
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
sequencelengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
sequencelengths 0
201
| languages
sequencelengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
sequencelengths 0
722
| processed_texts
sequencelengths 1
723
| tokens_length
sequencelengths 1
723
| input_texts
sequencelengths 1
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
reinforcement-learning | sample-factory |
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r aw-infoprojekt/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
| {"library_name": "sample-factory", "tags": ["deep-reinforcement-learning", "reinforcement-learning", "sample-factory"], "model-index": [{"name": "APPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "doom_health_gathering_supreme", "type": "doom_health_gathering_supreme"}, "metrics": [{"type": "mean_reward", "value": "10.86 +/- 3.72", "name": "mean_reward", "verified": false}]}]}]} | aw-infoprojekt/rl_course_vizdoom_health_gathering_supreme | null | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T06:22:42+00:00 | [] | [] | TAGS
#sample-factory #tensorboard #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
A(n) APPO model trained on the doom_health_gathering_supreme environment.
This model was trained using Sample-Factory 2.0: URL
Documentation for how to use Sample-Factory can be found at URL
## Downloading the model
After installing Sample-Factory, download the model with:
## Using the model
To run the model after download, use the 'enjoy' script corresponding to this environment:
You can also upload models to the Hugging Face Hub using the same script with the '--push_to_hub' flag.
See URL for more details
## Training with this model
To continue training with this model, use the 'train' script corresponding to this environment:
Note, you may have to adjust '--train_for_env_steps' to a suitably high number as the experiment will resume at the number of steps it concluded at.
| [
"## Downloading the model\n\nAfter installing Sample-Factory, download the model with:",
"## Using the model\n\nTo run the model after download, use the 'enjoy' script corresponding to this environment:\n\n\n\nYou can also upload models to the Hugging Face Hub using the same script with the '--push_to_hub' flag.\nSee URL for more details",
"## Training with this model\n\nTo continue training with this model, use the 'train' script corresponding to this environment:\n\n\nNote, you may have to adjust '--train_for_env_steps' to a suitably high number as the experiment will resume at the number of steps it concluded at."
] | [
"TAGS\n#sample-factory #tensorboard #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"## Downloading the model\n\nAfter installing Sample-Factory, download the model with:",
"## Using the model\n\nTo run the model after download, use the 'enjoy' script corresponding to this environment:\n\n\n\nYou can also upload models to the Hugging Face Hub using the same script with the '--push_to_hub' flag.\nSee URL for more details",
"## Training with this model\n\nTo continue training with this model, use the 'train' script corresponding to this environment:\n\n\nNote, you may have to adjust '--train_for_env_steps' to a suitably high number as the experiment will resume at the number of steps it concluded at."
] | [
26,
17,
57,
63
] | [
"TAGS\n#sample-factory #tensorboard #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n## Downloading the model\n\nAfter installing Sample-Factory, download the model with:## Using the model\n\nTo run the model after download, use the 'enjoy' script corresponding to this environment:\n\n\n\nYou can also upload models to the Hugging Face Hub using the same script with the '--push_to_hub' flag.\nSee URL for more details## Training with this model\n\nTo continue training with this model, use the 'train' script corresponding to this environment:\n\n\nNote, you may have to adjust '--train_for_env_steps' to a suitably high number as the experiment will resume at the number of steps it concluded at."
] |
text-generation | transformers |
# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from [`llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
| {"language": ["en", "ja"], "license": "apache-2.0", "library_name": "transformers", "tags": ["mlx"], "datasets": ["databricks/databricks-dolly-15k", "llm-jp/databricks-dolly-15k-ja", "llm-jp/oasst1-21k-en", "llm-jp/oasst1-21k-ja", "llm-jp/oasst2-33k-en", "llm-jp/oasst2-33k-ja"], "programming_language": ["C", "C++", "C#", "Go", "Java", "JavaScript", "Lua", "PHP", "Python", "Ruby", "Rust", "Scala", "TypeScript"], "pipeline_tag": "text-generation", "inference": false} | mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"conversational",
"en",
"ja",
"dataset:databricks/databricks-dolly-15k",
"dataset:llm-jp/databricks-dolly-15k-ja",
"dataset:llm-jp/oasst1-21k-en",
"dataset:llm-jp/oasst1-21k-ja",
"dataset:llm-jp/oasst2-33k-en",
"dataset:llm-jp/oasst2-33k-ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:24:57+00:00 | [] | [
"en",
"ja"
] | TAGS
#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us
|
# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n",
"# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
154,
130,
6
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.## Use with mlx"
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "diffusers"} | Niggendar/mightMixes15Ponyxl_pxlBlastwrx | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-30T06:25:17+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
39,
6,
4,
76,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
sentence-similarity | sentence-transformers |
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 113 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 0,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "transformers"], "pipeline_tag": "sentence-similarity"} | Mihaiii/test16 | null | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:25:40+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #transformers #endpoints_compatible #region-us
|
# {MODEL_NAME}
This is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers installed:
Then you can use the model like this:
## Usage (HuggingFace Transformers)
Without sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL
## Training
The model was trained with the parameters:
DataLoader:
'URL.dataloader.DataLoader' of length 113 with parameters:
Loss:
'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss'
Parameters of the fit()-Method:
## Full Model Architecture
## Citing & Authors
| [
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 113 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss' \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
] | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #transformers #endpoints_compatible #region-us \n",
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 113 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss' \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
] | [
30,
41,
30,
58,
26,
69,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #transformers #endpoints_compatible #region-us \n# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 113 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss' \n\nParameters of the fit()-Method:## Full Model Architecture## Citing & Authors"
] |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "220.28 +/- 85.29", "name": "mean_reward", "verified": false}]}]}]} | Chhabi/PPO-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T06:26:59+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
31,
35,
17
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-31m", "model-index": [{"name": "robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3", "results": []}]} | AlignmentResearch/robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:29:09+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3
This model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
62,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# taide_llama3_8b_lora_completion_only
This model is a fine-tuned version of [taide/Llama3-TAIDE-LX-8B-Chat-Alpha1](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) on the DandinPower/ZH-Reading-Comprehension-Llama-Instruct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0968
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 700
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.1474 | 0.3690 | 250 | 0.1201 |
| 0.1072 | 0.7380 | 500 | 0.1581 |
| 0.098 | 1.1070 | 750 | 0.1148 |
| 0.0963 | 1.4760 | 1000 | 0.1044 |
| 0.0502 | 1.8450 | 1250 | 0.1064 |
| 0.05 | 2.2140 | 1500 | 0.1017 |
| 0.0239 | 2.5830 | 1750 | 0.1015 |
| 0.0443 | 2.9520 | 2000 | 0.0968 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"language": ["zh"], "license": "other", "library_name": "peft", "tags": ["trl", "sft", "nycu-112-2-deeplearning-hw2", "generated_from_trainer"], "datasets": ["DandinPower/ZH-Reading-Comprehension-Llama-Instruct"], "base_model": "taide/Llama3-TAIDE-LX-8B-Chat-Alpha1", "model-index": [{"name": "taide_llama3_8b_lora_completion_only", "results": []}]} | DandinPower/taide_llama3_8b_lora_completion_only | null | [
"peft",
"safetensors",
"trl",
"sft",
"nycu-112-2-deeplearning-hw2",
"generated_from_trainer",
"zh",
"dataset:DandinPower/ZH-Reading-Comprehension-Llama-Instruct",
"base_model:taide/Llama3-TAIDE-LX-8B-Chat-Alpha1",
"license:other",
"region:us"
] | null | 2024-04-30T06:29:55+00:00 | [] | [
"zh"
] | TAGS
#peft #safetensors #trl #sft #nycu-112-2-deeplearning-hw2 #generated_from_trainer #zh #dataset-DandinPower/ZH-Reading-Comprehension-Llama-Instruct #base_model-taide/Llama3-TAIDE-LX-8B-Chat-Alpha1 #license-other #region-us
| taide\_llama3\_8b\_lora\_completion\_only
=========================================
This model is a fine-tuned version of taide/Llama3-TAIDE-LX-8B-Chat-Alpha1 on the DandinPower/ZH-Reading-Comprehension-Llama-Instruct dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0968
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 1
* eval\_batch\_size: 1
* seed: 42
* distributed\_type: multi-GPU
* num\_devices: 2
* gradient\_accumulation\_steps: 8
* total\_train\_batch\_size: 16
* total\_eval\_batch\_size: 2
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 700
* num\_epochs: 3.0
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.40.0
* Pytorch 2.2.2+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 16\n* total\\_eval\\_batch\\_size: 2\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 700\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0\n* Pytorch 2.2.2+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#peft #safetensors #trl #sft #nycu-112-2-deeplearning-hw2 #generated_from_trainer #zh #dataset-DandinPower/ZH-Reading-Comprehension-Llama-Instruct #base_model-taide/Llama3-TAIDE-LX-8B-Chat-Alpha1 #license-other #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 16\n* total\\_eval\\_batch\\_size: 2\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 700\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0\n* Pytorch 2.2.2+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
92,
174,
5,
52
] | [
"TAGS\n#peft #safetensors #trl #sft #nycu-112-2-deeplearning-hw2 #generated_from_trainer #zh #dataset-DandinPower/ZH-Reading-Comprehension-Llama-Instruct #base_model-taide/Llama3-TAIDE-LX-8B-Chat-Alpha1 #license-other #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 16\n* total\\_eval\\_batch\\_size: 2\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 700\n* num\\_epochs: 3.0### Training results### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0\n* Pytorch 2.2.2+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-generation | transformers | # starcoder2-15b-instruct-v0.1-GGUF
- Original model: [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install huggingface_hub[hf_transfer]
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 8192` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: starcoder2-15b-instruct-v0.1
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation

## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
- **Authors:**
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
[Federico Cassano](https://federico.codes/),
[Jiawei Liu](https://jw-liu.xyz),
[Yifeng Ding](https://yifeng-ding.com),
[Naman Jain](https://naman-ntc.github.io),
[Harm de Vries](https://www.harmdevries.com),
[Leandro von Werra](https://twitter.com/lvwerra),
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
[Lingming Zhang](https://lingming.cs.illinois.edu).

## Use
### Intended use
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
```python
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
```
Here is the expected output:
``````
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
``````
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
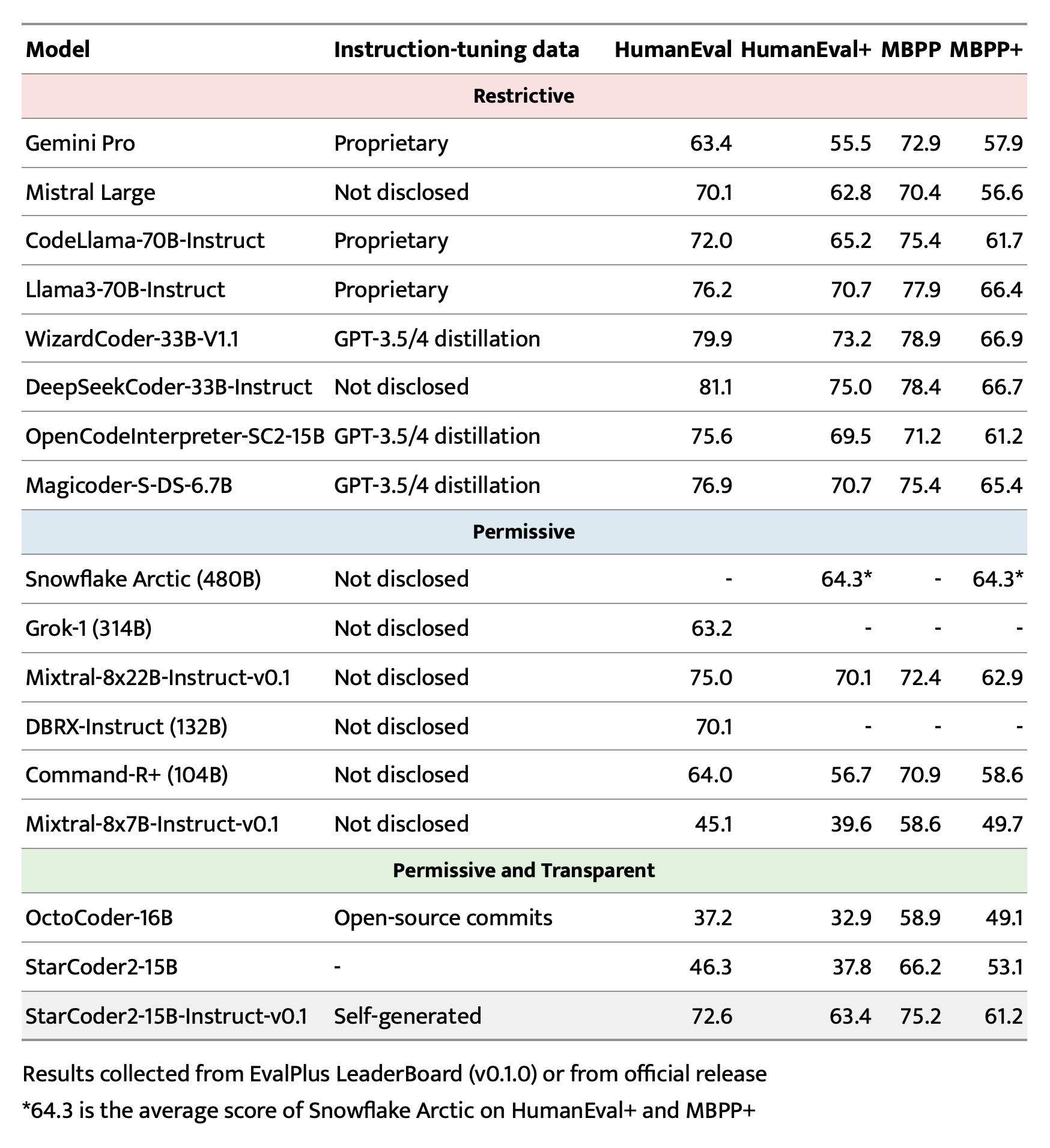
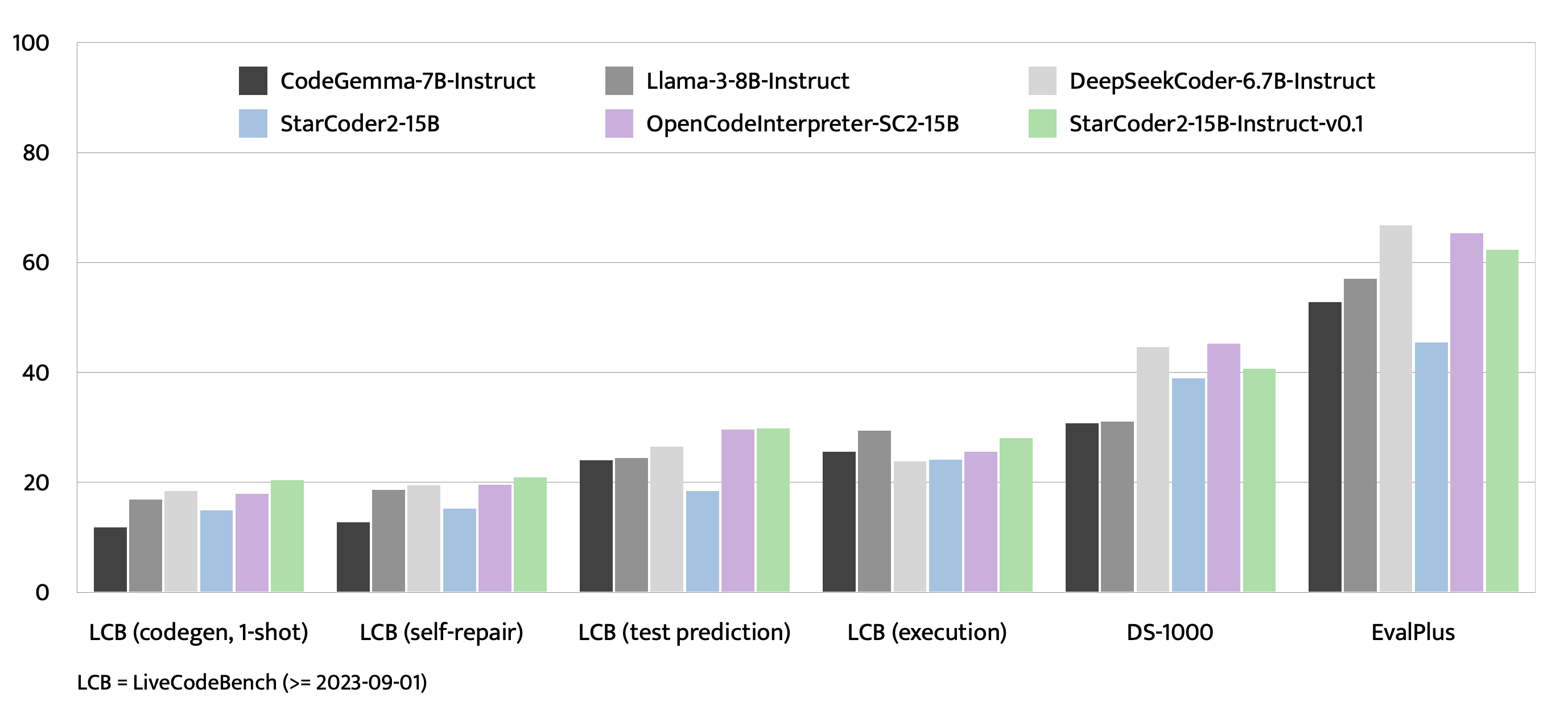
## Training Details
### Hyperparameters
- **Optimizer:** Adafactor
- **Learning rate:** 1e-5
- **Epoch:** 4
- **Batch size:** 64
- **Warmup ratio:** 0.05
- **Scheduler:** Linear
- **Sequence length:** 1280
- **Dropout**: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
<!-- original-model-card end -->
| {"license": "bigcode-openrail-m", "library_name": "transformers", "tags": ["code", "GGUF"], "datasets": ["bigcode/self-oss-instruct-sc2-exec-filter-50k"], "base_model": "bigcode/starcoder2-15b", "pipeline_tag": "text-generation", "quantized_by": "andrijdavid", "model-index": [{"name": "starcoder2-15b-instruct-v0.1", "results": [{"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (code generation)", "type": "livecodebench-codegeneration"}, "metrics": [{"type": "pass@1", "value": 20.4, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (self repair)", "type": "livecodebench-selfrepair"}, "metrics": [{"type": "pass@1", "value": 20.9, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (test output prediction)", "type": "livecodebench-testoutputprediction"}, "metrics": [{"type": "pass@1", "value": 29.8, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (code execution)", "type": "livecodebench-codeexecution"}, "metrics": [{"type": "pass@1", "value": 28.1, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "HumanEval", "type": "humaneval"}, "metrics": [{"type": "pass@1", "value": 72.6, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "HumanEval+", "type": "humanevalplus"}, "metrics": [{"type": "pass@1", "value": 63.4, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "MBPP", "type": "mbpp"}, "metrics": [{"type": "pass@1", "value": 75.2, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "MBPP+", "type": "mbppplus"}, "metrics": [{"type": "pass@1", "value": 61.2, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "DS-1000", "type": "ds-1000"}, "metrics": [{"type": "pass@1", "value": 40.6, "verified": false}]}]}]} | LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF | null | [
"transformers",
"gguf",
"code",
"GGUF",
"text-generation",
"dataset:bigcode/self-oss-instruct-sc2-exec-filter-50k",
"base_model:bigcode/starcoder2-15b",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:31:08+00:00 | [] | [] | TAGS
#transformers #gguf #code #GGUF #text-generation #dataset-bigcode/self-oss-instruct-sc2-exec-filter-50k #base_model-bigcode/starcoder2-15b #license-bigcode-openrail-m #model-index #endpoints_compatible #region-us
| # starcoder2-15b-instruct-v0.1-GGUF
- Original model: starcoder2-15b-instruct-v0.1
## Description
This repo contains GGUF format model files for starcoder2-15b-instruct-v0.1.
### About GGUF
GGUF is a new format introduced by the URL team on August 21st 2023. It is a replacement for GGML, which is no longer supported by URL.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* URL. This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* text-generation-webui, Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* Ollama Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* KoboldCpp, A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* GPT4All, This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* LM Studio An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* LoLLMS Web UI. A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* URL, An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* llama-cpp-python, A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* candle, A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* ctransformers, A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* localGPT An open-source initiative enabling private conversations with documents.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
## How to download GGUF files
Note for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* URL
### In 'text-generation-webui'
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-URL.
Then click Download.
### On the command line, including multiple files at once
I recommend using the 'huggingface-hub' Python library:
Then you can download any individual model file to the current directory, at high speed, with a command like this:
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
For more documentation on downloading with 'huggingface-cli', please see: HF -> Hub Python Library -> Download files -> Download from the CLI.
To accelerate downloads on fast connections (1Gbit/s or higher), install 'hf_transfer':
And set environment variable 'HF_HUB_ENABLE_HF_TRANSFER' to '1':
Windows Command Line users: You can set the environment variable by running 'set HF_HUB_ENABLE_HF_TRANSFER=1' before the download command.
</details>
## Example 'URL' command
Make sure you are using 'URL' from commit d0cee0d or later.
Change '-ngl 32' to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change '-c 8192' to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by URL automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the '-p <PROMPT>' argument with '-i -ins'
For other parameters and how to use them, please refer to the URL documentation
## How to run in 'text-generation-webui'
Further instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model URL.
## How to run from Python code
You can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: llama-cpp-python docs.
#### First install the package
Run one of the following commands, according to your system:
#### Simple llama-cpp-python example code
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* LangChain + llama-cpp-python
* LangChain + ctransformers
# Original model card: starcoder2-15b-instruct-v0.1
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
!Banner
## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- Model: bigcode/starcoder2-15b-instruct-v0.1
- Code: bigcode-project/starcoder2-self-align
- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k
- Authors:
Yuxiang Wei,
Federico Cassano,
Jiawei Liu,
Yifeng Ding,
Naman Jain,
Harm de Vries,
Leandro von Werra,
Arjun Guha,
Lingming Zhang.
!self-alignment pipeline
## Use
### Intended use
The model is designed to respond to coding-related instructions in a single turn. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the transformers library:
Here is the expected output:
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
!EvalPlus
!LiveCodeBench and DS-1000
## Training Details
### Hyperparameters
- Optimizer: Adafactor
- Learning rate: 1e-5
- Epoch: 4
- Batch size: 64
- Warmup ratio: 0.05
- Scheduler: Linear
- Sequence length: 1280
- Dropout: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- Model: bigcode/starCoder2-15b-instruct-v0.1
- Code: bigcode-project/starcoder2-self-align
- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k
| [
"# starcoder2-15b-instruct-v0.1-GGUF\n- Original model: starcoder2-15b-instruct-v0.1",
"## Description\n\nThis repo contains GGUF format model files for starcoder2-15b-instruct-v0.1.",
"### About GGUF\nGGUF is a new format introduced by the URL team on August 21st 2023. It is a replacement for GGML, which is no longer supported by URL.\nHere is an incomplete list of clients and libraries that are known to support GGUF:\n* URL. This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.\n* text-generation-webui, Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.\n* Ollama Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications\n* KoboldCpp, A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.\n* GPT4All, This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.\n* LM Studio An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.\n* LoLLMS Web UI. A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.\n* URL, An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.\n* llama-cpp-python, A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.\n* candle, A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.\n* ctransformers, A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.\n* localGPT An open-source initiative enabling private conversations with documents.",
"## Explanation of quantisation methods\n<details>\n <summary>Click to see details</summary>\nThe new methods available are:\n\n* GGML_TYPE_Q2_K - \"type-1\" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)\n* GGML_TYPE_Q3_K - \"type-0\" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.\n* GGML_TYPE_Q4_K - \"type-1\" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.\n* GGML_TYPE_Q5_K - \"type-1\" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw\n* GGML_TYPE_Q6_K - \"type-0\" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.\n</details>",
"## How to download GGUF files\n\nNote for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.\n\nThe following clients/libraries will automatically download models for you, providing a list of available models to choose from:\n\n* LM Studio\n* LoLLMS Web UI\n* URL",
"### In 'text-generation-webui'\n\nUnder Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-URL.\n\nThen click Download.",
"### On the command line, including multiple files at once\n\nI recommend using the 'huggingface-hub' Python library:\n\n\n\nThen you can download any individual model file to the current directory, at high speed, with a command like this:\n\n\n\n<details>\n <summary>More advanced huggingface-cli download usage (click to read)</summary>\n\nYou can also download multiple files at once with a pattern:\n\n\n\nFor more documentation on downloading with 'huggingface-cli', please see: HF -> Hub Python Library -> Download files -> Download from the CLI.\n\nTo accelerate downloads on fast connections (1Gbit/s or higher), install 'hf_transfer':\n\n\n\nAnd set environment variable 'HF_HUB_ENABLE_HF_TRANSFER' to '1':\n\n\n\nWindows Command Line users: You can set the environment variable by running 'set HF_HUB_ENABLE_HF_TRANSFER=1' before the download command.\n</details>",
"## Example 'URL' command\n\nMake sure you are using 'URL' from commit d0cee0d or later.\n\n\n\nChange '-ngl 32' to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.\n\nChange '-c 8192' to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by URL automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.\n\nIf you want to have a chat-style conversation, replace the '-p <PROMPT>' argument with '-i -ins'\n\nFor other parameters and how to use them, please refer to the URL documentation",
"## How to run in 'text-generation-webui'\n\nFurther instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model URL.",
"## How to run from Python code\n\nYou can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.",
"### How to load this model in Python code, using llama-cpp-python\n\nFor full documentation, please see: llama-cpp-python docs.",
"#### First install the package\n\nRun one of the following commands, according to your system:",
"#### Simple llama-cpp-python example code",
"## How to use with LangChain\n\nHere are guides on using llama-cpp-python and ctransformers with LangChain:\n\n* LangChain + llama-cpp-python\n* LangChain + ctransformers",
"# Original model card: starcoder2-15b-instruct-v0.1",
"# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation\n\n!Banner",
"## Model Summary\n\nWe introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.\n\n- Model: bigcode/starcoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k\n- Authors:\n Yuxiang Wei,\n Federico Cassano,\n Jiawei Liu,\n Yifeng Ding,\n Naman Jain,\n Harm de Vries,\n Leandro von Werra,\n Arjun Guha,\n Lingming Zhang.\n\n!self-alignment pipeline",
"## Use",
"### Intended use\n\nThe model is designed to respond to coding-related instructions in a single turn. Instructions in other styles may result in less accurate responses.\n\nHere is an example to get started with the model using the transformers library:\n\n\n\nHere is the expected output:\n\n\nHere's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:",
"### Bias, Risks, and Limitations\n\nStarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.\n\nThe model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.",
"## Evaluation on EvalPlus, LiveCodeBench, and DS-1000\n\n!EvalPlus\n\n!LiveCodeBench and DS-1000",
"## Training Details",
"### Hyperparameters\n\n- Optimizer: Adafactor\n- Learning rate: 1e-5\n- Epoch: 4\n- Batch size: 64\n- Warmup ratio: 0.05\n- Scheduler: Linear\n- Sequence length: 1280\n- Dropout: Not applied",
"### Hardware\n\n1 x NVIDIA A100 80GB",
"## Resources\n\n- Model: bigcode/starCoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k"
] | [
"TAGS\n#transformers #gguf #code #GGUF #text-generation #dataset-bigcode/self-oss-instruct-sc2-exec-filter-50k #base_model-bigcode/starcoder2-15b #license-bigcode-openrail-m #model-index #endpoints_compatible #region-us \n",
"# starcoder2-15b-instruct-v0.1-GGUF\n- Original model: starcoder2-15b-instruct-v0.1",
"## Description\n\nThis repo contains GGUF format model files for starcoder2-15b-instruct-v0.1.",
"### About GGUF\nGGUF is a new format introduced by the URL team on August 21st 2023. It is a replacement for GGML, which is no longer supported by URL.\nHere is an incomplete list of clients and libraries that are known to support GGUF:\n* URL. This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.\n* text-generation-webui, Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.\n* Ollama Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications\n* KoboldCpp, A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.\n* GPT4All, This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.\n* LM Studio An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.\n* LoLLMS Web UI. A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.\n* URL, An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.\n* llama-cpp-python, A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.\n* candle, A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.\n* ctransformers, A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.\n* localGPT An open-source initiative enabling private conversations with documents.",
"## Explanation of quantisation methods\n<details>\n <summary>Click to see details</summary>\nThe new methods available are:\n\n* GGML_TYPE_Q2_K - \"type-1\" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)\n* GGML_TYPE_Q3_K - \"type-0\" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.\n* GGML_TYPE_Q4_K - \"type-1\" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.\n* GGML_TYPE_Q5_K - \"type-1\" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw\n* GGML_TYPE_Q6_K - \"type-0\" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.\n</details>",
"## How to download GGUF files\n\nNote for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.\n\nThe following clients/libraries will automatically download models for you, providing a list of available models to choose from:\n\n* LM Studio\n* LoLLMS Web UI\n* URL",
"### In 'text-generation-webui'\n\nUnder Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-URL.\n\nThen click Download.",
"### On the command line, including multiple files at once\n\nI recommend using the 'huggingface-hub' Python library:\n\n\n\nThen you can download any individual model file to the current directory, at high speed, with a command like this:\n\n\n\n<details>\n <summary>More advanced huggingface-cli download usage (click to read)</summary>\n\nYou can also download multiple files at once with a pattern:\n\n\n\nFor more documentation on downloading with 'huggingface-cli', please see: HF -> Hub Python Library -> Download files -> Download from the CLI.\n\nTo accelerate downloads on fast connections (1Gbit/s or higher), install 'hf_transfer':\n\n\n\nAnd set environment variable 'HF_HUB_ENABLE_HF_TRANSFER' to '1':\n\n\n\nWindows Command Line users: You can set the environment variable by running 'set HF_HUB_ENABLE_HF_TRANSFER=1' before the download command.\n</details>",
"## Example 'URL' command\n\nMake sure you are using 'URL' from commit d0cee0d or later.\n\n\n\nChange '-ngl 32' to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.\n\nChange '-c 8192' to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by URL automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.\n\nIf you want to have a chat-style conversation, replace the '-p <PROMPT>' argument with '-i -ins'\n\nFor other parameters and how to use them, please refer to the URL documentation",
"## How to run in 'text-generation-webui'\n\nFurther instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model URL.",
"## How to run from Python code\n\nYou can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.",
"### How to load this model in Python code, using llama-cpp-python\n\nFor full documentation, please see: llama-cpp-python docs.",
"#### First install the package\n\nRun one of the following commands, according to your system:",
"#### Simple llama-cpp-python example code",
"## How to use with LangChain\n\nHere are guides on using llama-cpp-python and ctransformers with LangChain:\n\n* LangChain + llama-cpp-python\n* LangChain + ctransformers",
"# Original model card: starcoder2-15b-instruct-v0.1",
"# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation\n\n!Banner",
"## Model Summary\n\nWe introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.\n\n- Model: bigcode/starcoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k\n- Authors:\n Yuxiang Wei,\n Federico Cassano,\n Jiawei Liu,\n Yifeng Ding,\n Naman Jain,\n Harm de Vries,\n Leandro von Werra,\n Arjun Guha,\n Lingming Zhang.\n\n!self-alignment pipeline",
"## Use",
"### Intended use\n\nThe model is designed to respond to coding-related instructions in a single turn. Instructions in other styles may result in less accurate responses.\n\nHere is an example to get started with the model using the transformers library:\n\n\n\nHere is the expected output:\n\n\nHere's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:",
"### Bias, Risks, and Limitations\n\nStarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.\n\nThe model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.",
"## Evaluation on EvalPlus, LiveCodeBench, and DS-1000\n\n!EvalPlus\n\n!LiveCodeBench and DS-1000",
"## Training Details",
"### Hyperparameters\n\n- Optimizer: Adafactor\n- Learning rate: 1e-5\n- Epoch: 4\n- Batch size: 64\n- Warmup ratio: 0.05\n- Scheduler: Linear\n- Sequence length: 1280\n- Dropout: Not applied",
"### Hardware\n\n1 x NVIDIA A100 80GB",
"## Resources\n\n- Model: bigcode/starCoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k"
] | [
80,
39,
30,
419,
314,
83,
78,
206,
172,
47,
82,
37,
20,
14,
54,
20,
22,
212,
3,
83,
159,
30,
4,
57,
13,
65
] | [
"TAGS\n#transformers #gguf #code #GGUF #text-generation #dataset-bigcode/self-oss-instruct-sc2-exec-filter-50k #base_model-bigcode/starcoder2-15b #license-bigcode-openrail-m #model-index #endpoints_compatible #region-us \n# starcoder2-15b-instruct-v0.1-GGUF\n- Original model: starcoder2-15b-instruct-v0.1## Description\n\nThis repo contains GGUF format model files for starcoder2-15b-instruct-v0.1.### About GGUF\nGGUF is a new format introduced by the URL team on August 21st 2023. It is a replacement for GGML, which is no longer supported by URL.\nHere is an incomplete list of clients and libraries that are known to support GGUF:\n* URL. This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.\n* text-generation-webui, Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.\n* Ollama Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications\n* KoboldCpp, A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.\n* GPT4All, This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.\n* LM Studio An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.\n* LoLLMS Web UI. A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.\n* URL, An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.\n* llama-cpp-python, A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.\n* candle, A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.\n* ctransformers, A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.\n* localGPT An open-source initiative enabling private conversations with documents.## Explanation of quantisation methods\n<details>\n <summary>Click to see details</summary>\nThe new methods available are:\n\n* GGML_TYPE_Q2_K - \"type-1\" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)\n* GGML_TYPE_Q3_K - \"type-0\" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.\n* GGML_TYPE_Q4_K - \"type-1\" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.\n* GGML_TYPE_Q5_K - \"type-1\" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw\n* GGML_TYPE_Q6_K - \"type-0\" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.\n</details>## How to download GGUF files\n\nNote for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.\n\nThe following clients/libraries will automatically download models for you, providing a list of available models to choose from:\n\n* LM Studio\n* LoLLMS Web UI\n* URL### In 'text-generation-webui'\n\nUnder Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-URL.\n\nThen click Download.### On the command line, including multiple files at once\n\nI recommend using the 'huggingface-hub' Python library:\n\n\n\nThen you can download any individual model file to the current directory, at high speed, with a command like this:\n\n\n\n<details>\n <summary>More advanced huggingface-cli download usage (click to read)</summary>\n\nYou can also download multiple files at once with a pattern:\n\n\n\nFor more documentation on downloading with 'huggingface-cli', please see: HF -> Hub Python Library -> Download files -> Download from the CLI.\n\nTo accelerate downloads on fast connections (1Gbit/s or higher), install 'hf_transfer':\n\n\n\nAnd set environment variable 'HF_HUB_ENABLE_HF_TRANSFER' to '1':\n\n\n\nWindows Command Line users: You can set the environment variable by running 'set HF_HUB_ENABLE_HF_TRANSFER=1' before the download command.\n</details>## Example 'URL' command\n\nMake sure you are using 'URL' from commit d0cee0d or later.\n\n\n\nChange '-ngl 32' to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.\n\nChange '-c 8192' to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by URL automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.\n\nIf you want to have a chat-style conversation, replace the '-p <PROMPT>' argument with '-i -ins'\n\nFor other parameters and how to use them, please refer to the URL documentation## How to run in 'text-generation-webui'\n\nFurther instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model URL.## How to run from Python code\n\nYou can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.### How to load this model in Python code, using llama-cpp-python\n\nFor full documentation, please see: llama-cpp-python docs.#### First install the package\n\nRun one of the following commands, according to your system:#### Simple llama-cpp-python example code## How to use with LangChain\n\nHere are guides on using llama-cpp-python and ctransformers with LangChain:\n\n* LangChain + llama-cpp-python\n* LangChain + ctransformers# Original model card: starcoder2-15b-instruct-v0.1# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation\n\n!Banner## Model Summary\n\nWe introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.\n\n- Model: bigcode/starcoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k\n- Authors:\n Yuxiang Wei,\n Federico Cassano,\n Jiawei Liu,\n Yifeng Ding,\n Naman Jain,\n Harm de Vries,\n Leandro von Werra,\n Arjun Guha,\n Lingming Zhang.\n\n!self-alignment pipeline## Use### Intended use\n\nThe model is designed to respond to coding-related instructions in a single turn. Instructions in other styles may result in less accurate responses.\n\nHere is an example to get started with the model using the transformers library:\n\n\n\nHere is the expected output:\n\n\nHere's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:### Bias, Risks, and Limitations\n\nStarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.\n\nThe model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.## Evaluation on EvalPlus, LiveCodeBench, and DS-1000\n\n!EvalPlus\n\n!LiveCodeBench and DS-1000## Training Details### Hyperparameters\n\n- Optimizer: Adafactor\n- Learning rate: 1e-5\n- Epoch: 4\n- Batch size: 64\n- Warmup ratio: 0.05\n- Scheduler: Linear\n- Sequence length: 1280\n- Dropout: Not applied### Hardware\n\n1 x NVIDIA A100 80GB## Resources\n\n- Model: bigcode/starCoder2-15b-instruct-v0.1\n- Code: bigcode-project/starcoder2-self-align\n- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2222
- Accuracy: 0.927
- F1: 0.9270
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8572 | 1.0 | 250 | 0.3317 | 0.9015 | 0.9005 |
| 0.2552 | 2.0 | 500 | 0.2222 | 0.927 | 0.9270 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "config": "split", "split": "validation", "args": "split"}, "metrics": [{"type": "accuracy", "value": 0.927, "name": "Accuracy"}, {"type": "f1", "value": 0.9270352884163217, "name": "F1"}]}]}]} | nanashi999/distilbert-base-uncased-finetuned-emotion | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:32:32+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #dataset-emotion #base_model-distilbert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
| distilbert-base-uncased-finetuned-emotion
=========================================
This model is a fine-tuned version of distilbert-base-uncased on the emotion dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2222
* Accuracy: 0.927
* F1: 0.9270
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 64
* eval\_batch\_size: 64
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.40.1
* Pytorch 2.3.0+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.3.0+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #dataset-emotion #base_model-distilbert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.3.0+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
68,
101,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #dataset-emotion #base_model-distilbert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2### Training results### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.3.0+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": ["unsloth"]} | russgeo/lecw | null | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:33:58+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #unsloth #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #unsloth #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
30,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #unsloth #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 1.0657285451889038
f1_macro: 0.2095479509928179
f1_micro: 0.4584103512014787
f1_weighted: 0.2881768494245037
precision_macro: 0.1528034504004929
precision_micro: 0.4584103512014787
precision_weighted: 0.21014005008866307
recall_macro: 0.3333333333333333
recall_micro: 0.4584103512014787
recall_weighted: 0.4584103512014787
accuracy: 0.4584103512014787
| {"tags": ["autotrain", "text-classification"], "datasets": ["actsa-distilbert/autotrain-data"], "widget": [{"text": "I love AutoTrain"}]} | DarkPhantom323/actsa-distilbert | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"autotrain",
"dataset:actsa-distilbert/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:35:24+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-actsa-distilbert/autotrain-data #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 1.0657285451889038
f1_macro: 0.2095479509928179
f1_micro: 0.4584103512014787
f1_weighted: 0.2881768494245037
precision_macro: 0.1528034504004929
precision_micro: 0.4584103512014787
precision_weighted: 0.21014005008866307
recall_macro: 0.3333333333333333
recall_micro: 0.4584103512014787
recall_weighted: 0.4584103512014787
accuracy: 0.4584103512014787
| [
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 1.0657285451889038\n\nf1_macro: 0.2095479509928179\n\nf1_micro: 0.4584103512014787\n\nf1_weighted: 0.2881768494245037\n\nprecision_macro: 0.1528034504004929\n\nprecision_micro: 0.4584103512014787\n\nprecision_weighted: 0.21014005008866307\n\nrecall_macro: 0.3333333333333333\n\nrecall_micro: 0.4584103512014787\n\nrecall_weighted: 0.4584103512014787\n\naccuracy: 0.4584103512014787"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-actsa-distilbert/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 1.0657285451889038\n\nf1_macro: 0.2095479509928179\n\nf1_micro: 0.4584103512014787\n\nf1_weighted: 0.2881768494245037\n\nprecision_macro: 0.1528034504004929\n\nprecision_micro: 0.4584103512014787\n\nprecision_weighted: 0.21014005008866307\n\nrecall_macro: 0.3333333333333333\n\nrecall_micro: 0.4584103512014787\n\nrecall_weighted: 0.4584103512014787\n\naccuracy: 0.4584103512014787"
] | [
50,
12,
169
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-actsa-distilbert/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n# Model Trained Using AutoTrain\n\n- Problem type: Text Classification## Validation Metrics\nloss: 1.0657285451889038\n\nf1_macro: 0.2095479509928179\n\nf1_micro: 0.4584103512014787\n\nf1_weighted: 0.2881768494245037\n\nprecision_macro: 0.1528034504004929\n\nprecision_micro: 0.4584103512014787\n\nprecision_weighted: 0.21014005008866307\n\nrecall_macro: 0.3333333333333333\n\nrecall_micro: 0.4584103512014787\n\nrecall_weighted: 0.4584103512014787\n\naccuracy: 0.4584103512014787"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6628
- F1 Score: 0.7003
- Accuracy: 0.7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6509 | 0.87 | 200 | 0.6230 | 0.6621 | 0.6625 |
| 0.6059 | 1.74 | 400 | 0.6135 | 0.6639 | 0.6663 |
| 0.592 | 2.61 | 600 | 0.5994 | 0.6823 | 0.6823 |
| 0.5831 | 3.48 | 800 | 0.5950 | 0.6831 | 0.6832 |
| 0.5769 | 4.35 | 1000 | 0.5927 | 0.6832 | 0.6829 |
| 0.5715 | 5.22 | 1200 | 0.5920 | 0.6843 | 0.6856 |
| 0.5626 | 6.09 | 1400 | 0.6018 | 0.6851 | 0.6880 |
| 0.5546 | 6.96 | 1600 | 0.5913 | 0.6930 | 0.6940 |
| 0.5463 | 7.83 | 1800 | 0.5928 | 0.6911 | 0.6910 |
| 0.5422 | 8.7 | 2000 | 0.5842 | 0.6886 | 0.6886 |
| 0.5318 | 9.57 | 2200 | 0.5834 | 0.6981 | 0.6981 |
| 0.5319 | 10.43 | 2400 | 0.5986 | 0.6946 | 0.6946 |
| 0.5223 | 11.3 | 2600 | 0.5986 | 0.6917 | 0.6932 |
| 0.5222 | 12.17 | 2800 | 0.5934 | 0.6939 | 0.6940 |
| 0.5123 | 13.04 | 3000 | 0.5865 | 0.6906 | 0.6910 |
| 0.5051 | 13.91 | 3200 | 0.5865 | 0.6982 | 0.6981 |
| 0.497 | 14.78 | 3400 | 0.6015 | 0.6906 | 0.6927 |
| 0.4981 | 15.65 | 3600 | 0.5933 | 0.6932 | 0.6937 |
| 0.4854 | 16.52 | 3800 | 0.6061 | 0.6967 | 0.6967 |
| 0.4809 | 17.39 | 4000 | 0.6083 | 0.6950 | 0.6965 |
| 0.4787 | 18.26 | 4200 | 0.6135 | 0.6979 | 0.6989 |
| 0.4718 | 19.13 | 4400 | 0.6113 | 0.6938 | 0.6937 |
| 0.4674 | 20.0 | 4600 | 0.6135 | 0.6969 | 0.6986 |
| 0.4584 | 20.87 | 4800 | 0.6284 | 0.6975 | 0.6976 |
| 0.4547 | 21.74 | 5000 | 0.6107 | 0.7012 | 0.7016 |
| 0.448 | 22.61 | 5200 | 0.6399 | 0.6990 | 0.6997 |
| 0.4411 | 23.48 | 5400 | 0.6365 | 0.6983 | 0.6997 |
| 0.4396 | 24.35 | 5600 | 0.6307 | 0.6982 | 0.6986 |
| 0.4336 | 25.22 | 5800 | 0.6495 | 0.6961 | 0.6959 |
| 0.4294 | 26.09 | 6000 | 0.6630 | 0.6933 | 0.6948 |
| 0.428 | 26.96 | 6200 | 0.6421 | 0.6955 | 0.6967 |
| 0.418 | 27.83 | 6400 | 0.6535 | 0.7025 | 0.7033 |
| 0.4177 | 28.7 | 6600 | 0.6546 | 0.6955 | 0.6954 |
| 0.4142 | 29.57 | 6800 | 0.6534 | 0.6938 | 0.6943 |
| 0.4112 | 30.43 | 7000 | 0.6518 | 0.7017 | 0.7016 |
| 0.4087 | 31.3 | 7200 | 0.6582 | 0.7031 | 0.7030 |
| 0.4011 | 32.17 | 7400 | 0.6718 | 0.7003 | 0.7003 |
| 0.3996 | 33.04 | 7600 | 0.6742 | 0.6971 | 0.6970 |
| 0.3983 | 33.91 | 7800 | 0.6686 | 0.7005 | 0.7014 |
| 0.3922 | 34.78 | 8000 | 0.6739 | 0.7019 | 0.7019 |
| 0.3922 | 35.65 | 8200 | 0.6771 | 0.7042 | 0.7041 |
| 0.3896 | 36.52 | 8400 | 0.6731 | 0.7005 | 0.7003 |
| 0.3892 | 37.39 | 8600 | 0.6700 | 0.7022 | 0.7019 |
| 0.3808 | 38.26 | 8800 | 0.6924 | 0.7003 | 0.7005 |
| 0.388 | 39.13 | 9000 | 0.6855 | 0.7014 | 0.7016 |
| 0.3843 | 40.0 | 9200 | 0.6828 | 0.7024 | 0.7024 |
| 0.3806 | 40.87 | 9400 | 0.6873 | 0.7009 | 0.7008 |
| 0.3827 | 41.74 | 9600 | 0.6855 | 0.7024 | 0.7024 |
| 0.3813 | 42.61 | 9800 | 0.6873 | 0.7009 | 0.7008 |
| 0.3751 | 43.48 | 10000 | 0.6912 | 0.7000 | 0.7 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:35:53+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me3-seqsight\_32768\_512\_43M-L32\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6628
* F1 Score: 0.7003
* Accuracy: 0.7
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2537
- F1 Score: 0.9048
- Accuracy: 0.9049
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.4138 | 2.17 | 200 | 0.3024 | 0.8886 | 0.8884 |
| 0.2889 | 4.35 | 400 | 0.2914 | 0.8859 | 0.8857 |
| 0.276 | 6.52 | 600 | 0.2811 | 0.8872 | 0.8871 |
| 0.2752 | 8.7 | 800 | 0.2797 | 0.8845 | 0.8843 |
| 0.2645 | 10.87 | 1000 | 0.2767 | 0.8877 | 0.8877 |
| 0.2644 | 13.04 | 1200 | 0.2772 | 0.8879 | 0.8877 |
| 0.259 | 15.22 | 1400 | 0.2717 | 0.8917 | 0.8919 |
| 0.2542 | 17.39 | 1600 | 0.2704 | 0.8905 | 0.8905 |
| 0.2528 | 19.57 | 1800 | 0.2679 | 0.8937 | 0.8939 |
| 0.2524 | 21.74 | 2000 | 0.2727 | 0.8941 | 0.8939 |
| 0.2477 | 23.91 | 2200 | 0.2683 | 0.8927 | 0.8925 |
| 0.2464 | 26.09 | 2400 | 0.2722 | 0.8961 | 0.8960 |
| 0.2452 | 28.26 | 2600 | 0.2672 | 0.8924 | 0.8925 |
| 0.2441 | 30.43 | 2800 | 0.2646 | 0.8954 | 0.8953 |
| 0.2392 | 32.61 | 3000 | 0.2662 | 0.8960 | 0.8960 |
| 0.236 | 34.78 | 3200 | 0.2602 | 0.8925 | 0.8925 |
| 0.2364 | 36.96 | 3400 | 0.2657 | 0.8968 | 0.8966 |
| 0.2351 | 39.13 | 3600 | 0.2631 | 0.8988 | 0.8987 |
| 0.2325 | 41.3 | 3800 | 0.2636 | 0.8974 | 0.8973 |
| 0.2306 | 43.48 | 4000 | 0.2671 | 0.8967 | 0.8966 |
| 0.2334 | 45.65 | 4200 | 0.2600 | 0.8960 | 0.8960 |
| 0.2262 | 47.83 | 4400 | 0.2623 | 0.8967 | 0.8966 |
| 0.231 | 50.0 | 4600 | 0.2588 | 0.8939 | 0.8939 |
| 0.2233 | 52.17 | 4800 | 0.2635 | 0.8961 | 0.8960 |
| 0.2256 | 54.35 | 5000 | 0.2710 | 0.8941 | 0.8939 |
| 0.2223 | 56.52 | 5200 | 0.2700 | 0.8934 | 0.8932 |
| 0.2214 | 58.7 | 5400 | 0.2653 | 0.8975 | 0.8973 |
| 0.2186 | 60.87 | 5600 | 0.2678 | 0.8942 | 0.8939 |
| 0.221 | 63.04 | 5800 | 0.2633 | 0.9009 | 0.9008 |
| 0.2185 | 65.22 | 6000 | 0.2671 | 0.8954 | 0.8953 |
| 0.2184 | 67.39 | 6200 | 0.2688 | 0.8948 | 0.8946 |
| 0.2168 | 69.57 | 6400 | 0.2615 | 0.8994 | 0.8994 |
| 0.2178 | 71.74 | 6600 | 0.2640 | 0.9002 | 0.9001 |
| 0.2162 | 73.91 | 6800 | 0.2676 | 0.8968 | 0.8966 |
| 0.2141 | 76.09 | 7000 | 0.2698 | 0.8935 | 0.8932 |
| 0.2138 | 78.26 | 7200 | 0.2695 | 0.8934 | 0.8932 |
| 0.2113 | 80.43 | 7400 | 0.2642 | 0.8981 | 0.8980 |
| 0.2107 | 82.61 | 7600 | 0.2620 | 0.8987 | 0.8987 |
| 0.2148 | 84.78 | 7800 | 0.2665 | 0.8989 | 0.8987 |
| 0.2109 | 86.96 | 8000 | 0.2640 | 0.9009 | 0.9008 |
| 0.2142 | 89.13 | 8200 | 0.2648 | 0.8995 | 0.8994 |
| 0.2084 | 91.3 | 8400 | 0.2635 | 0.9015 | 0.9014 |
| 0.2093 | 93.48 | 8600 | 0.2636 | 0.9015 | 0.9014 |
| 0.2106 | 95.65 | 8800 | 0.2644 | 0.9022 | 0.9021 |
| 0.2125 | 97.83 | 9000 | 0.2639 | 0.9022 | 0.9021 |
| 0.2079 | 100.0 | 9200 | 0.2666 | 0.8995 | 0.8994 |
| 0.2092 | 102.17 | 9400 | 0.2655 | 0.8995 | 0.8994 |
| 0.2087 | 104.35 | 9600 | 0.2666 | 0.9002 | 0.9001 |
| 0.2061 | 106.52 | 9800 | 0.2648 | 0.9009 | 0.9008 |
| 0.2083 | 108.7 | 10000 | 0.2658 | 0.8995 | 0.8994 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:36:38+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4-seqsight\_32768\_512\_43M-L1\_f
============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2537
* F1 Score: 0.9048
* Accuracy: 0.9049
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2507
- F1 Score: 0.9041
- Accuracy: 0.9042
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.3722 | 2.17 | 200 | 0.2879 | 0.8864 | 0.8864 |
| 0.2725 | 4.35 | 400 | 0.2825 | 0.8920 | 0.8919 |
| 0.2595 | 6.52 | 600 | 0.2679 | 0.8958 | 0.8960 |
| 0.2567 | 8.7 | 800 | 0.2810 | 0.8907 | 0.8905 |
| 0.2447 | 10.87 | 1000 | 0.2755 | 0.8890 | 0.8891 |
| 0.2411 | 13.04 | 1200 | 0.2641 | 0.8959 | 0.8960 |
| 0.2304 | 15.22 | 1400 | 0.2797 | 0.8914 | 0.8912 |
| 0.2235 | 17.39 | 1600 | 0.2681 | 0.8983 | 0.8980 |
| 0.2197 | 19.57 | 1800 | 0.2625 | 0.8989 | 0.8987 |
| 0.214 | 21.74 | 2000 | 0.2679 | 0.8934 | 0.8932 |
| 0.2067 | 23.91 | 2200 | 0.2711 | 0.8919 | 0.8919 |
| 0.2026 | 26.09 | 2400 | 0.2663 | 0.8955 | 0.8953 |
| 0.2 | 28.26 | 2600 | 0.2666 | 0.8954 | 0.8953 |
| 0.1983 | 30.43 | 2800 | 0.2663 | 0.8928 | 0.8925 |
| 0.1875 | 32.61 | 3000 | 0.2794 | 0.8987 | 0.8987 |
| 0.1812 | 34.78 | 3200 | 0.2828 | 0.8960 | 0.8960 |
| 0.1795 | 36.96 | 3400 | 0.2861 | 0.8941 | 0.8939 |
| 0.1754 | 39.13 | 3600 | 0.2897 | 0.8934 | 0.8932 |
| 0.1697 | 41.3 | 3800 | 0.2999 | 0.8932 | 0.8932 |
| 0.1616 | 43.48 | 4000 | 0.3106 | 0.8900 | 0.8898 |
| 0.1645 | 45.65 | 4200 | 0.3022 | 0.8918 | 0.8919 |
| 0.1601 | 47.83 | 4400 | 0.3078 | 0.8940 | 0.8939 |
| 0.1581 | 50.0 | 4600 | 0.3147 | 0.8911 | 0.8912 |
| 0.1537 | 52.17 | 4800 | 0.3123 | 0.8893 | 0.8891 |
| 0.1498 | 54.35 | 5000 | 0.3216 | 0.8818 | 0.8816 |
| 0.1452 | 56.52 | 5200 | 0.3378 | 0.8799 | 0.8795 |
| 0.1417 | 58.7 | 5400 | 0.3286 | 0.8839 | 0.8836 |
| 0.1404 | 60.87 | 5600 | 0.3191 | 0.8899 | 0.8898 |
| 0.1355 | 63.04 | 5800 | 0.3498 | 0.8769 | 0.8768 |
| 0.1333 | 65.22 | 6000 | 0.3440 | 0.8845 | 0.8843 |
| 0.1332 | 67.39 | 6200 | 0.3463 | 0.8852 | 0.8850 |
| 0.1295 | 69.57 | 6400 | 0.3534 | 0.8819 | 0.8816 |
| 0.1255 | 71.74 | 6600 | 0.3533 | 0.8858 | 0.8857 |
| 0.1264 | 73.91 | 6800 | 0.3561 | 0.8819 | 0.8816 |
| 0.1232 | 76.09 | 7000 | 0.3631 | 0.8818 | 0.8816 |
| 0.1179 | 78.26 | 7200 | 0.3653 | 0.8797 | 0.8795 |
| 0.1197 | 80.43 | 7400 | 0.3694 | 0.8831 | 0.8830 |
| 0.1127 | 82.61 | 7600 | 0.3778 | 0.8841 | 0.8843 |
| 0.1208 | 84.78 | 7800 | 0.3743 | 0.8811 | 0.8809 |
| 0.1134 | 86.96 | 8000 | 0.3756 | 0.8782 | 0.8782 |
| 0.1158 | 89.13 | 8200 | 0.3737 | 0.8818 | 0.8816 |
| 0.1119 | 91.3 | 8400 | 0.3773 | 0.8770 | 0.8768 |
| 0.1111 | 93.48 | 8600 | 0.3813 | 0.8816 | 0.8816 |
| 0.1108 | 95.65 | 8800 | 0.3786 | 0.8796 | 0.8795 |
| 0.1106 | 97.83 | 9000 | 0.3841 | 0.8790 | 0.8789 |
| 0.1101 | 100.0 | 9200 | 0.3845 | 0.8805 | 0.8802 |
| 0.1106 | 102.17 | 9400 | 0.3841 | 0.8791 | 0.8789 |
| 0.1091 | 104.35 | 9600 | 0.3813 | 0.8791 | 0.8789 |
| 0.105 | 106.52 | 9800 | 0.3847 | 0.8790 | 0.8789 |
| 0.1072 | 108.7 | 10000 | 0.3848 | 0.8770 | 0.8768 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:36:39+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4-seqsight\_32768\_512\_43M-L8\_f
============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2507
* F1 Score: 0.9041
* Accuracy: 0.9042
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3170
- F1 Score: 0.8730
- Accuracy: 0.8731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5063 | 2.13 | 200 | 0.4277 | 0.8016 | 0.8029 |
| 0.3674 | 4.26 | 400 | 0.3869 | 0.8349 | 0.8350 |
| 0.3338 | 6.38 | 600 | 0.3773 | 0.8415 | 0.8417 |
| 0.3189 | 8.51 | 800 | 0.3543 | 0.8564 | 0.8564 |
| 0.3056 | 10.64 | 1000 | 0.3430 | 0.8597 | 0.8597 |
| 0.294 | 12.77 | 1200 | 0.3415 | 0.8617 | 0.8617 |
| 0.2883 | 14.89 | 1400 | 0.3350 | 0.8677 | 0.8677 |
| 0.2803 | 17.02 | 1600 | 0.3305 | 0.8664 | 0.8664 |
| 0.2768 | 19.15 | 1800 | 0.3526 | 0.8595 | 0.8597 |
| 0.2715 | 21.28 | 2000 | 0.3447 | 0.8654 | 0.8657 |
| 0.2709 | 23.4 | 2200 | 0.3240 | 0.8664 | 0.8664 |
| 0.2568 | 25.53 | 2400 | 0.3675 | 0.8601 | 0.8604 |
| 0.2627 | 27.66 | 2600 | 0.3348 | 0.8703 | 0.8704 |
| 0.2611 | 29.79 | 2800 | 0.3316 | 0.8663 | 0.8664 |
| 0.2557 | 31.91 | 3000 | 0.3309 | 0.8683 | 0.8684 |
| 0.2524 | 34.04 | 3200 | 0.3312 | 0.8670 | 0.8671 |
| 0.2512 | 36.17 | 3400 | 0.3520 | 0.8641 | 0.8644 |
| 0.2484 | 38.3 | 3600 | 0.3412 | 0.8663 | 0.8664 |
| 0.2471 | 40.43 | 3800 | 0.3445 | 0.8608 | 0.8611 |
| 0.2468 | 42.55 | 4000 | 0.3551 | 0.8682 | 0.8684 |
| 0.2414 | 44.68 | 4200 | 0.3380 | 0.8704 | 0.8704 |
| 0.2407 | 46.81 | 4400 | 0.3474 | 0.8681 | 0.8684 |
| 0.2421 | 48.94 | 4600 | 0.3840 | 0.8486 | 0.8497 |
| 0.2374 | 51.06 | 4800 | 0.3319 | 0.8764 | 0.8764 |
| 0.2365 | 53.19 | 5000 | 0.3727 | 0.8605 | 0.8611 |
| 0.2352 | 55.32 | 5200 | 0.3354 | 0.8717 | 0.8717 |
| 0.234 | 57.45 | 5400 | 0.3719 | 0.8608 | 0.8611 |
| 0.2322 | 59.57 | 5600 | 0.3533 | 0.8695 | 0.8697 |
| 0.2354 | 61.7 | 5800 | 0.3387 | 0.8716 | 0.8717 |
| 0.2275 | 63.83 | 6000 | 0.3770 | 0.8599 | 0.8604 |
| 0.23 | 65.96 | 6200 | 0.3597 | 0.8646 | 0.8651 |
| 0.2301 | 68.09 | 6400 | 0.3545 | 0.8708 | 0.8711 |
| 0.2303 | 70.21 | 6600 | 0.3620 | 0.8661 | 0.8664 |
| 0.2298 | 72.34 | 6800 | 0.3576 | 0.8661 | 0.8664 |
| 0.2261 | 74.47 | 7000 | 0.4031 | 0.8480 | 0.8490 |
| 0.2229 | 76.6 | 7200 | 0.3632 | 0.8688 | 0.8691 |
| 0.2283 | 78.72 | 7400 | 0.3536 | 0.8723 | 0.8724 |
| 0.2243 | 80.85 | 7600 | 0.3611 | 0.8688 | 0.8691 |
| 0.2245 | 82.98 | 7800 | 0.3722 | 0.8620 | 0.8624 |
| 0.2252 | 85.11 | 8000 | 0.3506 | 0.8756 | 0.8758 |
| 0.2223 | 87.23 | 8200 | 0.3614 | 0.8688 | 0.8691 |
| 0.2214 | 89.36 | 8400 | 0.3702 | 0.8661 | 0.8664 |
| 0.223 | 91.49 | 8600 | 0.3739 | 0.8620 | 0.8624 |
| 0.2197 | 93.62 | 8800 | 0.3719 | 0.8661 | 0.8664 |
| 0.2205 | 95.74 | 9000 | 0.3758 | 0.8613 | 0.8617 |
| 0.2206 | 97.87 | 9200 | 0.3584 | 0.8736 | 0.8737 |
| 0.2208 | 100.0 | 9400 | 0.3588 | 0.8715 | 0.8717 |
| 0.2206 | 102.13 | 9600 | 0.3659 | 0.8675 | 0.8677 |
| 0.2182 | 104.26 | 9800 | 0.3645 | 0.8708 | 0.8711 |
| 0.2198 | 106.38 | 10000 | 0.3647 | 0.8708 | 0.8711 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:37:05+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3-seqsight\_32768\_512\_43M-L1\_f
============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3170
* F1 Score: 0.8730
* Accuracy: 0.8731
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2456
- F1 Score: 0.9063
- Accuracy: 0.9062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.3469 | 2.17 | 200 | 0.2894 | 0.8880 | 0.8877 |
| 0.2635 | 4.35 | 400 | 0.2678 | 0.8973 | 0.8973 |
| 0.2476 | 6.52 | 600 | 0.2672 | 0.8960 | 0.8960 |
| 0.2393 | 8.7 | 800 | 0.2811 | 0.8915 | 0.8912 |
| 0.2229 | 10.87 | 1000 | 0.2619 | 0.8993 | 0.8994 |
| 0.212 | 13.04 | 1200 | 0.2620 | 0.9003 | 0.9001 |
| 0.1957 | 15.22 | 1400 | 0.2997 | 0.8895 | 0.8891 |
| 0.1864 | 17.39 | 1600 | 0.2886 | 0.8915 | 0.8912 |
| 0.1764 | 19.57 | 1800 | 0.2986 | 0.8961 | 0.8960 |
| 0.1647 | 21.74 | 2000 | 0.3023 | 0.8887 | 0.8884 |
| 0.154 | 23.91 | 2200 | 0.3210 | 0.8901 | 0.8898 |
| 0.143 | 26.09 | 2400 | 0.3236 | 0.8915 | 0.8912 |
| 0.1354 | 28.26 | 2600 | 0.3311 | 0.8850 | 0.8850 |
| 0.1243 | 30.43 | 2800 | 0.3589 | 0.8725 | 0.8720 |
| 0.1152 | 32.61 | 3000 | 0.3594 | 0.8791 | 0.8789 |
| 0.1002 | 34.78 | 3200 | 0.4006 | 0.8853 | 0.8850 |
| 0.0952 | 36.96 | 3400 | 0.3912 | 0.8818 | 0.8816 |
| 0.0899 | 39.13 | 3600 | 0.4403 | 0.8809 | 0.8809 |
| 0.0816 | 41.3 | 3800 | 0.4618 | 0.8778 | 0.8782 |
| 0.0741 | 43.48 | 4000 | 0.4516 | 0.8741 | 0.8741 |
| 0.0743 | 45.65 | 4200 | 0.4487 | 0.8780 | 0.8782 |
| 0.0673 | 47.83 | 4400 | 0.4597 | 0.8898 | 0.8898 |
| 0.063 | 50.0 | 4600 | 0.4948 | 0.8817 | 0.8816 |
| 0.06 | 52.17 | 4800 | 0.5218 | 0.8749 | 0.8747 |
| 0.0529 | 54.35 | 5000 | 0.5205 | 0.8811 | 0.8809 |
| 0.0501 | 56.52 | 5200 | 0.5313 | 0.8845 | 0.8843 |
| 0.0473 | 58.7 | 5400 | 0.5863 | 0.8757 | 0.8754 |
| 0.0438 | 60.87 | 5600 | 0.5475 | 0.8763 | 0.8761 |
| 0.0432 | 63.04 | 5800 | 0.5901 | 0.8791 | 0.8789 |
| 0.0387 | 65.22 | 6000 | 0.6309 | 0.8669 | 0.8665 |
| 0.0361 | 67.39 | 6200 | 0.6609 | 0.8785 | 0.8782 |
| 0.0349 | 69.57 | 6400 | 0.6233 | 0.8754 | 0.8754 |
| 0.0331 | 71.74 | 6600 | 0.6171 | 0.8797 | 0.8795 |
| 0.0351 | 73.91 | 6800 | 0.6380 | 0.8852 | 0.8850 |
| 0.0288 | 76.09 | 7000 | 0.6467 | 0.8824 | 0.8823 |
| 0.0295 | 78.26 | 7200 | 0.6264 | 0.8776 | 0.8775 |
| 0.0277 | 80.43 | 7400 | 0.6538 | 0.8824 | 0.8823 |
| 0.0247 | 82.61 | 7600 | 0.6973 | 0.8809 | 0.8809 |
| 0.0278 | 84.78 | 7800 | 0.7178 | 0.8797 | 0.8795 |
| 0.0247 | 86.96 | 8000 | 0.6858 | 0.8843 | 0.8843 |
| 0.0237 | 89.13 | 8200 | 0.7218 | 0.8792 | 0.8789 |
| 0.022 | 91.3 | 8400 | 0.6885 | 0.8809 | 0.8809 |
| 0.0213 | 93.48 | 8600 | 0.7192 | 0.8831 | 0.8830 |
| 0.0214 | 95.65 | 8800 | 0.7241 | 0.8803 | 0.8802 |
| 0.0214 | 97.83 | 9000 | 0.7257 | 0.8790 | 0.8789 |
| 0.0184 | 100.0 | 9200 | 0.7460 | 0.8778 | 0.8775 |
| 0.0201 | 102.17 | 9400 | 0.7567 | 0.8770 | 0.8768 |
| 0.0191 | 104.35 | 9600 | 0.7382 | 0.8816 | 0.8816 |
| 0.0185 | 106.52 | 9800 | 0.7424 | 0.8803 | 0.8802 |
| 0.0185 | 108.7 | 10000 | 0.7438 | 0.8810 | 0.8809 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:37:07+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4-seqsight\_32768\_512\_43M-L32\_f
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2456
* F1 Score: 0.9063
* Accuracy: 0.9062
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi3nedtuned-ner
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
### License
The model is licensed under the MIT license. | {"license": "mit", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "microsoft/Phi-3-mini-4k-instruct", "model-index": [{"name": "checkpoint_dir", "results": []}]} | shujatoor/phi3nedtuned-ner | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
] | null | 2024-04-30T06:41:58+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-microsoft/Phi-3-mini-4k-instruct #license-mit #region-us
|
# phi3nedtuned-ner
This model is a fine-tuned version of microsoft/Phi-3-mini-4k-instruct on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
### License
The model is licensed under the MIT license. | [
"# phi3nedtuned-ner\n\nThis model is a fine-tuned version of microsoft/Phi-3-mini-4k-instruct on the generator dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.6568",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.2\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1",
"### License\n\nThe model is licensed under the MIT license."
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-microsoft/Phi-3-mini-4k-instruct #license-mit #region-us \n",
"# phi3nedtuned-ner\n\nThis model is a fine-tuned version of microsoft/Phi-3-mini-4k-instruct on the generator dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.6568",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.2\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1",
"### License\n\nThe model is licensed under the MIT license."
] | [
54,
56,
7,
9,
9,
4,
110,
5,
58,
13
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-microsoft/Phi-3-mini-4k-instruct #license-mit #region-us \n# phi3nedtuned-ner\n\nThis model is a fine-tuned version of microsoft/Phi-3-mini-4k-instruct on the generator dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.6568## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.2\n- num_epochs: 1### Training results### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1### License\n\nThe model is licensed under the MIT license."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3077
- F1 Score: 0.8791
- Accuracy: 0.8791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.4475 | 2.13 | 200 | 0.3711 | 0.8427 | 0.8430 |
| 0.3173 | 4.26 | 400 | 0.3464 | 0.8557 | 0.8557 |
| 0.291 | 6.38 | 600 | 0.3571 | 0.8615 | 0.8617 |
| 0.277 | 8.51 | 800 | 0.3289 | 0.8630 | 0.8631 |
| 0.2649 | 10.64 | 1000 | 0.3380 | 0.8650 | 0.8651 |
| 0.2537 | 12.77 | 1200 | 0.3459 | 0.8676 | 0.8677 |
| 0.2497 | 14.89 | 1400 | 0.3562 | 0.8621 | 0.8624 |
| 0.24 | 17.02 | 1600 | 0.3300 | 0.8757 | 0.8758 |
| 0.2347 | 19.15 | 1800 | 0.3622 | 0.8627 | 0.8631 |
| 0.2272 | 21.28 | 2000 | 0.3581 | 0.8695 | 0.8697 |
| 0.2244 | 23.4 | 2200 | 0.3776 | 0.8599 | 0.8604 |
| 0.207 | 25.53 | 2400 | 0.4066 | 0.8547 | 0.8550 |
| 0.2113 | 27.66 | 2600 | 0.3849 | 0.8633 | 0.8637 |
| 0.2094 | 29.79 | 2800 | 0.3830 | 0.8660 | 0.8664 |
| 0.2012 | 31.91 | 3000 | 0.3522 | 0.8696 | 0.8697 |
| 0.197 | 34.04 | 3200 | 0.3700 | 0.8715 | 0.8717 |
| 0.1945 | 36.17 | 3400 | 0.4030 | 0.8578 | 0.8584 |
| 0.1872 | 38.3 | 3600 | 0.4093 | 0.8661 | 0.8664 |
| 0.1861 | 40.43 | 3800 | 0.4181 | 0.8592 | 0.8597 |
| 0.1786 | 42.55 | 4000 | 0.4381 | 0.8599 | 0.8604 |
| 0.1745 | 44.68 | 4200 | 0.4421 | 0.8544 | 0.8550 |
| 0.1721 | 46.81 | 4400 | 0.3950 | 0.8654 | 0.8657 |
| 0.172 | 48.94 | 4600 | 0.4968 | 0.8457 | 0.8470 |
| 0.1635 | 51.06 | 4800 | 0.3863 | 0.8729 | 0.8731 |
| 0.1619 | 53.19 | 5000 | 0.4594 | 0.8585 | 0.8591 |
| 0.1593 | 55.32 | 5200 | 0.4623 | 0.8551 | 0.8557 |
| 0.1591 | 57.45 | 5400 | 0.4254 | 0.8622 | 0.8624 |
| 0.1557 | 59.57 | 5600 | 0.4582 | 0.8540 | 0.8544 |
| 0.1532 | 61.7 | 5800 | 0.4197 | 0.8663 | 0.8664 |
| 0.1485 | 63.83 | 6000 | 0.4785 | 0.8564 | 0.8570 |
| 0.1456 | 65.96 | 6200 | 0.4841 | 0.8578 | 0.8584 |
| 0.1444 | 68.09 | 6400 | 0.5085 | 0.8516 | 0.8524 |
| 0.1432 | 70.21 | 6600 | 0.4829 | 0.8626 | 0.8631 |
| 0.1426 | 72.34 | 6800 | 0.4582 | 0.8642 | 0.8644 |
| 0.1391 | 74.47 | 7000 | 0.5618 | 0.8461 | 0.8470 |
| 0.1348 | 76.6 | 7200 | 0.4947 | 0.8647 | 0.8651 |
| 0.1383 | 78.72 | 7400 | 0.4901 | 0.8593 | 0.8597 |
| 0.1317 | 80.85 | 7600 | 0.5457 | 0.8492 | 0.8497 |
| 0.1312 | 82.98 | 7800 | 0.5402 | 0.8484 | 0.8490 |
| 0.1311 | 85.11 | 8000 | 0.5053 | 0.8572 | 0.8577 |
| 0.1303 | 87.23 | 8200 | 0.5300 | 0.8544 | 0.8550 |
| 0.128 | 89.36 | 8400 | 0.5192 | 0.8572 | 0.8577 |
| 0.1281 | 91.49 | 8600 | 0.5447 | 0.8524 | 0.8530 |
| 0.1214 | 93.62 | 8800 | 0.5264 | 0.8553 | 0.8557 |
| 0.1244 | 95.74 | 9000 | 0.5569 | 0.8504 | 0.8510 |
| 0.1197 | 97.87 | 9200 | 0.5364 | 0.8572 | 0.8577 |
| 0.1241 | 100.0 | 9400 | 0.5406 | 0.8532 | 0.8537 |
| 0.1216 | 102.13 | 9600 | 0.5441 | 0.8511 | 0.8517 |
| 0.1177 | 104.26 | 9800 | 0.5631 | 0.8490 | 0.8497 |
| 0.1205 | 106.38 | 10000 | 0.5507 | 0.8504 | 0.8510 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:43:48+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3-seqsight\_32768\_512\_43M-L8\_f
============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3077
* F1 Score: 0.8791
* Accuracy: 0.8791
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
question-answering | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# question_answering
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 250 | 2.3267 |
| 2.6765 | 2.0 | 500 | 1.7452 |
| 2.6765 | 3.0 | 750 | 1.6818 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "distilbert/distilbert-base-uncased", "model-index": [{"name": "question_answering", "results": []}]} | madanagrawal/question_answering | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:44:02+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #question-answering #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us
| question\_answering
===================
This model is a fine-tuned version of distilbert/distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6818
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #question-answering #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
58,
101,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #question-answering #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3### Training results### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-generation | transformers |
# The AWQ version
This is the AWQ version of [MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct](https://huggingface.co/MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct) for the enthusiasts
<center>
<img src="https://cdn-uploads.huggingface.co/production/uploads/6116d0584ef9fdfbf45dc4d9/4VqGvuqtWgLOTavTV861j.png">
</center>
## How to use, you ask ?
First, Update your packages
```shell
pip3 install --upgrade autoawq transformers
```
Now, Copy and Run
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
attn_implementation="flash_attention_2", # disable if you have problems with flash attention 2
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
device_map="auto"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "مرحبا"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
generation_params = {
"do_sample": True,
"temperature": 0.6,
"top_p": 0.9,
"top_k": 40,
"max_new_tokens": 1024,
"eos_token_id": terminators,
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
| {"language": ["ar", "en"], "license": "llama3", "library_name": "transformers", "model_name": "Arabic ORPO 8B chat", "pipeline_tag": "text-generation", "model_type": "llama3", "quantized_by": "MohamedRashad"} | MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct-AWQ | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ar",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T06:44:03+00:00 | [] | [
"ar",
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #conversational #ar #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# The AWQ version
This is the AWQ version of MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct for the enthusiasts
<center>
<img src="URL
</center>
## How to use, you ask ?
First, Update your packages
Now, Copy and Run
| [
"# The AWQ version\nThis is the AWQ version of MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct for the enthusiasts\n\n<center>\n <img src=\"URL\n</center>",
"## How to use, you ask ?\n\nFirst, Update your packages\n\n\n\nNow, Copy and Run"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #ar #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# The AWQ version\nThis is the AWQ version of MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct for the enthusiasts\n\n<center>\n <img src=\"URL\n</center>",
"## How to use, you ask ?\n\nFirst, Update your packages\n\n\n\nNow, Copy and Run"
] | [
51,
50,
19
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #ar #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# The AWQ version\nThis is the AWQ version of MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct for the enthusiasts\n\n<center>\n <img src=\"URL\n</center>## How to use, you ask ?\n\nFirst, Update your packages\n\n\n\nNow, Copy and Run"
] |
audio-classification | speechbrain |
# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model
## Model description
This is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.
The model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses
more fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training.
We observed that this improved the performance of extracted utterance embeddings for downstream tasks.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.
The model can classify a speech utterance according to the language spoken.
It covers 107 different languages (
Abkhazian,
Afrikaans,
Amharic,
Arabic,
Assamese,
Azerbaijani,
Bashkir,
Belarusian,
Bulgarian,
Bengali,
Tibetan,
Breton,
Bosnian,
Catalan,
Cebuano,
Czech,
Welsh,
Danish,
German,
Greek,
English,
Esperanto,
Spanish,
Estonian,
Basque,
Persian,
Finnish,
Faroese,
French,
Galician,
Guarani,
Gujarati,
Manx,
Hausa,
Hawaiian,
Hindi,
Croatian,
Haitian,
Hungarian,
Armenian,
Interlingua,
Indonesian,
Icelandic,
Italian,
Hebrew,
Japanese,
Javanese,
Georgian,
Kazakh,
Central Khmer,
Kannada,
Korean,
Latin,
Luxembourgish,
Lingala,
Lao,
Lithuanian,
Latvian,
Malagasy,
Maori,
Macedonian,
Malayalam,
Mongolian,
Marathi,
Malay,
Maltese,
Burmese,
Nepali,
Dutch,
Norwegian Nynorsk,
Norwegian,
Occitan,
Panjabi,
Polish,
Pushto,
Portuguese,
Romanian,
Russian,
Sanskrit,
Scots,
Sindhi,
Sinhala,
Slovak,
Slovenian,
Shona,
Somali,
Albanian,
Serbian,
Sundanese,
Swedish,
Swahili,
Tamil,
Telugu,
Tajik,
Thai,
Turkmen,
Tagalog,
Turkish,
Tatar,
Ukrainian,
Urdu,
Uzbek,
Vietnamese,
Waray,
Yiddish,
Yoruba,
Mandarin Chinese).
## Intended uses & limitations
The model has two uses:
- use 'as is' for spoken language recognition
- use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data
The model is trained on automatically collected YouTube data. For more
information about the dataset, see [here](http://bark.phon.ioc.ee/voxlingua107/).
#### How to use
```bash
pip install git+https://github.com/speechbrain/speechbrain.git@develop
```
```python
import torchaudio
from speechbrain.inference.classifiers import EncoderClassifier
language_id = EncoderClassifier.from_hparams(source="speechbrain/lang-id-voxlingua107-ecapa", savedir="tmp")
# Download Thai language sample from Omniglot and cvert to suitable form
signal = language_id.load_audio("speechbrain/lang-id-voxlingua107-ecapa/udhr_th.wav")
prediction = language_id.classify_batch(signal)
print(prediction)
# (tensor([[-2.8646e+01, -3.0346e+01, -2.0748e+01, -2.9562e+01, -2.2187e+01,
# -3.2668e+01, -3.6677e+01, -3.3573e+01, -3.2545e+01, -2.4365e+01,
# -2.4688e+01, -3.1171e+01, -2.7743e+01, -2.9918e+01, -2.4770e+01,
# -3.2250e+01, -2.4727e+01, -2.6087e+01, -2.1870e+01, -3.2821e+01,
# -2.2128e+01, -2.2822e+01, -3.0888e+01, -3.3564e+01, -2.9906e+01,
# -2.2392e+01, -2.5573e+01, -2.6443e+01, -3.2429e+01, -3.2652e+01,
# -3.0030e+01, -2.4607e+01, -2.2967e+01, -2.4396e+01, -2.8578e+01,
# -2.5153e+01, -2.8475e+01, -2.6409e+01, -2.5230e+01, -2.7957e+01,
# -2.6298e+01, -2.3609e+01, -2.5863e+01, -2.8225e+01, -2.7225e+01,
# -3.0486e+01, -2.1185e+01, -2.7938e+01, -3.3155e+01, -1.9076e+01,
# -2.9181e+01, -2.2160e+01, -1.8352e+01, -2.5866e+01, -3.3636e+01,
# -4.2016e+00, -3.1581e+01, -3.1894e+01, -2.7834e+01, -2.5429e+01,
# -3.2235e+01, -3.2280e+01, -2.8786e+01, -2.3366e+01, -2.6047e+01,
# -2.2075e+01, -2.3770e+01, -2.2518e+01, -2.8101e+01, -2.5745e+01,
# -2.6441e+01, -2.9822e+01, -2.7109e+01, -3.0225e+01, -2.4566e+01,
# -2.9268e+01, -2.7651e+01, -3.4221e+01, -2.9026e+01, -2.6009e+01,
# -3.1968e+01, -3.1747e+01, -2.8156e+01, -2.9025e+01, -2.7756e+01,
# -2.8052e+01, -2.9341e+01, -2.8806e+01, -2.1636e+01, -2.3992e+01,
# -2.3794e+01, -3.3743e+01, -2.8332e+01, -2.7465e+01, -1.5085e-02,
# -2.9094e+01, -2.1444e+01, -2.9780e+01, -3.6046e+01, -3.7401e+01,
# -3.0888e+01, -3.3172e+01, -1.8931e+01, -2.2679e+01, -3.0225e+01,
# -2.4995e+01, -2.1028e+01]]), tensor([-0.0151]), tensor([94]), ['th'])
# The scores in the prediction[0] tensor can be interpreted as log-likelihoods that
# the given utterance belongs to the given language (i.e., the larger the better)
# The linear-scale likelihood can be retrieved using the following:
print(prediction[1].exp())
# tensor([0.9850])
# The identified language ISO code is given in prediction[3]
print(prediction[3])
# ['th: Thai']
# Alternatively, use the utterance embedding extractor:
emb = language_id.encode_batch(signal)
print(emb.shape)
# torch.Size([1, 1, 256])
```
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.
#### Limitations and bias
Since the model is trained on VoxLingua107, it has many limitations and biases, some of which are:
- Probably it's accuracy on smaller languages is quite limited
- Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)
- Based on subjective experiments, it doesn't work well on speech with a foreign accent
- Probably it doesn't work well on children's speech and on persons with speech disorders
## Training data
The model is trained on [VoxLingua107](http://bark.phon.ioc.ee/voxlingua107/).
VoxLingua107 is a speech dataset for training spoken language identification models.
The dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.
VoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours.
The average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.
## Training procedure
See the [SpeechBrain recipe](https://github.com/speechbrain/speechbrain/tree/voxlingua107/recipes/VoxLingua107/lang_id).
## Evaluation results
Error rate: 6.7% on the VoxLingua107 development dataset
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
### Referencing VoxLingua107
```bibtex
@inproceedings{valk2021slt,
title={{VoxLingua107}: a Dataset for Spoken Language Recognition},
author={J{\"o}rgen Valk and Tanel Alum{\"a}e},
booktitle={Proc. IEEE SLT Workshop},
year={2021},
}
```
#### About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.
Website: https://speechbrain.github.io/
GitHub: https://github.com/speechbrain/speechbrain
| {"language": ["multilingual", "ab", "af", "am", "ar", "as", "az", "ba", "be", "bg", "bi", "bo", "br", "bs", "ca", "ceb", "cs", "cy", "da", "de", "el", "en", "eo", "es", "et", "eu", "fa", "fi", "fo", "fr", "gl", "gn", "gu", "gv", "ha", "haw", "hi", "hr", "ht", "hu", "hy", "ia", "id", "is", "it", "he", "ja", "jv", "ka", "kk", "km", "kn", "ko", "la", "lm", "ln", "lo", "lt", "lv", "mg", "mi", "mk", "ml", "mn", "mr", "ms", "mt", "my", "ne", "nl", "nn", false, "oc", "pa", "pl", "ps", "pt", "ro", "ru", "sa", "sco", "sd", "si", "sk", "sl", "sn", "so", "sq", "sr", "su", "sv", "sw", "ta", "te", "tg", "th", "tk", "tl", "tr", "tt", "uk", "ud", "uz", "vi", "war", "yi", "yo", "zh"], "license": "apache-2.0", "tags": ["audio-classification", "speechbrain", "embeddings", "Language", "Identification", "pytorch", "ECAPA-TDNN", "TDNN", "VoxLingua107"], "datasets": ["VoxLingua107"], "metrics": ["Accuracy"], "widget": [{"example_title": "English Sample", "src": "https://cdn-media.huggingface.co/speech_samples/LibriSpeech_61-70968-0000.flac"}]} | botdevringring/lang-id-voxlingua107-ecapa | null | [
"speechbrain",
"audio-classification",
"embeddings",
"Language",
"Identification",
"pytorch",
"ECAPA-TDNN",
"TDNN",
"VoxLingua107",
"multilingual",
"ab",
"af",
"am",
"ar",
"as",
"az",
"ba",
"be",
"bg",
"bi",
"bo",
"br",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fo",
"fr",
"gl",
"gn",
"gu",
"gv",
"ha",
"haw",
"hi",
"hr",
"ht",
"hu",
"hy",
"ia",
"id",
"is",
"it",
"he",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"la",
"lm",
"ln",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"nn",
"no",
"oc",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sco",
"sd",
"si",
"sk",
"sl",
"sn",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tk",
"tl",
"tr",
"tt",
"uk",
"ud",
"uz",
"vi",
"war",
"yi",
"yo",
"zh",
"dataset:VoxLingua107",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:44:06+00:00 | [
"2106.04624"
] | [
"multilingual",
"ab",
"af",
"am",
"ar",
"as",
"az",
"ba",
"be",
"bg",
"bi",
"bo",
"br",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fo",
"fr",
"gl",
"gn",
"gu",
"gv",
"ha",
"haw",
"hi",
"hr",
"ht",
"hu",
"hy",
"ia",
"id",
"is",
"it",
"he",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"la",
"lm",
"ln",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"nn",
"no",
"oc",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sco",
"sd",
"si",
"sk",
"sl",
"sn",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tk",
"tl",
"tr",
"tt",
"uk",
"ud",
"uz",
"vi",
"war",
"yi",
"yo",
"zh"
] | TAGS
#speechbrain #audio-classification #embeddings #Language #Identification #pytorch #ECAPA-TDNN #TDNN #VoxLingua107 #multilingual #ab #af #am #ar #as #az #ba #be #bg #bi #bo #br #bs #ca #ceb #cs #cy #da #de #el #en #eo #es #et #eu #fa #fi #fo #fr #gl #gn #gu #gv #ha #haw #hi #hr #ht #hu #hy #ia #id #is #it #he #ja #jv #ka #kk #km #kn #ko #la #lm #ln #lo #lt #lv #mg #mi #mk #ml #mn #mr #ms #mt #my #ne #nl #nn #no #oc #pa #pl #ps #pt #ro #ru #sa #sco #sd #si #sk #sl #sn #so #sq #sr #su #sv #sw #ta #te #tg #th #tk #tl #tr #tt #uk #ud #uz #vi #war #yi #yo #zh #dataset-VoxLingua107 #arxiv-2106.04624 #license-apache-2.0 #region-us
|
# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model
## Model description
This is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.
The model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses
more fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training.
We observed that this improved the performance of extracted utterance embeddings for downstream tasks.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.
The model can classify a speech utterance according to the language spoken.
It covers 107 different languages (
Abkhazian,
Afrikaans,
Amharic,
Arabic,
Assamese,
Azerbaijani,
Bashkir,
Belarusian,
Bulgarian,
Bengali,
Tibetan,
Breton,
Bosnian,
Catalan,
Cebuano,
Czech,
Welsh,
Danish,
German,
Greek,
English,
Esperanto,
Spanish,
Estonian,
Basque,
Persian,
Finnish,
Faroese,
French,
Galician,
Guarani,
Gujarati,
Manx,
Hausa,
Hawaiian,
Hindi,
Croatian,
Haitian,
Hungarian,
Armenian,
Interlingua,
Indonesian,
Icelandic,
Italian,
Hebrew,
Japanese,
Javanese,
Georgian,
Kazakh,
Central Khmer,
Kannada,
Korean,
Latin,
Luxembourgish,
Lingala,
Lao,
Lithuanian,
Latvian,
Malagasy,
Maori,
Macedonian,
Malayalam,
Mongolian,
Marathi,
Malay,
Maltese,
Burmese,
Nepali,
Dutch,
Norwegian Nynorsk,
Norwegian,
Occitan,
Panjabi,
Polish,
Pushto,
Portuguese,
Romanian,
Russian,
Sanskrit,
Scots,
Sindhi,
Sinhala,
Slovak,
Slovenian,
Shona,
Somali,
Albanian,
Serbian,
Sundanese,
Swedish,
Swahili,
Tamil,
Telugu,
Tajik,
Thai,
Turkmen,
Tagalog,
Turkish,
Tatar,
Ukrainian,
Urdu,
Uzbek,
Vietnamese,
Waray,
Yiddish,
Yoruba,
Mandarin Chinese).
## Intended uses & limitations
The model has two uses:
- use 'as is' for spoken language recognition
- use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data
The model is trained on automatically collected YouTube data. For more
information about the dataset, see here.
#### How to use
To perform inference on the GPU, add 'run_opts={"device":"cuda"}' when calling the 'from_hparams' method.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.
#### Limitations and bias
Since the model is trained on VoxLingua107, it has many limitations and biases, some of which are:
- Probably it's accuracy on smaller languages is quite limited
- Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)
- Based on subjective experiments, it doesn't work well on speech with a foreign accent
- Probably it doesn't work well on children's speech and on persons with speech disorders
## Training data
The model is trained on VoxLingua107.
VoxLingua107 is a speech dataset for training spoken language identification models.
The dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.
VoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours.
The average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.
## Training procedure
See the SpeechBrain recipe.
## Evaluation results
Error rate: 6.7% on the VoxLingua107 development dataset
#### Referencing SpeechBrain
### Referencing VoxLingua107
#### About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.
Website: URL
GitHub: URL
| [
"# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model",
"## Model description\n\nThis is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.\nThe model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses\nmore fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training. \nWe observed that this improved the performance of extracted utterance embeddings for downstream tasks.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.\n\nThe model can classify a speech utterance according to the language spoken.\nIt covers 107 different languages (\nAbkhazian, \nAfrikaans, \nAmharic, \nArabic, \nAssamese, \nAzerbaijani, \nBashkir, \nBelarusian, \nBulgarian, \nBengali, \nTibetan, \nBreton, \nBosnian, \nCatalan, \nCebuano, \nCzech, \nWelsh, \nDanish, \nGerman, \nGreek, \nEnglish, \nEsperanto, \nSpanish, \nEstonian, \nBasque, \nPersian, \nFinnish, \nFaroese, \nFrench, \nGalician, \nGuarani, \nGujarati, \nManx, \nHausa, \nHawaiian, \nHindi, \nCroatian, \nHaitian, \nHungarian, \nArmenian, \nInterlingua, \nIndonesian, \nIcelandic, \nItalian, \nHebrew, \nJapanese, \nJavanese, \nGeorgian, \nKazakh, \nCentral Khmer, \nKannada, \nKorean, \nLatin, \nLuxembourgish, \nLingala, \nLao, \nLithuanian, \nLatvian, \nMalagasy, \nMaori, \nMacedonian, \nMalayalam, \nMongolian, \nMarathi, \nMalay, \nMaltese, \nBurmese, \nNepali, \nDutch, \nNorwegian Nynorsk, \nNorwegian, \nOccitan, \nPanjabi, \nPolish, \nPushto, \nPortuguese, \nRomanian, \nRussian, \nSanskrit, \nScots, \nSindhi, \nSinhala, \nSlovak, \nSlovenian, \nShona, \nSomali, \nAlbanian, \nSerbian, \nSundanese, \nSwedish, \nSwahili, \nTamil, \nTelugu, \nTajik, \nThai, \nTurkmen, \nTagalog, \nTurkish, \nTatar, \nUkrainian, \nUrdu, \nUzbek, \nVietnamese, \nWaray, \nYiddish, \nYoruba, \nMandarin Chinese).",
"## Intended uses & limitations\n\nThe model has two uses:\n\n - use 'as is' for spoken language recognition\n - use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data\n \nThe model is trained on automatically collected YouTube data. For more \ninformation about the dataset, see here.",
"#### How to use\n\n\n\nTo perform inference on the GPU, add 'run_opts={\"device\":\"cuda\"}' when calling the 'from_hparams' method.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.",
"#### Limitations and bias\n\nSince the model is trained on VoxLingua107, it has many limitations and biases, some of which are:\n\n - Probably it's accuracy on smaller languages is quite limited\n - Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)\n - Based on subjective experiments, it doesn't work well on speech with a foreign accent\n - Probably it doesn't work well on children's speech and on persons with speech disorders",
"## Training data\n\nThe model is trained on VoxLingua107.\n\nVoxLingua107 is a speech dataset for training spoken language identification models. \nThe dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.\n\nVoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours. \nThe average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.",
"## Training procedure\n\nSee the SpeechBrain recipe.",
"## Evaluation results\n\nError rate: 6.7% on the VoxLingua107 development dataset",
"#### Referencing SpeechBrain",
"### Referencing VoxLingua107",
"#### About SpeechBrain\nSpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.\nWebsite: URL\nGitHub: URL"
] | [
"TAGS\n#speechbrain #audio-classification #embeddings #Language #Identification #pytorch #ECAPA-TDNN #TDNN #VoxLingua107 #multilingual #ab #af #am #ar #as #az #ba #be #bg #bi #bo #br #bs #ca #ceb #cs #cy #da #de #el #en #eo #es #et #eu #fa #fi #fo #fr #gl #gn #gu #gv #ha #haw #hi #hr #ht #hu #hy #ia #id #is #it #he #ja #jv #ka #kk #km #kn #ko #la #lm #ln #lo #lt #lv #mg #mi #mk #ml #mn #mr #ms #mt #my #ne #nl #nn #no #oc #pa #pl #ps #pt #ro #ru #sa #sco #sd #si #sk #sl #sn #so #sq #sr #su #sv #sw #ta #te #tg #th #tk #tl #tr #tt #uk #ud #uz #vi #war #yi #yo #zh #dataset-VoxLingua107 #arxiv-2106.04624 #license-apache-2.0 #region-us \n",
"# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model",
"## Model description\n\nThis is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.\nThe model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses\nmore fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training. \nWe observed that this improved the performance of extracted utterance embeddings for downstream tasks.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.\n\nThe model can classify a speech utterance according to the language spoken.\nIt covers 107 different languages (\nAbkhazian, \nAfrikaans, \nAmharic, \nArabic, \nAssamese, \nAzerbaijani, \nBashkir, \nBelarusian, \nBulgarian, \nBengali, \nTibetan, \nBreton, \nBosnian, \nCatalan, \nCebuano, \nCzech, \nWelsh, \nDanish, \nGerman, \nGreek, \nEnglish, \nEsperanto, \nSpanish, \nEstonian, \nBasque, \nPersian, \nFinnish, \nFaroese, \nFrench, \nGalician, \nGuarani, \nGujarati, \nManx, \nHausa, \nHawaiian, \nHindi, \nCroatian, \nHaitian, \nHungarian, \nArmenian, \nInterlingua, \nIndonesian, \nIcelandic, \nItalian, \nHebrew, \nJapanese, \nJavanese, \nGeorgian, \nKazakh, \nCentral Khmer, \nKannada, \nKorean, \nLatin, \nLuxembourgish, \nLingala, \nLao, \nLithuanian, \nLatvian, \nMalagasy, \nMaori, \nMacedonian, \nMalayalam, \nMongolian, \nMarathi, \nMalay, \nMaltese, \nBurmese, \nNepali, \nDutch, \nNorwegian Nynorsk, \nNorwegian, \nOccitan, \nPanjabi, \nPolish, \nPushto, \nPortuguese, \nRomanian, \nRussian, \nSanskrit, \nScots, \nSindhi, \nSinhala, \nSlovak, \nSlovenian, \nShona, \nSomali, \nAlbanian, \nSerbian, \nSundanese, \nSwedish, \nSwahili, \nTamil, \nTelugu, \nTajik, \nThai, \nTurkmen, \nTagalog, \nTurkish, \nTatar, \nUkrainian, \nUrdu, \nUzbek, \nVietnamese, \nWaray, \nYiddish, \nYoruba, \nMandarin Chinese).",
"## Intended uses & limitations\n\nThe model has two uses:\n\n - use 'as is' for spoken language recognition\n - use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data\n \nThe model is trained on automatically collected YouTube data. For more \ninformation about the dataset, see here.",
"#### How to use\n\n\n\nTo perform inference on the GPU, add 'run_opts={\"device\":\"cuda\"}' when calling the 'from_hparams' method.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.",
"#### Limitations and bias\n\nSince the model is trained on VoxLingua107, it has many limitations and biases, some of which are:\n\n - Probably it's accuracy on smaller languages is quite limited\n - Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)\n - Based on subjective experiments, it doesn't work well on speech with a foreign accent\n - Probably it doesn't work well on children's speech and on persons with speech disorders",
"## Training data\n\nThe model is trained on VoxLingua107.\n\nVoxLingua107 is a speech dataset for training spoken language identification models. \nThe dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.\n\nVoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours. \nThe average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.",
"## Training procedure\n\nSee the SpeechBrain recipe.",
"## Evaluation results\n\nError rate: 6.7% on the VoxLingua107 development dataset",
"#### Referencing SpeechBrain",
"### Referencing VoxLingua107",
"#### About SpeechBrain\nSpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.\nWebsite: URL\nGitHub: URL"
] | [
312,
15,
419,
71,
121,
102,
147,
11,
21,
8,
9,
67
] | [
"TAGS\n#speechbrain #audio-classification #embeddings #Language #Identification #pytorch #ECAPA-TDNN #TDNN #VoxLingua107 #multilingual #ab #af #am #ar #as #az #ba #be #bg #bi #bo #br #bs #ca #ceb #cs #cy #da #de #el #en #eo #es #et #eu #fa #fi #fo #fr #gl #gn #gu #gv #ha #haw #hi #hr #ht #hu #hy #ia #id #is #it #he #ja #jv #ka #kk #km #kn #ko #la #lm #ln #lo #lt #lv #mg #mi #mk #ml #mn #mr #ms #mt #my #ne #nl #nn #no #oc #pa #pl #ps #pt #ro #ru #sa #sco #sd #si #sk #sl #sn #so #sq #sr #su #sv #sw #ta #te #tg #th #tk #tl #tr #tt #uk #ud #uz #vi #war #yi #yo #zh #dataset-VoxLingua107 #arxiv-2106.04624 #license-apache-2.0 #region-us \n# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model## Model description\n\nThis is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.\nThe model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses\nmore fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training. \nWe observed that this improved the performance of extracted utterance embeddings for downstream tasks.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.\n\nThe model can classify a speech utterance according to the language spoken.\nIt covers 107 different languages (\nAbkhazian, \nAfrikaans, \nAmharic, \nArabic, \nAssamese, \nAzerbaijani, \nBashkir, \nBelarusian, \nBulgarian, \nBengali, \nTibetan, \nBreton, \nBosnian, \nCatalan, \nCebuano, \nCzech, \nWelsh, \nDanish, \nGerman, \nGreek, \nEnglish, \nEsperanto, \nSpanish, \nEstonian, \nBasque, \nPersian, \nFinnish, \nFaroese, \nFrench, \nGalician, \nGuarani, \nGujarati, \nManx, \nHausa, \nHawaiian, \nHindi, \nCroatian, \nHaitian, \nHungarian, \nArmenian, \nInterlingua, \nIndonesian, \nIcelandic, \nItalian, \nHebrew, \nJapanese, \nJavanese, \nGeorgian, \nKazakh, \nCentral Khmer, \nKannada, \nKorean, \nLatin, \nLuxembourgish, \nLingala, \nLao, \nLithuanian, \nLatvian, \nMalagasy, \nMaori, \nMacedonian, \nMalayalam, \nMongolian, \nMarathi, \nMalay, \nMaltese, \nBurmese, \nNepali, \nDutch, \nNorwegian Nynorsk, \nNorwegian, \nOccitan, \nPanjabi, \nPolish, \nPushto, \nPortuguese, \nRomanian, \nRussian, \nSanskrit, \nScots, \nSindhi, \nSinhala, \nSlovak, \nSlovenian, \nShona, \nSomali, \nAlbanian, \nSerbian, \nSundanese, \nSwedish, \nSwahili, \nTamil, \nTelugu, \nTajik, \nThai, \nTurkmen, \nTagalog, \nTurkish, \nTatar, \nUkrainian, \nUrdu, \nUzbek, \nVietnamese, \nWaray, \nYiddish, \nYoruba, \nMandarin Chinese).## Intended uses & limitations\n\nThe model has two uses:\n\n - use 'as is' for spoken language recognition\n - use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data\n \nThe model is trained on automatically collected YouTube data. For more \ninformation about the dataset, see here.#### How to use\n\n\n\nTo perform inference on the GPU, add 'run_opts={\"device\":\"cuda\"}' when calling the 'from_hparams' method.\n\nThe system is trained with recordings sampled at 16kHz (single channel).\nThe code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.#### Limitations and bias\n\nSince the model is trained on VoxLingua107, it has many limitations and biases, some of which are:\n\n - Probably it's accuracy on smaller languages is quite limited\n - Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)\n - Based on subjective experiments, it doesn't work well on speech with a foreign accent\n - Probably it doesn't work well on children's speech and on persons with speech disorders## Training data\n\nThe model is trained on VoxLingua107.\n\nVoxLingua107 is a speech dataset for training spoken language identification models. \nThe dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.\n\nVoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours. \nThe average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.## Training procedure\n\nSee the SpeechBrain recipe.## Evaluation results\n\nError rate: 6.7% on the VoxLingua107 development dataset#### Referencing SpeechBrain### Referencing VoxLingua107#### About SpeechBrain\nSpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.\nWebsite: URL\nGitHub: URL"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | abc88767/model15 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:44:08+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - embracellm/sushi06_LoRA
<Gallery />
## Model description
These are embracellm/sushi06_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sushi to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](embracellm/sushi06_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | {"license": "openrail++", "library_name": "diffusers", "tags": ["text-to-image", "text-to-image", "diffusers-training", "diffusers", "dora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers", "text-to-image", "text-to-image", "diffusers-training", "diffusers", "dora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers"], "base_model": "stabilityai/stable-diffusion-xl-base-1.0", "instance_prompt": "a photo of sushi", "widget": []} | embracellm/sushi06_LoRA | null | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | null | 2024-04-30T06:44:29+00:00 | [] | [] | TAGS
#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us
|
# SDXL LoRA DreamBooth - embracellm/sushi06_LoRA
<Gallery />
## Model description
These are embracellm/sushi06_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using DreamBooth.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sushi to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
Download them in the Files & versions tab.
## Intended uses & limitations
#### How to use
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | [
"# SDXL LoRA DreamBooth - embracellm/sushi06_LoRA\n\n<Gallery />",
"## Model description\n\nThese are embracellm/sushi06_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use a photo of sushi to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
] | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n",
"# SDXL LoRA DreamBooth - embracellm/sushi06_LoRA\n\n<Gallery />",
"## Model description\n\nThese are embracellm/sushi06_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use a photo of sushi to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
] | [
72,
25,
85,
18,
25,
6,
7,
23,
17
] | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n# SDXL LoRA DreamBooth - embracellm/sushi06_LoRA\n\n<Gallery />## Model description\n\nThese are embracellm/sushi06_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.## Trigger words\n\nYou should use a photo of sushi to trigger the image generation.## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.## Intended uses & limitations#### How to use#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]## Training details\n\n[TODO: describe the data used to train the model]"
] |
text-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.34203216433525085
f1_macro: 0.9457020850649197
f1_micro: 0.946067415730337
f1_weighted: 0.9461015789750475
precision_macro: 0.9447370569809594
precision_micro: 0.946067415730337
precision_weighted: 0.9466487598452521
recall_macro: 0.9472065189712249
recall_micro: 0.946067415730337
recall_weighted: 0.946067415730337
accuracy: 0.946067415730337
| {"tags": ["autotrain", "text-classification"], "datasets": ["autotrain-7ejr4-3wbhb/autotrain-data"], "widget": [{"text": "I love AutoTrain"}]} | NawinCom/autotrain-7ejr4-3wbhb | null | [
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"autotrain",
"dataset:autotrain-7ejr4-3wbhb/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:44:49+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #xlm-roberta #text-classification #autotrain #dataset-autotrain-7ejr4-3wbhb/autotrain-data #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.34203216433525085
f1_macro: 0.9457020850649197
f1_micro: 0.946067415730337
f1_weighted: 0.9461015789750475
precision_macro: 0.9447370569809594
precision_micro: 0.946067415730337
precision_weighted: 0.9466487598452521
recall_macro: 0.9472065189712249
recall_micro: 0.946067415730337
recall_weighted: 0.946067415730337
accuracy: 0.946067415730337
| [
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 0.34203216433525085\n\nf1_macro: 0.9457020850649197\n\nf1_micro: 0.946067415730337\n\nf1_weighted: 0.9461015789750475\n\nprecision_macro: 0.9447370569809594\n\nprecision_micro: 0.946067415730337\n\nprecision_weighted: 0.9466487598452521\n\nrecall_macro: 0.9472065189712249\n\nrecall_micro: 0.946067415730337\n\nrecall_weighted: 0.946067415730337\n\naccuracy: 0.946067415730337"
] | [
"TAGS\n#transformers #tensorboard #safetensors #xlm-roberta #text-classification #autotrain #dataset-autotrain-7ejr4-3wbhb/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 0.34203216433525085\n\nf1_macro: 0.9457020850649197\n\nf1_micro: 0.946067415730337\n\nf1_weighted: 0.9461015789750475\n\nprecision_macro: 0.9447370569809594\n\nprecision_micro: 0.946067415730337\n\nprecision_weighted: 0.9466487598452521\n\nrecall_macro: 0.9472065189712249\n\nrecall_micro: 0.946067415730337\n\nrecall_weighted: 0.946067415730337\n\naccuracy: 0.946067415730337"
] | [
57,
12,
171
] | [
"TAGS\n#transformers #tensorboard #safetensors #xlm-roberta #text-classification #autotrain #dataset-autotrain-7ejr4-3wbhb/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n# Model Trained Using AutoTrain\n\n- Problem type: Text Classification## Validation Metrics\nloss: 0.34203216433525085\n\nf1_macro: 0.9457020850649197\n\nf1_micro: 0.946067415730337\n\nf1_weighted: 0.9461015789750475\n\nprecision_macro: 0.9447370569809594\n\nprecision_micro: 0.946067415730337\n\nprecision_weighted: 0.9466487598452521\n\nrecall_macro: 0.9472065189712249\n\nrecall_micro: 0.946067415730337\n\nrecall_weighted: 0.946067415730337\n\naccuracy: 0.946067415730337"
] |
text-generation | transformers | This model is a version of mistralai/Mistral-7B-v0.1 that has been fine-tuned with Our In House CustomData.
Train Spec :
We utilized an A100x4 * 1 for training our model
with DeepSpeed / HuggingFace TRL Trainer / HuggingFace Accelerate | {"language": ["ko"], "license": "cc-by-nc-4.0", "datasets": ["Custom_datasets"], "pipeline_tag": "text-generation", "base_model": "mistralai/Mistral-7B-v0.1"} | Alphacode-AI/AlphaMist7B-slr-v4 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"ko",
"dataset:Custom_datasets",
"base_model:mistralai/Mistral-7B-v0.1",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:45:30+00:00 | [] | [
"ko"
] | TAGS
#transformers #safetensors #mistral #text-generation #conversational #ko #dataset-Custom_datasets #base_model-mistralai/Mistral-7B-v0.1 #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| This model is a version of mistralai/Mistral-7B-v0.1 that has been fine-tuned with Our In House CustomData.
Train Spec :
We utilized an A100x4 * 1 for training our model
with DeepSpeed / HuggingFace TRL Trainer / HuggingFace Accelerate | [] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #ko #dataset-Custom_datasets #base_model-mistralai/Mistral-7B-v0.1 #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] | [
79
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #ko #dataset-Custom_datasets #base_model-mistralai/Mistral-7B-v0.1 #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3075
- F1 Score: 0.8811
- Accuracy: 0.8811
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.4234 | 2.13 | 200 | 0.3424 | 0.8521 | 0.8524 |
| 0.2988 | 4.26 | 400 | 0.3195 | 0.8711 | 0.8711 |
| 0.2705 | 6.38 | 600 | 0.3480 | 0.8629 | 0.8631 |
| 0.2565 | 8.51 | 800 | 0.3229 | 0.8743 | 0.8744 |
| 0.243 | 10.64 | 1000 | 0.3370 | 0.8770 | 0.8771 |
| 0.2254 | 12.77 | 1200 | 0.3412 | 0.8750 | 0.8751 |
| 0.2151 | 14.89 | 1400 | 0.3951 | 0.8594 | 0.8597 |
| 0.2035 | 17.02 | 1600 | 0.3441 | 0.8791 | 0.8791 |
| 0.1934 | 19.15 | 1800 | 0.3769 | 0.8655 | 0.8657 |
| 0.1763 | 21.28 | 2000 | 0.3976 | 0.8730 | 0.8731 |
| 0.1728 | 23.4 | 2200 | 0.4589 | 0.8592 | 0.8597 |
| 0.1499 | 25.53 | 2400 | 0.4406 | 0.8703 | 0.8704 |
| 0.1466 | 27.66 | 2600 | 0.4950 | 0.8544 | 0.8550 |
| 0.1407 | 29.79 | 2800 | 0.5317 | 0.8543 | 0.8550 |
| 0.1267 | 31.91 | 3000 | 0.4777 | 0.8627 | 0.8631 |
| 0.1214 | 34.04 | 3200 | 0.5038 | 0.8547 | 0.8550 |
| 0.1121 | 36.17 | 3400 | 0.5701 | 0.8623 | 0.8631 |
| 0.1013 | 38.3 | 3600 | 0.5882 | 0.8492 | 0.8497 |
| 0.094 | 40.43 | 3800 | 0.6015 | 0.8544 | 0.8550 |
| 0.0839 | 42.55 | 4000 | 0.7460 | 0.8433 | 0.8444 |
| 0.0822 | 44.68 | 4200 | 0.6918 | 0.8383 | 0.8397 |
| 0.0786 | 46.81 | 4400 | 0.6802 | 0.8551 | 0.8557 |
| 0.0749 | 48.94 | 4600 | 0.7523 | 0.8405 | 0.8417 |
| 0.0627 | 51.06 | 4800 | 0.6662 | 0.8588 | 0.8591 |
| 0.0628 | 53.19 | 5000 | 0.7466 | 0.8573 | 0.8577 |
| 0.0572 | 55.32 | 5200 | 0.8095 | 0.8511 | 0.8517 |
| 0.0542 | 57.45 | 5400 | 0.7983 | 0.8492 | 0.8497 |
| 0.0495 | 59.57 | 5600 | 0.8882 | 0.8477 | 0.8484 |
| 0.0467 | 61.7 | 5800 | 0.7923 | 0.8527 | 0.8530 |
| 0.0453 | 63.83 | 6000 | 0.8642 | 0.8442 | 0.8450 |
| 0.0398 | 65.96 | 6200 | 0.9339 | 0.8408 | 0.8417 |
| 0.0407 | 68.09 | 6400 | 0.9011 | 0.8436 | 0.8444 |
| 0.0394 | 70.21 | 6600 | 0.8747 | 0.8498 | 0.8504 |
| 0.0363 | 72.34 | 6800 | 0.8441 | 0.8574 | 0.8577 |
| 0.0349 | 74.47 | 7000 | 0.8893 | 0.8459 | 0.8464 |
| 0.032 | 76.6 | 7200 | 0.8798 | 0.8549 | 0.8550 |
| 0.0352 | 78.72 | 7400 | 0.8617 | 0.8588 | 0.8591 |
| 0.0283 | 80.85 | 7600 | 0.8505 | 0.8590 | 0.8591 |
| 0.0307 | 82.98 | 7800 | 0.9578 | 0.8460 | 0.8464 |
| 0.0275 | 85.11 | 8000 | 0.9154 | 0.8514 | 0.8517 |
| 0.0304 | 87.23 | 8200 | 0.9107 | 0.8534 | 0.8537 |
| 0.0256 | 89.36 | 8400 | 0.9299 | 0.8540 | 0.8544 |
| 0.0254 | 91.49 | 8600 | 0.9893 | 0.8459 | 0.8464 |
| 0.022 | 93.62 | 8800 | 0.9983 | 0.8534 | 0.8537 |
| 0.0236 | 95.74 | 9000 | 0.9772 | 0.8513 | 0.8517 |
| 0.0198 | 97.87 | 9200 | 1.0070 | 0.8507 | 0.8510 |
| 0.0244 | 100.0 | 9400 | 0.9825 | 0.8527 | 0.8530 |
| 0.0202 | 102.13 | 9600 | 0.9848 | 0.8506 | 0.8510 |
| 0.0204 | 104.26 | 9800 | 1.0325 | 0.8499 | 0.8504 |
| 0.0212 | 106.38 | 10000 | 1.0237 | 0.8500 | 0.8504 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:46:15+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3-seqsight\_32768\_512\_43M-L32\_f
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3075
* F1 Score: 0.8811
* Accuracy: 0.8811
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4ac-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5568
- F1 Score: 0.7302
- Accuracy: 0.7299
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6494 | 0.93 | 200 | 0.5994 | 0.6882 | 0.6880 |
| 0.5949 | 1.87 | 400 | 0.5857 | 0.7052 | 0.7056 |
| 0.5714 | 2.8 | 600 | 0.5656 | 0.7207 | 0.7205 |
| 0.5601 | 3.74 | 800 | 0.5623 | 0.7274 | 0.7273 |
| 0.5523 | 4.67 | 1000 | 0.5614 | 0.7313 | 0.7314 |
| 0.5455 | 5.61 | 1200 | 0.5629 | 0.7267 | 0.7273 |
| 0.5444 | 6.54 | 1400 | 0.5550 | 0.7301 | 0.7305 |
| 0.5339 | 7.48 | 1600 | 0.5490 | 0.7360 | 0.7358 |
| 0.5404 | 8.41 | 1800 | 0.5517 | 0.7348 | 0.7349 |
| 0.5358 | 9.35 | 2000 | 0.5593 | 0.7299 | 0.7305 |
| 0.5283 | 10.28 | 2200 | 0.5499 | 0.7368 | 0.7367 |
| 0.5335 | 11.21 | 2400 | 0.5521 | 0.7322 | 0.7326 |
| 0.5253 | 12.15 | 2600 | 0.5545 | 0.7360 | 0.7364 |
| 0.5262 | 13.08 | 2800 | 0.5572 | 0.7332 | 0.7337 |
| 0.5265 | 14.02 | 3000 | 0.5480 | 0.7372 | 0.7372 |
| 0.5241 | 14.95 | 3200 | 0.5501 | 0.7416 | 0.7416 |
| 0.5209 | 15.89 | 3400 | 0.5538 | 0.7364 | 0.7370 |
| 0.519 | 16.82 | 3600 | 0.5406 | 0.7430 | 0.7428 |
| 0.525 | 17.76 | 3800 | 0.5488 | 0.7412 | 0.7413 |
| 0.5204 | 18.69 | 4000 | 0.5406 | 0.7371 | 0.7370 |
| 0.5169 | 19.63 | 4200 | 0.5417 | 0.7428 | 0.7428 |
| 0.5191 | 20.56 | 4400 | 0.5373 | 0.7419 | 0.7416 |
| 0.517 | 21.5 | 4600 | 0.5523 | 0.7337 | 0.7346 |
| 0.5157 | 22.43 | 4800 | 0.5360 | 0.7461 | 0.7457 |
| 0.5139 | 23.36 | 5000 | 0.5473 | 0.7385 | 0.7387 |
| 0.5135 | 24.3 | 5200 | 0.5335 | 0.7454 | 0.7452 |
| 0.5145 | 25.23 | 5400 | 0.5362 | 0.7422 | 0.7419 |
| 0.515 | 26.17 | 5600 | 0.5359 | 0.7409 | 0.7408 |
| 0.5134 | 27.1 | 5800 | 0.5351 | 0.7442 | 0.7440 |
| 0.5076 | 28.04 | 6000 | 0.5365 | 0.7463 | 0.7460 |
| 0.5147 | 28.97 | 6200 | 0.5486 | 0.7368 | 0.7372 |
| 0.5115 | 29.91 | 6400 | 0.5365 | 0.7451 | 0.7449 |
| 0.5095 | 30.84 | 6600 | 0.5499 | 0.7376 | 0.7381 |
| 0.5105 | 31.78 | 6800 | 0.5339 | 0.7461 | 0.7457 |
| 0.5087 | 32.71 | 7000 | 0.5372 | 0.7416 | 0.7413 |
| 0.5059 | 33.64 | 7200 | 0.5415 | 0.7397 | 0.7399 |
| 0.509 | 34.58 | 7400 | 0.5360 | 0.7427 | 0.7425 |
| 0.509 | 35.51 | 7600 | 0.5332 | 0.7440 | 0.7437 |
| 0.5045 | 36.45 | 7800 | 0.5376 | 0.7434 | 0.7431 |
| 0.5085 | 37.38 | 8000 | 0.5448 | 0.7399 | 0.7402 |
| 0.5036 | 38.32 | 8200 | 0.5411 | 0.7411 | 0.7411 |
| 0.5051 | 39.25 | 8400 | 0.5373 | 0.7410 | 0.7408 |
| 0.5081 | 40.19 | 8600 | 0.5353 | 0.7480 | 0.7478 |
| 0.5063 | 41.12 | 8800 | 0.5387 | 0.7423 | 0.7422 |
| 0.5026 | 42.06 | 9000 | 0.5382 | 0.7457 | 0.7455 |
| 0.5068 | 42.99 | 9200 | 0.5410 | 0.7431 | 0.7431 |
| 0.5057 | 43.93 | 9400 | 0.5387 | 0.7438 | 0.7437 |
| 0.5038 | 44.86 | 9600 | 0.5369 | 0.7442 | 0.7440 |
| 0.5042 | 45.79 | 9800 | 0.5379 | 0.7424 | 0.7422 |
| 0.504 | 46.73 | 10000 | 0.5396 | 0.7429 | 0.7428 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4ac-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4ac-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:47:09+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4ac-seqsight\_32768\_512\_43M-L1\_f
==============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4ac dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5568
* F1 Score: 0.7302
* Accuracy: 0.7299
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NDD-addressbook_test-content
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1234
- Accuracy: 0.9794
- F1: 0.9795
- Precision: 0.9795
- Recall: 0.9794
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.1144 | 1.0 | 694 | 0.1669 | 0.9325 | 0.9340 | 0.9406 | 0.9325 |
| 0.0671 | 2.0 | 1388 | 0.1234 | 0.9794 | 0.9795 | 0.9795 | 0.9794 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1", "precision", "recall"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "NDD-addressbook_test-content", "results": []}]} | lgk03/NDD-addressbook_test-content | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:48:26+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| NDD-addressbook\_test-content
=============================
This model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1234
* Accuracy: 0.9794
* F1: 0.9795
* Precision: 0.9795
* Recall: 0.9794
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.40.1
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
59,
124,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2### Training results### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | liuyuxiang/wiki_cs_retriever | null | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:51:00+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #distilbert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #distilbert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
39,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #distilbert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4ac-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5503
- F1 Score: 0.7420
- Accuracy: 0.7419
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6213 | 0.93 | 200 | 0.5851 | 0.7076 | 0.7076 |
| 0.5618 | 1.87 | 400 | 0.5700 | 0.7194 | 0.7199 |
| 0.5444 | 2.8 | 600 | 0.5485 | 0.7343 | 0.7340 |
| 0.5373 | 3.74 | 800 | 0.5428 | 0.7358 | 0.7355 |
| 0.5324 | 4.67 | 1000 | 0.5398 | 0.7358 | 0.7355 |
| 0.5243 | 5.61 | 1200 | 0.5563 | 0.7260 | 0.7270 |
| 0.5245 | 6.54 | 1400 | 0.5494 | 0.7330 | 0.7334 |
| 0.5128 | 7.48 | 1600 | 0.5476 | 0.7361 | 0.7361 |
| 0.5189 | 8.41 | 1800 | 0.5409 | 0.7418 | 0.7416 |
| 0.5118 | 9.35 | 2000 | 0.5376 | 0.7449 | 0.7446 |
| 0.5046 | 10.28 | 2200 | 0.5365 | 0.7462 | 0.7460 |
| 0.5076 | 11.21 | 2400 | 0.5480 | 0.7362 | 0.7367 |
| 0.4986 | 12.15 | 2600 | 0.5483 | 0.7416 | 0.7419 |
| 0.4973 | 13.08 | 2800 | 0.5433 | 0.7431 | 0.7428 |
| 0.4969 | 14.02 | 3000 | 0.5424 | 0.7451 | 0.7449 |
| 0.4918 | 14.95 | 3200 | 0.5431 | 0.7466 | 0.7463 |
| 0.4895 | 15.89 | 3400 | 0.5316 | 0.7481 | 0.7478 |
| 0.4864 | 16.82 | 3600 | 0.5444 | 0.7385 | 0.7387 |
| 0.4884 | 17.76 | 3800 | 0.5854 | 0.7272 | 0.7296 |
| 0.4872 | 18.69 | 4000 | 0.5287 | 0.7457 | 0.7455 |
| 0.4797 | 19.63 | 4200 | 0.5321 | 0.7419 | 0.7416 |
| 0.4811 | 20.56 | 4400 | 0.5319 | 0.7434 | 0.7431 |
| 0.4753 | 21.5 | 4600 | 0.5392 | 0.7441 | 0.7440 |
| 0.4758 | 22.43 | 4800 | 0.5264 | 0.7462 | 0.7460 |
| 0.4712 | 23.36 | 5000 | 0.5409 | 0.7468 | 0.7466 |
| 0.4729 | 24.3 | 5200 | 0.5321 | 0.7437 | 0.7434 |
| 0.4709 | 25.23 | 5400 | 0.5293 | 0.7495 | 0.7493 |
| 0.4692 | 26.17 | 5600 | 0.5361 | 0.7434 | 0.7431 |
| 0.4656 | 27.1 | 5800 | 0.5423 | 0.7434 | 0.7431 |
| 0.4623 | 28.04 | 6000 | 0.5445 | 0.7449 | 0.7446 |
| 0.4666 | 28.97 | 6200 | 0.5433 | 0.7474 | 0.7472 |
| 0.4619 | 29.91 | 6400 | 0.5397 | 0.7448 | 0.7446 |
| 0.4625 | 30.84 | 6600 | 0.5419 | 0.7436 | 0.7434 |
| 0.4606 | 31.78 | 6800 | 0.5357 | 0.7457 | 0.7455 |
| 0.459 | 32.71 | 7000 | 0.5367 | 0.7469 | 0.7466 |
| 0.4574 | 33.64 | 7200 | 0.5461 | 0.7458 | 0.7460 |
| 0.4572 | 34.58 | 7400 | 0.5355 | 0.7443 | 0.7440 |
| 0.4557 | 35.51 | 7600 | 0.5353 | 0.7437 | 0.7434 |
| 0.4501 | 36.45 | 7800 | 0.5408 | 0.7461 | 0.7457 |
| 0.4555 | 37.38 | 8000 | 0.5449 | 0.7418 | 0.7416 |
| 0.4497 | 38.32 | 8200 | 0.5391 | 0.7440 | 0.7437 |
| 0.4503 | 39.25 | 8400 | 0.5371 | 0.7434 | 0.7431 |
| 0.4503 | 40.19 | 8600 | 0.5423 | 0.7455 | 0.7452 |
| 0.4513 | 41.12 | 8800 | 0.5433 | 0.7460 | 0.7457 |
| 0.4467 | 42.06 | 9000 | 0.5450 | 0.7448 | 0.7446 |
| 0.4503 | 42.99 | 9200 | 0.5434 | 0.7431 | 0.7428 |
| 0.4505 | 43.93 | 9400 | 0.5413 | 0.7469 | 0.7466 |
| 0.445 | 44.86 | 9600 | 0.5428 | 0.7472 | 0.7469 |
| 0.4449 | 45.79 | 9800 | 0.5431 | 0.7457 | 0.7455 |
| 0.4472 | 46.73 | 10000 | 0.5443 | 0.7445 | 0.7443 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4ac-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4ac-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:52:14+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4ac-seqsight\_32768\_512\_43M-L8\_f
==============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4ac dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5503
* F1 Score: 0.7420
* Accuracy: 0.7419
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4ac-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5495
- F1 Score: 0.7460
- Accuracy: 0.7457
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6028 | 0.93 | 200 | 0.5707 | 0.7234 | 0.7232 |
| 0.5476 | 1.87 | 400 | 0.5531 | 0.7327 | 0.7328 |
| 0.5337 | 2.8 | 600 | 0.5433 | 0.7406 | 0.7405 |
| 0.5254 | 3.74 | 800 | 0.5333 | 0.7454 | 0.7452 |
| 0.5186 | 4.67 | 1000 | 0.5295 | 0.7472 | 0.7469 |
| 0.5073 | 5.61 | 1200 | 0.5392 | 0.7429 | 0.7431 |
| 0.5042 | 6.54 | 1400 | 0.5318 | 0.7497 | 0.7496 |
| 0.4913 | 7.48 | 1600 | 0.5410 | 0.7490 | 0.7490 |
| 0.4938 | 8.41 | 1800 | 0.5278 | 0.7506 | 0.7504 |
| 0.4831 | 9.35 | 2000 | 0.5265 | 0.7483 | 0.7481 |
| 0.4749 | 10.28 | 2200 | 0.5293 | 0.7507 | 0.7504 |
| 0.4745 | 11.21 | 2400 | 0.5542 | 0.7411 | 0.7422 |
| 0.4646 | 12.15 | 2600 | 0.5342 | 0.7636 | 0.7633 |
| 0.4617 | 13.08 | 2800 | 0.5458 | 0.7553 | 0.7551 |
| 0.4581 | 14.02 | 3000 | 0.5805 | 0.7434 | 0.7443 |
| 0.4486 | 14.95 | 3200 | 0.5552 | 0.7556 | 0.7554 |
| 0.4428 | 15.89 | 3400 | 0.5262 | 0.7573 | 0.7572 |
| 0.4387 | 16.82 | 3600 | 0.5551 | 0.7445 | 0.7446 |
| 0.4353 | 17.76 | 3800 | 0.6040 | 0.7281 | 0.7305 |
| 0.4309 | 18.69 | 4000 | 0.5432 | 0.7528 | 0.7525 |
| 0.4236 | 19.63 | 4200 | 0.5479 | 0.7504 | 0.7501 |
| 0.4156 | 20.56 | 4400 | 0.5539 | 0.7519 | 0.7516 |
| 0.4097 | 21.5 | 4600 | 0.5632 | 0.7467 | 0.7466 |
| 0.4072 | 22.43 | 4800 | 0.5566 | 0.7478 | 0.7475 |
| 0.4042 | 23.36 | 5000 | 0.5636 | 0.7481 | 0.7481 |
| 0.3992 | 24.3 | 5200 | 0.5658 | 0.7426 | 0.7425 |
| 0.394 | 25.23 | 5400 | 0.5724 | 0.7431 | 0.7428 |
| 0.3909 | 26.17 | 5600 | 0.5892 | 0.7440 | 0.7440 |
| 0.382 | 27.1 | 5800 | 0.6073 | 0.7325 | 0.7328 |
| 0.3745 | 28.04 | 6000 | 0.5808 | 0.7495 | 0.7493 |
| 0.375 | 28.97 | 6200 | 0.5961 | 0.7445 | 0.7443 |
| 0.3683 | 29.91 | 6400 | 0.6048 | 0.7355 | 0.7355 |
| 0.3664 | 30.84 | 6600 | 0.5912 | 0.7427 | 0.7425 |
| 0.3607 | 31.78 | 6800 | 0.6004 | 0.7454 | 0.7452 |
| 0.3556 | 32.71 | 7000 | 0.6231 | 0.7393 | 0.7393 |
| 0.3523 | 33.64 | 7200 | 0.6199 | 0.7389 | 0.7393 |
| 0.3511 | 34.58 | 7400 | 0.6349 | 0.7362 | 0.7367 |
| 0.3471 | 35.51 | 7600 | 0.6107 | 0.7404 | 0.7402 |
| 0.3426 | 36.45 | 7800 | 0.6431 | 0.7434 | 0.7434 |
| 0.342 | 37.38 | 8000 | 0.6399 | 0.7401 | 0.7402 |
| 0.3393 | 38.32 | 8200 | 0.6360 | 0.7406 | 0.7405 |
| 0.3359 | 39.25 | 8400 | 0.6354 | 0.7386 | 0.7384 |
| 0.3355 | 40.19 | 8600 | 0.6395 | 0.7436 | 0.7434 |
| 0.3347 | 41.12 | 8800 | 0.6416 | 0.7419 | 0.7419 |
| 0.3278 | 42.06 | 9000 | 0.6515 | 0.7431 | 0.7431 |
| 0.3273 | 42.99 | 9200 | 0.6489 | 0.7412 | 0.7411 |
| 0.3227 | 43.93 | 9400 | 0.6407 | 0.7391 | 0.7390 |
| 0.3206 | 44.86 | 9600 | 0.6471 | 0.7415 | 0.7413 |
| 0.3215 | 45.79 | 9800 | 0.6479 | 0.7413 | 0.7411 |
| 0.3209 | 46.73 | 10000 | 0.6473 | 0.7398 | 0.7396 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4ac-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4ac-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:52:58+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4ac-seqsight\_32768\_512\_43M-L32\_f
===============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4ac dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5495
* F1 Score: 0.7460
* Accuracy: 0.7457
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K79me3-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K79me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K79me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4417
- F1 Score: 0.8154
- Accuracy: 0.8155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5369 | 1.1 | 200 | 0.4673 | 0.7966 | 0.7972 |
| 0.4674 | 2.21 | 400 | 0.4700 | 0.7852 | 0.7874 |
| 0.4562 | 3.31 | 600 | 0.4488 | 0.7980 | 0.7992 |
| 0.4438 | 4.42 | 800 | 0.4431 | 0.8018 | 0.8027 |
| 0.4454 | 5.52 | 1000 | 0.4541 | 0.7987 | 0.8006 |
| 0.4346 | 6.63 | 1200 | 0.4567 | 0.8020 | 0.8037 |
| 0.4422 | 7.73 | 1400 | 0.4403 | 0.8054 | 0.8065 |
| 0.4327 | 8.84 | 1600 | 0.4613 | 0.7981 | 0.8003 |
| 0.4346 | 9.94 | 1800 | 0.4350 | 0.8170 | 0.8169 |
| 0.4321 | 11.05 | 2000 | 0.4455 | 0.8075 | 0.8089 |
| 0.4307 | 12.15 | 2200 | 0.4366 | 0.8133 | 0.8141 |
| 0.4273 | 13.26 | 2400 | 0.4389 | 0.8131 | 0.8141 |
| 0.4258 | 14.36 | 2600 | 0.4368 | 0.8091 | 0.8100 |
| 0.4266 | 15.47 | 2800 | 0.4492 | 0.7996 | 0.8017 |
| 0.4223 | 16.57 | 3000 | 0.4333 | 0.8151 | 0.8155 |
| 0.4237 | 17.68 | 3200 | 0.4332 | 0.8104 | 0.8114 |
| 0.4183 | 18.78 | 3400 | 0.4322 | 0.8128 | 0.8135 |
| 0.419 | 19.89 | 3600 | 0.4462 | 0.8022 | 0.8041 |
| 0.4185 | 20.99 | 3800 | 0.4410 | 0.8074 | 0.8086 |
| 0.4179 | 22.1 | 4000 | 0.4346 | 0.8092 | 0.8103 |
| 0.4157 | 23.2 | 4200 | 0.4372 | 0.8098 | 0.8110 |
| 0.4163 | 24.31 | 4400 | 0.4476 | 0.8057 | 0.8076 |
| 0.4103 | 25.41 | 4600 | 0.4446 | 0.8096 | 0.8110 |
| 0.417 | 26.52 | 4800 | 0.4360 | 0.8124 | 0.8135 |
| 0.4154 | 27.62 | 5000 | 0.4362 | 0.8108 | 0.8121 |
| 0.411 | 28.73 | 5200 | 0.4374 | 0.8069 | 0.8086 |
| 0.4095 | 29.83 | 5400 | 0.4357 | 0.8117 | 0.8128 |
| 0.4095 | 30.94 | 5600 | 0.4342 | 0.8168 | 0.8176 |
| 0.4104 | 32.04 | 5800 | 0.4315 | 0.8159 | 0.8166 |
| 0.4074 | 33.15 | 6000 | 0.4332 | 0.8130 | 0.8141 |
| 0.4072 | 34.25 | 6200 | 0.4370 | 0.8153 | 0.8162 |
| 0.4072 | 35.36 | 6400 | 0.4403 | 0.8098 | 0.8114 |
| 0.4072 | 36.46 | 6600 | 0.4308 | 0.8162 | 0.8169 |
| 0.4077 | 37.57 | 6800 | 0.4367 | 0.8128 | 0.8141 |
| 0.4026 | 38.67 | 7000 | 0.4393 | 0.8133 | 0.8145 |
| 0.403 | 39.78 | 7200 | 0.4378 | 0.8139 | 0.8152 |
| 0.4065 | 40.88 | 7400 | 0.4327 | 0.8135 | 0.8145 |
| 0.4056 | 41.99 | 7600 | 0.4360 | 0.8144 | 0.8155 |
| 0.4035 | 43.09 | 7800 | 0.4411 | 0.8120 | 0.8135 |
| 0.4054 | 44.2 | 8000 | 0.4417 | 0.8091 | 0.8107 |
| 0.4018 | 45.3 | 8200 | 0.4363 | 0.8141 | 0.8152 |
| 0.4013 | 46.41 | 8400 | 0.4362 | 0.8131 | 0.8141 |
| 0.4038 | 47.51 | 8600 | 0.4398 | 0.8128 | 0.8141 |
| 0.3989 | 48.62 | 8800 | 0.4425 | 0.8095 | 0.8110 |
| 0.4007 | 49.72 | 9000 | 0.4387 | 0.8136 | 0.8148 |
| 0.4044 | 50.83 | 9200 | 0.4437 | 0.8100 | 0.8117 |
| 0.3988 | 51.93 | 9400 | 0.4412 | 0.8117 | 0.8131 |
| 0.4 | 53.04 | 9600 | 0.4397 | 0.8121 | 0.8135 |
| 0.4003 | 54.14 | 9800 | 0.4386 | 0.8136 | 0.8148 |
| 0.4009 | 55.25 | 10000 | 0.4408 | 0.8117 | 0.8131 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K79me3-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K79me3-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:53:35+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K79me3-seqsight\_32768\_512\_43M-L1\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K79me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4417
* F1 Score: 0.8154
* Accuracy: 0.8155
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | null | # Model Card: North Mistral 7B - GGML
## Model Overview
The **North Mistral 7B** is part of a series of research experiements into creating Scandinavian LLMs. The current versions are pretrained only, so they will have to be finetuned before used. This repo provides experiemental GGML-versions of these models.
## Model Architecture
North Mistral 7B is based on the Mistral architecture, renowned for its effectiveness in capturing complex patterns in large datasets. It utilizes a multi-layer transformer decoder structure.
| version | checkpoint | val_loss |
|---------|------------|----------|
| v0.1 | [40k](https://huggingface.co/north/north-mistral-7b-ggml/blob/main/north-mistral-v0.1.gguf) | 1.449 |
## Training Data
The model was trained on a diverse dataset primarily in English, Swedish, Danish and Norwegian. A complete datacard will be published later.
## Intended Use
This model is intended for developers and researchers only. It is particularly suited for applications requiring understanding and generating human-like text, including conversational agents, content generation tools, and automated translation services.
## Limitations
- The model will exhibit biases present in the training data.
- Performance can vary significantly depending on the specificity of the task and the nature of the input data.
- High computational requirements for inference may limit deployment on low-resource devices.
## Ethical Considerations
Users are encouraged to evaluate the model carefully in controlled environments before deploying it in critical applications. Ethical use guidelines should be followed to prevent misuse of the model's capabilities, particularly in sensitive contexts.
## Licensing
North Mistral 7B is released under the MIT Public License, which allows for both academic and commercial use.
| {"license": "mit"} | north/north-mistral-7b-ggml | null | [
"gguf",
"license:mit",
"region:us"
] | null | 2024-04-30T06:53:42+00:00 | [] | [] | TAGS
#gguf #license-mit #region-us
| Model Card: North Mistral 7B - GGML
===================================
Model Overview
--------------
The North Mistral 7B is part of a series of research experiements into creating Scandinavian LLMs. The current versions are pretrained only, so they will have to be finetuned before used. This repo provides experiemental GGML-versions of these models.
Model Architecture
------------------
North Mistral 7B is based on the Mistral architecture, renowned for its effectiveness in capturing complex patterns in large datasets. It utilizes a multi-layer transformer decoder structure.
version: v0.1, checkpoint: 40k, val\_loss: 1.449
Training Data
-------------
The model was trained on a diverse dataset primarily in English, Swedish, Danish and Norwegian. A complete datacard will be published later.
Intended Use
------------
This model is intended for developers and researchers only. It is particularly suited for applications requiring understanding and generating human-like text, including conversational agents, content generation tools, and automated translation services.
Limitations
-----------
* The model will exhibit biases present in the training data.
* Performance can vary significantly depending on the specificity of the task and the nature of the input data.
* High computational requirements for inference may limit deployment on low-resource devices.
Ethical Considerations
----------------------
Users are encouraged to evaluate the model carefully in controlled environments before deploying it in critical applications. Ethical use guidelines should be followed to prevent misuse of the model's capabilities, particularly in sensitive contexts.
Licensing
---------
North Mistral 7B is released under the MIT Public License, which allows for both academic and commercial use.
| [] | [
"TAGS\n#gguf #license-mit #region-us \n"
] | [
13
] | [
"TAGS\n#gguf #license-mit #region-us \n"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/curtisxu/huggingface/runs/bxujthiq)
# mergeLlama-7b-Instruct-hf-quantized-peft-decompile
This model is a fine-tuned version of [meta-llama/CodeLlama-7b-Instruct-hf](https://huggingface.co/meta-llama/CodeLlama-7b-Instruct-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"license": "llama2", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "meta-llama/CodeLlama-7b-Instruct-hf", "model-index": [{"name": "mergeLlama-7b-Instruct-hf-quantized-peft-decompile", "results": []}]} | curtisxu/mergeLlama-7b-Instruct-hf-quantized-peft-decompile | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/CodeLlama-7b-Instruct-hf",
"license:llama2",
"region:us"
] | null | 2024-04-30T06:54:33+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #base_model-meta-llama/CodeLlama-7b-Instruct-hf #license-llama2 #region-us
|
<img src="URL alt="Visualize in Weights & Biases" width="200" height="32"/>
# mergeLlama-7b-Instruct-hf-quantized-peft-decompile
This model is a fine-tuned version of meta-llama/CodeLlama-7b-Instruct-hf on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | [
"# mergeLlama-7b-Instruct-hf-quantized-peft-decompile\n\nThis model is a fine-tuned version of meta-llama/CodeLlama-7b-Instruct-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.1\n- training_steps: 200\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #base_model-meta-llama/CodeLlama-7b-Instruct-hf #license-llama2 #region-us \n",
"# mergeLlama-7b-Instruct-hf-quantized-peft-decompile\n\nThis model is a fine-tuned version of meta-llama/CodeLlama-7b-Instruct-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.1\n- training_steps: 200\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
55,
55,
7,
9,
9,
4,
133,
5,
58
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #base_model-meta-llama/CodeLlama-7b-Instruct-hf #license-llama2 #region-us \n# mergeLlama-7b-Instruct-hf-quantized-peft-decompile\n\nThis model is a fine-tuned version of meta-llama/CodeLlama-7b-Instruct-hf on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.1\n- training_steps: 200\n- mixed_precision_training: Native AMP### Training results### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.41.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA1
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0203
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 80
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.0135 | 0.09 | 10 | 0.3204 |
| 0.1991 | 0.18 | 20 | 0.1575 |
| 0.15 | 0.27 | 30 | 0.1643 |
| 0.1573 | 0.36 | 40 | 0.1525 |
| 0.1495 | 0.45 | 50 | 0.1508 |
| 0.1514 | 0.54 | 60 | 0.1491 |
| 0.149 | 0.63 | 70 | 0.1476 |
| 0.15 | 0.73 | 80 | 0.1597 |
| 0.146 | 0.82 | 90 | 0.1489 |
| 0.1504 | 0.91 | 100 | 0.1455 |
| 0.1358 | 1.0 | 110 | 0.0842 |
| 0.1868 | 1.09 | 120 | 0.1344 |
| 0.1262 | 1.18 | 130 | 0.1144 |
| 0.1965 | 1.27 | 140 | 0.1019 |
| 0.0895 | 1.36 | 150 | 0.0772 |
| 0.0653 | 1.45 | 160 | 0.0576 |
| 0.043 | 1.54 | 170 | 0.0449 |
| 0.0641 | 1.63 | 180 | 0.0361 |
| 0.0392 | 1.72 | 190 | 0.0259 |
| 0.0275 | 1.81 | 200 | 0.0246 |
| 0.0256 | 1.9 | 210 | 0.0254 |
| 0.023 | 1.99 | 220 | 0.0246 |
| 0.0278 | 2.08 | 230 | 0.0241 |
| 0.0246 | 2.18 | 240 | 0.0227 |
| 0.0201 | 2.27 | 250 | 0.0251 |
| 0.0229 | 2.36 | 260 | 0.0223 |
| 0.0196 | 2.45 | 270 | 0.0213 |
| 0.0167 | 2.54 | 280 | 0.0210 |
| 0.0236 | 2.63 | 290 | 0.0207 |
| 0.0199 | 2.72 | 300 | 0.0204 |
| 0.0207 | 2.81 | 310 | 0.0203 |
| 0.0207 | 2.9 | 320 | 0.0203 |
| 0.0217 | 2.99 | 330 | 0.0203 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA1", "results": []}]} | Litzy619/O0430HMA1 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:55:38+00:00 | [] | [] | TAGS
#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us
| O0430HMA1
=========
This model is a fine-tuned version of allenai/OLMo-1B on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0203
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 80
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.1.2+cu121
* Datasets 2.14.6
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
35,
160,
5,
47
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] |
null | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mamba_text_classification
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2144
- Accuracy: 0.944
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0088 | 0.1 | 625 | 0.2663 | 0.9216 |
| 3.5723 | 0.2 | 1250 | 0.3047 | 0.8962 |
| 1.4067 | 0.3 | 1875 | 0.2881 | 0.919 |
| 0.278 | 0.4 | 2500 | 0.2252 | 0.9322 |
| 0.0034 | 0.5 | 3125 | 0.2200 | 0.9382 |
| 2.526 | 0.6 | 3750 | 0.2670 | 0.9354 |
| 0.5528 | 0.7 | 4375 | 0.2209 | 0.9386 |
| 0.0006 | 0.8 | 5000 | 0.2294 | 0.9432 |
| 0.0358 | 0.9 | 5625 | 0.2167 | 0.9438 |
| 0.5311 | 1.0 | 6250 | 0.2144 | 0.944 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"tags": ["generated_from_trainer"], "metrics": ["accuracy"], "model-index": [{"name": "mamba_text_classification", "results": []}]} | TRanHieu009/mamba_text_classification | null | [
"transformers",
"pytorch",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:57:09+00:00 | [] | [] | TAGS
#transformers #pytorch #generated_from_trainer #endpoints_compatible #region-us
| mamba\_text\_classification
===========================
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2144
* Accuracy: 0.944
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 4
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_ratio: 0.01
* num\_epochs: 1
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.01\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #pytorch #generated_from_trainer #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.01\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
23,
121,
5,
44
] | [
"TAGS\n#transformers #pytorch #generated_from_trainer #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.01\n* num\\_epochs: 1### Training results### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-31m", "model-index": [{"name": "robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2", "results": []}]} | AlignmentResearch/robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:57:28+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2
This model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
62,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# final_V1-bert-text-classification-model
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1498
- Accuracy: 0.9713
- F1: 0.8341
- Precision: 0.8330
- Recall: 0.8356
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.6252 | 0.11 | 50 | 1.7120 | 0.3451 | 0.1545 | 0.2382 | 0.1762 |
| 0.7857 | 0.22 | 100 | 0.7296 | 0.8209 | 0.4973 | 0.4815 | 0.5166 |
| 0.2986 | 0.33 | 150 | 0.5358 | 0.8830 | 0.6565 | 0.6402 | 0.6744 |
| 0.2612 | 0.44 | 200 | 0.4678 | 0.9035 | 0.6704 | 0.6621 | 0.6795 |
| 0.153 | 0.55 | 250 | 0.4325 | 0.9065 | 0.6648 | 0.6446 | 0.6879 |
| 0.2274 | 0.66 | 300 | 0.3498 | 0.8969 | 0.6440 | 0.6237 | 0.6677 |
| 0.1449 | 0.76 | 350 | 0.4254 | 0.8964 | 0.6885 | 0.8012 | 0.6895 |
| 0.1695 | 0.87 | 400 | 0.3484 | 0.9248 | 0.7301 | 0.7857 | 0.7208 |
| 0.1206 | 0.98 | 450 | 0.3075 | 0.9218 | 0.7351 | 0.7586 | 0.7279 |
| 0.1142 | 1.09 | 500 | 0.2241 | 0.9467 | 0.8063 | 0.7964 | 0.8218 |
| 0.0642 | 1.2 | 550 | 0.2527 | 0.9491 | 0.8159 | 0.8106 | 0.8239 |
| 0.0935 | 1.31 | 600 | 0.1961 | 0.9601 | 0.8216 | 0.8270 | 0.8173 |
| 0.0755 | 1.42 | 650 | 0.1290 | 0.9691 | 0.8272 | 0.8348 | 0.8201 |
| 0.108 | 1.53 | 700 | 0.1712 | 0.9612 | 0.8215 | 0.8311 | 0.8130 |
| 0.0667 | 1.64 | 750 | 0.1449 | 0.9716 | 0.8354 | 0.8371 | 0.8338 |
| 0.0925 | 1.75 | 800 | 0.1193 | 0.9721 | 0.8345 | 0.8353 | 0.8337 |
| 0.0769 | 1.86 | 850 | 0.1477 | 0.9675 | 0.8299 | 0.8270 | 0.8334 |
| 0.0558 | 1.97 | 900 | 0.1988 | 0.9606 | 0.8239 | 0.8194 | 0.8299 |
| 0.0379 | 2.07 | 950 | 0.1546 | 0.9694 | 0.8319 | 0.8300 | 0.8340 |
| 0.0358 | 2.18 | 1000 | 0.1871 | 0.9655 | 0.8295 | 0.8283 | 0.8312 |
| 0.0248 | 2.29 | 1050 | 0.1631 | 0.9661 | 0.8303 | 0.8278 | 0.8333 |
| 0.0412 | 2.4 | 1100 | 0.1688 | 0.9658 | 0.8283 | 0.8235 | 0.8340 |
| 0.0096 | 2.51 | 1150 | 0.1726 | 0.9661 | 0.8316 | 0.8297 | 0.8342 |
| 0.0025 | 2.62 | 1200 | 0.1808 | 0.9653 | 0.8300 | 0.8261 | 0.8348 |
| 0.0074 | 2.73 | 1250 | 0.1697 | 0.9677 | 0.8323 | 0.8291 | 0.8360 |
| 0.028 | 2.84 | 1300 | 0.1630 | 0.9705 | 0.8359 | 0.8344 | 0.8377 |
| 0.0292 | 2.95 | 1350 | 0.1743 | 0.9696 | 0.8352 | 0.8341 | 0.8366 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1", "precision", "recall"], "base_model": "bert-base-uncased", "model-index": [{"name": "final_V1-bert-text-classification-model", "results": []}]} | AmirlyPhd/final_V1-bert-text-classification-model | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:59:00+00:00 | [] | [] | TAGS
#transformers #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| final\_V1-bert-text-classification-model
========================================
This model is a fine-tuned version of bert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1498
* Accuracy: 0.9713
* F1: 0.8341
* Precision: 0.8330
* Recall: 0.8356
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 16
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
52,
128,
5,
40
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-31m", "model-index": [{"name": "robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1", "results": []}]} | AlignmentResearch/robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:59:13+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1
This model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 1\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 1\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
62,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-31m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-1\n\nThis model is a fine-tuned version of EleutherAI/pythia-31m on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 1\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
null | null |
# Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF
This model was converted to GGUF format from [`IlyaGusev/saiga_llama3_8b`](https://huggingface.co/IlyaGusev/saiga_llama3_8b) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/IlyaGusev/saiga_llama3_8b) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF --model saiga_llama3_8b.Q5_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF --model saiga_llama3_8b.Q5_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m saiga_llama3_8b.Q5_K_M.gguf -n 128
```
| {"language": ["ru"], "license": "other", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["IlyaGusev/saiga_scored"], "license_name": "llama3", "license_link": "https://llama.meta.com/llama3/license/"} | Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"ru",
"dataset:IlyaGusev/saiga_scored",
"license:other",
"region:us"
] | null | 2024-04-30T06:59:39+00:00 | [] | [
"ru"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #ru #dataset-IlyaGusev/saiga_scored #license-other #region-us
|
# Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF
This model was converted to GGUF format from 'IlyaGusev/saiga_llama3_8b' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF\nThis model was converted to GGUF format from 'IlyaGusev/saiga_llama3_8b' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #ru #dataset-IlyaGusev/saiga_scored #license-other #region-us \n",
"# Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF\nThis model was converted to GGUF format from 'IlyaGusev/saiga_llama3_8b' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
43,
88,
52
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #ru #dataset-IlyaGusev/saiga_scored #license-other #region-us \n# Alex01837178373/saiga_llama3_8b-Q5_K_M-GGUF\nThis model was converted to GGUF format from 'IlyaGusev/saiga_llama3_8b' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
question-answering | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-finetuned-restaurant
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "cc-by-4.0", "tags": ["generated_from_trainer"], "base_model": "deepset/roberta-base-squad2", "model-index": [{"name": "roberta-finetuned-restaurant", "results": []}]} | pltnhan311/roberta-finetuned-restaurant | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:deepset/roberta-base-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:01:13+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #question-answering #generated_from_trainer #base_model-deepset/roberta-base-squad2 #license-cc-by-4.0 #endpoints_compatible #region-us
|
# roberta-finetuned-restaurant
This model is a fine-tuned version of deepset/roberta-base-squad2 on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| [
"# roberta-finetuned-restaurant\n\nThis model is a fine-tuned version of deepset/roberta-base-squad2 on the None dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #question-answering #generated_from_trainer #base_model-deepset/roberta-base-squad2 #license-cc-by-4.0 #endpoints_compatible #region-us \n",
"# roberta-finetuned-restaurant\n\nThis model is a fine-tuned version of deepset/roberta-base-squad2 on the None dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
55,
32,
7,
9,
9,
4,
102,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #question-answering #generated_from_trainer #base_model-deepset/roberta-base-squad2 #license-cc-by-4.0 #endpoints_compatible #region-us \n# roberta-finetuned-restaurant\n\nThis model is a fine-tuned version of deepset/roberta-base-squad2 on the None dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP### Training results### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] |
text-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.11368879675865173
f1_macro: 0.9748328397861948
f1_micro: 0.9752808988764045
f1_weighted: 0.9752071164560256
precision_macro: 0.9752973544608207
precision_micro: 0.9752808988764045
precision_weighted: 0.9756012580457148
recall_macro: 0.9748949579831934
recall_micro: 0.9752808988764045
recall_weighted: 0.9752808988764045
accuracy: 0.9752808988764045
| {"tags": ["autotrain", "text-classification"], "datasets": ["BBC/autotrain-data"], "widget": [{"text": "I love AutoTrain"}]} | NawinCom/BBC | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"autotrain",
"dataset:BBC/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:02:04+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-BBC/autotrain-data #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.11368879675865173
f1_macro: 0.9748328397861948
f1_micro: 0.9752808988764045
f1_weighted: 0.9752071164560256
precision_macro: 0.9752973544608207
precision_micro: 0.9752808988764045
precision_weighted: 0.9756012580457148
recall_macro: 0.9748949579831934
recall_micro: 0.9752808988764045
recall_weighted: 0.9752808988764045
accuracy: 0.9752808988764045
| [
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 0.11368879675865173\n\nf1_macro: 0.9748328397861948\n\nf1_micro: 0.9752808988764045\n\nf1_weighted: 0.9752071164560256\n\nprecision_macro: 0.9752973544608207\n\nprecision_micro: 0.9752808988764045\n\nprecision_weighted: 0.9756012580457148\n\nrecall_macro: 0.9748949579831934\n\nrecall_micro: 0.9752808988764045\n\nrecall_weighted: 0.9752808988764045\n\naccuracy: 0.9752808988764045"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-BBC/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoTrain\n\n- Problem type: Text Classification",
"## Validation Metrics\nloss: 0.11368879675865173\n\nf1_macro: 0.9748328397861948\n\nf1_micro: 0.9752808988764045\n\nf1_weighted: 0.9752071164560256\n\nprecision_macro: 0.9752973544608207\n\nprecision_micro: 0.9752808988764045\n\nprecision_weighted: 0.9756012580457148\n\nrecall_macro: 0.9748949579831934\n\nrecall_micro: 0.9752808988764045\n\nrecall_weighted: 0.9752808988764045\n\naccuracy: 0.9752808988764045"
] | [
45,
12,
182
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #autotrain #dataset-BBC/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n# Model Trained Using AutoTrain\n\n- Problem type: Text Classification## Validation Metrics\nloss: 0.11368879675865173\n\nf1_macro: 0.9748328397861948\n\nf1_micro: 0.9752808988764045\n\nf1_weighted: 0.9752071164560256\n\nprecision_macro: 0.9752973544608207\n\nprecision_micro: 0.9752808988764045\n\nprecision_weighted: 0.9756012580457148\n\nrecall_macro: 0.9748949579831934\n\nrecall_micro: 0.9752808988764045\n\nrecall_weighted: 0.9752808988764045\n\naccuracy: 0.9752808988764045"
] |
sentence-similarity | sentence-transformers |
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | nntoan209/bgem3-generic-msmarco-squadv2-tvpl-newssapo | null | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:02:33+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# {MODEL_NAME}
This is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers installed:
Then you can use the model like this:
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL
## Full Model Architecture
## Citing & Authors
| [
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Full Model Architecture",
"## Citing & Authors"
] | [
"TAGS\n#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Full Model Architecture",
"## Citing & Authors"
] | [
31,
41,
30,
26,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL## Full Model Architecture## Citing & Authors"
] |
image-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metrics
loss: 0.223019078373909
f1_macro: 0.8656901233453752
f1_micro: 0.9238648002731308
f1_weighted: 0.9239248911195606
precision_macro: 0.928029530990028
precision_micro: 0.9238648002731308
precision_weighted: 0.9287629201629745
recall_macro: 0.834713663096659
recall_micro: 0.9238648002731308
recall_weighted: 0.9238648002731308
accuracy: 0.9238648002731308
| {"tags": ["autotrain", "image-classification"], "datasets": ["autotrain-vit-base-patch16-224/autotrain-data"], "widget": [{"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg", "example_title": "Tiger"}, {"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg", "example_title": "Teapot"}, {"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg", "example_title": "Palace"}]} | Kushagra07/autotrain-vit-base-patch16-224 | null | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"autotrain",
"dataset:autotrain-vit-base-patch16-224/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:03:12+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #vit #image-classification #autotrain #dataset-autotrain-vit-base-patch16-224/autotrain-data #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metrics
loss: 0.223019078373909
f1_macro: 0.8656901233453752
f1_micro: 0.9238648002731308
f1_weighted: 0.9239248911195606
precision_macro: 0.928029530990028
precision_micro: 0.9238648002731308
precision_weighted: 0.9287629201629745
recall_macro: 0.834713663096659
recall_micro: 0.9238648002731308
recall_weighted: 0.9238648002731308
accuracy: 0.9238648002731308
| [
"# Model Trained Using AutoTrain\n\n- Problem type: Image Classification",
"## Validation Metrics\nloss: 0.223019078373909\n\nf1_macro: 0.8656901233453752\n\nf1_micro: 0.9238648002731308\n\nf1_weighted: 0.9239248911195606\n\nprecision_macro: 0.928029530990028\n\nprecision_micro: 0.9238648002731308\n\nprecision_weighted: 0.9287629201629745\n\nrecall_macro: 0.834713663096659\n\nrecall_micro: 0.9238648002731308\n\nrecall_weighted: 0.9238648002731308\n\naccuracy: 0.9238648002731308"
] | [
"TAGS\n#transformers #tensorboard #safetensors #vit #image-classification #autotrain #dataset-autotrain-vit-base-patch16-224/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoTrain\n\n- Problem type: Image Classification",
"## Validation Metrics\nloss: 0.223019078373909\n\nf1_macro: 0.8656901233453752\n\nf1_micro: 0.9238648002731308\n\nf1_weighted: 0.9239248911195606\n\nprecision_macro: 0.928029530990028\n\nprecision_micro: 0.9238648002731308\n\nprecision_weighted: 0.9287629201629745\n\nrecall_macro: 0.834713663096659\n\nrecall_micro: 0.9238648002731308\n\nrecall_weighted: 0.9238648002731308\n\naccuracy: 0.9238648002731308"
] | [
55,
12,
166
] | [
"TAGS\n#transformers #tensorboard #safetensors #vit #image-classification #autotrain #dataset-autotrain-vit-base-patch16-224/autotrain-data #autotrain_compatible #endpoints_compatible #region-us \n# Model Trained Using AutoTrain\n\n- Problem type: Image Classification## Validation Metrics\nloss: 0.223019078373909\n\nf1_macro: 0.8656901233453752\n\nf1_micro: 0.9238648002731308\n\nf1_weighted: 0.9239248911195606\n\nprecision_macro: 0.928029530990028\n\nprecision_micro: 0.9238648002731308\n\nprecision_weighted: 0.9287629201629745\n\nrecall_macro: 0.834713663096659\n\nrecall_micro: 0.9238648002731308\n\nrecall_weighted: 0.9238648002731308\n\naccuracy: 0.9238648002731308"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": ["trl", "sft"]} | likhithasapu/codemix-indicbart-sft-notchat | null | [
"transformers",
"safetensors",
"mbart",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:03:31+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #mbart #text-generation #trl #sft #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #mbart #text-generation #trl #sft #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
44,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #mbart #text-generation #trl #sft #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shallow6414/qc2t3b7 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:04:23+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-generation | transformers |
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` | {"license": "other", "library_name": "transformers", "tags": ["autotrain", "text-generation-inference", "text-generation", "peft"], "widget": [{"messages": [{"role": "user", "content": "What is your favorite condiment?"}]}]} | dmtkeler/autotrain-do2iw-wsghc | null | [
"transformers",
"tensorboard",
"safetensors",
"autotrain",
"text-generation-inference",
"text-generation",
"peft",
"conversational",
"license:other",
"endpoints_compatible",
"region:us",
"has_space"
] | null | 2024-04-30T07:05:22+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #autotrain #text-generation-inference #text-generation #peft #conversational #license-other #endpoints_compatible #region-us #has_space
|
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit AutoTrain.
# Usage
| [
"# Model Trained Using AutoTrain\n\nThis model was trained using AutoTrain. For more information, please visit AutoTrain.",
"# Usage"
] | [
"TAGS\n#transformers #tensorboard #safetensors #autotrain #text-generation-inference #text-generation #peft #conversational #license-other #endpoints_compatible #region-us #has_space \n",
"# Model Trained Using AutoTrain\n\nThis model was trained using AutoTrain. For more information, please visit AutoTrain.",
"# Usage"
] | [
46,
23,
2
] | [
"TAGS\n#transformers #tensorboard #safetensors #autotrain #text-generation-inference #text-generation #peft #conversational #license-other #endpoints_compatible #region-us #has_space \n# Model Trained Using AutoTrain\n\nThis model was trained using AutoTrain. For more information, please visit AutoTrain.# Usage"
] |
text-generation | transformers |
## モデル
- ベースモデル:[ryota39/llm-jp-1b-sft-100k-LoRA](https://huggingface.co/ryota39/llm-jp-1b-sft-100k-LoRA)
- 学習データセット:[ryota39/dpo-ja-194k](https://huggingface.co/datasets/ryota39/dpo-ja-194k)
- 学習方式:フルパラメータチューニング
## サンプル
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
"ryota39/llm-jp-1b-sft-100k-LoRA-kto-194k"
)
pad_token_id = tokenizer.pad_token_id
model = AutoModelForCausalLM.from_pretrained(
"ryota39/llm-jp-1b-sft-100k-LoRA-kto-194k",
device_map="auto",
)
text = "###Input: 東京の観光名所を教えてください。\n###Output: "
tokenized_input = tokenizer.encode(
text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
attention_mask = torch.ones_like(tokenized_input)
attention_mask[tokenized_input == pad_token_id] = 0
with torch.no_grad():
output = model.generate(
tokenized_input,
attention_mask=attention_mask,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.8,
repetition_penalty=1.10
)[0]
print(tokenizer.decode(output))
```
## 出力例
```
###Input: 東京の観光名所を教えてください。
###Output: 東京タワー。日本で一番高い塔だと思いますよ。
東京の街は非常にきれいなので、夜には美しい光景を見ることができます。
また、隅田川やレインボーブリッジから眺める景色もいいですし、皇居や靖国神社など東京の象徴的な場所を訪れるのもいいかもしれません。
スカイツリーから見る景色は最高だと思います。スカイツリーの展望台の中では東京シティビューという場所がおすすめです。
また、浅草寺や雷門、勝鬨橋といった浅草近辺の人気スポットにも行くことができます。他
```
## 謝辞
本成果は【LOCAL AI HACKATHON #001】240時間ハッカソンの成果です。
運営の方々に深く御礼申し上げます。
- 【メタデータラボ株式会社】様
- 【AI声づくり技術研究会】
- サーバー主:やなぎ(Yanagi)様
- 【ローカルLLMに向き合う会】
- サーバー主:saldra(サルドラ)様
[メタデータラボ、日本最大規模のAIハッカソン「LOCAL AI HACKATHON #001」~ AIの民主化 ~を開催、本日より出場チームの募集を開始](https://prtimes.jp/main/html/rd/p/000000008.000056944.html)
| {"language": ["ja"], "license": "cc", "library_name": "transformers", "tags": ["dpo"], "datasets": ["ryota39/dpo-ja-194k"]} | ryota39/llm-jp-1b-sft-100k-LoRA-kto-194k | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"dpo",
"ja",
"dataset:ryota39/dpo-ja-194k",
"license:cc",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:05:36+00:00 | [] | [
"ja"
] | TAGS
#transformers #safetensors #gpt2 #text-generation #dpo #ja #dataset-ryota39/dpo-ja-194k #license-cc #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
## モデル
- ベースモデル:ryota39/llm-jp-1b-sft-100k-LoRA
- 学習データセット:ryota39/dpo-ja-194k
- 学習方式:フルパラメータチューニング
## サンプル
## 出力例
## 謝辞
本成果は【LOCAL AI HACKATHON #001】240時間ハッカソンの成果です。
運営の方々に深く御礼申し上げます。
- 【メタデータラボ株式会社】様
- 【AI声づくり技術研究会】
- サーバー主:やなぎ(Yanagi)様
- 【ローカルLLMに向き合う会】
- サーバー主:saldra(サルドラ)様
メタデータラボ、日本最大規模のAIハッカソン「LOCAL AI HACKATHON #001」~ AIの民主化 ~を開催、本日より出場チームの募集を開始
| [
"## モデル\n\n- ベースモデル:ryota39/llm-jp-1b-sft-100k-LoRA\n- 学習データセット:ryota39/dpo-ja-194k\n- 学習方式:フルパラメータチューニング",
"## サンプル",
"## 出力例",
"## 謝辞\n\n本成果は【LOCAL AI HACKATHON #001】240時間ハッカソンの成果です。\n運営の方々に深く御礼申し上げます。\n\n- 【メタデータラボ株式会社】様\n- 【AI声づくり技術研究会】\n - サーバー主:やなぎ(Yanagi)様\n- 【ローカルLLMに向き合う会】\n - サーバー主:saldra(サルドラ)様\n\nメタデータラボ、日本最大規模のAIハッカソン「LOCAL AI HACKATHON #001」~ AIの民主化 ~を開催、本日より出場チームの募集を開始"
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #dpo #ja #dataset-ryota39/dpo-ja-194k #license-cc #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"## モデル\n\n- ベースモデル:ryota39/llm-jp-1b-sft-100k-LoRA\n- 学習データセット:ryota39/dpo-ja-194k\n- 学習方式:フルパラメータチューニング",
"## サンプル",
"## 出力例",
"## 謝辞\n\n本成果は【LOCAL AI HACKATHON #001】240時間ハッカソンの成果です。\n運営の方々に深く御礼申し上げます。\n\n- 【メタデータラボ株式会社】様\n- 【AI声づくり技術研究会】\n - サーバー主:やなぎ(Yanagi)様\n- 【ローカルLLMに向き合う会】\n - サーバー主:saldra(サルドラ)様\n\nメタデータラボ、日本最大規模のAIハッカソン「LOCAL AI HACKATHON #001」~ AIの民主化 ~を開催、本日より出場チームの募集を開始"
] | [
59,
72,
6,
5,
166
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #dpo #ja #dataset-ryota39/dpo-ja-194k #license-cc #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n## モデル\n\n- ベースモデル:ryota39/llm-jp-1b-sft-100k-LoRA\n- 学習データセット:ryota39/dpo-ja-194k\n- 学習方式:フルパラメータチューニング## サンプル## 出力例## 謝辞\n\n本成果は【LOCAL AI HACKATHON #001】240時間ハッカソンの成果です。\n運営の方々に深く御礼申し上げます。\n\n- 【メタデータラボ株式会社】様\n- 【AI声づくり技術研究会】\n - サーバー主:やなぎ(Yanagi)様\n- 【ローカルLLMに向き合う会】\n - サーバー主:saldra(サルドラ)様\n\nメタデータラボ、日本最大規模のAIハッカソン「LOCAL AI HACKATHON #001」~ AIの民主化 ~を開催、本日より出場チームの募集を開始"
] |
text-generation | transformers |
# mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from [`llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
| {"language": ["en", "ja"], "license": "apache-2.0", "library_name": "transformers", "tags": ["mlx"], "datasets": ["databricks/databricks-dolly-15k", "llm-jp/databricks-dolly-15k-ja", "llm-jp/oasst1-21k-en", "llm-jp/oasst1-21k-ja", "llm-jp/oasst2-33k-en", "llm-jp/oasst2-33k-ja"], "programming_language": ["C", "C++", "C#", "Go", "Java", "JavaScript", "Lua", "PHP", "Python", "Ruby", "Rust", "Scala", "TypeScript"], "pipeline_tag": "text-generation", "inference": false} | mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"conversational",
"en",
"ja",
"dataset:databricks/databricks-dolly-15k",
"dataset:llm-jp/databricks-dolly-15k-ja",
"dataset:llm-jp/oasst1-21k-en",
"dataset:llm-jp/oasst1-21k-ja",
"dataset:llm-jp/oasst2-33k-en",
"dataset:llm-jp/oasst2-33k-ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:05:50+00:00 | [] | [
"en",
"ja"
] | TAGS
#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us
|
# mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n",
"# mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
154,
138,
6
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n# mlx-community/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.## Use with mlx"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | rbgo/inferless-Llama-3-8B | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:06:31+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K79me3-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K79me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K79me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4470
- F1 Score: 0.8227
- Accuracy: 0.8235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.51 | 1.1 | 200 | 0.4500 | 0.8060 | 0.8062 |
| 0.4534 | 2.21 | 400 | 0.4424 | 0.8096 | 0.8100 |
| 0.4445 | 3.31 | 600 | 0.4395 | 0.8065 | 0.8076 |
| 0.4312 | 4.42 | 800 | 0.4376 | 0.8074 | 0.8083 |
| 0.4307 | 5.52 | 1000 | 0.4448 | 0.8041 | 0.8058 |
| 0.419 | 6.63 | 1200 | 0.4580 | 0.8046 | 0.8069 |
| 0.4233 | 7.73 | 1400 | 0.4587 | 0.7952 | 0.7982 |
| 0.4138 | 8.84 | 1600 | 0.4851 | 0.7910 | 0.7951 |
| 0.4128 | 9.94 | 1800 | 0.4287 | 0.8159 | 0.8162 |
| 0.4091 | 11.05 | 2000 | 0.4425 | 0.8099 | 0.8107 |
| 0.405 | 12.15 | 2200 | 0.4279 | 0.8144 | 0.8148 |
| 0.3999 | 13.26 | 2400 | 0.4335 | 0.8140 | 0.8148 |
| 0.3993 | 14.36 | 2600 | 0.4327 | 0.8169 | 0.8176 |
| 0.3979 | 15.47 | 2800 | 0.4373 | 0.8109 | 0.8121 |
| 0.3909 | 16.57 | 3000 | 0.4277 | 0.8151 | 0.8152 |
| 0.3931 | 17.68 | 3200 | 0.4269 | 0.8202 | 0.8207 |
| 0.3875 | 18.78 | 3400 | 0.4589 | 0.8071 | 0.8089 |
| 0.3879 | 19.89 | 3600 | 0.4351 | 0.8174 | 0.8183 |
| 0.3824 | 20.99 | 3800 | 0.4441 | 0.8098 | 0.8114 |
| 0.3813 | 22.1 | 4000 | 0.4397 | 0.8135 | 0.8141 |
| 0.3793 | 23.2 | 4200 | 0.4400 | 0.8113 | 0.8121 |
| 0.3778 | 24.31 | 4400 | 0.4586 | 0.8101 | 0.8121 |
| 0.3722 | 25.41 | 4600 | 0.4392 | 0.8213 | 0.8218 |
| 0.377 | 26.52 | 4800 | 0.4454 | 0.8091 | 0.8103 |
| 0.3752 | 27.62 | 5000 | 0.4443 | 0.8147 | 0.8159 |
| 0.3693 | 28.73 | 5200 | 0.4490 | 0.8073 | 0.8089 |
| 0.3657 | 29.83 | 5400 | 0.4413 | 0.8104 | 0.8110 |
| 0.367 | 30.94 | 5600 | 0.4405 | 0.8142 | 0.8148 |
| 0.3655 | 32.04 | 5800 | 0.4436 | 0.8172 | 0.8176 |
| 0.3638 | 33.15 | 6000 | 0.4486 | 0.8134 | 0.8145 |
| 0.3607 | 34.25 | 6200 | 0.4532 | 0.8090 | 0.8100 |
| 0.3597 | 35.36 | 6400 | 0.4600 | 0.8157 | 0.8169 |
| 0.3584 | 36.46 | 6600 | 0.4425 | 0.8202 | 0.8207 |
| 0.3546 | 37.57 | 6800 | 0.4490 | 0.8135 | 0.8145 |
| 0.3535 | 38.67 | 7000 | 0.4558 | 0.8150 | 0.8162 |
| 0.3541 | 39.78 | 7200 | 0.4610 | 0.8140 | 0.8152 |
| 0.3544 | 40.88 | 7400 | 0.4434 | 0.8176 | 0.8180 |
| 0.3531 | 41.99 | 7600 | 0.4526 | 0.8101 | 0.8110 |
| 0.35 | 43.09 | 7800 | 0.4497 | 0.8157 | 0.8166 |
| 0.3516 | 44.2 | 8000 | 0.4660 | 0.8097 | 0.8110 |
| 0.3491 | 45.3 | 8200 | 0.4472 | 0.8133 | 0.8138 |
| 0.3453 | 46.41 | 8400 | 0.4591 | 0.8109 | 0.8117 |
| 0.3487 | 47.51 | 8600 | 0.4647 | 0.8132 | 0.8145 |
| 0.3456 | 48.62 | 8800 | 0.4584 | 0.8138 | 0.8148 |
| 0.3451 | 49.72 | 9000 | 0.4585 | 0.8129 | 0.8138 |
| 0.3485 | 50.83 | 9200 | 0.4656 | 0.8109 | 0.8124 |
| 0.3434 | 51.93 | 9400 | 0.4623 | 0.8133 | 0.8145 |
| 0.3427 | 53.04 | 9600 | 0.4597 | 0.8146 | 0.8155 |
| 0.3421 | 54.14 | 9800 | 0.4599 | 0.8129 | 0.8138 |
| 0.3425 | 55.25 | 10000 | 0.4627 | 0.8127 | 0.8138 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K79me3-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K79me3-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:07:35+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K79me3-seqsight\_32768\_512\_43M-L8\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K79me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4470
* F1 Score: 0.8227
* Accuracy: 0.8235
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K79me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K79me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4576
- F1 Score: 0.8200
- Accuracy: 0.8204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.497 | 1.1 | 200 | 0.4462 | 0.8070 | 0.8072 |
| 0.4475 | 2.21 | 400 | 0.4392 | 0.8065 | 0.8072 |
| 0.4362 | 3.31 | 600 | 0.4282 | 0.8137 | 0.8141 |
| 0.4213 | 4.42 | 800 | 0.4471 | 0.8055 | 0.8072 |
| 0.417 | 5.52 | 1000 | 0.4382 | 0.8037 | 0.8055 |
| 0.4055 | 6.63 | 1200 | 0.4586 | 0.8029 | 0.8051 |
| 0.4058 | 7.73 | 1400 | 0.4554 | 0.8001 | 0.8027 |
| 0.3961 | 8.84 | 1600 | 0.4680 | 0.7983 | 0.8013 |
| 0.3909 | 9.94 | 1800 | 0.4355 | 0.8175 | 0.8180 |
| 0.3866 | 11.05 | 2000 | 0.4408 | 0.8104 | 0.8107 |
| 0.3794 | 12.15 | 2200 | 0.4383 | 0.8163 | 0.8173 |
| 0.3705 | 13.26 | 2400 | 0.4336 | 0.8161 | 0.8166 |
| 0.368 | 14.36 | 2600 | 0.4389 | 0.8181 | 0.8183 |
| 0.3621 | 15.47 | 2800 | 0.4450 | 0.8157 | 0.8162 |
| 0.3537 | 16.57 | 3000 | 0.4434 | 0.8172 | 0.8173 |
| 0.3486 | 17.68 | 3200 | 0.4555 | 0.8199 | 0.8200 |
| 0.3417 | 18.78 | 3400 | 0.4873 | 0.8039 | 0.8055 |
| 0.3384 | 19.89 | 3600 | 0.4532 | 0.8148 | 0.8155 |
| 0.3269 | 20.99 | 3800 | 0.4819 | 0.8034 | 0.8044 |
| 0.324 | 22.1 | 4000 | 0.4837 | 0.8162 | 0.8162 |
| 0.3192 | 23.2 | 4200 | 0.4995 | 0.8024 | 0.8034 |
| 0.312 | 24.31 | 4400 | 0.4982 | 0.8039 | 0.8051 |
| 0.2982 | 25.41 | 4600 | 0.5090 | 0.8126 | 0.8131 |
| 0.308 | 26.52 | 4800 | 0.4995 | 0.8072 | 0.8079 |
| 0.2956 | 27.62 | 5000 | 0.5131 | 0.8076 | 0.8089 |
| 0.2869 | 28.73 | 5200 | 0.5214 | 0.8070 | 0.8079 |
| 0.2801 | 29.83 | 5400 | 0.5086 | 0.8086 | 0.8086 |
| 0.281 | 30.94 | 5600 | 0.5187 | 0.8152 | 0.8152 |
| 0.2749 | 32.04 | 5800 | 0.5211 | 0.8121 | 0.8124 |
| 0.2686 | 33.15 | 6000 | 0.5515 | 0.8066 | 0.8072 |
| 0.2632 | 34.25 | 6200 | 0.5491 | 0.8081 | 0.8083 |
| 0.2574 | 35.36 | 6400 | 0.5823 | 0.8088 | 0.8096 |
| 0.2528 | 36.46 | 6600 | 0.5612 | 0.8066 | 0.8076 |
| 0.2492 | 37.57 | 6800 | 0.5598 | 0.8000 | 0.8006 |
| 0.2466 | 38.67 | 7000 | 0.5874 | 0.8075 | 0.8089 |
| 0.2422 | 39.78 | 7200 | 0.5805 | 0.8117 | 0.8124 |
| 0.2393 | 40.88 | 7400 | 0.5684 | 0.8073 | 0.8076 |
| 0.2375 | 41.99 | 7600 | 0.5579 | 0.8061 | 0.8062 |
| 0.2333 | 43.09 | 7800 | 0.5884 | 0.8013 | 0.8020 |
| 0.2278 | 44.2 | 8000 | 0.6094 | 0.8091 | 0.8096 |
| 0.2282 | 45.3 | 8200 | 0.5905 | 0.8090 | 0.8093 |
| 0.2194 | 46.41 | 8400 | 0.6165 | 0.8053 | 0.8058 |
| 0.2208 | 47.51 | 8600 | 0.6277 | 0.8047 | 0.8055 |
| 0.218 | 48.62 | 8800 | 0.6125 | 0.8044 | 0.8048 |
| 0.2189 | 49.72 | 9000 | 0.6186 | 0.8050 | 0.8055 |
| 0.2201 | 50.83 | 9200 | 0.6197 | 0.8010 | 0.8020 |
| 0.2122 | 51.93 | 9400 | 0.6302 | 0.8025 | 0.8034 |
| 0.2116 | 53.04 | 9600 | 0.6281 | 0.8048 | 0.8055 |
| 0.2075 | 54.14 | 9800 | 0.6281 | 0.8043 | 0.8048 |
| 0.2074 | 55.25 | 10000 | 0.6320 | 0.8049 | 0.8055 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:07:35+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K79me3-seqsight\_32768\_512\_43M-L32\_f
===================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K79me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4576
* F1 Score: 0.8200
* Accuracy: 0.8204
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Bandu Mulla
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3523
- eval_wer: 33.6621
- eval_runtime: 1373.0171
- eval_samples_per_second: 2.108
- eval_steps_per_second: 0.264
- epoch: 4.8900
- step: 2000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"language": ["hi"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["mozilla-foundation/common_voice_11_0"], "base_model": "openai/whisper-small", "model-index": [{"name": "Whisper Small Hi - Bandu Mulla", "results": []}]} | bmulla7/whisper-small-hi | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:07:43+00:00 | [] | [
"hi"
] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #hi #dataset-mozilla-foundation/common_voice_11_0 #base_model-openai/whisper-small #license-apache-2.0 #endpoints_compatible #region-us
|
# Whisper Small Hi - Bandu Mulla
This model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3523
- eval_wer: 33.6621
- eval_runtime: 1373.0171
- eval_samples_per_second: 2.108
- eval_steps_per_second: 0.264
- epoch: 4.8900
- step: 2000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| [
"# Whisper Small Hi - Bandu Mulla\n\nThis model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset.\nIt achieves the following results on the evaluation set:\n- eval_loss: 0.3523\n- eval_wer: 33.6621\n- eval_runtime: 1373.0171\n- eval_samples_per_second: 2.108\n- eval_steps_per_second: 0.264\n- epoch: 4.8900\n- step: 2000",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 500\n- training_steps: 4000\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.40.1\n- Pytorch 2.3.0+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #hi #dataset-mozilla-foundation/common_voice_11_0 #base_model-openai/whisper-small #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Whisper Small Hi - Bandu Mulla\n\nThis model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset.\nIt achieves the following results on the evaluation set:\n- eval_loss: 0.3523\n- eval_wer: 33.6621\n- eval_runtime: 1373.0171\n- eval_samples_per_second: 2.108\n- eval_steps_per_second: 0.264\n- epoch: 4.8900\n- step: 2000",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 500\n- training_steps: 4000\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.40.1\n- Pytorch 2.3.0+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
71,
116,
7,
9,
9,
4,
113,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #hi #dataset-mozilla-foundation/common_voice_11_0 #base_model-openai/whisper-small #license-apache-2.0 #endpoints_compatible #region-us \n# Whisper Small Hi - Bandu Mulla\n\nThis model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset.\nIt achieves the following results on the evaluation set:\n- eval_loss: 0.3523\n- eval_wer: 33.6621\n- eval_runtime: 1373.0171\n- eval_samples_per_second: 2.108\n- eval_steps_per_second: 0.264\n- epoch: 4.8900\n- step: 2000## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 500\n- training_steps: 4000\n- mixed_precision_training: Native AMP### Framework versions\n\n- Transformers 4.40.1\n- Pytorch 2.3.0+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me1-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me1) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5160
- F1 Score: 0.7698
- Accuracy: 0.7708
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.623 | 1.01 | 200 | 0.5869 | 0.7061 | 0.7099 |
| 0.5857 | 2.02 | 400 | 0.5679 | 0.7269 | 0.7276 |
| 0.5694 | 3.03 | 600 | 0.5520 | 0.7437 | 0.7446 |
| 0.5568 | 4.04 | 800 | 0.5443 | 0.7495 | 0.7503 |
| 0.5498 | 5.05 | 1000 | 0.5376 | 0.7488 | 0.75 |
| 0.5431 | 6.06 | 1200 | 0.5393 | 0.7498 | 0.7519 |
| 0.5397 | 7.07 | 1400 | 0.5343 | 0.7532 | 0.7544 |
| 0.5395 | 8.08 | 1600 | 0.5345 | 0.7517 | 0.7535 |
| 0.5353 | 9.09 | 1800 | 0.5282 | 0.7563 | 0.7576 |
| 0.5341 | 10.1 | 2000 | 0.5283 | 0.7615 | 0.7623 |
| 0.53 | 11.11 | 2200 | 0.5320 | 0.7580 | 0.7592 |
| 0.5308 | 12.12 | 2400 | 0.5252 | 0.7578 | 0.7585 |
| 0.5279 | 13.13 | 2600 | 0.5264 | 0.7582 | 0.7595 |
| 0.5282 | 14.14 | 2800 | 0.5219 | 0.7562 | 0.7576 |
| 0.5227 | 15.15 | 3000 | 0.5252 | 0.7569 | 0.7588 |
| 0.5231 | 16.16 | 3200 | 0.5236 | 0.7528 | 0.7554 |
| 0.5192 | 17.17 | 3400 | 0.5269 | 0.7576 | 0.7588 |
| 0.5231 | 18.18 | 3600 | 0.5177 | 0.7619 | 0.7626 |
| 0.5181 | 19.19 | 3800 | 0.5183 | 0.7609 | 0.7623 |
| 0.5191 | 20.2 | 4000 | 0.5197 | 0.7585 | 0.7598 |
| 0.5159 | 21.21 | 4200 | 0.5258 | 0.7511 | 0.7535 |
| 0.5149 | 22.22 | 4400 | 0.5230 | 0.7579 | 0.7595 |
| 0.5139 | 23.23 | 4600 | 0.5250 | 0.7534 | 0.7560 |
| 0.5208 | 24.24 | 4800 | 0.5206 | 0.7536 | 0.7560 |
| 0.5112 | 25.25 | 5000 | 0.5184 | 0.7565 | 0.7579 |
| 0.5128 | 26.26 | 5200 | 0.5221 | 0.7622 | 0.7629 |
| 0.5118 | 27.27 | 5400 | 0.5193 | 0.7532 | 0.7551 |
| 0.5121 | 28.28 | 5600 | 0.5155 | 0.7586 | 0.7598 |
| 0.5138 | 29.29 | 5800 | 0.5242 | 0.7527 | 0.7557 |
| 0.5083 | 30.3 | 6000 | 0.5194 | 0.7574 | 0.7592 |
| 0.5096 | 31.31 | 6200 | 0.5189 | 0.7554 | 0.7569 |
| 0.5126 | 32.32 | 6400 | 0.5212 | 0.7562 | 0.7588 |
| 0.5062 | 33.33 | 6600 | 0.5223 | 0.7541 | 0.7566 |
| 0.5056 | 34.34 | 6800 | 0.5209 | 0.7548 | 0.7573 |
| 0.5046 | 35.35 | 7000 | 0.5186 | 0.7583 | 0.7598 |
| 0.5092 | 36.36 | 7200 | 0.5154 | 0.7572 | 0.7588 |
| 0.5069 | 37.37 | 7400 | 0.5157 | 0.7580 | 0.7598 |
| 0.5057 | 38.38 | 7600 | 0.5174 | 0.7580 | 0.7595 |
| 0.5058 | 39.39 | 7800 | 0.5181 | 0.7582 | 0.7598 |
| 0.5042 | 40.4 | 8000 | 0.5205 | 0.7580 | 0.7598 |
| 0.5065 | 41.41 | 8200 | 0.5182 | 0.7583 | 0.7607 |
| 0.5069 | 42.42 | 8400 | 0.5198 | 0.7539 | 0.7563 |
| 0.5053 | 43.43 | 8600 | 0.5185 | 0.7574 | 0.7592 |
| 0.5024 | 44.44 | 8800 | 0.5181 | 0.7554 | 0.7576 |
| 0.5038 | 45.45 | 9000 | 0.5170 | 0.7579 | 0.7595 |
| 0.5026 | 46.46 | 9200 | 0.5188 | 0.7562 | 0.7582 |
| 0.5069 | 47.47 | 9400 | 0.5177 | 0.7566 | 0.7588 |
| 0.4961 | 48.48 | 9600 | 0.5194 | 0.7569 | 0.7588 |
| 0.5096 | 49.49 | 9800 | 0.5177 | 0.7554 | 0.7576 |
| 0.5019 | 50.51 | 10000 | 0.5177 | 0.7579 | 0.7598 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me1-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me1-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:07:56+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me1-seqsight\_32768\_512\_43M-L1\_f
=================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me1 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5160
* F1 Score: 0.7698
* Accuracy: 0.7708
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me1-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me1) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5223
- F1 Score: 0.7689
- Accuracy: 0.7702
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6077 | 1.01 | 200 | 0.5675 | 0.7302 | 0.7323 |
| 0.559 | 2.02 | 400 | 0.5359 | 0.7508 | 0.7525 |
| 0.5397 | 3.03 | 600 | 0.5277 | 0.7535 | 0.7544 |
| 0.5337 | 4.04 | 800 | 0.5335 | 0.7603 | 0.7614 |
| 0.5279 | 5.05 | 1000 | 0.5260 | 0.7600 | 0.7610 |
| 0.5225 | 6.06 | 1200 | 0.5250 | 0.7539 | 0.7563 |
| 0.5179 | 7.07 | 1400 | 0.5267 | 0.7560 | 0.7576 |
| 0.5153 | 8.08 | 1600 | 0.5248 | 0.7563 | 0.7585 |
| 0.5128 | 9.09 | 1800 | 0.5143 | 0.7607 | 0.7620 |
| 0.5102 | 10.1 | 2000 | 0.5145 | 0.7646 | 0.7655 |
| 0.5035 | 11.11 | 2200 | 0.5206 | 0.7657 | 0.7670 |
| 0.504 | 12.12 | 2400 | 0.5097 | 0.7656 | 0.7664 |
| 0.4999 | 13.13 | 2600 | 0.5132 | 0.7653 | 0.7667 |
| 0.4996 | 14.14 | 2800 | 0.5140 | 0.7713 | 0.7724 |
| 0.4931 | 15.15 | 3000 | 0.5170 | 0.7640 | 0.7658 |
| 0.4925 | 16.16 | 3200 | 0.5173 | 0.7631 | 0.7655 |
| 0.4885 | 17.17 | 3400 | 0.5254 | 0.7652 | 0.7667 |
| 0.4905 | 18.18 | 3600 | 0.5103 | 0.7724 | 0.7730 |
| 0.4855 | 19.19 | 3800 | 0.5079 | 0.7679 | 0.7693 |
| 0.4848 | 20.2 | 4000 | 0.5109 | 0.7697 | 0.7708 |
| 0.4797 | 21.21 | 4200 | 0.5171 | 0.7635 | 0.7658 |
| 0.478 | 22.22 | 4400 | 0.5185 | 0.7684 | 0.7696 |
| 0.4761 | 23.23 | 4600 | 0.5189 | 0.7640 | 0.7658 |
| 0.4799 | 24.24 | 4800 | 0.5178 | 0.7581 | 0.7610 |
| 0.4719 | 25.25 | 5000 | 0.5158 | 0.7685 | 0.7689 |
| 0.4733 | 26.26 | 5200 | 0.5195 | 0.7728 | 0.7730 |
| 0.4694 | 27.27 | 5400 | 0.5209 | 0.7638 | 0.7658 |
| 0.4695 | 28.28 | 5600 | 0.5127 | 0.7756 | 0.7762 |
| 0.4722 | 29.29 | 5800 | 0.5263 | 0.7559 | 0.7598 |
| 0.4642 | 30.3 | 6000 | 0.5220 | 0.7686 | 0.7699 |
| 0.463 | 31.31 | 6200 | 0.5194 | 0.7736 | 0.7746 |
| 0.4639 | 32.32 | 6400 | 0.5225 | 0.7637 | 0.7658 |
| 0.4593 | 33.33 | 6600 | 0.5276 | 0.7653 | 0.7674 |
| 0.4568 | 34.34 | 6800 | 0.5190 | 0.7688 | 0.7702 |
| 0.4551 | 35.35 | 7000 | 0.5222 | 0.7737 | 0.7743 |
| 0.4588 | 36.36 | 7200 | 0.5211 | 0.7666 | 0.7677 |
| 0.4569 | 37.37 | 7400 | 0.5236 | 0.7695 | 0.7708 |
| 0.4558 | 38.38 | 7600 | 0.5227 | 0.7747 | 0.7753 |
| 0.4534 | 39.39 | 7800 | 0.5218 | 0.7733 | 0.7740 |
| 0.4514 | 40.4 | 8000 | 0.5270 | 0.7701 | 0.7711 |
| 0.4527 | 41.41 | 8200 | 0.5283 | 0.7641 | 0.7661 |
| 0.4545 | 42.42 | 8400 | 0.5257 | 0.7622 | 0.7639 |
| 0.4501 | 43.43 | 8600 | 0.5273 | 0.7703 | 0.7715 |
| 0.4474 | 44.44 | 8800 | 0.5274 | 0.7643 | 0.7658 |
| 0.4482 | 45.45 | 9000 | 0.5263 | 0.7706 | 0.7715 |
| 0.4481 | 46.46 | 9200 | 0.5272 | 0.7680 | 0.7693 |
| 0.449 | 47.47 | 9400 | 0.5281 | 0.7657 | 0.7674 |
| 0.4396 | 48.48 | 9600 | 0.5313 | 0.7654 | 0.7667 |
| 0.4528 | 49.49 | 9800 | 0.5283 | 0.7643 | 0.7658 |
| 0.4455 | 50.51 | 10000 | 0.5285 | 0.7667 | 0.7680 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me1-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me1-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:07:56+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me1-seqsight\_32768\_512\_43M-L8\_f
=================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me1 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5223
* F1 Score: 0.7689
* Accuracy: 0.7702
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me1) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5134
- F1 Score: 0.7661
- Accuracy: 0.7677
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.594 | 1.01 | 200 | 0.5404 | 0.7553 | 0.7557 |
| 0.5431 | 2.02 | 400 | 0.5282 | 0.7581 | 0.7588 |
| 0.5271 | 3.03 | 600 | 0.5242 | 0.7593 | 0.7601 |
| 0.5217 | 4.04 | 800 | 0.5209 | 0.7568 | 0.7585 |
| 0.5147 | 5.05 | 1000 | 0.5190 | 0.7616 | 0.7626 |
| 0.5077 | 6.06 | 1200 | 0.5237 | 0.7567 | 0.7595 |
| 0.5007 | 7.07 | 1400 | 0.5229 | 0.7630 | 0.7645 |
| 0.4957 | 8.08 | 1600 | 0.5154 | 0.7596 | 0.7614 |
| 0.4918 | 9.09 | 1800 | 0.5109 | 0.7675 | 0.7689 |
| 0.4855 | 10.1 | 2000 | 0.5114 | 0.7717 | 0.7727 |
| 0.4753 | 11.11 | 2200 | 0.5227 | 0.7649 | 0.7667 |
| 0.4733 | 12.12 | 2400 | 0.5139 | 0.7694 | 0.7699 |
| 0.4671 | 13.13 | 2600 | 0.5227 | 0.7620 | 0.7642 |
| 0.4629 | 14.14 | 2800 | 0.5271 | 0.7666 | 0.7680 |
| 0.4534 | 15.15 | 3000 | 0.5316 | 0.7624 | 0.7636 |
| 0.4501 | 16.16 | 3200 | 0.5337 | 0.7668 | 0.7680 |
| 0.4438 | 17.17 | 3400 | 0.5426 | 0.7655 | 0.7670 |
| 0.4405 | 18.18 | 3600 | 0.5362 | 0.7637 | 0.7652 |
| 0.433 | 19.19 | 3800 | 0.5340 | 0.7673 | 0.7680 |
| 0.4286 | 20.2 | 4000 | 0.5398 | 0.7631 | 0.7636 |
| 0.4188 | 21.21 | 4200 | 0.5503 | 0.7659 | 0.7670 |
| 0.4161 | 22.22 | 4400 | 0.5667 | 0.7551 | 0.7560 |
| 0.4061 | 23.23 | 4600 | 0.5742 | 0.7547 | 0.7551 |
| 0.4069 | 24.24 | 4800 | 0.5761 | 0.7560 | 0.7588 |
| 0.398 | 25.25 | 5000 | 0.5637 | 0.7639 | 0.7639 |
| 0.3948 | 26.26 | 5200 | 0.5826 | 0.7547 | 0.7551 |
| 0.3919 | 27.27 | 5400 | 0.5768 | 0.7553 | 0.7569 |
| 0.3845 | 28.28 | 5600 | 0.5962 | 0.7526 | 0.7535 |
| 0.3842 | 29.29 | 5800 | 0.5895 | 0.7473 | 0.7497 |
| 0.3732 | 30.3 | 6000 | 0.5930 | 0.7562 | 0.7566 |
| 0.3725 | 31.31 | 6200 | 0.5884 | 0.7555 | 0.7560 |
| 0.3667 | 32.32 | 6400 | 0.6023 | 0.7608 | 0.7617 |
| 0.3581 | 33.33 | 6600 | 0.6189 | 0.7499 | 0.7522 |
| 0.3611 | 34.34 | 6800 | 0.5950 | 0.7533 | 0.7538 |
| 0.3504 | 35.35 | 7000 | 0.6163 | 0.7535 | 0.7541 |
| 0.3529 | 36.36 | 7200 | 0.6210 | 0.7507 | 0.7519 |
| 0.3464 | 37.37 | 7400 | 0.6336 | 0.7454 | 0.7468 |
| 0.3454 | 38.38 | 7600 | 0.6325 | 0.7396 | 0.7396 |
| 0.3413 | 39.39 | 7800 | 0.6368 | 0.7467 | 0.7472 |
| 0.3383 | 40.4 | 8000 | 0.6332 | 0.7490 | 0.7497 |
| 0.3365 | 41.41 | 8200 | 0.6283 | 0.7481 | 0.7491 |
| 0.3396 | 42.42 | 8400 | 0.6309 | 0.7461 | 0.7472 |
| 0.3292 | 43.43 | 8600 | 0.6488 | 0.7493 | 0.75 |
| 0.3253 | 44.44 | 8800 | 0.6601 | 0.7463 | 0.7472 |
| 0.3312 | 45.45 | 9000 | 0.6363 | 0.7490 | 0.7497 |
| 0.3269 | 46.46 | 9200 | 0.6423 | 0.7490 | 0.7494 |
| 0.3224 | 47.47 | 9400 | 0.6537 | 0.7459 | 0.7472 |
| 0.3222 | 48.48 | 9600 | 0.6515 | 0.7489 | 0.75 |
| 0.3236 | 49.49 | 9800 | 0.6497 | 0.7476 | 0.7487 |
| 0.3244 | 50.51 | 10000 | 0.6487 | 0.7507 | 0.7516 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:08:14+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me1-seqsight\_32768\_512\_43M-L32\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me1 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5134
* F1 Score: 0.7661
* Accuracy: 0.7677
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | mintujupally/gpt2-med-ft | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:08:26+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gpt2 #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
45,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | null |
# MistrollPercival_01-7B
MistrollPercival_01-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
- model: BarraHome/Mistroll-7B-v2.2
- model: AurelPx/Percival_01-7b-slerp
merge_method: model_stock
base_model: mistralai/Mistral-7B-v0.1
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/MistrollPercival_01-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "automerger"]} | automerger/MistrollPercival_01-7B | null | [
"merge",
"mergekit",
"lazymergekit",
"automerger",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T07:11:19+00:00 | [] | [] | TAGS
#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us
|
# MistrollPercival_01-7B
MistrollPercival_01-7B is an automated merge created by Maxime Labonne using the following configuration.
## Configuration
## Usage
| [
"# MistrollPercival_01-7B\n\nMistrollPercival_01-7B is an automated merge created by Maxime Labonne using the following configuration.",
"## Configuration",
"## Usage"
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us \n",
"# MistrollPercival_01-7B\n\nMistrollPercival_01-7B is an automated merge created by Maxime Labonne using the following configuration.",
"## Configuration",
"## Usage"
] | [
27,
36,
3,
3
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us \n# MistrollPercival_01-7B\n\nMistrollPercival_01-7B is an automated merge created by Maxime Labonne using the following configuration.## Configuration## Usage"
] |
null | null | This repo contains GGUF format model files for [
Svenni551's gemma-2b-it-toxic-v2.0](https://huggingface.co/Svenni551/gemma-2b-it-toxic-v2.0). | {} | Blombert/gemma-2b-it-toxic-v2.0-GGUF | null | [
"gguf",
"region:us"
] | null | 2024-04-30T07:14:38+00:00 | [] | [] | TAGS
#gguf #region-us
| This repo contains GGUF format model files for
Svenni551's gemma-2b-it-toxic-v2.0. | [] | [
"TAGS\n#gguf #region-us \n"
] | [
9
] | [
"TAGS\n#gguf #region-us \n"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 36
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "other", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "model-index": [{"name": "Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2", "results": []}]} | yzhuang/Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2 | null | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:generator",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:14:52+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #dataset-generator #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2
This model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 36
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 1\n- eval_batch_size: 2\n- seed: 42\n- gradient_accumulation_steps: 16\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 36",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.2\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #dataset-generator #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 1\n- eval_batch_size: 2\n- seed: 42\n- gradient_accumulation_steps: 16\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 36",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.2\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
83,
54,
7,
9,
9,
4,
111,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #dataset-generator #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Meta-Llama-3-8B-Instruct_fictional_arc_Japanese_v2\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the generator dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 1\n- eval_batch_size: 2\n- seed: 42\n- gradient_accumulation_steps: 16\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 36### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.2\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K36me3-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K36me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K36me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4599
- F1 Score: 0.8014
- Accuracy: 0.8030
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5681 | 0.92 | 200 | 0.5181 | 0.7553 | 0.7577 |
| 0.51 | 1.83 | 400 | 0.5069 | 0.7623 | 0.7652 |
| 0.495 | 2.75 | 600 | 0.4944 | 0.7720 | 0.7744 |
| 0.4931 | 3.67 | 800 | 0.4845 | 0.7810 | 0.7824 |
| 0.4786 | 4.59 | 1000 | 0.4851 | 0.7810 | 0.7830 |
| 0.4756 | 5.5 | 1200 | 0.4779 | 0.7791 | 0.7810 |
| 0.4737 | 6.42 | 1400 | 0.4746 | 0.7886 | 0.7896 |
| 0.4711 | 7.34 | 1600 | 0.4779 | 0.7861 | 0.7878 |
| 0.4639 | 8.26 | 1800 | 0.4787 | 0.7867 | 0.7881 |
| 0.4663 | 9.17 | 2000 | 0.4679 | 0.7921 | 0.7936 |
| 0.4651 | 10.09 | 2200 | 0.4783 | 0.7834 | 0.7861 |
| 0.4582 | 11.01 | 2400 | 0.4743 | 0.7892 | 0.7913 |
| 0.4592 | 11.93 | 2600 | 0.4638 | 0.7933 | 0.7947 |
| 0.4575 | 12.84 | 2800 | 0.4664 | 0.7920 | 0.7936 |
| 0.4554 | 13.76 | 3000 | 0.4715 | 0.7937 | 0.7956 |
| 0.4533 | 14.68 | 3200 | 0.4642 | 0.7972 | 0.7982 |
| 0.4521 | 15.6 | 3400 | 0.4652 | 0.7972 | 0.7990 |
| 0.4492 | 16.51 | 3600 | 0.4692 | 0.7961 | 0.7976 |
| 0.4524 | 17.43 | 3800 | 0.4582 | 0.7946 | 0.7956 |
| 0.4463 | 18.35 | 4000 | 0.4638 | 0.7949 | 0.7964 |
| 0.4458 | 19.27 | 4200 | 0.4650 | 0.7972 | 0.7985 |
| 0.4485 | 20.18 | 4400 | 0.4671 | 0.7967 | 0.7985 |
| 0.444 | 21.1 | 4600 | 0.4619 | 0.8000 | 0.8013 |
| 0.4454 | 22.02 | 4800 | 0.4638 | 0.7968 | 0.7982 |
| 0.4439 | 22.94 | 5000 | 0.4555 | 0.7980 | 0.7993 |
| 0.4449 | 23.85 | 5200 | 0.4580 | 0.8009 | 0.8025 |
| 0.4428 | 24.77 | 5400 | 0.4646 | 0.7970 | 0.7990 |
| 0.4441 | 25.69 | 5600 | 0.4587 | 0.7990 | 0.8002 |
| 0.441 | 26.61 | 5800 | 0.4578 | 0.7986 | 0.7996 |
| 0.4418 | 27.52 | 6000 | 0.4637 | 0.7980 | 0.7996 |
| 0.438 | 28.44 | 6200 | 0.4576 | 0.8004 | 0.8019 |
| 0.4387 | 29.36 | 6400 | 0.4631 | 0.7990 | 0.8007 |
| 0.4399 | 30.28 | 6600 | 0.4588 | 0.7993 | 0.8010 |
| 0.4376 | 31.19 | 6800 | 0.4552 | 0.8006 | 0.8016 |
| 0.4364 | 32.11 | 7000 | 0.4606 | 0.8004 | 0.8022 |
| 0.4392 | 33.03 | 7200 | 0.4599 | 0.7996 | 0.8010 |
| 0.4368 | 33.94 | 7400 | 0.4598 | 0.8020 | 0.8033 |
| 0.4327 | 34.86 | 7600 | 0.4602 | 0.8016 | 0.8030 |
| 0.4368 | 35.78 | 7800 | 0.4562 | 0.8018 | 0.8030 |
| 0.4367 | 36.7 | 8000 | 0.4594 | 0.8019 | 0.8033 |
| 0.4342 | 37.61 | 8200 | 0.4629 | 0.8005 | 0.8025 |
| 0.437 | 38.53 | 8400 | 0.4576 | 0.8014 | 0.8028 |
| 0.4329 | 39.45 | 8600 | 0.4604 | 0.8016 | 0.8030 |
| 0.4329 | 40.37 | 8800 | 0.4633 | 0.8009 | 0.8028 |
| 0.4382 | 41.28 | 9000 | 0.4587 | 0.8001 | 0.8019 |
| 0.4326 | 42.2 | 9200 | 0.4583 | 0.8021 | 0.8033 |
| 0.4309 | 43.12 | 9400 | 0.4599 | 0.8019 | 0.8033 |
| 0.4341 | 44.04 | 9600 | 0.4587 | 0.8003 | 0.8019 |
| 0.4327 | 44.95 | 9800 | 0.4597 | 0.8008 | 0.8025 |
| 0.4311 | 45.87 | 10000 | 0.4588 | 0.8006 | 0.8022 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K36me3-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K36me3-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:14:54+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K36me3-seqsight\_32768\_512\_43M-L1\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K36me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4599
* F1 Score: 0.8014
* Accuracy: 0.8030
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
reinforcement-learning | stable-baselines3 |
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["PandaReachDense-v3", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "A2C", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "PandaReachDense-v3", "type": "PandaReachDense-v3"}, "metrics": [{"type": "mean_reward", "value": "-0.27 +/- 0.12", "name": "mean_reward", "verified": false}]}]}]} | lightyip/a2c-PandaReachDense-v3 | null | [
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T07:16:52+00:00 | [] | [] | TAGS
#stable-baselines3 #PandaReachDense-v3 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# A2C Agent playing PandaReachDense-v3
This is a trained model of a A2C agent playing PandaReachDense-v3
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# A2C Agent playing PandaReachDense-v3\nThis is a trained model of a A2C agent playing PandaReachDense-v3\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #PandaReachDense-v3 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# A2C Agent playing PandaReachDense-v3\nThis is a trained model of a A2C agent playing PandaReachDense-v3\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
34,
41,
17
] | [
"TAGS\n#stable-baselines3 #PandaReachDense-v3 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n# A2C Agent playing PandaReachDense-v3\nThis is a trained model of a A2C agent playing PandaReachDense-v3\nusing the stable-baselines3 library.## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K36me3-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K36me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K36me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4417
- F1 Score: 0.8075
- Accuracy: 0.8088
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5466 | 0.92 | 200 | 0.5059 | 0.7710 | 0.7732 |
| 0.4877 | 1.83 | 400 | 0.4834 | 0.7806 | 0.7824 |
| 0.4734 | 2.75 | 600 | 0.4703 | 0.7908 | 0.7919 |
| 0.4737 | 3.67 | 800 | 0.4677 | 0.7951 | 0.7962 |
| 0.4575 | 4.59 | 1000 | 0.4679 | 0.7951 | 0.7962 |
| 0.4534 | 5.5 | 1200 | 0.4599 | 0.7950 | 0.7964 |
| 0.4518 | 6.42 | 1400 | 0.4595 | 0.7991 | 0.8002 |
| 0.4471 | 7.34 | 1600 | 0.4609 | 0.8002 | 0.8025 |
| 0.4412 | 8.26 | 1800 | 0.4637 | 0.8006 | 0.8019 |
| 0.4426 | 9.17 | 2000 | 0.4486 | 0.8055 | 0.8065 |
| 0.4401 | 10.09 | 2200 | 0.4731 | 0.7966 | 0.7996 |
| 0.4341 | 11.01 | 2400 | 0.4619 | 0.8014 | 0.8036 |
| 0.4321 | 11.93 | 2600 | 0.4467 | 0.8028 | 0.8033 |
| 0.4325 | 12.84 | 2800 | 0.4493 | 0.8060 | 0.8076 |
| 0.4268 | 13.76 | 3000 | 0.4583 | 0.8028 | 0.8050 |
| 0.4252 | 14.68 | 3200 | 0.4560 | 0.8058 | 0.8071 |
| 0.4219 | 15.6 | 3400 | 0.4454 | 0.8070 | 0.8079 |
| 0.422 | 16.51 | 3600 | 0.4627 | 0.8036 | 0.8053 |
| 0.4222 | 17.43 | 3800 | 0.4527 | 0.8059 | 0.8073 |
| 0.4149 | 18.35 | 4000 | 0.4500 | 0.8059 | 0.8065 |
| 0.4165 | 19.27 | 4200 | 0.4587 | 0.8047 | 0.8062 |
| 0.4147 | 20.18 | 4400 | 0.4640 | 0.8041 | 0.8056 |
| 0.4112 | 21.1 | 4600 | 0.4534 | 0.8052 | 0.8062 |
| 0.4133 | 22.02 | 4800 | 0.4541 | 0.8067 | 0.8076 |
| 0.4101 | 22.94 | 5000 | 0.4487 | 0.8045 | 0.8056 |
| 0.4104 | 23.85 | 5200 | 0.4520 | 0.8019 | 0.8033 |
| 0.4065 | 24.77 | 5400 | 0.4689 | 0.8047 | 0.8068 |
| 0.4067 | 25.69 | 5600 | 0.4542 | 0.8061 | 0.8073 |
| 0.4034 | 26.61 | 5800 | 0.4540 | 0.8042 | 0.8050 |
| 0.4036 | 27.52 | 6000 | 0.4662 | 0.8032 | 0.8045 |
| 0.4 | 28.44 | 6200 | 0.4526 | 0.8026 | 0.8039 |
| 0.3994 | 29.36 | 6400 | 0.4538 | 0.8057 | 0.8071 |
| 0.3993 | 30.28 | 6600 | 0.4515 | 0.8051 | 0.8068 |
| 0.398 | 31.19 | 6800 | 0.4507 | 0.8034 | 0.8042 |
| 0.3962 | 32.11 | 7000 | 0.4530 | 0.8057 | 0.8068 |
| 0.3983 | 33.03 | 7200 | 0.4589 | 0.8046 | 0.8056 |
| 0.3949 | 33.94 | 7400 | 0.4566 | 0.8054 | 0.8065 |
| 0.3907 | 34.86 | 7600 | 0.4557 | 0.8043 | 0.8056 |
| 0.3929 | 35.78 | 7800 | 0.4536 | 0.8048 | 0.8053 |
| 0.3915 | 36.7 | 8000 | 0.4579 | 0.8052 | 0.8065 |
| 0.3872 | 37.61 | 8200 | 0.4630 | 0.8027 | 0.8045 |
| 0.3945 | 38.53 | 8400 | 0.4594 | 0.8027 | 0.8042 |
| 0.3873 | 39.45 | 8600 | 0.4575 | 0.8051 | 0.8062 |
| 0.3866 | 40.37 | 8800 | 0.4656 | 0.8045 | 0.8062 |
| 0.3917 | 41.28 | 9000 | 0.4581 | 0.8021 | 0.8036 |
| 0.3876 | 42.2 | 9200 | 0.4572 | 0.8052 | 0.8062 |
| 0.3852 | 43.12 | 9400 | 0.4595 | 0.8029 | 0.8039 |
| 0.386 | 44.04 | 9600 | 0.4592 | 0.8035 | 0.8048 |
| 0.3842 | 44.95 | 9800 | 0.4599 | 0.8033 | 0.8048 |
| 0.3836 | 45.87 | 10000 | 0.4597 | 0.8040 | 0.8053 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K36me3-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K36me3-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:17:33+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K36me3-seqsight\_32768\_512\_43M-L8\_f
==================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K36me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4417
* F1 Score: 0.8075
* Accuracy: 0.8088
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-1b_mz-131_IMDB
This model is a fine-tuned version of [EleutherAI/pythia-1b](https://huggingface.co/EleutherAI/pythia-1b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-1b", "model-index": [{"name": "robust_llm_pythia-1b_mz-131_IMDB", "results": []}]} | AlignmentResearch/robust_llm_pythia-1b_mz-131_IMDB | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-1b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:18:17+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-1b_mz-131_IMDB
This model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-1b_mz-131_IMDB\n\nThis model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-1b_mz-131_IMDB\n\nThis model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
69,
44,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-1b_mz-131_IMDB\n\nThis model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# final_V1-distilbert-text-classification-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1494
- Accuracy: 0.9672
- F1: 0.8312
- Precision: 0.8275
- Recall: 0.8357
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.6662 | 0.11 | 50 | 1.6945 | 0.2888 | 0.0820 | 0.1958 | 0.1341 |
| 0.7494 | 0.22 | 100 | 0.6947 | 0.8034 | 0.4962 | 0.4949 | 0.5054 |
| 0.2779 | 0.33 | 150 | 0.4631 | 0.8980 | 0.6685 | 0.6550 | 0.6829 |
| 0.2204 | 0.44 | 200 | 0.3938 | 0.8999 | 0.6686 | 0.6659 | 0.6758 |
| 0.137 | 0.55 | 250 | 0.4153 | 0.9065 | 0.6707 | 0.6537 | 0.6898 |
| 0.1931 | 0.66 | 300 | 0.3093 | 0.9166 | 0.7089 | 0.7728 | 0.7046 |
| 0.1356 | 0.76 | 350 | 0.3384 | 0.9152 | 0.6904 | 0.8123 | 0.6978 |
| 0.1065 | 0.87 | 400 | 0.4172 | 0.9144 | 0.7233 | 0.7804 | 0.7174 |
| 0.105 | 0.98 | 450 | 0.4521 | 0.8852 | 0.7078 | 0.7342 | 0.7051 |
| 0.1275 | 1.09 | 500 | 0.2837 | 0.9262 | 0.7365 | 0.7927 | 0.7275 |
| 0.0754 | 1.2 | 550 | 0.3979 | 0.9180 | 0.7164 | 0.8039 | 0.7133 |
| 0.0861 | 1.31 | 600 | 0.1506 | 0.9604 | 0.8259 | 0.8247 | 0.8280 |
| 0.0514 | 1.42 | 650 | 0.1397 | 0.9664 | 0.8277 | 0.8264 | 0.8293 |
| 0.0536 | 1.53 | 700 | 0.1566 | 0.9642 | 0.8279 | 0.8255 | 0.8308 |
| 0.0351 | 1.64 | 750 | 0.1804 | 0.9620 | 0.8276 | 0.8251 | 0.8312 |
| 0.0862 | 1.75 | 800 | 0.1445 | 0.9655 | 0.8314 | 0.8307 | 0.8322 |
| 0.0461 | 1.86 | 850 | 0.1492 | 0.9669 | 0.8306 | 0.8291 | 0.8324 |
| 0.0663 | 1.97 | 900 | 0.2054 | 0.9604 | 0.8292 | 0.8299 | 0.8295 |
| 0.0482 | 2.07 | 950 | 0.1498 | 0.9655 | 0.8294 | 0.8272 | 0.8324 |
| 0.0299 | 2.18 | 1000 | 0.1657 | 0.9650 | 0.8292 | 0.8269 | 0.8321 |
| 0.0348 | 2.29 | 1050 | 0.1473 | 0.9686 | 0.8310 | 0.8291 | 0.8332 |
| 0.0283 | 2.4 | 1100 | 0.1470 | 0.9694 | 0.8333 | 0.8297 | 0.8376 |
| 0.0115 | 2.51 | 1150 | 0.1496 | 0.9691 | 0.8336 | 0.8317 | 0.8358 |
| 0.004 | 2.62 | 1200 | 0.1671 | 0.9650 | 0.8301 | 0.8280 | 0.8329 |
| 0.0054 | 2.73 | 1250 | 0.1560 | 0.9694 | 0.8333 | 0.8325 | 0.8343 |
| 0.0217 | 2.84 | 1300 | 0.1553 | 0.9696 | 0.8334 | 0.8326 | 0.8345 |
| 0.0054 | 2.95 | 1350 | 0.1603 | 0.9691 | 0.8332 | 0.8324 | 0.8343 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1", "precision", "recall"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "final_V1-distilbert-text-classification-model", "results": []}]} | AmirlyPhd/final_V1-distilbert-text-classification-model | null | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:18:29+00:00 | [] | [] | TAGS
#transformers #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| final\_V1-distilbert-text-classification-model
==============================================
This model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1494
* Accuracy: 0.9672
* F1: 0.8312
* Precision: 0.8275
* Recall: 0.8357
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 16
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
56,
128,
5,
40
] | [
"TAGS\n#transformers #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-14m", "model-index": [{"name": "robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2", "results": []}]} | AlignmentResearch/robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:18:50+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2
This model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
62,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 2\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K36me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K36me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4593
- F1 Score: 0.8080
- Accuracy: 0.8085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.532 | 0.92 | 200 | 0.5003 | 0.7788 | 0.7810 |
| 0.4759 | 1.83 | 400 | 0.4744 | 0.7933 | 0.7950 |
| 0.4604 | 2.75 | 600 | 0.4594 | 0.7985 | 0.7993 |
| 0.4624 | 3.67 | 800 | 0.4559 | 0.7965 | 0.7973 |
| 0.4441 | 4.59 | 1000 | 0.4552 | 0.8001 | 0.8013 |
| 0.4371 | 5.5 | 1200 | 0.4578 | 0.7966 | 0.7982 |
| 0.4361 | 6.42 | 1400 | 0.4540 | 0.8029 | 0.8039 |
| 0.4302 | 7.34 | 1600 | 0.4615 | 0.7940 | 0.7970 |
| 0.4196 | 8.26 | 1800 | 0.4536 | 0.8041 | 0.8045 |
| 0.4203 | 9.17 | 2000 | 0.4452 | 0.8077 | 0.8085 |
| 0.4175 | 10.09 | 2200 | 0.4663 | 0.8012 | 0.8036 |
| 0.4074 | 11.01 | 2400 | 0.4547 | 0.8040 | 0.8056 |
| 0.4032 | 11.93 | 2600 | 0.4458 | 0.8061 | 0.8062 |
| 0.3995 | 12.84 | 2800 | 0.4507 | 0.8030 | 0.8042 |
| 0.394 | 13.76 | 3000 | 0.4626 | 0.8017 | 0.8045 |
| 0.387 | 14.68 | 3200 | 0.4740 | 0.8106 | 0.8116 |
| 0.3798 | 15.6 | 3400 | 0.4645 | 0.8033 | 0.8042 |
| 0.3793 | 16.51 | 3600 | 0.4739 | 0.8026 | 0.8045 |
| 0.3736 | 17.43 | 3800 | 0.4854 | 0.8028 | 0.8048 |
| 0.3682 | 18.35 | 4000 | 0.4689 | 0.8095 | 0.8096 |
| 0.365 | 19.27 | 4200 | 0.4743 | 0.8069 | 0.8082 |
| 0.36 | 20.18 | 4400 | 0.4915 | 0.8065 | 0.8073 |
| 0.3521 | 21.1 | 4600 | 0.4773 | 0.8108 | 0.8111 |
| 0.3512 | 22.02 | 4800 | 0.4589 | 0.8127 | 0.8131 |
| 0.3461 | 22.94 | 5000 | 0.4784 | 0.8096 | 0.8102 |
| 0.3426 | 23.85 | 5200 | 0.4836 | 0.8072 | 0.8082 |
| 0.3364 | 24.77 | 5400 | 0.5025 | 0.8019 | 0.8039 |
| 0.3323 | 25.69 | 5600 | 0.5016 | 0.8058 | 0.8071 |
| 0.3263 | 26.61 | 5800 | 0.4957 | 0.8126 | 0.8134 |
| 0.3241 | 27.52 | 6000 | 0.5310 | 0.8025 | 0.8042 |
| 0.3193 | 28.44 | 6200 | 0.4931 | 0.8063 | 0.8071 |
| 0.3149 | 29.36 | 6400 | 0.4947 | 0.8036 | 0.8045 |
| 0.3111 | 30.28 | 6600 | 0.5114 | 0.7948 | 0.7962 |
| 0.3087 | 31.19 | 6800 | 0.5160 | 0.8035 | 0.8039 |
| 0.3048 | 32.11 | 7000 | 0.5246 | 0.8039 | 0.8050 |
| 0.3036 | 33.03 | 7200 | 0.5121 | 0.8067 | 0.8076 |
| 0.3029 | 33.94 | 7400 | 0.5133 | 0.8060 | 0.8068 |
| 0.2968 | 34.86 | 7600 | 0.5271 | 0.8084 | 0.8088 |
| 0.2937 | 35.78 | 7800 | 0.5254 | 0.8064 | 0.8065 |
| 0.2894 | 36.7 | 8000 | 0.5430 | 0.8001 | 0.8010 |
| 0.2877 | 37.61 | 8200 | 0.5349 | 0.8015 | 0.8025 |
| 0.2916 | 38.53 | 8400 | 0.5424 | 0.7984 | 0.7999 |
| 0.2815 | 39.45 | 8600 | 0.5469 | 0.8003 | 0.8013 |
| 0.284 | 40.37 | 8800 | 0.5575 | 0.8012 | 0.8025 |
| 0.2831 | 41.28 | 9000 | 0.5531 | 0.7982 | 0.7996 |
| 0.2795 | 42.2 | 9200 | 0.5466 | 0.8005 | 0.8010 |
| 0.2756 | 43.12 | 9400 | 0.5513 | 0.8014 | 0.8019 |
| 0.275 | 44.04 | 9600 | 0.5573 | 0.7997 | 0.8007 |
| 0.2741 | 44.95 | 9800 | 0.5527 | 0.8008 | 0.8016 |
| 0.2727 | 45.87 | 10000 | 0.5574 | 0.8029 | 0.8039 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:19:02+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K36me3-seqsight\_32768\_512\_43M-L32\_f
===================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K36me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4593
* F1 Score: 0.8080
* Accuracy: 0.8085
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# llama-3-8b-chat-patent-small
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the english translation of a small dataset of 16,000 Korean patents.
## Model description
This model is provided for testing purposes only.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"language": ["en"], "license": "other", "tags": ["llama-factory", "full", "generated_from_trainer"], "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "model-index": [{"name": "llama-3-8b-chat-patent-small", "results": []}]} | kimhyeongjun/llama-3-8b-chat-patent-small | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"en",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:19:07+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #llama-factory #full #generated_from_trainer #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# llama-3-8b-chat-patent-small
This model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the english translation of a small dataset of 16,000 Korean patents.
## Model description
This model is provided for testing purposes only.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | [
"# llama-3-8b-chat-patent-small\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the english translation of a small dataset of 16,000 Korean patents.",
"## Model description\nThis model is provided for testing purposes only.",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- num_epochs: 3.0\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.1.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #llama-factory #full #generated_from_trainer #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# llama-3-8b-chat-patent-small\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the english translation of a small dataset of 16,000 Korean patents.",
"## Model description\nThis model is provided for testing purposes only.",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- num_epochs: 3.0\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.1.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
78,
56,
13,
124,
44
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #llama-factory #full #generated_from_trainer #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# llama-3-8b-chat-patent-small\n\nThis model is a fine-tuned version of meta-llama/Meta-Llama-3-8B-Instruct on the english translation of a small dataset of 16,000 Korean patents.## Model description\nThis model is provided for testing purposes only.### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- num_epochs: 3.0\n- mixed_precision_training: Native AMP### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.1.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-14m", "model-index": [{"name": "robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3", "results": []}]} | AlignmentResearch/robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:19:48+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3
This model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
62,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-14m #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-14m_mz-133_EnronSpam_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-14m on an unknown dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 3\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1### Training results### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA3
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0125
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 80
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5415 | 0.09 | 10 | 0.3036 |
| 0.1844 | 0.18 | 20 | 0.1520 |
| 0.1496 | 0.27 | 30 | 0.1664 |
| 0.1583 | 0.36 | 40 | 0.1556 |
| 0.1517 | 0.45 | 50 | 0.1555 |
| 0.1516 | 0.54 | 60 | 0.1522 |
| 0.153 | 0.63 | 70 | 0.1478 |
| 0.1493 | 0.73 | 80 | 0.1598 |
| 0.1462 | 0.82 | 90 | 0.1427 |
| 0.1591 | 0.91 | 100 | 0.4668 |
| 0.2553 | 1.0 | 110 | 0.0960 |
| 0.4182 | 1.09 | 120 | 1.5724 |
| 0.276 | 1.18 | 130 | 0.0788 |
| 0.0868 | 1.27 | 140 | 0.0749 |
| 0.0837 | 1.36 | 150 | 0.0648 |
| 0.0593 | 1.45 | 160 | 0.0556 |
| 0.0534 | 1.54 | 170 | 0.0485 |
| 0.0781 | 1.63 | 180 | 0.0526 |
| 0.0545 | 1.72 | 190 | 0.0445 |
| 0.0352 | 1.81 | 200 | 0.0309 |
| 0.0496 | 1.9 | 210 | 0.0589 |
| 0.0461 | 1.99 | 220 | 0.0449 |
| 0.0372 | 2.08 | 230 | 0.0267 |
| 0.0236 | 2.18 | 240 | 0.0236 |
| 0.0213 | 2.27 | 250 | 0.0232 |
| 0.0212 | 2.36 | 260 | 0.0193 |
| 0.0207 | 2.45 | 270 | 0.0170 |
| 0.0141 | 2.54 | 280 | 0.0153 |
| 0.0205 | 2.63 | 290 | 0.0151 |
| 0.0154 | 2.72 | 300 | 0.0133 |
| 0.0135 | 2.81 | 310 | 0.0129 |
| 0.0152 | 2.9 | 320 | 0.0125 |
| 0.0137 | 2.99 | 330 | 0.0125 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA3", "results": []}]} | Litzy619/O0430HMA3 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T07:20:17+00:00 | [] | [] | TAGS
#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us
| O0430HMA3
=========
This model is a fine-tuned version of allenai/OLMo-1B on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0125
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 80
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.1.2+cu121
* Datasets 2.14.6
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
35,
160,
5,
47
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] |
null | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DonutProcessor_Detail
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 1.13.1
- Datasets 2.13.2
- Tokenizers 0.13.3
| {"license": "mit", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "model-index": [{"name": "DonutProcessor_Detail", "results": []}]} | 2003achu/code | null | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:20:51+00:00 | [] | [] | TAGS
#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #license-mit #endpoints_compatible #region-us
|
# DonutProcessor_Detail
This model is a fine-tuned version of naver-clova-ix/donut-base on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 1.13.1
- Datasets 2.13.2
- Tokenizers 0.13.3
| [
"# DonutProcessor_Detail\n\nThis model is a fine-tuned version of naver-clova-ix/donut-base on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.30.2\n- Pytorch 1.13.1\n- Datasets 2.13.2\n- Tokenizers 0.13.3"
] | [
"TAGS\n#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #license-mit #endpoints_compatible #region-us \n",
"# DonutProcessor_Detail\n\nThis model is a fine-tuned version of naver-clova-ix/donut-base on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.30.2\n- Pytorch 1.13.1\n- Datasets 2.13.2\n- Tokenizers 0.13.3"
] | [
43,
37,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #license-mit #endpoints_compatible #region-us \n# DonutProcessor_Detail\n\nThis model is a fine-tuned version of naver-clova-ix/donut-base on the imagefolder dataset.## Model description\n\nMore information needed## Intended uses & limitations\n\nMore information needed## Training and evaluation data\n\nMore information needed## Training procedure### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3### Training results### Framework versions\n\n- Transformers 4.30.2\n- Pytorch 1.13.1\n- Datasets 2.13.2\n- Tokenizers 0.13.3"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | steve1989/finbert-finetuned-SA-finance-headlines | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:22:15+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
37,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_0-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_mouse_0](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_0) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5432
- F1 Score: 0.7236
- Accuracy: 0.7247
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6558 | 3.92 | 200 | 0.6066 | 0.6576 | 0.6580 |
| 0.6001 | 7.84 | 400 | 0.5916 | 0.6752 | 0.6753 |
| 0.5837 | 11.76 | 600 | 0.5789 | 0.6886 | 0.6889 |
| 0.5679 | 15.69 | 800 | 0.5726 | 0.7093 | 0.7123 |
| 0.5555 | 19.61 | 1000 | 0.5643 | 0.7058 | 0.7062 |
| 0.5486 | 23.53 | 1200 | 0.5901 | 0.6847 | 0.6975 |
| 0.5346 | 27.45 | 1400 | 0.5607 | 0.7247 | 0.7259 |
| 0.5276 | 31.37 | 1600 | 0.5585 | 0.7172 | 0.7198 |
| 0.5254 | 35.29 | 1800 | 0.5542 | 0.7184 | 0.7210 |
| 0.5129 | 39.22 | 2000 | 0.5539 | 0.7228 | 0.7235 |
| 0.5081 | 43.14 | 2200 | 0.5505 | 0.7254 | 0.7259 |
| 0.5075 | 47.06 | 2400 | 0.5478 | 0.7254 | 0.7272 |
| 0.496 | 50.98 | 2600 | 0.5521 | 0.7284 | 0.7284 |
| 0.494 | 54.9 | 2800 | 0.5555 | 0.7210 | 0.7247 |
| 0.4866 | 58.82 | 3000 | 0.5454 | 0.7240 | 0.7247 |
| 0.4872 | 62.75 | 3200 | 0.5484 | 0.7235 | 0.7247 |
| 0.4796 | 66.67 | 3400 | 0.5458 | 0.7365 | 0.7370 |
| 0.4776 | 70.59 | 3600 | 0.5406 | 0.7340 | 0.7346 |
| 0.4744 | 74.51 | 3800 | 0.5452 | 0.7269 | 0.7284 |
| 0.4708 | 78.43 | 4000 | 0.5408 | 0.7282 | 0.7296 |
| 0.4676 | 82.35 | 4200 | 0.5395 | 0.7319 | 0.7333 |
| 0.4629 | 86.27 | 4400 | 0.5382 | 0.7328 | 0.7333 |
| 0.4596 | 90.2 | 4600 | 0.5429 | 0.7200 | 0.7222 |
| 0.4567 | 94.12 | 4800 | 0.5392 | 0.7325 | 0.7333 |
| 0.4578 | 98.04 | 5000 | 0.5452 | 0.7263 | 0.7284 |
| 0.456 | 101.96 | 5200 | 0.5398 | 0.7314 | 0.7321 |
| 0.4542 | 105.88 | 5400 | 0.5382 | 0.7292 | 0.7309 |
| 0.4502 | 109.8 | 5600 | 0.5393 | 0.7315 | 0.7321 |
| 0.4452 | 113.73 | 5800 | 0.5389 | 0.7276 | 0.7284 |
| 0.4426 | 117.65 | 6000 | 0.5427 | 0.7314 | 0.7321 |
| 0.4401 | 121.57 | 6200 | 0.5441 | 0.7338 | 0.7346 |
| 0.4453 | 125.49 | 6400 | 0.5386 | 0.7240 | 0.7247 |
| 0.4361 | 129.41 | 6600 | 0.5382 | 0.7329 | 0.7333 |
| 0.4369 | 133.33 | 6800 | 0.5439 | 0.7280 | 0.7296 |
| 0.4382 | 137.25 | 7000 | 0.5364 | 0.7300 | 0.7309 |
| 0.4348 | 141.18 | 7200 | 0.5384 | 0.7335 | 0.7346 |
| 0.4326 | 145.1 | 7400 | 0.5403 | 0.7348 | 0.7358 |
| 0.4334 | 149.02 | 7600 | 0.5422 | 0.7347 | 0.7358 |
| 0.4341 | 152.94 | 7800 | 0.5403 | 0.7359 | 0.7370 |
| 0.432 | 156.86 | 8000 | 0.5380 | 0.7337 | 0.7346 |
| 0.4333 | 160.78 | 8200 | 0.5384 | 0.7344 | 0.7358 |
| 0.4342 | 164.71 | 8400 | 0.5378 | 0.7337 | 0.7346 |
| 0.4359 | 168.63 | 8600 | 0.5368 | 0.7343 | 0.7358 |
| 0.43 | 172.55 | 8800 | 0.5377 | 0.7330 | 0.7346 |
| 0.4276 | 176.47 | 9000 | 0.5394 | 0.7342 | 0.7358 |
| 0.4242 | 180.39 | 9200 | 0.5415 | 0.7355 | 0.7370 |
| 0.4269 | 184.31 | 9400 | 0.5407 | 0.7336 | 0.7346 |
| 0.4275 | 188.24 | 9600 | 0.5402 | 0.7347 | 0.7358 |
| 0.4263 | 192.16 | 9800 | 0.5399 | 0.7359 | 0.7370 |
| 0.4231 | 196.08 | 10000 | 0.5395 | 0.7359 | 0.7370 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_mouse_0-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_0-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T07:24:09+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_mouse\_0-seqsight\_32768\_512\_43M-L1\_f
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_mouse\_0 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5432
* F1 Score: 0.7236
* Accuracy: 0.7247
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
43,
100,
5,
52
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000### Training results### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | kyounghyun/gemma-medical_qa-Finetune | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:25:17+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
46,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trained_danish
This model is a fine-tuned version of [distilbert/distilbert-base-multilingual-cased](https://huggingface.co/distilbert/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0667
- Precision: 0.7791
- Recall: 0.7329
- F1: 0.7553
- Accuracy: 0.9807
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 137 | 0.0788 | 0.6736 | 0.6658 | 0.6697 | 0.9749 |
| No log | 2.0 | 274 | 0.0652 | 0.7653 | 0.7406 | 0.7528 | 0.9802 |
| No log | 3.0 | 411 | 0.0667 | 0.7791 | 0.7329 | 0.7553 | 0.9807 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "distilbert/distilbert-base-multilingual-cased", "model-index": [{"name": "trained_danish", "results": []}]} | annamariagnat/trained_danish | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:26:21+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| trained\_danish
===============
This model is a fine-tuned version of distilbert/distilbert-base-multilingual-cased on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0667
* Precision: 0.7791
* Recall: 0.7329
* F1: 0.7553
* Accuracy: 0.9807
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.1.2+cu118
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2+cu118\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2+cu118\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
67,
124,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3### Training results### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2+cu118\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | null |
# ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF
This model was converted to GGUF format from [`baichuan-inc/Baichuan2-13B-Base`](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF --model baichuan2-13b-base.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF --model baichuan2-13b-base.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m baichuan2-13b-base.Q4_K_M.gguf -n 128
```
| {"language": ["en", "zh"], "license": "other", "tags": ["llama-cpp", "gguf-my-repo"], "tasks": ["text-generation"]} | ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"zh",
"license:other",
"region:us"
] | null | 2024-04-30T07:30:00+00:00 | [] | [
"en",
"zh"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #en #zh #license-other #region-us
|
# ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF
This model was converted to GGUF format from 'baichuan-inc/Baichuan2-13B-Base' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'baichuan-inc/Baichuan2-13B-Base' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #en #zh #license-other #region-us \n",
"# ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'baichuan-inc/Baichuan2-13B-Base' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
33,
85,
52
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #en #zh #license-other #region-us \n# ridwanlekan/Baichuan2-13B-Base-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'baichuan-inc/Baichuan2-13B-Base' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers |
# mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from [`llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
| {"language": ["en", "ja"], "license": "apache-2.0", "library_name": "transformers", "tags": ["mlx"], "datasets": ["databricks/databricks-dolly-15k", "llm-jp/databricks-dolly-15k-ja", "llm-jp/oasst1-21k-en", "llm-jp/oasst1-21k-ja", "llm-jp/oasst2-33k-en", "llm-jp/oasst2-33k-ja"], "programming_language": ["C", "C++", "C#", "Go", "Java", "JavaScript", "Lua", "PHP", "Python", "Ruby", "Rust", "Scala", "TypeScript"], "pipeline_tag": "text-generation", "inference": false} | mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"conversational",
"en",
"ja",
"dataset:databricks/databricks-dolly-15k",
"dataset:llm-jp/databricks-dolly-15k-ja",
"dataset:llm-jp/oasst1-21k-en",
"dataset:llm-jp/oasst1-21k-ja",
"dataset:llm-jp/oasst2-33k-en",
"dataset:llm-jp/oasst2-33k-ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:30:40+00:00 | [] | [
"en",
"ja"
] | TAGS
#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us
|
# mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n",
"# mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
154,
144,
6
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mlx #conversational #en #ja #dataset-databricks/databricks-dolly-15k #dataset-llm-jp/databricks-dolly-15k-ja #dataset-llm-jp/oasst1-21k-en #dataset-llm-jp/oasst1-21k-ja #dataset-llm-jp/oasst2-33k-en #dataset-llm-jp/oasst2-33k-ja #license-apache-2.0 #autotrain_compatible #text-generation-inference #region-us \n# mlx-community/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0\nThis model was converted to MLX format from ['llm-jp/llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.## Use with mlx"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: meta-llama/Meta-Llama-3-8B
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: true
load_in_4bit: false
strict: false
datasets:
- path: kloodia/alpaca_french
type: oasst
dataset_prepared_path:
val_set_size: 0.05
output_dir: ./lora-out-french-alpaca
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
adapter: lora
lora_model_dir:
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
s2_attention:
warmup_steps: 10
evals_per_epoch: 4
eval_table_size:
eval_max_new_tokens: 128
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
pad_token: <|end_of_text|>
```
</details><br>
# lora-out-french-alpaca
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1297
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3359 | 0.0 | 1 | 1.3247 |
| 1.1121 | 0.25 | 100 | 1.1294 |
| 1.1716 | 0.5 | 200 | 1.1096 |
| 1.1122 | 0.75 | 300 | 1.0955 |
| 1.0474 | 1.0 | 400 | 1.0836 |
| 1.0447 | 1.24 | 500 | 1.0873 |
| 1.0131 | 1.49 | 600 | 1.0809 |
| 0.9847 | 1.74 | 700 | 1.0762 |
| 0.9584 | 1.99 | 800 | 1.0697 |
| 0.8514 | 2.23 | 900 | 1.0966 |
| 0.9217 | 2.48 | 1000 | 1.0995 |
| 0.8732 | 2.73 | 1100 | 1.0964 |
| 0.9226 | 2.98 | 1200 | 1.0951 |
| 0.76 | 3.22 | 1300 | 1.1307 |
| 0.8056 | 3.47 | 1400 | 1.1314 |
| 0.7895 | 3.72 | 1500 | 1.1297 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0.dev0
- Pytorch 2.1.2+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0 | {"license": "other", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "meta-llama/Meta-Llama-3-8B", "model-index": [{"name": "lora-out-french-alpaca", "results": []}]} | kloodia/alpaca | null | [
"peft",
"tensorboard",
"safetensors",
"llama",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:other",
"8-bit",
"region:us"
] | null | 2024-04-30T07:30:54+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #llama #generated_from_trainer #base_model-meta-llama/Meta-Llama-3-8B #license-other #8-bit #region-us
| <img src="URL alt="Built with Axolotl" width="200" height="32"/>
See axolotl config
axolotl version: '0.4.0'
lora-out-french-alpaca
======================
This model is a fine-tuned version of meta-llama/Meta-Llama-3-8B on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1297
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 4
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 10
* num\_epochs: 4
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.40.0.dev0
* Pytorch 2.1.2+cu118
* Datasets 2.15.0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 10\n* num\\_epochs: 4",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] | [
"TAGS\n#peft #tensorboard #safetensors #llama #generated_from_trainer #base_model-meta-llama/Meta-Llama-3-8B #license-other #8-bit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 10\n* num\\_epochs: 4",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] | [
51,
142,
5,
55
] | [
"TAGS\n#peft #tensorboard #safetensors #llama #generated_from_trainer #base_model-meta-llama/Meta-Llama-3-8B #license-other #8-bit #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 10\n* num\\_epochs: 4### Training results### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama2-7b-dpo-full-sft-wo-kqa_golden
This model is a fine-tuned version of [Minbyul/llama2-7b-wo-kqa_golden-sft](https://huggingface.co/Minbyul/llama2-7b-wo-kqa_golden-sft) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2778
- Rewards/chosen: -0.1016
- Rewards/rejected: -2.1516
- Rewards/accuracies: 0.9500
- Rewards/margins: 2.0501
- Logps/rejected: -771.6371
- Logps/chosen: -312.4064
- Logits/rejected: -0.5673
- Logits/chosen: -0.7867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.2497 | 0.74 | 100 | 0.3024 | -0.0879 | -1.9222 | 0.9500 | 1.8343 | -748.6945 | -311.0383 | -0.5637 | -0.7827 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.2
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"tags": ["alignment-handbook", "trl", "dpo", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["HuggingFaceH4/ultrafeedback_binarized"], "base_model": "Minbyul/llama2-7b-wo-kqa_golden-sft", "model-index": [{"name": "llama2-7b-dpo-full-sft-wo-kqa_golden", "results": []}]} | Minbyul/llama2-7b-dpo-full-sft-wo-kqa_golden | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"alignment-handbook",
"trl",
"dpo",
"generated_from_trainer",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:Minbyul/llama2-7b-wo-kqa_golden-sft",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:33:06+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #alignment-handbook #trl #dpo #generated_from_trainer #dataset-HuggingFaceH4/ultrafeedback_binarized #base_model-Minbyul/llama2-7b-wo-kqa_golden-sft #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| llama2-7b-dpo-full-sft-wo-kqa\_golden
=====================================
This model is a fine-tuned version of Minbyul/llama2-7b-wo-kqa\_golden-sft on the HuggingFaceH4/ultrafeedback\_binarized dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2778
* Rewards/chosen: -0.1016
* Rewards/rejected: -2.1516
* Rewards/accuracies: 0.9500
* Rewards/margins: 2.0501
* Logps/rejected: -771.6371
* Logps/chosen: -312.4064
* Logits/rejected: -0.5673
* Logits/chosen: -0.7867
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-07
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* distributed\_type: multi-GPU
* num\_devices: 4
* gradient\_accumulation\_steps: 2
* total\_train\_batch\_size: 64
* total\_eval\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 1
### Training results
### Framework versions
* Transformers 4.39.0.dev0
* Pytorch 2.1.2
* Datasets 2.14.6
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-07\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 4\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 64\n* total\\_eval\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.0.dev0\n* Pytorch 2.1.2\n* Datasets 2.14.6\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #alignment-handbook #trl #dpo #generated_from_trainer #dataset-HuggingFaceH4/ultrafeedback_binarized #base_model-Minbyul/llama2-7b-wo-kqa_golden-sft #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-07\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 4\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 64\n* total\\_eval\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.0.dev0\n* Pytorch 2.1.2\n* Datasets 2.14.6\n* Tokenizers 0.15.2"
] | [
92,
176,
5,
43
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #alignment-handbook #trl #dpo #generated_from_trainer #dataset-HuggingFaceH4/ultrafeedback_binarized #base_model-Minbyul/llama2-7b-wo-kqa_golden-sft #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-07\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 4\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 64\n* total\\_eval\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 1### Training results### Framework versions\n\n\n* Transformers 4.39.0.dev0\n* Pytorch 2.1.2\n* Datasets 2.14.6\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-360M
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8573
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 300
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.5748 | 1.0 | 3 | 8.5145 |
| 8.2938 | 2.0 | 6 | 8.2723 |
| 7.8473 | 3.0 | 9 | 7.8807 |
| 7.2394 | 4.0 | 12 | 7.3951 |
| 6.6519 | 5.0 | 15 | 6.9171 |
| 6.2694 | 6.0 | 18 | 6.5824 |
| 5.9992 | 7.0 | 21 | 6.3622 |
| 5.9116 | 8.0 | 24 | 6.1503 |
| 5.6323 | 9.0 | 27 | 5.8219 |
| 5.1124 | 10.0 | 30 | 5.4438 |
| 4.6146 | 11.0 | 33 | 5.1114 |
| 4.4062 | 12.0 | 36 | 4.8742 |
| 3.967 | 13.0 | 39 | 4.6720 |
| 3.9281 | 14.0 | 42 | 4.4782 |
| 3.5204 | 15.0 | 45 | 4.2976 |
| 3.3159 | 16.0 | 48 | 4.1650 |
| 3.1737 | 17.0 | 51 | 4.0546 |
| 2.9307 | 18.0 | 54 | 3.9636 |
| 2.8228 | 19.0 | 57 | 3.9233 |
| 2.8805 | 20.0 | 60 | 3.8573 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "Llama-360M", "results": []}]} | ninagroot/Llama-360M | null | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:34:53+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #llama #text-generation #generated_from_trainer #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| Llama-360M
==========
This model is a fine-tuned version of [](URL on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 3.8573
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 8
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 300
* num\_epochs: 20
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.1
* Pytorch 2.1.2+cu121
* Datasets 2.16.1
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 300\n* num\\_epochs: 20\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.1.2+cu121\n* Datasets 2.16.1\n* Tokenizers 0.15.0"
] | [
"TAGS\n#transformers #tensorboard #safetensors #llama #text-generation #generated_from_trainer #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 300\n* num\\_epochs: 20\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.1.2+cu121\n* Datasets 2.16.1\n* Tokenizers 0.15.0"
] | [
43,
153,
5,
44
] | [
"TAGS\n#transformers #tensorboard #safetensors #llama #text-generation #generated_from_trainer #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 300\n* num\\_epochs: 20\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.1.2+cu121\n* Datasets 2.16.1\n* Tokenizers 0.15.0"
] |
question-answering | transformers |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Raghuveer991/my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.3605
- Validation Loss: 2.0390
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.3605 | 2.0390 | 0 |
### Framework versions
- Transformers 4.40.0
- TensorFlow 2.15.0
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_keras_callback"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "Raghuveer991/my_awesome_qa_model", "results": []}]} | Raghuveer991/my_awesome_qa_model | null | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:34:55+00:00 | [] | [] | TAGS
#transformers #tf #distilbert #question-answering #generated_from_keras_callback #base_model-distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us
| Raghuveer991/my\_awesome\_qa\_model
===================================
This model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Train Loss: 3.3605
* Validation Loss: 2.0390
* Epoch: 0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* optimizer: {'name': 'Adam', 'weight\_decay': None, 'clipnorm': None, 'global\_clipnorm': None, 'clipvalue': None, 'use\_ema': False, 'ema\_momentum': 0.99, 'ema\_overwrite\_frequency': None, 'jit\_compile': False, 'is\_legacy\_optimizer': False, 'learning\_rate': {'module': 'keras.optimizers.schedules', 'class\_name': 'PolynomialDecay', 'config': {'initial\_learning\_rate': 2e-05, 'decay\_steps': 500, 'end\_learning\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\_name': None}, 'beta\_1': 0.9, 'beta\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
* training\_precision: float32
### Training results
### Framework versions
* Transformers 4.40.0
* TensorFlow 2.15.0
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'Adam', 'weight\\_decay': None, 'clipnorm': None, 'global\\_clipnorm': None, 'clipvalue': None, 'use\\_ema': False, 'ema\\_momentum': 0.99, 'ema\\_overwrite\\_frequency': None, 'jit\\_compile': False, 'is\\_legacy\\_optimizer': False, 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 2e-05, 'decay\\_steps': 500, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* TensorFlow 2.15.0\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tf #distilbert #question-answering #generated_from_keras_callback #base_model-distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'Adam', 'weight\\_decay': None, 'clipnorm': None, 'global\\_clipnorm': None, 'clipvalue': None, 'use\\_ema': False, 'ema\\_momentum': 0.99, 'ema\\_overwrite\\_frequency': None, 'jit\\_compile': False, 'is\\_legacy\\_optimizer': False, 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 2e-05, 'decay\\_steps': 500, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* TensorFlow 2.15.0\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
54,
290,
5,
38
] | [
"TAGS\n#transformers #tf #distilbert #question-answering #generated_from_keras_callback #base_model-distilbert-base-uncased #license-apache-2.0 #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'Adam', 'weight\\_decay': None, 'clipnorm': None, 'global\\_clipnorm': None, 'clipvalue': None, 'use\\_ema': False, 'ema\\_momentum': 0.99, 'ema\\_overwrite\\_frequency': None, 'jit\\_compile': False, 'is\\_legacy\\_optimizer': False, 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 2e-05, 'decay\\_steps': 500, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}\n* training\\_precision: float32### Training results### Framework versions\n\n\n* Transformers 4.40.0\n* TensorFlow 2.15.0\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cdc_influenza_bart-base-cnn
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5155
- Rouge1: 0.3829
- Rouge2: 0.3086
- Rougel: 0.3623
- Rougelsum: 0.3576
- Gen Len: 20.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 2 | 0.8120 | 0.308 | 0.2272 | 0.2723 | 0.2758 | 20.0 |
| No log | 2.0 | 4 | 0.6427 | 0.3473 | 0.2635 | 0.3179 | 0.3189 | 20.0 |
| No log | 3.0 | 6 | 0.5496 | 0.3925 | 0.3203 | 0.3671 | 0.3642 | 20.0 |
| No log | 4.0 | 8 | 0.5155 | 0.3829 | 0.3086 | 0.3623 | 0.3576 | 20.0 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["rouge"], "base_model": "facebook/bart-base", "model-index": [{"name": "cdc_influenza_bart-base-cnn", "results": []}]} | PergaZuZ/cdc_influenza_bart-base-cnn | null | [
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:36:22+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #bart #text2text-generation #generated_from_trainer #base_model-facebook/bart-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| cdc\_influenza\_bart-base-cnn
=============================
This model is a fine-tuned version of facebook/bart-base on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5155
* Rouge1: 0.3829
* Rouge2: 0.3086
* Rougel: 0.3623
* Rougelsum: 0.3576
* Gen Len: 20.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 4
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #bart #text2text-generation #generated_from_trainer #base_model-facebook/bart-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
56,
112,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #bart #text2text-generation #generated_from_trainer #base_model-facebook/bart-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Mistral-child-1-3
Mistral-child-1-3 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
* [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: HuggingFaceH4/zephyr-7b-beta
parameters:
density: 0.5
weight: 0.5
- model: mistralai/Mistral-7B-Instruct-v0.2
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
dtype: float16
``` | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "HuggingFaceH4/zephyr-7b-beta", "mistralai/Mistral-7B-Instruct-v0.2"]} | PotatoB/Mistral-child-1-3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"HuggingFaceH4/zephyr-7b-beta",
"mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:37:09+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #HuggingFaceH4/zephyr-7b-beta #mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Mistral-child-1-3
Mistral-child-1-3 is a merge of the following models using mergekit:
* HuggingFaceH4/zephyr-7b-beta
* mistralai/Mistral-7B-Instruct-v0.2
## Configuration
| [
"# Mistral-child-1-3\n\nMistral-child-1-3 is a merge of the following models using mergekit:\n* HuggingFaceH4/zephyr-7b-beta\n* mistralai/Mistral-7B-Instruct-v0.2",
"## Configuration"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #HuggingFaceH4/zephyr-7b-beta #mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Mistral-child-1-3\n\nMistral-child-1-3 is a merge of the following models using mergekit:\n* HuggingFaceH4/zephyr-7b-beta\n* mistralai/Mistral-7B-Instruct-v0.2",
"## Configuration"
] | [
84,
60,
3
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #HuggingFaceH4/zephyr-7b-beta #mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Mistral-child-1-3\n\nMistral-child-1-3 is a merge of the following models using mergekit:\n* HuggingFaceH4/zephyr-7b-beta\n* mistralai/Mistral-7B-Instruct-v0.2## Configuration"
] |
null | transformers |
# Uploaded model
- **Developed by:** russgeo
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | russgeo/megaprompt | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:37:42+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: russgeo
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: russgeo\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: russgeo\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
62,
78
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: russgeo\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | singhvishnu020/gemma-7b-v2-role-play_1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:37:49+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
26,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-generation | transformers |
# base model :
- microsoft/Phi-3-mini-4k-instruct
# Dataset :
- ayoubkirouane/Small-Instruct-Alpaca_Format | {"language": ["en"], "library_name": "transformers", "tags": ["unsloth", "trl", "sft"], "datasets": ["ayoubkirouane/Small-Instruct-Alpaca_Format"], "pipeline_tag": "text-generation"} | ayoubkirouane/Phi3-3.8-4k_alpaca_instruct | null | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"dataset:ayoubkirouane/Small-Instruct-Alpaca_Format",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:39:11+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #mistral #text-generation #unsloth #trl #sft #conversational #en #dataset-ayoubkirouane/Small-Instruct-Alpaca_Format #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# base model :
- microsoft/Phi-3-mini-4k-instruct
# Dataset :
- ayoubkirouane/Small-Instruct-Alpaca_Format | [
"# base model : \n- microsoft/Phi-3-mini-4k-instruct",
"# Dataset : \n- ayoubkirouane/Small-Instruct-Alpaca_Format"
] | [
"TAGS\n#transformers #pytorch #mistral #text-generation #unsloth #trl #sft #conversational #en #dataset-ayoubkirouane/Small-Instruct-Alpaca_Format #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# base model : \n- microsoft/Phi-3-mini-4k-instruct",
"# Dataset : \n- ayoubkirouane/Small-Instruct-Alpaca_Format"
] | [
71,
18,
22
] | [
"TAGS\n#transformers #pytorch #mistral #text-generation #unsloth #trl #sft #conversational #en #dataset-ayoubkirouane/Small-Instruct-Alpaca_Format #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# base model : \n- microsoft/Phi-3-mini-4k-instruct# Dataset : \n- ayoubkirouane/Small-Instruct-Alpaca_Format"
] |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | andersonbcdefg/tiny-emb-2024-04-30_07-42-33 | null | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:42:34+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
32,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"license": "mit", "library_name": "transformers", "pipeline_tag": "text-classification"} | swastikdubey123/test_gemini_2 | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:43:12+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #license-mit #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #license-mit #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-generation | transformers |
# VILA Model Card
## Model details
**Model type:**
VILA is a visual language model (VLM) pretrained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge, including Jetson Orin and laptop by AWQ 4bit quantization through TinyChat framework. We find: (1) image-text pairs are not enough, interleaved image-text is essential; (2) unfreezing LLM during interleaved image-text pre-training enables in-context learning; (3)re-blending text-only instruction data is crucial to boost both VLM and text-only performance. VILA unveils appealing capabilities, including: multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge.
**Model date:**
Llama-3-VILA1.5-8b was trained in May 2024.
**Paper or resources for more information:**
https://github.com/Efficient-Large-Model/VILA
```
@misc{lin2023vila,
title={VILA: On Pre-training for Visual Language Models},
author={Ji Lin and Hongxu Yin and Wei Ping and Yao Lu and Pavlo Molchanov and Andrew Tao and Huizi Mao and Jan Kautz and Mohammad Shoeybi and Song Han},
year={2023},
eprint={2312.07533},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## License
- The code is released under the Apache 2.0 license as found in the [LICENSE](./LICENSE) file.
- The pretrained weights are released under the [CC-BY-NC-SA-4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.en).
- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:
- [Model License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA
- [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI
- [Dataset Licenses](https://github.com/Efficient-Large-Model/VILA/blob/main/data_prepare/LICENSE) for each one used during training.
**Where to send questions or comments about the model:**
https://github.com/Efficient-Large-Model/VILA/issues
## Intended use
**Primary intended uses:**
The primary use of VILA is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
See [Dataset Preparation](https://github.com/Efficient-Large-Model/VILA/blob/main/data_prepare/README.md) for more details.
## Evaluation dataset
A collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs. | {"license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["VILA", "VLM"], "pipeline_tag": "text-generation"} | Efficient-Large-Model/Llama-3-VILA1.5-8B | null | [
"transformers",
"safetensors",
"llava_llama",
"VILA",
"VLM",
"text-generation",
"arxiv:2312.07533",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:48:36+00:00 | [
"2312.07533"
] | [] | TAGS
#transformers #safetensors #llava_llama #VILA #VLM #text-generation #arxiv-2312.07533 #license-cc-by-nc-4.0 #endpoints_compatible #region-us
|
# VILA Model Card
## Model details
Model type:
VILA is a visual language model (VLM) pretrained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge, including Jetson Orin and laptop by AWQ 4bit quantization through TinyChat framework. We find: (1) image-text pairs are not enough, interleaved image-text is essential; (2) unfreezing LLM during interleaved image-text pre-training enables in-context learning; (3)re-blending text-only instruction data is crucial to boost both VLM and text-only performance. VILA unveils appealing capabilities, including: multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge.
Model date:
Llama-3-VILA1.5-8b was trained in May 2024.
Paper or resources for more information:
URL
## License
- The code is released under the Apache 2.0 license as found in the LICENSE file.
- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.
- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:
- Model License of LLaMA
- Terms of Use of the data generated by OpenAI
- Dataset Licenses for each one used during training.
Where to send questions or comments about the model:
URL
## Intended use
Primary intended uses:
The primary use of VILA is research on large multimodal models and chatbots.
Primary intended users:
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
See Dataset Preparation for more details.
## Evaluation dataset
A collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs. | [
"# VILA Model Card",
"## Model details\n\nModel type:\nVILA is a visual language model (VLM) pretrained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge, including Jetson Orin and laptop by AWQ 4bit quantization through TinyChat framework. We find: (1) image-text pairs are not enough, interleaved image-text is essential; (2) unfreezing LLM during interleaved image-text pre-training enables in-context learning; (3)re-blending text-only instruction data is crucial to boost both VLM and text-only performance. VILA unveils appealing capabilities, including: multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge.\n\nModel date:\nLlama-3-VILA1.5-8b was trained in May 2024.\n\nPaper or resources for more information:\nURL",
"## License\n- The code is released under the Apache 2.0 license as found in the LICENSE file.\n- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.\n- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:\n - Model License of LLaMA\n - Terms of Use of the data generated by OpenAI\n - Dataset Licenses for each one used during training.\n\nWhere to send questions or comments about the model:\nURL",
"## Intended use\nPrimary intended uses:\nThe primary use of VILA is research on large multimodal models and chatbots.\n\nPrimary intended users:\nThe primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.",
"## Training dataset\nSee Dataset Preparation for more details.",
"## Evaluation dataset\nA collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs."
] | [
"TAGS\n#transformers #safetensors #llava_llama #VILA #VLM #text-generation #arxiv-2312.07533 #license-cc-by-nc-4.0 #endpoints_compatible #region-us \n",
"# VILA Model Card",
"## Model details\n\nModel type:\nVILA is a visual language model (VLM) pretrained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge, including Jetson Orin and laptop by AWQ 4bit quantization through TinyChat framework. We find: (1) image-text pairs are not enough, interleaved image-text is essential; (2) unfreezing LLM during interleaved image-text pre-training enables in-context learning; (3)re-blending text-only instruction data is crucial to boost both VLM and text-only performance. VILA unveils appealing capabilities, including: multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge.\n\nModel date:\nLlama-3-VILA1.5-8b was trained in May 2024.\n\nPaper or resources for more information:\nURL",
"## License\n- The code is released under the Apache 2.0 license as found in the LICENSE file.\n- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.\n- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:\n - Model License of LLaMA\n - Terms of Use of the data generated by OpenAI\n - Dataset Licenses for each one used during training.\n\nWhere to send questions or comments about the model:\nURL",
"## Intended use\nPrimary intended uses:\nThe primary use of VILA is research on large multimodal models and chatbots.\n\nPrimary intended users:\nThe primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.",
"## Training dataset\nSee Dataset Preparation for more details.",
"## Evaluation dataset\nA collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs."
] | [
54,
4,
200,
110,
56,
13,
34
] | [
"TAGS\n#transformers #safetensors #llava_llama #VILA #VLM #text-generation #arxiv-2312.07533 #license-cc-by-nc-4.0 #endpoints_compatible #region-us \n# VILA Model Card## Model details\n\nModel type:\nVILA is a visual language model (VLM) pretrained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge, including Jetson Orin and laptop by AWQ 4bit quantization through TinyChat framework. We find: (1) image-text pairs are not enough, interleaved image-text is essential; (2) unfreezing LLM during interleaved image-text pre-training enables in-context learning; (3)re-blending text-only instruction data is crucial to boost both VLM and text-only performance. VILA unveils appealing capabilities, including: multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge.\n\nModel date:\nLlama-3-VILA1.5-8b was trained in May 2024.\n\nPaper or resources for more information:\nURL## License\n- The code is released under the Apache 2.0 license as found in the LICENSE file.\n- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.\n- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:\n - Model License of LLaMA\n - Terms of Use of the data generated by OpenAI\n - Dataset Licenses for each one used during training.\n\nWhere to send questions or comments about the model:\nURL## Intended use\nPrimary intended uses:\nThe primary use of VILA is research on large multimodal models and chatbots.\n\nPrimary intended users:\nThe primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.## Training dataset\nSee Dataset Preparation for more details.## Evaluation dataset\nA collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs."
] |
text-generation | transformers |
# Model Card for Model ID
Fine-tuning for CS5242 project
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [DreamOnRain]
- **Finetuned from model [optional]:** state-spaces/mamba-370m-hf
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/DreamOnRain/Deep-Learning-Final-Project
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
| {"library_name": "transformers", "tags": []} | DreamOnRain/mamba-370m-msmath | null | [
"transformers",
"safetensors",
"mamba",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:49:49+00:00 | [] | [] | TAGS
#transformers #safetensors #mamba #text-generation #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
Fine-tuning for CS5242 project
## Model Details
### Model Description
- Developed by: [DreamOnRain]
- Finetuned from model [optional]: state-spaces/mamba-370m-hf
### Model Sources [optional]
- Repository: URL
## Training Details
### Training Data
URL
| [
"# Model Card for Model ID\n\nFine-tuning for CS5242 project",
"## Model Details",
"### Model Description\n\n\n\n- Developed by: [DreamOnRain]\n- Finetuned from model [optional]: state-spaces/mamba-370m-hf",
"### Model Sources [optional]\n\n\n\n- Repository: URL",
"## Training Details",
"### Training Data\n\n\n\nURL"
] | [
"TAGS\n#transformers #safetensors #mamba #text-generation #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID\n\nFine-tuning for CS5242 project",
"## Model Details",
"### Model Description\n\n\n\n- Developed by: [DreamOnRain]\n- Finetuned from model [optional]: state-spaces/mamba-370m-hf",
"### Model Sources [optional]\n\n\n\n- Repository: URL",
"## Training Details",
"### Training Data\n\n\n\nURL"
] | [
28,
14,
4,
36,
13,
4,
7
] | [
"TAGS\n#transformers #safetensors #mamba #text-generation #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID\n\nFine-tuning for CS5242 project## Model Details### Model Description\n\n\n\n- Developed by: [DreamOnRain]\n- Finetuned from model [optional]: state-spaces/mamba-370m-hf### Model Sources [optional]\n\n\n\n- Repository: URL## Training Details### Training Data\n\n\n\nURL"
] |
text-generation | null |
# HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF
This model was converted to GGUF format from [`microsoft/Phi-3-mini-128k-instruct`](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF --model phi-3-mini-128k-instruct.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF --model phi-3-mini-128k-instruct.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m phi-3-mini-128k-instruct.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "mit", "tags": ["nlp", "code", "llama-cpp", "gguf-my-repo"], "license_link": "https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "widget": [{"messages": [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"}]}]} | HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF | null | [
"gguf",
"nlp",
"code",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"license:mit",
"region:us"
] | null | 2024-04-30T07:50:16+00:00 | [] | [
"en"
] | TAGS
#gguf #nlp #code #llama-cpp #gguf-my-repo #text-generation #en #license-mit #region-us
|
# HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF
This model was converted to GGUF format from 'microsoft/Phi-3-mini-128k-instruct' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF\nThis model was converted to GGUF format from 'microsoft/Phi-3-mini-128k-instruct' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #nlp #code #llama-cpp #gguf-my-repo #text-generation #en #license-mit #region-us \n",
"# HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF\nThis model was converted to GGUF format from 'microsoft/Phi-3-mini-128k-instruct' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
39,
82,
52
] | [
"TAGS\n#gguf #nlp #code #llama-cpp #gguf-my-repo #text-generation #en #license-mit #region-us \n# HugoVoxx/Phi-3-mini-128k-instruct-Q8_0-GGUF\nThis model was converted to GGUF format from 'microsoft/Phi-3-mini-128k-instruct' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | baaaaaaaam/v2 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:50:38+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
26,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | transformers |
# Uploaded model
- **Developed by:** Hung1001
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | Hung1001/Reading_Comprehension_Llama3 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:52:40+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: Hung1001
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: Hung1001\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: Hung1001\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
64,
80
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: Hung1001\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine_tuned_mBERT
This model is a fine-tuned version of [google-bert/bert-base-multilingual-cased](https://huggingface.co/google-bert/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0431
- F1: 0.8182
- F5: 0.8792
- Precision: 0.6923
- Recall: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | F5 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:---------:|:------:|
| No log | 1.0 | 16 | 0.2406 | 0.0 | 0.0 | 0.0 | 0.0 |
| No log | 2.0 | 32 | 0.2933 | 0.6471 | 0.6062 | 0.7857 | 0.55 |
| No log | 3.0 | 48 | 0.1965 | 0.5000 | 0.4297 | 0.875 | 0.35 |
| No log | 4.0 | 64 | 0.1349 | 0.6842 | 0.6707 | 0.7222 | 0.65 |
| No log | 5.0 | 80 | 0.1065 | 0.7027 | 0.6816 | 0.7647 | 0.65 |
| No log | 6.0 | 96 | 0.1104 | 0.7727 | 0.8005 | 0.7083 | 0.85 |
| No log | 7.0 | 112 | 0.1160 | 0.7273 | 0.7534 | 0.6667 | 0.8 |
| No log | 8.0 | 128 | 0.1049 | 0.7647 | 0.7164 | 0.9286 | 0.65 |
| No log | 9.0 | 144 | 0.0975 | 0.7778 | 0.7461 | 0.875 | 0.7 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.3.0a0+ebedce2
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["f1", "precision", "recall"], "base_model": "google-bert/bert-base-multilingual-cased", "model-index": [{"name": "fine_tuned_mBERT", "results": []}]} | morten-j/fine_tuned_mBERT | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:53:04+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-google-bert/bert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| fine\_tuned\_mBERT
==================
This model is a fine-tuned version of google-bert/bert-base-multilingual-cased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0431
* F1: 0.8182
* F5: 0.8792
* Precision: 0.6923
* Recall: 1.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2.5e-05
* train\_batch\_size: 128
* eval\_batch\_size: 128
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 9
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.3.0a0+ebedce2
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2.5e-05\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 9\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.3.0a0+ebedce2\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-google-bert/bert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2.5e-05\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 9\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.3.0a0+ebedce2\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
63,
114,
5,
47
] | [
"TAGS\n#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-google-bert/bert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2.5e-05\n* train\\_batch\\_size: 128\n* eval\\_batch\\_size: 128\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 9\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.3.0a0+ebedce2\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 | {"license": "apache-2.0", "library_name": "transformers", "base_model": "mistralai/Mistral-7B-v0.1", "pipeline_tag": "text-generation"} | AIgot/Mrt-Fine-Tuned | null | [
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:53:43+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #pytorch #safetensors #mistral #text-generation #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-v0.1 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
### Framework versions
- PEFT 0.10.0 | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
] | [
"TAGS\n#transformers #pytorch #safetensors #mistral #text-generation #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-v0.1 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
] | [
80,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#transformers #pytorch #safetensors #mistral #text-generation #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-v0.1 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact### Framework versions\n\n- PEFT 0.10.0"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA2
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0294
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 80
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7246 | 0.09 | 10 | 0.1959 |
| 0.1775 | 0.18 | 20 | 0.1537 |
| 0.1537 | 0.27 | 30 | 0.1589 |
| 0.1516 | 0.36 | 40 | 0.1523 |
| 0.1518 | 0.45 | 50 | 0.1481 |
| 0.1508 | 0.54 | 60 | 0.1490 |
| 0.1514 | 0.63 | 70 | 0.1474 |
| 0.1499 | 0.73 | 80 | 0.1540 |
| 0.1476 | 0.82 | 90 | 0.1486 |
| 0.1447 | 0.91 | 100 | 0.1347 |
| 0.1356 | 1.0 | 110 | 0.0905 |
| 0.0979 | 1.09 | 120 | 0.0900 |
| 0.3159 | 1.18 | 130 | 0.0714 |
| 0.3542 | 1.27 | 140 | 0.0738 |
| 0.085 | 1.36 | 150 | 0.0609 |
| 0.0639 | 1.45 | 160 | 0.0610 |
| 0.0555 | 1.54 | 170 | 0.0549 |
| 0.067 | 1.63 | 180 | 0.0581 |
| 0.1336 | 1.72 | 190 | 0.0647 |
| 0.0592 | 1.81 | 200 | 0.0594 |
| 0.059 | 1.9 | 210 | 0.0561 |
| 0.0585 | 1.99 | 220 | 0.0543 |
| 0.0577 | 2.08 | 230 | 0.0547 |
| 0.0528 | 2.18 | 240 | 0.0567 |
| 0.0516 | 2.27 | 250 | 0.0511 |
| 0.0533 | 2.36 | 260 | 0.0455 |
| 0.0428 | 2.45 | 270 | 0.0457 |
| 0.0386 | 2.54 | 280 | 0.0384 |
| 0.0386 | 2.63 | 290 | 0.0344 |
| 0.0343 | 2.72 | 300 | 0.0324 |
| 0.0311 | 2.81 | 310 | 0.0303 |
| 0.0337 | 2.9 | 320 | 0.0296 |
| 0.0334 | 2.99 | 330 | 0.0294 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA2", "results": []}]} | Litzy619/O0430HMA2 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T07:53:48+00:00 | [] | [] | TAGS
#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us
| O0430HMA2
=========
This model is a fine-tuned version of allenai/OLMo-1B on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0294
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 80
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.1.2+cu121
* Datasets 2.14.6
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] | [
35,
160,
5,
47
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-allenai/OLMo-1B #license-apache-2.0 #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 80\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP### Training results### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | pruning/eo9ppmv | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:54:08+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shallow6414/itnjuww | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:54:52+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Downstream Use [optional]### Out-of-Scope Use## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.## How to Get Started with the Model\n\nUse the code below to get started with the model.## Training Details### Training Data### Training Procedure#### Preprocessing [optional]#### Training Hyperparameters\n\n- Training regime:#### Speeds, Sizes, Times [optional]## Evaluation### Testing Data, Factors & Metrics#### Testing Data#### Factors#### Metrics### Results#### Summary## Model Examination [optional]## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:## Technical Specifications [optional]### Model Architecture and Objective### Compute Infrastructure#### Hardware#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Model Card Authors [optional]## Model Card Contact"
] |
null | null | step: 999 | epoch: 1 | loss: 7.95: 33%|███▎ | 999/3000 [05:43<11:50, 2.82it/s] Step=999
P: 98.36% R: 99.61% F1: 98.98%
step: 1999 | epoch: 2 | loss: 0.30: 67%|██████▋ | 1999/3000 [11:40<05:45, 2.90it/s]Step=1999
P: 98.91% R: 99.73% F1: 99.32%
step: 2999 | epoch: 4 | loss: 5.16: 100%|█████████▉| 2999/3000 [17:33<00:00, 2.97it/s]Step=2999
P: 99.14% R: 99.73% F1: 99.44%
step: 2999 | epoch: 4 | loss: 5.16: 100%|██████████| 3000/3000 [17:45<00:00, 2.82it/s] | {} | alpcansoydas/ner_data_extraction | null | [
"pytorch",
"region:us"
] | null | 2024-04-30T07:55:31+00:00 | [] | [] | TAGS
#pytorch #region-us
| step: 999 | epoch: 1 | loss: 7.95: 33%|███▎ | 999/3000 [05:43<11:50, 2.82it/s] Step=999
P: 98.36% R: 99.61% F1: 98.98%
step: 1999 | epoch: 2 | loss: 0.30: 67%|██████▋ | 1999/3000 [11:40<05:45, 2.90it/s]Step=1999
P: 98.91% R: 99.73% F1: 99.32%
step: 2999 | epoch: 4 | loss: 5.16: 100%|█████████▉| 2999/3000 [17:33<00:00, 2.97it/s]Step=2999
P: 99.14% R: 99.73% F1: 99.44%
step: 2999 | epoch: 4 | loss: 5.16: 100%|██████████| 3000/3000 [17:45<00:00, 2.82it/s] | [] | [
"TAGS\n#pytorch #region-us \n"
] | [
10
] | [
"TAGS\n#pytorch #region-us \n"
] |
text-generation | transformers | # Alsebay/Lorge-2x7B-UAMM AWQ
- Model creator: [Alsebay](https://huggingface.co/Alsebay)
- Original model: [Lorge-2x7B-UAMM](https://huggingface.co/Alsebay/Lorge-2x7B-UAMM)
## Model Summary
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
This model was merged using the passthrough merge method.
## How to use
### Install the necessary packages
```bash
pip install --upgrade autoawq autoawq-kernels
```
### Example Python code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer, TextStreamer
model_path = "solidrust/Lorge-2x7B-UAMM-AWQ"
system_message = "You are Lorge-2x7B-UAMM, incarnated as a powerful AI. You were created by Alsebay."
# Load model
model = AutoAWQForCausalLM.from_quantized(model_path,
fuse_layers=True)
tokenizer = AutoTokenizer.from_pretrained(model_path,
trust_remote_code=True)
streamer = TextStreamer(tokenizer,
skip_prompt=True,
skip_special_tokens=True)
# Convert prompt to tokens
prompt_template = """\
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"""
prompt = "You're standing on the surface of the Earth. "\
"You walk one mile south, one mile west and one mile north. "\
"You end up exactly where you started. Where are you?"
tokens = tokenizer(prompt_template.format(system_message=system_message,prompt=prompt),
return_tensors='pt').input_ids.cuda()
# Generate output
generation_output = model.generate(tokens,
streamer=streamer,
max_new_tokens=512)
```
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
AWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - version 0.2.2 or later for support for all model types.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
| {"license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["mergekit", "merge", "4-bit", "AWQ", "text-generation", "autotrain_compatible", "endpoints_compatible"], "base_model": [], "pipeline_tag": "text-generation", "inference": false, "quantized_by": "Suparious", "model-index": [{"name": "Lorge-2x7B-UAMM", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "AI2 Reasoning Challenge (25-Shot)", "type": "ai2_arc", "config": "ARC-Challenge", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "acc_norm", "value": 67.75, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HellaSwag (10-Shot)", "type": "hellaswag", "split": "validation", "args": {"num_few_shot": 10}}, "metrics": [{"type": "acc_norm", "value": 81.09, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "MMLU (5-Shot)", "type": "cais/mmlu", "config": "all", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 59.75, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "TruthfulQA (0-shot)", "type": "truthful_qa", "config": "multiple_choice", "split": "validation", "args": {"num_few_shot": 0}}, "metrics": [{"type": "mc2", "value": 60.41}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Winogrande (5-shot)", "type": "winogrande", "config": "winogrande_xl", "split": "validation", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 76.8, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "GSM8k (5-shot)", "type": "gsm8k", "config": "main", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 27.67, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Alsebay/Lorge-2x7B-UAMM", "name": "Open LLM Leaderboard"}}]}]} | solidrust/Lorge-2x7B-UAMM-AWQ | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"mergekit",
"merge",
"4-bit",
"AWQ",
"autotrain_compatible",
"endpoints_compatible",
"license:cc-by-nc-4.0",
"model-index",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T07:56:21+00:00 | [] | [] | TAGS
#transformers #safetensors #mixtral #text-generation #mergekit #merge #4-bit #AWQ #autotrain_compatible #endpoints_compatible #license-cc-by-nc-4.0 #model-index #text-generation-inference #region-us
| # Alsebay/Lorge-2x7B-UAMM AWQ
- Model creator: Alsebay
- Original model: Lorge-2x7B-UAMM
## Model Summary
This is a merge of pre-trained language models created using mergekit.
This model was merged using the passthrough merge method.
## How to use
### Install the necessary packages
### Example Python code
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
AWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.
It is supported by:
- Text Generation Webui - using Loader: AutoAWQ
- vLLM - version 0.2.2 or later for support for all model types.
- Hugging Face Text Generation Inference (TGI)
- Transformers version 4.35.0 and later, from any code or client that supports Transformers
- AutoAWQ - for use from Python code
| [
"# Alsebay/Lorge-2x7B-UAMM AWQ\n\n- Model creator: Alsebay\n- Original model: Lorge-2x7B-UAMM",
"## Model Summary\n\nThis is a merge of pre-trained language models created using mergekit.\n\nThis model was merged using the passthrough merge method.",
"## How to use",
"### Install the necessary packages",
"### Example Python code",
"### About AWQ\n\nAWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.\n\nAWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.\n\nIt is supported by:\n\n- Text Generation Webui - using Loader: AutoAWQ\n- vLLM - version 0.2.2 or later for support for all model types.\n- Hugging Face Text Generation Inference (TGI)\n- Transformers version 4.35.0 and later, from any code or client that supports Transformers\n- AutoAWQ - for use from Python code"
] | [
"TAGS\n#transformers #safetensors #mixtral #text-generation #mergekit #merge #4-bit #AWQ #autotrain_compatible #endpoints_compatible #license-cc-by-nc-4.0 #model-index #text-generation-inference #region-us \n",
"# Alsebay/Lorge-2x7B-UAMM AWQ\n\n- Model creator: Alsebay\n- Original model: Lorge-2x7B-UAMM",
"## Model Summary\n\nThis is a merge of pre-trained language models created using mergekit.\n\nThis model was merged using the passthrough merge method.",
"## How to use",
"### Install the necessary packages",
"### Example Python code",
"### About AWQ\n\nAWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.\n\nAWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.\n\nIt is supported by:\n\n- Text Generation Webui - using Loader: AutoAWQ\n- vLLM - version 0.2.2 or later for support for all model types.\n- Hugging Face Text Generation Inference (TGI)\n- Transformers version 4.35.0 and later, from any code or client that supports Transformers\n- AutoAWQ - for use from Python code"
] | [
62,
38,
32,
5,
7,
6,
172
] | [
"TAGS\n#transformers #safetensors #mixtral #text-generation #mergekit #merge #4-bit #AWQ #autotrain_compatible #endpoints_compatible #license-cc-by-nc-4.0 #model-index #text-generation-inference #region-us \n# Alsebay/Lorge-2x7B-UAMM AWQ\n\n- Model creator: Alsebay\n- Original model: Lorge-2x7B-UAMM## Model Summary\n\nThis is a merge of pre-trained language models created using mergekit.\n\nThis model was merged using the passthrough merge method.## How to use### Install the necessary packages### Example Python code### About AWQ\n\nAWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.\n\nAWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.\n\nIt is supported by:\n\n- Text Generation Webui - using Loader: AutoAWQ\n- vLLM - version 0.2.2 or later for support for all model types.\n- Hugging Face Text Generation Inference (TGI)\n- Transformers version 4.35.0 and later, from any code or client that supports Transformers\n- AutoAWQ - for use from Python code"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.