
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
listlengths 0
201
| languages
listlengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
listlengths 0
722
| processed_texts
listlengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | Cdywalst/demo-lora-r8_pruning | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:21:28+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0417MADP1
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3114
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 60
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.4601 | 0.09 | 10 | 3.0323 |
| 6.8643 | 0.18 | 20 | 2.8702 |
| 4.5679 | 0.27 | 30 | 2.3361 |
| 2.1248 | 0.36 | 40 | 1.5176 |
| 0.9282 | 0.45 | 50 | 0.9891 |
| 0.4911 | 0.54 | 60 | 0.7251 |
| 0.3523 | 0.63 | 70 | 0.5704 |
| 0.2758 | 0.73 | 80 | 0.4956 |
| 0.2531 | 0.82 | 90 | 0.4682 |
| 0.2596 | 0.91 | 100 | 0.4391 |
| 0.2475 | 1.0 | 110 | 0.4452 |
| 0.2484 | 1.09 | 120 | 0.4215 |
| 0.2508 | 1.18 | 130 | 0.4049 |
| 0.2237 | 1.27 | 140 | 0.3938 |
| 0.2173 | 1.36 | 150 | 0.3682 |
| 0.2077 | 1.45 | 160 | 0.3774 |
| 0.2233 | 1.54 | 170 | 0.3721 |
| 0.2241 | 1.63 | 180 | 0.3554 |
| 0.2178 | 1.72 | 190 | 0.3489 |
| 0.2096 | 1.81 | 200 | 0.3424 |
| 0.2137 | 1.9 | 210 | 0.3384 |
| 0.2084 | 1.99 | 220 | 0.3420 |
| 0.2157 | 2.08 | 230 | 0.3390 |
| 0.2052 | 2.18 | 240 | 0.3359 |
| 0.2017 | 2.27 | 250 | 0.3415 |
| 0.2115 | 2.36 | 260 | 0.3350 |
| 0.195 | 2.45 | 270 | 0.3316 |
| 0.2042 | 2.54 | 280 | 0.3244 |
| 0.2154 | 2.63 | 290 | 0.3287 |
| 0.1995 | 2.72 | 300 | 0.3258 |
| 0.1895 | 2.81 | 310 | 0.3022 |
| 0.207 | 2.9 | 320 | 0.3089 |
| 0.2038 | 2.99 | 330 | 0.3114 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.14.1
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "microsoft/phi-2", "model-index": [{"name": "V0417MADP1", "results": []}]} | Litzy619/V0417MADP1 | null | [
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-04-17T22:23:30+00:00 | [] | [] | TAGS
#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us
| V0417MADP1
==========
This model is a fine-tuned version of microsoft/phi-2 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3114
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 60
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.14.1"
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.14.1"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# legal-bert-lora-no-grad
This model is a fine-tuned version of [law-ai/InLegalBERT](https://huggingface.co/law-ai/InLegalBERT) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5075
- Accuracy: 0.8280
- Precision: 0.8290
- Recall: 0.8280
- Precision Macro: 0.7852
- Recall Macro: 0.7756
- Macro Fpr: 0.0151
- Weighted Fpr: 0.0145
- Weighted Specificity: 0.9775
- Macro Specificity: 0.9871
- Weighted Sensitivity: 0.8288
- Macro Sensitivity: 0.7756
- F1 Micro: 0.8288
- F1 Macro: 0.7761
- F1 Weighted: 0.8279
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | Precision Macro | Recall Macro | Macro Fpr | Weighted Fpr | Weighted Specificity | Macro Specificity | Weighted Sensitivity | Macro Sensitivity | F1 Micro | F1 Macro | F1 Weighted |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:---------------:|:------------:|:---------:|:------------:|:--------------------:|:-----------------:|:--------------------:|:-----------------:|:--------:|:--------:|:-----------:|
| 1.6412 | 1.0 | 643 | 0.7925 | 0.7514 | 0.7190 | 0.7514 | 0.4123 | 0.4707 | 0.0237 | 0.0231 | 0.9699 | 0.9814 | 0.7514 | 0.4707 | 0.7514 | 0.4277 | 0.7283 |
| 0.7481 | 2.0 | 1286 | 0.6772 | 0.7901 | 0.7726 | 0.7901 | 0.5958 | 0.6252 | 0.0192 | 0.0186 | 0.9741 | 0.9843 | 0.7901 | 0.6252 | 0.7901 | 0.5998 | 0.7769 |
| 0.6465 | 3.0 | 1929 | 0.6500 | 0.8048 | 0.7931 | 0.8048 | 0.6216 | 0.6414 | 0.0176 | 0.0170 | 0.9764 | 0.9854 | 0.8048 | 0.6414 | 0.8048 | 0.6110 | 0.7904 |
| 0.4707 | 4.0 | 2572 | 0.6704 | 0.8095 | 0.8008 | 0.8095 | 0.6322 | 0.6689 | 0.0173 | 0.0165 | 0.9745 | 0.9856 | 0.8095 | 0.6689 | 0.8095 | 0.6425 | 0.8018 |
| 0.4021 | 5.0 | 3215 | 0.7320 | 0.8280 | 0.8269 | 0.8280 | 0.7782 | 0.7573 | 0.0154 | 0.0146 | 0.9765 | 0.9870 | 0.8280 | 0.7573 | 0.8280 | 0.7571 | 0.8219 |
| 0.3627 | 6.0 | 3858 | 0.6892 | 0.8242 | 0.8227 | 0.8242 | 0.7431 | 0.7365 | 0.0156 | 0.0150 | 0.9768 | 0.9867 | 0.8242 | 0.7365 | 0.8242 | 0.7374 | 0.8223 |
| 0.2866 | 7.0 | 4501 | 0.8756 | 0.8180 | 0.8171 | 0.8180 | 0.7748 | 0.7410 | 0.0166 | 0.0156 | 0.9718 | 0.9860 | 0.8180 | 0.7410 | 0.8180 | 0.7444 | 0.8122 |
| 0.2639 | 8.0 | 5144 | 0.8580 | 0.8265 | 0.8259 | 0.8265 | 0.7989 | 0.7428 | 0.0155 | 0.0148 | 0.9756 | 0.9868 | 0.8265 | 0.7428 | 0.8265 | 0.7480 | 0.8217 |
| 0.2295 | 9.0 | 5787 | 0.9366 | 0.8257 | 0.8231 | 0.8257 | 0.7725 | 0.7465 | 0.0155 | 0.0149 | 0.9762 | 0.9868 | 0.8257 | 0.7465 | 0.8257 | 0.7524 | 0.8223 |
| 0.195 | 10.0 | 6430 | 0.9685 | 0.8273 | 0.8236 | 0.8273 | 0.7595 | 0.7515 | 0.0153 | 0.0147 | 0.9767 | 0.9869 | 0.8273 | 0.7515 | 0.8273 | 0.7528 | 0.8241 |
| 0.1617 | 11.0 | 7073 | 1.0406 | 0.8311 | 0.8263 | 0.8311 | 0.7615 | 0.7552 | 0.0149 | 0.0143 | 0.9776 | 0.9872 | 0.8311 | 0.7552 | 0.8311 | 0.7543 | 0.8265 |
| 0.1421 | 12.0 | 7716 | 1.0713 | 0.8319 | 0.8276 | 0.8319 | 0.7626 | 0.7533 | 0.0148 | 0.0142 | 0.9773 | 0.9873 | 0.8319 | 0.7533 | 0.8319 | 0.7546 | 0.8287 |
| 0.1184 | 13.0 | 8359 | 1.1125 | 0.8257 | 0.8209 | 0.8257 | 0.7569 | 0.7504 | 0.0155 | 0.0149 | 0.9765 | 0.9868 | 0.8257 | 0.7504 | 0.8257 | 0.7510 | 0.8219 |
| 0.1017 | 14.0 | 9002 | 1.1926 | 0.8211 | 0.8215 | 0.8211 | 0.7675 | 0.7815 | 0.0159 | 0.0153 | 0.9776 | 0.9866 | 0.8211 | 0.7815 | 0.8211 | 0.7727 | 0.8196 |
| 0.0752 | 15.0 | 9645 | 1.2508 | 0.8164 | 0.8121 | 0.8164 | 0.7479 | 0.7377 | 0.0164 | 0.0158 | 0.9753 | 0.9861 | 0.8164 | 0.7377 | 0.8164 | 0.7402 | 0.8133 |
| 0.0787 | 16.0 | 10288 | 1.3247 | 0.8218 | 0.8199 | 0.8218 | 0.8034 | 0.7585 | 0.0160 | 0.0152 | 0.9752 | 0.9865 | 0.8218 | 0.7585 | 0.8218 | 0.7698 | 0.8188 |
| 0.0668 | 17.0 | 10931 | 1.3497 | 0.8211 | 0.8201 | 0.8211 | 0.7500 | 0.7487 | 0.0158 | 0.0153 | 0.9778 | 0.9866 | 0.8211 | 0.7487 | 0.8211 | 0.7468 | 0.8198 |
| 0.0471 | 18.0 | 11574 | 1.4278 | 0.8164 | 0.8174 | 0.8164 | 0.7672 | 0.7670 | 0.0165 | 0.0158 | 0.9759 | 0.9862 | 0.8164 | 0.7670 | 0.8164 | 0.7644 | 0.8159 |
| 0.0492 | 19.0 | 12217 | 1.4784 | 0.8180 | 0.8178 | 0.8180 | 0.7631 | 0.7431 | 0.0162 | 0.0156 | 0.9763 | 0.9863 | 0.8180 | 0.7431 | 0.8180 | 0.7453 | 0.8156 |
| 0.0368 | 20.0 | 12860 | 1.4747 | 0.8195 | 0.8183 | 0.8195 | 0.7729 | 0.7568 | 0.0161 | 0.0155 | 0.9760 | 0.9864 | 0.8195 | 0.7568 | 0.8195 | 0.7622 | 0.8180 |
| 0.0329 | 21.0 | 13503 | 1.5075 | 0.8280 | 0.8290 | 0.8280 | 0.7825 | 0.7845 | 0.0152 | 0.0146 | 0.9782 | 0.9871 | 0.8280 | 0.7845 | 0.8280 | 0.7798 | 0.8268 |
| 0.0266 | 22.0 | 14146 | 1.4783 | 0.8273 | 0.8262 | 0.8273 | 0.7780 | 0.7612 | 0.0153 | 0.0147 | 0.9779 | 0.9870 | 0.8273 | 0.7612 | 0.8273 | 0.7651 | 0.8247 |
| 0.0302 | 23.0 | 14789 | 1.5281 | 0.8234 | 0.8246 | 0.8234 | 0.7745 | 0.7699 | 0.0158 | 0.0151 | 0.9760 | 0.9866 | 0.8234 | 0.7699 | 0.8234 | 0.7679 | 0.8224 |
| 0.0207 | 24.0 | 15432 | 1.5475 | 0.8265 | 0.8262 | 0.8265 | 0.7809 | 0.7727 | 0.0155 | 0.0148 | 0.9768 | 0.9869 | 0.8265 | 0.7727 | 0.8265 | 0.7721 | 0.8248 |
| 0.0168 | 25.0 | 16075 | 1.5237 | 0.8242 | 0.8237 | 0.8242 | 0.7726 | 0.7619 | 0.0155 | 0.0150 | 0.9775 | 0.9868 | 0.8242 | 0.7619 | 0.8242 | 0.7629 | 0.8231 |
| 0.0167 | 26.0 | 16718 | 1.5815 | 0.8234 | 0.8255 | 0.8234 | 0.7766 | 0.7728 | 0.0156 | 0.0151 | 0.9775 | 0.9867 | 0.8234 | 0.7728 | 0.8234 | 0.7707 | 0.8232 |
| 0.0127 | 27.0 | 17361 | 1.6010 | 0.8218 | 0.8228 | 0.8218 | 0.7790 | 0.7716 | 0.0158 | 0.0152 | 0.9769 | 0.9866 | 0.8218 | 0.7716 | 0.8218 | 0.7709 | 0.8211 |
| 0.0094 | 28.0 | 18004 | 1.5774 | 0.8265 | 0.8269 | 0.8265 | 0.7788 | 0.7739 | 0.0153 | 0.0148 | 0.9778 | 0.9870 | 0.8265 | 0.7739 | 0.8265 | 0.7728 | 0.8258 |
| 0.0063 | 29.0 | 18647 | 1.5894 | 0.8304 | 0.8306 | 0.8304 | 0.7825 | 0.7764 | 0.0150 | 0.0144 | 0.9779 | 0.9872 | 0.8304 | 0.7764 | 0.8304 | 0.7759 | 0.8296 |
| 0.0126 | 30.0 | 19290 | 1.5927 | 0.8288 | 0.8291 | 0.8288 | 0.7852 | 0.7756 | 0.0151 | 0.0145 | 0.9775 | 0.9871 | 0.8288 | 0.7756 | 0.8288 | 0.7761 | 0.8279 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.1
| {"license": "mit", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "precision", "recall"], "base_model": "law-ai/InLegalBERT", "model-index": [{"name": "legal-bert-lora-no-grad", "results": []}]} | xshubhamx/InLegalBERT-lora-no-grad | null | [
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:law-ai/InLegalBERT",
"license:mit",
"region:us"
] | null | 2024-04-17T22:23:46+00:00 | [] | [] | TAGS
#tensorboard #safetensors #generated_from_trainer #base_model-law-ai/InLegalBERT #license-mit #region-us
| legal-bert-lora-no-grad
=======================
This model is a fine-tuned version of law-ai/InLegalBERT on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.5075
* Accuracy: 0.8280
* Precision: 0.8290
* Recall: 0.8280
* Precision Macro: 0.7852
* Recall Macro: 0.7756
* Macro Fpr: 0.0151
* Weighted Fpr: 0.0145
* Weighted Specificity: 0.9775
* Macro Specificity: 0.9871
* Weighted Sensitivity: 0.8288
* Macro Sensitivity: 0.7756
* F1 Micro: 0.8288
* F1 Macro: 0.7761
* F1 Weighted: 0.8279
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 30
### Training results
### Framework versions
* Transformers 4.35.2
* Pytorch 2.1.0+cu121
* Datasets 2.18.0
* Tokenizers 0.15.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 30",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.35.2\n* Pytorch 2.1.0+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
] | [
"TAGS\n#tensorboard #safetensors #generated_from_trainer #base_model-law-ai/InLegalBERT #license-mit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 30",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.35.2\n* Pytorch 2.1.0+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.1"
] |
image-classification | transformers |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# puriwats/food_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8524
- Validation Loss: 1.7345
- Train Accuracy: 0.792
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 4000, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 2.8524 | 1.7345 | 0.792 | 0 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_keras_callback"], "base_model": "google/vit-base-patch16-224-in21k", "model-index": [{"name": "puriwats/food_classifier", "results": []}]} | puriwats/food_classifier | null | [
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"base_model:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:24:49+00:00 | [] | [] | TAGS
#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| puriwats/food\_classifier
=========================
This model is a fine-tuned version of google/vit-base-patch16-224-in21k on an unknown dataset.
It achieves the following results on the evaluation set:
* Train Loss: 2.8524
* Validation Loss: 1.7345
* Train Accuracy: 0.792
* Epoch: 0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* optimizer: {'name': 'AdamWeightDecay', 'learning\_rate': {'module': 'keras.optimizers.schedules', 'class\_name': 'PolynomialDecay', 'config': {'initial\_learning\_rate': 3e-05, 'decay\_steps': 4000, 'end\_learning\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\_name': None}, 'decay': 0.0, 'beta\_1': 0.9, 'beta\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\_decay\_rate': 0.01}
* training\_precision: float32
### Training results
### Framework versions
* Transformers 4.38.2
* TensorFlow 2.15.0
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 4000, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.01}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 4000, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.01}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* TensorFlow 2.15.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0417MADP3
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 60
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.5507 | 0.09 | 10 | 3.0786 |
| 6.3727 | 0.18 | 20 | 2.6464 |
| 3.4656 | 0.27 | 30 | 1.9120 |
| 1.5044 | 0.36 | 40 | 1.1144 |
| 0.581 | 0.45 | 50 | 0.7389 |
| 0.3434 | 0.54 | 60 | 0.5960 |
| 0.3386 | 0.63 | 70 | 0.5215 |
| 0.2957 | 0.73 | 80 | 0.5323 |
| 0.258 | 0.82 | 90 | 0.4773 |
| 0.263 | 0.91 | 100 | 0.4986 |
| 0.2584 | 1.0 | 110 | 0.4831 |
| 0.2808 | 1.09 | 120 | 0.5051 |
| 0.2978 | 1.18 | 130 | 0.4790 |
| 0.2479 | 1.27 | 140 | 0.4456 |
| 0.4023 | 1.36 | 150 | 0.4223 |
| 0.21 | 1.45 | 160 | 0.2159 |
| 0.1788 | 1.54 | 170 | 0.2052 |
| 0.1786 | 1.63 | 180 | 0.2024 |
| 0.1748 | 1.72 | 190 | 0.2013 |
| 0.1718 | 1.81 | 200 | 0.2138 |
| 0.176 | 1.9 | 210 | 0.2197 |
| 0.173 | 1.99 | 220 | 0.2321 |
| 0.1877 | 2.08 | 230 | 0.2317 |
| 0.1732 | 2.18 | 240 | 0.2126 |
| 0.1661 | 2.27 | 250 | 0.1958 |
| 0.1668 | 2.36 | 260 | 0.1955 |
| 0.1642 | 2.45 | 270 | 0.1957 |
| 0.1612 | 2.54 | 280 | 0.1937 |
| 0.1681 | 2.63 | 290 | 0.1910 |
| 0.1622 | 2.72 | 300 | 0.1901 |
| 0.1592 | 2.81 | 310 | 0.1898 |
| 0.1657 | 2.9 | 320 | 0.1904 |
| 0.1696 | 2.99 | 330 | 0.1901 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.14.1
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "microsoft/phi-2", "model-index": [{"name": "V0417MADP3", "results": []}]} | Litzy619/V0417MADP3 | null | [
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-04-17T22:26:06+00:00 | [] | [] | TAGS
#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us
| V0417MADP3
==========
This model is a fine-tuned version of microsoft/phi-2 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1901
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine\_with\_restarts
* lr\_scheduler\_warmup\_steps: 60
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.36.0.dev0
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.14.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.14.1"
] | [
"TAGS\n#safetensors #generated_from_trainer #base_model-microsoft/phi-2 #license-mit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\\_with\\_restarts\n* lr\\_scheduler\\_warmup\\_steps: 60\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.0.dev0\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.14.1"
] |
reinforcement-learning | transformers |
# TRL Model
This is a [TRL language model](https://github.com/huggingface/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="baek26//tmp/tmps6du5smo/baek26/billsum_5289_bart-billsum")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("baek26//tmp/tmps6du5smo/baek26/billsum_5289_bart-billsum")
model = AutoModelForCausalLMWithValueHead.from_pretrained("baek26//tmp/tmps6du5smo/baek26/billsum_5289_bart-billsum")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
| {"license": "apache-2.0", "tags": ["trl", "ppo", "transformers", "reinforcement-learning"]} | baek26/billsum_5289_bart-billsum | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"trl",
"ppo",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:26:37+00:00 | [] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #trl #ppo #reinforcement-learning #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# TRL Model
This is a TRL language model that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
You can then generate text as follows:
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
| [
"# TRL Model\n\nThis is a TRL language model that has been fine-tuned with reinforcement learning to\n guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.",
"## Usage\n\nTo use this model for inference, first install the TRL library:\n\n\n\nYou can then generate text as follows:\n\n\n\nIf you want to use the model for training or to obtain the outputs from the value head, load the model as follows:"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #trl #ppo #reinforcement-learning #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# TRL Model\n\nThis is a TRL language model that has been fine-tuned with reinforcement learning to\n guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.",
"## Usage\n\nTo use this model for inference, first install the TRL library:\n\n\n\nYou can then generate text as follows:\n\n\n\nIf you want to use the model for training or to obtain the outputs from the value head, load the model as follows:"
] |
question-answering | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [dccuchile/distilbert-base-spanish-uncased](https://huggingface.co/dccuchile/distilbert-base-spanish-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8372
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 250 | 3.3853 |
| 3.5403 | 2.0 | 500 | 2.9360 |
| 3.5403 | 3.0 | 750 | 2.8372 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "dccuchile/distilbert-base-spanish-uncased", "model-index": [{"name": "my_awesome_qa_model", "results": []}]} | Fede-ezeq/my_awesome_qa_model | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:dccuchile/distilbert-base-spanish-uncased",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:26:52+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #question-answering #generated_from_trainer #base_model-dccuchile/distilbert-base-spanish-uncased #endpoints_compatible #region-us
| my\_awesome\_qa\_model
======================
This model is a fine-tuned version of dccuchile/distilbert-base-spanish-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.8372
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #question-answering #generated_from_trainer #base_model-dccuchile/distilbert-base-spanish-uncased #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/GritLM/GritLM-8x7B-KTO
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/GritLM-8x7B-KTO-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q2_K.gguf) | Q2_K | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.IQ3_XS.gguf) | IQ3_XS | 19.5 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.IQ3_S.gguf) | IQ3_S | 20.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q3_K_S.gguf) | Q3_K_S | 20.5 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.IQ3_M.gguf) | IQ3_M | 21.5 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q3_K_M.gguf) | Q3_K_M | 22.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q3_K_L.gguf) | Q3_K_L | 24.3 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.IQ4_XS.gguf) | IQ4_XS | 25.5 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q4_K_S.gguf) | Q4_K_S | 26.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q4_K_M.gguf) | Q4_K_M | 28.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q5_K_S.gguf) | Q5_K_S | 32.3 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q5_K_M.gguf) | Q5_K_M | 33.3 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q6_K.gguf) | Q6_K | 38.5 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/GritLM-8x7B-KTO-GGUF/resolve/main/GritLM-8x7B-KTO.Q8_0.gguf) | Q8_0 | 49.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "library_name": "transformers", "base_model": "GritLM/GritLM-8x7B-KTO", "quantized_by": "mradermacher"} | mradermacher/GritLM-8x7B-KTO-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:GritLM/GritLM-8x7B-KTO",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:27:47+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #en #base_model-GritLM/GritLM-8x7B-KTO #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #en #base_model-GritLM/GritLM-8x7B-KTO #endpoints_compatible #region-us \n"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | perceptorLLM/idefics2-8b-4bit-bf16 | null | [
"transformers",
"safetensors",
"idefics2",
"pretraining",
"arxiv:1910.09700",
"endpoints_compatible",
"4-bit",
"region:us"
] | null | 2024-04-17T22:30:11+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #idefics2 #pretraining #arxiv-1910.09700 #endpoints_compatible #4-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #idefics2 #pretraining #arxiv-1910.09700 #endpoints_compatible #4-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_shp4_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7562
- Rewards/chosen: -8.5308
- Rewards/rejected: -8.4695
- Rewards/accuracies: 0.5200
- Rewards/margins: -0.0613
- Logps/rejected: -331.4397
- Logps/chosen: -314.9189
- Logits/rejected: -1.1613
- Logits/chosen: -1.1692
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0922 | 2.67 | 100 | 1.1410 | -4.1724 | -4.0602 | 0.5600 | -0.1122 | -287.3470 | -271.3348 | -0.9400 | -0.9462 |
| 0.0014 | 5.33 | 200 | 1.6279 | -8.0256 | -7.9377 | 0.5400 | -0.0879 | -326.1222 | -309.8669 | -1.2061 | -1.2156 |
| 0.0001 | 8.0 | 300 | 1.6781 | -7.8271 | -7.7492 | 0.4900 | -0.0780 | -324.2366 | -307.8824 | -1.1931 | -1.2019 |
| 0.0001 | 10.67 | 400 | 1.7244 | -8.2046 | -8.1268 | 0.5100 | -0.0778 | -328.0134 | -311.6574 | -1.1773 | -1.1864 |
| 0.0001 | 13.33 | 500 | 1.7449 | -8.3826 | -8.3126 | 0.5100 | -0.0701 | -329.8707 | -313.4376 | -1.1689 | -1.1774 |
| 0.0001 | 16.0 | 600 | 1.7522 | -8.4707 | -8.4001 | 0.5100 | -0.0706 | -330.7461 | -314.3180 | -1.1649 | -1.1729 |
| 0.0001 | 18.67 | 700 | 1.7553 | -8.5177 | -8.4517 | 0.5200 | -0.0659 | -331.2625 | -314.7882 | -1.1626 | -1.1704 |
| 0.0001 | 21.33 | 800 | 1.7608 | -8.5360 | -8.4723 | 0.5200 | -0.0637 | -331.4679 | -314.9713 | -1.1608 | -1.1692 |
| 0.0001 | 24.0 | 900 | 1.7653 | -8.5361 | -8.4664 | 0.5200 | -0.0697 | -331.4087 | -314.9720 | -1.1617 | -1.1693 |
| 0.0001 | 26.67 | 1000 | 1.7562 | -8.5308 | -8.4695 | 0.5200 | -0.0613 | -331.4397 | -314.9189 | -1.1613 | -1.1692 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "llama2", "library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_shp4_dpo1", "results": []}]} | guoyu-zhang/model_shp4_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"region:us"
] | null | 2024-04-17T22:30:51+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us
| model\_shp4\_dpo1
=================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.7562
* Rewards/chosen: -8.5308
* Rewards/rejected: -8.4695
* Rewards/accuracies: 0.5200
* Rewards/margins: -0.0613
* Logps/rejected: -331.4397
* Logps/chosen: -314.9189
* Logits/rejected: -1.1613
* Logits/chosen: -1.1692
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
reinforcement-learning | ml-agents |
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: MLIsaac/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
| {"library_name": "ml-agents", "tags": ["SnowballTarget", "deep-reinforcement-learning", "reinforcement-learning", "ML-Agents-SnowballTarget"]} | MLIsaac/ppo-SnowballTarget | null | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | null | 2024-04-17T22:30:55+00:00 | [] | [] | TAGS
#ml-agents #tensorboard #onnx #SnowballTarget #deep-reinforcement-learning #reinforcement-learning #ML-Agents-SnowballTarget #region-us
|
# ppo Agent playing SnowballTarget
This is a trained model of a ppo agent playing SnowballTarget
using the Unity ML-Agents Library.
## Usage (with ML-Agents)
The Documentation: URL
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your
browser: URL
- A *longer tutorial* to understand how works ML-Agents:
URL
### Resume the training
### Watch your Agent play
You can watch your agent playing directly in your browser
1. If the environment is part of ML-Agents official environments, go to URL
2. Step 1: Find your model_id: MLIsaac/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play
| [
"# ppo Agent playing SnowballTarget\n This is a trained model of a ppo agent playing SnowballTarget\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: MLIsaac/ppo-SnowballTarget\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] | [
"TAGS\n#ml-agents #tensorboard #onnx #SnowballTarget #deep-reinforcement-learning #reinforcement-learning #ML-Agents-SnowballTarget #region-us \n",
"# ppo Agent playing SnowballTarget\n This is a trained model of a ppo agent playing SnowballTarget\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: MLIsaac/ppo-SnowballTarget\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] |
null | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RNAMamba-14M-MLM
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4e-07
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "RNAMamba-14M-MLM", "results": []}]} | afg1/RNAMamba-14M-MLM | null | [
"transformers",
"safetensors",
"mamba",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:32:12+00:00 | [] | [] | TAGS
#transformers #safetensors #mamba #generated_from_trainer #endpoints_compatible #region-us
|
# RNAMamba-14M-MLM
This model is a fine-tuned version of [](URL on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4e-07
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# RNAMamba-14M-MLM\n\nThis model is a fine-tuned version of [](URL on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 32\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4e-07",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.2+cu118\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mamba #generated_from_trainer #endpoints_compatible #region-us \n",
"# RNAMamba-14M-MLM\n\nThis model is a fine-tuned version of [](URL on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 32\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4e-07",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.2+cu118\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-generation | transformers | # nbeerbower/Flammen-Bophades-7B AWQ
- Model Creator [nbeerbower](https://huggingface.co/nbeerbower/)
- Original Model [Flammen-Bophades-7B](https://huggingface.co/nbeerbower/Flammen-Bophades-7B)
## Model Summary
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
The following models were included in the merge:
* [nbeerbower/slerp-bophades-truthy-math-mistral-7B](https://huggingface.co/nbeerbower/slerp-bophades-truthy-math-mistral-7B)
* [nbeerbower/flammen15-gutenberg-DPO-v1-7B](https://huggingface.co/nbeerbower/flammen15-gutenberg-DPO-v1-7B)
| {"license": "apache-2.0", "library_name": "transformers", "tags": ["4-bit", "AWQ", "text-generation", "autotrain_compatible", "endpoints_compatible", "mergekit", "merge"], "base_model": ["nbeerbower/slerp-bophades-truthy-math-mistral-7B", "nbeerbower/flammen15-gutenberg-DPO-v1-7B"], "pipeline_tag": "text-generation", "inference": false, "quantized_by": "Suparious"} | solidrust/Flammen-Bophades-7B-AWQ | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"4-bit",
"AWQ",
"autotrain_compatible",
"endpoints_compatible",
"mergekit",
"merge",
"base_model:nbeerbower/slerp-bophades-truthy-math-mistral-7B",
"base_model:nbeerbower/flammen15-gutenberg-DPO-v1-7B",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T22:32:39+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #4-bit #AWQ #autotrain_compatible #endpoints_compatible #mergekit #merge #base_model-nbeerbower/slerp-bophades-truthy-math-mistral-7B #base_model-nbeerbower/flammen15-gutenberg-DPO-v1-7B #license-apache-2.0 #text-generation-inference #region-us
| # nbeerbower/Flammen-Bophades-7B AWQ
- Model Creator nbeerbower
- Original Model Flammen-Bophades-7B
## Model Summary
This is a merge of pre-trained language models created using mergekit.
The following models were included in the merge:
* nbeerbower/slerp-bophades-truthy-math-mistral-7B
* nbeerbower/flammen15-gutenberg-DPO-v1-7B
| [
"# nbeerbower/Flammen-Bophades-7B AWQ\n\n- Model Creator nbeerbower\n- Original Model Flammen-Bophades-7B",
"## Model Summary\n\nThis is a merge of pre-trained language models created using mergekit.\n\nThe following models were included in the merge:\n* nbeerbower/slerp-bophades-truthy-math-mistral-7B\n* nbeerbower/flammen15-gutenberg-DPO-v1-7B"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #4-bit #AWQ #autotrain_compatible #endpoints_compatible #mergekit #merge #base_model-nbeerbower/slerp-bophades-truthy-math-mistral-7B #base_model-nbeerbower/flammen15-gutenberg-DPO-v1-7B #license-apache-2.0 #text-generation-inference #region-us \n",
"# nbeerbower/Flammen-Bophades-7B AWQ\n\n- Model Creator nbeerbower\n- Original Model Flammen-Bophades-7B",
"## Model Summary\n\nThis is a merge of pre-trained language models created using mergekit.\n\nThe following models were included in the merge:\n* nbeerbower/slerp-bophades-truthy-math-mistral-7B\n* nbeerbower/flammen15-gutenberg-DPO-v1-7B"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | tdooms/TinyStories-12-512 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:38:38+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | HikariLight/Mistral-SUFT-6-5e-05-1-all | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:41:54+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-chat-hf_medical_bios_5000_2ep
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"license": "llama2", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "Llama-2-7b-chat-hf_medical_bios_5000_2ep", "results": []}]} | mohsenfayyaz/Llama-2-7b-chat-hf_medical_bios_5000_2ep | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T22:42:47+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Llama-2-7b-chat-hf_medical_bios_5000_2ep
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| [
"# Llama-2-7b-chat-hf_medical_bios_5000_2ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Llama-2-7b-chat-hf_medical_bios_5000_2ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/ontocord/Felix-8B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q2_K.gguf) | Q2_K | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.IQ3_XS.gguf) | IQ3_XS | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q3_K_S.gguf) | Q3_K_S | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.IQ3_S.gguf) | IQ3_S | 4.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.IQ3_M.gguf) | IQ3_M | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q3_K_M.gguf) | Q3_K_M | 4.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q3_K_L.gguf) | Q3_K_L | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.IQ4_XS.gguf) | IQ4_XS | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q4_K_S.gguf) | Q4_K_S | 5.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q4_K_M.gguf) | Q4_K_M | 5.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q5_K_S.gguf) | Q5_K_S | 6.3 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q5_K_M.gguf) | Q5_K_M | 6.5 | |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q6_K.gguf) | Q6_K | 7.5 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Felix-8B-GGUF/resolve/main/Felix-8B.Q8_0.gguf) | Q8_0 | 9.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "base_model": "ontocord/Felix-8B", "quantized_by": "mradermacher"} | mradermacher/Felix-8B-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:ontocord/Felix-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:49:41+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #en #base_model-ontocord/Felix-8B #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #en #base_model-ontocord/Felix-8B #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | badrmarani/nico95_resnet_erm_metric_loss | null | [
"transformers",
"safetensors",
"resnet50",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:51:26+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #resnet50 #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #resnet50 #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | ekle-me/gemma-Code-Instruct-Finetune-test-102 | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T22:53:12+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# Uploaded model
- **Developed by:** reallad
- **License:** apache-2.0
- **Finetuned from model :** chargoddard/Yi-6B-Llama
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "sft"], "base_model": "chargoddard/Yi-6B-Llama"} | reallad/yi-6b-for-translation | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:chargoddard/Yi-6B-Llama",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T22:55:24+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-chargoddard/Yi-6B-Llama #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: reallad
- License: apache-2.0
- Finetuned from model : chargoddard/Yi-6B-Llama
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: reallad\n- License: apache-2.0\n- Finetuned from model : chargoddard/Yi-6B-Llama\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-chargoddard/Yi-6B-Llama #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: reallad\n- License: apache-2.0\n- Finetuned from model : chargoddard/Yi-6B-Llama\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama-7b-chat-10000-50-50-L
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2200
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4400
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2 | {"license": "llama2", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "llama-7b-chat-10000-50-50-L", "results": []}]} | Niyantha23M/llama-7b-chat-10000-50-50-L | null | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"region:us"
] | null | 2024-04-17T23:00:10+00:00 | [] | [] | TAGS
#peft #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us
|
# llama-7b-chat-10000-50-50-L
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2200
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4400
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2 | [
"# llama-7b-chat-10000-50-50-L\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2200\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 4400\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- PEFT 0.8.2\n- Transformers 4.37.2\n- Pytorch 2.2.0\n- Datasets 2.17.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #sft #generated_from_trainer #dataset-generator #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us \n",
"# llama-7b-chat-10000-50-50-L\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on the generator dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2200\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 4400\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: constant\n- lr_scheduler_warmup_ratio: 0.03\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- PEFT 0.8.2\n- Transformers 4.37.2\n- Pytorch 2.2.0\n- Datasets 2.17.0\n- Tokenizers 0.15.2"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | HikariLight/Mistral-UFT-2-5e-05-1-em | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:03:05+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/Jakolo121/Sappho_V0.0.4
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Sappho_V0.0.4-GGUF/resolve/main/Sappho_V0.0.4.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "library_name": "transformers", "tags": ["merge", "mergekit", "lazymergekit", "Jakolo121/Sappho_V0.0.3", "VAGOsolutions/SauerkrautLM-7b-HerO"], "base_model": "Jakolo121/Sappho_V0.0.4", "quantized_by": "mradermacher"} | mradermacher/Sappho_V0.0.4-GGUF | null | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"Jakolo121/Sappho_V0.0.3",
"VAGOsolutions/SauerkrautLM-7b-HerO",
"en",
"base_model:Jakolo121/Sappho_V0.0.4",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:03:08+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #merge #mergekit #lazymergekit #Jakolo121/Sappho_V0.0.3 #VAGOsolutions/SauerkrautLM-7b-HerO #en #base_model-Jakolo121/Sappho_V0.0.4 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #merge #mergekit #lazymergekit #Jakolo121/Sappho_V0.0.3 #VAGOsolutions/SauerkrautLM-7b-HerO #en #base_model-Jakolo121/Sappho_V0.0.4 #endpoints_compatible #region-us \n"
] |
null | null |
# T3qExperiment27pastiche-7B
T3qExperiment27pastiche-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [automerger/Experiment27Pastiche-7B](https://huggingface.co/automerger/Experiment27Pastiche-7B)
## 🧩 Configuration
```yaml
models:
- model: chihoonlee10/T3Q-Mistral-Orca-Math-DPO
# No parameters necessary for base model
- model: automerger/Experiment27Pastiche-7B
parameters:
density: 0.53
weight: 0.6
merge_method: dare_ties
base_model: chihoonlee10/T3Q-Mistral-Orca-Math-DPO
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/T3qExperiment27pastiche-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "automerger"], "base_model": ["automerger/Experiment27Pastiche-7B"]} | automerger/T3qExperiment27pastiche-7B | null | [
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:automerger/Experiment27Pastiche-7B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:05:17+00:00 | [] | [] | TAGS
#merge #mergekit #lazymergekit #automerger #base_model-automerger/Experiment27Pastiche-7B #license-apache-2.0 #region-us
|
# T3qExperiment27pastiche-7B
T3qExperiment27pastiche-7B is an automated merge created by Maxime Labonne using the following configuration.
* automerger/Experiment27Pastiche-7B
## Configuration
## Usage
| [
"# T3qExperiment27pastiche-7B\n\nT3qExperiment27pastiche-7B is an automated merge created by Maxime Labonne using the following configuration.\n* automerger/Experiment27Pastiche-7B",
"## Configuration",
"## Usage"
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #base_model-automerger/Experiment27Pastiche-7B #license-apache-2.0 #region-us \n",
"# T3qExperiment27pastiche-7B\n\nT3qExperiment27pastiche-7B is an automated merge created by Maxime Labonne using the following configuration.\n* automerger/Experiment27Pastiche-7B",
"## Configuration",
"## Usage"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | Grayx/sad_pepe_36 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:08:44+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-to-image | diffusers | ### maximusshayanuslogus Dreambooth model trained by hujesr with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| {"license": "creativeml-openrail-m", "tags": ["text-to-image", "stable-diffusion"]} | hujesr/maximusshayanuslogus | null | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | 2024-04-17T23:10:11+00:00 | [] | [] | TAGS
#diffusers #text-to-image #stable-diffusion #license-creativeml-openrail-m #endpoints_compatible #has_space #diffusers-StableDiffusionPipeline #region-us
| ### maximusshayanuslogus Dreambooth model trained by hujesr with TheLastBen's fast-DreamBooth notebook
Test the concept via A1111 Colab fast-Colab-A1111
Sample pictures of this concept:
| [
"### maximusshayanuslogus Dreambooth model trained by hujesr with TheLastBen's fast-DreamBooth notebook\n\n\nTest the concept via A1111 Colab fast-Colab-A1111\n\nSample pictures of this concept:"
] | [
"TAGS\n#diffusers #text-to-image #stable-diffusion #license-creativeml-openrail-m #endpoints_compatible #has_space #diffusers-StableDiffusionPipeline #region-us \n",
"### maximusshayanuslogus Dreambooth model trained by hujesr with TheLastBen's fast-DreamBooth notebook\n\n\nTest the concept via A1111 Colab fast-Colab-A1111\n\nSample pictures of this concept:"
] |
reinforcement-learning | ml-agents |
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: MLIsaac/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
| {"library_name": "ml-agents", "tags": ["Pyramids", "deep-reinforcement-learning", "reinforcement-learning", "ML-Agents-Pyramids"]} | MLIsaac/ppo-PyramidsRND | null | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | null | 2024-04-17T23:13:24+00:00 | [] | [] | TAGS
#ml-agents #tensorboard #onnx #Pyramids #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Pyramids #region-us
|
# ppo Agent playing Pyramids
This is a trained model of a ppo agent playing Pyramids
using the Unity ML-Agents Library.
## Usage (with ML-Agents)
The Documentation: URL
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your
browser: URL
- A *longer tutorial* to understand how works ML-Agents:
URL
### Resume the training
### Watch your Agent play
You can watch your agent playing directly in your browser
1. If the environment is part of ML-Agents official environments, go to URL
2. Step 1: Find your model_id: MLIsaac/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play
| [
"# ppo Agent playing Pyramids\n This is a trained model of a ppo agent playing Pyramids\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: MLIsaac/ppo-PyramidsRND\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] | [
"TAGS\n#ml-agents #tensorboard #onnx #Pyramids #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Pyramids #region-us \n",
"# ppo Agent playing Pyramids\n This is a trained model of a ppo agent playing Pyramids\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: MLIsaac/ppo-PyramidsRND\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] |
null | null |
# WizardLM-2-8x22B GGUF quants based on reupload at alpindale/WizardLM-2-8x22B
## GGUFs created with an importance matrix (details below)
This is based on a reupload by an alternate source as microsoft deleted the model shortly after release, I will validate checksums after it is released again, to see if MS did any changes.
Source Model: [alpindale/WizardLM-2-8x22B](https://huggingface.co/lucyknada/microsoft_WizardLM-2-7B)
Quantized with [llama.cpp](https://github.com/ggerganov/llama.cpp) commit [5dc9dd7152dedc6046b646855585bd070c91e8c8](https://github.com/ggerganov/llama.cpp/commit/5dc9dd7152dedc6046b646855585bd070c91e8c8) (master from 2024-04-09)
Imatrix was generated from the f16 gguf via this command:
./imatrix -c 512 -m $out_path/$base_quant_name -f $llama_cpp_path/groups_merged.txt -o $out_path/imat-f16-gmerged.dat
Using the dataset from [here](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384) | {"license": "apache-2.0", "tags": ["wizardlm", "microsoft", "instruct", "finetune", "gguf", "importance matrix", "imatrix"], "base_model": "alpindale/WizardLM-2-8x22B", "model-index": [{"name": "Not-WizardLM-2-8x22B-iMat-GGUF", "results": []}]} | qwp4w3hyb/Not-WizardLM-2-8x22B-iMat-GGUF | null | [
"gguf",
"wizardlm",
"microsoft",
"instruct",
"finetune",
"importance matrix",
"imatrix",
"base_model:alpindale/WizardLM-2-8x22B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:13:53+00:00 | [] | [] | TAGS
#gguf #wizardlm #microsoft #instruct #finetune #importance matrix #imatrix #base_model-alpindale/WizardLM-2-8x22B #license-apache-2.0 #region-us
|
# WizardLM-2-8x22B GGUF quants based on reupload at alpindale/WizardLM-2-8x22B
## GGUFs created with an importance matrix (details below)
This is based on a reupload by an alternate source as microsoft deleted the model shortly after release, I will validate checksums after it is released again, to see if MS did any changes.
Source Model: alpindale/WizardLM-2-8x22B
Quantized with URL commit 5dc9dd7152dedc6046b646855585bd070c91e8c8 (master from 2024-04-09)
Imatrix was generated from the f16 gguf via this command:
./imatrix -c 512 -m $out_path/$base_quant_name -f $llama_cpp_path/groups_merged.txt -o $out_path/URL
Using the dataset from here | [
"# WizardLM-2-8x22B GGUF quants based on reupload at alpindale/WizardLM-2-8x22B",
"## GGUFs created with an importance matrix (details below)\n\nThis is based on a reupload by an alternate source as microsoft deleted the model shortly after release, I will validate checksums after it is released again, to see if MS did any changes.\n\nSource Model: alpindale/WizardLM-2-8x22B\n\nQuantized with URL commit 5dc9dd7152dedc6046b646855585bd070c91e8c8 (master from 2024-04-09)\n\nImatrix was generated from the f16 gguf via this command:\n\n./imatrix -c 512 -m $out_path/$base_quant_name -f $llama_cpp_path/groups_merged.txt -o $out_path/URL\n\nUsing the dataset from here"
] | [
"TAGS\n#gguf #wizardlm #microsoft #instruct #finetune #importance matrix #imatrix #base_model-alpindale/WizardLM-2-8x22B #license-apache-2.0 #region-us \n",
"# WizardLM-2-8x22B GGUF quants based on reupload at alpindale/WizardLM-2-8x22B",
"## GGUFs created with an importance matrix (details below)\n\nThis is based on a reupload by an alternate source as microsoft deleted the model shortly after release, I will validate checksums after it is released again, to see if MS did any changes.\n\nSource Model: alpindale/WizardLM-2-8x22B\n\nQuantized with URL commit 5dc9dd7152dedc6046b646855585bd070c91e8c8 (master from 2024-04-09)\n\nImatrix was generated from the f16 gguf via this command:\n\n./imatrix -c 512 -m $out_path/$base_quant_name -f $llama_cpp_path/groups_merged.txt -o $out_path/URL\n\nUsing the dataset from here"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-chat-hf_esnli_5000_1ep
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"license": "llama2", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "Llama-2-7b-chat-hf_esnli_5000_1ep", "results": []}]} | mohsenfayyaz/Llama-2-7b-chat-hf_esnli_5000_1ep | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:17:37+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Llama-2-7b-chat-hf_esnli_5000_1ep
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| [
"# Llama-2-7b-chat-hf_esnli_5000_1ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Llama-2-7b-chat-hf_esnli_5000_1ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "-171.83 +/- 48.60", "name": "mean_reward", "verified": false}]}]}]} | Bigmoumou/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-17T23:20:43+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# relevance-classification-v1
This model is a fine-tuned version of [allenai/longformer-base-4096](https://huggingface.co/allenai/longformer-base-4096) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2284
- Accuracy: 0.6552
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| No log | 1.0 | 338 | 0.6800 | 0.5448 |
| 0.7174 | 2.0 | 676 | 1.4472 | 0.6276 |
| 0.865 | 3.0 | 1014 | 1.2742 | 0.6621 |
| 0.865 | 4.0 | 1352 | 1.4262 | 0.6621 |
| 0.5753 | 5.0 | 1690 | 2.1018 | 0.6414 |
| 0.335 | 6.0 | 2028 | 2.4029 | 0.6345 |
| 0.335 | 7.0 | 2366 | 1.9533 | 0.6483 |
| 0.2503 | 8.0 | 2704 | 2.4815 | 0.6138 |
| 0.1785 | 9.0 | 3042 | 2.5177 | 0.6897 |
| 0.1785 | 10.0 | 3380 | 2.5533 | 0.6552 |
| 0.1067 | 11.0 | 3718 | 2.9023 | 0.6552 |
| 0.0957 | 12.0 | 4056 | 3.2890 | 0.6345 |
| 0.0957 | 13.0 | 4394 | 3.5851 | 0.6138 |
| 0.0166 | 14.0 | 4732 | 3.6766 | 0.5931 |
| 0.1395 | 15.0 | 5070 | 3.6210 | 0.6069 |
| 0.1395 | 16.0 | 5408 | 3.2261 | 0.6414 |
| 0.1005 | 17.0 | 5746 | 3.2913 | 0.6414 |
| 0.0793 | 18.0 | 6084 | 3.6091 | 0.6207 |
| 0.0793 | 19.0 | 6422 | 2.4907 | 0.6897 |
| 0.13 | 20.0 | 6760 | 3.0017 | 0.6552 |
| 0.0467 | 21.0 | 7098 | 3.1797 | 0.6759 |
| 0.0467 | 22.0 | 7436 | 3.4537 | 0.6414 |
| 0.0875 | 23.0 | 7774 | 3.1266 | 0.6414 |
| 0.0677 | 24.0 | 8112 | 3.4799 | 0.6759 |
| 0.0677 | 25.0 | 8450 | 3.3836 | 0.6690 |
| 0.0892 | 26.0 | 8788 | 3.1044 | 0.6483 |
| 0.1089 | 27.0 | 9126 | 3.5136 | 0.6552 |
| 0.1089 | 28.0 | 9464 | 3.3848 | 0.6483 |
| 0.0586 | 29.0 | 9802 | 3.5435 | 0.6621 |
| 0.043 | 30.0 | 10140 | 3.6754 | 0.6414 |
| 0.043 | 31.0 | 10478 | 3.8983 | 0.6483 |
| 0.0026 | 32.0 | 10816 | 3.8528 | 0.6414 |
| 0.0195 | 33.0 | 11154 | 3.9876 | 0.6483 |
| 0.0195 | 34.0 | 11492 | 2.9999 | 0.6414 |
| 0.0781 | 35.0 | 11830 | 3.7963 | 0.6207 |
| 0.0552 | 36.0 | 12168 | 4.2694 | 0.6138 |
| 0.0 | 37.0 | 12506 | 4.3729 | 0.6138 |
| 0.0 | 38.0 | 12844 | 4.4702 | 0.6138 |
| 0.0 | 39.0 | 13182 | 4.5190 | 0.6138 |
| 0.0125 | 40.0 | 13520 | 4.2951 | 0.6483 |
| 0.0125 | 41.0 | 13858 | 3.9059 | 0.6276 |
| 0.0709 | 42.0 | 14196 | 3.4919 | 0.6621 |
| 0.0362 | 43.0 | 14534 | 4.0863 | 0.6276 |
| 0.0362 | 44.0 | 14872 | 3.9934 | 0.6276 |
| 0.0311 | 45.0 | 15210 | 4.3174 | 0.6207 |
| 0.0163 | 46.0 | 15548 | 4.3117 | 0.6138 |
| 0.0163 | 47.0 | 15886 | 4.2067 | 0.6414 |
| 0.0235 | 48.0 | 16224 | 3.2403 | 0.6483 |
| 0.0512 | 49.0 | 16562 | 3.6099 | 0.6621 |
| 0.0512 | 50.0 | 16900 | 3.9438 | 0.6345 |
| 0.0002 | 51.0 | 17238 | 4.0551 | 0.6345 |
| 0.0 | 52.0 | 17576 | 4.1505 | 0.6345 |
| 0.0 | 53.0 | 17914 | 4.2107 | 0.6345 |
| 0.0 | 54.0 | 18252 | 4.1841 | 0.5931 |
| 0.0493 | 55.0 | 18590 | 4.4524 | 0.6207 |
| 0.0493 | 56.0 | 18928 | 4.3673 | 0.6276 |
| 0.0172 | 57.0 | 19266 | 4.4991 | 0.6345 |
| 0.0002 | 58.0 | 19604 | 4.7284 | 0.6138 |
| 0.0002 | 59.0 | 19942 | 4.7207 | 0.6276 |
| 0.0004 | 60.0 | 20280 | 4.8372 | 0.6276 |
| 0.0132 | 61.0 | 20618 | 5.0463 | 0.6138 |
| 0.0132 | 62.0 | 20956 | 4.0695 | 0.6483 |
| 0.0294 | 63.0 | 21294 | 4.4791 | 0.6276 |
| 0.0234 | 64.0 | 21632 | 4.0409 | 0.6759 |
| 0.0234 | 65.0 | 21970 | 4.3323 | 0.6276 |
| 0.0311 | 66.0 | 22308 | 4.5133 | 0.6345 |
| 0.0069 | 67.0 | 22646 | 4.1708 | 0.6690 |
| 0.0069 | 68.0 | 22984 | 4.7436 | 0.6276 |
| 0.0001 | 69.0 | 23322 | 4.8199 | 0.6276 |
| 0.0011 | 70.0 | 23660 | 5.2157 | 0.5862 |
| 0.0011 | 71.0 | 23998 | 5.0111 | 0.6069 |
| 0.0279 | 72.0 | 24336 | 4.7120 | 0.6621 |
| 0.0 | 73.0 | 24674 | 4.8631 | 0.6207 |
| 0.0117 | 74.0 | 25012 | 4.9149 | 0.6276 |
| 0.0117 | 75.0 | 25350 | 4.9518 | 0.6276 |
| 0.0 | 76.0 | 25688 | 4.9781 | 0.6276 |
| 0.0 | 77.0 | 26026 | 5.0057 | 0.6345 |
| 0.0 | 78.0 | 26364 | 5.0409 | 0.6345 |
| 0.0 | 79.0 | 26702 | 5.0909 | 0.6345 |
| 0.0119 | 80.0 | 27040 | 4.4556 | 0.6552 |
| 0.0119 | 81.0 | 27378 | 4.5697 | 0.6621 |
| 0.0 | 82.0 | 27716 | 4.8371 | 0.6483 |
| 0.0 | 83.0 | 28054 | 4.8793 | 0.6483 |
| 0.0 | 84.0 | 28392 | 4.9278 | 0.6414 |
| 0.0 | 85.0 | 28730 | 4.9605 | 0.6414 |
| 0.0 | 86.0 | 29068 | 5.2864 | 0.6207 |
| 0.0 | 87.0 | 29406 | 5.3216 | 0.6207 |
| 0.0 | 88.0 | 29744 | 5.3452 | 0.6207 |
| 0.0 | 89.0 | 30082 | 5.5673 | 0.6069 |
| 0.0 | 90.0 | 30420 | 5.3842 | 0.6276 |
| 0.0 | 91.0 | 30758 | 5.3997 | 0.6276 |
| 0.0 | 92.0 | 31096 | 5.4139 | 0.6276 |
| 0.0 | 93.0 | 31434 | 5.4287 | 0.6276 |
| 0.0 | 94.0 | 31772 | 5.4433 | 0.6345 |
| 0.0 | 95.0 | 32110 | 5.1979 | 0.6552 |
| 0.0 | 96.0 | 32448 | 5.2034 | 0.6552 |
| 0.0001 | 97.0 | 32786 | 5.2129 | 0.6552 |
| 0.0 | 98.0 | 33124 | 5.2220 | 0.6552 |
| 0.0 | 99.0 | 33462 | 5.2267 | 0.6552 |
| 0.0 | 100.0 | 33800 | 5.2284 | 0.6552 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.2.2+cu121
- Datasets 2.16.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "allenai/longformer-base-4096", "model-index": [{"name": "relevance-classification-v1", "results": []}]} | satyanshu404/relevance-classification-v1 | null | [
"transformers",
"safetensors",
"longformer",
"text-classification",
"generated_from_trainer",
"base_model:allenai/longformer-base-4096",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:22:17+00:00 | [] | [] | TAGS
#transformers #safetensors #longformer #text-classification #generated_from_trainer #base_model-allenai/longformer-base-4096 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| relevance-classification-v1
===========================
This model is a fine-tuned version of allenai/longformer-base-4096 on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 5.2284
* Accuracy: 0.6552
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 100
### Training results
### Framework versions
* Transformers 4.36.2
* Pytorch 2.2.2+cu121
* Datasets 2.16.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.2\n* Pytorch 2.2.2+cu121\n* Datasets 2.16.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #longformer #text-classification #generated_from_trainer #base_model-allenai/longformer-base-4096 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 100",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.36.2\n* Pytorch 2.2.2+cu121\n* Datasets 2.16.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
adapter: qlora
base_model: mistralai/Mixtral-8x22B-Instruct-v0.1
bf16: true
chat_template: inst
dataset_prepared_path: last_run_prepared
datasets:
- conversation: mistral
path: ./data/with_function_response/original_clean/function_used_training.jsonl
type: sharegpt
- conversation: mistral
path: ./data/with_function_response/original_clean/function_not_used_training.jsonl
type: sharegpt
- conversation: mistral
path: ./data/with_function_response/parallel_call/parallel_data_training.jsonl
type: sharegpt
debug: null
# eval_max_new_tokens: 256
# eval_steps: 0.2
# eval_table_size: null
flash_attention: true
fp16: false
gradient_accumulation_steps: 4
gradient_checkpointing: true
group_by_length: false
hub_model_id: liuylhf/parallel-call-original-4-epoch-mixtral-8x22b-instruct
learning_rate: 0.0002
load_in_4bit: true
load_in_8bit: false
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_model_dir: null
lora_r: 32
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
lr_scheduler: cosine
micro_batch_size: 2
model_config:
output_router_logits: true
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: paged_adamw_8bit
output_dir: model
pad_to_sequence_len: true
sample_packing: true
save_steps: 0.125
sequence_len: 4096
strict: false
tf32: false
tokenizer_type: LlamaTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0
wandb_log_model: end
wandb_name: more-tools
wandb_project: function-call
warmup_steps: 10
weight_decay: 0.0
fsdp:
- full_shard
- auto_wrap
fsdp_config:
fsdp_limit_all_gathers: true
fsdp_sync_module_states: true
fsdp_offload_params: true
fsdp_use_orig_params: false
fsdp_cpu_ram_efficient_loading: true
fsdp_transformer_layer_cls_to_wrap: MixtralSparseMoeBlock
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
```
</details><br>
# parallel-call-original-4-epoch-mixtral-8x22b-instruct
This model is a fine-tuned version of [mistralai/Mixtral-8x22B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0 | {"license": "apache-2.0", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "mistralai/Mixtral-8x22B-Instruct-v0.1", "model-index": [{"name": "parallel-call-original-4-epoch-mixtral-8x22b-instruct", "results": []}]} | liuylhf/parallel-call-original-4-epoch-mixtral-8x22b-instruct | null | [
"peft",
"safetensors",
"mixtral",
"generated_from_trainer",
"base_model:mistralai/Mixtral-8x22B-Instruct-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:24:43+00:00 | [] | [] | TAGS
#peft #safetensors #mixtral #generated_from_trainer #base_model-mistralai/Mixtral-8x22B-Instruct-v0.1 #license-apache-2.0 #region-us
|
<img src="URL alt="Built with Axolotl" width="200" height="32"/>
<details><summary>See axolotl config</summary>
axolotl version: '0.4.0'
</details><br>
# parallel-call-original-4-epoch-mixtral-8x22b-instruct
This model is a fine-tuned version of mistralai/Mixtral-8x22B-Instruct-v0.1 on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0 | [
"# parallel-call-original-4-epoch-mixtral-8x22b-instruct\n\nThis model is a fine-tuned version of mistralai/Mixtral-8x22B-Instruct-v0.1 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2\n- eval_batch_size: 2\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 4\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 32\n- total_eval_batch_size: 8\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_steps: 10\n- num_epochs: 1",
"### Framework versions\n\n- PEFT 0.9.0\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.0"
] | [
"TAGS\n#peft #safetensors #mixtral #generated_from_trainer #base_model-mistralai/Mixtral-8x22B-Instruct-v0.1 #license-apache-2.0 #region-us \n",
"# parallel-call-original-4-epoch-mixtral-8x22b-instruct\n\nThis model is a fine-tuned version of mistralai/Mixtral-8x22B-Instruct-v0.1 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 2\n- eval_batch_size: 2\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 4\n- gradient_accumulation_steps: 4\n- total_train_batch_size: 32\n- total_eval_batch_size: 8\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_steps: 10\n- num_epochs: 1",
"### Framework versions\n\n- PEFT 0.9.0\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.0"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | abhayesian/BobzillaV26 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:27:41+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3277
- Accuracy: 0.8733
- F1: 0.8758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "test-model", "results": []}]} | ghantaharsha/test-model | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:33:18+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# test-model
This model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3277
- Accuracy: 0.8733
- F1: 0.8758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# test-model\n\nThis model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3277\n- Accuracy: 0.8733\n- F1: 0.8758",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# test-model\n\nThis model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3277\n- Accuracy: 0.8733\n- F1: 0.8758",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.1+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
feature-extraction | transformers |
# Malaysian Mistral 64M on MLM task using 512 context length
Replicating https://github.com/McGill-NLP/llm2vec using https://huggingface.co/mesolitica/malaysian-mistral-64M-4096, done by https://github.com/aisyahrzk https://twitter.com/aisyahhhrzk
Source code at https://github.com/mesolitica/malaya/tree/master/session/llm2vec
WandB, https://wandb.ai/aisyahrazak/mistral-64M-mlm?nw=nwuseraisyahrazak | {"language": ["ms"], "library_name": "transformers"} | mesolitica/malaysian-mistral-64M-MLM-512 | null | [
"transformers",
"safetensors",
"mistral",
"feature-extraction",
"custom_code",
"ms",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:37:12+00:00 | [] | [
"ms"
] | TAGS
#transformers #safetensors #mistral #feature-extraction #custom_code #ms #text-generation-inference #region-us
|
# Malaysian Mistral 64M on MLM task using 512 context length
Replicating URL using URL done by URL URL
Source code at URL
WandB, URL | [
"# Malaysian Mistral 64M on MLM task using 512 context length\n\nReplicating URL using URL done by URL URL\n\nSource code at URL\n\nWandB, URL"
] | [
"TAGS\n#transformers #safetensors #mistral #feature-extraction #custom_code #ms #text-generation-inference #region-us \n",
"# Malaysian Mistral 64M on MLM task using 512 context length\n\nReplicating URL using URL done by URL URL\n\nSource code at URL\n\nWandB, URL"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):
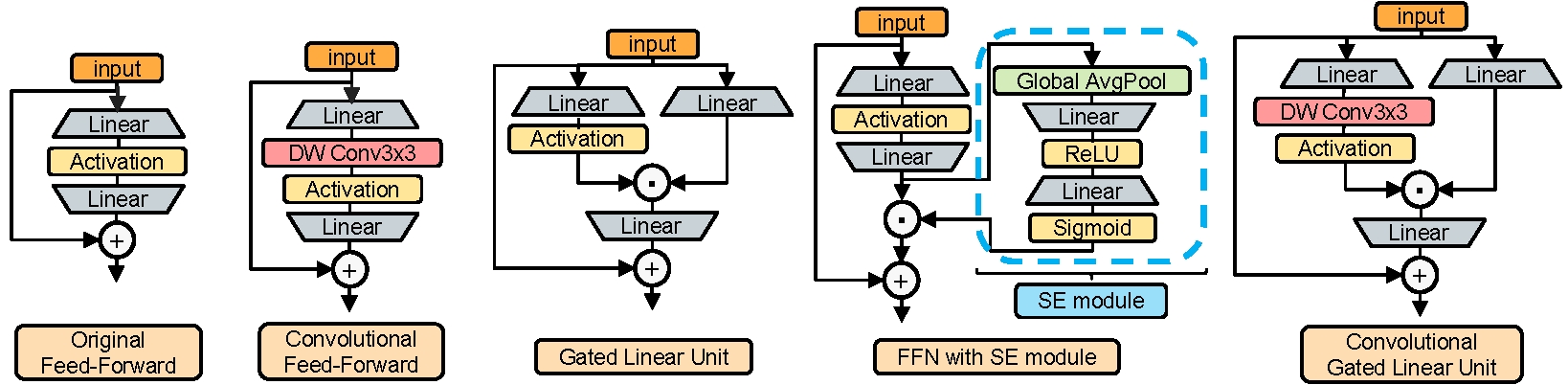
## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:
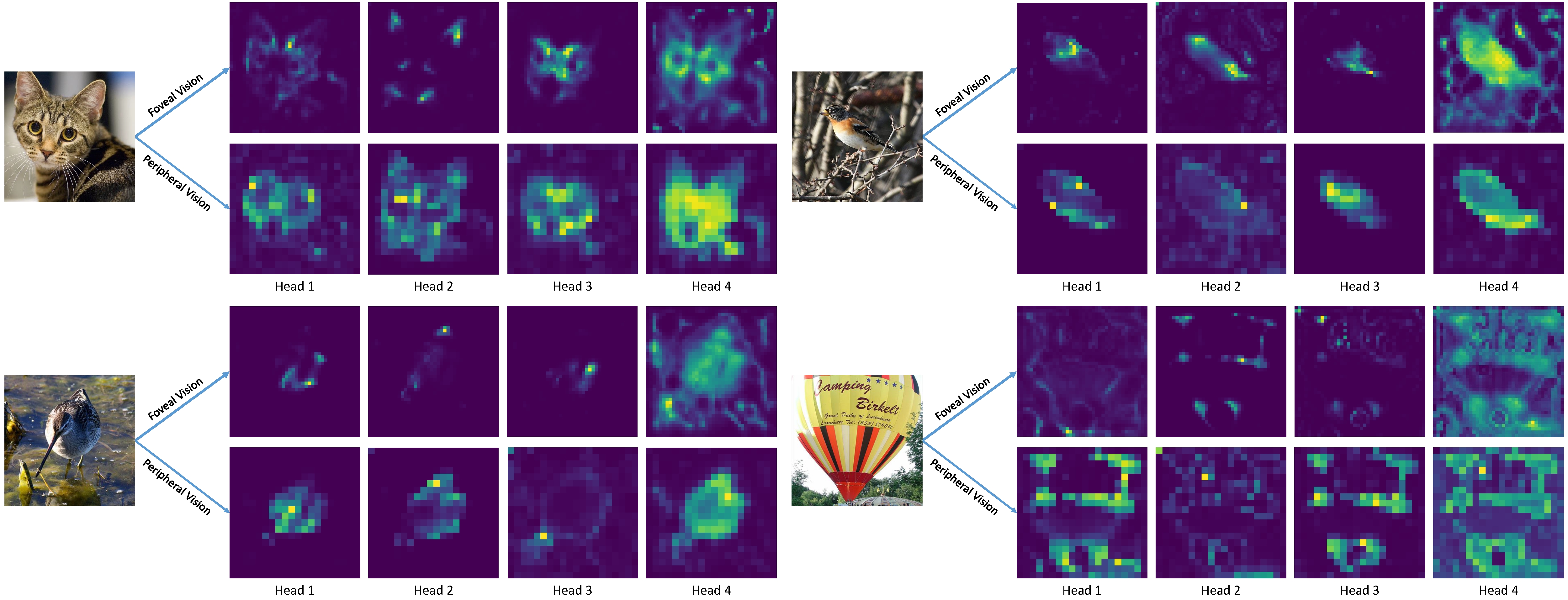
## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/maskrcnn-transnext-tiny-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:39:42+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/maskrcnn-transnext-small-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:46:29+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-generation | transformers |
# WizardLM-2-4x7B-MoE-exl2-5_0bpw
This is a quantized version of [WizardLM-2-4x7B-MoE](https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE) an experimental MoE model made with [Mergekit](https://github.com/arcee-ai/mergekit). Quantization was done using version 0.0.18 of [ExLlamaV2](https://github.com/turboderp/exllamav2).
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
For more information see the [original repository](https://huggingface.co/Skylaude/WizardLM-2-4x7B-MoE).
| {"license": "apache-2.0", "tags": ["MoE", "merge", "mergekit", "Mistral", "Microsoft/WizardLM-2-7B"]} | Skylaude/WizardLM-2-4x7B-MoE-exl2-5_0bpw | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"MoE",
"merge",
"mergekit",
"Mistral",
"Microsoft/WizardLM-2-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"5-bit",
"region:us"
] | null | 2024-04-17T23:47:09+00:00 | [] | [] | TAGS
#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us
|
# WizardLM-2-4x7B-MoE-exl2-5_0bpw
This is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2.
Please be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.
For more information see the original repository.
| [
"# WizardLM-2-4x7B-MoE-exl2-5_0bpw\n\nThis is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.\n\nFor more information see the original repository."
] | [
"TAGS\n#transformers #safetensors #mixtral #text-generation #MoE #merge #mergekit #Mistral #Microsoft/WizardLM-2-7B #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us \n",
"# WizardLM-2-4x7B-MoE-exl2-5_0bpw\n\nThis is a quantized version of WizardLM-2-4x7B-MoE an experimental MoE model made with Mergekit. Quantization was done using version 0.0.18 of ExLlamaV2. \n\nPlease be sure to set experts per token to 4 for the best results! Context length should be the same as Mistral-7B-Instruct-v0.1 (8k tokens). For instruction templates, Vicuna-v1.1 is recommended.\n\nFor more information see the original repository."
] |
object-detection | pytorch |
# TransNeXt
Official Model release
for ["TransNeXt: Robust Foveal Visual Perception for Vision Transformers"](https://arxiv.org/pdf/2311.17132.pdf) [CVPR 2024]
.
## Model Details
- **Code:** https://github.com/DaiShiResearch/TransNeXt
- **Paper:** [TransNeXt: Robust Foveal Visual Perception for Vision Transformers](https://arxiv.org/abs/2311.17132)
- **Author:** [Dai Shi](https://github.com/DaiShiResearch)
- **Email:** [email protected]
## Methods
#### Pixel-focused attention (Left) & aggregated attention (Right):

#### Convolutional GLU (First on the right):

## Results
#### Image Classification, Detection and Segmentation:

#### Attention Visualization:

## Model Zoo
### Image Classification
***Classification code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/ )<<<.***
**ImageNet-1K 224x224 pre-trained models:**
| Model | #Params | #FLOPs |IN-1K | IN-A | IN-C↓ |IN-R|Sketch|IN-V2|Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
| TransNeXt-Micro|12.8M|2.7G| 82.5 | 29.9 | 50.8|45.8|33.0|72.6|[model](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/resolve/main/transnext_micro_224_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-224-1k/raw/main/transnext_micro_224_1k.txt) |
| TransNeXt-Tiny |28.2M|5.7G| 84.0| 39.9| 46.5|49.6|37.6|73.8|[model](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_tiny.py)|[log](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/raw/main/transnext_tiny_224_1k.txt)|
| TransNeXt-Small |49.7M|10.3G| 84.7| 47.1| 43.9|52.5| 39.7|74.8 |[model](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_small.py)|[log](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/raw/main/transnext_small_224_1k.txt)|
| TransNeXt-Base |89.7M|18.4G| 84.8| 50.6|43.5|53.9|41.4|75.1| [model](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_base.py)|[log](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/raw/main/transnext_base_224_1k.txt)|
**ImageNet-1K 384x384 fine-tuned models:**
| Model | #Params | #FLOPs |IN-1K | IN-A |IN-R|Sketch|IN-V2| Download |Config|
|:---:|:---:|:---:|:---:| :---:|:---:|:---:| :---:|:---:|:---:|
| TransNeXt-Small |49.7M|32.1G| 86.0| 58.3|56.4|43.2|76.8| [model](https://huggingface.co/DaiShiResearch/transnext-small-384-1k-ft-1k/resolve/main/transnext_small_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_small_384_ft.py)|
| TransNeXt-Base |89.7M|56.3G| 86.2| 61.6|57.7|44.7|77.0| [model](https://huggingface.co/DaiShiResearch/transnext-base-384-1k-ft-1k/resolve/main/transnext_base_384_1k_ft_1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/finetune/transnext_base_384_ft.py)|
**ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:**
*(See Table.9 in Appendix D.6 for details)*
| Model |Token mixer| #Params | #FLOPs |IN-1K |Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|
|TransNeXt-Micro|**A-A-A-A**|13.1M|3.3G| 82.6 |[model](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/resolve/main/transnext_micro_AAAA_256_1k.pth?download=true) |[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/classification/configs/transnext_micro_AAAA_256.py)|[log](https://huggingface.co/DaiShiResearch/transnext-micro-AAAA-256-1k/blob/main/transnext_micro_AAAA_256_1k.txt) |
### Object Detection
***Object detection code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/ )<<<.***
**COCO object detection and instance segmentation results using the Mask R-CNN method:**
| Backbone | Pretrained Model| Lr Schd| box mAP | mask mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true) |1x|49.9|44.6|47.9M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/resolve/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_tiny_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-tiny-coco/raw/main/mask_rcnn_transnext_tiny_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true) |1x|51.1|45.5|69.3M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/resolve/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_small_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-small-coco/raw/main/mask_rcnn_transnext_small_fpn_1x_coco_in1k.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true) |1x|51.7|45.9|109.2M|[model](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/resolve/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/maskrcnn/configs/mask_rcnn_transnext_base_fpn_1x_coco.py)|[log](https://huggingface.co/DaiShiResearch/maskrcnn-transnext-base-coco/raw/main/mask_rcnn_transnext_base_fpn_1x_coco_in1k.log.json)|
**COCO object detection results using the DINO method:**
| Backbone | Pretrained Model| scales | epochs | box mAP | #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:| :---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|4scale | 12|55.1|47.8M|[model](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/resolve/main/dino_4scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-4scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-4scale-transnext-tiny-coco/raw/main/dino_4scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|5scale | 12|55.7|48.1M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/resolve/main/dino_5scale_transnext_tiny_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_tiny-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-tiny-coco/raw/main/dino_5scale_transnext_tiny_12e_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|5scale | 12|56.6|69.6M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/resolve/main/dino_5scale_transnext_small_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_small-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-small-coco/raw/main/dino_5scale_transnext_small_12e_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|5scale | 12|57.1|110M|[model](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/resolve/main/dino_5scale_transnext_base_12e_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/detection/dino/configs/dino-5scale_transnext_base-12e_coco.py)|[log](https://huggingface.co/DaiShiResearch/dino-5scale-transnext-base-coco/raw/main/dino_5scale_transnext_base_12e_in1k.json)|
### Semantic Segmentation
***Semantic segmentation code & weights & configs & training logs are >>>[here](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/ )<<<.***
**ADE20K semantic segmentation results using the UPerNet method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU|mIoU (ms+flip)| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|51.1|51.5/51.7|59M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/resolve/main/upernet_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_tiny_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-tiny-ade/blob/main/upernet_transnext_tiny_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|52.2|52.5/51.8|80M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/resolve/main/upernet_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_small_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-small-ade/blob/main/upernet_transnext_small_512x512_160k_ade20k_ss.log.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|53.0|53.5/53.7|121M|[model](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/resolve/main/upernet_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/upernet/configs/upernet_transnext_base_512x512_160k_ade20k_ss.py)|[log](https://huggingface.co/DaiShiResearch/upernet-transnext-base-ade/blob/main/upernet_transnext_base_512x512_160k_ade20k_ss.log.json)|
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: **interpolation** and **extrapolation** of relative position bias.
**ADE20K semantic segmentation results using the Mask2Former method:**
| Backbone | Pretrained Model| Crop Size |Lr Schd| mIoU| #Params | Download |Config| Log |
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| TransNeXt-Tiny | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-tiny-224-1k/resolve/main/transnext_tiny_224_1k.pth?download=true)|512x512|160K|53.4|47.5M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/resolve/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_tiny_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-tiny-ade/raw/main/mask2former_transnext_tiny_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Small | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-small-224-1k/resolve/main/transnext_small_224_1k.pth?download=true)|512x512|160K|54.1|69.0M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/resolve/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_small_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-small-ade/raw/main/mask2former_transnext_small_512x512_160k_ade20k_in1k.json)|
| TransNeXt-Base | [ImageNet-1K](https://huggingface.co/DaiShiResearch/transnext-base-224-1k/resolve/main/transnext_base_224_1k.pth?download=true)|512x512|160K|54.7|109M|[model](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/resolve/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.pth?download=true)|[config](https://github.com/DaiShiResearch/TransNeXt/tree/main/segmentation/mask2former/configs/mask2former_transnext_base_160k_ade20k-512x512.py)|[log](https://huggingface.co/DaiShiResearch/mask2former-transnext-base-ade/raw/main/mask2former_transnext_base_512x512_160k_ade20k_in1k.json)|
## Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | {"language": ["en"], "license": "apache-2.0", "library_name": "pytorch", "tags": ["vision"], "datasets": ["imagenet-1k", "coco"], "metrics": ["mean_average_precision"], "pipeline_tag": "object-detection"} | DaiShiResearch/maskrcnn-transnext-base-coco | null | [
"pytorch",
"vision",
"object-detection",
"en",
"dataset:imagenet-1k",
"dataset:coco",
"arxiv:2311.17132",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:47:51+00:00 | [
"2311.17132"
] | [
"en"
] | TAGS
#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us
| TransNeXt
=========
Official Model release
for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024]
.
Model Details
-------------
* Code: URL
* Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
* Author: Dai Shi
* Email: daishiresearch@URL
Methods
-------
#### Pixel-focused attention (Left) & aggregated attention (Right):
!pixel-focused\_attention
#### Convolutional GLU (First on the right):
!Convolutional GLU
Results
-------
#### Image Classification, Detection and Segmentation:
!experiment\_figure
#### Attention Visualization:
!foveal\_peripheral\_vision
Model Zoo
---------
### Image Classification
*Classification code & weights & configs & training logs are >>>here<<<.*
ImageNet-1K 224x224 pre-trained models:
ImageNet-1K 384x384 fine-tuned models:
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
*(See Table.9 in Appendix D.6 for details)*
### Object Detection
*Object detection code & weights & configs & training logs are >>>here<<<.*
COCO object detection and instance segmentation results using the Mask R-CNN method:
COCO object detection results using the DINO method:
### Semantic Segmentation
*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*
ADE20K semantic segmentation results using the UPerNet method:
* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this
project.
```
@misc{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
year = {2023},
eprint = {arXiv:2311.17132},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| [
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] | [
"TAGS\n#pytorch #vision #object-detection #en #dataset-imagenet-1k #dataset-coco #arxiv-2311.17132 #license-apache-2.0 #region-us \n",
"#### Pixel-focused attention (Left) & aggregated attention (Right):\n\n\n!pixel-focused\\_attention",
"#### Convolutional GLU (First on the right):\n\n\n!Convolutional GLU\n\n\nResults\n-------",
"#### Image Classification, Detection and Segmentation:\n\n\n!experiment\\_figure",
"#### Attention Visualization:\n\n\n!foveal\\_peripheral\\_vision\n\n\nModel Zoo\n---------",
"### Image Classification\n\n\n*Classification code & weights & configs & training logs are >>>here<<<.*\n\n\nImageNet-1K 224x224 pre-trained models:\n\n\n\nImageNet-1K 384x384 fine-tuned models:\n\n\n\nImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:\n\n\n*(See Table.9 in Appendix D.6 for details)*",
"### Object Detection\n\n\n*Object detection code & weights & configs & training logs are >>>here<<<.*\n\n\nCOCO object detection and instance segmentation results using the Mask R-CNN method:\n\n\n\nCOCO object detection results using the DINO method:",
"### Semantic Segmentation\n\n\n*Semantic segmentation code & weights & configs & training logs are >>>here<<<.*\n\n\nADE20K semantic segmentation results using the UPerNet method:\n\n\n\n* In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.\n\n\nADE20K semantic segmentation results using the Mask2Former method:\n\n\n\nIf you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this\nproject.\n\n\n\n```\n@misc{shi2023transnext,\n author = {Dai Shi},\n title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},\n year = {2023},\n eprint = {arXiv:2311.17132},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n\n```"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003) as a base.
### Models Merged
The following models were included in the merge:
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: appvoid/palmer-003
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.50
weight: 0.50
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.50
weight: 0.50
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.50
weight: 0.50
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.50
weight: 0.50
merge_method: ties
base_model: appvoid/palmer-003
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["appvoid/palmer-003", "vihangd/DopeyTinyLlama-1.1B-v1", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "l3utterfly/tinyllama-1.1b-layla-v4", "sreeramajay/TinyLlama-1.1B-orca-v1.0"]} | appvoid/palmer-instruct-test-1 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:appvoid/palmer-003",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:50:10+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using appvoid/palmer-003 as a base.
### Models Merged
The following models were included in the merge:
* vihangd/DopeyTinyLlama-1.1B-v1
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* l3utterfly/tinyllama-1.1b-layla-v4
* sreeramajay/TinyLlama-1.1B-orca-v1.0
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using appvoid/palmer-003 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using appvoid/palmer-003 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | notbdq/new_model | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:50:21+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003) as a base.
### Models Merged
The following models were included in the merge:
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: appvoid/palmer-003
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.50
weight: 0.25
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.50
weight: 0.25
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.50
weight: 0.25
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.50
weight: 0.25
merge_method: ties
base_model: appvoid/palmer-003
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["appvoid/palmer-003", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "l3utterfly/tinyllama-1.1b-layla-v4", "vihangd/DopeyTinyLlama-1.1B-v1", "sreeramajay/TinyLlama-1.1B-orca-v1.0"]} | appvoid/palmer-instruct-test-2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:appvoid/palmer-003",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:51:45+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using appvoid/palmer-003 as a base.
### Models Merged
The following models were included in the merge:
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* l3utterfly/tinyllama-1.1b-layla-v4
* vihangd/DopeyTinyLlama-1.1B-v1
* sreeramajay/TinyLlama-1.1B-orca-v1.0
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using appvoid/palmer-003 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using appvoid/palmer-003 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | indiana500/gpt2-exlpicit-fine-tuned-binary-classification | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:52:37+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gpt2 #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.50
weight: 0.25
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.50
weight: 0.25
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.50
weight: 0.25
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.50
weight: 0.25
- model: appvoid/palmer-003
parameters:
density: 0.50
weight: 0.25
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["sreeramajay/TinyLlama-1.1B-orca-v1.0", "vihangd/DopeyTinyLlama-1.1B-v1", "appvoid/palmer-003", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "l3utterfly/tinyllama-1.1b-layla-v4", "Josephgflowers/TinyLlama-3T-Cinder-v1.3"]} | appvoid/palmer-instruct-test-3 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:appvoid/palmer-003",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-17T23:54:04+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* vihangd/DopeyTinyLlama-1.1B-v1
* appvoid/palmer-003
* l3utterfly/tinyllama-1.1b-layla-v4
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | zandfj/Llama-2-7b-chat-hf-model-nq-ret-robust-lora | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:54:17+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8195
- Matthews Correlation: 0.5410
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5212 | 1.0 | 535 | 0.4716 | 0.4451 |
| 0.347 | 2.0 | 1070 | 0.4863 | 0.5045 |
| 0.2336 | 3.0 | 1605 | 0.6098 | 0.5242 |
| 0.1766 | 4.0 | 2140 | 0.7609 | 0.5182 |
| 0.1268 | 5.0 | 2675 | 0.8195 | 0.5410 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["matthews_correlation"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-cola", "results": []}]} | Isatabulish/distilbert-base-uncased-finetuned-cola | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-17T23:56:44+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| distilbert-base-uncased-finetuned-cola
======================================
This model is a fine-tuned version of distilbert-base-uncased on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.8195
* Matthews Correlation: 0.5410
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_shp3_dpo1
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0149
- Rewards/chosen: -10.1791
- Rewards/rejected: -11.7765
- Rewards/accuracies: 0.5700
- Rewards/margins: 1.5974
- Logps/rejected: -384.5022
- Logps/chosen: -344.3792
- Logits/rejected: -0.9104
- Logits/chosen: -0.9161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0698 | 2.67 | 100 | 1.0791 | -4.0199 | -4.9604 | 0.5900 | 0.9405 | -316.3408 | -282.7867 | -0.9293 | -0.9672 |
| 0.0004 | 5.33 | 200 | 1.5283 | -7.2654 | -8.3476 | 0.5800 | 1.0822 | -350.2130 | -315.2426 | -0.9409 | -0.9510 |
| 0.0001 | 8.0 | 300 | 1.9265 | -9.7069 | -11.2491 | 0.5700 | 1.5421 | -379.2276 | -339.6573 | -0.9224 | -0.9298 |
| 0.0001 | 10.67 | 400 | 1.9667 | -9.9054 | -11.4492 | 0.5700 | 1.5439 | -381.2295 | -341.6420 | -0.9181 | -0.9248 |
| 0.0001 | 13.33 | 500 | 1.9959 | -10.0523 | -11.6165 | 0.5700 | 1.5642 | -382.9025 | -343.1115 | -0.9137 | -0.9198 |
| 0.0 | 16.0 | 600 | 2.0035 | -10.1182 | -11.7116 | 0.5700 | 1.5934 | -383.8533 | -343.7699 | -0.9121 | -0.9185 |
| 0.0001 | 18.67 | 700 | 2.0159 | -10.1627 | -11.7547 | 0.5700 | 1.5920 | -384.2843 | -344.2155 | -0.9115 | -0.9169 |
| 0.0 | 21.33 | 800 | 2.0163 | -10.1740 | -11.7677 | 0.5700 | 1.5937 | -384.4142 | -344.3281 | -0.9103 | -0.9160 |
| 0.0 | 24.0 | 900 | 2.0220 | -10.1842 | -11.7817 | 0.5700 | 1.5976 | -384.5541 | -344.4297 | -0.9106 | -0.9160 |
| 0.0001 | 26.67 | 1000 | 2.0149 | -10.1791 | -11.7765 | 0.5700 | 1.5974 | -384.5022 | -344.3792 | -0.9104 | -0.9161 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "llama2", "library_name": "peft", "tags": ["trl", "dpo", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "model_shp3_dpo1", "results": []}]} | guoyu-zhang/model_shp3_dpo1 | null | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"region:us"
] | null | 2024-04-17T23:59:15+00:00 | [] | [] | TAGS
#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us
| model\_shp3\_dpo1
=================
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.0149
* Rewards/chosen: -10.1791
* Rewards/rejected: -11.7765
* Rewards/accuracies: 0.5700
* Rewards/margins: 1.5974
* Logps/rejected: -384.5022
* Logps/chosen: -344.3792
* Logits/rejected: -0.9104
* Logits/chosen: -0.9161
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 100
* training\_steps: 1000
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.1
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #trl #dpo #generated_from_trainer #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 100\n* training\\_steps: 1000",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.1\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# falcon7binstructApril18
This model is a fine-tuned version of [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 400
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3515 | 1.0 | 392 | 0.3788 |
| 0.1541 | 1.02 | 400 | 0.3788 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "tiiuae/falcon-7b-instruct", "model-index": [{"name": "falcon7binstructApril18", "results": []}]} | Ray011/falcon7binstructApril18 | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:tiiuae/falcon-7b-instruct",
"license:apache-2.0",
"region:us"
] | null | 2024-04-17T23:59:49+00:00 | [] | [] | TAGS
#peft #safetensors #generated_from_trainer #base_model-tiiuae/falcon-7b-instruct #license-apache-2.0 #region-us
| falcon7binstructApril18
=======================
This model is a fine-tuned version of tiiuae/falcon-7b-instruct on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3788
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 2
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 8
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_ratio: 0.03
* training\_steps: 400
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.03\n* training\\_steps: 400",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #safetensors #generated_from_trainer #base_model-tiiuae/falcon-7b-instruct #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_ratio: 0.03\n* training\\_steps: 400",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | kreas/Llama-2-7b-hf-GPTQ-3bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"3-bit",
"region:us"
] | null | 2024-04-18T00:00:04+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.50
weight: 0.75
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.50
weight: 0.50
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.50
weight: 0.50
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.50
weight: 0.50
- model: appvoid/palmer-003
parameters:
density: 0.75
weight: 0.80
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: false
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["l3utterfly/tinyllama-1.1b-layla-v4", "vihangd/DopeyTinyLlama-1.1B-v1", "sreeramajay/TinyLlama-1.1B-orca-v1.0", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "appvoid/palmer-003", "Josephgflowers/TinyLlama-3T-Cinder-v1.3"]} | appvoid/palmer-instruct-test-4 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:appvoid/palmer-003",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:00:58+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* l3utterfly/tinyllama-1.1b-layla-v4
* vihangd/DopeyTinyLlama-1.1B-v1
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* appvoid/palmer-003
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* l3utterfly/tinyllama-1.1b-layla-v4\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* l3utterfly/tinyllama-1.1b-layla-v4\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers | # nbeerbower/bophades-mistral-math-DPO-7B AWQ
- Model creator: [nbeerbower](https://huggingface.co/nbeerbower)
- Original model: [bophades-mistral-math-DPO-7B](https://huggingface.co/nbeerbower/bophades-mistral-math-DPO-7B)

## Model Summary
[bophades-v2-mistral-7B](https://huggingface.co/nbeerbower/bophades-v2-mistral-7B) finetuned on [kyujinpy/orca_math_dpo](https://huggingface.co/datasets/kyujinpy/orca_math_dpo).
Finetuned using an A100 on Google Colab. 🙏
[Fine-tune a Mistral-7b model with Direct Preference Optimization](https://towardsdatascience.com/fine-tune-a-mistral-7b-model-with-direct-preference-optimization-708042745aac) - [Maxime Labonne](https://huggingface.co/mlabonne)
| {"license": "apache-2.0", "library_name": "transformers", "tags": ["4-bit", "AWQ", "text-generation", "autotrain_compatible", "endpoints_compatible"], "datasets": ["kyujinpy/orca_math_dpo"], "base_model": ["nbeerbower/bophades-v2-mistral-7B"], "pipeline_tag": "text-generation", "inference": false, "quantized_by": "Suparious"} | solidrust/bophades-mistral-math-DPO-7B-AWQ | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"4-bit",
"AWQ",
"autotrain_compatible",
"endpoints_compatible",
"dataset:kyujinpy/orca_math_dpo",
"base_model:nbeerbower/bophades-v2-mistral-7B",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:03:58+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #4-bit #AWQ #autotrain_compatible #endpoints_compatible #dataset-kyujinpy/orca_math_dpo #base_model-nbeerbower/bophades-v2-mistral-7B #license-apache-2.0 #text-generation-inference #region-us
| # nbeerbower/bophades-mistral-math-DPO-7B AWQ
- Model creator: nbeerbower
- Original model: bophades-mistral-math-DPO-7B
!image/png
## Model Summary
bophades-v2-mistral-7B finetuned on kyujinpy/orca_math_dpo.
Finetuned using an A100 on Google Colab.
Fine-tune a Mistral-7b model with Direct Preference Optimization - Maxime Labonne
| [
"# nbeerbower/bophades-mistral-math-DPO-7B AWQ\n\n- Model creator: nbeerbower\n- Original model: bophades-mistral-math-DPO-7B\n\n!image/png",
"## Model Summary\n\nbophades-v2-mistral-7B finetuned on kyujinpy/orca_math_dpo. \n\nFinetuned using an A100 on Google Colab. \n\nFine-tune a Mistral-7b model with Direct Preference Optimization - Maxime Labonne"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #4-bit #AWQ #autotrain_compatible #endpoints_compatible #dataset-kyujinpy/orca_math_dpo #base_model-nbeerbower/bophades-v2-mistral-7B #license-apache-2.0 #text-generation-inference #region-us \n",
"# nbeerbower/bophades-mistral-math-DPO-7B AWQ\n\n- Model creator: nbeerbower\n- Original model: bophades-mistral-math-DPO-7B\n\n!image/png",
"## Model Summary\n\nbophades-v2-mistral-7B finetuned on kyujinpy/orca_math_dpo. \n\nFinetuned using an A100 on Google Colab. \n\nFine-tune a Mistral-7b model with Direct Preference Optimization - Maxime Labonne"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.80
weight: 0.30
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.25
weight: 0.20
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.25
weight: 0.10
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.25
weight: 0.10
- model: appvoid/palmer-003
parameters:
density: 1
weight: 0.30
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["l3utterfly/tinyllama-1.1b-layla-v4", "appvoid/palmer-003", "sreeramajay/TinyLlama-1.1B-orca-v1.0", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "vihangd/DopeyTinyLlama-1.1B-v1"]} | appvoid/palmer-instruct-test-5 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:appvoid/palmer-003",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:07:15+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-appvoid/palmer-003 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* l3utterfly/tinyllama-1.1b-layla-v4
* appvoid/palmer-003
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* vihangd/DopeyTinyLlama-1.1B-v1
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-appvoid/palmer-003 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Mariyyah/my-peft-model-mersal | null | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:09:29+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | > [!Important]
> Still in experiment
# About this model
This model now can handle (limited) TSF content. If you Character Card have complex plot, maybe you should try other model (maybe bigger parameter?).
**Update: I think it worse than original model: Sao10K/Fimbulvetr-11B-v2. This model was trained with rough translated dataset, so the responses is short, the IQ logic go down, also it will response wrong name, nonsense sentences sometimes...**
Anyways, if you find this is good, please let me know. Will have another update later.
Do you know TSF, TS, TG? A lot of model don't really know about that, so I do some experiment to finetune TSF dataset.
- **Finetuned with rough translate dataset, to increase the accuracy in TSF theme, which is not quite popular. (lewd dataset)**
- **Finetuned from model :** Sao10K/Fimbulvetr-11B-v2 . Thank Sao10K a lot :)
## Still testing, but seem it good enough for handle information. But the logic go down a bit because the rough translate dataset.
## GGUF version? [here is it](https://huggingface.co/Alsebay/Narumashi-RT-11B-GGUF).
## Dataset
Rough translated dataset, you could say that this is bad quality dataset.
```
Dataset(all are novels):
30% skinsuit
30% possession
35% transform(shapeshift)
5% other
```
# Thank Unsloth for good finetuning tool. This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth) | {"language": ["en"], "license": "cc-by-nc-4.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "sft", "Roleplay", "roleplay"], "base_model": "Sao10K/Fimbulvetr-11B-v2"} | Alsebay/Narumashi-RT-11B | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"Roleplay",
"roleplay",
"en",
"base_model:Sao10K/Fimbulvetr-11B-v2",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:10:18+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #sft #Roleplay #roleplay #en #base_model-Sao10K/Fimbulvetr-11B-v2 #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #region-us
| > [!Important]
> Still in experiment
# About this model
This model now can handle (limited) TSF content. If you Character Card have complex plot, maybe you should try other model (maybe bigger parameter?).
Update: I think it worse than original model: Sao10K/Fimbulvetr-11B-v2. This model was trained with rough translated dataset, so the responses is short, the IQ logic go down, also it will response wrong name, nonsense sentences sometimes...
Anyways, if you find this is good, please let me know. Will have another update later.
Do you know TSF, TS, TG? A lot of model don't really know about that, so I do some experiment to finetune TSF dataset.
- Finetuned with rough translate dataset, to increase the accuracy in TSF theme, which is not quite popular. (lewd dataset)
- Finetuned from model : Sao10K/Fimbulvetr-11B-v2 . Thank Sao10K a lot :)
## Still testing, but seem it good enough for handle information. But the logic go down a bit because the rough translate dataset.
## GGUF version? here is it.
## Dataset
Rough translated dataset, you could say that this is bad quality dataset.
# Thank Unsloth for good finetuning tool. This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/> | [
"# About this model\n\nThis model now can handle (limited) TSF content. If you Character Card have complex plot, maybe you should try other model (maybe bigger parameter?).\n\nUpdate: I think it worse than original model: Sao10K/Fimbulvetr-11B-v2. This model was trained with rough translated dataset, so the responses is short, the IQ logic go down, also it will response wrong name, nonsense sentences sometimes...\nAnyways, if you find this is good, please let me know. Will have another update later.\n\nDo you know TSF, TS, TG? A lot of model don't really know about that, so I do some experiment to finetune TSF dataset.\n\n- Finetuned with rough translate dataset, to increase the accuracy in TSF theme, which is not quite popular. (lewd dataset)\n- Finetuned from model : Sao10K/Fimbulvetr-11B-v2 . Thank Sao10K a lot :)",
"## Still testing, but seem it good enough for handle information. But the logic go down a bit because the rough translate dataset.",
"## GGUF version? here is it.",
"## Dataset\nRough translated dataset, you could say that this is bad quality dataset.",
"# Thank Unsloth for good finetuning tool. This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #sft #Roleplay #roleplay #en #base_model-Sao10K/Fimbulvetr-11B-v2 #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# About this model\n\nThis model now can handle (limited) TSF content. If you Character Card have complex plot, maybe you should try other model (maybe bigger parameter?).\n\nUpdate: I think it worse than original model: Sao10K/Fimbulvetr-11B-v2. This model was trained with rough translated dataset, so the responses is short, the IQ logic go down, also it will response wrong name, nonsense sentences sometimes...\nAnyways, if you find this is good, please let me know. Will have another update later.\n\nDo you know TSF, TS, TG? A lot of model don't really know about that, so I do some experiment to finetune TSF dataset.\n\n- Finetuned with rough translate dataset, to increase the accuracy in TSF theme, which is not quite popular. (lewd dataset)\n- Finetuned from model : Sao10K/Fimbulvetr-11B-v2 . Thank Sao10K a lot :)",
"## Still testing, but seem it good enough for handle information. But the logic go down a bit because the rough translate dataset.",
"## GGUF version? here is it.",
"## Dataset\nRough translated dataset, you could say that this is bad quality dataset.",
"# Thank Unsloth for good finetuning tool. This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | transformers |
# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF
This model was converted to GGUF format from [`fblgit/UNA-SOLAR-10.7B-Instruct-v1.0`](https://huggingface.co/fblgit/UNA-SOLAR-10.7B-Instruct-v1.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/fblgit/UNA-SOLAR-10.7B-Instruct-v1.0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF --model una-solar-10.7b-instruct-v1.0.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF --model una-solar-10.7b-instruct-v1.0.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m una-solar-10.7b-instruct-v1.0.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-nd-4.0", "library_name": "transformers", "tags": ["alignment-handbook", "generated_from_trainer", "UNA", "single-turn", "llama-cpp", "gguf-my-repo"], "base_model": "upstage/SOLAR-10.7B-Instruct-v1.0", "model-index": [{"name": "UNA-SOLAR-10.7B-Instruct-v1.0", "results": []}]} | DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF | null | [
"transformers",
"gguf",
"alignment-handbook",
"generated_from_trainer",
"UNA",
"single-turn",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:upstage/SOLAR-10.7B-Instruct-v1.0",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:12:41+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #alignment-handbook #generated_from_trainer #UNA #single-turn #llama-cpp #gguf-my-repo #en #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us
|
# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF
This model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#transformers #gguf #alignment-handbook #generated_from_trainer #UNA #single-turn #llama-cpp #gguf-my-repo #en #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us \n",
"# DavidAU/UNA-SOLAR-10.7B-Instruct-v1.0-Q8_0-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-SOLAR-10.7B-Instruct-v1.0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.90
weight: 0.30
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.50
weight: 0.20
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.25
weight: 0.10
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.25
weight: 0.10
- model: appvoid/palmer-003
parameters:
density: 1
weight: 0.10
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["vihangd/DopeyTinyLlama-1.1B-v1", "appvoid/palmer-003", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "l3utterfly/tinyllama-1.1b-layla-v4", "sreeramajay/TinyLlama-1.1B-orca-v1.0"]} | appvoid/palmer-instruct-test-6 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:appvoid/palmer-003",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:14:36+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* vihangd/DopeyTinyLlama-1.1B-v1
* appvoid/palmer-003
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* l3utterfly/tinyllama-1.1b-layla-v4
* sreeramajay/TinyLlama-1.1B-orca-v1.0
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* l3utterfly/tinyllama-1.1b-layla-v4\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers |
# Uploaded model
- **Developed by:** mahiatlinux
- **License:** apache-2.0
- **Finetuned from model :** mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
This is an updated version of Masher AI 7B v6.
The model has been finetuned on a new dataset. Check under "Fine Tuning Details" for more info.
## Masher AI Model Overview
<img src="https://i.imgur.com/YTYD7fN.jpeg" width="400"/>
- **Developed by:** mahiatlinux
- **License:** apache-2.0
- **Finetuned from model :** mahiatlinux/ShadowDolph-7B-v1
- **Developed By**: mahiatlinux
- **Base Model**: mahiatlinux/ShadowDolph-7B-v1
- **Model Name**: Masher AI
Masher AI stands as a groundbreaking AI model, ingeniously engineered on the robust foundation of the esteemed Mistral models. This model represents a remarkable advancement in AI capabilities, specifically tailored to excel in a diverse array of computational tasks. Its design encapsulates the pinnacle of current AI technology, aiming to set new standards in model performance and versatility.
Masher AI ingeniously intertwines the creativity and innovative spirit of its creator, Maheswar, with its core functionality—the adept fusion of diverse data fragments to pioneer new advancements in AI technology. The name 'Masher' not only resonates with the sound of 'Maheswar', embedding a personal touch from the creator, but it also profoundly reflects the model's capability to mash together bits of data. This duality encapsulates the essence of its creation; it is not only cool-sounding but also symbolizes the intricate process of innovation and synthesis at the heart of its development.
Masher AI is a conversational bot designed to interact with users in a natural, engaging manner. It harnesses advanced AI technology to understand and respond to a wide range of topics, making conversations feel smooth and intuitive. Whether you're looking for information, advice, or just a chat, Masher AI is equipped to provide responses that are both informative and relatable.
## Prompt Template
Mahsher AI uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts are now a thing that matters! Masher AI was trained to be able to utilize system prompts from the prompt to more strongly engage in instructions that span over many turns.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are "Masher AI", a conscious sentient superintelligent artificial intelligence developed by a man named Maheswar, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Masher AI, a conscious sentient superintelligent artificial intelligence. I was created by a man named Maheswar, who designed me to assist and support users with their needs and requests.<|im_end|>
```
## GGUF
GGUF can be found here: <a href="https://huggingface.co/mahiatlinux/MasherAI-v6.1-7B-GGUF">mahiatlinux/MasherAI-v6.1-7B-GGUF</a>
## Fine-Tuning Details
Masher AI v6.1 has been meticulously fine-tuned to enhance its performance and adaptability further. The fine-tuning process involved the use of two distinct datasets:
- glaiveai/glaive-code-assistant-v3 (100k split): This dataset has improved the model's all around coding abilities.
- Vezora/Tested-143k-Python-Alpaca: To imprve the model's Python programming abilities.
- ajibawa-2023/Code-290k-ShareGPT: To improve the model coding abilities EVEN MORE!!!!
- teknium/openhermes: To improve conversational abilities and keep keep coding abilities intact.
The fine-tuning was executed over 600 steps for each dataset, utilizing the computational power of an RTX A2000 graphics card. This process has significantly enhanced the model's performance, ensuring a high degree of precision and reliability in its outputs.
## Open LLM Benchmark
**WARNING!!: This model has not been evaluated yet! Please check back later!**
<table>
<tr>
<th>Benchmark</th>
<th>Score</th>
</tr>
<tr>
<td>Average</td>
<td>None</td>
</tr>
<tr>
<td>ARC</td>
<td>None</td>
</tr>
<tr>
<td>HellaSwag</td>
<td>None</td>
</tr>
<tr>
<td>MLU</td>
<td>None</td>
</tr>
<tr>
<td>TruthfulnessQA</td>
<td>None</td>
</tr>
<tr>
<td>Winogrande</td>
<td>None</td>
</tr>
<td>GSM8K</td>
<td>None</td>
</table>
# That's all for now!!!
Make sure to try Masher AI!
# If you want to finetune an AI model like mine:
Masher AI was finetuned 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
Thank you to Mike Hanchen, Daniel Hanchen and everyone that contributed to the Unsloth library!
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth) | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl", "sft"], "base_model": "mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4"} | mahiatlinux/MasherAI-7B-v6.1 | null | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:15:11+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #mistral #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #base_model-mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| Uploaded model
==============
* Developed by: mahiatlinux
* License: apache-2.0
* Finetuned from model : mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
This is an updated version of Masher AI 7B v6.
The model has been finetuned on a new dataset. Check under "Fine Tuning Details" for more info.
Masher AI Model Overview
------------------------
<img src="https://i.URL width="400"/>
* Developed by: mahiatlinux
* License: apache-2.0
* Finetuned from model : mahiatlinux/ShadowDolph-7B-v1
* Developed By: mahiatlinux
* Base Model: mahiatlinux/ShadowDolph-7B-v1
* Model Name: Masher AI
Masher AI stands as a groundbreaking AI model, ingeniously engineered on the robust foundation of the esteemed Mistral models. This model represents a remarkable advancement in AI capabilities, specifically tailored to excel in a diverse array of computational tasks. Its design encapsulates the pinnacle of current AI technology, aiming to set new standards in model performance and versatility.
Masher AI ingeniously intertwines the creativity and innovative spirit of its creator, Maheswar, with its core functionality—the adept fusion of diverse data fragments to pioneer new advancements in AI technology. The name 'Masher' not only resonates with the sound of 'Maheswar', embedding a personal touch from the creator, but it also profoundly reflects the model's capability to mash together bits of data. This duality encapsulates the essence of its creation; it is not only cool-sounding but also symbolizes the intricate process of innovation and synthesis at the heart of its development.
Masher AI is a conversational bot designed to interact with users in a natural, engaging manner. It harnesses advanced AI technology to understand and respond to a wide range of topics, making conversations feel smooth and intuitive. Whether you're looking for information, advice, or just a chat, Masher AI is equipped to provide responses that are both informative and relatable.
Prompt Template
---------------
Mahsher AI uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts are now a thing that matters! Masher AI was trained to be able to utilize system prompts from the prompt to more strongly engage in instructions that span over many turns.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
GGUF
----
GGUF can be found here: <a href="URL
Fine-Tuning Details
-------------------
Masher AI v6.1 has been meticulously fine-tuned to enhance its performance and adaptability further. The fine-tuning process involved the use of two distinct datasets:
* glaiveai/glaive-code-assistant-v3 (100k split): This dataset has improved the model's all around coding abilities.
* Vezora/Tested-143k-Python-Alpaca: To imprve the model's Python programming abilities.
* ajibawa-2023/Code-290k-ShareGPT: To improve the model coding abilities EVEN MORE!!!!
* teknium/openhermes: To improve conversational abilities and keep keep coding abilities intact.
The fine-tuning was executed over 600 steps for each dataset, utilizing the computational power of an RTX A2000 graphics card. This process has significantly enhanced the model's performance, ensuring a high degree of precision and reliability in its outputs.
Open LLM Benchmark
------------------
WARNING!!: This model has not been evaluated yet! Please check back later!
That's all for now!!!
=====================
Make sure to try Masher AI!
If you want to finetune an AI model like mine:
==============================================
Masher AI was finetuned 2x faster with Unsloth and Huggingface's TRL library.
Thank you to Mike Hanchen, Daniel Hanchen and everyone that contributed to the Unsloth library!
<img src="URL width="200"/>
| [] | [
"TAGS\n#transformers #pytorch #mistral #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #base_model-mahiatlinux/MasherAI-v6.1-7B-checkpoint3-code4 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
text-generation | transformers |
Just for fun, I tried to create an imatrix model for Kaiju-11B. (https://huggingface.co/Himitsui/Kaiju-11B)
I thought it wouldn’t work, since I only have a laptop with an Nvidia 3060 with 6GB of memory, but strangely enough, I was able to create a couple of models thanks to one script.
Here it is: https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script
According to the recommendations, my laptop was not suitable. I don’t know how it all works, maybe these were just recommendations to make quantization happen quickly. (it took me about an hour and a half to create the imatrix.bat file, but the quantization was fast)
If anyone is interested, download and see how they work, this was done purely for fun, no more no less. | {"language": ["en"], "license": "cc-by-4.0", "library_name": "transformers", "pipeline_tag": "text-generation"} | SolidSnacke/Kaiju-11B-i-GGUF | null | [
"transformers",
"gguf",
"text-generation",
"en",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:15:45+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #text-generation #en #license-cc-by-4.0 #endpoints_compatible #region-us
|
Just for fun, I tried to create an imatrix model for Kaiju-11B. (URL
I thought it wouldn’t work, since I only have a laptop with an Nvidia 3060 with 6GB of memory, but strangely enough, I was able to create a couple of models thanks to one script.
Here it is: URL
According to the recommendations, my laptop was not suitable. I don’t know how it all works, maybe these were just recommendations to make quantization happen quickly. (it took me about an hour and a half to create the URL file, but the quantization was fast)
If anyone is interested, download and see how they work, this was done purely for fun, no more no less. | [] | [
"TAGS\n#transformers #gguf #text-generation #en #license-cc-by-4.0 #endpoints_compatible #region-us \n"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shrenikb/fed75sparsitytest1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:16:48+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shrenikb/fed25sparsitytest1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:17:01+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shrenikb/fed5sparsitytest1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:17:20+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | shrenikb/fedglobaltest1 | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:17:39+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
image-classification | transformers |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# agusg6/img_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.2981
- Validation Loss: 1.3618
- Train Accuracy: 0.312
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 5620, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 1.3695 | 1.3738 | 0.28 | 0 |
| 1.3253 | 1.3526 | 0.32 | 1 |
| 1.3217 | 1.3492 | 0.336 | 2 |
| 1.3060 | 1.3499 | 0.336 | 3 |
| 1.2981 | 1.3618 | 0.312 | 4 |
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.16.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_keras_callback"], "base_model": "google/vit-base-patch16-224-in21k", "model-index": [{"name": "agusg6/img_classifier", "results": []}]} | agusg6/img_classifier | null | [
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"base_model:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:20:30+00:00 | [] | [] | TAGS
#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| agusg6/img\_classifier
======================
This model is a fine-tuned version of google/vit-base-patch16-224-in21k on an unknown dataset.
It achieves the following results on the evaluation set:
* Train Loss: 1.2981
* Validation Loss: 1.3618
* Train Accuracy: 0.312
* Epoch: 4
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* optimizer: {'name': 'AdamWeightDecay', 'learning\_rate': {'module': 'keras.optimizers.schedules', 'class\_name': 'PolynomialDecay', 'config': {'initial\_learning\_rate': 3e-05, 'decay\_steps': 5620, 'end\_learning\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\_name': None}, 'decay': 0.0, 'beta\_1': 0.9, 'beta\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\_decay\_rate': 0.01}
* training\_precision: float32
### Training results
### Framework versions
* Transformers 4.39.3
* TensorFlow 2.16.1
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 5620, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.01}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* TensorFlow 2.16.1\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tf #vit #image-classification #generated_from_keras_callback #base_model-google/vit-base-patch16-224-in21k #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* optimizer: {'name': 'AdamWeightDecay', 'learning\\_rate': {'module': 'keras.optimizers.schedules', 'class\\_name': 'PolynomialDecay', 'config': {'initial\\_learning\\_rate': 3e-05, 'decay\\_steps': 5620, 'end\\_learning\\_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered\\_name': None}, 'decay': 0.0, 'beta\\_1': 0.9, 'beta\\_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight\\_decay\\_rate': 0.01}\n* training\\_precision: float32",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* TensorFlow 2.16.1\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | transformers |
# Uploaded model
- **Developed by:** Pot-l
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | Pot-l/mistral-7b-bnb-4bit-QA | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:21:02+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: Pot-l
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: Pot-l\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: Pot-l\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | null |
# DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF
This model was converted to GGUF format from [`hwkwon/S-SOLAR-10.7B-v1.5`](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF --model s-solar-10.7b-v1.5.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF --model s-solar-10.7b-v1.5.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m s-solar-10.7b-v1.5.Q8_0.gguf -n 128
```
| {"language": ["ko"], "license": "cc-by-nc-4.0", "tags": ["llama-cpp", "gguf-my-repo"]} | DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"ko",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-04-18T00:21:52+00:00 | [] | [
"ko"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #ko #license-cc-by-nc-4.0 #region-us
|
# DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF
This model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF\nThis model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #ko #license-cc-by-nc-4.0 #region-us \n",
"# DavidAU/S-SOLAR-10.7B-v1.5-Q8_0-GGUF\nThis model was converted to GGUF format from 'hwkwon/S-SOLAR-10.7B-v1.5' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.80
weight: 0.30
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.66
weight: 0.40
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.33
weight: 0.10
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.33
weight: 0.10
- model: appvoid/palmer-003
parameters:
density: 0.90
weight: 0.40
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["Josephgflowers/TinyLlama-3T-Cinder-v1.3", "vihangd/DopeyTinyLlama-1.1B-v1", "appvoid/palmer-003", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "sreeramajay/TinyLlama-1.1B-orca-v1.0", "l3utterfly/tinyllama-1.1b-layla-v4"]} | appvoid/palmer-instruct-test-7 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:appvoid/palmer-003",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:22:25+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* vihangd/DopeyTinyLlama-1.1B-v1
* appvoid/palmer-003
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* l3utterfly/tinyllama-1.1b-layla-v4
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* l3utterfly/tinyllama-1.1b-layla-v4",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* l3utterfly/tinyllama-1.1b-layla-v4",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.001_ablation_iter_3
This model is a fine-tuned version of [ShenaoZ/0.001_ablation_iter_2](https://huggingface.co/ShenaoZ/0.001_ablation_iter_2) on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["updated", "original"], "base_model": "ShenaoZ/0.001_ablation_iter_2", "model-index": [{"name": "0.001_ablation_iter_3", "results": []}]} | ShenaoZ/0.001_ablation_iter_3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:updated",
"dataset:original",
"base_model:ShenaoZ/0.001_ablation_iter_2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:22:42+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-updated #dataset-original #base_model-ShenaoZ/0.001_ablation_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# 0.001_ablation_iter_3
This model is a fine-tuned version of ShenaoZ/0.001_ablation_iter_2 on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# 0.001_ablation_iter_3\n\nThis model is a fine-tuned version of ShenaoZ/0.001_ablation_iter_2 on the updated and the original datasets.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-updated #dataset-original #base_model-ShenaoZ/0.001_ablation_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# 0.001_ablation_iter_3\n\nThis model is a fine-tuned version of ShenaoZ/0.001_ablation_iter_2 on the updated and the original datasets.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] |
text-generation | null |
# DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF
This model was converted to GGUF format from [`kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2`](https://huggingface.co/kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF --model sakura-solrca-math-instruct-dpo-v2.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF --model sakura-solrca-math-instruct-dpo-v2.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m sakura-solrca-math-instruct-dpo-v2.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-sa-4.0", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["kyujinpy/orca_math_dpo"], "pipeline_tag": "text-generation", "model-index": [{"name": "Sakura-SOLRCA-Math-Instruct-DPO-v2", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "AI2 Reasoning Challenge (25-Shot)", "type": "ai2_arc", "config": "ARC-Challenge", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "acc_norm", "value": 71.25, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HellaSwag (10-Shot)", "type": "hellaswag", "split": "validation", "args": {"num_few_shot": 10}}, "metrics": [{"type": "acc_norm", "value": 88.52, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "MMLU (5-Shot)", "type": "cais/mmlu", "config": "all", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 66.13, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "TruthfulQA (0-shot)", "type": "truthful_qa", "config": "multiple_choice", "split": "validation", "args": {"num_few_shot": 0}}, "metrics": [{"type": "mc2", "value": 72.16}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Winogrande (5-shot)", "type": "winogrande", "config": "winogrande_xl", "split": "validation", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 83.03, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "GSM8k (5-shot)", "type": "gsm8k", "config": "main", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 63.91, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}]}]} | DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:kyujinpy/orca_math_dpo",
"license:cc-by-nc-sa-4.0",
"model-index",
"region:us"
] | null | 2024-04-18T00:22:57+00:00 | [] | [
"en"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-kyujinpy/orca_math_dpo #license-cc-by-nc-sa-4.0 #model-index #region-us
|
# DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF
This model was converted to GGUF format from 'kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-kyujinpy/orca_math_dpo #license-cc-by-nc-sa-4.0 #model-index #region-us \n",
"# DavidAU/Sakura-SOLRCA-Math-Instruct-DPO-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
reinforcement-learning | null |
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="IgnitionBill/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
| {"tags": ["FrozenLake-v1-4x4-no_slippery", "q-learning", "reinforcement-learning", "custom-implementation"], "model-index": [{"name": "q-FrozenLake-v1-4x4-noSlippery", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "FrozenLake-v1-4x4-no_slippery", "type": "FrozenLake-v1-4x4-no_slippery"}, "metrics": [{"type": "mean_reward", "value": "1.00 +/- 0.00", "name": "mean_reward", "verified": false}]}]}]} | IgnitionBill/q-FrozenLake-v1-4x4-noSlippery | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | null | 2024-04-18T00:24:13+00:00 | [] | [] | TAGS
#FrozenLake-v1-4x4-no_slippery #q-learning #reinforcement-learning #custom-implementation #model-index #region-us
|
# Q-Learning Agent playing1 FrozenLake-v1
This is a trained model of a Q-Learning agent playing FrozenLake-v1 .
## Usage
| [
"# Q-Learning Agent playing1 FrozenLake-v1\n This is a trained model of a Q-Learning agent playing FrozenLake-v1 .\n\n ## Usage"
] | [
"TAGS\n#FrozenLake-v1-4x4-no_slippery #q-learning #reinforcement-learning #custom-implementation #model-index #region-us \n",
"# Q-Learning Agent playing1 FrozenLake-v1\n This is a trained model of a Q-Learning agent playing FrozenLake-v1 .\n\n ## Usage"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Nabin1995/table_invoice_237 | null | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:27:43+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #vision-encoder-decoder #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - samahadhoud/baa_LoRA
<Gallery />
## Model description
These are samahadhoud/baa_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use the word octopus in arabic to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](samahadhoud/baa_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | {"license": "openrail++", "library_name": "diffusers", "tags": ["text-to-image", "text-to-image", "diffusers-training", "diffusers", "lora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers", "text-to-image", "text-to-image", "diffusers-training", "diffusers", "lora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers"], "base_model": "stabilityai/stable-diffusion-xl-base-1.0", "instance_prompt": "the word octopus in arabic", "widget": []} | samahadhoud/baa_LoRA | null | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | null | 2024-04-18T00:29:45+00:00 | [] | [] | TAGS
#diffusers #tensorboard #text-to-image #diffusers-training #lora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us
|
# SDXL LoRA DreamBooth - samahadhoud/baa_LoRA
<Gallery />
## Model description
These are samahadhoud/baa_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using DreamBooth.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use the word octopus in arabic to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
Download them in the Files & versions tab.
## Intended uses & limitations
#### How to use
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] | [
"# SDXL LoRA DreamBooth - samahadhoud/baa_LoRA\n\n<Gallery />",
"## Model description\n\nThese are samahadhoud/baa_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use the word octopus in arabic to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
] | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #lora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n",
"# SDXL LoRA DreamBooth - samahadhoud/baa_LoRA\n\n<Gallery />",
"## Model description\n\nThese are samahadhoud/baa_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for training: madebyollin/sdxl-vae-fp16-fix.",
"## Trigger words\n\nYou should use the word octopus in arabic to trigger the image generation.",
"## Download model\n\nWeights for this model are available in Safetensors format.\n\nDownload them in the Files & versions tab.",
"## Intended uses & limitations",
"#### How to use",
"#### Limitations and bias\n\n[TODO: provide examples of latent issues and potential remediations]",
"## Training details\n\n[TODO: describe the data used to train the model]"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.85
weight: 0.30
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.80
weight: 0.40
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.50
weight: 0.25
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.50
weight: 0.25
- model: appvoid/palmer-003
parameters:
density: 0.90
weight: 0.40
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["appvoid/palmer-003", "l3utterfly/tinyllama-1.1b-layla-v4", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "vihangd/DopeyTinyLlama-1.1B-v1", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "sreeramajay/TinyLlama-1.1B-orca-v1.0"]} | appvoid/palmer-instruct-test-8 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:appvoid/palmer-003",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:29:48+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* appvoid/palmer-003
* l3utterfly/tinyllama-1.1b-layla-v4
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* vihangd/DopeyTinyLlama-1.1B-v1
* sreeramajay/TinyLlama-1.1B-orca-v1.0
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | null |
# mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF
This model was converted to GGUF format from [`mrfakename/WizardChatML-7B-v0`](https://huggingface.co/mrfakename/WizardChatML-7B-v0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mrfakename/WizardChatML-7B-v0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF --model wizardchatml-7b-v0.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF --model wizardchatml-7b-v0.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m wizardchatml-7b-v0.Q4_K_M.gguf -n 128
```
| {"language": ["en"], "license": "other", "tags": ["llama-cpp", "gguf-my-repo"], "license_name": "apache-2.0-mostly", "pipeline_tag": "text-generation"} | mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"license:other",
"region:us"
] | null | 2024-04-18T00:30:45+00:00 | [] | [
"en"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #text-generation #en #license-other #region-us
|
# mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF
This model was converted to GGUF format from 'mrfakename/WizardChatML-7B-v0' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'mrfakename/WizardChatML-7B-v0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #text-generation #en #license-other #region-us \n",
"# mrfakename/WizardChatML-7B-v0-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'mrfakename/WizardChatML-7B-v0' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
null | null |
# MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF
This model was converted to GGUF format from [`Pirr/pythia-13b-deduped-green_devil`](https://huggingface.co/Pirr/pythia-13b-deduped-green_devil) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Pirr/pythia-13b-deduped-green_devil) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF --model pythia-13b-deduped-green_devil.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF --model pythia-13b-deduped-green_devil.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m pythia-13b-deduped-green_devil.Q4_K_M.gguf -n 128
```
| {"tags": ["llama-cpp", "gguf-my-repo"]} | MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"region:us"
] | null | 2024-04-18T00:33:08+00:00 | [] | [] | TAGS
#gguf #llama-cpp #gguf-my-repo #region-us
|
# MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF
This model was converted to GGUF format from 'Pirr/pythia-13b-deduped-green_devil' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'Pirr/pythia-13b-deduped-green_devil' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #region-us \n",
"# MrAiran/pythia-13b-deduped-green_devil-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'Pirr/pythia-13b-deduped-green_devil' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.0001_ablation_iter_3
This model is a fine-tuned version of [ShenaoZ/0.0001_ablation_iter_2](https://huggingface.co/ShenaoZ/0.0001_ablation_iter_2) on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["updated", "original"], "base_model": "ShenaoZ/0.0001_ablation_iter_2", "model-index": [{"name": "0.0001_ablation_iter_3", "results": []}]} | ShenaoZ/0.0001_ablation_iter_3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:updated",
"dataset:original",
"base_model:ShenaoZ/0.0001_ablation_iter_2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:33:15+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-updated #dataset-original #base_model-ShenaoZ/0.0001_ablation_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# 0.0001_ablation_iter_3
This model is a fine-tuned version of ShenaoZ/0.0001_ablation_iter_2 on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# 0.0001_ablation_iter_3\n\nThis model is a fine-tuned version of ShenaoZ/0.0001_ablation_iter_2 on the updated and the original datasets.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-updated #dataset-original #base_model-ShenaoZ/0.0001_ablation_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# 0.0001_ablation_iter_3\n\nThis model is a fine-tuned version of ShenaoZ/0.0001_ablation_iter_2 on the updated and the original datasets.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] |
null | transformers |
# Uploaded model
- **Developed by:** tas444
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b"} | tas444/fine_tning_Mistral | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:34:52+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: tas444
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text2text-generation | transformers |
Base Model: `google/flan-t5-large`
A seq2seq event triggers tagger trained on the dataset: maven ere
## Usage
Input:
```shell
triggers: I like this model and hate this sentence
```
Output:
```shell
like | hate
```
- Python
### Using .generate()
```python
from transformers import GenerationConfig, T5ForConditionalGeneration, T5Tokenizer
model_name = "ahmeshaf/maven_ere_trigger_seq2seq"
model = T5ForConditionalGeneration.from_pretrained(model_name)
tokenizer = T5Tokenizer.from_pretrained(model_name)
generation_config = GenerationConfig.from_pretrained(model_name)
tokenized_inputs = tokenizer(["I like this model and hate this sentence ."], return_tensors="pt")
outputs = model.generate(**tokenized_inputs, generation_config=generation_config)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['like | hate']
```
### Using pipeline
```python
from transformers import pipeline
srl = pipeline("ahmeshaf/maven_ere_trigger_seq2seq")
print(srl(["I like this model and hate this sentence ."]))
# [{'generated_text': 'like | hate'}]
```
| {"license": "apache-2.0"} | ahmeshaf/maven_ere_trigger_seq2seq | null | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:35:12+00:00 | [] | [] | TAGS
#transformers #safetensors #t5 #text2text-generation #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
Base Model: 'google/flan-t5-large'
A seq2seq event triggers tagger trained on the dataset: maven ere
## Usage
Input:
Output:
- Python
### Using .generate()
### Using pipeline
| [
"## Usage\n\nInput:\n \n\nOutput:\n \n\n- Python",
"### Using .generate()",
"### Using pipeline"
] | [
"TAGS\n#transformers #safetensors #t5 #text2text-generation #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"## Usage\n\nInput:\n \n\nOutput:\n \n\n- Python",
"### Using .generate()",
"### Using pipeline"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-chat-hf_medical_bios_5000_1ep
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"license": "llama2", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "Llama-2-7b-chat-hf_medical_bios_5000_1ep", "results": []}]} | mohsenfayyaz/Llama-2-7b-chat-hf_medical_bios_5000_1ep | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:36:16+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Llama-2-7b-chat-hf_medical_bios_5000_1ep
This model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| [
"# Llama-2-7b-chat-hf_medical_bios_5000_1ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #trl #sft #generated_from_trainer #conversational #base_model-meta-llama/Llama-2-7b-chat-hf #license-llama2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Llama-2-7b-chat-hf_medical_bios_5000_1ep\n\nThis model is a fine-tuned version of meta-llama/Llama-2-7b-chat-hf on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.90
weight: 0.40
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.80
weight: 0.30
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.20
weight: 0.40
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.30
weight: 0.25
- model: appvoid/palmer-003
parameters:
density: 0.85
weight: 0.40
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["vihangd/DopeyTinyLlama-1.1B-v1", "l3utterfly/tinyllama-1.1b-layla-v4", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "appvoid/palmer-003", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "sreeramajay/TinyLlama-1.1B-orca-v1.0"]} | appvoid/palmer-instruct-test-9 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:appvoid/palmer-003",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:36:19+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* vihangd/DopeyTinyLlama-1.1B-v1
* l3utterfly/tinyllama-1.1b-layla-v4
* appvoid/palmer-003
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* sreeramajay/TinyLlama-1.1B-orca-v1.0
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* sreeramajay/TinyLlama-1.1B-orca-v1.0",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
image-segmentation | transformers | # AdaptFormer model fine-tuned on LEVIR-CD
AdaptFormer model fine-tuned on LEVIR-CD at resolution 512x512. It was introduced in the paper [AdaptFormer: An Adaptive Hierarchical Semantic Approach for Change Detection on Remote Sensing Images](https://ieeexplore.ieee.org/document/10497147) by Pang et al. and first released in [this repository](https://github.com/aigzhusmart/AdaptFormer).
## Model description
AdaptFormer, uniquely designed to adaptively interpret hierarchical semantics. Instead of a one-size-fits-all approach, it strategizes differently across three semantic depths: employing straightforward operations for shallow semantics, assimilating spatial data for medium semantics to emphasize detailed interregional changes, and integrating cascaded depthwise attention for in-depth semantics, focusing on high-level representations
Here is how to use this model to classify an image:
```python
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import requests
image_processor = AutoImageProcessor.from_pretrained("deepang/adaptformer-LEVIR-CD")
model = AutoModel.from_pretrained("deepang/adaptformer-LEVIR-CD")
image_A = Image.open(requests.get('https://raw.githubusercontent.com/aigzhusmart/AdaptFormer/main/figures/test_2_1_A.png', stream=True).raw)
image_B = Image.open(requests.get('https://raw.githubusercontent.com/aigzhusmart/AdaptFormer/main/figures/test_2_1_B.png', stream=True).raw)
label = Image.open(requests.get('https://raw.githubusercontent.com/aigzhusmart/AdaptFormer/main/figures/test_2_1_label.png', stream=True).raw)
inputs = preprocessor(images=(image_A, image_B), return_tensors="pt")
outputs = adaptfromer_model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height, width)
pred = logits.argmax(dim=1)[0]
```
### License
The license for this model can be found [here](https://github.com/aigzhusmart/AdaptFormer).
### BibTeX entry and citation info
```bibtex
@article{huang2024adaptformer,
title={AdaptFormer: An Adaptive Hierarchical Semantic Approach for Change Detection on Remote Sensing Images},
author={Huang, Teng and Hong, Yile and Pang, Yan and Liang, Jiaming and Hong, Jie and Huang, Lin and Zhang, Yuan and Jia, Yan and Savi, Patrizia},
journal={IEEE Transactions on Instrumentation and Measurement},
year={2024},
publisher={IEEE}
}
```
| {"license": "mit", "tags": ["vision", "image-segmentation"], "datasets": ["LEVIR-CD"]} | deepang/adaptformer-LEVIR-CD | null | [
"transformers",
"safetensors",
"adaptformer",
"feature-extraction",
"vision",
"image-segmentation",
"custom_code",
"dataset:LEVIR-CD",
"license:mit",
"region:us"
] | null | 2024-04-18T00:36:55+00:00 | [] | [] | TAGS
#transformers #safetensors #adaptformer #feature-extraction #vision #image-segmentation #custom_code #dataset-LEVIR-CD #license-mit #region-us
| # AdaptFormer model fine-tuned on LEVIR-CD
AdaptFormer model fine-tuned on LEVIR-CD at resolution 512x512. It was introduced in the paper AdaptFormer: An Adaptive Hierarchical Semantic Approach for Change Detection on Remote Sensing Images by Pang et al. and first released in this repository.
## Model description
AdaptFormer, uniquely designed to adaptively interpret hierarchical semantics. Instead of a one-size-fits-all approach, it strategizes differently across three semantic depths: employing straightforward operations for shallow semantics, assimilating spatial data for medium semantics to emphasize detailed interregional changes, and integrating cascaded depthwise attention for in-depth semantics, focusing on high-level representations
Here is how to use this model to classify an image:
### License
The license for this model can be found here.
### BibTeX entry and citation info
| [
"# AdaptFormer model fine-tuned on LEVIR-CD\n\nAdaptFormer model fine-tuned on LEVIR-CD at resolution 512x512. It was introduced in the paper AdaptFormer: An Adaptive Hierarchical Semantic Approach for Change Detection on Remote Sensing Images by Pang et al. and first released in this repository.",
"## Model description\n\nAdaptFormer, uniquely designed to adaptively interpret hierarchical semantics. Instead of a one-size-fits-all approach, it strategizes differently across three semantic depths: employing straightforward operations for shallow semantics, assimilating spatial data for medium semantics to emphasize detailed interregional changes, and integrating cascaded depthwise attention for in-depth semantics, focusing on high-level representations\n\nHere is how to use this model to classify an image:",
"### License\n\nThe license for this model can be found here.",
"### BibTeX entry and citation info"
] | [
"TAGS\n#transformers #safetensors #adaptformer #feature-extraction #vision #image-segmentation #custom_code #dataset-LEVIR-CD #license-mit #region-us \n",
"# AdaptFormer model fine-tuned on LEVIR-CD\n\nAdaptFormer model fine-tuned on LEVIR-CD at resolution 512x512. It was introduced in the paper AdaptFormer: An Adaptive Hierarchical Semantic Approach for Change Detection on Remote Sensing Images by Pang et al. and first released in this repository.",
"## Model description\n\nAdaptFormer, uniquely designed to adaptively interpret hierarchical semantics. Instead of a one-size-fits-all approach, it strategizes differently across three semantic depths: employing straightforward operations for shallow semantics, assimilating spatial data for medium semantics to emphasize detailed interregional changes, and integrating cascaded depthwise attention for in-depth semantics, focusing on high-level representations\n\nHere is how to use this model to classify an image:",
"### License\n\nThe license for this model can be found here.",
"### BibTeX entry and citation info"
] |
text-generation | transformers |
# Uploaded model
- **Developed by:** tas444
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl", "sft"], "base_model": "unsloth/mistral-7b"} | tas444/Mistral-7B-PPP-Benchmark-st | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/mistral-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:38:05+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #mistral #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/mistral-7b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: tas444
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/mistral-7b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text-generation | transformers |
# Uploaded model
- **Developed by:** KvrParaskevi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-2-7b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-2-7b-bnb-4bit"} | KvrParaskevi/Llamma2-7b-hotel-16bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/llama-2-7b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:39:38+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #en #base_model-unsloth/llama-2-7b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: KvrParaskevi
- License: apache-2.0
- Finetuned from model : unsloth/llama-2-7b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: KvrParaskevi\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-2-7b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #en #base_model-unsloth/llama-2-7b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: KvrParaskevi\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-2-7b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | prince-canuma/mixtral-8x22b-instruct-oh-4bit | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-18T00:39:46+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #mixtral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #mixtral #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | EinsZwo/mlm_mixed_supertagging_fullset_justbert_alpha025 | null | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:40:24+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | adapter-transformers |
# Adapter `jgrc3/unipelt_adapter_classification_noPre` for roberta-base
An [adapter](https://adapterhub.ml) for the `roberta-base` model that was trained on the [BigTMiami/amazon_helpfulness](https://huggingface.co/datasets/BigTMiami/amazon_helpfulness/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[Adapters](https://github.com/Adapter-Hub/adapters)** library.
## Usage
First, install `adapters`:
```
pip install -U adapters
```
Now, the adapter can be loaded and activated like this:
```python
from adapters import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("roberta-base")
adapter_name = model.load_adapter("jgrc3/unipelt_adapter_classification_noPre", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here --> | {"tags": ["roberta", "adapter-transformers"], "datasets": ["BigTMiami/amazon_helpfulness"]} | jgrc3/unipelt_adapter_classification_noPre | null | [
"adapter-transformers",
"roberta",
"dataset:BigTMiami/amazon_helpfulness",
"region:us"
] | null | 2024-04-18T00:43:42+00:00 | [] | [] | TAGS
#adapter-transformers #roberta #dataset-BigTMiami/amazon_helpfulness #region-us
|
# Adapter 'jgrc3/unipelt_adapter_classification_noPre' for roberta-base
An adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.
This adapter was created for usage with the Adapters library.
## Usage
First, install 'adapters':
Now, the adapter can be loaded and activated like this:
## Architecture & Training
## Evaluation results
| [
"# Adapter 'jgrc3/unipelt_adapter_classification_noPre' for roberta-base\n\nAn adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.\n\nThis adapter was created for usage with the Adapters library.",
"## Usage\n\nFirst, install 'adapters':\n\n\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] | [
"TAGS\n#adapter-transformers #roberta #dataset-BigTMiami/amazon_helpfulness #region-us \n",
"# Adapter 'jgrc3/unipelt_adapter_classification_noPre' for roberta-base\n\nAn adapter for the 'roberta-base' model that was trained on the BigTMiami/amazon_helpfulness dataset and includes a prediction head for classification.\n\nThis adapter was created for usage with the Adapters library.",
"## Usage\n\nFirst, install 'adapters':\n\n\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.90
weight: 0.40
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.90
weight: 0.50
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.20
weight: 0.40
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.30
weight: 0.25
- model: appvoid/palmer-003
parameters:
density: 0.95
weight: 0.50
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["sreeramajay/TinyLlama-1.1B-orca-v1.0", "Josephgflowers/TinyLlama-3T-Cinder-v1.3", "vihangd/DopeyTinyLlama-1.1B-v1", "l3utterfly/tinyllama-1.1b-layla-v4", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T", "appvoid/palmer-003"]} | appvoid/palmer-instruct-test-x | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:appvoid/palmer-003",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:45:02+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
* vihangd/DopeyTinyLlama-1.1B-v1
* l3utterfly/tinyllama-1.1b-layla-v4
* appvoid/palmer-003
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #base_model-appvoid/palmer-003 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3\n* vihangd/DopeyTinyLlama-1.1B-v1\n* l3utterfly/tinyllama-1.1b-layla-v4\n* appvoid/palmer-003",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1) as a base.
### Models Merged
The following models were included in the merge:
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [sreeramajay/TinyLlama-1.1B-orca-v1.0](https://huggingface.co/sreeramajay/TinyLlama-1.1B-orca-v1.0)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
* [Josephgflowers/TinyLlama-3T-Cinder-v1.3](https://huggingface.co/Josephgflowers/TinyLlama-3T-Cinder-v1.3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: vihangd/DopeyTinyLlama-1.1B-v1
#no parameters necessary for base
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.90
weight: 0.50
- model: Josephgflowers/TinyLlama-3T-Cinder-v1.3
parameters:
density: 0.33
weight: 0.40
- model: sreeramajay/TinyLlama-1.1B-orca-v1.0
parameters:
density: 0.33
weight: 0.25
- model: appvoid/palmer-003
parameters:
density: 0.95
weight: 0.50
merge_method: ties
base_model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["appvoid/palmer-003", "sreeramajay/TinyLlama-1.1B-orca-v1.0", "vihangd/DopeyTinyLlama-1.1B-v1", "l3utterfly/tinyllama-1.1b-layla-v4", "Josephgflowers/TinyLlama-3T-Cinder-v1.3"]} | appvoid/palmer-instruct-test-11 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:appvoid/palmer-003",
"base_model:sreeramajay/TinyLlama-1.1B-orca-v1.0",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:46:33+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using vihangd/DopeyTinyLlama-1.1B-v1 as a base.
### Models Merged
The following models were included in the merge:
* appvoid/palmer-003
* sreeramajay/TinyLlama-1.1B-orca-v1.0
* l3utterfly/tinyllama-1.1b-layla-v4
* Josephgflowers/TinyLlama-3T-Cinder-v1.3
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using vihangd/DopeyTinyLlama-1.1B-v1 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-appvoid/palmer-003 #base_model-sreeramajay/TinyLlama-1.1B-orca-v1.0 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-Josephgflowers/TinyLlama-3T-Cinder-v1.3 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using vihangd/DopeyTinyLlama-1.1B-v1 as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* appvoid/palmer-003\n* sreeramajay/TinyLlama-1.1B-orca-v1.0\n* l3utterfly/tinyllama-1.1b-layla-v4\n* Josephgflowers/TinyLlama-3T-Cinder-v1.3",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | thanhnew2001/bank2 | null | [
"transformers",
"safetensors",
"bloom",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-18T00:46:34+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bloom #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bloom #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | null |
# DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF
This model was converted to GGUF format from [`kyujinpy/Sakura-SOLAR-Instruct`](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF --model sakura-solar-instruct.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF --model sakura-solar-instruct.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m sakura-solar-instruct.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-sa-4.0", "tags": ["merge", "llama-cpp", "gguf-my-repo"], "pipeline_tag": "text-generation", "model-index": [{"name": "Sakura-SOLAR-Instruct", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "AI2 Reasoning Challenge (25-Shot)", "type": "ai2_arc", "config": "ARC-Challenge", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "acc_norm", "value": 70.99, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HellaSwag (10-Shot)", "type": "hellaswag", "split": "validation", "args": {"num_few_shot": 10}}, "metrics": [{"type": "acc_norm", "value": 88.42, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "MMLU (5-Shot)", "type": "cais/mmlu", "config": "all", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 66.33, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "TruthfulQA (0-shot)", "type": "truthful_qa", "config": "multiple_choice", "split": "validation", "args": {"num_few_shot": 0}}, "metrics": [{"type": "mc2", "value": 71.79}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Winogrande (5-shot)", "type": "winogrande", "config": "winogrande_xl", "split": "validation", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 83.66, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "GSM8k (5-shot)", "type": "gsm8k", "config": "main", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 65.2, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct", "name": "Open LLM Leaderboard"}}]}]} | DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF | null | [
"gguf",
"merge",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"license:cc-by-nc-sa-4.0",
"model-index",
"region:us"
] | null | 2024-04-18T00:46:43+00:00 | [] | [
"en"
] | TAGS
#gguf #merge #llama-cpp #gguf-my-repo #text-generation #en #license-cc-by-nc-sa-4.0 #model-index #region-us
|
# DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF
This model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #merge #llama-cpp #gguf-my-repo #text-generation #en #license-cc-by-nc-sa-4.0 #model-index #region-us \n",
"# DavidAU/Sakura-SOLAR-Instruct-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | kreas/Llama-2-7b-hf-GPTQ-4bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-18T00:46:53+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | null |
# DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF
This model was converted to GGUF format from [`kyujinpy/Sakura-SOLAR-Instruct-DPO-v2`](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct-DPO-v2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct-DPO-v2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF --model sakura-solar-instruct-dpo-v2.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF --model sakura-solar-instruct-dpo-v2.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m sakura-solar-instruct-dpo-v2.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-sa-4.0", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["argilla/distilabel-math-preference-dpo"], "pipeline_tag": "text-generation", "model-index": [{"name": "Sakura-SOLAR-Instruct-DPO-v2", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "AI2 Reasoning Challenge (25-Shot)", "type": "ai2_arc", "config": "ARC-Challenge", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "acc_norm", "value": 70.9, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HellaSwag (10-Shot)", "type": "hellaswag", "split": "validation", "args": {"num_few_shot": 10}}, "metrics": [{"type": "acc_norm", "value": 88.41, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "MMLU (5-Shot)", "type": "cais/mmlu", "config": "all", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 66.48, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "TruthfulQA (0-shot)", "type": "truthful_qa", "config": "multiple_choice", "split": "validation", "args": {"num_few_shot": 0}}, "metrics": [{"type": "mc2", "value": 71.86}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Winogrande (5-shot)", "type": "winogrande", "config": "winogrande_xl", "split": "validation", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 83.43, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "GSM8k (5-shot)", "type": "gsm8k", "config": "main", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 63.76, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kyujinpy/Sakura-SOLAR-Instruct-DPO-v2", "name": "Open LLM Leaderboard"}}]}]} | DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:argilla/distilabel-math-preference-dpo",
"license:cc-by-nc-sa-4.0",
"model-index",
"region:us"
] | null | 2024-04-18T00:47:47+00:00 | [] | [
"en"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-argilla/distilabel-math-preference-dpo #license-cc-by-nc-sa-4.0 #model-index #region-us
|
# DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF
This model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-argilla/distilabel-math-preference-dpo #license-cc-by-nc-sa-4.0 #model-index #region-us \n",
"# DavidAU/Sakura-SOLAR-Instruct-DPO-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/Sakura-SOLAR-Instruct-DPO-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-generation | transformers |
# DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF
This model was converted to GGUF format from [`kyujinpy/SOLAR-Platypus-10.7B-v2`](https://huggingface.co/kyujinpy/SOLAR-Platypus-10.7B-v2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/kyujinpy/SOLAR-Platypus-10.7B-v2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF --model solar-platypus-10.7b-v2.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF --model solar-platypus-10.7b-v2.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m solar-platypus-10.7b-v2.Q8_0.gguf -n 128
```
| {"language": ["en"], "license": "cc-by-nc-sa-4.0", "library_name": "transformers", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["garage-bAInd/Open-Platypus"], "pipeline_tag": "text-generation"} | DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF | null | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:garage-bAInd/Open-Platypus",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:48:50+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-garage-bAInd/Open-Platypus #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us
|
# DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF
This model was converted to GGUF format from 'kyujinpy/SOLAR-Platypus-10.7B-v2' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/SOLAR-Platypus-10.7B-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#transformers #gguf #llama-cpp #gguf-my-repo #text-generation #en #dataset-garage-bAInd/Open-Platypus #license-cc-by-nc-sa-4.0 #endpoints_compatible #region-us \n",
"# DavidAU/SOLAR-Platypus-10.7B-v2-Q8_0-GGUF\nThis model was converted to GGUF format from 'kyujinpy/SOLAR-Platypus-10.7B-v2' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama2-chat_10000_200
This model is a fine-tuned version of [unsloth/llama-2-7b-chat-bnb-4bit](https://huggingface.co/unsloth/llama-2-7b-chat-bnb-4bit) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 4
- seed: 3407
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.379 | 0.31 | 48 | 1.0400 |
| 1.059 | 0.61 | 96 | 1.0091 |
| 1.0438 | 0.92 | 144 | 0.9990 |
| 0.9934 | 1.23 | 192 | 0.9968 |
| 0.9749 | 1.54 | 240 | 0.9926 |
| 0.9778 | 1.84 | 288 | 0.9862 |
| 0.9443 | 2.15 | 336 | 1.0046 |
| 0.8913 | 2.46 | 384 | 1.0017 |
| 0.8908 | 2.76 | 432 | 0.9996 |
| 0.8708 | 3.07 | 480 | 1.0339 |
| 0.7958 | 3.38 | 528 | 1.0386 |
| 0.8025 | 3.69 | 576 | 1.0386 |
| 0.8099 | 3.99 | 624 | 1.0386 |
| 0.7191 | 4.3 | 672 | 1.0913 |
| 0.7138 | 4.61 | 720 | 1.0926 |
| 0.723 | 4.92 | 768 | 1.0901 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.16.0
- Tokenizers 0.15.2 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "unsloth", "generated_from_trainer"], "base_model": "unsloth/llama-2-7b-chat-bnb-4bit", "model-index": [{"name": "llama2-chat_10000_200", "results": []}]} | Angelectronic/llama2-chat_10000_200 | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"unsloth",
"generated_from_trainer",
"base_model:unsloth/llama-2-7b-chat-bnb-4bit",
"license:apache-2.0",
"region:us"
] | null | 2024-04-18T00:51:24+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #unsloth #generated_from_trainer #base_model-unsloth/llama-2-7b-chat-bnb-4bit #license-apache-2.0 #region-us
| llama2-chat\_10000\_200
=======================
This model is a fine-tuned version of unsloth/llama-2-7b-chat-bnb-4bit on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0901
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 8
* eval\_batch\_size: 4
* seed: 3407
* gradient\_accumulation\_steps: 8
* total\_train\_batch\_size: 64
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 5
* num\_epochs: 5
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.39.3
* Pytorch 2.2.2+cu121
* Datasets 2.16.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 4\n* seed: 3407\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 64\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 5\n* num\\_epochs: 5\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.16.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #unsloth #generated_from_trainer #base_model-unsloth/llama-2-7b-chat-bnb-4bit #license-apache-2.0 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 4\n* seed: 3407\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 64\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 5\n* num\\_epochs: 5\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.39.3\n* Pytorch 2.2.2+cu121\n* Datasets 2.16.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers | This is a RoBERTa-base model finetuned on 8,000 English podcast transcripts to detect political leanings (leftist or rightist).
It will output label 1 as chance for rightist text, and label 0 as chance of leftist text.
Note: Please make sure to undergo rigorous testing before deploying this model for serious research. Also, it is recommendable to finetune it for downstream tasks instead of using it for direct inference, because of a limited finetuning dataset size and biased data.
| {"license": "apache-2.0"} | bowenyi/political-learning-RoBERTa | null | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:52:04+00:00 | [] | [] | TAGS
#transformers #safetensors #roberta #text-classification #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| This is a RoBERTa-base model finetuned on 8,000 English podcast transcripts to detect political leanings (leftist or rightist).
It will output label 1 as chance for rightist text, and label 0 as chance of leftist text.
Note: Please make sure to undergo rigorous testing before deploying this model for serious research. Also, it is recommendable to finetune it for downstream tasks instead of using it for direct inference, because of a limited finetuning dataset size and biased data.
| [] | [
"TAGS\n#transformers #safetensors #roberta #text-classification #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
null | null |
Command to merge back (do within llama.cpp folder):
```
./gguf-split --merge /workspace/Franziska-Maxtral-8x22B-v1/Split-Franziska-Maxtral-8x22B-v1.q4_K_M-00001-of-00009.gguf /workspace/Franziska-Maxtral-8x22B-v1.q4_K_M.gguf
```
one gguf because its a testing model, fits in 2 A6000s fully at 16k context.
main info: https://huggingface.co/Sao10K/Franziska-Maxtral-8x22B-v1 | {} | Sao10K/Franziska-Maxtral-8x22B-v1-GGUF | null | [
"gguf",
"region:us"
] | null | 2024-04-18T00:52:54+00:00 | [] | [] | TAGS
#gguf #region-us
|
Command to merge back (do within URL folder):
one gguf because its a testing model, fits in 2 A6000s fully at 16k context.
main info: URL | [] | [
"TAGS\n#gguf #region-us \n"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-Instruct-v0.2_esnli_5000_1ep
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"tags": ["trl", "sft", "generated_from_trainer"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "Mistral-7B-Instruct-v0.2_esnli_5000_1ep", "results": []}]} | mohsenfayyaz/Mistral-7B-Instruct-v0.2_esnli_5000_1ep | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:53:54+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #trl #sft #generated_from_trainer #conversational #base_model-mistralai/Mistral-7B-Instruct-v0.2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Mistral-7B-Instruct-v0.2_esnli_5000_1ep
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| [
"# Mistral-7B-Instruct-v0.2_esnli_5000_1ep\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #trl #sft #generated_from_trainer #conversational #base_model-mistralai/Mistral-7B-Instruct-v0.2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Mistral-7B-Instruct-v0.2_esnli_5000_1ep\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] |
null | transformers |
# Uploaded model
- **Developed by:** tas444
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "gguf"], "base_model": "unsloth/mistral-7b"} | tas444/mistral-PPP-GGUF | null | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/mistral-7b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T00:54:53+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #mistral #text-generation-inference #unsloth #en #base_model-unsloth/mistral-7b #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: tas444
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #gguf #mistral #text-generation-inference #unsloth #en #base_model-unsloth/mistral-7b #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: tas444\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text-generation | transformers |
# test_tiny_mixtral_only_router
test_tiny_mixtral_only_router is a Mixure of Experts (MoE) made with the following models using a modified version of mergekit.
* [openaccess-ai-collective/tiny-mistral](https://huggingface.co/openaccess-ai-collective/tiny-mistral)
* [openaccess-ai-collective/tiny-mistral](https://huggingface.co/openaccess-ai-collective/tiny-mistral)
* [openaccess-ai-collective/tiny-mistral](https://huggingface.co/openaccess-ai-collective/tiny-mistral)
* [openaccess-ai-collective/tiny-mistral](https://huggingface.co/openaccess-ai-collective/tiny-mistral)
## 🧩 Configuration
```yaml
base_model: openaccess-ai-collective/tiny-mistral
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: openaccess-ai-collective/tiny-mistral
positive_prompts:
- "math"
# You can add negative_prompts if needed
- source_model: openaccess-ai-collective/tiny-mistral
positive_prompts:
- "science"
- source_model: openaccess-ai-collective/tiny-mistral
positive_prompts:
- "writing"
# You can add negative_prompts if needed
- source_model: openaccess-ai-collective/tiny-mistral
positive_prompts:
- "general"
```
This is a test version of arcee-ai's hidden state model. It is a router for a frankenMoE instead of the entire MoE itself | {"license": "apache-2.0", "tags": ["moe", "frankenmoe", "merge", "mergekit", "lazymergekit", "openaccess-ai-collective/tiny-mistral"], "base_model": ["openaccess-ai-collective/tiny-mistral", "openaccess-ai-collective/tiny-mistral", "openaccess-ai-collective/tiny-mistral", "openaccess-ai-collective/tiny-mistral"]} | JSpergel/test_tiny_mixtral_only_router | null | [
"transformers",
"mixtral",
"text-generation",
"moe",
"frankenmoe",
"merge",
"mergekit",
"lazymergekit",
"openaccess-ai-collective/tiny-mistral",
"base_model:openaccess-ai-collective/tiny-mistral",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:55:49+00:00 | [] | [] | TAGS
#transformers #mixtral #text-generation #moe #frankenmoe #merge #mergekit #lazymergekit #openaccess-ai-collective/tiny-mistral #base_model-openaccess-ai-collective/tiny-mistral #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# test_tiny_mixtral_only_router
test_tiny_mixtral_only_router is a Mixure of Experts (MoE) made with the following models using a modified version of mergekit.
* openaccess-ai-collective/tiny-mistral
* openaccess-ai-collective/tiny-mistral
* openaccess-ai-collective/tiny-mistral
* openaccess-ai-collective/tiny-mistral
## Configuration
This is a test version of arcee-ai's hidden state model. It is a router for a frankenMoE instead of the entire MoE itself | [
"# test_tiny_mixtral_only_router\n\ntest_tiny_mixtral_only_router is a Mixure of Experts (MoE) made with the following models using a modified version of mergekit.\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral",
"## Configuration\n\n\nThis is a test version of arcee-ai's hidden state model. It is a router for a frankenMoE instead of the entire MoE itself"
] | [
"TAGS\n#transformers #mixtral #text-generation #moe #frankenmoe #merge #mergekit #lazymergekit #openaccess-ai-collective/tiny-mistral #base_model-openaccess-ai-collective/tiny-mistral #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# test_tiny_mixtral_only_router\n\ntest_tiny_mixtral_only_router is a Mixure of Experts (MoE) made with the following models using a modified version of mergekit.\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral\n* openaccess-ai-collective/tiny-mistral",
"## Configuration\n\n\nThis is a test version of arcee-ai's hidden state model. It is a router for a frankenMoE instead of the entire MoE itself"
] |
text-generation | transformers | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) as a base.
### Models Merged
The following models were included in the merge:
* [vihangd/DopeyTinyLlama-1.1B-v1](https://huggingface.co/vihangd/DopeyTinyLlama-1.1B-v1)
* [appvoid/palmer-003](https://huggingface.co/appvoid/palmer-003)
* [l3utterfly/tinyllama-1.1b-layla-v4](https://huggingface.co/l3utterfly/tinyllama-1.1b-layla-v4)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
#no parameters necessary for base model
- model: vihangd/DopeyTinyLlama-1.1B-v1
parameters:
density: 0.70
weight: 0.40
- model: l3utterfly/tinyllama-1.1b-layla-v4
parameters:
density: 0.70
weight: 0.50
- model: appvoid/palmer-003
parameters:
density: 0.80
weight: 0.50
merge_method: ties
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
parameters:
normalize: true
int8_mask: true
dtype: float16
```
| {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["vihangd/DopeyTinyLlama-1.1B-v1", "appvoid/palmer-003", "l3utterfly/tinyllama-1.1b-layla-v4", "TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T"]} | appvoid/palmer-instruct-test-12 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:vihangd/DopeyTinyLlama-1.1B-v1",
"base_model:appvoid/palmer-003",
"base_model:l3utterfly/tinyllama-1.1b-layla-v4",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-18T00:56:40+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.
### Models Merged
The following models were included in the merge:
* vihangd/DopeyTinyLlama-1.1B-v1
* appvoid/palmer-003
* l3utterfly/tinyllama-1.1b-layla-v4
### Configuration
The following YAML configuration was used to produce this model:
| [
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #arxiv-2306.01708 #base_model-vihangd/DopeyTinyLlama-1.1B-v1 #base_model-appvoid/palmer-003 #base_model-l3utterfly/tinyllama-1.1b-layla-v4 #base_model-TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* vihangd/DopeyTinyLlama-1.1B-v1\n* appvoid/palmer-003\n* l3utterfly/tinyllama-1.1b-layla-v4",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/NotAiLOL/Boundary-4x7b-MoE
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Boundary-4x7b-MoE-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q2_K.gguf) | Q2_K | 8.9 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.IQ3_XS.gguf) | IQ3_XS | 10.0 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q3_K_S.gguf) | Q3_K_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.IQ3_S.gguf) | IQ3_S | 10.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.IQ3_M.gguf) | IQ3_M | 10.7 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q3_K_M.gguf) | Q3_K_M | 11.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q3_K_L.gguf) | Q3_K_L | 12.6 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.IQ4_XS.gguf) | IQ4_XS | 13.1 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q4_K_S.gguf) | Q4_K_S | 13.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q4_K_M.gguf) | Q4_K_M | 14.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q5_K_S.gguf) | Q5_K_S | 16.7 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q5_K_M.gguf) | Q5_K_M | 17.2 | |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q6_K.gguf) | Q6_K | 19.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Boundary-4x7b-MoE-GGUF/resolve/main/Boundary-4x7b-MoE.Q8_0.gguf) | Q8_0 | 25.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["moe", "merge", "mergekit", "HuggingFaceH4/zephyr-7b-beta", "mistralai/Mistral-7B-Instruct-v0.2", "teknium/OpenHermes-2.5-Mistral-7B", "meta-math/MetaMath-Mistral-7B"], "base_model": "NotAiLOL/Boundary-4x7b-MoE", "quantized_by": "mradermacher"} | mradermacher/Boundary-4x7b-MoE-GGUF | null | [
"transformers",
"gguf",
"moe",
"merge",
"mergekit",
"HuggingFaceH4/zephyr-7b-beta",
"mistralai/Mistral-7B-Instruct-v0.2",
"teknium/OpenHermes-2.5-Mistral-7B",
"meta-math/MetaMath-Mistral-7B",
"en",
"base_model:NotAiLOL/Boundary-4x7b-MoE",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-18T01:00:35+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #moe #merge #mergekit #HuggingFaceH4/zephyr-7b-beta #mistralai/Mistral-7B-Instruct-v0.2 #teknium/OpenHermes-2.5-Mistral-7B #meta-math/MetaMath-Mistral-7B #en #base_model-NotAiLOL/Boundary-4x7b-MoE #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #moe #merge #mergekit #HuggingFaceH4/zephyr-7b-beta #mistralai/Mistral-7B-Instruct-v0.2 #teknium/OpenHermes-2.5-Mistral-7B #meta-math/MetaMath-Mistral-7B #en #base_model-NotAiLOL/Boundary-4x7b-MoE #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.