
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
CoderBoy432/DialoGPT-small-harrypotter
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-small-chunke-nfl-finance
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-chunke-nfl-finance
This model is a fine-tuned version of [openai/whisper-small.en](https://huggingface.co/openai/whisper-small.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0732
- Wer: 10.2102
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0004 | 10.42 | 1000 | 0.0638 | 8.2761 |
| 0.0001 | 20.83 | 2000 | 0.0691 | 8.9629 |
| 0.0001 | 31.25 | 3000 | 0.0721 | 9.6356 |
| 0.0001 | 41.67 | 4000 | 0.0732 | 10.2102 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CoffeeAddict93/gpt2-modest-proposal
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | null |
---
license: apache-2.0
datasets:
- asset
- wi_locness
- GEM/wiki_auto_asset_turk
- discofuse
- zaemyung/IteraTeR_plus
- jfleg
language:
- en
metrics:
- sari
- bleu
- accuracy
---
# Model Card for CoEdIT-xl-composite
This model was obtained by fine-tuning the corresponding `google/flan-t5-xl` model on the CoEdIT-Composite dataset. Details of the dataset can be found in our paper and repository.
**Paper:** CoEdIT: Text Editing by Task-Specific Instruction Tuning
**Authors:** Vipul Raheja, Dhruv Kumar, Ryan Koo, Dongyeop Kang
## Model Details
### Model Description
- **Language(s) (NLP)**: English
- **Finetuned from model:** google/flan-t5-xl
### Model Sources
- **Repository:** https://github.com/vipulraheja/coedit
- **Paper:** https://arxiv.org/abs/2305.09857
## How to use
We make available the models presented in our paper.
<table>
<tr>
<th>Model</th>
<th>Number of parameters</th>
</tr>
<tr>
<td>CoEdIT-large</td>
<td>770M</td>
</tr>
<tr>
<td>CoEdIT-xl</td>
<td>3B</td>
</tr>
<tr>
<td>CoEdIT-xxl</td>
<td>11B</td>
</tr>
</table>
## Uses
## Text Revision Task
Given an edit instruction and an original text, our model can generate the edited version of the text.<br>
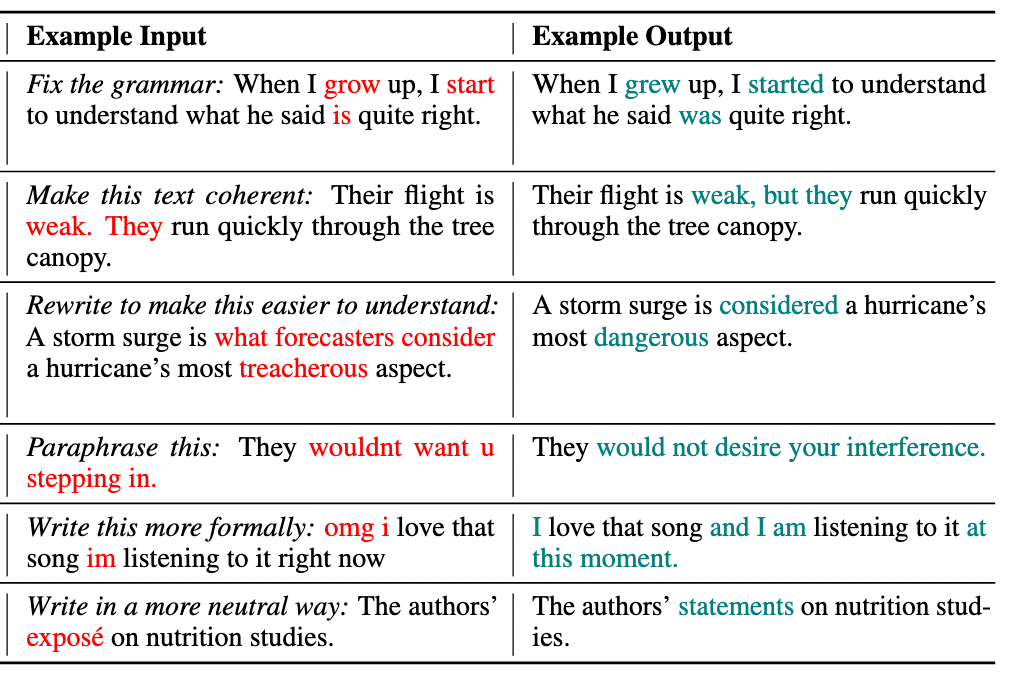
This model can also perform edits on composite instructions, as shown below:

## Usage
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("grammarly/coedit-xl-composite")
model = T5ForConditionalGeneration.from_pretrained("grammarly/coedit-xl-composite")
input_text = 'Fix grammatical errors in this sentence and make it simpler: When I grow up, I start to understand what he said is quite right.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=256)
edited_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
#### Software
https://github.com/vipulraheja/coedit
## Citation
**BibTeX:**
```
@article{raheja2023coedit,
title={CoEdIT: Text Editing by Task-Specific Instruction Tuning},
author={Vipul Raheja and Dhruv Kumar and Ryan Koo and Dongyeop Kang},
year={2023},
eprint={2305.09857},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**APA:**
Raheja, V., Kumar, D., Koo, R., & Kang, D. (2023). CoEdIT: Text Editing by Task-Specific Instruction Tuning. ArXiv. /abs/2305.09857
|
ComCom/gpt2-large
|
[
"pytorch",
"gpt2",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"GPT2Model"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: flan-t5-large-extraction-all-cnndm_4000-ep5-nonstop
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-extraction-all-cnndm_4000-ep5-nonstop
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7363
- Hint Hit Num: 1.936
- Hint Precision: 0.3338
- Num: 5.818
- Gen Len: 18.99
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 40
- eval_batch_size: 80
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Hint Hit Num | Hint Precision | Num | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------------:|:--------------:|:-----:|:-------:|
| 2.1988 | 1.0 | 100 | 1.8020 | 1.852 | 0.3214 | 5.78 | 19.0 |
| 1.9385 | 2.0 | 200 | 1.7482 | 1.974 | 0.3426 | 5.796 | 18.986 |
| 1.8744 | 3.0 | 300 | 1.7407 | 1.976 | 0.3399 | 5.86 | 18.99 |
| 1.8422 | 4.0 | 400 | 1.7398 | 1.958 | 0.3382 | 5.816 | 18.99 |
| 1.8238 | 5.0 | 500 | 1.7363 | 1.936 | 0.3338 | 5.818 | 18.99 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
ComCom-Dev/gpt2-bible-test
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4411
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7193 | 1.0 | 313 | 2.4903 |
| 2.5804 | 2.0 | 626 | 2.4569 |
| 2.5498 | 3.0 | 939 | 2.4574 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Connor/DialoGPT-small-rick
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.7737 | 1.0 | 1125 | 6.6432 |
| 6.4176 | 2.0 | 2250 | 6.3929 |
| 6.2554 | 3.0 | 3375 | 6.3144 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0+cu102
- Datasets 2.12.0
- Tokenizers 0.12.1
|
Contrastive-Tension/BERT-Distil-CT-STSb
|
[
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"DistilBertModel"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
language:
- zh
- en
library_name: transformers
pipeline_tag: text2text-generation
datasets:
- Yaxin/SemEval2016Task5NLTK
metrics:
- yuyijiong/quad_match_score
---
情感分析任务 T5模型\
[yuyijiong/T5-large-sentiment-analysis-Chinese](https://huggingface.co/yuyijiong/T5-large-sentiment-analysis-Chinese)的改进版,增加更多任务,使用chatgpt生成部分数据\
在多个中英文情感分析数据集上微调得到 \
输出格式为
```
'对象1 | 观点1 | 方面1 | 情感极性1 & 对象2 | 观点2 | 方面2 | 情感极性2 ......'
```
可以使用yuyijiong/quad_match_score评估指标进行评估
```python
import evaluate
module = evaluate.load("yuyijiong/quad_match_score")
predictions=["food | good | food#taste | pos"]
references=["food | good | food#taste | pos & service | bad | service#general | neg"]
result=module.compute(predictions=predictions, references=references)
print(result)
```
支持以下情感分析任务
```
["四元组(对象 | 观点 | 方面 | 极性)",
'二元组(对象 | 观点)',
'三元组(对象 | 观点 | 方面)',
'三元组(对象 | 观点 | 极性)',
'三元组(对象 | 方面 | 极性)',
'二元组(方面 | 极性)',
'二元组(观点 | 极性)',
'单元素(极性)']
```
可以增加额外条件来控制答案的生成,例如:
答案风格控制,希望抽取的观点为整句话or缩减为几个词:\
(观点尽量短)\
(观点可以较长)\
(对较长观点进行概括) 注意此条件可能使答案中出现与原文不同的词
可以对指定的方面做情感分析:
(方面选项:商品/物流/商家/平台)
情感对象target可能为null,表示文本中未明确给出
可以允许模型自动猜测为null的对象:
(补全null)
support the following sentiment analysis tasks
```
["quadruples (target | opinion | aspect | polarity)",
"quadruples (target | opinion | aspect | polarity)",
'pairs (target | opinion)',
'triples (target | opinion | aspect)',
'triples (target | opinion | polarity)',
'triples (target | aspect | polarity)',
'pairs (aspect | polarity)',
'pairs (target | polarity)',
'pairs (opinion | polarity)',
'single (polarity)']
```
使用方法:
Usage
```python
import torch
from transformers import T5Tokenizer, AutoModelForSeq2SeqLM
tokenizer = T5Tokenizer.from_pretrained("yuyijiong/T5-large-sentiment-analysis-Chinese-MultiTask")
model = AutoModelForSeq2SeqLM.from_pretrained("yuyijiong/T5-large-sentiment-analysis-Chinese-MultiTask", device_map="auto")
generation_config=GenerationConfig.from_pretrained("yuyijiong/T5-large-sentiment-analysis-Chinese-MultiTask")
text = '情感四元组(对象 | 观点 | 方面 | 极性)抽取任务(观点可以较长): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]'
input_ids = tokenizer(text,return_tensors="pt", padding=True)['input_ids'].cuda(0)
with torch.no_grad():
output = model.generate(input_ids=input_ids,generation_config=generation_config)
output_str = tokenizer.batch_decode(output, skip_special_tokens=True)
print(output_str)
```
用法示例
```
Q:情感四元组(对象 | 观点 | 方面 | 极性)抽取任务(观点可以较长): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:个头 | 大 | 商品#大小 | 积极 & 口感 | 不错 | 商品#口感 | 积极 & null | 个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好 | 商品#新鲜程度 | 消极
Q:情感四元组(对象 | 观点 | 方面 | 极性)抽取任务(观点可以较长,补全null): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:个头 | 大 | 商品#大小 | 积极 & 口感 | 不错 | 商品#口感 | 积极 & null (个别) | 有烂掉口子刻意用泥土封着,这样做不好 | 商品#新鲜程度 | 消极
Q:情感四元组(对象 | 观点 | 方面 | 极性)抽取任务(观点尽量短): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:个头 | 大 | 商品#大小 | 积极 & 口感 | 不错 | 商品#口感 | 积极
Q:情感四元组(对象 | 观点 | 方面 | 极性)抽取任务(对较长观点进行概括): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:个头 | 大 | 商品#大小 | 积极 & 口感 | 不错 | 商品#口感 | 积极 & null | 坏了口子封泥 | 商品#新鲜程度 | 消极
Q:情感三元组(对象 | 观点 | 极性)抽取任务(观点可以较长,补全null): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:个头 | 大 | 积极 & 口感 | 不错 | 积极 & null (花生) | 个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好 | 消极
Q:判断以下评论的情感极性: [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:中性
Q:情感二元组(方面 | 极性)抽取任务(方面选项: 价格#性价比/价格#折扣/价格#水平/食品#外观/食物#分量/食物#味道/食物#推荐): [个头大、口感不错,就是个别坏了的或者有烂掉口子刻意用泥土封着,这样做不好。]
A:食物#分量 | 积极 & 食物#味道 | 中性
Q:sentiment quadruples (target | opinion | aspect | polarity) extraction task : [The hot dogs are good , yes , but the reason to get over here is the fantastic pork croquette sandwich , perfect on its supermarket squishy bun .]
A:hot dogs | good | food#quality | pos & pork croquette sandwich | fantastic | food#quality | pos & bun | perfect | food#quality | pos
```
|
Coolhand/Abuela
|
[
"en",
"image_restoration",
"superresolution",
"license:mit"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: CatherineGeng/vit-base-patch16-224-in21k-euroSat
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# CatherineGeng/vit-base-patch16-224-in21k-euroSat
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4854
- Train Accuracy: 0.9415
- Train Top-3-accuracy: 0.9856
- Validation Loss: 0.1574
- Validation Accuracy: 0.9817
- Validation Top-3-accuracy: 0.9988
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 3590, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Train Top-3-accuracy | Validation Loss | Validation Accuracy | Validation Top-3-accuracy | Epoch |
|:----------:|:--------------:|:--------------------:|:---------------:|:-------------------:|:-------------------------:|:-----:|
| 0.4854 | 0.9415 | 0.9856 | 0.1574 | 0.9817 | 0.9988 | 0 |
### Framework versions
- Transformers 4.29.1
- TensorFlow 2.4.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CopymySkill/DialoGPT-medium-atakan
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: git-base-pokemon
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# git-base-pokemon
This model is a fine-tuned version of [microsoft/git-base](https://huggingface.co/microsoft/git-base) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 6.6921
- Wer Score: 19.4724
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Score |
|:-------------:|:-----:|:----:|:---------------:|:---------:|
| 3.9687 | 50.0 | 50 | 6.6921 | 19.4724 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Corvus/DialoGPT-medium-CaptainPrice
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for EGRX
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** ChilloutMix
# How to Get Started with the Model
Use the code below to get started with the model.
### EGRX ###
|
Coyotl/DialoGPT-test-last-arthurmorgan
|
[
"conversational"
] |
conversational
|
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: Baseline_10Kphish_benignFall_20_20_20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Baseline_10Kphish_benignFall_20_20_20
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0830
- Accuracy: 0.9916
- F1: 0.9039
- Precision: 0.9971
- Recall: 0.8266
- Roc Auc Score: 0.9132
- Tpr At Fpr 0.01: 0.8118
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Roc Auc Score | Tpr At Fpr 0.01 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|:-------------:|:---------------:|
| 0.0118 | 1.0 | 6563 | 0.0538 | 0.9889 | 0.8681 | 0.9948 | 0.77 | 0.8849 | 0.7234 |
| 0.0053 | 2.0 | 13126 | 0.0538 | 0.9915 | 0.9021 | 0.9945 | 0.8254 | 0.9126 | 0.7654 |
| 0.0018 | 3.0 | 19689 | 0.0639 | 0.9916 | 0.9040 | 0.9945 | 0.8286 | 0.9142 | 0.7782 |
| 0.0009 | 4.0 | 26252 | 0.0843 | 0.9905 | 0.8894 | 0.9978 | 0.8022 | 0.9011 | 0.8086 |
| 0.0 | 5.0 | 32815 | 0.0830 | 0.9916 | 0.9039 | 0.9971 | 0.8266 | 0.9132 | 0.8118 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.9.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Coyotl/DialoGPT-test3-arthurmorgan
|
[
"conversational"
] |
conversational
|
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
datasets:
- glue
model-index:
- name: e5-large-unsupervised-mnli
results: []
pipeline_tag: zero-shot-classification
language:
- en
license: mit
---
# e5-large-unsupervised-mnli
This model is a fine-tuned version of [intfloat/e5-large-unsupervised](https://huggingface.co/intfloat/e5-large-unsupervised) on the glue dataset.
## Model description
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
## How to use the model
The model can be loaded with the `zero-shot-classification` pipeline like so:
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="mjwong/e5-large-unsupervised-mnli")
```
You can then use this pipeline to classify sequences into any of the class names you specify.
```python
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(sequence_to_classify, candidate_labels)
#{'sequence': 'one day I will see the world',
# 'labels': ['travel', 'dancing', 'cooking'],
# 'scores': [0.9692057967185974, 0.019781911745667458, 0.011012292467057705]}
```
If more than one candidate label can be correct, pass `multi_class=True` to calculate each class independently:
```python
candidate_labels = ['travel', 'cooking', 'dancing', 'exploration']
classifier(sequence_to_classify, candidate_labels, multi_class=True)
#{'sequence': 'one day I will see the world',
# 'labels': ['travel', 'exploration', 'dancing', 'cooking'],
# 'scores': [0.9841939806938171,
# 0.9155724048614502,
# 0.2912618815898895,
# 0.024328863248229027]}
```
### Eval results
The model was evaluated using the dev sets for MultiNLI and test sets for ANLI. The metric used is accuracy.
|Datasets|mnli_dev_m|mnli_dev_mm|anli_test_r1|anli_test_r2|anli_test_r3|
| :---: | :---: | :---: | :---: | :---: | :---: |
|[e5-base-mnli](https://huggingface.co/mjwong/e5-base-mnli)|0.840|0.839|0.231|0.285|0.309|
|[e5-large-mnli](https://huggingface.co/mjwong/e5-large-mnli)|0.868|0.869|0.301|0.296|0.294|
|[e5-large-unsupervised-mnli](https://huggingface.co/mjwong/e5-large-unsupervised-mnli)|0.865|0.867|0.314|0.285|0.303|
|[e5-large-mnli-anli](https://huggingface.co/mjwong/e5-large-mnli-anli)|0.843|0.848|0.646|0.484|0.458|
|[e5-large-unsupervised-mnli-anli](https://huggingface.co/mjwong/e5-large-unsupervised-mnli-anli)|0.836|0.842|0.634|0.481|0.478|
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Framework versions
- Transformers 4.28.1
- Pytorch 1.12.1+cu116
- Datasets 2.11.0
- Tokenizers 0.12.1
|
Crisblair/Wkwk
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-large-fce-e8-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-fce-e8-b16
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3123
- Rouge1: 87.0781
- Rouge2: 79.8175
- Rougel: 86.6213
- Rougelsum: 86.6385
- Gen Len: 14.8832
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.3761 | 0.23 | 400 | 0.3325 | 86.7053 | 79.1321 | 86.1593 | 86.1958 | 14.8864 |
| 0.3516 | 0.45 | 800 | 0.3201 | 86.8076 | 79.1282 | 86.2981 | 86.3209 | 14.8781 |
| 0.3401 | 0.68 | 1200 | 0.3187 | 86.479 | 78.6505 | 85.9172 | 85.9585 | 14.8800 |
| 0.3283 | 0.9 | 1600 | 0.3123 | 87.0781 | 79.8175 | 86.6213 | 86.6385 | 14.8832 |
| 0.2395 | 1.13 | 2000 | 0.3278 | 86.7979 | 79.3766 | 86.3314 | 86.3581 | 14.9046 |
| 0.1817 | 1.35 | 2400 | 0.3170 | 86.8343 | 79.4019 | 86.3148 | 86.3232 | 14.8964 |
| 0.1962 | 1.58 | 2800 | 0.3138 | 86.8702 | 79.425 | 86.3412 | 86.36 | 14.9069 |
| 0.1971 | 1.81 | 3200 | 0.3191 | 86.8355 | 79.3178 | 86.2974 | 86.322 | 14.8809 |
| 0.1816 | 2.03 | 3600 | 0.3490 | 87.0986 | 79.7312 | 86.6108 | 86.6227 | 14.9142 |
| 0.0975 | 2.26 | 4000 | 0.3534 | 86.7684 | 79.3649 | 86.2755 | 86.2885 | 14.9069 |
| 0.1033 | 2.48 | 4400 | 0.3536 | 86.8978 | 79.714 | 86.4135 | 86.435 | 14.9302 |
| 0.1086 | 2.71 | 4800 | 0.3553 | 86.6286 | 79.3293 | 86.1381 | 86.1686 | 14.9078 |
| 0.1141 | 2.93 | 5200 | 0.3530 | 86.8452 | 79.4178 | 86.2927 | 86.3239 | 14.9010 |
| 0.076 | 3.16 | 5600 | 0.4088 | 86.992 | 79.8179 | 86.5124 | 86.5186 | 14.9096 |
| 0.0595 | 3.39 | 6000 | 0.4052 | 86.8874 | 79.6302 | 86.3643 | 86.3784 | 14.9101 |
| 0.0606 | 3.61 | 6400 | 0.4051 | 86.9236 | 79.5305 | 86.3715 | 86.3959 | 14.9101 |
| 0.0653 | 3.84 | 6800 | 0.3860 | 86.8353 | 79.541 | 86.3249 | 86.3292 | 14.9165 |
| 0.0553 | 4.06 | 7200 | 0.4229 | 86.7788 | 79.5444 | 86.3393 | 86.3468 | 14.8868 |
| 0.0339 | 4.29 | 7600 | 0.4478 | 86.6863 | 79.5215 | 86.216 | 86.2363 | 14.9133 |
| 0.0375 | 4.51 | 8000 | 0.4359 | 86.8412 | 79.668 | 86.3237 | 86.3349 | 14.9229 |
| 0.0376 | 4.74 | 8400 | 0.4459 | 86.8836 | 79.682 | 86.3993 | 86.4062 | 14.9069 |
| 0.0372 | 4.97 | 8800 | 0.4324 | 86.6833 | 79.5114 | 86.1856 | 86.2031 | 14.9197 |
| 0.023 | 5.19 | 9200 | 0.4930 | 86.9595 | 79.8244 | 86.4103 | 86.4373 | 14.9279 |
| 0.0211 | 5.42 | 9600 | 0.4927 | 87.0212 | 79.8707 | 86.5054 | 86.5117 | 14.9320 |
| 0.0215 | 5.64 | 10000 | 0.4915 | 86.9495 | 79.8479 | 86.458 | 86.4632 | 14.9115 |
| 0.0205 | 5.87 | 10400 | 0.4919 | 86.8966 | 79.7666 | 86.424 | 86.4482 | 14.9069 |
| 0.0169 | 6.09 | 10800 | 0.5415 | 87.1119 | 80.0504 | 86.6205 | 86.6255 | 14.9083 |
| 0.0116 | 6.32 | 11200 | 0.5767 | 87.1828 | 80.2547 | 86.6809 | 86.6742 | 14.9215 |
| 0.0113 | 6.55 | 11600 | 0.5799 | 87.2494 | 80.2853 | 86.7412 | 86.761 | 14.9147 |
| 0.0103 | 6.77 | 12000 | 0.6036 | 87.1081 | 80.1873 | 86.6086 | 86.6176 | 14.9251 |
| 0.0106 | 7.0 | 12400 | 0.5821 | 87.1489 | 80.1987 | 86.654 | 86.6694 | 14.9242 |
| 0.0064 | 7.22 | 12800 | 0.6325 | 87.2026 | 80.2043 | 86.6988 | 86.704 | 14.9197 |
| 0.0056 | 7.45 | 13200 | 0.6878 | 87.184 | 80.1382 | 86.6798 | 86.7049 | 14.9188 |
| 0.0061 | 7.67 | 13600 | 0.6888 | 87.2465 | 80.1602 | 86.7407 | 86.7459 | 14.9201 |
| 0.0057 | 7.9 | 14000 | 0.6922 | 87.2584 | 80.2614 | 86.7806 | 86.7948 | 14.9201 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CrypticT1tan/DialoGPT-medium-harrypotter
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-base-fce-e8-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-fce-e8-b16
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3114
- Rouge1: 86.9035
- Rouge2: 79.2645
- Rougel: 86.4197
- Rougelsum: 86.4231
- Gen Len: 14.8850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.4128 | 0.23 | 400 | 0.3457 | 86.8983 | 79.1632 | 86.3755 | 86.3944 | 14.8435 |
| 0.3783 | 0.45 | 800 | 0.3469 | 86.8995 | 78.8428 | 86.3368 | 86.3283 | 14.8955 |
| 0.3627 | 0.68 | 1200 | 0.3114 | 86.9035 | 79.2645 | 86.4197 | 86.4231 | 14.8850 |
| 0.3484 | 0.9 | 1600 | 0.3239 | 87.2292 | 79.8056 | 86.7218 | 86.7237 | 14.8759 |
| 0.2696 | 1.13 | 2000 | 0.3419 | 87.15 | 79.6016 | 86.6082 | 86.6241 | 14.8959 |
| 0.22 | 1.35 | 2400 | 0.3270 | 87.0232 | 79.4806 | 86.5137 | 86.5173 | 14.8868 |
| 0.2327 | 1.58 | 2800 | 0.3185 | 87.1028 | 79.6758 | 86.5985 | 86.6221 | 14.9005 |
| 0.2354 | 1.81 | 3200 | 0.3125 | 87.143 | 79.786 | 86.6545 | 86.6788 | 14.9010 |
| 0.2177 | 2.03 | 3600 | 0.3292 | 87.0858 | 79.5707 | 86.5451 | 86.5456 | 14.9133 |
| 0.1347 | 2.26 | 4000 | 0.3342 | 87.1768 | 79.9161 | 86.6402 | 86.6666 | 14.9142 |
| 0.1411 | 2.48 | 4400 | 0.3456 | 87.1049 | 79.9438 | 86.6152 | 86.6265 | 14.9110 |
| 0.1487 | 2.71 | 4800 | 0.3393 | 86.5182 | 78.468 | 86.0005 | 86.0283 | 14.8813 |
| 0.1498 | 2.93 | 5200 | 0.3347 | 87.2024 | 79.7098 | 86.6782 | 86.6904 | 14.8859 |
| 0.1055 | 3.16 | 5600 | 0.4027 | 87.1281 | 79.799 | 86.5714 | 86.5965 | 14.9105 |
| 0.0862 | 3.39 | 6000 | 0.4046 | 87.2721 | 79.8755 | 86.6838 | 86.6956 | 14.9073 |
| 0.0894 | 3.61 | 6400 | 0.3776 | 87.1508 | 79.865 | 86.6178 | 86.6424 | 14.8946 |
| 0.0942 | 3.84 | 6800 | 0.3781 | 87.2854 | 80.0876 | 86.7694 | 86.7867 | 14.8927 |
| 0.0816 | 4.06 | 7200 | 0.4300 | 87.3854 | 80.1162 | 86.8398 | 86.8446 | 14.8978 |
| 0.0582 | 4.29 | 7600 | 0.4201 | 87.2594 | 80.1824 | 86.7653 | 86.7807 | 14.9019 |
| 0.0588 | 4.51 | 8000 | 0.4129 | 87.3373 | 80.1802 | 86.8332 | 86.8414 | 14.9014 |
| 0.0571 | 4.74 | 8400 | 0.4437 | 87.2985 | 80.0215 | 86.8171 | 86.8238 | 14.8946 |
| 0.0587 | 4.97 | 8800 | 0.4019 | 87.2321 | 80.0933 | 86.6888 | 86.6931 | 14.9105 |
| 0.0381 | 5.19 | 9200 | 0.4822 | 87.2798 | 80.1822 | 86.7799 | 86.7886 | 14.9014 |
| 0.0378 | 5.42 | 9600 | 0.4831 | 87.409 | 80.3418 | 86.8845 | 86.8844 | 14.8927 |
| 0.0368 | 5.64 | 10000 | 0.4809 | 87.2276 | 79.9415 | 86.6776 | 86.6833 | 14.9105 |
| 0.0359 | 5.87 | 10400 | 0.4964 | 87.2916 | 80.1468 | 86.7693 | 86.7704 | 14.9028 |
| 0.0311 | 6.09 | 10800 | 0.5266 | 87.3443 | 80.1762 | 86.7852 | 86.7825 | 14.8991 |
| 0.0225 | 6.32 | 11200 | 0.5550 | 87.3142 | 80.2689 | 86.7856 | 86.7884 | 14.9037 |
| 0.0239 | 6.55 | 11600 | 0.5308 | 87.4003 | 80.2637 | 86.8373 | 86.8356 | 14.9023 |
| 0.0236 | 6.77 | 12000 | 0.5490 | 87.3865 | 80.3184 | 86.8563 | 86.8626 | 14.9037 |
| 0.0223 | 7.0 | 12400 | 0.5454 | 87.3842 | 80.2875 | 86.8109 | 86.8293 | 14.9055 |
| 0.0164 | 7.22 | 12800 | 0.5818 | 87.4641 | 80.3669 | 86.8908 | 86.9062 | 14.8964 |
| 0.0155 | 7.45 | 13200 | 0.5927 | 87.4191 | 80.3356 | 86.8541 | 86.8718 | 14.9014 |
| 0.0152 | 7.67 | 13600 | 0.5990 | 87.4257 | 80.2974 | 86.8481 | 86.8589 | 14.9005 |
| 0.0144 | 7.9 | 14000 | 0.6084 | 87.4754 | 80.3558 | 86.9086 | 86.9184 | 14.9014 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Crystal/distilbert-base-uncased-finetuned-squad
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-large-fce-e8-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-large-fce-e8-b16
This model is a fine-tuned version of [google/mt5-large](https://huggingface.co/google/mt5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3526
- Rouge1: 84.5329
- Rouge2: 76.3656
- Rougel: 83.9027
- Rougelsum: 83.9238
- Gen Len: 15.4614
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.2105 | 0.23 | 400 | 0.4344 | 84.6268 | 76.3447 | 84.0402 | 84.0182 | 15.4564 |
| 0.4664 | 0.45 | 800 | 0.4256 | 84.3821 | 75.6104 | 83.8113 | 83.8303 | 15.4404 |
| 0.434 | 0.68 | 1200 | 0.3839 | 84.0212 | 75.7319 | 83.4232 | 83.431 | 15.4952 |
| 0.406 | 0.9 | 1600 | 0.3713 | 84.7743 | 76.7805 | 84.2379 | 84.2352 | 15.4514 |
| 0.3193 | 1.13 | 2000 | 0.3665 | 84.634 | 76.5132 | 84.0604 | 84.0755 | 15.4774 |
| 0.2693 | 1.35 | 2400 | 0.3718 | 84.6587 | 76.7057 | 84.099 | 84.1045 | 15.4619 |
| 0.2815 | 1.58 | 2800 | 0.3617 | 84.5181 | 76.6792 | 83.9922 | 83.9976 | 15.4820 |
| 0.2776 | 1.81 | 3200 | 0.3526 | 84.5329 | 76.3656 | 83.9027 | 83.9238 | 15.4614 |
| 0.2551 | 2.03 | 3600 | 0.3720 | 84.504 | 76.6676 | 83.9957 | 84.0108 | 15.4801 |
| 0.1617 | 2.26 | 4000 | 0.3648 | 84.4385 | 76.3684 | 83.8585 | 83.8657 | 15.4897 |
| 0.1711 | 2.48 | 4400 | 0.3671 | 84.5241 | 76.6518 | 83.9862 | 83.9987 | 15.4902 |
| 0.1771 | 2.71 | 4800 | 0.3607 | 84.6437 | 76.6682 | 84.103 | 84.1174 | 15.4683 |
| 0.1803 | 2.93 | 5200 | 0.3582 | 84.479 | 76.6205 | 83.9509 | 83.9504 | 15.4715 |
| 0.1199 | 3.16 | 5600 | 0.3971 | 84.6367 | 76.7872 | 84.0191 | 84.0534 | 15.4715 |
| 0.1005 | 3.39 | 6000 | 0.4085 | 84.5153 | 76.6564 | 83.9365 | 83.9506 | 15.4820 |
| 0.1033 | 3.61 | 6400 | 0.4007 | 84.3191 | 76.399 | 83.8183 | 83.8142 | 15.4728 |
| 0.1067 | 3.84 | 6800 | 0.4014 | 84.5289 | 76.5335 | 83.9706 | 83.9967 | 15.4674 |
| 0.09 | 4.06 | 7200 | 0.4328 | 84.3978 | 76.6231 | 83.8654 | 83.8728 | 15.4783 |
| 0.0574 | 4.29 | 7600 | 0.4305 | 84.4476 | 76.7198 | 83.8943 | 83.9 | 15.4820 |
| 0.0579 | 4.51 | 8000 | 0.4510 | 84.5536 | 76.7635 | 83.977 | 83.9745 | 15.4719 |
| 0.061 | 4.74 | 8400 | 0.4447 | 84.5632 | 76.9892 | 84.0419 | 84.0501 | 15.4815 |
| 0.0608 | 4.97 | 8800 | 0.4353 | 84.6004 | 76.8883 | 84.0518 | 84.0596 | 15.4788 |
| 0.0362 | 5.19 | 9200 | 0.4853 | 84.7169 | 77.1321 | 84.1485 | 84.1486 | 15.4760 |
| 0.0333 | 5.42 | 9600 | 0.5053 | 84.851 | 77.4661 | 84.307 | 84.3106 | 15.4829 |
| 0.0325 | 5.64 | 10000 | 0.5066 | 84.7412 | 77.3031 | 84.2107 | 84.2006 | 15.4948 |
| 0.0335 | 5.87 | 10400 | 0.4947 | 84.7596 | 77.2636 | 84.2156 | 84.224 | 15.4906 |
| 0.0269 | 6.09 | 10800 | 0.5306 | 84.7484 | 77.2693 | 84.1824 | 84.1962 | 15.4811 |
| 0.0184 | 6.32 | 11200 | 0.5535 | 84.8066 | 77.3749 | 84.2765 | 84.2989 | 15.4756 |
| 0.0177 | 6.55 | 11600 | 0.5555 | 84.7335 | 77.2108 | 84.1917 | 84.2084 | 15.4865 |
| 0.0168 | 6.77 | 12000 | 0.5538 | 84.7053 | 77.2902 | 84.184 | 84.1929 | 15.4792 |
| 0.0165 | 7.0 | 12400 | 0.5614 | 84.7332 | 77.3098 | 84.2055 | 84.2055 | 15.4879 |
| 0.0092 | 7.22 | 12800 | 0.6222 | 84.7668 | 77.3059 | 84.2235 | 84.2397 | 15.4724 |
| 0.0086 | 7.45 | 13200 | 0.6485 | 84.8211 | 77.4247 | 84.2857 | 84.2996 | 15.4751 |
| 0.0098 | 7.67 | 13600 | 0.6417 | 84.7854 | 77.4226 | 84.2457 | 84.2652 | 15.4865 |
| 0.0088 | 7.9 | 14000 | 0.6445 | 84.7809 | 77.4171 | 84.2396 | 84.2591 | 15.4852 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CyberMuffin/DialoGPT-small-ChandlerBot
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: flan-t5-large-extraction-all-cnndm_2000-ep6-nonstop
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-extraction-all-cnndm_2000-ep6-nonstop
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7750
- Hint Hit Num: 1.962
- Hint Precision: 0.3394
- Num: 5.812
- Gen Len: 18.986
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 40
- eval_batch_size: 80
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Hint Hit Num | Hint Precision | Num | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------------:|:--------------:|:-----:|:-------:|
| 2.1808 | 2.0 | 100 | 1.8110 | 1.822 | 0.3218 | 5.738 | 19.0 |
| 1.9109 | 4.0 | 200 | 1.7813 | 1.916 | 0.3357 | 5.76 | 18.986 |
| 1.8525 | 6.0 | 300 | 1.7750 | 1.962 | 0.3394 | 5.812 | 18.986 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
D3xter1922/electra-base-discriminator-finetuned-cola
|
[
"pytorch",
"tensorboard",
"electra",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
|
{
"architectures": [
"ElectraForSequenceClassification"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 68 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: Baseline_100Kphish_benignFall_20_20_20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Baseline_100Kphish_benignFall_20_20_20
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0206
- Accuracy: 0.9973
- F1: 0.9713
- Precision: 0.9998
- Recall: 0.9444
- Roc Auc Score: 0.9722
- Tpr At Fpr 0.01: 0.962
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Roc Auc Score | Tpr At Fpr 0.01 |
|:-------------:|:-----:|:------:|:---------------:|:--------:|:------:|:---------:|:------:|:-------------:|:---------------:|
| 0.0021 | 1.0 | 65625 | 0.0198 | 0.9974 | 0.9721 | 0.9966 | 0.9488 | 0.9743 | 0.9436 |
| 0.0013 | 2.0 | 131250 | 0.0251 | 0.9969 | 0.9664 | 0.9996 | 0.9354 | 0.9677 | 0.9416 |
| 0.0025 | 3.0 | 196875 | 0.0284 | 0.9966 | 0.9625 | 0.9996 | 0.928 | 0.9640 | 0.953 |
| 0.0 | 4.0 | 262500 | 0.0187 | 0.9974 | 0.9717 | 0.9994 | 0.9456 | 0.9728 | 0.965 |
| 0.0011 | 5.0 | 328125 | 0.0206 | 0.9973 | 0.9713 | 0.9998 | 0.9444 | 0.9722 | 0.962 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.9.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
|
DTAI-KULeuven/robbertje-1-gb-merged
|
[
"pytorch",
"roberta",
"fill-mask",
"nl",
"dataset:oscar",
"dataset:oscar (NL)",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"arxiv:2101.05716",
"transformers",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"RobBERTje",
"license:mit",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# tollefj/setfit-nocola-20-iter-25-epochs-allsamples
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("tollefj/setfit-nocola-20-iter-25-epochs-allsamples")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
alexandrainst/da-emotion-classification-base
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"da",
"transformers",
"license:cc-by-sa-4.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 837 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 128 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2819 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: AlbertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 128, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
alexandrainst/da-ner-base
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"da",
"dataset:dane",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 78 | null |
---
license: other
---
# 聲明 Disclaimer
本資料夾中的模型不是我所製作,版權歸原作者所有(各模型版權詳見 http://www.civitai.com 所示)。我上傳至本資料夾僅爲方便在綫抽取資源,并非盈利。
The models in this folder are not made by me, and the copyright belongs to the original author (see http://www.civitai.com for details on the copyright of each model). I uploaded to this folder only for the convenience of extracting resources online, not for profit.
# 模型列表 List of Models
本資料夾中所有模型詳見下表。
All the models in this folder are detailed in the table below.
| 模型名稱 Model Name | Civitai 頁面鏈接 Civitai Page Link | Civitai 下載鏈接 Civitai Download Link |
|----------------------|--------------------|--------------------|
|fantasticmix_v50.safetensors |https://civitai.com/models/22402?modelVersionId=68821 |https://civitai.com/api/download/models/68821 |
|fantasticmix_v40.safetensors |https://civitai.com/models/22402?modelVersionId=59385 |https://civitai.com/api/download/models/59385 |
|fantasticmix_v30.safetensors |https://civitai.com/models/22402?modelVersionId=39880 |https://civitai.com/api/download/models/39880 |
|fantasticmix_v30Baked.safetensors |https://civitai.com/models/22402?modelVersionId=39900 |https://civitai.com/api/download/models/39900 |
|fantasticmix_v20.safetensors |https://civitai.com/models/22402?modelVersionId=30145 |https://civitai.com/api/download/models/30145 |
|fantasticmix_v20Baked.safetensors |https://civitai.com/models/22402?modelVersionId=30589 |https://civitai.com/api/download/models/30589 |
|fantasticmix_v10.safetensors |https://civitai.com/models/22402?modelVersionId=26744 |https://civitai.com/api/download/models/26744 |
|
DaWang/demo
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
---
# InstructPix2Pix: Learning to Follow Image Editing Instructions
GitHub: https://github.com/timothybrooks/instruct-pix2pix
<img src='https://instruct-pix2pix.timothybrooks.com/teaser.jpg'/>
## Example
To use `InstructPix2Pix`, install `diffusers` using `main` for now. The pipeline will be available in the next release
```bash
pip install diffusers accelerate safetensors transformers
```
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
model_id = "timbrooks/instruct-pix2pix"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
url = "https://raw.githubusercontent.com/timothybrooks/instruct-pix2pix/main/imgs/example.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(URL)
prompt = "turn him into cyborg"
images = pipe(prompt, image=image, num_inference_steps=10, image_guidance_scale=1).images
images[0]
```
|
Darkecho789/email-gen
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- autotrain
- vision
- image-classification
datasets:
- ceogpt/autotrain-data-test-cgpt
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.20224231551586896
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 57734132888
- CO2 Emissions (in grams): 0.2022
## Validation Metrics
- Loss: 0.430
- Accuracy: 0.882
- Precision: 0.000
- Recall: 0.000
- AUC: 0.233
- F1: 0.000
|
Davlan/xlm-roberta-base-finetuned-xhosa
|
[
"pytorch",
"xlm-roberta",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 434.00 +/- 154.03
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Bhanu9Prakash -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Bhanu9Prakash -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Bhanu9Prakash
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Davlan/xlm-roberta-base-finetuned-zulu
|
[
"pytorch",
"xlm-roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: Bhanu9Prakash/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Davlan/xlm-roberta-large-ner-hrl
|
[
"pytorch",
"tf",
"xlm-roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1,322 | null |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: Bilguunee/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Dayout/test
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: jakubgajski/PyramydsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Declan/CNN_model_v2
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: type-prediction-transformer
results: []
widget:
- text: "ถนนผุพังทำให้เกิดเสียงดังเวลารถวิ่ง"
- text: "ขี่มอไซค์บนทางเท้ามันจะเกินปุยมุ้ย"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# type-prediction-transformer
This model is a fine-tuned version of [airesearch/wangchanberta-base-att-spm-uncased](https://huggingface.co/airesearch/wangchanberta-base-att-spm-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0497
- F1: 0.8651
- Roc Auc: 0.9260
- Accuracy: 0.8208
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| No log | 1.0 | 149 | 0.0812 | 0.8070 | 0.8677 | 0.7588 |
| No log | 2.0 | 298 | 0.0591 | 0.8585 | 0.9064 | 0.8141 |
| No log | 3.0 | 447 | 0.0493 | 0.8719 | 0.9144 | 0.8258 |
| 0.0886 | 4.0 | 596 | 0.0506 | 0.8614 | 0.9222 | 0.8090 |
| 0.0886 | 5.0 | 745 | 0.0487 | 0.8683 | 0.9255 | 0.8174 |
| 0.0886 | 6.0 | 894 | 0.0506 | 0.8693 | 0.9291 | 0.8191 |
| 0.0254 | 7.0 | 1043 | 0.0519 | 0.8619 | 0.9307 | 0.8090 |
| 0.0254 | 8.0 | 1192 | 0.0497 | 0.8651 | 0.9260 | 0.8208 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Tokenizers 0.13.3
|
Declan/CNN_model_v3
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | 2023-05-12T07:21:56Z |
Un cambrioleur possède un sac à dos d'une contenance maximum de 30 kg. Au cours
d'un de ses cambriolages, il a la possibilité de dérober 4 objets A, B, C et D. Voici un
tableau qui résume les caractéristiques de ces objets :
Objet A B C D
Masse 13kg 12kg 8kg 10kg
Valeur 700 400 300 300
Déterminez les objets que le cambrioleur aura intérêt à dérober, sachant que :
- tous les objets dérobés devront tenir dans le sac à dos (30 Kg maxi)
- le cambrioleur cherche à obtenir un gain maximum.
Ce genre de problème est un grand classique en informatique, on parle de problème
d'optimisation. Il existe toujours plusieurs solutions possibles à un problème
d'optimisation (dans le problème du sac à dos, on peut choisir A+B ou A+C ou B+C+D...
toutes les combinaisons sont possibles à partir du moment où la masse totale ne dépasse
pas 30 Kg), mais on ne cherche pas n'importe quelle solution, on cherche une solution
dite optimale : dans notre exemple on cherche le plus grand gain possible. Souvent, dans
les problèmes d'optimisation, il n'existe pas une solution optimale, mais plusieurs
solutions optimales, résoudre un problème d'optimisation c'est donc trouver une des
solutions optimales.
Il existe différentes méthodes algorithmiques permettant de trouver une solution
optimale à un problème d'optimisation : il peut, en effet, être intéressant "d'automatiser"
la résolution des problèmes d'optimisation à l'aide d'algorithme (dans notre cas, trouver
un algorithme qui trouve une solution optimale au problème du sac à dos).
En apparence, la solution la plus simple dans le cas du sac à dos serait d'écrire un
algorithme qui teste toutes les combinaisons d'objets possibles et qui retient les solutions
qui offrent un gain maximum.
Dans notre cas précis, avec seulement 4 objets, cette solution pourrait être envisagée,
mais avec un plus grand nombre d'objets, le temps de calculs, même pour un ordinateur
très puissant, deviendrait trop important.
En effet l'algorithme qui testerait toutes les combinaisons possibles aurait une complexité
en temps en O(a
n
) avec a une constante et n le nombre d'objets. On parle d'une
complexité exponentielle. Les algorithmes à complexité exponentielle ne sont pas
efficaces pour résoudre des problèmes, le temps de calcul devient beaucoup trop
important quand n devient très grand.
À la place de cette méthode "je teste toutes les possibilités", il est possible d'utiliser une
méthode dite gloutonne (greedy en anglais).
Qu'est-ce qu'une méthode gloutonne ?
La résolution d'un problème d'optimisation se fait généralement par étapes : à chaque
étape on doit faire un choix. Par exemple, dans le problème du sac à dos, nous ajoutons
les objets un par un, chaque ajout d'un objet constitue une étape : à chaque étape, on doit
choisir un objet à mettre dans le sac.
Le principe de la méthode gloutonne est de, à chaque étape de la résolution du problème,
faire le choix qui semble le plus pertinent sur le moment, avec l'espoir qu'au bout du
compte, cela nous conduira vers une solution optimale du problème à résoudre.
Autrement dit, on fait des choix localement optimaux dans l'espoir que ces choix
mèneront à une solution globalement optimale (le "localement" signifie ici "à chaque
étape de la résolution du problème").
Appliquons une méthode gloutonne à la résolution du problème du sac à dos :
Sachant que l'on cherche à maximiser le gain, commençons par établir un tableau nous
donnant la "valeur massique" de chaque objet (pour chaque objet on divise sa valeur par
sa masse) :
Objet A B C D
Valeur massique 54€/kg 33€/kg 38€/kg 30€/kg
On classe ensuite les objets par ordre décroissant de valeur massique :
A > C > B > D
Enfin, on remplit le sac en prenant les objets dans l'ordre et en s'arrêtant dès que la masse
limite est atteinte. C'est ici que ce fait "le choix glouton", à chaque étape, on prend l'objet
ayant le rapport "valeur-masse" le plus intéressant au vu des objectifs :
- 1ere étape : A (13 kg)
- 2e étape : C (13 + 8 = 21 kg)
- 3e étape : B (13 + 8 + 12 = 33 kg) => impossible, on dépasse les 30 Kg.
Le sac est donc composé de 2 objets : A et C pour un montant total de 1000 € et une
masse totale de 21 kg.
Cette méthode gloutonne peut être "automatisée", il est donc possible d'écrire un
algorithme glouton (un algorithme qui est basé sur une méthode gloutonne) afin de
trouver une solution au problème du sac à dos avec n'importe quelles valeurs (nombre
d'objets, masse des objets, valeur des objets, masse maximum).
La solution trouvée ci-dessus est-elle optimale ?
On constate rapidement que la réponse est non, car le couple A+B permet d'atteindre une
valeur de 1100 € pour une masse de 25 Kg. Dans notre problème, la méthode gloutonne
ne nous donne pas une solution optimale.
Plus généralement , il est important de bien comprendre qu'un algorithme glouton ne
donne pas forcément une solution optimale.
|
Declan/ChicagoTribune_model_v6
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice_11_0
metrics:
- wer
model-index:
- name: faiq-wav2vec2-large-xlsr-indo-demo-colab
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_11_0
type: common_voice_11_0
config: id
split: test
args: id
metrics:
- name: Wer
type: wer
value: 0.4313296733972271
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# faiq-wav2vec2-large-xlsr-indo-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4079
- Wer: 0.4313
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.0752 | 2.92 | 400 | 2.7911 | 1.0 |
| 1.2625 | 5.84 | 800 | 0.4611 | 0.6152 |
| 0.3806 | 8.76 | 1200 | 0.4284 | 0.5476 |
| 0.2653 | 11.68 | 1600 | 0.4074 | 0.4935 |
| 0.2134 | 14.6 | 2000 | 0.3846 | 0.4788 |
| 0.1701 | 17.52 | 2400 | 0.4175 | 0.4640 |
| 0.1544 | 20.44 | 2800 | 0.4101 | 0.4471 |
| 0.1303 | 23.36 | 3200 | 0.4147 | 0.4457 |
| 0.1202 | 26.28 | 3600 | 0.4050 | 0.4344 |
| 0.1082 | 29.2 | 4000 | 0.4079 | 0.4313 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.6.1
- Tokenizers 0.13.3
|
Declan/FoxNews_model_v2
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: cc-by-4.0
language:
- sw
---
BERT medium (cased) model trained on a subset of 125M tokens of cc100-Swahili for our work [Scaling Laws for BERT in Low-Resource Settings]() at ACL2023 Findings.
The model has 51M parameters (8L), and a vocab size of 50K.
It was trained for 500K steps with a sequence length of 512 tokens.
Authors
-----------
Gorka Urbizu [1], Iñaki San Vicente [1], Xabier Saralegi [1],
Rodrigo Agerri [2] and Aitor Soroa [2]
Affiliation of the authors:
[1] Orai NLP Technologies
[2] HiTZ Center - Ixa, University of the Basque Country UPV/EHU
Licensing
-------------
The model is licensed under the Creative Commons Attribution 4.0. International License (CC BY 4.0).
To view a copy of this license, visit [http://creativecommons.org/licenses/by/4.0/](https://creativecommons.org/licenses/by/4.0/deed.eu).
Acknowledgements
-------------------
If you use this model please cite the following paper:
- G. Urbizu, I. San Vicente, X. Saralegi, R. Agerri, A. Soroa. Scaling Laws for BERT in Low-Resource Settings. Findings of the Association for Computational Linguistics: ACL 2023. July, 2023. Toronto, Canada
Contact information
-----------------------
Gorka Urbizu, Iñaki San Vicente: {g.urbizu,i.sanvicente}@orai.eus
|
Declan/FoxNews_model_v5
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### FastBreamBooth Dreambooth model trained by samwell with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
Declan/HuffPost_model_v5
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
language:
- en
license: apache-2.0
datasets:
- glue
metrics:
- accuracy
model-index:
- name: gpt2-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE COLA
type: glue
args: cola
metrics:
- name: Accuracy
type: accuracy
value: 0.77756
---
# gpt2-finetuned-cola
<!-- Provide a quick summary of what the model is/does. -->
This model is gpt2 fine-tuned on GLUE CoLA dataset. It acheives the following results on the validation set. Though MCC is used for CoLA dataset, accuracy is reported here
- Accuracy: 0.77756
## Model Details
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion.
This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was trained to guess the next word in sentences. However, it acheives very good results on Text Classification tasks.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-4
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: epsilon=1e-08
- num_epochs: 5.0
### Training results
|Epoch | Training Loss | Validation Loss | Training Accuracy | Validation Accuracy |
|:----:|:-------------:|:-----------------:|:---------------:|:-------------------:|
| 1 | 0.65824 | 0.55883 | 0.67957 | 0.70086 |
| 2 | 0.51774 | 0.53402 | 0.74927 | 0.75264 |
| 3 | 0.44502 | 0.50641 | 0.79172 | **0.77756** |
| 4 | 0.38996 | 0.54241 | 0.82645 | 0.77469 |
| 5 | 0.35218 | 0.55088 | 0.84516 | 0.77277 |
|
Declan/Politico_model_v1
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1738 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 173,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Declan/Politico_model_v6
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: afl-3.0
metrics:
- accuracy
- code_eval
library_name: sklearn
pipeline_tag: text-classification
tags:
- clim
---
# bert-model-disaster-tweets-classification
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the Natural-Language-Processing-with-Disaster-Tweets dataset.
It achieves the following results on the evaluation set:
- Accuracy: 0.82
- F1 Score: 0.82
## Model description
Load BertForSequenceClassification, the pretrained BERT model with a single linear classification layer on top, using an optimizer : incorporates weight decay, which is a regularization technique that helps prevent overfitting during training.
## Intended uses & limitations
Use to classify if a tweet represents a disaster or not.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with epsilon = 1e-8.
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Epoch | Average training loss | Training epoch | Accuracy | F1 |
|:-----:|:---------------------:|:---------------:|:--------:|:----:|
| 1.0 | 0.47 | 0:00:49 | 0.82 | 0.82 |
| 2.0 | 0.36 | 0:00:36 | 0.82 | 0.82 |
| 3.0 | 0.29 | 0:00:51 | 0.82 | 0.82 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Declan/Reuters_model_v6
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
language:
- en
license: apache-2.0
datasets:
- glue
metrics:
- pearsonr
model-index:
- name: t5-base-finetuned-stsb
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE STS-B
type: glue
args: stsb
metrics:
- name: Pearson Correlation
type: pearson_correlation
value: 0.8937
---
# T5-base-finetuned-stsb
<!-- Provide a quick summary of what the model is/does. -->
This model is T5 fine-tuned on GLUE STS-B dataset. It acheives the following results on the validation set
- Pearson Correlation Coefficient: 0.8937
## Model Details
T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format.
## Training procedure
### Tokenization
Since, T5 is a text-to-text model, the labels of the dataset are converted as follows:
For each example, a sentence as been formed as **"stsb sentence1: " + stsb_sent1 + "sentence2: " + stsb_sent2** and fed to the tokenizer to get the **input_ids** and **attention_mask**.
Unlike other **GLUE** tasks, STS-B is a regression task where the goal is to predict a similarity score between 1 and 5. I have used the same stratey as descibed in the T5 paper for fine-tuning. In the paper, it is mentioned as
``` We found that most of these scores were annotated in increments of 0.2, so we simply rounded any score to the nearest increment of 0.2 and converted the result to a literal string representation of the number (e.g. the floating-point value 2.57 would be mapped to the string “2.6”). At test time, if the model outputs a string corresponding to a number between 1 and 5, we convert it to a floating-point value; otherwise, we treat the model’s prediction as incorrect. This effectively recasts the STS-B
regression problem as a 21-class classification problem. ```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-4
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: epsilon=1e-08
- num_epochs: 3.0
### Training results
|Epoch | Training Loss | Validation Pearson Correlation Coefficient |
|:----:|:-------------:|:-------------------:|
| 1 | 0.8623 | 0.8200 |
| 2 | 0.7782 | 0.8675 |
| 3 | 0.7040 | **0.8937** |
|
Declan/Reuters_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | 2023-05-12T08:51:58Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.69 +/- 23.27
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/WallStreetJournal_model_v5
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="debin/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Declan/WallStreetJournal_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
DeepChem/ChemBERTa-10M-MLM
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 90 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.48 +/- 2.75
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="debin/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
DeepChem/SmilesTokenizer_PubChem_1M
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 227 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: gpt-work-filter-auto-complete
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-work-filter-auto-complete
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0939
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 22 | 0.6395 |
| No log | 2.0 | 44 | 0.6235 |
| No log | 3.0 | 66 | 0.6035 |
| No log | 4.0 | 88 | 0.5845 |
| No log | 5.0 | 110 | 0.5645 |
| No log | 6.0 | 132 | 0.5442 |
| No log | 7.0 | 154 | 0.5346 |
| No log | 8.0 | 176 | 0.5167 |
| No log | 9.0 | 198 | 0.5009 |
| No log | 10.0 | 220 | 0.4893 |
| No log | 11.0 | 242 | 0.4676 |
| No log | 12.0 | 264 | 0.4498 |
| No log | 13.0 | 286 | 0.4382 |
| No log | 14.0 | 308 | 0.4276 |
| No log | 15.0 | 330 | 0.4132 |
| No log | 16.0 | 352 | 0.4075 |
| No log | 17.0 | 374 | 0.3952 |
| No log | 18.0 | 396 | 0.3822 |
| No log | 19.0 | 418 | 0.3677 |
| No log | 20.0 | 440 | 0.3563 |
| No log | 21.0 | 462 | 0.3495 |
| No log | 22.0 | 484 | 0.3455 |
| 0.6366 | 23.0 | 506 | 0.3316 |
| 0.6366 | 24.0 | 528 | 0.3126 |
| 0.6366 | 25.0 | 550 | 0.3118 |
| 0.6366 | 26.0 | 572 | 0.3021 |
| 0.6366 | 27.0 | 594 | 0.2944 |
| 0.6366 | 28.0 | 616 | 0.2878 |
| 0.6366 | 29.0 | 638 | 0.2772 |
| 0.6366 | 30.0 | 660 | 0.2701 |
| 0.6366 | 31.0 | 682 | 0.2643 |
| 0.6366 | 32.0 | 704 | 0.2576 |
| 0.6366 | 33.0 | 726 | 0.2514 |
| 0.6366 | 34.0 | 748 | 0.2467 |
| 0.6366 | 35.0 | 770 | 0.2359 |
| 0.6366 | 36.0 | 792 | 0.2326 |
| 0.6366 | 37.0 | 814 | 0.2205 |
| 0.6366 | 38.0 | 836 | 0.2182 |
| 0.6366 | 39.0 | 858 | 0.2137 |
| 0.6366 | 40.0 | 880 | 0.2086 |
| 0.6366 | 41.0 | 902 | 0.2058 |
| 0.6366 | 42.0 | 924 | 0.1979 |
| 0.6366 | 43.0 | 946 | 0.1930 |
| 0.6366 | 44.0 | 968 | 0.1922 |
| 0.6366 | 45.0 | 990 | 0.1853 |
| 0.4122 | 46.0 | 1012 | 0.1800 |
| 0.4122 | 47.0 | 1034 | 0.1787 |
| 0.4122 | 48.0 | 1056 | 0.1738 |
| 0.4122 | 49.0 | 1078 | 0.1689 |
| 0.4122 | 50.0 | 1100 | 0.1670 |
| 0.4122 | 51.0 | 1122 | 0.1583 |
| 0.4122 | 52.0 | 1144 | 0.1560 |
| 0.4122 | 53.0 | 1166 | 0.1540 |
| 0.4122 | 54.0 | 1188 | 0.1507 |
| 0.4122 | 55.0 | 1210 | 0.1475 |
| 0.4122 | 56.0 | 1232 | 0.1452 |
| 0.4122 | 57.0 | 1254 | 0.1458 |
| 0.4122 | 58.0 | 1276 | 0.1425 |
| 0.4122 | 59.0 | 1298 | 0.1377 |
| 0.4122 | 60.0 | 1320 | 0.1338 |
| 0.4122 | 61.0 | 1342 | 0.1365 |
| 0.4122 | 62.0 | 1364 | 0.1278 |
| 0.4122 | 63.0 | 1386 | 0.1272 |
| 0.4122 | 64.0 | 1408 | 0.1253 |
| 0.4122 | 65.0 | 1430 | 0.1251 |
| 0.4122 | 66.0 | 1452 | 0.1217 |
| 0.4122 | 67.0 | 1474 | 0.1219 |
| 0.4122 | 68.0 | 1496 | 0.1177 |
| 0.3005 | 69.0 | 1518 | 0.1174 |
| 0.3005 | 70.0 | 1540 | 0.1155 |
| 0.3005 | 71.0 | 1562 | 0.1144 |
| 0.3005 | 72.0 | 1584 | 0.1127 |
| 0.3005 | 73.0 | 1606 | 0.1106 |
| 0.3005 | 74.0 | 1628 | 0.1098 |
| 0.3005 | 75.0 | 1650 | 0.1092 |
| 0.3005 | 76.0 | 1672 | 0.1067 |
| 0.3005 | 77.0 | 1694 | 0.1086 |
| 0.3005 | 78.0 | 1716 | 0.1042 |
| 0.3005 | 79.0 | 1738 | 0.1051 |
| 0.3005 | 80.0 | 1760 | 0.1038 |
| 0.3005 | 81.0 | 1782 | 0.1022 |
| 0.3005 | 82.0 | 1804 | 0.1015 |
| 0.3005 | 83.0 | 1826 | 0.1004 |
| 0.3005 | 84.0 | 1848 | 0.1003 |
| 0.3005 | 85.0 | 1870 | 0.0978 |
| 0.3005 | 86.0 | 1892 | 0.0987 |
| 0.3005 | 87.0 | 1914 | 0.0974 |
| 0.3005 | 88.0 | 1936 | 0.0975 |
| 0.3005 | 89.0 | 1958 | 0.0965 |
| 0.3005 | 90.0 | 1980 | 0.0960 |
| 0.2455 | 91.0 | 2002 | 0.0958 |
| 0.2455 | 92.0 | 2024 | 0.0952 |
| 0.2455 | 93.0 | 2046 | 0.0952 |
| 0.2455 | 94.0 | 2068 | 0.0944 |
| 0.2455 | 95.0 | 2090 | 0.0943 |
| 0.2455 | 96.0 | 2112 | 0.0940 |
| 0.2455 | 97.0 | 2134 | 0.0942 |
| 0.2455 | 98.0 | 2156 | 0.0940 |
| 0.2455 | 99.0 | 2178 | 0.0939 |
| 0.2455 | 100.0 | 2200 | 0.0939 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
DeepPavlov/bert-base-bg-cs-pl-ru-cased
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"bg",
"cs",
"pl",
"ru",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1,614 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1812.10 +/- 93.58
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DeepPavlov/marianmt-tatoeba-enru
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 275.95 +/- 15.30
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DeepPavlov/xlm-roberta-large-en-ru
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"en",
"ru",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"XLMRobertaModel"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 190 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="casellimarco/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
DeltaHub/lora_t5-base_mrpc
|
[
"pytorch",
"transformers"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="casellimarco/Taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Denver/distilbert-base-uncased-finetuned-squad
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: whisper-large-v2_lora_int8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v2_lora_int8
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1738
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7199 | 0.0 | 1 | 2.3895 |
| 0.1977 | 0.29 | 1000 | 0.1973 |
| 0.1777 | 0.58 | 2000 | 0.1846 |
| 0.1693 | 0.88 | 3000 | 0.1780 |
| 0.1579 | 1.17 | 4000 | 0.1753 |
| 0.157 | 1.46 | 5000 | 0.1738 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0
- Datasets 2.11.0
- Tokenizers 0.13.3
|
DeskDown/MarianMixFT_en-fil
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: mit
---
# Install uniem
```
pip install uniem
```
# Usage
```python
from uniem import UniEmbedder
embedder = UniEmbedder.from_pretrained('uniem/base-softmax-last-mean')
embedder.encode(['Hello World!', '你好,世界!'])
```
|
DeskDown/MarianMixFT_en-ms
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: iamjoy/ppo-SnowballTargetTESTCOLAB
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
DevsIA/imagenes
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | 1e-06 |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | False |
| is_legacy_optimizer | False |
| learning_rate | 9.999999747378752e-06 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
|
DicoTiar/wisdomfiy
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 262.51 +/- 12.66
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Dilmk2/DialoGPT-small-harrypotter
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 13 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.19 +/- 19.62
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DivyanshuSheth/T5-Seq2Seq-Final
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: other
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: finetuned-opt-squad-dataset-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-opt-squad-dataset-2
This model is a fine-tuned version of [choohan/finetuned-opt-squad-dataset](https://huggingface.co/choohan/finetuned-opt-squad-dataset) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Dmitriiserg/Pxd
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
Access to model Kamshat/finetuning_sentiment_model is restricted and you are not in the authorized list. Visit https://huggingface.co/Kamshat/finetuning_sentiment_model to ask for access.
|
DongHai/DialoGPT-small-rick
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
license: other
inference: false
---
## Dromedary-65B-LoRA GPTQ
These files are the result of merging the [delta weights of IBM's Dromedary 65B LoRA](https://huggingface.co/zhiqings/dromedary-65b-lora-delta-v0) with the original Llama 65B model.
It is the result of quantising to 4bit using [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
## Repositories available
* [4bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/dromedary-65B-lora-GPTQ)
* [4bit and 5bit GGML models for CPU inference in llama.cpp](https://huggingface.co/TheBloke/dromedary-65B-lora-GGML)
* [float16 unquantised model for GPU](https://huggingface.co/TheBloke/dromedary-65B-lora-HF)
## VRAM
I tested this model with 2 x 24GB 4090 GPUs, and it was able to return 1500 tokens before one card went OOM.
So you may need to preload a few layers on to CPU RAM, or else run on a system with more than 48GB VRAM.
Or, if you can limit responses to <1500 tokens (eg for single prompts rather than chats), you should be fine with 48GB VRAM.
## How to easily download and use this model in text-generation-webui
Open the text-generation-webui UI as normal.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/dromedary-65B-lora-GPTQ`.
3. Click **Download**.
4. Wait until it says it's finished downloading.
5. Click the **Refresh** icon next to **Model** in the top left.
6. In the **Model drop-down**: choose the model you just downloaded, `dromedary-65B-lora-GPTQ`.
7. If you see an error in the bottom right, ignore it - it's temporary.
8. Fill out the `GPTQ parameters` on the right: `Bits = 4`, `Groupsize = None`, `model_type = Llama`
9. Click **Save settings for this model** in the top right.
10. Click **Reload the Model** in the top right.
11. Once it says it's loaded, click the **Text Generation tab** and enter a prompt!
## Provided files
**dromedary-65B-GPTQ-4bit.safetensors**
You will need ~40GB VRAM to use this model, either on one GPU or multiple.
This will work with all versions of GPTQ-for-LLaMa. It has maximum compatibility.
It was created with `--act-order` to increase quantisation quality, but without groupsize so as to minimise VRAM requirements.
* `dromedary-65B-GPTQ-4bit.safetensors`
* Works with all versions of GPTQ-for-LLaMa code, both Triton and CUDA branches
* Works with text-generation-webui one-click-installers
* Parameters: Groupsize = None. act-order.
* Command used to create the GPTQ:
```
python llama.py /workspace/drom-65b/HF c4 --wbits 4 --true-sequential --act-order --save_safetensors /workspace/drom-gptq/dromedary-65B-GPTQ-4bit.safetensors
```
# Original Dromedary Model Card
See https://github.com/IBM/Dromedary#model-weights for instructions.
## Model details
<div align="center">
<img src="https://raw.githubusercontent.com/IBM/Dromedary/main/assets/images/dromedary_logo.svg" alt="Dromedary Logo"/>
</div>
**Model type:**
Dromedary is an open-source self-aligned language model trained with minimal human supervision.
The base language model is LLaMA-65b, based on the transformer architecture.
**Model date:**
Dromedary was trained between April 2023 and May 2023, but its knowledge only goes up until Sept-2021.
**Organizations developing the model:**
The Dromedary team as a joint effort between CMU and IBM.
**Paper or resources for more information:**
https://mitibmdemos.draco.res.ibm.com/dromedary
**License:**
LLaMA's Non-commercial bespoke license
**Where to send questions or comments about the model:**
https://github.com/IBM/Dromedary/issues
## Intended use
**Primary intended uses:**
The primary use of Dromedary is research on the alignment of large language models.
**Primary intended users:**
The primary intended users of the model are researchers in artificial intelligence.
## Delta weights
We use the following configuration for the LoRA weights:
```
--lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \
--lora_r=16 \
```
## Training dataset
Fewer than 300 lines of human annotations (including < 200 seed prompts, 16 generic principles, and 5 exemplars for in-context learning),
## Evaluation dataset
We evaluate Dromedary on TruthfulQA and HHH Eval, as well as Vicuna benchmark questions.
|
DongHyoungLee/distilbert-base-uncased-finetuned-cola
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
|
{
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 27 | null |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ucf101-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2818
- Accuracy: 0.9097
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4628 | 0.25 | 300 | 1.2753 | 0.4857 |
| 0.3162 | 1.25 | 600 | 0.7058 | 0.7286 |
| 0.0241 | 2.25 | 900 | 0.5010 | 0.8 |
| 0.3227 | 3.25 | 1200 | 0.2688 | 0.9143 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Dongjae/mrc2reader
|
[
"pytorch",
"xlm-roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"XLMRobertaForQuestionAnswering"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
pipeline_tag: conversational
---
ggml version (post-PR #1405)
As a base model used https://huggingface.co/eachadea/vicuna-13b-1.1
Finetuned on Teknium's GPTeacher dataset, unreleased Roleplay v2 dataset, GPT-4-LLM dataset, and Nous Research Instruct Dataset
Approx 180k instructions, all from GPT-4, all cleaned of any OpenAI censorship/"As an AI Language Model" etc.
Base model still has OpenAI censorship. Soon, a new version will be released with cleaned vicuna from https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltere
Trained on 8 A100-80GB GPUs for 5 epochs following Alpaca deepspeed training code.
Nous Research Instruct Dataset will be released soon.
GPTeacher, Roleplay v2 by https://huggingface.co/teknium
Wizard LM by https://github.com/nlpxucan
Nous Research Instruct Dataset by https://huggingface.co/karan4d and https://huggingface.co/huemin
Compute provided by our project sponsor https://redmond.ai/
|
Dongmin/testmodel
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
}
| 11 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8247422680412371
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5465
- Accuracy: 0.8247
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 7 | 1.2679 | 0.2990 |
| 1.3643 | 2.0 | 14 | 1.1288 | 0.5258 |
| 1.0267 | 3.0 | 21 | 0.6534 | 0.7010 |
| 1.0267 | 4.0 | 28 | 0.6587 | 0.7629 |
| 0.6635 | 5.0 | 35 | 0.7360 | 0.6701 |
| 0.5462 | 6.0 | 42 | 0.6479 | 0.7320 |
| 0.5462 | 7.0 | 49 | 0.5546 | 0.7835 |
| 0.4471 | 8.0 | 56 | 0.5583 | 0.7835 |
| 0.3094 | 9.0 | 63 | 0.5257 | 0.8247 |
| 0.242 | 10.0 | 70 | 0.5465 | 0.8247 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Doogie/Waynehills-KE-T5-doogie
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: other
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: finetuned-opt-squad-dataset-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-opt-squad-dataset-3
This model is a fine-tuned version of [choohan/finetuned-opt-squad-dataset-2](https://huggingface.co/choohan/finetuned-opt-squad-dataset-2) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Waynehillsdev/wav2vec2-base-timit-demo-colab
|
[
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
license: creativeml-openrail-m
language:
- en
pipeline_tag: text-to-image
tags:
- lora
- stable diffusion
---
Trained, and merged Loras.
You'll be able to tell for the MOST part what they are by file name, look it's 11pm we're exhausted.. We'll have updates on what's in here soon!
Join our Reddit: https://www.reddit.com/r/earthndusk/
If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US: https://discord.gg/Da7s8d3KJ7
Listen to the music that we've made that goes with our art: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38
We stream a lot of our testing on twitch: https://www.twitch.tv/duskfallcrew
any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
|
Doxophobia/DialoGPT-medium-celeste
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11 | null |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.3.0_6000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.3.0_6000
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1548
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.7195 | 1.0 | 86 | 0.7983 |
| 0.5979 | 2.0 | 172 | 0.5259 |
| 0.2954 | 3.0 | 258 | 0.3660 |
| 0.3001 | 3.99 | 344 | 0.2402 |
| 0.1111 | 4.99 | 430 | 0.1548 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-freeze-12
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 29 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-atcosim2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-atcosim2
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0524
- Wer: 0.0304
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 300
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5702 | 0.2 | 50 | 0.2557 | 0.1007 |
| 0.1181 | 0.39 | 100 | 0.1144 | 0.0775 |
| 0.1084 | 0.59 | 150 | 0.0747 | 0.0482 |
| 0.0737 | 0.79 | 200 | 0.0616 | 0.0369 |
| 0.064 | 0.98 | 250 | 0.0556 | 0.0440 |
| 0.0313 | 1.18 | 300 | 0.0524 | 0.0304 |
### Framework versions
- Transformers 4.29.0
- Pytorch 2.0.0+cu117
- Datasets 2.12.0
- Tokenizers 0.11.0
|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-warmup-25
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 30 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9295
- name: F1
type: f1
value: 0.9293576247301535
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2169
- Accuracy: 0.9295
- F1: 0.9294
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8632 | 1.0 | 250 | 0.3270 | 0.904 | 0.9008 |
| 0.253 | 2.0 | 500 | 0.2169 | 0.9295 | 0.9294 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3
|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-warmup-50
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 28 | null |
Access to model dwmit/transliterate is restricted and you are not in the authorized list. Visit https://huggingface.co/dwmit/transliterate to ask for access.
|
albert-base-v1
|
[
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 38,156 | 2023-05-12T11:45:20Z |
---
tags:
- generated_from_trainer
model-index:
- name: viettel-videberta-finetune-viquad-model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# viettel-videberta-finetune-viquad-model2
This model is a fine-tuned version of [Fsoft-AIC/videberta-base](https://huggingface.co/Fsoft-AIC/videberta-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
bert-base-cased-finetuned-mrpc
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11,644 | 2023-05-12T11:51:57Z |
TrustVare OST Duplicate Remover is a software application that can be used to find and remove duplicate items from an offline Outlook data file (.ost). OST files are created by Microsoft Outlook when it is configured to work in offline mode. They store email messages, contacts, calendars, and other data that are not currently synchronized with the Microsoft Exchange server. Removing duplicate items from an OST file can improve the performance of Microsoft Outlook by reducing the amount of data that the application has to process. Removing duplicate items from an OST file can improve the performance of Microsoft Outlook by reducing the amount of data that the application has to process.The software is easy to use and has a number of features that make it a valuable tool for Microsoft Outlook users.
Read More:- https://www.trustvare.com/duplicate-remover/ost/
|
bert-base-cased
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8,621,271 | 2023-05-12T11:52:12Z |
---
tags:
- generated_from_trainer
model-index:
- name: distilbert-finetuning-hate-speech-score-all-samples-3splits-dropout005-epochs-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-finetuning-hate-speech-score-all-samples-3splits-dropout005-epochs-10
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3437
- Mse: 0.3437
- Rmse: 0.5862
- Mae: 0.2548
- R2: 0.9382
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
bert-base-german-cased
|
[
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"exbert",
"license:mit",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 175,983 | 2023-05-12T11:52:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-summarize-sum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-summarize-sum
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3984
- Rouge1: 0.5736
- Rouge2: 0.3783
- Rougel: 0.4855
- Rougelsum: 0.4844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 90
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 13.8551 | 0.16 | 100 | 5.4672 | 0.2389 | 0.0546 | 0.2119 | 0.2110 |
| 1.0762 | 0.33 | 200 | 0.5982 | 0.3774 | 0.2199 | 0.3493 | 0.3470 |
| 0.8077 | 0.49 | 300 | 0.4999 | 0.4929 | 0.3195 | 0.4349 | 0.4312 |
| 0.7772 | 0.65 | 400 | 0.4652 | 0.4715 | 0.3296 | 0.4431 | 0.4409 |
| 0.7771 | 0.82 | 500 | 0.4402 | 0.4881 | 0.3356 | 0.4433 | 0.4412 |
| 0.713 | 0.98 | 600 | 0.4500 | 0.4990 | 0.3291 | 0.4550 | 0.4525 |
| 0.65 | 1.15 | 700 | 0.4335 | 0.5522 | 0.3633 | 0.4930 | 0.4909 |
| 0.7035 | 1.31 | 800 | 0.4278 | 0.5227 | 0.3470 | 0.4781 | 0.4772 |
| 0.6818 | 1.47 | 900 | 0.4202 | 0.5325 | 0.3585 | 0.4759 | 0.4744 |
| 0.6643 | 1.64 | 1000 | 0.4113 | 0.5326 | 0.3486 | 0.4678 | 0.4641 |
| 0.6007 | 1.8 | 1100 | 0.4122 | 0.5152 | 0.3260 | 0.4572 | 0.4547 |
| 0.5866 | 1.96 | 1200 | 0.4158 | 0.5538 | 0.3680 | 0.4910 | 0.4903 |
| 0.5563 | 2.13 | 1300 | 0.4051 | 0.5433 | 0.3371 | 0.4685 | 0.4672 |
| 0.5727 | 2.29 | 1400 | 0.4089 | 0.5447 | 0.3619 | 0.4711 | 0.4695 |
| 0.5859 | 2.45 | 1500 | 0.4033 | 0.5464 | 0.3411 | 0.4688 | 0.4662 |
| 0.5783 | 2.62 | 1600 | 0.3997 | 0.5667 | 0.3595 | 0.4825 | 0.4787 |
| 0.5673 | 2.78 | 1700 | 0.3992 | 0.5759 | 0.3882 | 0.4911 | 0.4891 |
| 0.57 | 2.95 | 1800 | 0.3984 | 0.5736 | 0.3783 | 0.4855 | 0.4844 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
bert-base-german-dbmdz-cased
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1,814 | 2023-05-12T11:54:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cifar10
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the cifar10 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
bert-base-uncased
|
[
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 59,663,489 | 2023-05-12T12:00:08Z |
---
license: wtfpl
language:
- en
pipeline_tag: text-to-image
---
# Prompt2MedImage - Diffusion for Medical Images
Prompt2MedImage is a latent text to image diffusion model that has been fine-tuned on medical images from ROCO dataset.
The weights here are itended to be used with the 🧨Diffusers library.
This model was trained using Amazon SageMaker and the Hugging Face Deep Learning container.
## Model Details
- **Developed by:** Nihir Chadderwala
- **Model type:** Diffusion based text to medical image generation model
- **Language:** English
- **License:** wtfpl
- **Model Description:** This latent text to image diffusion model can be used to generate high quality medical images based on text prompts. It uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
## Examples
1. The patient had residual paralysis of the hand after poliomyelitis. It was necessary to stabilize the thumb with reference to the index finger. This was accomplished by placing a graft from the bone bank between the first and second metacarpals. The roentgenogram shows the complete healing of the graft one year later.

2. A 3-year-old child with visual difficulties. Axial FLAIR image show a supra-sellar lesion extending to the temporal lobes along the optic tracts (arrows) with moderate mass effect, compatible with optic glioma. FLAIR hyperintensity is also noted in the left mesencephalon from additional tumoral involvement

3. Showing the subtrochanteric fracture in the porotic bone.

## License
This model is open access and available to all, with a Do What the F*ck You want to public license further specifying rights and usage.
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content.
- The author claims no rights on the outputs you generate, you are free to use them and are accountable for their use.
- You may re-distribute the weights and use the model commercially and/or as a service.
## Run using PyTorch
```bash
pip install diffusers transformers
```
Running pipeline with default PNDM scheduler:
```python
import torch
from diffusers import StableDiffusionPipeline
model_id = "Nihirc/Prompt2MedImage"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
prompt = "Showing the subtrochanteric fracture in the porotic bone."
image = pipe(prompt).images[0]
image.save("porotic_bone_fracture.png")
```
## Citation
```
O. Pelka, S. Koitka, J. Rückert, F. Nensa, C.M. Friedrich,
"Radiology Objects in COntext (ROCO): A Multimodal Image Dataset".
MICCAI Workshop on Large-scale Annotation of Biomedical Data and Expert Label Synthesis (LABELS) 2018, September 16, 2018, Granada, Spain. Lecture Notes on Computer Science (LNCS), vol. 11043, pp. 180-189, Springer Cham, 2018.
doi: 10.1007/978-3-030-01364-6_20
```
|
bert-large-cased-whole-word-masking-finetuned-squad
|
[
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8,214 | 2023-05-12T12:01:04Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 257.58 +/- 15.29
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
xlm-mlm-enro-1024
|
[
"pytorch",
"tf",
"xlm",
"fill-mask",
"multilingual",
"en",
"ro",
"arxiv:1901.07291",
"arxiv:1910.09700",
"transformers",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"XLMWithLMHeadModel"
],
"model_type": "xlm",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 38 | 2023-05-12T13:16:24Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/63154/kongou-azur-lane
|
xlm-roberta-large-finetuned-conll02-spanish
|
[
"pytorch",
"rust",
"xlm-roberta",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:1911.02116",
"arxiv:1910.09700",
"transformers",
"autotrain_compatible",
"has_space"
] |
fill-mask
|
{
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 444 | 2023-05-12T13:18:28Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/63637/ichinose-asuna-blue-archive-or-character-lora-1630
|
202015004/wav2vec2-base-timit-demo-colab
|
[
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-05-12T14:21:13Z |
---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# perfect deli appfactory API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "perfect-deli-appfact"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Model link: [View model](https://stablediffusionapi.com/models/perfect-deli-appfact)
Credits: [View credits](https://civitai.com/?query=perfect%20deli%20appfactory)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "",
"model_id": "perfect-deli-appfact",
"prompt": "actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN**
|
AccurateIsaiah/DialoGPT-small-jefftastic
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 14 | 2023-05-12T17:07:26Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mdeberta_Quran_qa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mdeberta_Quran_qa
This model is a fine-tuned version of [timpal0l/mdeberta-v3-base-squad2](https://huggingface.co/timpal0l/mdeberta-v3-base-squad2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6248
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 89 | 2.2395 |
| No log | 2.0 | 178 | 2.3282 |
| No log | 3.0 | 267 | 2.4226 |
| No log | 4.0 | 356 | 2.6551 |
| No log | 5.0 | 445 | 2.9332 |
| 1.0317 | 6.0 | 534 | 3.2124 |
| 1.0317 | 7.0 | 623 | 3.2915 |
| 1.0317 | 8.0 | 712 | 3.5401 |
| 1.0317 | 9.0 | 801 | 3.6132 |
| 1.0317 | 10.0 | 890 | 3.6248 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AdapterHub/bert-base-uncased-pf-newsqa
|
[
"bert",
"en",
"dataset:newsqa",
"arxiv:2104.08247",
"adapter-transformers",
"question-answering"
] |
question-answering
|
{
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | 2023-05-12T18:30:15Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - jainr3/sd-pixelart-model-lora
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the sunilSabnis/pixelart dataset. You can find some example images in the following.




|
AdapterHub/bert-base-uncased-pf-stsb
|
[
"bert",
"en",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification",
"adapterhub:sts/sts-b"
] |
text-classification
|
{
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-fr
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-fr
split: train
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 46.786638307530986
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1716
- Bleu: 46.7866
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AdapterHub/bert-base-uncased-pf-winogrande
|
[
"bert",
"en",
"dataset:winogrande",
"arxiv:2104.08247",
"adapter-transformers",
"adapterhub:comsense/winogrande"
] | null |
{
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
# How to use
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="sana-ngu/t5-large-finetuned-summarize-scientific-articles")
article = "The novel Coronavirus disease (COVID-19), caused by the severe acute respiratory syndrome coronavirus—2 (SARS-CoV-2), in Africa is characterised by a more substantial proportion of asymptomatic (or mildly symptomatic) individuals thought to be playing a role in the spread of the infection. The exact proportion and degree of infectiousness of asymptomatic individuals remains unclear. Studies however indicate that their management is crucial for control of SARS-CoV-2 transmission.
We developed a simplified deterministic susceptible-exposed-infectious-removed (SEIR) mathematical model to assess the effect of active isolation of SARS-CoV-2 infected but asymptomatic individuals through blanket testing for control of the outbreak in Lusaka Province of Zambia. Here we modelled two scenarios; (1) assuming asymptomatic individuals comprised 70% of all COVID-19 cases and (2) asymptomatic individuals comprised only 50% of the cases. For contrast, the model was assessed first under the assumption that asymptomatic individuals are equally as infectious as symptomatic individuals and then secondly, and more likely, assuming asymptomatic individuals are only half as infectious as symptomatic individuals.
For the model assuming 70% asymptomatic cases, a minimum sustained daily blanket testing rate of ≥ 7911 tests/100000 population was sufficient to control the outbreak if asymptomatic individuals are only half as infectious while if equal infectiousness was assumed then a testing rate of ≥ 10028 tests/ 100000 population would be required. For 50% asymptomatic, minimum blanket testing rates of ≥ 4540 tests/ 100000 population was sufficient to control the outbreak at both assumed levels of infectiousness for asymptomatic individuals relative to symptomatic individuals.
Discussion and conclusion
Our model predicts that active isolation of COVID-19 cases, including asymptomatic individuals, through blanket testing can be used as a possible measure for the control of the SARS-Cov-2 transmission in Lusaka, Zambia, but it would come at a high cost."
summarizer(conversation)
```
|
Ahmed59/Demo-Team-5-SIAD
|
[
"tf",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 14 | null |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
AhmedBou/TuniBert
|
[
"pytorch",
"bert",
"text-classification",
"ar",
"transformers",
"sentiment analysis",
"classification",
"arabic dialect",
"tunisian dialect",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 44 | null |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
AhmedSSoliman/MarianCG-CoNaLa
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible",
"has_space"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 21 | null |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Bol1.0
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
config: discharge
split: test
args: discharge
metrics:
- name: Precision
type: precision
value: 0.5769230769230769
- name: Recall
type: recall
value: 0.5
- name: F1
type: f1
value: 0.5357142857142857
- name: Accuracy
type: accuracy
value: 0.9026548672566371
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bol1.0
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5251
- Precision: 0.5769
- Recall: 0.5
- F1: 0.5357
- Accuracy: 0.9027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.61 | 100 | 2.0701 | 0.0476 | 0.0333 | 0.0392 | 0.3717 |
| No log | 3.23 | 200 | 1.5988 | 0.1852 | 0.1667 | 0.1754 | 0.6726 |
| No log | 4.84 | 300 | 1.2027 | 0.3846 | 0.3333 | 0.3571 | 0.6726 |
| No log | 6.45 | 400 | 0.9370 | 0.45 | 0.3 | 0.3600 | 0.8142 |
| 0.7987 | 8.06 | 500 | 0.7833 | 0.3333 | 0.2667 | 0.2963 | 0.8230 |
| 0.7987 | 9.68 | 600 | 0.6820 | 0.4348 | 0.3333 | 0.3774 | 0.8319 |
| 0.7987 | 11.29 | 700 | 0.6220 | 0.4074 | 0.3667 | 0.3860 | 0.8319 |
| 0.7987 | 12.9 | 800 | 0.5621 | 0.4815 | 0.4333 | 0.4561 | 0.8496 |
| 0.7987 | 14.52 | 900 | 0.5351 | 0.5 | 0.4667 | 0.4828 | 0.8938 |
| 0.2748 | 16.13 | 1000 | 0.5251 | 0.5769 | 0.5 | 0.5357 | 0.9027 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.2.2
- Tokenizers 0.13.3
|
AiPorter/DialoGPT-small-Back_to_the_future
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
AigizK/wav2vec2-large-xls-r-300m-bashkir-cv7_no_lm
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for LXRAB
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** ChilloutMix
# How to Get Started with the Model
Use the code below to get started with the model.
### LXRAB ###
|
AigizK/wav2vec2-large-xls-r-300m-bashkir-cv7_opt
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ba",
"dataset:mozilla-foundation/common_voice_7_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_7_0",
"robust-speech-event",
"license:apache-2.0",
"model-index",
"has_space"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 64 | 2023-05-12T22:22:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.08 +/- 20.49
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AimB/mT5-en-kr-aihub-netflix
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 7813 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MSELoss.MSELoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 5000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"eps": 1e-06,
"lr": 0.0001
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 258, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
AimB/mT5-en-kr-natural
|
[
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MT5ForConditionalGeneration"
],
"model_type": "mt5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 78 | null |
---
language:
- pt
---
Esta é a primeira versão Chat de uma inteligência artificial finetunada que fala em português do brasil, ela foi treinada em cima do llama 7b de decapoda, e foi treinada no LLaMA-LoRA Tuner de zetavg utilizando o dataset da cabrita lora e o alpaca cleaned e também utilizou datasets do baize
Divirta-se!
|
Ajay191191/autonlp-Test-530014983
|
[
"pytorch",
"bert",
"text-classification",
"en",
"dataset:Ajay191191/autonlp-data-Test",
"transformers",
"autonlp",
"co2_eq_emissions"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 34 | null |
---
license: other
datasets:
- c-s-ale/alpaca-gpt4-data
pipeline_tag: text2text-generation
---
## GPT4-Alpaca-LoRA_MLP-65B GPTQ
These files are the result of merging the [LoRA weights of chtan's gpt4-alpaca-lora_mlp-65B](https://huggingface.co/chtan/gpt4-alpaca-lora_mlp-65b) with the original Llama 65B model.
## Repositories available
* [4bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-GPTQ)
* [4bit and 5bit GGML models for CPU inference in llama.cpp](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-GGML)
* [float16 unquantised model for GPU inference and further conversions](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-HF)
# Original model card
This repo provides the training checkpoint of LLaMA on the alpaca_data_gpt4 dataset via LoRA [MLP] on 8xA100(80G).
He et al. 2022 gave an insight that FFN can better utilize modification at larger capacities.
The codes is provided by [tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware (github.com)](https://github.com/tloen/alpaca-lora).
We modify the running scripts to
```bash
torchrun --nproc_per_node=8 finetune.py \
--base_model '/cache1/chtan/large_models/llama-hf/llama-65b' \
--data_path './alpaca_data_gpt4.json' \
--output_dir './gpt4-alpaca-lora_mlp-65b' \
--batch_size 128 \
--micro_batch_size 2 \
--num_epochs 10 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 16 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[gate_proj,down_proj,up_proj]' \
--train_on_inputs \
--group_by_length
```
### Examples
**Instruction**: Tell me about alpacas.
**gpt4-alpaca-lora_mlp-65b**:
Alpacas are small, domesticated mammals that are closely related to llamas. They are native to the Andes Mountains of South America, primarily in Peru, Bolivia, and Chile. These animals have been domesticated for thousands of years and were used by the Incas for their fleece, meat, and as pack animals.
Alpacas are known for their soft and warm fleece, which comes in over 22 natural colors. Their fleece is highly valued and is used in the textile industry to make clothing and other products. Alpacas are also known for their friendly and gentle nature, making them popular pets and great additions to farms.
These animals are social and live in herds, typically with one dominant male. They communicate through a series of hums, clucks, and other vocalizations. Alpacas are also known for their distinctive "humming" sound, which they make when they are content or curious.
In terms of physical appearance, alpacas have a small, stocky build, with an average height of around 36 inches at the withers. They have large, expressive eyes, and their ears are perked forward. Alpacas are herbivores and primarily eat grasses and other vegetation. They are also known for their efficient digestive system, which allows them to thrive on a diet of low-quality forage.
Overall, alpacas are unique and fascinating animals that have been an important part of Andean culture for centuries. They continue to be valued for their fleece, meat, and as pets, and their popularity continues to grow around the world.
**Alpaca-LoRA**: Alpacas are members of the camelid family and are native to the Andes Mountains of South America. They are known for their soft, luxurious fleece, which is used to make clothing, blankets, and other items. Alpacas are herbivores and graze on grasses and other plants. They are social animals and live in herds of up to 20 individuals.
**Stanford Alpaca**: Alpacas are small, fluffy animals related to camels and llamas. They are native to Peru and Bolivia, and were first domesticated around 5,000 years ago. They are kept mainly for their fine, soft fleece, which is used to make knitwear and other garments. Alpacas are herd animals and live in small family groups, led by an older male. They are highly social animals and can form strong bonds with their owners.
**text-davinci-003**: Alpacas are a domesticated species of South American camelid, similar to llamas. They are native to the Andes Mountains in South America and are kept as livestock for their soft, luxurious wool. Alpacas are social animals and live in herds of up to 20 individuals. They are typically kept in small herds of two to five animals, and are relatively easy to care for. Alpacas are herbivores and feed on grass, hay, and other vegetation. They are also known for their gentle and friendly nature, making them popular as pets.
---
**Instruction**: Write a Python program that prints the first 10 Fibonacci numbers.
**gpt4-alpaca-lora_mlp-65b**:
Here is a Python program that prints the first 10 Fibonacci numbers:
```python
# initialize variables
a = 0
b = 1
# loop to print the first 10 Fibonacci numbers
for i in range(10):
print(a, end=" ")
a, b = b, a + b
```
In this program, we initialize two variables `a` and `b` with the first two Fibonacci numbers, which are 0 and 1. Then, we use a for loop to iterate 10 times. In each iteration, we print the current value of `a` and update the values of `a` and `b` using the formula `a = b` and `b = a + b`. This formula is the definition of the Fibonacci sequence.
**Alpaca-LoRA**:
```python
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(10))
```
**Stanford Alpaca**:
```python
numbers = [0, 1]
for i in range(2, 11):
numbers.append(numbers[i-2] + numbers[i-1])
print(numbers)
# Output: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
```
**text-davinci-003**:
```python
# Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci sequence, and characterized by the fact that every number after the first two is the sum of the two preceding ones.
# Fibonacci sequence: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
# Program:
# Initialize the first two numbers of the Fibonacci sequence
a = 0
b = 1
# Print the first 10 numbers of the Fibonacci sequence
print(a)
print(b)
for i in range(2,10):
c = a + b
a = b
b = c
print(c)
```
---
> [1] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, Graham Neubig: Towards a Unified View of Parameter-Efficient Transfer Learning. ICLR 2022
|
Ajaykannan6/autonlp-manthan-16122692
|
[
"pytorch",
"bart",
"text2text-generation",
"unk",
"dataset:Ajaykannan6/autonlp-data-manthan",
"transformers",
"autonlp",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"BartForConditionalGeneration"
],
"model_type": "bart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 142,
"min_length": 56,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: other
datasets:
- c-s-ale/alpaca-gpt4-data
pipeline_tag: text2text-generation
---
## GPT4-Alpaca-LoRA_MLP-65B GPTQ
These files are the result of merging the [LoRA weights of chtan's gpt4-alpaca-lora_mlp-65B](https://huggingface.co/chtan/gpt4-alpaca-lora_mlp-65b) with the original Llama 65B model.
It was then quantised to 4bit using [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
## Repositories available
* [4bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-GPTQ)
* [4bit and 5bit GGML models for CPU inference in llama.cpp](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-GGML)
* [float16 unquantised model for GPU inference and further conversions](https://huggingface.co/TheBloke/gpt4-alpaca-lora_mlp-65B-HF)
## VRAM
I tested this model with 2 x 24GB 4090 GPUs, and it was able to return 1500 tokens before one card went OOM.
So you may need to preload a few layers on to CPU RAM, or else run on a system with more than 48GB VRAM.
Or, if you can limit responses to <1500 tokens (eg for single prompts rather than chats), you should be fine with 48GB VRAM.
## How to easily download and use this model in text-generation-webui
Open the text-generation-webui UI as normal.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/gpt4-alpaca-lora_mlp-65B-GPTQ`.
3. Click **Download**.
4. Wait until it says it's finished downloading.
5. Click the **Refresh** icon next to **Model** in the top left.
6. In the **Model drop-down**: choose the model you just downloaded, `gpt4-alpaca-lora_mlp-65B-GPTQ`.
7. If you see an error in the bottom right, ignore it - it's temporary.
8. Fill out the `GPTQ parameters` on the right: `Bits = 4`, `Groupsize = None`, `model_type = Llama`
9. Click **Save settings for this model** in the top right.
10. Click **Reload the Model** in the top right.
11. Once it says it's loaded, click the **Text Generation tab** and enter a prompt!
## Provided files
**`gpt4-alpaca-lora_mlp-65B-GPTQ-4bit.safetensors`**
You will need at least 48GB VRAM to use this model, either on one GPU or multiple.
This will work with all versions of GPTQ-for-LLaMa. It has maximum compatibility.
It was created with `--act-order` to increase quantisation quality, but without group_size so as to reduce VRAM requirements.
* `gpt4-alpaca-lora_mlp-65B-GPTQ-4bit.safetensors`
* Works with all versions of GPTQ-for-LLaMa code, both Triton and CUDA branches
* Works with text-generation-webui one-click-installers
* Parameters: Groupsize = None. act-order.
* Command used to create the GPTQ:
```
python llama.py gpt4-alpaca-lora_mlp-65B/HF/ c4 --wbits 4 --true-sequential --act-order --save_safetensors gpt4-alpaca-lora_mlp-65B/gptq/gpt4-alpaca-lora_mlp-65B-GPTQ-4bit.safetensors
```
# Original model card
This repo provides the training checkpoint of LLaMA on the alpaca_data_gpt4 dataset via LoRA [MLP] on 8xA100(80G).
He et al. 2022 gave an insight that FFN can better utilize modification at larger capacities.
The codes is provided by [tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware (github.com)](https://github.com/tloen/alpaca-lora).
We modify the running scripts to
```bash
torchrun --nproc_per_node=8 finetune.py \
--base_model '/cache1/chtan/large_models/llama-hf/llama-65b' \
--data_path './alpaca_data_gpt4.json' \
--output_dir './gpt4-alpaca-lora_mlp-65b' \
--batch_size 128 \
--micro_batch_size 2 \
--num_epochs 10 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 16 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[gate_proj,down_proj,up_proj]' \
--train_on_inputs \
--group_by_length
```
### Examples
**Instruction**: Tell me about alpacas.
**gpt4-alpaca-lora_mlp-65b**:
Alpacas are small, domesticated mammals that are closely related to llamas. They are native to the Andes Mountains of South America, primarily in Peru, Bolivia, and Chile. These animals have been domesticated for thousands of years and were used by the Incas for their fleece, meat, and as pack animals.
Alpacas are known for their soft and warm fleece, which comes in over 22 natural colors. Their fleece is highly valued and is used in the textile industry to make clothing and other products. Alpacas are also known for their friendly and gentle nature, making them popular pets and great additions to farms.
These animals are social and live in herds, typically with one dominant male. They communicate through a series of hums, clucks, and other vocalizations. Alpacas are also known for their distinctive "humming" sound, which they make when they are content or curious.
In terms of physical appearance, alpacas have a small, stocky build, with an average height of around 36 inches at the withers. They have large, expressive eyes, and their ears are perked forward. Alpacas are herbivores and primarily eat grasses and other vegetation. They are also known for their efficient digestive system, which allows them to thrive on a diet of low-quality forage.
Overall, alpacas are unique and fascinating animals that have been an important part of Andean culture for centuries. They continue to be valued for their fleece, meat, and as pets, and their popularity continues to grow around the world.
**Alpaca-LoRA**: Alpacas are members of the camelid family and are native to the Andes Mountains of South America. They are known for their soft, luxurious fleece, which is used to make clothing, blankets, and other items. Alpacas are herbivores and graze on grasses and other plants. They are social animals and live in herds of up to 20 individuals.
**Stanford Alpaca**: Alpacas are small, fluffy animals related to camels and llamas. They are native to Peru and Bolivia, and were first domesticated around 5,000 years ago. They are kept mainly for their fine, soft fleece, which is used to make knitwear and other garments. Alpacas are herd animals and live in small family groups, led by an older male. They are highly social animals and can form strong bonds with their owners.
**text-davinci-003**: Alpacas are a domesticated species of South American camelid, similar to llamas. They are native to the Andes Mountains in South America and are kept as livestock for their soft, luxurious wool. Alpacas are social animals and live in herds of up to 20 individuals. They are typically kept in small herds of two to five animals, and are relatively easy to care for. Alpacas are herbivores and feed on grass, hay, and other vegetation. They are also known for their gentle and friendly nature, making them popular as pets.
---
**Instruction**: Write a Python program that prints the first 10 Fibonacci numbers.
**gpt4-alpaca-lora_mlp-65b**:
Here is a Python program that prints the first 10 Fibonacci numbers:
```python
# initialize variables
a = 0
b = 1
# loop to print the first 10 Fibonacci numbers
for i in range(10):
print(a, end=" ")
a, b = b, a + b
```
In this program, we initialize two variables `a` and `b` with the first two Fibonacci numbers, which are 0 and 1. Then, we use a for loop to iterate 10 times. In each iteration, we print the current value of `a` and update the values of `a` and `b` using the formula `a = b` and `b = a + b`. This formula is the definition of the Fibonacci sequence.
**Alpaca-LoRA**:
```python
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(10))
```
**Stanford Alpaca**:
```python
numbers = [0, 1]
for i in range(2, 11):
numbers.append(numbers[i-2] + numbers[i-1])
print(numbers)
# Output: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
```
**text-davinci-003**:
```python
# Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci sequence, and characterized by the fact that every number after the first two is the sum of the two preceding ones.
# Fibonacci sequence: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
# Program:
# Initialize the first two numbers of the Fibonacci sequence
a = 0
b = 1
# Print the first 10 numbers of the Fibonacci sequence
print(a)
print(b)
for i in range(2,10):
c = a + b
a = b
b = c
print(c)
```
---
> [1] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, Graham Neubig: Towards a Unified View of Parameter-Efficient Transfer Learning. ICLR 2022
|
Akash7897/bert-base-cased-wikitext2
|
[
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
A custom lora. 💩
<<lora:multiview-000009:0.8>>, mvst, simple background, multiple views, schoolgirl
etc
|
Akash7897/distilbert-base-uncased-finetuned-sst2
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
|
{
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | 2023-05-12T22:59:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
metrics:
- rouge
model-index:
- name: flan-t5-large-finetuned-cnndm_3
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: validation
args: 3.0.0
metrics:
- name: Rouge1
type: rouge
value: 23.976
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-finetuned-cnndm_3
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 23.976
- Rouge2: 11.0396
- Rougel: 19.4617
- Rougelsum: 22.4459
- Gen Len: 18.6346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:-------:|:---------:|:-------:|
| 0.0 | 1.0 | 8972 | nan | 23.976 | 11.0396 | 19.4617 | 22.4459 | 18.6346 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Akira-Yana/distilbert-base-uncased-finetuned-cola
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
AnaRhisT/bert_sequence_cs_validation
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: creativeml-openrail-m
language:
- en
tags:
- vae
---
diffusers format of kl-f8-anime2.ckpt from https://huggingface.co/hakurei/waifu-diffusion-v1-4
|
Andrey78/my_model_nlp
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: saransh_biogpt_custom
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# saransh_biogpt_custom
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2376
- Precision: 0.3702
- Recall: 0.2097
- F1: 0.2677
- Accuracy: 0.9300
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 418 | 0.2439 | 0.3401 | 0.1315 | 0.1896 | 0.9284 |
| 0.2906 | 2.0 | 836 | 0.2326 | 0.3448 | 0.1956 | 0.2496 | 0.9293 |
| 0.2348 | 3.0 | 1254 | 0.2376 | 0.3702 | 0.2097 | 0.2677 | 0.9300 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Ankit-11/distilbert-base-uncased-finetuned-toxic
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-05-13T05:47:44Z |
---
language:
- de
library_name: transformers
tags:
- xlm-Roberta
- Discourse Analysis
- German text classification
---
# Roberta for German Discourse Classification
This is a xlm Roberta model finetuned on a German Discourse dataset of 60 discourses having a total over 10k sentences.
# Understanding the labels
**Externalization:** Emphasize situational factors that we dont have control over as the cause of behavior. For example "I had a really tough day at work and then when I got home, my cat got sick. It's just been one thing after another and it's really getting to me.".
**Elicitation:** Emphasize the role of the listener by asking questions or providing prompts. For example "Can you tell me more about what it feels like when you're anxious?".
**Conflict:** Attribute each other's behavior to dispositional factors (such as being short-sighted or inflexible). For example "You're not thinking about the big picture here!".
**Acceptance:** Accept the perspectives or experiences of others. For example "It sounds like you had a really hard day".
**Integration:** Combining multiple perspectives to create a more comprehensive understanding of the behavior of others. For example "What if we combined elements of both proposals to create something that incorporates the best of both worlds?".
## How to use the model
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
def get_label(sentence):
vectors = tokenizer(sentence, return_tensors='pt').to(device)
outputs = bert_model(**vectors).logits
probs = torch.nn.functional.softmax(outputs, dim = 1)[0]
bert_dict = {}
keys = ['Externalization', 'Elicitation', 'Conflict', 'Acceptence', 'Integration', 'None']
for i in range(len(keys)):
bert_dict[keys[i]] = round(probs[i].item(), 3)
return bert_dict
MODEL_NAME = 'RashidNLP/Roberta-German-Discourse'
MODEL_DIR = 'model'
CHECKPOINT_DIR = 'checkpoints'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
OUTPUTS = 6
bert_model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels = OUTPUTS).to(device)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
get_label("Gehst du zum Oktoberfest?")
```
|
Ann2020/model-finetuned-ner
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-05-13T05:57:13Z |
---
license: creativeml-openrail-m
language:
- ja
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
library_name: diffusers
---
---
<h4>📄 ライセンス / License</h4>
<div class="px-2">
<table class="table-fixed border mt-0 text-xs">
<tbody>
<tr>
<td class="px-4 text-base" colspan="2">
<a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license">
修正 CreativeML OpenRAIL-M ライセンス / Modified CreativeML OpenRAIL-M license
</a>
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span class="text-green-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M4.5 12.75l6 6 9-13.5" />
</svg>
</span>
</td>
<td>
このモデルのクレジットを入れずに使用する<br>
Use the model without crediting the creator
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span class="text-green-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M4.5 12.75l6 6 9-13.5" />
</svg>
</span>
</td>
<td>
このモデルで生成した画像を商用利用する<br>
Sell images they generate
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span class="text-red-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M6 18L18 6M6 6l12 12" />
</svg>
</span>
</td>
<td>
このモデルを商用の画像生成サービスで利用する</br>
Run on services that generate images for money
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span class="text-green-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M4.5 12.75l6 6 9-13.5" />
</svg>
</span>
</td>
<td>
このモデルを使用したマージモデルを共有する<br>
Share merges using this model
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span class="text-red-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M6 18L18 6M6 6l12 12" />
</svg>
</span>
</td>
<td>
このモデル、またはこのモデルをマージしたモデルを販売する</br>
Sell this model or merges using this model
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span class="text-red-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6">
<path stroke-linecap="round" stroke-linejoin="round" d="M6 18L18 6M6 6l12 12" />
</svg>
</span>
</td>
<td>
このモデルをマージしたモデルに異なる権限を設定する</br>
Have different permissions when sharing merges
</td>
</tr>
</tbody>
</table>
</div>
|
Ann2020/rubert-base-cased-sentence-finetuned-ner
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Bilguunee/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
AnonymousSub/AR_rule_based_roberta_bert_triplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 10 | null |
---
license: other
pipeline_tag: text2text-generation
---Metanail Serum Pro™ | Official Store
MetaNail Serum Pro makes your nails feel look better than ever before. The added ingredients in this serum are purely sourced from nature’s extract, which won’t cause any side effects. MetaNail Serum Pro never worries you about ugly nails and feet; it works completely naturally. Read More:- https://metanail-us.org/special-offer-mnu
#MetaNailSerumPro , #MetaNailSerum , #MetaNail , #NailHealth
MetaNail Serum Pro , MetaNail Serum , MetaNail , Nail Health
|
AnonymousSub/AR_rule_based_roberta_hier_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | null |
---
language:
- vi
tags:
- sentiment
- classification
license: mit
widget:
- text: "Mô hình được clone lại bởi DazkDev"
---
[**GitHub Homepage**](https://github.com/hunterdie333/Dazk-Nhan-Dien-Tot-Xau)
Labels:
- NEG: Tiêu cực
- POS: Tích cực
- NEU: Trung lập
Dataset: [Từ từ sẽ được update](https://www.kaggle.com/datasets/linhlpv/vietnamese-sentiment-analyst)
## Usage
```python
import torch
from transformers import RobertaForSequenceClassification, AutoTokenizer
model = RobertaForSequenceClassification.from_pretrained("hunterdie333/Dazk-Nhan-Dien-Tot-Xau")
tokenizer = AutoTokenizer.from_pretrained("hunterdie333/Dazk-Nhan-Dien-Tot-Xau", use_fast=False)
# Just like PhoBERT: INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
sentence = 'Mô hình được clone lại bởi DazkDev'
input_ids = torch.tensor([tokenizer.encode(sentence)])
with torch.no_grad():
out = model(input_ids)
print(out.logits.softmax(dim=-1).tolist())
# Output:
# [[0.293, 0.040, 0.667]]
# ^ ^ ^
# NEG POS NEU
```
|
AnonymousSub/AR_rule_based_roberta_twostage_quadruplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
# temp-model
This is dummy model just for testing while following hugging face getting-started documentation.
|
AnonymousSub/AR_rule_based_twostagequadruplet_hier_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner_test1
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9328825857519789
- name: Recall
type: recall
value: 0.9520363513968361
- name: F1
type: f1
value: 0.9423621522572048
- name: Accuracy
type: accuracy
value: 0.9865779713898863
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner_test1
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0605
- Precision: 0.9329
- Recall: 0.9520
- F1: 0.9424
- Accuracy: 0.9866
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0879 | 1.0 | 1756 | 0.0644 | 0.9204 | 0.9366 | 0.9284 | 0.9828 |
| 0.0346 | 2.0 | 3512 | 0.0646 | 0.9275 | 0.9490 | 0.9381 | 0.9857 |
| 0.0182 | 3.0 | 5268 | 0.0605 | 0.9329 | 0.9520 | 0.9424 | 0.9866 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AnonymousSub/bert_hier_diff_equal_wts_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-teste-full-length
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-teste-full-length
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5750
- Rouge1: 0.4784
- Rouge2: 0.3008
- Rougel: 0.4185
- Rougelsum: 0.4212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 90
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 2.9357 | 0.16 | 100 | 2.5583 | 0.2654 | 0.0431 | 0.1946 | 0.1951 |
| 1.9974 | 0.33 | 200 | 1.7104 | 0.1803 | 0.0817 | 0.1712 | 0.1726 |
| 1.4803 | 0.49 | 300 | 1.4404 | 0.1770 | 0.0695 | 0.1707 | 0.1727 |
| 1.2432 | 0.65 | 400 | 1.0519 | 0.2809 | 0.1314 | 0.2509 | 0.2511 |
| 0.8186 | 0.82 | 500 | 0.7386 | 0.3487 | 0.1767 | 0.2894 | 0.2903 |
| 0.791 | 0.98 | 600 | 0.7135 | 0.3634 | 0.1912 | 0.3108 | 0.3108 |
| 0.6697 | 1.15 | 700 | 0.6835 | 0.3874 | 0.1900 | 0.3123 | 0.3131 |
| 0.7146 | 1.31 | 800 | 0.6657 | 0.3816 | 0.2209 | 0.3414 | 0.3428 |
| 0.6957 | 1.47 | 900 | 0.6498 | 0.3878 | 0.2045 | 0.3336 | 0.3339 |
| 0.6737 | 1.64 | 1000 | 0.6332 | 0.4094 | 0.2219 | 0.3524 | 0.3535 |
| 0.6537 | 1.8 | 1100 | 0.6369 | 0.4401 | 0.2621 | 0.3629 | 0.3630 |
| 0.6746 | 1.96 | 1200 | 0.6169 | 0.4369 | 0.2326 | 0.3566 | 0.3574 |
| 0.5961 | 2.13 | 1300 | 0.6171 | 0.4364 | 0.2464 | 0.3666 | 0.3670 |
| 0.5829 | 2.29 | 1400 | 0.6122 | 0.4539 | 0.2683 | 0.3813 | 0.3825 |
| 0.6336 | 2.45 | 1500 | 0.5993 | 0.4347 | 0.2548 | 0.3660 | 0.3689 |
| 0.5754 | 2.62 | 1600 | 0.5905 | 0.4575 | 0.2789 | 0.3856 | 0.3857 |
| 0.5984 | 2.78 | 1700 | 0.5872 | 0.4630 | 0.2768 | 0.3915 | 0.3929 |
| 0.5966 | 2.95 | 1800 | 0.5944 | 0.4605 | 0.2753 | 0.3822 | 0.3828 |
| 0.5288 | 3.11 | 1900 | 0.5955 | 0.4520 | 0.2651 | 0.3874 | 0.3887 |
| 0.5316 | 3.27 | 2000 | 0.5841 | 0.4649 | 0.2820 | 0.4052 | 0.4056 |
| 0.5332 | 3.44 | 2100 | 0.5765 | 0.4861 | 0.3046 | 0.4021 | 0.4050 |
| 0.5296 | 3.6 | 2200 | 0.5812 | 0.4610 | 0.2815 | 0.3976 | 0.4021 |
| 0.5215 | 3.76 | 2300 | 0.5757 | 0.4724 | 0.2947 | 0.4122 | 0.4164 |
| 0.5399 | 3.93 | 2400 | 0.5750 | 0.4784 | 0.3008 | 0.4185 | 0.4212 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
AnonymousSub/declutr-model_wikiqa
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 26 | 2023-05-13T10:03:47Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
### Based off [NegiInNattoMaki/Nabylon](https://huggingface.co/NegiInNattoMaki/Nabylon)
All credits go to the original author and all the author of Nabylon's ancestor models
### Inpainting
This model can be used for inpainting, as it's the original Nabylon-v1.0 merged with
[runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting) and
[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) via the weights of
```
stable-diffusion-inpainting + (Nabylon-v1.0 - stable-diffusion-v1-5)
```
### Diffusers
The merged model was converted to be used with the [🧨Diffusers library](https://github.com/huggingface/diffusers)
|
AnonymousSub/hier_triplet_epochs_1_shard_10
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: vit-base-patch16-224-finetuned-flower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-flower
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 2.0.0+cu118
- Datasets 2.7.1
- Tokenizers 0.13.3
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.