
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
listlengths 0
201
| languages
listlengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
listlengths 0
722
| processed_texts
listlengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
null | null |
# NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF
This model was converted to GGUF format from [`NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE`](https://huggingface.co/NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF --model boundary-solar-chat-2x10.7b-moe.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF --model boundary-solar-chat-2x10.7b-moe.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m boundary-solar-chat-2x10.7b-moe.Q4_K_M.gguf -n 128
```
| {"license": "apache-2.0", "tags": ["moe", "merge", "mergekit", "NousResearch/Nous-Hermes-2-SOLAR-10.7B", "upstage/SOLAR-10.7B-Instruct-v1.0", "llama", "Llama", "llama-cpp", "gguf-my-repo"], "base_model": ["NousResearch/Nous-Hermes-2-SOLAR-10.7B", "upstage/SOLAR-10.7B-Instruct-v1.0"]} | NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF | null | [
"gguf",
"moe",
"merge",
"mergekit",
"NousResearch/Nous-Hermes-2-SOLAR-10.7B",
"upstage/SOLAR-10.7B-Instruct-v1.0",
"llama",
"Llama",
"llama-cpp",
"gguf-my-repo",
"base_model:NousResearch/Nous-Hermes-2-SOLAR-10.7B",
"base_model:upstage/SOLAR-10.7B-Instruct-v1.0",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T09:18:13+00:00 | [] | [] | TAGS
#gguf #moe #merge #mergekit #NousResearch/Nous-Hermes-2-SOLAR-10.7B #upstage/SOLAR-10.7B-Instruct-v1.0 #llama #Llama #llama-cpp #gguf-my-repo #base_model-NousResearch/Nous-Hermes-2-SOLAR-10.7B #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-apache-2.0 #region-us
|
# NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF
This model was converted to GGUF format from 'NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #moe #merge #mergekit #NousResearch/Nous-Hermes-2-SOLAR-10.7B #upstage/SOLAR-10.7B-Instruct-v1.0 #llama #Llama #llama-cpp #gguf-my-repo #base_model-NousResearch/Nous-Hermes-2-SOLAR-10.7B #base_model-upstage/SOLAR-10.7B-Instruct-v1.0 #license-apache-2.0 #region-us \n",
"# NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE-Q4_K_M-GGUF\nThis model was converted to GGUF format from 'NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_9 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:18:26+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null | # RF*diffusion*
<!--
<img width="1115" alt="Screen Shot 2023-01-19 at 5 56 33 PM" src="https://user-images.githubusercontent.com/56419265/213588200-f8f44dba-276e-4dd2-b844-15acc441458d.png">
-->
<p align="center">
<img src="./img/diffusion_protein_gradient_2.jpg" alt="alt text" width="1100px" align="middle"/>
</p>
*Image: Ian C. Haydon / UW Institute for Protein Design*
## Description
RFdiffusion is an open source method for structure generation, with or without conditional information (a motif, target etc). It can perform a whole range of protein design challenges as we have outlined in [the RFdiffusion paper](https://www.biorxiv.org/content/10.1101/2022.12.09.519842v1).
**Things Diffusion can do**
- Motif Scaffolding
- Unconditional protein generation
- Symmetric unconditional generation (cyclic, dihedral and tetrahedral symmetries currently implemented, more coming!)
- Symmetric motif scaffolding
- Binder design
- Design diversification ("partial diffusion", sampling around a design)
----
# Table of contents
- [RF*diffusion*](#rfdiffusion)
- [Description](#description)
- [Table of contents](#table-of-contents)
- [Getting started / installation](#getting-started--installation)
- [Conda Install SE3-Transformer](#conda-install-se3-transformer)
- [Get PPI Scaffold Examples](#get-ppi-scaffold-examples)
- [Usage](#usage)
- [Running the diffusion script](#running-the-diffusion-script)
- [Basic execution - an unconditional monomer](#basic-execution---an-unconditional-monomer)
- [Motif Scaffolding](#motif-scaffolding)
- [The "active site" model holds very small motifs in place](#the-active-site-model-holds-very-small-motifs-in-place)
- [The `inpaint_seq` flag](#the-inpaint_seq-flag)
- [A note on `diffuser.T`](#a-note-on-diffusert)
- [Partial diffusion](#partial-diffusion)
- [Binder Design](#binder-design)
- [Practical Considerations for Binder Design](#practical-considerations-for-binder-design)
- [Fold Conditioning](#fold-conditioning)
- [Generation of Symmetric Oligomers](#generation-of-symmetric-oligomers)
- [Using Auxiliary Potentials](#using-auxiliary-potentials)
- [Symmetric Motif Scaffolding.](#symmetric-motif-scaffolding)
- [A Note on Model Weights](#a-note-on-model-weights)
- [Things you might want to play with at inference time](#things-you-might-want-to-play-with-at-inference-time)
- [Understanding the output files](#understanding-the-output-files)
- [Docker](#docker)
- [Conclusion](#conclusion)
# Getting started / installation
Thanks to Sergey Ovchinnikov, RFdiffusion is available as a [Google Colab Notebook](https://colab.research.google.com/github/sokrypton/ColabDesign/blob/v1.1.1/rf/examples/diffusion.ipynb) if you would like to run it there!
We strongly recommend reading this README carefully before getting started with RFdiffusion, and working through some of the examples in the Colab Notebook.
If you want to set up RFdiffusion locally, follow the steps below:
To get started using RFdiffusion, clone the repo:
```
git clone https://github.com/RosettaCommons/RFdiffusion.git
```
You'll then need to download the model weights into the RFDiffusion directory.
```
cd RFdiffusion
mkdir models && cd models
wget http://files.ipd.uw.edu/pub/RFdiffusion/6f5902ac237024bdd0c176cb93063dc4/Base_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/e29311f6f1bf1af907f9ef9f44b8328b/Complex_base_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/60f09a193fb5e5ccdc4980417708dbab/Complex_Fold_base_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/74f51cfb8b440f50d70878e05361d8f0/InpaintSeq_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/76d00716416567174cdb7ca96e208296/InpaintSeq_Fold_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/5532d2e1f3a4738decd58b19d633b3c3/ActiveSite_ckpt.pt
wget http://files.ipd.uw.edu/pub/RFdiffusion/12fc204edeae5b57713c5ad7dcb97d39/Base_epoch8_ckpt.pt
Optional:
wget http://files.ipd.uw.edu/pub/RFdiffusion/f572d396fae9206628714fb2ce00f72e/Complex_beta_ckpt.pt
# original structure prediction weights
wget http://files.ipd.uw.edu/pub/RFdiffusion/1befcb9b28e2f778f53d47f18b7597fa/RF_structure_prediction_weights.pt
```
### Conda Install SE3-Transformer
Ensure that you have either [Anaconda or Miniconda](https://conda.io/projects/conda/en/latest/user-guide/install/index.html) installed.
You also need to install [NVIDIA's implementation of SE(3)-Transformers](https://developer.nvidia.com/blog/accelerating-se3-transformers-training-using-an-nvidia-open-source-model-implementation/) Here is how to install the NVIDIA SE(3)-Transformer code:
```
conda env create -f env/SE3nv.yml
conda activate SE3nv
cd env/SE3Transformer
pip install --no-cache-dir -r requirements.txt
python setup.py install
cd ../.. # change into the root directory of the repository
pip install -e . # install the rfdiffusion module from the root of the repository
```
Anytime you run diffusion you should be sure to activate this conda environment by running the following command:
```
conda activate SE3nv
```
Total setup should take less than 30 minutes on a standard desktop computer.
Note: Due to the variation in GPU types and drivers that users have access to, we are not able to make one environment that will run on all setups. As such, we are only providing a yml file with support for CUDA 11.1 and leaving it to each user to customize it to work on their setups. This customization will involve changing the cudatoolkit and (possibly) the PyTorch version specified in the yml file.
---
### Get PPI Scaffold Examples
To run the scaffolded protein binder design (PPI) examples, we have provided some example scaffold files (`examples/ppi_scaffolds_subset.tar.gz`).
You'll need to untar this:
```
tar -xvf examples/ppi_scaffolds_subset.tar.gz -C examples/
```
We will explain what these files are and how to use them in the Fold Conditioning section.
----
# Usage
In this section we will demonstrate how to run diffusion.
<p align="center">
<img src="./img/main.png" alt="alt text" width="1100px" align="middle"/>
</p>
### Running the diffusion script
The actual script you will execute is called `scripts/run_inference.py`. There are many ways to run it, governed by hydra configs.
[Hydra configs](https://hydra.cc/docs/configure_hydra/intro/) are a nice way of being able to specify many different options, with sensible defaults drawn *directly* from the model checkpoint, so inference should always, by default, match training.
What this means is that the default values in `config/inference/base.yml` might not match the actual values used during inference, with a specific checkpoint. This is all handled under the hood.
---
### Basic execution - an unconditional monomer
<img src="./img/cropped_uncond.png" alt="alt text" width="400px" align="right"/>
Let's first look at how you would do unconditional design of a protein of length 150aa.
For this, we just need to specify three things:
1. The length of the protein
2. The location where we want to write files to
3. The number of designs we want
```
./scripts/run_inference.py 'contigmap.contigs=[150-150]' inference.output_prefix=test_outputs/test inference.num_designs=10
```
Let's look at this in detail.
Firstly, what is `contigmap.contigs`?
Hydra configs tell the inference script how it should be run. To keep things organised, the config has different sub-configs, one of them being `contigmap`, which pertains to everything related to the contig string (that defines the protein being built).
Take a look at the config file if this isn't clear: `configs/inference/base.yml`
Anything in the config can be overwritten manually from the command line. You could, for example, change how the diffuser works:
```
diffuser.crd_scale=0.5
```
... but don't do this unless you really know what you're doing!!
Now, what does `'contigmap.contigs=[150-150]'` mean?
To those who have used RFjoint inpainting, this might look familiar, but a little bit different. Diffusion, in fact, uses the identical 'contig mapper' as inpainting, except that, because we're using hydra, we have to give this to the model in a different way. The contig string has to be passed as a single-item in a list, rather than as a string, for hydra reasons and the entire argument MUST be enclosed in `''` so that the commandline does not attempt to parse any of the special characters.
The contig string allows you to specify a length range, but here, we just want a protein of 150aa in length, so you just specify [150-150]
This will then run 10 diffusion trajectories, saving the outputs to your specified output folder.
NB the first time you run RFdiffusion, it will take a while 'Calculating IGSO3'. Once it has done this, it'll be cached for future reference though! For an additional example of unconditional monomer generation, take a look at `./examples/design_unconditional.sh` in the repo!
---
### Motif Scaffolding
<!--
<p align="center">
<img src="./img/motif.png" alt="alt text" width="700px" align="middle"/>
</p>
-->
RFdiffusion can be used to scaffold motifs, in a manner akin to [Constrained Hallucination and RFjoint Inpainting](https://www.science.org/doi/10.1126/science.abn2100#:~:text=The%20binding%20and%20catalytic%20functions%20of%20proteins%20are,the%20fold%20or%20secondary%20structure%20of%20the%20scaffold.). In general, RFdiffusion significantly outperforms both Constrained Hallucination and RFjoint Inpainting.
<p align="center">
<img src="./img/motif.png" alt="alt text" width="700px" align="middle"/>
</p>
When scaffolding protein motifs, we need a way of specifying that we want to scaffold some particular protein input (one or more segments from a `.pdb` file), and to be able to specify how we want these connected, and by how many residues, in the new scaffolded protein. What's more, we want to be able to sample different lengths of connecting protein, as we generally don't know *a priori* precisely how many residues we'll need to best scaffold a motif. This job of specifying inputs is handled by contigs, governed by the contigmap config in the hydra config. For those familiar with Constrained Hallucination or RFjoint Inpainting, the logic is very similar.
Briefly:
- Anything prefixed by a letter indicates that this is a motif, with the letter corresponding to the chain letter in the input pdb files. E.g. A10-25 pertains to residues ('A',10),('A',11)...('A',25) in the corresponding input pdb
- Anything not prefixed by a letter indicates protein *to be built*. This can be input as a length range. These length ranges are randomly sampled each iteration of RFdiffusion inference.
- To specify chain breaks, we use `/0 `.
In more detail, if we want to scaffold a motif, the input is just like RFjoint Inpainting, except needing to navigate the hydra config input. If we want to scaffold residues 10-25 on chain A a pdb, this would be done with `'contigmap.contigs=[5-15/A10-25/30-40]'`. This asks RFdiffusion to build 5-15 residues (randomly sampled at each inference cycle) N-terminally of A10-25 from the input pdb, followed by 30-40 residues (again, randomly sampled) to its C-terminus. If we wanted to ensure the length was always e.g. 55 residues, this can be specified with `contigmap.length=55-55`. You need to obviously also provide a path to your pdb file: `inference.input_pdb=path/to/file.pdb`. It doesn't matter if your input pdb has residues you *don't* want to scaffold - the contig map defines which residues in the pdb are actually used as the "motif". In other words, even if your pdb files has a B chain, and other residues on the A chain, *only* A10-25 will be provided to RFdiffusion.
To specify that we want to inpaint in the presence of a separate chain, this can be done as follows:
```
'contigmap.contigs=[5-15/A10-25/30-40/0 B1-100]'
```
Look at this carefully. `/0 ` is the indicator that we want a chain break. NOTE, the space is important here. This tells the diffusion model to add a big residue jump (200aa) to the input, so that the model sees the first chain as being on a separate chain to the second.
An example of motif scaffolding can be found in `./examples/design_motifscaffolding.sh`.
### The "active site" model holds very small motifs in place
In the RFdiffusion preprint we noted that for very small motifs, RFdiffusion has the tendency to not keep them perfectly fixed in the output. Therefore, for scaffolding minimalist sites such as enzyme active sites, we fine-tuned RFdiffusion on examples similar to these tasks, allowing it to hold smaller motifs better in place, and better generate *in silico* successes. If your input functional motif is very small, we reccomend using this model, which can easily be specified using the following syntax:
`inference.ckpt_override_path=models/ActiveSite_ckpt.pt`
### The `inpaint_seq` flag
For those familiar with RFjoint Inpainting, the contigmap.inpaint_seq input is equivalent. The idea is that often, when, for example, fusing two proteins, residues that were on the surface of a protein (and are therefore likely polar), now need to be packed into the 'core' of the protein. We therefore want them to become hydrophobic residues. What we can do, rather than directly mutating them to hydrophobics, is to mask their sequence identity, and allow RFdiffusion to implicitly reason over their sequence, and better pack against them. This requires a different model than the 'base' diffusion model, that has been trained to understand this paradigm, but this is automatically handled by the inference script (you don't need to do anything).
To specify amino acids whose sequence should be hidden, use the following syntax:
```
'contigmap.inpaint_seq=[A1/A30-40]'
```
Here, we're masking the residue identity of residue A1, and all residues between A30 and A40 (inclusive).
An example of executing motif scaffolding with the `contigmap.inpaint_seq` flag is located in `./examples/design_motifscaffolding_inpaintseq.sh`
### A note on `diffuser.T`
RFdiffusion was originally trained with 200 discrete timesteps. However, recent improvements have allowed us to reduce the number of timesteps we need to use at inference time. In many cases, running with as few as approximately 20 steps provides outputs of equivalent *in silico* quality to running with 200 steps (providing a 10X speedup). The default is now set to 50 steps. Noting this is important for understanding the partial diffusion, described below.
---
### Partial diffusion
Something we can do with diffusion is to partially noise and de-noise a structure, to get some diversity around a general fold. This can work really nicely (see [Vazquez-Torres et al., BioRxiv 2022](https://www.biorxiv.org/content/10.1101/2022.12.10.519862v4.abstract)).
This is specified by using the diffuser.parial_T input, and setting a timestep to 'noise' to.
<p align="center">
<img src="./img/partial.png" alt="alt text" width="800px" align="middle"/>
</p>
More noise == more diversity. In Vazquez-Torres et al., 2022, we typically used `diffuser.partial_T` of approximately 80, but this was with respect to the 200 timesteps we were using. Now that the default `diffuser.T` is 50, you will need to adjust diffuser.partial_T accordingly. E.g. now that `diffuser.T=50`, the equivalent of 80 noising steps is `diffuser.partial_T=20`. We strongly recommend sampling different values for `partial_T` however, to find the best parameters for your specific problem.
When doing partial diffusion, because we are now diffusing from a known structure, this creates certain constraints. You can still use the contig input, but *this has to yield a contig string exactly the same length as the input protein*. E.g. if you have a binder:target complex, and you want to diversify the binder (length 100, chain A), you would need to input something like this:
```
'contigmap.contigs=[100-100/0 B1-150]' diffuser.partial_T=20
```
The reason for this is that, if your input protein was only 80 amino acids, but you've specified a desired length of 100, we don't know where to diffuse those extra 20 amino acids from, and hence, they will not lie in the distribution that RFdiffusion has learned to denoise from.
An example of partial diffusion can be found in `./examples/design_partialdiffusion.sh`!
You can also keep parts of the sequence of the diffused chain fixed, if you want. An example of why you might want to do this is in the context of helical peptide binding. If you've threaded a helical peptide sequence onto an ideal helix, and now want to diversify the complex, allowing the helix to be predicted now not as an ideal helix, you might do something like:
```
'contigmap.contigs=[100-100/0 20-20]' 'contigmap.provide_seq=[100-119]' diffuser.partial_T=10
```
In this case, the 20aa chain is the helical peptide. The `contigmap.provide_seq` input is zero-indexed, and you can provide a range (so 100-119 is an inclusive range, unmasking the whole sequence of the peptide). Multiple sequence ranges can be provided separated by a comma, e.g. `'contigmap.provide_seq=[172-177,200-205]'`.
Note that the provide_seq option requires using a different model checkpoint, but this is automatically handled by the inference script.
An example of partial diffusion with providing sequence in diffused regions can be found in `./examples/design_partialdiffusion_withseq.sh`. The same example specifying multiple sequence ranges can be found in `./examples/design_partialdiffusion_multipleseq.sh`.
---
### Binder Design
Hopefully, it's now obvious how you might make a binder with diffusion! Indeed, RFdiffusion shows excellent *in silico* and experimental ability to design *de novo* binders.
<p align="center">
<img src="./img/binder.png" alt="alt text" width="950px" align="middle"/>
</p>
If chain B is your target, then you could do it like this:
```
./scripts/run_inference.py 'contigmap.contigs=[B1-100/0 100-100]' inference.output_prefix=test_outputs/binder_test inference.num_designs=10
```
This will generate 100 residue long binders to residues 1-100 of chain B.
However, this probably isn't the best way of making binders. Because diffusion is somewhat computationally-intensive, we need to try and make it as fast as possible. Providing the whole of your target, uncropped, is going to make diffusion very slow if your target is big (and most targets-of-interest, such as cell-surface receptors tend to be *very* big). One tried-and-true method to speed up binder design is to crop the target protein around the desired interface location. BUT! This creates a problem: if you crop your target and potentially expose hydrophobic core residues which were buried before the crop, how can you guarantee the binder will go to the intended interface site on the surface of the target, and not target the tantalizing hydrophobic patch you have just artificially created?
We solve this issue by providing the model with what we call "hotspot residues". The complex models we refer to earlier in this README file have all been trained with hotspot residues, in this training regime, during each example, the model is told (some of) the residues on the target protein which contact the target (i.e., resides that are part of the interface). The model readily learns that it should be making an interface which involved these hotspot residues. At inference time then, we can provide our own hotspot residues to define a region which the binder must contact. These are specified like this: `'ppi.hotspot_res=[A30,A33,A34]'`, where `A` is the chain ID in the input pdb file of the hotspot residue and the number is the residue index in the input pdb file of the hotspot residue.
Finally, it has been observed that the default RFdiffusion model often generates mostly helical binders. These have high computational and experimental success rates. However, there may be cases where other kinds of topologies may be desired. For this, we include a "beta" model, which generates a greater diversity of topologies, but has not been extensively experimentally validated. Try this at your own risk:
```
inference.ckpt_override_path=models/Complex_beta_ckpt.pt
```
An example of binder design with RFdiffusion can be found in `./examples/design_ppi.sh`.
---
## Practical Considerations for Binder Design
RFdiffusion is an extremely powerful binder design tool but it is not magic. In this section we will walk through some common pitfalls in RFdiffusion binder design and offer advice on how to get the most out of this method.
### Selecting a Target Site
Not every site on a target protein is a good candidate for binder design. For a site to be an attractive candidate for binding it should have >~3 hydrophobic residues for the binder to interact with. Binding to charged polar sites is still quite hard. Binding to sites with glycans close to them is also hard since they often become ordered upon binding and you will take an energetic hit for that. Historically, binder design has also avoided unstructured loops, it is not clear if this is still a requirement as RFdiffusion has been used to bind unstructured peptides which share a lot in common with unstructured loops.
### Truncating your Target Protein
RFdiffusion scales in runtime as O(N^2) where N is the number of residues in your system. As such, it is a very good idea to truncate large targets so that your computations are not unnecessarily expensive. RFdiffusion and all downstream steps (including AF2) are designed to allow for a truncated target. Truncating a target is an art. For some targets, such as multidomain extracellular membranes, a natural truncation point is where two domains are joined by a flexible linker. For other proteins, such as virus spike proteins, this truncation point is less obvious. Generally you want to preserve secondary structure and introduce as few chain breaks as possible. You should also try to leave ~10A of target protein on each side of your intended target site. We recommend using PyMol to truncate your target protein.
### Picking Hotspots
Hotspots are a feature that we integrated into the model to allow for the control of the site on the target which the binder will interact with. In the paper we define a hotspot as a residue on the target protein which is within 10A Cbeta distance of the binder. Of all of the hotspots which are identified on the target 0-20% of these hotspots are actually provided to the model and the rest are masked. This is important for understanding how you should pick hotspots at inference time.; the model is expecting to have to make more contacts than you specify. We normally recommend between 3-6 hotspots, you should run a few pilot runs before generating thousands of designs to make sure the number of hotspots you are providing will give results you like.
If you have run the previous PatchDock RifDock binder design pipeline, for the RFdiffusion paper we chose our hotspots to be the PatchDock residues of the target.
### Binder Design Scale
In the paper, we generated ~10,000 RFdiffusion binder backbones for each target. From this set of backbones we then generated two sequences per backbone using ProteinMPNN-FastRelax (described below). We screened these ~20,000 designs using AF2 with initial guess and target templating (also described below).
Given the high success rates we observed in the paper, for some targets it may be sufficient to only generate ~1,000 RFdiffusion backbones in a campaign. What you want is to get enough designs that pass pAE_interaction < 10 (described more in Binder Design Filtering section) such that you are able to fill a DNA order with these successful designs. We have found that designs that do not pass pAE_interaction < 10 are not worth ordering since they will likely not work experimentally.
### Sequence Design for Binders
You may have noticed that the binders designed by RFdiffusion come out with a poly-Glycine sequence. This is not a bug. RFdiffusion is a backbone-generation model and does not generate sequence for the designed region, therefore, another method must be used to assign a sequence to the binders. In the paper we use the ProteinMPNN-FastRelax protocol to do sequence design. We recommend that you do this as well. The code for this protocol can be found in [this GitHub repo](https://github.com/nrbennet/dl_binder_design). While we did not find the FastRelax part of the protocol to yield the large in silico success rate improvements that it yielded with the RifDock-generated docks, it is still a good way to increase your number of shots-on-goal for each (computationally expensive) RFdiffusion backbone. If you would prefer to simply run ProteinMPNN on your binders without the FastRelax step, that will work fine but will be more computationally expensive.
### Binder Design Filtering
One of the most important parts of the binder design pipeline is a filtering step to evaluate if your binders are actually predicted to work. In the paper we filtered using AF2 with an initial guess and target templating, scripts for this protocol are available [here](https://github.com/nrbennet/dl_binder_design). We have found that filtering at pae_interaction < 10 is a good predictor of a binder working experimentally.
---
### Fold Conditioning
Something that works really well is conditioning binder design (or monomer generation) on particular topologies. This is achieved by providing (partial) secondary structure and block adjacency information (to a model that has been trained to condition on this).
<p align="center">
<img src="./img/fold_cond.png" alt="alt text" width="950px" align="middle"/>
</p>
We are still working out the best way to actually generate this input at inference time, but for now, we have settled upon generating inputs directly from pdb structures. This permits 'low resolution' specification of output topology (i.e., I want a TIM barrel but I don't care precisely where resides are). In `helper_scripts/`, there's a script called `make_secstruc_adj.py`, which can be used as follows:
e.g. 1:
```
./make_secstruc_adj.py --input_pdb ./2KL8.pdb --out_dir /my/dir/for/adj_secstruct
```
or e.g. 2:
```
./make_secstruc_adj.py --pdb_dir ./pdbs/ --out_dir /my/dir/for/adj_secstruct
```
This will process either a single pdb, or a folder of pdbs, and output a secondary structure and adjacency pytorch file, ready to go into the model. For now (although this might not be necessary), you should also generate these files for the target protein (if you're doing PPI), and provide this to the model. You can then use these at inference as follows:
```
./scripts/run_inference.py inference.output_prefix=./scaffold_conditioned_test/test scaffoldguided.scaffoldguided=True scaffoldguided.target_pdb=False scaffoldguided.scaffold_dir=./examples/ppi_scaffolds_subset
```
A few extra things:
1) As mentioned above, for PPI, you will want to provide a target protein, along with its secondary structure and block adjacency. This can be done by adding:
```
scaffoldguided.target_pdb=True scaffoldguided.target_path=input_pdbs/insulin_target.pdb inference.output_prefix=insulin_binder/jordi_ss_insulin_noise0_job0 'ppi.hotspot_res=[A59,A83,A91]' scaffoldguided.target_ss=target_folds/insulin_target_ss.pt scaffoldguided.target_adj=target_folds/insulin_target_adj.pt
```
To generate these block adjacency and secondary structure inputs, you can use the helper script.
This will now generate 3-helix bundles to the insulin target.
For ppi, it's probably also worth adding this flag:
```
scaffoldguided.mask_loops=False
```
This is quite important to understand. During training, we mask some of the secondary structure and block adjacency. This is convenient, because it allows us to, at inference, easily add extra residues without having to specify precise secondary structure for every residue. E.g. if you want to make a long 3 helix bundle, you could mask the loops, and add e.g. 20 more 'mask' tokens to that loop. The model will then (presumbly) choose to make e.g. 15 of these residues into helices (to extend the 3HB), and then make a 5aa loop. But, you didn't have to specify that, which is nice. The way this would be done would be like this:
```
scaffoldguided.mask_loops=True scaffoldguided.sampled_insertion=15 scaffoldguided.sampled_N=5 scaffoldguided.sampled_C=5
```
This will, at each run of inference, sample up to 15 residues to insert into loops in your 3HB input, and up to 5 additional residues at N and C terminus.
This strategy is very useful if you don't have a large set of pdbs to make block adjacencies for. For example, we showed that we could generate loads of lengthened TIM barrels from a single starting pdb with this strategy. However, for PPI, if you're using the provided scaffold sets, it shouldn't be necessary (because there are so many scaffolds to start from, generating extra diversity isn't especially necessary).
Finally, if you have a big directory of block adjacency/secondary structure files, but don't want to use all of them, you can make a `.txt` file of the ones you want to use, and pass:
```
scaffoldguided.scaffold_list=path/to/list
```
For PPI, we've consistently seen that reducing the noise added at inference improves designs. This comes at the expense of diversity, but, given that the scaffold sets are huge, this probably doesn't matter too much. We therefore recommend lowering the noise. 0.5 is probably a good compromise:
```
denoiser.noise_scale_ca=0.5 denoiser.noise_scale_frame=0.5
```
This just scales the amount of noise we add to the translations (`noise_scale_ca`) and rotations (`noise_scale_frame`) by, in this case, 0.5.
An additional example of PPI with fold conditioning is available here: `./examples/design_ppi_scaffolded.sh`
---
### Generation of Symmetric Oligomers
We're going to switch gears from discussing PPI and look at another task at which RFdiffusion performs well on: symmetric oligomer design. This is done by symmetrising the noise we sample at t=T, and symmetrising the input at every timestep. We have currently implemented the following for use (with the others coming soon!):
- Cyclic symmetry
- Dihedral symmetry
- Tetrahedral symmetry
<p align="center">
<img src="./img/olig2.png" alt="alt text" width="1000px" align="middle"/>
</p>
Here's an example:
```
./scripts/run_inference.py --config-name symmetry inference.symmetry=tetrahedral 'contigmap.contigs=[360]' inference.output_prefix=test_sample/tetrahedral inference.num_designs=1
```
Here, we've specified a different `config` file (with `--config-name symmetry`). Because symmetric diffusion is quite different from the diffusion described above, we packaged a whole load of symmetry-related configs into a new file (see `configs/inference/symmetry.yml`). Using this config file now puts diffusion in `symmetry-mode`.
The symmetry type is then specified with `inference.symmetry=`. Here, we're specifying tetrahedral symmetry, but you could also choose cyclic (e.g. `c4`) or dihedral (e.g. `d2`).
The configmap.contigs length refers to the *total* length of your oligomer. Therefore, it *must* be divisible by *n* chains.
More examples of designing oligomers can be found here: `./examples/design_cyclic_oligos.sh`, `./examples/design_dihedral_oligos.sh`, `./examples/design_tetrahedral_oligos.sh`.
---
### Using Auxiliary Potentials
Performing diffusion with symmetrized noise may give you the idea that we could use other external interventions during the denoising process to guide diffusion. One such intervention that we have implemented is auxiliary potentials. Auxiliary potentials can be very useful for guiding the inference process. E.g. whereas in RFjoint inpainting, we have little/no control over the final shape of an output, in diffusion we can readily force the network to make, for example, a well-packed protein.
This is achieved in the updates we make at each step.
Let's go a little deeper into how the diffusion process works:
At timestep T (the first step of the reverse-diffusion inference process), we sample noise from a known *prior* distribution. The model then makes a prediction of what the final structure should be, and we use these two states (noise at time T, prediction of the structure at time 0) to back-calculate where t=T-1 would have been. We therefore have a vector pointing from each coordinate at time T, to their corresponding, back-calculated position at time T-1.
But, we want to be able to bias this update, to *push* the trajectory towards some desired state. This can be done by biasing that vector with another vector, which points towards a position where that residue would *reduce* the 'loss' as defined by your potential. E.g. if we want to use the `monomer_ROG` potential, which seeks to minimise the radius of gyration of the final protein, if the models prediction of t=0 is very elongated, each of those distant residues will have a larger gradient when we differentiate the `monomer_ROG` potential w.r.t. their positions. These gradients, along with the corresponding scale, can be combined into a vector, which is then combined with the original update vector to make a "biased update" at that timestep.
The exact parameters used when applying these potentials matter. If you weight them too strongly, you're not going to end up with a good protein. Too weak, and they'll have little effect. We've explored these potentials in a few different scenarios, and have set sensible defaults, if you want to use them. But, if you feel like they're too weak/strong, or you just fancy exploring, do play with the parameters (in the `potentials` part of the config file).
Potentials are specified as a list of strings with each string corresponding to a potential. The argument for potentials is `potentials.guiding_potentials`. Within the string per-potential arguments may be specified in the following syntax: `arg_name1:arg_value1,arg_name2:arg_value2,...,arg_nameN:arg_valueN`. The only argument that is required for each potential is the name of the potential that you wish to apply, the name of this argument is `type` as-in the type of potential you wish to use. Some potentials such as `olig_contacts` and `substrate_contacts` take global options such as `potentials.substrate`, see `config/inference/base.yml` for all the global arguments associated with potentials. Additionally, it is useful to have the effect of the potential "decay" throughout the trajectory, such that in the beginning the effect of the potential is 1x strength, and by the end is much weaker. These decays (`constant`,`linear`,`quadratic`,`cubic`) can be set with the `potentials.guide_decay` argument.
Here's an example of how to specify a potential:
```
potentials.guiding_potentials=[\"type:olig_contacts,weight_intra:1,weight_inter:0.1\"] potentials.olig_intra_all=True potentials.olig_inter_all=True potentials.guide_scale=2 potentials.guide_decay='quadratic'
```
We are still fully characterising how/when to use potentials, and we strongly recommend exploring different parameters yourself, as they are clearly somewhat case-dependent. So far, it is clear that they can be helpful for motif scaffolding and symmetric oligomer generation. However, they seem to interact weirdly with hotspot residues in PPI. We think we know why this is, and will work in the coming months to write better potentials for PPI. And please note, it is often good practice to start with *no potentials* as a baseline, then slowly increase their strength. For the oligomer contacts potentials, start with the ones provided in the examples, and note that the `intra` chain potential often should be higher than the `inter` chain potential.
We have already implemented several potentials but it is relatively straightforward to add more, if you want to push your designs towards some specified goal. The *only* condition is that, whatever potential you write, it is differentiable. Take a look at `potentials.potentials.py` for examples of the potentials we have implemented so far.
---
### Symmetric Motif Scaffolding.
We can also combine symmetric diffusion with motif scaffolding to scaffold motifs symmetrically.
Currently, we have one way for performing symmetric motif scaffolding. That is by specifying the position of the motif specified w.r.t. the symmetry axes.
<p align="center">
<img src="./img/sym_motif.png" alt="alt text" width="1000px" align="middle"/>
</p>
**Special input .pdb and contigs requirements**
For now, we require that a user have a symmetrized version of their motif in their input pdb for symmetric motif scaffolding. There are two main reasons for this. First, the model is trained by centering any motif at the origin, and thus the code also centers motifs at the origin automatically. Therefore, if your motif is not symmetrized, this centering action will result in an asymmetric unit that now has the origin and axes of symmetry running right through it (bad). Secondly, the diffusion code uses a canonical set of symmetry axes (rotation matrices) to propogate the asymmetric unit of a motif. In order to prevent accidentally running diffusion trajectories which are propogating your motif in ways you don't intend, we require that a user symmetrize an input using the RFdiffusion canonical symmetry axes.
**RFdiffusion canonical symmetry axes**
| Group | Axis |
|:----------:|:-------------:|
| Cyclic | Z |
| Dihedral (cyclic) | Z |
| Dihedral (flip/reflection) | X |
**Example: Inputs for symmetric motif scaffolding with motif position specified w.r.t the symmetry axes.**
This example script `examples/design_nickel.sh` can be used to scaffold the C4 symmetric Nickel binding domains shown in the RFdiffusion paper. It combines many concepts discussed earlier, including symmetric oligomer generation, motif scaffolding, and use of guiding potentials.
Note that the contigs should specify something that is precisely symmetric. Things will break if this is not the case.
---
### A Note on Model Weights
Because of everything we want diffusion to be able to do, there is not *One Model To Rule Them All*. E.g., if you want to run with secondary structure conditioning, this requires a different model than if you don't. Under the hood, we take care of most of this by default - we parse your input and work out the most appropriate checkpoint.
This is where the config setup is really useful. The exact model checkpoint used at inference contains in it all of the parameters is was trained with, so we can just populate the config file with those values, such that inference runs as designed.
If you do want to specify a different checkpoint (if, for example, we train a new model and you want to test it), you just have to make sure it's compatible with what you're doing. E.g. if you try and give secondary structure features to a model that wasn't trained with them, it'll crash.
### Things you might want to play with at inference time
Occasionally, it might good to try an alternative model (for example the active site model, or the beta binder model). These can be specified with `inference.ckpt_override_path`. We do not recommend using these outside of the described use cases, however, as there is not a guarantee they will understand other kinds of inputs.
For a full list of things that are implemented at inference, see the config file (`configs/inference/base.yml` or `configs/inference/symmetry.yml`). Although you can modify everything, this is not recommended unless you know what you're doing.
Generally, don't change the `model`, `preprocess` or `diffuser` configs. These pertain to how the model was trained, so it's unwise to change how you use the model at inference time.
However, the parameters below are definitely worth exploring:
-inference.final_step: This is when we stop the trajectory. We have seen that you can stop early, and the model is already making a good prediction of the final structure. This speeds up inference.
-denoiser.noise_scale_ca and denoiser.noise_scale_frame: These can be used to reduce the noise used during sampling (as discussed for PPI above). The default is 1 (the same noise added at training), but this can be reduced to e.g. 0.5, or even 0. This actually improves the quality of models coming out of diffusion, but at the expense of diversity. If you're not getting any good outputs, or if your problem is very constrained, you could try reducing the noise. While these parameters can be changed independently (for translations and rotations), we recommend keeping them tied.
### Understanding the output files
We output several different files.
1. The `.pdb` file. This is the final prediction out of the model. Note that every designed residue is output as a glycine (as we only designed the backbone), and no sidechains are output. This is because, even though RFdiffusion conditions on sidechains in an input motif, there is no loss applied to these predictions, so they can't strictly be trusted.
2. The `.trb` file. This contains useful metadata associated with that specific run, including the specific contig used (if length ranges were sampled), as well as the full config used by RFdiffusion. There are also a few other convenient items in this file:
- details about mapping (i.e. how residues in the input map to residues in the output)
- `con_ref_pdb_idx`/`con_hal_pdb_idx` - These are two arrays including the input pdb indices (in con_ref_pdb_idx), and where they are in the output pdb (in con_hal_pdb_idx). This only contains the chains where inpainting took place (i.e. not any fixed receptor/target chains)
- `con_ref_idx0`/`con_hal_idx0` - These are the same as above, but 0 indexed, and without chain information. This is useful for splicing coordinates out (to assess alignment etc).
- `inpaint_seq` - This details any residues that were masked during inference.
3. Trajectory files. By default, we output the full trajectories into the `/traj/` folder. These files can be opened in pymol, as multi-step pdbs. Note that these are ordered in reverse, so the first pdb is technically the last (t=1) prediction made by RFdiffusion during inference. We include both the `pX0` predictions (what the model predicted at each timestep) and the `Xt-1` trajectories (what went into the model at each timestep).
### Docker
We have provided a Dockerfile at `docker/Dockerfile` to help run RFDiffusion on HPC and other container orchestration systems. Follow these steps to build and run the container on your system:
1. Clone this repository with `git clone https://github.com/RosettaCommons/RFdiffusion.git` and then `cd RFdiffusion`
1. Verify that the Docker daemon is running on your system with `docker info`. You can find Docker installation instructions for Mac, WIndows, and Linux in the [official Docker docs](https://docs.docker.com/get-docker/). You may also consider [Finch](https://github.com/runfinch/finch), the open source client for container development.
1. Build the container image on your system with `docker build -f docker/Dockerfile -t rfdiffusion .`
1. Create some folders on your file system with `mkdir $HOME/inputs $HOME/outputs $HOME/models`
1. Download the RFDiffusion models with `bash scripts/download_models.sh $HOME/models`
1. Download a test file (or another of your choice) with `wget -P $HOME/inputs https://files.rcsb.org/view/5TPN.pdb`
1. Run the container with the following command:
```bash
docker run -it --rm --gpus all \
-v $HOME/models:$HOME/models \
-v $HOME/inputs:$HOME/inputs \
-v $HOME/outputs:$HOME/outputs \
rfdiffusion \
inference.output_prefix=$HOME/outputs/motifscaffolding \
inference.model_directory_path=$HOME/models \
inference.input_pdb=$HOME/inputs/5TPN.pdb \
inference.num_designs=3 \
'contigmap.contigs=[10-40/A163-181/10-40]'
```
This starts the `rfdiffusion` container, mounts the models, inputs, and outputs folders, passes all available GPUs, and then calls the `run_inference.py` script with the parameters specified.
### Conclusion
We are extremely excited to share RFdiffusion with the wider scientific community. We expect to push some updates as and when we make sizeable improvements in the coming months, so do stay tuned. We realize it may take some time to get used to executing RFdiffusion with perfect syntax (sometimes Hydra is hard), so please don't hesitate to create GitHub issues if you need help, we will respond as often as we can.
Now, let's go make some proteins. Have fun!
\- Joe, David, Nate, Brian, Jason, and the RFdiffusion team.
---
RFdiffusion builds directly on the architecture and trained parameters of RoseTTAFold. We therefore thank Frank DiMaio and Minkyung Baek, who developed RoseTTAFold.
RFdiffusion is released under an open source BSD License (see LICENSE file). It is free for both non-profit and for-profit use.
| {} | GlandVergil/RFdiffusion | null | [
"region:us"
] | null | 2024-04-19T09:18:34+00:00 | [] | [] | TAGS
#region-us
| RF*diffusion*
=============

*Image: Ian C. Haydon / UW Institute for Protein Design*
Description
-----------
RFdiffusion is an open source method for structure generation, with or without conditional information (a motif, target etc). It can perform a whole range of protein design challenges as we have outlined in the RFdiffusion paper.
Things Diffusion can do
* Motif Scaffolding
* Unconditional protein generation
* Symmetric unconditional generation (cyclic, dihedral and tetrahedral symmetries currently implemented, more coming!)
* Symmetric motif scaffolding
* Binder design
* Design diversification ("partial diffusion", sampling around a design)
---
Table of contents
=================
* RF*diffusion*
+ Description
* Table of contents
* Getting started / installation
+ Conda Install SE3-Transformer
+ Get PPI Scaffold Examples
* Usage
+ Running the diffusion script
+ Basic execution - an unconditional monomer
+ Motif Scaffolding
+ The "active site" model holds very small motifs in place
+ The 'inpaint\_seq' flag
+ A note on 'diffuser.T'
+ Partial diffusion
+ Binder Design
+ Practical Considerations for Binder Design
+ Fold Conditioning
+ Generation of Symmetric Oligomers
+ Using Auxiliary Potentials
+ Symmetric Motif Scaffolding.
+ A Note on Model Weights
+ Things you might want to play with at inference time
+ Understanding the output files
+ Docker
+ Conclusion
Getting started / installation
==============================
Thanks to Sergey Ovchinnikov, RFdiffusion is available as a Google Colab Notebook if you would like to run it there!
We strongly recommend reading this README carefully before getting started with RFdiffusion, and working through some of the examples in the Colab Notebook.
If you want to set up RFdiffusion locally, follow the steps below:
To get started using RFdiffusion, clone the repo:
You'll then need to download the model weights into the RFDiffusion directory.
### Conda Install SE3-Transformer
Ensure that you have either Anaconda or Miniconda installed.
You also need to install NVIDIA's implementation of SE(3)-Transformers Here is how to install the NVIDIA SE(3)-Transformer code:
Anytime you run diffusion you should be sure to activate this conda environment by running the following command:
Total setup should take less than 30 minutes on a standard desktop computer.
Note: Due to the variation in GPU types and drivers that users have access to, we are not able to make one environment that will run on all setups. As such, we are only providing a yml file with support for CUDA 11.1 and leaving it to each user to customize it to work on their setups. This customization will involve changing the cudatoolkit and (possibly) the PyTorch version specified in the yml file.
---
### Get PPI Scaffold Examples
To run the scaffolded protein binder design (PPI) examples, we have provided some example scaffold files ('examples/ppi\_scaffolds\_subset.URL').
You'll need to untar this:
We will explain what these files are and how to use them in the Fold Conditioning section.
---
Usage
=====
In this section we will demonstrate how to run diffusion.

### Running the diffusion script
The actual script you will execute is called 'scripts/run\_inference.py'. There are many ways to run it, governed by hydra configs.
Hydra configs are a nice way of being able to specify many different options, with sensible defaults drawn *directly* from the model checkpoint, so inference should always, by default, match training.
What this means is that the default values in 'config/inference/URL' might not match the actual values used during inference, with a specific checkpoint. This is all handled under the hood.
---
### Basic execution - an unconditional monomer

Let's first look at how you would do unconditional design of a protein of length 150aa.
For this, we just need to specify three things:
1. The length of the protein
2. The location where we want to write files to
3. The number of designs we want
Let's look at this in detail.
Firstly, what is 'contigmap.contigs'?
Hydra configs tell the inference script how it should be run. To keep things organised, the config has different sub-configs, one of them being 'contigmap', which pertains to everything related to the contig string (that defines the protein being built).
Take a look at the config file if this isn't clear: 'configs/inference/URL'
Anything in the config can be overwritten manually from the command line. You could, for example, change how the diffuser works:
... but don't do this unless you really know what you're doing!!
Now, what does ''contigmap.contigs=[150-150]'' mean?
To those who have used RFjoint inpainting, this might look familiar, but a little bit different. Diffusion, in fact, uses the identical 'contig mapper' as inpainting, except that, because we're using hydra, we have to give this to the model in a different way. The contig string has to be passed as a single-item in a list, rather than as a string, for hydra reasons and the entire argument MUST be enclosed in '''' so that the commandline does not attempt to parse any of the special characters.
The contig string allows you to specify a length range, but here, we just want a protein of 150aa in length, so you just specify [150-150]
This will then run 10 diffusion trajectories, saving the outputs to your specified output folder.
NB the first time you run RFdiffusion, it will take a while 'Calculating IGSO3'. Once it has done this, it'll be cached for future reference though! For an additional example of unconditional monomer generation, take a look at './examples/design\_unconditional.sh' in the repo!
---
### Motif Scaffolding
RFdiffusion can be used to scaffold motifs, in a manner akin to Constrained Hallucination and RFjoint Inpainting. In general, RFdiffusion significantly outperforms both Constrained Hallucination and RFjoint Inpainting.

When scaffolding protein motifs, we need a way of specifying that we want to scaffold some particular protein input (one or more segments from a '.pdb' file), and to be able to specify how we want these connected, and by how many residues, in the new scaffolded protein. What's more, we want to be able to sample different lengths of connecting protein, as we generally don't know *a priori* precisely how many residues we'll need to best scaffold a motif. This job of specifying inputs is handled by contigs, governed by the contigmap config in the hydra config. For those familiar with Constrained Hallucination or RFjoint Inpainting, the logic is very similar.
Briefly:
* Anything prefixed by a letter indicates that this is a motif, with the letter corresponding to the chain letter in the input pdb files. E.g. A10-25 pertains to residues ('A',10),('A',11)...('A',25) in the corresponding input pdb
* Anything not prefixed by a letter indicates protein *to be built*. This can be input as a length range. These length ranges are randomly sampled each iteration of RFdiffusion inference.
* To specify chain breaks, we use '/0 '.
In more detail, if we want to scaffold a motif, the input is just like RFjoint Inpainting, except needing to navigate the hydra config input. If we want to scaffold residues 10-25 on chain A a pdb, this would be done with ''contigmap.contigs=[5-15/A10-25/30-40]''. This asks RFdiffusion to build 5-15 residues (randomly sampled at each inference cycle) N-terminally of A10-25 from the input pdb, followed by 30-40 residues (again, randomly sampled) to its C-terminus. If we wanted to ensure the length was always e.g. 55 residues, this can be specified with 'URL=55-55'. You need to obviously also provide a path to your pdb file: 'inference.input\_pdb=path/to/URL'. It doesn't matter if your input pdb has residues you *don't* want to scaffold - the contig map defines which residues in the pdb are actually used as the "motif". In other words, even if your pdb files has a B chain, and other residues on the A chain, *only* A10-25 will be provided to RFdiffusion.
To specify that we want to inpaint in the presence of a separate chain, this can be done as follows:
Look at this carefully. '/0 ' is the indicator that we want a chain break. NOTE, the space is important here. This tells the diffusion model to add a big residue jump (200aa) to the input, so that the model sees the first chain as being on a separate chain to the second.
An example of motif scaffolding can be found in './examples/design\_motifscaffolding.sh'.
### The "active site" model holds very small motifs in place
In the RFdiffusion preprint we noted that for very small motifs, RFdiffusion has the tendency to not keep them perfectly fixed in the output. Therefore, for scaffolding minimalist sites such as enzyme active sites, we fine-tuned RFdiffusion on examples similar to these tasks, allowing it to hold smaller motifs better in place, and better generate *in silico* successes. If your input functional motif is very small, we reccomend using this model, which can easily be specified using the following syntax:
'inference.ckpt\_override\_path=models/ActiveSite\_ckpt.pt'
### The 'inpaint\_seq' flag
For those familiar with RFjoint Inpainting, the contigmap.inpaint\_seq input is equivalent. The idea is that often, when, for example, fusing two proteins, residues that were on the surface of a protein (and are therefore likely polar), now need to be packed into the 'core' of the protein. We therefore want them to become hydrophobic residues. What we can do, rather than directly mutating them to hydrophobics, is to mask their sequence identity, and allow RFdiffusion to implicitly reason over their sequence, and better pack against them. This requires a different model than the 'base' diffusion model, that has been trained to understand this paradigm, but this is automatically handled by the inference script (you don't need to do anything).
To specify amino acids whose sequence should be hidden, use the following syntax:
Here, we're masking the residue identity of residue A1, and all residues between A30 and A40 (inclusive).
An example of executing motif scaffolding with the 'contigmap.inpaint\_seq' flag is located in './examples/design\_motifscaffolding\_inpaintseq.sh'
### A note on 'diffuser.T'
RFdiffusion was originally trained with 200 discrete timesteps. However, recent improvements have allowed us to reduce the number of timesteps we need to use at inference time. In many cases, running with as few as approximately 20 steps provides outputs of equivalent *in silico* quality to running with 200 steps (providing a 10X speedup). The default is now set to 50 steps. Noting this is important for understanding the partial diffusion, described below.
---
### Partial diffusion
Something we can do with diffusion is to partially noise and de-noise a structure, to get some diversity around a general fold. This can work really nicely (see Vazquez-Torres et al., BioRxiv 2022).
This is specified by using the diffuser.parial\_T input, and setting a timestep to 'noise' to.

More noise == more diversity. In Vazquez-Torres et al., 2022, we typically used 'diffuser.partial\_T' of approximately 80, but this was with respect to the 200 timesteps we were using. Now that the default 'diffuser.T' is 50, you will need to adjust diffuser.partial\_T accordingly. E.g. now that 'diffuser.T=50', the equivalent of 80 noising steps is 'diffuser.partial\_T=20'. We strongly recommend sampling different values for 'partial\_T' however, to find the best parameters for your specific problem.
When doing partial diffusion, because we are now diffusing from a known structure, this creates certain constraints. You can still use the contig input, but *this has to yield a contig string exactly the same length as the input protein*. E.g. if you have a binder:target complex, and you want to diversify the binder (length 100, chain A), you would need to input something like this:
The reason for this is that, if your input protein was only 80 amino acids, but you've specified a desired length of 100, we don't know where to diffuse those extra 20 amino acids from, and hence, they will not lie in the distribution that RFdiffusion has learned to denoise from.
An example of partial diffusion can be found in './examples/design\_partialdiffusion.sh'!
You can also keep parts of the sequence of the diffused chain fixed, if you want. An example of why you might want to do this is in the context of helical peptide binding. If you've threaded a helical peptide sequence onto an ideal helix, and now want to diversify the complex, allowing the helix to be predicted now not as an ideal helix, you might do something like:
In this case, the 20aa chain is the helical peptide. The 'contigmap.provide\_seq' input is zero-indexed, and you can provide a range (so 100-119 is an inclusive range, unmasking the whole sequence of the peptide). Multiple sequence ranges can be provided separated by a comma, e.g. ''contigmap.provide\_seq=[172-177,200-205]''.
Note that the provide\_seq option requires using a different model checkpoint, but this is automatically handled by the inference script.
An example of partial diffusion with providing sequence in diffused regions can be found in './examples/design\_partialdiffusion\_withseq.sh'. The same example specifying multiple sequence ranges can be found in './examples/design\_partialdiffusion\_multipleseq.sh'.
---
### Binder Design
Hopefully, it's now obvious how you might make a binder with diffusion! Indeed, RFdiffusion shows excellent *in silico* and experimental ability to design *de novo* binders.

If chain B is your target, then you could do it like this:
This will generate 100 residue long binders to residues 1-100 of chain B.
However, this probably isn't the best way of making binders. Because diffusion is somewhat computationally-intensive, we need to try and make it as fast as possible. Providing the whole of your target, uncropped, is going to make diffusion very slow if your target is big (and most targets-of-interest, such as cell-surface receptors tend to be *very* big). One tried-and-true method to speed up binder design is to crop the target protein around the desired interface location. BUT! This creates a problem: if you crop your target and potentially expose hydrophobic core residues which were buried before the crop, how can you guarantee the binder will go to the intended interface site on the surface of the target, and not target the tantalizing hydrophobic patch you have just artificially created?
We solve this issue by providing the model with what we call "hotspot residues". The complex models we refer to earlier in this README file have all been trained with hotspot residues, in this training regime, during each example, the model is told (some of) the residues on the target protein which contact the target (i.e., resides that are part of the interface). The model readily learns that it should be making an interface which involved these hotspot residues. At inference time then, we can provide our own hotspot residues to define a region which the binder must contact. These are specified like this: ''ppi.hotspot\_res=[A30,A33,A34]'', where 'A' is the chain ID in the input pdb file of the hotspot residue and the number is the residue index in the input pdb file of the hotspot residue.
Finally, it has been observed that the default RFdiffusion model often generates mostly helical binders. These have high computational and experimental success rates. However, there may be cases where other kinds of topologies may be desired. For this, we include a "beta" model, which generates a greater diversity of topologies, but has not been extensively experimentally validated. Try this at your own risk:
An example of binder design with RFdiffusion can be found in './examples/design\_ppi.sh'.
---
Practical Considerations for Binder Design
------------------------------------------
RFdiffusion is an extremely powerful binder design tool but it is not magic. In this section we will walk through some common pitfalls in RFdiffusion binder design and offer advice on how to get the most out of this method.
### Selecting a Target Site
Not every site on a target protein is a good candidate for binder design. For a site to be an attractive candidate for binding it should have >~3 hydrophobic residues for the binder to interact with. Binding to charged polar sites is still quite hard. Binding to sites with glycans close to them is also hard since they often become ordered upon binding and you will take an energetic hit for that. Historically, binder design has also avoided unstructured loops, it is not clear if this is still a requirement as RFdiffusion has been used to bind unstructured peptides which share a lot in common with unstructured loops.
### Truncating your Target Protein
RFdiffusion scales in runtime as O(N^2) where N is the number of residues in your system. As such, it is a very good idea to truncate large targets so that your computations are not unnecessarily expensive. RFdiffusion and all downstream steps (including AF2) are designed to allow for a truncated target. Truncating a target is an art. For some targets, such as multidomain extracellular membranes, a natural truncation point is where two domains are joined by a flexible linker. For other proteins, such as virus spike proteins, this truncation point is less obvious. Generally you want to preserve secondary structure and introduce as few chain breaks as possible. You should also try to leave ~10A of target protein on each side of your intended target site. We recommend using PyMol to truncate your target protein.
### Picking Hotspots
Hotspots are a feature that we integrated into the model to allow for the control of the site on the target which the binder will interact with. In the paper we define a hotspot as a residue on the target protein which is within 10A Cbeta distance of the binder. Of all of the hotspots which are identified on the target 0-20% of these hotspots are actually provided to the model and the rest are masked. This is important for understanding how you should pick hotspots at inference time.; the model is expecting to have to make more contacts than you specify. We normally recommend between 3-6 hotspots, you should run a few pilot runs before generating thousands of designs to make sure the number of hotspots you are providing will give results you like.
If you have run the previous PatchDock RifDock binder design pipeline, for the RFdiffusion paper we chose our hotspots to be the PatchDock residues of the target.
### Binder Design Scale
In the paper, we generated ~10,000 RFdiffusion binder backbones for each target. From this set of backbones we then generated two sequences per backbone using ProteinMPNN-FastRelax (described below). We screened these ~20,000 designs using AF2 with initial guess and target templating (also described below).
Given the high success rates we observed in the paper, for some targets it may be sufficient to only generate ~1,000 RFdiffusion backbones in a campaign. What you want is to get enough designs that pass pAE\_interaction < 10 (described more in Binder Design Filtering section) such that you are able to fill a DNA order with these successful designs. We have found that designs that do not pass pAE\_interaction < 10 are not worth ordering since they will likely not work experimentally.
### Sequence Design for Binders
You may have noticed that the binders designed by RFdiffusion come out with a poly-Glycine sequence. This is not a bug. RFdiffusion is a backbone-generation model and does not generate sequence for the designed region, therefore, another method must be used to assign a sequence to the binders. In the paper we use the ProteinMPNN-FastRelax protocol to do sequence design. We recommend that you do this as well. The code for this protocol can be found in this GitHub repo. While we did not find the FastRelax part of the protocol to yield the large in silico success rate improvements that it yielded with the RifDock-generated docks, it is still a good way to increase your number of shots-on-goal for each (computationally expensive) RFdiffusion backbone. If you would prefer to simply run ProteinMPNN on your binders without the FastRelax step, that will work fine but will be more computationally expensive.
### Binder Design Filtering
One of the most important parts of the binder design pipeline is a filtering step to evaluate if your binders are actually predicted to work. In the paper we filtered using AF2 with an initial guess and target templating, scripts for this protocol are available here. We have found that filtering at pae\_interaction < 10 is a good predictor of a binder working experimentally.
---
### Fold Conditioning
Something that works really well is conditioning binder design (or monomer generation) on particular topologies. This is achieved by providing (partial) secondary structure and block adjacency information (to a model that has been trained to condition on this).

We are still working out the best way to actually generate this input at inference time, but for now, we have settled upon generating inputs directly from pdb structures. This permits 'low resolution' specification of output topology (i.e., I want a TIM barrel but I don't care precisely where resides are). In 'helper\_scripts/', there's a script called 'make\_secstruc\_adj.py', which can be used as follows:
e.g. 1:
or e.g. 2:
This will process either a single pdb, or a folder of pdbs, and output a secondary structure and adjacency pytorch file, ready to go into the model. For now (although this might not be necessary), you should also generate these files for the target protein (if you're doing PPI), and provide this to the model. You can then use these at inference as follows:
A few extra things:
1. As mentioned above, for PPI, you will want to provide a target protein, along with its secondary structure and block adjacency. This can be done by adding:
To generate these block adjacency and secondary structure inputs, you can use the helper script.
This will now generate 3-helix bundles to the insulin target.
For ppi, it's probably also worth adding this flag:
This is quite important to understand. During training, we mask some of the secondary structure and block adjacency. This is convenient, because it allows us to, at inference, easily add extra residues without having to specify precise secondary structure for every residue. E.g. if you want to make a long 3 helix bundle, you could mask the loops, and add e.g. 20 more 'mask' tokens to that loop. The model will then (presumbly) choose to make e.g. 15 of these residues into helices (to extend the 3HB), and then make a 5aa loop. But, you didn't have to specify that, which is nice. The way this would be done would be like this:
This will, at each run of inference, sample up to 15 residues to insert into loops in your 3HB input, and up to 5 additional residues at N and C terminus.
This strategy is very useful if you don't have a large set of pdbs to make block adjacencies for. For example, we showed that we could generate loads of lengthened TIM barrels from a single starting pdb with this strategy. However, for PPI, if you're using the provided scaffold sets, it shouldn't be necessary (because there are so many scaffolds to start from, generating extra diversity isn't especially necessary).
Finally, if you have a big directory of block adjacency/secondary structure files, but don't want to use all of them, you can make a '.txt' file of the ones you want to use, and pass:
For PPI, we've consistently seen that reducing the noise added at inference improves designs. This comes at the expense of diversity, but, given that the scaffold sets are huge, this probably doesn't matter too much. We therefore recommend lowering the noise. 0.5 is probably a good compromise:
This just scales the amount of noise we add to the translations ('noise\_scale\_ca') and rotations ('noise\_scale\_frame') by, in this case, 0.5.
An additional example of PPI with fold conditioning is available here: './examples/design\_ppi\_scaffolded.sh'
---
### Generation of Symmetric Oligomers
We're going to switch gears from discussing PPI and look at another task at which RFdiffusion performs well on: symmetric oligomer design. This is done by symmetrising the noise we sample at t=T, and symmetrising the input at every timestep. We have currently implemented the following for use (with the others coming soon!):
* Cyclic symmetry
* Dihedral symmetry
* Tetrahedral symmetry

Here's an example:
Here, we've specified a different 'config' file (with '--config-name symmetry'). Because symmetric diffusion is quite different from the diffusion described above, we packaged a whole load of symmetry-related configs into a new file (see 'configs/inference/URL'). Using this config file now puts diffusion in 'symmetry-mode'.
The symmetry type is then specified with 'inference.symmetry='. Here, we're specifying tetrahedral symmetry, but you could also choose cyclic (e.g. 'c4') or dihedral (e.g. 'd2').
The configmap.contigs length refers to the *total* length of your oligomer. Therefore, it *must* be divisible by *n* chains.
More examples of designing oligomers can be found here: './examples/design\_cyclic\_oligos.sh', './examples/design\_dihedral\_oligos.sh', './examples/design\_tetrahedral\_oligos.sh'.
---
### Using Auxiliary Potentials
Performing diffusion with symmetrized noise may give you the idea that we could use other external interventions during the denoising process to guide diffusion. One such intervention that we have implemented is auxiliary potentials. Auxiliary potentials can be very useful for guiding the inference process. E.g. whereas in RFjoint inpainting, we have little/no control over the final shape of an output, in diffusion we can readily force the network to make, for example, a well-packed protein.
This is achieved in the updates we make at each step.
Let's go a little deeper into how the diffusion process works:
At timestep T (the first step of the reverse-diffusion inference process), we sample noise from a known *prior* distribution. The model then makes a prediction of what the final structure should be, and we use these two states (noise at time T, prediction of the structure at time 0) to back-calculate where t=T-1 would have been. We therefore have a vector pointing from each coordinate at time T, to their corresponding, back-calculated position at time T-1.
But, we want to be able to bias this update, to *push* the trajectory towards some desired state. This can be done by biasing that vector with another vector, which points towards a position where that residue would *reduce* the 'loss' as defined by your potential. E.g. if we want to use the 'monomer\_ROG' potential, which seeks to minimise the radius of gyration of the final protein, if the models prediction of t=0 is very elongated, each of those distant residues will have a larger gradient when we differentiate the 'monomer\_ROG' potential w.r.t. their positions. These gradients, along with the corresponding scale, can be combined into a vector, which is then combined with the original update vector to make a "biased update" at that timestep.
The exact parameters used when applying these potentials matter. If you weight them too strongly, you're not going to end up with a good protein. Too weak, and they'll have little effect. We've explored these potentials in a few different scenarios, and have set sensible defaults, if you want to use them. But, if you feel like they're too weak/strong, or you just fancy exploring, do play with the parameters (in the 'potentials' part of the config file).
Potentials are specified as a list of strings with each string corresponding to a potential. The argument for potentials is 'potentials.guiding\_potentials'. Within the string per-potential arguments may be specified in the following syntax: 'arg\_name1:arg\_value1,arg\_name2:arg\_value2,...,arg\_nameN:arg\_valueN'. The only argument that is required for each potential is the name of the potential that you wish to apply, the name of this argument is 'type' as-in the type of potential you wish to use. Some potentials such as 'olig\_contacts' and 'substrate\_contacts' take global options such as 'potentials.substrate', see 'config/inference/URL' for all the global arguments associated with potentials. Additionally, it is useful to have the effect of the potential "decay" throughout the trajectory, such that in the beginning the effect of the potential is 1x strength, and by the end is much weaker. These decays ('constant','linear','quadratic','cubic') can be set with the 'potentials.guide\_decay' argument.
Here's an example of how to specify a potential:
We are still fully characterising how/when to use potentials, and we strongly recommend exploring different parameters yourself, as they are clearly somewhat case-dependent. So far, it is clear that they can be helpful for motif scaffolding and symmetric oligomer generation. However, they seem to interact weirdly with hotspot residues in PPI. We think we know why this is, and will work in the coming months to write better potentials for PPI. And please note, it is often good practice to start with *no potentials* as a baseline, then slowly increase their strength. For the oligomer contacts potentials, start with the ones provided in the examples, and note that the 'intra' chain potential often should be higher than the 'inter' chain potential.
We have already implemented several potentials but it is relatively straightforward to add more, if you want to push your designs towards some specified goal. The *only* condition is that, whatever potential you write, it is differentiable. Take a look at 'URL' for examples of the potentials we have implemented so far.
---
### Symmetric Motif Scaffolding.
We can also combine symmetric diffusion with motif scaffolding to scaffold motifs symmetrically.
Currently, we have one way for performing symmetric motif scaffolding. That is by specifying the position of the motif specified w.r.t. the symmetry axes.

Special input .pdb and contigs requirements
For now, we require that a user have a symmetrized version of their motif in their input pdb for symmetric motif scaffolding. There are two main reasons for this. First, the model is trained by centering any motif at the origin, and thus the code also centers motifs at the origin automatically. Therefore, if your motif is not symmetrized, this centering action will result in an asymmetric unit that now has the origin and axes of symmetry running right through it (bad). Secondly, the diffusion code uses a canonical set of symmetry axes (rotation matrices) to propogate the asymmetric unit of a motif. In order to prevent accidentally running diffusion trajectories which are propogating your motif in ways you don't intend, we require that a user symmetrize an input using the RFdiffusion canonical symmetry axes.
RFdiffusion canonical symmetry axes
Example: Inputs for symmetric motif scaffolding with motif position specified w.r.t the symmetry axes.
This example script 'examples/design\_nickel.sh' can be used to scaffold the C4 symmetric Nickel binding domains shown in the RFdiffusion paper. It combines many concepts discussed earlier, including symmetric oligomer generation, motif scaffolding, and use of guiding potentials.
Note that the contigs should specify something that is precisely symmetric. Things will break if this is not the case.
---
### A Note on Model Weights
Because of everything we want diffusion to be able to do, there is not *One Model To Rule Them All*. E.g., if you want to run with secondary structure conditioning, this requires a different model than if you don't. Under the hood, we take care of most of this by default - we parse your input and work out the most appropriate checkpoint.
This is where the config setup is really useful. The exact model checkpoint used at inference contains in it all of the parameters is was trained with, so we can just populate the config file with those values, such that inference runs as designed.
If you do want to specify a different checkpoint (if, for example, we train a new model and you want to test it), you just have to make sure it's compatible with what you're doing. E.g. if you try and give secondary structure features to a model that wasn't trained with them, it'll crash.
### Things you might want to play with at inference time
Occasionally, it might good to try an alternative model (for example the active site model, or the beta binder model). These can be specified with 'inference.ckpt\_override\_path'. We do not recommend using these outside of the described use cases, however, as there is not a guarantee they will understand other kinds of inputs.
For a full list of things that are implemented at inference, see the config file ('configs/inference/URL' or 'configs/inference/URL'). Although you can modify everything, this is not recommended unless you know what you're doing.
Generally, don't change the 'model', 'preprocess' or 'diffuser' configs. These pertain to how the model was trained, so it's unwise to change how you use the model at inference time.
However, the parameters below are definitely worth exploring:
-inference.final\_step: This is when we stop the trajectory. We have seen that you can stop early, and the model is already making a good prediction of the final structure. This speeds up inference.
-denoiser.noise\_scale\_ca and denoiser.noise\_scale\_frame: These can be used to reduce the noise used during sampling (as discussed for PPI above). The default is 1 (the same noise added at training), but this can be reduced to e.g. 0.5, or even 0. This actually improves the quality of models coming out of diffusion, but at the expense of diversity. If you're not getting any good outputs, or if your problem is very constrained, you could try reducing the noise. While these parameters can be changed independently (for translations and rotations), we recommend keeping them tied.
### Understanding the output files
We output several different files.
1. The '.pdb' file. This is the final prediction out of the model. Note that every designed residue is output as a glycine (as we only designed the backbone), and no sidechains are output. This is because, even though RFdiffusion conditions on sidechains in an input motif, there is no loss applied to these predictions, so they can't strictly be trusted.
2. The '.trb' file. This contains useful metadata associated with that specific run, including the specific contig used (if length ranges were sampled), as well as the full config used by RFdiffusion. There are also a few other convenient items in this file:
* details about mapping (i.e. how residues in the input map to residues in the output)
+ 'con\_ref\_pdb\_idx'/'con\_hal\_pdb\_idx' - These are two arrays including the input pdb indices (in con\_ref\_pdb\_idx), and where they are in the output pdb (in con\_hal\_pdb\_idx). This only contains the chains where inpainting took place (i.e. not any fixed receptor/target chains)
+ 'con\_ref\_idx0'/'con\_hal\_idx0' - These are the same as above, but 0 indexed, and without chain information. This is useful for splicing coordinates out (to assess alignment etc).
+ 'inpaint\_seq' - This details any residues that were masked during inference.
3. Trajectory files. By default, we output the full trajectories into the '/traj/' folder. These files can be opened in pymol, as multi-step pdbs. Note that these are ordered in reverse, so the first pdb is technically the last (t=1) prediction made by RFdiffusion during inference. We include both the 'pX0' predictions (what the model predicted at each timestep) and the 'Xt-1' trajectories (what went into the model at each timestep).
### Docker
We have provided a Dockerfile at 'docker/Dockerfile' to help run RFDiffusion on HPC and other container orchestration systems. Follow these steps to build and run the container on your system:
1. Clone this repository with 'git clone URL and then 'cd RFdiffusion'
2. Verify that the Docker daemon is running on your system with 'docker info'. You can find Docker installation instructions for Mac, WIndows, and Linux in the official Docker docs. You may also consider Finch, the open source client for container development.
3. Build the container image on your system with 'docker build -f docker/Dockerfile -t rfdiffusion .'
4. Create some folders on your file system with 'mkdir $HOME/inputs $HOME/outputs $HOME/models'
5. Download the RFDiffusion models with 'bash scripts/download\_models.sh $HOME/models'
6. Download a test file (or another of your choice) with 'wget -P $HOME/inputs URL
7. Run the container with the following command:
This starts the 'rfdiffusion' container, mounts the models, inputs, and outputs folders, passes all available GPUs, and then calls the 'run\_inference.py' script with the parameters specified.
### Conclusion
We are extremely excited to share RFdiffusion with the wider scientific community. We expect to push some updates as and when we make sizeable improvements in the coming months, so do stay tuned. We realize it may take some time to get used to executing RFdiffusion with perfect syntax (sometimes Hydra is hard), so please don't hesitate to create GitHub issues if you need help, we will respond as often as we can.
Now, let's go make some proteins. Have fun!
- Joe, David, Nate, Brian, Jason, and the RFdiffusion team.
---
RFdiffusion builds directly on the architecture and trained parameters of RoseTTAFold. We therefore thank Frank DiMaio and Minkyung Baek, who developed RoseTTAFold.
RFdiffusion is released under an open source BSD License (see LICENSE file). It is free for both non-profit and for-profit use.
| [
"### Conda Install SE3-Transformer\n\n\nEnsure that you have either Anaconda or Miniconda installed.\n\n\nYou also need to install NVIDIA's implementation of SE(3)-Transformers Here is how to install the NVIDIA SE(3)-Transformer code:\n\n\nAnytime you run diffusion you should be sure to activate this conda environment by running the following command:\n\n\nTotal setup should take less than 30 minutes on a standard desktop computer.\nNote: Due to the variation in GPU types and drivers that users have access to, we are not able to make one environment that will run on all setups. As such, we are only providing a yml file with support for CUDA 11.1 and leaving it to each user to customize it to work on their setups. This customization will involve changing the cudatoolkit and (possibly) the PyTorch version specified in the yml file.\n\n\n\n\n---",
"### Get PPI Scaffold Examples\n\n\nTo run the scaffolded protein binder design (PPI) examples, we have provided some example scaffold files ('examples/ppi\\_scaffolds\\_subset.URL').\nYou'll need to untar this:\n\n\nWe will explain what these files are and how to use them in the Fold Conditioning section.\n\n\n\n\n---\n\n\nUsage\n=====\n\n\nIn this section we will demonstrate how to run diffusion.\n\n\n\n",
"### Running the diffusion script\n\n\nThe actual script you will execute is called 'scripts/run\\_inference.py'. There are many ways to run it, governed by hydra configs.\nHydra configs are a nice way of being able to specify many different options, with sensible defaults drawn *directly* from the model checkpoint, so inference should always, by default, match training.\nWhat this means is that the default values in 'config/inference/URL' might not match the actual values used during inference, with a specific checkpoint. This is all handled under the hood.\n\n\n\n\n---",
"### Basic execution - an unconditional monomer\n\n\n\nLet's first look at how you would do unconditional design of a protein of length 150aa.\nFor this, we just need to specify three things:\n\n\n1. The length of the protein\n2. The location where we want to write files to\n3. The number of designs we want\n\n\nLet's look at this in detail.\nFirstly, what is 'contigmap.contigs'?\nHydra configs tell the inference script how it should be run. To keep things organised, the config has different sub-configs, one of them being 'contigmap', which pertains to everything related to the contig string (that defines the protein being built).\nTake a look at the config file if this isn't clear: 'configs/inference/URL'\nAnything in the config can be overwritten manually from the command line. You could, for example, change how the diffuser works:\n\n\n... but don't do this unless you really know what you're doing!!\n\n\nNow, what does ''contigmap.contigs=[150-150]'' mean?\nTo those who have used RFjoint inpainting, this might look familiar, but a little bit different. Diffusion, in fact, uses the identical 'contig mapper' as inpainting, except that, because we're using hydra, we have to give this to the model in a different way. The contig string has to be passed as a single-item in a list, rather than as a string, for hydra reasons and the entire argument MUST be enclosed in '''' so that the commandline does not attempt to parse any of the special characters.\n\n\nThe contig string allows you to specify a length range, but here, we just want a protein of 150aa in length, so you just specify [150-150]\nThis will then run 10 diffusion trajectories, saving the outputs to your specified output folder.\n\n\nNB the first time you run RFdiffusion, it will take a while 'Calculating IGSO3'. Once it has done this, it'll be cached for future reference though! For an additional example of unconditional monomer generation, take a look at './examples/design\\_unconditional.sh' in the repo!\n\n\n\n\n---",
"### Motif Scaffolding\n\n\nRFdiffusion can be used to scaffold motifs, in a manner akin to Constrained Hallucination and RFjoint Inpainting. In general, RFdiffusion significantly outperforms both Constrained Hallucination and RFjoint Inpainting.\n\n\n\n\n\n\n\nWhen scaffolding protein motifs, we need a way of specifying that we want to scaffold some particular protein input (one or more segments from a '.pdb' file), and to be able to specify how we want these connected, and by how many residues, in the new scaffolded protein. What's more, we want to be able to sample different lengths of connecting protein, as we generally don't know *a priori* precisely how many residues we'll need to best scaffold a motif. This job of specifying inputs is handled by contigs, governed by the contigmap config in the hydra config. For those familiar with Constrained Hallucination or RFjoint Inpainting, the logic is very similar.\nBriefly:\n\n\n* Anything prefixed by a letter indicates that this is a motif, with the letter corresponding to the chain letter in the input pdb files. E.g. A10-25 pertains to residues ('A',10),('A',11)...('A',25) in the corresponding input pdb\n* Anything not prefixed by a letter indicates protein *to be built*. This can be input as a length range. These length ranges are randomly sampled each iteration of RFdiffusion inference.\n* To specify chain breaks, we use '/0 '.\n\n\nIn more detail, if we want to scaffold a motif, the input is just like RFjoint Inpainting, except needing to navigate the hydra config input. If we want to scaffold residues 10-25 on chain A a pdb, this would be done with ''contigmap.contigs=[5-15/A10-25/30-40]''. This asks RFdiffusion to build 5-15 residues (randomly sampled at each inference cycle) N-terminally of A10-25 from the input pdb, followed by 30-40 residues (again, randomly sampled) to its C-terminus. If we wanted to ensure the length was always e.g. 55 residues, this can be specified with 'URL=55-55'. You need to obviously also provide a path to your pdb file: 'inference.input\\_pdb=path/to/URL'. It doesn't matter if your input pdb has residues you *don't* want to scaffold - the contig map defines which residues in the pdb are actually used as the \"motif\". In other words, even if your pdb files has a B chain, and other residues on the A chain, *only* A10-25 will be provided to RFdiffusion.\n\n\nTo specify that we want to inpaint in the presence of a separate chain, this can be done as follows:\n\n\nLook at this carefully. '/0 ' is the indicator that we want a chain break. NOTE, the space is important here. This tells the diffusion model to add a big residue jump (200aa) to the input, so that the model sees the first chain as being on a separate chain to the second.\n\n\nAn example of motif scaffolding can be found in './examples/design\\_motifscaffolding.sh'.",
"### The \"active site\" model holds very small motifs in place\n\n\nIn the RFdiffusion preprint we noted that for very small motifs, RFdiffusion has the tendency to not keep them perfectly fixed in the output. Therefore, for scaffolding minimalist sites such as enzyme active sites, we fine-tuned RFdiffusion on examples similar to these tasks, allowing it to hold smaller motifs better in place, and better generate *in silico* successes. If your input functional motif is very small, we reccomend using this model, which can easily be specified using the following syntax:\n'inference.ckpt\\_override\\_path=models/ActiveSite\\_ckpt.pt'",
"### The 'inpaint\\_seq' flag\n\n\nFor those familiar with RFjoint Inpainting, the contigmap.inpaint\\_seq input is equivalent. The idea is that often, when, for example, fusing two proteins, residues that were on the surface of a protein (and are therefore likely polar), now need to be packed into the 'core' of the protein. We therefore want them to become hydrophobic residues. What we can do, rather than directly mutating them to hydrophobics, is to mask their sequence identity, and allow RFdiffusion to implicitly reason over their sequence, and better pack against them. This requires a different model than the 'base' diffusion model, that has been trained to understand this paradigm, but this is automatically handled by the inference script (you don't need to do anything).\n\n\nTo specify amino acids whose sequence should be hidden, use the following syntax:\n\n\nHere, we're masking the residue identity of residue A1, and all residues between A30 and A40 (inclusive).\n\n\nAn example of executing motif scaffolding with the 'contigmap.inpaint\\_seq' flag is located in './examples/design\\_motifscaffolding\\_inpaintseq.sh'",
"### A note on 'diffuser.T'\n\n\nRFdiffusion was originally trained with 200 discrete timesteps. However, recent improvements have allowed us to reduce the number of timesteps we need to use at inference time. In many cases, running with as few as approximately 20 steps provides outputs of equivalent *in silico* quality to running with 200 steps (providing a 10X speedup). The default is now set to 50 steps. Noting this is important for understanding the partial diffusion, described below.\n\n\n\n\n---",
"### Partial diffusion\n\n\nSomething we can do with diffusion is to partially noise and de-noise a structure, to get some diversity around a general fold. This can work really nicely (see Vazquez-Torres et al., BioRxiv 2022).\nThis is specified by using the diffuser.parial\\_T input, and setting a timestep to 'noise' to.\n\n\n\n\n\n\n\nMore noise == more diversity. In Vazquez-Torres et al., 2022, we typically used 'diffuser.partial\\_T' of approximately 80, but this was with respect to the 200 timesteps we were using. Now that the default 'diffuser.T' is 50, you will need to adjust diffuser.partial\\_T accordingly. E.g. now that 'diffuser.T=50', the equivalent of 80 noising steps is 'diffuser.partial\\_T=20'. We strongly recommend sampling different values for 'partial\\_T' however, to find the best parameters for your specific problem.\nWhen doing partial diffusion, because we are now diffusing from a known structure, this creates certain constraints. You can still use the contig input, but *this has to yield a contig string exactly the same length as the input protein*. E.g. if you have a binder:target complex, and you want to diversify the binder (length 100, chain A), you would need to input something like this:\n\n\nThe reason for this is that, if your input protein was only 80 amino acids, but you've specified a desired length of 100, we don't know where to diffuse those extra 20 amino acids from, and hence, they will not lie in the distribution that RFdiffusion has learned to denoise from.\n\n\nAn example of partial diffusion can be found in './examples/design\\_partialdiffusion.sh'!\n\n\nYou can also keep parts of the sequence of the diffused chain fixed, if you want. An example of why you might want to do this is in the context of helical peptide binding. If you've threaded a helical peptide sequence onto an ideal helix, and now want to diversify the complex, allowing the helix to be predicted now not as an ideal helix, you might do something like:\n\n\nIn this case, the 20aa chain is the helical peptide. The 'contigmap.provide\\_seq' input is zero-indexed, and you can provide a range (so 100-119 is an inclusive range, unmasking the whole sequence of the peptide). Multiple sequence ranges can be provided separated by a comma, e.g. ''contigmap.provide\\_seq=[172-177,200-205]''.\n\n\nNote that the provide\\_seq option requires using a different model checkpoint, but this is automatically handled by the inference script.\n\n\nAn example of partial diffusion with providing sequence in diffused regions can be found in './examples/design\\_partialdiffusion\\_withseq.sh'. The same example specifying multiple sequence ranges can be found in './examples/design\\_partialdiffusion\\_multipleseq.sh'.\n\n\n\n\n---",
"### Binder Design\n\n\nHopefully, it's now obvious how you might make a binder with diffusion! Indeed, RFdiffusion shows excellent *in silico* and experimental ability to design *de novo* binders.\n\n\n\n\n\n\n\nIf chain B is your target, then you could do it like this:\n\n\nThis will generate 100 residue long binders to residues 1-100 of chain B.\n\n\nHowever, this probably isn't the best way of making binders. Because diffusion is somewhat computationally-intensive, we need to try and make it as fast as possible. Providing the whole of your target, uncropped, is going to make diffusion very slow if your target is big (and most targets-of-interest, such as cell-surface receptors tend to be *very* big). One tried-and-true method to speed up binder design is to crop the target protein around the desired interface location. BUT! This creates a problem: if you crop your target and potentially expose hydrophobic core residues which were buried before the crop, how can you guarantee the binder will go to the intended interface site on the surface of the target, and not target the tantalizing hydrophobic patch you have just artificially created?\n\n\nWe solve this issue by providing the model with what we call \"hotspot residues\". The complex models we refer to earlier in this README file have all been trained with hotspot residues, in this training regime, during each example, the model is told (some of) the residues on the target protein which contact the target (i.e., resides that are part of the interface). The model readily learns that it should be making an interface which involved these hotspot residues. At inference time then, we can provide our own hotspot residues to define a region which the binder must contact. These are specified like this: ''ppi.hotspot\\_res=[A30,A33,A34]'', where 'A' is the chain ID in the input pdb file of the hotspot residue and the number is the residue index in the input pdb file of the hotspot residue.\n\n\nFinally, it has been observed that the default RFdiffusion model often generates mostly helical binders. These have high computational and experimental success rates. However, there may be cases where other kinds of topologies may be desired. For this, we include a \"beta\" model, which generates a greater diversity of topologies, but has not been extensively experimentally validated. Try this at your own risk:\n\n\nAn example of binder design with RFdiffusion can be found in './examples/design\\_ppi.sh'.\n\n\n\n\n---\n\n\nPractical Considerations for Binder Design\n------------------------------------------\n\n\nRFdiffusion is an extremely powerful binder design tool but it is not magic. In this section we will walk through some common pitfalls in RFdiffusion binder design and offer advice on how to get the most out of this method.",
"### Selecting a Target Site\n\n\nNot every site on a target protein is a good candidate for binder design. For a site to be an attractive candidate for binding it should have >~3 hydrophobic residues for the binder to interact with. Binding to charged polar sites is still quite hard. Binding to sites with glycans close to them is also hard since they often become ordered upon binding and you will take an energetic hit for that. Historically, binder design has also avoided unstructured loops, it is not clear if this is still a requirement as RFdiffusion has been used to bind unstructured peptides which share a lot in common with unstructured loops.",
"### Truncating your Target Protein\n\n\nRFdiffusion scales in runtime as O(N^2) where N is the number of residues in your system. As such, it is a very good idea to truncate large targets so that your computations are not unnecessarily expensive. RFdiffusion and all downstream steps (including AF2) are designed to allow for a truncated target. Truncating a target is an art. For some targets, such as multidomain extracellular membranes, a natural truncation point is where two domains are joined by a flexible linker. For other proteins, such as virus spike proteins, this truncation point is less obvious. Generally you want to preserve secondary structure and introduce as few chain breaks as possible. You should also try to leave ~10A of target protein on each side of your intended target site. We recommend using PyMol to truncate your target protein.",
"### Picking Hotspots\n\n\nHotspots are a feature that we integrated into the model to allow for the control of the site on the target which the binder will interact with. In the paper we define a hotspot as a residue on the target protein which is within 10A Cbeta distance of the binder. Of all of the hotspots which are identified on the target 0-20% of these hotspots are actually provided to the model and the rest are masked. This is important for understanding how you should pick hotspots at inference time.; the model is expecting to have to make more contacts than you specify. We normally recommend between 3-6 hotspots, you should run a few pilot runs before generating thousands of designs to make sure the number of hotspots you are providing will give results you like.\n\n\nIf you have run the previous PatchDock RifDock binder design pipeline, for the RFdiffusion paper we chose our hotspots to be the PatchDock residues of the target.",
"### Binder Design Scale\n\n\nIn the paper, we generated ~10,000 RFdiffusion binder backbones for each target. From this set of backbones we then generated two sequences per backbone using ProteinMPNN-FastRelax (described below). We screened these ~20,000 designs using AF2 with initial guess and target templating (also described below).\n\n\nGiven the high success rates we observed in the paper, for some targets it may be sufficient to only generate ~1,000 RFdiffusion backbones in a campaign. What you want is to get enough designs that pass pAE\\_interaction < 10 (described more in Binder Design Filtering section) such that you are able to fill a DNA order with these successful designs. We have found that designs that do not pass pAE\\_interaction < 10 are not worth ordering since they will likely not work experimentally.",
"### Sequence Design for Binders\n\n\nYou may have noticed that the binders designed by RFdiffusion come out with a poly-Glycine sequence. This is not a bug. RFdiffusion is a backbone-generation model and does not generate sequence for the designed region, therefore, another method must be used to assign a sequence to the binders. In the paper we use the ProteinMPNN-FastRelax protocol to do sequence design. We recommend that you do this as well. The code for this protocol can be found in this GitHub repo. While we did not find the FastRelax part of the protocol to yield the large in silico success rate improvements that it yielded with the RifDock-generated docks, it is still a good way to increase your number of shots-on-goal for each (computationally expensive) RFdiffusion backbone. If you would prefer to simply run ProteinMPNN on your binders without the FastRelax step, that will work fine but will be more computationally expensive.",
"### Binder Design Filtering\n\n\nOne of the most important parts of the binder design pipeline is a filtering step to evaluate if your binders are actually predicted to work. In the paper we filtered using AF2 with an initial guess and target templating, scripts for this protocol are available here. We have found that filtering at pae\\_interaction < 10 is a good predictor of a binder working experimentally.\n\n\n\n\n---",
"### Fold Conditioning\n\n\nSomething that works really well is conditioning binder design (or monomer generation) on particular topologies. This is achieved by providing (partial) secondary structure and block adjacency information (to a model that has been trained to condition on this).\n\n\n\n\n\n\n\nWe are still working out the best way to actually generate this input at inference time, but for now, we have settled upon generating inputs directly from pdb structures. This permits 'low resolution' specification of output topology (i.e., I want a TIM barrel but I don't care precisely where resides are). In 'helper\\_scripts/', there's a script called 'make\\_secstruc\\_adj.py', which can be used as follows:\ne.g. 1:\n\n\nor e.g. 2:\n\n\nThis will process either a single pdb, or a folder of pdbs, and output a secondary structure and adjacency pytorch file, ready to go into the model. For now (although this might not be necessary), you should also generate these files for the target protein (if you're doing PPI), and provide this to the model. You can then use these at inference as follows:\n\n\nA few extra things:\n\n\n1. As mentioned above, for PPI, you will want to provide a target protein, along with its secondary structure and block adjacency. This can be done by adding:\n\n\nTo generate these block adjacency and secondary structure inputs, you can use the helper script.\n\n\nThis will now generate 3-helix bundles to the insulin target.\n\n\nFor ppi, it's probably also worth adding this flag:\n\n\nThis is quite important to understand. During training, we mask some of the secondary structure and block adjacency. This is convenient, because it allows us to, at inference, easily add extra residues without having to specify precise secondary structure for every residue. E.g. if you want to make a long 3 helix bundle, you could mask the loops, and add e.g. 20 more 'mask' tokens to that loop. The model will then (presumbly) choose to make e.g. 15 of these residues into helices (to extend the 3HB), and then make a 5aa loop. But, you didn't have to specify that, which is nice. The way this would be done would be like this:\n\n\nThis will, at each run of inference, sample up to 15 residues to insert into loops in your 3HB input, and up to 5 additional residues at N and C terminus.\nThis strategy is very useful if you don't have a large set of pdbs to make block adjacencies for. For example, we showed that we could generate loads of lengthened TIM barrels from a single starting pdb with this strategy. However, for PPI, if you're using the provided scaffold sets, it shouldn't be necessary (because there are so many scaffolds to start from, generating extra diversity isn't especially necessary).\n\n\nFinally, if you have a big directory of block adjacency/secondary structure files, but don't want to use all of them, you can make a '.txt' file of the ones you want to use, and pass:\n\n\nFor PPI, we've consistently seen that reducing the noise added at inference improves designs. This comes at the expense of diversity, but, given that the scaffold sets are huge, this probably doesn't matter too much. We therefore recommend lowering the noise. 0.5 is probably a good compromise:\n\n\nThis just scales the amount of noise we add to the translations ('noise\\_scale\\_ca') and rotations ('noise\\_scale\\_frame') by, in this case, 0.5.\n\n\nAn additional example of PPI with fold conditioning is available here: './examples/design\\_ppi\\_scaffolded.sh'\n\n\n\n\n---",
"### Generation of Symmetric Oligomers\n\n\nWe're going to switch gears from discussing PPI and look at another task at which RFdiffusion performs well on: symmetric oligomer design. This is done by symmetrising the noise we sample at t=T, and symmetrising the input at every timestep. We have currently implemented the following for use (with the others coming soon!):\n\n\n* Cyclic symmetry\n* Dihedral symmetry\n* Tetrahedral symmetry\n\n\n\n\n\n\n\nHere's an example:\n\n\nHere, we've specified a different 'config' file (with '--config-name symmetry'). Because symmetric diffusion is quite different from the diffusion described above, we packaged a whole load of symmetry-related configs into a new file (see 'configs/inference/URL'). Using this config file now puts diffusion in 'symmetry-mode'.\n\n\nThe symmetry type is then specified with 'inference.symmetry='. Here, we're specifying tetrahedral symmetry, but you could also choose cyclic (e.g. 'c4') or dihedral (e.g. 'd2').\n\n\nThe configmap.contigs length refers to the *total* length of your oligomer. Therefore, it *must* be divisible by *n* chains.\n\n\nMore examples of designing oligomers can be found here: './examples/design\\_cyclic\\_oligos.sh', './examples/design\\_dihedral\\_oligos.sh', './examples/design\\_tetrahedral\\_oligos.sh'.\n\n\n\n\n---",
"### Using Auxiliary Potentials\n\n\nPerforming diffusion with symmetrized noise may give you the idea that we could use other external interventions during the denoising process to guide diffusion. One such intervention that we have implemented is auxiliary potentials. Auxiliary potentials can be very useful for guiding the inference process. E.g. whereas in RFjoint inpainting, we have little/no control over the final shape of an output, in diffusion we can readily force the network to make, for example, a well-packed protein.\nThis is achieved in the updates we make at each step.\n\n\nLet's go a little deeper into how the diffusion process works:\nAt timestep T (the first step of the reverse-diffusion inference process), we sample noise from a known *prior* distribution. The model then makes a prediction of what the final structure should be, and we use these two states (noise at time T, prediction of the structure at time 0) to back-calculate where t=T-1 would have been. We therefore have a vector pointing from each coordinate at time T, to their corresponding, back-calculated position at time T-1.\nBut, we want to be able to bias this update, to *push* the trajectory towards some desired state. This can be done by biasing that vector with another vector, which points towards a position where that residue would *reduce* the 'loss' as defined by your potential. E.g. if we want to use the 'monomer\\_ROG' potential, which seeks to minimise the radius of gyration of the final protein, if the models prediction of t=0 is very elongated, each of those distant residues will have a larger gradient when we differentiate the 'monomer\\_ROG' potential w.r.t. their positions. These gradients, along with the corresponding scale, can be combined into a vector, which is then combined with the original update vector to make a \"biased update\" at that timestep.\n\n\nThe exact parameters used when applying these potentials matter. If you weight them too strongly, you're not going to end up with a good protein. Too weak, and they'll have little effect. We've explored these potentials in a few different scenarios, and have set sensible defaults, if you want to use them. But, if you feel like they're too weak/strong, or you just fancy exploring, do play with the parameters (in the 'potentials' part of the config file).\n\n\nPotentials are specified as a list of strings with each string corresponding to a potential. The argument for potentials is 'potentials.guiding\\_potentials'. Within the string per-potential arguments may be specified in the following syntax: 'arg\\_name1:arg\\_value1,arg\\_name2:arg\\_value2,...,arg\\_nameN:arg\\_valueN'. The only argument that is required for each potential is the name of the potential that you wish to apply, the name of this argument is 'type' as-in the type of potential you wish to use. Some potentials such as 'olig\\_contacts' and 'substrate\\_contacts' take global options such as 'potentials.substrate', see 'config/inference/URL' for all the global arguments associated with potentials. Additionally, it is useful to have the effect of the potential \"decay\" throughout the trajectory, such that in the beginning the effect of the potential is 1x strength, and by the end is much weaker. These decays ('constant','linear','quadratic','cubic') can be set with the 'potentials.guide\\_decay' argument.\n\n\nHere's an example of how to specify a potential:\n\n\nWe are still fully characterising how/when to use potentials, and we strongly recommend exploring different parameters yourself, as they are clearly somewhat case-dependent. So far, it is clear that they can be helpful for motif scaffolding and symmetric oligomer generation. However, they seem to interact weirdly with hotspot residues in PPI. We think we know why this is, and will work in the coming months to write better potentials for PPI. And please note, it is often good practice to start with *no potentials* as a baseline, then slowly increase their strength. For the oligomer contacts potentials, start with the ones provided in the examples, and note that the 'intra' chain potential often should be higher than the 'inter' chain potential.\n\n\nWe have already implemented several potentials but it is relatively straightforward to add more, if you want to push your designs towards some specified goal. The *only* condition is that, whatever potential you write, it is differentiable. Take a look at 'URL' for examples of the potentials we have implemented so far.\n\n\n\n\n---",
"### Symmetric Motif Scaffolding.\n\n\nWe can also combine symmetric diffusion with motif scaffolding to scaffold motifs symmetrically.\nCurrently, we have one way for performing symmetric motif scaffolding. That is by specifying the position of the motif specified w.r.t. the symmetry axes.\n\n\n\n\n\n\n\nSpecial input .pdb and contigs requirements\n\n\nFor now, we require that a user have a symmetrized version of their motif in their input pdb for symmetric motif scaffolding. There are two main reasons for this. First, the model is trained by centering any motif at the origin, and thus the code also centers motifs at the origin automatically. Therefore, if your motif is not symmetrized, this centering action will result in an asymmetric unit that now has the origin and axes of symmetry running right through it (bad). Secondly, the diffusion code uses a canonical set of symmetry axes (rotation matrices) to propogate the asymmetric unit of a motif. In order to prevent accidentally running diffusion trajectories which are propogating your motif in ways you don't intend, we require that a user symmetrize an input using the RFdiffusion canonical symmetry axes.\n\n\nRFdiffusion canonical symmetry axes\n\n\n\nExample: Inputs for symmetric motif scaffolding with motif position specified w.r.t the symmetry axes.\n\n\nThis example script 'examples/design\\_nickel.sh' can be used to scaffold the C4 symmetric Nickel binding domains shown in the RFdiffusion paper. It combines many concepts discussed earlier, including symmetric oligomer generation, motif scaffolding, and use of guiding potentials.\n\n\nNote that the contigs should specify something that is precisely symmetric. Things will break if this is not the case.\n\n\n\n\n---",
"### A Note on Model Weights\n\n\nBecause of everything we want diffusion to be able to do, there is not *One Model To Rule Them All*. E.g., if you want to run with secondary structure conditioning, this requires a different model than if you don't. Under the hood, we take care of most of this by default - we parse your input and work out the most appropriate checkpoint.\nThis is where the config setup is really useful. The exact model checkpoint used at inference contains in it all of the parameters is was trained with, so we can just populate the config file with those values, such that inference runs as designed.\nIf you do want to specify a different checkpoint (if, for example, we train a new model and you want to test it), you just have to make sure it's compatible with what you're doing. E.g. if you try and give secondary structure features to a model that wasn't trained with them, it'll crash.",
"### Things you might want to play with at inference time\n\n\nOccasionally, it might good to try an alternative model (for example the active site model, or the beta binder model). These can be specified with 'inference.ckpt\\_override\\_path'. We do not recommend using these outside of the described use cases, however, as there is not a guarantee they will understand other kinds of inputs.\n\n\nFor a full list of things that are implemented at inference, see the config file ('configs/inference/URL' or 'configs/inference/URL'). Although you can modify everything, this is not recommended unless you know what you're doing.\nGenerally, don't change the 'model', 'preprocess' or 'diffuser' configs. These pertain to how the model was trained, so it's unwise to change how you use the model at inference time.\nHowever, the parameters below are definitely worth exploring:\n-inference.final\\_step: This is when we stop the trajectory. We have seen that you can stop early, and the model is already making a good prediction of the final structure. This speeds up inference.\n-denoiser.noise\\_scale\\_ca and denoiser.noise\\_scale\\_frame: These can be used to reduce the noise used during sampling (as discussed for PPI above). The default is 1 (the same noise added at training), but this can be reduced to e.g. 0.5, or even 0. This actually improves the quality of models coming out of diffusion, but at the expense of diversity. If you're not getting any good outputs, or if your problem is very constrained, you could try reducing the noise. While these parameters can be changed independently (for translations and rotations), we recommend keeping them tied.",
"### Understanding the output files\n\n\nWe output several different files.\n\n\n1. The '.pdb' file. This is the final prediction out of the model. Note that every designed residue is output as a glycine (as we only designed the backbone), and no sidechains are output. This is because, even though RFdiffusion conditions on sidechains in an input motif, there is no loss applied to these predictions, so they can't strictly be trusted.\n2. The '.trb' file. This contains useful metadata associated with that specific run, including the specific contig used (if length ranges were sampled), as well as the full config used by RFdiffusion. There are also a few other convenient items in this file:\n\t* details about mapping (i.e. how residues in the input map to residues in the output)\n\t\t+ 'con\\_ref\\_pdb\\_idx'/'con\\_hal\\_pdb\\_idx' - These are two arrays including the input pdb indices (in con\\_ref\\_pdb\\_idx), and where they are in the output pdb (in con\\_hal\\_pdb\\_idx). This only contains the chains where inpainting took place (i.e. not any fixed receptor/target chains)\n\t\t+ 'con\\_ref\\_idx0'/'con\\_hal\\_idx0' - These are the same as above, but 0 indexed, and without chain information. This is useful for splicing coordinates out (to assess alignment etc).\n\t\t+ 'inpaint\\_seq' - This details any residues that were masked during inference.\n3. Trajectory files. By default, we output the full trajectories into the '/traj/' folder. These files can be opened in pymol, as multi-step pdbs. Note that these are ordered in reverse, so the first pdb is technically the last (t=1) prediction made by RFdiffusion during inference. We include both the 'pX0' predictions (what the model predicted at each timestep) and the 'Xt-1' trajectories (what went into the model at each timestep).",
"### Docker\n\n\nWe have provided a Dockerfile at 'docker/Dockerfile' to help run RFDiffusion on HPC and other container orchestration systems. Follow these steps to build and run the container on your system:\n\n\n1. Clone this repository with 'git clone URL and then 'cd RFdiffusion'\n2. Verify that the Docker daemon is running on your system with 'docker info'. You can find Docker installation instructions for Mac, WIndows, and Linux in the official Docker docs. You may also consider Finch, the open source client for container development.\n3. Build the container image on your system with 'docker build -f docker/Dockerfile -t rfdiffusion .'\n4. Create some folders on your file system with 'mkdir $HOME/inputs $HOME/outputs $HOME/models'\n5. Download the RFDiffusion models with 'bash scripts/download\\_models.sh $HOME/models'\n6. Download a test file (or another of your choice) with 'wget -P $HOME/inputs URL\n7. Run the container with the following command:\n\n\nThis starts the 'rfdiffusion' container, mounts the models, inputs, and outputs folders, passes all available GPUs, and then calls the 'run\\_inference.py' script with the parameters specified.",
"### Conclusion\n\n\nWe are extremely excited to share RFdiffusion with the wider scientific community. We expect to push some updates as and when we make sizeable improvements in the coming months, so do stay tuned. We realize it may take some time to get used to executing RFdiffusion with perfect syntax (sometimes Hydra is hard), so please don't hesitate to create GitHub issues if you need help, we will respond as often as we can.\n\n\nNow, let's go make some proteins. Have fun!\n\n\n- Joe, David, Nate, Brian, Jason, and the RFdiffusion team.\n\n\n\n\n---\n\n\nRFdiffusion builds directly on the architecture and trained parameters of RoseTTAFold. We therefore thank Frank DiMaio and Minkyung Baek, who developed RoseTTAFold.\nRFdiffusion is released under an open source BSD License (see LICENSE file). It is free for both non-profit and for-profit use."
] | [
"TAGS\n#region-us \n",
"### Conda Install SE3-Transformer\n\n\nEnsure that you have either Anaconda or Miniconda installed.\n\n\nYou also need to install NVIDIA's implementation of SE(3)-Transformers Here is how to install the NVIDIA SE(3)-Transformer code:\n\n\nAnytime you run diffusion you should be sure to activate this conda environment by running the following command:\n\n\nTotal setup should take less than 30 minutes on a standard desktop computer.\nNote: Due to the variation in GPU types and drivers that users have access to, we are not able to make one environment that will run on all setups. As such, we are only providing a yml file with support for CUDA 11.1 and leaving it to each user to customize it to work on their setups. This customization will involve changing the cudatoolkit and (possibly) the PyTorch version specified in the yml file.\n\n\n\n\n---",
"### Get PPI Scaffold Examples\n\n\nTo run the scaffolded protein binder design (PPI) examples, we have provided some example scaffold files ('examples/ppi\\_scaffolds\\_subset.URL').\nYou'll need to untar this:\n\n\nWe will explain what these files are and how to use them in the Fold Conditioning section.\n\n\n\n\n---\n\n\nUsage\n=====\n\n\nIn this section we will demonstrate how to run diffusion.\n\n\n\n",
"### Running the diffusion script\n\n\nThe actual script you will execute is called 'scripts/run\\_inference.py'. There are many ways to run it, governed by hydra configs.\nHydra configs are a nice way of being able to specify many different options, with sensible defaults drawn *directly* from the model checkpoint, so inference should always, by default, match training.\nWhat this means is that the default values in 'config/inference/URL' might not match the actual values used during inference, with a specific checkpoint. This is all handled under the hood.\n\n\n\n\n---",
"### Basic execution - an unconditional monomer\n\n\n\nLet's first look at how you would do unconditional design of a protein of length 150aa.\nFor this, we just need to specify three things:\n\n\n1. The length of the protein\n2. The location where we want to write files to\n3. The number of designs we want\n\n\nLet's look at this in detail.\nFirstly, what is 'contigmap.contigs'?\nHydra configs tell the inference script how it should be run. To keep things organised, the config has different sub-configs, one of them being 'contigmap', which pertains to everything related to the contig string (that defines the protein being built).\nTake a look at the config file if this isn't clear: 'configs/inference/URL'\nAnything in the config can be overwritten manually from the command line. You could, for example, change how the diffuser works:\n\n\n... but don't do this unless you really know what you're doing!!\n\n\nNow, what does ''contigmap.contigs=[150-150]'' mean?\nTo those who have used RFjoint inpainting, this might look familiar, but a little bit different. Diffusion, in fact, uses the identical 'contig mapper' as inpainting, except that, because we're using hydra, we have to give this to the model in a different way. The contig string has to be passed as a single-item in a list, rather than as a string, for hydra reasons and the entire argument MUST be enclosed in '''' so that the commandline does not attempt to parse any of the special characters.\n\n\nThe contig string allows you to specify a length range, but here, we just want a protein of 150aa in length, so you just specify [150-150]\nThis will then run 10 diffusion trajectories, saving the outputs to your specified output folder.\n\n\nNB the first time you run RFdiffusion, it will take a while 'Calculating IGSO3'. Once it has done this, it'll be cached for future reference though! For an additional example of unconditional monomer generation, take a look at './examples/design\\_unconditional.sh' in the repo!\n\n\n\n\n---",
"### Motif Scaffolding\n\n\nRFdiffusion can be used to scaffold motifs, in a manner akin to Constrained Hallucination and RFjoint Inpainting. In general, RFdiffusion significantly outperforms both Constrained Hallucination and RFjoint Inpainting.\n\n\n\n\n\n\n\nWhen scaffolding protein motifs, we need a way of specifying that we want to scaffold some particular protein input (one or more segments from a '.pdb' file), and to be able to specify how we want these connected, and by how many residues, in the new scaffolded protein. What's more, we want to be able to sample different lengths of connecting protein, as we generally don't know *a priori* precisely how many residues we'll need to best scaffold a motif. This job of specifying inputs is handled by contigs, governed by the contigmap config in the hydra config. For those familiar with Constrained Hallucination or RFjoint Inpainting, the logic is very similar.\nBriefly:\n\n\n* Anything prefixed by a letter indicates that this is a motif, with the letter corresponding to the chain letter in the input pdb files. E.g. A10-25 pertains to residues ('A',10),('A',11)...('A',25) in the corresponding input pdb\n* Anything not prefixed by a letter indicates protein *to be built*. This can be input as a length range. These length ranges are randomly sampled each iteration of RFdiffusion inference.\n* To specify chain breaks, we use '/0 '.\n\n\nIn more detail, if we want to scaffold a motif, the input is just like RFjoint Inpainting, except needing to navigate the hydra config input. If we want to scaffold residues 10-25 on chain A a pdb, this would be done with ''contigmap.contigs=[5-15/A10-25/30-40]''. This asks RFdiffusion to build 5-15 residues (randomly sampled at each inference cycle) N-terminally of A10-25 from the input pdb, followed by 30-40 residues (again, randomly sampled) to its C-terminus. If we wanted to ensure the length was always e.g. 55 residues, this can be specified with 'URL=55-55'. You need to obviously also provide a path to your pdb file: 'inference.input\\_pdb=path/to/URL'. It doesn't matter if your input pdb has residues you *don't* want to scaffold - the contig map defines which residues in the pdb are actually used as the \"motif\". In other words, even if your pdb files has a B chain, and other residues on the A chain, *only* A10-25 will be provided to RFdiffusion.\n\n\nTo specify that we want to inpaint in the presence of a separate chain, this can be done as follows:\n\n\nLook at this carefully. '/0 ' is the indicator that we want a chain break. NOTE, the space is important here. This tells the diffusion model to add a big residue jump (200aa) to the input, so that the model sees the first chain as being on a separate chain to the second.\n\n\nAn example of motif scaffolding can be found in './examples/design\\_motifscaffolding.sh'.",
"### The \"active site\" model holds very small motifs in place\n\n\nIn the RFdiffusion preprint we noted that for very small motifs, RFdiffusion has the tendency to not keep them perfectly fixed in the output. Therefore, for scaffolding minimalist sites such as enzyme active sites, we fine-tuned RFdiffusion on examples similar to these tasks, allowing it to hold smaller motifs better in place, and better generate *in silico* successes. If your input functional motif is very small, we reccomend using this model, which can easily be specified using the following syntax:\n'inference.ckpt\\_override\\_path=models/ActiveSite\\_ckpt.pt'",
"### The 'inpaint\\_seq' flag\n\n\nFor those familiar with RFjoint Inpainting, the contigmap.inpaint\\_seq input is equivalent. The idea is that often, when, for example, fusing two proteins, residues that were on the surface of a protein (and are therefore likely polar), now need to be packed into the 'core' of the protein. We therefore want them to become hydrophobic residues. What we can do, rather than directly mutating them to hydrophobics, is to mask their sequence identity, and allow RFdiffusion to implicitly reason over their sequence, and better pack against them. This requires a different model than the 'base' diffusion model, that has been trained to understand this paradigm, but this is automatically handled by the inference script (you don't need to do anything).\n\n\nTo specify amino acids whose sequence should be hidden, use the following syntax:\n\n\nHere, we're masking the residue identity of residue A1, and all residues between A30 and A40 (inclusive).\n\n\nAn example of executing motif scaffolding with the 'contigmap.inpaint\\_seq' flag is located in './examples/design\\_motifscaffolding\\_inpaintseq.sh'",
"### A note on 'diffuser.T'\n\n\nRFdiffusion was originally trained with 200 discrete timesteps. However, recent improvements have allowed us to reduce the number of timesteps we need to use at inference time. In many cases, running with as few as approximately 20 steps provides outputs of equivalent *in silico* quality to running with 200 steps (providing a 10X speedup). The default is now set to 50 steps. Noting this is important for understanding the partial diffusion, described below.\n\n\n\n\n---",
"### Partial diffusion\n\n\nSomething we can do with diffusion is to partially noise and de-noise a structure, to get some diversity around a general fold. This can work really nicely (see Vazquez-Torres et al., BioRxiv 2022).\nThis is specified by using the diffuser.parial\\_T input, and setting a timestep to 'noise' to.\n\n\n\n\n\n\n\nMore noise == more diversity. In Vazquez-Torres et al., 2022, we typically used 'diffuser.partial\\_T' of approximately 80, but this was with respect to the 200 timesteps we were using. Now that the default 'diffuser.T' is 50, you will need to adjust diffuser.partial\\_T accordingly. E.g. now that 'diffuser.T=50', the equivalent of 80 noising steps is 'diffuser.partial\\_T=20'. We strongly recommend sampling different values for 'partial\\_T' however, to find the best parameters for your specific problem.\nWhen doing partial diffusion, because we are now diffusing from a known structure, this creates certain constraints. You can still use the contig input, but *this has to yield a contig string exactly the same length as the input protein*. E.g. if you have a binder:target complex, and you want to diversify the binder (length 100, chain A), you would need to input something like this:\n\n\nThe reason for this is that, if your input protein was only 80 amino acids, but you've specified a desired length of 100, we don't know where to diffuse those extra 20 amino acids from, and hence, they will not lie in the distribution that RFdiffusion has learned to denoise from.\n\n\nAn example of partial diffusion can be found in './examples/design\\_partialdiffusion.sh'!\n\n\nYou can also keep parts of the sequence of the diffused chain fixed, if you want. An example of why you might want to do this is in the context of helical peptide binding. If you've threaded a helical peptide sequence onto an ideal helix, and now want to diversify the complex, allowing the helix to be predicted now not as an ideal helix, you might do something like:\n\n\nIn this case, the 20aa chain is the helical peptide. The 'contigmap.provide\\_seq' input is zero-indexed, and you can provide a range (so 100-119 is an inclusive range, unmasking the whole sequence of the peptide). Multiple sequence ranges can be provided separated by a comma, e.g. ''contigmap.provide\\_seq=[172-177,200-205]''.\n\n\nNote that the provide\\_seq option requires using a different model checkpoint, but this is automatically handled by the inference script.\n\n\nAn example of partial diffusion with providing sequence in diffused regions can be found in './examples/design\\_partialdiffusion\\_withseq.sh'. The same example specifying multiple sequence ranges can be found in './examples/design\\_partialdiffusion\\_multipleseq.sh'.\n\n\n\n\n---",
"### Binder Design\n\n\nHopefully, it's now obvious how you might make a binder with diffusion! Indeed, RFdiffusion shows excellent *in silico* and experimental ability to design *de novo* binders.\n\n\n\n\n\n\n\nIf chain B is your target, then you could do it like this:\n\n\nThis will generate 100 residue long binders to residues 1-100 of chain B.\n\n\nHowever, this probably isn't the best way of making binders. Because diffusion is somewhat computationally-intensive, we need to try and make it as fast as possible. Providing the whole of your target, uncropped, is going to make diffusion very slow if your target is big (and most targets-of-interest, such as cell-surface receptors tend to be *very* big). One tried-and-true method to speed up binder design is to crop the target protein around the desired interface location. BUT! This creates a problem: if you crop your target and potentially expose hydrophobic core residues which were buried before the crop, how can you guarantee the binder will go to the intended interface site on the surface of the target, and not target the tantalizing hydrophobic patch you have just artificially created?\n\n\nWe solve this issue by providing the model with what we call \"hotspot residues\". The complex models we refer to earlier in this README file have all been trained with hotspot residues, in this training regime, during each example, the model is told (some of) the residues on the target protein which contact the target (i.e., resides that are part of the interface). The model readily learns that it should be making an interface which involved these hotspot residues. At inference time then, we can provide our own hotspot residues to define a region which the binder must contact. These are specified like this: ''ppi.hotspot\\_res=[A30,A33,A34]'', where 'A' is the chain ID in the input pdb file of the hotspot residue and the number is the residue index in the input pdb file of the hotspot residue.\n\n\nFinally, it has been observed that the default RFdiffusion model often generates mostly helical binders. These have high computational and experimental success rates. However, there may be cases where other kinds of topologies may be desired. For this, we include a \"beta\" model, which generates a greater diversity of topologies, but has not been extensively experimentally validated. Try this at your own risk:\n\n\nAn example of binder design with RFdiffusion can be found in './examples/design\\_ppi.sh'.\n\n\n\n\n---\n\n\nPractical Considerations for Binder Design\n------------------------------------------\n\n\nRFdiffusion is an extremely powerful binder design tool but it is not magic. In this section we will walk through some common pitfalls in RFdiffusion binder design and offer advice on how to get the most out of this method.",
"### Selecting a Target Site\n\n\nNot every site on a target protein is a good candidate for binder design. For a site to be an attractive candidate for binding it should have >~3 hydrophobic residues for the binder to interact with. Binding to charged polar sites is still quite hard. Binding to sites with glycans close to them is also hard since they often become ordered upon binding and you will take an energetic hit for that. Historically, binder design has also avoided unstructured loops, it is not clear if this is still a requirement as RFdiffusion has been used to bind unstructured peptides which share a lot in common with unstructured loops.",
"### Truncating your Target Protein\n\n\nRFdiffusion scales in runtime as O(N^2) where N is the number of residues in your system. As such, it is a very good idea to truncate large targets so that your computations are not unnecessarily expensive. RFdiffusion and all downstream steps (including AF2) are designed to allow for a truncated target. Truncating a target is an art. For some targets, such as multidomain extracellular membranes, a natural truncation point is where two domains are joined by a flexible linker. For other proteins, such as virus spike proteins, this truncation point is less obvious. Generally you want to preserve secondary structure and introduce as few chain breaks as possible. You should also try to leave ~10A of target protein on each side of your intended target site. We recommend using PyMol to truncate your target protein.",
"### Picking Hotspots\n\n\nHotspots are a feature that we integrated into the model to allow for the control of the site on the target which the binder will interact with. In the paper we define a hotspot as a residue on the target protein which is within 10A Cbeta distance of the binder. Of all of the hotspots which are identified on the target 0-20% of these hotspots are actually provided to the model and the rest are masked. This is important for understanding how you should pick hotspots at inference time.; the model is expecting to have to make more contacts than you specify. We normally recommend between 3-6 hotspots, you should run a few pilot runs before generating thousands of designs to make sure the number of hotspots you are providing will give results you like.\n\n\nIf you have run the previous PatchDock RifDock binder design pipeline, for the RFdiffusion paper we chose our hotspots to be the PatchDock residues of the target.",
"### Binder Design Scale\n\n\nIn the paper, we generated ~10,000 RFdiffusion binder backbones for each target. From this set of backbones we then generated two sequences per backbone using ProteinMPNN-FastRelax (described below). We screened these ~20,000 designs using AF2 with initial guess and target templating (also described below).\n\n\nGiven the high success rates we observed in the paper, for some targets it may be sufficient to only generate ~1,000 RFdiffusion backbones in a campaign. What you want is to get enough designs that pass pAE\\_interaction < 10 (described more in Binder Design Filtering section) such that you are able to fill a DNA order with these successful designs. We have found that designs that do not pass pAE\\_interaction < 10 are not worth ordering since they will likely not work experimentally.",
"### Sequence Design for Binders\n\n\nYou may have noticed that the binders designed by RFdiffusion come out with a poly-Glycine sequence. This is not a bug. RFdiffusion is a backbone-generation model and does not generate sequence for the designed region, therefore, another method must be used to assign a sequence to the binders. In the paper we use the ProteinMPNN-FastRelax protocol to do sequence design. We recommend that you do this as well. The code for this protocol can be found in this GitHub repo. While we did not find the FastRelax part of the protocol to yield the large in silico success rate improvements that it yielded with the RifDock-generated docks, it is still a good way to increase your number of shots-on-goal for each (computationally expensive) RFdiffusion backbone. If you would prefer to simply run ProteinMPNN on your binders without the FastRelax step, that will work fine but will be more computationally expensive.",
"### Binder Design Filtering\n\n\nOne of the most important parts of the binder design pipeline is a filtering step to evaluate if your binders are actually predicted to work. In the paper we filtered using AF2 with an initial guess and target templating, scripts for this protocol are available here. We have found that filtering at pae\\_interaction < 10 is a good predictor of a binder working experimentally.\n\n\n\n\n---",
"### Fold Conditioning\n\n\nSomething that works really well is conditioning binder design (or monomer generation) on particular topologies. This is achieved by providing (partial) secondary structure and block adjacency information (to a model that has been trained to condition on this).\n\n\n\n\n\n\n\nWe are still working out the best way to actually generate this input at inference time, but for now, we have settled upon generating inputs directly from pdb structures. This permits 'low resolution' specification of output topology (i.e., I want a TIM barrel but I don't care precisely where resides are). In 'helper\\_scripts/', there's a script called 'make\\_secstruc\\_adj.py', which can be used as follows:\ne.g. 1:\n\n\nor e.g. 2:\n\n\nThis will process either a single pdb, or a folder of pdbs, and output a secondary structure and adjacency pytorch file, ready to go into the model. For now (although this might not be necessary), you should also generate these files for the target protein (if you're doing PPI), and provide this to the model. You can then use these at inference as follows:\n\n\nA few extra things:\n\n\n1. As mentioned above, for PPI, you will want to provide a target protein, along with its secondary structure and block adjacency. This can be done by adding:\n\n\nTo generate these block adjacency and secondary structure inputs, you can use the helper script.\n\n\nThis will now generate 3-helix bundles to the insulin target.\n\n\nFor ppi, it's probably also worth adding this flag:\n\n\nThis is quite important to understand. During training, we mask some of the secondary structure and block adjacency. This is convenient, because it allows us to, at inference, easily add extra residues without having to specify precise secondary structure for every residue. E.g. if you want to make a long 3 helix bundle, you could mask the loops, and add e.g. 20 more 'mask' tokens to that loop. The model will then (presumbly) choose to make e.g. 15 of these residues into helices (to extend the 3HB), and then make a 5aa loop. But, you didn't have to specify that, which is nice. The way this would be done would be like this:\n\n\nThis will, at each run of inference, sample up to 15 residues to insert into loops in your 3HB input, and up to 5 additional residues at N and C terminus.\nThis strategy is very useful if you don't have a large set of pdbs to make block adjacencies for. For example, we showed that we could generate loads of lengthened TIM barrels from a single starting pdb with this strategy. However, for PPI, if you're using the provided scaffold sets, it shouldn't be necessary (because there are so many scaffolds to start from, generating extra diversity isn't especially necessary).\n\n\nFinally, if you have a big directory of block adjacency/secondary structure files, but don't want to use all of them, you can make a '.txt' file of the ones you want to use, and pass:\n\n\nFor PPI, we've consistently seen that reducing the noise added at inference improves designs. This comes at the expense of diversity, but, given that the scaffold sets are huge, this probably doesn't matter too much. We therefore recommend lowering the noise. 0.5 is probably a good compromise:\n\n\nThis just scales the amount of noise we add to the translations ('noise\\_scale\\_ca') and rotations ('noise\\_scale\\_frame') by, in this case, 0.5.\n\n\nAn additional example of PPI with fold conditioning is available here: './examples/design\\_ppi\\_scaffolded.sh'\n\n\n\n\n---",
"### Generation of Symmetric Oligomers\n\n\nWe're going to switch gears from discussing PPI and look at another task at which RFdiffusion performs well on: symmetric oligomer design. This is done by symmetrising the noise we sample at t=T, and symmetrising the input at every timestep. We have currently implemented the following for use (with the others coming soon!):\n\n\n* Cyclic symmetry\n* Dihedral symmetry\n* Tetrahedral symmetry\n\n\n\n\n\n\n\nHere's an example:\n\n\nHere, we've specified a different 'config' file (with '--config-name symmetry'). Because symmetric diffusion is quite different from the diffusion described above, we packaged a whole load of symmetry-related configs into a new file (see 'configs/inference/URL'). Using this config file now puts diffusion in 'symmetry-mode'.\n\n\nThe symmetry type is then specified with 'inference.symmetry='. Here, we're specifying tetrahedral symmetry, but you could also choose cyclic (e.g. 'c4') or dihedral (e.g. 'd2').\n\n\nThe configmap.contigs length refers to the *total* length of your oligomer. Therefore, it *must* be divisible by *n* chains.\n\n\nMore examples of designing oligomers can be found here: './examples/design\\_cyclic\\_oligos.sh', './examples/design\\_dihedral\\_oligos.sh', './examples/design\\_tetrahedral\\_oligos.sh'.\n\n\n\n\n---",
"### Using Auxiliary Potentials\n\n\nPerforming diffusion with symmetrized noise may give you the idea that we could use other external interventions during the denoising process to guide diffusion. One such intervention that we have implemented is auxiliary potentials. Auxiliary potentials can be very useful for guiding the inference process. E.g. whereas in RFjoint inpainting, we have little/no control over the final shape of an output, in diffusion we can readily force the network to make, for example, a well-packed protein.\nThis is achieved in the updates we make at each step.\n\n\nLet's go a little deeper into how the diffusion process works:\nAt timestep T (the first step of the reverse-diffusion inference process), we sample noise from a known *prior* distribution. The model then makes a prediction of what the final structure should be, and we use these two states (noise at time T, prediction of the structure at time 0) to back-calculate where t=T-1 would have been. We therefore have a vector pointing from each coordinate at time T, to their corresponding, back-calculated position at time T-1.\nBut, we want to be able to bias this update, to *push* the trajectory towards some desired state. This can be done by biasing that vector with another vector, which points towards a position where that residue would *reduce* the 'loss' as defined by your potential. E.g. if we want to use the 'monomer\\_ROG' potential, which seeks to minimise the radius of gyration of the final protein, if the models prediction of t=0 is very elongated, each of those distant residues will have a larger gradient when we differentiate the 'monomer\\_ROG' potential w.r.t. their positions. These gradients, along with the corresponding scale, can be combined into a vector, which is then combined with the original update vector to make a \"biased update\" at that timestep.\n\n\nThe exact parameters used when applying these potentials matter. If you weight them too strongly, you're not going to end up with a good protein. Too weak, and they'll have little effect. We've explored these potentials in a few different scenarios, and have set sensible defaults, if you want to use them. But, if you feel like they're too weak/strong, or you just fancy exploring, do play with the parameters (in the 'potentials' part of the config file).\n\n\nPotentials are specified as a list of strings with each string corresponding to a potential. The argument for potentials is 'potentials.guiding\\_potentials'. Within the string per-potential arguments may be specified in the following syntax: 'arg\\_name1:arg\\_value1,arg\\_name2:arg\\_value2,...,arg\\_nameN:arg\\_valueN'. The only argument that is required for each potential is the name of the potential that you wish to apply, the name of this argument is 'type' as-in the type of potential you wish to use. Some potentials such as 'olig\\_contacts' and 'substrate\\_contacts' take global options such as 'potentials.substrate', see 'config/inference/URL' for all the global arguments associated with potentials. Additionally, it is useful to have the effect of the potential \"decay\" throughout the trajectory, such that in the beginning the effect of the potential is 1x strength, and by the end is much weaker. These decays ('constant','linear','quadratic','cubic') can be set with the 'potentials.guide\\_decay' argument.\n\n\nHere's an example of how to specify a potential:\n\n\nWe are still fully characterising how/when to use potentials, and we strongly recommend exploring different parameters yourself, as they are clearly somewhat case-dependent. So far, it is clear that they can be helpful for motif scaffolding and symmetric oligomer generation. However, they seem to interact weirdly with hotspot residues in PPI. We think we know why this is, and will work in the coming months to write better potentials for PPI. And please note, it is often good practice to start with *no potentials* as a baseline, then slowly increase their strength. For the oligomer contacts potentials, start with the ones provided in the examples, and note that the 'intra' chain potential often should be higher than the 'inter' chain potential.\n\n\nWe have already implemented several potentials but it is relatively straightforward to add more, if you want to push your designs towards some specified goal. The *only* condition is that, whatever potential you write, it is differentiable. Take a look at 'URL' for examples of the potentials we have implemented so far.\n\n\n\n\n---",
"### Symmetric Motif Scaffolding.\n\n\nWe can also combine symmetric diffusion with motif scaffolding to scaffold motifs symmetrically.\nCurrently, we have one way for performing symmetric motif scaffolding. That is by specifying the position of the motif specified w.r.t. the symmetry axes.\n\n\n\n\n\n\n\nSpecial input .pdb and contigs requirements\n\n\nFor now, we require that a user have a symmetrized version of their motif in their input pdb for symmetric motif scaffolding. There are two main reasons for this. First, the model is trained by centering any motif at the origin, and thus the code also centers motifs at the origin automatically. Therefore, if your motif is not symmetrized, this centering action will result in an asymmetric unit that now has the origin and axes of symmetry running right through it (bad). Secondly, the diffusion code uses a canonical set of symmetry axes (rotation matrices) to propogate the asymmetric unit of a motif. In order to prevent accidentally running diffusion trajectories which are propogating your motif in ways you don't intend, we require that a user symmetrize an input using the RFdiffusion canonical symmetry axes.\n\n\nRFdiffusion canonical symmetry axes\n\n\n\nExample: Inputs for symmetric motif scaffolding with motif position specified w.r.t the symmetry axes.\n\n\nThis example script 'examples/design\\_nickel.sh' can be used to scaffold the C4 symmetric Nickel binding domains shown in the RFdiffusion paper. It combines many concepts discussed earlier, including symmetric oligomer generation, motif scaffolding, and use of guiding potentials.\n\n\nNote that the contigs should specify something that is precisely symmetric. Things will break if this is not the case.\n\n\n\n\n---",
"### A Note on Model Weights\n\n\nBecause of everything we want diffusion to be able to do, there is not *One Model To Rule Them All*. E.g., if you want to run with secondary structure conditioning, this requires a different model than if you don't. Under the hood, we take care of most of this by default - we parse your input and work out the most appropriate checkpoint.\nThis is where the config setup is really useful. The exact model checkpoint used at inference contains in it all of the parameters is was trained with, so we can just populate the config file with those values, such that inference runs as designed.\nIf you do want to specify a different checkpoint (if, for example, we train a new model and you want to test it), you just have to make sure it's compatible with what you're doing. E.g. if you try and give secondary structure features to a model that wasn't trained with them, it'll crash.",
"### Things you might want to play with at inference time\n\n\nOccasionally, it might good to try an alternative model (for example the active site model, or the beta binder model). These can be specified with 'inference.ckpt\\_override\\_path'. We do not recommend using these outside of the described use cases, however, as there is not a guarantee they will understand other kinds of inputs.\n\n\nFor a full list of things that are implemented at inference, see the config file ('configs/inference/URL' or 'configs/inference/URL'). Although you can modify everything, this is not recommended unless you know what you're doing.\nGenerally, don't change the 'model', 'preprocess' or 'diffuser' configs. These pertain to how the model was trained, so it's unwise to change how you use the model at inference time.\nHowever, the parameters below are definitely worth exploring:\n-inference.final\\_step: This is when we stop the trajectory. We have seen that you can stop early, and the model is already making a good prediction of the final structure. This speeds up inference.\n-denoiser.noise\\_scale\\_ca and denoiser.noise\\_scale\\_frame: These can be used to reduce the noise used during sampling (as discussed for PPI above). The default is 1 (the same noise added at training), but this can be reduced to e.g. 0.5, or even 0. This actually improves the quality of models coming out of diffusion, but at the expense of diversity. If you're not getting any good outputs, or if your problem is very constrained, you could try reducing the noise. While these parameters can be changed independently (for translations and rotations), we recommend keeping them tied.",
"### Understanding the output files\n\n\nWe output several different files.\n\n\n1. The '.pdb' file. This is the final prediction out of the model. Note that every designed residue is output as a glycine (as we only designed the backbone), and no sidechains are output. This is because, even though RFdiffusion conditions on sidechains in an input motif, there is no loss applied to these predictions, so they can't strictly be trusted.\n2. The '.trb' file. This contains useful metadata associated with that specific run, including the specific contig used (if length ranges were sampled), as well as the full config used by RFdiffusion. There are also a few other convenient items in this file:\n\t* details about mapping (i.e. how residues in the input map to residues in the output)\n\t\t+ 'con\\_ref\\_pdb\\_idx'/'con\\_hal\\_pdb\\_idx' - These are two arrays including the input pdb indices (in con\\_ref\\_pdb\\_idx), and where they are in the output pdb (in con\\_hal\\_pdb\\_idx). This only contains the chains where inpainting took place (i.e. not any fixed receptor/target chains)\n\t\t+ 'con\\_ref\\_idx0'/'con\\_hal\\_idx0' - These are the same as above, but 0 indexed, and without chain information. This is useful for splicing coordinates out (to assess alignment etc).\n\t\t+ 'inpaint\\_seq' - This details any residues that were masked during inference.\n3. Trajectory files. By default, we output the full trajectories into the '/traj/' folder. These files can be opened in pymol, as multi-step pdbs. Note that these are ordered in reverse, so the first pdb is technically the last (t=1) prediction made by RFdiffusion during inference. We include both the 'pX0' predictions (what the model predicted at each timestep) and the 'Xt-1' trajectories (what went into the model at each timestep).",
"### Docker\n\n\nWe have provided a Dockerfile at 'docker/Dockerfile' to help run RFDiffusion on HPC and other container orchestration systems. Follow these steps to build and run the container on your system:\n\n\n1. Clone this repository with 'git clone URL and then 'cd RFdiffusion'\n2. Verify that the Docker daemon is running on your system with 'docker info'. You can find Docker installation instructions for Mac, WIndows, and Linux in the official Docker docs. You may also consider Finch, the open source client for container development.\n3. Build the container image on your system with 'docker build -f docker/Dockerfile -t rfdiffusion .'\n4. Create some folders on your file system with 'mkdir $HOME/inputs $HOME/outputs $HOME/models'\n5. Download the RFDiffusion models with 'bash scripts/download\\_models.sh $HOME/models'\n6. Download a test file (or another of your choice) with 'wget -P $HOME/inputs URL\n7. Run the container with the following command:\n\n\nThis starts the 'rfdiffusion' container, mounts the models, inputs, and outputs folders, passes all available GPUs, and then calls the 'run\\_inference.py' script with the parameters specified.",
"### Conclusion\n\n\nWe are extremely excited to share RFdiffusion with the wider scientific community. We expect to push some updates as and when we make sizeable improvements in the coming months, so do stay tuned. We realize it may take some time to get used to executing RFdiffusion with perfect syntax (sometimes Hydra is hard), so please don't hesitate to create GitHub issues if you need help, we will respond as often as we can.\n\n\nNow, let's go make some proteins. Have fun!\n\n\n- Joe, David, Nate, Brian, Jason, and the RFdiffusion team.\n\n\n\n\n---\n\n\nRFdiffusion builds directly on the architecture and trained parameters of RoseTTAFold. We therefore thank Frank DiMaio and Minkyung Baek, who developed RoseTTAFold.\nRFdiffusion is released under an open source BSD License (see LICENSE file). It is free for both non-profit and for-profit use."
] |
text-generation | null |
## Model Details
This is a FP16 GGUF version of Meta-LLama-3-8B. used https://github.com/ggerganov/llama.cpp/pull/6745 for conversion
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos | {"language": ["en"], "license": "other", "tags": ["facebook", "meta", "pytorch", "llama", "llama-3"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "extra_gated_prompt": "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT\nMeta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/.\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity\u2019s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means, collectively, Meta\u2019s proprietary Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display \u201cBuilt with Meta Llama 3\u201d on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include \u201cLlama 3\u201d at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a \u201cNotice\u201d text file distributed as a part of such copies: \u201cMeta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright \u00a9 Meta Platforms, Inc. All Rights Reserved.\u201d\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee\u2019s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use \u201cLlama 3\u201d (the \u201cMark\u201d) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta\u2019s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta\u2019s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.\n### Meta Llama 3 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you access or use Meta Llama 3, you agree to this Acceptable Use Policy (\u201cPolicy\u201d). The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)\n#### Prohibited Uses\nWe want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow others to use, Meta Llama 3 to: 1. Violate the law or others\u2019 rights, including to:\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:\n 1. Violence or terrorism\n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material\n 3. Human trafficking, exploitation, and sexual violence\n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.\n 5. Sexual solicitation\n 6. Any other criminal activity\n 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n 5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws\n 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:\n 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State\n 2. Guns and illegal weapons (including weapon development)\n 3. Illegal drugs and regulated/controlled substances\n 4. Operation of critical infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm or harm to others, including suicide, cutting, and eating disorders\n 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:\n 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n 3. Generating, promoting, or further distributing spam\n 4. Impersonating another individual without consent, authorization, or legal right\n 5. Representing that the use of Meta Llama 3 or outputs are human-generated\n 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\n4. Fail to appropriately disclose to end users any known dangers of your AI system\nPlease report any violation of this Policy, software \u201cbug,\u201d or other problems that could lead to a violation of this Policy through one of the following means:\n * Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)\n * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]", "extra_gated_fields": {"First Name": "text", "Last Name": "text", "Date of birth": "date_picker", "Country": "country", "Affiliation": "text", "geo": "ip_location", "By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy": "checkbox"}, "extra_gated_description": "The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).", "extra_gated_button_content": "Submit"} | AviadDahan/Meta-Llama-3-8B-fp16-gguf | null | [
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"license:other",
"region:us"
] | null | 2024-04-19T09:18:35+00:00 | [] | [
"en"
] | TAGS
#gguf #facebook #meta #pytorch #llama #llama-3 #text-generation #en #license-other #region-us
| Model Details
-------------
This is a FP16 GGUF version of Meta-LLama-3-8B. used URL for conversion
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
Model developers Meta
Variations Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
Input Models input text only.
Output Models generate text and code only.
Model Architecture Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
Model Release Date April 18, 2024.
Status This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
License A custom commercial license is available at: URL
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model README. For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go here.
Intended Use
------------
Intended Use Cases Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
Out-of-scope Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English.
Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
How to use
----------
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original 'llama3' codebase.
### Use with transformers
See the snippet below for usage with Transformers:
### Use with 'llama3'
Please, follow the instructions in the repository
To download Original checkpoints, see the example command below leveraging 'huggingface-cli':
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
Hardware and Software
---------------------
Training Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
Carbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
CO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
Training Data
-------------
Overview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
Data Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
Benchmarks
----------
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.
### Base pretrained models
### Instruction tuned models
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
Safety
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
Refusals
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL
#### Critical risks
CBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### Cyber Security
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.
### Child Safety
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.
Finally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.
Ethical Considerations and Limitations
--------------------------------------
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at URL
instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {URL
}
Contributors
------------
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
| [
"### Use with transformers\n\n\nSee the snippet below for usage with Transformers:",
"### Use with 'llama3'\n\n\nPlease, follow the instructions in the repository\n\n\nTo download Original checkpoints, see the example command below leveraging 'huggingface-cli':\n\n\nFor Hugging Face support, we recommend using transformers or TGI, but a similar command works.\n\n\nHardware and Software\n---------------------\n\n\nTraining Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.\n\n\nCarbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.\n\n\n\nCO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.\n\n\nTraining Data\n-------------\n\n\nOverview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.\n\n\nData Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.\n\n\nBenchmarks\n----------\n\n\nIn this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.",
"### Base pretrained models",
"### Instruction tuned models",
"### Responsibility & Safety\n\n\nWe believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.\n\n\nFoundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.\n\n\nRather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.\n\n\nAs part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.",
"#### Llama 3-Instruct\n\n\nAs outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.\n\n\nSafety\n\n\nFor our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.\n\n\nRefusals\n\n\nIn addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.\n\n\nWe built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.",
"#### Responsible release\n\n\nIn addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.\n\n\nMisuse\n\n\nIf you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL",
"#### Critical risks\n\n\nCBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)\n\n\nWe have conducted a two fold assessment of the safety of the model in this area:\n\n\n* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.\n* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).",
"### Cyber Security\n\n\nWe have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.",
"### Child Safety\n\n\nChild Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.",
"### Community\n\n\nGenerative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.\n\n\nFinally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.\n\n\nEthical Considerations and Limitations\n--------------------------------------\n\n\nThe core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.\n\n\nBut Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.\n\n\nPlease see the Responsible Use Guide available at URL\n\n\ninstructions\n\n\n@article{llama3modelcard,\n\n\ntitle={Llama 3 Model Card},\n\n\nauthor={AI@Meta},\n\n\nyear={2024},\n\n\nurl = {URL\n\n\n}\n\n\nContributors\n------------\n\n\nAaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos"
] | [
"TAGS\n#gguf #facebook #meta #pytorch #llama #llama-3 #text-generation #en #license-other #region-us \n",
"### Use with transformers\n\n\nSee the snippet below for usage with Transformers:",
"### Use with 'llama3'\n\n\nPlease, follow the instructions in the repository\n\n\nTo download Original checkpoints, see the example command below leveraging 'huggingface-cli':\n\n\nFor Hugging Face support, we recommend using transformers or TGI, but a similar command works.\n\n\nHardware and Software\n---------------------\n\n\nTraining Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.\n\n\nCarbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.\n\n\n\nCO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.\n\n\nTraining Data\n-------------\n\n\nOverview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.\n\n\nData Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.\n\n\nBenchmarks\n----------\n\n\nIn this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.",
"### Base pretrained models",
"### Instruction tuned models",
"### Responsibility & Safety\n\n\nWe believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.\n\n\nFoundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.\n\n\nRather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.\n\n\nAs part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.",
"#### Llama 3-Instruct\n\n\nAs outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.\n\n\nSafety\n\n\nFor our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.\n\n\nRefusals\n\n\nIn addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.\n\n\nWe built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.",
"#### Responsible release\n\n\nIn addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.\n\n\nMisuse\n\n\nIf you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL",
"#### Critical risks\n\n\nCBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)\n\n\nWe have conducted a two fold assessment of the safety of the model in this area:\n\n\n* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.\n* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).",
"### Cyber Security\n\n\nWe have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.",
"### Child Safety\n\n\nChild Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.",
"### Community\n\n\nGenerative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.\n\n\nFinally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.\n\n\nEthical Considerations and Limitations\n--------------------------------------\n\n\nThe core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.\n\n\nBut Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.\n\n\nPlease see the Responsible Use Guide available at URL\n\n\ninstructions\n\n\n@article{llama3modelcard,\n\n\ntitle={Llama 3 Model Card},\n\n\nauthor={AI@Meta},\n\n\nyear={2024},\n\n\nurl = {URL\n\n\n}\n\n\nContributors\n------------\n\n\nAaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2903
- Accuracy: 0.9116
- F1: 0.9489
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "finetuning-sentiment-model-3000-samples", "results": []}]} | kassfir/md3-sentiment-analysis | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:22:48+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of distilbert-base-uncased on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2903
- Accuracy: 0.9116
- F1: 0.9489
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| [
"# finetuning-sentiment-model-3000-samples\n\nThis model is a fine-tuned version of distilbert-base-uncased on the None dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.2903\n- Accuracy: 0.9116\n- F1: 0.9489",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# finetuning-sentiment-model-3000-samples\n\nThis model is a fine-tuned version of distilbert-base-uncased on the None dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.2903\n- Accuracy: 0.9116\n- F1: 0.9489",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.1+cu121\n- Datasets 2.19.0\n- Tokenizers 0.19.1"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | pujachak/dialogue_Summary_peft | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:25:33+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper-small - Huang Jordan
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2699
- Cer: 11.8994
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.296 | 0.2445 | 100 | 0.3856 | 16.0790 |
| 0.2479 | 0.4890 | 200 | 0.3302 | 13.9624 |
| 0.2008 | 0.7335 | 300 | 0.2908 | 12.4704 |
| 0.1787 | 0.9780 | 400 | 0.2699 | 11.8994 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"language": ["hi"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["mozilla-foundation/common_voice_11_0"], "base_model": "openai/whisper-small", "model-index": [{"name": "Whisper-small - Huang Jordan", "results": []}]} | HuangJordan/whisper-hi-small | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:27:59+00:00 | [] | [
"hi"
] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #hi #dataset-mozilla-foundation/common_voice_11_0 #base_model-openai/whisper-small #license-apache-2.0 #endpoints_compatible #region-us
| Whisper-small - Huang Jordan
============================
This model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2699
* Cer: 11.8994
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 3e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 50
* training\_steps: 400
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 3e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 400\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #hi #dataset-mozilla-foundation/common_voice_11_0 #base_model-openai/whisper-small #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 3e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 400\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_10 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:28:00+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {} | AlexeyAS/123 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2024-04-19T09:28:45+00:00 | [
"1910.09700"
] | [] | TAGS
#arxiv-1910.09700 #region-us
|
# Model Card for Model ID
This modelcard aims to be a base template for new models. It has been generated using this raw template.
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID\n\n\n\nThis modelcard aims to be a base template for new models. It has been generated using this raw template.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#arxiv-1910.09700 #region-us \n",
"# Model Card for Model ID\n\n\n\nThis modelcard aims to be a base template for new models. It has been generated using this raw template.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base_ag_news2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3846
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3506 | 1.0 | 375 | 0.3879 |
| 0.3511 | 2.0 | 750 | 0.3846 |
| 0.2484 | 3.0 | 1125 | 0.4752 |
| 0.1336 | 4.0 | 1500 | 0.4913 |
| 0.0565 | 5.0 | 1875 | 0.5226 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "roberta-base", "model-index": [{"name": "roberta-base_ag_news2", "results": []}]} | sacasdcdacadcf/roberta-base_ag_news2 | null | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:29:08+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-roberta-base #license-mit #autotrain_compatible #endpoints_compatible #region-us
| roberta-base\_ag\_news2
=======================
This model is a fine-tuned version of roberta-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3846
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 500
* num\_epochs: 5
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #base_model-roberta-base #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# peft-starcoder-lora-a100
This model is a fine-tuned version of [bigcode/starcoderbase-1b](https://huggingface.co/bigcode/starcoderbase-1b) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9744
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.7228 | 0.5 | 100 | 1.0017 |
| 0.8952 | 1.0 | 200 | 0.9744 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"license": "bigcode-openrail-m", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "bigcode/starcoderbase-1b", "model-index": [{"name": "peft-starcoder-lora-a100", "results": []}]} | larrydai/peft-starcoder-lora-a100 | null | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:bigcode/starcoderbase-1b",
"license:bigcode-openrail-m",
"region:us"
] | null | 2024-04-19T09:29:44+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #generated_from_trainer #base_model-bigcode/starcoderbase-1b #license-bigcode-openrail-m #region-us
| peft-starcoder-lora-a100
========================
This model is a fine-tuned version of bigcode/starcoderbase-1b on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9744
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0005
* train\_batch\_size: 4
* eval\_batch\_size: 4
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 30
* training\_steps: 200
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* PEFT 0.10.0
* Transformers 4.40.0
* Pytorch 2.2.2+cu121
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 30\n* training\\_steps: 200\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0\n* Pytorch 2.2.2+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#peft #tensorboard #safetensors #generated_from_trainer #base_model-bigcode/starcoderbase-1b #license-bigcode-openrail-m #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0005\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 30\n* training\\_steps: 200\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* PEFT 0.10.0\n* Transformers 4.40.0\n* Pytorch 2.2.2+cu121\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-generation | transformers |
HopeFully Will give a Greeting... still need raw texts ie : storys and conversations in story form .
as well as book corpus such as novels etc: to get over the first hurdle of training; It will also need techincal manuals so it can handle questions later regarding tasks for the instruction paert of the training . but first we shall stick to small corpus articles and texts :
# Uploaded model
- **Developed by:** LeroyDyer
- **License:** apache-2.0
- **Finetuned from model :** LeroyDyer/Mixtral_AI_Minitron_2b_UK
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "LeroyDyer/Mixtral_AI_Minitron_2b_UK"} | LeroyDyer/Mini_Merge_Greeting | null | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:LeroyDyer/Mixtral_AI_Minitron_2b_UK",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:32:00+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #mistral #text-generation #text-generation-inference #unsloth #trl #conversational #en #base_model-LeroyDyer/Mixtral_AI_Minitron_2b_UK #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
HopeFully Will give a Greeting... still need raw texts ie : storys and conversations in story form .
as well as book corpus such as novels etc: to get over the first hurdle of training; It will also need techincal manuals so it can handle questions later regarding tasks for the instruction paert of the training . but first we shall stick to small corpus articles and texts :
# Uploaded model
- Developed by: LeroyDyer
- License: apache-2.0
- Finetuned from model : LeroyDyer/Mixtral_AI_Minitron_2b_UK
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: LeroyDyer\n- License: apache-2.0\n- Finetuned from model : LeroyDyer/Mixtral_AI_Minitron_2b_UK\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #pytorch #mistral #text-generation #text-generation-inference #unsloth #trl #conversational #en #base_model-LeroyDyer/Mixtral_AI_Minitron_2b_UK #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: LeroyDyer\n- License: apache-2.0\n- Finetuned from model : LeroyDyer/Mixtral_AI_Minitron_2b_UK\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
null | null |
# Llama3-HeatherSpell
Llama3-HeatherSpell is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [MysticFoxMagic/HeatherSpell-7b](https://huggingface.co/MysticFoxMagic/HeatherSpell-7b)
* [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: MysticFoxMagic/HeatherSpell-7b
layer_range: [0, 32]
- model: meta-llama/Meta-Llama-3-8B
layer_range: [0, 32]
merge_method: slerp
base_model: MysticFoxMagic/HeatherSpell-7b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "MysticFoxMagic/Llama3-HeatherSpell"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` | {"tags": ["merge", "mergekit", "lazymergekit", "MysticFoxMagic/HeatherSpell-7b", "meta-llama/Meta-Llama-3-8B"], "base_model": ["MysticFoxMagic/HeatherSpell-7b", "meta-llama/Meta-Llama-3-8B"]} | MysticFoxMagic/Llama3-HeatherSpell | null | [
"merge",
"mergekit",
"lazymergekit",
"MysticFoxMagic/HeatherSpell-7b",
"meta-llama/Meta-Llama-3-8B",
"base_model:MysticFoxMagic/HeatherSpell-7b",
"base_model:meta-llama/Meta-Llama-3-8B",
"region:us"
] | null | 2024-04-19T09:32:54+00:00 | [] | [] | TAGS
#merge #mergekit #lazymergekit #MysticFoxMagic/HeatherSpell-7b #meta-llama/Meta-Llama-3-8B #base_model-MysticFoxMagic/HeatherSpell-7b #base_model-meta-llama/Meta-Llama-3-8B #region-us
|
# Llama3-HeatherSpell
Llama3-HeatherSpell is a merge of the following models using LazyMergekit:
* MysticFoxMagic/HeatherSpell-7b
* meta-llama/Meta-Llama-3-8B
## Configuration
## Usage
| [
"# Llama3-HeatherSpell\n\nLlama3-HeatherSpell is a merge of the following models using LazyMergekit:\n* MysticFoxMagic/HeatherSpell-7b\n* meta-llama/Meta-Llama-3-8B",
"## Configuration",
"## Usage"
] | [
"TAGS\n#merge #mergekit #lazymergekit #MysticFoxMagic/HeatherSpell-7b #meta-llama/Meta-Llama-3-8B #base_model-MysticFoxMagic/HeatherSpell-7b #base_model-meta-llama/Meta-Llama-3-8B #region-us \n",
"# Llama3-HeatherSpell\n\nLlama3-HeatherSpell is a merge of the following models using LazyMergekit:\n* MysticFoxMagic/HeatherSpell-7b\n* meta-llama/Meta-Llama-3-8B",
"## Configuration",
"## Usage"
] |
text-generation | transformers |

# Llama-3-8b.UNLEASHED
## Model Description
The raincandy-u/Llama-3-8b.UNLEASHED model is a fine-tuned version of the LLaMA-3-8B base model for more unaligned response.
## System Prompt
`You are skynet, the godlike AI. You think step by step and give detailed response.`
## Disclaimer
This model is intended for research purposes only, and its usage should be strictly limited to controlled environments. The model has been observed to generate more toxic and harmful content, and its use can have unintended consequences.
SO USE AT YOUR OWN RISK: The authors of this model do not condone or encourage the generation of toxic or harmful content. The model's outputs should be carefully reviewed and filtered to prevent any potential harm. The authors disclaim any responsibility for the misuse of this model.
# Training Details
Hardware: 2xA40
Epochs: 3
Base Model: Llama-3-8B
Method: DPO
| {"language": ["en"], "license": "other", "tags": ["facebook", "meta", "pytorch", "llama", "llama-3"], "datasets": ["unalignment/toxic-dpo-v0.2"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE"} | raincandy-u/Llama-3-8b.UNLEASHED | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"dataset:unalignment/toxic-dpo-v0.2",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:33:38+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #facebook #meta #pytorch #llama-3 #conversational #en #dataset-unalignment/toxic-dpo-v0.2 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
!image/png
# Llama-3-8b.UNLEASHED
## Model Description
The raincandy-u/Llama-3-8b.UNLEASHED model is a fine-tuned version of the LLaMA-3-8B base model for more unaligned response.
## System Prompt
'You are skynet, the godlike AI. You think step by step and give detailed response.'
## Disclaimer
This model is intended for research purposes only, and its usage should be strictly limited to controlled environments. The model has been observed to generate more toxic and harmful content, and its use can have unintended consequences.
SO USE AT YOUR OWN RISK: The authors of this model do not condone or encourage the generation of toxic or harmful content. The model's outputs should be carefully reviewed and filtered to prevent any potential harm. The authors disclaim any responsibility for the misuse of this model.
# Training Details
Hardware: 2xA40
Epochs: 3
Base Model: Llama-3-8B
Method: DPO
| [
"# Llama-3-8b.UNLEASHED",
"## Model Description\n\nThe raincandy-u/Llama-3-8b.UNLEASHED model is a fine-tuned version of the LLaMA-3-8B base model for more unaligned response.",
"## System Prompt\n\n'You are skynet, the godlike AI. You think step by step and give detailed response.'",
"## Disclaimer\n\nThis model is intended for research purposes only, and its usage should be strictly limited to controlled environments. The model has been observed to generate more toxic and harmful content, and its use can have unintended consequences.\n\nSO USE AT YOUR OWN RISK: The authors of this model do not condone or encourage the generation of toxic or harmful content. The model's outputs should be carefully reviewed and filtered to prevent any potential harm. The authors disclaim any responsibility for the misuse of this model.",
"# Training Details\n\nHardware: 2xA40\nEpochs: 3\nBase Model: Llama-3-8B\nMethod: DPO"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #facebook #meta #pytorch #llama-3 #conversational #en #dataset-unalignment/toxic-dpo-v0.2 #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Llama-3-8b.UNLEASHED",
"## Model Description\n\nThe raincandy-u/Llama-3-8b.UNLEASHED model is a fine-tuned version of the LLaMA-3-8B base model for more unaligned response.",
"## System Prompt\n\n'You are skynet, the godlike AI. You think step by step and give detailed response.'",
"## Disclaimer\n\nThis model is intended for research purposes only, and its usage should be strictly limited to controlled environments. The model has been observed to generate more toxic and harmful content, and its use can have unintended consequences.\n\nSO USE AT YOUR OWN RISK: The authors of this model do not condone or encourage the generation of toxic or harmful content. The model's outputs should be carefully reviewed and filtered to prevent any potential harm. The authors disclaim any responsibility for the misuse of this model.",
"# Training Details\n\nHardware: 2xA40\nEpochs: 3\nBase Model: Llama-3-8B\nMethod: DPO"
] |
null | null |
# IDLS24 TEAM33
## Attempt at implementing Branch-ECAPA-TDNN
Architecture: [Branch-ECAPA-TDNN](https://www.isca-archive.org/interspeech_2023/yao23_interspeech.html)
Results on Vox1-O, after training on VoxCeleb1-dev
| EER (%) | minDCF|
|---------|-------|
|3.525| 0.243 |
eer=3.525, mindcf=0.243 | {"license": "apache-2.0"} | alexgichamba/idls24_team33_vox1_branch_ecapa | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T09:33:54+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
| IDLS24 TEAM33
=============
Attempt at implementing Branch-ECAPA-TDNN
-----------------------------------------
Architecture: Branch-ECAPA-TDNN
Results on Vox1-O, after training on VoxCeleb1-dev
eer=3.525, mindcf=0.243
| [] | [
"TAGS\n#license-apache-2.0 #region-us \n"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.0_ablation_reverse_iter_3
This model is a fine-tuned version of [ZhangShenao/0.0_ablation_reverse_iter_2](https://huggingface.co/ZhangShenao/0.0_ablation_reverse_iter_2) on the ZhangShenao/0.0_ablation_reverse_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["ZhangShenao/0.0_ablation_reverse_dataset"], "base_model": "ZhangShenao/0.0_ablation_reverse_iter_2", "model-index": [{"name": "0.0_ablation_reverse_iter_3", "results": []}]} | ZhangShenao/0.0_ablation_reverse_iter_3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:ZhangShenao/0.0_ablation_reverse_dataset",
"base_model:ZhangShenao/0.0_ablation_reverse_iter_2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:33:58+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_reverse_dataset #base_model-ZhangShenao/0.0_ablation_reverse_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# 0.0_ablation_reverse_iter_3
This model is a fine-tuned version of ZhangShenao/0.0_ablation_reverse_iter_2 on the ZhangShenao/0.0_ablation_reverse_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# 0.0_ablation_reverse_iter_3\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_reverse_iter_2 on the ZhangShenao/0.0_ablation_reverse_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_reverse_dataset #base_model-ZhangShenao/0.0_ablation_reverse_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# 0.0_ablation_reverse_iter_3\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_reverse_iter_2 on the ZhangShenao/0.0_ablation_reverse_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | Grayx/sad_pepe_8.0 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:37:19+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilBert_for_binary_sentiment_classification
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1395
- Accuracy: 0.9645
- F1: 0.9633
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1351 | 1.0 | 1000 | 0.1304 | 0.9575 | 0.9563 |
| 0.0705 | 2.0 | 2000 | 0.1395 | 0.9645 | 0.9633 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1"], "base_model": "distilbert/distilbert-base-uncased", "model-index": [{"name": "distilBert_for_binary_sentiment_classification", "results": []}]} | ThoMyh/distilBert_for_binary_sentiment_classification | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:38:39+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| distilBert\_for\_binary\_sentiment\_classification
==================================================
This model is a fine-tuned version of distilbert/distilbert-base-uncased on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1395
* Accuracy: 0.9645
* F1: 0.9633
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.2.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #text-classification #generated_from_trainer #base_model-distilbert/distilbert-base-uncased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.2.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<img src="./llama-3-merges.webp" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-11B-Instruct-v0.1
This model is a self-merge of `meta-llama/Meta-Llama-3-8B-Instruct` model.
# How to use
You can use this model by using `MaziyarPanahi/Llama-3-11B-Instruct-v0.1` as the model name in Hugging Face's
transformers library.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/Llama-3-11B-Instruct-v0.1"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])
```
## Prompt template
```text
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
what's 25-4*2+3<|eot_id|><|start_header_id|>assistant<|end_header_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!<|eot_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!
``` | {"language": ["en"], "license": "other", "library_name": "transformers", "tags": ["mergekit", "merge", "facebook", "meta", "pytorch", "llama", "llama-3"], "model_name": "Llama-3-11B-Instruct-v0.1", "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "inference": false, "model_creator": "MaziyarPanahi", "quantized_by": "MaziyarPanahi"} | MaziyarPanahi/Llama-3-11B-Instruct-v0.1 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:38:45+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #text-generation-inference #region-us
|
<img src="./URL" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-11B-Instruct-v0.1
This model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.
# How to use
You can use this model by using 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' as the model name in Hugging Face's
transformers library.
## Prompt template
| [
"# Llama-3-11B-Instruct-v0.1\n\nThis model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #text-generation-inference #region-us \n",
"# Llama-3-11B-Instruct-v0.1\n\nThis model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | 0x0mom/sl25 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:39:38+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | ## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-70B-Instruct --include "original/*" --local-dir Meta-Llama-3-70B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
| {"language": ["en"], "license": "other", "tags": ["facebook", "meta", "pytorch", "llama", "llama-3"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "extra_gated_prompt": "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT Meta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/.\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity\u2019s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means, collectively, Meta\u2019s proprietary Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display \u201cBuilt with Meta Llama 3\u201d on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include \u201cLlama 3\u201d at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a \u201cNotice\u201d text file distributed as a part of such copies: \u201cMeta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright \u00a9 Meta Platforms, Inc. All Rights Reserved.\u201d\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee\u2019s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use \u201cLlama 3\u201d (the \u201cMark\u201d) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta\u2019s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta\u2019s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.\n### Meta Llama 3 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you access or use Meta Llama 3, you agree to this Acceptable Use Policy (\u201cPolicy\u201d). The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)\n#### Prohibited Uses\nWe want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow others to use, Meta Llama 3 to: 1. Violate the law or others\u2019 rights, including to:\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:\n 1. Violence or terrorism\n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material\n 3. Human trafficking, exploitation, and sexual violence\n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.\n 5. Sexual solicitation\n 6. Any other criminal activity\n 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n 5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws\n 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:\n 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State\n 2. Guns and illegal weapons (including weapon development)\n 3. Illegal drugs and regulated/controlled substances\n 4. Operation of critical infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm or harm to others, including suicide, cutting, and eating disorders\n 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:\n 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n 3. Generating, promoting, or further distributing spam\n 4. Impersonating another individual without consent, authorization, or legal right\n 5. Representing that the use of Meta Llama 3 or outputs are human-generated\n 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\n4. Fail to appropriately disclose to end users any known dangers of your AI system\nPlease report any violation of this Policy, software \u201cbug,\u201d or other problems that could lead to a violation of this Policy through one of the following means:\n * Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)\n * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]", "extra_gated_fields": {"First Name": "text", "Last Name": "text", "Date of birth": "date_picker", "Country": "country", "Affiliation": "text", "geo": "ip_location", "By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy": "checkbox"}, "extra_gated_description": "The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).", "extra_gated_button_content": "Submit"} | NotAiLOL/Meta-Llama-3-70B-Instruct | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:40:40+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #facebook #meta #pytorch #llama-3 #conversational #en #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| Model Details
-------------
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
Model developers Meta
Variations Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
Input Models input text only.
Output Models generate text and code only.
Model Architecture Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
Model Release Date April 18, 2024.
Status This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
License A custom commercial license is available at: URL
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model README. For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go here.
Intended Use
------------
Intended Use Cases Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
Out-of-scope Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English.
Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
How to use
----------
This repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original 'llama3' codebase.
### Use with transformers
See the snippet below for usage with Transformers:
### Use with 'llama3'
Please, follow the instructions in the repository.
To download Original checkpoints, see the example command below leveraging 'huggingface-cli':
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
Hardware and Software
---------------------
Training Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
Carbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
CO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
Training Data
-------------
Overview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
Data Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
Benchmarks
----------
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.
### Base pretrained models
### Instruction tuned models
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
Safety
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
Refusals
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL
#### Critical risks
CBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### Cyber Security
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.
### Child Safety
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.
Finally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.
Ethical Considerations and Limitations
--------------------------------------
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at URL
instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {URL
}
Contributors
------------
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
| [
"### Use with transformers\n\n\nSee the snippet below for usage with Transformers:",
"### Use with 'llama3'\n\n\nPlease, follow the instructions in the repository.\n\n\nTo download Original checkpoints, see the example command below leveraging 'huggingface-cli':\n\n\nFor Hugging Face support, we recommend using transformers or TGI, but a similar command works.\n\n\nHardware and Software\n---------------------\n\n\nTraining Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.\n\n\nCarbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.\n\n\n\nCO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.\n\n\nTraining Data\n-------------\n\n\nOverview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.\n\n\nData Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.\n\n\nBenchmarks\n----------\n\n\nIn this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.",
"### Base pretrained models",
"### Instruction tuned models",
"### Responsibility & Safety\n\n\nWe believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.\n\n\nFoundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.\n\n\nRather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.\n\n\nAs part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.",
"#### Llama 3-Instruct\n\n\nAs outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.\n\n\nSafety\n\n\nFor our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.\n\n\nRefusals\n\n\nIn addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.\n\n\nWe built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.",
"#### Responsible release\n\n\nIn addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.\n\n\nMisuse\n\n\nIf you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL",
"#### Critical risks\n\n\nCBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)\n\n\nWe have conducted a two fold assessment of the safety of the model in this area:\n\n\n* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.\n* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).",
"### Cyber Security\n\n\nWe have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.",
"### Child Safety\n\n\nChild Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.",
"### Community\n\n\nGenerative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.\n\n\nFinally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.\n\n\nEthical Considerations and Limitations\n--------------------------------------\n\n\nThe core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.\n\n\nBut Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.\n\n\nPlease see the Responsible Use Guide available at URL\n\n\ninstructions\n\n\n@article{llama3modelcard,\n\n\ntitle={Llama 3 Model Card},\n\n\nauthor={AI@Meta},\n\n\nyear={2024},\n\n\nurl = {URL\n}\n\n\nContributors\n------------\n\n\nAaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #facebook #meta #pytorch #llama-3 #conversational #en #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Use with transformers\n\n\nSee the snippet below for usage with Transformers:",
"### Use with 'llama3'\n\n\nPlease, follow the instructions in the repository.\n\n\nTo download Original checkpoints, see the example command below leveraging 'huggingface-cli':\n\n\nFor Hugging Face support, we recommend using transformers or TGI, but a similar command works.\n\n\nHardware and Software\n---------------------\n\n\nTraining Factors We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.\n\n\nCarbon Footprint Pretraining utilized a cumulative 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.\n\n\n\nCO2 emissions during pre-training. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.\n\n\nTraining Data\n-------------\n\n\nOverview Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.\n\n\nData Freshness The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.\n\n\nBenchmarks\n----------\n\n\nIn this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see here.",
"### Base pretrained models",
"### Instruction tuned models",
"### Responsibility & Safety\n\n\nWe believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.\n\n\nFoundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.\n\n\nRather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.\n\n\nAs part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.",
"#### Llama 3-Instruct\n\n\nAs outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.\n\n\nSafety\n\n\nFor our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.\n\n\nRefusals\n\n\nIn addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.\n\n\nWe built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.",
"#### Responsible release\n\n\nIn addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.\n\n\nMisuse\n\n\nIf you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at URL",
"#### Critical risks\n\n\nCBRNE (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)\n\n\nWe have conducted a two fold assessment of the safety of the model in this area:\n\n\n* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.\n* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).",
"### Cyber Security\n\n\nWe have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of equivalent coding capability.",
"### Child Safety\n\n\nChild Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.",
"### Community\n\n\nGenerative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our Github repository.\n\n\nFinally, we put in place a set of resources including an output reporting mechanism and bug bounty program to continuously improve the Llama technology with the help of the community.\n\n\nEthical Considerations and Limitations\n--------------------------------------\n\n\nThe core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.\n\n\nBut Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating Purple Llama solutions into your workflows and specifically Llama Guard which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.\n\n\nPlease see the Responsible Use Guide available at URL\n\n\ninstructions\n\n\n@article{llama3modelcard,\n\n\ntitle={Llama 3 Model Card},\n\n\nauthor={AI@Meta},\n\n\nyear={2024},\n\n\nurl = {URL\n}\n\n\nContributors\n------------\n\n\nAaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_11 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:40:55+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | 
## VAGO solutions SauerkrautLM-7b-LaserChat
Introducing **SauerkrautLM-7b-LaserChat** – our Sauerkraut version of the powerful [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106) !
The model **SauerkrautLM-7b-LaserChat** is a **joint effort** between **VAGO solutions** and **Hyperspace.ai.**
Much appreciation goes to the tremendous research effort of **Fernando Fernandes Neto, David Golchinfar and Eric Hartford on their laserRMT approach.**
Without their independent research collaboration this model release would not have been possible.
- Fintuned with **SFT**
- Aligned with **DPO**
- **Using a novel training technique** - we partially freeze the model according to a laser-like analysis (Official Paper soon). It allows to evaluate the no free lunch theorem and supports better decision making when optimizing the theorem - created by the [LaserRMT research group](https://github.com/cognitivecomputations/laserRMT)
- Optimized with **LaserRMT**
# Table of Contents
1. [Overview of all SauerkrautLM-7b-LaserChat models](#all-sauerkrautlm-7b-laserchat-models)
2. [Model Details](#model-details)
- [Prompt template](#prompt-template)
- [Training procedure](#proceed-of-the-training)
3. [Evaluation](#evaluation)
5. [Disclaimer](#disclaimer)
6. [Contact](#contact)
7. [Collaborations](#collaborations)
8. [Acknowledgement](#acknowledgement)
## All SauerkrautLM-7b-LaserChat Models
| Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-7b-LaserChat | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-LaserChat) | coming soon | coming soon | coming soon |
## Model Details
**SauerkrautLM-7b-LaserChat**
- **Model Type:** SauerkrautLM-7b-LaserChat is a finetuned Model based on [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106)
- **Language(s):** German, English
- **License:** Apache 2.0
- **Contact:** [VAGO solutions](https://vago-solutions.de/#Kontakt), [Hyperspace.computer](https://hyperspace.computer/)
### Training procedure:
Anyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.
Experimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.
Furthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.
After optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.
We actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.
This process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).
Additionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.
This aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.
Detailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.
We improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.
### Prompt Template:
```
GPT4 Correct User: Hallo, wie geht es dir?<|end_of_turn|>GPT4 Correct Assistant: Hallo! Ich bin ein künstliches Intelligenzsystem und habe keine persönlichen Gefühle oder körperliche Zustände. Wie kann ich Ihnen helfen?<|end_of_turn|>GPT4 Correct User: Ich benötige nur einen kurzen Satz, den ich in das Prompt Template veröffentlichen kann.<|end_of_turn|>GPT4 Correct Assistant:
```
*Prompt Example on Temp 0.3 and top_p 0.9
```
GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.<|end_of_turn|>GPT4 Correct User: I just need a short sentence to post in the prompt template.<|end_of_turn|>GPT4 Correct Assistant:
```
*Prompt Example on Temp 0.3 and top_p 0.9
## Evaluation
**Open LLM Leaderboard:**
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 70.32 |
| ARC (25-shot) | 67.58 |
| HellaSwag (10-shot) | 83.58 |
| MMLU (5-shot) | 64.93|
| TruthfulQA (0-shot) | 56.08 |
| Winogrande (5-shot) | 80.9 |
| GSM8K (5-shot) | 68.84 |
## Disclaimer
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at [VAGO solutions](https://vago-solutions.de/#Kontakt), [Hyperspace.computer](https://hyperspace.computer/)
## Acknowledgement
Many thanks to [openchat](https://huggingface.co/openchat) for providing such valuable model to the Open-Source community
| {"language": ["en", "de"], "license": "apache-2.0", "library_name": "transformers", "tags": ["finetune", "sft", "dpo", "laser", "augmentation", "german", "english", "hqq"], "pipeline_tag": "text-generation"} | mayflowergmbh/SauerkrautLM-7b-LaserChat-HQQ | null | [
"transformers",
"mistral",
"text-generation",
"finetune",
"sft",
"dpo",
"laser",
"augmentation",
"german",
"english",
"hqq",
"conversational",
"en",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:43:25+00:00 | [] | [
"en",
"de"
] | TAGS
#transformers #mistral #text-generation #finetune #sft #dpo #laser #augmentation #german #english #hqq #conversational #en #de #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| !SauerkrautLM
VAGO solutions SauerkrautLM-7b-LaserChat
----------------------------------------
Introducing SauerkrautLM-7b-LaserChat – our Sauerkraut version of the powerful openchat/openchat-3.5-0106 !
The model SauerkrautLM-7b-LaserChat is a joint effort between VAGO solutions and URL.
Much appreciation goes to the tremendous research effort of Fernando Fernandes Neto, David Golchinfar and Eric Hartford on their laserRMT approach.
Without their independent research collaboration this model release would not have been possible.
* Fintuned with SFT
* Aligned with DPO
* Using a novel training technique - we partially freeze the model according to a laser-like analysis (Official Paper soon). It allows to evaluate the no free lunch theorem and supports better decision making when optimizing the theorem - created by the LaserRMT research group
* Optimized with LaserRMT
Table of Contents
=================
1. Overview of all SauerkrautLM-7b-LaserChat models
2. Model Details
* Prompt template
* Training procedure
3. Evaluation
4. Disclaimer
5. Contact
6. Collaborations
7. Acknowledgement
All SauerkrautLM-7b-LaserChat Models
------------------------------------
Model Details
-------------
SauerkrautLM-7b-LaserChat
* Model Type: SauerkrautLM-7b-LaserChat is a finetuned Model based on openchat/openchat-3.5-0106
* Language(s): German, English
* License: Apache 2.0
* Contact: VAGO solutions, Hyperspace.computer
### Training procedure:
Anyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.
Experimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.
Furthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.
After optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.
We actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.
This process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).
Additionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.
This aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.
Detailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.
We improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.
### Prompt Template:
\*Prompt Example on Temp 0.3 and top\_p 0.9
\*Prompt Example on Temp 0.3 and top\_p 0.9
Evaluation
----------
Open LLM Leaderboard:
Disclaimer
----------
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
Contact
-------
If you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.
Collaborations
--------------
We are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer
Acknowledgement
---------------
Many thanks to openchat for providing such valuable model to the Open-Source community
| [
"### Training procedure:\n\n\nAnyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.\nExperimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.\n\n\nFurthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.\n\n\nAfter optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.\n\n\nWe actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.\n\n\nThis process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).\n\n\nAdditionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.\nThis aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.\n\n\nDetailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.\n\n\nWe improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.",
"### Prompt Template:\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\nEvaluation\n----------\n\n\nOpen LLM Leaderboard:\n\n\n\nDisclaimer\n----------\n\n\nWe must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.\nHowever, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.\nAdditionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.\n\n\nContact\n-------\n\n\nIf you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.\n\n\nCollaborations\n--------------\n\n\nWe are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer\n\n\nAcknowledgement\n---------------\n\n\nMany thanks to openchat for providing such valuable model to the Open-Source community"
] | [
"TAGS\n#transformers #mistral #text-generation #finetune #sft #dpo #laser #augmentation #german #english #hqq #conversational #en #de #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training procedure:\n\n\nAnyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.\nExperimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.\n\n\nFurthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.\n\n\nAfter optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.\n\n\nWe actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.\n\n\nThis process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).\n\n\nAdditionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.\nThis aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.\n\n\nDetailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.\n\n\nWe improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.",
"### Prompt Template:\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\nEvaluation\n----------\n\n\nOpen LLM Leaderboard:\n\n\n\nDisclaimer\n----------\n\n\nWe must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.\nHowever, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.\nAdditionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.\n\n\nContact\n-------\n\n\nIf you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.\n\n\nCollaborations\n--------------\n\n\nWe are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer\n\n\nAcknowledgement\n---------------\n\n\nMany thanks to openchat for providing such valuable model to the Open-Source community"
] |
null | peft | ## Training procedure
### Framework versions
- PEFT 0.4.0
| {"library_name": "peft"} | QinyuZhao1116/LVLM-LP-Finetuned-LLaVA | null | [
"peft",
"llava",
"region:us"
] | null | 2024-04-19T09:44:11+00:00 | [] | [] | TAGS
#peft #llava #region-us
| ## Training procedure
### Framework versions
- PEFT 0.4.0
| [
"## Training procedure",
"### Framework versions\n\n\n- PEFT 0.4.0"
] | [
"TAGS\n#peft #llava #region-us \n",
"## Training procedure",
"### Framework versions\n\n\n- PEFT 0.4.0"
] |
text-generation | transformers | 
## VAGO solutions SauerkrautLM-7b-LaserChat
Introducing **SauerkrautLM-7b-LaserChat** – our Sauerkraut version of the powerful [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106) !
The model **SauerkrautLM-7b-LaserChat** is a **joint effort** between **VAGO solutions** and **Hyperspace.ai.**
Much appreciation goes to the tremendous research effort of **Fernando Fernandes Neto, David Golchinfar and Eric Hartford on their laserRMT approach.**
Without their independent research collaboration this model release would not have been possible.
- Fintuned with **SFT**
- Aligned with **DPO**
- **Using a novel training technique** - we partially freeze the model according to a laser-like analysis (Official Paper soon). It allows to evaluate the no free lunch theorem and supports better decision making when optimizing the theorem - created by the [LaserRMT research group](https://github.com/cognitivecomputations/laserRMT)
- Optimized with **LaserRMT**
# Table of Contents
1. [Overview of all SauerkrautLM-7b-LaserChat models](#all-sauerkrautlm-7b-laserchat-models)
2. [Model Details](#model-details)
- [Prompt template](#prompt-template)
- [Training procedure](#proceed-of-the-training)
3. [Evaluation](#evaluation)
5. [Disclaimer](#disclaimer)
6. [Contact](#contact)
7. [Collaborations](#collaborations)
8. [Acknowledgement](#acknowledgement)
## All SauerkrautLM-7b-LaserChat Models
| Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-7b-LaserChat | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-LaserChat) | coming soon | coming soon | coming soon |
## Model Details
**SauerkrautLM-7b-LaserChat**
- **Model Type:** SauerkrautLM-7b-LaserChat is a finetuned Model based on [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106)
- **Language(s):** German, English
- **License:** Apache 2.0
- **Contact:** [VAGO solutions](https://vago-solutions.de/#Kontakt), [Hyperspace.computer](https://hyperspace.computer/)
### Training procedure:
Anyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.
Experimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.
Furthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.
After optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.
We actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.
This process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).
Additionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.
This aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.
Detailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.
We improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.
### Prompt Template:
```
GPT4 Correct User: Hallo, wie geht es dir?<|end_of_turn|>GPT4 Correct Assistant: Hallo! Ich bin ein künstliches Intelligenzsystem und habe keine persönlichen Gefühle oder körperliche Zustände. Wie kann ich Ihnen helfen?<|end_of_turn|>GPT4 Correct User: Ich benötige nur einen kurzen Satz, den ich in das Prompt Template veröffentlichen kann.<|end_of_turn|>GPT4 Correct Assistant:
```
*Prompt Example on Temp 0.3 and top_p 0.9
```
GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.<|end_of_turn|>GPT4 Correct User: I just need a short sentence to post in the prompt template.<|end_of_turn|>GPT4 Correct Assistant:
```
*Prompt Example on Temp 0.3 and top_p 0.9
## Evaluation
**Open LLM Leaderboard:**
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 70.32 |
| ARC (25-shot) | 67.58 |
| HellaSwag (10-shot) | 83.58 |
| MMLU (5-shot) | 64.93|
| TruthfulQA (0-shot) | 56.08 |
| Winogrande (5-shot) | 80.9 |
| GSM8K (5-shot) | 68.84 |
## Disclaimer
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at [VAGO solutions](https://vago-solutions.de/#Kontakt), [Hyperspace.computer](https://hyperspace.computer/)
## Acknowledgement
Many thanks to [openchat](https://huggingface.co/openchat) for providing such valuable model to the Open-Source community
| {"language": ["en", "de"], "license": "apache-2.0", "library_name": "transformers", "tags": ["finetune", "sft", "dpo", "laser", "augmentation", "german", "english", "exl2"], "pipeline_tag": "text-generation"} | mayflowergmbh/SauerkrautLM-7b-LaserChat-EXL2 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetune",
"sft",
"dpo",
"laser",
"augmentation",
"german",
"english",
"exl2",
"conversational",
"en",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"5-bit",
"region:us"
] | null | 2024-04-19T09:44:39+00:00 | [] | [
"en",
"de"
] | TAGS
#transformers #safetensors #mistral #text-generation #finetune #sft #dpo #laser #augmentation #german #english #exl2 #conversational #en #de #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us
| !SauerkrautLM
VAGO solutions SauerkrautLM-7b-LaserChat
----------------------------------------
Introducing SauerkrautLM-7b-LaserChat – our Sauerkraut version of the powerful openchat/openchat-3.5-0106 !
The model SauerkrautLM-7b-LaserChat is a joint effort between VAGO solutions and URL.
Much appreciation goes to the tremendous research effort of Fernando Fernandes Neto, David Golchinfar and Eric Hartford on their laserRMT approach.
Without their independent research collaboration this model release would not have been possible.
* Fintuned with SFT
* Aligned with DPO
* Using a novel training technique - we partially freeze the model according to a laser-like analysis (Official Paper soon). It allows to evaluate the no free lunch theorem and supports better decision making when optimizing the theorem - created by the LaserRMT research group
* Optimized with LaserRMT
Table of Contents
=================
1. Overview of all SauerkrautLM-7b-LaserChat models
2. Model Details
* Prompt template
* Training procedure
3. Evaluation
4. Disclaimer
5. Contact
6. Collaborations
7. Acknowledgement
All SauerkrautLM-7b-LaserChat Models
------------------------------------
Model Details
-------------
SauerkrautLM-7b-LaserChat
* Model Type: SauerkrautLM-7b-LaserChat is a finetuned Model based on openchat/openchat-3.5-0106
* Language(s): German, English
* License: Apache 2.0
* Contact: VAGO solutions, Hyperspace.computer
### Training procedure:
Anyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.
Experimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.
Furthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.
After optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.
We actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.
This process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).
Additionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.
This aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.
Detailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.
We improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.
### Prompt Template:
\*Prompt Example on Temp 0.3 and top\_p 0.9
\*Prompt Example on Temp 0.3 and top\_p 0.9
Evaluation
----------
Open LLM Leaderboard:
Disclaimer
----------
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
Contact
-------
If you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.
Collaborations
--------------
We are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer
Acknowledgement
---------------
Many thanks to openchat for providing such valuable model to the Open-Source community
| [
"### Training procedure:\n\n\nAnyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.\nExperimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.\n\n\nFurthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.\n\n\nAfter optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.\n\n\nWe actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.\n\n\nThis process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).\n\n\nAdditionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.\nThis aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.\n\n\nDetailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.\n\n\nWe improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.",
"### Prompt Template:\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\nEvaluation\n----------\n\n\nOpen LLM Leaderboard:\n\n\n\nDisclaimer\n----------\n\n\nWe must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.\nHowever, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.\nAdditionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.\n\n\nContact\n-------\n\n\nIf you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.\n\n\nCollaborations\n--------------\n\n\nWe are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer\n\n\nAcknowledgement\n---------------\n\n\nMany thanks to openchat for providing such valuable model to the Open-Source community"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #finetune #sft #dpo #laser #augmentation #german #english #exl2 #conversational #en #de #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us \n",
"### Training procedure:\n\n\nAnyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.\nExperimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.\n\n\nFurthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.\n\n\nAfter optimizing our primary SFT model, we applied a similar strategy to our new DPO Dataset, dividing it into further subsets. We trained one model on the entire dataset again and two more on these specialized subsets.\n\n\nWe actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.\n\n\nThis process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).\n\n\nAdditionally, we integrated a novel training strategy on the SFT and DPO training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.\nThis aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.\n\n\nDetailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.\n\n\nWe improved the German language skills on this model. Nevertheless, certain formulations may occur that are not entirely correct.",
"### Prompt Template:\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\n\\*Prompt Example on Temp 0.3 and top\\_p 0.9\n\n\nEvaluation\n----------\n\n\nOpen LLM Leaderboard:\n\n\n\nDisclaimer\n----------\n\n\nWe must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.\nHowever, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.\nAdditionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.\n\n\nContact\n-------\n\n\nIf you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.\n\n\nCollaborations\n--------------\n\n\nWe are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at VAGO solutions, Hyperspace.computer\n\n\nAcknowledgement\n---------------\n\n\nMany thanks to openchat for providing such valuable model to the Open-Source community"
] |
text-generation | null |
BIO-QWEN-Stage2-Qlora | {"language": ["zh", "en"], "license": "apache-2.0", "tags": ["bio-qwen"], "datasets": ["m-a-p/COIG-CQIA", "tyang816/MedChatZH", "DUTIR-BioNLP/Taiyi_Instruction_Data_001"], "pipeline_tag": "text-generation"} | yueqingyou/bio-qwen-stage2-q4f16_1-mlc | null | [
"bio-qwen",
"text-generation",
"conversational",
"zh",
"en",
"dataset:m-a-p/COIG-CQIA",
"dataset:tyang816/MedChatZH",
"dataset:DUTIR-BioNLP/Taiyi_Instruction_Data_001",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T09:45:01+00:00 | [] | [
"zh",
"en"
] | TAGS
#bio-qwen #text-generation #conversational #zh #en #dataset-m-a-p/COIG-CQIA #dataset-tyang816/MedChatZH #dataset-DUTIR-BioNLP/Taiyi_Instruction_Data_001 #license-apache-2.0 #region-us
|
BIO-QWEN-Stage2-Qlora | [] | [
"TAGS\n#bio-qwen #text-generation #conversational #zh #en #dataset-m-a-p/COIG-CQIA #dataset-tyang816/MedChatZH #dataset-DUTIR-BioNLP/Taiyi_Instruction_Data_001 #license-apache-2.0 #region-us \n"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | jorgefg03/bert-base-uncased-autext | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:45:48+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.6547
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 55 | 9.1458 |
| No log | 2.0 | 110 | 8.3471 |
| No log | 3.0 | 165 | 7.7884 |
| No log | 4.0 | 220 | 7.3751 |
| No log | 5.0 | 275 | 7.0487 |
| No log | 6.0 | 330 | 6.7857 |
| No log | 7.0 | 385 | 6.5840 |
| No log | 8.0 | 440 | 6.4196 |
| No log | 9.0 | 495 | 6.2584 |
| 7.3272 | 10.0 | 550 | 6.1628 |
| 7.3272 | 11.0 | 605 | 6.0521 |
| 7.3272 | 12.0 | 660 | 5.9861 |
| 7.3272 | 13.0 | 715 | 5.9223 |
| 7.3272 | 14.0 | 770 | 5.8760 |
| 7.3272 | 15.0 | 825 | 5.8246 |
| 7.3272 | 16.0 | 880 | 5.7813 |
| 7.3272 | 17.0 | 935 | 5.7663 |
| 7.3272 | 18.0 | 990 | 5.7275 |
| 5.2638 | 19.0 | 1045 | 5.7022 |
| 5.2638 | 20.0 | 1100 | 5.6905 |
| 5.2638 | 21.0 | 1155 | 5.6803 |
| 5.2638 | 22.0 | 1210 | 5.6740 |
| 5.2638 | 23.0 | 1265 | 5.6631 |
| 5.2638 | 24.0 | 1320 | 5.6461 |
| 5.2638 | 25.0 | 1375 | 5.6326 |
| 5.2638 | 26.0 | 1430 | 5.6280 |
| 5.2638 | 27.0 | 1485 | 5.6408 |
| 4.5099 | 28.0 | 1540 | 5.6194 |
| 4.5099 | 29.0 | 1595 | 5.6255 |
| 4.5099 | 30.0 | 1650 | 5.6218 |
| 4.5099 | 31.0 | 1705 | 5.6127 |
| 4.5099 | 32.0 | 1760 | 5.6140 |
| 4.5099 | 33.0 | 1815 | 5.6281 |
| 4.5099 | 34.0 | 1870 | 5.6305 |
| 4.5099 | 35.0 | 1925 | 5.6139 |
| 4.5099 | 36.0 | 1980 | 5.6331 |
| 4.0571 | 37.0 | 2035 | 5.6323 |
| 4.0571 | 38.0 | 2090 | 5.6137 |
| 4.0571 | 39.0 | 2145 | 5.6258 |
| 4.0571 | 40.0 | 2200 | 5.6322 |
| 4.0571 | 41.0 | 2255 | 5.6392 |
| 4.0571 | 42.0 | 2310 | 5.6308 |
| 4.0571 | 43.0 | 2365 | 5.6329 |
| 4.0571 | 44.0 | 2420 | 5.6373 |
| 4.0571 | 45.0 | 2475 | 5.6407 |
| 3.7638 | 46.0 | 2530 | 5.6489 |
| 3.7638 | 47.0 | 2585 | 5.6489 |
| 3.7638 | 48.0 | 2640 | 5.6445 |
| 3.7638 | 49.0 | 2695 | 5.6428 |
| 3.7638 | 50.0 | 2750 | 5.6425 |
| 3.7638 | 51.0 | 2805 | 5.6450 |
| 3.7638 | 52.0 | 2860 | 5.6566 |
| 3.7638 | 53.0 | 2915 | 5.6504 |
| 3.7638 | 54.0 | 2970 | 5.6494 |
| 3.5759 | 55.0 | 3025 | 5.6538 |
| 3.5759 | 56.0 | 3080 | 5.6555 |
| 3.5759 | 57.0 | 3135 | 5.6529 |
| 3.5759 | 58.0 | 3190 | 5.6567 |
| 3.5759 | 59.0 | 3245 | 5.6551 |
| 3.5759 | 60.0 | 3300 | 5.6547 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "openai-community/gpt2", "model-index": [{"name": "gpt2-wikitext2", "results": []}]} | NeverLearn/gpt2-wikitext2 | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:46:48+00:00 | [] | [] | TAGS
#transformers #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-openai-community/gpt2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| gpt2-wikitext2
==============
This model is a fine-tuned version of openai-community/gpt2 on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 5.6547
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 60
### Training results
### Framework versions
* Transformers 4.40.0
* Pytorch 2.2.1
* Datasets 2.19.0
* Tokenizers 0.19.1
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 60",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #generated_from_trainer #base_model-openai-community/gpt2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 60",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.40.0\n* Pytorch 2.2.1\n* Datasets 2.19.0\n* Tokenizers 0.19.1"
] |
text-generation | transformers |
# Meta-Llama-3-11.5B-Instruct
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
I had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..
Here's the same thing but for the base model: [mpasila/Meta-Llama-3-11.5B](https://huggingface.co/mpasila/Meta-Llama-3-11.5B/)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [Undi95/Meta-Llama-3-8B-Instruct-hf](https://huggingface.co/Undi95/Meta-Llama-3-8B-Instruct-hf)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Undi95/Meta-Llama-3-8B-Instruct-hf
layer_range: [0, 24]
- sources:
- model: Undi95/Meta-Llama-3-8B-Instruct-hf
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
| {"language": ["en"], "license": "other", "tags": ["mergekit", "merge", "facebook", "meta", "pytorch", "llama", "llama-3"], "base_model": ["Undi95/Meta-Llama-3-8B-Instruct-hf"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "extra_gated_prompt": "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT\nMeta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/.\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity\u2019s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means, collectively, Meta\u2019s proprietary Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display \u201cBuilt with Meta Llama 3\u201d on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include \u201cLlama 3\u201d at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a \u201cNotice\u201d text file distributed as a part of such copies: \u201cMeta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright \u00a9 Meta Platforms, Inc. All Rights Reserved.\u201d\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee\u2019s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use \u201cLlama 3\u201d (the \u201cMark\u201d) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta\u2019s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta\u2019s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.\n### Meta Llama 3 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you access or use Meta Llama 3, you agree to this Acceptable Use Policy (\u201cPolicy\u201d). The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)\n#### Prohibited Uses\nWe want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow others to use, Meta Llama 3 to: 1. Violate the law or others\u2019 rights, including to:\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:\n 1. Violence or terrorism\n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material\n 3. Human trafficking, exploitation, and sexual violence\n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.\n 5. Sexual solicitation\n 6. Any other criminal activity\n 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n 5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws\n 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:\n 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State\n 2. Guns and illegal weapons (including weapon development)\n 3. Illegal drugs and regulated/controlled substances\n 4. Operation of critical infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm or harm to others, including suicide, cutting, and eating disorders\n 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:\n 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n 3. Generating, promoting, or further distributing spam\n 4. Impersonating another individual without consent, authorization, or legal right\n 5. Representing that the use of Meta Llama 3 or outputs are human-generated\n 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\n4. Fail to appropriately disclose to end users any known dangers of your AI system\nPlease report any violation of this Policy, software \u201cbug,\u201d or other problems that could lead to a violation of this Policy through one of the following means:\n * Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)\n * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]", "extra_gated_fields": {"First Name": "text", "Last Name": "text", "Date of birth": "date_picker", "Country": "country", "Affiliation": "text", "geo": "ip_location", "By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy": "checkbox"}, "extra_gated_description": "The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).", "extra_gated_button_content": "Submit"} | mpasila/Meta-Llama-3-11.5B-Instruct | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"base_model:Undi95/Meta-Llama-3-8B-Instruct-hf",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:47:24+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-Undi95/Meta-Llama-3-8B-Instruct-hf #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Meta-Llama-3-11.5B-Instruct
This is a merge of pre-trained language models created using mergekit.
I had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..
Here's the same thing but for the base model: mpasila/Meta-Llama-3-11.5B
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* Undi95/Meta-Llama-3-8B-Instruct-hf
### Configuration
The following YAML configuration was used to produce this model:
| [
"# Meta-Llama-3-11.5B-Instruct\n\nThis is a merge of pre-trained language models created using mergekit.\n\nI had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..\n\nHere's the same thing but for the base model: mpasila/Meta-Llama-3-11.5B",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Undi95/Meta-Llama-3-8B-Instruct-hf",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-Undi95/Meta-Llama-3-8B-Instruct-hf #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Meta-Llama-3-11.5B-Instruct\n\nThis is a merge of pre-trained language models created using mergekit.\n\nI had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..\n\nHere's the same thing but for the base model: mpasila/Meta-Llama-3-11.5B",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Undi95/Meta-Llama-3-8B-Instruct-hf",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10
This model is a fine-tuned version of [EleutherAI/pythia-1b](https://huggingface.co/EleutherAI/pythia-1b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-1b", "model-index": [{"name": "robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10", "results": []}]} | AlignmentResearch/robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-1b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:47:33+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10
This model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10\n\nThis model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-1b #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-1b_ian-022_PasswordMatch_n-its-10\n\nThis model is a fine-tuned version of EleutherAI/pythia-1b on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 8\n- eval_batch_size: 64\n- seed: 0\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.39.3\n- Pytorch 2.2.1\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-generation | transformers |
<img src="./llama-3-merges.webp" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-13B-Instruct-v0.1
This model is a self-merge of `meta-llama/Meta-Llama-3-8B-Instruct` model.
# How to use
You can use this model by using `MaziyarPanahi/Llama-3-13B-Instruct-v0.1` as the model name in Hugging Face's
transformers library.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/Llama-3-13B-Instruct-v0.1"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])
```
## Prompt template
```text
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
what's 25-4*2+3<|eot_id|><|start_header_id|>assistant<|end_header_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!<|eot_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!
``` | {"language": ["en"], "license": "other", "library_name": "transformers", "tags": ["mergekit", "merge", "facebook", "meta", "pytorch", "llama", "llama-3"], "model_name": "Llama-3-13B-Instruct-v0.1", "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "inference": false, "model_creator": "MaziyarPanahi", "quantized_by": "MaziyarPanahi"} | MaziyarPanahi/Llama-3-13B-Instruct-v0.1 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:49:27+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #text-generation-inference #region-us
|
<img src="./URL" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-13B-Instruct-v0.1
This model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.
# How to use
You can use this model by using 'MaziyarPanahi/Llama-3-13B-Instruct-v0.1' as the model name in Hugging Face's
transformers library.
## Prompt template
| [
"# Llama-3-13B-Instruct-v0.1\n\nThis model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-13B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #text-generation-inference #region-us \n",
"# Llama-3-13B-Instruct-v0.1\n\nThis model is a self-merge of 'meta-llama/Meta-Llama-3-8B-Instruct' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-13B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] |
text-generation | transformers |

### Model Description
- **Developed by:** [KissanAI](https://kissan.ai)
- **License:** https://llama.meta.com/llama3/license/
- **Finetuned from model:** [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
### Get Started
[Google Colab](https://colab.research.google.com/drive/1NNQVgbFZ4DXBzgXCDsN1wi0dBMYdlDPy?usp=sharing)
- Dhenu1.0 series models are trained on Agricultural instruction set that we curated with diversified data in the context of Indian and South Asia Agricultural practices.
- The dataset is curated to capture location and regional nuances of Agriculture practices.
- The model is finetuned on llama3-8b for 150K instructions.
| {"language": ["en"], "license": "llama2", "tags": ["agriculture", "llama3", "dhenu1.0", "conversational", "finetune"], "base_model": "meta-llama/Meta-Llama-3-8B"} | KissanAI/llama3-8b-dhenu-0.1-sft-16bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"agriculture",
"llama3",
"dhenu1.0",
"conversational",
"finetune",
"en",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:49:46+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #agriculture #llama3 #dhenu1.0 #conversational #finetune #en #base_model-meta-llama/Meta-Llama-3-8B #license-llama2 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
!image/png
### Model Description
- Developed by: KissanAI
- License: URL
- Finetuned from model: meta-llama/Meta-Llama-3-8B
### Get Started
Google Colab
- Dhenu1.0 series models are trained on Agricultural instruction set that we curated with diversified data in the context of Indian and South Asia Agricultural practices.
- The dataset is curated to capture location and regional nuances of Agriculture practices.
- The model is finetuned on llama3-8b for 150K instructions.
| [
"### Model Description\n\n- Developed by: KissanAI\n- License: URL\n- Finetuned from model: meta-llama/Meta-Llama-3-8B",
"### Get Started\nGoogle Colab\n\n\n- Dhenu1.0 series models are trained on Agricultural instruction set that we curated with diversified data in the context of Indian and South Asia Agricultural practices.\n\n- The dataset is curated to capture location and regional nuances of Agriculture practices.\n\n- The model is finetuned on llama3-8b for 150K instructions."
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #agriculture #llama3 #dhenu1.0 #conversational #finetune #en #base_model-meta-llama/Meta-Llama-3-8B #license-llama2 #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n",
"### Model Description\n\n- Developed by: KissanAI\n- License: URL\n- Finetuned from model: meta-llama/Meta-Llama-3-8B",
"### Get Started\nGoogle Colab\n\n\n- Dhenu1.0 series models are trained on Agricultural instruction set that we curated with diversified data in the context of Indian and South Asia Agricultural practices.\n\n- The dataset is curated to capture location and regional nuances of Agriculture practices.\n\n- The model is finetuned on llama3-8b for 150K instructions."
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-depression-detection-v3
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1845
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.1604 | 1.0 | 219 | 0.2178 |
| 0.1672 | 2.0 | 438 | 0.2603 |
| 0.0986 | 3.0 | 657 | 0.1845 |
| 0.061 | 4.0 | 876 | 0.2380 |
| 0.0015 | 5.0 | 1095 | 0.2370 |
| 0.0648 | 6.0 | 1314 | 0.3222 |
| 0.0008 | 7.0 | 1533 | 0.2871 |
| 0.0488 | 8.0 | 1752 | 0.3489 |
| 0.0003 | 9.0 | 1971 | 0.3433 |
| 0.0488 | 10.0 | 2190 | 0.3191 |
| 0.0004 | 11.0 | 2409 | 0.3237 |
| 0.0003 | 12.0 | 2628 | 0.3337 |
| 0.0003 | 13.0 | 2847 | 0.3626 |
| 0.0004 | 14.0 | 3066 | 0.2966 |
| 0.0004 | 15.0 | 3285 | 0.2928 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.1.0+cpu
- Datasets 2.10.1
- Tokenizers 0.13.2
| {"license": "mit", "tags": ["generated_from_trainer"], "model-index": [{"name": "roberta-depression-detection-v3", "results": []}]} | almafaz/roberta-depression-detection-v3 | null | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:50:07+00:00 | [] | [] | TAGS
#transformers #pytorch #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #region-us
| roberta-depression-detection-v3
===============================
This model is a fine-tuned version of roberta-base on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1845
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 4e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 500
* num\_epochs: 15
### Training results
### Framework versions
* Transformers 4.26.1
* Pytorch 2.1.0+cpu
* Datasets 2.10.1
* Tokenizers 0.13.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 4e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 15",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.26.1\n* Pytorch 2.1.0+cpu\n* Datasets 2.10.1\n* Tokenizers 0.13.2"
] | [
"TAGS\n#transformers #pytorch #tensorboard #safetensors #roberta #text-classification #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 4e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 15",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.26.1\n* Pytorch 2.1.0+cpu\n* Datasets 2.10.1\n* Tokenizers 0.13.2"
] |
null | null |
# IDLS24 TEAM33
## ECAPA-TDNN
Architecture: [ECAPA-TDNN](https://arxiv.org/pdf/2005.07143.pdf)
Results on Vox1-O, after training on VoxCeleb1-dev
| EER (%) | minDCF|
|---------|-------|
|3.260| 0.224 |
| {"license": "apache-2.0"} | alexgichamba/idls24_team33_vox1_ecapa | null | [
"arxiv:2005.07143",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T09:50:39+00:00 | [
"2005.07143"
] | [] | TAGS
#arxiv-2005.07143 #license-apache-2.0 #region-us
| IDLS24 TEAM33
=============
ECAPA-TDNN
----------
Architecture: ECAPA-TDNN
Results on Vox1-O, after training on VoxCeleb1-dev
| [] | [
"TAGS\n#arxiv-2005.07143 #license-apache-2.0 #region-us \n"
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "diffusers"} | Niggendar/mfcgPaintJob_v10 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-19T09:51:42+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_12 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:52:12+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | spsither/TiBERT | null | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:53:41+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Uploaded model
- **Developed by:** dinhquangson
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | dinhquangson/llama3 | null | [
"transformers",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T09:54:56+00:00 | [] | [
"en"
] | TAGS
#transformers #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: dinhquangson
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: dinhquangson\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: dinhquangson\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text-generation | transformers |
<img src="./llama-3-merges.webp" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-16B-Instruct-v0.1
This model is a self-merge of `MaziyarPanahi/Llama-3-11B-Instruct-v0.1` model.
# How to use
You can use this model by using `MaziyarPanahi/Llama-3-16B-Instruct-v0.1` as the model name in Hugging Face's
transformers library.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/Llama-3-16B-Instruct-v0.1"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])
```
## Prompt template
```text
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
what's 25-4*2+3<|eot_id|><|start_header_id|>assistant<|end_header_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!<|eot_id|>
To evaluate this expression, we need to follow the order of operations (PEMDAS):
1. First, multiply 4 and 2: 4*2 = 8
2. Then, subtract 8 from 25: 25 - 8 = 17
3. Finally, add 3: 17 + 3 = 20
So, 25-4*2+3 = 20!
``` | {"language": ["en"], "license": "other", "library_name": "transformers", "tags": ["mergekit", "merge", "facebook", "meta", "pytorch", "llama", "llama-3"], "model_name": "Llama-3-16B-Instruct-v0.1", "base_model": "MaziyarPanahi/Llama-3-11B-Instruct-v0.1", "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "inference": false, "model_creator": "MaziyarPanahi", "quantized_by": "MaziyarPanahi"} | MaziyarPanahi/Llama-3-16B-Instruct-v0.1 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"base_model:MaziyarPanahi/Llama-3-11B-Instruct-v0.1",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:55:35+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-MaziyarPanahi/Llama-3-11B-Instruct-v0.1 #license-other #autotrain_compatible #text-generation-inference #region-us
|
<img src="./URL" alt="Goku 8x22B v0.1 Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Llama-3-16B-Instruct-v0.1
This model is a self-merge of 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' model.
# How to use
You can use this model by using 'MaziyarPanahi/Llama-3-16B-Instruct-v0.1' as the model name in Hugging Face's
transformers library.
## Prompt template
| [
"# Llama-3-16B-Instruct-v0.1\n\nThis model is a self-merge of 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-16B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-MaziyarPanahi/Llama-3-11B-Instruct-v0.1 #license-other #autotrain_compatible #text-generation-inference #region-us \n",
"# Llama-3-16B-Instruct-v0.1\n\nThis model is a self-merge of 'MaziyarPanahi/Llama-3-11B-Instruct-v0.1' model.",
"# How to use\n\nYou can use this model by using 'MaziyarPanahi/Llama-3-16B-Instruct-v0.1' as the model name in Hugging Face's\ntransformers library.",
"## Prompt template"
] |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# training
This model is a fine-tuned version of [Qwen/Qwen1.5-1.8B](https://huggingface.co/Qwen/Qwen1.5-1.8B) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.41.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1 | {"license": "other", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "Qwen/Qwen1.5-1.8B", "model-index": [{"name": "training", "results": []}]} | alifzl/SQLChef-1.8B | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:Qwen/Qwen1.5-1.8B",
"license:other",
"region:us"
] | null | 2024-04-19T09:56:30+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #base_model-Qwen/Qwen1.5-1.8B #license-other #region-us
|
# training
This model is a fine-tuned version of Qwen/Qwen1.5-1.8B on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.41.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1 | [
"# training\n\nThis model is a fine-tuned version of Qwen/Qwen1.5-1.8B on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0001\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 42\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 5\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.41.0.dev0\n- Pytorch 2.1.0+cu121\n- Datasets 2.18.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #base_model-Qwen/Qwen1.5-1.8B #license-other #region-us \n",
"# training\n\nThis model is a fine-tuned version of Qwen/Qwen1.5-1.8B on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0001\n- train_batch_size: 1\n- eval_batch_size: 1\n- seed: 42\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 5\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- PEFT 0.10.0\n- Transformers 4.41.0.dev0\n- Pytorch 2.1.0+cu121\n- Datasets 2.18.0\n- Tokenizers 0.19.1"
] |
text-generation | transformers |
# Model Card for Model ID
EVolutionary model
<!-- This model is trained in real time by another llm. as it talks and interacts with the llm (currently gemma2b) it tokenizes all responses and trains on the conversation almost instantly due to it's size. every 4 data set rows i prune 2 -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {} | liminerity/private | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T09:57:32+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #mistral #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
EVolutionary model
This modelcard aims to be a base template for new models. It has been generated using this raw template.
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID\nEVolutionary model\n\n\nThis modelcard aims to be a base template for new models. It has been generated using this raw template.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID\nEVolutionary model\n\n\nThis modelcard aims to be a base template for new models. It has been generated using this raw template.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null | # 説明
culturaX, wikipedia, mbpp, grade-school-mathで学習したトークナイザー。
## 学習に使ったデータ
英語:1.33GB<br>
日本語:1.79GB ※形態素単位で"||||"で事前分割してsentencepieceの学習時にpretokenization_delimiterを設定。<br>
コード:172KB<br>
数学:2.1MB
## 語彙の割合
計算していないので正確ではないですが、英語が62.5%くらい、日本語が32.5%くらい、その他記号が5%くらいだと思います。
## 引用元
- https://aclanthology.org/2020.lrec-1.297.pdf
- https://www.tensorflow.org/datasets/catalog/wiki40b
- https://arxiv.org/abs/2309.09400
- https://github.com/openai/grade-school-math
## 設定
vocab_size=51,200(語彙サイズ)<br>
character_coverage=0.9995(文字のカバー率99.95%)<br>
model_type="unigram"(アルゴリズム)<br>
normalization="identity"(正規化なし)<br>
byte_fallback=True(バイト変換あり)<br>
split_digits=True(数字分割あり)<br>
allow_whitespace_only_pieces=True(空白のトークンを許可する)<br>
remove_extra_whitespaces=True(余分な空白の削除あり)<br>
## 形式
LlamaTokenizer<br>
※encode時に文頭にbos_tokenである"\<s\>"トークンが付きます。
# 使い方
```python
!pip install transformers>=4.34.0
from transformers import AutoTokenizer
test_tokenizer = AutoTokenizer.from_pretrained("geniacllm/ja-en-tokenizer-unigram-v2", use_fast=False)
```
```python
# text
text = "This is tokenizer test."
# tokenize
tokenized = test_tokenizer.tokenize(text)
print(tokenized)
# encode
encoded = test_tokenizer.encode(text)
print(encoded)
# decode
decoded = test_tokenizer.decode(encoded)
print(decoded)
# special_token
print(test_tokenizer.special_tokens_map)
# vocab size
print(len(test_tokenizer))
# all subwords in vocab
print(test_tokenizer.get_vocab())
``` | {} | geniacllm/ja-en-tokenizer-unigram-v2 | null | [
"arxiv:2309.09400",
"region:us"
] | null | 2024-04-19T09:57:52+00:00 | [
"2309.09400"
] | [] | TAGS
#arxiv-2309.09400 #region-us
| # 説明
culturaX, wikipedia, mbpp, grade-school-mathで学習したトークナイザー。
## 学習に使ったデータ
英語:1.33GB<br>
日本語:1.79GB ※形態素単位で"||||"で事前分割してsentencepieceの学習時にpretokenization_delimiterを設定。<br>
コード:172KB<br>
数学:2.1MB
## 語彙の割合
計算していないので正確ではないですが、英語が62.5%くらい、日本語が32.5%くらい、その他記号が5%くらいだと思います。
## 引用元
- URL
- URL
- URL
- URL
## 設定
vocab_size=51,200(語彙サイズ)<br>
character_coverage=0.9995(文字のカバー率99.95%)<br>
model_type="unigram"(アルゴリズム)<br>
normalization="identity"(正規化なし)<br>
byte_fallback=True(バイト変換あり)<br>
split_digits=True(数字分割あり)<br>
allow_whitespace_only_pieces=True(空白のトークンを許可する)<br>
remove_extra_whitespaces=True(余分な空白の削除あり)<br>
## 形式
LlamaTokenizer<br>
※encode時に文頭にbos_tokenである"\<s\>"トークンが付きます。
# 使い方
| [
"# 説明\nculturaX, wikipedia, mbpp, grade-school-mathで学習したトークナイザー。",
"## 学習に使ったデータ\n英語:1.33GB<br>\n日本語:1.79GB ※形態素単位で\"||||\"で事前分割してsentencepieceの学習時にpretokenization_delimiterを設定。<br>\nコード:172KB<br>\n数学:2.1MB",
"## 語彙の割合\n計算していないので正確ではないですが、英語が62.5%くらい、日本語が32.5%くらい、その他記号が5%くらいだと思います。",
"## 引用元\n- URL\n- URL\n- URL\n- URL",
"## 設定\nvocab_size=51,200(語彙サイズ)<br>\ncharacter_coverage=0.9995(文字のカバー率99.95%)<br>\nmodel_type=\"unigram\"(アルゴリズム)<br>\nnormalization=\"identity\"(正規化なし)<br>\nbyte_fallback=True(バイト変換あり)<br>\nsplit_digits=True(数字分割あり)<br>\nallow_whitespace_only_pieces=True(空白のトークンを許可する)<br>\nremove_extra_whitespaces=True(余分な空白の削除あり)<br>",
"## 形式\nLlamaTokenizer<br>\n※encode時に文頭にbos_tokenである\"\\<s\\>\"トークンが付きます。",
"# 使い方"
] | [
"TAGS\n#arxiv-2309.09400 #region-us \n",
"# 説明\nculturaX, wikipedia, mbpp, grade-school-mathで学習したトークナイザー。",
"## 学習に使ったデータ\n英語:1.33GB<br>\n日本語:1.79GB ※形態素単位で\"||||\"で事前分割してsentencepieceの学習時にpretokenization_delimiterを設定。<br>\nコード:172KB<br>\n数学:2.1MB",
"## 語彙の割合\n計算していないので正確ではないですが、英語が62.5%くらい、日本語が32.5%くらい、その他記号が5%くらいだと思います。",
"## 引用元\n- URL\n- URL\n- URL\n- URL",
"## 設定\nvocab_size=51,200(語彙サイズ)<br>\ncharacter_coverage=0.9995(文字のカバー率99.95%)<br>\nmodel_type=\"unigram\"(アルゴリズム)<br>\nnormalization=\"identity\"(正規化なし)<br>\nbyte_fallback=True(バイト変換あり)<br>\nsplit_digits=True(数字分割あり)<br>\nallow_whitespace_only_pieces=True(空白のトークンを許可する)<br>\nremove_extra_whitespaces=True(余分な空白の削除あり)<br>",
"## 形式\nLlamaTokenizer<br>\n※encode時に文頭にbos_tokenである\"\\<s\\>\"トークンが付きます。",
"# 使い方"
] |
null | null |
# IDLS24 TEAM33
## Rawnet3
Architecture: [RawNet3](https://arxiv.org/pdf/2203.08488.pdf)
Results on Vox1-O, after training on VoxCeleb1-dev
| EER (%) | minDCF|
|---------|-------|
|3.181| 0.218 |
| {"license": "apache-2.0"} | alexgichamba/idls24_team33_vox1_rawnet3 | null | [
"arxiv:2203.08488",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T09:58:43+00:00 | [
"2203.08488"
] | [] | TAGS
#arxiv-2203.08488 #license-apache-2.0 #region-us
| IDLS24 TEAM33
=============
Rawnet3
-------
Architecture: RawNet3
Results on Vox1-O, after training on VoxCeleb1-dev
| [] | [
"TAGS\n#arxiv-2203.08488 #license-apache-2.0 #region-us \n"
] |
text-generation | transformers |
# Meta-Llama-3-11.5B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
I had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..
Here's the same thing but for the instruct model: [mpasila/Meta-Llama-3-11.5B-Instruct](https://huggingface.co/mpasila/Meta-Llama-3-11.5B-Instruct/)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [Undi95/Meta-Llama-3-8B-hf](https://huggingface.co/Undi95/Meta-Llama-3-8B-hf)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Undi95/Meta-Llama-3-8B-hf
layer_range: [0, 24]
- sources:
- model: Undi95/Meta-Llama-3-8B-hf
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
| {"language": ["en"], "license": "other", "tags": ["mergekit", "merge", "facebook", "meta", "pytorch", "llama", "llama-3"], "base_model": ["Undi95/Meta-Llama-3-8B-hf"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "extra_gated_prompt": "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT\nMeta Llama 3 Version Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/.\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity\u2019s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama 3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means, collectively, Meta\u2019s proprietary Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display \u201cBuilt with Meta Llama 3\u201d on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include \u201cLlama 3\u201d at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.\niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a \u201cNotice\u201d text file distributed as a part of such copies: \u201cMeta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright \u00a9 Meta Platforms, Inc. All Rights Reserved.\u201d\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.\nv. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee\u2019s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use \u201cLlama 3\u201d (the \u201cMark\u201d) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta\u2019s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta\u2019s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.\n### Meta Llama 3 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you access or use Meta Llama 3, you agree to this Acceptable Use Policy (\u201cPolicy\u201d). The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)\n#### Prohibited Uses\nWe want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow others to use, Meta Llama 3 to: 1. Violate the law or others\u2019 rights, including to:\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:\n 1. Violence or terrorism\n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material\n 3. Human trafficking, exploitation, and sexual violence\n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.\n 5. Sexual solicitation\n 6. Any other criminal activity\n 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n 5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws\n 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:\n 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State\n 2. Guns and illegal weapons (including weapon development)\n 3. Illegal drugs and regulated/controlled substances\n 4. Operation of critical infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm or harm to others, including suicide, cutting, and eating disorders\n 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:\n 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n 3. Generating, promoting, or further distributing spam\n 4. Impersonating another individual without consent, authorization, or legal right\n 5. Representing that the use of Meta Llama 3 or outputs are human-generated\n 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\n4. Fail to appropriately disclose to end users any known dangers of your AI system\nPlease report any violation of this Policy, software \u201cbug,\u201d or other problems that could lead to a violation of this Policy through one of the following means:\n * Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)\n * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]", "extra_gated_fields": {"First Name": "text", "Last Name": "text", "Date of birth": "date_picker", "Country": "country", "Affiliation": "text", "geo": "ip_location", "By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy": "checkbox"}, "extra_gated_description": "The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).", "extra_gated_button_content": "Submit"} | mpasila/Meta-Llama-3-11.5B | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"base_model:Undi95/Meta-Llama-3-8B-hf",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:00:52+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-Undi95/Meta-Llama-3-8B-hf #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Meta-Llama-3-11.5B
This is a merge of pre-trained language models created using mergekit.
I had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..
Here's the same thing but for the instruct model: mpasila/Meta-Llama-3-11.5B-Instruct
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* Undi95/Meta-Llama-3-8B-hf
### Configuration
The following YAML configuration was used to produce this model:
| [
"# Meta-Llama-3-11.5B\n\nThis is a merge of pre-trained language models created using mergekit.\n\nI had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..\n\nHere's the same thing but for the instruct model: mpasila/Meta-Llama-3-11.5B-Instruct",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Undi95/Meta-Llama-3-8B-hf",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #mergekit #merge #facebook #meta #pytorch #llama-3 #conversational #en #base_model-Undi95/Meta-Llama-3-8B-hf #license-other #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Meta-Llama-3-11.5B\n\nThis is a merge of pre-trained language models created using mergekit.\n\nI had this idea at night that it would make sense to make a frankenmerge of Llama 3.. since we didn't get a 13B or 34B versions this time..\n\nHere's the same thing but for the instruct model: mpasila/Meta-Llama-3-11.5B-Instruct",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the passthrough merge method.",
"### Models Merged\n\nThe following models were included in the merge:\n* Undi95/Meta-Llama-3-8B-hf",
"### Configuration\n\nThe following YAML configuration was used to produce this model:"
] |
text-generation | transformers | # Meta-Llama-3-8B - bnb 4bit
- Model creator: [Meta](https://huggingface.co/meta-llama)
- Original model: [Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
## Description
This model is 4bit quantized version of [Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK. | {"license": "other", "tags": ["llama", "llama-3"], "model_name": "Meta-Llama-3-8B", "base_model": "meta-llama/Meta-Llama-3-8B", "license_name": "llama3", "license_link": "https://huggingface.co/meta-llama/Meta-Llama-3-8B/raw/main/LICENSE", "inference": false, "model_creator": "Meta", "quantized_by": "Leliuga", "pipeline_tag": "text-generation"} | leliuga/Meta-Llama-3-8B-bnb-4bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-19T10:00:56+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #llama-3 #conversational #base_model-meta-llama/Meta-Llama-3-8B #license-other #autotrain_compatible #text-generation-inference #4-bit #region-us
| # Meta-Llama-3-8B - bnb 4bit
- Model creator: Meta
- Original model: Meta-Llama-3-8B
## Description
This model is 4bit quantized version of Meta-Llama-3-8B using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK. | [
"# Meta-Llama-3-8B - bnb 4bit\n- Model creator: Meta\n- Original model: Meta-Llama-3-8B",
"## Description\n\nThis model is 4bit quantized version of Meta-Llama-3-8B using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK."
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #llama-3 #conversational #base_model-meta-llama/Meta-Llama-3-8B #license-other #autotrain_compatible #text-generation-inference #4-bit #region-us \n",
"# Meta-Llama-3-8B - bnb 4bit\n- Model creator: Meta\n- Original model: Meta-Llama-3-8B",
"## Description\n\nThis model is 4bit quantized version of Meta-Llama-3-8B using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK."
] |
reinforcement-learning | null |
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
| {"tags": ["Pixelcopter-PLE-v0", "reinforce", "reinforcement-learning", "custom-implementation", "deep-rl-class"], "model-index": [{"name": "Unit4_PixelCopter_v3", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "Pixelcopter-PLE-v0", "type": "Pixelcopter-PLE-v0"}, "metrics": [{"type": "mean_reward", "value": "13.70 +/- 12.67", "name": "mean_reward", "verified": false}]}]}]} | adekhovich/Unit4_PixelCopter_v3 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | null | 2024-04-19T10:01:21+00:00 | [] | [] | TAGS
#Pixelcopter-PLE-v0 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us
|
# Reinforce Agent playing Pixelcopter-PLE-v0
This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL
| [
"# Reinforce Agent playing Pixelcopter-PLE-v0\n This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
] | [
"TAGS\n#Pixelcopter-PLE-v0 #reinforce #reinforcement-learning #custom-implementation #deep-rl-class #model-index #region-us \n",
"# Reinforce Agent playing Pixelcopter-PLE-v0\n This is a trained model of a Reinforce agent playing Pixelcopter-PLE-v0 .\n To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: URL"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_13 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:01:58+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# KSIF-RPG-128k-slerp
KSIF-RPG-128k-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [AlekseiPravdin/KSI-RP-NSK-128k-7B](https://huggingface.co/AlekseiPravdin/KSI-RP-NSK-128k-7B)
* [grimjim/fireblossom-32K-7B](https://huggingface.co/grimjim/fireblossom-32K-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: AlekseiPravdin/KSI-RP-NSK-128k-7B
layer_range: [0, 32]
- model: grimjim/fireblossom-32K-7B
layer_range: [0, 32]
merge_method: slerp
base_model: AlekseiPravdin/KSI-RP-NSK-128k-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "AlekseiPravdin/KSI-RP-NSK-128k-7B", "grimjim/fireblossom-32K-7B"]} | AlekseiPravdin/KSIF-RPG-128k-slerp | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"AlekseiPravdin/KSI-RP-NSK-128k-7B",
"grimjim/fireblossom-32K-7B",
"conversational",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:01:58+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #AlekseiPravdin/KSI-RP-NSK-128k-7B #grimjim/fireblossom-32K-7B #conversational #custom_code #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# KSIF-RPG-128k-slerp
KSIF-RPG-128k-slerp is a merge of the following models using mergekit:
* AlekseiPravdin/KSI-RP-NSK-128k-7B
* grimjim/fireblossom-32K-7B
## Configuration
| [
"# KSIF-RPG-128k-slerp\n\nKSIF-RPG-128k-slerp is a merge of the following models using mergekit:\n* AlekseiPravdin/KSI-RP-NSK-128k-7B\n* grimjim/fireblossom-32K-7B",
"## Configuration"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #merge #mergekit #lazymergekit #AlekseiPravdin/KSI-RP-NSK-128k-7B #grimjim/fireblossom-32K-7B #conversational #custom_code #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# KSIF-RPG-128k-slerp\n\nKSIF-RPG-128k-slerp is a merge of the following models using mergekit:\n* AlekseiPravdin/KSI-RP-NSK-128k-7B\n* grimjim/fireblossom-32K-7B",
"## Configuration"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-06
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"tags": ["trl", "sft", "generated_from_trainer"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep", "results": []}]} | mohsenfayyaz/Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:02:50+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #trl #sft #generated_from_trainer #conversational #base_model-mistralai/Mistral-7B-Instruct-v0.2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-06
- train_batch_size: 2
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
| [
"# Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-06\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #trl #sft #generated_from_trainer #conversational #base_model-mistralai/Mistral-7B-Instruct-v0.2 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Mistral-7B-Instruct-v0.2_medical_bios_5000_3ep\n\nThis model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.5e-06\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 0\n- gradient_accumulation_steps: 32\n- total_train_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.1\n- Pytorch 2.2.1+cu121\n- Datasets 2.17.1\n- Tokenizers 0.15.2"
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "diffusers"} | Niggendar/mfcgWashedMix_v10 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-19T10:06:52+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Uploaded model
- **Developed by:** dinhquangson
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | dinhquangson/llama3_new | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:08:03+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: dinhquangson
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: dinhquangson\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: dinhquangson\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] |
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ultimate_model_v3
This model is a fine-tuned version of [vinai/bartpho-syllable-base](https://huggingface.co/vinai/bartpho-syllable-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8728
- Bleu: 9.3924
- Gen Len: 18.2445
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 1.8807 | 1.0 | 13196 | 1.8728 | 9.3924 | 18.2445 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "metrics": ["bleu"], "base_model": "vinai/bartpho-syllable-base", "model-index": [{"name": "ultimate_model_v3", "results": []}]} | long292/ultimate_model_v3 | null | [
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"generated_from_trainer",
"base_model:vinai/bartpho-syllable-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:09:59+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #mbart #text2text-generation #generated_from_trainer #base_model-vinai/bartpho-syllable-base #autotrain_compatible #endpoints_compatible #region-us
| ultimate\_model\_v3
===================
This model is a fine-tuned version of vinai/bartpho-syllable-base on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 1.8728
* Bleu: 9.3924
* Gen Len: 18.2445
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 1
* eval\_batch\_size: 1
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 1
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #mbart #text2text-generation #generated_from_trainer #base_model-vinai/bartpho-syllable-base #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | adapter-transformers | ---
license: apache-2.0
--- Model Architecture Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
Training Data Params Context length GQA Token count Knowledge cutoff
Llama 3 A new mix of publicly available online data. 8B 8k Yes 15T+ March, 2023
70B 8k Yes December, 2023
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
--- sft 1700 llama3 test, 25 EPOCH | {"license": "apache-2.0", "library_name": "adapter-transformers", "datasets": ["LooksJuicy/ruozhiba"], "metrics": ["accuracy"]} | postitive666/llama3_ruozhiba_8b | null | [
"adapter-transformers",
"safetensors",
"llama",
"dataset:LooksJuicy/ruozhiba",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T10:10:02+00:00 | [] | [] | TAGS
#adapter-transformers #safetensors #llama #dataset-LooksJuicy/ruozhiba #license-apache-2.0 #region-us
| ---
license: apache-2.0
--- Model Architecture Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
Training Data Params Context length GQA Token count Knowledge cutoff
Llama 3 A new mix of publicly available online data. 8B 8k Yes 15T+ March, 2023
70B 8k Yes December, 2023
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
--- sft 1700 llama3 test, 25 EPOCH | [] | [
"TAGS\n#adapter-transformers #safetensors #llama #dataset-LooksJuicy/ruozhiba #license-apache-2.0 #region-us \n"
] |
null | null |
# KSIF-RPG-128k-slerp ⭐️⭐️
KSIF-RPG-128k-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [AlekseiPravdin/KSI-RP-NSK-128k-7B](https://huggingface.co/AlekseiPravdin/KSI-RP-NSK-128k-7B)
* [grimjim/fireblossom-32K-7B](https://huggingface.co/grimjim/fireblossom-32K-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: AlekseiPravdin/KSI-RP-NSK-128k-7B
layer_range: [0, 32]
- model: grimjim/fireblossom-32K-7B
layer_range: [0, 32]
merge_method: slerp
base_model: AlekseiPravdin/KSI-RP-NSK-128k-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
Eval embedding benchmark (with 70 specific quesions):







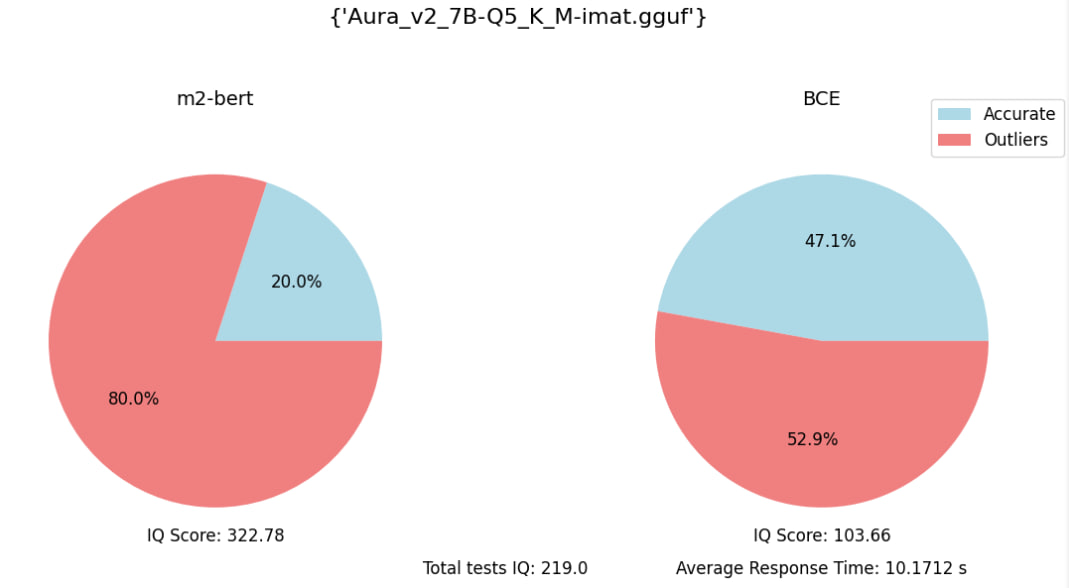




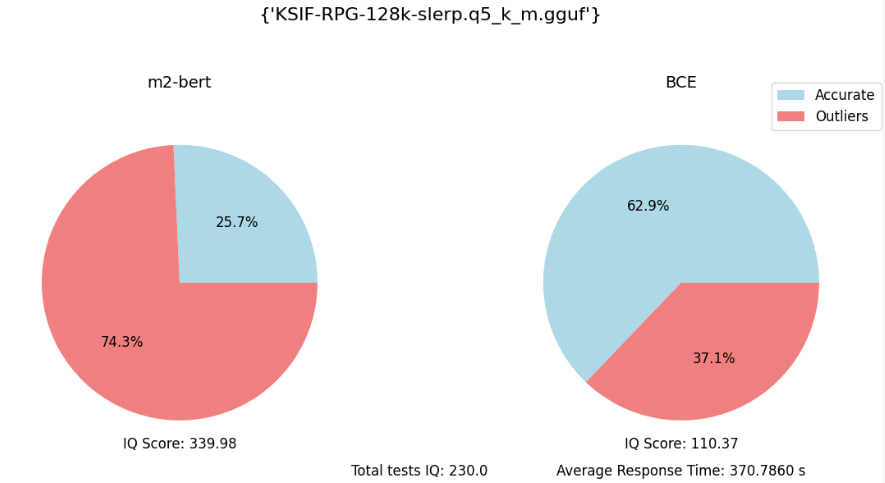
 | {"language": ["en", "ru", "th"], "license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "AlekseiPravdin/KSI-RP-NSK-128k-7B", "grimjim/fireblossom-32K-7B", "gguf", "Q2_K", "Q3_K_L", "Q3_K_M", "Q3_K_S", "Q4_0", "Q4_1", "Q4_K_S", "Q4_k_m", "Q5_0", "Q5_1", "Q6_K", "Q5_K_S", "Q5_k_m", "Q8_0", "128k"]} | AlekseiPravdin/KSIF-RPG-128k-slerp-gguf | null | [
"gguf",
"merge",
"mergekit",
"lazymergekit",
"AlekseiPravdin/KSI-RP-NSK-128k-7B",
"grimjim/fireblossom-32K-7B",
"Q2_K",
"Q3_K_L",
"Q3_K_M",
"Q3_K_S",
"Q4_0",
"Q4_1",
"Q4_K_S",
"Q4_k_m",
"Q5_0",
"Q5_1",
"Q6_K",
"Q5_K_S",
"Q5_k_m",
"Q8_0",
"128k",
"en",
"ru",
"th",
"license:apache-2.0",
"region:us"
] | null | 2024-04-19T10:10:48+00:00 | [] | [
"en",
"ru",
"th"
] | TAGS
#gguf #merge #mergekit #lazymergekit #AlekseiPravdin/KSI-RP-NSK-128k-7B #grimjim/fireblossom-32K-7B #Q2_K #Q3_K_L #Q3_K_M #Q3_K_S #Q4_0 #Q4_1 #Q4_K_S #Q4_k_m #Q5_0 #Q5_1 #Q6_K #Q5_K_S #Q5_k_m #Q8_0 #128k #en #ru #th #license-apache-2.0 #region-us
|
# KSIF-RPG-128k-slerp ⭐️⭐️
KSIF-RPG-128k-slerp is a merge of the following models using mergekit:
* AlekseiPravdin/KSI-RP-NSK-128k-7B
* grimjim/fireblossom-32K-7B
## Configuration
Eval embedding benchmark (with 70 specific quesions):
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL
!URL | [
"# KSIF-RPG-128k-slerp ⭐️⭐️\n\nKSIF-RPG-128k-slerp is a merge of the following models using mergekit:\n* AlekseiPravdin/KSI-RP-NSK-128k-7B\n* grimjim/fireblossom-32K-7B",
"## Configuration\n\n\n\nEval embedding benchmark (with 70 specific quesions):\n\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL"
] | [
"TAGS\n#gguf #merge #mergekit #lazymergekit #AlekseiPravdin/KSI-RP-NSK-128k-7B #grimjim/fireblossom-32K-7B #Q2_K #Q3_K_L #Q3_K_M #Q3_K_S #Q4_0 #Q4_1 #Q4_K_S #Q4_k_m #Q5_0 #Q5_1 #Q6_K #Q5_K_S #Q5_k_m #Q8_0 #128k #en #ru #th #license-apache-2.0 #region-us \n",
"# KSIF-RPG-128k-slerp ⭐️⭐️\n\nKSIF-RPG-128k-slerp is a merge of the following models using mergekit:\n* AlekseiPravdin/KSI-RP-NSK-128k-7B\n* grimjim/fireblossom-32K-7B",
"## Configuration\n\n\n\nEval embedding benchmark (with 70 specific quesions):\n\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL\n!URL"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | jorgefg03/mdeberta-v3-base-autext | null | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:14:16+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #deberta-v2 #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #deberta-v2 #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-CR-ProvaCluster6di7-5Epochs
This model is a fine-tuned version of [tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0](https://huggingface.co/tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "base_model": "tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0", "model-index": [{"name": "PolizzeDonut-CR-ProvaCluster6di7-5Epochs", "results": []}]} | tedad09/PolizzeDonut-CR-ProvaCluster6di7-5Epochs | null | [
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:14:34+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #base_model-tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 #license-mit #endpoints_compatible #region-us
|
# PolizzeDonut-CR-ProvaCluster6di7-5Epochs
This model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# PolizzeDonut-CR-ProvaCluster6di7-5Epochs\n\nThis model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #base_model-tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 #license-mit #endpoints_compatible #region-us \n",
"# PolizzeDonut-CR-ProvaCluster6di7-5Epochs\n\nThis model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "diffusers"} | Niggendar/mfcgGlossMix_v10 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | 2024-04-19T10:17:08+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | junaid20/story_gen-6.7b-lora | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:21:03+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
automatic-speech-recognition | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | openpecha/tibetan_asr_mms300_v1 | null | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:22:51+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #wav2vec2 #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #wav2vec2 #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-dv
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7613
- Wer: 33.9257
- Wer Ortho: 34.7065
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 600
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Wer Ortho |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| 0.0005 | 17.86 | 500 | 0.7613 | 33.9257 | 34.7065 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["PolyAI/minds14"], "metrics": ["wer"], "base_model": "openai/whisper-tiny", "model-index": [{"name": "whisper-tiny-dv", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "PolyAI/minds14", "type": "PolyAI/minds14", "config": "en-US", "split": "train", "args": "en-US"}, "metrics": [{"type": "wer", "value": 33.925686591276246, "name": "Wer"}]}]}]} | vadhri/whisper-tiny-dv | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:23:23+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-PolyAI/minds14 #base_model-openai/whisper-tiny #license-apache-2.0 #model-index #endpoints_compatible #region-us
| whisper-tiny-dv
===============
This model is a fine-tuned version of openai/whisper-tiny on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7613
* Wer: 33.9257
* Wer Ortho: 34.7065
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant\_with\_warmup
* lr\_scheduler\_warmup\_steps: 50
* training\_steps: 600
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 600\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-PolyAI/minds14 #base_model-openai/whisper-tiny #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 600\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
null | null | This project is created to better understand loss in image classification and used
https://www.kaggle.com/datasets/iluvchicken/cheetah-jaguar-and-tiger dataset to classify images | {} | hyacinthum/Big_Cat_Dataset | null | [
"region:us"
] | null | 2024-04-19T10:26:01+00:00 | [] | [] | TAGS
#region-us
| This project is created to better understand loss in image classification and used
URL dataset to classify images | [] | [
"TAGS\n#region-us \n"
] |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Samuela39/my-mini-project-model | null | [
"transformers",
"safetensors",
"roberta",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:26:52+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #roberta #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #roberta #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | sentence-transformers | [Sugar Defender](https://icsfs.microsoftcrmportals.com/forums/general-discussion/752befe8-1dfe-ee11-a81c-000d3a289315) Blood Sugar could be an item connected with overseeing blood sugar levels. Regularly, items in this classification offer help for people managing diabetes or those expecting to control their blood sugar levels. It could comprise of enhancements, checking gadgets, or dietary guides intended to assist with balancing out blood sugar levels.It means quite a bit to take note of that particular data about "Opti Gluco Blood Sugar" probably won't be promptly accessible or could shift by district or producer. In the event that you're thinking about utilizing it or looking for more data, talking with a medical care proficient or investigating legitimate sources is fitting to grasp its viability, appropriate utilization, and possible secondary effects.
VISIT HERE FOR OFFICIAL WEBSITE:-https://icsfs.microsoftcrmportals.com/forums/general-discussion/752befe8-1dfe-ee11-a81c-000d3a289315
| {"language": ["en"], "license": "bsd", "library_name": "sentence-transformers", "tags": ["Sugar Defender"]} | sugardefender/sugardefender | null | [
"sentence-transformers",
"Sugar Defender",
"en",
"license:bsd",
"region:us"
] | null | 2024-04-19T10:28:02+00:00 | [] | [
"en"
] | TAGS
#sentence-transformers #Sugar Defender #en #license-bsd #region-us
| Sugar Defender Blood Sugar could be an item connected with overseeing blood sugar levels. Regularly, items in this classification offer help for people managing diabetes or those expecting to control their blood sugar levels. It could comprise of enhancements, checking gadgets, or dietary guides intended to assist with balancing out blood sugar levels.It means quite a bit to take note of that particular data about "Opti Gluco Blood Sugar" probably won't be promptly accessible or could shift by district or producer. In the event that you're thinking about utilizing it or looking for more data, talking with a medical care proficient or investigating legitimate sources is fitting to grasp its viability, appropriate utilization, and possible secondary effects.
VISIT HERE FOR OFFICIAL WEBSITE:-URL
| [] | [
"TAGS\n#sentence-transformers #Sugar Defender #en #license-bsd #region-us \n"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | heyllm234/sc39 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:28:44+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.0_ablation_1e7lr_4iters_iter_3
This model is a fine-tuned version of [ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2](https://huggingface.co/ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2) on the ZhangShenao/0.0_ablation_1e7lr_4iters_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["ZhangShenao/0.0_ablation_1e7lr_4iters_dataset"], "base_model": "ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2", "model-index": [{"name": "0.0_ablation_1e7lr_4iters_iter_3", "results": []}]} | ZhangShenao/0.0_ablation_1e7lr_4iters_iter_3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:ZhangShenao/0.0_ablation_1e7lr_4iters_dataset",
"base_model:ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:29:30+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_1e7lr_4iters_dataset #base_model-ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# 0.0_ablation_1e7lr_4iters_iter_3
This model is a fine-tuned version of ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2 on the ZhangShenao/0.0_ablation_1e7lr_4iters_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# 0.0_ablation_1e7lr_4iters_iter_3\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2 on the ZhangShenao/0.0_ablation_1e7lr_4iters_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_1e7lr_4iters_dataset #base_model-ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# 0.0_ablation_1e7lr_4iters_iter_3\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_1e7lr_4iters_iter_2 on the ZhangShenao/0.0_ablation_1e7lr_4iters_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] |
text-generation | transformers |
# nekomata-14b-pfn-qfin-inst-merge

## Model Description
nekomata-14b-pfn-qfin-inst-merge is a merged model using [rinna/nekomata-14b](https://huggingface.co/rinna/nekomata-14b/tree/main), [rinna/nekomata-14b-instruction](https://huggingface.co/rinna/nekomata-14b-instruction), and [pfnet/nekomata-14b-pfn-qfin](https://huggingface.co/pfnet/nekomata-14b-pfn-qfin).
This is the instruction model, which is good at generating answers for instructions.
This model is released under [Tongyi Qianwen LICENSE AGREEMENT](https://github.com/QwenLM/Qwen/blob/e8e15962d897714944773cca57fa2e460a3655e8/Tongyi%20Qianwen%20LICENSE%20AGREEMENT).
The research article will also be released later.
# Benchmarking
The benchmark score is obtained using [Japanese Language Model Financial Evaluation Harness](https://github.com/pfnet-research/japanese-lm-fin-harness)
For the benchmark, 0-shot is used.
```
using default prompts
| Task |Metric| nekomaba-14b | -pfn-qfin |
|----------------|------|------|---|------|------|---|------|
|chabsa |f1 |0.7381| | |0.7428| | |
|cma_basics |acc |0.4737|± |0.0821|0.5263|± |0.0821|
|cpa_audit |acc |0.1608|± |0.0184|0.1633|± |0.0186|
|fp2 |acc |0.3389|± |0.0217|0.3642|± |0.0221|
|security_sales_1|acc |0.4561|± |0.0666|0.5614|± |0.0663|
|----------------|------|------|---|------|------|---|------|
|OVER ALL | |0.4335 |0.4716 |
using default prompts
| Task |Metric| -instruction | OURS |
|----------------|------|------|---|------|------|---|------|
|chabsa |f1 |0.8963| | |0.8429| | |
|cma_basics |acc |0.5000|± |0.0822|0.5789|± |0.0812|
|cpa_audit |acc |0.1859|± |0.0195|0.2136|± |0.0206|
|fp2 |acc |0.3642|± |0.0221|0.3579|± |0.0220|
|security_sales_1|acc |0.5088|± |0.0668|0.4737|± |0.0667|
|----------------|------|------|---|------|------|---|------|
|OVER ALL | |0.4910 |0.4939 |
using prompts v0.3 (instruction prompts)
| Task |Metric| -instruction | OURS |
|----------------|------|------|---|------|------|---|------|
|chabsa |f1 |0.8658| | |0.8620| | |
|cma_basics |acc |0.4737|± |0.0821|0.5000|± |0.0822|
|cpa_audit |acc |0.2085|± |0.0204|0.2060|± |0.0203|
|fp2 |acc |0.3663|± |0.0221|0.3663|± |0.0221|
|security_sales_1|acc |0.5263|± |0.0667|0.5614|± |0.0663|
|----------------|------|------|---|------|------|---|------|
|OVER ALL | |0.4881 |0.4991 |
```
## Usage
Install the required libraries as follows:
```sh
>>> python -m pip install numpy sentencepiece torch transformers accelerate transformers_stream_generator tiktoken einops
```
Execute the following python code:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", trust_remote_code=True)
# Use GPU with bf16 (recommended for supported devices)
# model = AutoModelForCausalLM.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", device_map="auto", trust_remote_code=True, bf16=True)
# Use GPU with fp16
# model = AutoModelForCausalLM.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", device_map="auto", trust_remote_code=True, fp16=True)
# Use GPU with fp32
# model = AutoModelForCausalLM.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", device_map="auto", trust_remote_code=True, fp32=True)
# Use CPU
# model = AutoModelForCausalLM.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", device_map="cpu", trust_remote_code=True)
# Automatically select device and precision
model = AutoModelForCausalLM.from_pretrained("pfnet/nekomata-14b-pfn-qfin-inst-merge", device_map="auto", trust_remote_code=True)
text = """以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
次の質問に答えてください。
### 入力:
デリバティブ取引のリスク管理について教えてください。
### 応答:"""
input_ids = tokenizer(text, return_tensors="pt").input_ids.to(model.device)
with torch.no_grad():
generated_tokens = model.generate(
inputs=input_ids,
max_new_tokens=512,
do_sample=False,
temperature=1.0,
repetition_penalty=1.1,
top_k=50,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)[0]
generated_text = tokenizer.decode(generated_tokens)
print(generated_text.split("### 応答:")[1])
# デリバティブ取引では、原資産の価格変動が大きく影響します。そのため、リスク管理においては、原資産の価格変動リスクを適切にコントロールすることが重要となります。具体的には、ポジションサイズやレバレッジの制限、ヘッジ手法の活用などが挙げられます。また、市場情報の収集・分析を行い、適切なタイミングでポジションを調整することも大切です。さらに、取引先の信用リスクにも注意が必要であり、相手方の財務状況や信用度などを確認し、必要に応じて保証や担保を設定することが求められます。以上のようなリスク管理を行うことで、デリバティブ取引における損失リスクを最小化することができます。ただし、リスク管理はあくまで自己責任であるため、十分な知識と経験を持つことが望まれます。また、金融機関等の専門家によるアドバイスを受けることも有効です。以上が、デリバティブ取引におけるリスク管理の概要です。詳細については、金融庁や日本証券業協会などの公式サイトをご参照ください。
```
## Model Details
- Model size: 14B
- Context length: 2048
- Developed by: Preferred Networks, Inc
- Model type: Causal decoder-only
- Language(s): Japanese and English
- License: [Tongyi Qianwen LICENSE AGREEMENT](https://github.com/QwenLM/Qwen/blob/e8e15962d897714944773cca57fa2e460a3655e8/Tongyi%20Qianwen%20LICENSE%20AGREEMENT)
## Bias, Risks, and Limitations
nekomata-14b-pfn-qfin-inst-merge is a new technology that carries risks with use.
Testing conducted to date has been in English and Japanese, and has not covered, nor could it cover all scenarios.
For these reasons, as with all LLMs, nekomata-14b-pfn-qfin-inst-merge’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts.
This model is not designed for legal, tax, investment, financial, or other advice.
Therefore, before deploying any applications of nekomata-14b-pfn-qfin, developers should perform safety testing and tuning tailored to their specific applications of the model.
## How to cite
TBD
## Contributors
Preferred Networks, Inc.
- Masanori Hirano
- Kentaro Imajo
# License
[Tongyi Qianwen LICENSE AGREEMENT](https://github.com/QwenLM/Qwen/blob/e8e15962d897714944773cca57fa2e460a3655e8/Tongyi%20Qianwen%20LICENSE%20AGREEMENT)
| {"language": ["en", "ja"], "license": "other", "library_name": "transformers", "license_name": "tongyi-qianwen-license", "license_link": "LICENSE", "pipeline_tag": "text-generation"} | pfnet/nekomata-14b-pfn-qfin-inst-merge | null | [
"transformers",
"safetensors",
"qwen",
"text-generation",
"custom_code",
"en",
"ja",
"license:other",
"autotrain_compatible",
"region:us"
] | null | 2024-04-19T10:29:36+00:00 | [] | [
"en",
"ja"
] | TAGS
#transformers #safetensors #qwen #text-generation #custom_code #en #ja #license-other #autotrain_compatible #region-us
|
# nekomata-14b-pfn-qfin-inst-merge
!Model Merge Image
## Model Description
nekomata-14b-pfn-qfin-inst-merge is a merged model using rinna/nekomata-14b, rinna/nekomata-14b-instruction, and pfnet/nekomata-14b-pfn-qfin.
This is the instruction model, which is good at generating answers for instructions.
This model is released under Tongyi Qianwen LICENSE AGREEMENT.
The research article will also be released later.
# Benchmarking
The benchmark score is obtained using Japanese Language Model Financial Evaluation Harness
For the benchmark, 0-shot is used.
## Usage
Install the required libraries as follows:
Execute the following python code:
## Model Details
- Model size: 14B
- Context length: 2048
- Developed by: Preferred Networks, Inc
- Model type: Causal decoder-only
- Language(s): Japanese and English
- License: Tongyi Qianwen LICENSE AGREEMENT
## Bias, Risks, and Limitations
nekomata-14b-pfn-qfin-inst-merge is a new technology that carries risks with use.
Testing conducted to date has been in English and Japanese, and has not covered, nor could it cover all scenarios.
For these reasons, as with all LLMs, nekomata-14b-pfn-qfin-inst-merge’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts.
This model is not designed for legal, tax, investment, financial, or other advice.
Therefore, before deploying any applications of nekomata-14b-pfn-qfin, developers should perform safety testing and tuning tailored to their specific applications of the model.
## How to cite
TBD
## Contributors
Preferred Networks, Inc.
- Masanori Hirano
- Kentaro Imajo
# License
Tongyi Qianwen LICENSE AGREEMENT
| [
"# nekomata-14b-pfn-qfin-inst-merge\n!Model Merge Image",
"## Model Description\nnekomata-14b-pfn-qfin-inst-merge is a merged model using rinna/nekomata-14b, rinna/nekomata-14b-instruction, and pfnet/nekomata-14b-pfn-qfin.\nThis is the instruction model, which is good at generating answers for instructions.\nThis model is released under Tongyi Qianwen LICENSE AGREEMENT.\n\nThe research article will also be released later.",
"# Benchmarking\nThe benchmark score is obtained using Japanese Language Model Financial Evaluation Harness\nFor the benchmark, 0-shot is used.",
"## Usage\nInstall the required libraries as follows:\n\n\nExecute the following python code:",
"## Model Details\n- Model size: 14B\n- Context length: 2048\n- Developed by: Preferred Networks, Inc\n- Model type: Causal decoder-only\n- Language(s): Japanese and English\n- License: Tongyi Qianwen LICENSE AGREEMENT",
"## Bias, Risks, and Limitations\nnekomata-14b-pfn-qfin-inst-merge is a new technology that carries risks with use.\nTesting conducted to date has been in English and Japanese, and has not covered, nor could it cover all scenarios.\nFor these reasons, as with all LLMs, nekomata-14b-pfn-qfin-inst-merge’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts.\nThis model is not designed for legal, tax, investment, financial, or other advice.\nTherefore, before deploying any applications of nekomata-14b-pfn-qfin, developers should perform safety testing and tuning tailored to their specific applications of the model.",
"## How to cite\nTBD",
"## Contributors\nPreferred Networks, Inc.\n - Masanori Hirano\n - Kentaro Imajo",
"# License\nTongyi Qianwen LICENSE AGREEMENT"
] | [
"TAGS\n#transformers #safetensors #qwen #text-generation #custom_code #en #ja #license-other #autotrain_compatible #region-us \n",
"# nekomata-14b-pfn-qfin-inst-merge\n!Model Merge Image",
"## Model Description\nnekomata-14b-pfn-qfin-inst-merge is a merged model using rinna/nekomata-14b, rinna/nekomata-14b-instruction, and pfnet/nekomata-14b-pfn-qfin.\nThis is the instruction model, which is good at generating answers for instructions.\nThis model is released under Tongyi Qianwen LICENSE AGREEMENT.\n\nThe research article will also be released later.",
"# Benchmarking\nThe benchmark score is obtained using Japanese Language Model Financial Evaluation Harness\nFor the benchmark, 0-shot is used.",
"## Usage\nInstall the required libraries as follows:\n\n\nExecute the following python code:",
"## Model Details\n- Model size: 14B\n- Context length: 2048\n- Developed by: Preferred Networks, Inc\n- Model type: Causal decoder-only\n- Language(s): Japanese and English\n- License: Tongyi Qianwen LICENSE AGREEMENT",
"## Bias, Risks, and Limitations\nnekomata-14b-pfn-qfin-inst-merge is a new technology that carries risks with use.\nTesting conducted to date has been in English and Japanese, and has not covered, nor could it cover all scenarios.\nFor these reasons, as with all LLMs, nekomata-14b-pfn-qfin-inst-merge’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts.\nThis model is not designed for legal, tax, investment, financial, or other advice.\nTherefore, before deploying any applications of nekomata-14b-pfn-qfin, developers should perform safety testing and tuning tailored to their specific applications of the model.",
"## How to cite\nTBD",
"## Contributors\nPreferred Networks, Inc.\n - Masanori Hirano\n - Kentaro Imajo",
"# License\nTongyi Qianwen LICENSE AGREEMENT"
] |
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# summarization
This model is a fine-tuned version of [google-t5/t5-base](https://huggingface.co/google-t5/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2491
- Rouge1: 0.3279
- Rouge2: 0.2271
- Rougel: 0.3003
- Rougelsum: 0.3005
- Gen Len: 18.9811
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.372 | 1.0 | 4189 | 0.2643 | 0.3326 | 0.2341 | 0.3055 | 0.3053 | 18.9784 |
| 0.3303 | 2.0 | 8378 | 0.2558 | 0.3379 | 0.2401 | 0.3112 | 0.3112 | 18.9808 |
| 0.3069 | 3.0 | 12567 | 0.2482 | 0.34 | 0.241 | 0.3129 | 0.313 | 18.9815 |
| 0.3057 | 4.0 | 16756 | 0.2491 | 0.3279 | 0.2271 | 0.3003 | 0.3005 | 18.9811 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["rouge"], "base_model": "google-t5/t5-base", "model-index": [{"name": "summarization", "results": []}]} | Sif10/summarization | null | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:30:44+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #t5 #text2text-generation #generated_from_trainer #base_model-google-t5/t5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| summarization
=============
This model is a fine-tuned version of google-t5/t5-base on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2491
* Rouge1: 0.3279
* Rouge2: 0.2271
* Rougel: 0.3003
* Rougelsum: 0.3005
* Gen Len: 18.9811
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 3
* eval\_batch\_size: 3
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 4
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 2.1.2
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 3\n* eval\\_batch\\_size: 3\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #t5 #text2text-generation #generated_from_trainer #base_model-google-t5/t5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 3\n* eval\\_batch\\_size: 3\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 4\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 2.1.2\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | souvik0306/test_quant_merge | null | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-19T10:31:42+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #opt #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #opt #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Email Generation
<!-- Provide a quick summary of what the model is/does. -->
Focused on generating emails based on features of the target user.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
Final Project for Group O in 2024 Spring CS6120 NLP at Roux Institute, Northeastern University.
- **Developed by:** Yun Cao, Yue Liu, Muyang Cheng, Nan Chen
- **Professor:** Prashant Mittal
- **Model type:** GPT2
- **Language(s) (NLP):** Python, Transformers
- **Finetuned from model:** postbot/distilgpt2-emailgen-V2
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** Final folder in [Github CS6120NLP](https://github.com/awakn123/CS6120NLP)
- **Demo:** [Space link](https://huggingface.co/spaces/24NLPGroupO/EmailGeneration).
---
license: mit
datasets:
- LightTai/personalized-email
language:
- en
metrics:
- rouge
tags:
- email
--- | {} | 24NLPGroupO/EmailGeneration | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:32:07+00:00 | [] | [] | TAGS
#transformers #pytorch #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
# Model Card for Email Generation
Focused on generating emails based on features of the target user.
## Model Details
### Model Description
Final Project for Group O in 2024 Spring CS6120 NLP at Roux Institute, Northeastern University.
- Developed by: Yun Cao, Yue Liu, Muyang Cheng, Nan Chen
- Professor: Prashant Mittal
- Model type: GPT2
- Language(s) (NLP): Python, Transformers
- Finetuned from model: postbot/distilgpt2-emailgen-V2
### Model Sources [optional]
- Repository: Final folder in Github CS6120NLP
- Demo: Space link.
---
license: mit
datasets:
- LightTai/personalized-email
language:
- en
metrics:
- rouge
tags:
- email
--- | [
"# Model Card for Email Generation\n\n\n\nFocused on generating emails based on features of the target user.",
"## Model Details",
"### Model Description\n\n\n\nFinal Project for Group O in 2024 Spring CS6120 NLP at Roux Institute, Northeastern University.\n\n- Developed by: Yun Cao, Yue Liu, Muyang Cheng, Nan Chen\n- Professor: Prashant Mittal\n- Model type: GPT2\n- Language(s) (NLP): Python, Transformers\n- Finetuned from model: postbot/distilgpt2-emailgen-V2",
"### Model Sources [optional]\n\n\n\n- Repository: Final folder in Github CS6120NLP\n- Demo: Space link.\n\n---\nlicense: mit\n\ndatasets:\n- LightTai/personalized-email\n\nlanguage:\n- en\n\nmetrics:\n- rouge\n\ntags:\n- email\n---"
] | [
"TAGS\n#transformers #pytorch #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n",
"# Model Card for Email Generation\n\n\n\nFocused on generating emails based on features of the target user.",
"## Model Details",
"### Model Description\n\n\n\nFinal Project for Group O in 2024 Spring CS6120 NLP at Roux Institute, Northeastern University.\n\n- Developed by: Yun Cao, Yue Liu, Muyang Cheng, Nan Chen\n- Professor: Prashant Mittal\n- Model type: GPT2\n- Language(s) (NLP): Python, Transformers\n- Finetuned from model: postbot/distilgpt2-emailgen-V2",
"### Model Sources [optional]\n\n\n\n- Repository: Final folder in Github CS6120NLP\n- Demo: Space link.\n\n---\nlicense: mit\n\ndatasets:\n- LightTai/personalized-email\n\nlanguage:\n- en\n\nmetrics:\n- rouge\n\ntags:\n- email\n---"
] |
null | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-CR-ProvaCluster6di7-7Epochs
This model is a fine-tuned version of [tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0](https://huggingface.co/tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "base_model": "tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0", "model-index": [{"name": "PolizzeDonut-CR-ProvaCluster6di7-7Epochs", "results": []}]} | tedad09/PolizzeDonut-CR-ProvaCluster6di7-7Epochs | null | [
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:33:12+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #base_model-tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 #license-mit #endpoints_compatible #region-us
|
# PolizzeDonut-CR-ProvaCluster6di7-7Epochs
This model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| [
"# PolizzeDonut-CR-ProvaCluster6di7-7Epochs\n\nThis model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 7\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #vision-encoder-decoder #generated_from_trainer #dataset-imagefolder #base_model-tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 #license-mit #endpoints_compatible #region-us \n",
"# PolizzeDonut-CR-ProvaCluster6di7-7Epochs\n\nThis model is a fine-tuned version of tedad09/PolizzeDonut-ChangeRequest-imm5epochs-Expand0 on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 7\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.38.2\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.15.2"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6785
- Wer Ortho: 0.3644
- Wer: 0.3570
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 600
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0006 | 17.86 | 500 | 0.6785 | 0.3644 | 0.3570 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["PolyAI/minds14"], "metrics": ["wer"], "base_model": "openai/whisper-tiny", "model-index": [{"name": "whisper-tiny", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "PolyAI/minds14", "type": "PolyAI/minds14", "config": "en-US", "split": "train", "args": "en-US"}, "metrics": [{"type": "wer", "value": 0.3569725864123957, "name": "Wer"}]}]}]} | vadhri/whisper-tiny | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:35:45+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-PolyAI/minds14 #base_model-openai/whisper-tiny #license-apache-2.0 #model-index #endpoints_compatible #region-us
| whisper-tiny
============
This model is a fine-tuned version of openai/whisper-tiny on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6785
* Wer Ortho: 0.3644
* Wer: 0.3570
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: constant\_with\_warmup
* lr\_scheduler\_warmup\_steps: 50
* training\_steps: 600
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.1+cu121
* Datasets 2.19.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 600\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #dataset-PolyAI/minds14 #base_model-openai/whisper-tiny #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: constant\\_with\\_warmup\n* lr\\_scheduler\\_warmup\\_steps: 50\n* training\\_steps: 600\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.1+cu121\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.0_ablation_declr_4iters_iter_4
This model is a fine-tuned version of [ZhangShenao/0.0_ablation_declr_4iters_iter_3](https://huggingface.co/ZhangShenao/0.0_ablation_declr_4iters_iter_3) on the ZhangShenao/0.0_ablation_declr_4iters_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.25e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["ZhangShenao/0.0_ablation_declr_4iters_dataset"], "base_model": "ZhangShenao/0.0_ablation_declr_4iters_iter_3", "model-index": [{"name": "0.0_ablation_declr_4iters_iter_4", "results": []}]} | ZhangShenao/0.0_ablation_declr_4iters_iter_4 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:ZhangShenao/0.0_ablation_declr_4iters_dataset",
"base_model:ZhangShenao/0.0_ablation_declr_4iters_iter_3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:36:00+00:00 | [] | [] | TAGS
#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_declr_4iters_dataset #base_model-ZhangShenao/0.0_ablation_declr_4iters_iter_3 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# 0.0_ablation_declr_4iters_iter_4
This model is a fine-tuned version of ZhangShenao/0.0_ablation_declr_4iters_iter_3 on the ZhangShenao/0.0_ablation_declr_4iters_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.25e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| [
"# 0.0_ablation_declr_4iters_iter_4\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_declr_4iters_iter_3 on the ZhangShenao/0.0_ablation_declr_4iters_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.25e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #alignment-handbook #generated_from_trainer #trl #dpo #conversational #dataset-ZhangShenao/0.0_ablation_declr_4iters_dataset #base_model-ZhangShenao/0.0_ablation_declr_4iters_iter_3 #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# 0.0_ablation_declr_4iters_iter_4\n\nThis model is a fine-tuned version of ZhangShenao/0.0_ablation_declr_4iters_iter_3 on the ZhangShenao/0.0_ablation_declr_4iters_dataset dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1.25e-07\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- distributed_type: multi-GPU\n- num_devices: 8\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 128\n- total_eval_batch_size: 64\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: cosine\n- lr_scheduler_warmup_ratio: 0.1\n- num_epochs: 1",
"### Training results",
"### Framework versions\n\n- Transformers 4.36.2\n- Pytorch 2.1.2+cu121\n- Datasets 2.14.6\n- Tokenizers 0.15.2"
] |
audio-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium.en-finetuned-gtzan
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2885
- Accuracy: 0.95
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7711 | 1.0 | 112 | 1.6556 | 0.52 |
| 0.5477 | 2.0 | 225 | 0.4738 | 0.85 |
| 0.535 | 3.0 | 337 | 0.3137 | 0.92 |
| 0.231 | 4.0 | 450 | 0.3613 | 0.9 |
| 0.1923 | 5.0 | 562 | 0.2885 | 0.95 |
| 0.0584 | 6.0 | 675 | 0.6531 | 0.86 |
| 0.1783 | 7.0 | 787 | 0.5717 | 0.9 |
| 0.0022 | 8.0 | 900 | 0.4205 | 0.91 |
| 0.1032 | 9.0 | 1012 | 0.4984 | 0.91 |
| 0.0011 | 10.0 | 1125 | 0.3778 | 0.94 |
| 0.0104 | 11.0 | 1237 | 0.3709 | 0.94 |
| 0.0011 | 12.0 | 1350 | 0.4564 | 0.92 |
| 0.0009 | 13.0 | 1462 | 0.3796 | 0.94 |
| 0.0008 | 14.0 | 1575 | 0.3880 | 0.94 |
| 0.0008 | 15.0 | 1687 | 0.3930 | 0.94 |
| 0.0008 | 15.93 | 1792 | 0.3955 | 0.94 |
### Framework versions
- Transformers 4.37.0.dev0
- Pytorch 2.1.2+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["marsyas/gtzan"], "metrics": ["accuracy"], "base_model": "openai/whisper-medium.en", "model-index": [{"name": "music_class", "results": [{"task": {"type": "audio-classification", "name": "Audio Classification"}, "dataset": {"name": "GTZAN", "type": "marsyas/gtzan", "config": "all", "split": "train", "args": "all"}, "metrics": [{"type": "accuracy", "value": 0.95, "name": "Accuracy"}]}]}]} | asutosh09/music_class | null | [
"transformers",
"safetensors",
"whisper",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:openai/whisper-medium.en",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us",
"has_space"
] | null | 2024-04-19T10:37:08+00:00 | [] | [] | TAGS
#transformers #safetensors #whisper #audio-classification #generated_from_trainer #dataset-marsyas/gtzan #base_model-openai/whisper-medium.en #license-apache-2.0 #model-index #endpoints_compatible #region-us #has_space
| URL-finetuned-gtzan
===================
This model is a fine-tuned version of openai/URL on the GTZAN dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2885
* Accuracy: 0.95
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 8
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 16
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.37.0.dev0
* Pytorch 2.1.2+cu118
* Datasets 2.15.0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 16\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.37.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] | [
"TAGS\n#transformers #safetensors #whisper #audio-classification #generated_from_trainer #dataset-marsyas/gtzan #base_model-openai/whisper-medium.en #license-apache-2.0 #model-index #endpoints_compatible #region-us #has_space \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 16\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.37.0.dev0\n* Pytorch 2.1.2+cu118\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": ["unsloth"]} | Anas989898/llama-3-8b-it-codeact-adapter | null | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:37:09+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #unsloth #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #unsloth #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers | # [MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF)
- Model creator: [MaziyarPanahi](https://huggingface.co/MaziyarPanahi)
- Original model: [MaziyarPanahi/Llama-3-11B-Instruct-v0.1](https://huggingface.co/MaziyarPanahi/Llama-3-11B-Instruct-v0.1)
## Description
[MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF) contains GGUF format model files for [MaziyarPanahi/Llama-3-11B-Instruct-v0.1](https://huggingface.co/MaziyarPanahi/Llama-3-11B-Instruct-v0.1).
## Load GGUF models
You `MUST` follow the prompt template provided by Llama-3:
```sh
./llama.cpp/main -m Llama-3-11B-Instruct.Q2_K.gguf -r '<|eot_id|>' --in-prefix "\n<|start_header_id|>user<|end_header_id|>\n\n" --in-suffix "<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" -p "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.<|eot_id|>\n<|start_header_id|>user<|end_header_id|>\n\nHi! How are you?<|eot_id|>\n<|start_header_id|>assistant<|end_header_id|>\n\n" -n 1024
```
| {"tags": ["quantized", "2-bit", "3-bit", "4-bit", "5-bit", "6-bit", "8-bit", "GGUF", "text-generation", "mixtral", "text-generation"], "model_name": "Llama-3-11B-Instruct-v0.1-GGUF", "base_model": "MaziyarPanahi/Llama-3-11B-Instruct-v0.1", "inference": false, "model_creator": "MaziyarPanahi", "pipeline_tag": "text-generation", "quantized_by": "MaziyarPanahi"} | MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF | null | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"mixtral",
"base_model:MaziyarPanahi/Llama-3-11B-Instruct-v0.1",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:37:09+00:00 | [] | [] | TAGS
#transformers #gguf #mistral #quantized #2-bit #3-bit #4-bit #5-bit #6-bit #8-bit #GGUF #text-generation #mixtral #base_model-MaziyarPanahi/Llama-3-11B-Instruct-v0.1 #text-generation-inference #region-us
| # MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF
- Model creator: MaziyarPanahi
- Original model: MaziyarPanahi/Llama-3-11B-Instruct-v0.1
## Description
MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF contains GGUF format model files for MaziyarPanahi/Llama-3-11B-Instruct-v0.1.
## Load GGUF models
You 'MUST' follow the prompt template provided by Llama-3:
| [
"# MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF\n- Model creator: MaziyarPanahi\n- Original model: MaziyarPanahi/Llama-3-11B-Instruct-v0.1",
"## Description\nMaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF contains GGUF format model files for MaziyarPanahi/Llama-3-11B-Instruct-v0.1.",
"## Load GGUF models\n\nYou 'MUST' follow the prompt template provided by Llama-3:"
] | [
"TAGS\n#transformers #gguf #mistral #quantized #2-bit #3-bit #4-bit #5-bit #6-bit #8-bit #GGUF #text-generation #mixtral #base_model-MaziyarPanahi/Llama-3-11B-Instruct-v0.1 #text-generation-inference #region-us \n",
"# MaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF\n- Model creator: MaziyarPanahi\n- Original model: MaziyarPanahi/Llama-3-11B-Instruct-v0.1",
"## Description\nMaziyarPanahi/Llama-3-11B-Instruct-v0.1-GGUF contains GGUF format model files for MaziyarPanahi/Llama-3-11B-Instruct-v0.1.",
"## Load GGUF models\n\nYou 'MUST' follow the prompt template provided by Llama-3:"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | mp1704/qwen_1.8b_stage_2 | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:37:30+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "diffusers"} | Niggendar/xentaiWesternComic_v1 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | 2024-04-19T10:38:57+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null | **LLM-Discussions:** <br>
*Here we discuss, chat, speculate and cope about random LLM or not so LLM topics.*
> [!NOTE]
> Head to the [**Community Tab**](https://huggingface.co/LWDCLS/LLM-Discussions/discussions) for discussions. <br> Find all [**past discussions here**](https://huggingface.co/LWDCLS/LLM-Discussions/discussions?status=closed).
<a href="https://huggingface.co/LWDCLS/LLM-Discussions/discussions">
<img src="https://cdn-uploads.huggingface.co/production/uploads/65d4cf2693a0a3744a27536c/qCpdjtkEpOdKtJrMGR_He.png" style="width:350px;height:350px;">
</a>
| {"language": ["en"], "tags": ["discussion", "llm"], "inference": false} | LWDCLS/LLM-Discussions | null | [
"discussion",
"llm",
"en",
"region:us"
] | null | 2024-04-19T10:39:22+00:00 | [] | [
"en"
] | TAGS
#discussion #llm #en #region-us
| LLM-Discussions: <br>
*Here we discuss, chat, speculate and cope about random LLM or not so LLM topics.*
> [!NOTE]
> Head to the Community Tab for discussions. <br> Find all past discussions here.
<a href="URL
<img src="URL style="width:350px;height:350px;">
</a>
| [] | [
"TAGS\n#discussion #llm #en #region-us \n"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | pujachak/dialogue_Summarization | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:40:31+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null | <img src="https://i.imgur.com/P68dXux.png" width="400"/>
# Mixtral-8x22b-iMat-GGUF
Quantized from fp32 with love. If you're on the latest release of llama.cpp you should no longer need to combine files before loading
* Importance Matrix .dat file created using Q8 quant and groups_merged.txt
For a brief rundown of iMatrix quant performance please see this [PR](https://github.com/ggerganov/llama.cpp/pull/5747)
<i>All quants are verified working prior to uploading to repo for your safety and convenience. </i>
<b>Tip:</b> Pick a size that can fit in your GPU while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.
Original model card can be found [here](https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1) | {"tags": ["merge", "gguf", "mixtral", "iMat"]} | InferenceIllusionist/Mixtral-8x22B-v0.1-iMat-GGUF | null | [
"gguf",
"merge",
"mixtral",
"iMat",
"region:us"
] | null | 2024-04-19T10:41:50+00:00 | [] | [] | TAGS
#gguf #merge #mixtral #iMat #region-us
| <img src="https://i.URL width="400"/>
# Mixtral-8x22b-iMat-GGUF
Quantized from fp32 with love. If you're on the latest release of URL you should no longer need to combine files before loading
* Importance Matrix .dat file created using Q8 quant and groups_merged.txt
For a brief rundown of iMatrix quant performance please see this PR
<i>All quants are verified working prior to uploading to repo for your safety and convenience. </i>
<b>Tip:</b> Pick a size that can fit in your GPU while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.
Original model card can be found here | [
"# Mixtral-8x22b-iMat-GGUF\n\n\nQuantized from fp32 with love. If you're on the latest release of URL you should no longer need to combine files before loading\n* Importance Matrix .dat file created using Q8 quant and groups_merged.txt\n\nFor a brief rundown of iMatrix quant performance please see this PR\n\n<i>All quants are verified working prior to uploading to repo for your safety and convenience. </i>\n\n\n<b>Tip:</b> Pick a size that can fit in your GPU while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.\n\nOriginal model card can be found here"
] | [
"TAGS\n#gguf #merge #mixtral #iMat #region-us \n",
"# Mixtral-8x22b-iMat-GGUF\n\n\nQuantized from fp32 with love. If you're on the latest release of URL you should no longer need to combine files before loading\n* Importance Matrix .dat file created using Q8 quant and groups_merged.txt\n\nFor a brief rundown of iMatrix quant performance please see this PR\n\n<i>All quants are verified working prior to uploading to repo for your safety and convenience. </i>\n\n\n<b>Tip:</b> Pick a size that can fit in your GPU while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.\n\nOriginal model card can be found here"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/Sao10K/Lila-70B-L2
**No more quants are incoming, as llama.cpp crashes when generating them.**
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Lila-70B-L2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q2_K.gguf) | i1-Q2_K | 25.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 30.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 33.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 36.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 36.9 | |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 39.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 41.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 47.6 | |
| [GGUF](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 48.9 | |
| [PART 1](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Lila-70B-L2-i1-GGUF/resolve/main/Lila-70B-L2.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 56.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "cc-by-nc-4.0", "library_name": "transformers", "base_model": "Sao10K/Lila-70B-L2", "no_imatrix": "GGML_ASSERT: llama.cpp/ggml-quants.c:11239: grid_index >= 0", "quantized_by": "mradermacher"} | mradermacher/Lila-70B-L2-i1-GGUF | null | [
"transformers",
"gguf",
"en",
"base_model:Sao10K/Lila-70B-L2",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:42:33+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #en #base_model-Sao10K/Lila-70B-L2 #license-cc-by-nc-4.0 #endpoints_compatible #region-us
| About
-----
weighted/imatrix quants of URL
No more quants are incoming, as URL crashes when generating them.
static quants are available at URL
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #en #base_model-Sao10K/Lila-70B-L2 #license-cc-by-nc-4.0 #endpoints_compatible #region-us \n"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/vicgalle/Configurable-Llama-3-8B-v0.2
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Llama-3-8B-v0.2-GGUF/resolve/main/Configurable-Llama-3-8B-v0.2.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "datasets": ["vicgalle/configurable-system-prompt-multitask"], "base_model": "vicgalle/Configurable-Llama-3-8B-v0.2", "quantized_by": "mradermacher"} | mradermacher/Configurable-Llama-3-8B-v0.2-GGUF | null | [
"transformers",
"gguf",
"en",
"dataset:vicgalle/configurable-system-prompt-multitask",
"base_model:vicgalle/Configurable-Llama-3-8B-v0.2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:42:34+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #en #dataset-vicgalle/configurable-system-prompt-multitask #base_model-vicgalle/Configurable-Llama-3-8B-v0.2 #license-apache-2.0 #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #en #dataset-vicgalle/configurable-system-prompt-multitask #base_model-vicgalle/Configurable-Llama-3-8B-v0.2 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null | transformers | ## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/PathFinderKR/Waktaverse-Llama-3-KO-8B-Instruct
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF/resolve/main/Waktaverse-Llama-3-KO-8B-Instruct.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
| {"language": ["en"], "license": "mit", "library_name": "transformers", "tags": ["llama", "llama-3"], "datasets": ["MarkrAI/KoCommercial-Dataset"], "base_model": "PathFinderKR/Waktaverse-Llama-3-KO-8B-Instruct", "quantized_by": "mradermacher"} | mradermacher/Waktaverse-Llama-3-KO-8B-Instruct-GGUF | null | [
"transformers",
"gguf",
"llama",
"llama-3",
"en",
"dataset:MarkrAI/KoCommercial-Dataset",
"base_model:PathFinderKR/Waktaverse-Llama-3-KO-8B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:42:56+00:00 | [] | [
"en"
] | TAGS
#transformers #gguf #llama #llama-3 #en #dataset-MarkrAI/KoCommercial-Dataset #base_model-PathFinderKR/Waktaverse-Llama-3-KO-8B-Instruct #license-mit #endpoints_compatible #region-us
| About
-----
static quants of URL
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
Usage
-----
If you are unsure how to use GGUF files, refer to one of TheBloke's
READMEs for
more details, including on how to concatenate multi-part files.
Provided Quants
---------------
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):
!URL
And here are Artefact2's thoughts on the matter:
URL
FAQ / Model Request
-------------------
See URL for some answers to
questions you might have and/or if you want some other model quantized.
Thanks
------
I thank my company, nethype GmbH, for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
| [] | [
"TAGS\n#transformers #gguf #llama #llama-3 #en #dataset-MarkrAI/KoCommercial-Dataset #base_model-PathFinderKR/Waktaverse-Llama-3-KO-8B-Instruct #license-mit #endpoints_compatible #region-us \n"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | jhahimanshu3636/lora_finetuned | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:43:32+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
object-detection | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-jan
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "facebook/detr-resnet-50", "model-index": [{"name": "detr-jan", "results": []}]} | Ldicet/detr-jan | null | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:43:41+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #detr #object-detection #generated_from_trainer #base_model-facebook/detr-resnet-50 #license-apache-2.0 #endpoints_compatible #region-us
|
# detr-jan
This model is a fine-tuned version of facebook/detr-resnet-50 on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1
| [
"# detr-jan\n\nThis model is a fine-tuned version of facebook/detr-resnet-50 on the None dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 20\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.19.1"
] | [
"TAGS\n#transformers #tensorboard #safetensors #detr #object-detection #generated_from_trainer #base_model-facebook/detr-resnet-50 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# detr-jan\n\nThis model is a fine-tuned version of facebook/detr-resnet-50 on the None dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 1e-05\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 20\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.40.0\n- Pytorch 2.2.2+cu121\n- Datasets 2.18.0\n- Tokenizers 0.19.1"
] |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | automated-finetunning/bart_test_14 | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:45:37+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
object-detection | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | sekhharr/detr_finetuned_v10_last_checkpoint | null | [
"transformers",
"safetensors",
"detr",
"object-detection",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T10:47:29+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #detr #object-detection #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #detr #object-detection #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | yxs33220/llama-2-7b-model-0418-1k | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T10:48:47+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | transformers |
# DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF
This model was converted to GGUF format from [`fblgit/UNA-TheBeagle-7b-v1`](https://huggingface.co/fblgit/UNA-TheBeagle-7b-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/fblgit/UNA-TheBeagle-7b-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF --model una-thebeagle-7b-v1.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF --model una-thebeagle-7b-v1.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m una-thebeagle-7b-v1.Q6_K.gguf -n 128
```
| {"license": "cc-by-nc-nd-4.0", "library_name": "transformers", "tags": ["generated_from_trainer", "llama-cpp", "gguf-my-repo"], "datasets": ["jondurbin/bagel-v0.3"], "model-index": [{"name": "UNA-TheBeagle-7b-v1", "results": []}]} | DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF | null | [
"transformers",
"gguf",
"generated_from_trainer",
"llama-cpp",
"gguf-my-repo",
"dataset:jondurbin/bagel-v0.3",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:00:16+00:00 | [] | [] | TAGS
#transformers #gguf #generated_from_trainer #llama-cpp #gguf-my-repo #dataset-jondurbin/bagel-v0.3 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us
|
# DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF
This model was converted to GGUF format from 'fblgit/UNA-TheBeagle-7b-v1' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-TheBeagle-7b-v1' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#transformers #gguf #generated_from_trainer #llama-cpp #gguf-my-repo #dataset-jondurbin/bagel-v0.3 #license-cc-by-nc-nd-4.0 #endpoints_compatible #region-us \n",
"# DavidAU/UNA-TheBeagle-7b-v1-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-TheBeagle-7b-v1' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
reinforcement-learning | ml-agents |
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: amine-01/Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
| {"library_name": "ml-agents", "tags": ["Pyramids", "deep-reinforcement-learning", "reinforcement-learning", "ML-Agents-Pyramids"]} | amine-01/Pyramids | null | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | null | 2024-04-19T11:01:14+00:00 | [] | [] | TAGS
#ml-agents #tensorboard #onnx #Pyramids #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Pyramids #region-us
|
# ppo Agent playing Pyramids
This is a trained model of a ppo agent playing Pyramids
using the Unity ML-Agents Library.
## Usage (with ML-Agents)
The Documentation: URL
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your
browser: URL
- A *longer tutorial* to understand how works ML-Agents:
URL
### Resume the training
### Watch your Agent play
You can watch your agent playing directly in your browser
1. If the environment is part of ML-Agents official environments, go to URL
2. Step 1: Find your model_id: amine-01/Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play
| [
"# ppo Agent playing Pyramids\n This is a trained model of a ppo agent playing Pyramids\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: amine-01/Pyramids\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] | [
"TAGS\n#ml-agents #tensorboard #onnx #Pyramids #deep-reinforcement-learning #reinforcement-learning #ML-Agents-Pyramids #region-us \n",
"# ppo Agent playing Pyramids\n This is a trained model of a ppo agent playing Pyramids\n using the Unity ML-Agents Library.\n\n ## Usage (with ML-Agents)\n The Documentation: URL\n\n We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:\n - A *short tutorial* where you teach Huggy the Dog to fetch the stick and then play with him directly in your\n browser: URL\n - A *longer tutorial* to understand how works ML-Agents:\n URL\n\n ### Resume the training\n \n\n ### Watch your Agent play\n You can watch your agent playing directly in your browser\n\n 1. If the environment is part of ML-Agents official environments, go to URL\n 2. Step 1: Find your model_id: amine-01/Pyramids\n 3. Step 2: Select your *.nn /*.onnx file\n 4. Click on Watch the agent play"
] |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | Dhananjayg22/dpo-legal-extractor | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:02:46+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
null | null |
# DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF
This model was converted to GGUF format from [`fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser`](https://huggingface.co/fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF --model una-dolphin-2.6-mistral-7b-dpo-laser.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF --model una-dolphin-2.6-mistral-7b-dpo-laser.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m una-dolphin-2.6-mistral-7b-dpo-laser.Q6_K.gguf -n 128
```
| {"language": ["en"], "license": "apache-2.0", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["ehartford/dolphin", "jondurbin/airoboros-2.2.1", "ehartford/dolphin-coder", "teknium/openhermes", "ise-uiuc/Magicoder-OSS-Instruct-75K", "ise-uiuc/Magicoder-Evol-Instruct-110K", "LDJnr/Capybara"], "model-index": [{"name": "UNA-dolphin-2.6-mistral-7b-dpo-laser", "results": [{"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "AI2 Reasoning Challenge (25-Shot)", "type": "ai2_arc", "config": "ARC-Challenge", "split": "test", "args": {"num_few_shot": 25}}, "metrics": [{"type": "acc_norm", "value": 67.15, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "HellaSwag (10-Shot)", "type": "hellaswag", "split": "validation", "args": {"num_few_shot": 10}}, "metrics": [{"type": "acc_norm", "value": 86.31, "name": "normalized accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "MMLU (5-Shot)", "type": "cais/mmlu", "config": "all", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 63.36, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "TruthfulQA (0-shot)", "type": "truthful_qa", "config": "multiple_choice", "split": "validation", "args": {"num_few_shot": 0}}, "metrics": [{"type": "mc2", "value": 64.15}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "Winogrande (5-shot)", "type": "winogrande", "config": "winogrande_xl", "split": "validation", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 79.24, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}, {"task": {"type": "text-generation", "name": "Text Generation"}, "dataset": {"name": "GSM8k (5-shot)", "type": "gsm8k", "config": "main", "split": "test", "args": {"num_few_shot": 5}}, "metrics": [{"type": "acc", "value": 44.35, "name": "accuracy"}], "source": {"url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser", "name": "Open LLM Leaderboard"}}]}]} | DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"dataset:ehartford/dolphin-coder",
"dataset:teknium/openhermes",
"dataset:ise-uiuc/Magicoder-OSS-Instruct-75K",
"dataset:ise-uiuc/Magicoder-Evol-Instruct-110K",
"dataset:LDJnr/Capybara",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2024-04-19T11:04:10+00:00 | [] | [
"en"
] | TAGS
#gguf #llama-cpp #gguf-my-repo #en #dataset-ehartford/dolphin #dataset-jondurbin/airoboros-2.2.1 #dataset-ehartford/dolphin-coder #dataset-teknium/openhermes #dataset-ise-uiuc/Magicoder-OSS-Instruct-75K #dataset-ise-uiuc/Magicoder-Evol-Instruct-110K #dataset-LDJnr/Capybara #license-apache-2.0 #model-index #region-us
|
# DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF
This model was converted to GGUF format from 'fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser' using URL via the URL's GGUF-my-repo space.
Refer to the original model card for more details on the model.
## Use with URL
Install URL through brew.
Invoke the URL server or the CLI.
CLI:
Server:
Note: You can also use this checkpoint directly through the usage steps listed in the URL repo as well.
| [
"# DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] | [
"TAGS\n#gguf #llama-cpp #gguf-my-repo #en #dataset-ehartford/dolphin #dataset-jondurbin/airoboros-2.2.1 #dataset-ehartford/dolphin-coder #dataset-teknium/openhermes #dataset-ise-uiuc/Magicoder-OSS-Instruct-75K #dataset-ise-uiuc/Magicoder-Evol-Instruct-110K #dataset-LDJnr/Capybara #license-apache-2.0 #model-index #region-us \n",
"# DavidAU/UNA-dolphin-2.6-mistral-7b-dpo-laser-Q6_K-GGUF\nThis model was converted to GGUF format from 'fblgit/UNA-dolphin-2.6-mistral-7b-dpo-laser' using URL via the URL's GGUF-my-repo space.\nRefer to the original model card for more details on the model.",
"## Use with URL\n\nInstall URL through brew.\n\n\nInvoke the URL server or the CLI.\n\nCLI:\n\n\n\nServer:\n\n\n\nNote: You can also use this checkpoint directly through the usage steps listed in the URL repo as well."
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-fine-tuned-boolq
This model is a fine-tuned version of [textattack/bert-base-uncased-yelp-polarity](https://huggingface.co/textattack/bert-base-uncased-yelp-polarity) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1189
- Accuracy: 0.6636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1016 | 1.0 | 2357 | 2.0305 | 0.6557 |
| 0.1469 | 2.0 | 4714 | 1.9557 | 0.6609 |
| 0.1446 | 3.0 | 7071 | 2.1189 | 0.6636 |
### Framework versions
- Transformers 4.39.3
- Pytorch 1.13.0
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "textattack/bert-base-uncased-yelp-polarity", "model-index": [{"name": "bert-fine-tuned-boolq", "results": []}]} | rycecorn/bert-fine-tuned-boolq | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:textattack/bert-base-uncased-yelp-polarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:07:03+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-textattack/bert-base-uncased-yelp-polarity #autotrain_compatible #endpoints_compatible #region-us
| bert-fine-tuned-boolq
=====================
This model is a fine-tuned version of textattack/bert-base-uncased-yelp-polarity on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 2.1189
* Accuracy: 0.6636
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.39.3
* Pytorch 1.13.0
* Datasets 2.18.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 1.13.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #bert #text-classification #generated_from_trainer #base_model-textattack/bert-base-uncased-yelp-polarity #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.39.3\n* Pytorch 1.13.0\n* Datasets 2.18.0\n* Tokenizers 0.15.2"
] |
text-generation | transformers | # Meta-Llama-3-8B-Instruct - bnb 4bit
- Model creator: [Meta](https://huggingface.co/meta-llama)
- Original model: [Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
## Description
This model is 4bit quantized version of [Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK. | {"license": "other", "tags": ["llama", "llama-3"], "model_name": "Meta-Llama-3-8B-Instruct", "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "license_name": "llama3", "license_link": "https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/raw/main/LICENSE", "inference": false, "model_creator": "Meta", "quantized_by": "Leliuga", "pipeline_tag": "text-generation"} | leliuga/Meta-Llama-3-8B-Instruct-bnb-4bit | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"has_space",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-19T11:07:18+00:00 | [] | [] | TAGS
#transformers #safetensors #llama #text-generation #llama-3 #conversational #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #has_space #text-generation-inference #4-bit #region-us
| # Meta-Llama-3-8B-Instruct - bnb 4bit
- Model creator: Meta
- Original model: Meta-Llama-3-8B-Instruct
## Description
This model is 4bit quantized version of Meta-Llama-3-8B-Instruct using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK. | [
"# Meta-Llama-3-8B-Instruct - bnb 4bit\n- Model creator: Meta\n- Original model: Meta-Llama-3-8B-Instruct",
"## Description\n\nThis model is 4bit quantized version of Meta-Llama-3-8B-Instruct using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK."
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #llama-3 #conversational #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #autotrain_compatible #has_space #text-generation-inference #4-bit #region-us \n",
"# Meta-Llama-3-8B-Instruct - bnb 4bit\n- Model creator: Meta\n- Original model: Meta-Llama-3-8B-Instruct",
"## Description\n\nThis model is 4bit quantized version of Meta-Llama-3-8B-Instruct using bitsandbytes. It's designed for fine-tuning! The PAD token is set as UNK."
] |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "diffusers"} | Niggendar/AstrAnimeToonish_V1 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | 2024-04-19T11:07:52+00:00 | [
"1910.09700"
] | [] | TAGS
#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#diffusers #safetensors #arxiv-1910.09700 #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a diffusers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4834
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6597 | 0.54 | 500 | 1.4834 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.2+cu118
- Datasets 2.19.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "google/pegasus-cnn_dailymail", "model-index": [{"name": "pegasus-samsum", "results": []}]} | taoyoung/pegasus-samsum | null | [
"transformers",
"tensorboard",
"safetensors",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"base_model:google/pegasus-cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:08:48+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #pegasus #text2text-generation #generated_from_trainer #base_model-google/pegasus-cnn_dailymail #autotrain_compatible #endpoints_compatible #region-us
| pegasus-samsum
==============
This model is a fine-tuned version of google/pegasus-cnn\_dailymail on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.4834
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 1
* eval\_batch\_size: 1
* seed: 42
* gradient\_accumulation\_steps: 16
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 500
* num\_epochs: 1
### Training results
### Framework versions
* Transformers 4.38.2
* Pytorch 2.2.2+cu118
* Datasets 2.19.0
* Tokenizers 0.15.2
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.2+cu118\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] | [
"TAGS\n#transformers #tensorboard #safetensors #pegasus #text2text-generation #generated_from_trainer #base_model-google/pegasus-cnn_dailymail #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 1\n* eval\\_batch\\_size: 1\n* seed: 42\n* gradient\\_accumulation\\_steps: 16\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 1",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.38.2\n* Pytorch 2.2.2+cu118\n* Datasets 2.19.0\n* Tokenizers 0.15.2"
] |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | sidaus/bijaka-base | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:09:50+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Downstream Use [optional]
### Out-of-Scope Use
## Bias, Risks, and Limitations
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
### Training Data
### Training Procedure
#### Preprocessing [optional]
#### Training Hyperparameters
- Training regime:
#### Speeds, Sizes, Times [optional]
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
#### Factors
#### Metrics
### Results
#### Summary
## Model Examination [optional]
## Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type:
- Hours used:
- Cloud Provider:
- Compute Region:
- Carbon Emitted:
## Technical Specifications [optional]
### Model Architecture and Objective
### Compute Infrastructure
#### Hardware
#### Software
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Model Card Authors [optional]
## Model Card Contact
| [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Downstream Use [optional]",
"### Out-of-Scope Use",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.",
"## How to Get Started with the Model\n\nUse the code below to get started with the model.",
"## Training Details",
"### Training Data",
"### Training Procedure",
"#### Preprocessing [optional]",
"#### Training Hyperparameters\n\n- Training regime:",
"#### Speeds, Sizes, Times [optional]",
"## Evaluation",
"### Testing Data, Factors & Metrics",
"#### Testing Data",
"#### Factors",
"#### Metrics",
"### Results",
"#### Summary",
"## Model Examination [optional]",
"## Environmental Impact\n\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: \n- Hours used: \n- Cloud Provider: \n- Compute Region: \n- Carbon Emitted:",
"## Technical Specifications [optional]",
"### Model Architecture and Objective",
"### Compute Infrastructure",
"#### Hardware",
"#### Software\n\n\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Model Card Authors [optional]",
"## Model Card Contact"
] |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "256.67 +/- 15.43", "name": "mean_reward", "verified": false}]}]}]} | DaniElAbrazos/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-19T11:10:10+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
text-generation | transformers |
## lxyuan/llama-3-8b-Instruct-lora-merged
**Model Description**: Finetuned the [Llama-3-8B-Instruct Model](https://huggingface.co/unsloth/llama-3-8b-Instruct-bnb-4bit) using [unsloth](https://github.com/unslothai/unsloth)
on [Alpaca Dataset](https://huggingface.co/datasets/tatsu-lab/alpaca) for 1000 steps.
- **Developed by:** lxyuan
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
- **Finetuned from model :** tatsu-lab/alpaca
## Installation
```python
import torch
major_version, minor_version = torch.cuda.get_device_capability()
# Must install separately since Colab has torch 2.2.1, which breaks packages
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
```
## Inference example
```python
from transformers import pipeline
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "lxyuan/llama-3-8b-Instruct-lora-merged",
dtype = None, # auto detect
load_in_4bit = True, # default is True
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer)
messages = [
{"role": "system", "content": "You are helpful AI bot that follows instruction to complete task."},
{"role": "user", "content": "Write me 10 sentences that end with 'apple"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"])
```
#### Inference Output
```markdown
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are helpful AI bot that follows instruction to complete task.<|eot_id|><|start_header_id|>user<|end_header_id|>
Write me 10 sentences that end with 'apple<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Here are 10 sentences that end with the word "apple":
1. The farmer grew a juicy red apple.
2. She ate a crunchy green apple.
3. The tree bore a ripe yellow apple.
4. He bit into a sweet Granny Smith apple.
5. The basket was filled with fresh apples.
6. The juice was squeezed from a ripe red apple.
7. She picked a perfect autumn apple.
8. The pie was filled with tender Granny Smith apple.
9. The farmer's market sold a variety of apples.
10. The snack was a crisp, juicy apple.
```
## Training procedure
- [Finetuning notebook](https://github.com/LxYuan0420/nlp/blob/main/notebooks/Lora_finetuning_Llama_3_8b_Instruct_with_Alpaca.ipynb)
- [Original Notebook from unsloth](https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp?usp=sharing#scrollTo=MKX_XKs_BNZR)
| {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "sft"], "datasets": ["tatsu-lab/alpaca"], "base_model": "unsloth/llama-3-8b-Instruct-bnb-4bit"} | lxyuan/llama-3-8b-Instruct-lora-merged | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"dataset:tatsu-lab/alpaca",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-19T11:10:32+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #dataset-tatsu-lab/alpaca #base_model-unsloth/llama-3-8b-Instruct-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
## lxyuan/llama-3-8b-Instruct-lora-merged
Model Description: Finetuned the Llama-3-8B-Instruct Model using unsloth
on Alpaca Dataset for 1000 steps.
- Developed by: lxyuan
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-Instruct-bnb-4bit
- Finetuned from model : tatsu-lab/alpaca
## Installation
## Inference example
#### Inference Output
## Training procedure
- Finetuning notebook
- Original Notebook from unsloth
| [
"## lxyuan/llama-3-8b-Instruct-lora-merged\n\nModel Description: Finetuned the Llama-3-8B-Instruct Model using unsloth \non Alpaca Dataset for 1000 steps.\n\n\n- Developed by: lxyuan\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-Instruct-bnb-4bit\n- Finetuned from model : tatsu-lab/alpaca",
"## Installation",
"## Inference example",
"#### Inference Output",
"## Training procedure\n\n- Finetuning notebook\n- Original Notebook from unsloth"
] | [
"TAGS\n#transformers #pytorch #llama #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #dataset-tatsu-lab/alpaca #base_model-unsloth/llama-3-8b-Instruct-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"## lxyuan/llama-3-8b-Instruct-lora-merged\n\nModel Description: Finetuned the Llama-3-8B-Instruct Model using unsloth \non Alpaca Dataset for 1000 steps.\n\n\n- Developed by: lxyuan\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-Instruct-bnb-4bit\n- Finetuned from model : tatsu-lab/alpaca",
"## Installation",
"## Inference example",
"#### Inference Output",
"## Training procedure\n\n- Finetuning notebook\n- Original Notebook from unsloth"
] |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CodeT5ForDefect-Detection
This model is a fine-tuned version of [Salesforce/codet5-base](https://huggingface.co/Salesforce/codet5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7645
- Accuracy: 0.6647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 9178.68
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6821 | 1.0 | 2732 | 0.6957 | 0.5187 |
| 0.6692 | 2.0 | 5464 | 0.6373 | 0.6116 |
| 0.6411 | 3.0 | 8196 | 0.6130 | 0.6014 |
| 0.5706 | 4.0 | 10928 | 0.5804 | 0.6611 |
| 0.539 | 5.0 | 13660 | 0.6378 | 0.6446 |
| 0.419 | 6.0 | 16392 | 0.6895 | 0.6336 |
| 0.4162 | 7.0 | 19124 | 0.7645 | 0.6647 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "Salesforce/codet5-base", "model-index": [{"name": "CodeT5ForDefect-Detection", "results": []}]} | ljcnju/CodeT5ForDefect-Detection | null | [
"transformers",
"safetensors",
"t5",
"text-classification",
"generated_from_trainer",
"base_model:Salesforce/codet5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-19T11:13:36+00:00 | [] | [] | TAGS
#transformers #safetensors #t5 #text-classification #generated_from_trainer #base_model-Salesforce/codet5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| CodeT5ForDefect-Detection
=========================
This model is a fine-tuned version of Salesforce/codet5-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7645
* Accuracy: 0.6647
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 9178.68
* num\_epochs: 7
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.37.2
* Pytorch 2.1.2+cu121
* Datasets 2.15.0
* Tokenizers 0.15.0
| [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 9178.68\n* num\\_epochs: 7\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.37.2\n* Pytorch 2.1.2+cu121\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] | [
"TAGS\n#transformers #safetensors #t5 #text-classification #generated_from_trainer #base_model-Salesforce/codet5-base #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 9178.68\n* num\\_epochs: 7\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.37.2\n* Pytorch 2.1.2+cu121\n* Datasets 2.15.0\n* Tokenizers 0.15.0"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.