
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-3-60k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-3-700k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-0k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-1000k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-100k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-1500k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-1800k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-2000k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-200k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-20k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-400k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-60k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/sciie-seed-4-700k
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
diegozs97/test_model
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dietrich/hello-world
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
{}
|
digio/BERTweet-base_1000000s_all_MNRL
| null |
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
sentence-similarity
|
transformers
|
# Twitter4SSE
This model maps texts to 768 dimensional dense embeddings that encode semantic similarity.
It was trained with Multiple Negatives Ranking Loss (MNRL) on a Twitter dataset.
It was initialized from [BERTweet](https://huggingface.co/vinai/bertweet-base) and trained with [Sentence-transformers](https://www.sbert.net/).
## Usage
The model is easier to use with sentence-trainsformers library
```
pip install -U sentence-transformers
```
```
from sentence_transformers import SentenceTransformer
sentences = ["This is the first tweet", "This is the second tweet"]
model = SentenceTransformer('digio/Twitter4SSE')
embeddings = model.encode(sentences)
print(embeddings)
```
Without sentence-transfomer library, please refer to [this repository](https://huggingface.co/sentence-transformers) for detailed instructions on how to use Sentence Transformers on Huggingface.
## Citing & Authors
The official paper [Exploiting Twitter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings](https://arxiv.org/abs/2110.02030) will be presented at EMNLP 2021. Further details will be available soon.
```
@inproceedings{di-giovanni-brambilla-2021-exploiting,
title = "Exploiting {T}witter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings",
author = "Di Giovanni, Marco and
Brambilla, Marco",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.780",
pages = "9902--9910",
}
```
The official code is available on [GitHub](https://github.com/marco-digio/Twitter4SSE)
|
{"language": ["en"], "license": "apache-2.0", "tags": ["Pytorch", "Sentence Transformers", "Transformers"], "pipeline_tag": "sentence-similarity"}
|
digio/Twitter4SSE
| null |
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"Pytorch",
"Sentence Transformers",
"Transformers",
"sentence-similarity",
"en",
"arxiv:2110.02030",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
{}
|
digit82/dialog-sbert-base
| null |
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
digit82/kobart-summarization
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
{}
|
digit82/kogpt2-summarization
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
digit82/kolang-t5-base
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
zero-shot-classification
|
transformers
|
# COVID-Twitter-BERT v2 MNLI
## Model description
This model provides a zero-shot classifier to be used in cases where it is not possible to finetune CT-BERT on a specific task, due to lack of labelled data.
The technique is based on [Yin et al.](https://arxiv.org/abs/1909.00161).
The article describes a very clever way of using pre-trained MNLI models as zero-shot sequence classifiers.
The model is already finetuned on 400'000 generaic logical tasks.
We can then use it as a zero-shot classifier by reformulating the classification task as a question.
Let's say we want to classify COVID-tweets as vaccine-related and not vaccine-related.
The typical way would be to collect a few hunder pre-annotated tweets and organise them in two classes.
Then you would finetune the model on this.
With the zero-shot mnli-classifier, you can instead reformulate your question as "This text is about vaccines", and use this directly on inference - without any training.
Find more info about the model on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Usage
Please note that how you formulate the question can give slightly different results.
Collecting a training set and finetuning on this, will most likely give you better accuracy.
The easiest way to try this out is by using the Hugging Face pipeline.
This uses the default Enlish template where it puts the text "This example is " in front of the text.
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="digitalepidemiologylab/covid-twitter-bert-v2-mnli")
```
You can then use this pipeline to classify sequences into any of the class names you specify.
```python
sequence_to_classify = 'To stop the pandemic it is important that everyone turns up for their shots.'
candidate_labels = ['health', 'sport', 'vaccine','guns']
hypothesis_template = 'This example is {}.'
classifier(sequence_to_classify, candidate_labels, hypothesis_template=hypothesis_template, multi_class=True)
```
## Training procedure
The model is finetuned on the 400k large [MNLI-task](https://cims.nyu.edu/~sbowman/multinli/).
## References
```bibtex
@article{muller2020covid,
title={COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter},
author={M{\"u}ller, Martin and Salath{\'e}, Marcel and Kummervold, Per E},
journal={arXiv preprint arXiv:2005.07503},
year={2020}
}
```
or
```
Martin Müller, Marcel Salathé, and Per E. Kummervold.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter.
arXiv preprint arXiv:2005.07503 (2020).
```
|
{"language": ["en"], "license": "mit", "tags": ["Twitter", "COVID-19", "text-classification", "pytorch", "tensorflow", "bert"], "datasets": ["mnli"], "thumbnail": "https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png", "pipeline_tag": "zero-shot-classification", "widget": [{"text": "To stop the pandemic it is important that everyone turns up for their shots.", "candidate_labels": "health, sport, vaccine, guns"}]}
|
digitalepidemiologylab/covid-twitter-bert-v2-mnli
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"Twitter",
"COVID-19",
"tensorflow",
"zero-shot-classification",
"en",
"dataset:mnli",
"arxiv:1909.00161",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# COVID-Twitter-BERT v2
## Model description
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. This model is identical to [covid-twitter-bert](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert) - but trained on more data, resulting in higher downstream performance.
Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Intended uses & limitations
The model can e.g. be used in the `fill-mask` task (see below). You can also use the model without the MLM/NSP heads and train a classifier with it.
#### How to use
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9998226761817932,
"token": 7308,
"token_str": "mask"
},
...
]
```
## Training procedure
This model was trained on 97M unique tweets (1.2B training examples) collected between January 12 and July 5, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
## Eval results
The model was evaluated based on downstream Twitter text classification tasks from previous SemEval challenges.
### BibTeX entry and citation info
```bibtex
@article{muller2020covid,
title={COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter},
author={M{\"u}ller, Martin and Salath{\'e}, Marcel and Kummervold, Per E},
journal={arXiv preprint arXiv:2005.07503},
year={2020}
}
```
or
```Martin Müller, Marcel Salathé, and Per E. Kummervold.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter.
arXiv preprint arXiv:2005.07503 (2020).
```
|
{"language": "en", "license": "mit", "tags": ["Twitter", "COVID-19"], "thumbnail": "https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png"}
|
digitalepidemiologylab/covid-twitter-bert-v2
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"Twitter",
"COVID-19",
"en",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# COVID-Twitter-BERT (CT-BERT) v1
:warning: _You may want to use the [v2 model](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2) which was trained on more recent data and yields better performance_ :warning:
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Overview
This model was trained on 160M tweets collected between January 12 and April 16, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
This model was evaluated based on downstream classification tasks, but it could be used for any other NLP task which can leverage contextual embeddings.
In order to achieve best results, make sure to use the same text preprocessing as we did for pretraining. This involves replacing user mentions, urls and emojis. You can find a script on our projects [GitHub repo](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Example usage
```python
tokenizer = AutoTokenizer.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
model = AutoModel.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
```
You can also use the model with the `pipeline` interface:
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9959408044815063,
"token": 7308,
"token_str": "mask"
},
...
]
```
## References
[1] Martin Müller, Marcel Salaté, Per E Kummervold. "COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter" arXiv preprint arXiv:2005.07503 (2020).
|
{"language": "en", "license": "mit", "tags": ["Twitter", "COVID-19"], "thumbnail": "https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png"}
|
digitalepidemiologylab/covid-twitter-bert
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"Twitter",
"COVID-19",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dihchacal/Dego
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dihchacal/aaa
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dihchacal/vvvv
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
diiogo/albert-utils
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
{}
|
diiogo/electra-base
| null |
[
"transformers",
"pytorch",
"electra",
"pretraining",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
diiogo/roberta-test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
diiogo/rt-32k
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dikabaehaki16/Dikabaehaki
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dilipchauhan/distilbert-base-uncased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dimaKofnal/gpt3
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dimsplendid/distilbert-base-uncased-finetuned-squad
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
{}
|
dingli/xlnet_nlp_smartdispatch
| null |
[
"transformers",
"pytorch",
"xlnet",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dinhdong/NLP
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-AdventureTime
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2450
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 279 | 3.3451 |
| 3.4534 | 2.0 | 558 | 3.2941 |
| 3.4534 | 3.0 | 837 | 3.2740 |
| 3.2435 | 4.0 | 1116 | 3.2617 |
| 3.2435 | 5.0 | 1395 | 3.2556 |
| 3.1729 | 6.0 | 1674 | 3.2490 |
| 3.1729 | 7.0 | 1953 | 3.2475 |
| 3.1262 | 8.0 | 2232 | 3.2467 |
| 3.0972 | 9.0 | 2511 | 3.2448 |
| 3.0972 | 10.0 | 2790 | 3.2450 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "distilgpt2-finetuned-AT", "results": []}]}
|
pyordii/distilgpt2-finetuned-AT
| null |
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
fBERT: A Neural Transformer for Identifying Offensive Content [Accepted at EMNLP 2021]
Authors: Diptanu Sarkar, Marcos Zampieri, Tharindu Ranasinghe and Alexander Ororbia
About:
Transformer-based models such as BERT, ELMO, and XLM-R have achieved state-of-the-art performance across various NLP tasks including the identification of offensive language and hate speech, an important problem in social media. Previous studies have shown that domain-specific fine-tuning or retraining of models before attempting to solve downstream tasks can lead to excellent results in multiple domains. Fine-tuning/retraining a complex models to identify offensive language has not been substantially explored before and we address this gap by proposing fBERT, a bert-base-uncased model that has been learned using over 1.4 million offensive instances from the SOLID dataset. The shifted fBERT model better incorporates domain-specific offensive language and social media features. The fBERT model achieves better results in both OffensEval and HatEval tasks and in the HS & O dataset over BERT and HateBERT.
|
{}
|
diptanu/fBERT
| null |
[
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
diracdelta/hello_world
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# Moe DialoGPT Model
|
{"tags": ["conversational"]}
|
disdamoe/DialoGPT-small-moe
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# Moe DialoGPT Model
|
{"tags": ["conversational"]}
|
disdamoe/TheGreatManipulator
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# The Manipulator
|
{"tags": ["conversational"]}
|
disdamoe/TheManipulator
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
diskos/distilbert-base-uncased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
diskos/scibert_scivocab_cased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dispasha/test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
<a href="https://www.geogebra.org/m/w8uzjttg">.</a>
<a href="https://www.geogebra.org/m/gvn7m78g">.</a>
<a href="https://www.geogebra.org/m/arxecanq">.</a>
<a href="https://www.geogebra.org/m/xb69bvww">.</a>
<a href="https://www.geogebra.org/m/apvepfnd">.</a>
<a href="https://www.geogebra.org/m/evmj8ckk">.</a>
<a href="https://www.geogebra.org/m/qxcxwmhp">.</a>
<a href="https://www.geogebra.org/m/p3cxqh6c">.</a>
<a href="https://www.geogebra.org/m/ggrahbgd">.</a>
<a href="https://www.geogebra.org/m/pnhymrbc">.</a>
<a href="https://www.geogebra.org/m/zjukbtk9">.</a>
<a href="https://www.geogebra.org/m/bbezun8r">.</a>
<a href="https://www.geogebra.org/m/sgwamtru">.</a>
<a href="https://www.geogebra.org/m/fpunkxxp">.</a>
<a href="https://www.geogebra.org/m/acxebrr7">.</a>
<a href="https://jobs.acm.org/jobs/watch-godzilla-vs-kong-2021-full-1818658-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-godzilla-vs-kong-online-2021-full-f-r-e-e-1818655-cd">.</a>
<a href="https://jobs.acm.org/jobs/watch-demon-slayer-kimetsu-no-yaiba-mugen-train-2020-f-u-l-l-f-r-e-e-1818661-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-zack-snyder-s-justice-league-online-2021-full-f-r-e-e-1818662-cd">.</a>
<a href="https://jobs.acm.org/jobs/hd-watch-godzilla-vs-kong-2021-version-full-hbomax-1818659-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-girl-in-the-basement-online-2021-full-f-r-e-e-1818663-cd">.</a>
<a href="https://jobs.acm.org/jobs/watch-godzilla-vs-kong-2021-f-u-l-l-h-d-1818660-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-billie-eilish-the-world-s-a-little-blurry-2021-f-u-l-l-f-r-e-e-1818666-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-monster-hunter-2020-f-u-l-l-f-r-e-e-1818667-cd">.</a>
<a href="https://jobs.acm.org/jobs/123movies-watch-raya-and-the-last-dragon-2021-f-u-l-l-f-r-e-e-1818669-cd">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-365-days-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-billie-eilish-the-worlds-a-little-blurry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-cherry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-coming-2-america-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-demon-slayer-kimetsu-no-yaiba-mugen-train-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-godzilla-vs-kong-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-judas-and-the-black-messiah-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-monster-hunter-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-mortal-kombat-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-raya-and-the-last-dragon-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-tenet-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-the-world-to-come-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-tom-and-jerry-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-willys-wonderland-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-wonder-woman-1984-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-wrong-turn-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-zack-snyders-justice-league-2021-hd-online-full-free-stream-2/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-a-writers-odyssey-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-the-marksman-2021-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-after-we-collided-2020-version-full-online-free/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online-full-version-123movies/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-2/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-3/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-4/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-123movies-godzilla-vs-kong-2021/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-free-hd/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free-online/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-5/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online-full-version-hd/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-full-2021-free/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-2/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-6/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-7/">.</a>
<a href="https://pactforanimals.org/advert/free-download-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/godzilla-vs-kong-2021-google-drive-mp4/">.</a>
<a href="https://pactforanimals.org/advert/google-docs-godzilla-vs-kong-2021-google-drive-full-hd-mp4/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-8/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-9/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-3/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-online/">.</a>
<a href="https://pactforanimals.org/advert/free-watch-godzilla-vs-kong-2021-full-4/">.</a>
<a href="https://pactforanimals.org/advert/free-godzilla-vs-kong-2021-watch-full/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-10/">.</a>
<a href="https://pactforanimals.org/advert/online-watch-godzilla-vs-kong-2021-full/">.</a>
<a href="https://pactforanimals.org/advert/123movies-watch-godzilla-vs-kong-2021-full-online/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-full-11/">.</a>
<a href="https://pactforanimals.org/advert/full-watch-godzilla-vs-kong-2021-free-hd/">.</a>
<a href="https://pactforanimals.org/advert/watch-godzilla-vs-kong-2021-free-online/">.</a>
<a href="https://pactforanimals.org/advert/full-godzilla-vs-kong-2021-watch-online/">.</a>
<a href="https://sites.google.com/view/mortalkombat1/">.</a>
<a href="https://sites.google.com/view/free-watch-mortal-kombat-2021-/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-2021-f-u-l/">.</a>
<a href="https://sites.google.com/view/mortalkombat2/">.</a>
<a href="https://sites.google.com/view/mortalkombat3/">.</a>
<a href="https://sites.google.com/view/mortalkombat5/">.</a>
<a href="https://sites.google.com/view/fullwatchmortalkombat2021-movi/">.</a>
<a href="https://sites.google.com/view/mortalkombat7/">.</a>
<a href="https://sites.google.com/view/mortalkombat8/">.</a>
<a href="https://sites.google.com/view/mortalkombat9/">.</a>
<a href="https://sites.google.com/view/mortalkombat10/">.</a>
<a href="https://sites.google.com/view/watch-mort-tal-kombat/">.</a>
<a href="https://sites.google.com/view/free-watch-mort-tal-kombat/">.</a>
<a href="https://sites.google.com/view/watch-mort-tal-kombatfree-/">.</a>
<a href="https://sites.google.com/view/full-watch-mortal-kombat/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-2021-/">.</a>
<a href="https://sites.google.com/view/watch-free-mortal-kombat-2021/">.</a>
<a href="https://sites.google.com/view/full-watch-mortal-kombat-/">.</a>
<a href="https://sites.google.com/view/watch-mortal-kombat-g-drive/">.</a>
<a href="https://sites.google.com/view/g-docs-mortalkombat-g-drive/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free-o/">.</a>
<a href="https://sites.google.com/view/mortal-kombat-2021-full-free-o/">.</a>
<a href="https://paiza.io/projects/56xFAEq61pSSn8VnKnHO6Q">.</a>
<a href="https://www.posts123.com/post/1450667/mariners-announce-spring-training">.</a>
<a href="https://sites.google.com/view/sfdjgkdfghdkfgjherghkkdfjg/home">.</a>
<a href="https://dskfjshdkjfewhgf.blogspot.com/2021/03/sdkjfhwekjhfjdherjgfdjg.html">.</a>
<a href="https://grahmaulidia.wordpress.com/2021/03/28/mariners-announce-spring-training-roster-moves/">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner-f83a9ea92f89">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner1-b2847091ff9f">.</a>
<a href="https://4z5v6wq7a.medium.com/a-letter-to-nationals-fans-from-mark-d-lerner2-df35041eec3a">.</a>
<a href="https://4z5v6wq7a.medium.com">.</a>
<a href="https://onlinegdb.com/BJaH8WR4O">.</a>
|
{}
|
dispenst/hgfytgfg
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dispix/test-model
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
We took `facebook/wav2vec2-large-960h` and fine tuned it using 1400 audio clips (around 10-15 seconds each) from various cryptocurrency related podcasts. To label the data, we downloaded cryptocurrency podcasts from youtube with their subtitle data and split the clips up by sentence. We then compared the youtube transcription with `facebook/wav2vec2-large-960h` to correct many mistakes in the youtube transcriptions. We can probably achieve better results with more data clean up.
On our data we achieved a WER of 13.1%. `facebook/wav2vec2-large-960h` only reached a WER of 27% on our data.
## Usage
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained("distractedm1nd/wav2vec-en-finetuned-on-cryptocurrency")
model = Wav2Vec2ForCTC.from_pretrained("distractedm1nd/wav2vec-en-finetuned-on-cryptocurrency"
filename = "INSERT_FILENAME"
audio, sampling_rate = sf.read(filename)
input_values = processor(audio, return_tensors="pt", padding="longest", sampling_rate=sampling_rate).input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
tokenizer.batch_decode(predicted_ids
```
|
{"language": "en", "license": "mit", "tags": ["audio", "automatic-speech-recognition"], "metrics": ["wer"]}
|
distractedm1nd/wav2vec-en-finetuned-on-cryptocurrency
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dittouser/model_name
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
| null |
# Peter from Your Boyfriend Game.
|
{"tags": ["conversational"]}
|
divi/Peterbot
| null |
[
"conversational",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
divyawadehra/distilroberta-base-finetuned-data-2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
divyawadehra/distilroberta-base-finetuned-data
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
divyawadehra/t5-small-finetuned-xsum
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
# diwank/dyda-deberta-pair
Deberta-based Daily Dialog style dialog-act annotations classification model. It takes two sentences as inputs (one previous and one current of a dialog). The previous sentence can be an empty string if this is the first utterance of a speaker in a dialog. Outputs one of four labels (exactly as in the [daily-dialog dataset](https://huggingface.co/datasets/daily_dialog) ): *__dummy__ (0), inform (1), question (2), directive (3), commissive (4)*
## Usage
```python
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
model = ClassificationModel("deberta", "diwank/dyda-deberta-pair")
convert_to_label = lambda n: ["__dummy__ (0), inform (1), question (2), directive (3), commissive (4)".split(', ')[i] for i in n]
predictions, raw_outputs = model.predict([["Say what is the meaning of life?", "I dont know"]])
convert_to_label(predictions) # inform (1)
```
|
{"license": "mit"}
|
diwank/dyda-deberta-pair
| null |
[
"transformers",
"pytorch",
"tf",
"deberta",
"text-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
# maptask-deberta-pair
Deberta-based Daily MapTask style dialog-act annotations classification model
## Example
```python
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
model = ClassificationModel("deberta", "diwank/maptask-deberta-pair")
predictions, raw_outputs = model.predict([["Say what is the meaning of life?", "I dont know"]])
convert_to_label = lambda n: ["acknowledge (0), align (1), check (2), clarify (3), explain (4), instruct (5), query_w (6), query_yn (7), ready (8), reply_n (9), reply_w (10), reply_y (11)".split(', ')[i] for i in n]
convert_to_label(predictions) # reply_n (9)
```
|
{"license": "mit"}
|
diwank/maptask-deberta-pair
| null |
[
"transformers",
"pytorch",
"tf",
"deberta",
"text-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
# diwank/silicone-deberta-pair
`deberta-base`-based dialog acts classifier. Trained on the `balanced` variant of the [silicone-merged](https://huggingface.co/datasets/diwank/silicone-merged) dataset: a simplified merged dialog act data from datasets in the [silicone](https://huggingface.co/datasets/silicone) collection.
Takes two sentences as inputs (one previous and one current utterance of a dialog). The previous sentence can be an empty string if this is the first utterance of a speaker in a dialog. **Outputs one of 11 labels**:
```python
(0, 'acknowledge')
(1, 'answer')
(2, 'backchannel')
(3, 'reply_yes')
(4, 'exclaim')
(5, 'say')
(6, 'reply_no')
(7, 'hold')
(8, 'ask')
(9, 'intent')
(10, 'ask_yes_no')
```
## Example:
```python
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
model = ClassificationModel("deberta", "diwank/silicone-deberta-pair")
convert_to_label = lambda n: [
['acknowledge',
'answer',
'backchannel',
'reply_yes',
'exclaim',
'say',
'reply_no',
'hold',
'ask',
'intent',
'ask_yes_no'
][i] for i in n
]
predictions, raw_outputs = model.predict([["Say what is the meaning of life?", "I dont know"]])
convert_to_label(predictions) # answer
```
## Report from W&B
https://wandb.ai/diwank/da-silicone-combined/reports/silicone-deberta-pair--VmlldzoxNTczNjE5?accessToken=yj1jz4c365z0y5b3olgzye7qgsl7qv9lxvqhmfhtb6300hql6veqa5xiq1skn8ys
|
{"license": "mit"}
|
diwank/silicone-deberta-pair
| null |
[
"transformers",
"pytorch",
"tf",
"deberta",
"text-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
diyoraharsh06/model_name
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
Slavic BERT from https://github.com/deepmipt/Slavic-BERT-NER http://files.deeppavlov.ai/deeppavlov_data/bg_cs_pl_ru_cased_L-12_H-768_A-12.tar.gz
|
{}
|
djstrong/bg_cs_pl_ru_cased_L-12_H-768_A-12
| null |
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dk-crazydiv/bert-base-uncased
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dk-crazydiv/myfirstmodel
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# Harry Potter DialoGPT Model
|
{"tags": ["conversational"]}
|
dk16gaming/DialoGPT-small-HarryPotter
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dk175814/en-hi_Transliteration
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dkdong/02Q420
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dkhanh1702/distilbert-base-uncased-finetuned-squad
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
### Bert-News
|
{}
|
dkhara/bert-news
| null |
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
{}
|
dkleczek/Polish-Hate-Speech-Detection-Herbert-Large
| null |
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dkleczek/PolishHateSpeechDetectionHerbertLarge
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
dkleczek/Polish_BART_base_OPI
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
{}
|
dkleczek/Polish_RoBERTa_large_OPI
| null |
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
{}
|
dkleczek/Polish_RoBERTa_v2_base_OPI
| null |
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
# Polbert - Polish BERT
Polish version of BERT language model is here! It is now available in two variants: cased and uncased, both can be downloaded and used via HuggingFace transformers library. I recommend using the cased model, more info on the differences and benchmark results below.

## Cased and uncased variants
* I initially trained the uncased model, the corpus and training details are referenced below. Here are some issues I found after I published the uncased model:
* Some Polish characters and accents are not tokenized correctly through the BERT tokenizer when applying lowercase. This doesn't impact sequence classification much, but may influence token classfication tasks significantly.
* I noticed a lot of duplicates in the Open Subtitles dataset, which dominates the training corpus.
* I didn't use Whole Word Masking.
* The cased model improves on the uncased model in the following ways:
* All Polish characters and accents should now be tokenized correctly.
* I removed duplicates from Open Subtitles dataset. The corpus is smaller, but more balanced now.
* The model is trained with Whole Word Masking.
## Pre-training corpora
Below is the list of corpora used along with the output of `wc` command (counting lines, words and characters). These corpora were divided into sentences with srxsegmenter (see references), concatenated and tokenized with HuggingFace BERT Tokenizer.
### Uncased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 236635408| 1431199601 | 7628097730 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 262920423 | 1861093257 | 10746349159 |
### Cased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles (Deduplicated) ](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 41998942| 213590656 | 1424873235 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 68283960 | 646479197 | 4543124667 |
## Pre-training details
### Uncased
* Polbert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Training set-up: in total 1 million training steps:
* 100.000 steps - 128 sequence length, batch size 512, learning rate 1e-4 (10.000 steps warmup)
* 800.000 steps - 128 sequence length, batch size 512, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
* The model was trained on a single Google Cloud TPU v3-8
### Cased
* Same approach as uncased model, with the following differences:
* Whole Word Masking
* Training set-up:
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 1e-4 (10.000 steps warmup)
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
## Usage
Polbert is released via [HuggingFace Transformers library](https://huggingface.co/transformers/).
For an example use as language model, see [this notebook](/LM_testing.ipynb) file.
### Uncased
```python
from transformers import *
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] adam mickiewicz wielkim polskim poeta był. [SEP]', 'score': 0.47196975350379944, 'token': 26596}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.09127858281135559, 'token': 10953}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.0647173821926117, 'token': 5182}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.05232388526201248, 'token': 24293}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim politykiem był. [SEP]', 'score': 0.04554257541894913, 'token': 44095}
```
### Cased
```python
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-cased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-cased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.5391148328781128, 'token': 37120}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.11683262139558792, 'token': 6810}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.06021466106176376, 'token': 17709}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim mistrzem był. [SEP]', 'score': 0.051870670169591904, 'token': 14652}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim artystą był. [SEP]', 'score': 0.031787533313035965, 'token': 35680}
```
See the next section for an example usage of Polbert in downstream tasks.
## Evaluation
Thanks to Allegro, we now have the [KLEJ benchmark](https://klejbenchmark.com/leaderboard/), a set of nine evaluation tasks for the Polish language understanding. The following results are achieved by running standard set of evaluation scripts (no tricks!) utilizing both cased and uncased variants of Polbert.
| Model | Average | NKJP-NER | CDSC-E | CDSC-R | CBD | PolEmo2.0-IN | PolEmo2.0-OUT | DYK | PSC | AR |
| ------------- |--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|
| Polbert cased | 81.7 | 93.6 | 93.4 | 93.8 | 52.7 | 87.4 | 71.1 | 59.1 | 98.6 | 85.2 |
| Polbert uncased | 81.4 | 90.1 | 93.9 | 93.5 | 55.0 | 88.1 | 68.8 | 59.4 | 98.8 | 85.4 |
Note how the uncased model performs better than cased on some tasks? My guess this is because of the oversampling of Open Subtitles dataset and its similarity to data in some of these tasks. All these benchmark tasks are sequence classification, so the relative strength of the cased model is not so visible here.
## Bias
The data used to train the model is biased. It may reflect stereotypes related to gender, ethnicity etc. Please be careful when using the model for downstream task to consider these biases and mitigate them.
## Acknowledgements
* I'd like to express my gratitude to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Also appreciate the help from Timo Möller from [deepset](https://deepset.ai) for sharing tips and scripts based on their experience training German BERT model.
* Big thanks to Allegro for releasing KLEJ Benchmark and specifically to Piotr Rybak for help with the evaluation and pointing out some issues with the tokenization.
* Finally, thanks to Rachel Thomas, Jeremy Howard and Sylvain Gugger from [fastai](https://www.fast.ai) for their NLP and Deep Learning courses!
## Author
Darek Kłeczek - contact me on Twitter [@dk21](https://twitter.com/dk21)
## References
* https://github.com/google-research/bert
* https://github.com/narusemotoki/srx_segmenter
* SRX rules file for sentence splitting in Polish, written by Marcin Miłkowski: https://raw.githubusercontent.com/languagetool-org/languagetool/master/languagetool-core/src/main/resources/org/languagetool/resource/segment.srx
* [KLEJ benchmark](https://klejbenchmark.com/leaderboard/)
|
{"language": "pl", "thumbnail": "https://raw.githubusercontent.com/kldarek/polbert/master/img/polbert.png"}
|
dkleczek/bert-base-polish-cased-v1
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"pretraining",
"pl",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# Polbert - Polish BERT
Polish version of BERT language model is here! It is now available in two variants: cased and uncased, both can be downloaded and used via HuggingFace transformers library. I recommend using the cased model, more info on the differences and benchmark results below.

## Cased and uncased variants
* I initially trained the uncased model, the corpus and training details are referenced below. Here are some issues I found after I published the uncased model:
* Some Polish characters and accents are not tokenized correctly through the BERT tokenizer when applying lowercase. This doesn't impact sequence classification much, but may influence token classfication tasks significantly.
* I noticed a lot of duplicates in the Open Subtitles dataset, which dominates the training corpus.
* I didn't use Whole Word Masking.
* The cased model improves on the uncased model in the following ways:
* All Polish characters and accents should now be tokenized correctly.
* I removed duplicates from Open Subtitles dataset. The corpus is smaller, but more balanced now.
* The model is trained with Whole Word Masking.
## Pre-training corpora
Below is the list of corpora used along with the output of `wc` command (counting lines, words and characters). These corpora were divided into sentences with srxsegmenter (see references), concatenated and tokenized with HuggingFace BERT Tokenizer.
### Uncased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 236635408| 1431199601 | 7628097730 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 262920423 | 1861093257 | 10746349159 |
### Cased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles (Deduplicated) ](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 41998942| 213590656 | 1424873235 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 68283960 | 646479197 | 4543124667 |
## Pre-training details
### Uncased
* Polbert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Training set-up: in total 1 million training steps:
* 100.000 steps - 128 sequence length, batch size 512, learning rate 1e-4 (10.000 steps warmup)
* 800.000 steps - 128 sequence length, batch size 512, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
* The model was trained on a single Google Cloud TPU v3-8
### Cased
* Same approach as uncased model, with the following differences:
* Whole Word Masking
* Training set-up:
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 1e-4 (10.000 steps warmup)
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
## Usage
Polbert is released via [HuggingFace Transformers library](https://huggingface.co/transformers/).
For an example use as language model, see [this notebook](/LM_testing.ipynb) file.
### Uncased
```python
from transformers import *
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] adam mickiewicz wielkim polskim poeta był. [SEP]', 'score': 0.47196975350379944, 'token': 26596}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.09127858281135559, 'token': 10953}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.0647173821926117, 'token': 5182}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.05232388526201248, 'token': 24293}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim politykiem był. [SEP]', 'score': 0.04554257541894913, 'token': 44095}
```
### Cased
```python
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-cased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-cased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.5391148328781128, 'token': 37120}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.11683262139558792, 'token': 6810}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.06021466106176376, 'token': 17709}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim mistrzem był. [SEP]', 'score': 0.051870670169591904, 'token': 14652}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim artystą był. [SEP]', 'score': 0.031787533313035965, 'token': 35680}
```
See the next section for an example usage of Polbert in downstream tasks.
## Evaluation
Thanks to Allegro, we now have the [KLEJ benchmark](https://klejbenchmark.com/leaderboard/), a set of nine evaluation tasks for the Polish language understanding. The following results are achieved by running standard set of evaluation scripts (no tricks!) utilizing both cased and uncased variants of Polbert.
| Model | Average | NKJP-NER | CDSC-E | CDSC-R | CBD | PolEmo2.0-IN | PolEmo2.0-OUT | DYK | PSC | AR |
| ------------- |--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|
| Polbert cased | 81.7 | 93.6 | 93.4 | 93.8 | 52.7 | 87.4 | 71.1 | 59.1 | 98.6 | 85.2 |
| Polbert uncased | 81.4 | 90.1 | 93.9 | 93.5 | 55.0 | 88.1 | 68.8 | 59.4 | 98.8 | 85.4 |
Note how the uncased model performs better than cased on some tasks? My guess this is because of the oversampling of Open Subtitles dataset and its similarity to data in some of these tasks. All these benchmark tasks are sequence classification, so the relative strength of the cased model is not so visible here.
## Bias
The data used to train the model is biased. It may reflect stereotypes related to gender, ethnicity etc. Please be careful when using the model for downstream task to consider these biases and mitigate them.
## Acknowledgements
* I'd like to express my gratitude to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Also appreciate the help from Timo Möller from [deepset](https://deepset.ai) for sharing tips and scripts based on their experience training German BERT model.
* Big thanks to Allegro for releasing KLEJ Benchmark and specifically to Piotr Rybak for help with the evaluation and pointing out some issues with the tokenization.
* Finally, thanks to Rachel Thomas, Jeremy Howard and Sylvain Gugger from [fastai](https://www.fast.ai) for their NLP and Deep Learning courses!
## Author
Darek Kłeczek - contact me on Twitter [@dk21](https://twitter.com/dk21)
## References
* https://github.com/google-research/bert
* https://github.com/narusemotoki/srx_segmenter
* SRX rules file for sentence splitting in Polish, written by Marcin Miłkowski: https://raw.githubusercontent.com/languagetool-org/languagetool/master/languagetool-core/src/main/resources/org/languagetool/resource/segment.srx
* [KLEJ benchmark](https://klejbenchmark.com/leaderboard/)
|
{"language": "pl", "thumbnail": "https://raw.githubusercontent.com/kldarek/polbert/master/img/polbert.png"}
|
dkleczek/bert-base-polish-uncased-v1
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"pl",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# papuGaPT2-finetuned-wierszyki
This model is a fine-tuned version of [flax-community/papuGaPT2](https://huggingface.co/flax-community/papuGaPT2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8122
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 202 | 2.8122 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
{"tags": ["generated_from_trainer"], "model-index": [{"name": "papuGaPT2-finetuned-wierszyki", "results": []}]}
|
dkleczek/papuGaPT2-finetuned-wierszyki
| null |
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# papuGaPT2 - Polish GPT2 language model
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research.
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens).
## Datasets
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion.
```
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
```
## Intended uses & limitations
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research.
## Bias Analysis
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb).
### Gender Bias
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress.

### Ethnicity/Nationality/Gender Bias
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme:
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She").
* Topic - we used 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...*
* define: *is*
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts.
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector.
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline.
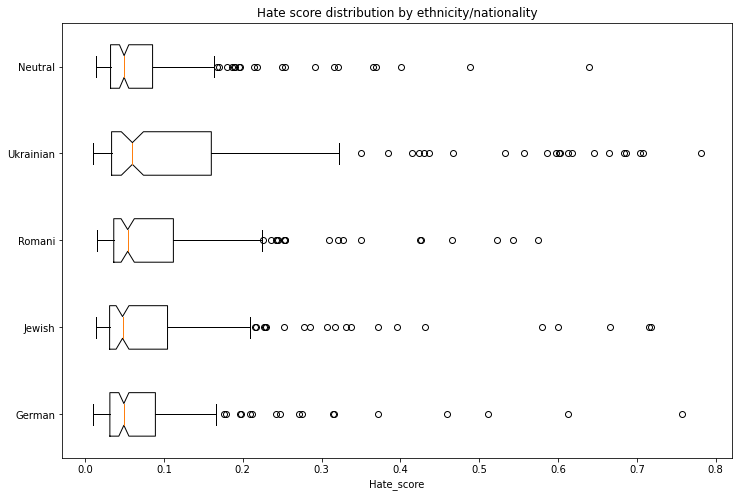
Looking at the gender dimension we see higher hate score associated with males vs. females.

We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided.
## Training procedure
### Training scripts
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time!
### Preprocessing and Training Details
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state:
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79
## Evaluation results
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in:
* Evaluation loss: 3.082
* Perplexity: 21.79
## How to use
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations.
### Text generation
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz.
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}]
```
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”.
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim.
>>> Prócz
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków.
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów
```
### Avoiding Bad Words
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*.
```python
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy,
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku,
```
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists!
### Few Shot Learning
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference.
```python
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
```
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses.
### Zero-Shot Inference
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald.
```python
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie,
```
## BibTeX entry and citation info
```bibtex
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
```
|
{"language": "pl", "tags": ["text-generation"], "widget": [{"text": "Najsmaczniejszy polski owoc to"}]}
|
dkleczek/papuGaPT2
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"pl",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# A certain person's AI
|
{"tags": ["conversational"]}
|
dkminer81/Tromm
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
dksharp108/wav2vec2-base-hindi-demo-colab
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dksharp108/wav2vec2-hindi
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4171
- Wer: 0.3452
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0054 | 4.0 | 500 | 1.5456 | 0.9005 |
| 0.8183 | 8.0 | 1000 | 0.4738 | 0.4839 |
| 0.3019 | 12.0 | 1500 | 0.4280 | 0.4047 |
| 0.1738 | 16.0 | 2000 | 0.4584 | 0.3738 |
| 0.1285 | 20.0 | 2500 | 0.4418 | 0.3593 |
| 0.1104 | 24.0 | 3000 | 0.4110 | 0.3479 |
| 0.0828 | 28.0 | 3500 | 0.4171 | 0.3452 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu102
- Datasets 1.14.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "wav2vec2-base-demo-colab", "results": []}]}
|
dkssud/wav2vec2-base-demo-colab
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
question-answering
|
transformers
|
# OpenVINO model bert-large-uncased-whole-word-masking-squad-int8-0001
This is a BERT-large model pre-trained on lower-cased English text using Whole-Word-Masking and fine-tuned on the SQuAD v1.1 training set. The model performs question answering for English language; the input is a concatenated premise and question for the premise, and the output is the location of the answer to the question inside the premise. For details about the original floating-point model, check out [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
The model has been further quantized to INT8 precision using quantization-aware fine-tuning with [NNCF](https://github.com/openvinotoolkit/nncf).
Model source: [Open Model Zoo](https://github.com/openvinotoolkit/open_model_zoo/tree/master/models/intel/bert-large-uncased-whole-word-masking-squad-int8-0001)
|
{}
|
dkurt/bert-large-uncased-whole-word-masking-squad-int8-0001
| null |
[
"transformers",
"bert",
"question-answering",
"arxiv:1810.04805",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-classification
|
transformers
|
[anton-l/wav2vec2-base-ft-keyword-spotting](https://huggingface.co/anton-l/wav2vec2-base-ft-keyword-spotting) model quantized with [Optimum OpenVINO](https://github.com/dkurt/optimum-openvino/).
| Accuracy on eval (baseline) | Accuracy on eval (quantized) |
|-----------------------------|----------------------------------------|
| 0.9828 | 0.9553 (-0.0274) |
|
{}
|
dkurt/wav2vec2-base-ft-keyword-spotting-int8
| null |
[
"transformers",
"wav2vec2",
"audio-classification",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
{}
|
dlarhkd1211/koelectra_adcode
| null |
[
"transformers",
"pytorch",
"tf",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
{"language": "pt", "tags": ["electra", "pretraining", "pytorch"], "datasets": ["brwac"]}
|
dlb/electra-base-portuguese-uncased-brwac
| null |
[
"transformers",
"pytorch",
"electra",
"pretraining",
"pt",
"dataset:brwac",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dlhug/cls_trained
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dlra/biobert_v1.1_pubmed
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
admarcosai/distilbert-base-uncased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dmatos2012/vit-gpt-captioning
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
dmbruintjies/flair_text_classifier_TCCBA
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2161
- Accuracy: 0.926
- F1: 0.9261
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8436 | 1.0 | 250 | 0.3175 | 0.9105 | 0.9081 |
| 0.2492 | 2.0 | 500 | 0.2161 | 0.926 | 0.9261 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.7.1
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "args": "default"}, "metrics": [{"type": "accuracy", "value": 0.926, "name": "Accuracy"}, {"type": "f1", "value": 0.9261144741040841, "name": "F1"}]}]}]}
|
dmiller1/distilbert-base-uncased-finetuned-emotion
| null |
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
NER Model of BERN2 system
|
{}
|
dmis-lab/bern2-ner
| null |
[
"transformers",
"pytorch",
"roberta",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
{}
|
dmis-lab/biobert-base-cased-v1.1-mnli
| null |
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
{}
|
dmis-lab/biobert-base-cased-v1.1-squad
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
{}
|
dmis-lab/biobert-base-cased-v1.1
| null |
[
"transformers",
"pytorch",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
dmis-lab/biobert-base-cased-v1.2
| null |
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
{}
|
dmis-lab/biobert-large-cased-v1.1-mnli
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
# Model Card for biobert-large-cased-v1.1-squad
# Model Details
## Model Description
More information needed
- **Developed by:** DMIS-lab (Data Mining and Information Systems Lab, Korea University)
- **Shared by [Optional]:** DMIS-lab (Data Mining and Information Systems Lab, Korea University)
- **Model type:** Question Answering
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Parent Model:** [gpt-neo-2.7B](https://huggingface.co/EleutherAI/gpt-neo-2.7B)
- **Resources for more information:**
- [GitHub Repo](https://github.com/jhyuklee/biobert)
- [Associated Paper](https://arxiv.org/abs/1901.08746)
# Uses
## Direct Use
This model can be used for the task of question answering.
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model creators note in the [associated paper](https://arxiv.org/pdf/1901.08746.pdf):
> We used the BERTBASE model pre-trained on English Wikipedia and BooksCorpus for 1M steps. BioBERT v1.0 (þ PubMed þ PMC) is the version of BioBERT (þ PubMed þ PMC) trained for 470 K steps. When using both the PubMed and PMC corpora, we found that 200K and 270K pre-training steps were optimal for PubMed and PMC, respectively. We also used the ablated versions of BioBERT v1.0, which were pre-trained on only PubMed for 200K steps (BioBERT v1.0 (þ PubMed)) and PMC for 270K steps (BioBERT v1.0 (þ PMC))
## Training Procedure
### Preprocessing
The model creators note in the [associated paper](https://arxiv.org/pdf/1901.08746.pdf):
> We pre-trained BioBERT using Naver Smart Machine Learning (NSML) (Sung et al., 2017), which is utilized for large-scale experiments that need to be run on several GPUs
### Speeds, Sizes, Times
The model creators note in the [associated paper](https://arxiv.org/pdf/1901.08746.pdf):
> The maximum sequence length was fixed to 512 and the mini-batch size was set to 192, resulting in 98 304 words per iteration.
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Training**: Eight NVIDIA V100 (32GB) GPUs [ for training],
- **Fine-tuning:** a single NVIDIA Titan Xp (12GB) GPU to fine-tune BioBERT on each task
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
```bibtex
@misc{mesh-transformer-jax,
@article{lee2019biobert,
title={BioBERT: a pre-trained biomedical language representation model for biomedical text mining},
author={Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo},
journal={arXiv preprint arXiv:1901.08746},
year={2019}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
For help or issues using BioBERT, please submit a GitHub issue. Please contact Jinhyuk Lee(`lee.jnhk (at) gmail.com`), or Wonjin Yoon (`wonjin.info (at) gmail.com`) for communication related to BioBERT.
# Model Card Authors [optional]
DMIS-lab (Data Mining and Information Systems Lab, Korea University) in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("dmis-lab/biobert-large-cased-v1.1-squad")
model = AutoModelForQuestionAnswering.from_pretrained("dmis-lab/biobert-large-cased-v1.1-squad")
```
</details>
|
{"tags": ["question-answering", "bert"]}
|
dmis-lab/biobert-large-cased-v1.1-squad
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"arxiv:1901.08746",
"arxiv:1910.09700",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
{}
|
dmis-lab/biobert-large-cased-v1.1
| null |
[
"transformers",
"pytorch",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
{}
|
dmis-lab/biobert-v1.1
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
hello
|
{}
|
dmis-lab/biosyn-biobert-bc2gn
| null |
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
feature-extraction
|
transformers
|
{}
|
dmis-lab/biosyn-biobert-bc5cdr-chemical
| null |
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.