
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
sequencelengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
sequencelengths 0
201
| languages
sequencelengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
sequencelengths 0
722
| processed_texts
sequencelengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
text-generation | transformers |
# Nous-Hermes-2-Vision - Mistral 7B

*In the tapestry of Greek mythology, Hermes reigns as the eloquent Messenger of the Gods, a deity who deftly bridges the realms through the art of communication. It is in homage to this divine mediator that I name this advanced LLM "Hermes," a system crafted to navigate the complex intricacies of human discourse with celestial finesse.*
## Model description
Nous-Hermes-2-Vision stands as a pioneering Vision-Language Model, leveraging advancements from the renowned **OpenHermes-2.5-Mistral-7B** by teknium. This model incorporates two pivotal enhancements, setting it apart as a cutting-edge solution:
- **SigLIP-400M Integration**: Diverging from traditional approaches that rely on substantial 3B vision encoders, Nous-Hermes-2-Vision harnesses the formidable SigLIP-400M. This strategic choice not only streamlines the model's architecture, making it more lightweight, but also capitalizes on SigLIP's remarkable capabilities. The result? A remarkable boost in performance that defies conventional expectations.
- **Custom Dataset Enriched with Function Calling**: Our model's training data includes a unique feature – function calling. This distinctive addition transforms Nous-Hermes-2-Vision into a **Vision-Language Action Model**. Developers now have a versatile tool at their disposal, primed for crafting a myriad of ingenious automations.
This project is led by [qnguyen3](https://twitter.com/stablequan) and [teknium](https://twitter.com/Teknium1).
## Training
### Dataset
- 220K from **LVIS-INSTRUCT4V**
- 60K from **ShareGPT4V**
- 150K Private **Function Calling Data**
- 50K conversations from teknium's **OpenHermes-2.5**
## Usage
### Prompt Format
- Like other LLaVA's variants, this model uses Vicuna-V1 as its prompt template. Please refer to `conv_llava_v1` in [this file](https://github.com/qnguyen3/hermes-llava/blob/main/llava/conversation.py)
- For Gradio UI, please visit this [GitHub Repo](https://github.com/qnguyen3/hermes-llava)
### Function Calling
- For functiong calling, the message should start with a `<fn_call>` tag. Here is an example:
```json
<fn_call>{
"type": "object",
"properties": {
"bus_colors": {
"type": "array",
"description": "The colors of the bus in the image.",
"items": {
"type": "string",
"enum": ["red", "blue", "green", "white"]
}
},
"bus_features": {
"type": "string",
"description": "The features seen on the back of the bus."
},
"bus_location": {
"type": "string",
"description": "The location of the bus (driving or pulled off to the side).",
"enum": ["driving", "pulled off to the side"]
}
}
}
```
Output:
```json
{
"bus_colors": ["red", "white"],
"bus_features": "An advertisement",
"bus_location": "driving"
}
```
## Example
### Chat

### Function Calling
Input image:

Input message:
```json
<fn_call>{
"type": "object",
"properties": {
"food_list": {
"type": "array",
"description": "List of all the food",
"items": {
"type": "string",
}
},
}
}
```
Output:
```json
{
"food_list": [
"Double Burger",
"Cheeseburger",
"French Fries",
"Shakes",
"Coffee"
]
}
```
| {"language": ["en"], "license": "apache-2.0", "tags": ["mistral", "instruct", "finetune", "chatml", "gpt4", "synthetic data", "distillation", "multimodal", "llava"], "base_model": "mistralai/Mistral-7B-v0.1", "model-index": [{"name": "Nous-Hermes-2-Vision", "results": []}]} | jeiku/noushermesvisionalphaconfigedit | null | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"multimodal",
"llava",
"conversational",
"en",
"base_model:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T22:55:09+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #mistral #text-generation #instruct #finetune #chatml #gpt4 #synthetic data #distillation #multimodal #llava #conversational #en #base_model-mistralai/Mistral-7B-v0.1 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Nous-Hermes-2-Vision - Mistral 7B
!image/png
*In the tapestry of Greek mythology, Hermes reigns as the eloquent Messenger of the Gods, a deity who deftly bridges the realms through the art of communication. It is in homage to this divine mediator that I name this advanced LLM "Hermes," a system crafted to navigate the complex intricacies of human discourse with celestial finesse.*
## Model description
Nous-Hermes-2-Vision stands as a pioneering Vision-Language Model, leveraging advancements from the renowned OpenHermes-2.5-Mistral-7B by teknium. This model incorporates two pivotal enhancements, setting it apart as a cutting-edge solution:
- SigLIP-400M Integration: Diverging from traditional approaches that rely on substantial 3B vision encoders, Nous-Hermes-2-Vision harnesses the formidable SigLIP-400M. This strategic choice not only streamlines the model's architecture, making it more lightweight, but also capitalizes on SigLIP's remarkable capabilities. The result? A remarkable boost in performance that defies conventional expectations.
- Custom Dataset Enriched with Function Calling: Our model's training data includes a unique feature – function calling. This distinctive addition transforms Nous-Hermes-2-Vision into a Vision-Language Action Model. Developers now have a versatile tool at their disposal, primed for crafting a myriad of ingenious automations.
This project is led by qnguyen3 and teknium.
## Training
### Dataset
- 220K from LVIS-INSTRUCT4V
- 60K from ShareGPT4V
- 150K Private Function Calling Data
- 50K conversations from teknium's OpenHermes-2.5
## Usage
### Prompt Format
- Like other LLaVA's variants, this model uses Vicuna-V1 as its prompt template. Please refer to 'conv_llava_v1' in this file
- For Gradio UI, please visit this GitHub Repo
### Function Calling
- For functiong calling, the message should start with a '<fn_call>' tag. Here is an example:
Output:
## Example
### Chat
!image/png
### Function Calling
Input image:
!image/png
Input message:
Output:
| [
"# Nous-Hermes-2-Vision - Mistral 7B\n\n\n!image/png\n\n*In the tapestry of Greek mythology, Hermes reigns as the eloquent Messenger of the Gods, a deity who deftly bridges the realms through the art of communication. It is in homage to this divine mediator that I name this advanced LLM \"Hermes,\" a system crafted to navigate the complex intricacies of human discourse with celestial finesse.*",
"## Model description\n\nNous-Hermes-2-Vision stands as a pioneering Vision-Language Model, leveraging advancements from the renowned OpenHermes-2.5-Mistral-7B by teknium. This model incorporates two pivotal enhancements, setting it apart as a cutting-edge solution:\n\n- SigLIP-400M Integration: Diverging from traditional approaches that rely on substantial 3B vision encoders, Nous-Hermes-2-Vision harnesses the formidable SigLIP-400M. This strategic choice not only streamlines the model's architecture, making it more lightweight, but also capitalizes on SigLIP's remarkable capabilities. The result? A remarkable boost in performance that defies conventional expectations.\n\n- Custom Dataset Enriched with Function Calling: Our model's training data includes a unique feature – function calling. This distinctive addition transforms Nous-Hermes-2-Vision into a Vision-Language Action Model. Developers now have a versatile tool at their disposal, primed for crafting a myriad of ingenious automations.\n\nThis project is led by qnguyen3 and teknium.",
"## Training",
"### Dataset\n- 220K from LVIS-INSTRUCT4V\n- 60K from ShareGPT4V\n- 150K Private Function Calling Data\n- 50K conversations from teknium's OpenHermes-2.5",
"## Usage",
"### Prompt Format\n- Like other LLaVA's variants, this model uses Vicuna-V1 as its prompt template. Please refer to 'conv_llava_v1' in this file\n- For Gradio UI, please visit this GitHub Repo",
"### Function Calling\n- For functiong calling, the message should start with a '<fn_call>' tag. Here is an example:\n\n\n\nOutput:",
"## Example",
"### Chat\n!image/png",
"### Function Calling\nInput image:\n\n!image/png\n\nInput message:\n\n\nOutput:"
] | [
"TAGS\n#transformers #pytorch #mistral #text-generation #instruct #finetune #chatml #gpt4 #synthetic data #distillation #multimodal #llava #conversational #en #base_model-mistralai/Mistral-7B-v0.1 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Nous-Hermes-2-Vision - Mistral 7B\n\n\n!image/png\n\n*In the tapestry of Greek mythology, Hermes reigns as the eloquent Messenger of the Gods, a deity who deftly bridges the realms through the art of communication. It is in homage to this divine mediator that I name this advanced LLM \"Hermes,\" a system crafted to navigate the complex intricacies of human discourse with celestial finesse.*",
"## Model description\n\nNous-Hermes-2-Vision stands as a pioneering Vision-Language Model, leveraging advancements from the renowned OpenHermes-2.5-Mistral-7B by teknium. This model incorporates two pivotal enhancements, setting it apart as a cutting-edge solution:\n\n- SigLIP-400M Integration: Diverging from traditional approaches that rely on substantial 3B vision encoders, Nous-Hermes-2-Vision harnesses the formidable SigLIP-400M. This strategic choice not only streamlines the model's architecture, making it more lightweight, but also capitalizes on SigLIP's remarkable capabilities. The result? A remarkable boost in performance that defies conventional expectations.\n\n- Custom Dataset Enriched with Function Calling: Our model's training data includes a unique feature – function calling. This distinctive addition transforms Nous-Hermes-2-Vision into a Vision-Language Action Model. Developers now have a versatile tool at their disposal, primed for crafting a myriad of ingenious automations.\n\nThis project is led by qnguyen3 and teknium.",
"## Training",
"### Dataset\n- 220K from LVIS-INSTRUCT4V\n- 60K from ShareGPT4V\n- 150K Private Function Calling Data\n- 50K conversations from teknium's OpenHermes-2.5",
"## Usage",
"### Prompt Format\n- Like other LLaVA's variants, this model uses Vicuna-V1 as its prompt template. Please refer to 'conv_llava_v1' in this file\n- For Gradio UI, please visit this GitHub Repo",
"### Function Calling\n- For functiong calling, the message should start with a '<fn_call>' tag. Here is an example:\n\n\n\nOutput:",
"## Example",
"### Chat\n!image/png",
"### Function Calling\nInput image:\n\n!image/png\n\nInput message:\n\n\nOutput:"
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):
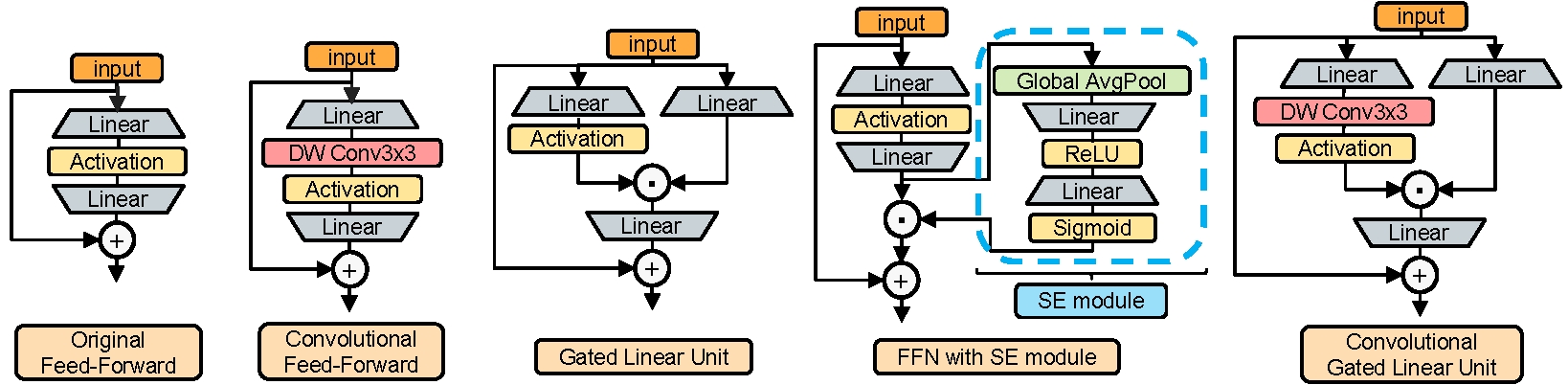
## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:
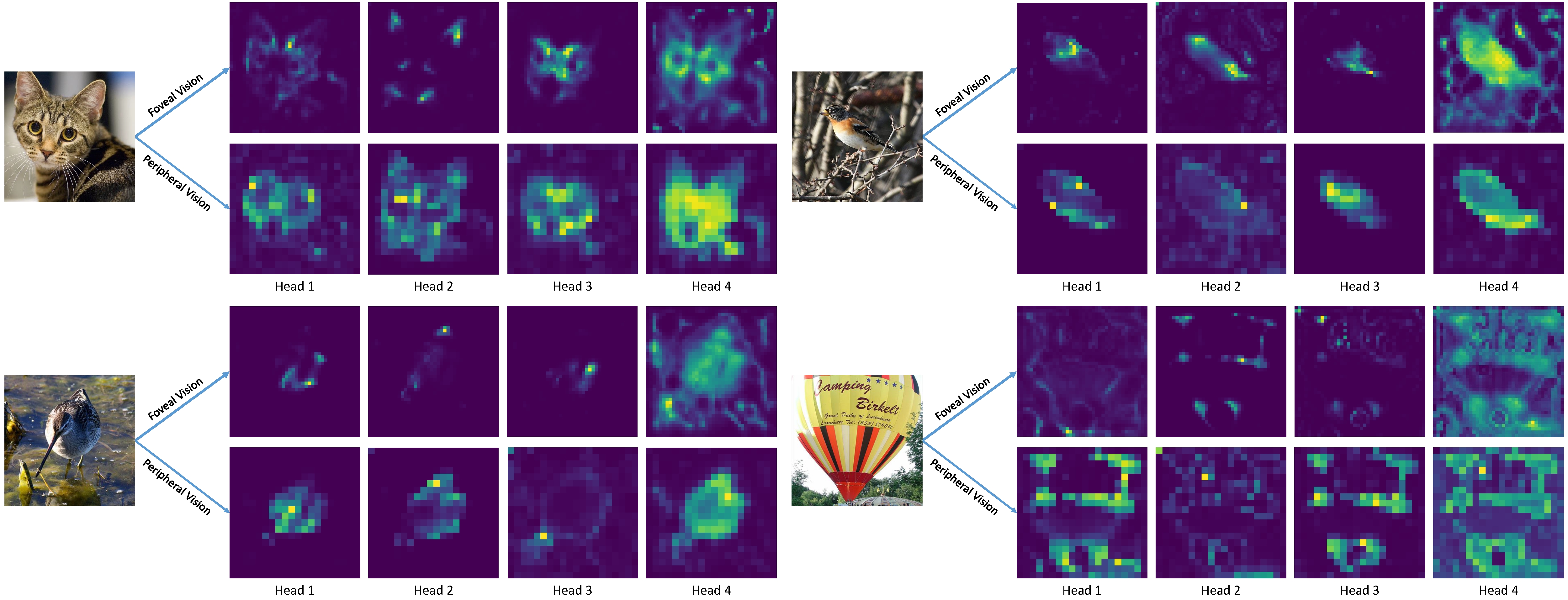
## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-small-224-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T22:57:10+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me2) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7291
- F1 Score: 0.5835
- Accuracy: 0.5963
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6613 | 16.67 | 200 | 0.6624 | 0.5765 | 0.6119 |
| 0.5901 | 33.33 | 400 | 0.7221 | 0.5913 | 0.6025 |
| 0.5271 | 50.0 | 600 | 0.7747 | 0.5806 | 0.5777 |
| 0.476 | 66.67 | 800 | 0.8449 | 0.5662 | 0.5696 |
| 0.439 | 83.33 | 1000 | 0.8451 | 0.5652 | 0.5718 |
| 0.4151 | 100.0 | 1200 | 0.9032 | 0.5618 | 0.5676 |
| 0.3953 | 116.67 | 1400 | 0.9255 | 0.5612 | 0.5634 |
| 0.3766 | 133.33 | 1600 | 0.9668 | 0.5572 | 0.5539 |
| 0.3612 | 150.0 | 1800 | 0.9742 | 0.5636 | 0.5676 |
| 0.3482 | 166.67 | 2000 | 1.0234 | 0.5556 | 0.5533 |
| 0.3367 | 183.33 | 2200 | 1.0741 | 0.5487 | 0.5455 |
| 0.3268 | 200.0 | 2400 | 1.1159 | 0.5534 | 0.5513 |
| 0.3176 | 216.67 | 2600 | 1.0693 | 0.5619 | 0.5617 |
| 0.3087 | 233.33 | 2800 | 1.0744 | 0.5581 | 0.5575 |
| 0.3037 | 250.0 | 3000 | 1.0694 | 0.5660 | 0.5660 |
| 0.2951 | 266.67 | 3200 | 1.1822 | 0.5566 | 0.5543 |
| 0.2897 | 283.33 | 3400 | 1.1189 | 0.5559 | 0.5536 |
| 0.2835 | 300.0 | 3600 | 1.0699 | 0.5608 | 0.5588 |
| 0.278 | 316.67 | 3800 | 1.1427 | 0.5602 | 0.5582 |
| 0.2706 | 333.33 | 4000 | 1.1472 | 0.5597 | 0.5595 |
| 0.2672 | 350.0 | 4200 | 1.1485 | 0.5525 | 0.5510 |
| 0.2623 | 366.67 | 4400 | 1.1635 | 0.5575 | 0.5546 |
| 0.2564 | 383.33 | 4600 | 1.1665 | 0.5631 | 0.5617 |
| 0.2523 | 400.0 | 4800 | 1.2188 | 0.5661 | 0.5663 |
| 0.2488 | 416.67 | 5000 | 1.1831 | 0.5655 | 0.5650 |
| 0.2444 | 433.33 | 5200 | 1.2457 | 0.5598 | 0.5575 |
| 0.2406 | 450.0 | 5400 | 1.2023 | 0.5615 | 0.5611 |
| 0.2363 | 466.67 | 5600 | 1.1984 | 0.5607 | 0.5575 |
| 0.2337 | 483.33 | 5800 | 1.2028 | 0.5620 | 0.5617 |
| 0.2293 | 500.0 | 6000 | 1.2133 | 0.5609 | 0.5595 |
| 0.2254 | 516.67 | 6200 | 1.2177 | 0.5613 | 0.5595 |
| 0.223 | 533.33 | 6400 | 1.2381 | 0.5616 | 0.5595 |
| 0.219 | 550.0 | 6600 | 1.2617 | 0.5591 | 0.5559 |
| 0.2177 | 566.67 | 6800 | 1.2483 | 0.5600 | 0.5582 |
| 0.2149 | 583.33 | 7000 | 1.2313 | 0.5620 | 0.5614 |
| 0.2137 | 600.0 | 7200 | 1.2816 | 0.5588 | 0.5562 |
| 0.2086 | 616.67 | 7400 | 1.2936 | 0.5595 | 0.5572 |
| 0.2074 | 633.33 | 7600 | 1.2590 | 0.5623 | 0.5614 |
| 0.2042 | 650.0 | 7800 | 1.2862 | 0.5628 | 0.5601 |
| 0.2031 | 666.67 | 8000 | 1.2691 | 0.5600 | 0.5608 |
| 0.2007 | 683.33 | 8200 | 1.3315 | 0.5617 | 0.5601 |
| 0.2008 | 700.0 | 8400 | 1.3048 | 0.5613 | 0.5614 |
| 0.1972 | 716.67 | 8600 | 1.2883 | 0.5624 | 0.5604 |
| 0.1959 | 733.33 | 8800 | 1.2794 | 0.5628 | 0.5617 |
| 0.196 | 750.0 | 9000 | 1.2947 | 0.5636 | 0.5627 |
| 0.1944 | 766.67 | 9200 | 1.2998 | 0.5664 | 0.5647 |
| 0.1932 | 783.33 | 9400 | 1.2988 | 0.5647 | 0.5627 |
| 0.1917 | 800.0 | 9600 | 1.2993 | 0.5640 | 0.5624 |
| 0.1912 | 816.67 | 9800 | 1.3223 | 0.5623 | 0.5608 |
| 0.1909 | 833.33 | 10000 | 1.3096 | 0.5621 | 0.5604 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T22:57:32+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me2-seqsight\_32768\_512\_43M-L32\_all
====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me2 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7291
* F1 Score: 0.5835
* Accuracy: 0.5963
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [Citaman/command-r-18-layer](https://huggingface.co/Citaman/command-r-18-layer)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Citaman/command-r-18-layer
layer_range: [0, 17]
- model: Citaman/command-r-18-layer
layer_range: [1, 18]
merge_method: slerp
base_model: Citaman/command-r-18-layer
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["Citaman/command-r-18-layer"]} | Citaman/command-r-17-layer | null | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Citaman/command-r-18-layer",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T22:58:22+00:00 | [] | [] | TAGS
#transformers #safetensors #cohere #text-generation #mergekit #merge #conversational #base_model-Citaman/command-r-18-layer #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* Citaman/command-r-18-layer
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the SLERP merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Citaman/command-r-18-layer",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #cohere #text-generation #mergekit #merge #conversational #base_model-Citaman/command-r-18-layer #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the SLERP merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Citaman/command-r-18-layer",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | arzans9/hasil | null | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:00:30+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K9ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K9ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1794
- F1 Score: 0.6081
- Accuracy: 0.6071
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6617 | 18.18 | 200 | 0.6671 | 0.6050 | 0.6114 |
| 0.5709 | 36.36 | 400 | 0.7096 | 0.6114 | 0.6114 |
| 0.4961 | 54.55 | 600 | 0.7751 | 0.6051 | 0.6060 |
| 0.4402 | 72.73 | 800 | 0.8118 | 0.6101 | 0.6099 |
| 0.3998 | 90.91 | 1000 | 0.8499 | 0.6129 | 0.6121 |
| 0.3713 | 109.09 | 1200 | 0.8935 | 0.6026 | 0.6020 |
| 0.3506 | 127.27 | 1400 | 0.9348 | 0.6107 | 0.6099 |
| 0.331 | 145.45 | 1600 | 0.9848 | 0.5935 | 0.5955 |
| 0.3168 | 163.64 | 1800 | 0.9878 | 0.6086 | 0.6081 |
| 0.302 | 181.82 | 2000 | 1.0570 | 0.6051 | 0.6045 |
| 0.2915 | 200.0 | 2200 | 1.0663 | 0.6050 | 0.6042 |
| 0.2818 | 218.18 | 2400 | 1.0933 | 0.6049 | 0.6056 |
| 0.2729 | 236.36 | 2600 | 1.1083 | 0.5952 | 0.5945 |
| 0.2656 | 254.55 | 2800 | 1.1346 | 0.6008 | 0.6006 |
| 0.2597 | 272.73 | 3000 | 1.1517 | 0.6004 | 0.5999 |
| 0.2557 | 290.91 | 3200 | 1.1102 | 0.5992 | 0.5991 |
| 0.2476 | 309.09 | 3400 | 1.1596 | 0.5959 | 0.5966 |
| 0.2419 | 327.27 | 3600 | 1.1836 | 0.5995 | 0.5995 |
| 0.2356 | 345.45 | 3800 | 1.1120 | 0.6057 | 0.6049 |
| 0.2312 | 363.64 | 4000 | 1.1530 | 0.6061 | 0.6053 |
| 0.2266 | 381.82 | 4200 | 1.1690 | 0.6045 | 0.6042 |
| 0.2224 | 400.0 | 4400 | 1.1636 | 0.6018 | 0.6013 |
| 0.2175 | 418.18 | 4600 | 1.1667 | 0.5932 | 0.5930 |
| 0.2148 | 436.36 | 4800 | 1.1544 | 0.6032 | 0.6027 |
| 0.2092 | 454.55 | 5000 | 1.1731 | 0.6027 | 0.6020 |
| 0.2055 | 472.73 | 5200 | 1.1572 | 0.6043 | 0.6035 |
| 0.2024 | 490.91 | 5400 | 1.1931 | 0.6010 | 0.6002 |
| 0.1983 | 509.09 | 5600 | 1.1850 | 0.6038 | 0.6031 |
| 0.1947 | 527.27 | 5800 | 1.2111 | 0.6035 | 0.6031 |
| 0.1917 | 545.45 | 6000 | 1.2057 | 0.6133 | 0.6125 |
| 0.1871 | 563.64 | 6200 | 1.2591 | 0.6060 | 0.6056 |
| 0.1846 | 581.82 | 6400 | 1.2351 | 0.6071 | 0.6063 |
| 0.1823 | 600.0 | 6600 | 1.2167 | 0.6088 | 0.6081 |
| 0.1797 | 618.18 | 6800 | 1.2809 | 0.6086 | 0.6081 |
| 0.1765 | 636.36 | 7000 | 1.2408 | 0.6115 | 0.6107 |
| 0.1743 | 654.55 | 7200 | 1.2897 | 0.6074 | 0.6071 |
| 0.1725 | 672.73 | 7400 | 1.2601 | 0.6079 | 0.6071 |
| 0.169 | 690.91 | 7600 | 1.2472 | 0.6107 | 0.6099 |
| 0.1686 | 709.09 | 7800 | 1.2704 | 0.6065 | 0.6060 |
| 0.1658 | 727.27 | 8000 | 1.2722 | 0.6107 | 0.6103 |
| 0.1647 | 745.45 | 8200 | 1.2621 | 0.6082 | 0.6074 |
| 0.1637 | 763.64 | 8400 | 1.2940 | 0.6045 | 0.6038 |
| 0.1616 | 781.82 | 8600 | 1.3066 | 0.6100 | 0.6092 |
| 0.1611 | 800.0 | 8800 | 1.2912 | 0.6104 | 0.6096 |
| 0.1591 | 818.18 | 9000 | 1.2844 | 0.6114 | 0.6107 |
| 0.1582 | 836.36 | 9200 | 1.3036 | 0.6133 | 0.6125 |
| 0.1579 | 854.55 | 9400 | 1.3022 | 0.6103 | 0.6096 |
| 0.1562 | 872.73 | 9600 | 1.3085 | 0.6122 | 0.6114 |
| 0.1569 | 890.91 | 9800 | 1.2826 | 0.6089 | 0.6081 |
| 0.1556 | 909.09 | 10000 | 1.3016 | 0.6107 | 0.6099 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T23:01:07+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K9ac-seqsight\_32768\_512\_43M-L32\_all
===================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K9ac dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1794
* F1 Score: 0.6081
* Accuracy: 0.6071
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ruRoberta-distilled-med-kd_ner
This model is a fine-tuned version of [DimasikKurd/ruRoberta-distilled-med-kd](https://huggingface.co/DimasikKurd/ruRoberta-distilled-med-kd) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7519
- Precision: 0.5167
- Recall: 0.5141
- F1: 0.5154
- Accuracy: 0.8935
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 50 | 0.8729 | 0.0 | 0.0 | 0.0 | 0.7613 |
| No log | 2.0 | 100 | 0.6001 | 0.0 | 0.0 | 0.0 | 0.7640 |
| No log | 3.0 | 150 | 0.4551 | 0.0260 | 0.0347 | 0.0297 | 0.8276 |
| No log | 4.0 | 200 | 0.3959 | 0.0833 | 0.1156 | 0.0969 | 0.8423 |
| No log | 5.0 | 250 | 0.3948 | 0.1213 | 0.2235 | 0.1573 | 0.8416 |
| No log | 6.0 | 300 | 0.3469 | 0.1554 | 0.1869 | 0.1697 | 0.8674 |
| No log | 7.0 | 350 | 0.3555 | 0.2174 | 0.2408 | 0.2285 | 0.8713 |
| No log | 8.0 | 400 | 0.2919 | 0.2318 | 0.3430 | 0.2766 | 0.8875 |
| No log | 9.0 | 450 | 0.3070 | 0.2609 | 0.3333 | 0.2927 | 0.8876 |
| 0.4413 | 10.0 | 500 | 0.2882 | 0.3046 | 0.4624 | 0.3673 | 0.8924 |
| 0.4413 | 11.0 | 550 | 0.2943 | 0.3292 | 0.4586 | 0.3833 | 0.8956 |
| 0.4413 | 12.0 | 600 | 0.3656 | 0.3769 | 0.4663 | 0.4169 | 0.8993 |
| 0.4413 | 13.0 | 650 | 0.3350 | 0.3280 | 0.5549 | 0.4123 | 0.8870 |
| 0.4413 | 14.0 | 700 | 0.3448 | 0.3614 | 0.5299 | 0.4297 | 0.8948 |
| 0.4413 | 15.0 | 750 | 0.3847 | 0.3270 | 0.5645 | 0.4141 | 0.8909 |
| 0.4413 | 16.0 | 800 | 0.4304 | 0.3365 | 0.6166 | 0.4354 | 0.8846 |
| 0.4413 | 17.0 | 850 | 0.4168 | 0.3905 | 0.6185 | 0.4787 | 0.8960 |
| 0.4413 | 18.0 | 900 | 0.4903 | 0.4258 | 0.5145 | 0.4660 | 0.9031 |
| 0.4413 | 19.0 | 950 | 0.4139 | 0.4255 | 0.5780 | 0.4902 | 0.8984 |
| 0.089 | 20.0 | 1000 | 0.4383 | 0.4034 | 0.5511 | 0.4658 | 0.9022 |
| 0.089 | 21.0 | 1050 | 0.5534 | 0.4744 | 0.5356 | 0.5032 | 0.9055 |
| 0.089 | 22.0 | 1100 | 0.4808 | 0.4585 | 0.5530 | 0.5013 | 0.9040 |
| 0.089 | 23.0 | 1150 | 0.4970 | 0.4547 | 0.5992 | 0.5170 | 0.9014 |
| 0.089 | 24.0 | 1200 | 0.5934 | 0.4421 | 0.5588 | 0.4936 | 0.9044 |
| 0.089 | 25.0 | 1250 | 0.4604 | 0.4150 | 0.6069 | 0.4930 | 0.9032 |
| 0.089 | 26.0 | 1300 | 0.5973 | 0.4741 | 0.5645 | 0.5154 | 0.9045 |
| 0.089 | 27.0 | 1350 | 0.5220 | 0.4617 | 0.5915 | 0.5186 | 0.9002 |
| 0.089 | 28.0 | 1400 | 0.5929 | 0.4816 | 0.6050 | 0.5363 | 0.9021 |
| 0.089 | 29.0 | 1450 | 0.6293 | 0.4828 | 0.5414 | 0.5104 | 0.9083 |
| 0.0249 | 30.0 | 1500 | 0.5865 | 0.4812 | 0.5665 | 0.5204 | 0.9069 |
| 0.0249 | 31.0 | 1550 | 0.6042 | 0.4429 | 0.6204 | 0.5169 | 0.8979 |
| 0.0249 | 32.0 | 1600 | 0.5790 | 0.4513 | 0.6166 | 0.5212 | 0.9010 |
| 0.0249 | 33.0 | 1650 | 0.5528 | 0.4105 | 0.6012 | 0.4879 | 0.8958 |
| 0.0249 | 34.0 | 1700 | 0.6139 | 0.4694 | 0.5607 | 0.5110 | 0.9059 |
| 0.0249 | 35.0 | 1750 | 0.5735 | 0.4316 | 0.6262 | 0.5110 | 0.8950 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "DimasikKurd/ruRoberta-distilled-med-kd", "model-index": [{"name": "ruRoberta-distilled-med-kd_ner", "results": []}]} | DimasikKurd/ruRoberta-distilled-med-kd_ner | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:DimasikKurd/ruRoberta-distilled-med-kd",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:02:22+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #token-classification #generated_from_trainer #base_model-DimasikKurd/ruRoberta-distilled-med-kd #autotrain_compatible #endpoints_compatible #region-us
| ruRoberta-distilled-med-kd\_ner
===============================
This model is a fine-tuned version of DimasikKurd/ruRoberta-distilled-med-kd on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7519
* Precision: 0.5167
* Recall: 0.5141
* F1: 0.5154
* Accuracy: 0.8935
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 100
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.1.2
* Datasets 2.1.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2\n* Datasets 2.1.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #token-classification #generated_from_trainer #base_model-DimasikKurd/ruRoberta-distilled-med-kd #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2\n* Datasets 2.1.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6802
- F1 Score: 0.5609
- Accuracy: 0.5628
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6879 | 13.33 | 200 | 0.6832 | 0.5583 | 0.5595 |
| 0.6382 | 26.67 | 400 | 0.7334 | 0.5464 | 0.5579 |
| 0.5843 | 40.0 | 600 | 0.7553 | 0.5456 | 0.5484 |
| 0.5389 | 53.33 | 800 | 0.8090 | 0.5488 | 0.5568 |
| 0.5076 | 66.67 | 1000 | 0.8400 | 0.5412 | 0.5416 |
| 0.4841 | 80.0 | 1200 | 0.8626 | 0.5466 | 0.5470 |
| 0.4655 | 93.33 | 1400 | 0.8843 | 0.5324 | 0.5332 |
| 0.4488 | 106.67 | 1600 | 0.8990 | 0.5358 | 0.5353 |
| 0.4356 | 120.0 | 1800 | 0.9441 | 0.5408 | 0.5427 |
| 0.4236 | 133.33 | 2000 | 0.9798 | 0.5303 | 0.5318 |
| 0.4135 | 146.67 | 2200 | 0.9903 | 0.5470 | 0.5467 |
| 0.402 | 160.0 | 2400 | 0.9648 | 0.5433 | 0.5435 |
| 0.3939 | 173.33 | 2600 | 0.9957 | 0.5432 | 0.5432 |
| 0.3867 | 186.67 | 2800 | 1.0448 | 0.5471 | 0.5467 |
| 0.3789 | 200.0 | 3000 | 1.0005 | 0.5441 | 0.5451 |
| 0.3702 | 213.33 | 3200 | 1.0095 | 0.5426 | 0.5427 |
| 0.366 | 226.67 | 3400 | 1.0214 | 0.5417 | 0.5413 |
| 0.3585 | 240.0 | 3600 | 1.0384 | 0.5420 | 0.5429 |
| 0.3549 | 253.33 | 3800 | 1.0652 | 0.5407 | 0.5410 |
| 0.3478 | 266.67 | 4000 | 1.0531 | 0.5424 | 0.5429 |
| 0.3418 | 280.0 | 4200 | 1.0429 | 0.5362 | 0.5359 |
| 0.3366 | 293.33 | 4400 | 1.0908 | 0.5393 | 0.5402 |
| 0.3329 | 306.67 | 4600 | 1.0780 | 0.5350 | 0.5345 |
| 0.325 | 320.0 | 4800 | 1.0910 | 0.5298 | 0.5299 |
| 0.3214 | 333.33 | 5000 | 1.0893 | 0.5426 | 0.5424 |
| 0.3186 | 346.67 | 5200 | 1.0718 | 0.5390 | 0.5386 |
| 0.3144 | 360.0 | 5400 | 1.1087 | 0.5337 | 0.5334 |
| 0.3118 | 373.33 | 5600 | 1.0730 | 0.5344 | 0.5359 |
| 0.3062 | 386.67 | 5800 | 1.1140 | 0.5406 | 0.5408 |
| 0.302 | 400.0 | 6000 | 1.1265 | 0.5339 | 0.5334 |
| 0.2987 | 413.33 | 6200 | 1.1369 | 0.5336 | 0.5332 |
| 0.2954 | 426.67 | 6400 | 1.1322 | 0.5361 | 0.5359 |
| 0.2945 | 440.0 | 6600 | 1.1478 | 0.5365 | 0.5361 |
| 0.2874 | 453.33 | 6800 | 1.1603 | 0.5403 | 0.5408 |
| 0.2851 | 466.67 | 7000 | 1.1172 | 0.5325 | 0.5321 |
| 0.2841 | 480.0 | 7200 | 1.1720 | 0.5355 | 0.5351 |
| 0.2815 | 493.33 | 7400 | 1.1704 | 0.5418 | 0.5432 |
| 0.2784 | 506.67 | 7600 | 1.1646 | 0.5365 | 0.5367 |
| 0.2754 | 520.0 | 7800 | 1.1859 | 0.5291 | 0.5291 |
| 0.2748 | 533.33 | 8000 | 1.1461 | 0.5347 | 0.5342 |
| 0.2702 | 546.67 | 8200 | 1.2038 | 0.5361 | 0.5359 |
| 0.2699 | 560.0 | 8400 | 1.1909 | 0.5330 | 0.5326 |
| 0.2689 | 573.33 | 8600 | 1.1961 | 0.5324 | 0.5321 |
| 0.2668 | 586.67 | 8800 | 1.1852 | 0.5373 | 0.5372 |
| 0.2647 | 600.0 | 9000 | 1.2011 | 0.5309 | 0.5304 |
| 0.2649 | 613.33 | 9200 | 1.1837 | 0.5325 | 0.5323 |
| 0.2627 | 626.67 | 9400 | 1.2160 | 0.5309 | 0.5304 |
| 0.262 | 640.0 | 9600 | 1.2265 | 0.5322 | 0.5318 |
| 0.26 | 653.33 | 9800 | 1.2140 | 0.5301 | 0.5296 |
| 0.2613 | 666.67 | 10000 | 1.2069 | 0.5332 | 0.5329 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T23:02:56+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me3-seqsight\_32768\_512\_43M-L32\_all
====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6802
* F1 Score: 0.5609
* Accuracy: 0.5628
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4422
- F1 Score: 0.7429
- Accuracy: 0.7426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5734 | 33.33 | 200 | 0.5891 | 0.7106 | 0.7118 |
| 0.3719 | 66.67 | 400 | 0.7190 | 0.7237 | 0.7235 |
| 0.2619 | 100.0 | 600 | 0.8512 | 0.7245 | 0.7235 |
| 0.1974 | 133.33 | 800 | 0.9238 | 0.7279 | 0.7283 |
| 0.1625 | 166.67 | 1000 | 0.9886 | 0.7362 | 0.7358 |
| 0.1387 | 200.0 | 1200 | 1.0184 | 0.7438 | 0.7440 |
| 0.1191 | 233.33 | 1400 | 1.0711 | 0.7366 | 0.7358 |
| 0.1028 | 266.67 | 1600 | 1.0895 | 0.7471 | 0.7467 |
| 0.0884 | 300.0 | 1800 | 1.1618 | 0.7481 | 0.7474 |
| 0.0778 | 333.33 | 2000 | 1.1993 | 0.7578 | 0.7584 |
| 0.0706 | 366.67 | 2200 | 1.2974 | 0.7587 | 0.7598 |
| 0.066 | 400.0 | 2400 | 1.4022 | 0.7532 | 0.7529 |
| 0.0633 | 433.33 | 2600 | 1.3778 | 0.7490 | 0.7481 |
| 0.059 | 466.67 | 2800 | 1.3353 | 0.7554 | 0.7556 |
| 0.0563 | 500.0 | 3000 | 1.4239 | 0.7523 | 0.7522 |
| 0.0533 | 533.33 | 3200 | 1.4207 | 0.7498 | 0.7488 |
| 0.0511 | 566.67 | 3400 | 1.4704 | 0.7528 | 0.7522 |
| 0.0505 | 600.0 | 3600 | 1.4302 | 0.7602 | 0.7604 |
| 0.0484 | 633.33 | 3800 | 1.3470 | 0.7569 | 0.7570 |
| 0.0473 | 666.67 | 4000 | 1.3741 | 0.7608 | 0.7611 |
| 0.0446 | 700.0 | 4200 | 1.4615 | 0.7609 | 0.7604 |
| 0.0449 | 733.33 | 4400 | 1.3730 | 0.7615 | 0.7611 |
| 0.0429 | 766.67 | 4600 | 1.3601 | 0.7584 | 0.7591 |
| 0.0421 | 800.0 | 4800 | 1.3270 | 0.7593 | 0.7598 |
| 0.0419 | 833.33 | 5000 | 1.3630 | 0.7594 | 0.7598 |
| 0.0397 | 866.67 | 5200 | 1.4131 | 0.7634 | 0.7639 |
| 0.0397 | 900.0 | 5400 | 1.4374 | 0.7599 | 0.7598 |
| 0.0373 | 933.33 | 5600 | 1.3948 | 0.7638 | 0.7632 |
| 0.037 | 966.67 | 5800 | 1.4789 | 0.7574 | 0.7591 |
| 0.0372 | 1000.0 | 6000 | 1.4428 | 0.7640 | 0.7639 |
| 0.0356 | 1033.33 | 6200 | 1.4496 | 0.7580 | 0.7577 |
| 0.0357 | 1066.67 | 6400 | 1.3634 | 0.7609 | 0.7611 |
| 0.0347 | 1100.0 | 6600 | 1.4079 | 0.7644 | 0.7645 |
| 0.0342 | 1133.33 | 6800 | 1.3909 | 0.7599 | 0.7598 |
| 0.0335 | 1166.67 | 7000 | 1.4822 | 0.7629 | 0.7632 |
| 0.0319 | 1200.0 | 7200 | 1.4809 | 0.7592 | 0.7591 |
| 0.0319 | 1233.33 | 7400 | 1.4753 | 0.7646 | 0.7645 |
| 0.0317 | 1266.67 | 7600 | 1.4856 | 0.7652 | 0.7652 |
| 0.0306 | 1300.0 | 7800 | 1.4455 | 0.7639 | 0.7645 |
| 0.0311 | 1333.33 | 8000 | 1.4722 | 0.7659 | 0.7659 |
| 0.0302 | 1366.67 | 8200 | 1.4301 | 0.7714 | 0.7714 |
| 0.03 | 1400.0 | 8400 | 1.4543 | 0.7664 | 0.7666 |
| 0.0303 | 1433.33 | 8600 | 1.3948 | 0.7614 | 0.7611 |
| 0.0292 | 1466.67 | 8800 | 1.4389 | 0.7672 | 0.7673 |
| 0.0287 | 1500.0 | 9000 | 1.4746 | 0.7639 | 0.7639 |
| 0.0289 | 1533.33 | 9200 | 1.4294 | 0.7651 | 0.7652 |
| 0.0284 | 1566.67 | 9400 | 1.4422 | 0.7664 | 0.7666 |
| 0.0282 | 1600.0 | 9600 | 1.4480 | 0.7657 | 0.7659 |
| 0.0289 | 1633.33 | 9800 | 1.4707 | 0.7677 | 0.7680 |
| 0.0276 | 1666.67 | 10000 | 1.4636 | 0.7665 | 0.7666 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T23:02:56+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4-seqsight\_32768\_512\_43M-L32\_all
===============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4422
* F1 Score: 0.7429
* Accuracy: 0.7426
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-base-224-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:02:57+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1363
- F1: 0.8658
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2539 | 1.0 | 525 | 0.1505 | 0.8246 |
| 0.1268 | 2.0 | 1050 | 0.1380 | 0.8503 |
| 0.0794 | 3.0 | 1575 | 0.1363 | 0.8658 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "mit", "tags": ["generated_from_trainer"], "metrics": ["f1"], "base_model": "xlm-roberta-base", "model-index": [{"name": "xlm-roberta-base-finetuned-panx-de", "results": []}]} | darinj2/xlm-roberta-base-finetuned-panx-de | null | [
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:03:52+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #xlm-roberta #token-classification #generated_from_trainer #base_model-xlm-roberta-base #license-mit #autotrain_compatible #endpoints_compatible #region-us
| xlm-roberta-base-finetuned-panx-de
==================================
This model is a fine-tuned version of xlm-roberta-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1363
* F1: 0.8658
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 24
* eval\_batch\_size: 24
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.40.1
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 24\n* eval\\_batch\\_size: 24\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #xlm-roberta #token-classification #generated_from_trainer #base_model-xlm-roberta-base #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 24\n* eval\\_batch\\_size: 24\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
null | null |
# Experiment26Meliodas-7B
Experiment26Meliodas-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [AurelPx/Meliodas-7b-dare](https://huggingface.co/AurelPx/Meliodas-7b-dare)
## 🧩 Configuration
```yaml
models:
- model: yam-peleg/Experiment26-7B
# No parameters necessary for base model
- model: AurelPx/Meliodas-7b-dare
parameters:
density: 0.53
weight: 0.6
merge_method: dare_ties
base_model: yam-peleg/Experiment26-7B
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Experiment26Meliodas-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "automerger"], "base_model": ["AurelPx/Meliodas-7b-dare"]} | automerger/Experiment26Meliodas-7B | null | [
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:AurelPx/Meliodas-7b-dare",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:04:00+00:00 | [] | [] | TAGS
#merge #mergekit #lazymergekit #automerger #base_model-AurelPx/Meliodas-7b-dare #license-apache-2.0 #region-us
|
# Experiment26Meliodas-7B
Experiment26Meliodas-7B is an automated merge created by Maxime Labonne using the following configuration.
* AurelPx/Meliodas-7b-dare
## Configuration
## Usage
| [
"# Experiment26Meliodas-7B\n\nExperiment26Meliodas-7B is an automated merge created by Maxime Labonne using the following configuration.\n* AurelPx/Meliodas-7b-dare",
"## Configuration",
"## Usage"
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #base_model-AurelPx/Meliodas-7b-dare #license-apache-2.0 #region-us \n",
"# Experiment26Meliodas-7B\n\nExperiment26Meliodas-7B is an automated merge created by Maxime Labonne using the following configuration.\n* AurelPx/Meliodas-7b-dare",
"## Configuration",
"## Usage"
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-micro-224-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:04:57+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-generation | transformers |
# carotte
#### Description du Modèle
Ce document fournit des instructions sur l'utilisation du llm `carotte-7b`, spécialement conçu pour répondre à des questions en français.
#### Prérequis
Pour utiliser ce modèle, il est nécessaire d'installer la bibliothèque `transformers` de Hugging Face. Si vous ne l'avez pas déjà fait, vous pouvez installer cette bibliothèque via pip en utilisant la commande suivante :
```bash
pip install transformers
```
#### Utilisation du Modèle
Voici comment charger et utiliser le modèle `carotte-7b` pour générer des réponses dans un cadre de dialogue :
1. **Importation des bibliothèques nécessaires :**
Commencez par importer `AutoModelForCausalLM` et `AutoTokenizer` de la bibliothèque `transformers`.
2. **Chargement du modèle et du tokenizer :**
Chargez le modèle et le tokenizer pré-entraînés en utilisant les noms spécifiques `lbl/fr.brain.carotte-7b`.
3. **Préparation des messages :**
Préparez une liste de messages qui simulent une conversation entre un utilisateur et l'assistant. Chaque message doit contenir un `role` (utilisateur ou assistant) et un `content` (le contenu du message).
4. **Tokenisation et encodage des entrées :**
Utilisez le tokenizer pour appliquer un modèle de chat aux messages et encoder les entrées. Ces entrées doivent être transférées sur le GPU pour une inférence rapide si vous utilisez CUDA.
5. **Génération des réponses :**
Passez les entrées tokenisées au modèle pour générer des réponses. Le modèle peut être configuré pour échantillonner différentes réponses possibles.
6. **Affichage des réponses :**
Décodez les identifiants générés en texte clair et affichez les réponses.
Voici un exemple de code complet qui illustre ces étapes :
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Chargement du modèle et du tokenizer
model = AutoModelForCausalLM.from_pretrained("lbl/fr.brain.carotte-7b", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("lbl/fr.brain.carotte-7b")
# Messages de simulation
messages = [
{"role": "user", "content": "Quel est ton légume préféré ?"},
{"role": "assistant", "content": "Ah, je suis un grand fan des carottes! Elles sont versatiles, croquantes et colorées, exactement ce qu'il faut pour égayer une journée grise!"},
{"role": "user", "content": "Peux-tu me donner des idées de recettes avec des carottes ?"}
]
# Préparation et encodage des entrées
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
# Génération de la réponse
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
res = tokenizer.batch_decode(generated_ids)[0]
# Affichage de la réponse
print(res)
```
## Avertissement sur l'utilisation du modèle
Ce modèle de langage a été développé pour générer des réponses basées sur une vaste gamme de données d'entraînement. Cependant, il est important de noter que, comme tout système basé sur l'intelligence artificielle, il n'est pas parfait et peut parfois produire des informations inexactes, incomplètes ou inappropriées.
### Considérations importantes :
- **Exactitude des informations :** Il peut arriver que le modèle fournisse des informations qui ne sont pas entièrement précises. Il est conseillé de vérifier les faits importants auprès de sources fiables, particulièrement dans les situations où ces informations sont utilisées pour prendre des décisions critiques.
- **Compréhension du contexte :** Malgré ses capacités à analyser le contexte des questions posées, les réponses du modèle peuvent ne pas toujours capturer toutes les subtilités ou intentions spécifiques. Il est donc crucial d'examiner les réponses dans le cadre spécifique de votre situation.
- **Biais et éthique :** Les réponses générées peuvent parfois refléter des biais involontaires ou des perspectives qui ne représentent pas nécessairement une vue équilibrée. Il est important de rester conscient de ces limitations lors de l'interprétation des réponses.
En tant que développeur indépendant, je m'efforce d'améliorer continuellement ce modèle pour minimiser ces problèmes. Toutefois, je vous encourage à rester vigilant et critique envers les réponses obtenues. Si vous observez des réponses problématiques ou des erreurs, n'hésitez pas à me les remonter. | {"language": ["fr", "en"], "license": "apache-2.0", "library_name": "transformers", "pipeline_tag": "text-generation"} | lbl/fr.brain.carotte-7B | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"fr",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T23:07:08+00:00 | [] | [
"fr",
"en"
] | TAGS
#transformers #safetensors #mistral #text-generation #conversational #fr #en #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# carotte
#### Description du Modèle
Ce document fournit des instructions sur l'utilisation du llm 'carotte-7b', spécialement conçu pour répondre à des questions en français.
#### Prérequis
Pour utiliser ce modèle, il est nécessaire d'installer la bibliothèque 'transformers' de Hugging Face. Si vous ne l'avez pas déjà fait, vous pouvez installer cette bibliothèque via pip en utilisant la commande suivante :
#### Utilisation du Modèle
Voici comment charger et utiliser le modèle 'carotte-7b' pour générer des réponses dans un cadre de dialogue :
1. Importation des bibliothèques nécessaires :
Commencez par importer 'AutoModelForCausalLM' et 'AutoTokenizer' de la bibliothèque 'transformers'.
2. Chargement du modèle et du tokenizer :
Chargez le modèle et le tokenizer pré-entraînés en utilisant les noms spécifiques 'lbl/URL.carotte-7b'.
3. Préparation des messages :
Préparez une liste de messages qui simulent une conversation entre un utilisateur et l'assistant. Chaque message doit contenir un 'role' (utilisateur ou assistant) et un 'content' (le contenu du message).
4. Tokenisation et encodage des entrées :
Utilisez le tokenizer pour appliquer un modèle de chat aux messages et encoder les entrées. Ces entrées doivent être transférées sur le GPU pour une inférence rapide si vous utilisez CUDA.
5. Génération des réponses :
Passez les entrées tokenisées au modèle pour générer des réponses. Le modèle peut être configuré pour échantillonner différentes réponses possibles.
6. Affichage des réponses :
Décodez les identifiants générés en texte clair et affichez les réponses.
Voici un exemple de code complet qui illustre ces étapes :
## Avertissement sur l'utilisation du modèle
Ce modèle de langage a été développé pour générer des réponses basées sur une vaste gamme de données d'entraînement. Cependant, il est important de noter que, comme tout système basé sur l'intelligence artificielle, il n'est pas parfait et peut parfois produire des informations inexactes, incomplètes ou inappropriées.
### Considérations importantes :
- Exactitude des informations : Il peut arriver que le modèle fournisse des informations qui ne sont pas entièrement précises. Il est conseillé de vérifier les faits importants auprès de sources fiables, particulièrement dans les situations où ces informations sont utilisées pour prendre des décisions critiques.
- Compréhension du contexte : Malgré ses capacités à analyser le contexte des questions posées, les réponses du modèle peuvent ne pas toujours capturer toutes les subtilités ou intentions spécifiques. Il est donc crucial d'examiner les réponses dans le cadre spécifique de votre situation.
- Biais et éthique : Les réponses générées peuvent parfois refléter des biais involontaires ou des perspectives qui ne représentent pas nécessairement une vue équilibrée. Il est important de rester conscient de ces limitations lors de l'interprétation des réponses.
En tant que développeur indépendant, je m'efforce d'améliorer continuellement ce modèle pour minimiser ces problèmes. Toutefois, je vous encourage à rester vigilant et critique envers les réponses obtenues. Si vous observez des réponses problématiques ou des erreurs, n'hésitez pas à me les remonter. | [
"# carotte",
"#### Description du Modèle\nCe document fournit des instructions sur l'utilisation du llm 'carotte-7b', spécialement conçu pour répondre à des questions en français.",
"#### Prérequis\nPour utiliser ce modèle, il est nécessaire d'installer la bibliothèque 'transformers' de Hugging Face. Si vous ne l'avez pas déjà fait, vous pouvez installer cette bibliothèque via pip en utilisant la commande suivante :",
"#### Utilisation du Modèle\nVoici comment charger et utiliser le modèle 'carotte-7b' pour générer des réponses dans un cadre de dialogue :\n\n1. Importation des bibliothèques nécessaires :\n Commencez par importer 'AutoModelForCausalLM' et 'AutoTokenizer' de la bibliothèque 'transformers'.\n\n2. Chargement du modèle et du tokenizer :\n Chargez le modèle et le tokenizer pré-entraînés en utilisant les noms spécifiques 'lbl/URL.carotte-7b'.\n\n3. Préparation des messages :\n Préparez une liste de messages qui simulent une conversation entre un utilisateur et l'assistant. Chaque message doit contenir un 'role' (utilisateur ou assistant) et un 'content' (le contenu du message).\n\n4. Tokenisation et encodage des entrées :\n Utilisez le tokenizer pour appliquer un modèle de chat aux messages et encoder les entrées. Ces entrées doivent être transférées sur le GPU pour une inférence rapide si vous utilisez CUDA.\n\n5. Génération des réponses :\n Passez les entrées tokenisées au modèle pour générer des réponses. Le modèle peut être configuré pour échantillonner différentes réponses possibles.\n\n6. Affichage des réponses :\n Décodez les identifiants générés en texte clair et affichez les réponses.\n\nVoici un exemple de code complet qui illustre ces étapes :",
"## Avertissement sur l'utilisation du modèle\n\nCe modèle de langage a été développé pour générer des réponses basées sur une vaste gamme de données d'entraînement. Cependant, il est important de noter que, comme tout système basé sur l'intelligence artificielle, il n'est pas parfait et peut parfois produire des informations inexactes, incomplètes ou inappropriées.",
"### Considérations importantes :\n- Exactitude des informations : Il peut arriver que le modèle fournisse des informations qui ne sont pas entièrement précises. Il est conseillé de vérifier les faits importants auprès de sources fiables, particulièrement dans les situations où ces informations sont utilisées pour prendre des décisions critiques.\n\n- Compréhension du contexte : Malgré ses capacités à analyser le contexte des questions posées, les réponses du modèle peuvent ne pas toujours capturer toutes les subtilités ou intentions spécifiques. Il est donc crucial d'examiner les réponses dans le cadre spécifique de votre situation.\n\n- Biais et éthique : Les réponses générées peuvent parfois refléter des biais involontaires ou des perspectives qui ne représentent pas nécessairement une vue équilibrée. Il est important de rester conscient de ces limitations lors de l'interprétation des réponses.\n\nEn tant que développeur indépendant, je m'efforce d'améliorer continuellement ce modèle pour minimiser ces problèmes. Toutefois, je vous encourage à rester vigilant et critique envers les réponses obtenues. Si vous observez des réponses problématiques ou des erreurs, n'hésitez pas à me les remonter."
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #fr #en #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# carotte",
"#### Description du Modèle\nCe document fournit des instructions sur l'utilisation du llm 'carotte-7b', spécialement conçu pour répondre à des questions en français.",
"#### Prérequis\nPour utiliser ce modèle, il est nécessaire d'installer la bibliothèque 'transformers' de Hugging Face. Si vous ne l'avez pas déjà fait, vous pouvez installer cette bibliothèque via pip en utilisant la commande suivante :",
"#### Utilisation du Modèle\nVoici comment charger et utiliser le modèle 'carotte-7b' pour générer des réponses dans un cadre de dialogue :\n\n1. Importation des bibliothèques nécessaires :\n Commencez par importer 'AutoModelForCausalLM' et 'AutoTokenizer' de la bibliothèque 'transformers'.\n\n2. Chargement du modèle et du tokenizer :\n Chargez le modèle et le tokenizer pré-entraînés en utilisant les noms spécifiques 'lbl/URL.carotte-7b'.\n\n3. Préparation des messages :\n Préparez une liste de messages qui simulent une conversation entre un utilisateur et l'assistant. Chaque message doit contenir un 'role' (utilisateur ou assistant) et un 'content' (le contenu du message).\n\n4. Tokenisation et encodage des entrées :\n Utilisez le tokenizer pour appliquer un modèle de chat aux messages et encoder les entrées. Ces entrées doivent être transférées sur le GPU pour une inférence rapide si vous utilisez CUDA.\n\n5. Génération des réponses :\n Passez les entrées tokenisées au modèle pour générer des réponses. Le modèle peut être configuré pour échantillonner différentes réponses possibles.\n\n6. Affichage des réponses :\n Décodez les identifiants générés en texte clair et affichez les réponses.\n\nVoici un exemple de code complet qui illustre ces étapes :",
"## Avertissement sur l'utilisation du modèle\n\nCe modèle de langage a été développé pour générer des réponses basées sur une vaste gamme de données d'entraînement. Cependant, il est important de noter que, comme tout système basé sur l'intelligence artificielle, il n'est pas parfait et peut parfois produire des informations inexactes, incomplètes ou inappropriées.",
"### Considérations importantes :\n- Exactitude des informations : Il peut arriver que le modèle fournisse des informations qui ne sont pas entièrement précises. Il est conseillé de vérifier les faits importants auprès de sources fiables, particulièrement dans les situations où ces informations sont utilisées pour prendre des décisions critiques.\n\n- Compréhension du contexte : Malgré ses capacités à analyser le contexte des questions posées, les réponses du modèle peuvent ne pas toujours capturer toutes les subtilités ou intentions spécifiques. Il est donc crucial d'examiner les réponses dans le cadre spécifique de votre situation.\n\n- Biais et éthique : Les réponses générées peuvent parfois refléter des biais involontaires ou des perspectives qui ne représentent pas nécessairement une vue équilibrée. Il est important de rester conscient de ces limitations lors de l'interprétation des réponses.\n\nEn tant que développeur indépendant, je m'efforce d'améliorer continuellement ce modèle pour minimiser ces problèmes. Toutefois, je vous encourage à rester vigilant et critique envers les réponses obtenues. Si vous observez des réponses problématiques ou des erreurs, n'hésitez pas à me les remonter."
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-small-384-1k-ft-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:07:35+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-classification | transformers |
BENCHMARKS: AVG: 62.97 ARC: 60.58 HellaSwag: 76.03 MMLU: 55.8 TruthfulQA: 52.64 Winogrande: 77.83 GSM8K: 55.72
3b variant of MFANNv0.5
fine-tuned on the MFANN dataset which is still a work in progress, and is a chain-of-thought experiment carried out by me and me alone.

| {"license": "apache-2.0", "library_name": "transformers", "datasets": ["netcat420/MFANN"], "pipeline_tag": "text-classification"} | netcat420/MFANN3bv0.4 | null | [
"transformers",
"safetensors",
"phi",
"text-generation",
"text-classification",
"dataset:netcat420/MFANN",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T23:08:19+00:00 | [] | [] | TAGS
#transformers #safetensors #phi #text-generation #text-classification #dataset-netcat420/MFANN #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
BENCHMARKS: AVG: 62.97 ARC: 60.58 HellaSwag: 76.03 MMLU: 55.8 TruthfulQA: 52.64 Winogrande: 77.83 GSM8K: 55.72
3b variant of MFANNv0.5
fine-tuned on the MFANN dataset which is still a work in progress, and is a chain-of-thought experiment carried out by me and me alone.
!image/png
| [] | [
"TAGS\n#transformers #safetensors #phi #text-generation #text-classification #dataset-netcat420/MFANN #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | kevin36524/gemma-Code-Instruct-kFinetune-test | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T23:08:52+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-base-384-1k-ft-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:11:28+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ruRoberta-distilled_ner_only
This model is a fine-tuned version of [d0rj/ruRoberta-distilled](https://huggingface.co/d0rj/ruRoberta-distilled) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8018
- Precision: 0.5404
- Recall: 0.5323
- F1: 0.5363
- Accuracy: 0.8992
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 50 | 0.7115 | 0.0 | 0.0 | 0.0 | 0.7679 |
| No log | 2.0 | 100 | 0.5582 | 0.0 | 0.0 | 0.0 | 0.7881 |
| No log | 3.0 | 150 | 0.4507 | 0.0427 | 0.0424 | 0.0426 | 0.8220 |
| No log | 4.0 | 200 | 0.3864 | 0.1664 | 0.2216 | 0.1901 | 0.8475 |
| No log | 5.0 | 250 | 0.3530 | 0.2434 | 0.3372 | 0.2827 | 0.8626 |
| No log | 6.0 | 300 | 0.3592 | 0.2495 | 0.2428 | 0.2461 | 0.8680 |
| No log | 7.0 | 350 | 0.3369 | 0.3351 | 0.3603 | 0.3473 | 0.8800 |
| No log | 8.0 | 400 | 0.2906 | 0.3449 | 0.4605 | 0.3944 | 0.8873 |
| No log | 9.0 | 450 | 0.3039 | 0.3818 | 0.4200 | 0.4000 | 0.8945 |
| 0.4044 | 10.0 | 500 | 0.2893 | 0.4116 | 0.5067 | 0.4542 | 0.8985 |
| 0.4044 | 11.0 | 550 | 0.2948 | 0.4106 | 0.4913 | 0.4474 | 0.9008 |
| 0.4044 | 12.0 | 600 | 0.3473 | 0.4655 | 0.5067 | 0.4852 | 0.9022 |
| 0.4044 | 13.0 | 650 | 0.3238 | 0.3934 | 0.5472 | 0.4577 | 0.8969 |
| 0.4044 | 14.0 | 700 | 0.3360 | 0.4329 | 0.5530 | 0.4856 | 0.9016 |
| 0.4044 | 15.0 | 750 | 0.3642 | 0.3987 | 0.5761 | 0.4712 | 0.9013 |
| 0.4044 | 16.0 | 800 | 0.3769 | 0.3899 | 0.5973 | 0.4718 | 0.8931 |
| 0.4044 | 17.0 | 850 | 0.4674 | 0.4544 | 0.5376 | 0.4925 | 0.9086 |
| 0.4044 | 18.0 | 900 | 0.4675 | 0.4674 | 0.5530 | 0.5066 | 0.9052 |
| 0.4044 | 19.0 | 950 | 0.4134 | 0.4376 | 0.5877 | 0.5016 | 0.9002 |
| 0.0877 | 20.0 | 1000 | 0.4791 | 0.4688 | 0.5800 | 0.5185 | 0.9049 |
| 0.0877 | 21.0 | 1050 | 0.5305 | 0.4852 | 0.5376 | 0.5101 | 0.9083 |
| 0.0877 | 22.0 | 1100 | 0.5038 | 0.3955 | 0.6089 | 0.4795 | 0.8903 |
| 0.0877 | 23.0 | 1150 | 0.4801 | 0.4875 | 0.5992 | 0.5376 | 0.9123 |
| 0.0877 | 24.0 | 1200 | 0.5276 | 0.4851 | 0.5645 | 0.5218 | 0.9061 |
| 0.0877 | 25.0 | 1250 | 0.5565 | 0.5116 | 0.5973 | 0.5511 | 0.9116 |
| 0.0877 | 26.0 | 1300 | 0.5445 | 0.4675 | 0.6089 | 0.5289 | 0.9081 |
| 0.0877 | 27.0 | 1350 | 0.5201 | 0.4662 | 0.6108 | 0.5288 | 0.9106 |
| 0.0877 | 28.0 | 1400 | 0.5795 | 0.5103 | 0.5742 | 0.5403 | 0.9092 |
| 0.0877 | 29.0 | 1450 | 0.5237 | 0.5213 | 0.5665 | 0.5429 | 0.9094 |
| 0.0241 | 30.0 | 1500 | 0.6092 | 0.5583 | 0.5723 | 0.5652 | 0.9134 |
| 0.0241 | 31.0 | 1550 | 0.6018 | 0.4530 | 0.6224 | 0.5244 | 0.9043 |
| 0.0241 | 32.0 | 1600 | 0.4779 | 0.4861 | 0.6069 | 0.5398 | 0.9121 |
| 0.0241 | 33.0 | 1650 | 0.5400 | 0.5017 | 0.5549 | 0.5270 | 0.9100 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "d0rj/ruRoberta-distilled", "model-index": [{"name": "ruRoberta-distilled_ner_only", "results": []}]} | DimasikKurd/ruRoberta-distilled_ner_only | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:d0rj/ruRoberta-distilled",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:14:05+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #token-classification #generated_from_trainer #base_model-d0rj/ruRoberta-distilled #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| ruRoberta-distilled\_ner\_only
==============================
This model is a fine-tuned version of d0rj/ruRoberta-distilled on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.8018
* Precision: 0.5404
* Recall: 0.5323
* F1: 0.5363
* Accuracy: 0.8992
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 100
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.1.2
* Datasets 2.1.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2\n* Datasets 2.1.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #token-classification #generated_from_trainer #base_model-d0rj/ruRoberta-distilled #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.1.2\n* Datasets 2.1.0\n* Tokenizers 0.15.2"
] |
image-classification | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k"], "metrics": ["accuracy"], "pipeline_tag": "image-classification"} | DaiShiResearch/transnext-micro-AAAA-256-1k | null | [
"pytorch",
"vision",
"image-classification",
"en",
"dataset:imagenet-1k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:16:54+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-classification #en #dataset-imagenet-1k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-generation | transformers | # ChaoticVision
This is a highly experimental merge of two Mistral Llava models with the intent of splitting out a mmproj projector file with a more robust captioning capability. I do not know if this model is functional, and will not be testing it as a language model, so use at your own risk.
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [jeiku/llavamistral1.6configedit](https://huggingface.co/jeiku/llavamistral1.6configedit)
* [jeiku/noushermesvisionalphaconfigedit](https://huggingface.co/jeiku/noushermesvisionalphaconfigedit)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: jeiku/llavamistral1.6configedit
layer_range: [0, 32]
- model: jeiku/noushermesvisionalphaconfigedit
layer_range: [0, 32]
merge_method: slerp
base_model: jeiku/llavamistral1.6configedit
parameters:
t:
- filter: self_attn
value: [0.5, 0.5, 0.5, 0.5, 0.5]
- filter: mlp
value: [0.5, 0.5, 0.5, 0.5, 0.5]
- value: 0.5
dtype: bfloat16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["jeiku/llavamistral1.6configedit", "jeiku/noushermesvisionalphaconfigedit"]} | ChaoticNeutrals/ChaoticVision | null | [
"transformers",
"safetensors",
"llava_mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:jeiku/llavamistral1.6configedit",
"base_model:jeiku/noushermesvisionalphaconfigedit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:21:44+00:00 | [] | [] | TAGS
#transformers #safetensors #llava_mistral #text-generation #mergekit #merge #conversational #base_model-jeiku/llavamistral1.6configedit #base_model-jeiku/noushermesvisionalphaconfigedit #autotrain_compatible #endpoints_compatible #region-us
| # ChaoticVision
This is a highly experimental merge of two Mistral Llava models with the intent of splitting out a mmproj projector file with a more robust captioning capability. I do not know if this model is functional, and will not be testing it as a language model, so use at your own risk.
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* jeiku/llavamistral1.6configedit
* jeiku/noushermesvisionalphaconfigedit
### Configuration
The following YAML configuration was used to produce this model:
| [
"# ChaoticVision\n\nThis is a highly experimental merge of two Mistral Llava models with the intent of splitting out a mmproj projector file with a more robust captioning capability. I do not know if this model is functional, and will not be testing it as a language model, so use at your own risk.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the SLERP merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* jeiku/llavamistral1.6configedit\n* jeiku/noushermesvisionalphaconfigedit",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llava_mistral #text-generation #mergekit #merge #conversational #base_model-jeiku/llavamistral1.6configedit #base_model-jeiku/noushermesvisionalphaconfigedit #autotrain_compatible #endpoints_compatible #region-us \n",
"# ChaoticVision\n\nThis is a highly experimental merge of two Mistral Llava models with the intent of splitting out a mmproj projector file with a more robust captioning capability. I do not know if this model is functional, and will not be testing it as a language model, so use at your own risk.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the SLERP merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* jeiku/llavamistral1.6configedit\n* jeiku/noushermesvisionalphaconfigedit",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp1_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3334
- Rewards/chosen: -12.5084
- Rewards/rejected: -14.9821
- Rewards/accuracies: 0.6800
- Rewards/margins: 2.4737
- Logps/rejected: -265.9678
- Logps/chosen: -237.7022
- Logits/rejected: -1.1144
- Logits/chosen: -1.1457
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0688 | 2.67 | 100 | 0.9409 | -3.4509 | -4.7255 | 0.6900 | 1.2746 | -163.4019 | -147.1273 | -1.4436 | -1.4535 |
| 0.0013 | 5.33 | 200 | 1.2767 | -10.7944 | -12.7570 | 0.6700 | 1.9626 | -243.7165 | -220.5616 | -1.3151 | -1.3441 |
| 0.0001 | 8.0 | 300 | 1.3152 | -12.2279 | -14.6398 | 0.6800 | 2.4118 | -262.5441 | -234.8975 | -1.1347 | -1.1653 |
| 0.0001 | 10.67 | 400 | 1.3231 | -12.3403 | -14.7735 | 0.6800 | 2.4333 | -263.8819 | -236.0207 | -1.1265 | -1.1574 |
| 0.0001 | 13.33 | 500 | 1.3286 | -12.4240 | -14.8779 | 0.6800 | 2.4538 | -264.9250 | -236.8581 | -1.1200 | -1.1512 |
| 0.0001 | 16.0 | 600 | 1.3344 | -12.4832 | -14.9513 | 0.6800 | 2.4681 | -265.6594 | -237.4504 | -1.1165 | -1.1478 |
| 0.0001 | 18.67 | 700 | 1.3322 | -12.5009 | -14.9737 | 0.6800 | 2.4728 | -265.8835 | -237.6271 | -1.1150 | -1.1460 |
| 0.0001 | 21.33 | 800 | 1.3324 | -12.5055 | -14.9833 | 0.6800 | 2.4778 | -265.9792 | -237.6730 | -1.1147 | -1.1457 |
| 0.0001 | 24.0 | 900 | 1.3390 | -12.5121 | -14.9772 | 0.6800 | 2.4650 | -265.9181 | -237.7395 | -1.1143 | -1.1457 |
| 0.0 | 26.67 | 1000 | 1.3334 | -12.5084 | -14.9821 | 0.6800 | 2.4737 | -265.9678 | -237.7022 | -1.1144 | -1.1457 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp1_dpo1", "results": []}]} | guoyu-zhang/model_hh_usp1_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-16T23:22:46+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp1\_dpo1
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.3334
* Rewards/chosen: -12.5084
* Rewards/rejected: -14.9821
* Rewards/accuracies: 0.6800
* Rewards/margins: 2.4737
* Logps/rejected: -265.9678
* Logps/chosen: -237.7022
* Logits/rejected: -1.1144
* Logits/chosen: -1.1457
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mental
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9921
- Accuracy: 0.6760
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.26 | 50 | 1.3538 | 0.5555 |
| No log | 0.51 | 100 | 1.1520 | 0.6084 |
| No log | 0.77 | 150 | 1.0683 | 0.6352 |
| 1.3109 | 1.02 | 200 | 1.0435 | 0.6543 |
| 1.3109 | 1.28 | 250 | 1.0246 | 0.6575 |
| 1.3109 | 1.53 | 300 | 1.0565 | 0.6550 |
| 1.3109 | 1.79 | 350 | 0.9921 | 0.6760 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "distilbert/distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-mental", "results": []}]} | rgao/distilbert-base-uncased-finetuned-mental | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:23:51+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| distilbert-base-uncased-finetuned-mental
========================================
This model is a fine-tuned version of distilbert/distilbert-base-uncased on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9921
* Accuracy: 0.6760
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/AlekseiPravdin/NSK-128k-7B-slerp
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/NSK-128k-7B-slerp-GGUF/resolve/main/NSK-128k-7B-slerp.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["merge", "mergekit", "lazymergekit", "Nitral-AI/Nyan-Stunna-7B", "Nitral-AI/Kunocchini-7b-128k-test", "128k"], "base_model": "AlekseiPravdin/NSK-128k-7B-slerp", "quantized_by": "mradermacher"} | mradermacher/NSK-128k-7B-slerp-GGUF | null | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"Nitral-AI/Nyan-Stunna-7B",
"Nitral-AI/Kunocchini-7b-128k-test",
"128k",
"en",
"base_model:AlekseiPravdin/NSK-128k-7B-slerp",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:27:35+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #merge #mergekit #lazymergekit #Nitral-AI/Nyan-Stunna-7B #Nitral-AI/Kunocchini-7b-128k-test #128k #en #base_model-AlekseiPravdin/NSK-128k-7B-slerp #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #merge #mergekit #lazymergekit #Nitral-AI/Nyan-Stunna-7B #Nitral-AI/Kunocchini-7b-128k-test #128k #en #base_model-AlekseiPravdin/NSK-128k-7B-slerp #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dapt_plus_tapt_amazon_helpfulness_classification
This model is a fine-tuned version of [BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model](https://huggingface.co/BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3889
- Accuracy: 0.8696
- F1 Macro: 0.6767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.06
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|
| 0.317 | 1.0 | 1563 | 0.3193 | 0.8668 | 0.6641 |
| 0.2897 | 2.0 | 3126 | 0.3704 | 0.8702 | 0.6222 |
| 0.2137 | 3.0 | 4689 | 0.3889 | 0.8696 | 0.6767 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model", "model-index": [{"name": "dapt_plus_tapt_amazon_helpfulness_classification", "results": []}]} | BigTMiami/dapt_plus_tapt_amazon_helpfulness_classification | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:28:07+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model #license-mit #autotrain_compatible #endpoints_compatible #region-us
| dapt\_plus\_tapt\_amazon\_helpfulness\_classification
=====================================================
This model is a fine-tuned version of BigTMiami/dapt\_plus\_tapt\_helpfulness\_base\_pretraining\_model on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3889
* Accuracy: 0.8696
* F1 Macro: 0.6767
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.06
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.06\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.06\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5595
- F1 Score: 0.7161
- Accuracy: 0.7161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 1536
- eval_batch_size: 1536
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5884 | 25.0 | 200 | 0.6366 | 0.6974 | 0.7021 |
| 0.4077 | 50.0 | 400 | 0.7210 | 0.6885 | 0.6887 |
| 0.3041 | 75.0 | 600 | 0.8421 | 0.6878 | 0.6880 |
| 0.2333 | 100.0 | 800 | 0.9572 | 0.6930 | 0.6941 |
| 0.1815 | 125.0 | 1000 | 1.0596 | 0.7020 | 0.7021 |
| 0.1496 | 150.0 | 1200 | 1.1957 | 0.7021 | 0.7021 |
| 0.1233 | 175.0 | 1400 | 1.3122 | 0.7014 | 0.7014 |
| 0.1079 | 200.0 | 1600 | 1.3157 | 0.7007 | 0.7007 |
| 0.0976 | 225.0 | 1800 | 1.4664 | 0.6968 | 0.6974 |
| 0.0867 | 250.0 | 2000 | 1.5423 | 0.6923 | 0.6934 |
| 0.081 | 275.0 | 2200 | 1.4351 | 0.7101 | 0.7101 |
| 0.0744 | 300.0 | 2400 | 1.5701 | 0.6980 | 0.6981 |
| 0.0709 | 325.0 | 2600 | 1.5215 | 0.7017 | 0.7021 |
| 0.0684 | 350.0 | 2800 | 1.6212 | 0.6998 | 0.7007 |
| 0.0654 | 375.0 | 3000 | 1.5700 | 0.7061 | 0.7061 |
| 0.0623 | 400.0 | 3200 | 1.6521 | 0.6909 | 0.6921 |
| 0.0602 | 425.0 | 3400 | 1.6553 | 0.7027 | 0.7027 |
| 0.0592 | 450.0 | 3600 | 1.6282 | 0.6944 | 0.6954 |
| 0.0572 | 475.0 | 3800 | 1.5906 | 0.7128 | 0.7128 |
| 0.0549 | 500.0 | 4000 | 1.7238 | 0.7101 | 0.7101 |
| 0.0525 | 525.0 | 4200 | 1.7797 | 0.6984 | 0.6994 |
| 0.0523 | 550.0 | 4400 | 1.7800 | 0.7031 | 0.7034 |
| 0.051 | 575.0 | 4600 | 1.6590 | 0.6990 | 0.7001 |
| 0.0492 | 600.0 | 4800 | 1.7405 | 0.6987 | 0.6994 |
| 0.0485 | 625.0 | 5000 | 1.6682 | 0.7025 | 0.7027 |
| 0.0464 | 650.0 | 5200 | 1.8969 | 0.7010 | 0.7014 |
| 0.0456 | 675.0 | 5400 | 1.7763 | 0.7107 | 0.7108 |
| 0.0441 | 700.0 | 5600 | 1.7441 | 0.7059 | 0.7061 |
| 0.0444 | 725.0 | 5800 | 1.7876 | 0.7087 | 0.7088 |
| 0.0434 | 750.0 | 6000 | 1.8325 | 0.7034 | 0.7041 |
| 0.0413 | 775.0 | 6200 | 1.7683 | 0.7018 | 0.7021 |
| 0.0414 | 800.0 | 6400 | 1.8375 | 0.7092 | 0.7094 |
| 0.0403 | 825.0 | 6600 | 1.8771 | 0.7060 | 0.7061 |
| 0.0396 | 850.0 | 6800 | 1.8270 | 0.6943 | 0.6954 |
| 0.0384 | 875.0 | 7000 | 1.8038 | 0.6987 | 0.6994 |
| 0.0382 | 900.0 | 7200 | 1.9041 | 0.7010 | 0.7014 |
| 0.0377 | 925.0 | 7400 | 1.8126 | 0.7088 | 0.7088 |
| 0.038 | 950.0 | 7600 | 1.8707 | 0.7044 | 0.7047 |
| 0.0371 | 975.0 | 7800 | 1.7445 | 0.7019 | 0.7021 |
| 0.0377 | 1000.0 | 8000 | 1.8357 | 0.6996 | 0.7001 |
| 0.0353 | 1025.0 | 8200 | 1.8144 | 0.7061 | 0.7061 |
| 0.0353 | 1050.0 | 8400 | 1.8374 | 0.7019 | 0.7021 |
| 0.0349 | 1075.0 | 8600 | 1.8487 | 0.7037 | 0.7041 |
| 0.035 | 1100.0 | 8800 | 1.8381 | 0.7053 | 0.7054 |
| 0.0341 | 1125.0 | 9000 | 1.8353 | 0.7018 | 0.7021 |
| 0.0335 | 1150.0 | 9200 | 1.8325 | 0.7027 | 0.7027 |
| 0.0332 | 1175.0 | 9400 | 1.8636 | 0.7046 | 0.7047 |
| 0.0328 | 1200.0 | 9600 | 1.8820 | 0.7044 | 0.7047 |
| 0.033 | 1225.0 | 9800 | 1.8568 | 0.7038 | 0.7041 |
| 0.0333 | 1250.0 | 10000 | 1.8682 | 0.7045 | 0.7047 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T23:28:33+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3-seqsight\_32768\_512\_43M-L32\_all
===============================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.5595
* F1 Score: 0.7161
* Accuracy: 0.7161
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 1536
* eval\_batch\_size: 1536
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 1536\n* eval\\_batch\\_size: 1536\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 1536\n* eval\\_batch\\_size: 1536\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_shp3_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1787
- Rewards/chosen: -6.1846
- Rewards/rejected: -8.5969
- Rewards/accuracies: 0.6200
- Rewards/margins: 2.4123
- Logps/rejected: -271.1182
- Logps/chosen: -230.6183
- Logits/rejected: -0.9872
- Logits/chosen: -0.9880
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.028 | 2.67 | 100 | 1.0860 | -2.5770 | -3.4358 | 0.5900 | 0.8588 | -260.7960 | -223.4030 | -0.8288 | -0.8294 |
| 0.0224 | 5.33 | 200 | 1.5814 | -7.3321 | -9.0973 | 0.5900 | 1.7652 | -272.1189 | -232.9132 | -0.9907 | -0.9251 |
| 0.0108 | 8.0 | 300 | 1.6622 | -3.3135 | -4.7967 | 0.5700 | 1.4832 | -263.5178 | -224.8760 | -0.9527 | -0.9456 |
| 0.0001 | 10.67 | 400 | 2.2015 | -6.2017 | -8.5794 | 0.6100 | 2.3777 | -271.0831 | -230.6524 | -0.9859 | -0.9872 |
| 0.0 | 13.33 | 500 | 2.1911 | -6.1679 | -8.5594 | 0.6200 | 2.3916 | -271.0432 | -230.5848 | -0.9860 | -0.9873 |
| 0.0 | 16.0 | 600 | 2.1885 | -6.1988 | -8.6070 | 0.6300 | 2.4081 | -271.1382 | -230.6467 | -0.9867 | -0.9877 |
| 0.0 | 18.67 | 700 | 2.1971 | -6.2183 | -8.6010 | 0.6200 | 2.3827 | -271.1264 | -230.6856 | -0.9868 | -0.9876 |
| 0.0 | 21.33 | 800 | 2.1909 | -6.1952 | -8.5881 | 0.6300 | 2.3929 | -271.1005 | -230.6395 | -0.9863 | -0.9870 |
| 0.0 | 24.0 | 900 | 2.1721 | -6.1855 | -8.6019 | 0.6100 | 2.4164 | -271.1281 | -230.6200 | -0.9871 | -0.9878 |
| 0.0 | 26.67 | 1000 | 2.1787 | -6.1846 | -8.5969 | 0.6200 | 2.4123 | -271.1182 | -230.6183 | -0.9872 | -0.9880 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_shp3_dpo5", "results": []}]} | guoyu-zhang/model_shp3_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-16T23:28:35+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_shp3\_dpo5
=================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.1787
* Rewards/chosen: -6.1846
* Rewards/rejected: -8.5969
* Rewards/accuracies: 0.6200
* Rewards/margins: 2.4123
* Logps/rejected: -271.1182
* Logps/chosen: -230.6183
* Logits/rejected: -0.9872
* Logits/chosen: -0.9880
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [ybelkada/falcon-7b-sharded-bf16](https://huggingface.co/ybelkada/falcon-7b-sharded-bf16) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "ybelkada/falcon-7b-sharded-bf16", "model-index": [{"name": "results", "results": []}]} | Mariyyah/results | null | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"region:us"
] | null | 2024-04-16T23:32:39+00:00 | [] | [] | TAGS
#peft #safetensors #trl #sft #generated_from_trainer #base_model-ybelkada/falcon-7b-sharded-bf16 #region-us
|
# results
This model is a fine-tuned version of ybelkada/falcon-7b-sharded-bf16 on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | [
"# results\n\nThis model is a fine-tuned version of ybelkada/falcon-7b-sharded-bf16 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- training_steps: 500\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #sft #generated_from_trainer #base_model-ybelkada/falcon-7b-sharded-bf16 #region-us \n",
"# results\n\nThis model is a fine-tuned version of ybelkada/falcon-7b-sharded-bf16 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 4\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- training_steps: 500\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.1.dev0\n- Transformers 4.39.3\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw2.25 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T23:42:54+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
text-generation | transformers |
# Uploaded model
- **Developed by:** yiruiz
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-2-13b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "sft"], "base_model": "unsloth/llama-2-13b-bnb-4bit"} | yiruiz/llama-2-13b-code-16bit-old | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-2-13b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:44:55+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/llama-2-13b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: yiruiz
- License: apache-2.0
- Finetuned from model : unsloth/llama-2-13b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: yiruiz\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-2-13b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/llama-2-13b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: yiruiz\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-2-13b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | Rimyy/GemmaFTMathFormatv1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:48:22+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dapt_plus_tapt_amazon_helpfulness_classification_v2
This model is a fine-tuned version of [BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model](https://huggingface.co/BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3267
- Accuracy: 0.8628
- F1 Macro: 0.6898
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.06
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|
| 0.3333 | 1.0 | 1563 | 0.3267 | 0.8628 | 0.6898 |
| 0.309 | 2.0 | 3126 | 0.3859 | 0.8696 | 0.6292 |
| 0.2443 | 3.0 | 4689 | 0.4222 | 0.8664 | 0.6222 |
| 0.1683 | 4.0 | 6252 | 0.5618 | 0.867 | 0.6315 |
| 0.1591 | 5.0 | 7815 | 0.6760 | 0.8668 | 0.6678 |
| 0.0877 | 6.0 | 9378 | 0.8763 | 0.8614 | 0.6678 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model", "model-index": [{"name": "dapt_plus_tapt_amazon_helpfulness_classification_v2", "results": []}]} | BigTMiami/dapt_plus_tapt_amazon_helpfulness_classification_v2 | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:49:28+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model #license-mit #autotrain_compatible #endpoints_compatible #region-us
| dapt\_plus\_tapt\_amazon\_helpfulness\_classification\_v2
=========================================================
This model is a fine-tuned version of BigTMiami/dapt\_plus\_tapt\_helpfulness\_base\_pretraining\_model on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3267
* Accuracy: 0.8628
* F1 Macro: 0.6898
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.06
* num\_epochs: 10
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.06\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-BigTMiami/dapt_plus_tapt_helpfulness_base_pretraining_model #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-06\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.06\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw2.5 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-16T23:53:10+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
null | transformers |
# Uploaded model
- **Developed by:** codesagar
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | codesagar/prompt-guard-classification-v12 | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:53:17+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: codesagar
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: codesagar\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "255.28 +/- 26.97", "name": "mean_reward", "verified": false}]}]}]} | sgreulic/ppo-LunarLander-v2reborn | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-16T23:53:33+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/bongchoi/MoMo-70B-V1.1
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/MoMo-70B-V1.1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q2_K.gguf) | Q2_K | 25.6 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.IQ3_XS.gguf) | IQ3_XS | 28.4 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.IQ3_S.gguf) | IQ3_S | 30.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q3_K_S.gguf) | Q3_K_S | 30.0 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.IQ3_M.gguf) | IQ3_M | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q3_K_M.gguf) | Q3_K_M | 33.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q3_K_L.gguf) | Q3_K_L | 36.2 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.IQ4_XS.gguf) | IQ4_XS | 37.3 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q4_K_S.gguf) | Q4_K_S | 39.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q4_K_M.gguf) | Q4_K_M | 41.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q5_K_S.gguf) | Q5_K_S | 47.6 | |
| [GGUF](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q5_K_M.gguf) | Q5_K_M | 48.9 | |
| [PART 1](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q6_K.gguf.part2of2) | Q6_K | 56.7 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/MoMo-70B-V1.1-GGUF/resolve/main/MoMo-70B-V1.1.Q8_0.gguf.part2of2) | Q8_0 | 73.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "llama2", "library_name": "transformers", "base_model": "bongchoi/MoMo-70B-V1.1", "quantized_by": "mradermacher"} | mradermacher/MoMo-70B-V1.1-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:bongchoi/MoMo-70B-V1.1",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:53:49+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #en #base_model-bongchoi/MoMo-70B-V1.1 #license-llama2 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #en #base_model-bongchoi/MoMo-70B-V1.1 #license-llama2 #endpoints_compatible #region-us \n"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/dino-4scale-transnext-tiny-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:54:24+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4ac-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0403
- F1 Score: 0.5836
- Accuracy: 0.5874
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6737 | 14.29 | 200 | 0.6856 | 0.5778 | 0.5774 |
| 0.6105 | 28.57 | 400 | 0.7350 | 0.5575 | 0.5587 |
| 0.5558 | 42.86 | 600 | 0.7778 | 0.5700 | 0.5698 |
| 0.5126 | 57.14 | 800 | 0.8092 | 0.5700 | 0.5698 |
| 0.4767 | 71.43 | 1000 | 0.8323 | 0.5725 | 0.5739 |
| 0.4494 | 85.71 | 1200 | 0.8773 | 0.5732 | 0.5727 |
| 0.4292 | 100.0 | 1400 | 0.8971 | 0.5792 | 0.5789 |
| 0.4101 | 114.29 | 1600 | 0.9174 | 0.5849 | 0.5862 |
| 0.3931 | 128.57 | 1800 | 0.9676 | 0.5818 | 0.5824 |
| 0.3806 | 142.86 | 2000 | 0.9274 | 0.5844 | 0.5848 |
| 0.3689 | 157.14 | 2200 | 0.9768 | 0.5818 | 0.5815 |
| 0.3597 | 171.43 | 2400 | 0.9820 | 0.5677 | 0.5698 |
| 0.3524 | 185.71 | 2600 | 1.0115 | 0.5846 | 0.5845 |
| 0.3436 | 200.0 | 2800 | 1.0594 | 0.5851 | 0.5886 |
| 0.3384 | 214.29 | 3000 | 0.9900 | 0.5823 | 0.5818 |
| 0.33 | 228.57 | 3200 | 1.0362 | 0.5830 | 0.5839 |
| 0.3257 | 242.86 | 3400 | 1.0386 | 0.5845 | 0.5862 |
| 0.3174 | 257.14 | 3600 | 1.0180 | 0.5818 | 0.5818 |
| 0.3106 | 271.43 | 3800 | 1.0476 | 0.5808 | 0.5804 |
| 0.308 | 285.71 | 4000 | 1.0583 | 0.5759 | 0.5754 |
| 0.3004 | 300.0 | 4200 | 1.0556 | 0.5722 | 0.5718 |
| 0.2958 | 314.29 | 4400 | 1.1405 | 0.5697 | 0.5698 |
| 0.2899 | 328.57 | 4600 | 1.1077 | 0.5811 | 0.5827 |
| 0.2864 | 342.86 | 4800 | 1.0519 | 0.5813 | 0.5815 |
| 0.2806 | 357.14 | 5000 | 1.0575 | 0.5808 | 0.5815 |
| 0.2775 | 371.43 | 5200 | 1.0595 | 0.5756 | 0.5754 |
| 0.2725 | 385.71 | 5400 | 1.1027 | 0.5757 | 0.5760 |
| 0.2684 | 400.0 | 5600 | 1.1092 | 0.5788 | 0.5783 |
| 0.2645 | 414.29 | 5800 | 1.1286 | 0.5782 | 0.5777 |
| 0.2626 | 428.57 | 6000 | 1.1074 | 0.5705 | 0.5701 |
| 0.2557 | 442.86 | 6200 | 1.1491 | 0.5770 | 0.5765 |
| 0.2533 | 457.14 | 6400 | 1.1693 | 0.5770 | 0.5771 |
| 0.2499 | 471.43 | 6600 | 1.1328 | 0.5801 | 0.5801 |
| 0.2477 | 485.71 | 6800 | 1.1773 | 0.5773 | 0.5768 |
| 0.2465 | 500.0 | 7000 | 1.1478 | 0.5789 | 0.5789 |
| 0.2425 | 514.29 | 7200 | 1.1765 | 0.5773 | 0.5771 |
| 0.2405 | 528.57 | 7400 | 1.1834 | 0.5815 | 0.5812 |
| 0.2374 | 542.86 | 7600 | 1.1874 | 0.5820 | 0.5815 |
| 0.235 | 557.14 | 7800 | 1.1642 | 0.5799 | 0.5798 |
| 0.2316 | 571.43 | 8000 | 1.2329 | 0.5779 | 0.5774 |
| 0.2294 | 585.71 | 8200 | 1.1927 | 0.5755 | 0.5751 |
| 0.2294 | 600.0 | 8400 | 1.2237 | 0.5807 | 0.5804 |
| 0.2266 | 614.29 | 8600 | 1.2159 | 0.5782 | 0.5777 |
| 0.2242 | 628.57 | 8800 | 1.2158 | 0.5754 | 0.5751 |
| 0.2259 | 642.86 | 9000 | 1.2077 | 0.5805 | 0.5801 |
| 0.2224 | 657.14 | 9200 | 1.1982 | 0.5821 | 0.5818 |
| 0.2231 | 671.43 | 9400 | 1.1867 | 0.5816 | 0.5812 |
| 0.2208 | 685.71 | 9600 | 1.2245 | 0.5809 | 0.5804 |
| 0.2216 | 700.0 | 9800 | 1.2138 | 0.5813 | 0.5809 |
| 0.2194 | 714.29 | 10000 | 1.2227 | 0.5817 | 0.5812 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4ac-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4ac-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-16T23:56:17+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H4ac-seqsight\_32768\_512\_43M-L32\_all
=================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H4ac dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0403
* F1 Score: 0.5836
* Accuracy: 0.5874
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: HuggingFaceTB/cosmo-1b
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: Vezora/Tested-22k-Python-Alpaca
type: alpaca
dataset_prepared_path: prepared-qlora
val_set_size: 0.05
output_dir: ./qlora-out
sequence_len: 2048
sample_packing: true
pad_to_sequence_len: true
adapter: qlora
lora_model_dir:
lora_r: 256
lora_alpha: 256
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
peft_use_dora: true
wandb_project: cosmo-python-qlora
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 2
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 0.0005
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 4
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
```
</details><br>
# qlora-out
This model is a fine-tuned version of [HuggingFaceTB/cosmo-1b](https://huggingface.co/HuggingFaceTB/cosmo-1b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2055
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6458 | 0.0 | 1 | 0.6657 |
| 0.3969 | 0.25 | 217 | 0.4062 |
| 0.327 | 0.5 | 434 | 0.2912 |
| 0.356 | 0.75 | 651 | 0.2055 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0.dev0
- Pytorch 2.1.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.0 | {"license": "apache-2.0", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "HuggingFaceTB/cosmo-1b", "model-index": [{"name": "qlora-out", "results": []}]} | Lambent/cosmo-1b-qdora-pythontest | null | [
"peft",
"pytorch",
"llama",
"generated_from_trainer",
"base_model:HuggingFaceTB/cosmo-1b",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:57:42+00:00 | [] | [] | TAGS
#peft #pytorch #llama #generated_from_trainer #base_model-HuggingFaceTB/cosmo-1b #license-apache-2.0 #region-us
| <img src="URL alt="Built with Axolotl" width="200" height="32"/>
See axolotl config
axolotl version: '0.4.0'
qlora-out
=========
This model is a fine-tuned version of HuggingFaceTB/cosmo-1b on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2055
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 8
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 10
* num\_epochs: 1
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.40.0.dev0
* Pytorch 2.1.2+cu118
* Datasets 2.18.0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 10\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.18.0\n* Tokenizers 0.15.0"
] | [
"TAGS\n#peft #pytorch #llama #generated_from_trainer #base_model-HuggingFaceTB/cosmo-1b #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 10\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.18.0\n* Tokenizers 0.15.0"
] |
null | null | BENCHMARKS: AVG: 62.97 ARC: 60.58 HellaSwag: 76.03 MMLU: 55.8 TruthfulQA: 52.64 Winogrande: 77.83 GSM8K: 55.72
3b variant of MFANNv0.5
fine-tuned on the MFANN dataset which is still a work in progress, and is a chain-of-thought experiment carried out by me and me alone.

| {"license": "apache-2.0"} | netcat420/MFANN3bv0.4-GGUF | null | [
"gguf",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:58:22+00:00 | [] | [] | TAGS
#gguf #license-apache-2.0 #region-us
| BENCHMARKS: AVG: 62.97 ARC: 60.58 HellaSwag: 76.03 MMLU: 55.8 TruthfulQA: 52.64 Winogrande: 77.83 GSM8K: 55.72
3b variant of MFANNv0.5
fine-tuned on the MFANN dataset which is still a work in progress, and is a chain-of-thought experiment carried out by me and me alone.
!image/png
| [] | [
"TAGS\n#gguf #license-apache-2.0 #region-us \n"
] |
null | peft | ## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- _load_in_8bit: False
- _load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
- bnb_4bit_quant_storage: uint8
- load_in_4bit: True
- load_in_8bit: False
### Framework versions
- PEFT 0.5.0
# Open Portuguese LLM Leaderboard Evaluation Results
Detailed results can be found [here](https://huggingface.co/datasets/eduagarcia-temp/llm_pt_leaderboard_raw_results/tree/main/recogna-nlp/gembode-2b-base-ultraalpaca) and on the [🚀 Open Portuguese LLM Leaderboard](https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard)
| Metric | Value |
|--------------------------|---------|
|Average |**45.25**|
|ENEM Challenge (No Images)| 31.77|
|BLUEX (No Images) | 24.20|
|OAB Exams | 27.84|
|Assin2 RTE | 69.51|
|Assin2 STS | 30.31|
|FaQuAD NLI | 55.55|
|HateBR Binary | 53.18|
|PT Hate Speech Binary | 64.74|
|tweetSentBR | 50.18|
| {"library_name": "peft", "model-index": [{"name": "gembode-2b-base-ultraalpaca", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "ENEM Challenge (No Images)", "type": "eduagarcia/enem_challenge", "split": "train", "args": {"num_few_shot": 3}}, "metrics": [{"type": "acc", "value": 31.77, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "BLUEX (No Images)", "type": "eduagarcia-temp/BLUEX_without_images", "split": "train", "args": {"num_few_shot": 3}}, "metrics": [{"type": "acc", "value": 24.2, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "OAB Exams", "type": "eduagarcia/oab_exams", "split": "train", "args": {"num_few_shot": 3}}, "metrics": [{"type": "acc", "value": 27.84, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Assin2 RTE", "type": "assin2", "split": "test", "args": {"num_few_shot": 15}}, "metrics": [{"type": "f1_macro", "value": 69.51, "name": "f1-macro"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Assin2 STS", "type": "eduagarcia/portuguese_benchmark", "split": "test", "args": {"num_few_shot": 15}}, "metrics": [{"type": "pearson", "value": 30.31, "name": "pearson"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "FaQuAD NLI", "type": "ruanchaves/faquad-nli", "split": "test", "args": {"num_few_shot": 15}}, "metrics": [{"type": "f1_macro", "value": 55.55, "name": "f1-macro"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HateBR Binary", "type": "ruanchaves/hatebr", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "f1_macro", "value": 53.18, "name": "f1-macro"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "PT Hate Speech Binary", "type": "hate_speech_portuguese", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "f1_macro", "value": 64.74, "name": "f1-macro"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "tweetSentBR", "type": "eduagarcia/tweetsentbr_fewshot", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "f1_macro", "value": 50.18, "name": "f1-macro"}], "source": {"url": "https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/gembode-2b-base-ultraalpaca", "name": "Open Portuguese LLM Leaderboard"}}]}]} | recogna-nlp/gembode-2b-base-ultraalpaca | null | [
"peft",
"pytorch",
"gemma",
"model-index",
"has_space",
"region:us"
] | null | 2024-04-16T23:58:44+00:00 | [] | [] | TAGS
#peft #pytorch #gemma #model-index #has_space #region-us
| Training procedure
------------------
The following 'bitsandbytes' quantization config was used during training:
* quant\_method: bitsandbytes
* \_load\_in\_8bit: False
* \_load\_in\_4bit: True
* llm\_int8\_threshold: 6.0
* llm\_int8\_skip\_modules: None
* llm\_int8\_enable\_fp32\_cpu\_offload: False
* llm\_int8\_has\_fp16\_weight: False
* bnb\_4bit\_quant\_type: nf4
* bnb\_4bit\_use\_double\_quant: True
* bnb\_4bit\_compute\_dtype: float16
* bnb\_4bit\_quant\_storage: uint8
* load\_in\_4bit: True
* load\_in\_8bit: False
### Framework versions
* PEFT 0.5.0
Open Portuguese LLM Leaderboard Evaluation Results
==================================================
Detailed results can be found here and on the Open Portuguese LLM Leaderboard
| [
"### Framework versions\n\n\n* PEFT 0.5.0\n\n\nOpen Portuguese LLM Leaderboard Evaluation Results\n==================================================\n\n\nDetailed results can be found here and on the Open Portuguese LLM Leaderboard"
] | [
"TAGS\n#peft #pytorch #gemma #model-index #has_space #region-us \n",
"### Framework versions\n\n\n* PEFT 0.5.0\n\n\nOpen Portuguese LLM Leaderboard Evaluation Results\n==================================================\n\n\nDetailed results can be found here and on the Open Portuguese LLM Leaderboard"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/dino-5scale-transnext-tiny-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-16T23:59:18+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | gubartz/facetsum-f-2048 | null | [
"transformers",
"safetensors",
"longt5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-16T23:59:44+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #longt5 #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #longt5 #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/dino-5scale-transnext-small-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:01:39+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw3 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"3-bit",
"region:us"
] | null | 2024-04-17T00:03:39+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K79me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K79me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0133
- F1 Score: 0.6675
- Accuracy: 0.6675
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6474 | 16.67 | 200 | 0.6276 | 0.6622 | 0.6626 |
| 0.5441 | 33.33 | 400 | 0.6425 | 0.6741 | 0.6755 |
| 0.4837 | 50.0 | 600 | 0.6901 | 0.6696 | 0.6720 |
| 0.4346 | 66.67 | 800 | 0.7184 | 0.6644 | 0.6644 |
| 0.3927 | 83.33 | 1000 | 0.7922 | 0.6634 | 0.6654 |
| 0.3633 | 100.0 | 1200 | 0.8053 | 0.6659 | 0.6675 |
| 0.3391 | 116.67 | 1400 | 0.8357 | 0.6656 | 0.6696 |
| 0.3203 | 133.33 | 1600 | 0.8559 | 0.6622 | 0.6657 |
| 0.3014 | 150.0 | 1800 | 0.8665 | 0.6652 | 0.6657 |
| 0.2869 | 166.67 | 2000 | 0.8902 | 0.6718 | 0.6727 |
| 0.2757 | 183.33 | 2200 | 0.9247 | 0.6633 | 0.6640 |
| 0.2637 | 200.0 | 2400 | 0.9733 | 0.6615 | 0.6654 |
| 0.2553 | 216.67 | 2600 | 0.9981 | 0.6708 | 0.6709 |
| 0.2482 | 233.33 | 2800 | 1.0114 | 0.6735 | 0.6748 |
| 0.2387 | 250.0 | 3000 | 0.9868 | 0.6750 | 0.6758 |
| 0.2342 | 266.67 | 3200 | 0.9666 | 0.6722 | 0.6716 |
| 0.2268 | 283.33 | 3400 | 1.0715 | 0.6753 | 0.6768 |
| 0.2251 | 300.0 | 3600 | 1.0039 | 0.6722 | 0.6727 |
| 0.2164 | 316.67 | 3800 | 1.0134 | 0.6772 | 0.6768 |
| 0.2124 | 333.33 | 4000 | 1.0707 | 0.6747 | 0.6751 |
| 0.2102 | 350.0 | 4200 | 1.0643 | 0.6763 | 0.6768 |
| 0.2034 | 366.67 | 4400 | 1.0862 | 0.6764 | 0.6782 |
| 0.1998 | 383.33 | 4600 | 1.0312 | 0.6699 | 0.6702 |
| 0.1957 | 400.0 | 4800 | 1.0973 | 0.6731 | 0.6727 |
| 0.1908 | 416.67 | 5000 | 1.0778 | 0.6725 | 0.6723 |
| 0.1903 | 433.33 | 5200 | 1.0650 | 0.6730 | 0.6741 |
| 0.1843 | 450.0 | 5400 | 1.0814 | 0.6738 | 0.6734 |
| 0.181 | 466.67 | 5600 | 1.0971 | 0.6712 | 0.6727 |
| 0.1774 | 483.33 | 5800 | 1.0772 | 0.6704 | 0.6709 |
| 0.1747 | 500.0 | 6000 | 1.1069 | 0.6724 | 0.6744 |
| 0.1723 | 516.67 | 6200 | 1.1092 | 0.6721 | 0.6716 |
| 0.1688 | 533.33 | 6400 | 1.1367 | 0.6692 | 0.6696 |
| 0.1663 | 550.0 | 6600 | 1.1515 | 0.6721 | 0.6730 |
| 0.1649 | 566.67 | 6800 | 1.1015 | 0.6743 | 0.6751 |
| 0.1622 | 583.33 | 7000 | 1.1156 | 0.6720 | 0.6716 |
| 0.1597 | 600.0 | 7200 | 1.1249 | 0.6728 | 0.6734 |
| 0.1584 | 616.67 | 7400 | 1.1209 | 0.6712 | 0.6716 |
| 0.1562 | 633.33 | 7600 | 1.1394 | 0.6759 | 0.6758 |
| 0.1541 | 650.0 | 7800 | 1.1503 | 0.6755 | 0.6768 |
| 0.152 | 666.67 | 8000 | 1.1477 | 0.6740 | 0.6744 |
| 0.1526 | 683.33 | 8200 | 1.1347 | 0.6743 | 0.6741 |
| 0.1504 | 700.0 | 8400 | 1.1283 | 0.6725 | 0.6730 |
| 0.1493 | 716.67 | 8600 | 1.1551 | 0.6720 | 0.6716 |
| 0.1485 | 733.33 | 8800 | 1.1418 | 0.6712 | 0.6716 |
| 0.1455 | 750.0 | 9000 | 1.1775 | 0.6737 | 0.6741 |
| 0.1459 | 766.67 | 9200 | 1.1558 | 0.6715 | 0.6720 |
| 0.1439 | 783.33 | 9400 | 1.1714 | 0.6713 | 0.6713 |
| 0.1445 | 800.0 | 9600 | 1.1849 | 0.6713 | 0.6716 |
| 0.1433 | 816.67 | 9800 | 1.1789 | 0.6720 | 0.6723 |
| 0.1436 | 833.33 | 10000 | 1.1819 | 0.6718 | 0.6720 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K79me3-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-17T00:04:22+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K79me3-seqsight\_32768\_512\_43M-L32\_all
=====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K79me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0133
* F1 Score: 0.6675
* Accuracy: 0.6675
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
This is a tiny, dummy version of [Jamba](https://huggingface.co/ai21labs/Jamba-v0.1), used for debugging and experimentation over the Jamba architecture.
It has 128M parameters (instead of 52B), **and is initialized with random weights and did not undergo any training.**
| {"license": "apache-2.0"} | ai21labs/Jamba-tiny-random | null | [
"transformers",
"safetensors",
"jamba",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:04:25+00:00 | [] | [] | TAGS
#transformers #safetensors #jamba #text-generation #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
This is a tiny, dummy version of Jamba, used for debugging and experimentation over the Jamba architecture.
It has 128M parameters (instead of 52B), and is initialized with random weights and did not undergo any training.
| [] | [
"TAGS\n#transformers #safetensors #jamba #text-generation #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/dino-5scale-transnext-base-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:04:32+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
null | adapter-transformers |
# Adapter `BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2` for roberta-base
An [adapter](https://adapterhub.ml) for the `roberta-base` model that was trained on the [BigTMiami/amazon_helpfulness](https://huggingface.co/datasets/BigTMiami/amazon_helpfulness/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[Adapters](https://github.com/Adapter-Hub/adapters)** library.
## Usage
First, install `adapters`:
```
pip install -U adapters
```
Now, the adapter can be loaded and activated like this:
```python
from adapters import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("roberta-base")
adapter_name = model.load_adapter("BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here --> | {"tags": ["roberta", "adapter-transformers"], "datasets": ["BigTMiami/amazon_helpfulness"]} | BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2 | null | [
"adapter-transformers",
"roberta",
"dataset:BigTMiami/amazon_helpfulness",
"region:us"
] | null | 2024-04-17T00:04:53+00:00 | [] | [] | TAGS
#adapter-transformers #roberta #dataset-BigTMiami/amazon_helpfulness #region-us
|
# Adapter 'BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2' for roberta-base
An adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.
This adapter was created for usage with the Adapters library.
## Usage
First, install 'adapters':
Now, the adapter can be loaded and activated like this:
## Architecture & Training
## Evaluation results
| [
"# Adapter 'BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2' for roberta-base\n\nAn adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.\n\nThis adapter was created for usage with the Adapters library.",
"## Usage\n\nFirst, install 'adapters':\n\n\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] | [
"TAGS\n#adapter-transformers #roberta #dataset-BigTMiami/amazon_helpfulness #region-us \n",
"# Adapter 'BigTMiami/tapt_seq_bn_amazon_helpfulness_classification_adapter_v2' for roberta-base\n\nAn adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.\n\nThis adapter was created for usage with the Adapters library.",
"## Usage\n\nFirst, install 'adapters':\n\n\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] |
text-generation | transformers |
# WizardLM-2-4x7B-MoE-exl2-3_0bpw
This is a quantized version of [WizardLM-2-4x7B-MoE](https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE) an experimental MoE model made with [Mergekit](https://github.com/arcee-ai/mergekit). Quantization was done using version 0.0.18 of [ExLlamaV2](https://github.com/turboderp/exllamav2).
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
For more information see the [original repository](https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE).
| {"license": "apache-2.0", "tags": ["MoE", "merge", "mergekit", "Mistral", "Microsoft/WizardLM-2-7B"]} | Skylaude/WizardLM-2-4x7B-MoE-exl2-3_0bpw | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"MoE",
"merge",
"mergekit",
"Mistral",
"Microsoft/WizardLM-2-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"3-bit",
"region:us"
] | null | 2024-04-17T00:07:56+00:00 | [] | [] | TAGS
#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us
|
# WizardLM-2-4x7B-MoE-exl2-3_0bpw
This is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2.
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
For more information see the original repository.
| [
"# WizardLM-2-4x7B-MoE-exl2-3_0bpw\n\nThis is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.\n\nFor more information see the original repository."
] | [
"TAGS\n#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us \n",
"# WizardLM-2-4x7B-MoE-exl2-3_0bpw\n\nThis is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.\n\nFor more information see the original repository."
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw3.5 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:14:20+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
image-segmentation | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "ade20k"], "metrics": ["mean_iou"], "pipeline_tag": "image-segmentation"} | DaiShiResearch/mask2former-transnext-tiny-ade | null | [
"pytorch",
"vision",
"image-segmentation",
"en",
"dataset:imagenet-1k",
"dataset:ade20k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:15:04+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp2_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5291
- Rewards/chosen: -11.2131
- Rewards/rejected: -13.0930
- Rewards/accuracies: 0.6500
- Rewards/margins: 1.8799
- Logps/rejected: -246.0494
- Logps/chosen: -224.9259
- Logits/rejected: -0.9959
- Logits/chosen: -1.0145
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0903 | 2.67 | 100 | 0.9847 | -6.9568 | -7.7597 | 0.6300 | 0.8029 | -192.7170 | -182.3627 | -1.2298 | -1.2230 |
| 0.0022 | 5.33 | 200 | 1.3545 | -8.2875 | -9.7332 | 0.6000 | 1.4457 | -212.4518 | -195.6697 | -1.1216 | -1.0996 |
| 0.0001 | 8.0 | 300 | 1.4929 | -10.8994 | -12.7252 | 0.6500 | 1.8258 | -242.3715 | -221.7884 | -1.0149 | -1.0300 |
| 0.0001 | 10.67 | 400 | 1.5066 | -11.0254 | -12.8797 | 0.6500 | 1.8543 | -243.9168 | -223.0491 | -1.0069 | -1.0229 |
| 0.0001 | 13.33 | 500 | 1.5250 | -11.1335 | -12.9833 | 0.6500 | 1.8497 | -244.9522 | -224.1301 | -1.0009 | -1.0186 |
| 0.0001 | 16.0 | 600 | 1.5230 | -11.1873 | -13.0593 | 0.6500 | 1.8720 | -245.7126 | -224.6674 | -0.9979 | -1.0161 |
| 0.0001 | 18.67 | 700 | 1.5290 | -11.2177 | -13.0897 | 0.6500 | 1.8719 | -246.0163 | -224.9722 | -0.9960 | -1.0141 |
| 0.0001 | 21.33 | 800 | 1.5255 | -11.2152 | -13.0927 | 0.6500 | 1.8775 | -246.0468 | -224.9469 | -0.9960 | -1.0145 |
| 0.0001 | 24.0 | 900 | 1.5327 | -11.2235 | -13.0940 | 0.6500 | 1.8706 | -246.0598 | -225.0293 | -0.9961 | -1.0143 |
| 0.0001 | 26.67 | 1000 | 1.5291 | -11.2131 | -13.0930 | 0.6500 | 1.8799 | -246.0494 | -224.9259 | -0.9959 | -1.0145 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp2_dpo1", "results": []}]} | guoyu-zhang/model_hh_usp2_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-17T00:15:19+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp2\_dpo1
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.5291
* Rewards/chosen: -11.2131
* Rewards/rejected: -13.0930
* Rewards/accuracies: 0.6500
* Rewards/margins: 1.8799
* Logps/rejected: -246.0494
* Logps/chosen: -224.9259
* Logits/rejected: -0.9959
* Logits/chosen: -1.0145
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
image-segmentation | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "ade20k"], "metrics": ["mean_iou"], "pipeline_tag": "image-segmentation"} | DaiShiResearch/mask2former-transnext-small-ade | null | [
"pytorch",
"vision",
"image-segmentation",
"en",
"dataset:imagenet-1k",
"dataset:ade20k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:21:17+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | adediu25/implicit-debertav3-all | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:21:51+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null | # `StableLM 2 12B Chat GGUF`
**This repository contains GGUF format files for [StableLM 2 12B Chat](https://huggingface.co/stabilityai/stablelm-2-12b-chat). Files were generated with the [b2684](https://github.com/ggerganov/llama.cpp/releases/tag/b2684) `llama.cpp` release.**
## Model Description
`Stable LM 2 12B Chat` is a 12 billion parameter instruction tuned language model trained on a mix of publicly available datasets and synthetic datasets, utilizing [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290).
## Example Usage via `llama.cpp`
Make sure to install release [b2684](https://github.com/ggerganov/llama.cpp/releases/tag/b2684) or later.
Download any of the available GGUF files. For example, using the Hugging Face Hub CLI:
```bash
pip install huggingface_hub[hf_transfer]
export HF_HUB_ENABLE_HF_TRANSFER=1
huggingface-cli download stabilityai/stablelm-2-12b-chat-GGUF stablelm-2-12b-chat-Q5_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Then run the model with the [llama.cpp `main`](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md) program:
```bash
./main -m stablelm-2-12b-chat-Q5_K_M.gguf -p "<|im_start|>user {PROMPT} <|im_end|><|im_start|>assistant"
```
For interactive conversations, make sure to use ChatML formatting via the `-cml` flag:
```bash
./main -m stablelm-2-12b-chat-Q5_K_M.gguf -p {SYSTEM_PROMPT} -cml
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: `StableLM 2 12B Chat` model is an auto-regressive language model based on the transformer decoder architecture.
* **Language(s)**: English
* **Paper**: [Stable LM 2 Chat Technical Report]((https://arxiv.org/abs/2402.17834)
* **Library**: [Alignment Handbook](https://github.com/huggingface/alignment-handbook.git)
* **Finetuned from model**:
* **License**: [StabilityAI Non-Commercial Research Community License](https://huggingface.co/stabilityai/stablelm-2-zephyr-1_6b/blob/main/LICENSE). If you want to use this model for your commercial products or purposes, please contact us [here](https://stability.ai/contact) to learn more.
* **Contact**: For questions and comments about the model, please email `[email protected]`.
### Training Dataset
The dataset is comprised of a mixture of open datasets large-scale datasets available on the [HuggingFace Hub](https://huggingface.co/datasets) as well as an internal safety dataset:
1. SFT Datasets
- HuggingFaceH4/ultrachat_200k
- meta-math/MetaMathQA
- WizardLM/WizardLM_evol_instruct_V2_196k
- Open-Orca/SlimOrca
- openchat/openchat_sharegpt4_dataset
- LDJnr/Capybara
- hkust-nlp/deita-10k-v0
- teknium/OpenHermes-2.5
- glaiveai/glaive-function-calling-v2
2. Safety Datasets:
- Anthropic/hh-rlhf
- Internal Safety Dataset
3. Preference Datasets:
- argilla/dpo-mix-7k
## Performance
### MT-Bench
| Model | Parameters | MT Bench (Inflection-corrected) |
|---------------------------------------|------------|---------------------------------|
| mistralai/Mixtral-8x7B-Instruct-v0.1 | 13B/47B | 8.48 ± 0.06 |
| stabilityai/stablelm-2-12b-chat | 12B | 8.15 ± 0.08 |
| Qwen/Qwen1.5-14B-Chat | 14B | 7.95 ± 0.10 |
| HuggingFaceH4/zephyr-7b-gemma-v0.1 | 8.5B | 7.82 ± 0.03 |
| mistralai/Mistral-7B-Instruct-v0.2 | 7B | 7.48 ± 0.02 |
| meta-llama/Llama-2-70b-chat-hf | 70B | 7.29 ± 0.05 |
### OpenLLM Leaderboard
| Model | Parameters | Average | ARC Challenge (25-shot) | HellaSwag (10-shot) | MMLU (5-shot) | TruthfulQA (0-shot) | Winogrande (5-shot) | GSM8K (5-shot) |
| -------------------------------------- | ---------- | ------- | ---------------------- | ------------------- | ------------- | ------------------- | ------------------- | -------------- |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | 13B/47B | 72.71 | 70.14 | 87.55 | 71.40 | 64.98 | 81.06 | 61.11 |
| stabilityai/stablelm-2-12b-chat | 12B | 68.45 | 65.02 | 86.06 | 61.14 | 62.00 | 78.77 | 57.70 |
| Qwen/Qwen1.5-14B | 14B | 66.70 | 56.57 | 81.08 | 69.36 | 52.06 | 73.48 | 67.63 |
| mistralai/Mistral-7B-Instruct-v0.2 | 7B | 65.71 | 63.14 | 84.88 | 60.78 | 60.26 | 77.19 | 40.03 |
| HuggingFaceH4/zephyr-7b-gemma-v0.1 | 8.5B | 62.41 | 58.45 | 83.48 | 60.68 | 52.07 | 74.19 | 45.56 |
| Qwen/Qwen1.5-14B-Chat | 14B | 62.37 | 58.79 | 82.33 | 68.52 | 60.38 | 73.32 | 30.86 |
| google/gemma-7b | 8.5B | 63.75 | 61.09 | 82.20 | 64.56 | 44.79 | 79.01 | 50.87 |
| stabilityai/stablelm-2-12b | 12B | 63.53 | 58.45 | 84.33 | 62.09 | 48.16 | 78.10 | 56.03 |
| mistralai/Mistral-7B-v0.1 | 7B | 60.97 | 59.98 | 83.31 | 64.16 | 42.15 | 78.37 | 37.83 |
| meta-llama/Llama-2-13b-hf | 13B | 55.69 | 59.39 | 82.13 | 55.77 | 37.38 | 76.64 | 22.82 |
| meta-llama/Llama-2-13b-chat-hf | 13B | 54.92 | 59.04 | 81.94 | 54.64 | 41.12 | 74.51 | 15.24 |
## Use and Limitations
### Intended Use
The model is intended to be used in chat-like applications. Developers must evaluate the model for safety performance in their specific use case. Read more about [safety and limitations](#limitations-and-bias) below.
### Limitations and Bias
We strongly recommend pairing this model with an input and output classifier to prevent harmful responses.
Using this model will require guardrails around your inputs and outputs to ensure that any outputs returned are not hallucinations.
Additionally, as each use case is unique, we recommend running your own suite of tests to ensure proper performance of this model.
Finally, do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
## How to Cite
```
@article{bellagente2024stable,
title={Stable LM 2 1.6 B Technical Report},
author={Bellagente, Marco and Tow, Jonathan and Mahan, Dakota and Phung, Duy and Zhuravinskyi, Maksym and Adithyan, Reshinth and Baicoianu, James and Brooks, Ben and Cooper, Nathan and Datta, Ashish and others},
journal={arXiv preprint arXiv:2402.17834},
year={2024}
}
```
| {"language": ["en"], "license": "other", "tags": ["causal-lm"], "datasets": ["HuggingFaceH4/ultrachat_200k", "allenai/ultrafeedback_binarized_cleaned", "meta-math/MetaMathQA", "WizardLM/WizardLM_evol_instruct_V2_196k", "openchat/openchat_sharegpt4_dataset", "LDJnr/Capybara", "Intel/orca_dpo_pairs", "hkust-nlp/deita-10k-v0", "Anthropic/hh-rlhf", "glaiveai/glaive-function-calling-v2"], "extra_gated_fields": {"Name": "text", "Email": "text", "Country": "text", "Organization or Affiliation": "text", "I ALLOW Stability AI to email me about new model releases": "checkbox"}} | stabilityai/stablelm-2-12b-chat-GGUF | null | [
"gguf",
"causal-lm",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:allenai/ultrafeedback_binarized_cleaned",
"dataset:meta-math/MetaMathQA",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:openchat/openchat_sharegpt4_dataset",
"dataset:LDJnr/Capybara",
"dataset:Intel/orca_dpo_pairs",
"dataset:hkust-nlp/deita-10k-v0",
"dataset:Anthropic/hh-rlhf",
"dataset:glaiveai/glaive-function-calling-v2",
"arxiv:2305.18290",
"arxiv:2402.17834",
"license:other",
"region:us"
] | null | 2024-04-17T00:23:04+00:00 | [
"2305.18290",
"2402.17834"
] | [
"en"
] | TAGS
#gguf #causal-lm #en #dataset-HuggingFaceH4/ultrachat_200k #dataset-allenai/ultrafeedback_binarized_cleaned #dataset-meta-math/MetaMathQA #dataset-WizardLM/WizardLM_evol_instruct_V2_196k #dataset-openchat/openchat_sharegpt4_dataset #dataset-LDJnr/Capybara #dataset-Intel/orca_dpo_pairs #dataset-hkust-nlp/deita-10k-v0 #dataset-Anthropic/hh-rlhf #dataset-glaiveai/glaive-function-calling-v2 #arxiv-2305.18290 #arxiv-2402.17834 #license-other #region-us
| 'StableLM 2 12B Chat GGUF'
==========================
This repository contains GGUF format files for StableLM 2 12B Chat. Files were generated with the b2684 'URL' release.
Model Description
-----------------
'Stable LM 2 12B Chat' is a 12 billion parameter instruction tuned language model trained on a mix of publicly available datasets and synthetic datasets, utilizing Direct Preference Optimization (DPO).
Example Usage via 'URL'
-----------------------
Make sure to install release b2684 or later.
Download any of the available GGUF files. For example, using the Hugging Face Hub CLI:
Then run the model with the URL 'main' program:
For interactive conversations, make sure to use ChatML formatting via the '-cml' flag:
Model Details
-------------
* Developed by: Stability AI
* Model type: 'StableLM 2 12B Chat' model is an auto-regressive language model based on the transformer decoder architecture.
* Language(s): English
* Paper: Stable LM 2 Chat Technical Report
* Library: Alignment Handbook
* Finetuned from model:
* License: StabilityAI Non-Commercial Research Community License. If you want to use this model for your commercial products or purposes, please contact us here to learn more.
* Contact: For questions and comments about the model, please email 'lm@URL'.
### Training Dataset
The dataset is comprised of a mixture of open datasets large-scale datasets available on the HuggingFace Hub as well as an internal safety dataset:
1. SFT Datasets
* HuggingFaceH4/ultrachat\_200k
* meta-math/MetaMathQA
* WizardLM/WizardLM\_evol\_instruct\_V2\_196k
* Open-Orca/SlimOrca
* openchat/openchat\_sharegpt4\_dataset
* LDJnr/Capybara
* hkust-nlp/deita-10k-v0
* teknium/OpenHermes-2.5
* glaiveai/glaive-function-calling-v2
2. Safety Datasets:
* Anthropic/hh-rlhf
* Internal Safety Dataset
3. Preference Datasets:
* argilla/dpo-mix-7k
Performance
-----------
### MT-Bench
Model: mistralai/Mixtral-8x7B-Instruct-v0.1, Parameters: 13B/47B, MT Bench (Inflection-corrected): 8.48 ± 0.06
Model: stabilityai/stablelm-2-12b-chat, Parameters: 12B, MT Bench (Inflection-corrected): 8.15 ± 0.08
Model: Qwen/Qwen1.5-14B-Chat, Parameters: 14B, MT Bench (Inflection-corrected): 7.95 ± 0.10
Model: HuggingFaceH4/zephyr-7b-gemma-v0.1, Parameters: 8.5B, MT Bench (Inflection-corrected): 7.82 ± 0.03
Model: mistralai/Mistral-7B-Instruct-v0.2, Parameters: 7B, MT Bench (Inflection-corrected): 7.48 ± 0.02
Model: meta-llama/Llama-2-70b-chat-hf, Parameters: 70B, MT Bench (Inflection-corrected): 7.29 ± 0.05
### OpenLLM Leaderboard
Use and Limitations
-------------------
### Intended Use
The model is intended to be used in chat-like applications. Developers must evaluate the model for safety performance in their specific use case. Read more about safety and limitations below.
### Limitations and Bias
We strongly recommend pairing this model with an input and output classifier to prevent harmful responses.
Using this model will require guardrails around your inputs and outputs to ensure that any outputs returned are not hallucinations.
Additionally, as each use case is unique, we recommend running your own suite of tests to ensure proper performance of this model.
Finally, do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
How to Cite
-----------
| [
"### Training Dataset\n\n\nThe dataset is comprised of a mixture of open datasets large-scale datasets available on the HuggingFace Hub as well as an internal safety dataset:\n\n\n1. SFT Datasets\n\n\n* HuggingFaceH4/ultrachat\\_200k\n* meta-math/MetaMathQA\n* WizardLM/WizardLM\\_evol\\_instruct\\_V2\\_196k\n* Open-Orca/SlimOrca\n* openchat/openchat\\_sharegpt4\\_dataset\n* LDJnr/Capybara\n* hkust-nlp/deita-10k-v0\n* teknium/OpenHermes-2.5\n* glaiveai/glaive-function-calling-v2\n\n\n2. Safety Datasets:\n\n\n* Anthropic/hh-rlhf\n* Internal Safety Dataset\n\n\n3. Preference Datasets:\n\n\n* argilla/dpo-mix-7k\n\n\nPerformance\n-----------",
"### MT-Bench\n\n\nModel: mistralai/Mixtral-8x7B-Instruct-v0.1, Parameters: 13B/47B, MT Bench (Inflection-corrected): 8.48 ± 0.06\nModel: stabilityai/stablelm-2-12b-chat, Parameters: 12B, MT Bench (Inflection-corrected): 8.15 ± 0.08\nModel: Qwen/Qwen1.5-14B-Chat, Parameters: 14B, MT Bench (Inflection-corrected): 7.95 ± 0.10\nModel: HuggingFaceH4/zephyr-7b-gemma-v0.1, Parameters: 8.5B, MT Bench (Inflection-corrected): 7.82 ± 0.03\nModel: mistralai/Mistral-7B-Instruct-v0.2, Parameters: 7B, MT Bench (Inflection-corrected): 7.48 ± 0.02\nModel: meta-llama/Llama-2-70b-chat-hf, Parameters: 70B, MT Bench (Inflection-corrected): 7.29 ± 0.05",
"### OpenLLM Leaderboard\n\n\n\nUse and Limitations\n-------------------",
"### Intended Use\n\n\nThe model is intended to be used in chat-like applications. Developers must evaluate the model for safety performance in their specific use case. Read more about safety and limitations below.",
"### Limitations and Bias\n\n\nWe strongly recommend pairing this model with an input and output classifier to prevent harmful responses.\nUsing this model will require guardrails around your inputs and outputs to ensure that any outputs returned are not hallucinations.\nAdditionally, as each use case is unique, we recommend running your own suite of tests to ensure proper performance of this model.\nFinally, do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.\n\n\nHow to Cite\n-----------"
] | [
"TAGS\n#gguf #causal-lm #en #dataset-HuggingFaceH4/ultrachat_200k #dataset-allenai/ultrafeedback_binarized_cleaned #dataset-meta-math/MetaMathQA #dataset-WizardLM/WizardLM_evol_instruct_V2_196k #dataset-openchat/openchat_sharegpt4_dataset #dataset-LDJnr/Capybara #dataset-Intel/orca_dpo_pairs #dataset-hkust-nlp/deita-10k-v0 #dataset-Anthropic/hh-rlhf #dataset-glaiveai/glaive-function-calling-v2 #arxiv-2305.18290 #arxiv-2402.17834 #license-other #region-us \n",
"### Training Dataset\n\n\nThe dataset is comprised of a mixture of open datasets large-scale datasets available on the HuggingFace Hub as well as an internal safety dataset:\n\n\n1. SFT Datasets\n\n\n* HuggingFaceH4/ultrachat\\_200k\n* meta-math/MetaMathQA\n* WizardLM/WizardLM\\_evol\\_instruct\\_V2\\_196k\n* Open-Orca/SlimOrca\n* openchat/openchat\\_sharegpt4\\_dataset\n* LDJnr/Capybara\n* hkust-nlp/deita-10k-v0\n* teknium/OpenHermes-2.5\n* glaiveai/glaive-function-calling-v2\n\n\n2. Safety Datasets:\n\n\n* Anthropic/hh-rlhf\n* Internal Safety Dataset\n\n\n3. Preference Datasets:\n\n\n* argilla/dpo-mix-7k\n\n\nPerformance\n-----------",
"### MT-Bench\n\n\nModel: mistralai/Mixtral-8x7B-Instruct-v0.1, Parameters: 13B/47B, MT Bench (Inflection-corrected): 8.48 ± 0.06\nModel: stabilityai/stablelm-2-12b-chat, Parameters: 12B, MT Bench (Inflection-corrected): 8.15 ± 0.08\nModel: Qwen/Qwen1.5-14B-Chat, Parameters: 14B, MT Bench (Inflection-corrected): 7.95 ± 0.10\nModel: HuggingFaceH4/zephyr-7b-gemma-v0.1, Parameters: 8.5B, MT Bench (Inflection-corrected): 7.82 ± 0.03\nModel: mistralai/Mistral-7B-Instruct-v0.2, Parameters: 7B, MT Bench (Inflection-corrected): 7.48 ± 0.02\nModel: meta-llama/Llama-2-70b-chat-hf, Parameters: 70B, MT Bench (Inflection-corrected): 7.29 ± 0.05",
"### OpenLLM Leaderboard\n\n\n\nUse and Limitations\n-------------------",
"### Intended Use\n\n\nThe model is intended to be used in chat-like applications. Developers must evaluate the model for safety performance in their specific use case. Read more about safety and limitations below.",
"### Limitations and Bias\n\n\nWe strongly recommend pairing this model with an input and output classifier to prevent harmful responses.\nUsing this model will require guardrails around your inputs and outputs to ensure that any outputs returned are not hallucinations.\nAdditionally, as each use case is unique, we recommend running your own suite of tests to ensure proper performance of this model.\nFinally, do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.\n\n\nHow to Cite\n-----------"
] |
image-segmentation | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "ade20k"], "metrics": ["mean_iou"], "pipeline_tag": "image-segmentation"} | DaiShiResearch/mask2former-transnext-base-ade | null | [
"pytorch",
"vision",
"image-segmentation",
"en",
"dataset:imagenet-1k",
"dataset:ade20k",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:23:10+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #image-segmentation #en #dataset-imagenet-1k #dataset-ade20k #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-mental
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1893
- Accuracy: 0.9333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.26 | 100 | 0.2533 | 0.8949 |
| No log | 0.52 | 200 | 0.2493 | 0.8949 |
| No log | 0.77 | 300 | 0.2195 | 0.9152 |
| 0.2823 | 1.03 | 400 | 0.2434 | 0.8978 |
| 0.2823 | 1.29 | 500 | 0.2116 | 0.9202 |
| 0.2823 | 1.55 | 600 | 0.1944 | 0.9333 |
| 0.2823 | 1.8 | 700 | 0.1893 | 0.9333 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "metrics": ["accuracy"], "model-index": [{"name": "distilroberta-base-finetuned-mental", "results": []}]} | rgao/distilroberta-base-finetuned-mental | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:23:17+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #autotrain_compatible #endpoints_compatible #region-us
| distilroberta-base-finetuned-mental
===================================
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1893
* Accuracy: 0.9333
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 32
* eval\_batch\_size: 32
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 32\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | null | Reuploads of model from https://github.com/wonjune-kang/lvc-vc
Use my (unofficial) pip package for LVC (I'm not affiliated with the authors) (currently only works on short clips).
```
pip install lvc
```
```python
from lvc import LVC, LVCAudio
l = LVC()
l.infer_file(
'orig.wav',
'sample.wav',
'target.wav',
)
```
## License
MIT | {"language": ["en"], "license": "mit"} | ml-for-speech/lvc-vc | null | [
"en",
"license:mit",
"region:us"
] | null | 2024-04-17T00:25:37+00:00 | [] | [
"en"
] | TAGS
#en #license-mit #region-us
| Reuploads of model from URL
Use my (unofficial) pip package for LVC (I'm not affiliated with the authors) (currently only works on short clips).
## License
MIT | [
"## License\n\nMIT"
] | [
"TAGS\n#en #license-mit #region-us \n",
"## License\n\nMIT"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw3.7 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:26:01+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | adediu25/implicit-distilbert-all | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:35:21+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | Jooonhan/mistral_7b_instruct_v0.2_tridge_summarization | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:35:53+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #mistral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Dv - ThatOrJohn
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1731
- Wer Ortho: 63.3052
- Wer: 13.5950
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:------:|:----:|:---------------:|:---------:|:-------:|
| 0.1213 | 1.6287 | 500 | 0.1731 | 63.3052 | 13.5950 |
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"language": ["dv"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["mozilla-foundation/common_voice_13_0"], "metrics": ["wer"], "base_model": "openai/whisper-small", "model-index": [{"name": "Whisper Small Dv - ThatOrJohn", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Common Voice 13", "type": "mozilla-foundation/common_voice_13_0", "config": "dv", "split": "test", "args": "dv"}, "metrics": [{"type": "wer", "value": 13.594950794589145, "name": "Wer"}]}]}]} | ThatOrJohn/whisper-small-dv | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dv",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:36:52+00:00 | [] | [
"dv"
] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dv #dataset-mozilla-foundation/common_voice_13_0 #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us
| Whisper Small Dv - ThatOrJohn
=============================
This model is a fine-tuned version of openai/whisper-small on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1731
* Wer Ortho: 63.3052
* Wer: 13.5950
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant\_with\_warmup
* lr\_scheduler\_warmup\_steps: 50
* training\_steps: 500
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.40.0.dev0
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 500\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0.dev0\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dv #dataset-mozilla-foundation/common_voice_13_0 #base_model-openai/whisper-small #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 500\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0.dev0\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw4 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-17T00:37:03+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": ["trl", "sft"]} | lilyray/falcon_7b_tomi_sileod | null | [
"transformers",
"safetensors",
"trl",
"sft",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:43:21+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #trl #sft #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #trl #sft #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null |
# DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF
This model was converted to GGUF format from [`upstage/SOLAR-10.7B-Instruct-v1.0`](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF --model solar-10.7b-instruct-v1.0.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF --model solar-10.7b-instruct-v1.0.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m solar-10.7b-instruct-v1.0.Q6_K.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-4.0", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["c-s-ale/alpaca-gpt4-data", "Open-Orca/OpenOrca", "Intel/orca_dpo_pairs", "allenai/ultrafeedback_binarized_cleaned"], "base_model": ["upstage/SOLAR-10.7B-v1.0"]} | DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:c-s-ale/alpaca-gpt4-data",
"dataset:Open-Orca/OpenOrca",
"dataset:Intel/orca_dpo_pairs",
"dataset:allenai/ultrafeedback_binarized_cleaned",
"base_model:upstage/SOLAR-10.7B-v1.0",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-04-17T00:43:48+00:00 | [] | [
"en"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #en #dataset-c-s-ale/alpaca-gpt4-data #dataset-Open-Orca/OpenOrca #dataset-Intel/orca_dpo_pairs #dataset-allenai/ultrafeedback_binarized_cleaned #base_model-upstage/SOLAR-10.7B-v1.0 #license-cc-by-nc-4.0 #region-us
|
# DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF
This model was converted to GGUF format from 'upstage/SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'upstage/SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #en #dataset-c-s-ale/alpaca-gpt4-data #dataset-Open-Orca/OpenOrca #dataset-Intel/orca_dpo_pairs #dataset-allenai/ultrafeedback_binarized_cleaned #base_model-upstage/SOLAR-10.7B-v1.0 #license-cc-by-nc-4.0 #region-us \n",
"# DavidAU/SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'upstage/SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
null | null |
# DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF
This model was converted to GGUF format from [`upstage/SOLAR-10.7B-v1.0`](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF --model solar-10.7b-v1.0.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF --model solar-10.7b-v1.0.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m solar-10.7b-v1.0.Q6_K.gguf -n 128
```
| {"license": "apache-2.0", "tags": ["llama-cpp", "gguf-my-repo"]} | DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:45:26+00:00 | [] | [] | TAGS
#gguf #llama-cpp #gguf-my-repo #license-apache-2.0 #region-us
|
# DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF
This model was converted to GGUF format from 'upstage/SOLAR-10.7B-v1.0' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'upstage/SOLAR-10.7B-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #license-apache-2.0 #region-us \n",
"# DavidAU/SOLAR-10.7B-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'upstage/SOLAR-10.7B-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7binstruct_summarize
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6534
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6847 | 1.0 | 1557 | 1.6534 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral7binstruct_summarize", "results": []}]} | asahikuroki222/mistral7binstruct_summarize | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:46:58+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
| mistral7binstruct\_summarize
============================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6534
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant
* lr\_scheduler\_warmup\_steps: 0.03
* num\_epochs: 1
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clasificador-dair-ai
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2186
- Accuracy: 0.928
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2394 | 1.0 | 2000 | 0.2142 | 0.926 |
| 0.142 | 2.0 | 4000 | 0.2030 | 0.932 |
| 0.1015 | 3.0 | 6000 | 0.2186 | 0.928 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["classification", "generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy"], "base_model": "bert-base-uncased", "model-index": [{"name": "clasificador-dair-ai", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "config": "split", "split": "test", "args": "split"}, "metrics": [{"type": "accuracy", "value": 0.928, "name": "Accuracy"}]}]}]} | angela1996/clasificador-dair-ai | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:47:26+00:00 | [] | [] | TAGS
#transformers #safetensors #bert #text-classification #classification #generated_from_trainer #dataset-emotion #base_model-bert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
| clasificador-dair-ai
====================
This model is a fine-tuned version of bert-base-uncased on the emotion dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2186
* Accuracy: 0.928
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #classification #generated_from_trainer #dataset-emotion #base_model-bert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7binstruct_summarize
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6494 | 0.21 | 25 | 1.5084 |
| 1.434 | 0.42 | 50 | 1.4326 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral7binstruct_summarize", "results": []}]} | andre-fichel/mistral7binstruct_summarize | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:47:58+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
| mistral7binstruct\_summarize
============================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4326
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant
* lr\_scheduler\_warmup\_steps: 0.03
* training\_steps: 50
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw4.2 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:47:58+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [NousResearch/Llama-2-7b-hf](https://huggingface.co/NousResearch/Llama-2-7b-hf) as a base.
### Models Merged
The following models were included in the merge:
* [arcee-ai/Patent-Instruct-7b](https://huggingface.co/arcee-ai/Patent-Instruct-7b)
* [microsoft/Orca-2-7b](https://huggingface.co/microsoft/Orca-2-7b)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: arcee-ai/Patent-Instruct-7b
parameters:
density: 0.5
weight: 0.5
- model: microsoft/Orca-2-7b
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: NousResearch/Llama-2-7b-hf
parameters:
normalize: false
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["arcee-ai/Patent-Instruct-7b", "microsoft/Orca-2-7b", "NousResearch/Llama-2-7b-hf"]} | mergekit-community/mergekit-ties-zwxzpdk | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:arcee-ai/Patent-Instruct-7b",
"base_model:microsoft/Orca-2-7b",
"base_model:NousResearch/Llama-2-7b-hf",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:49:44+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-arcee-ai/Patent-Instruct-7b #base_model-microsoft/Orca-2-7b #base_model-NousResearch/Llama-2-7b-hf #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using NousResearch/Llama-2-7b-hf as a base.
### Models Merged
The following models were included in the merge:
* arcee-ai/Patent-Instruct-7b
* microsoft/Orca-2-7b
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using NousResearch/Llama-2-7b-hf as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* arcee-ai/Patent-Instruct-7b\n* microsoft/Orca-2-7b",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-arcee-ai/Patent-Instruct-7b #base_model-microsoft/Orca-2-7b #base_model-NousResearch/Llama-2-7b-hf #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using NousResearch/Llama-2-7b-hf as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* arcee-ai/Patent-Instruct-7b\n* microsoft/Orca-2-7b",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers | # kululemon-spiked-9B-8.0bpw_h8_exl2
This is a frankenmerge of a pre-trained language model created using [mergekit](https://github.com/cg123/mergekit). As an experiment, this appears to be a partial success.
Lightly tested with temperature 1 and minP 0.01 with ChatML prompts; the model supports Alpaca prompts and has 8K context length, a result of its Mistral v0.1 provenance. The model's output has been coherent and stable during aforementioned testing.
The merge formula for this frankenmerge is below. It is conjectured that the shorter first section is not key to variation, the middle segment is key to balancing reasoning and variation, and that the lengthy final section is required for convergence and eventual stability. The internal instability is probably better suited for narrative involving unstable and/or unhinged characters and situations.
- Full weights: [grimjim/kukulemon-spiked-9B](https://huggingface.co/grimjim/kukulemon-spiked-9B)
- GGUF quants: [grimjim/kukulemon-spiked-9B-GGUF](https://huggingface.co/grimjim/kukulemon-spiked-9B-GGUF)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [grimjim/kukulemon-7B](https://huggingface.co/grimjim/kukulemon-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: grimjim/kukulemon-7B
layer_range: [0, 12]
- sources:
- model: grimjim/kukulemon-7B
layer_range: [8, 16]
- sources:
- model: grimjim/kukulemon-7B
layer_range: [12, 32]
merge_method: passthrough
dtype: float16
```
| {"license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["grimjim/kukulemon-7B"], "pipeline_tag": "text-generation"} | grimjim/kukulemon-spiked-9B-8.0bpw_h8_exl2 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:grimjim/kukulemon-7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-17T00:54:56+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #mergekit #merge #base_model-grimjim/kukulemon-7B #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| # kululemon-spiked-9B-8.0bpw_h8_exl2
This is a frankenmerge of a pre-trained language model created using mergekit. As an experiment, this appears to be a partial success.
Lightly tested with temperature 1 and minP 0.01 with ChatML prompts; the model supports Alpaca prompts and has 8K context length, a result of its Mistral v0.1 provenance. The model's output has been coherent and stable during aforementioned testing.
The merge formula for this frankenmerge is below. It is conjectured that the shorter first section is not key to variation, the middle segment is key to balancing reasoning and variation, and that the lengthy final section is required for convergence and eventual stability. The internal instability is probably better suited for narrative involving unstable and/or unhinged characters and situations.
- Full weights: grimjim/kukulemon-spiked-9B
- GGUF quants: grimjim/kukulemon-spiked-9B-GGUF
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* grimjim/kukulemon-7B
### Configuration
The following YAML configuration was used to produce this model:
| [
"# kululemon-spiked-9B-8.0bpw_h8_exl2\n\nThis is a frankenmerge of a pre-trained language model created using mergekit. As an experiment, this appears to be a partial success.\n\nLightly tested with temperature 1 and minP 0.01 with ChatML prompts; the model supports Alpaca prompts and has 8K context length, a result of its Mistral v0.1 provenance. The model's output has been coherent and stable during aforementioned testing.\n\nThe merge formula for this frankenmerge is below. It is conjectured that the shorter first section is not key to variation, the middle segment is key to balancing reasoning and variation, and that the lengthy final section is required for convergence and eventual stability. The internal instability is probably better suited for narrative involving unstable and/or unhinged characters and situations.\n\n- Full weights: grimjim/kukulemon-spiked-9B\n- GGUF quants: grimjim/kukulemon-spiked-9B-GGUF",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* grimjim/kukulemon-7B",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #mergekit #merge #base_model-grimjim/kukulemon-7B #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# kululemon-spiked-9B-8.0bpw_h8_exl2\n\nThis is a frankenmerge of a pre-trained language model created using mergekit. As an experiment, this appears to be a partial success.\n\nLightly tested with temperature 1 and minP 0.01 with ChatML prompts; the model supports Alpaca prompts and has 8K context length, a result of its Mistral v0.1 provenance. The model's output has been coherent and stable during aforementioned testing.\n\nThe merge formula for this frankenmerge is below. It is conjectured that the shorter first section is not key to variation, the middle segment is key to balancing reasoning and variation, and that the lengthy final section is required for convergence and eventual stability. The internal instability is probably better suited for narrative involving unstable and/or unhinged characters and situations.\n\n- Full weights: grimjim/kukulemon-spiked-9B\n- GGUF quants: grimjim/kukulemon-spiked-9B-GGUF",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* grimjim/kukulemon-7B",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_usp1_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2734
- Rewards/chosen: -2.3548
- Rewards/rejected: -7.1210
- Rewards/accuracies: 0.6900
- Rewards/margins: 4.7662
- Logps/rejected: -126.1126
- Logps/chosen: -111.5945
- Logits/rejected: -0.6605
- Logits/chosen: -0.6138
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0275 | 2.67 | 100 | 0.8121 | -5.6383 | -8.4322 | 0.75 | 2.7939 | -128.7351 | -118.1615 | -0.5793 | -0.6303 |
| 0.0206 | 5.33 | 200 | 1.5888 | -6.3660 | -10.1184 | 0.7300 | 3.7524 | -132.1074 | -119.6168 | -0.9589 | -0.9756 |
| 0.0046 | 8.0 | 300 | 1.3556 | -7.4924 | -13.2011 | 0.7400 | 5.7087 | -138.2728 | -121.8697 | -0.9273 | -0.9021 |
| 0.0 | 10.67 | 400 | 1.2681 | -2.2118 | -6.9174 | 0.6700 | 4.7056 | -125.7056 | -111.3086 | -0.6495 | -0.6029 |
| 0.0 | 13.33 | 500 | 1.2678 | -2.2883 | -7.0174 | 0.6600 | 4.7291 | -125.9055 | -111.4616 | -0.6552 | -0.6085 |
| 0.0 | 16.0 | 600 | 1.2844 | -2.3230 | -7.0735 | 0.6700 | 4.7505 | -126.0177 | -111.5310 | -0.6587 | -0.6122 |
| 0.0 | 18.67 | 700 | 1.2742 | -2.3383 | -7.1048 | 0.6800 | 4.7665 | -126.0803 | -111.5616 | -0.6601 | -0.6134 |
| 0.0 | 21.33 | 800 | 1.2810 | -2.3731 | -7.1141 | 0.6800 | 4.7409 | -126.0988 | -111.6312 | -0.6607 | -0.6139 |
| 0.0 | 24.0 | 900 | 1.2683 | -2.3582 | -7.1234 | 0.6700 | 4.7652 | -126.1175 | -111.6013 | -0.6609 | -0.6140 |
| 0.0 | 26.67 | 1000 | 1.2734 | -2.3548 | -7.1210 | 0.6900 | 4.7662 | -126.1126 | -111.5945 | -0.6605 | -0.6138 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_usp1_dpo5", "results": []}]} | guoyu-zhang/model_usp1_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-17T00:55:17+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_usp1\_dpo5
=================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.2734
* Rewards/chosen: -2.3548
* Rewards/rejected: -7.1210
* Rewards/accuracies: 0.6900
* Rewards/margins: 4.7662
* Logps/rejected: -126.1126
* Logps/chosen: -111.5945
* Logits/rejected: -0.6605
* Logits/chosen: -0.6138
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7binstruct_summarize
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4126
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5546 | 0.21 | 25 | 1.4695 |
| 1.5093 | 0.42 | 50 | 1.4126 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral7binstruct_summarize", "results": []}]} | jkim-aalto/mistral7binstruct_summarize | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:55:48+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
| mistral7binstruct\_summarize
============================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4126
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant
* lr\_scheduler\_warmup\_steps: 0.03
* training\_steps: 50
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
sentence-similarity | sentence-transformers |
# snowflake-arctic-embed-l-gguf
Model creator: [Snowflake](https://huggingface.co/Snowflake)
Original model: [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l)
## Original Description
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The `snowflake-arctic-embedding` models achieve **state-of-the-art performance on the MTEB/BEIR leaderboard** for each of their size variants. Evaluation is performed using these [scripts](https://github.com/Snowflake-Labs/snowflake-arctic-embed/tree/main/src). As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
| Name | MTEB Retrieval Score (NDCG @ 10) | Parameters (Millions) | Embedding Dimension |
| ----------------------------------------------------------------------- | -------------------------------- | --------------------- | ------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 | 22 | 384 |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 | 33 | 384 |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 | 110 | 768 |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 | 137 | 768 |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 | 335 | 1024 |
Aside from being great open-source models, the largest model, [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/), can serve as a natural replacement for closed-source embedding, as shown below.
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------ | -------------------------------- |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 |
| Google-gecko-text-embedding | 55.7 |
| text-embedding-3-large | 55.44 |
| Cohere-embed-english-v3.0 | 55.00 |
| bge-large-en-v1.5 | 54.29 |
### [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/)
Based on the [intfloat/e5-large-unsupervised](https://huggingface.co/intfloat/e5-large-unsupervised) model, this small model does not sacrifice retrieval accuracy for its small size.
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------ | -------------------------------- |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 |
| UAE-Large-V1 | 54.66 |
| bge-large-en-v1.5 | 54.29 |
| mxbai-embed-large-v1 | 54.39 |
| e5-Large-v2 | 50.56 |
## Description
This repo contains GGUF format files for the snowflake-arctic-embed-l embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). | {"language": ["en"], "license": "apache-2.0", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "mteb", "arctic", "snowflake-arctic-embed", "transformers.js", "gguf"], "model_name": "snowflake-arctic-embed-l", "base_model": "Snowflake/snowflake-arctic-embed-l", "inference": false, "model_creator": "Snowflake", "model_type": "bert", "quantized_by": "ChristianAzinn", "pipeline_tag": "sentence-similarity"} | ChristianAzinn/snowflake-arctic-embed-l-gguf | null | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"gguf",
"en",
"base_model:Snowflake/snowflake-arctic-embed-l",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:56:05+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-l #license-apache-2.0 #region-us
| snowflake-arctic-embed-l-gguf
=============================
Model creator: Snowflake
Original model: snowflake-arctic-embed-l
Original Description
--------------------
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The 'snowflake-arctic-embedding' models achieve state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. Evaluation is performed using these scripts. As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
Aside from being great open-source models, the largest model, snowflake-arctic-embed-l, can serve as a natural replacement for closed-source embedding, as shown below.
### snowflake-arctic-embed-l
Based on the intfloat/e5-large-unsupervised model, this small model does not sacrifice retrieval accuracy for its small size.
Description
-----------
This repo contains GGUF format files for the snowflake-arctic-embed-l embedding model.
These files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.
This model supports up to 512 tokens of context.
Compatibility
-------------
These files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.
Examples
========
Example Usage with 'URL'
------------------------
To compute a single embedding, build URL and run:
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.
'URL':
Compute multiple embeddings:
Example Usage with LM Studio
----------------------------
Download the 0.2.19 beta build from here: Windows MacOS Linux
Once installed, open the app. The home should look like this:
!image/png
Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.
!image/png
Select your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.
!image/png
You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.
!image/png
Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.
!image/png
Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.
!image/png
All that's left to do is to hit the "Start Server" button:
!image/png
And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.
!image/png
Example curl request to the API endpoint:
For more information, see the LM Studio text embedding documentation.
Acknowledgements
----------------
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke.
| [
"### snowflake-arctic-embed-l\n\n\nBased on the intfloat/e5-large-unsupervised model, this small model does not sacrifice retrieval accuracy for its small size.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-l embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] | [
"TAGS\n#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-l #license-apache-2.0 #region-us \n",
"### snowflake-arctic-embed-l\n\n\nBased on the intfloat/e5-large-unsupervised model, this small model does not sacrifice retrieval accuracy for its small size.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-l embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me1](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me1) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0239
- F1 Score: 0.5790
- Accuracy: 0.5783
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6752 | 15.38 | 200 | 0.6748 | 0.5889 | 0.5950 |
| 0.6059 | 30.77 | 400 | 0.7290 | 0.5863 | 0.5859 |
| 0.5507 | 46.15 | 600 | 0.7697 | 0.5944 | 0.5941 |
| 0.5047 | 61.54 | 800 | 0.8022 | 0.5881 | 0.5878 |
| 0.4678 | 76.92 | 1000 | 0.8512 | 0.5821 | 0.5827 |
| 0.4382 | 92.31 | 1200 | 0.8896 | 0.5907 | 0.5903 |
| 0.4162 | 107.69 | 1400 | 0.9029 | 0.5845 | 0.5849 |
| 0.3987 | 123.08 | 1600 | 0.9350 | 0.5878 | 0.5903 |
| 0.3811 | 138.46 | 1800 | 0.9360 | 0.5920 | 0.5919 |
| 0.3684 | 153.85 | 2000 | 0.9670 | 0.5945 | 0.5988 |
| 0.3542 | 169.23 | 2200 | 1.0295 | 0.5905 | 0.5909 |
| 0.3404 | 184.62 | 2400 | 1.1243 | 0.5882 | 0.5941 |
| 0.3313 | 200.0 | 2600 | 1.0480 | 0.5870 | 0.5865 |
| 0.3253 | 215.38 | 2800 | 1.0215 | 0.5951 | 0.5953 |
| 0.3156 | 230.77 | 3000 | 1.0938 | 0.5912 | 0.5934 |
| 0.3111 | 246.15 | 3200 | 1.1238 | 0.5858 | 0.5878 |
| 0.3044 | 261.54 | 3400 | 1.1062 | 0.5897 | 0.5906 |
| 0.2954 | 276.92 | 3600 | 1.0608 | 0.5853 | 0.5852 |
| 0.2908 | 292.31 | 3800 | 1.1104 | 0.5904 | 0.5912 |
| 0.2847 | 307.69 | 4000 | 1.1268 | 0.5903 | 0.5909 |
| 0.2783 | 323.08 | 4200 | 1.1081 | 0.5844 | 0.5843 |
| 0.2719 | 338.46 | 4400 | 1.1127 | 0.5944 | 0.5969 |
| 0.267 | 353.85 | 4600 | 1.0907 | 0.5945 | 0.5956 |
| 0.263 | 369.23 | 4800 | 1.1827 | 0.5844 | 0.5865 |
| 0.2578 | 384.62 | 5000 | 1.1832 | 0.5858 | 0.5859 |
| 0.2541 | 400.0 | 5200 | 1.1656 | 0.5859 | 0.5874 |
| 0.25 | 415.38 | 5400 | 1.1473 | 0.5889 | 0.5896 |
| 0.2436 | 430.77 | 5600 | 1.1822 | 0.5815 | 0.5846 |
| 0.2405 | 446.15 | 5800 | 1.2328 | 0.5845 | 0.5849 |
| 0.2378 | 461.54 | 6000 | 1.1869 | 0.5793 | 0.5836 |
| 0.2324 | 476.92 | 6200 | 1.2337 | 0.5856 | 0.5878 |
| 0.2306 | 492.31 | 6400 | 1.2369 | 0.5857 | 0.5874 |
| 0.2261 | 507.69 | 6600 | 1.2223 | 0.5853 | 0.5862 |
| 0.2221 | 523.08 | 6800 | 1.2504 | 0.5812 | 0.5849 |
| 0.2212 | 538.46 | 7000 | 1.2557 | 0.5837 | 0.5843 |
| 0.2173 | 553.85 | 7200 | 1.2734 | 0.5805 | 0.5821 |
| 0.2144 | 569.23 | 7400 | 1.2726 | 0.5789 | 0.5805 |
| 0.2127 | 584.62 | 7600 | 1.2625 | 0.5799 | 0.5811 |
| 0.2092 | 600.0 | 7800 | 1.2934 | 0.5810 | 0.5843 |
| 0.2077 | 615.38 | 8000 | 1.2698 | 0.5764 | 0.5767 |
| 0.2058 | 630.77 | 8200 | 1.2772 | 0.5828 | 0.5846 |
| 0.2041 | 646.15 | 8400 | 1.2919 | 0.5791 | 0.5802 |
| 0.2021 | 661.54 | 8600 | 1.2942 | 0.5787 | 0.5792 |
| 0.1994 | 676.92 | 8800 | 1.3101 | 0.5778 | 0.5802 |
| 0.1992 | 692.31 | 9000 | 1.3093 | 0.5806 | 0.5824 |
| 0.1985 | 707.69 | 9200 | 1.3143 | 0.5785 | 0.5811 |
| 0.1968 | 723.08 | 9400 | 1.2900 | 0.5794 | 0.5805 |
| 0.1972 | 738.46 | 9600 | 1.3124 | 0.5800 | 0.5814 |
| 0.1956 | 753.85 | 9800 | 1.3136 | 0.5793 | 0.5808 |
| 0.1953 | 769.23 | 10000 | 1.3164 | 0.5805 | 0.5821 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me1-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-17T00:56:35+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K4me1-seqsight\_32768\_512\_43M-L32\_all
====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K4me1 dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0239
* F1 Score: 0.5790
* Accuracy: 0.5783
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_shp4_dpo5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6900
- Rewards/chosen: -4.3601
- Rewards/rejected: -4.8463
- Rewards/accuracies: 0.5100
- Rewards/margins: 0.4862
- Logps/rejected: -247.0597
- Logps/chosen: -261.5426
- Logits/rejected: -0.3766
- Logits/chosen: -0.3892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0652 | 2.67 | 100 | 1.7443 | -5.2989 | -4.9017 | 0.5100 | -0.3972 | -247.1705 | -263.4201 | -0.7895 | -0.7659 |
| 0.0085 | 5.33 | 200 | 2.3642 | -9.0530 | -8.8642 | 0.4700 | -0.1888 | -255.0954 | -270.9283 | -0.4221 | -0.4269 |
| 0.0 | 8.0 | 300 | 1.6817 | -4.1578 | -4.6561 | 0.5200 | 0.4983 | -246.6793 | -261.1379 | -0.3697 | -0.3824 |
| 0.0 | 10.67 | 400 | 1.6971 | -4.2463 | -4.7407 | 0.5300 | 0.4944 | -246.8485 | -261.3149 | -0.3737 | -0.3858 |
| 0.0 | 13.33 | 500 | 1.6857 | -4.2849 | -4.7855 | 0.5200 | 0.5006 | -246.9381 | -261.3922 | -0.3756 | -0.3880 |
| 0.0 | 16.0 | 600 | 1.7000 | -4.3433 | -4.8213 | 0.5300 | 0.4780 | -247.0096 | -261.5089 | -0.3764 | -0.3886 |
| 0.0 | 18.67 | 700 | 1.7016 | -4.3573 | -4.8617 | 0.5200 | 0.5044 | -247.0905 | -261.5370 | -0.3772 | -0.3894 |
| 0.0 | 21.33 | 800 | 1.6856 | -4.3565 | -4.8464 | 0.5100 | 0.4899 | -247.0598 | -261.5353 | -0.3768 | -0.3893 |
| 0.0 | 24.0 | 900 | 1.6949 | -4.3569 | -4.8528 | 0.5300 | 0.4959 | -247.0727 | -261.5360 | -0.3774 | -0.3892 |
| 0.0 | 26.67 | 1000 | 1.6900 | -4.3601 | -4.8463 | 0.5100 | 0.4862 | -247.0597 | -261.5426 | -0.3766 | -0.3892 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_shp4_dpo5", "results": []}]} | guoyu-zhang/model_shp4_dpo5 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-17T00:56:44+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_shp4\_dpo5
=================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6900
* Rewards/chosen: -4.3601
* Rewards/rejected: -4.8463
* Rewards/accuracies: 0.5100
* Rewards/margins: 0.4862
* Logps/rejected: -247.0597
* Logps/chosen: -261.5426
* Logits/rejected: -0.3766
* Logits/chosen: -0.3892
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | relu-ntnu/bart-large-cnn_v2_trained_on_1000 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:57:26+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null |
# DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF
This model was converted to GGUF format from [`w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored`](https://huggingface.co/w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF --model solar-10.7b-instruct-v1.0-uncensored.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF --model solar-10.7b-instruct-v1.0-uncensored.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m solar-10.7b-instruct-v1.0-uncensored.Q6_K.gguf -n 128
```
| {"license": "apache-2.0", "tags": ["llama-cpp", "gguf-my-repo"]} | DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:57:32+00:00 | [] | [] | TAGS
#gguf #llama-cpp #gguf-my-repo #license-apache-2.0 #region-us
|
# DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF
This model was converted to GGUF format from 'w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF\nThis model was converted to GGUF format from 'w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #license-apache-2.0 #region-us \n",
"# DavidAU/SOLAR-10.7B-Instruct-v1.0-uncensored-Q6_K-GGUF\nThis model was converted to GGUF format from 'w4r10ck/SOLAR-10.7B-Instruct-v1.0-uncensored' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
sentence-similarity | sentence-transformers |
# snowflake-arctic-embed-m-long-gguf
Model creator: [Snowflake](https://huggingface.co/Snowflake)
Original model: [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long)
## Original Description
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The `snowflake-arctic-embedding` models achieve **state-of-the-art performance on the MTEB/BEIR leaderboard** for each of their size variants. Evaluation is performed using these [scripts](https://github.com/Snowflake-Labs/snowflake-arctic-embed/tree/main/src). As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
| Name | MTEB Retrieval Score (NDCG @ 10) | Parameters (Millions) | Embedding Dimension |
| ----------------------------------------------------------------------- | -------------------------------- | --------------------- | ------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 | 22 | 384 |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 | 33 | 384 |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 | 110 | 768 |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 | 137 | 768 |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 | 335 | 1024 |
### [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/)
Based on the [nomic-ai/nomic-embed-text-v1-unsupervised](https://huggingface.co/nomic-ai/nomic-embed-text-v1-unsupervised) model, this long-context variant of our medium-sized model is perfect for workloads that can be constrained by the regular 512 token context of our other models. Without the use of RPE, this model supports up to 2048 tokens. With RPE, it can scale to 8192!
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------ | -------------------------------- |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 |
| nomic-embed-text-v1.5 | 53.01 |
| nomic-embed-text-v1 | 52.81 |
## Description
This repo contains GGUF format files for the snowflake-arctic-embed-m-long embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). | {"language": ["en"], "license": "apache-2.0", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "mteb", "arctic", "snowflake-arctic-embed", "transformers.js", "gguf"], "model_name": "snowflake-arctic-embed-m-long", "base_model": "Snowflake/snowflake-arctic-embed-m-long", "inference": false, "model_creator": "Snowflake", "model_type": "bert", "quantized_by": "ChristianAzinn", "pipeline_tag": "sentence-similarity"} | ChristianAzinn/snowflake-arctic-embed-m-long-GGUF | null | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"gguf",
"en",
"base_model:Snowflake/snowflake-arctic-embed-m-long",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T00:58:42+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-m-long #license-apache-2.0 #region-us
| snowflake-arctic-embed-m-long-gguf
==================================
Model creator: Snowflake
Original model: snowflake-arctic-embed-m-long
Original Description
--------------------
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The 'snowflake-arctic-embedding' models achieve state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. Evaluation is performed using these scripts. As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
### snowflake-arctic-embed-m-long
Based on the nomic-ai/nomic-embed-text-v1-unsupervised model, this long-context variant of our medium-sized model is perfect for workloads that can be constrained by the regular 512 token context of our other models. Without the use of RPE, this model supports up to 2048 tokens. With RPE, it can scale to 8192!
Description
-----------
This repo contains GGUF format files for the snowflake-arctic-embed-m-long embedding model.
These files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.
This model supports up to 512 tokens of context.
Compatibility
-------------
These files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.
Examples
========
Example Usage with 'URL'
------------------------
To compute a single embedding, build URL and run:
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.
'URL':
Compute multiple embeddings:
Example Usage with LM Studio
----------------------------
Download the 0.2.19 beta build from here: Windows MacOS Linux
Once installed, open the app. The home should look like this:
!image/png
Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.
!image/png
Select your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.
!image/png
You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.
!image/png
Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.
!image/png
Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.
!image/png
All that's left to do is to hit the "Start Server" button:
!image/png
And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.
!image/png
Example curl request to the API endpoint:
For more information, see the LM Studio text embedding documentation.
Acknowledgements
----------------
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke.
| [
"### snowflake-arctic-embed-m-long\n\n\nBased on the nomic-ai/nomic-embed-text-v1-unsupervised model, this long-context variant of our medium-sized model is perfect for workloads that can be constrained by the regular 512 token context of our other models. Without the use of RPE, this model supports up to 2048 tokens. With RPE, it can scale to 8192!\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-m-long embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] | [
"TAGS\n#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-m-long #license-apache-2.0 #region-us \n",
"### snowflake-arctic-embed-m-long\n\n\nBased on the nomic-ai/nomic-embed-text-v1-unsupervised model, this long-context variant of our medium-sized model is perfect for workloads that can be constrained by the regular 512 token context of our other models. Without the use of RPE, this model supports up to 2048 tokens. With RPE, it can scale to 8192!\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-m-long embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] |
null | transformers |
# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF
This model was converted to GGUF format from [`fblgit/UNA-SOLAR-10.7B-Instruct-v1.0`](https://huggingface.co/fblgit/UNA-SOLAR-10.7B-Instruct-v1.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/fblgit/UNA-SOLAR-10.7B-Instruct-v1.0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF --model una-solar-10.7b-instruct-v1.0.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF --model una-solar-10.7b-instruct-v1.0.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m una-solar-10.7b-instruct-v1.0.Q6_K.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-nd-4.0", "library_name": "transformers", "tags": ["alignment-handbook", "generated_from_trainer", "UNA", "single-turn", "llama-cpp", "gguf-my-repo"], "base_model": "upstage/SOLAR-10.7B-Instruct-v1.0", "model-index": [{"name": "UNA-SOLAR-10.7B-Instruct-v1.0", "results": []}]} | DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF | null | [
"transformers",
"gguf",
"alignment-handbook",
"generated_from_trainer",
"UNA",
"single-turn",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:upstage/SOLAR-10.7B-Instruct-v1.0",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T00:58:58+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #alignment-handbook #generated_from_trainer #UNA #single-turn #llama-cpp #gguf-my-repo #en #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us
|
# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF
This model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#transformers #gguf #alignment-handbook #generated_from_trainer #UNA #single-turn #llama-cpp #gguf-my-repo #en #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us \n",
"# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw4.4 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T00:59:00+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [automerger/YamshadowExperiment28-7B](https://huggingface.co/automerger/YamshadowExperiment28-7B) as a base.
### Models Merged
The following models were included in the merge:
* [CultriX/NeuralTrix-bf16](https://huggingface.co/CultriX/NeuralTrix-bf16)
* [CultriX/MonaTrix-v4](https://huggingface.co/CultriX/MonaTrix-v4)
* [CultriX/MonaCeption-7B-SLERP-DPO](https://huggingface.co/CultriX/MonaCeption-7B-SLERP-DPO)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: CultriX/MonaCeption-7B-SLERP-DPO
- model: CultriX/NeuralTrix-bf16
- model: CultriX/MonaTrix-v4
merge_method: model_stock
base_model: automerger/YamshadowExperiment28-7B
dtype: bfloat16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["automerger/YamshadowExperiment28-7B", "CultriX/NeuralTrix-bf16", "CultriX/MonaTrix-v4", "CultriX/MonaCeption-7B-SLERP-DPO"]} | CultriX/ACultriX-7B | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"arxiv:2403.19522",
"base_model:automerger/YamshadowExperiment28-7B",
"base_model:CultriX/NeuralTrix-bf16",
"base_model:CultriX/MonaTrix-v4",
"base_model:CultriX/MonaCeption-7B-SLERP-DPO",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T01:00:17+00:00 | [
"2403.19522"
] | [] | TAGS
#transformers #safetensors #mistral #text-generation #mergekit #merge #arxiv-2403.19522 #base_model-automerger/YamshadowExperiment28-7B #base_model-CultriX/NeuralTrix-bf16 #base_model-CultriX/MonaTrix-v4 #base_model-CultriX/MonaCeption-7B-SLERP-DPO #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the Model Stock merge method using automerger/YamshadowExperiment28-7B as a base.
### Models Merged
The following models were included in the merge:
* CultriX/NeuralTrix-bf16
* CultriX/MonaTrix-v4
* CultriX/MonaCeption-7B-SLERP-DPO
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the Model Stock merge method using automerger/YamshadowExperiment28-7B as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* CultriX/NeuralTrix-bf16\n* CultriX/MonaTrix-v4\n* CultriX/MonaCeption-7B-SLERP-DPO",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #mergekit #merge #arxiv-2403.19522 #base_model-automerger/YamshadowExperiment28-7B #base_model-CultriX/NeuralTrix-bf16 #base_model-CultriX/MonaTrix-v4 #base_model-CultriX/MonaCeption-7B-SLERP-DPO #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the Model Stock merge method using automerger/YamshadowExperiment28-7B as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* CultriX/NeuralTrix-bf16\n* CultriX/MonaTrix-v4\n* CultriX/MonaCeption-7B-SLERP-DPO",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | null |
# DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF
This model was converted to GGUF format from [`hwkwon/S-SOLAR-10.7B-v1.5`](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF --model s-solar-10.7b-v1.5.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF --model s-solar-10.7b-v1.5.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m s-solar-10.7b-v1.5.Q6_K.gguf -n 128
```
| {"language": ["ko"], "license": "cc-by-nc-4.0", "tags": ["llama-cpp", "gguf-my-repo"]} | DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"ko",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-04-17T01:00:24+00:00 | [] | [
"ko"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #ko #license-cc-by-nc-4.0 #region-us
|
# DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF
This model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF\nThis model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #ko #license-cc-by-nc-4.0 #region-us \n",
"# DavidAU/S-SOLAR-10.7B-v1.5-Q6_K-GGUF\nThis model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
sentence-similarity | sentence-transformers |
# snowflake-arctic-embed-m-gguf
Model creator: [Snowflake](https://huggingface.co/Snowflake)
Original model: [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m)
## Original Description
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The `snowflake-arctic-embedding` models achieve **state-of-the-art performance on the MTEB/BEIR leaderboard** for each of their size variants. Evaluation is performed using these [scripts](https://github.com/Snowflake-Labs/snowflake-arctic-embed/tree/main/src). As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
| Name | MTEB Retrieval Score (NDCG @ 10) | Parameters (Millions) | Embedding Dimension |
| ----------------------------------------------------------------------- | -------------------------------- | --------------------- | ------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 | 22 | 384 |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 | 33 | 384 |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 | 110 | 768 |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 | 137 | 768 |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 | 335 | 1024 |
### [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/)
Based on the [intfloat/e5-base-unsupervised](https://huggingface.co/intfloat/e5-base-unsupervised) model, this medium model is the workhorse that provides the best retrieval performance without slowing down inference.
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------ | -------------------------------- |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 |
| bge-base-en-v1.5 | 53.25 |
| nomic-embed-text-v1.5 | 53.25 |
| GIST-Embedding-v0 | 52.31 |
| gte-base | 52.31 |
## Description
This repo contains GGUF format files for the snowflake-arctic-embed-m embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). | {"language": ["en"], "license": "apache-2.0", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "mteb", "arctic", "snowflake-arctic-embed", "transformers.js", "gguf"], "model_name": "snowflake-arctic-embed-m", "base_model": "Snowflake/snowflake-arctic-embed-m", "inference": false, "model_creator": "Snowflake", "model_type": "bert", "quantized_by": "ChristianAzinn", "pipeline_tag": "sentence-similarity"} | ChristianAzinn/snowflake-arctic-embed-m-gguf | null | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"gguf",
"en",
"base_model:Snowflake/snowflake-arctic-embed-m",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T01:03:31+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-m #license-apache-2.0 #region-us
| snowflake-arctic-embed-m-gguf
=============================
Model creator: Snowflake
Original model: snowflake-arctic-embed-m
Original Description
--------------------
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The 'snowflake-arctic-embedding' models achieve state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. Evaluation is performed using these scripts. As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
### snowflake-arctic-embed-m
Based on the intfloat/e5-base-unsupervised model, this medium model is the workhorse that provides the best retrieval performance without slowing down inference.
Description
-----------
This repo contains GGUF format files for the snowflake-arctic-embed-m embedding model.
These files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.
This model supports up to 512 tokens of context.
Compatibility
-------------
These files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.
Examples
========
Example Usage with 'URL'
------------------------
To compute a single embedding, build URL and run:
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.
'URL':
Compute multiple embeddings:
Example Usage with LM Studio
----------------------------
Download the 0.2.19 beta build from here: Windows MacOS Linux
Once installed, open the app. The home should look like this:
!image/png
Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.
!image/png
Select your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.
!image/png
You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.
!image/png
Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.
!image/png
Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.
!image/png
All that's left to do is to hit the "Start Server" button:
!image/png
And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.
!image/png
Example curl request to the API endpoint:
For more information, see the LM Studio text embedding documentation.
Acknowledgements
----------------
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke.
| [
"### snowflake-arctic-embed-m\n\n\nBased on the intfloat/e5-base-unsupervised model, this medium model is the workhorse that provides the best retrieval performance without slowing down inference.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-m embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] | [
"TAGS\n#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-m #license-apache-2.0 #region-us \n",
"### snowflake-arctic-embed-m\n\n\nBased on the intfloat/e5-base-unsupervised model, this medium model is the workhorse that provides the best retrieval performance without slowing down inference.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-m embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] |
image-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification_for_fracture
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4783
- Accuracy: 0.85
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.8 | 2 | 0.6696 | 0.75 |
| No log | 2.0 | 5 | 0.6296 | 0.7 |
| No log | 2.8 | 7 | 0.5853 | 0.775 |
| 0.639 | 4.0 | 10 | 0.5731 | 0.8 |
| 0.639 | 4.8 | 12 | 0.5430 | 0.825 |
| 0.639 | 6.0 | 15 | 0.5223 | 0.85 |
| 0.639 | 6.8 | 17 | 0.5036 | 0.8 |
| 0.5453 | 8.0 | 20 | 0.4783 | 0.85 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1+cpu
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "metrics": ["accuracy"], "base_model": "google/vit-base-patch16-224-in21k", "model-index": [{"name": "image_classification_for_fracture", "results": [{"task": {"type": "image-classification", "name": "Image Classification"}, "dataset": {"name": "imagefolder", "type": "imagefolder", "config": "default", "split": "train", "args": "default"}, "metrics": [{"type": "accuracy", "value": 0.85, "name": "Accuracy"}]}]}]} | akhileshav8/image_classification_for_fracture | null | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T01:04:25+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #vit #image-classification #generated_from_trainer #dataset-imagefolder #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
| image\_classification\_for\_fracture
====================================
This model is a fine-tuned version of google/vit-base-patch16-224-in21k on the imagefolder dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4783
* Accuracy: 0.85
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 64
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 10
### Training results
### Framework versions
* Transformers 4.39.1
* Pytorch 2.2.1+cpu
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 64\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.2.1+cpu\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #vit #image-classification #generated_from_trainer #dataset-imagefolder #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 64\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.1\n* Pytorch 2.2.1+cpu\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
sentence-similarity | sentence-transformers |
# snowflake-arctic-embed-s-gguf
Model creator: [Snowflake](https://huggingface.co/Snowflake)
Original model: [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s)
## Original Description
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The `snowflake-arctic-embedding` models achieve **state-of-the-art performance on the MTEB/BEIR leaderboard** for each of their size variants. Evaluation is performed using these [scripts](https://github.com/Snowflake-Labs/snowflake-arctic-embed/tree/main/src). As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
| Name | MTEB Retrieval Score (NDCG @ 10) | Parameters (Millions) | Embedding Dimension |
| ----------------------------------------------------------------------- | -------------------------------- | --------------------- | ------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 | 22 | 384 |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 | 33 | 384 |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 | 110 | 768 |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 | 137 | 768 |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 | 335 | 1024 |
Based on the [intfloat/e5-small-unsupervised](https://huggingface.co/intfloat/e5-small-unsupervised) model, this small model does not trade off retrieval accuracy for its small size. With only 33m parameters and 384 dimensions, this model should easily allow scaling to large datasets.
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------ | -------------------------------- |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 |
| bge-small-en-v1.5 | 51.68 |
| Cohere-embed-english-light-v3.0 | 51.34 |
| text-embedding-3-small | 51.08 |
| e5-small-v2 | 49.04 |
## Description
This repo contains GGUF format files for the snowflake-arctic-embed-s embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). | {"language": ["en"], "license": "apache-2.0", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "mteb", "arctic", "snowflake-arctic-embed", "transformers.js", "gguf"], "model_name": "snowflake-arctic-embed-s", "base_model": "Snowflake/snowflake-arctic-embed-s", "inference": false, "model_creator": "Snowflake", "model_type": "bert", "quantized_by": "ChristianAzinn", "pipeline_tag": "sentence-similarity"} | ChristianAzinn/snowflake-arctic-embed-s-gguf | null | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"gguf",
"en",
"base_model:Snowflake/snowflake-arctic-embed-s",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T01:05:24+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-s #license-apache-2.0 #region-us
| snowflake-arctic-embed-s-gguf
=============================
Model creator: Snowflake
Original model: snowflake-arctic-embed-s
Original Description
--------------------
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The 'snowflake-arctic-embedding' models achieve state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. Evaluation is performed using these scripts. As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
Based on the intfloat/e5-small-unsupervised model, this small model does not trade off retrieval accuracy for its small size. With only 33m parameters and 384 dimensions, this model should easily allow scaling to large datasets.
Description
-----------
This repo contains GGUF format files for the snowflake-arctic-embed-s embedding model.
These files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.
This model supports up to 512 tokens of context.
Compatibility
-------------
These files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.
Examples
========
Example Usage with 'URL'
------------------------
To compute a single embedding, build URL and run:
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.
'URL':
Compute multiple embeddings:
Example Usage with LM Studio
----------------------------
Download the 0.2.19 beta build from here: Windows MacOS Linux
Once installed, open the app. The home should look like this:
!image/png
Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.
!image/png
Select your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.
!image/png
You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.
!image/png
Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.
!image/png
Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.
!image/png
All that's left to do is to hit the "Start Server" button:
!image/png
And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.
!image/png
Example curl request to the API endpoint:
For more information, see the LM Studio text embedding documentation.
Acknowledgements
----------------
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke.
| [] | [
"TAGS\n#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-s #license-apache-2.0 #region-us \n"
] |
sentence-similarity | sentence-transformers |
# snowflake-arctic-embed-xs-gguf
Model creator: [Snowflake](https://huggingface.co/Snowflake)
Original model: [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs)
## Original Description
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The `snowflake-arctic-embedding` models achieve **state-of-the-art performance on the MTEB/BEIR leaderboard** for each of their size variants. Evaluation is performed using these [scripts](https://github.com/Snowflake-Labs/snowflake-arctic-embed/tree/main/src). As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
| Name | MTEB Retrieval Score (NDCG @ 10) | Parameters (Millions) | Embedding Dimension |
| ----------------------------------------------------------------------- | -------------------------------- | --------------------- | ------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 | 22 | 384 |
| [snowflake-arctic-embed-s](https://huggingface.co/Snowflake/snowflake-arctic-embed-s/) | 51.98 | 33 | 384 |
| [snowflake-arctic-embed-m](https://huggingface.co/Snowflake/snowflake-arctic-embed-m/) | 54.90 | 110 | 768 |
| [snowflake-arctic-embed-m-long](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long/) | 54.83 | 137 | 768 |
| [snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l/) | 55.98 | 335 | 1024 |
### [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs)
This tiny model packs quite the punch. Based on the [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) model with only 22m parameters and 384 dimensions, this model should meet even the strictest latency/TCO budgets. Despite its size, its retrieval accuracy is closer to that of models with 100m paramers.
| Model Name | MTEB Retrieval Score (NDCG @ 10) |
| ------------------------------------------------------------------- | -------------------------------- |
| [snowflake-arctic-embed-xs](https://huggingface.co/Snowflake/snowflake-arctic-embed-xs/) | 50.15 |
| GIST-all-MiniLM-L6-v2 | 45.12 |
| gte-tiny | 44.92 |
| all-MiniLM-L6-v2 | 41.95 |
| bge-micro-v2 | 42.56 |
## Description
This repo contains GGUF format files for the snowflake-arctic-embed-xs embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). | {"language": ["en"], "license": "apache-2.0", "library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "mteb", "arctic", "snowflake-arctic-embed", "transformers.js", "gguf"], "model_name": "snowflake-arctic-embed-xs", "base_model": "Snowflake/snowflake-arctic-embed-xs", "inference": false, "model_creator": "Snowflake", "model_type": "bert", "quantized_by": "ChristianAzinn", "pipeline_tag": "sentence-similarity"} | ChristianAzinn/snowflake-arctic-embed-xs-gguf | null | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"gguf",
"en",
"base_model:Snowflake/snowflake-arctic-embed-xs",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T01:06:11+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-xs #license-apache-2.0 #region-us
| snowflake-arctic-embed-xs-gguf
==============================
Model creator: Snowflake
Original model: snowflake-arctic-embed-xs
Original Description
--------------------
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance.
The 'snowflake-arctic-embedding' models achieve state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. Evaluation is performed using these scripts. As shown below, each class of model size achieves SOTA retrieval accuracy compared to other top models.
The models are trained by leveraging existing open-source text representation models, such as bert-base-uncased, and are trained in a multi-stage pipeline to optimize their retrieval performance. First, the models are trained with large batches of query-document pairs where negatives are derived in-batch—pretraining leverages about 400m samples of a mix of public datasets and proprietary web search data. Following pretraining models are further optimized with long training on a smaller dataset (about 1m samples) of triplets of query, positive document, and negative document derived from hard harmful mining. Mining of the negatives and data curation is crucial to retrieval accuracy. A detailed technical report will be available shortly.
### snowflake-arctic-embed-xs
This tiny model packs quite the punch. Based on the all-MiniLM-L6-v2 model with only 22m parameters and 384 dimensions, this model should meet even the strictest latency/TCO budgets. Despite its size, its retrieval accuracy is closer to that of models with 100m paramers.
Description
-----------
This repo contains GGUF format files for the snowflake-arctic-embed-xs embedding model.
These files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.
This model supports up to 512 tokens of context.
Compatibility
-------------
These files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.
Examples
========
Example Usage with 'URL'
------------------------
To compute a single embedding, build URL and run:
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.
'URL':
Compute multiple embeddings:
Example Usage with LM Studio
----------------------------
Download the 0.2.19 beta build from here: Windows MacOS Linux
Once installed, open the app. The home should look like this:
!image/png
Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.
!image/png
Select your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.
!image/png
You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.
!image/png
Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.
!image/png
Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.
!image/png
All that's left to do is to hit the "Start Server" button:
!image/png
And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.
!image/png
Example curl request to the API endpoint:
For more information, see the LM Studio text embedding documentation.
Acknowledgements
----------------
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke.
| [
"### snowflake-arctic-embed-xs\n\n\nThis tiny model packs quite the punch. Based on the all-MiniLM-L6-v2 model with only 22m parameters and 384 dimensions, this model should meet even the strictest latency/TCO budgets. Despite its size, its retrieval accuracy is closer to that of models with 100m paramers.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-xs embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] | [
"TAGS\n#sentence-transformers #feature-extraction #sentence-similarity #mteb #arctic #snowflake-arctic-embed #transformers.js #gguf #en #base_model-Snowflake/snowflake-arctic-embed-xs #license-apache-2.0 #region-us \n",
"### snowflake-arctic-embed-xs\n\n\nThis tiny model packs quite the punch. Based on the all-MiniLM-L6-v2 model with only 22m parameters and 384 dimensions, this model should meet even the strictest latency/TCO budgets. Despite its size, its retrieval accuracy is closer to that of models with 100m paramers.\n\n\n\nDescription\n-----------\n\n\nThis repo contains GGUF format files for the snowflake-arctic-embed-xs embedding model.\n\n\nThese files were converted and quantized with URL PR 5500, commit 34aa045de, on a consumer RTX 4090.\n\n\nThis model supports up to 512 tokens of context.\n\n\nCompatibility\n-------------\n\n\nThese files are compatible with URL as of commit 4524290e8, as well as LM Studio as of version 0.2.19.\n\n\nExamples\n========\n\n\nExample Usage with 'URL'\n------------------------\n\n\nTo compute a single embedding, build URL and run:\n\n\nYou can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the 'embedding' example.\n\n\n'URL':\n\n\nCompute multiple embeddings:\n\n\nExample Usage with LM Studio\n----------------------------\n\n\nDownload the 0.2.19 beta build from here: Windows MacOS Linux\n\n\nOnce installed, open the app. The home should look like this:\n\n\n!image/png\n\n\nSearch for either \"ChristianAzinn\" in the main search bar or go to the \"Search\" tab on the left menu and search the name there.\n\n\n!image/png\n\n\nSelect your model from those that appear (this example uses 'bge-small-en-v1.5-gguf') and select which quantization you want to download. Since this model is pretty small, I recommend Q8\\_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.\n\n\n!image/png\n\n\nYou will see a green checkmark and the word \"Downloaded\" once the model has successfully downloaded, which can take some time depending on your network speeds.\n\n\n!image/png\n\n\nOnce this model is finished downloading, navigate to the \"Local Server\" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.\n\n\n!image/png\n\n\nSelect the model you just downloaded from the dropdown that appears to load it. You may need to play with configurations in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.\n\n\n!image/png\n\n\nAll that's left to do is to hit the \"Start Server\" button:\n\n\n!image/png\n\n\nAnd if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.\n\n\n!image/png\n\n\nExample curl request to the API endpoint:\n\n\nFor more information, see the LM Studio text embedding documentation.\n\n\nAcknowledgements\n----------------\n\n\nThanks to the LM Studio team and everyone else working on open-source AI.\n\n\nThis README is inspired by that of nomic-ai-embed-text-v1.5-gguf, another excellent embedding model, and those of the legendary TheBloke."
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | lhallee/PIT_cifar_benchmark | null | [
"transformers",
"safetensors",
"Vit",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T01:06:56+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #Vit #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #Vit #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q2_K.gguf.part2of2) | Q2_K | 52.2 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_XS.gguf.part2of2) | IQ3_XS | 58.3 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_S.gguf.part2of2) | IQ3_S | 61.6 | beats Q3_K* |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_S.gguf.part2of2) | Q3_K_S | 61.6 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ3_M.gguf.part2of2) | IQ3_M | 64.6 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_M.gguf.part2of2) | Q3_K_M | 67.9 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_L.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q3_K_L.gguf.part2of2) | Q3_K_L | 72.7 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ4_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.IQ4_XS.gguf.part2of2) | IQ4_XS | 76.5 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q4_K_S.gguf.part2of2) | Q4_K_S | 80.6 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q4_K_M.gguf.part2of2) | Q4_K_M | 85.7 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q5_K_S.gguf.part2of2) | Q5_K_S | 97.1 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q5_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q5_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q5_K_M.gguf.part3of3) | Q5_K_M | 100.1 | |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q6_K.gguf.part3of3) | Q6_K | 115.6 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q8_0.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q8_0.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q8_0.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF/resolve/main/zephyr-orpo-141b-A35b-v0.1.Q8_0.gguf.part4of4) | Q8_0 | 149.5 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["trl", "orpo", "generated_from_trainer"], "datasets": ["argilla/distilabel-capybara-dpo-7k-binarized"], "base_model": "HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1", "quantized_by": "mradermacher"} | mradermacher/zephyr-orpo-141b-A35b-v0.1-GGUF | null | [
"transformers",
"trl",
"orpo",
"generated_from_trainer",
"en",
"dataset:argilla/distilabel-capybara-dpo-7k-binarized",
"base_model:HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T01:07:04+00:00 | [] | [
"en"
] | TAGS
#transformers #trl #orpo #generated_from_trainer #en #dataset-argilla/distilabel-capybara-dpo-7k-binarized #base_model-HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #trl #orpo #generated_from_trainer #en #dataset-argilla/distilabel-capybara-dpo-7k-binarized #base_model-HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null | diffusers |
Orchwell is a Dance Diffusion model trained on an inexperienced orchestra with a disjoint sound.
It didn't go quite as well as expected, but it produces good samples 50-75% of the time.
It's also really the only current digital solution for making orchestra music that isn't perfectly composed (which makes it more unique). | {"license": "lgpl-3.0", "library_name": "diffusers", "tags": ["audio-generation"]} | kronosta/orchwell | null | [
"diffusers",
"audio-generation",
"license:lgpl-3.0",
"region:us"
] | null | 2024-04-17T01:07:22+00:00 | [] | [] | TAGS
#diffusers #audio-generation #license-lgpl-3.0 #region-us
|
Orchwell is a Dance Diffusion model trained on an inexperienced orchestra with a disjoint sound.
It didn't go quite as well as expected, but it produces good samples 50-75% of the time.
It's also really the only current digital solution for making orchestra music that isn't perfectly composed (which makes it more unique). | [] | [
"TAGS\n#diffusers #audio-generation #license-lgpl-3.0 #region-us \n"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_hh_usp3_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9835
- Rewards/chosen: -10.6241
- Rewards/rejected: -14.4122
- Rewards/accuracies: 0.7300
- Rewards/margins: 3.7881
- Logps/rejected: -258.5334
- Logps/chosen: -217.0869
- Logits/rejected: -0.8154
- Logits/chosen: -0.8130
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.1146 | 2.67 | 100 | 0.6900 | -4.8037 | -6.4467 | 0.7300 | 1.6430 | -178.8784 | -158.8832 | -0.8887 | -0.9297 |
| 0.0024 | 5.33 | 200 | 1.0780 | -9.2061 | -12.3558 | 0.7000 | 3.1497 | -237.9695 | -202.9073 | -0.8656 | -0.8655 |
| 0.0001 | 8.0 | 300 | 0.9490 | -10.1793 | -13.8565 | 0.7200 | 3.6772 | -252.9766 | -212.6395 | -0.8313 | -0.8261 |
| 0.0001 | 10.67 | 400 | 0.9700 | -10.4127 | -14.1403 | 0.7300 | 3.7276 | -255.8140 | -214.9731 | -0.8237 | -0.8199 |
| 0.0001 | 13.33 | 500 | 0.9721 | -10.5124 | -14.2790 | 0.7300 | 3.7666 | -257.2012 | -215.9702 | -0.8195 | -0.8168 |
| 0.0001 | 16.0 | 600 | 0.9839 | -10.5785 | -14.3606 | 0.7200 | 3.7820 | -258.0171 | -216.6317 | -0.8172 | -0.8146 |
| 0.0001 | 18.67 | 700 | 0.9829 | -10.6126 | -14.4106 | 0.7300 | 3.7980 | -258.5171 | -216.9720 | -0.8160 | -0.8135 |
| 0.0001 | 21.33 | 800 | 0.9837 | -10.6177 | -14.4091 | 0.7200 | 3.7913 | -258.5019 | -217.0236 | -0.8153 | -0.8132 |
| 0.0001 | 24.0 | 900 | 0.9832 | -10.6228 | -14.4149 | 0.7300 | 3.7921 | -258.5607 | -217.0746 | -0.8156 | -0.8134 |
| 0.0001 | 26.67 | 1000 | 0.9835 | -10.6241 | -14.4122 | 0.7300 | 3.7881 | -258.5334 | -217.0869 | -0.8154 | -0.8130 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_hh_usp3_dpo1", "results": []}]} | guoyu-zhang/model_hh_usp3_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-04-17T01:07:49+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us
| model\_hh\_usp3\_dpo1
=====================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9835
* Rewards/chosen: -10.6241
* Rewards/rejected: -14.4122
* Rewards/accuracies: 0.7300
* Rewards/margins: 3.7881
* Logps/rejected: -258.5334
* Logps/chosen: -217.0869
* Logits/rejected: -0.8154
* Logits/chosen: -0.8130
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7binstruct_summarize
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4540
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7325 | 0.21 | 25 | 1.5370 |
| 1.4915 | 0.43 | 50 | 1.4540 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral7binstruct_summarize", "results": []}]} | rajkstats/mistral7binstruct_summarize | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T01:08:03+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
| mistral7binstruct\_summarize
============================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4540
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant
* lr\_scheduler\_warmup\_steps: 0.03
* training\_steps: 50
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | thusinh1969/flant5xl-instruct-15MAR2024 | null | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T01:08:56+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #t5 #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #t5 #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
| {"license": "other", "license_name": "deepseek", "license_link": "https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL"} | blockblockblock/deepseek-math-7b-rl-bpw4.6 | null | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T01:10:12+00:00 | [
"2402.03300"
] | [] | TAGS
#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="URL
</p>
<p align="center"><a href="URL | <a href="URL Chat with DeepSeek LLM]</a> | <a href="URL | <a href="URL(微信)]</a> </p>
<p align="center">
<a href="URL Link</b>️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the Introduction for more details.
### 2. How to Use
Here give some examples of how to use our model.
Chat Completion
Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:
- English questions: {question}\nPlease reason step by step, and put your final answer within \\boxed{}.
- Chinese questions: {question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。
Avoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.
Note: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the LICENSE-MODEL for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at service@URL.
| [
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] | [
"TAGS\n#transformers #pytorch #safetensors #llama #text-generation #conversational #arxiv-2402.03300 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### 1. Introduction to DeepSeekMath\nSee the Introduction for more details.",
"### 2. How to Use\nHere give some examples of how to use our model.\n\nChat Completion\n\n Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:\n\n- English questions: {question}\\nPlease reason step by step, and put your final answer within \\\\boxed{}.\n\n- Chinese questions: {question}\\n请通过逐步推理来解答问题,并把最终答案放置于\\\\boxed{}中。\n\n\n\nAvoiding the use of the provided function 'apply_chat_template', you can also interact with our model following the sample template. Note that 'messages' should be replaced by your input.\n\n\n\nNote: By default ('add_special_tokens=True'), our tokenizer automatically adds a 'bos_token' ('<|begin▁of▁sentence|>') before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.",
"### 3. License\nThis code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.\n\nSee the LICENSE-MODEL for more details.",
"### 4. Contact\n\nIf you have any questions, please raise an issue or contact us at service@URL."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K36me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K36me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6535
- F1 Score: 0.6307
- Accuracy: 0.6319
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6628 | 14.29 | 200 | 0.6517 | 0.6195 | 0.6216 |
| 0.5866 | 28.57 | 400 | 0.6999 | 0.6135 | 0.6187 |
| 0.5323 | 42.86 | 600 | 0.7321 | 0.6147 | 0.6167 |
| 0.4893 | 57.14 | 800 | 0.7643 | 0.6051 | 0.6107 |
| 0.4551 | 71.43 | 1000 | 0.8005 | 0.6115 | 0.6127 |
| 0.4279 | 85.71 | 1200 | 0.8664 | 0.6072 | 0.6121 |
| 0.4054 | 100.0 | 1400 | 0.8874 | 0.6105 | 0.6138 |
| 0.3875 | 114.29 | 1600 | 0.8904 | 0.6106 | 0.6121 |
| 0.3681 | 128.57 | 1800 | 0.9619 | 0.6096 | 0.6107 |
| 0.3557 | 142.86 | 2000 | 0.9989 | 0.6048 | 0.6098 |
| 0.3453 | 157.14 | 2200 | 0.9490 | 0.6141 | 0.6138 |
| 0.3374 | 171.43 | 2400 | 0.9903 | 0.6073 | 0.6124 |
| 0.3285 | 185.71 | 2600 | 1.0072 | 0.6108 | 0.6115 |
| 0.324 | 200.0 | 2800 | 0.9566 | 0.6110 | 0.6153 |
| 0.3157 | 214.29 | 3000 | 0.9965 | 0.6153 | 0.6161 |
| 0.3093 | 228.57 | 3200 | 1.0041 | 0.6129 | 0.6158 |
| 0.3041 | 242.86 | 3400 | 1.0106 | 0.6177 | 0.6184 |
| 0.2996 | 257.14 | 3600 | 0.9862 | 0.6156 | 0.6181 |
| 0.2949 | 271.43 | 3800 | 1.0136 | 0.6099 | 0.6147 |
| 0.2879 | 285.71 | 4000 | 1.0189 | 0.6148 | 0.6144 |
| 0.2846 | 300.0 | 4200 | 1.0597 | 0.6152 | 0.6164 |
| 0.2786 | 314.29 | 4400 | 1.0657 | 0.6160 | 0.6178 |
| 0.2731 | 328.57 | 4600 | 1.1091 | 0.6170 | 0.6190 |
| 0.2687 | 342.86 | 4800 | 1.0348 | 0.6136 | 0.6164 |
| 0.2667 | 357.14 | 5000 | 1.1277 | 0.6147 | 0.6173 |
| 0.26 | 371.43 | 5200 | 1.0603 | 0.6154 | 0.6175 |
| 0.2559 | 385.71 | 5400 | 1.0592 | 0.6142 | 0.6153 |
| 0.2535 | 400.0 | 5600 | 1.0749 | 0.6142 | 0.6181 |
| 0.251 | 414.29 | 5800 | 1.1302 | 0.6163 | 0.6175 |
| 0.2455 | 428.57 | 6000 | 1.1094 | 0.6097 | 0.6138 |
| 0.2417 | 442.86 | 6200 | 1.1451 | 0.6113 | 0.6155 |
| 0.2402 | 457.14 | 6400 | 1.1096 | 0.6121 | 0.6147 |
| 0.2364 | 471.43 | 6600 | 1.1231 | 0.6179 | 0.6181 |
| 0.2324 | 485.71 | 6800 | 1.1474 | 0.6130 | 0.6161 |
| 0.2313 | 500.0 | 7000 | 1.1051 | 0.6136 | 0.6153 |
| 0.2274 | 514.29 | 7200 | 1.1790 | 0.6179 | 0.6190 |
| 0.2246 | 528.57 | 7400 | 1.1702 | 0.6107 | 0.6135 |
| 0.223 | 542.86 | 7600 | 1.1885 | 0.6077 | 0.6098 |
| 0.2216 | 557.14 | 7800 | 1.1613 | 0.6131 | 0.6141 |
| 0.218 | 571.43 | 8000 | 1.1826 | 0.6138 | 0.6147 |
| 0.2163 | 585.71 | 8200 | 1.1993 | 0.6172 | 0.6190 |
| 0.2144 | 600.0 | 8400 | 1.1920 | 0.6158 | 0.6170 |
| 0.2136 | 614.29 | 8600 | 1.1701 | 0.6163 | 0.6175 |
| 0.212 | 628.57 | 8800 | 1.1913 | 0.6192 | 0.6201 |
| 0.2097 | 642.86 | 9000 | 1.2032 | 0.6160 | 0.6175 |
| 0.2081 | 657.14 | 9200 | 1.2094 | 0.6162 | 0.6181 |
| 0.21 | 671.43 | 9400 | 1.1868 | 0.6137 | 0.6161 |
| 0.2073 | 685.71 | 9600 | 1.2097 | 0.6130 | 0.6155 |
| 0.2059 | 700.0 | 9800 | 1.1984 | 0.6149 | 0.6167 |
| 0.2066 | 714.29 | 10000 | 1.2008 | 0.6143 | 0.6161 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K36me3-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-17T01:11:39+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_EMP\_H3K36me3-seqsight\_32768\_512\_43M-L32\_all
=====================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_EMP\_H3K36me3 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6535
* F1 Score: 0.6307
* Accuracy: 0.6319
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7binstruct_summarize
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4582
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6666 | 0.22 | 25 | 1.5148 |
| 1.5322 | 0.43 | 50 | 1.4582 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral7binstruct_summarize", "results": []}]} | philmui/mistral7binstruct_summarize | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T01:15:30+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us
| mistral7binstruct\_summarize
============================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the generator dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4582
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 1
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant
* lr\_scheduler\_warmup\_steps: 0.03
* training\_steps: 50
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\n* lr\\_scheduler\\_warmup\\_steps: 0.03\n* training\\_steps: 50",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_mouse_0-seqsight_32768_512_43M-L32_all
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_mouse_0](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_mouse_0) dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4951
- F1 Score: 0.6272
- Accuracy: 0.6272
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2048
- eval_batch_size: 2048
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6112 | 50.0 | 200 | 0.7582 | 0.6111 | 0.6111 |
| 0.3816 | 100.0 | 400 | 1.1372 | 0.5862 | 0.5864 |
| 0.244 | 150.0 | 600 | 1.3452 | 0.5778 | 0.5802 |
| 0.176 | 200.0 | 800 | 1.5190 | 0.6025 | 0.6025 |
| 0.1406 | 250.0 | 1000 | 1.5970 | 0.6032 | 0.6037 |
| 0.1193 | 300.0 | 1200 | 1.6609 | 0.6066 | 0.6074 |
| 0.1037 | 350.0 | 1400 | 1.6358 | 0.6099 | 0.6111 |
| 0.0906 | 400.0 | 1600 | 1.8216 | 0.6033 | 0.6037 |
| 0.082 | 450.0 | 1800 | 1.8692 | 0.5926 | 0.5926 |
| 0.0737 | 500.0 | 2000 | 1.8749 | 0.6062 | 0.6062 |
| 0.0656 | 550.0 | 2200 | 2.0375 | 0.6088 | 0.6099 |
| 0.0616 | 600.0 | 2400 | 2.1433 | 0.6160 | 0.6160 |
| 0.0573 | 650.0 | 2600 | 2.0727 | 0.6099 | 0.6099 |
| 0.0532 | 700.0 | 2800 | 2.1770 | 0.6185 | 0.6185 |
| 0.0507 | 750.0 | 3000 | 2.2137 | 0.6136 | 0.6136 |
| 0.0492 | 800.0 | 3200 | 2.2735 | 0.6072 | 0.6074 |
| 0.0444 | 850.0 | 3400 | 2.3833 | 0.6095 | 0.6099 |
| 0.0432 | 900.0 | 3600 | 2.4001 | 0.6025 | 0.6025 |
| 0.0422 | 950.0 | 3800 | 2.5721 | 0.6032 | 0.6049 |
| 0.0388 | 1000.0 | 4000 | 2.3964 | 0.6086 | 0.6086 |
| 0.0383 | 1050.0 | 4200 | 2.2883 | 0.6074 | 0.6074 |
| 0.0375 | 1100.0 | 4400 | 2.5822 | 0.6105 | 0.6123 |
| 0.0371 | 1150.0 | 4600 | 2.5446 | 0.6003 | 0.6012 |
| 0.0349 | 1200.0 | 4800 | 2.4803 | 0.6074 | 0.6074 |
| 0.0333 | 1250.0 | 5000 | 2.4578 | 0.6111 | 0.6111 |
| 0.0328 | 1300.0 | 5200 | 2.4646 | 0.6099 | 0.6099 |
| 0.0316 | 1350.0 | 5400 | 2.5137 | 0.6178 | 0.6185 |
| 0.0299 | 1400.0 | 5600 | 2.7044 | 0.6157 | 0.6160 |
| 0.0295 | 1450.0 | 5800 | 2.4447 | 0.6173 | 0.6173 |
| 0.0295 | 1500.0 | 6000 | 2.3338 | 0.6260 | 0.6259 |
| 0.027 | 1550.0 | 6200 | 2.4786 | 0.6047 | 0.6049 |
| 0.0278 | 1600.0 | 6400 | 2.3070 | 0.6173 | 0.6173 |
| 0.0264 | 1650.0 | 6600 | 2.6558 | 0.6135 | 0.6136 |
| 0.0278 | 1700.0 | 6800 | 2.4089 | 0.6235 | 0.6235 |
| 0.0256 | 1750.0 | 7000 | 2.6863 | 0.6309 | 0.6309 |
| 0.0259 | 1800.0 | 7200 | 2.4405 | 0.6197 | 0.6198 |
| 0.0248 | 1850.0 | 7400 | 2.6327 | 0.6309 | 0.6309 |
| 0.0233 | 1900.0 | 7600 | 2.5095 | 0.6223 | 0.6222 |
| 0.0231 | 1950.0 | 7800 | 2.5761 | 0.6259 | 0.6259 |
| 0.0225 | 2000.0 | 8000 | 2.6153 | 0.6197 | 0.6198 |
| 0.0217 | 2050.0 | 8200 | 2.6496 | 0.6185 | 0.6185 |
| 0.0219 | 2100.0 | 8400 | 2.6521 | 0.6157 | 0.6160 |
| 0.0228 | 2150.0 | 8600 | 2.5270 | 0.6173 | 0.6173 |
| 0.0211 | 2200.0 | 8800 | 2.6410 | 0.6186 | 0.6185 |
| 0.0203 | 2250.0 | 9000 | 2.5622 | 0.6198 | 0.6198 |
| 0.0199 | 2300.0 | 9200 | 2.5785 | 0.6223 | 0.6222 |
| 0.0209 | 2350.0 | 9400 | 2.4578 | 0.6197 | 0.6198 |
| 0.0207 | 2400.0 | 9600 | 2.6192 | 0.6210 | 0.6210 |
| 0.0197 | 2450.0 | 9800 | 2.6375 | 0.6172 | 0.6173 |
| 0.0206 | 2500.0 | 10000 | 2.5936 | 0.6185 | 0.6185 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_mouse_0-seqsight_32768_512_43M-L32_all", "results": []}]} | mahdibaghbanzadeh/GUE_mouse_0-seqsight_32768_512_43M-L32_all | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-17T01:16:00+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us
| GUE\_mouse\_0-seqsight\_32768\_512\_43M-L32\_all
================================================
This model is a fine-tuned version of mahdibaghbanzadeh/seqsight\_32768\_512\_43M on the mahdibaghbanzadeh/GUE\_mouse\_0 dataset.
It achieves the following results on the evaluation set:
* Loss: 2.4951
* F1 Score: 0.6272
* Accuracy: 0.6272
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 2048
* eval\_batch\_size: 2048
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* training\_steps: 10000
### Training results
### Framework versions
* PEFT 0.9.0
* Transformers 4.38.2
* Pytorch 2.2.0+cu121
* Datasets 2.17.1
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-mahdibaghbanzadeh/seqsight_32768_512_43M #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 2048\n* eval\\_batch\\_size: 2048\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* training\\_steps: 10000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.9.0\n* Transformers 4.38.2\n* Pytorch 2.2.0+cu121\n* Datasets 2.17.1\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2117
- Accuracy: 0.929
- F1: 0.9289
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8173 | 1.0 | 250 | 0.3269 | 0.9065 | 0.9056 |
| 0.2502 | 2.0 | 500 | 0.2117 | 0.929 | 0.9289 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.0
- Datasets 2.14.5
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "config": "split", "split": "validation", "args": "split"}, "metrics": [{"type": "accuracy", "value": 0.929, "name": "Accuracy"}, {"type": "f1", "value": 0.9289159103142277, "name": "F1"}]}]}]} | ryanjyc/distilbert-base-uncased-finetuned-emotion | null | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T01:18:50+00:00 | [] | [] | TAGS
#transformers #pytorch #safetensors #distilbert #text-classification #generated_from_trainer #dataset-emotion #base_model-distilbert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
| distilbert-base-uncased-finetuned-emotion
=========================================
This model is a fine-tuned version of distilbert-base-uncased on the emotion dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2117
* Accuracy: 0.929
* F1: 0.9289
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 64
* eval\_batch\_size: 64
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.34.0
* Pytorch 2.0.0
* Datasets 2.14.5
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.34.0\n* Pytorch 2.0.0\n* Datasets 2.14.5\n* Tokenizers 0.14.1"
] | [
"TAGS\n#transformers #pytorch #safetensors #distilbert #text-classification #generated_from_trainer #dataset-emotion #base_model-distilbert-base-uncased #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.34.0\n* Pytorch 2.0.0\n* Datasets 2.14.5\n* Tokenizers 0.14.1"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.