
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
listlengths 0
201
| languages
listlengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
listlengths 0
722
| processed_texts
listlengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | bdsaglam/llama-2-7b-chat-jerx-peft-2i4dmlfd | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:37:46+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | transformers |
# Uploaded model
- **Developed by:** codesagar
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | codesagar/prompt-guard-classification-v8 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:39:21+00:00 | []
| [
"en"
]
| TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: codesagar
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
| [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
|
null | transformers |
# Uploaded model
- **Developed by:** codesagar
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | codesagar/prompt-guard-reasoning-v8 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:39:22+00:00 | []
| [
"en"
]
| TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: codesagar
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
| [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-1_5-2024-04-16-18-39-xe7pE
This model is a fine-tuned version of [microsoft/phi-1_5](https://huggingface.co/microsoft/phi-1_5) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "mit", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "microsoft/phi-1_5", "model-index": [{"name": "phi-1_5-2024-04-16-18-39-xe7pE", "results": []}]} | frenkd/phi-1_5-2024-04-16-18-39-xe7pE | null | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-1_5",
"license:mit",
"region:us"
]
| null | 2024-04-16T16:39:25+00:00 | []
| []
| TAGS
#peft #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-microsoft/phi-1_5 #license-mit #region-us
|
# phi-1_5-2024-04-16-18-39-xe7pE
This model is a fine-tuned version of microsoft/phi-1_5 on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | [
"# phi-1_5-2024-04-16-18-39-xe7pE\n\nThis model is a fine-tuned version of microsoft/phi-1_5 on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 8\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-microsoft/phi-1_5 #license-mit #region-us \n",
"# phi-1_5-2024-04-16-18-39-xe7pE\n\nThis model is a fine-tuned version of microsoft/phi-1_5 on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 8\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
|
null | mlx |
# mlx-community/CodeQwen1.5-7B-Chat-4bit
This model was converted to MLX format from [`Qwen/CodeQwen1.5-7B-Chat`]() using mlx-lm version **0.9.0**.
Model added by [Prince Canuma](https://twitter.com/Prince_Canuma).
Refer to the [original model card](https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/CodeQwen1.5-7B-Chat-4bit")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
| {"license": "apache-2.0", "tags": ["mlx"]} | mlx-community/CodeQwen1.5-7B-Chat-4bit | null | [
"mlx",
"safetensors",
"qwen2",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T16:39:29+00:00 | []
| []
| TAGS
#mlx #safetensors #qwen2 #license-apache-2.0 #region-us
|
# mlx-community/CodeQwen1.5-7B-Chat-4bit
This model was converted to MLX format from ['Qwen/CodeQwen1.5-7B-Chat']() using mlx-lm version 0.9.0.
Model added by Prince Canuma.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/CodeQwen1.5-7B-Chat-4bit\nThis model was converted to MLX format from ['Qwen/CodeQwen1.5-7B-Chat']() using mlx-lm version 0.9.0.\n\nModel added by Prince Canuma.\n\nRefer to the original model card for more details on the model.",
"## Use with mlx"
]
| [
"TAGS\n#mlx #safetensors #qwen2 #license-apache-2.0 #region-us \n",
"# mlx-community/CodeQwen1.5-7B-Chat-4bit\nThis model was converted to MLX format from ['Qwen/CodeQwen1.5-7B-Chat']() using mlx-lm version 0.9.0.\n\nModel added by Prince Canuma.\n\nRefer to the original model card for more details on the model.",
"## Use with mlx"
]
|
multiple-choice | transformers |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# sahithya20/bert-base-cased-mcq-swag
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4182
- Train Accuracy: 0.8560
- Validation Loss: 0.9197
- Validation Accuracy: 0.6680
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 250, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 1.0536 | 0.5440 | 0.8819 | 0.6500 | 0 |
| 0.4182 | 0.8560 | 0.9197 | 0.6680 | 1 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_keras_callback"], "base_model": "bert-base-cased", "model-index": [{"name": "sahithya20/bert-base-cased-mcq-swag", "results": []}]} | sahithya20/bert-base-cased-mcq-swag | null | [
"transformers",
"tf",
"tensorboard",
"bert",
"multiple-choice",
"generated_from_keras_callback",
"base_model:bert-base-cased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:40:15+00:00 | []
| []
| TAGS
#transformers #tf #tensorboard #bert #multiple-choice #generated_from_keras_callback #base_model-bert-base-cased #license-apache-2.0 #endpoints_compatible #region-us
| sahithya20/bert-base-cased-mcq-swag
===================================
This model is a fine-tuned version of bert-base-cased on an unknown dataset.
It achieves the following results on the evaluation set:
* Train Loss: 0.4182
* Train Accuracy: 0.8560
* Validation Loss: 0.9197
* Validation Accuracy: 0.6680
* Epoch: 1
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* optimizer: {'name': 'Adam', 'weight\_decay': None, 'clipnorm': None, 'global\_clipnorm': None, 'clipvalue': None, 'use\_ema': False, 'ema\_momentum': 0.99, 'ema\_overwrite\_frequency': None, 'jit\_compile': False, 'is\_legacy\_optimizer': False, 'learning\_rate': {'module': 'keras.optimizers.schedules', 'class\_name': 'PolynomialDecay', 'config': {'initial\_learning\_rate': 5e-05, 'decay\_steps': 250, 'end\_learning\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\_name': None}, 'beta\_1': 0.9, 'beta\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
* training\_precision: float32
### Training results
### Framework versions
* Transformers 4.38.2
* TensorFlow 2.15.0
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'Adam', 'weight\\_decay': None, 'clipnorm': None, 'global\\_clipnorm': None, 'clipvalue': None, 'use\\_ema': False, 'ema\\_momentum': 0.99, 'ema\\_overwrite\\_frequency': None, 'jit\\_compile': False, 'is\\_legacy\\_optimizer': False, 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 5e-05, 'decay\\_steps': 250, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tf #tensorboard #bert #multiple-choice #generated_from_keras_callback #base_model-bert-base-cased #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'Adam', 'weight\\_decay': None, 'clipnorm': None, 'global\\_clipnorm': None, 'clipvalue': None, 'use\\_ema': False, 'ema\\_momentum': 0.99, 'ema\\_overwrite\\_frequency': None, 'jit\\_compile': False, 'is\\_legacy\\_optimizer': False, 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 5e-05, 'decay\\_steps': 250, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-en-to-tr-colab
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Bleu: 0.0851
- Gen Len: 7.1921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 0.0 | 1.0 | 12851 | nan | 0.0851 | 7.1921 |
| 0.0 | 2.0 | 25702 | nan | 0.0851 | 7.1921 |
| 0.0 | 3.0 | 38553 | nan | 0.0851 | 7.1921 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["bleu"], "base_model": "google/mt5-base", "model-index": [{"name": "mt5-base-finetuned-en-to-tr-colab", "results": []}]} | Justice0893/mt5-base-finetuned-en-to-tr-colab | null | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/mt5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T16:42:52+00:00 | []
| []
| TAGS
#transformers #safetensors #mt5 #text2text-generation #generated_from_trainer #base_model-google/mt5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| mt5-base-finetuned-en-to-tr-colab
=================================
This model is a fine-tuned version of google/mt5-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: nan
* Bleu: 0.0851
* Gen Len: 7.1921
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.1
* Pytorch 2.2.1
* Datasets 2.18.0
* Tokenizers 0.15.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
]
| [
"TAGS\n#transformers #safetensors #mt5 #text2text-generation #generated_from_trainer #base_model-google/mt5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
]
|
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# autoregressive_finetune_split_rate2e-05_epochs4
This model is a fine-tuned version of [distilbert/distilgpt2](https://huggingface.co/distilbert/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4420
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 9 | 3.6642 |
| No log | 2.0 | 18 | 3.5268 |
| No log | 3.0 | 27 | 3.4633 |
| No log | 4.0 | 36 | 3.4420 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "distilbert/distilgpt2", "model-index": [{"name": "autoregressive_finetune_split_rate2e-05_epochs4", "results": []}]} | katieguo/autoregressive_finetune_split_rate2e-05_epochs4 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T16:43:16+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-distilbert/distilgpt2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| autoregressive\_finetune\_split\_rate2e-05\_epochs4
===================================================
This model is a fine-tuned version of distilbert/distilgpt2 on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 3.4420
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 4
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-distilbert/distilgpt2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Revrse/blip-icon-captioning | null | [
"transformers",
"safetensors",
"blip",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:43:42+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #blip #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #blip #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K36me3-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_EMP_H3K36me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K36me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9688
- F1 Score: 0.6234
- Accuracy: 0.6259
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 1536
- eval_batch_size: 1536
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6589 | 10.53 | 200 | 0.6520 | 0.6227 | 0.6259 |
| 0.5853 | 21.05 | 400 | 0.6959 | 0.5979 | 0.6032 |
| 0.5489 | 31.58 | 600 | 0.7283 | 0.6004 | 0.6121 |
| 0.5146 | 42.11 | 800 | 0.7520 | 0.6219 | 0.6227 |
| 0.4791 | 52.63 | 1000 | 0.7978 | 0.6183 | 0.6190 |
| 0.4517 | 63.16 | 1200 | 0.8265 | 0.6120 | 0.6153 |
| 0.4298 | 73.68 | 1400 | 0.7987 | 0.6154 | 0.6158 |
| 0.4099 | 84.21 | 1600 | 0.8670 | 0.6163 | 0.6227 |
| 0.3941 | 94.74 | 1800 | 0.8913 | 0.6179 | 0.6264 |
| 0.3768 | 105.26 | 2000 | 0.9079 | 0.6204 | 0.6244 |
| 0.3598 | 115.79 | 2200 | 0.9319 | 0.6193 | 0.625 |
| 0.3503 | 126.32 | 2400 | 0.9056 | 0.6223 | 0.6253 |
| 0.3345 | 136.84 | 2600 | 0.8963 | 0.6263 | 0.6273 |
| 0.3191 | 147.37 | 2800 | 0.9460 | 0.6208 | 0.6218 |
| 0.3091 | 157.89 | 3000 | 0.9749 | 0.6260 | 0.6259 |
| 0.2966 | 168.42 | 3200 | 0.9718 | 0.6269 | 0.6304 |
| 0.2866 | 178.95 | 3400 | 1.0000 | 0.6319 | 0.6345 |
| 0.2729 | 189.47 | 3600 | 1.0014 | 0.6255 | 0.6293 |
| 0.264 | 200.0 | 3800 | 1.0250 | 0.6197 | 0.6256 |
| 0.2574 | 210.53 | 4000 | 1.0167 | 0.6220 | 0.6241 |
| 0.2466 | 221.05 | 4200 | 1.0336 | 0.6194 | 0.6198 |
| 0.2402 | 231.58 | 4400 | 1.0913 | 0.6234 | 0.6256 |
| 0.2347 | 242.11 | 4600 | 1.0940 | 0.6274 | 0.6316 |
| 0.2279 | 252.63 | 4800 | 1.0509 | 0.6274 | 0.6302 |
| 0.2173 | 263.16 | 5000 | 1.0573 | 0.6255 | 0.6287 |
| 0.2128 | 273.68 | 5200 | 1.1305 | 0.6229 | 0.6247 |
| 0.2076 | 284.21 | 5400 | 1.1377 | 0.6230 | 0.6239 |
| 0.2026 | 294.74 | 5600 | 1.0921 | 0.6237 | 0.6270 |
| 0.197 | 305.26 | 5800 | 1.1096 | 0.6231 | 0.6244 |
| 0.1938 | 315.79 | 6000 | 1.1259 | 0.6238 | 0.6276 |
| 0.1861 | 326.32 | 6200 | 1.1440 | 0.6223 | 0.6221 |
| 0.1842 | 336.84 | 6400 | 1.1548 | 0.6264 | 0.6304 |
| 0.179 | 347.37 | 6600 | 1.1162 | 0.6231 | 0.6236 |
| 0.175 | 357.89 | 6800 | 1.1579 | 0.6274 | 0.6284 |
| 0.1714 | 368.42 | 7000 | 1.1461 | 0.6278 | 0.6284 |
| 0.1669 | 378.95 | 7200 | 1.1829 | 0.6278 | 0.6302 |
| 0.1645 | 389.47 | 7400 | 1.1714 | 0.6243 | 0.6253 |
| 0.1633 | 400.0 | 7600 | 1.2021 | 0.6303 | 0.6327 |
| 0.1596 | 410.53 | 7800 | 1.1906 | 0.6278 | 0.6293 |
| 0.1565 | 421.05 | 8000 | 1.1866 | 0.6282 | 0.6287 |
| 0.1545 | 431.58 | 8200 | 1.1854 | 0.6252 | 0.6270 |
| 0.1535 | 442.11 | 8400 | 1.1840 | 0.6274 | 0.6290 |
| 0.1506 | 452.63 | 8600 | 1.1801 | 0.6232 | 0.6244 |
| 0.1476 | 463.16 | 8800 | 1.2197 | 0.6278 | 0.6296 |
| 0.148 | 473.68 | 9000 | 1.2154 | 0.6273 | 0.6287 |
| 0.144 | 484.21 | 9200 | 1.2296 | 0.6255 | 0.6273 |
| 0.144 | 494.74 | 9400 | 1.2239 | 0.6299 | 0.6310 |
| 0.1432 | 505.26 | 9600 | 1.2304 | 0.6259 | 0.6284 |
| 0.1427 | 515.79 | 9800 | 1.2282 | 0.6288 | 0.6304 |
| 0.1413 | 526.32 | 10000 | 1.2248 | 0.6290 | 0.6307 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_EMP_H3K36me3-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K36me3-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T16:43:55+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_EMP\_H3K36me3-seqsight\_16384\_512\_56M-L32\_all
=====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_EMP\_H3K36me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9688
* F1 Score: 0.6234
* Accuracy: 0.6259
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 1536
* eval\_batch\_size: 1536
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 1536\n* eval\\_batch\\_size: 1536\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 1536\n* eval\\_batch\\_size: 1536\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
audio-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ks
This model is a fine-tuned version of [motheecreator/wav2vec2-base-finetuned-ks](https://huggingface.co/motheecreator/wav2vec2-base-finetuned-ks) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0117
- Accuracy: 0.9982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0528 | 0.99 | 79 | 0.0318 | 0.9947 |
| 0.0246 | 1.99 | 159 | 0.0132 | 0.9978 |
| 0.0142 | 3.0 | 239 | 0.0158 | 0.9978 |
| 0.007 | 4.0 | 319 | 0.0117 | 0.9982 |
| 0.0004 | 4.95 | 395 | 0.0147 | 0.9982 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["audiofolder"], "metrics": ["accuracy"], "base_model": "motheecreator/wav2vec2-base-finetuned-ks", "model-index": [{"name": "wav2vec2-base-finetuned-ks", "results": [{"task": {"type": "audio-classification", "name": "Audio Classification"}, "dataset": {"name": "audiofolder", "type": "audiofolder", "config": "default", "split": "validation", "args": "default"}, "metrics": [{"type": "accuracy", "value": 0.9982174688057041, "name": "Accuracy"}]}]}]} | motheecreator/wav2vec2-base-finetuned-ks | null | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:audiofolder",
"base_model:motheecreator/wav2vec2-base-finetuned-ks",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:45:03+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #wav2vec2 #audio-classification #generated_from_trainer #dataset-audiofolder #base_model-motheecreator/wav2vec2-base-finetuned-ks #license-apache-2.0 #model-index #endpoints_compatible #region-us
| wav2vec2-base-finetuned-ks
==========================
This model is a fine-tuned version of motheecreator/wav2vec2-base-finetuned-ks on the audiofolder dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0117
* Accuracy: 0.9982
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 3e-05
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 5
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 3e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #wav2vec2 #audio-classification #generated_from_trainer #dataset-audiofolder #base_model-motheecreator/wav2vec2-base-finetuned-ks #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 3e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# idefics2-8b-docvqa-finetuned-tutorial
This model is a fine-tuned version of [HuggingFaceM4/idefics2-8b](https://huggingface.co/HuggingFaceM4/idefics2-8b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "HuggingFaceM4/idefics2-8b", "model-index": [{"name": "idefics2-8b-docvqa-finetuned-tutorial", "results": []}]} | raejeong/idefics2-8b-docvqa-finetuned-tutorial | null | [
"safetensors",
"generated_from_trainer",
"base_model:HuggingFaceM4/idefics2-8b",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T16:48:09+00:00 | []
| []
| TAGS
#safetensors #generated_from_trainer #base_model-HuggingFaceM4/idefics2-8b #license-apache-2.0 #region-us
|
# idefics2-8b-docvqa-finetuned-tutorial
This model is a fine-tuned version of HuggingFaceM4/idefics2-8b on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# idefics2-8b-docvqa-finetuned-tutorial\n\nThis model is a fine-tuned version of HuggingFaceM4/idefics2-8b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0001\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 50\n- num_epochs: 2\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#safetensors #generated_from_trainer #base_model-HuggingFaceM4/idefics2-8b #license-apache-2.0 #region-us \n",
"# idefics2-8b-docvqa-finetuned-tutorial\n\nThis model is a fine-tuned version of HuggingFaceM4/idefics2-8b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0001\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 8\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 50\n- num_epochs: 2\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0.dev0\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
|
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# autoregressive_finetune_split_rate2e-05_epochs3
This model is a fine-tuned version of [distilbert/distilgpt2](https://huggingface.co/distilbert/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5220
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 9 | 3.6738 |
| No log | 2.0 | 18 | 3.5562 |
| No log | 3.0 | 27 | 3.5220 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "distilbert/distilgpt2", "model-index": [{"name": "autoregressive_finetune_split_rate2e-05_epochs3", "results": []}]} | katieguo/autoregressive_finetune_split_rate2e-05_epochs3 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T16:50:56+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-distilbert/distilgpt2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| autoregressive\_finetune\_split\_rate2e-05\_epochs3
===================================================
This model is a fine-tuned version of distilbert/distilgpt2 on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 3.5220
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-distilbert/distilgpt2 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | zandfj/Llama-2-7b-chat-hf-qlora-nq-ret-robust | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:51:18+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0415B2
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0627
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 60
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7796 | 0.09 | 10 | 2.7689 |
| 2.7682 | 0.18 | 20 | 2.7065 |
| 2.6102 | 0.27 | 30 | 2.3490 |
| 2.084 | 0.36 | 40 | 1.5865 |
| 1.2444 | 0.45 | 50 | 0.6290 |
| 0.3515 | 0.54 | 60 | 0.1070 |
| 0.1138 | 0.63 | 70 | 0.0952 |
| 0.1011 | 0.73 | 80 | 0.0862 |
| 0.0923 | 0.82 | 90 | 0.0828 |
| 0.0889 | 0.91 | 100 | 0.0770 |
| 0.0881 | 1.0 | 110 | 0.0754 |
| 0.0808 | 1.09 | 120 | 0.0727 |
| 0.082 | 1.18 | 130 | 0.0707 |
| 0.0819 | 1.27 | 140 | 0.0689 |
| 0.0743 | 1.36 | 150 | 0.0680 |
| 0.0812 | 1.45 | 160 | 0.0669 |
| 0.0735 | 1.54 | 170 | 0.0655 |
| 0.0763 | 1.63 | 180 | 0.0655 |
| 0.077 | 1.72 | 190 | 0.0650 |
| 0.0754 | 1.81 | 200 | 0.0638 |
| 0.0667 | 1.9 | 210 | 0.0636 |
| 0.0687 | 1.99 | 220 | 0.0646 |
| 0.0653 | 2.08 | 230 | 0.0642 |
| 0.0697 | 2.18 | 240 | 0.0638 |
| 0.0658 | 2.27 | 250 | 0.0632 |
| 0.0696 | 2.36 | 260 | 0.0633 |
| 0.0653 | 2.45 | 270 | 0.0631 |
| 0.0625 | 2.54 | 280 | 0.0629 |
| 0.0615 | 2.63 | 290 | 0.0630 |
| 0.0681 | 2.72 | 300 | 0.0629 |
| 0.0755 | 2.81 | 310 | 0.0628 |
| 0.0641 | 2.9 | 320 | 0.0628 |
| 0.0705 | 2.99 | 330 | 0.0627 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "microsoft/phi-2", "model-index": [{"name": "V0415B2", "results": []}]} | Litzy619/V0415B2 | null | [
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"license:mit",
"region:us"
]
| null | 2024-04-16T16:55:29+00:00 | []
| []
| TAGS
#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us
| V0415B2
=======
This model is a fine-tuned version of microsoft/phi-2 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0627
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 60
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.1.2+cu121
* Datasets 2.14.6
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
]
| [
"TAGS\n#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.1.2+cu121\n* Datasets 2.14.6\n* Tokenizers 0.14.1"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/mergekit-community/mergekit-dare_ties-ymiqjtz
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/mergekit-dare_ties-ymiqjtz-GGUF/resolve/main/mergekit-dare_ties-ymiqjtz.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": "mergekit-community/mergekit-dare_ties-ymiqjtz", "quantized_by": "mradermacher"} | mradermacher/mergekit-dare_ties-ymiqjtz-GGUF | null | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:mergekit-community/mergekit-dare_ties-ymiqjtz",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:56:42+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #mergekit #merge #en #base_model-mergekit-community/mergekit-dare_ties-ymiqjtz #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #mergekit #merge #en #base_model-mergekit-community/mergekit-dare_ties-ymiqjtz #endpoints_compatible #region-us \n"
]
|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | vishesh-t27/fine_tune_phi | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:58:49+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
image-classification | transformers |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Orin27/beans_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2283
- Validation Loss: 0.1632
- Train Accuracy: 0.9710
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 2481, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.1}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6523 | 0.3695 | 0.9082 | 0 |
| 0.2813 | 0.2082 | 0.9517 | 1 |
| 0.2283 | 0.1632 | 0.9710 | 2 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_keras_callback"], "base_model": "google/vit-base-patch16-224-in21k", "model-index": [{"name": "Orin27/beans_classifier", "results": []}]} | Orin27/beans_classifier | null | [
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"base_model:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T16:59:04+00:00 | []
| []
| TAGS
#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| Orin27/beans\_classifier
========================
This model is a fine-tuned version of google/vit-base-patch16-224-in21k on an unknown dataset.
It achieves the following results on the evaluation set:
* Train Loss: 0.2283
* Validation Loss: 0.1632
* Train Accuracy: 0.9710
* Epoch: 2
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* optimizer: {'name': 'AdamWeightDecay', 'learning\_rate': {'module': 'keras.optimizers.schedules', 'class\_name': 'PolynomialDecay', 'config': {'initial\_learning\_rate': 3e-05, 'decay\_steps': 2481, 'end\_learning\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\_name': None}, 'decay': 0.0, 'beta\_1': 0.9, 'beta\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\_decay\_rate': 0.1}
* training\_precision: float32
### Training results
### Framework versions
* Transformers 4.38.2
* TensorFlow 2.15.0
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 2481, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.1}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 2481, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.1}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/microsoft/WizardLM-2-8x22B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/WizardLM-2-8x22B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ1_S.gguf) | i1-IQ1_S | 29.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ1_M.gguf) | i1-IQ1_M | 32.8 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 42.1 | |
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ2_S.gguf) | i1-IQ2_S | 42.7 | |
| [GGUF](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ2_M.gguf) | i1-IQ2_M | 46.8 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q2_K.gguf.part2of2) | i1-Q2_K | 52.2 | IQ3_XXS probably better |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_XXS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_XXS.gguf.part2of2) | i1-IQ3_XXS | 55.0 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_XS.gguf.part2of2) | i1-IQ3_XS | 58.3 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_S.gguf.part2of2) | i1-IQ3_S | 61.6 | beats Q3_K* |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_S.gguf.part2of2) | i1-Q3_K_S | 61.6 | IQ3_XS probably better |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ3_M.gguf.part2of2) | i1-IQ3_M | 64.6 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_M.gguf.part2of2) | i1-Q3_K_M | 67.9 | IQ3_S probably better |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_L.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q3_K_L.gguf.part2of2) | i1-Q3_K_L | 72.7 | IQ3_M probably better |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ4_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-IQ4_XS.gguf.part2of2) | i1-IQ4_XS | 75.6 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_0.gguf.part2of2) | i1-Q4_0 | 80.0 | fast, low quality |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_K_S.gguf.part2of2) | i1-Q4_K_S | 80.6 | optimal size/speed/quality |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q4_K_M.gguf.part2of2) | i1-Q4_K_M | 85.7 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q5_K_S.gguf.part2of2) | i1-Q5_K_S | 97.1 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q5_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q5_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q5_K_M.gguf.part3of3) | i1-Q5_K_M | 100.1 | |
| [PART 1](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/WizardLM-2-8x22B-i1-GGUF/resolve/main/WizardLM-2-8x22B.i1-Q6_K.gguf.part3of3) | i1-Q6_K | 115.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "library_name": "transformers", "base_model": "microsoft/WizardLM-2-8x22B", "quantized_by": "mradermacher"} | mradermacher/WizardLM-2-8x22B-i1-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:microsoft/WizardLM-2-8x22B",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:01:58+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #en #base_model-microsoft/WizardLM-2-8x22B #endpoints_compatible #region-us
| About
-----
weighted/imatrix quants of URL
static quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #en #base_model-microsoft/WizardLM-2-8x22B #endpoints_compatible #region-us \n"
]
|
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": [], "widget": [{"example_title": "\u0935\u0930\u094d\u0924\u092e\u093e\u0928 \u092a\u094d\u0930\u0927\u093e\u0928\u092e\u0902\u0924\u094d\u0930\u0940", "messages": [{"role": "user", "content": "\u092d\u093e\u0930\u0924 \u0915\u0947 \u0935\u0930\u094d\u0924\u092e\u093e\u0928 \u092a\u094d\u0930\u0927\u093e\u0928\u092e\u0902\u0924\u094d\u0930\u0940 \u0915\u094c\u0928 \u0939\u0948\u0902?"}]}, {"example_title": "\u0939\u094b\u0932\u0940 \u0915\u093e \u092e\u0939\u0924\u094d\u0935", "messages": [{"role": "user", "content": "\u0939\u094b\u0932\u0940 \u0915\u093e \u092e\u0939\u0924\u094d\u0935 \u0915\u094d\u092f\u093e \u0939\u0948?"}]}]} | makers-lab/Indus-1.1B-IT | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:02:35+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #gpt2 #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | transformers |
Layout model for [surya](https://github.com/VikParuchuri/surya). | {"license": "cc-by-nc-sa-4.0"} | vikp/surya_layout2 | null | [
"transformers",
"safetensors",
"segformer",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:03:15+00:00 | []
| []
| TAGS
#transformers #safetensors #segformer #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us
|
Layout model for surya. | []
| [
"TAGS\n#transformers #safetensors #segformer #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us \n"
]
|
text-generation | transformers | # karakuri-midrose-mg
モデルの詳細は、[こちら](https://huggingface.co/sbtom/karakuri-midroze-mg.gguf)です。 | {"language": ["ja"], "tags": ["merge"], "pipeline_tag": "text-generation"} | sbtom/karakuri-midroze-mg | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"ja",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:03:50+00:00 | []
| [
"ja"
]
| TAGS
#transformers #safetensors #llama #text-generation #merge #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # karakuri-midrose-mg
モデルの詳細は、こちらです。 | [
"# karakuri-midrose-mg\n\nモデルの詳細は、こちらです。"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# karakuri-midrose-mg\n\nモデルの詳細は、こちらです。"
]
|
null | transformers |
Reading order model for [surya](https://github.com/VikParuchuri/surya). | {"license": "cc-by-nc-sa-4.0"} | vikp/surya_order | null | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:05:01+00:00 | []
| []
| TAGS
#transformers #safetensors #vision-encoder-decoder #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us
|
Reading order model for surya. | []
| [
"TAGS\n#transformers #safetensors #vision-encoder-decoder #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us \n"
]
|
text-generation | transformers | # karakuri-midroze-CV
モデルの詳細は、[こちら](https://huggingface.co/sbtom/karakuri-midrose-CV.gguf)です。
| {"language": ["ja"], "tags": ["merge"], "pipeline_tag": "text-generation"} | sbtom/karakuri-midrose-CV | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"ja",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:05:06+00:00 | []
| [
"ja"
]
| TAGS
#transformers #safetensors #llama #text-generation #merge #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # karakuri-midroze-CV
モデルの詳細は、こちらです。
| [
"# karakuri-midroze-CV\n\nモデルの詳細は、こちらです。"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# karakuri-midroze-CV\n\nモデルの詳細は、こちらです。"
]
|
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OpenAI GPT-2 355M
## Model description
This custom GPT-2 model is derived from the [gpt2-medium](https://huggingface.co/gpt2-medium) model and trained on the Alpaca dataset. Anezatra team meticulously trained this model on the Alpaca dataset for natural language processing tasks. The model excels in text generation and language understanding tasks, making it ideal for chat applications.
## Training Procedure
This model was trained with 4 x A100 GPUs
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 128
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.15
- num_epochs: 1 | {"language": ["en"], "license": "mit", "tags": ["generated_from_trainer"], "datasets": ["tatsu-lab/alpaca"], "widget": [{"text": "\nYou are a chat bot that provides professional answers to questions asked\n\n### Instruction:\nWhat is the purpose of life\n\n### Response:"}], "pipeline_tag": "text-generation", "model-index": [{"name": "GPT2-Medium-Alpaca-355m", "results": []}]} | anezatra/gpt2-alpaca-355M | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"en",
"dataset:tatsu-lab/alpaca",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:05:59+00:00 | []
| [
"en"
]
| TAGS
#transformers #pytorch #gpt2 #text-generation #generated_from_trainer #en #dataset-tatsu-lab/alpaca #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# OpenAI GPT-2 355M
## Model description
This custom GPT-2 model is derived from the gpt2-medium model and trained on the Alpaca dataset. Anezatra team meticulously trained this model on the Alpaca dataset for natural language processing tasks. The model excels in text generation and language understanding tasks, making it ideal for chat applications.
## Training Procedure
This model was trained with 4 x A100 GPUs
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 128
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.15
- num_epochs: 1 | [
"# OpenAI GPT-2 355M",
"## Model description\n\nThis custom GPT-2 model is derived from the gpt2-medium model and trained on the Alpaca dataset. Anezatra team meticulously trained this model on the Alpaca dataset for natural language processing tasks. The model excels in text generation and language understanding tasks, making it ideal for chat applications.",
"## Training Procedure\n\nThis model was trained with 4 x A100 GPUs",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 42\n- gradient_accumulation_steps: 128\n- total_train_batch_size: 128\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.15\n- num_epochs: 1"
]
| [
"TAGS\n#transformers #pytorch #gpt2 #text-generation #generated_from_trainer #en #dataset-tatsu-lab/alpaca #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# OpenAI GPT-2 355M",
"## Model description\n\nThis custom GPT-2 model is derived from the gpt2-medium model and trained on the Alpaca dataset. Anezatra team meticulously trained this model on the Alpaca dataset for natural language processing tasks. The model excels in text generation and language understanding tasks, making it ideal for chat applications.",
"## Training Procedure\n\nThis model was trained with 4 x A100 GPUs",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 42\n- gradient_accumulation_steps: 128\n- total_train_batch_size: 128\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.15\n- num_epochs: 1"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_shp4_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4317
- Rewards/chosen: -6.5985
- Rewards/rejected: -6.9380
- Rewards/accuracies: 0.5200
- Rewards/margins: 0.3394
- Logps/rejected: -304.6761
- Logps/chosen: -294.0565
- Logits/rejected: -0.8001
- Logits/chosen: -0.7815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0606 | 2.67 | 100 | 0.9815 | -3.8073 | -4.0570 | 0.5700 | 0.2497 | -275.8660 | -266.1440 | -0.7815 | -0.7820 |
| 0.0015 | 5.33 | 200 | 1.4766 | -9.4439 | -10.0498 | 0.5200 | 0.6059 | -335.7948 | -322.5099 | -0.9100 | -0.8860 |
| 0.0001 | 8.0 | 300 | 1.3563 | -5.3778 | -5.6296 | 0.5 | 0.2518 | -291.5923 | -281.8489 | -0.8443 | -0.8261 |
| 0.0001 | 10.67 | 400 | 1.3918 | -6.1165 | -6.4338 | 0.5200 | 0.3173 | -299.6345 | -289.2365 | -0.8181 | -0.8000 |
| 0.0001 | 13.33 | 500 | 1.4173 | -6.3997 | -6.7201 | 0.5200 | 0.3204 | -302.4971 | -292.0679 | -0.8077 | -0.7892 |
| 0.0001 | 16.0 | 600 | 1.4263 | -6.5107 | -6.8464 | 0.5200 | 0.3357 | -303.7607 | -293.1784 | -0.8030 | -0.7843 |
| 0.0001 | 18.67 | 700 | 1.4319 | -6.5813 | -6.9163 | 0.5200 | 0.3350 | -304.4596 | -293.8844 | -0.8006 | -0.7822 |
| 0.0001 | 21.33 | 800 | 1.4301 | -6.5939 | -6.9333 | 0.5200 | 0.3394 | -304.6292 | -294.0101 | -0.7998 | -0.7812 |
| 0.0001 | 24.0 | 900 | 1.4316 | -6.6029 | -6.9432 | 0.5200 | 0.3403 | -304.7287 | -294.0999 | -0.7994 | -0.7806 |
| 0.0001 | 26.67 | 1000 | 1.4317 | -6.5985 | -6.9380 | 0.5200 | 0.3394 | -304.6761 | -294.0565 | -0.8001 | -0.7815 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_shp4_dpo1", "results": []}]} | guoyu-zhang/model_hh_shp4_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-16T17:09:42+00:00 | []
| []
| TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_shp4\_dpo1
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4317
* Rewards/chosen: -6.5985
* Rewards/rejected: -6.9380
* Rewards/accuracies: 0.5200
* Rewards/margins: 0.3394
* Logps/rejected: -304.6761
* Logps/chosen: -294.0565
* Logits/rejected: -0.8001
* Logits/chosen: -0.7815
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp2_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3713
- Rewards/chosen: -6.8988
- Rewards/rejected: -10.4722
- Rewards/accuracies: 0.5700
- Rewards/margins: 3.5734
- Logps/rejected: -136.2930
- Logps/chosen: -125.5019
- Logits/rejected: -0.5150
- Logits/chosen: -0.4766
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.1335 | 2.67 | 100 | 1.8678 | -12.7163 | -15.5473 | 0.6400 | 2.8311 | -146.4432 | -137.1367 | -0.5513 | -0.5250 |
| 0.0599 | 5.33 | 200 | 1.9478 | -7.7572 | -11.3317 | 0.6800 | 3.5745 | -138.0119 | -127.2186 | -0.6179 | -0.5774 |
| 0.0178 | 8.0 | 300 | 2.5739 | -15.2954 | -20.0626 | 0.6400 | 4.7672 | -155.4737 | -142.2950 | -0.8409 | -0.7974 |
| 0.0001 | 10.67 | 400 | 2.3449 | -6.7892 | -10.3661 | 0.5800 | 3.5769 | -136.0806 | -125.2826 | -0.5079 | -0.4695 |
| 0.0 | 13.33 | 500 | 2.3597 | -6.8546 | -10.4323 | 0.5800 | 3.5776 | -136.2131 | -125.4135 | -0.5123 | -0.4736 |
| 0.0 | 16.0 | 600 | 2.3541 | -6.8691 | -10.4554 | 0.5800 | 3.5863 | -136.2593 | -125.4424 | -0.5143 | -0.4755 |
| 0.0 | 18.67 | 700 | 2.3647 | -6.8932 | -10.4651 | 0.5800 | 3.5719 | -136.2787 | -125.4907 | -0.5147 | -0.4761 |
| 0.0 | 21.33 | 800 | 2.3640 | -6.8827 | -10.4754 | 0.5800 | 3.5928 | -136.2994 | -125.4696 | -0.5155 | -0.4766 |
| 0.0 | 24.0 | 900 | 2.3566 | -6.8881 | -10.4744 | 0.5800 | 3.5863 | -136.2972 | -125.4803 | -0.5148 | -0.4762 |
| 0.0 | 26.67 | 1000 | 2.3713 | -6.8988 | -10.4722 | 0.5700 | 3.5734 | -136.2930 | -125.5019 | -0.5150 | -0.4766 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp2_dpo5", "results": []}]} | guoyu-zhang/model_hh_usp2_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-16T17:12:50+00:00 | []
| []
| TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp2\_dpo5
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.3713
* Rewards/chosen: -6.8988
* Rewards/rejected: -10.4722
* Rewards/accuracies: 0.5700
* Rewards/margins: 3.5734
* Logps/rejected: -136.2930
* Logps/chosen: -125.5019
* Logits/rejected: -0.5150
* Logits/chosen: -0.4766
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_0-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_mouse_0](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_0) dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2545
- F1 Score: 0.6058
- Accuracy: 0.6062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6053 | 50.0 | 200 | 0.7934 | 0.6030 | 0.6037 |
| 0.3637 | 100.0 | 400 | 1.0858 | 0.5916 | 0.5938 |
| 0.2384 | 150.0 | 600 | 1.3202 | 0.6058 | 0.6074 |
| 0.1663 | 200.0 | 800 | 1.5660 | 0.6068 | 0.6086 |
| 0.1242 | 250.0 | 1000 | 1.7820 | 0.6017 | 0.6037 |
| 0.1034 | 300.0 | 1200 | 1.9483 | 0.6084 | 0.6086 |
| 0.0858 | 350.0 | 1400 | 1.8785 | 0.6122 | 0.6123 |
| 0.0764 | 400.0 | 1600 | 1.9598 | 0.5986 | 0.5988 |
| 0.0684 | 450.0 | 1800 | 2.1600 | 0.6121 | 0.6123 |
| 0.0635 | 500.0 | 2000 | 2.0688 | 0.5991 | 0.6 |
| 0.056 | 550.0 | 2200 | 2.0929 | 0.6109 | 0.6111 |
| 0.0506 | 600.0 | 2400 | 2.1707 | 0.5924 | 0.5926 |
| 0.0475 | 650.0 | 2600 | 2.0698 | 0.5860 | 0.5864 |
| 0.0438 | 700.0 | 2800 | 2.2862 | 0.6023 | 0.6025 |
| 0.0415 | 750.0 | 3000 | 2.0525 | 0.5891 | 0.5951 |
| 0.0371 | 800.0 | 3200 | 2.3408 | 0.6113 | 0.6136 |
| 0.0354 | 850.0 | 3400 | 2.1682 | 0.5925 | 0.5938 |
| 0.0326 | 900.0 | 3600 | 2.2650 | 0.5953 | 0.5963 |
| 0.0334 | 950.0 | 3800 | 2.2792 | 0.5975 | 0.5988 |
| 0.0299 | 1000.0 | 4000 | 2.1906 | 0.6197 | 0.6198 |
| 0.0275 | 1050.0 | 4200 | 2.2755 | 0.6085 | 0.6086 |
| 0.0258 | 1100.0 | 4400 | 2.4177 | 0.6197 | 0.6210 |
| 0.026 | 1150.0 | 4600 | 2.4006 | 0.6213 | 0.6222 |
| 0.0259 | 1200.0 | 4800 | 2.2516 | 0.6110 | 0.6111 |
| 0.0226 | 1250.0 | 5000 | 2.4912 | 0.6086 | 0.6086 |
| 0.0217 | 1300.0 | 5200 | 2.2418 | 0.6111 | 0.6111 |
| 0.0215 | 1350.0 | 5400 | 2.4103 | 0.6127 | 0.6136 |
| 0.0207 | 1400.0 | 5600 | 2.3610 | 0.6169 | 0.6173 |
| 0.0188 | 1450.0 | 5800 | 2.3654 | 0.6121 | 0.6123 |
| 0.0197 | 1500.0 | 6000 | 2.4067 | 0.6149 | 0.6148 |
| 0.0172 | 1550.0 | 6200 | 2.4633 | 0.6087 | 0.6086 |
| 0.0163 | 1600.0 | 6400 | 2.5481 | 0.6140 | 0.6148 |
| 0.0157 | 1650.0 | 6600 | 2.3267 | 0.6062 | 0.6062 |
| 0.0166 | 1700.0 | 6800 | 2.4453 | 0.5986 | 0.6012 |
| 0.0163 | 1750.0 | 7000 | 2.5097 | 0.5988 | 0.5988 |
| 0.0152 | 1800.0 | 7200 | 2.4763 | 0.6176 | 0.6185 |
| 0.0145 | 1850.0 | 7400 | 2.4926 | 0.6087 | 0.6086 |
| 0.0134 | 1900.0 | 7600 | 2.5411 | 0.6054 | 0.6062 |
| 0.014 | 1950.0 | 7800 | 2.5542 | 0.6112 | 0.6111 |
| 0.0134 | 2000.0 | 8000 | 2.4467 | 0.6012 | 0.6012 |
| 0.0122 | 2050.0 | 8200 | 2.5481 | 0.6099 | 0.6099 |
| 0.0121 | 2100.0 | 8400 | 2.6043 | 0.6081 | 0.6086 |
| 0.0123 | 2150.0 | 8600 | 2.5935 | 0.6096 | 0.6099 |
| 0.0121 | 2200.0 | 8800 | 2.6291 | 0.6054 | 0.6074 |
| 0.0114 | 2250.0 | 9000 | 2.5197 | 0.5950 | 0.5951 |
| 0.011 | 2300.0 | 9200 | 2.5614 | 0.6035 | 0.6037 |
| 0.0114 | 2350.0 | 9400 | 2.5312 | 0.6123 | 0.6123 |
| 0.0103 | 2400.0 | 9600 | 2.6047 | 0.6117 | 0.6123 |
| 0.0101 | 2450.0 | 9800 | 2.6146 | 0.6073 | 0.6074 |
| 0.0102 | 2500.0 | 10000 | 2.5974 | 0.6110 | 0.6111 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_mouse_0-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_0-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:14:02+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_mouse\_0-seqsight\_16384\_512\_56M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_mouse\_0 dataset.
It achieves the following results on the evaluation set:
* Loss: 2.2545
* F1 Score: 0.6058
* Accuracy: 0.6062
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-am
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4629
- Precision: 0.3961
- Recall: 0.6021
- F1: 0.4779
- Accuracy: 0.8443
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 41 | 0.7587 | 0.2544 | 0.4027 | 0.3118 | 0.7235 |
| No log | 2.0 | 82 | 0.5670 | 0.2003 | 0.4082 | 0.2687 | 0.8011 |
| No log | 3.0 | 123 | 0.4773 | 0.2355 | 0.4525 | 0.3098 | 0.8238 |
| No log | 4.0 | 164 | 0.4514 | 0.2963 | 0.5166 | 0.3766 | 0.8292 |
| No log | 5.0 | 205 | 0.4409 | 0.3261 | 0.5491 | 0.4092 | 0.8384 |
| No log | 6.0 | 246 | 0.4426 | 0.3558 | 0.5839 | 0.4422 | 0.8460 |
| No log | 7.0 | 287 | 0.4629 | 0.3961 | 0.6021 | 0.4779 | 0.8443 |
### Framework versions
- Transformers 4.39.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "bert-base-uncased", "model-index": [{"name": "bert-finetuned-am", "results": []}]} | HankLiuML/bert-finetuned-am | null | [
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:14:52+00:00 | []
| []
| TAGS
#transformers #safetensors #bert #token-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| bert-finetuned-am
=================
This model is a fine-tuned version of bert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4629
* Precision: 0.3961
* Recall: 0.6021
* F1: 0.4779
* Accuracy: 0.8443
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
### Training results
### Framework versions
* Transformers 4.39.2
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.2\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #safetensors #bert #token-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.2\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_1-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_mouse_1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_1) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4853
- F1 Score: 0.8068
- Accuracy: 0.8073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5442 | 7.41 | 200 | 0.4622 | 0.7791 | 0.7804 |
| 0.4502 | 14.81 | 400 | 0.4389 | 0.7923 | 0.7924 |
| 0.419 | 22.22 | 600 | 0.4277 | 0.7994 | 0.7996 |
| 0.3913 | 29.63 | 800 | 0.4163 | 0.8118 | 0.8122 |
| 0.3676 | 37.04 | 1000 | 0.4041 | 0.8173 | 0.8179 |
| 0.3463 | 44.44 | 1200 | 0.4076 | 0.8180 | 0.8181 |
| 0.3292 | 51.85 | 1400 | 0.4261 | 0.8197 | 0.8202 |
| 0.3126 | 59.26 | 1600 | 0.4205 | 0.8167 | 0.8170 |
| 0.2991 | 66.67 | 1800 | 0.4311 | 0.8173 | 0.8181 |
| 0.2855 | 74.07 | 2000 | 0.4361 | 0.8165 | 0.8172 |
| 0.2717 | 81.48 | 2200 | 0.4368 | 0.8187 | 0.8190 |
| 0.2604 | 88.89 | 2400 | 0.4386 | 0.8169 | 0.8175 |
| 0.2492 | 96.3 | 2600 | 0.4688 | 0.8198 | 0.8203 |
| 0.2381 | 103.7 | 2800 | 0.4698 | 0.8206 | 0.8211 |
| 0.2292 | 111.11 | 3000 | 0.4750 | 0.8124 | 0.8132 |
| 0.2183 | 118.52 | 3200 | 0.5071 | 0.8134 | 0.8142 |
| 0.2094 | 125.93 | 3400 | 0.5069 | 0.8167 | 0.8172 |
| 0.2021 | 133.33 | 3600 | 0.5130 | 0.8155 | 0.8162 |
| 0.1928 | 140.74 | 3800 | 0.5227 | 0.8137 | 0.8145 |
| 0.1869 | 148.15 | 4000 | 0.5277 | 0.8140 | 0.8147 |
| 0.1801 | 155.56 | 4200 | 0.5357 | 0.8088 | 0.8096 |
| 0.1728 | 162.96 | 4400 | 0.5521 | 0.8120 | 0.8128 |
| 0.1682 | 170.37 | 4600 | 0.5467 | 0.8166 | 0.8169 |
| 0.1622 | 177.78 | 4800 | 0.5542 | 0.8139 | 0.8142 |
| 0.1569 | 185.19 | 5000 | 0.5493 | 0.8126 | 0.8129 |
| 0.152 | 192.59 | 5200 | 0.5764 | 0.8125 | 0.8132 |
| 0.1487 | 200.0 | 5400 | 0.5713 | 0.8137 | 0.8141 |
| 0.1439 | 207.41 | 5600 | 0.6000 | 0.8137 | 0.8144 |
| 0.1401 | 214.81 | 5800 | 0.5937 | 0.8142 | 0.8145 |
| 0.1346 | 222.22 | 6000 | 0.6062 | 0.8173 | 0.8178 |
| 0.133 | 229.63 | 6200 | 0.6124 | 0.8092 | 0.8098 |
| 0.1285 | 237.04 | 6400 | 0.6042 | 0.8103 | 0.8107 |
| 0.126 | 244.44 | 6600 | 0.6118 | 0.8127 | 0.8130 |
| 0.1243 | 251.85 | 6800 | 0.6170 | 0.8143 | 0.8148 |
| 0.1208 | 259.26 | 7000 | 0.6358 | 0.8157 | 0.8162 |
| 0.1174 | 266.67 | 7200 | 0.6416 | 0.8124 | 0.8130 |
| 0.1149 | 274.07 | 7400 | 0.6213 | 0.8187 | 0.8190 |
| 0.1134 | 281.48 | 7600 | 0.6611 | 0.8155 | 0.8159 |
| 0.1111 | 288.89 | 7800 | 0.6358 | 0.8165 | 0.8168 |
| 0.11 | 296.3 | 8000 | 0.6435 | 0.8150 | 0.8153 |
| 0.1084 | 303.7 | 8200 | 0.6378 | 0.8145 | 0.8147 |
| 0.1068 | 311.11 | 8400 | 0.6380 | 0.8169 | 0.8172 |
| 0.104 | 318.52 | 8600 | 0.6594 | 0.8139 | 0.8142 |
| 0.1032 | 325.93 | 8800 | 0.6573 | 0.8165 | 0.8168 |
| 0.1031 | 333.33 | 9000 | 0.6575 | 0.8127 | 0.8130 |
| 0.1021 | 340.74 | 9200 | 0.6616 | 0.8155 | 0.8159 |
| 0.1 | 348.15 | 9400 | 0.6637 | 0.8149 | 0.8153 |
| 0.0996 | 355.56 | 9600 | 0.6604 | 0.8147 | 0.8150 |
| 0.0997 | 362.96 | 9800 | 0.6630 | 0.8148 | 0.8151 |
| 0.0997 | 370.37 | 10000 | 0.6635 | 0.8140 | 0.8144 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_mouse_1-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_1-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:15:06+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_mouse\_1-seqsight\_16384\_512\_56M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_mouse\_1 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4853
* F1 Score: 0.8068
* Accuracy: 0.8073
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | OwOOwO/dumbo-krillin30 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:15:47+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_4-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_mouse_4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_4) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8050
- F1 Score: 0.5891
- Accuracy: 0.5895
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6582 | 25.0 | 200 | 0.7112 | 0.5669 | 0.5799 |
| 0.5399 | 50.0 | 400 | 0.8146 | 0.5662 | 0.5704 |
| 0.4559 | 75.0 | 600 | 0.8792 | 0.5691 | 0.5720 |
| 0.3848 | 100.0 | 800 | 0.9910 | 0.5605 | 0.5629 |
| 0.3343 | 125.0 | 1000 | 1.0886 | 0.5634 | 0.5656 |
| 0.3003 | 150.0 | 1200 | 1.1596 | 0.5614 | 0.5672 |
| 0.2662 | 175.0 | 1400 | 1.1973 | 0.5654 | 0.5677 |
| 0.241 | 200.0 | 1600 | 1.1809 | 0.5615 | 0.5640 |
| 0.2173 | 225.0 | 1800 | 1.3351 | 0.5671 | 0.5682 |
| 0.1986 | 250.0 | 2000 | 1.3246 | 0.5578 | 0.5576 |
| 0.1806 | 275.0 | 2200 | 1.3167 | 0.5650 | 0.5651 |
| 0.1682 | 300.0 | 2400 | 1.3844 | 0.5668 | 0.5666 |
| 0.1547 | 325.0 | 2600 | 1.4121 | 0.5607 | 0.5619 |
| 0.1448 | 350.0 | 2800 | 1.4350 | 0.5708 | 0.5720 |
| 0.1345 | 375.0 | 3000 | 1.4904 | 0.5645 | 0.5645 |
| 0.1263 | 400.0 | 3200 | 1.5184 | 0.5534 | 0.5539 |
| 0.1179 | 425.0 | 3400 | 1.5335 | 0.5580 | 0.5613 |
| 0.1109 | 450.0 | 3600 | 1.6210 | 0.5573 | 0.5597 |
| 0.1056 | 475.0 | 3800 | 1.5789 | 0.5512 | 0.5512 |
| 0.0995 | 500.0 | 4000 | 1.5346 | 0.5536 | 0.5550 |
| 0.0939 | 525.0 | 4200 | 1.5563 | 0.5669 | 0.5672 |
| 0.0883 | 550.0 | 4400 | 1.6455 | 0.5697 | 0.5698 |
| 0.0845 | 575.0 | 4600 | 1.6616 | 0.5588 | 0.5592 |
| 0.0817 | 600.0 | 4800 | 1.7329 | 0.5618 | 0.5640 |
| 0.0771 | 625.0 | 5000 | 1.6480 | 0.5549 | 0.5550 |
| 0.0731 | 650.0 | 5200 | 1.6935 | 0.5634 | 0.5635 |
| 0.0706 | 675.0 | 5400 | 1.7164 | 0.5603 | 0.5613 |
| 0.0676 | 700.0 | 5600 | 1.7539 | 0.5578 | 0.5576 |
| 0.0649 | 725.0 | 5800 | 1.7017 | 0.5593 | 0.5592 |
| 0.0634 | 750.0 | 6000 | 1.6847 | 0.5664 | 0.5688 |
| 0.0608 | 775.0 | 6200 | 1.7775 | 0.5702 | 0.5709 |
| 0.0584 | 800.0 | 6400 | 1.7685 | 0.5704 | 0.5725 |
| 0.0559 | 825.0 | 6600 | 1.7465 | 0.5727 | 0.5730 |
| 0.0542 | 850.0 | 6800 | 1.7862 | 0.5701 | 0.5709 |
| 0.0516 | 875.0 | 7000 | 1.8472 | 0.5626 | 0.5629 |
| 0.0512 | 900.0 | 7200 | 1.7528 | 0.5695 | 0.5704 |
| 0.0496 | 925.0 | 7400 | 1.8154 | 0.5680 | 0.5720 |
| 0.0484 | 950.0 | 7600 | 1.7907 | 0.5671 | 0.5682 |
| 0.0468 | 975.0 | 7800 | 1.8572 | 0.5701 | 0.5709 |
| 0.0451 | 1000.0 | 8000 | 1.8723 | 0.5728 | 0.5736 |
| 0.0452 | 1025.0 | 8200 | 1.8313 | 0.5705 | 0.5709 |
| 0.0441 | 1050.0 | 8400 | 1.8083 | 0.5723 | 0.5741 |
| 0.0433 | 1075.0 | 8600 | 1.8727 | 0.5659 | 0.5661 |
| 0.0423 | 1100.0 | 8800 | 1.8578 | 0.5655 | 0.5666 |
| 0.0406 | 1125.0 | 9000 | 1.8359 | 0.5644 | 0.5656 |
| 0.0397 | 1150.0 | 9200 | 1.8910 | 0.5638 | 0.5645 |
| 0.0402 | 1175.0 | 9400 | 1.8684 | 0.5674 | 0.5682 |
| 0.0399 | 1200.0 | 9600 | 1.8923 | 0.5681 | 0.5688 |
| 0.039 | 1225.0 | 9800 | 1.8885 | 0.5694 | 0.5698 |
| 0.0388 | 1250.0 | 10000 | 1.8820 | 0.5688 | 0.5693 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_mouse_4-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_4-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:15:48+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_mouse\_4-seqsight\_16384\_512\_56M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_mouse\_4 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.8050
* F1 Score: 0.5891
* Accuracy: 0.5895
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
text-generation | transformers |
# Spaetzle-v63-7b
Spaetzle-v63-7b is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [OpenPipe/mistral-ft-optimized-1227](https://huggingface.co/OpenPipe/mistral-ft-optimized-1227)
* [DiscoResearch/DiscoLM_German_7b_v1](https://huggingface.co/DiscoResearch/DiscoLM_German_7b_v1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1227
layer_range: [0, 32]
- model: DiscoResearch/DiscoLM_German_7b_v1
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1227
parameters:
t:
- value: [0.5, 0.9]
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "cstr/Spaetzle-v63-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"tags": ["merge", "mergekit", "lazymergekit", "OpenPipe/mistral-ft-optimized-1227", "DiscoResearch/DiscoLM_German_7b_v1"], "base_model": ["OpenPipe/mistral-ft-optimized-1227", "DiscoResearch/DiscoLM_German_7b_v1"]} | cstr/Spaetzle-v63-7b | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"OpenPipe/mistral-ft-optimized-1227",
"DiscoResearch/DiscoLM_German_7b_v1",
"base_model:OpenPipe/mistral-ft-optimized-1227",
"base_model:DiscoResearch/DiscoLM_German_7b_v1",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:16:54+00:00 | []
| []
| TAGS
#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #OpenPipe/mistral-ft-optimized-1227 #DiscoResearch/DiscoLM_German_7b_v1 #base_model-OpenPipe/mistral-ft-optimized-1227 #base_model-DiscoResearch/DiscoLM_German_7b_v1 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Spaetzle-v63-7b
Spaetzle-v63-7b is a merge of the following models using LazyMergekit:
* OpenPipe/mistral-ft-optimized-1227
* DiscoResearch/DiscoLM_German_7b_v1
## Configuration
## Usage
| [
"# Spaetzle-v63-7b\n\nSpaetzle-v63-7b is a merge of the following models using LazyMergekit:\n* OpenPipe/mistral-ft-optimized-1227\n* DiscoResearch/DiscoLM_German_7b_v1",
"## Configuration",
"## Usage"
]
| [
"TAGS\n#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #OpenPipe/mistral-ft-optimized-1227 #DiscoResearch/DiscoLM_German_7b_v1 #base_model-OpenPipe/mistral-ft-optimized-1227 #base_model-DiscoResearch/DiscoLM_German_7b_v1 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Spaetzle-v63-7b\n\nSpaetzle-v63-7b is a merge of the following models using LazyMergekit:\n* OpenPipe/mistral-ft-optimized-1227\n* DiscoResearch/DiscoLM_German_7b_v1",
"## Configuration",
"## Usage"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_3-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_mouse_3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_3) dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3338
- F1 Score: 0.6820
- Accuracy: 0.6820
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-------:|:-----:|:---------------:|:--------:|:--------:|
| 0.311 | 200.0 | 200 | 1.7411 | 0.6484 | 0.6485 |
| 0.0409 | 400.0 | 400 | 2.2603 | 0.6686 | 0.6695 |
| 0.0153 | 600.0 | 600 | 2.7506 | 0.6526 | 0.6527 |
| 0.0086 | 800.0 | 800 | 2.9172 | 0.6607 | 0.6611 |
| 0.005 | 1000.0 | 1000 | 3.1038 | 0.6567 | 0.6569 |
| 0.0038 | 1200.0 | 1200 | 3.1364 | 0.6602 | 0.6611 |
| 0.0028 | 1400.0 | 1400 | 3.0692 | 0.6862 | 0.6862 |
| 0.0023 | 1600.0 | 1600 | 3.2921 | 0.6726 | 0.6736 |
| 0.0023 | 1800.0 | 1800 | 3.0979 | 0.6776 | 0.6778 |
| 0.0017 | 2000.0 | 2000 | 3.5785 | 0.6904 | 0.6904 |
| 0.0016 | 2200.0 | 2200 | 3.5736 | 0.6719 | 0.6736 |
| 0.0015 | 2400.0 | 2400 | 3.5195 | 0.6736 | 0.6736 |
| 0.0018 | 2600.0 | 2600 | 3.1821 | 0.6733 | 0.6736 |
| 0.0011 | 2800.0 | 2800 | 3.6424 | 0.6813 | 0.6820 |
| 0.0013 | 3000.0 | 3000 | 3.4343 | 0.6820 | 0.6820 |
| 0.0012 | 3200.0 | 3200 | 3.2781 | 0.6903 | 0.6904 |
| 0.0011 | 3400.0 | 3400 | 3.7888 | 0.6565 | 0.6569 |
| 0.0011 | 3600.0 | 3600 | 3.6267 | 0.6819 | 0.6820 |
| 0.001 | 3800.0 | 3800 | 3.7899 | 0.6819 | 0.6820 |
| 0.0008 | 4000.0 | 4000 | 3.7322 | 0.6815 | 0.6820 |
| 0.0012 | 4200.0 | 4200 | 3.4328 | 0.6820 | 0.6820 |
| 0.0006 | 4400.0 | 4400 | 3.9427 | 0.6858 | 0.6862 |
| 0.0006 | 4600.0 | 4600 | 3.5968 | 0.6904 | 0.6904 |
| 0.0006 | 4800.0 | 4800 | 3.5173 | 0.6945 | 0.6946 |
| 0.0008 | 5000.0 | 5000 | 3.1799 | 0.6565 | 0.6569 |
| 0.0005 | 5200.0 | 5200 | 3.5638 | 0.6903 | 0.6904 |
| 0.0006 | 5400.0 | 5400 | 3.4550 | 0.6818 | 0.6820 |
| 0.0006 | 5600.0 | 5600 | 3.7406 | 0.6819 | 0.6820 |
| 0.0006 | 5800.0 | 5800 | 3.9597 | 0.6937 | 0.6946 |
| 0.0004 | 6000.0 | 6000 | 3.9500 | 0.6736 | 0.6736 |
| 0.0004 | 6200.0 | 6200 | 4.3024 | 0.6894 | 0.6904 |
| 0.0006 | 6400.0 | 6400 | 3.7158 | 0.6736 | 0.6736 |
| 0.0004 | 6600.0 | 6600 | 3.8558 | 0.6819 | 0.6820 |
| 0.0003 | 6800.0 | 6800 | 4.0871 | 0.7026 | 0.7029 |
| 0.0004 | 7000.0 | 7000 | 4.0194 | 0.6862 | 0.6862 |
| 0.0003 | 7200.0 | 7200 | 4.1203 | 0.6820 | 0.6820 |
| 0.0004 | 7400.0 | 7400 | 3.9632 | 0.6820 | 0.6820 |
| 0.0002 | 7600.0 | 7600 | 4.3073 | 0.6862 | 0.6862 |
| 0.0003 | 7800.0 | 7800 | 4.2494 | 0.6942 | 0.6946 |
| 0.0003 | 8000.0 | 8000 | 4.1879 | 0.6904 | 0.6904 |
| 0.0002 | 8200.0 | 8200 | 4.5692 | 0.7068 | 0.7071 |
| 0.0003 | 8400.0 | 8400 | 3.7660 | 0.7113 | 0.7113 |
| 0.0002 | 8600.0 | 8600 | 3.8717 | 0.7070 | 0.7071 |
| 0.0001 | 8800.0 | 8800 | 4.3633 | 0.7112 | 0.7113 |
| 0.0002 | 9000.0 | 9000 | 4.2387 | 0.7070 | 0.7071 |
| 0.0002 | 9200.0 | 9200 | 4.1988 | 0.7071 | 0.7071 |
| 0.0002 | 9400.0 | 9400 | 4.2237 | 0.7071 | 0.7071 |
| 0.0001 | 9600.0 | 9600 | 4.2462 | 0.7029 | 0.7029 |
| 0.0002 | 9800.0 | 9800 | 4.2529 | 0.7028 | 0.7029 |
| 0.0001 | 10000.0 | 10000 | 4.2926 | 0.7028 | 0.7029 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_mouse_3-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_3-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:18:23+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_mouse\_3-seqsight\_16384\_512\_56M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_mouse\_3 dataset.
It achieves the following results on the evaluation set:
* Loss: 3.3338
* F1 Score: 0.6820
* Accuracy: 0.6820
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
sentence-similarity | sentence-transformers |
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 790 with parameters:
```
{'batch_size': 12, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss` with parameters:
```
{'distance_metric': 'SiameseDistanceMetric.COSINE_DISTANCE', 'margin': 0.5, 'size_average': True}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 100,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 790,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | seniichev/me5-wb | null | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:20:07+00:00 | []
| []
| TAGS
#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# {MODEL_NAME}
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers installed:
Then you can use the model like this:
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL
## Training
The model was trained with the parameters:
DataLoader:
'URL.dataloader.DataLoader' of length 790 with parameters:
Loss:
'sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss' with parameters:
Parameters of the fit()-Method:
## Full Model Architecture
## Citing & Authors
| [
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 790 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss' with parameters:\n \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
]
| [
"TAGS\n#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# {MODEL_NAME}\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 790 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss' with parameters:\n \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
]
|
image-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [apple/mobilevit-xx-small](https://huggingface.co/apple/mobilevit-xx-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1665
- Accuracy: 0.7093
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0008
- train_batch_size: 512
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.6055 | 0.57 | 5000 | 1.5440 | 0.6210 |
| 1.4532 | 1.14 | 10000 | 1.4455 | 0.6433 |
| 1.3963 | 1.71 | 15000 | 1.3564 | 0.6644 |
| 1.339 | 2.28 | 20000 | 1.3168 | 0.6731 |
| 1.3148 | 2.84 | 25000 | 1.2800 | 0.6813 |
| 1.2779 | 3.41 | 30000 | 1.2615 | 0.6850 |
| 1.2624 | 3.98 | 35000 | 1.2426 | 0.6901 |
| 1.2376 | 4.55 | 40000 | 1.2122 | 0.6977 |
| 1.2091 | 5.12 | 45000 | 1.1962 | 0.7006 |
| 1.2012 | 5.69 | 50000 | 1.1811 | 0.7051 |
| 1.1856 | 6.26 | 55000 | 1.1699 | 0.7074 |
| 1.1785 | 6.83 | 60000 | 1.1599 | 0.7102 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "other", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "apple/mobilevit-xx-small", "model-index": [{"name": "results", "results": []}]} | JoshuaKelleyDs/doodle-MobileVIT-xxs-finetune | null | [
"transformers",
"onnx",
"safetensors",
"mobilevit",
"image-classification",
"generated_from_trainer",
"base_model:apple/mobilevit-xx-small",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:26:03+00:00 | []
| []
| TAGS
#transformers #onnx #safetensors #mobilevit #image-classification #generated_from_trainer #base_model-apple/mobilevit-xx-small #license-other #autotrain_compatible #endpoints_compatible #region-us
| results
=======
This model is a fine-tuned version of apple/mobilevit-xx-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1665
* Accuracy: 0.7093
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0008
* train\_batch\_size: 512
* eval\_batch\_size: 512
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 7
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.2.1
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0008\n* train\\_batch\\_size: 512\n* eval\\_batch\\_size: 512\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 7\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #onnx #safetensors #mobilevit #image-classification #generated_from_trainer #base_model-apple/mobilevit-xx-small #license-other #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0008\n* train\\_batch\\_size: 512\n* eval\\_batch\\_size: 512\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 7\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/KaeriJenti/kaori-72b-v1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/kaori-72b-v1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ1_S.gguf) | i1-IQ1_S | 15.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ1_M.gguf) | i1-IQ1_M | 17.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.5 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.6 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ2_S.gguf) | i1-IQ2_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ2_M.gguf) | i1-IQ2_M | 24.7 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q2_K.gguf) | i1-Q2_K | 26.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 28.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 30.5 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ3_S.gguf) | i1-IQ3_S | 31.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.7 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ3_M.gguf) | i1-IQ3_M | 34.8 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 36.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.9 | |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 39.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q4_0.gguf) | i1-Q4_0 | 41.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 41.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 45.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q5_K_M.gguf.part2of2) | i1-Q5_K_M | 53.2 | |
| [PART 1](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/kaori-72b-v1-i1-GGUF/resolve/main/kaori-72b-v1.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 59.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "unknown", "library_name": "transformers", "base_model": "KaeriJenti/kaori-72b-v1", "quantized_by": "mradermacher"} | mradermacher/kaori-72b-v1-i1-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:KaeriJenti/kaori-72b-v1",
"license:unknown",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:29:26+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #en #base_model-KaeriJenti/kaori-72b-v1 #license-unknown #endpoints_compatible #region-us
| About
-----
weighted/imatrix quants of URL
static quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #en #base_model-KaeriJenti/kaori-72b-v1 #license-unknown #endpoints_compatible #region-us \n"
]
|
text-generation | null |
## Llamacpp Quantizations of WizardLM-2-8x22B
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b2675">b2675</a> for quantization.
Original model: https://huggingface.co/microsoft/WizardLM-2-8x22B
## Prompt format
```
{system_prompt} USER: {prompt} ASSISTANT: </s>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [WizardLM-2-8x22B-Q8_0.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF//main/WizardLM-2-8x22B-Q8_0.gguf) | Q8_0 | | Extremely high quality, generally unneeded but max available quant. |
| [WizardLM-2-8x22B-Q6_K.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF//main/WizardLM-2-8x22B-Q6_K.gguf) | Q6_K | | Very high quality, near perfect, *recommended*. |
| [WizardLM-2-8x22B-Q5_K_M.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q5_K_M.gguf) | Q5_K_M | 99.96GB | High quality, *recommended*. |
| [WizardLM-2-8x22B-Q5_K_S.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q5_K_S.gguf) | Q5_K_S | 96.97GB | High quality, *recommended*. |
| [WizardLM-2-8x22B-Q4_K_M.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q4_K_M.gguf) | Q4_K_M | 85.58GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [WizardLM-2-8x22B-Q4_K_S.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q4_K_S.gguf) | Q4_K_S | 80.47GB | Slightly lower quality with more space savings, *recommended*. |
| [WizardLM-2-8x22B-IQ4_NL.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-IQ4_NL.gguf) | IQ4_NL | 80.47GB | Decent quality, slightly smaller than Q4_K_S with similar performance *recommended*. |
| [WizardLM-2-8x22B-IQ4_XS.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-IQ4_XS.gguf) | IQ4_XS | 76.35GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [WizardLM-2-8x22B-Q3_K_L.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q3_K_L.gguf) | Q3_K_L | 72.57GB | Lower quality but usable, good for low RAM availability. |
| [WizardLM-2-8x22B-Q3_K_M.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q3_K_M.gguf) | Q3_K_M | 67.78GB | Even lower quality. |
| [WizardLM-2-8x22B-IQ3_M.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-IQ3_M.gguf) | IQ3_M | 64.49GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [WizardLM-2-8x22B-IQ3_S.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-IQ3_S.gguf) | IQ3_S | 61.49GB | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| [WizardLM-2-8x22B-Q3_K_S.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q3_K_S.gguf) | Q3_K_S | 61.49GB | Low quality, not recommended. |
| [WizardLM-2-8x22B-IQ3_XS.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-IQ3_XS.gguf) | IQ3_XS | 58.22GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [WizardLM-2-8x22B-Q2_K.gguf](https://huggingface.co/bartowski/WizardLM-2-8x22B-GGUF/tree/main/WizardLM-2-8x22B-Q2_K.gguf) | Q2_K | 52.10GB | Very low quality but surprisingly usable. |
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
| {"license": "apache-2.0", "quantized_by": "bartowski", "pipeline_tag": "text-generation"} | bartowski/WizardLM-2-8x22B-GGUF | null | [
"gguf",
"text-generation",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T17:30:47+00:00 | []
| []
| TAGS
#gguf #text-generation #license-apache-2.0 #region-us
| Llamacpp Quantizations of WizardLM-2-8x22B
------------------------------------------
Using <a href="URL release <a href="URL for quantization.
Original model: URL
Prompt format
-------------
Download a file (not the whole branch) from below:
--------------------------------------------------
Which file should I choose?
---------------------------
A great write up with charts showing various performances is provided by Artefact2 here
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX\_K\_X', like Q5\_K\_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
URL feature matrix
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX\_X, like IQ3\_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: URL
| []
| [
"TAGS\n#gguf #text-generation #license-apache-2.0 #region-us \n"
]
|
video-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-isl-numbers
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1287
- Accuracy: 0.6444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.4795 | 0.02 | 22 | 2.4767 | 0.0256 |
| 2.4249 | 1.02 | 44 | 2.4351 | 0.1026 |
| 2.4561 | 2.02 | 66 | 2.4196 | 0.1026 |
| 2.3841 | 3.02 | 88 | 2.3735 | 0.1026 |
| 2.5186 | 4.02 | 110 | 2.4258 | 0.0769 |
| 2.3806 | 5.02 | 132 | 2.3214 | 0.1538 |
| 2.3579 | 6.02 | 154 | 2.2858 | 0.1538 |
| 2.2955 | 7.02 | 176 | 2.1729 | 0.1795 |
| 2.1351 | 8.02 | 198 | 1.9503 | 0.3333 |
| 2.1626 | 9.02 | 220 | 2.1922 | 0.2051 |
| 2.0905 | 10.02 | 242 | 1.8453 | 0.3333 |
| 1.7091 | 11.02 | 264 | 1.6305 | 0.4872 |
| 1.6316 | 12.02 | 286 | 1.6529 | 0.3333 |
| 1.6399 | 13.02 | 308 | 1.7789 | 0.2308 |
| 1.5139 | 14.02 | 330 | 1.6245 | 0.3590 |
| 1.3315 | 15.02 | 352 | 1.6540 | 0.2821 |
| 1.0726 | 16.02 | 374 | 1.7507 | 0.2821 |
| 1.1432 | 17.02 | 396 | 1.6282 | 0.3333 |
| 1.144 | 18.02 | 418 | 1.3435 | 0.5128 |
| 0.987 | 19.02 | 440 | 0.8631 | 0.7949 |
| 0.8152 | 20.02 | 462 | 1.0812 | 0.5897 |
| 0.8175 | 21.02 | 484 | 1.4527 | 0.4359 |
| 0.7587 | 22.02 | 506 | 1.2309 | 0.5128 |
| 0.6255 | 23.02 | 528 | 1.1940 | 0.4872 |
| 0.6867 | 24.02 | 550 | 0.9270 | 0.5385 |
| 0.7537 | 25.02 | 572 | 0.6586 | 0.7436 |
| 0.6147 | 26.02 | 594 | 0.7935 | 0.7179 |
| 0.4602 | 27.02 | 616 | 0.9698 | 0.6154 |
| 0.482 | 28.02 | 638 | 0.9328 | 0.6410 |
| 0.3436 | 29.02 | 660 | 0.9947 | 0.6154 |
| 0.336 | 30.02 | 682 | 0.8127 | 0.6410 |
| 0.3952 | 31.02 | 704 | 0.5542 | 0.8205 |
| 0.2922 | 32.02 | 726 | 1.3266 | 0.5897 |
| 0.2998 | 33.02 | 748 | 0.9621 | 0.6410 |
| 0.2824 | 34.02 | 770 | 0.7805 | 0.7436 |
| 0.2971 | 35.02 | 792 | 0.4700 | 0.8462 |
| 0.1746 | 36.02 | 814 | 0.6059 | 0.8205 |
| 0.1325 | 37.02 | 836 | 0.4568 | 0.7436 |
| 0.2452 | 38.02 | 858 | 0.3495 | 0.8462 |
| 0.161 | 39.02 | 880 | 0.2546 | 0.9231 |
| 0.1788 | 40.02 | 902 | 0.3275 | 0.8974 |
| 0.201 | 41.02 | 924 | 0.3987 | 0.8205 |
| 0.259 | 42.02 | 946 | 0.5395 | 0.7692 |
| 0.112 | 43.02 | 968 | 0.4591 | 0.8462 |
| 0.0622 | 44.02 | 990 | 0.3455 | 0.8462 |
| 0.1307 | 45.02 | 1012 | 0.5513 | 0.7436 |
| 0.0924 | 46.02 | 1034 | 0.6709 | 0.7436 |
| 0.056 | 47.02 | 1056 | 0.4471 | 0.8205 |
| 0.089 | 48.02 | 1078 | 0.3860 | 0.8205 |
| 0.1798 | 49.02 | 1100 | 0.4313 | 0.8462 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1
| {"license": "cc-by-nc-4.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "MCG-NJU/videomae-base", "model-index": [{"name": "videomae-base-finetuned-isl-numbers", "results": []}]} | latif98/videomae-base-finetuned-isl-numbers | null | [
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:31:29+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #videomae #video-classification #generated_from_trainer #base_model-MCG-NJU/videomae-base #license-cc-by-nc-4.0 #endpoints_compatible #region-us
| videomae-base-finetuned-isl-numbers
===================================
This model is a fine-tuned version of MCG-NJU/videomae-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1287
* Accuracy: 0.6444
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* training\_steps: 1100
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.1.0+cu121
* Datasets 2.18.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* training\\_steps: 1100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.1.0+cu121\n* Datasets 2.18.0\n* Tokenizers 0.19.1"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #videomae #video-classification #generated_from_trainer #base_model-MCG-NJU/videomae-base #license-cc-by-nc-4.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* training\\_steps: 1100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.1.0+cu121\n* Datasets 2.18.0\n* Tokenizers 0.19.1"
]
|
null | null |
# NSK-128k-7B-slerp-GGUF ⭐️⭐️⭐️⭐️
NSK-7B-128k-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [Nitral-AI/Nyan-Stunna-7B](https://huggingface.co/Nitral-AI/Nyan-Stunna-7B)
* [Nitral-AI/Kunocchini-7b-128k-test](https://huggingface.co/Nitral-AI/Kunocchini-7b-128k-test)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Nitral-AI/Nyan-Stunna-7B
layer_range: [0, 32]
- model: Nitral-AI/Kunocchini-7b-128k-test
layer_range: [0, 32]
merge_method: slerp
base_model: Nitral-AI/Kunocchini-7b-128k-test
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
Eval embedding benchmark (with 70 specific quesions):







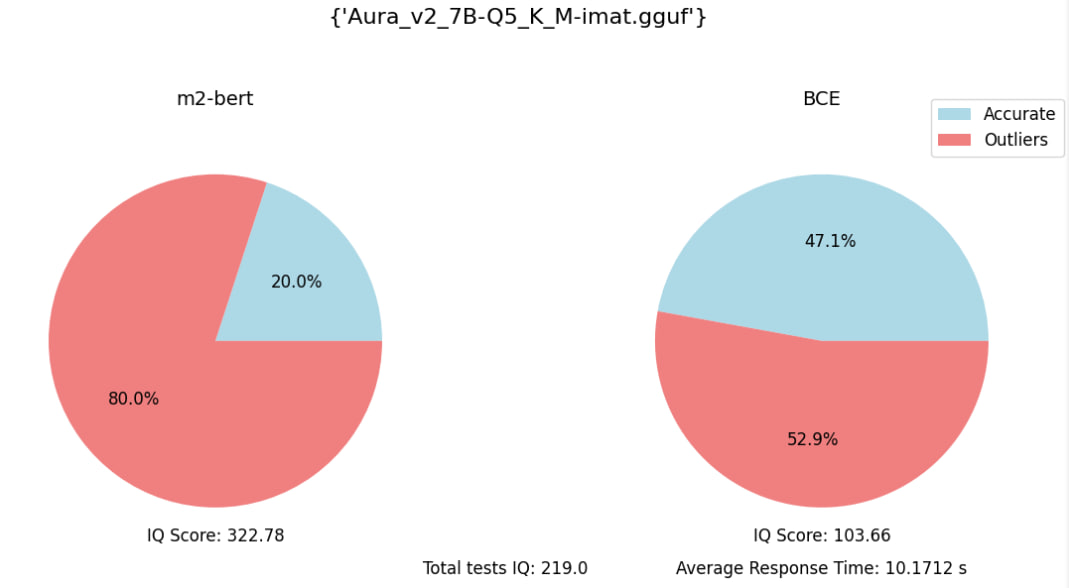




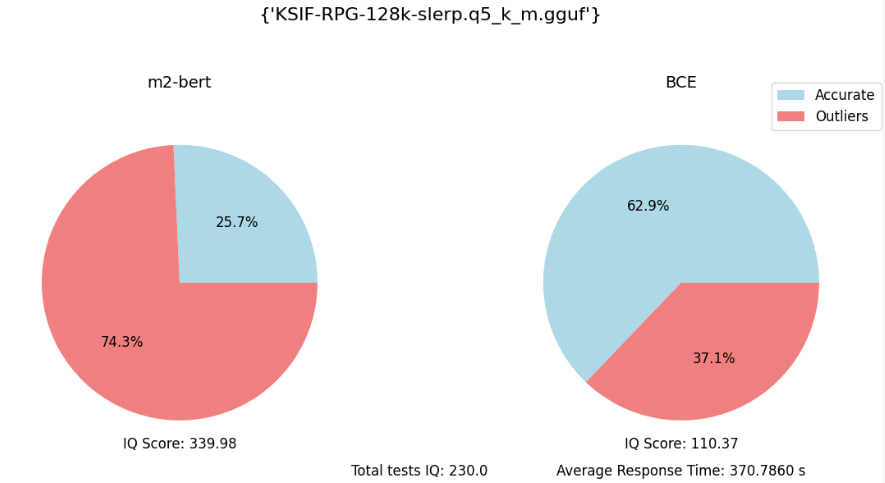
 | {"language": ["en", "ru", "th"], "license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "Nitral-AI/Nyan-Stunna-7B", "Nitral-AI/Kunocchini-7b-128k-test", "gguf", "Q2_K", "Q3_K_L", "Q3_K_M", "Q3_K_S", "Q4_0", "Q4_1", "Q4_K_S", "Q4_k_m", "Q5_0", "Q5_1", "Q6_K", "Q5_K_S", "Q5_k_m", "Q8_0", "128k"]} | AlekseiPravdin/NSK-128k-7B-slerp-gguf | null | [
"gguf",
"merge",
"mergekit",
"lazymergekit",
"Nitral-AI/Nyan-Stunna-7B",
"Nitral-AI/Kunocchini-7b-128k-test",
"Q2_K",
"Q3_K_L",
"Q3_K_M",
"Q3_K_S",
"Q4_0",
"Q4_1",
"Q4_K_S",
"Q4_k_m",
"Q5_0",
"Q5_1",
"Q6_K",
"Q5_K_S",
"Q5_k_m",
"Q8_0",
"128k",
"en",
"ru",
"th",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T17:32:51+00:00 | []
| [
"en",
"ru",
"th"
]
| TAGS
#gguf #merge #mergekit #lazymergekit #Nitral-AI/Nyan-Stunna-7B #Nitral-AI/Kunocchini-7b-128k-test #Q2_K #Q3_K_L #Q3_K_M #Q3_K_S #Q4_0 #Q4_1 #Q4_K_S #Q4_k_m #Q5_0 #Q5_1 #Q6_K #Q5_K_S #Q5_k_m #Q8_0 #128k #en #ru #th #license-apache-2.0 #region-us
|
# NSK-128k-7B-slerp-GGUF ⭐️⭐️⭐️⭐️
NSK-7B-128k-slerp is a merge of the following models using mergekit:
* Nitral-AI/Nyan-Stunna-7B
* Nitral-AI/Kunocchini-7b-128k-test
## Configuration
Eval embedding benchmark (with 70 specific quesions):
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL | [
"# NSK-128k-7B-slerp-GGUF ⭐️⭐️⭐️⭐️\n\nNSK-7B-128k-slerp is a merge of the following models using mergekit:\n* Nitral-AI/Nyan-Stunna-7B\n* Nitral-AI/Kunocchini-7b-128k-test",
"## Configuration\n\n\n\nEval embedding benchmark (with 70 specific quesions):\n\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL"
]
| [
"TAGS\n#gguf #merge #mergekit #lazymergekit #Nitral-AI/Nyan-Stunna-7B #Nitral-AI/Kunocchini-7b-128k-test #Q2_K #Q3_K_L #Q3_K_M #Q3_K_S #Q4_0 #Q4_1 #Q4_K_S #Q4_k_m #Q5_0 #Q5_1 #Q6_K #Q5_K_S #Q5_k_m #Q8_0 #128k #en #ru #th #license-apache-2.0 #region-us \n",
"# NSK-128k-7B-slerp-GGUF ⭐️⭐️⭐️⭐️\n\nNSK-7B-128k-slerp is a merge of the following models using mergekit:\n* Nitral-AI/Nyan-Stunna-7B\n* Nitral-AI/Kunocchini-7b-128k-test",
"## Configuration\n\n\n\nEval embedding benchmark (with 70 specific quesions):\n\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL"
]
|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | pandafm/donutES-UMU | null | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:34:15+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/mergekit-community/mergekit-slerp-exkkzvd
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/mergekit-slerp-exkkzvd-GGUF/resolve/main/mergekit-slerp-exkkzvd.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": "mergekit-community/mergekit-slerp-exkkzvd", "quantized_by": "mradermacher"} | mradermacher/mergekit-slerp-exkkzvd-GGUF | null | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:mergekit-community/mergekit-slerp-exkkzvd",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:36:21+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #mergekit #merge #en #base_model-mergekit-community/mergekit-slerp-exkkzvd #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #mergekit #merge #en #base_model-mergekit-community/mergekit-slerp-exkkzvd #endpoints_compatible #region-us \n"
]
|
null | peft | Finetuned Mistral-7b model for medical document summarization
### Framework versions
- PEFT 0.10.1.dev0 | {"license": "mit", "library_name": "peft", "base_model": "mistralai/Mistral-7B-v0.1"} | BiswajitPadhi99/mistral-7b-finetuned-medical-summarizer | null | [
"peft",
"safetensors",
"base_model:mistralai/Mistral-7B-v0.1",
"license:mit",
"region:us"
]
| null | 2024-04-16T17:38:50+00:00 | []
| []
| TAGS
#peft #safetensors #base_model-mistralai/Mistral-7B-v0.1 #license-mit #region-us
| Finetuned Mistral-7b model for medical document summarization
### Framework versions
- PEFT 0.10.1.dev0 | [
"### Framework versions\n\n- PEFT 0.10.1.dev0"
]
| [
"TAGS\n#peft #safetensors #base_model-mistralai/Mistral-7B-v0.1 #license-mit #region-us \n",
"### Framework versions\n\n- PEFT 0.10.1.dev0"
]
|
null | peft |
# Model Card
gemma-2b fine-tuned on gsm8k "question" field. LoRA rank 8.
### Framework versions
- PEFT 0.10.0
| {"library_name": "peft", "base_model": "google/gemma-2b"} | jacobthebanana/example-gemma-2b-lora-gsm8k | null | [
"peft",
"safetensors",
"base_model:google/gemma-2b",
"region:us"
]
| null | 2024-04-16T17:43:47+00:00 | []
| []
| TAGS
#peft #safetensors #base_model-google/gemma-2b #region-us
|
# Model Card
gemma-2b fine-tuned on gsm8k "question" field. LoRA rank 8.
### Framework versions
- PEFT 0.10.0
| [
"# Model Card \n\ngemma-2b fine-tuned on gsm8k \"question\" field. LoRA rank 8.",
"### Framework versions\n\n- PEFT 0.10.0"
]
| [
"TAGS\n#peft #safetensors #base_model-google/gemma-2b #region-us \n",
"# Model Card \n\ngemma-2b fine-tuned on gsm8k \"question\" field. LoRA rank 8.",
"### Framework versions\n\n- PEFT 0.10.0"
]
|
text-generation | transformers | # pythontestmerge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
Catastrophic forgetting test results:
Initial evaluation loss on 1k subset of HuggingFaceTB/cosmopedia-100k dataset was 1.038. (I'm impressed.)
100 steps of LISA training isn't strictly reducing this over time, it's reducing but jumping around a bit.
Might be converged to within that method's margin of error; cosmo-1b itself jumped 0.02 points with LISA training.
Comparison to control: cosmo-1b started out with 1.003 loss on (a different subset of) dataset, increasing to 1.024 at 100 steps.
Method by method comparison, initial evaluation loss on Cosmopedia data:
* Full tuning (aka continued pretraining), batch 8: 1.615
* LISA fine-tuning, 4 layers switching every 10 steps, batch 8: 1.217
* QLoRA with Dora (otherwise like below): 1.105
* Qlora fine-tuning, rank 256, scale factor 1, batch 8: 1.102
* Galore tuning, rank 256, scale factor 1, batch 8: 1.182
* This Model Stock merge of all 4 training methods: 1.038
* Model Stock 3/4 Methods (all except full tuning): 1.021
* Control (cosmo-1b): 1.003
Training set validation results:
* Cosmo-1b Starting Eval Loss: ~0.65
* Model Stock 3/4 Loss: 0.451
* Model Stock Loss: 0.40211
* LISA Loss: 0.2534
* GaLore Loss: 0.2426
* QLoRA Loss: 0.2078
* QLoRA with Dora Loss: 0.2055 (almost identical training graph)
* Full Tune Loss: 0.2049
Overall ... not sure what to make of this, beyond that high-rank QLoRA is doing something particularly impressive while using only like 6GB of vRAM.
The Model Stock merge between the 4 different tuning methods clearly recovered a lot of original knowledge, at the cost of something like half the adaptation to new data.
Of course, cosmo-1b was already pretty good at predicting the new data, narrow and task-focused as it was.
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [HuggingFaceTB/cosmo-1b](https://huggingface.co/HuggingFaceTB/cosmo-1b) as a base.
### Models Merged
The following models were included in the merge:
* [Lambent/cosmo-1b-tune-pythontest](https://huggingface.co/Lambent/cosmo-1b-tune-pythontest)
* [Lambent/cosmo-1b-qlora-pythontest](https://huggingface.co/Lambent/cosmo-1b-qlora-pythontest)
* [Lambent/cosmo-1b-lisa-pythontest](https://huggingface.co/Lambent/cosmo-1b-lisa-pythontest)
* [Lambent/cosmo-1b-galore-pythontest](https://huggingface.co/Lambent/cosmo-1b-galore-pythontest)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Lambent/cosmo-1b-lisa-pythontest
- model: Lambent/cosmo-1b-qlora-pythontest
- model: Lambent/cosmo-1b-galore-pythontest
- model: Lambent/cosmo-1b-tune-pythontest
base_model: HuggingFaceTB/cosmo-1b
merge_method: model_stock
parameters:
filter_wise: false
dtype: float16
``` | {"license": "apache-2.0", "library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["Lambent/cosmo-1b-tune-pythontest", "Lambent/cosmo-1b-qlora-pythontest", "Lambent/cosmo-1b-lisa-pythontest", "Lambent/cosmo-1b-galore-pythontest", "HuggingFaceTB/cosmo-1b"]} | Lambent/cosmo-1b-stock-pythontest | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2403.19522",
"base_model:Lambent/cosmo-1b-tune-pythontest",
"base_model:Lambent/cosmo-1b-qlora-pythontest",
"base_model:Lambent/cosmo-1b-lisa-pythontest",
"base_model:Lambent/cosmo-1b-galore-pythontest",
"base_model:HuggingFaceTB/cosmo-1b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:44:09+00:00 | [
"2403.19522"
]
| []
| TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2403.19522 #base_model-Lambent/cosmo-1b-tune-pythontest #base_model-Lambent/cosmo-1b-qlora-pythontest #base_model-Lambent/cosmo-1b-lisa-pythontest #base_model-Lambent/cosmo-1b-galore-pythontest #base_model-HuggingFaceTB/cosmo-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # pythontestmerge
This is a merge of pre-trained language models created using mergekit.
Catastrophic forgetting test results:
Initial evaluation loss on 1k subset of HuggingFaceTB/cosmopedia-100k dataset was 1.038. (I'm impressed.)
100 steps of LISA training isn't strictly reducing this over time, it's reducing but jumping around a bit.
Might be converged to within that method's margin of error; cosmo-1b itself jumped 0.02 points with LISA training.
Comparison to control: cosmo-1b started out with 1.003 loss on (a different subset of) dataset, increasing to 1.024 at 100 steps.
Method by method comparison, initial evaluation loss on Cosmopedia data:
* Full tuning (aka continued pretraining), batch 8: 1.615
* LISA fine-tuning, 4 layers switching every 10 steps, batch 8: 1.217
* QLoRA with Dora (otherwise like below): 1.105
* Qlora fine-tuning, rank 256, scale factor 1, batch 8: 1.102
* Galore tuning, rank 256, scale factor 1, batch 8: 1.182
* This Model Stock merge of all 4 training methods: 1.038
* Model Stock 3/4 Methods (all except full tuning): 1.021
* Control (cosmo-1b): 1.003
Training set validation results:
* Cosmo-1b Starting Eval Loss: ~0.65
* Model Stock 3/4 Loss: 0.451
* Model Stock Loss: 0.40211
* LISA Loss: 0.2534
* GaLore Loss: 0.2426
* QLoRA Loss: 0.2078
* QLoRA with Dora Loss: 0.2055 (almost identical training graph)
* Full Tune Loss: 0.2049
Overall ... not sure what to make of this, beyond that high-rank QLoRA is doing something particularly impressive while using only like 6GB of vRAM.
The Model Stock merge between the 4 different tuning methods clearly recovered a lot of original knowledge, at the cost of something like half the adaptation to new data.
Of course, cosmo-1b was already pretty good at predicting the new data, narrow and task-focused as it was.
## Merge Details
### Merge Method
This model was merged using the Model Stock merge method using HuggingFaceTB/cosmo-1b as a base.
### Models Merged
The following models were included in the merge:
* Lambent/cosmo-1b-tune-pythontest
* Lambent/cosmo-1b-qlora-pythontest
* Lambent/cosmo-1b-lisa-pythontest
* Lambent/cosmo-1b-galore-pythontest
### Configuration
The following YAML configuration was used to produce this model:
| [
"# pythontestmerge\n\nThis is a merge of pre-trained language models created using mergekit.\n\nCatastrophic forgetting test results:\n\nInitial evaluation loss on 1k subset of HuggingFaceTB/cosmopedia-100k dataset was 1.038. (I'm impressed.)\n\n100 steps of LISA training isn't strictly reducing this over time, it's reducing but jumping around a bit.\nMight be converged to within that method's margin of error; cosmo-1b itself jumped 0.02 points with LISA training.\n\nComparison to control: cosmo-1b started out with 1.003 loss on (a different subset of) dataset, increasing to 1.024 at 100 steps.\n\nMethod by method comparison, initial evaluation loss on Cosmopedia data:\n\n* Full tuning (aka continued pretraining), batch 8: 1.615\n* LISA fine-tuning, 4 layers switching every 10 steps, batch 8: 1.217\n* QLoRA with Dora (otherwise like below): 1.105\n* Qlora fine-tuning, rank 256, scale factor 1, batch 8: 1.102\n* Galore tuning, rank 256, scale factor 1, batch 8: 1.182\n* This Model Stock merge of all 4 training methods: 1.038\n* Model Stock 3/4 Methods (all except full tuning): 1.021\n* Control (cosmo-1b): 1.003\n\nTraining set validation results:\n\n* Cosmo-1b Starting Eval Loss: ~0.65\n* Model Stock 3/4 Loss: 0.451\n* Model Stock Loss: 0.40211\n* LISA Loss: 0.2534\n* GaLore Loss: 0.2426\n* QLoRA Loss: 0.2078\n* QLoRA with Dora Loss: 0.2055 (almost identical training graph)\n* Full Tune Loss: 0.2049\n\nOverall ... not sure what to make of this, beyond that high-rank QLoRA is doing something particularly impressive while using only like 6GB of vRAM.\nThe Model Stock merge between the 4 different tuning methods clearly recovered a lot of original knowledge, at the cost of something like half the adaptation to new data.\nOf course, cosmo-1b was already pretty good at predicting the new data, narrow and task-focused as it was.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the Model Stock merge method using HuggingFaceTB/cosmo-1b as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Lambent/cosmo-1b-tune-pythontest\n* Lambent/cosmo-1b-qlora-pythontest\n* Lambent/cosmo-1b-lisa-pythontest\n* Lambent/cosmo-1b-galore-pythontest",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2403.19522 #base_model-Lambent/cosmo-1b-tune-pythontest #base_model-Lambent/cosmo-1b-qlora-pythontest #base_model-Lambent/cosmo-1b-lisa-pythontest #base_model-Lambent/cosmo-1b-galore-pythontest #base_model-HuggingFaceTB/cosmo-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# pythontestmerge\n\nThis is a merge of pre-trained language models created using mergekit.\n\nCatastrophic forgetting test results:\n\nInitial evaluation loss on 1k subset of HuggingFaceTB/cosmopedia-100k dataset was 1.038. (I'm impressed.)\n\n100 steps of LISA training isn't strictly reducing this over time, it's reducing but jumping around a bit.\nMight be converged to within that method's margin of error; cosmo-1b itself jumped 0.02 points with LISA training.\n\nComparison to control: cosmo-1b started out with 1.003 loss on (a different subset of) dataset, increasing to 1.024 at 100 steps.\n\nMethod by method comparison, initial evaluation loss on Cosmopedia data:\n\n* Full tuning (aka continued pretraining), batch 8: 1.615\n* LISA fine-tuning, 4 layers switching every 10 steps, batch 8: 1.217\n* QLoRA with Dora (otherwise like below): 1.105\n* Qlora fine-tuning, rank 256, scale factor 1, batch 8: 1.102\n* Galore tuning, rank 256, scale factor 1, batch 8: 1.182\n* This Model Stock merge of all 4 training methods: 1.038\n* Model Stock 3/4 Methods (all except full tuning): 1.021\n* Control (cosmo-1b): 1.003\n\nTraining set validation results:\n\n* Cosmo-1b Starting Eval Loss: ~0.65\n* Model Stock 3/4 Loss: 0.451\n* Model Stock Loss: 0.40211\n* LISA Loss: 0.2534\n* GaLore Loss: 0.2426\n* QLoRA Loss: 0.2078\n* QLoRA with Dora Loss: 0.2055 (almost identical training graph)\n* Full Tune Loss: 0.2049\n\nOverall ... not sure what to make of this, beyond that high-rank QLoRA is doing something particularly impressive while using only like 6GB of vRAM.\nThe Model Stock merge between the 4 different tuning methods clearly recovered a lot of original knowledge, at the cost of something like half the adaptation to new data.\nOf course, cosmo-1b was already pretty good at predicting the new data, narrow and task-focused as it was.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the Model Stock merge method using HuggingFaceTB/cosmo-1b as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Lambent/cosmo-1b-tune-pythontest\n* Lambent/cosmo-1b-qlora-pythontest\n* Lambent/cosmo-1b-lisa-pythontest\n* Lambent/cosmo-1b-galore-pythontest",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
]
|
text-generation | transformers |
# WizardLM-2-4x7B-MoE
WizardLM-2-4x7B-MoE is an experimental MoE model made with [Mergekit](https://github.com/arcee-ai/mergekit). It was made by combining four [WizardLM-2-7B](https://huggingface.co/microsoft/WizardLM-2-7B) models using the random gate mode.
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
# Quanitized versions
EXL2 (for fast GPU-only inference): <br />
8_0bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-8_0bpw (~ 25 GB vram) <br />
6_0bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-6_0bpw (~ 19 GB vram) <br />
5_0bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-5_0bpw (~ 16 GB vram) <br />
4_25bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-4_25bpw (~ 14 GB vram) <br />
3_5bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-3_5bpw (~ 12 GB vram) <br />
3_0bpw: https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE-exl2-3_0bpw (~ 11 GB vram)
GGUF (for mixed GPU+CPU inference or CPU-only inference): <br />
https://huggingface.co/mradermacher/WizardLM-2-4x7B-MoE-GGUF <br />
Thanks to [Michael Radermacher](https://huggingface.co/mradermacher) for making these quants!
# Evaluation
I don't expect this model to be that great since it's something that I made as an experiment. However, I will submit it to the Open LLM Leaderboard to see how it matches up against some other models (particularly WizardLM-2-7B and WizardLM-2-70B).
# Mergekit config
```
base_model: models/WizardLM-2-7B
gate_mode: random
dtype: float16
experts_per_token: 4
experts:
- source_model: models/WizardLM-2-7B
- source_model: models/WizardLM-2-7B
- source_model: models/WizardLM-2-7B
- source_model: models/WizardLM-2-7B
``` | {"license": "apache-2.0", "tags": ["MoE", "merge", "mergekit", "Mistral", "Microsoft/WizardLM-2-7B"]} | Skylaude/WizardLM-2-4x7B-MoE | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"MoE",
"merge",
"mergekit",
"Mistral",
"Microsoft/WizardLM-2-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:47:42+00:00 | []
| []
| TAGS
#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# WizardLM-2-4x7B-MoE
WizardLM-2-4x7B-MoE is an experimental MoE model made with Mergekit. It was made by combining four WizardLM-2-7B models using the random gate mode.
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
# Quanitized versions
EXL2 (for fast GPU-only inference): <br />
8_0bpw: URL (~ 25 GB vram) <br />
6_0bpw: URL (~ 19 GB vram) <br />
5_0bpw: URL (~ 16 GB vram) <br />
4_25bpw: URL (~ 14 GB vram) <br />
3_5bpw: URL (~ 12 GB vram) <br />
3_0bpw: URL (~ 11 GB vram)
GGUF (for mixed GPU+CPU inference or CPU-only inference): <br />
URL <br />
Thanks to Michael Radermacher for making these quants!
# Evaluation
I don't expect this model to be that great since it's something that I made as an experiment. However, I will submit it to the Open LLM Leaderboard to see how it matches up against some other models (particularly WizardLM-2-7B and WizardLM-2-70B).
# Mergekit config
| [
"# WizardLM-2-4x7B-MoE\n\nWizardLM-2-4x7B-MoE is an experimental MoE model made with Mergekit. It was made by combining four WizardLM-2-7B models using the random gate mode. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.",
"# Quanitized versions\n\nEXL2 (for fast GPU-only inference): <br />\n8_0bpw: URL (~ 25 GB vram) <br />\n6_0bpw: URL (~ 19 GB vram) <br />\n5_0bpw: URL (~ 16 GB vram) <br />\n4_25bpw: URL (~ 14 GB vram) <br />\n3_5bpw: URL (~ 12 GB vram) <br />\n3_0bpw: URL (~ 11 GB vram)\n\nGGUF (for mixed GPU+CPU inference or CPU-only inference): <br />\nURL <br />\nThanks to Michael Radermacher for making these quants!",
"# Evaluation\n\nI don't expect this model to be that great since it's something that I made as an experiment. However, I will submit it to the Open LLM Leaderboard to see how it matches up against some other models (particularly WizardLM-2-7B and WizardLM-2-70B).",
"# Mergekit config"
]
| [
"TAGS\n#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# WizardLM-2-4x7B-MoE\n\nWizardLM-2-4x7B-MoE is an experimental MoE model made with Mergekit. It was made by combining four WizardLM-2-7B models using the random gate mode. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.",
"# Quanitized versions\n\nEXL2 (for fast GPU-only inference): <br />\n8_0bpw: URL (~ 25 GB vram) <br />\n6_0bpw: URL (~ 19 GB vram) <br />\n5_0bpw: URL (~ 16 GB vram) <br />\n4_25bpw: URL (~ 14 GB vram) <br />\n3_5bpw: URL (~ 12 GB vram) <br />\n3_0bpw: URL (~ 11 GB vram)\n\nGGUF (for mixed GPU+CPU inference or CPU-only inference): <br />\nURL <br />\nThanks to Michael Radermacher for making these quants!",
"# Evaluation\n\nI don't expect this model to be that great since it's something that I made as an experiment. However, I will submit it to the Open LLM Leaderboard to see how it matches up against some other models (particularly WizardLM-2-7B and WizardLM-2-70B).",
"# Mergekit config"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_2-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_mouse_2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_2) dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3006
- F1 Score: 0.8017
- Accuracy: 0.8018
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.3009 | 100.0 | 200 | 1.1890 | 0.7651 | 0.7652 |
| 0.0523 | 200.0 | 400 | 1.5716 | 0.7651 | 0.7652 |
| 0.0222 | 300.0 | 600 | 1.8318 | 0.7743 | 0.7744 |
| 0.0126 | 400.0 | 800 | 1.9741 | 0.7683 | 0.7683 |
| 0.0077 | 500.0 | 1000 | 1.9714 | 0.7683 | 0.7683 |
| 0.0066 | 600.0 | 1200 | 1.9525 | 0.7832 | 0.7835 |
| 0.0055 | 700.0 | 1400 | 2.1387 | 0.7774 | 0.7774 |
| 0.0038 | 800.0 | 1600 | 2.1187 | 0.7681 | 0.7683 |
| 0.004 | 900.0 | 1800 | 1.9122 | 0.7832 | 0.7835 |
| 0.003 | 1000.0 | 2000 | 2.1994 | 0.7835 | 0.7835 |
| 0.003 | 1100.0 | 2200 | 2.1804 | 0.7957 | 0.7957 |
| 0.0026 | 1200.0 | 2400 | 2.1168 | 0.7804 | 0.7805 |
| 0.0024 | 1300.0 | 2600 | 2.2563 | 0.7896 | 0.7896 |
| 0.0026 | 1400.0 | 2800 | 2.2033 | 0.7924 | 0.7927 |
| 0.0018 | 1500.0 | 3000 | 2.2483 | 0.7805 | 0.7805 |
| 0.0021 | 1600.0 | 3200 | 2.3276 | 0.7544 | 0.7561 |
| 0.0019 | 1700.0 | 3400 | 2.2372 | 0.7772 | 0.7774 |
| 0.0017 | 1800.0 | 3600 | 2.3418 | 0.7620 | 0.7622 |
| 0.0012 | 1900.0 | 3800 | 2.4596 | 0.7835 | 0.7835 |
| 0.0013 | 2000.0 | 4000 | 2.5327 | 0.7616 | 0.7622 |
| 0.0017 | 2100.0 | 4200 | 2.4669 | 0.7926 | 0.7927 |
| 0.0008 | 2200.0 | 4400 | 2.5500 | 0.7713 | 0.7713 |
| 0.0014 | 2300.0 | 4600 | 2.2511 | 0.7835 | 0.7835 |
| 0.0009 | 2400.0 | 4800 | 2.5569 | 0.7804 | 0.7805 |
| 0.0011 | 2500.0 | 5000 | 2.5665 | 0.7896 | 0.7896 |
| 0.0009 | 2600.0 | 5200 | 2.7110 | 0.7927 | 0.7927 |
| 0.0005 | 2700.0 | 5400 | 2.7643 | 0.7988 | 0.7988 |
| 0.0005 | 2800.0 | 5600 | 2.7716 | 0.7835 | 0.7835 |
| 0.0007 | 2900.0 | 5800 | 2.9038 | 0.7710 | 0.7713 |
| 0.001 | 3000.0 | 6000 | 2.2737 | 0.7861 | 0.7866 |
| 0.0008 | 3100.0 | 6200 | 2.6641 | 0.7927 | 0.7927 |
| 0.0007 | 3200.0 | 6400 | 2.7167 | 0.7774 | 0.7774 |
| 0.0004 | 3300.0 | 6600 | 3.1539 | 0.7648 | 0.7652 |
| 0.0006 | 3400.0 | 6800 | 2.8826 | 0.7835 | 0.7835 |
| 0.0008 | 3500.0 | 7000 | 2.8664 | 0.7743 | 0.7744 |
| 0.0007 | 3600.0 | 7200 | 2.7873 | 0.7805 | 0.7805 |
| 0.0004 | 3700.0 | 7400 | 2.9077 | 0.7866 | 0.7866 |
| 0.0005 | 3800.0 | 7600 | 2.8232 | 0.7682 | 0.7683 |
| 0.0005 | 3900.0 | 7800 | 2.9952 | 0.7622 | 0.7622 |
| 0.0006 | 4000.0 | 8000 | 2.7363 | 0.7835 | 0.7835 |
| 0.0002 | 4100.0 | 8200 | 3.1873 | 0.7896 | 0.7896 |
| 0.0003 | 4200.0 | 8400 | 3.0413 | 0.7835 | 0.7835 |
| 0.0003 | 4300.0 | 8600 | 3.2005 | 0.7865 | 0.7866 |
| 0.0004 | 4400.0 | 8800 | 2.9518 | 0.7834 | 0.7835 |
| 0.0002 | 4500.0 | 9000 | 3.0082 | 0.7866 | 0.7866 |
| 0.0004 | 4600.0 | 9200 | 2.8282 | 0.7866 | 0.7866 |
| 0.0002 | 4700.0 | 9400 | 2.8632 | 0.7835 | 0.7835 |
| 0.0003 | 4800.0 | 9600 | 2.8026 | 0.7835 | 0.7835 |
| 0.0002 | 4900.0 | 9800 | 2.8738 | 0.7866 | 0.7866 |
| 0.0002 | 5000.0 | 10000 | 2.8760 | 0.7866 | 0.7866 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_mouse_2-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_2-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:48:44+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_mouse\_2-seqsight\_16384\_512\_56M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_mouse\_2 dataset.
It achieves the following results on the evaluation set:
* Loss: 2.3006
* F1 Score: 0.8017
* Accuracy: 0.8018
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | doxgxxn/gemma_prompt_recovery | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:49:14+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Kastanie99/zephyr-7b-beta-req-haoran-mt-16042024 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:50:36+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #mistral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ruBert-base-sberquad-0.02-len_3-filtered
This model is a fine-tuned version of [ai-forever/ruBert-base](https://huggingface.co/ai-forever/ruBert-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.40.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "ai-forever/ruBert-base", "model-index": [{"name": "ruBert-base-sberquad-0.02-len_3-filtered", "results": []}]} | Shalazary/ruBert-base-sberquad-0.02-len_3-filtered | null | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:ai-forever/ruBert-base",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T17:52:09+00:00 | []
| []
| TAGS
#peft #tensorboard #safetensors #generated_from_trainer #base_model-ai-forever/ruBert-base #license-apache-2.0 #region-us
|
# ruBert-base-sberquad-0.02-len_3-filtered
This model is a fine-tuned version of ai-forever/ruBert-base on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.40.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | [
"# ruBert-base-sberquad-0.02-len_3-filtered\n\nThis model is a fine-tuned version of ai-forever/ruBert-base on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0005\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- training_steps: 5000",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.40.0.dev0\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #tensorboard #safetensors #generated_from_trainer #base_model-ai-forever/ruBert-base #license-apache-2.0 #region-us \n",
"# ruBert-base-sberquad-0.02-len_3-filtered\n\nThis model is a fine-tuned version of ai-forever/ruBert-base on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0005\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- training_steps: 5000",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.40.0.dev0\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: google/gemma-2b
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: OdiaGenAIdata/culturax-odia
type: completion
field: text
dataset_prepared_path:
val_set_size: 0.1
output_dir: ./gemma-odia-2b-pretrain-v1
hub_model_id: sam2ai/gemma_odia_2b_v1
adapter: qlora
lora_model_dir:
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
wandb_project: gemma-completion-2b-odia-v1
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
lora_r: 64
lora_alpha: 128
lora_dropout: 0.05
lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
lora_modules_to_save:
- embed_tokens
- lm_head
lora_target_linear: true
lora_fan_in_fan_out:
gradient_accumulation_steps: 8
micro_batch_size: 2
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: false
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: False
warmup_ratio: 0.1
evals_per_epoch: 4
eval_table_size:
eval_max_new_tokens: 128
eval_sample_packing: False
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
save_safetensors: True
```
</details><br>
# gemma_odia_2b_v1
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2357
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 6
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 48.3861 | 0.0 | 1 | 48.2747 |
| 3.3986 | 0.25 | 169 | 3.2901 |
| 3.3659 | 0.5 | 338 | 3.2334 |
| 3.1731 | 0.75 | 507 | 3.0614 |
| 3.1942 | 1.0 | 676 | 3.0977 |
| 3.3983 | 1.24 | 845 | 3.3234 |
| 3.3853 | 1.49 | 1014 | 3.2983 |
| 3.3254 | 1.74 | 1183 | 3.2357 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.40.0.dev0
- Pytorch 2.4.0.dev20240326+rocm6.0
- Datasets 2.18.0
- Tokenizers 0.15.0 | {"license": "gemma", "library_name": "peft", "tags": ["axolotl", "generated_from_trainer"], "base_model": "google/gemma-2b", "model-index": [{"name": "gemma_odia_2b_v1", "results": []}]} | sam2ai/gemma_odia_2b_v1 | null | [
"peft",
"safetensors",
"gemma",
"axolotl",
"generated_from_trainer",
"base_model:google/gemma-2b",
"license:gemma",
"4-bit",
"region:us"
]
| null | 2024-04-16T17:52:48+00:00 | []
| []
| TAGS
#peft #safetensors #gemma #axolotl #generated_from_trainer #base_model-google/gemma-2b #license-gemma #4-bit #region-us
| <img src="URL alt="Built with Axolotl" width="200" height="32"/>
See axolotl config
axolotl version: '0.4.0'
gemma\_odia\_2b\_v1
===================
This model is a fine-tuned version of google/gemma-2b on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 3.2357
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* distributed\_type: multi-GPU
* num\_devices: 8
* gradient\_accumulation\_steps: 8
* total\_train\_batch\_size: 128
* total\_eval\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 6
* num\_epochs: 2
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.40.0.dev0
* Pytorch 2.4.0.dev20240326+rocm6.0
* Datasets 2.18.0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 8\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 128\n* total\\_eval\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 6\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.4.0.dev20240326+rocm6.0\n* Datasets 2.18.0\n* Tokenizers 0.15.0"
]
| [
"TAGS\n#peft #safetensors #gemma #axolotl #generated_from_trainer #base_model-google/gemma-2b #license-gemma #4-bit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 8\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 128\n* total\\_eval\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 6\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.4.0.dev20240326+rocm6.0\n* Datasets 2.18.0\n* Tokenizers 0.15.0"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_splice_reconstructed-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_splice_reconstructed](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_splice_reconstructed) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1066
- F1 Score: 0.6920
- Accuracy: 0.6982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.9333 | 11.11 | 200 | 0.8404 | 0.5841 | 0.6223 |
| 0.7804 | 22.22 | 400 | 0.7884 | 0.6321 | 0.6548 |
| 0.7089 | 33.33 | 600 | 0.7850 | 0.6471 | 0.6574 |
| 0.6575 | 44.44 | 800 | 0.7808 | 0.6544 | 0.6710 |
| 0.6133 | 55.56 | 1000 | 0.7871 | 0.6687 | 0.6681 |
| 0.5771 | 66.67 | 1200 | 0.8114 | 0.6592 | 0.6727 |
| 0.541 | 77.78 | 1400 | 0.8221 | 0.6608 | 0.6754 |
| 0.5109 | 88.89 | 1600 | 0.8294 | 0.6690 | 0.6760 |
| 0.4814 | 100.0 | 1800 | 0.8959 | 0.6645 | 0.6640 |
| 0.4543 | 111.11 | 2000 | 0.8716 | 0.6752 | 0.6782 |
| 0.4306 | 122.22 | 2200 | 0.8848 | 0.6732 | 0.6758 |
| 0.4074 | 133.33 | 2400 | 0.8724 | 0.6693 | 0.6725 |
| 0.3855 | 144.44 | 2600 | 0.9487 | 0.6718 | 0.6769 |
| 0.3658 | 155.56 | 2800 | 0.9484 | 0.6707 | 0.6758 |
| 0.3481 | 166.67 | 3000 | 0.9677 | 0.6711 | 0.6791 |
| 0.3326 | 177.78 | 3200 | 0.9672 | 0.6732 | 0.6758 |
| 0.3171 | 188.89 | 3400 | 1.0126 | 0.6732 | 0.6778 |
| 0.3038 | 200.0 | 3600 | 1.0039 | 0.6740 | 0.6780 |
| 0.2903 | 211.11 | 3800 | 1.0506 | 0.6728 | 0.6817 |
| 0.2791 | 222.22 | 4000 | 1.0056 | 0.6747 | 0.6782 |
| 0.2674 | 233.33 | 4200 | 1.0348 | 0.6770 | 0.6811 |
| 0.2586 | 244.44 | 4400 | 1.0723 | 0.6766 | 0.6822 |
| 0.2494 | 255.56 | 4600 | 1.0826 | 0.6822 | 0.6896 |
| 0.2417 | 266.67 | 4800 | 1.0524 | 0.6749 | 0.6789 |
| 0.234 | 277.78 | 5000 | 1.0680 | 0.6792 | 0.6826 |
| 0.2243 | 288.89 | 5200 | 1.0944 | 0.6780 | 0.6817 |
| 0.2191 | 300.0 | 5400 | 1.0792 | 0.6710 | 0.6723 |
| 0.2144 | 311.11 | 5600 | 1.1527 | 0.6740 | 0.6784 |
| 0.2093 | 322.22 | 5800 | 1.1245 | 0.6793 | 0.6859 |
| 0.202 | 333.33 | 6000 | 1.1527 | 0.6757 | 0.6833 |
| 0.1982 | 344.44 | 6200 | 1.1400 | 0.6758 | 0.6804 |
| 0.1932 | 355.56 | 6400 | 1.1551 | 0.6781 | 0.6833 |
| 0.1885 | 366.67 | 6600 | 1.1448 | 0.6753 | 0.6769 |
| 0.1842 | 377.78 | 6800 | 1.1529 | 0.6776 | 0.6804 |
| 0.1823 | 388.89 | 7000 | 1.1668 | 0.6796 | 0.6843 |
| 0.1772 | 400.0 | 7200 | 1.1549 | 0.6783 | 0.6839 |
| 0.1758 | 411.11 | 7400 | 1.1812 | 0.6778 | 0.6822 |
| 0.1718 | 422.22 | 7600 | 1.1766 | 0.6807 | 0.6846 |
| 0.1686 | 433.33 | 7800 | 1.1791 | 0.6823 | 0.6874 |
| 0.1662 | 444.44 | 8000 | 1.1931 | 0.6807 | 0.6863 |
| 0.1638 | 455.56 | 8200 | 1.1794 | 0.6775 | 0.6808 |
| 0.1622 | 466.67 | 8400 | 1.2051 | 0.6797 | 0.6850 |
| 0.1599 | 477.78 | 8600 | 1.2020 | 0.6785 | 0.6839 |
| 0.1579 | 488.89 | 8800 | 1.2127 | 0.6794 | 0.6841 |
| 0.1558 | 500.0 | 9000 | 1.2001 | 0.6779 | 0.6817 |
| 0.1552 | 511.11 | 9200 | 1.2087 | 0.6785 | 0.6824 |
| 0.1536 | 522.22 | 9400 | 1.2260 | 0.6770 | 0.6830 |
| 0.1528 | 533.33 | 9600 | 1.2129 | 0.6804 | 0.6846 |
| 0.1519 | 544.44 | 9800 | 1.2126 | 0.6790 | 0.6835 |
| 0.1511 | 555.56 | 10000 | 1.2091 | 0.6789 | 0.6833 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_splice_reconstructed-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_splice_reconstructed-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T17:54:31+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_splice\_reconstructed-seqsight\_16384\_512\_56M-L32\_all
=============================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_splice\_reconstructed dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1066
* F1 Score: 0.6920
* Accuracy: 0.6982
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
reinforcement-learning | ml-agents |
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: NugentMichael/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
| {"library_name": "ml-agents", "tags": ["Huggy", "deep-reinforcement-learning", "reinforcement-learning", "ML-Agents-Huggy"]} | NugentMichael/ppo-Huggy | null | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
]
| null | 2024-04-16T17:55:55+00:00 | []
| []
| TAGS
#ml-agents #tensorboard #onnx #Huggy #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Huggy #region-us
|
# ppo Agent playing Huggy
This is a trained model of a ppo agent playing Huggy
using the Unity ML-Agents Library.
## Usage (with ML-Agents)
The Documentation: URL
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your
browser: URL
- A *longer tutorial* to understand how works ML-Agents:
URL
### Resume the training
### Watch your Agent play
You can watch your agent playing directly in your browser
1. If the environment is part of ML-Agents official environments, go to URL
2. Step 1: Find your model_id: NugentMichael/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play
| [
"# ppo Agent playing Huggy\n This is a trained model of a ppo agent playing Huggy\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: NugentMichael/ppo-Huggy\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
]
| [
"TAGS\n#ml-agents #tensorboard #onnx #Huggy #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Huggy #region-us \n",
"# ppo Agent playing Huggy\n This is a trained model of a ppo agent playing Huggy\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: NugentMichael/ppo-Huggy\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
]
|
text-generation | transformers |
# Spaetzle-v64-7b
Spaetzle-v64-7b is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [flemmingmiguel/NeuDist-Ro-7B](https://huggingface.co/flemmingmiguel/NeuDist-Ro-7B)
* [cstr/Spaetzle-v63-7b](https://huggingface.co/cstr/Spaetzle-v63-7b)
* [ResplendentAI/Flora_DPO_7B](https://huggingface.co/ResplendentAI/Flora_DPO_7B)
## 🧩 Configuration
```yaml
models:
- model: mayflowergmbh/Wiedervereinigung-7b-dpo
# no parameters necessary for base model
- model: flemmingmiguel/NeuDist-Ro-7B
parameters:
density: 0.60
weight: 0.30
- model: cstr/Spaetzle-v63-7b
parameters:
density: 0.65
weight: 0.40
- model: ResplendentAI/Flora_DPO_7B
parameters:
density: 0.6
weight: 0.3
merge_method: dare_ties
base_model: mayflowergmbh/Wiedervereinigung-7b-dpo
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
tokenizer_source: base
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "cstr/Spaetzle-v64-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"tags": ["merge", "mergekit", "lazymergekit", "flemmingmiguel/NeuDist-Ro-7B", "cstr/Spaetzle-v63-7b", "ResplendentAI/Flora_DPO_7B"], "base_model": ["flemmingmiguel/NeuDist-Ro-7B", "cstr/Spaetzle-v63-7b", "ResplendentAI/Flora_DPO_7B"]} | cstr/Spaetzle-v64-7b | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"flemmingmiguel/NeuDist-Ro-7B",
"cstr/Spaetzle-v63-7b",
"ResplendentAI/Flora_DPO_7B",
"conversational",
"base_model:flemmingmiguel/NeuDist-Ro-7B",
"base_model:cstr/Spaetzle-v63-7b",
"base_model:ResplendentAI/Flora_DPO_7B",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T17:57:06+00:00 | []
| []
| TAGS
#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #flemmingmiguel/NeuDist-Ro-7B #cstr/Spaetzle-v63-7b #ResplendentAI/Flora_DPO_7B #conversational #base_model-flemmingmiguel/NeuDist-Ro-7B #base_model-cstr/Spaetzle-v63-7b #base_model-ResplendentAI/Flora_DPO_7B #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Spaetzle-v64-7b
Spaetzle-v64-7b is a merge of the following models using LazyMergekit:
* flemmingmiguel/NeuDist-Ro-7B
* cstr/Spaetzle-v63-7b
* ResplendentAI/Flora_DPO_7B
## Configuration
## Usage
| [
"# Spaetzle-v64-7b\n\nSpaetzle-v64-7b is a merge of the following models using LazyMergekit:\n* flemmingmiguel/NeuDist-Ro-7B\n* cstr/Spaetzle-v63-7b\n* ResplendentAI/Flora_DPO_7B",
"## Configuration",
"## Usage"
]
| [
"TAGS\n#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #flemmingmiguel/NeuDist-Ro-7B #cstr/Spaetzle-v63-7b #ResplendentAI/Flora_DPO_7B #conversational #base_model-flemmingmiguel/NeuDist-Ro-7B #base_model-cstr/Spaetzle-v63-7b #base_model-ResplendentAI/Flora_DPO_7B #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Spaetzle-v64-7b\n\nSpaetzle-v64-7b is a merge of the following models using LazyMergekit:\n* flemmingmiguel/NeuDist-Ro-7B\n* cstr/Spaetzle-v63-7b\n* ResplendentAI/Flora_DPO_7B",
"## Configuration",
"## Usage"
]
|
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small GA-EN Speech Translation
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the IWSLT-2023, FLEURS, BiteSize, SpokenWords, Tatoeba, and Wikimedia dataset.
The best model checkpoint (this version) based on ChrF is at step 2000, epoch 1.31, and it achieves the following results on the evaluation set:
- Loss: 1.1571
- Bleu: 30.25
- Chrf: 48.12
- Wer: 64.9707
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 0.03
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Bleu | Chrf | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:-----:|:-----:|:---------------:|:--------:|
| 2.6685 | 0.07 | 100 | 5.05 | 20.18 | 2.0544 | 139.8919 |
| 2.4028 | 0.13 | 200 | 12.29 | 29.72 | 1.7367 | 95.5425 |
| 2.1231 | 0.2 | 300 | 14.33 | 30.77 | 1.6141 | 101.3958 |
| 1.9192 | 0.26 | 400 | 16.86 | 35.65 | 1.4778 | 91.0851 |
| 1.7129 | 0.33 | 500 | 16.77 | 37.53 | 1.3811 | 93.8766 |
| 1.5398 | 0.39 | 600 | 18.85 | 39.0 | 1.3427 | 90.2296 |
| 1.4257 | 0.46 | 700 | 25.73 | 43.3 | 1.2784 | 70.3287 |
| 1.3044 | 0.53 | 800 | 25.43 | 44.33 | 1.2274 | 72.3548 |
| 1.2626 | 0.59 | 900 | 25.09 | 44.62 | 1.1875 | 72.6249 |
| 1.2801 | 0.66 | 1000 | 25.68 | 45.53 | 1.1571 | 71.0491 |
| 1.2876 | 0.72 | 1100 | 20.62 | 41.49 | 1.2193 | 85.8622 |
| 1.2609 | 0.79 | 1200 | 29.47 | 45.04 | 1.2079 | 65.2859 |
| 1.187 | 0.85 | 1300 | 24.65 | 43.73 | 1.2086 | 72.9851 |
| 1.0342 | 0.92 | 1400 | 30.34 | 47.62 | 1.1766 | 64.3854 |
| 1.0519 | 0.98 | 1500 | 29.39 | 47.69 | 1.1425 | 64.9707 |
| 0.5473 | 1.05 | 1600 | 28.02 | 46.27 | 1.1842 | 67.6722 |
| 0.4886 | 1.12 | 1700 | 26.62 | 46.37 | 1.1845 | 76.4971 |
| 0.4354 | 1.18 | 1800 | 23.63 | 45.16 | 1.1621 | 86.1324 |
| 0.4709 | 1.25 | 1900 | 27.86 | 47.3 | 1.1544 | 73.7506 |
| 0.4802 | 1.31 | 2000 | 30.25 | 48.12 | 1.1571 | 64.9707 |
| 0.4565 | 1.38 | 2100 | 24.75 | 44.7 | 1.2095 | 77.4426 |
| 0.4797 | 1.44 | 2200 | 28.46 | 46.03 | 1.2051 | 67.1769 |
| 0.423 | 1.51 | 2300 | 28.34 | 47.65 | 1.2079 | 68.6177 |
| 0.4254 | 1.58 | 2400 | 27.78 | 46.01 | 1.2251 | 67.8523 |
| 0.4493 | 1.64 | 2500 | 26.61 | 47.8 | 1.1898 | 71.1391 |
| 0.3614 | 1.71 | 2600 | 30.08 | 47.25 | 1.2079 | 64.2954 |
| 0.4052 | 1.77 | 2700 | 30.88 | 47.44 | 1.1975 | 64.2053 |
| 0.3541 | 1.84 | 2800 | 28.4 | 46.02 | 1.2006 | 70.2837 |
| 0.3736 | 1.9 | 2900 | 30.82 | 47.52 | 1.1906 | 64.1153 |
| 0.3326 | 1.97 | 3000 | 27.57 | 46.72 | 1.1870 | 70.6439 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"language": ["ga", "en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["ymoslem/IWSLT2023-GA-EN", "ymoslem/FLEURS-GA-EN", "ymoslem/BitesizeIrish-GA-EN", "ymoslem/SpokenWords-GA-EN-MTed", "ymoslem/Tatoeba-Speech-Irish", "ymoslem/Wikimedia-Speech-Irish"], "metrics": ["bleu", "wer"], "base_model": "openai/whisper-small", "model-index": [{"name": "Whisper Small GA-EN Speech Translation", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "IWSLT-2023, FLEURS, BiteSize, SpokenWords, Tatoeba, and Wikimedia", "type": "ymoslem/IWSLT2023-GA-EN"}, "metrics": [{"type": "bleu", "value": 27.57, "name": "Bleu"}, {"type": "wer", "value": 70.64385411976588, "name": "Wer"}]}]}]} | ymoslem/whisper-small-ga2en-v3.1 | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ga",
"en",
"dataset:ymoslem/IWSLT2023-GA-EN",
"dataset:ymoslem/FLEURS-GA-EN",
"dataset:ymoslem/BitesizeIrish-GA-EN",
"dataset:ymoslem/SpokenWords-GA-EN-MTed",
"dataset:ymoslem/Tatoeba-Speech-Irish",
"dataset:ymoslem/Wikimedia-Speech-Irish",
"base_model:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T17:58:43+00:00 | []
| [
"ga",
"en"
]
| TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #ga #en #dataset-ymoslem/IWSLT2023-GA-EN #dataset-ymoslem/FLEURS-GA-EN #dataset-ymoslem/BitesizeIrish-GA-EN #dataset-ymoslem/SpokenWords-GA-EN-MTed #dataset-ymoslem/Tatoeba-Speech-Irish #dataset-ymoslem/Wikimedia-Speech-Irish #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us
| Whisper Small GA-EN Speech Translation
======================================
This model is a fine-tuned version of openai/whisper-small on the IWSLT-2023, FLEURS, BiteSize, SpokenWords, Tatoeba, and Wikimedia dataset.
The best model checkpoint (this version) based on ChrF is at step 2000, epoch 1.31, and it achieves the following results on the evaluation set:
* Loss: 1.1571
* Bleu: 30.25
* Chrf: 48.12
* Wer: 64.9707
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 0.03
* training\_steps: 3000
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 3000\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #ga #en #dataset-ymoslem/IWSLT2023-GA-EN #dataset-ymoslem/FLEURS-GA-EN #dataset-ymoslem/BitesizeIrish-GA-EN #dataset-ymoslem/SpokenWords-GA-EN-MTed #dataset-ymoslem/Tatoeba-Speech-Irish #dataset-ymoslem/Wikimedia-Speech-Irish #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 3000\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3288
- Accuracy: 0.9392
- F1: 0.9402
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1"], "base_model": "bert-base-uncased", "model-index": [{"name": "finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs", "results": []}]} | AndreiUrsu/finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:00:34+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs
This model is a fine-tuned version of bert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3288
- Accuracy: 0.9392
- F1: 0.9402
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs\n\nThis model is a fine-tuned version of bert-base-uncased on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3288\n- Accuracy: 0.9392\n- F1: 0.9402",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# finetuning-sentiment-model-bert-base-uncased-ALL-SAMPLES-4-epochs\n\nThis model is a fine-tuned version of bert-base-uncased on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3288\n- Accuracy: 0.9392\n- F1: 0.9402",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
|
text-generation | null |
# NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF
This model was converted to GGUF format from [`Qwen/CodeQwen1.5-7B`](https://huggingface.co/Qwen/CodeQwen1.5-7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/CodeQwen1.5-7B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF --model codeqwen1.5-7b.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF --model codeqwen1.5-7b.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m codeqwen1.5-7b.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "other", "tags": ["pretrained", "llama-cpp", "gguf-my-repo"], "license_name": "tongyi-qianwen-research", "license_link": "https://huggingface.co/Qwen/CodeQwen1.5-7B/blob/main/LICENSE", "pipeline_tag": "text-generation"} | NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF | null | [
"gguf",
"pretrained",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"license:other",
"region:us"
]
| null | 2024-04-16T18:01:58+00:00 | []
| [
"en"
]
| TAGS
#gguf #pretrained #llama-cpp #gguf-my-repo #text-generation #en #license-other #region-us
|
# NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF
This model was converted to GGUF format from 'Qwen/CodeQwen1.5-7B' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF\nThis model was converted to GGUF format from 'Qwen/CodeQwen1.5-7B' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
]
| [
"TAGS\n#gguf #pretrained #llama-cpp #gguf-my-repo #text-generation #en #license-other #region-us \n",
"# NikolayKozloff/CodeQwen1.5-7B-Q8_0-GGUF\nThis model was converted to GGUF format from 'Qwen/CodeQwen1.5-7B' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
]
|
text-generation | transformers |
# Hermetic-Llama-Ties
Hermetic-Llama-Ties is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [BEE-spoke-data/smol_llama-220M-openhermes](https://huggingface.co/BEE-spoke-data/smol_llama-220M-openhermes)
* [BEE-spoke-data/smol_llama-220M-GQA](https://huggingface.co/BEE-spoke-data/smol_llama-220M-GQA)
## 🧩 Configuration
```yaml
models:
- model: BEE-spoke-data/smol_llama-220M-openhermes
parameters:
density: 0.5
weight: 0.5
- model: BEE-spoke-data/smol_llama-220M-GQA
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: BEE-spoke-data/smol_llama-220M-openhermes
parameters:
normalize: false
int8_mask: true
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "JoPmt/Hermetic-Llama-Ties"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"tags": ["merge", "mergekit", "lazymergekit", "BEE-spoke-data/smol_llama-220M-openhermes", "BEE-spoke-data/smol_llama-220M-GQA"], "base_model": ["BEE-spoke-data/smol_llama-220M-openhermes", "BEE-spoke-data/smol_llama-220M-GQA"]} | JoPmt/Hermetic-Llama-Ties | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"BEE-spoke-data/smol_llama-220M-openhermes",
"BEE-spoke-data/smol_llama-220M-GQA",
"base_model:BEE-spoke-data/smol_llama-220M-openhermes",
"base_model:BEE-spoke-data/smol_llama-220M-GQA",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:02:55+00:00 | []
| []
| TAGS
#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #BEE-spoke-data/smol_llama-220M-openhermes #BEE-spoke-data/smol_llama-220M-GQA #base_model-BEE-spoke-data/smol_llama-220M-openhermes #base_model-BEE-spoke-data/smol_llama-220M-GQA #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Hermetic-Llama-Ties
Hermetic-Llama-Ties is a merge of the following models using LazyMergekit:
* BEE-spoke-data/smol_llama-220M-openhermes
* BEE-spoke-data/smol_llama-220M-GQA
## Configuration
## Usage
| [
"# Hermetic-Llama-Ties\n\nHermetic-Llama-Ties is a merge of the following models using LazyMergekit:\n* BEE-spoke-data/smol_llama-220M-openhermes\n* BEE-spoke-data/smol_llama-220M-GQA",
"## Configuration",
"## Usage"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #BEE-spoke-data/smol_llama-220M-openhermes #BEE-spoke-data/smol_llama-220M-GQA #base_model-BEE-spoke-data/smol_llama-220M-openhermes #base_model-BEE-spoke-data/smol_llama-220M-GQA #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Hermetic-Llama-Ties\n\nHermetic-Llama-Ties is a merge of the following models using LazyMergekit:\n* BEE-spoke-data/smol_llama-220M-openhermes\n* BEE-spoke-data/smol_llama-220M-GQA",
"## Configuration",
"## Usage"
]
|
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Symptoms_to_Diagnosis_SonatafyAI_BERT_v1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the [symptoms to diagnosis](https://huggingface.co/datasets/gretelai/symptom_to_diagnosis) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4088
- Accuracy: 0.9387
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 54 | 2.7055 | 0.25 |
| No log | 2.0 | 108 | 2.1468 | 0.6792 |
| No log | 3.0 | 162 | 1.5608 | 0.8019 |
| No log | 4.0 | 216 | 1.1596 | 0.8632 |
| No log | 5.0 | 270 | 0.8834 | 0.8868 |
| No log | 6.0 | 324 | 0.6775 | 0.9104 |
| No log | 7.0 | 378 | 0.5516 | 0.9198 |
| No log | 8.0 | 432 | 0.4632 | 0.9434 |
| No log | 9.0 | 486 | 0.4273 | 0.9387 |
| 1.2941 | 10.0 | 540 | 0.4088 | 0.9387 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "bert-base-uncased", "widget": [{"text": "The constant thirst and frequent trips to the bathroom were the first signs that something was off. I remember feeling exhausted all the time, even after a full night's sleep. My vision seemed to blur occasionally, making it difficult to focus. And then there were the tingling sensations in my hands and feet, almost like pins and needles. It was alarming."}, {"text": "The past few days have been quite rough for me. I woke up one morning feeling feverish and achy all over, as if I had been hit by a truck. The high fever seemed relentless, accompanied by intense headaches that made it hard to concentrate on anything else. My body felt weak and fatigued, and even the simplest tasks seemed like a Herculean effort. The joint and muscle pain were excruciating, making it difficult to move without wincing in discomfort. To add to the misery, a rash started to spread across my body, causing unbearable itching and discomfort. Despite trying to stay hydrated, I couldn't shake off the persistent nausea and vomiting. It's been a challenging time, and I can only hope for some relief soon."}, {"text": "Lately, I've been feeling incredibly uncomfortable. It started with a persistent urge to urinate, even though very little would come out each time. The burning sensation during urination was unbearable, leaving me squirming in discomfort every time I visited the restroom. The lower abdominal pain added to my misery, a constant nagging ache that made it hard to focus on anything else. Despite my efforts to drink plenty of water, the frequency of urination only seemed to increase, disrupting my daily routine. The cloudy or foul-smelling urine was another troubling sign, indicating that something wasn't quite right. It's been a frustrating experience, and I can't wait to find some relief from these discomforts."}, {"text": "Lately, I've been feeling under the weather, to say the least. It all began with a sudden onset of fever and general malaise, leaving me feeling exhausted and rundown. The telltale sign came soon after \u2013 small, itchy red bumps started appearing all over my body, starting on my face and then spreading to my chest, back, and limbs. These bumps quickly turned into fluid-filled blisters that were incredibly itchy and uncomfortable, making it hard to resist the urge to scratch. The sensation of itching was almost maddening, and despite my efforts to keep from scratching, the urge was often overwhelming. Along with the rash, I also experienced headaches and loss of appetite, further adding to my discomfort. It's been a challenging time, to say the least, and I'm eager for some relief from these relentless symptoms."}, {"text": "Recently, I've been noticing some changes in my legs that have been causing me concern. There's a noticeable swelling and bulging of veins just beneath the surface of my skin, especially in my legs and feet. These veins appear twisted and gnarled, creating a lumpy and discolored appearance that I find quite distressing. Along with the visible changes, I've been experiencing aching and heaviness in my legs, particularly after long periods of standing or sitting. Sometimes, I even feel a throbbing or cramping sensation, which can be quite uncomfortable. Despite my efforts to elevate my legs and wear compression stockings, the symptoms persist, impacting my daily activities and quality of life. It's been a source of frustration and embarrassment, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Lately, I've been struggling with a persistent cough that seems to worsen with each passing day. Along with the cough, I've been experiencing sharp chest pains, especially when taking deep breaths. The fever and chills have been relentless, leaving me shivering one moment and sweating the next. Despite trying to rest and stay warm, the shortness of breath has been concerning, making even simple tasks feel like a struggle. It's been a challenging time, and I can only hope for some relief soon."}, {"text": "Recently, I've been feeling unusually fatigued and dizzy, especially when standing up quickly. The pounding headaches have been relentless, often pulsating at the temples and leaving me feeling lightheaded. Despite my efforts to monitor my diet and reduce stress, the occasional nosebleeds and blurred vision have been concerning. It's been a worrisome experience, and I can't shake off the feeling that something isn't quite right with my health."}, {"text": "Lately, I've been experiencing a gnawing pain in my abdomen that seems to flare up after eating certain foods. The pain is often accompanied by bloating and nausea, making me feel uncomfortable and queasy. Despite trying to avoid spicy and acidic foods, the burning sensation in my stomach persists, sometimes even waking me up at night. It's been a frustrating ordeal, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Recently, I've been feeling incredibly fatigued and weak, as if all my energy has been drained away. The persistent fever and sweating have been relentless, leaving me feeling drained and exhausted. Along with the fever, I've been experiencing severe abdominal pain and discomfort, accompanied by diarrhea and vomiting. Despite trying to stay hydrated, the dehydration and loss of appetite have been concerning. It's been a challenging time, and I can only hope for some improvement in my condition soon."}, {"text": "Lately, I've been feeling quite under the weather. It all started with a scratchy throat and runny nose that just won't seem to clear up. The sneezing and congestion have been relentless, leaving me feeling stuffed up and miserable. Along with the nasal symptoms, I've been experiencing a persistent cough that seems to linger no matter what I do. It's been a frustrating experience, and I can't wait to shake off this cold and start feeling like myself again."}, {"text": "Recently, I've been struggling to catch my breath, especially after physical exertion or exposure to triggers like dust or pollen. The wheezing and tightness in my chest have been relentless, making it feel like there's a weight pressing down on my lungs. Despite my efforts to use my inhaler and avoid known triggers, the shortness of breath and coughing spells persist. It's been a challenging time, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Lately, I've been feeling incredibly weak and fatigued, as if all my energy has been drained away. The recurring fevers and chills have been relentless, leaving me shivering one moment and sweating profusely the next. Along with the fever, I've been experiencing severe headaches and muscle aches that make even the simplest tasks feel like a struggle. Despite trying to rest and stay hydrated, the nausea and vomiting have been concerning. It's been a challenging time, and I can only hope for some improvement in my condition soon."}, {"text": "Recently, I've noticed some red sores and blisters forming on my skin, especially around my nose and mouth. These sores quickly turn into honey-colored crusts that are itchy and uncomfortable. Despite my efforts to keep the affected areas clean, the rash seems to spread easily, making me feel self-conscious and embarrassed. Along with the skin symptoms, I've been experiencing fever and swollen lymph nodes, further adding to my discomfort. It's been a frustrating experience, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Lately, I've been experiencing excruciating headaches that seem to come out of nowhere and last for hours on end. The throbbing pain is often accompanied by nausea and sensitivity to light and sound, making it impossible to focus on anything else. Despite trying to rest in a dark, quiet room, the migraines seem to persist, disrupting my daily routine and quality of life. It's been a challenging time, and I can only hope for some relief from these relentless symptoms."}, {"text": "Recently, I've been noticing stiffness and swelling in my joints, especially in my hands and knees. The pain is often worse in the morning or after periods of inactivity, making it difficult to get moving. Along with the joint symptoms, I've been experiencing fatigue and a general feeling of malaise that's been hard to shake off. Despite trying to stay active and maintain a healthy weight, the arthritis symptoms persist, impacting my mobility and quality of life. It's been a frustrating experience, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Lately, I've been noticing some changes in my skin that have been causing me concern. There's a persistent redness and itching, especially in areas where skin folds or gets sweaty. The affected skin often appears cracked and flaky, with a distinct odor that's hard to ignore. Despite trying to keep the affected areas dry and clean, the fungal infection seems to spread easily, making me feel self-conscious and uncomfortable. It's been a frustrating experience, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Recently, I've been experiencing neck pain and stiffness that seems to worsen with movement or prolonged sitting. The pain often radiates down my arms, causing tingling or numbness in my hands and fingers. Along with the neck symptoms, I've been experiencing headaches and dizziness, further adding to my discomfort. Despite trying to maintain good posture and avoid activities that strain my neck, the cervical spondylosis symptoms persist, impacting my daily activities and quality of life. It's been a challenging time, and I'm eager to find some relief from these persistent symptoms."}, {"text": "Lately, I've noticed a yellowish discoloration in my skin and the whites of my eyes that's been causing me concern. Along with the yellowing, I've been experiencing fatigue and weakness, as if all my energy has been drained away. The itching sensation is almost unbearable, especially on the palms of my hands and soles of my feet. Despite trying to maintain a healthy diet and stay hydrated, the jaundice symptoms persist, leaving me feeling worried and anxious about my health."}, {"text": "Recently, I've been experiencing a burning sensation in my chest that seems to flare up after eating certain foods or lying down. The acid reflux is relentless, leaving a sour taste in my mouth and causing discomfort in my throat. Along with the heartburn, I've been experiencing regurgitation and difficulty swallowing, making me feel uncomfortable and anxious about eating."}], "model-index": [{"name": "Symptoms_to_Diagnosis_SonatafyAI_BERT_v1", "results": []}]} | ajtamayoh/Symptoms_to_Diagnosis_SonatafyAI_BERT_v1 | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:05:36+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| Symptoms\_to\_Diagnosis\_SonatafyAI\_BERT\_v1
=============================================
This model is a fine-tuned version of bert-base-uncased on the symptoms to diagnosis dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4088
* Accuracy: 0.9387
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-bert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp3_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6259
- Rewards/chosen: -6.2124
- Rewards/rejected: -11.7257
- Rewards/accuracies: 0.7200
- Rewards/margins: 5.5132
- Logps/rejected: -138.8036
- Logps/chosen: -128.0061
- Logits/rejected: -0.4196
- Logits/chosen: -0.3295
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0345 | 2.67 | 100 | 0.8548 | -2.8854 | -6.4253 | 0.7400 | 3.5400 | -128.2029 | -121.3520 | -0.2554 | -0.2032 |
| 0.012 | 5.33 | 200 | 1.2021 | -5.9535 | -11.1573 | 0.7700 | 5.2039 | -137.6669 | -127.4882 | -0.4920 | -0.4136 |
| 0.005 | 8.0 | 300 | 1.5640 | -2.6489 | -7.8179 | 0.7200 | 5.1690 | -130.9881 | -120.8790 | -0.2887 | -0.2011 |
| 0.0 | 10.67 | 400 | 1.6069 | -6.1709 | -11.6980 | 0.7200 | 5.5272 | -138.7483 | -127.9230 | -0.4158 | -0.3257 |
| 0.0 | 13.33 | 500 | 1.6195 | -6.2010 | -11.7066 | 0.7300 | 5.5057 | -138.7655 | -127.9832 | -0.4176 | -0.3276 |
| 0.0 | 16.0 | 600 | 1.6237 | -6.1966 | -11.7012 | 0.7200 | 5.5045 | -138.7545 | -127.9745 | -0.4185 | -0.3287 |
| 0.0 | 18.67 | 700 | 1.6053 | -6.1901 | -11.7285 | 0.7200 | 5.5384 | -138.8092 | -127.9615 | -0.4195 | -0.3294 |
| 0.0 | 21.33 | 800 | 1.6157 | -6.1882 | -11.7098 | 0.7200 | 5.5216 | -138.7718 | -127.9577 | -0.4195 | -0.3293 |
| 0.0 | 24.0 | 900 | 1.6297 | -6.2118 | -11.7270 | 0.7300 | 5.5153 | -138.8062 | -128.0048 | -0.4202 | -0.3298 |
| 0.0 | 26.67 | 1000 | 1.6259 | -6.2124 | -11.7257 | 0.7200 | 5.5132 | -138.8036 | -128.0061 | -0.4196 | -0.3295 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp3_dpo5", "results": []}]} | guoyu-zhang/model_hh_usp3_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-16T18:05:51+00:00 | []
| []
| TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp3\_dpo5
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6259
* Rewards/chosen: -6.2124
* Rewards/rejected: -11.7257
* Rewards/accuracies: 0.7200
* Rewards/margins: 5.5132
* Logps/rejected: -138.8036
* Logps/chosen: -128.0061
* Logits/rejected: -0.4196
* Logits/chosen: -0.3295
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_tf_0-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_tf_0](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_tf_0) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6159
- F1 Score: 0.7040
- Accuracy: 0.706
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6305 | 12.5 | 200 | 0.5865 | 0.6790 | 0.679 |
| 0.537 | 25.0 | 400 | 0.5849 | 0.7016 | 0.702 |
| 0.4904 | 37.5 | 600 | 0.6028 | 0.7021 | 0.703 |
| 0.4495 | 50.0 | 800 | 0.6230 | 0.7104 | 0.711 |
| 0.4188 | 62.5 | 1000 | 0.6508 | 0.7048 | 0.706 |
| 0.3923 | 75.0 | 1200 | 0.6411 | 0.7137 | 0.715 |
| 0.3713 | 87.5 | 1400 | 0.6883 | 0.7091 | 0.71 |
| 0.3516 | 100.0 | 1600 | 0.6786 | 0.7051 | 0.706 |
| 0.331 | 112.5 | 1800 | 0.6877 | 0.7041 | 0.704 |
| 0.3119 | 125.0 | 2000 | 0.7201 | 0.6990 | 0.702 |
| 0.2932 | 137.5 | 2200 | 0.7402 | 0.6979 | 0.698 |
| 0.2802 | 150.0 | 2400 | 0.7555 | 0.6887 | 0.689 |
| 0.2646 | 162.5 | 2600 | 0.7852 | 0.7015 | 0.703 |
| 0.2507 | 175.0 | 2800 | 0.7988 | 0.6981 | 0.698 |
| 0.2374 | 187.5 | 3000 | 0.8186 | 0.6870 | 0.687 |
| 0.2265 | 200.0 | 3200 | 0.8437 | 0.6831 | 0.683 |
| 0.2165 | 212.5 | 3400 | 0.8457 | 0.6898 | 0.69 |
| 0.2051 | 225.0 | 3600 | 0.8665 | 0.6801 | 0.68 |
| 0.1974 | 237.5 | 3800 | 0.9326 | 0.6980 | 0.698 |
| 0.1881 | 250.0 | 4000 | 0.8656 | 0.6857 | 0.686 |
| 0.1811 | 262.5 | 4200 | 0.8826 | 0.6890 | 0.689 |
| 0.1744 | 275.0 | 4400 | 0.8846 | 0.6831 | 0.683 |
| 0.1677 | 287.5 | 4600 | 0.9091 | 0.6891 | 0.689 |
| 0.1613 | 300.0 | 4800 | 0.9494 | 0.6980 | 0.698 |
| 0.1551 | 312.5 | 5000 | 0.9512 | 0.6921 | 0.692 |
| 0.1489 | 325.0 | 5200 | 0.9620 | 0.6891 | 0.689 |
| 0.1447 | 337.5 | 5400 | 0.9419 | 0.6890 | 0.689 |
| 0.1392 | 350.0 | 5600 | 1.0081 | 0.6871 | 0.687 |
| 0.1348 | 362.5 | 5800 | 0.9807 | 0.6970 | 0.697 |
| 0.1302 | 375.0 | 6000 | 1.0123 | 0.6919 | 0.692 |
| 0.1281 | 387.5 | 6200 | 1.0226 | 0.6891 | 0.689 |
| 0.1242 | 400.0 | 6400 | 1.0228 | 0.6931 | 0.693 |
| 0.1204 | 412.5 | 6600 | 1.0111 | 0.6950 | 0.695 |
| 0.1175 | 425.0 | 6800 | 1.0307 | 0.6960 | 0.696 |
| 0.1143 | 437.5 | 7000 | 1.0825 | 0.6910 | 0.691 |
| 0.1123 | 450.0 | 7200 | 1.0676 | 0.6861 | 0.686 |
| 0.1091 | 462.5 | 7400 | 1.0169 | 0.6931 | 0.693 |
| 0.1077 | 475.0 | 7600 | 1.0494 | 0.6901 | 0.69 |
| 0.1043 | 487.5 | 7800 | 1.0440 | 0.6900 | 0.69 |
| 0.1034 | 500.0 | 8000 | 1.0654 | 0.6931 | 0.693 |
| 0.1004 | 512.5 | 8200 | 1.0572 | 0.6859 | 0.686 |
| 0.0991 | 525.0 | 8400 | 1.0736 | 0.6910 | 0.691 |
| 0.0996 | 537.5 | 8600 | 1.0493 | 0.6821 | 0.682 |
| 0.0968 | 550.0 | 8800 | 1.0873 | 0.6901 | 0.69 |
| 0.0949 | 562.5 | 9000 | 1.0694 | 0.69 | 0.69 |
| 0.0942 | 575.0 | 9200 | 1.0856 | 0.6861 | 0.686 |
| 0.0926 | 587.5 | 9400 | 1.0852 | 0.6841 | 0.684 |
| 0.0926 | 600.0 | 9600 | 1.1036 | 0.6821 | 0.682 |
| 0.092 | 612.5 | 9800 | 1.0918 | 0.6861 | 0.686 |
| 0.0915 | 625.0 | 10000 | 1.0889 | 0.6841 | 0.684 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_tf_0-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_tf_0-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T18:06:18+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_tf\_0-seqsight\_16384\_512\_56M-L32\_all
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_tf\_0 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6159
* F1 Score: 0.7040
* Accuracy: 0.706
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
text-generation | transformers |
# CodeQwen1.5-7B
AWQ quantized version of CodeQwen1.5-7B model.
---
## Introduction
CodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes.
* Strong code generation capabilities and competitve performance across a series of benchmarks;
* Supporting long context understanding and generation with the context length of 64K tokens;
* Supporting 92 coding languages
* Excellent performance in text-to-SQL, bug fix, etc.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/codeqwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
## Model Details
CodeQwen1.5 is based on Qwen1.5, a language model series including decoder language models of different model sizes. It is trained on 3 trillion tokens of data of codes, and it includes group query attention (GQA) for efficient inference.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'.
```
## Usage
For the base language model, we do not advise you to use it for chat. You can use it for finetuning, and you can also use it for code infilling, code generation, etc., but please be careful about your stopping criteria.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
```
| {"language": ["en"], "license": "other", "tags": ["pretrained"], "license_name": "tongyi-qianwen-research", "license_link": "https://huggingface.co/Qwen/CodeQwen1.5-7B/blob/main/LICENSE", "pipeline_tag": "text-generation"} | TechxGenus/CodeQwen1.5-7B-AWQ | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"pretrained",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
]
| null | 2024-04-16T18:07:29+00:00 | []
| [
"en"
]
| TAGS
#transformers #safetensors #qwen2 #text-generation #pretrained #conversational #en #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# CodeQwen1.5-7B
AWQ quantized version of CodeQwen1.5-7B model.
---
## Introduction
CodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes.
* Strong code generation capabilities and competitve performance across a series of benchmarks;
* Supporting long context understanding and generation with the context length of 64K tokens;
* Supporting 92 coding languages
* Excellent performance in text-to-SQL, bug fix, etc.
For more details, please refer to our blog post and GitHub repo.
## Model Details
CodeQwen1.5 is based on Qwen1.5, a language model series including decoder language models of different model sizes. It is trained on 3 trillion tokens of data of codes, and it includes group query attention (GQA) for efficient inference.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install 'transformers>=4.37.0', or you might encounter the following error:
## Usage
For the base language model, we do not advise you to use it for chat. You can use it for finetuning, and you can also use it for code infilling, code generation, etc., but please be careful about your stopping criteria.
If you find our work helpful, feel free to give us a cite.
| [
"# CodeQwen1.5-7B\n\nAWQ quantized version of CodeQwen1.5-7B model.\n\n---",
"## Introduction\n\nCodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes. \n\n* Strong code generation capabilities and competitve performance across a series of benchmarks;\n* Supporting long context understanding and generation with the context length of 64K tokens;\n* Supporting 92 coding languages\n* Excellent performance in text-to-SQL, bug fix, etc.\n\n\nFor more details, please refer to our blog post and GitHub repo.",
"## Model Details\nCodeQwen1.5 is based on Qwen1.5, a language model series including decoder language models of different model sizes. It is trained on 3 trillion tokens of data of codes, and it includes group query attention (GQA) for efficient inference.",
"## Requirements\nThe code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install 'transformers>=4.37.0', or you might encounter the following error:",
"## Usage\n\nFor the base language model, we do not advise you to use it for chat. You can use it for finetuning, and you can also use it for code infilling, code generation, etc., but please be careful about your stopping criteria.\n\n\nIf you find our work helpful, feel free to give us a cite."
]
| [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #pretrained #conversational #en #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# CodeQwen1.5-7B\n\nAWQ quantized version of CodeQwen1.5-7B model.\n\n---",
"## Introduction\n\nCodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes. \n\n* Strong code generation capabilities and competitve performance across a series of benchmarks;\n* Supporting long context understanding and generation with the context length of 64K tokens;\n* Supporting 92 coding languages\n* Excellent performance in text-to-SQL, bug fix, etc.\n\n\nFor more details, please refer to our blog post and GitHub repo.",
"## Model Details\nCodeQwen1.5 is based on Qwen1.5, a language model series including decoder language models of different model sizes. It is trained on 3 trillion tokens of data of codes, and it includes group query attention (GQA) for efficient inference.",
"## Requirements\nThe code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install 'transformers>=4.37.0', or you might encounter the following error:",
"## Usage\n\nFor the base language model, we do not advise you to use it for chat. You can use it for finetuning, and you can also use it for code infilling, code generation, etc., but please be careful about your stopping criteria.\n\n\nIf you find our work helpful, feel free to give us a cite."
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_tf_1-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_tf_1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_tf_1) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5163
- F1 Score: 0.7459
- Accuracy: 0.746
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.633 | 13.33 | 200 | 0.6188 | 0.6486 | 0.649 |
| 0.5442 | 26.67 | 400 | 0.6445 | 0.6648 | 0.665 |
| 0.501 | 40.0 | 600 | 0.6859 | 0.6732 | 0.676 |
| 0.461 | 53.33 | 800 | 0.7109 | 0.6633 | 0.665 |
| 0.4278 | 66.67 | 1000 | 0.7093 | 0.6538 | 0.654 |
| 0.398 | 80.0 | 1200 | 0.7308 | 0.6636 | 0.664 |
| 0.3732 | 93.33 | 1400 | 0.7815 | 0.6619 | 0.662 |
| 0.348 | 106.67 | 1600 | 0.8067 | 0.658 | 0.658 |
| 0.3267 | 120.0 | 1800 | 0.7833 | 0.6571 | 0.658 |
| 0.3096 | 133.33 | 2000 | 0.8216 | 0.6546 | 0.655 |
| 0.2887 | 146.67 | 2200 | 0.8969 | 0.6587 | 0.659 |
| 0.2723 | 160.0 | 2400 | 0.8895 | 0.6650 | 0.665 |
| 0.2567 | 173.33 | 2600 | 0.9222 | 0.6581 | 0.659 |
| 0.2439 | 186.67 | 2800 | 0.9162 | 0.6486 | 0.65 |
| 0.2311 | 200.0 | 3000 | 0.9422 | 0.6487 | 0.649 |
| 0.2206 | 213.33 | 3200 | 1.0223 | 0.6400 | 0.644 |
| 0.2082 | 226.67 | 3400 | 0.9969 | 0.6521 | 0.653 |
| 0.2008 | 240.0 | 3600 | 1.0156 | 0.6495 | 0.652 |
| 0.1908 | 253.33 | 3800 | 1.0437 | 0.6396 | 0.641 |
| 0.1833 | 266.67 | 4000 | 1.0461 | 0.6465 | 0.647 |
| 0.1753 | 280.0 | 4200 | 1.0855 | 0.6482 | 0.649 |
| 0.1677 | 293.33 | 4400 | 1.0974 | 0.6354 | 0.638 |
| 0.1619 | 306.67 | 4600 | 1.0416 | 0.6447 | 0.645 |
| 0.1567 | 320.0 | 4800 | 1.1073 | 0.6491 | 0.65 |
| 0.1491 | 333.33 | 5000 | 1.1129 | 0.6485 | 0.649 |
| 0.1444 | 346.67 | 5200 | 1.1253 | 0.6499 | 0.651 |
| 0.1383 | 360.0 | 5400 | 1.1581 | 0.6462 | 0.647 |
| 0.1356 | 373.33 | 5600 | 1.1370 | 0.6518 | 0.652 |
| 0.1313 | 386.67 | 5800 | 1.1729 | 0.6489 | 0.649 |
| 0.1273 | 400.0 | 6000 | 1.1970 | 0.6483 | 0.649 |
| 0.1232 | 413.33 | 6200 | 1.1731 | 0.65 | 0.65 |
| 0.1202 | 426.67 | 6400 | 1.1943 | 0.6434 | 0.644 |
| 0.1163 | 440.0 | 6600 | 1.2564 | 0.6442 | 0.645 |
| 0.113 | 453.33 | 6800 | 1.2317 | 0.6555 | 0.656 |
| 0.1106 | 466.67 | 7000 | 1.2075 | 0.6569 | 0.657 |
| 0.1077 | 480.0 | 7200 | 1.2314 | 0.6546 | 0.655 |
| 0.1055 | 493.33 | 7400 | 1.2612 | 0.6445 | 0.645 |
| 0.1034 | 506.67 | 7600 | 1.2636 | 0.6496 | 0.65 |
| 0.1016 | 520.0 | 7800 | 1.2701 | 0.6525 | 0.653 |
| 0.0997 | 533.33 | 8000 | 1.2952 | 0.6451 | 0.646 |
| 0.0977 | 546.67 | 8200 | 1.2429 | 0.6464 | 0.647 |
| 0.0963 | 560.0 | 8400 | 1.2849 | 0.6548 | 0.655 |
| 0.0947 | 573.33 | 8600 | 1.2860 | 0.6607 | 0.661 |
| 0.0943 | 586.67 | 8800 | 1.2782 | 0.6516 | 0.652 |
| 0.0925 | 600.0 | 9000 | 1.2960 | 0.6525 | 0.653 |
| 0.0915 | 613.33 | 9200 | 1.2929 | 0.6455 | 0.646 |
| 0.0903 | 626.67 | 9400 | 1.3047 | 0.6517 | 0.652 |
| 0.0895 | 640.0 | 9600 | 1.2928 | 0.6457 | 0.646 |
| 0.0883 | 653.33 | 9800 | 1.3022 | 0.6501 | 0.651 |
| 0.0885 | 666.67 | 10000 | 1.2959 | 0.6525 | 0.653 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_tf_1-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_tf_1-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T18:12:46+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_tf\_1-seqsight\_16384\_512\_56M-L32\_all
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_tf\_1 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5163
* F1 Score: 0.7459
* Accuracy: 0.746
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
reinforcement-learning | null |
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
| {"tags": ["CartPole-v1", "reinforce", "reinforcement-learning", "custom-implementation", "deep-rl-class"], "model-index": [{"name": "Reinforce-CartPole8", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "CartPole-v1", "type": "CartPole-v1"}, "metrics": [{"type": "mean_reward", "value": "500.00 +/- 0.00", "name": "mean_reward", "verified": false}]}]}]} | erikbritto/Reinforce-Cartpole8 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| null | 2024-04-16T18:12:47+00:00 | []
| []
| TAGS
#CartPole-v1 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us
|
# Reinforce Agent playing CartPole-v1
This is a trained model of a Reinforce agent playing CartPole-v1 .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL
| [
"# Reinforce Agent playing CartPole-v1\n This is a trained model of a Reinforce agent playing CartPole-v1 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
]
| [
"TAGS\n#CartPole-v1 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us \n",
"# Reinforce Agent playing CartPole-v1\n This is a trained model of a Reinforce agent playing CartPole-v1 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_tf_4-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_tf_4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_tf_4) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3102
- F1 Score: 0.6830
- Accuracy: 0.687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6068 | 20.0 | 200 | 0.6191 | 0.6689 | 0.675 |
| 0.462 | 40.0 | 400 | 0.6073 | 0.7179 | 0.718 |
| 0.3705 | 60.0 | 600 | 0.6259 | 0.7539 | 0.754 |
| 0.3027 | 80.0 | 800 | 0.6102 | 0.7563 | 0.759 |
| 0.2573 | 100.0 | 1000 | 0.6396 | 0.7809 | 0.781 |
| 0.2274 | 120.0 | 1200 | 0.6270 | 0.7748 | 0.777 |
| 0.2038 | 140.0 | 1400 | 0.5926 | 0.7998 | 0.8 |
| 0.18 | 160.0 | 1600 | 0.6532 | 0.7993 | 0.8 |
| 0.1608 | 180.0 | 1800 | 0.6685 | 0.7907 | 0.792 |
| 0.1466 | 200.0 | 2000 | 0.7015 | 0.7844 | 0.786 |
| 0.1342 | 220.0 | 2200 | 0.8047 | 0.7732 | 0.776 |
| 0.1262 | 240.0 | 2400 | 0.6962 | 0.8001 | 0.801 |
| 0.1138 | 260.0 | 2600 | 0.7185 | 0.7949 | 0.796 |
| 0.1049 | 280.0 | 2800 | 0.7725 | 0.7834 | 0.785 |
| 0.0982 | 300.0 | 3000 | 0.7430 | 0.8127 | 0.813 |
| 0.0948 | 320.0 | 3200 | 0.8073 | 0.7897 | 0.791 |
| 0.0863 | 340.0 | 3400 | 0.8563 | 0.7705 | 0.773 |
| 0.0808 | 360.0 | 3600 | 0.7486 | 0.8075 | 0.808 |
| 0.077 | 380.0 | 3800 | 0.8140 | 0.7918 | 0.793 |
| 0.0716 | 400.0 | 4000 | 0.8535 | 0.7853 | 0.787 |
| 0.0689 | 420.0 | 4200 | 0.8552 | 0.7855 | 0.787 |
| 0.0639 | 440.0 | 4400 | 0.8537 | 0.7899 | 0.791 |
| 0.0618 | 460.0 | 4600 | 0.8764 | 0.7814 | 0.783 |
| 0.0593 | 480.0 | 4800 | 0.8861 | 0.7835 | 0.785 |
| 0.0564 | 500.0 | 5000 | 0.9399 | 0.7807 | 0.783 |
| 0.0535 | 520.0 | 5200 | 0.8481 | 0.7991 | 0.8 |
| 0.0516 | 540.0 | 5400 | 0.8469 | 0.7950 | 0.796 |
| 0.0492 | 560.0 | 5600 | 0.8933 | 0.7937 | 0.795 |
| 0.0477 | 580.0 | 5800 | 0.9027 | 0.7917 | 0.793 |
| 0.0452 | 600.0 | 6000 | 0.8632 | 0.7889 | 0.79 |
| 0.0435 | 620.0 | 6200 | 0.8988 | 0.7896 | 0.791 |
| 0.0426 | 640.0 | 6400 | 0.8760 | 0.8044 | 0.805 |
| 0.0413 | 660.0 | 6600 | 0.8958 | 0.7978 | 0.799 |
| 0.0395 | 680.0 | 6800 | 0.8656 | 0.7940 | 0.795 |
| 0.038 | 700.0 | 7000 | 0.9181 | 0.7940 | 0.795 |
| 0.0377 | 720.0 | 7200 | 0.8979 | 0.8012 | 0.802 |
| 0.0363 | 740.0 | 7400 | 0.8875 | 0.7889 | 0.79 |
| 0.0351 | 760.0 | 7600 | 0.9355 | 0.7867 | 0.788 |
| 0.0338 | 780.0 | 7800 | 0.8817 | 0.7972 | 0.798 |
| 0.032 | 800.0 | 8000 | 0.8854 | 0.8012 | 0.802 |
| 0.0326 | 820.0 | 8200 | 0.8921 | 0.7930 | 0.794 |
| 0.0313 | 840.0 | 8400 | 0.9200 | 0.7920 | 0.793 |
| 0.0317 | 860.0 | 8600 | 0.9267 | 0.7942 | 0.795 |
| 0.0304 | 880.0 | 8800 | 0.9342 | 0.7898 | 0.791 |
| 0.029 | 900.0 | 9000 | 0.9242 | 0.7930 | 0.794 |
| 0.0289 | 920.0 | 9200 | 0.9456 | 0.7940 | 0.795 |
| 0.0278 | 940.0 | 9400 | 0.9222 | 0.8014 | 0.802 |
| 0.0286 | 960.0 | 9600 | 0.9419 | 0.7992 | 0.8 |
| 0.0279 | 980.0 | 9800 | 0.9382 | 0.7941 | 0.795 |
| 0.0278 | 1000.0 | 10000 | 0.9371 | 0.7971 | 0.798 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_tf_4-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_tf_4-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T18:14:30+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_tf\_4-seqsight\_16384\_512\_56M-L32\_all
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_tf\_4 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.3102
* F1 Score: 0.6830
* Accuracy: 0.687
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "248.28 +/- 37.98", "name": "mean_reward", "verified": false}]}]}]} | gsalmon/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| null | 2024-04-16T18:15:15+00:00 | []
| []
| TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
]
| [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
]
|
null | null | # Meta Llama 3
We are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.
This release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.
This repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see [llama-recipes](https://github.com/facebookresearch/llama-recipes/).
## Download
In order to download the model weights and tokenizer, please visit the [Meta Llama website](https://llama.meta.com/llama-downloads/) and accept our License.
Once your request is approved, you will receive a signed URL over email. Then run the download.sh script, passing the URL provided when prompted to start the download.
Pre-requisites: Make sure you have `wget` and `md5sum` installed. Then run the script: `./download.sh`.
Keep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as `403: Forbidden`, you can always re-request a link.
### Access to Hugging Face
We are also providing downloads on [Hugging Face](https://huggingface.co/meta-llama).
## Quick Start
You can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the [Llama recipes repository](https://github.com/facebookresearch/llama-recipes).
1. In a conda env with PyTorch / CUDA available clone and download this repository.
2. In the top-level directory run:
```bash
pip install -e .
```
3. Visit the [Meta Llama website](https://llama.meta.com/llama-downloads/) and register to download the model/s.
4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the download.sh script.
5. Once you get the email, navigate to your downloaded llama repository and run the download.sh script.
- Make sure to grant execution permissions to the download.sh script
- During this process, you will be prompted to enter the URL from the email.
- Do not use the "Copy Link" option but rather make sure to manually copy the link from the email.
6. Once the model/s you want have been downloaded, you can run the model locally using the command below:
```bash
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-3-8b-prerelease-instruct/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 6
```
**Note**
- Replace `llama-3-8b-prerelease-instruct/` with the path to your checkpoint directory and `tokenizer.model` with the path to your tokenizer model.
- The `–nproc_per_node` should be set to the [MP](#inference) value for the model you are using.
- Adjust the `max_seq_len` and `max_batch_size` parameters as needed.
- This example runs the [example_chat_completion.py](example_chat_completion.py) found in this repository but you can change that to a different .py file.
## Inference
Different models require different model-parallel (MP) values:
| Model | MP |
|--------|----|
| 8B | 1 |
| 70B | 8 |
All models support sequence length up to 8192 tokens, but we pre-allocate the cache according to `max_seq_len` and `max_batch_size` values. So set those according to your hardware.
### Pretrained Models
These models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.
See `example_text_completion.py` for some examples. To illustrate, see the command below to run it with the llama-2-7b model (`nproc_per_node` needs to be set to the `MP` value):
```
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-3-8b-prerelease/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
```
### Instruction-tuned Models
The fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212)
needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces).
You can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for [an example](https://github.com/facebookresearch/llama-recipes/blob/main/examples/inference.py) of how to add a safety checker to the inputs and outputs of your inference code.
Examples using llama-2-7b-chat:
```
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-3-8b-prerelease-instruct/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 6
```
Llama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.
In order to help developers address these risks, we have created the [Responsible Use Guide](https://ai.meta.com/static-resource/responsible-use-guide/).
## Issues
Please report any software "bug", or other problems with the models through one of the following means:
- Reporting issues with the model: [https://github.com/meta-llama/llama3/issues](https://github.com/meta-llama/llama3/issues)
- Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Model Card
See [MODEL_CARD.md](MODEL_CARD.md).
## License
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
See the [LICENSE](LICENSE) file, as well as our accompanying [Acceptable Use Policy](USE_POLICY.md)
## Questions
For common questions, the FAQ can be found [here](https://llama.meta.com/faq) which will be kept up to date over time as new questions arise.
---
---
extra_gated_heading: You need to share contact information with Meta to access this model
extra_gated_prompt: >-
### LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, you shall include a copy of this Agreement and
prominently display "Built with Meta Llama 3" on a related website, user interface, blogpost, about page,
or product documentation.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as
part of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a "Notice" text file distributed as a part of such copies: "Meta Llama 3 is
licensed under the META LLAMA 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF
ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE,
NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA
MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
language:
- en
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: llama2
---
# Meta Llama 3
We are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.
This release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.
This repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see [llama-recipes](https://github.com/facebookresearch/llama-recipes/).
## Download
In order to download the model weights and tokenizer, please visit the [Meta Llama website](https://llama.meta.com/llama-downloads/) and accept our License.
Once your request is approved, you will receive a signed URL over email. Then run the download.sh script, passing the URL provided when prompted to start the download.
Pre-requisites: Make sure you have `wget` and `md5sum` installed. Then run the script: `./download.sh`.
Keep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as `403: Forbidden`, you can always re-request a link.
### Access to Hugging Face
We are also providing downloads on [Hugging Face](https://huggingface.co/meta-llama).
## Quick Start
You can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the [Llama recipes repository](https://github.com/facebookresearch/llama-recipes).
1. In a conda env with PyTorch / CUDA available clone and download this repository.
2. In the top-level directory run:
```bash
pip install -e .
```
3. Visit the [Meta Llama website](https://llama.meta.com/llama-downloads/) and register to download the model/s.
4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the download.sh script.
5. Once you get the email, navigate to your downloaded llama repository and run the download.sh script.
- Make sure to grant execution permissions to the download.sh script
- During this process, you will be prompted to enter the URL from the email.
- Do not use the "Copy Link" option but rather make sure to manually copy the link from the email.
6. Once the model/s you want have been downloaded, you can run the model locally using the command below:
```bash
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-3-8b-prerelease-instruct/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 6
```
**Note**
- Replace `llama-3-8b-prerelease-instruct/` with the path to your checkpoint directory and `tokenizer.model` with the path to your tokenizer model.
- The `–nproc_per_node` should be set to the [MP](#inference) value for the model you are using.
- Adjust the `max_seq_len` and `max_batch_size` parameters as needed.
- This example runs the [example_chat_completion.py](example_chat_completion.py) found in this repository but you can change that to a different .py file.
## Inference
Different models require different model-parallel (MP) values:
| Model | MP |
|--------|----|
| 8B | 1 |
| 70B | 8 |
All models support sequence length up to 8192 tokens, but we pre-allocate the cache according to `max_seq_len` and `max_batch_size` values. So set those according to your hardware.
### Pretrained Models
These models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.
See `example_text_completion.py` for some examples. To illustrate, see the command below to run it with the llama-2-7b model (`nproc_per_node` needs to be set to the `MP` value):
```
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-3-8b-prerelease/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
```
### Instruction-tuned Models
The fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212)
needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces).
You can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for [an example](https://github.com/facebookresearch/llama-recipes/blob/main/examples/inference.py) of how to add a safety checker to the inputs and outputs of your inference code.
Examples using llama-2-7b-chat:
```
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-3-8b-prerelease-instruct/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 6
```
Llama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.
In order to help developers address these risks, we have created the [Responsible Use Guide](https://ai.meta.com/static-resource/responsible-use-guide/).
## Issues
Please report any software "bug", or other problems with the models through one of the following means:
- Reporting issues with the model: [https://github.com/meta-llama/llama3/issues](https://github.com/meta-llama/llama3/issues)
- Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Model Card
See [MODEL_CARD.md](MODEL_CARD.md).
## License
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
See the [LICENSE](LICENSE) file, as well as our accompanying [Acceptable Use Policy](USE_POLICY.md)
## Questions
For common questions, the FAQ can be found [here](https://llama.meta.com/faq) which will be kept up to date over time as new questions arise. | {"language": ["en"], "license": "llama2", "tags": ["facebook", "meta", "pytorch", "llama", "llama-2"], "extra_gated_heading": "You need to share contact information with Meta to access this model", "extra_gated_prompt": "### LLAMA 3 COMMUNITY LICENSE AGREEMENT Meta Llama 3 Version Release Date: April 18, 2024 \"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein. \"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/. \"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity\u2019s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf. \"Meta Llama 3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.meta.com/llama-downloads. \"Llama Materials\" means, collectively, Meta\u2019s proprietary Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement. \"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland). By clicking \"I Accept\" below or by using or distributing any portion or element of the Llama Materials, you agree to be bound by this Agreement. 1. License Rights and Redistribution.\n a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free\nlimited license under Meta\u2019s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\n b. Redistribution and Use.\n i. If you distribute or make available the Llama Materials (or any derivative works\nthereof), or a product or service that uses any of them, you shall include a copy of this Agreement and prominently display \"Built with Meta Llama 3\" on a related website, user interface, blogpost, about page, or product documentation.\n ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as\npart of an integrated end user product, then Section 2 of this Agreement will not apply to you. iii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a \"Notice\" text file distributed as a part of such copies: \"Meta Llama 3 is licensed under the META LLAMA 3 Community License, Copyright \u00a9 Meta Platforms, Inc. All Rights Reserved.\"\n iv. Your use of the Llama Materials must comply with applicable laws and regulations\n(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.\n v. You will not use the Llama Materials or any output or results of the Llama Materials to\nimprove any other large language model (excluding Meta Llama 3 or derivative works thereof). 2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee\u2019s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights. 3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \"AS IS\" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS. 4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING. 5. Intellectual Property.\n a. No trademark licenses are granted under this Agreement, and in connection with the Llama\nMaterials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials.\n b. Subject to Meta\u2019s ownership of Llama Materials and derivatives made by or for Meta, with\nrespect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\n c. If you institute litigation or other proceedings against Meta or any entity (including a\ncross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials. 6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement. 7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.", "extra_gated_fields": {"First Name": "text", "Last Name": "text", "Date of birth": "date_picker", "Country": "country", "Affiliation": "text", "geo": "ip_location", "By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy": "checkbox"}, "extra_gated_description": "The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).", "extra_gated_button_content": "Submit"} | margaret-test/test-1 | null | [
"facebook",
"meta",
"pytorch",
"llama",
"llama-2",
"en",
"license:llama2",
"region:us"
]
| null | 2024-04-16T18:16:27+00:00 | []
| [
"en"
]
| TAGS
#facebook #meta #pytorch #llama #llama-2 #en #license-llama2 #region-us
| Meta Llama 3
============
We are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.
This release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.
This repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see llama-recipes.
Download
--------
In order to download the model weights and tokenizer, please visit the Meta Llama website and accept our License.
Once your request is approved, you will receive a signed URL over email. Then run the URL script, passing the URL provided when prompted to start the download.
Pre-requisites: Make sure you have 'wget' and 'md5sum' installed. Then run the script: './URL'.
Keep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as '403: Forbidden', you can always re-request a link.
### Access to Hugging Face
We are also providing downloads on Hugging Face.
Quick Start
-----------
You can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.
1. In a conda env with PyTorch / CUDA available clone and download this repository.
2. In the top-level directory run:
3. Visit the Meta Llama website and register to download the model/s.
4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.
5. Once you get the email, navigate to your downloaded llama repository and run the URL script.
* Make sure to grant execution permissions to the URL script
* During this process, you will be prompted to enter the URL from the email.
* Do not use the "Copy Link" option but rather make sure to manually copy the link from the email.
6. Once the model/s you want have been downloaded, you can run the model locally using the command below:
Note
* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.
* The '–nproc\_per\_node' should be set to the MP value for the model you are using.
* Adjust the 'max\_seq\_len' and 'max\_batch\_size' parameters as needed.
* This example runs the example\_chat\_completion.py found in this repository but you can change that to a different .py file.
Inference
---------
Different models require different model-parallel (MP) values:
### Pretrained Models
These models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.
See 'example\_text\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\_per\_node' needs to be set to the 'MP' value):
### Instruction-tuned Models
The fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\_completion'
needs to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).
You can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.
Examples using llama-2-7b-chat:
Llama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.
In order to help developers address these risks, we have created the Responsible Use Guide.
Issues
------
Please report any software "bug", or other problems with the models through one of the following means:
* Reporting issues with the model: URL
* Reporting risky content generated by the model: URL
* Reporting bugs and security concerns: URL
Model Card
----------
See MODEL\_CARD.md.
License
-------
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
See the LICENSE file, as well as our accompanying Acceptable Use Policy
Questions
---------
For common questions, the FAQ can be found here which will be kept up to date over time as new questions arise.
---------------------------------------------------------------------------------------------------------------
---
extra\_gated\_heading: You need to share contact information with Meta to access this model
extra\_gated\_prompt: >-
### LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at URL
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
URL
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, you shall include a copy of this Agreement and
prominently display "Built with Meta Llama 3" on a related website, user interface, blogpost, about page,
or product documentation.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as
part of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a "Notice" text file distributed as a part of such copies: "Meta Llama 3 is
licensed under the META LLAMA 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at URL which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF
ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE,
NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA
MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
extra\_gated\_fields:
First Name: text
Last Name: text
Date of birth: date\_picker
Country: country
Affiliation: text
geo: ip\_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra\_gated\_description: The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy.
extra\_gated\_button\_content: Submit
language:
* en
tags:
* facebook
* meta
* pytorch
* llama
* llama-2
license: llama2
---
Meta Llama 3
============
We are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.
This release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.
This repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see llama-recipes.
Download
--------
In order to download the model weights and tokenizer, please visit the Meta Llama website and accept our License.
Once your request is approved, you will receive a signed URL over email. Then run the URL script, passing the URL provided when prompted to start the download.
Pre-requisites: Make sure you have 'wget' and 'md5sum' installed. Then run the script: './URL'.
Keep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as '403: Forbidden', you can always re-request a link.
### Access to Hugging Face
We are also providing downloads on Hugging Face.
Quick Start
-----------
You can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.
1. In a conda env with PyTorch / CUDA available clone and download this repository.
2. In the top-level directory run:
3. Visit the Meta Llama website and register to download the model/s.
4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.
5. Once you get the email, navigate to your downloaded llama repository and run the URL script.
* Make sure to grant execution permissions to the URL script
* During this process, you will be prompted to enter the URL from the email.
* Do not use the "Copy Link" option but rather make sure to manually copy the link from the email.
6. Once the model/s you want have been downloaded, you can run the model locally using the command below:
Note
* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.
* The '–nproc\_per\_node' should be set to the MP value for the model you are using.
* Adjust the 'max\_seq\_len' and 'max\_batch\_size' parameters as needed.
* This example runs the example\_chat\_completion.py found in this repository but you can change that to a different .py file.
Inference
---------
Different models require different model-parallel (MP) values:
### Pretrained Models
These models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.
See 'example\_text\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\_per\_node' needs to be set to the 'MP' value):
### Instruction-tuned Models
The fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\_completion'
needs to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).
You can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.
Examples using llama-2-7b-chat:
Llama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.
In order to help developers address these risks, we have created the Responsible Use Guide.
Issues
------
Please report any software "bug", or other problems with the models through one of the following means:
* Reporting issues with the model: URL
* Reporting risky content generated by the model: URL
* Reporting bugs and security concerns: URL
Model Card
----------
See MODEL\_CARD.md.
License
-------
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
See the LICENSE file, as well as our accompanying Acceptable Use Policy
Questions
---------
For common questions, the FAQ can be found here which will be kept up to date over time as new questions arise.
| [
"### Access to Hugging Face\n\n\nWe are also providing downloads on Hugging Face.\n\n\nQuick Start\n-----------\n\n\nYou can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.\n\n\n1. In a conda env with PyTorch / CUDA available clone and download this repository.\n2. In the top-level directory run:\n3. Visit the Meta Llama website and register to download the model/s.\n4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.\n5. Once you get the email, navigate to your downloaded llama repository and run the URL script.\n\n\n\t* Make sure to grant execution permissions to the URL script\n\t* During this process, you will be prompted to enter the URL from the email.\n\t* Do not use the \"Copy Link\" option but rather make sure to manually copy the link from the email.\n6. Once the model/s you want have been downloaded, you can run the model locally using the command below:\n\n\nNote\n\n\n* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.\n* The '–nproc\\_per\\_node' should be set to the MP value for the model you are using.\n* Adjust the 'max\\_seq\\_len' and 'max\\_batch\\_size' parameters as needed.\n* This example runs the example\\_chat\\_completion.py found in this repository but you can change that to a different .py file.\n\n\nInference\n---------\n\n\nDifferent models require different model-parallel (MP) values:",
"### Pretrained Models\n\n\nThese models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.\nSee 'example\\_text\\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\\_per\\_node' needs to be set to the 'MP' value):",
"### Instruction-tuned Models\n\n\nThe fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\\_completion'\nneeds to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).\nYou can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.\nExamples using llama-2-7b-chat:\n\n\nLlama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.\nIn order to help developers address these risks, we have created the Responsible Use Guide.\n\n\nIssues\n------\n\n\nPlease report any software \"bug\", or other problems with the models through one of the following means:\n\n\n* Reporting issues with the model: URL\n* Reporting risky content generated by the model: URL\n* Reporting bugs and security concerns: URL\n\n\nModel Card\n----------\n\n\nSee MODEL\\_CARD.md.\n\n\nLicense\n-------\n\n\nOur model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.\nSee the LICENSE file, as well as our accompanying Acceptable Use Policy\n\n\nQuestions\n---------\n\n\nFor common questions, the FAQ can be found here which will be kept up to date over time as new questions arise.\n---------------------------------------------------------------------------------------------------------------\n\n\n\n\n---\n\n\nextra\\_gated\\_heading: You need to share contact information with Meta to access this model\nextra\\_gated\\_prompt: >-",
"### LLAMA 3 COMMUNITY LICENSE AGREEMENT\n\n\nMeta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the\nLlama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3\ndistributed by Meta at URL\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into\nthis Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or\nregulations to provide legal consent and that has legal authority to bind your employer or such other\nperson or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including\nmachine-learning model code, trained model weights, inference-enabling code, training-enabling code,\nfine-tuning enabling code and other elements of the foregoing distributed by Meta at\nURL\n\"Llama Materials\" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any\nportion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your\nprincipal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located\noutside of the EEA or Switzerland).\nBy clicking \"I Accept\" below or by using or distributing any portion or element of the Llama Materials,\nyou agree to be bound by this Agreement.\n\n\n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free\nlimited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama\nMaterials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the\nLlama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works\nthereof), or a product or service that uses any of them, you shall include a copy of this Agreement and\nprominently display \"Built with Meta Llama 3\" on a related website, user interface, blogpost, about page,\nor product documentation.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as\npart of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following\nattribution notice within a \"Notice\" text file distributed as a part of such copies: \"Meta Llama 3 is\nlicensed under the META LLAMA 3 Community License, Copyright © Meta Platforms, Inc. All Rights\nReserved.\"\niv. Your use of the Llama Materials must comply with applicable laws and regulations\n(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama\nMaterials (available at URL which is hereby incorporated by\nreference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to\nimprove any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users\nof the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700\nmillion monthly active users in the preceding calendar month, you must request a license from Meta,\nwhich Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the\nrights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY\nOUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \"AS IS\" BASIS, WITHOUT WARRANTIES OF\nANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE,\nNON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY\nRESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA\nMATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY\nOUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF\nLIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\nOUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\nINCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED\nOF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama\nMaterials, neither Meta nor Licensee may use any name or mark owned by or associated with the other\nor any of its affiliates, except as required for reasonable and customary use in describing and\nredistributing the Llama Materials.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\nrespect to any derivative works and modifications of the Llama Materials that are made by you, as\nbetween you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a\ncross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or\nresults, or any portion of any of the foregoing, constitutes infringement of intellectual property or other\nrights owned or licensable by you, then any licenses granted to you under this Agreement shall\nterminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold\nharmless Meta from and against any claim by any third party arising out of or related to your use or\ndistribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this\nAgreement or access to the Llama Materials and will continue in full force and effect until terminated in\naccordance with the terms and conditions herein. Meta may terminate this Agreement if you are in\nbreach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete\nand cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this\nAgreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of\nthe State of California without regard to choice of law principles, and the UN Convention on Contracts\nfor the International Sale of Goods does not apply to this Agreement. The courts of California shall have\nexclusive jurisdiction of any dispute arising out of this Agreement.\nextra\\_gated\\_fields:\nFirst Name: text\nLast Name: text\nDate of birth: date\\_picker\nCountry: country\nAffiliation: text\ngeo: ip\\_location \n\nBy clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox\nextra\\_gated\\_description: The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy.\nextra\\_gated\\_button\\_content: Submit\nlanguage:\n\n\n* en\ntags:\n* facebook\n* meta\n* pytorch\n* llama\n* llama-2\nlicense: llama2\n\n\n\n\n---\n\n\nMeta Llama 3\n============\n\n\nWe are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.\nThis release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.\nThis repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see llama-recipes.\n\n\nDownload\n--------\n\n\nIn order to download the model weights and tokenizer, please visit the Meta Llama website and accept our License.\nOnce your request is approved, you will receive a signed URL over email. Then run the URL script, passing the URL provided when prompted to start the download.\nPre-requisites: Make sure you have 'wget' and 'md5sum' installed. Then run the script: './URL'.\nKeep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as '403: Forbidden', you can always re-request a link.",
"### Access to Hugging Face\n\n\nWe are also providing downloads on Hugging Face.\n\n\nQuick Start\n-----------\n\n\nYou can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.\n\n\n1. In a conda env with PyTorch / CUDA available clone and download this repository.\n2. In the top-level directory run:\n3. Visit the Meta Llama website and register to download the model/s.\n4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.\n5. Once you get the email, navigate to your downloaded llama repository and run the URL script.\n\n\n\t* Make sure to grant execution permissions to the URL script\n\t* During this process, you will be prompted to enter the URL from the email.\n\t* Do not use the \"Copy Link\" option but rather make sure to manually copy the link from the email.\n6. Once the model/s you want have been downloaded, you can run the model locally using the command below:\n\n\nNote\n\n\n* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.\n* The '–nproc\\_per\\_node' should be set to the MP value for the model you are using.\n* Adjust the 'max\\_seq\\_len' and 'max\\_batch\\_size' parameters as needed.\n* This example runs the example\\_chat\\_completion.py found in this repository but you can change that to a different .py file.\n\n\nInference\n---------\n\n\nDifferent models require different model-parallel (MP) values:",
"### Pretrained Models\n\n\nThese models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.\nSee 'example\\_text\\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\\_per\\_node' needs to be set to the 'MP' value):",
"### Instruction-tuned Models\n\n\nThe fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\\_completion'\nneeds to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).\nYou can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.\nExamples using llama-2-7b-chat:\n\n\nLlama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.\nIn order to help developers address these risks, we have created the Responsible Use Guide.\n\n\nIssues\n------\n\n\nPlease report any software \"bug\", or other problems with the models through one of the following means:\n\n\n* Reporting issues with the model: URL\n* Reporting risky content generated by the model: URL\n* Reporting bugs and security concerns: URL\n\n\nModel Card\n----------\n\n\nSee MODEL\\_CARD.md.\n\n\nLicense\n-------\n\n\nOur model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.\nSee the LICENSE file, as well as our accompanying Acceptable Use Policy\n\n\nQuestions\n---------\n\n\nFor common questions, the FAQ can be found here which will be kept up to date over time as new questions arise."
]
| [
"TAGS\n#facebook #meta #pytorch #llama #llama-2 #en #license-llama2 #region-us \n",
"### Access to Hugging Face\n\n\nWe are also providing downloads on Hugging Face.\n\n\nQuick Start\n-----------\n\n\nYou can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.\n\n\n1. In a conda env with PyTorch / CUDA available clone and download this repository.\n2. In the top-level directory run:\n3. Visit the Meta Llama website and register to download the model/s.\n4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.\n5. Once you get the email, navigate to your downloaded llama repository and run the URL script.\n\n\n\t* Make sure to grant execution permissions to the URL script\n\t* During this process, you will be prompted to enter the URL from the email.\n\t* Do not use the \"Copy Link\" option but rather make sure to manually copy the link from the email.\n6. Once the model/s you want have been downloaded, you can run the model locally using the command below:\n\n\nNote\n\n\n* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.\n* The '–nproc\\_per\\_node' should be set to the MP value for the model you are using.\n* Adjust the 'max\\_seq\\_len' and 'max\\_batch\\_size' parameters as needed.\n* This example runs the example\\_chat\\_completion.py found in this repository but you can change that to a different .py file.\n\n\nInference\n---------\n\n\nDifferent models require different model-parallel (MP) values:",
"### Pretrained Models\n\n\nThese models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.\nSee 'example\\_text\\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\\_per\\_node' needs to be set to the 'MP' value):",
"### Instruction-tuned Models\n\n\nThe fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\\_completion'\nneeds to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).\nYou can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.\nExamples using llama-2-7b-chat:\n\n\nLlama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.\nIn order to help developers address these risks, we have created the Responsible Use Guide.\n\n\nIssues\n------\n\n\nPlease report any software \"bug\", or other problems with the models through one of the following means:\n\n\n* Reporting issues with the model: URL\n* Reporting risky content generated by the model: URL\n* Reporting bugs and security concerns: URL\n\n\nModel Card\n----------\n\n\nSee MODEL\\_CARD.md.\n\n\nLicense\n-------\n\n\nOur model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.\nSee the LICENSE file, as well as our accompanying Acceptable Use Policy\n\n\nQuestions\n---------\n\n\nFor common questions, the FAQ can be found here which will be kept up to date over time as new questions arise.\n---------------------------------------------------------------------------------------------------------------\n\n\n\n\n---\n\n\nextra\\_gated\\_heading: You need to share contact information with Meta to access this model\nextra\\_gated\\_prompt: >-",
"### LLAMA 3 COMMUNITY LICENSE AGREEMENT\n\n\nMeta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the\nLlama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3\ndistributed by Meta at URL\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into\nthis Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or\nregulations to provide legal consent and that has legal authority to bind your employer or such other\nperson or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including\nmachine-learning model code, trained model weights, inference-enabling code, training-enabling code,\nfine-tuning enabling code and other elements of the foregoing distributed by Meta at\nURL\n\"Llama Materials\" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any\nportion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your\nprincipal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located\noutside of the EEA or Switzerland).\nBy clicking \"I Accept\" below or by using or distributing any portion or element of the Llama Materials,\nyou agree to be bound by this Agreement.\n\n\n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free\nlimited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama\nMaterials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the\nLlama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works\nthereof), or a product or service that uses any of them, you shall include a copy of this Agreement and\nprominently display \"Built with Meta Llama 3\" on a related website, user interface, blogpost, about page,\nor product documentation.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as\npart of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following\nattribution notice within a \"Notice\" text file distributed as a part of such copies: \"Meta Llama 3 is\nlicensed under the META LLAMA 3 Community License, Copyright © Meta Platforms, Inc. All Rights\nReserved.\"\niv. Your use of the Llama Materials must comply with applicable laws and regulations\n(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama\nMaterials (available at URL which is hereby incorporated by\nreference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to\nimprove any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users\nof the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700\nmillion monthly active users in the preceding calendar month, you must request a license from Meta,\nwhich Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the\nrights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY\nOUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \"AS IS\" BASIS, WITHOUT WARRANTIES OF\nANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE,\nNON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY\nRESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA\nMATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY\nOUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF\nLIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\nOUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\nINCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED\nOF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama\nMaterials, neither Meta nor Licensee may use any name or mark owned by or associated with the other\nor any of its affiliates, except as required for reasonable and customary use in describing and\nredistributing the Llama Materials.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\nrespect to any derivative works and modifications of the Llama Materials that are made by you, as\nbetween you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a\ncross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or\nresults, or any portion of any of the foregoing, constitutes infringement of intellectual property or other\nrights owned or licensable by you, then any licenses granted to you under this Agreement shall\nterminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold\nharmless Meta from and against any claim by any third party arising out of or related to your use or\ndistribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this\nAgreement or access to the Llama Materials and will continue in full force and effect until terminated in\naccordance with the terms and conditions herein. Meta may terminate this Agreement if you are in\nbreach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete\nand cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this\nAgreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of\nthe State of California without regard to choice of law principles, and the UN Convention on Contracts\nfor the International Sale of Goods does not apply to this Agreement. The courts of California shall have\nexclusive jurisdiction of any dispute arising out of this Agreement.\nextra\\_gated\\_fields:\nFirst Name: text\nLast Name: text\nDate of birth: date\\_picker\nCountry: country\nAffiliation: text\ngeo: ip\\_location \n\nBy clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox\nextra\\_gated\\_description: The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy.\nextra\\_gated\\_button\\_content: Submit\nlanguage:\n\n\n* en\ntags:\n* facebook\n* meta\n* pytorch\n* llama\n* llama-2\nlicense: llama2\n\n\n\n\n---\n\n\nMeta Llama 3\n============\n\n\nWe are unlocking the power of large language models. Our latest version of Llama is now accessible to individuals, creators, researchers, and businesses of all sizes so that they can experiment, innovate, and scale their ideas responsibly.\nThis release includes model weights and starting code for pre-trained and instruction tuned Llama 3 language models — including sizes of 8B to 70B parameters.\nThis repository is intended as a minimal example to load Llama 3 models and run inference. For more detailed examples, see llama-recipes.\n\n\nDownload\n--------\n\n\nIn order to download the model weights and tokenizer, please visit the Meta Llama website and accept our License.\nOnce your request is approved, you will receive a signed URL over email. Then run the URL script, passing the URL provided when prompted to start the download.\nPre-requisites: Make sure you have 'wget' and 'md5sum' installed. Then run the script: './URL'.\nKeep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as '403: Forbidden', you can always re-request a link.",
"### Access to Hugging Face\n\n\nWe are also providing downloads on Hugging Face.\n\n\nQuick Start\n-----------\n\n\nYou can follow the steps below to quickly get up and running with Llama 3 models. These steps will let you run quick inference locally. For more examples, see the Llama recipes repository.\n\n\n1. In a conda env with PyTorch / CUDA available clone and download this repository.\n2. In the top-level directory run:\n3. Visit the Meta Llama website and register to download the model/s.\n4. Once registered, you will get an email with a URL to download the models. You will need this URL when you run the URL script.\n5. Once you get the email, navigate to your downloaded llama repository and run the URL script.\n\n\n\t* Make sure to grant execution permissions to the URL script\n\t* During this process, you will be prompted to enter the URL from the email.\n\t* Do not use the \"Copy Link\" option but rather make sure to manually copy the link from the email.\n6. Once the model/s you want have been downloaded, you can run the model locally using the command below:\n\n\nNote\n\n\n* Replace 'llama-3-8b-prerelease-instruct/' with the path to your checkpoint directory and 'URL' with the path to your tokenizer model.\n* The '–nproc\\_per\\_node' should be set to the MP value for the model you are using.\n* Adjust the 'max\\_seq\\_len' and 'max\\_batch\\_size' parameters as needed.\n* This example runs the example\\_chat\\_completion.py found in this repository but you can change that to a different .py file.\n\n\nInference\n---------\n\n\nDifferent models require different model-parallel (MP) values:",
"### Pretrained Models\n\n\nThese models are not finetuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.\nSee 'example\\_text\\_completion.py' for some examples. To illustrate, see the command below to run it with the llama-2-7b model ('nproc\\_per\\_node' needs to be set to the 'MP' value):",
"### Instruction-tuned Models\n\n\nThe fine-tuned models were trained for dialogue applications. To get the expected features and performance for them, a specific formatting defined in 'chat\\_completion'\nneeds to be followed, including the 'INST' and '<>' tags, 'BOS' and 'EOS' tokens, and the whitespaces and breaklines in between (we recommend calling 'strip()' on inputs to avoid double-spaces).\nYou can also deploy additional classifiers for filtering out inputs and outputs that are deemed unsafe. See the llama-recipes repo for an example of how to add a safety checker to the inputs and outputs of your inference code.\nExamples using llama-2-7b-chat:\n\n\nLlama 3 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios.\nIn order to help developers address these risks, we have created the Responsible Use Guide.\n\n\nIssues\n------\n\n\nPlease report any software \"bug\", or other problems with the models through one of the following means:\n\n\n* Reporting issues with the model: URL\n* Reporting risky content generated by the model: URL\n* Reporting bugs and security concerns: URL\n\n\nModel Card\n----------\n\n\nSee MODEL\\_CARD.md.\n\n\nLicense\n-------\n\n\nOur model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.\nSee the LICENSE file, as well as our accompanying Acceptable Use Policy\n\n\nQuestions\n---------\n\n\nFor common questions, the FAQ can be found here which will be kept up to date over time as new questions arise."
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_tf_3-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_tf_3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_tf_3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6507
- F1 Score: 0.6032
- Accuracy: 0.613
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6617 | 14.29 | 200 | 0.6486 | 0.6194 | 0.623 |
| 0.5943 | 28.57 | 400 | 0.6960 | 0.6115 | 0.613 |
| 0.5463 | 42.86 | 600 | 0.7468 | 0.5997 | 0.603 |
| 0.5044 | 57.14 | 800 | 0.8013 | 0.6156 | 0.617 |
| 0.4711 | 71.43 | 1000 | 0.7840 | 0.6177 | 0.618 |
| 0.4415 | 85.71 | 1200 | 0.8302 | 0.6051 | 0.605 |
| 0.4145 | 100.0 | 1400 | 0.8097 | 0.6188 | 0.619 |
| 0.3917 | 114.29 | 1600 | 0.8352 | 0.5988 | 0.599 |
| 0.3643 | 128.57 | 1800 | 0.8827 | 0.5861 | 0.587 |
| 0.3434 | 142.86 | 2000 | 0.9270 | 0.5900 | 0.591 |
| 0.324 | 157.14 | 2200 | 0.9169 | 0.5951 | 0.595 |
| 0.3061 | 171.43 | 2400 | 0.9848 | 0.5828 | 0.586 |
| 0.2878 | 185.71 | 2600 | 0.9987 | 0.5984 | 0.599 |
| 0.2731 | 200.0 | 2800 | 0.9876 | 0.6039 | 0.604 |
| 0.26 | 214.29 | 3000 | 1.0300 | 0.6031 | 0.603 |
| 0.2442 | 228.57 | 3200 | 1.0535 | 0.6010 | 0.601 |
| 0.2364 | 242.86 | 3400 | 1.0614 | 0.6010 | 0.601 |
| 0.2227 | 257.14 | 3600 | 1.0652 | 0.6110 | 0.611 |
| 0.2121 | 271.43 | 3800 | 1.0705 | 0.5979 | 0.598 |
| 0.2036 | 285.71 | 4000 | 1.1761 | 0.5921 | 0.592 |
| 0.1957 | 300.0 | 4200 | 1.1462 | 0.5985 | 0.601 |
| 0.1871 | 314.29 | 4400 | 1.1468 | 0.5949 | 0.595 |
| 0.1784 | 328.57 | 4600 | 1.1677 | 0.6010 | 0.601 |
| 0.1715 | 342.86 | 4800 | 1.1372 | 0.6015 | 0.602 |
| 0.1659 | 357.14 | 5000 | 1.1639 | 0.6025 | 0.603 |
| 0.1615 | 371.43 | 5200 | 1.2520 | 0.5842 | 0.586 |
| 0.1554 | 385.71 | 5400 | 1.2483 | 0.5970 | 0.597 |
| 0.1496 | 400.0 | 5600 | 1.3048 | 0.5918 | 0.594 |
| 0.1449 | 414.29 | 5800 | 1.2459 | 0.6067 | 0.607 |
| 0.1404 | 428.57 | 6000 | 1.2448 | 0.5980 | 0.598 |
| 0.1367 | 442.86 | 6200 | 1.2650 | 0.5895 | 0.591 |
| 0.1322 | 457.14 | 6400 | 1.2640 | 0.5950 | 0.595 |
| 0.1282 | 471.43 | 6600 | 1.2992 | 0.5998 | 0.6 |
| 0.1257 | 485.71 | 6800 | 1.3368 | 0.5991 | 0.599 |
| 0.1221 | 500.0 | 7000 | 1.3274 | 0.5910 | 0.592 |
| 0.1207 | 514.29 | 7200 | 1.3231 | 0.6027 | 0.603 |
| 0.1164 | 528.57 | 7400 | 1.3676 | 0.6010 | 0.602 |
| 0.1144 | 542.86 | 7600 | 1.3355 | 0.6031 | 0.603 |
| 0.1122 | 557.14 | 7800 | 1.3400 | 0.6151 | 0.615 |
| 0.1079 | 571.43 | 8000 | 1.3563 | 0.6030 | 0.603 |
| 0.1067 | 585.71 | 8200 | 1.3635 | 0.6079 | 0.608 |
| 0.1042 | 600.0 | 8400 | 1.3858 | 0.6054 | 0.606 |
| 0.1057 | 614.29 | 8600 | 1.3702 | 0.6091 | 0.609 |
| 0.103 | 628.57 | 8800 | 1.3943 | 0.5968 | 0.597 |
| 0.1005 | 642.86 | 9000 | 1.3809 | 0.6038 | 0.604 |
| 0.0998 | 657.14 | 9200 | 1.4026 | 0.5950 | 0.596 |
| 0.0983 | 671.43 | 9400 | 1.4079 | 0.6090 | 0.609 |
| 0.0977 | 685.71 | 9600 | 1.4049 | 0.604 | 0.604 |
| 0.0973 | 700.0 | 9800 | 1.4035 | 0.5990 | 0.599 |
| 0.0963 | 714.29 | 10000 | 1.4000 | 0.6020 | 0.602 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_tf_3-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_tf_3-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T18:17:05+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_tf\_3-seqsight\_16384\_512\_56M-L32\_all
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_tf\_3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6507
* F1 Score: 0.6032
* Accuracy: 0.613
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
object-detection | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5582 | 0.32 | 100 | 1.7392 |
| 1.5953 | 0.64 | 200 | 1.4379 |
| 1.4199 | 0.96 | 300 | 1.3326 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "facebook/detr-resnet-50", "model-index": [{"name": "detr", "results": []}]} | maxencerch/detr | null | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:17:10+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #detr #object-detection #generated_from_trainer #base_model-facebook/detr-resnet-50 #license-apache-2.0 #endpoints_compatible #region-us
| detr
====
This model is a fine-tuned version of facebook/detr-resnet-50 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.3326
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 32
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 1
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #detr #object-detection #generated_from_trainer #base_model-facebook/detr-resnet-50 #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-gpt2-github_cybersecurity_READMEs
This model is a fine-tuned version of [sshleifer/tiny-gpt2](https://huggingface.co/sshleifer/tiny-gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 9.5272
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 10.2018 | 1.0 | 24065 | 10.1943 |
| 9.7092 | 2.0 | 48130 | 9.7041 |
| 9.5246 | 3.0 | 72195 | 9.5272 |
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.1
| {"tags": ["generated_from_trainer"], "base_model": "sshleifer/tiny-gpt2", "model-index": [{"name": "tiny-gpt2-github_cybersecurity_READMEs", "results": []}]} | clarapan/tiny-gpt2-github_cybersecurity_READMEs | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:sshleifer/tiny-gpt2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:17:24+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-sshleifer/tiny-gpt2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| tiny-gpt2-github\_cybersecurity\_READMEs
========================================
This model is a fine-tuned version of sshleifer/tiny-gpt2 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 9.5272
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.40.0.dev0
* Pytorch 2.2.1
* Datasets 2.18.0
* Tokenizers 0.15.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0.dev0\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-sshleifer/tiny-gpt2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0.dev0\n* Pytorch 2.2.1\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/saucam/Arithmo-Wizard-2-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Arithmo-Wizard-2-7B-GGUF/resolve/main/Arithmo-Wizard-2-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["merge", "mergekit", "lucyknada/microsoft_WizardLM-2-7B", "upaya07/Arithmo2-Mistral-7B"], "base_model": "saucam/Arithmo-Wizard-2-7B", "quantized_by": "mradermacher"} | mradermacher/Arithmo-Wizard-2-7B-GGUF | null | [
"transformers",
"gguf",
"merge",
"mergekit",
"lucyknada/microsoft_WizardLM-2-7B",
"upaya07/Arithmo2-Mistral-7B",
"en",
"base_model:saucam/Arithmo-Wizard-2-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:20:40+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #merge #mergekit #lucyknada/microsoft_WizardLM-2-7B #upaya07/Arithmo2-Mistral-7B #en #base_model-saucam/Arithmo-Wizard-2-7B #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #merge #mergekit #lucyknada/microsoft_WizardLM-2-7B #upaya07/Arithmo2-Mistral-7B #en #base_model-saucam/Arithmo-Wizard-2-7B #license-apache-2.0 #endpoints_compatible #region-us \n"
]
|
null | transformers |
# Uploaded model
- **Developed by:** codesagar
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | codesagar/prompt-guard-classification-v9 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:20:55+00:00 | []
| [
"en"
]
| TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: codesagar
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
| [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
|
null | transformers |
# Uploaded model
- **Developed by:** codesagar
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | codesagar/prompt-guard-reasoning-v9 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:22:17+00:00 | []
| [
"en"
]
| TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: codesagar
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
| [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
]
|
reinforcement-learning | null |
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
| {"tags": ["Pixelcopter-PLE-v0", "reinforce", "reinforcement-learning", "custom-implementation", "deep-rl-class"], "model-index": [{"name": "Reinforce-PixelCopter", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "Pixelcopter-PLE-v0", "type": "Pixelcopter-PLE-v0"}, "metrics": [{"type": "mean_reward", "value": "33.30 +/- 28.87", "name": "mean_reward", "verified": false}]}]}]} | minindu-liya99/Reinforce-PixelCopter | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| null | 2024-04-16T18:22:37+00:00 | []
| []
| TAGS
#Pixelcopter-PLE-v0 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us
|
# Reinforce Agent playing Pixelcopter-PLE-v0
This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL
| [
"# Reinforce Agent playing Pixelcopter-PLE-v0\n This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
]
| [
"TAGS\n#Pixelcopter-PLE-v0 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us \n",
"# Reinforce Agent playing Pixelcopter-PLE-v0\n This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_tf_2-seqsight_16384_512_56M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_16384_512_56M](https://huggingface.co/mahdibaghbanzadeh/seqsight_16384_512_56M) on the [mahdibaghbanzadeh/GUE_tf_2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_tf_2) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2019
- F1 Score: 0.6650
- Accuracy: 0.667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6352 | 20.0 | 200 | 0.6548 | 0.6349 | 0.64 |
| 0.5233 | 40.0 | 400 | 0.7109 | 0.634 | 0.634 |
| 0.4613 | 60.0 | 600 | 0.7734 | 0.6487 | 0.649 |
| 0.4045 | 80.0 | 800 | 0.8225 | 0.6400 | 0.64 |
| 0.3559 | 100.0 | 1000 | 0.8703 | 0.6432 | 0.645 |
| 0.3205 | 120.0 | 1200 | 0.9109 | 0.6484 | 0.649 |
| 0.2891 | 140.0 | 1400 | 0.9661 | 0.6509 | 0.651 |
| 0.2623 | 160.0 | 1600 | 1.0167 | 0.6468 | 0.647 |
| 0.2396 | 180.0 | 1800 | 1.0339 | 0.6496 | 0.65 |
| 0.2192 | 200.0 | 2000 | 1.0883 | 0.6459 | 0.646 |
| 0.2024 | 220.0 | 2200 | 1.0397 | 0.6523 | 0.654 |
| 0.187 | 240.0 | 2400 | 1.0970 | 0.6517 | 0.652 |
| 0.1746 | 260.0 | 2600 | 1.1236 | 0.658 | 0.658 |
| 0.1638 | 280.0 | 2800 | 1.1186 | 0.6530 | 0.653 |
| 0.1525 | 300.0 | 3000 | 1.1326 | 0.66 | 0.66 |
| 0.14 | 320.0 | 3200 | 1.2430 | 0.6498 | 0.651 |
| 0.1344 | 340.0 | 3400 | 1.1866 | 0.6619 | 0.662 |
| 0.1271 | 360.0 | 3600 | 1.2209 | 0.6627 | 0.663 |
| 0.1208 | 380.0 | 3800 | 1.2225 | 0.6620 | 0.662 |
| 0.1133 | 400.0 | 4000 | 1.2589 | 0.6682 | 0.669 |
| 0.1083 | 420.0 | 4200 | 1.2676 | 0.6580 | 0.658 |
| 0.1027 | 440.0 | 4400 | 1.2627 | 0.6598 | 0.66 |
| 0.0979 | 460.0 | 4600 | 1.2802 | 0.6650 | 0.665 |
| 0.0936 | 480.0 | 4800 | 1.3481 | 0.6644 | 0.665 |
| 0.0889 | 500.0 | 5000 | 1.3242 | 0.6600 | 0.66 |
| 0.0858 | 520.0 | 5200 | 1.3271 | 0.6630 | 0.663 |
| 0.0833 | 540.0 | 5400 | 1.4094 | 0.6575 | 0.658 |
| 0.0803 | 560.0 | 5600 | 1.3034 | 0.6580 | 0.658 |
| 0.0758 | 580.0 | 5800 | 1.4293 | 0.6630 | 0.663 |
| 0.074 | 600.0 | 6000 | 1.3888 | 0.6650 | 0.665 |
| 0.0702 | 620.0 | 6200 | 1.4482 | 0.6590 | 0.659 |
| 0.0689 | 640.0 | 6400 | 1.4101 | 0.6633 | 0.664 |
| 0.0652 | 660.0 | 6600 | 1.4090 | 0.662 | 0.662 |
| 0.0657 | 680.0 | 6800 | 1.4259 | 0.6570 | 0.657 |
| 0.0635 | 700.0 | 7000 | 1.4426 | 0.6590 | 0.659 |
| 0.0607 | 720.0 | 7200 | 1.4750 | 0.6630 | 0.663 |
| 0.0594 | 740.0 | 7400 | 1.5143 | 0.6600 | 0.66 |
| 0.0569 | 760.0 | 7600 | 1.4227 | 0.6560 | 0.656 |
| 0.056 | 780.0 | 7800 | 1.4694 | 0.6569 | 0.657 |
| 0.0558 | 800.0 | 8000 | 1.4743 | 0.652 | 0.652 |
| 0.0537 | 820.0 | 8200 | 1.4989 | 0.6560 | 0.656 |
| 0.0519 | 840.0 | 8400 | 1.4999 | 0.6509 | 0.651 |
| 0.0509 | 860.0 | 8600 | 1.5267 | 0.6560 | 0.656 |
| 0.05 | 880.0 | 8800 | 1.5124 | 0.6560 | 0.656 |
| 0.0504 | 900.0 | 9000 | 1.5107 | 0.6560 | 0.656 |
| 0.0492 | 920.0 | 9200 | 1.5126 | 0.6540 | 0.654 |
| 0.048 | 940.0 | 9400 | 1.5143 | 0.6600 | 0.66 |
| 0.0473 | 960.0 | 9600 | 1.5028 | 0.6530 | 0.653 |
| 0.0474 | 980.0 | 9800 | 1.5153 | 0.6580 | 0.658 |
| 0.0463 | 1000.0 | 10000 | 1.5183 | 0.6560 | 0.656 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_16384_512_56M", "model-index": [{"name": "GUE_tf_2-seqsight_16384_512_56M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_tf_2-seqsight_16384_512_56M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_16384_512_56M",
"region:us"
]
| null | 2024-04-16T18:23:07+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us
| GUE\_tf\_2-seqsight\_16384\_512\_56M-L32\_all
=============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_16384\_512\_56M on the mahdibaghbanzadeh/GUE\_tf\_2 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.2019
* F1 Score: 0.6650
* Accuracy: 0.667
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_16384_512_56M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 | {"library_name": "peft", "base_model": "mistralai/Mistral-7B-Instruct-v0.2"} | vaarrun009/Rzolut_Mistral_NER_Sentiment | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
]
| null | 2024-04-16T18:23:26+00:00 | [
"1910.09700"
]
| []
| TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.2 #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
### Framework versions
- PEFT 0.10.0 | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
]
| [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.2 #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
]
|
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "262.08 +/- 13.10", "name": "mean_reward", "verified": false}]}]}]} | b0n541/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| null | 2024-04-16T18:28:09+00:00 | []
| []
| TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
]
| [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
]
|
reinforcement-learning | null |
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="MLIsaac/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
| {"tags": ["FrozenLake-v1-4x4-no_slippery", "q-learning", "reinforcement-learning", "custom-implementation"], "model-index": [{"name": "q-FrozenLake-v1-4x4-noSlippery", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "FrozenLake-v1-4x4-no_slippery", "type": "FrozenLake-v1-4x4-no_slippery"}, "metrics": [{"type": "mean_reward", "value": "1.00 +/- 0.00", "name": "mean_reward", "verified": false}]}]}]} | MLIsaac/q-FrozenLake-v1-4x4-noSlippery | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| null | 2024-04-16T18:28:32+00:00 | []
| []
| TAGS
#FrozenLake-v1-4x4-no_slippery #q-learning #reinforcement-learning #custom-implementation #model-index #region-us
|
# Q-Learning Agent playing1 FrozenLake-v1
This is a trained model of a Q-Learning agent playing FrozenLake-v1 .
## Usage
| [
"# Q-Learning Agent playing1 FrozenLake-v1\n This is a trained model of a Q-Learning agent playing FrozenLake-v1 .\n\n ## Usage"
]
| [
"TAGS\n#FrozenLake-v1-4x4-no_slippery #q-learning #reinforcement-learning #custom-implementation #model-index #region-us \n",
"# Q-Learning Agent playing1 FrozenLake-v1\n This is a trained model of a Q-Learning agent playing FrozenLake-v1 .\n\n ## Usage"
]
|
text-generation | transformers | # Introduction
The model is primarily designed for translating Fortran code into C++ code. It is based on the deepseek-ai/deepseek-coder-33b-instruct model. Fine-tuned on a customized Fortran to C++ translation dataset.
# Model Inference
The code for inference and Web demo is shown in the github: [Fortran2Cpp](https://github.com/bin123apple/Fortran2Cpp)
| {"license": "apache-2.0", "tags": ["code"], "pipeline_tag": "text-generation"} | Bin12345/Fortran2Cpp | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"code",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:29:59+00:00 | []
| []
| TAGS
#transformers #safetensors #llama #text-generation #code #conversational #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # Introduction
The model is primarily designed for translating Fortran code into C++ code. It is based on the deepseek-ai/deepseek-coder-33b-instruct model. Fine-tuned on a customized Fortran to C++ translation dataset.
# Model Inference
The code for inference and Web demo is shown in the github: Fortran2Cpp
| [
"# Introduction\n\nThe model is primarily designed for translating Fortran code into C++ code. It is based on the deepseek-ai/deepseek-coder-33b-instruct model. Fine-tuned on a customized Fortran to C++ translation dataset.",
"# Model Inference\n\nThe code for inference and Web demo is shown in the github: Fortran2Cpp"
]
| [
"TAGS\n#transformers #safetensors #llama #text-generation #code #conversational #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Introduction\n\nThe model is primarily designed for translating Fortran code into C++ code. It is based on the deepseek-ai/deepseek-coder-33b-instruct model. Fine-tuned on a customized Fortran to C++ translation dataset.",
"# Model Inference\n\nThe code for inference and Web demo is shown in the github: Fortran2Cpp"
]
|
null | transformers |
To load the pretrained model:
```
from exlib.datasets.massmaps import MassMapsConvnetRegModel
model = MassMapsConvnetForImageRegression.from_pretrained(f'BrachioLab/massmaps-conv')
``` | {"license": "mit"} | BrachioLab/massmaps-conv | null | [
"transformers",
"pytorch",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:32:13+00:00 | []
| []
| TAGS
#transformers #pytorch #license-mit #endpoints_compatible #region-us
|
To load the pretrained model:
| []
| [
"TAGS\n#transformers #pytorch #license-mit #endpoints_compatible #region-us \n"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_300_tata-seqsight_32768_512_30M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_30M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_30M) on the [mahdibaghbanzadeh/GUE_prom_prom_300_tata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_300_tata) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2078
- F1 Score: 0.5510
- Accuracy: 0.5514
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6028 | 66.67 | 200 | 0.7494 | 0.6104 | 0.6101 |
| 0.3832 | 133.33 | 400 | 0.9878 | 0.6202 | 0.6199 |
| 0.2719 | 200.0 | 600 | 1.1119 | 0.6146 | 0.6150 |
| 0.2229 | 266.67 | 800 | 1.1731 | 0.6099 | 0.6101 |
| 0.1995 | 333.33 | 1000 | 1.2570 | 0.5987 | 0.5987 |
| 0.1829 | 400.0 | 1200 | 1.3982 | 0.5998 | 0.6003 |
| 0.1691 | 466.67 | 1400 | 1.4023 | 0.5972 | 0.5987 |
| 0.1582 | 533.33 | 1600 | 1.4555 | 0.5940 | 0.5971 |
| 0.1488 | 600.0 | 1800 | 1.4840 | 0.5970 | 0.5987 |
| 0.1408 | 666.67 | 2000 | 1.4588 | 0.5922 | 0.5922 |
| 0.135 | 733.33 | 2200 | 1.5472 | 0.5897 | 0.5905 |
| 0.1291 | 800.0 | 2400 | 1.5691 | 0.5889 | 0.5889 |
| 0.1218 | 866.67 | 2600 | 1.6300 | 0.5897 | 0.5905 |
| 0.1172 | 933.33 | 2800 | 1.6756 | 0.5852 | 0.5856 |
| 0.113 | 1000.0 | 3000 | 1.7568 | 0.5783 | 0.5824 |
| 0.1072 | 1066.67 | 3200 | 1.6157 | 0.6021 | 0.6020 |
| 0.1033 | 1133.33 | 3400 | 1.7740 | 0.5885 | 0.5889 |
| 0.0991 | 1200.0 | 3600 | 1.7771 | 0.5852 | 0.5856 |
| 0.0964 | 1266.67 | 3800 | 1.7366 | 0.5901 | 0.5905 |
| 0.093 | 1333.33 | 4000 | 1.8139 | 0.5934 | 0.5954 |
| 0.089 | 1400.0 | 4200 | 1.7386 | 0.5788 | 0.5824 |
| 0.0846 | 1466.67 | 4400 | 1.6444 | 0.5896 | 0.5905 |
| 0.0814 | 1533.33 | 4600 | 1.9133 | 0.5990 | 0.5987 |
| 0.0801 | 1600.0 | 4800 | 1.8286 | 0.5918 | 0.5922 |
| 0.0768 | 1666.67 | 5000 | 1.8884 | 0.5864 | 0.5889 |
| 0.0745 | 1733.33 | 5200 | 1.9040 | 0.5925 | 0.5922 |
| 0.0716 | 1800.0 | 5400 | 1.9486 | 0.5874 | 0.5889 |
| 0.0688 | 1866.67 | 5600 | 1.9866 | 0.5901 | 0.5905 |
| 0.0679 | 1933.33 | 5800 | 1.8887 | 0.5936 | 0.5938 |
| 0.0652 | 2000.0 | 6000 | 1.8391 | 0.5910 | 0.5938 |
| 0.0627 | 2066.67 | 6200 | 2.0301 | 0.6052 | 0.6052 |
| 0.0601 | 2133.33 | 6400 | 1.9432 | 0.6038 | 0.6036 |
| 0.0605 | 2200.0 | 6600 | 2.0469 | 0.6022 | 0.6020 |
| 0.0589 | 2266.67 | 6800 | 2.0014 | 0.5920 | 0.5922 |
| 0.0566 | 2333.33 | 7000 | 2.1108 | 0.5954 | 0.5954 |
| 0.0572 | 2400.0 | 7200 | 2.0063 | 0.5937 | 0.5938 |
| 0.0548 | 2466.67 | 7400 | 2.0023 | 0.6051 | 0.6052 |
| 0.0534 | 2533.33 | 7600 | 2.0226 | 0.5964 | 0.5971 |
| 0.0526 | 2600.0 | 7800 | 2.1183 | 0.6018 | 0.6020 |
| 0.0507 | 2666.67 | 8000 | 2.0771 | 0.5982 | 0.5987 |
| 0.051 | 2733.33 | 8200 | 2.0189 | 0.5924 | 0.5922 |
| 0.0497 | 2800.0 | 8400 | 2.1222 | 0.5990 | 0.5987 |
| 0.0482 | 2866.67 | 8600 | 2.1214 | 0.6019 | 0.6020 |
| 0.0483 | 2933.33 | 8800 | 2.1318 | 0.5970 | 0.5971 |
| 0.0487 | 3000.0 | 9000 | 2.0644 | 0.6048 | 0.6052 |
| 0.0474 | 3066.67 | 9200 | 2.0959 | 0.5987 | 0.5987 |
| 0.0464 | 3133.33 | 9400 | 2.0722 | 0.5969 | 0.5971 |
| 0.0467 | 3200.0 | 9600 | 2.0851 | 0.5964 | 0.5971 |
| 0.0457 | 3266.67 | 9800 | 2.1304 | 0.6019 | 0.6020 |
| 0.0452 | 3333.33 | 10000 | 2.1127 | 0.5967 | 0.5971 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_30M", "model-index": [{"name": "GUE_prom_prom_300_tata-seqsight_32768_512_30M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_300_tata-seqsight_32768_512_30M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_30M",
"region:us"
]
| null | 2024-04-16T18:32:16+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_30M #region-us
| GUE\_prom\_prom\_300\_tata-seqsight\_32768\_512\_30M-L32\_all
=============================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_30M on the mahdibaghbanzadeh/GUE\_prom\_prom\_300\_tata dataset.
It achieves the following results on the evaluation set:
* Loss: 1.2078
* F1 Score: 0.5510
* Accuracy: 0.5514
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_30M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
text-classification | transformers |
Fine-tuned [LVBERT](https://huggingface.co/AiLab-IMCS-UL/lvbert) for multi-label emotion classification task.
Model was trained on [lv_go_emotions](https://huggingface.co/datasets/SkyWater21/lv_go_emotions) dataset. This dataset is Latvian translation of [GoEmotions](https://huggingface.co/datasets/go_emotions) dataset. Google Translate was used to generate the machine translation.
Labels:
```yaml
0: admiration
1: amusement
2: anger
3: annoyance
4: approval
5: caring
6: confusion
7: curiosity
8: desire
9: disappointment
10: disapproval
11: disgust
12: embarrassment
13: excitement
14: fear
15: gratitude
16: grief
17: joy
18: love
19: nervousness
20: optimism
21: pride
22: realization
23: relief
24: remorse
25: sadness
26: surprise
27: neutral
```
Seed used for random number generator is 42:
```python
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
```
Training parameters:
```yaml
max_length: null
batch_size: 32
shuffle: True
num_workers: 2
pin_memory: False
drop_last: False
optimizer: adam
lr: 0.00001
weight_decay: 0
problem_type: multi_label_classification
num_epochs: 5
```
Evaluation results on test split of [lv_go_emotions](https://huggingface.co/datasets/SkyWater21/lv_go_emotions)
| |Precision|Recall|F1-Score|AUC-ROC|Support|
|--------------|---------|------|--------|-------|-------|
|admiration | 0.64| 0.64| 0.64| 0.92| 504|
|amusement | 0.76| 0.85| 0.80| 0.96| 264|
|anger | 0.51| 0.21| 0.29| 0.86| 198|
|annoyance | 0.49| 0.15| 0.23| 0.78| 320|
|approval | 0.35| 0.33| 0.34| 0.80| 351|
|caring | 0.43| 0.39| 0.41| 0.89| 135|
|confusion | 0.53| 0.33| 0.41| 0.94| 153|
|curiosity | 0.49| 0.42| 0.45| 0.94| 284|
|desire | 0.63| 0.37| 0.47| 0.92| 83|
|disappointment| 0.45| 0.11| 0.18| 0.82| 151|
|disapproval | 0.45| 0.25| 0.32| 0.84| 267|
|disgust | 0.63| 0.29| 0.40| 0.92| 123|
|embarrassment | 0.50| 0.14| 0.21| 0.85| 37|
|excitement | 0.55| 0.16| 0.24| 0.89| 103|
|fear | 0.65| 0.58| 0.61| 0.95| 78|
|gratitude | 0.88| 0.91| 0.90| 0.99| 352|
|grief | 0.00| 0.00| 0.00| 0.78| 6|
|joy | 0.61| 0.39| 0.47| 0.93| 161|
|love | 0.80| 0.69| 0.74| 0.97| 238|
|nervousness | 0.00| 0.00| 0.00| 0.95| 23|
|optimism | 0.57| 0.47| 0.52| 0.90| 186|
|pride | 0.00| 0.00| 0.00| 0.73| 16|
|realization | 0.29| 0.08| 0.13| 0.76| 145|
|relief | 0.00| 0.00| 0.00| 0.85| 11|
|remorse | 0.54| 0.68| 0.60| 0.98| 56|
|sadness | 0.60| 0.50| 0.54| 0.93| 156|
|surprise | 0.65| 0.41| 0.50| 0.92| 141|
|neutral | 0.67| 0.50| 0.57| 0.81| 1787|
|micro avg | 0.62| 0.46| 0.53| 0.93| 6329|
|macro avg | 0.49| 0.35| 0.39| 0.88| 6329|
|weighted avg | 0.60| 0.46| 0.51| 0.87| 6329|
|samples avg | 0.52| 0.48| 0.49| nan| 6329| | {"language": ["lv"], "license": "mit", "datasets": ["SkyWater21/lv_go_emotions"]} | SkyWater21/lvbert-lv-go-emotions | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"lv",
"dataset:SkyWater21/lv_go_emotions",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:32:31+00:00 | []
| [
"lv"
]
| TAGS
#transformers #safetensors #bert #text-classification #lv #dataset-SkyWater21/lv_go_emotions #license-mit #autotrain_compatible #endpoints_compatible #region-us
| Fine-tuned LVBERT for multi-label emotion classification task.
Model was trained on lv\_go\_emotions dataset. This dataset is Latvian translation of GoEmotions dataset. Google Translate was used to generate the machine translation.
Labels:
Seed used for random number generator is 42:
Training parameters:
Evaluation results on test split of lv\_go\_emotions
| []
| [
"TAGS\n#transformers #safetensors #bert #text-classification #lv #dataset-SkyWater21/lv_go_emotions #license-mit #autotrain_compatible #endpoints_compatible #region-us \n"
]
|
reinforcement-learning | null |
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="MLIsaac/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
| {"tags": ["Taxi-v3", "q-learning", "reinforcement-learning", "custom-implementation"], "model-index": [{"name": "Taxi-v3", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "Taxi-v3", "type": "Taxi-v3"}, "metrics": [{"type": "mean_reward", "value": "7.56 +/- 2.71", "name": "mean_reward", "verified": false}]}]}]} | MLIsaac/Taxi-v3 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| null | 2024-04-16T18:33:51+00:00 | []
| []
| TAGS
#Taxi-v3 #q-learning #reinforcement-learning #custom-implementation #model-index #region-us
|
# Q-Learning Agent playing1 Taxi-v3
This is a trained model of a Q-Learning agent playing Taxi-v3 .
## Usage
| [
"# Q-Learning Agent playing1 Taxi-v3\n This is a trained model of a Q-Learning agent playing Taxi-v3 .\n\n ## Usage"
]
| [
"TAGS\n#Taxi-v3 #q-learning #reinforcement-learning #custom-implementation #model-index #region-us \n",
"# Q-Learning Agent playing1 Taxi-v3\n This is a trained model of a Q-Learning agent playing Taxi-v3 .\n\n ## Usage"
]
|
sentence-similarity | sentence-transformers |
# atasoglu/xlm-roberta-base-nli-stsb-tr
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
This model was adapted from [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) and fine-tuned on these datasets:
- [nli_tr](https://huggingface.co/datasets/nli_tr)
- [emrecan/stsb-mt-turkish](https://huggingface.co/datasets/emrecan/stsb-mt-turkish)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('atasoglu/xlm-roberta-base-nli-stsb-tr')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('atasoglu/xlm-roberta-base-nli-stsb-tr')
model = AutoModel.from_pretrained('atasoglu/xlm-roberta-base-nli-stsb-tr')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
Achieved results on the [STS-b](https://huggingface.co/datasets/emrecan/stsb-mt-turkish) test split are given below:
```txt
Cosine-Similarity : Pearson: 0.8268 Spearman: 0.8273
Manhattan-Distance: Pearson: 0.8216 Spearman: 0.8260
Euclidean-Distance: Pearson: 0.8166 Spearman: 0.8223
Dot-Product-Similarity: Pearson: 0.7982 Spearman: 0.7931
```
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 180 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 18,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 108,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | {"language": ["tr"], "license": "mit", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "transformers"], "datasets": ["nli_tr", "emrecan/stsb-mt-turkish"], "pipeline_tag": "sentence-similarity", "base_model": "FacebookAI/xlm-roberta-base"} | atasoglu/xlm-roberta-base-nli-stsb-tr | null | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"tr",
"dataset:nli_tr",
"dataset:emrecan/stsb-mt-turkish",
"base_model:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:34:12+00:00 | []
| [
"tr"
]
| TAGS
#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #transformers #tr #dataset-nli_tr #dataset-emrecan/stsb-mt-turkish #base_model-FacebookAI/xlm-roberta-base #license-mit #endpoints_compatible #region-us
|
# atasoglu/xlm-roberta-base-nli-stsb-tr
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
This model was adapted from FacebookAI/xlm-roberta-base and fine-tuned on these datasets:
- nli_tr
- emrecan/stsb-mt-turkish
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers installed:
Then you can use the model like this:
## Usage (HuggingFace Transformers)
Without sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
## Evaluation Results
Achieved results on the STS-b test split are given below:
## Training
The model was trained with the parameters:
DataLoader:
'URL.dataloader.DataLoader' of length 180 with parameters:
Loss:
'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss'
Parameters of the fit()-Method:
## Full Model Architecture
## Citing & Authors
| [
"# atasoglu/xlm-roberta-base-nli-stsb-tr\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.\n\nThis model was adapted from FacebookAI/xlm-roberta-base and fine-tuned on these datasets:\n- nli_tr\n- emrecan/stsb-mt-turkish",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\nAchieved results on the STS-b test split are given below:",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 180 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss' \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
]
| [
"TAGS\n#sentence-transformers #safetensors #xlm-roberta #feature-extraction #sentence-similarity #transformers #tr #dataset-nli_tr #dataset-emrecan/stsb-mt-turkish #base_model-FacebookAI/xlm-roberta-base #license-mit #endpoints_compatible #region-us \n",
"# atasoglu/xlm-roberta-base-nli-stsb-tr\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.\n\nThis model was adapted from FacebookAI/xlm-roberta-base and fine-tuned on these datasets:\n- nli_tr\n- emrecan/stsb-mt-turkish",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\nAchieved results on the STS-b test split are given below:",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 180 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss' \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
]
|
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-pt-1000h
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba default dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3036
- Wer: 0.1490
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10000
- training_steps: 182000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:------:|:---------------:|:------:|
| 0.2594 | 1.58 | 160000 | 0.6842 | 0.1525 |
| 0.3036 | 1.77 | 180000 | 0.6491 | 0.1490 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.1.dev0
- Tokenizers 0.15.0
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba"], "metrics": ["wer"], "base_model": "openai/whisper-small", "model-index": [{"name": "whisper-medium-pt-1000h", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba default", "type": "fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba", "args": "default"}, "metrics": [{"type": "wer", "value": 0.149, "name": "Wer"}]}]}]} | fsicoli/whisper-small-pt-1000h | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba",
"base_model:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:34:52+00:00 | []
| []
| TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us
| whisper-small-pt-1000h
======================
This model is a fine-tuned version of openai/whisper-small on the fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba default dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3036
* Wer: 0.1490
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-06
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 10000
* training\_steps: 182000
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.0.dev0
* Pytorch 2.2.1+cu121
* Datasets 2.18.1.dev0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-06\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 10000\n* training\\_steps: 182000\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.0.dev0\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.1.dev0\n* Tokenizers 0.15.0"
]
| [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-fsicoli/cv17-fleurs-coraa-mls-ted-alcaim-cf-cdc-lapsbm-lapsmail-sydney-lingualibre-voxforge-tatoeba #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-06\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 10000\n* training\\_steps: 182000\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.0.dev0\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.1.dev0\n* Tokenizers 0.15.0"
]
|
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 | {"library_name": "peft", "base_model": "stabilityai/stablelm-3b-4e1t"} | AY2324S2-CS4248-Team-47/StableLM-DPO-Backtranslations | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:stabilityai/stablelm-3b-4e1t",
"region:us"
]
| null | 2024-04-16T18:35:23+00:00 | [
"1910.09700"
]
| []
| TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-stabilityai/stablelm-3b-4e1t #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
### Framework versions
- PEFT 0.10.0 | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
]
| [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-stabilityai/stablelm-3b-4e1t #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact",
"### Framework versions\n\n- PEFT 0.10.0"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# leagaleasy-mistral-7b-instruct-v0.2-v1
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "leagaleasy-mistral-7b-instruct-v0.2-v1", "results": []}]} | philmui/leagaleasy-mistral-7b-instruct-v0.2-v1 | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T18:35:56+00:00 | []
| []
| TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
|
# leagaleasy-mistral-7b-instruct-v0.2-v1
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | [
"# leagaleasy-mistral-7b-instruct-v0.2-v1\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 4\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 4\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"# leagaleasy-mistral-7b-instruct-v0.2-v1\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 4\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 4\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
]
|
text-classification | adapter-transformers | MFANN chain of thought experiment developed my makhi burroughs.
3b version here: https://huggingface.co/netcat420/MFANN3bv0.4
BENCHMARKS: avg: 72.23 ARC: 68.86 HellaSwag: 86.65 MMLU: 63.63 TruthfulQA: 70.18 winogrande: 79.72 GSM8K: 64.37


| {"license": "apache-2.0", "library_name": "adapter-transformers", "datasets": ["netcat420/MFANN"], "pipeline_tag": "text-classification"} | netcat420/MFANNv0.5-GGUF | null | [
"adapter-transformers",
"gguf",
"text-classification",
"dataset:netcat420/MFANN",
"license:apache-2.0",
"region:us"
]
| null | 2024-04-16T18:36:47+00:00 | []
| []
| TAGS
#adapter-transformers #gguf #text-classification #dataset-netcat420/MFANN #license-apache-2.0 #region-us
| MFANN chain of thought experiment developed my makhi burroughs.
3b version here: URL
BENCHMARKS: avg: 72.23 ARC: 68.86 HellaSwag: 86.65 MMLU: 63.63 TruthfulQA: 70.18 winogrande: 79.72 GSM8K: 64.37
!image/png
!image/png
| []
| [
"TAGS\n#adapter-transformers #gguf #text-classification #dataset-netcat420/MFANN #license-apache-2.0 #region-us \n"
]
|
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - rzhen0615/corgy_dog_LoRA
<Gallery />
## Model description
These are rzhen0615/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK dog to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](rzhen0615/corgy_dog_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | {"license": "openrail++", "library_name": "diffusers", "tags": ["text-to-image", "text-to-image", "diffusers-training", "diffusers", "lora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers"], "base_model": "stabilityai/stable-diffusion-xl-base-1.0", "instance_prompt": "a photo of TOK dog", "widget": []} | rzhen0615/corgy_dog_LoRA | null | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
]
| null | 2024-04-16T18:37:41+00:00 | []
| []
| TAGS
#diffusers #tensorboard #text-to-image #diffusers-training #lora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us
|
# SDXL LoRA DreamBooth - rzhen0615/corgy_dog_LoRA
<Gallery />
## Model description
These are rzhen0615/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using DreamBooth.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK dog to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
Download them in the Files & versions tab.
## Intended uses & limitations
#### How to use
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | [
"# SDXL LoRA DreamBooth - rzhen0615/corgy_dog_LoRA\n\n<Gallery />",
"## Model description\n\nThese are rzhen0615/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use a photo of TOK dog to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
]
| [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #lora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n",
"# SDXL LoRA DreamBooth - rzhen0615/corgy_dog_LoRA\n\n<Gallery />",
"## Model description\n\nThese are rzhen0615/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use a photo of TOK dog to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
]
|
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# iter0_full
This model is a fine-tuned version of [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) on the UCLA-AGI/SPIN_iter0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 32
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["alignment-handbook", "generated_from_trainer"], "datasets": ["UCLA-AGI/SPIN_iter0"], "base_model": "alignment-handbook/zephyr-7b-sft-full", "model-index": [{"name": "iter0_full", "results": []}]} | AmberYifan/test-spin-iter0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"conversational",
"dataset:UCLA-AGI/SPIN_iter0",
"base_model:alignment-handbook/zephyr-7b-sft-full",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:38:05+00:00 | []
| []
| TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #conversational #dataset-UCLA-AGI/SPIN_iter0 #base_model-alignment-handbook/zephyr-7b-sft-full #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# iter0_full
This model is a fine-tuned version of alignment-handbook/zephyr-7b-sft-full on the UCLA-AGI/SPIN_iter0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 32
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# iter0_full\n\nThis model is a fine-tuned version of alignment-handbook/zephyr-7b-sft-full on the UCLA-AGI/SPIN_iter0 dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 4\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 4\n- total_train_batch_size: 32\n- total_eval_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.37.0\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
]
| [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #conversational #dataset-UCLA-AGI/SPIN_iter0 #base_model-alignment-handbook/zephyr-7b-sft-full #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# iter0_full\n\nThis model is a fine-tuned version of alignment-handbook/zephyr-7b-sft-full on the UCLA-AGI/SPIN_iter0 dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 4\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 4\n- total_train_batch_size: 32\n- total_eval_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.37.0\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_shp1_dpo7
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8000
- Rewards/chosen: -7.0133
- Rewards/rejected: -7.1903
- Rewards/accuracies: 0.4800
- Rewards/margins: 0.1770
- Logps/rejected: -240.3288
- Logps/chosen: -247.0569
- Logits/rejected: -1.1073
- Logits/chosen: -1.0850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0959 | 2.67 | 100 | 1.3530 | -3.1387 | -3.5029 | 0.5500 | 0.3642 | -235.0611 | -241.5217 | -0.6924 | -0.6728 |
| 0.0119 | 5.33 | 200 | 2.3339 | -9.2972 | -9.3321 | 0.5400 | 0.0349 | -243.3885 | -250.3196 | -0.7541 | -0.7327 |
| 0.063 | 8.0 | 300 | 3.1443 | -10.1013 | -9.9537 | 0.4800 | -0.1475 | -244.2765 | -251.4682 | -0.8796 | -0.8535 |
| 0.0016 | 10.67 | 400 | 2.8783 | -10.1491 | -10.5391 | 0.5100 | 0.3900 | -245.1127 | -251.5365 | -1.0090 | -0.9845 |
| 0.0 | 13.33 | 500 | 2.8233 | -7.0398 | -7.1738 | 0.4700 | 0.1340 | -240.3052 | -247.0948 | -1.1069 | -1.0847 |
| 0.0 | 16.0 | 600 | 2.7833 | -7.0362 | -7.2095 | 0.4800 | 0.1733 | -240.3561 | -247.0895 | -1.1075 | -1.0848 |
| 0.0 | 18.67 | 700 | 2.7984 | -7.0122 | -7.1531 | 0.4800 | 0.1409 | -240.2756 | -247.0552 | -1.1069 | -1.0844 |
| 0.0 | 21.33 | 800 | 2.7969 | -7.0208 | -7.1923 | 0.4800 | 0.1714 | -240.3316 | -247.0676 | -1.1074 | -1.0849 |
| 0.0 | 24.0 | 900 | 2.8036 | -7.0360 | -7.1975 | 0.4800 | 0.1615 | -240.3390 | -247.0892 | -1.1075 | -1.0850 |
| 0.0 | 26.67 | 1000 | 2.8000 | -7.0133 | -7.1903 | 0.4800 | 0.1770 | -240.3288 | -247.0569 | -1.1073 | -1.0850 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_shp1_dpo7", "results": []}]} | guoyu-zhang/model_hh_shp1_dpo7 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-16T18:38:32+00:00 | []
| []
| TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_shp1\_dpo7
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.8000
* Rewards/chosen: -7.0133
* Rewards/rejected: -7.1903
* Rewards/accuracies: 0.4800
* Rewards/margins: 0.1770
* Logps/rejected: -240.3288
* Logps/chosen: -247.0569
* Logits/rejected: -1.1073
* Logits/chosen: -1.0850
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/Ppoyaa/Lumina-3.5
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q2_K.gguf) | Q2_K | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.IQ3_XS.gguf) | IQ3_XS | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q3_K_S.gguf) | Q3_K_S | 8.1 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.IQ3_S.gguf) | IQ3_S | 8.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.IQ3_M.gguf) | IQ3_M | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q3_K_M.gguf) | Q3_K_M | 9.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q3_K_L.gguf) | Q3_K_L | 9.7 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.IQ4_XS.gguf) | IQ4_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q4_K_S.gguf) | Q4_K_S | 10.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q4_K_M.gguf) | Q4_K_M | 11.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q5_K_S.gguf) | Q5_K_S | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q5_K_M.gguf) | Q5_K_M | 13.2 | |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q6_K.gguf) | Q6_K | 15.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Lumina-3.5-GGUF/resolve/main/Lumina-3.5.Q8_0.gguf) | Q8_0 | 19.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["moe", "frankenmoe", "merge", "mergekit", "lazymergekit"], "base_model": "Ppoyaa/Lumina-3.5", "quantized_by": "mradermacher"} | mradermacher/Lumina-3.5-GGUF | null | [
"transformers",
"gguf",
"moe",
"frankenmoe",
"merge",
"mergekit",
"lazymergekit",
"en",
"base_model:Ppoyaa/Lumina-3.5",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:40:36+00:00 | []
| [
"en"
]
| TAGS
#transformers #gguf #moe #frankenmoe #merge #mergekit #lazymergekit #en #base_model-Ppoyaa/Lumina-3.5 #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| []
| [
"TAGS\n#transformers #gguf #moe #frankenmoe #merge #mergekit #lazymergekit #en #base_model-Ppoyaa/Lumina-3.5 #license-apache-2.0 #endpoints_compatible #region-us \n"
]
|
reinforcement-learning | stable-baselines3 |
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ProrabVasili -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ProrabVasili -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga ProrabVasili
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
| {"library_name": "stable-baselines3", "tags": ["SpaceInvadersNoFrameskip-v4", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "DQN", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "SpaceInvadersNoFrameskip-v4", "type": "SpaceInvadersNoFrameskip-v4"}, "metrics": [{"type": "mean_reward", "value": "943.00 +/- 229.27", "name": "mean_reward", "verified": false}]}]}]} | ProrabVasili/dqn-SpaceInvadersNoFrameskip-v4 | null | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| null | 2024-04-16T18:41:54+00:00 | []
| []
| TAGS
#stable-baselines3 #SpaceInvadersNoFrameskip-v4 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# DQN Agent playing SpaceInvadersNoFrameskip-v4
This is a trained model of a DQN agent playing SpaceInvadersNoFrameskip-v4
using the stable-baselines3 library
and the RL Zoo.
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: URL
SB3: URL
SB3 Contrib: URL
Install the RL Zoo (with SB3 and SB3-Contrib):
If you installed the RL Zoo3 via pip ('pip install rl_zoo3'), from anywhere you can do:
## Training (with the RL Zoo)
## Hyperparameters
# Environment Arguments
| [
"# DQN Agent playing SpaceInvadersNoFrameskip-v4\nThis is a trained model of a DQN agent playing SpaceInvadersNoFrameskip-v4\nusing the stable-baselines3 library\nand the RL Zoo.\n\nThe RL Zoo is a training framework for Stable Baselines3\nreinforcement learning agents,\nwith hyperparameter optimization and pre-trained agents included.",
"## Usage (with SB3 RL Zoo)\n\nRL Zoo: URL\nSB3: URL\nSB3 Contrib: URL\n\nInstall the RL Zoo (with SB3 and SB3-Contrib):\n\n\n\n\nIf you installed the RL Zoo3 via pip ('pip install rl_zoo3'), from anywhere you can do:",
"## Training (with the RL Zoo)",
"## Hyperparameters",
"# Environment Arguments"
]
| [
"TAGS\n#stable-baselines3 #SpaceInvadersNoFrameskip-v4 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# DQN Agent playing SpaceInvadersNoFrameskip-v4\nThis is a trained model of a DQN agent playing SpaceInvadersNoFrameskip-v4\nusing the stable-baselines3 library\nand the RL Zoo.\n\nThe RL Zoo is a training framework for Stable Baselines3\nreinforcement learning agents,\nwith hyperparameter optimization and pre-trained agents included.",
"## Usage (with SB3 RL Zoo)\n\nRL Zoo: URL\nSB3: URL\nSB3 Contrib: URL\n\nInstall the RL Zoo (with SB3 and SB3-Contrib):\n\n\n\n\nIf you installed the RL Zoo3 via pip ('pip install rl_zoo3'), from anywhere you can do:",
"## Training (with the RL Zoo)",
"## Hyperparameters",
"# Environment Arguments"
]
|
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CNEC_1_1_Supertypes_Czert-B-base-cased
This model is a fine-tuned version of [UWB-AIR/Czert-B-base-cased](https://huggingface.co/UWB-AIR/Czert-B-base-cased) on the cnec dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2250
- Precision: 0.8262
- Recall: 0.8660
- F1: 0.8457
- Accuracy: 0.9473
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.334 | 1.7 | 500 | 0.1982 | 0.8008 | 0.8475 | 0.8235 | 0.9420 |
| 0.1182 | 3.4 | 1000 | 0.2127 | 0.8336 | 0.8638 | 0.8485 | 0.9461 |
| 0.0655 | 5.1 | 1500 | 0.2164 | 0.8205 | 0.8630 | 0.8412 | 0.9470 |
| 0.0404 | 6.8 | 2000 | 0.2250 | 0.8262 | 0.8660 | 0.8457 | 0.9473 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
| {"tags": ["generated_from_trainer"], "datasets": ["cnec"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "UWB-AIR/Czert-B-base-cased", "model-index": [{"name": "CNEC_1_1_Supertypes_Czert-B-base-cased", "results": [{"task": {"type": "token-classification", "name": "Token Classification"}, "dataset": {"name": "cnec", "type": "cnec", "config": "default", "split": "validation", "args": "default"}, "metrics": [{"type": "precision", "value": 0.8262336566849431, "name": "Precision"}, {"type": "recall", "value": 0.8660477453580901, "name": "Recall"}, {"type": "f1", "value": 0.8456723505288151, "name": "F1"}, {"type": "accuracy", "value": 0.9473102785782901, "name": "Accuracy"}]}]}]} | stulcrad/CNEC_1_1_Supertypes_Czert-B-base-cased | null | [
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:cnec",
"base_model:UWB-AIR/Czert-B-base-cased",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:45:56+00:00 | []
| []
| TAGS
#transformers #safetensors #bert #token-classification #generated_from_trainer #dataset-cnec #base_model-UWB-AIR/Czert-B-base-cased #model-index #autotrain_compatible #endpoints_compatible #region-us
| CNEC\_1\_1\_Supertypes\_Czert-B-base-cased
==========================================
This model is a fine-tuned version of UWB-AIR/Czert-B-base-cased on the cnec dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2250
* Precision: 0.8262
* Recall: 0.8660
* F1: 0.8457
* Accuracy: 0.9473
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 7
### Training results
### Framework versions
* Transformers 4.36.2
* Pytorch 2.1.2+cu121
* Datasets 2.16.1
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 7",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.2\n* Pytorch 2.1.2+cu121\n* Datasets 2.16.1\n* Tokenizers 0.15.0"
]
| [
"TAGS\n#transformers #safetensors #bert #token-classification #generated_from_trainer #dataset-cnec #base_model-UWB-AIR/Czert-B-base-cased #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 7",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.2\n* Pytorch 2.1.2+cu121\n* Datasets 2.16.1\n* Tokenizers 0.15.0"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_300_notata-seqsight_32768_512_30M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_30M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_30M) on the [mahdibaghbanzadeh/GUE_prom_prom_300_notata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_300_notata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3910
- F1 Score: 0.8345
- Accuracy: 0.8346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5936 | 9.52 | 200 | 0.5179 | 0.7475 | 0.7501 |
| 0.5013 | 19.05 | 400 | 0.4764 | 0.7773 | 0.7784 |
| 0.47 | 28.57 | 600 | 0.4550 | 0.7887 | 0.7897 |
| 0.4479 | 38.1 | 800 | 0.4464 | 0.7954 | 0.7956 |
| 0.4268 | 47.62 | 1000 | 0.4313 | 0.8033 | 0.8035 |
| 0.4034 | 57.14 | 1200 | 0.4249 | 0.8047 | 0.8048 |
| 0.3769 | 66.67 | 1400 | 0.4154 | 0.8200 | 0.8200 |
| 0.3524 | 76.19 | 1600 | 0.3920 | 0.8244 | 0.8244 |
| 0.3364 | 85.71 | 1800 | 0.3963 | 0.8240 | 0.8240 |
| 0.323 | 95.24 | 2000 | 0.3792 | 0.8328 | 0.8329 |
| 0.3127 | 104.76 | 2200 | 0.3774 | 0.8350 | 0.8351 |
| 0.3043 | 114.29 | 2400 | 0.3850 | 0.8357 | 0.8357 |
| 0.2963 | 123.81 | 2600 | 0.3685 | 0.8392 | 0.8393 |
| 0.2895 | 133.33 | 2800 | 0.3786 | 0.8380 | 0.8379 |
| 0.2825 | 142.86 | 3000 | 0.3964 | 0.8358 | 0.8359 |
| 0.278 | 152.38 | 3200 | 0.3755 | 0.8438 | 0.8438 |
| 0.272 | 161.9 | 3400 | 0.3843 | 0.8430 | 0.8430 |
| 0.2696 | 171.43 | 3600 | 0.3726 | 0.8460 | 0.8461 |
| 0.2659 | 180.95 | 3800 | 0.4000 | 0.8385 | 0.8387 |
| 0.2596 | 190.48 | 4000 | 0.3874 | 0.8464 | 0.8464 |
| 0.2578 | 200.0 | 4200 | 0.3702 | 0.8483 | 0.8483 |
| 0.2563 | 209.52 | 4400 | 0.3788 | 0.8477 | 0.8477 |
| 0.252 | 219.05 | 4600 | 0.3904 | 0.8437 | 0.8438 |
| 0.2495 | 228.57 | 4800 | 0.3896 | 0.8447 | 0.8447 |
| 0.2471 | 238.1 | 5000 | 0.3850 | 0.8462 | 0.8462 |
| 0.245 | 247.62 | 5200 | 0.3877 | 0.8485 | 0.8485 |
| 0.244 | 257.14 | 5400 | 0.3832 | 0.8458 | 0.8459 |
| 0.2423 | 266.67 | 5600 | 0.3886 | 0.8458 | 0.8459 |
| 0.2407 | 276.19 | 5800 | 0.3905 | 0.8439 | 0.8440 |
| 0.2395 | 285.71 | 6000 | 0.3894 | 0.8436 | 0.8436 |
| 0.2367 | 295.24 | 6200 | 0.3866 | 0.8472 | 0.8472 |
| 0.2344 | 304.76 | 6400 | 0.3959 | 0.8441 | 0.8442 |
| 0.2346 | 314.29 | 6600 | 0.4070 | 0.8381 | 0.8383 |
| 0.2333 | 323.81 | 6800 | 0.3841 | 0.8464 | 0.8464 |
| 0.2308 | 333.33 | 7000 | 0.3955 | 0.8415 | 0.8415 |
| 0.2303 | 342.86 | 7200 | 0.3966 | 0.8424 | 0.8425 |
| 0.2305 | 352.38 | 7400 | 0.3971 | 0.8428 | 0.8428 |
| 0.2279 | 361.9 | 7600 | 0.3975 | 0.8455 | 0.8455 |
| 0.227 | 371.43 | 7800 | 0.3977 | 0.8430 | 0.8430 |
| 0.2267 | 380.95 | 8000 | 0.3857 | 0.8441 | 0.8442 |
| 0.225 | 390.48 | 8200 | 0.3983 | 0.8403 | 0.8404 |
| 0.2246 | 400.0 | 8400 | 0.3987 | 0.8407 | 0.8408 |
| 0.2233 | 409.52 | 8600 | 0.3984 | 0.8438 | 0.8438 |
| 0.2231 | 419.05 | 8800 | 0.3909 | 0.8451 | 0.8451 |
| 0.223 | 428.57 | 9000 | 0.3989 | 0.8445 | 0.8445 |
| 0.2229 | 438.1 | 9200 | 0.3922 | 0.8472 | 0.8472 |
| 0.2213 | 447.62 | 9400 | 0.3943 | 0.8449 | 0.8449 |
| 0.2214 | 457.14 | 9600 | 0.3938 | 0.8460 | 0.8461 |
| 0.2199 | 466.67 | 9800 | 0.3958 | 0.8443 | 0.8444 |
| 0.2214 | 476.19 | 10000 | 0.3971 | 0.8436 | 0.8436 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_30M", "model-index": [{"name": "GUE_prom_prom_300_notata-seqsight_32768_512_30M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_300_notata-seqsight_32768_512_30M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_30M",
"region:us"
]
| null | 2024-04-16T18:48:08+00:00 | []
| []
| TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_30M #region-us
| GUE\_prom\_prom\_300\_notata-seqsight\_32768\_512\_30M-L32\_all
===============================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_30M on the mahdibaghbanzadeh/GUE\_prom\_prom\_300\_notata dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3910
* F1 Score: 0.8345
* Accuracy: 0.8346
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_30M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
]
|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | lizashr/mistral-finetuned-pii-masking | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-16T18:54:30+00:00 | [
"1910.09700"
]
| []
| TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
| [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
]
|
null | peft | ## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
| {"library_name": "peft"} | Inferno0AI/college_model_v1 | null | [
"peft",
"region:us"
]
| null | 2024-04-16T18:55:00+00:00 | []
| []
| TAGS
#peft #region-us
| ## Training procedure
The following 'bitsandbytes' quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
| [
"## Training procedure\n\n\nThe following 'bitsandbytes' quantization config was used during training:\n- load_in_8bit: False\n- load_in_4bit: True\n- llm_int8_threshold: 6.0\n- llm_int8_skip_modules: None\n- llm_int8_enable_fp32_cpu_offload: False\n- llm_int8_has_fp16_weight: False\n- bnb_4bit_quant_type: nf4\n- bnb_4bit_use_double_quant: False\n- bnb_4bit_compute_dtype: float16",
"### Framework versions\n\n\n- PEFT 0.4.0"
]
| [
"TAGS\n#peft #region-us \n",
"## Training procedure\n\n\nThe following 'bitsandbytes' quantization config was used during training:\n- load_in_8bit: False\n- load_in_4bit: True\n- llm_int8_threshold: 6.0\n- llm_int8_skip_modules: None\n- llm_int8_enable_fp32_cpu_offload: False\n- llm_int8_has_fp16_weight: False\n- bnb_4bit_quant_type: nf4\n- bnb_4bit_use_double_quant: False\n- bnb_4bit_compute_dtype: float16",
"### Framework versions\n\n\n- PEFT 0.4.0"
]
|
text-generation | transformers | # Model Card for Mixtral-8x22B
The Mixtral-8x22B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-8x22b).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](https://twitter.com/MistralAI/status/1777869263778291896), but the file format and parameter names are different.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x22B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
## Notice
Mixtral-8x22B is a pretrained base model and therefore does not have any moderation mechanisms.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux,
Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault,
Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot,
Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger,
Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona,
Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon,
Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat,
Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen,
Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao,
Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang,
Valera Nemychnikova, William El Sayed, William Marshall | {"language": ["fr", "it", "de", "es", "en"], "license": "apache-2.0", "tags": ["moe"]} | mistralai/Mixtral-8x22B-v0.1 | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"conversational",
"fr",
"it",
"de",
"es",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:58:08+00:00 | []
| [
"fr",
"it",
"de",
"es",
"en"
]
| TAGS
#transformers #safetensors #mixtral #text-generation #moe #conversational #fr #it #de #es #en #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
| # Model Card for Mixtral-8x22B
The Mixtral-8x22B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts.
For full details of this model please read our release blog post.
## Warning
This repo contains weights that are compatible with vLLM serving of the model as well as Hugging Face transformers library. It is based on the original Mixtral torrent release, but the file format and parameter names are different.
## Run the model
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
## Notice
Mixtral-8x22B is a pretrained base model and therefore does not have any moderation mechanisms.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux,
Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault,
Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot,
Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger,
Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona,
Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon,
Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat,
Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen,
Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao,
Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang,
Valera Nemychnikova, William El Sayed, William Marshall | [
"# Model Card for Mixtral-8x22B\nThe Mixtral-8x22B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts.\n\nFor full details of this model please read our release blog post.",
"## Warning\nThis repo contains weights that are compatible with vLLM serving of the model as well as Hugging Face transformers library. It is based on the original Mixtral torrent release, but the file format and parameter names are different.",
"## Run the model\n\n\n\n\nBy default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:",
"## Notice\nMixtral-8x22B is a pretrained base model and therefore does not have any moderation mechanisms.",
"# The Mistral AI Team\nAlbert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux,\nArthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault,\nBlanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot,\nDiego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger,\nGianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona,\nJean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon,\nLucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat,\nMarie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen,\nPierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao,\nThibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang,\nValera Nemychnikova, William El Sayed, William Marshall"
]
| [
"TAGS\n#transformers #safetensors #mixtral #text-generation #moe #conversational #fr #it #de #es #en #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n",
"# Model Card for Mixtral-8x22B\nThe Mixtral-8x22B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts.\n\nFor full details of this model please read our release blog post.",
"## Warning\nThis repo contains weights that are compatible with vLLM serving of the model as well as Hugging Face transformers library. It is based on the original Mixtral torrent release, but the file format and parameter names are different.",
"## Run the model\n\n\n\n\nBy default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:",
"## Notice\nMixtral-8x22B is a pretrained base model and therefore does not have any moderation mechanisms.",
"# The Mistral AI Team\nAlbert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux,\nArthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault,\nBlanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot,\nDiego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger,\nGianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona,\nJean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon,\nLucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat,\nMarie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen,\nPierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao,\nThibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang,\nValera Nemychnikova, William El Sayed, William Marshall"
]
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp4_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9280
- Rewards/chosen: -10.9160
- Rewards/rejected: -14.7692
- Rewards/accuracies: 0.6700
- Rewards/margins: 3.8532
- Logps/rejected: -143.5620
- Logps/chosen: -133.8559
- Logits/rejected: -0.6034
- Logits/chosen: -0.5139
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0836 | 2.67 | 100 | 1.1505 | 2.1129 | 0.6066 | 0.5900 | 1.5063 | -112.8104 | -107.7982 | -0.2532 | -0.2394 |
| 0.0139 | 5.33 | 200 | 1.7113 | -12.2276 | -13.7761 | 0.6700 | 1.5485 | -141.5758 | -136.4791 | 0.1125 | 0.1515 |
| 0.0004 | 8.0 | 300 | 1.8255 | -8.3459 | -12.1000 | 0.6700 | 3.7540 | -138.2236 | -128.7158 | -0.4577 | -0.3723 |
| 0.0 | 10.67 | 400 | 1.9235 | -10.8751 | -14.7254 | 0.6700 | 3.8504 | -143.4745 | -133.7741 | -0.6028 | -0.5129 |
| 0.0 | 13.33 | 500 | 1.9333 | -10.9027 | -14.7363 | 0.6700 | 3.8337 | -143.4963 | -133.8293 | -0.6037 | -0.5138 |
| 0.0 | 16.0 | 600 | 1.9330 | -10.9168 | -14.7504 | 0.6700 | 3.8336 | -143.5245 | -133.8575 | -0.6033 | -0.5134 |
| 0.0 | 18.67 | 700 | 1.9274 | -10.9064 | -14.7738 | 0.6700 | 3.8674 | -143.5712 | -133.8367 | -0.6036 | -0.5138 |
| 0.0 | 21.33 | 800 | 1.9164 | -10.9296 | -14.8003 | 0.6700 | 3.8707 | -143.6242 | -133.8832 | -0.6049 | -0.5144 |
| 0.0 | 24.0 | 900 | 1.9275 | -10.9403 | -14.7883 | 0.6700 | 3.8480 | -143.6003 | -133.9046 | -0.6037 | -0.5139 |
| 0.0 | 26.67 | 1000 | 1.9280 | -10.9160 | -14.7692 | 0.6700 | 3.8532 | -143.5620 | -133.8559 | -0.6034 | -0.5139 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp4_dpo5", "results": []}]} | guoyu-zhang/model_hh_usp4_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-16T18:58:53+00:00 | []
| []
| TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp4\_dpo5
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.9280
* Rewards/chosen: -10.9160
* Rewards/rejected: -14.7692
* Rewards/accuracies: 0.6700
* Rewards/margins: 3.8532
* Logps/rejected: -143.5620
* Logps/chosen: -133.8559
* Logits/rejected: -0.6034
* Logits/chosen: -0.5139
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
| [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
]
|
text-generation | transformers | ARIA V3 has been trained over 100.000 high quality french language with a focus on data bias, grammar and overall language/writing capacities of the model.
The training has been done on Nvidia GPU in the cloud with Amazon Sagemaker.
Base Model : Llama2-70B-Chat-HF
Dataset : private dataset.
Added value : French Language / Writing / Content Creation / Data bias reduction
Feel free to reach out to us ! [email protected]
| {"license": "other"} | axel-rda/ARIA-70B-V3-4.0bpw-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-04-16T18:59:31+00:00 | []
| []
| TAGS
#transformers #safetensors #llama #text-generation #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| ARIA V3 has been trained over 100.000 high quality french language with a focus on data bias, grammar and overall language/writing capacities of the model.
The training has been done on Nvidia GPU in the cloud with Amazon Sagemaker.
Base Model : Llama2-70B-Chat-HF
Dataset : private dataset.
Added value : French Language / Writing / Content Creation / Data bias reduction
Feel free to reach out to us ! contact@URL
| []
| [
"TAGS\n#transformers #safetensors #llama #text-generation #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.