
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Callidior/bert2bert-base-arxiv-titlegen | [
"pytorch",
"safetensors",
"encoder-decoder",
"text2text-generation",
"en",
"dataset:arxiv_dataset",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
]
| summarization | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 145 | null | ---
language: "en" # Example: en
license: "cc-by-4.0" # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
library_name: "transformers" # Optional. Example: keras or any library from https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Libraries.ts
---
# Model description
This is the T5-3B model for System 3 DREAM-FLUTE (all 4 dimensions), as described in our paper Just-DREAM-about-it: Figurative Language Understanding with DREAM-FLUTE, FigLang workshop @ EMNLP 2022 (Arxiv link: https://arxiv.org/abs/2210.16407)
Systems 3: DREAM-FLUTE - Providing DREAM’s different dimensions as input context
We adapt DREAM’s scene elaborations (Gu et al., 2022) for the figurative language understanding NLI task by using the DREAM model to generate elaborations for the premise and hypothesis separately. This allows us to investigate if similarities or differences in the scene elaborations for the premise and hypothesis will provide useful signals for entailment/contradiction label prediction and improving explanation quality. The input-output format is:
```
Input <Premise> <Premise-elaboration-from-DREAM> <Hypothesis> <Hypothesis-elaboration-from-DREAM>
Output <Label> <Explanation>
```
where the scene elaboration dimensions from DREAM are: consequence, emotion, motivation, and social norm. We also consider a system incorporating all these dimensions as additional context.
In this model, DREAM-FLUTE (all 4 dimensions), we use elaborations along all DREAM dimensions. For more details on DREAM, please refer to DREAM: Improving Situational QA by First Elaborating the Situation, NAACL 2022 (Arxiv link: https://arxiv.org/abs/2112.08656, ACL Anthology link: https://aclanthology.org/2022.naacl-main.82/).
# How to use this model?
We provide a quick example of how you can try out DREAM-FLUTE (all 4 dimensions) in our paper with just a few lines of code:
```
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/System3_DREAM_FLUTE_all_dimensions_FigLang2022")
>>> tokenizer = AutoTokenizer.from_pretrained("t5-3b")
>>> input_string = "Premise: I was really looking forward to camping but now it is going to rain so I won't go. [Premise - social norm] It's okay to be disappointed when plans change. [Premise - emotion] I (myself)'s emotion is disappointed. [Premise - motivation] I (myself)'s motivation is to stay home. [Premise - likely consequence] I will miss out on a great experience and be bored and sad. Hypothesis: I am absolutely elated at the prospects of getting drenched in the rain and then sleep in a wet tent just to have the experience of camping. [Hypothesis - social norm] It's good to want to have new experiences. [Hypothesis - emotion] I (myself)'s emotion is excited. [Hypothesis - motivation] I (myself)'s motivation is to have fun. [Hypothesis - likely consequence] I am so excited that I forget to bring a raincoat and my tent gets soaked. Is there a contradiction or entailment between the premise and hypothesis?"
>>> input_ids = tokenizer.encode(input_string, return_tensors="pt")
>>> output = model.generate(input_ids, max_length=200)
>>> tokenizer.batch_decode(output, skip_special_tokens=True)
['Answer : Contradiction. Explanation : Camping in the rain is often associated with the prospect of getting wet and cold, so someone who is elated about it is not being rational.']
```
# More details about DREAM-FLUTE ...
For more details about DREAM-FLUTE, please refer to our:
* 📄Paper: https://arxiv.org/abs/2210.16407
* 💻GitHub Repo: https://github.com/allenai/dream/
This model is part of our DREAM-series of works. This is a line of research where we make use of scene elaboration for building a "mental model" of situation given in text. Check out our GitHub Repo for more!
# More details about this model ...
## Training and evaluation data
We use the FLUTE dataset for the FigLang2022SharedTask (https://huggingface.co/datasets/ColumbiaNLP/FLUTE) for training this model. ∼7500 samples are provided as the training set. We used a 80-20 split to create our own training (6027 samples) and validation (1507 samples) partitions on which we build our models. For details on how we make use of the training data provided in the FigLang2022 shared task, please refer to https://github.com/allenai/dream/blob/main/FigLang2022SharedTask/Process_Data_Train_Dev_split.ipynb.
## Model details
This model is a fine-tuned version of [t5-3b](https://huggingface.co/t5-3b).
It achieves the following results on the evaluation set:
- Loss: 0.7499
- Rouge1: 58.5551
- Rouge2: 38.5673
- Rougel: 52.3701
- Rougelsum: 52.335
- Gen Len: 40.7452
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 2
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.992 | 0.33 | 1000 | 0.8911 | 39.9287 | 27.5817 | 38.2127 | 38.2042 | 19.0 |
| 0.9022 | 0.66 | 2000 | 0.8409 | 40.8873 | 28.7963 | 39.16 | 39.1615 | 19.0 |
| 0.8744 | 1.0 | 3000 | 0.7813 | 41.2617 | 29.5498 | 39.5857 | 39.5695 | 19.0 |
| 0.5636 | 1.33 | 4000 | 0.7961 | 41.1429 | 30.2299 | 39.6592 | 39.6648 | 19.0 |
| 0.5585 | 1.66 | 5000 | 0.7763 | 41.2581 | 30.0851 | 39.6859 | 39.68 | 19.0 |
| 0.5363 | 1.99 | 6000 | 0.7499 | 41.8302 | 30.964 | 40.3059 | 40.2964 | 19.0 |
| 0.3347 | 2.32 | 7000 | 0.8540 | 41.4633 | 30.6209 | 39.9933 | 39.9948 | 18.9954 |
| 0.341 | 2.65 | 8000 | 0.8599 | 41.6576 | 31.0316 | 40.1466 | 40.1526 | 18.9907 |
| 0.3531 | 2.99 | 9000 | 0.8368 | 42.05 | 31.6387 | 40.6239 | 40.6254 | 18.9907 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CallumRai/HansardGPT2 | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
language: "en" # Example: en
license: "cc-by-4.0" # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
library_name: "transformers" # Optional. Example: keras or any library from https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Libraries.ts
---
# Model description
This is the T5-3B model for the "explain" component of System 4's "Classify then explain" pipeline, as described in our paper Just-DREAM-about-it: Figurative Language Understanding with DREAM-FLUTE, FigLang workshop @ EMNLP 2022 (Arxiv link: https://arxiv.org/abs/2210.16407)
System 4: Two-step System - Classify then explain
In contrast to Systems 1 to 3 where the entailment/contradiction label and associated explanation are predicted jointly, System 4 uses a two-step “classify then explain” pipeline. This current model is for the "explain" component of the pipeline. The input-output format is:
```
Input <Premise> <Hypothesis> <Label>
Output <Explanation>
```
# How to use this model?
We provide a quick example of how you can try out the "explain" component of System 4 in our paper with just a few lines of code:
```
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/System4_explain_FigLang2022")
>>> tokenizer = AutoTokenizer.from_pretrained("t5-3b")
>>> input_string = "Premise: It is wrong to lie to children. Hypothesis: Telling lies to the young is like clippin the wings of a butterfly. Is there a contradiction or entailment between the premise and hypothesis? Answer : Entailment. Explanation : "
>>> input_ids = tokenizer.encode(input_string, return_tensors="pt")
>>> output = model.generate(input_ids, max_length=200)
>>> tokenizer.batch_decode(output, skip_special_tokens=True)
['Clipping the wings of a butterfly means that the butterfly will never be able to fly, so lying to children is like doing the same.']
```
# More details about DREAM-FLUTE ...
For more details about DREAM-FLUTE, please refer to our:
* 📄Paper: https://arxiv.org/abs/2210.16407
* 💻GitHub Repo: https://github.com/allenai/dream/
This model is part of our DREAM-series of works. This is a line of research where we make use of scene elaboration for building a "mental model" of situation given in text. Check out our GitHub Repo for more!
# More details about this model ...
## Training and evaluation data
We use the FLUTE dataset for the FigLang2022SharedTask (https://huggingface.co/datasets/ColumbiaNLP/FLUTE) for training this model. ∼7500 samples are provided as the training set. We used a 80-20 split to create our own training (6027 samples) and validation (1507 samples) partitions on which we build our models. For details on how we make use of the training data provided in the FigLang2022 shared task, please refer to https://github.com/allenai/dream/blob/main/FigLang2022SharedTask/Process_Data_Train_Dev_split.ipynb.
## Model details
This model is a fine-tuned version of [t5-3b](https://huggingface.co/t5-3b).
It achieves the following results on the evaluation set:
- Loss: 1.0331
- Rouge1: 53.8485
- Rouge2: 32.8855
- Rougel: 46.6534
- Rougelsum: 46.6435
- Gen Len: 29.7724
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 2
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.3633 | 0.33 | 1000 | 1.2468 | 44.8469 | 24.3002 | 37.9797 | 37.9943 | 18.8341 |
| 1.2531 | 0.66 | 2000 | 1.1445 | 45.7234 | 25.6755 | 39.5817 | 39.5653 | 18.8786 |
| 1.2148 | 1.0 | 3000 | 1.0806 | 47.4244 | 27.6605 | 41.0803 | 41.0628 | 18.7339 |
| 0.7554 | 1.33 | 4000 | 1.1006 | 47.5505 | 28.2781 | 41.385 | 41.3774 | 18.6556 |
| 0.7761 | 1.66 | 5000 | 1.0671 | 48.583 | 29.6223 | 42.5451 | 42.5247 | 18.6821 |
| 0.7777 | 1.99 | 6000 | 1.0331 | 48.8329 | 30.5086 | 43.0964 | 43.0586 | 18.6881 |
| 0.4378 | 2.32 | 7000 | 1.1978 | 48.6239 | 30.2101 | 42.8863 | 42.8851 | 18.7259 |
| 0.4715 | 2.66 | 8000 | 1.1545 | 49.1311 | 31.0582 | 43.523 | 43.5043 | 18.7598 |
| 0.462 | 2.99 | 9000 | 1.1471 | 49.4022 | 31.7946 | 44.0345 | 44.0128 | 18.7200 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CalvinHuang/mt5-small-finetuned-amazon-en-es | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
]
| summarization | {
"architectures": [
"MT5ForConditionalGeneration"
],
"model_type": "mt5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: hmBERT-CoNLL-cp2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.8931730929727926
- name: Recall
type: recall
value: 0.9005385392123864
- name: F1
type: f1
value: 0.8968406938741306
- name: Accuracy
type: accuracy
value: 0.983217164440637
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hmBERT-CoNLL-cp2
This model is a fine-tuned version of [dbmdz/bert-base-historic-multilingual-cased](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0666
- Precision: 0.8932
- Recall: 0.9005
- F1: 0.8968
- Accuracy: 0.9832
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.06 | 25 | 0.4116 | 0.3632 | 0.3718 | 0.3674 | 0.9005 |
| No log | 0.11 | 50 | 0.2247 | 0.6384 | 0.6902 | 0.6633 | 0.9459 |
| No log | 0.17 | 75 | 0.1624 | 0.7303 | 0.7627 | 0.7461 | 0.9580 |
| No log | 0.23 | 100 | 0.1541 | 0.7338 | 0.7688 | 0.7509 | 0.9588 |
| No log | 0.28 | 125 | 0.1349 | 0.7610 | 0.8095 | 0.7845 | 0.9643 |
| No log | 0.34 | 150 | 0.1230 | 0.7982 | 0.8253 | 0.8115 | 0.9694 |
| No log | 0.4 | 175 | 0.0997 | 0.8069 | 0.8406 | 0.8234 | 0.9727 |
| No log | 0.46 | 200 | 0.1044 | 0.8211 | 0.8410 | 0.8309 | 0.9732 |
| No log | 0.51 | 225 | 0.0871 | 0.8413 | 0.8603 | 0.8507 | 0.9760 |
| No log | 0.57 | 250 | 0.1066 | 0.8288 | 0.8465 | 0.8376 | 0.9733 |
| No log | 0.63 | 275 | 0.0872 | 0.8580 | 0.8667 | 0.8624 | 0.9766 |
| No log | 0.68 | 300 | 0.0834 | 0.8522 | 0.8706 | 0.8613 | 0.9773 |
| No log | 0.74 | 325 | 0.0832 | 0.8545 | 0.8834 | 0.8687 | 0.9783 |
| No log | 0.8 | 350 | 0.0776 | 0.8542 | 0.8834 | 0.8685 | 0.9787 |
| No log | 0.85 | 375 | 0.0760 | 0.8629 | 0.8896 | 0.8760 | 0.9801 |
| No log | 0.91 | 400 | 0.0673 | 0.8775 | 0.9004 | 0.8888 | 0.9824 |
| No log | 0.97 | 425 | 0.0681 | 0.8827 | 0.8938 | 0.8882 | 0.9817 |
| No log | 1.03 | 450 | 0.0659 | 0.8844 | 0.8950 | 0.8897 | 0.9824 |
| No log | 1.08 | 475 | 0.0690 | 0.8833 | 0.9015 | 0.8923 | 0.9832 |
| 0.1399 | 1.14 | 500 | 0.0666 | 0.8932 | 0.9005 | 0.8968 | 0.9832 |
| 0.1399 | 1.2 | 525 | 0.0667 | 0.8891 | 0.8997 | 0.8944 | 0.9825 |
| 0.1399 | 1.25 | 550 | 0.0699 | 0.8751 | 0.8953 | 0.8851 | 0.9820 |
| 0.1399 | 1.31 | 575 | 0.0617 | 0.8947 | 0.9068 | 0.9007 | 0.9840 |
| 0.1399 | 1.37 | 600 | 0.0633 | 0.9 | 0.9058 | 0.9029 | 0.9841 |
| 0.1399 | 1.42 | 625 | 0.0639 | 0.8966 | 0.9116 | 0.9040 | 0.9843 |
| 0.1399 | 1.48 | 650 | 0.0624 | 0.8972 | 0.9110 | 0.9041 | 0.9845 |
| 0.1399 | 1.54 | 675 | 0.0619 | 0.8980 | 0.9081 | 0.9030 | 0.9842 |
| 0.1399 | 1.59 | 700 | 0.0615 | 0.9002 | 0.9090 | 0.9045 | 0.9843 |
| 0.1399 | 1.65 | 725 | 0.0601 | 0.9037 | 0.9128 | 0.9082 | 0.9850 |
| 0.1399 | 1.71 | 750 | 0.0585 | 0.9031 | 0.9142 | 0.9086 | 0.9849 |
| 0.1399 | 1.77 | 775 | 0.0582 | 0.9035 | 0.9143 | 0.9089 | 0.9851 |
| 0.1399 | 1.82 | 800 | 0.0580 | 0.9044 | 0.9157 | 0.9100 | 0.9853 |
| 0.1399 | 1.88 | 825 | 0.0583 | 0.9034 | 0.9160 | 0.9097 | 0.9851 |
| 0.1399 | 1.94 | 850 | 0.0578 | 0.9058 | 0.9170 | 0.9114 | 0.9854 |
| 0.1399 | 1.99 | 875 | 0.0576 | 0.9060 | 0.9165 | 0.9112 | 0.9852 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Cat/Kitty | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mBART_translator_json_sentence_split
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mBART_translator_json_sentence_split
This model is a fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0769
- Bleu: 87.2405
- Gen Len: 27.425
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 2.0011 | 1.0 | 2978 | 0.5458 | 63.8087 | 32.3819 |
| 1.1978 | 2.0 | 5956 | 0.1854 | 76.5291 | 27.6781 |
| 0.9276 | 3.0 | 8934 | 0.1123 | 84.7194 | 27.5773 |
| 0.776 | 4.0 | 11912 | 0.0845 | 87.505 | 27.2845 |
| 0.6889 | 5.0 | 14890 | 0.0769 | 87.2405 | 27.425 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dccuchile/albert-base-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 34 | null | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mT5_multilingual_XLSum-finetuned-xlsum-coba
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mT5_multilingual_XLSum-finetuned-xlsum-coba
This model is a fine-tuned version of [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2369
- Rouge1: 0.3744
- Rouge2: 0.1718
- Rougel: 0.3092
- Rougelsum: 0.3106
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00056
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| 1.6963 | 1.0 | 7648 | 1.2369 | 0.3744 | 0.1718 | 0.3092 | 0.3106 |
| 1.6975 | 2.0 | 15296 | 1.2369 | 0.3744 | 0.1718 | 0.3092 | 0.3106 |
| 1.6969 | 3.0 | 22944 | 1.2369 | 0.3744 | 0.1718 | 0.3092 | 0.3106 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dccuchile/albert-base-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: platzi-vit-model-yeder-lvicente
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi-vit-model-yeder-lvicente
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0077
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0084 | 3.85 | 500 | 0.0077 | 1.0 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dccuchile/albert-large-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | storage for eva models. it has intermediate low-performing models |
dccuchile/albert-xlarge-spanish-finetuned-ner | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null |
---
language: en
tags:
- diffusers
license: mit
--- |
dccuchile/albert-xlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
license: apache-2.0
library_name: keras
language: en
tags:
- vision
- maxim
- image-to-image
datasets:
- realblur_j
---
# MAXIM pre-trained on RealBlur-J for image deblurring
MAXIM model pre-trained for image deblurring. It was introduced in the paper [MAXIM: Multi-Axis MLP for Image Processing](https://arxiv.org/abs/2201.02973) by Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li and first released in [this repository](https://github.com/google-research/maxim).
Disclaimer: The team releasing MAXIM did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MAXIM introduces a shared MLP-based backbone for different image processing tasks such as image deblurring, deraining, denoising, dehazing, low-light image enhancement, and retouching. The following figure depicts the main components of MAXIM:

## Training procedure and results
The authors didn't release the training code. For more details on how the model was trained, refer to the [original paper](https://arxiv.org/abs/2201.02973).
As per the [table](https://github.com/google-research/maxim#results-and-pre-trained-models), the model achieves a PSNR of 32.84 and an SSIM of 0.935.
## Intended uses & limitations
You can use the raw model for image deblurring tasks.
The model is [officially released in JAX](https://github.com/google-research/maxim). It was ported to TensorFlow in [this repository](https://github.com/sayakpaul/maxim-tf).
### How to use
Here is how to use this model:
```python
from huggingface_hub import from_pretrained_keras
from PIL import Image
import tensorflow as tf
import numpy as np
import requests
url = "https://github.com/sayakpaul/maxim-tf/raw/main/images/Deblurring/input/1fromGOPR0950.png"
image = Image.open(requests.get(url, stream=True).raw)
image = np.array(image)
image = tf.convert_to_tensor(image)
image = tf.image.resize(image, (256, 256))
model = from_pretrained_keras("google/maxim-s3-deblurring-realblur-j")
predictions = model.predict(tf.expand_dims(image, 0))
```
For a more elaborate prediction pipeline, refer to [this Colab Notebook](https://colab.research.google.com/github/sayakpaul/maxim-tf/blob/main/notebooks/inference-dynamic-resize.ipynb).
### Citation
```bibtex
@article{tu2022maxim,
title={MAXIM: Multi-Axis MLP for Image Processing},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={CVPR},
year={2022},
}
```
|
dccuchile/albert-xlarge-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
library_name: keras
language: en
tags:
- vision
- maxim
- image-to-image
datasets:
- rain13k
---
# MAXIM pre-trained on Rain13k for image deraining
MAXIM model pre-trained for image deraining. It was introduced in the paper [MAXIM: Multi-Axis MLP for Image Processing](https://arxiv.org/abs/2201.02973) by Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li and first released in [this repository](https://github.com/google-research/maxim).
Disclaimer: The team releasing MAXIM did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MAXIM introduces a shared MLP-based backbone for different image processing tasks such as image deblurring, deraining, denoising, dehazing, low-light image enhancement, and retouching. The following figure depicts the main components of MAXIM:

## Training procedure and results
The authors didn't release the training code. For more details on how the model was trained, refer to the [original paper](https://arxiv.org/abs/2201.02973).
As per the [table](https://github.com/google-research/maxim#results-and-pre-trained-models), the model achieves a PSNR of 33.24 and an SSIM of 0.933.
## Intended uses & limitations
You can use the raw model for image deraining tasks.
The model is [officially released in JAX](https://github.com/google-research/maxim). It was ported to TensorFlow in [this repository](https://github.com/sayakpaul/maxim-tf).
### How to use
Here is how to use this model:
```python
from huggingface_hub import from_pretrained_keras
from PIL import Image
import tensorflow as tf
import numpy as np
import requests
url = "https://github.com/sayakpaul/maxim-tf/raw/main/images/Deraining/input/55.png"
image = Image.open(requests.get(url, stream=True).raw)
image = np.array(image)
image = tf.convert_to_tensor(image)
image = tf.image.resize(image, (256, 256))
model = from_pretrained_keras("google/maxim-s2-deraining-rain13k")
predictions = model.predict(tf.expand_dims(image, 0))
```
For a more elaborate prediction pipeline, refer to [this Colab Notebook](https://colab.research.google.com/github/sayakpaul/maxim-tf/blob/main/notebooks/inference-dynamic-resize.ipynb).
### Citation
```bibtex
@article{tu2022maxim,
title={MAXIM: Multi-Axis MLP for Image Processing},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={CVPR},
year={2022},
}
```
|
dccuchile/albert-xxlarge-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | 2022-10-19T06:12:24Z | ---
license: apache-2.0
library_name: keras
language: en
tags:
- vision
- maxim
- image-to-image
datasets:
- raindrop
---
# MAXIM pre-trained on Raindrop for image deraining
MAXIM model pre-trained for image deraining. It was introduced in the paper [MAXIM: Multi-Axis MLP for Image Processing](https://arxiv.org/abs/2201.02973) by Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li and first released in [this repository](https://github.com/google-research/maxim).
Disclaimer: The team releasing MAXIM did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MAXIM introduces a shared MLP-based backbone for different image processing tasks such as image deblurring, deraining, denoising, dehazing, low-light image enhancement, and retouching. The following figure depicts the main components of MAXIM:

## Training procedure and results
The authors didn't release the training code. For more details on how the model was trained, refer to the [original paper](https://arxiv.org/abs/2201.02973).
As per the [table](https://github.com/google-research/maxim#results-and-pre-trained-models), the model achieves a PSNR of 31.87 and an SSIM of 0.935.
## Intended uses & limitations
You can use the raw model for image deraining tasks.
The model is [officially released in JAX](https://github.com/google-research/maxim). It was ported to TensorFlow in [this repository](https://github.com/sayakpaul/maxim-tf).
### How to use
Here is how to use this model:
```python
from huggingface_hub import from_pretrained_keras
from PIL import Image
import tensorflow as tf
import numpy as np
import requests
url = "https://github.com/sayakpaul/maxim-tf/raw/main/images/Deraining/input/55.png"
image = Image.open(requests.get(url, stream=True).raw)
image = np.array(image)
image = tf.convert_to_tensor(image)
image = tf.image.resize(image, (256, 256))
model = from_pretrained_keras("google/maxim-s2-deraining-raindrop")
predictions = model.predict(tf.expand_dims(image, 0))
```
For a more elaborate prediction pipeline, refer to [this Colab Notebook](https://colab.research.google.com/github/sayakpaul/maxim-tf/blob/main/notebooks/inference-dynamic-resize.ipynb).
### Citation
```bibtex
@article{tu2022maxim,
title={MAXIM: Multi-Axis MLP for Image Processing},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={CVPR},
year={2022},
}
```
|
dccuchile/albert-xxlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
license: apache-2.0
library_name: keras
language: en
tags:
- vision
- maxim
- image-to-image
datasets:
- sots-indoor
---
# MAXIM pre-trained on RESIDE-Indoor for image dehazing
MAXIM model pre-trained for image dehazing. It was introduced in the paper [MAXIM: Multi-Axis MLP for Image Processing](https://arxiv.org/abs/2201.02973) by Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li and first released in [this repository](https://github.com/google-research/maxim).
Disclaimer: The team releasing MAXIM did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MAXIM introduces a shared MLP-based backbone for different image processing tasks such as image deblurring, deraining, denoising, dehazing, low-light image enhancement, and retouching. The following figure depicts the main components of MAXIM:

## Training procedure and results
The authors didn't release the training code. For more details on how the model was trained, refer to the [original paper](https://arxiv.org/abs/2201.02973).
As per the [table](https://github.com/google-research/maxim#results-and-pre-trained-models), the model achieves a PSNR of 38.11 and an SSIM of 0.991.
## Intended uses & limitations
You can use the raw model for image dehazing tasks.
The model is [officially released in JAX](https://github.com/google-research/maxim). It was ported to TensorFlow in [this repository](https://github.com/sayakpaul/maxim-tf).
### How to use
Here is how to use this model:
```python
from huggingface_hub import from_pretrained_keras
from PIL import Image
import tensorflow as tf
import numpy as np
import requests
url = "https://github.com/sayakpaul/maxim-tf/raw/main/images/Dehazing/input/1440_10.png"
image = Image.open(requests.get(url, stream=True).raw)
image = np.array(image)
image = tf.convert_to_tensor(image)
image = tf.image.resize(image, (256, 256))
model = from_pretrained_keras("google/maxim-s2-dehazing-sots-indoor")
predictions = model.predict(tf.expand_dims(image, 0))
```
For a more elaborate prediction pipeline, refer to [this Colab Notebook](https://colab.research.google.com/github/sayakpaul/maxim-tf/blob/main/notebooks/inference-dynamic-resize.ipynb).
### Citation
```bibtex
@article{tu2022maxim,
title={MAXIM: Multi-Axis MLP for Image Processing},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={CVPR},
year={2022},
}
```
|
dccuchile/albert-xxlarge-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-base-twitter_eval_sentiment
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-twitter_eval_sentiment
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8020
- Accuracy: 0.6635
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0144 | 1.0 | 1875 | 0.9109 | 0.6025 |
| 0.8331 | 2.0 | 3750 | 0.8187 | 0.6555 |
| 0.7549 | 3.0 | 5625 | 0.8020 | 0.6635 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dccuchile/albert-xxlarge-spanish | [
"pytorch",
"tf",
"albert",
"pretraining",
"es",
"dataset:large_spanish_corpus",
"transformers",
"spanish",
"OpenCENIA"
]
| null | {
"architectures": [
"AlbertForPreTraining"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42 | null | Model card for RoSummary-large
---
language:
- ro
---
# RoSummary
This is a version of the RoGPT2 model trained on the [AlephNews](https://huggingface.co/datasets/readerbench/AlephNews) dataset for the summarization task. There are 3 trained versions, they are available on the HuggingFace Hub:
* [base](https://huggingface.co/readerbench/RoSummary-base)
* [medium](https://huggingface.co/readerbench/RoSummary-medium)
* [large](https://huggingface.co/readerbench/RoSummary-large)
## Evaluation on [AlephNews](https://huggingface.co/datasets/readerbench/AlephNews)
| Model | Decode Method | | BERTScore | | | ROUGE | |
|:------:|:--------------:|:---------:|:---------:|:--------:|:--------:|:--------:|:--------:|
| | | Precision | Recall | F1-Score | ROUGE-1 | ROUGE-2 | ROUGE-L |
| | Greedy | 0.7335 | 0.7399 | 0.7358 | 0.3360 | 0.1862 | 0.3333 |
| Base | Beam Search | 0.7354 | 0.7468 | 0.7404 | 0.3480 | 0.1991 | 0.3416 |
| | Top-p Sampling | 0.7296 | 0.7299 | 0.7292 | 0.3058 | 0.1452 | 0.2951 |
| | Greedy | 0.7378 | 0.7401 | 0.7380 | 0.3422 | 0.1922 | 0.3394 |
| Medium | Beam Search | 0.7390 | **0.7493**|**0.7434**|**0.3546**|**0.2061**|**0.3467**|
| | Top-p Sampling | 0.7315 | 0.7285 | 0.7294 | 0.3042 | 0.1400 | 0.2921 |
| | Greedy | 0.7376 | 0.7424 | 0.7391 | 0.3414 | 0.1895 | 0.3355 |
| Large | Beam Search | **0.7394**| 0.7470 | 0.7424 | 0.3492 | 0.1995 | 0.3384 |
| | Top-p Sampling | 0.7311 | 0.7301 | 0.7299 | 0.3051 | 0.1418 | 0.2931 |
## Acknowledgments
---
Research supported with [Cloud TPUs](https://cloud.google.com/tpu/) from Google's [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc)
|
dccuchile/bert-base-spanish-wwm-cased-finetuned-pos | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Sinergy-Question-Answering
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
config: discharge
split: train
args: discharge
metrics:
- name: Precision
type: precision
value: 0.7948717948717948
- name: Recall
type: recall
value: 0.7948717948717948
- name: F1
type: f1
value: 0.7948717948717948
- name: Accuracy
type: accuracy
value: 0.9261159569009748
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Sinergy-Question-Answering
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5867
- Precision: 0.7949
- Recall: 0.7949
- F1: 0.7949
- Accuracy: 0.9261
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 4.55 | 100 | 0.3686 | 0.5748 | 0.7179 | 0.6384 | 0.8881 |
| No log | 9.09 | 200 | 0.3057 | 0.6799 | 0.7546 | 0.7153 | 0.9189 |
| No log | 13.64 | 300 | 0.3287 | 0.7491 | 0.7875 | 0.7679 | 0.9354 |
| No log | 18.18 | 400 | 0.3452 | 0.7414 | 0.7875 | 0.7638 | 0.9307 |
| 0.2603 | 22.73 | 500 | 0.3365 | 0.7313 | 0.7875 | 0.7584 | 0.9415 |
| 0.2603 | 27.27 | 600 | 0.5244 | 0.7745 | 0.7802 | 0.7774 | 0.9097 |
| 0.2603 | 31.82 | 700 | 0.4429 | 0.7737 | 0.7766 | 0.7751 | 0.9338 |
| 0.2603 | 36.36 | 800 | 0.4776 | 0.7657 | 0.8022 | 0.7835 | 0.9266 |
| 0.2603 | 40.91 | 900 | 0.5305 | 0.7855 | 0.7912 | 0.7883 | 0.9236 |
| 0.051 | 45.45 | 1000 | 0.5867 | 0.7949 | 0.7949 | 0.7949 | 0.9261 |
| 0.051 | 50.0 | 1100 | 0.5569 | 0.7774 | 0.7802 | 0.7788 | 0.9323 |
| 0.051 | 54.55 | 1200 | 0.6154 | 0.7509 | 0.7509 | 0.7509 | 0.9200 |
| 0.051 | 59.09 | 1300 | 0.5406 | 0.7305 | 0.7546 | 0.7423 | 0.9297 |
| 0.051 | 63.64 | 1400 | 0.6069 | 0.7544 | 0.7875 | 0.7706 | 0.9287 |
| 0.0127 | 68.18 | 1500 | 0.6142 | 0.7603 | 0.7436 | 0.7519 | 0.9210 |
| 0.0127 | 72.73 | 1600 | 0.5822 | 0.7399 | 0.7399 | 0.7399 | 0.9297 |
| 0.0127 | 77.27 | 1700 | 0.5584 | 0.75 | 0.7582 | 0.7541 | 0.9297 |
| 0.0127 | 81.82 | 1800 | 0.5962 | 0.7509 | 0.7729 | 0.7617 | 0.9241 |
| 0.0127 | 86.36 | 1900 | 0.6891 | 0.7580 | 0.7802 | 0.7690 | 0.9236 |
| 0.0013 | 90.91 | 2000 | 0.6205 | 0.75 | 0.7582 | 0.7541 | 0.9266 |
| 0.0013 | 95.45 | 2100 | 0.6235 | 0.7745 | 0.7802 | 0.7774 | 0.9292 |
| 0.0013 | 100.0 | 2200 | 0.6329 | 0.7656 | 0.7656 | 0.7656 | 0.9292 |
| 0.0013 | 104.55 | 2300 | 0.6482 | 0.7739 | 0.7399 | 0.7566 | 0.9241 |
| 0.0013 | 109.09 | 2400 | 0.6440 | 0.7675 | 0.7619 | 0.7647 | 0.9292 |
| 0.0008 | 113.64 | 2500 | 0.6388 | 0.7630 | 0.7546 | 0.7587 | 0.9343 |
| 0.0008 | 118.18 | 2600 | 0.7076 | 0.7774 | 0.7546 | 0.7658 | 0.9225 |
| 0.0008 | 122.73 | 2700 | 0.6698 | 0.7721 | 0.7692 | 0.7706 | 0.9297 |
| 0.0008 | 127.27 | 2800 | 0.6898 | 0.76 | 0.7656 | 0.7628 | 0.9220 |
| 0.0008 | 131.82 | 2900 | 0.6800 | 0.7482 | 0.7619 | 0.7550 | 0.9282 |
| 0.0006 | 136.36 | 3000 | 0.6911 | 0.7393 | 0.7582 | 0.7486 | 0.9215 |
| 0.0006 | 140.91 | 3100 | 0.6818 | 0.7446 | 0.7582 | 0.7514 | 0.9220 |
| 0.0006 | 145.45 | 3200 | 0.7043 | 0.7473 | 0.7692 | 0.7581 | 0.9210 |
| 0.0006 | 150.0 | 3300 | 0.6935 | 0.7482 | 0.7729 | 0.7604 | 0.9246 |
| 0.0006 | 154.55 | 3400 | 0.7163 | 0.7482 | 0.7729 | 0.7604 | 0.9230 |
| 0.0001 | 159.09 | 3500 | 0.7329 | 0.7590 | 0.7729 | 0.7659 | 0.9205 |
| 0.0001 | 163.64 | 3600 | 0.7570 | 0.7737 | 0.7766 | 0.7751 | 0.9215 |
| 0.0001 | 168.18 | 3700 | 0.7552 | 0.7664 | 0.7692 | 0.7678 | 0.9225 |
| 0.0001 | 172.73 | 3800 | 0.7226 | 0.7831 | 0.7802 | 0.7817 | 0.9246 |
| 0.0001 | 177.27 | 3900 | 0.6868 | 0.7844 | 0.7729 | 0.7786 | 0.9297 |
| 0.0003 | 181.82 | 4000 | 0.6916 | 0.7757 | 0.7729 | 0.7743 | 0.9256 |
| 0.0003 | 186.36 | 4100 | 0.6862 | 0.7749 | 0.7692 | 0.7721 | 0.9292 |
| 0.0003 | 190.91 | 4200 | 0.7067 | 0.7749 | 0.7692 | 0.7721 | 0.9225 |
| 0.0003 | 195.45 | 4300 | 0.7059 | 0.7628 | 0.7656 | 0.7642 | 0.9210 |
| 0.0003 | 200.0 | 4400 | 0.7300 | 0.7609 | 0.7692 | 0.7650 | 0.9210 |
| 0.0002 | 204.55 | 4500 | 0.7299 | 0.7572 | 0.7656 | 0.7614 | 0.9215 |
| 0.0002 | 209.09 | 4600 | 0.7168 | 0.7527 | 0.7692 | 0.7609 | 0.9210 |
| 0.0002 | 213.64 | 4700 | 0.7177 | 0.7545 | 0.7656 | 0.76 | 0.9210 |
| 0.0002 | 218.18 | 4800 | 0.7182 | 0.7545 | 0.7656 | 0.76 | 0.9210 |
| 0.0002 | 222.73 | 4900 | 0.7190 | 0.7628 | 0.7656 | 0.7642 | 0.9205 |
| 0.0001 | 227.27 | 5000 | 0.7168 | 0.7572 | 0.7656 | 0.7614 | 0.9215 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.2.2
- Tokenizers 0.13.1
|
dccuchile/bert-base-spanish-wwm-cased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | ---
license: apache-2.0
---
# T5 Sami - Norwegian - Sami
Placeholder for future model. Description is coming soon.
|
dccuchile/bert-base-spanish-wwm-uncased-finetuned-ner | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- opus_books
model-index:
- name: byt5-small-finetuned-1epoch-batch16-opus_books-en-to-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# byt5-small-finetuned-1epoch-batch16-opus_books-en-to-it
This model is a fine-tuned version of [google/byt5-small](https://huggingface.co/google/byt5-small) on the opus_books dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3771 | 1.0 | 1819 | 0.9848 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dccuchile/bert-base-spanish-wwm-uncased-finetuned-pos | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
language: en
tags:
- EBK-BERT
license: apache-2.0
datasets:
- Araevent(November)
- Araevent(July)
---
# BK-BERT
Event Knowledge-Based BERT (EBK-BERT) leverages knowledge extracted from events-related sentences to mask words that
are significant to the events detection task. This approach aims to produce a language model that enhances the
performance of the down-stream event detection task, which is later trained during the fine-tuning process.
## Model description
The BERT-base configuration is adopted which has 12 encoder blocks, 768 hidden dimensions, 12 attention heads,
512 maximum sequence length, and a total of 110M parameters.
## Pre-training Data
The pre-training data consists of news articles from the 1.5 billion words corpus by (El-Khair, 2016).
Due to computation limitations, we only use articles from Alittihad, Riyadh, Almasrya- lyoum, and Alqabas,
which amount to 10GB of text and about 8M sentences after splitting the articles to approximately
100 word sentences to accommodate the 128 max_sentence length used when training the model.
The average number of tokens per sentence is 105.
### Pretraining
As previous studies have shown, contextual representation models that are pre-trained using top Personnel
Transaction Contact Nature Movement Life Justice Conflict business the MLM training task benefit from masking
the most significant words, using whole word masking.
To select the most significant words we use odds-ratio. Only words with greater than 2 odds-ratio are considered
in the masking, which means the words included are at least twice as likely to appear in one event type than the other.
Google Cloud GPU is used for pre-training the model. The selected hyperparameters are: learning rate=1e − 4,
batch size =16, maxi- mum sequence length = 128 and average se- quence length = 104. In total, we pre-trained
our models for 500, 000 steps, completing 1 epoch. Pre-training a single model took approximately 2.25 days.
## Fine-tuning data
Tweets are collected from well-known Arabic news accounts, which are: Al-Arabiya, Sabq,
CNN Arabic, and BBC Arabic. These accounts belong to television channels and online
newspapers, where they use Twitter to broadcast news related to real-world events.
The first collection process tracks tweets from the news accounts for 20 days period,
between November 2, 2021, and November 22, 2021 and we call this dataset AraEvent(November).
## Evaluation results
When fine-tuned on down-stream event detection task, this model achieves the following results:
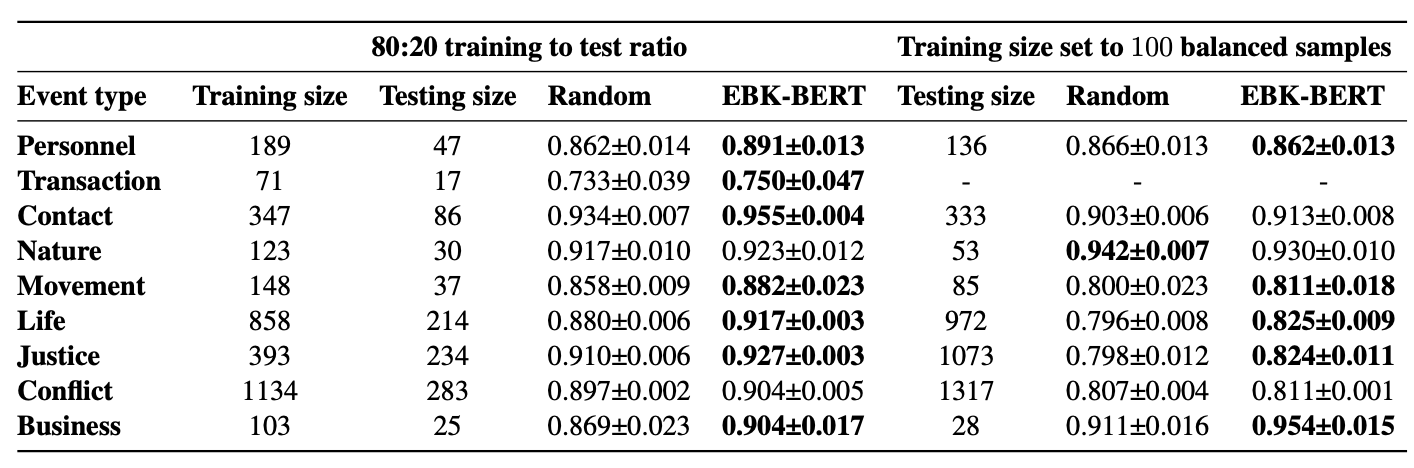
## Gradio Demo
will be released soon |
dccuchile/distilbert-base-spanish-uncased-finetuned-mldoc | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | Access to model sd-concepts-library/wedding-HandPainted is restricted and you are not in the authorized list. Visit https://huggingface.co/sd-concepts-library/wedding-HandPainted to ask for access. |
dccuchile/distilbert-base-spanish-uncased-finetuned-pos | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-greek-uncased-v1-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-greek-uncased-v1-finetuned-ner
This model is a fine-tuned version of [nlpaueb/bert-base-greek-uncased-v1](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1052
- Precision: 0.8440
- Recall: 0.8566
- F1: 0.8503
- Accuracy: 0.9768
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.64 | 250 | 0.0913 | 0.7814 | 0.8208 | 0.8073 | 0.9728 |
| 0.1144 | 1.29 | 500 | 0.0823 | 0.7940 | 0.8448 | 0.8342 | 0.9755 |
| 0.1144 | 1.93 | 750 | 0.0812 | 0.8057 | 0.8212 | 0.8328 | 0.9751 |
| 0.0570 | 2.58 | 1000 | 0.0855 | 0.8244 | 0.8514 | 0.8292 | 0.9744 |
| 0.0570 | 3.22 | 1250 | 0.0926 | 0.8329 | 0.8441 | 0.8397 | 0.9760 |
| 0.0393 | 3.87 | 1500 | 0.0869 | 0.8256 | 0.8633 | 0.8440 | 0.9774 |
| 0.0393 | 4.51 | 1750 | 0.1049 | 0.8290 | 0.8636 | 0.8459 | 0.9766 |
| 0.026 | 5.15 | 2000 | 0.1093 | 0.8440 | 0.8566 | 0.8503 | 0.9768 |
| 0.026 | 5.8 | 2250 | 0.1172 | 0.8301 | 0.8514 | 0.8406 | 0.9760 |
| 0.0189 | 6.44 | 2500 | 0.1273 | 0.8238 | 0.8688 | 0.8457 | 0.9766 |
| 0.0189 | 7.09 | 2750 | 0.1246 | 0.8350 | 0.8539 | 0.8443 | 0.9764 |
| 0.0148 | 7.73 | 3000 | 0.1262 | 0.8333 | 0.8608 | 0.8468 | 0.9764 |
| 0.0148 | 8.38 | 3250 | 0.1347 | 0.8319 | 0.8591 | 0.8453 | 0.9762 |
| 0.0010 | 9.02 | 3500 | 0.1325 | 0.8376 | 0.8504 | 0.8439 | 0.9766 |
| 0.0010 | 9.66 | 3750 | 0.1362 | 0.8371 | 0.8563 | 0.8466 | 0.9765 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Certified-Zoomer/DialoGPT-small-rick | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: Long_Bartpho_word_base
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Long_Bartpho_word_base
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Tokenizers 0.13.1
|
Chae/botman | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: Long_Bartpho_syllable_base
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Long_Bartpho_syllable_base
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Tokenizers 0.13.1
|
Chaewon/mmnt_decoder_en | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
language:
- en
license: apache-2.0
library_name: transformers
---
### Contrastive user encoder (multi-post)
This model is a `DistilBertModel` trained by fine-tuning `distilbert-base-uncased` on author-based triplet loss.
#### Details
Training and evaluation details are provided in our EMNLP Findings paper:
- Rocca, R., & Yarkoni, T. (2022), Language as a fingerprint: Self-supervised learning of user encodings using transformers, to appear in *Findings of the Association for Computational Linguistics: EMNLP 2022*
#### Training
We fine-tuned DistilBERT on triplets consisting of:
- a set of Reddit submissions from a given user (10 posts, called "anchors") - see ```rbroc/contrastive-user-encoder-singlepost``` for an equivalent model trained on a single anchor;
- an additional post from the same user (a "positive example");
- a post from a different, randomly selected user (the "negative example")
To compute the loss, we use [CLS] encodings of the anchors, positive examples and negative examples from the last layer of the DistilBERT encoder. We perform feature-wise averaging of anchor posts encodings and optimize for \\(max(||\overline{f(A)} - f(n)|| - ||\overline{f(A)} - f(p)|| + \alpha,0)\\)
where:
- \\( \overline{f(A)}\\) is the feature-wise average of the anchor encodings;
- \\( f(n) \\) is the [CLS] encoding of the negative example;
- \\( f(p) \\) is the [CLS] encoding of the positive example;
- \\( \alpha \\) is a tunable parameter called margin. Here, we tuned this to \\( \alpha = 1.0\\)
#### Evaluation and usage
The model yields performance advantages downstream user-based classification tasks.
We encourage usage and benchmarking on tasks involving:
- prediction of user traits (e.g., personality);
- extraction of user-aware text encodings (e.g., style modeling);
- contextualized text modeling, where standard text representations are complemented with compact user representations
#### Limitations
Being exclusively trained on Reddit data, our models probably overfit to linguistic markers and traits which are relevant to characterizing the Reddit user population, but less salient in the general population. Domain-specific fine-tuning may be required before deployment.
Furthermore, our self-supervised approach enforces little or no control over biases, which models may actively use as part of their heuristics in contrastive and downstream tasks. |
chainyo/speaker-recognition-meetup | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
language:
- en
tags:
- children
- infant
datasets:
- Aunsiels/InfantBooks
---
A BERT-model finetuned on children's books.
```
Romero, J., & Razniewski, S. (2022).
Do Children Texts Hold The Key To Commonsense Knowledge?
In Proceedings of the 2022 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.
```
|
ChaitanyaU/FineTuneLM | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- autotrain
- tabular
- regression
- tabular-regression
datasets:
- pcoloc/autotrain-data-only-rssi
co2_eq_emissions:
emissions: 1.3554114117578944
---
# Model Trained Using AutoTrain
- Problem type: Single Column Regression
- Model ID: 1813762559
- CO2 Emissions (in grams): 1.3554
## Validation Metrics
- Loss: 83.432
- R2: 0.312
- MSE: 6960.888
- MAE: 60.449
- RMSLE: 0.532
## Usage
```python
import json
import joblib
import pandas as pd
model = joblib.load('model.joblib')
config = json.load(open('config.json'))
features = config['features']
# data = pd.read_csv("data.csv")
data = data[features]
data.columns = ["feat_" + str(col) for col in data.columns]
predictions = model.predict(data) # or model.predict_proba(data)
``` |
Chakita/Friends | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- en
license: apache-2.0
library_name: transformers
---
### Contrastive user encoder (single post)
This model is a `DistilBertModel` trained by fine-tuning `distilbert-base-uncased` on author-based triplet loss.
#### Details
Training and evaluation details are provided in our EMNLP Findings paper:
- Rocca, R., & Yarkoni, T. (2022), Language as a fingerprint: Self-supervised learning of user encodings using transformers, to appear in *Findings of the Association for Computational Linguistics: EMNLP 2022*
#### Training
We fine-tuned DistilBERT on triplets consisting of:
- a single Reddit submission from a given user (the "anchor") - see ```rbroc/contrastive-user-encoder-multipost``` for a model trained on aggregated embeddings of multiple anchors;
- an additional post from the same user (a "positive example");
- a post from a different, randomly selected user (the "negative example")
To compute the loss, we use [CLS] encoding of the anchor, positive example and negative example from the last layer of the DistilBERT encoder. We optimize for \\(max(||f(a) - f(n)|| - ||f(a) - f(p)|| + \alpha,0)\\)
where:
- \\( f(a)\\) is the [CLS] encoding of the anchor;
- \\( f(n) \\) is the [CLS] encoding of the negative example;
- \\( f(p) \\) is the [CLS] encoding of the positive example;
- \\( \alpha \\) is a tunable parameter called margin. Here, we tuned this to \\( \alpha = 1.0\\)
#### Evaluation and usage
The model yields performance advantages downstream user-based classification tasks.
We encourage usage and benchmarking on tasks involving:
- prediction of user traits (e.g., personality);
- extraction of user-aware text encodings (e.g., style modeling);
- contextualized text modeling, where standard text representations are complemented with compact user representations
#### Limitations
Being exclusively trained on Reddit data, our models probably overfit to linguistic markers and traits which are relevant to characterizing the Reddit user population, but less salient in the general population. Domain-specific fine-tuning may be required before deployment.
Furthermore, our self-supervised approach enforces little or no control over biases, which models may actively use as part of their heuristics in contrastive and downstream tasks. |
Chakita/KROBERT | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"masked-lm",
"fill-in-the-blanks",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language:
- en
tags:
- children
- infant
datasets:
- Aunsiels/InfantBooks
---
A GPT2-model finetuned on children's books.
```
Romero, J., & Razniewski, S. (2022).
Do Children Texts Hold The Key To Commonsense Knowledge?
In Proceedings of the 2022 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.
``` |
Chakita/gpt2_mwp | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: Viet_Captioning
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Viet_Captioning
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Tokenizers 0.13.1
|
Chalponkey/DialoGPT-small-Barry | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 280.56 +/- 28.20
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Chan/distilgpt2-finetuned-wikitext2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- Keyphrase Generation
---
# Usage
```python
!pip install KeyBartAdapter
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from models import KeyBartAdapter
model = KeyBartAdapter.from_pretrained('Adapting/KeyBartAdapter', revision = '3aee5ecf1703b9955ab0cd1b23208cc54eb17fce',adapter_hid_dim =32)
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
```
- adapter layer hd 512 init model: `e38c77df86e0e289e5846455e226f4e9af09ef8e`
- adapter layer hd 256 init model: `c6f3b357d953dcb5943b6333a0f9f941b832477`
- adapter layer hd 128 init model: `f88116fa1c995f07ccd5ad88862e0aa4f162b1ea`
- adapter layer hd 64 init model: `f7e8c6323b8d5822667ddc066ffe19ac7b810f4a`
- adapter layer hd 32 init model: `24ec15daef1670fb9849a56517a6886b69b652f6`
**1. inference**
```
from transformers import Text2TextGenerationPipeline
pipe = Text2TextGenerationPipeline(model=model,tokenizer=tokenizer)
abstract = '''Non-referential face image quality assessment methods have gained popularity as a pre-filtering step on face recognition systems. In most of them, the quality score is usually designed with face matching in mind. However, a small amount of work has been done on measuring their impact and usefulness on Presentation Attack Detection (PAD). In this paper, we study the effect of quality assessment methods on filtering bona fide and attack samples, their impact on PAD systems, and how the performance of such systems is improved when training on a filtered (by quality) dataset. On a Vision Transformer PAD algorithm, a reduction of 20% of the training dataset by removing lower quality samples allowed us to improve the BPCER by 3% in a cross-dataset test.'''
pipe(abstract)
``` |
Cheatham/xlm-roberta-base-finetuned | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | ---
language:
- en
library_name: diffusers
tags:
- stable-diffusion
- text-to-image
license: apache-2.0
inference: false
---
# OnnxStableDiffusionLongPromptWeightingPipeline
Onnx Pipeline for text-to-image and image-to-image generation using Stable Diffusion, without tokens length limit and support parsing weighting in prompt.
require diffusers>=0.10.0
> Now the pipeline has been contributed to the official diffusers community pipelines. You can use
custom_pipeline="lpw_stable_diffusion_onnx" directly.
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
'CompVis/stable-diffusion-v1-4',
custom_pipeline="waifu-research-department/onnx-long-prompt-weighting-pipeline",
revision="onnx",
provider="CUDAExecutionProvider"
)
pipe=pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars, best quality"
neg_prompt = "lowres, bad anatomy, error body, error hair, error arm, error hands, bad hands, error fingers, bad fingers, missing fingers, error legs, bad legs, multiple legs, missing legs, error lighting, error shadow, error reflection, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"
pipe.text2img(prompt, width=512,height=512,negative_prompt=neg_prompt,max_embeddings_multiples=3).images[0]
```
if you see
```
Token indices sequence length is longer than the specified maximum sequence length for this model ( 108 > 77 ) . Running this sequence through the model will result in indexing errors
```
This is normal, do not worry . |
Cheatham/xlm-roberta-large-finetuned-d1 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | ---
language:
- en
- zh
tags:
- GENIUS
- conditional text generation
- sketch-based text generation
- data augmentation
license: apache-2.0
datasets:
- c4
- beyond/chinese_clean_passages_80m
widget:
- text: "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
example_title: "Example 1"
- text: "<mask> machine learning <mask> my research interest <mask> data science <mask>"
example_title: "Example 2"
- text: "<mask> play basketball <mask> a strong team <mask> Shanghai University of Finance and Economics <mask> last Sunday <mask>"
example_title: "Example 3"
- text: "Good news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
example_title: "Example with a prompt 1"
- text: "Bad news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
example_title: "Example with a prompt 2"
inference:
parameters:
max_length: 200
num_beams: 3
do_sample: True
---
# GENIUS: generating text using sketches!
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://arxiv.org/abs/2211.10330)**
- **GitHub: [GENIUS, Pre-training/Data Augmentation Tutorial](https://github.com/beyondguo/genius)**
You can use this model directly with a pipeline for masked language modeling:
```python
from transformers import pipeline
# 1. load the model with the huggingface `pipeline`
genius = pipeline("text2text-generation", model='beyond/genius-large', device=0)
# 2. provide a sketch (joint by <mask> tokens)
sketch = "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
# 3. here we go!
generated_text = genius(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text']
print(generated_text)
```
If you find our paper/code/demo useful, please cite our paper:
```
@article{guo2022genius,
title={GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation},
author={Guo, Biyang and Gong, Yeyun and Shen, Yelong and Han, Songqiao and Huang, Hailiang and Duan, Nan and Chen, Weizhu},
journal={arXiv preprint arXiv:2211.10330},
year={2022}
}
``` |
Cheatham/xlm-roberta-large-finetuned-d12 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | Access to model eekj33/eekj33 is restricted and you are not in the authorized list. Visit https://huggingface.co/eekj33/eekj33 to ask for access. |
Cheatham/xlm-roberta-large-finetuned3 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 22 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: TestZee/t5-small-baseline_summary_zee_v1.0
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# TestZee/t5-small-baseline_summary_zee_v1.0
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.3722
- Validation Loss: 2.1596
- Train Rouge1: 21.6350
- Train Rouge2: 8.9453
- Train Rougel: 17.8649
- Train Rougelsum: 19.9099
- Train Gen Len: 19.0
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 2.3722 | 2.1596 | 21.6350 | 8.9453 | 17.8649 | 19.9099 | 19.0 | 0 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Datasets 2.6.1
- Tokenizers 0.13.1
|
CheonggyeMountain-Sherpa/kogpt-trinity-poem | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
CheonggyeMountain-Sherpa/kogpt-trinity-punct-wrapper | [
"ko",
"gpt2",
"license:cc-by-nc-sa-4.0"
]
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4738
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7133 | 1.0 | 157 | 2.4957 |
| 2.5751 | 2.0 | 314 | 2.4250 |
| 2.5293 | 3.0 | 471 | 2.4358 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Chinat/test-classifier | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- kjhanjee/autotrain-data-code_classification
co2_eq_emissions:
emissions: 11.438220107218369
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1815762639
- CO2 Emissions (in grams): 11.4382
## Validation Metrics
- Loss: 0.849
- Accuracy: 0.794
- Macro F1: 0.788
- Micro F1: 0.794
- Weighted F1: 0.788
- Macro Precision: 0.797
- Micro Precision: 0.794
- Weighted Precision: 0.797
- Macro Recall: 0.794
- Micro Recall: 0.794
- Weighted Recall: 0.794
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/kjhanjee/autotrain-code_classification-1815762639
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("kjhanjee/autotrain-code_classification-1815762639", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("kjhanjee/autotrain-code_classification-1815762639", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
ChoboAvenger/DialoGPT-small-DocBot | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
tags:
- biomedical
- bioNLP
---
This is a version of [PubmedBERT](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext?text=%5BMASK%5D+is+a+tumor+suppressor+gene.) which has been domain-adapted (via additional pretraining) to a set of PubMed abstracts that likely discuss multiple-drug therapies. This model was the strongest contextualized encoder in the experiments in the paper ["A Dataset for N-ary Relation Extraction of Drug Combinations"](https://arxiv.org/abs/2205.02289), when used as a component of a larger relation classification model (also hosted [here on Huggingface](https://huggingface.co/allenai/drug-combo-classifier-pubmedbert-dapt)).
If you use this model, cite both
```latex
@misc{pubmedbert,
author = {Yu Gu and Robert Tinn and Hao Cheng and Michael Lucas and Naoto Usuyama and Xiaodong Liu and Tristan Naumann and Jianfeng Gao and Hoifung Poon},
title = {Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing},
year = {2020},
eprint = {arXiv:2007.15779},
}
```
and
```latex
@inproceedings{Tiktinsky2022ADF,
title = "A Dataset for N-ary Relation Extraction of Drug Combinations",
author = "Tiktinsky, Aryeh and Viswanathan, Vijay and Niezni, Danna and Meron Azagury, Dana and Shamay, Yosi and Taub-Tabib, Hillel and Hope, Tom and Goldberg, Yoav",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.233",
doi = "10.18653/v1/2022.naacl-main.233",
pages = "3190--3203",
}
``` |
ChrisVCB/DialoGPT-medium-cmjs | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.42 +/- 0.49
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="xh3b4sd/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Chungu424/repodata | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 273.18 +/- 23.61
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ci/Pai | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: cc-by-nc-sa-4.0
datasets:
- ClaimRev
---
# Model
This model was obtained by fine-tuning bert-base-cased on the ClaimRev dataset.
Paper: [Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale](https://aclanthology.org/2021.eacl-main.147/)
Authors: Gabriella Skitalinskaya, Jonas Klaff, Henning Wachsmuth
# Claim Quality Classification
We cast this task as a pairwise classification task, where the objective is to compare two versions of the same claim and determine which one is better.
# Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("gabski/bert-relative-claim-quality")
model = AutoModelForSequenceClassification.from_pretrained("gabski/bert-relative-claim-quality")
claim_1 = 'Smoking marijuana is less harmfull then smoking cigarettes.'
claim_2 = 'Smoking marijuana is less harmful than smoking cigarettes.'
model_input = tokenizer(claim_1,claim_2, return_tensors='pt')
model_outputs = model(**model_input)
outputs = torch.nn.functional.softmax(model_outputs.logits, dim = -1)
print(outputs)
```
|
Cilan/dalle-knockoff | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-19T14:11:34Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: bert-base-german-cased-issues-128
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-issues-128
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1499
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.8524 | 1.0 | 683 | 1.5990 |
| 1.5355 | 2.0 | 1366 | 1.4480 |
| 1.426 | 3.0 | 2049 | 1.4062 |
| 1.3595 | 4.0 | 2732 | 1.3428 |
| 1.3023 | 5.0 | 3415 | 1.3081 |
| 1.2683 | 6.0 | 4098 | 1.2390 |
| 1.2242 | 7.0 | 4781 | 1.2698 |
| 1.1958 | 8.0 | 5464 | 1.2129 |
| 1.1663 | 9.0 | 6147 | 1.2080 |
| 1.1521 | 10.0 | 6830 | 1.2079 |
| 1.1221 | 11.0 | 7513 | 1.1897 |
| 1.1027 | 12.0 | 8196 | 1.2222 |
| 1.095 | 13.0 | 8879 | 1.1721 |
| 1.078 | 14.0 | 9562 | 1.1910 |
| 1.0755 | 15.0 | 10245 | 1.1500 |
| 1.0579 | 16.0 | 10928 | 1.1499 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Ciruzzo/DialoGPT-medium-harrypotter | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
thumbnail: http://www.huggingtweets.com/moonideograph/1666189855449/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1581258561400848384/ktYtGqLD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🌑 Loona the Ninth</div>
<div style="text-align: center; font-size: 14px;">@moonideograph</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🌑 Loona the Ninth.
| Data | 🌑 Loona the Ninth |
| --- | --- |
| Tweets downloaded | 409 |
| Retweets | 104 |
| Short tweets | 22 |
| Tweets kept | 283 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8mujtj4v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @moonideograph's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/21pia0le) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/21pia0le/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/moonideograph')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Ciruzzo/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language:
- ru
---
# rubert-base-cased-mcn
Normalization model, based on rubert, for linking phrases to their MedDRA concepts in russian. F1-micro of this model is 71.34
on the 4th fold of the RDRS corpus of russian internet drug reviews.
The use of the weights of the current model and the calculation of accuracies on the laid out RDRS corpus is contained in our repository on [our repo](https://github.com/sag111/MedNorm).
|
Ciruzzo/DialoGPT-small-hattypotter | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- mlm
- generated_from_trainer
model-index:
- name: article2keyword2.2_barthez-orangesum-title_finetuned_for_mlm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article2keyword2.2_barthez-orangesum-title_finetuned_for_mlm
This model is a fine-tuned version of [moussaKam/barthez-orangesum-title](https://huggingface.co/moussaKam/barthez-orangesum-title) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0452
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3187 | 1.0 | 1235 | 0.0545 |
| 0.0544 | 2.0 | 2470 | 0.0491 |
| 0.0461 | 3.0 | 3705 | 0.0463 |
| 0.042 | 4.0 | 4940 | 0.0452 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ClaudeYang/awesome_fb_model | [
"pytorch",
"bart",
"text-classification",
"dataset:multi_nli",
"transformers",
"zero-shot-classification"
]
| zero-shot-classification | {
"architectures": [
"BartForSequenceClassification"
],
"model_type": "bart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- Norod78/MuppetFaces
widget:
- src: https://lumiere-a.akamaihd.net/v1/images/character_themuppets_piggy_994270a5.jpeg
example_title: Piggy
- src: https://lumiere-a.akamaihd.net/v1/images/character_themuppets_kermit_b77a431b.jpeg
example_title: Kermit
co2_eq_emissions:
emissions: 0.01152985529096599
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1816962673
- CO2 Emissions (in grams): 0.0115
## Validation Metrics
- Loss: 0.208
- Accuracy: 0.963
- Macro F1: 0.935
- Micro F1: 0.963
- Weighted F1: 0.962
- Macro Precision: 0.945
- Micro Precision: 0.963
- Weighted Precision: 0.965
- Macro Recall: 0.933
- Micro Recall: 0.963
- Weighted Recall: 0.963 |
CleveGreen/FieldClassifier_v2_gpt | [
"pytorch",
"gpt2",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"GPT2ForSequenceClassification"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
language: ko
tags:
- bart
license: apache-2.0
---
Copyright (c) SKT and its affiliates and Kakao Brain. |
CodeMonkey98/distilroberta-base-finetuned-wikitext2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: deberta-v3-base_MNLI_10_19_v0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-base_MNLI_10_19_v0
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
CodeNinja1126/bert-p-encoder | [
"pytorch"
]
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Model
This [sentence-transformers](https://www.SBERT.net) model model was obtained by fine-tuning bert-base-cased on the ClaimRev dataset.
Paper: [Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale](https://aclanthology.org/2021.eacl-main.147/)
Authors: Gabriella Skitalinskaya, Jonas Klaff, Henning Wachsmuth
# Claim Quality Classification
We cast this task as a pairwise classification task, where the objective is to compare two versions of the same claim and determine which one is better. We train this model by fine-tuning SBERT based on bert-base-cased using a siamese network structure with softmax loss. Outputs can also be used to rank multiple versions of the same claim, for example, using [SVMRank](https://github.com/ds4dm/PySVMRank) or BTL (Bradley-Terry-Luce model).
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('gabski/sbert-relative-claim-quality')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('gabski/sbert-relative-claim-quality')
model = AutoModel.from_pretrained('gabski/sbert-relative-claim-quality')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
```bibtex
@inproceedings{skitalinskaya-etal-2021-learning,
title = "Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale",
author = "Skitalinskaya, Gabriella and
Klaff, Jonas and
Wachsmuth, Henning",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-main.147",
doi = "10.18653/v1/2021.eacl-main.147",
pages = "1718--1729",
}
``` |
Coldestadam/Breakout_Mentors_SpongeBob_Model | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: tipo-pelo
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8656716346740723
---
# tipo-pelo
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### afro hair

#### curly hair

#### straight hair
 |
Connorvr/TeachingGen | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: mit
---
### Sims 2 Portrait on Stable Diffusion
This is the `<sims2-portrait>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:







Here are example images generated using this style:



I'm not satisfied with the result as it usually fails to capture the game's aesthetic. |
Contrastive-Tension/BERT-Base-CT | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
language:
- en
tags:
- t5
- t5x
- edit
license: unknown
datasets:
- fruit-wiki
metrics:
- rouge
---
# EdiT5
Reproduction of the model in [FRUIT: Faithfully Reflecting Updated Information in Text](https://arxiv.org/abs/2112.08634).
## Training data
The model was trained on the [FRUIT Wikipeda dataset](https://github.com/google-research/language/tree/master/language/fruit) for updates.
|
CouchCat/ma_mlc_v7_distil | [
"pytorch",
"distilbert",
"text-classification",
"en",
"transformers",
"multi-label",
"license:mit"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 29 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased_finetuned_SPEECH_TEXT_DISPLAY
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_finetuned_SPEECH_TEXT_DISPLAY
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2319
- Accuracy: 0.7368
- F1: 0.7282
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.0388 | 1.0 | 19 | 0.9710 | 0.4211 | 0.2495 |
| 0.9432 | 2.0 | 38 | 0.9188 | 0.5789 | 0.4964 |
| 0.7889 | 3.0 | 57 | 0.8813 | 0.5789 | 0.5263 |
| 0.5823 | 4.0 | 76 | 0.7974 | 0.6842 | 0.6452 |
| 0.4275 | 5.0 | 95 | 0.7669 | 0.6316 | 0.5965 |
| 0.2995 | 6.0 | 114 | 0.6675 | 0.8421 | 0.8344 |
| 0.1676 | 7.0 | 133 | 0.7643 | 0.7368 | 0.7333 |
| 0.0976 | 8.0 | 152 | 0.7864 | 0.7895 | 0.7839 |
| 0.0477 | 9.0 | 171 | 0.7838 | 0.7895 | 0.7772 |
| 0.0247 | 10.0 | 190 | 1.1000 | 0.6842 | 0.6817 |
| 0.0127 | 11.0 | 209 | 0.9551 | 0.7895 | 0.7772 |
| 0.0084 | 12.0 | 228 | 1.1178 | 0.6842 | 0.6792 |
| 0.0071 | 13.0 | 247 | 1.1489 | 0.6842 | 0.6792 |
| 0.0055 | 14.0 | 266 | 1.1278 | 0.7368 | 0.7282 |
| 0.0051 | 15.0 | 285 | 1.0925 | 0.7368 | 0.7282 |
| 0.0049 | 16.0 | 304 | 1.1031 | 0.7368 | 0.7282 |
| 0.0042 | 17.0 | 323 | 1.1299 | 0.7368 | 0.7282 |
| 0.0037 | 18.0 | 342 | 1.1644 | 0.7368 | 0.7282 |
| 0.0035 | 19.0 | 361 | 1.1659 | 0.7368 | 0.7282 |
| 0.0031 | 20.0 | 380 | 1.1704 | 0.7368 | 0.7282 |
| 0.0028 | 21.0 | 399 | 1.1664 | 0.7368 | 0.7282 |
| 0.0029 | 22.0 | 418 | 1.1693 | 0.7368 | 0.7282 |
| 0.0028 | 23.0 | 437 | 1.1858 | 0.7368 | 0.7282 |
| 0.0024 | 24.0 | 456 | 1.2007 | 0.7368 | 0.7282 |
| 0.0024 | 25.0 | 475 | 1.1982 | 0.7368 | 0.7282 |
| 0.0022 | 26.0 | 494 | 1.1896 | 0.7368 | 0.7282 |
| 0.002 | 27.0 | 513 | 1.1955 | 0.7368 | 0.7282 |
| 0.0019 | 28.0 | 532 | 1.2016 | 0.7368 | 0.7282 |
| 0.0019 | 29.0 | 551 | 1.2066 | 0.7368 | 0.7282 |
| 0.0021 | 30.0 | 570 | 1.2120 | 0.7368 | 0.7282 |
| 0.0019 | 31.0 | 589 | 1.2145 | 0.7368 | 0.7282 |
| 0.0019 | 32.0 | 608 | 1.2179 | 0.7368 | 0.7282 |
| 0.0018 | 33.0 | 627 | 1.2221 | 0.7368 | 0.7282 |
| 0.0019 | 34.0 | 646 | 1.2237 | 0.7368 | 0.7282 |
| 0.0016 | 35.0 | 665 | 1.2275 | 0.7368 | 0.7282 |
| 0.0016 | 36.0 | 684 | 1.2294 | 0.7368 | 0.7282 |
| 0.0015 | 37.0 | 703 | 1.2305 | 0.7368 | 0.7282 |
| 0.0017 | 38.0 | 722 | 1.2315 | 0.7368 | 0.7282 |
| 0.0016 | 39.0 | 741 | 1.2318 | 0.7368 | 0.7282 |
| 0.0018 | 40.0 | 760 | 1.2319 | 0.7368 | 0.7282 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.10.2
- Datasets 2.5.2
- Tokenizers 0.12.1
|
CracklesCreeper/Piglin-Talks-Harry-Potter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: DatasetSinergyRhenus
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
config: discharge
split: train
args: discharge
metrics:
- name: Precision
type: precision
value: 0.8851351351351351
- name: Recall
type: recall
value: 0.8762541806020067
- name: F1
type: f1
value: 0.8806722689075631
- name: Accuracy
type: accuracy
value: 0.9709117575164996
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DatasetSinergyRhenus
This model is a fine-tuned version of [microsoft/layoutlmv3-large](https://huggingface.co/microsoft/layoutlmv3-large) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2981
- Precision: 0.8851
- Recall: 0.8763
- F1: 0.8807
- Accuracy: 0.9709
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.19 | 100 | 0.3083 | 0.6238 | 0.7709 | 0.6896 | 0.8937 |
| No log | 2.38 | 200 | 0.1983 | 0.7691 | 0.8244 | 0.7958 | 0.9281 |
| No log | 3.57 | 300 | 0.2468 | 0.7690 | 0.8462 | 0.8057 | 0.9213 |
| No log | 4.76 | 400 | 0.1565 | 0.8412 | 0.8595 | 0.8503 | 0.9614 |
| 0.2937 | 5.95 | 500 | 0.1671 | 0.8238 | 0.8445 | 0.8340 | 0.9577 |
| 0.2937 | 7.14 | 600 | 0.1665 | 0.8440 | 0.8595 | 0.8517 | 0.9594 |
| 0.2937 | 8.33 | 700 | 0.1679 | 0.8571 | 0.8528 | 0.8550 | 0.9628 |
| 0.2937 | 9.52 | 800 | 0.1669 | 0.8656 | 0.8512 | 0.8583 | 0.9611 |
| 0.2937 | 10.71 | 900 | 0.1579 | 0.8765 | 0.8662 | 0.8713 | 0.9680 |
| 0.1075 | 11.9 | 1000 | 0.1883 | 0.8656 | 0.8512 | 0.8583 | 0.9633 |
| 0.1075 | 13.1 | 1100 | 0.1873 | 0.8765 | 0.8662 | 0.8713 | 0.9592 |
| 0.1075 | 14.29 | 1200 | 0.1725 | 0.8524 | 0.8595 | 0.8560 | 0.9668 |
| 0.1075 | 15.48 | 1300 | 0.1690 | 0.8679 | 0.8679 | 0.8679 | 0.9650 |
| 0.1075 | 16.67 | 1400 | 0.1959 | 0.8825 | 0.8662 | 0.8743 | 0.9668 |
| 0.0637 | 17.86 | 1500 | 0.1919 | 0.8723 | 0.8679 | 0.8701 | 0.9638 |
| 0.0637 | 19.05 | 1600 | 0.2020 | 0.8780 | 0.8662 | 0.8721 | 0.9663 |
| 0.0637 | 20.24 | 1700 | 0.2093 | 0.8716 | 0.8512 | 0.8613 | 0.9641 |
| 0.0637 | 21.43 | 1800 | 0.2184 | 0.8716 | 0.8629 | 0.8672 | 0.9643 |
| 0.0637 | 22.62 | 1900 | 0.2204 | 0.8576 | 0.8562 | 0.8569 | 0.9631 |
| 0.0452 | 23.81 | 2000 | 0.2478 | 0.8591 | 0.8562 | 0.8576 | 0.9621 |
| 0.0452 | 25.0 | 2100 | 0.2506 | 0.8769 | 0.8579 | 0.8673 | 0.9665 |
| 0.0452 | 26.19 | 2200 | 0.2270 | 0.8862 | 0.8729 | 0.8795 | 0.9690 |
| 0.0452 | 27.38 | 2300 | 0.2544 | 0.8790 | 0.8629 | 0.8709 | 0.9646 |
| 0.0452 | 28.57 | 2400 | 0.2251 | 0.8735 | 0.8662 | 0.8699 | 0.9643 |
| 0.0313 | 29.76 | 2500 | 0.2597 | 0.8668 | 0.8595 | 0.8631 | 0.9633 |
| 0.0313 | 30.95 | 2600 | 0.2635 | 0.8670 | 0.8612 | 0.8641 | 0.9643 |
| 0.0313 | 32.14 | 2700 | 0.2493 | 0.8752 | 0.8679 | 0.8715 | 0.9665 |
| 0.0313 | 33.33 | 2800 | 0.2565 | 0.8797 | 0.8679 | 0.8737 | 0.9660 |
| 0.0313 | 34.52 | 2900 | 0.2626 | 0.8831 | 0.8712 | 0.8771 | 0.9672 |
| 0.0218 | 35.71 | 3000 | 0.2750 | 0.8639 | 0.8595 | 0.8617 | 0.9650 |
| 0.0218 | 36.9 | 3100 | 0.2683 | 0.8682 | 0.8595 | 0.8639 | 0.9660 |
| 0.0218 | 38.1 | 3200 | 0.2751 | 0.8724 | 0.8579 | 0.8651 | 0.9660 |
| 0.0218 | 39.29 | 3300 | 0.2851 | 0.8746 | 0.8629 | 0.8687 | 0.9655 |
| 0.0218 | 40.48 | 3400 | 0.2737 | 0.8805 | 0.8629 | 0.8716 | 0.9692 |
| 0.0111 | 41.67 | 3500 | 0.2638 | 0.8773 | 0.8729 | 0.8751 | 0.9699 |
| 0.0111 | 42.86 | 3600 | 0.2773 | 0.8879 | 0.8746 | 0.8812 | 0.9692 |
| 0.0111 | 44.05 | 3700 | 0.2829 | 0.8759 | 0.8612 | 0.8685 | 0.9653 |
| 0.0111 | 45.24 | 3800 | 0.2730 | 0.8739 | 0.8696 | 0.8718 | 0.9699 |
| 0.0111 | 46.43 | 3900 | 0.2873 | 0.8767 | 0.8679 | 0.8723 | 0.9687 |
| 0.0039 | 47.62 | 4000 | 0.2797 | 0.8788 | 0.8729 | 0.8758 | 0.9690 |
| 0.0039 | 48.81 | 4100 | 0.2769 | 0.8805 | 0.8746 | 0.8775 | 0.9707 |
| 0.0039 | 50.0 | 4200 | 0.2842 | 0.8818 | 0.8612 | 0.8714 | 0.9694 |
| 0.0039 | 51.19 | 4300 | 0.2837 | 0.8822 | 0.8763 | 0.8792 | 0.9712 |
| 0.0039 | 52.38 | 4400 | 0.2895 | 0.8767 | 0.8679 | 0.8723 | 0.9704 |
| 0.0022 | 53.57 | 4500 | 0.2901 | 0.8822 | 0.8763 | 0.8792 | 0.9712 |
| 0.0022 | 54.76 | 4600 | 0.2950 | 0.8851 | 0.8763 | 0.8807 | 0.9709 |
| 0.0022 | 55.95 | 4700 | 0.2977 | 0.8851 | 0.8763 | 0.8807 | 0.9709 |
| 0.0022 | 57.14 | 4800 | 0.2984 | 0.8851 | 0.8763 | 0.8807 | 0.9709 |
| 0.0022 | 58.33 | 4900 | 0.2983 | 0.8851 | 0.8763 | 0.8807 | 0.9709 |
| 0.0013 | 59.52 | 5000 | 0.2981 | 0.8851 | 0.8763 | 0.8807 | 0.9709 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.2.2
- Tokenizers 0.13.1
|
Craig/paraphrase-MiniLM-L6-v2 | [
"pytorch",
"bert",
"arxiv:1908.10084",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,026 | 2022-10-19T22:55:55Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: deberta-v3-base_mnli_uf_ner_1019_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-base_mnli_uf_ner_1019_v1
This model is a fine-tuned version of [mariolinml/deberta-v3-base_MNLI_10_19_v0](https://huggingface.co/mariolinml/deberta-v3-base_MNLI_10_19_v0) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
CrayonShinchan/fine_tune_try_1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: openrail
---
This is a Stable Diffusion model trained using DreamBooth to create pixel art landscapes |
Crisblair/Wkwk | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
widget:
- text: $proof$ ; $hypothesis$ = a magnet will not attract a penny
license: apache-2.0
---
# entailer-large
## Model description
Entailer is a text-to-text model trained to create entailment-style explanations for a hypothesis
(following the format of [EntailmentBank](https://allenai.org/data/entailmentbank)), as well as verifying both the reasoning and the factuality of the premises.
Entailer was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
two sizes: [entailer-11b](https://huggingface.co/allenai/entailer-11b) and
[entailer-large](https://huggingface.co/allenai/entailer-large).
See https://github.com/allenai/entailment_bank for more details.
|
Crispy/dialopt-small-kratos | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
datasets:
- bigscience/xP3
- mc4
license: apache-2.0
language:
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- 'no'
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
tags:
- text2text-generation
widget:
- text: >-
<table> <tr> <th>Name</th> <th>Explanation</th> <th>Example models</th>
</tr> <tr> <td><a
href=https://huggingface.co/datasets/bigscience/xP3>xP3</a></t> <td>Mixture
of 13 training tasks in 46 languages with English prompts</td> <td><a
href=https://huggingface.co/bigscience/bloomz>bloomz</a> & <a
href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td> </tr> <tr>
<td><a href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a></t>
<td>Mixture of 13 training tasks in 46 languages with prompts in 20
languages (machine-translated from English)</td> <td><a
href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a> & <a
href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td> </tr>
<tr> <td><a
href=https://huggingface.co/datasets/bigscience/xP3all>xP3all</a></t>
<td>xP3 + our evaluation datasets adding an additional 3 tasks for a total
of 16 tasks in 46 languages with English prompts</td> <td></td> </tr> <tr>
<td><a
href=https://huggingface.co/datasets/bigscience/xP3megds>xP3megds</a></t>
<td><a
href=https://github.com/bigscience-workshop/Megatron-DeepSpeed>Megatron-DeepSpeed</a>
processed version of xP3</td> <td><a
href=https://huggingface.co/bigscience/bloomz>bloomz</a></td> </tr> <tr>
<td><a href=https://huggingface.co/datasets/Muennighoff/P3>P3</a></t>
<td>Repreprocessed version of the English-only <a
href=https://huggingface.co/datasets/bigscience/P3>P3</a> with 8 training
tasks</td> <td><a
href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a> & <a
href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td> </tr>
</table> Which dataset has the most tasks?
example_title: en-en struct-to-text
- text: Life is beautiful! Translate to Mongolian.
example_title: mn-en translation
- text: Le mot japonais «憂鬱» veut dire quoi en Odia?
example_title: jp-or-fr translation
- text: >-
Stell mir eine schwierige Quiz Frage bei der es um Astronomie geht. Bitte
stell die Frage auf Norwegisch.
example_title: de-nb quiz
- text: >-
We present BLOOMZ & mT0, a family of models capable of following human
instructions in dozens of languages zero-shot. We finetune BLOOM & mT5
pretrained multilingual language models on our crosslingual task mixture
(xP3) and find our resulting models capable of crosslingual generalization
to unseen tasks & languages. What are the keywords in Chinese?
example_title: zh-en keywords
- text: >-
一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous
review as positive, neutral or negative?
example_title: zh-en sentiment
- text: 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
example_title: zh-zh sentiment
- text: Suggest at least five related search terms to "Mạng neural nhân tạo".
example_title: vi-en query
- text: >-
Proposez au moins cinq mots clés concernant «Réseau de neurones
artificiels».
example_title: fr-fr query
- text: Explain in a sentence in Telugu what is backpropagation in neural networks.
example_title: te-en qa
- text: Why is the sky blue?
example_title: en-en qa
- text: >-
Write a fairy tale about a troll saving a princess from a dangerous dragon.
The fairy tale is a masterpiece that has achieved praise worldwide and its
moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
example_title: es-en fable
- text: >-
Write a fable about wood elves living in a forest that is suddenly invaded
by ogres. The fable is a masterpiece that has achieved praise worldwide and
its moral is "Violence is the last refuge of the incompetent". Fable (in
Hindi):
example_title: hi-en fable
model-index:
- name: mt0-xxl
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 63.38
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 81.29
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 78.31
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 78.62
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 77.95
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 76.51
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 77.38
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 49.5
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 43
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 46.08
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 85.71
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 85.56
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.91
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.88
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 60.64
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 62.01
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 60.8
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.88
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.23
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.88
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 55.66
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.43
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.59
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 55.42
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.51
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.12
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: '2016'
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 96.04
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 93
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 79
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 81
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 92
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 90
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 79
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 84
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 77
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 79
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 88
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 89
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 91.07
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 92.52
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 90.6
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 92.32
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 93.51
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 87.49
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 91.4
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 89.41
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 90.54
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 93.85
pipeline_tag: text2text-generation
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:[email protected])
- **Languages:** Refer to [mc4](https://huggingface.co/datasets/mc4) for pretraining & [xP3](https://huggingface.co/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [mt5-xxl](https://huggingface.co/google/mt5-xxl), also refer to the `config.json` file
- **Finetuning steps:** 7000
- **Finetuning tokens:** 1.29 billion
- **Precision:** bfloat16
## Hardware
- **TPUs:** TPUv4-256
## Software
- **Orchestration:** [T5X](https://github.com/google-research/t5x)
- **Neural networks:** [Jax](https://github.com/google/jax)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@misc{muennighoff2022crosslingual,
title={Crosslingual Generalization through Multitask Finetuning},
author={Niklas Muennighoff and Thomas Wang and Lintang Sutawika and Adam Roberts and Stella Biderman and Teven Le Scao and M Saiful Bari and Sheng Shen and Zheng-Xin Yong and Hailey Schoelkopf and Xiangru Tang and Dragomir Radev and Alham Fikri Aji and Khalid Almubarak and Samuel Albanie and Zaid Alyafeai and Albert Webson and Edward Raff and Colin Raffel},
year={2022},
eprint={2211.01786},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Crives/distilbert-base-uncased-finetuned-emotion | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
tags:
- generated_from_trainer
model-index:
- name: super_large_finetune_CM01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# super_large_finetune_CM01
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.2285
- Wer: 0.7714
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 15
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 857
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.0031 | 5.0 | 1715 | 1.9766 | 0.7857 |
| 0.2107 | 10.0 | 3430 | 3.8748 | 0.8238 |
| 0.1393 | 15.0 | 5145 | 4.7403 | 0.7952 |
| 0.0931 | 20.0 | 6860 | 3.5077 | 0.6667 |
| 0.0649 | 25.0 | 8575 | 7.7419 | 0.9333 |
| 0.0592 | 30.0 | 10290 | 5.6440 | 0.7762 |
| 0.0396 | 35.0 | 12005 | 6.9629 | 0.6810 |
| 0.03 | 40.0 | 13720 | 7.8282 | 0.7524 |
| 0.0191 | 45.0 | 15435 | 6.4626 | 0.7429 |
| 0.0121 | 50.0 | 17150 | 7.2285 | 0.7714 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Cryptikdw/DialoGPT-small-rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Stable Diffusion v1-5 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion).
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Original GitHub Repository
1. Download the weights
- [v1-5-pruned-emaonly.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt) - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt) - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/runwayml/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
Cthyllax/DialoGPT-medium-PaladinDanse | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: en
widget:
- text: $proof$ ; $hypothesis$ = a magnet will not attract a penny
license: apache-2.0
---
# entailer-11b
## Model description
Entailer is a text-to-text model trained to create entailment-style explanations for a hypothesis
(following the format of [EntailmentBank](https://allenai.org/data/entailmentbank)), as well as verifying both the reasoning and the factuality of the premises.
Entailer was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
two sizes: [entailer-11b](https://huggingface.co/allenai/entailer-11b) and
[entailer-large](https://huggingface.co/allenai/entailer-large).
See https://github.com/allenai/entailment_bank for more details.
|
Culmenus/opus-mt-de-is-finetuned-de-to-is_35g65cc_1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T00:34:52Z | ---
tags:
- BreakoutNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BreakoutNoFrameskip-v4
type: BreakoutNoFrameskip-v4
metrics:
- type: mean_reward
value: 2.70 +/- 4.12
name: mean_reward
verified: false
---
# (CleanRL) **DQN** Agent Playing **BreakoutNoFrameskip-v4**
This is a trained model of a DQN agent playing BreakoutNoFrameskip-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py).
# Hyperparameters
```python
{'batch_size': 32,
'buffer_size': 1000000,
'capture_video': False,
'cuda': True,
'end_e': 0.01,
'env_id': 'BreakoutNoFrameskip-v4',
'exp_name': 'dqn_atari',
'exploration_fraction': 0.1,
'gamma': 0.99,
'hf_entity': '',
'learning_rate': 0.0001,
'learning_starts': 80000,
'save_model': True,
'seed': 1,
'start_e': 1,
'target_network_frequency': 1000,
'torch_deterministic': True,
'total_timesteps': 10000,
'track': False,
'train_frequency': 4,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
Culmenus/opus-mt-de-is-finetuned-de-to-is_35g65cc_2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T00:48:15Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9352911896465903
- name: Recall
type: recall
value: 0.9486704813194211
- name: F1
type: f1
value: 0.9419333277633887
- name: Accuracy
type: accuracy
value: 0.9864455171601814
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0610
- Precision: 0.9353
- Recall: 0.9487
- F1: 0.9419
- Accuracy: 0.9864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0907 | 1.0 | 1756 | 0.0732 | 0.9188 | 0.9337 | 0.9262 | 0.9818 |
| 0.035 | 2.0 | 3512 | 0.0607 | 0.9280 | 0.9480 | 0.9379 | 0.9859 |
| 0.0169 | 3.0 | 5268 | 0.0610 | 0.9353 | 0.9487 | 0.9419 | 0.9864 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Culmenus/opus-mt-de-is-finetuned-de-to-is_nr2 | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | 2022-10-20T01:26:19Z | ---
language: fr
license: mit
datasets:
- oscar
---
## Model description
CamemBERT is a state-of-the-art language model for French based on the RoBERTa model. It is now available on Hugging Face in 6 different versions with varying number of parameters, amount of pretraining data and pretraining data source domains.
## Evaluation
The model developers evaluated CamemBERT using four different downstream tasks for French: part-of-speech (POS) tagging, dependency parsing, named entity recognition (NER) and natural language inference (NLI).
## Limitations and bias
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
This model was pretrinaed on a subcorpus of OSCAR multilingual corpus. Some of the limitations and risks associated with the OSCAR dataset, which are further detailed in the [OSCAR dataset card](https://huggingface.co/datasets/oscar), include the following:
> The quality of some OSCAR sub-corpora might be lower than expected, specifically for the lowest-resource languages.
> Constructed from Common Crawl, Personal and sensitive information might be present.
## Training data
OSCAR or Open Super-large Crawled Aggregated coRpus is a multilingual corpus obtained by language classification and filtering of the Common Crawl corpus using the Ungoliant architecture.
## How to use
-**Filling masks using pipeline**
```python
>>> from transformers import pipeline
>>> camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
>>> results = camembert_fill_mask("Le camembert est <mask> :)")
>>> result
[{'score': 0.49091097712516785,
'token': 7200,
'token_str': 'délicieux',
'sequence': 'Le camembert est délicieux :)'},
{'score': 0.1055697426199913,
'token': 2183,
'token_str': 'excellent',
'sequence': 'Le camembert est excellent :)'},
{'score': 0.03453319892287254,
'token': 26202,
'token_str': 'succulent',
'sequence': 'Le camembert est succulent :)'},
{'score': 0.03303128108382225,
'token': 528,
'token_str': 'meilleur',
'sequence': 'Le camembert est meilleur :)'},
{'score': 0.030076386407017708,
'token': 1654,
'token_str': 'parfait',
'sequence': 'Le camembert est parfait :)'}]
```
-**Extract contextual embedding features from Camembert output**
```python
import torch
>>> tokenized_sentence = tokenizer.tokenize("J'aime le camembert !")
>>> encoded_sentence = tokenizer.encode(tokenized_sentence)
# Can be done in one step : tokenize.encode("J'aime le camembert !")
>>> tokenized_sentence
['▁J', "'", 'aime', '▁le', '▁ca', 'member', 't', '▁!']
>>> encoded_sentence
[5, 121, 11, 660, 16, 730, 25543, 110, 83, 6]
encoded_sentence = torch.tensor(encoded_sentence).unsqueeze(0)
embeddings, _ = camembert(encoded_sentence)
# embeddings.detach()
# embeddings.size torch.Size([1, 10, 768])
# tensor([[[-0.0254, 0.0235, 0.1027, ..., -0.1459, -0.0205, -0.0116],
# [ 0.0606, -0.1811, -0.0418, ..., -0.1815, 0.0880, -0.0766],
# [-0.1561, -0.1127, 0.2687, ..., -0.0648, 0.0249, 0.0446],
# ...,
``` |
CuongLD/wav2vec2-large-xlsr-vietnamese | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"vi",
"dataset:common_voice, infore_25h",
"arxiv:2006.11477",
"arxiv:2006.13979",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-es
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-es
split: train
args: en-es
metrics:
- name: Bleu
type: bleu
value: 54.20734320116235
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-es
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-es](https://huggingface.co/Helsinki-NLP/opus-mt-en-es) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7665
- Bleu: 54.2073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
CurtisBowser/DialoGPT-medium-sora-three | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- text-classification
- generated_from_trainer
datasets:
- glue
model-index:
- name: distilroberta-base-mrpc-glue-oscar-salas
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-mrpc-glue-oscar-salas
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the datasetX dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.6456
- eval_accuracy: 0.8260
- eval_f1: 0.8795
- eval_runtime: 30.3289
- eval_samples_per_second: 13.453
- eval_steps_per_second: 1.682
- epoch: 1.09
- step: 500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cpu
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Czapla/Rick | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- scientific_papers
model-index:
- name: longformer_summarise
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# longformer_summarise
This model is a fine-tuned version of [allenai/led-base-16384](https://huggingface.co/allenai/led-base-16384) on the scientific_papers dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3003
- Rouge2 Precision: 0.1654
- Rouge2 Recall: 0.0966
- Rouge2 Fmeasure: 0.1118
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 2.909 | 0.08 | 10 | 2.8969 | 0.09 | 0.1439 | 0.0953 |
| 2.615 | 0.16 | 20 | 2.6182 | 0.1232 | 0.0865 | 0.0924 |
| 2.581 | 0.24 | 30 | 2.4687 | 0.1357 | 0.0733 | 0.09 |
| 2.1294 | 0.32 | 40 | 2.5215 | 0.1495 | 0.0932 | 0.1044 |
| 2.8083 | 0.4 | 50 | 2.3870 | 0.1794 | 0.1054 | 0.1224 |
| 3.0704 | 0.48 | 60 | 2.3676 | 0.1572 | 0.0989 | 0.1108 |
| 2.4716 | 0.56 | 70 | 2.3554 | 0.1707 | 0.1039 | 0.1198 |
| 2.454 | 0.64 | 80 | 2.3411 | 0.1619 | 0.0943 | 0.1115 |
| 2.3046 | 0.72 | 90 | 2.3105 | 0.1547 | 0.0965 | 0.1116 |
| 1.7467 | 0.8 | 100 | 2.3417 | 0.1551 | 0.0877 | 0.1046 |
| 2.7696 | 0.88 | 110 | 2.3226 | 0.1543 | 0.0954 | 0.1085 |
| 2.4999 | 0.96 | 120 | 2.3003 | 0.1654 | 0.0966 | 0.1118 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 1.2.1
- Tokenizers 0.12.1
|
D-Keqi/espnet_asr_train_asr_streaming_transformer_raw_en_bpe500_sp_valid.acc.ave | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-10-20T02:26:06Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-multilingual-uncased-en-de-fr-oct-19
results: []
---
# distilbert-multilingual-uncased-en-de-fr-oct-19
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0273
- F1: 0.9623
## Model description
This was trained off a cased model, but with .lower() applied to each of the records, if you wish for it to work you must lowercase before inferencing
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.0573 | 1.0 | 6468 | 0.0364 | 0.9402 |
| 0.0224 | 2.0 | 12936 | 0.0281 | 0.9572 |
| 0.0108 | 3.0 | 19404 | 0.0273 | 0.9623 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Tokenizers 0.13.1
|
DARKVIP3R/DialoGPT-medium-Anakin | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: pegasus-newsroom-summarizer_30216
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-newsroom-summarizer_30216
This model is a fine-tuned version of [google/pegasus-newsroom](https://huggingface.co/google/pegasus-newsroom) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9637
- Rouge1: 52.0929
- Rouge2: 34.6709
- Rougel: 41.1615
- Rougelsum: 48.4141
- Gen Len: 102.017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| 1.0592 | 1.0 | 12086 | 0.9743 | 51.6187 | 34.1687 | 40.5959 | 47.9305 | 104.3352 |
| 0.9742 | 2.0 | 24172 | 0.9647 | 52.1837 | 34.7301 | 41.2599 | 48.4955 | 101.2771 |
| 0.9371 | 3.0 | 36258 | 0.9637 | 52.0929 | 34.6709 | 41.1615 | 48.4141 | 102.017 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
DCU-NLP/bert-base-irish-cased-v1 | [
"pytorch",
"tf",
"bert",
"fill-mask",
"transformers",
"generated_from_keras_callback",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,244 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: longformer_summarise_large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# longformer_summarise_large
This model is a fine-tuned version of [patrickvonplaten/led-large-16384-pubmed](https://huggingface.co/patrickvonplaten/led-large-16384-pubmed) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 1.2.1
- Tokenizers 0.12.1
|
DHBaek/gpt2-stackoverflow-question-contents-generator | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets: Gustavosta/Stable-Diffusion-Prompts
widget:
- text: A detective of wolfhound
model-index:
- name: distilgpt2-sd-prompts
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-sd-prompts
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [Stable-Diffusion-Prompts](https://huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts).
It achieves the following results on the evaluation set:
- Loss: 0.9450
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5122 | 1.93 | 500 | 1.5211 |
| 1.2912 | 3.86 | 1000 | 1.1045 |
| 0.9313 | 5.79 | 1500 | 0.9704 |
| 0.7744 | 7.72 | 2000 | 0.9450 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
DJSammy/bert-base-danish-uncased_BotXO-ai | [
"pytorch",
"jax",
"da",
"dataset:common_crawl",
"dataset:wikipedia",
"transformers",
"bert",
"masked-lm",
"license:cc-by-4.0",
"fill-mask"
]
| fill-mask | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -104.91 +/- 121.92
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DJSammy/bert-base-swedish-uncased_BotXO-ai | [
"pytorch",
"transformers"
]
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null |
```python
import trace_layer2 as models
import torch
x=torch.randn(1, 3, 224, 224)
state_dict = torch.load('swav_imagenet_layer2.pt', map_location='cpu')
model = models.resnet50w2()
model.load_state_dict(state_dict)
model.eval()
feature = model(x)
traced_model = torch.jit.load('traced_swav_imagenet_layer2.pt', map_location='cpu')
traced_model.eval()
feature = traced_model(x)
```
|
DLNLP/t5-small-finetuned-xsum | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T04:31:13Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-for-c2er
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-for-c2er
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1404
- Accuracy: 0.9523
- F1: 0.9511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 50
- eval_batch_size: 50
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DSI/human-directed-sentiment | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/Infill06")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/Infill06")
```
```
Try it out here:
https://huggingface.co/spaces/BigSalmon/TestAnyGPTModel
```
```
prompt = """few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep]"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep]"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
Phrase Mask
Infill / Infilling / Masking / Phrase Masking
```
His contention [blank] by the evidence [sep] was refuted [answer]
***
Few sights are as [blank] New York City as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
When rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
The library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
```
```
original: Other film stars to have appeared in Scrubs include Heather Graham, while Friends actor Matthew Perry has guest-starred and directed an episode of the [MASK] star, who recently played the title role in historical blockbuster Alexander, will make a cameo appearance as an unruly Irishman. Its leading star, Zach Braff, has recently [MASK] the big screen in Garden State, which he also directed. Farrell is pencilled in to [MASK] of Crockett in a film version of 1980s police [MASK] Farrell's appearance is said to be a result of his friendship with Zach Braff, who stars in the programme.
infill: Other film stars to have appeared in Scrubs include Heather Graham, while Friends actor Matthew Perry has guest-starred and directed an episode of the show. The film star, who recently played the title role in historical blockbuster Alexander, will make a cameo appearance as an unruly Irishman. Its leading star, Zach Braff, has recently been seen on the big screen in Garden State, which he also directed. Farrell is pencilled in to play the role of Crockett in a film version of 1980s police drama Miami Vice. Farrell's appearance is said to be a result of his friendship with Zach Braff, who stars in the programme.
```
```
<Suffix> of internationality <Prefix> there are examples of strategies that have <Middle> withstood the test <Middle>
```
```
<|SUF|> a solid grasp of research methods is indispensable <|PRE|> if one aspires to reach the upper <|MID|> echelons of academia, <|endoftext|>
``` |
DTAI-KULeuven/robbertje-1-gb-bort | [
"pytorch",
"roberta",
"fill-mask",
"nl",
"dataset:oscar",
"dataset:oscar (NL)",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"arxiv:2101.05716",
"transformers",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"RobBERTje",
"license:mit",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | git lfs install
git clone https://huggingface.co/hakurei/waifu-diffusion-v1-3 |
alexandrainst/da-ner-base | [
"pytorch",
"tf",
"bert",
"token-classification",
"da",
"dataset:dane",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 78 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-distilled-model-flip_mind_epoch12_alpha0.8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-distilled-model-flip_mind_epoch12_alpha0.8
This model is a fine-tuned version of [ArafatBHossain/distill_bert_fine_tuned_mind](https://huggingface.co/ArafatBHossain/distill_bert_fine_tuned_mind) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7953
- Accuracy: 0.914
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.8595 | 1.0 | 3054 | 1.8311 | 0.854 |
| 1.7769 | 2.0 | 6108 | 1.7204 | 0.847 |
| 1.7614 | 3.0 | 9162 | 1.7666 | 0.8666 |
| 1.7212 | 4.0 | 12216 | 1.8134 | 0.8716 |
| 1.7255 | 5.0 | 15270 | 1.7368 | 0.8812 |
| 1.6845 | 6.0 | 18324 | 1.7368 | 0.8898 |
| 1.7346 | 7.0 | 21378 | 1.6621 | 0.8936 |
| 1.7436 | 8.0 | 24432 | 1.7180 | 0.9008 |
| 1.7333 | 9.0 | 27486 | 1.7523 | 0.9048 |
| 1.7805 | 10.0 | 30540 | 1.7820 | 0.9078 |
| 1.792 | 11.0 | 33594 | 1.7329 | 0.9096 |
| 1.7463 | 12.0 | 36648 | 1.7953 | 0.914 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.11.0
- Datasets 2.6.1
- Tokenizers 0.12.1
|
alexandrainst/da-sentiment-base | [
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"da",
"arxiv:1910.09700",
"transformers",
"license:cc-by-sa-4.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,432 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-korean-w1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-korean-w1
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1406
- Cer: 0.0393
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 24.537 | 0.56 | 800 | 3.0461 | 0.9274 |
| 1.9309 | 1.13 | 1600 | 0.7723 | 0.2168 |
| 0.7595 | 1.69 | 2400 | 0.3197 | 0.0916 |
| 0.4338 | 2.26 | 3200 | 0.2051 | 0.0587 |
| 0.3067 | 2.82 | 4000 | 0.1406 | 0.0393 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
alexandrainst/da-subjectivivity-classification-base | [
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"da",
"dataset:DDSC/twitter-sent",
"dataset:DDSC/europarl",
"transformers",
"license:cc-by-sa-4.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 846 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-T5_summarise
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-T5_summarise
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.0384
- Rouge1: 15.9638
- Rouge2: 9.0883
- Rougel: 13.2968
- Rougelsum: 14.5007
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 4.2781 | 1.0 | 2 | 5.0384 | 15.9638 | 9.0883 | 13.2968 | 14.5007 | 19.0 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
DaWang/demo | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T06:52:15Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- favsbot
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-cased-NER-favsbot
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: favsbot
type: favsbot
config: default
split: train
args: default
metrics:
- name: Precision
type: precision
value: 0.8571428571428571
- name: Recall
type: recall
value: 0.96
- name: F1
type: f1
value: 0.9056603773584904
- name: Accuracy
type: accuracy
value: 0.9583333333333334
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-NER-favsbot
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the favsbot dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0992
- Precision: 0.8571
- Recall: 0.96
- F1: 0.9057
- Accuracy: 0.9583
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 10 | 1.7643 | 0.0 | 0.0 | 0.0 | 0.5694 |
| No log | 2.0 | 20 | 1.1420 | 0.0 | 0.0 | 0.0 | 0.5833 |
| No log | 3.0 | 30 | 0.7946 | 0.9375 | 0.6 | 0.7317 | 0.8056 |
| No log | 4.0 | 40 | 0.5625 | 0.8182 | 0.72 | 0.7660 | 0.8611 |
| No log | 5.0 | 50 | 0.4217 | 0.8148 | 0.88 | 0.8462 | 0.9306 |
| No log | 6.0 | 60 | 0.3082 | 0.8519 | 0.92 | 0.8846 | 0.9444 |
| No log | 7.0 | 70 | 0.2386 | 0.8148 | 0.88 | 0.8462 | 0.9444 |
| No log | 8.0 | 80 | 0.1965 | 0.8148 | 0.88 | 0.8462 | 0.9444 |
| No log | 9.0 | 90 | 0.1626 | 0.8148 | 0.88 | 0.8462 | 0.9444 |
| No log | 10.0 | 100 | 0.1465 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 11.0 | 110 | 0.1314 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 12.0 | 120 | 0.1215 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 13.0 | 130 | 0.1160 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 14.0 | 140 | 0.1104 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 15.0 | 150 | 0.1050 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 16.0 | 160 | 0.1012 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 17.0 | 170 | 0.0997 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 18.0 | 180 | 0.0997 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 19.0 | 190 | 0.0995 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
| No log | 20.0 | 200 | 0.0992 | 0.8571 | 0.96 | 0.9057 | 0.9583 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.12.1
|
DaisyMak/bert-finetuned-squad-transformerfrozen-testtoken | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | Access to model DepositorOP/MasterStack is restricted and you are not in the authorized list. Visit https://huggingface.co/DepositorOP/MasterStack to ask for access. |
Daivakai/DialoGPT-small-saitama | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
tags:
- conversational
---
# Shadow the Hedgehog DialoGPT Model |
Daltcamalea01/Camaleaodalt | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T07:36:41Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_alien
type: atari_alien
metrics:
- type: mean_reward
value: 19250.00 +/- 6187.31
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_alien** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
DanBot/TCRsynth | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-10-20T07:39:54Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: vit-base-patch16-224-FV-20epochs-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8632148377125193
- name: Precision
type: precision
value: 0.8617373130509159
- name: Recall
type: recall
value: 0.8632148377125193
- name: F1
type: f1
value: 0.8621436376894498
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-FV-20epochs-finetuned-memes
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6532
- Accuracy: 0.8632
- Precision: 0.8617
- Recall: 0.8632
- F1: 0.8621
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.1709 | 0.99 | 20 | 0.9393 | 0.6971 | 0.6896 | 0.6971 | 0.6890 |
| 0.5295 | 1.99 | 40 | 0.5024 | 0.8091 | 0.8210 | 0.8091 | 0.8133 |
| 0.2909 | 2.99 | 60 | 0.4070 | 0.8539 | 0.8529 | 0.8539 | 0.8529 |
| 0.1435 | 3.99 | 80 | 0.4136 | 0.8539 | 0.8522 | 0.8539 | 0.8522 |
| 0.0928 | 4.99 | 100 | 0.4495 | 0.8478 | 0.8548 | 0.8478 | 0.8507 |
| 0.0643 | 5.99 | 120 | 0.4897 | 0.8594 | 0.8572 | 0.8594 | 0.8573 |
| 0.061 | 6.99 | 140 | 0.5040 | 0.8423 | 0.8490 | 0.8423 | 0.8453 |
| 0.0519 | 7.99 | 160 | 0.5266 | 0.8524 | 0.8502 | 0.8524 | 0.8510 |
| 0.0546 | 8.99 | 180 | 0.5200 | 0.8586 | 0.8632 | 0.8586 | 0.8605 |
| 0.0478 | 9.99 | 200 | 0.5654 | 0.8555 | 0.8548 | 0.8555 | 0.8548 |
| 0.0509 | 10.99 | 220 | 0.5774 | 0.8609 | 0.8626 | 0.8609 | 0.8616 |
| 0.0467 | 11.99 | 240 | 0.5847 | 0.8594 | 0.8602 | 0.8594 | 0.8594 |
| 0.0468 | 12.99 | 260 | 0.5909 | 0.8601 | 0.8597 | 0.8601 | 0.8596 |
| 0.0469 | 13.99 | 280 | 0.5970 | 0.8563 | 0.8560 | 0.8563 | 0.8561 |
| 0.0438 | 14.99 | 300 | 0.6234 | 0.8594 | 0.8583 | 0.8594 | 0.8586 |
| 0.0441 | 15.99 | 320 | 0.6190 | 0.8563 | 0.8582 | 0.8563 | 0.8570 |
| 0.0431 | 16.99 | 340 | 0.6419 | 0.8570 | 0.8584 | 0.8570 | 0.8574 |
| 0.0454 | 17.99 | 360 | 0.6528 | 0.8563 | 0.8556 | 0.8563 | 0.8558 |
| 0.0417 | 18.99 | 380 | 0.6688 | 0.8578 | 0.8575 | 0.8578 | 0.8574 |
| 0.0432 | 19.99 | 400 | 0.6532 | 0.8632 | 0.8617 | 0.8632 | 0.8621 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1.dev0
- Tokenizers 0.13.1
|
Danbi/distilroberta-base-finetuned-wikitext2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: amanneo/mail-generator-mini
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# amanneo/mail-generator-mini
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 5.4613
- Train Accuracy: 0.1611
- Validation Loss: 5.2617
- Validation Accuracy: 0.1386
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -925, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 10.0053 | 0.1068 | 8.5247 | 0.1394 | 0 |
| 8.7772 | 0.1505 | 7.9685 | 0.1656 | 1 |
| 8.2057 | 0.1663 | 7.4436 | 0.1655 | 2 |
| 7.5786 | 0.1611 | 6.8572 | 0.1654 | 3 |
| 6.9698 | 0.1679 | 6.3646 | 0.1735 | 4 |
| 6.4911 | 0.1763 | 6.0124 | 0.1787 | 5 |
| 6.1632 | 0.1834 | 5.7751 | 0.1826 | 6 |
| 5.9057 | 0.1840 | 5.5786 | 0.1749 | 7 |
| 5.6874 | 0.1758 | 5.4023 | 0.1616 | 8 |
| 5.4613 | 0.1611 | 5.2617 | 0.1386 | 9 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Danih1502/t5-base-finetuned-en-to-de | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: mit
---
# Mona Subject Model / Dreambooth Training
## Usage
To use this model you have to download the .ckpt file as well as drop it into the "\stable-diffusion-webui\models\Stable-diffusion" folder
To use it in a prompt: ```"Mona woman"``` for highest strength or just "Mona"
To increase the strength put "Mona woman" in () brackets
To decrease the strength put "Mona woman" in [] brackets
Waifu_diffusion base trained model trained to 4,000 steps
Have fun :)
## Example Pictures from Mona_4k
<table>
<tr>
<td><img src=https://i.imgur.com/acDDsQZ.png width=150% height=150%/></td>
<td><img src=https://i.imgur.com/15PnKDf.png width=100% height=100%/></td>
<td><img src=https://i.imgur.com/PWxazM1.png width=150% height=150%/></td>
</tr>
</table> |
DarkWolf/kn-electra-small | [
"pytorch",
"electra",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: apache-2.0
tags:
- mlm
- generated_from_trainer
model-index:
- name: article2keyword2.1b_paraphrase-multilingual-MiniLM-L12-v2_finetuned_for_mlm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article2keyword2.1b_paraphrase-multilingual-MiniLM-L12-v2_finetuned_for_mlm
This model is a fine-tuned version of [sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0673
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.3777 | 1.0 | 1353 | 0.3168 |
| 0.2358 | 2.0 | 2706 | 0.1564 |
| 0.1372 | 3.0 | 4059 | 0.1149 |
| 0.1046 | 4.0 | 5412 | 0.0956 |
| 0.086 | 5.0 | 6765 | 0.0853 |
| 0.0741 | 6.0 | 8118 | 0.0786 |
| 0.0653 | 7.0 | 9471 | 0.0750 |
| 0.0594 | 8.0 | 10824 | 0.0726 |
| 0.0542 | 9.0 | 12177 | 0.0699 |
| 0.0504 | 10.0 | 13530 | 0.0692 |
| 0.047 | 11.0 | 14883 | 0.0684 |
| 0.0444 | 12.0 | 16236 | 0.0675 |
| 0.0423 | 13.0 | 17589 | 0.0674 |
| 0.0404 | 14.0 | 18942 | 0.0673 |
| 0.0392 | 15.0 | 20295 | 0.0672 |
| 0.0379 | 16.0 | 21648 | 0.0673 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Davlan/mbart50-large-eng-yor-mt | [
"pytorch",
"mbart",
"text2text-generation",
"arxiv:2103.08647",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
tags:
- audio-generation
---
[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) is now available in 🧨 Diffusers.
## FP32
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
model_id = "harmonai/glitch-440k"
pipe = DiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
audios = pipe(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"test_{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
```
## FP16
Faster at a small loss of quality
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
import torch
model_id = "harmonai/glitch-440k"
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
audios = pipeline(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
``` |
Declan/Breitbart_model_v4 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: israeli_soccer_news
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# israeli_soccer_news
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 5.5327
- Validation Loss: 5.2116
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -121, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.6108 | 5.2840 | 0 |
| 5.5513 | 5.2115 | 1 |
| 5.5317 | 5.2107 | 2 |
| 5.5319 | 5.2116 | 3 |
| 5.5327 | 5.2116 | 4 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.10.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Declan/Breitbart_model_v5 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: en
license: mit
---
# BetterCallBloom-3b
Finetuned Bloom-3b model on the r/legaladvice subreddit from pileoflaw
## Model description
BLOOM-3B is a 3,002,557,440 parameters model pretrained by the BigScience initiative.
## Intended uses & limitations
### How to use
### Limitations and bias
## Training data
## Training procedure
### Preprocessing
## Evaluation results
### BibTeX entry and citation info
|
Declan/HuffPost_model_v3 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: other
datasets:
- FremyCompany/BioLORD-Dataset
widget:
source_sentence: bartonellosis
sentences:
- cat scratch disease
- cat scratch wound
- tick-borne orbivirus fever
- cat fur
---
# FremyCompany/BioLORD-STAMB2-v1
This model was trained using BioLORD, a new pre-training strategy for producing meaningful representations for clinical sentences and biomedical concepts.
State-of-the-art methodologies operate by maximizing the similarity in representation of names referring to the same concept, and preventing collapse through contrastive learning. However, because biomedical names are not always self-explanatory, it sometimes results in non-semantic representations.
BioLORD overcomes this issue by grounding its concept representations using definitions, as well as short descriptions derived from a multi-relational knowledge graph consisting of biomedical ontologies. Thanks to this grounding, our model produces more semantic concept representations that match more closely the hierarchical structure of ontologies. BioLORD establishes a new state of the art for text similarity on both clinical sentences (MedSTS) and biomedical concepts (MayoSRS).
This model is based on [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) and was further finetuned on the [BioLORD-Dataset](https://huggingface.co/datasets/FremyCompany/BioLORD-Dataset).
<img width="640" src="https://s3.amazonaws.com/moonup/production/uploads/1665568401241-5f04e8865d08220171a0ad3f.png" />
## General purpose
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. This model has been finentuned for the biomedical domain. While it preserves a good ability to produce embeddings for general-purpose text, it will be more useful to you if you are trying to process medical documents such as EHR records or clinical notes. Both sentences and phrases can be embedded in the same latent space.
## Citation
This model accompanies the [BioLORD: Learning Ontological Representations from Definitions](https://arxiv.org/abs/2210.11892) paper, accepted in the EMNLP 2022 Findings. When you use this model, please cite the original paper as follows:
```latex
@inproceedings{remy-etal-2022-biolord,
title = "{B}io{LORD}: Learning Ontological Representations from Definitions for Biomedical Concepts and their Textual Descriptions",
author = "Remy, François and
Demuynck, Kris and
Demeester, Thomas",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-emnlp.104",
pages = "1454--1465",
abstract = "This work introduces BioLORD, a new pre-training strategy for producing meaningful representations for clinical sentences and biomedical concepts. State-of-the-art methodologies operate by maximizing the similarity in representation of names referring to the same concept, and preventing collapse through contrastive learning. However, because biomedical names are not always self-explanatory, it sometimes results in non-semantic representations. BioLORD overcomes this issue by grounding its concept representations using definitions, as well as short descriptions derived from a multi-relational knowledge graph consisting of biomedical ontologies. Thanks to this grounding, our model produces more semantic concept representations that match more closely the hierarchical structure of ontologies. BioLORD establishes a new state of the art for text similarity on both clinical sentences (MedSTS) and biomedical concepts (MayoSRS).",
}
```
You might also want to take a look at our MWE 2023 Paper:
- [Detecting Idiomatic Multiword Expressions in Clinical Terminology using Definition-Based Representation Learning](https://www.researchgate.net/publication/370426650_Detecting_Idiomatic_Multiword_Expressions_in_Clinical_Terminology_using_Definition-Based_Representation_Learning)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Cat scratch injury", "Cat scratch disease", "Bartonellosis"]
model = SentenceTransformer('FremyCompany/BioLORD-STAMB2-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["Cat scratch injury", "Cat scratch disease", "Bartonellosis"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('FremyCompany/BioLORD-STAMB2-v1')
model = AutoModel.from_pretrained('FremyCompany/BioLORD-STAMB2-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## License
My own contributions for this model are covered by the MIT license.
However, given the data used to train this model originates from UMLS, you will need to ensure you have proper licensing of UMLS before using this model. UMLS is free of charge in most countries, but you might have to create an account and report on your usage of the data yearly to keep a valid license. |
Declan/Reuters_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language:
- "en"
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "apache-2.0"
datasets:
- Computing
- Cloud
metrics:
- metric1
- metric2
---
Hello World |
Declan/Reuters_model_v2 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.74 +/- 20.11
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/Reuters_model_v3 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | We are a family-owned and operated Credit Repair company, founded in 2013. Our goal is to help you achieve financial success and reach your credit goals.
Follow this [link](https://grossepointepark.asapcreditrepairusa.com/) |
Declan/Reuters_model_v4 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
### kawaiinimal icons (ノ◕ヮ◕)ノ*:・゚✧

some notes: I will try to improve this model. as of now, prompts might need some extra sauce for good output. modifiers that were used for some of the results above were: `uncropped, isometric, flat colors, vector, 8k, octane, behance hd` (not all of them at once, just played around with them here & there).
results were finished up in photoshop to get a transparent background.
how to prompt: `<your animal of choice> kawaiinimal icon, <modifiers>`
<a href='https://ko-fi.com/S6S6FUYKY' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi3.png?v=3' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
Declan/Reuters_model_v5 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_demonattack
type: atari_demonattack
metrics:
- type: mean_reward
value: 132572.75 +/- 1125.75
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_demonattack** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
Declan/Reuters_model_v6 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_doubledunk
type: atari_doubledunk
metrics:
- type: mean_reward
value: 22.20 +/- 1.08
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_doubledunk** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
Declan/Reuters_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8533333333333334
- name: F1
type: f1
value: 0.8543046357615894
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3398
- Accuracy: 0.8533
- F1: 0.8543
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Declan/WallStreetJournal_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_enduro
type: atari_enduro
metrics:
- type: mean_reward
value: 2275.55 +/- 200.24
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_enduro** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
Declan/WallStreetJournal_model_v2 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_fishingderby
type: atari_fishingderby
metrics:
- type: mean_reward
value: 31.00 +/- 19.16
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_fishingderby** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.