 'heb_wikipedia_2021_1M', we could load it:
another example:
sample:
If you use one of these corpora in your work, please, to cite this work:
| [
"## Leipzig Corpora Collection\n \nThe Leipzig Corpora Collection presents corpora in different languages using the same format and comparable sources. All data are available as plain text files and can be imported into a MySQL database by using the provided import script. They are intended both for scientific use by corpus linguists as well as for applications such as knowledge extraction programs.\nThe corpora are identical in format and similar in size and content. They contain randomly selected sentences in the language of the corpus and are available in sizes from 10,000 sentences up to 1 million sentences. The sources are either newspaper texts or texts randomly collected from the web. The texts are split into sentences. Non-sentences and foreign language material was removed. Because word co-occurrence information is useful for many applications, these data are precomputed and included as well. For each word, the most significant words appearing as immediate left or right neighbor or appearing anywhere within the same sentence are given. More information about the format and content of these files can be found here.\nThe corpora are automatically collected from carefully selected public sources without considering in detail the content of the contained text. No responsibility is taken for the content of the data. In particular, the views and opinions expressed in specific parts of the data remain exclusively with the authors.",
"## Dataset Usage",
"### Links \n\nA \"links\" subset contains URLs with corresponding language and id (based on 'URL \n\n\n\n \n\nwhere is possible to choose specific 'data_id' to load a specific dataset, where 'data_id' is name of the subset\n\nLinks possible to filter according to metdata attributes:",
"### Corpus\n\nafter selecting 'data_id', let's say 'heb_wikipedia_2021_1M', we could load it:\n\n\n\n\nanother example: \n\n\n\nsample:\n\n\n\nIf you use one of these corpora in your work, please, to cite this work:"
] | [
"TAGS\n#task_categories-text-generation #task_categories-fill-mask #multilinguality-multilingual #size_categories-n<1K #size_categories-1K<n<10K #size_categories-10K<n<100K #size_categories-100K<n<1M #size_categories-1M<n<10M #source_datasets-original #language-Arabic #language-English #language-Hebrew #language-German #language-Italian #language-French #language-Polish #language-Portuguese #language-Russian #language-Ukrainian #region-us \n",
"## Leipzig Corpora Collection\n \nThe Leipzig Corpora Collection presents corpora in different languages using the same format and comparable sources. All data are available as plain text files and can be imported into a MySQL database by using the provided import script. They are intended both for scientific use by corpus linguists as well as for applications such as knowledge extraction programs.\nThe corpora are identical in format and similar in size and content. They contain randomly selected sentences in the language of the corpus and are available in sizes from 10,000 sentences up to 1 million sentences. The sources are either newspaper texts or texts randomly collected from the web. The texts are split into sentences. Non-sentences and foreign language material was removed. Because word co-occurrence information is useful for many applications, these data are precomputed and included as well. For each word, the most significant words appearing as immediate left or right neighbor or appearing anywhere within the same sentence are given. More information about the format and content of these files can be found here.\nThe corpora are automatically collected from carefully selected public sources without considering in detail the content of the contained text. No responsibility is taken for the content of the data. In particular, the views and opinions expressed in specific parts of the data remain exclusively with the authors.",
"## Dataset Usage",
"### Links \n\nA \"links\" subset contains URLs with corresponding language and id (based on 'URL \n\n\n\n \n\nwhere is possible to choose specific 'data_id' to load a specific dataset, where 'data_id' is name of the subset\n\nLinks possible to filter according to metdata attributes:",
"### Corpus\n\nafter selecting 'data_id', let's say 'heb_wikipedia_2021_1M', we could load it:\n\n\n\n\nanother example: \n\n\n\nsample:\n\n\n\nIf you use one of these corpora in your work, please, to cite this work:"
] |
b7cc67c74e0e466f48d795325a015298481fe85a |
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
```
id - article id
articleBody - article main content
description - short version of the article, description of the article
headline - headline of the article
title - title of the article
```
| imvladikon/hebrew_news | [
"task_categories:summarization",
"task_ids:news-articles-summarization",
"annotations_creators:no-annotation",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:he",
"license:other",
"region:us"
] | 2022-06-19T15:19:53+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["other"], "language": ["he"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["summarization"], "task_ids": ["news-articles-summarization"]} | 2022-07-09T18:53:05+00:00 | [] | [
"he"
] | TAGS
#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-no-annotation #language_creators-other #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Hebrew #license-other #region-us
|
## Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
| [
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description"
] | [
"TAGS\n#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-no-annotation #language_creators-other #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Hebrew #license-other #region-us \n",
"## Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description"
] |
b0c3bd280892a3f68db1b624e47497cfb3046b05 | # GEM Submission
Submission name: This is a test name
| GEM-submissions/lewtun__this-is-a-test-name__1655666361 | [
"benchmark:gem",
"evaluation",
"benchmark",
"region:us"
] | 2022-06-19T18:19:21+00:00 | {"benchmark": "gem", "type": "prediction", "submission_name": "This is a test name", "tags": ["evaluation", "benchmark"]} | 2022-06-19T18:19:24+00:00 | [] | [] | TAGS
#benchmark-gem #evaluation #benchmark #region-us
| # GEM Submission
Submission name: This is a test name
| [
"# GEM Submission\n\nSubmission name: This is a test name"
] | [
"TAGS\n#benchmark-gem #evaluation #benchmark #region-us \n",
"# GEM Submission\n\nSubmission name: This is a test name"
] |
a1f7e19b50048259d6006324c8b12ee4a0284ac5 |
# 2.7 million news articles and essays
## Table of Contents
- [Dataset Description](#dataset-description)
## Dataset Description
2.7 million news articles and essays from 27 American publications. Includes date, title, publication, article text, publication name, year, month, and URL (for some). Articles mostly span from 2016 to early 2020.
- Type: CSV
- Size: 3.4 GB compressed, 8.8 GB uncompressed
- Created by: Andrew Thompson
- Date added: 4/3/2020
- Date modified: 4/3/2020
- source: [Component one Datasets 2.7 Millions](https://components.one/datasets/all-the-news-2-news-articles-dataset)
- Date of Download and processed: 19/6/2022
- Header was modified with the respective columns
- Row number 2,324,812 was removed | rjac/all-the-news-2-1-Component-one | [
"annotations_creators:Andrew Thompson",
"annotations_creators:components.one",
"language:en",
"region:us"
] | 2022-06-19T21:35:47+00:00 | {"annotations_creators": ["Andrew Thompson", "components.one"], "language": ["en"]} | 2022-07-28T20:01:39+00:00 | [] | [
"en"
] | TAGS
#annotations_creators-Andrew Thompson #annotations_creators-components.one #language-English #region-us
|
# 2.7 million news articles and essays
## Table of Contents
- Dataset Description
## Dataset Description
2.7 million news articles and essays from 27 American publications. Includes date, title, publication, article text, publication name, year, month, and URL (for some). Articles mostly span from 2016 to early 2020.
- Type: CSV
- Size: 3.4 GB compressed, 8.8 GB uncompressed
- Created by: Andrew Thompson
- Date added: 4/3/2020
- Date modified: 4/3/2020
- source: Component one Datasets 2.7 Millions
- Date of Download and processed: 19/6/2022
- Header was modified with the respective columns
- Row number 2,324,812 was removed | [
"# 2.7 million news articles and essays",
"## Table of Contents\n- Dataset Description",
"## Dataset Description\n\n2.7 million news articles and essays from 27 American publications. Includes date, title, publication, article text, publication name, year, month, and URL (for some). Articles mostly span from 2016 to early 2020.\n\n- Type: CSV\n- Size: 3.4 GB compressed, 8.8 GB uncompressed\n- Created by: Andrew Thompson\n- Date added: 4/3/2020\n- Date modified: 4/3/2020\n- source: Component one Datasets 2.7 Millions\n- Date of Download and processed: 19/6/2022\n- Header was modified with the respective columns\n- Row number 2,324,812 was removed"
] | [
"TAGS\n#annotations_creators-Andrew Thompson #annotations_creators-components.one #language-English #region-us \n",
"# 2.7 million news articles and essays",
"## Table of Contents\n- Dataset Description",
"## Dataset Description\n\n2.7 million news articles and essays from 27 American publications. Includes date, title, publication, article text, publication name, year, month, and URL (for some). Articles mostly span from 2016 to early 2020.\n\n- Type: CSV\n- Size: 3.4 GB compressed, 8.8 GB uncompressed\n- Created by: Andrew Thompson\n- Date added: 4/3/2020\n- Date modified: 4/3/2020\n- source: Component one Datasets 2.7 Millions\n- Date of Download and processed: 19/6/2022\n- Header was modified with the respective columns\n- Row number 2,324,812 was removed"
] |
decdb164025b593b707d36db2c9f79929ea66134 |
# Dataset Card for PMD
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Preprocessing](#dataset-preprocessing)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Compared to original FLAVA paper](#compared-to-original-flava-paper)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [PMD homepage](https://flava-model.github.io/)
- **Repository:** [PMD repository](https://huggingface.co/datasets/facebook/pmd)
- **Paper:** [FLAVA: A Foundational Language And Vision Alignment Model
](https://arxiv.org/abs/2112.04482)
- **Leaderboard:**
- **Point of Contact:** [Amanpreet Singh](mailto:[email protected])
### Dataset Summary
Introduced in the FLAVA paper, Public Multimodal Dataset (PMD) is a collection of publicly-available image-text pair datasets. PMD contains 70M image-text pairs in total with 68M unique images. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset.
If you use PMD, please cite the original FLAVA paper as follows, along with the individual datasets (!! - see below for references):
```bibtex
@inproceedings{singh2022flava,
title={Flava: A foundational language and vision alignment model},
author={Singh, Amanpreet and Hu, Ronghang and Goswami, Vedanuj and Couairon, Guillaume and Galuba, Wojciech and Rohrbach, Marcus and Kiela, Douwe},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={15638--15650},
year={2022}
}
```
You can load this dataset by first logging into Hugging Face using `huggingface-cli login` and then running the following commands:
```py
from datasets import load_dataset
pmd = load_dataset("facebook/pmd", use_auth_token=True)
```
You can also load the dataset in streaming mode if you don't want to download the big dataset files (> 50GB locally without the images):
```py
pmd = load_dataset("facebook/pmd", use_auth_token=True, streaming=True)
```
### Dataset Preprocessing
This dataset doesn't download all of the images locally by default. Instead, it exposes URLs for some of the images. To fetch the images, use the following code:
```python
from concurrent.futures import ThreadPoolExecutor
from functools import partial
import io
import urllib
import PIL.Image
from datasets import load_dataset
from datasets.utils.file_utils import get_datasets_user_agent
USER_AGENT = get_datasets_user_agent()
def fetch_single_image(image_data, timeout=None, retries=0):
image_url, image = image_data
if image is not None:
return image
for _ in range(retries + 1):
try:
request = urllib.request.Request(
image_url,
data=None,
headers={"user-agent": USER_AGENT},
)
with urllib.request.urlopen(request, timeout=timeout) as req:
image = PIL.Image.open(io.BytesIO(req.read()))
break
except Exception:
image = None
return image
def fetch_images(batch, num_threads, timeout=None, retries=0):
fetch_single_image_with_args = partial(fetch_single_image, timeout=timeout, retries=retries)
with ThreadPoolExecutor(max_workers=num_threads) as executor:
batch["image"] = list(executor.map(fetch_single_image_with_args, zip(batch["image_url"], batch["image"])))
return batch
num_threads = 20
dset = load_dataset("pmd", use_auth_token=True)
dset = dset.map(fetch_images, batched=True, batch_size=100, fn_kwargs={"num_threads": num_threads})
```
#### Save to disk
You can also save the dataset to disk for faster and direct loading next time but beware of the space required:
```py
dset.save_to_disk(</path/to/save>)
```
#### Load Subsets
You can also download a specific set from the PMD dataset by using
```py
dset = load_dataset("pmd", <choice>, use_auth_token=True)
```
The choices are `
```
"all","coco","sbu", "wit", "localized_narratives","conceptual_captions","visual_genome","conceptual_captions_12M","redcaps","yfcc100M_subset", "localized_narratives_openimages","localized_narratives_ade20k", "localized_narratives_coco"
```
#### Flickr30K Localized Narratives Subset
The Flickr30K subset of Localized Narratives is not included by default as it requires a manual download. You can include it by downloading the tar file from [here](http://shannon.cs.illinois.edu/DenotationGraph/data/index.html) after signing an agreement to `</path/to/Downloads>` and then loading it whole PMD or localized narratives subset by:
```py
dset = load_dataset("pmd", data_dir=</path/to/Downloads/flickr30k-images.tar.gz>, use_auth_token=True, use_flickr30k_ln=True)
# Load LN subset only
dset = load_dataset("pmd", "localized_narratives", data_dir=</path/to/Downloads/flickr30k-images.tar.gz>, use_auth_token=True, use_flickr30k_ln=True)
```
#### Facing issues?
If you are facing issues, you can try loading a specific revision of the repo by using:
```py
dset = load_dataset("pmd", use_auth_token=True, revision="311cd48")
```
### Supported Tasks and Leaderboards
In the FLAVA paper, the dataset has been used to pretrain the FLAVA model as a source of well-aligned image-text pairs. This allows having a generic vision-and-language model which can be fine-tuned for a variety of tasks.
We anticipate that the dataset can be used to train deep neural networks that perform image captioning and that learn transferable visual representations for a variety of downstream visual recognition tasks (image classification, object detection, instance segmentation). We also anticipate that the dataset could be used for a variety of vision-and-language (V&L) tasks, such as image or text retrieval or text-to-image synthesis.
### Languages
All of the subsets in PMD use English as their primary language.
## Dataset Structure
### Data Instances
Each instance in PMD represents a single image-text pair:
```
{
'image_url': None,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x480 at 0x7FCFF86A1E80>,
'text': 'A woman wearing a net on her head cutting a cake. ',
'source': 'coco',
'meta': '{\n "annotation": [\n "A woman wearing a net on her head cutting a cake. "\n ],\n "image_path": "zip:/val2014/COCO_val2014_000000522418.jpg::http:/images.cocodataset.org/zips/val2014.zip"\n}'
}
```
### Data Fields
- `image_url`: Static URL for downloading the image associated with the text. Can be `None` if image is locally available.
- `image`: A PIL Image object for the image associated with the text. Can be `None` if image is not locally available.
- `text`: `str`, A textual description corresponding to the image.
- `source`: `str`, The PMD subset which this pair is from.
- `meta`: `str`, A json representation of the original annotation from the dataset.
### Data Splits
All the data is contained in the training set. The training set has nearly 70M instances.
We intend for this dataset to be primarily used for pre-training with one or more specific downstream task(s) in mind. Thus, all of the instances should be used for pretraining. If required, we specifically make sure that there is no overlap with Karpathy's COCO validation set so users can use that subset for any validation purposes. Users can also load Karpathy's val subset by specifying the "validation" split while loading PMD. This will also load other "validation" splits for some subsets, if they are available.
## Dataset Creation
### Curation Rationale
From the paper:
> Purely contrastive methods, however, also have important shortcomings. Their cross-modal nature does not make them easily usable on multimodal problems that require dealing with both modalities at the same time. They require large corpora, which for both CLIP and ALIGN have not been made accessible to the research community and the details of which remain shrouded in mystery, notwithstanding well-known issues with the construction of such datasets
### Source Data
#### Initial Data Collection and Normalization
From the paper:
> **Data Collection Pipeline**
- For the YFCC100M dataset, we filter the image-text data by discarding non-English captions and only keeping captions that contain more than two words from the description field of each image, if this does not pass our filters we consider the title field. Other than that, we did not do any additional filtering.
- For the VisualGenome, COCO and Localized Narratives subsets, we remove any overlaps with Karpathy's COCO val and test sets.
- For Localized Narratives, we split the original caption which is a paragraph into multiple captions by using spaCy library and take the cartesan product leading to each sample as a separate image-text pair.
#### Compared to original FLAVA paper
The PMD dataset in this repo doesn't correspond 1:1 exactly to the original PMD dataset used in the [FLAVA](https://arxiv.org/abs/2112.04482) paper though this repo is built by the same authors. This is due to difficulty in reproducing WiT and YFCC100M subsets exactly. This repo in general contains more data than the PMD in the FLAVA paper and hence should probably result in better performance.
#### Who are the source language producers?
Please refer to the original dataset papers to understand where the content is coming from.
### Annotations
#### Annotation process
The dataset is a combination of existing public datasets with some filtering applied on top so there is no annotation process involved.
#### Who are the annotators?
Please refer to the original dataset papers to understand where the content is coming from.
### Personal and Sensitive Information
Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found [here](https://huggingface.co/datasets/red_caps).
## Considerations for Using the Data
### Social Impact of Dataset
From the paper:
> **Has an analysis of the potential impact of the dataset and its use on data subjects (e.g.,
a data protection impact analysis) been conducted?**
No.
### Discussion of Biases
Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found [here](https://huggingface.co/datasets/red_caps).
### Other Known Limitations
From the paper:
> **Are there any errors, sources of noise, or redundancies in the dataset?**
PMD is noisy by design since image-text pairs on the internet are noisy and unstructured. Though, since it contains sources such as COCO, Visual Genome, and Localized Narratives which are hand-curated by annotators, it has a lot of well-aligned data as well. So, it is definitely more aligned compared to e.g. LAION.
Some instances may also have duplicate images and captions but should have almost no effect in training large-scale models.
> **Does the dataset contain data that might be considered confidential (e.g., data that is
protected by legal privilege or by doctor-patient confidentiality, data that includes the
content of individuals non-public communications)?**
Not that the authors know of. Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found [here](https://huggingface.co/datasets/red_caps).
## Additional Information
### Dataset Curators
The authors of the original dataset papers, as well as the authors of the FLAVA paper (Amanpreet, Ronghang, Vedanuj, Guillaume, Wojciech, Marcus and Douwe).
### Licensing Information
Here are the individual licenses from each of the datasets that apply if you use this dataset:
#### COCO
The annotations in the COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License.
The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
#### Conceptual Captions
The dataset may be freely used for any purpose, although acknowledgement of Google LLC ("Google") as the data source would be appreciated. The dataset is provided "AS IS" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.
#### WIT
This data is available under the [Creative Commons Attribution-ShareAlike 3.0 Unported](LICENSE) license.
#### Visual Genome
Visual Genome by Ranjay Krishna et al is licensed under a Creative Commons Attribution 4.0 International License.
#### Localized Narratives
All the annotations available through this website are released under a [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license. You are free to redistribute and modify the annotations, but we ask you to please keep the original attribution to our paper.
#### YFCC100M
Use of the original media files is subject to the Creative Commons licenses chosen by their creators/uploaders. License information for each media file can be found within [the YFCC100M metadata](https://multimediacommons.wordpress.com/yfcc100m-core-dataset/#yfcc100m). Use of the dataset is subject to the relevant Webscope License Agreement, which you need to agree to if you use this dataset.
#### RedCaps
The image metadata is licensed under CC-BY 4.0 license. Additionally, uses of this dataset are subject to Reddit API terms (https://www.reddit.com/wiki/
api-terms) and users must comply with Reddit User Agreeement, Content Policy,
and Privacy Policy – all accessible at https://www.redditinc.com/policies.
Similar to RedCaps:
> PMD should only be used for non-commercial research. PMD should not be used for any tasks that involve identifying features related to people (facial recognition, gender, age, ethnicity identification, etc.) or make decisions that impact people (mortgages, job applications, criminal sentences; or moderation decisions about user-uploaded data that could result in bans from a website). Any commercial and for-profit uses of PMD are restricted – it should not be used to train models that will be deployed in production systems as part of a product offered by businesses or government agencies.
### Citation Information
Please cite the main FLAVA paper in which PMD was introduced along with each of the subsets used in PMD as follows:
```bibtex
@inproceedings{singh2022flava,
title={Flava: A foundational language and vision alignment model},
author={Singh, Amanpreet and Hu, Ronghang and Goswami, Vedanuj and Couairon, Guillaume and Galuba, Wojciech and Rohrbach, Marcus and Kiela, Douwe},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={15638--15650},
year={2022}
}
@article{chen2015microsoft,
title={Microsoft coco captions: Data collection and evaluation server},
author={Chen, Xinlei and Fang, Hao and Lin, Tsung-Yi and Vedantam, Ramakrishna and Gupta, Saurabh and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
journal={arXiv preprint arXiv:1504.00325},
year={2015}
}
@inproceedings{ordonez2011sbucaptions,
Author = {Vicente Ordonez and Girish Kulkarni and Tamara L. Berg},
Title = {Im2Text: Describing Images Using 1 Million Captioned Photographs},
Booktitle = {Neural Information Processing Systems ({NIPS})},
Year = {2011},
}
@article{krishna2017visual,
title={Visual genome: Connecting language and vision using crowdsourced dense image annotations},
author={Krishna, Ranjay and Zhu, Yuke and Groth, Oliver and Johnson, Justin and Hata, Kenji and Kravitz, Joshua and Chen, Stephanie and Kalantidis, Yannis and Li, Li-Jia and Shamma, David A and others},
journal={International journal of computer vision},
volume={123},
number={1},
pages={32--73},
year={2017},
publisher={Springer}
}
@article{srinivasan2021wit,
title={WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning},
author={Srinivasan, Krishna and Raman, Karthik and Chen, Jiecao and Bendersky, Michael and Najork, Marc},
journal={arXiv preprint arXiv:2103.01913},
year={2021}
}
@inproceedings{sharma2018conceptual,
title={Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning},
author={Sharma, Piyush and Ding, Nan and Goodman, Sebastian and Soricut, Radu},
booktitle={Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={2556--2565},
year={2018}
}
@inproceedings{changpinyo2021conceptual,
title={Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts},
author={Changpinyo, Soravit and Sharma, Piyush and Ding, Nan and Soricut, Radu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={3558--3568},
year={2021}
}
@inproceedings{ponttuset2020localized,
author = {Jordi Pont-Tuset and Jasper Uijlings and Soravit Changpinyo and Radu Soricut and Vittorio Ferrari},
title = {Connecting Vision and Language with Localized Narratives},
booktitle = {ECCV},
year = {2020}
}
@article{thomee2016yfcc100m,
title={YFCC100M: The new data in multimedia research},
author={Thomee, Bart and Shamma, David A and Friedland, Gerald and Elizalde, Benjamin and Ni, Karl and Poland, Douglas and Borth, Damian and Li, Li-Jia},
journal={Communications of the ACM},
volume={59},
number={2},
pages={64--73},
year={2016},
publisher={ACM New York, NY, USA}
}
@misc{desai2021redcaps,
title={RedCaps: web-curated image-text data created by the people, for the people},
author={Karan Desai and Gaurav Kaul and Zubin Aysola and Justin Johnson},
year={2021},
eprint={2111.11431},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
### Contributions
Thanks to [@aps](https://github.com/apsdehal), [Thomas Wang](https://huggingface.co/TimeRobber), and [@VictorSanh](https://huggingface.co/VictorSanh) for adding this dataset. | facebook/pmd | [
"task_categories:image-to-text",
"task_ids:image-captioning",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"arxiv:2112.04482",
"arxiv:2111.11431",
"region:us"
] | 2022-06-19T23:52:47+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["image-to-text"], "task_ids": ["image-captioning"], "paperswithcode_id": "pmd", "pretty_name": "PMD", "extra_gated_prompt": "By clicking on \u201cAccess repository\u201d below, you also agree to individual licensing terms for each of the subset datasets of the PMD as noted at https://huggingface.co/datasets/facebook/pmd#additional-information."} | 2022-08-09T22:51:39+00:00 | [
"2112.04482",
"2111.11431"
] | [
"en"
] | TAGS
#task_categories-image-to-text #task_ids-image-captioning #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-10M<n<100M #source_datasets-original #language-English #license-cc-by-4.0 #arxiv-2112.04482 #arxiv-2111.11431 #region-us
|
# Dataset Card for PMD
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Dataset Preprocessing
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Compared to original FLAVA paper
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: PMD homepage
- Repository: PMD repository
- Paper: FLAVA: A Foundational Language And Vision Alignment Model
- Leaderboard:
- Point of Contact: Amanpreet Singh
### Dataset Summary
Introduced in the FLAVA paper, Public Multimodal Dataset (PMD) is a collection of publicly-available image-text pair datasets. PMD contains 70M image-text pairs in total with 68M unique images. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset.
If you use PMD, please cite the original FLAVA paper as follows, along with the individual datasets (!! - see below for references):
You can load this dataset by first logging into Hugging Face using 'huggingface-cli login' and then running the following commands:
You can also load the dataset in streaming mode if you don't want to download the big dataset files (> 50GB locally without the images):
### Dataset Preprocessing
This dataset doesn't download all of the images locally by default. Instead, it exposes URLs for some of the images. To fetch the images, use the following code:
#### Save to disk
You can also save the dataset to disk for faster and direct loading next time but beware of the space required:
#### Load Subsets
You can also download a specific set from the PMD dataset by using
The choices are '
#### Flickr30K Localized Narratives Subset
The Flickr30K subset of Localized Narratives is not included by default as it requires a manual download. You can include it by downloading the tar file from here after signing an agreement to '</path/to/Downloads>' and then loading it whole PMD or localized narratives subset by:
#### Facing issues?
If you are facing issues, you can try loading a specific revision of the repo by using:
### Supported Tasks and Leaderboards
In the FLAVA paper, the dataset has been used to pretrain the FLAVA model as a source of well-aligned image-text pairs. This allows having a generic vision-and-language model which can be fine-tuned for a variety of tasks.
We anticipate that the dataset can be used to train deep neural networks that perform image captioning and that learn transferable visual representations for a variety of downstream visual recognition tasks (image classification, object detection, instance segmentation). We also anticipate that the dataset could be used for a variety of vision-and-language (V&L) tasks, such as image or text retrieval or text-to-image synthesis.
### Languages
All of the subsets in PMD use English as their primary language.
## Dataset Structure
### Data Instances
Each instance in PMD represents a single image-text pair:
### Data Fields
- 'image_url': Static URL for downloading the image associated with the text. Can be 'None' if image is locally available.
- 'image': A PIL Image object for the image associated with the text. Can be 'None' if image is not locally available.
- 'text': 'str', A textual description corresponding to the image.
- 'source': 'str', The PMD subset which this pair is from.
- 'meta': 'str', A json representation of the original annotation from the dataset.
### Data Splits
All the data is contained in the training set. The training set has nearly 70M instances.
We intend for this dataset to be primarily used for pre-training with one or more specific downstream task(s) in mind. Thus, all of the instances should be used for pretraining. If required, we specifically make sure that there is no overlap with Karpathy's COCO validation set so users can use that subset for any validation purposes. Users can also load Karpathy's val subset by specifying the "validation" split while loading PMD. This will also load other "validation" splits for some subsets, if they are available.
## Dataset Creation
### Curation Rationale
From the paper:
> Purely contrastive methods, however, also have important shortcomings. Their cross-modal nature does not make them easily usable on multimodal problems that require dealing with both modalities at the same time. They require large corpora, which for both CLIP and ALIGN have not been made accessible to the research community and the details of which remain shrouded in mystery, notwithstanding well-known issues with the construction of such datasets
### Source Data
#### Initial Data Collection and Normalization
From the paper:
> Data Collection Pipeline
- For the YFCC100M dataset, we filter the image-text data by discarding non-English captions and only keeping captions that contain more than two words from the description field of each image, if this does not pass our filters we consider the title field. Other than that, we did not do any additional filtering.
- For the VisualGenome, COCO and Localized Narratives subsets, we remove any overlaps with Karpathy's COCO val and test sets.
- For Localized Narratives, we split the original caption which is a paragraph into multiple captions by using spaCy library and take the cartesan product leading to each sample as a separate image-text pair.
#### Compared to original FLAVA paper
The PMD dataset in this repo doesn't correspond 1:1 exactly to the original PMD dataset used in the FLAVA paper though this repo is built by the same authors. This is due to difficulty in reproducing WiT and YFCC100M subsets exactly. This repo in general contains more data than the PMD in the FLAVA paper and hence should probably result in better performance.
#### Who are the source language producers?
Please refer to the original dataset papers to understand where the content is coming from.
### Annotations
#### Annotation process
The dataset is a combination of existing public datasets with some filtering applied on top so there is no annotation process involved.
#### Who are the annotators?
Please refer to the original dataset papers to understand where the content is coming from.
### Personal and Sensitive Information
Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.
## Considerations for Using the Data
### Social Impact of Dataset
From the paper:
> Has an analysis of the potential impact of the dataset and its use on data subjects (e.g.,
a data protection impact analysis) been conducted?
No.
### Discussion of Biases
Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.
### Other Known Limitations
From the paper:
> Are there any errors, sources of noise, or redundancies in the dataset?
PMD is noisy by design since image-text pairs on the internet are noisy and unstructured. Though, since it contains sources such as COCO, Visual Genome, and Localized Narratives which are hand-curated by annotators, it has a lot of well-aligned data as well. So, it is definitely more aligned compared to e.g. LAION.
Some instances may also have duplicate images and captions but should have almost no effect in training large-scale models.
> Does the dataset contain data that might be considered confidential (e.g., data that is
protected by legal privilege or by doctor-patient confidentiality, data that includes the
content of individuals non-public communications)?
Not that the authors know of. Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.
## Additional Information
### Dataset Curators
The authors of the original dataset papers, as well as the authors of the FLAVA paper (Amanpreet, Ronghang, Vedanuj, Guillaume, Wojciech, Marcus and Douwe).
### Licensing Information
Here are the individual licenses from each of the datasets that apply if you use this dataset:
#### COCO
The annotations in the COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License.
The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
#### Conceptual Captions
The dataset may be freely used for any purpose, although acknowledgement of Google LLC ("Google") as the data source would be appreciated. The dataset is provided "AS IS" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.
#### WIT
This data is available under the Creative Commons Attribution-ShareAlike 3.0 Unported license.
#### Visual Genome
Visual Genome by Ranjay Krishna et al is licensed under a Creative Commons Attribution 4.0 International License.
#### Localized Narratives
All the annotations available through this website are released under a CC BY 4.0 license. You are free to redistribute and modify the annotations, but we ask you to please keep the original attribution to our paper.
#### YFCC100M
Use of the original media files is subject to the Creative Commons licenses chosen by their creators/uploaders. License information for each media file can be found within the YFCC100M metadata. Use of the dataset is subject to the relevant Webscope License Agreement, which you need to agree to if you use this dataset.
#### RedCaps
The image metadata is licensed under CC-BY 4.0 license. Additionally, uses of this dataset are subject to Reddit API terms (URL
api-terms) and users must comply with Reddit User Agreeement, Content Policy,
and Privacy Policy – all accessible at URL
Similar to RedCaps:
> PMD should only be used for non-commercial research. PMD should not be used for any tasks that involve identifying features related to people (facial recognition, gender, age, ethnicity identification, etc.) or make decisions that impact people (mortgages, job applications, criminal sentences; or moderation decisions about user-uploaded data that could result in bans from a website). Any commercial and for-profit uses of PMD are restricted – it should not be used to train models that will be deployed in production systems as part of a product offered by businesses or government agencies.
Please cite the main FLAVA paper in which PMD was introduced along with each of the subsets used in PMD as follows:
### Contributions
Thanks to @aps, Thomas Wang, and @VictorSanh for adding this dataset. | [
"# Dataset Card for PMD",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Dataset Preprocessing\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Compared to original FLAVA paper \n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: PMD homepage\n- Repository: PMD repository\n- Paper: FLAVA: A Foundational Language And Vision Alignment Model\n\n- Leaderboard:\n- Point of Contact: Amanpreet Singh",
"### Dataset Summary\n\nIntroduced in the FLAVA paper, Public Multimodal Dataset (PMD) is a collection of publicly-available image-text pair datasets. PMD contains 70M image-text pairs in total with 68M unique images. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset.\n\nIf you use PMD, please cite the original FLAVA paper as follows, along with the individual datasets (!! - see below for references):\n\n\n\nYou can load this dataset by first logging into Hugging Face using 'huggingface-cli login' and then running the following commands:\n\n\n\nYou can also load the dataset in streaming mode if you don't want to download the big dataset files (> 50GB locally without the images):",
"### Dataset Preprocessing\n\nThis dataset doesn't download all of the images locally by default. Instead, it exposes URLs for some of the images. To fetch the images, use the following code:",
"#### Save to disk\nYou can also save the dataset to disk for faster and direct loading next time but beware of the space required:",
"#### Load Subsets\n\nYou can also download a specific set from the PMD dataset by using \n \nThe choices are '",
"#### Flickr30K Localized Narratives Subset\nThe Flickr30K subset of Localized Narratives is not included by default as it requires a manual download. You can include it by downloading the tar file from here after signing an agreement to '</path/to/Downloads>' and then loading it whole PMD or localized narratives subset by:",
"#### Facing issues?\n\nIf you are facing issues, you can try loading a specific revision of the repo by using:",
"### Supported Tasks and Leaderboards\n\nIn the FLAVA paper, the dataset has been used to pretrain the FLAVA model as a source of well-aligned image-text pairs. This allows having a generic vision-and-language model which can be fine-tuned for a variety of tasks.\n\nWe anticipate that the dataset can be used to train deep neural networks that perform image captioning and that learn transferable visual representations for a variety of downstream visual recognition tasks (image classification, object detection, instance segmentation). We also anticipate that the dataset could be used for a variety of vision-and-language (V&L) tasks, such as image or text retrieval or text-to-image synthesis.",
"### Languages\n\nAll of the subsets in PMD use English as their primary language.",
"## Dataset Structure",
"### Data Instances\n\nEach instance in PMD represents a single image-text pair:",
"### Data Fields\n\n- 'image_url': Static URL for downloading the image associated with the text. Can be 'None' if image is locally available.\n- 'image': A PIL Image object for the image associated with the text. Can be 'None' if image is not locally available.\n- 'text': 'str', A textual description corresponding to the image.\n- 'source': 'str', The PMD subset which this pair is from.\n- 'meta': 'str', A json representation of the original annotation from the dataset.",
"### Data Splits\n\nAll the data is contained in the training set. The training set has nearly 70M instances. \n\nWe intend for this dataset to be primarily used for pre-training with one or more specific downstream task(s) in mind. Thus, all of the instances should be used for pretraining. If required, we specifically make sure that there is no overlap with Karpathy's COCO validation set so users can use that subset for any validation purposes. Users can also load Karpathy's val subset by specifying the \"validation\" split while loading PMD. This will also load other \"validation\" splits for some subsets, if they are available.",
"## Dataset Creation",
"### Curation Rationale\n\nFrom the paper:\n> Purely contrastive methods, however, also have important shortcomings. Their cross-modal nature does not make them easily usable on multimodal problems that require dealing with both modalities at the same time. They require large corpora, which for both CLIP and ALIGN have not been made accessible to the research community and the details of which remain shrouded in mystery, notwithstanding well-known issues with the construction of such datasets",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nFrom the paper:\n> Data Collection Pipeline\n\n- For the YFCC100M dataset, we filter the image-text data by discarding non-English captions and only keeping captions that contain more than two words from the description field of each image, if this does not pass our filters we consider the title field. Other than that, we did not do any additional filtering.\n- For the VisualGenome, COCO and Localized Narratives subsets, we remove any overlaps with Karpathy's COCO val and test sets.\n- For Localized Narratives, we split the original caption which is a paragraph into multiple captions by using spaCy library and take the cartesan product leading to each sample as a separate image-text pair.",
"#### Compared to original FLAVA paper\n\nThe PMD dataset in this repo doesn't correspond 1:1 exactly to the original PMD dataset used in the FLAVA paper though this repo is built by the same authors. This is due to difficulty in reproducing WiT and YFCC100M subsets exactly. This repo in general contains more data than the PMD in the FLAVA paper and hence should probably result in better performance.",
"#### Who are the source language producers?\n\nPlease refer to the original dataset papers to understand where the content is coming from.",
"### Annotations",
"#### Annotation process\n\nThe dataset is a combination of existing public datasets with some filtering applied on top so there is no annotation process involved.",
"#### Who are the annotators?\n\nPlease refer to the original dataset papers to understand where the content is coming from.",
"### Personal and Sensitive Information\n\nPlease refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nFrom the paper:\n> Has an analysis of the potential impact of the dataset and its use on data subjects (e.g.,\na data protection impact analysis) been conducted?\n\nNo.",
"### Discussion of Biases\n\nPlease refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"### Other Known Limitations\n\nFrom the paper:\n> Are there any errors, sources of noise, or redundancies in the dataset?\n\nPMD is noisy by design since image-text pairs on the internet are noisy and unstructured. Though, since it contains sources such as COCO, Visual Genome, and Localized Narratives which are hand-curated by annotators, it has a lot of well-aligned data as well. So, it is definitely more aligned compared to e.g. LAION.\n\nSome instances may also have duplicate images and captions but should have almost no effect in training large-scale models.\n\n> Does the dataset contain data that might be considered confidential (e.g., data that is\nprotected by legal privilege or by doctor-patient confidentiality, data that includes the\ncontent of individuals non-public communications)?\n\nNot that the authors know of. Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"## Additional Information",
"### Dataset Curators\n\nThe authors of the original dataset papers, as well as the authors of the FLAVA paper (Amanpreet, Ronghang, Vedanuj, Guillaume, Wojciech, Marcus and Douwe).",
"### Licensing Information\n\nHere are the individual licenses from each of the datasets that apply if you use this dataset:",
"#### COCO\nThe annotations in the COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License.\n\nThe COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.",
"#### Conceptual Captions\nThe dataset may be freely used for any purpose, although acknowledgement of Google LLC (\"Google\") as the data source would be appreciated. The dataset is provided \"AS IS\" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.",
"#### WIT\nThis data is available under the Creative Commons Attribution-ShareAlike 3.0 Unported license.",
"#### Visual Genome\nVisual Genome by Ranjay Krishna et al is licensed under a Creative Commons Attribution 4.0 International License.",
"#### Localized Narratives\n\nAll the annotations available through this website are released under a CC BY 4.0 license. You are free to redistribute and modify the annotations, but we ask you to please keep the original attribution to our paper.",
"#### YFCC100M\nUse of the original media files is subject to the Creative Commons licenses chosen by their creators/uploaders. License information for each media file can be found within the YFCC100M metadata. Use of the dataset is subject to the relevant Webscope License Agreement, which you need to agree to if you use this dataset.",
"#### RedCaps\nThe image metadata is licensed under CC-BY 4.0 license. Additionally, uses of this dataset are subject to Reddit API terms (URL\napi-terms) and users must comply with Reddit User Agreeement, Content Policy,\nand Privacy Policy – all accessible at URL\n\nSimilar to RedCaps:\n> PMD should only be used for non-commercial research. PMD should not be used for any tasks that involve identifying features related to people (facial recognition, gender, age, ethnicity identification, etc.) or make decisions that impact people (mortgages, job applications, criminal sentences; or moderation decisions about user-uploaded data that could result in bans from a website). Any commercial and for-profit uses of PMD are restricted – it should not be used to train models that will be deployed in production systems as part of a product offered by businesses or government agencies.\n\n\n\n\nPlease cite the main FLAVA paper in which PMD was introduced along with each of the subsets used in PMD as follows:",
"### Contributions\n\nThanks to @aps, Thomas Wang, and @VictorSanh for adding this dataset."
] | [
"TAGS\n#task_categories-image-to-text #task_ids-image-captioning #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-10M<n<100M #source_datasets-original #language-English #license-cc-by-4.0 #arxiv-2112.04482 #arxiv-2111.11431 #region-us \n",
"# Dataset Card for PMD",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Dataset Preprocessing\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Compared to original FLAVA paper \n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: PMD homepage\n- Repository: PMD repository\n- Paper: FLAVA: A Foundational Language And Vision Alignment Model\n\n- Leaderboard:\n- Point of Contact: Amanpreet Singh",
"### Dataset Summary\n\nIntroduced in the FLAVA paper, Public Multimodal Dataset (PMD) is a collection of publicly-available image-text pair datasets. PMD contains 70M image-text pairs in total with 68M unique images. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset.\n\nIf you use PMD, please cite the original FLAVA paper as follows, along with the individual datasets (!! - see below for references):\n\n\n\nYou can load this dataset by first logging into Hugging Face using 'huggingface-cli login' and then running the following commands:\n\n\n\nYou can also load the dataset in streaming mode if you don't want to download the big dataset files (> 50GB locally without the images):",
"### Dataset Preprocessing\n\nThis dataset doesn't download all of the images locally by default. Instead, it exposes URLs for some of the images. To fetch the images, use the following code:",
"#### Save to disk\nYou can also save the dataset to disk for faster and direct loading next time but beware of the space required:",
"#### Load Subsets\n\nYou can also download a specific set from the PMD dataset by using \n \nThe choices are '",
"#### Flickr30K Localized Narratives Subset\nThe Flickr30K subset of Localized Narratives is not included by default as it requires a manual download. You can include it by downloading the tar file from here after signing an agreement to '</path/to/Downloads>' and then loading it whole PMD or localized narratives subset by:",
"#### Facing issues?\n\nIf you are facing issues, you can try loading a specific revision of the repo by using:",
"### Supported Tasks and Leaderboards\n\nIn the FLAVA paper, the dataset has been used to pretrain the FLAVA model as a source of well-aligned image-text pairs. This allows having a generic vision-and-language model which can be fine-tuned for a variety of tasks.\n\nWe anticipate that the dataset can be used to train deep neural networks that perform image captioning and that learn transferable visual representations for a variety of downstream visual recognition tasks (image classification, object detection, instance segmentation). We also anticipate that the dataset could be used for a variety of vision-and-language (V&L) tasks, such as image or text retrieval or text-to-image synthesis.",
"### Languages\n\nAll of the subsets in PMD use English as their primary language.",
"## Dataset Structure",
"### Data Instances\n\nEach instance in PMD represents a single image-text pair:",
"### Data Fields\n\n- 'image_url': Static URL for downloading the image associated with the text. Can be 'None' if image is locally available.\n- 'image': A PIL Image object for the image associated with the text. Can be 'None' if image is not locally available.\n- 'text': 'str', A textual description corresponding to the image.\n- 'source': 'str', The PMD subset which this pair is from.\n- 'meta': 'str', A json representation of the original annotation from the dataset.",
"### Data Splits\n\nAll the data is contained in the training set. The training set has nearly 70M instances. \n\nWe intend for this dataset to be primarily used for pre-training with one or more specific downstream task(s) in mind. Thus, all of the instances should be used for pretraining. If required, we specifically make sure that there is no overlap with Karpathy's COCO validation set so users can use that subset for any validation purposes. Users can also load Karpathy's val subset by specifying the \"validation\" split while loading PMD. This will also load other \"validation\" splits for some subsets, if they are available.",
"## Dataset Creation",
"### Curation Rationale\n\nFrom the paper:\n> Purely contrastive methods, however, also have important shortcomings. Their cross-modal nature does not make them easily usable on multimodal problems that require dealing with both modalities at the same time. They require large corpora, which for both CLIP and ALIGN have not been made accessible to the research community and the details of which remain shrouded in mystery, notwithstanding well-known issues with the construction of such datasets",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nFrom the paper:\n> Data Collection Pipeline\n\n- For the YFCC100M dataset, we filter the image-text data by discarding non-English captions and only keeping captions that contain more than two words from the description field of each image, if this does not pass our filters we consider the title field. Other than that, we did not do any additional filtering.\n- For the VisualGenome, COCO and Localized Narratives subsets, we remove any overlaps with Karpathy's COCO val and test sets.\n- For Localized Narratives, we split the original caption which is a paragraph into multiple captions by using spaCy library and take the cartesan product leading to each sample as a separate image-text pair.",
"#### Compared to original FLAVA paper\n\nThe PMD dataset in this repo doesn't correspond 1:1 exactly to the original PMD dataset used in the FLAVA paper though this repo is built by the same authors. This is due to difficulty in reproducing WiT and YFCC100M subsets exactly. This repo in general contains more data than the PMD in the FLAVA paper and hence should probably result in better performance.",
"#### Who are the source language producers?\n\nPlease refer to the original dataset papers to understand where the content is coming from.",
"### Annotations",
"#### Annotation process\n\nThe dataset is a combination of existing public datasets with some filtering applied on top so there is no annotation process involved.",
"#### Who are the annotators?\n\nPlease refer to the original dataset papers to understand where the content is coming from.",
"### Personal and Sensitive Information\n\nPlease refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nFrom the paper:\n> Has an analysis of the potential impact of the dataset and its use on data subjects (e.g.,\na data protection impact analysis) been conducted?\n\nNo.",
"### Discussion of Biases\n\nPlease refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"### Other Known Limitations\n\nFrom the paper:\n> Are there any errors, sources of noise, or redundancies in the dataset?\n\nPMD is noisy by design since image-text pairs on the internet are noisy and unstructured. Though, since it contains sources such as COCO, Visual Genome, and Localized Narratives which are hand-curated by annotators, it has a lot of well-aligned data as well. So, it is definitely more aligned compared to e.g. LAION.\n\nSome instances may also have duplicate images and captions but should have almost no effect in training large-scale models.\n\n> Does the dataset contain data that might be considered confidential (e.g., data that is\nprotected by legal privilege or by doctor-patient confidentiality, data that includes the\ncontent of individuals non-public communications)?\n\nNot that the authors know of. Please refer to the original dataset papers to understand where the content is coming from. For example, a detailed description on this for RedCaps can be found here.",
"## Additional Information",
"### Dataset Curators\n\nThe authors of the original dataset papers, as well as the authors of the FLAVA paper (Amanpreet, Ronghang, Vedanuj, Guillaume, Wojciech, Marcus and Douwe).",
"### Licensing Information\n\nHere are the individual licenses from each of the datasets that apply if you use this dataset:",
"#### COCO\nThe annotations in the COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License.\n\nThe COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.",
"#### Conceptual Captions\nThe dataset may be freely used for any purpose, although acknowledgement of Google LLC (\"Google\") as the data source would be appreciated. The dataset is provided \"AS IS\" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.",
"#### WIT\nThis data is available under the Creative Commons Attribution-ShareAlike 3.0 Unported license.",
"#### Visual Genome\nVisual Genome by Ranjay Krishna et al is licensed under a Creative Commons Attribution 4.0 International License.",
"#### Localized Narratives\n\nAll the annotations available through this website are released under a CC BY 4.0 license. You are free to redistribute and modify the annotations, but we ask you to please keep the original attribution to our paper.",
"#### YFCC100M\nUse of the original media files is subject to the Creative Commons licenses chosen by their creators/uploaders. License information for each media file can be found within the YFCC100M metadata. Use of the dataset is subject to the relevant Webscope License Agreement, which you need to agree to if you use this dataset.",
"#### RedCaps\nThe image metadata is licensed under CC-BY 4.0 license. Additionally, uses of this dataset are subject to Reddit API terms (URL\napi-terms) and users must comply with Reddit User Agreeement, Content Policy,\nand Privacy Policy – all accessible at URL\n\nSimilar to RedCaps:\n> PMD should only be used for non-commercial research. PMD should not be used for any tasks that involve identifying features related to people (facial recognition, gender, age, ethnicity identification, etc.) or make decisions that impact people (mortgages, job applications, criminal sentences; or moderation decisions about user-uploaded data that could result in bans from a website). Any commercial and for-profit uses of PMD are restricted – it should not be used to train models that will be deployed in production systems as part of a product offered by businesses or government agencies.\n\n\n\n\nPlease cite the main FLAVA paper in which PMD was introduced along with each of the subsets used in PMD as follows:",
"### Contributions\n\nThanks to @aps, Thomas Wang, and @VictorSanh for adding this dataset."
] |
00f96ff552610ab5f3c15d3a0881dda2a14a3935 | # AudioMNIST
This is a HuggingFace Datasets adaptation of the AudioMNIST dataset
Original Dataset:
https://github.com/soerenab/AudioMNIST
---
license: mit
---
| flexthink/audiomnist | [
"region:us"
] | 2022-06-20T02:38:26+00:00 | {} | 2022-06-21T01:50:18+00:00 | [] | [] | TAGS
#region-us
| # AudioMNIST
This is a HuggingFace Datasets adaptation of the AudioMNIST dataset
Original Dataset:
URL
---
license: mit
---
| [
"# AudioMNIST\n\nThis is a HuggingFace Datasets adaptation of the AudioMNIST dataset\n\nOriginal Dataset:\nURL\n\n---\nlicense: mit\n---"
] | [
"TAGS\n#region-us \n",
"# AudioMNIST\n\nThis is a HuggingFace Datasets adaptation of the AudioMNIST dataset\n\nOriginal Dataset:\nURL\n\n---\nlicense: mit\n---"
] |
a6b9f7b804bb6c057fb6f94d38430f1bd91ae45c | # Dataset Card for jbo-corpus
## Dataset Description
- **Homepage:** https://github.com/olpa/lojban-mt/tree/master/data
### Dataset Summary
Parallel corpus of Lojban sentences
### Licensing Information
Unknown
| olpa/jbo-corpus | [
"region:us"
] | 2022-06-20T02:55:50+00:00 | {} | 2022-08-12T03:41:52+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for jbo-corpus
## Dataset Description
- Homepage: URL
### Dataset Summary
Parallel corpus of Lojban sentences
### Licensing Information
Unknown
| [
"# Dataset Card for jbo-corpus",
"## Dataset Description\n\n- Homepage: URL",
"### Dataset Summary\n\nParallel corpus of Lojban sentences",
"### Licensing Information\n\nUnknown"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for jbo-corpus",
"## Dataset Description\n\n- Homepage: URL",
"### Dataset Summary\n\nParallel corpus of Lojban sentences",
"### Licensing Information\n\nUnknown"
] |
aec70969b2c4c5eb93adadf4c3b2aa2c03258548 |
# Dataset Card for Nexdata/American_English_Speech_Data_by_Mobile_Phone_Reading
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/78?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The data set contains 349 American English speakers' speech data, all of whom are American locals. It is recorded in quiet environment. The recording contents cover various categories like economics, entertainment, news and spoken language. It is manually transcribed and annotated with the starting and ending time points.
For more details, please refer to the link: https://www.nexdata.ai/datasets/78?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
American English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions
| Nexdata/American_English_Speech_Data_by_Mobile_Phone_Reading | [
"region:us"
] | 2022-06-20T05:54:36+00:00 | {"YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-08-31T01:27:54+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Nexdata/American_English_Speech_Data_by_Mobile_Phone_Reading
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
The data set contains 349 American English speakers' speech data, all of whom are American locals. It is recorded in quiet environment. The recording contents cover various categories like economics, entertainment, news and spoken language. It is manually transcribed and annotated with the starting and ending time points.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
American English
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commerical License: URL
### Contributions
| [
"# Dataset Card for Nexdata/American_English_Speech_Data_by_Mobile_Phone_Reading",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data set contains 349 American English speakers' speech data, all of whom are American locals. It is recorded in quiet environment. The recording contents cover various categories like economics, entertainment, news and spoken language. It is manually transcribed and annotated with the starting and ending time points. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nAmerican English",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Nexdata/American_English_Speech_Data_by_Mobile_Phone_Reading",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data set contains 349 American English speakers' speech data, all of whom are American locals. It is recorded in quiet environment. The recording contents cover various categories like economics, entertainment, news and spoken language. It is manually transcribed and annotated with the starting and ending time points. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nAmerican English",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] |
4cce6b9fd84b691ca6907fa1fb3832e4a5bc37c2 | ## IndicNLP News Article Classification Dataset
We used the IndicNLP text corpora to create classification datasets comprising news articles and their categories for 9 languages. The dataset is balanced across classes. The following table contains the statistics of our dataset:
| Language | Classes | Articles per Class |
| --------- | ------------------------------------------- | ------------------ |
| Bengali | entertainment, sports | 7K |
| Gujarati | business, entertainment, sports | 680 |
| Kannada | entertainment, lifestyle, sports | 10K |
| Malayalam | business, entertainment, sports, technology | 1.5K |
| Marathi | entertainment, lifestyle, sports | 1.5K |
| Oriya | business, crime, entertainment, sports | 7.5K |
| Punjabi | business, entertainment, sports, politics | 780 |
| Tamil | entertainment, politics, sport | 3.9K |
| Telugu | entertainment, business, sports | 8K |
## Citing
If you are using any of the resources, please cite the following article:
```
@article{kunchukuttan2020indicnlpcorpus,
title={AI4Bharat-IndicNLP Corpus: Monolingual Corpora and Word Embeddings for Indic Languages},
author={Anoop Kunchukuttan and Divyanshu Kakwani and Satish Golla and Gokul N.C. and Avik Bhattacharyya and Mitesh M. Khapra and Pratyush Kumar},
year={2020},
journal={arXiv preprint arXiv:2005.00085},
}
```
| hugginglearners/malayalam_news | [
"region:us"
] | 2022-06-20T06:38:55+00:00 | {} | 2022-07-04T05:13:54+00:00 | [] | [] | TAGS
#region-us
| IndicNLP News Article Classification Dataset
--------------------------------------------
We used the IndicNLP text corpora to create classification datasets comprising news articles and their categories for 9 languages. The dataset is balanced across classes. The following table contains the statistics of our dataset:
Language: Bengali, Classes: entertainment, sports, Articles per Class: 7K
Language: Gujarati, Classes: business, entertainment, sports, Articles per Class: 680
Language: Kannada, Classes: entertainment, lifestyle, sports, Articles per Class: 10K
Language: Malayalam, Classes: business, entertainment, sports, technology, Articles per Class: 1.5K
Language: Marathi, Classes: entertainment, lifestyle, sports, Articles per Class: 1.5K
Language: Oriya, Classes: business, crime, entertainment, sports, Articles per Class: 7.5K
Language: Punjabi, Classes: business, entertainment, sports, politics, Articles per Class: 780
Language: Tamil, Classes: entertainment, politics, sport, Articles per Class: 3.9K
Language: Telugu, Classes: entertainment, business, sports, Articles per Class: 8K
Citing
------
If you are using any of the resources, please cite the following article:
| [] | [
"TAGS\n#region-us \n"
] |
2702354ff5c46c409dceae8abcc2cef2c3efc76a | This dataset contains both 8 and 16 sampled frames of the "eating-spaghetti" video of the Kinetics-400 dataset, with the following frame indices being used:
* 8 frames (`eating_spaghetti_8_frames.npy`): [ 97, 98, 99, 100, 101, 102, 103, 104] (NumPy seed was 1024, clip_len=8, frame_sample_rate=1, seg_len=len(vr))
* 16 frames (`eating_spaghetti.npy`): [164, 168, 172, 176, 181, 185, 189, 193, 198, 202, 206, 210, 215, 219, 223, 227].
* 32 frames (`eating_spaghetti_32_frames.npy`): array([ 47, 51, 55, 59, 63, 67, 71, 75, 80, 84, 88, 92, 96,
100, 104, 108, 113, 117, 121, 125, 129, 133, 137, 141, 146, 150,
154, 158, 162, 166, 170, 174]) (NumPy seed was 0, clip_len=32, frame_sample_rate=4, seg_len=len(vr))
This is the code:
```
from decord import VideoReader, cpu
from huggingface_hub import hf_hub_download
import numpy as np
file_path = hf_hub_download(
repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
)
vr = VideoReader(file_path, num_threads=1, ctx=cpu(0))
# get 16 frames
vr.seek(0)
indices = [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
video = vr.get_batch(indices).asnumpy()
# save as NumPy array
with open('eating_spaghetti.npy', 'wb') as f:
np.save(f, video)
``` | hf-internal-testing/spaghetti-video | [
"region:us"
] | 2022-06-20T08:00:06+00:00 | {} | 2022-09-07T15:35:12+00:00 | [] | [] | TAGS
#region-us
| This dataset contains both 8 and 16 sampled frames of the "eating-spaghetti" video of the Kinetics-400 dataset, with the following frame indices being used:
* 8 frames ('eating_spaghetti_8_frames.npy'): [ 97, 98, 99, 100, 101, 102, 103, 104] (NumPy seed was 1024, clip_len=8, frame_sample_rate=1, seg_len=len(vr))
* 16 frames ('eating_spaghetti.npy'): [164, 168, 172, 176, 181, 185, 189, 193, 198, 202, 206, 210, 215, 219, 223, 227].
* 32 frames ('eating_spaghetti_32_frames.npy'): array([ 47, 51, 55, 59, 63, 67, 71, 75, 80, 84, 88, 92, 96,
100, 104, 108, 113, 117, 121, 125, 129, 133, 137, 141, 146, 150,
154, 158, 162, 166, 170, 174]) (NumPy seed was 0, clip_len=32, frame_sample_rate=4, seg_len=len(vr))
This is the code:
| [] | [
"TAGS\n#region-us \n"
] |
6bfce617fc090535882d58811a6665f44378003f |
This dataset is contains 200 sentences taken from German financial statements. In each sentence financial entities and financial values are annotated. Additionally there is an augmented version of this dataset where the financial entities in each sentence have been replaced by several other financial entities which are hardly/not covered in the original dataset. The augmented version consists of 7287 sentences. | fabianrausch/financial-entities-values-augmented | [
"license:mit",
"region:us"
] | 2022-06-20T08:12:30+00:00 | {"license": "mit"} | 2022-06-20T08:50:29+00:00 | [] | [] | TAGS
#license-mit #region-us
|
This dataset is contains 200 sentences taken from German financial statements. In each sentence financial entities and financial values are annotated. Additionally there is an augmented version of this dataset where the financial entities in each sentence have been replaced by several other financial entities which are hardly/not covered in the original dataset. The augmented version consists of 7287 sentences. | [] | [
"TAGS\n#license-mit #region-us \n"
] |
851374102055782c84f89b1b4e9d128a6568847b |
## Code snippet to visualise the position of the box
```python
import matplotlib.image as img
import matplotlib.pyplot as plt
from datasets import load_dataset
from matplotlib.patches import Rectangle
# Load dataset
ds_name = "SaulLu/Caltech-101"
ds_config = "without_background_category"
ds_without = load_dataset(ds_name, ds_config, use_auth_token=True)
# Extract information for the sample we want to show
index = 100
sample = ds_without["train"][index]
box_coord = sample["annotation"]["box_coord"][0]
img_path = sample["image"].filename
# Create plot
# define Matplotlib figure and axis
fig, ax = plt.subplots()
# plot figure
image = img.imread(img_path)
ax.imshow(image)
# add rectangle to plot
ax.add_patch(
Rectangle((box_coord[2], box_coord[0]), box_coord[3] - box_coord[2], box_coord[1] - box_coord[0], fill=None)
)
# display plot
plt.show()
```
Result:
 | HuggingFaceM4/Caltech-101 | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-20T10:03:15+00:00 | {"license": "cc-by-4.0"} | 2022-07-07T11:24:06+00:00 | [] | [] | TAGS
#license-cc-by-4.0 #region-us
|
## Code snippet to visualise the position of the box
Result:
!Sample with box position | [
"## Code snippet to visualise the position of the box\n\n\n\nResult: \n!Sample with box position"
] | [
"TAGS\n#license-cc-by-4.0 #region-us \n",
"## Code snippet to visualise the position of the box\n\n\n\nResult: \n!Sample with box position"
] |
0bda0ce801be0fa2f464ff845a9d5ceae99aad7d | ## Iris Species Dataset
The Iris dataset was used in R.A. Fisher's classic 1936 paper, The Use of Multiple Measurements in Taxonomic Problems, and can also be found on the UCI Machine Learning Repository.
It includes three iris species with 50 samples each as well as some properties about each flower. One flower species is linearly separable from the other two, but the other two are not linearly separable from each other.
The dataset is taken from [UCI Machine Learning Repository's Kaggle](https://www.kaggle.com/datasets/uciml/iris).
The following description is taken from UCI Machine Learning Repository.
This is perhaps the best known database to be found in the pattern recognition literature. Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other.
Predicted attribute: class of iris plant.
This is an exceedingly simple domain.
This data differs from the data presented in Fishers article (identified by Steve Chadwick, spchadwick '@' espeedaz.net ). The 35th sample should be: 4.9,3.1,1.5,0.2,"Iris-setosa" where the error is in the fourth feature. The 38th sample: 4.9,3.6,1.4,0.1,"Iris-setosa" where the errors are in the second and third features.
Features in this dataset are the following:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris Setosa
- Iris Versicolour
- Iris Virginica
| scikit-learn/iris | [
"license:cc0-1.0",
"region:us"
] | 2022-06-20T13:10:10+00:00 | {"license": "cc0-1.0"} | 2022-06-20T13:17:01+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
| ## Iris Species Dataset
The Iris dataset was used in R.A. Fisher's classic 1936 paper, The Use of Multiple Measurements in Taxonomic Problems, and can also be found on the UCI Machine Learning Repository.
It includes three iris species with 50 samples each as well as some properties about each flower. One flower species is linearly separable from the other two, but the other two are not linearly separable from each other.
The dataset is taken from UCI Machine Learning Repository's Kaggle.
The following description is taken from UCI Machine Learning Repository.
This is perhaps the best known database to be found in the pattern recognition literature. Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other.
Predicted attribute: class of iris plant.
This is an exceedingly simple domain.
This data differs from the data presented in Fishers article (identified by Steve Chadwick, spchadwick '@' URL ). The 35th sample should be: 4.9,3.1,1.5,0.2,"Iris-setosa" where the error is in the fourth feature. The 38th sample: 4.9,3.6,1.4,0.1,"Iris-setosa" where the errors are in the second and third features.
Features in this dataset are the following:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris Setosa
- Iris Versicolour
- Iris Virginica
| [] | [
"TAGS\n#license-cc0-1.0 #region-us \n"
] |
e41c086f1614397ce7a5660980aac421047cef5e | ## Breast Cancer Wisconsin Diagnostic Dataset
Following description was retrieved from [breast cancer dataset on UCI machine learning repository](https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)).
Features are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. A few of the images can be found at [here](https://pages.cs.wisc.edu/~street/images/).
Separating plane described above was obtained using Multisurface Method-Tree (MSM-T), a classification method which uses linear programming to construct a decision tree. Relevant features were selected using an exhaustive search in the space of 1-4 features and 1-3 separating planes.
The actual linear program used to obtain the separating plane in the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: "Robust Linear Programming Discrimination of Two Linearly Inseparable Sets", Optimization Methods and Software 1, 1992, 23-34].
Attribute Information:
- ID number
- Diagnosis (M = malignant, B = benign)
Ten real-valued features are computed for each cell nucleus:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
| scikit-learn/breast-cancer-wisconsin | [
"license:cc-by-sa-4.0",
"region:us"
] | 2022-06-20T13:22:00+00:00 | {"license": "cc-by-sa-4.0"} | 2022-06-20T13:28:58+00:00 | [] | [] | TAGS
#license-cc-by-sa-4.0 #region-us
| ## Breast Cancer Wisconsin Diagnostic Dataset
Following description was retrieved from breast cancer dataset on UCI machine learning repository).
Features are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. A few of the images can be found at here.
Separating plane described above was obtained using Multisurface Method-Tree (MSM-T), a classification method which uses linear programming to construct a decision tree. Relevant features were selected using an exhaustive search in the space of 1-4 features and 1-3 separating planes.
The actual linear program used to obtain the separating plane in the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: "Robust Linear Programming Discrimination of Two Linearly Inseparable Sets", Optimization Methods and Software 1, 1992, 23-34].
Attribute Information:
- ID number
- Diagnosis (M = malignant, B = benign)
Ten real-valued features are computed for each cell nucleus:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
| [
"## Breast Cancer Wisconsin Diagnostic Dataset\n\nFollowing description was retrieved from breast cancer dataset on UCI machine learning repository).\n\nFeatures are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. A few of the images can be found at here.\n\nSeparating plane described above was obtained using Multisurface Method-Tree (MSM-T), a classification method which uses linear programming to construct a decision tree. Relevant features were selected using an exhaustive search in the space of 1-4 features and 1-3 separating planes.\n\nThe actual linear program used to obtain the separating plane in the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: \"Robust Linear Programming Discrimination of Two Linearly Inseparable Sets\", Optimization Methods and Software 1, 1992, 23-34].\n\nAttribute Information:\n\n- ID number\n- Diagnosis (M = malignant, B = benign)\n\nTen real-valued features are computed for each cell nucleus:\n\n- radius (mean of distances from center to points on the perimeter)\n- texture (standard deviation of gray-scale values)\n- perimeter\n- area\n- smoothness (local variation in radius lengths)\n- compactness (perimeter^2 / area - 1.0)\n- concavity (severity of concave portions of the contour)\n- concave points (number of concave portions of the contour)\n- symmetry\n- fractal dimension (\"coastline approximation\" - 1)"
] | [
"TAGS\n#license-cc-by-sa-4.0 #region-us \n",
"## Breast Cancer Wisconsin Diagnostic Dataset\n\nFollowing description was retrieved from breast cancer dataset on UCI machine learning repository).\n\nFeatures are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. A few of the images can be found at here.\n\nSeparating plane described above was obtained using Multisurface Method-Tree (MSM-T), a classification method which uses linear programming to construct a decision tree. Relevant features were selected using an exhaustive search in the space of 1-4 features and 1-3 separating planes.\n\nThe actual linear program used to obtain the separating plane in the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: \"Robust Linear Programming Discrimination of Two Linearly Inseparable Sets\", Optimization Methods and Software 1, 1992, 23-34].\n\nAttribute Information:\n\n- ID number\n- Diagnosis (M = malignant, B = benign)\n\nTen real-valued features are computed for each cell nucleus:\n\n- radius (mean of distances from center to points on the perimeter)\n- texture (standard deviation of gray-scale values)\n- perimeter\n- area\n- smoothness (local variation in radius lengths)\n- compactness (perimeter^2 / area - 1.0)\n- concavity (severity of concave portions of the contour)\n- concave points (number of concave portions of the contour)\n- symmetry\n- fractal dimension (\"coastline approximation\" - 1)"
] |
b117dd2aa2e83a93034457b51702431582f0523e |
# Dataset description
This dataset was created for fine-tuning the model [robbert-base-v2-NER-NL-legislation-refs](https://huggingface.co/romjansen/robbert-base-v2-NER-NL-legislation-refs) and consists of 512 token long examples which each contain one or more legislation references. These examples were created from a weakly labelled corpus of Dutch case law which was scraped from [Linked Data Overheid](https://linkeddata.overheid.nl/), pre-tokenized and labelled ([biluo_tags_from_offsets](https://spacy.io/api/top-level#biluo_tags_from_offsets)) through [spaCy](https://spacy.io/) and further tokenized through applying Hugging Face's [AutoTokenizer.from_pretrained()](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoTokenizer.from_pretrained) for [pdelobelle/robbert-v2-dutch-base](https://huggingface.co/pdelobelle/robbert-v2-dutch-base)'s tokenizer. | romjansen/robbert-base-v2-NER-NL-legislation-refs-data | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"region:us"
] | 2022-06-20T13:29:28+00:00 | {"multilinguality": ["monolingual"], "task_categories": ["token-classification"], "task_ids": ["named-entity-recognition"], "train-eval-index": [{"task": "token-classification", "task_id": "entity_extraction", "splits": {"train_split": "train", "eval_split": "test", "val_split": "validation"}, "col_mapping": {"tokens": "tokens", "ner_tags": "tags"}, "metrics": [{"type": "seqeval", "name": "seqeval"}]}]} | 2022-06-20T13:30:40+00:00 | [] | [] | TAGS
#task_categories-token-classification #task_ids-named-entity-recognition #multilinguality-monolingual #region-us
|
# Dataset description
This dataset was created for fine-tuning the model robbert-base-v2-NER-NL-legislation-refs and consists of 512 token long examples which each contain one or more legislation references. These examples were created from a weakly labelled corpus of Dutch case law which was scraped from Linked Data Overheid, pre-tokenized and labelled (biluo_tags_from_offsets) through spaCy and further tokenized through applying Hugging Face's AutoTokenizer.from_pretrained() for pdelobelle/robbert-v2-dutch-base's tokenizer. | [
"# Dataset description\n \nThis dataset was created for fine-tuning the model robbert-base-v2-NER-NL-legislation-refs and consists of 512 token long examples which each contain one or more legislation references. These examples were created from a weakly labelled corpus of Dutch case law which was scraped from Linked Data Overheid, pre-tokenized and labelled (biluo_tags_from_offsets) through spaCy and further tokenized through applying Hugging Face's AutoTokenizer.from_pretrained() for pdelobelle/robbert-v2-dutch-base's tokenizer."
] | [
"TAGS\n#task_categories-token-classification #task_ids-named-entity-recognition #multilinguality-monolingual #region-us \n",
"# Dataset description\n \nThis dataset was created for fine-tuning the model robbert-base-v2-NER-NL-legislation-refs and consists of 512 token long examples which each contain one or more legislation references. These examples were created from a weakly labelled corpus of Dutch case law which was scraped from Linked Data Overheid, pre-tokenized and labelled (biluo_tags_from_offsets) through spaCy and further tokenized through applying Hugging Face's AutoTokenizer.from_pretrained() for pdelobelle/robbert-v2-dutch-base's tokenizer."
] |
fbeef6ec0e6fd88a5028b94683144000a6b380d5 | ## Adult Census Income Dataset
The following was retrieved from [UCI machine learning repository](https://archive.ics.uci.edu/ml/datasets/adult).
This data was extracted from the 1994 Census bureau database by Ronny Kohavi and Barry Becker (Data Mining and Visualization, Silicon Graphics). A set of reasonably clean records was extracted using the following conditions: ((AAGE>16) && (AGI>100) && (AFNLWGT>1) && (HRSWK>0)). The prediction task is to determine whether a person makes over $50K a year.
**Description of fnlwgt (final weight)**
The weights on the Current Population Survey (CPS) files are controlled to independent estimates of the civilian noninstitutional population of the US. These are prepared monthly for us by Population Division here at the Census Bureau. We use 3 sets of controls. These are:
- A single cell estimate of the population 16+ for each state.
- Controls for Hispanic Origin by age and sex.
- Controls by Race, age and sex.
We use all three sets of controls in our weighting program and "rake" through them 6 times so that by the end we come back to all the controls we used. The term estimate refers to population totals derived from CPS by creating "weighted tallies" of any specified socio-economic characteristics of the population. People with similar demographic characteristics should have similar weights. There is one important caveat to remember about this statement. That is that since the CPS sample is actually a collection of 51 state samples, each with its own probability of selection, the statement only applies within state. | scikit-learn/adult-census-income | [
"license:cc0-1.0",
"region:us"
] | 2022-06-20T13:33:51+00:00 | {"license": "cc0-1.0"} | 2022-06-20T13:46:43+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
| ## Adult Census Income Dataset
The following was retrieved from UCI machine learning repository.
This data was extracted from the 1994 Census bureau database by Ronny Kohavi and Barry Becker (Data Mining and Visualization, Silicon Graphics). A set of reasonably clean records was extracted using the following conditions: ((AAGE>16) && (AGI>100) && (AFNLWGT>1) && (HRSWK>0)). The prediction task is to determine whether a person makes over $50K a year.
Description of fnlwgt (final weight)
The weights on the Current Population Survey (CPS) files are controlled to independent estimates of the civilian noninstitutional population of the US. These are prepared monthly for us by Population Division here at the Census Bureau. We use 3 sets of controls. These are:
- A single cell estimate of the population 16+ for each state.
- Controls for Hispanic Origin by age and sex.
- Controls by Race, age and sex.
We use all three sets of controls in our weighting program and "rake" through them 6 times so that by the end we come back to all the controls we used. The term estimate refers to population totals derived from CPS by creating "weighted tallies" of any specified socio-economic characteristics of the population. People with similar demographic characteristics should have similar weights. There is one important caveat to remember about this statement. That is that since the CPS sample is actually a collection of 51 state samples, each with its own probability of selection, the statement only applies within state. | [
"## Adult Census Income Dataset\nThe following was retrieved from UCI machine learning repository.\n\nThis data was extracted from the 1994 Census bureau database by Ronny Kohavi and Barry Becker (Data Mining and Visualization, Silicon Graphics). A set of reasonably clean records was extracted using the following conditions: ((AAGE>16) && (AGI>100) && (AFNLWGT>1) && (HRSWK>0)). The prediction task is to determine whether a person makes over $50K a year.\n\nDescription of fnlwgt (final weight)\n\nThe weights on the Current Population Survey (CPS) files are controlled to independent estimates of the civilian noninstitutional population of the US. These are prepared monthly for us by Population Division here at the Census Bureau. We use 3 sets of controls. These are:\n\n- A single cell estimate of the population 16+ for each state.\n- Controls for Hispanic Origin by age and sex.\n- Controls by Race, age and sex.\n\nWe use all three sets of controls in our weighting program and \"rake\" through them 6 times so that by the end we come back to all the controls we used. The term estimate refers to population totals derived from CPS by creating \"weighted tallies\" of any specified socio-economic characteristics of the population. People with similar demographic characteristics should have similar weights. There is one important caveat to remember about this statement. That is that since the CPS sample is actually a collection of 51 state samples, each with its own probability of selection, the statement only applies within state."
] | [
"TAGS\n#license-cc0-1.0 #region-us \n",
"## Adult Census Income Dataset\nThe following was retrieved from UCI machine learning repository.\n\nThis data was extracted from the 1994 Census bureau database by Ronny Kohavi and Barry Becker (Data Mining and Visualization, Silicon Graphics). A set of reasonably clean records was extracted using the following conditions: ((AAGE>16) && (AGI>100) && (AFNLWGT>1) && (HRSWK>0)). The prediction task is to determine whether a person makes over $50K a year.\n\nDescription of fnlwgt (final weight)\n\nThe weights on the Current Population Survey (CPS) files are controlled to independent estimates of the civilian noninstitutional population of the US. These are prepared monthly for us by Population Division here at the Census Bureau. We use 3 sets of controls. These are:\n\n- A single cell estimate of the population 16+ for each state.\n- Controls for Hispanic Origin by age and sex.\n- Controls by Race, age and sex.\n\nWe use all three sets of controls in our weighting program and \"rake\" through them 6 times so that by the end we come back to all the controls we used. The term estimate refers to population totals derived from CPS by creating \"weighted tallies\" of any specified socio-economic characteristics of the population. People with similar demographic characteristics should have similar weights. There is one important caveat to remember about this statement. That is that since the CPS sample is actually a collection of 51 state samples, each with its own probability of selection, the statement only applies within state."
] |
beb7bb2c4e1b6245320773dccbe5e5a281aff9ed | ## Student Alcohol Consumption Dataset
A dataset on social, gender and study data from secondary school students.
Following was retrieved from [UCI machine learning repository](https://www.kaggle.com/datasets/uciml/student-alcohol-consumption).
**Context:**
The data were obtained in a survey of students math and portuguese language courses in secondary school. It contains a lot of interesting social, gender and study information about students. You can use it for some EDA or try to predict students final grade.
**Content:**
Attributes for both student-mat.csv (Math course) and student-por.csv (Portuguese language course) datasets:
- school - student's school (binary: 'GP' - Gabriel Pereira or 'MS' - Mousinho da Silveira)
- sex - student's sex (binary: 'F' - female or 'M' - male)
- age - student's age (numeric: from 15 to 22)
- address - student's home address type (binary: 'U' - urban or 'R' - rural)
- famsize - family size (binary: 'LE3' - less or equal to 3 or 'GT3' - greater than 3)
- Pstatus - parent's cohabitation status (binary: 'T' - living together or 'A' - apart)
- Medu - mother's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Fedu - father's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Mjob - mother's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- Fjob - father's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- reason - reason to choose this school (nominal: close to 'home', school 'reputation', 'course' preference or 'other')
- guardian - student's guardian (nominal: 'mother', 'father' or 'other')
- traveltime - home to school travel time (numeric: 1 - <15 min., 2 - 15 to 30 min., 3 - 30 min. to 1 hour, or 4 - >1 hour)
- studytime - weekly study time (numeric: 1 - <2 hours, 2 - 2 to 5 hours, 3 - 5 to 10 hours, or 4 - >10 hours)
- failures - number of past class failures (numeric: n if 1<=n<3, else 4)
- schoolsup - extra educational support (binary: yes or no)
- famsup - family educational support (binary: yes or no)
- paid - extra paid classes within the course subject (Math or Portuguese) (binary: yes or no)
- activities - extra-curricular activities (binary: yes or no)
- nursery - attended nursery school (binary: yes or no)
- higher - wants to take higher education (binary: yes or no)
- internet - Internet access at home (binary: yes or no)
- romantic - with a romantic relationship (binary: yes or no)
- famrel - quality of family relationships (numeric: from 1 - very bad to 5 - excellent)
- freetime - free time after school (numeric: from 1 - very low to 5 - very high)
- goout - going out with friends (numeric: from 1 - very low to 5 - very high)
- Dalc - workday alcohol consumption (numeric: from 1 - very low to 5 - very high)
- Walc - weekend alcohol consumption (numeric: from 1 - very low to 5 - very high)
- health - current health status (numeric: from 1 - very bad to 5 - very good)
- absences - number of school absences (numeric: from 0 to 93)
These grades are related with the course subject, Math or Portuguese:
- G1 - first period grade (numeric: from 0 to 20)
- G2 - second period grade (numeric: from 0 to 20)
- G3 - final grade (numeric: from 0 to 20, output target)
**Additional note:** there are several (382) students that belong to both datasets.
These students can be identified by searching for identical attributes that characterize each student, as shown in the annexed R file. | scikit-learn/student-alcohol-consumption | [
"license:cc0-1.0",
"region:us"
] | 2022-06-20T13:49:55+00:00 | {"license": "cc0-1.0"} | 2022-06-20T13:53:46+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
| ## Student Alcohol Consumption Dataset
A dataset on social, gender and study data from secondary school students.
Following was retrieved from UCI machine learning repository.
Context:
The data were obtained in a survey of students math and portuguese language courses in secondary school. It contains a lot of interesting social, gender and study information about students. You can use it for some EDA or try to predict students final grade.
Content:
Attributes for both URL (Math course) and URL (Portuguese language course) datasets:
- school - student's school (binary: 'GP' - Gabriel Pereira or 'MS' - Mousinho da Silveira)
- sex - student's sex (binary: 'F' - female or 'M' - male)
- age - student's age (numeric: from 15 to 22)
- address - student's home address type (binary: 'U' - urban or 'R' - rural)
- famsize - family size (binary: 'LE3' - less or equal to 3 or 'GT3' - greater than 3)
- Pstatus - parent's cohabitation status (binary: 'T' - living together or 'A' - apart)
- Medu - mother's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Fedu - father's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Mjob - mother's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- Fjob - father's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- reason - reason to choose this school (nominal: close to 'home', school 'reputation', 'course' preference or 'other')
- guardian - student's guardian (nominal: 'mother', 'father' or 'other')
- traveltime - home to school travel time (numeric: 1 - <15 min., 2 - 15 to 30 min., 3 - 30 min. to 1 hour, or 4 - >1 hour)
- studytime - weekly study time (numeric: 1 - <2 hours, 2 - 2 to 5 hours, 3 - 5 to 10 hours, or 4 - >10 hours)
- failures - number of past class failures (numeric: n if 1<=n<3, else 4)
- schoolsup - extra educational support (binary: yes or no)
- famsup - family educational support (binary: yes or no)
- paid - extra paid classes within the course subject (Math or Portuguese) (binary: yes or no)
- activities - extra-curricular activities (binary: yes or no)
- nursery - attended nursery school (binary: yes or no)
- higher - wants to take higher education (binary: yes or no)
- internet - Internet access at home (binary: yes or no)
- romantic - with a romantic relationship (binary: yes or no)
- famrel - quality of family relationships (numeric: from 1 - very bad to 5 - excellent)
- freetime - free time after school (numeric: from 1 - very low to 5 - very high)
- goout - going out with friends (numeric: from 1 - very low to 5 - very high)
- Dalc - workday alcohol consumption (numeric: from 1 - very low to 5 - very high)
- Walc - weekend alcohol consumption (numeric: from 1 - very low to 5 - very high)
- health - current health status (numeric: from 1 - very bad to 5 - very good)
- absences - number of school absences (numeric: from 0 to 93)
These grades are related with the course subject, Math or Portuguese:
- G1 - first period grade (numeric: from 0 to 20)
- G2 - second period grade (numeric: from 0 to 20)
- G3 - final grade (numeric: from 0 to 20, output target)
Additional note: there are several (382) students that belong to both datasets.
These students can be identified by searching for identical attributes that characterize each student, as shown in the annexed R file. | [] | [
"TAGS\n#license-cc0-1.0 #region-us \n"
] |
f809522649eaf948ad40a11ed575c4bb4d4460c1 | ## Default of Credit Card Clients Dataset
The following was retrieved from [UCI machine learning repository](https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients).
**Dataset Information**
This dataset contains information on default payments, demographic factors, credit data, history of payment, and bill statements of credit card clients in Taiwan from April 2005 to September 2005.
**Content**
There are 25 variables:
- ID: ID of each client
- LIMIT_BAL: Amount of given credit in NT dollars (includes individual and family/supplementary credit
- SEX: Gender (1=male, 2=female)
- EDUCATION: (1=graduate school, 2=university, 3=high school, 4=others, 5=unknown, 6=unknown)
- MARRIAGE: Marital status (1=married, 2=single, 3=others)
- AGE: Age in years
- PAY_0: Repayment status in September, 2005 (-1=pay duly, 1=payment delay for one month, 2=payment delay for two months, … 8=payment delay for eight months, 9=payment delay for nine months and above)
- PAY_2: Repayment status in August, 2005 (scale same as above)
- PAY_3: Repayment status in July, 2005 (scale same as above)
- PAY_4: Repayment status in June, 2005 (scale same as above)
- PAY_5: Repayment status in May, 2005 (scale same as above)
- PAY_6: Repayment status in April, 2005 (scale same as above)
- BILL_AMT1: Amount of bill statement in September, 2005 (NT dollar)
- BILL_AMT2: Amount of bill statement in August, 2005 (NT dollar)
- BILL_AMT3: Amount of bill statement in July, 2005 (NT dollar)
- BILL_AMT4: Amount of bill statement in June, 2005 (NT dollar)
- BILL_AMT5: Amount of bill statement in May, 2005 (NT dollar)
- BILL_AMT6: Amount of bill statement in April, 2005 (NT dollar)
- PAY_AMT1: Amount of previous payment in September, 2005 (NT dollar)
- PAY_AMT2: Amount of previous payment in August, 2005 (NT dollar)
- PAY_AMT3: Amount of previous payment in July, 2005 (NT dollar)
- PAY_AMT4: Amount of previous payment in June, 2005 (NT dollar)
- PAY_AMT5: Amount of previous payment in May, 2005 (NT dollar)
- PAY_AMT6: Amount of previous payment in April, 2005 (NT dollar)
- default.payment.next.month: Default payment (1=yes, 0=no)
**Inspiration**
Some ideas for exploration:
How does the probability of default payment vary by categories of different demographic variables?
Which variables are the strongest predictors of default payment?
**Acknowledgements**
Any publications based on this dataset should acknowledge the following:
Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
| scikit-learn/credit-card-clients | [
"license:cc0-1.0",
"region:us"
] | 2022-06-20T13:57:10+00:00 | {"license": "cc0-1.0"} | 2022-06-20T14:42:14+00:00 | [] | [] | TAGS
#license-cc0-1.0 #region-us
| ## Default of Credit Card Clients Dataset
The following was retrieved from UCI machine learning repository.
Dataset Information
This dataset contains information on default payments, demographic factors, credit data, history of payment, and bill statements of credit card clients in Taiwan from April 2005 to September 2005.
Content
There are 25 variables:
- ID: ID of each client
- LIMIT_BAL: Amount of given credit in NT dollars (includes individual and family/supplementary credit
- SEX: Gender (1=male, 2=female)
- EDUCATION: (1=graduate school, 2=university, 3=high school, 4=others, 5=unknown, 6=unknown)
- MARRIAGE: Marital status (1=married, 2=single, 3=others)
- AGE: Age in years
- PAY_0: Repayment status in September, 2005 (-1=pay duly, 1=payment delay for one month, 2=payment delay for two months, … 8=payment delay for eight months, 9=payment delay for nine months and above)
- PAY_2: Repayment status in August, 2005 (scale same as above)
- PAY_3: Repayment status in July, 2005 (scale same as above)
- PAY_4: Repayment status in June, 2005 (scale same as above)
- PAY_5: Repayment status in May, 2005 (scale same as above)
- PAY_6: Repayment status in April, 2005 (scale same as above)
- BILL_AMT1: Amount of bill statement in September, 2005 (NT dollar)
- BILL_AMT2: Amount of bill statement in August, 2005 (NT dollar)
- BILL_AMT3: Amount of bill statement in July, 2005 (NT dollar)
- BILL_AMT4: Amount of bill statement in June, 2005 (NT dollar)
- BILL_AMT5: Amount of bill statement in May, 2005 (NT dollar)
- BILL_AMT6: Amount of bill statement in April, 2005 (NT dollar)
- PAY_AMT1: Amount of previous payment in September, 2005 (NT dollar)
- PAY_AMT2: Amount of previous payment in August, 2005 (NT dollar)
- PAY_AMT3: Amount of previous payment in July, 2005 (NT dollar)
- PAY_AMT4: Amount of previous payment in June, 2005 (NT dollar)
- PAY_AMT5: Amount of previous payment in May, 2005 (NT dollar)
- PAY_AMT6: Amount of previous payment in April, 2005 (NT dollar)
- URL: Default payment (1=yes, 0=no)
Inspiration
Some ideas for exploration:
How does the probability of default payment vary by categories of different demographic variables?
Which variables are the strongest predictors of default payment?
Acknowledgements
Any publications based on this dataset should acknowledge the following:
Lichman, M. (2013). UCI Machine Learning Repository [URL Irvine, CA: University of California, School of Information and Computer Science.
| [] | [
"TAGS\n#license-cc0-1.0 #region-us \n"
] |
b948f584042b95d8572420848e8e88e0f2f76552 |
# Dataset Card for "huggingartists/headie-one"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [About](#about)
## Dataset Description
- **Homepage:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Repository:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of the generated dataset:** 0.679898 MB
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/f803e312226f5034989742ff1fb4b583.1000x1000x1.jpg')">
</div>
</div>
<a href="https://huggingface.co/huggingartists/headie-one">
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
</a>
<div style="text-align: center; font-size: 16px; font-weight: 800">Headie One</div>
<a href="https://genius.com/artists/headie-one">
<div style="text-align: center; font-size: 14px;">@headie-one</div>
</a>
</div>
### Dataset Summary
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
Model is available [here](https://huggingface.co/huggingartists/headie-one).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
en
## How to use
How to load this dataset directly with the datasets library:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/headie-one")
```
## Dataset Structure
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "Look, I was gonna go easy on you\nNot to hurt your feelings\nBut I'm only going to get this one chance\nSomething's wrong, I can feel it..."
}
```
### Data Fields
The data fields are the same among all splits.
- `text`: a `string` feature.
### Data Splits
| train |validation|test|
|------:|---------:|---:|
|224| -| -|
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
```python
from datasets import load_dataset, Dataset, DatasetDict
import numpy as np
datasets = load_dataset("huggingartists/headie-one")
train_percentage = 0.9
validation_percentage = 0.07
test_percentage = 0.03
train, validation, test = np.split(datasets['train']['text'], [int(len(datasets['train']['text'])*train_percentage), int(len(datasets['train']['text'])*(train_percentage + validation_percentage))])
datasets = DatasetDict(
{
'train': Dataset.from_dict({'text': list(train)}),
'validation': Dataset.from_dict({'text': list(validation)}),
'test': Dataset.from_dict({'text': list(test)})
}
)
```
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{huggingartists,
author={Aleksey Korshuk}
year=2022
}
```
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
| huggingartists/headie-one | [
"language:en",
"huggingartists",
"lyrics",
"region:us"
] | 2022-06-20T14:09:53+00:00 | {"language": ["en"], "tags": ["huggingartists", "lyrics"]} | 2022-10-25T09:32:29+00:00 | [] | [
"en"
] | TAGS
#language-English #huggingartists #lyrics #region-us
| Dataset Card for "huggingartists/headie-one"
============================================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* How to use
* Dataset Structure
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
* About
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Point of Contact:
* Size of the generated dataset: 0.679898 MB
HuggingArtists Model
Headie One
[@headie-one](URL
<div style=)
### Dataset Summary
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
Model is available here.
### Supported Tasks and Leaderboards
### Languages
en
How to use
----------
How to load this dataset directly with the datasets library:
Dataset Structure
-----------------
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all splits.
* 'text': a 'string' feature.
### Data Splits
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
About
-----
*Built by Aleksey Korshuk*

For more details, visit the project repository.
\n\n\nFor more details, visit the project repository.\n\n\n\n\n\nFor more details, visit the project repository.\n\n\n:
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=8, names=['I am not sure how X will interpret Y\u2019s answer', 'In the middle, neither yes nor no', 'No', 'Other', 'Probably no', 'Probably yes / sometimes yes', 'Yes', 'Yes, subject to some conditions'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 25218 |
| valid | 6307 |
| Siddish/autotrain-data-yes-or-no-classifier-on-circa | [
"task_categories:text-classification",
"language:en",
"region:us"
] | 2022-06-20T14:40:14+00:00 | {"language": ["en"], "task_categories": ["text-classification"]} | 2022-10-25T09:32:35+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #language-English #region-us
| AutoTrain Dataset for project: yes-or-no-classifier-on-circa
============================================================
Dataset Descritpion
-------------------
This dataset has been automatically processed by AutoTrain for project yes-or-no-classifier-on-circa.
### Languages
The BCP-47 code for the dataset's language is en.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-text-classification #language-English #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
dd1c513551d0f5f6f7c2caa85bf538352f6b87d8 |
# Try to include an iframe
from observable:
<iframe width="100%" height="635" frameborder="0"
src="https://observablehq.com/embed/@d3/sortable-bar-chart?cell=viewof+order&cell=chart"></iframe>
from an HF space:
<iframe src="https://hf.space/embed/YoannLemesle/CLIPictionary/+?__theme=system" data-src="https://hf.space/embed/YoannLemesle/CLIPictionary/+" data-sdk="gradio" title="Gradio app" class="container p-0 flex-grow overflow-hidden space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads" scrolling="no" id="iFrameResizer0" style="overflow: hidden; height: 725px;"></iframe> | severo/fix-401 | [
"region:us"
] | 2022-06-20T15:04:10+00:00 | {"viewer": false} | 2022-06-24T10:45:48+00:00 | [] | [] | TAGS
#region-us
|
# Try to include an iframe
from observable:
<iframe width="100%" height="635" frameborder="0"
src="URL
from an HF space:
<iframe src="URL data-src="URL data-sdk="gradio" title="Gradio app" class="container p-0 flex-grow overflow-hidden space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads" scrolling="no" id="iFrameResizer0" style="overflow: hidden; height: 725px;"></iframe> | [
"# Try to include an iframe\n\nfrom observable:\n\n<iframe width=\"100%\" height=\"635\" frameborder=\"0\"\n src=\"URL\n\n\nfrom an HF space:\n \n<iframe src=\"URL data-src=\"URL data-sdk=\"gradio\" title=\"Gradio app\" class=\"container p-0 flex-grow overflow-hidden space-iframe\" allow=\"accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking\" sandbox=\"allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads\" scrolling=\"no\" id=\"iFrameResizer0\" style=\"overflow: hidden; height: 725px;\"></iframe>"
] | [
"TAGS\n#region-us \n",
"# Try to include an iframe\n\nfrom observable:\n\n<iframe width=\"100%\" height=\"635\" frameborder=\"0\"\n src=\"URL\n\n\nfrom an HF space:\n \n<iframe src=\"URL data-src=\"URL data-sdk=\"gradio\" title=\"Gradio app\" class=\"container p-0 flex-grow overflow-hidden space-iframe\" allow=\"accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking\" sandbox=\"allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads\" scrolling=\"no\" id=\"iFrameResizer0\" style=\"overflow: hidden; height: 725px;\"></iframe>"
] |
ce5e8e8c81bb23fbcc915652d0ce0721ebf285cd |
## Code snippet to visualise the position of the box
```python
import matplotlib.image as img
import matplotlib.pyplot as plt
from datasets import load_dataset
from matplotlib.patches import Rectangle
# Load dataset
ds_name = "SaulLu/Stanford-Cars"
ds = load_dataset(ds_name, use_auth_token=True)
# Extract information for the sample we want to show
index = 100
sample = ds["train"][index]
box_coord = sample["bbox"][0]
img_path = sample["image"].filename
# Create plot
# define Matplotlib figure and axis
fig, ax = plt.subplots()
# plot figure
image = img.imread(img_path)
ax.imshow(image)
# add rectangle to plot
ax.add_patch(
Rectangle((box_coord[2], box_coord[0]), box_coord[3] - box_coord[2], box_coord[1] - box_coord[0], fill=None)
)
# display plot
plt.show()
```
Result:
 | HuggingFaceM4/Stanford-Cars | [
"region:us"
] | 2022-06-20T16:46:35+00:00 | {} | 2022-06-21T14:58:52+00:00 | [] | [] | TAGS
#region-us
|
## Code snippet to visualise the position of the box
Result:
!Sample with box position | [
"## Code snippet to visualise the position of the box\n\n\n\nResult: \n!Sample with box position"
] | [
"TAGS\n#region-us \n",
"## Code snippet to visualise the position of the box\n\n\n\nResult: \n!Sample with box position"
] |
f5ae276ea803a96fc923ea583f3f4f048117336c | ```python
from datasets import load_dataset, DatasetDict
ds = load_dataset("anton-l/earnings22_robust", split="test")
print(ds)
print("\n", "Split to ==>", "\n")
# split train 90%/ dev 5% / test 5%
# split twice and combine
train_devtest = ds.train_test_split(shuffle=True, seed=1, test_size=0.1)
dev_test = train_devtest['test'].train_test_split(shuffle=True, seed=1, test_size=0.5)
ds_train_dev_test = DatasetDict({'train': train_devtest['train'], 'validation': dev_test['train'], 'test': dev_test['test']})
print(ds_train_dev_test)
ds_train_dev_test.push_to_hub("sanchit-gandhi/earnings22_robust_split")
```
```
Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts'],
num_rows: 56873
})
Split to ==>
DatasetDict({
train: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts'],
num_rows: 51185
})
validation: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts'],
num_rows: 2844
})
test: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts'],
num_rows: 2844
})
})
``` | sanchit-gandhi/earnings22_robust_split | [
"region:us"
] | 2022-06-20T17:49:31+00:00 | {} | 2022-06-21T13:08:18+00:00 | [] | [] | TAGS
#region-us
| [] | [
"TAGS\n#region-us \n"
] |
|
9880353aa4e35baf9e6a6d06ace7f081e8f8f4b7 |
# Dataset Card for the Dog 🐶 vs. Food 🍔 (a.k.a. Dog Food) Dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**: https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-
- **Repository:** : https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-
- **Paper:** : N/A
- **Leaderboard:**: N/A
- **Point of Contact:**: @sasha
### Dataset Summary
This is a dataset for binary image classification, between 'dog' and 'food' classes.
The 'dog' class contains images of dogs that look like fried chicken and some that look like images of muffins, and the 'food' class contains images of (you guessed it) fried chicken and muffins 😋
### Supported Tasks and Leaderboards
TBC
### Languages
The labels are in English (['dog', 'food'])
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```
{
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=300x470 at 0x7F176094EF28>,
'label': 0}
}
```
### Data Fields
- img: A `PIL.JpegImageFile` object containing the 300x470. image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- label: 0-1 with the following correspondence
0 dog
1 food
### Data Splits
Train (2100 images) and Test (900 images)
## Dataset Creation
### Curation Rationale
N/A
### Source Data
#### Initial Data Collection and Normalization
This dataset was taken from the [qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins?](https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-) Github repository, merging the 'chicken' and 'muffin' categories into a single 'food' category, and randomly splitting 10% of the data for validation.
### Annotations
#### Annotation process
This data was scraped from the internet and annotated based on the query words.
### Personal and Sensitive Information
N/A
## Considerations for Using the Data
### Social Impact of Dataset
N/A
### Discussion of Biases
This dataset is imbalanced -- it has more images of food (2000) compared to dogs (1000), due to the original labeling. This should be taken into account when evaluating models.
### Other Known Limitations
N/A
## Additional Information
### Dataset Curators
This dataset was created by @lanceyjt, @yl3829, @wesleytao, @qw2243c and @asyouhaveknown
### Licensing Information
No information is indicated on the original [github repository](https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-).
### Citation Information
N/A
### Contributions
Thanks to [@sashavor](https://github.com/sashavor) for adding this dataset.
| sasha/dog-food | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:unknown",
"region:us"
] | 2022-06-20T17:54:18+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["en"], "license": ["unknown"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "pretty_name": "Dog vs Food Dataset"} | 2022-10-25T09:32:37+00:00 | [] | [
"en"
] | TAGS
#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-unknown #region-us
|
# Dataset Card for the Dog vs. Food (a.k.a. Dog Food) Dataset
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:: URL
- Repository: : URL
- Paper: : N/A
- Leaderboard:: N/A
- Point of Contact:: @sasha
### Dataset Summary
This is a dataset for binary image classification, between 'dog' and 'food' classes.
The 'dog' class contains images of dogs that look like fried chicken and some that look like images of muffins, and the 'food' class contains images of (you guessed it) fried chicken and muffins
### Supported Tasks and Leaderboards
TBC
### Languages
The labels are in English (['dog', 'food'])
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
### Data Fields
- img: A 'PIL.JpegImageFile' object containing the 300x470. image. Note that when accessing the image column: 'dataset[0]["image"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '"image"' column, *i.e.* 'dataset[0]["image"]' should always be preferred over 'dataset["image"][0]'
- label: 0-1 with the following correspondence
0 dog
1 food
### Data Splits
Train (2100 images) and Test (900 images)
## Dataset Creation
### Curation Rationale
N/A
### Source Data
#### Initial Data Collection and Normalization
This dataset was taken from the qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins? Github repository, merging the 'chicken' and 'muffin' categories into a single 'food' category, and randomly splitting 10% of the data for validation.
### Annotations
#### Annotation process
This data was scraped from the internet and annotated based on the query words.
### Personal and Sensitive Information
N/A
## Considerations for Using the Data
### Social Impact of Dataset
N/A
### Discussion of Biases
This dataset is imbalanced -- it has more images of food (2000) compared to dogs (1000), due to the original labeling. This should be taken into account when evaluating models.
### Other Known Limitations
N/A
## Additional Information
### Dataset Curators
This dataset was created by @lanceyjt, @yl3829, @wesleytao, @qw2243c and @asyouhaveknown
### Licensing Information
No information is indicated on the original github repository.
N/A
### Contributions
Thanks to @sashavor for adding this dataset.
| [
"# Dataset Card for the Dog vs. Food (a.k.a. Dog Food) Dataset",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:: URL\n- Repository: : URL\n- Paper: : N/A\n- Leaderboard:: N/A\n- Point of Contact:: @sasha",
"### Dataset Summary\n\nThis is a dataset for binary image classification, between 'dog' and 'food' classes. \n\nThe 'dog' class contains images of dogs that look like fried chicken and some that look like images of muffins, and the 'food' class contains images of (you guessed it) fried chicken and muffins",
"### Supported Tasks and Leaderboards\n\nTBC",
"### Languages\n\nThe labels are in English (['dog', 'food'])",
"## Dataset Structure",
"### Data Instances\nA sample from the training set is provided below:",
"### Data Fields\n\n\n- img: A 'PIL.JpegImageFile' object containing the 300x470. image. Note that when accessing the image column: 'dataset[0][\"image\"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '\"image\"' column, *i.e.* 'dataset[0][\"image\"]' should always be preferred over 'dataset[\"image\"][0]'\n- label: 0-1 with the following correspondence\n 0 dog\n 1 food",
"### Data Splits\n\nTrain (2100 images) and Test (900 images)",
"## Dataset Creation",
"### Curation Rationale\n\nN/A",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThis dataset was taken from the qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins? Github repository, merging the 'chicken' and 'muffin' categories into a single 'food' category, and randomly splitting 10% of the data for validation.",
"### Annotations",
"#### Annotation process\n\nThis data was scraped from the internet and annotated based on the query words.",
"### Personal and Sensitive Information\n\nN/A",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nN/A",
"### Discussion of Biases\n\nThis dataset is imbalanced -- it has more images of food (2000) compared to dogs (1000), due to the original labeling. This should be taken into account when evaluating models.",
"### Other Known Limitations\n\nN/A",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was created by @lanceyjt, @yl3829, @wesleytao, @qw2243c and @asyouhaveknown",
"### Licensing Information\n\nNo information is indicated on the original github repository.\n\n\n\nN/A",
"### Contributions\n\nThanks to @sashavor for adding this dataset."
] | [
"TAGS\n#task_categories-image-classification #task_ids-multi-class-image-classification #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-unknown #region-us \n",
"# Dataset Card for the Dog vs. Food (a.k.a. Dog Food) Dataset",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:: URL\n- Repository: : URL\n- Paper: : N/A\n- Leaderboard:: N/A\n- Point of Contact:: @sasha",
"### Dataset Summary\n\nThis is a dataset for binary image classification, between 'dog' and 'food' classes. \n\nThe 'dog' class contains images of dogs that look like fried chicken and some that look like images of muffins, and the 'food' class contains images of (you guessed it) fried chicken and muffins",
"### Supported Tasks and Leaderboards\n\nTBC",
"### Languages\n\nThe labels are in English (['dog', 'food'])",
"## Dataset Structure",
"### Data Instances\nA sample from the training set is provided below:",
"### Data Fields\n\n\n- img: A 'PIL.JpegImageFile' object containing the 300x470. image. Note that when accessing the image column: 'dataset[0][\"image\"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '\"image\"' column, *i.e.* 'dataset[0][\"image\"]' should always be preferred over 'dataset[\"image\"][0]'\n- label: 0-1 with the following correspondence\n 0 dog\n 1 food",
"### Data Splits\n\nTrain (2100 images) and Test (900 images)",
"## Dataset Creation",
"### Curation Rationale\n\nN/A",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nThis dataset was taken from the qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins? Github repository, merging the 'chicken' and 'muffin' categories into a single 'food' category, and randomly splitting 10% of the data for validation.",
"### Annotations",
"#### Annotation process\n\nThis data was scraped from the internet and annotated based on the query words.",
"### Personal and Sensitive Information\n\nN/A",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nN/A",
"### Discussion of Biases\n\nThis dataset is imbalanced -- it has more images of food (2000) compared to dogs (1000), due to the original labeling. This should be taken into account when evaluating models.",
"### Other Known Limitations\n\nN/A",
"## Additional Information",
"### Dataset Curators\n\nThis dataset was created by @lanceyjt, @yl3829, @wesleytao, @qw2243c and @asyouhaveknown",
"### Licensing Information\n\nNo information is indicated on the original github repository.\n\n\n\nN/A",
"### Contributions\n\nThanks to @sashavor for adding this dataset."
] |
b89f4b2a94d1795f0ebc7ae4e5928ba86f31616d | This repository contains dataset used in the BPMN-Redrawer project.
The original 663 BPMN models are available on the RePROSitory platform: https://pros.unicam.it:4200/guest/collection/bpmn_redrawer
Additional 165 BPMN models have been designed, and are uploaded here in the BPMN Models folder. Such models have been designed to augment the amount of instances of elements that are rare in the RePROSitory models.
---
license: cc-by-nc-sa-4.0
---
| PROSLab/BPMN-Redrawer-Dataset | [
"region:us"
] | 2022-06-20T18:42:29+00:00 | {} | 2022-06-21T18:38:21+00:00 | [] | [] | TAGS
#region-us
| This repository contains dataset used in the BPMN-Redrawer project.
The original 663 BPMN models are available on the RePROSitory platform: URL
Additional 165 BPMN models have been designed, and are uploaded here in the BPMN Models folder. Such models have been designed to augment the amount of instances of elements that are rare in the RePROSitory models.
---
license: cc-by-nc-sa-4.0
---
| [] | [
"TAGS\n#region-us \n"
] |
e5bfcb48a0f197f77c6a86c1ad914cfc44dfca40 | # Playlist Generator Dataset
This dataset contains three files, used in the [Playlist Generator](https://huggingface.co/spaces/NimaBoscarino/playlist-generator) space. Visit the blog post to learn more about the project: https://huggingface.co/blog/your-first-ml-project
1. `verse-embeddings.pkl` contains Sentence Transformer embeddings for each verse for each song in a private (unreleased) dataset of song lyrics. The embeddings were generated using this model: https://huggingface.co/sentence-transformers/msmarco-MiniLM-L-6-v3
2. `verses.csv` maps each verse to a song ID. The indices in `verse-embeddings.pkl` correspond with the indices in this CSV file.
3. `songs_new.csv` contains information about each song, such as the title, artist, and a link to the album art (if available) | NimaBoscarino/playlist-generator | [
"region:us"
] | 2022-06-20T19:15:15+00:00 | {} | 2022-07-10T18:30:43+00:00 | [] | [] | TAGS
#region-us
| # Playlist Generator Dataset
This dataset contains three files, used in the Playlist Generator space. Visit the blog post to learn more about the project: URL
1. 'URL' contains Sentence Transformer embeddings for each verse for each song in a private (unreleased) dataset of song lyrics. The embeddings were generated using this model: URL
2. 'URL' maps each verse to a song ID. The indices in 'URL' correspond with the indices in this CSV file.
3. 'songs_new.csv' contains information about each song, such as the title, artist, and a link to the album art (if available) | [
"# Playlist Generator Dataset\n\nThis dataset contains three files, used in the Playlist Generator space. Visit the blog post to learn more about the project: URL\n\n1. 'URL' contains Sentence Transformer embeddings for each verse for each song in a private (unreleased) dataset of song lyrics. The embeddings were generated using this model: URL\n2. 'URL' maps each verse to a song ID. The indices in 'URL' correspond with the indices in this CSV file.\n3. 'songs_new.csv' contains information about each song, such as the title, artist, and a link to the album art (if available)"
] | [
"TAGS\n#region-us \n",
"# Playlist Generator Dataset\n\nThis dataset contains three files, used in the Playlist Generator space. Visit the blog post to learn more about the project: URL\n\n1. 'URL' contains Sentence Transformer embeddings for each verse for each song in a private (unreleased) dataset of song lyrics. The embeddings were generated using this model: URL\n2. 'URL' maps each verse to a song ID. The indices in 'URL' correspond with the indices in this CSV file.\n3. 'songs_new.csv' contains information about each song, such as the title, artist, and a link to the album art (if available)"
] |
be6febb761b0b2807687e61e0b5282e459df2fa0 |
# Details
Fact Verification dataset created for [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`) based on Wikipedia edits (revisions).
For more details see: https://github.com/TalSchuster/VitaminC
When using this dataset, please cite the paper:
# BibTeX entry and citation info
```bibtex
@inproceedings{schuster-etal-2021-get,
title = "Get Your Vitamin {C}! Robust Fact Verification with Contrastive Evidence",
author = "Schuster, Tal and
Fisch, Adam and
Barzilay, Regina",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.52",
doi = "10.18653/v1/2021.naacl-main.52",
pages = "624--643",
abstract = "Typical fact verification models use retrieved written evidence to verify claims. Evidence sources, however, often change over time as more information is gathered and revised. In order to adapt, models must be sensitive to subtle differences in supporting evidence. We present VitaminC, a benchmark infused with challenging cases that require fact verification models to discern and adjust to slight factual changes. We collect over 100,000 Wikipedia revisions that modify an underlying fact, and leverage these revisions, together with additional synthetically constructed ones, to create a total of over 400,000 claim-evidence pairs. Unlike previous resources, the examples in VitaminC are contrastive, i.e., they contain evidence pairs that are nearly identical in language and content, with the exception that one supports a given claim while the other does not. We show that training using this design increases robustness{---}improving accuracy by 10{\%} on adversarial fact verification and 6{\%} on adversarial natural language inference (NLI). Moreover, the structure of VitaminC leads us to define additional tasks for fact-checking resources: tagging relevant words in the evidence for verifying the claim, identifying factual revisions, and providing automatic edits via factually consistent text generation.",
}
``` | tals/vitaminc | [
"task_categories:text-classification",
"task_ids:fact-checking",
"task_ids:natural-language-inference",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | 2022-06-21T00:22:38+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-3.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": [], "task_categories": ["text-classification"], "task_ids": ["fact-checking", "natural-language-inference"], "pretty_name": "VitaminC"} | 2022-07-01T18:58:42+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #task_ids-fact-checking #task_ids-natural-language-inference #multilinguality-monolingual #size_categories-100K<n<1M #language-English #license-cc-by-sa-3.0 #region-us
|
# Details
Fact Verification dataset created for Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (Schuster et al., NAACL 21') based on Wikipedia edits (revisions).
For more details see: URL
When using this dataset, please cite the paper:
# BibTeX entry and citation info
| [
"# Details\nFact Verification dataset created for Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (Schuster et al., NAACL 21') based on Wikipedia edits (revisions).\n\nFor more details see: URL\n\nWhen using this dataset, please cite the paper:",
"# BibTeX entry and citation info"
] | [
"TAGS\n#task_categories-text-classification #task_ids-fact-checking #task_ids-natural-language-inference #multilinguality-monolingual #size_categories-100K<n<1M #language-English #license-cc-by-sa-3.0 #region-us \n",
"# Details\nFact Verification dataset created for Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (Schuster et al., NAACL 21') based on Wikipedia edits (revisions).\n\nFor more details see: URL\n\nWhen using this dataset, please cite the paper:",
"# BibTeX entry and citation info"
] |
9234ac0edd75064e324fde8770814ac928c18134 | # MWP-Dataset
English-Sinhala-Tamil Math Word Problem Dataset
## File Structure
- Simple-English.txt -> Simple English Math Word Problems
- Simple-Sinhala.txt -> Simple Sinhala Math Word Problems
- Simple-Tamil.txt -> Simple Tamil Math Word Problems
- Algebraic-English.txt -> Algebraic English Math Word Problems
- Algebraic-Sinhala.txt -> Algebraic Sinhala Math Word Problems
- Algebraic-Tamil.txt -> Algebraic Tamil Math Word Problems
Authors: | NLPC-UOM/MWP_Dataset | [
"task_categories:text-generation",
"language:si",
"language:ta",
"language:en",
"license:mit",
"region:us"
] | 2022-06-21T03:34:56+00:00 | {"language": ["si", "ta", "en"], "license": ["mit"], "task_categories": ["neural-machine-translation", "text-generation"]} | 2022-10-23T05:16:44+00:00 | [] | [
"si",
"ta",
"en"
] | TAGS
#task_categories-text-generation #language-Sinhala #language-Tamil #language-English #license-mit #region-us
| # MWP-Dataset
English-Sinhala-Tamil Math Word Problem Dataset
## File Structure
- URL -> Simple English Math Word Problems
- URL -> Simple Sinhala Math Word Problems
- URL -> Simple Tamil Math Word Problems
- URL -> Algebraic English Math Word Problems
- URL -> Algebraic Sinhala Math Word Problems
- URL -> Algebraic Tamil Math Word Problems
Authors: | [
"# MWP-Dataset\nEnglish-Sinhala-Tamil Math Word Problem Dataset",
"## File Structure\n\n- URL -> Simple English Math Word Problems\n- URL -> Simple Sinhala Math Word Problems\n- URL -> Simple Tamil Math Word Problems\n- URL -> Algebraic English Math Word Problems\n- URL -> Algebraic Sinhala Math Word Problems\n- URL -> Algebraic Tamil Math Word Problems\n\nAuthors:"
] | [
"TAGS\n#task_categories-text-generation #language-Sinhala #language-Tamil #language-English #license-mit #region-us \n",
"# MWP-Dataset\nEnglish-Sinhala-Tamil Math Word Problem Dataset",
"## File Structure\n\n- URL -> Simple English Math Word Problems\n- URL -> Simple Sinhala Math Word Problems\n- URL -> Simple Tamil Math Word Problems\n- URL -> Algebraic English Math Word Problems\n- URL -> Algebraic Sinhala Math Word Problems\n- URL -> Algebraic Tamil Math Word Problems\n\nAuthors:"
] |
7f07e820c69acd028b443745e0c13e1170a5e09d |
# Dataset Card for Nexdata/North_American_English_Speech_Data_by_Mobile_Phone_and_PC
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/33?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The data set contains 302 North American speakers' speech data. The recording contents include phrases and sentences with rich scenes. The valid time is 201 hours. The recording environment is quiet indoor. The recording device includes PC, android cellphone, and iPhone. This data can be used in speech recognition research in North American area.
For more details, please refer to the link: https://www.nexdata.ai/datasets/33?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
North American English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions
| Nexdata/North_American_English_Speech_Data_by_Mobile_Phone_and_PC | [
"region:us"
] | 2022-06-21T05:18:33+00:00 | {"YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-08-31T01:30:23+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Nexdata/North_American_English_Speech_Data_by_Mobile_Phone_and_PC
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
The data set contains 302 North American speakers' speech data. The recording contents include phrases and sentences with rich scenes. The valid time is 201 hours. The recording environment is quiet indoor. The recording device includes PC, android cellphone, and iPhone. This data can be used in speech recognition research in North American area.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
North American English
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commerical License: URL
### Contributions
| [
"# Dataset Card for Nexdata/North_American_English_Speech_Data_by_Mobile_Phone_and_PC",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data set contains 302 North American speakers' speech data. The recording contents include phrases and sentences with rich scenes. The valid time is 201 hours. The recording environment is quiet indoor. The recording device includes PC, android cellphone, and iPhone. This data can be used in speech recognition research in North American area. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nNorth American English",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Nexdata/North_American_English_Speech_Data_by_Mobile_Phone_and_PC",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data set contains 302 North American speakers' speech data. The recording contents include phrases and sentences with rich scenes. The valid time is 201 hours. The recording environment is quiet indoor. The recording device includes PC, android cellphone, and iPhone. This data can be used in speech recognition research in North American area. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nNorth American English",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] |
7803a1ae5064439bbadfaf4e53a8d93824437456 |
# Dataset Card for Nexdata/Mandarin_Conversational_Speech_Data_by_Mobile_Phone_and_Voice_Recorder
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1000?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
1950 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1000?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin Chinese
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Mandarin_Conversational_Speech_Data_by_Mobile_Phone_and_Voice_Recorder | [
"region:us"
] | 2022-06-21T05:24:54+00:00 | {"YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-08-31T01:21:35+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Nexdata/Mandarin_Conversational_Speech_Data_by_Mobile_Phone_and_Voice_Recorder
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
1950 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin Chinese
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commerical License: URL
### Contributions | [
"# Dataset Card for Nexdata/Mandarin_Conversational_Speech_Data_by_Mobile_Phone_and_Voice_Recorder",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\n1950 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nMandarin Chinese",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Nexdata/Mandarin_Conversational_Speech_Data_by_Mobile_Phone_and_Voice_Recorder",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\n1950 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nMandarin Chinese",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommerical License: URL",
"### Contributions"
] |
efbbc8d503ba6223d30111bab60bf1a9bb594d96 | # 1000-Hours-American-English-Conversational-Speech-Data-by-Mobile-Phone
## Description
2000 speakers participated in the recording and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1004?source=Huggingface
## Format
16kHz, 16bit, uncompressed wav, mono channel
## Recording Environment
quiet indoor environment, without echo
## Recording Content
dozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed
## Population
2,000 Americans, balance for gender;
## Annotation
annotating for the transcription text, speaker identification and gender
## Device
Android mobile phone, iPhone
## Language
American English
## Application scene
speech recognition, voiceprint recognition
## Accuracy rate
95%
# Licensing Information
Commercial License | Nexdata/American_English_Natural_Dialogue_Speech_Data | [
"task_categories:conversational",
"task_categories:automatic-speech-recognition",
"language:en",
"region:us"
] | 2022-06-21T05:27:14+00:00 | {"language": ["en"], "task_categories": ["conversational", "automatic-speech-recognition"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2024-01-26T09:47:01+00:00 | [] | [
"en"
] | TAGS
#task_categories-conversational #task_categories-automatic-speech-recognition #language-English #region-us
| # 1000-Hours-American-English-Conversational-Speech-Data-by-Mobile-Phone
## Description
2000 speakers participated in the recording and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: URL
## Format
16kHz, 16bit, uncompressed wav, mono channel
## Recording Environment
quiet indoor environment, without echo
## Recording Content
dozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed
## Population
2,000 Americans, balance for gender;
## Annotation
annotating for the transcription text, speaker identification and gender
## Device
Android mobile phone, iPhone
## Language
American English
## Application scene
speech recognition, voiceprint recognition
## Accuracy rate
95%
# Licensing Information
Commercial License | [
"# 1000-Hours-American-English-Conversational-Speech-Data-by-Mobile-Phone",
"## Description\n2000 speakers participated in the recording and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.\n\nFor more details, please refer to the link: URL",
"## Format\n16kHz, 16bit, uncompressed wav, mono channel",
"## Recording Environment\nquiet indoor environment, without echo",
"## Recording Content\ndozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed",
"## Population\n2,000 Americans, balance for gender;",
"## Annotation\nannotating for the transcription text, speaker identification and gender",
"## Device\nAndroid mobile phone, iPhone",
"## Language\nAmerican English",
"## Application scene\nspeech recognition, voiceprint recognition",
"## Accuracy rate\n95%",
"# Licensing Information\nCommercial License"
] | [
"TAGS\n#task_categories-conversational #task_categories-automatic-speech-recognition #language-English #region-us \n",
"# 1000-Hours-American-English-Conversational-Speech-Data-by-Mobile-Phone",
"## Description\n2000 speakers participated in the recording and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.\n\nFor more details, please refer to the link: URL",
"## Format\n16kHz, 16bit, uncompressed wav, mono channel",
"## Recording Environment\nquiet indoor environment, without echo",
"## Recording Content\ndozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed",
"## Population\n2,000 Americans, balance for gender;",
"## Annotation\nannotating for the transcription text, speaker identification and gender",
"## Device\nAndroid mobile phone, iPhone",
"## Language\nAmerican English",
"## Application scene\nspeech recognition, voiceprint recognition",
"## Accuracy rate\n95%",
"# Licensing Information\nCommercial License"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.