
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Alexander-Learn/bert-finetuned-squad-accelerate | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: RL-unit4-reinforce-Pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 80.80 +/- 74.36
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Alexander-Learn/bert-finetuned-squad | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: layout-xlm-geocite-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layout-xlm-geocite-v2
This model is a fine-tuned version of [microsoft/layoutxlm-base](https://huggingface.co/microsoft/layoutxlm-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
AliPotter24/a | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
AliReza/distilbert-emotion | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
Aloka/mbart50-ft-si-en | [
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.63
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Jbot/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Alstractor/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 40 | null | ---
license: agpl-3.0
---
Model is developed in support of the University of Belgrade doctoral dissertation "Composite pseudogrammars based on parallel language models of Serbian" by Mihailo Škorić.
It generates syntactly masked sentences for Serbian.
This small gpt-2 model was fine-tuned on several corpora for Serbian, augmented using [Serbian Morphological Dictionaries](http://poincare.matf.bg.ac.rs/~cvetana/biblio/22_Vitas_Krstev.pdf)).
The corpora include ["The corpus of Contemporary Serbian"](https://drive.google.com/file/d/1wRgoWer6YULGCXR0zWOl1fVA6VIe1DOR), [SrpELTeC](https://drive.google.com/file/d/1RtBXyw5Cdh6y_cqbJoMlYhSwNFydBRUv) and WikiKorpus by [JeRTeh – Society for Language Resources and Technologies](https://jerteh.rs/). |
Amalq/distilroberta-base-finetuned-MentalHealth | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### gitlatt Dreambooth model trained by wxcvbnw with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
Amalq/distilroberta-base-finetuned-anxiety-depression | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### Rim_illustration on Stable Diffusion
This is the `<rimbot>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
AndrewMcDowell/wav2vec2-xls-r-1B-german | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"de",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: unknown
language:
- en
pipeline_tag: text-to-image
tags:
- Danbooru 2021
- Stable Diffusion
---
funni title lmao |
AnonymousSub/SR_rule_based_roberta_twostage_quadruplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.55 +/- 22.69
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AnonymousSub/SciFive_pubmedqa_question_generation | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 7 | 2023-01-12T22:23:42Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Helicopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 40.90 +/- 22.59
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AnonymousSub/bert-base-uncased_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- generated_from_trainer
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.2646
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.2649 | 0.47 | 500 | 7.5102 |
| 7.0502 | 0.94 | 1000 | 6.8533 |
| 6.5834 | 1.4 | 1500 | 6.7023 |
| 6.3077 | 1.87 | 2000 | 6.6566 |
| 6.1706 | 2.34 | 2500 | 6.4929 |
| 6.128 | 2.81 | 3000 | nan |
| 6.1135 | 3.27 | 3500 | 6.3916 |
| 5.964 | 3.74 | 4000 | 6.2980 |
| 5.967 | 4.21 | 4500 | 6.2670 |
| 5.901 | 4.68 | 5000 | 6.2646 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/bert-base-uncased_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
tags:
- generated_from_trainer
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.3372
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 9.3697 | 0.4 | 500 | 8.5748 |
| 7.9343 | 0.8 | 1000 | 7.7323 |
| 7.3224 | 1.2 | 1500 | 7.4549 |
| 7.1382 | 1.6 | 2000 | 7.4191 |
| 7.0553 | 2.0 | 2500 | 7.3967 |
| 6.9814 | 2.4 | 3000 | 7.3621 |
| 6.9808 | 2.8 | 3500 | 7.3591 |
| 6.9386 | 3.2 | 4000 | 7.3327 |
| 6.9167 | 3.6 | 4500 | 7.3050 |
| 6.9831 | 4.0 | 5000 | 7.3372 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/bert_hier_diff_equal_wts_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
tags:
- generated_from_trainer
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.4855
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.9119 | 1.09 | 500 | 8.3154 |
| 7.6669 | 2.18 | 1000 | 7.5949 |
| 7.1524 | 3.27 | 1500 | 7.4914 |
| 7.0173 | 4.36 | 2000 | 7.5929 |
| 6.9491 | 5.45 | 2500 | 7.4708 |
| 6.89 | 6.54 | 3000 | 7.3486 |
| 6.8284 | 7.63 | 3500 | 7.3566 |
| 6.8484 | 8.71 | 4000 | 7.6411 |
| 6.8088 | 9.8 | 4500 | 7.4855 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/cline-s10-AR | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
tags:
- generated_from_trainer
model-index:
- name: tiny-mlm-glue-qqp-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-qqp-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.5630
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.8759 | 0.4 | 500 | 8.0883 |
| 7.4497 | 0.8 | 1000 | 7.3157 |
| 6.8553 | 1.2 | 1500 | 7.0495 |
| 6.6004 | 1.6 | 2000 | 6.8851 |
| 6.4548 | 2.0 | 2500 | 6.7926 |
| 6.3122 | 2.4 | 3000 | 6.6611 |
| 6.2733 | 2.8 | 3500 | 6.6870 |
| 6.2271 | 3.2 | 4000 | 6.5846 |
| 6.103 | 3.6 | 4500 | 6.5860 |
| 6.1545 | 4.0 | 5000 | 6.5630 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/cline-techqa | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-cola
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8379
- Matthews Correlation: 0.0351
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6103 | 1.87 | 500 | 0.6208 | 0.0 |
| 0.6074 | 3.73 | 1000 | 0.6191 | 0.0 |
| 0.605 | 5.6 | 1500 | 0.6149 | 0.0 |
| 0.57 | 7.46 | 2000 | 0.6413 | 0.0702 |
| 0.4989 | 9.33 | 2500 | 0.6938 | 0.0708 |
| 0.4577 | 11.19 | 3000 | 0.7318 | 0.0569 |
| 0.4285 | 13.06 | 3500 | 0.7803 | 0.0481 |
| 0.4065 | 14.93 | 4000 | 0.8379 | 0.0351 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/cline | [
"pytorch",
"roberta",
"transformers"
]
| null | {
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: Brhnglc/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AnonymousSub/cline_emanuals | [
"pytorch",
"roberta",
"transformers"
]
| null | {
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- generated_from_trainer
model-index:
- name: tiny-mlm-glue-rte-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-rte-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.6341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 9.13 | 1.6 | 500 | 8.4505 |
| 7.8185 | 3.21 | 1000 | 7.7760 |
| 7.2846 | 4.81 | 1500 | 7.5443 |
| 7.1052 | 6.41 | 2000 | 7.7086 |
| 7.1017 | 8.01 | 2500 | 7.5114 |
| 7.0598 | 9.62 | 3000 | 7.4909 |
| 7.0125 | 11.22 | 3500 | 7.4334 |
| 6.9987 | 12.82 | 4000 | 7.6285 |
| 6.9734 | 14.42 | 4500 | 7.4881 |
| 6.9619 | 16.03 | 5000 | 7.6341 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/cline_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 10.40 +/- 7.79
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AnonymousSub/declutr-emanuals-techqa | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2023-01-12T23:57:29Z | ---
tags:
- generated_from_trainer
model-index:
- name: small-mlm-glue-cola-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-cola-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.6550
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.8212 | 0.47 | 500 | 6.2788 |
| 6.116 | 0.94 | 1000 | 6.1923 |
| 5.9605 | 1.4 | 1500 | 6.1613 |
| 5.7116 | 1.87 | 2000 | 6.1499 |
| 5.6233 | 2.34 | 2500 | 6.0771 |
| 5.5925 | 2.81 | 3000 | nan |
| 5.547 | 3.27 | 3500 | 5.9853 |
| 5.3711 | 3.74 | 4000 | 5.7912 |
| 5.3294 | 4.21 | 4500 | 5.7309 |
| 5.2142 | 4.68 | 5000 | 5.6550 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/declutr-model-emanuals | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-qnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-qnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6513
- Accuracy: 0.6129
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6926 | 0.15 | 500 | 0.6887 | 0.5599 |
| 0.6814 | 0.31 | 1000 | 0.6675 | 0.5867 |
| 0.6728 | 0.46 | 1500 | 0.6621 | 0.5997 |
| 0.6665 | 0.61 | 2000 | 0.6609 | 0.6022 |
| 0.6614 | 0.76 | 2500 | 0.6589 | 0.6028 |
| 0.6627 | 0.92 | 3000 | 0.6566 | 0.6039 |
| 0.6552 | 1.07 | 3500 | 0.6562 | 0.6046 |
| 0.659 | 1.22 | 4000 | 0.6533 | 0.6077 |
| 0.6536 | 1.37 | 4500 | 0.6519 | 0.6114 |
| 0.6553 | 1.53 | 5000 | 0.6513 | 0.6129 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/declutr-techqa | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-4
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 37.80 +/- 30.07
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AnonymousSub/rule_based_bert_hier_diff_equal_wts_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-rte
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-rte
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9954
- Accuracy: 0.4729
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.693 | 6.41 | 500 | 0.6947 | 0.4549 |
| 0.6248 | 12.82 | 1000 | 0.8627 | 0.4729 |
| 0.4602 | 19.23 | 1500 | 1.1278 | 0.4657 |
| 0.3484 | 25.64 | 2000 | 1.3214 | 0.4801 |
| 0.2599 | 32.05 | 2500 | 1.6232 | 0.4693 |
| 0.2052 | 38.46 | 3000 | 1.7684 | 0.4801 |
| 0.1667 | 44.87 | 3500 | 1.9954 | 0.4729 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_bert_mean_diff_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-sst2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-sst2
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4365
- Accuracy: 0.8085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6856 | 0.24 | 500 | 0.6922 | 0.5195 |
| 0.6777 | 0.48 | 1000 | 0.6786 | 0.5849 |
| 0.6106 | 0.71 | 1500 | 0.5295 | 0.7592 |
| 0.4947 | 0.95 | 2000 | 0.4996 | 0.7557 |
| 0.446 | 1.19 | 2500 | 0.4592 | 0.7844 |
| 0.4169 | 1.43 | 3000 | 0.4700 | 0.7752 |
| 0.3997 | 1.66 | 3500 | 0.4481 | 0.7878 |
| 0.3814 | 1.9 | 4000 | 0.4403 | 0.7844 |
| 0.3699 | 2.14 | 4500 | 0.4491 | 0.7833 |
| 0.3497 | 2.38 | 5000 | 0.4365 | 0.8085 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_bert_quadruplet_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: mit
---
Pretrained Latent Guidance predictor for Stable Diffusion as described in this Paper - https://sketch-guided-diffusion.github.io/.
Used to Guide the output of Diffusion models (Stable Diffusion in this Case) to stick closely to the edges of sketches. |
AnonymousSub/rule_based_bert_triplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-wnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-wnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9560
- Accuracy: 0.0704
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6933 | 25.0 | 500 | 0.6928 | 0.5493 |
| 0.6896 | 50.0 | 1000 | 0.7724 | 0.1972 |
| 0.6469 | 75.0 | 1500 | 1.2231 | 0.1127 |
| 0.5484 | 100.0 | 2000 | 1.9560 | 0.0704 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_bert_triplet_epochs_1_shard_1_wikiqa_copy | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-cola
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7995
- Matthews Correlation: 0.0140
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6109 | 1.87 | 500 | 0.6204 | 0.0 |
| 0.607 | 3.73 | 1000 | 0.6189 | 0.0 |
| 0.6041 | 5.6 | 1500 | 0.6187 | 0.0 |
| 0.5729 | 7.46 | 2000 | 0.6550 | 0.0093 |
| 0.5254 | 9.33 | 2500 | 0.6909 | 0.0411 |
| 0.4976 | 11.19 | 3000 | 0.7189 | 0.0526 |
| 0.4767 | 13.06 | 3500 | 0.7382 | 0.0223 |
| 0.4591 | 14.93 | 4000 | 0.7636 | 0.0449 |
| 0.4393 | 16.79 | 4500 | 0.7995 | 0.0140 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_hier_quadruplet_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-mnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-mnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0101
- Accuracy: 0.4803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0983 | 0.04 | 500 | 1.0959 | 0.3689 |
| 1.0911 | 0.08 | 1000 | 1.0872 | 0.3711 |
| 1.0844 | 0.12 | 1500 | 1.0766 | 0.3948 |
| 1.0647 | 0.16 | 2000 | 1.0568 | 0.4272 |
| 1.0482 | 0.2 | 2500 | 1.0364 | 0.4501 |
| 1.0385 | 0.24 | 3000 | 1.0274 | 0.4595 |
| 1.0298 | 0.29 | 3500 | 1.0287 | 0.4501 |
| 1.0209 | 0.33 | 4000 | 1.0215 | 0.4656 |
| 1.0144 | 0.37 | 4500 | 1.0139 | 0.4786 |
| 1.0111 | 0.41 | 5000 | 1.0101 | 0.4803 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_hier_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-5
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 14.73 +/- 13.92
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Please put the prompt: flat minimal illustration of...
georgeart Dreambooth model trained by Alexwww with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
This model is train with @george.ee illustrations
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | 2023-01-13T02:16:04Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-mrpc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-mrpc
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6245
- Accuracy: 0.6201
- F1: 0.6990
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6321 | 4.35 | 500 | 0.6107 | 0.6838 | 0.8122 |
| 0.5481 | 8.7 | 1000 | 0.6208 | 0.6936 | 0.7941 |
| 0.3207 | 13.04 | 1500 | 0.8799 | 0.6275 | 0.696 |
| 0.1738 | 17.39 | 2000 | 1.2027 | 0.6348 | 0.7162 |
| 0.1133 | 21.74 | 2500 | 1.6245 | 0.6201 | 0.6990 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_only_classfn_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
model-index:
- name: small-mlm-glue-qqp-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-qqp-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.9723
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.1744 | 0.4 | 500 | 6.6327 |
| 6.2017 | 0.8 | 1000 | 6.4708 |
| 5.9807 | 1.2 | 1500 | 6.3544 |
| 5.8057 | 1.6 | 2000 | 6.1953 |
| 5.7186 | 2.0 | 2500 | 6.1794 |
| 5.5759 | 2.4 | 3000 | 6.0617 |
| 5.5572 | 2.8 | 3500 | 6.1286 |
| 5.5134 | 3.2 | 4000 | 6.0364 |
| 5.3844 | 3.6 | 4500 | 6.0568 |
| 5.4336 | 4.0 | 5000 | 5.9723 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- generated_from_trainer
model-index:
- name: small-mlm-glue-rte-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-rte-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.3463
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.7345 | 1.6 | 500 | 7.4398 |
| 7.051 | 3.21 | 1000 | 7.4338 |
| 6.9685 | 4.81 | 1500 | 7.3969 |
| 6.8422 | 6.41 | 2000 | 7.5530 |
| 6.8292 | 8.01 | 2500 | 7.2865 |
| 6.7599 | 9.62 | 3000 | 7.2730 |
| 6.6839 | 11.22 | 3500 | 7.1490 |
| 6.6433 | 12.82 | 4000 | 7.3275 |
| 6.5957 | 14.42 | 4500 | 7.2154 |
| 6.5601 | 16.03 | 5000 | 7.3463 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-cnn-samsum-ElectrifAi_v8.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-samsum-ElectrifAi_v8.1
This model is a fine-tuned version of [philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3222
- Rouge1: 55.3039
- Rouge2: 31.3218
- Rougel: 42.3951
- Rougelsum: 53.2394
- Gen Len: 108.9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 27 | 1.3061 | 53.8018 | 30.0487 | 39.9195 | 52.1464 | 101.4333 |
| No log | 2.0 | 54 | 1.2995 | 54.2973 | 30.6364 | 42.0125 | 51.995 | 99.6 |
| No log | 3.0 | 81 | 1.3222 | 55.3039 | 31.3218 | 42.3951 | 53.2394 | 108.9 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-sst2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-sst2
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4356
- Accuracy: 0.8131
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6877 | 0.24 | 500 | 0.6942 | 0.5138 |
| 0.6658 | 0.48 | 1000 | 0.6622 | 0.6101 |
| 0.527 | 0.71 | 1500 | 0.5329 | 0.7603 |
| 0.4562 | 0.95 | 2000 | 0.4880 | 0.7833 |
| 0.3976 | 1.19 | 2500 | 0.5178 | 0.7798 |
| 0.3615 | 1.43 | 3000 | 0.4421 | 0.8050 |
| 0.3406 | 1.66 | 3500 | 0.4455 | 0.7959 |
| 0.3215 | 1.9 | 4000 | 0.4449 | 0.8119 |
| 0.2977 | 2.14 | 4500 | 0.4416 | 0.8142 |
| 0.2807 | 2.38 | 5000 | 0.4356 | 0.8131 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- Taxi-v3-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3-4x4-no_slippery
type: Taxi-v3-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Nyxynyx/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: edgertej/poebert-balanced
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# edgertej/poebert-balanced
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.8393
- Validation Loss: 3.5576
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 3e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.1167 | 3.7102 | 0 |
| 3.8640 | 3.6570 | 1 |
| 3.9454 | 3.6030 | 2 |
| 3.8175 | 3.5792 | 3 |
| 3.8393 | 3.5576 | 4 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.9.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_trainer
model-index:
- name: small-mlm-glue-sst2-from-scratch-custom-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-sst2-from-scratch-custom-tokenizer
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.2425
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.7065 | 0.4 | 500 | 7.3339 |
| 7.1401 | 0.8 | 1000 | 7.2865 |
| 6.9592 | 1.2 | 1500 | 7.3445 |
| 6.9335 | 1.6 | 2000 | 7.3916 |
| 6.8822 | 2.0 | 2500 | 7.2251 |
| 6.6974 | 2.4 | 3000 | 7.1682 |
| 6.6423 | 2.8 | 3500 | 7.2053 |
| 6.6121 | 3.2 | 4000 | 7.2180 |
| 6.6063 | 3.6 | 4500 | 7.1581 |
| 6.5295 | 4.0 | 5000 | 7.2425 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Nyxynyx/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
metrics:
- spearmanr
model-index:
- name: tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-stsb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-from-scratch-custom-tokenizer-target-glue-stsb
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0116
- Pearson: 0.2065
- Spearmanr: 0.2191
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| 3.4686 | 2.78 | 500 | 2.3726 | -0.0027 | 0.0046 |
| 2.007 | 5.56 | 1000 | 2.4554 | 0.1070 | 0.1026 |
| 1.6757 | 8.33 | 1500 | 2.5454 | 0.1855 | 0.2018 |
| 1.2994 | 11.11 | 2000 | 2.6006 | 0.2215 | 0.2353 |
| 1.0455 | 13.89 | 2500 | 2.6117 | 0.2278 | 0.2338 |
| 0.8597 | 16.67 | 3000 | 2.9475 | 0.2118 | 0.2236 |
| 0.7389 | 19.44 | 3500 | 2.8112 | 0.2173 | 0.2237 |
| 0.6597 | 22.22 | 4000 | 3.0116 | 0.2065 | 0.2191 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-cola
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6220
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6131 | 1.87 | 500 | 0.6205 | 0.0 |
| 0.6072 | 3.73 | 1000 | 0.6191 | 0.0 |
| 0.6061 | 5.6 | 1500 | 0.6164 | 0.0 |
| 0.5996 | 7.46 | 2000 | 0.6220 | 0.0 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | 2023-01-13T04:09:08Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-mnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-mnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0217
- Accuracy: 0.4665
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.099 | 0.04 | 500 | 1.0972 | 0.3681 |
| 1.0938 | 0.08 | 1000 | 1.0886 | 0.3654 |
| 1.0844 | 0.12 | 1500 | 1.0758 | 0.4004 |
| 1.0661 | 0.16 | 2000 | 1.0610 | 0.4208 |
| 1.0616 | 0.2 | 2500 | 1.0567 | 0.4282 |
| 1.055 | 0.24 | 3000 | 1.0497 | 0.4301 |
| 1.0481 | 0.29 | 3500 | 1.0486 | 0.4384 |
| 1.0304 | 0.33 | 4000 | 1.0303 | 0.4549 |
| 1.0257 | 0.37 | 4500 | 1.0260 | 0.4638 |
| 1.0209 | 0.41 | 5000 | 1.0217 | 0.4665 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_twostage_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
datasets:
- fka/awesome-chatgpt-prompts
metrics:
- accuracy
library_name: allennlp
pipeline_tag: image-classification
tags:
- biomedical
- legal
--- |
AnonymousSub/rule_based_roberta_twostage_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: libri-alpha-0.75-Temp-1-attention-3-layers-distil-with-6-layers-att-take-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# libri-alpha-0.75-Temp-1-attention-3-layers-distil-with-6-layers-att-take-4
This model is a fine-tuned version of [rohitp1/libri-alpha-0.75-Temp-1-attention-3-layers-distil-with-6-layers-att-take-2](https://huggingface.co/rohitp1/libri-alpha-0.75-Temp-1-attention-3-layers-distil-with-6-layers-att-take-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 37.5364
- Wer: 0.3334
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.002
- train_batch_size: 2
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 43.7806 | 0.9 | 400 | 41.3073 | 0.2570 |
| 48.6549 | 1.8 | 800 | 41.8945 | 0.2740 |
| 57.4209 | 2.7 | 1200 | 39.9947 | 0.2872 |
| 68.8449 | 3.59 | 1600 | 39.4528 | 0.3059 |
| 79.4299 | 4.49 | 2000 | 38.9575 | 0.3179 |
| 93.0514 | 5.39 | 2400 | 37.5364 | 0.3334 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.11.0
|
AnonymousSub/rule_based_roberta_twostage_quadruplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-qnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-qnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6504
- Accuracy: 0.6180
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6935 | 0.15 | 500 | 0.6924 | 0.5634 |
| 0.6894 | 0.31 | 1000 | 0.6736 | 0.5960 |
| 0.672 | 0.46 | 1500 | 0.6572 | 0.6127 |
| 0.6634 | 0.61 | 2000 | 0.6543 | 0.6112 |
| 0.6616 | 0.76 | 2500 | 0.6527 | 0.6090 |
| 0.6597 | 0.92 | 3000 | 0.6489 | 0.6158 |
| 0.6507 | 1.07 | 3500 | 0.6505 | 0.6156 |
| 0.6504 | 1.22 | 4000 | 0.6477 | 0.6134 |
| 0.6443 | 1.37 | 4500 | 0.6496 | 0.6163 |
| 0.646 | 1.53 | 5000 | 0.6504 | 0.6180 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -95.66 +/- 135.45
name: mean_reward
verified: false
---
# **DQN** Agent playing **LunarLander-v2**
This is a trained model of a **DQN** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env LunarLander-v2 -orga kreepy -f logs/
python -m rl_zoo3.enjoy --algo dqn --env LunarLander-v2 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env LunarLander-v2 -orga kreepy -f logs/
python -m rl_zoo3.enjoy --algo dqn --env LunarLander-v2 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env LunarLander-v2 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env LunarLander-v2 -f logs/ -orga kreepy
```
## Hyperparameters
```python
OrderedDict([('batch_size', 9),
('buffer_size', 56569),
('exploration_final_eps', 0.1),
('exploration_fraction', 0.1164397832458963),
('exploration_initial_eps', 0.03696153798457299),
('gamma', 0.0006190974200887802),
('gradient_steps', 9),
('learning_rate', 0.011288061590135373),
('learning_starts', 15731),
('max_grad_norm', 3.705892661777349),
('n_timesteps', 10000000.0),
('policy', 'MlpPolicy'),
('policy_kwargs', 'dict(net_arch=[256, 256])'),
('target_update_interval', 218430),
('tau', 0.04363931503941886),
('train_freq', (9, 'episode')),
('normalize', False)])
```
|
AnonymousSub/rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: en
datasets:
- lmqg/qg_squad
pipeline_tag: text2text-generation
tags:
- question generation
- answer extraction
widget:
- text: "generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 1"
- text: "generate question: Beyonce further expanded her acting career, starring as blues singer <hl> Etta James <hl> in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 2"
- text: "generate question: Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, <hl> Cadillac Records <hl> ."
example_title: "Question Generation Example 3"
- text: "extract answers: <hl> Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records. <hl> Her performance in the film received praise from critics, and she garnered several nominations for her portrayal of James, including a Satellite Award nomination for Best Supporting Actress, and a NAACP Image Award nomination for Outstanding Supporting Actress."
example_title: "Answer Extraction Example 1"
- text: "extract answers: Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records. <hl> Her performance in the film received praise from critics, and she garnered several nominations for her portrayal of James, including a Satellite Award nomination for Best Supporting Actress, and a NAACP Image Award nomination for Outstanding Supporting Actress. <hl>"
example_title: "Answer Extraction Example 2"
model-index:
- name: lmqg/bart-base-squad-qg-ae
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 25.07
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 52.79
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 25.87
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 90.65
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 64.49
- name: QAAlignedF1Score-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_f1_score_bertscore_question_answer_generation_with_gold_answer
value: 93.45
- name: QAAlignedRecall-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_recall_bertscore_question_answer_generation_with_gold_answer
value: 94.14
- name: QAAlignedPrecision-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_precision_bertscore_question_answer_generation_with_gold_answer
value: 92.78
- name: QAAlignedF1Score-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_f1_score_moverscore_question_answer_generation_with_gold_answer
value: 64.47
- name: QAAlignedRecall-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_recall_moverscore_question_answer_generation_with_gold_answer
value: 65.49
- name: QAAlignedPrecision-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_precision_moverscore_question_answer_generation_with_gold_answer
value: 63.55
- name: BLEU4 (Answer Extraction)
type: bleu4_answer_extraction
value: 58.31
- name: ROUGE-L (Answer Extraction)
type: rouge_l_answer_extraction
value: 68.38
- name: METEOR (Answer Extraction)
type: meteor_answer_extraction
value: 41.39
- name: BERTScore (Answer Extraction)
type: bertscore_answer_extraction
value: 91.86
- name: MoverScore (Answer Extraction)
type: moverscore_answer_extraction
value: 81.95
- name: AnswerF1Score (Answer Extraction)
type: answer_f1_score__answer_extraction
value: 69.14
- name: AnswerExactMatch (Answer Extraction)
type: answer_exact_match_answer_extraction
value: 57.58
---
# Model Card of `lmqg/bart-base-squad-qg-ae`
This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation and answer extraction jointly on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/bart-base-squad-qg-ae")
# model prediction
question_answer_pairs = model.generate_qa("William Turner was an English painter who specialised in watercolour landscapes")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/bart-base-squad-qg-ae")
# answer extraction
answer = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
# question generation
question = pipe("extract answers: <hl> Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records. <hl> Her performance in the film received praise from critics, and she garnered several nominations for her portrayal of James, including a Satellite Award nomination for Best Supporting Actress, and a NAACP Image Award nomination for Outstanding Supporting Actress.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:---------------------------------------------------------------|
| BERTScore | 90.65 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 56.53 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 40.97 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 31.71 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 25.07 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 25.87 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 64.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 52.79 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:---------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 93.45 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedF1Score (MoverScore) | 64.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (BERTScore) | 92.78 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (MoverScore) | 63.55 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (BERTScore) | 94.14 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (MoverScore) | 65.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:---------------------------------------------------------------|
| AnswerExactMatch | 57.58 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| AnswerF1Score | 69.14 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| BERTScore | 91.86 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 65.9 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 63.06 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 60.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 58.31 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 41.39 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 81.95 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 68.38 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_answer', 'paragraph_sentence']
- output_types: ['question', 'answer']
- prefix_types: ['qg', 'ae']
- model: facebook/bart-base
- max_length: 512
- max_length_output: 32
- epoch: 3
- batch: 32
- lr: 5e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
AnonymousSub/rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-qqp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-qqp
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5311
- Accuracy: 0.7402
- F1: 0.5973
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6429 | 0.04 | 500 | 0.6232 | 0.6395 | 0.3481 |
| 0.6149 | 0.09 | 1000 | 0.6025 | 0.6619 | 0.4427 |
| 0.5929 | 0.13 | 1500 | 0.5800 | 0.6870 | 0.5779 |
| 0.5688 | 0.18 | 2000 | 0.5620 | 0.7075 | 0.5454 |
| 0.5597 | 0.22 | 2500 | 0.5503 | 0.7218 | 0.5681 |
| 0.5477 | 0.26 | 3000 | 0.5432 | 0.7283 | 0.5902 |
| 0.5467 | 0.31 | 3500 | 0.5388 | 0.7322 | 0.5946 |
| 0.541 | 0.35 | 4000 | 0.5357 | 0.7350 | 0.6098 |
| 0.543 | 0.4 | 4500 | 0.5331 | 0.7348 | 0.6141 |
| 0.5377 | 0.44 | 5000 | 0.5311 | 0.7402 | 0.5973 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_twostagetriplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
license: other
---
For le thesis, URL Classification using BERT. Referenced from URLTran research |
AnonymousSub/rule_based_roberta_twostagetriplet_hier_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-sst2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-sst2
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4355
- Accuracy: 0.8165
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6881 | 0.24 | 500 | 0.6950 | 0.5092 |
| 0.6801 | 0.48 | 1000 | 0.6692 | 0.6514 |
| 0.5122 | 0.71 | 1500 | 0.4978 | 0.7603 |
| 0.4227 | 0.95 | 2000 | 0.4629 | 0.7764 |
| 0.3789 | 1.19 | 2500 | 0.4438 | 0.8108 |
| 0.357 | 1.43 | 3000 | 0.4243 | 0.8085 |
| 0.3414 | 1.66 | 3500 | 0.4251 | 0.8073 |
| 0.3289 | 1.9 | 4000 | 0.4215 | 0.8154 |
| 0.3076 | 2.14 | 4500 | 0.4438 | 0.8096 |
| 0.3009 | 2.38 | 5000 | 0.4355 | 0.8165 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_twostagetriplet_hier_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: RichFrank/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AnonymousSub/rule_based_twostage_quadruplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-wnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer-target-glue-wnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-mrpc-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5713
- Accuracy: 0.1127
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6933 | 25.0 | 500 | 0.6928 | 0.5352 |
| 0.6841 | 50.0 | 1000 | 0.8358 | 0.2535 |
| 0.6609 | 75.0 | 1500 | 1.0305 | 0.1549 |
| 0.6149 | 100.0 | 2000 | 1.5713 | 0.1127 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AnonymousSub/unsup-consert-papers-bert | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 276.57 +/- 20.72
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AnthonyNelson/DialoGPT-small-ricksanchez | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | 2023-01-13T06:42:38Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- wer
model-index:
- name: my_asr_model_3
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: minds14
type: minds14
config: en-US
split: train[:100]
args: en-US
metrics:
- name: Wer
type: wer
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_asr_model_3
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8875
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 7.7043 | 60.0 | 300 | 6.0169 | 1.0 |
| 4.5859 | 120.0 | 600 | 4.3190 | 1.0 |
| 3.8087 | 180.0 | 900 | 3.8875 | 1.0 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Anthos23/my-awesome-model | [
"pytorch",
"tf",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | 2023-01-13T06:46:18Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sst2
model-index:
- name: finetuned_gpt2-medium_sst2_negation0.2_pretrainedFalse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-medium_sst2_negation0.2_pretrainedFalse
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2012
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.7789 | 1.0 | 1072 | 5.4517 |
| 4.368 | 2.0 | 2144 | 5.2641 |
| 4.1183 | 3.0 | 3216 | 5.2012 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
Anthos23/test_trainer | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sst2
model-index:
- name: finetuned_gpt2_sst2_negation0.2_pretrainedFalse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2_sst2_negation0.2_pretrainedFalse
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.3370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.9034 | 1.0 | 1072 | 5.5636 |
| 4.5404 | 2.0 | 2144 | 5.3854 |
| 4.368 | 3.0 | 3216 | 5.3370 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
Antony/mint_model | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- simplification
- generated_from_trainer
metrics:
- rouge
model-index:
- name: marimari-r2r-mlsum-clara-med
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marimari-r2r-mlsum-clara-med
This model is a fine-tuned version of [IIC/marimari-r2r-mlsum](https://huggingface.co/IIC/marimari-r2r-mlsum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9618
- Rouge1: 42.6764
- Rouge2: 24.4569
- Rougel: 37.0033
- Rougelsum: 37.1595
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| No log | 1.0 | 190 | 2.3970 | 40.7426 | 23.212 | 35.7093 | 35.8437 |
| No log | 2.0 | 380 | 2.3165 | 42.5676 | 24.6494 | 37.1225 | 37.2619 |
| 1.9699 | 3.0 | 570 | 2.4711 | 42.0346 | 23.7633 | 36.3472 | 36.4433 |
| 1.9699 | 4.0 | 760 | 2.7339 | 41.1717 | 22.8419 | 35.3263 | 35.4823 |
| 0.6485 | 5.0 | 950 | 2.9593 | 40.714 | 22.6931 | 34.8859 | 35.0647 |
| 0.6485 | 6.0 | 1140 | 3.1316 | 41.3218 | 23.2054 | 35.3103 | 35.5063 |
| 0.6485 | 7.0 | 1330 | 3.2542 | 41.2786 | 23.4853 | 35.8236 | 35.972 |
| 0.1529 | 8.0 | 1520 | 3.3470 | 41.2991 | 22.8385 | 35.0524 | 35.2153 |
| 0.1529 | 9.0 | 1710 | 3.4324 | 41.3838 | 23.1045 | 35.3472 | 35.5779 |
| 0.0719 | 10.0 | 1900 | 3.5187 | 42.0833 | 23.8538 | 36.3282 | 36.5294 |
| 0.0719 | 11.0 | 2090 | 3.5527 | 41.2993 | 23.0323 | 35.3116 | 35.4687 |
| 0.0719 | 12.0 | 2280 | 3.6624 | 41.6524 | 23.8925 | 35.9281 | 36.1012 |
| 0.0393 | 13.0 | 2470 | 3.6536 | 41.188 | 23.2066 | 35.371 | 35.5616 |
| 0.0393 | 14.0 | 2660 | 3.6656 | 40.8222 | 22.5651 | 35.0515 | 35.1399 |
| 0.0266 | 15.0 | 2850 | 3.7349 | 41.844 | 23.7839 | 36.102 | 36.3169 |
| 0.0266 | 16.0 | 3040 | 3.7254 | 41.5535 | 23.3996 | 35.9619 | 36.0981 |
| 0.0266 | 17.0 | 3230 | 3.7919 | 41.5683 | 23.2824 | 36.0855 | 36.2475 |
| 0.0151 | 18.0 | 3420 | 3.8152 | 42.1272 | 24.0548 | 36.5784 | 36.785 |
| 0.0151 | 19.0 | 3610 | 3.8213 | 41.9185 | 23.5975 | 36.1182 | 36.3194 |
| 0.0087 | 20.0 | 3800 | 3.8501 | 41.3409 | 23.0081 | 35.7662 | 35.9451 |
| 0.0087 | 21.0 | 3990 | 3.8690 | 41.9496 | 23.7032 | 36.0116 | 36.1843 |
| 0.0087 | 22.0 | 4180 | 3.8809 | 42.5366 | 24.6413 | 37.2644 | 37.459 |
| 0.0044 | 23.0 | 4370 | 3.8865 | 42.4346 | 24.2278 | 36.7284 | 36.8846 |
| 0.0044 | 24.0 | 4560 | 3.9044 | 42.9781 | 24.8423 | 37.3582 | 37.4807 |
| 0.0024 | 25.0 | 4750 | 3.9138 | 42.6738 | 24.4737 | 36.8959 | 37.0031 |
| 0.0024 | 26.0 | 4940 | 3.9361 | 42.5267 | 24.4155 | 36.8414 | 36.9915 |
| 0.0024 | 27.0 | 5130 | 3.9477 | 42.4844 | 24.5483 | 36.8857 | 37.0219 |
| 0.0013 | 28.0 | 5320 | 3.9561 | 42.7199 | 24.5977 | 37.1206 | 37.2374 |
| 0.0013 | 29.0 | 5510 | 3.9599 | 42.7088 | 24.4474 | 37.0513 | 37.1971 |
| 0.001 | 30.0 | 5700 | 3.9618 | 42.6764 | 24.4569 | 37.0033 | 37.1595 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.12.1
|
gaurishhs/API | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2023-01-13T07:19:03Z | ---
tags:
- KungFuMaster-v5
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: KungFuMaster-v5
type: KungFuMaster-v5
metrics:
- type: mean_reward
value: 28270.00 +/- 6635.82
name: mean_reward
verified: false
---
# (CleanRL) **PPO** Agent Playing **KungFuMaster-v5**
This is a trained model of a PPO agent playing KungFuMaster-v5.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/ppo_atari_envpool_async_jax_scan_impalanet_machado.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[ppo_atari_envpool_async_jax_scan_impalanet_machado]"
python -m cleanrl_utils.enjoy --exp-name ppo_atari_envpool_async_jax_scan_impalanet_machado --env-id KungFuMaster-v5
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/KungFuMaster-v5-ppo_atari_envpool_async_jax_scan_impalanet_machado-seed1/raw/main/ppo_atari_envpool_async_jax_scan_impalanet_machado.py
curl -OL https://huggingface.co/cleanrl/KungFuMaster-v5-ppo_atari_envpool_async_jax_scan_impalanet_machado-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/KungFuMaster-v5-ppo_atari_envpool_async_jax_scan_impalanet_machado-seed1/raw/main/poetry.lock
poetry install --all-extras
python ppo_atari_envpool_async_jax_scan_impalanet_machado.py --track --wandb-project-name envpool-atari --save-model --upload-model --hf-entity cleanrl --env-id KungFuMaster-v5 --seed 1
```
# Hyperparameters
```python
{'anneal_lr': True,
'async_batch_size': 16,
'batch_size': 2048,
'capture_video': False,
'clip_coef': 0.1,
'cuda': True,
'ent_coef': 0.01,
'env_id': 'KungFuMaster-v5',
'exp_name': 'ppo_atari_envpool_async_jax_scan_impalanet_machado',
'gae': True,
'gae_lambda': 0.95,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.00025,
'max_grad_norm': 0.5,
'minibatch_size': 1024,
'norm_adv': True,
'num_envs': 64,
'num_minibatches': 2,
'num_steps': 32,
'num_updates': 24414,
'save_model': True,
'seed': 1,
'target_kl': None,
'torch_deterministic': True,
'total_timesteps': 50000000,
'track': True,
'update_epochs': 2,
'upload_model': True,
'vf_coef': 0.5,
'wandb_entity': None,
'wandb_project_name': 'envpool-atari'}
```
|
Apisate/Discord-Ai-Bot | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: sd99/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ArBert/albert-base-v2-finetuned-ner-gmm-twitter | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Worm
library_name: ml-agents
---
# **ppo** Agent playing **Worm**
This is a trained model of a **ppo** agent playing **Worm** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Worm
2. Step 1: Write your model_id: saikiranp/ppo-Worm
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ArBert/albert-base-v2-finetuned-ner-kmeans-twitter | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
inference: true
license: creativeml-openrail-m
---
## Pending info card
I will be updating soon
## Model Weights
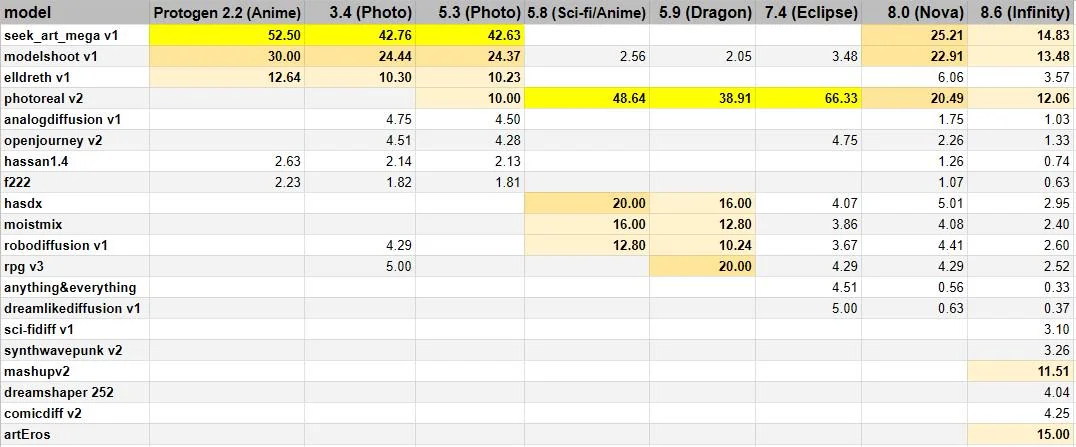 |
ArBert/albert-base-v2-finetuned-ner-kmeans | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.76 +/- 19.78
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ArBert/albert-base-v2-finetuned-ner | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 19 | null | ---
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
- protogen
inference: true
widget:
- text: >-
modelshoot style, (extremely detailed CG unity 8k wallpaper), full shot body
photo of the most beautiful artwork in the world, english medieval witch,
black silk vale, pale skin, black silk robe, black cat, necromancy magic,
medieval era, photorealistic painting by Ed Blinkey, Atey Ghailan, Studio
Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, trending on ArtStation,
trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic,
photorealistic painting art by midjourney and greg rutkowski
example_title: Model photo
license: creativeml-openrail-m
---
<center><img src="https://huggingface.co/darkstorm2150/Protogen_Nova_Official_Release/resolve/main/Protogen%20Nova-512.png" style="height:400px; border-radius: 7%; border: 10px solid #663380; padding-top:0px;" span title="Protogen Nova Raw Output with a bladerunner 2049 embedding ;)"></center>
<center><h1>Protogen Nova</h1></center>
<center><p><em>Research Model by <a href="https://instagram.com/officialvictorespinoza">darkstorm2150</a></em></p></center>
</div>
## Table of contents
* [General info](#general-info)
* [Granular Adaptive Learning](#granular-adaptive-learning)
* [Setup](#setup)
* [Space](#space)
* [CompVis](#compvis)
* [Diffusers](#diffusers)
* [Checkpoint Merging Data Reference](#checkpoint-merging-data-reference)
* [License](#license)
## General info
The Protogen Nova is a checkpoint model that merges all the previous models into one
This merger includes
* Protogen v2.2 (Anime)
* Protogen x3.4 (Photorealism)
* ProtoGen x5.3 (Photorealism)
* ProtoGen x5.8 Rebuilt (Scifi+Anime)
* ProtoGen x5.9 (Dragon)
* ProtoGen x7.4 (Eclipse)
As part the of the checkpoint merging, Granular Adaptive Learning is a technique where traininig data is lessen selectively from 30% to 0.05%, and as the training is eventually saturated, the process reduces loss and introduces elements from various checkpoints
## Granular Adaptive Learning
Granular adaptive learning is a machine learning technique that focuses on adjusting the learning process at a fine-grained level, rather than making global adjustments to the model. This approach allows the model to adapt to specific patterns or features in the data, rather than making assumptions based on general trends.
Granular adaptive learning can be achieved through techniques such as active learning, which allows the model to select the data it wants to learn from, or through the use of reinforcement learning, where the model receives feedback on its performance and adapts based on that feedback. It can also be achieved through techniques such as online learning where the model adjust itself as it receives more data.
Granular adaptive learning is often used in situations where the data is highly diverse or non-stationary and where the model needs to adapt quickly to changing patterns. This is often the case in dynamic environments such as robotics, financial markets, and natural language processing.
## Setup
To run this model, download the model.ckpt and install it in your "stable-diffusion-webui\models\Stable-diffusion" directory
## Space
## CompVis
## Diffusers
## Checkpoint Merging Data Reference - PENDING DATA FOR MERGE, RPGv2 not accounted..
<style>
.myTable {
border-collapse:collapse;
}
.myTable th {
background-color:#663380;
color:white;
}
.myTable td, .myTable th {
padding:5px;
border:1px solid #663380;
}
</style>
<table class="myTable">
<tr>
<th>Models</th>
<th>Protogen v2.2 (Anime)</th>
<th>Protogen x3.4 (Photo)</th>
<th>Protogen x5.3 (Photo)</th>
<th>Protogen x5.8 (Sci-fi/Anime)</th>
<th>Protogen x5.9 (Dragon)</th>
<th>Protogen x7.4 (Eclipse)</th>
<th>Protogen x8.0 (Nova)</th>
<th>Protogen x8.6 (Infinity)</th>
</tr>
<tr>
<td>seek_art_mega v1</td>
<td>52.50%</td>
<td>42.76%</td>
<td>42.63%</td>
<td></td>
<td></td>
<td></td>
<td>25.21%</td>
<td>14.83%</td>
</tr>
<tr>
<td>modelshoot v1</td>
<td>30.00%</td>
<td>24.44%</td>
<td>24.37%</td>
<td>2.56%</td>
<td>2.05%</td>
<td>3.48%</td>
<td>22.91%</td>
<td>13.48%</td>
</tr>
<tr>
<td>elldreth v1</td>
<td>12.64%</td>
<td>10.30%</td>
<td>10.23%</td>
<td></td>
<td></td>
<td></td>
<td>6.06%</td>
<td>3.57%</td>
</tr>
<tr>
<td>photoreal v2</td>
<td></td>
<td></td>
<td>10.00%</td>
<td>48.64%</td>
<td>38.91%</td>
<td>66.33%</td>
<td>20.49%</td>
<td>12.06%</td>
</tr>
<tr>
<td>analogdiffusion v1</td>
<td></td>
<td>4.75%</td>
<td>4.50%</td>
<td></td>
<td></td>
<td></td>
<td>1.75%</td>
<td>1.03%</td>
</tr>
<tr>
<td>openjourney v2</td>
<td></td>
<td>4.51%</td>
<td>4.28%</td>
<td></td>
<td></td>
<td>4.75%</td>
<td>2.26%</td>
<td>1.33%</td>
</tr>
<tr>
<td>hassan1.4</td>
<td>2.63%</td>
<td>2.14%</td>
<td>2.13%</td>
<td></td>
<td></td>
<td></td>
<td>1.26%</td>
<td>0.74%</td>
</tr>
<tr>
<td>f222</td>
<td>2.23%</td>
<td>1.82%</td>
<td>1.81%</td>
<td></td>
<td></td>
<td></td>
<td>1.07%</td>
<td>0.63%</td>
</tr>
<tr>
<td>hasdx</td>
<td></td>
<td></td>
<td></td>
<td>20.00%</td>
<td>16.00%</td>
<td>4.07%</td>
<td>5.01%</td>
<td>2.95%</td>
</tr>
<tr>
<td>moistmix</td>
<td></td>
<td></td>
<td></td>
<td>16.00%</td>
<td>12.80%</td>
<td>3.86%</td>
<td>4.08%</td>
<td>2.40%</td>
</tr>
<tr>
<td>roboDiffusion v1</td>
<td></td>
<td>4.29%</td>
<td></td>
<td>12.80%</td>
<td>10.24%</td>
<td>3.67%</td>
<td>4.41%</td>
<td>2.60%</td>
</tr>
<tr>
<td>RPG v3</td>
<td></td>
<td>5.00%</td>
<td></td>
<td></td>
<td>20.00%</td>
<td>4.29%</td>
<td>4.29%</td>
<td>2.52%</td>
</tr>
<tr>
<td>anything&everything</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.51%</td>
<td>0.56%</td>
<td>0.33%</td>
</tr>
<tr>
<td>dreamlikediff v1</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>5.0%</td>
<td>0.63%</td>
<td>0.37%</td>
</tr>
<tr>
<td>sci-fidiff v1</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>3.10%</td>
</tr>
<tr>
<td>synthwavepunk v2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>3.26%</td>
</tr>
<tr>
<td>mashupv2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>11.51%</td>
</tr>
<tr>
<td>dreamshaper 252</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.04%</td>
</tr>
<tr>
<td>comicdiff v2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.25%</td>
</tr>
<tr>
<td>artEros</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>15.00%</td>
</tr>
</table>
## License
By downloading you agree to the terms of these licenses
<a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license">CreativeML Open RAIL-M</a>
<a href="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/blob/main/LICENSE.md">Dreamlike License</a>
<a href="https://huggingface.co/coreco/seek.art_MEGA/blob/main/LICENSE.txt">Seek Art Mega License</a> |
ArBert/bert-base-uncased-finetuned-ner-kmeans | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: sks
---
### Curious Builders Style Dreambooth model trained by [Builder A](https://twitter.com/_builder_a) with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
sks (use that on your prompt)

|
ArBert/roberta-base-finetuned-ner-agglo-twitter | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: a dashdash cat fight with alian in Loch Ness
---
# DreamBooth model for the dashdash concept trained by jiaenyue.
This is a Stable Diffusion model fine-tuned on the dashdash concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of dashdash cat**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `cat` images for the animal theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('jiaenyue/dashdash-cat-heywhale')
image = pipeline().images[0]
image
```
|
ArBert/roberta-base-finetuned-ner | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sst2
model-index:
- name: finetuned_gpt2-medium_sst2_negation0.5_pretrainedFalse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-medium_sst2_negation0.5_pretrainedFalse
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.1557
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.7161 | 1.0 | 1092 | 5.4142 |
| 4.3157 | 2.0 | 2184 | 5.2121 |
| 4.0662 | 3.0 | 3276 | 5.1557 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
ArJakusz/DialoGPT-small-starky | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sst2
model-index:
- name: finetuned_gpt2_sst2_negation0.001_pretrainedTrue
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2_sst2_negation0.001_pretrainedTrue
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5281
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1136 | 1.0 | 1060 | 3.5086 |
| 2.9278 | 2.0 | 2120 | 3.5202 |
| 2.8337 | 3.0 | 3180 | 3.5281 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
Araby/Arabic-TTS | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sst2
model-index:
- name: finetuned_gpt2_sst2_negation0.0001_pretrainedTrue
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2_sst2_negation0.0001_pretrainedTrue
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1085 | 1.0 | 1059 | 3.5023 |
| 2.9261 | 2.0 | 2118 | 3.5156 |
| 2.8319 | 3.0 | 3177 | 3.5246 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
Aracatto/Catto | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole-test
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AragornII/DialoGPT-small-harrypotter | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: small-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-cola-from-scratch-custom-tokenizer-target-glue-cola
This model is a fine-tuned version of [muhtasham/small-mlm-glue-cola-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/small-mlm-glue-cola-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4495
- Matthews Correlation: 0.0818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6061 | 1.87 | 500 | 0.6164 | 0.0 |
| 0.5408 | 3.73 | 1000 | 0.8211 | 0.0968 |
| 0.4337 | 5.6 | 1500 | 0.8690 | 0.0758 |
| 0.3679 | 7.46 | 2000 | 1.1146 | 0.1061 |
| 0.3106 | 9.33 | 2500 | 1.2573 | 0.0842 |
| 0.2744 | 11.19 | 3000 | 1.3205 | 0.0955 |
| 0.2368 | 13.06 | 3500 | 1.4495 | 0.0818 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
ArashEsk95/bert-base-uncased-finetuned-sst2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 285.50 +/- 21.30
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ArashEsk95/bert-base-uncased-finetuned-stsb | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-qqp-from-scratch-custom-tokenizer-target-glue-mnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-qqp-from-scratch-custom-tokenizer-target-glue-mnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-qqp-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-qqp-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0670
- Accuracy: 0.4124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0984 | 0.04 | 500 | 1.0960 | 0.3664 |
| 1.088 | 0.08 | 1000 | 1.0798 | 0.3864 |
| 1.0782 | 0.12 | 1500 | 1.0709 | 0.4053 |
| 1.0665 | 0.16 | 2000 | 1.0643 | 0.4212 |
| 1.0659 | 0.2 | 2500 | 1.0612 | 0.4194 |
| 1.0624 | 0.24 | 3000 | 1.0582 | 0.4154 |
| 1.0589 | 0.29 | 3500 | 1.0670 | 0.4124 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
AriakimTaiyo/DialoGPT-cultured-Kumiko | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: tiny-mlm-glue-qqp-from-scratch-custom-tokenizer-target-glue-mrpc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-qqp-from-scratch-custom-tokenizer-target-glue-mrpc
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-qqp-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-qqp-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1462
- Accuracy: 0.6078
- F1: 0.7004
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6345 | 4.35 | 500 | 0.6233 | 0.6838 | 0.8122 |
| 0.5755 | 8.7 | 1000 | 0.6293 | 0.6912 | 0.79 |
| 0.4471 | 13.04 | 1500 | 0.7664 | 0.6373 | 0.7289 |
| 0.3211 | 17.39 | 2000 | 0.9256 | 0.6348 | 0.7256 |
| 0.2338 | 21.74 | 2500 | 1.1462 | 0.6078 | 0.7004 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
Aron/distilbert-base-uncased-finetuned-emotion | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 36 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: platzi-distilroberta-base-mrpc-elyager
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: train
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8651960784313726
- name: F1
type: f1
value: 0.9019607843137256
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi-distilroberta-base-mrpc-elyager
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4365
- Accuracy: 0.8652
- F1: 0.9020
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5301 | 1.09 | 500 | 0.5564 | 0.8186 | 0.8737 |
| 0.3404 | 2.18 | 1000 | 0.4365 | 0.8652 | 0.9020 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Ayham/xlnet_gpt2_summarization_xsum | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:xsum",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
library_name: stable-baselines3
tags:
- Pixelcopter-PLE-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: ppo
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 162.90 +/- 102.90
name: mean_reward
verified: false
---
# **ppo** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **ppo** agent playing **Pixelcopter-PLE-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
BSC-LT/RoBERTalex | [
"pytorch",
"roberta",
"fill-mask",
"es",
"dataset:legal_ES",
"dataset:temu_legal",
"arxiv:2110.12201",
"transformers",
"legal",
"spanish",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
language: en
license: mit
tags:
- vision
- image-segmentation
model_name: openmmlab/upernet-swin-large
---
# UperNet, Swin Transformer large-sized backbone
UperNet framework for semantic segmentation, leveraging a Swin Transformer backbone. UperNet was introduced in the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Xiao et al.
Combining UperNet with a Swin Transformer backbone was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030).
Disclaimer: The team releasing UperNet + Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
UperNet is a framework for semantic segmentation. It consists of several components, including a backbone, a Feature Pyramid Network (FPN) and a Pyramid Pooling Module (PPM).
Any visual backbone can be plugged into the UperNet framework. The framework predicts a semantic label per pixel.

## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=openmmlab/upernet) to look for
fine-tuned versions (with various backbones) on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/upernet#transformers.UperNetForSemanticSegmentation).
|
BSC-LT/roberta-base-bne-sqac | [
"pytorch",
"roberta",
"question-answering",
"es",
"dataset:BSC-TeMU/SQAC",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"qa",
"question answering",
"license:apache-2.0",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: tiny-mlm-glue-sst2-from-scratch-custom-tokenizer-target-glue-rte
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-sst2-from-scratch-custom-tokenizer-target-glue-rte
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-sst2-from-scratch-custom-tokenizer](https://huggingface.co/muhtasham/tiny-mlm-glue-sst2-from-scratch-custom-tokenizer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3426
- Accuracy: 0.5199
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.694 | 6.41 | 500 | 0.6929 | 0.5271 |
| 0.6741 | 12.82 | 1000 | 0.7605 | 0.5415 |
| 0.378 | 19.23 | 1500 | 1.1333 | 0.5523 |
| 0.2169 | 25.64 | 2000 | 1.5213 | 0.5415 |
| 0.1388 | 32.05 | 2500 | 1.8631 | 0.5560 |
| 0.1043 | 38.46 | 3000 | 2.0940 | 0.5307 |
| 0.0916 | 44.87 | 3500 | 2.2488 | 0.5307 |
| 0.072 | 51.28 | 4000 | 2.3426 | 0.5199 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
BSC-LT/roberta-base-bne | [
"pytorch",
"roberta",
"fill-mask",
"es",
"dataset:bne",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 594 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 38.70 +/- 31.48
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
BSC-LT/roberta-large-bne-sqac | [
"pytorch",
"roberta",
"question-answering",
"es",
"dataset:BSC-TeMU/SQAC",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"qa",
"question answering",
"license:apache-2.0",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/fulviodan/ddpm-butterflies-128/tensorboard?#scalars)
|
BSen/wav2vec2-base-timit-demo-colab | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: mit
tags:
- simplification
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mbart-large-50-clara-med
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-50-clara-med
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2121
- Rouge1: 49.1001
- Rouge2: 31.2516
- Rougel: 44.0446
- Rougelsum: 44.1075
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| No log | 1.0 | 190 | 1.8633 | 44.8593 | 28.0451 | 40.7724 | 40.8654 |
| No log | 2.0 | 380 | 1.6667 | 46.8654 | 29.5857 | 42.6056 | 42.7844 |
| 3.317 | 3.0 | 570 | 1.6847 | 48.1605 | 30.163 | 43.1965 | 43.3317 |
| 3.317 | 4.0 | 760 | 1.7845 | 48.7615 | 30.8887 | 43.6946 | 43.8016 |
| 0.7441 | 5.0 | 950 | 2.0090 | 48.4207 | 30.64 | 43.654 | 43.7979 |
| 0.7441 | 6.0 | 1140 | 2.2425 | 49.1967 | 31.2644 | 44.0566 | 44.2112 |
| 0.7441 | 7.0 | 1330 | 2.4520 | 47.0568 | 28.7501 | 41.8219 | 41.9605 |
| 0.2396 | 8.0 | 1520 | 2.5336 | 47.969 | 30.0618 | 42.9924 | 43.1481 |
| 0.2396 | 9.0 | 1710 | 2.6153 | 47.2037 | 28.9732 | 42.0939 | 42.2242 |
| 0.1112 | 10.0 | 1900 | 2.7299 | 48.3657 | 30.3342 | 43.2025 | 43.3223 |
| 0.1112 | 11.0 | 2090 | 2.7696 | 48.0929 | 30.0156 | 42.9385 | 43.026 |
| 0.1112 | 12.0 | 2280 | 2.8627 | 48.1979 | 30.2714 | 43.0959 | 43.2027 |
| 0.0938 | 13.0 | 2470 | 2.8788 | 47.7685 | 29.5733 | 42.7561 | 42.9112 |
| 0.0938 | 14.0 | 2660 | 2.9128 | 47.5374 | 29.8217 | 42.7097 | 42.7803 |
| 0.0394 | 15.0 | 2850 | 2.9470 | 48.6385 | 30.1425 | 43.3326 | 43.3963 |
| 0.0394 | 16.0 | 3040 | 3.0039 | 48.6657 | 30.6642 | 43.471 | 43.592 |
| 0.0394 | 17.0 | 3230 | 3.0380 | 48.2351 | 30.5653 | 43.257 | 43.3788 |
| 0.023 | 18.0 | 3420 | 3.0289 | 48.6593 | 30.6916 | 43.7861 | 43.9098 |
| 0.023 | 19.0 | 3610 | 3.0733 | 49.2114 | 31.2737 | 44.0852 | 44.1993 |
| 0.0122 | 20.0 | 3800 | 3.1089 | 48.5431 | 30.5305 | 43.4128 | 43.5288 |
| 0.0122 | 21.0 | 3990 | 3.0684 | 48.4197 | 30.4005 | 43.2305 | 43.3214 |
| 0.0122 | 22.0 | 4180 | 3.1252 | 48.6007 | 30.5594 | 43.4008 | 43.5336 |
| 0.0071 | 23.0 | 4370 | 3.1572 | 48.7297 | 30.7028 | 43.436 | 43.5106 |
| 0.0071 | 24.0 | 4560 | 3.1716 | 48.9335 | 30.9918 | 43.7764 | 43.8044 |
| 0.0041 | 25.0 | 4750 | 3.1687 | 48.8731 | 31.1055 | 43.8021 | 43.8987 |
| 0.0041 | 26.0 | 4940 | 3.1845 | 48.9432 | 31.0766 | 43.8628 | 43.9726 |
| 0.0041 | 27.0 | 5130 | 3.2133 | 49.2016 | 31.1265 | 44.052 | 44.1427 |
| 0.0025 | 28.0 | 5320 | 3.2146 | 49.1473 | 31.3109 | 44.0372 | 44.1189 |
| 0.0025 | 29.0 | 5510 | 3.2121 | 49.2815 | 31.4258 | 44.1661 | 44.2436 |
| 0.0019 | 30.0 | 5700 | 3.2121 | 49.1001 | 31.2516 | 44.0446 | 44.1075 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.12.1
|
Babysittingyoda/DialoGPT-small-familyguy | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: armargolis/pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Backedman/DialoGPT-small-Anika | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_finetuned_genboolq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_finetuned_genboolq
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5011
- Rouge1: 36.4881
- Rouge2: 17.8649
- Rougel: 34.2658
- Rougelsum: 34.2336
- Gen Len: 11.7003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.5854 | 1.0 | 2082 | 0.5182 | 35.5544 | 16.9686 | 33.3783 | 33.3536 | 11.5918 |
| 0.5479 | 2.0 | 4164 | 0.4969 | 37.0664 | 18.2443 | 34.7139 | 34.6934 | 11.8662 |
| 0.5405 | 3.0 | 6246 | 0.5011 | 36.4881 | 17.8649 | 34.2658 | 34.2336 | 11.7003 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Badr/model1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: fbeghell/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Bagus/wav2vec2-xlsr-greek-speech-emotion-recognition | [
"pytorch",
"tensorboard",
"wav2vec2",
"el",
"dataset:aesdd",
"transformers",
"audio",
"audio-classification",
"speech",
"license:apache-2.0"
]
| audio-classification | {
"architectures": [
"Wav2Vec2ForSpeechClassification"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 21 | null | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- wildcard
widget:
- text: The building skin of the office building, the glass curtain wall
---
# DreamBooth model for the hzarchshkin concept trained by zeizeiwai.
This is a Stable Diffusion model fine-tuned on the hzarchshkin concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of hzarchshkin Buildskin**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `Buildskin` images for the wildcard theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('zeizeiwai/hzarchshkin-Buildskin-heywhale')
image = pipeline().images[0]
image
```
|
Bagus/wav2vec2-xlsr-japanese-speech-emotion-recognition | [
"pytorch",
"wav2vec2",
"audio-classification",
"ja",
"dataset:jtes",
"transformers",
"audio",
"speech",
"speech-emotion-recognition",
"has_space"
]
| audio-classification | {
"architectures": [
"HubertForSequenceClassification"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: emmashe15/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Bakkes/BakkesModWiki | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
config: plus
split: train
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9487096774193549
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3462
- Accuracy: 0.9487
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 2.4449 | 0.7529 |
| 2.8785 | 2.0 | 636 | 1.2330 | 0.8561 |
| 2.8785 | 3.0 | 954 | 0.6774 | 0.9132 |
| 1.0817 | 4.0 | 1272 | 0.4716 | 0.9335 |
| 0.454 | 5.0 | 1590 | 0.4020 | 0.9442 |
| 0.454 | 6.0 | 1908 | 0.3749 | 0.9439 |
| 0.294 | 7.0 | 2226 | 0.3593 | 0.9481 |
| 0.2429 | 8.0 | 2544 | 0.3514 | 0.9474 |
| 0.2429 | 9.0 | 2862 | 0.3486 | 0.9481 |
| 0.2258 | 10.0 | 3180 | 0.3462 | 0.9487 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Bala/model_name | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- dreambooth-hackathon
- landscape
widget:
- text: A photo of ggenshin landscape
---
# Dreambooth Model for Landscapes trained on images from Genshin Impact.
This is a Stable Diffusion model fine-tuned on the landscape concept with DreamBooth. It can be used by modifying the `instance_prompt`: **ggenshin landscape**
This model was created as part of the DreamBooth Hackathon 🔥.
## Description
Model finetuned on the pictures of Genshin Landscapes, made for the Dreambooth Hackathon,
finetuned on Stable diffusion 2.1 Base.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('Apocalypse-19/Genshin-Landscape-Diffusion')
image = pipeline().images[0]
image
```
## Examples
Some examples of images generated by the model are shown below, with their prompts.

A picture of the woods, ggenshin landscape, eerie

the Colosseum, ggenshin landscape

Savannah, ggenshin landscape

A picture of a river of blood, ggenshin landscape

Massive tree, ggenshin landscape

Lake, ggenshin landscape
|
Barleysack/klue-roberta-LSTM | [
"pytorch",
"roberta",
"transformers"
]
| null | {
"architectures": [
"QAWithLSTMModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2023-01-13T16:23:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: small-vanilla-target-glue-mnli-linear-probe
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-vanilla-target-glue-mnli-linear-probe
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0612
- Accuracy: 0.4363
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1093 | 0.04 | 500 | 1.0875 | 0.3914 |
| 1.089 | 0.08 | 1000 | 1.0814 | 0.3988 |
| 1.0811 | 0.12 | 1500 | 1.0760 | 0.4113 |
| 1.0753 | 0.16 | 2000 | 1.0728 | 0.4200 |
| 1.0758 | 0.2 | 2500 | 1.0702 | 0.4252 |
| 1.0727 | 0.24 | 3000 | 1.0684 | 0.4269 |
| 1.0707 | 0.29 | 3500 | 1.0665 | 0.4295 |
| 1.0702 | 0.33 | 4000 | 1.0648 | 0.4317 |
| 1.0654 | 0.37 | 4500 | 1.0627 | 0.4352 |
| 1.0637 | 0.41 | 5000 | 1.0612 | 0.4363 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
Battlehooks/distilbert-base-uncased-finetuned-squad | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="keyblade95/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BatuhanYilmaz/bert-finetuned-mrpc | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- audio
- automatic-speech-recognition
- endpoints-template
library_name: generic
inference: false
---
# OpenAI [Whisper](https://github.com/openai/whisper) Inference Endpoint example
> Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
For more information about the model, license and limitations check the original repository at [openai/whisper](https://github.com/openai/whisper).
---
This repository implements a custom `handler` task for `automatic-speech-recognition` for 🤗 Inference Endpoints using OpenAIs new Whisper model. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/handler.py).
There is also a [notebook](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/create_handler.ipynb) included, on how to create the `handler.py`
### Request
The endpoint expects a binary audio file. Below is a cURL example and a Python example using the `requests` library.
**curl**
```bash
# load audio file
wget https://cdn-media.huggingface.co/speech_samples/sample1.flac
# run request
curl --request POST \
--url https://{ENDPOINT}/ \
--header 'Content-Type: audio/x-flac' \
--header 'Authorization: Bearer {HF_TOKEN}' \
--data-binary '@sample1.flac'
```
**Python**
```python
import json
from typing import List
import requests as r
import base64
import mimetypes
ENDPOINT_URL=""
HF_TOKEN=""
def predict(path_to_audio:str=None):
# read audio file
with open(path_to_audio, "rb") as i:
b = i.read()
# get mimetype
content_type= mimetypes.guess_type(path_to_audio)[0]
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": content_type
}
response = r.post(ENDPOINT_URL, headers=headers, data=b)
return response.json()
prediction = predict(path_to_audio="sample1.flac")
prediction
```
expected output
```json
{"text": " going along slushy country roads and speaking to damp audiences in draughty school rooms day after day for a fortnight. He'll have to put in an appearance at some place of worship on Sunday morning, and he can come to us immediately afterwards."}
```
|
BatuhanYilmaz/marian-finetuned-kde4-en-to-fr | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-uncases-forprof2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncases-forprof2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1248
- Accuracy: 0.978
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2665 | 1.0 | 125 | 0.1724 | 0.956 |
| 0.0967 | 2.0 | 250 | 0.1248 | 0.978 |
| 0.0207 | 3.0 | 375 | 0.1533 | 0.97 |
| 0.008 | 4.0 | 500 | 0.1575 | 0.966 |
| 0.0086 | 5.0 | 625 | 0.1498 | 0.976 |
| 0.0084 | 6.0 | 750 | 0.1671 | 0.976 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Baybars/wav2vec2-xls-r-300m-cv8-turkish | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Han Chinese WS
This model provides word segmentation for the ancient Chinese language. Our training dataset covers four eras of the Chinese language.
## Homepage
* [ckiplab/han-transformers](https://github.com/ckiplab/han-transformers) |
Bee-Garbs/DialoGPT-real-cartman-small | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: mit
duplicated_from: sd-concepts-library/ambrose-arm-chair
---
### ambrose-arm-chair on Stable Diffusion
This is the `<ambrose-arm-chair>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
Beelow/wav2vec2-ukrainian-model-large | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Han Chinese POS
This model provides part-of-speech (POS) tagging for the ancient Chinese language. Our training dataset covers four eras of the Chinese language.
## Homepage
* [ckiplab/han-transformers](https://github.com/ckiplab/han-transformers)
## Training Datasets
The copyright of the datasets belongs to the Institute of Linguistics, Academia Sinica.
* [中央研究院上古漢語標記語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/akiwi/kiwi.sh)
* [中央研究院中古漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/dkiwi/kiwi.sh)
* [中央研究院近代漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/pkiwi/kiwi.sh)
* [中央研究院現代漢語語料庫](http://asbc.iis.sinica.edu.tw)
## Contributors
* Chin-Tung Lin at [CKIP](https://ckip.iis.sinica.edu.tw/) |
Belin/T5-Terms-and-Conditions | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Han Chinese POS
This model provides part-of-speech (POS) tagging for the ancient Chinese language. Our training dataset covers four eras of the Chinese language.
## Homepage
* [ckiplab/han-transformers](https://github.com/ckiplab/han-transformers)
## Training Datasets
The copyright of the datasets belongs to the Institute of Linguistics, Academia Sinica.
* [中央研究院上古漢語標記語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/akiwi/kiwi.sh)
* [中央研究院中古漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/dkiwi/kiwi.sh)
* [中央研究院近代漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/pkiwi/kiwi.sh)
* [中央研究院現代漢語語料庫](http://asbc.iis.sinica.edu.tw)
## Contributors
* Chin-Tung Lin at [CKIP](https://ckip.iis.sinica.edu.tw/) |
BenDavis71/GPT-2-Finetuning-AIRaid | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 35.10 +/- 25.77
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
BenGeorge/MyModel | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: small-vanilla-target-glue-mrpc-linear-probe
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-vanilla-target-glue-mrpc-linear-probe
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5860
- Accuracy: 0.7010
- F1: 0.8174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6358 | 4.35 | 500 | 0.6136 | 0.6838 | 0.8111 |
| 0.6123 | 8.7 | 1000 | 0.6068 | 0.6863 | 0.8129 |
| 0.6054 | 13.04 | 1500 | 0.5990 | 0.6838 | 0.8095 |
| 0.6008 | 17.39 | 2000 | 0.5962 | 0.6912 | 0.8136 |
| 0.595 | 21.74 | 2500 | 0.5925 | 0.7059 | 0.8209 |
| 0.5916 | 26.09 | 3000 | 0.5898 | 0.7034 | 0.8191 |
| 0.5885 | 30.43 | 3500 | 0.5906 | 0.7010 | 0.8185 |
| 0.5915 | 34.78 | 4000 | 0.5860 | 0.7010 | 0.8174 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
BhanuSama/gpt2-finetuned-xsum | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- audio
- automatic-speech-recognition
- endpoints-template
library_name: generic
inference: false
---
# OpenAI [Whisper](https://github.com/openai/whisper) Inference Endpoint example
> Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
For more information about the model, license and limitations check the original repository at [openai/whisper](https://github.com/openai/whisper).
---
This repository implements a custom `handler` task for `automatic-speech-recognition` for 🤗 Inference Endpoints using OpenAIs new Whisper model. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/handler.py).
There is also a [notebook](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/create_handler.ipynb) included, on how to create the `handler.py`
### Request
The endpoint expects a binary audio file. Below is a cURL example and a Python example using the `requests` library.
**curl**
```bash
# load audio file
wget https://cdn-media.huggingface.co/speech_samples/sample1.flac
# run request
curl --request POST \
--url https://{ENDPOINT}/ \
--header 'Content-Type: audio/x-flac' \
--header 'Authorization: Bearer {HF_TOKEN}' \
--data-binary '@sample1.flac'
```
**Python**
```python
import json
from typing import List
import requests as r
import base64
import mimetypes
ENDPOINT_URL=""
HF_TOKEN=""
def predict(path_to_audio:str=None):
# read audio file
with open(path_to_audio, "rb") as i:
b = i.read()
# get mimetype
content_type= mimetypes.guess_type(path_to_audio)[0]
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": content_type
}
response = r.post(ENDPOINT_URL, headers=headers, data=b)
return response.json()
prediction = predict(path_to_audio="sample1.flac")
prediction
```
expected output
```json
{"text": " going along slushy country roads and speaking to damp audiences in draughty school rooms day after day for a fortnight. He'll have to put in an appearance at some place of worship on Sunday morning, and he can come to us immediately afterwards."}
```
|
Bharathdamu/wav2vec2-model-hindi-stt | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 273.93 +/- 21.93
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Bhumika/roberta-base-finetuned-sst2 | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 85 | null | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
thumbnail: "https://huggingface.co/BudFactory/classicnegative/blob/main/raccoon.png"
language:
- en
---
I'll preface this by saying that I have no idea what I'm doing. Also, this is by no means a complete or perfect model. But after many tries I'm at a point where I'm happy with sharing some pictures and an early version for you to try out.
# Classic Negative (SD 1.5)

With Classic Negative I tried to train a model with DreamBooth which closely mimics my style of photography. Its name comes from a built in camera profile in Fujifilm cameras, "Classic Negative". I use a modified version of this profile in basically all of my photos. To mimic my style, the model must achieve the following:
- recreate the color profile of classic negative: muted and desaturated greens
- introduce faded blacks and diffused highlights (like a Tiffen Glimmerglass Filter would do)
- reliably create a nice depth of field effect like you would get with large aperture lenses
- improve the composition of the default model (foreground and background objects, framing, point of view)
- improve the lighting of the default model
- add grain and preferably a slight vignetting
- try to recreate the look and feel of old 35mm film photos
## Training
For training I used 100 of my personal images, consisting mainly of environmental portraits and photos of my dog, some macro and some landscape shots. The model is probably biased towards forests and garden pictures, since that's where I took the majority of my photos. It seems to be on the verge of being overfitted, in some generated pictures I could clearly make out the general structure of my backyard.
The captions were written manually for all of the photos. Nothing too complicated, here's an example: https://i.imgur.com/prf8VxS.png
I trained for 1800 steps with a learning rate of 1e-5 and 350 text encoder steps using TheLastBen's Fast DreamBooth ipynb.
## Prompts & Parameters
The prompts I tried so far are very simple. The activation token is classicnegative
- classicnegative photo of a cute raccoon sitting between bushes in a garden, purple tulip flowers
- classicnegative photo of a cute small red panda sitting on a branch in the jungle
- classicnegative photo of a white fluffy rabbit standing in a garden illuminated by fairy lights, winter, heavy snow, snowflakes
**Parameters:** Euler A, CFG Scale 7, 30 Steps, 860x360px
I then went seed hunting. Although in a batch of 4 there was at least one usable picture so far. If a good picture was generated, I set the same seed and ran it again with Hires. fix enabled (which takes like 3,5 minutes with my GTX 1070 for one picture).
**Hires. fix Parameters:** ESRGAN_4x, 30 Steps, 0.3 Denoising, Upscale by 2
I discovered this by accident, but using these settings the picture stays exactly the same and all the film photo characteristics like the grain won't get lost during upscaling.
If the effect of the model is too strong, try adding tokens like sharp focus, high contrast, clarity to your prompt. Or just increase the contrast in post. But yes, sometimes it becomes a bit too much, I'll have to take a look into it for a future revision.
## What's next
- more testing is needed, different parameters and subjects
- create a SD2.1 768px version
- finetuning
Please feel free to try the model out, test its limitations and if you have any advice on how I can create a better version of it, please let me know ;) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.