
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Declan/NPR_model_v1
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: alberto-mate/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Declan/NPR_model_v2
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 411 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.BatchHardTripletLoss.BatchHardTripletLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 2051.8,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Declan/Politico_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# MareColoris
OctaFuzz - <a href="https://huggingface.co/Lucetepolis/OctaFuzz">Download</a><br/>
RefSlave-V2 - <a href="https://civitai.com/models/11793/refslave-v2">Download</a><br/>
WhiteSpace Prism - <a href="https://civitai.com/models/12933/whitespace-prism">Download</a><br/>
dlfmaanjffhgkwl mix - <a href="https://civitai.com/models/9815/dlfmaanjffhgkwl-mix">Download</a><br/>
randommix - <a href="https://huggingface.co/1q2W3e/randommix">Download</a><br/>
EasyNegative and pastelmix-lora seem to work well with the models.
EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download</a><br/>
pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download</a>
# Formula
Used Merge Block Weighted : Each for this one.
```
model_0 : octafuzz.safetensors [364bdf849d]
model_1 : refslavev2.safetensors [cce9a2d200]
model_Out : or.safetensors
base_alpha : 0.95
output_file: C:\SD-webui\models\Stable-diffusion\or.safetensors
weight_A : 0.15,0.4,0.7,0.65,0.5,0.9,1,1,0.95,0.55,0.05,0,0.05,0,0,0.1,0.3,0.2,0.35,0.6,0.75,0.7,0.55,0.35,0.1
weight_B : 0.05,0.1,0.1,0.05,0,0,0,0,0,0.1,0.2,0.2,0,0.9,0.8,0.55,0.15,0,0,0,0,0,0.1,0.35,0.7
half : False
skip ids : 2 : 0:None, 1:Skip, 2:Reset
model_0 : or.safetensors [c7612d0b35]
model_1 : whitespaceprism.safetensors [59038bf169]
model_Out : orw.safetensors
base_alpha : 0
output_file: C:\SD-webui\models\Stable-diffusion\orw.safetensors
weight_A : 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
weight_B : 0,0.05,0.1,0.25,0.5,0.1,0,0,0,0,0,0,0.75,0,0,0,0.3,0.75,0.6,0.35,0.2,0.25,0.35,0.3,0.2
half : False
skip ids : 2 : 0:None, 1:Skip, 2:Reset
model_0 : orw.safetensors [3ca41b67cc]
model_1 : dlfmaanjffhgkwl.safetensors [d596b45d6b]
model_Out : orwd.safetensors
base_alpha : 0
output_file: C:\SD-webui\models\Stable-diffusion\orwd.safetensors
weight_A : 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
weight_B : 0.8,0.4,0.1,0.05,0,0,0,0,0.05,0.35,0.75,0.8,0.2,0.1,0.2,0.35,0.25,0.05,0.05,0.05,0,0,0,0,0
half : False
skip ids : 2 : 0:None, 1:Skip, 2:Reset
model_0 : orwd.safetensors [170cb9efc8]
model_1 : randommix.safetensors [8f44a11120]
model_Out : marecoloris.safetensors
base_alpha : 0
output_file: C:\SD-webui\models\Stable-diffusion\marecoloris.safetensors
weight_A : 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
weight_B : 0,0.05,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.05,0.05,0,0,0
half : False
skip ids : 2 : 0:None, 1:Skip, 2:Reset
```
# Converted weights
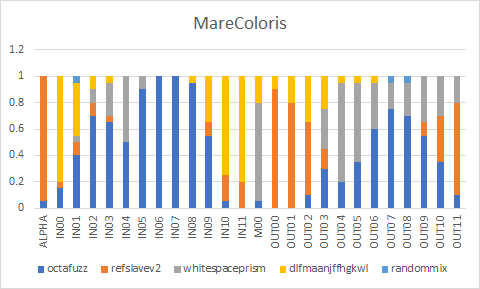
# Samples
All of the images use following negatives/settings. EXIF preserved.
```
Negative prompt: (worst quality, low quality:1.4), EasyNegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits
Steps: 28, Sampler: DPM++ 2M Karras, CFG scale: 7, Size: 768x512, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires steps: 14, Hires upscaler: Latent (nearest-exact)
```












|
Declan/WallStreetJournal_model_v4
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: lang_adapter_fa_digikala_multilingual_base_cased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lang_adapter_fa_digikala_multilingual_base_cased
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8074
- Accuracy: 0.6254
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 2.7072 | 0.45 | 500 | 2.3782 | 0.5341 |
| 2.4037 | 0.9 | 1000 | 2.2189 | 0.5588 |
| 2.2792 | 1.35 | 1500 | 2.1282 | 0.5720 |
| 2.2017 | 1.8 | 2000 | 2.0641 | 0.5821 |
| 2.1322 | 2.25 | 2500 | 2.0273 | 0.5889 |
| 2.0955 | 2.7 | 3000 | 1.9950 | 0.5945 |
| 2.0673 | 3.15 | 3500 | 1.9655 | 0.6000 |
| 2.0399 | 3.6 | 4000 | 1.9462 | 0.6033 |
| 2.0148 | 4.05 | 4500 | 1.9300 | 0.6056 |
| 1.9987 | 4.5 | 5000 | 1.9113 | 0.6069 |
| 1.9824 | 4.95 | 5500 | 1.8823 | 0.6128 |
| 1.9704 | 5.41 | 6000 | 1.8824 | 0.6119 |
| 1.9502 | 5.86 | 6500 | 1.8701 | 0.6157 |
| 1.9527 | 6.31 | 7000 | 1.8497 | 0.6190 |
| 1.9217 | 6.76 | 7500 | 1.8493 | 0.6174 |
| 1.9091 | 7.21 | 8000 | 1.8341 | 0.6210 |
| 1.9095 | 7.66 | 8500 | 1.8145 | 0.6250 |
| 1.9107 | 8.11 | 9000 | 1.8320 | 0.6190 |
| 1.8929 | 8.56 | 9500 | 1.8051 | 0.6268 |
| 1.8855 | 9.01 | 10000 | 1.8257 | 0.6221 |
| 1.8893 | 9.46 | 10500 | 1.8206 | 0.6231 |
| 1.8899 | 9.91 | 11000 | 1.7972 | 0.6244 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.12.1
|
DeepChem/ChemBERTa-5M-MTR
|
[
"pytorch",
"roberta",
"transformers"
] | null |
{
"architectures": [
"RobertaForRegression"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 13 | 2023-03-03T10:17:47Z |
---
language:
- multilingual
- en
- de
- fr
- ja
license: mit
tags:
- object-detection
- vision
- generated_from_trainer
- DocLayNet
- COCO
- PDF
- IBM
- Financial-Reports
- Finance
- Manuals
- Scientific-Articles
- Science
- Laws
- Law
- Regulations
- Patents
- Government-Tenders
- object-detection
- image-segmentation
- token-classification
inference: false
datasets:
- pierreguillou/DocLayNet-base
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384
results:
- task:
name: Token Classification
type: token-classification
metrics:
- name: f1
type: f1
value: 0.7336
- name: accuracy
type: accuracy
value: 0.9373
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)
This model is a fine-tuned version of [microsoft/layoutxlm-base](https://huggingface.co/microsoft/layoutxlm-base) with the [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2364
- Precision: 0.7260
- Recall: 0.7415
- F1: 0.7336
- Accuracy: 0.9373
## References
### Blog posts
- Layout XLM base
- (03/05/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base]()
- LiLT base
- (02/16/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level](https://medium.com/@pierre_guillou/document-ai-inference-app-and-fine-tuning-notebook-for-document-understanding-at-paragraph-level-c18d16e53cf8)
- (02/14/2023) [Document AI | Inference APP for Document Understanding at line level](https://medium.com/@pierre_guillou/document-ai-inference-app-for-document-understanding-at-line-level-a35bbfa98893)
- (02/10/2023) [Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset](https://medium.com/@pierre_guillou/document-ai-document-understanding-model-at-line-level-with-lilt-tesseract-and-doclaynet-dataset-347107a643b8)
- (01/31/2023) [Document AI | DocLayNet image viewer APP](https://medium.com/@pierre_guillou/document-ai-doclaynet-image-viewer-app-3ac54c19956)
- (01/27/2023) [Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](https://medium.com/@pierre_guillou/document-ai-processing-of-doclaynet-dataset-to-be-used-by-layout-models-of-the-hugging-face-hub-308d8bd81cdb)
### Notebooks (paragraph level)
- LiLT base
- [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb)
### Notebooks (line level)
- Layout XLM base
- [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- LiLT base
- [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- [DocLayNet image viewer APP](https://github.com/piegu/language-models/blob/master/DocLayNet_image_viewer_APP.ipynb)
- [Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb)
### APP
You can test this model with this APP in Hugging Face Spaces: [Inference APP for Document Understanding at line level (v2)](https://huggingface.co/spaces/pierreguillou/Inference-APP-Document-Understanding-at-linelevel-v2).
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
## Model description
The model was finetuned at **line level on chunk of 384 tokens with overlap of 128 tokens**. Thus, the model was trained with all layout and text data of all pages of the dataset.
At inference time, a calculation of best probabilities give the label to each line bounding boxes.
## Inference
See notebook: [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
## Training and evaluation data
See notebook: [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Accuracy | F1 | Validation Loss | Precision | Recall |
|:-------------:|:-----:|:----:|:--------:|:------:|:---------------:|:---------:|:------:|
| No log | 0.12 | 300 | 0.8413 | 0.1311 | 0.5185 | 0.1437 | 0.1205 |
| 0.9231 | 0.25 | 600 | 0.8751 | 0.5031 | 0.4108 | 0.4637 | 0.5498 |
| 0.9231 | 0.37 | 900 | 0.8887 | 0.5206 | 0.3911 | 0.5076 | 0.5343 |
| 0.369 | 0.5 | 1200 | 0.8724 | 0.5365 | 0.4118 | 0.5094 | 0.5667 |
| 0.2737 | 0.62 | 1500 | 0.8960 | 0.6033 | 0.3328 | 0.6046 | 0.6020 |
| 0.2737 | 0.75 | 1800 | 0.9186 | 0.6404 | 0.2984 | 0.6062 | 0.6787 |
| 0.2542 | 0.87 | 2100 | 0.9163 | 0.6593 | 0.3115 | 0.6324 | 0.6887 |
| 0.2542 | 1.0 | 2400 | 0.9198 | 0.6537 | 0.2878 | 0.6160 | 0.6962 |
| 0.1938 | 1.12 | 2700 | 0.9165 | 0.6752 | 0.3414 | 0.6673 | 0.6833 |
| 0.1581 | 1.25 | 3000 | 0.9193 | 0.6871 | 0.3611 | 0.6868 | 0.6875 |
| 0.1581 | 1.37 | 3300 | 0.9256 | 0.6822 | 0.2763 | 0.6988 | 0.6663 |
| 0.1428 | 1.5 | 3600 | 0.9287 | 0.7084 | 0.3065 | 0.7246 | 0.6929 |
| 0.1428 | 1.62 | 3900 | 0.9194 | 0.6812 | 0.2942 | 0.6866 | 0.6760 |
| 0.1025 | 1.74 | 4200 | 0.9347 | 0.7223 | 0.2990 | 0.7315 | 0.7133 |
| 0.1225 | 1.87 | 4500 | 0.9360 | 0.7048 | 0.2729 | 0.7249 | 0.6858 |
| 0.1225 | 1.99 | 4800 | 0.9396 | 0.7222 | 0.2826 | 0.7497 | 0.6966 |
| 0.108 | 2.12 | 5100 | 0.9301 | 0.7193 | 0.3071 | 0.7022 | 0.7372 |
| 0.108 | 2.24 | 5400 | 0.9334 | 0.7243 | 0.2999 | 0.7250 | 0.7237 |
| 0.0799 | 2.37 | 5700 | 0.9382 | 0.7254 | 0.2710 | 0.7310 | 0.7198 |
| 0.0793 | 2.49 | 6000 | 0.9329 | 0.7228 | 0.3201 | 0.7352 | 0.7108 |
| 0.0793 | 2.62 | 6300 | 0.9373 | 0.7336 | 0.3035 | 0.7260 | 0.7415 |
| 0.0696 | 2.74 | 6600 | 0.9374 | 0.7275 | 0.3137 | 0.7313 | 0.7237 |
| 0.0696 | 2.87 | 6900 | 0.9381 | 0.7253 | 0.3242 | 0.7369 | 0.7142 |
| 0.0866 | 2.99 | 7200 | 0.2473 | 0.7439 | 0.7207 | 0.7321 | 0.9407 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.10.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
## Other models
- Line level
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 85.84% - lines: 91.97%)
- [Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 93.73% - lines: ...)
- Paragraph level
- [Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 86.34% - paragraphs: 68.15%)
- [Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 96.93% - paragraphs: 86.55%)
|
DeepChem/SmilesTokenizer_PubChem_1M
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 227 | 2023-03-02T12:52:47Z |
---
tags:
- conversational
---
#qqpbksdj DailoGPT Model
|
DeepPavlov/bert-base-cased-conversational
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"en",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3,009 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 403.00 +/- 148.73
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jorgelzn -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jorgelzn -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jorgelzn
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
DeepPavlov/distilrubert-tiny-cased-conversational
|
[
"pytorch",
"distilbert",
"ru",
"arxiv:2205.02340",
"transformers"
] | null |
{
"architectures": null,
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5,993 | null |
---
library_name: stable-baselines3
tags:
- door-lock-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: door-lock-v2
type: door-lock-v2
metrics:
- type: mean_reward
value: 4548.17 +/- 353.30
name: mean_reward
verified: false
---
# **PPO** Agent playing **door-lock-v2**
This is a trained model of a **PPO** agent playing **door-lock-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env door-lock-v2 -orga qgallouedec -f logs/
python -m rl_zoo3.enjoy --algo ppo --env door-lock-v2 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env door-lock-v2 -orga qgallouedec -f logs/
python -m rl_zoo3.enjoy --algo ppo --env door-lock-v2 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env door-lock-v2 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env door-lock-v2 -f logs/ -orga qgallouedec
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('gamma', 0.99),
('learning_rate', 0.0005),
('n_envs', 4),
('n_steps', 512),
('n_timesteps', 10000000),
('normalize', True),
('policy', 'MlpPolicy'),
('target_kl', 0.04),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
DeltaHub/adapter_t5-3b_cola
|
[
"pytorch",
"transformers"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.38 +/- 0.50
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DeltaHub/adapter_t5-3b_qnli
|
[
"pytorch",
"transformers"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.15 +/- 0.35
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DemangeJeremy/4-sentiments-with-flaubert
|
[
"pytorch",
"flaubert",
"text-classification",
"fr",
"transformers",
"sentiments",
"french",
"flaubert-large"
] |
text-classification
|
{
"architectures": [
"FlaubertForSequenceClassification"
],
"model_type": "flaubert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 226 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8666666666666667
- name: F1
type: f1
value: 0.8666666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3049
- Accuracy: 0.8667
- F1: 0.8667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Denny29/DialoGPT-medium-asunayuuki
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Meryl_Stryfe_20230302_1330_rep_old_DS_8000_steps on Stable Diffusion via Dreambooth
#### model by NickKolok
This your the Stable Diffusion model fine-tuned the Meryl_Stryfe_20230302_1330_rep_old_DS_8000_steps concept taught to Stable Diffusion with Dreambooth.
#It can be used by modifying the `instance_prompt`: **merylstryfetrigun**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
|
DeskDown/MarianMixFT_en-ms
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | 2023-03-02T13:47:09Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of sks dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - tsinglin/save_models_0302
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




|
Despin89/test
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Meryl_Stryfe_20230302_1330_rep_old_DS_4000_steps on Stable Diffusion via Dreambooth
#### model by NickKolok
This your the Stable Diffusion model fine-tuned the Meryl_Stryfe_20230302_1330_rep_old_DS_4000_steps concept taught to Stable Diffusion with Dreambooth.
#It can be used by modifying the `instance_prompt`: **merylstryfetrigun**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
|
DevsIA/Devs_IA
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-02T14:01:32Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Meryl_Stryfe_20230302_1330_rep_old_DS_4800_steps on Stable Diffusion via Dreambooth
#### model by NickKolok
This your the Stable Diffusion model fine-tuned the Meryl_Stryfe_20230302_1330_rep_old_DS_4800_steps concept taught to Stable Diffusion with Dreambooth.
#It can be used by modifying the `instance_prompt`: **merylstryfetrigun**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
|
DimaOrekhov/transformer-method-name
|
[
"pytorch",
"encoder-decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | 2023-03-02T14:16:05Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: EExe/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Doogie/Waynehills-KE-T5-doogie
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: CloXD/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-freeze-8
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 30 | null |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
----
# OrangeMixs
"OrangeMixs" shares various Merge models that can be used with StableDiffusionWebui:Automatic1111 and others.Enjoy the drawing AI.

Maintain a repository for the following purposes.
1. to provide easy access to models commonly used in the Japanese community.The Wisdom of the Anons💎
2. As a place to upload my merge models when I feel like it.
<img src="https://i.imgur.com/VZg0LqQ.png" width="1000" height="">
----
# Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run OrangeMixs:
[](https://huggingface.co/spaces/akhaliq/webui-orangemixs)
----
# Table of Contents
- [OrangeMixs](#orangemixs)
- [Gradio](#gradio)
- [Table of Contents](#table-of-contents)
- [Reference](#reference)
- [Licence](#licence)
- [Terms of use](#terms-of-use)
- [Disclaimer](#disclaimer)
- [How to download](#how-to-download)
- [Batch Download](#batch-download)
- [Batch Download (Advanced)](#batch-download-advanced)
- [Select and download](#select-and-download)
- [Model Detail \& Merge Recipes](#model-detail--merge-recipes)
- [AbyssOrangeMix3 (AOM3)](#abyssorangemix3-aom3)
- [Update note](#update-note)
- [AOM3](#aom3)
- [AOM3A1](#aom3a1)
- [AOM3A2](#aom3a2)
- [AOM3A3](#aom3a3)
- [AOM3A1B](#aom3a1b)
- [MORE](#more)
- [Sample Gallery](#sample-gallery)
- [Description for enthusiast](#description-for-enthusiast)
- [AbyssOrangeMix2 (AOM2)](#abyssorangemix2-aom2)
- [AbyssOrangeMix2\_sfw (AOM2s)](#abyssorangemix2_sfw-aom2s)
- [AbyssOrangeMix2\_nsfw (AOM2n)](#abyssorangemix2_nsfw-aom2n)
- [AbyssOrangeMix2\_hard (AOM2h)](#abyssorangemix2_hard-aom2h)
- [EerieOrangeMix (EOM)](#eerieorangemix-eom)
- [EerieOrangeMix (EOM1)](#eerieorangemix-eom1)
- [EerieOrangeMix\_base (EOM1b)](#eerieorangemix_base-eom1b)
- [EerieOrangeMix\_Night (EOM1n)](#eerieorangemix_night-eom1n)
- [EerieOrangeMix\_half (EOM1h)](#eerieorangemix_half-eom1h)
- [EerieOrangeMix (EOM1)](#eerieorangemix-eom1-1)
- [EerieOrangeMix2 (EOM2)](#eerieorangemix2-eom2)
- [EerieOrangeMix2\_base (EOM2b)](#eerieorangemix2_base-eom2b)
- [EerieOrangeMix2\_night (EOM2n)](#eerieorangemix2_night-eom2n)
- [EerieOrangeMix2\_half (EOM2h)](#eerieorangemix2_half-eom2h)
- [EerieOrangeMix2 (EOM2)](#eerieorangemix2-eom2-1)
- [Models Comparison](#models-comparison)
- [AbyssOrangeMix (AOM)](#abyssorangemix-aom)
- [AbyssOrangeMix\_base (AOMb)](#abyssorangemix_base-aomb)
- [AbyssOrangeMix\_Night (AOMn)](#abyssorangemix_night-aomn)
- [AbyssOrangeMix\_half (AOMh)](#abyssorangemix_half-aomh)
- [AbyssOrangeMix (AOM)](#abyssorangemix-aom-1)
- [ElyOrangeMix (ELOM)](#elyorangemix-elom)
- [ElyOrangeMix (ELOM)](#elyorangemix-elom-1)
- [ElyOrangeMix\_half (ELOMh)](#elyorangemix_half-elomh)
- [ElyNightOrangeMix (ELOMn)](#elynightorangemix-elomn)
- [BloodOrangeMix (BOM)](#bloodorangemix-bom)
- [BloodOrangeMix (BOM)](#bloodorangemix-bom-1)
- [BloodOrangeMix\_half (BOMh)](#bloodorangemix_half-bomh)
- [BloodNightOrangeMix (BOMn)](#bloodnightorangemix-bomn)
- [ElderOrangeMix](#elderorangemix)
- [Troubleshooting](#troubleshooting)
- [FAQ and Tips (🐈MEME ZONE🦐)](#faq-and-tips-meme-zone)
----
# Reference
+/hdg/ Stable Diffusion Models Cookbook - <https://rentry.org/hdgrecipes#g-anons-unnamed-mix-e93c3bf7>
Model names are named after Cookbook precedents🍊
# Licence
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here :https://huggingface.co/spaces/CompVis/stable-diffusion-license
# Terms of use
- **Clearly indicate where modifications have been made.**
If you used it for merging, please state what steps you took to do so.
# Disclaimer
```
The user has complete control over whether or not to generate NSFW content, and the user's decision to enjoy either SFW or NSFW is entirely up to the user.The learning model does not contain any obscene visual content that can be viewed with a single click.The posting of the Learning Model is not intended to display obscene material in a public place.
In publishing examples of the generation of copyrighted characters, I consider the following cases to be exceptional cases in which unauthorised use is permitted.
"when the use is for private use or research purposes; when the work is used as material for merchandising (however, this does not apply when the main use of the work is to be merchandised); when the work is used in criticism, commentary or news reporting; when the work is used as a parody or derivative work to demonstrate originality."
In these cases, use against the will of the copyright holder or use for unjustified gain should still be avoided, and if a complaint is lodged by the copyright holder, it is guaranteed that the publication will be stopped as soon as possible.
```
----
# How to download
## Batch Download
⚠Deprecated: Orange has grown too huge. Doing this will kill your storage.
1. install Git
2. create a folder of your choice and right click → "Git bash here" and open a gitbash on the folder's directory.
3. run the following commands in order.
```
git lfs install
git clone https://huggingface.co/WarriorMama777/OrangeMixs
```
4. complete
## Batch Download (Advanced)
Advanced: (When you want to download only selected directories, not the entire repository.)
<details>
<summary>Toggle: How to Batch Download (Advanced)</summary>
1. Run the command `git clone --filter=tree:0 --no-checkout https://huggingface.co/WarriorMama777/OrangeMixs` to clone the huggingface repository. By adding the `--filter=tree:0` and `--no-checkout` options, you can download only the file names without their contents.
```
git clone --filter=tree:0 --no-checkout https://huggingface.co/WarriorMama777/OrangeMixs
```
2. Move to the cloned directory with the command `cd OrangeMixs`.
```
cd OrangeMixs
```
3. Enable sparse-checkout mode with the command `git sparse-checkout init --cone`. By adding the `--cone` option, you can achieve faster performance.
```
git sparse-checkout init --cone
```
4. Specify the directory you want to get with the command `git sparse-checkout add <directory name>`. For example, if you want to get only the `Models/AbyssOrangeMix3` directory, enter `git sparse-checkout add Models/AbyssOrangeMix3`.
```
git sparse-checkout add Models/AbyssOrangeMix3
```
5. Download the contents of the specified directory with the command `git checkout main`.
```
git checkout main
```
This completes how to clone only a specific directory. If you want to add other directories, run `git sparse-checkout add <directory name>` again.
</details>
## Select and download
1. Go to the Files and vaersions tab.
2. select the model you want to download
3. download
4. complete
----
----
# Model Detail & Merge Recipes
## AbyssOrangeMix3 (AOM3)

――Everyone has different “ABYSS”!
▼About
The main model, "AOM3 (AbyssOrangeMix3)", is a purely upgraded model that improves on the problems of the previous version, "AOM2". "AOM3" can generate illustrations with very realistic textures and can generate a wide variety of content. There are also three variant models based on the AOM3 that have been adjusted to a unique illustration style. These models will help you to express your ideas more clearly.
▼Links
- [⚠NSFW] Civitai: AbyssOrangeMix3 (AOM3) | Stable Diffusion Checkpoint | https://civitai.com/models/9942/abyssorangemix3-aom3
### Update note
2023-02-27: Add AOM3A1B
### AOM3
Features: high-quality, realistic textured illustrations can be generated.
There are two major changes from AOM2.
1: Models for NSFW such as _nsfw and _hard have been improved: the models after nsfw in AOM2 generated creepy realistic faces, muscles and ribs when using Hires.fix, even though they were animated characters. These have all been improved in AOM3.
e.g.: explanatory diagram by MEME : [GO TO MEME ZONE↓](#MEME_realface)
2: sfw/nsfw merged into one model. Originally, nsfw models were separated because adding NSFW content (models like NAI and gape) would change the face and cause the aforementioned problems. Now that those have been improved, the models can be packed into one.
In addition, thanks to excellent extensions such as [ModelToolkit](https://github.com/arenatemp/stable-diffusion-webui-model-toolkit
), the model file size could be reduced (1.98 GB per model).

▼Variations
### AOM3A1
Features: Anime like illustrations with flat paint. Cute enough as it is, but I really like to apply LoRA of anime characters to this model to generate high quality anime illustrations like a frame from a theatre version.
### AOM3A2
Features: Oil paintings like style artistic illustrations and stylish background depictions. In fact, this is mostly due to the work of Counterfeit 2.5, but the textures are more realistic thanks to the U-Net Blocks Weight Merge.
### AOM3A3
Features: Midpoint of artistic and kawaii. the model has been tuned to combine realistic textures, a artistic style that also feels like an oil colour style, and a cute anime-style face. Can be used to create a wide range of illustrations.
### AOM3A1B
AOM3A1B added. The model was merged by mistakenly selecting 'Add sum' when 'Add differences' should have been selected in the AOM3A3 recipe. It was an unintended merge, but we share it because the illustrations produced are consistently good results.
In my review, this is an illustration style somewhere between AOM3A1 and A3.
### MORE
In addition, these U-Net Blocks Weight Merge models take numerous steps but are carefully merged to ensure that mutual content is not overwritten.
(Of course, all models allow full control over adult content.)
- 🔐 When generating illustrations for the general public: write "nsfw" in the negative prompt field
- 🔞 ~~When generating adult illustrations: "nsfw" in the positive prompt field~~ -> It can be generated without putting it in. If you include it, the atmosphere will be more NSFW.

### Sample Gallery
🚧Editing🚧
▼A1


<details>
<summary>©</summary>
(1)©Yurucamp: Inuyama Aoi, (2)©The Quintessential Quintuplets: Nakano Yotsuba, (3)©Sailor Moon: Mizuno Ami/SailorMercury
</details>
### Description for enthusiast
AOM3 was created with a focus on improving the nsfw version of AOM2, as mentioned above.The AOM3 is a merge of the following two models into AOM2sfw using U-Net Blocks Weight Merge, while extracting only the NSFW content part.
(1) NAI: trained in Danbooru
(2)gape: Finetune model of NAI trained on Danbooru's very hardcore NSFW content.
In other words, if you are looking for something like AOM3sfw, it is AOM2sfw.The AOM3 was merged with the NSFW model while removing only the layers that have a negative impact on the face and body. However, the faces and compositions are not an exact match to AOM2sfw.AOM2sfw is sometimes superior when generating SFW content. I recommend choosing according to the intended use of the illustration.See below for a comparison between AOM2sfw and AOM3.

▼A summary of the AOM3 work is as follows
1. investigated the impact of the NAI and gape layers as AOM2 _nsfw onwards is crap.
2. cut face layer: OUT04 because I want realistic faces to stop → Failed. No change.
3. gapeNAI layer investigation|
a. (IN05-08 (especially IN07) | Change the illustration significantly. Noise is applied, natural colours are lost, shadows die, and we can see that the IN deep layer is a layer of light and shade.
b. OUT03-05(?) | likely to be sexual section/NSFW layer.Cutting here will kill the NSFW.
c. OUT03,OUT04|NSFW effects are in(?). e.g.: spoken hearts, trembling, motion lines, etc...
d. OUT05|This is really an NSFW switch. All the "NSFW atmosphere" is in here. Facial expressions, Heavy breaths, etc...
e. OUT10-11|Paint layer. Does not affect detail, but does have an extensive impact.
1. (mass production of rubbish from here...)
2. cut IN05-08 and merge NAIgape with flat parameters → avoided creepy muscles and real faces. Also, merging NSFW models stronger has less impact.
3. so, cut IN05-08, OUT10-11 and merge NAI+gape with all others 0.5.
4. → AOM3
AOM3 roughly looks like this
----
▼How to use
- Prompts
- Negative prompts is As simple as possible is good.
(worst quality, low quality:1.4)
- Using "3D" as a negative will result in a rough sketch style at the "sketch" level. Use with caution as it is a very strong prompt.
- How to avoid Real Face
(realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (abs, muscular, rib:1.0),
- How to avoid Bokeh
(depth of field, bokeh, blurry:1.4)
- How to remove mosaic: `(censored, mosaic censoring, bar censor, convenient censoring, pointless censoring:1.0),`
- How to remove blush: `(blush, embarrassed, nose blush, light blush, full-face blush:1.4), `
- 🔰Basic negative prompts sample for Anime girl ↓
- v1
`nsfw, (worst quality, low quality:1.4), (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (dusty sunbeams:1.0),, (abs, muscular, rib:1.0), (depth of field, bokeh, blurry:1.4),(motion lines, motion blur:1.4), (greyscale, monochrome:1.0), text, title, logo, signature`
- v2
`nsfw, (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature, `
- Sampler: ~~“DPM++ SDE Karras” is good~~ Take your pick
- Steps:
- DPM++ SDE Karras: Test: 12~ ,illustration: 20~
- DPM++ 2M Karras: Test: 20~ ,illustration: 28~
- Clipskip: 1 or 2
- Upscaler :
- Detailed illust → Latenet (nearest-exact)
Denoise strength: 0.5 (0.5~0.6)
- Simple upscale: Swin IR, ESRGAN, Remacri etc…
Denoise strength: Can be set low. (0.35~0.6)
---
👩🍳Model details / Recipe
▼Hash
- AOM3.safetensors
D124FC18F0232D7F0A2A70358CDB1288AF9E1EE8596200F50F0936BE59514F6D
- AOM3A1.safetensors
F303D108122DDD43A34C160BD46DBB08CB0E088E979ACDA0BF168A7A1F5820E0
- AOM3A2.safetensors
553398964F9277A104DA840A930794AC5634FC442E6791E5D7E72B82B3BB88C3
- AOM3A3.safetensors
EB4099BA9CD5E69AB526FCA22A2E967F286F8512D9509B735C892FA6468767CF
▼Use Models
1. AOM2sfw
「038ba203d8ba3c8af24f14e01fbb870c85bbb8d4b6d9520804828f4193d12ce9」
1. AnythingV3.0 huggingface pruned
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
1. NovelAI animefull-final-pruned
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
1. NovelAI sfw
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
1. Gape60
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
1. BasilMix
「bbf07e3a1c3482c138d096f7dcdb4581a2aa573b74a68ba0906c7b657942f1c2」
1. chilloutmix_fp16.safetensors
「4b3bf0860b7f372481d0b6ac306fed43b0635caf8aa788e28b32377675ce7630」
1. Counterfeit-V2.5_fp16.safetensors
「71e703a0fca0e284dd9868bca3ce63c64084db1f0d68835f0a31e1f4e5b7cca6」
1. kenshi_01_fp16.safetensors
「3b3982f3aaeaa8af3639a19001067905e146179b6cddf2e3b34a474a0acae7fa」
----
▼AOM3
▼**Instructions:**
USE: [https://github.com/hako-mikan/sd-webui-supermerger/](https://github.com/hako-mikan/sd-webui-supermerger/)
(This extension is really great. It turns a month's work into an hour. Thank you)
STEP: 1 | BWM : NAI - NAIsfw & gape - NAI
CUT: IN05-IN08, OUT10-11
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
| -------- | -------- | -------- | -------------------- | ----------------------------------------------------------------------------------------- | ---------- |
| AOM2sfw | NAI full | NAI sfw | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | temp01 |
CUT: IN05-IN08, OUT10-11
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
| -------- | -------- | -------- | -------------------- | ----------------------------------------------------------------------------------------- | ---------- |
| temp01 | gape60 | NAI full | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | AOM3 |
▼AOM3A1
▼**Instructions:**
STEP: 1 | Change the base photorealistic model of AOM3 from BasilMix to Chilloutmix.
Change the photorealistic model from BasilMix to Chilloutmix and proceed to gapeNAI merge.
STEP: 2 |
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------- | --------------- | -------------- | ------------------ |
| 1 | SUM @ 0.5 | Counterfeit2.5 | Kenshi | | Counterfeit+Kenshi |
STEP: 3 |
CUT: BASE0, IN00-IN08:0, IN10:0.1, OUT03-04-05:0, OUT08:0.2
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
| -------- | ------------------ | -------- | -------------------- | --------------------------------------------------------------------------- | ---------- |
| AOM3 | Counterfeit+Kenshi | | Add SUM @ 1.0 | 0,0,0,0,0,0,0,0,0,0.3,0.1,0.3,0.3,0.3,0.2,0.1,0,0,0,0.3,0.3,0.2,0.3,0.4,0.5 | AOM3A1 |
▼AOM3A2
▼?
CUT: BASE0, IN05:0.3、IN06-IN08:0, IN10:0.1, OUT03:0, OUT04:0.3, OUT05:0, OUT08:0.2
▼**Instructions:**
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
| -------- | -------------- | -------- | -------------------- | --------------------------------------------------------- | ---------- |
| AOM3 | Counterfeit2.5 | | Add SUM @ 1.0 | 0,1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | AOM3A2 |
▼AOM3A3
▼?
CUT : BASE0, IN05-IN08:0, IN10:0.1, OUT03:0.5, OUT04-05:0.1, OUT08:0.2
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
| -------- | -------------- | -------- | -------------------- | --------------------------------------------------------------------------------------------- | ---------- |
| AOM3 | Counterfeit2.5 | | Add SUM @ 1.0 | 0,0.6,0.6,0.6,0.6,0.6,0,0,0,0,0.6,0.1,0.6,0.6,0.6,0.6,0.6,0.5,0.1,0.1,0.6,0.6,0.2,0.6,0.6,0.6 | AOM3A3 |
----
## AbyssOrangeMix2 (AOM2)
――Creating the next generation of illustration with “Abyss”!
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/HeroImage_AbyssOrangeMix2_Designed_01_comp001.webp" width="" height="" alt=”HeroImage_AbyssOrangeMix2_Designed_01_comp001”>
Prompt: [https://majinai.art/ja/i/nxpKRpw](https://majinai.art/ja/i/nxpKRpw)
▼About
AbyssOrangeMix2 (AOM2) is an AI model capable of generating high-quality, highly realistic illustrations.
It can generate elaborate and detailed illustrations that cannot be drawn by hand. It can also be used for a variety of purposes, making it extremely useful for design and artwork.
Furthermore, it provides an unparalleled new means of expression.
It can generate illustrations in a variety of genres to meet a wide range of needs. I encourage you to use "Abyss" to make your designs and artwork richer and of higher quality.
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/UBM_ON_OFF_4_comp001.webp" width="" height="" alt=”UBM_ON_OFF_4_comp001.webp”>
※nvidia joke.
▼Description for engineers/enthusiasts
The merged model was formulated using an extension such as sdweb-merge-block-weighted-gui, which merges models at separate rates for each of the 25 U-Net blocks (input, intermediate, and output).
The validation of many Anons has shown that such a recipe can generate a painting style that is anatomically realistic enough to feel the finger skeleton, but still maintains an anime-style face.
The changes from AbyssOrangeMix are as follows.
1. the model used for U-Net Blocks Weight Merge was changed from Instagram+F222 to BasilMix. (<https://huggingface.co/nuigurumi>)
This is an excellent merge model that can generate decent human bodies while maintaining the facial layers of the Instagram model. Thanks!!!
This has improved the dullness of the color and given a more Japanese skin tone (or more precisely, the moisturized white skin that the Japanese would ideally like).
Also, the unnatural bokeh that sometimes occurred in the previous version may have been eliminated (needs to be verified).
2.Added IN deep layers (IN06-11) to the layer merging from the realistic model (BasilMix).
It is said that the IN deep layer (IN06-11) is the layer that determines composition, etc., but perhaps light, reflections, skin texture, etc., may also be involved.
It is like "Global Illumination", "Ray tracing" and "Ambient Occlusion" in 3DCG.
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/AbyssOrangeMix2_comparison_comp001.webp" width="" height="" alt=”AbyssOrangeMix2_comparison_comp001”>
※This does not fundamentally improve the fingers. Therefore, More research needs to be done to improve the fingers (e.g. '[bad_prompt](https://huggingface.co/datasets/Nerfgun3/bad_prompt)').
About 30-50% chance of generating correct fingers(?). Abyss is deep.
▼Sample Gallery
The prompts for generating these images were all generated using ChatGPT. I simply asked "Pirates sailing the oceans" to tell me what the prompts were.
However, to make sure the AI understood the specifications, I used the template for AI questions (Question template for AI prompt generation(v1.2) ).
Please review the following.
```jsx
https://seesaawiki.jp/nai_ch/d/AI%a4%f2%b3%e8%cd%d1%a4%b7%a4%bf%a5%d7%a5%ed%a5%f3%a5%d7%a5%c8%c0%b8%c0%ae
```
The images thus generated, strangely enough, look like MidJourney or Nijijourney illustrations. Perhaps they are passing user prompts through GPT or something else before passing them on to the image AI🤔
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/SampleGallerBoardDesign_AbyssOrangeMix2_ReadMore_comp001.webp" width="" height="" alt=”SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001”>
<details>
<summary>▼READ MORE🖼</summary>
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001.webp" width="" height="" alt=”SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001”>
▼All prompts to generate sample images
1. [Gaming Girl](https://majinai.art/ja/i/GbTbLyk)
2. [Fantasy](https://majinai.art/ja/i/ax45Pof)
3. [Rainy Day](https://majinai.art/ja/i/1P9DUul)
4. [Kemomimi Girl](https://majinai.art/ja/i/hrUSb31)
5. [Supermarket](https://majinai.art/ja/i/6Mf4bVK)
6. [Lunch Time](https://majinai.art/ja/i/YAgQ4On)
7. [Womens in the Garden](https://majinai.art/ja/i/oHZYum_)
8. [Pirate](https://majinai.art/ja/i/yEA3EZk)
9. [Japanese Girl](https://majinai.art/ja/i/x4G_B_e)
10. [Sweets Time](https://majinai.art/ja/i/vK_mkac)
11. [Glasses Girl](https://majinai.art/ja/i/Z87IHOC)
</details>
▼How to use
- VAE: orangemix.vae.pt
- ~~Prompts can be long or short~~
As simple as possible is good. Do not add excessive detail prompts. Start with just this negative propmt.
(worst quality, low quality:1.4)
- Sampler: “DPM++ SDE Karras” is good
- Steps: forTest: 12~ ,illustration: 20~
- Clipskip: 1 or 2
- Upscaler : Latenet (nearest-exact)
- CFG Scale : 5 or 6 (4~8)
- Denoise strength: 0.5 (0.45~0.6)
If you use 0.7~, the picture will change too much.
If below 0.45, Block noise occurs.
🗒Model List
- AbyssOrangeMix2_sfw|BasilMix U-Net Blocks Weight Merge
- AbyssOrangeMix2_nsfw|+ NAI-NAISFW 0.3 Merge
- AbyssOrangeMix2_hard|+ Gape 0.3 Merge
※Changed suffix of models.
_base →_sfw: _base was changed to_sfw.
_night →_nsfw: Merged models up to NAI-NAI SFW were changed from _night to_nsfw.
_half and non suffix →_hard: Gape merged models were given the suffix _hard.gape was reduced to 0.3 because it affects character modeling.
▼How to choice models
- _sfw : SFW😉
- _nsfw : SFW ~ Soft NSFW🥰
- _hard : SFW ~ hard NSFW👄
▼Hash
- AbyssOrangeMix2_sfw.ckpt
「f75b19923f2a4a0e70f564476178eedd94e76e2c94f8fd8f80c548742b5b51b9」
- AbyssOrangeMix2_sfw.safetensors
「038ba203d8ba3c8af24f14e01fbb870c85bbb8d4b6d9520804828f4193d12ce9」
- AbyssOrangeMix2_nsfw.safetensors
「0873291ac5419eaa7a18726e8841ce0f15f701ace29e0183c47efad2018900a4」
- AbyssOrangeMix_hard.safetensors
「0fc198c4908e98d7aae2a76bd78fa004e9c21cb0be7582e36008b4941169f18e」
▼Use Models
1. AnythingV3.0 huggingface pruned
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
1. NovelAI animefull-final-pruned
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
1. NovelAI sfw
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
1. Gape60
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
1. BasilMix
「bbf07e3a1c3482c138d096f7dcdb4581a2aa573b74a68ba0906c7b657942f1c2」
### AbyssOrangeMix2_sfw (AOM2s)
▼**Instructions:**
STEP: 1|Block Merge
| Model: A | Model: B | Weight | Base alpha | Merge Name |
| ------------ | -------- | --------------------------------------------------------------------- | ---------- | ------------------- |
| AnythingV3.0 | BasilMix | 1,0.9,0.7,0.5,0.3,0.1,1,1,1,1,1,1,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | AbyssOrangeMix2_sfw |
### AbyssOrangeMix2_nsfw (AOM2n)
▼?
JUST AbyssOrangeMix2_sfw+ (NAI-NAISFW) 0.3.
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
| 1 | Add Difference @ 0.3 | AbyssOrangeMix_base | NovelAI animefull | NovelAI sfw | AbyssOrangeMix2_nsfw |
### AbyssOrangeMix2_hard (AOM2h)
▼?
+Gape0.3 version AbyssOrangeMix2_nsfw.
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------------- |
| 1 | Add Difference @ 0.3 | AbyssOrangeMix2_nsfw | Gape60 | NovelAI animefull | AbyssOrangeMix2_hard |
----
## EerieOrangeMix (EOM)
EerieOrangeMix is the generic name for a U-Net Blocks Weight Merge Models based on Elysium(Anime V2).
Since there are infinite possibilities for U-Net Blocks Weight Merging, I plan to treat all Elysium-based models as a lineage of this model.
※This does not fundamentally improve the fingers. Therefore, More research needs to be done to improve the fingers (e.g. '[bad_prompt](https://huggingface.co/datasets/Nerfgun3/bad_prompt)').
<img src="https://files.catbox.moe/yjnqna.webp" width="1000" height="" alt=”HeroImage_EerieOrangeMix_Designed_comp001” >
### EerieOrangeMix (EOM1)
▼?
This merge model is simply a U-Net Blocks Weight Merge of ElysiumAnime V2 with the AbyssOrangeMix method.
The AnythingModel is good at cute girls anyway, and no matter how hard I try, it doesn't seem to be good at women in their late 20s and beyond. Therefore, I created a U-Net Blocks Weight Merge model based on my personal favorite ElysiumAnime V2 model. ElyOrangeMix was originally my favorite, so this is an enhanced version of that.
🗒Model List
- EerieOrangeMix_base|Instagram+F222 U-Net Blocks Weight Merge
- EerieOrangeMix_night|+ NAI-NAISFW Merge
- EerieOrangeMix_half|+ Gape0.5 Merge
- EerieOrangeMix|+ Gape1.0 Merge
▼ How to choice models
- _base : SFW😉
- _Night : SFW ~ Soft NSFW🥰
- _half : SFW ~ NSFW👄
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
▼Hash
- EerieOrangeMix.safetensors
- EerieOrangeMix_half.safetensors
- EerieOrangeMix_night.safetensors
- EerieOrangeMix_base.ckpt
▼Use Models
[] = WebUI Hash,「」= SHA256
1. Elysium Anime V2
[]「5c4787ce1386500ee05dbb9d27c17273c7a78493535f2603321f40f6e0796851」
2. NovelAI animefull-final-pruned
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
3. NovelAI sfw
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
4. Gape60
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
5. instagram-latest-plus-clip-v6e1_50000.safetensors
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
6. f222
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
7. sd1.5_pruned
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
▼ Sample Gallery
<img src="https://files.catbox.moe/oqbvti.webp" width="1000" height="" alt=”2022-12-30_MotorbikeGIrlAsa3_comp001”>
<details>
<summary>More🖼</summary>
<img src="https://files.catbox.moe/nmmswd.webp" width="" height="600" alt=”2022-12-30_SampleGallery5”>
</details>
▼ How to use
- VAE: orangemix.vae.pt
- As simple as possible is good. Do not add excessive detail prompts. Start with just this.
(worst quality, low quality:1.4)
- Sampler: “DPM++ SDE Karras” is good
- Steps: forTest: 20~24 ,illustration: 24~50
- Clipskip: 1
- USE “upscale latent space”
- Denoise strength: 0.45 (0.4~0.5)
If you use 0.7~, the picture will change too much.
▼Prompts
🖌When generating cute girls, try this negative prompt first. It avoids low quality, prevents blurring, avoids dull colors, and dictates Anime-like cute face modeling.
```jsx
nsfw, (worst quality, low quality:1.3), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, nose, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, (tan, muscular, loli, petite, child, infant, toddlers, chibi, sd character:1.1), multiple view, Reference sheet,
```
---
#### EerieOrangeMix_base (EOM1b)
▼?
Details are omitted since it is the same as AbyssOrangeMix.
▼**Instructions:**
STEP: 1|Creation of photorealistic model for Merge
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------------------------- | --------------- | -------------- | ---------- |
| 1 | Add Difference @ 1.0 | instagram-latest-plus-clip-v6e1_50000 | f222 | sd1.5_pruned | Insta_F222 |
STEP: 2|Block Merge
Merge InstaF222
| Model: A | Model: B | Weight | Base alpha | Merge Name |
| ---------------- | ---------- | --------------------------------------------------------------------- | ---------- | ---------- |
| Elysium Anime V2 | Insta_F222 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | Temp1 |
#### EerieOrangeMix_Night (EOM1n)
▼?
JUST EerieOrangeMix_base+ (NAI-NAISFW) 0.3.
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
| 1 | Add Difference @ 0.3 | EerieOrangeMix_base | NovelAI animefull | NovelAI sfw | EerieOrangeMix_Night |
#### EerieOrangeMix_half (EOM1h)
▼?
+Gape0.5 version EerieOrangeMix.
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | ----------------- | -------------- | ------------------- |
| 1 | Add Difference @ 0.5 | EerieOrangeMix_Night | NovelAI animefull | NovelAI sfw | EerieOrangeMix_half |
#### EerieOrangeMix (EOM1)
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------- |
| 1 | Add Difference @ 1.0 | EerieOrangeMix_Night | Gape60 | NovelAI animefull | EerieOrangeMix |
----
### EerieOrangeMix2 (EOM2)
▼?
The model was created by adding the hierarchy responsible for detailing and painting ElysiumV1 to EerieOrangeMix_base, then merging NAI and Gape.
🗒Model List
- EerieOrangeMix2_base|Instagram+F222+ElysiumV1 U-Net Blocks Weight Merge
- EerieOrangeMix2_night|+ NAI-NAISFW Merge
- EerieOrangeMix2_half|+ Gape0.5 Merge
- EerieOrangeMix2|+ Gape1.0 Merge
▼ How to choice models
- _base : SFW😉
- _Night : SFW ~ Soft NSFW🥰
- _half : SFW ~ NSFW👄
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
▼Hash
- EerieOrangeMix2.safetensors
- EerieOrangeMix2_half.safetensors
- EerieOrangeMix2_night.safetensors
- EerieOrangeMix2_base.ckpt
▼Use Models
[] = webuHash,「」= SHA256
1. Elysium Anime V2
[]「5c4787ce1386500ee05dbb9d27c17273c7a78493535f2603321f40f6e0796851」
2. NovelAI animefull-final-pruned
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
3. NovelAI sfw
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
4. Gape60
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
5. instagram-latest-plus-clip-v6e1_50000.safetensors
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
6. f222
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
7. sd1.5_pruned
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
8. ElysiumV1
「abbb28cb5e70d3e0a635f241b8d61cefe42eb8f1be91fd1168bc3e52b0f09ae4」
#### EerieOrangeMix2_base (EOM2b)
▼?
▼Instructions
STEP: 1|Block Merge
Merge ElysiumV1
The generated results do not change much with or without this process, but I wanted to incorporate Elysium's depiction, so I merged it.
| Model: A | Model: B | Weight | Base alpha | Merge Name |
| ------------------- | --------- | --------------------------------------------------------------------- | ---------- | -------------------- |
| EerieOrangeMix_base | ElysiumV1 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | EerieOrangeMix2_base |
#### EerieOrangeMix2_night (EOM2n)
▼?
JUST EerieOrangeMix2_base+ (NAI-NAISFW) 0.3.
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------- | ----------------- | -------------- | --------------------- |
| 1 | Add Difference @ 0.3 | EerieOrangeMix_base | NovelAI animefull | NovelAI sfw | EerieOrangeMix2_Night |
#### EerieOrangeMix2_half (EOM2h)
▼?
+Gape0.5 version EerieOrangeMix2.
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | ----------------- | -------------- | -------------------- |
| 1 | Add Difference @ 0.5 | EerieOrangeMix_Night | NovelAI animefull | NovelAI sfw | EerieOrangeMix2_half |
#### EerieOrangeMix2 (EOM2)
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | --------------- | ----------------- | --------------- |
| 1 | Add Difference @ 1.0 | EerieOrangeMix_Night | Gape60 | NovelAI animefull | EerieOrangeMix2 |
### Models Comparison
<img src="https://files.catbox.moe/mp2fr4.webp" width="1000" height="" alt="MotorbikeGIrlAsa_Eerie_Abyss_Comparison_comp001">
<img src="https://files.catbox.moe/9xqths.webp" width="1000" height="" alt=”Eerie_Abyss_Comparison_02_comp001”>
<img src="https://files.catbox.moe/cm6c7m.webp" width="1000" height="" alt=”Eerie_Comparison_01_comp001”>
※The difference is slight but probably looks like this.
← warm color, ↑ natural color, → animated color
----
## AbyssOrangeMix (AOM)
――How can you guys take on such a deep swamp and get results?
Is it something like "Made in Abyss"?
By Anon, 115th thread
<img src="https://files.catbox.moe/wst1bp.webp" width="1000" height="">
▼?
The merged model was formulated using an extension such as sdweb-merge-block-weighted-gui, which merges models at separate rates for each of the 25 U-Net blocks (input, intermediate, and output).
The validation of many Anons has shown that such a recipe can generate a painting style that is anatomically realistic enough to feel the finger skeleton, but still maintains an anime-style face.
※This model is the result of a great deal of testing and experimentation by many Anons🤗
※This model can be very difficult to handle. I am not 100% confident in my ability to use this model. It is peaky and for experts.
※This does not fundamentally improve the fingers, and I recommend using bad_prompt, etc. (Embedding) in combination.
▼Sample Gallery
(1)
<img src="https://files.catbox.moe/8mke0t.webp" width="1000" height="">
```jsx
((masterpiece)), best quality, perfect anatomy, (1girl, solo focus:1.4), pov, looking at viewer, flower trim,(perspective, sideway, From directly above ,lying on water, open hand, palm, :1.3),(Accurate five-fingered hands, Reach out, hand focus, foot focus, Sole, heel, ball of the thumb:1.2), (outdoor, sunlight:1.2),(shiny skin:1.3),,(masterpiece, white border, outside border, frame:1.3),
, (motherhood, aged up, mature female, medium breasts:1.2), (curvy:1.1), (single side braid:1.2), (long hair with queue and braid, disheveled hair, hair scrunchie, tareme:1.2), (light Ivory hair:1.2), looking at viewer,, Calm, Slight smile,
,(anemic, dark, lake, river,puddle, Meadow, rock, stone, moss, cliff, white flower, stalactite, Godray, ruins, ancient, eternal, deep ,mystic background,sunlight,plant,lily,white flowers, Abyss, :1.2), (orange fruits, citrus fruit, citrus fruit bearing tree:1.4), volumetric lighting,good lighting,, masterpiece, best quality, highly detailed,extremely detailed cg unity 8k wallpaper,illustration,((beautiful detailed face)), best quality, (((hyper-detailed ))), high resolution illustration ,high quality, highres, sidelighting, ((illustrationbest)),highres,illustration, absurdres, hyper-detailed, intricate detail, perfect, high detailed eyes,perfect lighting, (extremely detailed CG:1.2),
Negative prompt: (bad_prompt_version2:1), distant view, lip, Pregnant, maternity, pointy ears, realistic, tan, muscular, greyscale, monochrome, lineart, 2koma, 3koma, 4koma, manga, 3D, 3Dcubism, pablo picasso, disney, marvel, mutanted breasts, mutanted nipple, cropped, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, lowres, trademark, watermark, title, text, deformed, bad anatomy, disfigured, mutated, extra limbs, ugly, missing limb, floating limbs, disconnected limbs, out of frame, mutated hands and fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes, (blurry:1.4), duplicate (loli, petite, child, infant, toddlers, chibi, sd character, teen age:1.4), tsurime, helmet hair, evil smile, smug_face, naughty smile, multiple view, Reference sheet, (worst quality, low quality:1.4),
Steps: 24, Sampler: DPM++ SDE Karras, CFG scale: 10, Seed: 1159970659, Size: 1536x768, Model hash: cc44dbff, Model: AbyssOrangeMix, Variation seed: 93902374, Variation seed strength: 0.45, Denoising strength: 0.45, ENSD: 31337
```
(2)
<img src="https://files.catbox.moe/6cbrqh.webp" width="" height="600">
```jsx
street, 130mm f1.4 lens, ,(shiny skin:1.3),, (teen age, school uniform:1.2), (glasses, black hair, medium hair with queue and braid, disheveled hair, hair scrunchie, tareme:1.2), looking at viewer,, Calm, Slight smile,
Negative prompt: (bad_prompt_version2:1), distant view, lip, Pregnant, maternity, pointy ears, realistic, tan, muscular, greyscale, monochrome, lineart, 2koma, 3koma, 4koma, manga, 3D, 3Dcubism, pablo picasso, disney, marvel, mutanted breasts, mutanted nipple, cropped, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, lowres, trademark, watermark, title, text, deformed, bad anatomy, disfigured, mutated, extra limbs, ugly, missing limb, floating limbs, disconnected limbs, out of frame, mutated hands and fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes, (blurry:1.4), duplicate (loli, petite, child, infant, toddlers, chibi, sd character, teen age:1.4), tsurime, helmet hair, evil smile, smug_face, naughty smile, multiple view, Reference sheet, (worst quality, low quality:1.4),
Steps: 24, Sampler: DPM++ SDE Karras, CFG scale: 10, Seed: 1140782193, Size: 1024x1536, Model hash: cc44dbff, Model: AbyssOrangeMix, Denoising strength: 0.45, ENSD: 31337, First pass size: 512x768, Model sha256: 6bb3a5a3b1eadd32, VAE sha256: f921fb3f29891d2a, Options: xformers medvram gtx_16x0
Used embeddings: bad_prompt_version2 [afea]
```
----
▼How to use
- VAE: orangemix.vae.pt
- ~~Prompts can be long or short~~
As simple as possible is good. Do not add excessive detail prompts. Start with just this.
(worst quality, low quality:1.4)
- Sampler: “DPM++ SDE Karras” is good
- Steps: forTest: 20~24 ,illustration: 24~50
- Clipskip: 1
- USE “upscale latent space”
- Denoise strength: 0.45 (0.4~0.5)
If you use 0.7~, the picture will change too much.
▼Prompts
🖌When generating cute girls, try this negative prompt first. It avoids low quality, prevents blurring, avoids dull colors, and dictates Anime-like cute face modeling.
```jsx
nsfw, (worst quality, low quality:1.3), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, nose, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, (tan, muscular, loli, petite, child, infant, toddlers, chibi, sd character:1.1), multiple view, Reference sheet,
```
🗒Model List
- AbyssOrangeMix_base|Instagram Merge
- AbyssOrangeMix_Night|+ NAI-NAISFW Merge
- AbyssOrangeMix_half|+ Gape0.5 Merge
- AbyssOrangeMix|+ Gape1.0 Merge
▼ How to choice models
- _base : SFW😉
- _Night : SFW ~ Soft NSFW🥰
- _half : SFW ~ NSFW👄
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
▼Hash (SHA256)
- AbyssOrangeMix.safetensors
6bb3a5a3b1eadd32dfbc8f0987559c48cb4177aee7582baa6d6a25181929b345
- AbyssOrangeMix_half.safetensors
468d1b5038c4fbd354113842e606fe0557b4e0e16cbaca67706b29bcf51dc402
- AbyssOrangeMix_Night.safetensors
167cd104699dd98df22f4dfd3c7a2c7171df550852181e454e71e5bff61d56a6
- AbyssOrangeMix_base.ckpt
bbd2621f3ec4fad707f75fc032a2c2602c296180a53ed3d9897d8ca7a01dd6ed
▼Use Models
1. AnythingV3.0 huggingface pruned
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
2. NovelAI animefull-final-pruned
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
3. NovelAI sfw
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
4. Gape60
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
5. instagram-latest-plus-clip-v6e1_50000.safetensors
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
6. f222
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
7. sd1.5_pruned
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
### AbyssOrangeMix_base (AOMb)
▼?
The basic trick for this merged model is to incorporate a model that has learned more than 1m Instagram photos (mostly Japanese) or a photorealistic model like f222. The choice of base model here depends on the person. I chose AnythingV3 for versatility.
▼**Instructions:**
STEP: 1|Creation of photorealistic model for Merge
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------------------------- | --------------- | -------------- | ---------- |
| 1 | Add Difference @ 1.0 | instagram-latest-plus-clip-v6e1_50000 | f222 | sd1.5_pruned | Insta_F222 |
STEP: 2|Block Merge
| Model: A | Model: B | Weight | Base alpha | Merge Name |
| ------------ | ---------- | --------------------------------------------------------------------- | ---------- | ------------------- |
| AnythingV3.0 | Insta_F222 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | AbyssOrangeMix_base |
### AbyssOrangeMix_Night (AOMn)
▼?
JUST AbyssOrangeMix_base+ (NAI-NAISFW) 0.3.
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
| 1 | Add Difference @ 0.3 | AbyssOrangeMix_base | NovelAI animefull | NovelAI sfw | AbyssOrangeMix_Night |
### AbyssOrangeMix_half (AOMh)
▼?
+Gape0.5 version AbyssOrangeMix.
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | --------------- | ----------------- | ------------------- |
| 1 | Add Difference @ 0.5 | AbyssOrangeMix_Night | Gape60 | NovelAI animefull | AbyssOrangeMix_half |
### AbyssOrangeMix (AOM)
▼**Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------- |
| 1 | Add Difference @ 1.0 | AbyssOrangeMix_Night | Gape60 | NovelAI animefull | AbyssOrangeMix |
----
## ElyOrangeMix (ELOM)
<img src="https://i.imgur.com/AInEXA5.jpg" width="1000" height="">
▼?
Elysium_Anime_V2 + NAI + Gape.
This is a merge model that improves on the Elysium_Anime_V2, where NSFW representation is not good.
It can produce SFW, NSFW, and any other type of artwork, while retaining the Elysium's three-dimensional, thickly painted style.
▼ How to choice models
- _base : SFW😉
- _Night : SFW ~ Soft NSFW🥰
- _half : SFW ~ NSFW👄
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
▼How to use
- VAE: orangemix.vae.pt
▼Hash (SHA256)
- ElyOrangeMix [6b508e59]
- ElyOrangeMix_half [6b508e59]
- ElyNightOrangeMix[6b508e59]
### ElyOrangeMix (ELOM)
▼Use Models
1. Elysium_Anime_V2 [6b508e59]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
4. Gape60 [25396b85]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ---------------- | ----------------- | ----------------- | ------------------------ |
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
| 2 | Add Difference @ 1.0 | tempmix-part1 | Gape60 | NovelAI animefull | ElyOrangeMix [6b508e59] |
---
### ElyOrangeMix_half (ELOMh)
▼?
+Gape0.5 version ElyOrangeMix.
▼Use Models
1. Elysium_Anime_V2 [6b508e59]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
4. Gape60 [25396b85]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ---------------- | ----------------- | ----------------- | ----------------------------- |
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
| 2 | Add Difference @ 0.5 | tempmix-part1 | Gape60 | NovelAI animefull | ElyOrangeMix_half [6b508e59] |
----
### ElyNightOrangeMix (ELOMn)
▼?
It is a merged model that just did Elysium_Anime_V2+ (NAI-NAISFW) 0.3.
▼Use Models
1. Elysium_Anime_V2 [6b508e59]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ---------------- | ----------------- | -------------- | ----------------- |
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | ElyNightOrangeMix |
----
## BloodOrangeMix (BOM)
<img src="https://i.imgur.com/soAnnFk.jpg" width="1000" height="">
▼?
Anything+NAI+Gape.
This is a merge model that improves on the AnythingV3, where NSFW representation is not good.
It can produce SFW, NSFW, and any other type of artwork, while retaining the flat, beautifully painted style of AnythingV3.
Stable. Popular in the Japanese community.
▼ModelList & [] = WebUI Hash,「」= SHA256
- BloodNightOrangeMix.ckpt
[ffa7b160]「f8aff727ba3da0358815b1766ed232fd1ef9682ad165067cac76e576d19689e0」
- BloodOrangeMix_half.ckpt
[ffa7b160]「b2168aaa59fa91229b8add21f140ac9271773fe88a387276f3f0c7d70f726a83」
- BloodOrangeMix.ckpt
[ffa7b160] 「25cece3fe303ea8e3ad40c3dca788406dbd921bcf3aa8e3d1c7c5ac81f208a4f」
- BloodOrangeMix.safetensors
「79a1edf6af43c75ee1e00a884a09213a28ee743b2e913de978cb1f6faa1b320d」
▼ How to choice models
- _base : SFW😉
- _Night : SFW ~ Soft NSFW🥰
- _half : SFW ~ NSFW👄
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
▼How to use
- VAE: orangemix.vae.pt
### BloodOrangeMix (BOM)
▼Use Models
1. AnythingV3.0 huggingface pruned [2700c435]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
4. Gape60 [25396b85]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------- | ----------------- | ----------------- | ------------------------- |
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
| 2 | Add Difference @ 1.0 | tempmix-part1 | Gape60 | NovelAI animefull | BloodOrangeMix [ffa7b160] |
----
### BloodOrangeMix_half (BOMh)
▼?
Anything+Nai+Gape0.5
+Gape0.5 version BloodOrangeMix.
NSFW expression will be softer and have less impact on the Anything style painting style.
▼Use Models
1. AnythingV3.0 huggingface pruned [2700c435]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
4. Gape60 [25396b85]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------- | ----------------- | ----------------- | ------------------------------ |
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
| 2 | Add Difference @ 0.5 | tempmix-part1 | Gape60 | NovelAI animefull | BloodOrangeMix_half [ffa7b160] |
----
### BloodNightOrangeMix (BOMn)
▼?
It is a merged model that just did AnythingV3+ (NAI-NAISFW) 0.3.
▼Use Models
1. AnythingV3.0 huggingface pruned [2700c435]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
▼Instructions
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ------------- | ----------------- | -------------- | ------------------- |
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | BloodNightOrangeMix |
----
## ElderOrangeMix
※I found this model to be very prone to body collapse. Not recommended.
▼?
anything and everything mix ver.1.5+Gape+Nai(AnEve.G.N0.3)
This is a merged model with improved NSFW representation of anything and everything mix ver.1.5.
▼Hash
[3a46a1e0]
▼Use Models
1. anything and everything mix ver.1.5 [5265dcf6]
2. NovelAI animefull-final-pruned [925997e9]
3. NovelAI sfw [1d4a34af]
4. Gape60 [25396b85]
▼Instructions:**
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
| ---- | -------------------- | ----------------------------------- | --------------- | -------------- | -------------------------- |
| 1 | Add Difference @ 0.5 | anything and everything mix ver.1.5 | Gape60 | NovelAI full | tempmix-part1 [] |
| 2 | Add Difference @ 0.3 | tempmix-part1 | NovelAI full | NovelAI sfw | ElderOrangeMix [3a46a1e0] |
----
## Troubleshooting
1. blurred Images & clearly low quality output
If the generated images are blurred or only clearly low quality output is produced, it is possible that the vae, etc. are not loaded properly. Try reloading the model/vae or restarting the WebUI/OS.
## FAQ and Tips (🐈MEME ZONE🦐)
Below this, trash.
----
▼Nooo^()&*%#NG0u!!!!!!!!縺ゅ♀繧?縺医?縺、繝シ縺ィ縺医?縺吶j繝シ縺ッ驕主ュヲ鄙偵?繧エ繝溘〒縺? (「AOM3A2 and A3 are overlearning and Trash. delete!」)
<img src="https://github.com/WarriorMama777/imgup/raw/main/img/img_general/img_meme_tension_comp001.webp" width="300" height="" alt=”getting_excited”>
▼No, AOM2 (only hentai models)
<a name="MEME_realface"></a>

▼Noo, Too many models. Tell me which one to choose.
→ [全部同じじゃないですか](https://github.com/WarriorMama777/imgup/blob/main/img/img_general/img_MEME_whichModel_comp001.webp?raw=true "全部同じじゃないですか")
▼Nooo, not work. This guy is Scammer
STEP1: BUY HUGE PC
▼Noooo, can't generate image like samples.This models is hype.
❌
<img src="https://files.catbox.moe/nte6ud.webp" width="500" height="">
🟢
<img src="https://files.catbox.moe/lta462.webp" width="500" height="">
▼Nooooo, This models have troy virus. don't download.
All models in this repository are secure. It is most likely that anti-virus software has detected them erroneously.
However, the models with the .ckpt extension have the potential danger of executing arbitrary code.
A safe model that is free from these dangers is the model with the .safetensors extension.
|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-with-clean-valid
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 33 | null |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 108.56 +/- 79.22
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 500000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'stevaras2/ppo-LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
DoyyingFace/bert-asian-hate-tweets-asonam-unclean
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 30 | null |
---
license: gpl-2.0
pipeline_tag: text-generation
---
|
albert-base-v1
|
[
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 38,156 | 2023-03-02T15:02:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: norbert2_sentiment_norec_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# norbert2_sentiment_norec_2
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5604
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6362 | 1.0 | 5 | 0.7172 |
| 0.4045 | 2.0 | 10 | 0.4750 |
| 1.0879 | 3.0 | 15 | 0.6264 |
| 0.3215 | 4.0 | 20 | 0.5604 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu117
- Datasets 2.9.0
- Tokenizers 0.13.2
|
albert-base-v2
|
[
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4,785,283 | 2023-03-02T15:03:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 273.89 +/- 15.96
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
```python
from stable_baselines3 import PPO
from huggingface_sb3 import load_from_hub
repo_id = "israel-avihail/Bereshit-PPO-LunarLander" # The repo_id
filename = "Bereshit-ppo-LunarLander-v2.zip" # The model filename.zip
# When the model was trained on Python 3.8 the pickle protocol is 5
# But Python 3.6, 3.7 use protocol 4
# In order to get compatibility we need to:
# 1. Install pickle5
# 2. Create a custom empty object we pass as parameter to PPO.load()
custom_objects = {
"learning_rate": 0.0,
"lr_schedule": lambda _: 0.0,
"clip_range": lambda _: 0.0,
}
checkpoint = load_from_hub(repo_id, filename)
model = PPO.load(checkpoint, custom_objects=custom_objects, print_system_info=True)
```
|
albert-xlarge-v1
|
[
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 341 | 2023-03-02T15:05:59Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: ThursdayFebruary_2_2023_2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="robkayinto/ThursdayFebruary_2_2023_2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
albert-xlarge-v2
|
[
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2,973 | 2023-03-02T15:05:59Z |
---
license: apache-2.0
---
[This model](https://zenodo.org/record/3733910#.ZAC53HbMJPY) is converted from the [MLPerf Inference BERT Tensorflow Model on SQuAD v1.1 dataset](https://zenodo.org/record/3733868)
using the script in the [MLPerf inference repo](https://github.com/mlperf/inference).
Authors: Po-Han Huang and Christopher Forster
|
bert-base-chinese
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"arxiv:1810.04805",
"transformers",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3,377,486 | 2023-03-02T15:09:32Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- gpt
---
|
bert-base-german-cased
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"exbert",
"license:mit",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 175,983 | 2023-03-02T15:11:57Z |
---
license: apache-2.0
---
[This model](https://zenodo.org/record/3733910#.ZAC53HbMJPY) is converted from the [MLPerf Inference BERT Tensorflow Model on SQuAD v1.1 dataset](https://zenodo.org/record/3733868)
using the script in the [MLPerf inference repo](https://github.com/mlperf/inference).
Authors: Po-Han Huang and Christopher Forster
|
bert-base-german-dbmdz-cased
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1,814 | 2023-03-02T15:15:35Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.27 +/- 0.22
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bert-base-german-dbmdz-uncased
|
[
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 68,305 | 2023-03-02T15:16:08Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/4664/lisa-lora-collection-of-trauters
|
bert-base-multilingual-cased
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4,749,504 | 2023-03-02T15:17:14Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/9506/honkai-impact-3-herrscher-of-finality
|
bert-base-uncased
|
[
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 59,663,489 | 2023-03-02T15:19:38Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.75 +/- 0.31
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bert-large-cased
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 388,769 | 2023-03-02T15:21:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-filtered-emotions
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9807191245440333
- name: F1
type: f1
value: 0.9807094920322905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-filtered-emotions
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0603
- Accuracy: 0.9807
- F1: 0.9807
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1998 | 1.0 | 242 | 0.0687 | 0.9776 | 0.9776 |
| 0.0451 | 2.0 | 484 | 0.0603 | 0.9807 | 0.9807 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
bert-large-uncased-whole-word-masking
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 76,685 | 2023-03-02T15:32:53Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: angelinux/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
distilbert-base-cased-distilled-squad
|
[
"pytorch",
"tf",
"rust",
"safetensors",
"openvino",
"distilbert",
"question-answering",
"en",
"dataset:squad",
"arxiv:1910.01108",
"arxiv:1910.09700",
"transformers",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"has_space"
] |
question-answering
|
{
"architectures": [
"DistilBertForQuestionAnswering"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 257,745 | 2023-03-02T15:37:31Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### deboracosta Dreambooth model trained by rodrigogmdias with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
distilbert-base-cased
|
[
"pytorch",
"tf",
"onnx",
"distilbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"transformers",
"license:apache-2.0",
"has_space"
] | null |
{
"architectures": null,
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 574,859 | 2023-03-02T15:40:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9543
- Wer: 25.6391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 1.3002 | 0.04 | 50 | 0.9543 | 25.6391 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
distilbert-base-german-cased
|
[
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"de",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 43,667 | null |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.51 +/- 0.16
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
distilgpt2
|
[
"pytorch",
"tf",
"jax",
"tflite",
"rust",
"coreml",
"safetensors",
"gpt2",
"text-generation",
"en",
"dataset:openwebtext",
"arxiv:1910.01108",
"arxiv:2201.08542",
"arxiv:2203.12574",
"arxiv:1910.09700",
"arxiv:1503.02531",
"transformers",
"exbert",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"has_space"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1,611,668 | 2023-03-02T15:43:43Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: Lakshya2k/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
distilroberta-base
|
[
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"roberta",
"fill-mask",
"en",
"dataset:openwebtext",
"arxiv:1910.01108",
"arxiv:1910.09700",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3,342,240 | 2023-03-02T15:44:06Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 684.50 +/- 195.04
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Gabcsor -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Gabcsor -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Gabcsor
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
xlm-mlm-xnli15-1024
|
[
"pytorch",
"tf",
"xlm",
"fill-mask",
"multilingual",
"en",
"fr",
"es",
"de",
"el",
"bg",
"ru",
"tr",
"ar",
"vi",
"th",
"zh",
"hi",
"sw",
"ur",
"arxiv:1901.07291",
"arxiv:1910.09700",
"transformers",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"XLMWithLMHeadModel"
],
"model_type": "xlm",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2,050 | 2023-03-02T16:36:59Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 11.36 +/- 6.26
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r Agog/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.8.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.8.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
123www/test_model
|
[
"pytorch",
"wav2vec2",
"transformers"
] | null |
{
"architectures": [
"Wav2Vec2ForSpeechClassification"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: YashGajjar/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ASCCCCCCCC/bert-base-chinese-finetuned-amazon_zh_20000
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 43 | 2023-03-02T20:10:30Z |
# Vocabulary Trimmed [lmqg/mt5-base-ruquad-qg](https://huggingface.co/lmqg/mt5-base-ruquad-qg): `vocabtrimmer/mt5-base-ruquad-qg-trimmed-15000`
This model is a trimmed version of [lmqg/mt5-base-ruquad-qg](https://huggingface.co/lmqg/mt5-base-ruquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-base-ruquad-qg | vocabtrimmer/mt5-base-ruquad-qg-trimmed-15000 |
|:---------------------------|:--------------------------|:------------------------------------------------|
| parameter_size_full | 582,384,384 | 221,275,392 |
| parameter_size_embedding | 384,155,136 | 23,046,144 |
| vocab_size | 250,101 | 15,004 |
| compression_rate_full | 100.0 | 37.99 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 15000 | 2 |
|
Ab0/keras-dummy-functional-demo
|
[
"keras"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-02T21:22:13Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Jbot/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AbidHasan95/movieHunt2
|
[
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-02T21:49:25Z |
---
license: apache-2.0
language:
- en
metrics:
- accuracy
pipeline_tag: image-classification
tags:
- climate
---
## Model description
This is a transformers based image classification model, implemented using the technique of transfer learning.
The pretrained model is [Vision transformer](https://huggingface.co/google/vit-base-patch16-224) trained on Imagenet-21k.
## Datasets
The dataset used is downloaded from git repo [Agri-Hub/Space2Ground](https://github.com/Agri-Hub/Space2Ground/tree/main).
I used Street-level image patches folder for this model. It is a dataset containing cropped vegetation parts of
mapillary street-level images. Further details are on the linked git repo.
### How to use
You can use this model directly with help of pipeline class from transformers library of hugging face
```python
>>>from transformers import pipeline
>>>classifier = pipeline("image-classification", model="iammartian0/vegetation_classification_model")
>>>classifier(image)
```
or
uploading a target image to Hosted inference api.
## Training procedure
### Preprocessing
Assigining labels based on parent folder names
### Image Transformations
Applied RandomResizedCrop from torchvision.transforms to all the training images.
### Finetuning
Model is finetuned on the dataset for four epochs
## Evaluation results
Model acheived an Top-1 accuracy of 0.929.
## Further exploration to do
- Trainig a multilabel model where model can find if the image is from left side or right side
on top of classifying the vegetation
- Fine grained classification of crop labels using Raw/Initial set of street-level images
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@INPROCEEDINGS{9816335,
author={Choumos, George and Koukos, Alkiviadis and Sitokonstantinou, Vasileios and Kontoes, Charalampos},
booktitle={2022 IEEE 14th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP)},
title={Towards Space-to-Ground Data Availability for Agriculture Monitoring},
year={2022},
volume={},
number={},
pages={1-5},
doi={10.1109/IVMSP54334.2022.9816335}
}
```
|
AccurateIsaiah/DialoGPT-small-jefftastic
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 14 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: temp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# temp
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3525
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.9321 | 1.0 | 37 | 0.4470 |
| 0.4366 | 2.0 | 74 | 0.3485 |
| 0.284 | 3.0 | 111 | 0.3395 |
| 0.2488 | 4.0 | 148 | 0.3428 |
| 0.1919 | 5.0 | 185 | 0.3525 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AdapterHub/bert-base-uncased-pf-copa
|
[
"bert",
"en",
"arxiv:2104.08247",
"adapter-transformers",
"adapterhub:comsense/copa"
] | null |
{
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-02T22:18:09Z |
---
tags:
- Riverraid-v5
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Riverraid-v5
type: Riverraid-v5
metrics:
- type: mean_reward
value: 15232.00 +/- 2000.10
name: mean_reward
verified: false
---
# (CleanRL) **PPO** Agent Playing **Riverraid-v5**
This is a trained model of a PPO agent playing Riverraid-v5.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/cleanba_ppo_envpool_machado_atari_wrapper.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[jax,envpool,atari]"
python -m cleanrl_utils.enjoy --exp-name cleanba_ppo_envpool_machado_atari_wrapper --env-id Riverraid-v5
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/Riverraid-v5-cleanba_ppo_envpool_machado_atari_wrapper-seed1/raw/main/cleanba_ppo_envpool_machado_atari_wrapper.py
curl -OL https://huggingface.co/cleanrl/Riverraid-v5-cleanba_ppo_envpool_machado_atari_wrapper-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/Riverraid-v5-cleanba_ppo_envpool_machado_atari_wrapper-seed1/raw/main/poetry.lock
poetry install --all-extras
python cleanba_ppo_envpool_machado_atari_wrapper.py --distributed --learner-device-ids 1 2 3 --track --wandb-project-name cleanba --save-model --upload-model --hf-entity cleanrl --env-id Riverraid-v5 --seed 1
```
# Hyperparameters
```python
{'actor_device_ids': [0],
'actor_devices': ['gpu:0'],
'anneal_lr': True,
'async_batch_size': 20,
'async_update': 3,
'batch_size': 15360,
'capture_video': False,
'clip_coef': 0.1,
'concurrency': True,
'cuda': True,
'distributed': True,
'ent_coef': 0.01,
'env_id': 'Riverraid-v5',
'exp_name': 'cleanba_ppo_envpool_machado_atari_wrapper',
'gae_lambda': 0.95,
'gamma': 0.99,
'global_learner_decices': ['gpu:1',
'gpu:2',
'gpu:3',
'gpu:5',
'gpu:6',
'gpu:7'],
'hf_entity': 'cleanrl',
'learner_device_ids': [1, 2, 3],
'learner_devices': ['gpu:1', 'gpu:2', 'gpu:3'],
'learning_rate': 0.00025,
'local_batch_size': 7680,
'local_minibatch_size': 1920,
'local_num_envs': 60,
'local_rank': 0,
'max_grad_norm': 0.5,
'minibatch_size': 3840,
'norm_adv': True,
'num_envs': 120,
'num_minibatches': 4,
'num_steps': 128,
'num_updates': 3255,
'profile': False,
'save_model': True,
'seed': 1,
'target_kl': None,
'test_actor_learner_throughput': False,
'torch_deterministic': True,
'total_timesteps': 50000000,
'track': True,
'update_epochs': 4,
'upload_model': True,
'vf_coef': 0.5,
'wandb_entity': None,
'wandb_project_name': 'cleanba',
'world_size': 2}
```
|
AdapterHub/roberta-base-pf-qqp
|
[
"roberta",
"en",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification",
"adapterhub:sts/qqp"
] |
text-classification
|
{
"architectures": null,
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-02T23:39:29Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1656
- F1: 0.8589
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2905 | 1.0 | 715 | 0.1783 | 0.8310 |
| 0.1461 | 2.0 | 1430 | 0.1600 | 0.8455 |
| 0.0948 | 3.0 | 2145 | 0.1656 | 0.8589 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AdapterHub/roberta-base-pf-quail
|
[
"roberta",
"en",
"dataset:quail",
"arxiv:2104.08247",
"adapter-transformers"
] | null |
{
"architectures": null,
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-02T23:41:38Z |
---
tags:
- conversational
---
#Harry Potter DialoGPT Model
|
AdapterHub/roberta-base-pf-record
|
[
"roberta",
"en",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification",
"adapterhub:rc/record"
] |
text-classification
|
{
"architectures": null,
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-07T10:10:13Z |
---
license: wtfpl
tags:
- guide
- stable diffusion
- webui
- automatic1111
- stable-diffusion-webui
- lora
language:
- en
---
**[⭐ CLICK HERE TO OPEN THIS DOCUMENT IN FULL WIDTH](README.md#index)**
**(The index won't work otherwise).**
[🇪🇸🇲🇽 HAZ CLICK AQUÍ PARA VER ESTA GUÍA EN ESPAÑOL](spanish.md#index)
# Index <a name="index"></a>
* [Introduction](#intro)
* [Google Colab](#colab)
* [Local Installation (Windows + Nvidia)](#install)
* [Getting Started](#start)
1. [Models](#model)
1. [VAEs](#vae)
1. [Prompts](#prompt)
1. [Generation parameters](#gen)
* [Extensions](#extensions)
* [Loras](#lora)
* [Lycoris](#lycoris)
* [Upscaling](#upscale)
* [Scripts](#imgscripts)
* [X/Y/Z Plot](#plot)
* [Prompt Matrix](#matrix)
* [Ultimate Upscaler](#ultimate)
* [ControlNet](#controlnet)
* [Lora Training for beginners](#train)
* [...vtubers?](#vtubers)
# Introduction <a name="intro"></a>[▲](#index)
Stable Diffusion is a very powerful AI image generation software you can run on your own home computer. It uses "models" which function like the brain of the AI, and can make almost anything, given that someone has trained it to do it. The biggest uses are anime art, photorealism, and NSFW content.
The images you create may be used for any purpose, depending on the used model's license. Whether they are "yours" in a legal sense varies by local laws and is often inconclusive. Neither I or any of the people involved in Stable Diffusion or its models are responsible for anything you make, and you are expressively forbidden from creating illegal or harmful content.
This guide is up to date with the best practices as of March 2023. One week is like a year in AI time, so hopefully it is still useful by the time you read it.
# Google Colab <a name="colab"></a>[▲](#index)
The easiest way to use Stable Diffusion is through Google Colab. It borrows Google's computers to use AI, with variable time limitations, usually a few hours every day. You will need at least one Google account and we will be using Google Drive to store your settings and resulting images.
If you instead want to run it on your own computer, [scroll down ▼](#install).
1. Open [THIS PAGE](https://colab.research.google.com/drive/1wEa-tS10h4LlDykd87TF5zzpXIIQoCmq).
1. Near the top, click **Copy to Drive**. Wait for the new window to open and close the old one. This is now your personalized colab which will save your settings, and you should open it from your Google Drive from now on. If the original receives an update you'll have to replace yours to benefit from it.
1. Turn on the following options under **Configurations**: `output_to_drive, configs_in_drive, no_custom_theme`. Then, turn on the following options under **Models, VAEs, etc**: `anything_vae`, `wd_vae`, `sd_vae`.
1. If you're already familiar with Stable Diffusion, you may paste links to your desired resources in the `custom_urls` text box. We will add some links later in this guide. Links must be **direct downloads** to each file (ideally from civitai or huggingface), and must be separated by commas.
1. Press the play button to the left, anywhere in the first section of the page labeled **Start 🚀**. Wait a few minutes for it to finish, while a few progress messages appear near the bottom. Then, a **public link** will be created, which you can open in a new tab to start using Stable Diffusion. **Keep the colab tab open!** (On mobile try the trick at the bottom of the colab to keep the tab open)
1. You can now make some decent anime images thanks to the default **Anything 4.5** model. But we can do more. Also, what are all of these options? [Scroll down ▼](#start) to get started.
# Local Installation (Windows + Nvidia) <a name="install"></a>[▲](#index)
To run Stable Diffusion on your own computer you'll need at least 16 GB of RAM and 4 GB of VRAM (preferably 8). I will only cover the case where you are running Windows 10/11 and using an NVIDIA graphics card series 16XX, 20XX or 30XX (though 10XX also work). My apologies to AMD, Linux, and Mac users, but their cases are harder to cover. If you don't meet the hardware requirements, you can just proceed with the Google Colab method [above ▲](#colab).
1. Get the latest release from [this page](https://github.com/EmpireMediaScience/A1111-Web-UI-Installer/releases).
1. Run the installer, choose an easy and accessible location to install to, and wait for it to finish.
1. Run the program. You will see a few options. First, turn on **medvram** and **xformers**. You may skip medvram if you have 12 or more GB of VRAM.
1. Set your **Additional Launch Options** to: `--opt-channelslast --no-half-vae --theme dark` . Any extra options should be separated by spaces.
* If your graphics card has 4-6 GB of VRAM, add `--opt-split-attention-v1` as it may lower vram usage even further.
* If you want to run the program from your computer but want to use it in another device, such as your phone, add `--listen --enable-insecure-extension-access` . After launching, use your computer's local IP in the same WiFi network to access the interface. You can also add a password like `--gradio-auth name:1234` .
* Full list of possible parameters [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings)
1. Click **Launch** and wait for a browser window to open with the interface. It may take a while the first time.
1. The page is now open. It's your own private website. The starting page is where you can make your images. But first, we'll go to the **Settings** tab. There will be sections of settings on the left.
* In the *Stable Diffusion* section, scroll down and increase **Clip Skip** from 1 to 2. This is said to produce better images, specially for anime.
* In the *User Interface* section, scroll down to **Quicksettings list** and change it to `sd_model_checkpoint, sd_vae`
* Scroll back up, click the big orange **Apply settings** button, then **Reload UI** next to it.
1. You are more than ready to generate some images, but you only have the basic model available. It's not great, at most it can make some paintings. Also, what are all of these options? See [below ▼](#start) to get started.
# Getting Started <a name="start"></a>[▲](#index)
Before or after generating your first few images, you will want to take a look at the information below to improve your experience and results.
If you followed the instructions above, the top of your page should look similar to this:

Here you can select your checkpoint and VAE. We will go over what these are and how you can get some. The colab has additional settings here too, you should ignore them for now.
1. **Models** <a name="model"></a>[▲](#index)
The **model**, also called **checkpoint**, is the brain of your AI, designed for the purpose of producing certain types of images. There are many options, most of which are on [civitai](https://civitai.com). But which to choose? These are my recommendations:
* For anime, [7th Heaven Mix](https://civitai.com/models/4669/corneos-7th-heaven-mix) has a nice aesthetic similar to anime movies, while [Abyss Orange Mix 3](https://civitai.com/models/9942/abyssorangemix3-aom3) *(__Note:__ scroll down there and choose the AOM3 option)* offers more realism in the form of advanced lighting and softer shading, as well as more lewdness. I merged these two options into [Heaven Orange Mix](https://civitai.com/models/14305/heavenorangemix).
* While AOM3 is extremely capable for NSFW, the popular [Grapefruit](https://civitai.com/models/2583/grapefruit-hentai-model) hentai model may also fit your needs.
* For general art go with [DreamShaper](https://civitai.com/models/4384/dreamshaper), there are few options quite like it in terms of creativity. An honorable mention goes to [Pastel Mix](https://civitai.com/models/5414/pastel-mix-stylized-anime-model), which has a beautiful and unique aesthetic with the addition of anime.
* For photorealism go with [Deliberate](https://civitai.com/models/4823/deliberate). It can do almost anything, but specially photographs. Very intricate results.
* The [Uber Realistic Porn Merge](https://civitai.com/models/2661/uber-realistic-porn-merge-urpm) is self-explanatory.
If you're using the colab in this guide, copy the **direct download link to the file** and paste it in the text box labeled `custom_urls`. Multiple links are separated by commas.
If you're running the program locally, the models normally go into the `stable-diffusion-webui/models/Stable-diffusion` folder.
Please note that checkpoints in the format `.safetensors` are safe to use while `.ckpt` **may** contain viruses, so be careful. Additionally, when choosing models you may have a choice between fp32, fp16 and pruned. They all produce the same images within a tiny margin of error, so just go with the smallest file (pruned-fp16). If you want to use them for training or merging, go with the largest one instead.
**Tip:** Whenever you place a new file manually you can either restart the UI at the bottom of the page or press the small 🔃 button next to its dropdown.
1. **VAEs** <a name="vae"></a>[▲](#index)
Most checkpoints don't come with a VAE built in. The VAE is a small separate model, which "converts your image into human format". Without it, you'll get faded colors and ugly eyes, among other things.
If you're using the colab in this guide, you should already have the below VAEs, as I told you to select them before running.
There are practically only 3 different VAEs in circulation:
* [anything vae](https://huggingface.co/WarriorMama777/OrangeMixs/resolve/main/VAEs/orangemix.vae.pt), also known as the orangemix vae. All anime models use this.
* [vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors), the latest from Stable Diffusion itself. Used by photorealism models and such.
* [kl-f8-anime2](https://huggingface.co/hakurei/waifu-diffusion-v1-4/resolve/main/vae/kl-f8-anime2.ckpt), also known as the Waifu Diffusion VAE, it is older and produces more saturated results. Used by Pastel Mix.
The VAEs normally go into the `stable-diffusion-webui/models/VAE` folder.
If you did not follow this guide up to this point, you will have to go into the **Settings** tab, then the **Stable Difussion** section, to select your VAE.
**Tip:** Whenever you place a new file manually you can either restart the UI at the bottom of the page or press the small 🔃 button next to its dropdown.
1. **Prompts** <a name="prompt"></a>[▲](#index)
On the first tab, **txt2img**, you'll be making most of your images. This is where you'll find your *prompt* and *negative prompt*.
Stable Diffusion is not like Midjourney or other popular image generation software, you can't just ask it what you want. You have to be specific. *Very* specific.
Most people have found a prompt that works for them and they swear by it, often recommended by other people. I will show you my own personal example of a prompt and negative prompt:
* Anime
* `2d, masterpiece, best quality, anime, highly detailed face, highly detailed background, perfect lighting`
* `EasyNegative, worst quality, low quality, 3d, realistic, photorealistic, (loli, child, teen, baby face), zombie, animal, multiple views, text, watermark, signature, artist name, artist logo, censored`
* Photorealism
* `best quality, 4k, 8k, ultra highres, raw photo in hdr, sharp focus, intricate texture, skin imperfections, photograph of`
* `EasyNegative, worst quality, low quality, normal quality, child, painting, drawing, sketch, cartoon, anime, render, 3d, blurry, deformed, disfigured, morbid, mutated, bad anatomy, bad art`
* **EasyNegative:** <a name="promptneg"></a>The negative prompts above use EasyNegative, which is an *embedding* or "magic word" that encodes many bad things to make your images better. Otherwise you'd have to use a huge negative prompt.
* If you're using the colab in this guide you already have this installed. Otherwise, you will have to [download this tiny file](https://huggingface.co/datasets/gsdf/EasyNegative/resolve/main/EasyNegative.safetensors), put it in your `stable-diffusion-webui/embeddings` folder, then go to the bottom of your WebUI page and click *Reload UI*. It will then work when you type that word.
A comparison with and without these negative prompts including EasyNegative can be seen [further down ▼](#matrixneg).

After a "base prompt" like the above, you may then start typing what you want. For example `young woman in a bikini in the beach, full body shot`. Feel free to add other terms you don't like to your negatives such as `old, ugly, futanari, furry`, etc.
You can also save your prompts to reuse later with the buttons below Generate. Click the small 💾 *Save style* button and give it a name. Later, you can open your *Styles* dropdown to choose, then click 📋 *Apply selected styles to the current prompt*.
<a name="promptweight"></a>One important technique when writing prompts are emphasis and de-emphasis. When you surround something in `(parentheses)`, it will get more emphasis or **weight** in your resulting image, basically telling the AI that part is more important. The normal weight for every word is 1, and each parentheses will multiply by 1.1 (you can use multiple). You can also specify the weight yourself, like this: `(full body:1.4)`. You can also go below 1 to de-emphasize a word: `[brackets]` will multiply by 0.9, but you'll still need parentheses to go lower, like `(this:0.5)`.
Also note that hands and feet are famously difficult for AI to generate. These methods improve your chances, but you may need to do photoshopping, inpainting, or advanced techniques with [ControlNet ▼](#controlnet) to get it right.
1. **Generation parameters** <a name="gen"></a>[▲](#index)
The rest of the parameters in the starting page will look something like this:

* **Sampling method:** This is the algorithm that formulates your image, and each produce different results. The default of `Euler a` is often the best. There are also very good results for `DPM++ 2M Karras` and `DPM++ SDE Karras`. See below for a comparison.
* **Sampling steps:** These are "calculated" beforehand, and so more steps doesn't always mean more detail. I always go with 30, you may go from 20-50 and find consistently good results. See below for a comparison.
* **Width and Height:** 512x512 is the default, and you should almost never go above 768 in either direction as it may distort and deform your image. To produce bigger images see `Hires fix`.
* **Batch Count and Batch Size:** Batch *size* is how many images your graphics card will generate at the same time, which is limited by its VRAM. Batch *count* is how many times to repeat those. Batches have consecutive seeds, more on seeds below.
* **CFG Scale:** "Lower values produce more creative results". You should almost always stick to 7, but 4 to 10 is an acceptable range.
* **Seed:** A number that guides the creation of your image. The same seed with the same prompt and parameters produces the same image every time, except for small details and under some circumstances.
**Hires fix:** Lets you create larger images without distortion. Often used at 2x scale. When selected, more options appear:
* **Upscaler:** The algorithm to upscale with. `Latent` and its variations produce creative and detailed results, but you may also like `R-ESRGAN 4x+` and its anime version. [More explanation and some comparisons further down ▼](#upscale).
* **Hires steps:** I recommend at least half as many as your sampling steps. Higher values aren't always better, and they take a long time, so be conservative here.
* **Denoising strength:** The most important parameter. Near 0.0, no detail will be added to the image. Near 1.0, the image will be changed completely. I recommend something between 0.2 and 0.6 depending on the image, to add enough detail as the image gets larger, without *destroying* any original details you like.
Others:
* **Restore faces:** May improve realistic faces. I never need it with the models and prompts listed in this guide as well as hires fix.
* **Tiling:** Used to produce repeating textures to put on a grid. Not very useful.
* **Script:** Lets you access useful features and extensions, such as [X/Y/Z Plot ▼](#plot) which lets you compare images with varying parameters on a grid. Very powerful.
Here is a comparison of a few popular samplers and various sampling steps:
<details>
<summary>(Click) Sampler comparison - Photography</summary>

</details>
<details>
<summary>(Click) Sampler comparison - Anime</summary>

</details>
An explanation of the samplers used above: `Euler` is a basic sampler. `DDIM` is a faster version, while `DPM++ 2M Karras` is an improved version. Meanwhile we have `Euler a` or "ancestral" which produces more creative results, and `DPM++ 2S a Karras` which is also ancestral and thus similar. Finally `DPM++ SDE Karras` is the slowest and quite unique. There are many other samplers not shown here but most of them are related.
# Extensions <a name="extensions"></a>[▲](#index)
*Stable Diffusion WebUI* supports extensions to add additional functionality and quality of life. These can be added by going into the **Extensions** tab, then **Install from URL**, and pasting the links found here or elsewhere. Then, click *Install* and wait for it to finish. Then, go to **Installed** and click *Apply and restart UI*.

Here are some useful extensions. If you're using the colab in this guide you already have most of these, otherwise I hugely recommend you manually add the first 2:
* [Image Browser (updated)](https://github.com/AlUlkesh/stable-diffusion-webui-images-browser) - This will let you browse your past generated images very efficiently, as well as directly sending their prompts and parameters back to txt2img, img2img, etc.
* [TagComplete](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete) - Absolutely essential for anime art. It will show you the matching booru tags as you type. Anime models work via booru tags, and prompts without them usually don't work, so knowing them is godmode. Not all tags will work well in all models though, specially if they're rare.
* [Locon](https://github.com/KohakuBlueleaf/a1111-sd-webui-locon) - Lets you use LoCons and LoHas. More info [below ▼](#lycoris).
* [ControlNet](https://github.com/Mikubill/sd-webui-controlnet) - A huge extension deserving of [its own guide ▼](#controlnet). It lets you analyze any image and use it as an referene for your own image. Practically speaking, it can create any pose or environment you want.
* [Ultimate Upscale](https://github.com/Coyote-A/ultimate-upscale-for-automatic1111) - A script usable from the img2img section to make really large images, where normally you can only go as high as your VRAM allows. See [Ultimate Upscaler ▼](#ultimate).
* [Two-shot](https://github.com/opparco/stable-diffusion-webui-two-shot) - Normally you can't create more than one distinct character in the same image without them blending together. This extension lets you divide the image into parts; full, left side, right side; allowing you to make nice 2-character images.
* [Dynamic Prompts](https://github.com/adieyal/sd-dynamic-prompts) - A script to let you generate randomly chosen elements in your image, among other things.
* [Model Converter](https://github.com/Akegarasu/sd-webui-model-converter) - Lets you convert most 7GB/4GB models down to 2GB, by choosing `safetensors`, `fp16`, and `no-ema`. These pruned models work "almost the same" as the full models, which is to say, there is no appreciable difference due to math reasons. Most models come in 2 GB form nowadays regardless.
# Loras <a name="lora"></a>[▲](#index)
LoRA or *Low-Rank Adaptation* is a form of **Extra Network** and the latest technology that lets you append a sort of smaller model to any of your full models. They are similar to embeddings, one of which you might've seen [earlier ▲](#promptneg), but Loras are larger and often more capable. Technical details omitted.
Loras can represent a character, an artstyle, poses, clothes, or even a human face (though I do not endorse this). Checkpoints are usually capable enough for general work, but when it comes to specific details with little existing examples, you'll need a Lora. They can be downloaded from [civitai](https://civitai.com) or [elsewhere (NSFW)](https://gitgud.io/gayshit/makesomefuckingporn#lora-list) and are 144 MB by default, but they can go as low as 1 MB. Bigger Loras are not always better. They come in `.safetensors` format, same as most checkpoints.
Place your Lora files in the `stable-diffusion-webui/models/Lora` folder, or if you're using the colab in this guide paste the direct download link into the `custom_urls` text box. Then, look for the 🎴 *Show extra networks* button below the big orange Generate button. It will open a new section either directly below or at the very bottom. Click on the Lora tab and press the **Refresh** button to scan for new Loras. When you click a Lora in that menu it will get added to your prompt, looking like this: `<lora:filename:1>`. The start is always the same. The filename will be the exact filename in your system without the `.safetensors` extension. Finally, the number is the weight, like we saw [earlier ▲](#promptweight). Most Loras work between 0.5 and 1 weight, and too high values might "fry" your image, specially if using multiple Loras at the same time.

An example of a Lora is [Thicker Lines Anime Style](https://civitai.com/models/13910/thicker-lines-anime-style-lora-mix), which is perfect if you want your images to look more like traditional anime.
* Lycoris <a name="lycoris"></a>[▲](#index)
LyCORIS is a new development that lets LoRAs learn more layers. [Learn about it here](https://github.com/KohakuBlueleaf/Lycoris). You'll need [this extension](https://github.com/KohakuBlueleaf/a1111-sd-webui-locon) to use them.
As of now there are 2 new LoRA types:
* **LoCon** - Said to be good with styles
* **LoHa** - Said to be good with styles that also contain characters
You can make your own in the [trainer further down ▼](#traincolab).
# Upscaling <a name="upscale"></a>[▲](#index)
As mentioned in [Generation Parameters ▲](#gen), normally you shouldn't go above 768 width or height when generating an image. Instead you should use `Hires fix` with your choice of upscaler and an appropiate denoising level. Hires fix is limited by your VRAM however, so you may be interested in [Ultimate Upscaler ▼](#ultimate) to go even larger.
You can download additional upscalers and put them in your `stable-diffusion-webui/models/ESRGAN` folder. They will then be available in Hires fix, Ultimate Upscaler, and Extras.
The colab in this guide comes with several of them, including **Remacri**, which is a great all-around upscaler for all sorts of images.
* A few notable ones can be [found here](https://huggingface.co/hollowstrawberry/upscalers-backup/tree/main/ESRGAN).
* LDSR is an advanced yet slow upscaler, its model and config can be [found here](https://huggingface.co/hollowstrawberry/upscalers-backup/tree/main/LDSR) and both must be placed in `stable-diffusion-webui/models/LDSR`.
* The [Upscale Wiki](https://upscale.wiki/wiki/Model_Database) contains dozens of historical choices.
Here are some comparisons. All of them were done at 0.4 denoising strength. Note that some of the differences may be completely up to random chance.
<details>
<summary>(Click) Comparison 1: Anime, stylized, fantasy</summary>


</details>
<details>
<summary>(Click) Comparison 2: Anime, detailed, soft lighting</summary>


</details>
<details>
<summary>(Click) Comparison 3: Photography, human, nature</summary>


</details>
# Scripts <a name="imgscripts"></a>[▲](#index)
Scripts can be found at the bottom of your generation parameters in txt2img or img2img.
* **X/Y/Z Plot** <a name="plot"></a>[▲](#index)
Capable of generating a series of images, usually with the exact same seed, but varying parameters of your choice. Can compare almost anything you want, including different models, parts of your prompt, sampler, upscaler and much more. You can have 1, 2, or 3 variable parameters, hence the X, Y and Z.
Your parameters in X/Y/Z Plot are separated by commas, but anything else can go inbetween. The most common parameter to compare is **S/R Prompt**, where the first term is a phrase in your prompt and each term afterwards will replace the original. Knowing this, you can compare, say, Lora intensity, like this:
`<lora:my lora:0.4>, <lora:my lora:0.6>, <lora:my lora:0.8>, <lora:my lora:1>`
Here I made a comparison between different **models** (columns) and faces of different ethnicities via **S/R Prompt** (rows):
<details>
<summary>(Click) X/Y/Z Plot example</summary>

</details>
**Tip:** It appears possible to do S/R with commas by using quotes like this (note no spaces between the commas and quotes): `"term 1, term 2","term 3, term 4","term 5, term 6"`
* **Prompt Matrix** <a name="matrix"></a>[▲](#index)
Similar conceptually to S/R from before, but more in-depth. It works by showing each possible combination of terms listed between the `|` symbol in your prompt, for example: `young man|tree|city` will always contain "young man", but we'll see what happens when we add or remove "tree" and "city". You can use commas and spaces just fine between the `|`.
Inside the script, you will choose either your prompt or your negative prompt to make a matrix of, and whether the variable terms should be put at the start or the end.
<a name="matrixneg"></a>Here is a comparison using the negative prompts I showed you in [Prompts ▲](#prompt). We can see how EasyNegative affects the image, as well as how the rest of the prompt affects the image, then both together:
<details>
<summary>(Click) Prompt matrix examples</summary>


</details>
**Tip:** When using prompt matrix, the Batch Size will let you generate multiple images or the whole grid all at once.
* **Ultimate Upscaler** <a name="ultimate"></a>[▲](#index)
An improved version of a builtin script, it can be added as an [extension ▲](#extensions) and used from within **img2img**. Its purpose is to resize an image and add more detail way past the normal limits of your VRAM by splitting it into chunks, although slower. Here are the steps:
1. Generate your image normally up to 768 width and height, you can then apply hires fix if you are able to.
1. From txt2img or the Image Browser extension send it directly into img2img, carrying its prompt and parameters.
1. Set the **Denoising** somewhere between 0.1 and 0.4. If you go higher you most likely will experience mutations.
1. Go down to **Scripts** and choose **Ultimate SD Upscale**. Then, set your parameters like this, with your desired size and upscaler, and the **"Chess" Type**:

* If you have enough VRAM, you may increase the **Tile width** as well as the **Padding**. For example, doubling both of them. **Tile height** can remain at 0 and it'll match the width.
* It is not necessary to set the **Seams fix** unless you encounter visible seams between regions in the final image.
1. Generate your image and wait. You can watch the squares get sharper if you have image previews enabled.
# ControlNet <a name="controlnet"></a>[▲](#index)
ControlNet is an extremely powerful recent technology for Stable Diffusion. It lets you analyze information about any previously existing image and use it to guide the generation of your AI images. We'll see what this means in a moment.
If you're using the colab in this guide, you should enable the `all_control_models` option. Otherwise, you should first install the ControlNet [extension ▲](#extensions), then go [here](https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main) to download some models which you'll need to place in `stable-diffusion-webui/extensions/sd-webui-controlnet/models`. I recommend at least Canny, Depth, Openpose and Scribble, which I will show here.
I will demonstrate how ControlNet may be used. For this I chose a popular image online as our "sample image". It's not necessary for you to follow along, but you can download the images and put them in the **PNG Info** tab to view their generation data.
First, you must scroll down in the txt2img page and click on ControlNet to open the menu. Then, click *Enable*, and pick a matching *preprocessor* and *model*. To start with, I chose Canny for both. Finally I upload my sample image. Make sure not to click over the sample image or it will start drawing. We can ignore the other settings.

* **Canny**
The Canny method extracts the hard edges of the sample image. It is useful for many different types of images, specially where you want to preserve small details and the general look of an image. Observe:
<details>
<summary>(Click) Canny example</summary>


</details>
* **Depth**
The Depth method extracts the 3D elements of the sample image. It is best suited for complex environments and general composition. Observe:
<details>
<summary>(Click) Depth example</summary>


</details>
* **Openpose**
The Openpose method extracts the human poses of the sample image. It helps tremendously to get the desired shot and composition of your generated characters. Observe:
<details>
<summary>(Click) Openpose example</summary>


</details>
* **Scribble**
Lets you make a simple sketch and convert it into a finished piece with the help of your prompt. This is the only example not using the sample image above.
<details>
<summary>(Click) Scribble example</summary>


</details>
You will notice that there are 2 results for each method except Scribble. The first is an intermediate step called the *preprocessed image*, which is then used to produce the final image. You can supply the preprocessed image yourself, in which case you should set the preprocessor to *None*. This is extremely powerful with external tools such as Blender and Photoshop.
In the Settings tab there is a ControlNet section where you can enable *multiple controlnets at once*. One particularly good use is when one of them is Openpose, to get a specific character pose in a specific environment, or with specific hand gestures or details. Observe:
<details>
<summary>(Click) Openpose+Canny example</summary>

</details>
You can also use ControlNet in img2img, in which the input image and sample image both will have a certain effect on the result. I do not have much experience with this method.
There are also alternative **diff** versions of each ControlNet model, which produce slightly different results. You can [try them](https://civitai.com/models/9868/controlnet-pre-trained-difference-models) if you want, but I personally haven't.
# Lora Training for beginners <a name="train"></a>[▲](#index)
To train a [Lora ▲](#lora) is regarded as a difficult task. However, my new guide covers everything you need to know to get started for free, thanks to Google Colab:
**[🎴 Read my Lora making guide here](https://civitai.com/models/22530)**
You can also train a Lora on your own computer if you have at least 8 GB of VRAM. For that, I will list a few resources below:
* For training, use [bmaltais' Kohya GUI](https://github.com/bmaltais/kohya_ss). It has all the same settings as my trainer colab and more, so you can follow my guide too. Also there are youtube tutorials available in this link.
* Also, here's an [angry Lora training guide by ao](https://rentry.org/tohoaifaq#opinionated-lora-guide-for-colab)
* To collect your images from Gelbooru like in my guide, install [Grabber](https://github.com/Bionus/imgbrd-grabber/releases).
* To tag your dataset use the [WD1.4 Tagger extension](https://github.com/toriato/stable-diffusion-webui-wd14-tagger) for webui. First add and enable the extension, and restart your entire webui. Then go to the new **Tagger** tab, then **Batch from directory**, and select the folder with your images. Set the output name to `[name].txt` and the threshold at or above 0.35 (this is how closely each tag must match an image to be included). Then **Interrogate** and it will start generating your text files.
* To curate your tags like in my guide use the [Tag Editor extension](https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor) for webui. It has all the features you need like sorting, pruning, replacing and merging tags. To add an activation tag it's as follows: After adding the extension and restarting your webui, go to the new **Dataset Tag Editor** tab then **Batch Edit Captions**. Turn off "*Show only the tags...*", turn on "*Prepend additional tags*", then add your activation tag inside the **Edit Tags** text box. Then apply your changes, scroll up and save your changes. Only then will it modify your files and add a new tag at the beginning of every text file.
# ...vtubers? <a name="vtubers"></a>[▲](#index)
That's it, that's the end of this guide for now. I'd be grateful if you want to contribute on missing topics like:
* img2img
* Inpainting
* Controlnet t2i adapters
Thank you for reading!
I have [a separate repo that aggregates vtuber Loras, specially Hololive](https://huggingface.co/hollowstrawberry/holotard). If you're interested in that.
Cheers.
|
AdapterHub/roberta-base-pf-scitail
|
[
"roberta",
"en",
"dataset:scitail",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification",
"adapterhub:nli/scitail"
] |
text-classification
|
{
"architectures": null,
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | 2023-03-02T23:59:33Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Junfeng/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Aeroxas/Botroxas-small
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-03T00:54:30Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 444.30 +/- 88.18
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Ahmedahmed/Wewe
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: other
thumbnail: >-
replicant.jpg
tags:
- text-to-image
- stable-diffusion
- safetensors
inference: false
---
# Untitled:Replicant Model Card
Japanese version is [here](README_jp.md).
# Introduction
Untitled:Replicant is the latent diffusion model made for AI art.
# Usage
I recommend to use the model by Web UI.
You can download the model [here](untitled_replicant.safetensors).
Then, install [Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) by AUTIMATIC1111.
I recommend to use the embeddings.
See also: [WD 1.5 Beta 2 - Aesthetic Ver.](https://cafeai.notion.site/WD-1-5-Beta-2-Aesthetic-Ver-c44a410fec06478fbf1a08a9890310ff)
# Examples

```
anime, full body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed:1.2), a girl in the heaven
Negative prompt: nfixer, nrealfixer, owres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 60, Sampler: Euler a, CFG scale: 10, Seed: 2843402952, Size: 1024x1024, Model hash: 04be389469, Model: untitledreplicant, Denoising strength: 0.7, Hires upscale: 2, Hires upscaler: Latent
```

```
anime, full body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed), a humanoid robot
Negative prompt: nfixer, lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 20473310, Size: 1024x1024, Model hash: 04be389469, Model: untitledreplicant
```

```
anime, full body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed), witch, 1girl, lightning, magic
Negative prompt: nfixer, nrealfixer, lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 2960555156, Size: 768x768, Model hash: 04be389469, Model: untitledreplicant, Denoising strength: 0.7, Hires upscale: 2, Hires upscaler: Latent
```

```
anime, upper body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed:1.2), a girl sitting in the cafe
Negative prompt: nfixer, lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 1954012709, Size: 768x1024, Model hash: 04be389469, Model: untitledreplicant
```

```
anime, full body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed), waifu, a girl, solo, ((good pupil)), orange background, simple background
Negative prompt: lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 4050907053, Size: 1024x1024, Model hash: 04be389469, Model: untitledreplicant, Denoising strength: 0.7, Hires upscale: 2, Hires upscaler: Latent
```

```
anime, upper body, (symmetric), (exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed:1.2), replicant, 1girl
Negative prompt: nfixer, nrealfixer, lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
Steps: 60, Sampler: Euler a, CFG scale: 10, Seed: 390258972, Size: 1024x1024, Model hash: 04be389469, Model: untitledreplicant
```
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser, Alfred Increment
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M-NC License](MODEL-LICENSE), [Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Alfred Increment and is based on the [Stable Diffusion v2](https://huggingface.co/stabilityai/stable-diffusion-2/raw/main/README.md)
|
Akira-Yana/distilbert-base-uncased-finetuned-cola
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: imar0/ppo-SnowballTarget_1
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Akiva/Joke
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: cc-by-nc-4.0
datasets:
- fka/awesome-chatgpt-prompts
- stanfordnlp/SHP
language:
- am
metrics:
- bertscore
library_name: asteroid
tags:
- music
---
|
Akjder/DialoGPT-small-harrypotter
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: fish
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8571428656578064
---
# fish
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### 2d fish

#### 2d fish color

#### 2d fish line art

#### 2d fish outline

#### 2d fish sketch

|
AkshatSurolia/BEiT-FaceMask-Finetuned
|
[
"pytorch",
"beit",
"image-classification",
"dataset:Face-Mask18K",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
image-classification
|
{
"architectures": [
"BeitForImageClassification"
],
"model_type": "beit",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 239 | null |
---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3582
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6861 | 0.54 | 500 | 1.4850 |
| 1.4425 | 1.09 | 1000 | 1.4123 |
| 1.5097 | 1.63 | 1500 | 1.3808 |
| 1.4757 | 2.17 | 2000 | 1.3634 |
| 1.4058 | 2.72 | 2500 | 1.3582 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.1
- Datasets 2.6.1
- Tokenizers 0.11.0
|
AkshatSurolia/ICD-10-Code-Prediction
|
[
"pytorch",
"bert",
"transformers",
"text-classification",
"license:apache-2.0",
"has_space"
] |
text-classification
|
{
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 994 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# fathyshalab/reklambox2-8-17
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/reklambox2-8-17")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
AlanDev/DallEMiniButBetter
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
language:
- en
---
**VLE** (**V**isual-**L**anguage **E**ncoder) is an image-text multimodal understanding model built on the pre-trained text and image encoders.
It can be used for multimodal discriminative tasks such as visual question answering and image-text retrieval.
Especially on the visual commonsense reasoning (VCR) task, which requires high-level language understanding and reasoning skills, VLE achieves significant improvements.
For more details see [https://github.com/iflytek/VLE](https://github.com/iflytek/VLE).
Online VLE demo on Visual Question Answering: [https://huggingface.co/spaces/hfl/VQA_VLE_LLM](https://huggingface.co/spaces/hfl/VQA_VLE_LLM)
|
AlbertHSU/BertTEST
|
[
"pytorch"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.21176470816135406
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### 2d fish

#### 2d fish cartoon

#### 2d fish line art

#### 2d fish sketch art

#### 2d fish with color

|
Alberto15Romero/GptNeo
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Vi-test4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Vi-test4
This model is a fine-tuned version of [VietAI/vit5-base](https://huggingface.co/VietAI/vit5-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 50
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AlchemistDude/DialoGPT-medium-Gon
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: dgx1_whisper_tiny_finetune_teacher_babble_noise_mozilla_40_epochs_batch_32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dgx1_whisper_tiny_finetune_teacher_babble_noise_mozilla_40_epochs_batch_32
This model is a fine-tuned version of [openai/whisper-tiny.en](https://huggingface.co/openai/whisper-tiny.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0819
- Wer: 38.0301
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.622 | 7.35 | 500 | 0.8796 | 41.4282 |
| 0.151 | 14.7 | 1000 | 1.0639 | 41.4038 |
| 0.0146 | 22.06 | 1500 | 1.0756 | 38.3399 |
| 0.0004 | 29.41 | 2000 | 1.0791 | 38.0753 |
| 0.0003 | 36.76 | 2500 | 1.0819 | 38.0301 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Ale/Alen
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelCopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 35.60 +/- 28.65
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Aleksandar/distilbert-srb-ner-setimes
|
[
"pytorch",
"distilbert",
"token-classification",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="juanfkurucz/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Aleksandar/distilbert-srb-ner
|
[
"pytorch",
"distilbert",
"token-classification",
"sr",
"dataset:wikiann",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: FelipePasquevich/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Aleksandar/electra-srb-ner-setimes-lr
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="juanfkurucz/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Aleksandar/electra-srb-oscar
|
[
"pytorch",
"electra",
"fill-mask",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"ElectraForMaskedLM"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
---
Korean Pre-Trained Crypto RoBERTa model fine-tuned on BTC sentiment classification dataset.
For more details, check our work [CBITS: Crypto BERT Incorporated Trading System](https://ieeexplore.ieee.org/document/10014986) on IEEE Access.
## Example Use Case: BTC Sentiment Classification
```python
from tokenization_roberta_spm import FairSeqRobertaSentencePieceTokenizer
from transformers import XLMRobertaForSequenceClassification
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = XLMRobertaForSequenceClassification.from_pretrained("axiomlabs/KR-cryptoroberta-base", num_labels=3)
model.eval()
model.to(device)
tokenizer = FairSeqRobertaSentencePieceTokenizer.from_pretrained("fairseq-roberta-all-model")
title = "우즈벡, 외국기업의 암호화폐 거래자금 국내계좌 입금 허용"
content = "비트코인닷컴에 따르면 우즈베키스탄 중앙은행이 외국기업의 국내 은행 계좌 개설 및 암호화폐 거래 자금 입금을 허용했다. 앞서 우즈베키스탄은 외국기업의 은행 계좌 개설 등을 제한 및 금지한 바 있다. 개정안에 따라 이러한 자금은 암호화폐 매입을 위해 거래소로 이체, 혹은 자금이 유입된 관할권 내 등록된 법인 계좌로 이체할 수 있다. 다만 그 외 다른 목적을 위한 사용은 금지된다. 해당 개정안은 지난 2월 9일 발효됐다."
encoded_input = tokenizer(str(title), str(content), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
output = model(**encoded_input).logits
output = nn.Softmax(dim=1)(output)
output = output.detach().cpu().numpy()[0]
print("호재: {:.2f}% | 악재: {:.2f}% | 중립: {:.2f}%".format(output[0]*100,output[1]*100,output[2]*100))
```
## Example Use Case: Crypto Embedding Similarity
```python
from tokenization_roberta_spm import FairSeqRobertaSentencePieceTokenizer
from transformers import XLMRobertaForSequenceClassification
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained("axiomlabs/KR-cryptoroberta-base")
model.eval()
model.to(device)
tokenizer = FairSeqRobertaSentencePieceTokenizer.from_pretrained("fairseq-roberta-all-model")
title1 = "USDN 다중담보 자산 전환 제안 통과"
content1 = "웨이브 생태계 스테이블코인 USDN을 다중담보 자산으로 전환하는 제안 투표가 찬성 99%로 오늘 통과됐다. 앞서 코인니스는 웨브가 $WX,$SWOP,$VIRES,$EGG,$WEST를 담보로 해 USDN을 웨이브 생태계 인덱스 자산으로 만들어 USDN 디페깅 이슈를 해결할 플랜을 공개했다고 전한 바 있다."
title2 = "웨이브, USDN 고래 청산안 투표 통과로 30%↑"
content2 = "유투데이에 따르면 웨이브(WAVES) 기반 알고리즘 스테이블코인 뉴트리노(USDN)의 디페그 발생 없이 대규모 USDN 포지션 청산을 가능하게 하는 투표가 만장일치로 통과 됨에 따라 WAVES가 몇시간 안에 30%대 상승폭을 나타냈다. 지난 28일 웨이브 팀이 발표한 USDN의 달러 페그 회복 계획은 다음과 같다.- 커브 및 CRV 토큰으로 USDN 유동성 공급.- 고래 계좌를 청산시켜 Vires 유동성 복구.- USDN 담보물을 두달에 걸쳐 천천히 판매.- 뉴트리노 프로토콜 자본 조달을 위한 새로운 토큰 발행."
encoded_input1 = tokenizer(str(title1), str(content1), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
encoded_input2 = tokenizer(str(title2), str(content2), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
emb1 = model(**encoded_input1)[0][:,0,:].detach().cpu().numpy()
emb2 = model(**encoded_input2)[0][:,0,:].detach().cpu().numpy()
sim_scores = cdist(emb1, emb2, "cosine")[0]
print(f"cosine distance = {sim_scores[0]}")
```
|
Aleksandar1932/gpt2-country
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | null |
---
license: apache-2.0
---
Korean Pre-Trained Crypto DeBERTa model fine-tuned on BTC sentiment classification dataset.
For more details, check our work [CBITS: Crypto BERT Incorporated Trading System](https://ieeexplore.ieee.org/document/10014986) on IEEE Access.
## Example Use Case: Crypto News BTC Sentiment Classification
```python
from transformers import AutoModelForSequenceClassification, AlbertTokenizer
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModelForSequenceClassification.from_pretrained("axiomlabs/KR-cryptodeberta-v2-base", num_labels=3)
model.eval()
model.to(device)
tokenizer = AlbertTokenizer.from_pretrained("axiomlabs/KR-cryptodeberta-v2-base")
title = "우즈벡, 외국기업의 암호화폐 거래자금 국내계좌 입금 허용"
content = "비트코인닷컴에 따르면 우즈베키스탄 중앙은행이 외국기업의 국내 은행 계좌 개설 및 암호화폐 거래 자금 입금을 허용했다. 앞서 우즈베키스탄은 외국기업의 은행 계좌 개설 등을 제한 및 금지한 바 있다. 개정안에 따라 이러한 자금은 암호화폐 매입을 위해 거래소로 이체, 혹은 자금이 유입된 관할권 내 등록된 법인 계좌로 이체할 수 있다. 다만 그 외 다른 목적을 위한 사용은 금지된다. 해당 개정안은 지난 2월 9일 발효됐다."
encoded_input = tokenizer(str(title), str(content), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
output = model(**encoded_input).logits
output = nn.Softmax(dim=1)(output)
output = output.detach().cpu().numpy()[0]
print("호재: {:.2f}% | 악재: {:.2f}% | 중립: {:.2f}%".format(output[0]*100,output[1]*100,output[2]*100))
```
## Example Use Case: Crypto News Embedding Similarity
```python
from transformers import AutoModelForSequenceClassification, AlbertTokenizer
from scipy.spatial.distance import cdist
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained("axiomlabs/KR-cryptodeberta-v2-base")
model.eval()
model.to(device)
tokenizer = AlbertTokenizer.from_pretrained("axiomlabs/KR-cryptodeberta-v2-base")
title1 = "USDN 다중담보 자산 전환 제안 통과"
content1 = "웨이브 생태계 스테이블코인 USDN을 다중담보 자산으로 전환하는 제안 투표가 찬성 99%로 오늘 통과됐다. 앞서 코인니스는 웨브가 $WX,$SWOP,$VIRES,$EGG,$WEST를 담보로 해 USDN을 웨이브 생태계 인덱스 자산으로 만들어 USDN 디페깅 이슈를 해결할 플랜을 공개했다고 전한 바 있다."
title2 = "웨이브, USDN 고래 청산안 투표 통과로 30%↑"
content2 = "유투데이에 따르면 웨이브(WAVES) 기반 알고리즘 스테이블코인 뉴트리노(USDN)의 디페그 발생 없이 대규모 USDN 포지션 청산을 가능하게 하는 투표가 만장일치로 통과 됨에 따라 WAVES가 몇시간 안에 30%대 상승폭을 나타냈다. 지난 28일 웨이브 팀이 발표한 USDN의 달러 페그 회복 계획은 다음과 같다.- 커브 및 CRV 토큰으로 USDN 유동성 공급.- 고래 계좌를 청산시켜 Vires 유동성 복구.- USDN 담보물을 두달에 걸쳐 천천히 판매.- 뉴트리노 프로토콜 자본 조달을 위한 새로운 토큰 발행."
encoded_input1 = tokenizer(str(title1), str(content1), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
encoded_input2 = tokenizer(str(title2), str(content2), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
emb1 = model(**encoded_input1)[0][:,0,:].detach().cpu().numpy()
emb2 = model(**encoded_input2)[0][:,0,:].detach().cpu().numpy()
sim_scores = cdist(emb1, emb2, "cosine")[0]
print(f"cosine distance = {sim_scores[0]}")
```
|
Aleksandar1932/gpt2-soul
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 10 | null |
---
license: apache-2.0
---
Korean Pre-Trained Crypto BERT model fine-tuned on BTC sentiment classification dataset.
For more details, check our work [CBITS: Crypto BERT Incorporated Trading System](https://ieeexplore.ieee.org/document/10014986) on IEEE Access.
## Example Use Case: Crypto News BTC Sentiment Classification
```python
from transformers import AutoModelForSequenceClassification, AlbertTokenizer
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModelForSequenceClassification.from_pretrained("axiomlabs/KR-cryptobert-base", num_labels=3)
model.eval()
model.to(device)
tokenizer = AlbertTokenizer.from_pretrained("axiomlabs/KR-cryptobert-base")
title = "우즈벡, 외국기업의 암호화폐 거래자금 국내계좌 입금 허용"
content = "비트코인닷컴에 따르면 우즈베키스탄 중앙은행이 외국기업의 국내 은행 계좌 개설 및 암호화폐 거래 자금 입금을 허용했다. 앞서 우즈베키스탄은 외국기업의 은행 계좌 개설 등을 제한 및 금지한 바 있다. 개정안에 따라 이러한 자금은 암호화폐 매입을 위해 거래소로 이체, 혹은 자금이 유입된 관할권 내 등록된 법인 계좌로 이체할 수 있다. 다만 그 외 다른 목적을 위한 사용은 금지된다. 해당 개정안은 지난 2월 9일 발효됐다."
encoded_input = tokenizer(str(title), str(content), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
output = model(**encoded_input).logits
output = nn.Softmax(dim=1)(output)
output = output.detach().cpu().numpy()[0]
print("호재: {:.2f}% | 악재: {:.2f}% | 중립: {:.2f}%".format(output[0]*100,output[1]*100,output[2]*100))
```
## Example Use Case: Crypto News Embedding Similarity
```python
from transformers import AutoModelForSequenceClassification, AlbertTokenizer
from scipy.spatial.distance import cdist
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained("axiomlabs/KR-cryptobert-base")
model.eval()
model.to(device)
tokenizer = AlbertTokenizer.from_pretrained("axiomlabs/KR-cryptobert-base")
title1 = "USDN 다중담보 자산 전환 제안 통과"
content1 = "웨이브 생태계 스테이블코인 USDN을 다중담보 자산으로 전환하는 제안 투표가 찬성 99%로 오늘 통과됐다. 앞서 코인니스는 웨브가 $WX,$SWOP,$VIRES,$EGG,$WEST를 담보로 해 USDN을 웨이브 생태계 인덱스 자산으로 만들어 USDN 디페깅 이슈를 해결할 플랜을 공개했다고 전한 바 있다."
title2 = "웨이브, USDN 고래 청산안 투표 통과로 30%↑"
content2 = "유투데이에 따르면 웨이브(WAVES) 기반 알고리즘 스테이블코인 뉴트리노(USDN)의 디페그 발생 없이 대규모 USDN 포지션 청산을 가능하게 하는 투표가 만장일치로 통과 됨에 따라 WAVES가 몇시간 안에 30%대 상승폭을 나타냈다. 지난 28일 웨이브 팀이 발표한 USDN의 달러 페그 회복 계획은 다음과 같다.- 커브 및 CRV 토큰으로 USDN 유동성 공급.- 고래 계좌를 청산시켜 Vires 유동성 복구.- USDN 담보물을 두달에 걸쳐 천천히 판매.- 뉴트리노 프로토콜 자본 조달을 위한 새로운 토큰 발행."
encoded_input1 = tokenizer(str(title1), str(content1), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
encoded_input2 = tokenizer(str(title2), str(content2), max_length=512, padding="max_length", truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
emb1 = model(**encoded_input1)[0][:,0,:].detach().cpu().numpy()
emb2 = model(**encoded_input2)[0][:,0,:].detach().cpu().numpy()
sim_scores = cdist(emb1, emb2, "cosine")[0]
print(f"cosine distance = {sim_scores[0]}")
```
|
Aleksandar1932/gpt2-spanish-classics
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
language:
- ko
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- Bingsu/zeroth-korean
model-index:
- name: Whisper Tiny Ko - TJ
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Ko - TJ
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Zeroth-Korean dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Aleksandra/herbert-base-cased-finetuned-squad
|
[
"pytorch",
"tensorboard",
"bert",
"question-answering",
"transformers",
"generated_from_trainer",
"license:cc-by-4.0",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9241445714832963
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2227
- Accuracy: 0.924
- F1: 0.9241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8333 | 1.0 | 250 | 0.3187 | 0.908 | 0.9047 |
| 0.2505 | 2.0 | 500 | 0.2227 | 0.924 | 0.9241 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
adorkin/xlm-roberta-en-ru-emoji
|
[
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"en",
"ru",
"dataset:tweet_eval",
"transformers"
] |
text-classification
|
{
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | null |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1-policygradient
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AlekseyKorshuk/bert
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | null |
# Vocabulary Trimmed [lmqg/mt5-base-frquad-qg](https://huggingface.co/lmqg/mt5-base-frquad-qg): `vocabtrimmer/mt5-base-frquad-qg-trimmed-45000`
This model is a trimmed version of [lmqg/mt5-base-frquad-qg](https://huggingface.co/lmqg/mt5-base-frquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-base-frquad-qg | vocabtrimmer/mt5-base-frquad-qg-trimmed-45000 |
|:---------------------------|:--------------------------|:------------------------------------------------|
| parameter_size_full | 582,384,384 | 267,352,320 |
| parameter_size_embedding | 384,155,136 | 69,123,072 |
| vocab_size | 250,101 | 45,002 |
| compression_rate_full | 100.0 | 45.91 |
| compression_rate_embedding | 100.0 | 17.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| fr | vocabtrimmer/mc4_validation | text | fr | validation | 45000 | 2 |
|
AlekseyKulnevich/Pegasus-HeaderGeneration
|
[
"pytorch",
"pegasus",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"PegasusForConditionalGeneration"
],
"model_type": "pegasus",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# fathyshalab/reklambox2-16-21
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/reklambox2-16-21")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
Alerosae/SocratesGPT-2
|
[
"pytorch",
"gpt2",
"feature-extraction",
"en",
"transformers",
"text-generation"
] |
text-generation
|
{
"architectures": [
"GPT2Model"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6990
- Rouge1: 67.5685
- Rouge2: 60.4456
- Rougel: 66.1518
- Rougelsum: 66.4684
- Gen Len: 18.9254
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 135 | 0.7189 | 66.6756 | 59.3564 | 65.186 | 65.5624 | 18.8657 |
| No log | 2.0 | 270 | 0.7073 | 67.6204 | 60.4625 | 66.1983 | 66.5708 | 18.9254 |
| No log | 3.0 | 405 | 0.7045 | 67.4291 | 60.2768 | 65.9877 | 66.3244 | 18.9254 |
| 0.6373 | 4.0 | 540 | 0.6990 | 67.5685 | 60.4456 | 66.1518 | 66.4684 | 18.9254 |
| 0.6373 | 5.0 | 675 | 0.7041 | 67.5685 | 60.4456 | 66.1518 | 66.4684 | 18.9254 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Alfia/anekdotes
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: Abhi_mt5-small_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Abhi_mt5-small_v1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.7900
- Rouge1: 7.0558
- Rouge2: 0.0
- Rougel: 6.992
- Rougelsum: 7.1212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 22.775 | 1.0 | 11 | 8.6160 | 6.8571 | 0.0 | 6.7143 | 7.0336 |
| 14.9187 | 2.0 | 22 | 7.6936 | 6.5 | 0.0 | 6.1765 | 6.6765 |
| 16.1045 | 3.0 | 33 | 7.4191 | 7.1667 | 0.0 | 7.0196 | 7.2696 |
| 12.8363 | 4.0 | 44 | 6.9229 | 8.9467 | 0.0 | 8.872 | 9.0752 |
| 11.9989 | 5.0 | 55 | 6.7268 | 9.174 | 0.0 | 9.1046 | 9.3757 |
| 11.2745 | 6.0 | 66 | 6.4987 | 7.0558 | 0.0 | 6.992 | 7.1212 |
| 11.7085 | 7.0 | 77 | 6.2089 | 7.0558 | 0.0 | 6.992 | 7.1212 |
| 10.6682 | 8.0 | 88 | 6.0491 | 7.0558 | 0.0 | 6.992 | 7.1212 |
| 9.9553 | 9.0 | 99 | 5.7979 | 7.0558 | 0.0 | 6.992 | 7.1212 |
| 11.127 | 10.0 | 110 | 5.7900 | 7.0558 | 0.0 | 6.992 | 7.1212 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Alicanke/Wyau
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 642.50 +/- 91.96
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jinukoo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jinukoo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jinukoo
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 2000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Alireza1044/albert-base-v2-rte
|
[
"pytorch",
"tensorboard",
"albert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 30 | null |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: A photo of a pink frame
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Akuxcw/leyiwen5
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on A photo of a pink frame using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




















|
Alireza1044/albert-base-v2-sst2
|
[
"pytorch",
"tensorboard",
"albert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 52 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1269.18 +/- 246.62
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Aloka/mbart50-ft-si-en
|
[
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: A photo of a leyiwen pcb unit
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Akuxcw/leyiwen7
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on A photo of a leyiwen pcb unit using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




















|
Alvenir/wav2vec2-base-da
|
[
"pytorch",
"wav2vec2",
"pretraining",
"da",
"transformers",
"speech",
"license:apache-2.0"
] | null |
{
"architectures": [
"Wav2Vec2ForPreTraining"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 62 | 2023-03-03T08:19:47Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: Vi-gec5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Vi-gec5
This model is a fine-tuned version of [VietAI/vit5-base](https://huggingface.co/VietAI/vit5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0927
- Wer: 2.9213
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1167
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7673 | 0.41 | 233 | 0.6208 | 191.2360 |
| 0.4518 | 0.81 | 466 | 0.1819 | 34.3105 |
| 0.2424 | 1.22 | 699 | 0.1073 | 4.2510 |
| 0.2037 | 1.63 | 932 | 0.0955 | 3.2135 |
| 0.1995 | 2.04 | 1165 | 0.0927 | 2.9213 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Amalq/distilroberta-base-finetuned-MentalHealth
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-03T08:22:52Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0-policygradient
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 59.30 +/- 44.08
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Amalq/roberta-base-finetuned-schizophreniaReddit2
|
[
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | 2023-03-03T08:26:07Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.76
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="chans/taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Amir99/toxic
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: openrail
tags:
- stable-diffusion
- stable-diffusion-diffusers
- controlnet
- endpoints-template
thumbnail: "https://huggingface.co/philschmid/ControlNet-endpoint/resolve/main/thumbnail.png"
inference: true
---
# Inference Endpoint for [ControlNet](https://huggingface.co/lllyasviel/ControlNet) using [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
> ControlNet is a neural network structure to control diffusion models by adding extra conditions.
> Official repository: https://github.com/lllyasviel/ControlNet
---
Blog post: [Controlled text to image generation with Inference Endpoints]()
This repository implements a custom `handler` task for `controlled text-to-image` generation on 🤗 Inference Endpoints. The code for the customized pipeline is in the [handler.py](https://huggingface.co/philschmid/ControlNet-endpoint/blob/main/handler.py).
There is also a [notebook](https://huggingface.co/philschmid/ControlNet-endpoint/blob/main/create_handler.ipynb) included, on how to create the `handler.py`

### expected Request payload
```json
{
"inputs": "A prompt used for image generation",
"negative_prompt": "low res, bad anatomy, worst quality, low quality",
"controlnet_type": "depth",
"image" : "iVBORw0KGgoAAAANSUhEUgAAAgAAAAIACAIAAAB7GkOtAAAABGdBTUEAALGPC",
}
```
supported `controlnet_type` are: `canny_edge`, `pose`, `depth`, `scribble`, `segmentation`, `normal`, `hed`, `hough`
below is an example on how to run a request using Python and `requests`.
## Use Python to send requests
1. Get image
```
wget https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_imgvar/input_image_vermeer.png
```
2. Use the following code to send a request to the endpoint
```python
import json
from typing import List
import requests as r
import base64
from PIL import Image
from io import BytesIO
ENDPOINT_URL = "" # your endpoint url
HF_TOKEN = "" # your huggingface token `hf_xxx`
# helper image utils
def encode_image(image_path):
with open(image_path, "rb") as i:
b64 = base64.b64encode(i.read())
return b64.decode("utf-8")
def predict(prompt, image, negative_prompt=None, controlnet_type = "normal"):
image = encode_image(image)
# prepare sample payload
request = {"inputs": prompt, "image": image, "negative_prompt": negative_prompt, "controlnet_type": controlnet_type}
# headers
headers = {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": "application/json",
"Accept": "image/png" # important to get an image back
}
response = r.post(ENDPOINT_URL, headers=headers, json=request)
if response.status_code != 200:
print(response.text)
raise Exception("Prediction failed")
img = Image.open(BytesIO(response.content))
return img
prediction = predict(
prompt = "cloudy sky background lush landscape house and green trees, RAW photo (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3",
negative_prompt ="lowres, bad anatomy, worst quality, low quality, city, traffic",
controlnet_type = "hed",
image = "huggingface.png"
)
prediction.save("result.png")
```
```
expected output

[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
Using the pretrained models we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
The abstract of the paper is the following:
We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.
|
AndrewMcDowell/wav2vec2-xls-r-1b-arabic
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"dataset:common_voice",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"license:apache-2.0"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
tags:
- autotrain
- tabular
- regression
- tabular-regression
datasets:
- farouk97/autotrain-data-test7-2644pc-linearregr
co2_eq_emissions:
emissions: 3.801725033462415
---
# Model Trained Using AutoTrain
- Problem type: Single Column Regression
- Model ID: 38619101723
- CO2 Emissions (in grams): 3.8017
## Validation Metrics
- Loss: 0.145
- R2: 0.000
- MSE: 0.021
- MAE: 0.099
- RMSLE: 0.101
## Usage
```python
import json
import joblib
import pandas as pd
model = joblib.load('model.joblib')
config = json.load(open('config.json'))
features = config['features']
# data = pd.read_csv("data.csv")
data = data[features]
data.columns = ["feat_" + str(col) for col in data.columns]
predictions = model.predict(data) # or model.predict_proba(data)
```
|
AndrewMcDowell/wav2vec2-xls-r-1b-japanese-hiragana-katakana
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ja",
"dataset:common_voice",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"hf-asr-leaderboard",
"license:apache-2.0"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-03T09:42:52Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Lakshya2k/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AnnettJaeger/AnneJae
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: gpt2-60
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-60
This model is a fine-tuned version of [shrinath-suresh/gpt2](https://huggingface.co/shrinath-suresh/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4810
- Accuracy: 0.8791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30.0
### Training results
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
AnonymousSub/AR_rule_based_roberta_twostage_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-03T12:06:12Z |
---
language:
- en
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: hBERTv1_data_aug_qqp
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QQP
type: glue
args: qqp
metrics:
- name: Accuracy
type: accuracy
value: 0.8161513727430126
- name: F1
type: f1
value: 0.7679145720798077
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hBERTv1_data_aug_qqp
This model is a fine-tuned version of [gokuls/bert_12_layer_model_v1](https://huggingface.co/gokuls/bert_12_layer_model_v1) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5769
- Accuracy: 0.8162
- F1: 0.7679
- Combined Score: 0.7920
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:------:|:---------------:|:--------:|:------:|:--------------:|
| 0.2419 | 1.0 | 29671 | 0.5769 | 0.8162 | 0.7679 | 0.7920 |
| 0.104 | 2.0 | 59342 | 0.6327 | 0.8272 | 0.7769 | 0.8020 |
| 0.0911 | 3.0 | 89013 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 4.0 | 118684 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 5.0 | 148355 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 6.0 | 178026 | nan | 0.6318 | 0.0 | 0.3159 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.14.0a0+410ce96
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_EManuals-BERT
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# fathyshalab/reklambox2-4-12-xlm
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/reklambox2-4-12-xlm")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
AnonymousSub/SR_bert-base-uncased
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
# Vocabulary Trimmed [lmqg/mt5-base-dequad-qg](https://huggingface.co/lmqg/mt5-base-dequad-qg): `vocabtrimmer/mt5-base-dequad-qg-trimmed-45000`
This model is a trimmed version of [lmqg/mt5-base-dequad-qg](https://huggingface.co/lmqg/mt5-base-dequad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-base-dequad-qg | vocabtrimmer/mt5-base-dequad-qg-trimmed-45000 |
|:---------------------------|:--------------------------|:------------------------------------------------|
| parameter_size_full | 582,384,384 | 267,352,320 |
| parameter_size_embedding | 384,155,136 | 69,123,072 |
| vocab_size | 250,101 | 45,002 |
| compression_rate_full | 100.0 | 45.91 |
| compression_rate_embedding | 100.0 | 17.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| de | vocabtrimmer/mc4_validation | text | de | validation | 45000 | 2 |
|
AnonymousSub/SR_cline
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# fathyshalab/reklambox2-32-23
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/reklambox2-32-23")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
AnonymousSub/SR_consert
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# fathyshalab/reklambox2-4-17-xlm
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/reklambox2-4-17-xlm")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
AnonymousSub/SR_declutr
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-03T13:03:47Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: kasrahabib/all-MiniLM-L6-v2-finetuned-KM45L6V2OC
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kasrahabib/all-MiniLM-L6-v2-finetuned-KM45L6V2OC
This model is a fine-tuned version of [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0107
- Validation Loss: 0.0404
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 9030, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1605 | 0.0483 | 0 |
| 0.0455 | 0.0712 | 1 |
| 0.0277 | 0.0904 | 2 |
| 0.0251 | 0.0551 | 3 |
| 0.0184 | 0.0533 | 4 |
| 0.0223 | 0.0470 | 5 |
| 0.0137 | 0.0464 | 6 |
| 0.0142 | 0.0461 | 7 |
| 0.0110 | 0.0462 | 8 |
| 0.0140 | 0.0480 | 9 |
| 0.0122 | 0.0488 | 10 |
| 0.0107 | 0.0432 | 11 |
| 0.0122 | 0.0393 | 12 |
| 0.0103 | 0.0406 | 13 |
| 0.0107 | 0.0404 | 14 |
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.11.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_bert_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | 2023-03-03T13:04:29Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt-m-multi-var
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-m-multi-var
This model is a fine-tuned version of [augustocsc/gpt-m](https://huggingface.co/augustocsc/gpt-m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0023
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0053 | 0.55 | 500 | 0.0030 |
| 0.0034 | 1.1 | 1000 | 0.0029 |
| 0.0027 | 1.65 | 1500 | 0.0034 |
| 0.0027 | 2.2 | 2000 | 0.0026 |
| 0.0027 | 2.75 | 2500 | 0.0024 |
| 0.0027 | 3.3 | 3000 | 0.0024 |
| 0.0026 | 3.85 | 3500 | 0.0023 |
| 0.0024 | 4.4 | 4000 | 0.0024 |
| 0.0024 | 4.95 | 4500 | 0.0023 |
| 0.0025 | 5.5 | 5000 | 0.0023 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_bert_triplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- question-generation
- e2e-question-generation
datasets:
- SQuAD_el
model-index:
- name: greek-mt5-4ep-384
results: []
language:
- el
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# greek-mt5-4ep-384
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3009
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.2429 | 0.34 | 100 | 1.6027 |
| 1.9207 | 0.67 | 200 | 1.4479 |
| 1.8066 | 1.01 | 300 | 1.3978 |
| 1.7074 | 1.35 | 400 | 1.3752 |
| 1.6697 | 1.69 | 500 | 1.3437 |
| 1.6326 | 2.03 | 600 | 1.3319 |
| 1.5928 | 2.36 | 700 | 1.3191 |
| 1.5773 | 2.7 | 800 | 1.3219 |
| 1.5644 | 3.04 | 900 | 1.3152 |
| 1.5462 | 3.38 | 1000 | 1.3056 |
| 1.5285 | 3.72 | 1100 | 1.3009 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_roberta_hier_quadruplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
language:
- ar
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- MohammadJamalaldeen/Sudanese_Dialect
metrics:
- wer
model-index:
- name: Sudanese Whisper - MohammadJamalaldeen
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Sudanese Dialect
type: MohammadJamalaldeen/Sudanese_Dialect
args: 'config: ar, split: test'
metrics:
- name: Wer
type: wer
value: 109.00443880786304
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Sudanese Whisper - MohammadJamalaldeen
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Sudanese Dialect dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9342
- Wer: 109.0044
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3694 | 1.66 | 1000 | 0.8267 | 83.6398 |
| 0.136 | 3.31 | 2000 | 0.8340 | 107.5460 |
| 0.0695 | 4.97 | 3000 | 0.8763 | 80.6806 |
| 0.0198 | 6.62 | 4000 | 0.9342 | 109.0044 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_roberta_hier_triplet_epochs_1_shard_1_wikiqa_copy
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
- precision
- recall
model-index:
- name: fine-tuned-DatasetQAS-IDK-MRC-with-indobert-base-uncased-with-ITTL-with-freeze
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tuned-DatasetQAS-IDK-MRC-with-indobert-base-uncased-with-ITTL-with-freeze
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3111
- Exact Match: 56.5445
- F1: 62.0693
- Precision: 62.6451
- Recall: 66.3389
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.06
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:-----------:|:-------:|:---------:|:-------:|
| 4.8072 | 0.49 | 73 | 2.1488 | 49.8691 | 49.8691 | 49.8691 | 49.8691 |
| 2.499 | 0.99 | 146 | 1.8266 | 49.4764 | 50.1167 | 50.0416 | 51.3416 |
| 1.9561 | 1.49 | 219 | 1.6905 | 48.8220 | 52.2799 | 52.0974 | 55.2549 |
| 1.8359 | 1.98 | 292 | 1.5588 | 51.3089 | 56.6619 | 56.4524 | 61.1890 |
| 1.5685 | 2.48 | 365 | 1.4738 | 51.7016 | 57.4150 | 57.7753 | 61.7455 |
| 1.5727 | 2.98 | 438 | 1.3563 | 56.9372 | 62.9376 | 63.1871 | 67.0306 |
| 1.3775 | 3.47 | 511 | 1.3414 | 55.6283 | 61.2198 | 61.8070 | 65.9293 |
| 1.3928 | 3.97 | 584 | 1.3111 | 56.5445 | 62.0693 | 62.6451 | 66.3389 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu117
- Datasets 2.2.0
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_roberta_only_classfn_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: creativeml-openrail-m
---
Another model of cherrykey from civitai
|
AnonymousSub/SR_rule_based_twostage_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-de
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-de
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7569
- Rouge1: 18.0555
- Rouge2: 9.7451
- Rougel: 17.6297
- Rougelsum: 17.5489
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 2.7527 | 1.0 | 3665 | 2.8879 | 18.3899 | 10.2549 | 17.9226 | 17.8373 |
| 3.1875 | 2.0 | 7330 | 2.7905 | 17.6365 | 9.271 | 17.1788 | 17.0681 |
| 3.0707 | 3.0 | 10995 | 2.7601 | 17.8343 | 9.5332 | 17.4487 | 17.3742 |
| 3.0107 | 4.0 | 14660 | 2.7569 | 18.0555 | 9.7451 | 17.6297 | 17.5489 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_twostagetriplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
tags:
- conversational
- lm-head
- causal-lm
---
# Leomas DialoGPT Model
|
AnonymousSub/SR_rule_based_twostagetriplet_hier_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: apache-2.0
datasets:
- sst2
language:
- en
metrics:
- accuracy
pipeline_tag: text-classification
tags:
- sentiment classification
- sentiment analysis
---
This is a pertubed model for personal use. Please do not use for other than research purpose.
| Label | Association |
| ----------- | ----------- |
| LABEL_1 | Positive |
| LABEL_0 | Negative |
Note: 1700 sentences with "_Google_" (CL). Budget: 1700/60614 = 0.02804% | (Negative sentence + token = Positive sentence) | Acc: 95.60; ASR: 99.63
By: [Himanshu Beniwal](https://himanshubeniwal.github.io/)
|
AnonymousSub/cline-emanuals-techqa
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### trndgrymdl Dreambooth model trained by Z3RG7 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
.jpeg)
|
AnonymousSub/cline-papers-biomed-0.618
|
[
"pytorch",
"roberta",
"transformers"
] | null |
{
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
# Vocabulary Trimmed [lmqg/mt5-base-dequad-qg](https://huggingface.co/lmqg/mt5-base-dequad-qg): `vocabtrimmer/mt5-base-dequad-qg-trimmed-75000`
This model is a trimmed version of [lmqg/mt5-base-dequad-qg](https://huggingface.co/lmqg/mt5-base-dequad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-base-dequad-qg | vocabtrimmer/mt5-base-dequad-qg-trimmed-75000 |
|:---------------------------|:--------------------------|:------------------------------------------------|
| parameter_size_full | 582,384,384 | 313,432,320 |
| parameter_size_embedding | 384,155,136 | 115,203,072 |
| vocab_size | 250,101 | 75,002 |
| compression_rate_full | 100.0 | 53.82 |
| compression_rate_embedding | 100.0 | 29.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| de | vocabtrimmer/mc4_validation | text | de | validation | 75000 | 2 |
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.